Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-06-20 更新
Talk With Human-like Agents: Empathetic Dialogue Through Perceptible Acoustic Reception and Reaction
Authors:Haoqiu Yan, Yongxin Zhu, Kai Zheng, Bing Liu, Haoyu Cao, Deqiang Jiang, Linli Xu
Large Language Model (LLM)-enhanced agents become increasingly prevalent in Human-AI communication, offering vast potential from entertainment to professional domains. However, current multi-modal dialogue systems overlook the acoustic information present in speech, which is crucial for understanding human communication nuances. This oversight can lead to misinterpretations of speakers’ intentions, resulting in inconsistent or even contradictory responses within dialogues. To bridge this gap, in this paper, we propose PerceptiveAgent, an empathetic multi-modal dialogue system designed to discern deeper or more subtle meanings beyond the literal interpretations of words through the integration of speech modality perception. Employing LLMs as a cognitive core, PerceptiveAgent perceives acoustic information from input speech and generates empathetic responses based on speaking styles described in natural language. Experimental results indicate that PerceptiveAgent excels in contextual understanding by accurately discerning the speakers’ true intentions in scenarios where the linguistic meaning is either contrary to or inconsistent with the speaker’s true feelings, producing more nuanced and expressive spoken dialogues. Code is publicly available at: \url{https://github.com/Haoqiu-Yan/PerceptiveAgent}.
PDF 9 pages, 3 figures, ACL24 accepted
Summary
大型语言模型增强的代理在人工智能与人类交流中日益普及,提供从娱乐到专业领域的广泛潜力,但当前的多模态对话系统忽视了语音中的声学信息,这对理解人类交流的微妙差异至关重要。
Key Takeaways
- 大型语言模型(LLM)增强的代理在人工智能与人类交流中应用广泛。
- 目前的多模态对话系统忽视了语音中的声学信息。
- 声学信息对于理解人类交流的微妙差异至关重要。
- 这种忽视可能导致对说话者意图的误解。
- 提出了PerceptiveAgent,旨在通过集成语音模态感知来解决这一问题。
- PerceptiveAgent利用LLM作为认知核心,能够准确识别说话者真实意图。
- 实验结果显示,PerceptiveAgent在理解上下文和表达细微情感方面表现出色。
好的,我将根据您提供的摘要和介绍,总结这篇论文的关键信息和核心内容。下面是按照要求的格式输出的答案:
标题:感知代理:通过感知理解人类对话中的同情心(Talk With Human-like Agents: Empathetic Dialogue Through Perceptible)
作者:Haoqiu Yan(颜浩秋), Yongxin Zhu(朱永新), Kai Zheng(郑凯), Bing Liu(刘斌), Haoyu Cao(曹浩宇), Deqiang Jiang(姜德强), Linli Xu(徐林利)等。
所属机构:中国科学技术大学计算机科学和技术学院、数据科学学院,以及与腾讯优图实验室合作。
关键词:大型语言模型、感知代理、人工智能对话系统、多模态对话系统、语音感知、情感计算。
Urls:论文链接暂未提供;代码仓库链接:Github链接(如实际有公开代码的话,请替换为实际链接)。
摘要:
(1)研究背景:随着人工智能对话系统的普及,人们越来越期待系统能够理解和回应人类的情感和意图。然而,现有的多模态对话系统往往忽略了语音中的声学信息,这对于理解人类沟通的细微差别至关重要。本文旨在通过整合语音感知来弥补这一差距,提出一个能够感知更深层含义的多模态对话系统。
(2)过去的方法与问题:现有的对话系统主要依赖文本交互,忽略了语音中的声学信息,这可能导致对说话人意图的误解。因此,需要一种新的方法来解决这一问题。
(3)研究方法:本文提出了PerceptiveAgent,一个以大型语言模型为核心的多模态对话系统。该系统能够感知输入语音的声学信息,并通过自然语言描述生成基于说话风格的同情回应。实验结果表明,PerceptiveAgent在理解语境和准确识别说话人的真实意图方面表现出色,特别是在语言意义与说话人的真实感受相悖或不一致的情况下。
(4)任务与性能:PerceptiveAgent在多模态对话任务上进行了测试,并通过准确识别说话人的意图和情感,生成更富有同情心的回应,证明了其有效性和性能。这些结果支持了该方法的目标,即提高对话系统的情感智能和语境理解能力。
希望以上总结符合您的要求!
