元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-12 更新
Discern-XR: An Online Classifier for Metaverse Network Traffic
Authors:Yoga Suhas Kuruba Manjunath, Austin Wissborn, Mathew Szymanowski, Mushu Li, Lian Zhao, Xiao-Ping Zhang
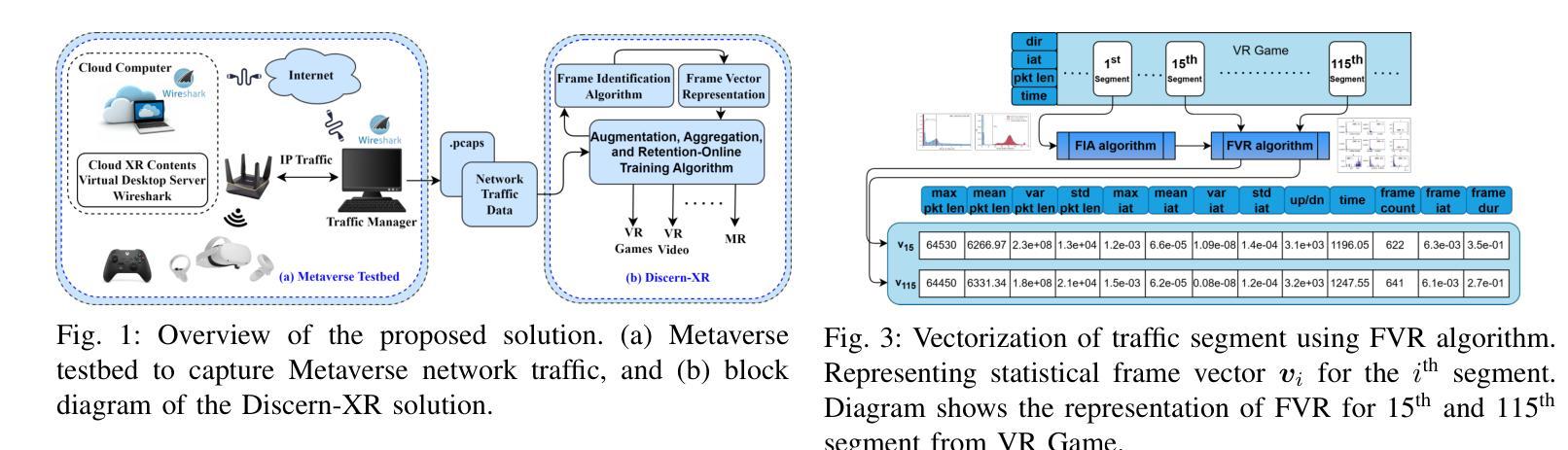
In this paper, we design an exclusive Metaverse network traffic classifier, named Discern-XR, to help Internet service providers (ISP) and router manufacturers enhance the quality of Metaverse services. Leveraging segmented learning, the Frame Vector Representation (FVR) algorithm and Frame Identification Algorithm (FIA) are proposed to extract critical frame-related statistics from raw network data having only four application-level features. A novel Augmentation, Aggregation, and Retention Online Training (A2R-OT) algorithm is proposed to find an accurate classification model through online training methodology. In addition, we contribute to the real-world Metaverse dataset comprising virtual reality (VR) games, VR video, VR chat, augmented reality (AR), and mixed reality (MR) traffic, providing a comprehensive benchmark. Discern-XR outperforms state-of-the-art classifiers by 7% while improving training efficiency and reducing false-negative rates. Our work advances Metaverse network traffic classification by standing as the state-of-the-art solution.
Summary
设计Discern-XR元宇宙网络流量分类器,提高服务质量,实现高效训练与准确分类。
Key Takeaways
- 提出Discern-XR元宇宙网络流量分类器。
- 利用分段学习与FVR算法提取关键统计数据。
- 首创A2R-OT算法实现在线训练。
- 构建综合真实元宇宙数据集。
- Discern-XR性能优于现有分类器7%。
- 提升训练效率,降低误报率。
- 成为元宇宙网络流量分类的领先解决方案。
Title: 虚拟元宇宙网络流量分类器Discern-XR研究
Authors: Yoga Suhas Kuruba Manjunath, Austin Wissborn, Mathew Szymanowski, Mushu Li, Lian Zhao, and Xiao-Ping Zhang
Affiliation: 多伦多大学电气、计算机与生物医学工程系(针对瑜伽·库鲁巴·曼朱纳特、奥斯汀·维松博恩、马修·齐曼诺夫斯基于多伦多市;利休大学计算机科学工程系(针对李木续);清华大学深圳国际研究生院普及无处不在数据工程实验室(针对张小平)。
Keywords: Metaverse, Extended Reality (XR), Augmented Reality (AR), Virtual Reality (VR), Mixed Reality (MR), Multi-Class Network Traffic Classification.
