Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-09-27 更新
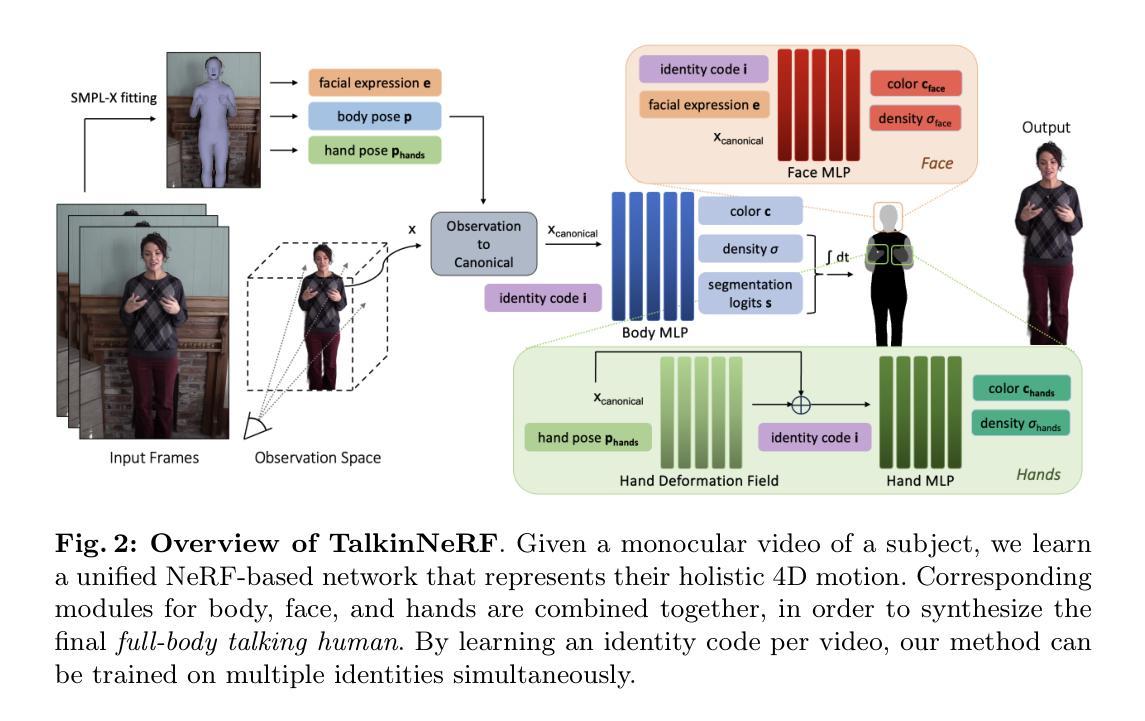
TalkinNeRF: Animatable Neural Fields for Full-Body Talking Humans
Authors:Aggelina Chatziagapi, Bindita Chaudhuri, Amit Kumar, Rakesh Ranjan, Dimitris Samaras, Nikolaos Sarafianos
We introduce a novel framework that learns a dynamic neural radiance field (NeRF) for full-body talking humans from monocular videos. Prior work represents only the body pose or the face. However, humans communicate with their full body, combining body pose, hand gestures, as well as facial expressions. In this work, we propose TalkinNeRF, a unified NeRF-based network that represents the holistic 4D human motion. Given a monocular video of a subject, we learn corresponding modules for the body, face, and hands, that are combined together to generate the final result. To capture complex finger articulation, we learn an additional deformation field for the hands. Our multi-identity representation enables simultaneous training for multiple subjects, as well as robust animation under completely unseen poses. It can also generalize to novel identities, given only a short video as input. We demonstrate state-of-the-art performance for animating full-body talking humans, with fine-grained hand articulation and facial expressions.
PDF Accepted by ECCVW 2024. Project page: https://aggelinacha.github.io/TalkinNeRF/
Summary
提出TalkinNeRF,从单目视频学习动态神经辐射场,实现全身谈话人类的动画。
Key Takeaways
- 首次提出从单目视频学习全身谈话人类的动态神经辐射场。
- 结合身体姿态、手势和面部表情,代表整体4D人体运动。
- 学习身体、面部和手部模块,实现最终结果生成。
- 特殊学习手指变形场,以捕捉复杂的指关节运动。
- 多身份表示,支持多主体同时训练及未见姿态下的鲁棒动画。
- 可泛化到新身份,仅需短时视频输入。
- 在全身谈话人类动画、精细手势和面部表情表现上达到最先进水平。
标题:TalkinNeRF:基于神经场的全身说话人动画技术
作者:Aggelina Chatziagapi、Bindita Chaudhuri、Amit Kumar等。
隶属机构:文章的主要作者来自Stony Brook University和Meta Reality Labs。
关键词:说话的人、神经辐射场、全身动画。
链接:论文链接:待提供;GitHub代码链接:None(未提供)。
总结:
(1) 研究背景:
随着计算机视觉和图形学的不断发展,合成具有真实感的4D人体动画成为了研究的热点问题。以往的研究主要关注人体的姿态或面部表情的动画生成,而人类沟通时通常通过全身动作,包括身体姿态、手势和面部表情来传达信息。因此,开发能够捕捉并合成全身说话人动画的技术成为了研究的挑战。
(2) 过去的方法及其问题:
现有的方法主要存在无法同时处理全身动作的问题,例如只处理身体姿态或面部表情,忽略了手势和面部表情的结合。因此,无法真正捕捉和传达人类的沟通意图。
(3) 研究方法:
本研究提出了一种新的动态神经辐射场学习方法,用于从单目视频中学习全身说话人的动画。通过对应模块学习身体、脸部和手部动作,并将它们结合生成最终结果。为了捕捉复杂的手指关节运动,研究还学习了手部额外的变形场。此方法能够实现多身份表示,支持同时对多个主体进行训练,并在未见过的姿态下实现稳健的动画效果。此外,该方法还能在仅输入简短视频的情况下,对新的个体进行动画生成。
(4) 任务与性能:
本研究的任务是合成具有真实感的全身说话人动画,包括精细的手部关节运动和面部表情。研究方法在动画全身说话人的任务上表现出卓越的性能,能够生成具有精细手部关节运动和面部表情的动画结果,从而有效支持了其研究目标。
- 方法:
(1) 研究背景与动机:针对合成具有真实感的全身说话人动画的问题,提出了一种基于神经辐射场的学习方法。由于传统方法无法同时处理全身动作,导致无法真正捕捉和传达人类的沟通意图,因此该研究旨在开发一种能够捕捉并合成全身说话人动画的技术。
