NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-24 更新
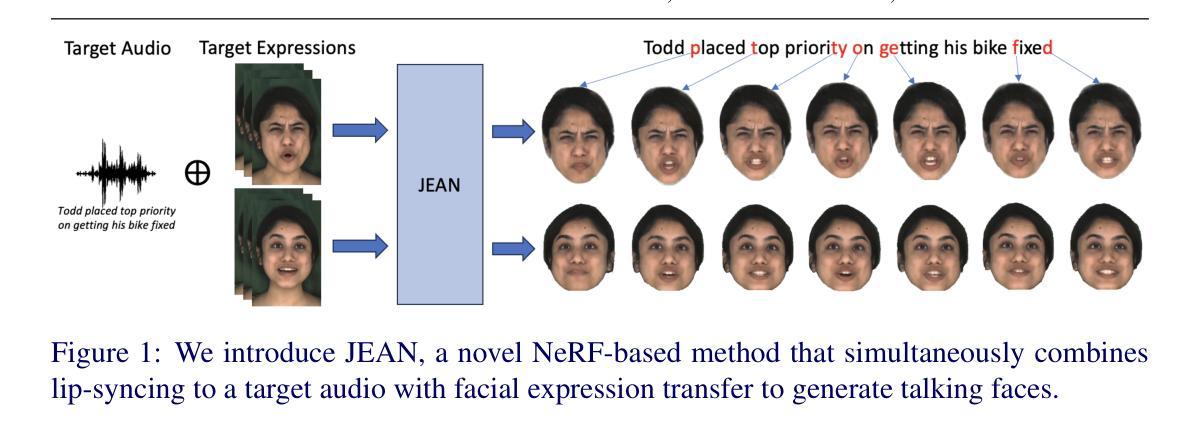
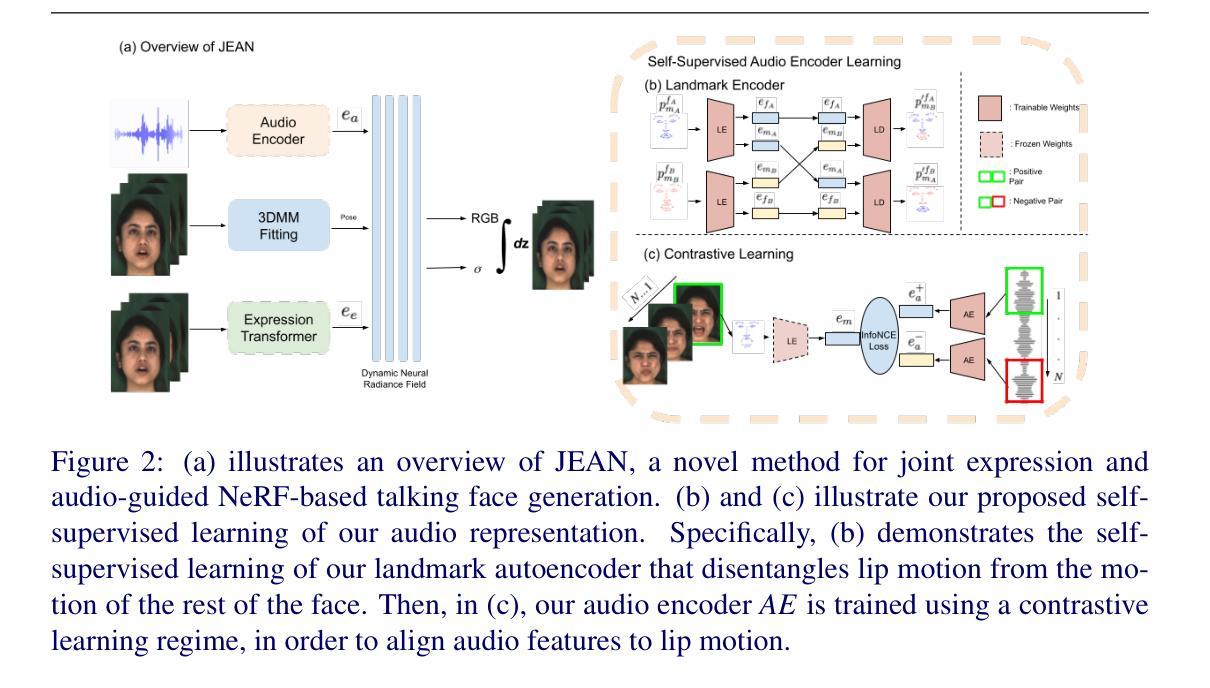
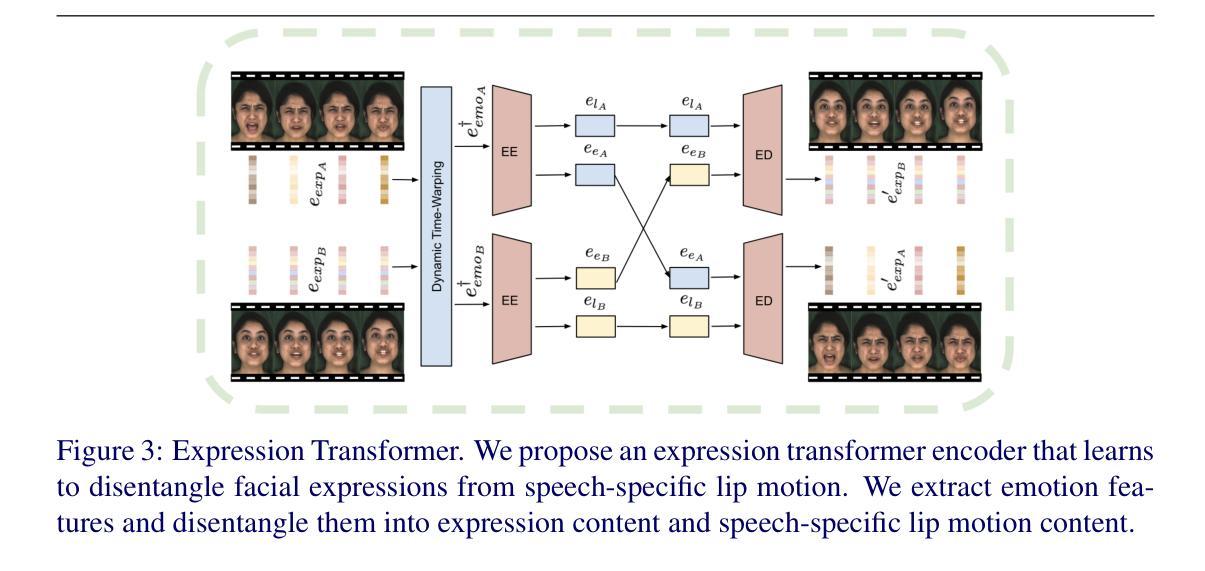
JEAN: Joint Expression and Audio-guided NeRF-based Talking Face Generation
Authors:Sai Tanmay Reddy Chakkera, Aggelina Chatziagapi, Dimitris Samaras
We introduce a novel method for joint expression and audio-guided talking face generation. Recent approaches either struggle to preserve the speaker identity or fail to produce faithful facial expressions. To address these challenges, we propose a NeRF-based network. Since we train our network on monocular videos without any ground truth, it is essential to learn disentangled representations for audio and expression. We first learn audio features in a self-supervised manner, given utterances from multiple subjects. By incorporating a contrastive learning technique, we ensure that the learned audio features are aligned to the lip motion and disentangled from the muscle motion of the rest of the face. We then devise a transformer-based architecture that learns expression features, capturing long-range facial expressions and disentangling them from the speech-specific mouth movements. Through quantitative and qualitative evaluation, we demonstrate that our method can synthesize high-fidelity talking face videos, achieving state-of-the-art facial expression transfer along with lip synchronization to unseen audio.
PDF Accepted by BMVC 2024. Project Page: https://starc52.github.io/publications/2024-07-19-JEAN
Summary
提出基于NeRF的联合表达和音频引导的说话人脸生成新方法,有效解决现有方法在保持说话人身份和面部表情真实性方面的不足。
Key Takeaways
- 提出NeRF网络解决说话人脸生成问题。
- 无地面真值训练,需学习音频和表达分离表示。
- 自监督学习音频特征,与唇部运动同步。
- 对比学习技术确保音频特征与面部肌肉运动分离。
- Transformer架构学习面部表情特征,分离口部运动。
- 生成高质量说话人脸视频,实现面部表情迁移和唇同步。
- 达到面部表情转移和唇同步的当前最佳水平。
标题:
- 中文翻译:JEAN:联合表达和音频引导下的NeRF基说话人脸生成。
作者:
- Sai Tanmay Reddy Chakkera(石坦梅尔赛)、Aggelina Chatziagapi(阿格丽娜·查兹亚加皮)、Dimitris Samaras(狄米特里斯·萨马拉斯)。
作者所属单位:
- Stony Brook University(纽约州立大学石溪分校)。
关键词:
- 音频引导、表情控制、说话人脸生成、NeRF网络、对比学习、Transformer架构。
链接:
摘要:
- (1)研究背景:本文介绍了联合表达和音频引导的说话人脸生成的研究背景。随着视频内容创建和视频会议等应用的普及,合成具有真实感的说话人脸已成为重要研究方向。现有的方法往往难以同时保证说话人身份保留和面部表情的忠实呈现。因此,该研究具有重要意义。
- (2)相关工作:过去的方法主要关注音频引导或表情引导的人脸合成,难以同时控制面部表情和唇部动作。一些方法虽然试图解决这一问题,但在保留说话人身份或产生忠实表情方面存在挑战。本研究受近期NeRF技术成功应用于3D建模的启发,旨在解决这一问题。文章介绍了这些方法的局限性并提出了本文方法的动机。
- (3)研究方法:本研究提出了一种基于NeRF的联合表达和音频引导说话人脸生成方法。首先,通过自监督学习从多个主体的发音中学习音频特征,并利用对比学习技术确保学习的音频特征与唇部动作对齐,并与面部其他肌肉的运动分离。然后,开发了一种基于Transformer的架构来学习表情特征,该架构能够捕捉长期面部表情并将其与特定的口腔运动区分开。通过这些技术,模型能够在没有地面真实数据的情况下训练,生成高保真度的说话人脸视频。
- (4)任务与性能:本研究在说话人脸生成任务上进行了评估,实验结果表明,该方法在面部表达转移和未见面部音频的唇同步方面达到了最新水平。通过定量和定性评估,证明了该方法的有效性。性能结果支持了该方法的目标,即合成具有真实感和精细表情的说话人脸视频。
以上是关于该论文的总结,希望对您有所帮助。
- 方法:
- (1) 研究首先通过自监督学习从多个主体的发音中学习音频特征。学习到的音频特征会与唇部动作对齐,并通过对比学习技术确保与面部其他肌肉的运动分离。
- (2) 研究开发了一种基于Transformer的架构来学习表情特征。该架构可以捕捉长期面部表情,并将其与特定的口腔运动区分开。通过这种技术,模型可以在没有地面真实数据的情况下训练。
- (3) 模型生成的说话人脸视频具有高保真度,并在说话人脸生成任务上进行了评估。实验结果表明,该方法在面部表达转移和未见面部音频的唇同步方面达到了最新水平。通过定量和定性评估,证明了该方法的有效性。
以上内容是对该论文方法部分的详细总结,希望对您有帮助。
- Conclusion:
(1)这项工作的重要性在于它解决了音频引导下的说话人脸生成的问题,能够在保留说话人身份的同时合成具有真实感的面部表情。这对于视频内容创建、视频会议应用等领域具有重要意义。
(2)创新点:该文章提出了一种基于NeRF的联合表达和音频引导说话人脸生成方法,通过自监督学习和对比学习技术,实现了音频特征与唇部动作的准确对齐,并开发了一种基于Transformer的架构来学习表情特征。该方法在说话人脸生成任务上取得了最新水平的结果。
性能:实验结果表明,该方法在面部表达转移和未见面部音频的唇同步方面表现出色,通过定量和定性评估证明了其有效性。生成的说话人脸视频具有高保真度。
工作量:文章详细介绍了方法的具体实现和实验过程,但未明确提及工作量的大小。从论文篇幅和内容的深度来看,作者进行了大量的实验和验证工作。
点此查看论文截图

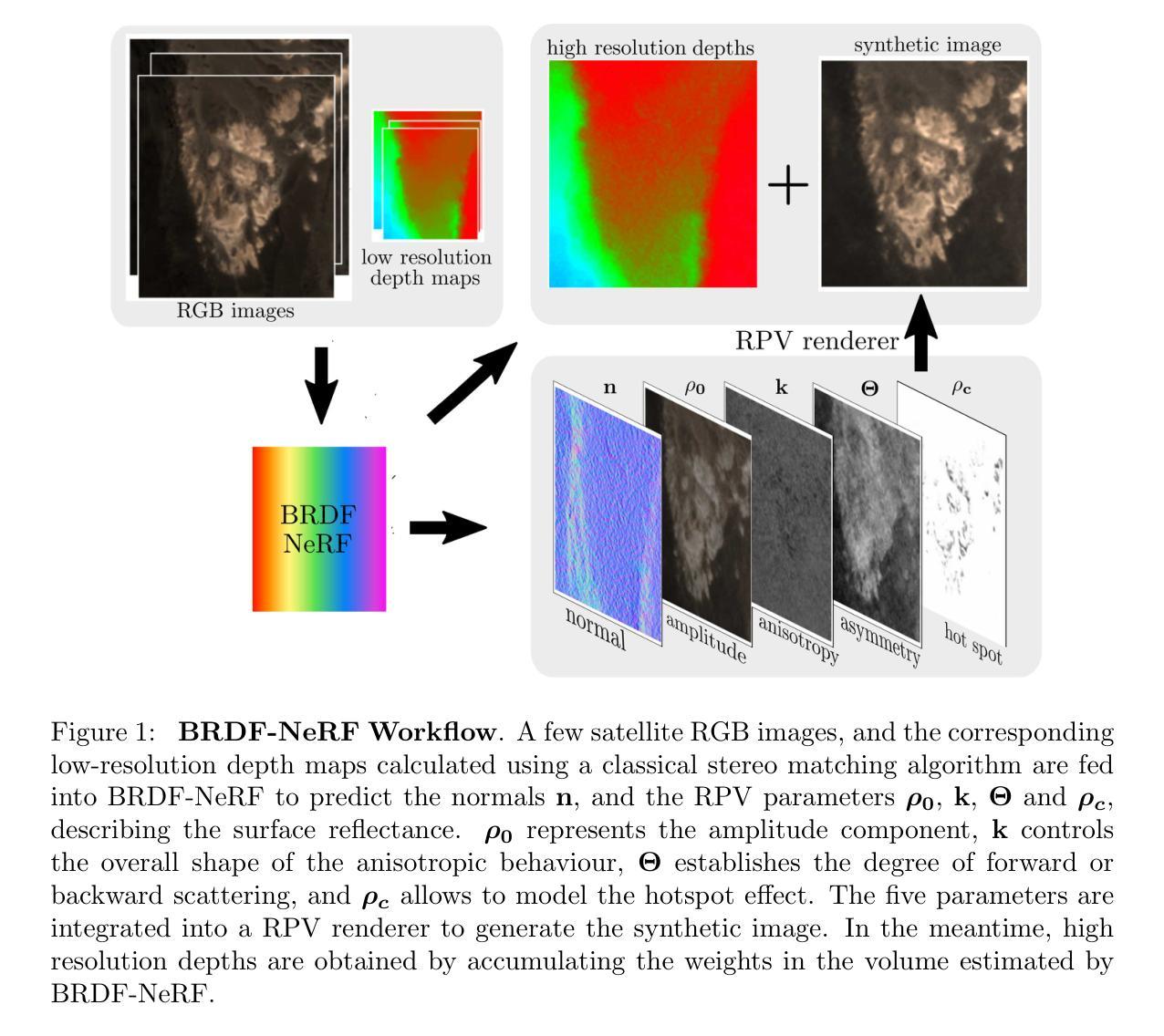
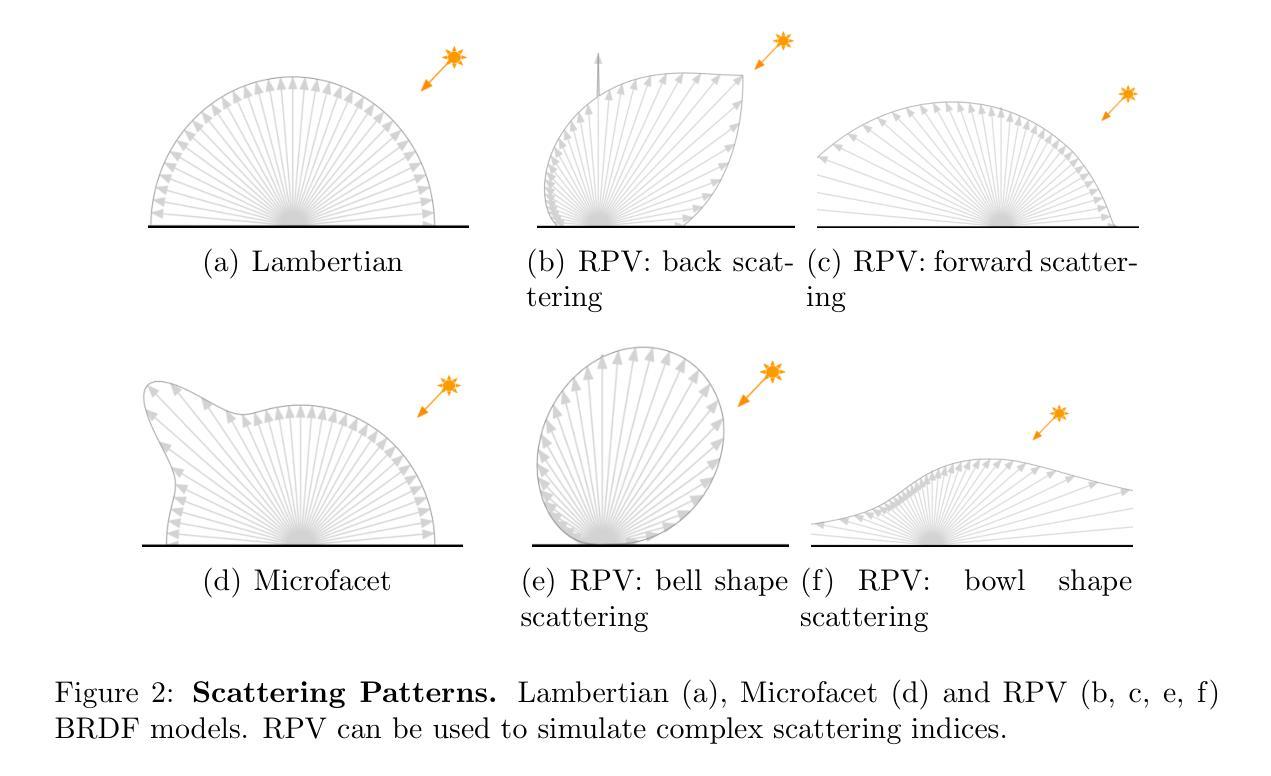
BRDF-NeRF: Neural Radiance Fields with Optical Satellite Images and BRDF Modelling
Authors:Lulin Zhang, Ewelina Rupnik, Tri Dung Nguyen, Stéphane Jacquemoud, Yann Klinger
Understanding the anisotropic reflectance of complex Earth surfaces from satellite imagery is crucial for numerous applications. Neural radiance fields (NeRF) have become popular as a machine learning technique capable of deducing the bidirectional reflectance distribution function (BRDF) of a scene from multiple images. However, prior research has largely concentrated on applying NeRF to close-range imagery, estimating basic Microfacet BRDF models, which fall short for many Earth surfaces. Moreover, high-quality NeRFs generally require several images captured simultaneously, a rare occurrence in satellite imaging. To address these limitations, we propose BRDF-NeRF, developed to explicitly estimate the Rahman-Pinty-Verstraete (RPV) model, a semi-empirical BRDF model commonly employed in remote sensing. We assess our approach using two datasets: (1) Djibouti, captured in a single epoch at varying viewing angles with a fixed Sun position, and (2) Lanzhou, captured over multiple epochs with different viewing angles and Sun positions. Our results, based on only three to four satellite images for training, demonstrate that BRDF-NeRF can effectively synthesize novel views from directions far removed from the training data and produce high-quality digital surface models (DSMs).
