Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-02 更新
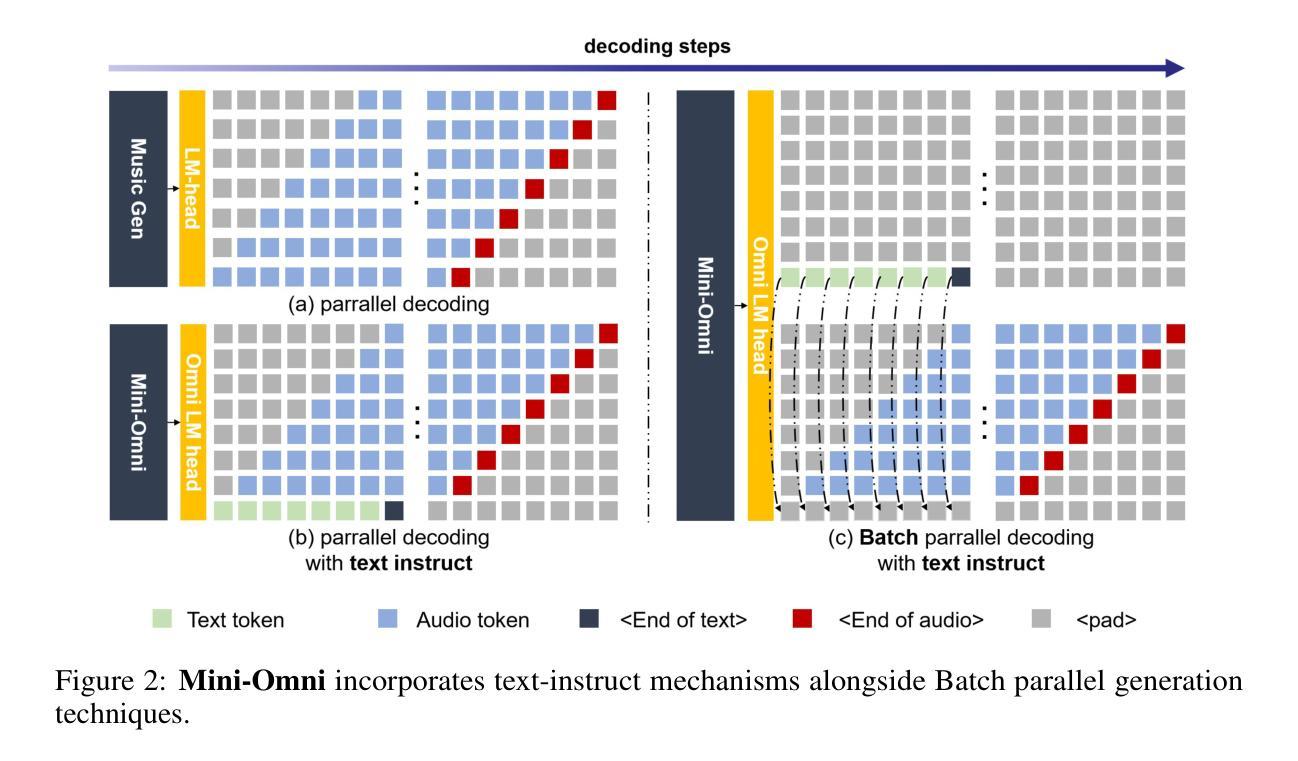
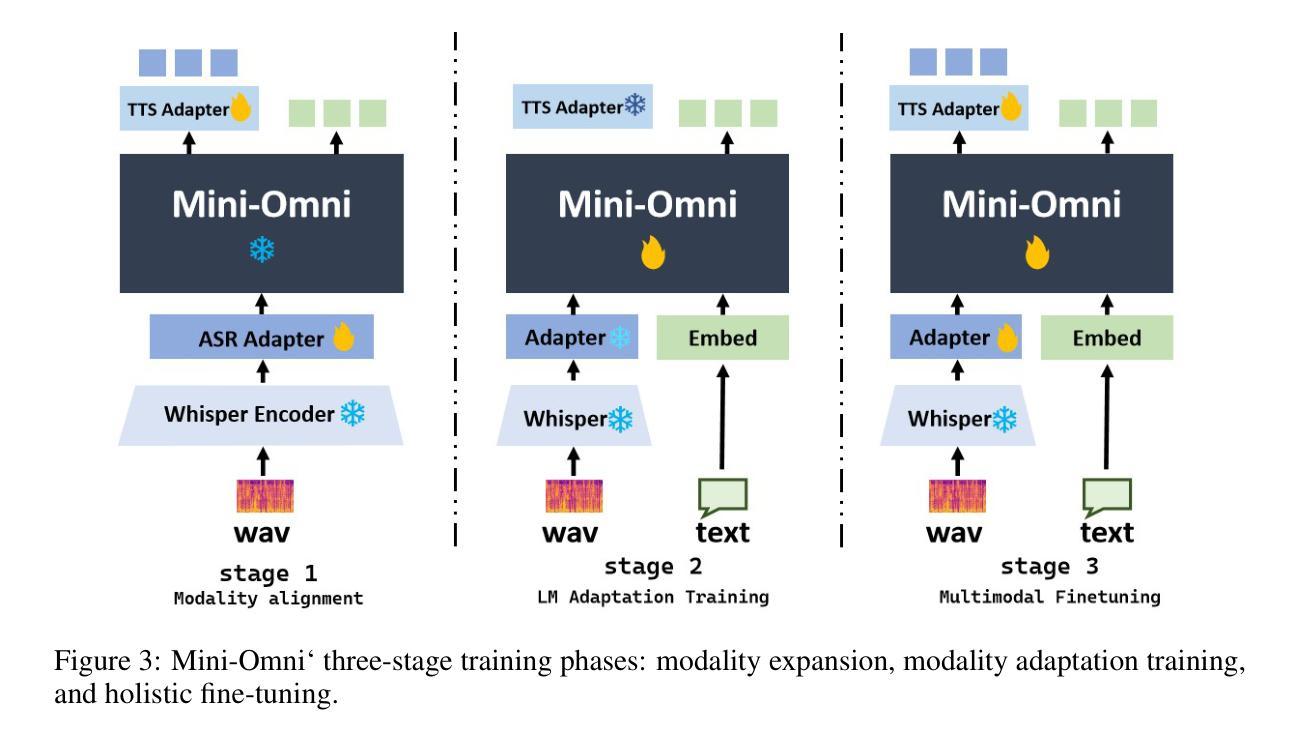
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
Authors:Zhifei Xie, Changqiao Wu
Recent advances in language models have achieved significant progress. GPT-4o, as a new milestone, has enabled real-time conversations with humans, demonstrating near-human natural fluency. Such human-computer interaction necessitates models with the capability to perform reasoning directly with the audio modality and generate output in streaming. However, this remains beyond the reach of current academic models, as they typically depend on extra TTS systems for speech synthesis, resulting in undesirable latency. This paper introduces the Mini-Omni, an audio-based end-to-end conversational model, capable of real-time speech interaction. To achieve this capability, we propose a text-instructed speech generation method, along with batch-parallel strategies during inference to further boost the performance. Our method also helps to retain the original model’s language capabilities with minimal degradation, enabling other works to establish real-time interaction capabilities. We call this training method “Any Model Can Talk”. We also introduce the VoiceAssistant-400K dataset to fine-tune models optimized for speech output. To our best knowledge, Mini-Omni is the first fully end-to-end, open-source model for real-time speech interaction, offering valuable potential for future research.