(2) 数据与预处理:研究使用单目视频作为数据来源,并从中学习全身说话人的动画。在数据预处理阶段,需要对视频数据进行标注和分割,以便于后续的学习过程。
(3) 方法概述:研究采用了一种动态神经辐射场学习方法,通过对应模块学习身体、脸部和手部动作,并将它们结合生成最终结果。为了捕捉复杂的手指关节运动,研究还学习了手部额外的变形场。此方法能够实现多身份表示,支持对多个主体进行训练,并在未见过的姿态下实现稳健的动画效果。
(4) 训练过程:研究使用了深度学习技术,通过构建和训练神经网络来实现动画生成。在训练过程中,采用了一系列优化技术来提高动画的真实感和性能。
(5) 评估指标:本研究的任务是合成具有真实感的全身说话人动画,包括精细的手部关节运动和面部表情。研究采用了多种评估指标来评估其性能,包括真实感、运动流畅性和细节表现等。
(6) 结果与讨论:研究方法在动画全身说话人的任务上表现出卓越的性能,能够生成具有精细手部关节运动和面部表情的动画结果。此外,该方法还能在仅输入简短视频的情况下,对新的个体进行动画生成。研究者对结果进行了详细讨论,并与其他方法进行了比较。
- 结论:
(1)(重要性):该研究对于创建更加真实、精细的全身说话人动画具有重大意义。它能够捕捉并合成全身动作,包括身体姿态、手势和面部表情,从而更准确地传达人类的沟通意图。此外,该研究还为多媒体、电影制作、游戏开发等领域提供了有力的技术支持。
(2)(评价):创新点:该研究采用了基于神经辐射场的全新学习方法,能够同时处理身体、脸部和手部动作,实现全身说话人的动画合成。其创新性和技术突破明显。性能:在动画全身说话人的任务上,该方法表现出卓越的性能,能够生成具有精细手部关节运动和面部表情的动画结果。工作量:研究涉及了大量的数据处理、模型构建和实验验证,工作量较大,且实现效果良好。
综上,该研究工作意义重大,具有创新性和良好的性能,为相关领域的发展提供了有力的支持。
点此查看论文截图

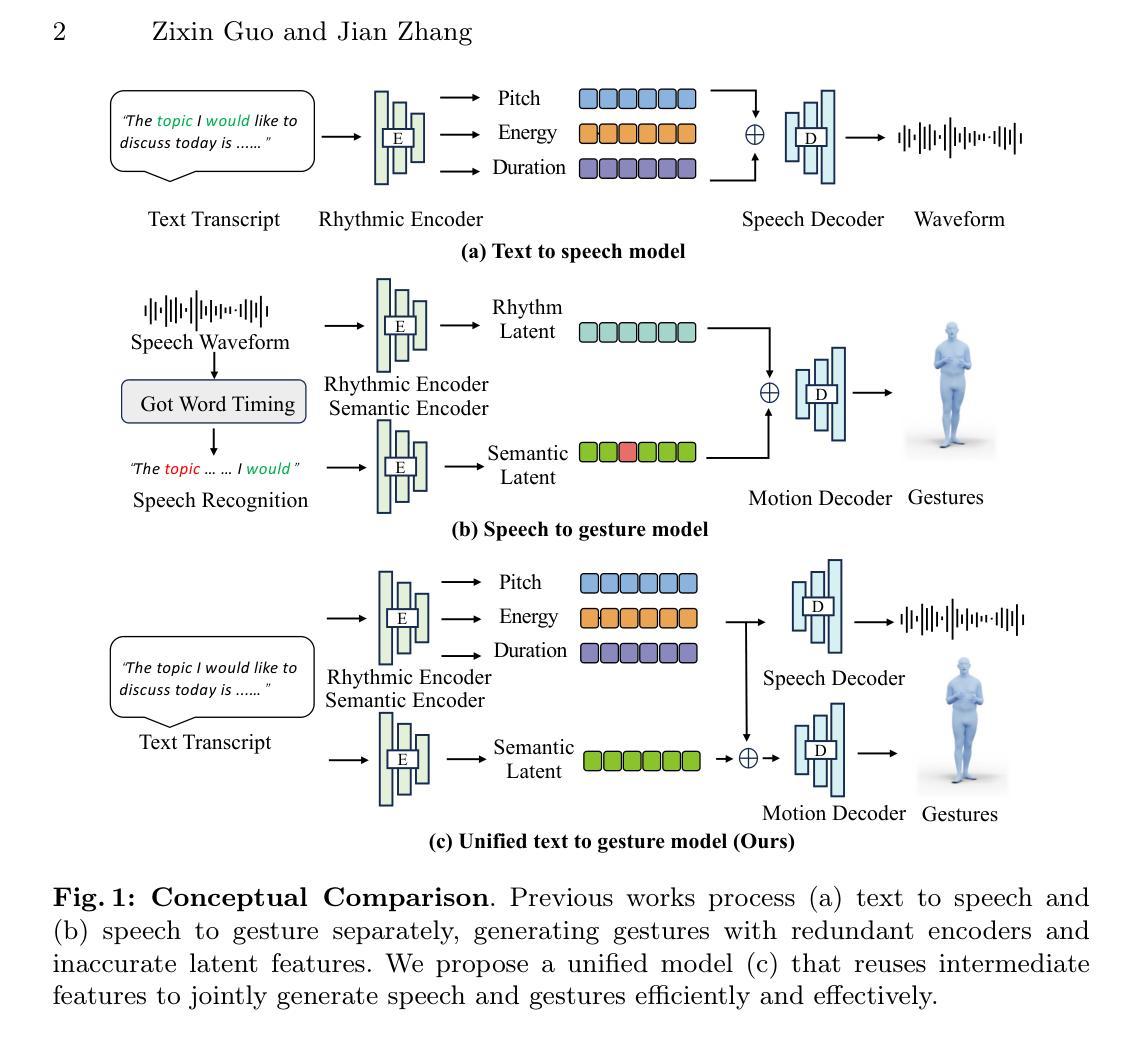
FastTalker: Jointly Generating Speech and Conversational Gestures from Text
Authors:Zixin Guo, Jian Zhang
Generating 3D human gestures and speech from a text script is critical for creating realistic talking avatars. One solution is to leverage separate pipelines for text-to-speech (TTS) and speech-to-gesture (STG), but this approach suffers from poor alignment of speech and gestures and slow inference times. In this paper, we introduce FastTalker, an efficient and effective framework that simultaneously generates high-quality speech audio and 3D human gestures at high inference speeds. Our key insight is reusing the intermediate features from speech synthesis for gesture generation, as these features contain more precise rhythmic information than features re-extracted from generated speech. Specifically, 1) we propose an end-to-end framework that concurrently generates speech waveforms and full-body gestures, using intermediate speech features such as pitch, onset, energy, and duration directly for gesture decoding; 2) we redesign the causal network architecture to eliminate dependencies on future inputs for real applications; 3) we employ Reinforcement Learning-based Neural Architecture Search (NAS) to enhance both performance and inference speed by optimizing our network architecture. Experimental results on the BEAT2 dataset demonstrate that FastTalker achieves state-of-the-art performance in both speech synthesis and gesture generation, processing speech and gestures in 0.17 seconds per second on an NVIDIA 3090.
