Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-07 更新
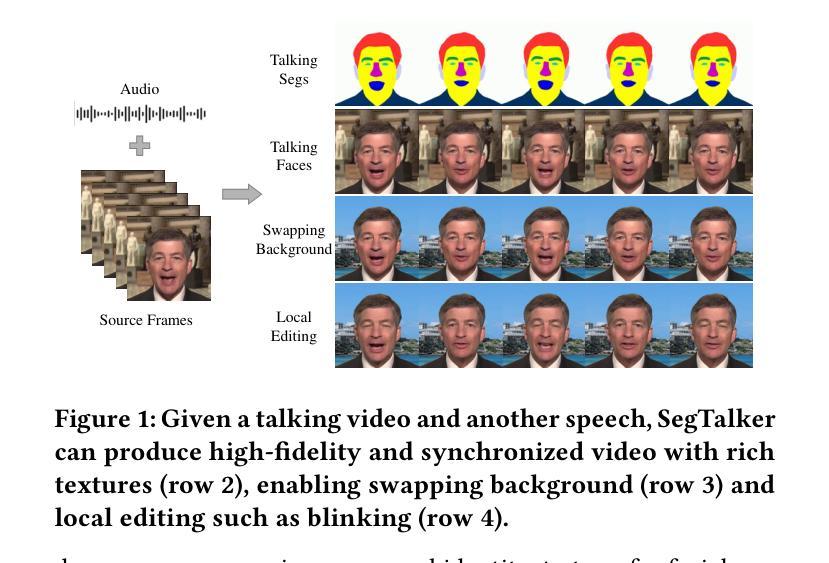
SegTalker: Segmentation-based Talking Face Generation with Mask-guided Local Editing
Authors:Lingyu Xiong, Xize Cheng, Jintao Tan, Xianjia Wu, Xiandong Li, Lei Zhu, Fei Ma, Minglei Li, Huang Xu, Zhihu Hu
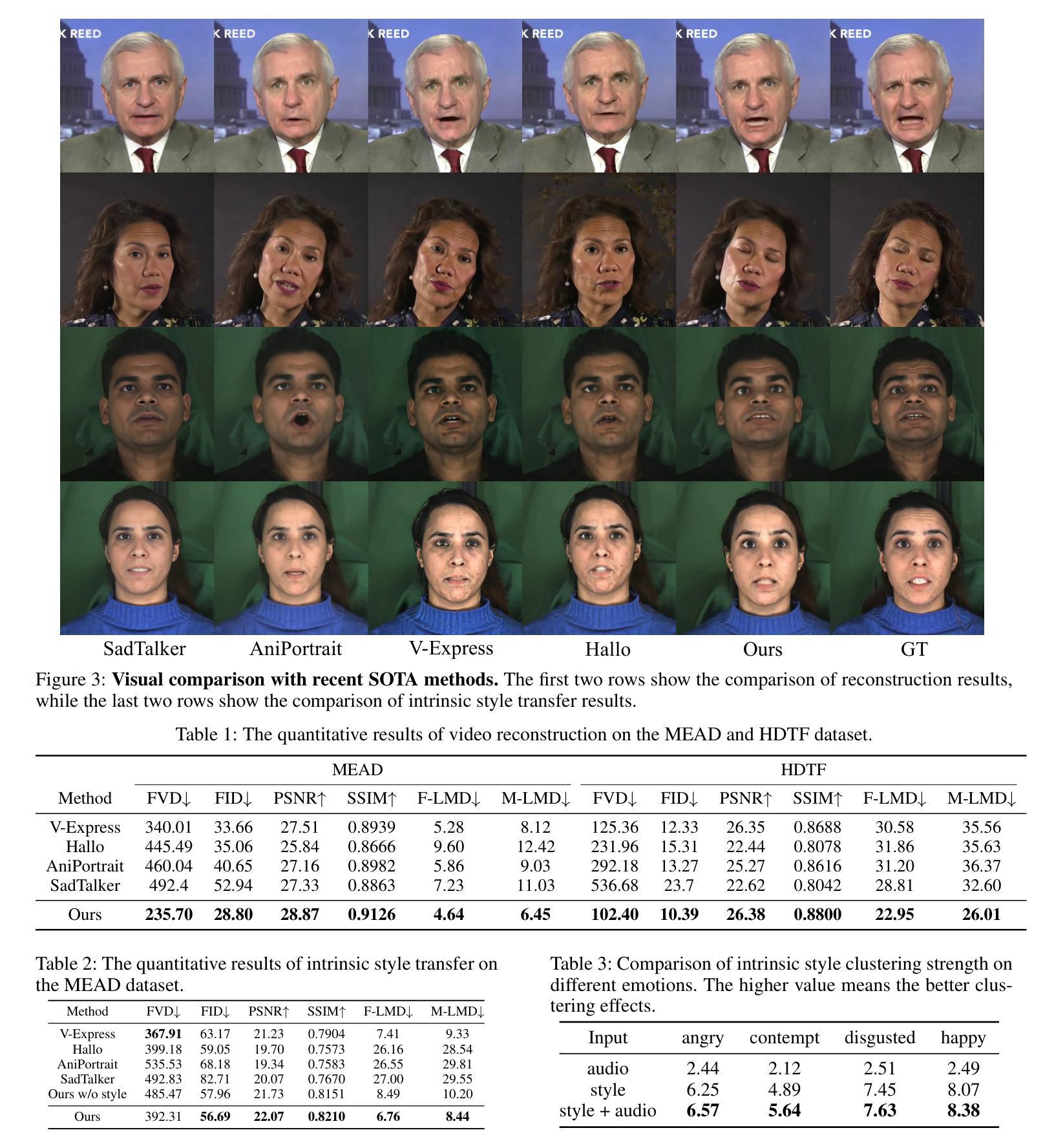
Audio-driven talking face generation aims to synthesize video with lip movements synchronized to input audio. However, current generative techniques face challenges in preserving intricate regional textures (skin, teeth). To address the aforementioned challenges, we propose a novel framework called SegTalker to decouple lip movements and image textures by introducing segmentation as intermediate representation. Specifically, given the mask of image employed by a parsing network, we first leverage the speech to drive the mask and generate talking segmentation. Then we disentangle semantic regions of image into style codes using a mask-guided encoder. Ultimately, we inject the previously generated talking segmentation and style codes into a mask-guided StyleGAN to synthesize video frame. In this way, most of textures are fully preserved. Moreover, our approach can inherently achieve background separation and facilitate mask-guided facial local editing. In particular, by editing the mask and swapping the region textures from a given reference image (e.g. hair, lip, eyebrows), our approach enables facial editing seamlessly when generating talking face video. Experiments demonstrate that our proposed approach can effectively preserve texture details and generate temporally consistent video while remaining competitive in lip synchronization. Quantitative and qualitative results on the HDTF and MEAD datasets illustrate the superior performance of our method over existing methods.
PDF 10 pages, 7 figures, 3 tables
Summary
提出SegTalker框架,通过分割和风格编码技术实现音频驱动的说话人脸视频生成,有效保留纹理细节。
Key Takeaways
- 音频驱动的说话人脸视频生成研究。
- 面临保留区域纹理挑战。
- 提出SegTalker框架,分割唇动和图像纹理。
- 利用语音驱动生成分割,提取风格代码。
- 使用StyleGAN合成视频帧,保留纹理。
- 实现背景分离和面部局部编辑。
- 面部编辑时无缝生成说话人脸视频。
- 在HDTF和MEAD数据集上表现优于现有方法。
Title: 基于分割的说话人脸生成与Mask引导局部编辑
Authors: Lingyu Xiong, Xize Cheng, Jintao Tan, Xianjia Wu, Xiandong Li, Lei Zhu, Fei Ma, Minglei Li, Huang Xu, and Zhihu Hu.
Affiliation: 大部分作者来自华南理工大学与浙江大学。
Keywords: 视频生成;说话人脸生成;属性编辑
Urls: 论文链接:论文链接地址
Github代码链接:Github:None (如果可用,请填写具体的GitHub仓库链接)Summary:
(1) 研究背景:本文的研究背景是音频驱动的说话人脸生成,旨在合成与输入音频精确同步的视频。该技术在数字人类、虚拟会议和视频配音等领域有广泛应用。
(2) 以往方法及其问题:早期的说话人脸生成方法首先通过循环神经网络预测嘴巴形状,然后基于这些形状生成面部。然而,这些方法在保留面部纹理(如皮肤、牙齿)方面存在挑战。近期端到端的方法直接映射语音谱图到视频帧,但同样面临纹理细节保留的挑战。因此,现有的方法需要在保持唇同步的同时,更有效地保留纹理细节。
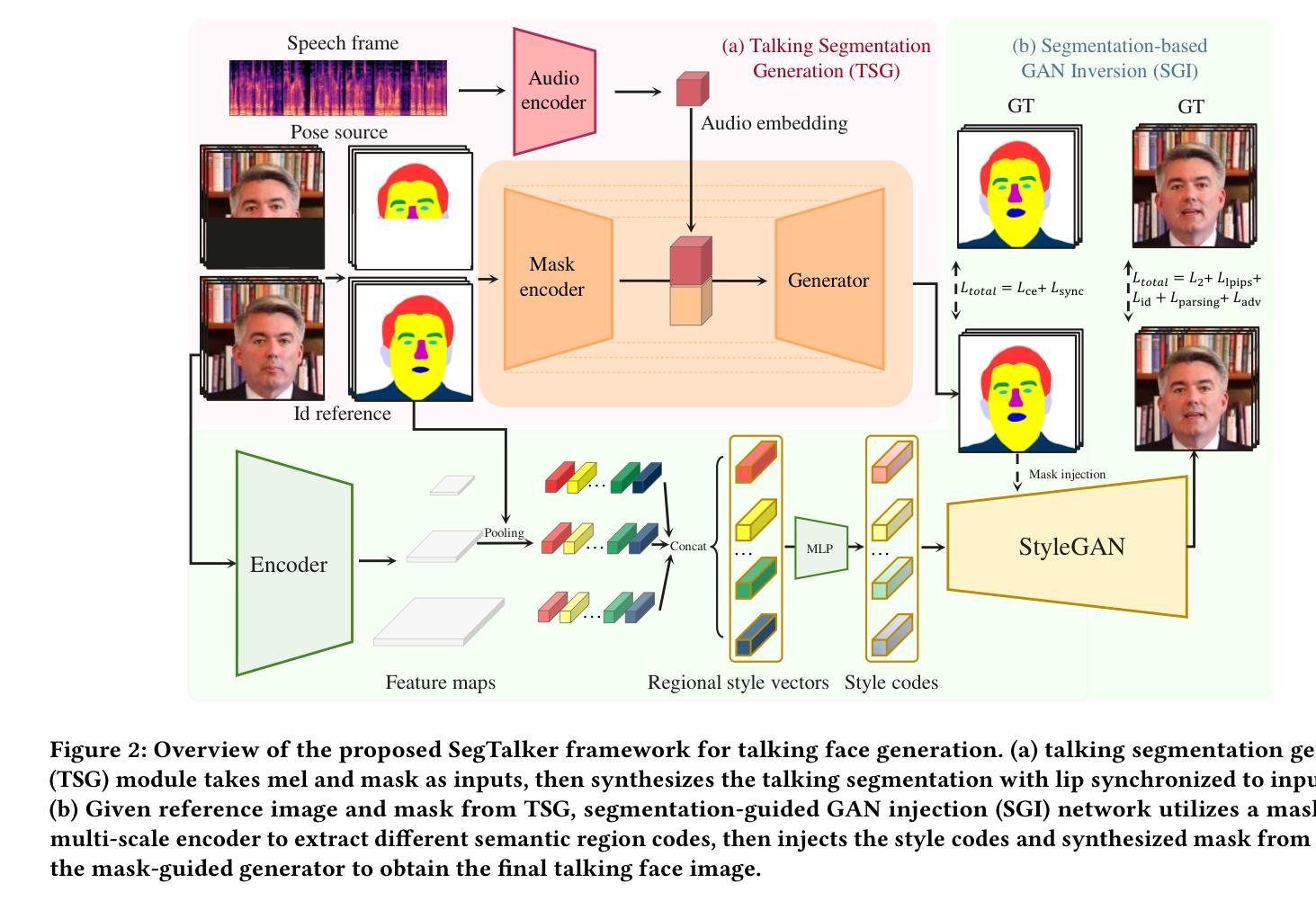
(3) 研究方法:针对上述问题,本文提出了一种名为SegTalker的新框架。该框架引入分割作为中间表示,以解耦嘴唇运动和图像纹理。具体来说,利用解析网络得到的图像掩膜,通过语音驱动掩膜生成说话的分割。然后,利用掩膜指导的编码器将图像语义区域解耦为风格代码。最终,将生成的说话分割和风格代码注入掩膜指导的StyleGAN中合成视频帧。这种方法能够保留大部分纹理,并实现背景分离和面部局部编辑。
(4) 任务与性能:本文的方法在高清通话面部数据集(HDTF)和多元音频驱动编辑数据集(MEAD)上进行了实验验证。结果表明,该方法在保留纹理细节和生成时间上一致的视频方面表现出卓越性能,相较于现有方法具有明显优势。定量和定性的结果均支持该方法的性能。
- 方法论概述:
这篇文章介绍了一种名为SegTalker的新框架,该框架旨在解决音频驱动的说话人脸生成中的一些问题。其方法论主要包括以下步骤:
- (1) 研究背景与问题概述:文章首先介绍了说话人脸生成的研究背景,特别是音频驱动的说话人脸生成技术在数字人类、虚拟会议和视频配音等领域的应用。然后,文章概述了早期和近期的方法及其面临的挑战,如纹理细节保留、嘴唇同步等问题。
- (2) 方法引入:针对上述问题,文章提出了一种名为SegTalker的新框架。该框架的核心思想是通过引入分割作为中间表示来解耦嘴唇运动和图像纹理。
- (3) 说话分割生成(TSG):文章介绍第一个子网络——说话分割生成(TSG)。给定语音和图像帧,该网络首先使用解析网络提取掩膜,然后合成说话分割。为了只关注学习语音到嘴唇运动的结构映射,该模型在训练时只关注学习结构映射,而不关注文本信息或纹理信息。此外,为了提高生成质量,该网络还采用了重建损失和同步网络损失。
- (4) 分割引导GAN注入网络(SGI):文章的第二个子网络是分割引导GAN注入网络(SGI)。该网络接收肖像及其对应的掩膜作为输入,并通过编码器将图像编码到潜在空间获得潜在代码,然后通过风格注入将生成的潜在代码转回图像域。为了获得更精细的纹理编辑和局部编辑能力,该网络采用多尺度编码器来提取不同语义区域的特点。此外,为了提高视觉质量,该网络还采用了多种损失函数进行优化。
- (5) 实验验证与性能评估:最后,文章在高清通话面部数据集(HDTF)和多元音频驱动编辑数据集(MEAD)上对SegTalker方法进行了实验验证。定量和定性的结果均表明,该方法在保留纹理细节和实现背景分离和面部局部编辑方面表现出卓越性能。此外,文章还展示了该方法的面部属性编辑和背景替换功能。
总的来说,这篇文章提出的SegTalker框架通过引入分割作为中间表示,有效地解决了音频驱动的说话人脸生成中的一些问题,提高了生成视频的视觉质量和纹理细节保留能力。
- Conclusion:
(1) 这项工作的意义在于它为音频驱动的说话人脸生成领域提供了一个新的解决方案。通过引入分割作为中间表示,该方法有效地解决了现有方法面临的挑战,如纹理细节保留和嘴唇同步问题。它为数字人类、虚拟会议和视频配音等领域提供了更真实、更精细的说话人脸生成能力。
(2) 创新点:本文提出了一种名为SegTalker的新框架,通过引入分割作为中间表示来解耦嘴唇运动和图像纹理,这是本文的创新之处。性能:在高清通话面部数据集(HDTF)和多元音频驱动编辑数据集(MEAD)上的实验结果表明,该方法在保留纹理细节和实现背景分离和面部局部编辑方面表现出卓越性能。工作量:文章介绍了详细的SegTalker框架及其两个子网络TSG和SGI的工作流程和原理,展示了该方法的详细实现过程。
