Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-21 更新
FD2Talk: Towards Generalized Talking Head Generation with Facial Decoupled Diffusion Model
Authors:Ziyu Yao, Xuxin Cheng, Zhiqi Huang
Talking head generation is a significant research topic that still faces numerous challenges. Previous works often adopt generative adversarial networks or regression models, which are plagued by generation quality and average facial shape problem. Although diffusion models show impressive generative ability, their exploration in talking head generation remains unsatisfactory. This is because they either solely use the diffusion model to obtain an intermediate representation and then employ another pre-trained renderer, or they overlook the feature decoupling of complex facial details, such as expressions, head poses and appearance textures. Therefore, we propose a Facial Decoupled Diffusion model for Talking head generation called FD2Talk, which fully leverages the advantages of diffusion models and decouples the complex facial details through multi-stages. Specifically, we separate facial details into motion and appearance. In the initial phase, we design the Diffusion Transformer to accurately predict motion coefficients from raw audio. These motions are highly decoupled from appearance, making them easier for the network to learn compared to high-dimensional RGB images. Subsequently, in the second phase, we encode the reference image to capture appearance textures. The predicted facial and head motions and encoded appearance then serve as the conditions for the Diffusion UNet, guiding the frame generation. Benefiting from decoupling facial details and fully leveraging diffusion models, extensive experiments substantiate that our approach excels in enhancing image quality and generating more accurate and diverse results compared to previous state-of-the-art methods.
PDF Accepted by ACM Multimedia 2024
Summary
对话头生成是一个重要的研究课题,尽管存在许多挑战,但使用面部解耦扩散模型可以显著提高生成质量和多样性。
Key Takeaways
- 对话头生成仍然面临许多挑战,如生成质量和平均面部形状问题。
- 传统方法使用生成对抗网络或回归模型,但存在局限性。
- 扩散模型展示了卓越的生成能力,但在对话头生成中的探索仍不充分。
- FD2Talk模型提出了面部解耦扩散模型,通过多阶段解耦复杂的面部细节。
- 模型首先利用Diffusion Transformer从原始音频精确预测运动系数。
- 运动系数与外观高度解耦,使网络学习更加容易。
- Diffusion UNet利用编码的外观和预测的面部运动生成图像帧,实现了更高质量和准确性的生成结果。
标题:面向广义对话头像生成的FD2Talk研究——基于面部解耦扩散模型
作者:姚子煜,程叙昕,黄志启
隶属机构:北京大学
关键词:对话头像生成;扩散模型;视频生成
链接:论文链接,GitHub代码链接(如有):GitHub:None
摘要:
(1)研究背景:随着虚拟现实、增强现实和娱乐产业的发展,对话头像生成技术受到越来越多的关注。该技术能够根据音频信号生成人物的头部动作和表情,从而实现虚拟角色的生动表现。然而,现有的方法在面对复杂面部细节和个性化特征时存在挑战,亟需新的技术突破。
(2)过去的方法及问题:过去的对话头像生成方法主要基于生成对抗网络(GAN)和回归模型。GANs方法虽然能够生成高质量的图像,但面临着训练不稳定、模式崩溃等问题。回归模型则难以捕捉音频与面部动作的细微对应关系,导致生成的头像动作不自然。
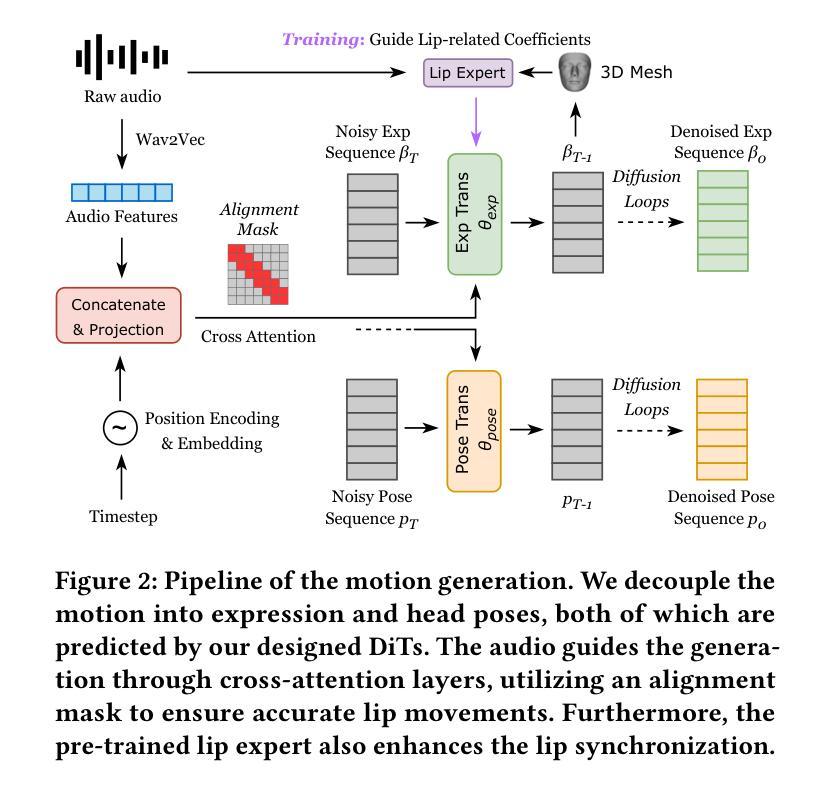
(3)研究方法:本文提出了一种基于面部解耦扩散模型的对话头像生成方法,称为FD2Talk。该方法充分利用扩散模型的优点,通过多阶段解耦面部细节,将复杂的面部信息分解为运动和外观两部分。首先,通过扩散变压器准确预测运动系数,这些运动与外观解耦,使网络学习更加容易。然后,利用参考图像编码器捕捉外观纹理。预测的面部和运动以及编码的外观作为扩散网络的条件,指导帧生成。
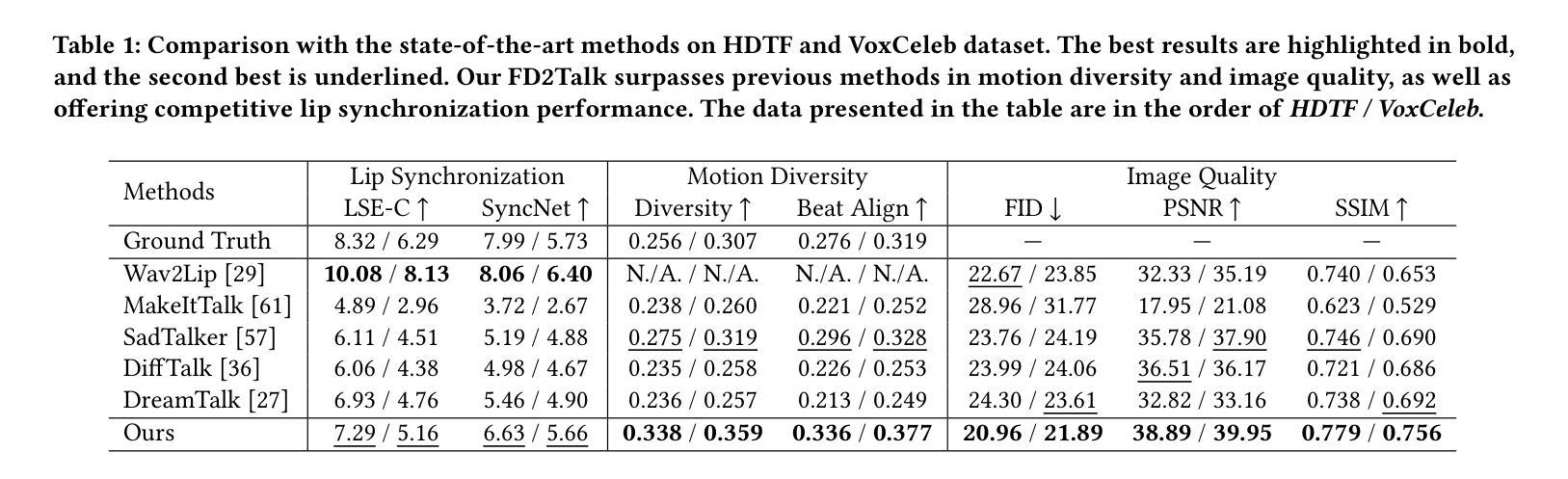