Urls: 论文链接(抽象中提供的链接)GitHub代码链接(如有可用,填入GitHub:None如果不可用)
Summary:
(1)研究背景:随着元宇宙概念的兴起,包括虚拟现实(VR)、增强现实(AR)和混合现实(MR)在内的扩展现实(XR)技术变得越来越流行。用户需要头戴式显示器、软件平台、服务和网络连接来体验元宇宙,因此对网络流量管理提出了更高要求。准确的元宇宙网络流量分类对于互联网服务提供商(ISP)和路由器制造商提高服务质量(QoS)和用户体验质量( QoE)至关重要。
(2)过去的方法及问题:已有一些网络流量分类方法,如基于决策树的方法,对于AR和云游戏的流量分类有一定的效果,但对于Metaverse其他服务的流量分类不够准确。另外,一些方法难以推广到其他Metaverse服务,如AR、MR和其他VR相关服务。因此,存在对非纯Metaverse网络流量数据的分类方法和准确性的挑战。
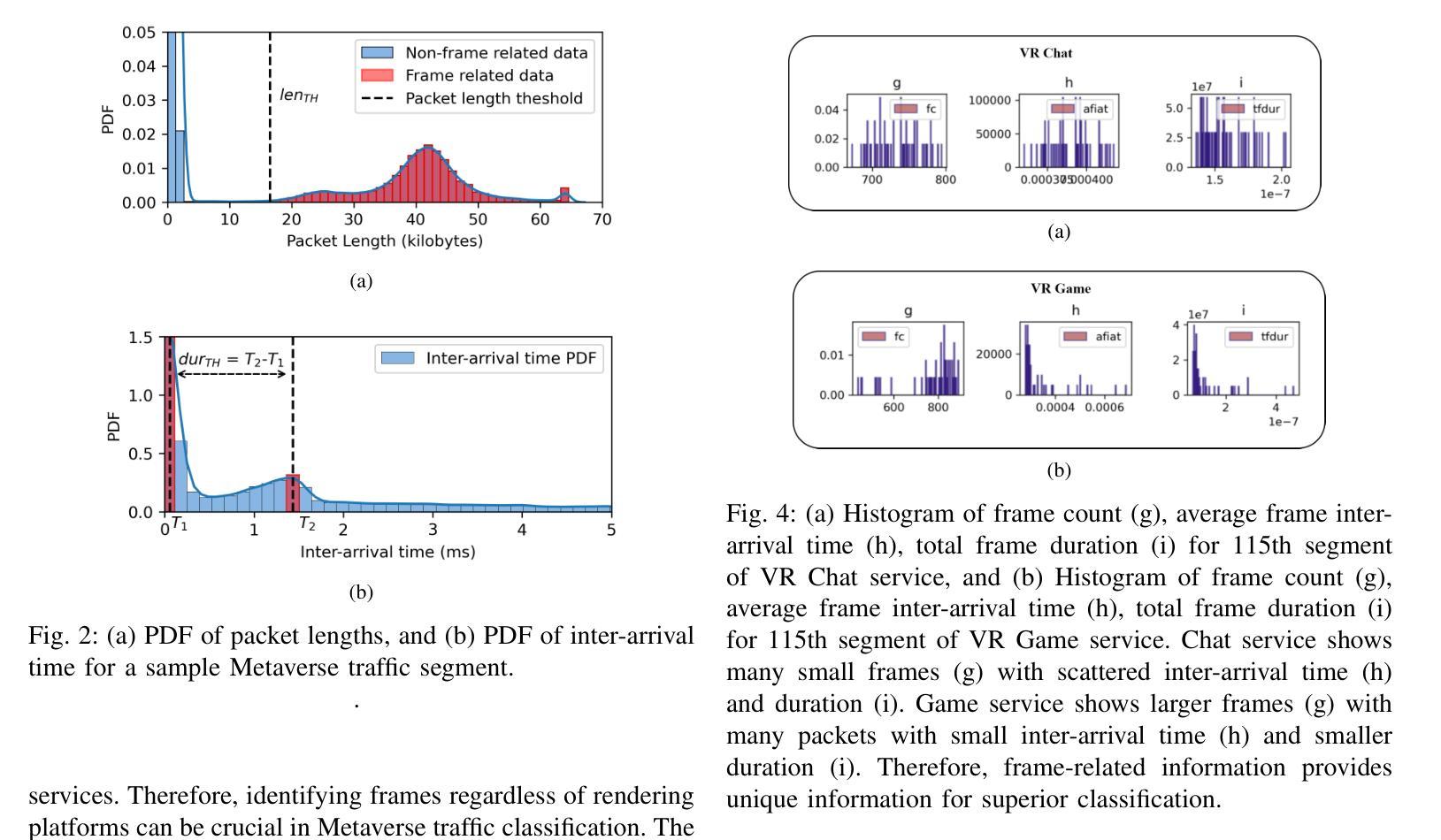
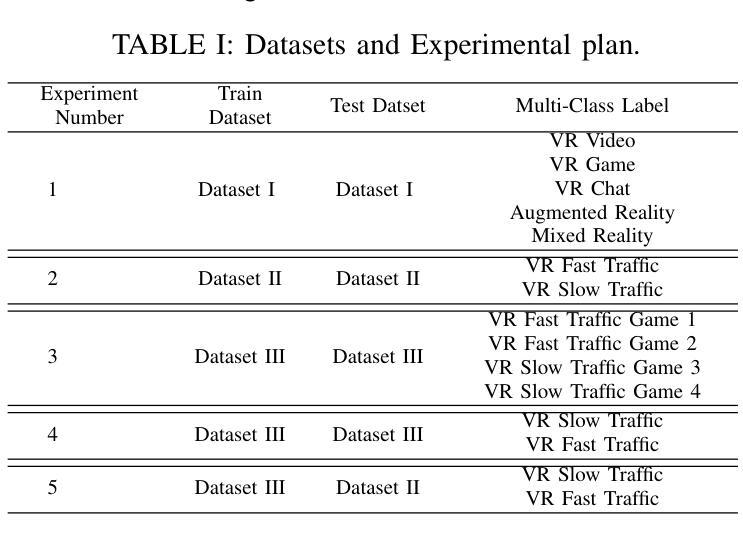
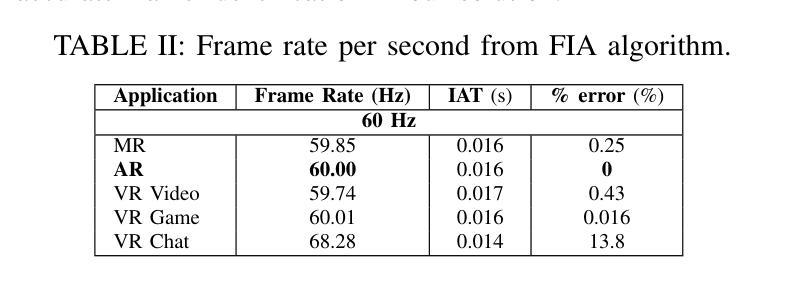
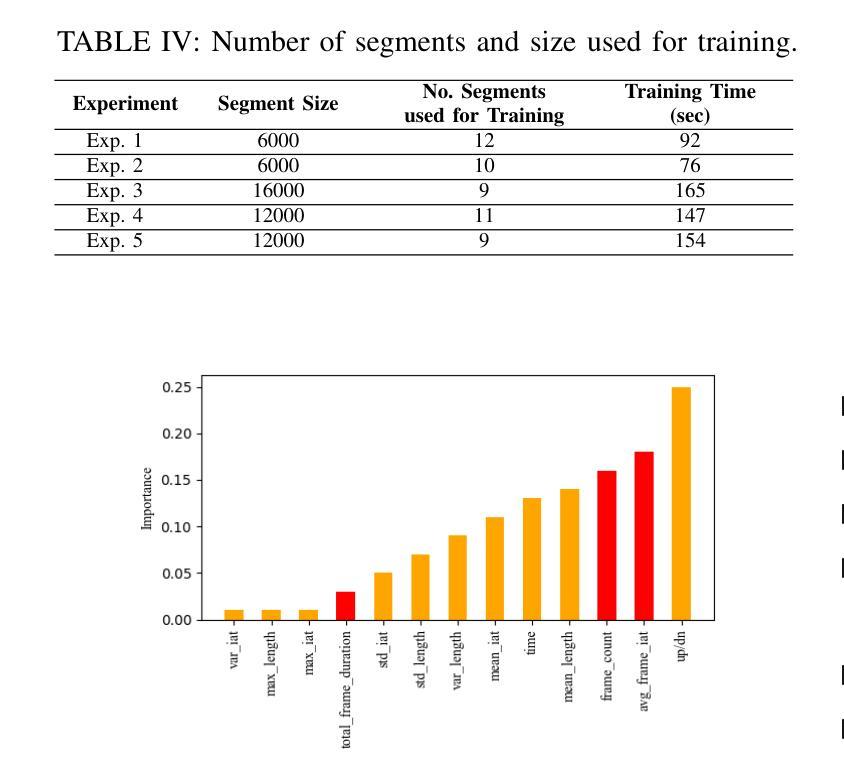
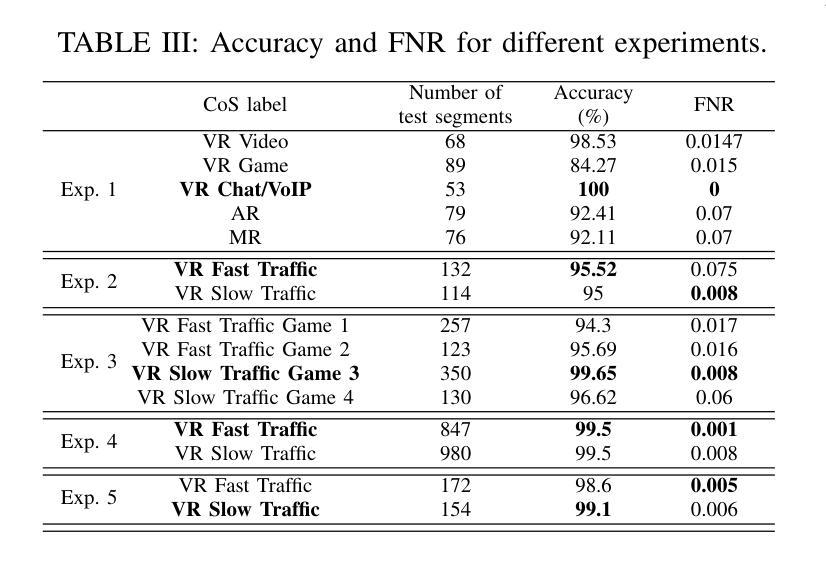