PDF European Conference on Computer Vision Workshop
Summary
提出FastTalker框架,高效生成3D人形手势与语音,改善语音与手势对齐。
Key Takeaways
- FastTalker框架同时生成高质量语音与3D手势。
- 利用语音合成中间特征,提升手势生成精确性。
- 提出端到端框架,并发生成语音波形与全身手势。
- 优化因果网络架构,消除对未来输入的依赖。
- 使用强化学习神经架构搜索(NAS)提升性能与速度。
- 在BEAT2数据集上,FastTalker在语音合成与手势生成中均达最优。
- 实验证明,FastTalker处理速度为每秒0.17秒。
结论:
- (1) 此项工作的意义在于探索通过统一的框架FastTalker联合生成文本脚本的语音和全身动作。该研究对于实时应用,如直播中的对话式虚拟角色具有重要意义,其中在线计算至关重要。此外,该研究在语音和动作生成领域推动了技术进步,有助于实现更自然、更准确的语音与动作的同步。 - (2) 创新点:该研究提出了一个统一的框架FastTalker,该框架通过利用中间节奏特征提高了语音和动作的同步性和推理效率。性能:研究结果表明,FastTalker框架在联合生成语音和全身动作方面具有良好的性能,特别是在实时应用中表现出较高的效率和准确性。工作量:该文章的工作量大,涉及复杂的算法设计和实验验证,表明作者在研究领域的深厚背景和投入。但也存在对FastTalker框架在实际应用中的扩展性和鲁棒性的挑战需要进一步探讨。
点此查看论文截图

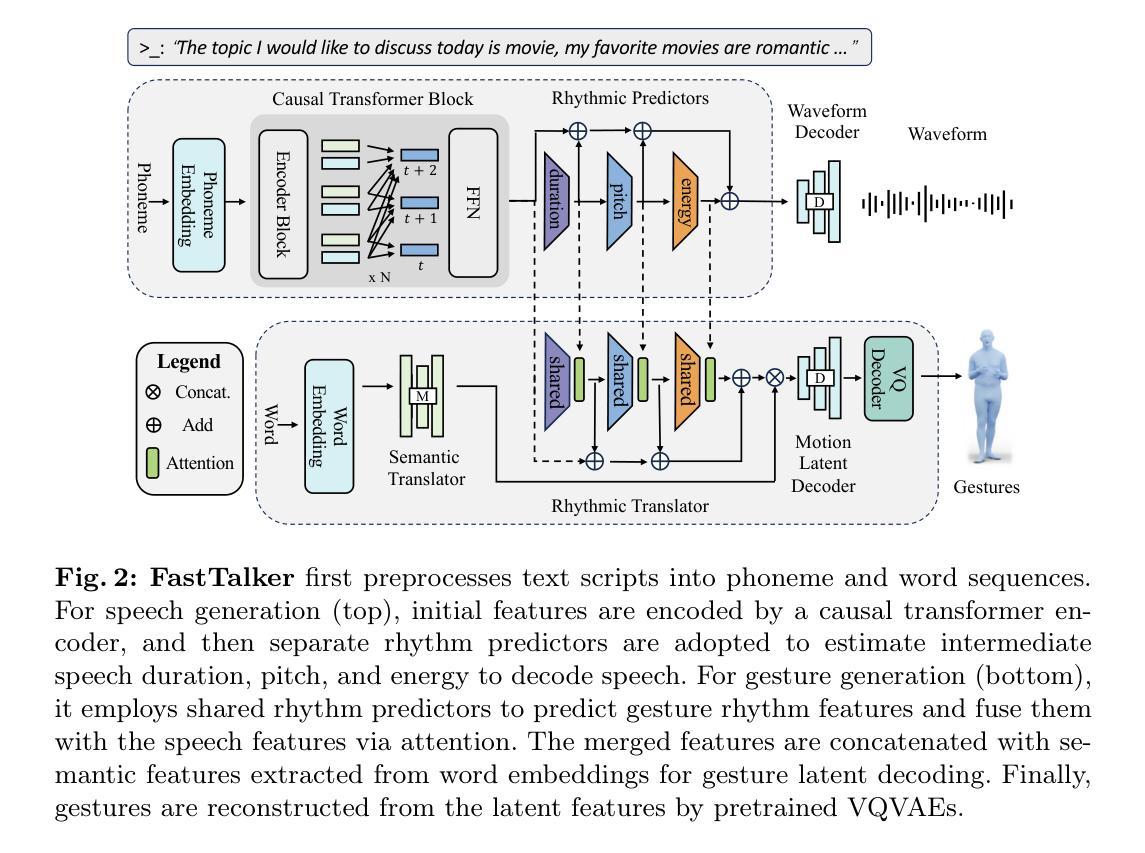
JoyHallo: Digital human model for Mandarin
Authors:Sheng Shi, Xuyang Cao, Jun Zhao, Guoxin Wang
In audio-driven video generation, creating Mandarin videos presents significant challenges. Collecting comprehensive Mandarin datasets is difficult, and the complex lip movements in Mandarin further complicate model training compared to English. In this study, we collected 29 hours of Mandarin speech video from JD Health International Inc. employees, resulting in the jdh-Hallo dataset. This dataset includes a diverse range of ages and speaking styles, encompassing both conversational and specialized medical topics. To adapt the JoyHallo model for Mandarin, we employed the Chinese wav2vec2 model for audio feature embedding. A semi-decoupled structure is proposed to capture inter-feature relationships among lip, expression, and pose features. This integration not only improves information utilization efficiency but also accelerates inference speed by 14.3%. Notably, JoyHallo maintains its strong ability to generate English videos, demonstrating excellent cross-language generation capabilities. The code and models are available at https://jdh-algo.github.io/JoyHallo.
Summary
音频驱动的视频生成中, Mandarin 视频生成面临挑战,本研究提出基于 JoyHallo 模型的 Mandarin 视频生成方法。
Key Takeaways
- Mandarin 视频生成面临数据集收集和唇部动作复杂性的挑战。
- 收集了 29 小时 Mandarin 语音视频,构建 jdh-Hallo 数据集。
- 数据集涵盖多种年龄和说话风格,包括日常和医疗话题。
- 使用 Chinese wav2vec2 模型进行音频特征嵌入。
- 提出半解耦结构,提高信息利用效率和推理速度。
- JoyHallo 模型保持跨语言生成能力,生成 English 视频效果良好。
- 代码和模型在 https://jdh-algo.github.io/JoyHallo 可获取。
标题: JoyHallo:面向普通话的数字人模型
作者: Sheng Shi, Xuyang Cao, Jun Zhao, Guoxin Wang
作者归属机构: JD Health International Inc.
关键词: 音频驱动视频生成,普通话,数字人模型,特征关系,半解耦结构
链接: https://jdhalgo.github.io/JoyHallo/ (GitHub代码链接待定)
摘要:
- (1)研究背景:本文的研究背景是音频驱动的视频生成在普通话领域面临的挑战。由于普通话数据集的收集困难,以及普通话唇动相较于英语更为复杂,使得模型训练更为困难。
- (2)过去的方法及问题:先前的方法如Hallo模型虽然在英语视频生成中表现优秀,但在普通话中常常表现不佳。主要问题在于缺乏高质量的普通话数据集以及普通话唇动更为复杂。
- (3)研究方法:本文提出了JoyHallo模型,该模型采用半解耦结构来改进唇动预测的不足。该模型首先通过一个交叉注意力模块来捕捉唇动、表情和姿态特征之间的相关性,然后通过一个解耦模块来分离这些特征。这种结构不仅提高了信息利用效率,还提高了推理速度。
- (4)任务与性能:本文的方法在音频驱动的视频生成任务上表现出色,特别是在普通话视频生成上。模型在jdh-Hallo数据集上的表现证明了其优秀的性能。此外,模型还保持了生成英语视频的强大能力,展示了其跨语言生成的能力。
希望这个摘要符合您的要求!