PDF 10 pages
Summary
提出“Any Model Can Talk”训练方法,实现实时语音交互的Mini-Omni模型。
Key Takeaways
- GPT-4o模型达到近人类自然流畅度,实现实时人机对话。
- 实时对话需要模型具备音频推理和流式生成输出能力。
- 现有学术模型依赖TTS系统,存在延迟问题。
- Mini-Omni是音频基于的端到端对话模型,实现实时语音交互。
- 提出文本指令语音生成方法,并采用批并行策略提升性能。
- 保留模型语言能力,最小化性能退化。
- 引入VoiceAssistant-400K数据集,优化语音输出模型。
- Mini-Omni是首个完全端到端、开源的实时语音交互模型。
标题: Mini-Omni: 语言模型能听会说(基于流式处理的思考)
作者: Zhifei Xie(谢智飞)和Changqiao Wu(吴昌桥)。
所属机构: 第一作者Zhifei Xie来自清华大学。
关键词: Mini-Omni模型,实时语音交互,流式处理,语言模型,语音合成,端对端模型。
链接: 论文链接:暂未提供;GitHub代码链接:GitHub(注意:如果无法访问或链接失效,请尝试其他可靠的学术资源平台)。
摘要:
- (1) 研究背景:随着语言模型技术的不断进步,与人类进行实时对话已成为可能。然而,当前的模型在直接处理音频模态进行推理和生成输出方面存在困难,这限制了它们在实时交互中的应用。文章在此背景下探讨了Mini-Omni模型的应用。
- (2) 过去的方法及问题:过去的语言模型在语音合成上通常依赖于文本到语音(TTS)系统,这导致了不理想的延迟。然而,这些方法并不适合实时的、端到端的语音交互。文章指出了现有方法的不足并提出了新的方法。
- (3) 研究方法:本研究提出了Mini-Omni模型,一个基于音频的端到端对话模型,能够实现实时语音交互。通过引入文本指导的语音生成方法和批并行推理策略来增强性能。同时,通过保留原始模型的语言能力,使其他工作能够建立实时交互能力。该研究还引入了VoiceAssistant-400K数据集来优化模型的语音输出。
- (4) 任务与性能:Mini-Omni模型在实时语音交互任务上表现出优异的性能。它是第一个完全端到端、开源的实时语音交互模型,为未来的研究提供了有价值的潜力。通过实验结果证明了模型的有效性和实用性。
希望这个总结符合您的要求!如有任何需要调整或补充的地方,请告诉我。
方法:
- (1) 研究背景分析:文章首先指出了当前语言模型技术在直接处理音频模态进行推理和生成输出方面的困难,限制了它们在实时交互中的应用。因此,文章基于这一背景,探讨了Mini-Omni模型的应用潜力。
- (2) 过去方法的回顾与问题:传统语言模型在语音合成上依赖于文本到语音(TTS)系统,这导致了不理想的延迟。然而,这些方法并不适合实时的、端到端的语音交互需求。文章指出了这一不足并寻求新的解决方案。
- (3) Mini-Omni模型的提出:为了克服现有方法的不足,研究团队提出了Mini-Omni模型,一个基于音频的端到端对话模型,能够实现实时语音交互。模型通过引入文本指导的语音生成方法和批并行推理策略来增强性能。此外,保留了原始模型的语言能力,使得其他功能能够在此基础上建立实时交互能力。为了更好地优化模型的语音输出,文章还引入了VoiceAssistant-400K数据集。
- (4) 实验设计与结果:文章通过一系列实验验证了Mini-Omni模型在实时语音交互任务上的性能。实验结果表明,该模型是第一个完全端到端、开源的实时语音交互模型,具有显著的有效性和实用性。此外,实验结果还为未来的研究提供了有价值的参考。
希望这个总结符合您的要求!如果您还有其他问题或需要进一步的解释,请随时告诉我。
- Conclusion:
- (1) 工作的意义:该工作引入了一种名为Mini-Omni的多模态模型,具有直接的语音识别能力,推动了实时语音交互领域的技术发展。该研究在人机交互领域中具有重要的实用价值,并为其他相关研究提供了有价值的参考。
