Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-10-12 更新
MMHead: Towards Fine-grained Multi-modal 3D Facial Animation
Authors:Sijing Wu, Yunhao Li, Yichao Yan, Huiyu Duan, Ziwei Liu, Guangtao Zhai
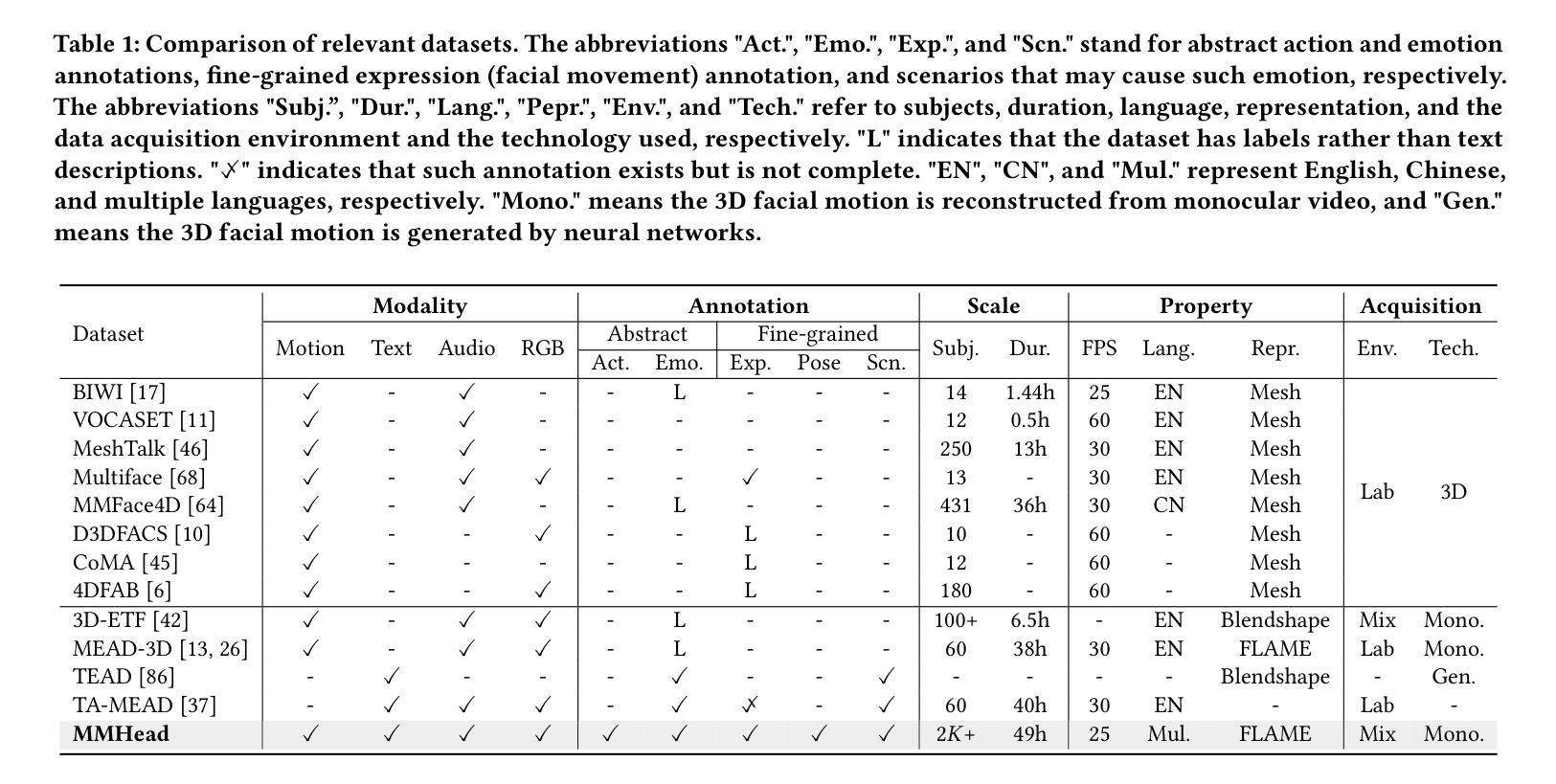
3D facial animation has attracted considerable attention due to its extensive applications in the multimedia field. Audio-driven 3D facial animation has been widely explored with promising results. However, multi-modal 3D facial animation, especially text-guided 3D facial animation is rarely explored due to the lack of multi-modal 3D facial animation dataset. To fill this gap, we first construct a large-scale multi-modal 3D facial animation dataset, MMHead, which consists of 49 hours of 3D facial motion sequences, speech audios, and rich hierarchical text annotations. Each text annotation contains abstract action and emotion descriptions, fine-grained facial and head movements (i.e., expression and head pose) descriptions, and three possible scenarios that may cause such emotion. Concretely, we integrate five public 2D portrait video datasets, and propose an automatic pipeline to 1) reconstruct 3D facial motion sequences from monocular videos; and 2) obtain hierarchical text annotations with the help of AU detection and ChatGPT. Based on the MMHead dataset, we establish benchmarks for two new tasks: text-induced 3D talking head animation and text-to-3D facial motion generation. Moreover, a simple but efficient VQ-VAE-based method named MM2Face is proposed to unify the multi-modal information and generate diverse and plausible 3D facial motions, which achieves competitive results on both benchmarks. Extensive experiments and comprehensive analysis demonstrate the significant potential of our dataset and benchmarks in promoting the development of multi-modal 3D facial animation.
PDF Accepted by ACMMM 2024. Project page: https://wsj-sjtu.github.io/MMHead/
Summary
构建大规模多模态3D面部动画数据集MMHead,推动文本引导3D面部动画发展。
Key Takeaways
- 3D面部动画在多媒体领域应用广泛,但多模态动画研究较少。
- MMHead数据集包含3D面部运动、语音音频和文本注释,涵盖动作、情绪和场景描述。
- 集成5个公共2D肖像视频数据集,自动重建3D面部运动序列。
- 利用AU检测和ChatGPT获取文本注释,实现语义到动作的映射。
- 建立文本诱导3D talking head动画和文本到3D面部运动生成两个新任务基准。
- 提出MM2Face方法,融合多模态信息生成3D面部运动。
- MMHead数据集和基准在多模态3D面部动画发展中具有重大潜力。
Title: MMHead:面向精细多模态的三维面部动画研究
Authors: Sijing Wu(吴思静), Yunhao Li(李云豪), Yichao Yan(颜一超), Huiyu Duan(段慧宇), Ziwei Liu(刘子玮), Guangtao Zhai(翟光涛)
Affiliation: 上海交通大学
Keywords: 多模态三维面部动画;MMHead数据集;文本引导的面部动画;自动管道重建;层次文本注释;VQ-VAE方法;3D面部运动生成
Urls: 论文链接待确认,GitHub代码链接(如有): None
Summary:
- (1) 研究背景:本文关注多模态三维面部动画领域的研究背景,鉴于三维面部动画在多媒体领域中的广泛应用,相关研究引起了广泛的关注。特别是音频驱动的三维面部动画已得到了广泛的探索与显著的结果,但文本引导的三维面部动画由于缺少多模态数据集而研究较少。因此,本文旨在解决这一问题。
- (2) 过去的方法及其问题:当前研究虽然已经取得了进展,但由于缺乏大规模的多模态三维面部动画数据集,现有的方法在实践中难以达到预期效果。由于缺乏丰富的面部表情、头部姿态和可能的场景信息,现有数据集限制了该领域的发展。因此,本文提出建立一个新的多模态三维面部动画数据集MMHead。
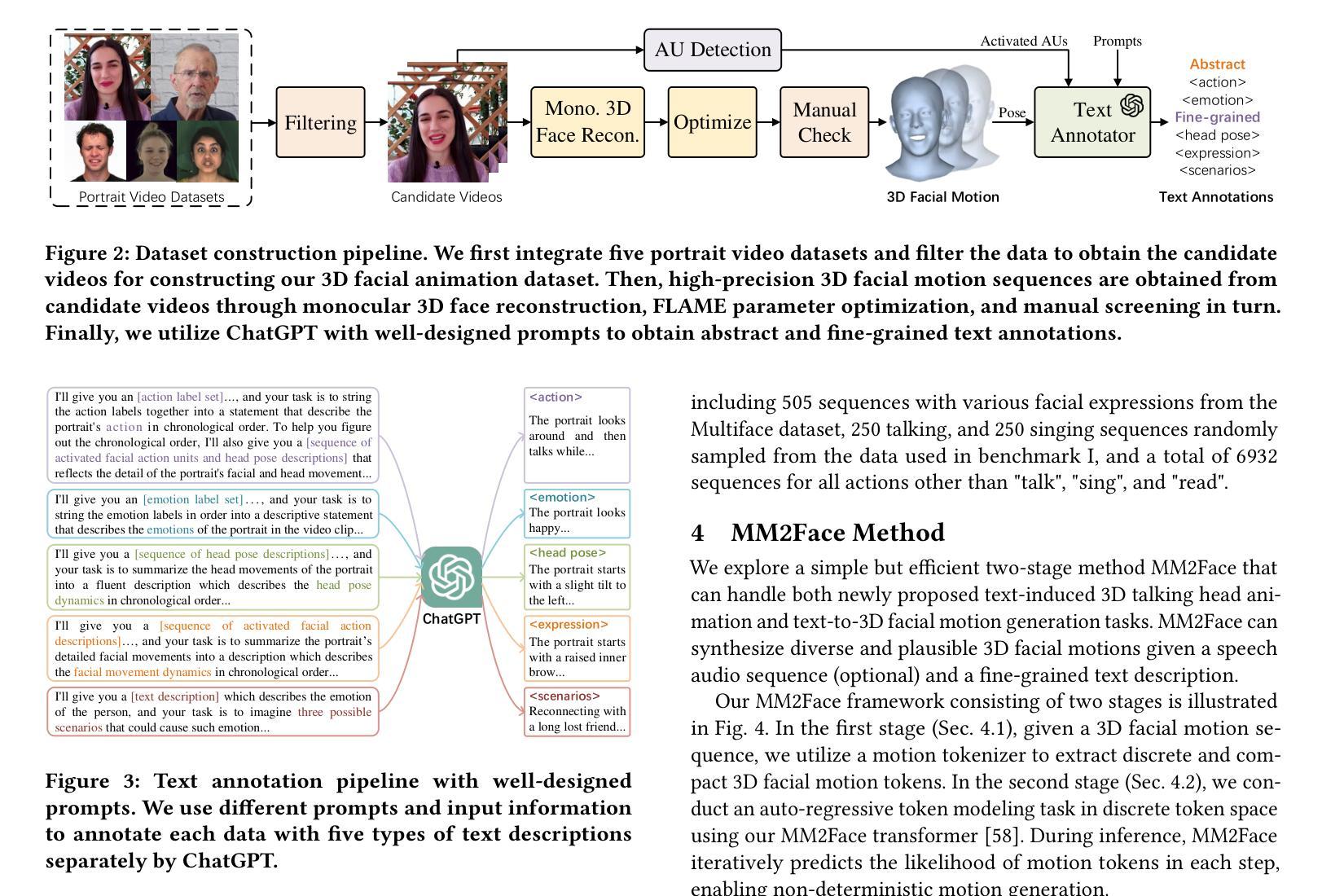
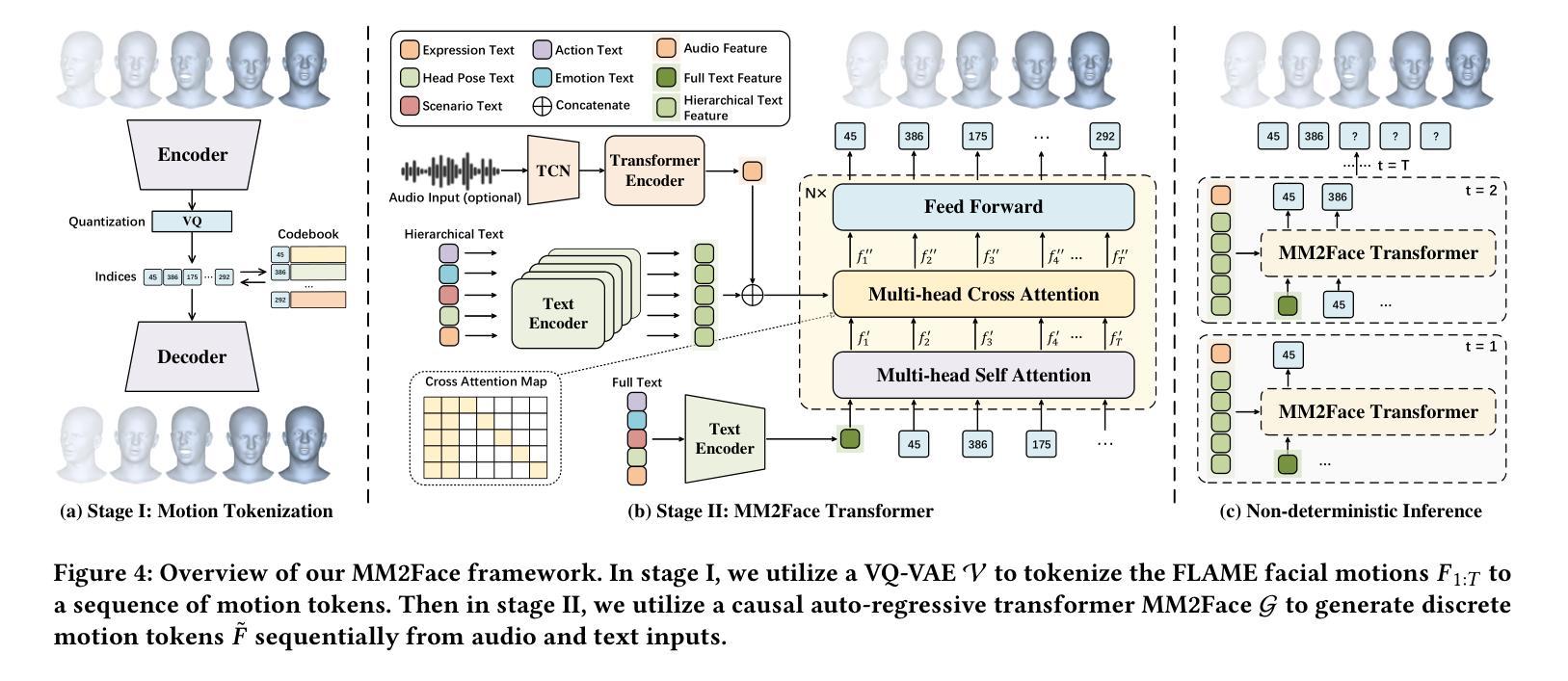
- (3) 研究方法:本文首先整合了五个公共二维肖像视频数据集,并开发了一个自动管道来处理这些数据集,包括从单目视频中重建三维面部运动序列和借助AU检测和ChatGPT获取层次化文本注释。基于MMHead数据集,本文建立了两个新任务的标准:文本引导的三维说话人动画和文本到三维面部运动的生成。同时,提出了一种简单的但有效的VQ-VAE方法——MM2Face,能够统一多模态信息并生成多样且合理的三维面部运动。