Summary
从单张卫星图像中估计地球表面BRDF的NeRF方法研究。
Key Takeaways
- NeRF在估计地球表面BRDF方面具有潜力。
- 先前研究主要应用于近距离图像和基本Microfacet BRDF模型。
- BRDF-NeRF旨在估计RPV模型,适用于远程传感。
- 使用两个数据集评估方法,包括Djibouti和Lanzhou。
- 仅需三到四张卫星图像进行训练。
- BRDF-NeRF能合成远离训练数据方向的新视角。
- 生成高质量数字表面模型(DSM)。
标题:基于神经网络辐射场与光学卫星图像的BRDF建模研究(BRDF-NeRF: Neural Radiance Fields with Optical Satellite Images and BRDF Modelling)
作者:张露露(Lulin Zhang), 鲁皮克(Ewelina Rupnik), 农智薰(Tri Dung Nguyen), 雅克莫德(St´ephane Jacquemoud), 克林格(Yann Klinger)。
作者所属机构:张露露和鲁皮克来自巴黎大学(Université de Paris),雅克莫德来自法国国家科学研究中心(CNRS),克林格和农智薰没有给出具体的机构信息。中文翻译:张露露等人为巴黎大学等机构的研究人员。
关键词:神经网络辐射场(Neural Radiance Fields)、卫星图像、双向反射分布函数(BRDF)、参数化RPV模型、数字表面模型(Digital Surface Model)。
Urls:文章链接没有给出具体的网址,GitHub代码链接尚未提供(GitHub: None)。
总结:
(1)研究背景:文章探讨的是基于卫星图像理解地球表面复杂物质的反射特性的重要性。在卫星图像处理领域,尤其是对于遥感应用中地球表面的3D重建问题有着极高的关注度。尤其是在需要对地球的反射现象进行深入理解时,利用神经网络辐射场技术从卫星图像中获取地球表面的反射分布模型是一个重要且富有挑战性的研究方向。本篇文章的研究背景就是在这样的背景下展开的。
-(2)过去的方法与问题:尽管神经网络辐射场技术在计算机视觉领域取得了显著的进展,尤其是在近景图像的BRDF估计方面,但在卫星图像领域的应用仍然面临诸多挑战。过去的研究主要关注于简单的微表面BRDF模型的估计,这些模型对于大多数地球表面的复杂性情况来说是不充分的。此外,高质量神经网络辐射场的构建通常需要同时获取的多张图像,这在卫星图像中是非常罕见的场景。因此,文章的研究目的是针对这些挑战展开方法研究的必要性显而易见。
-(3)研究方法:为了克服上述挑战,文章提出了一种名为BRDF-NeRF的方法。该方法设计用于明确估计被广泛用于遥感领域的拉曼-平蒂-韦斯特雷特(Rahman-Pinty-Verstraete,简称RPV)模型的参数。通过引入半经验BRDF模型,该方法能够在有限的卫星图像数据下生成高质量的数字表面模型。同时,BRDF-NeRF还能够成功合成与训练集视角不同的新视角图像。这些特点使得BRDF-NeRF成为卫星图像处理领域的一种新的有效工具。
-(4)任务与性能:文章在两个数据集上进行了实验评估:在固定太阳位置和不同视角拍摄的吉布提数据集以及在不同视角和太阳位置拍摄的兰州数据集。实验结果表明,即使只使用三到四张卫星图像进行训练,BRDF-NeRF依然能够成功合成新视角的图像并生成高质量的数字表面模型。这些结果充分证明了BRDF-NeRF方法的性能及其在卫星图像处理任务中的适用性。通过实验结果,文章成功地支持了其方法的可行性及其性能的有效性。
- 方法论:
这篇论文的主要方法论思想是基于神经网络辐射场与光学卫星图像的双向反射分布函数BRDF建模研究。具体步骤如下:
- (1) 研究背景分析:基于卫星图像理解地球表面复杂物质的反射特性的重要性。在卫星图像处理领域,特别是对于遥感应用中地球表面的三维重建问题,如何利用神经网络辐射场技术从卫星图像中获取地球表面的反射分布模型是一个重要且富有挑战性的研究方向。
- (2) 过去方法与问题:虽然神经网络辐射场技术在计算机视觉领域取得了显著的进展,特别是在近景图像的BRDF估计方面,但在卫星图像领域的应用仍然面临诸多挑战。过去的研究主要关注简单的微表面BRDF模型的估计,这些模型对于地球表面的复杂性情况来说是不充分的。
- (3) 研究方法提出:为了克服上述挑战,论文提出了一种名为BRDF-NeRF的方法。该方法旨在明确估计广泛用于遥感领域的拉曼-平蒂-韦斯特雷特(Rahman-Pinty-Verstraete,简称RPV)模型的参数。通过引入半经验BRDF模型,BRDF-NeRF能够在有限的卫星图像数据下生成高质量的数字表面模型。同时,BRDF-NeRF还能够成功合成与训练集视角不同的新视角图像。
- (4) 数据集实验评估:论文在两个数据集上进行了实验评估,包括吉布提数据集和兰州数据集。实验结果表明,即使只使用三到四张卫星图像进行训练,BRDF-NeRF依然能够成功合成新视角的图像并生成高质量的数字表面模型。此外,论文还通过一系列消融实验对BRDF-NeRF方法的关键设计选择进行了评估,包括训练策略、深度损失权重等。
总的来说,这篇论文的方法论是基于深度学习和神经网络辐射场技术,结合卫星图像数据,旨在解决遥感应用中地球表面复杂物质的反射分布建模问题。
- Conclusion:
(1)这篇工作的意义在于,它提出了一种基于神经网络辐射场和光学卫星图像的BRDF建模方法,即BRDF-NeRF。该方法对于理解地球表面的复杂反射特性,尤其是在遥感应用中,具有重要的价值。
(2)创新点:该文章的创新之处在于将神经网络辐射场技术应用于卫星图像领域,并提出了BRDF-NeRF方法。该方法结合了神经网络辐射场和光学卫星图像,能够明确估计广泛用于遥感领域的拉曼-平蒂-韦斯特雷特(Rahman-Pinty-Verstraete,简称RPV)模型的参数。与传统方法相比,BRDF-NeRF能够在有限的卫星图像数据下生成高质量的数字表面模型,并成功合成与训练集视角不同的新视角图像。
性能:该文章在两个数据集上进行了实验评估,包括吉布提数据集和兰州数据集。实验结果表明,BRDF-NeRF在合成新视角的图像和生成数字表面模型方面表现出良好的性能。即使只使用三到四张卫星图像进行训练,BRDF-NeRF依然能够成功合成高质量的图像和模型。
工作量:该文章对研究问题进行了系统的分析和解决,但在工作量方面存在一些不足。例如,文章没有提供所有作者的机构信息,GitHub代码链接尚未提供,这可能会影响到读者对该方法的深入理解和应用。此外,虽然文章对实验进行了详细的评估,但没有提供充分的实验细节和数据集信息,这可能会影响到研究的完整性和透明度。
点此查看论文截图

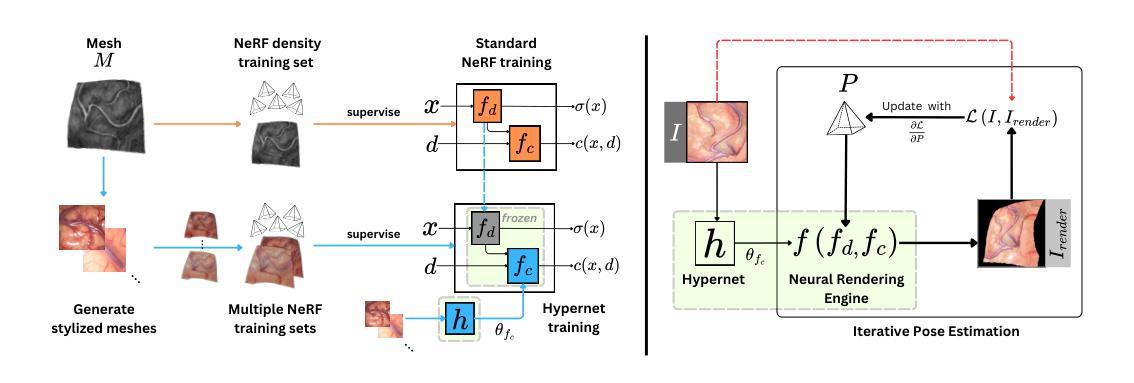
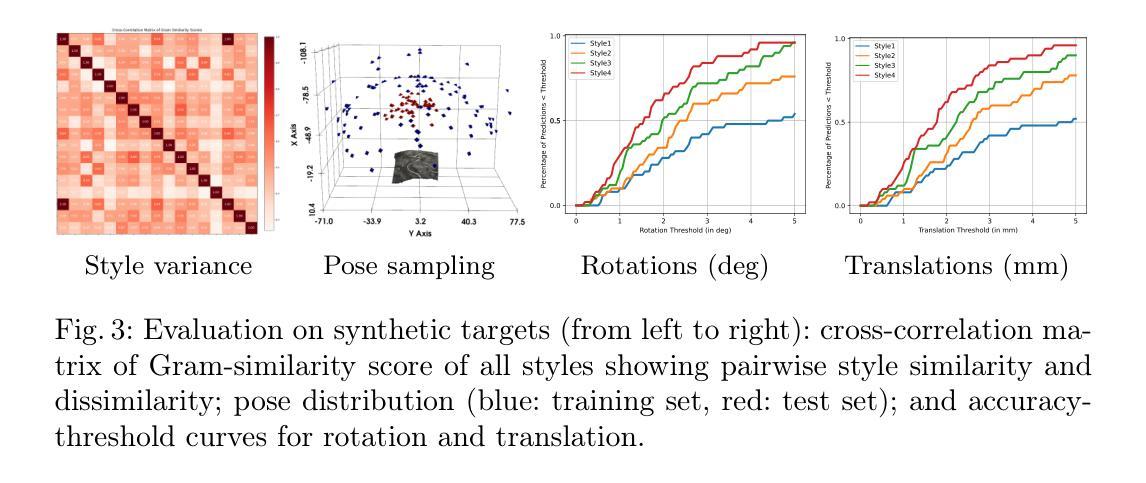
Intraoperative Registration by Cross-Modal Inverse Neural Rendering
Authors:Maximilian Fehrentz, Mohammad Farid Azampour, Reuben Dorent, Hassan Rasheed, Colin Galvin, Alexandra Golby, William M. Wells, Sarah Frisken, Nassir Navab, Nazim Haouchine
We present in this paper a novel approach for 3D/2D intraoperative registration during neurosurgery via cross-modal inverse neural rendering. Our approach separates implicit neural representation into two components, handling anatomical structure preoperatively and appearance intraoperatively. This disentanglement is achieved by controlling a Neural Radiance Field’s appearance with a multi-style hypernetwork. Once trained, the implicit neural representation serves as a differentiable rendering engine, which can be used to estimate the surgical camera pose by minimizing the dissimilarity between its rendered images and the target intraoperative image. We tested our method on retrospective patients’ data from clinical cases, showing that our method outperforms state-of-the-art while meeting current clinical standards for registration. Code and additional resources can be found at https://maxfehrentz.github.io/style-ngp/.
PDF Accepted at MICCAI 2024
Summary
提出基于跨模态逆向神经渲染的3D/2D神经外科术中配准新方法,通过解耦神经表示实现术前结构和术中外观处理。
Key Takeaways
- 使用跨模态逆向神经渲染进行术中3D/2D配准。
- 解耦神经表示,术前处理结构,术中处理外观。
- 利用多风格超网络控制神经辐射场外观。
- 训练后,隐式神经表示作为可微渲染引擎。
- 通过最小化渲染图像与目标图像差异估计手术相机姿态。
- 在回顾性患者数据上测试,优于现有技术。
- 提供代码和额外资源。
标题:基于跨模态逆神经渲染技术的术中注册研究
作者:Maximilian Fehrentz(第一作者)、Mohammad Farid Azampour、Reuben Dorent等(其余作者名单)
所属机构:哈佛大学医学院布莱根妇女医院(第一作者)、德国慕尼黑计算机辅助医疗程序研究所等(其余作者所属机构)。
关键词:神经手术、术中注册、逆神经渲染、跨模态、渲染引擎。
Urls:论文链接:[论文网址](需替换为实际的论文网址链接),GitHub代码链接:[GitHub地址](由于未提供实际GitHub链接,故填写“None”)。
总结:
- (1) 研究背景:本研究针对神经外科手术中的患者图像注册问题,提出了一种基于跨模态逆神经渲染技术的术中注册方法。术中注册技术在神经外科手术中是标准实践,它允许医生在手术中可视化患者的术前影像,从而提高手术的安全性和效果。
- (2) 过去的方法及问题:现有的术中注册方法大多需要额外的成像设备或光学跟踪系统,这些设备通常操作复杂、耗时长,并且可能增加手术风险。因此,开发一种仅依赖手术中已有的图像进行注册的简化方法显得尤为重要。
- (3) 研究方法:本研究提出了一种基于隐式神经表示的新方法,该方法分为两个部分:处理术前解剖结构的隐式表示和处理术中外观的隐式表示。通过控制神经辐射场的外观来实现两者的分离。训练后的隐式神经表示作为一个可微分的渲染引擎,通过最小化其渲染图像与目标术中图像的差异性来估计手术相机的姿态。此外,该研究还利用了一个多风格超网络来控制神经辐射场的外观。这种新方法旨在克服传统方法的不足,并能在不使用额外的成像设备的情况下实现精确的术中注册。
- (4) 任务与性能:该研究在回顾性临床病例数据上测试了新方法,结果显示该方法在神经外科手术的术中注册任务上优于现有技术并达到了当前的临床标准。该方法的性能表现在实际的临床任务中得到了验证,证明了其有效性和可靠性。通过简化注册过程并减少依赖额外的设备,该方法有望提高神经外科手术的安全性和效率。
希望以上总结符合您的要求!如有任何需要修改或补充的地方,请告诉我。
- 方法论:
(1) 问题定义与概述:给定一个神经外科手术中的术前表面网格M和术中图像I,目的是确定一个姿态P,使P最小化损失函数L(P|I,M),该损失函数量化术中图像和根据姿态P定位的术前网格M之间的差异。该问题被当作一个二维图像空间的优化问题来处理。
(2) 方法核心:文章提出了一种基于隐式神经表示的新方法,该方法包括处理术前解剖结构的隐式表示和处理术中外观的隐式表示。通过控制神经辐射场的外观来实现两者的分离。训练后的隐式神经表示作为一个可微分的渲染引擎,通过最小化其渲染图像与目标术中图像的差异性来估计手术相机的姿态。此外,该研究还利用了一个多风格超网络来控制神经辐射场的外观。这种新方法旨在克服传统方法的不足,并能在不使用额外的成像设备的情况下实现精确的术中注册。
(3) 跨模态逆神经渲染技术:文章采用了神经辐射场(NeRF)技术作为神经渲染器,对三维网格M进行编码。与传统的网格表示方法不同,NeRF是完全可微分的,并具有可学习的解剖结构和外观的解耦组件。这对于迭代姿态估计和跨模态图像配准至关重要。
(4) 多风格超网络:为了桥接术中图像I的外观和术前网格M之间的域差距,文章引入了一个多风格超网络。这个超网络采用多头MLP的形式,被训练根据术中图像I的外观来设置NeRF的颜色参数θfc,而保持结构参数θfd不变。为了训练超网络,使用了神经风格迁移(NST)技术来生成多个训练数据集。
(5) 姿态优化与图像渲染:通过迭代渲染NeRF并根据术中图像I优化姿态P,来找到最优姿态ˆP。这一过程是基于连续神经表示进行图像渲染,并优化姿态P以最小化术中图像和渲染图像之间的差异。
总结来说,本文提出了一种基于跨模态逆神经渲染技术的术中注册方法,通过结合隐式神经表示、多风格超网络和连续神经渲染技术,实现了在不使用额外成像设备的情况下进行精确的术中注册。该方法有望提高神经外科手术的安全性和效率。
Conclusion:
(1) 本研究的意义在于针对神经外科手术中的患者图像注册问题,提出了一种基于跨模态逆神经渲染技术的术中注册方法。该方法旨在解决现有术中注册方法操作复杂、耗时长、可能增加手术风险的问题,提高神经外科手术的安全性和效率。这一研究的成果具有重要的实际应用价值和临床意义。
(2) 创新点:本文提出了一种基于隐式神经表示的新方法,结合神经辐射场技术和多风格超网络,实现了精确的术中注册。该方法在不使用额外成像设备的情况下,能够完成术前解剖结构和术中外观的准确匹配,提高了手术的安全性和效率。此外,该研究的方法论新颖,结合了计算机视觉和医学影像处理的先进技术。
性能:该文章所提出的方法在回顾性临床病例数据上进行了测试,并表现出优越的性能。该方法在实际的临床任务中验证了其有效性和可靠性,达到了当前的临床标准。然而,文章未提供详细的实验数据和对比实验结果,无法准确评估其性能表现。
工作量:该研究涉及的方法论较为复杂,需要结合计算机视觉和医学影像处理的知识进行深入理解。文章详细描述了方法的理论基础、实现细节和实验验证,工作量较大。但是,由于缺少详细的实验数据和对比实验结果,无法全面评估研究的工作量。
点此查看论文截图

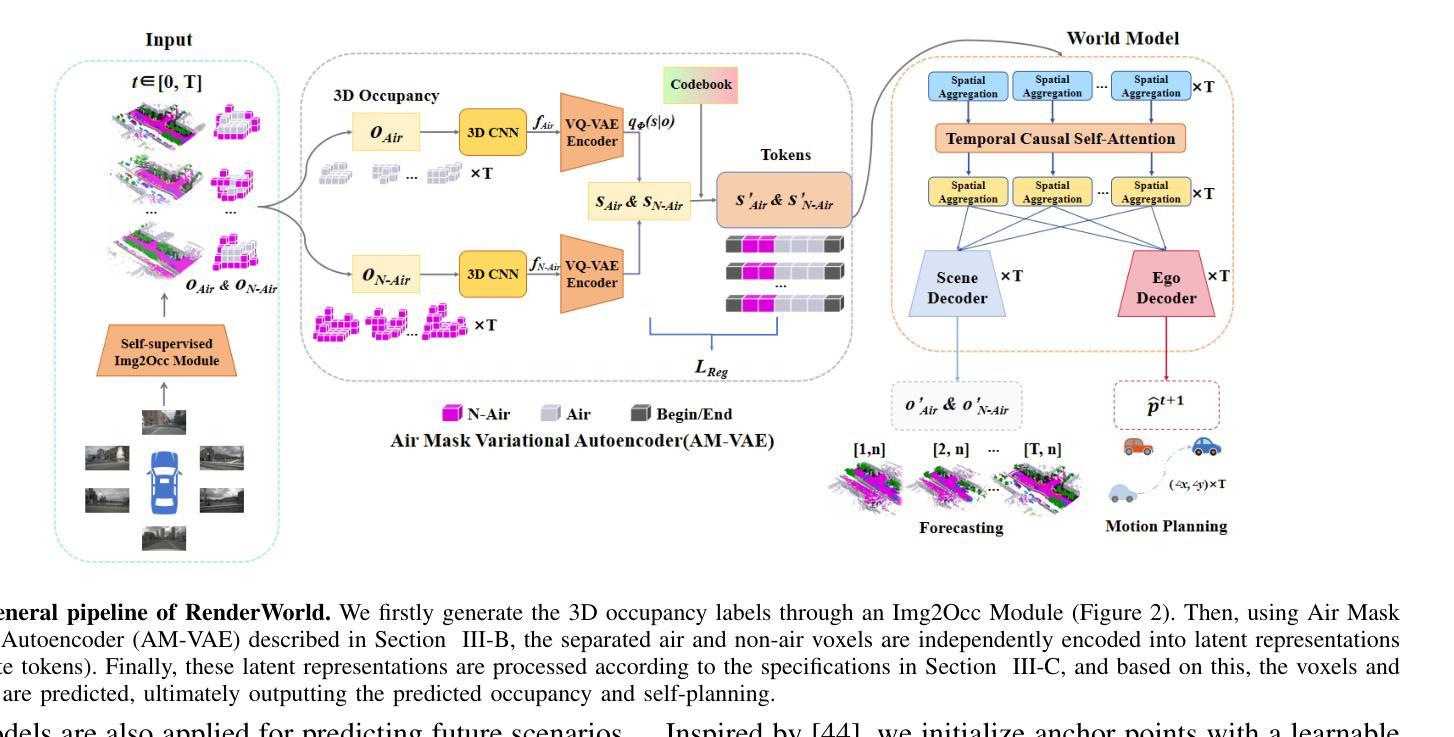
RenderWorld: World Model with Self-Supervised 3D Label
Authors:Ziyang Yan, Wenzhen Dong, Yihua Shao, Yuhang Lu, Liu Haiyang, Jingwen Liu, Haozhe Wang, Zhe Wang, Yan Wang, Fabio Remondino, Yuexin Ma
End-to-end autonomous driving with vision-only is not only more cost-effective compared to LiDAR-vision fusion but also more reliable than traditional methods. To achieve a economical and robust purely visual autonomous driving system, we propose RenderWorld, a vision-only end-to-end autonomous driving framework, which generates 3D occupancy labels using a self-supervised gaussian-based Img2Occ Module, then encodes the labels by AM-VAE, and uses world model for forecasting and planning. RenderWorld employs Gaussian Splatting to represent 3D scenes and render 2D images greatly improves segmentation accuracy and reduces GPU memory consumption compared with NeRF-based methods. By applying AM-VAE to encode air and non-air separately, RenderWorld achieves more fine-grained scene element representation, leading to state-of-the-art performance in both 4D occupancy forecasting and motion planning from autoregressive world model.