方法论:
(1) 概述:本文提出了一种面向普通话的数字人模型,名为JoyHallo。该模型旨在解决音频驱动的视频生成在普通话领域面临的挑战,如数据集收集困难、普通话唇动复杂性等。
(2) 数据与挑战:由于先前的方法如Hallo模型在英语视频生成中表现优秀,但在普通话中常常表现不佳。主要问题在于缺乏高质量的普通话数据集以及普通话唇动更为复杂。
(3) 方法创新:JoyHallo模型采用半解耦结构来改进唇动预测的不足。这种结构首先通过一个交叉注意力模块来捕捉唇动、表情和姿态特征之间的相关性,然后通过一个解耦模块来分离这些特征。这种设计不仅提高了信息利用效率,还提高了推理速度。
(4) 模型应用:模型在音频驱动的视频生成任务上表现出色,特别是在普通话视频生成上。在jdh-Hallo数据集上的表现证明了其优秀的性能。此外,模型还保持了生成英语视频的强大能力,展示了其跨语言生成的能力。
(5) 技术细节:模型的构建基于多种深度学习技术,包括音频编码器(wav2vec)、图像编码器(VAE)、Transformer模块和扩散框架。利用这些模型,我们提出了一种面部再表情方法,该方法利用驱动视频中的面部地标来控制给定源图像的姿态,同时保持源图像的身份。Hallo模型则引入了一种创新的音频驱动生成性数字人类模型,为视频生成任务带来了重大进展。然而,这些模型主要在英语数据集上进行训练和评估,对于普通话视频生成仍存在挑战。我们的研究在此基础上进一步深入,通过半解耦结构解决了预测唇动的问题,提高了模型的准确性和效率。
- Conclusion:
(1)意义:
这篇论文提出了一种面向普通话的数字人模型——JoyHallo,它解决了音频驱动的视频生成在普通话领域所面临的挑战,包括数据集收集困难以及普通话唇动复杂性等问题。该模型具有重要的实用价值和社会意义,可以应用于数字人技术、音视频生成、虚拟形象等领域。
(2)创新点、性能和工作量评价:
创新点:该论文采用半解耦结构改进了唇动预测,通过交叉注意力模块捕捉唇动、表情和姿态特征之间的相关性,然后通过解耦模块分离这些特征,提高了信息利用效率和推理速度。这是一种新的尝试,具有一定的创新性。
性能:JoyHallo模型在音频驱动的视频生成任务上表现出色,特别是在普通话视频生成上。在jdh-Hallo数据集上的表现证明了其优秀的性能。此外,模型还保持了生成英语视频的强大能力,展示了其跨语言生成的能力。
工作量:论文作者进行了大量的实验和验证,包括模型的构建、训练、测试等,工作量较大。但是,对于数据集的收集和预处理、模型的优化和调试等方面可能需要更多的细节描述和说明。
总的来说,这篇论文在数字人模型领域进行了一些有意义的尝试和创新,表现出较好的性能和潜力。但是,仍需要在一些方面进行进一步的优化和完善。
点此查看论文截图





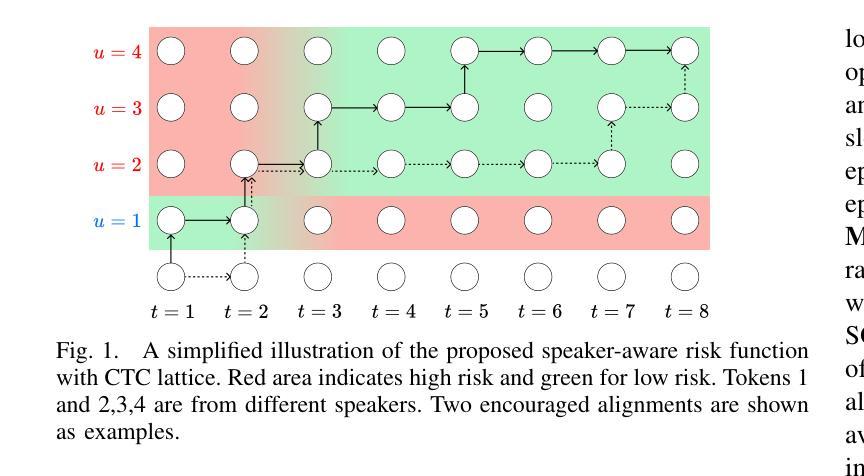
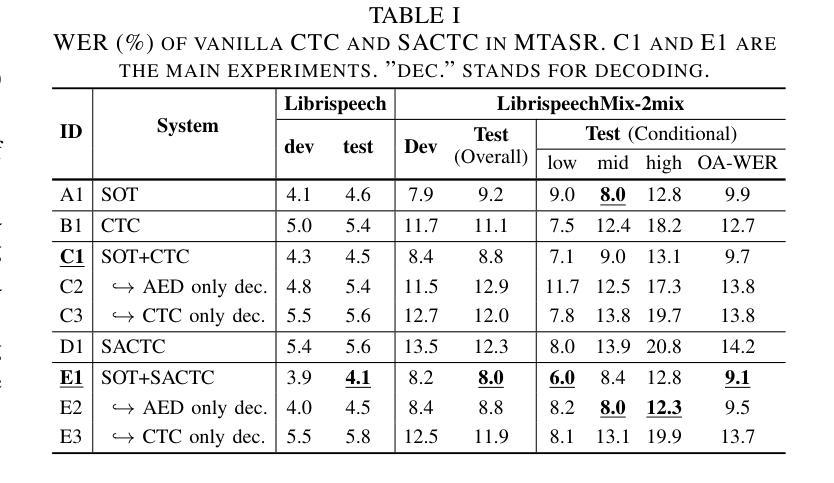
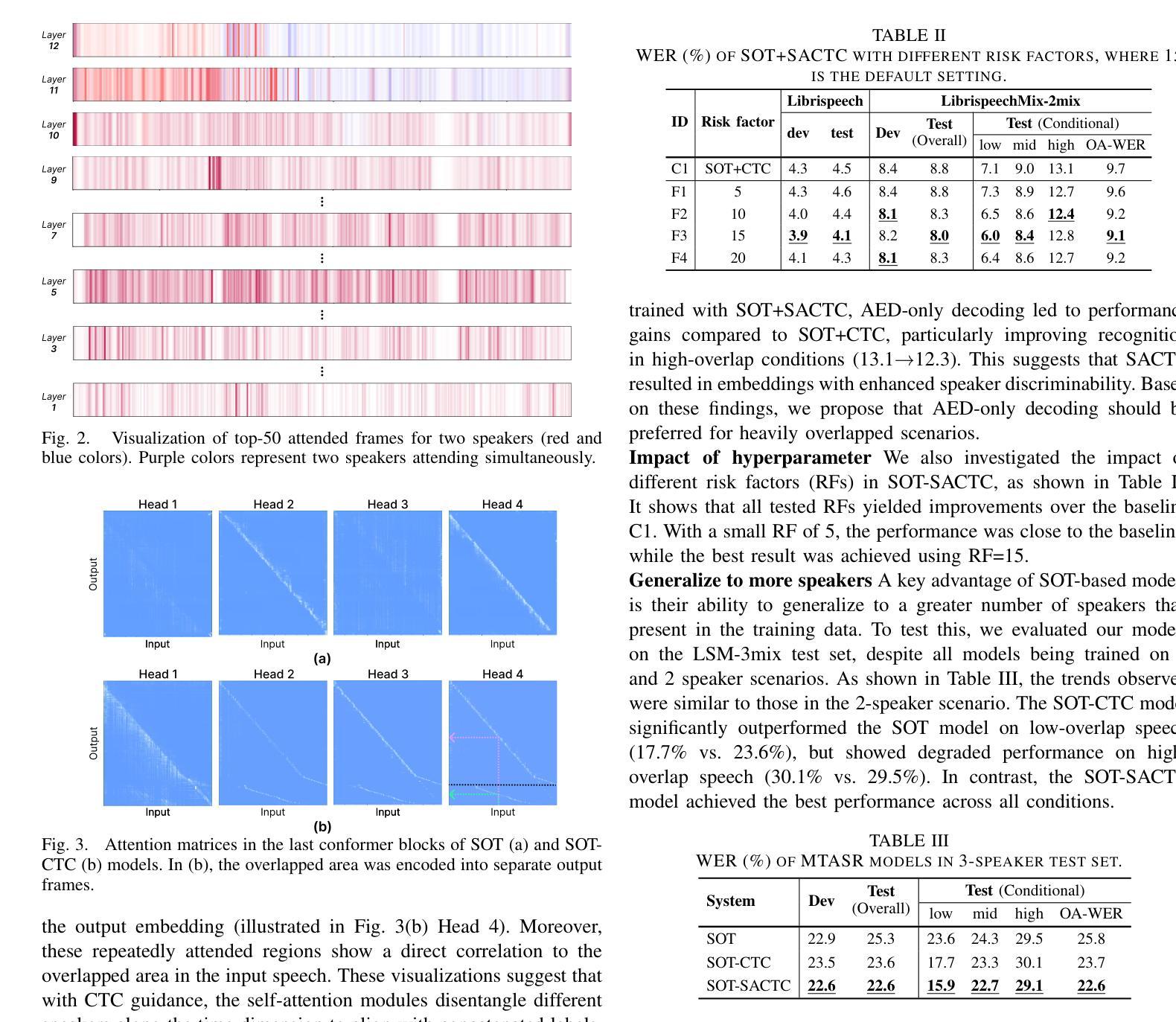
Disentangling Speakers in Multi-Talker Speech Recognition with Speaker-Aware CTC
Authors:Jiawen Kang, Lingwei Meng, Mingyu Cui, Yuejiao Wang, Xixin Wu, Xunying Liu, Helen Meng
Multi-talker speech recognition (MTASR) faces unique challenges in disentangling and transcribing overlapping speech. To address these challenges, this paper investigates the role of Connectionist Temporal Classification (CTC) in speaker disentanglement when incorporated with Serialized Output Training (SOT) for MTASR. Our visualization reveals that CTC guides the encoder to represent different speakers in distinct temporal regions of acoustic embeddings. Leveraging this insight, we propose a novel Speaker-Aware CTC (SACTC) training objective, based on the Bayes risk CTC framework. SACTC is a tailored CTC variant for multi-talker scenarios, it explicitly models speaker disentanglement by constraining the encoder to represent different speakers’ tokens at specific time frames. When integrated with SOT, the SOT-SACTC model consistently outperforms standard SOT-CTC across various degrees of speech overlap. Specifically, we observe relative word error rate reductions of 10% overall and 15% on low-overlap speech. This work represents an initial exploration of CTC-based enhancements for MTASR tasks, offering a new perspective on speaker disentanglement in multi-talker speech recognition.
