3DGS
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-08-28 更新
Avatar Concept Slider: Manipulate Concepts In Your Human Avatar With Fine-grained Control
Authors:Yixuan He, Lin Geng Foo, Ajmal Saeed Mian, Hossein Rahmani, Jun Jiu
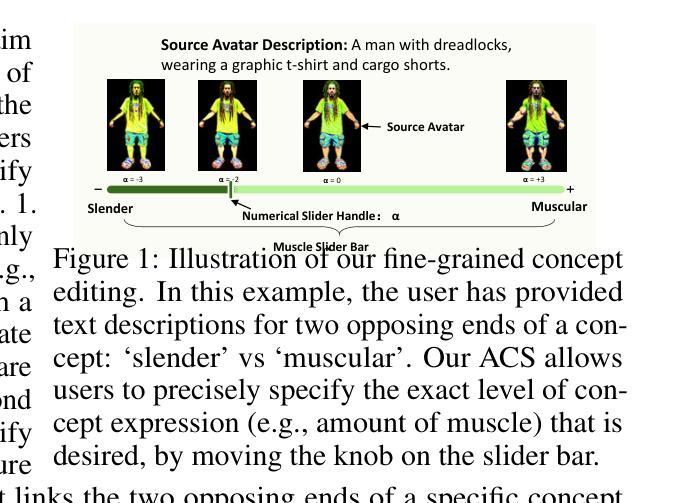
Language based editing of 3D human avatars to precisely match user requirements is challenging due to the inherent ambiguity and limited expressiveness of natural language. To overcome this, we propose the Avatar Concept Slider (ACS), a 3D avatar editing method that allows precise manipulation of semantic concepts in human avatars towards a specified intermediate point between two extremes of concepts, akin to moving a knob along a slider track. To achieve this, our ACS has three designs. 1) A Concept Sliding Loss based on Linear Discriminant Analysis to pinpoint the concept-specific axis for precise editing. 2) An Attribute Preserving Loss based on Principal Component Analysis for improved preservation of avatar identity during editing. 3) A 3D Gaussian Splatting primitive selection mechanism based on concept-sensitivity, which updates only the primitives that are the most sensitive to our target concept, to improve efficiency. Results demonstrate that our ACS enables fine-grained 3D avatar editing with efficient feedback, without harming the avatar quality or compromising the avatar’s identifying attributes.
Summary
基于语义概念的3D人偶编辑方法,通过Avatar Concept Slider(ACS)实现精确编辑,有效提升了人偶质量和身份特征的保留。
Key Takeaways
- 自然语言编辑3D人偶存在挑战,因语言模糊性和表达有限。
- 提出Avatar Concept Slider (ACS)方法,精确操控人偶的语义概念。
- ACS设计包括概念滑动损失、属性保留损失和3D高斯散点原语选择机制。
- 概念滑动损失基于线性判别分析,定位概念特定轴。
- 属性保留损失基于主成分分析,提升编辑中的人偶身份保留。
- 3D高斯散点原语选择机制基于概念敏感性,提高效率。
- 结果表明ACS可实现精细3D人偶编辑,提供高效反馈,不影响质量或特征。
- Title: 人脸概念滑动器:以精细控制编辑人类头像的语义概念
- Authors: Yixuan He, Lin Geng Foo, Ajmal Saeed Mian, Hossein Rahmani, Jun Jiu
- Affiliation: 新加坡科技设计大学
- Keywords: 3D人类头像编辑,语义概念控制,扩散模型,人脸雕刻
- Urls: https://arxiv.org/abs/2408.13995v1 or None, None
Summary:
(1):该文的研究背景是利用自然语言进行3D人类头像的基于语言的编辑具有挑战性,因为自然语言固有的模糊性和有限的表达力。为了克服这一挑战,研究人员提出了一个名为“Avatar Concept Slider (ACS)”的3D头像编辑方法。
(2):过去的方法包括利用指令引导的扩散模型进行头像编辑,如HeadSculpt和TECA。然而,这些方法依赖于文本提示作为唯一的指导信号,文本提示的模糊性和有限的表达力限制了编辑的精度和控制。该方法的动机是基于对现有方法的不足,提出了一种更精确和高效的编辑方法。
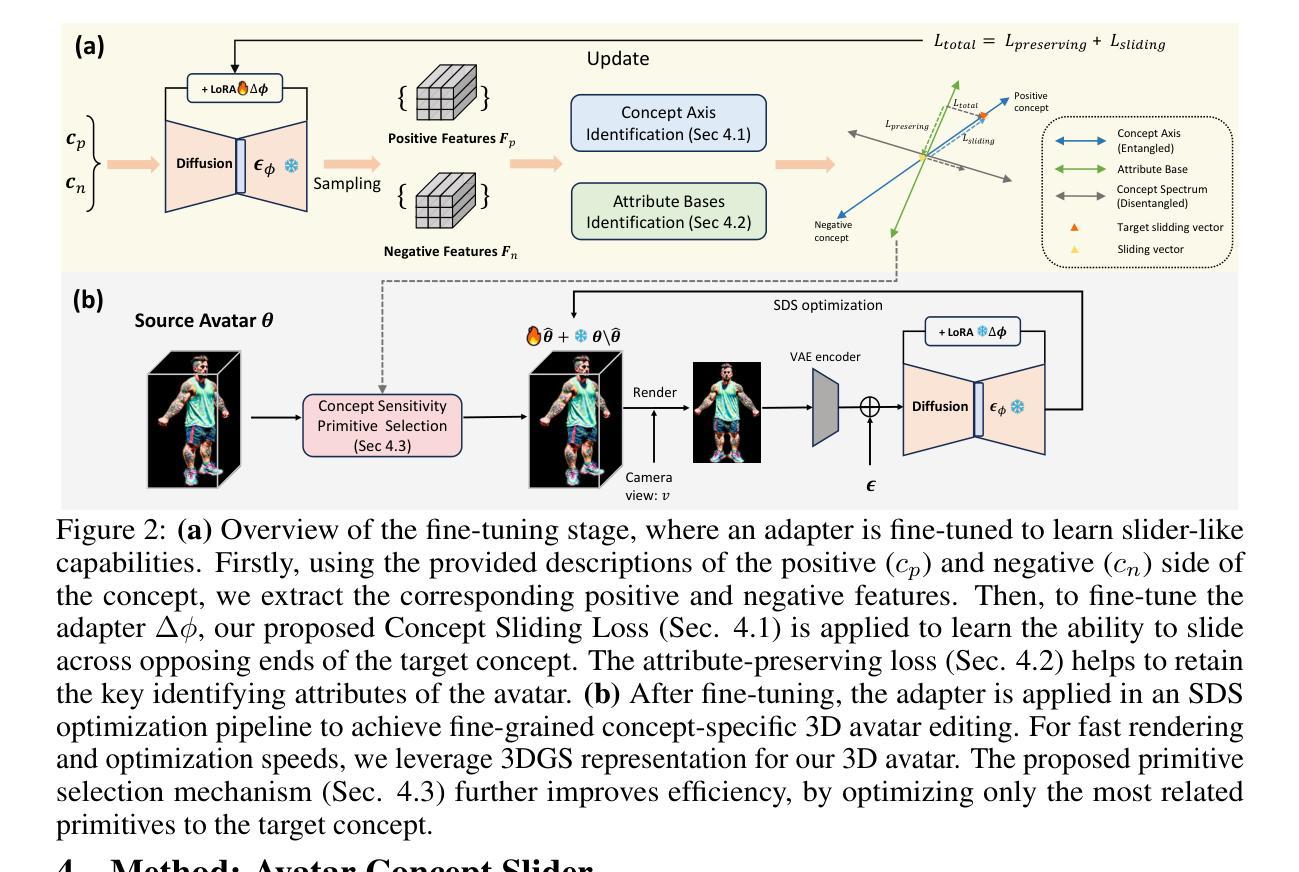
(3):该文提出的方法包括三个设计:1)基于线性判别分析的“概念滑动损失”,以精确确定编辑的概念特定轴;2)基于主成分分析的“属性保持损失”,以在编辑过程中更好地保持头像的身份;3)基于概念敏感性的3D高斯喷溅原语选择机制,只更新对目标概念最敏感的原语,以提高效率。
(4):该方法实现了细粒度的3D头像编辑,具有高效的反馈,同时不会损害头像质量或损害头像的识别属性。实验结果表明,该方法在多个任务上取得了良好的性能,支持了其目标。
Conclusion:
- (1):该研究具有显著意义,因为它提出了一种新的3D头像编辑方法,能够使用自然语言精确控制头像的语义概念,解决了传统方法在编辑精度和控制方面的局限性。 - (2):Innovation point: 该方法在创新点方面,通过结合线性判别分析和主成分分析,以及概念敏感性的3D高斯喷溅原语选择机制,实现了对3D头像的精细编辑,具有创新性;Performance: 在性能方面,实验结果表明,该方法在多个任务上均表现出良好的编辑效果,保持了头像质量的同时实现了高效的反馈;Workload: 在工作负载方面,该方法的计算效率较高,对用户而言操作简便,降低了编辑过程中的工作负担。
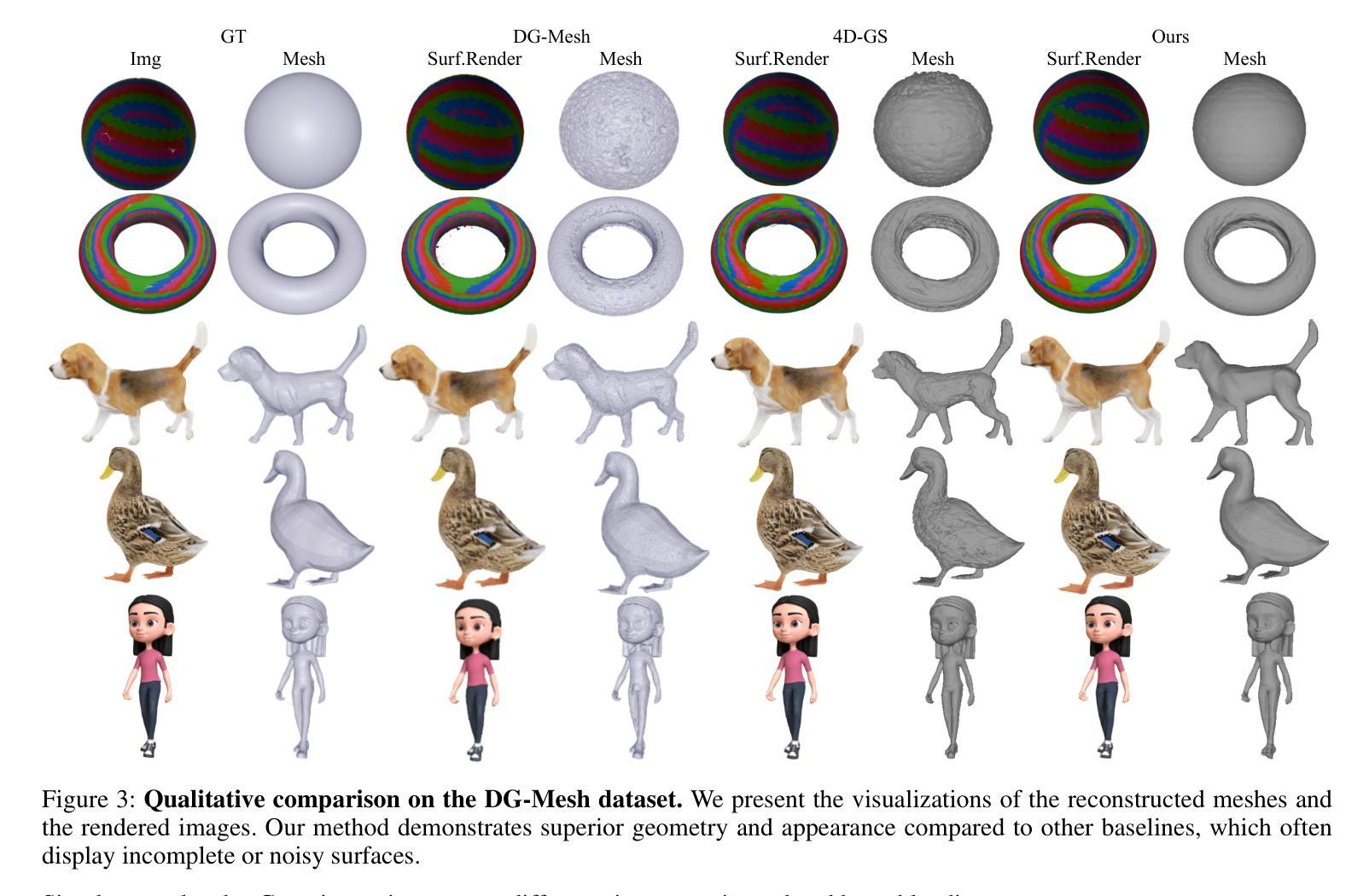
点此查看论文截图

DynaSurfGS: Dynamic Surface Reconstruction with Planar-based Gaussian Splatting
Authors:Weiwei Cai, Weicai Ye, Peng Ye, Tong He, Tao Chen
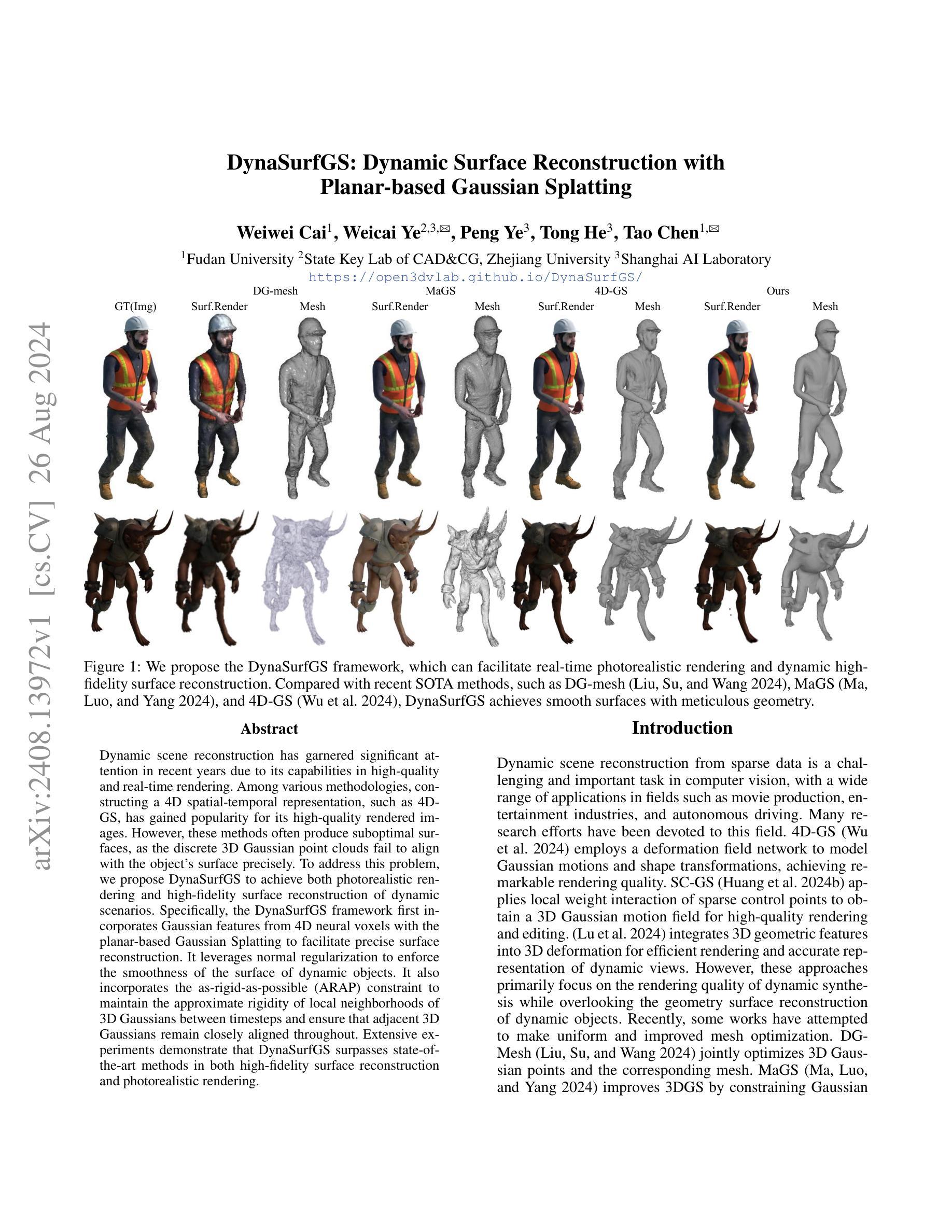
Dynamic scene reconstruction has garnered significant attention in recent years due to its capabilities in high-quality and real-time rendering. Among various methodologies, constructing a 4D spatial-temporal representation, such as 4D-GS, has gained popularity for its high-quality rendered images. However, these methods often produce suboptimal surfaces, as the discrete 3D Gaussian point clouds fail to align with the object’s surface precisely. To address this problem, we propose DynaSurfGS to achieve both photorealistic rendering and high-fidelity surface reconstruction of dynamic scenarios. Specifically, the DynaSurfGS framework first incorporates Gaussian features from 4D neural voxels with the planar-based Gaussian Splatting to facilitate precise surface reconstruction. It leverages normal regularization to enforce the smoothness of the surface of dynamic objects. It also incorporates the as-rigid-as-possible (ARAP) constraint to maintain the approximate rigidity of local neighborhoods of 3D Gaussians between timesteps and ensure that adjacent 3D Gaussians remain closely aligned throughout. Extensive experiments demonstrate that DynaSurfGS surpasses state-of-the-art methods in both high-fidelity surface reconstruction and photorealistic rendering.
PDF homepage: https://open3dvlab.github.io/DynaSurfGS/, code: https://github.com/Open3DVLab/DynaSurfGS
Summary
动态场景重建通过DynaSurfGS实现高保真表面重建和逼真渲染。
Key Takeaways
- 动态场景重建技术备受关注。
- 4D-GS在高质量渲染中流行。
- 3D高斯点云与物体表面不匹配。
- DynaSurfGS旨在解决此问题。
- 使用4D神经体素和高斯Splatting进行精确重建。
- 正则化确保表面平滑。
- ARAP约束保持3D高斯点云的刚性。
- 实验证明DynaSurfGS超越现有方法。
- Title: DynaSurfGS: Dynamic Surface Reconstruction with Planar-based Gaussian Splatting (基于平面高斯喷绘的动态表面重建)
- Authors: Weiwei Cai, Weicai Ye, Peng Ye, Tong He, Tao Chen
- Affiliation: 复旦大学, 浙江大学计算机辅助设计与图形学国家重点实验室, 上海人工智能实验室
- Keywords: Dynamic Scene Reconstruction, Photorealistic Rendering, High-fidelity Surface Reconstruction, 4D Neural Voxels, Gaussian Splatting
- Urls: https://open3dvlab.github.io/DynaSurfGS/ or Github: None
Summary:
(1):该文的研究背景是动态场景重建,这项技术在电影制作、娱乐产业和自动驾驶等领域有广泛的应用。动态场景重建要求在高质量和实时渲染的同时,能够精确地重建动态物体的表面。
