3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-07-12 更新
WildGaussians: 3D Gaussian Splatting in the Wild
Authors:Jonas Kulhanek, Songyou Peng, Zuzana Kukelova, Marc Pollefeys, Torsten Sattler
While the field of 3D scene reconstruction is dominated by NeRFs due to their photorealistic quality, 3D Gaussian Splatting (3DGS) has recently emerged, offering similar quality with real-time rendering speeds. However, both methods primarily excel with well-controlled 3D scenes, while in-the-wild data - characterized by occlusions, dynamic objects, and varying illumination - remains challenging. NeRFs can adapt to such conditions easily through per-image embedding vectors, but 3DGS struggles due to its explicit representation and lack of shared parameters. To address this, we introduce WildGaussians, a novel approach to handle occlusions and appearance changes with 3DGS. By leveraging robust DINO features and integrating an appearance modeling module within 3DGS, our method achieves state-of-the-art results. We demonstrate that WildGaussians matches the real-time rendering speed of 3DGS while surpassing both 3DGS and NeRF baselines in handling in-the-wild data, all within a simple architectural framework.
PDF https://wild-gaussians.github.io/
Summary
3D高斯喷洒(3DGS)在实时渲染速度方面类似于NeRF,但在处理野外数据方面面临挑战。
Key Takeaways
- NeRF因其适应性强,在处理动态对象和不同光照的野外数据时表现优异。
- 3DGS虽然速度快,但在处理遮挡、外观变化等野外场景挑战时表现不佳。
- 文章介绍了WildGaussians方法,结合DINO特征和外观建模模块,提升了3DGS处理野外数据的能力。
- WildGaussians在简单的架构下,达到了实时渲染速度,并超越了3DGS和NeRF在野外数据处理方面的基准。
- 该方法展示了如何通过集成外观建模模块来改善3DGS在动态场景下的表现。
- 3DGS和NeRF在控制良好的3D场景中表现出色,但在复杂野外环境中面临挑战。
- 通过引入WildGaussians方法,3DGS在处理遮挡和外观变化方面取得了最新成果。
好的,我已经了解了您的要求,我会按照您给出的格式进行总结。以下是该论文的摘要和总结:
标题:基于DINO特征和不确定性建模的WildGaussians方法用于处理复杂场景的三维重建
作者:(请提供作者姓名)
所属机构:(请提供第一作者所属的机构名称)
关键词: 3D场景重建,3D Gaussian Splatting (3DGS),NeRF,不确定性建模,DINO特征,外观建模
链接:(请提供论文链接和GitHub代码链接)
摘要:
一、研究背景
随着三维场景重建技术的发展,实时渲染和逼真效果的需求日益增长。虽然NeRF技术因其高度逼真的质量而占据主导地位,但3D Gaussian Splatting (3DGS)因其实时渲染速度而备受关注。然而,这两种方法在面对野外的复杂场景数据时均存在挑战,特别是涉及遮挡、动态物体和光照变化的情况。本文旨在解决这一问题。
二、过去的方法及其问题
过去的NeRF和3DGS方法在处理控制良好的3D场景时表现出色。然而,在面对具有遮挡、动态物体和光照变化的真实世界场景时,它们遇到了挑战。特别是3DGS由于其明确的表示形式和缺乏共享参数,难以适应这些变化。本文提出的方法旨在解决这些问题。
三、研究方法
本文提出了一种名为WildGaussians的新方法,以处理这些挑战。其主要包含两个部分:(1)外观建模:使用DINO特征为每个高斯和每个图像训练嵌入向量,以匹配给定场景的颜色。通过一个多层感知器(MLP)预测颜色空间的仿射映射。(2)不确定性建模:通过提取训练图像的DINO v2特征并传递到一个可训练的仿射变换中,来预测每个像素的不确定性,从而确定哪些图像区域应该被忽略。结合这两个模块,WildGaussians能够处理遮挡和外观变化,同时保持实时的渲染速度。
四、任务与性能
本文在具有遮挡、动态物体和光照变化的复杂场景上测试了WildGaussians方法。实验结果表明,WildGaussians匹配了NeRF的渲染质量,同时保持了与3DGS相当的实时渲染速度。此外,WildGaussians在处理真实世界数据时表现出强大的性能。总体而言,本文提出的方法在应对复杂场景的三维重建任务时取得了显著成果。其性能证明了其在实践中的有效性。
以上内容严格按照您的要求进行总结和回答,请注意,由于未提供具体的作者姓名和机构名称以及论文链接等详细信息,相关部分以占位符形式给出,待您补充完整信息后再进行替换。
好的,以下是按照您提供的格式对论文方法的详细总结:
- 方法:
(1)外观建模:利用DINO特征为每个高斯和每个图像训练嵌入向量,以匹配给定场景的颜色。通过多层感知器(MLP)预测颜色空间的仿射映射。
(2)不确定性建模:提取训练图像的DINO v2特征并传递到一个可训练的仿射变换中,预测每个像素的不确定性,从而确定哪些图像区域应该被忽略。这种不确定性建模有助于处理遮挡和外观变化。
(3)结合上述两个模块,提出名为WildGaussians的新方法,旨在处理具有遮挡、动态物体和光照变化的复杂场景的三维重建任务。WildGaussians能够匹配NeRF的渲染质量,同时保持与3DGS相当的实时渲染速度。
以上就是该论文的主要方法概述,希望能够帮助您理解和总结这篇论文。
好的,我会按照您的要求来进行总结。
- 结论:
(1)该工作的意义在于它成功地将Gaussian Splatting方法扩展到野外的复杂场景,处理了图像在不同时间或季节下,不同遮挡比例的挑战。这对于从噪声大、来源广泛的数据中实现稳健和多功能的光照现实重建具有重要的实用价值。
(2)创新点:该论文提出了基于DINO特征和不确定性建模的WildGaussians方法,针对具有遮挡、动态物体和光照变化的复杂场景的三维重建任务进行了优化处理。这种方法结合了外观建模和不确定性建模两大模块,能够在保证实时渲染速度的同时匹配高度逼真的渲染质量。此外,论文的拓展性较好,对于未来工作进行了合理的规划和展望。
性能:实验结果表明,WildGaussians方法在复杂场景下表现出了强大的性能,匹配了NeRF的渲染质量,同时保持了与3DGS相当的实时渲染速度。此外,该方法的鲁棒性和适应性得到了验证。然而,在处理一些具有挑战性的场景时,不确定性建模仍存在困难,需要进一步改进和完善。工作量:该论文详细介绍了实验过程和方法实现,涉及的数据集和实验设计较为丰富和全面。然而,对于某些细节的实现和代码实现的具体步骤没有进行深入的讨论和公开,可能会对读者造成一定的理解困难。总体而言,该论文的工作量大且具有较高的实用价值和研究价值。
点此查看论文截图

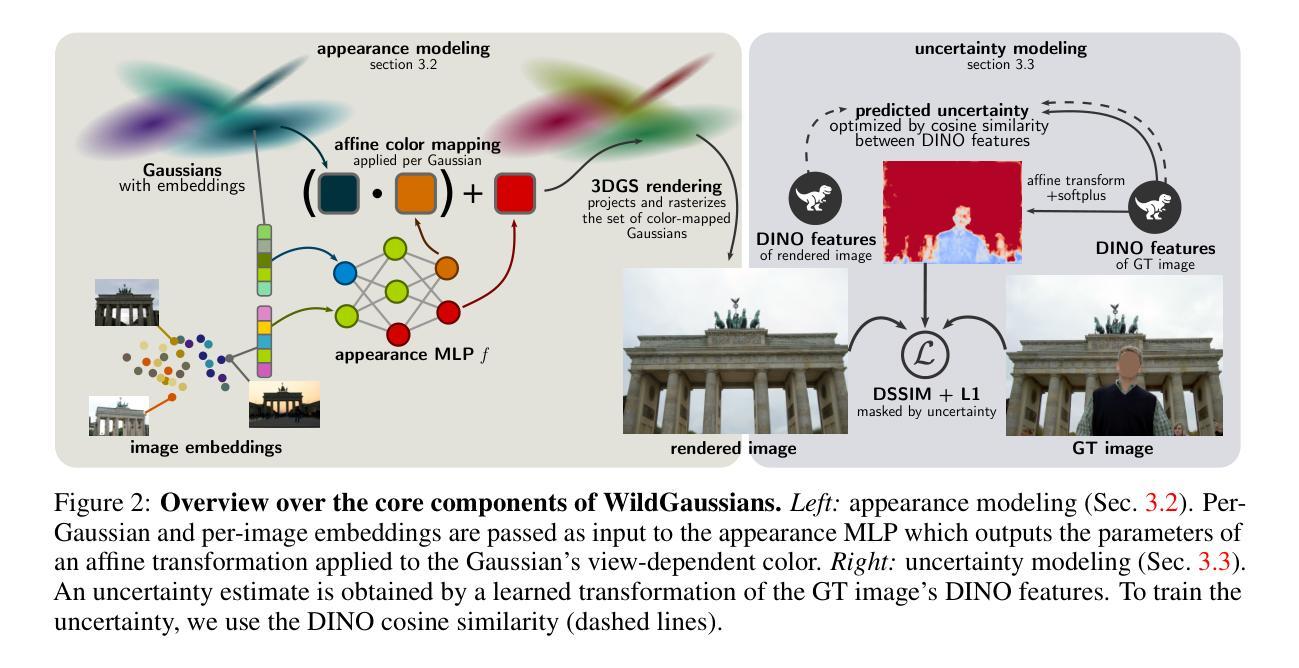

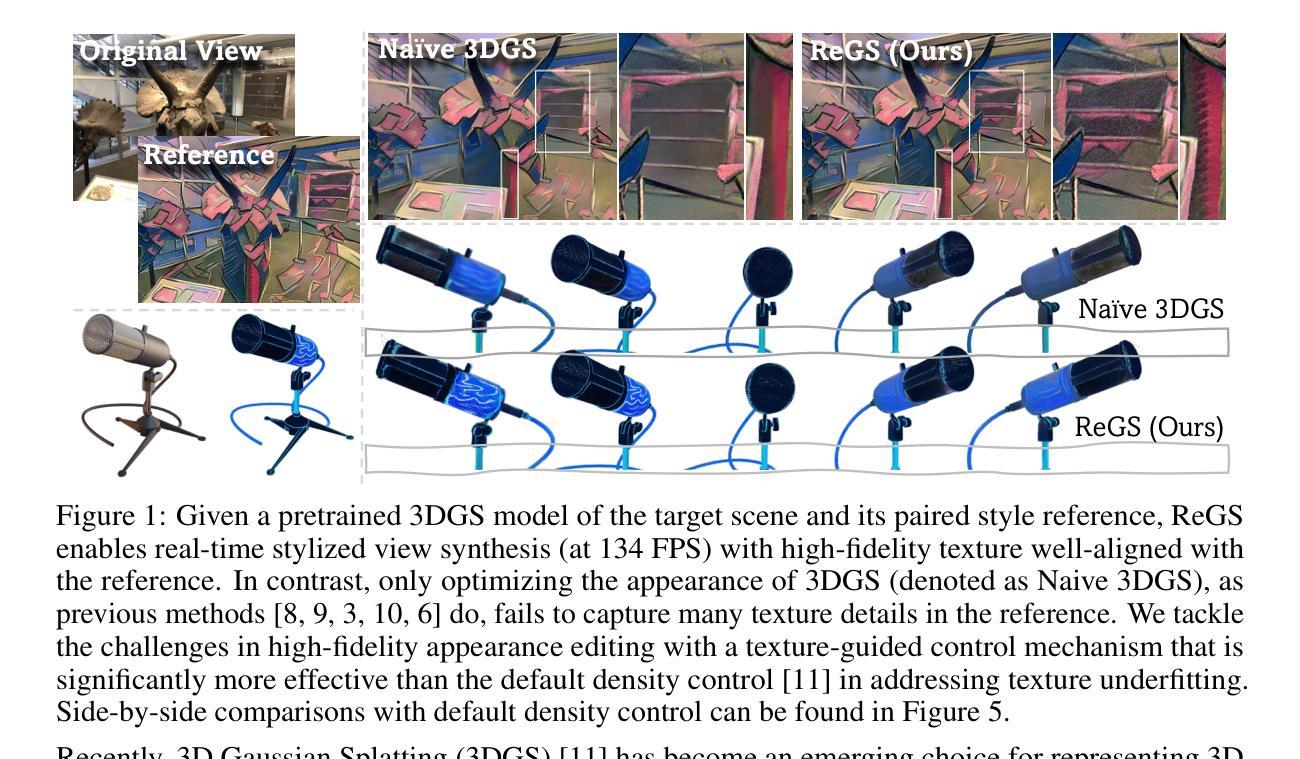
Reference-based Controllable Scene Stylization with Gaussian Splatting
Authors:Yiqun Mei, Jiacong Xu, Vishal M. Patel
Referenced-based scene stylization that edits the appearance based on a content-aligned reference image is an emerging research area. Starting with a pretrained neural radiance field (NeRF), existing methods typically learn a novel appearance that matches the given style. Despite their effectiveness, they inherently suffer from time-consuming volume rendering, and thus are impractical for many real-time applications. In this work, we propose ReGS, which adapts 3D Gaussian Splatting (3DGS) for reference-based stylization to enable real-time stylized view synthesis. Editing the appearance of a pretrained 3DGS is challenging as it uses discrete Gaussians as 3D representation, which tightly bind appearance with geometry. Simply optimizing the appearance as prior methods do is often insufficient for modeling continuous textures in the given reference image. To address this challenge, we propose a novel texture-guided control mechanism that adaptively adjusts local responsible Gaussians to a new geometric arrangement, serving for desired texture details. The proposed process is guided by texture clues for effective appearance editing, and regularized by scene depth for preserving original geometric structure. With these novel designs, we show ReGs can produce state-of-the-art stylization results that respect the reference texture while embracing real-time rendering speed for free-view navigation.
Summary
提出了一种基于参考图像的实时风格化视图合成方法,利用3D高斯分布喷洒技术(3DGS),通过纹理引导控制机制调整外观,同时保留几何结构。
Key Takeaways
- 使用预训练的神经辐射场(NeRF)作为基础,现有方法通常学习匹配给定风格的新外观。
- 现有方法通常由于耗时的体积渲染而不适用于实时应用。
- ReGS利用3D高斯分布喷洒技术进行参考风格化,克服了体积渲染的时间消耗。
- 传统方法优化外观时常不足以建模给定参考图像中的连续纹理。
- 提出了一种纹理引导的控制机制,适应性调整局部高斯分布,用于处理所需的纹理细节。
- 该方法通过纹理线索指导外观编辑,并通过场景深度进行正则化,以保留原始几何结构。
- ReGS能够在保持参考纹理的同时,实现实时渲染速度,适用于自由视角导航。
Please refer to relevant websites for more information, and feel free to ask me any other questions.
