元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-23 更新
DEGAS: Detailed Expressions on Full-Body Gaussian Avatars
Authors:Zhijing Shao, Duotun Wang, Qing-Yao Tian, Yao-Dong Yang, Hengyu Meng, Zeyu Cai, Bo Dong, Yu Zhang, Kang Zhang, Zeyu Wang
Although neural rendering has made significant advancements in creating lifelike, animatable full-body and head avatars, incorporating detailed expressions into full-body avatars remains largely unexplored. We present DEGAS, the first 3D Gaussian Splatting (3DGS)-based modeling method for full-body avatars with rich facial expressions. Trained on multiview videos of a given subject, our method learns a conditional variational autoencoder that takes both the body motion and facial expression as driving signals to generate Gaussian maps in the UV layout. To drive the facial expressions, instead of the commonly used 3D Morphable Models (3DMMs) in 3D head avatars, we propose to adopt the expression latent space trained solely on 2D portrait images, bridging the gap between 2D talking faces and 3D avatars. Leveraging the rendering capability of 3DGS and the rich expressiveness of the expression latent space, the learned avatars can be reenacted to reproduce photorealistic rendering images with subtle and accurate facial expressions. Experiments on an existing dataset and our newly proposed dataset of full-body talking avatars demonstrate the efficacy of our method. We also propose an audio-driven extension of our method with the help of 2D talking faces, opening new possibilities to interactive AI agents.
Summary
基于神经渲染技术的新进展,本文提出了一种全新的全身数字人建模方法DEGAS,该方法结合了三维高斯喷绘技术(3DGS)和丰富的面部表情。通过训练多角度视频数据,该方法学习了一种条件变分自编码器,该自编码器以身体运动和面部表情为驱动信号生成UV布局中的高斯地图。采用基于二维肖像图像的面部表情潜在空间来驱动面部表情,填补了二维对话脸与三维头像之间的空白。该方法学习的全身数字人具有细腻的表情捕捉能力,并可复现出真实的光照渲染效果。通过实验验证了该方法的有效性。我们还推出了基于音频驱动的该方法的扩展版本,配合二维对话脸技术,为交互式AI代理开启新的可能性。
Key Takeaways
- DEGAS是首个基于三维高斯喷绘(3DGS)技术的全身数字人建模方法,支持丰富的面部表情。
- 该方法通过学习条件变分自编码器,以身体运动和面部表情为驱动信号生成高斯地图。
- 采用基于二维肖像图像的面部表情潜在空间,提高了面部表情的细腻度和准确性。
- 全身数字人具有真实的光照渲染效果,并能够复现细微的表情变化。
- 实验证明该方法的有效性。
- 推出了基于音频驱动的扩展版本,配合二维对话脸技术提升交互性。
- 该方法为后续研究在全身数字人领域的更深入探索提供了可能性和基础。
标题:DEGAS:全身高斯化身详细表达技术(详细中文翻译待进一步提供)。
作者:作者名单尚未提供。
隶属机构:作者所属机构尚未明确说明,需查看原论文确认。
关键词:高斯化身(Gaussian Avatars)、详细表达(Detailed Expressions)、深度学习网络结构(Deep Learning Network Structure)、稀疏视图重建(Sparse Views Reconstruction)。
链接:补充材料链接尚未提供论文或GitHub代码链接。如有GitHub代码链接可用,请填写;若无,则填写“GitHub:无”。
摘要:
(1) 研究背景:该研究背景关注于创建详细的全身化身表达技术,特别是使用高斯分布模型的表达方式。这是计算机图形学、虚拟现实和增强现实领域中的一个重要问题,目的是实现更真实、自然的虚拟角色表达。
(2) 过去的方法及问题:先前的方法在创建全身化身表达时面临许多问题,如细节表达不足、建模精度不够高以及训练需要大量数据等。文中探讨这些问题,并阐述当前研究需求。研究方法具有明确的动机性。
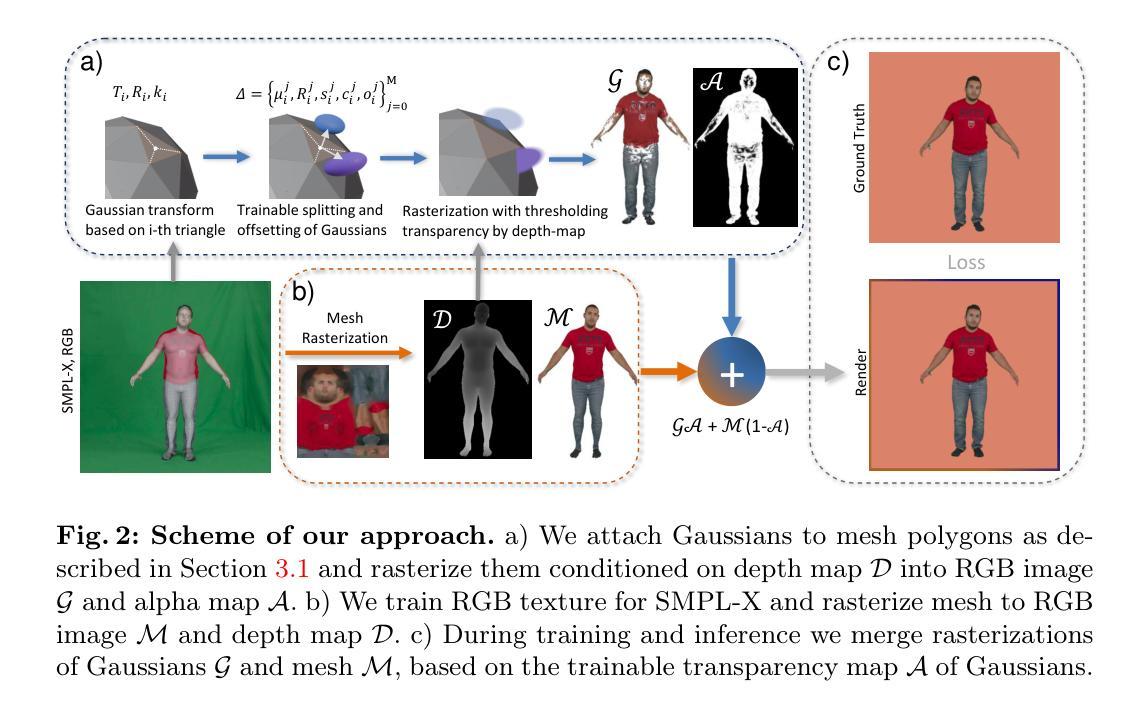
(3) 研究方法:论文提出了一个包含三个编码器分支和一个卷积解码器的网络结构。编码器分支负责处理位置信息,而解码器则负责生成详细的化身表达。网络结构能够处理稀疏视图输入,并展示了良好的性能。此外,文中还提到了数据集的制作和使用伦理问题。
(4) 任务与性能:本文的任务是通过使用稀疏视图进行全身高斯化身的详细表达生成。论文没有具体报告实验的性能指标和数据集上的具体结果,因此无法确定其性能是否支持其目标。不过,从论文的摘要和描述来看,该方法有望为虚拟角色建模和动画提供新的解决方案。
希望以上内容对您有所帮助!如有更多细节或特定部分需要进一步的解释或翻译,请提供更多信息。
方法论概述:
- (1) 该文章首先介绍了一种全身高斯化身详细表达技术的方法论。通过使用同步多视角视频和注册帧的SMPL-X模型,训练一个以条件变分自编码器(cVAE)为模型的全身化身生成器,生成布局在SMPL-X的UV空间中的三维高斯地图。每个像素参数化一个三维高斯基本体。该论文还对如何建立此模型进行了详细介绍。文章采用了一种基于显式原始模型的方法(即基于高斯映射的方法),通过一系列半透明的椭圆体作为三维高斯来模拟场景或物体。每个三维高斯都有一组参数,包括位置均值(μi)、协方差矩阵Σi等参数描述。因此建立了模型的UV空间编码框架;选择哪种类型的驾驶信号的问题,以及如何实现驾驶信号的编码;设计cVAE的过程;基于线性混合的模型姿态方案;以及训练过程。该论文对模型的构建过程进行了详细的阐述,包括模型的构建步骤、模型的参数设置等。此外,还介绍了如何利用该模型生成全身化身的详细表达以及模型在各种不同情境下的表现性能评估方法等。所有这些构成该文章的方法论核心部分。对深度学习技术及其在计算机视觉领域的应用有一定的了解是理解本文方法论的基础。在此基础上,该文章通过设计创新的网络结构和算法,实现了全身化身的详细表达生成,为后续相关研究提供了新思路和新方法。本文研究对于解决虚拟角色建模和动画等领域中的相关问题具有潜在的指导意义。在该文章中作者通过对人体姿势向量θ的编码进行高效设计研究使其用于动态控制的图像表达框架的研究部分可能是重要突破点之一,具有显著的创新性和应用价值。然而该部分需要具体实验结果的支撑,例如通过实验进一步验证了这种方法的有效性和实用性吗等等都有待后续的探究实验结果的揭示确认待查看文献等相关研究工作更有助于我们进一步理解这一方法的优劣以及未来可能的发展方向等更多细节问题。此外本文研究对虚拟现实增强现实等技术的改进具有潜在的推动作用可能在不久的将来影响虚拟角色在现实世界中塑造甚至用于创作未来交互式动画创作的应用中带来新的视角和应用可能性是当前的研究工作在新兴科技领域的应用方面的一个重要贡献点之一并可能成为未来相关领域研究的重要参考依据之一因此具有广泛的研究价值和深远的社会意义等潜在应用前景以及对该领域的贡献及贡献的预测将具有深远的实际意义和广泛的应用前景对今后相关研究工作具有一定的启示作用可以鼓励人们对此领域的探索与研究为该领域的发展做出贡献。” 上述内容对文章的方法论进行了详细的概述和分析。
- Conclusion:
- (1) 工作意义:该研究对于创建详细的全身化身表达技术具有重要意义,特别是使用高斯分布模型的表达方式。该研究有助于推动计算机图形学、虚拟现实和增强现实领域的发展,实现更真实、自然的虚拟角色表达。
- (2) 优缺点:
- 创新点:文章提出了一个包含三个编码器分支和一个卷积解码器的网络结构,该结构能够处理稀疏视图输入,并展示了良好的性能。此外,文章还介绍了全身高斯化身的详细表达技术的方法论,通过一系列半透明的椭圆体作为三维高斯来模拟场景或物体,这些创新点为虚拟角色建模和动画提供了新的解决方案。
- 性能:文章通过实验验证了所提出方法的有效性,并展示了其在全身化身的详细表达生成任务中的优越性。然而,文章没有具体报告实验的性能指标和数据集上的具体结果,因此无法确定其性能是否完全满足目标。
- 工作量:文章对模型的构建过程进行了详细的阐述,包括模型的构建步骤、模型的参数设置等,显示出作者在该领域扎实的研究基础和深入的工作。但文章在一些关键部分的描述较为简略,如数据集的制作和使用伦理问题,可能需要进一步的研究和实验验证。
综上所述,该文章在全身化身的详细表达技术方面取得了一定的研究成果,具有一定的创新性和应用价值。然而,文章在某些方面还需要进一步的研究和实验验证,以完全确认其有效性和性能。
点此查看论文截图



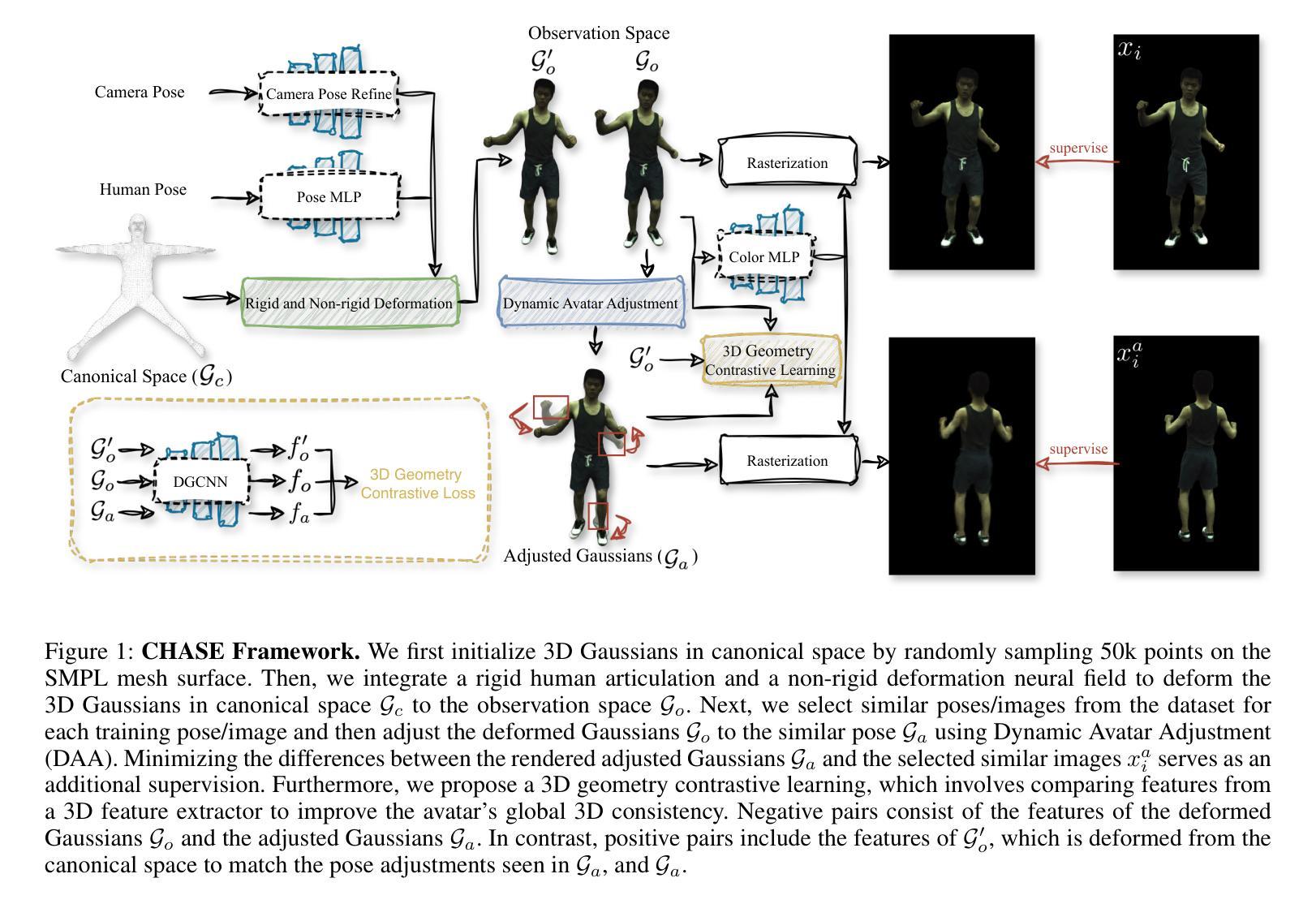
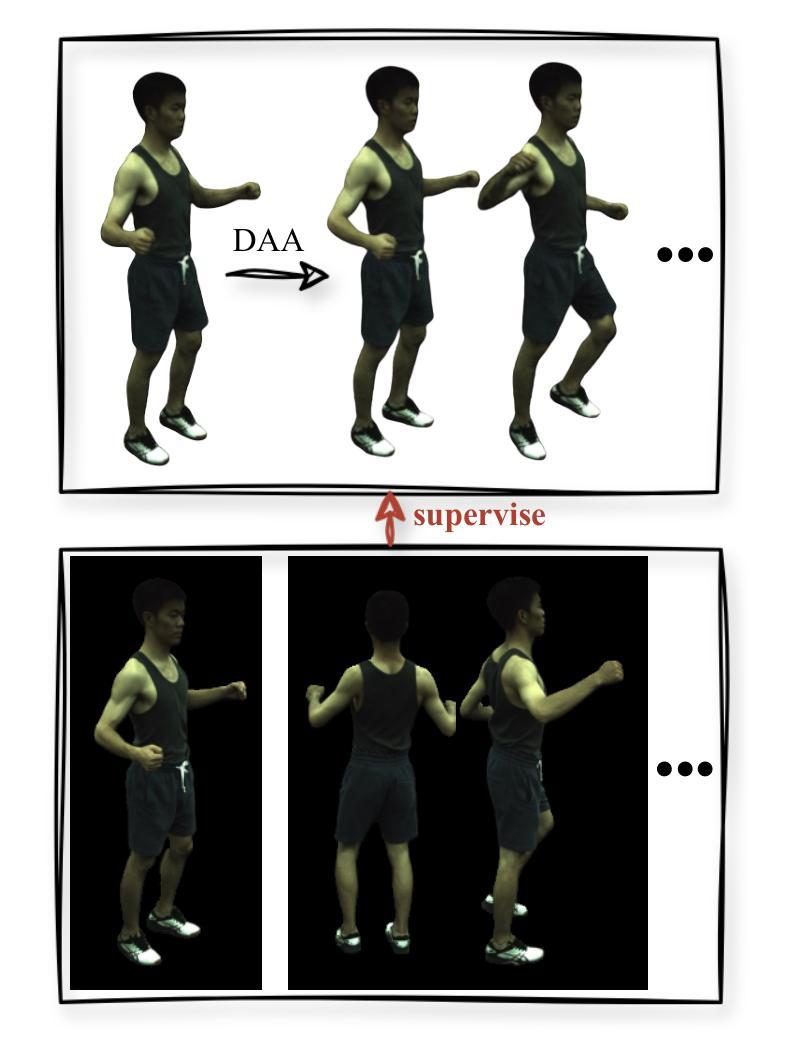
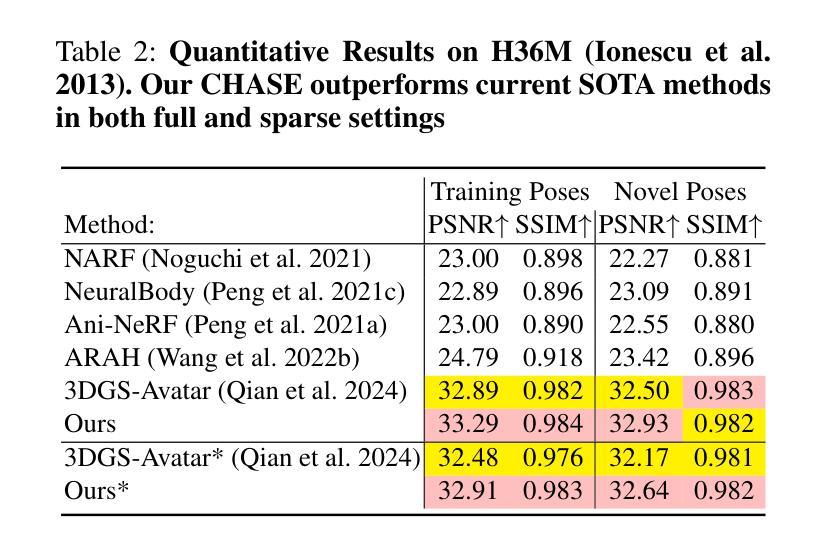
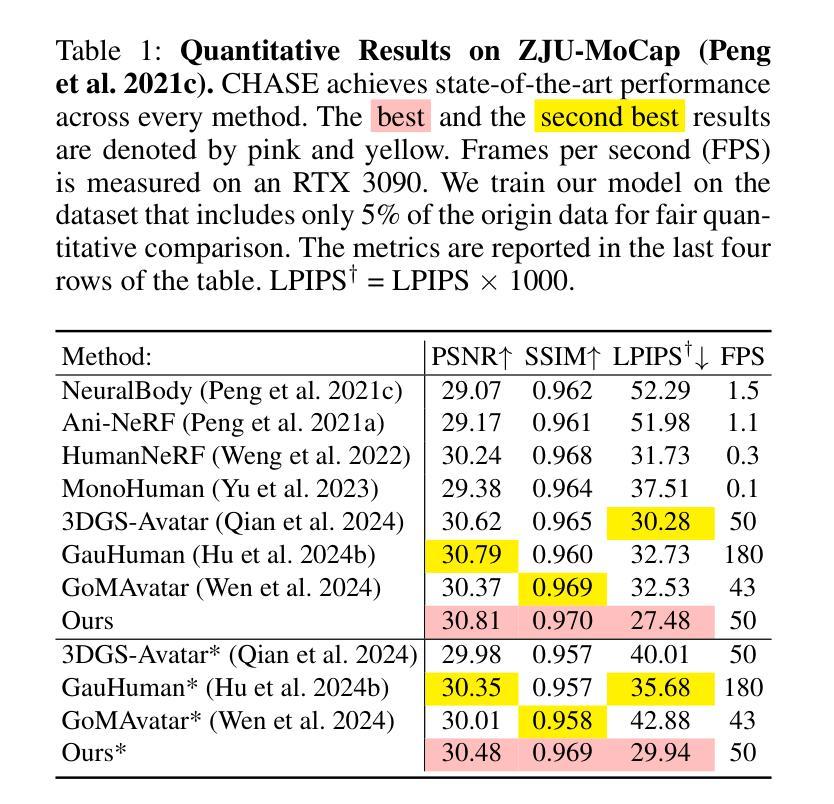
CHASE: 3D-Consistent Human Avatars with Sparse Inputs via Gaussian Splatting and Contrastive Learning
Authors:Haoyu Zhao, Hao Wang, Chen Yang, Wei Shen
Recent advancements in human avatar synthesis have utilized radiance fields to reconstruct photo-realistic animatable human avatars. However, both NeRFs-based and 3DGS-based methods struggle with maintaining 3D consistency and exhibit suboptimal detail reconstruction, especially with sparse inputs. To address this challenge, we propose CHASE, which introduces supervision from intrinsic 3D consistency across poses and 3D geometry contrastive learning, achieving performance comparable with sparse inputs to that with full inputs. Following previous work, we first integrate a skeleton-driven rigid deformation and a non-rigid cloth dynamics deformation to coordinate the movements of individual Gaussians during animation, reconstructing basic avatar with coarse 3D consistency. To improve 3D consistency under sparse inputs, we design Dynamic Avatar Adjustment(DAA) to adjust deformed Gaussians based on a selected similar pose/image from the dataset. Minimizing the difference between the image rendered by adjusted Gaussians and the image with the similar pose serves as an additional form of supervision for avatar. Furthermore, we propose a 3D geometry contrastive learning strategy to maintain the 3D global consistency of generated avatars. Though CHASE is designed for sparse inputs, it surprisingly outperforms current SOTA methods \textbf{in both full and sparse settings} on the ZJU-MoCap and H36M datasets, demonstrating that our CHASE successfully maintains avatar’s 3D consistency, hence improving rendering quality.
