NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-27 更新
G3FA: Geometry-guided GAN for Face Animation
Authors:Alireza Javanmardi, Alain Pagani, Didier Stricker
Animating human face images aims to synthesize a desired source identity in a natural-looking way mimicking a driving video’s facial movements. In this context, Generative Adversarial Networks have demonstrated remarkable potential in real-time face reenactment using a single source image, yet are constrained by limited geometry consistency compared to graphic-based approaches. In this paper, we introduce Geometry-guided GAN for Face Animation (G3FA) to tackle this limitation. Our novel approach empowers the face animation model to incorporate 3D information using only 2D images, improving the image generation capabilities of the talking head synthesis model. We integrate inverse rendering techniques to extract 3D facial geometry properties, improving the feedback loop to the generator through a weighted average ensemble of discriminators. In our face reenactment model, we leverage 2D motion warping to capture motion dynamics along with orthogonal ray sampling and volume rendering techniques to produce the ultimate visual output. To evaluate the performance of our G3FA, we conducted comprehensive experiments using various evaluation protocols on VoxCeleb2 and TalkingHead benchmarks to demonstrate the effectiveness of our proposed framework compared to the state-of-the-art real-time face animation methods.
PDF BMVC 2024, Accepted
Summary
生成人脸动画的关键是在保持自然外观的同时合成所需的源身份。本文介绍了一种新的几何引导的 GAN 方法(G3FA),通过二维图像引入三维信息,显著提升了面部动画生成能力。
Key Takeaways
- 生成人脸动画的目标是在仿效驾驶视频的面部动作时合成所需的源身份。
- 与基于图形的方法相比,生成对抗网络在单一源图像的实时面部再现中展示了显著的潜力,但受限于几何一致性。
- G3FA 引入了几何引导的方法,通过仅使用二维图像,提升了面部动画模型的图像生成能力。
- 采用反向渲染技术提取三维面部几何属性,通过鉴别器的加权平均集成改进生成器的反馈循环。
- 使用二维运动扭曲捕捉运动动态,结合正交射线采样和体积渲染技术生成最终的视觉输出。
- 在 VoxCeleb2 和 TalkingHead 数据集上进行了全面实验评估,展示了 G3FA 框架相对于现有的实时人脸动画方法的有效性。
- G3FA 的方法可以有效地合成具有良好视觉效果的动态面部表情,优化了生成模型的性能。
- 本文方法提出了一种新颖的面部再现模型,填补了现有技术中几何一致性限制的空白。
Title: G3FA:几何引导生成对抗网络在人脸动画中的应用(Geometry-guided GAN for Face Animation)
Authors: Alireza Javanmardi, Alain Pagani, Didier Stricker
Affiliation: 德国人工智能研究中心(German Research Center for Artificial Intelligence, DFKI)凯泽斯劳滕大学(Kaiserslautern University)等科研机构联合完成研究。
Keywords: Face Animation, Generative Adversarial Networks (GAN), 3D Information Integration, Face Reenactment, Geometric Consistency
Urls: github链接为:github.com/dfki-av/G3FA (注:具体链接是否可用需自行验证)。论文链接暂时未提供。
Summary:
(1)研究背景:本文的研究背景是关于人脸动画技术,旨在合成具有目标源身份的自然面部动画,模仿驱动视频的面部运动。目前,生成对抗网络(GAN)在实时面部重演绎方面表现出显著潜力,但相较于图形方法,其在几何一致性方面存在局限性。因此,本文旨在解决这一问题。
-(2)过去的方法及其问题:过去的方法主要围绕图形方法和基于GAN的方法展开。图形方法具有出色的几何建模能力,但计算复杂度高且难以捕捉表情和运动的细微差别。基于GAN的方法虽然能生成逼真的面部动画,但在几何一致性方面存在不足。因此,有必要提出一种融合两种方法优点的新方法。此外,针对目前方法存在的问题,本文提出了一种新的解决方案动机。
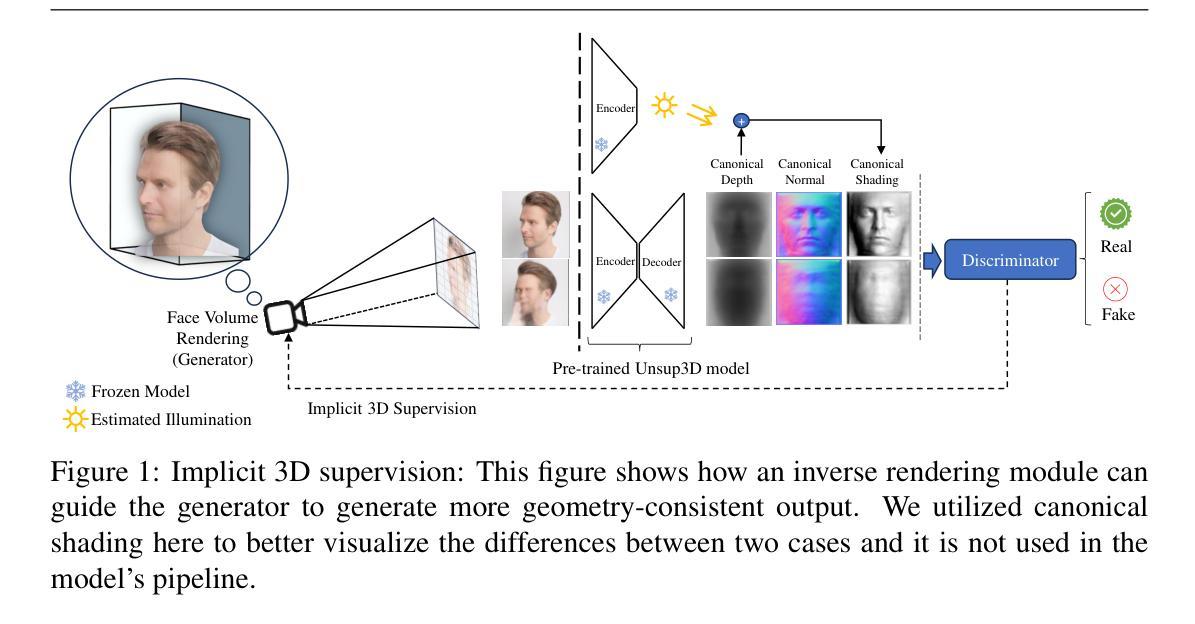
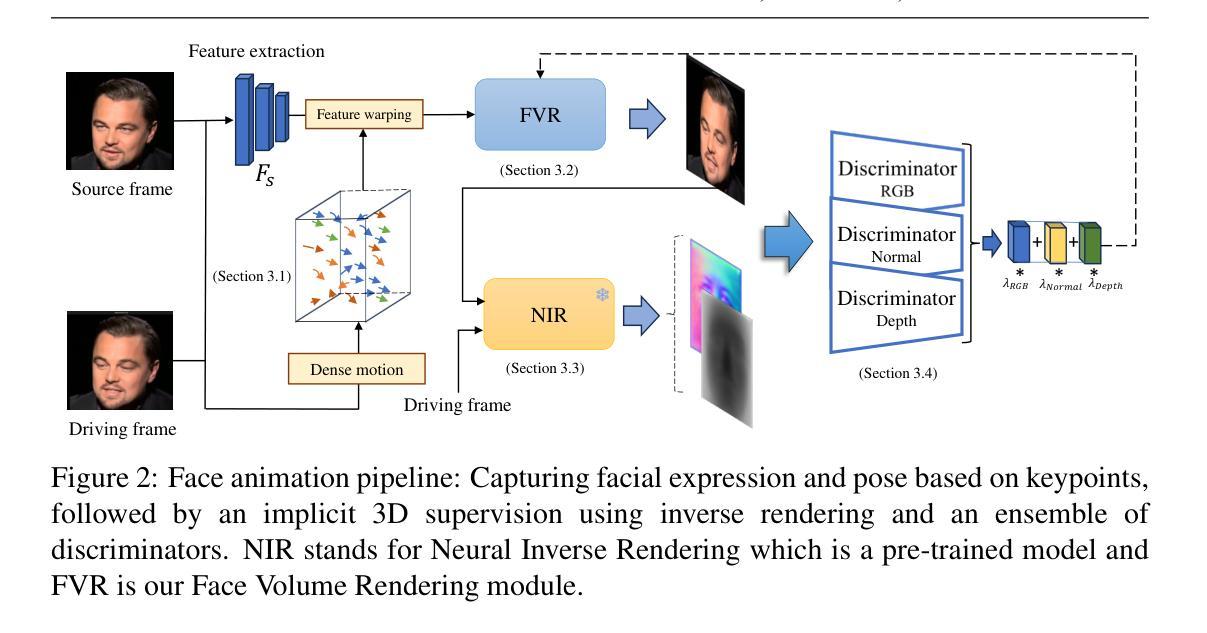
