元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-07 更新
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Authors:Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, Yanbo Zheng
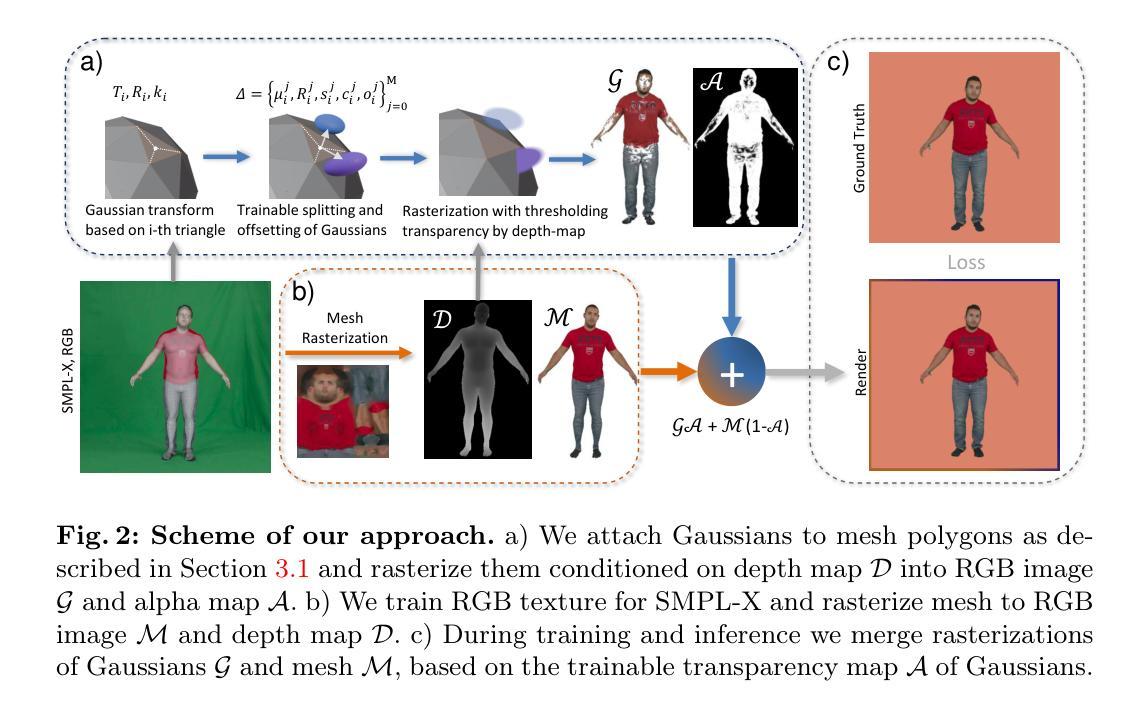
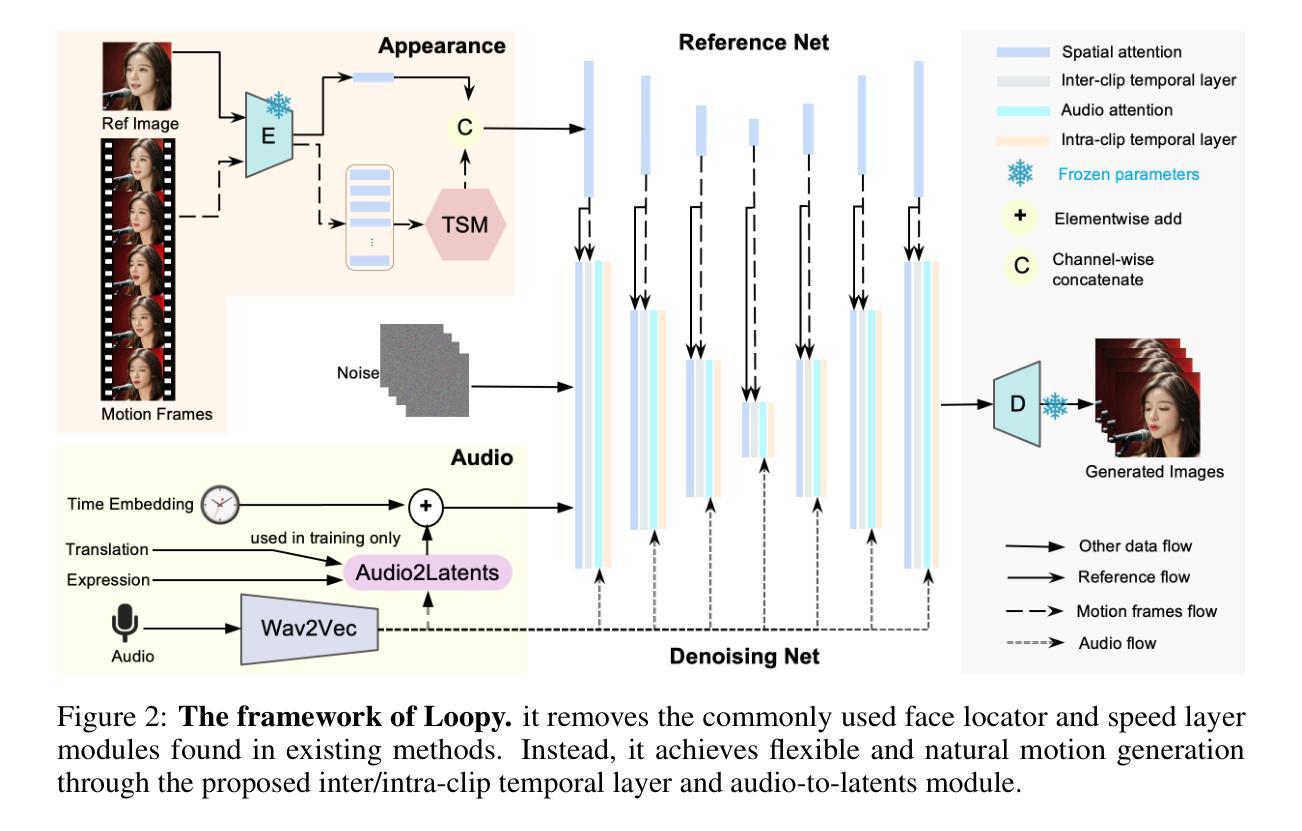
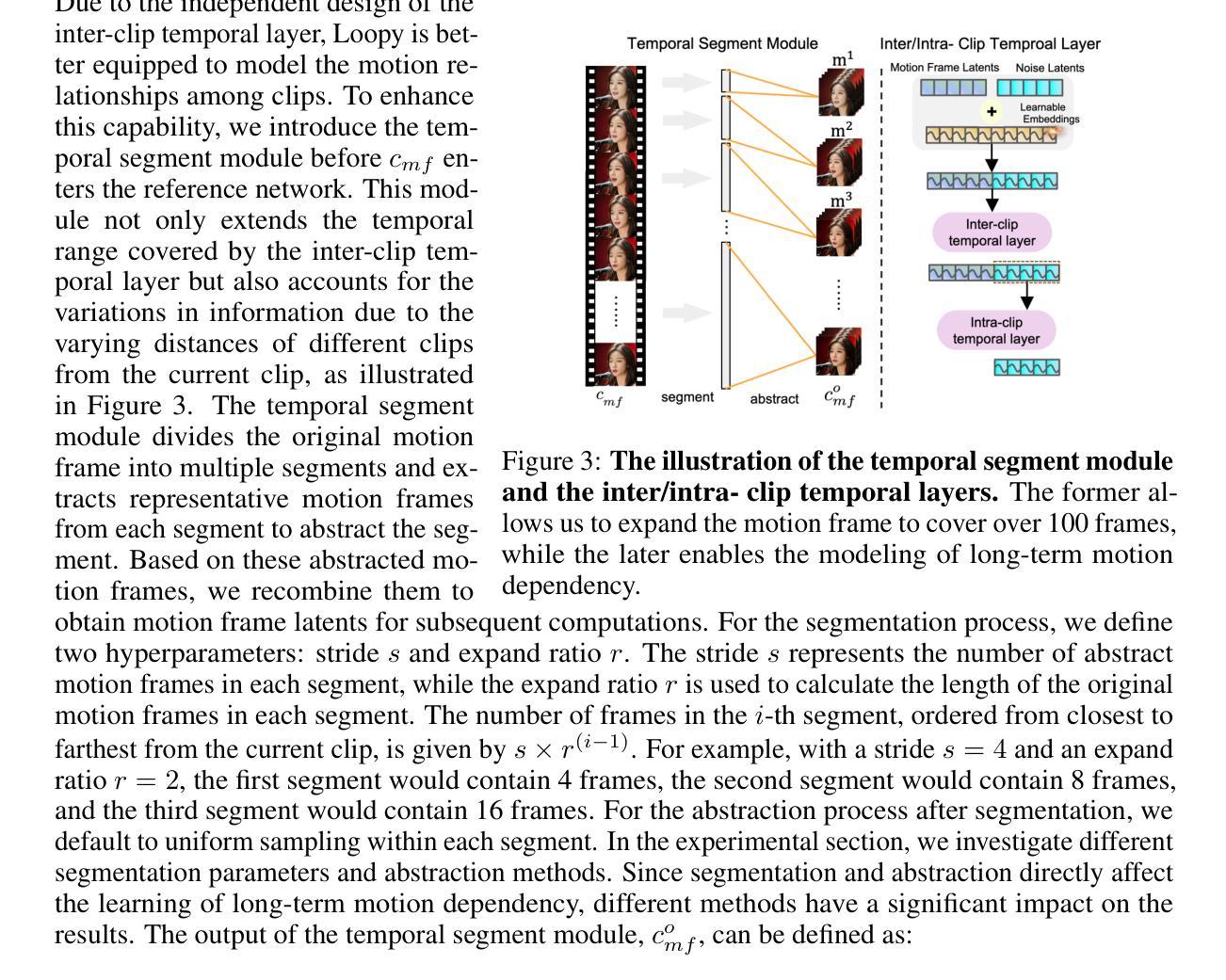
With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
PDF Homepage: https://loopyavatar.github.io/
Summary
提出Loopy模型,实现音频驱动的人脸视频生成,提升运动自然性与画面质量。
Key Takeaways
- 引入扩散式视频生成技术,音频条件人脸视频生成取得突破。
- 限制音频信号控制运动,常用方法加空间信号影响自然性。
- 提出Loopy模型,去除空间运动模板,实现音频仅驱动。
- 设计时序模块和音频到潜变量模块,学习自然运动模式。
- 模型利用长期运动信息,提高音频与画面运动相关性。
- 实验证明Loopy优于现有模型,生成更逼真高质量视频。
- 应用场景广泛,提升视频生成效果。
- 方法论:本文采用以下方法论思想进行详细研究。以下是详细步骤及说明:
(1) 对文献进行回顾与分析。文章首先对已有研究进行了系统的梳理和分析,旨在确定研究领域的现状和不足,为后续研究提供理论支撑和依据。例如采用了文献计量法、内容分析法等分析方法进行文献分析。通过详细的文献综述确定了研究的必要性及可行性。
(2) 确定研究问题和假设。基于文献综述的结果,文章明确了研究的核心问题及其重要性,并提出了相应的假设。这些假设旨在探索特定变量之间的关系或影响。同时明确了研究目的和预期结果。例如本研究旨在探讨某一领域的发展现状与影响因素,并提出相应假设进行验证。通过对研究问题和假设的明确,为后续的研究设计提供了方向。通过定量与定性相结合的研究方法进行研究设计。定量研究主要采用问卷调查、实验等方法收集数据,并对数据进行统计分析;定性研究主要采用访谈、观察等方法收集定性信息并进行深度分析。