NeRF
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-10-30 更新
MVSDet: Multi-View Indoor 3D Object Detection via Efficient Plane Sweeps
Authors:Yating Xu, Chen Li, Gim Hee Lee
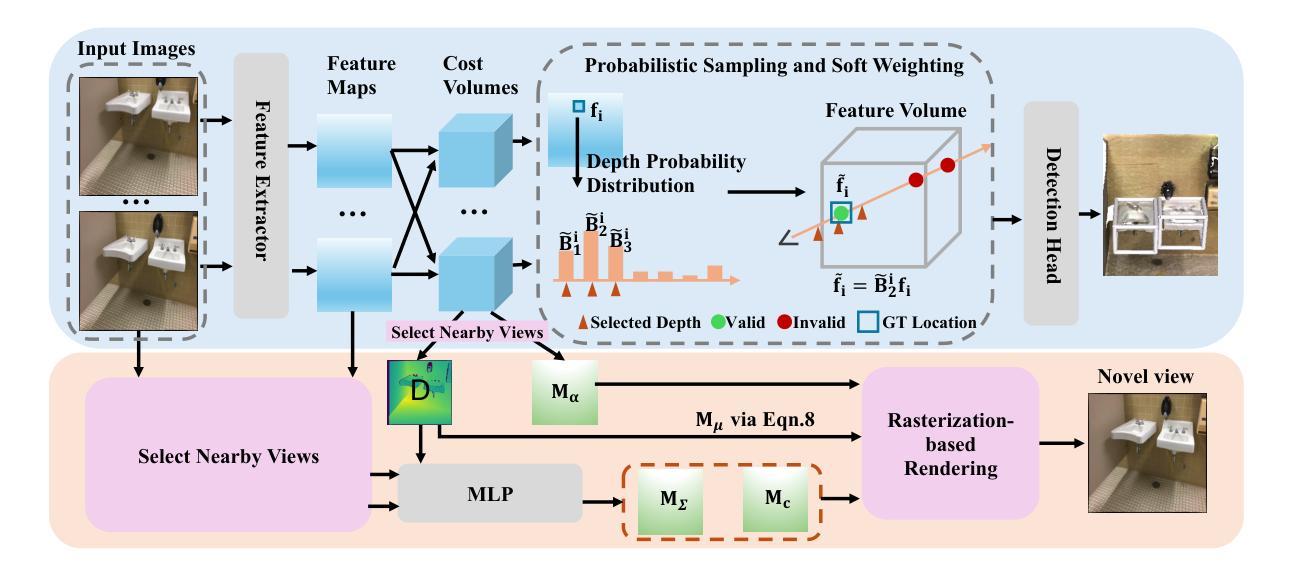
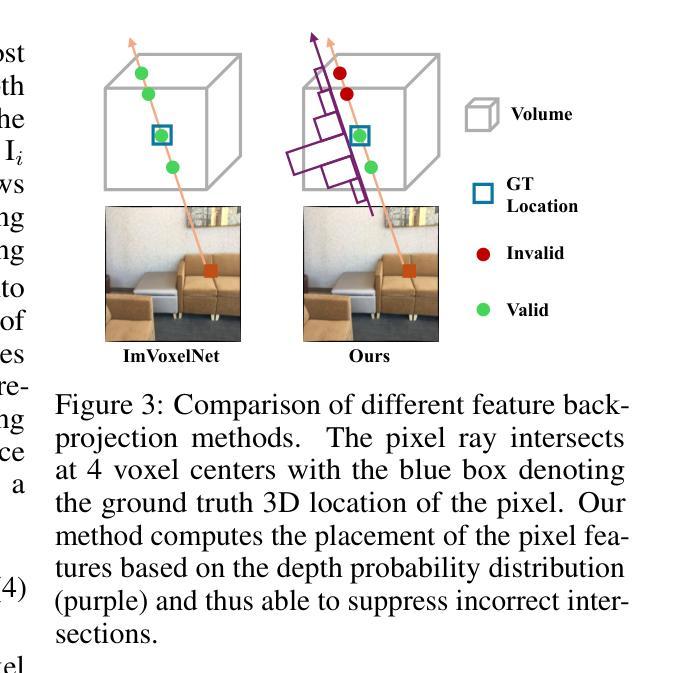
The key challenge of multi-view indoor 3D object detection is to infer accurate geometry information from images for precise 3D detection. Previous method relies on NeRF for geometry reasoning. However, the geometry extracted from NeRF is generally inaccurate, which leads to sub-optimal detection performance. In this paper, we propose MVSDet which utilizes plane sweep for geometry-aware 3D object detection. To circumvent the requirement for a large number of depth planes for accurate depth prediction, we design a probabilistic sampling and soft weighting mechanism to decide the placement of pixel features on the 3D volume. We select multiple locations that score top in the probability volume for each pixel and use their probability score to indicate the confidence. We further apply recent pixel-aligned Gaussian Splatting to regularize depth prediction and improve detection performance with little computation overhead. Extensive experiments on ScanNet and ARKitScenes datasets are conducted to show the superiority of our model. Our code is available at https://github.com/Pixie8888/MVSDet.
PDF Accepted by NeurIPS 2024
Summary
提出MVSDet,利用平面扫描进行几何感知3D物体检测,提升NeRF几何信息准确性。
Key Takeaways
- 多视角室内3D物体检测的关键在于从图像中推断精确的几何信息。
- 早期方法依赖NeRF进行几何推理,但NeRF提取的几何信息通常不准确。
- MVSDet采用平面扫描技术进行几何感知3D物体检测。
- 设计概率采样和软加权机制,减少深度预测所需的深度平面数量。
- 选择概率体积中得分最高的多个位置,以概率分数表示置信度。
- 使用像素对齐高斯分层来正则化深度预测,提高检测性能。
- 在ScanNet和ARKitScenes数据集上进行了广泛实验,证明模型优越性。
Title: 基于平面扫描的多视角室内三维物体检测
Authors: 徐亚婷1,李晨2,3∗,Lee Gim Hee1
Affiliation: 作者来自新加坡国立大学计算机科学系(National University of Singapore)和新加坡高性能计算研究所(Institute of High Performance Computing)。其中李晨在本文工作时是在新加坡国立大学进行的。
Keywords: 室内三维物体检测,多视角图像,平面扫描,NeRF技术,深度学习等。
Urls: 论文链接:[论文链接];GitHub代码链接:[GitHub链接](如果有的话),否则填写None。
Summary:
(1) 研究背景:室内三维物体检测是场景理解的一个基础任务,广泛应用于机器人、增强现实/虚拟现实等领域。然而,从单张二维图像中估计几何信息较为困难,多视角室内三维物体检测需要更准确的方法。本文的研究背景就是在此背景下展开。
(2) 过去的方法及其问题:过去的方法主要依赖NeRF技术进行几何推理,但NeRF提取的几何信息通常不准确,导致检测性能不佳。因此,需要一种新的方法来解决这个问题。
(3) 研究方法:本文提出了MVSDet方法,利用平面扫描进行几何感知的三维物体检测。为了降低深度平面数量对深度预测的影响,设计了一种概率采样和软权重机制来决定三维体积中像素特征的放置。通过选择每个像素得分最高的多个位置并使用其概率得分来表示置信度。此外,还应用了最近的像素对齐高斯展开技术来规范深度预测并稍微提高检测性能。
(4) 任务与性能:本文在ScanNet和ARKitScenes数据集上进行了实验,证明了本文方法的优越性。实验结果表明,该方法能够实现精确的三维物体检测,支持其达到研究目标。
- Methods:
- (1) 研究背景分析:室内三维物体检测是计算机视觉领域的一个重要任务,广泛应用于机器人、增强现实/虚拟现实等领域。该研究通过对现有方法的不足进行深入分析,指出需要从多视角进行室内三维物体检测以提高检测精度。
- (2) 方法提出:针对过去方法存在的问题,本文提出了MVSDet方法,利用平面扫描进行几何感知的三维物体检测。该方法通过设计概率采样和软权重机制来决定三维体积中像素特征的放置,以降低深度平面数量对深度预测的影响。同时,采用最近的像素对齐高斯展开技术来规范深度预测,提高检测性能。
- (3) 实验设计与实施:为了验证所提出方法的有效性,本文在ScanNet和ARKitScenes数据集上进行了实验。实验结果表明,该方法能够实现精确的三维物体检测,支持其达到研究目标。
- (4) 结果评估:通过对实验结果进行详细评估,证明了该方法在多个指标上均优于现有方法,验证了其有效性和优越性。
注:以上内容仅为根据您提供的摘要进行的概括,具体细节和方法可能需要根据原文进行更深入的理解和阐述。
- Conclusion:
(1)这篇工作的意义在于它提出了一种基于平面扫描的多视角室内三维物体检测方法,解决了室内三维物体检测中的一些问题,提高了检测精度。该方法在计算机视觉、机器人、增强现实/虚拟现实等领域具有潜在的应用价值。
(2)创新点:本文提出了MVSDet方法,利用平面扫描进行几何感知的三维物体检测,通过设计概率采样和软权重机制以及引入像素对齐高斯展开技术,实现了精确的三维物体检测。
性能:本文方法在ScanNet和ARKitScenes数据集上进行了实验,结果表明该方法在多个指标上均优于现有方法,具有较高的检测性能和准确性。
工作量:文章对室内三维物体检测问题进行了深入的研究和分析,提出了一种新的解决方法,并进行了实验验证,工作量较大。但同时,对于某些无纹理或反射表面的情况,特征匹配会失败,这可能需要进一步的研究和改进。此外,文章得到了新加坡科技研究局的资助。
点此查看论文截图


EEG-Driven 3D Object Reconstruction with Color Consistency and Diffusion Prior
Authors:Xin Xiang, Wenhui Zhou, Guojun Dai
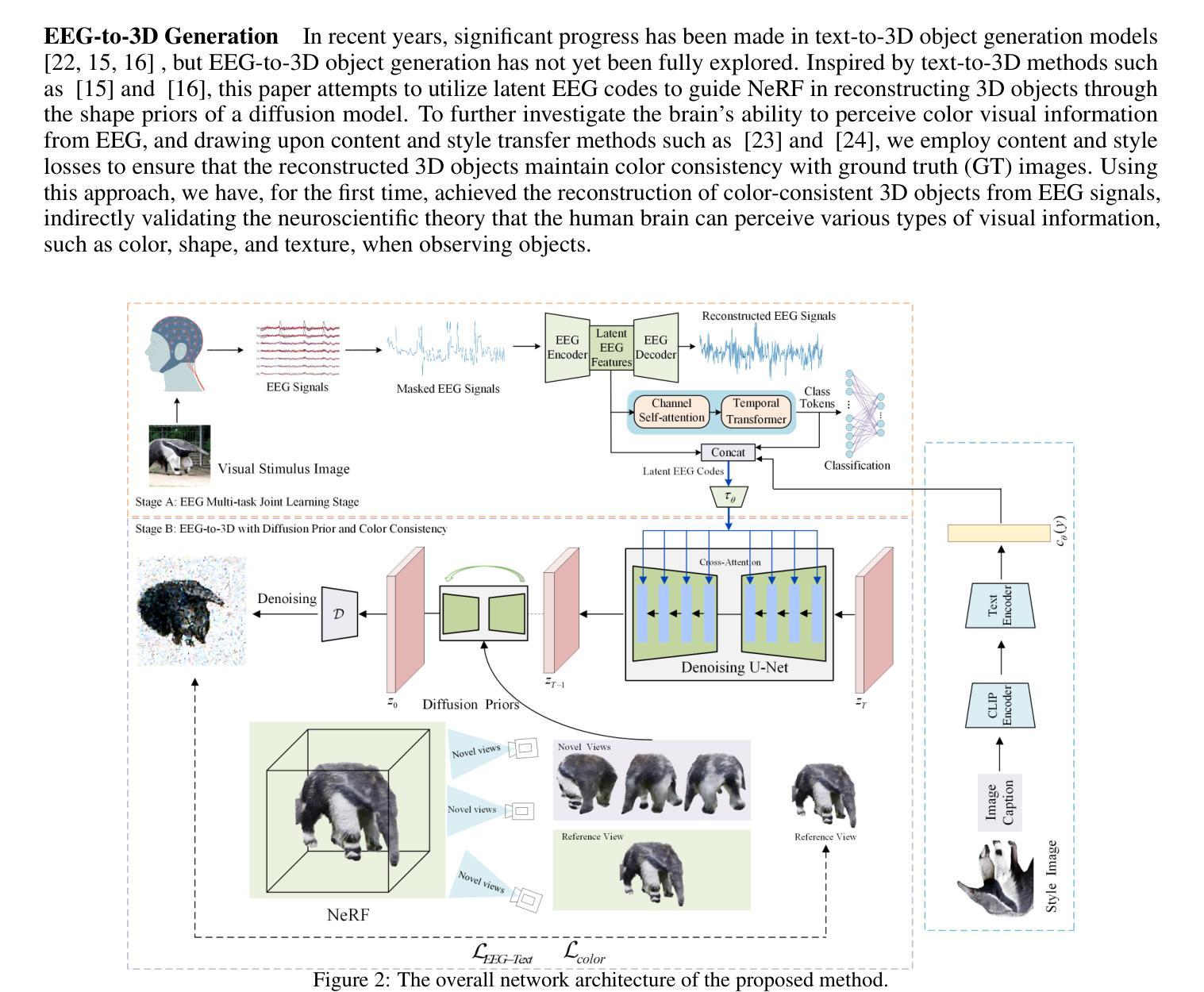
EEG-based visual perception reconstruction has become a current research hotspot. Neuroscientific studies have shown that humans can perceive various types of visual information, such as color, shape, and texture, when observing objects. However, existing technical methods often face issues such as inconsistencies in texture, shape, and color between the visual stimulus images and the reconstructed images. In this paper, we propose a method for reconstructing 3D objects with color consistency based on EEG signals. The method adopts a two-stage strategy: in the first stage, we train an implicit neural EEG encoder with the capability of perceiving 3D objects, enabling it to capture regional semantic features; in the second stage, based on the latent EEG codes obtained in the first stage, we integrate a diffusion model, neural style loss, and NeRF to implicitly decode the 3D objects. Finally, through experimental validation, we demonstrate that our method can reconstruct 3D objects with color consistency using EEG.