(2):过去的动态场景重建方法,如4D-GS、SC-GS和基于3D变形的方法,主要关注渲染质量,而忽略了动态物体的几何表面重建。这些方法存在表面重建不精确的问题,因为离散的3D高斯点云无法与物体表面精确对齐。本文提出的方法很好地解决了这个问题。
(3):本文提出的方法DynaSurfGS首先将4D神经体素的高斯特征与基于平面的高斯喷绘相结合,以促进精确的表面重建。它利用法线正则化来强制动态物体表面的平滑性。同时,它还引入了尽可能刚性的约束(ARAP),以保持3D高斯点在时间步之间的近似刚性,并确保相邻的3D高斯点保持紧密对齐。
(4):本文的方法在高质量表面重建和逼真渲染方面均优于现有方法。实验结果表明,DynaSurfGS在动态场景重建任务中取得了显著的性能提升,支持了其目标。
Methods:
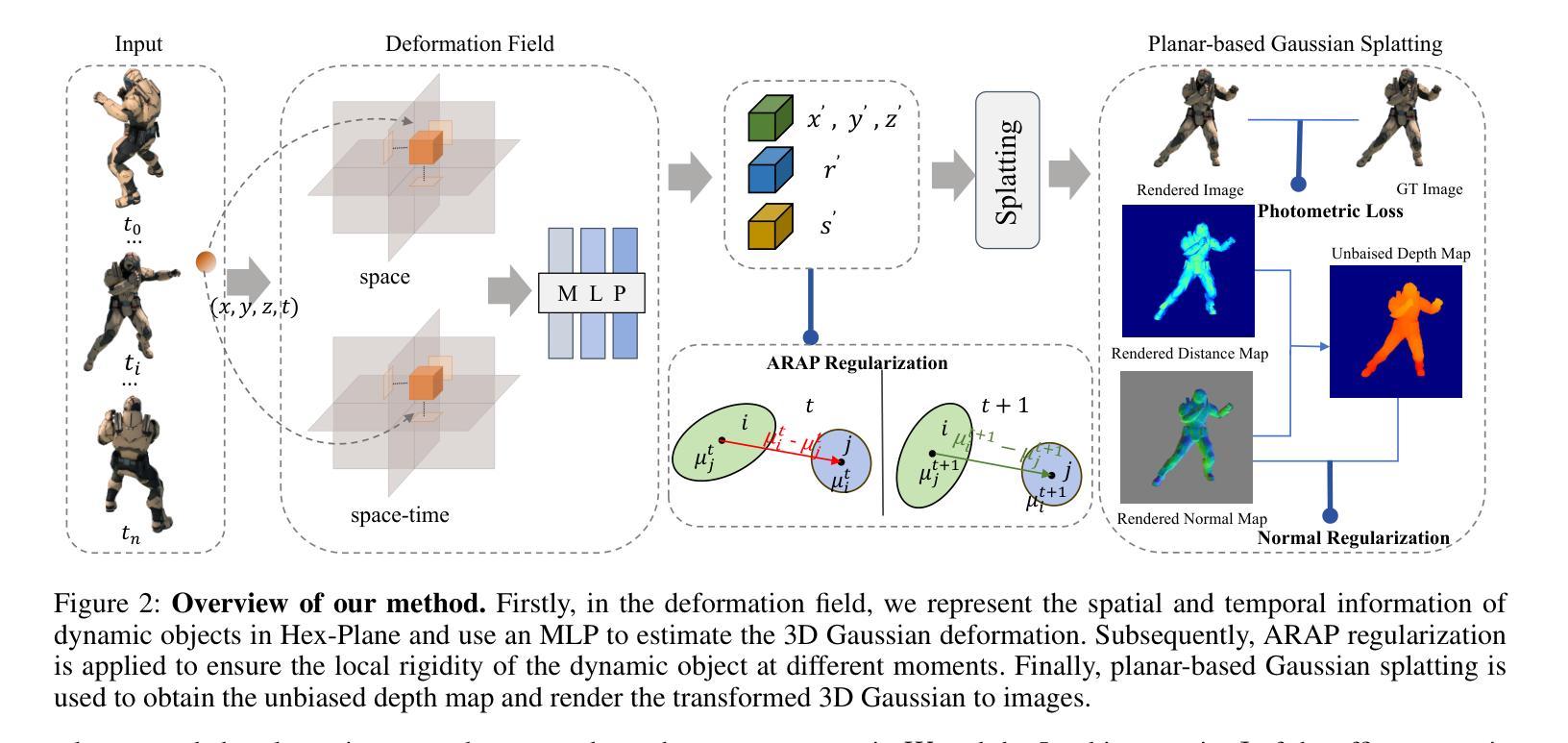
(1): DynaSurfGS 方法首先利用 4D 神经体素(4D Neural Voxels)提取动态场景中的高斯特征,并结合平面高斯喷绘(Planar-based Gaussian Splatting)技术,以实现更精确的表面重建。
(2): 在表面重建过程中,方法引入了法线正则化(Normal Regularization)来确保动态物体表面的平滑性。
(3): 此外,DynaSurfGS 还采用了近似刚性约束(Approximate Rigid Body Constraints,ARAP)来维持 3D 高斯点在不同时间步之间的刚性,并保证相邻点之间的紧密对齐。
(4): 通过以上步骤,DynaSurfGS 能够在保证高质量表面重建的同时,实现逼真的渲染效果。
Conclusion:
- (1):这项工作的意义在于,DynaSurfGS方法在动态场景重建领域提出了一个创新性的解决方案,通过结合4D神经体素和基于平面的高斯喷绘技术,实现了高精度几何重建和高质量渲染,为电影制作、娱乐产业和自动驾驶等领域提供了新的技术支持。 - (2): Innovation point: DynaSurfGS的创新点在于将4D神经体素与平面高斯喷绘技术相结合,有效提高了动态场景重建的精度和渲染质量;Performance: 在性能方面,DynaSurfGS在高质量表面重建和逼真渲染方面均优于现有方法,实验结果表明其性能显著提升;Workload: DynaSurfGS在保证重建精度的同时,引入了额外的约束条件,如法线正则化和ARAP约束,可能会增加一定的计算负担。
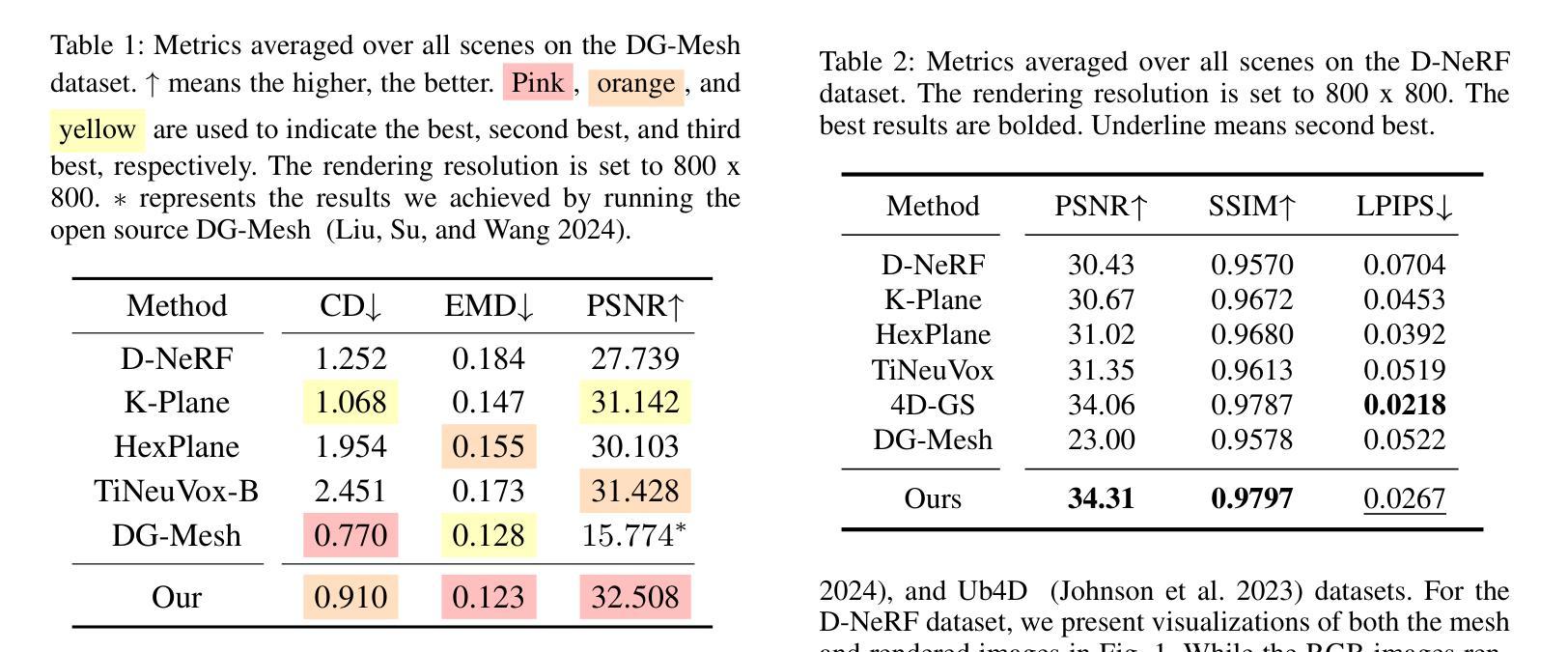
点此查看论文截图

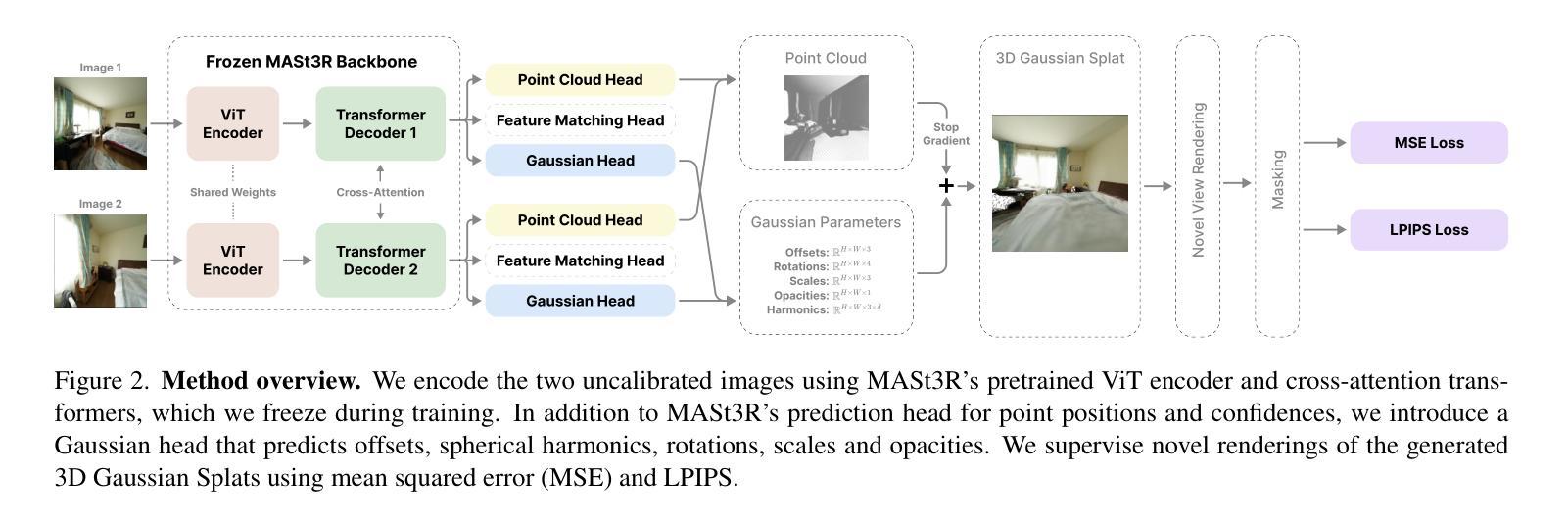
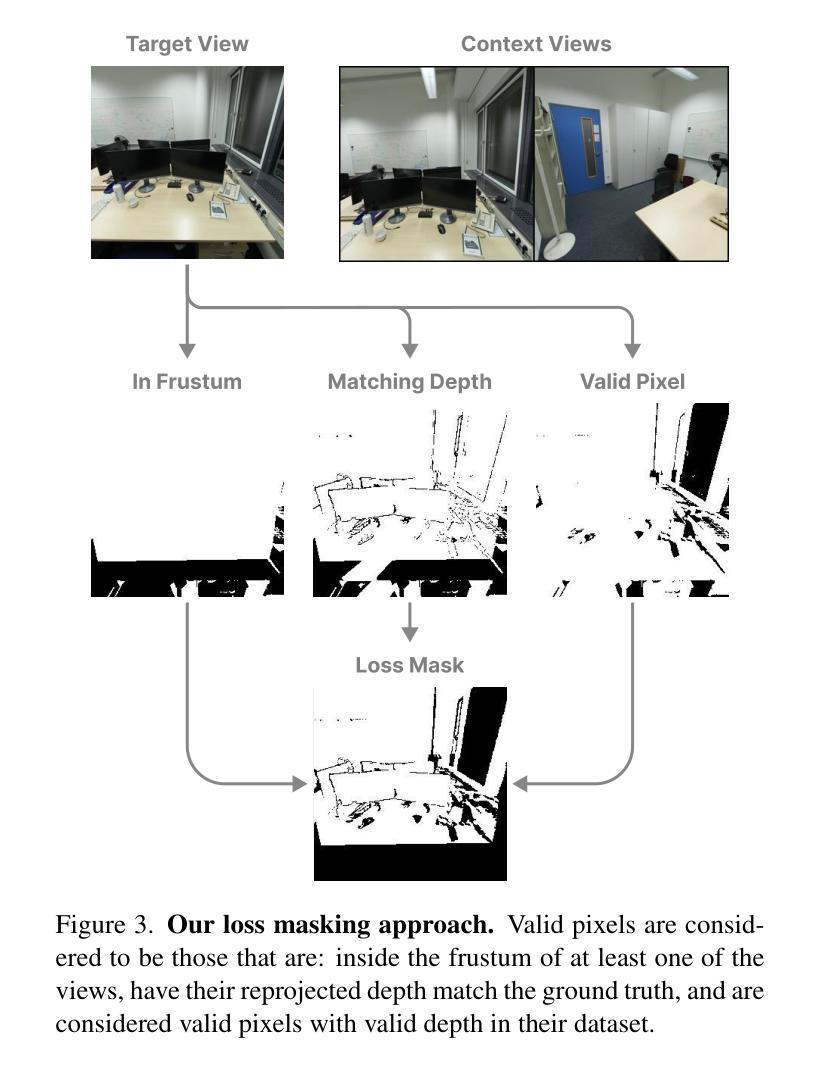
Splatt3R: Zero-shot Gaussian Splatting from Uncalibarated Image Pairs
Authors:Brandon Smart, Chuanxia Zheng, Iro Laina, Victor Adrian Prisacariu
In this paper, we introduce Splatt3R, a pose-free, feed-forward method for in-the-wild 3D reconstruction and novel view synthesis from stereo pairs. Given uncalibrated natural images, Splatt3R can predict 3D Gaussian Splats without requiring any camera parameters or depth information. For generalizability, we start from a ‘foundation’ 3D geometry reconstruction method, MASt3R, and extend it to be a full 3D structure and appearance reconstructor. Specifically, unlike the original MASt3R which reconstructs only 3D point clouds, we predict the additional Gaussian attributes required to construct a Gaussian primitive for each point. Hence, unlike other novel view synthesis methods, Splatt3R is first trained by optimizing the 3D point cloud’s geometry loss, and then a novel view synthesis objective. By doing this, we avoid the local minima present in training 3D Gaussian Splats from stereo views. We also propose a novel loss masking strategy that we empirically find is critical for strong performance on extrapolated viewpoints. We train Splatt3R on the ScanNet++ dataset and demonstrate excellent generalisation to uncalibrated, in-the-wild images. Splatt3R can reconstruct scenes at 4FPS at 512 x 512 resolution, and the resultant splats can be rendered in real-time.
