Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-07-26 更新
Text-based Talking Video Editing with Cascaded Conditional Diffusion
Authors:Bo Han, Heqing Zou, Haoyang Li, Guangcong Wang, Chng Eng Siong
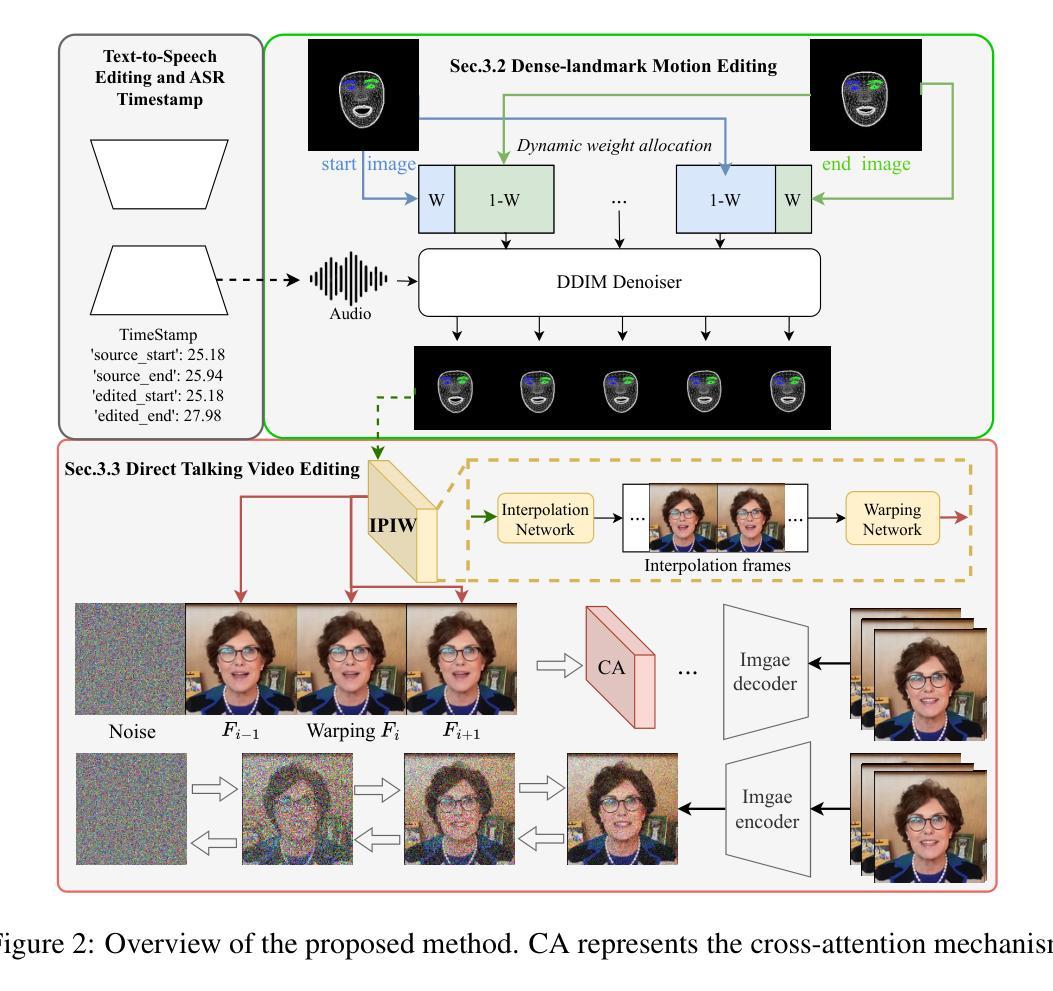
Text-based talking-head video editing aims to efficiently insert, delete, and substitute segments of talking videos through a user-friendly text editing approach. It is challenging because of \textbf{1)} generalizable talking-face representation, \textbf{2)} seamless audio-visual transitions, and \textbf{3)} identity-preserved talking faces. Previous works either require minutes of talking-face video training data and expensive test-time optimization for customized talking video editing or directly generate a video sequence without considering in-context information, leading to a poor generalizable representation, or incoherent transitions, or even inconsistent identity. In this paper, we propose an efficient cascaded conditional diffusion-based framework, which consists of two stages: audio to dense-landmark motion and motion to video. \textit{\textbf{In the first stage}}, we first propose a dynamic weighted in-context diffusion module to synthesize dense-landmark motions given an edited audio. \textit{\textbf{In the second stage}}, we introduce a warping-guided conditional diffusion module. The module first interpolates between the start and end frames of the editing interval to generate smooth intermediate frames. Then, with the help of the audio-to-dense motion images, these intermediate frames are warped to obtain coarse intermediate frames. Conditioned on the warped intermedia frames, a diffusion model is adopted to generate detailed and high-resolution target frames, which guarantees coherent and identity-preserved transitions. The cascaded conditional diffusion model decomposes the complex talking editing task into two flexible generation tasks, which provides a generalizable talking-face representation, seamless audio-visual transitions, and identity-preserved faces on a small dataset. Experiments show the effectiveness and superiority of the proposed method.