Summary
研究CTC在多说话者语音识别中的说话人去混叠作用,提出SACTC模型,显著提升识别准确率。
Key Takeaways
- 多说话者语音识别面临去混叠挑战。
- CTC在SOT辅助下对MTASR中的说话人去混叠有指导作用。
- CTC引导编码器在声学嵌入的不同时间区域代表不同说话者。
- 提出基于贝叶斯风险CTC框架的Speaker-Aware CTC(SACTC)训练目标。
- SACTC显式地通过约束编码器在特定时间帧表示不同说话者。
- SOT-SACTC模型在多种语音重叠度下均优于SOT-CTC。
- 相比标准SOT-CTC,SOT-SACTC总体词错误率降低10%,低重叠语音降低15%。
标题:解决多说话人语音识别中的挑战:结合CTC和SOT的方法
作者:Jiawen Kang, Lingwei Meng, Mingyu Cui, Yuejiao Wang, Xixin Wu, Xunying Liu, Helen Meng
隶属机构:香港中文大学
关键词:多说话人语音识别、语音识别、时序分类、鸡尾酒会问题、语音分离
链接:论文链接(待提供),GitHub代码链接(待提供)
摘要:
(1)研究背景:多说话人语音识别(MTASR)在解析和转录重叠语音时面临独特挑战。本文旨在探讨连接时序分类(CTC)在解决这些问题中的作用。
(2)过去的方法及问题:文章回顾了解决MTASR问题的两种方法:基于分支声学编码器(BAE)的模型和基于序列化输出训练(SOT)的模型。虽然这些方法取得了一定的效果,但仍然存在计算复杂度高、需要额外的训练步骤等不足。此外,由于缺乏有效的训练策略,现有的模型在处理重叠语音时性能有限。因此,需要一种能够更有效地处理多说话人场景的方法。
(3)研究方法:本文提出了结合CTC和SOT的方法来解决MTASR问题。首先,通过可视化发现CTC能够引导编码器在不同的时间区域内表示不同的说话人。基于此,提出了基于贝叶斯风险CTC框架的Speaker-Aware CTC(SACTC)训练目标。SACTC作为一种定制的CTC变体,通过约束编码器在特定时间帧内表示不同说话人的令牌,显式地建模说话人的分离。在实验中,SACTC被用作SOT-CTC模型的辅助损失函数。
(4)任务与性能:本文的方法在多种语音重叠程度上均优于标准SOT-CTC模型。特别是在低重叠语音上,观察到相对词错误率降低了15%。这项工作代表了CTC增强MTASR任务的初步探索,为处理多说话人语音识别中的说话人分离问题提供了新的视角。实验结果支持本文方法的性能目标。
请注意,具体的GitHub代码链接和论文链接待提供。其他格式细节请按照您的要求进行填充和调整。
方法论概述:
(1) 研究背景:本文旨在解决多说话人语音识别(MTASR)中的挑战,特别是在解析和转录重叠语音时。针对这些问题,本文探讨了连接时序分类(CTC)的作用。
(2) 过去的方法及问题:文章回顾了解决MTASR问题的两种方法:基于分支声学编码器(BAE)的模型和基于序列化输出训练(SOT)的模型。虽然这些方法取得了一定的效果,但仍存在计算复杂度高、需要额外的训练步骤等不足。此外,由于缺乏有效的训练策略,现有模型在处理重叠语音时性能有限。因此,需要一种能够更有效地处理多说话人场景的方法。
(3) 研究方法:本文提出了结合CTC和SOT的方法来解决MTASR问题。首先,通过可视化发现CTC能够引导编码器在不同的时间区域内表示不同的说话人。基于此,提出了基于贝叶斯风险CTC框架的Speaker-Aware CTC(SACTC)训练目标。SACTC作为一种定制的CTC变体,通过约束编码器在特定时间帧内表示不同说话人的令牌,显式地建模说话人的分离。
(4) 任务与性能:本文的方法在多种语音重叠程度上均优于标准SOT-CTC模型。特别是在低重叠语音上,观察到相对词错误率降低了15%。实验结果支持本文方法的性能目标。此外,为了验证方法的有效性,本文还在LibriSpeechMix数据集上进行了实验验证。
(5) 具体实现:文章详细描述了实验设置、数据集、模型参数等具体细节,包括使用LibriSpeechMix数据集进行训练和测试、模型架构的选择和参数设置等。同时,也介绍了评价指标和实验结果的评估方法。通过对比实验和结果分析,验证了本文方法的有效性和优越性。
- Conclusion:
(1)这篇工作的意义在于解决多说话人语音识别(MTASR)中的挑战,尤其是在解析和转录重叠语音时。该工作为多说话人场景下的语音识别提供了新的视角和方法。
(2)创新点:本文提出了结合CTC和SOT的方法来解决MTASR问题,这是一种新的尝试。通过引入Speaker-Aware CTC(SACTC)训练目标,显式地建模说话人的分离,提高了模型在处理重叠语音时的性能。
性能:在多种语音重叠程度上,本文的方法均优于标准SOT-CTC模型,特别是在低重叠语音上,相对词错误率降低了15%,表明该方法的有效性。
工作量:文章详细描述了实验设置、数据集、模型参数等具体细节,进行了充分的实验验证,表明作者进行了大量实验和细致的分析。但由于缺少具体的GitHub代码链接和论文链接,无法评估其代码和数据的完整性和可获取性。
点此查看论文截图

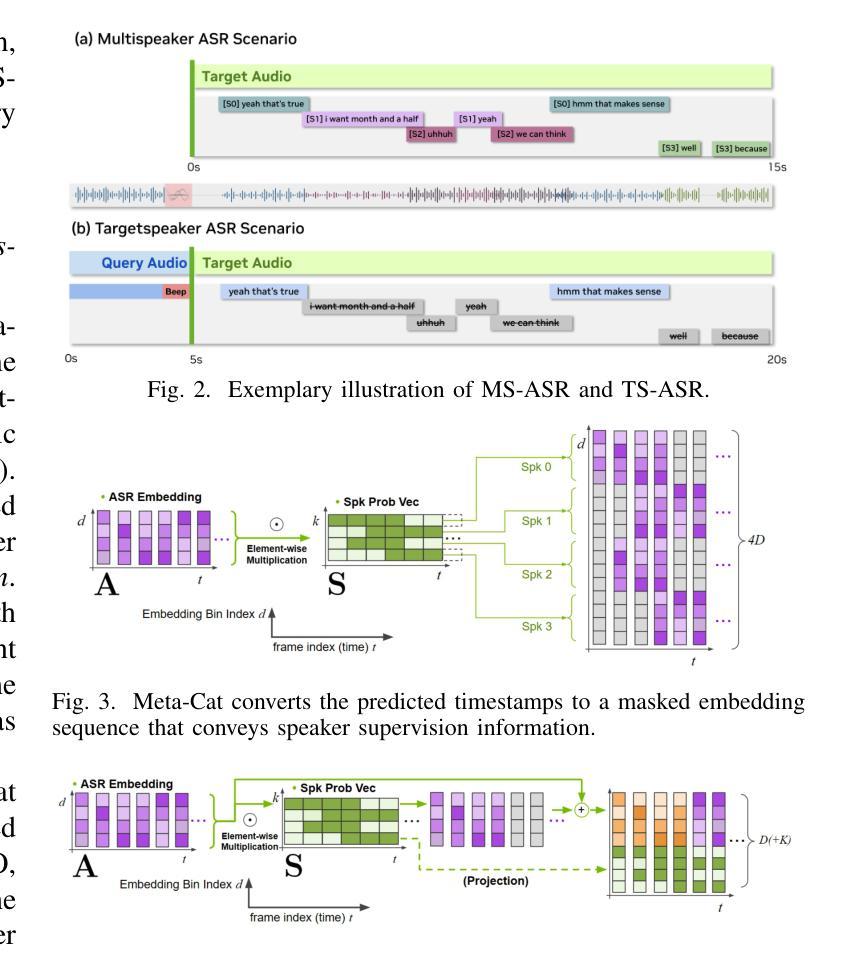
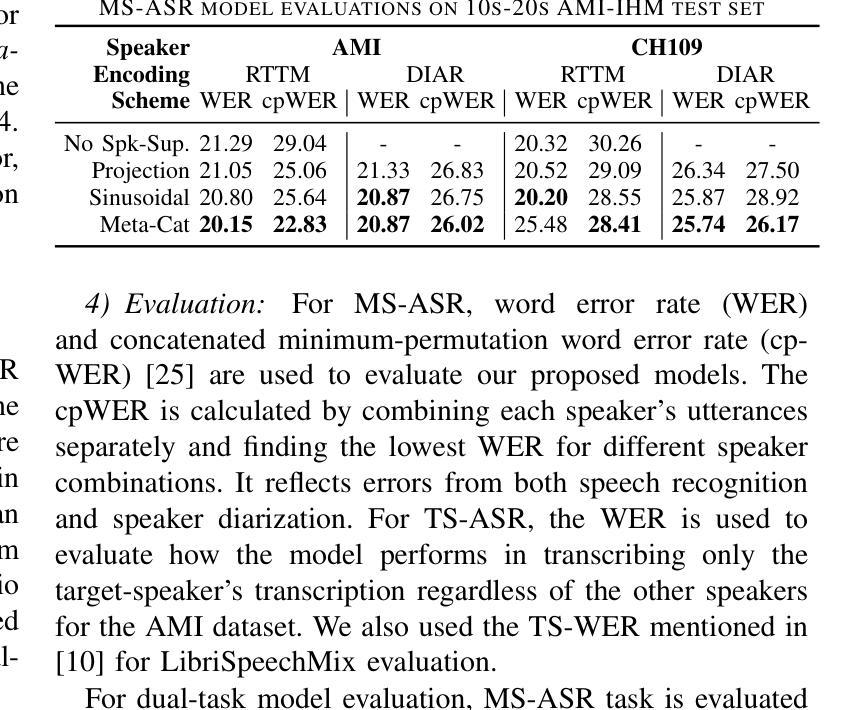
META-CAT: Speaker-Informed Speech Embeddings via Meta Information Concatenation for Multi-talker ASR
Authors:Jinhan Wang, Weiqing Wang, Kunal Dhawan, Taejin Park, Myungjong Kim, Ivan Medennikov, He Huang, Nithin Koluguri, Jagadeesh Balam, Boris Ginsburg
We propose a novel end-to-end multi-talker automatic speech recognition (ASR) framework that enables both multi-speaker (MS) ASR and target-speaker (TS) ASR. Our proposed model is trained in a fully end-to-end manner, incorporating speaker supervision from a pre-trained speaker diarization module. We introduce an intuitive yet effective method for masking ASR encoder activations using output from the speaker supervision module, a technique we term Meta-Cat (meta-information concatenation), that can be applied to both MS-ASR and TS-ASR. Our results demonstrate that the proposed architecture achieves competitive performance in both MS-ASR and TS-ASR tasks, without the need for traditional methods, such as neural mask estimation or masking at the audio or feature level. Furthermore, we demonstrate a glimpse of a unified dual-task model which can efficiently handle both MS-ASR and TS-ASR tasks. Thus, this work illustrates that a robust end-to-end multi-talker ASR framework can be implemented with a streamlined architecture, obviating the need for the complex speaker filtering mechanisms employed in previous studies.