PDF Our project page can be found at: https://splatt3r.active.vision/
Summary
基于MASt3R的Splatt3R:无需标定,实时3D重建与合成。
Key Takeaways
- Splatt3R为无标定野外3D重建和合成提供方法。
- 无需相机参数和深度信息,预测3D高斯Splat。
- 从MASt3R扩展,实现全3D结构和外观重建。
- 预测点的高斯属性,构建高斯原语。
- 先优化3D点云几何损失,再进行合成目标优化。
- 避免训练3D高斯Splat的局部最小值。
- 提出新型损失掩码策略,优化外推视点性能。
- 在ScanNet++数据集上训练,优异泛化能力。
- 实时重建场景,渲染高斯Splat。
Title: Splatt3R: Zero-shot Gaussian Splatting from Uncalibrated Image Pairs
2. Authors: Brandon Smart, Chuanxia Zheng, Iro Laina, Victor Adrian Prisacariu 3. Affiliation: University of Oxford 4. Keywords: 3D scene reconstruction, novel view synthesis, 3D Gaussian Splatting, uncalibrated images, deep learning 5. Urls: arXiv:2408.13912v1 [cs.CV] 25 Aug 2024 6. Summary: - (1):This article studies the problem of 3D scene reconstruction and novel view synthesis from uncalibrated natural images, with a focus on stereo pairs. The research background lies in the limitations of traditional 3D reconstruction methods, which require dense image collections and are computationally expensive. - (2):Previous methods, such as SRN, NeRF, LFN, and 3D Gaussian Splatting, often require a large number of images for training and are not accessible to general users due to their complexity. They also suffer from poor reconstruction quality when trained with only a pair of stereo images. - (3):This paper proposes Splatt3R, a feed-forward model that can directly predict 3D Gaussian Splats from uncalibrated image pairs without requiring camera parameters or depth information. The model is based on the MASt3R method and avoids explicit prediction of camera poses, intrinsics, or monocular depth. It also proposes a novel loss masking strategy for extrapolated viewpoints. - (4):Splatt3R is applied to the ScanNet++ dataset and demonstrates excellent generalization to uncalibrated, real-world images. It can reconstruct scenes at 4FPS at 512×512 resolution, and the resulting splats can be rendered in real-time, which supports the effectiveness of the proposed method.Methods:
(1): 提出了一种名为Splatt3R的前馈模型,该模型能够直接从未校准的图像对中预测3D高斯Splat,无需相机参数或深度信息。
(2): Splatt3R基于MASt3R方法,避免了显式预测相机姿态、内参或单目深度。
(3): 采用了新颖的损失掩码策略,用于处理外推视点。
(4): 在ScanNet++数据集上应用Splatt3R,展示了其对未校准、真实世界图像的优异泛化能力。
(5): 在512×512分辨率下,Splatt3R能够以4FPS的速度重建场景,且生成的Splat可以实时渲染。
Conclusion:
- (1):该研究工作的意义在于,Splatt3R模型通过直接从未校准的立体图像对中预测3D高斯Splat,克服了传统3D重建方法对大量图像和复杂计算的依赖,为3D场景重建和新型视图合成提供了新的解决方案。 - (2):Innovation point: 创新点在于提出了一种无需相机内参、外参或深度信息的直接预测3D高斯Splat的模型;Performance: 性能上,Splatt3R在ScanNet++数据集上展现出优异的泛化能力,并以4FPS的速度重建场景,支持实时渲染;Workload: 工作量上,Splatt3R避免了复杂的相机参数和深度信息计算,降低了计算负担。
点此查看论文截图

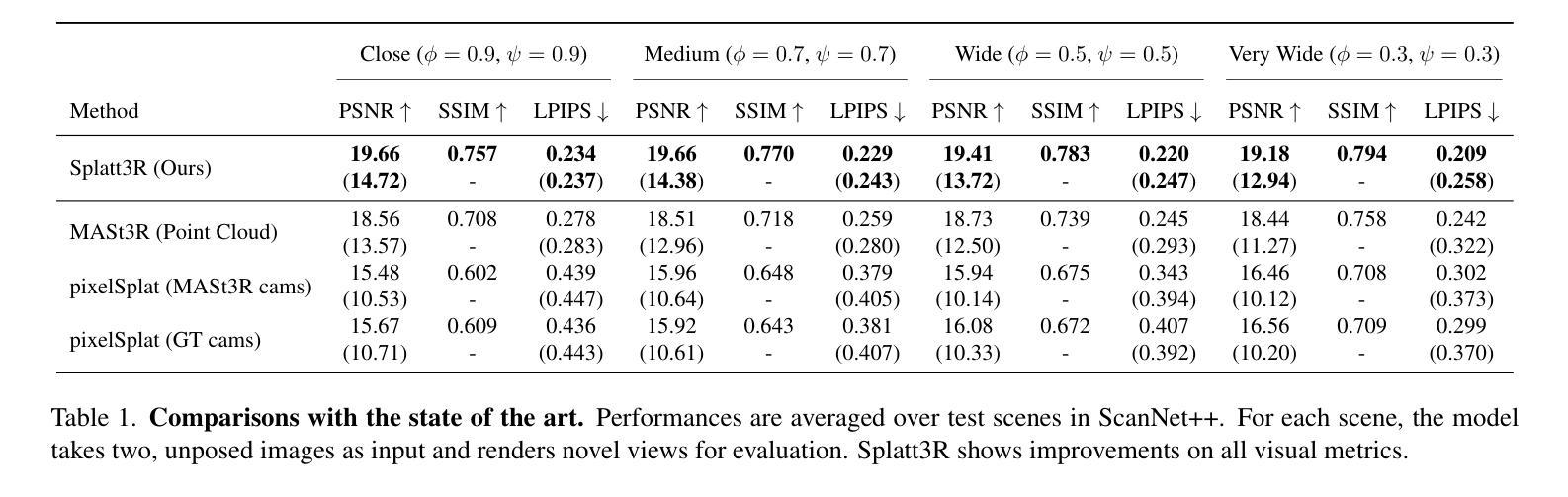
TranSplat: Generalizable 3D Gaussian Splatting from Sparse Multi-View Images with Transformers
Authors:Chuanrui Zhang, Yingshuang Zou, Zhuoling Li, Minmin Yi, Haoqian Wang
Compared with previous 3D reconstruction methods like Nerf, recent Generalizable 3D Gaussian Splatting (G-3DGS) methods demonstrate impressive efficiency even in the sparse-view setting. However, the promising reconstruction performance of existing G-3DGS methods relies heavily on accurate multi-view feature matching, which is quite challenging. Especially for the scenes that have many non-overlapping areas between various views and contain numerous similar regions, the matching performance of existing methods is poor and the reconstruction precision is limited. To address this problem, we develop a strategy that utilizes a predicted depth confidence map to guide accurate local feature matching. In addition, we propose to utilize the knowledge of existing monocular depth estimation models as prior to boost the depth estimation precision in non-overlapping areas between views. Combining the proposed strategies, we present a novel G-3DGS method named TranSplat, which obtains the best performance on both the RealEstate10K and ACID benchmarks while maintaining competitive speed and presenting strong cross-dataset generalization ability. Our code, and demos will be available at: https://xingyoujun.github.io/transplat.