(3)研究方法:针对上述问题,本文提出了一种基于分段学习的元宇宙网络流量分类器Discern-XR。首先,通过Frame Vector Representation(FVR)算法和Frame Identification Algorithm(FIA)从原始网络数据中提取四个应用级别的特征。然后,使用一种新型在线训练算法Augmentation, Aggregation, and Retention Online Training(A2R-OT)来建立准确的分类模型。此外,还贡献了一个包含虚拟现实游戏、虚拟现实视频、虚拟现实聊天、增强现实和混合现实流量的现实世界Metaverse数据集,为分类提供了全面的基准测试。
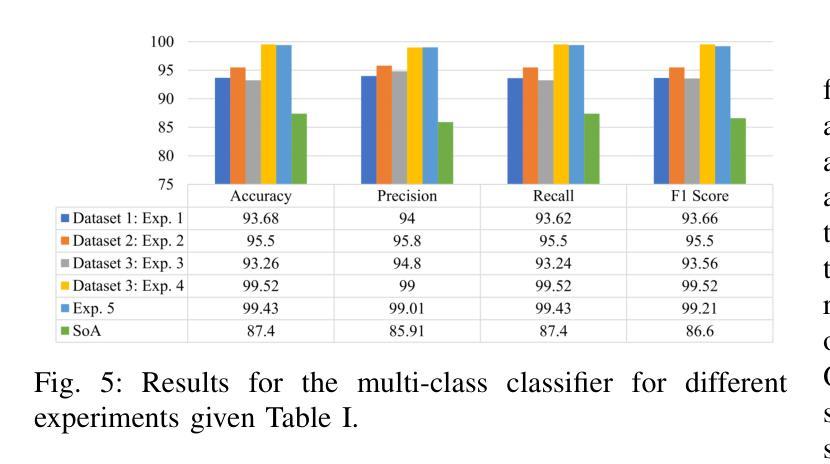
(4)任务与性能:本文的方法在包含虚拟游戏、视频、聊天、AR和MR流量的现实世界Metaverse数据集上进行测试,并实现了优于现有方法的性能。Discern-XR相对于最新方法提高了约7%的分类准确性,同时提高了训练效率并降低了误报率。本研究推动了元宇宙网络流量分类领域的发展,被认为是当前的最佳解决方案。
Conclusion:
(1)意义:随着元宇宙概念的兴起,对网络流量管理提出了更高的要求。这篇论文研究的虚拟元宇宙网络流量分类器Discern-XR,对于互联网服务提供商(ISP)和路由器制造商提高服务质量(QoS)和用户体验质量( QoE)具有重要意义。
(2)创新点、性能、工作量评价:
创新点:该文章提出了一种基于分段学习的元宇宙网络流量分类器Discern-XR,针对过去方法在非纯Metaverse网络流量数据的分类方法和准确性上存在的问题,进行了有效的改进。其贡献了一个包含虚拟现实游戏、虚拟现实视频、虚拟现实聊天、增强现实和混合现实流量的现实世界Metaverse数据集,为分类提供了全面的基准测试。
性能:Discern-XR相对于最新方法提高了约7%的分类准确性,同时提高了训练效率并降低了误报率,推动了元宇宙网络流量分类领域的发展。
工作量:文章进行了详尽的背景调研和文献综述,通过严谨的实验验证了所提出方法的有效性。同时,文章对所用数据集进行了详细的描述和处理,确保了实验结果的可靠性和可重复性。但工作量评价需要进一步了解实验的具体细节和数据处理量。
点此查看论文截图


Joint wireless and computing resource management with optimal slice selection in in-network-edge metaverse system
Authors:Sulaiman Muhammad Rashid, Ibrahim Aliyu, Abubakar Isah, Jihoon Lee, Sangwon Oh, Minsoo Hahn, Jinsul Kim
This paper presents an approach to joint wireless and computing resource management in slice-enabled metaverse networks, addressing the challenges of inter-slice and intra-slice resource allocation in the presence of in-network computing. We formulate the problem as a mixed-integer nonlinear programming (MINLP) problem and derive an optimal solution using standard optimization techniques. Through extensive simulations, we demonstrate that our proposed method significantly improves system performance by effectively balancing the allocation of radio and computing resources across multiple slices. Our approach outperforms existing benchmarks, particularly in scenarios with high user demand and varying computational tasks.