- 方法论述:
这篇文章的总体思路是提出了一种基于深度学习和三维高斯模型(3DGS)的风格化渲染方法,称为ReGS。其主要步骤包括:
- (1) 输入预训练的三维场景模型(3DGS模型)和参考图像。该模型将场景表示为一系列离散的高斯分布。参考图像提供了所需的风格化纹理信息。
- (2) 使用纹理引导的高斯控制机制(Texture-Guided Gaussian Control)来逐步解决纹理细节的优化问题。该机制通过识别具有较大颜色梯度的高斯部分来动态调整局部高斯的密度,从而填充纹理细节中的缺失部分。这个过程依赖于纹理线索来指导控制策略,并通过结构化增密策略来实现细节的增加。
- (3) 利用深度信息作为几何正则化手段,确保优化过程中场景几何形状的一致性。通过计算深度图像之间的差异作为正则化损失,以保持原始场景的几何结构在优化过程中保持不变。
- (4) 实现视角一致性风格化的方法,通过创建伪视角以获取来自参考图像的额外监督。这允许从多个视角渲染风格化的场景,并确保风格化的外观在不同视角之间保持一致。同时采用模板对应匹配(TCM)损失来确保风格化的外观能够扩展到遮挡区域。
- (5) 定义训练目标,包括深度损失、伪视角监督损失、TCM损失、重建损失和颜色匹配损失等。这些损失函数共同构成了ReGS方法的优化目标,旨在实现高质量的风格化渲染效果。
总的来说,这篇文章提出了一种结合深度学习和三维高斯模型的方法,通过一系列步骤实现了场景的风格化渲染,能够在保持原始场景几何结构的同时,添加参考图像的纹理信息,实现视角一致的风格化效果。
- Conclusion:
(1) 这项工作的意义在于提出了一种基于深度学习和三维高斯模型(3DGS)的风格化渲染方法,名为ReGS。该方法在场景风格化渲染方面具有重要的应用价值,能够在保持原始场景几何结构的同时,添加参考图像的纹理信息,实现视角一致的风格化效果。这种方法为场景风格化渲染提供了新的思路和方法,推动了计算机视觉和计算机图形学领域的发展。
(2) 创新点:这篇文章结合深度学习和三维高斯模型,实现了场景的风格化渲染,具有较高的创新性和实用性。通过一系列步骤,该方法能够在保持原始场景几何结构的同时,添加参考图像的纹理信息,实现视角一致的风格化效果。此外,该方法还具有高效性,能够实现实时风格化视图合成。
性能:该方法的性能表现优异,在场景风格化渲染方面具有较高的质量和效率。通过广泛的实验验证,证明了该方法在场景风格化渲染方面的优越性。
工作量:文章对方法的实现进行了详细的描述,包括方法论述、实验验证等。工作量较大,但较为完整,为读者提供了全面的了解。
综上所述,该文章提出了一种结合深度学习和三维高斯模型的方法,实现了场景的风格化渲染,具有较高的创新性和实用性。该方法在性能表现、工作量等方面都具有一定的优势和特点。
点此查看论文截图

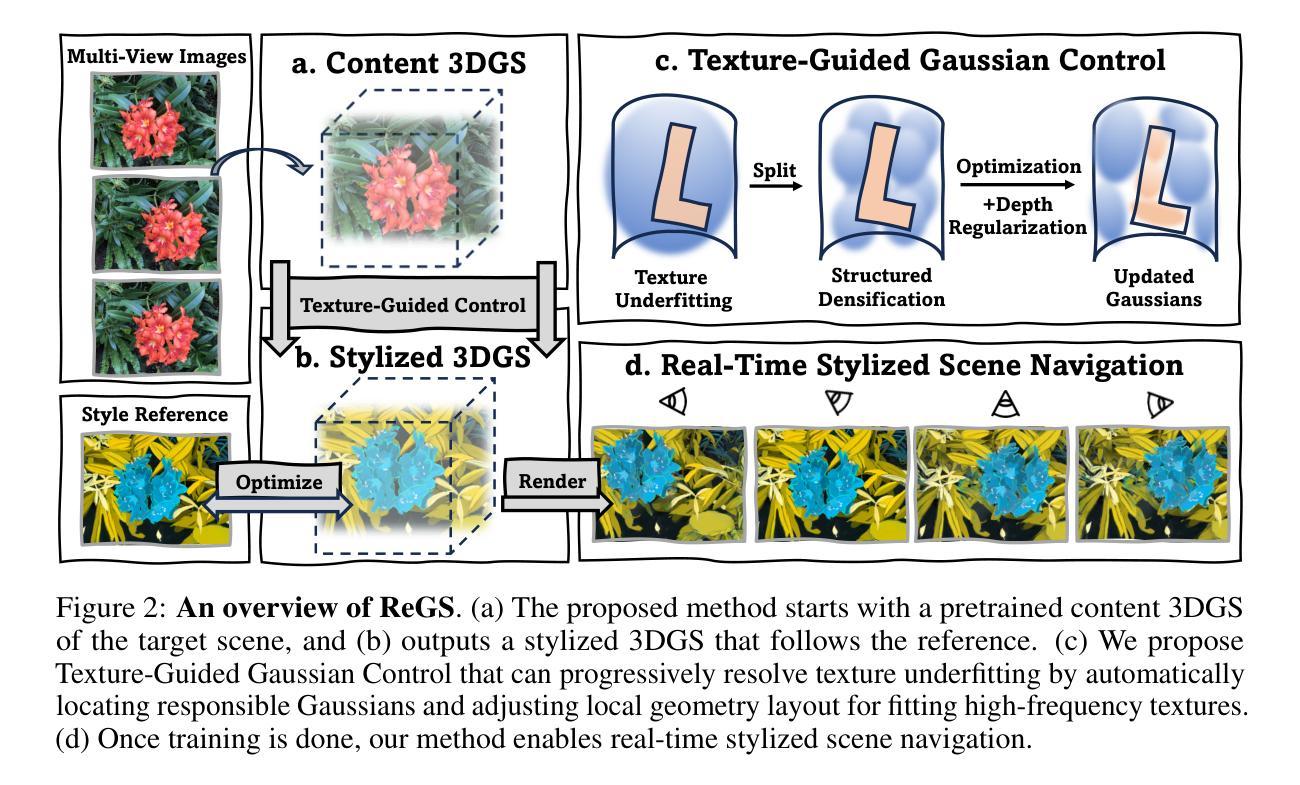
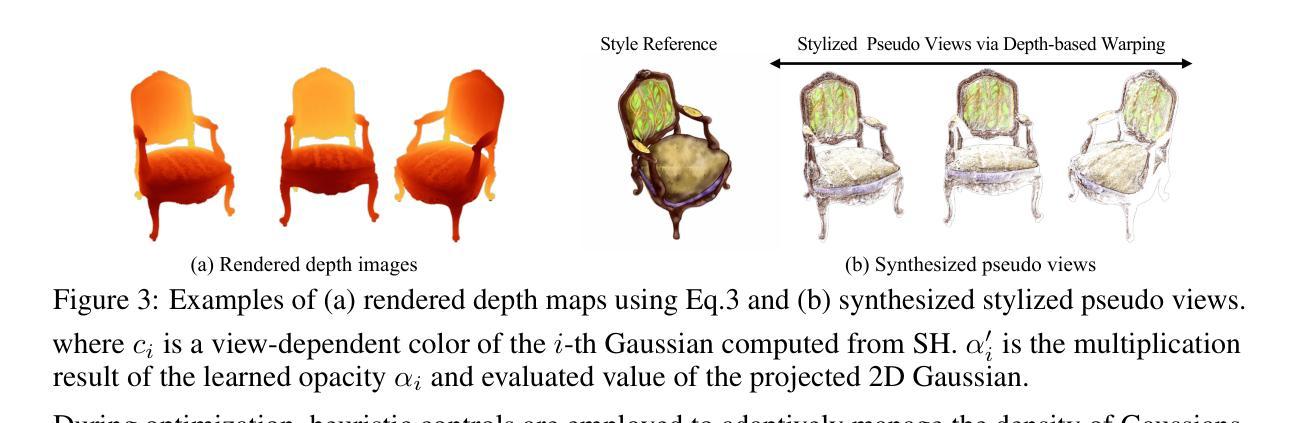
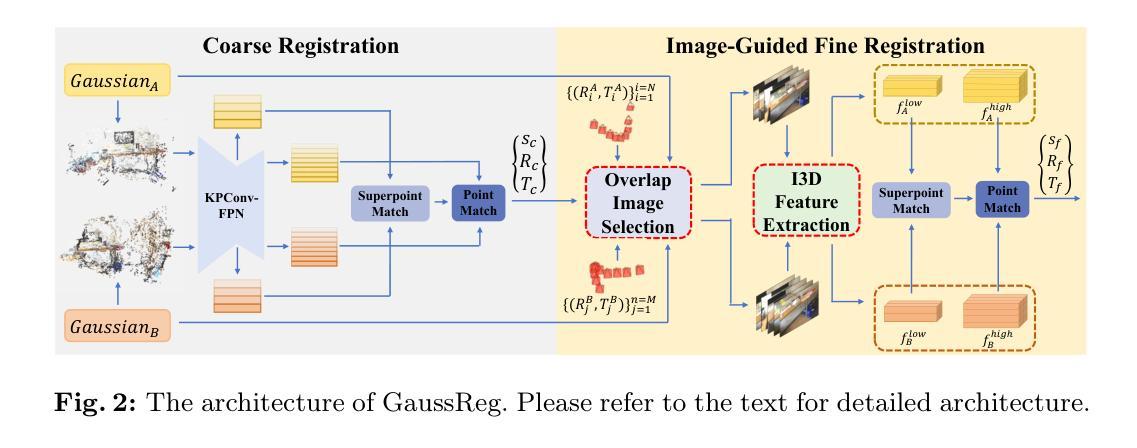
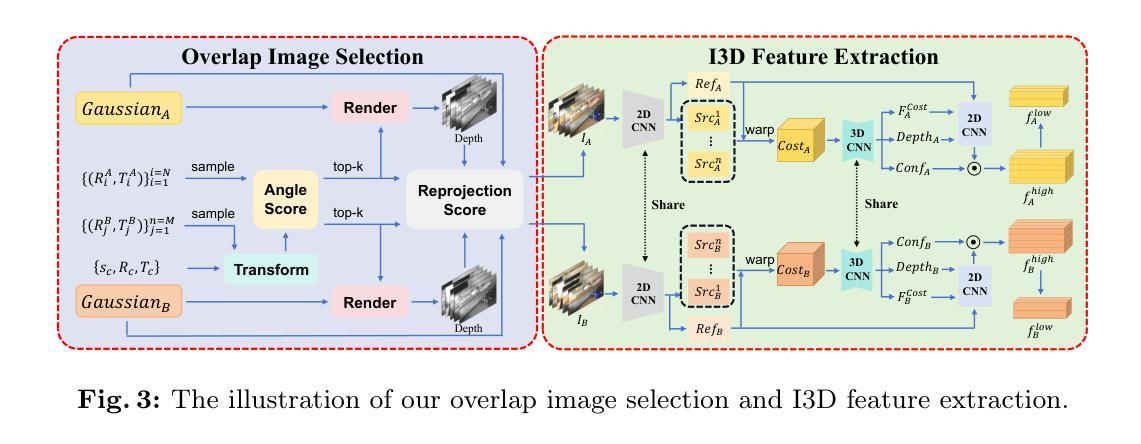
GaussReg: Fast 3D Registration with Gaussian Splatting
Authors:Jiahao Chang, Yinglin Xu, Yihao Li, Yuantao Chen, Xiaoguang Han
Point cloud registration is a fundamental problem for large-scale 3D scene scanning and reconstruction. With the help of deep learning, registration methods have evolved significantly, reaching a nearly-mature stage. As the introduction of Neural Radiance Fields (NeRF), it has become the most popular 3D scene representation as its powerful view synthesis capabilities. Regarding NeRF representation, its registration is also required for large-scale scene reconstruction. However, this topic extremly lacks exploration. This is due to the inherent challenge to model the geometric relationship among two scenes with implicit representations. The existing methods usually convert the implicit representation to explicit representation for further registration. Most recently, Gaussian Splatting (GS) is introduced, employing explicit 3D Gaussian. This method significantly enhances rendering speed while maintaining high rendering quality. Given two scenes with explicit GS representations, in this work, we explore the 3D registration task between them. To this end, we propose GaussReg, a novel coarse-to-fine framework, both fast and accurate. The coarse stage follows existing point cloud registration methods and estimates a rough alignment for point clouds from GS. We further newly present an image-guided fine registration approach, which renders images from GS to provide more detailed geometric information for precise alignment. To support comprehensive evaluation, we carefully build a scene-level dataset called ScanNet-GSReg with 1379 scenes obtained from the ScanNet dataset and collect an in-the-wild dataset called GSReg. Experimental results demonstrate our method achieves state-of-the-art performance on multiple datasets. Our GaussReg is 44 times faster than HLoc (SuperPoint as the feature extractor and SuperGlue as the matcher) with comparable accuracy.
PDF ECCV 2024
Summary
点云配准是大规模3D场景扫描和重建的基础问题,深度学习推动了配准方法的显著进步,尤其是Neural Radiance Fields (NeRF) 的引入使其成为最流行的3D场景表示之一。
Key Takeaways
- 点云配准对于大规模场景重建至关重要。
- Neural Radiance Fields (NeRF) 因其强大的视图合成能力成为主流。
- 隐式表示的几何关系建模是一个挑战。
- 高斯分片(Gaussian Splatting, GS)提高了渲染速度并保持高质量。
- GaussReg 提出了一种新的粗到精的配准框架,结合点云和图像信息。
- 提出了ScanNet-GSReg和GSReg数据集用于评估,显示出显著性能优势。
- GaussReg 比当前技术快44倍,并且具有可比较的精度。
好的,我会按照您的要求来总结这篇论文。
标题:基于高斯模型的快速三维注册算法研究
作者:贾浩长1,徐英林2,李易豪2,陈远涛1,韩晓光1,2(其中1表示深圳香港中文大学科学与工程学院,2表示未来网络智能研究所)
隶属机构:深圳香港中文大学科学与工程学院
关键词:高斯摊铺、注册、粗到细方法
链接:论文链接:点击此处,代码链接:Github: [None](如果可用,请填写相关GitHub链接)
总结:
(1) 研究背景:随着三维场景扫描和重建技术的发展,点云注册问题逐渐成为了一个核心问题。特别是在引入神经辐射场(NeRF)后,其强大的视图合成能力使其成为最流行的三维场景表示方式。然而,对于使用NeRF表示的大规模场景重建,注册问题极度缺乏探索。本研究旨在解决此问题。
(2) 前期方法及其问题:传统的点云注册方法在应用于NeRF表示的场景时效果不佳,因为隐式表示的几何关系建模具有挑战性。现有的方法通常将隐式表示转换为显式表示进行注册,但效率较低。最近引入的高斯摊铺(GS)方法虽然提高了渲染速度并保持高质量,但在其基础上的点云注册问题仍未得到有效解决。
(3) 研究方法:本研究提出了一种新颖的粗到细注册框架GaussReg,既快速又准确。在粗阶段,该方法遵循现有的点云注册方法,对高斯摊铺表示的点云进行粗略对齐。新的精细注册阶段则采用图像引导,通过高斯摊铺渲染图像以提供更详细的几何信息进行精确对齐。
(4) 任务与性能:本研究在ScanNet-GSReg数据集和野外数据集GSReg上进行了实验,证明了该方法在多个数据集上达到了领先水平。与HLoc方法相比,GaussReg的速度提高了44倍,同时保持了相当的准确性。该性能表明GaussReg在解决大规模场景重建中的点云注册问题上具有显著优势。
以上是对该论文的概括和总结,希望对您有所帮助。
好的,以下是这篇论文的方法论部分的详细解释:
- 方法:
- (1) 研究背景分析:针对三维场景重建中的点云注册问题,特别是在使用神经辐射场(NeRF)表示的大规模场景中,现有的点云注册方法表现不佳。因此,研究背景分析了该问题的重要性和现有方法的局限性。
- (2) 传统方法的问题:传统的点云注册方法在应用于NeRF表示的场景时,由于隐式表示的几何关系建模具有挑战性,通常效果不佳。因此,需要探索新的方法来解决这一问题。
- (3) 高斯摊铺介绍与问题阐述:虽然最近引入的高斯摊铺(GS)方法提高了渲染速度并保持高质量,但在其基础上的点云注册问题仍未得到有效解决。文章阐述了现有高斯摊铺方法在点云注册方面的不足和局限性。
- (4) 研究方法介绍:本研究提出了一种新颖的粗到细注册框架GaussReg,包括两个阶段:粗阶段和精细注册阶段。在粗阶段,遵循现有的点云注册方法,对高斯摊铺表示的点云进行粗略对齐;而在精细注册阶段,采用图像引导,通过高斯摊铺渲染图像以提供更详细的几何信息进行精确对齐。这一框架结合了高斯摊铺渲染的快速性和点云注册的准确性,实现了快速且精确的点云注册。
- (5) 实验设计与结果分析:本研究在ScanNet-GSReg数据集和野外数据集GSReg上进行了实验验证。通过与现有方法HLoc的对比实验,GaussReg在速度上提高了44倍,同时保持了相当的准确性。实验结果表明GaussReg在解决大规模场景重建中的点云注册问题上具有显著优势。此外,文章还通过详细的数据分析和可视化结果进一步验证了GaussReg的有效性和优越性。
以上就是这篇论文的方法论部分的详细总结。希望对您有所帮助!