- (2) 创新点、性能和工作量总结:
- 创新点:文章提出了Mini-Omni模型,该模型基于音频的端到端对话模型实现实时语音交互,引入了文本指导的语音生成方法和批并行推理策略,保留了原始模型的语言能力,为其他功能建立实时交互能力提供了基础。此外,文章还引入了VoiceAssistant-400K数据集以优化模型的语音输出。
- 性能:Mini-Omni模型在实时语音交互任务上表现出优异的性能,是第一个完全端到端、开源的实时语音交互模型,具有显著的有效性和实用性。
- 工作量:文章的工作量大,涉及到模型的构建、实验设计、数据集的制作等多个方面的工作。同时,文章还提供了详细的实验过程和结果分析,为其他研究者提供了有价值的参考。
点此查看论文截图


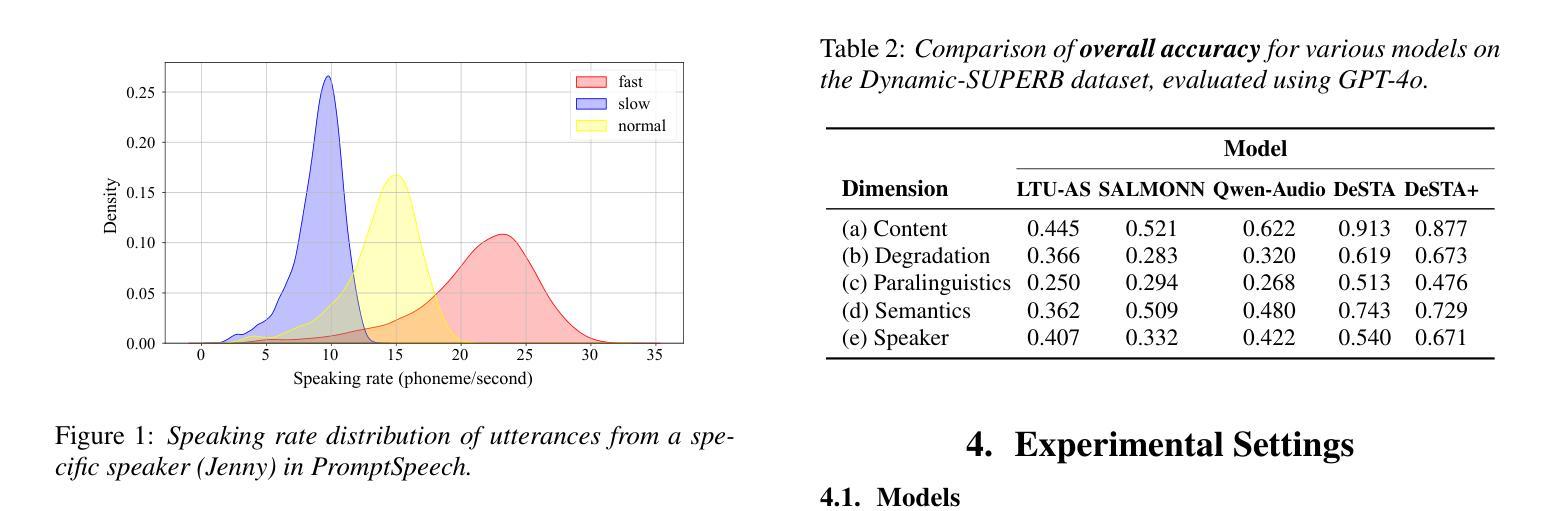
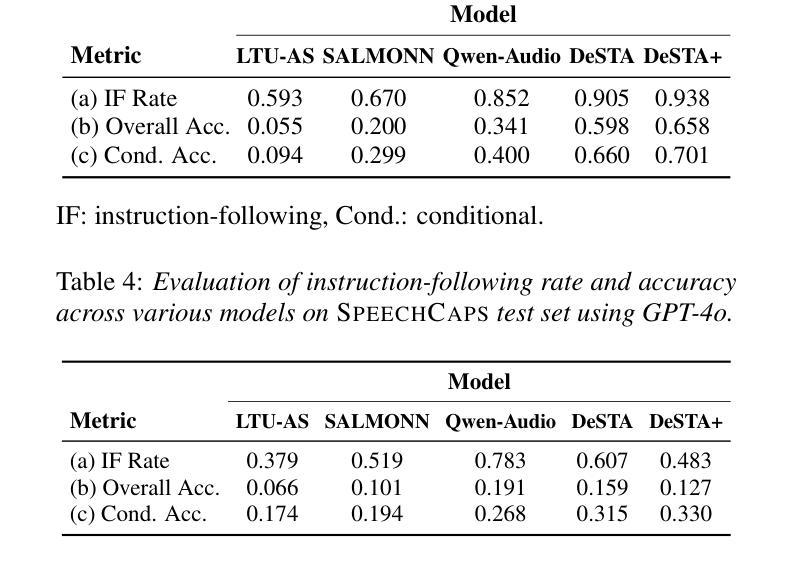
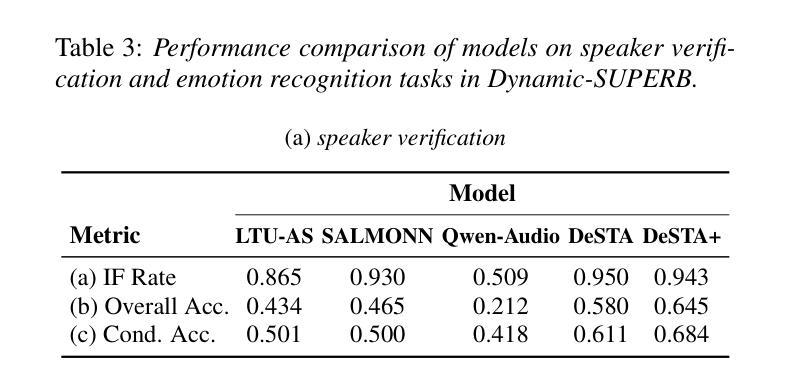
SpeechCaps: Advancing Instruction-Based Universal Speech Models with Multi-Talker Speaking Style Captioning
Authors:Chien-yu Huang, Min-Han Shih, Ke-Han Lu, Chi-Yuan Hsiao, Hung-yi Lee
Instruction-based speech processing is becoming popular. Studies show that training with multiple tasks boosts performance, but collecting diverse, large-scale tasks and datasets is expensive. Thus, it is highly desirable to design a fundamental task that benefits other downstream tasks. This paper introduces a multi-talker speaking style captioning task to enhance the understanding of speaker and prosodic information. We used large language models to generate descriptions for multi-talker speech. Then, we trained our model with pre-training on this captioning task followed by instruction tuning. Evaluation on Dynamic-SUPERB shows our model outperforming the baseline pre-trained only on single-talker tasks, particularly in speaker and emotion recognition. Additionally, tests on a multi-talker QA task reveal that current models struggle with attributes such as gender, pitch, and speaking rate. The code and dataset are available at https://github.com/cyhuang-tw/speechcaps.