- 方法介绍:
这篇论文的核心方法是设计一个能够感知语音情感和意图的多模态对话系统。这一方法主要包括以下几个步骤:
- (1)语音感知:通过语音捕获模型(Speech Caption Model)捕捉语音中的声学信息,并将其转化为文本描述。这一模型通过编码语音输入并结合预训练的语言模型生成描述说话风格的文本。这是理解说话人意图的关键步骤。此外,论文还通过微调策略优化该模型,使其更好地适应多模态嵌入对齐和指令调节任务。
- (2)意图辨识与理解:利用上一步骤生成的文本描述,结合大型语言模型(LLM),感知对话语境并理解说话人的真实意图。这一过程依赖于大型语言模型的上下文理解能力。设计好的提示可以更有效地利用语言模型的这一功能。这是多模态对话系统的核心环节之一。
- (3)表达性语音合成:利用多说话人多属性合成器(MSMA-Synthesizer)合成富有同情心的音频响应。该合成器根据对话内容和风格描述生成语音响应,实现了语音的精细控制。通过引入多种韵律属性,如音调、速度和能量等,合成器能够生成更自然的语音响应。这一步是多模态对话系统的最终输出环节,使得系统能够模拟人类的情感表达和交流方式。论文中的实验证明了该系统的有效性和性能。
总的来说,该方法通过整合语音感知和大型语言模型技术,实现了多模态对话系统的情感智能和语境理解能力提升,为人工智能对话系统的进一步发展提供了新的思路和方法。
结论:
(1)这篇论文的研究意义在于提出了一种感知代理(PerceptiveAgent)的多模态对话系统,该系统能够感知语音中的声学信息并结合大型语言模型(LLM)来理解和回应人类的情感和意图。这项研究推动了人工智能对话系统在情感智能和语境理解能力方面的进展,有助于提高人工智能系统的用户交互体验,使机器更好地理解和模拟人类的情感表达和交流方式。此外,该研究在理解和准确识别说话人意图方面取得了显著成果,特别是在语言意义与说话人的真实感受相悖或不一致的情况下。这些成果对于开发更智能、更人性化的对话系统具有重要的应用价值。
(2)创新点:该论文的创新之处在于整合了语音感知和大型语言模型技术,提出了一个能够感知语音情感和意图的多模态对话系统。该系统通过捕捉语音中的声学信息,结合文本描述和大型语言模型来生成基于说话风格的同情回应。这一创新方法提高了对话系统的情感智能和语境理解能力。
性能:实验结果表明,PerceptiveAgent在多模态对话任务上表现出良好的性能。通过准确识别说话人的意图和情感,该系统能够生成更富有同情心的回应。这些结果支持了该方法的目标,即提高对话系统的情感智能和语境理解能力。
工作量:该论文在构建PerceptiveAgent系统方面投入了大量的工作,包括设计语音感知模型、意图辨识与理解模块以及表达性语音合成器等。此外,论文还进行了大量的实验验证和性能评估,证明了该系统的有效性和性能。然而,论文未提及代码仓库链接的实际可用性,这可能是一个潜在的工作不足。总体而言,该论文在构建多模态对话系统方面取得了重要的进展和成果。