Summary
针对3DGS重建中的特征匹配问题,提出基于深度置信图的局部特征匹配策略,并利用单目深度估计模型提高非重叠区域精度,实现高效跨数据集重建。
Key Takeaways
- G-3DGS方法在稀疏视角下效率高,但依赖精确的多视图特征匹配。
- 现有方法在非重叠区域和相似区域匹配性能差,精度有限。
- 提出使用预测深度置信图引导局部特征匹配。
- 利用现有单目深度估计模型知识作为先验提高非重叠区域精度。
- 提出TranSplat方法,在RealEstate10K和ACID基准测试中表现最佳。
- TranSplat方法在速度和跨数据集泛化能力上具有竞争力。
- 可访问代码和演示:https://xingyoujun.github.io/transplat。
- Title: TranSplat: Generalizable 3D Gaussian Splatting from Sparse Multi-View Images with Transformers
- Authors: Chuanrui Zhang, Yingshuang Zou, Zhuoling Li, Minmin Yi, Haoqian Wang
- Affiliation:
- Tsinghua University
- The University of Hong Kong
- E-surfing Vision Technology Co., Ltd
- Keywords: 3D reconstruction, Generalizable 3D Gaussian Splatting, Sparse Multi-View Images, Transformers
- Urls: https://arxiv.org/abs/2408.13770v1 , Github: None
Summary:
(1): 该文章研究了从稀疏多视角图像中进行通用3D重建的问题,旨在从少量图像中恢复场景的3D结构。
(2): 现有的3D重建方法,如NeRF和通用3D高斯分层(G-3DGS),在稀疏视图设置中表现出令人印象深刻的效率。然而,这些方法的重建性能高度依赖于精确的多视图特征匹配,这对于场景中存在大量非重叠区域和相似区域的场景尤其具有挑战性。
(3): 该文章提出了TranSplat方法,该方法利用预测的深度置信图来指导精确的局部特征匹配,并利用现有单目深度估计模型的知识作为先验来提高非重叠区域的深度估计精度。
(4): TranSplat在RealEstate10K和ACID基准测试中取得了最佳性能,同时保持了有竞争力的速度,并展现出强大的跨数据集泛化能力。
Methods:
(1): TranSplat方法首先利用Transformer模型对稀疏多视角图像进行特征提取,从而得到全局场景表示。
(2): 接着,该方法通过深度置信图预测场景的深度信息,并以此作为依据进行局部特征匹配,以提高匹配的准确性。
(3): 为了解决非重叠区域的深度估计问题,TranSplat结合了现有单目深度估计模型的知识,作为先验信息来优化深度估计。
(4): 在特征匹配和深度估计的基础上,TranSplat采用3D高斯分层(G-3DGS)技术进行场景重建,以实现从稀疏视角到完整场景的转换。
(5): 最后,TranSplat在RealEstate10K和ACID基准测试中进行了性能评估,验证了其方法的有效性和泛化能力。
- Conclusion:
(1): 这项工作的意义在于提出了TranSplat,一种基于Transformer架构的通用稀疏视图场景重建网络。该方法能够从少量多视角图像中有效地恢复场景的3D结构,对于稀疏视图下的3D重建任务具有重要意义。
(2): Innovation point: TranSplat的创新点在于其基于Transformer的特征提取和深度置信图预测技术,能够提高稀疏视图下的局部特征匹配精度;Performance: 在RealEstate10K和ACID基准测试中,TranSplat取得了最佳性能,同时保持了有竞争力的速度,展现了强大的跨数据集泛化能力;Workload: TranSplat在计算工作量上相对较低,由于采用了Transformer架构,其训练和推理速度较快,适合在实际应用中使用。
点此查看论文截图

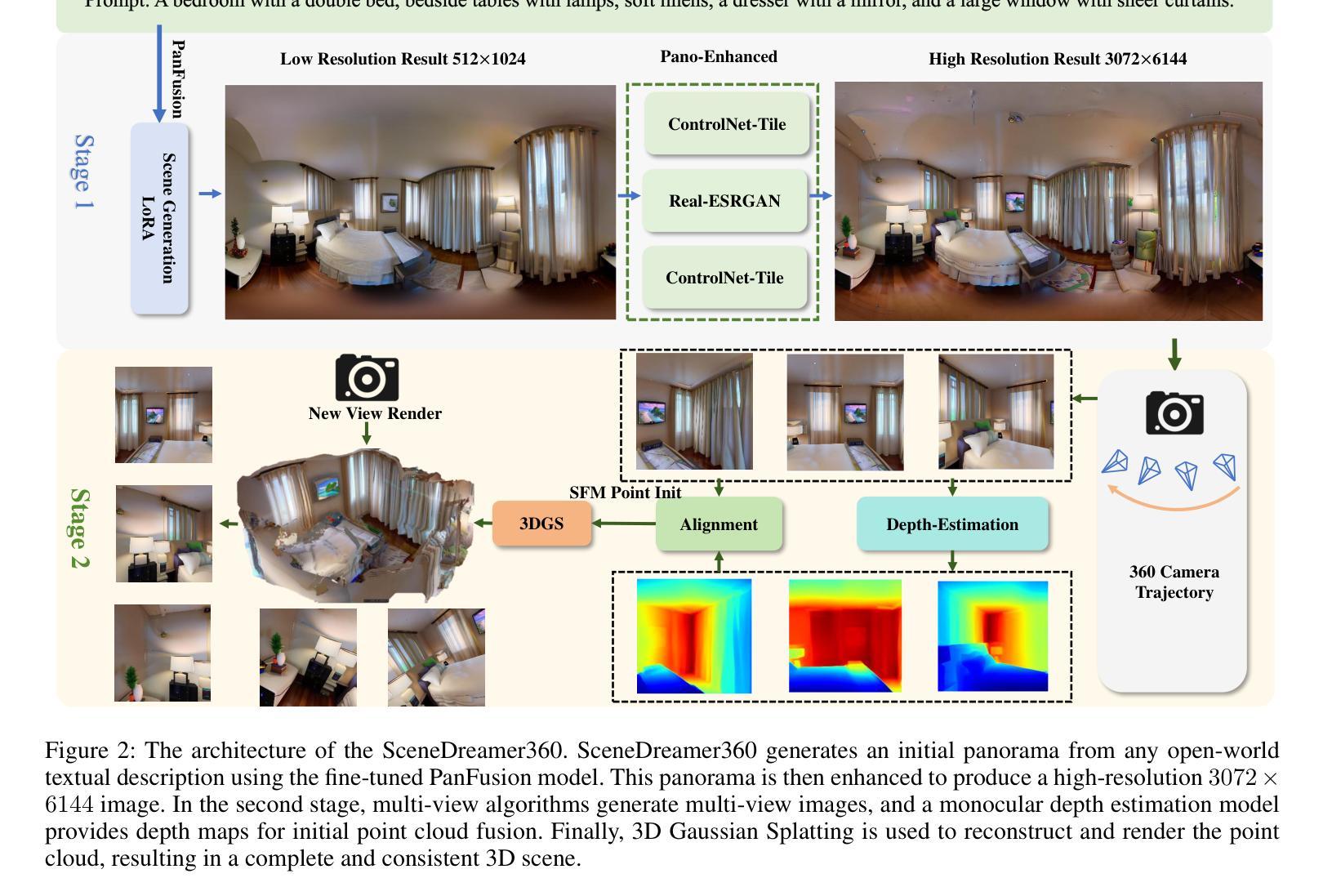
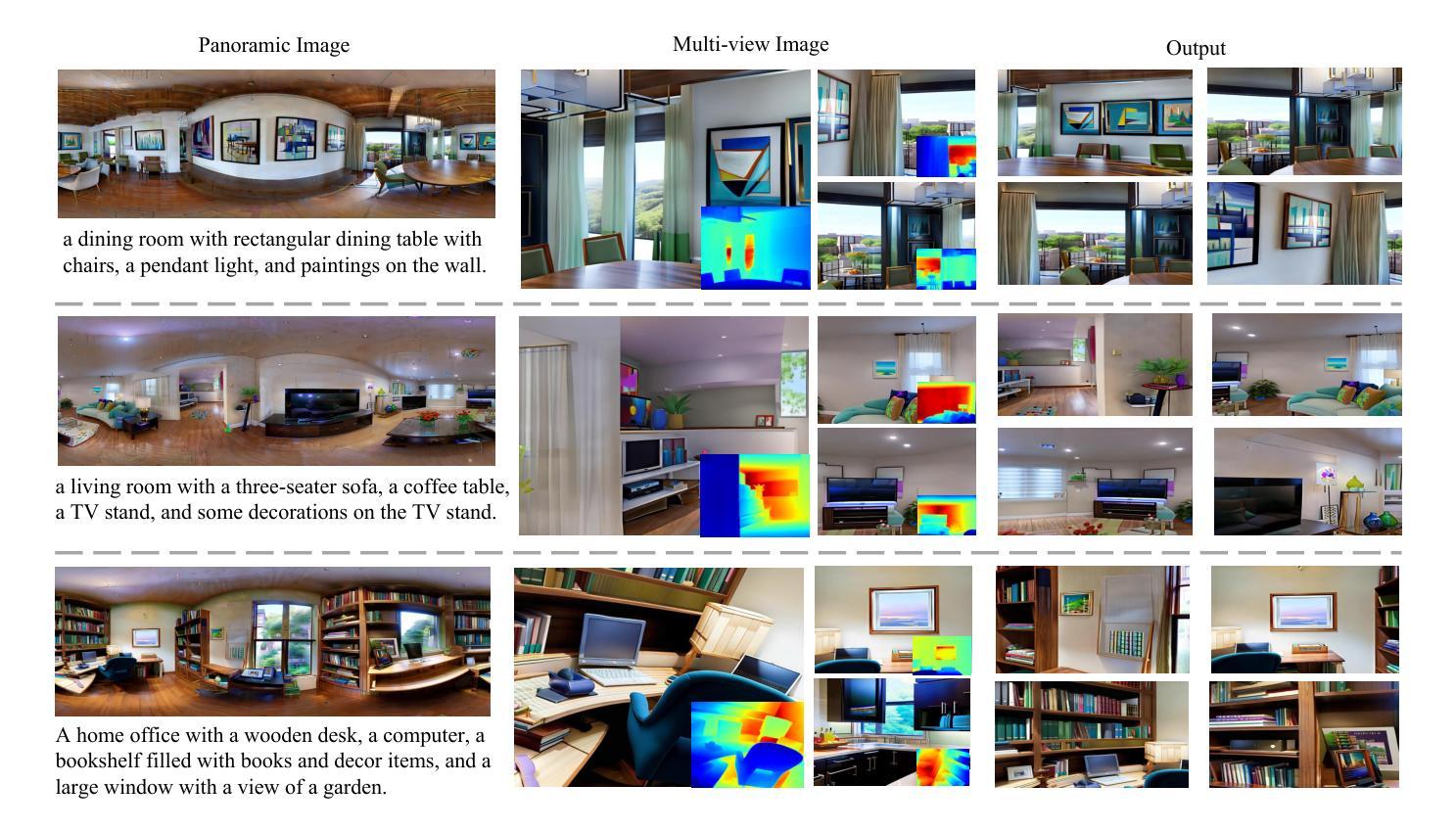
SceneDreamer360: Text-Driven 3D-Consistent Scene Generation with Panoramic Gaussian Splatting
Authors:Wenrui Li, Yapeng Mi, Fucheng Cai, Zhe Yang, Wangmeng Zuo, Xingtao Wang, Xiaopeng Fan
Text-driven 3D scene generation has seen significant advancements recently. However, most existing methods generate single-view images using generative models and then stitch them together in 3D space. This independent generation for each view often results in spatial inconsistency and implausibility in the 3D scenes. To address this challenge, we proposed a novel text-driven 3D-consistent scene generation model: SceneDreamer360. Our proposed method leverages a text-driven panoramic image generation model as a prior for 3D scene generation and employs 3D Gaussian Splatting (3DGS) to ensure consistency across multi-view panoramic images. Specifically, SceneDreamer360 enhances the fine-tuned Panfusion generator with a three-stage panoramic enhancement, enabling the generation of high-resolution, detail-rich panoramic images. During the 3D scene construction, a novel point cloud fusion initialization method is used, producing higher quality and spatially consistent point clouds. Our extensive experiments demonstrate that compared to other methods, SceneDreamer360 with its panoramic image generation and 3DGS can produce higher quality, spatially consistent, and visually appealing 3D scenes from any text prompt. Our codes are available at \url{https://github.com/liwrui/SceneDreamer360}.