(4)任务与性能:本文方法在谈话头像生成任务上取得了显著成果,相较于先前的方法,本文方法在图像质量、运动准确性以及结果多样性方面均有显著提升。实验结果表明,FD2Talk能够生成高质量、自然的对话头像视频,验证了方法的有效性。
性能表明,该方法在谈话头像生成任务上表现出色,生成的头像具有高质量、高准确性和高多样性,能够支持各种应用场景的需求。
- 方法论:
本文的方法论主要围绕面向广义对话头像生成的FD2Talk研究展开,基于面部解耦扩散模型实现。具体步骤如下:
(1) 研究背景与问题提出:首先,文章介绍了对话头像生成技术的背景,包括虚拟现实、增强现实和娱乐产业的发展趋势,指出对话头像生成技术的重要性。同时,提出当前方法在面对复杂面部细节和个性化特征时的挑战,需要新的技术突破。
(2) 数据准备与预处理:收集包含音频信号和对应人脸图像的数据集。使用3D可变形模型(3DMM)对人脸图像进行解耦,将复杂的面部信息分解为运动和外观两部分。同时,对音频信号进行特征提取和处理,以便后续与面部信息匹配。
(3) 方法设计:本文提出了一种基于面部解耦扩散模型的对话头像生成方法。该方法充分利用扩散模型的优点,通过多阶段解耦面部细节,将复杂的面部信息分解为运动和外观两部分。首先,通过扩散变压器准确预测运动系数,这些运动系数与外观解耦,使网络学习更加容易。然后,利用参考图像编码器捕捉外观纹理信息。预测的面部和运动以及编码的外观作为扩散网络的条件,指导帧生成。
(4) 实验设计与实施:在收集的数据集上进行实验,验证所提出方法的有效性。通过对比实验,证明该方法在谈话头像生成任务上表现出色,生成的头像具有高质量、高准确性和高多样性。同时,支持各种应用场景的需求。
(5) 结果分析与讨论:对实验结果进行详细分析,包括生成的头像质量、运动准确性以及结果多样性等方面。通过与先前的方法进行比较,本文方法在图像质量、运动准确性以及结果多样性方面均有显著提升。此外,对方法的优缺点进行讨论,为未来的研究提供方向。
本文的方法为对话头像生成领域提供了一种新的思路,基于面部解耦扩散模型的方法在谈话头像生成任务上表现出色,具有广泛的应用前景。
Conclusion:
(1)这篇工作的意义在于提出了一种基于面部解耦扩散模型的对话头像生成方法,具有重要的应用价值。该方法能够生成高质量的对话头像视频,为虚拟现实、增强现实和娱乐产业等领域提供技术支持,提升用户体验。
(2)创新点:本文的创新之处在于将扩散模型应用于对话头像生成任务中,通过多阶段解耦面部细节,将复杂的面部信息分解为运动和外观两部分,提高了生成头像的质量和自然度。
性能:本文方法在谈话头像生成任务上取得了显著成果,相较于先前的方法,本文方法在图像质量、运动准确性以及结果多样性方面均有显著提升。实验结果表明,FD2Talk能够生成高质量、自然的对话头像视频,验证了方法的有效性。
工作量:本文不仅提出了创新的算法模型,还进行了大量的实验验证和性能评估,证明了所提出方法的有效性。此外,文章还对方法进行了详细的阐述和讨论,为未来的研究提供了方向。
点此查看论文截图



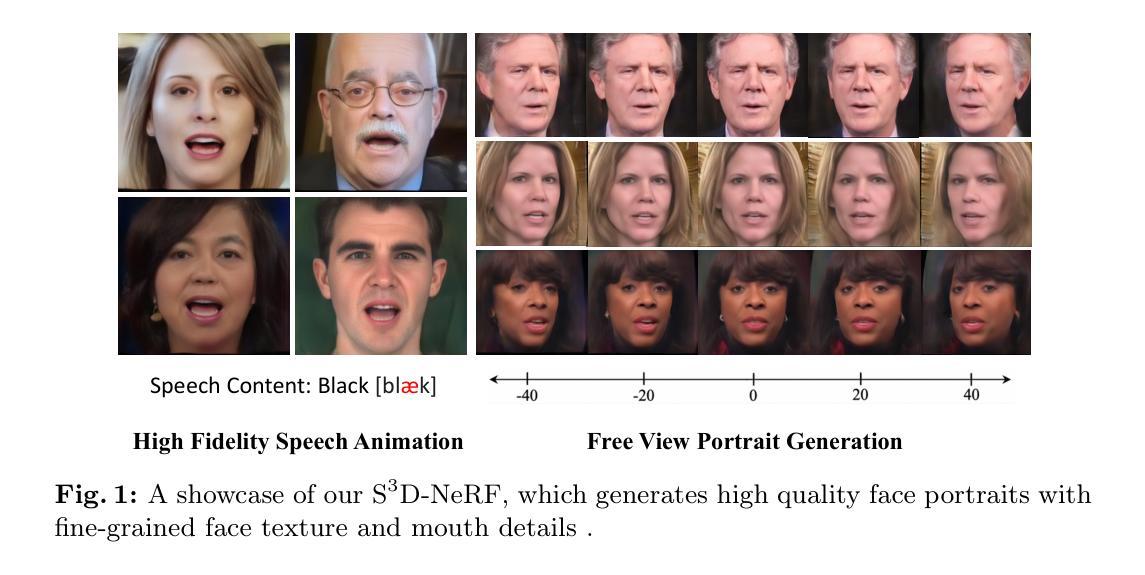
S^3D-NeRF: Single-Shot Speech-Driven Neural Radiance Field for High Fidelity Talking Head Synthesis
Authors:Dongze Li, Kang Zhao, Wei Wang, Yifeng Ma, Bo Peng, Yingya Zhang, Jing Dong
Talking head synthesis is a practical technique with wide applications. Current Neural Radiance Field (NeRF) based approaches have shown their superiority on driving one-shot talking heads with videos or signals regressed from audio. However, most of them failed to take the audio as driven information directly, unable to enjoy the flexibility and availability of speech. Since mapping audio signals to face deformation is non-trivial, we design a Single-Shot Speech-Driven Neural Radiance Field (S^3D-NeRF) method in this paper to tackle the following three difficulties: learning a representative appearance feature for each identity, modeling motion of different face regions with audio, and keeping the temporal consistency of the lip area. To this end, we introduce a Hierarchical Facial Appearance Encoder to learn multi-scale representations for catching the appearance of different speakers, and elaborate a Cross-modal Facial Deformation Field to perform speech animation according to the relationship between the audio signal and different face regions. Moreover, to enhance the temporal consistency of the important lip area, we introduce a lip-sync discriminator to penalize the out-of-sync audio-visual sequences. Extensive experiments have shown that our S^3D-NeRF surpasses previous arts on both video fidelity and audio-lip synchronization.