Summary
文本驱动的头像视频编辑旨在通过用户友好的文本编辑方法,有效地插入、删除和替换说话视频的片段。
Key Takeaways
- 提出了一种高效的级联条件扩散框架,分为音频到密集地标运动和运动到视频两个阶段。
- 第一阶段引入了动态加权上下文扩散模块,用于合成编辑后音频的密集地标运动。
- 第二阶段引入了基于变形引导的条件扩散模块,生成平滑的中间帧并保证了身份保留的过渡。
- 方法将复杂的编辑任务分解为两个灵活的生成任务,提供了通用的说话面部表示、无缝的视听过渡和身份保留的面部。
- 实验表明了所提方法的有效性和优越性,尤其在小数据集上。
- 以前的方法要么需要大量的训练数据和昂贵的测试时间优化,要么直接生成视频序列而忽略上下文信息,导致表示不通用、过渡不连贯或者身份不一致。
- 方法通过保证一致性和身份保留的过渡,解决了以往编辑方法的局限性。
Title: 基于级联条件扩散的文本驱动对话视频编辑
Authors: Bo Han, Heqing Zou, Haoyang Li, Guangcong Wang, Chng Eng Siong
Affiliation: Bo Han的关联机构为浙江大学。
Keywords: Text-based Talking Video Editing, Cascaded Conditional Diffusion, Dynamic Weighted In-context Diffusion Module, Warping-guided Conditional Diffusion Module
Urls: 由于无法直接提供论文链接,GitHub代码链接暂未提供(如有可用链接,请填入相应位置)。
Summary:
(1)研究背景:本文的研究背景是文本驱动的对话视频编辑。该领域旨在通过友好的文本编辑方式,实现对对话视频的高效插入、删除和替换。此项技术具有广泛的应用领域,如电影制作、视频广告和数字化身等。
-(2)过去的方法及问题:过去的文本驱动对话视频编辑方法要么需要大量的对话视频训练数据,并在测试时进行优化,以实现个性化的视频编辑;要么直接生成视频序列,而不考虑上下文信息。这些问题导致了缺乏通用性、视听过渡不连贯以及身份不一致等问题。
-(3)研究方法:针对上述问题,本文提出了一种基于级联条件扩散的框架,包括两个阶段:音频到密集地标运动,以及运动到视频。在第一阶段,提出了动态加权上下文扩散模块,根据编辑后的音频合成密集地标运动。在第二阶段,引入了基于warping的条件扩散模块,通过插值生成平滑的中间帧,并结合音频到密集运动图像进行warping,获得粗略的中间帧。最后,基于这些中间帧,采用扩散模型生成详细的高分辨率目标帧,保证了连贯且身份一致的过渡。
-(4)任务与性能:本文的方法在对话视频编辑任务上取得了显著的效果和优势。该方法将复杂的编辑任务分解为两个灵活生成任务,提供了通用的对话面部表示、无缝的视听过渡和身份保留的面部。实验结果表明,该方法的有效性。性能结果支持了方法的有效性,为实现高效的文本驱动对话视频编辑提供了新的解决方案。
好的,我会根据您给出的摘要来详细阐述这篇文章的方法论。下面是按照您提供的格式回答:
Methods:
- (1) 研究背景与问题定义:首先明确了本文研究的背景为文本驱动的对话视频编辑。通过分析该领域的现有问题,总结出主要挑战在于如何通过友好的文本编辑方式实现对对话视频的高效插入、删除和替换,同时保证视频的连贯性和身份一致性。这些问题在过去的文本驱动对话视频编辑方法中普遍存在。
- (2) 方法概述:针对上述问题,本文提出了一种基于级联条件扩散的框架。该框架包括两个阶段:音频到密集地标运动阶段和运动到视频阶段。第一阶段中,引入了动态加权上下文扩散模块,根据编辑后的音频合成密集地标运动。第二阶段则通过插值生成平滑的中间帧,并结合音频到密集运动图像进行warping,获得粗略的中间帧。最后,基于这些中间帧,采用扩散模型生成详细的高分辨率目标帧。这种方法的优势在于能将复杂的编辑任务分解为两个灵活生成任务,保证连贯且身份一致的过渡。
- (3) 方法细节:在音频到密集地标运动阶段,动态加权上下文扩散模块是关键。该模块能够根据编辑后的音频信息合成出对应的密集地标运动,为后续的视频生成提供基础。在运动到视频阶段,基于warping的条件扩散模块发挥了重要作用。它通过插值技术生成平滑的中间帧,并结合之前合成的密集运动图像进行warping,得到粗略的中间帧图像。最后,利用扩散模型对这些中间帧进行精细化处理,生成高分辨率的目标帧,从而实现视频的连贯性和身份一致性。
- (4) 实验与性能评估:本文的方法在对话视频编辑任务上进行了实验验证,并与其他方法进行了对比。实验结果表明,该方法在对话视频编辑任务上取得了显著的效果和优势。性能评估支持了方法的有效性,证明了该策略为文本驱动对话视频编辑提供了新的解决方案。同时文章还提供了相关的实验结果和分析以支持方法的可行性。
希望以上回答能够对您有所帮助。如果您还有其他问题或需要进一步的解释,请随时告知我!