-(3)研究方法:本文提出了基于几何引导的生成对抗网络(G3FA)进行人脸动画的方法。该方法通过集成逆渲染技术提取3D面部几何属性,并通过加权平均判别器集合改进反馈循环。在面部重演绎模型中,利用二维运动扭曲捕捉运动动态,结合正交射线采样和体积渲染技术生成最终视觉输出。此外,该方法还利用单张源图像进行实时面部动画,提高了图像生成能力。总体而言,该方法的创新之处在于将三维信息融入二维图像中,从而提高了面部动画模型的性能。
-(4)任务与性能:本文在VoxCeleb2和TalkingHead基准数据集上进行了实验验证,证明了所提出框架的有效性。与现有实时面部动画方法相比,该方法的性能表现出色。实验结果表明,该方法的几何一致性和面部动画质量均有所提高,达到了预期的目标。此外,该方法的代码已在GitHub上公开分享。总体而言,本文提出了一种新颖而有效的面部动画方法,对于实现自然逼真的面部动画具有重要意义。
希望上述回答能够满足您的要求。
- 方法:
(1)研究背景与问题提出:本研究针对人脸动画技术,旨在合成具有目标源身份的自然面部动画。过去的方法主要围绕图形方法和基于GAN的方法展开,但存在计算复杂度高、难以捕捉细微差别以及几何一致性不足等问题。因此,本研究旨在解决这些问题。
(2)研究方法概述:本研究提出了基于几何引导的生成对抗网络(G3FA)进行人脸动画的方法。该方法结合图形方法和GAN的优点,通过集成逆渲染技术提取3D面部几何属性,改进反馈循环,并利用二维运动扭曲捕捉运动动态,结合正交射线采样和体积渲染技术生成最终视觉输出。此外,该方法还利用单张源图像进行实时面部动画。
(3)具体步骤:
① 集成逆渲染技术:从输入的图像中提取3D面部几何属性,为后续的人脸动画提供基础数据。
② 改进反馈循环:通过加权平均判别器集合,提高模型的生成能力和判别能力。
③ 二维运动扭曲:利用该技术捕捉面部的运动动态,为生成动画提供动态信息。
④ 正交射线采样和体积渲染技术:结合这两种技术生成最终的视觉输出,提高面部动画的真实感和质量。
⑤ 利用单张源图像进行实时面部动画:通过这种方法,可以方便地利用已有的图像进行实时面部动画的生成。
(4)实验验证:本研究在VoxCeleb2和TalkingHead基准数据集上进行了实验验证,证明了所提出框架的有效性。与现有实时面部动画方法相比,该方法的性能表现出色,几何一致性和面部动画质量均有所提高。实验结果表明,该方法达到了预期的目标。此外,该方法的代码已在GitHub上公开分享。
- Conclusion:
(1)这篇工作的意义在于提出了一种基于几何引导的生成对抗网络(G3FA)进行人脸动画的新方法,该方法融合了图形方法和GAN的优点,旨在解决现有方法在计算复杂度、表情和运动细微差别的捕捉以及几何一致性等方面存在的问题。该研究对于实现自然逼真的面部动画具有重要意义。
(2)创新点:本文提出了基于几何引导的生成对抗网络(G3FA)进行人脸动画的方法,将三维信息融入二维图像中,提高了面部动画模型的性能。
性能:在VoxCeleb2和TalkingHead基准数据集上的实验结果表明,该方法的几何一致性和面部动画质量均有所提高,与现有方法相比性能表现出色。
工作量:文章对方法的原理、实现细节和实验验证进行了详细的描述,但工作量方面的描述未具体提及。
点此查看论文截图

 wechat
wechat- alipay