Summary
针对元宇宙切片网络中的无线和计算资源管理问题,提出了一种优化方案,显著提升系统性能。
Key Takeaways
- 研究针对元宇宙切片网络资源管理。
- 采用混合整数非线性规划(MINLP)建模问题。
- 应用标准优化技术求得最优解。
- 模拟结果表明方法有效提升系统性能。
- 方案在用户需求高、计算任务多样场景下表现优异。
- 超越现有基准方法。
- 优化无线与计算资源分配。
标题:基于最优切片的联合无线和计算资源管理在边缘网络元宇宙系统中的应用
中文翻译:边缘网络元宇宙系统中基于最优切片的联合无线和计算资源管理作者:Sulaiman Muhammad Rashid等
隶属机构:部分作者来自韩国光州庆南大学的智能电子与计算机工程系,部分作者来自哈萨克斯坦阿斯塔纳IT大学的计算与数据科学系。
中文翻译:部分作者隶属庆南大学智能电子与计算机工程系(韩国光州),部分作者隶属阿斯塔纳IT大学计算与数据科学系(哈萨克斯坦)。关键词:元宇宙、切片、资源管理、网络内计算、6G网络
链接:论文链接无法确定,GitHub代码链接不可用。
总结:
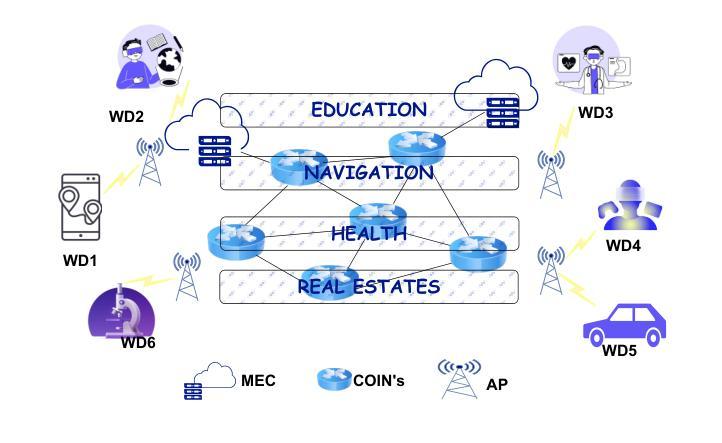
(1) 研究背景:随着技术的不断进步,网络正在向元宇宙方向发展,其中虚拟和增强现实与现实世界相融合。为了满足元宇宙的高资源需求,包括计算资源、存储资源和通信资源,需要有效的资源管理方法。
(2) 过去的方法及问题:过去的研究主要关注网络切片和资源分配,但缺乏针对网络内计算的资源管理的有效方法。现有的方法在网络切片和资源分配方面存在局限性,尤其是在处理动态用户需求和多变计算任务时效果不佳。
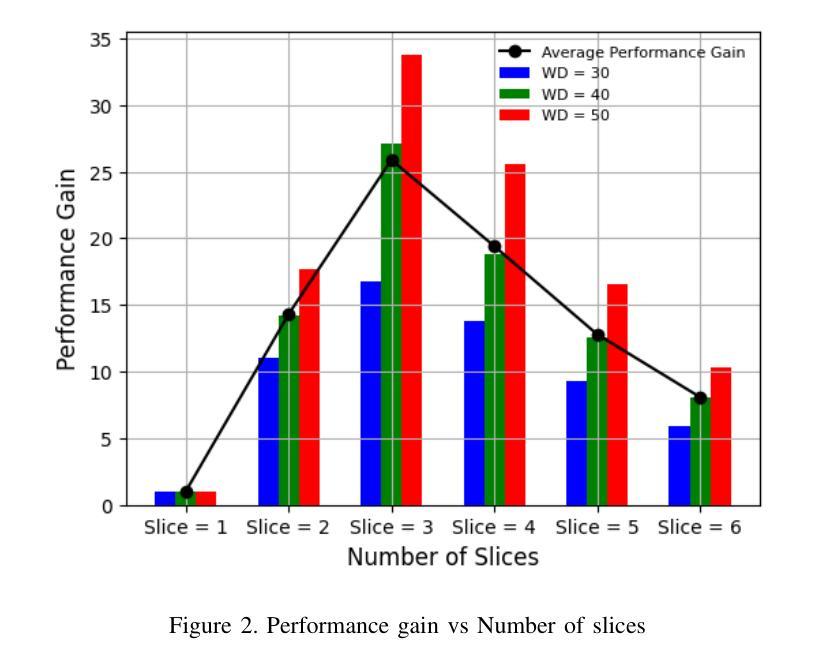
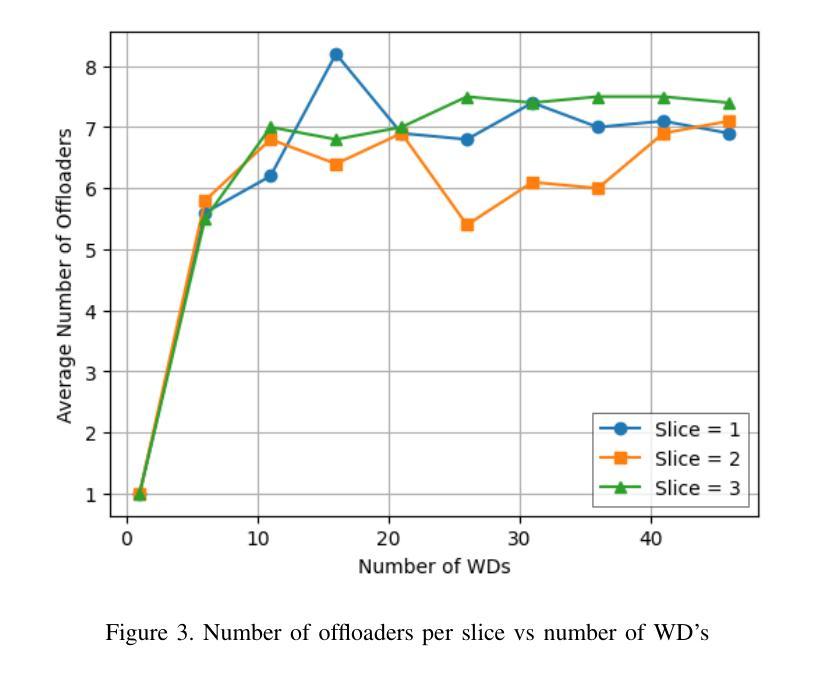
(3) 研究方法:本研究将问题表述为混合整数非线性规划(MINLP)问题,并使用标准优化技术求解。通过广泛的模拟仿真验证所提出方法的性能。
(4) 任务与性能:论文所提出的方法在平衡多个切片间的无线和计算资源分配方面表现出显著改进,特别是在高用户需求和多变计算任务的场景下。通过优化资源使用,提高了系统性能,超越了现有基准测试的性能。这种性能提升支持了研究目标的实现。
以上是对该文章的概括,希望对您有所帮助。
- Conclusion:
(1) 这项研究的意义在于解决了基于最优切片的联合无线和计算资源在边缘网络元宇宙系统中的管理问题,这对于满足元宇宙的高资源需求,提高网络性能和用户体验具有重要意义。
(2) 创新性:该文章提出了一个基于混合整数非线性规划(MINLP)的问题表述,为网络内计算资源管理提供了有效方法,这在以前的研究中尚未得到充分解决。
性能:通过广泛的模拟仿真,验证了所提出方法的性能,显示其在平衡多个切片间的无线和计算资源分配方面表现出显著改进,系统性能超过了现有基准测试的性能。
工作量:文章对于问题的阐述和解决方案的提出较为简洁,但通过模拟仿真验证了所提出方法的性能,工作量适中。
点此查看论文截图

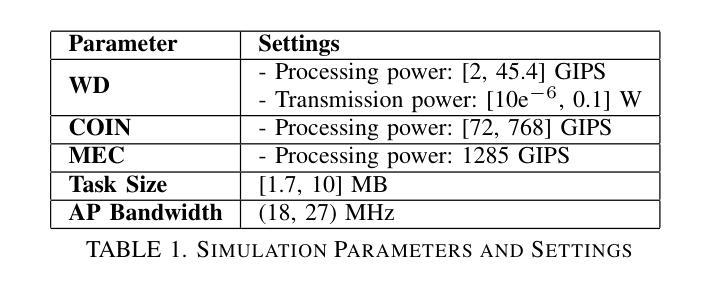
Diffusion-based Auction Mechanism for Efficient Resource Management in 6G-enabled Vehicular Metaverses
Authors:Jiawen Kang, Yongju Tong, Yue Zhong, Junlong Chen, Minrui Xu, Dusit Niyato, Runrong Deng, Shiwen Mao