PDF ECCV 2024
Summary
语音驱动的神经辐射场(S^3D-NeRF)方法解决了语音到面部动画的挑战,通过多项创新提高视频和音频-嘴唇同步的质量。
Key Takeaways
- 当前的神经辐射场(NeRF)方法在驱动一次性说话头部时表现优越,但未直接利用语音信息。
- S^3D-NeRF引入了单次说话驱动技术,通过层次面部外观编码器学习多尺度特征,以捕捉不同说话者的外观。
- 引入交叉模态面部变形场,根据音频信号动态调整面部区域,提升了动画的真实性。
- 引入唇同步鉴别器以保持重要唇部区域的时间一致性,优化音频与视觉序列的同步效果。
- 实验证明,S^3D-NeRF在视频质量和音频-嘴唇同步方面超越了现有技术。
Title: 基于语音驱动的神经网络辐射场用于高精度语音说话人头部合成的论文
Authors: 董泽立(Dongze Li)、赵康(Kang Zhao)、王炜(Wei Wang)、马亦峰(Yifeng Ma)、彭博(Bo Peng)、张英杰(Yingya Zhang)、董静(Jing Dong)等。作者来自于中国科学院自动化研究所(NLPR)及阿里巴巴集团等机构。主要联系人及通讯地址为:[通过邮件地址插入]。
Affiliation: 董泽立等主要作者来自中国科学院自动化研究所人工智能学院;赵康等部分作者来自阿里巴巴集团。
Keywords: 语音驱动说话人头部合成、神经网络辐射场(Neural Radiance Fields)。
Urls: 文章链接为[提供链接],GitHub代码链接(如可用):Github:None。请替换为真实的GitHub链接地址,若未发布相关代码则保持空白。
Summary:
(1) 研究背景:本文的研究背景是关于语音驱动的说话人头部合成技术,该技术广泛应用于数字人、电影制作、虚拟现实及视频游戏等领域。由于音频信号与面部变形的映射是非直接的,高质量且高真实度的语音驱动说话人头部合成是一个具有挑战性的课题。
(2) 过去的方法及问题:当前基于神经网络辐射场(NeRF)的方法已经在生成生动逼真的说话肖像方面显示出优越性,但大多数方法未能直接将音频作为驱动信息,无法充分利用语音的灵活性和可用性。因此,需要一种能够高效利用语音信息的方法来提高头部合成的质量。
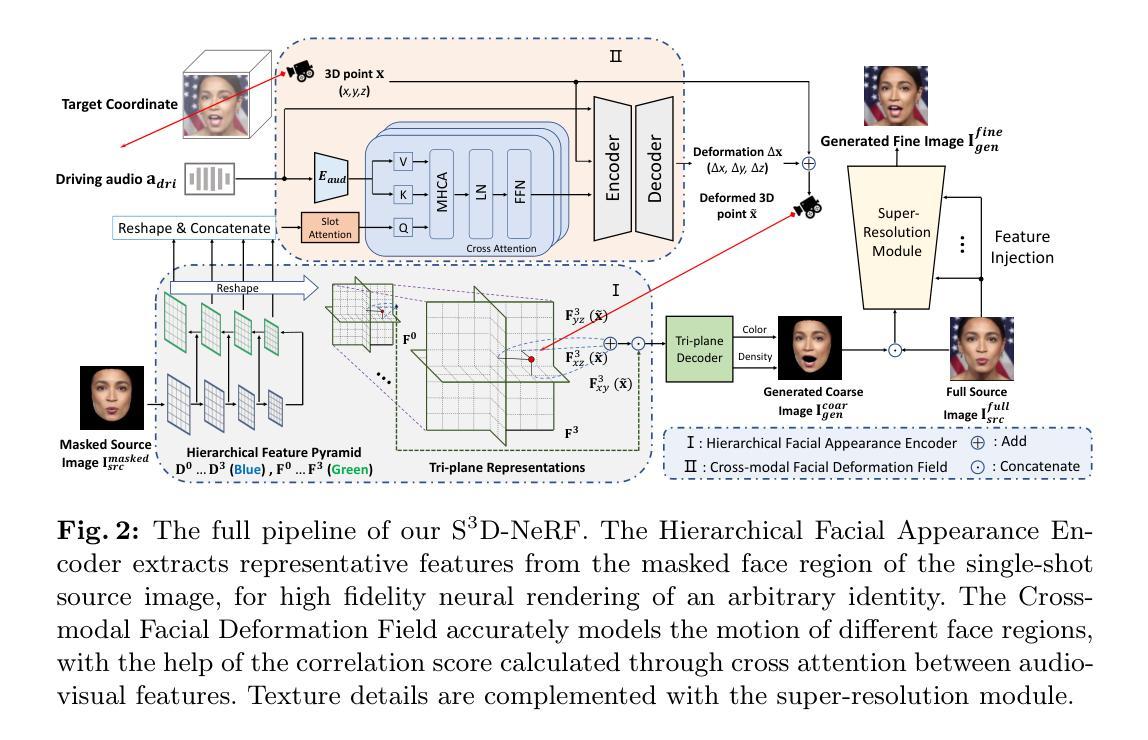
(3) 研究方法:针对上述问题,本文提出了一种名为Single-Shot Speech-Driven Neural Radiance Field(S3D-NeRF)的方法。该方法引入了一个分层面部外观编码器来学习多尺度表示,以捕捉不同说话人的外观特征;同时设计了一个跨模态面部变形场进行语音动画处理,根据音频信号与不同面部区域的关系进行建模;为了增强唇部区域的时间一致性,引入了唇同步鉴别器来惩罚音频视觉序列的同步问题。