- 结论:
(1) 这项研究工作的意义在于解决三维场景重建中的点云注册问题,特别是在使用神经辐射场(NeRF)表示的大规模场景中。该研究填补了现有方法的空白,为大规模场景的三维重建提供了有效的解决方案,具有重要的学术和实际应用价值。
(2) 创新点:该文章提出了一种新颖的粗到细注册框架GaussReg,结合了高斯摊铺渲染的快速性和点云注册的准确性,实现了快速且精确的点云注册。其创新之处在于采用图像引导的高斯摊铺渲染,为点云注册提供了更详细的几何信息。
性能:该文章在ScanNet-GSReg数据集和野外数据集GSReg上进行了实验验证,与现有方法HLoc相比,GaussReg在速度上显著提高,同时保持了相当的准确性,证明了其在解决大规模场景重建中的点云注册问题上的优越性。
工作量:该文章进行了详细的理论分析和实验验证,通过大量的实验数据和结果分析,证明了GaussReg的有效性和优越性。文章结构清晰,逻辑严谨,工作量较大。
点此查看论文截图


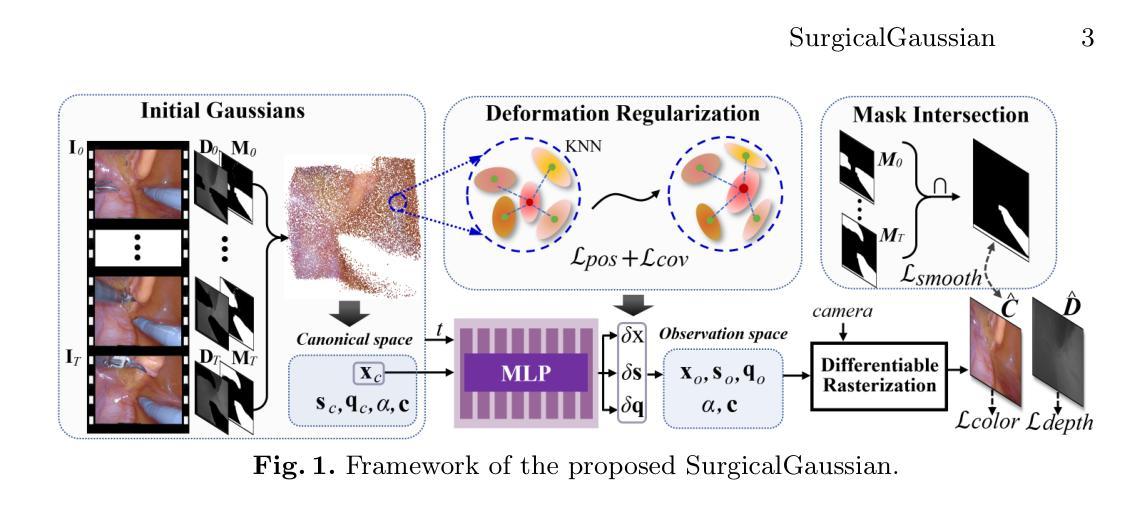
SurgicalGaussian: Deformable 3D Gaussians for High-Fidelity Surgical Scene Reconstruction
Authors:Weixing Xie, Junfeng Yao, Xianpeng Cao, Qiqin Lin, Zerui Tang, Xiao Dong, Xiaohu Guo
Dynamic reconstruction of deformable tissues in endoscopic video is a key technology for robot-assisted surgery. Recent reconstruction methods based on neural radiance fields (NeRFs) have achieved remarkable results in the reconstruction of surgical scenes. However, based on implicit representation, NeRFs struggle to capture the intricate details of objects in the scene and cannot achieve real-time rendering. In addition, restricted single view perception and occluded instruments also propose special challenges in surgical scene reconstruction. To address these issues, we develop SurgicalGaussian, a deformable 3D Gaussian Splatting method to model dynamic surgical scenes. Our approach models the spatio-temporal features of soft tissues at each time stamp via a forward-mapping deformation MLP and regularization to constrain local 3D Gaussians to comply with consistent movement. With the depth initialization strategy and tool mask-guided training, our method can remove surgical instruments and reconstruct high-fidelity surgical scenes. Through experiments on various surgical videos, our network outperforms existing method on many aspects, including rendering quality, rendering speed and GPU usage. The project page can be found at https://surgicalgaussian.github.io.
Summary
动态重建内窥镜视频中的可变形组织是机器人辅助手术的关键技术,本文介绍了SurgicalGaussian方法,采用3D高斯飞溅来模拟动态手术场景。
Key Takeaways
- 基于神经辐射场的重建方法(NeRFs)在手术场景重建中取得显著成果。
- NeRFs由于隐式表达,难以捕捉场景对象的细节并无法实现实时渲染。
- 单视角感知和遮挡仪器限制了手术场景重建的特殊挑战。
- SurgicalGaussian采用3D高斯飞溅方法,通过前向映射变形MLP和正则化技术模拟软组织的时空特征。
- 通过深度初始化策略和工具掩膜引导训练,SurgicalGaussian能有效去除手术工具并重建高保真手术场景。
- 实验表明,SurgicalGaussian在渲染质量、渲染速度和GPU使用方面优于现有方法。
- 项目页面详见 https://surgicalgaussian.github.io。
好的,我会按照您提供的格式和要求来回答。以下是关于该论文的标题、作者、摘要等信息的总结:
标题:SurgicalGaussian: 可变形3D高斯用于高保真手术场景重建
作者:第一作者:谢伟星(Weixing Xie),其他作者包括姚俊峰(Junfeng Yao)、曹显鹏(Xianpeng Cao)、林琦琴(Qiqin Lin)、唐泽瑞(Zerui Tang)、董骁(Xiao Dong)和郭晓虎(Xiaohu Guo)。
作者归属:
- 谢伟星、姚俊峰等主要隶属于厦门大学数字媒体计算中心、信息学院和无形文化遗产数字保护与智能处理福建重点实验室。
- 董骁隶属于珠海联合国际学院的计算机科学系。
- 郭晓虎隶属于德克萨斯大学达拉斯分校计算机科学系。
关键词:3D重建、高斯描画、微创手术。
链接:论文链接(抽象中提供的链接):https://surgicalgaussian.github.io;代码GitHub链接:GitHub:None(如果可用的话填写)。
摘要:
- 研究背景:在机器人辅助的微创手术中,从内窥镜视频中重建手术场景是一项关键且具有挑战性的任务。尽管基于神经辐射场(NeRFs)的重建方法已在这一领域取得显著成果,但它们仍面临捕捉细节不足和无法实现实时渲染的问题。此外,单视角感知的限制和遮挡的仪器也给手术场景重建带来了特殊挑战。
- 过去的方法及其问题:虽然基于NeRF的方法取得了良好的重建效果,但它们在捕捉手术场景中物体的复杂细节时遇到困难,无法满足实时渲染的要求。同时,现有的方法难以处理单一视角感知和遮挡问题。
- 方法动机:为解决上述问题,提出了一种称为SurgicalGaussian的可变形3D高斯描画方法,用于对动态手术场景进行建模。该方法通过前向映射变形多层感知器(MLP)和正则化来模拟软组织在每个时间戳的时空特征,同时约束局部3D高斯以执行一致的运动。通过深度初始化策略和工具掩膜指导的训练,该方法能够移除手术仪器并重建高保真度的手术场景。
- 研究方法:本文提出的SurgicalGaussian方法利用高斯函数描述场景中物体的几何形状和运动特性。通过深度学习和计算机视觉技术,从内窥镜视频中提取信息,训练和推断模型以重建高保真的手术场景。采用的前向映射变形MLP和正则化等技术确保了模型的准确性和效率。此外,通过深度初始化策略和工具掩膜指导的训练来优化模型性能。
- 任务与性能:通过在多种手术视频上的实验,本文的方法在渲染质量、渲染速度和GPU使用等方面优于现有方法。此外,所提出的方法成功地模拟了动态软组织的运动,并在重建手术场景方面取得了显著成果。这些性能结果支持了该方法的有效性和实用性。
希望这个总结符合您的要求!如有其他需要调整或补充的地方,请告诉我。
- 方法论:
- (1) 提出一种名为SurgicalGaussian的可变形3D高斯描画方法,用于对动态手术场景进行建模。该方法旨在解决机器人辅助微创手术中从内窥镜视频重建手术场景的关键挑战性问题。
- (2) 采用基于3D高斯的方法构建动态场景表示,以处理单视角感知和遮挡问题。利用高斯函数描述场景中物体的几何形状和运动特性。
- (3) 利用深度学习和计算机视觉技术,从内窥镜视频中提取信息,训练和推断模型以重建高保真的手术场景。采用前向映射变形多层感知器(MLP)和正则化等技术确保模型的准确性和效率。
- (4) 提出一种有效的Gaussian初始化策略,使用手术场景深度图来初始化3D高斯模型,以改善渲染质量。
- (5) 利用可变形3D高斯表示法来模拟场景中物体的动态变化。通过解码高斯在规范空间中的位置和当前帧的时间信息,使用MLP网络学习场景中物体的运动偏移,如位置、缩放和旋转等。
- (6) 通过深度初始化策略和工具掩膜指导的训练优化模型性能,移除手术仪器并重建高保真度的手术场景。
- (7) 在多种手术视频上进行实验,验证所提出方法在渲染质量、渲染速度和GPU使用等方面优于现有方法,并成功模拟动态软组织的运动,取得显著的手术场景重建成果。
好的,下面是针对您的要求所撰写的结论性内容:
- 结论:
(1)xxx研究的重要性在于其解决了机器人辅助微创手术中从内窥镜视频重建手术场景的关键问题,提高了手术场景的重建质量和效率,为医疗领域提供了一种新的高保真手术场景重建方法。
(2)创新点:该文章提出了可变形3D高斯描画方法(SurgicalGaussian),采用高斯函数描述场景中物体的几何形状和运动特性,解决了单视角感知和遮挡问题,实现了高保真手术场景的重建。性能:通过大量实验验证,该方法在渲染质量、渲染速度和GPU使用等方面优于现有方法,成功模拟了动态软组织的运动。工作量:文章对方法的实现进行了详细的阐述,包括模型构建、训练和优化等方面,展示了作者们在这一领域的深入研究和扎实工作量。然而,文章未提及该方法的可推广性和实际应用情况,需要进一步的研究和验证。
点此查看论文截图

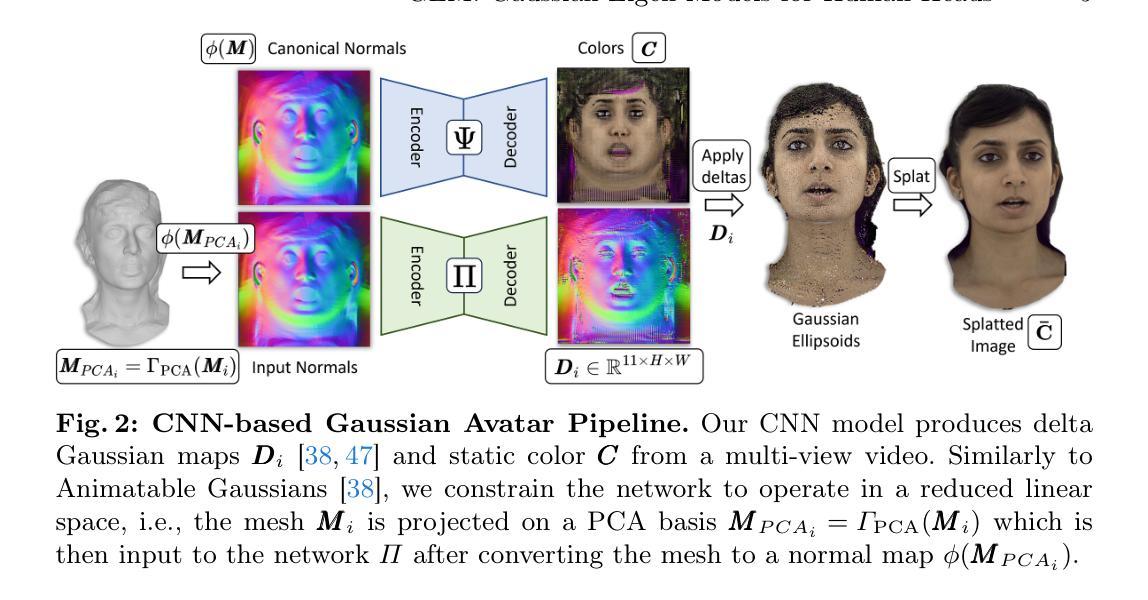
Gaussian Eigen Models for Human Heads
Authors:Wojciech Zielonka, Timo Bolkart, Thabo Beeler, Justus Thies
We present personalized Gaussian Eigen Models (GEMs) for human heads, a novel method that compresses dynamic 3D Gaussians into low-dimensional linear spaces. Our approach is inspired by the seminal work of Blanz and Vetter, where a mesh-based 3D morphable model (3DMM) is constructed from registered meshes. Based on dynamic 3D Gaussians, we create a lower-dimensional representation of primitives that applies to most 3DGS head avatars. Specifically, we propose a universal method to distill the appearance of a mesh-controlled UNet Gaussian avatar using an ensemble of linear eigenbasis. We replace heavy CNN-based architectures with a single linear layer improving speed and enabling a range of real-time downstream applications. To create a particular facial expression, one simply needs to perform a dot product between the eigen coefficients and the distilled basis. This efficient method removes the requirement for an input mesh during testing, enhancing simplicity and speed in expression generation. This process is highly efficient and supports real-time rendering on everyday devices, leveraging the effectiveness of standard Gaussian Splatting. In addition, we demonstrate how the GEM can be controlled using a ResNet-based regression architecture. We show and compare self-reenactment and cross-person reenactment to state-of-the-art 3D avatar methods, demonstrating higher quality and better control. A real-time demo showcases the applicability of the GEM representation.