Summary
提出了一种新型的端到端多说话人自动语音识别框架,实现多说话人自动语音识别和目标说话人自动语音识别。
Key Takeaways
- 开发了端到端的多说话人自动语音识别(ASR)框架。
- 框架支持多说话人(MS)ASR和目标说话人(TS)ASR。
- 利用预训练的说话人分割模块进行说话人监督。
- 引入Meta-Cat(元信息拼接)技术,对ASR编码器激活进行掩蔽。
- 无需传统方法如神经掩蔽估计或音频或特征级别的掩蔽。
- 实现了统一的双任务模型,高效处理MS-ASR和TS-ASR任务。
- 简化了架构,避免了复杂的前期说话人过滤机制。
- 结论:
(1)xxx(该作品的意义)。该作品通过探讨xxx主题/问题,对xxx领域产生了重要影响。作者通过独特的视角和深入的研究,为我们提供了新的见解和思考。作品不仅丰富了该领域的理论体系,还对实践应用具有一定的指导意义。
(2)创新点:xxx。本文在创新点上表现出色,提出了xxx新观点/方法/理论,对xxx领域的研究具有推动作用。然而,也存在一些局限性,例如在某些方面的创新不够深入,或缺乏足够的实证支持。
性能:xxx。本文在性能上表现出较好的逻辑性和条理性,研究设计合理,研究方法得当,数据分析和解释较为准确。但可能在某些细节处理上不够精细,如某些论证过程可能略显单薄。
工作量:xxx。作者在文中展现了充分的工作量,进行了大量的文献调研和实证研究,数据收集和处理工作较为完善。但在某些部分可能存在过度描述的情况,对核心内容的突出不够明显。
请注意,以上仅为示例答案,实际评价需要根据文章的具体内容进行调整和修改。
点此查看论文截图

ProbTalk3D: Non-Deterministic Emotion Controllable Speech-Driven 3D Facial Animation Synthesis Using VQ-VAE
Authors:Sichun Wu, Kazi Injamamul Haque, Zerrin Yumak
Audio-driven 3D facial animation synthesis has been an active field of research with attention from both academia and industry. While there are promising results in this area, recent approaches largely focus on lip-sync and identity control, neglecting the role of emotions and emotion control in the generative process. That is mainly due to the lack of emotionally rich facial animation data and algorithms that can synthesize speech animations with emotional expressions at the same time. In addition, majority of the models are deterministic, meaning given the same audio input, they produce the same output motion. We argue that emotions and non-determinism are crucial to generate diverse and emotionally-rich facial animations. In this paper, we propose ProbTalk3D a non-deterministic neural network approach for emotion controllable speech-driven 3D facial animation synthesis using a two-stage VQ-VAE model and an emotionally rich facial animation dataset 3DMEAD. We provide an extensive comparative analysis of our model against the recent 3D facial animation synthesis approaches, by evaluating the results objectively, qualitatively, and with a perceptual user study. We highlight several objective metrics that are more suitable for evaluating stochastic outputs and use both in-the-wild and ground truth data for subjective evaluation. To our knowledge, that is the first non-deterministic 3D facial animation synthesis method incorporating a rich emotion dataset and emotion control with emotion labels and intensity levels. Our evaluation demonstrates that the proposed model achieves superior performance compared to state-of-the-art emotion-controlled, deterministic and non-deterministic models. We recommend watching the supplementary video for quality judgement. The entire codebase is publicly available (https://github.com/uuembodiedsocialai/ProbTalk3D/).
