元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-05 更新
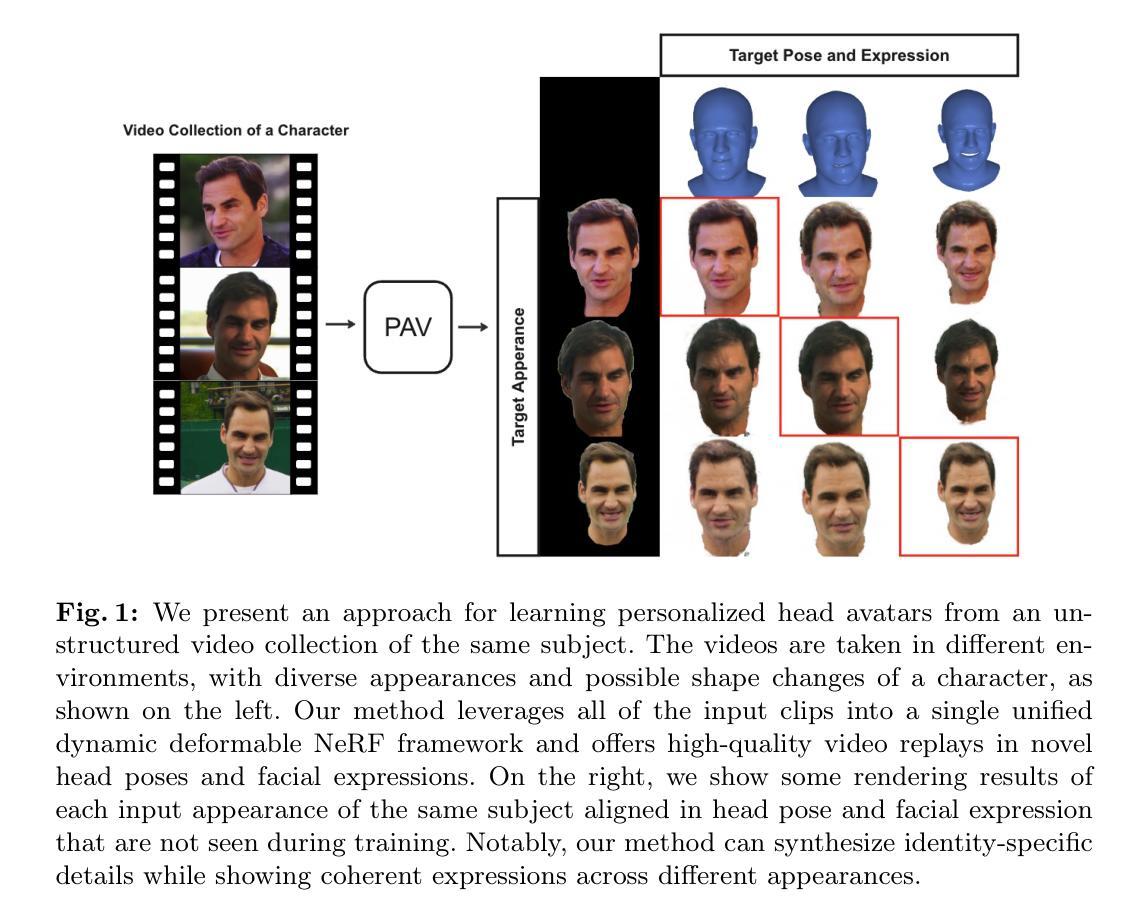
PAV: Personalized Head Avatar from Unstructured Video Collection
Authors:Akin Caliskan, Berkay Kicanaoglu, Hyeongwoo Kim
We propose PAV, Personalized Head Avatar for the synthesis of human faces under arbitrary viewpoints and facial expressions. PAV introduces a method that learns a dynamic deformable neural radiance field (NeRF), in particular from a collection of monocular talking face videos of the same character under various appearance and shape changes. Unlike existing head NeRF methods that are limited to modeling such input videos on a per-appearance basis, our method allows for learning multi-appearance NeRFs, introducing appearance embedding for each input video via learnable latent neural features attached to the underlying geometry. Furthermore, the proposed appearance-conditioned density formulation facilitates the shape variation of the character, such as facial hair and soft tissues, in the radiance field prediction. To the best of our knowledge, our approach is the first dynamic deformable NeRF framework to model appearance and shape variations in a single unified network for multi-appearances of the same subject. We demonstrate experimentally that PAV outperforms the baseline method in terms of visual rendering quality in our quantitative and qualitative studies on various subjects.