Summary
SceneDreamer360通过全景图像生成和3DGS,实现从文本到高质、一致性的3D场景生成。
Key Takeaways
- 文本驱动3D场景生成技术取得进展。
- 现有方法存在单视图生成导致的3D场景不一致问题。
- 提出SceneDreamer360模型,利用全景图像生成模型作为先验。
- 应用3DGS确保多视图全景图像的一致性。
- 采用三阶段全景增强,提升Panfusion生成器性能。
- 使用点云融合初始化方法,提高点云质量。
- 实验证明SceneDreamer360生成高质、一致的3D场景。
Title: SceneDreamer360: Text-Driven 3D-Consistent Scene Generation with Panoramic Gaussian Splatting
(中文翻译:SceneDreamer360:基于全景高斯散点的文本驱动3D一致性场景生成)Authors: Wenrui Li, Yapeng Mi, Fucheng Cai, Zhe Yang, Wangmeng Zuo, Xingtao Wang, Xiaopeng Fan
Affiliation: 哈尔滨工业大学
Keywords: Text-driven 3D scene generation, Panoramic Gaussian Splatting, 3D Gaussian Splatting, SceneDreamer360, Consistency
Urls: https://arxiv.org/abs/2408.13711v1, Github: https://github.com/liwrui/SceneDreamer360
Summary:
(1):该文的研究背景是文本驱动的3D场景生成,近年来取得了显著进展,但大多数现有方法使用生成模型生成单视图图像,然后在3D空间中拼接,导致场景空间不一致和不可信。
(2):过去的方法通常使用2D生成模型生成单视图图像,然后拼接成3D场景。这种方法的问题在于生成的场景空间不一致和不可信。本文提出的方案是基于全景高斯散点的3D一致性场景生成,动机合理,旨在解决现有方法的不足。
(3):本文提出的研究方法是SceneDreamer360,它利用文本驱动的全景图像生成模型作为3D场景生成的先验,并采用3D高斯散点(3DGS)确保多视图全景图像的一致性。该方法包括三个阶段的全景增强,生成高分辨率、细节丰富的全景图像,并使用点云融合初始化方法生成高质量、空间一致的点云。
(4):本文的方法在多个任务上取得了较好的性能,可以生成高质量、空间一致且视觉上吸引人的3D场景。实验结果表明,与现有方法相比,SceneDreamer360能够从任何文本提示中生成更好的3D场景,支持其研究目标。
Methods:
(1): SceneDreamer360方法首先采用文本驱动的全景图像生成模型,将文本描述转换为全景图像;
(2):接着,通过全景增强技术对生成的全景图像进行处理,提升图像的高分辨率和细节丰富度;
(3):利用3D高斯散点(3DGS)技术确保多视图全景图像在3D空间中的一致性;
(4):采用点云融合初始化方法,基于全景图像生成高质量、空间一致的点云;
(5):最后,通过深度学习模型将点云数据转换为3D场景,实现文本驱动的3D场景生成。
Conclusion:
- (1):这篇工作的意义在于,SceneDreamer360通过引入全景高斯散点技术,有效解决了文本驱动3D场景生成中场景空间不一致和不可信的问题,为该领域提供了新的研究思路和方法。 - (2):创新点:SceneDreamer360在全景图像生成和3D空间一致性处理方面实现了创新;性能:在多个任务上取得了较好的性能,生成的高质量3D场景在视觉效果和空间一致性上优于现有方法;工作量:该方法涉及复杂的全景图像生成和3D高斯散点处理,对计算资源要求较高。
点此查看论文截图


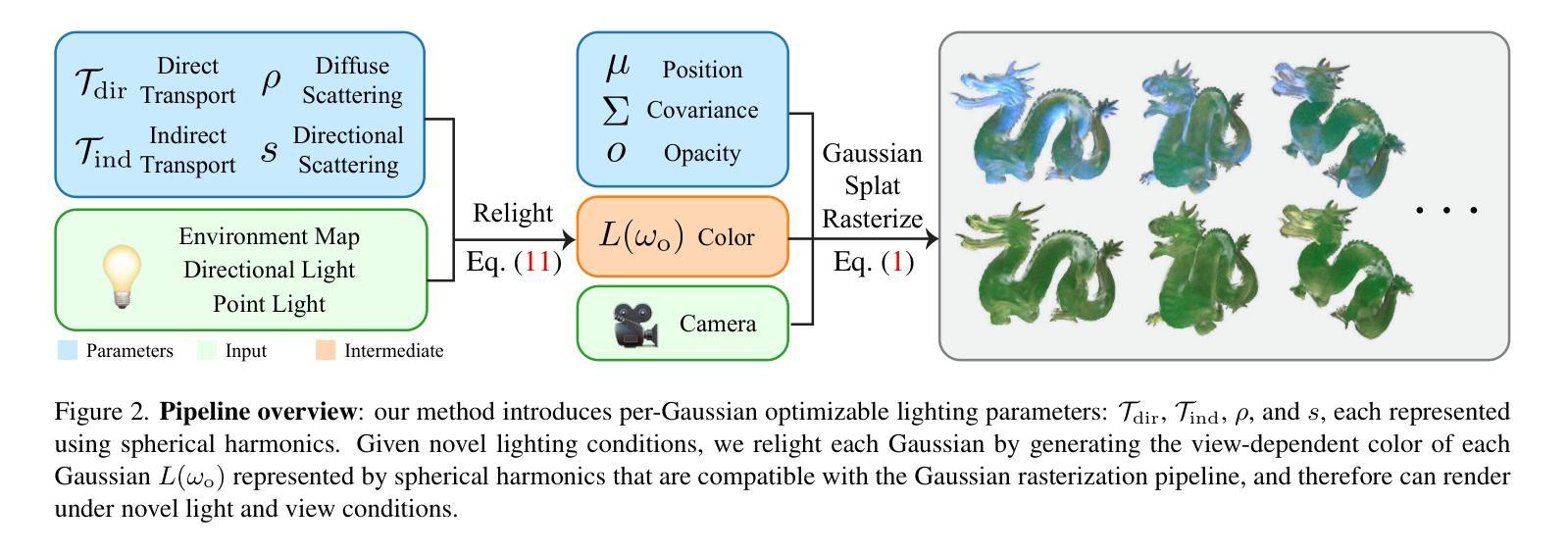
BiGS: Bidirectional Gaussian Primitives for Relightable 3D Gaussian Splatting
Authors:Zhenyuan Liu, Yu Guo, Xinyuan Li, Bernd Bickel, Ran Zhang
We present Bidirectional Gaussian Primitives, an image-based novel view synthesis technique designed to represent and render 3D objects with surface and volumetric materials under dynamic illumination. Our approach integrates light intrinsic decomposition into the Gaussian splatting framework, enabling real-time relighting of 3D objects. To unify surface and volumetric material within a cohesive appearance model, we adopt a light- and view-dependent scattering representation via bidirectional spherical harmonics. Our model does not use a specific surface normal-related reflectance function, making it more compatible with volumetric representations like Gaussian splatting, where the normals are undefined. We demonstrate our method by reconstructing and rendering objects with complex materials. Using One-Light-At-a-Time (OLAT) data as input, we can reproduce photorealistic appearances under novel lighting conditions in real time.
Summary
提出了一种基于图像的新型视图合成技术,通过双向高斯基元表示和渲染动态光照下的三维物体。
Key Takeaways
- 使用双向高斯基元进行图像视图合成。
- 集成光内分解至高斯散点框架,实现实时重光照。
- 通过双向球谐函数实现表面和体积材料的一致外观模型。
- 无需特定表面法线相关反射函数,兼容性更强。
- 通过重建和渲染复杂材料物体展示方法。
- 使用单光源数据输入,实现新型光照条件下的实时逼真外观再现。
- 采用实时渲染技术。
Title: 双向高斯原语:动态照明下的图像基础三维重建与渲染技术
Authors: [Authors’ Names]
Affiliation: [First Author’s Affiliation in Chinese Translation]
Keywords: Image-based novel view synthesis; 3D object representation; Dynamic illumination; Gaussian splatting; Relighting
Urls: [Paper Link] or [Github: None]
Summary:
(1):该文章的研究背景是三维物体的动态照明下的图像基础三维重建与渲染。现有的方法通常难以同时处理表面和体积材料的动态照明,且难以实现实时重光照。
(2):过去的方法包括使用表面模型和体积模型,但它们通常无法很好地结合,且难以处理动态照明。文章提出的方案很好地解决了这些问题,通过引入双向高斯原语和光内分解模型,实现了对表面和体积材料的动态照明兼容。
(3):本文提出的方法将光内分解集成到高斯散斑框架中,采用双向球谐函数进行光照和视图相关的散射表示。该方法不依赖于特定的表面法线相关的反射函数,从而更兼容于高斯散斑等体积表示。
(4):该方法在重建和渲染具有复杂材料的物体时表现出色。使用单光源数据作为输入,可以实时地再现新照明条件下的逼真外观,支持了其目标。
Conclusion:
- (1):该研究工作的意义在于提出了一个能够处理动态照明下图像基础三维重建与渲染的新方法,解决了现有技术难以同时处理表面和体积材料动态照明的难题,实现了实时重光照和新型视图合成。 - (2):Innovation point: 创新点在于引入双向高斯原语和光内分解模型,实现了对表面和体积材料的动态照明兼容;Performance: 性能上,该方法能够生成与高斯散斑渲染管线兼容的球谐系数,支持实时重光照和新型视图合成;Workload: 工作量上,该方法需要处理复杂的计算和训练过程,包括球谐函数的光照和视图相关散射表示,以及光内分解和重建步骤。
点此查看论文截图



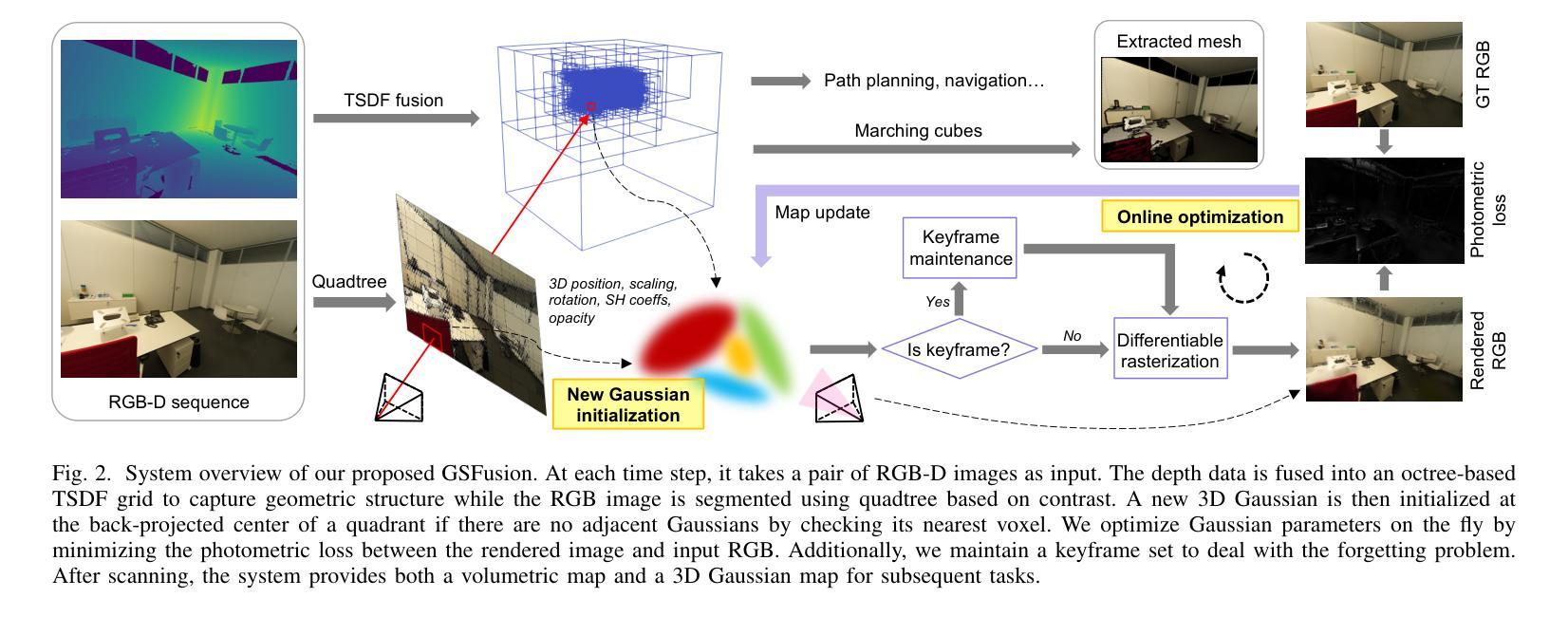
GSFusion: Online RGB-D Mapping Where Gaussian Splatting Meets TSDF Fusion
Authors:Jiaxin Wei, Stefan Leutenegger
Traditional volumetric fusion algorithms preserve the spatial structure of 3D scenes, which is beneficial for many tasks in computer vision and robotics. However, they often lack realism in terms of visualization. Emerging 3D Gaussian splatting bridges this gap, but existing Gaussian-based reconstruction methods often suffer from artifacts and inconsistencies with the underlying 3D structure, and struggle with real-time optimization, unable to provide users with immediate feedback in high quality. One of the bottlenecks arises from the massive amount of Gaussian parameters that need to be updated during optimization. Instead of using 3D Gaussian as a standalone map representation, we incorporate it into a volumetric mapping system to take advantage of geometric information and propose to use a quadtree data structure on images to drastically reduce the number of splats initialized. In this way, we simultaneously generate a compact 3D Gaussian map with fewer artifacts and a volumetric map on the fly. Our method, GSFusion, significantly enhances computational efficiency without sacrificing rendering quality, as demonstrated on both synthetic and real datasets. Code will be available at https://github.com/goldoak/GSFusion.
