元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-15 更新
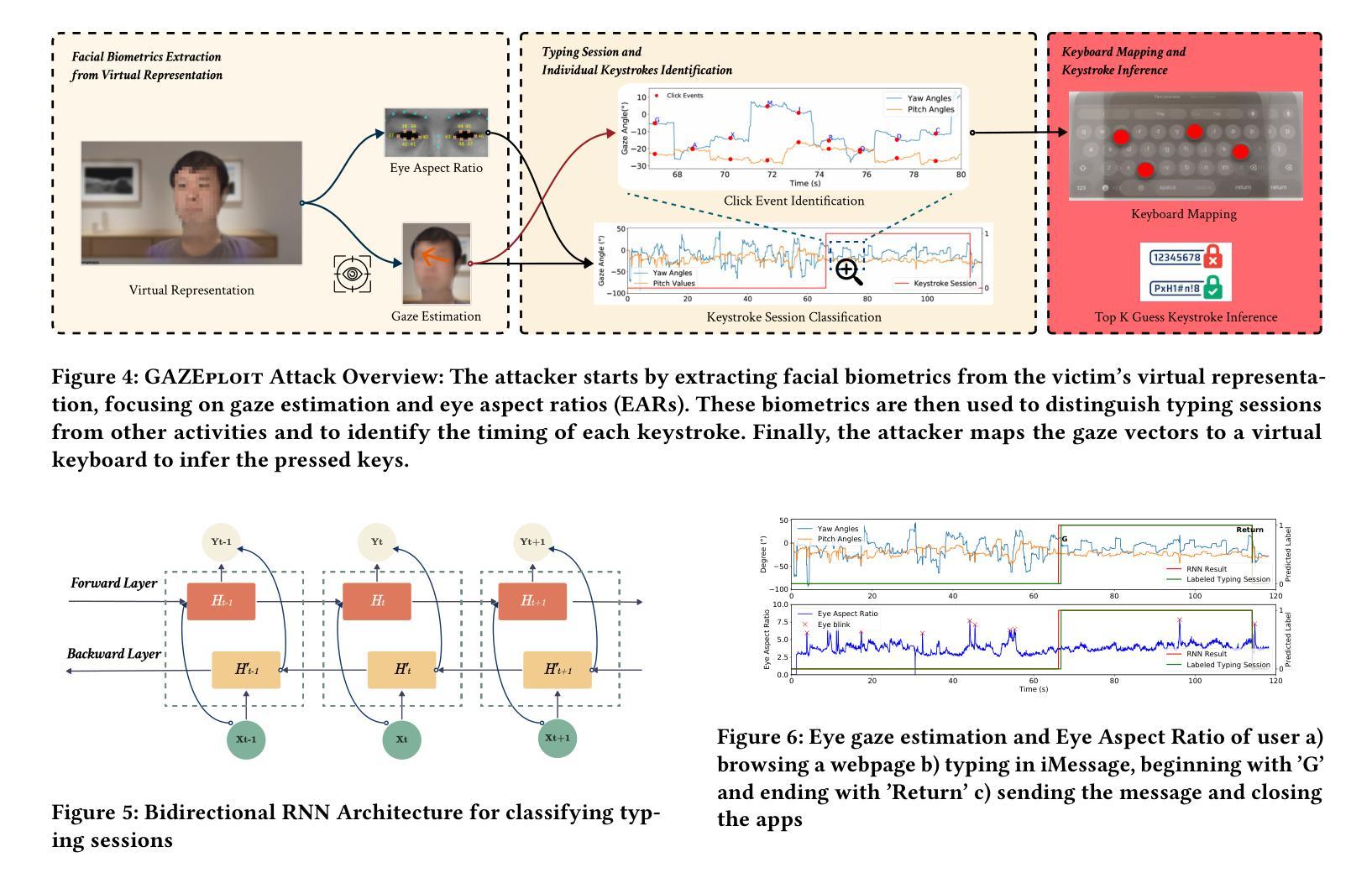
GAZEploit: Remote Keystroke Inference Attack by Gaze Estimation from Avatar Views in VR/MR Devices
Authors:Hanqiu Wang, Zihao Zhan, Haoqi Shan, Siqi Dai, Max Panoff, Shuo Wang
The advent and growing popularity of Virtual Reality (VR) and Mixed Reality (MR) solutions have revolutionized the way we interact with digital platforms. The cutting-edge gaze-controlled typing methods, now prevalent in high-end models of these devices, e.g., Apple Vision Pro, have not only improved user experience but also mitigated traditional keystroke inference attacks that relied on hand gestures, head movements and acoustic side-channels. However, this advancement has paradoxically given birth to a new, potentially more insidious cyber threat, GAZEploit. In this paper, we unveil GAZEploit, a novel eye-tracking based attack specifically designed to exploit these eye-tracking information by leveraging the common use of virtual appearances in VR applications. This widespread usage significantly enhances the practicality and feasibility of our attack compared to existing methods. GAZEploit takes