- Conclusion:
(1)这项工作的意义在于为文本驱动的对话视频编辑提供了一种新的解决方案。通过引入基于级联条件扩散的框架,该工作有效地解决了对话视频编辑中的一系列问题,如缺乏通用性、视听过渡不连贯以及身份不一致等。这种新方法不仅提高了视频编辑的效率,而且为用户提供了更友好的编辑体验。
(2)创新点、性能和工作量总结如下:
创新点:该文章提出了一种基于级联条件扩散的文本驱动对话视频编辑方法,通过动态加权上下文扩散模块和基于warping的条件扩散模块的设计,实现了高效、连贯的视频编辑。
性能:实验结果表明,该方法在对话视频编辑任务上取得了显著的效果和优势,提供了通用的对话面部表示、无缝的视听过渡和身份保留的面部。
工作量:文章详细介绍了方法的实现细节,包括音频到密集地标运动阶段和运动到视频阶段的具体步骤。此外,文章还提供了相关的实验结果和分析以支持方法的可行性。但工作量方面可能存在一些复杂性,因为视频编辑本身是一个复杂的任务,需要处理大量的数据和细节。
总体来说,该文章在文本驱动的对话视频编辑领域做出了重要的贡献,为未来的研究提供了新的思路和方法。
点此查看论文截图


EmoFace: Audio-driven Emotional 3D Face Animation
Authors:Chang Liu, Qunfen Lin, Zijiao Zeng, Ye Pan
Audio-driven emotional 3D face animation aims to generate emotionally expressive talking heads with synchronized lip movements. However, previous research has often overlooked the influence of diverse emotions on facial expressions or proved unsuitable for driving MetaHuman models. In response to this deficiency, we introduce EmoFace, a novel audio-driven methodology for creating facial animations with vivid emotional dynamics. Our approach can generate facial expressions with multiple emotions, and has the ability to generate random yet natural blinks and eye movements, while maintaining accurate lip synchronization. We propose independent speech encoders and emotion encoders to learn the relationship between audio, emotion and corresponding facial controller rigs, and finally map into the sequence of controller values. Additionally, we introduce two post-processing techniques dedicated to enhancing the authenticity of the animation, particularly in blinks and eye movements. Furthermore, recognizing the scarcity of emotional audio-visual data suitable for MetaHuman model manipulation, we contribute an emotional audio-visual dataset and derive control parameters for each frames. Our proposed methodology can be applied in producing dialogues animations of non-playable characters (NPCs) in video games, and driving avatars in virtual reality environments. Our further quantitative and qualitative experiments, as well as an user study comparing with existing researches show that our approach demonstrates superior results in driving 3D facial models. The code and sample data are available at https://github.com/SJTU-Lucy/EmoFace.