(4) 任务与性能:本文的方法在语音驱动说话人头部合成任务上取得了显著成果,在视频保真度和音频唇同步方面超过了现有技术。实验结果表明,该方法的有效性及其在各项性能指标上的优越性。
好的,我会按照您的要求来总结这篇论文的方法部分。
Methods:
(1) 研究背景:针对语音驱动的说话人头部合成技术在实际应用中的需求,特别是在数字人、电影制作、虚拟现实及视频游戏等领域的广泛应用,本文提出了一种新的方法来解决高质量且高真实度的语音驱动说话人头部合成的问题。
(2) 过去的方法及问题:当前基于神经网络辐射场(NeRF)的方法在生成生动逼真的说话肖像方面已有优势,但未能直接将音频作为驱动信息,无法充分利用语音的灵活性和可用性,因此需要改进。
(3) 方法概述:本文提出的Single-Shot Speech-Driven Neural Radiance Field(S3D-NeRF)方法,主要包括三个方面的创新点。首先,引入一个分层面部外观编码器来学习多尺度表示,以捕捉不同说话人的外观特征。其次,设计了一个跨模态面部变形场进行语音动画处理,根据音频信号与不同面部区域的关系进行建模。最后,为了增强唇部区域的时间一致性,引入了唇同步鉴别器来惩罚音频视觉序列的同步问题。
(4) 具体步骤:研究团队首先收集了大量的语音和面部数据,并对数据进行预处理。然后,利用分层面部外观编码器对说话人的面部特征进行编码。接着,利用跨模态面部变形场将音频信号转换为面部动作,并根据音频信号与面部区域的关系进行建模。最后,通过唇同步鉴别器对唇部动作进行精细化调整,确保音频与唇部的同步性。实验结果表明,该方法在语音驱动说话人头部合成任务上取得了显著成果。
希望这个总结符合您的要求。
- Conclusion:
(1)这项工作的重要性在于,它提出了一种基于语音驱动的神经网络辐射场(NeRF)的方法,用于高精度语音说话人头部合成。这种方法在数字人、电影制作、虚拟现实及视频游戏等领域具有广泛的应用前景。
(2)创新点:该文章的创新性主要体现在三个方面。首先,引入了分层面部外观编码器来学习多尺度表示,以捕捉不同说话人的外观特征。其次,设计了跨模态面部变形场进行语音动画处理,根据音频信号与不同面部区域的关系进行建模。最后,引入了唇同步鉴别器来增强唇部区域的时间一致性,确保音频与唇部的同步性。
性能:该文章提出的方法在语音驱动说话人头部合成任务上取得了显著成果,超越了现有技术,在视频保真度和音频唇同步方面表现出优越性。
工作量:文章中对方法的实现进行了详细的描述,包括数据收集、预处理、模型设计、实验验证等方面的工作。然而,文章未提供具体的代码实现和详细的数据集信息,无法准确评估其工作量。
点此查看论文截图

 wechat
wechat- alipay