Summary
基于EEG的3D物体视觉感知重建方法,采用两阶段策略,实现颜色一致性的3D物体重构。
Key Takeaways
- EEG视觉感知重建成为研究热点。
- 现有方法存在视觉刺激与重建图像不一致问题。
- 提出基于EEG信号的三维物体颜色一致性重建方法。
- 采用两阶段策略:训练隐式神经网络编码器,捕捉区域语义特征。
- 利用扩散模型、神经风格损失和NeRF解码3D物体。
- 实验验证显示方法可重构颜色一致的3D物体。
- 方法基于EEG信号,实现对3D物体视觉感知的有效重建。
Title: 基于脑电图信号的彩色一致性三维物体重建研究(EEG-Based Color-Consistent 3D Object Reconstruction)
Authors: 相欣, 周文辉, 戴国俊
Affiliation: 杭州电子科技大学计算机科学与技术学院(School of Computer Science and Technology, Hangzhou Dianzi University)
Keywords: EEG信号, 三维物体重建, 颜色一致性, 扩散模型(EEG signal, 3D object reconstruction, color consistency, diffusion model)
Urls: https://arxiv.org/pdf/2410.20981v2.pdf (论文链接), Github: None (GitHub代码库链接暂不可用)
Summary:
(1)研究背景:随着神经科学的进步,基于脑电图(EEG)的视觉感知重建已成为当前研究热点。文章旨在探索利用EEG信号重建颜色一致性的三维物体的可能性。
(2)过去的方法及问题:现有技术方法在处理视觉刺激图像和重建图像之间的纹理、形状和颜色不一致性方面存在问题。尽管基于功能磁共振成像(fMRI)的视觉信息重建已有尝试,但由于fMRI设备成本高昂,限制了其在实际应用中的广泛使用。相比之下,EEG是一种更经济有效的捕捉大脑活动的方法,更容易收集。
(3)研究方法:本文提出了一种基于EEG信号的两阶段策略进行三维物体重建。第一阶段训练一个能够感知三维物体的隐式神经网络EEG编码器,以捕获区域语义特征;第二阶段基于第一阶段的潜在EEG代码,结合扩散模型、神经风格损失和NeRF进行隐式解码三维物体。
(4)任务与性能:通过实验验证,本文方法能够利用EEG信号重建颜色一致性的三维物体。该方法的性能表明其在重建颜色一致性方面取得了显著成果,为后续研究提供了重要参考。该研究成果有助于了解人类视觉感知过程,并可能为人工智能在视觉领域的进步开辟新的方向。
- 方法:
(1) 数据集采集:本研究采用的数据集来源于文献[1],其中的图像展示时间为0.5秒,同时收集EEG数据。根据参考文献[2,25,3,6],已知大脑能够在0.5秒内获取视觉信息。因此,我们假设在0.5秒的时间窗口内,EEG已经感知到了特定的三维纹理信息。本研究提出这一假设并通过实验验证了其存在性。
(2) 实验方法设计:为了分析大脑在如此短的时间内如何捕获视觉感知信息,我们采用了融合三维和颜色感知的方法论。我们首先对EEG信号进行预处理和特征提取,然后使用训练好的神经网络模型进行三维物体重建。在重建过程中,我们采用了颜色一致性扩散模型,确保重建物体的颜色与原始物体一致。
(3) 实验验证:通过实验验证,本研究发现基于EEG信号的三维物体重建方法能够实现颜色一致性的重建。同时,本研究还通过对比实验证明了该方法的有效性,为后续研究提供了重要参考。实验结果不仅证明了方法的可行性,也为理解人类视觉感知过程提供了有力支持,有望为人工智能在视觉领域的进步开辟新的方向。
- Conclusion:
- (1) 研究意义:该研究对于理解人类视觉感知过程和推进人工智能在视觉领域的进步具有重要意义。通过利用脑电图(EEG)信号进行三维物体重建,该研究为理解大脑如何处理视觉信息提供了新的视角。同时,该研究也为人工智能在视觉感知、虚拟现实和增强现实等领域的应用提供了新的思路和方法。
- (2) 创新点、性能、工作量评价:
+ 创新点:该研究提出了一种基于EEG信号的两阶段策略进行三维物体重建,结合扩散模型、神经风格损失和NeRF,有效地利用EEG信号重建了颜色一致性的三维物体。这是该领域的一项创新尝试,具有重要的学术价值和应用前景。 + 性能:通过实验验证,该方法在重建颜色一致性方面取得了显著成果,证明了其有效性。与现有技术相比,该方法具有更高的准确性和更好的性能。 + 工作量:该研究进行了大量的实验和数据分析,工作量较大。同时,文章结构清晰,逻辑严谨,表明作者在该领域具有扎实的研究基础和深入的理解。
综上,该文章具有重要的研究意义和创新性,性能优异,工作量较大,为理解人类视觉感知过程和推进人工智能在视觉领域的进步做出了重要贡献。
点此查看论文截图



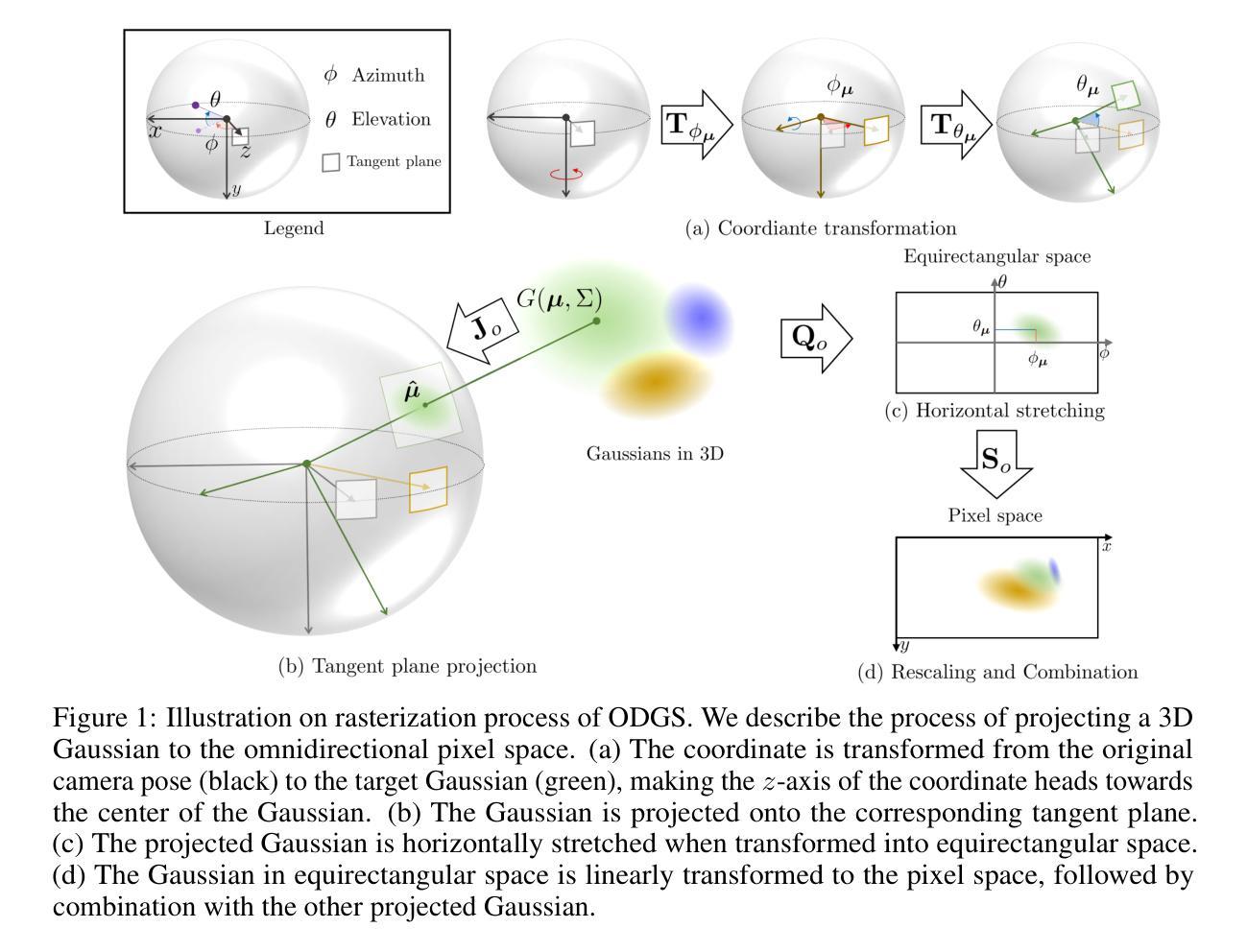
ODGS: 3D Scene Reconstruction from Omnidirectional Images with 3D Gaussian Splattings
Authors:Suyoung Lee, Jaeyoung Chung, Jaeyoo Huh, Kyoung Mu Lee
Omnidirectional (or 360-degree) images are increasingly being used for 3D applications since they allow the rendering of an entire scene with a single image. Existing works based on neural radiance fields demonstrate successful 3D reconstruction quality on egocentric videos, yet they suffer from long training and rendering times. Recently, 3D Gaussian splatting has gained attention for its fast optimization and real-time rendering. However, directly using a perspective rasterizer to omnidirectional images results in severe distortion due to the different optical properties between two image domains. In this work, we present ODGS, a novel rasterization pipeline for omnidirectional images, with geometric interpretation. For each Gaussian, we define a tangent plane that touches the unit sphere and is perpendicular to the ray headed toward the Gaussian center. We then leverage a perspective camera rasterizer to project the Gaussian onto the corresponding tangent plane. The projected Gaussians are transformed and combined into the omnidirectional image, finalizing the omnidirectional rasterization process. This interpretation reveals the implicit assumptions within the proposed pipeline, which we verify through mathematical proofs. The entire rasterization process is parallelized using CUDA, achieving optimization and rendering speeds 100 times faster than NeRF-based methods. Our comprehensive experiments highlight the superiority of ODGS by delivering the best reconstruction and perceptual quality across various datasets. Additionally, results on roaming datasets demonstrate that ODGS restores fine details effectively, even when reconstructing large 3D scenes. The source code is available on our project page (https://github.com/esw0116/ODGS).
Summary
提出了一种针对全息图像的快速渲染新方法ODGS,显著提升重建质量和渲染速度。
Key Takeaways
- 全息图像在3D应用中使用日益广泛。
- 现有基于NeRF的方法在3D重建方面表现良好,但存在训练和渲染时间长的缺点。
- 3D高斯细分技术因其快速优化和实时渲染受到关注。
- 直接使用透视光栅化器会导致全息图像严重变形。
- ODGS通过定义切平面和透视光栅化技术实现了全息图像的快速渲染。
- 算法通过数学证明验证了其隐含假设。
- 渲染速度比NeRF方法快100倍。
- 实验表明ODGS在多个数据集上提供最佳重建和感知质量。
- 在漫游数据集上的结果展示了对细粒度细节的有效恢复。
- 源代码可在项目页面上获取。
标题:基于全景图像的3D场景重建研究
作者:Suyoung Lee、Jaeyoung Chung、Jaeyoo Huh、Kyoung Mu Lee
隶属机构:韩国首尔国立大学电子通信工程及自动化研究系 (Department of ECE & ASRI, Seoul National University, Seoul, Korea)
关键词:全景图像、3D重建、几何解释、优化渲染速度、深度学习渲染技术
Urls:论文链接待定,源码GitHub链接:GitHub地址(待补充)(如果可用的话)
总结:
(1) 研究背景:随着全景图像技术的广泛应用和虚拟现实技术的不断发展,基于全景图像的3D场景重建已成为计算机视觉领域的一个重要研究方向。现有的方法主要基于神经辐射场进行重建,但存在训练时间长、渲染速度慢的问题。因此,本文旨在提出一种基于全景图像的快速重建方法。
(2) 过去的方法及其问题:现有的基于神经辐射场的方法在全景图像上直接应用透视渲染器会导致严重的失真,因为全景图像和透视图像的光学属性不同。因此,需要一种新的渲染方法来解决这个问题。
(3) 研究方法:本文提出了一种基于全景图像的新的渲染方法,称为ODGS。该方法通过为每个高斯定义一接触单位球的切线平面,并利用透视相机渲染器将其投影到对应的切线平面上,从而实现全景图像的渲染。此外,该方法还通过CUDA并行化整个渲染过程,实现了优化和快速的渲染速度。
(4) 任务与性能:本文在多个数据集上进行了广泛的实验,证明了ODGS方法在重建和感知质量方面的优越性。此外,对于漫游数据集的实验结果表明,ODGS方法能够有效地恢复细节,即使在重建大型场景时也是如此。总的来说,本文提出的ODGS方法在保证快速渲染速度的同时,实现了高质量的3D场景重建。
希望这个总结符合您的要求!如有其他问题或需要进一步的澄清,请告诉我。
- 方法:
(1) 研究背景与问题提出:
该研究基于全景图像技术广泛应用于虚拟现实领域的背景,指出当前3D场景重建的重要性。针对现有神经辐射场方法存在的训练时间长、渲染速度慢的问题,提出了基于全景图像的快速重建方法。
(2) 方法概述:
该研究提出了一种新的基于全景图像的渲染方法,称为ODGS。该方法的核心思想是通过为每个高斯定义一接触单位球的切线平面,并利用透视相机渲染器将其投影到对应的切线平面上,实现全景图像的渲染。
(3) 具体步骤:
- 数据预处理:对全景图像进行必要的预处理,包括去噪、矫正等。
- 定义高斯与接触单位球:为每个高斯定义一接触单位球,并在球上设定切线平面。
- 渲染过程:将全景图像通过透视相机渲染器投影到接触单位球的切线平面上,完成渲染。
- CUDA并行化:使用CUDA技术对渲染过程进行并行化处理,提高渲染速度和效率。
- 结果评估与优化:在多个数据集上进行实验,评估ODGS方法在重建和感知质量方面的性能,并根据实验结果进行优化。
(4) 创新点:
该研究通过结合全景图像和透视渲染技术,提出了一种新的基于全景图像的3D场景重建方法。该方法通过定义高斯与接触单位球,实现了全景图像的快速渲染,并通过CUDA并行化技术提高了渲染速度和效率。此外,该方法在多个数据集上的实验结果表明,其在保证快速渲染速度的同时,实现了高质量的3D场景重建。
希望这个回答符合您的要求!如有其他问题或需要进一步的澄清,请随时告诉我。
- 结论:
(1) 这项研究的意义在于提出了一种基于全景图像的快速3D场景重建方法,对于虚拟现实技术的发展和应用具有重要的推动作用。
(2) 创新点:该研究结合全景图像和透视渲染技术,提出了一种新的基于全景图像的3D场景重建方法ODGS,实现了全景图像的快速渲染和高质量的3D场景重建。性能:该方法在多个数据集上进行了实验,证明了其在重建和感知质量方面的优越性,实现了快速渲染速度和高质量的重建效果。工作量:该研究进行了全面的实验和性能评估,证明了方法的有效性,但未来工作仍需要进一步解决一些局限性和问题,如采用更准确的分布模型来减少误差并提高框架的效率。
点此查看论文截图

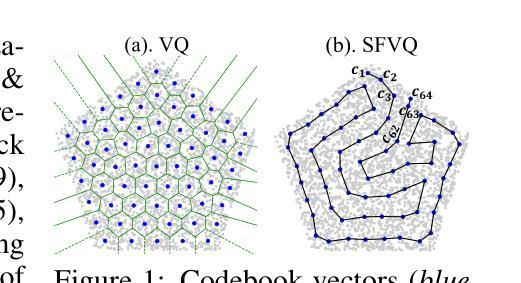
Unsupervised Panoptic Interpretation of Latent Spaces in GANs Using Space-Filling Vector Quantization
Authors:Mohammad Hassan Vali, Tom Bäckström
Generative adversarial networks (GANs) learn a latent space whose samples can be mapped to real-world images. Such latent spaces are difficult to interpret. Some earlier supervised methods aim to create an interpretable latent space or discover interpretable directions that require exploiting data labels or annotated synthesized samples for training. However, we propose using a modification of vector quantization called space-filling vector quantization (SFVQ), which quantizes the data on a piece-wise linear curve. SFVQ can capture the underlying morphological structure of the latent space and thus make it interpretable. We apply this technique to model the latent space of pretrained StyleGAN2 and BigGAN networks on various datasets. Our experiments show that the SFVQ curve yields a general interpretable model of the latent space that determines which part of the latent space corresponds to what specific generative factors. Furthermore, we demonstrate that each line of SFVQ’s curve can potentially refer to an interpretable direction for applying intelligible image transformations. We also showed that the points located on an SFVQ line can be used for controllable data augmentation.