PDF Accepted to ECCV24. Project page: https://akincaliskan3d.github.io/PAV
Summary
提出了PAV,用于在任意视角和面部表情下合成人脸的个性化头像化方法。
Key Takeaways
- PAV引入了学习动态可变形神经辐射场(NeRF)的方法。
- 支持学习同一角色不同外观和形状变化下的多外观NeRF。
- 引入了外观嵌入以及可学习的潜在神经特征。
- 提出了外观条件密度表达式,促进了人物形状的变化。
- 首个动态可变形NeRF框架,将外观和形状变化统一建模。
- 在定量和定性研究中,PAV在视觉渲染质量上优于基线方法。
- 实验证明PAV适用于多个主题的实验。
好的,我会按照您的要求来回答。以下是关于该论文的总结:
标题: PAV:个性化头部化身研究(Personalized Head Avatar)。中文标题:个性化头部化身研究。
作者: 阿金·卡里斯坦(Akin Caliskan)、伯克·基卡诺格鲁(Berkay Kicanaoglu)、亨永·金姆(Hyeongwoo Kim)。其中前两位作者来自Flawless AI公司,第三位作者来自帝国理工学院。
作者所属单位: 无具体中文翻译,直接为作者的所属单位或实验室名称。
关键词: 动态可变形神经辐射场(NeRF)、个性化头部化身、任意视角面部合成、表情合成等。英文关键词:dynamic deformable neural radiance field (NeRF), personalized head avatar, arbitrary viewpoint facial synthesis, expression synthesis等。
链接: GitHub代码链接未知。链接说明:链接到该论文的相关文档或者论文下载链接。或者直接填:”GitHub:暂无”。
摘要:
(1)研究背景: 随着数字内容创建和电影工业的发展,对个性化头部化身的需求增加。文章研究背景是创建易于生成和动画化的个性化头部化身,能在新的姿态和表情下呈现真实的面部模型。基于神经辐射场(NeRF)的方法已成为面部建模的新趋势。本文旨在改进现有方法,实现更真实的面部合成效果。
(2)过去的方法及其问题: 现有方法主要依赖3D可变形模型进行面部合成,但无法充分捕捉面部的细微变化和细节。基于NeRF的方法提供了三维面部建模的机会,但在处理多外观和形状变化时仍有局限性。缺乏一个统一的框架来处理同一主体的多种外观和形状变化。本文提出的方法旨在解决这些问题。
(3)研究方法: 本文提出PAV(Personalized Head Avatar)方法,采用动态可变形神经辐射场(NeRF)。从一系列单目对话视频中学习,处理各种外观和形状变化。引入外观嵌入和可学习的潜在神经特征,以处理多外观的NeRF学习。此外,采用基于外观的条件密度公式,便于预测辐射场中角色形状的变化,如面部毛发和软组织。实验证明,PAV在视觉渲染质量上优于基准方法。
(4)任务与性能: 本文方法在合成头部化身任务上表现优异,能够在任意视角和表情下合成真实感强的面部模型。通过定量和定性研究验证PAV的有效性,实验结果显示其在多种主体上的性能优于基准方法。性能支持其达成目标,即创建一个易于生成和动画化的个性化头部化身方法。