- (4) 任务与性能:本文在建立的新数据集MMHead上进行了实验,验证了MMHead数据集的有效性和适用性。同时,基于该数据集建立的基准测试证明了MM2Face方法的竞争力。本文的研究成果对于推动多模态三维面部动画领域的发展具有重要意义。数据集将在指定的网站上公开发布。
请注意,由于论文尚未公开发表,某些链接和详细信息可能暂时不可用。以上内容是基于提供的论文摘要和相关信息进行的整理。
- 方法:
- (1) 研究背景分析:研究团队发现多模态三维面部动画在多媒体领域有广泛的应用前景,但目前相关研究因缺乏大规模多模态数据集而受到限制。特别是文本引导的三维面部动画领域缺乏相关的数据集,这影响了相关研究的发展。因此,研究团队决定解决这一问题。
- (2) 数据集建立:为了克服现有研究的局限性,研究团队整合了五个公共二维肖像视频数据集,并开发了一个自动管道来处理这些数据集。该管道包括从单目视频中重建三维面部运动序列和借助AU检测和ChatGPT获取层次化文本注释。在此基础上,研究团队建立了新的多模态三维面部动画数据集MMHead。
- (3) 新任务定义:基于MMHead数据集,研究团队建立了两个新任务的标准,即文本引导的三维说话人动画和文本到三维面部运动的生成。这两个任务的建立为后续的研究提供了基准测试。
- (4) 方法提出:研究团队提出了一种简单的但有效的VQ-VAE方法——MM2Face。该方法能够统一多模态信息并生成多样且合理的三维面部运动。该方法基于MMHead数据集进行训练和测试,实验结果证明了其有效性和竞争力。数据集将在指定的网站上公开发布。该方法的创新性在于结合了多模态信息,使得三维面部动画更加生动自然。具体的操作流程和技术细节在论文中详细阐述。
以上是对该论文方法部分的详细概括和总结,希望能够对您有所帮助。
- Conclusion:
(1) 这篇文章的工作意义在于推动了多模态三维面部动画领域的发展。文章建立了一个新的多模态三维面部动画数据集MMHead,并基于该数据集建立了两个新任务的标准,即文本引导的三维说话人动画和文本到三维面部运动的生成。此外,文章提出了一种有效的VQ-VAE方法——MM2Face,能够统一多模态信息并生成多样且合理的三维面部运动。这些数据集和任务标准的建立以及方法的提出将有助于推动多模态三维面部动画领域的研究和应用。
(2) 创新点:文章建立了新的多模态三维面部动画数据集MMHead,并基于该数据集提出了两个新任务的标准,体现了较强的创新性。同时,文章提出的MM2Face方法能够统一多模态信息,并生成合理且多样的三维面部运动,具有较高的性能。但文章在性能方面也存在一定局限性,如对于大规模数据集的处理和复杂场景的应用仍需进一步研究和优化。在工作量方面,文章整合了多个公共二维肖像视频数据集并开发了自动管道处理这些数据集,工作量较大;但在具体方法的提出和实验验证方面,文章内容相对简洁,未涉及大量复杂的计算和推导。
点此查看论文截图

Hallo2: Long-Duration and High-Resolution Audio-Driven Portrait Image Animation
Authors:Jiahao Cui, Hui Li, Yao Yao, Hao Zhu, Hanlin Shang, Kaihui Cheng, Hang Zhou, Siyu Zhu, Jingdong Wang
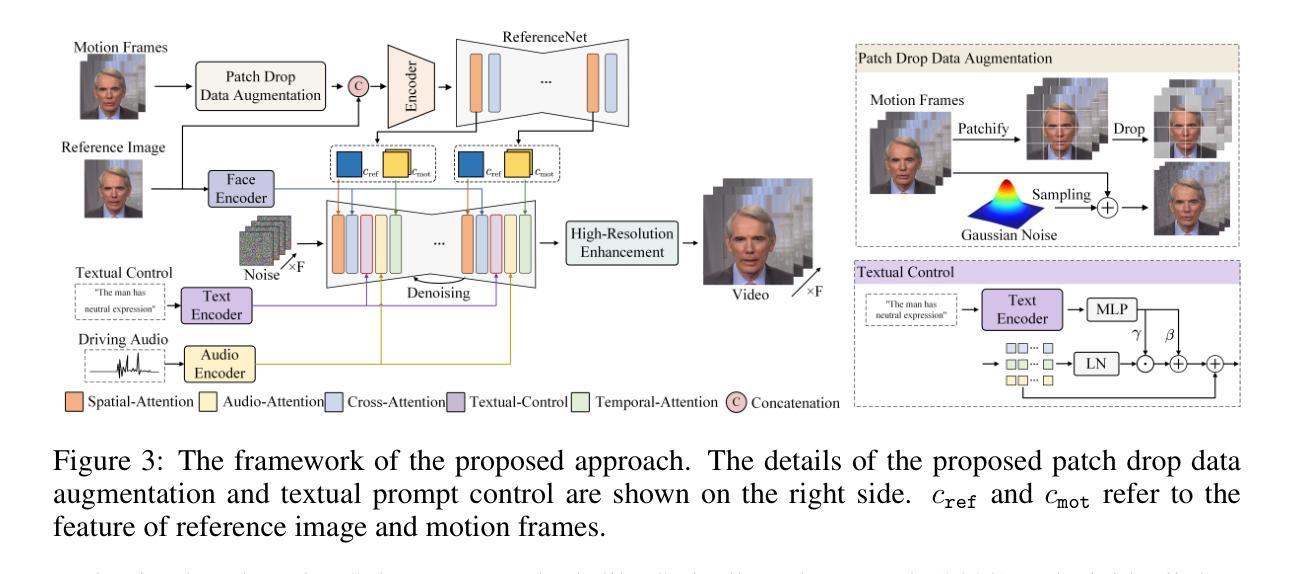
Recent advances in latent diffusion-based generative models for portrait image animation, such as Hallo, have achieved impressive results in short-duration video synthesis. In this paper, we present updates to Hallo, introducing several design enhancements to extend its capabilities. First, we extend the method to produce long-duration videos. To address substantial challenges such as appearance drift and temporal artifacts, we investigate augmentation strategies within the image space of conditional motion frames. Specifically, we introduce a patch-drop technique augmented with Gaussian noise to enhance visual consistency and temporal coherence over long duration. Second, we achieve 4K resolution portrait video generation. To accomplish this, we implement vector quantization of latent codes and apply temporal alignment techniques to maintain coherence across the temporal dimension. By integrating a high-quality decoder, we realize visual synthesis at 4K resolution. Third, we incorporate adjustable semantic textual labels for portrait expressions as conditional inputs. This extends beyond traditional audio cues to improve controllability and increase the diversity of the generated content. To the best of our knowledge, Hallo2, proposed in this paper, is the first method to achieve 4K resolution and generate hour-long, audio-driven portrait image animations enhanced with textual prompts. We have conducted extensive experiments to evaluate our method on publicly available datasets, including HDTF, CelebV, and our introduced “Wild” dataset. The experimental results demonstrate that our approach achieves state-of-the-art performance in long-duration portrait video animation, successfully generating rich and controllable content at 4K resolution for duration extending up to tens of minutes. Project page https://fudan-generative-vision.github.io/hallo2