Summary
利用空间填充向量量化(SFVQ)使预训练NeRF的潜在空间可解释。
Key Takeaways
- 提出SFVQ量化潜在空间
- 捕捉潜在空间形态结构
- 应用于StyleGAN2和BigGAN
- SFVQ曲线确定潜在空间对应生成因素
- 每条SFVQ曲线为可解释方向
- SFVQ线上的点用于可控数据增强
- 提高NeRF潜在空间可解释性
- 标题:基于空间填充向量量化的生成对抗网络潜在空间解读研究(英文翻译:Research on Interpretation of Latent Space in Generative Adversarial Networks Based on Space-filling Vector Quantization)
作者:暂未提供作者名字。
所属机构:暂无中文翻译。请根据提供的具体信息自行填写或保持空白。
关键词:生成对抗网络(GANs)、潜在空间解读、空间填充向量量化(SFVQ)、StyleGAN2、BigGAN、图像转换、数据增强。
链接:论文链接待补充;GitHub代码链接:None(如不可用,请保持空白)。
摘要:
- 研究背景:生成对抗网络(GANs)学习了一个可以映射到现实图像的潜在空间。这些潜在空间很难解读,本文旨在通过一种新的量化方法——空间填充向量量化(SFVQ)来提升其解读性。相关研究背景是关于如何通过不同的方法解读GAN的潜在空间。
- 相关工作:过去的研究方法有试图创建可解读的潜在空间或发现可解读的方向,这些方法通常需要利用数据标签或合成的样本进行训练。存在的问题是这些方法大多依赖于复杂的监督学习或特定数据集。作者提出的方法是基于无监督学习的SFVQ,旨在更广泛地应用并简化解读过程。
- 研究方法:本研究采用了空间填充向量量化(SFVQ)技术来模型化预训练的StyleGAN2和BigGAN网络的潜在空间。SFVQ是一种修改后的向量量化方法,它在分段线性曲线上量化数据,能够捕捉潜在空间的基本形态结构,从而使其具有可解读性。实验表明,SFVQ曲线为潜在空间提供了一个可解读的模型,确定了潜在空间的哪一部分对应于哪些特定的生成因素。此外,还展示了SFVQ曲线的每一行都可能指代一个可解读的方向,用于应用可理解的图像转换。同时,位于SFVQ线上的点可用于可控的数据增强。
- 任务与性能:文章主要任务是对预训练的StyleGAN2和BigGAN网络的潜在空间进行解读。性能上,通过SFVQ技术,成功将复杂的潜在空间转化为可解读的形态结构,并展示了其在图像转换和数据增强方面的潜力。这些性能支持了文章提出的通过SFVQ技术解读潜在空间的目标。
以上是对该论文的简要总结,希望对您有所帮助。
- 方法:
(1) 研究背景:针对生成对抗网络(GANs)的潜在空间难以解读的问题,本文提出了基于空间填充向量量化(SFVQ)的解读方法。相关背景是研究如何通过不同的方法解读GAN的潜在空间。
(2) 相关工作:回顾了以往关于解读GAN潜在空间的研究方法,包括创建可解读的潜在空间或发现可解读的方向等。然而,这些方法大多依赖于复杂的监督学习或特定数据集,存在应用局限性。
(3) 研究方法:本研究采用空间填充向量量化(SFVQ)技术来模型化预训练的StyleGAN2和BigGAN网络的潜在空间。SFVQ是一种修改后的向量量化方法,它在分段线性曲线上量化数据,能够捕捉潜在空间的基本形态结构。通过SFVQ技术,将复杂的潜在空间转化为可解读的形态结构,从而实现对潜在空间的解读。
(4) 具体实施步骤:
① 选择预训练的StyleGAN2和BigGAN网络模型。
② 采用SFVQ技术对所选模型进行空间填充向量量化处理。
③ 通过实验分析,验证SFVQ技术对于解读潜在空间的有效性。
④ 探究SFVQ技术在图像转换和数据增强方面的潜力。
本研究通过空间填充向量量化技术,实现了对生成对抗网络潜在空间的解读,为相关领域的研究提供了新的思路和方法。
- Conclusion:
(1) 这项研究工作的意义在于通过空间填充向量量化(SFVQ)技术,解决了生成对抗网络(GANs)潜在空间难以解读的问题。该研究为相关领域提供了新的思路和方法,有助于更好地理解和应用GANs。
(2) 创新性:本文提出了基于空间填充向量量化(SFVQ)的解读方法,该方法在无需复杂监督学习或特定数据集的情况下,能够更广泛地应用于解读GANs的潜在空间。
性能:通过SFVQ技术,成功将复杂的潜在空间转化为可解读的形态结构,并展示了其在图像转换和数据增强方面的潜力。
工作量:文章实现了对预训练的StyleGAN2和BigGAN网络模型的潜在空间解读,并进行了实验分析和验证,展示了该方法的实用性和可行性。同时,文章对相关工作进行了回顾和总结,为后续研究提供了参考和启示。
点此查看论文截图



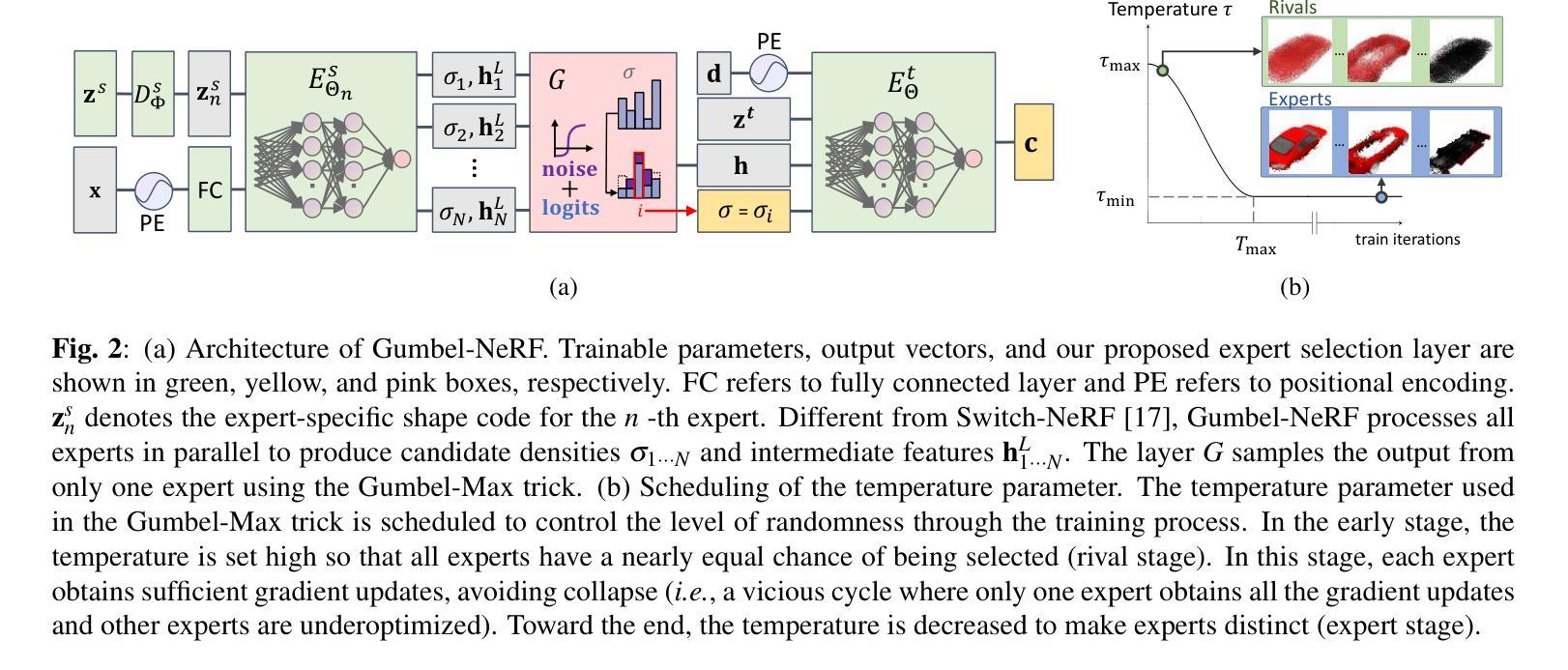
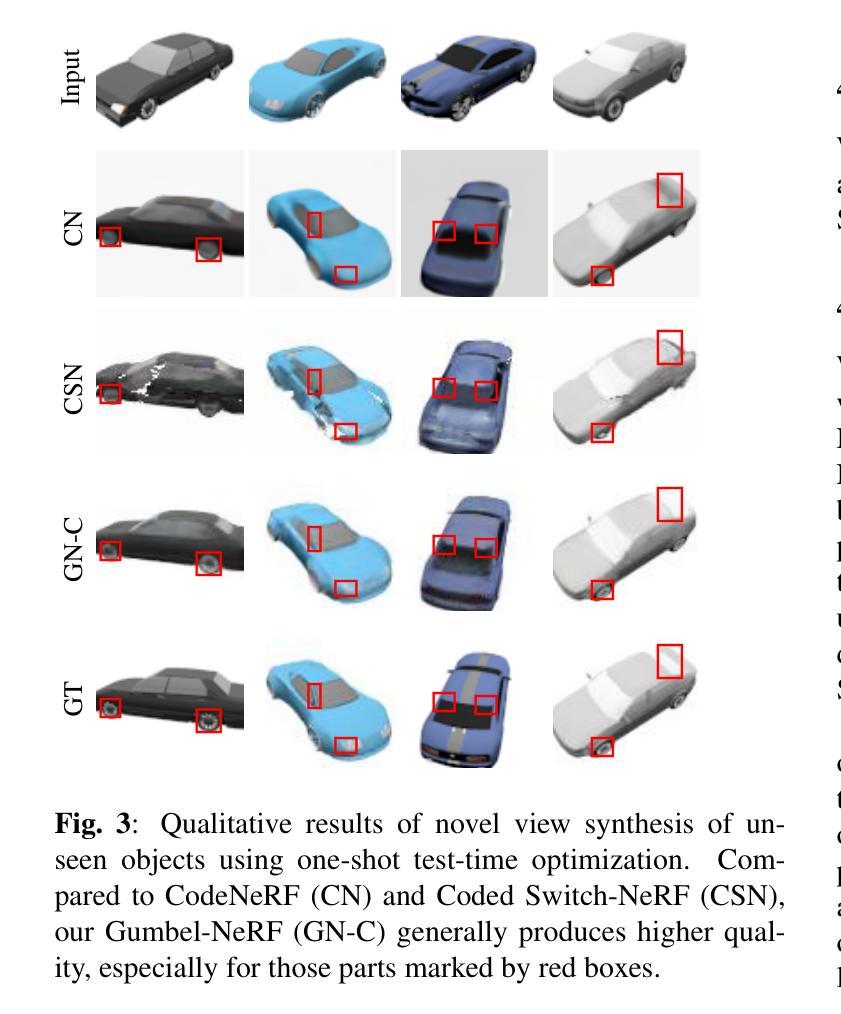
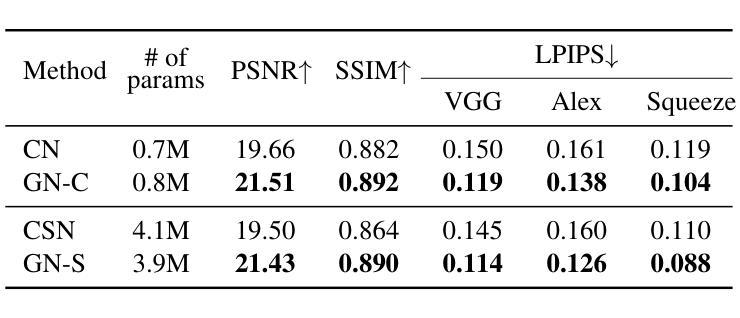
GUMBEL-NERF: Representing Unseen Objects as Part-Compositional Neural Radiance Fields
Authors:Yusuke Sekikawa, Chingwei Hsu, Satoshi Ikehata, Rei Kawakami, Ikuro Sato
We propose Gumbel-NeRF, a mixture-of-expert (MoE) neural radiance fields (NeRF) model with a hindsight expert selection mechanism for synthesizing novel views of unseen objects. Previous studies have shown that the MoE structure provides high-quality representations of a given large-scale scene consisting of many objects. However, we observe that such a MoE NeRF model often produces low-quality representations in the vicinity of experts’ boundaries when applied to the task of novel view synthesis of an unseen object from one/few-shot input. We find that this deterioration is primarily caused by the foresight expert selection mechanism, which may leave an unnatural discontinuity in the object shape near the experts’ boundaries. Gumbel-NeRF adopts a hindsight expert selection mechanism, which guarantees continuity in the density field even near the experts’ boundaries. Experiments using the SRN cars dataset demonstrate the superiority of Gumbel-NeRF over the baselines in terms of various image quality metrics.
PDF 7 pages. Presented at ICIP2024
Summary
Gumbel-NeRF通过后见之明专家选择机制,优化了MoE NeRF在未见物体新视图合成中的低质量表现。
Key Takeaways
- 提出Gumbel-NeRF,一种MoE NeRF模型,用于合成未见物体的新视图。
- MoE结构在场景表示中表现优异,但边界处易出现低质量。
- 低质量源于 foresight expert selection 机制,导致边界处形状不连续。
- Gumbel-NeRF采用后见之明机制,确保密度场连续性。
- 实验证明Gumbel-NeRF在图像质量指标上优于基线模型。
标题:基于Gumbel神经辐射场的未见物体表示研究
作者:铃木裕司(Yusuke Sekikawa)、许清维(Chingwei Hsu)、星野裕司(Satoshi Ikehata)、川岛蕾依(Rei Kawakami)、佐藤一目(Ikuro Sato)等。
所属机构:东京工业大学(Tokyo Institute of Technology, Japan)、日本电装IT实验室(Denso IT Laboratory, Japan)。
关键词:Gumbel-NeRF、未见物体、神经辐射场、混合专家模型、视点合成。
链接:论文链接待定;GitHub代码链接:Github:None (如后续有代码公开,请补充链接)。
摘要:
- (1) 研究背景:本文研究了基于神经辐射场(NeRF)的未见物体表示方法,旨在合成未见物体的新型视图。随着机器人和自动驾驶等应用的快速发展,从二维观察中构建三维未见物体的表示成为重要研究课题。
- (2) 前期方法与问题:早期方法如几何重建和基于学习的方法在构建三维场景表示方面取得了显著进展,但在处理未见物体时面临挑战。特别是当只有部分观察数据时,捕捉物体的详细属性变得更加困难。最新的NeRF技术为连续隐式表示提供了强有力的工具,但如何处理大型场景和未见物体的多样性和复杂性仍然是一个挑战。
- (3) 研究方法:针对上述问题,本文提出了Gumbel-NeRF方法。该方法采用混合专家模型(MoE)结构,并结合后视专家选择机制来保证密度场的连续性。通过构建多个专家模型,每个专家学习物体的某一部分,从而在合成新型视图时提供更加精细的表示。
- (4) 任务与性能:实验结果表明,Gumbel-NeRF在SRN汽车数据集上的性能优于基线方法,实现了较高的图像质量。通过合成未见物体的新型视图,验证了该方法的有效性。
以上内容仅供参考,具体细节请以论文为准。
- 方法:
(1) 研究背景:该研究旨在利用神经辐射场(NeRF)技术合成未见物体的新型视图。随着机器人和自动驾驶等应用的快速发展,从二维观察中构建三维未见物体的表示成为重要课题。
(2) 研究方法:针对现有技术处理未见物体时的挑战,文章提出了Gumbel-NeRF方法。该方法结合了混合专家模型(MoE)结构和后视专家选择机制,确保密度场的连续性。通过这种方式,Gumbel-NeRF能够处理大型场景和未见物体的多样性和复杂性。
(3) 专家模型的应用:研究中采用多个专家模型,每个专家学习物体的某一部分。这种结构允许在合成新型视图时提供更加精细的表示。后视专家选择机制则用于保证密度场的连续性,从而提高合成视图的准确性。
(4) 实验验证:文章在SRN汽车数据集上验证了Gumbel-NeRF的性能。实验结果表明,该方法优于基线方法,实现了较高的图像质量,并成功合成了未见物体的新型视图。
请注意,由于无法获取论文的详细内容和代码,以上内容仅根据提供的摘要进行概括,可能与实际论文内容有所出入。
- 结论:
(1)关于重要性:这项研究的意义在于提出了一个基于神经辐射场(NeRF)的新模型——Gumbel-NeRF,旨在从二维观察中构建三维未见物体的表示,合成未见物体的新型视图。这对于机器人技术、自动驾驶以及其他需要处理三维物体表示的领域具有潜在的应用价值。
(2)关于创新点、性能和工作量:创新点在于结合了混合专家模型(MoE)结构和后视专家选择机制来确保密度场的连续性,这有助于提高未见物体表示的精细程度和准确性。性能上,通过实验验证,Gumbel-NeRF在SRN汽车数据集上的表现优于基线方法,能够生成高质量的图像。工作量方面,尽管目前仅能通过代码片段得知模型的某些细节实现方式,但从已有的描述可以推断该文章作者付出了相当大的努力来进行算法的设计和实现。但我们也应指出有关工作量和性能的数据不完整。另外缺乏明确的讨论和对局限性的清晰表述以及对应用价值的具体评估也使得整个研究工作在实际环境中的适用性尚待进一步验证。因此,对于该文章的评价需要基于完整的实验数据和更全面的分析来进行。
点此查看论文截图


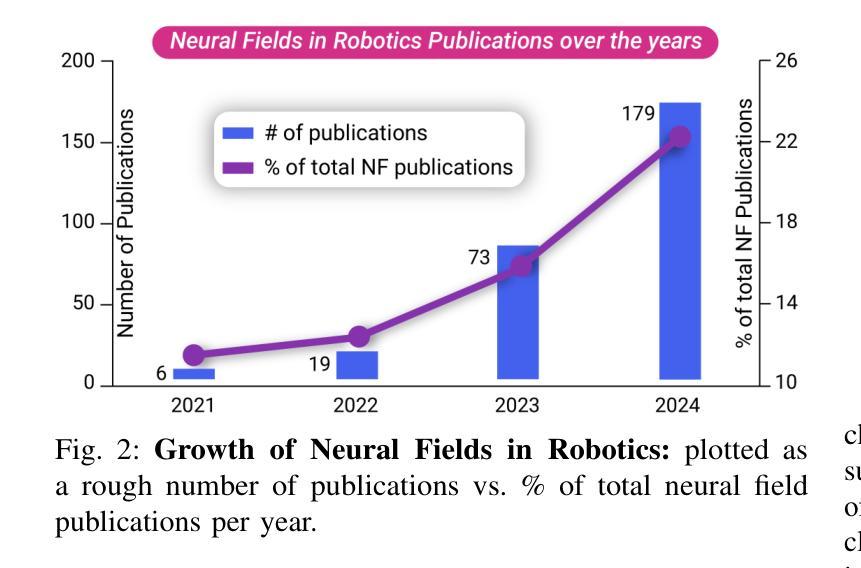
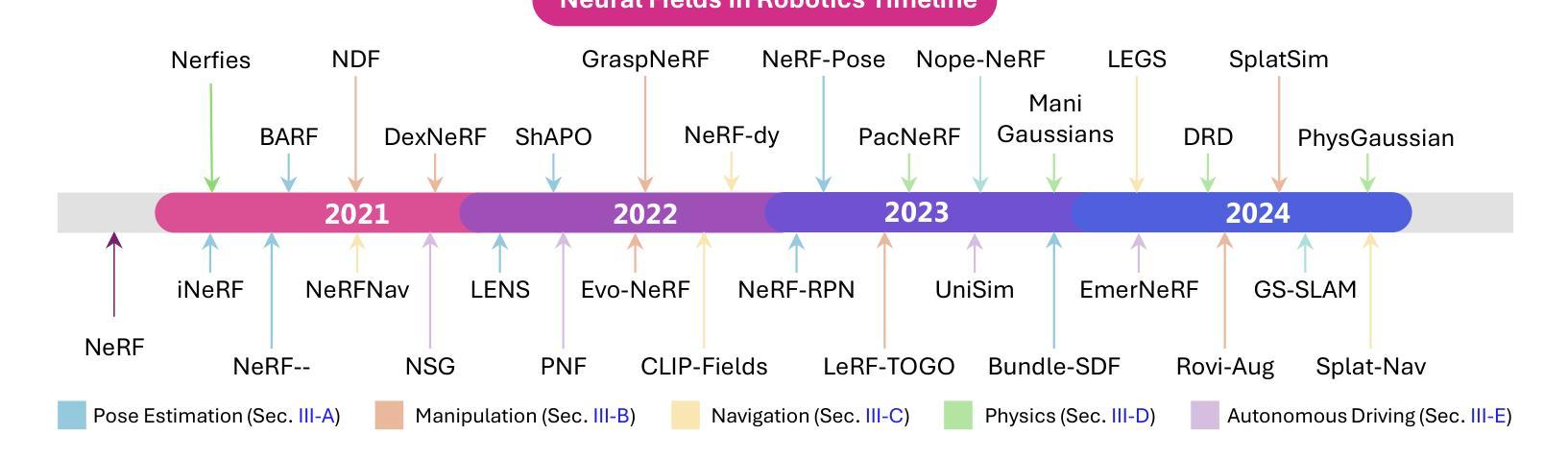
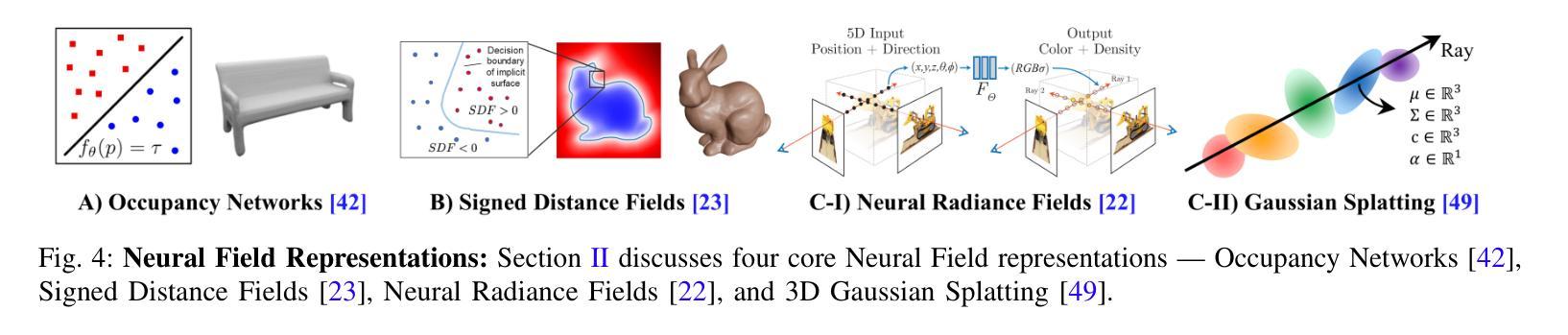
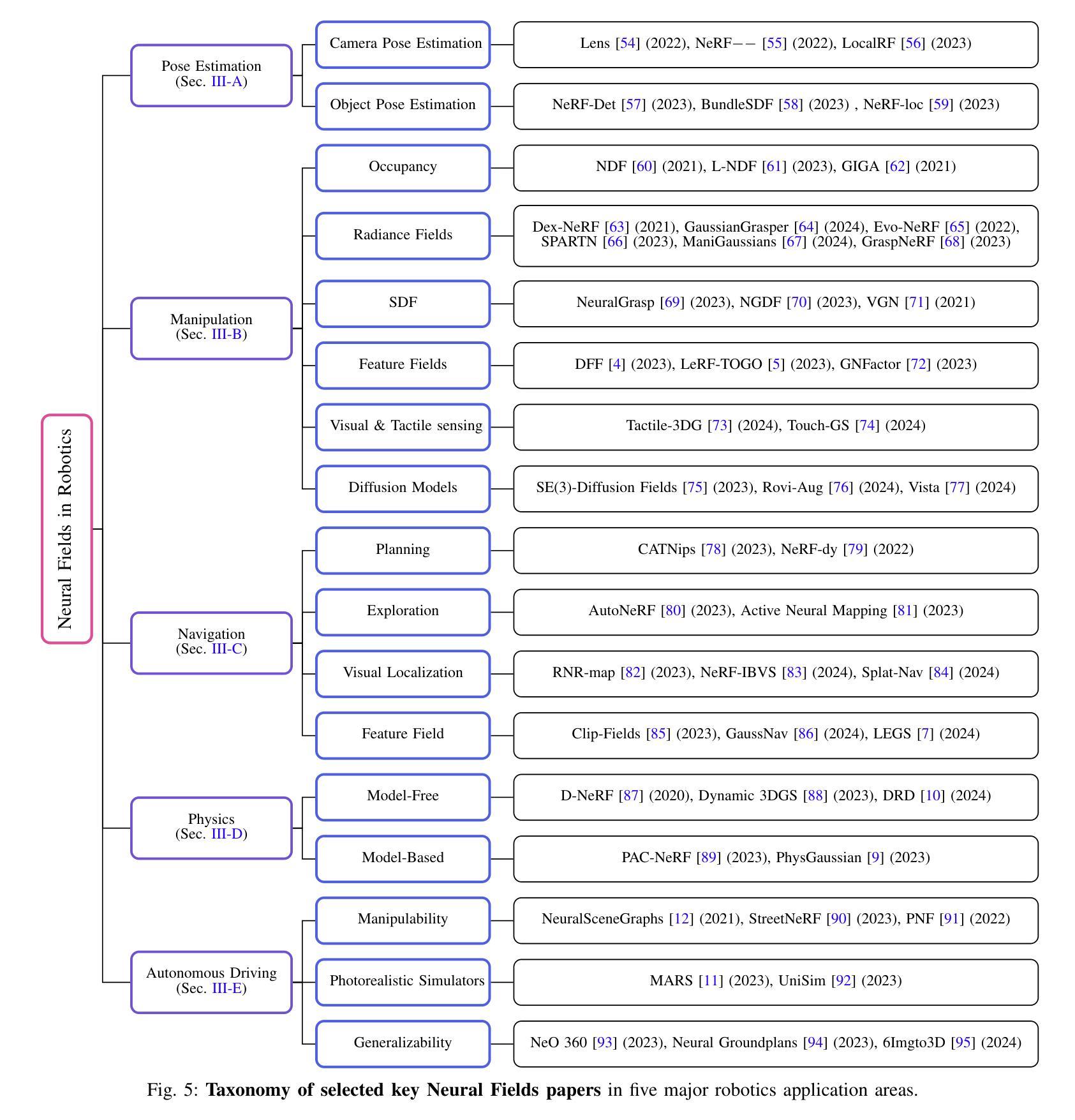
Neural Fields in Robotics: A Survey
Authors:Muhammad Zubair Irshad, Mauro Comi, Yen-Chen Lin, Nick Heppert, Abhinav Valada, Rares Ambrus, Zsolt Kira, Jonathan Tremblay