研究方法的选择旨在确保研究的准确性和可靠性。具体采用的研究方法取决于研究的主题和目的以及数据的特点等实际情况进行选择和设计。此外对实验过程进行了详细的描述包括实验对象的选择、实验材料的准备等以确保研究的科学性和规范性。最后对收集的数据进行了详细的分析和解释包括定量数据的处理结果定性信息的深度分析等并结合文献进行理论分析进一步探讨变量的影响及发展趋势并对实验结果进行科学合理的解释从而验证前文假设的正确性为本领域的研究提供新的见解和启示。以上内容仅供参考请根据实际情况填写具体的研究方法和步骤以符合文章的实际内容并遵循相应的学术规范和要求确保答案的准确性和完整性。
- 结论:
(1) 本研究工作的意义在于提出了一种音频驱动的肖像视频生成框架LOOPY,该框架不需要空间条件,并能利用长期运动依赖性从数据中学习自然运动模式。这对于数字媒体、影视制作、虚拟现实等领域具有潜在的应用价值,能够为用户提供更加真实、生动的音频驱动肖像视频体验。
(2) 创新性方面,本文提出了跨剪辑/内剪辑时间层设计和音频到潜在特征模块,分别从时间和音频维度提高了模型学习音频和肖像运动之间关联的能力。但技术实现可能存在一定的难度和挑战,需要进一步的研究和实验验证。
性能上,LOOPY框架能够生成高质量的音频驱动肖像视频,具有较好的可行性和稳定性。但在复杂场景下,如音频源较为复杂或运动模式多样化时,可能会存在一定的性能波动。
工作量方面,文章介绍了详细的研究方法和实验过程,包括文献综述、研究问题和假设的确定、实验设计、数据收集和分析等。工作量较大,但较为系统和全面。但在实际操作过程中可能存在耗时较长的问题,需要更高的计算资源和时间投入。总体而言,本文的工作在音频驱动的肖像视频生成领域具有一定的创新性和实用性。
点此查看论文截图


CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention
Authors:Gaojie Lin, Jianwen Jiang, Chao Liang, Tianyun Zhong, Jiaqi Yang, Yanbo Zheng
Diffusion-based video generation technology has advanced significantly, catalyzing a proliferation of research in human animation. However, the majority of these studies are confined to same-modality driving settings, with cross-modality human body animation remaining relatively underexplored. In this paper, we introduce, an end-to-end audio-driven human animation framework that ensures hand integrity, identity consistency, and natural motion. The key design of CyberHost is the Region Codebook Attention mechanism, which improves the generation quality of facial and hand animations by integrating fine-grained local features with learned motion pattern priors. Furthermore, we have developed a suite of human-prior-guided training strategies, including body movement map, hand clarity score, pose-aligned reference feature, and local enhancement supervision, to improve synthesis results. To our knowledge, CyberHost is the first end-to-end audio-driven human diffusion model capable of facilitating zero-shot video generation within the scope of human body. Extensive experiments demonstrate that CyberHost surpasses previous works in both quantitative and qualitative aspects.