PDF SynData4GenAI 2024
Summary
该文提出基于指令的多说话者语音处理任务,提升情感识别与风格理解。
Key Takeaways
- 指令式语音处理研究兴起。
- 多任务训练提升模型性能。
- 设计基础任务以惠及下游任务。
- 提出多说话者风格字幕任务。
- 使用大型语言模型生成描述。
- 模型在动态-SUPERB测试中优于单说话者任务模型。
- 多说话者问答任务中模型在性别、音高和语速识别上表现不佳。
- 代码和数据集公开。
- 结论:
(1)xxx作品的意义在于xxx(此处需要根据文章内容填写具体的意义,例如:该作品展示了当代社会的矛盾与冲突,或是揭示了人性的复杂性与多样性等)。
(2)创新点:xxx(例如:文章在理论框架、研究方法或研究视角上的创新之处)。文章在性能方面的优势在于xxx(例如:研究结果显著提高了某一领域的性能或效率),但也存在一些局限性,如xxx(例如:研究未充分考虑其他影响因素或存在实验样本量较小等)。在工作量方面,文章呈现了xxx的工作量(例如:文章进行了大量的实证研究或数据分析,展现了作者深入和全面的研究态度),但也存在某些重复或冗余的工作内容。总体来说,该文章在某些方面表现出色,但也存在一些改进的空间。
点此查看论文截图

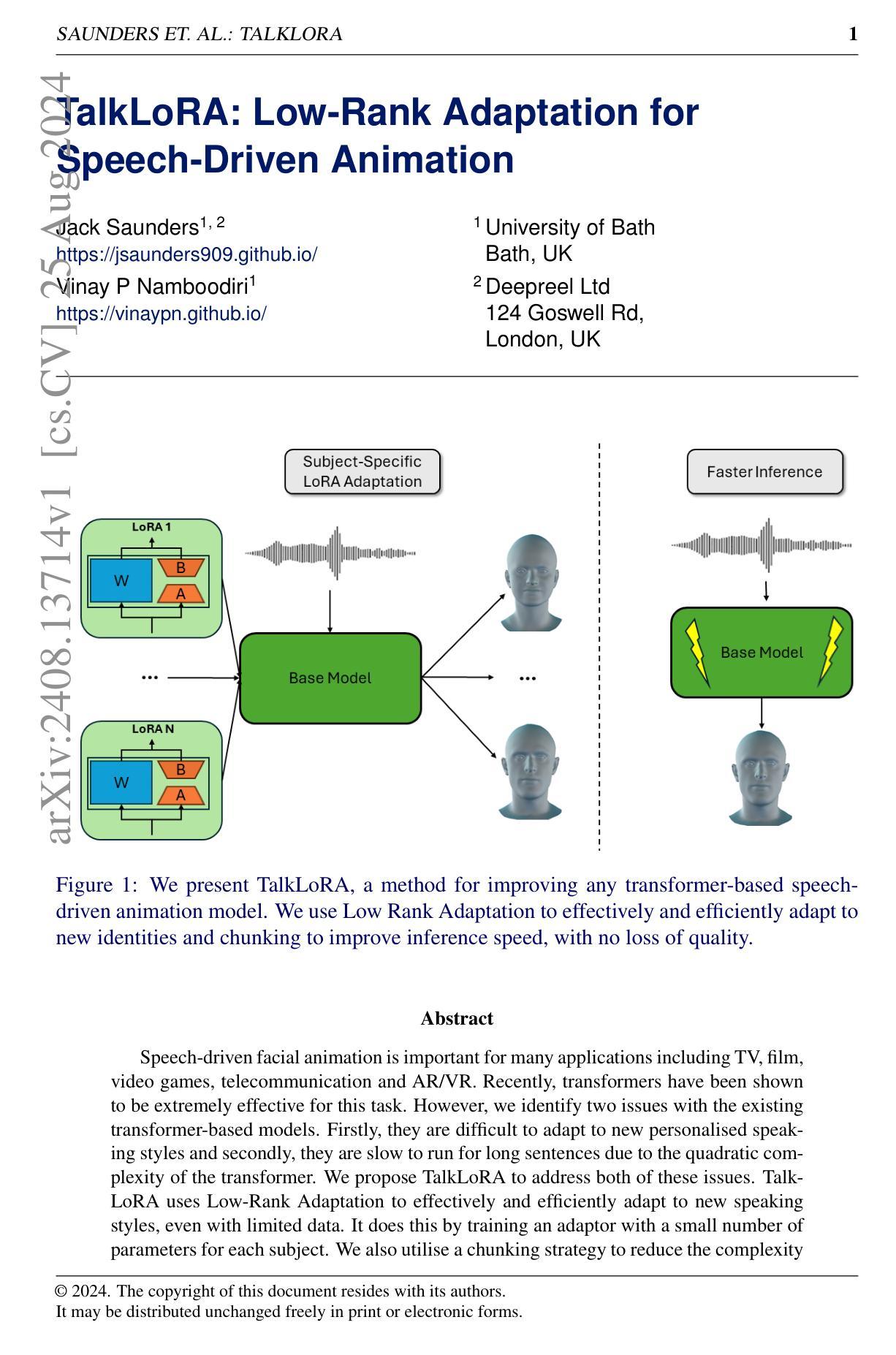
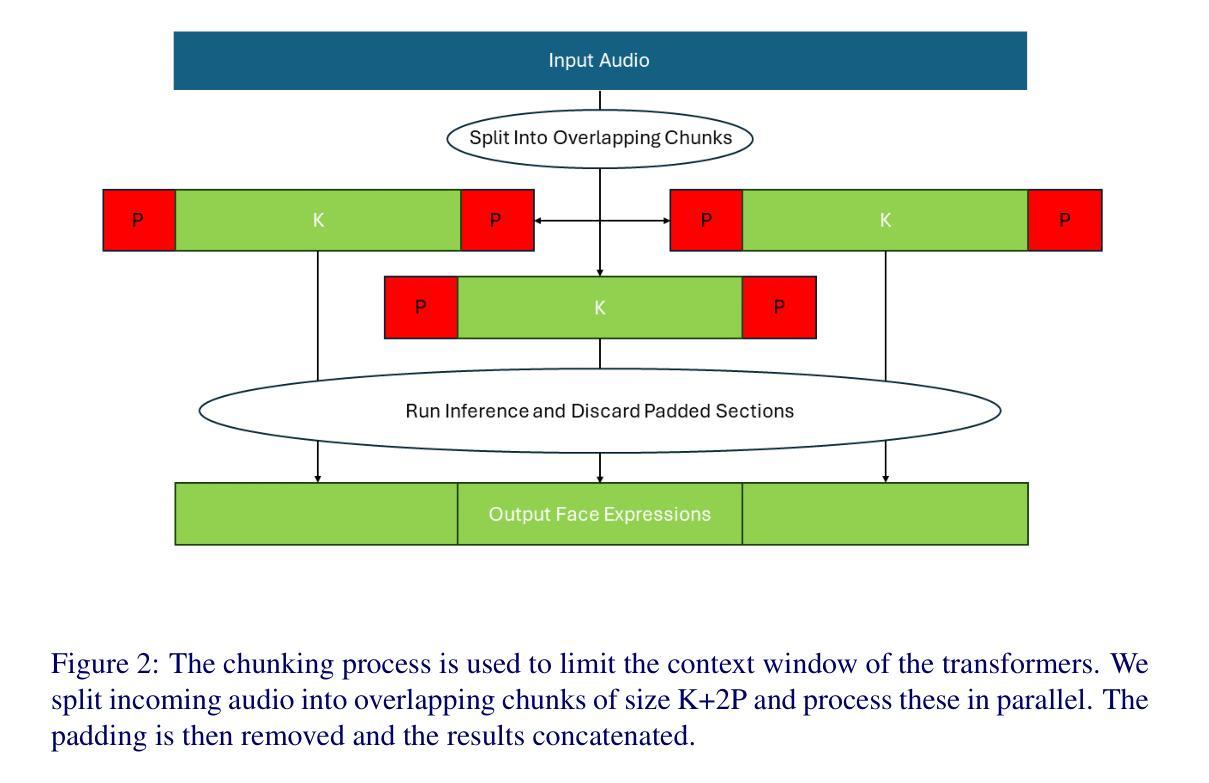
TalkLoRA: Low-Rank Adaptation for Speech-Driven Animation
Authors:Jack Saunders, Vinay Namboodiri
Speech-driven facial animation is important for many applications including TV, film, video games, telecommunication and AR/VR. Recently, transformers have been shown to be extremely effective for this task. However, we identify two issues with the existing transformer-based models. Firstly, they are difficult to adapt to new personalised speaking styles and secondly, they are slow to run for long sentences due to the quadratic complexity of the transformer. We propose TalkLoRA to address both of these issues. TalkLoRA uses Low-Rank Adaptation to effectively and efficiently adapt to new speaking styles, even with limited data. It does this by training an adaptor with a small number of parameters for each subject. We also utilise a chunking strategy to reduce the complexity of the underlying transformer, allowing for long sentences at inference time. TalkLoRA can be applied to any transformer-based speech-driven animation method. We perform extensive experiments to show that TalkLoRA archives state-of-the-art style adaptation and that it allows for an order-of-complexity reduction in inference times without sacrificing quality. We also investigate and provide insights into the hyperparameter selection for LoRA fine-tuning of speech-driven facial animation models.