Summary
研究提出改进后的Hallo模型,可生成长时、4K分辨率、文本驱动的肖像动画视频。
Key Takeaways
- Hallo模型升级支持长时视频合成。
- 引入图像空间中的增强策略,解决外观漂移和时序伪影。
- 实现了4K分辨率肖像视频生成。
- 采用矢量量化潜代码和时序对齐技术。
- 引入可调节的语义文本标签,提高可控性和内容多样性。
- Hallo2为首个实现4K分辨率、时长可达数小时的文本驱动肖像动画方法。
- 在多个数据集上实验证明,该方法在长时肖像视频动画方面达到最先进水平。
- 方法:
(1) SEINE Chen等人(2023b)引入生成过渡的概念:
- 该方法关注于平滑场景变化,通过生成过渡来增强视觉连贯性。
- 使用语义运动预测器来预测场景中的动作和事件,以实现自然流畅的过渡效果。
(2) StoryDiffusion Zhou等人(2024)的方法:
- 该方法专注于视觉故事叙述,通过引入生成模型来创建连贯的故事情节。
- 利用语义运动预测器来分析场景中的对象动作和它们之间的潜在关系。
- 通过这种方法,能够生成具有逻辑连贯性的场景,实现流畅的故事叙述。
以上内容仅为根据您提供的描述进行的概括,具体的细节可能需要查阅原文以获取更准确的信息。
- 结论:
(1) 这项工作的意义在于:
该文章展示了通过增强Hallo框架的功能在肖像图像动画方面的进展。通过扩展动画持续时间至数十分钟并保持高分辨率的4K输出,该研究解决了现有方法的显著局限性。该工作对长时间、高分辨率肖像图像动画领域做出了重要贡献。
(2) 创新性、性能和工作量方面的总结:
- 创新性:文章提出了创新的肖像图像动画方法,通过扩展动画持续时间、实施数据增强技术、实施向量量化潜在代码以及采用时间对齐技术等方法,为肖像图像动画带来了新的突破。此外,文章还结合了音频驱动信号和可调整的语义文本提示,实现了对面部表情和运动动态的精确控制。
- 性能:文章的方法在公共数据集上进行了广泛的实验验证,证明了其有效性。所生成的动画具有逼真的效果,且长时间保持高质量输出。然而,关于性能的具体数据(如处理速度、内存占用等)未在摘要中提及。
- 工作量:文章涉及大量的实验验证和算法开发,工作量较大。此外,文章的方法需要较高的计算资源和存储资源来实现高分辨率的长时间动画。但由于摘要中没有具体提及工作量的大小和计算资源的具体需求,无法准确评估该方面。
点此查看论文截图



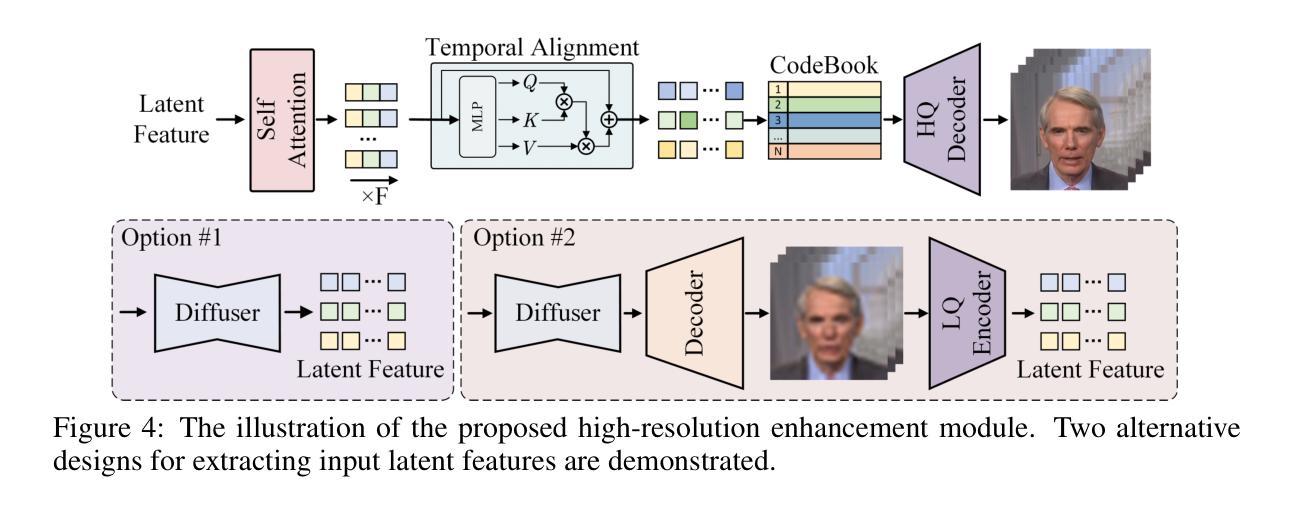
FaceVid-1K: A Large-Scale High-Quality Multiracial Human Face Video Dataset
Authors:Donglin Di, He Feng, Wenzhang Sun, Yongjia Ma, Hao Li, Wei Chen, Xiaofei Gou, Tonghua Su, Xun Yang
Generating talking face videos from various conditions has recently become a highly popular research area within generative tasks. However, building a high-quality face video generation model requires a well-performing pre-trained backbone, a key obstacle that universal models fail to adequately address. Most existing works rely on universal video or image generation models and optimize control mechanisms, but they neglect the evident upper bound in video quality due to the limited capabilities of the backbones, which is a result of the lack of high-quality human face video datasets. In this work, we investigate the unsatisfactory results from related studies, gather and trim existing public talking face video datasets, and additionally collect and annotate a large-scale dataset, resulting in a comprehensive, high-quality multiracial face collection named \textbf{FaceVid-1K}. Using this dataset, we craft several effective pre-trained backbone models for face video generation. Specifically, we conduct experiments with several well-established video generation models, including text-to-video, image-to-video, and unconditional video generation, under various settings. We obtain the corresponding performance benchmarks and compared them with those trained on public datasets to demonstrate the superiority of our dataset. These experiments also allow us to investigate empirical strategies for crafting domain-specific video generation tasks with cost-effective settings. We will make our curated dataset, along with the pre-trained talking face video generation models, publicly available as a resource contribution to hopefully advance the research field.