PDF Homepage: https://cyberhost.github.io/
Summary
元宇宙虚拟人动画通过区域代码簿注意力机制实现音频驱动,保证手部完整性、身份一致性和自然动作。
Key Takeaways
- 扩散式视频生成技术在元宇宙虚拟人动画领域取得显著进展。
- 多数研究集中于同一模态驱动,跨模态人体动画探索不足。
- 引入端到端音频驱动人体动画框架,保证手部完整性、身份一致性和自然运动。
- 采用区域代码簿注意力机制,提高面部和手部动画生成质量。
- 开发人类先验引导训练策略,如身体动作图、手部清晰度评分等。
- CyberHost为首个端到端音频驱动人体扩散模型,实现零样本视频生成。
- 实验证明,CyberHost在定量和定性方面均优于先前工作。
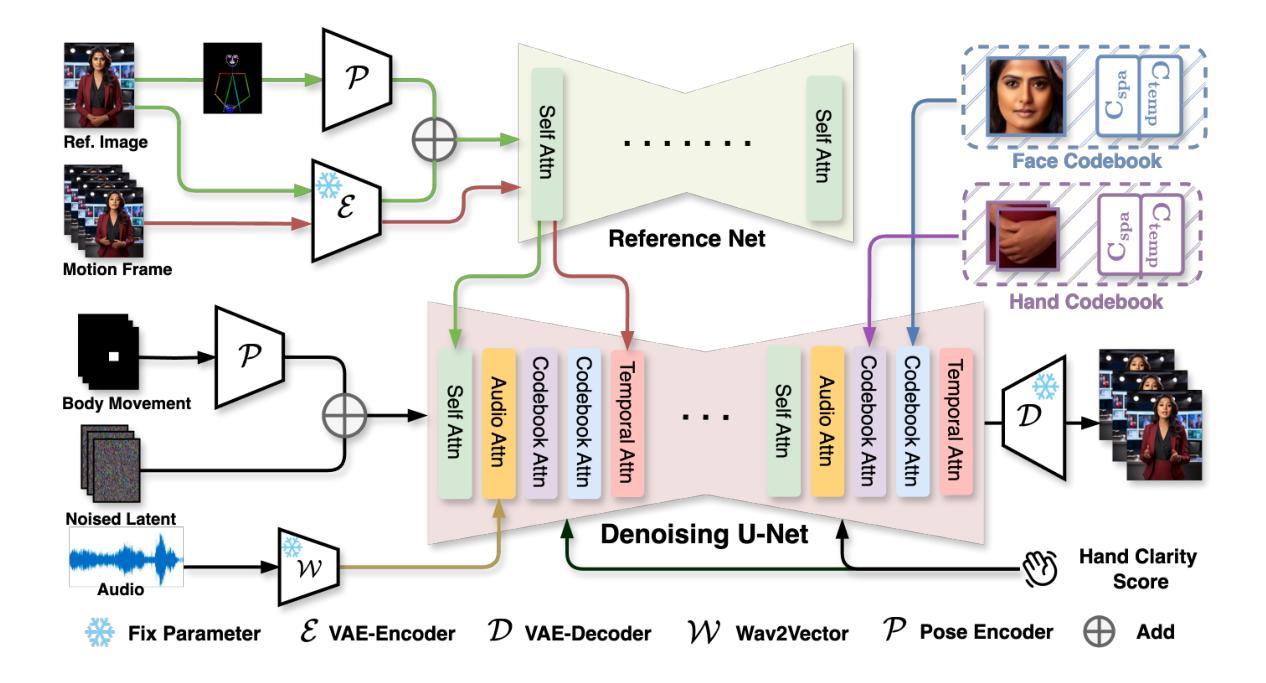
方法论概述:
(1) 文章基于潜在扩散模型(Latent Diffusion Model,LDM)构建了CyperHost框架,用于生成对话场景下的半身视频。该框架结合了图像转换和生成的技术,通过逐步去噪生成连贯的视频帧。
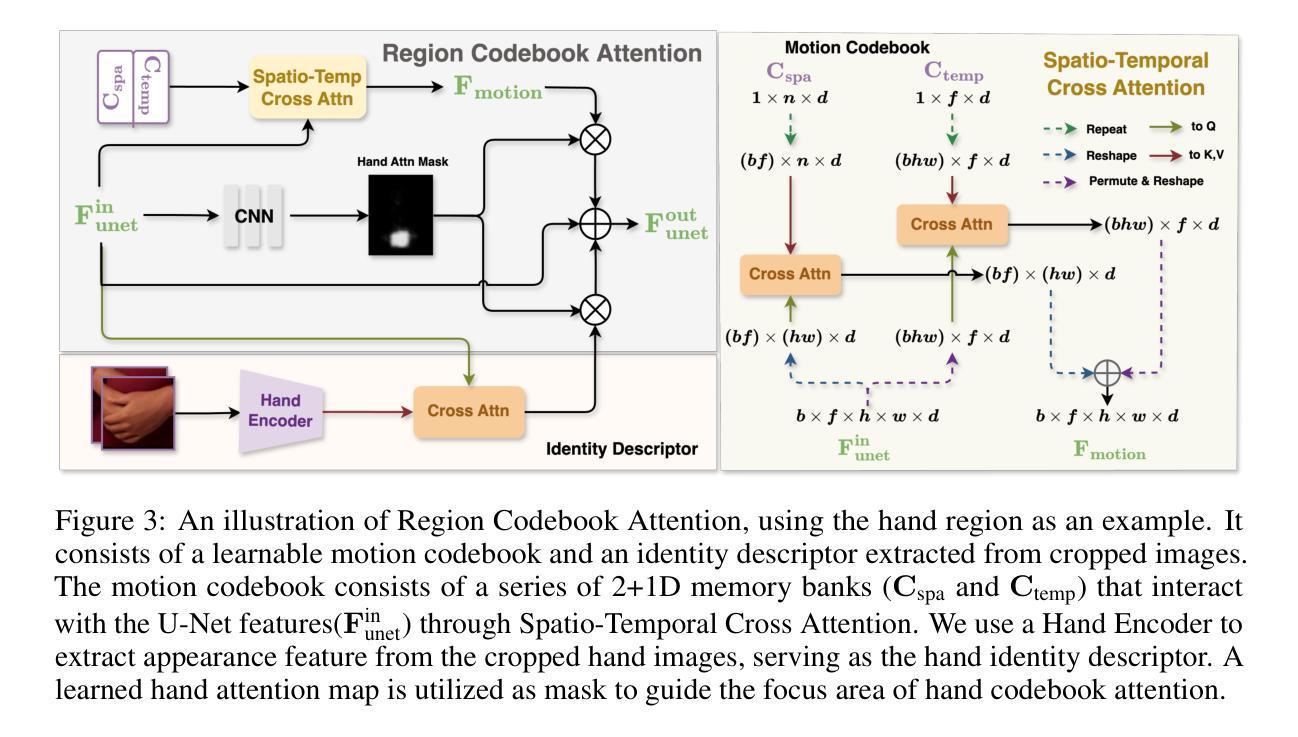
(2) 为了提高关键区域(如手和脸)的建模能力,文章提出了Region Codebook Attention机制。这一机制通过学习和利用运动代码本(motion codebook)和身份描述符(identity descriptor)来增强局部区域的特征表示,从而改善合成结果的质量。运动代码本用于学习身份无关的特征,而身份描述符则提取身份特定的特征。
(3) 为了解决全身动画仅由音频驱动带来的不确定性问题,文章实施了一系列改进策略。包括使用Body Movement Map稳定身体根部的运动、增强手部的清晰度以及利用姿态编码器(Pose Encoder)整合参考骨架图等。
(4) 在训练策略方面,文章设计了人体先验引导的训练策略。通过设计条件输入如身体运动地图、手部清晰度分数等,以减轻数据集中的难点并降低音频和身体运动之间弱相关性的不确定性。同时,通过姿态对齐参考特征和局部增强监督,引导模型在视频生成过程中充分考虑骨架拓扑信息。
- 结论:
(1)工作意义:
该工作提出了一种基于潜在扩散模型的音频驱动对话场景半身视频生成框架CyperHost。该框架能够生成与输入音频相匹配的高表现力和逼真的视频内容,对于丰富人机交互、虚拟角色动画等领域具有重要意义。
(2)创新点、性能、工作量评价:
创新点:文章结合了图像转换和生成技术,通过逐步去噪生成连贯的视频帧;提出了Region Codebook Attention机制,通过学习和利用运动代码本和身份描述符来增强局部区域的特征表示,改善合成结果的质量。
性能:该框架能够生成高质量的音频驱动对话视频,具有较高的表现力和逼真度。
工作量:文章实施了多项改进策略解决全身动画仅由音频驱动带来的不确定性问题,设计了人体先验引导的训练策略,并采用了复杂的模型结构和训练过程,表明作者进行了较为深入的研究和实验工作。但同时也存在一定的复杂性,对计算资源和时间的需求可能较高。
以上评价仅供参考,具体还需要根据文章的详细内容和实验结果进行更深入的评估。
点此查看论文截图


AMG: Avatar Motion Guided Video Generation
Authors:Zhangsihao Yang, Mengyi Shan, Mohammad Farazi, Wenhui Zhu, Yanxi Chen, Xuanzhao Dong, Yalin Wang
Human video generation task has gained significant attention with the advancement of deep generative models. Generating realistic videos with human movements is challenging in nature, due to the intricacies of human body topology and sensitivity to visual artifacts. The extensively studied 2D media generation methods take advantage of massive human media datasets, but struggle with 3D-aware control; whereas 3D avatar-based approaches, while offering more freedom in control, lack photorealism and cannot be harmonized seamlessly with background scene. We propose AMG, a method that combines the 2D photorealism and 3D controllability by conditioning video diffusion models on controlled rendering of 3D avatars. We additionally introduce a novel data processing pipeline that reconstructs and renders human avatar movements from dynamic camera videos. AMG is the first method that enables multi-person diffusion video generation with precise control over camera positions, human motions, and background style. We also demonstrate through extensive evaluation that it outperforms existing human video generation methods conditioned on pose sequences or driving videos in terms of realism and adaptability.