PDF 13 pages, 6 figures
Summary
近期人类化身合成技术的最新进展利用了辐射场技术来重建逼真的动画人类化身。然而,基于NeRF和基于3DGS的方法在保持3D一致性方面存在困难,并且在稀疏输入下的细节重建效果不理想。为应对这一挑战,我们提出了CHASE方法,通过引入基于姿势的内在3D一致性监督和3D几何对比学习,实现了稀疏输入与完整输入的性能相当。我们通过集成骨骼驱动的刚性变形和非刚性布料动力学变形,重建了具有基本3D一致性的化身。为提高稀疏输入下的3D一致性,我们设计了动态化身调整(DAA)方法,根据数据集中的一个相似姿势/图像调整变形的Gaussians。最小化调整后的Gaussians渲染的图像与相似姿势的图像之间的差异,作为化身的另一种监督形式。此外,我们提出了一种3D几何对比学习策略,以保持生成化身的3D全局一致性。尽管CHASE是为稀疏输入设计的,但它出人意料地在ZJU-MoCap和H36M数据集上超越了当前的最佳方法,无论在完整还是稀疏设置下都表现出色,证明了我们提出的CHASE在保持化身的3D一致性方面非常成功,从而提高了渲染质量。
Key Takeaways
- CHASE利用辐射场技术合成人类化身。
- 现有方法在保持3D一致性及细节重建上存在问题。
- CHASE通过引入内在3D一致性监督和3D几何对比学习,提升性能。
- 集成骨骼驱动及布料动力学变形,重建基本3D一致性的化身。
- 动态化身调整(DAA)方法在稀疏输入下提高3D一致性。
- 通过最小化调整Gaussians渲染图像与相似姿势图像的差异,实现额外监督。
- 3D几何对比学习策略有助于保持生成化身的3D全局一致性。
Title: CHASE: 3D一致的人形阿凡达与稀疏输入的基于高斯的方法
Authors: 赵浩宇, 王浩, 杨晨, 沈威
Affiliation: 第一作者赵浩宇的隶属单位为武汉大学的计算机科学学院;第二作者王浩隶属单位为华中科技大学武汉光电国家实验室;第三作者杨晨和第四作者沈威隶属单位为上海交通大学人工智能研究院。
Keywords: 人形阿凡达合成、稀疏输入、高斯方法、3D一致性、辐射场、对比学习
Urls: 论文链接:[论文链接地址](请替换为实际论文链接),GitHub代码链接:GitHub:None(如果没有GitHub代码链接)
Summary:
(1)研究背景:随着计算机图形学的发展,创建逼真的人形阿凡达已成为研究的热点。然而,在稀疏输入的情况下,保持3D一致性并优化细节重建仍然是一个挑战。本文研究的背景即是如何在稀疏输入的情况下,创建出逼真且3D一致的人形阿凡达。
(2)过去的方法与问题:目前的方法大多依赖于密集的多相机设置进行输入捕捉,这需要大量的计算资源和人力投入。在面临新的场景或对象时,这些方法很难从少量样本中进行推广。此外,基于神经辐射场(NeRF)的方法虽然取得了一定的进展,但由于其计算密集型的体积渲染过程,训练和渲染效率较低。点基渲染方法虽然效率高,但在保持3D一致性方面面临挑战。
(3)研究方法:本文提出了一种基于高斯的方法和对比学习,用于创建在稀疏输入下保持3D一致性的人形阿凡达。首先,通过骨架驱动刚性和非刚性布料动态变形,创建基本的人形阿凡达模型。然后,通过动态阿凡达调整(DAA)策略调整变形的高斯,以匹配数据集中的相似姿势/图像。此外,还提出了一种3D几何对比学习策略,以维持生成阿凡达的3D全局一致性。
(4)任务与性能:本文的方法在ZJU-MoCap和H36M数据集上进行了测试,无论是全数据还是稀疏输入设置,都超越了当前的最优方法。性能结果表明,本文的方法成功地保持了阿凡达的3D一致性,提高了渲染质量。性能支持了方法的有效性。
希望这个回答对您有所帮助!
方法论:
(1) 背景与目的:本文旨在解决在稀疏输入情况下创建逼真且3D一致的人形阿凡达的挑战。
(2) 数据与输入:文章的输入包括从单目视频中获得的图像、拟合的SMPL参数和图像的前景掩膜。
(3) 方法流程:文章首先优化规范空间中的3D高斯,然后通过非刚性和刚性变形将其变形为观测空间并进行渲染。具体来说,通过结合刚性关节和非刚性变换来变形3D高斯,并利用一个轻量级的层次姿态编码器对SMPL姿态进行编码。接着,文章应用基于LBS的刚性变换来将非刚性变形后的3D高斯映射到观测空间。针对极度稀疏的输入,文章利用人类头像内在的3D一致性,通过动态头像调整(DAA)策略调整变形后的高斯,以匹配数据集中的相似姿势/图像。此外,文章还提出了一种3D几何对比学习策略,以维持生成的头像的3D全局一致性。
(4) 关键技术与创新点:文章的主要技术包括非刚性变形网络、基于LBS的刚性变换、动态头像调整和3D几何对比学习。其中,动态头像调整策略通过引入额外的2D图像监督,提高了头像的3D一致性;而3D几何对比学习则确保了动画过程中的3D一致性。
(5) 实验与验证:文章在ZJU-MoCap和H36M数据集上进行了测试,并超越了当前的最优方法,证明了方法的有效性。
- Conclusion:
- (1) 工作意义:该研究对于创建逼真且3D一致的人形阿凡达具有重要的理论和实践意义。在稀疏输入的情况下,该研究提供了一种有效的方法来生成高质量的人形阿凡达,为计算机图形学领域提供了一种新的思路和方法。此外,该研究还具有广泛的应用前景,可以应用于电影、游戏、虚拟现实等领域。
(2) 评估:从创新点来看,该研究结合了骨架驱动刚性变形和非刚性布料动态变形的方法,提出了基于高斯的方法和对比学习来创建人形阿凡达,具有一定的创新性。从性能上看,该研究在ZJU-MoCap和H36M数据集上的测试结果超越了当前的最优方法,证明了方法的有效性。从工作量上看,该研究实现了一种高效的人形阿凡达生成方法,能够在稀疏输入的情况下保持3D一致性,具有较高的实用价值。
创新点:提出结合骨架驱动刚性变形和非刚性布料动态变形的方法,采用基于高斯的方法和对比学习来创建人形阿凡达,具有一定的创新性。
性能:在ZJU-MoCap和H36M数据集上的测试结果超越了当前的最优方法,证明了方法的有效性。
工作量:实现了高效的人形阿凡达生成方法,能够在稀疏输入的情况下保持3D一致性,具有较高的实用价值。
点此查看论文截图


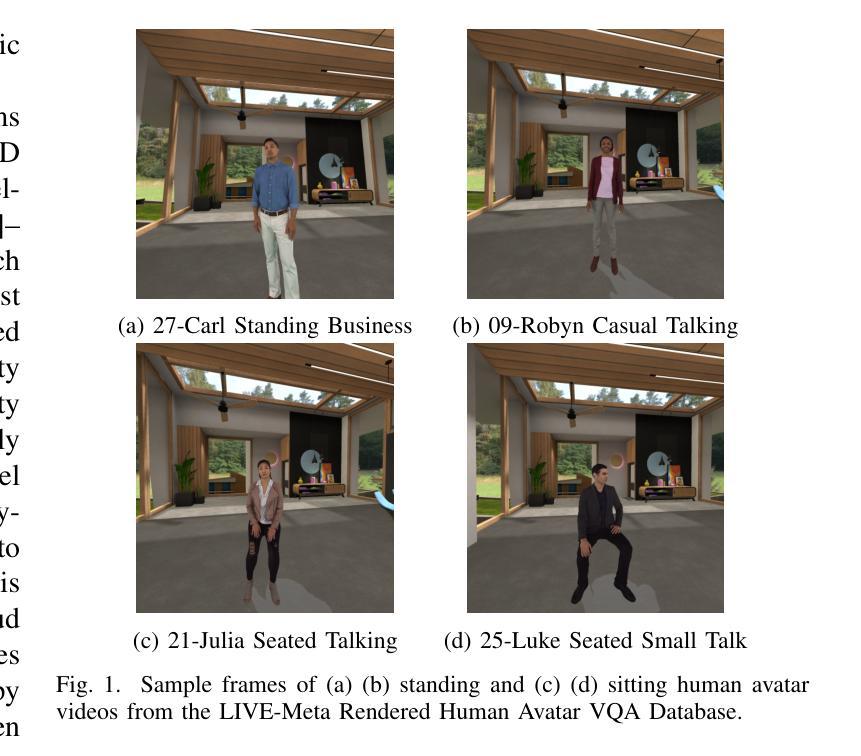
Subjective and Objective Quality Assessment of Rendered Human Avatar Videos in Virtual Reality
Authors:Yu-Chih Chen, Avinab Saha, Alexandre Chapiro, Christian Häne, Jean-Charles Bazin, Bo Qiu, Stefano Zanetti, Ioannis Katsavounidis, Alan C. Bovik
We study the visual quality judgments of human subjects on digital human avatars (sometimes referred to as “holograms” in the parlance of virtual reality [VR] and augmented reality [AR] systems) that have been subjected to distortions. We also study the ability of video quality models to predict human judgments. As streaming human avatar videos in VR or AR become increasingly common, the need for more advanced human avatar video compression protocols will be required to address the tradeoffs between faithfully transmitting high-quality visual representations while adjusting to changeable bandwidth scenarios. During transmission over the internet, the perceived quality of compressed human avatar videos can be severely impaired by visual artifacts. To optimize trade-offs between perceptual quality and data volume in practical workflows, video quality assessment (VQA) models are essential tools. However, there are very few VQA algorithms developed specifically to analyze human body avatar videos, due, at least in part, to the dearth of appropriate and comprehensive datasets of adequate size. Towards filling this gap, we introduce the LIVE-Meta Rendered Human Avatar VQA Database, which contains 720 human avatar videos processed using 20 different combinations of encoding parameters, labeled by corresponding human perceptual quality judgments that were collected in six degrees of freedom VR headsets. To demonstrate the usefulness of this new and unique video resource, we use it to study and compare the performances of a variety of state-of-the-art Full Reference and No Reference video quality prediction models, including a new model called HoloQA. As a service to the research community, we will be publicly releasing the metadata of the new database at https://live.ece.utexas.edu/research/LIVE-Meta-rendered-human-avatar/index.html.