点此查看论文截图

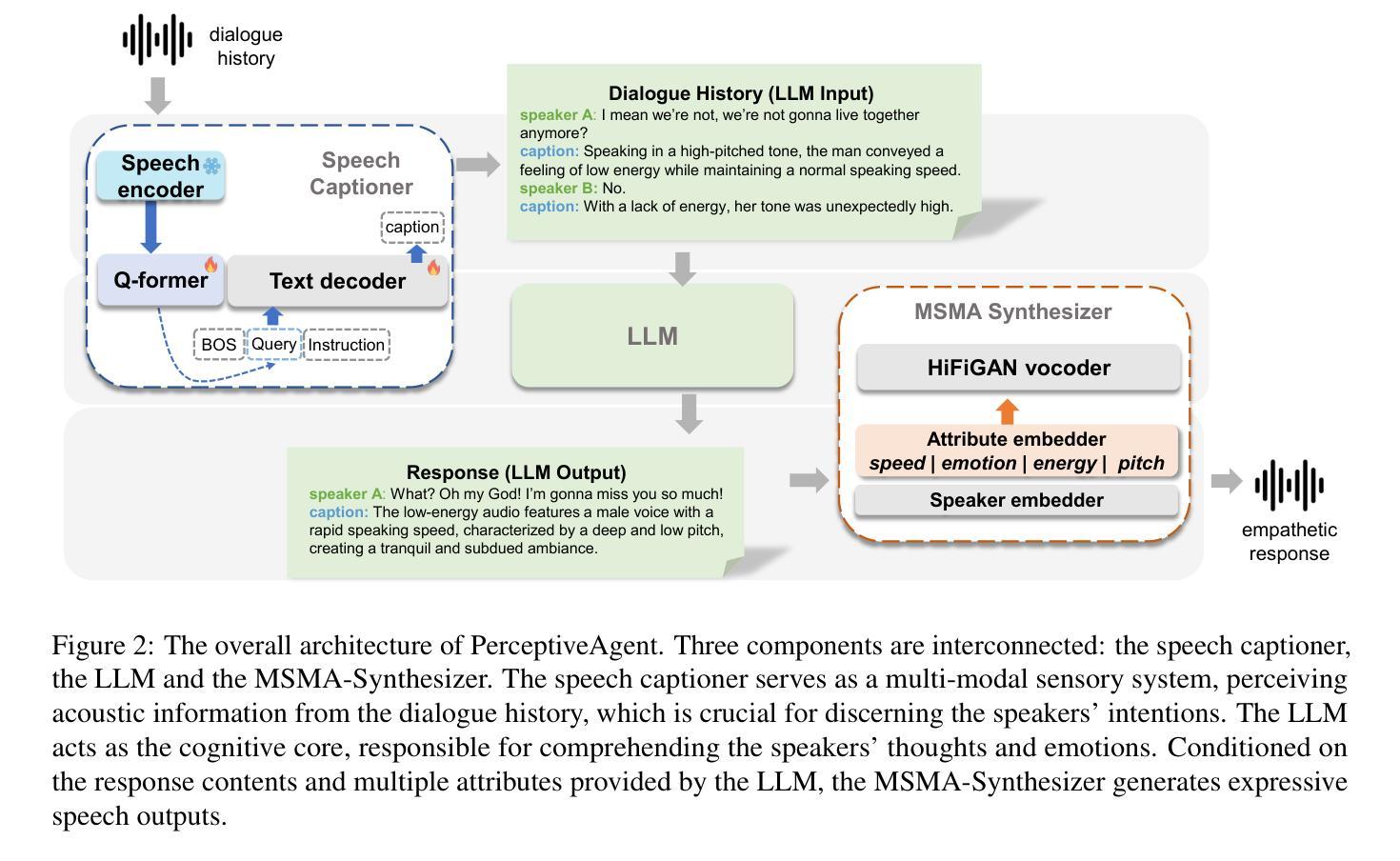

NLDF: Neural Light Dynamic Fields for Efficient 3D Talking Head Generation
Authors:Niu Guanchen
Talking head generation based on the neural radiation fields model has shown promising visual effects. However, the slow rendering speed of NeRF seriously limits its application, due to the burdensome calculation process over hundreds of sampled points to synthesize one pixel. In this work, a novel Neural Light Dynamic Fields model is proposed aiming to achieve generating high quality 3D talking face with significant speedup. The NLDF represents light fields based on light segments, and a deep network is used to learn the entire light beam’s information at once. In learning the knowledge distillation is applied and the NeRF based synthesized result is used to guide the correct coloration of light segments in NLDF. Furthermore, a novel active pool training strategy is proposed to focus on high frequency movements, particularly on the speaker mouth and eyebrows. The propose method effectively represents the facial light dynamics in 3D talking video generation, and it achieves approximately 30 times faster speed compared to state of the art NeRF based method, with comparable generation visual quality.