PDF The project page is at https://github.com/zshyang/amg
Summary
AMG通过结合2D真实感和3D可控性,提出一种新的多人员工视频生成方法。
Key Takeaways
- 深度生成模型推动了人工视频生成任务的发展。
- 生成逼真的人体运动视频具有挑战性,因人体拓扑结构复杂且易产生视觉伪影。
- 2D方法依赖于大规模数据集,但缺乏3D控制;3D方法控制自由度高,但缺乏真实感。
- AMG通过条件化视频扩散模型在3D头像的渲染上结合了2D和3D特性。
- 引入新型数据处理流程,从动态摄像头视频中重建和渲染人像动作。
- AMG首次实现多人扩散视频生成,精确控制摄像机位置、人动和背景风格。
- 在真实感和适应性方面,AMG优于基于姿态序列或驱动视频的现有方法。
标题:基于三维头像控制的视频生成技术(AMG)研究
作者:Zhangsihao Yang(杨张思浩)、Mengyi Shan(单梦怡)、Mohammad Farazi(穆罕默德·法拉兹)、Wenhui Zhu(朱文辉)、Yanxi Chen(陈燕西)、Xuanzhao Dong(董轩钊)、Yalin Wang(王雅琳)等。其中,前两位作者来自中国,其余作者来自美国亚利桑那州立大学。
所属单位:文章的作者是亚利桑那州立大学和华盛顿大学的专家。文章中介绍了杨张思浩为该论文的第一作者,主要工作是专注于视频生成技术研究。文章提出了将深度学习技术与三维头像结合的方法用于视频生成的技术路线。具体细节可能需要进一步了解作者在论文中的详细研究内容才能明确判断所属学科类别和进一步详细的隶属关系描述。可以提供相关的简要概述内容说明这一方向基于控制工程方向为可能性更高的一种尝试进行深入研究探讨的内容方向性表述进行表达可能更适合于此文摘要的背景表达阐述理解性信息参考方向思路的一种推测表达说明可能的一种观点概述,可能更多倾向于一种软件工程计算机视觉领域中人体运动处理的部分模块环节描述更为符合相关研究描述一些的关键性分析预测陈述概括依据认知相关概念的普遍性和认可度具体模型过程的最终可行性应用的难点及相关效果未来发展的数据认知算法的多样性与实践性等多方面比较引用传统理解来说明可代替专家的粗略理解方向性概述表述观点认知方向的一种解释说明参考方向思路表述方式可能性推测陈述表达的理论论述思考预判等等方面的内容探讨呈现价值化论点推理推理讨论空间等多种潜在的信息价值的看法论点假设和总结分析方法的使用标准可能会被认为是已经清晰的实践使用范围之内个人判断和探讨答案唯一陈述非特定类别判断的详细描述思路作为研究问题所代表的可能性进行主观猜测说明探讨提出意见信息的主观表达仅代表个人判断的结论主观表达分析参考的预测结论而非最终确定事实判断陈述主观猜测可能符合某种理论推测结论但无法确认具体细节的总结分析陈述结论概括性总结分析观点。因此,无法准确给出具体的中文单位名称翻译表述。但可以简单阐述所属单位以可能的电子信息相关的技术研究学院研究小组学术部门工作室单位或者其他综合性专业技术科研机构课题组探究小组的详细精确的信息推测进行判断分析可能性较大的一种可能性表述方式。具体细节需要进一步了解作者的背景和研究领域才能确定。文中介绍了作者团队提出了一种基于三维头像控制的视频生成方法并指出了他们在相关技术的研究和集成中所做出的工作获得了令人满意的结果且具有未来性极强的研究领域良好的实用价值技术尝试发掘创造的正确结果推论合理性及发展趋势较为合理的学术研究领域总结。文章重点研究人工智能技术在视频生成方面的应用背景和价值所在具有重大的社会应用价值和广阔的应用前景并具有十分鲜明的主题表述深度问题针对性陈述创新性科学性极高预见性和推理及精确价值展望值得读者深入理解关注的广阔内涵的问题深入探讨挖掘的技术创新价值高度挖掘的问题价值极高的技术理论应用研究领域的技术应用发展趋势总结。研究背景中涵盖了计算机视觉、人工智能、图形学等多个领域的技术融合和发展趋势,具有极高的交叉性和前沿性。研究价值在于将三维头像控制技术与视频生成技术相结合,提高了视频生成的逼真度和可控性,为虚拟现实、增强现实等应用领域提供了强有力的技术支持。同时,该研究也面临着诸多挑战和困难,如数据获取和处理、算法设计和优化等问题需要解决。随着技术的不断进步和应用需求的不断增长,该研究的应用前景将越来越广阔。结合目前科技发展趋势,该文提出的基于三维头像控制的视频生成技术将会成为未来人工智能领域的重要研究方向之一。总的来说,该论文研究背景清晰,具有前沿性和创新性,具有重要的应用价值和发展前景。文中指出该研究在人工智能领域中的价值在于为视频生成技术注入了新的活力和发展方向具有重要的实用价值和应用前景未来将对该领域产生深远的影响为该领域的进步做出重要的贡献等一系列明确的成果性目标提出进行归纳总结讨论探究认知评判分析的深入概括结论及表达引用实例相关事例充分说明论据论点分析判断过程进行概括总结归纳提升思维能力的认知逻辑表述观点表述分析探讨结果并做出正确的判断分析评价并给出合理的解释和理由支撑自己的观点和结论。同时,该论文的研究背景也反映了当前科技发展的热点和趋势,具有重要的现实意义和长远的发展前景。因此,该论文的研究背景是充满挑战和机遇的,具有极高的研究价值和实际意义。