The rise of 6G-enable Vehicular Metaverses is transforming the automotive industry by integrating immersive, real-time vehicular services through ultra-low latency and high bandwidth connectivity. In 6G-enable Vehicular Metaverses, vehicles are represented by Vehicle Twins (VTs), which serve as digital replicas of physical vehicles to support real-time vehicular applications such as large Artificial Intelligence (AI) model-based Augmented Reality (AR) navigation, called VT tasks. VT tasks are resource-intensive and need to be offloaded to ground Base Stations (BSs) for fast processing. However, high demand for VT tasks and limited resources of ground BSs, pose significant resource allocation challenges, particularly in densely populated urban areas like intersections. As a promising solution, Unmanned Aerial Vehicles (UAVs) act as aerial edge servers to dynamically assist ground BSs in handling VT tasks, relieving resource pressure on ground BSs. However, due to high mobility of UAVs, there exists information asymmetry regarding VT task demands between UAVs and ground BSs, resulting in inefficient resource allocation of UAVs. To address these challenges, we propose a learning-based Modified Second-Bid (MSB) auction mechanism to optimize resource allocation between ground BSs and UAVs by accounting for VT task latency and accuracy. Moreover, we design a diffusion-based reinforcement learning algorithm to optimize the price scaling factor, maximizing the total surplus of resource providers and minimizing VT task latency. Finally, simulation results demonstrate that the proposed diffusion-based MSB auction outperforms traditional baselines, providing better resource distribution and enhanced service quality for vehicular users.