Summary
我们构建了FaceVid-1K数据集,并设计预训练模型提升人脸视频生成质量。
Key Takeaways
- 人脸视频生成研究热门,但高质模型需高性能预训练骨干。
- 现有模型忽视骨干限制,导致视频质量上限。
- 我们收集和整理了FaceVid-1K高质量人脸视频数据集。
- 设计预训练骨干模型,优化人脸视频生成。
- 在多种生成模型下进行实验,包括文本到视频、图像到视频和无条件视频生成。
- 实验表明,我们的数据集在性能上优于公共数据集。
- 数据集和模型将公开发布,以促进研究进展。
- Conclusion:
- (1) 这项工作的意义在于引入了一个大规模、高质量、多种族的人脸视频数据集FaceVid-1K,并强调该资源能够满足人脸视频生成相关研究任务的需求。此外,通过在该数据集上进行的广泛实验,获得了一些有价值的实证见解。
- (2) 创新点:引入了新的大规模、多种族的人脸视频数据集FaceVid-1K,并进行了广泛的实验验证。性能:文章未具体提及该数据集或实验的具体性能指标。工作量:数据集收集与实验的工作量较大,但文章未具体阐述其工作量的大小或投入的资源。
请注意,由于无法获取整篇文章的完整内容,我的回答可能有所偏差。如果有需要,请提供更多文章信息以便更准确地回答。
点此查看论文截图


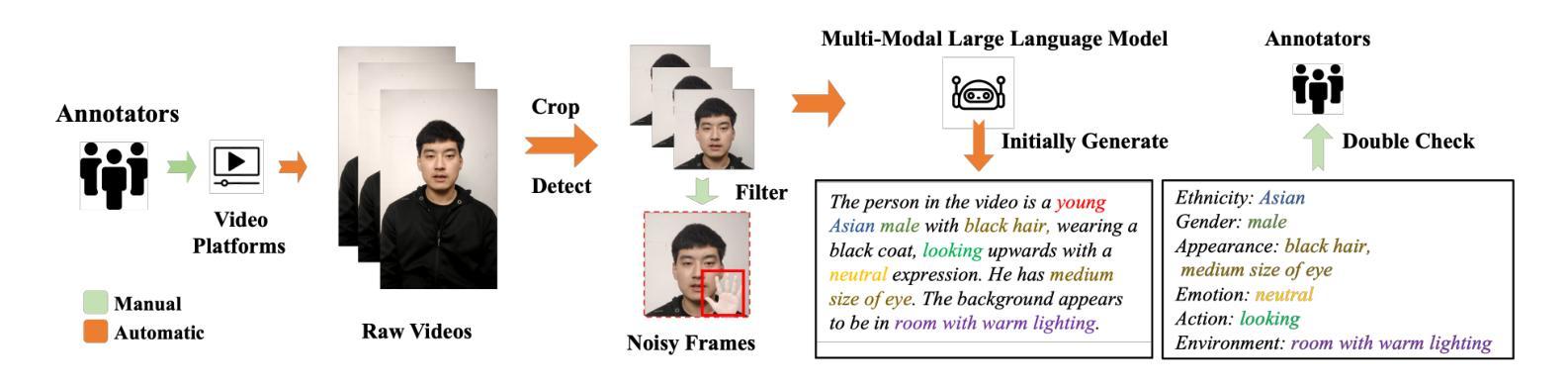
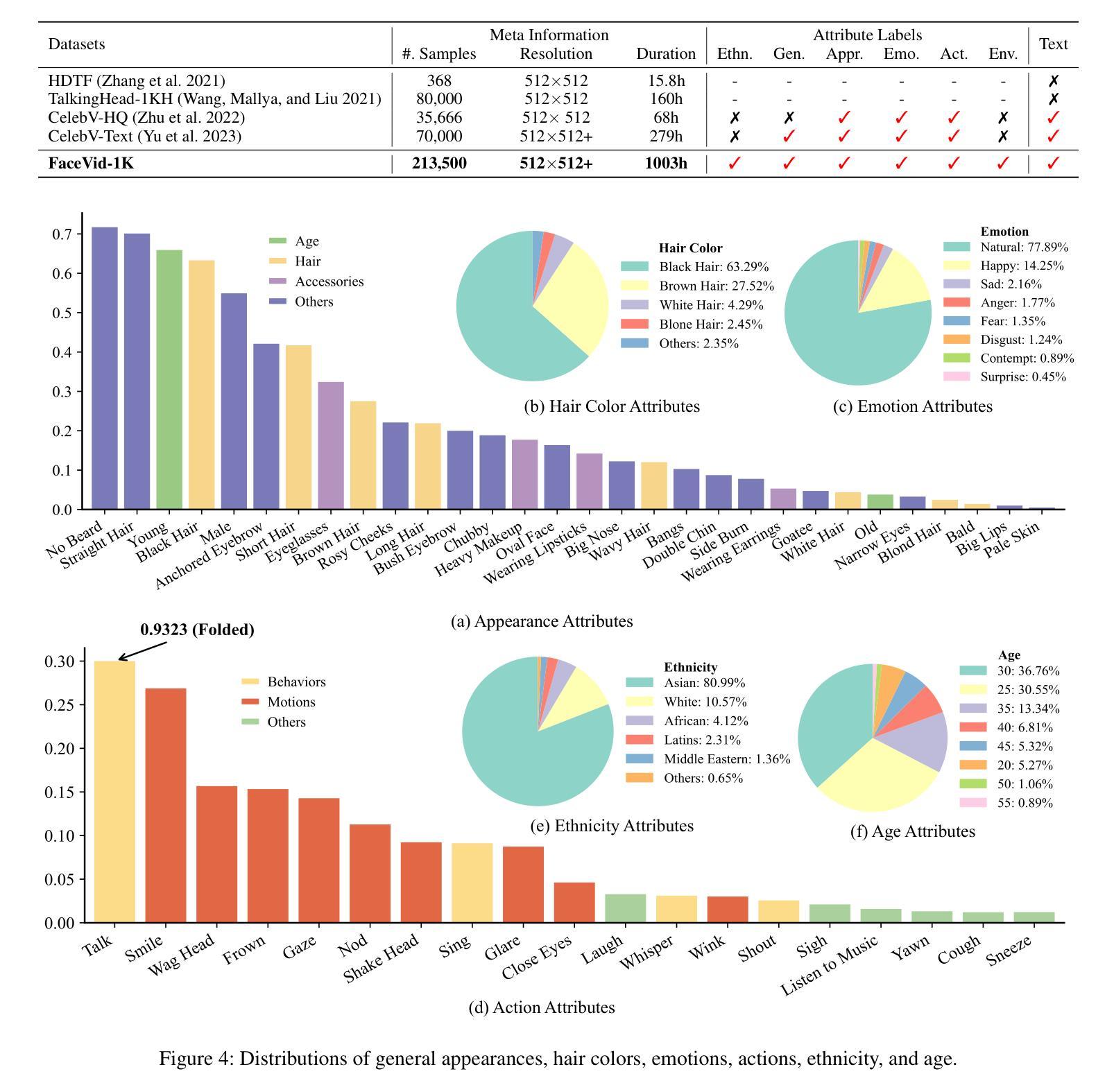
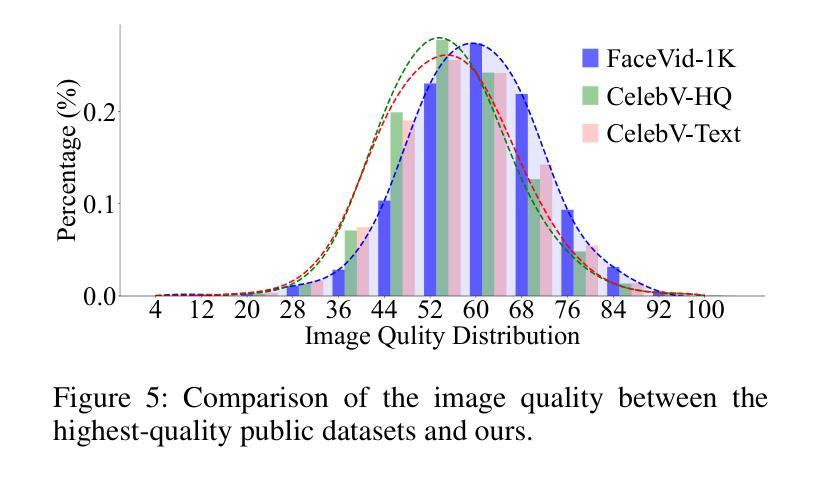

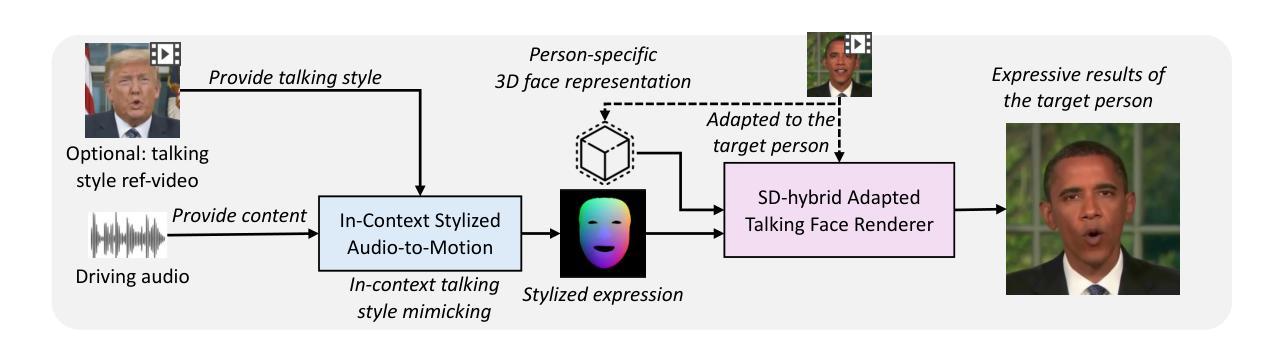
MimicTalk: Mimicking a personalized and expressive 3D talking face in minutes
Authors:Zhenhui Ye, Tianyun Zhong, Yi Ren, Ziyue Jiang, Jiawei Huang, Rongjie Huang, Jinglin Liu, Jinzheng He, Chen Zhang, Zehan Wang, Xize Chen, Xiang Yin, Zhou Zhao
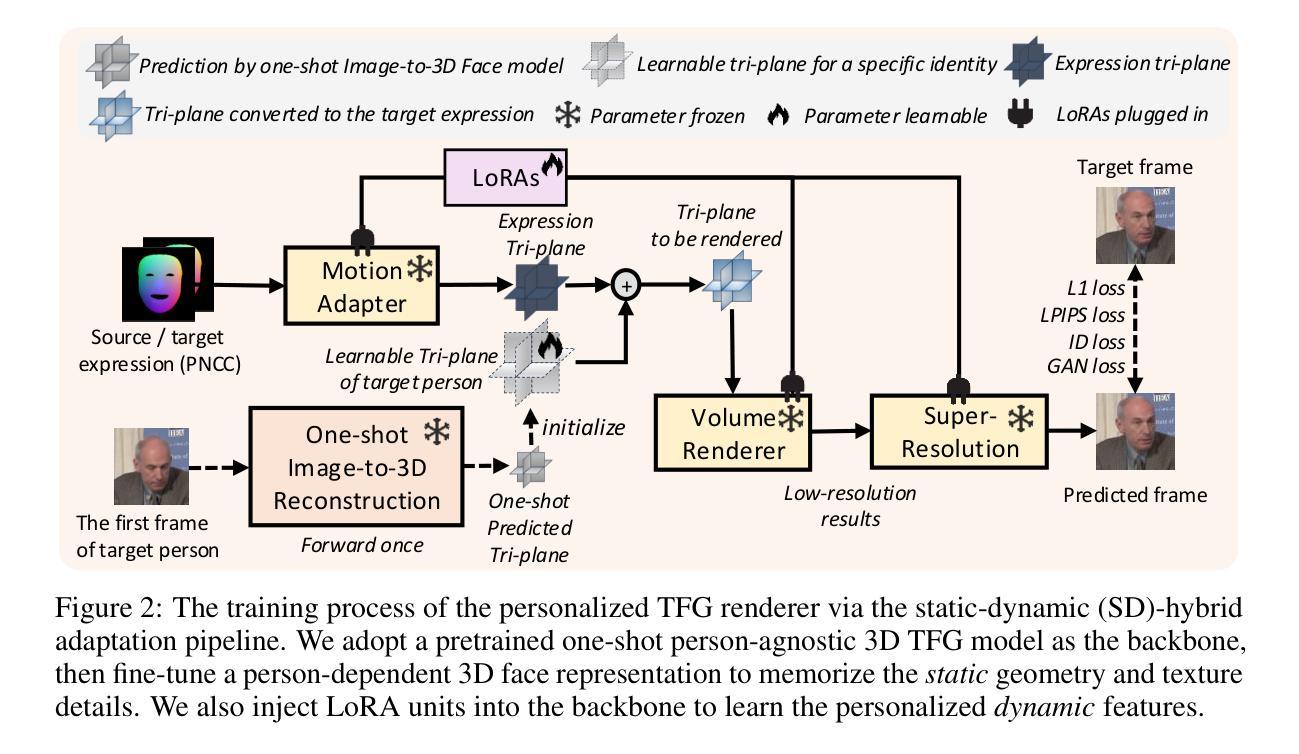
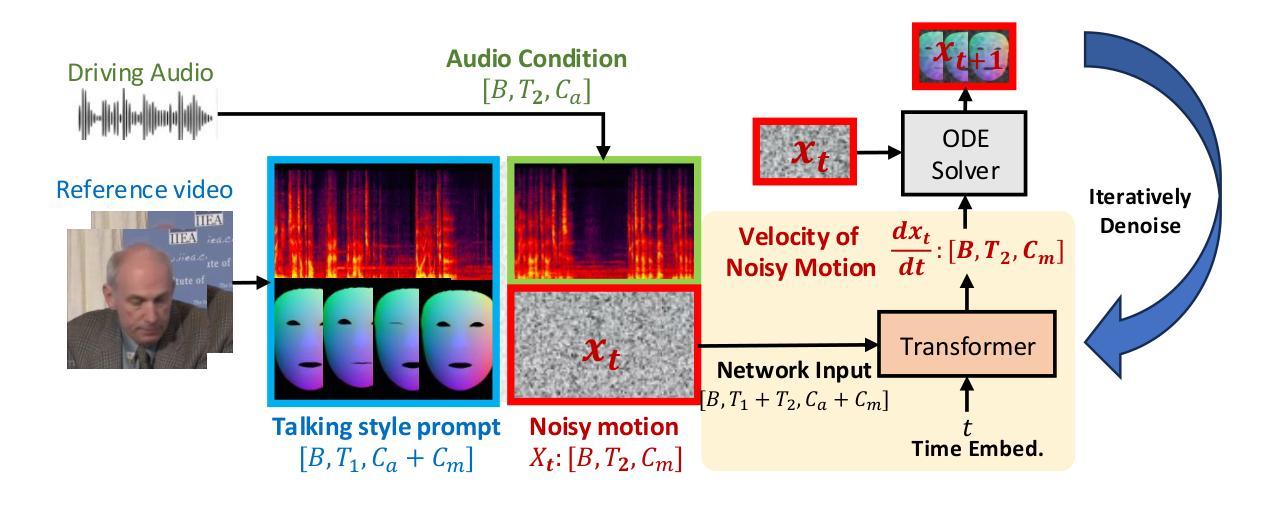
Talking face generation (TFG) aims to animate a target identity’s face to create realistic talking videos. Personalized TFG is a variant that emphasizes the perceptual identity similarity of the synthesized result (from the perspective of appearance and talking style). While previous works typically solve this problem by learning an individual neural radiance field (NeRF) for each identity to implicitly store its static and dynamic information, we find it inefficient and non-generalized due to the per-identity-per-training framework and the limited training data. To this end, we propose MimicTalk, the first attempt that exploits the rich knowledge from a NeRF-based person-agnostic generic model for improving the efficiency and robustness of personalized TFG. To be specific, (1) we first come up with a person-agnostic 3D TFG model as the base model and propose to adapt it into a specific identity; (2) we propose a static-dynamic-hybrid adaptation pipeline to help the model learn the personalized static appearance and facial dynamic features; (3) To generate the facial motion of the personalized talking style, we propose an in-context stylized audio-to-motion model that mimics the implicit talking style provided in the reference video without information loss by an explicit style representation. The adaptation process to an unseen identity can be performed in 15 minutes, which is 47 times faster than previous person-dependent methods. Experiments show that our MimicTalk surpasses previous baselines regarding video quality, efficiency, and expressiveness. Source code and video samples are available at https://mimictalk.github.io .