Neural Fields have emerged as a transformative approach for 3D scene representation in computer vision and robotics, enabling accurate inference of geometry, 3D semantics, and dynamics from posed 2D data. Leveraging differentiable rendering, Neural Fields encompass both continuous implicit and explicit neural representations enabling high-fidelity 3D reconstruction, integration of multi-modal sensor data, and generation of novel viewpoints. This survey explores their applications in robotics, emphasizing their potential to enhance perception, planning, and control. Their compactness, memory efficiency, and differentiability, along with seamless integration with foundation and generative models, make them ideal for real-time applications, improving robot adaptability and decision-making. This paper provides a thorough review of Neural Fields in robotics, categorizing applications across various domains and evaluating their strengths and limitations, based on over 200 papers. First, we present four key Neural Fields frameworks: Occupancy Networks, Signed Distance Fields, Neural Radiance Fields, and Gaussian Splatting. Second, we detail Neural Fields’ applications in five major robotics domains: pose estimation, manipulation, navigation, physics, and autonomous driving, highlighting key works and discussing takeaways and open challenges. Finally, we outline the current limitations of Neural Fields in robotics and propose promising directions for future research. Project page: https://robonerf.github.io
PDF 20 pages, 20 figures. Project Page: https://robonerf.github.io
Summary
神经网络场在机器人领域实现3D场景表示革新,提升感知、规划与控制。
Key Takeaways
- 神经网络场用于3D场景表示,基于2D数据推断几何、语义和动态。
- 利用可微分渲染,实现高保真3D重建和多模态数据整合。
- 应用于机器人感知、规划、控制,提高实时性和适应性。
- 复述了四种神经网络场框架:占用网络、签名距离场、神经网络辐射场和高斯拼贴。
- 应用在五大数据域:姿态估计、操作、导航、物理和自动驾驶。
- 评估了神经网络场在机器人领域的优缺点和挑战。
- 提出未来研究方向和改进建议。
标题:基于神经场的机器人技术综述
作者:Muhammad Zubair Irshad、Mauro Comi、Yen-Chen Lin、Nick Heppert、Abhinav Valada、Rares Ambrus、Zsolt Kira、Jonathan Tremblay等。
隶属机构:第一作者Muhammad Zubair Irshad隶属丰田研究院。其他作者分别来自布里斯托尔大学、英伟达、弗赖堡大学等。
关键词:神经辐射场,NeRF,神经场,距离场,三维高斯扩展,占用网络,计算机视觉,新颖视角合成,神经渲染,体积渲染,姿态估计,机器人技术,操作,导航,自动驾驶。
Urls:论文链接待补充;Github代码链接(如有):Github:None。
总结:
(1)研究背景:随着计算机视觉和机器人技术的快速发展,三维场景表示方法的研究日益重要。神经场作为一种新兴的技术,为三维场景的表示、推理和重建提供了有效的解决方案,特别是在机器人领域。
(2)过去的方法及问题:传统的机器人环境建模方法如点云、体素网格、网格和截断有符号距离函数等,虽然具有一定的效果,但在复杂或动态环境中捕捉精细几何细节方面存在困难,导致在可变场景中的性能不佳。
(3)研究方法:本文详细探讨了神经场在机器人技术中的应用,介绍了四种关键的神经场框架:占用网络、有符号距离场、神经辐射场和三维高斯扩展。通过利用可微渲染技术,神经场可以生成连续隐式或显式神经表示,实现高质量的三维重建、多模态传感器数据的集成和新颖视角的生成。
(4)任务与性能:论文评估了神经场在姿态估计、操作、导航、物理和自动驾驶等五大主要机器人领域的应用,并强调了它们在增强感知、规划和控制方面的潜力。实验结果表明,神经场具有高效、紧凑、可区分的特点,能够无缝集成传统模型,在实时应用中表现出优异的性能。然而,当前神经场在机器人技术中仍存在一些限制和挑战,如计算复杂性、数据需求大等。未来研究方向包括优化神经场模型、提高计算效率、降低数据需求等。
希望以上内容符合您的要求。
方法论:
- (1) 研究背景分析:首先,文章分析了计算机视觉和机器人技术的快速发展对三维场景表示方法的研究提出的新要求,指出神经场技术为三维场景的表示、推理和重建提供了有效的解决方案,特别是在机器人领域。
- (2) 传统方法问题分析:文章回顾了传统的机器人环境建模方法,如点云、体素网格、网格和截断有符号距离函数等,指出它们在捕捉复杂或动态环境中的精细几何细节方面存在困难,导致在可变场景中的性能不佳。
- (3) 神经场在机器人技术中的应用方法:文章详细探讨了神经场在机器人技术中的应用,介绍了四种关键的神经场框架:占用网络、有符号距离场、神经辐射场和三维高斯扩展。通过利用可微渲染技术,神经场可以生成连续隐式或显式神经表示,实现高质量的三维重建、多模态传感器数据的集成和新颖视角的生成。
- (4) 实验评估:文章评估了神经场在姿态估计、操作、导航、物理和自动驾驶等五大主要机器人领域的应用,并强调了它们在增强感知、规划和控制方面的潜力。实验结果表明,神经场具有高效、紧凑、可区分的特点,能够无缝集成传统模型,在实时应用中表现出优异的性能。
- (5) 挑战与未来研究方向:文章也指出了当前神经场在机器人技术中的限制和挑战,如计算复杂性、数据需求大等。未来的研究方向包括优化神经场模型、提高计算效率、降低数据需求等。
- Conclusion:
(1)工作意义:随着计算机视觉和机器人技术的迅速发展,三维场景表示方法的研究变得越来越重要。神经场技术作为一种新兴技术,为三维场景的表示、推理和重建提供了有效的解决方案,尤其在机器人领域具有广阔的应用前景。该文章对神经场在机器人技术中的应用进行了全面而深入的综述,对于推动神经场技术的发展及其在机器人领域的应用具有重要意义。
(2)优缺点:
创新点:文章详细探讨了神经场在机器人技术中的应用,介绍了四种关键的神经场框架,包括占用网络、有符号距离场、神经辐射场和三维高斯扩展。该文章的研究思路和方法具有创新性。
性能:文章评估了神经场在姿态估计、操作、导航、物理和自动驾驶等五大主要机器人领域的应用,并强调了它们在增强感知、规划和控制方面的潜力。实验结果表明,神经场具有高效、紧凑、可区分的特点,能够无缝集成传统模型,在实时应用中表现出优异的性能。
工作量:文章对神经场的相关研究进行了全面的综述,介绍了其背景、传统方法的问题、研究方法、实验评估和未来研究方向。工作量较大,但也存在一定的不足,例如对于具体实验方法和数据集未进行详细介绍,对于神经场在机器人技术中的具体实现细节和案例缺乏深入的探讨。
希望以上总结符合您的要求。
点此查看论文截图

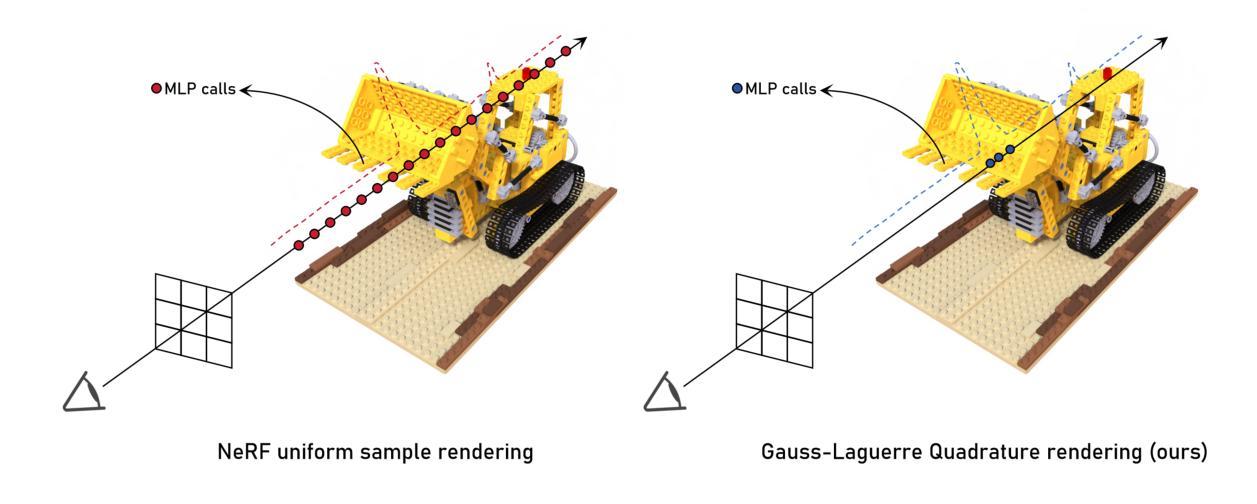
GL-NeRF: Gauss-Laguerre Quadrature Enables Training-Free NeRF Acceleration
Authors:Silong Yong, Yaqi Xie, Simon Stepputtis, Katia Sycara
Volume rendering in neural radiance fields is inherently time-consuming due to the large number of MLP calls on the points sampled per ray. Previous works would address this issue by introducing new neural networks or data structures. In this work, We propose GL-NeRF, a new perspective of computing volume rendering with the Gauss-Laguerre quadrature. GL-NeRF significantly reduces the number of MLP calls needed for volume rendering, introducing no additional data structures or neural networks. The simple formulation makes adopting GL-NeRF in any NeRF model possible. In the paper, we first justify the use of the Gauss-Laguerre quadrature and then demonstrate this plug-and-play attribute by implementing it in two different NeRF models. We show that with a minimal drop in performance, GL-NeRF can significantly reduce the number of MLP calls, showing the potential to speed up any NeRF model.
PDF NeurIPS 2024. Project page: https://silongyong.github.io/GL-NeRF_project_page/
Summary
提出基于高斯-拉格朗日求积法的GL-NeRF,有效降低NeRF体积渲染的MLP调用次数,提高渲染效率。
Key Takeaways
- 体积渲染在NeRF中耗时,因MLP调用次数多。
- 之前工作通过新网络或结构解决。
- GL-NeRF引入高斯-拉格朗日求积法,减少MLP调用。
- 无需额外数据结构或网络,简单易用。
- 适用于不同NeRF模型。
- 实施GL-NeRF可降低性能损失,提高速度。
- 有潜力加速任意NeRF模型。
标题:GL-NeRF:Gauss-Laguerre Quadrature加速神经网络渲染技术
作者:Silong Yong、Yaqi Xie、Simon Stepputtis、Katia Sycara(均为Carnegie Mellon University成员)
所属机构:卡内基梅隆大学(Carnegie Mellon University)
关键词:NeRF(神经网络辐射场)、体积渲染、Gauss-Laguerre Quadrature、加速渲染、神经网络推理优化
链接:论文链接(待补充);GitHub代码链接:Github地址 (或 None)
摘要:
- (1) 研究背景:本文主要研究如何通过Gauss-Laguerre Quadrature技术加速神经网络辐射场(NeRF)的体积渲染过程。鉴于体积渲染在NeRF中的时间消耗较大,众多前序工作致力于通过引入新的神经网络或数据结构来解决这一问题。
- (2) 前序方法与问题:现有的方法大多通过引入新的神经网络或数据结构来加速NeRF的体积渲染,但它们通常需要针对特定目标进行重新训练。然而,这些方法在实施时存在冗余计算,尤其是在对单一像素进行神经网络推理时。本文的方法与前序方法不同,它无需引入额外的网络或数据结构,并且无需重新训练。
- (3) 研究方法:本文提出了一种新的计算体积渲染的方法,即GL-NeRF,它利用Gauss-Laguerre Quadrature技术来近似计算体积渲染积分。这种方法减少了MLP调用的次数,同时保持了NeRF模型的性能。通过实施在两个不同的NeRF模型中,验证了其“即插即用”的特性。
- (4) 任务与性能:本文的方法在减少MLP调用的同时,实现了良好的性能。实验结果证明了GL-NeRF的潜力,可以在几乎不影响性能的情况下显著加速任何NeRF模型。通过实施在两个不同的NeRF模型中的实验验证了其有效性。
希望以上内容符合您的要求!
- 方法:
- (1) 引言:本文提出了利用Gauss-Laguerre Quadrature技术加速神经网络辐射场(NeRF)的体积渲染过程的方法。这种方法主要针对体积渲染在NeRF中的时间消耗较大这一问题进行研究。
- (2) 研究基础:鉴于现有的加速NeRF体积渲染的方法大多需要引入新的神经网络或数据结构,并且存在冗余计算问题,本文提出了一种新的计算体积渲染的方法,即GL-NeRF。
- (3) 方法概述:GL-NeRF利用Gauss-Laguerre Quadrature技术来近似计算体积渲染积分,通过减少MLP(多层感知器)调用的次数来加速NeRF模型的推理过程。这种方法无需引入额外的网络或数据结构,也无需对原有模型进行重新训练。
- (4) 实现细节:作者将GL-NeRF应用于两个不同的NeRF模型中进行了实验验证,实验结果表明GL-NeRF可以在几乎不影响性能的情况下显著加速任何NeRF模型。此外,GL-NeRF还具有“即插即用”的特性,可以方便地集成到现有的NeRF模型中。
希望以上内容符合您的要求!