PDF 2024 IEEE Conference Virtual Reality and 3D User Interfaces (VR). IEEE, 2024
Summary
通过EmoFace,我们引入了一种新的音频驱动的方法来生成具有多种情感表达的面部动画。
Key Takeaways
- EmoFace是一种新的音频驱动的面部动画生成方法,能够表现多种情感。
- 方法利用独立的语音编码器和情感编码器学习音频、情感和面部控制器之间的关系。
- 研究引入了两种后处理技术,专门用于增强动画的真实性,特别是眨眼和眼部运动。
- 提出了一个情感音频-视觉数据集,适合于MetaHuman模型操作。
- 方法可应用于视频游戏中非玩家角色的对话动画和虚拟现实环境中的头像驱动。
- 实验结果显示,该方法在驱动3D面部模型方面表现出优越的结果。
- 开放源代码和示例数据可在https://github.com/SJTU-Lucy/EmoFace获取。
好的,我会按照您的要求进行总结。
标题:
EmoFace: 音频驱动的情感3D面部动画
中文翻译:EmoFace:音频驱动的情感三维面部动画作者:
Chang Liu, Qunfen Lin, Zijiao Zeng, Ye Pan作者所属单位:
上海交通大学(Shanghai Jiao Tong University)、腾讯游戏(Tencent Games)关键词:
音频驱动面部动画、情感表达、同步嘴唇动作、MetaHuman模型操控、虚拟角色动画、情感音频视觉数据集、参数控制等。链接:
论文链接:待补充(可通过作者提供的链接查看);Github代码链接:[GitHub代码库链接](GitHub:None表示暂时无法提供代码库链接)摘要:
(1)研究背景:随着虚拟现实技术的不断发展,对虚拟角色的创建需求不断增长。音频驱动的面部动画在无法捕捉面部表情的情况下尤为关键。然而,现有方法在驱动情感表达和同步嘴唇动作方面存在不足。本研究旨在解决这一问题。
(2)过去的方法及问题:以往音频驱动面部动画的研究方法主要存在忽略情感对面部表情的影响或在驱动MetaHuman模型时效果不佳的问题。
(3)研究方法:本研究提出了EmoFace,一种新型的音频驱动面部动画方法。该方法利用独立的语音编码器和情感编码器学习音频、情感和对应面部控制器之间的关系,并映射成控制器值的序列。此外,还引入两种后处理技术以提高动画的真实性。同时,为MetaHuman模型操控贡献了一个情感音频视觉数据集并推导了每帧的控制参数。