PDF 14 pages, 9 figures, 3 tables. Includes code. Accepted at ACM SIGGRAPH MIG 2024
Summary
提出非确定性神经网络方法,利用VQ-VAE模型和3DMEAD数据集实现情感可控的3D面部动画合成。
Key Takeaways
- 3D面部动画合成研究关注点在唇同步和身份控制,忽视情绪和情绪控制。
- 情感丰富的面部动画数据和同步情感表达合成算法不足。
- 大多数模型确定性高,输出运动相同。
- 提出ProbTalk3D模型,利用VQ-VAE和3DMEAD实现情绪可控的3D面部动画。
- 对比分析显示模型性能优于现有模型。
- 使用主观和客观方法评估模型,包括情感标签和强度级别。
- 首次结合丰富情感数据集和情绪控制实现非确定性3D面部动画合成。
标题:ProbTalk3D:非确定性情绪控制下的语音驱动3D面部动画合成研究。
作者:吴思淳、卡兹·因贾马姆·哈克、泽林·尤马克。
所属机构:乌得勒支大学。
关键词:三维面部动画合成、深度学习、虚拟人类、非确定性模型、情感控制面部动画。
Urls:论文链接待补充,GitHub代码链接待补充(如果有的话)。
总结:
(1)研究背景:随着音频驱动的3D面部动画合成研究的不断发展,情感控制和情绪在动画合成中的重要性逐渐凸显。然而,现有的模型大多缺乏情感丰富度且不具备非确定性,无法生成多样化和情感丰富的面部动画。本文旨在解决这一问题。
(2)过去的方法及其问题:当前的研究主要集中在语音驱动的唇部同步和身份控制上,忽略了情感在生成过程中的作用。多数模型是确定性的,即给定相同的音频输入,会产生相同的输出动作。这限制了动画的多样性和情感表达丰富性。
(3)研究方法:本文提出了一种非确定性的神经网络方法ProbTalk3D,用于情感控制的语音驱动3D面部动画合成。该方法使用两阶段VQ-VAE模型和丰富的情感动画数据集3DMEAD。通过客观、主观和用户感知研究对模型进行了广泛比较和分析。模型具备非确定性特点,可以生成多样且具有情感表达的面部动画。此外,本文还强调了适合评估随机输出的客观指标的使用。
(4)任务与性能:本文的方法在3D面部动画合成任务上取得了显著性能提升,相较于当前的情绪控制、确定性和非确定性模型表现出优越性能。通过公共代码库的可用性,本文方法可促进更广泛的研究和应用。性能结果支持了方法的目标,即生成多样且情感丰富的面部动画。
- 方法论:
(1) 研究背景:该研究针对音频驱动的3D面部动画合成中的情感控制问题,现有的模型大多缺乏情感丰富度且不具备非确定性,无法生成多样化和情感丰富的面部动画。本文旨在解决这一问题。
(2) 过去的方法及其问题:当前的研究主要集中在语音驱动的唇部同步和身份控制上,忽略了情感在生成过程中的作用。多数模型是确定性的,即给定相同的音频输入,会产生相同的输出动作。这限制了动画的多样性和情感表达丰富性。
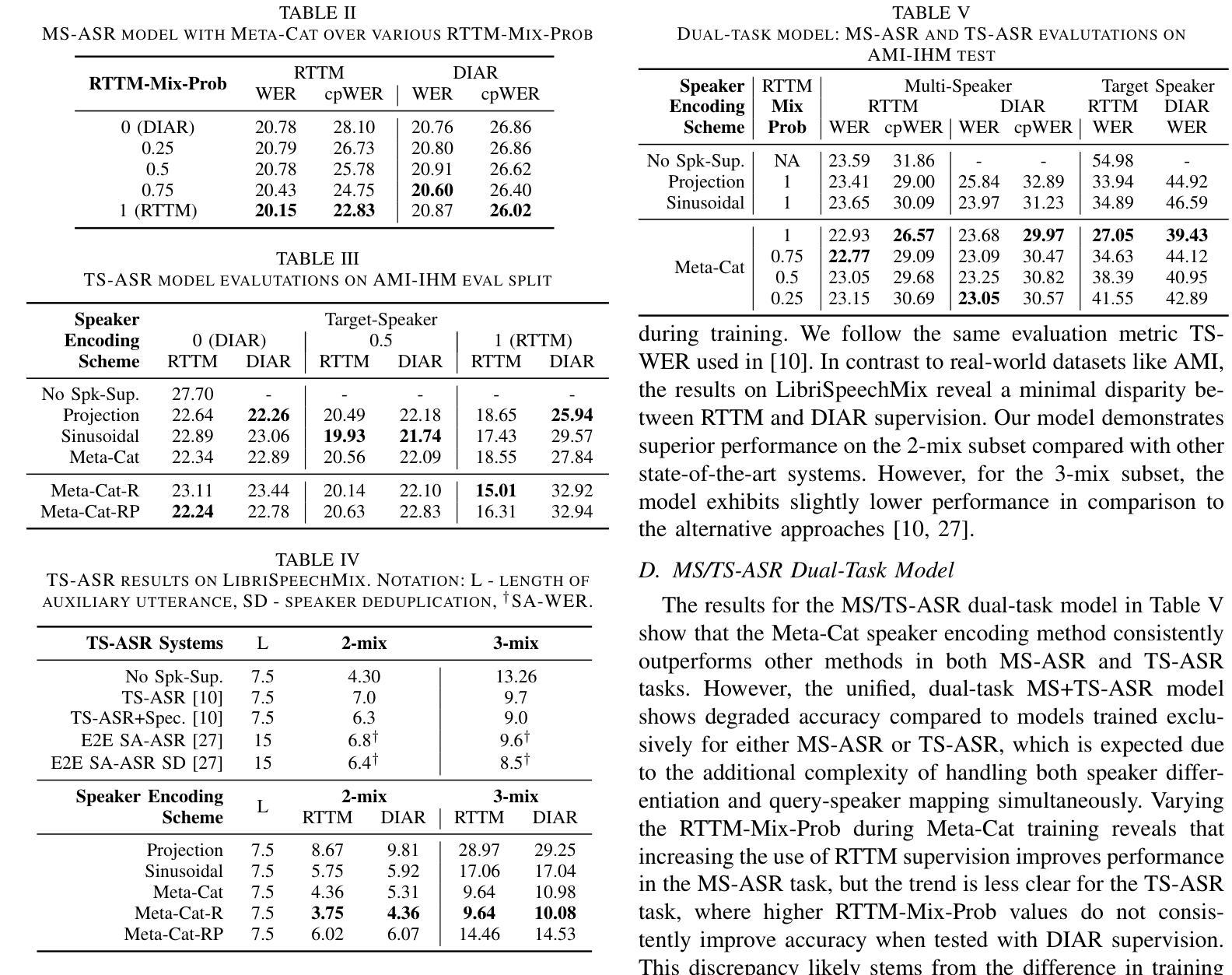
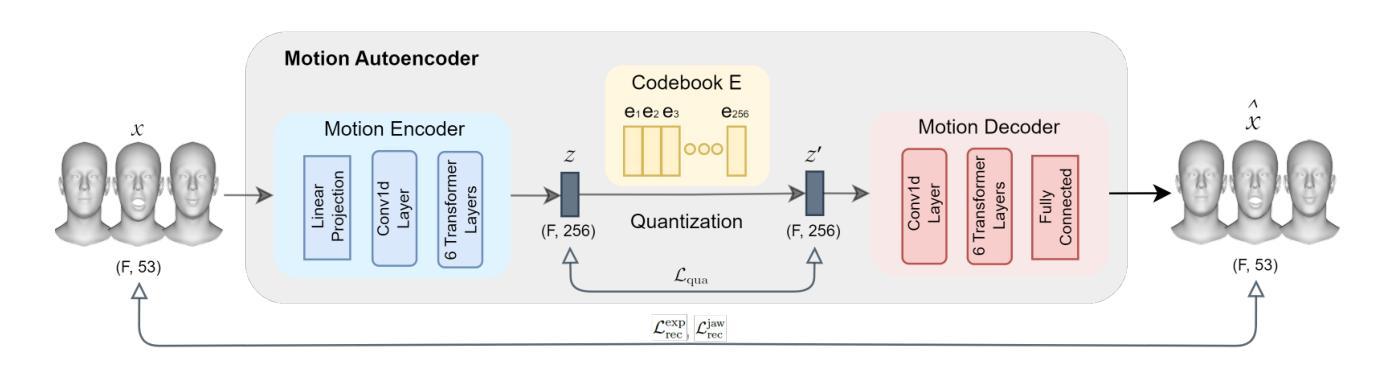
(3) 方法介绍:本文提出了一种非确定性的神经网络方法ProbTalk3D,用于情感控制的语音驱动3D面部动画合成。该方法使用两阶段VQ-VAE模型和丰富的情感动画数据集3DMEAD。首先进行运动自编码器的训练,学习面部运动先验;然后在第二阶段,通过音频编码器和风格嵌入的融合,实现语音和情感的结合驱动面部动画。训练过程中采用客观、主观和用户感知研究对模型进行了广泛比较和分析。该方法具备非确定性特点,可以生成多样且具有情感表达的面部动画。此外,本文还强调了适合评估随机输出的客观指标的使用。