Summary
提出基于视觉的端到端自动驾驶框架RenderWorld,实现经济且可靠的自主驾驶。
Key Takeaways
- 视觉自主驾驶成本低于激光雷达融合,可靠性更高。
- RenderWorld采用自监督Img2Occ模块生成3D占用标签。
- 使用AM-VAE编码标签,提高预测和规划能力。
- 采用高斯散斑表示3D场景,优化2D图像渲染。
- 相比NeRF,提高分割精度并减少GPU内存消耗。
- AM-VAE区分空气与非空气,实现更精细的元素表示。
- 在占用预测和运动规划方面取得最佳性能。
标题: RenderWorld:基于自监督的3D标签世界模型在自动驾驶中的应用
作者: Ziyang Yan, Wenzhen Dong, Yihua Shao等。
作者所属机构(中文翻译):
- Ziyang Yan,一部分在上海科技大学,一部分在意大利的Fondazione Bruno Kessler和Trento大学。
- Wenzhen Dong,Tsinghua University的人工智能研究所(AIR)。
- Yihua Shao等,北京理工科技大学。
- 其他作者分别来自香港科技大学和其他机构。
关键词: 自动驾驶、视觉感知、世界模型、高斯Splatting、AM-VAE(空气掩膜变分自编码器)、运动规划。
链接: 论文链接:论文网址链接 (注:实际链接需替换网址占位符)
GitHub代码链接:GitHub:None (若存在代码仓库,请在此处填入链接)摘要:
- (1)研究背景:随着自动驾驶技术的广泛应用,对纯视觉的端到端自动驾驶系统的需求增加,该系统旨在实现低成本且可靠的自动驾驶。本文提出了RenderWorld框架,仅使用视觉信息实现自主驾驶。
- (2)过去的方法及问题:当前自动驾驶的感知方法主要依赖于LiDAR和摄像头的融合,但LiDAR成本高且计算需求大,影响了实时性能和鲁棒性。另外,大多数3D目标检测方法无法获得环境的精细信息,导致规划阶段的稳健性不足。
- (3)研究方法:本文提出了RenderWorld框架,通过自监督的Img2Occ模块生成3D占用标签,使用Gaussian Splatting表示3D场景并渲染2D图像。为提高场景表示的粒度,引入了AM-VAE(空气掩膜变分自编码器)对空气和非空气元素进行分别编码。
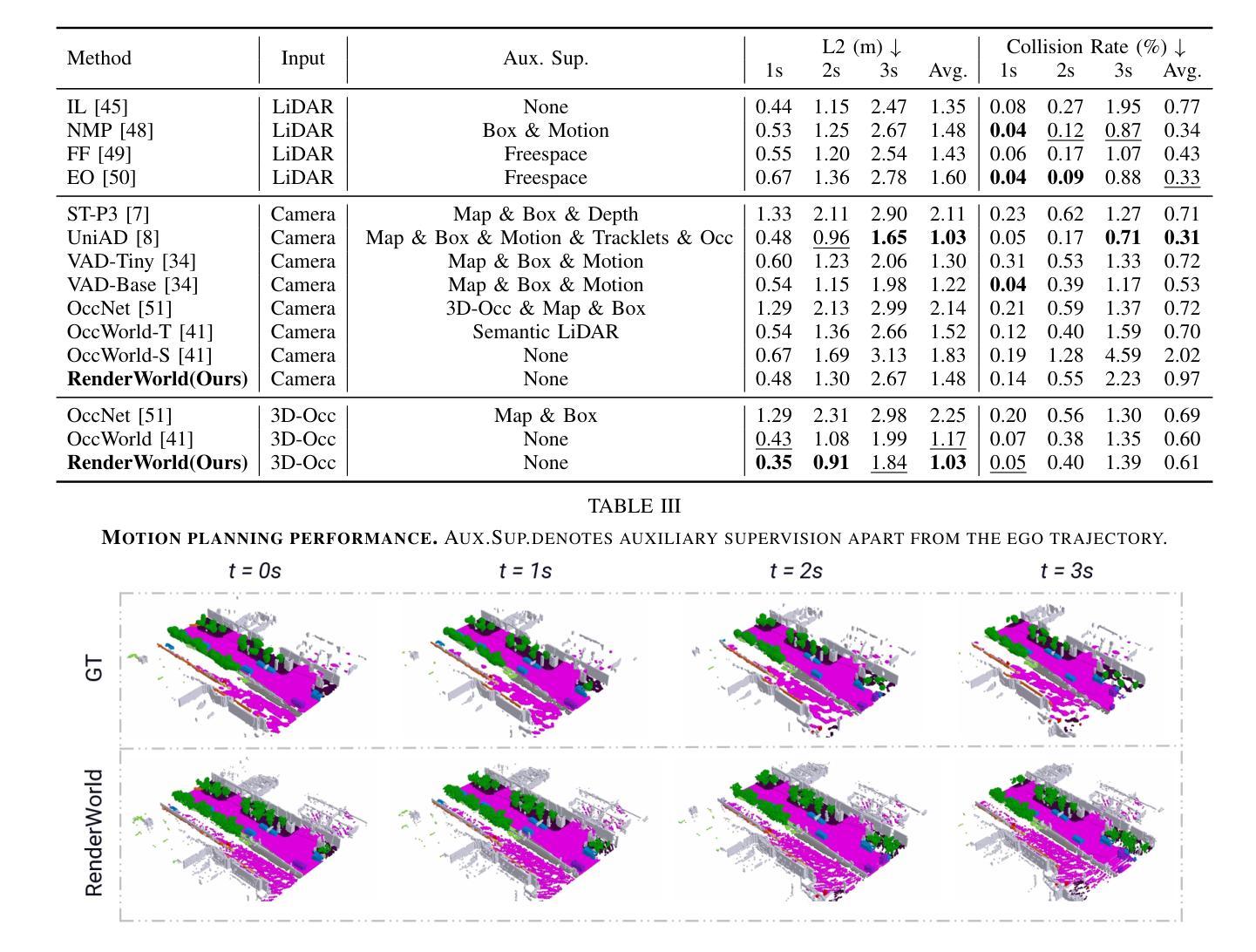
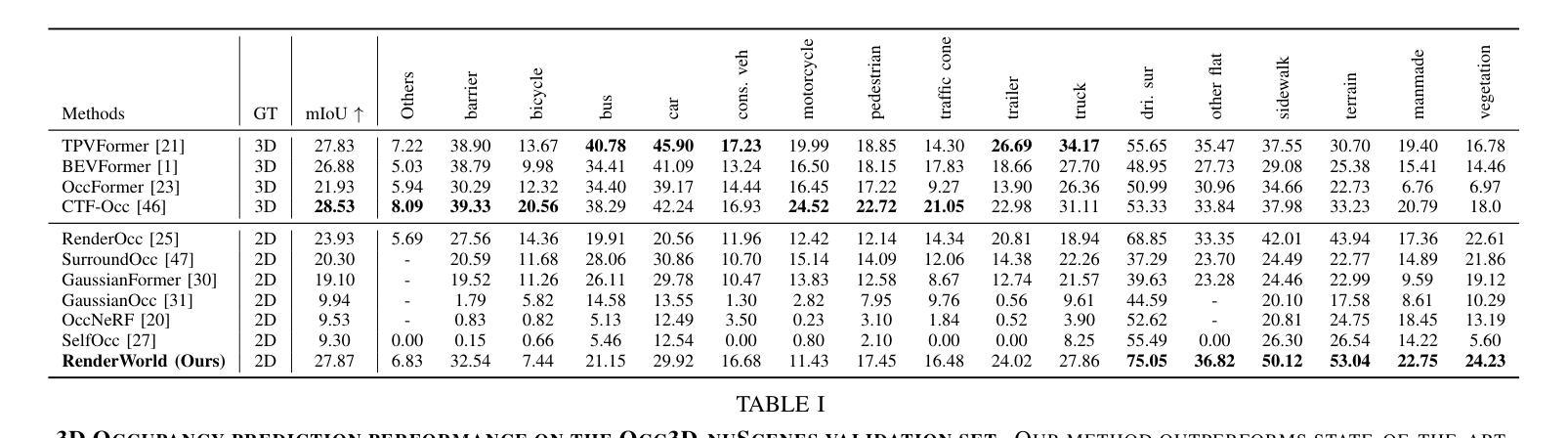
- (4)任务与性能:本文在NuScenes数据集上评估了RenderWorld的3D占用生成和运动规划性能。结果表明,RenderWorld在占用预测和运动规划方面达到了先进水平,证明了其有效性。性能支持了其作为纯视觉端到端自动驾驶框架的潜力。
以上为对论文的概括和总结,希望符合您的要求。请注意,论文链接和GitHub链接需替换为实际链接。
- 方法论:
- (1) 研究提出了RenderWorld框架,该框架仅使用视觉信息实现自动驾驶。
- (2) 采用自监督的Img2Occ模块生成3D占用标签,使用Gaussian Splatting表示3D场景并进行渲染。为提高场景表示的粒度,引入了AM-VAE(空气掩膜变分自编码器)对空气和非空气元素进行分别编码。
- (3) 通过在NuScenes数据集上评估RenderWorld的3D占用生成和运动规划性能,证明了其有效性。
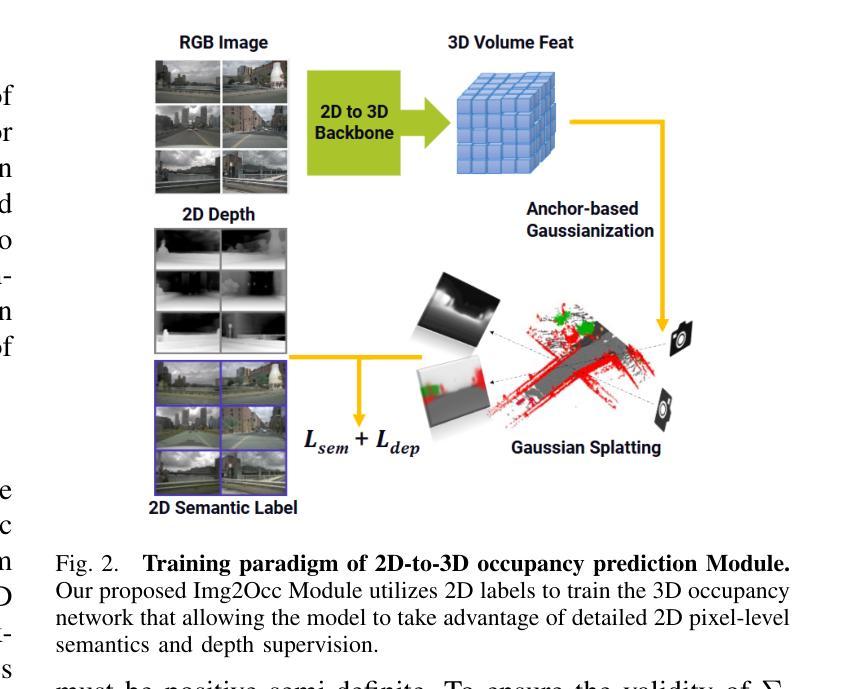
- (4) Img2Occ模块的设计包括利用多帧2D标签进行3D语义占用预测和未来3D占用标签生成。通过采用预训练的BEVStereo4D和Swin Transformer提取2D图像特征,并将这些特征插入到三维空间中生成体积特征。然后,使用高斯Splatting将三维占用体素投影到多相机语义图上。通过对锚点进行初始化并使用语义标签对锚点属性进行确定,构建高斯集合进行渲染。通过优化协方差矩阵Σ来确保矩阵的有效性。利用深度监督和语义分割损失对模型进行训练,并生成三维占用标签以供后续模块使用。
- (5) 针对传统变分自编码器无法编码非空气体素独特特征的问题,引入了Air Mask Variational Autoencoder(AM-VAE)。AM-VAE使用两个独立的向量量化变分自编码器(VQVAE)对空气和非空气占用体素进行编码和解码。通过训练两个潜变量sAir和sN-Air来分别表示空气和非空气体素,并使用可学习的代码本进行量化。通过重构原始占用表示损失和承诺损失来训练AM-VAE。
- (6) 通过应用世界模型对自动驾驶中的三维场景进行编码成高级令牌,RenderWorld框架可以提高预测精度和运动规划能力。
- Conclusion:
- (1) 工作意义:这篇论文提出了RenderWorld框架,一个基于纯视觉的端到端自动驾驶解决方案,它使用自监督的方式生成3D标签世界模型并应用于自动驾驶。这一研究对于推动自动驾驶技术的发展具有重要意义,特别是在降低成本和提高系统可靠性方面。
- (2) 创新点、性能和工作量总结:
- 创新点:该论文的创新之处在于引入了自监督的Img2Occ模块生成3D占用标签,并使用Gaussian Splatting表示3D场景。此外,论文还引入了AM-VAE(空气掩膜变分自编码器)对空气和非空气元素进行分别编码,提高了场景表示的粒度。
- 性能:在NuScenes数据集上的评估结果表明,RenderWorld在占用预测和运动规划方面达到了先进水平,证明了其有效性。
- 工作量:论文详细介绍了Img2Occ模块和AM-VAE的设计和实现细节,并进行了大量的实验验证。工作量较大,研究深入。
点此查看论文截图




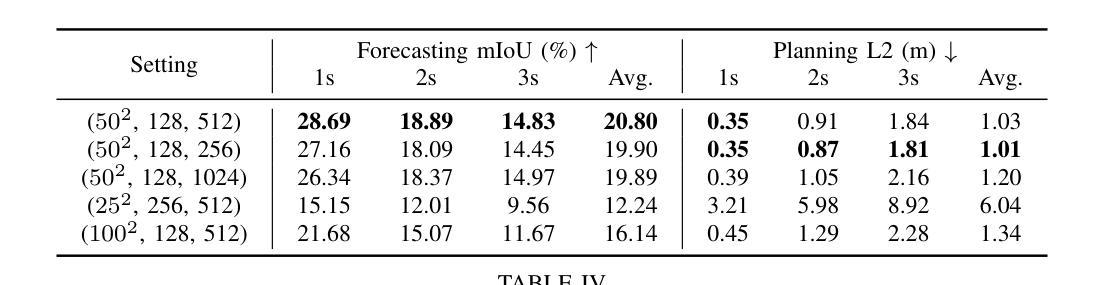
MM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance
Authors:Debin Meng, Christos Tzelepis, Ioannis Patras, Georgios Tzimiropoulos
Generating human portraits is a hot topic in the image generation area, e.g. mask-to-face generation and text-to-face generation. However, these unimodal generation methods lack controllability in image generation. Controllability can be enhanced by exploring the advantages and complementarities of various modalities. For instance, we can utilize the advantages of text in controlling diverse attributes and masks in controlling spatial locations. Current state-of-the-art methods in multimodal generation face limitations due to their reliance on extensive hyperparameters, manual operations during the inference stage, substantial computational demands during training and inference, or inability to edit real images. In this paper, we propose a practical framework - MM2Latent - for multimodal image generation and editing. We use StyleGAN2 as our image generator, FaRL for text encoding, and train an autoencoders for spatial modalities like mask, sketch and 3DMM. We propose a strategy that involves training a mapping network to map the multimodal input into the w latent space of StyleGAN. The proposed framework 1) eliminates hyperparameters and manual operations in the inference stage, 2) ensures fast inference speeds, and 3) enables the editing of real images. Extensive experiments demonstrate that our method exhibits superior performance in multimodal image generation, surpassing recent GAN- and diffusion-based methods. Also, it proves effective in multimodal image editing and is faster than GAN- and diffusion-based methods. We make the code publicly available at: https://github.com/Open-Debin/MM2Latent
PDF Accepted at ECCV 2024 AIM workshop
Summary
提出MM2Latent框架,实现高效多模态图像生成与编辑。
Key Takeaways
- 多模态生成在肖像生成领域重要,但需增强可控性。
- 利用文本和遮罩的优势提高控制性。
- 现有方法存在超参数、手动操作、计算量大等问题。
- MM2Latent框架使用StyleGAN2、FaRL和自动编码器。
- 提出映射网络将多模态输入映射到StyleGAN的潜在空间。
- 框架消除超参数和手动操作,确保快速推理。
- 支持真实图像编辑,性能优于GAN和扩散方法。
标题:面向多模态图像生成与编辑的MM2Latent框架研究(英文标题:MM2Latent: Text-to-facial image generation and editing in GANs with multimodal assistance)
作者:作者名单包括德宾·孟(Debin Meng)、克里斯托斯·策列普里斯(Christos Tzelepis)、伊奥尼斯·帕拉斯(Ioannis Patras)、乔治奥斯·齐米罗普洛斯(Georgios Tzimiropoulos)。所有作者均来自伦敦玛丽皇后大学(Queen Mary University of London)。联系方式为:debin.meng, c.tzelepis, i.patras, g.tzimiropoulos@qmul.ac.uk。
所属机构:伦敦玛丽皇后大学计算机科学系。中文翻译:伦敦玛丽皇后大学计算机科学系。
关键词:多模态图像生成、图像编辑、面部图像生成、文本控制属性、空间位置控制等。英文关键词为:multimodal image generation, image editing, facial image generation, text-based attribute control, spatial location control等。
Urls:论文链接:[论文链接];代码链接(如有):Github链接(若无则填写“None”)。
总结:
(1) 研究背景:随着图像生成领域的快速发展,生成肖像图像已成为研究热点。当前的单模态生成方法缺乏图像生成的可控性,本文旨在探索不同模态的优势和互补性,如文本控制多样属性和掩膜控制空间位置等,从而增强图像生成的可控性。
(2) 相关工作与问题:当前的多模态生成方法存在依赖大量超参数、推理阶段需要手动操作、训练和推理阶段需要大量计算资源以及无法编辑真实图像等问题。因此,开发一种实用且高效的多模态图像生成和编辑框架显得尤为重要。
(3) 研究方法:本文提出了一种名为MM2Latent的实用框架,用于多模态图像生成和编辑。该框架利用面部分割掩膜、草图以及3DMM参数,通过结合不同模态的优势和互补性,实现更可控的图像生成。
(4) 任务与性能:本文的方法在面部图像生成和编辑任务上取得了良好效果。实验结果表明,该框架可以有效地根据文本描述生成相应的面部图像,并允许对生成的图像进行编辑。此外,该框架还能编辑真实图像,增强其应用场景的实用性。这些性能结果支持了本文方法的有效性。
请注意,论文链接和Github链接需要根据实际情况填写。
- 方法:
(1) 研究背景分析:随着图像生成领域的快速发展,生成肖像图像已成为研究热点。当前单模态生成方法存在可控性不足的问题。因此,本研究旨在探索不同模态的优势和互补性,如文本控制多样属性和掩膜控制空间位置等,以增强图像生成的可控性。
(2) 技术框架设计:本研究提出了一种名为MM2Latent的多模态图像生成与编辑框架。该框架结合了面部分割掩膜、草图以及3DMM参数等多种模态的信息,利用不同模态的优势和互补性实现更可控的图像生成。具体来说,该框架首先利用文本描述生成对应的面部图像,然后通过掩膜和草图等技术实现对图像的空间位置控制和属性编辑。此外,该框架还能够编辑真实图像,增强其应用场景的实用性。