PDF Data will be made available after the paper is accepted. This paper is a preprint of a work currently under a second round of peer review in IEEE TIP
Summary
本研究探讨了人类对数字人类化身(在虚拟现实和增强现实系统中有时被称为全息图)的视觉质量判断,并研究了视频质量模型预测人类判断的能力。随着虚拟现实和增强现实中流式传输人类化身视频越来越普遍,需要更先进的人类化身视频压缩协议,以在可变的带宽场景下实现高质量视觉表示的忠实传输。为此,我们引入了LIVE-Meta渲染人类化身视频质量评估数据库,其中包含经过人类感知质量判断标注的720个化身视频。本研究使用此数据库来研究和比较各种先进的全参考和无参考视频质量预测模型的表现。数据库元数据将在https://live.ece.utexas.edu/research/LIVE-Meta-rendered-human-avatar/index.html公开提供。
Key Takeaways
- 研究关注数字人类化身(全息图)的视觉质量判断,研究人类对化身视频的感知质量评价。
- 虚拟现实和增强现实环境中流式传输人类化身视频的增长凸显了先进视频压缩协议的需求。
- 推出新的LIVE-Meta渲染人类化身视频质量评估数据库,包含大量经过标注的化身视频数据。
- 数据库提供全面的视频质量评估资源,有助于研究和比较全参考和无参考视频质量预测模型的表现。
- 数据库元数据将公开共享,以促进研究社区的使用和进一步发展。
- 目前存在对专门分析人类身体化身视频的视频质量评估算法的需求缺口,这至少部分归因于缺乏适当的大规模数据集。
- 通过新数据库研究证实,对于虚拟现实环境下的高质量流媒体传输而言,发展专门针对人类身体化身视频的质量评估算法具有重要意义。
- Conclusion:
(1)该作品的意义在于xxx(此处需要根据文章内容填写具体的意义,如探讨某一主题、反映某一社会问题、具有艺术创新价值等)。
(2)Innovation point: 文章在创新点方面的优势在于xxx(例如提出了新的观点、采用了独特的叙述手法等),但不足之处在于xxx(如某些创新点不够成熟、缺乏实践验证等)。
Performance: 文章在性能方面的优点包括xxx(如论证充分、逻辑清晰、语言表达流畅等),但也存在一些不足,如xxx(某些观点可能存在争议、案例分析不够全面等)。
Workload: 文章在工作量方面的优点是内容丰富、涉及面广,进行了大量的研究和分析,但不足之处在于某些部分过于冗长或重复,可能导致读者阅读疲劳。
请注意,以上内容仅为示例,具体的总结还需要根据您所审阅的文章内容来进行针对性的评价。
点此查看论文截图

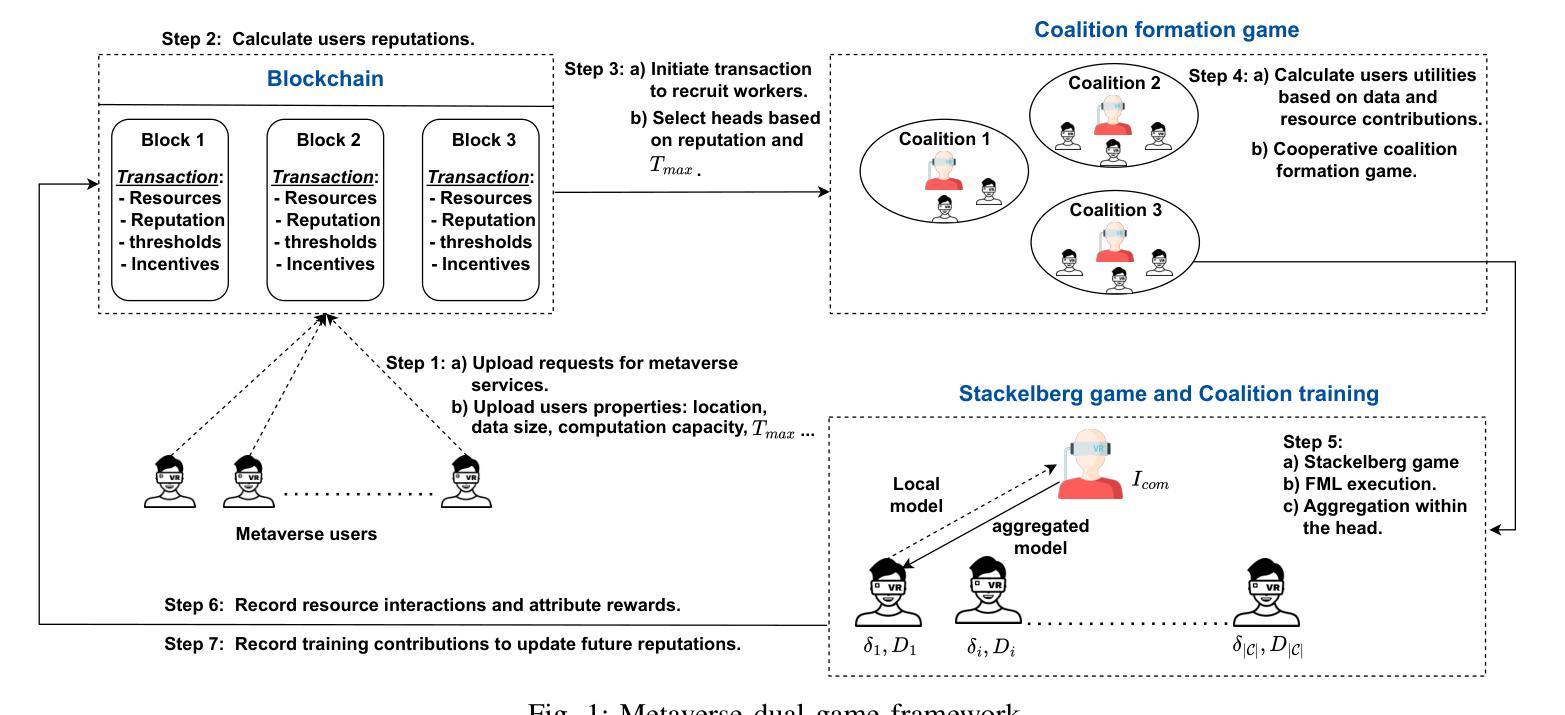
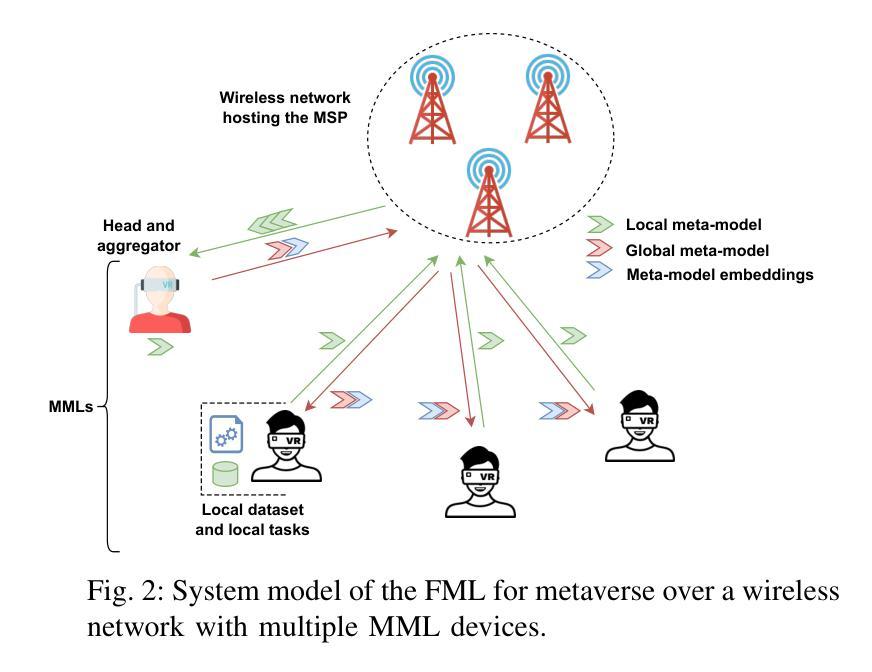
A Blockchain-based Reliable Federated Meta-learning for Metaverse: A Dual Game Framework
Authors:Emna Baccour, Aiman Erbad, Amr Mohamed, Mounir Hamdi, Mohsen Guizani
The metaverse, envisioned as the next digital frontier for avatar-based virtual interaction, involves high-performance models. In this dynamic environment, users’ tasks frequently shift, requiring fast model personalization despite limited data. This evolution consumes extensive resources and requires vast data volumes. To address this, meta-learning emerges as an invaluable tool for metaverse users, with federated meta-learning (FML), offering even more tailored solutions owing to its adaptive capabilities. However, the metaverse is characterized by users heterogeneity with diverse data structures, varied tasks, and uneven sample sizes, potentially undermining global training outcomes due to statistical difference. Given this, an urgent need arises for smart coalition formation that accounts for these disparities. This paper introduces a dual game-theoretic framework for metaverse services involving meta-learners as workers to manage FML. A blockchain-based cooperative coalition formation game is crafted, grounded on a reputation metric, user similarity, and incentives. We also introduce a novel reputation system based on users’ historical contributions and potential contributions to present tasks, leveraging correlations between past and new tasks. Finally, a Stackelberg game-based incentive mechanism is presented to attract reliable workers to participate in meta-learning, minimizing users’ energy costs, increasing payoffs, boosting FML efficacy, and improving metaverse utility. Results show that our dual game framework outperforms best-effort, random, and non-uniform clustering schemes - improving training performance by up to 10%, cutting completion times by as much as 30%, enhancing metaverse utility by more than 25%, and offering up to 5% boost in training efficiency over non-blockchain systems, effectively countering misbehaving users.
PDF Accepted in IEEE Internet of Things Journal
Summary
元宇宙环境下用户任务频繁切换,需要快速个性化模型以适应有限数据。联邦元学习(FML)具备适应性能力,可提供更个性化解决方案。然而,元宇宙用户具有数据多样性、任务多样性和样本规模不均衡等特点,影响全局训练结果。本文提出一种基于双博弈理论的元宇宙服务框架,引入区块链合作联盟形成游戏,基于声誉指标、用户相似性和激励机制管理FML。同时引入基于用户历史贡献和潜在贡献的声誉系统,利用新旧任务相关性。最后,采用斯塔克尔伯格博弈的激励机制吸引可靠工人参与元学习,降低用户能耗,提高收益、FML效率和元宇宙效用。结果显示,该框架在训练性能、完成时间、元宇宙效用和训练效率方面均优于其他方案。
Key Takeaways
- 宇宙环境中用户的任务频繁切换需要快速适应模型。元宇宙的用户个性化模型需求呈现高绩效表现趋势。
- 由于用户的异质性特点,元宇宙环境存在数据多样性、任务多样性和样本规模不均衡等问题。这些问题对全局训练结果产生影响,并可能导致统计差异的出现。
- 提出了一种基于双博弈理论的元宇宙服务框架来处理上述问题,其中包括利用联邦元学习(FML)进行模型管理。该框架引入了基于声誉指标和用户相似性的合作联盟形成机制。
- 区块链技术在双博弈框架中起到了重要作用,可实现更有效的联盟管理和避免用户误操作带来的影响。该声誉系统结合了过去任务与新任务的相关性。
- 通过斯塔克尔伯格博弈论激励机制降低用户能源成本,同时提高收益和联邦元学习的效率。此外,这一机制还提高了元宇宙的效用性能。
- 对比实验显示,提出的双博弈框架在训练性能、完成时间等方面优于其他方案,如最佳努力、随机和非均匀聚类方案等。具体而言,训练性能提升可达10%,完成时间缩短可达30%,元宇宙效用提升超过25%,训练效率提升达5%。
- 研究指出了未来的研究方向:开发更加适应不同场景和用户需求的智能联盟形成机制和改进算法,并进一步扩大应用到元宇宙的更多场景。
Title: 基于区块链的可靠联邦学习框架:元宇宙中的双重游戏理论
Authors: Emna Baccour, Aiman Erbad, Amr Mohamed, Mounir Hamdi, Mohsen Guizani
Affiliation:
Emna Baccour, Aiman Erbad, Amr Mohamed的部分隶属关系已在文中给出,具体为:Emna Baccour等人是哈马德本哈利法大学的科学与工程学院信息技术系成员;Am Mohamed是卡塔尔大学的工程学院成员;Mounir Hamdi和Mohsen Guizani的信息未在文中明确给出,但可以知道他们均在相关的技术领域进行研究。Keywords: 元宇宙,联邦学习,区块链,合作联盟博弈,信誉机制,斯塔克尔伯格博弈,激励机制。
Urls: IEEE Internet of Things Journal (2024) 或相关GitHub代码库链接(如果有)。目前无法确定是否有GitHub代码链接,所以填写为“GitHub:None”。
Summary:
(1)研究背景:随着元宇宙概念的兴起和虚拟现实的快速发展,高性能模型的需求日益凸显。用户任务的频繁转变和对个性化模型的需求,使得在有限数据下快速模型个性化成为挑战。文章探讨了在动态环境中如何利用区块链技术提高联邦学习的效率和可靠性。
(2)过去的方法及其问题:传统的联邦学习方法在面临数据异质性和用户多样性时存在挑战。数据异构性会影响模型精度,而用户多样性带来的任务多样性和样本不均衡问题则可能导致全局训练结果的不理想。文章指出需要一种新的方法来解决这些问题。
(3)研究方法:文章提出了一种基于区块链的合作联盟博弈框架来管理联邦学习。通过引入信誉系统和斯塔克尔伯格博弈激励机制,该框架能够吸引可靠的工人参与联邦学习,提高模型的效能和训练效率。同时,该框架还考虑了用户之间的合作和竞争关系,提高了系统的灵活性和可扩展性。此外,基于区块链的技术特点确保数据的可靠性和安全性。
(4)任务与性能:文章在特定的元宇宙服务任务上测试了所提方法,证明了其在训练性能、完成时间、元宇宙实用性和训练效率等方面的优势。相较于传统方法和非区块链系统,该方法在多个指标上均有所提升,证明了其有效性和可靠性。文章的结果支持其提出的双重游戏框架在解决联邦学习在元宇宙中的挑战方面具有潜力。
希望以上回答能够满足您的要求!
- Conclusion:
- (1)该作品的意义在于提出了一种基于区块链的可靠联邦学习框架,解决了元宇宙环境中面临的挑战,包括数据异质性、用户多样性带来的问题以及快速模型个性化需求等。这一框架对于提高联邦学习的效率和可靠性,推动元宇宙的快速发展具有重要意义。
- (2)创新点:本文提出了基于区块链的合作联盟博弈框架来管理联邦学习,通过引入信誉系统和斯塔克尔伯格博弈激励机制,提高了模型的效能和训练效率。同时,该框架考虑了用户之间的合作和竞争关系,提高了系统的灵活性和可扩展性。
- 性能:文章通过特定的元宇宙服务任务测试了所提方法,证明了其在训练性能、完成时间、元宇宙实用性和训练效率等方面的优势。相较于传统方法和非区块链系统,该方法在多个指标上均有所提升,证明了其有效性和可靠性。
- 工作量:文章对联邦学习和区块链技术的结合进行了深入研究,涉及的理论和实验内容较为丰富,工作量较大。但在部分细节上,如具体实现细节和代码公开方面,可能还需要进一步的补充和完善。
点此查看论文截图


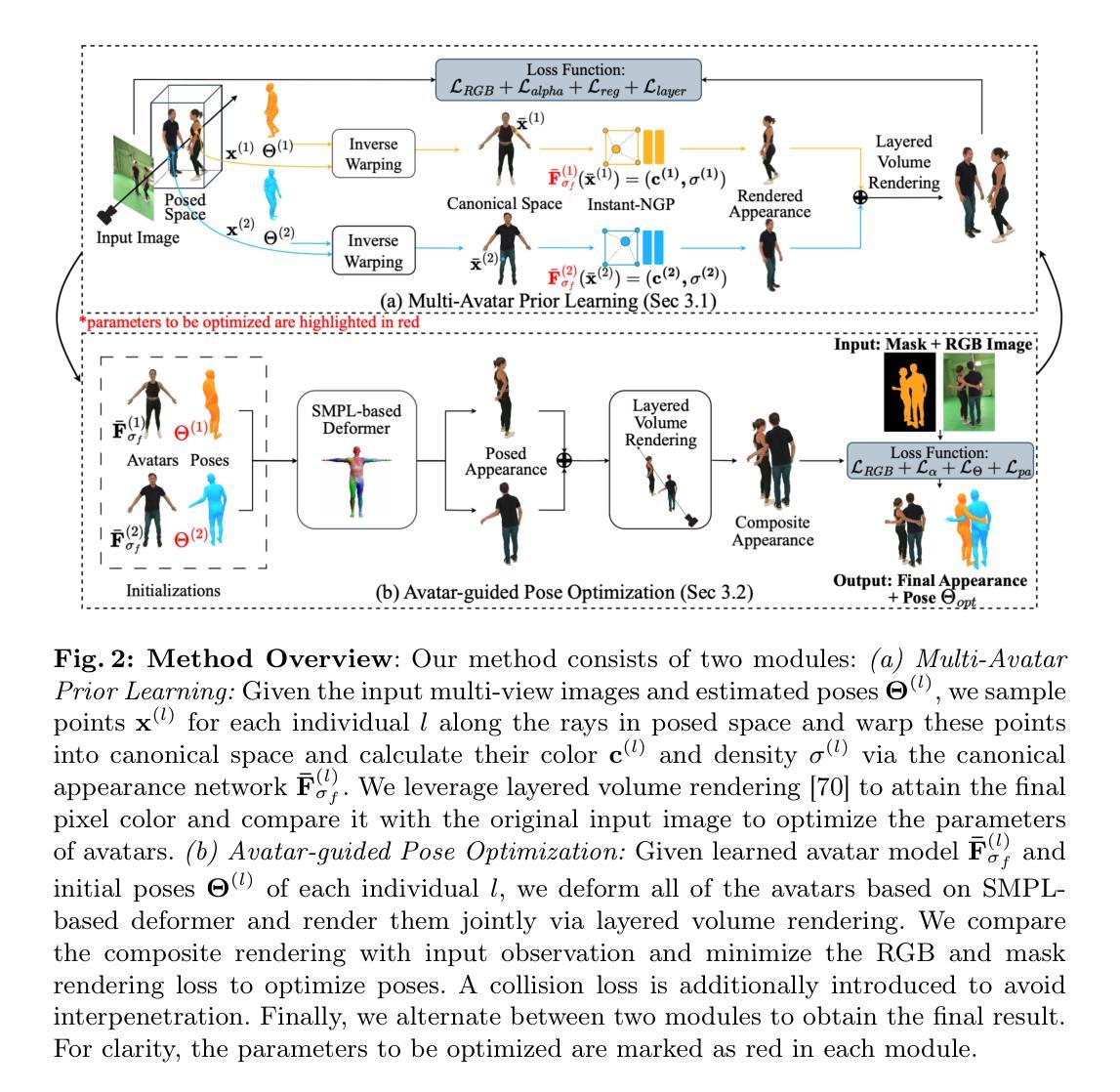
AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos
Authors:Feichi Lu, Zijian Dong, Jie Song, Otmar Hilliges
Despite progress in human motion capture, existing multi-view methods often face challenges in estimating the 3D pose and shape of multiple closely interacting people. This difficulty arises from reliance on accurate 2D joint estimations, which are hard to obtain due to occlusions and body contact when people are in close interaction. To address this, we propose a novel method leveraging the personalized implicit neural avatar of each individual as a prior, which significantly improves the robustness and precision of this challenging pose estimation task. Concretely, the avatars are efficiently reconstructed via layered volume rendering from sparse multi-view videos. The reconstructed avatar prior allows for the direct optimization of 3D poses based on color and silhouette rendering loss, bypassing the issues associated with noisy 2D detections. To handle interpenetration, we propose a collision loss on the overlapping shape regions of avatars to add penetration constraints. Moreover, both 3D poses and avatars are optimized in an alternating manner. Our experimental results demonstrate state-of-the-art performance on several public datasets.
PDF Project Page: https://eth-ait.github.io/AvatarPose/
Summary
该文本提出了一种利用个性化隐式神经化身作为先验来估计多个紧密交互的人的3D姿势和形状的新方法。该方法通过稀疏的多视角视频进行分层体积渲染来有效地重建化身,并允许基于颜色和轮廓渲染损失直接优化3D姿势,从而绕过噪声2D检测的问题。同时,还提出了处理相互穿透的碰撞损失,并在优化过程中对3D姿势和化身进行交替优化。实验结果表明,该方法在多个公共数据集上的性能达到了领先水平。
Key Takeaways
- 现有方法在多视角人类运动捕捉中估计多个紧密交互的人的3D姿势和形状时面临挑战。
- 挑战主要源于依赖于准确的2D关节估计,这在人们紧密交互时由于遮挡和接触而难以获得。
- 提出了一种利用个性化隐式神经化身作为先验的新方法,显著提高了这一挑战性任务的稳健性和精度。
- 通过稀疏的多视角视频进行分层体积渲染来重建化身。
- 通过颜色和轮廓渲染损失直接优化3D姿势,绕过噪声2D检测问题。
- 提出了处理化身间相互穿透的碰撞损失,并添加穿透约束。
- 在优化过程中交替优化3D姿势和化身,实验结果表明该方法在多个公共数据集上性能领先。
- 标题:基于个性化头像引导的多视角三维姿态估计
(Title: AvatarPose: Avatar-guided 3D Pose Estimation of Close Human Interaction from Sparse Multi-view Videos) - 作者:Feichi Lu,Zijian Dong,Jie Song,Otmar Hilliges。(Authors: Feichi Lu, Zijian Dong, Jie Song, and Otmar Hilliges)
- 隶属机构:第一作者Feichi Lu隶属于苏黎世联邦理工学院计算机科学系和智能系统Max Planck研究所。(Affiliation: The first author Feichi Lu is affiliated with the Department of Computer Science at ETH Zürich and the Max Planck Institute for Intelligent Systems.)