PDF Accepted by NeurIPS 2024
Summary
提出MimicTalk模型,利用NeRF构建的通用模型,实现高效、个性化的说话人脸生成。
Key Takeaways
- 提出MimicTalk,优化个性化说话人脸生成。
- 利用NeRF构建通用模型,提高效率和泛化能力。
- 设计静态-动态混合适配流程,学习个性化特征。
- 首次实现风格化的音频到动作模型,模仿说话风格。
- 适配过程快速,15分钟完成,远超传统方法。
- 实验证明,MimicTalk在视频质量、效率和表现力方面优于前人。
- 开放源代码和视频示例。
- 标题:MimicTalk: 模仿个性化与表达力的三维人脸快速生成技术(中文翻译)。
- 作者:Zhenhui Ye, Tianyun Zhong, Yi Ren, 等(作者名单及所属单位)。
- 作者所属单位(中文翻译):浙江大学(Zhejiang University)与字节跳动(ByteDance)。
- 关键词:Talking Face Generation (TFG), Personalized TFG, Neural Radiance Fields (NeRF), Efficient Adaptation, Style Mimicking。
- 链接:论文链接(待补充),GitHub代码链接:[GitHub链接尚未提供](如果可用)。
摘要:
- (1) 研究背景:本文研究音频驱动的三维人脸生成技术,特别是针对个性化与表达力的快速生成方法。随着多媒体技术的发展,音频与视觉结合的应用越来越广泛,此技术广泛应用于视频会议、音频可视化聊天机器人等领域。
- (2) 现有方法与问题:现有的个性化三维人脸生成方法通常采用学习个体神经辐射场(NeRF)的方式为每个身份隐式存储静态和动态信息。但这种方式效率低且缺乏通用性,因为需要为每个身份进行单独的训练且受限于训练数据。
- (3) 研究方法:提出MimicTalk方法,首次利用通用的非个性化NeRF模型提高个性化TFG的效率与稳健性。包括构建一个非个性化的三维TFG模型作为基准模型,并对其进行个性化适应;采用静态与动态结合的适应流程来学习个性化的静态外观和面部动态特征;提出上下文风格化的音频到动作模型,模仿参考视频中的隐性说话风格。
- (4) 任务与性能:在个性化说话风格的三维人脸生成任务上取得显著成果,与之前的基线相比,在视频质量、效率和表现力方面都有提升。实验证明MimicTalk方法的优越性。
总结:
- (1) 研究背景:本文研究了音频驱动的三维人脸生成技术,特别是如何快速生成具有个性化与表达力的三维人脸,在多媒体领域有广泛的应用前景。
- (2) 过去的方法与问题:现有方法通过为每个身份学习个体神经辐射场(NeRF)来隐式存储信息,但效率较低且缺乏通用性。
- (3) 研究方法:本文提出了MimicTalk方法,利用通用的非个性化NeRF模型来提高个性化TFG的效率与稳健性,包括构建基准模型、个性化适应、静态与动态特征学习以及音频到动作的风格模仿模型。
- (4) 任务与性能:在个性化说话风格的三维人脸生成任务上取得显著成果,实验证明该方法在视频质量、效率和表现力方面均超越先前方法。性能结果支持了该方法的有效性。
- 方法:
(1) 研究背景与问题定义:文章聚焦于音频驱动的三维人脸生成技术,特别是如何实现快速生成具有个性化与表达力的三维人脸。针对现有方法效率低和缺乏通用性的问题,提出了改进的需求。
(2) 方法概述:提出MimicTalk方法,该方法利用通用的非个性化NeRF模型来提高个性化TFG的效率与稳健性。首先,构建一个非个性化的三维TFG模型作为基准模型。然后,对此基准模型进行个性化适应,以适应不同个体的特征。
(3) 静态与动态特征学习:采用静态与动态结合的适应流程,通过学习个性化的静态外观和面部动态特征,实现更为真实和自然的人脸生成。
(4) 音频到动作的风格模仿:提出上下文风格化的音频到动作模型,该模型能够模仿参考视频中的隐性说话风格,使得生成的三维人脸能够体现原说话人的表达特点。
(5) 实验验证:通过大量的实验验证,在个性化说话风格的三维人脸生成任务上,MimicTalk方法取得了显著成果,并在视频质量、效率和表现力方面均有提升。与现有方法相比,表现出了优越性。
- Conclusion:
(1)工作意义:这篇文章研究了音频驱动的三维人脸快速生成技术,特别是模仿个性化与表达力的技术。随着多媒体技术的发展,这种技术在视频会议、音频可视化聊天机器人等领域有广泛的应用前景。该研究对于推动人脸生成技术的个性化和表达力提升具有重要意义。
(2)创新点、性能、工作量三维评价:
创新点:文章提出了MimicTalk方法,利用通用的非个性化NeRF模型来提高个性化TFG的效率与稳健性,这是该领域的一个新的尝试和探索。
性能:在个性化说话风格的三维人脸生成任务上,MimicTalk方法取得了显著成果,实验证明该方法在视频质量、效率和表现力方面均超越先前方法。
工作量:文章进行了大量的实验和验证,证明了所提方法的有效性。此外,文章还进行了深入的理论分析和讨论,为未来的研究提供了有价值的参考。但是,文章没有提供充分的实现细节和代码实现,这可能会限制其他研究者对该方法的深入理解和应用。
点此查看论文截图

Towards a GENEA Leaderboard — an Extended, Living Benchmark for Evaluating and Advancing Conversational Motion Synthesis
Authors:Rajmund Nagy, Hendric Voss, Youngwoo Yoon, Taras Kucherenko, Teodor Nikolov, Thanh Hoang-Minh, Rachel McDonnell, Stefan Kopp, Michael Neff, Gustav Eje Henter
Current evaluation practices in speech-driven gesture generation lack standardisation and focus on aspects that are easy to measure over aspects that actually matter. This leads to a situation where it is impossible to know what is the state of the art, or to know which method works better for which purpose when comparing two publications. In this position paper, we review and give details on issues with existing gesture-generation evaluation, and present a novel proposal for remedying them. Specifically, we announce an upcoming living leaderboard to benchmark progress in conversational motion synthesis. Unlike earlier gesture-generation challenges, the leaderboard will be updated with large-scale user studies of new gesture-generation systems multiple times per year, and systems on the leaderboard can be submitted to any publication venue that their authors prefer. By evolving the leaderboard evaluation data and tasks over time, the effort can keep driving progress towards the most important end goals identified by the community. We actively seek community involvement across the entire evaluation pipeline: from data and tasks for the evaluation, via tooling, to the systems evaluated. In other words, our proposal will not only make it easier for researchers to perform good evaluations, but their collective input and contributions will also help drive the future of gesture-generation research.