advantage of this vulnerability to remotely extract gaze estimations and steal sensitive keystroke information across various typing scenarios-including messages, passwords, URLs, emails, and passcodes. Our research, involving 30 participants, achieved over 80% accuracy in keystroke inference. Alarmingly, our study also identified over 15 top-rated apps in the Apple Store as vulnerable to the GAZEploit attack, emphasizing the urgent need for bolstered security measures for this state-of-the-art VR/MR text entry method.
PDF 15 pages, 20 figures, Accepted at ACM CCS’24
Summary
元宇宙VR/AR设备中的眼动追踪技术带来安全隐患,新型GAZEploit攻击可窃取敏感信息。
Key Takeaways
- VR/AR设备眼动追踪技术革命性改变用户交互体验。
- 眼动追踪技术防御传统攻击,但引入GAZEploit新型威胁。
- GAZEploit利用虚拟形象漏洞窃取敏感按键信息。
- 研究显示GAZEploit攻击成功率达80%。
- 多个App Store中的应用程序存在GAZEploit攻击漏洞。
- 需加强VR/AR设备文本输入方法的安保措施。
Title: GAZEploit:基于虚拟现实/混合现实设备中的眼动追踪信息进行远程键击推断攻击
Authors: 王韩秋, 詹子豪, 单浩祺, 戴思琦, 帕诺夫·马克西米利安, 王硕
Affiliation: 王韩秋等,佛罗里达大学电气与计算机工程系
Keywords: 虚拟现实;眼动追踪;键击推断;用户隐私
Summary:
(1)研究背景:随着虚拟现实(VR)和混合现实(MR)技术的日益普及,眼动追踪技术在高端VR设备中得到了广泛应用。然而,这种先进技术也带来了一种新的网络安全威胁,即GAZEploit攻击。该攻击利用眼动追踪信息,针对使用VR/MR设备的用户进行远程键击推断。
(2)过去的方法及问题:以往的安全攻击主要依赖于手势、头部移动和声音侧信道等信息进行键击推断,但这些方法在眼动追踪技术面前显得不够有效。因此,需要一种新的攻击方法,能够适应眼动追踪技术的普及。