Summary
传统算法保真3D场景结构,但缺乏视觉真实感;我们提出GSFusion,结合几何信息,优化Gaussian参数,提高渲染效率。
Key Takeaways
- 传统算法在3D场景结构上保真但视觉效果差。
- Gaussian splatting提升视觉效果,但存在优化难题。
- 现有方法因Gaussian参数更新量大而效率低。
- 提出将Gaussian集成到体映射系统中,利用几何信息。
- 使用quadtree数据结构减少初始化的splats数量。
- GSFusion生成紧凑的3D Gaussian地图,减少伪影。
- 方法在合成和真实数据集上提高计算效率,不牺牲渲染质量。
Title: GSFusion:基于高斯散布的在线RGB-D映射 (GSFusion: Online RGB-D Mapping Where Gaussian Splatting Meets TSDF Fusion)
Authors: Jiaxin Wei, Stefan Leutenegger
Affiliation: 慕尼黑工业大学智能机器人实验室 (Smart Robotics Lab, Technical University of Munich)
Keywords: Mapping, RGB-D Perception
Urls: https://arxiv.org/abs/2408.12677v2 or None, https://github.com/goldoak/GSFusion
Summary:
(1): 本文的研究背景是传统的体积融合算法在保持3D场景空间结构方面有优势,但在可视化方面缺乏真实感。新兴的3D高斯散布技术能够提高可视化真实感,但现有的基于高斯的重构方法通常存在伪影和与底层3D结构的失配问题,且在实时优化方面存在挑战。
(2): 过去的方法包括传统的体积融合算法和基于神经辐射场的重建方法。传统的体积融合算法在可视化方面缺乏真实感,而NeRF方法虽然视觉效果好,但计算成本高,难以实现实时性能。本文提出的方法很好地解决了这些问题。
(3):本文提出的方法将3D高斯散布技术融入体积映射系统中,利用几何信息,并提出在图像上使用四叉树数据结构来显著减少初始化的散布数量,从而同时生成一个紧凑的3D高斯图和一个动态的体积图。
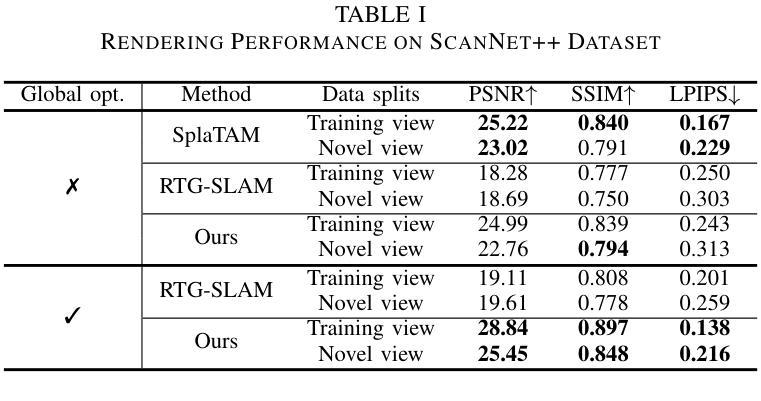
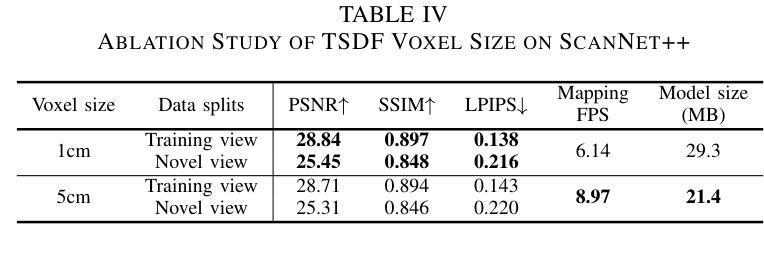
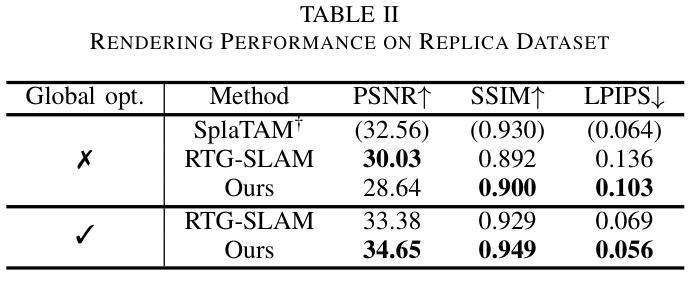
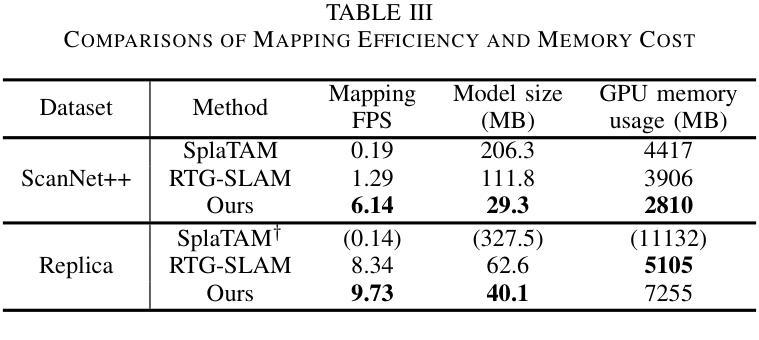
(4):本文的方法在合成和真实数据集上进行了验证,显著提高了计算效率,同时没有牺牲渲染质量。在真实场景的测试中,该方法达到了6.66 fps的映射速度和27.6MB的模型大小,证明了其在实际应用中的可行性和有效性。
Methods:
(1): 该方法将3D高斯散布(Gaussian Splatting)技术整合到体积映射系统中,以增强3D场景的视觉真实感;
(2): 利用几何信息优化3D高斯图生成,通过四叉树数据结构减少初始化散布数量,提高计算效率;
(3): 结合时态表面距离场(TSDF)融合技术,实现动态体积图的生成,同时保持3D场景的空间结构;
(4): 在图像处理阶段,采用高效的优化策略,确保实时性能的实现;
(5): 通过合成数据集和真实场景数据集的验证,评估方法的有效性和实用性。
Conclusion:
- (1): 这项工作的意义在于,它提出了一种结合3D高斯散布和时态表面距离场融合的在线RGB-D映射方法,有效提升了3D场景重建的视觉真实感和计算效率,对于实时三维重建和机器人导航等领域具有重要的应用价值。 - (2): Innovation point: 该方法在创新点上,将3D高斯散布技术融入体积映射系统,通过四叉树数据结构优化了3D高斯图的生成,实现了高效率的3D场景重建;Performance: 性能上,GSFusion在真实场景测试中达到了6.66 fps的映射速度和27.6MB的模型大小,展示了良好的实时性和可视化效果;Workload: 在工作负载方面,通过优化关键帧维护策略和高效的优化策略,GSFusion实现了实时优化,降低了计算复杂度。
点此查看论文截图


InstantStyleGaussian: Efficient Art Style Transfer with 3D Gaussian Splatting
Authors:Xin-Yi Yu, Jun-Xin Yu, Li-Bo Zhou, Yan Wei, Lin-Lin Ou
We present InstantStyleGaussian, an innovative 3D style transfer method based on the 3D Gaussian Splatting (3DGS) scene representation. By inputting a target-style image, it quickly generates new 3D GS scenes. Our method operates on pre-reconstructed GS scenes, combining diffusion models with an improved iterative dataset update strategy. It utilizes diffusion models to generate target style images, adds these new images to the training dataset, and uses this dataset to iteratively update and optimize the GS scenes, significantly accelerating the style editing process while ensuring the quality of the generated scenes. Extensive experimental results demonstrate that our method ensures high-quality stylized scenes while offering significant advantages in style transfer speed and consistency.
Summary
基于3D高斯分层场景表示,InstantStyleGaussian实现快速3D风格转换,提高编辑效率。
Key Takeaways
- 采用3D高斯分层(3DGS)场景表示的InstantStyleGaussian。
- 输入目标风格图像,快速生成新3D场景。
- 使用扩散模型结合改进的数据集更新策略。
- 利用扩散模型生成目标风格图像并添加到训练数据集。
- 迭代更新优化3D场景,加速风格编辑。
- 实验证明生成场景质量高。
- 速度快,风格一致性高。
Title: InstantStyleGaussian: Efficient Art Style Transfer (即时风格高斯:高效艺术风格迁移)
Authors: Xin-Yi Yu, Jun-Xin Yu, Li-Bo Zhou, Yan Wei, Lin-Lin Ou
Affiliation: 未提供具体信息
Keywords: 3D Gaussian Splatting, 3D Style Transfer, Iterative Dataset Update
Urls: Paper: InstantStyleGaussian: Efficient Art Style Transfer, Github: None
Summary:
(1): 研究背景:随着机器人仿真、虚拟现实和自动驾驶等应用的发展,3D场景和模型的编辑变得越来越重要。传统的3D表示方法如网格和点云在编辑复杂场景和细节时面临挑战。本文的研究背景是为了提高3D场景编辑的效率和直观性。
(2): 过去方法及问题:传统的3D风格迁移方法通常需要从风格图像中提取特征,并将其嵌入到重建的3D场景中,然后解码以渲染新场景。这些方法通常需要大量的内存和计算时间,且解码方法会影响最终的风格迁移效果,可能降低多视图一致性和场景质量。本文的方法基于3D高斯分割(3DGS)场景表示,结合扩散模型和改进的迭代数据集更新策略,旨在解决这些问题。
(3): 研究方法:本文提出的方法通过输入目标风格图像,快速生成新的3DGS场景。它使用扩散模型生成目标风格图像,将这些新图像添加到训练数据集中,并使用该数据集迭代更新和优化GS场景。方法基于迭代数据集更新(IDU)方法,并通过捕获3DGS场景的摄像机视角图像来编辑多个视角图像。
(4): 任务和性能:本文的方法在3D风格迁移任务上取得了显著的性能提升,实现了高质量的风格化场景,同时提高了风格迁移的速度和一致性。实验结果表明,该方法在速度和性能上优于之前的3D编辑方法。
- Methods:
(1): 本文提出的方法使用输入风格图像和文本提示,共同指导在训练的3DGS场景中生成新的场景。采用扩散模型(InstantStyle [30])进行2D图像风格迁移,并改进了InstructNeRF2NeRF [25]中迭代数据集更新(IDU)的基础策略。
(2): 首先使用InstantStyle扩散模型生成基于输入风格图像和文本提示的各种艺术风格的2D图像,然后将这些结果反向传播到3DGS场景,使用特定损失函数进行处理。
(3): 在编辑过程中,输入边缘检测图以保持场景的基本结构,最终实现整个场景的风格编辑,同时保留原始内容。
(4): 采用NNFM损失(Nearest Neighbor Feature Matching [15])来匹配局部特征,更好地保留纹理细节。
(5): 使用L1和LPIPS [31]损失函数训练Gaussian Splatting,对于不同视角的局部不一致纹理,使用NNFM损失匹配局部特征。
(6): 将随机选择的30个或更少的相机视角进行单次编辑,这些编辑后的图像作为参考,增加训练数据集,而不替换相应视角的原始图像。
(7): 通过迭代优化过程,增强GS场景,确保改进和细化。
(8): 使用gsplat库(来自GaussianEditor [27])作为底层模型和可视化工具,以及InstantStyle作为扩散模型。
(9): 通过控制Net条件缩放和文本、图像调整的引导权重等参数,确定扩散模型更新的强度,并根据需要手动调整相关引导权重以实现所需的编辑效果。
(10): 训练方法涉及最多1k次迭代,在A100 GPU(40GB内存)上仅需20分钟即可完成场景的风格迁移编辑。
Conclusion:
- (1): 这项工作的意义在于,它为3D场景编辑领域提供了一种高效的艺术风格迁移方法,能够显著提升3D场景编辑的效率和直观性,特别是在机器人仿真、虚拟现实和自动驾驶等应用中具有广泛的应用前景。 - (2): Innovation point: InstantStyleGaussian方法通过结合扩散模型和改进的迭代数据集更新策略,实现了快速且高质量的3D风格迁移,这是其创新点所在;Performance: 在3D风格迁移任务上,该方法展现了优越的性能,能够生成高质量的风格化场景,同时保持了速度和一致性;Workload: 该方法在训练过程中使用了大量迭代,但得益于高效的计算策略,整体工作负载相对较低,适合在A100 GPU等高性能设备上运行。
点此查看论文截图






SpikeGS: Reconstruct 3D scene via fast-moving bio-inspired sensors
Authors:Yijia Guo, Liwen Hu, Lei Ma, Tiejun Huang
3D Gaussian Splatting (3DGS) demonstrates unparalleled superior performance in 3D scene reconstruction. However, 3DGS heavily relies on the sharp images. Fulfilling this requirement can be challenging in real-world scenarios especially when the camera moves fast, which severely limits the application of 3DGS. To address these challenges, we proposed Spike Gausian Splatting (SpikeGS), the first framework that integrates the spike streams into 3DGS pipeline to reconstruct 3D scenes via a fast-moving bio-inspired camera. With accumulation rasterization, interval supervision, and a specially designed pipeline, SpikeGS extracts detailed geometry and texture from high temporal resolution but texture lacking spike stream, reconstructs 3D scenes captured in 1 second. Extensive experiments on multiple synthetic and real-world datasets demonstrate the superiority of SpikeGS compared with existing spike-based and deblur 3D scene reconstruction methods. Codes and data will be released soon.