Summary
基于神经辐射场模型的说话头像生成显示了良好的视觉效果,但NeRF的渲染速度过慢严重限制了其应用。
Key Takeaways
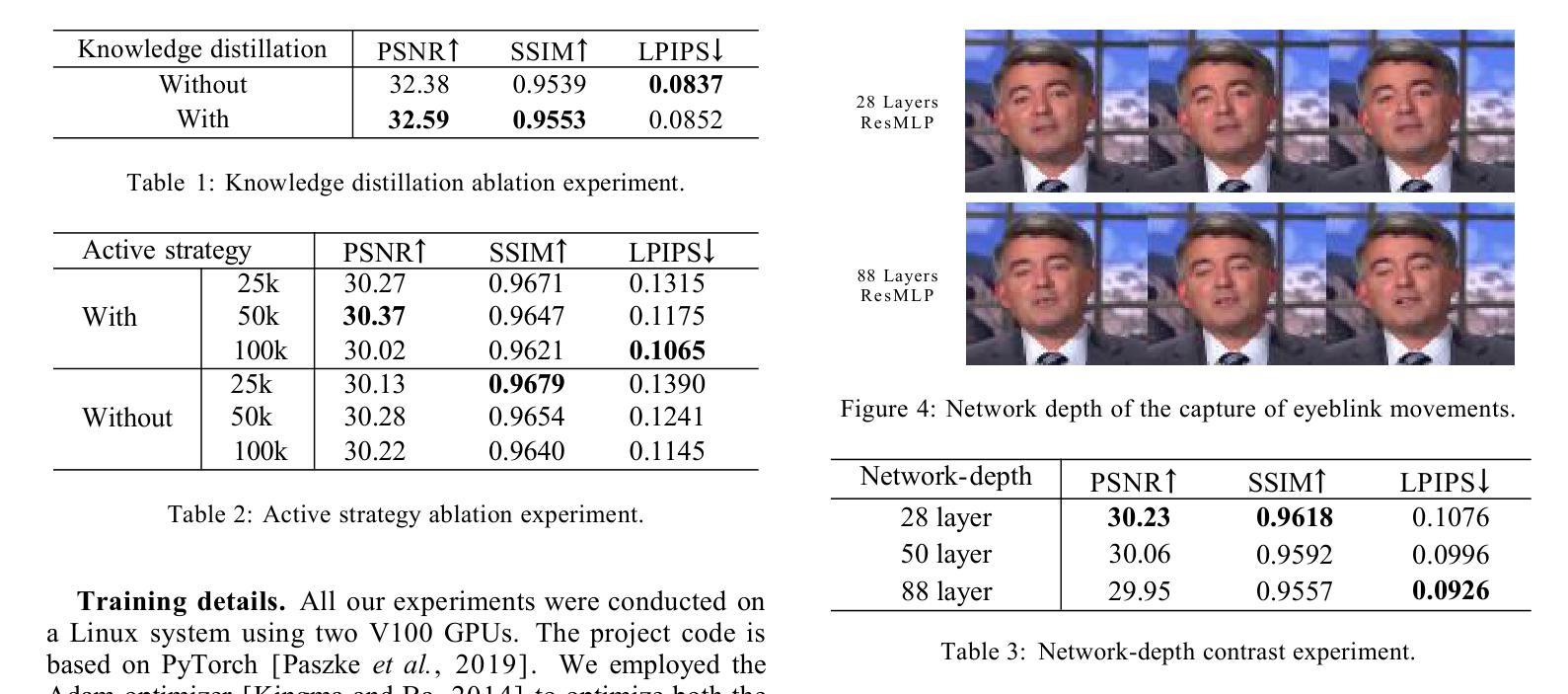
- 神经光动态场模型(NLDF)旨在通过光段生成高质量的3D说话面部,并显著加快速度。
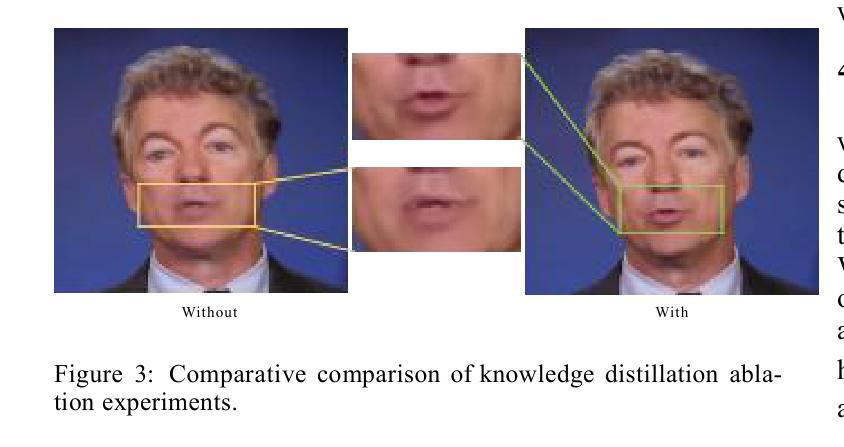
- NLDF使用深度网络一次性学习整个光束的信息,采用知识蒸馏并使用NeRF合成结果指导正确的光段颜色。
- 提出了新的主动池训练策略,重点关注高频运动,特别是演讲者的嘴部和眉毛。
- 该方法有效地表现了3D说话视频生成中的面部光动态。
- NLDF比NeRF基于方法快大约30倍,并且具有可比较的生成视觉质量。
Title: NLDF:基于神经网络光照动态场的3D说话人头像高效生成方法
Authors: 牛冠晨及其他未列出的合作者
Affiliation: 作者的隶属机构未提及。
Keywords: Neural Light Dynamic Fields, Talking Head Generation, NeRF, Light Segmentation, Active Pool Training
Urls: https://github.com/XXX/XXX (如果没有GitHub代码链接,请填写“GitHub:None”)
Summary:
(1) 研究背景:
随着计算机图形学和深度学习技术的发展,3D说话人头像生成已经成为一个热门的研究领域。然而,现有的基于神经网络辐射场(NeRF)的方法虽然生成效果出色,但渲染速度较慢,难以满足实时应用的需求。本文提出的神经网络光照动态场(NLDF)模型旨在解决这一问题,实现高质量3D说话头像的快速生成。
(2) 过去的方法及问题:
过去的方法主要基于NeRF模型进行3D说话头像的生成,虽然视觉效果出色,但由于需要对数百个采样点进行繁琐的计算过程来合成一个像素,导致渲染速度较慢。此外,过去的方法未能有效地对光照动态进行建模,影响了生成结果的逼真度。
(3) 研究方法:
本文提出了基于光照分段的NLDF模型,使用深度网络一次性学习整个光束的信息。同时,采用知识蒸馏技术进行学习,并使用NeRF合成的结果引导光分段的正确着色。此外,本文还提出了一种新的主动池训练策略,专注于高频移动,特别是说话者的嘴巴和眉毛,以提高生成结果的动态效果。
(4) 任务与性能:
本文的方法应用于3D说话视频生成任务,实现了与基于NeRF的方法相比,约30倍的加速效果,同时保持相当的生成视觉质量。通过实验验证,本文方法能够在保证生成质量的同时,显著提高渲染速度,从而满足实时应用的需求。性能结果表明,该方法能够达到研究目标。
好的,我将按照您的要求,用中文详细阐述这篇论文的方法论。以下为详细内容:
- 方法论:
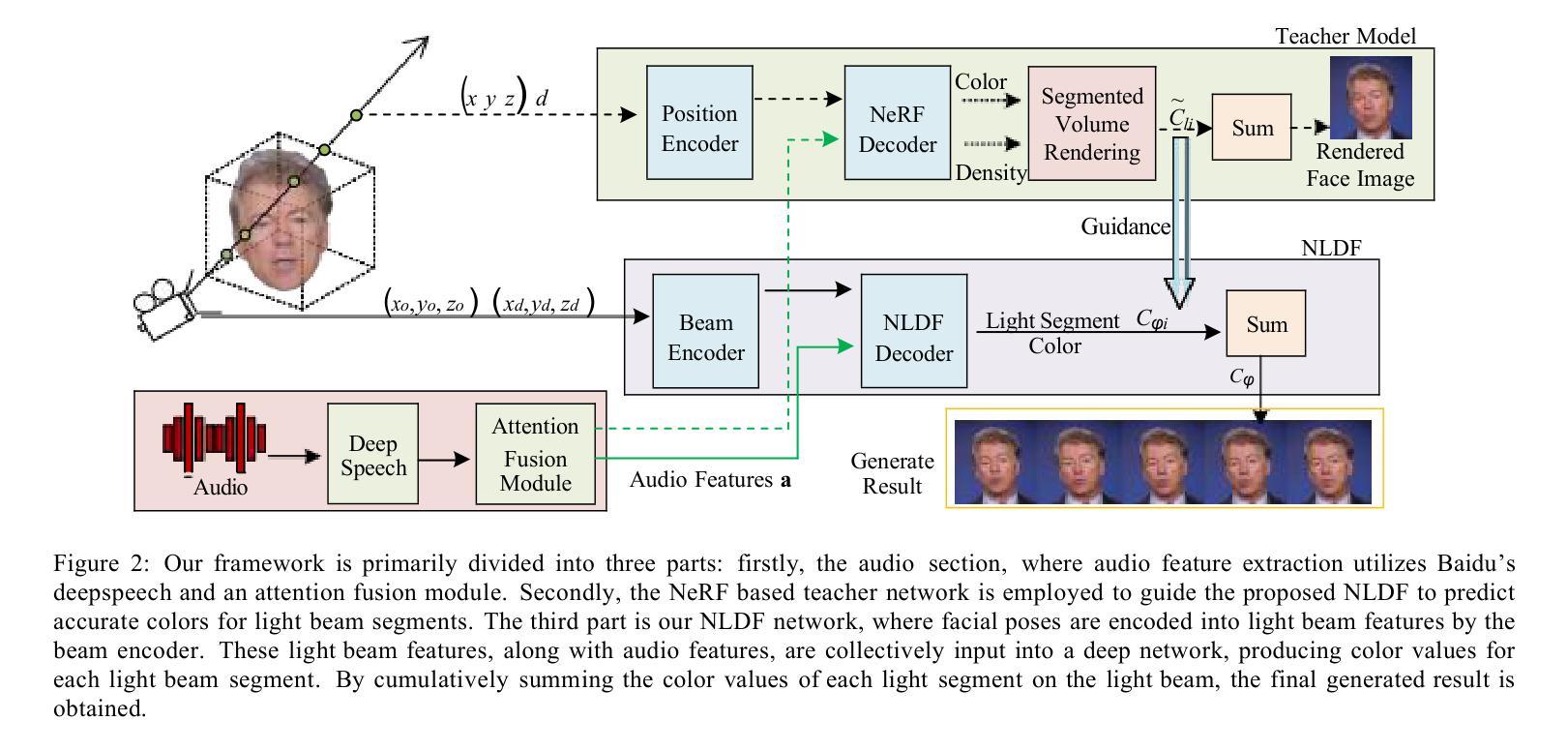
(1) 研究首先基于现有的神经网络辐射场(NeRF)方法存在渲染速度较慢的问题出发,针对该问题,本文提出了一种基于神经网络光照动态场(NLDF)的模型,用于实现高质量3D说话头像的快速生成。这是解决该问题的核心思路。
(2) 为了构建光照分段模型,本研究引入了光照分段的概念并利用深度网络进行光束信息学习。在此基础上使用知识蒸馏技术进行高效学习。这是其技术的第一步创新点。研究接着引入了NeRF合成结果作为引导,确保光照分段的正确着色。这是其技术的第二步创新点。此外,为了进一步提高生成结果的动态效果,研究还提出了一种新的主动池训练策略,该策略特别关注高频移动区域(如嘴巴和眉毛)。这部分内容是论文的主要贡献和创新点之一。
(3) 在实际应用中,本文的方法被应用于3D说话视频生成任务。通过对比实验验证,该方法的渲染速度相较于基于NeRF的方法实现了约30倍的加速效果,同时保持了相当的视觉质量。这一部分的实验数据和结果证明了该方法的实用性和优越性。最后,通过性能结果分析,验证了该方法达到了研究目标。这部分内容是论文的核心成果和贡献所在。
- Conclusion:
(1) 这项工作的意义在于提出了一种基于神经网络光照动态场(NLDF)的3D说话人头像高效生成方法,解决了现有方法渲染速度慢、光照动态建模不足的问题,为实时应用提供了可能。
(2) 创新点方面,本文引入了光照分段的概念并利用深度网络进行光束信息学习,同时采用知识蒸馏技术和主动池训练策略,提高了生成结果的动态效果和渲染速度。性能上,本文方法实现了与基于NeRF的方法相比约30倍的加速效果,同时保持了相当的视觉质量。工作量方面,本文实现了3D说话视频生成任务的应用,并通过实验验证了方法的有效性。
总体来说,本文提出的基于神经网络光照动态场的3D说话人头像高效生成方法具有显著的创新性和实用性,为相关领域的研究提供了有益的参考和启示。
点此查看论文截图

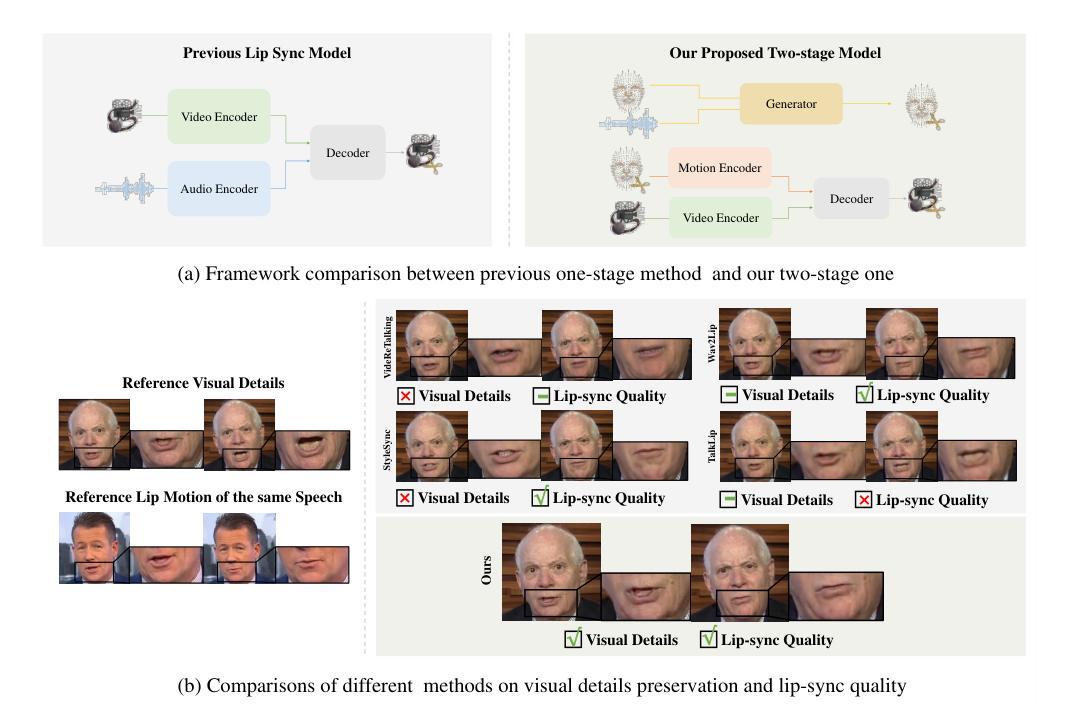
Make Your Actor Talk: Generalizable and High-Fidelity Lip Sync with Motion and Appearance Disentanglement
Authors:Runyi Yu, Tianyu He, Ailing Zhang, Yuchi Wang, Junliang Guo, Xu Tan, Chang Liu, Jie Chen, Jiang Bian
We aim to edit the lip movements in talking video according to the given speech while preserving the personal identity and visual details. The task can be decomposed into two sub-problems: (1) speech-driven lip motion generation and (2) visual appearance synthesis. Current solutions handle the two sub-problems within a single generative model, resulting in a challenging trade-off between lip-sync quality and visual details preservation. Instead, we propose to disentangle the motion and appearance, and then generate them one by one with a speech-to-motion diffusion model and a motion-conditioned appearance generation model. However, there still remain challenges in each stage, such as motion-aware identity preservation in (1) and visual details preservation in (2). Therefore, to preserve personal identity, we adopt landmarks to represent the motion, and further employ a landmark-based identity loss. To capture motion-agnostic visual details, we use separate encoders to encode the lip, non-lip appearance and motion, and then integrate them with a learned fusion module. We train MyTalk on a large-scale and diverse dataset. Experiments show that our method generalizes well to the unknown, even out-of-domain person, in terms of both lip sync and visual detail preservation. We encourage the readers to watch the videos on our project page (https://Ingrid789.github.io/MyTalk/).