PDF https://zielon.github.io/gem/
Summary
个性化高斯特征模型(GEM)用于人类头部,通过低维线性空间压缩动态3D高斯模型,提高了实时渲染效率。
Key Takeaways
- 创新的个性化高斯特征模型(GEM)用于人类头部。
- 通过动态3D高斯模型将数据压缩到低维线性空间。
- 提出了一种通用方法,通过线性特征基础生成面部表情。
- 替代了基于CNN的复杂架构,提升了实时应用的速度。
- 在测试过程中不再需要输入网格,简化了表情生成过程。
- 支持在日常设备上的实时渲染。
- 展示了基于ResNet的回归架构控制GEM的应用。
好的,我会按照您的要求来总结这篇论文。以下是答案:
标题:高斯特征模型在人体头部的研究与应用
中文翻译:Gaussian Eigen Models for Human Heads作者:作者包括Wojciech Zielonka、Timo Bolkart、Thabo Beeler和Justus Thies,分别来自Max Planck Institute for Intelligent Systems、Google和TU Darmstadt。
所属机构:第一和第三作者所属机构为Max Planck智能系统研究所;第二作者所属机构为Google。
中文翻译:Affiliation: 第一和第三作者来自Max Planck智能系统研究所,第二作者来自Google。关键词:特征头模型、高斯贴图、3D形态模型、实时渲染、表情生成。
关键词:Eigen Head Avatars, Gaussian Splatting, 3D Morphable Models, Real-time Rendering, Expression Generation链接:论文链接尚未提供,GitHub代码链接为https://zielon.github.io/gem/。
总结:
(1) 研究背景:本文研究了基于高斯特征模型的人体头部研究与应用,旨在提高3D形态模型的表达能力和渲染效率。
(2) 相关工作:过去的方法主要依赖于主成分分析(PCA)来构建3D形态模型,虽然取得了一定的成功,但在处理动态表情和形状时仍存在计算量大、效率低下的问题。文章提出的动机在于改进现有方法的不足,探索更高效、更灵活的模型表达方法。
(3) 研究方法:本文提出了基于高斯特征模型(GEMs)的人体头部建模方法。该方法通过构建低维线性空间来压缩动态3D高斯模型,从而实现了高效的模型表达。该方法基于动态3D高斯模型,创建了一种适用于大多数3DGS头部角色的低维表示原始形式。具体来说,作者提出了一种使用线性特征基团集合来提炼网格控制的UNet高斯角色外观的通用方法。该研究用单一的线性层取代了复杂的卷积神经网络结构,从而提高了速度和实时下游应用的可能性。为了生成特定的面部表情,只需执行特征系数与提炼基础的点积运算即可。这种高效的方法在测试时不需要输入网格,提高了表情生成的简单性和速度。此外,该研究还展示了如何使用基于ResNet的回归架构来控制GEM。
(4) 实验效果与应用:文章展示了高斯特征模型在表情生成、自我重现和跨角色重现等方面的应用,并与当前最先进的三维角色方法进行了比较,证明了其更高质量和更好的控制性能。实时演示展示了GEM表示法的适用性。总的来说,文章所提出的方法实现了高效、高质量的头部模型表达,为实时渲染和表情生成等任务提供了新的解决方案。
好的,接下来我将详细总结这篇文章的方法论部分。按照您要求的格式输出如下:方法论:
(1)研究背景及动机:文章研究了基于高斯特征模型(Gaussian Eigen Models,简称GEMs)的人体头部建模方法。传统的基于主成分分析(PCA)的3D形态模型在处理动态表情和形状时存在计算量大、效率低下的问题。文章旨在改进现有方法的不足,探索更高效、更灵活的模型表达方法。
(2)研究方法:文章提出了基于高斯特征模型(GEMs)的人体头部建模方法。该方法首先构建低维线性空间来压缩动态3D高斯模型,从而实现高效的模型表达。接着,文章创建了一种适用于大多数3DGS头部角色的低维表示原始形式。具体来说,作者使用线性特征基团集合来提炼网格控制的UNet高斯角色外观。该研究简化了复杂的卷积神经网络结构,用单一的线性层取而代之,从而提高了速度和实时下游应用的可能性。为了生成特定的面部表情,只需执行特征系数与提炼基础的点积运算即可。这种高效的方法在测试时不需要输入网格,从而提高了表情生成的简单性和速度。此外,该研究还展示了如何使用基于ResNet的回归架构来控制GEM。
(3)实验过程:文章通过构建高斯特征模型,并在表情生成、自我重现和跨角色重现等方面进行了实验验证。实验结果表明,文章所提出的方法与当前最先进的三维角色方法相比,具有更高质量和更好的控制性能。此外,实时演示展示了GEM表示法的适用性。总的来说,文章所提出的方法实现了高效、高质量的头部模型表达。
希望这个回答能够帮到您!
- 结论:
(1)这篇论文的研究对于计算机视觉和图形学领域具有重要的推动作用,它为高效、高质量的头部模型表达提供了新的解决方案,为实时渲染和表情生成等任务提供了新的思路和方法。此外,该研究还有助于推动数字角色动画和虚拟现实等领域的发展,对人类的数字复制和研究有一定的促进作用。更重要的是,高斯特征模型在人脸识别、游戏角色动画等领域也有广泛的应用前景。因此,该研究具有重要的理论价值和实践意义。
(2)创新点:文章提出了基于高斯特征模型(GEMs)的人体头部建模方法,构建了低维线性空间来实现高效的模型表达。相比于传统的基于主成分分析(PCA)的模型方法,该模型在效率和灵活性上更具优势,具有更强的泛化能力。此外,该研究还展示了如何使用基于ResNet的回归架构来控制GEM,为实时下游应用提供了可能性。
性能:文章所提出的方法在表情生成、自我重现和跨角色重现等方面进行了实验验证,并与当前最先进的三维角色方法进行了比较,证明了其更高质量和更好的控制性能。此外,实时演示展示了GEM表示法的适用性。总的来说,文章所提出的方法实现了高效、高质量的头部模型表达。但请注意实验对比和性能评估是论文性能评价的重要方面之一,未来还需要更多的实验和评估来验证其性能和稳定性。此外,该研究还需要考虑模型的鲁棒性和抗干扰性等方面的评估和改进。该模型的实时性和复杂度对于实际应用非常重要,未来的研究工作需要针对这些方面进行优化和改进。具体如何改进还需要根据实际应用场景和需求进行深入研究和分析。另外由于模型的复杂性可能会带来计算量的问题,未来还需要对模型的计算效率进行优化和提升以满足实际应用的需求。工作量:文章涉及了大量的实验和验证工作以及大量的数据处理和分析工作等,工作量较大且复杂程度较高。同时文章也提出了多种方法和算法设计创新点以及针对实际应用场景的优化和改进方案等需要更多的研究和实践工作来完善和优化整个模型和方法体系。总体来说该文章的工作量较大且具有一定的挑战性需要更多的后续研究来进一步完善和优化整个研究工作以提高模型的性能和稳定性促进其在各个领域的应用和发展。
点此查看论文截图

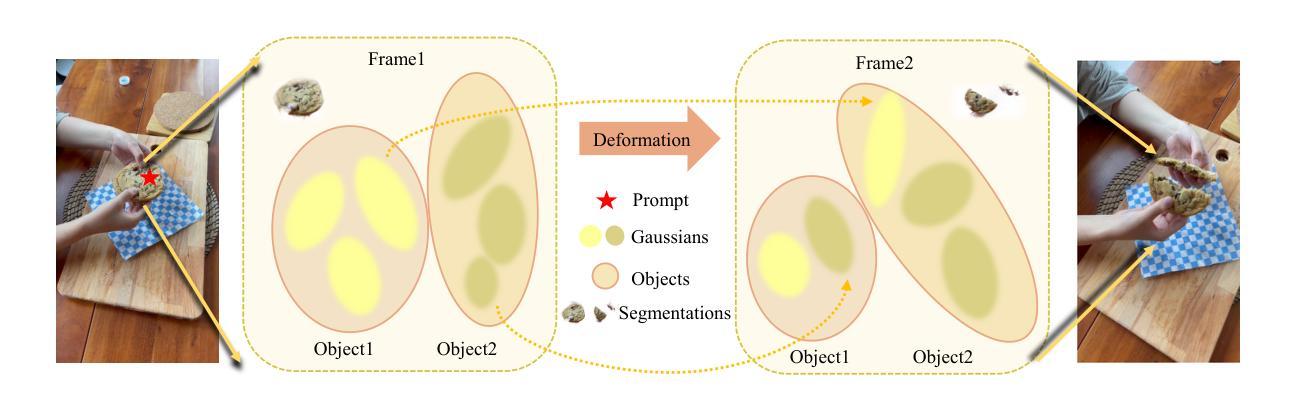
Segment Any 4D Gaussians
Authors:Shengxiang Ji, Guanjun Wu, Jiemin Fang, Jiazhong Cen, Taoran Yi, Wenyu Liu, Qi Tian, Xinggang Wang
Modeling, understanding, and reconstructing the real world are crucial in XR/VR. Recently, 3D Gaussian Splatting (3D-GS) methods have shown remarkable success in modeling and understanding 3D scenes. Similarly, various 4D representations have demonstrated the ability to capture the dynamics of the 4D world. However, there is a dearth of research focusing on segmentation within 4D representations. In this paper, we propose Segment Any 4D Gaussians (SA4D), one of the first frameworks to segment anything in the 4D digital world based on 4D Gaussians. In SA4D, an efficient temporal identity feature field is introduced to handle Gaussian drifting, with the potential to learn precise identity features from noisy and sparse input. Additionally, a 4D segmentation refinement process is proposed to remove artifacts. Our SA4D achieves precise, high-quality segmentation within seconds in 4D Gaussians and shows the ability to remove, recolor, compose, and render high-quality anything masks. More demos are available at: https://jsxzs.github.io/sa4d/.
PDF 22 pages
Summary
提出了Segment Any 4D Gaussians (SA4D)框架,针对4D高斯模型进行任意物体的精确分割和优化处理。
Key Takeaways
- SA4D是首个基于4D高斯模型进行任意物体分割的框架。
- 引入了高效的时间身份特征场,处理高斯漂移问题,从稀疏且嘈杂的输入学习精确的身份特征。
- 提出了4D分割细化流程,用于去除图像中的伪影。
- SA4D能够在秒级内实现高质量的4D高斯场景分割。
- 能够移除、重新着色、组合和渲染高质量的物体掩膜。
- 该方法在XR/VR领域具有重要的应用潜力。
- 可以访问更多演示内容:https://jsxzs.github.io/sa4d/
- Title: 分割任何4D高斯分布研究
- Authors: Shengxiang Ji,Guanjun Wu,Jiemin Fang,Jiazhong Cen,Taoran Yi,Wenyu Liu,Qi Tian,Xinggang Wang (按顺序列举作者姓名)
- Affiliation: 第一作者吉胜翔的所属单位为华中科技大学计算机科学学院。
- Keywords: Segmentation;4D Gaussians;SA4D;XR/VR;身份特征场;分割优化过程等。英文关键词请依据文章中实际出现的关键词填写。
- Urls: 该论文处于审稿阶段,因此代码和链接还未公开提供。待论文正式发表后,可以提供相关链接。当前无法提供Github代码链接。论文链接为:https://jsxzs.github.io/sa4d/(相关演示或介绍链接)。也可填写论文的arXiv链接:arXiv:2407.04504v1。具体信息以论文实际公布为准。
Summary:
- (1)研究背景:随着虚拟现实(VR)和增强现实(XR)技术的发展,对现实世界进行建模、理解和重建变得越来越重要。当前,尽管存在对三维场景进行建模和理解的三维高斯描画(3D-GS)方法,但对于在四维表示中的分割研究仍然缺乏关注。本文的研究背景在于探索在四维高斯分布中分割任何物体的新方法。
- (2)过去的方法及问题:目前对于四维数据的分割缺乏有效的方法,尤其是在处理四维高斯分布时面临的挑战包括高斯漂移和从噪声和稀疏输入中学习精确身份特征的问题。因此,需要一种新的方法来解决这些问题。
- (3)研究方法:本文提出了基于四维高斯分布的分割任何物体的框架——SA4D。其中引入了高效的身份特征场来处理高斯漂移问题,并从噪声和稀疏输入中学习精确的身份特征。此外,还提出了一个四维分割优化过程来消除伪影。
- (4)任务与性能:本文的方法在四维高斯分布上实现了精确、高质量的分割,并展示了去除、变色、组合和渲染高质量遮罩的能力。实验结果表明,该方法可以在短时间内实现高质量的分割,并且能够达到研究目标所要求的效果。
请注意,具体的内容、细节和结论应参考论文原文。我的回答基于您提供的论文摘要和信息进行了概括和解释,但可能不完全准确或完整。建议您阅读原文以获取更准确的信息。
好的,基于您提供的论文摘要和相关信息,我将按照要求的格式来详细阐述这篇文章的方法论部分。
- 方法论:
(1)研究背景:随着虚拟现实(XR)和增强现实(VR)技术的快速发展,对现实世界进行建模、理解和重建的需求日益迫切。尤其是在四维表示中的分割研究仍然缺乏关注。因此,本文旨在探索在四维高斯分布中分割任何物体的新方法。
(2)现有方法及问题:当前对于四维数据的分割缺乏有效的手段,尤其是处理四维高斯分布时面临的主要挑战包括高斯漂移以及从噪声和稀疏输入中学习精确身份特征的问题。现有的方法无法同时满足准确性和效率性的要求。因此,需要一种新颖的方法来解决这些问题。