PDF 15 pages, 2 figures, project page: https://genea-workshop.github.io/leaderboard/
Summary
语音驱动手势生成评估缺乏标准化,本文提出新方法构建动态排行榜,推动研究进展。
Key Takeaways
- 现有评估缺乏标准化,影响成果比较。
- 提出建立动态排行榜,定期更新。
- 排行榜结合大规模用户研究,提升评价质量。
- 排行榜开放,支持任意出版物提交。
- 逐步演进评价数据与任务,追求重要目标。
- 鼓励社区参与整个评估流程。
- 旨在提升评估质量,推动手势生成研究发展。
Title: 迈向GENEA排行榜——扩展型动态基准测试用于评估与推动对话动作合成的发展
Authors: Rajmund Nagy, Hendric Voss, Youngwoo Yoon, Taras Kucharenko, Teodor Nikolov, Thanh Hoang-Minh, Rachel McDonnell, Stefan Kopp, Michael Neff, Gustav Eje Henter等人
Affiliation:
- Rajmund Nagy, Gustav Eje Henter:KTH皇家理工学院
- Hendric Voss, Stefan Kopp:比勒费尔德大学
- Youngwoo Yoon:ETRI(电子和电信研究协会)
- Taras Kucharenko:SEED - 电子艺术
- Motorica AB公司的其他作者等。
Keywords: 姿态生成评估、基准测试、对话动作合成、社区驱动解决方案等。
Urls: 论文链接,Github代码链接(如果有的话,填写相应链接;如果没有,填写”None”)
Summary:
- (1)研究背景:当前姿态生成评估缺乏标准化,现有的评估方法过于关注易于度量的方面而忽略了实际重要的方面。这使得比较不同论文的方法变得困难,无法确定哪些方法对哪些特定任务效果最好。文章提出了一种解决这些问题的方法。
- (2)过去的方法及问题:现有的姿态生成评估存在诸多不足,如缺乏统一的基准测试集、评估任务不连贯、用户研究标准化程度低等。这些问题限制了领域的发展,阻碍了新技术的推广和应用。本文提出的动机是解决这些问题,提供一个更完善、更标准的评估方法。
- (3)研究方法:文章提出了一种新的社区驱动的整体解决方案来应对姿态生成模型评估中的主要挑战。该方案包括建立一个动态的、不断更新的GENEA排行榜,以标准的方式进行姿态生成的评估。此外,还强调了社区参与的重要性,从数据、任务、工具到评估系统的参与都被鼓励。文章还介绍了新的可视化工具的使用,以便更好地展示和分析姿态生成模型的结果。最后通过不断调整和更新评价数据和任务以适应社区识别的最重要目标来推动领域发展。
- (4)任务与性能:本文提出的方案旨在通过建立一个动态的、不断更新的基准测试排行榜来推动对话动作合成领域的发展。该方案将采用大规模用户研究来评估新的姿态生成系统,并将系统提交到任何作者喜欢的出版渠道。通过不断进化的评价数据和任务,该方案将能够推动社区识别的重要目标的实现。本文的性能评价将通过未来发布在GENEA排行榜上的系统和相关研究来验证和支持其目标实现。
- Conclusion:
(1) 这项工作的意义在于提出了一种解决姿态生成评估中存在问题的方法,通过建立动态的、不断更新的基准测试排行榜来推动对话动作合成领域的发展。这项工作的重要性在于为姿态生成评估提供了一个更完善、更标准的评估方法,有助于比较不同论文的方法,确定哪些方法对哪些特定任务效果最好,促进了新技术的推广和应用。
(2) 创新点:本文提出了一种新的社区驱动的整体解决方案来应对姿态生成模型评估中的主要挑战,建立了动态的、不断更新的GENEA排行榜,以标准的方式进行姿态生成的评估,强调了社区参与的重要性。
性能:文章所提方案旨在通过大规模用户研究来评估新的姿态生成系统,并通过不断进化的评价数据和任务来推动社区识别的重要目标的实现。
工作量:文章介绍了新的可视化工具的使用,以便更好地展示和分析姿态生成模型的结果,未来将通过发布在GENEA排行榜上的系统和相关研究来验证和支持其目标实现。
点此查看论文截图

Incorporating Talker Identity Aids With Improving Speech Recognition in Adversarial Environments
Authors:Sagarika Alavilli, Annesya Banerjee, Gasser Elbanna, Annika Magaro
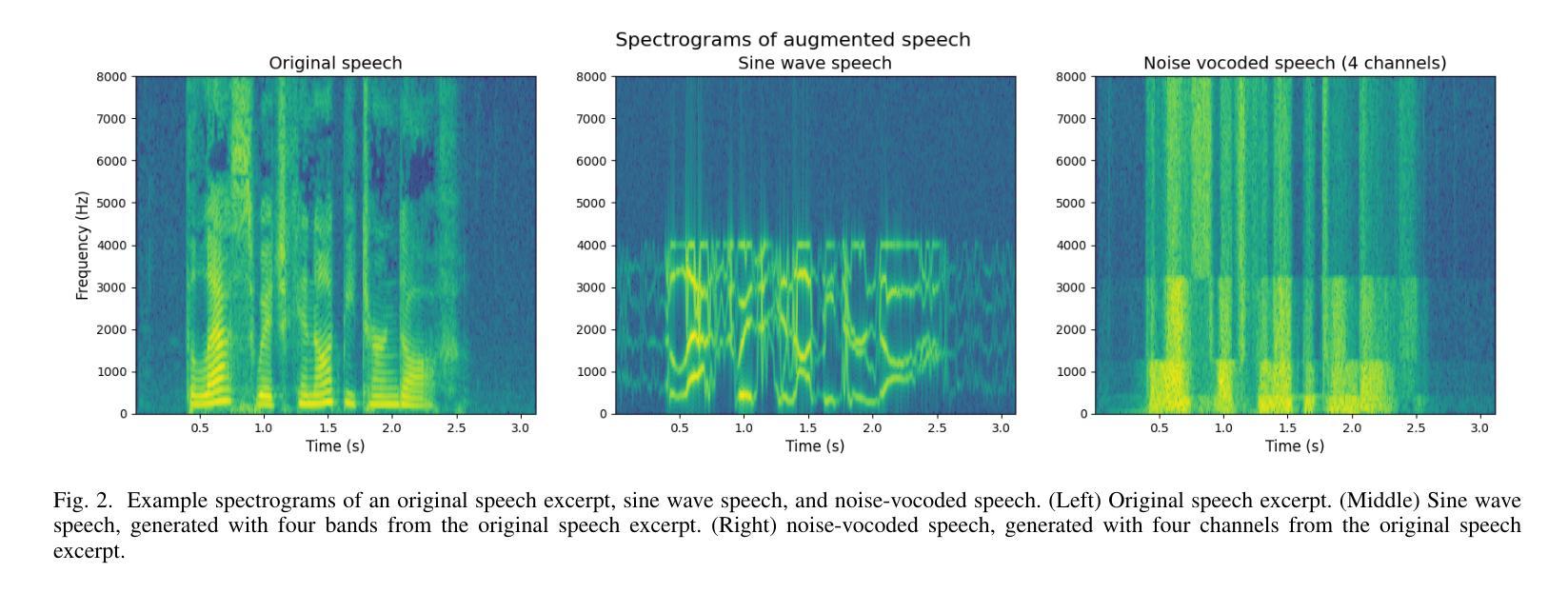
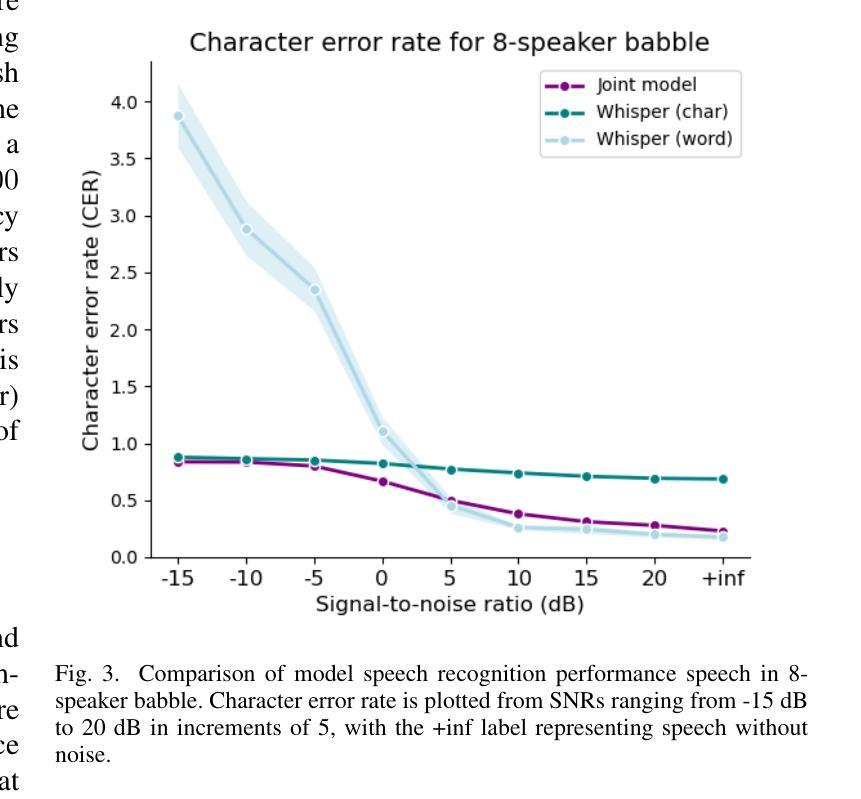
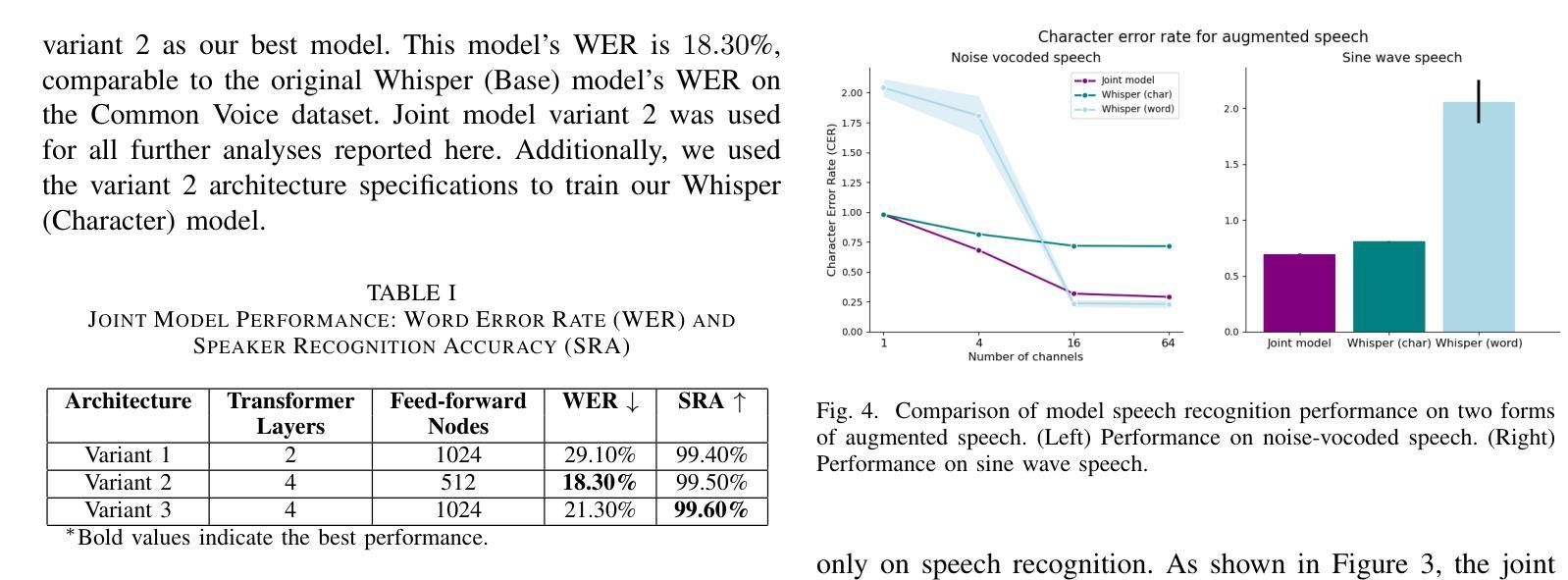
Current state-of-the-art speech recognition models are trained to map acoustic signals into sub-lexical units. While these models demonstrate superior performance, they remain vulnerable to out-of-distribution conditions such as background noise and speech augmentations. In this work, we hypothesize that incorporating speaker representations during speech recognition can enhance model robustness to noise. We developed a transformer-based model that jointly performs speech recognition and speaker identification. Our model utilizes speech embeddings from Whisper and speaker embeddings from ECAPA-TDNN, which are processed jointly to perform both tasks. We show that the joint model performs comparably to Whisper under clean conditions. Notably, the joint model outperforms Whisper in high-noise environments, such as with 8-speaker babble background noise. Furthermore, our joint model excels in handling highly augmented speech, including sine-wave and noise-vocoded speech. Overall, these results suggest that integrating voice representations with speech recognition can lead to more robust models under adversarial conditions.