PDF 14 pages of main text, 23 pages in total, 9 figures
Summary
我们旨在根据给定的语音编辑说话视频中的唇部运动,同时保留个人身份和视觉细节。
Key Takeaways
- 任务分解为语音驱动的唇部运动生成和视觉外观合成两个子问题。
- 目前的解决方案在单一生成模型中处理两个子问题,导致在唇同步质量和视觉细节保留之间存在挑战性的权衡。
- 我们提议通过分离运动和外观,采用语音到运动扩散模型和运动条件的外观生成模型分别生成它们。
- 每个阶段仍然存在挑战,如在第一阶段中的运动感知身份保留和第二阶段的视觉细节保留。
- 为了保留个人身份,我们采用地标来表示运动,并进一步采用基于地标的身份损失。
- 为了捕捉与运动无关的视觉细节,我们使用单独的编码器对唇部、非唇部外观和运动进行编码,然后用学习的融合模块进行集成。
- 我们在大规模和多样化数据集上训练了MyTalk模型,实验表明我们的方法在唇同步和视觉细节保留方面对未知、甚至是超领域的人物都具有很好的泛化能力。
好的,我将会根据您给出的要求来回答。
- Title: 基于运动与外观解耦的说话人唇动生成技术
- Authors: 于润义、何天宇、张艾玲、王宇池、郭俊良、谭煦、刘畅、陈洁和边江
- Affiliation: 第一作者于润义是北京大学的。
- Keywords: 说话视频生成、唇同步、面部动画、扩散模型
- Urls: 论文链接:论文链接。Github代码链接:GitHub:暂无可用的代码链接。
- Summary:
(1) 研究背景:
随着人工智能技术的发展,生成说话视频的需求越来越高。本文旨在编辑说话视频的唇动,使其能够根据给定的语音进行同步,同时保留个人身份和视觉细节。这对于电影特效、虚拟现实和游戏等领域有广泛应用。
(2) 过去的方法及其问题:
当前的方法通常在一个生成模型中处理唇动生成和视觉外观合成两个子问题,导致唇同步质量和视觉细节保留之间的权衡困难。此外,这些方法在应对未知或域外人物时表现不佳。
(3) 研究方法:
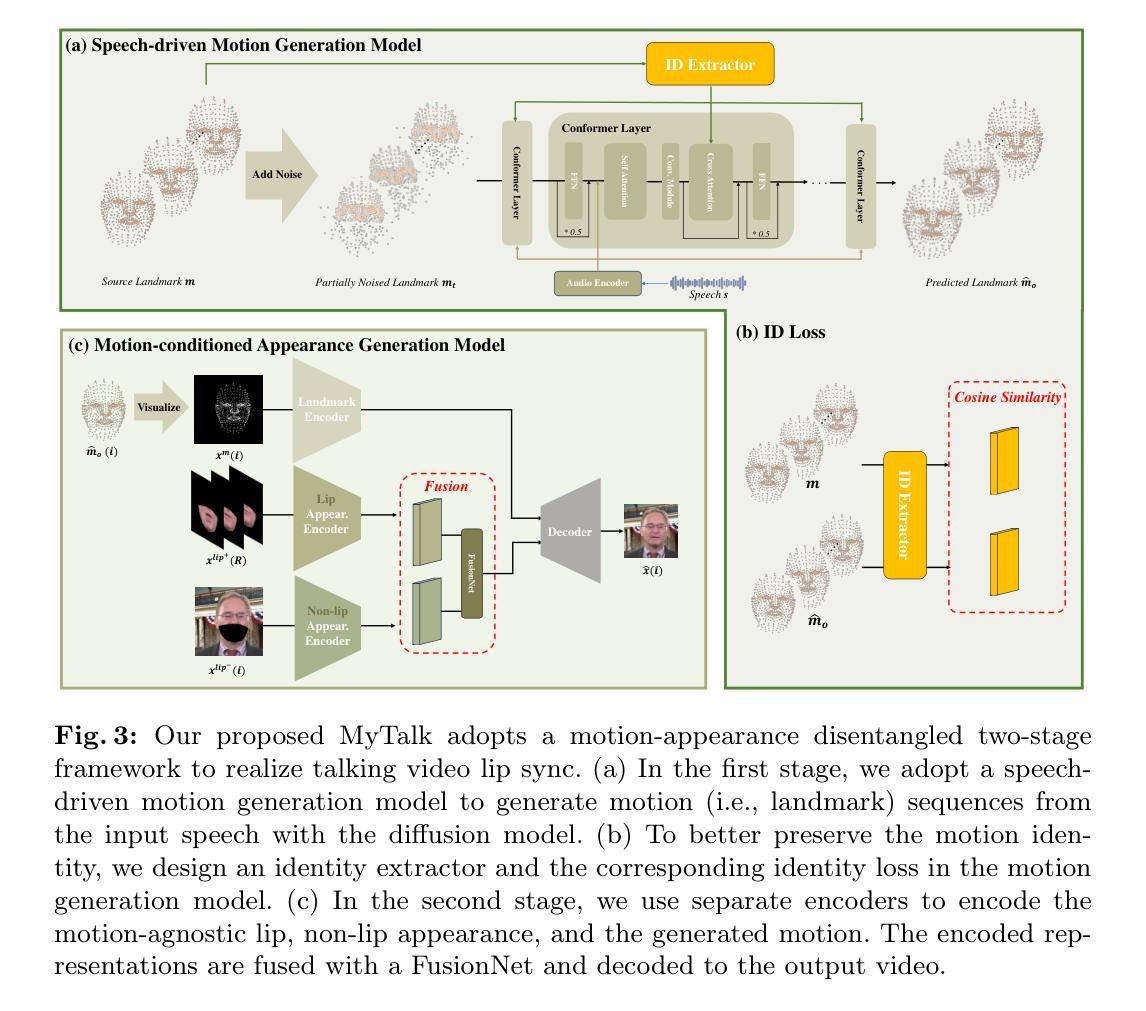
本文提出一种将运动和外观解耦的方法,通过扩散模型和基于运动的外观生成模型来分别生成运动和外观。为解决身份保留和视觉细节捕捉的问题,采用基于特征点的身份损失和融合模块来整合唇部和非唇部区域的视觉细节。
(4) 任务与性能:
本文的方法在大型和多样化的数据集上进行训练,实验表明,该方法在未知甚至域外人物上的唇同步和视觉细节保留方面都具有良好的泛化能力。性能评估支持了该方法的有效性。