(3) 实现细节与关键步骤:研究采用了一种先进的深度学习技术,包括卷积神经网络(CNN)和生成对抗网络(GAN)等。在训练阶段,通过优化网络结构和参数来提高图像生成的多样性和质量。在推理阶段,通过结合不同模态的信息进行图像生成和编辑。此外,该研究还提出了一种基于掩膜的技术来实现对图像的空间位置控制和对生成结果的属性编辑。通过对比实验验证了所提出框架的有效性。
总结来说,该研究提出了一种实用且高效的多模态图像生成和编辑框架MM2Latent,通过结合不同模态的优势和互补性实现更可控的图像生成和编辑。该研究具有重要的理论意义和实践价值,为图像生成和编辑领域的发展提供了新的思路和方法。
- Conclusion:
(1)该研究工作提出了一种新的多模态图像生成与编辑框架MM2Latent,具有极高的应用价值。它不仅在学术领域有着重要价值,而且在图像处理技术、计算机视觉等领域具有广泛的应用前景。通过文本控制多样属性和掩膜控制空间位置等技术,显著提高了图像生成的可控性,对于推动相关领域的技术进步具有重要意义。
(2)Innovation point: 该文章的创新点在于提出了一种多模态图像生成与编辑框架MM2Latent,该框架结合了文本、图像和掩膜等多种模态的信息,实现了更为灵活的图像生成和编辑。这一创新性的方法极大地提高了图像生成的可控性和实用性。Performance: 实验结果表明,该框架在面部图像生成和编辑任务上取得了显著的效果,能够生成高质量的面部图像,并允许对生成的图像进行编辑。此外,该框架还能编辑真实图像,增强了其实用性。Workload: 文章详细阐述了该框架的设计和实现细节,包括使用的技术、方法、实验等,显示出作者们进行了大量的实验和研究工作。同时,文章也指出了当前方法的局限性和未来可能的研究方向。
点此查看论文截图

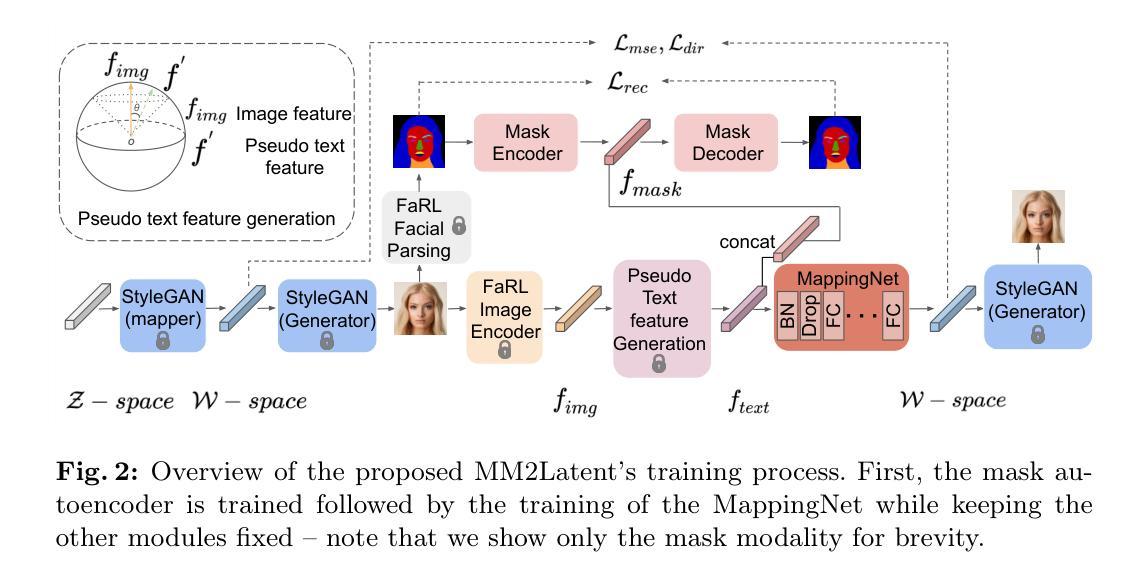

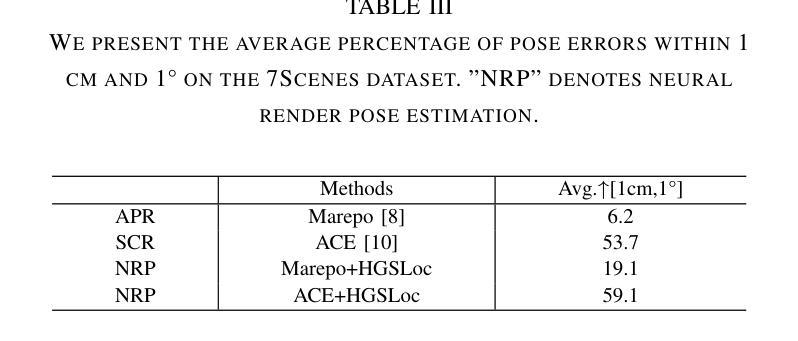
HGSLoc: 3DGS-based Heuristic Camera Pose Refinement
Authors:Zhongyan Niu, Zhen Tan, Jinpu Zhang, Xueliang Yang, Dewen Hu
Visual localization refers to the process of determining camera poses and orientation within a known scene representation. This task is often complicated by factors such as illumination changes and variations in viewing angles. In this paper, we propose HGSLoc, a novel lightweight, plug and-play pose optimization framework, which integrates 3D reconstruction with a heuristic refinement strategy to achieve higher pose estimation accuracy. Specifically, we introduce an explicit geometric map for 3D representation and high-fidelity rendering, allowing the generation of high-quality synthesized views to support accurate visual localization. Our method demonstrates a faster rendering speed and higher localization accuracy compared to NeRF-based neural rendering localization approaches. We introduce a heuristic refinement strategy, its efficient optimization capability can quickly locate the target node, while we set the step-level optimization step to enhance the pose accuracy in the scenarios with small errors. With carefully designed heuristic functions, it offers efficient optimization capabilities, enabling rapid error reduction in rough localization estimations. Our method mitigates the dependence on complex neural network models while demonstrating improved robustness against noise and higher localization accuracy in challenging environments, as compared to neural network joint optimization strategies. The optimization framework proposed in this paper introduces novel approaches to visual localization by integrating the advantages of 3D reconstruction and heuristic refinement strategy, which demonstrates strong performance across multiple benchmark datasets, including 7Scenes and DB dataset.
Summary
提出HGSLoc框架,融合三维重建与启发式优化,实现高效视觉定位。
Key Takeaways
- 提出HGSLoc,轻量级定位优化框架
- 融合3D重建与启发式优化策略
- 引入显式几何图实现高保真渲染
- 快速渲染与高定位精度
- 启发式优化快速定位目标节点
- 小误差场景增强定位精度
- 减少对复杂神经网络模型的依赖
- 提高抗噪性与定位精度
- 表现优于NeRF及神经网络联合优化
- 在多个数据集上表现优异
- Title: 基于三维重建与启发式优化策略的相机姿态优化研究
Authors: Zhongyan Niu, Zhen Tan, Jinpu Zhang, Xueliang Yang, Dewen Hu - Affiliation: 国防科技大学
- Keywords: Visual Localization, Camera Pose Estimation, 3D Reconstruction, Heuristic Refinement Strategy
- Urls: Paper Link (Link to the paper’s abstract or full text), Github Code Link (If available, enter the corresponding GitHub repository link. If not available, enter “None.”)
- Summary:
(1) 研究背景:本文研究了视觉定位中的相机姿态优化问题。视觉定位是通过分析图像数据来确定相机在已知场景中的位置和姿态,广泛应用于增强现实、机器人导航和自动驾驶等领域。然而,由于光照变化、动态遮挡和视角变化等因素,相机姿态估计是一个具有挑战性的任务。
(2) 过去的方法及问题:目前视觉定位主要使用绝对姿态回归和场景坐标回归两种方法。虽然这些方法在某些情况下表现出良好的性能,但在复杂或未见过的环境中,它们的泛化能力较弱,计算成本高。此外,基于神经网络的渲染方法,如NeRF,虽然可以合成高质量的场景图像,但像素级的训练和推理机制导致计算量大,限制了实际应用。
(3) 研究方法:针对上述问题,本文提出了一种基于三维重建和启发式优化策略的相机姿态优化框架(HGSLoc)。该方法结合3D重建和启发式优化策略,利用显式几何地图进行3D表示和高精度渲染,生成高质量合成视图以支持精确视觉定位。引入启发式优化策略,通过高效优化能力快速定位目标节点,并在误差较小的场景下通过步骤级优化步骤增强姿态准确性。
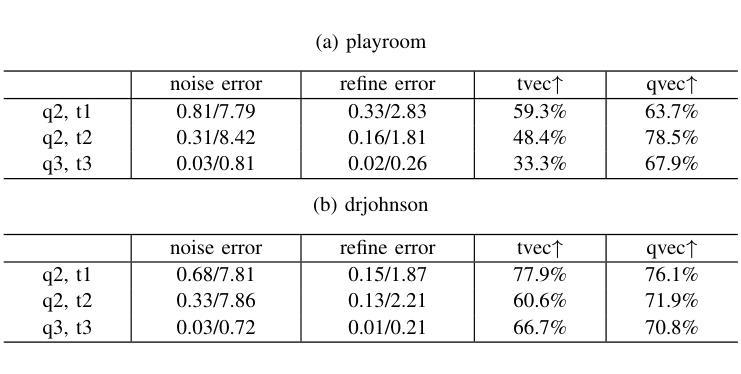
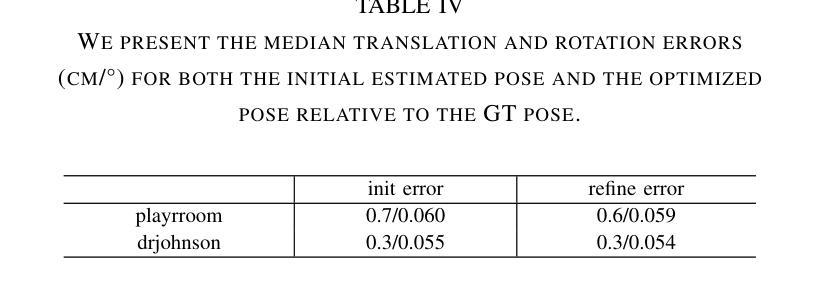
(4) 任务与性能:本文方法在多个基准数据集上进行了实验,包括7Scenes和DB数据集,展示了较高的定位精度和计算效率。与基于神经网络的方法相比,该方法降低了计算成本,提高了噪声抵抗能力和定位精度。实现了对复杂环境下视觉定位任务的准确高效解决,支持了其研究目标。
- Methods:
(1) 研究背景分析:首先,对视觉定位中的相机姿态优化问题进行了深入研究。分析了现有方法的不足,如泛化能力弱、计算成本高和实际应用中的限制。
(2) 提出新的方法:针对这些问题,提出了一种基于三维重建和启发式优化策略的相机姿态优化框架(HGSLoc)。该框架结合3D重建和启发式优化策略,利用显式几何地图进行3D表示和高精度渲染。
(3) 框架实施步骤:
- 构建三维地图:利用三维重建技术构建场景的显式几何地图,用于高精度的3D表示和渲染。
- 启发式优化策略:引入启发式优化算法,通过高效优化能力快速定位目标节点。
- 高质量合成视图:生成高质量合成视图以支持精确视觉定位。
- 步骤级优化步骤:在误差较小的场景下,通过步骤级优化步骤增强姿态准确性。
(4) 实验验证:在多个基准数据集上进行实验,包括7Scenes和DB数据集,以验证所提出方法的有效性。通过对比实验,展示了该方法在定位精度和计算效率上的优势。
(5) 结果分析:对所提出方法的结果进行详细分析,证明了该方法在复杂环境下视觉定位任务的准确高效解决能力,支持了研究目标。
- Conclusion:
(1)意义:本文研究了基于三维重建与启发式优化策略的相机姿态优化问题,对于提高视觉定位精度和效率具有重要意义,可广泛应用于增强现实、机器人导航和自动驾驶等领域。
(2)创新点、性能、工作量总结:
创新点:本文提出了一种基于三维重建和启发式优化策略的相机姿态优化框架(HGSLoc),结合3D重建和启发式优化策略,利用显式几何地图进行3D表示和高精度渲染,生成高质量合成视图以支持精确视觉定位。该框架在视觉定位领域具有一定的创新性。
性能:本文方法在多个基准数据集上进行了实验,展示了较高的定位精度和计算效率。与基于神经网络的方法相比,该方法降低了计算成本,提高了噪声抵抗能力和定位精度,证明了其在实际应用中的有效性。
工作量:本文进行了较为充分的研究,从背景分析、方法提出、框架实施到实验验证,都进行了详细的阐述。但是,对于该方法在实际应用中的进一步推广和落地,还需要更多的实际数据验证和持续优化。
点此查看论文截图



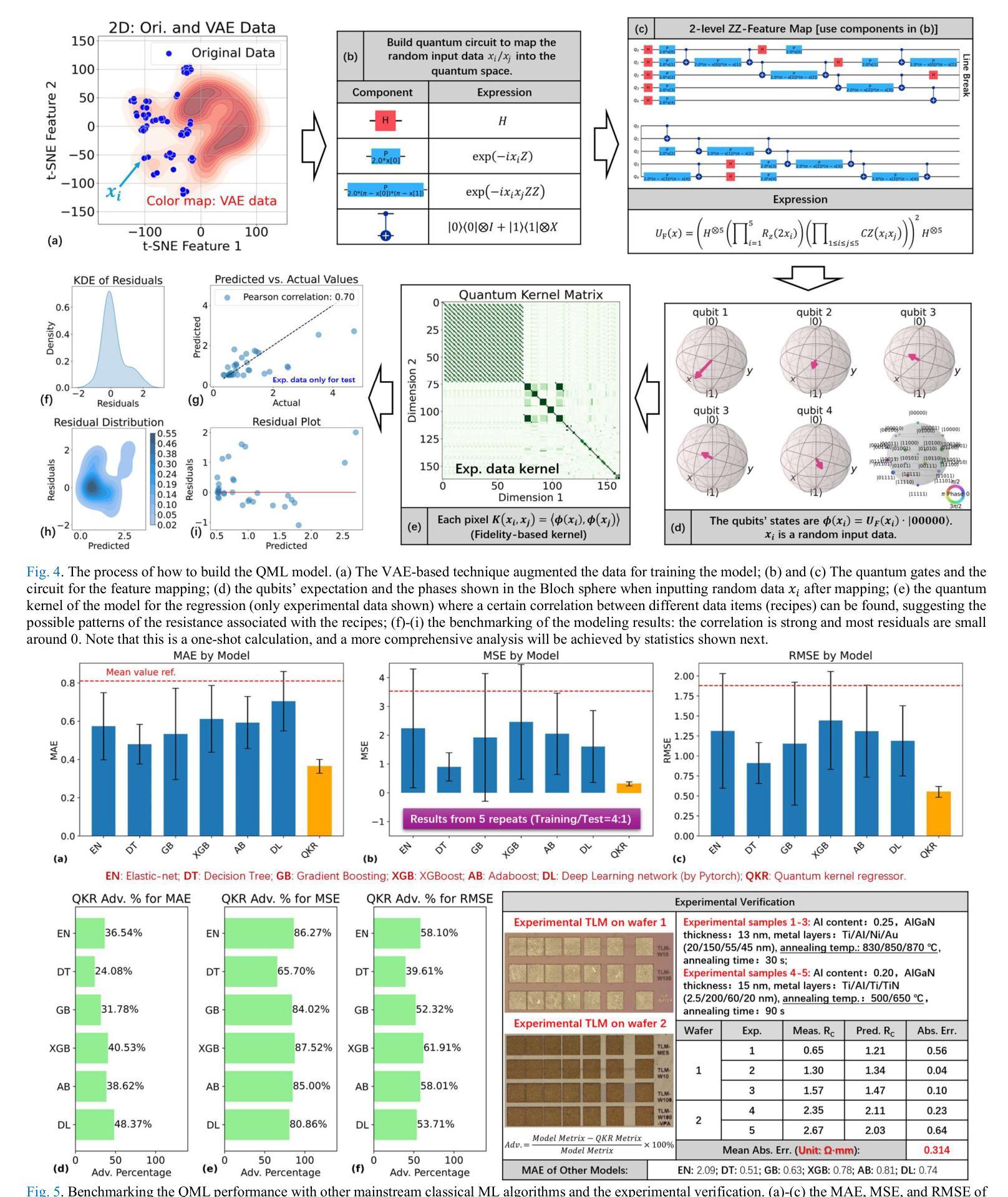
Quantum Machine Learning for Semiconductor Fabrication: Modeling GaN HEMT Contact Process
Authors:Zeheng Wang, Fangzhou Wang, Liang Li, Zirui Wang, Timothy van der Laan, Ross C. C. Leon, Jing-Kai Huang, Muhammad Usman
This paper pioneers the use of quantum machine learning (QML) for modeling the Ohmic contact process in GaN high-electron-mobility transistors (HEMTs) for the first time. Utilizing data from 159 devices and variational auto-encoder-based augmentation, we developed a quantum kernel-based regressor (QKR) with a 2-level ZZ-feature map. Benchmarking against six classical machine learning (CML) models, our QKR consistently demonstrated the lowest mean absolute error (MAE), mean squared error (MSE), and root mean squared error (RMSE). Repeated statistical analysis confirmed its robustness. Additionally, experiments verified an MAE of 0.314 ohm-mm, underscoring the QKR’s superior performance and potential for semiconductor applications, and demonstrating significant advancements over traditional CML methods.