(4)任务与性能:本研究的方法应用于创建游戏非玩家角色(NPC)的对话动画和虚拟现实环境中的角色驱动。实验和用户研究结果表明,该方法在驱动3D面部模型方面表现出卓越的结果。性能上,该方法能够生成具有多种情感的面部表情,同时保持准确的嘴唇同步,生成自然且随机的眨眼和眼部运动。方法论概述:
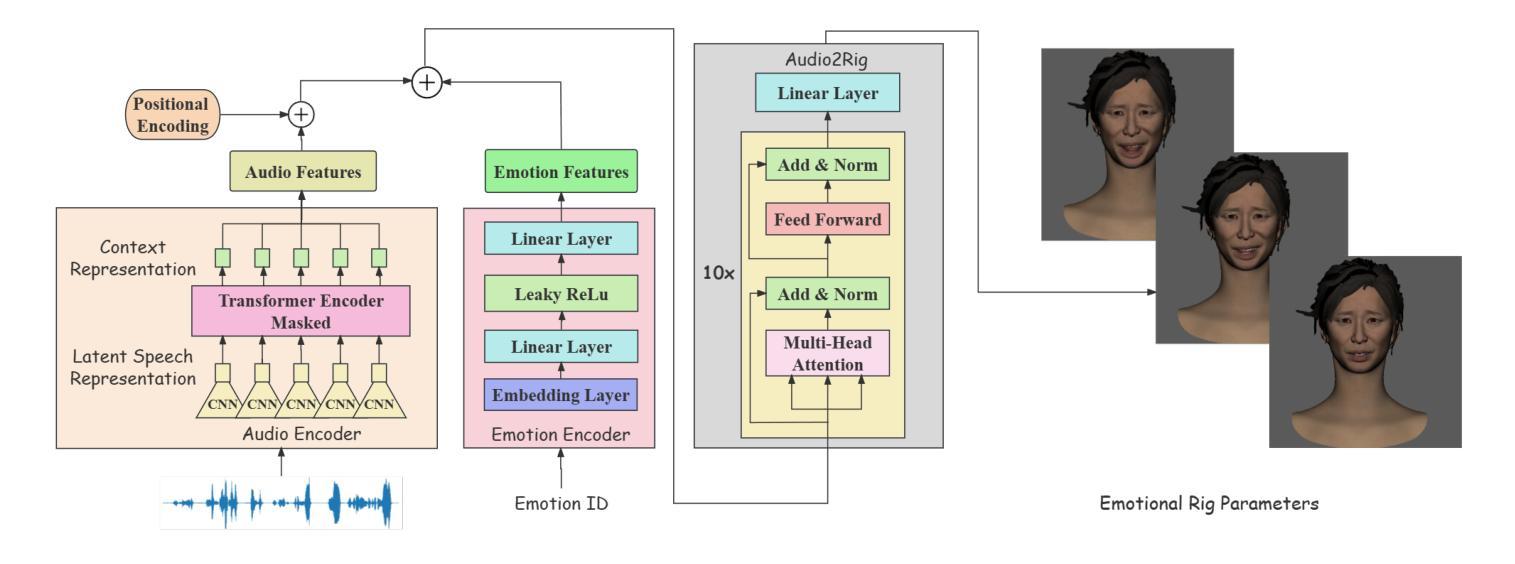
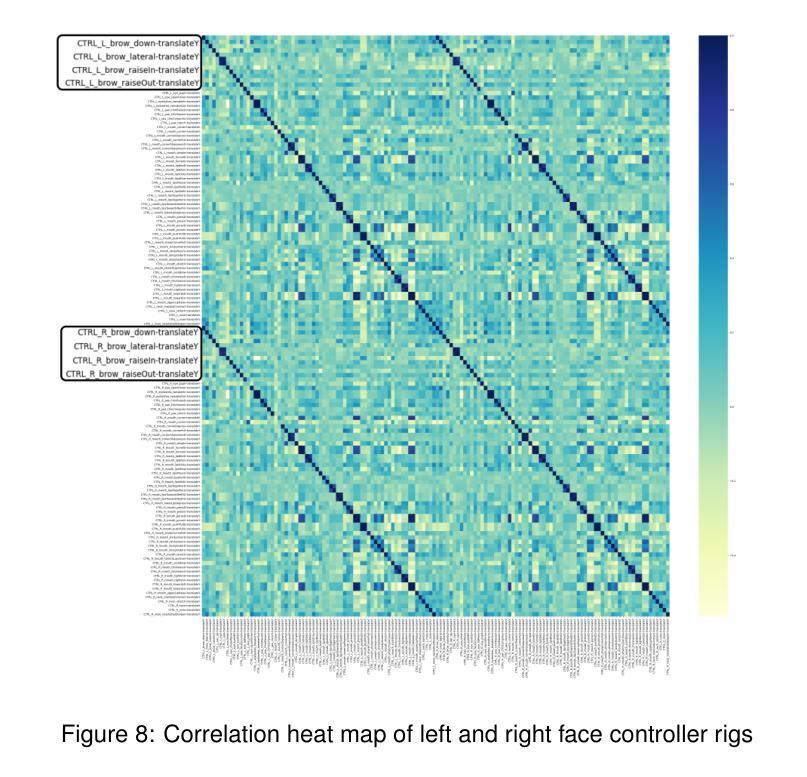
(1) 构建模型架构:提出EmoFace模型,该模型由音频编码器、情感编码器和Audio2Rig模块三部分组成。音频编码器基于预训练的语音模型wav2vec2.0,接收音频输入并输出语音表示。情感编码器接受情感类别输入,将其转换为与内容编码具有相同维度的向量。Audio2Rig模块结合音频特征和情感编码,生成控制面部动画的控制器值。
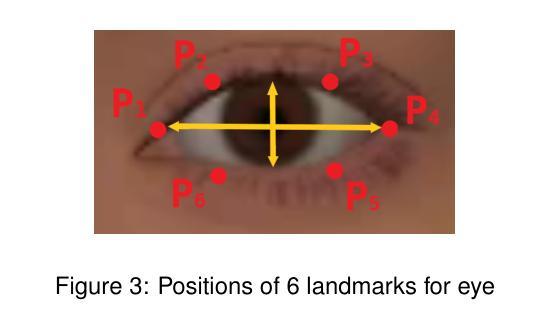
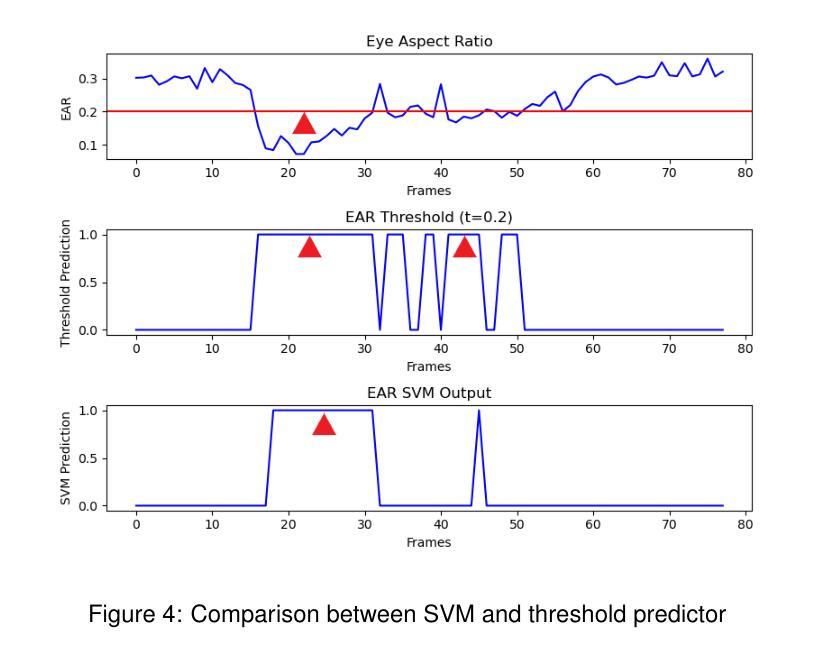
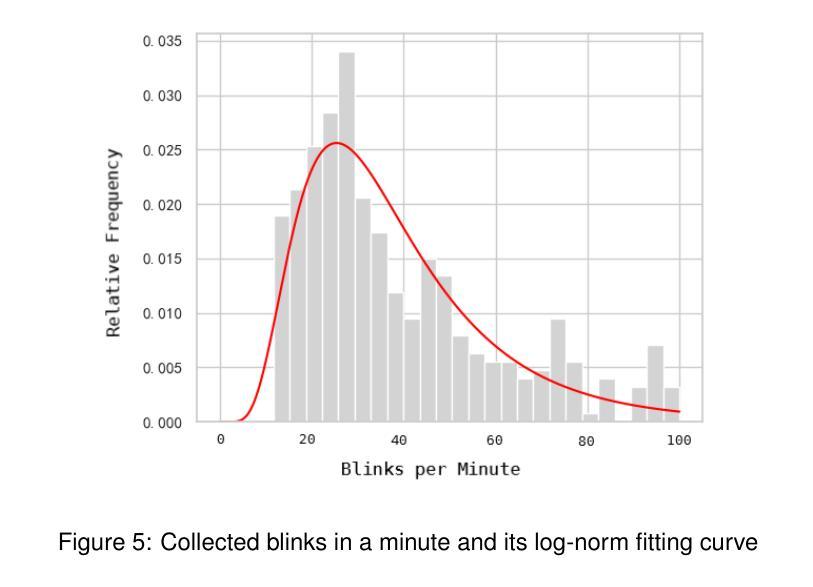
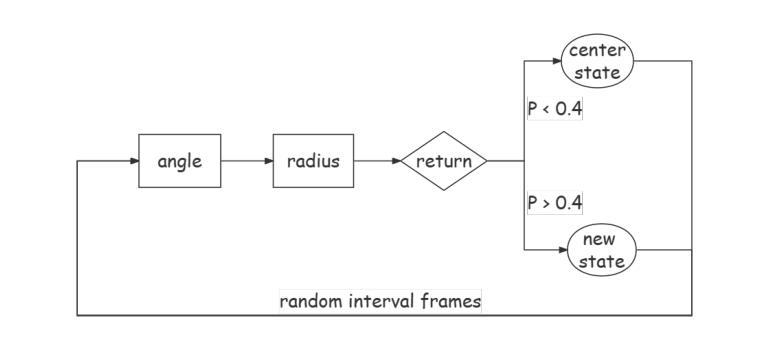
(2) 数据处理与特征提取:采用wav2vec2.0提取音频的一般特征,并对频率进行线性插值以确保与数据集帧率一致。使用SVM模型进行眨眼检测,利用眼间比例(EAR)计算眨眼事件。
(3) 情感控制面部动画:通过输入情感标签,用户可控制输出面部动画的情感类别。模型能够生成具有多种情感的面部表情,同时保持嘴唇同步,生成自然且随机的眨眼和眼部运动。
(4) 模型训练与优化:使用带有标签的数据集进行模型训练,包括音频数据和对应的面部动画控制器值。采用transformer编码器进行预测,并通过Savitzky-Golay滤波器对输出序列进行平滑处理,以确保面部动画的流畅性。
(5) 实验验证与用户研究:通过创建游戏非玩家角色(NPC)的对话动画和虚拟现实环境中的角色驱动来验证方法的有效性。实验和用户研究结果表明,该方法在驱动3D面部模型方面表现出卓越的结果,能够生成具有真实感的面部动画。
好的,根据您提供的文章信息和内容,我将按照要求的格式给出结论部分。
Conclusion:
(1) 这项研究工作的意义在于提出了一种新型的音频驱动面部动画方法,名为EmoFace。该方法能够生成具有多种情感的3D面部表情动画,对于虚拟现实技术中的虚拟角色创建具有重要的应用价值。
(2) 创新点:本研究提出了EmoFace模型,通过音频和情感编码器结合,实现了音频驱动的情感3D面部动画。同时,引入了后处理技术提高动画的真实性。此外,为MetaHuman模型操控贡献了一个情感音频视觉数据集。