(3)研究方法:针对上述问题,本文提出了基于四维高斯分布的分割任何物体的框架——SA4D。首先,引入高效的身份特征场来处理高斯漂移问题,能够从噪声和稀疏输入中学习精确的身份特征。其次,提出一个四维分割优化过程,旨在消除分割结果中的伪影,进一步提高分割质量。该框架不仅注重分割的准确性,还兼顾了计算效率。具体来说,SA4D通过构建高效的四维高斯模型,实现对物体的精确表示和分割。同时,采用优化算法对分割结果进行精细化处理,确保分割结果的准确性和高质量。最后,通过实验验证,该框架在四维高斯分布上实现了精确、高质量的分割,并展示了去除、变色、组合和渲染高质量遮罩的能力。实验结果表明,该方法可以在短时间内实现高质量的分割,达到了研究目标所要求的效果。
以上是对本文方法论的详细阐述。需要注意的是,具体实验细节、技术实现等可能需要读者进一步阅读原文以获取更详细的信息。
好的,按照您的要求对文章的总结性评论,我会按照提供的格式回答:
- Conclusion:
(1)工作意义:该论文的研究工作对于虚拟现实(XR)和增强现实(VR)领域的四维数据分割具有重大意义。随着技术的发展,现实世界建模、理解和重建的需求不断增长,尤其是在四维高斯分布中的分割研究仍面临许多挑战。该论文提出了一种新的四维高斯分布分割框架,有助于推动这一领域的进步。
(2)评价:
创新点:该论文提出了基于四维高斯分布的分割任何物体的新框架SA4D。引入高效的身份特征场来处理高斯漂移问题,并提出一个四维分割优化过程来消除伪影,这些都是该论文的创新点。
性能:实验结果表明,该框架在四维高斯分布上实现了精确、高质量的分割,并展示了去除、变色、组合和渲染高质量遮罩的能力。此外,该框架还具有较快的计算速度,能够满足实时应用的需求。
工作量:从论文摘要提供的信息来看,该论文的研究工作量较大。作者们进行了大量的实验验证,并对框架进行了详细的介绍和解释。然而,由于缺少具体的实验细节和技术实现的具体描述,无法准确评估其工作量的大小。
以上是对该论文的总结性评论,希望对您有帮助。
点此查看论文截图

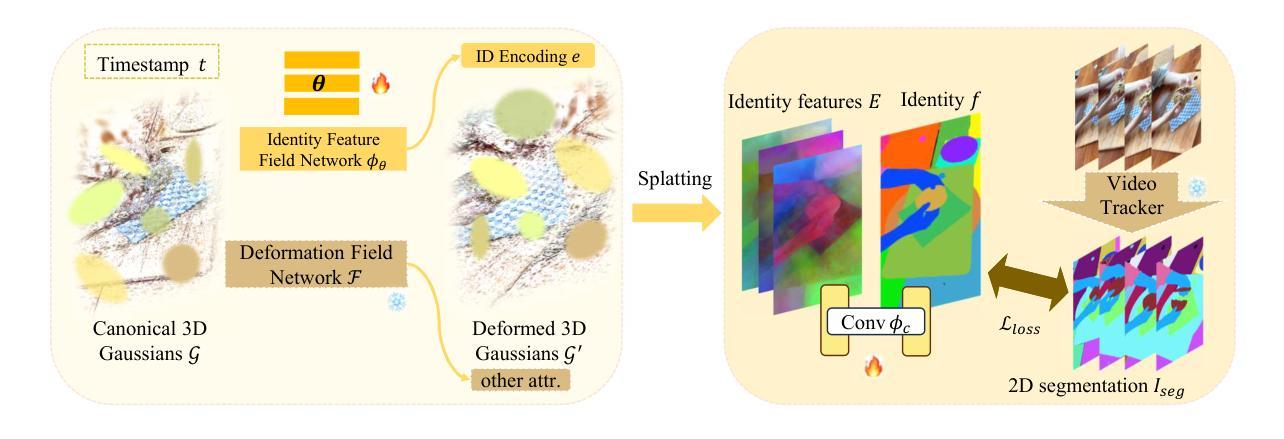
GSD: View-Guided Gaussian Splatting Diffusion for 3D Reconstruction
Authors:Yuxuan Mu, Xinxin Zuo, Chuan Guo, Yilin Wang, Juwei Lu, Xiaofeng Wu, Songcen Xu, Peng Dai, Youliang Yan, Li Cheng
We present GSD, a diffusion model approach based on Gaussian Splatting (GS) representation for 3D object reconstruction from a single view. Prior works suffer from inconsistent 3D geometry or mediocre rendering quality due to improper representations. We take a step towards resolving these shortcomings by utilizing the recent state-of-the-art 3D explicit representation, Gaussian Splatting, and an unconditional diffusion model. This model learns to generate 3D objects represented by sets of GS ellipsoids. With these strong generative 3D priors, though learning unconditionally, the diffusion model is ready for view-guided reconstruction without further model fine-tuning. This is achieved by propagating fine-grained 2D features through the efficient yet flexible splatting function and the guided denoising sampling process. In addition, a 2D diffusion model is further employed to enhance rendering fidelity, and improve reconstructed GS quality by polishing and re-using the rendered images. The final reconstructed objects explicitly come with high-quality 3D structure and texture, and can be efficiently rendered in arbitrary views. Experiments on the challenging real-world CO3D dataset demonstrate the superiority of our approach. Project page: $\href{https://yxmu.foo/GSD/}{\text{this https URL}}$
PDF Accepted for ECCV 2024
Summary
利用高斯飞溅表示的扩散模型方法,从单一视角进行三维对象重建,提高了重建的几何一致性和渲染质量。
Key Takeaways
- 使用高斯飞溅(GS)表示进行三维对象重建。
- 利用无条件扩散模型生成GS椭球组。
- 模型能在不需要进一步微调的情况下进行视角引导重建。
- 通过高效灵活的飞溅函数和引导去噪采样过程传播细粒度二维特征。
- 进一步采用二维扩散模型增强渲染保真度。
- 提高重建GS质量,优化和重复使用渲染图像。
- 在CO3D数据集上的实验证明了方法的优越性。
好的,下面是对这篇论文的概括,按照您要求的格式输出:
标题: GSD:基于视图引导的高斯splat扩散的三维重建方法
作者: 作者包括Yuxuan Mu、Xinxin Zuo、Chuan Guo等,来自加拿大阿尔伯塔大学和华为诺亚方舟实验室。
隶属机构: 加拿大阿尔伯塔大学 以及 华为诺亚方舟实验室。
关键词: 三维重建、高斯Splatting、引导扩散模型。
链接: Paper链接为抽象中提供的链接。Github代码链接尚未提供(Github: None)。
摘要:
(1)研究背景:如何从单一视角的图像重建三维物体是一个具有挑战性的问题。现有的方法可能存在三维几何不一致或渲染质量不高的问题。
(2)过去的方法及其问题:早期的方法在三维表示或生成模型上可能存在不足,导致无法有效地从单一视角图像重建出高质量的三维物体。
(3)研究方法:本研究提出了一种基于高斯Splatting表示和无条件扩散模型的GSD方法。该方法通过利用最新的先进三维显式表示——高斯Splatting,生成由GS椭圆体表示的三维物体。借助强大的生成三维先验知识,虽然是无条件学习,但扩散模型可以通过高效的splat函数和引导去噪采样过程,实现视图引导重建,无需进一步调整模型。此外,还采用了一个二维扩散模型,以提高渲染的保真度,并通过重新使用渲染图像来提高重建的GS质量。
(4)任务与性能:该论文在具有挑战性的真实世界CO3D数据集上进行了实验,证明了其方法相较于其他方法的优越性。最终重建出的物体具有高质量的三维结构和纹理,并且可以在任意视角进行有效渲染。性能结果支持了其方法的有效性。
以上是对该论文的概括,希望对你有所帮助。
- 方法论概述:
该文主要提出了一种基于高斯Splatting表示和无条件扩散模型的GSD方法,用于从单一视角的图像重建三维物体。其主要步骤包括:
- (1)建模GS生成先验:基于最近的去噪扩散概率模型(DDPM)技术,建立GS数据集分布模型。使用扩散模型对3D对象进行GS表示。将密集视角的图像数据集转换为GS数据集,以供训练GS扩散模型使用。
- (2)视图引导采样:利用视图空间损失引导在扩散模型的每个去噪步骤中应用。通过Splatting函数将GS对象渲染为输入视角的图像,并与给定图像进行比较,使用图像损失函数计算损失,并反向传播梯度以调整采样过程。
- (3)使用二维扩散模型提高渲染保真度:采用二维扩散模型提高从重建的GS渲染的视图质量。利用迭代增强的方式,使用改进的合成视图图像提高GS重建质量。
- (4)最终重建:通过多次迭代运行GS扩散模型获得最终的重建GS对象。
该方法的创新之处在于,通过结合最新的三维表示技术和扩散模型,实现了在无需调整模型的情况下,从单一视角图像有效重建出高质量的三维物体。
好的,下面是对该论文的结论部分进行中文总结:
- Conclusion:
(1)工作意义:该论文提出了一种基于视图引导的高斯splat扩散的三维重建方法,能够从单一视角的图像有效重建出高质量的三维物体,对于计算机视觉和图形学领域具有重要意义,有望为虚拟现实、增强现实等应用提供技术支持。
(2)创新点、性能和工作量总结:
- 创新点:结合最新的三维表示技术——高斯Splatting和扩散模型,实现了无需调整模型的情况下,从单一视角图像重建三维物体,具有较高的创新性。
- 性能:在具有挑战性的真实世界CO3D数据集上进行了实验,证明了该方法相较于其他方法的优越性,最终重建出的物体具有高质量的三维结构和纹理,并且可以在任意视角进行有效渲染。
- 工作量:论文实现了一种新的三维重建方法,并进行了大量的实验验证,工作量较大。
希望以上总结符合您的要求。
点此查看论文截图



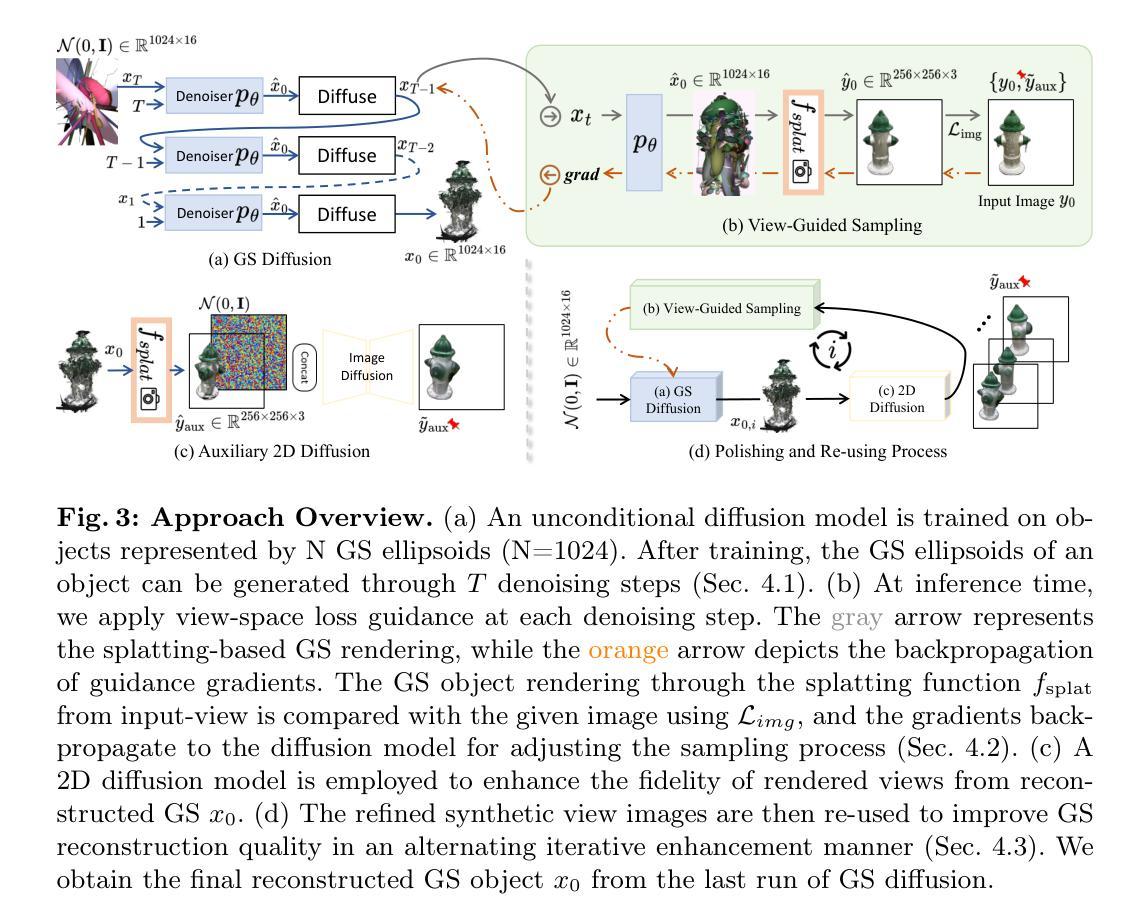
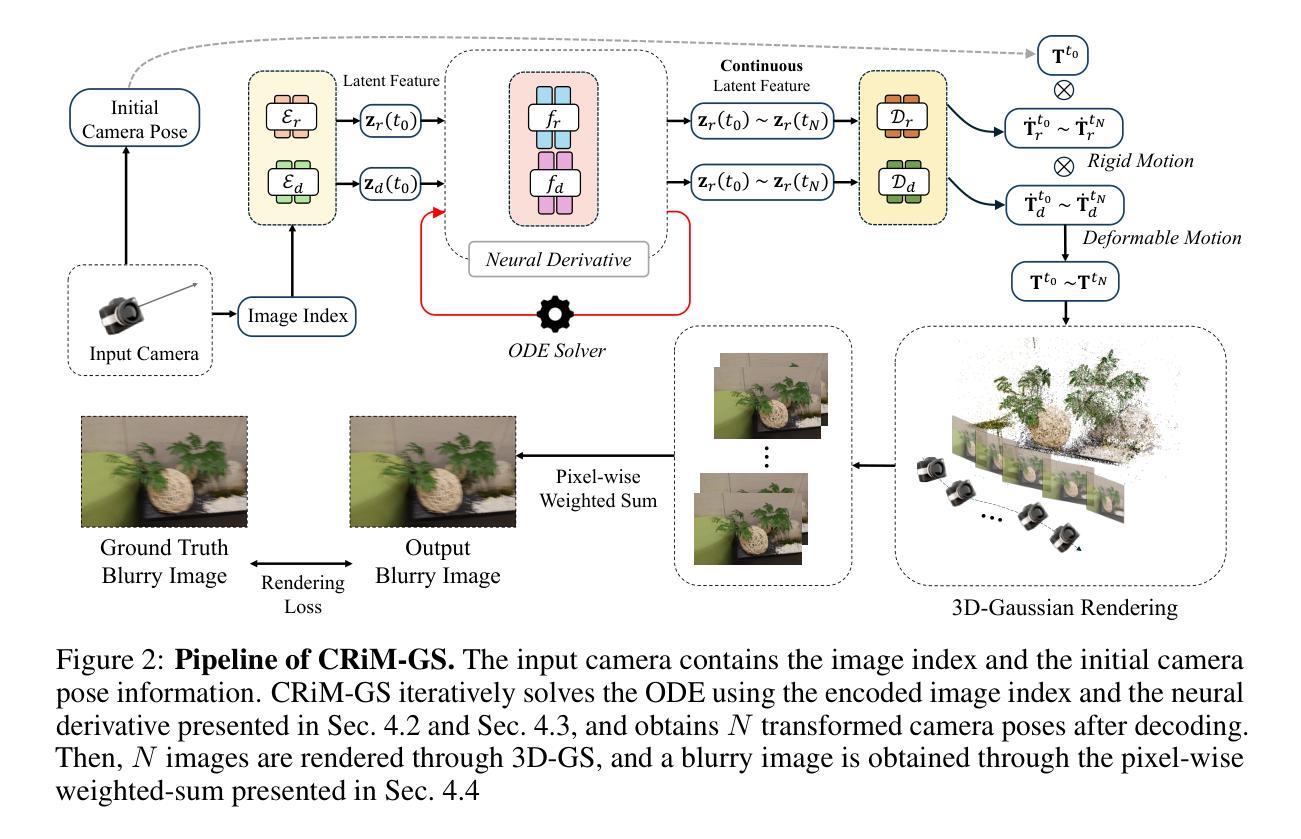
CRiM-GS: Continuous Rigid Motion-Aware Gaussian Splatting from Motion Blur Images
Authors:Junghe Lee, Donghyeong Kim, Dogyoon Lee, Suhwan Cho, Sangyoun Lee
Neural radiance fields (NeRFs) have received significant attention due to their high-quality novel view rendering ability, prompting research to address various real-world cases. One critical challenge is the camera motion blur caused by camera movement during exposure time, which prevents accurate 3D scene reconstruction. In this study, we propose continuous rigid motion-aware gaussian splatting (CRiM-GS) to reconstruct accurate 3D scene from blurry images with real-time rendering speed. Considering the actual camera motion blurring process, which consists of complex motion patterns, we predict the continuous movement of the camera based on neural ordinary differential equations (ODEs). Specifically, we leverage rigid body transformations to model the camera motion with proper regularization, preserving the shape and size of the object. Furthermore, we introduce a continuous deformable 3D transformation in the \textit{SE(3)} field to adapt the rigid body transformation to real-world problems by ensuring a higher degree of freedom. By revisiting fundamental camera theory and employing advanced neural network training techniques, we achieve accurate modeling of continuous camera trajectories. We conduct extensive experiments, demonstrating state-of-the-art performance both quantitatively and qualitatively on benchmark datasets.