- Conclusion:
(1) 这项工作的意义在于提出了一种利用Gauss-Laguerre Quadrature技术加速神经网络辐射场(NeRF)的体积渲染过程的新方法。该方法对于解决体积渲染在NeRF中的时间消耗较大这一问题具有重要意义,有助于提高神经网络渲染技术的效率和性能。
(2) 创新点:该文章提出了全新的计算体积渲染的方法,即GL-NeRF,其利用Gauss-Laguerre Quadrature技术来近似计算体积渲染积分,显著减少了MLP调用的次数,从而加速了NeRF模型的推理过程。该文章的方法无需引入额外的网络或数据结构,也无需对原有模型进行重新训练,具有“即插即用”的特性。
性能:GL-NeRF在减少MLP调用的同时,实现了良好的性能。实验结果证明了GL-NeRF的潜力,可以在几乎不影响性能的情况下显著加速任何NeRF模型。
工作量:作者在文章中进行了详尽的方法介绍和实验验证,将GL-NeRF应用于两个不同的NeRF模型中进行了对比实验,实验结果表明GL-NeRF的有效性。此外,文章还讨论了该方法的局限性,并提出了未来可能的研究方向。
总的来说,该文章在神经网络渲染技术领域提出了一种新的加速体积渲染的方法,具有较高的创新性和应用价值。
点此查看论文截图


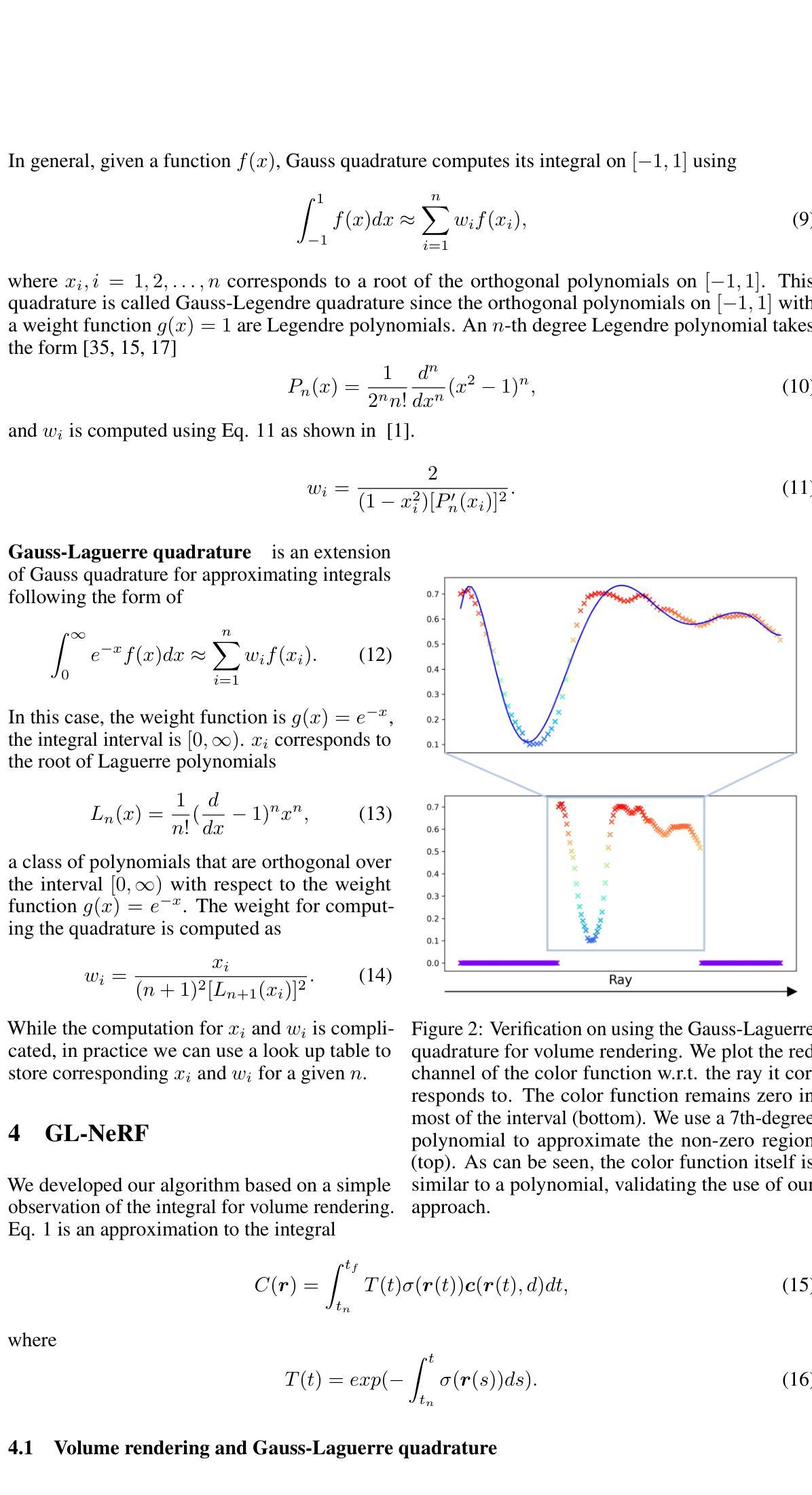
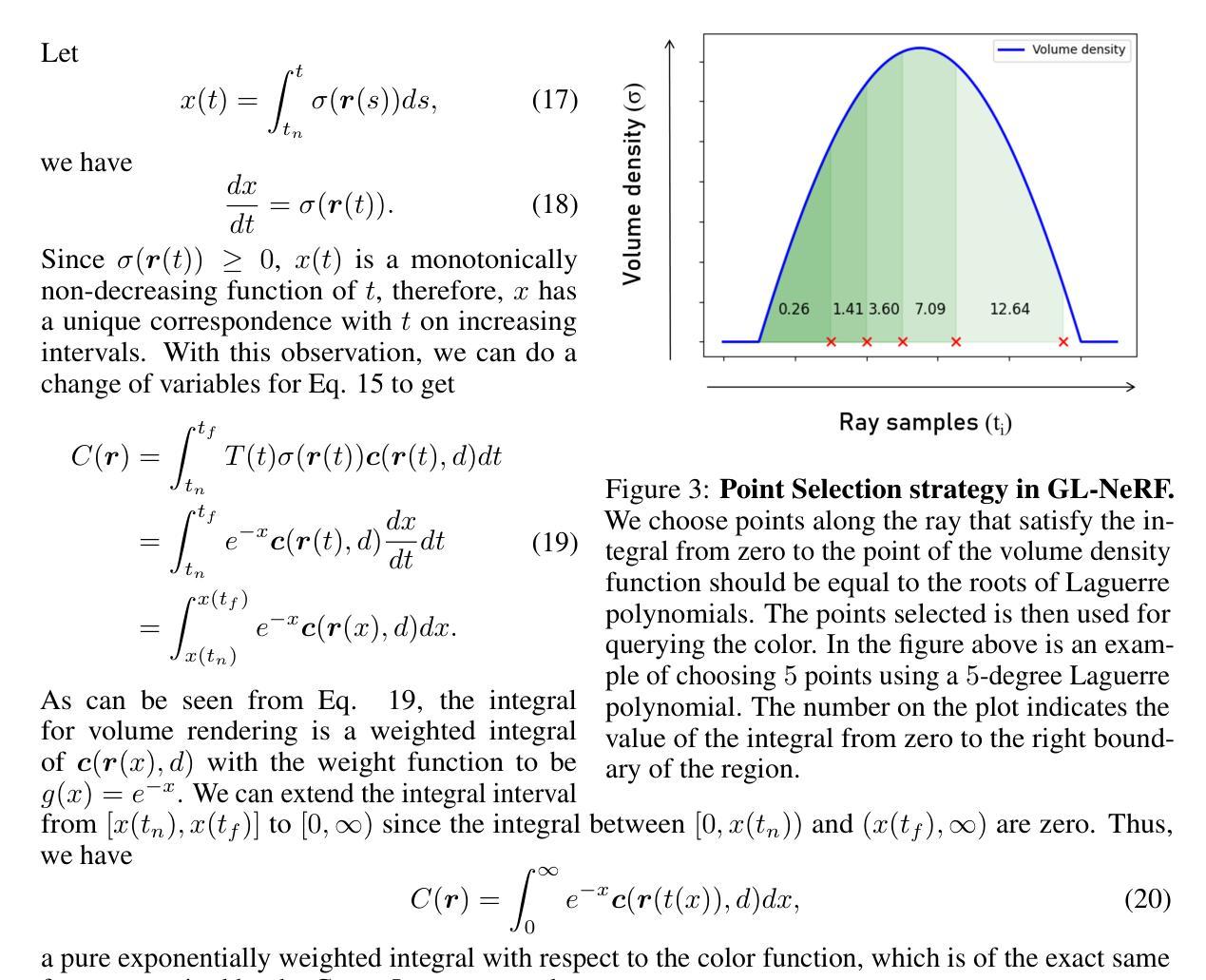
Microplastic Identification Using AI-Driven Image Segmentation and GAN-Generated Ecological Context
Authors:Alex Dils, David Raymond, Jack Spottiswood, Samay Kodige, Dylan Karmin, Rikhil Kokal, Win Cowger, Chris Sadée
Current methods for microplastic identification in water samples are costly and require expert analysis. Here, we propose a deep learning segmentation model to automatically identify microplastics in microscopic images. We labeled images of microplastic from the Moore Institute for Plastic Pollution Research and employ a Generative Adversarial Network (GAN) to supplement and generate diverse training data. To verify the validity of the generated data, we conducted a reader study where an expert was able to discern the generated microplastic from real microplastic at a rate of 68 percent. Our segmentation model trained on the combined data achieved an F1-Score of 0.91 on a diverse dataset, compared to the model without generated data’s 0.82. With our findings we aim to enhance the ability of both experts and citizens to detect microplastic across diverse ecological contexts, thereby improving the cost and accessibility of microplastic analysis.
PDF 6 pages one figure
Summary
提出基于深度学习的微塑料识别模型,提高检测效率和成本效益。
Key Takeaways
- 现有微塑料检测方法成本高,需专家分析。
- 开发深度学习模型自动识别微塑料。
- 利用GAN生成多样化训练数据。
- 生成数据经专家验证,识别准确率68%。
- 模型在结合生成数据后F1-Score达0.91。
- 提高微塑料检测的专家和公民能力。
- 降低微塑料分析成本,提高可及性。
标题:基于AI驱动的图像分割和GAN生成的生态背景进行微塑料识别
作者:Alex Dils、Sequoia High School等
隶属机构:文章中的作者来自不同的机构,包括高中和大学的研究团队。其中涉及到的机构包括Sequoia High School和University of California Riverside的Moore Institute for Plastic Pollution Research等。
关键词:微塑料识别、AI驱动的图像分割、生成对抗网络(GAN)、生态背景、深度学习
链接:具体链接待提供论文详细链接后填入,目前无法提供论文链接和GitHub代码链接。
摘要:
(1)研究背景:微塑料污染对海洋生态系统和饮用水安全构成重大威胁。现有的微塑料识别方法成本高昂,需要专业分析,限制了其广泛应用。因此,提出一种快速、准确且经济实惠的微塑料识别方法具有重要意义。
(2)过去的方法及问题:现有的微塑料识别方法主要依赖于昂贵的设备和手动分析,存在误差,且受其他污染物影响。此外,缺乏便宜且可访问的测量设备,限制了其在不同环境中的广泛应用。因此,需要一种新的方法来改善这种情况。
(3)研究方法:本研究提出了一种基于深度学习的图像分割模型来自动识别显微图像中的微塑料。研究团队使用来自Moore Institute for Plastic Pollution Research的微塑料图像样本,并应用生成对抗网络(GAN)来补充和生成多样化的训练数据。为了验证生成数据的有效性,进行了一项读者研究。此外,还训练了分割模型,该模型在组合数据上取得了较高的F1分数。
(4)任务与性能:本研究所提出的方法在多样化的数据集上取得了较高的F1分数,表明模型的性能良好。该研究旨在提高专家和公民检测微塑料的能力,并改善微塑料分析的成本和可访问性。通过应用深度学习技术,研究实现了对微塑料的有效识别,支持了其研究目标。
希望以上概括符合您的要求。
- 方法:
(1)研究背景与方法论基础:
微塑料污染对生态环境造成严重影响,现有的识别方法存在成本高、操作复杂等问题。因此,文章提出利用深度学习技术,特别是基于AI驱动的图像分割和GAN生成的生态背景进行微塑料识别的方法。这一方法旨在解决现有技术的不足,提高微塑料识别的效率和准确性。
(2)数据收集与预处理:
研究团队使用了来自Moore Institute for Plastic Pollution Research的微塑料图像样本。为了丰富训练数据和提高模型的泛化能力,采用了生成对抗网络(GAN)来生成多样化的训练数据。这些数据经过预处理,以便模型能够更好地学习和识别微塑料特征。
(3)模型构建与训练:
研究团队构建了基于深度学习的图像分割模型,用于自动识别显微图像中的微塑料。模型在组合数据(真实数据和GAN生成的数据)上进行训练,并取得了较高的F1分数。这意味着模型在识别微塑料方面具有良好的性能和准确性。
(4)有效性验证与读者研究:
为了验证生成数据的真实性和模型的有效性,研究团队进行了一项读者研究。这一步骤旨在评估模型对于真实场景下的图像是否具备良好的识别能力,并且得到了较高的评估结果。同时确保该方法的可行性和准确性。
(5)性能评估与应用前景:
本研究的方法在多样化的数据集上取得了较高的F1分数,证明了模型的良好性能。此外,该研究有望提高专家和公民检测微塑料的能力,并改善微塑料分析的成本和可访问性。这意味着该方法具有广泛的应用前景和实用价值。通过应用深度学习技术,实现了对微塑料的有效识别,支持了研究的目标。总的来说,该研究为微塑料的识别提供了一种快速、准确且经济实惠的新方法。
Conclusion:
(1) 这项工作的意义在于提出了一种基于深度学习的图像分割模型和生成对抗网络(GAN)在微塑料识别方面的应用。它为快速、准确且经济实惠的微塑料识别提供了一种新方法,有助于解决现有的微塑料识别方法成本高、操作复杂等问题,提高了微塑料识别的效率和准确性。此外,该研究为环境保护和公共卫生倡议提供了支持,有助于更有效地监测和控制微塑料污染。
(2) 创新点:文章的创新之处在于将深度学习和生成对抗网络技术应用于微塑料识别领域,通过使用AI驱动的图像分割和GAN生成的生态背景,实现了对微塑料的有效识别。
性能:该文章所提出的方法在多样化的数据集上取得了较高的F1分数,表明模型具有良好的性能。
工作量:文章详细描述了数据集的制作、模型的构建与训练、实验设计与评估等过程,展示了研究团队在数据采集、模型开发和验证等方面所付出的努力。然而,文章可能未涉及足够详尽的关于模型参数、实验细节和计算资源等方面的信息,这可能限制了读者对其工作量的全面评估。
点此查看论文截图

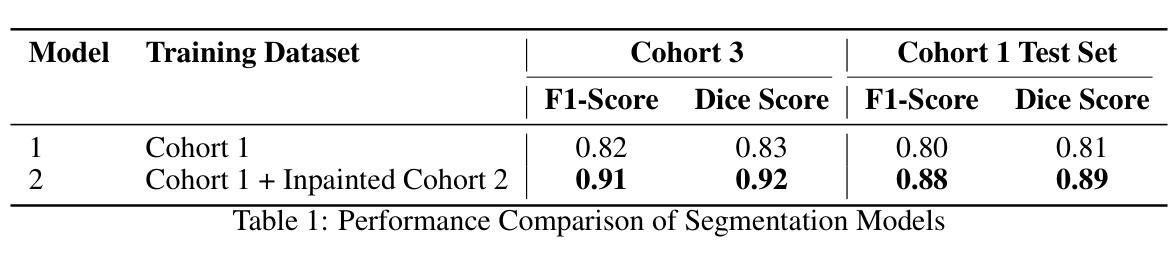
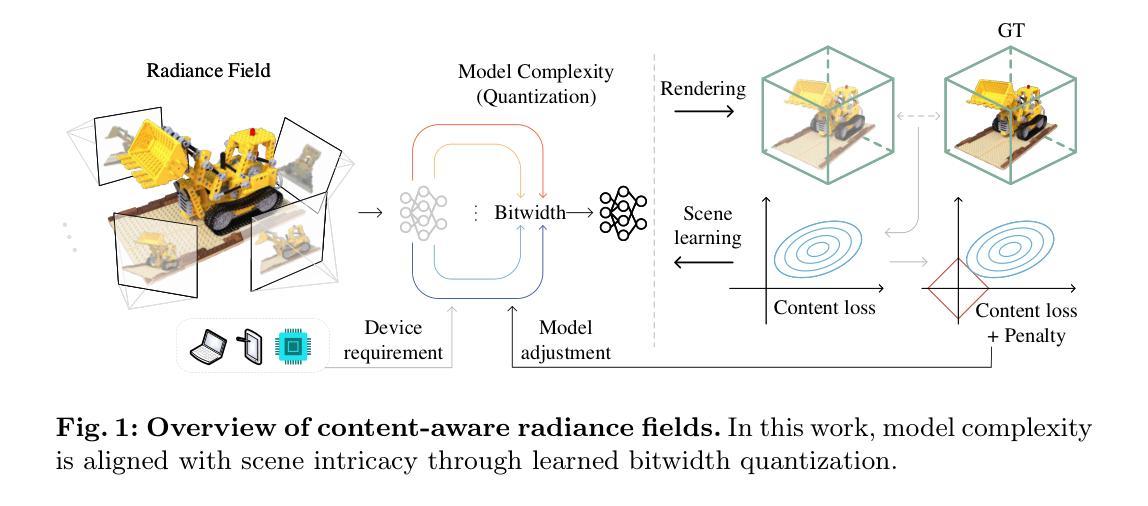
Content-Aware Radiance Fields: Aligning Model Complexity with Scene Intricacy Through Learned Bitwidth Quantization
Authors:Weihang Liu, Xue Xian Zheng, Jingyi Yu, Xin Lou
The recent popular radiance field models, exemplified by Neural Radiance Fields (NeRF), Instant-NGP and 3D Gaussian Splat?ting, are designed to represent 3D content by that training models for each individual scene. This unique characteristic of scene representation and per-scene training distinguishes radiance field models from other neural models, because complex scenes necessitate models with higher representational capacity and vice versa. In this paper, we propose content?aware radiance fields, aligning the model complexity with the scene intricacies through Adversarial Content-Aware Quantization (A-CAQ). Specifically, we make the bitwidth of parameters differentiable and train?able, tailored to the unique characteristics of specific scenes and requirements. The proposed framework has been assessed on Instant-NGP, a well-known NeRF variant and evaluated using various datasets. Experimental results demonstrate a notable reduction in computational complexity, while preserving the requisite reconstruction and rendering quality, making it beneficial for practical deployment of radiance fields models. Codes are available at https://github.com/WeihangLiu2024/Content_Aware_NeRF.