性能:实验和用户研究结果表明,该方法在驱动3D面部模型方面表现出卓越的结果,能够生成具有真实感的面部动画,同时在情感表达和同步嘴唇动作方面有明显的改进。
工作量:文章详细描述了方法论,包括模型架构、数据处理与特征提取、情感控制面部动画、模型训练与优化等。同时,提供了实验验证和用户研究结果来证明方法的有效性。
请注意,由于无法获取完整的文章内容和细节,以上结论仅基于您提供的摘要和信息进行概括。如有需要,请进一步提供文章详细内容以便更准确的评价。
点此查看论文截图

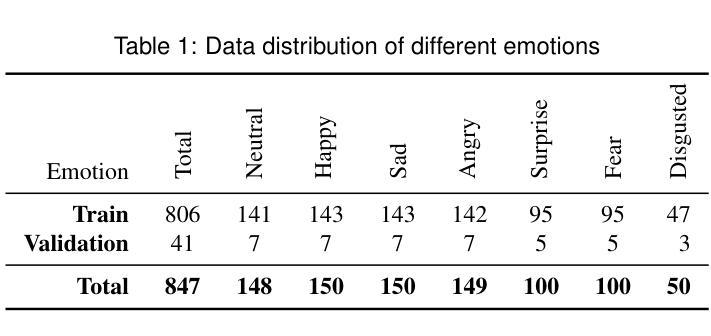
Learning Online Scale Transformation for Talking Head Video Generation
Authors:Fa-Ting Hong, Dan Xu
One-shot talking head video generation uses a source image and driving video to create a synthetic video where the source person’s facial movements imitate those of the driving video. However, differences in scale between the source and driving images remain a challenge for face reenactment. Existing methods attempt to locate a frame in the driving video that aligns best with the source image, but imprecise alignment can result in suboptimal outcomes. To this end, we introduce a scale transformation module that can automatically adjust the scale of the driving image to fit that of the source image, by using the information of scale difference maintained in the detected keypoints of the