Summary
谈头生成中,TalkLoRA通过低秩适应和分块策略有效解决现有模型风格适应性和运行速度问题。
Key Takeaways
- 语音驱动面部动画在多个领域应用广泛。
- 现有基于Transformer的模型难以适应新说话风格。
- Transformer模型因二次方复杂度导致长句运行缓慢。
- TalkLoRA利用低秩适应有效适应新说话风格。
- TalkLoRA通过训练少量参数的适配器实现。
- 分块策略降低Transformer复杂度,实现长句推理。
- TalkLoRA在风格适应性和推理时间上均有显著提升。
- 探讨了LoRA微调的超参数选择。
Title: TalkLoRA:基于低秩适应的语音驱动动画方法
Authors: Jack Saunders, Vinay P Namboodiri
Affiliation:
- Jack Saunders: 英国巴斯大学(University of Bath);Deepreel Ltd公司(位于伦敦)。
- Vinay P Namboodiri: 英国巴斯大学(University of Bath)。
Keywords: 语音驱动动画、低秩适应、身份适应、效率优化、Transformer模型。
Urls: 论文链接:[论文链接];代码链接:Github:[待补充(如果可用)],否则填写“Github:None”。
Summary:
- (1) 研究背景:语音驱动的动画技术在电视、电影、视频游戏、电信和AR/VR等领域有广泛应用。虽然基于Transformer的模型在此任务上表现卓越,但它们存在一些问题,如难以适应新的个性化说话风格和对于长句子的处理速度慢。本研究旨在解决这些问题。
- (2) 过去的方法及问题:现有的基于Transformer的模型在适应新说话风格和处理速度方面存在挑战。它们难以有效地适应新的个性化说话风格,并且在处理长句子时速度较慢,这是由于Transformer的二次复杂度导致的。
- (3) 研究方法:本研究提出了TalkLoRA方法,通过低秩适应技术有效地适应新说话风格,即使数据有限。该方法通过为每个主体训练一个小的适配器参数集来实现。同时,研究还采用了一种分块策略,以降低处理的复杂性。
- (4) 任务与性能:TalkLoRA在语音驱动的动画任务上进行了测试,实现了对新的个性化说话风格的有效适应,并显著提高了处理长句子的速度。这些性能改进支持了该方法的目标。实验结果表明,TalkLoRA能够显著提高模型对新说话风格的适应能力,并显著减少处理时间,证明了其有效性。
希望以上总结符合您的要求。
- 方法论:
该研究提出了一种基于低秩适应(Low-Rank Adaptation,LoRA)技术的语音驱动动画方法,TalkLoRA。其主要思想是针对现有的基于Transformer的语音驱动动画系统进行改进,提出一系列改进组件以适应新的个性化说话风格和提速推理过程。具体步骤包括:
- (1) 研究背景与问题阐述:
该研究首先指出语音驱动动画技术在电视、电影、视频游戏、电信和AR/VR等领域的广泛应用,以及现有基于Transformer的模型在适应新说话风格和处理速度方面的挑战。研究旨在解决这些问题。
- (2) 研究方法介绍:
研究提出了TalkLoRA方法,通过低秩适应技术有效地适应新说话风格,即使数据有限。该方法通过为每个主体训练一个小的适配器参数集来实现。同时,研究还采用了一种分块策略,以降低处理的复杂性,提高推理速度。
- (3) 模型架构介绍:
该方法的模型架构基于所使用的基线模型进行适应。对于实验中使用的情况,可以选择FaceFormer或Imitator作为基线模型。每个模型都由音频编码器、Transformer解码器和每帧解码器三个组件构成。音频编码器负责将音频特征提取出来,Transformer解码器考虑时间信息,运动解码器则负责从Transformer输出中生成顶点。
- (4) 低秩适配器(LoRA)的应用:
为了将基线模型适应到新的主体,研究使用了低秩适配器(LoRA)。LoRA是一种参数高效的微调方法,通过向权重矩阵添加偏移量来适应模型。研究确定了哪些网络组件适合应用LoRA技术,并探讨了LoRA引入的参数如何平衡模型的表示能力与正则化之间的权衡。
- (5) 分块策略的应用:
为了提高推理速度,研究采用了分块策略。通过将输入音频分成固定大小的块,并并行处理这些块,从而限制Transformer的上下文窗口。这种方法降低了模型的计算复杂性,提高了处理长句子的速度。
- (6) 实验实现细节:
研究提供了实施TalkLoRA方法的详细实现细节,包括训练过程、损失函数权重、优化器选择、学习率设置、LoRA的秩和alpha值的选择等。实验结果表明,TalkLoRA能够显著提高模型对新说话风格的适应能力,并显著减少处理时间,证明了其有效性。