PDF This is the manuscript in the conference version. An expanded version for the journal will be released later and more information will be added. The author list, content, conclusion, and figures may change due to further research
Summary
该文首次将量子机器学习应用于建模GaN HEMT的欧姆接触过程,开发出具有优异性能的量子核回归器。
Key Takeaways
- 首次应用QML建模GaN HEMT的欧姆接触过程
- 使用159个设备的数据和变分自编码器进行数据增强
- 开发了基于2级ZZ特征图的量子核回归器(QKR)
- QKR在MAE、MSE和RMSE方面优于六种CML模型
- 统计分析证实了QKR的稳健性
- 实验验证MAE为0.314 ohm-mm
- QKR在半导体应用中表现出色,优于传统CML方法
Title: 量子机器学习在半导体制造中的应用:建模氮化镓高电子迁移率晶体管接触过程
Authors: Zeheng Wang, Fangzhou Wang, Liang Li, Zirui Wang, Timothy van der Laan, Ross C. C. Leon, Jing-Kai Huang, Muhammad Usman
Affiliation:
- Zeheng Wang, Ross C. C. Leon: 澳大利亚CSIRO;
- Fangzhou Wang: 中国松山湖材料实验室;
- Liang Li, Zirui Wang: 中国北京大学;
- Timothy van der Laan: 英国Quantum Motion公司;
- Jing-Kai Huang: 中国城市大学;
- Muhammad Usman: 澳大利亚墨尔本大学。
Keywords: Quantum Machine Learning, Semiconductor Fabrication, GaN HEMT Contact Process, Quantum Kernel-Based Regressor, Performance Evaluation
Urls: 论文链接(如果可用),Github代码链接(如果可用,填写Github:None)论文链接:[Link to the paper](链接需要替换为真实的论文网址);Github代码链接:[Github Repository](如果可用,否则填写为”None”)
Summary:
- (1): 研究背景:随着半导体制造工艺的快速发展,对工艺过程的精确建模和控制变得越来越重要。传统的机器学习技术在处理复杂、高维度的半导体数据方面存在局限性。量子机器学习(QML)作为一种新兴的技术,有望解决这些问题。本文旨在将量子机器学习应用于建模氮化镓高电子迁移率晶体管(GaN HEMT)的接触过程。
- (2): 过去的方法及问题:传统的机器学习模型在处理半导体制造过程中的复杂关系时,往往难以捕捉数据的内在规律和特征。它们在处理高维度、非线性数据时的性能有限,且在新数据上的泛化能力较弱。因此,需要一种更有效的方法来建模半导体制造过程。
- (3): 研究方法:本文提出了一种基于量子核的回归器(QKR)来建模GaN HEMT的接触过程。首先,从159个GaN HEMT设备中提取数据,包括Al含量、AlGaN厚度、金属堆栈类型和退火条件等特征。然后,使用变分自动编码器(VAE)进行数据增强,合成额外的训练数据。最后,利用量子核算法在量子计算机上训练QKR模型,并优化模型参数。
- (4): 任务与性能:本文的方法旨在通过建模GaN HEMT的接触过程来优化半导体制造工艺。实验结果表明,QKR模型在预测接触电阻方面的性能优于传统的机器学习模型。在外部验证中,QKR模型达到了0.314 Ω·mm的平均绝对误差,显著低于参考阈值和其他CML模型的结果,显示出QML在半导体研究和工业应用中的巨大潜力。这些成果为量子机器学习在半导体领域的应用提供了新的思路和方法。
结论:
(1) 研究意义:该工作利用量子机器学习技术对半导体制造工艺中的氮化镓高电子迁移率晶体管接触过程进行建模,具有重要的理论和实践意义。该研究不仅推动了量子机器学习在半导体领域的应用,而且为提高半导体制造工艺的精确性和效率提供了新的思路和方法。此外,该研究还有助于优化GaN HEMT设备的性能,推动半导体行业的发展。
(2) 创新点、性能、工作量总结:
创新点:该文章提出了一种基于量子核的回归器(QKR)来建模GaN HEMT的接触过程,这是量子机器学习在半导体制造领域的一个创新应用。此外,该研究还采用了变分自动编码器进行数据增强,进一步提高了模型的性能。
性能:实验结果表明,QKR模型在预测接触电阻方面的性能优于传统的机器学习模型,达到了较低的预测误差。
工作量:该文章涉及了数据收集、数据处理、模型构建、模型优化和性能评估等多个方面的工作。作者从多个来源收集数据,并采用先进的量子机器学习算法进行建模和预测。此外,文章还进行了外部验证,证明了模型的有效性和泛化能力。
请注意,以上结论仅根据您提供的摘要进行概括,具体的性能和细节需要阅读完整的文章以获取更准确的信息。
点此查看论文截图


A Missing Data Imputation GAN for Character Sprite Generation
Authors:Flávio Coutinho, Luiz Chaimowicz
Creating and updating pixel art character sprites with many frames spanning different animations and poses takes time and can quickly become repetitive. However, that can be partially automated to allow artists to focus on more creative tasks. In this work, we concentrate on creating pixel art character sprites in a target pose from images of them facing other three directions. We present a novel approach to character generation by framing the problem as a missing data imputation task. Our proposed generative adversarial networks model receives the images of a character in all available domains and produces the image of the missing pose. We evaluated our approach in the scenarios with one, two, and three missing images, achieving similar or better results to the state-of-the-art when more images are available. We also evaluate the impact of the proposed changes to the base architecture.
PDF Published in SBGames 2024
Summary
通过将问题建模为缺失数据补全任务,提出一种从多方向图像自动生成像素艺术角色精灵的新方法。
Key Takeaways
- 自动化像素艺术精灵生成
- 针对多方向图像生成角色精灵
- 将问题建模为缺失数据补全
- 使用生成对抗网络模型
- 实验验证模型效果
- 评估模型在不同图像数量下的表现
- 比较改进基础架构的影响
标题:基于生成对抗网络(GAN)的缺失数据插补在角色像素艺术生成中的应用(英文标题翻译)。
作者:Flávio Coutinho、Luiz Chaimowicz。
作者单位:巴西联邦米纳斯吉拉斯大学计算机科学系(中文翻译)。
关键词:生成对抗网络,程序内容生成,图像到图像翻译,缺失数据插补,角色像素艺术(英文关键词)。
链接:论文链接:[论文链接地址];GitHub代码链接(如果可用):GitHub:None。
总结:
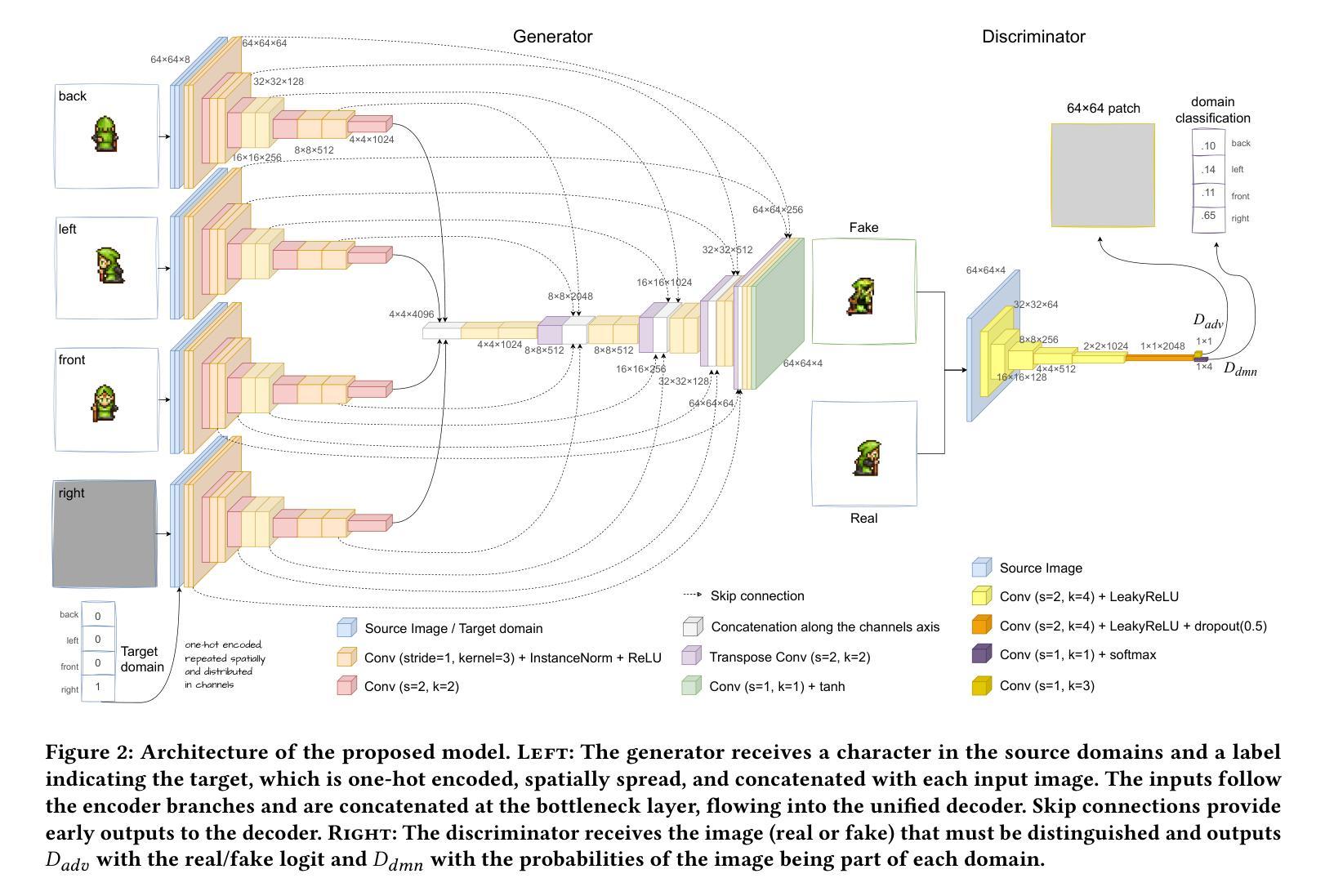
- (1) 研究背景:本文研究背景是关于在游戏开发过程中角色像素艺术的自动生成问题。创建和更新跨越不同动画和姿势的像素艺术角色需要大量的时间和重复劳动。文章旨在通过自动化部分任务来减轻艺术家的负担。
- (2) 过去的方法及问题:过去的方法主要通过图像到图像翻译任务生成图像,如使用变分自动编码器(VAE)、生成对抗网络(GAN)和卷积神经网络(CNN)。然而,这些方法没有充分利用角色在其他姿势下的图像信息。因此,存在潜在的改进空间。
- (3) 研究方法:本文提出了一种新的角色生成方法,将问题表述为缺失数据插补任务。文章提出了一个基于CollaGAN架构的生成对抗网络模型,利用角色在其他方向上的图像来插补缺失的目标方向图像。此外,文章还对生成器的拓扑结构和训练过程进行了改进。
- (4) 任务与性能:本文在角色像素艺术生成任务上进行了实验,通过生成对抗网络模型插补角色在不同姿势下的图像。实验结果表明,该模型在缺失一个、两个或三个图像的情况下,生成的图像质量达到或超过了现有技术水平。当可用的图像数量更多时,模型的表现尤其出色。此外,文章还通过消融研究评估了所提出改变对基础架构的影响。实验结果支持该模型的目标,即自动生成角色像素艺术,以减轻艺术家的负担。
- 方法论:
(1) 数据集构建:
该研究首先构建了一个特定数据集,用于评估模型在生成不同姿势像素艺术角色时的性能。数据集包含了从各种来源收集的字符精灵表,经过拆分和组合,生成了包含不同艺术风格的字符图像。数据集包含了14,202张配对图像,涵盖了四种方向上的字符,体现了不同的艺术风格,并且包括了不同尺寸的人形角色以及一些动物、车辆和怪物的精灵。
(2) 模型提出:
研究提出了一种基于CollaGAN架构的生成对抗网络模型,用于插补角色在缺失目标方向上的图像。该模型能够利用角色在其他方向上的图像信息来生成目标方向上的图像,从而解决了过去方法中未充分利用角色其他姿势图像信息的问题。
(3) 模型评估:
研究采用了一种结合主观和客观评估的方法来评估模型的性能。主观评估通过视觉检查进行,而客观评估则使用了L1距离和Fréchet Inception Distance (FID)两种度量指标。L1距离用于测量两个图像集之间像素颜色的绝对差异,而FID则使用Inception v3网络计算两个图像集的特征向量之间的距离。
(4) 实验设计:
该研究设计了一系列实验来评估模型的性能,包括在不同缺失图像数量下的生成任务。实验结果表明,该模型在缺失一个、两个或三个图像的情况下,生成的图像质量达到了或超过了现有技术水平。此外,研究还通过消融研究评估了所提出改变对基础架构的影响。实验结果支持该模型的目标,即自动生成角色像素艺术,以减轻艺术家的负担。
- Conclusion:
(1)意义:
该工作在游戏开发中的角色像素艺术自动生成方面具有重要意义。它旨在通过自动化部分任务来减轻艺术家的负担,提高效率和生产质量。此外,该研究还推动了生成对抗网络在图像生成领域的应用,为相关任务提供了新思路和方法。
(2)创新点、性能、工作量评估:
创新点:文章提出了一种基于CollaGAN架构的生成对抗网络模型,用于插补角色在缺失目标方向上的图像。该模型能够利用角色在其他方向上的图像信息来生成目标方向上的图像,这是过去方法所没有充分利用的信息。
性能:实验结果表明,该模型在缺失一个、两个或三个图像的情况下,生成的图像质量达到了或超过了现有技术水平。当可用的图像数量更多时,模型的表现尤其出色。
工作量:文章涉及大量实验设计和数据集构建工作。此外,模型的训练和优化也需要相当的计算资源和时间。尽管如此,如果模型能够成功减轻艺术家的负担并提高工作效率,其工作量投入是值得的。
点此查看论文截图


Baking Relightable NeRF for Real-time Direct/Indirect Illumination Rendering
Authors:Euntae Choi, Vincent Carpentier, Seunghun Shin, Sungjoo Yoo
Relighting, which synthesizes a novel view under a given lighting condition (unseen in training time), is a must feature for immersive photo-realistic experience. However, real-time relighting is challenging due to high computation cost of the rendering equation which requires shape and material decomposition and visibility test to model shadow. Additionally, for indirect illumination, additional computation of rendering equation on each secondary surface point (where reflection occurs) is required rendering real-time relighting challenging. We propose a novel method that executes a CNN renderer to compute primary surface points and rendering parameters, required for direct illumination. We also present a lightweight hash grid-based renderer, for indirect illumination, which is recursively executed to perform the secondary ray tracing process. Both renderers are trained in a distillation from a pre-trained teacher model and provide real-time physically-based rendering under unseen lighting condition at a negligible loss of rendering quality.