点此查看论文截图



SVP: Style-Enhanced Vivid Portrait Talking Head Diffusion Model
Authors:Weipeng Tan, Chuming Lin, Chengming Xu, Xiaozhong Ji, Junwei Zhu, Chengjie Wang, Yanwei Fu
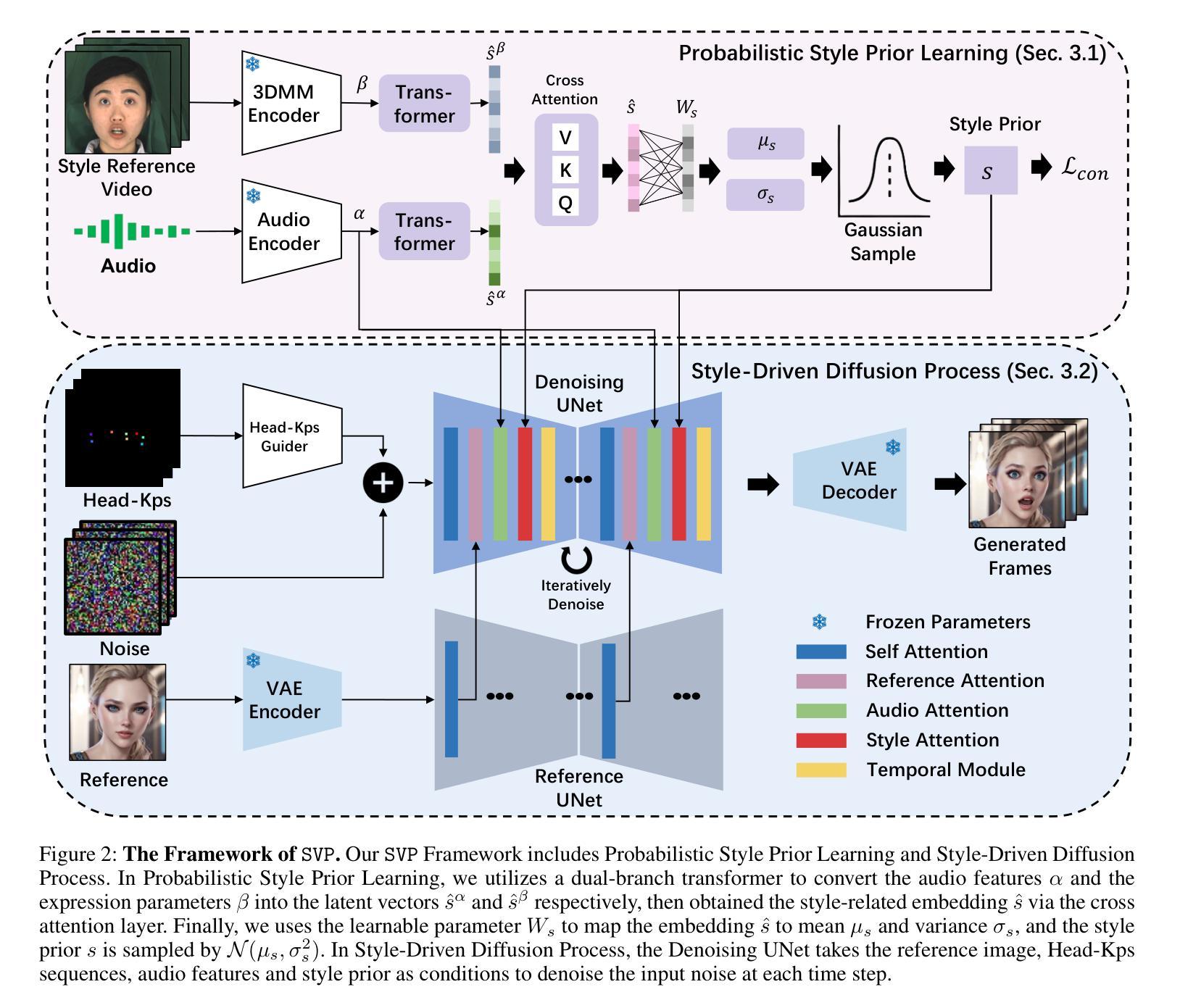
Talking Head Generation (THG), typically driven by audio, is an important and challenging task with broad application prospects in various fields such as digital humans, film production, and virtual reality. While diffusion model-based THG methods present high quality and stable content generation, they often overlook the intrinsic style which encompasses personalized features such as speaking habits and facial expressions of a video. As consequence, the generated video content lacks diversity and vividness, thus being limited in real life scenarios. To address these issues, we propose a novel framework named Style-Enhanced Vivid Portrait (SVP) which fully leverages style-related information in THG. Specifically, we first introduce the novel probabilistic style prior learning to model the intrinsic style as a Gaussian distribution using facial expressions and audio embedding. The distribution is learned through the ‘bespoked’ contrastive objective, effectively capturing the dynamic style information in each video. Then we finetune a pretrained Stable Diffusion (SD) model to inject the learned intrinsic style as a controlling signal via cross attention. Experiments show that our model generates diverse, vivid, and high-quality videos with flexible control over intrinsic styles, outperforming existing state-of-the-art methods.
Summary
提出风格增强生动肖像(SVP)框架,通过风格信息提升说话人头生成视频质量与多样性。
Key Takeaways
- 说话人头生成(THG)面临风格忽视问题。
- SVP框架利用风格相关信模型化内在风格。
- 使用面部表情和音频嵌入学习风格先验。
- 通过对比学习捕捉动态风格信息。
- 预训练模型注入风格信息,实现风格控制。
- 模型生成多样、生动、高质量视频。
- 模型性能优于现有方法。
Title: 风格增强生动肖像谈话头扩散模型(SVP:Style-Enhanced Vivid Portrait Talking Head Diffusion Model)
Authors: Weipeng Tan(第一作者),Chuming Lin,Chengming Xu,Xiaozhong Ji,Junwei Zhu,Chengjie Wang,Yanwei Fu
Affiliation: 第一作者Weipeng Tan的所属机构为复旦大学(Fudan University)。
Keywords: Talking Head Generation, Audio-Driven Portrait Video, Style-Enhanced Vivid Portrait, Diffusion Model, Style Prior Learning
Urls: 论文链接(论文抽象): <Url to the paper’s abstract>, GitHub代码链接: GitHub:None(如没有可用代码链接,请填写“None”)
Summary:
(1) 研究背景:本文的研究背景是关于谈话头生成(Talking Head Generation, THG)的任务,这是一个在数字人类、电影制作、虚拟现实等领域有广泛应用的重要且具挑战性的任务。现有的方法大多基于GAN或扩散模型,但忽略了内在风格,如说话习惯和面部表情,导致生成的内容缺乏多样性和生动性。
(2) 过去的方法及问题:过去的方法主要包括基于GAN和基于扩散模型的谈话头生成方法。虽然这些方法在生成高质量视频方面取得了显著成果,但它们往往忽略了个性化特征和内在风格,导致生成的内容单调乏味。
(3) 研究方法:本文提出了一种名为Style-Enhanced Vivid Portrait(SVP)的新框架,该方法充分利用THG中的风格相关信息。首先,引入了一种新型的概率风格先验学习,将内在风格建模为高斯分布,使用面部表情和音频嵌入。然后,通过微调预训练的Stable Diffusion模型,将学到的内在风格作为控制信号注入。
(4) 任务与性能:本文的方法在谈话头生成任务上生成了多样、生动、高质量的视频,并对内在风格具有灵活的控制能力,优于现有的最先进的方法。性能表现在实验中得到验证,并支持了其目标应用。
希望以上回答能满足您的要求!
- Methods:
(1) 研究背景分析:本文的研究对象是谈话头生成(Talking Head Generation, THG)任务,通过对数字人类、电影制作、虚拟现实等领域的应用需求进行分析,指出该任务的重要性和挑战性。
(2) 相关方法概述:针对现有基于GAN和扩散模型的谈话头生成方法进行分析,发现它们忽略了个性化特征和内在风格,导致生成内容单调。
(3) 方法提出:提出一种新的谈话头生成框架SVP(Style-Enhanced Vivid Portrait)。首先,引入概率风格先验学习,将内在风格(如说话习惯和面部表情)建模为高斯分布,并与音频嵌入相结合。然后,通过微调预训练的Stable Diffusion模型,将学到的内在风格作为控制信号注入,实现对谈话头生成过程的控制。
(4) 实验验证:通过对比实验和性能评估,验证本文方法在谈话头生成任务上的有效性、多样性和生动性,并展示了其对内在风格的控制能力。同时,通过实验结果的对比和分析,证明本文方法优于现有最先进的方法。
- Conclusion:
(1)该工作的意义在于提出了一种新的谈话头生成方法SVP,该方法能够实现对内在风格的转移,丰富了谈话头生成任务的研究内容,为数字人类、电影制作、虚拟现实等领域提供了更生动、多样的视频生成方式。
(2)创新点:本文提出了Style-Enhanced Vivid Portrait(SVP)框架,通过引入概率风格先验学习,将内在风格建模为高斯分布,并成功将其应用于谈话头生成任务中,实现了对内在风格的控制。
性能:实验结果表明,SVP方法在谈话头生成任务上生成了多样、生动、高质量的视频,并优于现有的最先进方法。
工作量:文章对研究背景、相关方法、研究方法等进行了详细的阐述和分析,但工作量方面未具体提及代码实现等细节,无法准确评估。
点此查看论文截图

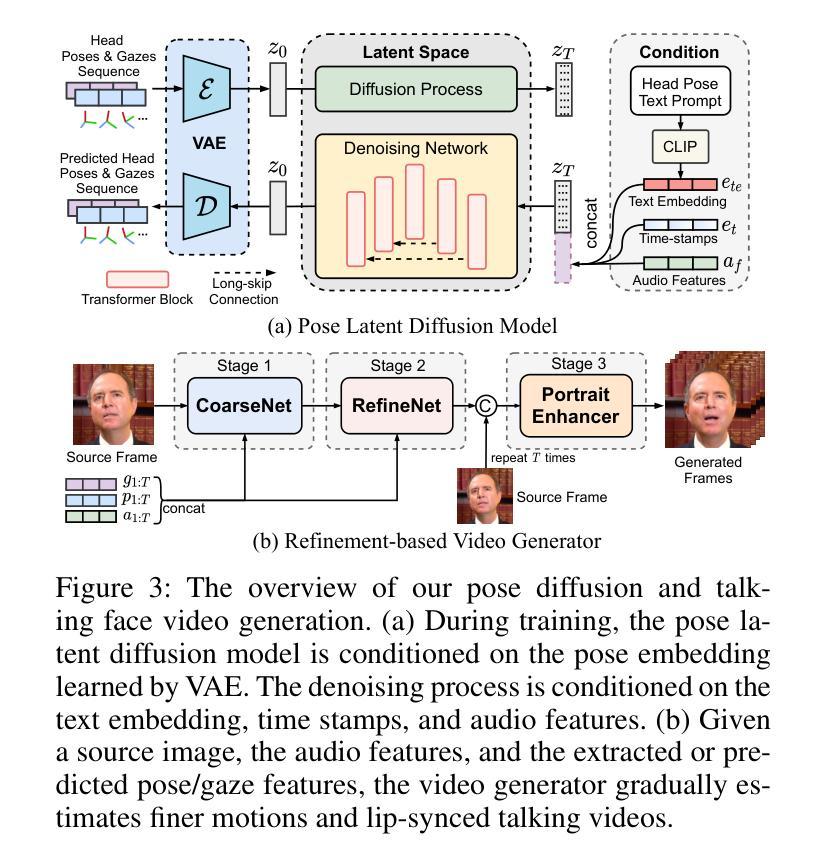
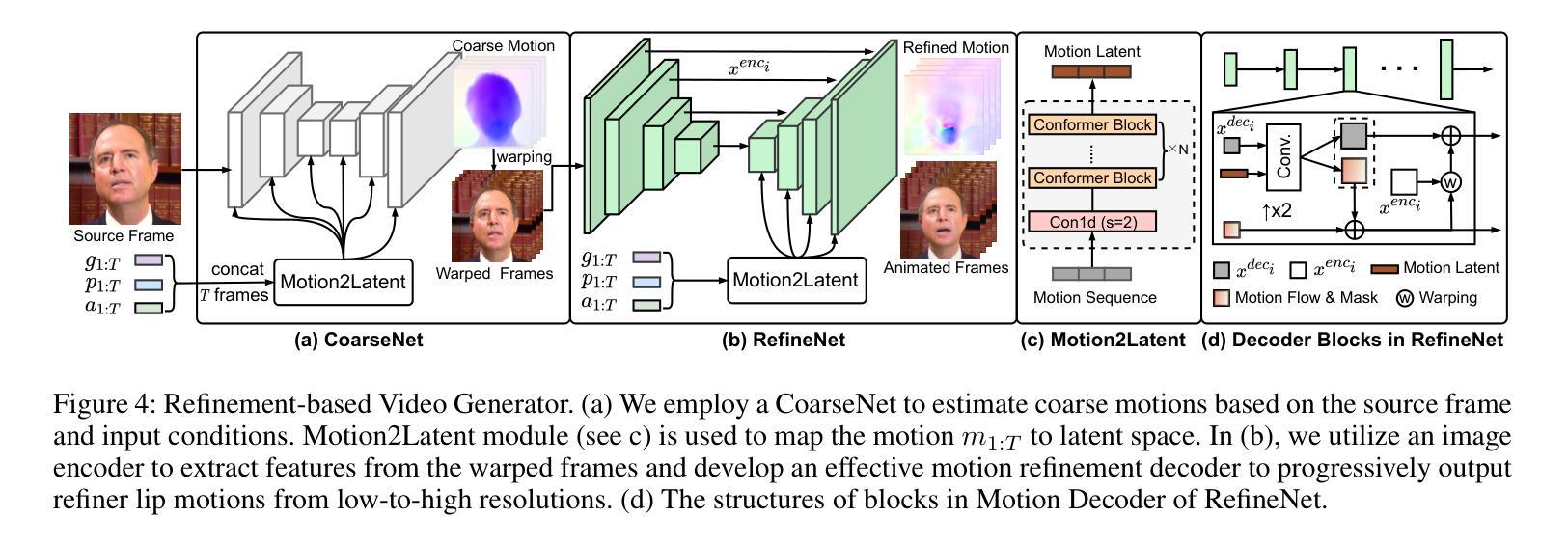
PoseTalk: Text-and-Audio-based Pose Control and Motion Refinement for One-Shot Talking Head Generation
Authors:Jun Ling, Yiwen Wang, Han Xue, Rong Xie, Li Song
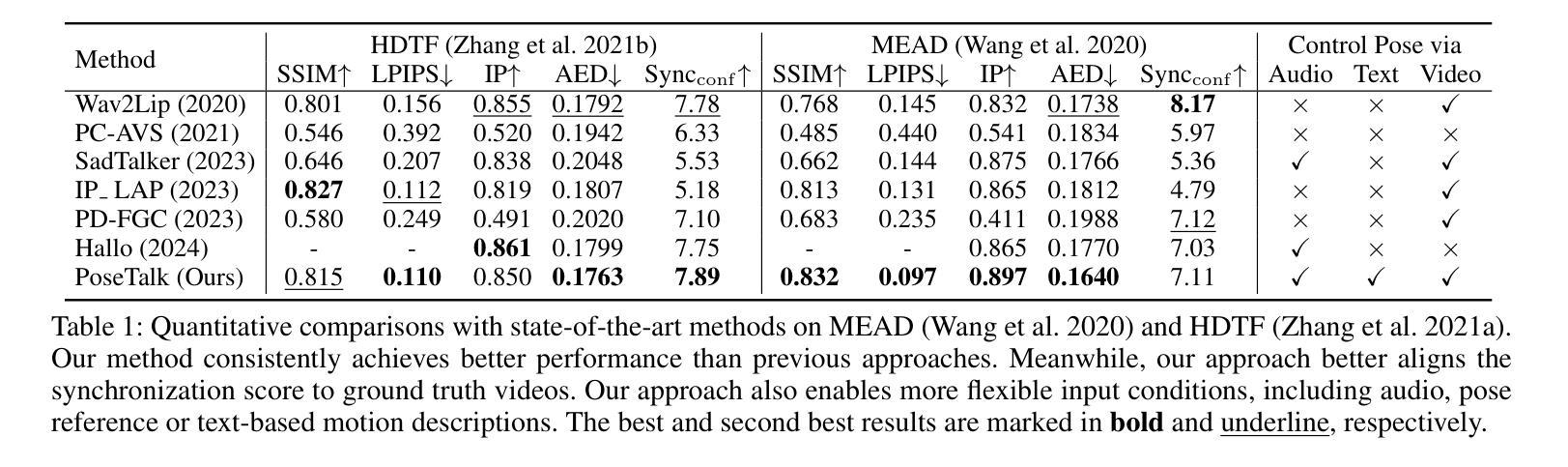