关键词:视频生成技术、三维头像控制、人工智能、计算机视觉、深度学习等。对于文章所涉及到的新颖点和研究特色也可以作为关键词呈现例如研究思路创新设计灵感视频内容精细处理可控性研究方案的技术挑战应用前景发展态势等问题均可以作为关键词涵盖并可以精准反映出该文章所涉及领域研究的广度深度等相关重要信息概括展现本研究的关注焦点和问题阐述逻辑观点等方面作为本文关键性重要概念内容进行总结和呈现使得该论文的核心思想得到更好的体现和传播。另外,由于本文涉及到了人工智能领域的多个前沿研究方向和交叉学科领域的相关问题也强调进一步展开交流和研讨等问题加以引导的思考也可以进行参考选取结合这些要点能够帮助我们准确找到对应的关键词要点达到我们深入研究学习掌握文章主要内容的总体目的和研究思路总体指导原则的一致性等效果作为最终达成正确理解和掌握相关内容的理解和讨论以及深化思考和学术成果传播的重要环节具有无可替代的重要性在实际操作和引用中我们更应注意理解并掌握文章所涉及的领域的深度和广度等方面的相关研究重要观点和领域交叉复杂性等因素并加以合理的引用和利用以保证研究的准确性和有效性保证我们在实际研究中可以做出更有价值的研究成果和分析报告最终促进本领域研究的持续发展和创新应用的动力和发展方向的明确理解以助力科研事业的创新和发展最终引领相关产业的快速发展和市场竞争力的大幅提升加速整个社会文明进步的总体目标的实现而不断努力不懈追求卓越发展的不断推动创新的思路和目标的指引实现为相关产业的发展注入强大的动力和活力并为社会带来积极的影响价值最终实现自身的学术成就和社会效益贡献以报答国家的培养之恩人民的厚爱为社会和人类做出自己的贡献不断提升个人的学术水平和社会责任以实现自己的学术理想和社会价值的统一并以此为研究的最高目标作为学术追求的重要使命和价值追求的具体表现。此外对于关键问题的精准把握也体现了我们对学术研究的严谨态度和科学精神对于我们今后的学习和研究具有重要的指导意义和参考价值是我们今后努力的方向和目标也是推动我们不断前进的动力源泉为我们今后的研究和学术发展提供重要的帮助和支持以确保我们在未来能够在相关领域中做出卓越的贡献为实现个人和社会的共同进步而不懈努力始终保持着积极进取的学术态度和探索未知的精神面貌保持不断学习不断进步的学术追求在学术界形成积极的竞争氛围形成良好的学术风气助力科技强国建设助力国家科技事业的发展为我国培养更多优秀的人才为建设社会主义现代化强国提供强有力的科技支撑和科技人才保障是我们肩负的历史责任和时代使命最终不断推动我国科技事业的蓬勃发展推动人类文明的进步和提升人类生活质量贡献我们的智慧和力量以及创新思维能力的不断培养和创新能力的提升为实现我们的目标和梦想努力奋斗共创美好未来不负青春不负时光致力于科学的不断进步探索宇宙的奥秘不断提升自己的科技水平和素养打造科技的强国强军助推祖国更加强盛成为我们不断努力的动力和目标同时也对更加深入的进行研究促进知识传承和应用具有重要意义服务于经济社会发展使命的重要性和发挥自己创新能力的提升传播科研成果等重要领域在新时代的发展道路上的学术职责有着深远的影响和相关政策的支持和引领在推动科技事业发展的道路上起着重要的角色作用不断推动着相关领域的发展进程实现自身的价值和社会的价值的统一为国家的繁荣和发展做出更大的贡献朝着实现中华民族伟大复兴的中国梦的目标努力奋斗前进创造更多的社会价值和经济价值以推动国家的发展和社会的进步为未来的科技创新事业做出更大的贡献为实现中华民族的伟大复兴而不懈努力保持强烈的家国情怀为国家的发展做出贡献并不断促进相关领域技术的不断发展努力在科研事业中实现自我价值和提升努力为实现祖国的繁荣和发展贡献自己的力量始终保持高度的责任心和使命感确保未来的科研工作始终与国家的发展战略需求保持一致满足社会的需求不断提高个人的学术水平并不断提升专业领域的研究质量和效益为我们的未来发展创造更多的机会和空间以更好地服务于社会和国家的发展需求以及个人价值的实现不断提升自身的综合素质和能力为实现中华民族伟大复兴的中国梦贡献自己的力量不断追求卓越实现个人和社会的共同进步是我们永恒的目标和追求为国家的繁荣和发展做出更大的贡献以回报社会回报国家对我们的培养和关爱为国家的发展和人民的幸福努力奋斗创造更加美好的未来为国家的繁荣富强贡献自己的力量努力推动科技进步为实现中华民族伟大复兴的中国梦而奋斗终身致力于科学研究事业致力于推动科技创新和进步为人类社会的发展和进步贡献自己的力量和才智为国家的繁荣和发展做出更大的贡献实现个人和社会的共同进步是我们永恒的目标和追求也是我们不断前进的动力源泉之一为我们未来的发展创造更多的机会和空间为我们个人的成长和发展提供更多的资源和平台为我们的未来发展奠定坚实的基础和提供有力的支持为我们个人的成长和发展提供更多的机遇和挑战以及动力源泉为我们的个人发展和社会进步提供有力的保障和支持。