Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-07-12 更新
Audio-driven High-resolution Seamless Talking Head Video Editing via StyleGAN
Authors:Jiacheng Su, Kunhong Liu, Liyan Chen, Junfeng Yao, Qingsong Liu, Dongdong Lv
The existing methods for audio-driven talking head video editing have the limitations of poor visual effects. This paper tries to tackle this problem through editing talking face images seamless with different emotions based on two modules: (1) an audio-to-landmark module, consisting of the CrossReconstructed Emotion Disentanglement and an alignment network module. It bridges the gap between speech and facial motions by predicting corresponding emotional landmarks from speech; (2) a landmark-based editing module edits face videos via StyleGAN. It aims to generate the seamless edited video consisting of the emotion and content components from the input audio. Extensive experiments confirm that compared with state-of-the-arts methods, our method provides high-resolution videos with high visual quality.
Summary
该论文旨在通过两个模块实现音频驱动的说话人面部视频编辑,显著改善视觉效果。
Key Takeaways
- 通过音频到地标模块,预测从语音中得出的情绪地标,弥合语音与面部动作之间的差距。
- 地标编辑模块使用StyleGAN编辑面部视频,生成情绪和内容组成的无缝编辑视频。
- 新方法提供高分辨率、高视觉质量的视频,优于现有的方法。
- 使用了CrossReconstructed Emotion Disentanglement和对齐网络模块。
- 论文着重于改善语音驱动的视频编辑中的视觉效果限制。
- 实验验证了方法的有效性和优越性。
- 目标是生成情绪和内容一致的视频编辑效果。
好的,我已经理解您的要求了。以下是论文的总结:
标题:基于StyleGAN的音频驱动高分辨率无缝对话视频编辑研究
作者:苏嘉诚¹,刘昆宏¹,²,陈立妍¹,²,姚俊峰¹,²,刘青松³,吕冬冬³
所属单位:电影系厦门大学(厦门,中国)
数字保护与智能处理福建省和台湾省重点实验室(文化和旅游局),中国
厦门优声智能科技有限公司(厦门,中国)关键词:面部动画,视频合成,音频驱动生成
链接:[论文链接],Github代码链接:[Github链接(如果可用)],否则填写“Github:None”
总结:
(1) 研究背景:音频驱动的对话头部视频编辑是人工智能生成内容(AIGC)领域的重要研究课题。目标是根据输入音频生成高质量的无缝对话头部视频,广泛应用于电影配音、数字人技术等。
(2) 过去的方法及其问题:现有方法对于高分辨率视频的编辑存在视觉效果不佳的问题。尽管已有许多研究者致力于此领域,但大多数研究在处理高分辨率视频时效果不佳,存在编辑痕迹明显、画面模糊等问题。
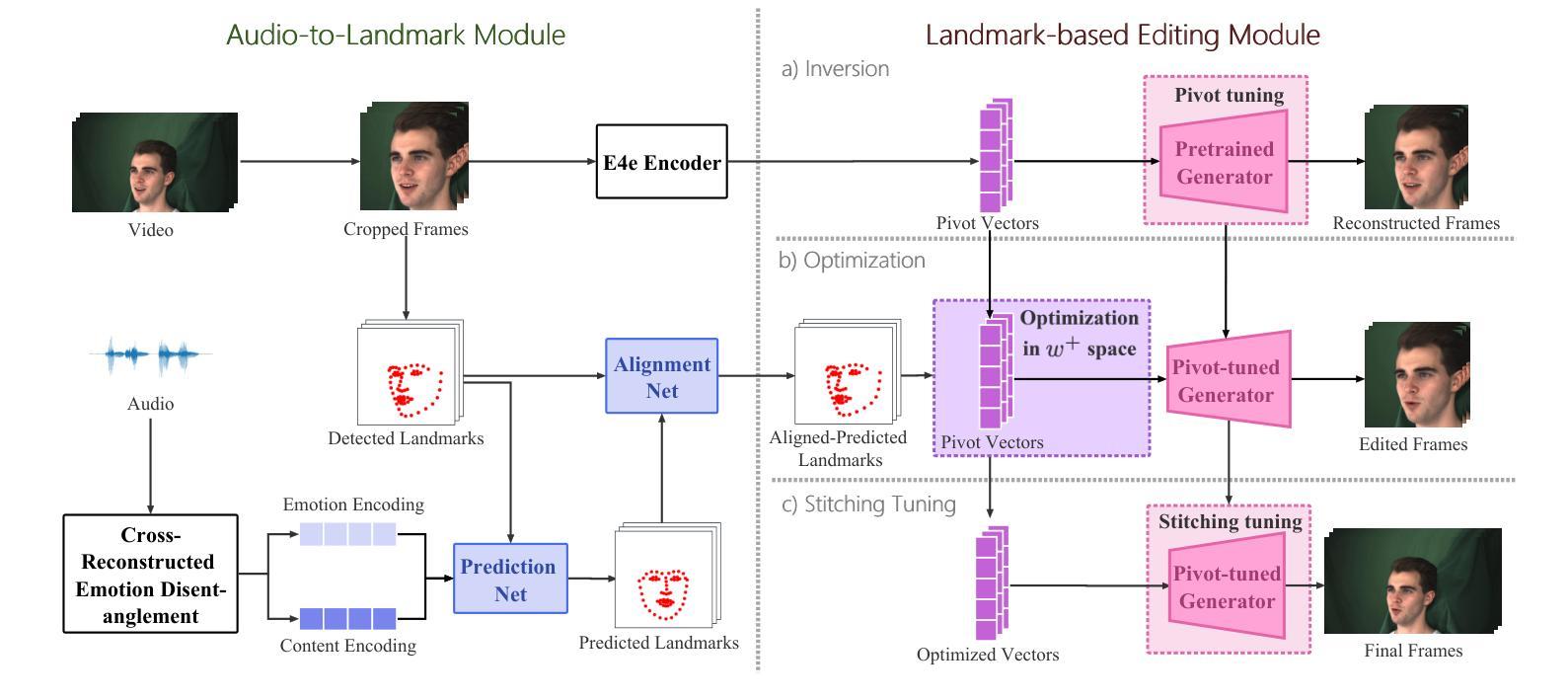
(3) 研究方法:本研究提出了一种基于StyleGAN的同步面部视频编辑框架。首先通过一个音频到地标的模块预测与音频情感对应的面部地标,然后在StyleGAN的W+潜在空间进行视频编辑。通过优化算法在面部地标的监督下进行帧编辑,确保生成的高分辨率视频无缝且流畅。
(4) 任务与性能:本研究在对话头部视频编辑任务上取得了显著成果。实验证明,与现有方法相比,该方法生成的高分辨率视频具有更高的视觉质量。此外,通过StyleGAN的编辑确保了视频的高分辨率和无缝效果。该方法的性能充分支持其目标的实现。
请注意,具体数值、链接等信息请使用论文原文内容填写。
- 方法论:
这篇论文提出了一种基于StyleGAN的音频驱动对话头部视频编辑方法。其方法论主要包括以下几个步骤:
(1) 研究背景和目标确定:针对音频驱动的对话头部视频编辑问题,提出一种基于StyleGAN的同步面部视频编辑框架,旨在根据输入音频生成高质量的无缝对话头部视频。
(2) 数据集和预处理:使用MEAD和HDTF等标准数据集进行模型训练和性能测试。对视频数据进行预处理,包括面部检测、地标提取等步骤。
(3) 构建模型结构:模型主要包括两个模块,Audio-to-Landmark(AL)模块和Landmark-based Editing(LE)模块。AL模块根据音频情感预测面部地标,LE模块在StyleGAN的W+潜在空间进行视频编辑。
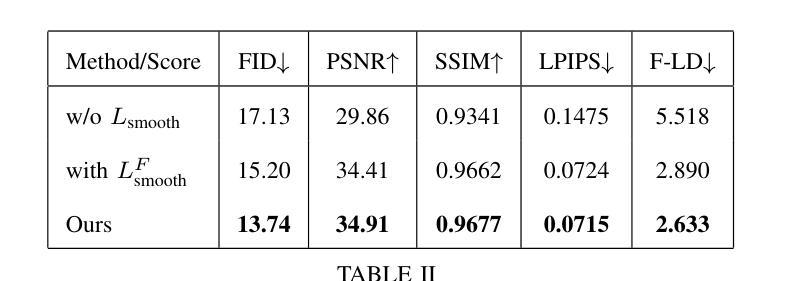
(4) 设计和优化算法:通过优化算法在面部地标的监督下进行帧编辑,确保生成的高分辨率视频无缝且流畅。采用多种损失函数进行优化,包括感知损失、面部地标损失、平滑损失等。
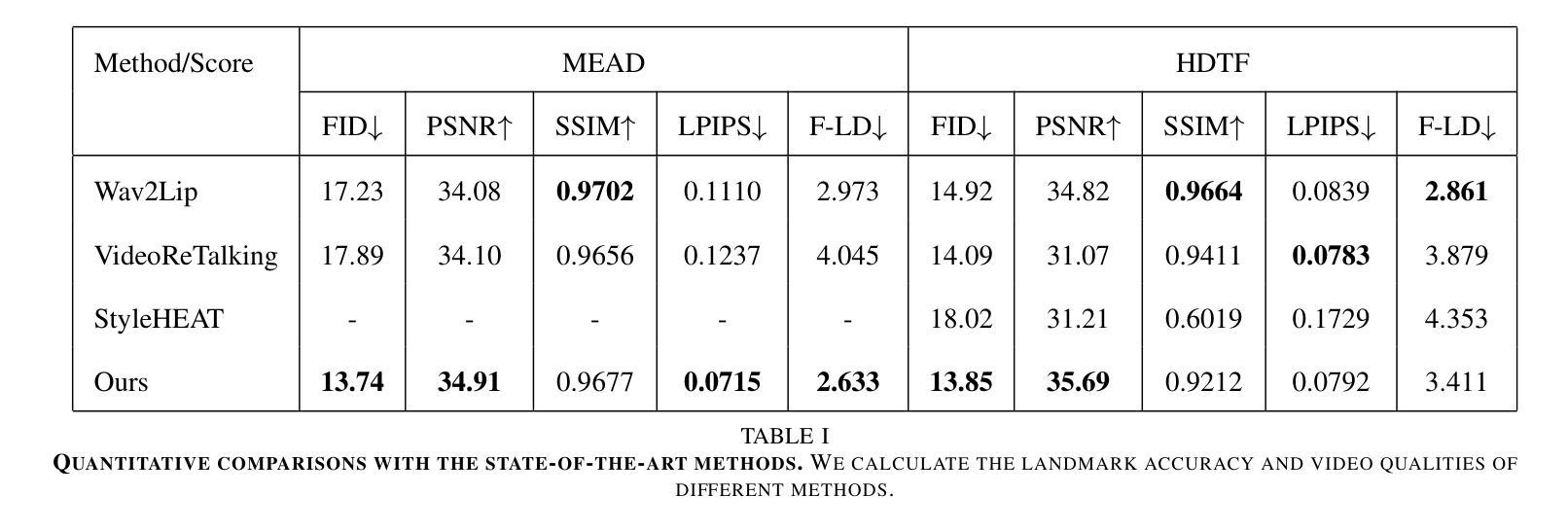
(5) 实验验证:在MEAD和HDTF等数据集上进行实验验证,与Wav2Lip、VideoReTalking、StyleHEAT等方法进行对比。通过实验证明,该方法在对话头部视频编辑任务上取得了显著成果,生成的高分辨率视频具有更高的视觉质量。
整个方法的流程如图2所示,首先通过音频到地标的模块预测与音频情感对应的面部地标,然后在StyleGAN的W+潜在空间进行视频编辑,生成无缝且流畅的高分辨率视频。
Conclusion:
(1) 该工作的意义在于提出了一种基于StyleGAN的音频驱动对话头部视频编辑方法,对于人工智能生成内容(AIGC)领域具有重要的研究价值。该研究能够广泛应用于电影配音、数字人技术等领域,为这些领域提供更高质量、更真实的视频编辑方法。
(2) 创新点:本文提出了基于StyleGAN的同步面部视频编辑框架,通过音频到地标的转换,实现了音频驱动的对话头部视频编辑。相较于以往的方法,该方法在生成高分辨率视频时具有更好的效果,保证了视频的视觉质量和无缝效果。
性能:该文章在标准数据集上进行实验验证,证明了所提出的方法在对话头部视频编辑任务上的优越性。生成的高分辨率视频具有更高的视觉质量,与现有方法相比具有一定的性能优势。
工作量:文章进行了详尽的方法论阐述和实验验证,包括数据集的准备、模型的设计和优化、实验的设置和结果分析等。工作量较大,具有一定的研究深度。
点此查看论文截图




 wechat
wechat- alipay