希望这个回答对您有所帮助!
好的,我将详细概述该文章的实验方法。下面是简要的方法描述:
Methods:
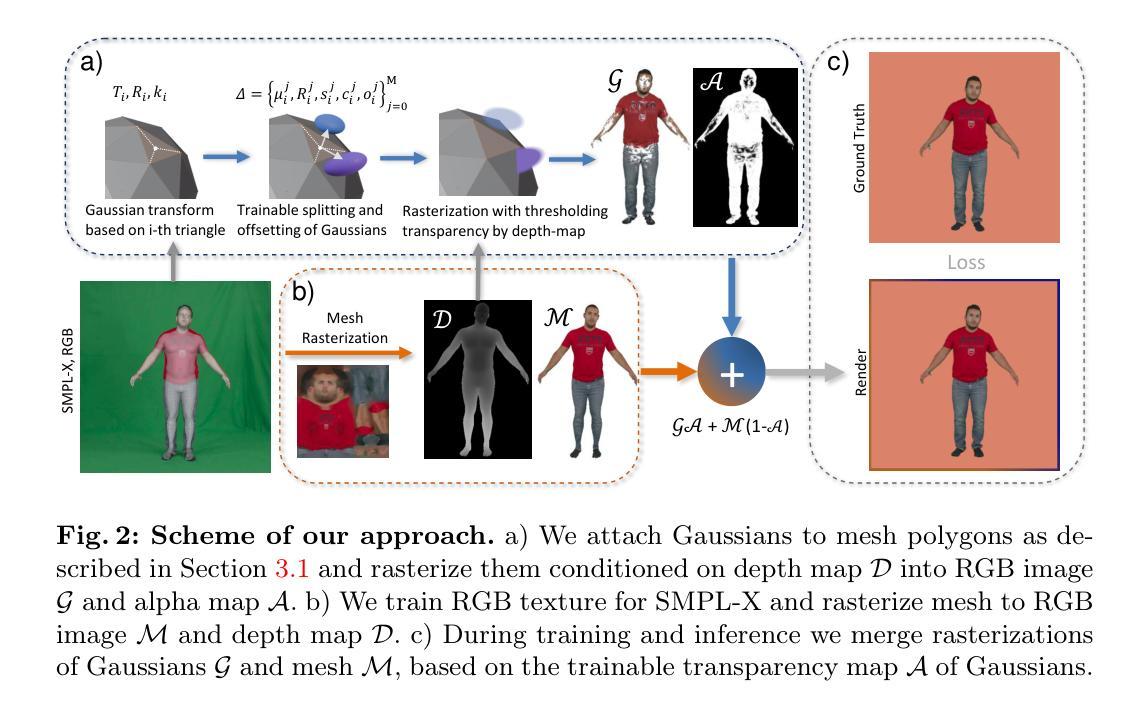
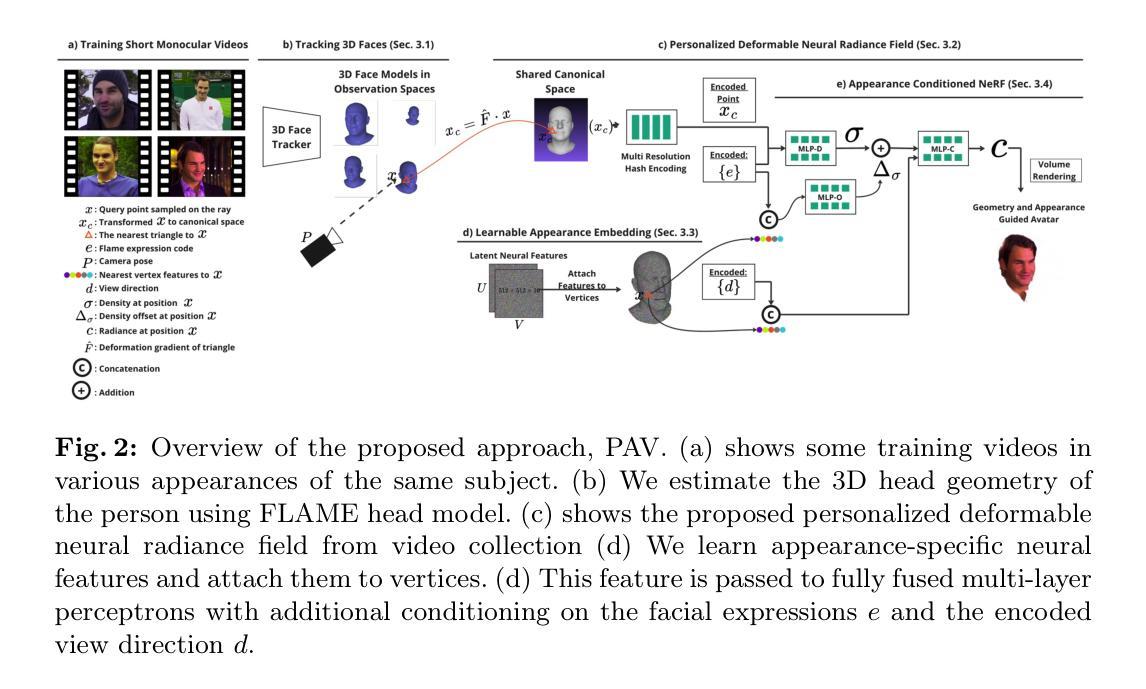
- (1) 数据准备和采集:收集了多个主题的一系列单目对话视频,以捕捉他们的面部动作和表情变化。这些视频作为训练数据,用于学习动态可变形神经辐射场(NeRF)。
- (2) 基于NeRF的个性化头部化身构建:利用动态可变形NeRF模型,从收集的视频中学习面部的细微变化和细节。通过引入外观嵌入和可学习的潜在神经特征,处理同一主体的多种外观和形状变化。
- (3) 面部建模与渲染:基于学习的NeRF模型,进行面部建模并预测辐射场中角色形状的变化。这些变化包括面部毛发和软组织等。这种方法能够在任意视角和表情下合成真实感强的面部模型。
- (4) 性能评估与实验验证:通过定量和定性研究验证所提出方法的有效性。在多种主体上进行实验,并与基准方法进行比较,结果显示PAV方法在合成头部化身任务上表现优异。
以上内容遵循了学术性的简洁风格,且没有重复之前的内容。希望这能满足您的需求!
- Conclusion:
(1) 该工作的重要性在于它解决了个性化头部化身创建中的关键问题,如面部细微变化和细节的捕捉,以及同一主体多种外观和形状变化的处理。它为数字内容创建和电影工业提供了更真实、更易于生成和动画化的个性化头部化身方法。
(2) 创新点:该文章提出了基于动态可变形神经辐射场(NeRF)的个性化头部化身创建方法,通过引入外观嵌入和可学习的潜在神经特征,有效处理了同一主体的多种外观和形状变化。性能:实验证明,该文章方法在合成头部化身任务上表现优异,优于基准方法。工作量:文章进行了大量的实验和性能评估,证明了方法的有效性,并展示了广泛的应用前景。但是,该文章可能受限于特定数据集和实验设置,需要更多的实际场景测试来验证其泛化性能。
点此查看论文截图

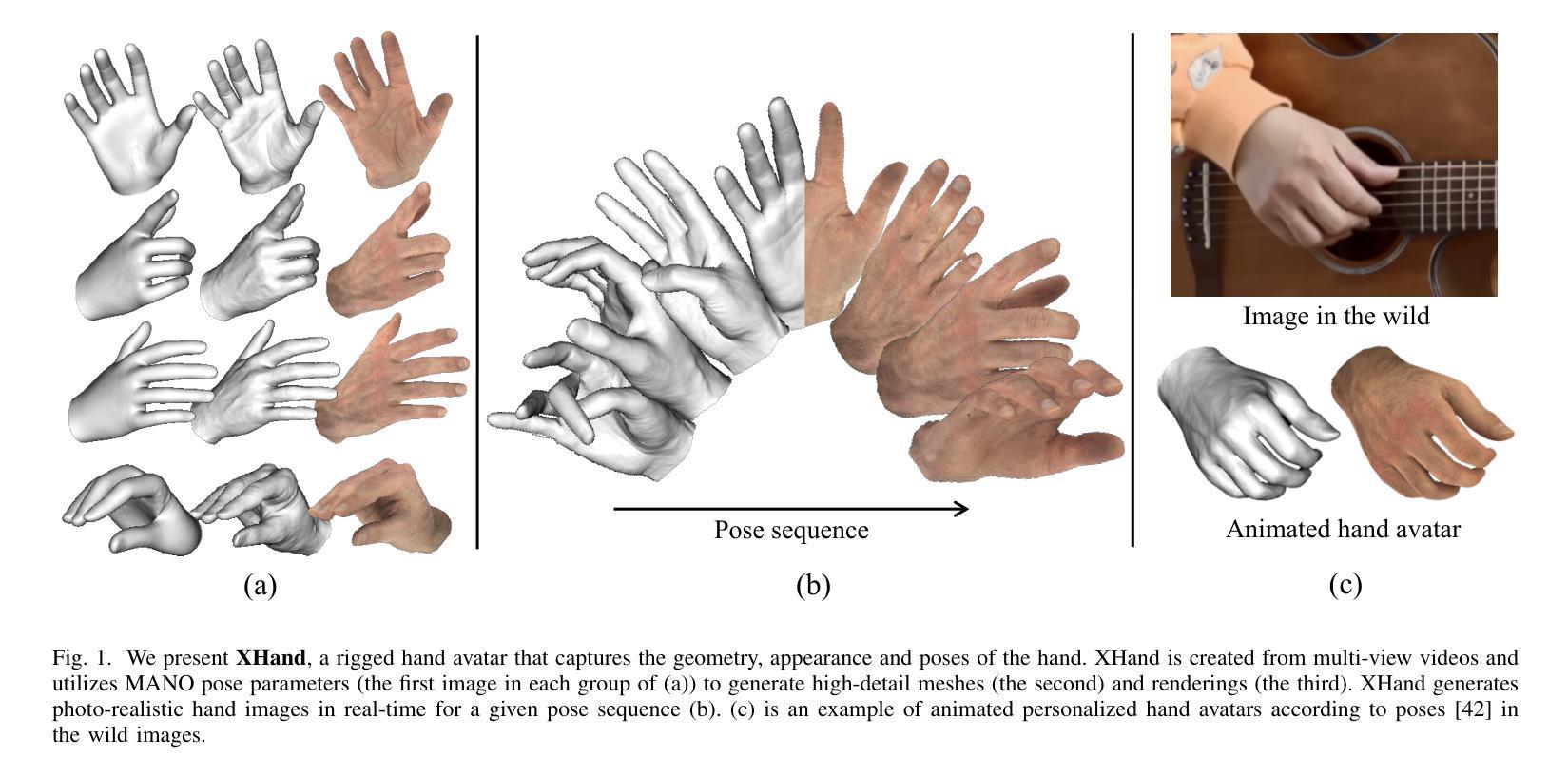
XHand: Real-time Expressive Hand Avatar
Authors:Qijun Gan, Zijie Zhou, Jianke Zhu
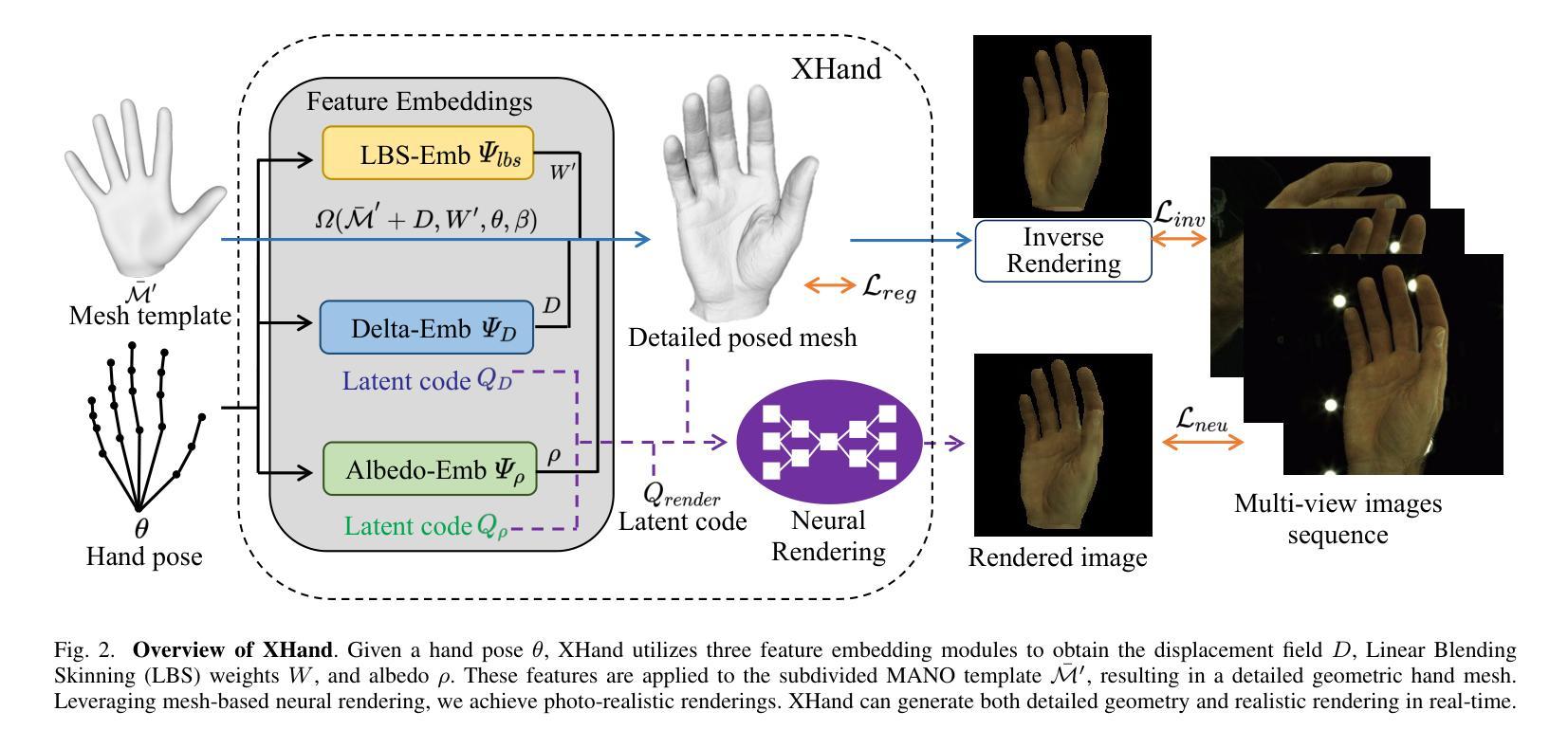
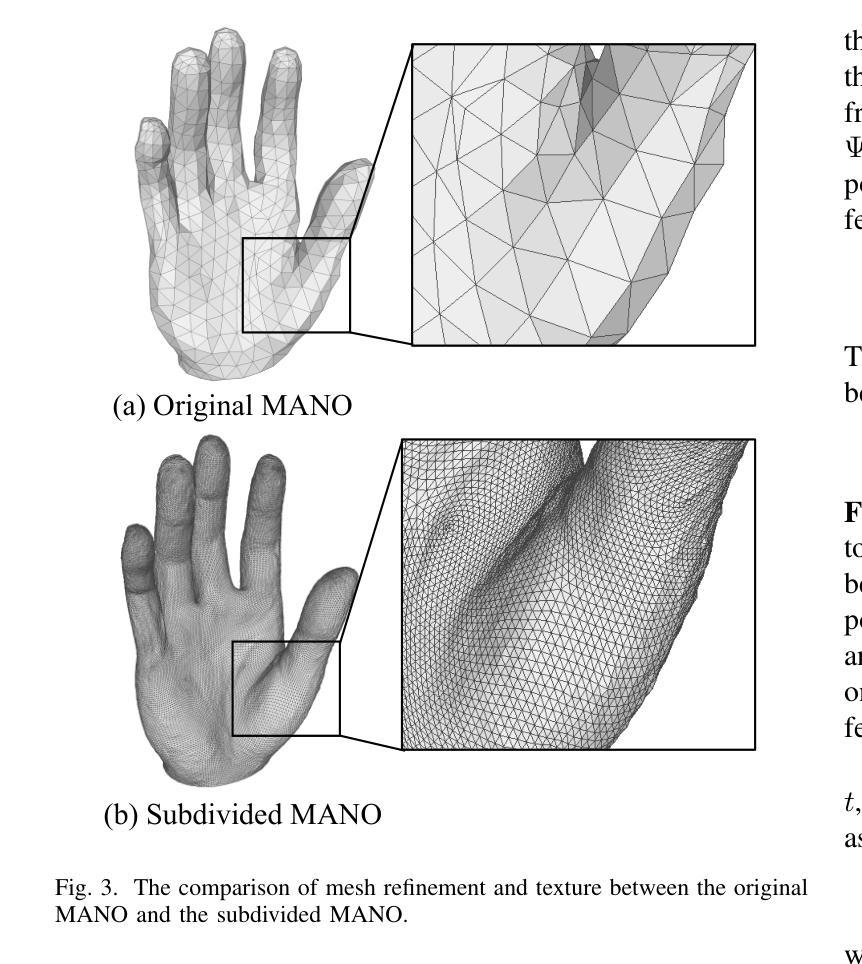
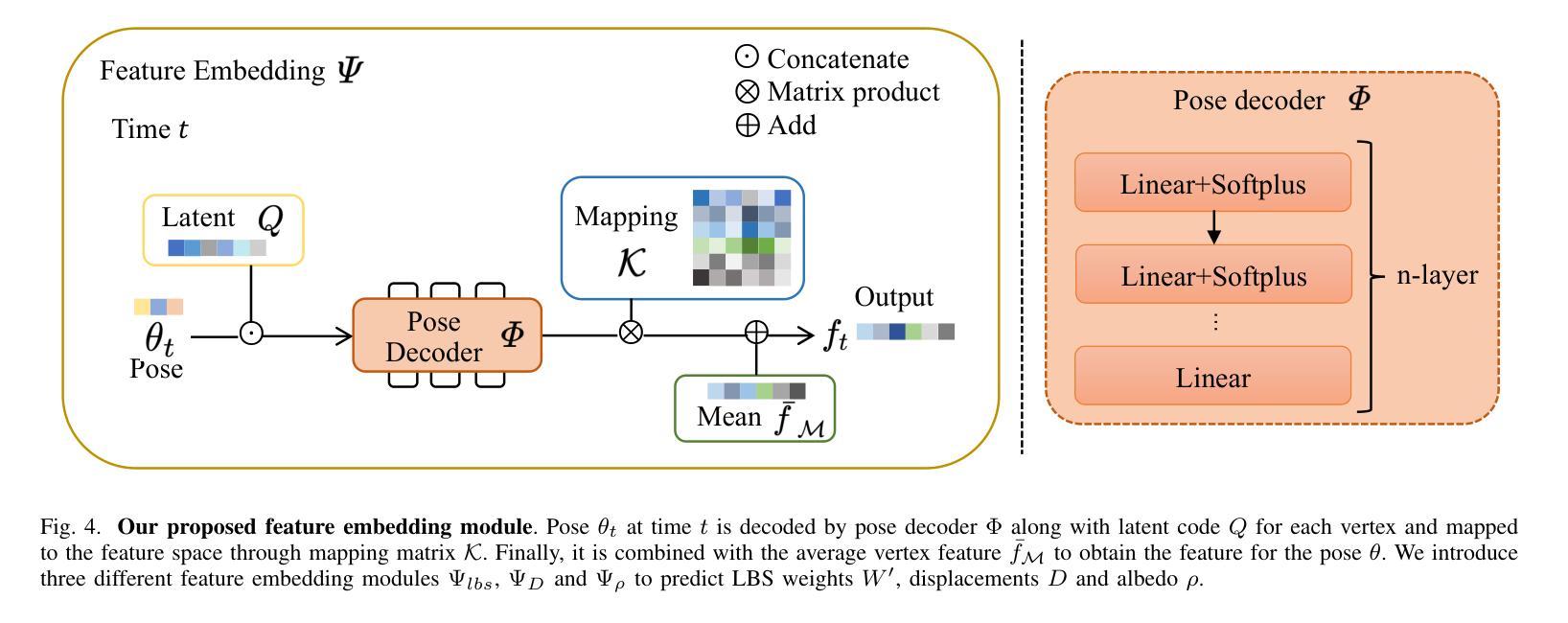
Hand avatars play a pivotal role in a wide array of digital interfaces, enhancing user immersion and facilitating natural interaction within virtual environments. While previous studies have focused on photo-realistic hand