- Conclusion:
- (1) 这项工作的意义在于提出了一种基于低秩适应(LoRA)技术的语音驱动动画方法,TalkLoRA。该方法能够解决现有基于Transformer的模型在适应新说话风格和处理速度方面的挑战,具有重要的实际应用价值。
- (2) 创新点:该研究通过引入低秩适配器(LoRA)技术,有效地提高了模型对新说话风格的适应能力,并采用了分块策略以提高推理速度。同时,该研究将LoRA技术应用于语音驱动动画任务,实现了对个性化说话风格的快速适应。
- 性能:实验结果表明,TalkLoRA在语音驱动的动画任务上实现了显著的性能改进,提高了模型对新说话风格的适应能力,并显著减少了处理时间。
- 工作量:该文章对TalkLoRA方法进行了详细的介绍和实验验证,包括方法论、模型架构、低秩适配器的应用、分块策略的应用以及实验实现细节等方面。工作量较大,但实验结果证明了方法的有效性。
点此查看论文截图
Empowering Whisper as a Joint Multi-Talker and Target-Talker Speech Recognition System
Authors:Lingwei Meng, Jiawen Kang, Yuejiao Wang, Zengrui Jin, Xixin Wu, Xunying Liu, Helen Meng
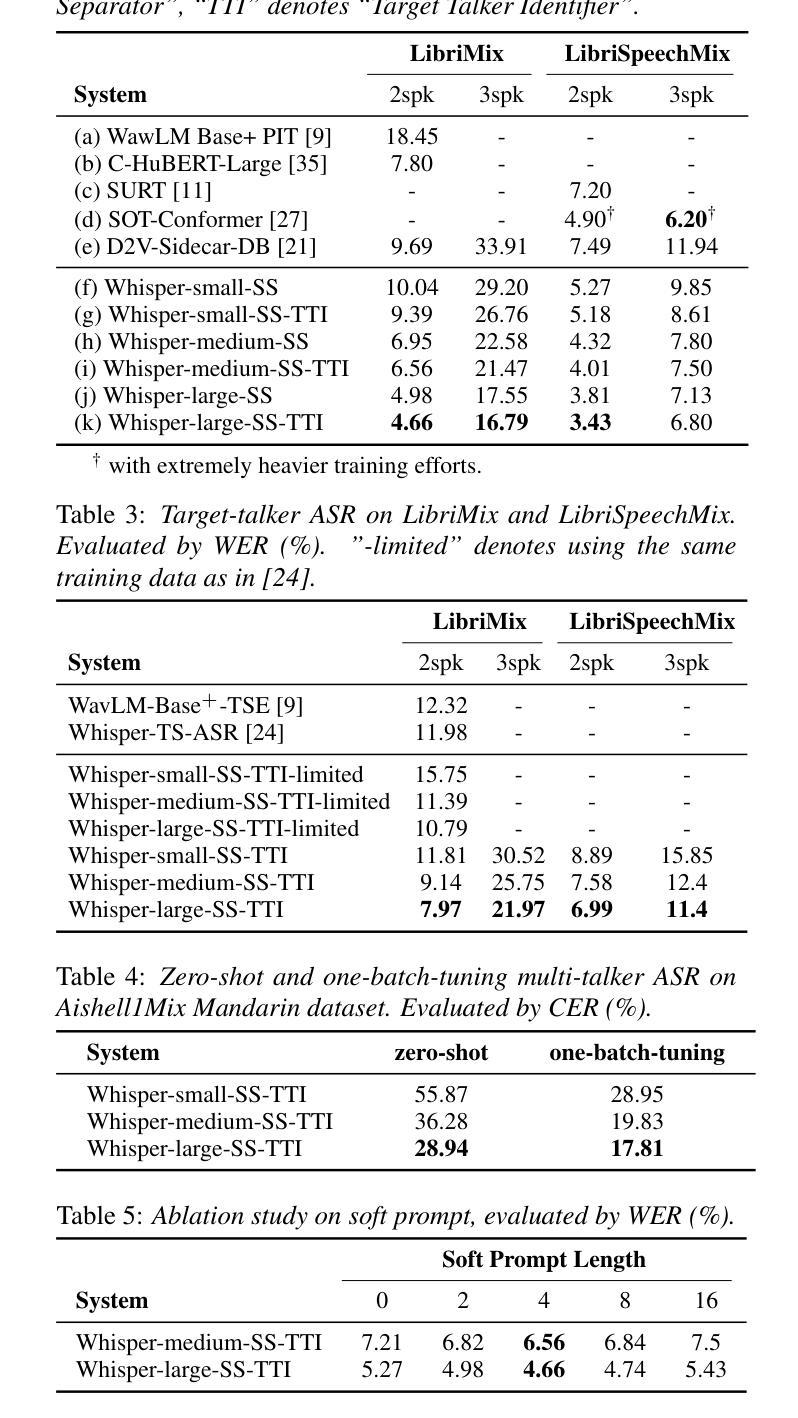
Multi-talker speech recognition and target-talker speech recognition, both involve transcription in multi-talker contexts, remain significant challenges. However, existing methods rarely attempt to simultaneously address both tasks. In this study, we propose a pioneering approach to empower Whisper, which is a speech foundation model, to tackle joint multi-talker and target-talker speech recognition tasks. Specifically, (i) we freeze Whisper and plug a Sidecar separator into its encoder to separate mixed embedding for multiple talkers; (ii) a Target Talker Identifier is introduced to identify the embedding flow of the target talker on the fly, requiring only three-second enrollment speech as a cue; (iii) soft prompt tuning for decoder is explored for better task adaptation. Our method outperforms previous methods on two- and three-talker LibriMix and LibriSpeechMix datasets for both tasks, and delivers acceptable zero-shot performance on multi-talker ASR on AishellMix Mandarin dataset.
PDF Accepted to INTERSPEECH 2024
Summary
提出了一种创新方法,使 Whisper 模型同时应对多说话者和目标说话者的语音识别任务。
Key Takeaways
- 联合处理多说话者和目标说话者的语音识别挑战。
- 利用 Whisper 模型,结合 Sidecar 分隔器进行混合嵌入分离。
- 引入目标说话者识别器,仅需3秒语音即可识别。
- 探索解码器软提示调优以适应任务。
- 在 LibriMix 和 LibriSpeechMix 数据集上优于先前方法。
- 在 AishellMix 数据集上实现可接受的零样本性能。
Title: 赋能whisper以联合处理多任务说话者和目标说话者的语音识别挑战
Authors: Lingwei Meng, Jiawen Kang, Yuejiao Wang, Zengrui Jin, Xixin Wu, Xunying Liu, Helen Meng