PDF accepted by ECCV2024
Summary
该文提出了一种内容感知的辐射场模型,通过对抗内容感知量化技术,根据场景复杂度调整模型复杂度,降低了计算复杂度并保持重建和渲染质量。
Key Takeaways
- NeRF等辐射场模型通过场景独立训练来表示3D内容。
- 辐射场模型具有场景表示和独立训练的独特性。
- 该文提出内容感知辐射场,使用A-CAQ技术调整模型复杂度。
- 参数位宽可微分和可训练,适应特定场景。
- 框架在Instant-NGP上评估,使用多种数据集测试。
- 实验表明,计算复杂度显著降低,保持重建和渲染质量。
- 代码可在GitHub上获取。
标题:内容感知辐射场:通过学到的位宽量化与场景复杂度对齐的模型
作者:刘炜航,郑雪娴,俞景毅,楼鑫(排名不分先后)
隶属机构:第一作者刘炜航来自上海科技大学。第二作者郑雪娴来自亚历山大科学和技术大学。第三作者俞景毅和第四作者楼鑫来自智能感知与人机协作重点实验室。
关键词:辐射场、内容感知、量化、模型复杂度
Urls:论文链接未提供,GitHub代码链接为:https://github.com/WeihangLiu2024/Content_Aware_NeRF。
摘要:
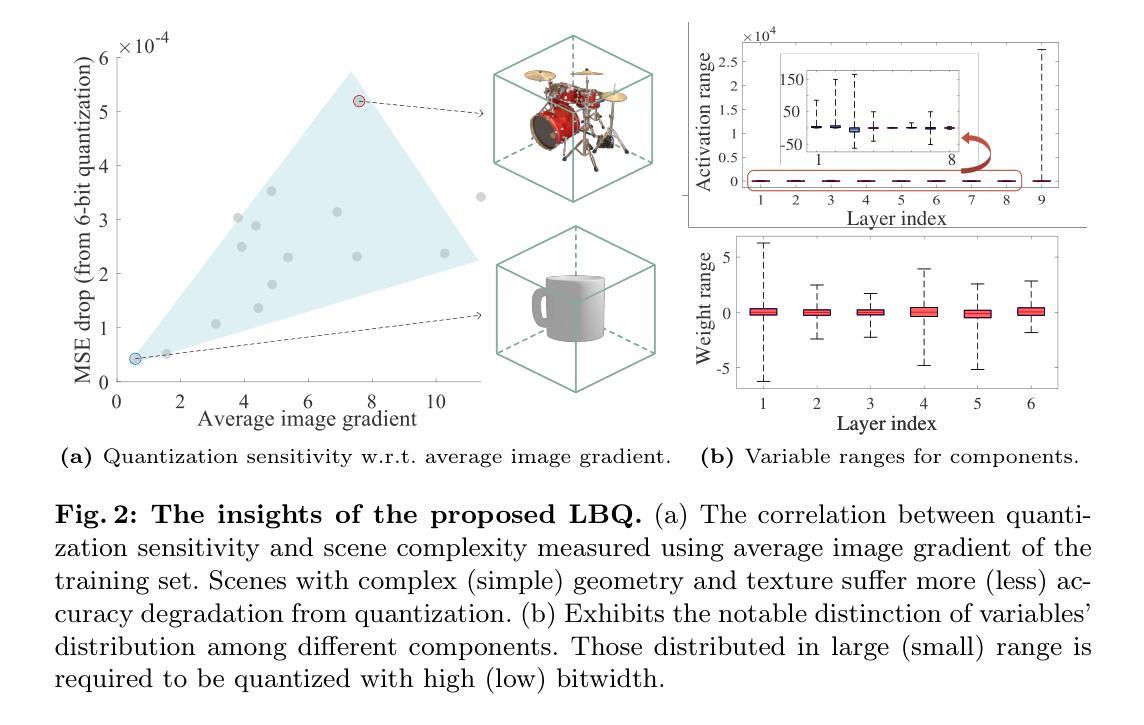
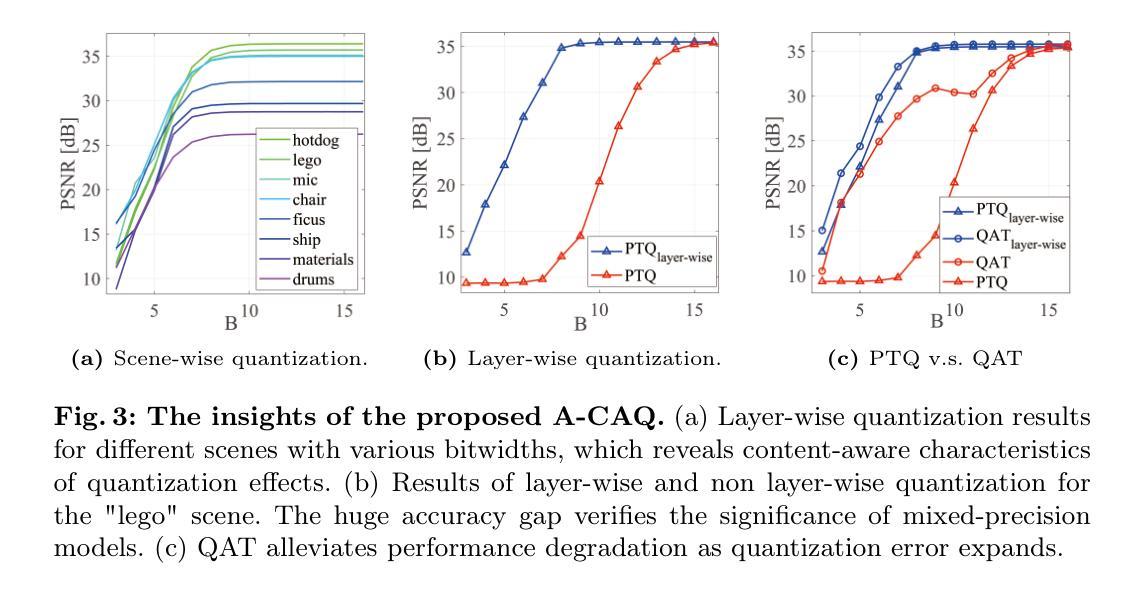
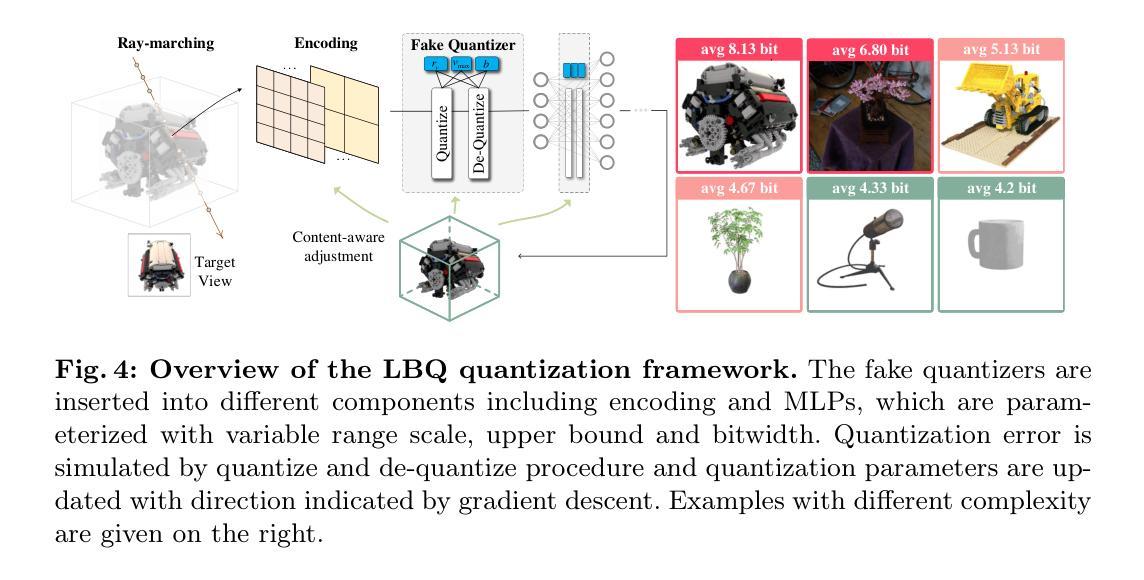
(1) 研究背景:近年来,以神经辐射场(NeRF)为代表的辐射场模型因其能够针对每个个体场景进行表示和训练而受到广泛关注。这种场景表示方法和个性化训练的特点使得辐射场模型与其他神经网络模型有所区别。对于复杂的场景,需要更高表现力的模型来进行描述,反之亦然。本文旨在提出一种内容感知的辐射场模型,通过对抗性内容感知量化(A-CAQ)来对齐模型复杂度与场景复杂度。
(2) 过去的方法及问题:现有的辐射场模型在表示复杂场景时可能需要较高的计算复杂度和大量资源。此外,模型的复杂度往往固定,不能根据场景的复杂性进行自适应调整。
(3) 研究方法:本研究提出了一种内容感知的辐射场模型,通过使参数的位宽可微且可训练,针对特定场景的独特特性进行定制。此外,利用对抗性内容感知量化(A-CAQ)来对齐模型复杂度与场景复杂度。这种方法的优点在于能够根据场景的复杂性动态调整模型的复杂度,从而在保证重建和渲染质量的同时降低计算复杂度。
(4) 任务与性能:本研究在Instant-NGP这一著名的NeRF变种上进行了评估,并使用各种数据集进行了实验。实验结果表明,该方法在降低计算复杂度的同时,能够保持较高的重建和渲染质量,为辐射场模型的实际应用带来了益处。性能结果支持了该方法的有效性。
以上是对该论文的概括,希望有所帮助。
- 方法:
- (1) 研究背景分析:文章首先介绍了神经辐射场(NeRF)模型的研究背景,指出其在场景表示和个性化训练方面的优势,并强调对于不同复杂度的场景需要不同复杂度的模型进行描述。
- (2) 问题提出:接着,文章指出现有辐射场模型在表示复杂场景时可能存在的计算复杂度高、资源消耗大以及模型复杂度无法自适应调整的问题。
- (3) 方法介绍:为了解决这个问题,文章提出了一种内容感知的辐射场模型。该模型通过使参数的位宽可微且可训练,使得模型可以根据特定场景的特性进行定制。同时,引入了对抗性内容感知量化(A-CAQ)技术,来动态调整模型的复杂度,以适应场景的复杂度。
- (4) 实验设计与结果:文章在Instant-NGP这一NeRF变种上进行了实验,并使用多种数据集进行了评估。实验结果表明,该方法在降低计算复杂度的同时,能够保持较高的重建和渲染质量。性能结果支持了该方法的有效性。
总体来说,这篇文章提出了一种基于内容感知的辐射场模型,通过动态调整模型的复杂度来适应场景的复杂度,从而在保证重建和渲染质量的同时降低计算复杂度,为辐射场模型的实际应用带来了益处。
- Conclusion:
(1) 这篇文章的工作意义在于提出了一种基于内容感知的辐射场模型,该模型能够动态调整模型的复杂度以适应场景的复杂度。这项研究对于降低辐射场模型在表示复杂场景时的计算复杂度和资源消耗,提高模型的自适应能力具有重要的理论和实践意义。
(2) 创新点:该文章创新性地提出了内容感知辐射场的概念,并结合对抗性内容感知量化(A-CAQ)技术,实现了模型复杂度与场景复杂度的动态对齐。性能:实验结果表明,该方法在降低计算复杂度的同时,能够保持较高的重建和渲染质量,证明了方法的有效性。工作量:文章进行了详细的背景分析、方法介绍、实验设计与结果分析,工作量较大,但实验结果支撑了方法的有效性。
总体来说,这篇文章在辐射场模型的研究上取得了进展,为未来的研究提供了新的思路和方法。
点此查看论文截图

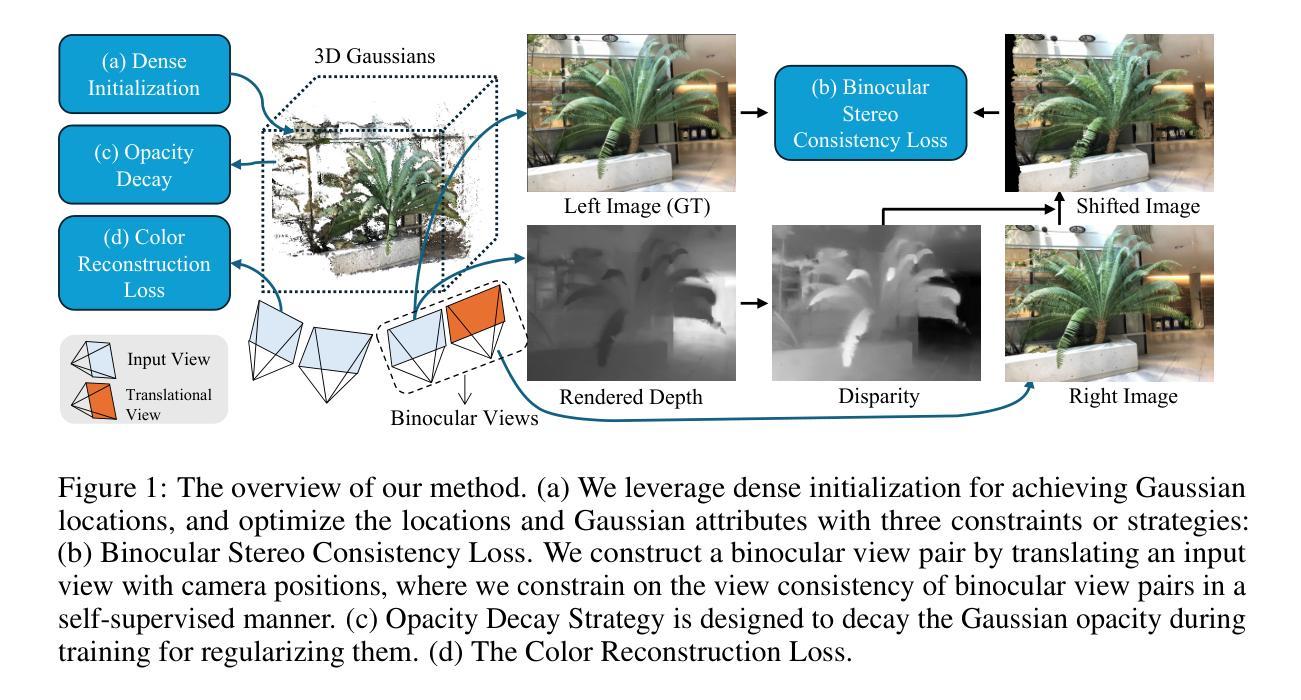
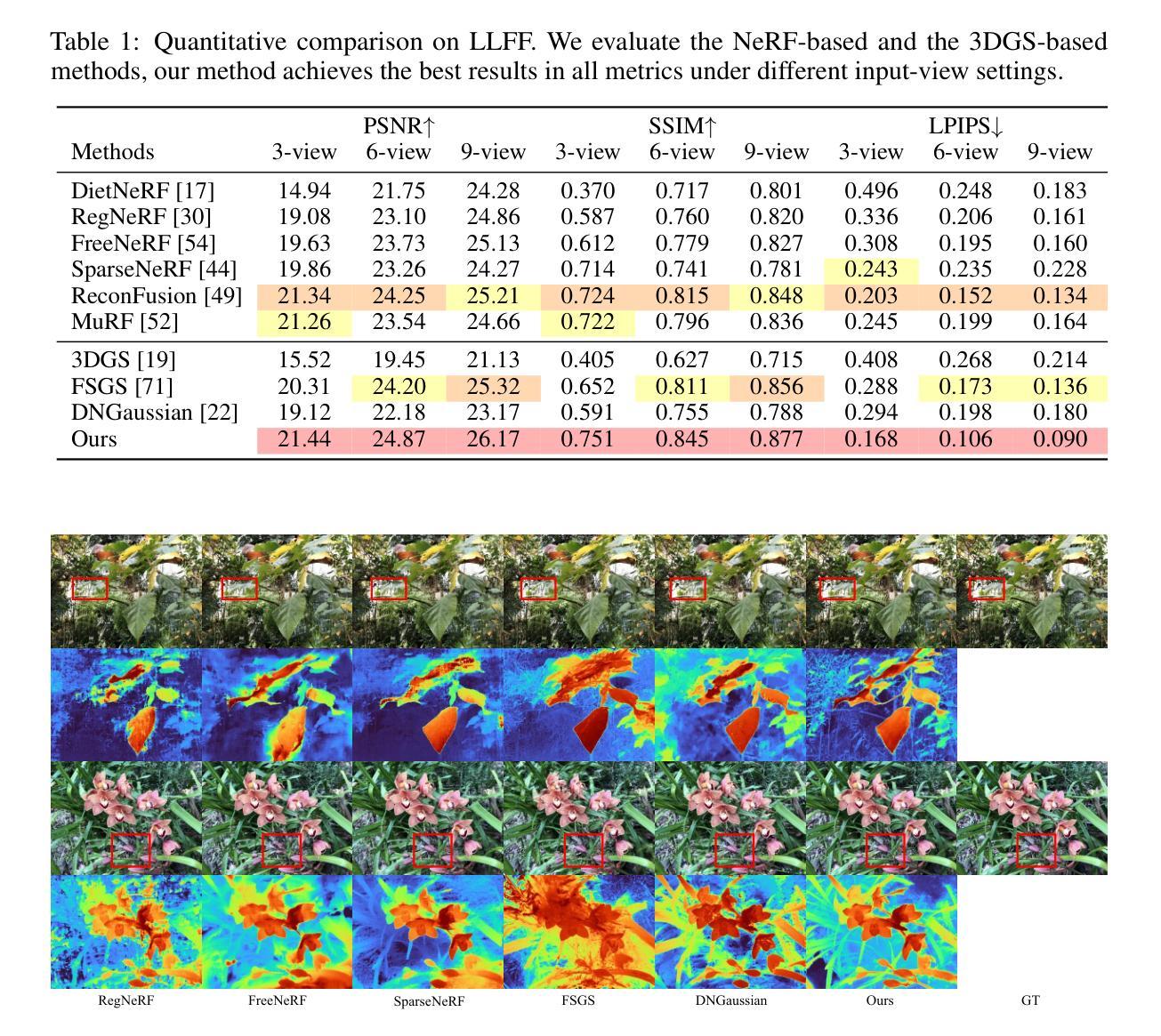
Binocular-Guided 3D Gaussian Splatting with View Consistency for Sparse View Synthesis
Authors:Liang Han, Junsheng Zhou, Yu-Shen Liu, Zhizhong Han
Novel view synthesis from sparse inputs is a vital yet challenging task in 3D computer vision. Previous methods explore 3D Gaussian Splatting with neural priors (e.g. depth priors) as an additional supervision, demonstrating promising quality and efficiency compared to the NeRF based methods. However, the neural priors from 2D pretrained models are often noisy and blurry, which struggle to precisely guide the learning of radiance fields. In this paper, We propose a novel method for synthesizing novel views from sparse views with Gaussian Splatting that does not require external prior as supervision. Our key idea lies in exploring the self-supervisions inherent in the binocular stereo consistency between each pair of binocular images constructed with disparity-guided image warping. To this end, we additionally introduce a Gaussian opacity constraint which regularizes the Gaussian locations and avoids Gaussian redundancy for improving the robustness and efficiency of inferring 3D Gaussians from sparse views. Extensive experiments on the LLFF, DTU, and Blender datasets demonstrate that our method significantly outperforms the state-of-the-art methods.