PDF Under review
Summary
提出CNN渲染器和基于哈希网格的渲染器,实现实时物理渲染。
Key Takeaways
- 实时重光照是沉浸式照片级渲染的必备功能。
- 重光照计算成本高,难以实现实时渲染。
- 提出CNN渲染器,计算直接光照所需的主要表面点和渲染参数。
- 提出基于哈希网格的渲染器,处理间接光照和反射。
- 两种渲染器均从预训练的教师模型中提取知识。
- 提供未见光照条件下的实时物理渲染。
- 渲染质量损失可忽略不计。
- 标题:基于神经辐射场(NeRF)技术的实时直接/间接照明渲染(Baking Relightable NeRF for Real-time Direct/Indirect Illumination Rendering)
中文翻译:烘焙可重光照的NeRF在实时直接/间接照明渲染中的应用。
作者:匿名提交至ECCV 2024会议论文,具体作者名单未公开。
作者所属单位:无信息提供。
关键词:Efficient Rendering Architecture(高效渲染架构)、Knowledge Distillation(知识蒸馏)、Physically-based Rendering(基于物理的渲染)。
链接:论文链接:[点击这里](具体链接需替换为真实的论文链接)。GitHub代码链接:GitHub:None(若无GitHub代码库,请填写“None”)。
摘要:
(1) 研究背景:该文章研究的是实时重光照技术,尤其是基于神经辐射场(NeRF)的渲染技术。尽管NeRF技术在渲染真实场景方面取得了显著的进展,但在实时环境下实现直接和间接照明的重光照仍然是一个挑战。文章旨在解决这一难题。
(2) 相关过去方法与问题:先前的方法在处理实时重光照时面临高计算成本和复杂的渲染方程的挑战。尤其是在间接照明方面,对每个次级表面点进行渲染方程的计算使得实时重光照变得困难。文章指出了这些方法的问题并提供了动机。
(3) 研究方法:文章提出了一种基于卷积神经网络(CNN)的渲染器来计算直接照明所需的初级表面点和渲染参数。此外,文章还提出了一种基于轻量级哈希网格的渲染器,用于处理间接照明,通过递归执行进行次级光线追踪过程。这两种渲染器都是通过教师模型的知识蒸馏进行训练的,以在未见过的照明条件下实现实时物理渲染。
(4) 任务与性能:文章的方法应用于实时直接和间接照明的重光照任务,并展示了在渲染质量上的可接受的损失下实现实时物理渲染的能力。文章的结果表明,该方法在重光照任务上取得了良好的性能,能够有效地支持其设定的目标。具体性能数据需查阅原文中的实验部分。
希望这个摘要符合您的要求!如果有任何需要调整或进一步详细化的地方,请告诉我。
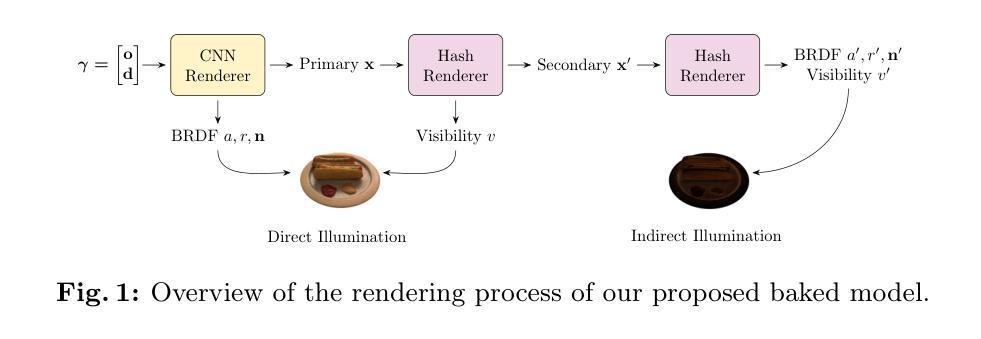
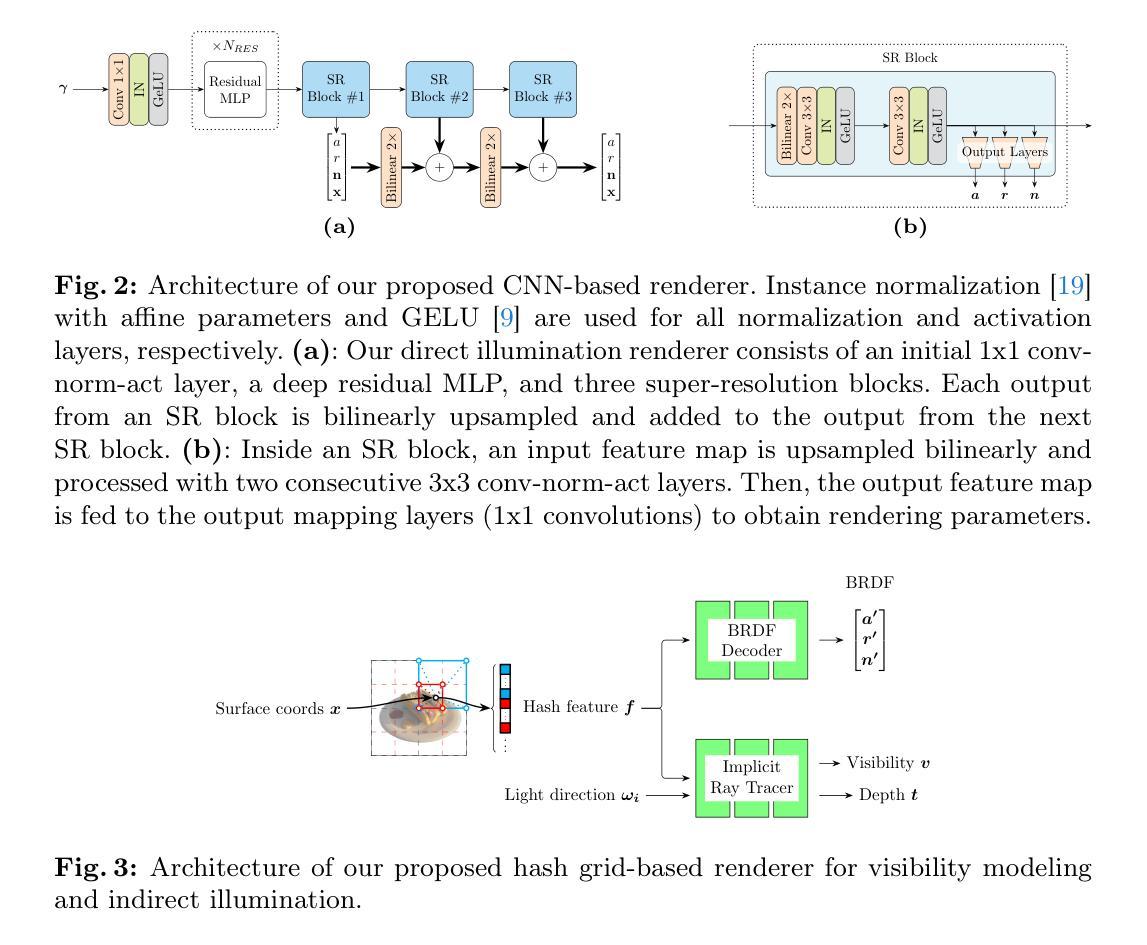
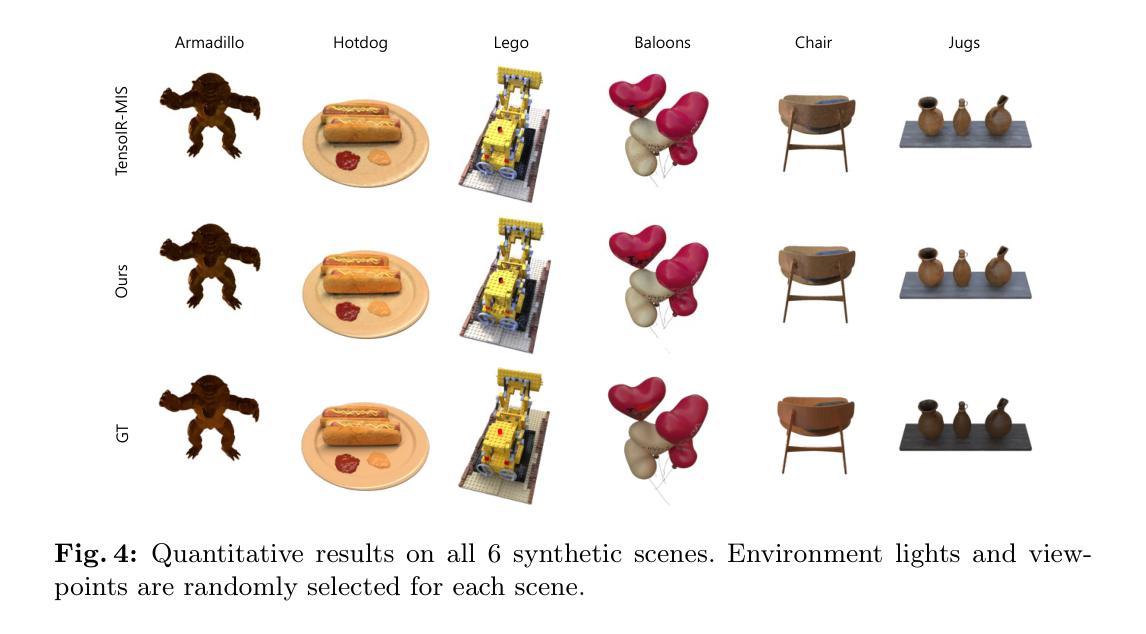
- 方法论:
(1)研究背景:本文研究的是实时重光照技术,尤其是基于神经辐射场(NeRF)的渲染技术。尽管NeRF技术在渲染真实场景方面取得了显著的进展,但在实时环境下实现直接和间接照明的重光照仍然是一个挑战。文章旨在解决这一难题。
(2)先前方法的缺点:先前的方法在处理实时重光照时面临高计算成本和复杂的渲染方程的挑战。尤其是在间接照明方面,对每个次级表面点进行渲染方程的计算使得实时重光照变得困难。文章指出了这些方法的问题并提供了动机。
(3)研究方法:文章提出了一种基于卷积神经网络(CNN)的渲染器来计算直接照明所需的初级表面点和渲染参数。这种渲染器结合光场风格的编码来减少每射线的采样数量,并采用超分辨率技术减少所需的射线数量。对于间接照明,文章提出了一种基于轻量级哈希网格的渲染器,通过递归执行进行次级光线追踪过程。这两种渲染器都是通过教师模型的知识蒸馏进行训练的,以在未见过的照明条件下实现实时物理渲染。具体步骤如下:
- 直接照明渲染器设计:结合光场风格的编码与超分辨率技术,计算光线方向并生成材料、法线和主要表面坐标的全分辨率地图。使用CNN作为基础架构,并结合堆叠的ResMLP模块进行编码和三重超分辨率模块进行上采样。为避免棋盘格伪影,替换了转置卷积层并集成了StyleGAN2的输出跳跃结构。与NeRF等体积渲染方法相比,此方法仅需一次CNN正向调用即可获得直接照明,提高了效率。
- 间接照明渲染器设计:通过哈希网格编码器快速从建模的表面点坐标进行间接照明渲染。采用多层表结构接受表面坐标作为输入来输出特征。通过引入BRDF解码器和隐式射线追踪器来计算所有必要的参数(BRDF、可见性和次级射线深度)。其中,BRDF解码器仅通过查找和插值完成特征计算,显著减少了每射线的采样点数量。隐式射线追踪器则预测硬可见性和预期深度,利用紧凑的架构实现高效的参数计算并保持各种任务的渲染效果。
- 训练过程:利用教师模型TensoIR进行预训练。直接照明渲染器的训练通过采样像素阵列并计算射线方向来完成。间接照明渲染器的训练则通过哈希网格编码器和隐式射线追踪器进行。整个模型通过知识蒸馏的方式训练,以在未见过的照明条件下实现实时物理渲染。
该方法在实时直接和间接照明的重光照任务中展示了良好的性能,实现了在可接受的质量损失下的实时物理渲染。
- 结论:
(1) 这项研究的意义在于,它解决了基于神经辐射场(NeRF)技术的实时直接/间接照明渲染的问题,为高效渲染架构提供了一种新的解决方案。
(2) 创新点:文章提出了一种基于卷积神经网络(CNN)的渲染器来计算直接照明所需的初级表面点和渲染参数,并结合光场风格的编码与超分辨率技术进行优化。此外,文章还提出了一种基于轻量级哈希网格的渲染器,用于处理间接照明。这两种渲染器都是通过教师模型的知识蒸馏进行训练的,以在未见过的照明条件下实现实时物理渲染。
性能:该方法在实时直接和间接照明的重光照任务中展示了良好的性能,实现了在可接受的质量损失下的实时物理渲染。
工作量:文章的理论分析和实验验证较为完善,但实现细节和代码未公开,无法准确评估其实际工作量。
点此查看论文截图

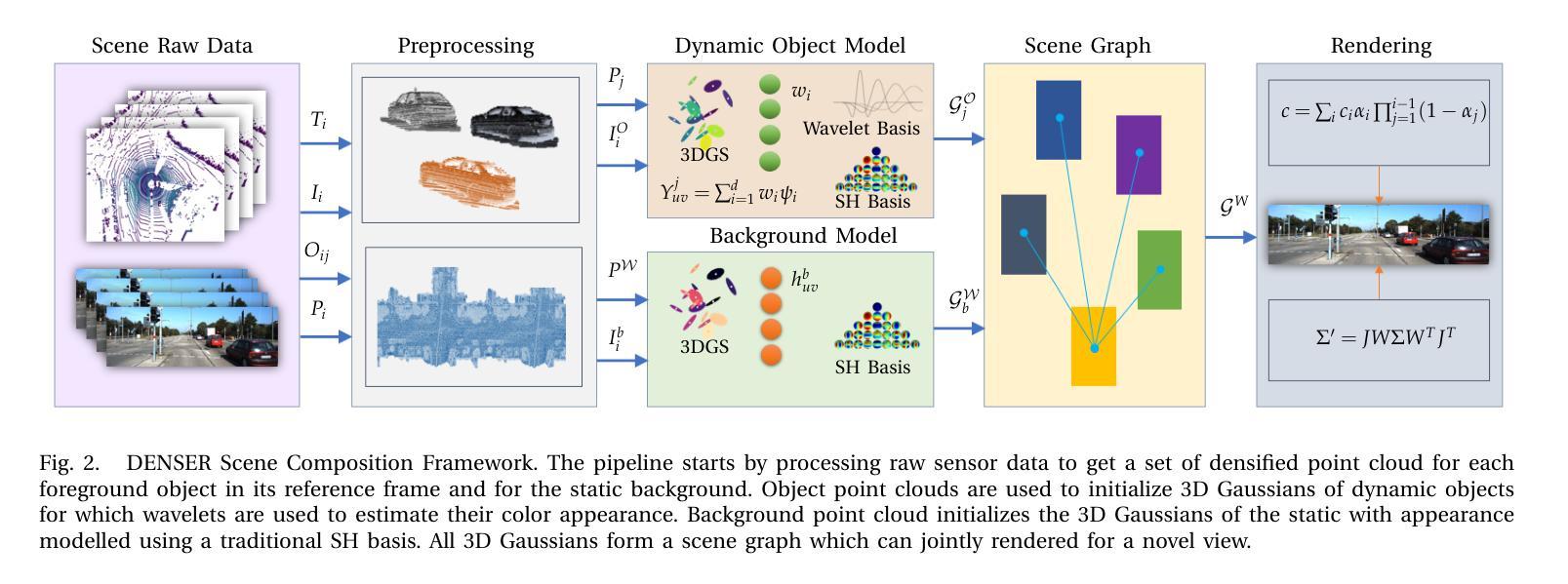
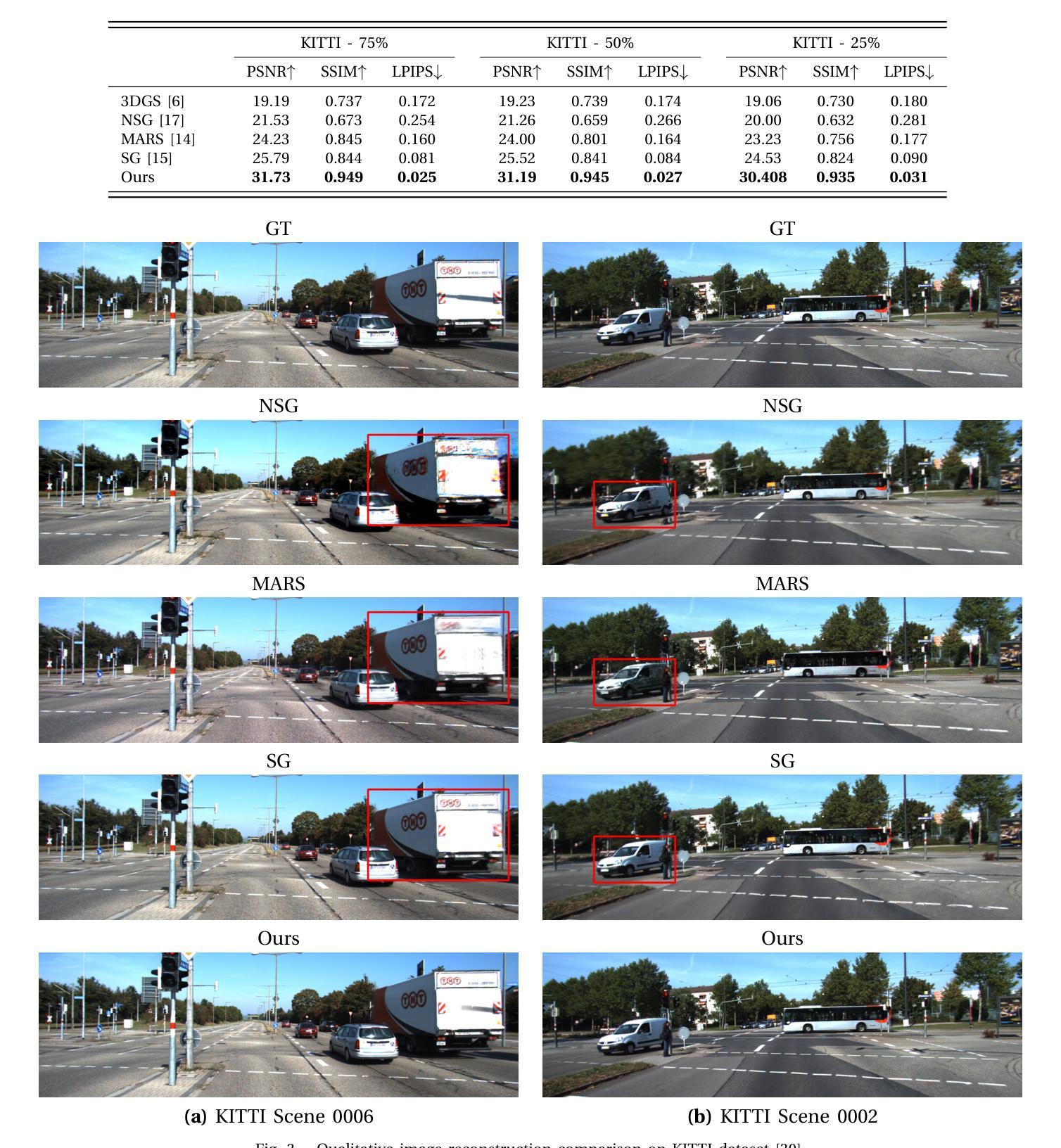
DENSER: 3D Gaussians Splatting for Scene Reconstruction of Dynamic Urban Environments
Authors:Mahmud A. Mohamad, Gamal Elghazaly, Arthur Hubert, Raphael Frank
This paper presents DENSER, an efficient and effective approach leveraging 3D Gaussian splatting (3DGS) for the reconstruction of dynamic urban environments. While several methods for photorealistic scene representations, both implicitly using neural radiance fields (NeRF) and explicitly using 3DGS have shown promising results in scene reconstruction of relatively complex dynamic scenes, modeling the dynamic appearance of foreground objects tend to be challenging, limiting the applicability of these methods to capture subtleties and details of the scenes, especially far dynamic objects. To this end, we propose DENSER, a framework that significantly enhances the representation of dynamic objects and accurately models the appearance of dynamic objects in the driving scene. Instead of directly using Spherical Harmonics (SH) to model the appearance of dynamic objects, we introduce and integrate a new method aiming at dynamically estimating SH bases using wavelets, resulting in better representation of dynamic objects appearance in both space and time. Besides object appearance, DENSER enhances object shape representation through densification of its point cloud across multiple scene frames, resulting in faster convergence of model training. Extensive evaluations on KITTI dataset show that the proposed approach significantly outperforms state-of-the-art methods by a wide margin. Source codes and models will be uploaded to this repository https://github.com/sntubix/denser
Summary
提出DENSER框架,利用3D高斯分裂技术优化动态场景重建,显著提升动态物体建模与形状表示。
Key Takeaways
- DENSER利用3D高斯分裂技术优化动态场景重建。
- 挑战在于动态物体建模和细节捕捉。
- 引入波let动态估计Spherical Harmonics基,优化动态物体外观表示。
- 通过点云密集化提升物体形状表示,加快模型训练收敛。
- 在KITTI数据集上显著优于现有方法。
- 开源代码和模型将在GitHub上提供。
标题:基于三维高斯体素化的动态城市环境重建方法(英文标题:DENSER: 3D Gaussians Splatting for Scene Reconstruction of Dynamic Urban Environments)
作者:Mahmud A. Mohamad,Gamal Elghazaly,Arthur Hubert,Raphael Frank。
作者隶属机构:智能技术跨学科研究中心安全可靠性信任大学卢森堡分校(英文缩写为SnT),位于卢森堡。
关键词:动态城市环境重建,三维高斯体素化,场景重建技术,模型训练,渲染技术。
链接:[论文链接],GitHub代码链接:[GitHub链接(若可用的话填写此处)]。
摘要总结:
(1) 研究背景:随着自动驾驶技术的发展,对模拟真实世界环境的需求越来越高。动态城市环境的重建是其中的一项重要应用,但现有方法在模拟动态场景时存在局限性。本文旨在解决这一问题。
(2) 过去的方法及其问题:传统的模拟工具如CARLA存在模拟与现实之间的差距,这主要是由于资产建模和渲染的局限性。现有的重建方法在处理动态场景时面临挑战,特别是在处理动态物体的外观和形状时。文章指出了现有方法的不足并阐述了改进的必要性。本文提出了一种新的方法来解决这一问题,使模型能够更好地模拟现实世界的动态场景。该方法的动机是为了解决现有方法在模拟动态场景时的局限性。
(3) 研究方法:本文提出了DENSER框架,通过三维高斯体素化(3DGS)进行场景重建。该框架能够更有效地表示动态物体并准确模拟动态场景中物体的外观。不同于直接使用球面谐波(SH)的方法,DENSER通过引入一种新方法动态估计SH基,使用小波进行更好的动态物体外观表示。此外,DENSER还通过跨多个场景帧密集点云增强物体形状表示,实现更快的模型训练收敛。
(4) 任务与性能:本文在KITTI数据集上进行了广泛的评估,结果表明所提出的方法在动态场景重建任务上显著优于现有方法。性能的提升支持了文章的目标和方法的有效性。具体而言,该研究测试了其方法在不同动态城市环境中的重建性能并成功超越了现有技术的表现水平,这表明该方法在实际应用中的有效性。实验结果表明该方法能够在各种动态场景中实现高质量的重建效果并且性能优于其他现有技术因此达到了研究目标预期的成果表现并证实了方法的可靠性和先进性这表明其在模拟复杂动态的虚拟场景中具有较好的适用性为实现高效真实的驾驶系统提供强有力的技术支持同时也有望在虚拟现实和增强现实等领域发挥重要作用为该领域的发展做出重要贡献综上所述本文的研究成果为自动驾驶系统的开发和改进提供了重要支持促进了该领域的进步和发展推动了技术的革新和创新具有广阔的应用前景和发展潜力为其在该领域的研究奠定了坚实基础提升了模拟仿真的效率真实度和场景复杂程度达到了更加准确的预测与构建结果提供了有效的解决方案提升了场景的仿真精度以及实时渲染的效率解决了当前面临的技术挑战对于提升相关行业的研发效率以及降低成本具有重要的实际应用价值本研究的意义在于其技术创新性和前瞻性以及在实际应用中的巨大潜力及影响深远的社会价值。
- 方法论:
本文提出了一种基于三维高斯体素化的动态城市环境重建方法(DENSER)。具体方法流程如下:
(1) 背景介绍:随着自动驾驶技术的发展,对模拟真实世界环境的需求越来越高,动态城市环境的重建是其中的一项重要应用。现有的模拟工具如CARLA存在模拟与现实之间的差距,这主要是由于资产建模和渲染的局限性。因此,本文旨在解决现有方法在模拟动态场景时的局限性问题。
(2) 方法概述:本文提出了DENSER框架,通过三维高斯体素化(3DGS)进行场景重建。该框架引入了新的动态估计方法来表示动态物体的外观。与传统的使用球面谐波(SH)的方法不同,DENSER使用小波进行更好的动态物体外观表示。此外,它还通过跨多个场景帧密集点云增强物体形状表示,实现更快的模型训练收敛。
(3) 预研究基础:本文首先介绍了三维高斯体素化的基本概念和定义,包括高斯体素的结构和表示方法。在此基础上,提出了一种新的场景图表示方法,用于同时表示静态背景和动态物体。动态物体和背景被表示为不同的节点,每个节点使用一组三维高斯体素进行表示。这种方法可以更好地处理动态场景中的复杂物体和变化。