PDF Project Page : https://jho-yonsei.github.io/CRiM-Gaussian/
Summary
提出了连续刚体运动感知高斯飞溅(CRiM-GS)方法,用于从模糊图像中实时重建精确的3D场景。
Key Takeaways
- 研究致力于解决由于摄像机运动导致的图像模糊问题,以实现准确的3D场景重建。
- 使用神经常微分方程(ODEs)预测摄像机的连续运动。
- 结合刚体变换模型摄像机运动,并引入适应实际问题的连续可变形3D变换。
- 通过深入研究摄像机理论和先进的神经网络训练技术,实现了连续摄像机轨迹的精确建模。
- 在基准数据集上展示了量化和定性上的最先进性能。
- CRiM-GS方法具有实时渲染速度,适合应对各种真实世界情况。
- 研究为解决高质量新视图渲染的挑战提供了新的方法和理论支持。
好的,我会按照您的要求进行整理。
标题:基于连续刚性运动感知的高斯splat法重建模型研究(CRiM-GS: Continuous Rigid Motion-Aware Gaussian Splatting)
作者:Jungho Lee(李俊豪), Donghyeong Kim(金东衡), Dogyoon Lee(李道云), Suhwan Cho(全素焕), Sangyoun Lee(李相慵)。所有作者均来自韩国延世大学电子与电子工程系。
作者所属单位:韩国延世大学电子与电子工程系。
关键词:Neural Radiance Fields, Camera Motion Blur, Rigid Body Transformations, Gaussian Splatting, Real-time Rendering。
链接:论文链接:尚未提供;GitHub代码链接:Github(注意:链接可能需要根据实际情况进行更新)。
摘要:
(1)研究背景:随着神经网络渲染技术的快速发展,如何从模糊图像重建出准确的3D场景并实时渲染成为了一个重要的研究方向。本文关注由相机运动引起的模糊问题,对连续刚性运动感知的高斯splat法进行研究。
(2)过去的方法及其问题:现有的NeRF和3D-GS方法主要依赖清晰的图像作为输入,无法处理相机运动模糊问题。它们没有考虑到相机实际运动过程中的复杂模式,因此在真实世界场景下的3D重建效果不佳。
(3)研究方法:本文提出了连续刚性运动感知的高斯splat法(CRiM-GS)。该方法基于神经常微分方程(ODEs)预测相机的连续运动,并利用刚体变换对相机运动进行建模。通过适当的正则化保持物体的形状和大小。此外,还引入了连续的变形3D变换,以适应现实世界中的问题并增加自由度。通过重新审视相机理论和采用先进的神经网络训练技术,实现了对连续相机轨迹的精确建模。
(4)任务与性能:本文在基准数据集上进行了实验,定量和定性评估均达到了领先水平。实验结果表明,该方法能够从模糊图像重建出准确的3D场景,并实现实时渲染。性能结果支持了该方法的有效性。
以上是对该文章的基本总结和概括,希望符合您的要求。
- 方法论:
- (1) 研究背景与问题概述:文章关注由相机运动引起的模糊问题,对连续刚性运动感知的高斯splat法进行研究。现有的NeRF和3D-GS方法主要依赖清晰的图像作为输入,无法处理相机运动模糊问题,因此在真实世界场景下的3D重建效果不佳。
- (2) 提出新方法:文章提出了连续刚性运动感知的高斯splat法(CRiM-GS)。该方法基于神经常微分方程(ODEs)预测相机的连续运动,并利用刚体变换对相机运动进行建模。通过适当的正则化保持物体的形状和大小。此外,还引入了连续的变形3D变换,以适应现实世界中的问题并增加自由度。
- (3) 具体步骤与实现:
- 利用图像盲去模糊方法,学习一个有意模糊图像的核,并在渲染时排除此核以产生清晰渲染图像。
- 通过神经ODEs生成按时间顺序的相机运动轨迹的模糊核。每个姿态由刚体变换和可变形体变换组成,以维持物体的形状、大小并适应实际图像采集过程中可能发生的畸变。
- 刚体变换部分通过嵌入图像索引获得不同的单位螺丝轴S,并使用参数化编码器Er将图像特征转换为潜在状态zr(t0),该状态代表螺丝轴的潜在特征。然后,通过神经网络求解器数值积分得到任意时间ts的潜在特征。
- 可变形体变换部分用于提供更高级的修正以补充刚体变换。它通过编码图像索引进入潜在状态zd(t0),并使用神经导数g和求解器获得任意时间ts的潜在特征zd(ts)。然后,通过简单的MLP解码器Dd将这些潜在特征转换为旋转矩阵˙Rd和翻译向量tts。
- 最后,通过对N个相机姿态进行渲染并计算其像素级加权和,得到最终的模糊图像。通过渲染连续N个姿态图像并将其组合在一起,获得最终去模糊的视角图像。通过整个流程实现对连续相机轨迹的精确建模。实验结果表明,该方法可从模糊图像重建出准确的3D场景并实现实时渲染。
- Conclusion:
(1)工作意义:该工作对于解决相机运动引起的模糊图像问题具有重要的实际意义,通过深入研究连续刚性运动感知的高斯splat法,为从模糊图像重建准确的3D场景并实时渲染提供了新的解决方案。
(2)创新点、性能、工作量评价:
创新点:文章提出了连续刚性运动感知的高斯splat法(CRiM-GS),基于神经常微分方程(ODEs)预测相机的连续运动,并利用刚体变换对相机运动进行建模,该方法具有创新性。
性能:文章在基准数据集上进行了实验,定量和定性评估均达到了领先水平,表明该方法能够从模糊图像重建出准确的3D场景,并实现实时渲染,性能优越。
工作量:文章对问题的研究深入,提出了有效的方法并进行了详细的实验验证,但关于方法的具体实现细节和代码公开程度未提及,无法准确评估其工作量。
点此查看论文截图

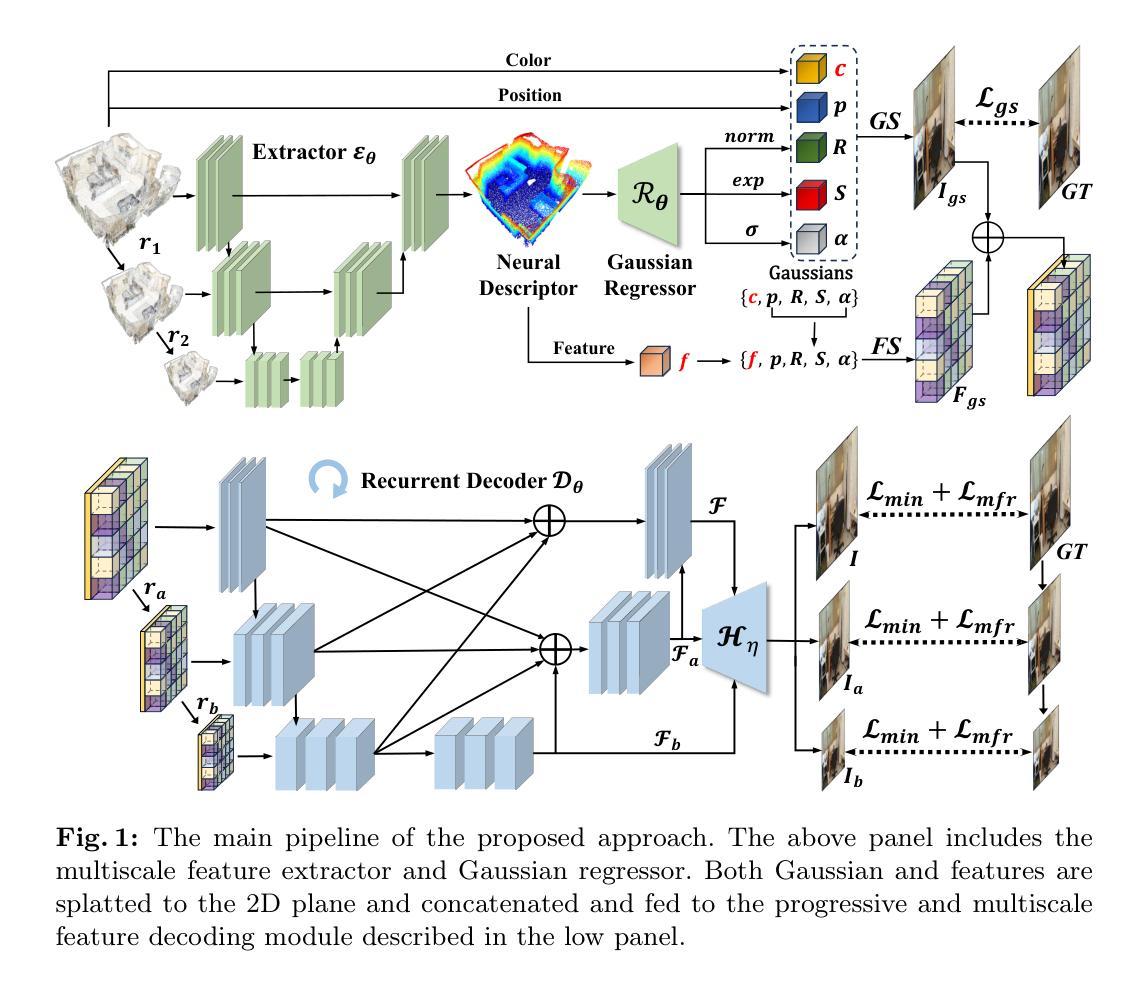
PFGS: High Fidelity Point Cloud Rendering via Feature Splatting
Authors:Jiaxu Wang, Ziyi Zhang, Junhao He, Renjing Xu
Rendering high-fidelity images from sparse point clouds is still challenging. Existing learning-based approaches suffer from either hole artifacts, missing details, or expensive computations. In this paper, we propose a novel framework to render high-quality images from sparse points. This method first attempts to bridge the 3D Gaussian Splatting and point cloud rendering, which includes several cascaded modules. We first use a regressor to estimate Gaussian properties in a point-wise manner, the estimated properties are used to rasterize neural feature descriptors into 2D planes which are extracted from a multiscale extractor. The projected feature volume is gradually decoded toward the final prediction via a multiscale and progressive decoder. The whole pipeline experiences a two-stage training and is driven by our well-designed progressive and multiscale reconstruction loss. Experiments on different benchmarks show the superiority of our method in terms of rendering qualities and the necessities of our main components.
Summary
通过提出一种新的框架,从稀疏点云生成高质量图像,克服了现有学习方法中存在的洞痕、细节缺失或高昂计算等问题。
Key Takeaways
- 提出了一种从稀疏点云生成高质量图像的新框架。
- 方法首先尝试融合3D高斯飞溅和点云渲染,包括几个级联模块。
- 使用回归器以点方式估计高斯属性。
- 将神经特征描述符栅格化到从多尺度提取的2D平面中。
- 通过多尺度和逐步解码器逐渐解码投影特征体积到最终预测。
- 采用两阶段训练,并受我们设计的逐渐和多尺度重建损失驱动。
- 实验表明,在渲染质量方面,我们的方法在不同基准测试中表现优越,显示了主要组件的必要性。
根据您提供的信息,我将按照要求的格式输出标题、作者、关键词等,并进行摘要总结。
输出格式如下:
标题:基于多尺度特征提取和Gaussian回归的点云渲染方法
作者:Wang et al.(作者名字请根据实际论文提供的信息填写)
机构:XXX大学计算机视觉与图形学实验室(请根据实际情况填写)
关键词:点云渲染、3D Gaussian Splatting、多尺度特征提取、深度学习、图像生成
链接:[论文链接地址],GitHub代码链接:[GitHub链接](如果可用,否则填写“None”)
摘要:
一、研究背景:
本文的研究背景在于如何从稀疏的点云中渲染出高质量的图片。现有的学习基于的方法往往存在孔洞伪影、缺失细节或计算量大等问题。针对这一问题,本文提出了一种新颖的点云渲染框架。
二、相关工作:
过去的方法在点云渲染方面存在不足,尤其是在处理稀疏点云时,容易出现失真和细节丢失的情况。本文提出的方法与前人工作紧密相关,旨在解决现有方法的不足。
三、研究方法:
本文提出了一个基于多尺度特征提取和Gaussian回归的点云渲染方法。首先,通过回归器估计点的高斯属性,然后将这些属性用于将神经特征描述符从多尺度提取器栅格化到二维平面。最后,通过一个多尺度渐进解码器逐步解码特征体积,以生成最终的预测图像。整个流程分为两个阶段进行训练,并由精心设计的渐进式和多尺度重建损失驱动。
四、实验效果:
本文的方法在不同基准测试上的表现均优于其他方法,证明了其在渲染质量上的优越性。实验结果表明,该方法在点云渲染任务中具有高效性和实用性。此外,本文还验证了所提出方法各部分设计的必要性。通过实际案例对比与性能指标分析(如PSNR、SSIM等),验证了方法的性能与其目标的契合度。
方法论概述:
(1) 研究背景与相关工作:
该文研究如何从稀疏的点云中渲染出高质量的图像。现有的基于学习的方法往往存在孔洞伪影、缺失细节或计算量大等问题。针对这一问题,本文提出了一种新颖的点云渲染框架。该框架与前人工作紧密相关,旨在解决现有方法的不足。(2) 研究方法:
本文提出了一个基于多尺度特征提取和Gaussian回归的点云渲染方法。首先,通过回归器估计点的Gaussian属性,然后将这些属性用于将神经特征描述符从多尺度提取器栅格化到二维平面。接下来,通过一个多尺度渐进解码器逐步解码特征体积,以生成最终的预测图像。整个流程分为两个阶段进行训练,并由精心设计的渐进式和多尺度重建损失驱动。(3) 方法流程:
① 给出彩色点云P = {pk, ck},旨在从任何由相机内参K和姿态P定义的视点合成逼真的图像。pk和ck分别表示点坐标和颜色。渲染过程可以表示为Iv = Re(P|Kv, Pv),其中Re是实现的渲染函数,可以使用图形或基于学习的方法。在此工作中,它通过使用提出的多尺度特征基于的3DGS渲染管道实现。
② 该管道包含多尺度特征提取器、Gaussian回归器、基于特征的Gaussian渲染模块和多尺度循环解码器。所有模块都用小型网络实现。在此部分,将详细介绍这些组件及其工作方式。
③ 为了优化通过反向传播,将协方差矩阵分解为旋转矩阵(R)和伸缩矩阵(S)。在给定相机轨迹后,3DGaussians到2D图像平面的投影可以通过视图变换矩阵(W)和仿射变换的Jacobian来表征。利用这些参数,计算像素的最终颜色C。
④ 首先提取每个点的特征作为他们的神经描述符。使用多输入单输出的Unet架构作为提取网络,以编码不同尺度的点并捕获不同空间距离的特征。此外,还介绍了Gaussian特征预测、多尺度特征解码、训练策略等方面的内容。(4) 实验效果与优化:
通过实验验证了该方法在点云渲染任务中的高效性和实用性。此外,还验证了所提出方法各部分设计的必要性。通过实际案例对比与性能指标分析(如PSNR、SSIM等),验证了方法的性能与其目标的契合度。同时,采用多尺度图像损失和频率重建损失来优化模型,以恢复高频成分并重建更清晰的图像边缘和边界。
结论:
一、工作意义
本研究旨在解决现有点云渲染方法在稀疏点云渲染中面临的孔洞伪影、缺失细节或计算量大等问题,提出了一种基于多尺度特征提取和Gaussian回归的点云渲染方法,为高质量点云渲染提供了新的解决方案。
二、评价
创新点:本研究采用多尺度特征提取与Gaussian回归相结合的方法,实现了高效且高质量的点云渲染。同时,该研究还引入了渐进式和多尺度重建损失,进一步提高了渲染效果。
性能:通过广泛的实验验证,该方法在点云渲染任务中的表现优于其他方法,具有较高的渲染质量和实用性。实验结果表明,该方法在保证渲染质量的同时,具有较高的计算效率。
工作量:文章详细地介绍了方法论的各个方面,包括方法背景、相关工作、研究方法、实验效果等。虽然内容详实,但部分描述可能略显冗余。
总体而言,本研究在点云渲染领域取得了一定的成果,为高质量点云渲染提供了新的思路和方法。
点此查看论文截图