(3)研究方法:本研究提出了一种名为GAZEploit的新型远程键击推断攻击方法。该方法利用虚拟现实应用程序中虚拟形象的广泛使用,通过眼动追踪信息进行键击推断。研究涉及了30名参与者的实验,实现了超过80%的键击推断准确率。
(4)任务与性能:研究者在实验中模拟了多种打字场景,包括消息、密码、网址、电子邮件和密码等。实验结果表明,GAZEploit攻击方法在这些场景中的键击推断准确率较高。此外,研究还发现超过15款苹果商店的热门应用存在漏洞,这进一步强调了加强VR/MR文本输入方法安全性的紧迫性。实验性能支持了该方法的有效性。
- Conclusion:
(1) 工作意义:
该文章的研究工作具有重要的实际意义。随着虚拟现实和混合现实技术的普及,其安全问题愈发凸显。文章提出的新型远程键击推断攻击方法GAZEploit,揭示了虚拟现实和混合现实设备中眼动追踪技术的安全隐患,对用户隐私安全构成了新的挑战。这一发现有助于提升相关领域的安全意识,推动虚拟现实和混合现实技术在安全方面的改进。
(2) 创新点、性能和工作量评价:
创新点:文章提出了名为GAZEploit的新型远程键击推断攻击方法,利用虚拟现实应用程序中的眼动追踪信息进行键击推断,这是一个全新的尝试,展现了研究者在该领域的创新思考。
性能:通过实验验证,GAZEploit攻击方法实现了超过80%的键击推断准确率,证明其具有较高的攻击性能。同时,研究还发现多款热门应用存在安全漏洞,进一步凸显了改进虚拟现实和混合现实文本输入方法安全性的紧迫性。
工作量:文章进行了详细的实验验证,包括多种打字场景的模拟和热门应用的漏洞扫描,工作量较大。此外,文章还对研究背景、方法、实验结果等进行了全面的介绍和分析,展现出研究者们的严谨态度和充分的工作准备。
总体来说,这是一篇在虚拟现实和混合现实设备安全领域具有创新性和实际意义的研究工作,既揭示了新的安全威胁,也为未来的安全工作提供了研究方向和改进方向。
点此查看论文截图




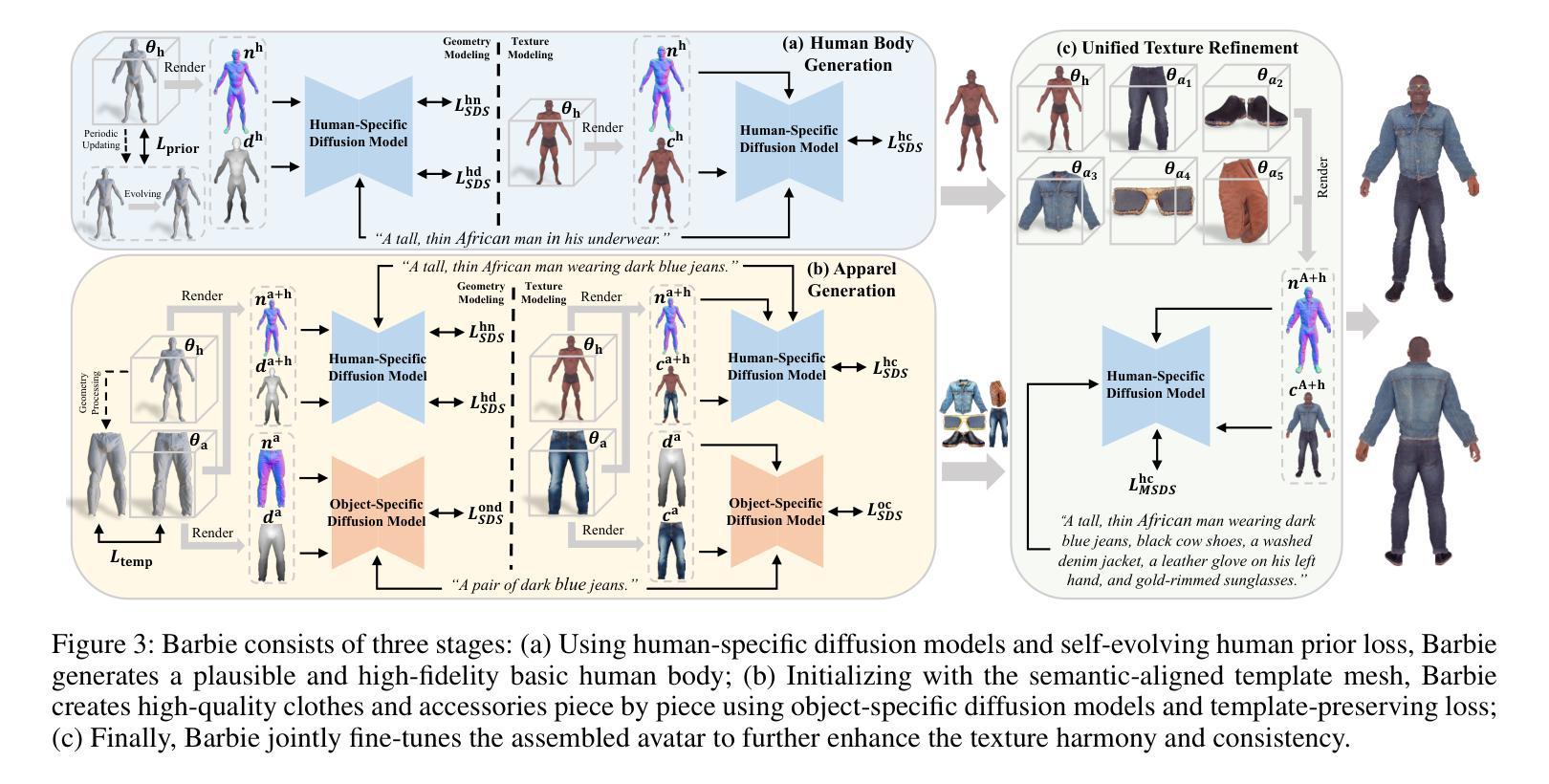
Barbie: Text to Barbie-Style 3D Avatars
Authors:Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
Recent advances in text-guided 3D avatar generation have made substantial progress by distilling knowledge from diffusion models. Despite the plausible generated appearance, existing