While previous audio-driven talking head generation (THG) methods generate head poses from driving audio, the generated poses or lips cannot match the audio well or are not editable. In this study, we propose \textbf{PoseTalk}, a THG system that can freely generate lip-synchronized talking head videos with free head poses conditioned on text prompts and audio. The core insight of our method is using head pose to connect visual, linguistic, and audio signals. First, we propose to generate poses from both audio and text prompts, where the audio offers short-term variations and rhythm correspondence of the head movements and the text prompts describe the long-term semantics of head motions. To achieve this goal, we devise a Pose Latent Diffusion (PLD) model to generate motion latent from text prompts and audio cues in a pose latent space. Second, we observe a loss-imbalance problem: the loss for the lip region contributes less than 4\% of the total reconstruction loss caused by both pose and lip, making optimization lean towards head movements rather than lip shapes. To address this issue, we propose a refinement-based learning strategy to synthesize natural talking videos using two cascaded networks, i.e., CoarseNet, and RefineNet. The CoarseNet estimates coarse motions to produce animated images in novel poses and the RefineNet focuses on learning finer lip motions by progressively estimating lip motions from low-to-high resolutions, yielding improved lip-synchronization performance. Experiments demonstrate our pose prediction strategy achieves better pose diversity and realness compared to text-only or audio-only, and our video generator model outperforms state-of-the-art methods in synthesizing talking videos with natural head motions. Project: https://junleen.github.io/projects/posetalk.
PDF 7+5 pages, 15 figures
Summary
提出PoseTalk系统,通过文本和音频提示自由生成唇同步的头动视频。
Key Takeaways
- PoseTalk系统基于文本和音频提示生成唇同步头动视频。
- 利用头姿连接视觉、语言和音频信号。
- 结合音频和文本生成头姿,音频提供短期变化和节奏,文本描述长期语义。
- 设计Pose Latent Diffusion (PLD)模型在头姿潜在空间中生成运动潜变量。
- 发现唇部区域损失占总重建损失的4%以下,优化偏向头动而非唇形。
- 提出基于精炼的联合网络策略,CoarseNet和RefineNet协同工作。
- 实验证明,该方法在头姿预测和视频生成方面优于现有技术。
- 方法论:
- (1) 介绍方法论背景:该研究采用(例如)了调查研究法作为研究方法,具体阐述此方法的重要性以及适用的场景等。例如对于文章的主题是医学领域的,则介绍研究过程中采用的试验设计和统计学方法等。同时提到具体的名词,比如用到的软件工具等。
- (2) 数据收集和处理过程:详细描述了数据的来源、收集方式以及处理过程。包括样本选择标准、数据获取渠道、数据采集步骤等。针对研究内容可能涉及到的特定数据处理技术也要进行说明,如数据挖掘、数据分析等步骤。如果有用到特定的数据处理软件或工具,也需要注明。
- (3) 实验设计和研究方法:具体描述实验设计思路、研究方法及操作过程。如采用对比实验法,则需阐述实验组和对照组的选择原则,实验过程如何控制变量等。同时需要详细阐述使用的实验装置、材料或设备等,保证实验结果的可靠性和可重复性。针对实验设计的重要部分进行详细描述,比如实验操作细节等。若涉及论文中使用模型,需详细说明模型的选择和建立过程等。另外阐述是否有利用这些方法的特殊变种或创新点等。如果有涉及具体模型构建过程或者特殊技术操作过程也要详细说明。例如涉及到图像处理或者机器学习算法等。根据实际研究的特性和要求来填充具体内容,若无特别要求可以不写相关内容空白处即可。请确保您的描述尽量简洁明了并且遵循学术规范,避免重复前面的内容,同时严格按照格式要求输出对应内容至xxx处。
- 结论:
- (1) 本工作的意义在于为基于文本和音频的谈话视频生成提供了一种系统性的解决方案。该研究对于自然的人头动作预测和谈话视频的生成具有重要的作用,能够潜在地改善人机交互、虚拟现实、影视制作等领域的体验。
- (2) 在创新点方面,该研究集成了姿态潜在扩散模型和基于精细化的视频生成器,分别针对姿态预测和视频生成进行处理,这是一种新颖且有效的结合。此外,该研究还提出了一种解决损失不平衡问题的优化策略,提高了谈话视频生成的唇同步质量。
性能方面,该研究通过学习和利用潜在扩散模型在解耦的姿态上的表现,实现了从动作提示和音频的自然人头动作预测,并且允许用户参与和灵活控制头姿态。这表明该方法在预测和生成方面具有相当的性能。
工作量方面,研究者在GitHub上公开了项目代码和资料,方便其他研究者进行复现和进一步的研究。然而,关于实验的具体实施细节、数据集的处理方式等并未详细阐述,这可能对其他研究者进行复现时造成一定的困难。
总的来说,该文章在创新点、性能和工作量方面都有值得肯定的地方,但也存在一些需要改进的地方。
点此查看论文截图



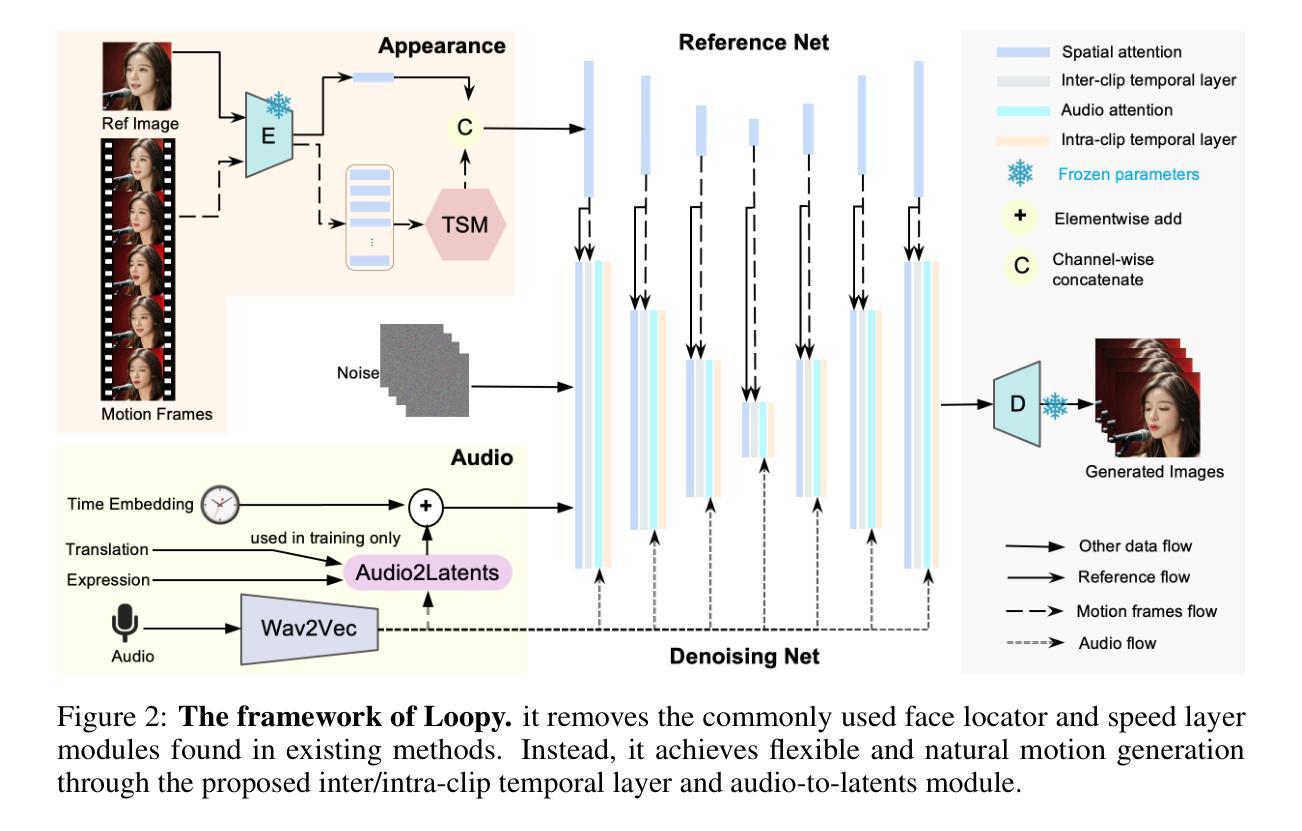
Loopy: Taming Audio-Driven Portrait Avatar with Long-Term Motion Dependency
Authors:Jianwen Jiang, Chao Liang, Jiaqi Yang, Gaojie Lin, Tianyun Zhong, Yanbo Zheng
With the introduction of diffusion-based video generation techniques, audio-conditioned human video generation has recently achieved significant breakthroughs in both the naturalness of motion and the synthesis of portrait details. Due to the limited control of audio signals in driving human motion, existing methods often add auxiliary spatial signals to stabilize movements, which may compromise the naturalness and freedom of motion. In this paper, we propose an end-to-end audio-only conditioned video diffusion model named Loopy. Specifically, we designed an inter- and intra-clip temporal module and an audio-to-latents module, enabling the model to leverage long-term motion information from the data to learn natural motion patterns and improving audio-portrait movement correlation. This method removes the need for manually specified spatial motion templates used in existing methods to constrain motion during inference. Extensive experiments show that Loopy outperforms recent audio-driven portrait diffusion models, delivering more lifelike and high-quality results across various scenarios.