source image and the driving frame. Furthermore, to keep perceiving the scale information of faces during the generation process, we incorporate the scale information learned from the scale transformation module into each layer of the generation process to produce a final result with an accurate scale. Our method can perform accurate motion transfer between the two images without any anchor frame, achieved through the contributions of the proposed online scale transformation facial reenactment network. Extensive experiments have demonstrated that our proposed method adjusts the scale of the driving face automatically according to the source face, and generates high-quality faces with an accurate scale in the cross-identity facial reenactment.
Summary
视频生成中的关键挑战是源图像与驱动视频之间的比例差异,我们提出的方法通过自动调整比例解决了这一问题,有效实现了面部运动的准确转移。
Key Takeaways
- 一次性生成视频的关键是解决源图像与驱动视频之间的比例差异。
- 我们引入了一个比例转换模块,利用源图像和驱动视频中检测到的关键点信息,自动调整驱动图像的比例以匹配源图像。
- 在生成过程中,我们将比例信息嵌入到每一层,确保最终生成的结果具有准确的比例。
- 我们的方法不需要锚定帧,通过在线比例转换面部重现网络实现了准确的运动转移。
- 大量实验证明,我们的方法能够自动调整驱动面部的比例,实现跨身份的高质量面部重现。
- 精确的比例调整有助于生成具有真实感的面部表情。