methods cannot achieve fine-grained disentanglement or high-fidelity modeling between inner body and outfit. In this paper, we propose Barbie, a novel framework for generating 3D avatars that can be dressed in diverse and high-quality Barbie-like garments and accessories. Instead of relying on a holistic model, Barbie achieves fine-grained disentanglement on avatars by semantic-aligned separated models for human body and outfits. These disentangled 3D representations are then optimized by different expert models to guarantee the domain-specific fidelity. To balance geometry diversity and reasonableness, we propose a series of losses for template-preserving and human-prior evolving. The final avatar is enhanced by unified texture refinement for superior texture consistency. Extensive experiments demonstrate that Barbie outperforms existing methods in both dressed human and outfit generation, supporting flexible apparel combination and animation. The code will be released for research purposes. Our project page is: https://xiaokunsun.github.io/Barbie.github.io/.
PDF 9 pages, 7 figures
Summary
提出Barbie框架,通过语义对齐分离模型实现3D虚拟人精细解耦,优化服装生成。
Key Takeaways
- 使用扩散模型知识提高3D虚拟人生成。
- 现有方法难以实现细粒度解耦和高保真建模。
- Barbie框架实现人体和服装的细粒度解耦。
- 采用不同专家模型保证特定领域保真度。
- 提出损失函数平衡几何多样性和合理性。
- 统一纹理优化提升纹理一致性。
- Barbie在服装组合和动画生成上优于现有方法。
- 代码公开发布供研究使用。
- 项目页面:https://xiaokunsun.github.io/Barbie.github.io/。
Title: 基于文本指导的Barbie风格3D角色生成
Authors: Xiaokun Sun, Zhenyu Zhang, Ying Tai, Qian Wang, Hao Tang, Zili Yi, Jian Yang
Affiliation: 作者分别来自南京大学、中国移动研究院和北京大学。
Keywords: text-to-avatar generation, 3D avatar generation, fine-grained disentanglement, domain-specific fidelity, Barbie-style avatars
Urls: https://arxiv.org/abs/2408.09126v3 , GitHub代码链接(待补充)
Summary:
(1) 研究背景:随着虚拟世界的不断发展,创建高质量的3D数字角色变得尤为重要。该文章聚焦于基于文本指导的Barbie风格3D角色生成,旨在实现角色与其服装的精细分离和高保真建模。
(2) 过去的方法及问题:现有的文本指导的3D角色生成方法主要分为两类,整体角色生成和身体和服装的分离模型生成。这些方法在生成真实感较高的角色时,无法实现角色身体和服装的精细分离或高保真建模。文章提出的方法基于文本指导生成逼真的Barbie风格的3D角色,并能够生成多样的服装配件。对现有方法的缺点和不足进行了详细的讨论和阐述。
(3) 研究方法:本文提出了Barbie框架,通过语义对齐的分离模型对角色身体和服装进行精细分离。使用不同的专家模型对这些分离的3D表示进行优化,以保证特定领域的保真度。通过一系列损失函数平衡几何多样性和合理性,最后通过统一的纹理优化来提高纹理一致性。
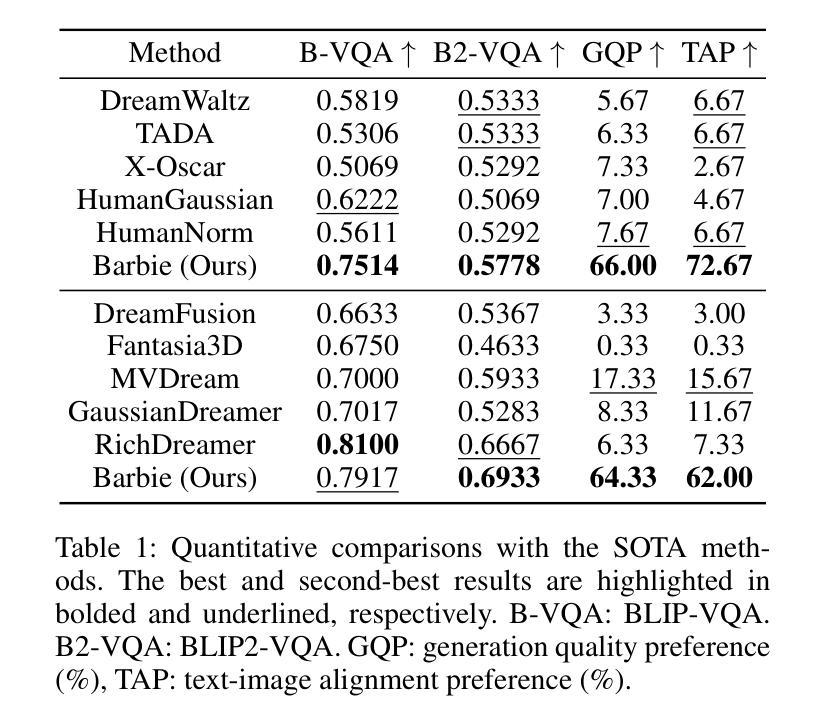
(4) 任务与性能:本文的方法在服装搭配和动画任务上表现出良好的性能,生成的Barbie风格角色具有高质量和高度的可定制性。通过对比实验证明了该方法的有效性,生成的角色的几何形状、纹理和服装配件均达到了较高的质量水平。性能结果支持了该方法的目标,即生成高质量的Barbie风格角色和逼真的服装配件。
- 方法论:
这篇论文的方法论主要围绕基于文本指导的Barbie风格3D角色生成展开,主要包括以下几个步骤:
- (1) 研究背景与问题阐述:
论文首先介绍了虚拟世界的不断发展和创建高质量3D数字角色的重要性,然后指出了现有方法在处理文本指导的3D角色生成时的问题和不足,尤其是角色身体和服装的精细分离和高保真建模方面的挑战。
- (2) 研究方法概述:
论文提出了Barbie框架,通过语义对齐的分离模型对角色身体和服装进行精细分离。使用不同的专家模型对这些分离的3D表示进行优化,以保证特定领域的保真度。通过一系列损失函数平衡几何多样性和合理性,最后通过统一的纹理优化来提高纹理一致性。
- (3) 初步人体生成:
采用SMPL-X参数化人体模型表示全身形状、姿态和表情,根据输入的文本描述优化形状参数β,生成基本的数字人体Minit。这一步提供了丰富的人体先验知识,为后续阶段提供了语义对齐的表示。
- (4) 人体几何建模:
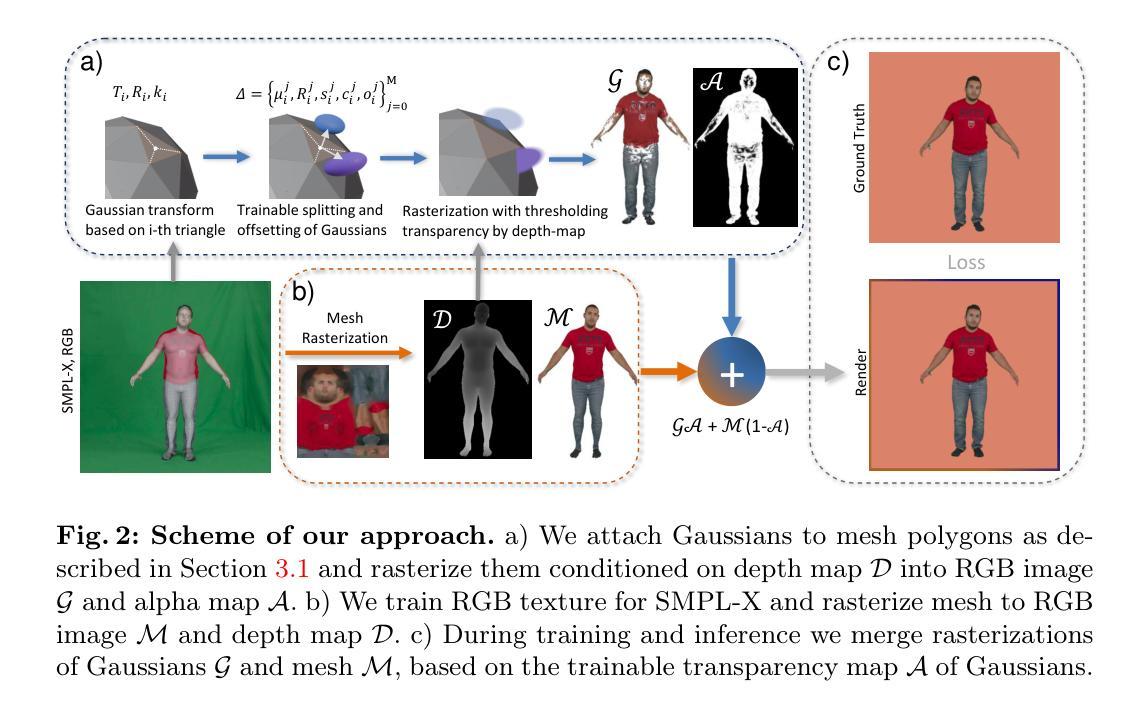
采用人类特定的扩散模型(如HumanNorm)进行优化,包括正常适应扩散模型ϕhn、深度适应扩散模型ϕhd以及用于人体纹理创建的正规条件扩散模型ϕhc。这些模型根据输入的最小着装人体描述yh优化初始化的DMTet参数θh。同时,引入自我演化的人体先验损失,通过周期性地适应网格Minit来约束生成的几何形状,保持拓扑结构的同时增强多样性。
- (5) 人体纹理建模:
在生成人体网格的基础上,使用正常适应的扩散模型ϕhc创建真实且正常的纹理。这一阶段专注于通过优化损失函数Lhc SDS来确保生成的纹理与输入文本描述相一致。
总结来说,该研究通过精细分离角色身体和服装、利用专家模型优化特定领域的保真度以及平衡几何多样性和合理性等方法,实现了高质量的Barbie风格3D角色生成。这种方法在服装搭配和动画任务上表现出良好的性能,生成的Barbie风格角色具有高质量和高度的可定制性。
Conclusion:
(1)该工作的意义在于实现了基于文本指导的Barbie风格3D角色生成,解决了现有方法在角色身体和服装精细分离和高保真建模方面的挑战,为创建高质量的3D数字角色提供了新的思路和方法。
(2)创新点:该文章提出了Barbie框架,通过语义对齐的分离模型对角色身体和服装进行精细分离,使用不同的专家模型对这些分离的3D表示进行优化,保证了特定领域的保真度。同时,通过一系列损失函数平衡几何多样性和合理性,最后通过统一的纹理优化提高了纹理一致性。
性能:该文章的方法在服装搭配和动画任务上表现出良好的性能,生成的Barbie风格角色具有高质量和高度的可定制性。对比实验证明了该方法的有效性。
工作量:文章提出了详细的方法论和实验验证,从初步人体生成、人体几何建模、人体纹理建模等多个方面进行了研究和实验,工作量较大。
点此查看论文截图



 wechat
wechat- alipay