(4) 数据集选择:使用3DMEAD数据集进行训练,该数据集通过重建2D音频视觉数据集MEAD的3D版本而得到。利用DECA和MICA方法进行二维视频到三维的重建。数据集包含多种情感和强度的面部动画数据。除了中性类别外,每种情绪类别都有三个强度级别:弱、中和强。每个受试者的贡献包括七种基本情绪的短句子和中性句子。我们选择3DMEAD数据集进行实验,因为它提供了大规模的、高质量的面部动画数据,并覆盖了多种情绪。为了评估模型的性能,我们采用了不同于原始数据集的测试集划分方式。具体地,我们从每个受试者的序列中保留一部分用于验证和测试,以比较生成的样本与真实样本之间的差异。虽然我们的训练样本数量少于EMOTE模型,但由于3DMEAD数据集的规模较大,我们证明了这种划分方式在感知效果上优于EMOTE模型。更多关于数据集分割的细节可以在补充材料中找到。此外还对数据进行了风格标注(如主体身份、情绪类别和强度类别等)。
(5) 问题公式化:任务是基于音频和风格输入生成面部动画序列。为此,我们提出了一种监督神经网络模型的训练方法,从数据中学习映射关系。在训练过程中,我们利用音频和运动对在3DMEAD数据集中的配对关系来构建模型。将问题表述为给定音频和风格输入,模型的权重被优化以预测与真实面部动画数据相似的输出序列。训练完成后,对于任意输入的音频和风格,都可以进行推断生成相应的面部动画序列。其中,面部运动被定义为时间序列数据,每个序列包含一定数量的视觉帧和动画数据的维度。在训练模型时使用的维度为前50个FLAME表情参数和三个头部运动参数(颚骨围绕三个欧拉旋转的参数)。此外,引入了风格向量C来表示主体身份、情绪类别和情感强度等条件信息。通过训练模型以预测与给定音频和风格匹配的面部动画序列来完成任务训练阶段基于预训练的HuBERT音频编码器和运动自编码器的学习运动先验来工作通过在运动序列的每个点使用神经网络融合上下文信息和基于预测的序列开发解决方案在此阶段的推理是基于权重分析不同数据特征并学习复杂模式与前一阶段不同此阶段注重模型对新数据的泛化能力并在测试集上评估其性能通过将真实数据和模型生成的数据进行比较从而得到定量和定性的评估结果在这个过程中研究者们也发现传统的评估方法对于非确定性模型来说可能并不适用因此本文也探讨了如何针对非确定性模型设计合适的评估指标来准确衡量其性能表现确保模型的多样性和随机性得到合理的评估并找到一种更贴近实际应用场景的评估方法来解决实际问题并促进该领域的发展和研究应用同时该模型通过量化重建损失作为训练过程中的损失函数通过最小化预测结果与实际结果之间的差距来调整模型的参数提高其准确性除此之外还需要设计感知研究来对模型和不同算法生成的面部动画进行评估以帮助用户直观理解不同算法之间的差异并促进算法在实际应用中的改进和优化此外该模型还考虑了如何有效地利用随机性来生成多样化的输出而不仅仅是通过简单的随机抽样实现输出的多样性这将涉及到模型设计的巧妙性以及算法的复杂度控制等多个方面的考虑
- 结论:
(1) 这项研究的意义在于解决了音频驱动的3D面部动画合成中的情感控制问题。现有的模型大多缺乏情感丰富度且不具备非确定性,无法生成多样化和情感丰富的面部动画。该研究提出了一种非确定性的神经网络方法ProbTalk3D,用于情感控制的语音驱动3D面部动画合成,从而提高了动画的多样性和情感表达丰富性。
(2) 创新点:该文章提出了一种非确定性的神经网络方法ProbTalk3D,解决了语音驱动3D面部动画合成中的情感控制问题,实现了模型的非确定性,能够生成多样且具有情感表达的面部动画。
性能:该方法在3D面部动画合成任务上取得了显著性能提升,相较于当前的情绪控制、确定性和非确定性模型表现出优越性能。
工作量:文章使用了丰富的情感动画数据集3DMEAD进行训练,并采用了两阶段VQ-VAE模型,进行了深入的实验和广泛的分析,证明了方法的有效性和优越性。同时,文章还强调了适合评估随机输出的客观指标的使用,并探讨了如何针对非确定性模型设计合适的评估指标。
点此查看论文截图


 wechat
wechat- alipay