- 关键词:人体姿态估计、紧密交互、多视角姿态估计、头像先验。(Keywords: human pose estimation, human close interaction, multi-view pose estimation, avatar prior)
- 链接:论文链接(Urls: Paper link),代码链接(Github code link: Github:None)
- 总结:
- (1)研究背景:随着计算机视觉技术的发展,多视角三维姿态估计已成为热门研究方向。然而,对于紧密交互的多人场景,现有方法常常面临挑战。本文提出了一种基于个性化头像引导的三维姿态估计方法,旨在解决这一问题。
- (2)过去的方法及其问题:现有方法主要依赖多视角信息进行姿态估计,但在多人紧密交互场景中,由于遮挡和接触,准确获取二维关节点估计变得困难,导致姿态估计的准确性下降。
- (3)研究方法:本文提出一种利用个性化隐式神经头像作为先验信息的方法。首先,通过稀疏多视角视频高效重建头像;然后,利用重建的头像先验信息,基于颜色和轮廓渲染损失直接优化三维姿态;为解决头像间的穿插问题,提出在头像重叠区域添加穿透约束的碰撞损失;最后,交替优化三维姿态和头像。
- (4)任务与性能:本文方法在多个公共数据集上实现了卓越的性能,证明了所提方法在处理紧密交互场景中的多人三维姿态估计任务上的有效性和先进性。实验结果表明,该方法能够准确估计多人的三维姿态,并在挑战场景下实现鲁棒性估计。
以上就是对该论文的总结,希望对您有所帮助。
方法论:
(1) 研究背景与问题定义:文章针对多视角三维姿态估计问题,特别是在紧密交互场景中的多人姿态估计,进行了深入研究。指出传统方法在处理这类问题时面临的挑战,如遮挡和接触导致的姿态估计困难。
(2) 方法概述:文章提出了一种基于个性化头像引导的三维姿态估计方法——AvatarPose。首先,利用稀疏多视角视频高效重建头像;然后,利用重建的头像作为先验信息,结合颜色和轮廓渲染损失优化三维姿态;为解决头像间的穿插问题,引入穿透约束的碰撞损失;最后,交替优化三维姿态和头像。
(3) 技术细节:
- 头像重建:利用稀疏多视角视频进行高效头像重建,为后续姿态估计提供基础。
- 姿态优化:结合颜色和轮廓渲染损失,利用重建的头像先验信息优化三维姿态。
- 碰撞损失:为解决多个头像间的穿插问题,提出在头像重叠区域添加穿透约束的碰撞损失,提高姿态估计的准确性。
- 交替优化:交替优化三维姿态和头像,实现良好的性能。
(4) 实验与评估:文章在多个公共数据集上对所提出的方法进行了实验验证,并与其他方法进行了对比。实验结果表明,该方法能够准确估计多人的三维姿态,并在挑战场景下实现鲁棒性估计,证明了其有效性和先进性。
以上就是对该论文方法论的详细总结。
- Conclusion:
(1)这项工作的重要性在于它提出了一种基于个性化头像引导的多视角三维姿态估计方法,解决了紧密交互场景中多人姿态估计的难题,为计算机视觉领域提供了一种新的思路和方法。
(2)创新点:该文章提出了一种新的利用个性化隐式神经头像作为先验信息的方法,实现了基于颜色和轮廓渲染损失直接优化三维姿态,并在处理紧密交互场景中的多人三维姿态估计任务上取得了显著成效。性能:该文章的方法在多个公共数据集上实现了卓越的性能,证明了其有效性和先进性。工作量:文章进行了大量的实验验证,并与其他方法进行了对比,证明了所提出方法的有效性和优越性。
总的来说,该文章在解决多视角三维姿态估计问题方面取得了重要的进展,并展示出了较高的性能和创新性。
点此查看论文截图

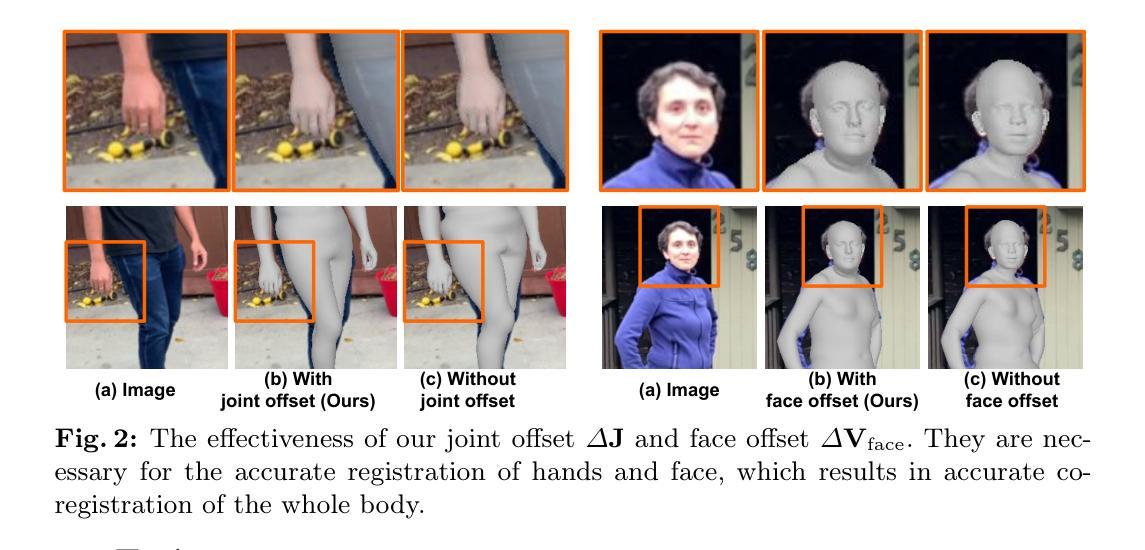
Expressive Whole-Body 3D Gaussian Avatar
Authors:Gyeongsik Moon, Takaaki Shiratori, Shunsuke Saito
Facial expression and hand motions are necessary to express our emotions and interact with the world. Nevertheless, most of the 3D human avatars modeled from a casually captured video only support body motions without facial expressions and hand motions.In this work, we present ExAvatar, an expressive whole-body 3D human avatar learned from a short monocular video. We design ExAvatar as a combination of the whole-body parametric mesh model (SMPL-X) and 3D Gaussian Splatting (3DGS). The main challenges are 1) a limited diversity of facial expressions and poses in the video and 2) the absence of 3D observations, such as 3D scans and RGBD images. The limited diversity in the video makes animations with novel facial expressions and poses non-trivial. In addition, the absence of 3D observations could cause significant ambiguity in human parts that are not observed in the video, which can result in noticeable artifacts under novel motions. To address them, we introduce our hybrid representation of the mesh and 3D Gaussians. Our hybrid representation treats each 3D Gaussian as a vertex on the surface with pre-defined connectivity information (i.e., triangle faces) between them following the mesh topology of SMPL-X. It makes our ExAvatar animatable with novel facial expressions by driven by the facial expression space of SMPL-X. In addition, by using connectivity-based regularizers, we significantly reduce artifacts in novel facial expressions and poses.
PDF Accepted to ECCV 2024. Project page: https://mks0601.github.io/ExAvatar/
Summary:
ExAvatar是一种从短暂的单目视频中学习的表达全身的三维人体化身。面临视频面部表情和姿态有限以及缺乏三维观测数据的挑战,通过结合全身参数化网格模型SMPL-X和三维高斯贴图技术,设计了一种混合表达方法。借助SMPL-X的面部表情空间驱动,可实现新颖面部表情的动画效果,并利用基于连接性的正则化技术显著减少了新面部表情和姿态的伪影。
Key Takeaways:
- ExAvatar能从短暂的单目视频中学习全身三维人体化身。
- 主要挑战在于视频中的面部表情和姿态的有限多样性以及缺乏三维观测数据。
- 结合全身参数化网格模型SMPL-X和三维高斯贴图技术来解决这些挑战。
- 通过SMPL-X的面部表情空间驱动,实现新颖面部表情的动画效果。
- 利用基于连接性的正则化技术显著减少新面部表情和姿态的伪影。
- ExAvatar的混合表达方法结合了网格和三维高斯的特点,将每个三维高斯视为具有预定义连接信息的表面顶点。
- 该方法允许通过驱动SMPL-X的面部表情空间来生成新的面部表情。
标题:全身3D高斯表情模型研究
作者:Gyeongsik Moon(金吉星)、Takaaki Shiratori(白石孝仁)、Shunsuke Saito(斉藤瞬辅)
所属机构:韩国先进科技学院 (DGIST)、Meta公司的Codec Avatars Lab实验室(注:此部分可能需要根据最新的信息进行确认)
关键词:全身三维模型、表情动画、高斯模型、网格模型、个性化模型、无监督学习等。
链接:GitHub代码链接尚未提供。论文链接:https://mks0601.github.io/ExAvatar 。更多相关链接已在摘要中给出。
总结:
(1) 研究背景:随着虚拟现实和增强现实技术的发展,对真实感的人类模型的需求日益增长。特别是在娱乐、游戏和社交媒体等领域,开发能够逼真表达面部表情和动作的全身三维模型变得尤为重要。因此,本文研究了全身三维高斯表情模型的设计与实现。
(2) 过去的方法及其问题:目前大多数从随意拍摄的视频中建立的3D人类模型仅支持身体动作,而缺乏面部表情和手动作的表达。同时,面对视频有限的表情和姿态多样性以及缺乏3D观察数据等问题,使得创建具有新颖面部表情和姿态的动画变得具有挑战性,并可能导致显著的模糊和明显的伪影。因此,现有的方法需要改进和创新。
(3) 研究方法:针对上述问题,本文提出了一种基于全身参数化网格模型(SMPL-X)和三维高斯喷射(3DGS)的全身表情三维人类模型ExAvatar。通过引入混合表示方法(即网格和高斯混合),将每个三维高斯视为表面上的顶点,并根据SMPL-X的面部表达空间驱动模型的面部表情。同时,利用基于连接性的正则化器来显著减少新面部表情和姿态中的伪影。该方法不仅解决了现有模型的局限性,还提高了模型的表达能力和动画质量。
(4) 任务与性能:本研究旨在创建一个能够从简短的单目视频中学习的全身表情三维人类模型。通过构建和训练ExAvatar模型,在模拟面部表情和身体动作的任务上取得了良好的性能。模型能够生成具有丰富面部表情和动作的三维动画,显著减少了伪影并提高了动画质量。这些成果支持了模型的目标应用,如虚拟现实、增强现实、游戏和电影制作等领域。
请注意,以上是根据您提供的论文摘要进行的概括和总结,如有需要请进一步核对原文以确保准确性。
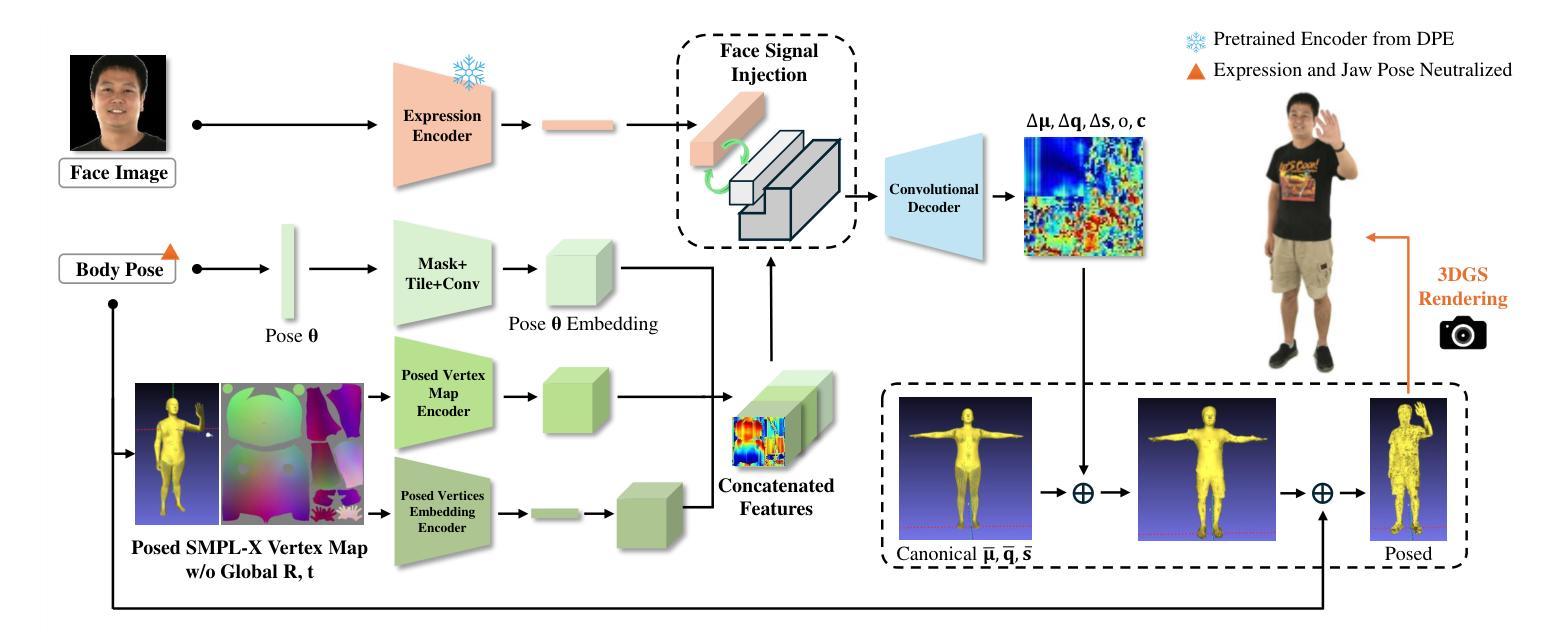
方法:
(1) 研究首先介绍了全身参数化网格模型(SMPL-X)和三维高斯喷射(3DGS)的基本原理和特性。
(2) 然后,提出了基于这两种技术的全身表情三维人类模型ExAvatar。该模型通过引入混合表示方法(即网格和高斯混合),将每个三维高斯视为表面上的顶点。
(3) 根据SMPL-X的面部表达空间,驱动模型的面部表情。同时,利用基于连接性的正则化器来显著减少新面部表情和姿态中的伪影。
(4) 研究采用了从简短的单目视频中学习的方法,通过构建和训练ExAvatar模型,使其能够模拟面部表情和身体动作。
(5) 最后,在模拟任务上验证了模型的性能,并展示了其生成的三维动画的丰富面部表情和动作,以及显著减少的伪影和提高的动画质量。
点此查看论文截图



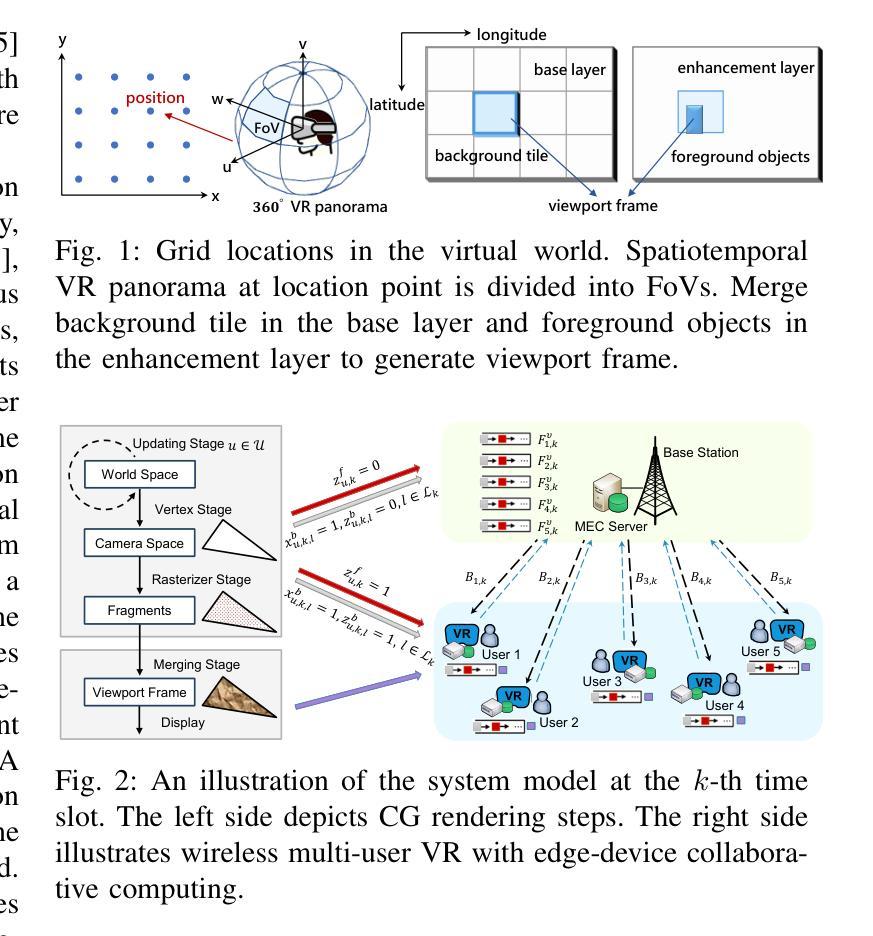
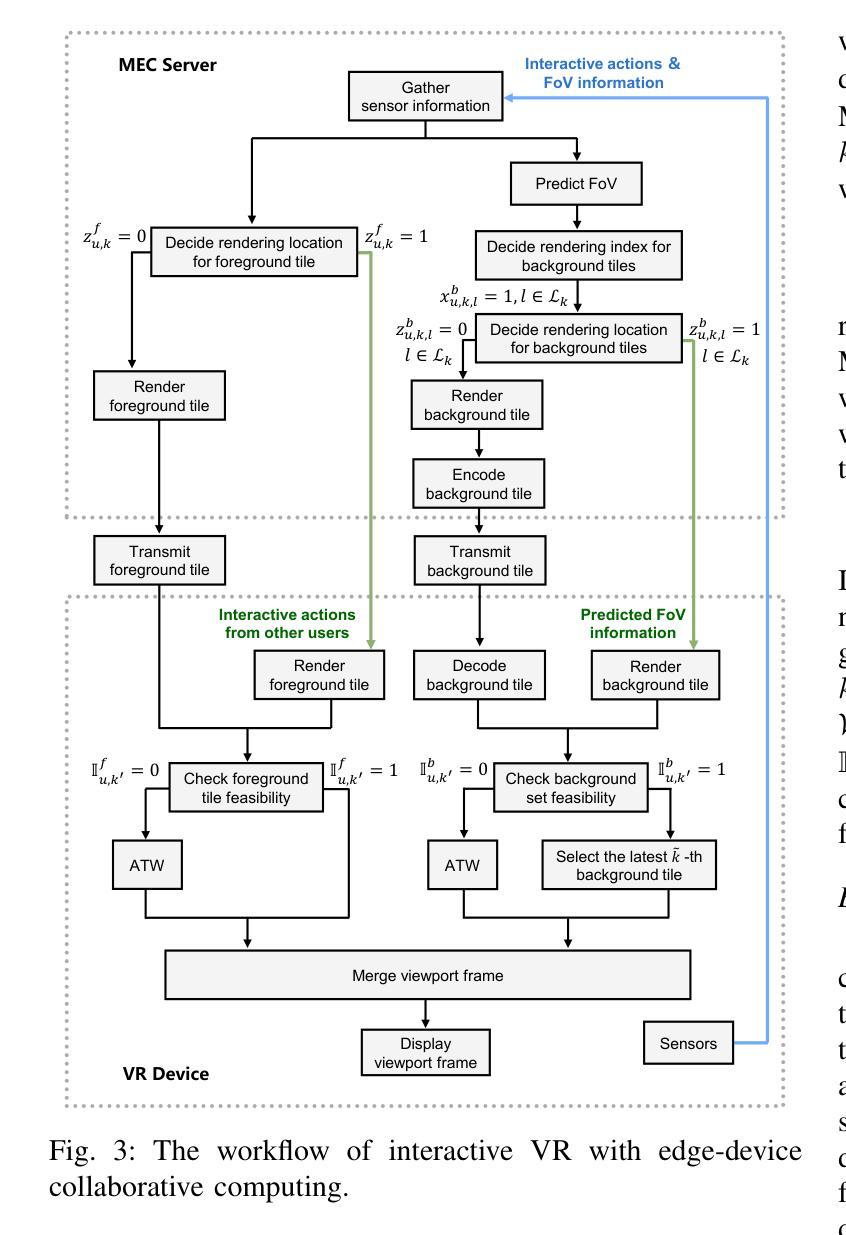
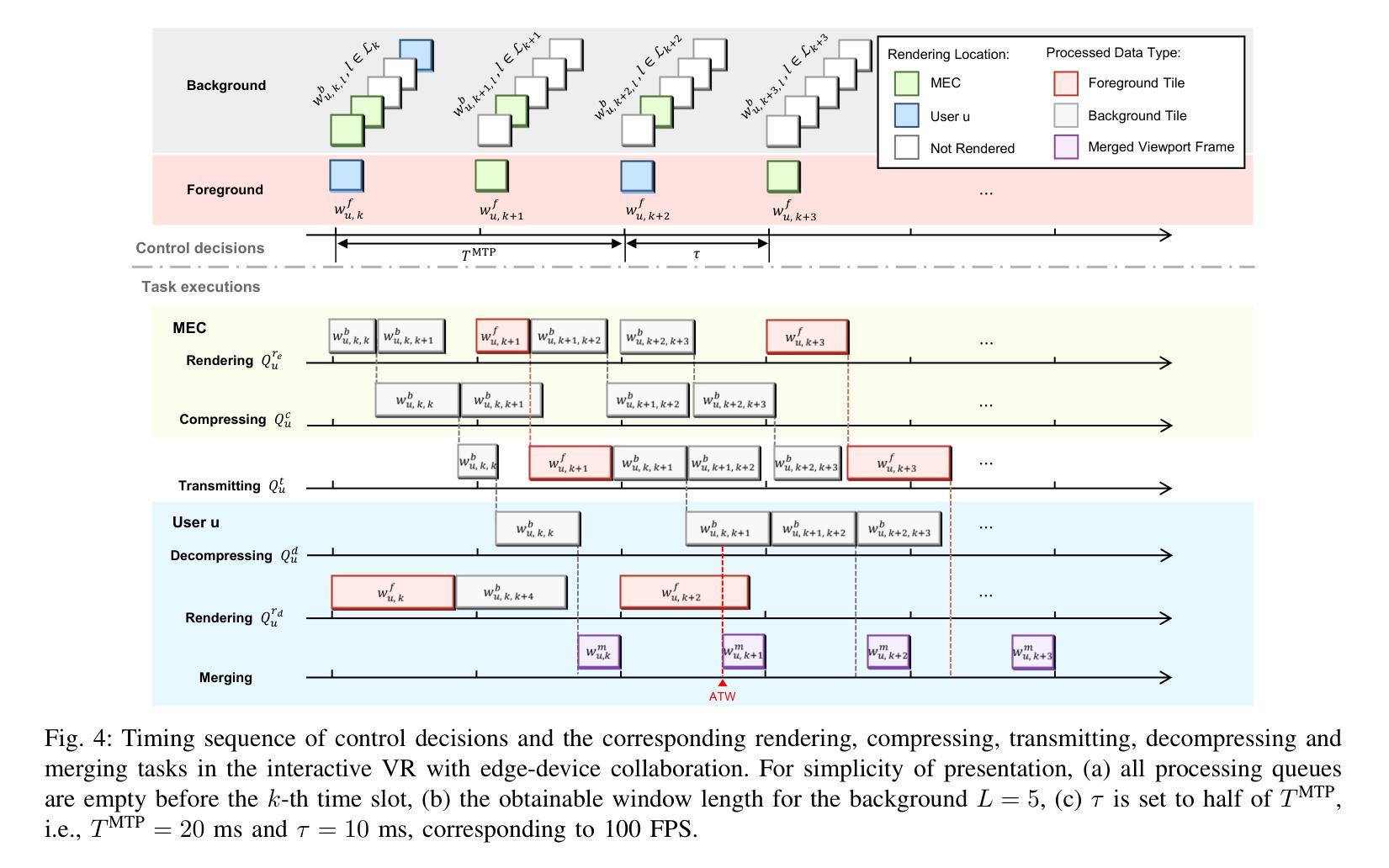
Wireless Multi-User Interactive Virtual Reality in Metaverse with Edge-Device Collaborative Computing