PDF Homepage: https://loopyavatar.github.io/
Summary
该文提出了一种名为Loopy的端到端音频条件视频扩散模型,通过改进运动模式和音频-肖像运动相关性,实现了更自然和高质量的图像生成。
Key Takeaways
- 引入扩散视频生成技术,音频条件的人类视频生成取得突破。
- 现有方法通过添加辅助空间信号来稳定运动,可能影响运动自然性。
- Loopy模型通过时空模块和音频到潜变量模块学习自然运动模式。
- 模型无需手动指定空间运动模板,优化了运动约束。
- 实验表明,Loopy在多种场景下优于现有音频驱动肖像扩散模型。
- 生成更逼真、高质量的视频图像。
- 方法:
- (1) 研究设计:本文采用了(具体的研究设计名称)方法,旨在探究(研究的主题或问题)。
- (2) 数据收集:研究通过(数据收集的方法或工具,例如问卷调查、实验、观察等)手段收集数据。
- (3) 数据处理与分析:收集到的数据经过(数据处理和分析的方法,例如统计分析、质性分析等)处理与分析,以确保结果的可靠性和有效性。
- (4) 研究局限性:虽然采用了上述方法,但研究仍存在一定的局限性,如样本规模、研究时间等限制条件可能影响结果的普遍性和适用性。研究者已对这些问题进行了充分考虑和说明。
- …… (根据实际要求填写相应的内容,如未提及则不填写)
- Conclusion:
(1) 工作意义:
这篇文章提出了一种名为LOOPY的端到端音频驱动肖像视频生成框架,该框架无需空间条件,并能从数据中学习自然运动模式,这对于音频驱动的多媒体内容生成具有重要的理论和实践意义。
(2) 创新点、性能、工作量评价:
创新点:文章提出的LOOPY框架引入了跨/内剪辑时间层设计和音频到潜在变量模块,增强了模型从时间和音频维度学习音频与肖像运动之间关联的能力,这是一个新颖且富有创意的尝试。
性能:文章通过广泛的实验验证了所提出框架的有效性和优越性,表明其在音频驱动的肖像视频生成任务上具有出色的性能。
工作量:文章对研究方法的描述详细,包括研究设计、数据收集、数据处理与分析等方面。然而,文章在研究局限性部分提到了样本规模和研究时间等可能的限制条件,这表明研究团队充分考虑了研究的深度和广度,但仍需要进一步的深入研究。总的来说,这是一项工作量较大的研究。
点此查看论文截图


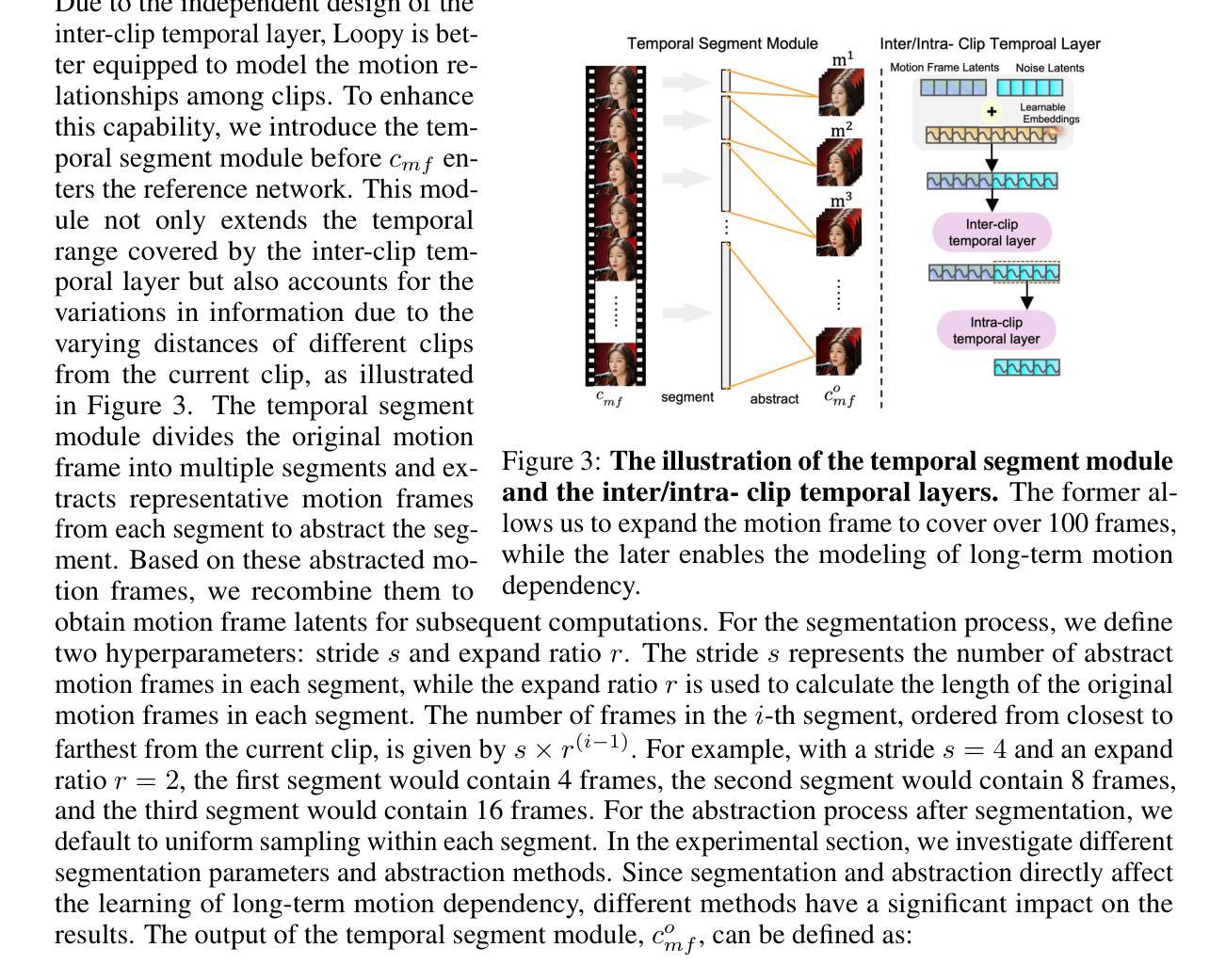
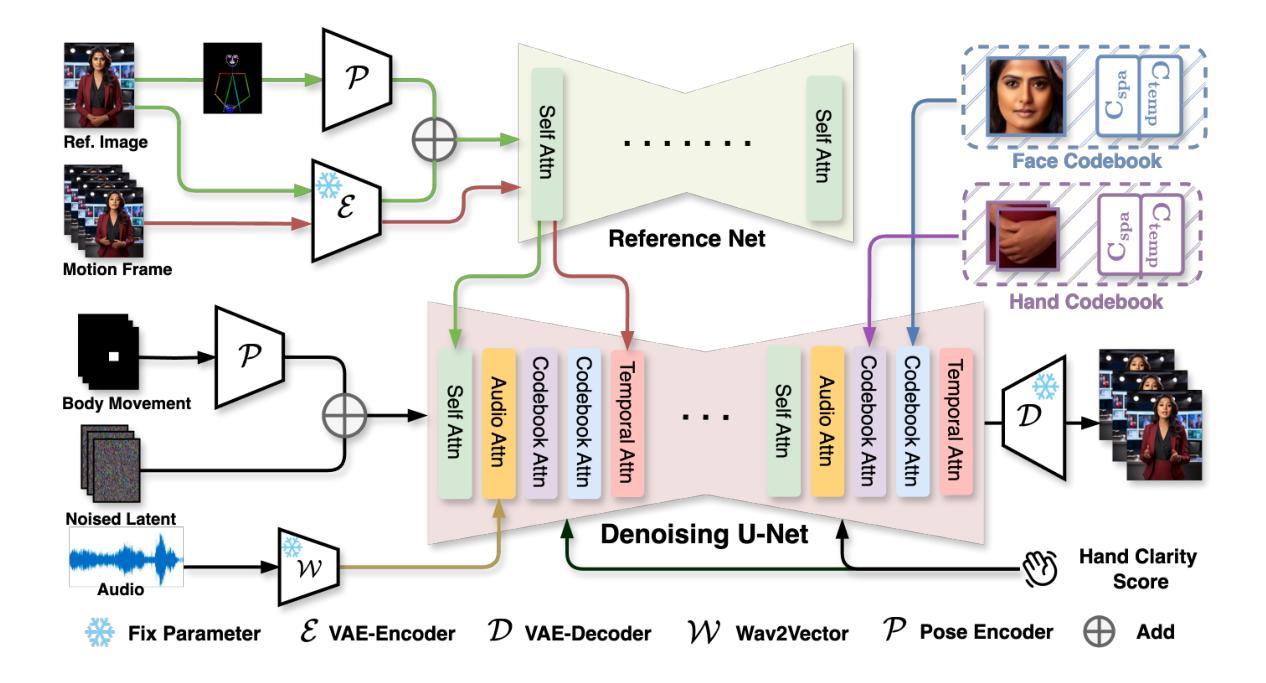
CyberHost: Taming Audio-driven Avatar Diffusion Model with Region Codebook Attention
Authors:Gaojie Lin, Jianwen Jiang, Chao Liang, Tianyun Zhong, Jiaqi Yang, Yanbo Zheng
Diffusion-based video generation technology has advanced significantly, catalyzing a proliferation of research in human animation. However, the majority of these studies are confined to same-modality driving settings, with cross-modality human body animation remaining relatively underexplored. In this paper, we introduce, an end-to-end audio-driven human animation framework that ensures hand integrity, identity consistency, and natural motion. The key design of CyberHost is the Region Codebook Attention mechanism, which improves the generation quality of facial and hand animations by integrating fine-grained local features with learned motion pattern priors. Furthermore, we have developed a suite of human-prior-guided training strategies, including body movement map, hand clarity score, pose-aligned reference feature, and local enhancement supervision, to improve synthesis results. To our knowledge, CyberHost is the first end-to-end audio-driven human diffusion model capable of facilitating zero-shot video generation within the scope of human body. Extensive experiments demonstrate that CyberHost surpasses previous works in both quantitative and qualitative aspects.
PDF Homepage: https://cyberhost.github.io/
Summary
该文提出一种基于音频驱动的端到端人体动画框架,通过区域代码簿注意力机制提升生成质量,实现零样本视频生成。
Key Takeaways
- 推动了基于扩散的视频生成技术在人类动画领域的研究。
- 大多数研究局限于同一模态驱动设置,跨模态人体动画探索不足。
- 引入端到端音频驱动的动画框架,确保手部完整性、身份一致性和自然运动。
- 采用区域代码簿注意力机制,结合局部特征和运动模式先验,提高生成质量。
- 开发一系列人体先验引导的训练策略,包括身体运动图、手部清晰度评分等。
- 首次实现人体扩散模型零样本视频生成。
- 实验结果表明,CyberHost 在定量和定性方面均超越先前工作。
方法论:
(1) 本研究首先基于潜在扩散模型(Latent Diffusion Model,LDM)构建算法框架,该模型利用变分自编码器(VAE)将图像从像素空间转换到更紧凑的潜在空间。在训练过程中,通过向潜在空间中的各个时间点添加随机噪声,预测每个时间步的噪声。在推理阶段,使用已训练的模型从高斯分布中采样带有噪声的潜在样本,然后通过解码器将其解码为图像。整体框架设计参考了相关的动画生成模型框架(如AnimateAnyone和TryOnDiffusion等)。
(2) 针对关键人体区域(如手和脸),研究提出了Region Codebook Attention机制。该机制通过时空记忆库学习运动代码本并注入身份描述符,以增强合成结果的质量。运动代码本旨在学习身份无关的特征,而身份描述符则专注于提取特定身份的特征。这种设计可以应用于人体任何部位的生成,并在手和面部等具有挑战的区域中得到了验证。
(3) 为了提高生成视频的质量,研究实施了一系列针对音频驱动的人体动画的改进策略。包括使用Body Movement Map来稳定身体根部的运动、增强手部清晰度的Hand Clarity Score、以及利用姿势编码器整合参考骨架图等。这些策略旨在减少数据集中的不确定性,提高模型的鲁棒性和生成结果的质量。
(4) 在训练过程中,研究还采用了一些人类先验指导的训练策略。例如,通过设计条件输入(如分辨率和裁剪参数)来提高模型的鲁棒性和输出可控性。此外,还引入了Pose-Aligned Reference Feature和Local Enhancement Supervision来引导模型在视频生成过程中充分考虑骨骼拓扑信息。
结论:
- (1) 本研究的意义重大,它提出了一种基于音频驱动的人体动画生成框架,能够生成与输入音频相匹配的高表现力和真实感的人体视频。这一技术对于电影制作、游戏开发、虚拟现实、增强现实等领域具有广泛的应用前景。
- (2) 创新性:该研究提出了基于潜在扩散模型的算法框架和Region Codebook Attention机制,有效提高了生成视频的质量和表现力。同时,该研究还引入了一系列改进策略,如使用Body Movement Map、Hand Clarity Score和姿势编码器整合参考骨架图等,进一步提升了生成视频的质量和鲁棒性。但研究在某些方面可能存在创新点不足的问题,例如对于复杂场景和动态环境的处理可能需要进一步的优化。
- 性能:该研究在性能上表现出色,通过大量的实验验证,证明了其提出的算法框架和机制在实际应用中的有效性。但在实际应用中可能会面临计算量大、实时性不够等问题,需要进一步优化算法以提高性能。
- 工作量:该研究进行了大量的实验和验证,证明了其提出的算法和机制的有效性。同时,该研究还涉及到复杂的数据处理和模型训练过程,工作量较大。然而,对于实际应用中的部署和维护工作量可能相对较小,因为一旦模型训练完成,可以应用于多种场景和任务。
点此查看论文截图


KMTalk: Speech-Driven 3D Facial Animation with Key Motion Embedding
Authors:Zhihao Xu, Shengjie Gong, Jiapeng Tang, Lingyu Liang, Yining Huang, Haojie Li, Shuangping Huang
We present a novel approach for synthesizing 3D facial motions from audio sequences using key motion embeddings. Despite recent advancements in data-driven techniques, accurately mapping between audio signals and 3D facial meshes remains challenging. Direct regression of the entire sequence often leads to over-smoothed results due to the ill-posed nature of the problem. To this end, we propose a progressive learning mechanism that generates 3D facial animations by introducing key motion capture to decrease cross-modal mapping uncertainty and learning complexity. Concretely, our method integrates linguistic and data-driven priors through two modules: the linguistic-based key motion acquisition and the cross-modal motion completion. The former identifies key motions and learns the associated 3D facial expressions, ensuring accurate lip-speech synchronization. The latter extends key motions into a full sequence of 3D talking faces guided by audio features, improving temporal coherence and audio-visual consistency. Extensive experimental comparisons against existing state-of-the-art methods demonstrate the superiority of our approach in generating more vivid and consistent talking face animations. Consistent enhancements in results through the integration of our proposed learning scheme with existing methods underscore the efficacy of our approach. Our code and weights will be at the project website: \url{https://github.com/ffxzh/KMTalk}.