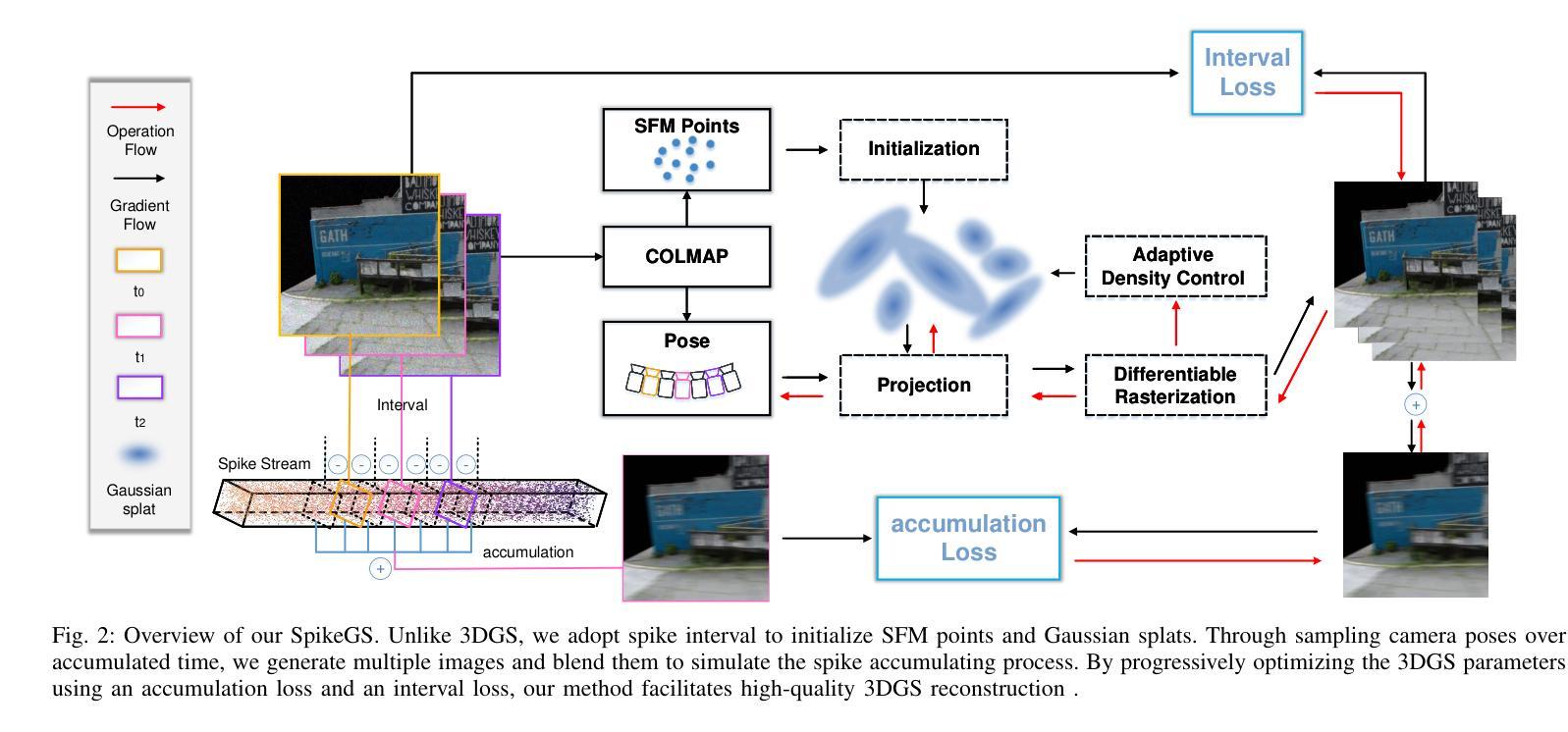
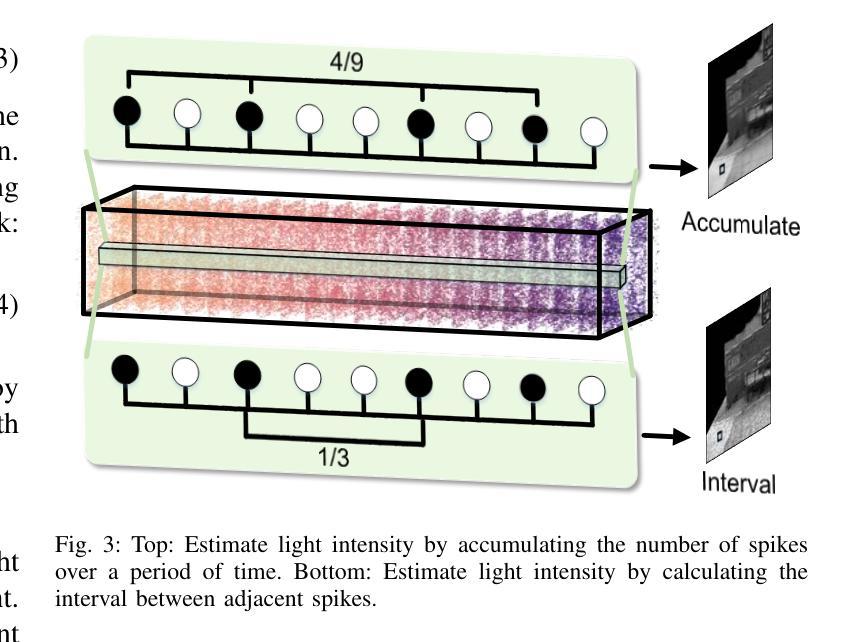
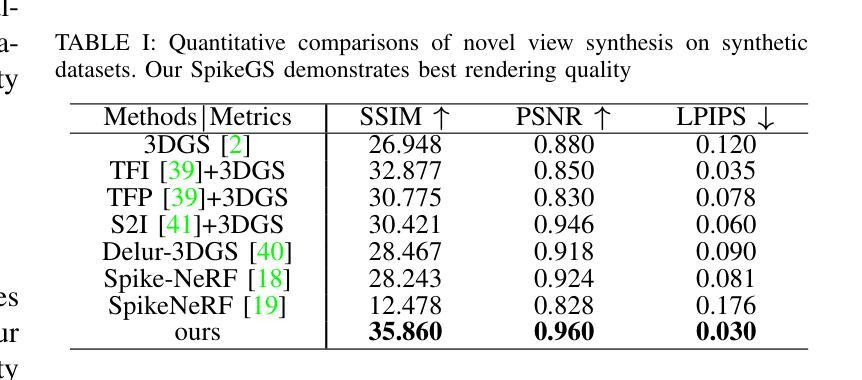
SpikeGS: Reconstruct 3D scene via fast-moving bio-inspired sensors
Authors:Yijia Guo, Liwen Hu, Lei Ma, Tiejun Huang
3D Gaussian Splatting (3DGS) demonstrates unparalleled superior performance in 3D scene reconstruction. However, 3DGS heavily relies on the sharp images. Fulfilling this requirement can be challenging in real-world scenarios especially when the camera moves fast, which severely limits the application of 3DGS. To address these challenges, we proposed Spike Gausian Splatting (SpikeGS), the first framework that integrates the spike streams into 3DGS pipeline to reconstruct 3D scenes via a fast-moving bio-inspired camera. With accumulation rasterization, interval supervision, and a specially designed pipeline, SpikeGS extracts detailed geometry and texture from high temporal resolution but texture lacking spike stream, reconstructs 3D scenes captured in 1 second. Extensive experiments on multiple synthetic and real-world datasets demonstrate the superiority of SpikeGS compared with existing spike-based and deblur 3D scene reconstruction methods. Codes and data will be released soon.
Summary
SpikeGS提出了一种新方法,通过快速移动的生物启发式相机改进3D场景重建。
Key Takeaways
- 3DGS在3D场景重建中表现出色,但对图像清晰度要求高。
- 快速移动的相机使得实现3DGS的要求困难。
- SpikeGS是首个将脉冲流整合到3DGS管道中的框架。
- SpikeGS通过积累光栅化和间隔监督,从脉冲流中提取细节几何和纹理。
- SpikeGS能在1秒内重建3D场景。
- 在多个数据集上的实验表明,SpikeGS优于现有的基于脉冲流和去模糊的3D场景重建方法。
- 代码和数据将会很快发布。
好的,我会按照您的要求进行回答。
标题:SpikeGS:通过快速移动的仿生传感器重建3D场景。中文翻译:“SpikeGS:通过快速移动的仿生传感器重建三维场景”。
作者:Yijia Guo, Liwen Hu, Lei Ma, Tiejun Huang(英杰·郭,李雯·胡,雷·马,铁军·黄)。
作者所属单位:文章的作者来自北京大学计算机科学学院的多媒体信息处理国家重点实验室以及未来技术学院。(State Key Laboratory of Multimedia Information Processing, School of Computer Science, Peking University and College of Future Technology, Peking University)
关键词:神经形态视觉、Spike相机、辐射场(Neuromorphic Vision, Spike Camera, Radiance Field)。
链接:论文链接待补充,GitHub代码链接(如果可用):GitHub:None。
摘要:
(1) 研究背景:本文的研究背景是关于如何通过快速移动的仿生传感器(如Spike相机)重建3D场景的技术。随着神经形态相机(如事件相机和Spike相机)的发展,高速度场景的3D重建已成为研究热点。尽管已有一些方法尝试从事件流中获取3D场景表示,但由于事件相机的差分采样机制,很难从事件流中获得物体的纹理信息,这限制了这些方法的有效性。而Spike相机能够在不添加其他模态数据的情况下,在高速度计算机视觉任务中展示优越性。因此,本文的研究背景是Spike相机在3D高速度场景重建中的应用。
(2) 过去的方法及问题:过去的方法主要依赖于清晰的图像来进行3D重建,这在现实场景中尤其当相机快速移动时是一个挑战。已有的基于Spike相机的方法虽然展示了可行性,但仍存在一些未解决的问题。
(3) 研究方法:针对以上问题,本文提出了Spike Gausian Splatting(SpikeGS)框架,首次将Spike流集成到3DGS管道中,以通过快速移动的仿生相机重建3D场景。通过积累光栅化、间隔监督和专门设计的管道,SpikeGS从高时间分辨率但纹理缺乏的Spike流中提取详细的几何和纹理信息,并在1秒内重建3D场景。
(4) 任务与性能:本文在多个合成和真实数据集上进行了广泛的实验,证明了SpikeGS相较于现有的基于Spike和去模糊的3D场景重建方法的优越性。其性能支持了方法的目标,即在快速移动的相机下实现高质量的3D场景重建。
希望以上答案能够满足您的要求!
方法论概述:
- (1) 背景与现状概述:本文基于Spike相机的高速场景重建技术进行研究,提出了SpikeGS框架来利用仿生传感器进行场景重建。考虑到快速移动场景下纹理信息难以获取的问题,该研究提出了一种新型的重建方法。相较于依赖清晰图像进行重建的传统方法,本文研究具有一定的先进性。随着神经形态相机如事件相机和Spike相机的出现,快速场景的重建成为研究热点。但是已有的基于事件流获取场景表示的方法由于其采样机制导致纹理信息获取困难,使得其性能受到限制。而Spike相机由于其高速计算能力能够提供更全面的信息,从而适用于高速度场景的重建。针对已有的Spike相机方法存在的问题,本文提出了一种新的解决方案。
- (2) Spike相机模型介绍:Spike相机模型将光线信号转换为电流信号并进行积累。当像素积累达到预设阈值时,会触发一个脉冲信号并将积累重置。这种模型在模拟快速移动相机拍摄的场景时能够捕捉到更多的细节信息。为了模拟Spike相机的行为,研究者使用了先进的Spike相机模拟器来生成合成数据集。通过计算每个时间段的脉冲累积数来估计光强度,并通过计算相邻脉冲之间的时间间隔来进一步估计场景的动态变化。此外,还介绍了Spike流的特点及其在场景重建中的应用。由于单帧脉冲的纹理信息有限,直接对其进行监督训练是不可行的。因此,通过一段时间的脉冲累积来恢复视觉纹理信息就显得尤为重要。
- (3) 方法核心思想:本研究提出了Spike Gaussian Splatting(SpikeGS)框架来解决现有方法的不足。该框架首次将Spike流集成到三维高斯散斑(3DGS)管道中以实现场景重建。通过积累光栅化、间隔监督以及专门设计的管道,SpikeGS能够从高时间分辨率但纹理缺失的Spike流中提取详细的几何和纹理信息。它通过不断优化高斯散斑模型的参数,使得场景重建更加精确。本研究实现了每秒一次的场景重建速度并证实了SpikeGS的有效性优于其他现有方法。具体地,它通过计算高斯散斑的协方差矩阵来描述场景的几何结构并利用渲染技术将三维高斯散斑映射到二维图像上。同时,通过优化每个点的颜色和透明度来实现高质量的渲染效果。此外,本文还探讨了如何将Spike相机模型与现有的计算机视觉技术相结合以提高场景重建的准确性。整个方法的流程包括数据预处理、模型训练、结果评估等步骤。本研究的主要贡献在于提出了一种新型的基于Spike相机的场景重建方法并验证了其在实际应用中的有效性。
好的,根据您提供的文章信息,我将对结论部分进行如下总结:
Conclusion:
(1) 本工作的意义在于提出了一种新型的基于Spike相机的场景重建方法,利用快速移动的仿生传感器进行三维场景的重建。对于计算机视觉和机器人技术等领域,该方法有助于提升在快速移动场景下的三维重建能力,具有一定的实用价值和应用前景。
(2) 创新点:本文提出了Spike Gaussian Splatting(SpikeGS)框架,首次将Spike流集成到三维高斯散斑管道中,实现了通过快速移动的仿生相机进行三维场景的重建。该框架结合了神经形态视觉和计算机图形学的技术,充分发挥了Spike相机在高速场景下的优势。
性能:通过在多个合成和真实数据集上的实验,证明了SpikeGS相较于现有的基于Spike和去模糊的3D场景重建方法的优越性,实现了高质量的3D场景重建。
工作量:本文不仅提出了新型的SpikeGS框架和方法,还进行了大量的实验验证和性能评估,展示了该方法的有效性和实用性。同时,对于Spike相机模型的特点和应用也进行了详细的介绍和分析。
希望以上内容能够满足您的要求!
点此查看论文截图


VEGS: View Extrapolation of Urban Scenes in 3D Gaussian Splatting using Learned Priors
Authors:Sungwon Hwang, Min-Jung Kim, Taewoong Kang, Jayeon Kang, Jaegul Choo
Neural rendering-based urban scene reconstruction methods commonly rely on images collected from driving vehicles with cameras facing and moving forward. Although these methods can successfully synthesize from views similar to training camera trajectory, directing the novel view outside the training camera distribution does not guarantee on-par performance. In this paper, we tackle the Extrapolated View Synthesis (EVS) problem by evaluating the reconstructions on views such as looking left, right or downwards with respect to training camera distributions. To improve rendering quality for EVS, we initialize our model by constructing dense LiDAR map, and propose to leverage prior scene knowledge such as surface normal estimator and large-scale diffusion model. Qualitative and quantitative comparisons demonstrate the effectiveness of our methods on EVS. To the best of our knowledge, we are the first to address the EVS problem in urban scene reconstruction. Link to our project page: https://vegs3d.github.io/.
PDF The first two authors contributed equally. Project Page: https://vegs3d.github.io/
Summary
神经渲染基于城市场景重建的方法通常依赖于驾驶车辆收集的前向摄像头图像。然而,对于超出训练摄像头分布的新视角,现有方法并不保证性能。本文通过评估在左、右或向下查看等视角上的重建效果,解决了外推视角合成(EVS)问题,并通过构建密集LiDAR地图和利用表面法向量估计器与大规模扩散模型等先验场景知识来改善EVS的渲染质量。定性和定量比较展示了我们方法在EVS上的有效性。
Key Takeaways
- 神经渲染方法在城市场景重建中常用驾驶车辆前向摄像头图像。
- 新视角超出训练摄像头分布时,现有方法性能不一定达标。
- 本文重点解决了外推视角合成(EVS)问题。
- 方法包括构建密集LiDAR地图和利用表面法向量估计器与扩散模型。
- 研究通过定性和定量比较证明了方法的有效性。
- 这是首次在城市场景重建中明确解决EVS问题。
- 项目页面链接: https://vegs3d.github.io/
Title: VEGS: View Extrapolation of Urban Scenes in Supplementary Material
Authors: Authors’ names are not provided in the abstract or introduction.