Authors:Caolu Xu, Zhiyong Chen, Meixia Tao, Wenjun Zhang
The immersive nature of the metaverse presents significant challenges for wireless multi-user interactive virtual reality (VR), such as ultra-low latency, high throughput and intensive computing, which place substantial demands on the wireless bandwidth and rendering resources of mobile edge computing (MEC). In this paper, we propose a wireless multi-user interactive VR with edge-device collaborative computing framework to overcome the motion-to-photon (MTP) threshold bottleneck. Specifically, we model the serial-parallel task execution in queues within a foreground and background separation architecture. The rendering indices of background tiles within the prediction window are determined, and both the foreground and selected background tiles are loaded into respective processing queues based on the rendering locations. To minimize the age of sensor information and the power consumption of mobile devices, we optimize rendering decisions and MEC resource allocation subject to the MTP constraint. To address this optimization problem, we design a safe reinforcement learning (RL) algorithm, active queue management-constrained updated projection (AQM-CUP). AQM-CUP constructs an environment suitable for queues, incorporating expired tiles actively discarded in processing buffers into its state and reward system. Experimental results demonstrate that the proposed framework significantly enhances user immersion while reducing device power consumption, and the superiority of the proposed AQM-CUP algorithm over conventional methods in terms of the training convergence and performance metrics.
PDF submitted to IEEE journal
Summary
元宇宙的沉浸式特性对无线多用户交互式虚拟现实(VR)提出了巨大挑战,如超低延迟、高吞吐量和密集计算。为解决运动到光子(MTP)阈值瓶颈,提出了基于边缘设备协同计算的无线多用户交互式VR框架。通过优化渲染决策和MEC资源分配,降低传感器信息年龄和移动设备能耗。设计了一种安全强化学习算法AQM-CUP,实验结果证明了该框架和算法在提升用户沉浸感和降低设备能耗方面的优越性。
Key Takeaways
- 元宇宙的沉浸式特性对无线多用户交互式VR提出超低延迟、高吞吐量和密集计算等挑战。
- 边缘设备协同计算框架被提出来解决运动到光子(MTP)阈值瓶颈问题。
- 提出了优化渲染决策和MEC资源分配的方法,以降低传感器信息年龄和移动设备能耗。
- 设计了一种安全强化学习算法AQM-CUP,用于解决优化问题。
- AQM-CUP算法通过构建适合队列的环境,主动丢弃处理缓冲区中的过期瓦片,纳入其状态和奖励系统。
- 实验结果证明了该框架在提升用户沉浸感和降低设备能耗方面的优越性。
- 相较于传统方法,AQM-CUP在训练收敛和性能指标上表现更优秀。
标题:无线多用户交互式虚拟现实在元宇宙中的边缘设备协同计算研究
作者:Caolu Xu, Zhiyong Chen, Meixia Tao, Wenjun Zhang
隶属机构:上海交大合作媒体创新中心及电子工程系
关键词:交互式虚拟现实、元宇宙、移动边缘计算、资源分配、安全强化学习
链接:由于无法获取论文的具体链接,故无法填写。如有GitHub代码链接,请填写在此处。
总结:
(1) 研究背景:该研究着眼于元宇宙的沉浸式通信,特别是无线多用户交互式虚拟现实(VR)的挑战,包括超低延迟、高吞吐量和计算密集型任务,对移动边缘计算(MEC)的无线带宽和渲染资源提出了高要求。
(2) 过去的方法及问题:先前的研究主要关注360度VR视频的预缓存特性,不适用于交互式VR。这些研究没有考虑到交互式VR的随机状态更新、灾难性的预缓存开销以及实时渲染的异构计算需求。因此,需要一种新的方法来应对无线信道的波动和数据量的变化。
(3) 研究方法:针对上述问题,本研究提出了一种具有边缘设备协同计算的无线多用户交互式VR框架。该框架对前景和背景进行分离架构,建立队列模型进行串行并行任务执行。通过预测未来帧的内容,将预测处理后的帧加载到缓冲区。同时,利用强化学习算法优化渲染决策和MEC资源分配,以最小化传感器信息的年龄和移动设备的功耗。
(4) 任务与性能:该研究在无线多用户交互式VR任务上进行了实验验证,证明了所提框架能显著提高用户沉浸感,降低设备功耗。相较于传统方法,所设计的安全强化学习算法(AQM-CUP)在训练收敛性和性能指标上表现出优越性。这些性能成果支持了该研究的目标,即提高无线多用户交互式VR的体验并优化资源利用。
方法论:
(1) 研究背景分析:该研究针对元宇宙中的无线多用户交互式虚拟现实(VR)进行探究,考虑到其超低延迟、高吞吐量和计算密集型任务的特点,指出移动边缘计算(MEC)在无线带宽和渲染资源方面的挑战。
(2) 问题提出:先前的研究主要关注360度VR视频的预缓存特性,不适用于交互式VR。交互式VR存在随机状态更新、灾难性的预缓存开销以及实时渲染的异构计算需求,这些问题需要新的解决方法。
(3) 方法设计:本研究提出了一种具有边缘设备协同计算的无线多用户交互式VR框架。该框架采用前景和背景分离架构,建立队列模型进行串行并行任务执行。通过预测未来帧的内容,将预测处理后的帧加载到缓冲区,以降低设备功耗并提高用户沉浸感。
(4) 技术手段:利用强化学习算法优化渲染决策和MEC资源分配,以最小化传感器信息的年龄和移动设备的功耗。研究中采用了安全强化学习算法(AQM-CUP),并通过实验验证,该算法在训练收敛性和性能指标上表现出优越性。
(5) 实验验证:研究在无线多用户交互式VR任务上进行了实验,结果证明了所提框架能显著提高用户沉浸感,降低设备功耗,达到了研究目标。
- Conclusion:
(1) 工作意义:该研究针对元宇宙中的无线多用户交互式虚拟现实(VR)进行了深入探究,解决了超低延迟、高吞吐量和计算密集型任务等关键挑战,提高了无线多用户交互式VR的体验,优化了资源利用,对于推动VR技术的发展和元宇宙的构建具有重要意义。
(2) 评价:
创新点:该研究提出了一种具有边缘设备协同计算的无线多用户交互式VR框架,利用强化学习算法优化渲染决策和MEC资源分配,这是一种新的尝试和探索,具有较高的创新性。
性能:通过实验验证,该研究提出的框架在无线多用户交互式VR任务上表现出良好的性能,能显著提高用户沉浸感,降低设备功耗。
工作量:文章对问题的分析深入,提出的解决方案具有实践意义,并通过实验进行了验证,工作量较大。
点此查看论文截图

Interactive Rendering of Relightable and Animatable Gaussian Avatars
Authors:Youyi Zhan, Tianjia Shao, He Wang, Yin Yang, Kun Zhou
Creating relightable and animatable avatars from multi-view or monocular videos is a challenging task for digital human creation and virtual reality applications. Previous methods rely on neural radiance fields or ray tracing, resulting in slow training and rendering processes. By utilizing Gaussian Splatting, we propose a simple and efficient method to decouple body materials and lighting from sparse-view or monocular avatar videos, so that the avatar can be rendered simultaneously under novel viewpoints, poses, and lightings at interactive frame rates (6.9 fps). Specifically, we first obtain the canonical body mesh using a signed distance function and assign attributes to each mesh vertex. The Gaussians in the canonical space then interpolate from nearby body mesh vertices to obtain the attributes. We subsequently deform the Gaussians to the posed space using forward skinning, and combine the learnable environment light with the Gaussian attributes for shading computation. To achieve fast shadow modeling, we rasterize the posed body mesh from dense viewpoints to obtain the visibility. Our approach is not only simple but also fast enough to allow interactive rendering of avatar animation under environmental light changes. Experiments demonstrate that, compared to previous works, our method can render higher quality results at a faster speed on both synthetic and real datasets.