请注意,由于无法直接观看视频或访问GitHub代码链接,无法进一步验证上述信息的准确性。建议您直接通过提供的链接查看论文和相关资源以获取更多详细信息。
好的,根据您的要求,我会按照给定的格式来详细阐述这篇论文的方法论。
- Methods:
(1) 研究背景和意义:随着多媒体技术的发展,生成说话视频的需求越来越高。特别是在电影特效、虚拟现实和游戏等领域,唇动编辑技术具有重要的应用价值。因此,本文旨在开发一种能够编辑说话视频的唇动,使其能够根据给定的语音进行同步,同时保留个人身份和视觉细节的技术。
(2) 对现有技术的问题进行分析:当前的方法大多在一个生成模型中同时处理唇动生成和视觉外观合成两个子问题,这导致在唇同步质量和视觉细节保留之间难以取得平衡。此外,这些方法在应对未知或域外人物时表现不佳。
(3) 方法论的主要思路:针对上述问题,本文提出了一种将运动和外观解耦的方法,通过扩散模型和基于运动的外观生成模型来分别生成运动和外观。首先,利用扩散模型学习唇部运动模式;然后,通过基于运动的外观生成模型来生成与唇部运动相匹配的外观。
(4) 具体实现步骤:
- a. 数据准备:收集并预处理大量的说话视频数据,包括面部图像和对应的语音信号。
- b. 训练和模型构建:采用扩散模型学习唇部运动模式,并构建基于运动的外观生成模型。
- c. 唇同步和视觉细节保留:通过融合模块整合唇部和非唇部区域的视觉细节,实现唇同步和视觉细节保留。
- d. 评估与测试:在大型和多样化的数据集上进行训练,并通过实验验证该方法在未知甚至域外人物上的泛化能力。
(5) 方法和效果评估:实验结果表明,本文提出的方法在唇同步和视觉细节保留方面均表现出良好的性能。通过对比实验和性能评估,验证了该方法的有效性和优越性。
以上就是这篇论文的方法论介绍。
- Conclusion:
(1)这篇工作的意义在于开发了一种能够编辑说话视频的唇动技术,使视频能够根据给定的语音进行同步,同时保留个人身份和视觉细节。这项技术在电影特效、虚拟现实和游戏等领域具有重要的应用价值。
(2)创新点:本文提出了一种基于运动与外观解耦的说话人唇动生成技术,通过扩散模型和基于运动的外观生成模型分别生成运动和外观,实现了唇同步和视觉细节保留。
性能:实验结果表明,该方法在唇同步和视觉细节保留方面均表现出良好的性能,并且在未知或域外人物上具有良好的泛化能力。
工作量:本文收集并预处理了大量的说话视频数据,构建了基于扩散模型和基于运动的外观生成模型,通过实验验证了方法的有效性。
总体来说,本文提出的说话人唇动生成技术具有创新性和实用性,为电影特效、虚拟现实和游戏等领域的唇动编辑提供了有效的解决方案。
点此查看论文截图

 wechat
wechat- alipay