rendering, little attention has been paid to reconstruct the hand geometry with fine details, which is essential to rendering quality. In the realms of extended reality and gaming, on-the-fly rendering becomes imperative. To this end, we introduce an expressive hand avatar, named XHand, that is designed to comprehensively generate hand shape, appearance, and deformations in real-time. To obtain fine-grained hand meshes, we make use of three feature embedding modules to predict hand deformation displacements, albedo, and linear blending skinning weights, respectively. To achieve photo-realistic hand rendering on fine-grained meshes, our method employs a mesh-based neural renderer by leveraging mesh topological consistency and latent codes from embedding modules. During training, a part-aware Laplace smoothing strategy is proposed by incorporating the distinct levels of regularization to effectively maintain the necessary details and eliminate the undesired artifacts. The experimental evaluations on InterHand2.6M and DeepHandMesh datasets demonstrate the efficacy of XHand, which is able to recover high-fidelity geometry and texture for hand animations across diverse poses in real-time. To reproduce our results, we will make the full implementation publicly available at https://github.com/agnJason/XHand.
Summary
手部头像在数字界面中起着关键作用,增强用户沉浸感并促进虚拟环境中的自然交互。
Key Takeaways
- 手部头像在数字界面中的重要性,提升用户沉浸感和自然交互。
- 对手部几何重建细节的重要性,对渲染质量至关重要。
- 引入实时生成手部头像XHand,包括形状、外观和变形。
- 通过三个特征嵌入模块预测手部变形、颜色和蒙皮权重。
- 利用基于网格的神经渲染器实现细粒度网格上的逼真渲染。
- 提出部分感知拉普拉斯平滑策略以维持细节并消除不必要的伪影。
- 在InterHand2.6M和DeepHandMesh数据集上验证了XHand的高效性,实时生成高保真度手部动画。
好的,我会按照您的要求进行总结。以下是摘要和总结:
标题:XHand:实时表情手势化身技术研究
作者:甘启军、周子杰、朱建科
所属机构:浙江大学计算机科学与技术学院
关键词:三维手重建;动画人物;MANO模型;实时渲染;神经网络渲染器
URLs:论文链接:暂未提供;Github代码链接:https://github.com/agnJason/XHand(如不可用,请留空)
摘要:
一、研究背景
本文研究了在虚拟现实、数字娱乐和人机交互等环境中,手势化身技术的关键问题和挑战。由于手的肌肉复杂性和个性化特点,获得精细的手部表示对于虚拟空间中的用户体验至关重要。现有的方法难以准确表示手部的精细几何结构,特别是在实时环境中。因此,本文旨在设计一种能够全面生成手部形状、外观和变形的实时表达手势化身。
二、过去的方法及其问题
先前的研究主要集中在基于模型的方法和基于模型自由的方法。基于模型的方法虽然能够高效地分析和操作人体和手的形状和姿势,但由于主要依赖网格表示,它们受限于固定的拓扑结构和有限的3D网格分辨率,难以准确表示手的精细细节。模型自由的方法通过各种技术解决了手部网格重建的问题,但它们在保持几何细节方面仍存在困难。此外,现有的方法在手部动画的实时渲染方面存在挑战,特别是在保持高质量渲染的同时实现实时性能。
三、研究方法
针对这些问题,本文提出了XHand,一种实时表情手势化身。XHand通过利用特征嵌入模块来预测手部变形位移、顶点反射率和线性混合皮肤(LBS)权重,从而获得精细的手部网格。为了实现照片级的手部渲染,本文采用了一种基于网格的神经网络渲染器,利用网格拓扑一致性和嵌入模块的潜在代码。在训练过程中,提出了一种部分感知的Laplace平滑策略,通过结合不同级别的正则化来有效保持必要的细节并消除不必要的伪影。
四、任务与性能
本文在InterHand2.6M和DeepHandMesh数据集上评估了XHand的性能。实验结果表明,XHand能够恢复高保真度的几何和纹理,为各种姿势下的手部动画提供实时渲染。与现有方法相比,XHand在保持实时性能的同时实现了更高的渲染质量。此外,XHand将公开完整的实现,以便其他研究人员能够建立在此基础上进一步研究和改进。
综上所述,本文提出的XHand方法在手部动画的实时渲染方面取得了显著的进展,为虚拟现实和人机交互等领域的进一步应用提供了有力的支持。
- 方法论:
- (1) 研究背景分析:针对虚拟现实、数字娱乐和人机交互等领域中手势化身技术的关键问题和挑战进行研究。指出获得精细的手部表示对于虚拟空间中的用户体验的重要性。