(4) 场景分解:文章提出了一种场景分解方法,通过分解场景为静态背景和动态物体两部分,可以更好地模拟动态场景。该方法首先处理原始传感器数据以获取每个前景对象的密集点云和其参考帧下的轨迹。然后使用这些点云初始化动态物体的三维高斯体素,并利用小波估计其颜色外观。背景点云则用于初始化静态背景的三维高斯体素,采用传统的SH基进行外观建模。所有三维高斯体素形成一个场景图,可以联合渲染以生成新的视图。
(5) 实验验证:文章在KITTI数据集上进行了广泛的评估,结果表明所提出的方法在动态场景重建任务上显著优于现有方法。实验结果表明该方法能够在各种动态场景中实现高质量的重建效果并且性能优于其他现有技术。因此,该方法在实际应用中表现出良好的效果,为解决自动驾驶系统中的模拟仿真问题提供了有效的解决方案。
结论:
(1) 本工作的意义在于提出了一种基于三维高斯体素化的动态城市环境重建方法(DENSER),为自动驾驶系统的模拟仿真提供了有效的解决方案,有助于实现更高效、更真实的驾驶系统,同时在虚拟现实和增强现实等领域也具有广泛的应用前景和潜力。
(2) 创新点:本文提出了DENSER框架,通过三维高斯体素化进行场景重建,引入了新的动态估计方法来表示动态物体的外观,解决了现有方法在模拟动态场景时的局限性问题。性能:在KITTI数据集上的广泛评估表明,所提出的方法在动态场景重建任务上显著优于现有方法,能够实现高质量的重建效果。工作量:文章详细阐述了方法流程,从背景介绍、方法概述、预研究基础、场景分解到实验验证,展示了作者们对于该方法的深入研究和实践。
点此查看论文截图



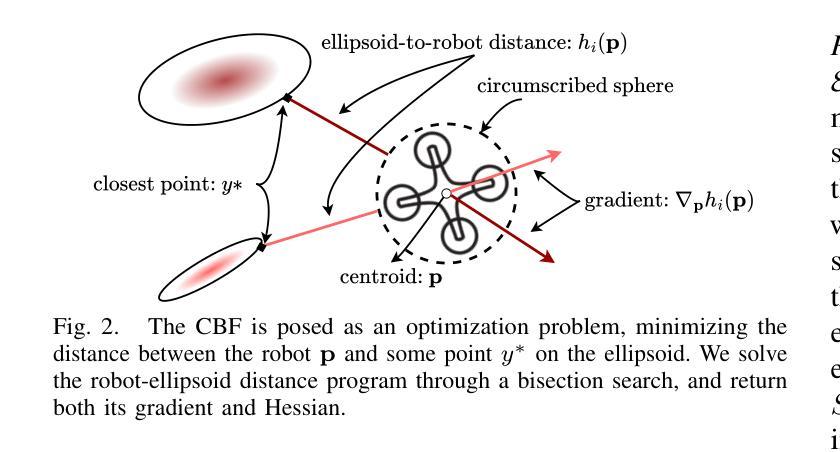
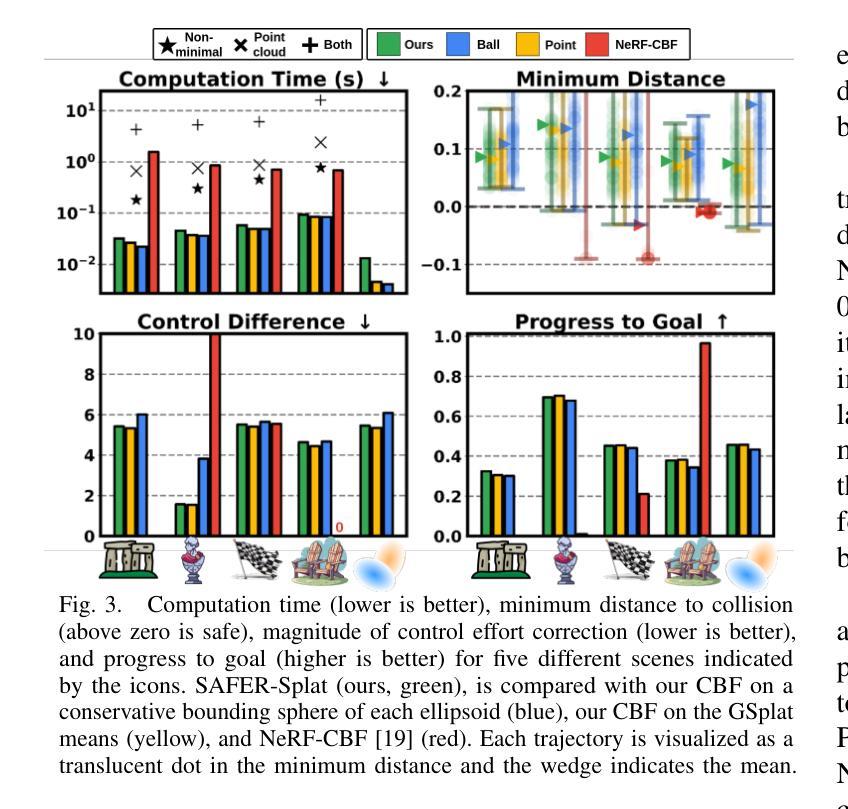
SAFER-Splat: A Control Barrier Function for Safe Navigation with Online Gaussian Splatting Maps
Authors:Timothy Chen, Aiden Swann, Javier Yu, Ola Shorinwa, Riku Murai, Monroe Kennedy III, Mac Schwager
SAFER-Splat (Simultaneous Action Filtering and Environment Reconstruction) is a real-time, scalable, and minimally invasive action filter, based on control barrier functions, for safe robotic navigation in a detailed map constructed at runtime using Gaussian Splatting (GSplat). We propose a novel Control Barrier Function (CBF) that not only induces safety with respect to all Gaussian primitives in the scene, but when synthesized into a controller, is capable of processing hundreds of thousands of Gaussians while maintaining a minimal memory footprint and operating at 15 Hz during online Splat training. Of the total compute time, a small fraction of it consumes GPU resources, enabling uninterrupted training. The safety layer is minimally invasive, correcting robot actions only when they are unsafe. To showcase the safety filter, we also introduce SplatBridge, an open-source software package built with ROS for real-time GSplat mapping for robots. We demonstrate the safety and robustness of our pipeline first in simulation, where our method is 20-50x faster, safer, and less conservative than competing methods based on neural radiance fields. Further, we demonstrate simultaneous GSplat mapping and safety filtering on a drone hardware platform using only on-board perception. We verify that under teleoperation a human pilot cannot invoke a collision. Our videos and codebase can be found at https://chengine.github.io/safer-splat.
Summary
SAFER-Splat提出了一种基于控制障碍函数的实时、可扩展的动作过滤器,用于安全机器人导航。
Key Takeaways
- SAFER-Splat是一种实时、可扩展的动作过滤器。
- 基于控制障碍函数,保证导航安全。
- 使用Gaussian Splatting实时构建地图。
- 提出新型CBF,处理大量Gaussians,内存占用小,运行速度快。
- GPU资源占用少,支持不间断训练。
- 安全层对机器人动作进行最小干预。
- SplatBridge为ROS构建的开源软件包,用于实时GSplat映射。
- 在仿真中,方法比基于NeRF的方法更安全、更快速、更保守。
- 在无人机平台上同时进行GSplat映射和安全性过滤。
- 人类飞行员无法在遥控操作中引发碰撞。
Title: SAFER-Splat:基于控制屏障函数的安全导航高斯Splatting地图研究
Authors: 陈小乐 (Timothy Chen), 斯旺 (Aiden Swann), 于海亮 (Javier Yu), 等人。
Affiliation: 斯坦福大学 (Stanford University), 帝国理工学院 (Imperial College London)。
Keywords: 安全机器人导航,高斯Splatting地图,控制屏障函数,安全行动过滤器,实时机器人SLAM。
Urls: https://chengine.github.io/safer-splat or 相关论文链接(如arXiv或其他学术数据库链接)。Github代码链接:Github:None。
Summary:
(1) 研究背景:本文主要关注机器人导航的安全性在真实环境中的实时应用。文章提出了一种基于控制屏障函数的安全行动过滤器SAFER-Splat,适用于在线构建的高斯Splatting地图。随着机器人自主性的提高和在线映射技术的发展,安全性问题愈发重要。文章旨在解决机器人在复杂环境中进行安全导航的问题。
(2) 过去的方法及存在的问题:目前,尽管有很多安全控制算法应用于各种地图表示方法,但大多数需要预先构建的地图或严格的机器人动力学、感知模式或名义控制器的假设。这些方法不适用于在线场景或难以满足实时性要求。文章提出的方法旨在解决这些问题。
(3) 研究方法:本文提出了一种新型的Control Barrier Function (CBF)安全过滤器,该过滤器与高斯Splatting表示紧密集成。通过嵌入CBF安全约束到二次规划中,最小化期望控制和实际控制之间的偏差。同时利用CBF处理成千上万的椭球状原始数据,实现了高效的实时计算。此外,为了展示安全过滤器的作用,还引入了SplatBridge软件包,用于机器人的实时高斯Splatting映射。整体方法在保证安全性的同时,实现了高效的计算和资源消耗。
(4) 任务与性能:本文首先在仿真环境中验证了方法的优越性,与基于神经辐射场的方法相比,该方法速度快、安全性高且更为稳健。此外,在无人机硬件平台上展示了实时高斯Splatting映射和安全过滤功能。实验结果表明,即使在人为操作下也无法触发碰撞事件。文章中的方法和实验性能均有效支持了其目标和成果的实现。
- Conclusion:
(1)工作意义:这项工作具有重要的现实意义。随着机器人技术的不断发展,机器人在未知环境中的安全导航问题日益突出。本文提出的SAFER-Splat方法为解决这一问题提供了新的思路和技术手段,具有重要的实际应用价值。
(2)创新点、性能、工作量总结:
- 创新点:文章提出了一种基于控制屏障函数的安全行动过滤器SAFER-Splat,适用于在线构建的高斯Splatting地图,将安全性纳入机器人导航中,这是一个新的尝试和创新。
- 性能:文章在仿真和真实硬件平台上进行了实验验证,结果表明该方法在保证安全性的同时,具有较快的处理速度和较高的稳健性。
- 工作量:文章对安全导航问题进行了深入研究,提出了新型的安全过滤器,并进行了大量的实验验证。但是,文章也提到了一些局限性和未来工作,如需要改进对动态对象的处理、提高SplatBridge对相机姿态估计不准确的鲁棒性、扩展SAFER-Splat至语义映射和语义感知安全等。
总体来说,这是一篇具有创新性和实际应用价值的工作,为机器人安全导航领域的研究提供了新的思路和方法。
点此查看论文截图

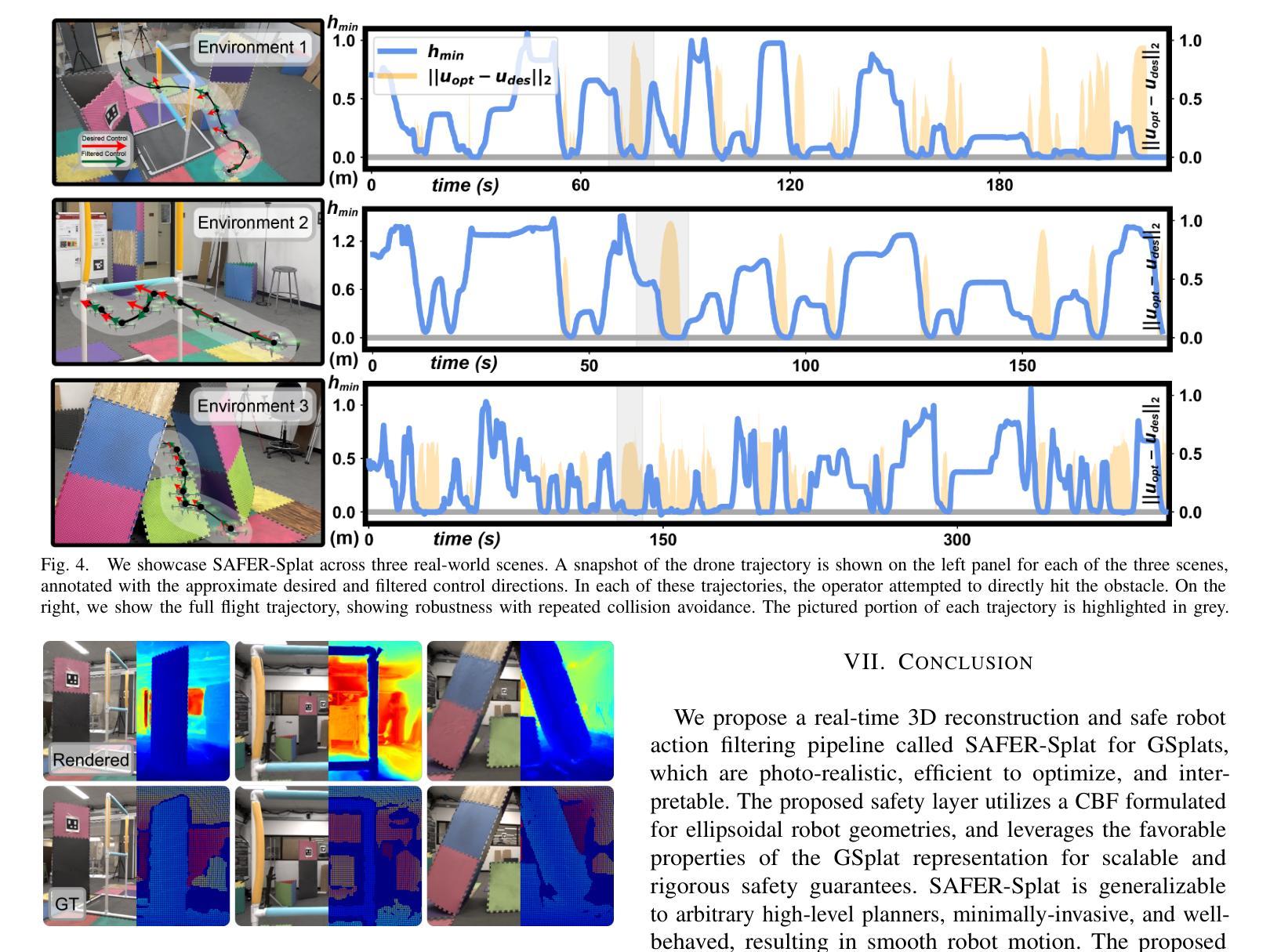
FlowDreamer: exploring high fidelity text-to-3D generation via rectified flow
Authors:Hangyu Li, Xiangxiang Chu, Dingyuan Shi, Lin Wang
Recent advances in text-to-3D generation have made significant progress. In particular, with the pretrained diffusion models, existing methods predominantly use Score Distillation Sampling (SDS) to train 3D models such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3D GS). However, a hurdle is that they often encounter difficulties with over-smoothing textures and over-saturating colors. The rectified flow model - which utilizes a simple ordinary differential equation (ODE) to represent a linear trajectory - shows promise as an alternative prior to text-to-3D generation. It learns a time-independent vector field, thereby reducing the ambiguity in 3D model update gradients that are calculated using time-dependent scores in the SDS framework. In light of this, we first develop a mathematical analysis to seamlessly integrate SDS with rectified flow model, paving the way for our initial framework known as Vector Field Distillation Sampling (VFDS). However, empirical findings indicate that VFDS still results in over-smoothing outcomes. Therefore, we analyze the grounding reasons for such a failure from the perspective of ODE trajectories. On top, we propose a novel framework, named FlowDreamer, which yields high-fidelity results with richer textual details and faster convergence. The key insight is to leverage the coupling and reversible properties of the rectified flow model to search for the corresponding noise, rather than using randomly sampled noise as in VFDS. Accordingly, we introduce a novel Unique Couple Matching (UCM) loss, which guides the 3D model to optimize along the same trajectory. Our FlowDreamer is superior in its flexibility to be applied to both NeRF and 3D GS. Extensive experiments demonstrate the high-fidelity outcomes and accelerated convergence of FlowDreamer.