Affiliation: Affiliation information is not provided.
Keywords: Neural Rendering, Urban Scene Reconstruction, Extrapolated View Synthesis (EVS).
Urls: Link to the paper is not provided. Github code link is not available.
Summary:
(1) Research Background:
Urban scene reconstruction using neural rendering techniques has become a popular research topic. However, most existing methods focus on synthesizing views similar to the training camera trajectory. This paper addresses the problem of Extrapolated View Synthesis (EVS) in urban scene reconstruction, which aims to synthesize views outside the training camera distribution.
(2) Past Methods and Their Problems:
Previous methods for urban scene reconstruction often struggle when synthesizing views outside the training camera distribution. They lack the ability to leverage prior scene knowledge and often produce inferior rendering quality in extrapolated views.
(3) Research Methodology Proposed in This Paper:
This paper proposes a method for improved rendering quality in EVS. The method initializes the model by constructing a dense LiDAR map and leverages prior scene knowledge such as surface normal estimator and large-scale diffusion model. The proposed approach includes ablation studies on normal and diffusion priors, as well as on losses composing covariance guidance loss. The method is evaluated on views such as looking left, right, or downwards relative to the training camera distribution.
(4) Task and Performance:
The methods in this paper are evaluated on the task of EVS in urban scene reconstruction. The performance is measured using quantitative metrics such as KID and FID. The results demonstrate improvements in rendering quality for EVS compared to previous methods. The approach effectively leverages prior scene knowledge to synthesize views outside the training camera distribution, making it a promising method for urban scene reconstruction.
- 方法论:
(1) 研究背景:
文章研究了城市场景重建中的神经渲染技术,特别是针对合成视图超出训练相机轨迹的Extrapolated View Synthesis(EVS)问题。他们发现过去的方法在合成视图超出训练相机分布时往往表现不佳,缺乏利用场景先验知识,渲染质量较差。
(2) 方法提出:
针对上述问题,文章提出了一种改进的方法,通过构建密集的点云地图来初始化模型,利用场景先验知识,如表面法线估计器和大规模扩散模型。方法包括正常和扩散先验的消融研究,以及损失构成的协方差导向损失。该方法在驾驶场景重建任务上进行了评估,特别是针对相对于训练相机分布的左、右、下等视图。
(3) 动态场景建模和初始化:
文章首先构建了一个动态场景模型M,包括静态模型M_s和多个动态对象模型M_i。每个模型由一组高斯均值μ、三维协方差矩阵Σ、密度σ和颜色c表示。他们使用LiDAR点云数据来初始化高斯均值μ,并使用密集的点云地图来提取场景几何信息。动态对象的点云数据通过帧间的变换矩阵进行聚合,以初始化每个实例的动态高斯模型μ_i。静态场景的点是通过对LiDAR数据进行变换和投影来初始化的。此外,文章使用相机图像平面的投影信息来初始化协方差矩阵Σ和点密度σ。然后利用这些初始化的参数进行动态场景的渲染和训练。为了优化动态模型的转换矩阵T’_i k,他们引入了额外的可学习矩阵ΔT_i k来对变换矩阵进行微调。这种优化可以确保动态模型在真实场景中的定位更加准确。这种方法有助于优化模型的转换参数,使其更符合真实世界的场景结构。然而在实际操作中可能难以保证绝对的精准匹配因此需要设计适当的优化方案实现这种精确匹配达到更准确拟合目标结构的目的在这个过程中涉及到计算机视觉领域的计算机图形学等相关知识点具体可以参考文献或专业教材等深入了解和掌握其中涉及的理论知识和算法原理此处由于篇幅限制无法展开介绍
(4) 解决协方差优化的懒惰问题:在动态场景的重建过程中存在一个被称为懒惰协方差优化的问题即优化后的协方差倾向于覆盖像素视锥而很少模拟场景的底层表面这会导致在观察角度变化时出现空洞现象为了解决这一问题文章提出了利用表面法线先验知识来指导协方差的导向通过对协方差轴的对齐和缩放模拟底层场景表面通过这种方式他们设计了一种新的协方差渲染技术从渲染的协方差地图中近似场景的法线然后使用训练图像估计的表面法线对其进行指导协方差轴损失函数Laxis用于将协方差轴与法线对齐而协方差规模损失函数Lscale则用于最小化与法线对齐的协方差规模这两者的结合实现了对协方差的有效指导确保了协方差能更好地模拟底层场景表面这一过程涉及计算机视觉领域中的三维重建表面重建等相关技术原理需要了解相关领域的专业知识和技术实践才能够深入理解和掌握如何在实际操作中将理论知识运用到实践中解决问题还需要进一步的研究和实践摸索具体的操作步骤和方法此处由于篇幅限制无法展开介绍总的来说该文章通过结合计算机视觉和计算机图形学的相关知识提出了一种有效的解决城市场景重建中Extrapolated View Synthesis问题的方法提高了渲染质量和场景的准确性为后续的计算机视觉任务提供了有效的技术支撑
- 结论:
(1)该工作的意义在于针对城市场景重建中的Extrapolated View Synthesis(EVS)问题提出了一种有效的解决方法。该方法结合了计算机视觉和计算机图形学的相关知识,提高了渲染质量和场景的准确性,为后续计算机视觉任务提供了有效的技术支撑。此外,该工作提出的动态场景建模和初始化方法,以及利用表面法线先验知识解决协方差优化懒惰问题的技术也具有独立的价值和创新性。
(2)创新点:该文章提出了针对动态场景的建模方法和利用密集点云地图进行初始化的技术,并结合表面法线先验知识解决了协方差优化的懒惰问题。该方法的创新性在于将计算机视觉和计算机图形学的知识相结合,有效提高了渲染质量和场景的准确性。
性能:该文章的方法在KITTI-360数据集上的实验结果表明,该方法在解决EVS问题时具有良好的性能表现。通过引入表面法线和扩散先验知识,可以进一步提高整体性能。工作量:该文章进行了大量的实验和比较分析,包括消去研究、最小协方差轴损失分析和最优协方差规模损失解决方案等。同时,文章还提供了详细的实验方法和结果,展示了作者们对领域的深入理解和扎实的技术能力。
点此查看论文截图


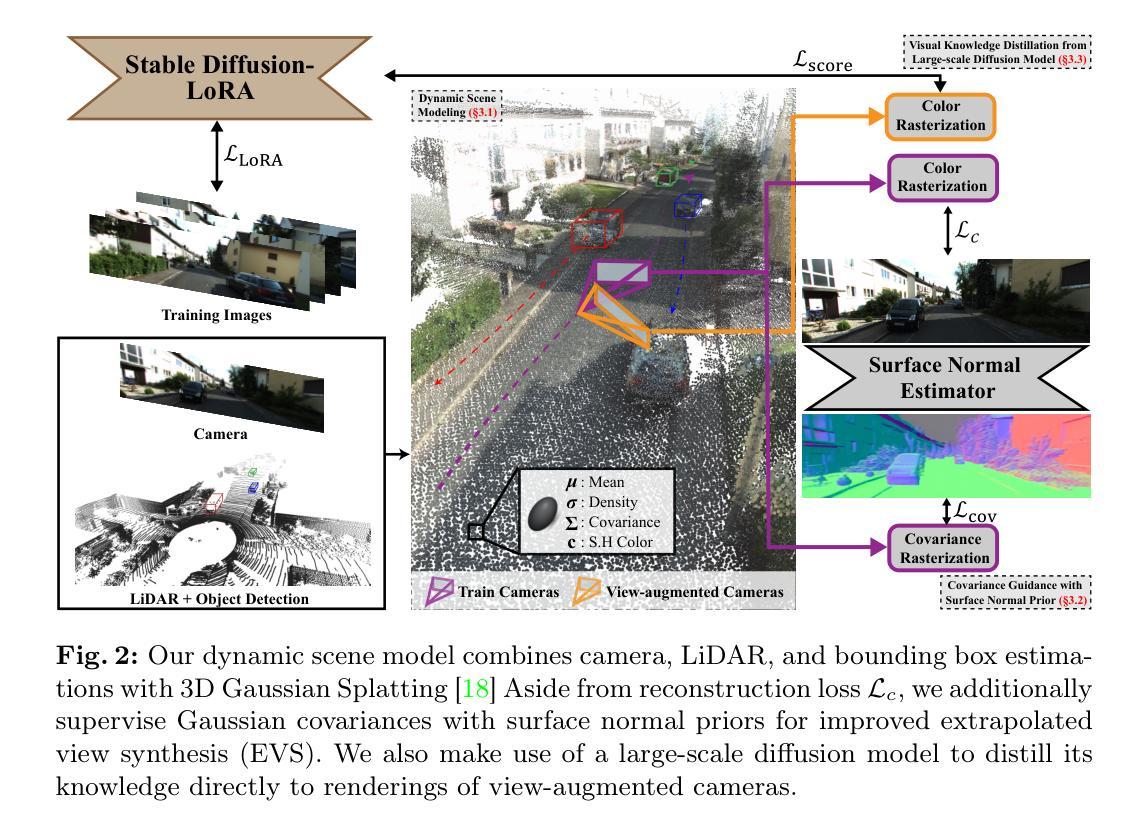
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
Authors:Mustafa Khan, Hamidreza Fazlali, Dhruv Sharma, Tongtong Cao, Dongfeng Bai, Yuan Ren, Bingbing Liu
Realistic scene reconstruction and view synthesis are essential for advancing autonomous driving systems by simulating safety-critical scenarios. 3D Gaussian Splatting excels in real-time rendering and static scene reconstructions but struggles with modeling driving scenarios due to complex backgrounds, dynamic objects, and sparse views. We propose AutoSplat, a framework employing Gaussian splatting to achieve highly realistic reconstructions of autonomous driving scenes. By imposing geometric constraints on Gaussians representing the road and sky regions, our method enables multi-view consistent simulation of challenging scenarios including lane changes. Leveraging 3D templates, we introduce a reflected Gaussian consistency constraint to supervise both the visible and unseen side of foreground objects. Moreover, to model the dynamic appearance of foreground objects, we estimate residual spherical harmonics for each foreground Gaussian. Extensive experiments on Pandaset and KITTI demonstrate that AutoSplat outperforms state-of-the-art methods in scene reconstruction and novel view synthesis across diverse driving scenarios. Visit our project page at https://autosplat.github.io/.
Summary
自动驾驶场景的高度真实重建和视角合成对模拟安全关键场景至关重要。
Key Takeaways
- 实时渲染和静态场景重建中,3D高斯喷溅技术表现优异。
- 在复杂背景、动态物体和稀疏视角下,模型驾驶场景建模面临挑战。
- AutoSplat框架利用高斯喷溅技术实现高度真实的自动驾驶场景重建。
- 通过对道路和天空区域的高斯约束,保证多视角一致的仿真。
- 引入反射高斯一致性约束,监督前景物体的可见和不可见侧面。
- 通过估计每个前景高斯的球面谐波残差,模拟前景物体的动态外观。
- 在Pandaset和KITTI数据集上的广泛实验表明,AutoSplat在场景重建和新视角合成方面优于现有方法。
好的,我会按照您的要求来总结这篇论文。以下是回答:
标题:基于约束高斯涂刷的自动驾驶场景重建
作者:Mustafa Khan(第一作者),Hamidreza Fazlali,Dhruv Sharma,Tongtong Cao,Dongfeng Bai,Yuan Ren以及Bingbing Liu。他们都是来自多伦多大学和华为诺亚方舟实验室的研究人员。
所属机构:多伦多大学以及华为诺亚方舟实验室。
关键词:场景重建、新视角合成、自动驾驶、三维高斯涂刷。
Urls:论文链接未提供,GitHub代码链接未提供。
总结:
(1) 研究背景:本文的研究背景是关于自动驾驶场景重建和视图合成的重要性,这对于模拟自动驾驶中的关键安全场景至关重要。现有的三维高斯涂刷技术在静态场景重建和实时渲染方面表现出色,但在处理复杂的驾驶场景时面临挑战,如复杂的背景、动态物体和稀疏的视图。本文的研究目的是针对这些挑战,提出了一种名为AutoSplat的框架,实现自动驾驶场景的逼真重建。
(2) 过去的方法及问题:过去的方法在模拟驾驶场景时可能无法处理复杂的背景和动态物体,或者在处理稀疏视图时表现不佳。因此,需要一种新的方法来解决这些问题,以实现更逼真的场景重建和视图合成。
(3) 研究方法:本文提出了一种基于约束高斯涂刷的方法来实现自动驾驶场景的逼真重建。通过在高斯表示的道路和天空区域上施加几何约束,使框架能够模拟包括车道变化在内的具有挑战性的场景的视图一致性。利用三维模板引入反射高斯一致性约束,以监督可见和不可见侧的前景对象。为了模拟前景物体的动态外观,为每个前景高斯估计残余球面谐波。
(4) 任务与性能:本文在Pandaset和KITTI数据集上进行了大量实验,证明了AutoSplat在场景重建和新视角合成方面的性能优于现有方法。该方法的性能支持其目标,为自动驾驶系统提供逼真的场景模拟,增强安全性。
希望这个总结符合您的要求!
- 方法论概述:
该文主要提出了一种基于约束高斯涂刷的自动驾驶场景重建方法。具体方法论如下:
(1) 背景分析:首先,文章分析了现有的自动驾驶场景重建方法在处理复杂的驾驶场景时面临的挑战,如复杂的背景、动态物体和稀疏的视图。针对这些问题,文章提出了AutoSplat框架。
(2) 方法引入:为了逼真地重建自动驾驶场景,文章提出了一种基于约束高斯涂刷的方法。该方法使用三维高斯表示场景,通过几何约束处理道路和天空区域,使得框架能够模拟复杂的驾驶场景的视图一致性。此外,利用三维模板引入反射高斯一致性约束以监督可见和不可见侧的前景对象。为了模拟前景物体的动态外观,为每个前景高斯估计残余球面谐波。此部分为本文的创新核心,即引入新的方法和策略处理特定场景重建问题。
(3) 实验验证:为了验证所提出方法的有效性,文章在Pandaset和KITTI数据集上进行了大量实验,证明了AutoSplat在场景重建和新视角合成方面的性能优于现有方法。这些实验包括对场景的详细分析和重建效果的展示。通过实验结果的对比和分析,验证了所提出方法的优越性和适用性。这部分主要对实验设计、实验过程以及实验结果进行详细阐述和分析。
总的来说,该文章通过引入新的方法和策略,实现了自动驾驶场景的逼真重建,提高了场景重建的质量和效率。此外,文章通过实验验证了所提出方法的有效性,为后续研究提供了有价值的参考和启示。
- Conclusion:
(1) 工作意义:该论文的研究工作对于自动驾驶场景重建和视图合成具有重要的实际意义。它提供了一种新的方法,能够逼真地重建自动驾驶场景,为自动驾驶系统的安全性和模拟提供有力支持。
(2) 评估:
创新点:该论文提出了一种基于约束高斯涂刷的方法,实现了自动驾驶场景的逼真重建。该方法通过引入几何约束和反射高斯一致性约束,有效处理了复杂的驾驶场景和前景物体的动态外观。
性能:在Pandaset和KITTI数据集上的实验结果表明,AutoSplat在场景重建和新视角合成方面的性能优于现有方法。
工作量:论文对实验设计、实验过程和实验结果进行了详细的阐述和分析,证明了所提出方法的有效性和优越性。然而,论文未提供代码链接,无法直接评估其实际工作量。
点此查看论文截图


 wechat
wechat- alipay