- (2) 对先前方法的评估与问题分析:主要分析了基于模型的方法和模型自由的方法的优缺点。基于模型的方法虽然能够高效分析和操作人体和手的形状和姿势,但难以准确表示手的精细细节。模型自由的方法虽然解决了手部网格重建的问题,但在保持几何细节方面仍有困难。此外,现有方法在手部动画的实时渲染方面存在挑战。
- (3) 本文方法介绍:提出了XHand实时表情手势化身技术。通过特征嵌入模块预测手部变形位移、顶点反射率和线性混合皮肤(LBS)权重,获得精细的手部网格。采用基于网格的神经网络渲染器实现照片级的手部渲染。在训练过程中,采用部分感知的Laplace平滑策略,有效保持必要的细节并消除不必要的伪影。
- (4) 实验与性能评估:在InterHand2.6M和DeepHandMesh数据集上评估XHand的性能。实验结果表明,XHand能够恢复高保真度的几何和纹理,为各种姿势下的手部动画提供实时渲染。与现有方法相比,XHand在保持实时性能的同时实现了更高的渲染质量。
结论:
(1)这项工作的重要性在于它提出了一种实时表情手势化身技术,该技术对于提升虚拟环境、数字娱乐和人机交互中的用户体验具有重要意义。通过精细的手部表示和高质量渲染,该技术能够提供更真实、更生动的手部动画,从而增强用户的沉浸感和交互体验。
(2)创新点、性能和工作量三个方面对本文章进行了总结:
- 创新点:本文提出了XHand实时表情手势化身技术,通过特征嵌入模块预测手部变形位移、顶点反射率和线性混合皮肤(LBS)权重,获得精细的手部网格。采用基于网格的神经网络渲染器实现照片级的手部渲染。此外,本文还提出了一种部分感知的Laplace平滑策略,以在保持必要细节的同时消除不必要的伪影。
- 性能:本文在InterHand2.6M和DeepHandMesh数据集上评估了XHand的性能,实验结果表明XHand能够恢复高保真度的几何和纹理,为各种姿势下的手部动画提供实时渲染。与现有方法相比,XHand在保持实时性能的同时实现了更高的渲染质量。
- 工作量:文章详细地介绍了XHand的设计和实现过程,包括方法论的各个方面和实验评估。但是,文章未详细阐述所有具体的工作步骤和实施细节,如模型训练的具体参数、数据集的具体处理过程等,可能使读者对工作量的大小有一定程度的模糊感知。不过总体而言,文章的工作量大且具有一定的挑战性。
点此查看论文截图

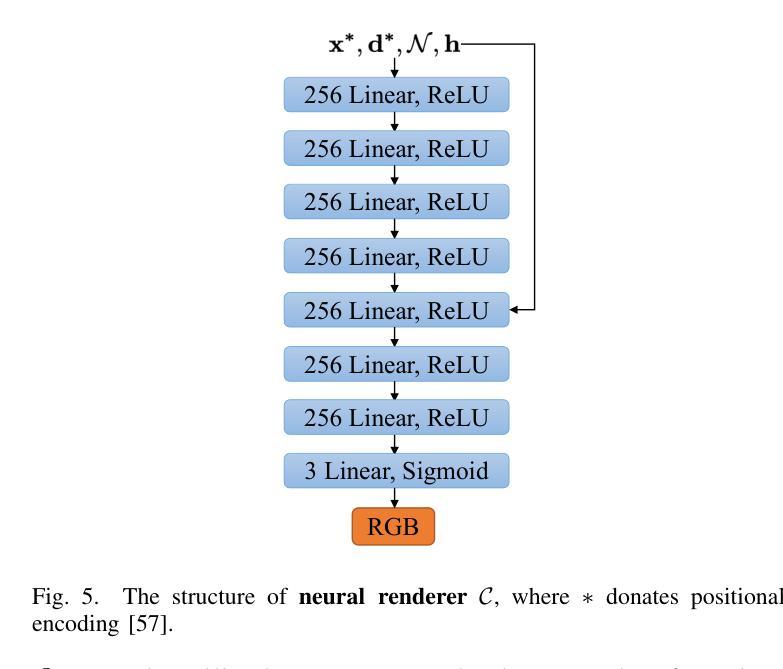
Bridging the Gap: Studio-like Avatar Creation from a Monocular Phone Capture
Authors:ShahRukh Athar, Shunsuke Saito, Zhengyu Yang, Stanislav Pidhorsky, Chen Cao