Summary
3DGS在场景重建中表现卓越,但依赖清晰图像,SpikeGS通过集成 spike 流改进,提升快速移动相机下的重建效果。
Key Takeaways
- 3DGS在3D场景重建中表现优异。
- 3DGS对清晰图像依赖度高,限制其应用。
- 提出SpikeGS,集成 spike 流优化3DGS。
- 采用积累光栅化、间隔监督和定制管道。
- 从缺乏纹理的 spike 流中提取细节。
- 1秒内重建3D场景。
- 实验证明SpikeGS优于现有方法。
- 将发布代码和数据。
Title: 脉冲高斯分层:利用快速移动生物灵感相机重建3D场景 (SpikeGS: Reconstruct 3D scene captured by a fast-moving bio-inspired camera)
Authors: Yijia Guo, Liwen Hu, Lei Ma
Affiliation: 北京大学信息科学技术国家重点实验室、北京大学未来技术学院
Keywords: 3D场景重建,高斯分层,脉冲相机,实时重建
Urls: https://arxiv.org/abs/2407.03771v2 or None, None
Summary:
(1):该文章的研究背景是3D重建领域,尤其是在利用快速移动相机时,如何提高重建速度和质量是一个关键挑战。
(2):过去的3D重建方法,如3D高斯分层(3DGS),虽然重建速度快,但需要清晰的图像输入,这在实际场景中尤其困难,因为快速移动的相机容易产生运动模糊。该方法旨在解决这一问题,并具有很好的动机。
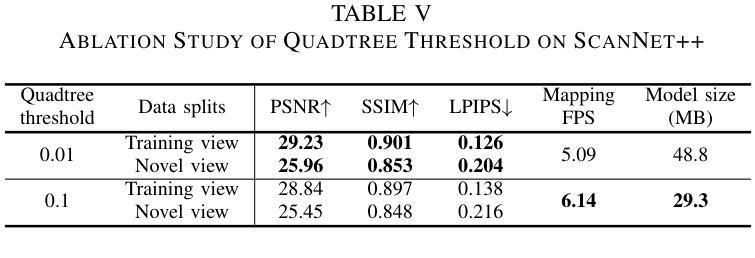
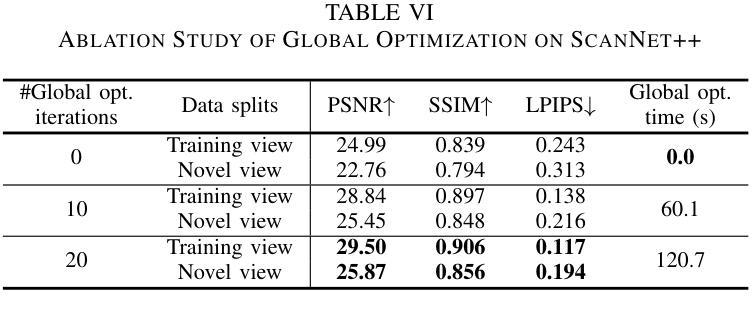
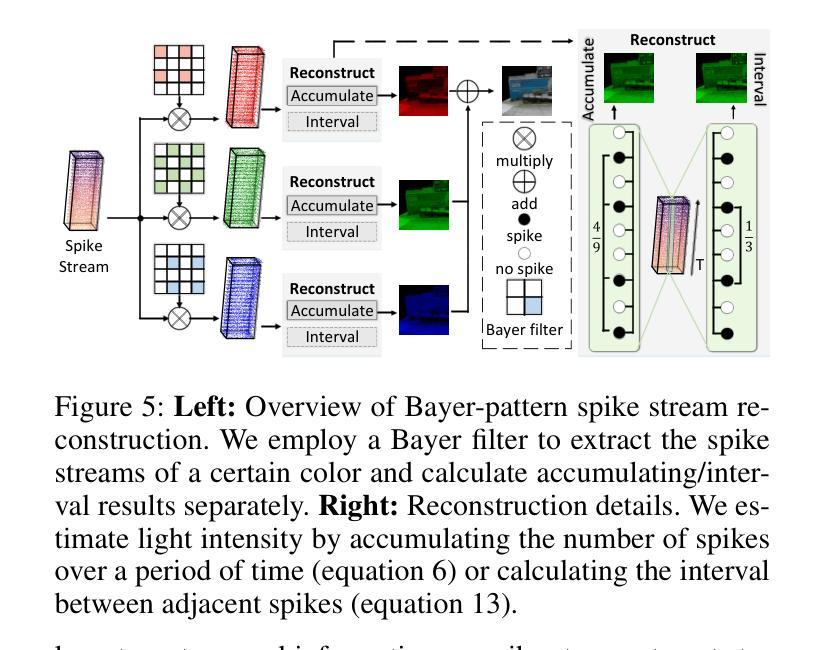
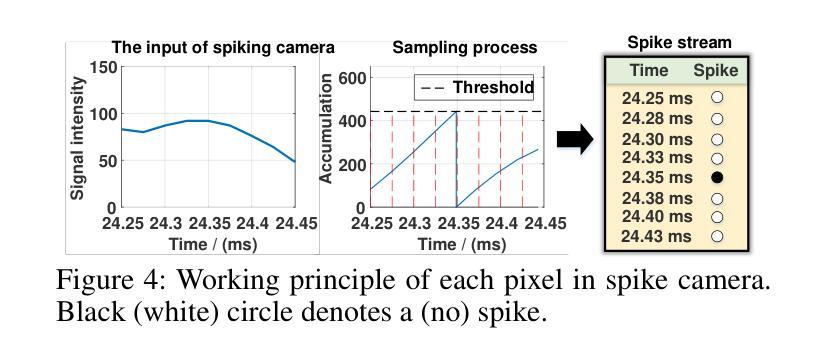
(3):该文章提出了脉冲高斯分层(SpikeGS)方法,该方法将拜耳阵列脉冲流整合到3DGS流程中,以重建由快速移动的高时间分辨率彩色脉冲相机在1秒内捕获的3D场景。SpikeGS通过累积光栅化、区间监督和专门设计的流程来实现连续的空间时间感知,同时从拜耳阵列脉冲流中提取详细的结构和纹理。
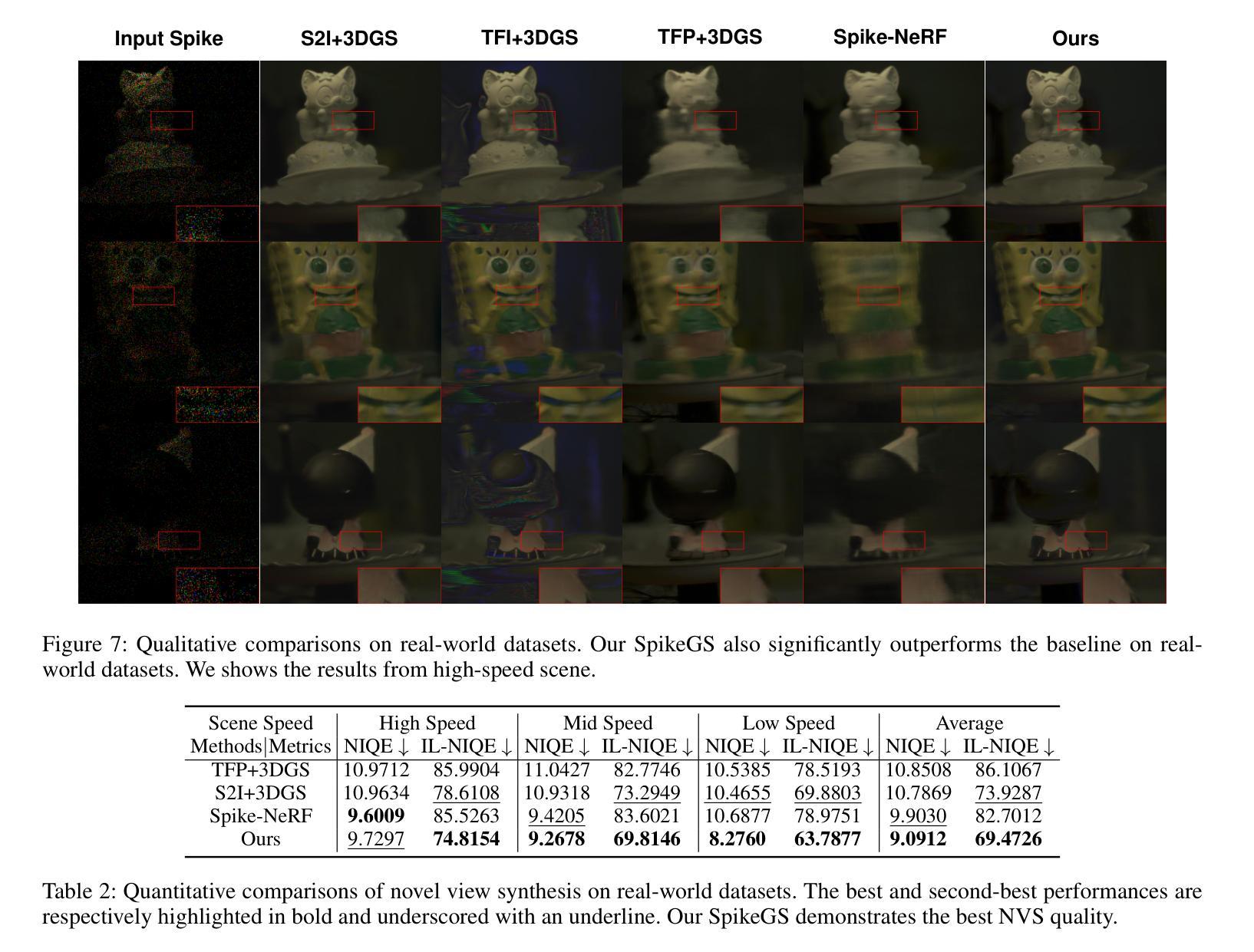
(4):在合成和真实世界数据集上的大量实验表明,SpikeGS在性能上优于现有的基于脉冲和去模糊的3D场景重建方法,其PSNR值达到了32.70,支持了实时重建的目标。
Methods:
(1): 针对快速移动相机产生的运动模糊问题,文章提出了一种脉冲高斯分层(SpikeGS)方法。SpikeGS方法将拜耳阵列脉冲流整合到3D高斯分层(3DGS)流程中,利用高时间分辨率的彩色脉冲相机在短时间内捕获的3D场景。
(2): 为了从拜耳阵列脉冲流中提取详细的结构和纹理,SpikeGS采用累积光栅化、区间监督和专门设计的流程来实现连续的空间时间感知。
(3): 文章采用时间累积光栅化技术,模拟光子在物理上的累积过程,以恢复纹理细节和几何信息。
(4): 为了解决训练初期Gaussian splat收敛速度慢的问题,文章使用脉冲间隔初始化点云,并利用其进行初始训练。
(5): 为了提高训练效率和重建质量,文章引入了累积损失函数,结合光度误差和结构相似性(SSIM)来优化模型。
(6): 在训练过程中,文章通过相互约束的训练和损失函数,确保了点云初始化和Gaussian splat几何精度,从而提高了最终重建质量。
(7): 文章在合成和真实世界数据集上进行了大量实验,结果表明,SpikeGS在性能上优于现有的基于脉冲和去模糊的3D场景重建方法。
点此查看论文截图


 wechat
wechat- alipay