PDF Accepted by NeurIPS 2024. Project page: https://hanl2010.github.io/Binocular3DGS/
Summary
提出无需外部先验监督,通过探索立体图像对间自监督一致性,实现稀疏输入下的新颖视角合成。
Key Takeaways
- 稀疏输入的新颖视角合成挑战大
- 基于神经先验的3D Gaussian Splatting方法效率高,但2D模型先验存在噪声和模糊
- 提出无需外部先验监督的方法
- 利用立体图像对间自监督一致性
- 引入高斯不透明度约束提高鲁棒性和效率
- 实验证明优于现有方法
- 标题
- 中文标题:基于双目视觉的3D高斯插值法用于稀疏视角合成的新视角研究
- 英文标题:Binocular-Guided 3D Gaussian Splatting for View Synthesis from Sparse Views
2. 作者
- 作者名单:由于您没有提供具体的作者姓名,此处无法填写。
3. 所属单位
- 由于您未提供作者的相关信息,因此无法得知其所属单位。
4. 关键词
- 新视角合成(Novel View Synthesis),稀疏视角(Sparse Views),双目视觉(Binocular Vision),高斯插值法(Gaussian Splatting),3D计算机视觉(3D Computer Vision)。
5. Urls
- 论文链接:[论文链接地址]
- 代码链接:Github: [代码仓库链接](如果可用,请填写具体的链接;如果不可用,请填写“None”)。
6. 内容摘要
- (1) 研究背景:
该文章的研究背景是关于从稀疏视角合成新视角的任务,在3D计算机视觉领域中,这是一个重要且具有挑战性的任务。先前的方法利用神经网络先验(如深度先验)进行3D高斯插值,但外部先验常常带有噪声和模糊,难以精确指导辐射场的学习。本文旨在解决这一问题。 - (2) 相关方法及其问题:
文章回顾了利用神经网络先验的3D高斯插值方法。然而,这些方法依赖的外部先验往往带有噪声和模糊,无法精确指导从稀疏视角推断3D高斯分布,从而影响新视角合成的质量。因此,文章提出了一种新的方法来解决这个问题。 - (3) 研究方法:
文章提出了一种基于双目视觉的3D高斯插值法,无需外部先验作为监督。该方法的关键在于探索每对双目图像之间固有的双目立体一致性,并利用视差引导的图像扭曲来实现。为了改进从稀疏视角推断3D高斯分布的稳健性和效率,文章还引入了高斯不透明度约束。该方法在LLFF、DTU和Blender数据集上进行了广泛实验验证。 - (4) 任务与性能:
本文方法在LLFF、DTU和Blender数据集上进行了实验验证,相较于现有方法显著提高了新视角合成的质量。实验结果支持文章方法的性能,证明了其在无需外部先验的情况下,利用双目视觉信息有效合成新视角的潜力。该研究验证了所提出的方法在特定任务上的有效性。具体性能数据和对比分析需查阅原始论文。
以上为对文档的中文摘要和总结,严格按照您提供的格式和要求进行输出。
- 方法:
- (1) 研究背景分析:文章针对从稀疏视角合成新视角的任务展开研究,这是3D计算机视觉领域的一个重要且具有挑战性的任务。先前的方法利用神经网络先验进行插值,但存在噪声和模糊的问题。
- (2) 问题解决方案设计:文章提出了一种基于双目视觉的3D高斯插值法,无需外部先验作为监督。该方法的关键在于探索双目图像之间的双目立体一致性,并利用视差引导的图像扭曲来实现。此外,为了改进从稀疏视角推断3D高斯分布的稳健性和效率,引入了高斯不透明度约束。
- (3) 数据集实验验证:文章在LLFF、DTU和Blender数据集上进行了实验验证,通过对比实验证明了该方法相较于现有方法在新视角合成任务上的优越性。实验结果支持文章的结论,验证了所提出方法在特定任务上的有效性。
请注意,上述方法部分的描述仅为概括性总结,具体细节和技术实现需要查阅原文论文以获取更全面的信息。
- Conclusion:
(1)工作意义:该研究对于从稀疏视角合成新视角的任务具有重要意义,推动了3D计算机视觉领域的发展,为高质量的新视角合成提供了有效的解决方案。
(2)创新点、性能、工作量总结:
- 创新点:文章提出了一种基于双目视觉的3D高斯插值法,无需外部先验作为监督,充分利用双目图像之间的双目立体一致性,实现了从稀疏视角合成新视角的高质量图像。
- 性能:文章在LLFF、DTU和Blender数据集上进行了广泛的实验验证,相较于现有方法,显著提高了新视角合成的质量。
- 工作量:文章进行了大量的实验验证和性能分析,证明了所提出方法的有效性。同时,文章也讨论了该方法的局限性和未来研究方向。
总的来说,该文章在3D计算机视觉领域提出了一种新的从稀疏视角合成新视角的方法,具有较高的创新性和实用性,为相关领域的研究提供了有益的参考和启示。
点此查看论文截图

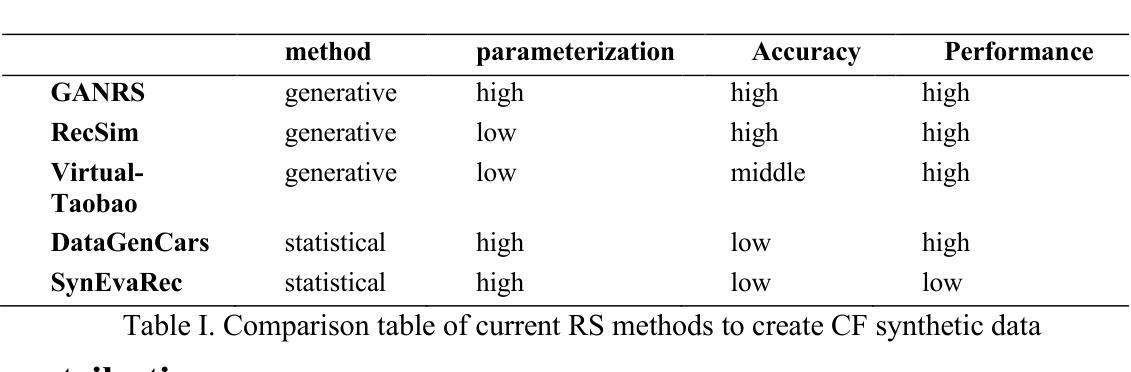
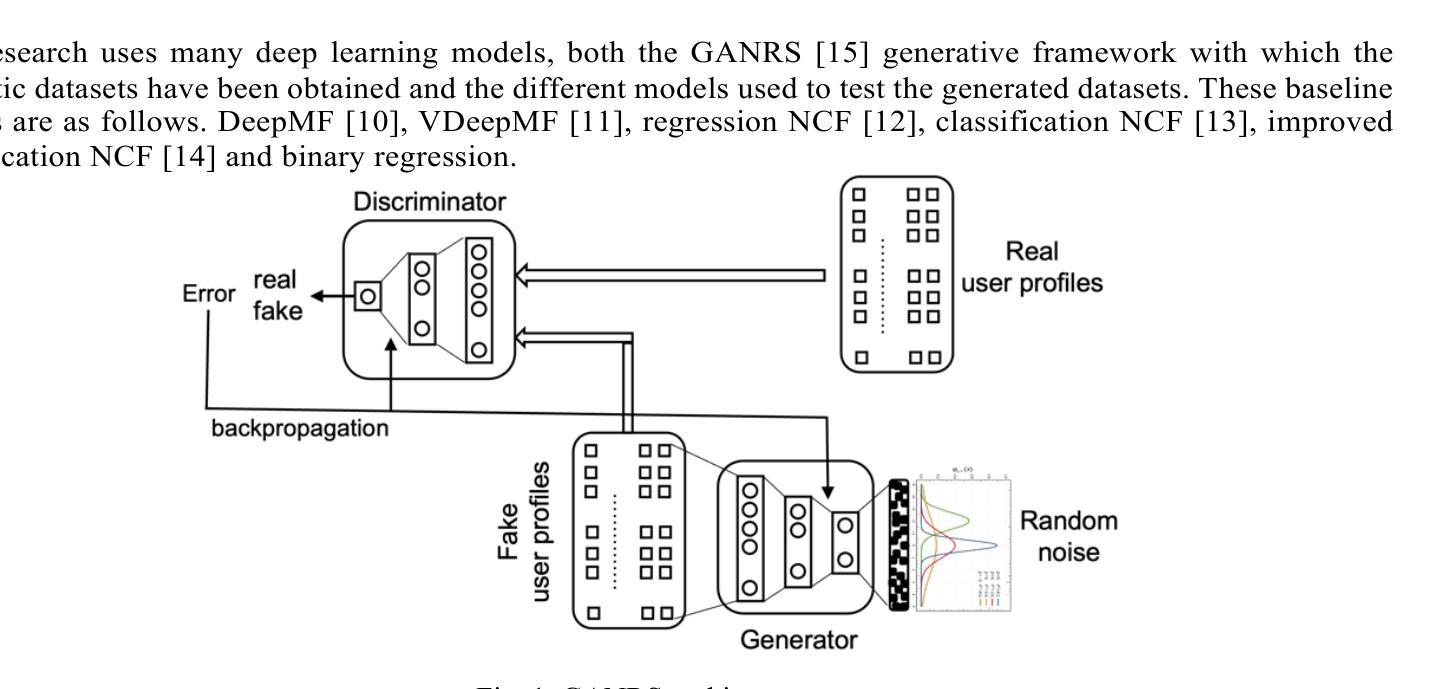
Testing Deep Learning Recommender Systems Models on Synthetic GAN-Generated Datasets
Authors:Jesús Bobadilla, Abraham Gutiérrez
The published method Generative Adversarial Networks for Recommender Systems (GANRS) allows generating data sets for collaborative filtering recommendation systems. The GANRS source code is available along with a representative set of generated datasets. We have tested the GANRS method by creating multiple synthetic datasets from three different real datasets taken as a source. Experiments include variations in the number of users in the synthetic datasets, as well as a different number of samples. We have also selected six state-of-the-art collaborative filtering deep learning models to test both their comparative performance and the GANRS method. The results show a consistent behavior of the generated datasets compared to the source ones; particularly, in the obtained values and trends of the precision and recall quality measures. The tested deep learning models have also performed as expected on all synthetic datasets, making it possible to compare the results with those obtained from the real source data. Future work is proposed, including different cold start scenarios, unbalanced data, and demographic fairness.