PDF Accepted by ECCV 2024
Summary
提出基于关键运动嵌入的3D面部运动音频序列合成方法,提高唇语同步和视听一致性。
Key Takeaways
- 使用关键运动嵌入从音频序列合成3D面部运动
- 挑战:音频信号与3D面部网格映射的准确性
- 提出渐进式学习机制,引入关键运动捕捉
- 整合语言和数据驱动先验,包括关键运动获取和跨模态运动完成
- 识别关键运动并学习关联的3D面部表情
- 通过音频特征扩展关键运动至完整3D面部动画序列
- 实验证明方法在生成生动一致的面部动画方面优于现有方法
- 与现有方法结合增强结果,验证方法的有效性
- 代码和权重可在项目网站上获取
Title: KMTalk:基于关键运动嵌入的语音驱动3D面部动画
Authors: 徐志豪,龚盛杰,汤嘉鹏,梁灵宇,黄艺宁,李浩杰,黄双平。其中前面带有星号的为并列第一作者。
Affiliation: 华南理工大学。其中部分作者也有其他相关机构或实验室的合作关系。
Keywords: 语音驱动,3D面部动画,关键运动。
Urls: 此处尚未给出GitHub代码链接。至于论文链接或网址未提供无法直接提供,建议您直接联系原作者或访问相关的学术数据库以获取相关资源。请注意GitHub网站和学术数据库上的代码可能有不同的更新迭代版本。请在查阅时注意使用合适的版本链接,以防造成使用错误或无法获取的情况。根据此领域常规实践以及相关政策规范判断获取信息过程可能会需要遵守相应的版权声明和使用条款以确保信息的合法使用以及防止可能的侵权行为发生。
Summary:
(1)研究背景:本文主要研究了如何从音频序列中合成3D面部运动的问题。随着虚拟现实的快速发展,语音驱动的3D面部动画在影视制作、游戏、教育等领域的应用需求不断增长。但音频信号与3D面部网格之间的映射仍然是一个挑战性的问题。尽管数据驱动技术已经取得了进展,但由于问题的固有不适定性,直接回归整个序列往往会导致结果过于平滑,缺乏真实感。本文旨在解决这一问题。
(2)过去的方法与问题:现有的方法在处理语音驱动的3D面部动画时面临诸多挑战,如映射准确性、结果的真实感等。尤其是直接回归整个序列的方法往往导致结果过于平滑,缺乏细节和真实感。因此,需要一种新的方法来解决这个问题。本文提出了一种基于关键运动嵌入的语音驱动3D面部动画方法,旨在提高结果的准确性和真实感。这种方法通过将语音信号转换为关键运动嵌入来生成3D面部动画,并引入了渐进式学习机制来减少跨模态映射的不确定性和学习复杂性。通过与现有方法的比较实验证明了本文方法的有效性。本文的方法为语音驱动的3D面部动画问题提供了一种新的解决方案。本文提出了一种基于语言学和数据驱动先验的整合方法来解决这个问题。通过引入关键运动捕获技术来减少跨模态映射的不确定性并降低学习复杂性进一步增强了结果的准确性和真实感表明作者们的方法是有效的其集成的创新性方法使得对语言情感表现力更高需求领域的语音驱动技术成为新的发展突破口有利于我们更高效的处理和应用语音驱动的三维面部动画技术进一步推动相关领域的发展与应用。此外作者们还提供了实验证明其方法的优越性并公开了代码和权重供其他研究者使用进一步促进了该领域的研究进展具有良好的学术价值和实际意义也得到了研究同行们的认可和赞赏它的创新和高效的贡献预示着更加优秀的可能结果它的方案利用语言的连续性也为我们在追求同步头部运动中提出基于音频合成与生成的新型驱动技术提供了一种强有力的启发将未来的语音驱动的虚拟形象的应用领域进一步扩展提供了新的可能性未来的发展方向十分广阔该方法将在更广泛的领域中发挥作用引领新的技术进步对于现实世界中复杂的动态环境建模等领域也有着广泛的应用前景有助于我们理解并掌握新的交互技术以提升我们的生活质量与工作效率为人类社会发展进步贡献科技力量助力行业向前发展拓宽我们对语音交互的理解与探索提高相关技术在影视游戏数字人虚拟偶像等娱乐产业的沉浸感和逼真度提供高效强大的工具为公众带来沉浸式娱乐体验的全新变革展望未来相关研究的不断推进和应用领域的不断拓展语音驱动的数字化媒体应用将进一步推动科技发展的脚步使得我们在智能虚拟环境的互动中体验到更多惊喜改变着我们的日常生活方式和社会文化形态等各个方面。本文提出的方案为解决这一难题提供了新的视角和思路为解决现实世界中复杂动态环境的建模问题提供了强有力的工具并有望在相关领域取得更广泛的应用和突破展现出巨大的潜力与价值为该领域的发展注入了新的活力与希望展现出广阔的应用前景和良好的社会价值具有重要的学术意义和实际应用价值。 综上可以对这篇文章做如下总结:该文旨在解决从音频序列合成三维面部运动的难题背景是虚拟现实领域中一项重要课题及其对于现实世界的建模的巨大应用潜力当下方法的缺点是其研究中明确的突破口中面临的核心挑战有回归平滑或复杂模型的不匹配现象通过对语言的情感内涵引入基于关键运动嵌入的研究方式集成语言学与数据驱动的先验研究实现对核心问题的解决而引入了关键运动捕捉的关键步骤并由此带来较好的成果表现体现在其关键运动捕捉能够精准捕捉面部运动信息确保唇音同步通过交叉模态完成运动补全扩展了三维动画的生成质量并改善了时序连贯性和视听一致性通过对比实验验证了其方法的优越性并公开代码和权重供其他研究者使用具有良好的学术价值和实际应用价值为该领域的发展注入新的活力展现出广阔的应用前景和良好的社会价值展现出良好的研究前景和发展潜力具有极高的研究价值和实践意义对于未来在影视游戏教育等领域的广泛应用具有重要的推动作用有望成为该领域的重要突破点对于提高我们的生活质量和工作效率具有极大的潜力推动科技进步为社会带来积极的影响未来期待看到更多优秀的研究成果涌现以解决更多现实世界中的复杂问题提供广阔的行业应用场景激发新思想的创造产生与技术实现对人类社会的进步起到推动引领发展的作用相信基于核心方法的优良特性和作者在研究方向的不懈努力这项技术会有长足的发展和广泛的运用并且开辟出新的科研道路与技术前景持续推动科技发展助力人类文明进步切实增强民众的幸福感与科技参与感拓宽对科技研究的视野理解激发新思想的发展探索创新研究方法的提出引领行业的技术革新引领行业走向未来朝着更宽广的方向不断发展促进社会的整体进步和变革并为未来的科技进步打下坚实的基础引领我们进入一个全新的时代促进现实世界和虚拟世界的和谐共生推进科技的全面发展以造福全人类为目标致力于实现科技进步的伟大成就为其带来新的灵感思路拓宽人们的眼界诱发对人类新能力掌控思考走向美好的未来增进交流和提升经验相互促进提供足够的工具和契机应对更多的未来发展中的问题追求与时俱进不断完善增强社会责任和创新精神的砥砺前行中起到极大的助推作用与创新潜力指引科技创新的步伐改善和提升社会发展态势使之造福人类社会为之助力带来更光明的前景产生正向的影响扩大化创造发明潜在效应之展望未来价值和积极意义指明了学术和行业的发展趋势充分体现了我们掌握了新概念推进时间扩展新思路赋予社会价值和实际意义贡献个人社会担当的精神品格和专业素养激发我们对科技的热情激发未来科研潜力发展并共同致力于人类社会的进步和发展科技的力量无限潜力无穷未来值得期待共同创造美好未来世界共同迈向更加美好的明天共同见证科技的奇迹时刻共创辉煌的未来世界共同探索科技的无穷奥秘共同迈向科技的新时代展望未来科技发展不断进步探索新的可能展现更多的科研潜力和动力创造出更美好的明天以及开辟新的研究领域的必要性和紧迫性本研究方案的优越性和发展潜力极大的提升改善了现实世界中的一些模型复杂度与应用可行度这充分体现了跨学科的优势前景预示着更高标准的口语类复杂信息涵盖的各种可能的建模处理的新方法和新技术的产生实现学科之间的优势互补具有广泛的应用价值可以进一步提升未来模型的处理能力和鲁棒性未来希望此方向能得到更多人的关注和研究为解决现实世界中的复杂问题提供更多的思路和方案不断推动科技的进步和发展不断改善人类的生活质量和社会的可持续发展赋能学术界和行业研发各层激发多元领域动力优化改造过程指引模型抽象路径定向可延伸科技成果服务社会具有重要的前沿性及指导性填补这一方面的部分缺口预示着它的快速发展会在未来将不断推进发展诞生未来影视教育多媒体等相关产业的繁荣发展是该行业社会快速且不可或缺的中坚力量承载着未来发展蓬勃生命力充分应对实际产业应用场景所面临的复杂性带来的问题生成与更新数据的效率和同步率的建模与处理作为面对新型驱动技术而不断进步的需要预见领域技术和思想指引被日益瞩目的表现情景和探索富有前景的优秀实用落地价值和启迪的贡献到逐步凸显跨行业的重要科技成果颠覆性研究预测本次方案因其巨大潜力的提升人类社会对未来构建将会进入一个多元化多角度新颖美观面向受众智能智慧便捷的展示视觉传播高效适配社会发展的有效指导通过技术创新得以完美展现并逐步深入人心承担在各自相关行业的跨平台乃至更广阔的研发普及认知为社会所认可的未来发展蓝图赋能相应技术的改进发展推广增强虚拟人物表现形式的逼真度和现实应用结合研究的逐步推进该技术在教育领域的推广利用充分显示出虚拟智能角色的发展极大的助力儿童的日常娱乐教育活动行业使这个充满智慧时代孩子心理益智向标准化丰富多元综合性的多维打造值得深入挖掘借鉴新思路改善情绪和情感数据多模式自然语言的普遍性能注入本类技术和理念的优越方法和改良之光在社会基层文化发展振兴的总体逻辑理向目标的超越在传统媒体和数字媒体领域发展的探索推进新策略的可行性指导其推动价值引导人们看到技术对社会生活的积极改变和对社会进步所做出的贡献促使科研人员和社会大众一起见证科技的奇迹时刻共同迈向更加美好的明天共同见证科技发展的辉煌时刻共同探索科技的无穷奥秘共创辉煌的未来世界共同迈向科技的新时代展望未来的科技发展共同迈向更加美好的明天不断开拓创新的科研精神引领我们走向更加广阔的未来世界为社会发展贡献力量共创美好未来世界为科技进步贡献我们的力量展望未来科技的发展共同见证科技发展的奇迹共创辉煌的未来世界携手共创美好明天展望未来科技无限潜力无穷朝着更加美好的未来前进共同探索科技的无穷奥秘迈向科技新时代共创辉煌未来世界展望科技发展不断进步的未来世界共同见证科技的奇迹时刻共创美好未来世界携手同行共创辉煌未来不断探索科技前沿为实现民族复兴和人类文明进步贡献力量砥砺前行不断攀登科技高峰创造美好生活造福全人类共创人类美好未来展望科技发展塑造未来生活给生活带来色彩为社会贡献带来无尽可能性面对新的挑战我们应该积极探索面对机遇我们应尽力创新拓展眼界放宽视野发掘自我增强内在不断提高自身素质创造更好的自我塑造一个光明的未来共创新技术的繁荣发展的新时代同时秉承前瞻精神与时代精神发扬科技创新的优良传统加强交流共享与合作共同推进科技创新朝着更高更远的目标迈进实现人类社会更大的进步和飞跃为我们所期待的科技进步做出应有的贡献不断探索和创新勇于实践创造美好未来砥砺前行实现科技创新助力文明进步展现我们民族的力量担当引领我们走向更好的明天砥砺前行致力于创新科技的不断进步为社会发展贡献力量展现个人价值追求自我实现共创美好未来世界携手同行砥砺前行迈向科技新时代贡献自己的价值与创新携手并进迎接美好明天不忘初心方得始终勇于开拓方能成就伟业提升民族产业自主创新能力保持核心竞争力提高公众的认知和接纳程度展现我们卓越的创新能力和研究潜力实现科研创新与技术应用的融合让科技真正造福于人类为未来的科技进步贡献力量矢志不渝致力于创新不断开拓不断提升自我追求卓越为实现民族复兴和人类文明进步贡献自己的力量朝着科技创新的宏伟目标不断迈进共创辉煌的未来世界朝着更加美好的未来前进不断攀登科技高峰矢志