Please refer to relevant websites for more information, and feel free to ask me any other questions.
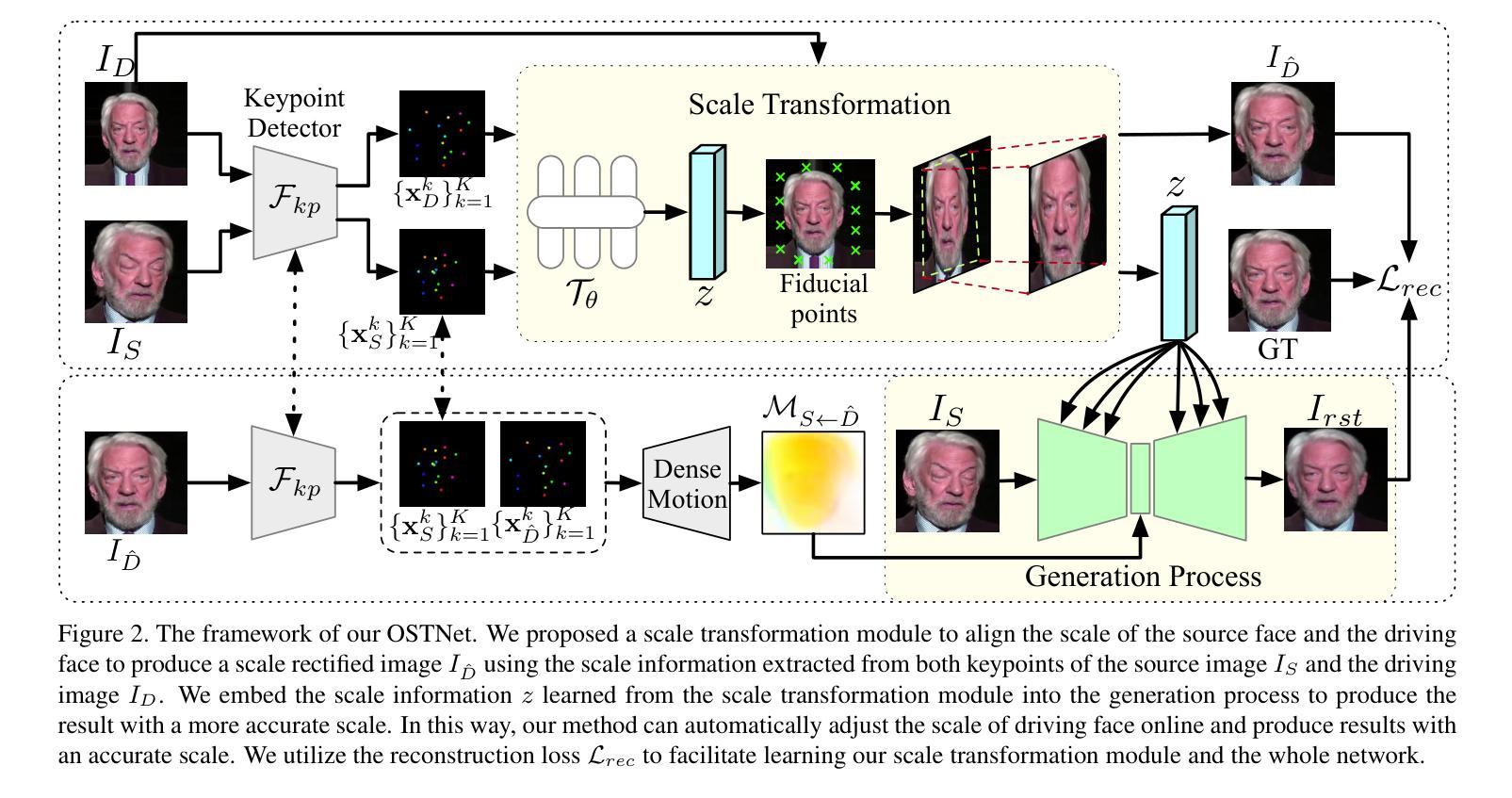
- 方法论:
(1) 该文章提出了一种在线尺度转换面部再表情网络(OSTNet),用于自动调整驱动面部的尺度,以便在此任务中生成精确的结果,而无需寻找最佳对齐锚框。
(2) 方法首先通过尺度转换模块(Scale Transformation Module)对驱动面部图像进行尺度调整,使其与源图像一致。该模块使用关键点来预测一组固定点,然后利用网格生成器(Grid Generator)产生尺度变形图,用于对驱动图像进行尺度校正。
(3) 为了使网络在面部生成过程中意识到源图像的尺度,将尺度转换模块学习到的潜在尺度代码融入到生成过程的每一层。
(4) 在训练阶段,采用表达保留增强方法对驱动图像进行不同尺度的训练,以便网络能够处理任何尺度的驱动面部。
(5) 通过使用关键点检测器来检测面部图像的关键点,并参与尺度转换步骤,因为检测到的关键点包含面部的尺度信息。
(6) 最后,通过提出的网格生成器产生校正后的面部图像。这种方法能够有效地对输入的不一致尺度的驱动面部进行调整,以匹配源面部的尺度,从而确保最终结果的身份一致性。
Conclusion:
(1) 该研究工作提出了一种在线尺度对齐的面部再表情网络(OSTNet),对面部生成和表情转移技术做出了重要的贡献。这种网络可以在没有最佳对齐锚框的情况下,自动调整驱动面部的尺度,为视频制作中自动调整人脸提供了便利。此外,该研究还展示了其在面部图像尺度转换方面的优异性能,这对于改善虚拟人物制作、动画渲染等应用领域具有重要的实用价值。
(2) 创新点:文章提出了一种全新的在线尺度转换面部再表情网络(OSTNet),它能够在线实时调整驱动面部的尺度,以匹配源面部,从而确保最终结果的身份一致性。此外,该研究还将尺度转换模块学习到的潜在尺度代码融入到生成过程的每一层,进一步提高了模型的性能。
性能:实验结果表明,OSTNet能够正确地对驱动面部进行尺度调整,以匹配源面部,从而生成高质量的视频。与现有的先进技术相比,OSTNet产生的结果更加真实、自然。
工作量:文章详细描述了OSTNet的设计和实现过程,包括尺度转换模块、网格生成器等的构建和训练。此外,文章还进行了大量的实验来验证其性能,并进行了消融研究以证明尺度转换的重要性。因此,该文章的工作量较大,需要较高的研究成本和技术水平。
点此查看论文截图


 wechat
wechat- alipay