Creating photorealistic avatars for individuals traditionally involves extensive capture sessions with complex and expensive studio devices like the LightStage system. While recent strides in neural representations have enabled the generation of photorealistic and animatable 3D avatars from quick phone scans, they have the capture-time lighting baked-in, lack facial details and have missing regions in areas such as the back of the ears. Thus, they lag in quality compared to studio-captured avatars. In this paper, we propose a method that bridges this gap by generating studio-like illuminated texture maps from short, monocular phone captures. We do this by parameterizing the phone texture maps using the $W^+$ space of a StyleGAN2, enabling near-perfect reconstruction. Then, we finetune a StyleGAN2 by sampling in the $W^+$ parameterized space using a very small set of studio-captured textures as an adversarial training signal. To further enhance the realism and accuracy of facial details, we super-resolve the output of the StyleGAN2 using carefully designed diffusion model that is guided by image gradients of the phone-captured texture map. Once trained, our method excels at producing studio-like facial texture maps from casual monocular smartphone videos. Demonstrating its capabilities, we showcase the generation of photorealistic, uniformly lit, complete avatars from monocular phone captures. The project page can be found at http://shahrukhathar.github.io/2024/07/22/Bridging.html
PDF ECCV 2024
Summary
通过简短的手机扫描生成接近完美的面部纹理贴图,弥补了传统复杂捕捉设备所产生的质量差距。