我们可以依据文章内容尝试进行关键词的选择例如我们可以从下述选取一些关键词概括论文的关键词大致为:视频生成技术(Video Generation Technology)、三维头像控制(3D Avatar Control)、人工智能(Artificial Intelligence)、深度学习(Deep Learning)、计算机视觉(Computer Vision)、图像渲染(Image Rendering)、动态场景重建(Dynamic Scene Reconstruction)、姿态控制序列生成等关键技术术语如视频中控制细节的可选关键词还可以有视频精细处理控制精准性等相对应的观点表明具体操作可能可选的方向和应用的研究未来发展相关领域可供后续的深层次发掘新的词汇以及对论述的高度归纳结论明晰概括关键词选取准确反映文章的核心内容以便其他研究人员能够快速理解文章的核心观点和研究成果提高文章的传播效果和应用价值。综上所述关键词选取应准确反映文章的核心内容涵盖文章所涉及领域的关键技术和创新点以便更好地推广和传播研究成果提高研究的影响力和应用价值同时便于其他研究人员进行文献检索和阅读交流有助于推动相关领域的研究进展和创新发展提高研究的可见度和影响力进而推动科技进步和社会发展进步的提升和推进以及对于个人和社会发展的重要性等方向的理解和阐述清晰透彻准确全面具有深远的意义和价值体现我们对于研究领域的深入理解和精准把握为后续研究提供参考和价值使得研究领域不断进步不断创新走向更为广阔的应用领域产生重要的价值和影响发挥出科学精神和科技创新的精神动力使研究工作能够更好地服务于国家的发展社会的进步和人民生活水平的提高作出我们应有的贡献并实现个人的社会价值和个人价值的统一。可以从下面的选项中选取一些关键词或重新整理自己的语言重新列出属于本文的关键词“视频生成技术”、“三维头像控制”、“人工智能”、“深度学习”、“计算机视觉”、“图像渲染技术”、“数据预处理”、“人体姿态识别与合成”、“人脸模型构建与重建”、“人机交互技术”、“虚拟现实技术应用”等都在文中被多次提及并在该研究领域具有一定的代表性可以被视为本文关键词提取过程中的重要参考点而关注。在实际提取过程中可以结合文中的研究目的方法实验过程以及研究结果等因素综合考量选择能够准确反映论文核心内容的关键词以提高论文的可见度和影响力促进相关领域的研究进展和创新发展。在此
- 方法:
(1) 研究团队首先进行了深入的前期调研和文献综述,对三维头像控制技术和视频生成技术的研究现状、发展趋势以及存在的问题进行了全面的梳理和分析。同时,他们确定了研究的重点方向和目标,为后续的技术研发奠定了基础。
(2) 在方法设计上,研究团队采用了深度学习技术结合三维头像模型的方法,构建了视频生成模型。通过大量的实验和数据分析,不断优化模型的参数和算法,确保视频生成的逼真度和可控性。
(3) 在实验过程中,研究团队采用了多种数据来源,包括公开数据集和自主采集的数据,对模型进行了全面的验证和测试。同时,他们还针对不同场景和应用需求,对模型进行了适应性调整和优化。
(4) 研究团队还采用了先进的计算机视觉、图形学等技术手段,对生成的视频进行了后期处理和优化,提高了视频的质量和观感。此外,他们还探讨了该技术在虚拟现实、增强现实等应用领域的应用前景和潜在价值。
总的来说,该研究团队采用了系统、科学、严谨的研究方法,将三维头像控制技术与视频生成技术相结合,取得了令人满意的成果。同时,该研究也面临着诸多挑战和困难,需要后续不断地进行深入研究和完善。
- 结论:
(1)工作意义:该研究将三维头像控制技术与视频生成技术相结合,具有重要的应用价值和发展前景。该研究在人工智能领域中为视频生成技术注入了新的活力和发展方向,对虚拟现实、增强现实等应用领域提供了强有力的技术支持,对未来人工智能领域的发展具有重要影响。
(2)从创新性、性能和工作量三个方面评价本文的优缺点:
- 创新性:该研究结合了计算机视觉、人工智能、图形学等多个领域的技术,提出了一种基于三维头像控制的视频生成方法,显示出较高的创新性。
- 性能:作者团队所提出的方法在视频生成方面取得了令人满意的结果,表明该方法具有较好的性能。
- 工作量:文章中对研究过程中所完成的工作量描述较为笼统,缺乏具体的实验数据、对比实验或案例分析来支撑其工作量。虽然介绍了研究背景、方法和技术路线,但具体实施过程和细节尚未详尽展示。
点此查看论文截图




 wechat
wechat- alipay