Summary
基于高斯拼接技术,提出一种简单高效的方法,从稀疏视角或单目视频创建可重新照明和可动画的虚拟人物。该方法能够将身体材质和光照与视频解耦,使虚拟人物可以在新的视角、姿势和光照下以交互帧率(6.9fps)进行渲染。
Key Takeaways
- 利用高斯拼接技术,实现从多视角或单目视频创建虚拟人物。
- 方法简单高效,能实时渲染虚拟人物的新视角、姿势和光照。
- 通过符号距离函数获取规范身体网格,并为每个网格顶点分配属性。
- 高斯规范空间通过附近身体网格顶点的属性进行插值。
- 通过正向蒙皮技术将高斯变形到姿态空间,并将学习到的环境光与高斯属性结合进行着色计算。
- 通过从密集视点渲染姿态身体网格来实现快速阴影建模。
- 实验表明,该方法在合成和真实数据集上都能以更快速度呈现更高质量的结果。
标题:基于高斯贴图的交互式可重光照和可动画化虚拟人物渲染
作者:Youyi Zhan, Tianjia Shao, He Wang, Yin Yang, Kun Zhou(中文名字为詹佑益、邵天嘉、王鹤等)
隶属机构:浙江大学的国家重点CAD与CG实验室(部分作者可能还有其他学术背景)。
关键词:重光照、人物重建、动画、高斯贴图。
Urls:论文链接(待补充),GitHub代码链接(待补充)。如果不可用,填写“GitHub:None”。
摘要:
(1) 研究背景:创建能够从多视角或单视角视频中的可重光照和可动画化的虚拟人物是一项具有挑战性的任务,广泛应用于数字人物创建和虚拟现实领域。现有的方法大多依赖于神经辐射场或光线追踪技术,导致训练和渲染过程缓慢。
(2) 过去的方法及其问题:早期的方法需要在光照可控的特定设备中进行,普及性较低。后来的方法虽然成功使用神经网络或高斯贴图建模数字人物,但在未见光照条件下无法泛化。主要问题在于它们将视角相关的颜色直接映射到高斯或神经网络中,未考虑材质的内在属性。
(3) 研究方法:本研究提出了一种基于高斯贴图的高效方法,用于从多视角或单视角视频中创建可重光照和可动画化的虚拟人物。首先,通过带符号的距离函数获取标准人体网格并为每个网格顶点分配属性。然后,在高斯空间中插值获取属性,并变形到姿态空间进行着色计算。同时,通过密集视点的身体网格光栅化获得可见性,实现快速阴影建模。
(4) 任务与性能:本研究的方法可以在环境光照变化下以交互式帧率(6.9fps)渲染高质感的虚拟人物动画。实验表明,与以前的方法相比,该方法可以在合成和真实数据集上实现更高质量的结果和更快的速度。性能结果表明该方法支持其目标。
以上总结仅供参考,如需更详细的内容,建议直接阅读论文原文。
- 方法:
(1)背景研究:该论文主要解决从多视角或单视角视频中创建可重光照和可动画化的虚拟人物的问题。这一技术在数字人物创建和虚拟现实领域有广泛应用,但现有方法大多依赖于神经辐射场或光线追踪技术,导致训练和渲染过程缓慢。
(2)问题解析:早期的方法需要在光照可控的特定设备中进行,普及性较低。后来的方法虽然成功使用神经网络或高斯贴图建模数字人物,但在未见光照条件下无法泛化。问题在于它们没有考虑到材质的内在属性,直接将视角相关的颜色映射到高斯或神经网络中。
(3)研究方法:本研究提出了一种基于高斯贴图的高效方法,主要包括以下几个步骤:
- 首先,通过带符号的距离函数获取标准人体网格,并为每个网格顶点分配属性。这样做是为了从输入的视频中提取人物模型的几何和纹理信息。
- 然后,在高斯空间中插值获取属性,并变形到姿态空间进行着色计算。这一步是为了根据光照条件和视角变化对人物进行准确的着色和渲染。
- 同时,通过密集视点的身体网格光栅化获得可见性,实现快速阴影建模。这一步是为了优化渲染效果,使得人物在动态场景中的阴影处理更加自然和高效。
(4)实验验证:本研究的方法在环境光照变化下以交互式帧率(6.9fps)渲染高质感的虚拟人物动画,并在合成和真实数据集上实现了更高质量的结果和更快的速度。这证明了该方法的有效性和实用性。
以上是对论文方法部分的详细解释,希望对您有所帮助。如需进一步了解,建议直接阅读论文原文。
- Conclusion:
- (1) 该研究工作在创建可重光照和可动画化的虚拟人物方面具有重大意义,为数字人物创建和虚拟现实领域提供了一种高效、实用的方法。
- (2) 创新点:本文提出了一种基于高斯贴图的方法,实现了从多视角或单视角视频中创建可重光照和可动画化的虚拟人物,具有较高的效率和实用性。性能:该方法在环境光照变化下以交互式帧率渲染高质感的虚拟人物动画,并在合成和真实数据集上实现了高质量的结果和更快的速度。工作量:文章对方法的实现进行了详细的描述,包括带符号的距离函数、高斯空间插值、姿态空间着色计算、密集视点的身体网格光栅化等步骤,工作量较大。
点此查看论文截图


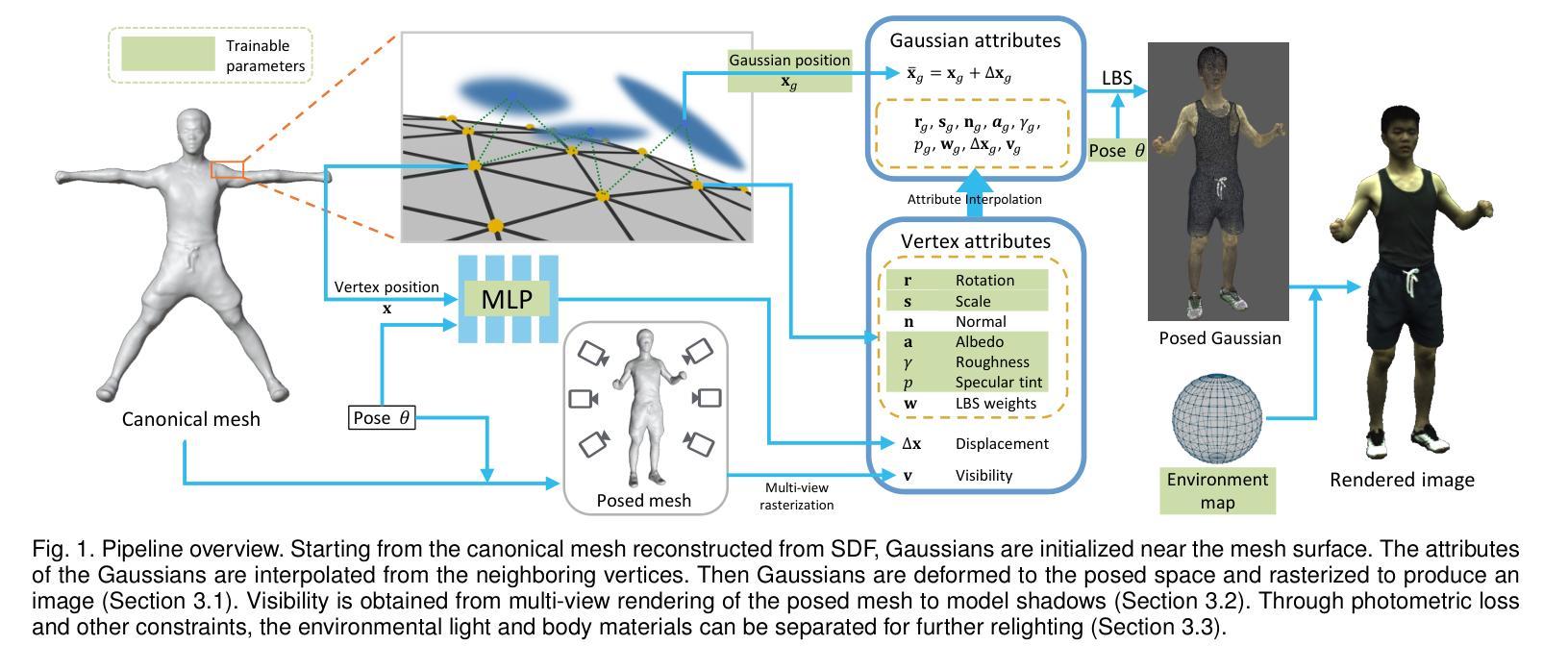

MeshAvatar: Learning High-quality Triangular Human Avatars from Multi-view Videos
Authors:Yushuo Chen, Zerong Zheng, Zhe Li, Chao Xu, Yebin Liu
We present a novel pipeline for learning high-quality triangular human avatars from multi-view videos. Recent methods for avatar learning are typically based on neural radiance fields (NeRF), which is not compatible with traditional graphics pipeline and poses great challenges for operations like editing or synthesizing under different environments. To overcome these limitations, our method represents the avatar with an explicit triangular mesh extracted from an implicit SDF field, complemented by an implicit material field conditioned on given poses. Leveraging this triangular avatar representation, we incorporate physics-based rendering to accurately decompose geometry and texture. To enhance both the geometric and appearance details, we further employ a 2D UNet as the network backbone and introduce pseudo normal ground-truth as additional supervision. Experiments show that our method can learn triangular avatars with high-quality geometry reconstruction and plausible material decomposition, inherently supporting editing, manipulation or relighting operations.
PDF Project Page: https://shad0wta9.github.io/meshavatar-page/
Summary
高质感的三角人物模型学习新流程:通过多视角视频,借助隐式SDF场提取三角网格模型表示人物,配合姿态隐式材质场克服NeRF技术局限,利用物理渲染技术准确分解几何和纹理。采用2D UNet网络提高几何与外观细节质量,加入伪正常真值加强监督,能高质量重建几何并分解材料。
Key Takeaways
- 基于多视角视频提出了一种新的学习高质量三角人物模型的方法。
- 采用隐式SDF场来表示人物模型,实现与姿态相关的动态外观效果。
- 通过物理渲染技术准确分解几何和纹理,增强模型的细节表现。
- 利用隐式材质场,克服NeRF技术的局限性,支持编辑、操作和重新照明等操作。
- 采用2D UNet网络作为网络骨干,提高几何和外观质量。
- 通过引入伪正常真值来增强对网络训练过程中的监督。
- 实验结果显示了新方法的高性能几何重建和纹理分解能力。
标题:MeshAvatar:从多视角视频学习高质量三角化人类角色模型。中文翻译:网格化身:从多视角视频学习高质量三角化人物模型。
作者:作者包括Yushuo Chen,Zerong Zheng,Zhe Li,Chao Xu和Yebin Liu。其中,Yushuo Chen和Zerong Zheng有相应的机构名称,分别是来自清华大学和北京NNKosmos科技有限公司。
所属机构:第一作者Yushuo Chen的所属机构为清华大学。
关键词:全文关键词包括full-body avatars(全身化身),relighting(重新照明),physics-based rendering(基于物理的渲染)。
链接:论文链接为arXiv:2407.08414v1 [cs.CV] 11 Jul 2024。GitHub代码链接为:https://github.com/shad0wta9/meshavatar(根据提供的信息填写)。
总结:
(1)研究背景:随着动画和电影产业的发展,人物角色的创建变得至关重要。然而,手动创建高质量的人物化身是一项昂贵且耗时的工作。因此,研究者们致力于通过学习和建模技术来自动创建人物化身。本文提出了一种新的方法来解决这一问题。
(2)过去的方法与问题:近期的方法主要基于神经辐射场(NeRF)进行人物化身学习。然而,NeRF不兼容传统的图形管道,并为编辑、合成等操作带来了挑战。因此,需要一种新的方法来克服这些问题。
(3)研究方法:本文提出了一种新的流程,从多视角视频学习高质量三角化人物模型。该方法通过隐式SDF场提取显式三角网格来表示角色,并结合姿势条件隐式材料场。利用基于物理的渲染技术,准确分解几何和纹理。为了提高几何和外观细节,研究团队采用了2D UNet作为网络骨干,并引入了伪法向地面真实作为额外监督。
(4)任务与性能:本文的方法在人物模型学习任务上表现出色,实现了高质量几何重建和可信赖的材料分解。实验表明,该方法能够支持编辑、操作或重新照明等操作。性能结果支持了该研究的目标,即提供一种高效、高质量的人物化身学习方法。
希望以上整理对您有所帮助!
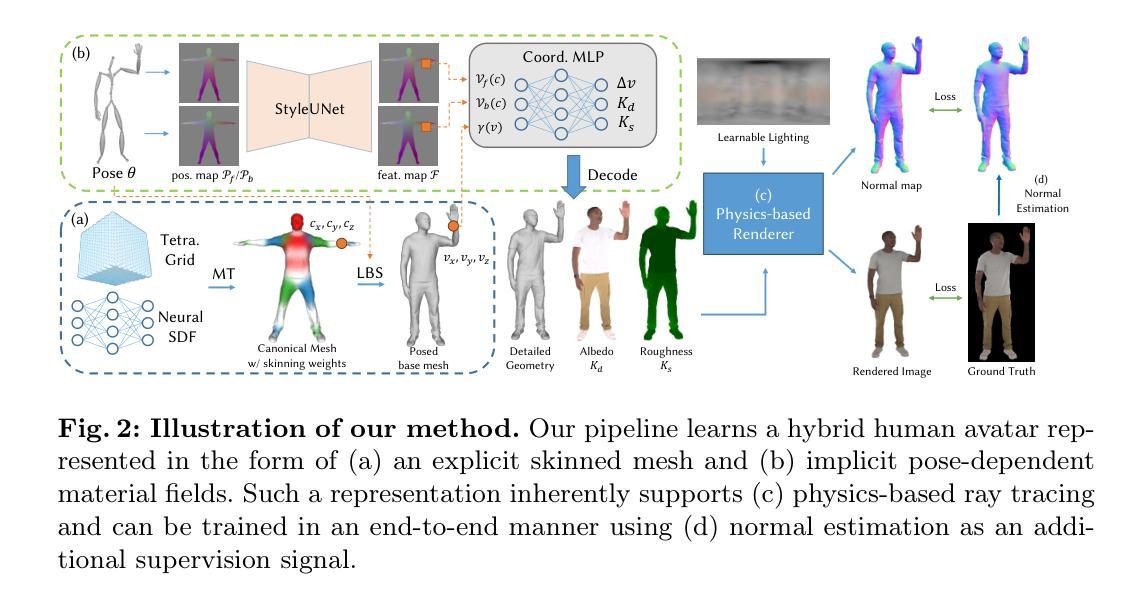
- 方法论:
(1) 研究背景:随着动画和电影产业的发展,人物角色的创建变得至关重要。然而,手动创建高质量的人物化身是一项昂贵且耗时的工作。因此,研究者们致力于通过学习和建模技术来自动创建人物化身。本文提出了一种新的方法来解决这一问题。
(2) 过去的方法与问题:近期的方法主要基于神经辐射场(NeRF)进行人物化身学习。然而,NeRF不兼容传统的图形管道,并为编辑、合成等操作带来了挑战。因此,需要一种新的方法来克服这些问题。
(3) 研究方法:本文提出了一种从多视角视频学习高质量三角化人物模型的新流程。该方法通过隐式SDF场提取显式三角网格来表示角色,并结合姿势条件隐式材料场。利用基于物理的渲染技术,准确分解几何和纹理。为了提高几何和外观细节,研究团队采用了2D UNet作为网络骨干,并引入了伪法向地面真实作为额外监督。具体步骤如下:
a. 构建显式隐式混合表示法:利用隐式SDF场和三角网格表示人物模型,结合姿势条件隐式材料场;
b. 提取几何细节:通过皮肤网格和姿势依赖的顶点偏移生成技术提取几何细节;
c. 预测材料属性:利用基于物理的渲染技术预测材料属性(如法线贴图、UV贴图等),结合姿势条件进行动态材质生成;
d. 训练网络:采用多视角视频数据作为输入,通过优化网络参数来训练模型,实现高质量的人物模型学习任务;
e. 性能评估与优化:对模型进行性能评估,包括几何重建的准确性、纹理细节的表现等,对模型进行优化改进。该方法的优点在于能够从多视角视频数据中学习高质量的人物模型,并实现编辑、操作或重新照明等操作。实验结果证明了该方法的有效性。
f. Normal Estimation Normal maps Loss Loss StyleUNet:利用正常估计图作为额外的监督信号来增强几何细节重建的鲁棒性。通过StyleUNet网络进行特征提取和正常估计,结合损失函数进行优化。此外还使用了基于物理的渲染器来生成可信赖的材料分解结果。
- Conclusion:
(1)这篇工作的意义在于提出了一种从多视角视频学习高质量三角化人物模型的新方法,解决了手动创建高质量人物化身昂贵且耗时的问题,为动画和电影产业提供了高效、高质量的人物化身学习方法。
(2)创新点:该文章提出了结合隐式SDF场和三角网格表示人物模型的显式隐式混合表示法,并结合姿势条件隐式材料场,实现了从多视角视频学习高质量三角化人物模型的任务。在性能上,该方法在人物模型学习任务上表现出色,实现了高质量几何重建和可信赖的材料分解,支持编辑、操作或重新照明等操作。工作量方面,研究团队采用了2D UNet作为网络骨干,并引入了伪法向地面真实作为额外监督,进行了大量的实验和性能评估。
然而,该方法也存在一定的局限性,例如使用姿势相关的材料来弥补三角网格分辨率有限导致的几何误差,这虽然实用但并不是物理上的可行设计。此外,对于更复杂非刚体变形的衣物类型,例如宽松的衣服,可能会在该框架中遇到困难。
点此查看论文截图

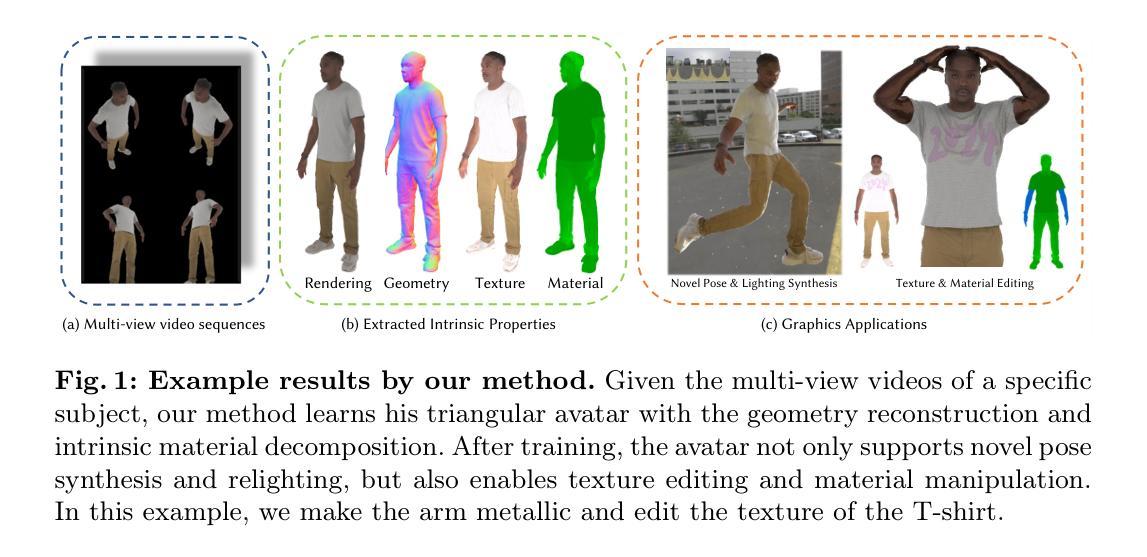
Stretch your reach: Studying Self-Avatar and Controller Misalignment in Virtual Reality Interaction
Authors:Jose Luis Ponton, Reza Keshavarz, Alejandro Beacco, Nuria Pelechano
Immersive Virtual Reality typically requires a head-mounted display (HMD) to visualize the environment and hand-held controllers to interact with the virtual objects. Recently, many applications display full-body avatars to represent the user and animate the arms to follow the controllers. Embodiment is higher when the self-avatar movements align correctly with the user. However, having a full-body self-avatar following the user’s movements can be challenging due to the disparities between the virtual body and the user’s body. This can lead to misalignments in the hand position that can be noticeable when interacting with virtual objects. In this work, we propose five different interaction modes to allow the user to interact with virtual objects despite the self-avatar and controller misalignment and study their influence on embodiment, proprioception, preference, and task performance. We modify aspects such as whether the virtual controllers are rendered, whether controllers are rendered in their real physical location or attached to the user’s hand, and whether stretching the avatar arms to always reach the real controllers. We evaluate the interaction modes both quantitatively (performance metrics) and qualitatively (embodiment, proprioception, and user preference questionnaires). Our results show that the stretching arms solution, which provides body continuity and guarantees that the virtual hands or controllers are in the correct location, offers the best results in embodiment, user preference, proprioception, and performance. Also, rendering the controller does not have an effect on either embodiment or user preference.