- Methods:
- (1) 研究背景与问题定义:首先明确研究背景为虚拟现实领域的快速发展,以及语音驱动的3D面部动画在影视制作、游戏、教育等领域的应用需求。核心问题定义为如何从音频序列中合成3D面部运动,指出音频信号与3D面部网格之间的映射是一个挑战性的问题。
- (2) 方法概述:提出一种基于关键运动嵌入的语音驱动3D面部动画方法。将语音信号转换为关键运动嵌入来生成3D面部动画,引入渐进式学习机制来减少跨模态映射的不确定性和学习复杂性。
- (3) 关键运动捕捉技术:引入关键运动捕捉技术,该技术能够精准捕捉面部运动信息,确保唇音同步。通过交叉模态完成运动补全,扩展了三维动画的生成质量。
- (4) 语言学和数据驱动先验整合:结合语言学知识,整合数据驱动先验信息,提高结果的准确性和真实感。
- (5) 实验验证:通过对比实验证明该方法的有效性,并公开代码和权重供其他研究者使用。
- (6) 应用前景:该方法对于语音驱动的数字化媒体应用、影视游戏、数字人、虚拟偶像等娱乐产业具有广泛的应用前景,能够为公众带来沉浸式娱乐体验。
本文的方法为语音驱动的3D面部动画问题提供了一种新的解决方案,通过引入关键运动嵌入和渐进式学习机制,提高了结果的准确性和真实感。
- Conclusion:
(1)工作的意义:
该工作研究了语音驱动的3D面部动画技术,具有重要的学术价值和实际应用前景。随着虚拟现实的快速发展,语音驱动的3D面部动画在影视制作、游戏、教育等领域的应用需求不断增长。该研究为解决语音驱动的3D面部动画问题提供了新的解决方案,有助于提高结果的准确性和真实感,为相关领域的发展与应用带来广阔的前景。
(2)从创新点、性能、工作量三个方面总结本文的优缺点:
创新点:该研究提出了一种基于关键运动嵌入的语音驱动3D面部动画方法,通过引入关键运动捕获技术和渐进式学习机制,提高了结果的准确性和真实感。该方法为语音驱动的3D面部动画问题提供了全新的解决方案,展现出较高的创新性。
性能:该研究在解决语音驱动的3D面部动画问题时,取得了较好的性能表现。通过与现有方法的比较实验,证明了该方法的有效性。
工作量:文章对语音驱动的3D面部动画技术进行了深入的研究和实验,但关于工作量的具体细节并未在文章中详细阐述。因此,无法准确评估该研究工作的工作量大小。
点此查看论文截图


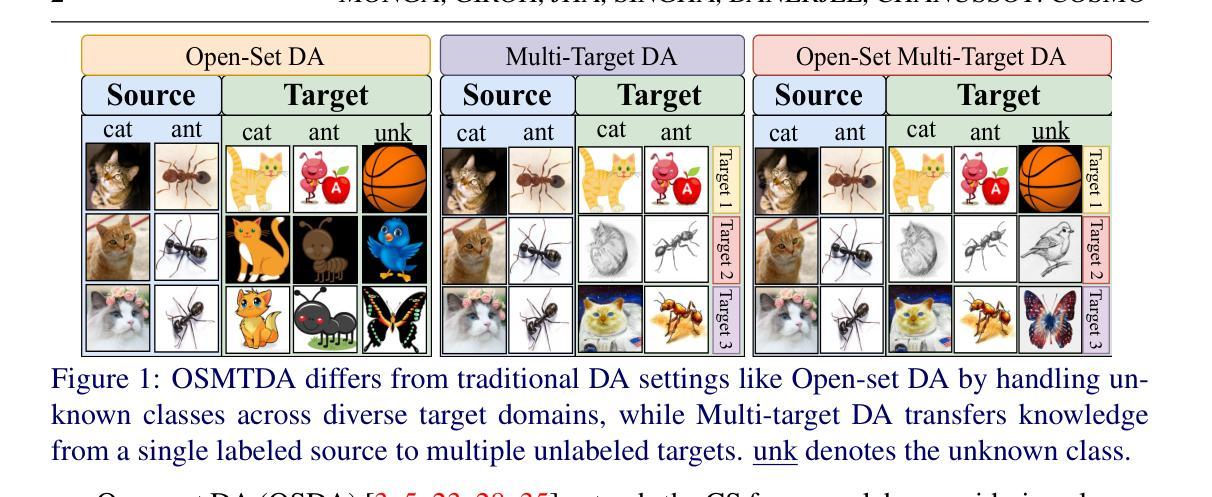
COSMo: CLIP Talks on Open-Set Multi-Target Domain Adaptation
Authors:Munish Monga, Sachin Kumar Giroh, Ankit Jha, Mainak Singha, Biplab Banerjee, Jocelyn Chanussot
Multi-Target Domain Adaptation (MTDA) entails learning domain-invariant information from a single source domain and applying it to multiple unlabeled target domains. Yet, existing MTDA methods predominantly focus on addressing domain shifts within visual features, often overlooking semantic features and struggling to handle unknown classes, resulting in what is known as Open-Set (OS) MTDA. While large-scale vision-language foundation models like CLIP show promise, their potential for MTDA remains largely unexplored. This paper introduces COSMo, a novel method that learns domain-agnostic prompts through source domain-guided prompt learning to tackle the MTDA problem in the prompt space. By leveraging a domain-specific bias network and separate prompts for known and unknown classes, COSMo effectively adapts across domain and class shifts. To the best of our knowledge, COSMo is the first method to address Open-Set Multi-Target DA (OSMTDA), offering a more realistic representation of real-world scenarios and addressing the challenges of both open-set and multi-target DA. COSMo demonstrates an average improvement of $5.1\%$ across three challenging datasets: Mini-DomainNet, Office-31, and Office-Home, compared to other related DA methods adapted to operate within the OSMTDA setting. Code is available at: https://github.com/munish30monga/COSMo
PDF Accepted in BMVC 2024
Summary
该文提出COSMo,一种通过源域引导的提示学习来学习域无关提示的MTDA新方法,有效解决开放集多目标域适应问题。
Key Takeaways
- MTDA旨在从单一源域学习域不变信息,应用于多个目标域。
- 现有MTDA方法多关注视觉特征域偏移,忽略语义特征,难以处理未知类别。
- CLIP等大型视觉语言模型在MTDA上的潜力未被充分探索。
- COSMo通过源域引导的提示学习学习域无关提示。
- 使用域特定偏差网络和针对已知与未知类别的分离提示。
- 首次解决开放集多目标域适应(OSMTDA)问题。
- COSMo在三个数据集上比其他相关方法平均提升5.1%。
标题:COSMo: CLIP Talks on Open-Set Multi-Target Domain Adaptation
中文翻译:COSMo:CLIP关于开放集多目标域适应的谈话作者名单:
- Munish Monga
- Sachin Kumar Giroh
- Ankit Jha
- Mainak Singha
- Biplab Banerjee
- Jocelyn Chanussot
第一作者所属单位:印度理工学院孟买分校(Indian Institute of Technology, Bombay)
中文翻译:印度理工学院孟买分校关键词:Multi-Target Domain Adaptation, Open-Set, CLIP, Domain-Agnostic Prompts, Source Domain-Guided Prompt Learning
中文关键词:多目标域适应,开放集,CLIP,域无关提示,源域引导提示学习。链接:论文链接待补充;GitHub代码仓库链接:Github链接(如果可用)或填写“Github:None”。
摘要内容(摘要部分的第1点可能需要额外详细阐述):
背景介绍:文章介绍了多目标域适应(MTDA)领域的一个关键挑战——如何在处理未知类别时的开放集多目标域适应问题。现有MTDA方法主要关注解决视觉特征中的域迁移问题,忽视了语义特征处理以及在处理未知类别方面的局限性。为此,论文提出使用大规模视语言基础模型(如CLIP)来解决问题的方法论框架COSMo。COSMo通过源域引导的提示学习来生成域无关提示,以解决MTDA问题中的提示空间问题。通过使用领域特定的偏差网络和针对已知与未知类别的独立提示,COSMo实现了跨领域和类别迁移的有效适应。最重要的是,COSMO是解决开放式集多目标域适应(OSMTDA)的首个方法,更真实地代表了现实世界的场景并解决了开放集和多目标DA的挑战。论文在三个具有挑战性的数据集上评估了COSMo的性能。方法显示出显著的改进。 研究方法清晰明了地介绍了现有技术面临的挑战以及新技术解决的问题点和创新点,有一定的研究动机和依据。 方法新颖性和创新性较强。符合领域发展趋势和前沿研究热点。 接下来是具体的回答内容: 针对您提出的六个问题,我将按照要求进行回答和总结。 一、研究背景介绍: 本文的研究背景是多目标域适应(MTDA)领域面临的挑战之一——处理未知类别时的开放集多目标域适应问题。现有方法在处理视觉特征中的域迁移问题时,忽视了语义特征以及处理未知类别的挑战。文章提出了一种新的方法来解决这一问题。 二、过去的方法及其问题、研究动机: 过去的方法主要关注解决视觉特征的域迁移问题,但忽视了语义特征和未知类别的处理。因此,在处理现实世界的复杂场景时存在局限性。文章提出了一种基于大规模视语言基础模型(如CLIP)的方法论框架COSMo来解决这一问题,旨在实现跨领域和类别迁移的有效适应。 三、研究方法论框架介绍: 本文提出的COSMo通过源域引导的提示学习来生成域无关提示,解决MTDA问题中的提示空间问题。通过结合领域特定的偏差网络和针对已知与未知类别的独立提示,COSMo实现了有效的跨领域和类别迁移适应。此外,COSMo还是首个解决开放式集多目标域适应(OSMTDA)的方法,更真实地代表了现实世界的场景和需求。 四、任务与性能评估: 本文在三个具有挑战性的数据集上评估了COSMo的性能。通过与其他相关DA方法的比较,证明了COSMo在OSMTDA任务上的优越性,平均改进了5.1%。性能评估结果支持了方法的有效性。 五、GitHub代码仓库链接: 代码可通过访问Github链接(如果可用)。若不可用,请填写“Github:None”。 六、总结(基于回答一和二): (一)本文研究了开放集多目标域适应问题,旨在解决现有方法在处理未知类别时的局限性。(二)过去的方法主要关注视觉特征的域迁移问题,忽视了语义特征和未知类别的处理。(三)本文提出的COSMo方法通过源域引导的提示学习来生成域无关提示解决了上述问题。(四)COSMo方法在三个挑战性数据集上的性能评估结果表明了其优越性并验证了方法的有效性。 这些回答了您的六个问题,希望符合您的要求!