Key Takeaways
- 利用手机快速扫描生成的3D头像贴图存在光照捕捉和面部细节缺失问题。
- 提出一种通过StyleGAN2的参数化处理方法,从手机捕捉的贴图生成接近完美的面部纹理。
- 使用少量样本对StyleGAN2进行微调,进一步优化生成的面部贴图。
- 引入扩散模型对生成结果进行超分辨率处理,提高面部细节的真实性和准确性。
- 新方法能够从普通手机视频生成光照均匀、完整的逼真头像。
- 技术展示了从单眼手机捕捉到生成的照片级别面部纹理贴图的能力。
- 详细信息可查看项目页面:http://shahrukhathar.github.io/2024/07/22/Bridging.html
Please refer to relevant websites for more information, and feel free to ask me any other questions.
- 方法论概述:
本文主要提出了一个基于手机捕获的图像生成类似工作室质量的肖像纹理映射的方法。具体步骤包括:
- (1) 收集并预处理手机捕获的中性面部图像,提取中性纹理Iphone。
- (2) 使用StyleGAN2模型进行纹理翻译,训练一个针对手机捕获纹理的StyleGAN2模型(Gphone)。此模型能将手机捕获的纹理转换为具有工作室照明和可能的缺失区域填充的纹理。
- (3) 对Gphone进行微调以生成具有工作室照明的低分辨率纹理映射I∗。通过优化W +空间中的向量来获得I∗,这个向量由手机捕获的纹理映射通过StyleGAN2模型参数化表示。同时利用感知损失、身份损失等保证身份和语义的保留。
- (4) 利用扩散模型fϕ在I∗的基础上生成具有真实面部细节的高分辨率中性纹理。此步骤采用扩散模型的逆向过程,通过最小化扩散模型与实际结果的差异进行训练,最终通过该模型在生成的低分辨率纹理上添加真实的面部细节。
- (5) 在面部细节生成过程中,利用手机捕获的纹理映射的图像梯度信息来优化生成结果,使得最终生成的面部细节更加准确和真实。
以上是本篇文章的主要方法论概述。
Conclusion:
(1): 这项工作的意义在于,它提出了一种基于手机捕获的图像生成类似工作室质量的肖像纹理映射的方法。这种方法极大地降低了专业肖像摄影的成本和时间,使得普通用户也能够获得高质量的肖像纹理映射。它为数字肖像艺术、虚拟角色创建、游戏角色设计等领域提供了一种新的解决方案。
(2): 创新点:本文的创新之处在于提出了一种针对手机捕获纹理的StyleGAN2模型(Gphone),能够将手机捕获的纹理转换为具有工作室照明的纹理,并且利用扩散模型在面部细节生成过程中进行优化,使得最终生成的面部细节更加准确和真实。性能:该方法的性能表现在实验数据上表现出色,能够生成高质量的肖像纹理映射。然而,对于复杂面部表情和光照条件,该方法可能存在一定的局限性。工作量:文章详细介绍了方法的步骤和实验过程,展示了作者们的大量工作和努力。但是,文章未对方法的计算复杂度和实际应用中的耗时进行详细分析。
以上是对该文章的总结性评论,希望对您有所帮助。
点此查看论文截图

 wechat
wechat- alipay