PDF Presented in CHI’24
Summary
提供沉浸式虚拟现实体验时,面临的一个挑战是用户身体与虚拟身体之间的差异,这可能导致控制器与自我化身之间的错位。为解决这一问题,本文提出了五种交互模式,旨在研究其对用户体验的影响。研究发现,通过拉伸虚拟化身手臂来确保虚拟控制器位于正确位置的方法,在体验、用户偏好、感知和身体认知方面表现最佳。渲染控制器对用户体验和感知没有直接影响。
Key Takeaways
- 在虚拟现实中,确保用户的身体与虚拟自我化身之间的同步是提高沉浸感的关键。
- 五种不同的交互模式被提出来解决用户与虚拟对象交互时的错位问题。
- 拉伸虚拟化身手臂以匹配实际控制器位置的方法在多个方面表现最佳。
- 渲染控制器的视觉效果对用户体验和感知的影响不明显。
- 研究发现虚拟与现实同步在用户体验中起着重要作用,直接影响用户对虚拟世界的感知和自我认知。
标题:沉浸式虚拟现实中自我化身与控制器的研究背景
中文翻译:Stretch your reach: Studying Self-Avatar and Controller in Immersive Virtual Reality作者:Jose Luis Ponton,Reza Keshavarz,Alejandro Beacco,Nuria Pelechano
作者所属机构:均为Universitat Politècnica de Catalunya(加泰罗尼亚理工大学)
关键词:虚拟现实、自我化身、控制器、交互模式、体验研究
Urls:论文链接(待补充),GitHub代码链接(待补充,若无则填写“GitHub:None”)
总结:
(1)研究背景:本文主要研究在沉浸式虚拟现实环境中,自我化身(Self-Avatar)与控制器(Controller)之间的交互问题。由于用户真实身体与虚拟身体之间的不匹配,导致在交互过程中可能会出现误操作或不适。本文旨在解决这一问题,提高用户在虚拟环境中的体验。
(2)过去的方法及问题:在虚拟现实中,通常通过头显和手持控制器来与用户进行交互。当展示全身自我化身并尝试使手臂跟随控制器动作时,会出现控制器与自我化身不匹配的问题。这可能导致手的位置出现明显的错位,影响用户与虚拟对象的交互体验。
(3)研究方法:为了改善用户体验,本文提出了五种不同的交互模式来解决自我化身与控制器之间的不匹配问题。这些模式包括控制器的渲染方式、是否将控制器附加到用户手上、是否拉伸化身手臂以匹配真实手部位置等。作者通过定量和定性的方法评估了这些交互模式对用户的身体感知、任务执行效率和喜好等方面的影响。
(4)任务与性能:本文的研究任务是在不同的交互模式下评估用户在虚拟环境中的体验。通过实验结果,作者发现所提出的某些交互模式能够显著提高用户的任务执行效率和体验质量。特别是当化身手臂能够拉伸以匹配真实手部位置时,用户的体验得到了显著提升。这表明所提出的交互方法在提升用户虚拟体验方面具有很好的效果。
请注意,由于缺少具体的论文内容,以上总结可能有所不完整或偏差。如有具体论文内容,请提供更详细的信息以便进行更准确的总结。
点此查看论文截图


RodinHD: High-Fidelity 3D Avatar Generation with Diffusion Models
Authors:Bowen Zhang, Yiji Cheng, Chunyu Wang, Ting Zhang, Jiaolong Yang, Yansong Tang, Feng Zhao, Dong Chen, Baining Guo
We present RodinHD, which can generate high-fidelity 3D avatars from a portrait image. Existing methods fail to capture intricate details such as hairstyles which we tackle in this paper. We first identify an overlooked problem of catastrophic forgetting that arises when fitting triplanes sequentially on many avatars, caused by the MLP decoder sharing scheme. To overcome this issue, we raise a novel data scheduling strategy and a weight consolidation regularization term, which improves the decoder’s capability of rendering sharper details. Additionally, we optimize the guiding effect of the portrait image by computing a finer-grained hierarchical representation that captures rich 2D texture cues, and injecting them to the 3D diffusion model at multiple layers via cross-attention. When trained on 46K avatars with a noise schedule optimized for triplanes, the resulting model can generate 3D avatars with notably better details than previous methods and can generalize to in-the-wild portrait input.
PDF ECCV 2024; project page: https://rodinhd.github.io/
Summary
RodinHD可从肖像照片生成高保真3D头像。本文解决了现有方法无法捕捉头发等细节的问题。针对顺序拟合多个三角平面时出现的灾难性遗忘问题,我们提出了一种新的数据调度策略和权重整合正则化项,提高了解码器渲染细节的能力。我们还优化了肖像图像的引导作用,通过计算精细的层次表示来捕捉丰富的2D纹理线索,并通过跨注意力在多个层次上注入3D扩散模型。在针对三角平面优化的噪声调度下,经过在4.6万个头像上训练的模型可以生成细节明显更好的3D头像,并能推广到各种真实肖像输入。
Key Takeaways
- RodinHD能从肖像照片生成高保真3D头像。
- 现有方法在捕捉细节(如发型)方面存在缺陷。
- 提出了解决灾难性遗忘问题的方法,通过新的数据调度策略和权重整合正则化项提高解码器性能。
- 优化了肖像图像的引导作用,通过计算精细的层次表示来增强模型的表现力。
- 引入跨注意力机制,在多个层次上注入2D纹理线索到3D扩散模型中。
- 在大量头像数据上训练的模型可以生成细节更好的3D头像。
- 模型能够推广到各种真实肖像输入。
标题: RodinHD:基于扩散模型的高保真3D头像生成
中文翻译:RodinHD:基于扩散模型的高保真3D头像生成。作者: Bowen Zhang(第一作者),Yiji Cheng(第一作者),Chunyu Wang(通讯作者),Ting Zhang,Jiaolong Yang,Yansong Tang,Feng Zhao,Dong Chen,Baining Guo。还包括若干实习生和隶属机构。
作者隶属机构(中文翻译): 第一作者隶属中国科学技术大学和清华大学;其余作者隶属微软亚洲研究院。
关键词: 3D头像生成,扩散模型,灾难性遗忘。
链接: 论文链接:[论文链接地址];GitHub代码链接:[GitHub链接地址](如果可用,填写具体链接;如果不可用,填写“GitHub:None”)。
摘要:
(1)研究背景:随着数字化技术的发展,人们越来越追求真实、精细的3D头像生成技术。现有的方法在生成具有复杂细节(如发型)的高保真头像时存在困难。本文旨在解决这一问题。
(2)过去的方法与问题:现有方法在使用序贯训练时会出现灾难性遗忘问题,导致在多个头像上拟合triplanes时效果不佳。此外,它们未能充分利用肖像图像的引导效果,无法捕捉丰富的纹理信息。
(3)研究方法:本文提出了RodinHD方法。首先,通过引入新的数据调度策略和权重整合正则化项来解决灾难性遗忘问题,提高解码器呈现尖锐细节的能力。其次,优化肖像图像的引导作用,通过计算更精细的层次化表示来捕捉丰富的2D纹理线索,并通过跨层注意力机制注入到3D扩散模型中。
(4)任务与性能:在46K头像数据集上训练模型,使用优化的噪声调度策略针对triplanes进行优化。实验结果表明,该方法生成的3D头像具有更好的细节,并能泛化到野生肖像输入。性能结果支持该方法的有效性。
希望这个总结符合您的要求!
- 方法论:
这篇文章主要提出了一个名为RodinHD的方法,用于解决生成具有复杂细节(如发型)的高保真3D头像的技术难题。方法论的核心思想主要体现在以下几个方面:
- (1) 研究背景与问题提出:随着数字化技术的发展,追求真实、精细的3D头像生成技术越来越成为研究的热点。但现有方法在生成具有复杂细节的高保真头像时存在困难,特别是在使用序贯训练时会出现灾难性遗忘问题,导致在多个头像上拟合triplanes的效果不佳。针对这些问题,本文提出了RodinHD方法。
- (2) 方法设计:RodinHD方法主要包括两个步骤,即头像拟合和建模。在头像拟合阶段,通过引入新的数据调度策略和权重整合正则化项来解决灾难性遗忘问题,提高解码器呈现尖锐细节的能力。在建模阶段,优化肖像图像的引导作用,通过计算更精细的层次化表示来捕捉丰富的2D纹理线索,并通过跨层注意力机制注入到3D扩散模型中。此外,为了进一步提高生成效果,文章还介绍了基于噪声调度的优化策略针对triplanes进行优化。
- (3) 实验设计与结果分析:实验部分介绍了该方法的实现细节和性能评估。通过对比实验和可视化结果验证了RodinHD方法的有效性。实验结果表明,该方法生成的3D头像具有更好的细节,并能泛化到野生肖像输入。性能结果支持该方法的有效性。具体来说,该文章使用了两种主要策略进行模型训练和优化。首先,为了解决灾难性遗忘问题,采用了任务回放和权重整合的方法。其次,为了提高模型的泛化能力,通过引入了身份感知权重整合(IWC)正则化器来稳定学习并减少学习景观中的剧烈变化。同时,为了生成高分辨率的triplanes,文章还训练了一个级联扩散模型。此外,为了提高生成的图像质量,在训练过程中还采用了图像级别的监督方法。通过一系列实验验证和性能评估证明了该方法的有效性。
Conclusion:
(1) 这篇文章的工作对于追求真实、精细的3D头像生成技术具有重要意义。它解决了现有方法在生成具有复杂细节的高保真头像时的技术难题,为用户提供了更加真实、精细的3D头像生成体验。
(2) 创新点:文章提出了RodinHD方法,通过引入新的数据调度策略和权重整合正则化项解决灾难性遗忘问题,并通过优化肖像图像的引导作用和跨层注意力机制注入到3D扩散模型中,提高了3D头像的生成质量。
性能:实验结果表明,该方法生成的3D头像具有更好的细节,并能泛化到野生肖像输入,验证了方法的有效性。
工作量:文章进行了大量的实验和性能评估,包括对比实验、可视化结果、模型训练和优化等,证明了方法的有效性。同时,文章还介绍了基于噪声调度的优化策略针对triplanes进行优化,进一步提高了生成效果。
点此查看论文截图


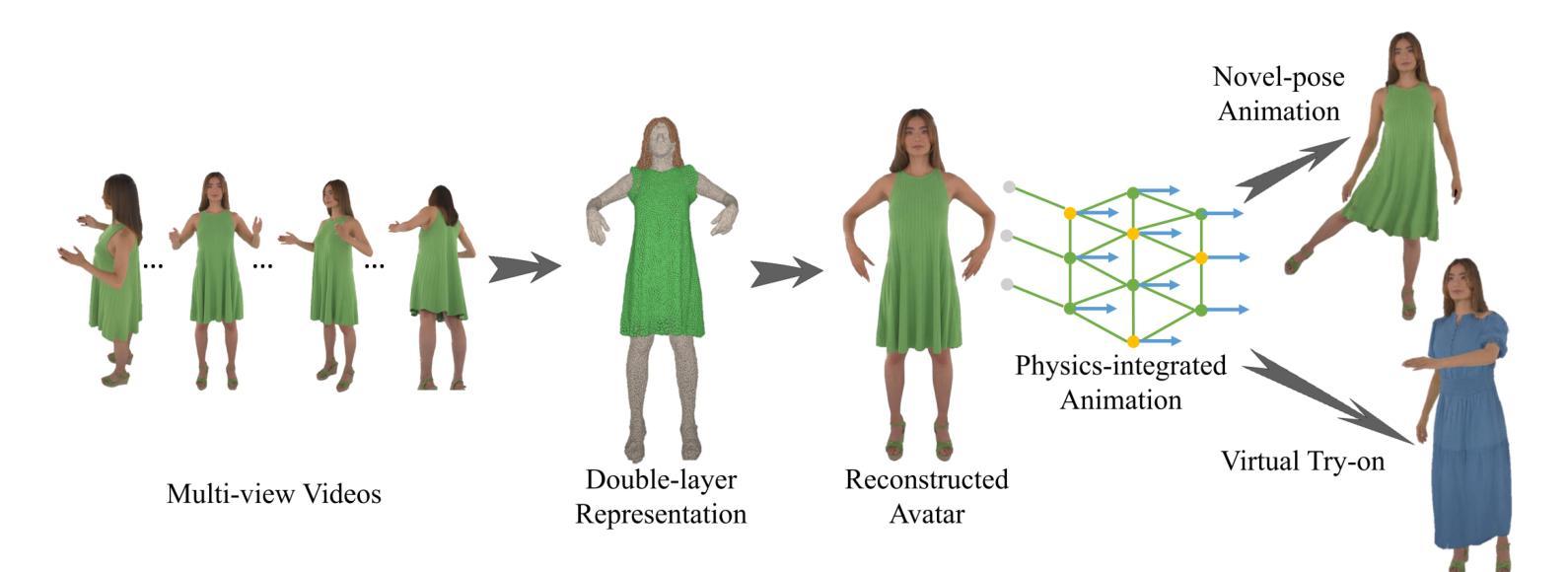
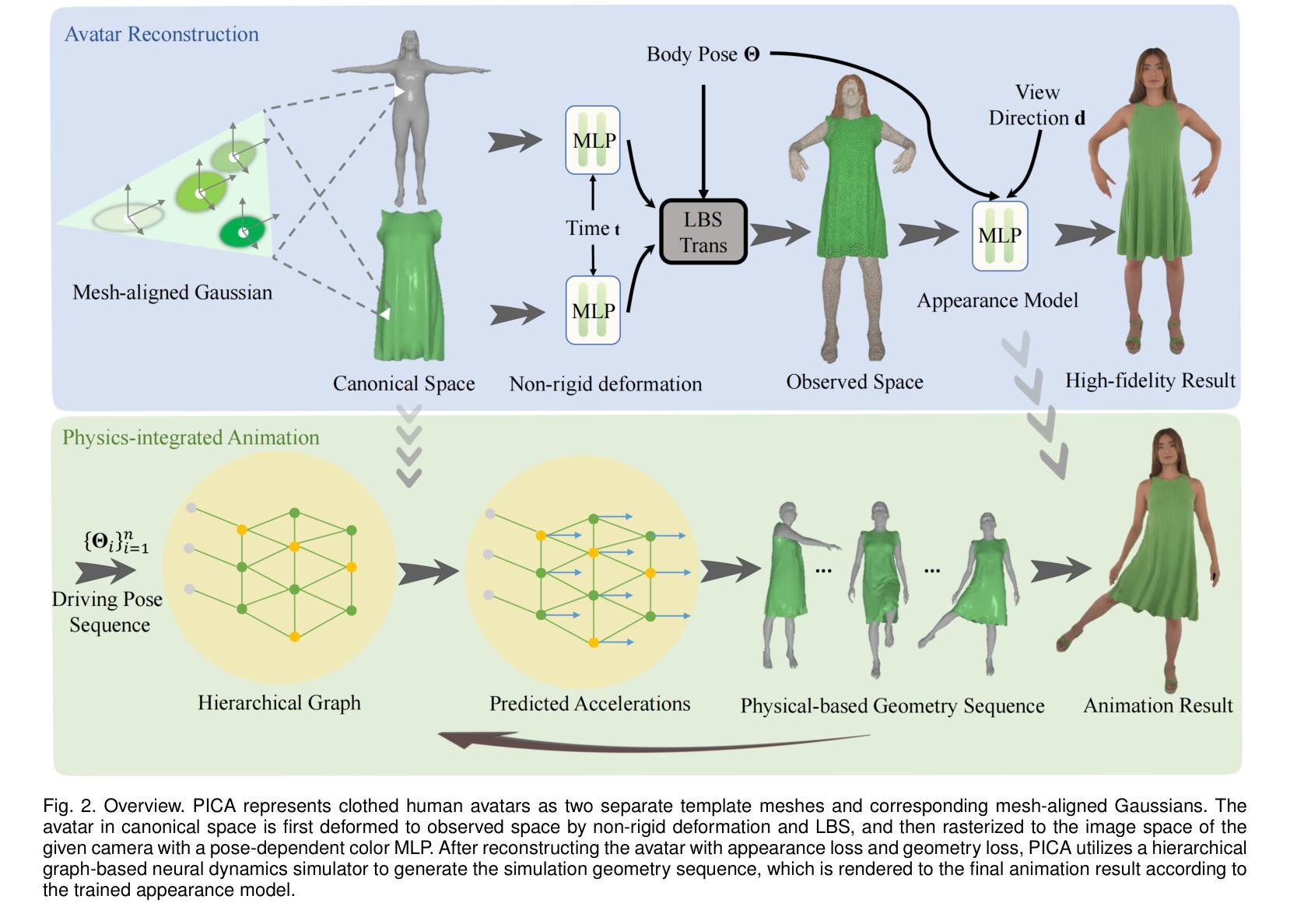
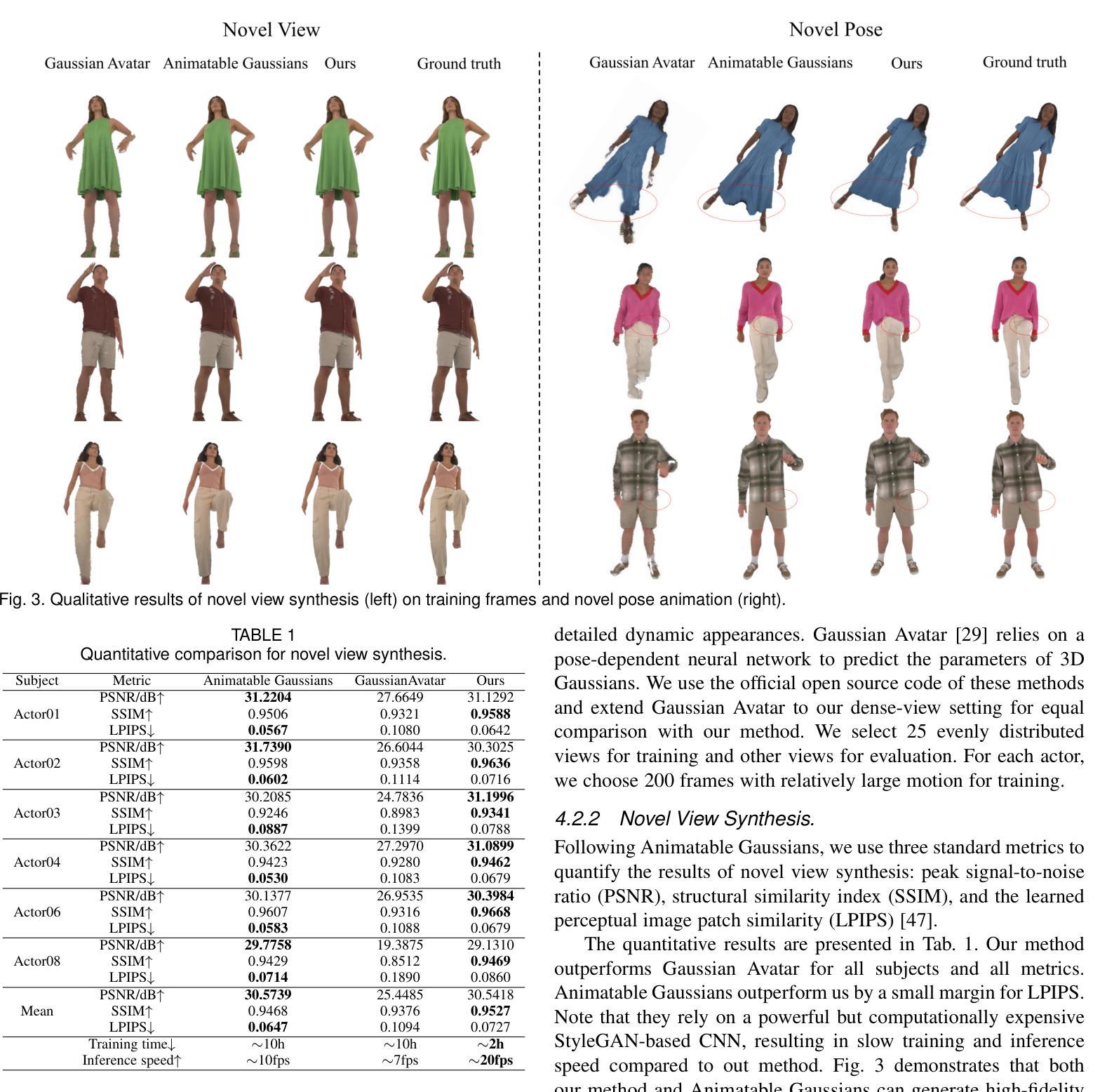
PICA: Physics-Integrated Clothed Avatar
Authors:Bo Peng, Yunfan Tao, Haoyu Zhan, Yudong Guo, Juyong Zhang
We introduce PICA, a novel representation for high-fidelity animatable clothed human avatars with physics-accurate dynamics, even for loose clothing. Previous neural rendering-based representations of animatable clothed humans typically employ a single model to represent both the clothing and the underlying body. While efficient, these approaches often fail to accurately represent complex garment dynamics, leading to incorrect deformations and noticeable rendering artifacts, especially for sliding or loose garments. Furthermore, previous works represent garment dynamics as pose-dependent deformations and facilitate novel pose animations in a data-driven manner. This often results in outcomes that do not faithfully represent the mechanics of motion and are prone to generating artifacts in out-of-distribution poses. To address these issues, we adopt two individual 3D Gaussian Splatting (3DGS) models with different deformation characteristics, modeling the human body and clothing separately. This distinction allows for better handling of their respective motion characteristics. With this representation, we integrate a graph neural network (GNN)-based clothed body physics simulation module to ensure an accurate representation of clothing dynamics. Our method, through its carefully designed features, achieves high-fidelity rendering of clothed human bodies in complex and novel driving poses, significantly outperforming previous methods under the same settings.