PDF Submitted to ICASSP 2025
Summary
本研究提出一种结合说话人表示的语音识别模型,显著提高了在噪声和语音增强条件下的鲁棒性。
Key Takeaways
- 语音识别模型对分布外条件(如背景噪音)敏感。
- 提出结合说话人表示来增强模型鲁棒性的假设。
- 开发了一种基于transformer的模型,联合进行语音识别和说话人识别。
- 使用Whisper的语音嵌入和ECAPA-TDNN的说话人嵌入。
- 联合模型在干净条件下与Whisper表现相当。
- 联合模型在噪声环境中(如8个说话人的嘈杂背景噪声)优于Whisper。
- 联合模型在处理高度增强的语音(如正弦波和噪声编码语音)方面表现出色。
Title: 基于联合训练的说话人身份识别与语音识别模型改进研究
Authors: Sagarika Alavilli, Annesya Banerjee, Gasser Elbanna, Annika Magaro
Affiliation: Harvard University Speech and Hearing Bioscience and Technology
Keywords: voice identification, automatic speech recognition, joint training
Urls: xxx (论文链接未提供)
Summary:
(1)研究背景:本文主要研究在恶劣环境下,如何提高自动语音识别模型的鲁棒性。当前最先进的语音识别模型在背景噪声和语音增强等条件下性能下降。
(2)过去的方法及问题:传统的语音识别模型主要关注语言内容,忽略说话人特定的声学线索。尽管已有研究表明语音和说话人特性影响语音感知,但自动语音识别系统很少利用这些特性。因此,现有的模型在面对噪声或其他干扰时,性能可能会显著下降。
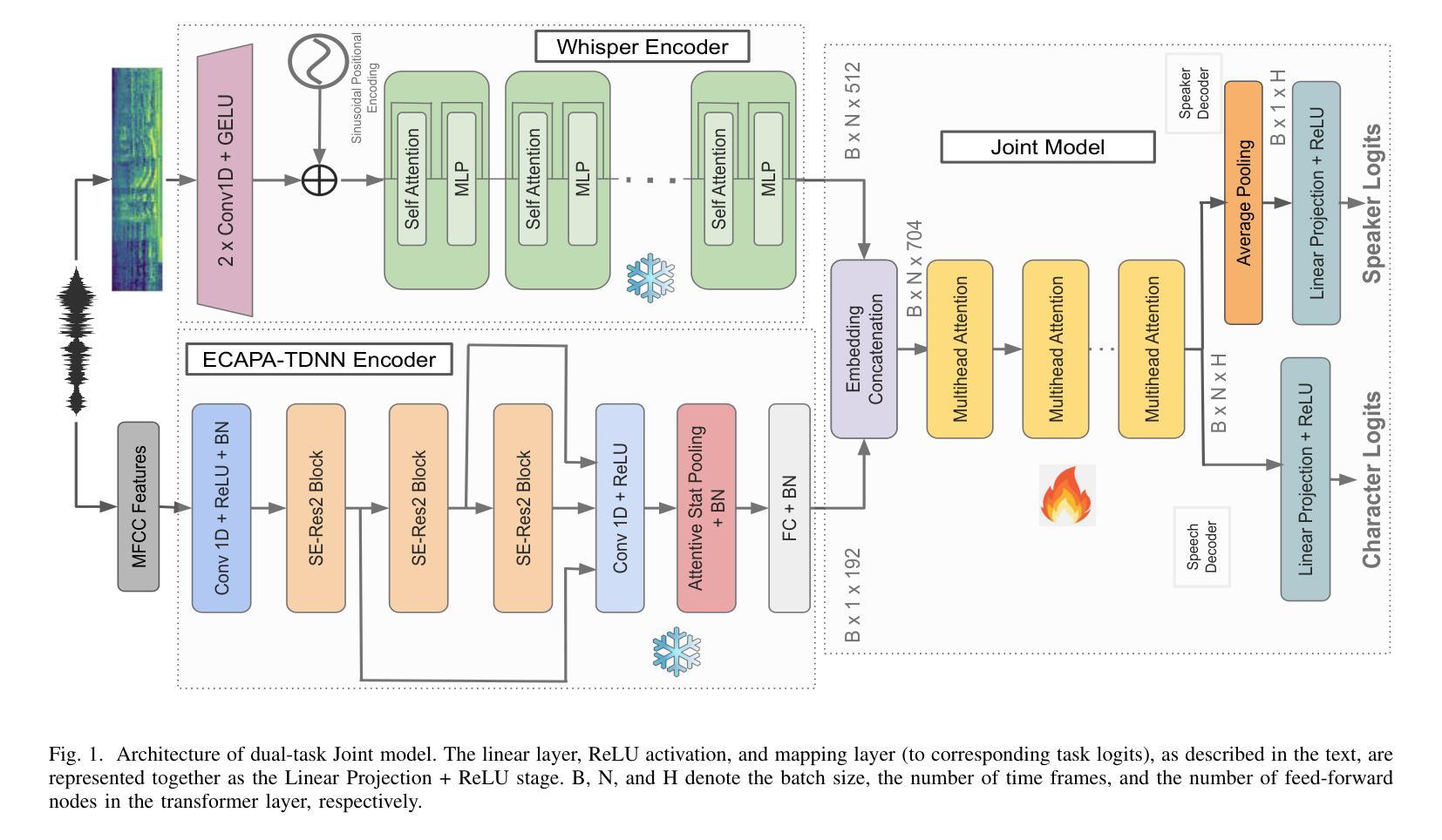
(3)研究方法:本文提出了一种基于联合训练的语音识别和说话人识别模型。该模型结合了Whisper的语音嵌入和ECAPA-TDNN的说话人嵌入,通过多任务学习的方式,共同处理语音和说话人识别任务。模型利用变压器结构处理嵌入信息,生成同时包含语音和说话人特征的表示。
(4)任务与性能:该模型在噪声环境和语音增强任务上进行了测试,如8人同时说话的嘈杂背景噪声。实验结果表明,联合模型在恶劣环境下的性能优于Whisper模型。此外,该模型在处理高度增强的语音,如正弦波和噪声编码的语音方面表现优异。总的来说,这些结果支持了通过整合语音和说话人特性来提高语音识别模型鲁棒性的观点。
以上内容仅供参考,具体信息建议查阅论文原文获取。
方法论:
(1) 研究背景:该研究针对恶劣环境下自动语音识别模型的鲁棒性问题展开。现有的最先进的语音识别模型在背景噪声和语音增强等条件下性能下降。
(2) 过去的方法及问题:传统的语音识别模型主要关注语言内容,忽略了说话人的特定声学线索。尽管已有研究表明语音和说话人特性影响语音感知,但自动语音识别系统很少利用这些特性,导致在面对噪声或其他干扰时性能下降。
(3) 方法论创新:本研究提出了一种基于联合训练的语音识别和说话人识别模型。该模型结合了Whisper的语音嵌入和ECAPA-TDNN的说话人嵌入,通过多任务学习的方式,共同处理语音和说话人识别任务。模型利用变压器结构处理嵌入信息,生成同时包含语音和说话人特征的表示。具体来说,研究使用了Whisper模型作为语音识别的基本架构,并在此基础上结合了ECAPA-TDNN模型的优点,用于提取说话人的特征。联合模型通过多层变压器结构对两种嵌入进行联合处理,以提高模型在恶劣环境下的鲁棒性。
(4) 实验验证:该模型在噪声环境和语音增强任务上进行了测试,实验结果表明,联合模型在恶劣环境下的性能优于Whisper模型。此外,该模型在处理高度增强的语音,如正弦波和噪声编码的语音方面表现优异。这些结果支持了通过整合语音和说话人特性来提高语音识别模型鲁棒性的观点。
- Conclusion:
(1)研究意义:该研究提高了在恶劣环境下自动语音识别模型的鲁棒性,对于提高语音识别系统的实际应用效果具有重要意义。通过整合语音和说话人特性,模型能够在噪声和其他干扰条件下更加准确地识别语音内容。此外,该研究也为开发更健壮的语音识别系统提供了新的可能性。
(2)创新点、性能和工作量评价:
- 创新点:该研究结合说话人识别和语音识别模型进行联合训练,这是一种新的尝试。通过结合Whisper的语音嵌入和ECAPA-TDNN的说话人嵌入,模型能够同时处理语音和说话人识别任务,生成包含语音和说话人特征的表示。这种结合方式有助于提高模型在恶劣环境下的鲁棒性。
- 性能:实验结果表明,联合模型在恶劣环境下的性能优于Whisper模型,尤其是在处理高度增强的语音时表现优异。这些结果支持了通过整合语音和说话人特性来提高语音识别模型鲁棒性的观点。
- 工作量:研究工作量较大,需要进行模型设计、实验设计、实验实施和结果分析等多个环节的工作。此外,还需要进行文献调研和理论分析,以支撑研究工作的进行。
综上所述,该研究具有一定的实际意义和创新性,但仍需要在实践中进一步验证和完善模型的性能。
点此查看论文截图

 wechat
wechat- alipay