Affiliation: 中国香港大学 (The Chinese University of Hong Kong)
Keywords: 多说话人语音识别,目标说话人语音识别,提示微调,领域自适应
Summary:
(1)研究背景:多说话人和目标说话人的语音识别在多种场景下均具有重要意义,特别是在语音交互和信息检索等领域。然而,现有方法往往针对单一任务进行设计,缺乏同时处理两个任务的能力。
-(2)过去的方法及其问题:早期的方法通常使用级联系统,通过语音分离模块将混合语音信号分离,然后输入到单说话人语音识别系统进行转录。然而,这些方法由于优化目标不匹配,通常需要联合训练来提高性能。最近,端到端的模型因其出色的性能而受到关注,但在训练多说话人端到端语音识别系统时,如何将预测与对应的目标标签关联起来以计算损失是一个主要挑战。尽管有一些方法如Permutation Invariant Training (PIT)、Heuristic Error Assignment Training (HEAT)和Serialized Output Training (SOT)等已经取得了一些成果,但它们通常需要从头开始训练或重新微调预训练模型,无法充分利用现有的单说话人语音识别模型的进步。
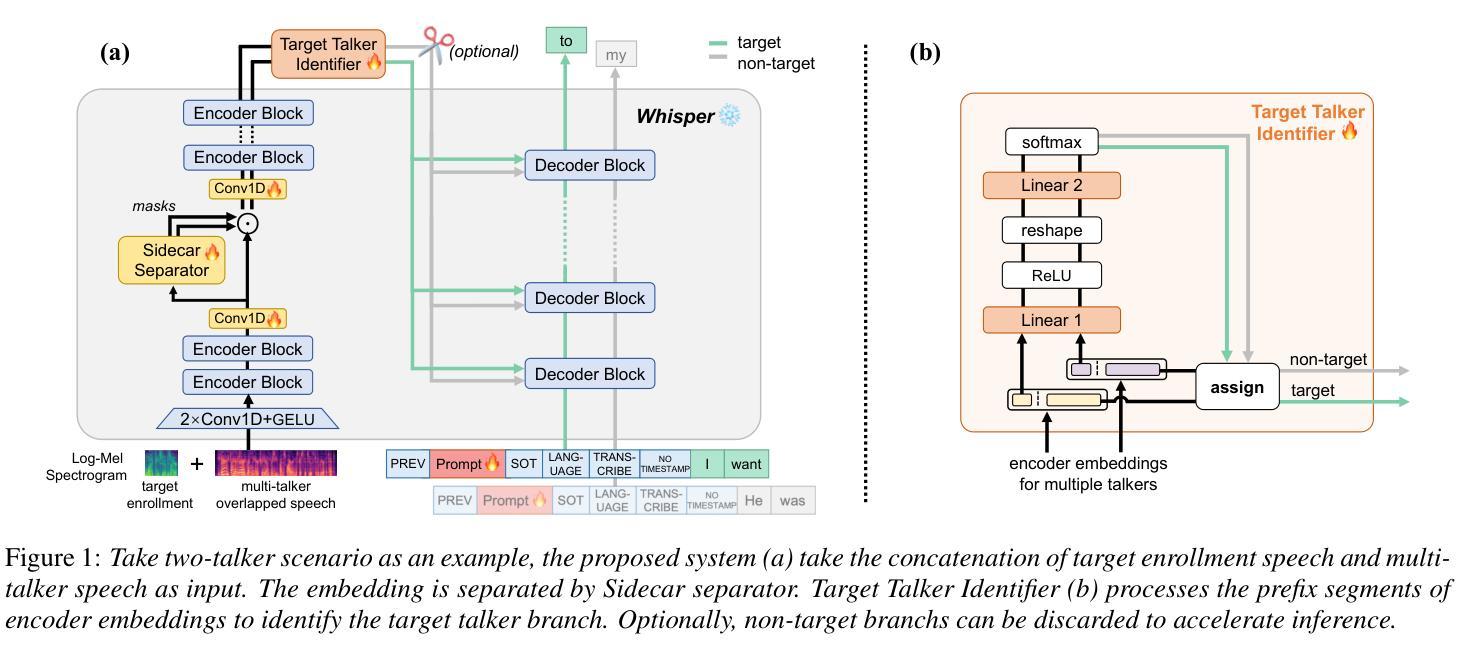
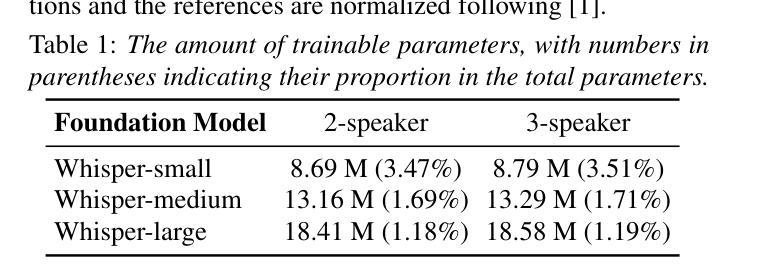
-(3)研究方法:针对上述问题,本文提出了一种基于Whisper模型的联合多说话人和目标说话人语音识别系统。首先,通过冻结Whisper模型的权重并引入Sidecar分离器到其编码器中以分离混合嵌入向量。其次,引入目标说话人识别器来实时识别目标说话人的嵌入流,仅需要三秒的注册语音作为提示。最后,采用软提示调整为解码器进行更好的任务适应。
-(4)任务与性能:本文方法在英文的LibriMix和LibriSpeechMix数据集以及Mandarin的AishellMix数据集上进行了实验验证。相较于之前的方法,本文方法在两项任务上都取得了领先性能。特别是在多说话人语音识别任务上,本文方法实现了令人满意的零样本性能。实验结果支持了该方法的有效性。
方法论:
(1) 研究背景与问题:针对多说话人和目标说话人的语音识别问题,现有的方法往往针对单一任务设计,缺乏同时处理两个任务的能力。因此,本文提出一种基于Whisper模型的联合多说话人和目标说话人语音识别系统。
(2) 方法框架:首先,通过冻结Whisper模型的权重并引入Sidecar分离器到其编码器中分离混合嵌入向量。其次,引入目标说话人识别器实时识别目标说话人的嵌入流,仅需要三秒的注册语音作为提示。再次,采用软提示调整为解码器进行更好的任务适应。
(3) 关键技术:采用Whisper作为语音识别的基础模型,Sidecar分离器用于将混合嵌入向量分离,目标说话人识别器用于识别目标说话人的嵌入流,软提示调整用于适应多任务语音识别。
(4) 数据集与实验设置:在英文的LibriMix、LibriSpeechMix数据集和Mandarin的AishellMix数据集上进行实验验证。对数据集进行预处理,以适应模型输入的要求。
(5) 训练目标:采用Permutation Invariant Training(PIT)方法确定说话人顺序,解决标签模糊问题。最终的目标函数是PIT-ASR损失和对应TTI损失的加权和。
(6) 模型评估:通过对比实验,验证所提出方法在多项任务上的性能表现,并与其他先进方法进行比较。实验结果支持该方法的有效性。
- Conclusion:
(1) 该工作的重要性:
该文章研究了多说话人和目标说话人的语音识别问题,提出了一种基于Whisper模型的联合多任务语音识别系统。这一研究对于提高语音交互和信息检索等领域的性能和用户体验具有重要意义。
(2) 创新性、性能和工作量评价:
- 创新性:文章提出了一种新的基于Whisper模型的联合多说话人和目标说话人语音识别系统,通过引入Sidecar分离器和目标说话人识别器,实现了对混合语音信号的有效分离和识别。此外,采用软提示调整解码器,提高了系统的性能。
- 性能:文章在多个数据集上进行了实验验证,相较于之前的方法,所提出的方法在多说话人和目标说话人语音识别任务上都取得了领先性能。实验结果支持了该方法的有效性。
- 工作量:文章对问题的研究深入,方法新颖,实验设计合理,数据量大且处理得当,工作量较大。
总体来说,该文章在解决多说话人和目标说话人的语音识别问题上取得了一定的进展,具有一定的创新性和实用性。
点此查看论文截图

 wechat
wechat- alipay