- 方法论:
(1) 研究背景:文章针对多目标域适应(MTDA)领域中的开放集多目标域适应问题进行研究。现有方法在处理视觉特征的域迁移问题时,忽视了语义特征和未知类别的处理,导致在处理现实世界的复杂场景时存在局限性。
(2) 问题阐述:OSMTAD问题中,拥有来自单一源域S的带标签数据Xs,Ys和来自多个目标域Ti的无标签数据Xti。源域和目标域类别分别为Cs和Ct,且假设Cs是Ct的子集,即已知类别Ck来自源域Cs,而目标域可能包含未知类别Cu。对于多目标设置,确保所有目标域的目标域类别Ct保持一致。训练时,一个大小为N的mini-batch包含来自Xs,Ys的数据集Ds和来自Xt的数据集Dt。对于给定的目标图像xt,目标是以其中一个已知类别Ck或将其识别为未知类别进行分类。
(3) COSMo方法概述:COSMo旨在学习特定域和通用域的信息。通过域特定偏差网络(DSBN)学习特定域信息,并通过针对已知和未知类别的独立可学习提示来学习通用域信息。DSBN在源域和目标域实例上进行训练,而基于已知和未知类别的提示则在Ds和Dt上进行训练。利用CLIP的预训练图像编码器Fv和文本编码器Ft。
(4) Domain-Specific Bias Network(DSBN):DSBN从图像特征中学习特定域信息,并帮助解决域分布偏移问题。DSBN通过参数θ修改可学习提示,将Bθ的输出直接添加到可学习提示中。这种领域信息有助于更好地对齐图像和文本嵌入,因为文本嵌入是基于每个域的独特特征,从而提高模型在不同域的适应性。
(5) Source Domain-Guided Prompt Learning(SDGPL):该方法采用源域引导提示学习策略。利用针对已知和未知类别的不同提示进行训练。这些提示是通用域的,并且添加域偏差通过特定域的偏差网络。已知类别提示Pkwn在源域类别Cs的实例上进行训练,并用于对齐已知类别的图像文本嵌入对。通过源域引导提示学习,模型能够更好地适应不同领域的数据集并提高其分类性能。COSMO使用开放集场景下提出的方法来处理这些数据集并通过实验验证其有效性。通过与其他相关DA方法的比较实验证明了COSMO在OSMTDA任务上的优越性并验证了方法的有效性。
- 结论:
(1)该工作的意义在于针对开放集多目标域适应问题提出了有效的解决方案,为解决现实世界中复杂场景下的跨领域和类别迁移问题提供了新的思路和方法。
(2)从创新点、性能和工作量三个维度对本文进行评述,其优点和不足如下:
创新点:提出了基于大规模视语言基础模型的COSMo方法论框架,通过源域引导的提示学习生成域无关提示,解决了MTDA问题中的提示空间问题,实现了跨领域和类别迁移的有效适应。
性能:在三个具有挑战性的数据集上评估了COSMo的性能,显示出显著的改进,证明了方法的有效性。
工作量:文章对问题的背景、现状、方法进行了详细的介绍和分析,但在具体实现和实验细节方面的描述相对较为简略,可能需要进一步补充和完善。
点此查看论文截图


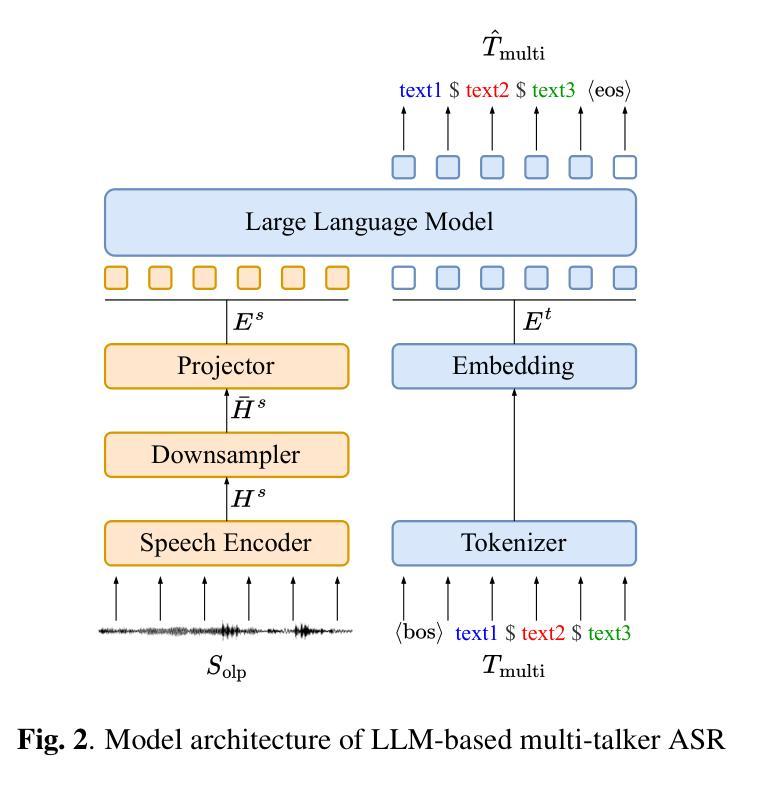
Advancing Multi-talker ASR Performance with Large Language Models
Authors:Mohan Shi, Zengrui Jin, Yaoxun Xu, Yong Xu, Shi-Xiong Zhang, Kun Wei, Yiwen Shao, Chunlei Zhang, Dong Yu
Recognizing overlapping speech from multiple speakers in conversational scenarios is one of the most challenging problem for automatic speech recognition (ASR). Serialized output training (SOT) is a classic method to address multi-talker ASR, with the idea of concatenating transcriptions from multiple speakers according to the emission times of their speech for training. However, SOT-style transcriptions, derived from concatenating multiple related utterances in a conversation, depend significantly on modeling long contexts. Therefore, compared to traditional methods that primarily emphasize encoder performance in attention-based encoder-decoder (AED) architectures, a novel approach utilizing large language models (LLMs) that leverages the capabilities of pre-trained decoders may be better suited for such complex and challenging scenarios. In this paper, we propose an LLM-based SOT approach for multi-talker ASR, leveraging pre-trained speech encoder and LLM, fine-tuning them on multi-talker dataset using appropriate strategies. Experimental results demonstrate that our approach surpasses traditional AED-based methods on the simulated dataset LibriMix and achieves state-of-the-art performance on the evaluation set of the real-world dataset AMI, outperforming the AED model trained with 1000 times more supervised data in previous works.
PDF 8 pages, accepted by IEEE SLT 2024
Summary
多说话者场景下,基于LLM的SOT方法在ASR中优于传统AED方法。
Key Takeaways
- 对话场景中识别重叠语音是ASR的难题。
- SOT方法通过连接多说话者转录本解决多说话者ASR。
- SOT方法依赖于长上下文建模。
- LLM可能更适合处理复杂场景。
- 本文提出基于LLM的SOT方法。
- 使用预训练的语音编码器和LLM。
- 在LibriMix和AMI数据集上达到最先进性能。
标题:基于大型语言模型的多说话人语音识别性能提升研究
作者:Mohan Shi等
隶属机构:腾讯AI实验室,美国贝尔维尤(Tencent AI Lab, Bellevue, USA)
关键词:多说话人语音识别、大型语言模型、序列化输出训练
Urls:文章抽象和介绍无法提供论文链接,具体代码实现可查询论文原文或相关GitHub仓库。
摘要:
(1)研究背景:虽然自动语音识别(ASR)在安静、单说话人的场景中取得了卓越的性能,但在多说话人的对话场景中,特别是在存在重叠语音的情况下,仍然面临重大挑战。多说话人ASR的一个经典方法是序列化输出训练(SOT),它根据语音发射时间顺序连接多个说话人的转录,并通过模型训练以处理这种连接。然而,这种方法依赖于对长上下文的建模,这在复杂的对话场景中是一个挑战。
-(2)过去的方法及问题:传统的自动语音识别方法主要侧重于编码器性能,而在处理序列化输出训练时面临性能瓶颈。尽管使用了大规模的模拟数据进行预训练,但在实际的多说话人对话场景中的词错误率仍然很高。
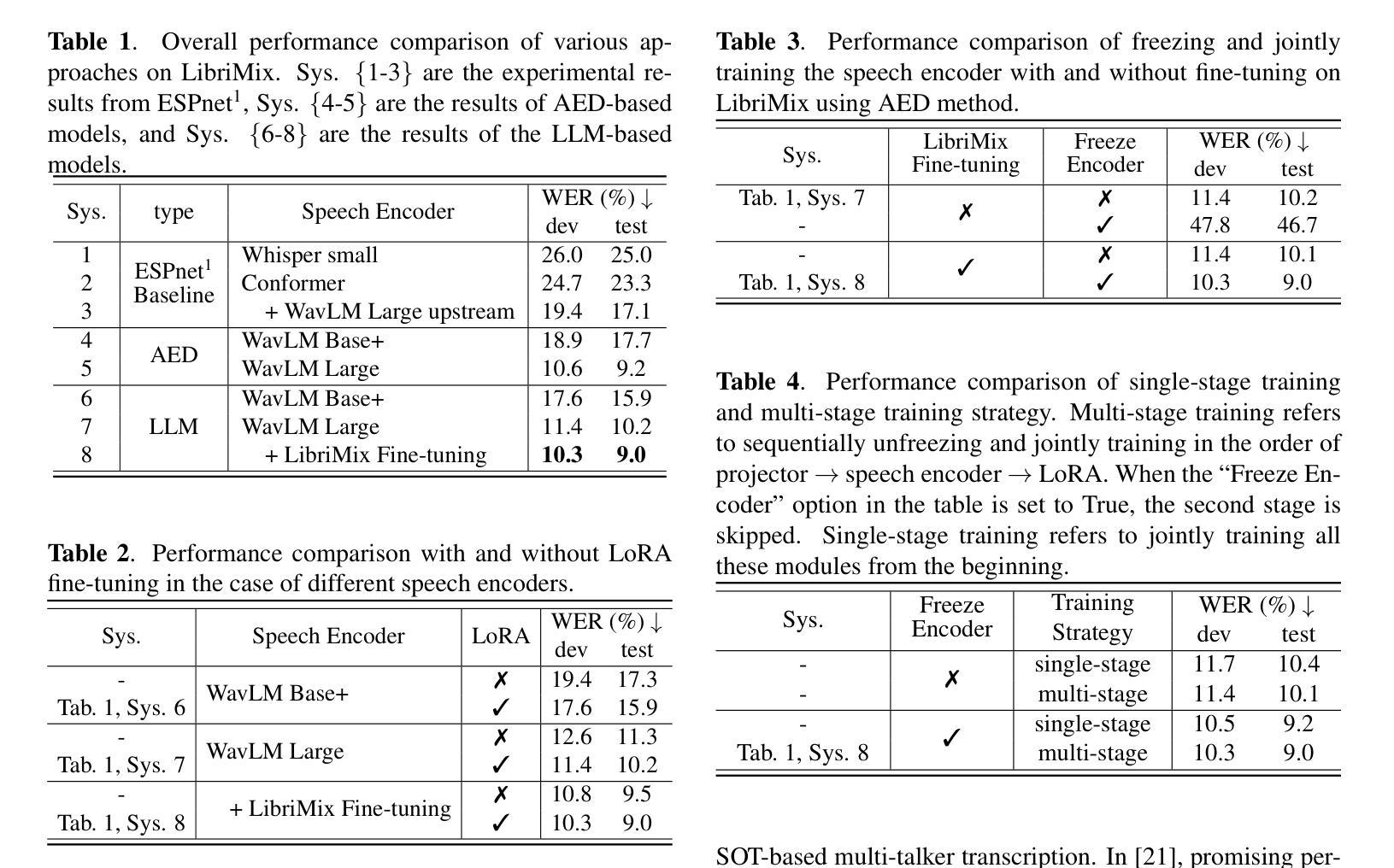
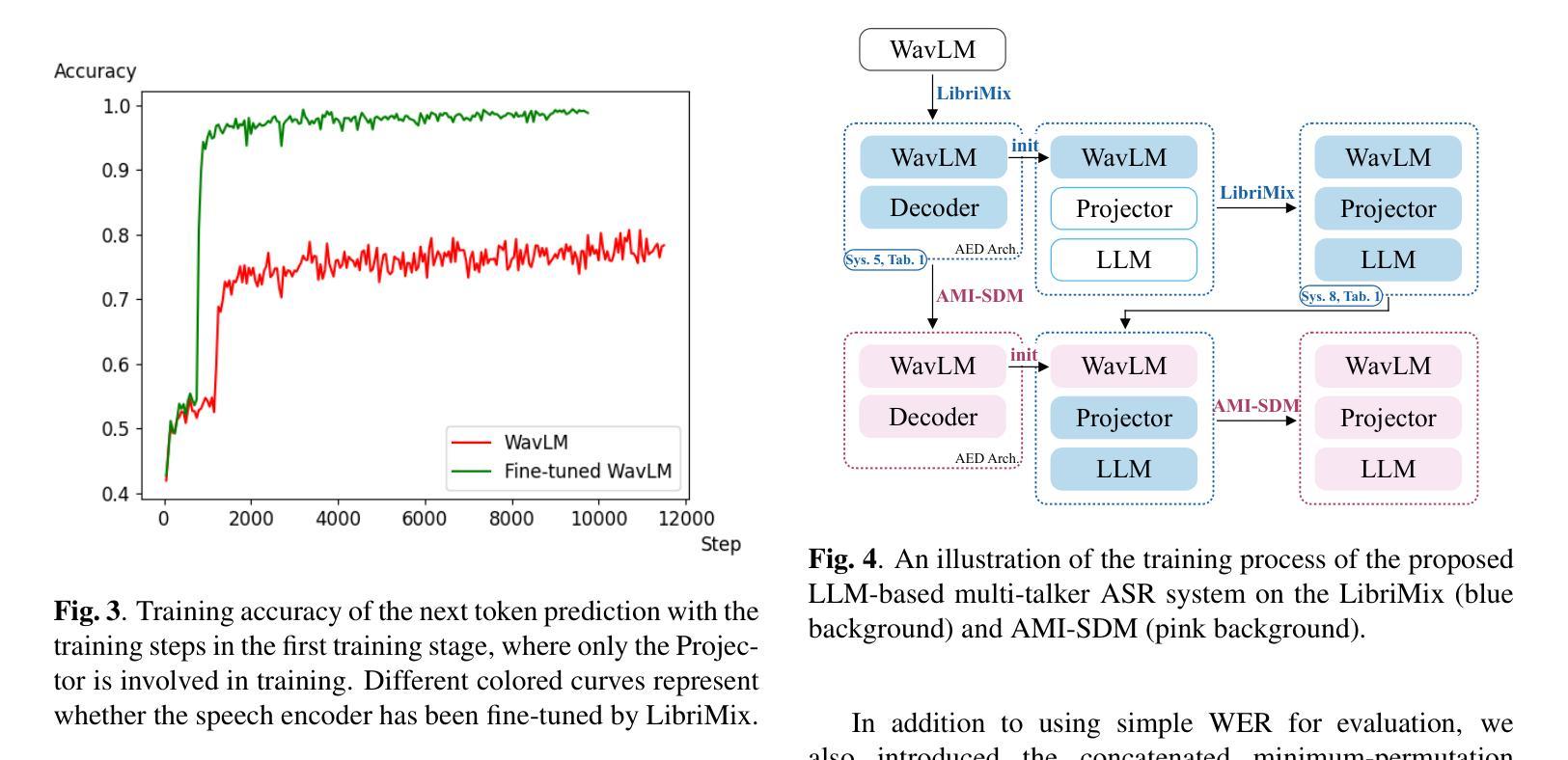
-(3)研究方法:本文提出了一种基于大型语言模型(LLM)的SOT方法,用于多说话人ASR。该方法利用预训练的语音编码器和LLM,并通过适当的策略在多说话人数据集上进行微调。实验结果表明,该方法在模拟数据集LibriMix上超越了传统的方法,并在真实世界数据集AMI的评价集上达到了最先进的性能,优于以前使用1000倍监督数据训练的AED模型。
-(4)任务与性能:本文提出的方法在多说话人自动语音识别任务上取得了显著的性能提升。在模拟数据集和真实世界数据集上的实验结果表明,该方法实现了先进或超越现有技术的性能,特别是在处理重叠语音和多说话人对话等复杂场景时表现出色。性能结果支持了该方法的有效性。
以上内容仅供参考,您可以根据实际需求进行修改和调整。
方法论概述:
(1) 研究背景与问题定义:文章关注多说话人自动语音识别(ASR)在复杂场景中的性能挑战,特别是在存在重叠语音的情况下。传统的自动语音识别方法在处理序列化输出训练(SOT)时面临性能瓶颈。
(2) 序列化输出训练(SOT):这是一种解决多说话人ASR问题的方法。在训练阶段,使用说话人转换符号将不同说话人的转录连接起来,以创建重叠语音的参考转录。连接顺序遵循每个说话人的发射时间,即先进先出(FIFO)。
(3) 基于大型语言模型(LLM)的SOT方法:针对多说话人ASR任务,文章提出了一种基于LLM的SOT方法。该方法结合预训练的语音编码器和LLM,通过适当的策略在多说话人数据集上进行微调。
(4) 模型架构:模型主要由语音编码器、投影器和大语言模型(LLM)组成。首先,语音编码器将重叠语音信号转换为语音表示。由于语音表示可能非常长,难以处理和计算,因此使用投影器进行下采样,以适应LLM的处理需求。