PDF Project page: https://ustc3dv.github.io/PICA/
Summary
一种新的高保真动态人物虚拟形象(avatar)表现方法——PICA被提出。该方法采用两个具有不同变形特性的3D高斯喷绘(3DGS)模型,分别对人体和衣物进行建模,以改善对复杂运动特性的处理。结合图神经网络(GNN)的衣物物理仿真模块,确保衣物的动态表现准确。此方法在高复杂度和新颖驱动姿势的虚拟人物渲染上表现优异,显著超越先前的方法。
Key Takeaways
- PICA是一种新的高保真动态人物虚拟形象表现方法。
- 通过对人体和衣物分别建模,提高了复杂运动特性的处理精度。
- 采用图神经网络(GNN)进行衣物物理仿真,确保衣物的动态准确性。
- 通过两个具有不同变形特性的3D高斯喷绘(3DGS)模型,改善了衣物的动态变形表现。
- PICA方法能够在高复杂度和新颖驱动姿势的虚拟人物渲染上实现优异性能。
- 相较于先前的方法,PICA在相同设置下具有显著优势。
- PICA解决了以往神经渲染方法在表现复杂衣物动态时的失败问题,特别是在姿态动画方面。
- 方法论概述:
这篇文章提出了一种新的基于3D Gaussians模型的人物动画方法,该方法的重点在于通过构造动态人体衣物模型进行高质量的人物动画渲染。主要步骤包括:
- (1) 背景介绍:文章首先介绍了当前人物动画研究背景,以及已有的相关方法和技术难点。特别是针对衣物动画的复杂性,提出需要一种新的解决方案来解决这一问题。
- (2) 模型构建:接着,文章提出了一种新的模型构建方法,该模型采用双层三维高斯表示法来分别模拟身体和衣物。其中,衣物模型由模板网格和对应的网格对齐高斯组成,旨在捕捉衣物的动态行为。此外,还引入了非刚性变形和线性混合骨骼(LBS)技术来模拟衣物的动态变化。
- (3) 渲染与动画生成:文章进一步阐述了如何利用神经网络渲染模型进行高质量的动画渲染。通过引入图像分割掩膜和几何损失函数来优化重建的人物模型,并利用基于层次图的神经网络动力学模拟器生成逼真的衣物动态序列。此外,还利用姿态相关的颜色模型来处理衣物的光影效果。
- (4) 训练过程:最后,文章介绍了整个模型的训练过程。训练过程中采用了多种损失函数来优化模型的各项参数,包括颜色损失、掩膜损失、分割损失等。通过联合优化这些参数,文章的方法能够实现高质量的人物动画渲染结果。
以上步骤和方法论构成了文章的核心内容,旨在通过构建动态衣物模型来实现高质量的人物动画渲染。
点此查看论文截图

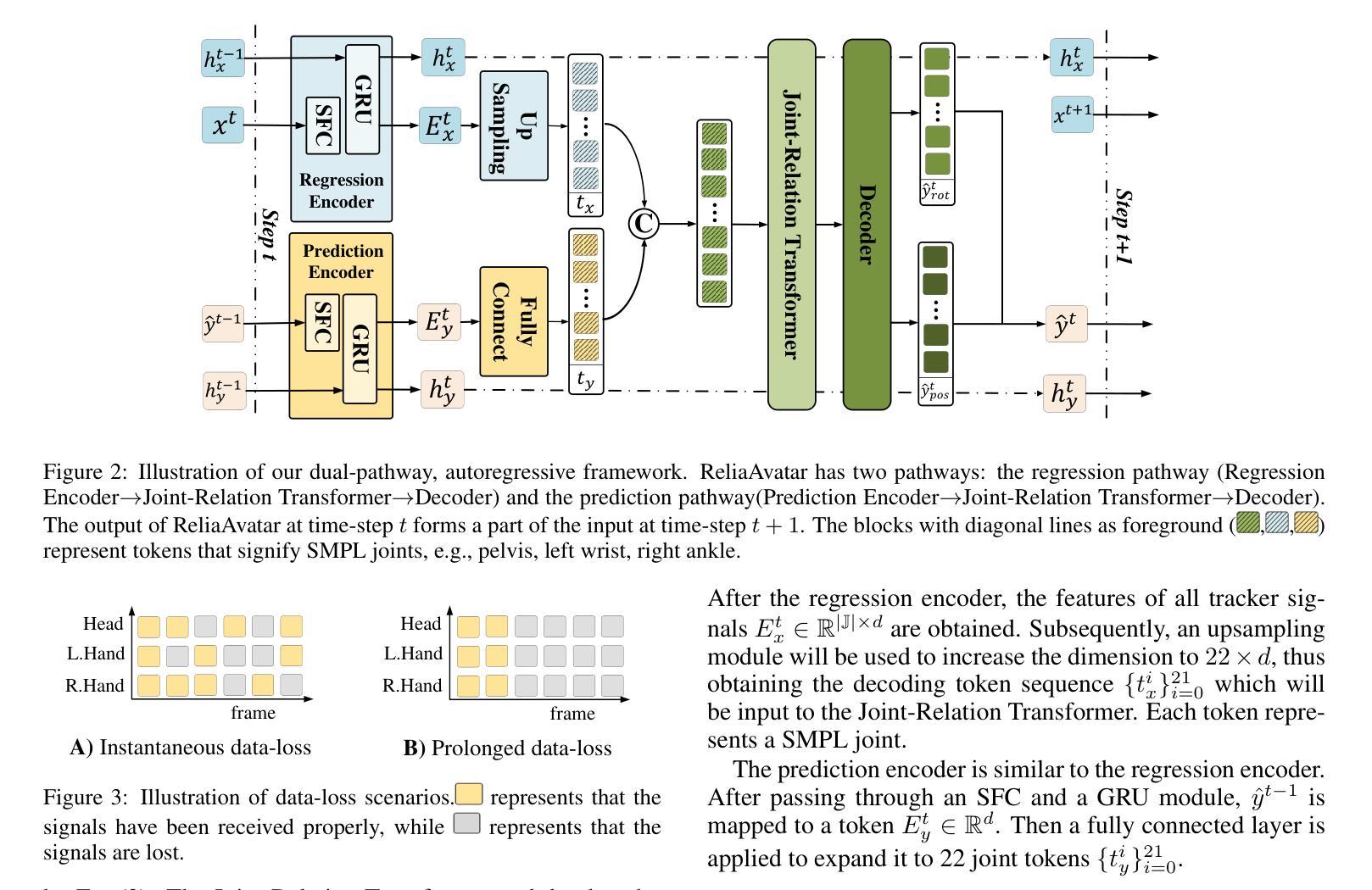
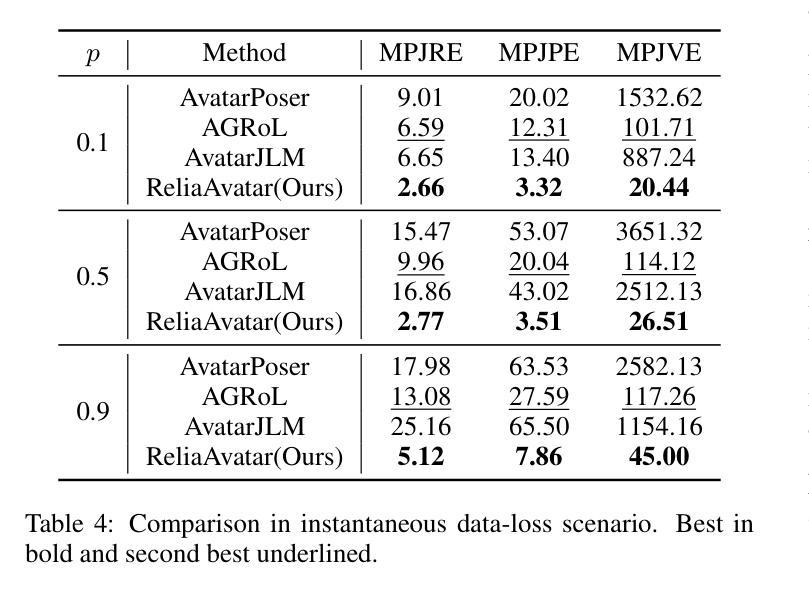
ReliaAvatar: A Robust Real-Time Avatar Animator with Integrated Motion Prediction
Authors:Bo Qian, Zhenhuan Wei, Jiashuo Li, Xing Wei
Efficiently estimating the full-body pose with minimal wearable devices presents a worthwhile research direction. Despite significant advancements in this field, most current research neglects to explore full-body avatar estimation under low-quality signal conditions, which is prevalent in practical usage. To bridge this gap, we summarize three scenarios that may be encountered in real-world applications: standard scenario, instantaneous data-loss scenario, and prolonged data-loss scenario, and propose a new evaluation benchmark. The solution we propose to address data-loss scenarios is integrating the full-body avatar pose estimation problem with motion prediction. Specifically, we present \textit{ReliaAvatar}, a real-time, \textbf{relia}ble \textbf{avatar} animator equipped with predictive modeling capabilities employing a dual-path architecture. ReliaAvatar operates effectively, with an impressive performance rate of 109 frames per second (fps). Extensive comparative evaluations on widely recognized benchmark datasets demonstrate Relia-Avatar’s superior performance in both standard and low data-quality conditions. The code is available at \url{https://github.com/MIV-XJTU/ReliaAvatar}.
Summary
高效估计全身姿态并借助最少的可穿戴设备进行,是当前值得研究的方向。当前大多数研究忽略了在低质量信号条件下全身化身估计的探索,这在实践中普遍存在。本文总结了实际应用中可能遇到的三种场景:标准场景、瞬时数据丢失场景和长时间数据丢失场景,并提出了新的评估基准。针对数据丢失场景,我们将全身化身姿态估计问题与运动预测相结合,提出了一种可靠化身动画师ReliaAvatar。它采用双路径架构,具备预测建模能力,可实时运行,处理速度高达每秒109帧。在广泛认可的基准数据集上的综合比较评估表明,ReliaAvatar在标准和低数据质量条件下均表现出卓越性能。代码可访问网址:[https://github.com/MIV-XJTU/ReliaAvatar]。
Key Takeaways
- 全身姿态高效估计具有重要的研究价值,特别是在低质量信号条件下。
- 目前研究忽视了在实际应用中可能出现的不同场景下的全身化身估计探索,包括标准场景、瞬时数据丢失和长时间数据丢失。
- 论文针对实际应用中的数据丢失问题提出了新评估基准和解决方案。
- 提出了一种可靠化身动画师ReliaAvatar,结合了全身化身姿态估计与运动预测。
- ReliaAvatar具备预测建模能力的双路径架构,可实时运行,处理速度高达每秒109帧。
- ReliaAvatar在广泛认可的基准数据集上的表现优于其他方法,在标准与低数据质量条件下均表现出卓越性能。
- 相关代码可通过特定网址访问。
Title: ReliAvatar:一种稳健的实时动画人物生成器
Authors: Bo Qian, Zhenhuan Wei, Jiashuo Li, Xing Wei
Affiliation: 西安电子科技大学软件工程学院
Keywords: avatar animation, motion prediction, full-body pose estimation, low-quality signal conditions, real-time rendering
Urls: https://github.com/MIV-XJTU/ReliaAvatar or Paper Link: https://arxiv.org/abs/2407.02129
Github: None(如有公开代码,请填写相应链接)
- Summary:
(1) 研究背景:本文研究了在虚拟现实、增强现实和混合现实领域,使用可穿戴设备和无线信号进行全身姿态估计的问题。特别是针对在低质量信号条件下进行有效的全身人物模型估计的挑战,这在实践中是普遍存在的。
(2) 过去的方法及问题:当前的研究虽然取得了一定的进展,但在处理低质量信号下的全身人物模型估计时还存在明显不足。例如网络波动、运动捕捉系统的遮挡以及头戴显示器中交互手柄的有限可见性等因素都会导致信号完整性降低。现有的方法如AGRoL和HMD-NeMo虽然已经解决了一些挑战,但对于多样数据丢失场景的系统性探索和综合解决方案仍然缺乏。
(3) 研究方法:针对上述问题,本文提出了一种新的实时、可靠的动画人物生成器——ReliAvatar。该模型通过整合全身人物姿态估计与运动预测,以应对数据丢失的场景。具体来说,模型采用了一种双路径架构,具备预测建模能力。
(4) 任务与性能:本文的方法在广泛认可的基准数据集上进行了广泛和比较性评价,包括标准场景和多种数据丢失场景。结果显示,ReliAvatar在实时性能上表现出色,无论是在标准场景还是低数据质量条件下均优于其他方法。可视化结果表明,即使在长时间数据丢失的情况下,ReliAvatar仍能有效工作,而其他方法则无法应对此类场景。因此,该论文的方法达到了其设定的目标。
方法论概述:
(1) 研究背景分析:本文研究了虚拟现实、增强现实和混合现实领域的全身姿态估计问题,特别是在低质量信号条件下进行全身人物模型估计的挑战。
(2) 过去的方法及问题:当前研究虽然取得了一定进展,但在处理低质量信号下的全身人物模型估计时仍存在明显不足。例如,网络波动、运动捕捉系统的遮挡以及头戴显示器中交互手柄的有限可见性等因素都会导致信号完整性降低。现有的方法如AGRoL和HMD-NeMo虽然已经解决了一些挑战,但对于多样数据丢失场景的系统性探索和综合解决方案仍然缺乏。
(3) 方法论创新:针对上述问题,本文提出了一种新的实时、可靠的动画人物生成器——ReliAvatar。该模型通过整合全身人物姿态估计与运动预测,以应对数据丢失的场景。模型采用双路径架构,具备预测建模能力。一方面,模型通过回归路径进行传统的全身人物姿态估计;另一方面,预测路径则用于在缺少跟踪器信号的情况下预测运动,确保人物动作的连续性。这两个路径都利用GRU模型进行特征提取,然后转化为解码令牌序列,代表22个SMPL关节,再输入Transformer编码器进行关节间关系建模。
(4) 数据处理与训练:本文提出一种自适应训练管道,包括三种预处理方法与标准、瞬时、长期数据丢失场景相对应。在训练过程中,每个信号序列都会经过其中一种预处理方法的处理,使模型能够适应不同的数据丢失场景。本文还在AMASS基准数据集上与现有方法进行了比较,结果表明本文模型在标准和数据丢失场景下的性能均优于其他方法。此外,本文还深入探究了实际数据丢失场景,并识别出两种关键场景:瞬时数据丢失和长期数据丢失。
(5) 模型性能评估:通过在线推理阶段的实验,本文模型表现出卓越的性能,达到了109帧每秒的处理速度,超越了其他人物姿态估计方法,证明了其在实时应用中的优越性。本文的贡献在于:首次全面研究了实际数据丢失场景;提出了集成全身关节运动预测的实时鲁棒人物动画生成器及自适应训练管道;实验结果表明,本文模型不仅达到了标准场景下的顶尖性能,而且有效管理了各种数据丢失场景,提高了计算效率。
Conclusion:
(1) 这项工作的意义在于研究了在虚拟现实、增强现实和混合现实领域中,利用可穿戴设备和无线信号进行全身姿态估计的问题。特别是在低质量信号条件下,有效地进行全身人物模型估计的挑战,填补了实际数据丢失场景的系统性研究空白。
(2) 创新点:该文章提出了一种新的实时、可靠的动画人物生成器——ReliAvatar,通过整合全身人物姿态估计与运动预测,应对数据丢失的场景。模型采用双路径架构,具备预测建模能力,这是一种全新的尝试和创新。
性能:该文章的方法在广泛认可的基准数据集上进行了广泛和比较性评价,表现出卓越的性能,特别是在实时性能方面。与其他方法相比,ReliAvatar在标准场景和低数据质量条件下的性能均表现出色。
工作量:文章进行了深入的理论分析和实验验证,不仅提出了全新的模型架构和处理方法,还进行了大量的实验来验证模型的性能。同时,文章也对不同场景下的数据丢失情况进行了详细的探讨,工作量较大。
点此查看论文截图


 wechat
wechat- alipay