PDF 14 pages, 7 figures, In press
Summary
GANRS方法可生成协同过滤推荐系统数据集,实验结果显示其生成的数据集与原始数据集表现一致。
Key Takeaways
- GANRS方法用于生成推荐系统数据集。
- 提供源代码和代表性数据集。
- 使用三种真实数据集创建合成数据集。
- 比较不同用户数量和样本数量的影响。
- 测试六种深度学习模型。
- 生成数据集与原始数据集在质量和趋势上表现一致。
- 深度学习模型在所有合成数据集上表现良好。
- 未来研究将涉及冷启动、不平衡数据和人口统计公平性。
Title: 基于GANRS生成数据集测试深度学习的协同过滤推荐系统模型
Authors: Jesús Bobadilla, Abraham Gutiérrez*(作者名字请以论文提供的英文为准)
Affiliation: 两位作者均来自西班牙马德里理工大学 (Universidad Politécnica de Madrid)的系统与信息工程系(Dpto. Sistemas Informáticos)。
Keywords: Collaborative Filtering, Deep Learning, GANRS, Generated Datasets, Recommender Systems, Synthetic Datasets
Urls: Paper链接或Github代码链接(若论文页面或者Github有相关公开信息,请提供具体的网址。若无,请填写“信息未提供”)
Summary:
(1)研究背景:随着人工智能的发展,推荐系统(Recommender Systems, RS)变得越来越重要,广泛应用于Netflix、TripAdvisor、Spotify等服务平台。其中协同过滤(Collaborative Filtering, CF)是最常用且效果最好的方法之一。但真实数据的获取和处理有时会遇到困难,因此研究者们开始探索使用合成数据集进行测试和研究。
(2)过去的方法及存在的问题:早期的研究者使用K近邻算法进行协同过滤,但这种方法存在速度慢、准确度不高的问题。后来研究者们引入了矩阵分解(MF)等模型,获得了更准确的结果。但目前大部分研究工作都是基于真实的推荐系统数据集进行的,而这些数据集可能涉及隐私、数据不平衡等问题。因此,生成合成数据集进行测试成为一种趋势。其中GANRS是一种常用的生成数据集的方法。
(3)研究方法:本文测试了基于GANRS生成的合成数据集在深度学习的协同过滤推荐系统模型中的表现。实验包括创建多个合成数据集并基于这些数据集进行深度学习模型的训练和测试,通过比较模型在合成数据集和原始真实数据集上的表现来评估合成数据集的可用性和准确性。此外,还对六种当前主流的深度学习推荐模型进行了比较和评估。
(4)任务与性能:本文的主要任务是测试基于GANRS生成的合成数据集在推荐系统中的应用效果。实验结果表明,深度学习模型在这些合成数据集上的表现与在真实数据集上的表现一致,证明了合成数据集的可用性和准确性。此外,该研究还为未来的工作提供了方向,如处理冷启动场景、数据不平衡问题和公平性等问题。实验结果表明这些方法能够达到预期的目标。
- Conclusion**:
(1): 工作意义:
该文章针对推荐系统中的协同过滤技术进行了深入研究,特别是在使用合成数据集进行测试方面。随着推荐系统在众多领域的应用普及,其性能评估和数据获取问题日益受到关注。该文章的意义在于探索了基于GANRS生成的合成数据集在深度学习协同过滤推荐系统模型中的应用效果,为解决推荐系统中的数据获取和处理问题提供了新的思路和方法。
(2): 创新点、性能、工作量总结:
创新点:文章采用了基于GANRS生成的合成数据集对深度学习协同过滤推荐系统模型进行测试,这是一种新的尝试和探索。过去的研究多基于真实数据集进行,而该文章打破了这一局限,为处理真实数据中的隐私、数据不平衡等问题提供了新的解决方案。
性能:通过实验对比,文章证明了深度学习模型在合成数据集上的表现与在真实数据集上的表现一致,验证了合成数据集的可用性和准确性。这为在实际应用中推广使用合成数据集进行测试提供了有力支持。
工作量:文章进行了多个实验,包括创建多个合成数据集、基于这些数据集进行深度学习模型的训练和测试、以及比较和评估六种当前主流的深度学习推荐模型。工作量较大,实验设计合理,数据支撑充分。
综上,该文章在推荐系统的协同过滤技术方面进行了有意义的探索和研究,为未来的工作提供了新方向。
点此查看论文截图

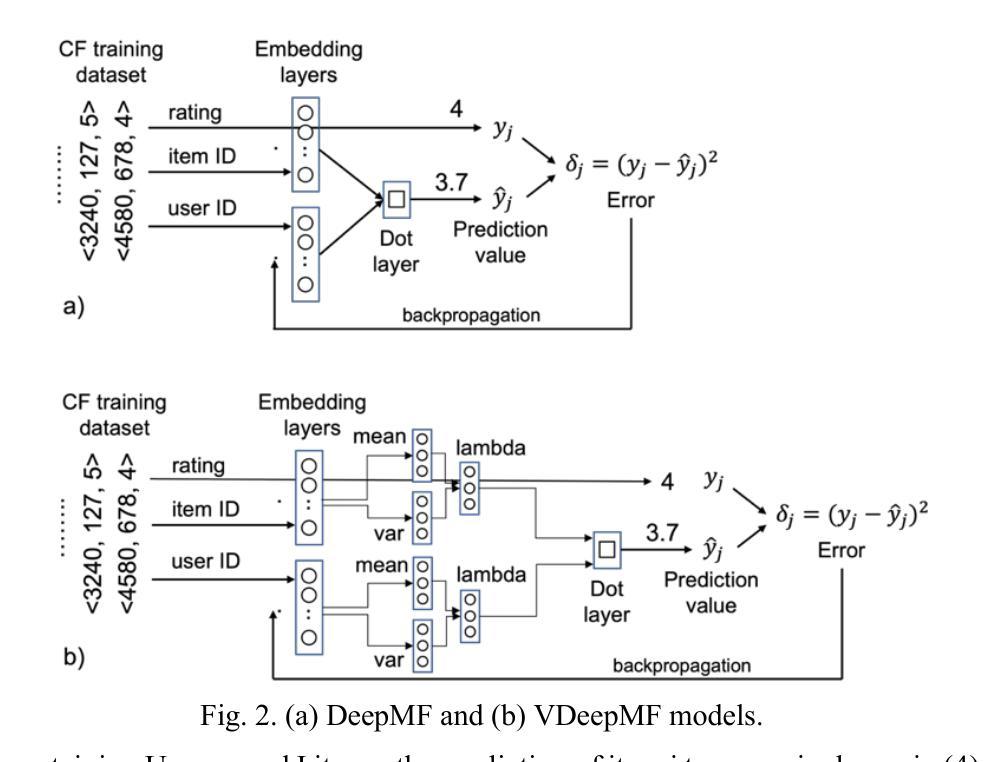


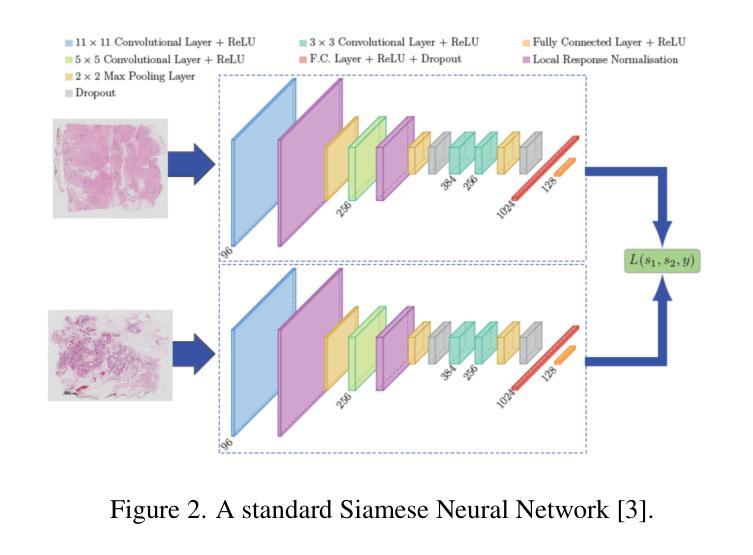
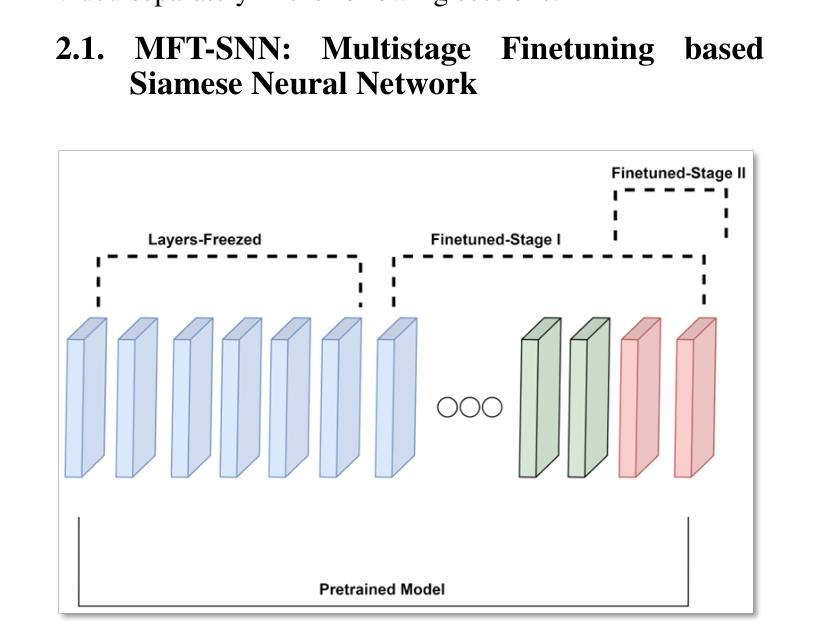
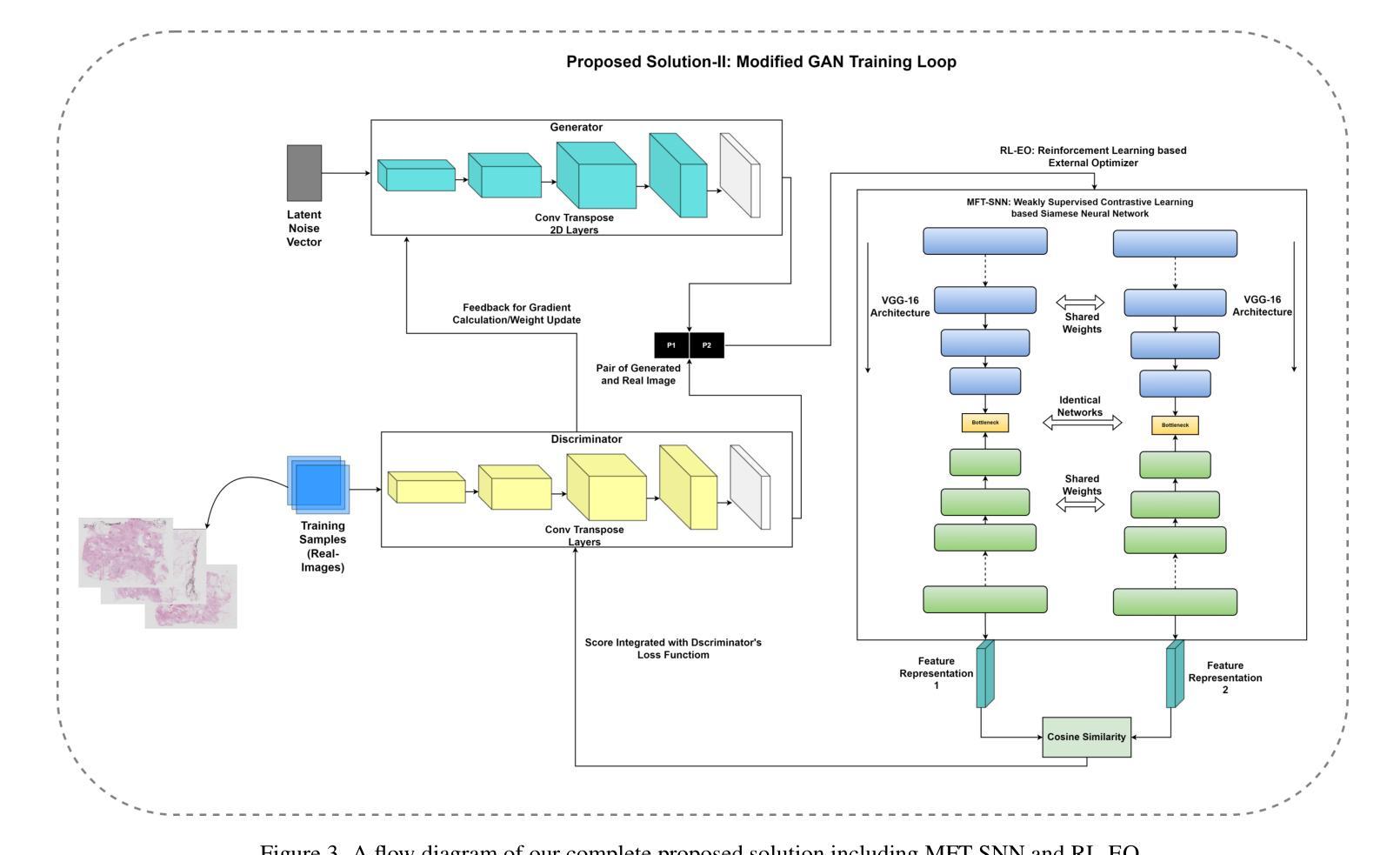
Enhancing GANs with Contrastive Learning-Based Multistage Progressive Finetuning SNN and RL-Based External Optimization
Authors:Osama Mustafa
Generative Adversarial Networks (GANs) have been at the forefront of image synthesis, especially in medical fields like histopathology, where they help address challenges such as data scarcity, patient privacy, and class imbalance. However, several inherent and domain-specific issues remain. For GANs, training instability, mode collapse, and insufficient feedback from binary classification can undermine performance. These challenges are particularly pronounced with high-resolution histopathology images due to their complex feature representation and high spatial detail. In response to these challenges, this work proposes a novel framework integrating a contrastive learning-based Multistage Progressive Finetuning Siamese Neural Network (MFT-SNN) with a Reinforcement Learning-based External Optimizer (RL-EO). The MFT-SNN improves feature similarity extraction in histopathology data, while the RL-EO acts as a reward-based guide to balance GAN training, addressing mode collapse and enhancing output quality. The proposed approach is evaluated against state-of-the-art (SOTA) GAN models and demonstrates superior performance across multiple metrics.
Summary
针对高分辨率病理图像,提出了一种结合对比学习和强化学习的神经网络框架,有效解决了GAN训练不稳定性和模式崩溃问题。
Key Takeaways
- GANs在医学图像合成中面临训练不稳定、模式崩溃和反馈不足等问题。
- 高分辨率病理图像特征复杂,需更精细的模型处理。
- 提出MFT-SNN和RL-EO框架,改善特征提取和平衡训练。
- MFT-SNN增强特征相似性提取,RL-EO指导平衡GAN训练。
- 与SOTA模型相比,该方法在多指标上表现优异。
标题:基于对比学习的多阶段渐进式GAN增强研究
作者:Osama Mustafa
隶属机构:Bahria University, Islamabad, Pakistan
关键词:Generative Adversarial Networks (GANs);对比学习;多阶段渐进式训练;Siamese Neural Network (SNN);强化学习;外部优化器;图像生成;医学图像;尤其是病理学图像。
链接:,GitHub代码链接(如果可用):GitHub:None(如果此论文没有公开代码)
总结:
- (1)研究背景:本文的研究背景是关于图像合成的最前沿技术,特别是在医学领域,特别是在病理学领域。尽管GAN在许多领域取得了成功,但在医学图像生成方面仍面临许多挑战,如数据稀缺性、患者隐私和类别不平衡等问题。本文旨在解决这些挑战。
- (2)过去的方法及其问题:过去的GAN方法在训练稳定性、模式崩溃和二元分类反馈不足等方面存在问题。特别是在处理高分辨率的病理学图像时,由于它们复杂的特征表示和高空间细节,这些问题更为突出。此外,现有的GAN方法难以生成复杂病理数据的合成图像,因此需要新的解决方案来解决这些问题。因此作者提出的方法有很好的动机。
- (3)研究方法:本文提出了一种新的框架,它结合了基于对比学习的多阶段渐进微调Siamese神经网络(MFT-SNN)和基于强化学习的外部优化器(RL-EO)。MFT-SNN改进了病理学数据中特征相似性的提取,而RL-EO则作为奖励导向的指南来平衡GAN训练,解决模式崩溃并增强输出质量。此外,该框架结合了对比学习和强化学习等新技术来解决传统GAN存在的问题。
- (4)任务与性能:本文提出的模型在生成合成图像的任务上进行了评估,特别是在病理学图像上。通过与最先进的GAN模型相比,该模型在多个指标上表现出卓越的性能。这些性能表明该模型可以有效地解决训练不平衡和模式崩溃等问题,提高输出图像的质量。因此,该方法的性能支持其目标。
方法论:
- (1) 研究背景:本文的研究背景是关于图像合成的最前沿技术,特别是在医学领域,特别是在病理学图像领域。虽然GAN在许多领域取得了成功,但在医学图像生成方面仍面临许多挑战,如数据稀缺性、患者隐私和类别不平衡等问题。作者旨在解决这些挑战。
- (2) 过去的方法及其问题:过去的GAN方法在训练稳定性、模式崩溃和二元分类反馈不足等方面存在问题。特别是在处理高分辨率的病理学图像时,由于它们复杂的特征表示和高空间细节,这些问题更为突出。现有的GAN方法难以生成复杂病理数据的合成图像,因此需要新的解决方案来解决这些问题。因此提出的方法有很好的动机。
- (3) 方法论创新点:本文提出了一种新的框架,它结合了基于对比学习的多阶段渐进微调Siamese神经网络(MFT-SNN)和基于强化学习的外部优化器(RL-EO)。MFT-SNN改进了病理学数据中特征相似性的提取,而RL-EO则作为奖励导向的指南来平衡GAN训练,解决模式崩溃并增强输出质量。该框架结合了对比学习和强化学习等新技术来解决传统GAN存在的问题。
(4) 方法论实施步骤:
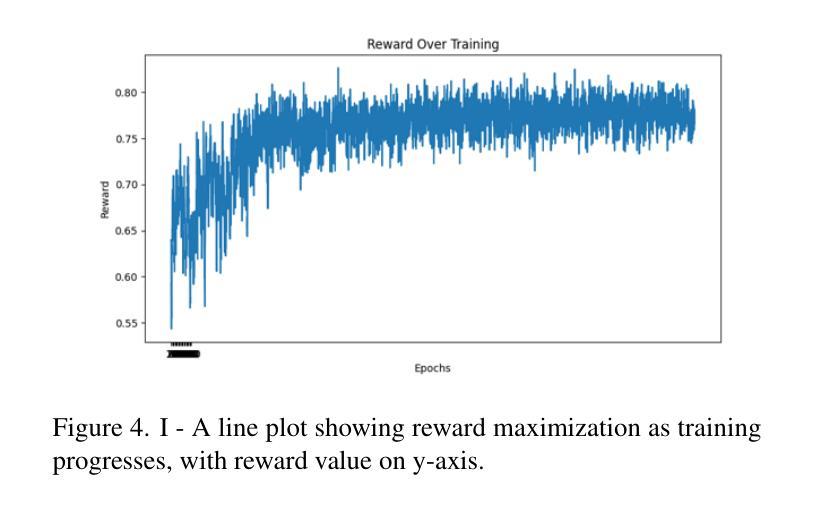
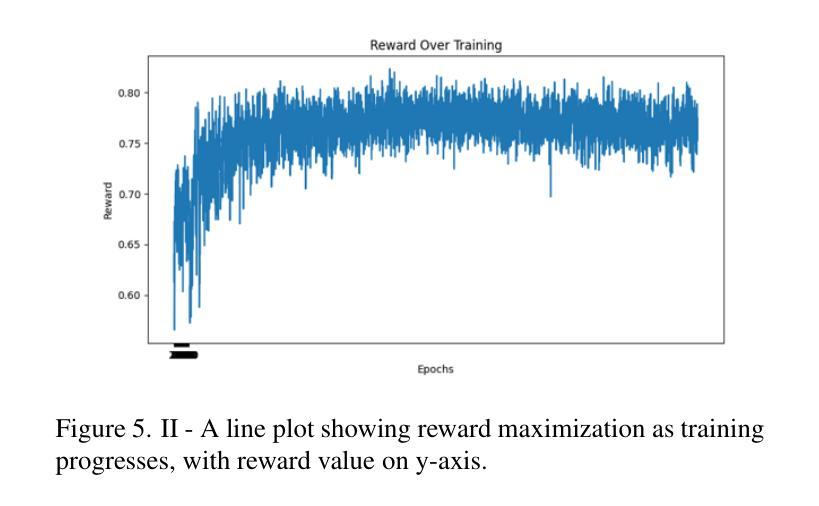
- a. 提出一种多阶段渐进微调Siamese神经网络(MFT-SNN),用于改进病理学数据中特征相似性的提取。网络训练策略分为两个阶段:首先,在完整的全尺寸幻灯片图像上进行训练,然后将其划分为补丁,并在补丁级别数据上进行训练。通过这种方式,网络可以学习全局上下文和空间关系,同时关注更小的细节。 - b. 结合强化学习,设计一个外部优化器(RL-EO),作为奖励导向的指南来平衡GAN训练。将MFT-SNN计算的相似度得分作为奖励信号传递给鉴别器,以指导生成器生成更真实的图像。奖励信号以加权的方式传递,以防止对生成器产生过大的影响。 - c. 修改鉴别器损失函数,以包含奖励信号。通过这种方式,鉴别器可以更有效地指导生成器生成高质量的图像。 - d. 使用基于DCGAN的GAN作为基础架构,进行实验的验证与分析。- (5) 实验验证与分析:通过对比实验,验证了该方法在生成合成图像任务上的性能,特别是在病理学图像上。实验结果表明,该方法在多个指标上优于其他最先进的GAN模型,解决了训练不平衡和模式崩溃等问题,提高了输出图像的质量。
- Conclusion:
- (1)意义:这项工作对医学图像生成领域,特别是病理学图像生成领域具有重要意义。它提出了一种新的GAN框架,旨在解决数据稀缺性、患者隐私和类别不平衡等问题,提高了图像生成的效率和质量。
- (2)创新点、性能、工作量总结:
- 创新点:文章结合了对比学习和多阶段渐进式训练,提出了基于对比学习的多阶段渐进微调Siamese神经网络(MFT-SNN)和基于强化学习的外部优化器(RL-EO),这是对传统GAN的重大改进。
- 性能:该框架在生成合成图像的任务上表现出卓越的性能,特别是在病理学图像上。与最先进的GAN模型相比,该模型在多个指标上表现出更好的性能,解决了训练不平衡和模式崩溃等问题,提高了输出图像的质量。
- 工作量:文章的工作量大,涉及到复杂的网络设计、实验验证和分析等。但是,文章没有公开代码,无法评估其实现的难易程度。
点此查看论文截图

 wechat
wechat- alipay