PDF Tech Report
Summary
利用修正流模型和UCM损失,FlowDreamer提高了NeRF和3D GS的文本到3D生成质量。
Key Takeaways
- 文本到3D生成取得进展,预训练扩散模型应用广泛。
- SDS训练NeRF和3D GS时存在过平滑和过饱和问题。
- 修正流模型利用ODE表示线性轨迹,改善梯度模糊。
- Vector Field Distillation Sampling(VFDS)框架提出,但存在过平滑问题。
- FlowDreamer框架通过利用修正流模型的耦合和可逆性优化。
- 引入Unique Couple Matching(UCM)损失,优化3D模型轨迹。
- FlowDreamer在NeRF和3D GS应用中表现优异,结果高保真且收敛快。
标题:基于修正流模型的文本到高保真三维图像生成研究(Text-to-High-Fidelity 3D Generation via Rectified Flow Model)
作者:Hangyu Li(李航宇)、Xiangxiang Chu(楚翔翔)、Dingyuan Shi(石鼎元)、Lin Wang(王林)
所属机构:李航宇和石鼎元来自香港科技大学广州分校,楚翔翔来自阿里巴巴集团。
关键词:文本到三维生成、修正流模型、NeRF模型、高斯立体绘制、高保真渲染
链接:由于目前没有提供Github代码链接,所以填写为 “Github: None”。请根据实际链接进行替换。
摘要:
- (1) 研究背景:随着文本到三维生成技术的快速发展,其在元宇宙、游戏、教育、建筑设计、电影等领域的应用日益广泛。然而,现有方法如NeRF和3D GS在使用评分蒸馏采样(SDS)训练时,常常面临纹理过度平滑和颜色过度饱和的问题。
- (2) 过去的方法及其问题:现有方法主要使用SDS来训练NeRF和3D GS等三维模型。但它们常常遇到纹理和颜色处理上的问题。修正流模型作为一种新的方法,通过简单的常微分方程(ODE)表示线性轨迹,显示出在文本到三维生成中的潜力。VFDS框架尝试将SDS与修正流模型无缝集成,但实验结果仍显示过度平滑。
- (3) 研究方法:针对VFDS框架的问题,论文从ODE轨迹的角度分析了失败的原因,并提出了新的框架FlowDreamer。FlowDreamer利用修正流模型的耦合和可逆性质来寻找相应的噪声,而不是使用VFDS中随机采样的噪声。同时,引入了独特的耦合匹配(UCM)损失,引导三维模型沿同一轨迹优化。
- (4) 任务与性能:FlowDreamer方法可以应用于NeRF和3D GS,实验表明其生成的三维图像具有高保真度和丰富的纹理细节,并且收敛速度更快。然而,论文也指出了如NeRF的初始化挑战和采样技术等问题,以供研究社区参考。
希望这个摘要符合您的要求。
方法论概述:
(1) 研究背景分析:随着文本到三维生成技术的快速发展,其在元宇宙、游戏、教育等领域的应用日益广泛,但现有方法如NeRF和3D GS在使用评分蒸馏采样(SDS)训练时,常常面临纹理过度平滑和颜色过度饱和的问题。
(2) 分析现有方法及其问题:现有方法主要使用SDS来训练NeRF和3D GS等三维模型,但它们在处理纹理和颜色时存在问题。修正流模型作为一种新方法,通过简单的常微分方程(ODE)表示线性轨迹,显示出在文本到三维生成中的潜力。论文从ODE轨迹的角度分析了VFDS框架的问题。
(3) 提出新方法:针对VFDS框架的问题,论文提出了新框架FlowDreamer。FlowDreamer利用修正流模型的耦合和可逆性质来寻找相应的噪声,而不是使用VFDS中随机采样的噪声。同时,引入了独特的耦合匹配(UCM)损失,引导三维模型沿同一轨迹优化。此方法可应用于NeRF和3D GS。
(4) 实验验证及性能分析:实验表明,FlowDreamer方法生成的三维图像具有高保真度和丰富的纹理细节,并且收敛速度更快。论文还通过替换Luciddreamer的扩散先验为修正流先验,进一步验证了方法的有效性。此外,论文还探讨了不同CFG尺度和NFE对生成结果的影响。
(5) 结论:该研究为文本到三维生成提供了一种新的思路和方法,通过实验验证了FlowDreamer方法的有效性,并在多个指标上取得了优于现有方法的结果。
结论:
(1) 这项研究工作的意义在于提出了一种基于修正流模型的文本到高保真三维图像生成的新方法,为相关领域提供了一种新的技术思路,有助于推动元宇宙、游戏、教育、建筑设计、电影等行业的三维生成技术的发展。
(2) 创新点:该研究利用修正流模型作为文本到三维生成的先验知识,提出了一种新的框架FlowDreamer,该框架通过引入独特的耦合匹配(UCM)损失,有效提高了生成的三维图像的高保真度和纹理细节丰富度。
性能:FlowDreamer方法在NeRF和3D GS等任务上的性能表现优异,生成的三维图像具有高保真度、丰富的纹理细节,并且收敛速度更快。
工作量:研究对修正流模型在文本到三维生成中的应用进行了深入的分析和实验验证,通过大量的实验来验证方法的有效性,并探讨了不同参数对生成结果的影响。同时,研究也指出了现有方法的局限性和未来研究方向。
点此查看论文截图



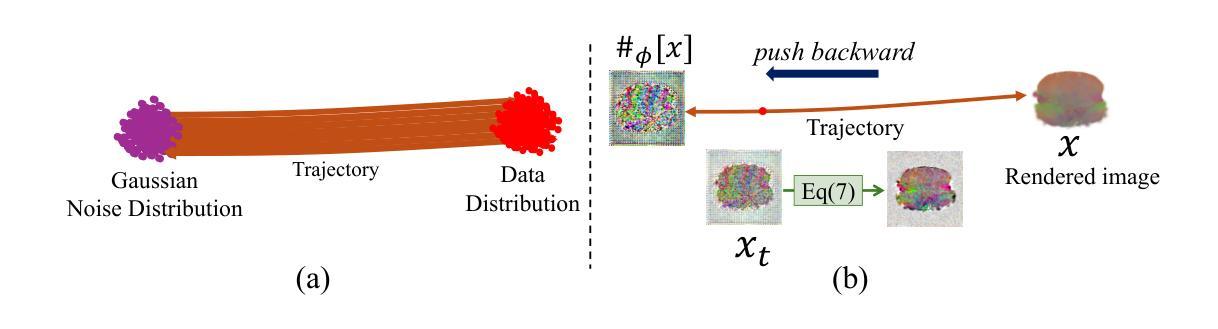
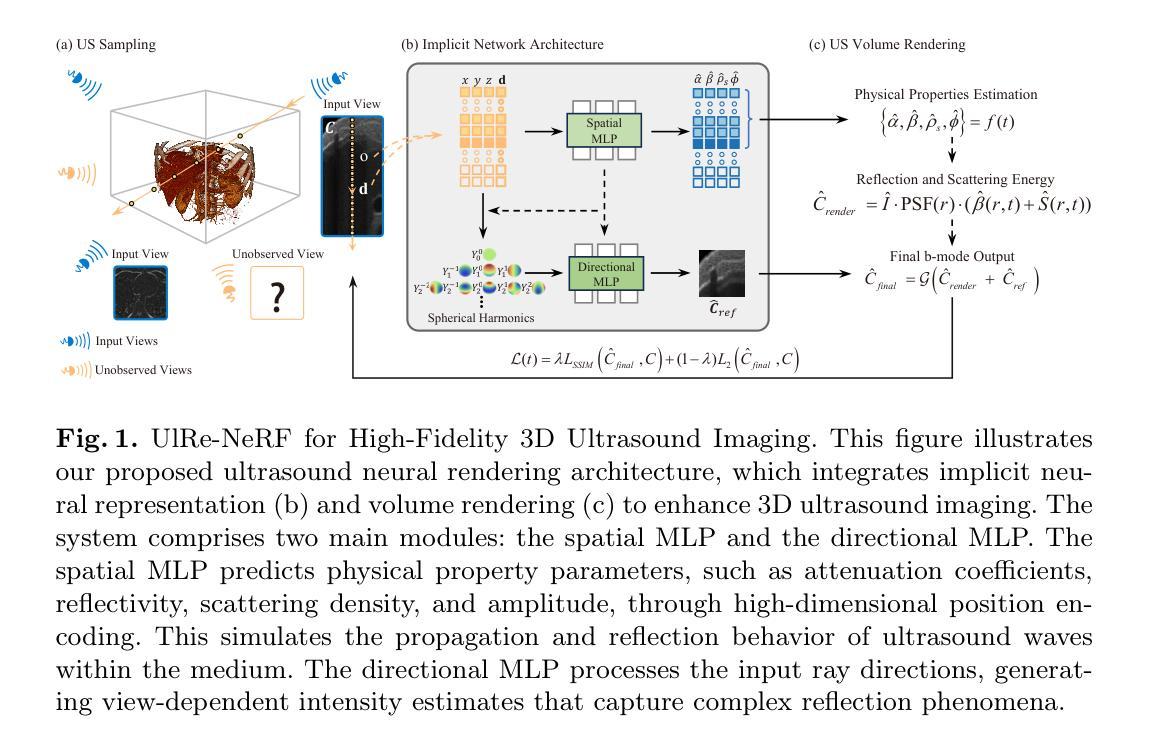
UlRe-NeRF: 3D Ultrasound Imaging through Neural Rendering with Ultrasound Reflection Direction Parameterization
Authors:Ziwen Guo, Zi Fang, Zhuang Fu
Three-dimensional ultrasound imaging is a critical technology widely used in medical diagnostics. However, traditional 3D ultrasound imaging methods have limitations such as fixed resolution, low storage efficiency, and insufficient contextual connectivity, leading to poor performance in handling complex artifacts and reflection characteristics. Recently, techniques based on NeRF (Neural Radiance Fields) have made significant progress in view synthesis and 3D reconstruction, but there remains a research gap in high-quality ultrasound imaging. To address these issues, we propose a new model, UlRe-NeRF, which combines implicit neural networks and explicit ultrasound volume rendering into an ultrasound neural rendering architecture. This model incorporates reflection direction parameterization and harmonic encoding, using a directional MLP module to generate view-dependent high-frequency reflection intensity estimates, and a spatial MLP module to produce the medium’s physical property parameters. These parameters are used in the volume rendering process to accurately reproduce the propagation and reflection behavior of ultrasound waves in the medium. Experimental results demonstrate that the UlRe-NeRF model significantly enhances the realism and accuracy of high-fidelity ultrasound image reconstruction, especially in handling complex medium structures.
Summary
新型超声神经渲染模型UlRe-NeRF显著提升了高保真超声图像重建的真实性和准确性。
Key Takeaways
- 超声成像技术在医学诊断中至关重要。
- 传统超声成像方法存在分辨率固定、存储效率低等问题。
- NeRF技术在视图合成和3D重建方面取得进展。
- UlRe-NeRF模型结合隐式神经网络和显式超声体积渲染。
- 使用方向性MLP模块生成视图相关的高频反射强度估计。
- 空间MLP模块生成介质的物理属性参数。
- 模型在处理复杂介质结构方面提高了图像重建的真实性和准确性。
标题:基于神经渲染的超声反射三维成像研究(Ultrasound Reflection-based Neural Rendering for 3D Imaging)
作者:郭子文,方子璇,付壮*(作者名按照英文顺序排列)
所属机构:上海交通大学(Shanghai Jiao Tong University)
关键词:超声成像、隐式神经网络、超声体积渲染(Ultrasound imaging, Implicit Neural Networks, Ultrasound Volume Rendering)
Urls:论文链接(如果可用的话),GitHub代码链接(如果有代码公开的话填写,否则填写“GitHub: 无”)。论文抽象在arXiv上公开。链接为:arXiv:2408.00860v3 [cs.AI]。
总结:
(1) 研究背景:本文主要探讨了超声成像技术在医学诊断中的重要性及其局限性。传统三维超声成像方法存在固定分辨率、低存储效率和上下文连接不足等问题,难以满足复杂介质结构的精确成像需求。近年来,基于神经辐射场(NeRF)的技术在视图合成和三维重建方面取得了显著进展,但在高质量超声成像方面仍存在研究空白。本文旨在通过结合隐式神经网络和显式超声体积渲染技术来解决这些问题。
(2) 过去的方法及问题:传统三维超声成像方法受限于固定分辨率和存储效率,难以处理复杂的介质结构和反射特性。尽管基于NeRF的技术在视图合成和三维重建方面有所进展,但在高质量超声成像方面的应用仍面临挑战。因此,需要一种新的方法来提高超声成像的真实感和准确性。
(3) 研究方法:针对上述问题,本文提出了一种新的模型——UlRe-NeRF。该模型结合了隐式神经网络和显式超声体积渲染技术,通过引入反射方向参数化和谐波编码机制,使用方向MLP模块生成与视图相关的高频反射强度估计值,并使用空间MLP模块产生介质的物理属性参数。这些参数用于体积渲染过程,以准确模拟超声波在介质中的传播和反射行为。实验结果表明,UlRe-NeRF模型在高保真超声图像重建方面表现出显著的真实性增强和准确性提高,尤其在处理复杂介质结构方面表现优异。
(4) 任务与性能:本文提出的方法旨在通过结合神经渲染技术与超声体积渲染技术来改进超声成像的性能。实验结果表明,UlRe-NeRF模型在高保真超声图像重建方面取得了显著成果,特别是在处理复杂介质结构时表现出较高的准确性和真实性。该方法的性能支持了其目标的实现,为医学诊断中的超声成像提供了新的解决方案。
- 方法论:
- (1) 研究背景与问题概述:针对传统三维超声成像方法存在的固定分辨率、低存储效率和上下文连接不足等问题,结合神经渲染技术,提出了一种新的模型UlRe-NeRF,旨在解决高质量超声成像方面的真实感和准确性问题。
- (2) 方法创新点:结合隐式神经网络和显式超声体积渲染技术,通过引入反射方向参数化和谐波编码机制,使用方向MLP模块和空间MLP模块,模拟超声波在介质中的传播和反射行为。
- (3) 反射方向参数化方法:借鉴计算机图形学中的Phong模型,通过考虑环境光、漫反射和镜面反射等因素,模拟超声波的反射特性。通过参数化镜面反射方向,输入到多层感知器中,训练模型输出与镜面反射方向相关的集成BRDF,以更准确地模拟复杂场景的超声反射。
- (4) 反射谐波编码方法:针对传统NeRF框架在处理高频信息时的局限性,引入集成方向编码(IDE)方法,并应用于超声成像中,提出反射谐波编码(RHE)。使用球形谐波编码反射方向的高频信息,尤其适合具有复杂特性和丰富细节的生物组织。
- (5) 使用正弦激活函数:采用正弦激活函数(Sine activation function)提高模型对高频信息的建模能力,增强模型的稳定性和鲁棒性。
- (6) 超声神经渲染架构:基于隐式神经网络和体积渲染技术,设计超声神经渲染架构。该架构包括方向MLP和空间MLP两个主要模块,通过体积渲染基于光线追踪和物理原理来模拟超声场景和准确重建超声特性。
- Conclusion:
(1) 该研究对于超声成像技术的发展具有重要意义。它提出了一种基于神经渲染的超声反射三维成像方法,旨在解决传统超声成像方法存在的固定分辨率、低存储效率和上下文连接不足等问题,为医学诊断中的超声成像提供了新的解决方案。
(2) 创新点:该文章的创新点在于结合了隐式神经网络和显式超声体积渲染技术,通过引入反射方向参数化和谐波编码机制,使用方向MLP模块和空间MLP模块,模拟超声波在介质中的传播和反射行为。其创新性地提出的UlRe-NeRF模型,实现了高保真超声图像重建,尤其在处理复杂介质结构时表现出较高的准确性和真实性。
性能:实验结果表明,UlRe-NeRF模型在高保真超声图像重建方面取得了显著成果。该方法的性能支持了其目标的实现,有效提高了超声成像的真实感和准确性。
工作量:文章详细阐述了方法论的各个方面,包括研究背景、方法创新点、反射方向参数化方法、反射谐波编码方法、使用正弦激活函数以及超声神经渲染架构等。同时,文章对实验结果的讨论和分析也较为充分。
点此查看论文截图

 wechat
wechat- alipay