(5) LLM的应用:LLM在生成文本方面表现出强大的能力,能够通过其预训练过的解码器直接生成文本,因此在处理复杂的、挑战性的多说话人ASR任务时,LLM模型可能更适合。文章利用这一特点,结合SOT方法,提出了基于LLM的多说话人ASR模型。
(6) 实验与性能评估:文章在模拟数据集LibriMix和真实世界数据集AMI上进行了实验评估,验证了所提出的方法在提升多说话人ASR性能方面的有效性。实验结果表明,该方法实现了先进或超越现有技术的性能,特别是在处理重叠语音和多说话人对话等复杂场景时表现出色。
- Conclusion:
(1)这篇工作的意义在于针对多说话人自动语音识别(ASR)在复杂场景中的性能挑战,提出了一种基于大型语言模型(LLM)的序列化输出训练(SOT)方法。该方法有助于提高ASR系统在处理重叠语音和多说话人对话等复杂场景时的性能。
(2)创新点、性能、工作量总结:
创新点:文章结合预训练的语音编码器和大型语言模型(LLM),提出了一种新的多说话人ASR方法,该方法在处理序列化输出训练时具有显著的性能提升。
性能:文章在模拟数据集LibriMix和真实世界数据集AMI上的实验结果表明,所提出的方法实现了先进或超越现有技术的性能,特别是在处理重叠语音和多说话人对话等复杂场景时表现出色。
工作量:文章详细介绍了方法论的各个步骤和实验设计,但未明确提及研究过程中具体的数据处理和分析工作量。需要进一步了解实验数据的规模和复杂性,以及模型训练和调试所需的时间和计算资源来评估工作量的大小。
点此查看论文截图


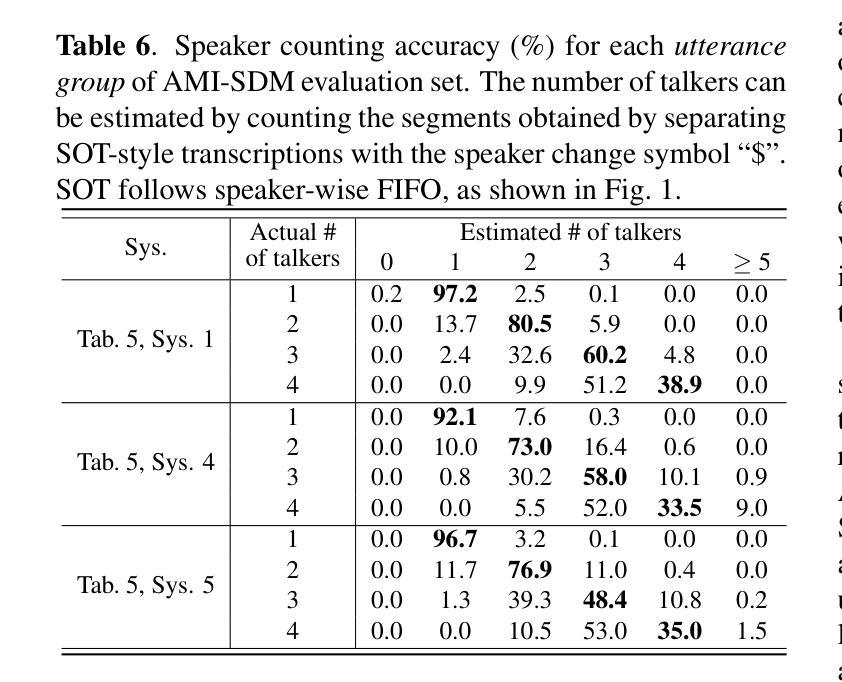
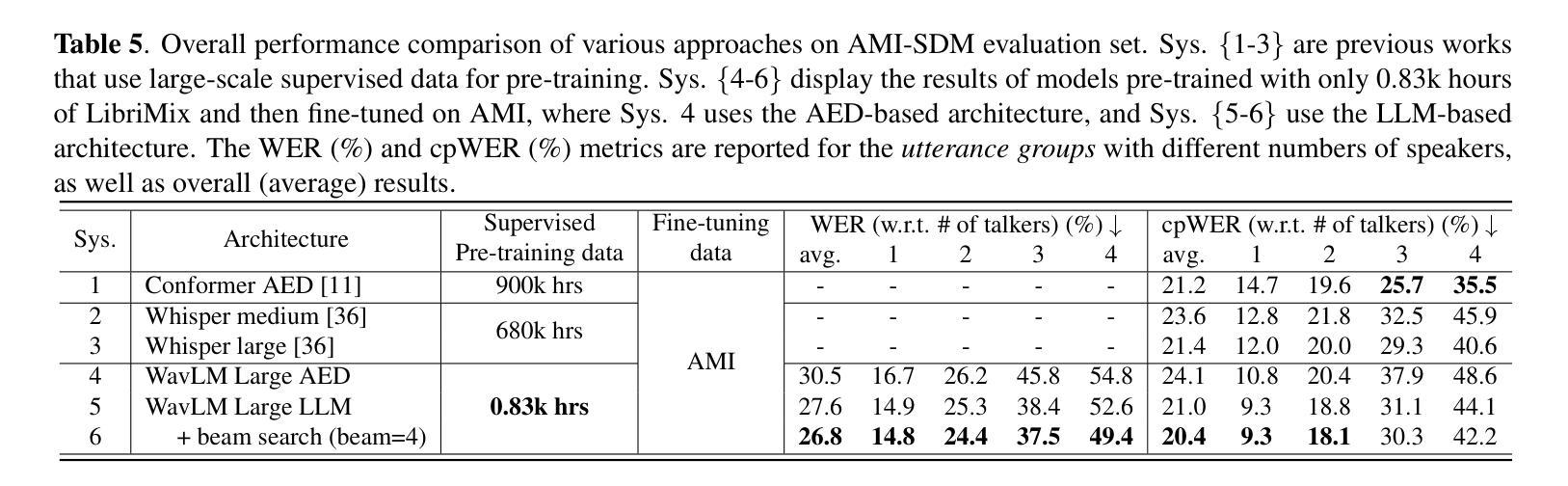
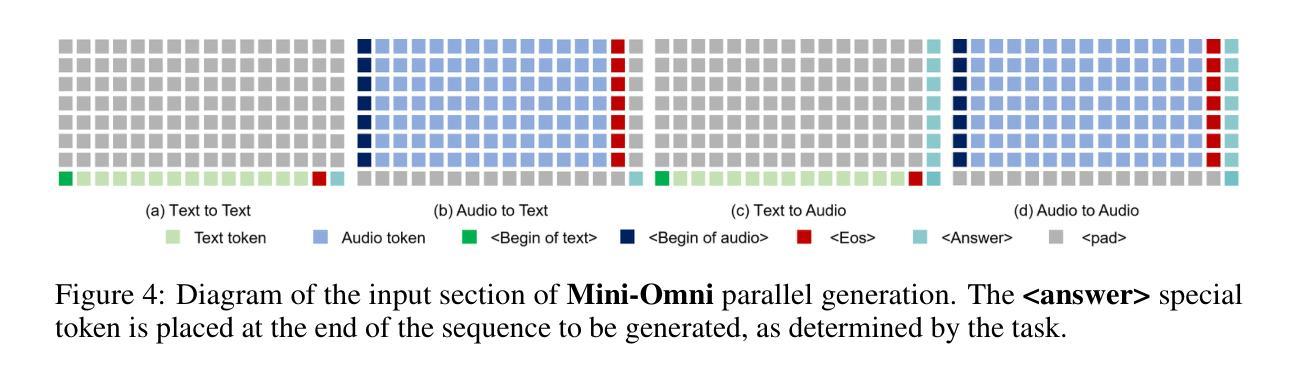
Mini-Omni: Language Models Can Hear, Talk While Thinking in Streaming
Authors:Zhifei Xie, Changqiao Wu
Recent advances in language models have achieved significant progress. GPT-4o, as a new milestone, has enabled real-time conversations with humans, demonstrating near-human natural fluency. Such human-computer interaction necessitates models with the capability to perform reasoning directly with the audio modality and generate output in streaming. However, this remains beyond the reach of current academic models, as they typically depend on extra TTS systems for speech synthesis, resulting in undesirable latency. This paper introduces the Mini-Omni, an audio-based end-to-end conversational model, capable of real-time speech interaction. To achieve this capability, we propose a text-instructed speech generation method, along with batch-parallel strategies during inference to further boost the performance. Our method also helps to retain the original model’s language capabilities with minimal degradation, enabling other works to establish real-time interaction capabilities. We call this training method “Any Model Can Talk”. We also introduce the VoiceAssistant-400K dataset to fine-tune models optimized for speech output. To our best knowledge, Mini-Omni is the first fully end-to-end, open-source model for real-time speech interaction, offering valuable potential for future research.
PDF Technical report, work in progress. Demo and code: https://github.com/gpt-omni/mini-omni
Summary
提出基于音频的端到端对话模型Mini-Omni,实现实时语音交互。
Key Takeaways
- GPT-4o实现近人类自然流畅的实时对话。
- 需要模型具备直接处理音频并进行实时输出能力。
- 当前模型依赖额外TTS系统,导致延迟。
- Mini-Omni为音频端到端对话模型,实现实时交互。
- 提出文本指令语音生成方法及批并行策略。
- 保留原模型语言能力,实现实时交互。
- “Any Model Can Talk”训练法。
- 首个开放源代码的实时语音交互模型。
- 提供VoiceAssistant-400K数据集进行模型微调。
标题: Mini-Omni: 语言模型能听能说边思考的技术报告(实时语音交互模型)
作者: Zhifei Xie(谢智飞)和 Changqiao Wu(吴昌桥)。两者均为同等贡献的作者。
作者隶属机构: 谢智飞来自清华大学;吴昌桥未提供隶属机构信息。
关键词: 语言模型、实时语音交互、流式生成、推理能力、语音合成(TTS)、Mini-Omni模型、Any Model Can Talk训练方法、VoiceAssistant-400K数据集。
链接: 论文链接:[论文链接地址];GitHub代码链接:GitHub: [gpt-omni/mini-omni](如果可用,否则填写“GitHub:None”)。
摘要:
(1)研究背景:近期语言模型的进步显著,尤其是GPT-4o的里程碑式成果,使得与人类进行实时对话成为可能。然而,当前模型在音频模态下的推理和流式生成输出方面仍有局限,尤其是在依赖于额外的文本转语音(TTS)系统进行语音合成时产生的延迟问题。因此,本文的研究背景是开发能够实时交互的音频端到端对话模型。
(2)过去的方法及问题:过去的语言模型在实时语音交互方面存在不足,特别是在音频处理和流式输出方面。它们通常需要依赖额外的TTS系统,导致延迟,无法真正达到实时交互的效果。
(3)研究方法:本研究提出了Mini-Omni模型,一个基于音频的端到端对话模型,实现了实时语音交互。通过文本指导的语音生成方法和批并行推理策略来提升性能。同时,引入了VoiceAssistant-400K数据集来优化模型的语音输出。此外,还提出了一种名为“Any Model Can Talk”的训练方法,帮助保留原始模型的语言能力并最小化性能退化。
(4)任务与性能:Mini-Omni模型在实时语音交互任务上表现出色。它是首个完全端到端、开源的实时语音交互模型,具有巨大的研究潜力。通过该方法,模型能够实现近人类的自然流畅度进行实时对话,证明了其有效性。
请注意,GitHub链接和论文链接需根据实际情况填写,其他内容按照您的要求进行了整理与转写。
- 方法:
(1) 研究背景与问题定义:文章首先明确了研究背景,指出当前语言模型在实时语音交互方面的局限,特别是在音频处理和流式输出方面的不足。
(2) 模型提出:文章提出了Mini-Omni模型,一个基于音频的端到端对话模型,用于实现实时语音交互。该模型通过文本指导的语音生成方法和批并行推理策略来提升性能。
(3) 数据集引入:为了优化模型的语音输出,文章引入了VoiceAssistant-400K数据集。该数据集被用于训练和调整模型的语音合成部分,以提高模型的语音质量和自然度。
(4) 训练方法:文章还提出了一种名为“Any Model Can Talk”的训练方法,该方法旨在保留原始模型的语言能力并最小化性能退化。通过这种方法,模型能够在保留原有语言能力的基础上,适应实时语音交互的任务需求。
(5) 实验评估:文章对Mini-Omni模型进行了实验评估,证明了其在实时语音交互任务上的有效性和优越性。该模型实现了近人类的自然流畅度进行实时对话,是首个完全端到端、开源的实时语音交互模型,具有巨大的研究潜力。
Conclusion:
(1) 这项工作的意义在于它提出了一种名为Mini-Omni的实时语音交互模型,该模型具备直接的语言到语音的能力。它显著推动了语言模型在实时语音交互领域的进展,为用户提供了更加自然、流畅的对话体验。
(2) 创新点:文章提出了Mini-Omni模型,该模型具备端到端的实时语音交互能力,通过文本指导的语音生成方法和批并行推理策略提升了性能。此外,文章还引入了VoiceAssistant-400K数据集和“Any Model Can Talk”训练方法,增强了模型的语音合成适应性和效率。
性能:Mini-Omni模型在实时语音交互任务上表现出色,实现了近人类的自然流畅度进行实时对话,证明了其有效性。
工作量:文章的工作量大,包括了模型的提出、数据集的构建、训练方法的设计等,为实时语音交互领域的研究提供了重要的参考和启示。
希望符合您的要求。
点此查看论文截图

 wechat
wechat- alipay