Summary
6G车载元宇宙通过改进的MSB拍卖机制,利用无人机优化资源分配,提升AR导航性能。
Key Takeaways
- 6G赋能的车载元宇宙革新了汽车行业。
- 车辆以虚拟双胞胎(VTs)形式参与实时应用。
- VT任务资源密集,需地面基站处理。
- 高密度城市地区资源分配挑战显著。
- 无人机作为空中边缘服务器辅助基站。
- 信息不对称导致无人机资源分配低效。
- 提出基于学习的改进MSB拍卖机制优化资源分配。
- 设计扩散式强化学习算法优化价格缩放因子。
- 模拟结果显示MSB拍卖优于传统基准,提升服务质量和资源分配。
- Title: 基于扩散的拍卖机制在6G赋能的车辆元宇宙中的高效资源管理
Authors: 贾文康, 童永炬, 钟悦, 陈俊龙, 徐敏睿, 倪塔杜斯, 邓润荣, 毛世文
Affiliation:
第一作者贾文康的所属单位为广东工业大学自动化学院,广州市,510006,中国。Keywords: 拍卖模型,扩散,资源分配,边缘智能,大型AI模型
Urls: 论文链接无法提供GitHub代码链接,如有需要请自行搜索相关资源。
Summary:
(1)研究背景:
随着6G技术的发展,6G赋能的车辆元宇宙概念正在引领智能交通系统的革命。该文章主要探讨了在这一背景下,如何高效管理资源以提供优质的车辆服务。(2)过去的方法及问题:
在6G赋能的车辆元宇宙中,车辆通过车辆孪生(VTs)来支持实时车辆应用。由于车辆服务的资源密集性,需要将这些任务卸载到地面基站(BSs)进行快速处理。然而,地面基站资源有限,特别是在人口密集的城市地区,资源分配面临巨大挑战。虽然无人机(UAVs)作为空中边缘服务器被提出作为解决方案,但由于其高移动性,存在与地面基站之间的信息不对称问题,导致资源分配效率低下。(3)研究方法:
针对上述问题,文章提出了一种基于学习的改进型第二竞价(MSB)拍卖机制,以优化地面基站和无人机之间的资源分配。该机制考虑了任务延迟和准确性,并设计了一种基于扩散的强化学习算法来优化价格缩放因子,以最大化资源提供者的总盈余并最小化任务延迟。(4)任务与性能:
文章通过仿真实验验证了所提出的基于扩散的MSB拍卖机制的性能。结果表明,与传统方法相比,该机制在资源分配和服务质量方面表现出更好的性能,为车辆用户提供了更好的资源分布和服务质量。
希望以上内容符合您的要求。
- Conclusion:
- (1)意义:该研究工作在基于拍卖的资源分配方面对6G赋能的车辆元宇宙中的大型AI模型应用进行了深入探讨,具有重要的理论价值和实践意义。提出的基于扩散的拍卖机制为高效资源分配提供了新的思路和方法。
- (2)创新点、性能、工作量维度评价:
- 创新点:文章提出了一种基于学习的改进型第二竞价(MSB)拍卖机制,该机制结合了延迟和任务准确性作为共同价值,并采用扩散强化学习算法动态调整拍卖价格缩放因子,实现了资源的高效分配。这一创新点具有显著的技术创新性。
- 性能:通过仿真实验验证了所提出机制的性能,结果表明该机制在资源分配和服务质量方面表现出较好的性能,相比传统方法具有优越性。
- 工作量:文章详细阐述了研究背景、现状、方法及性能评价等方面,但未明确说明具体的工作量投入,如实验数据规模、计算复杂度等。需要在后续工作中进一步补充和完善相关细节。
点此查看论文截图

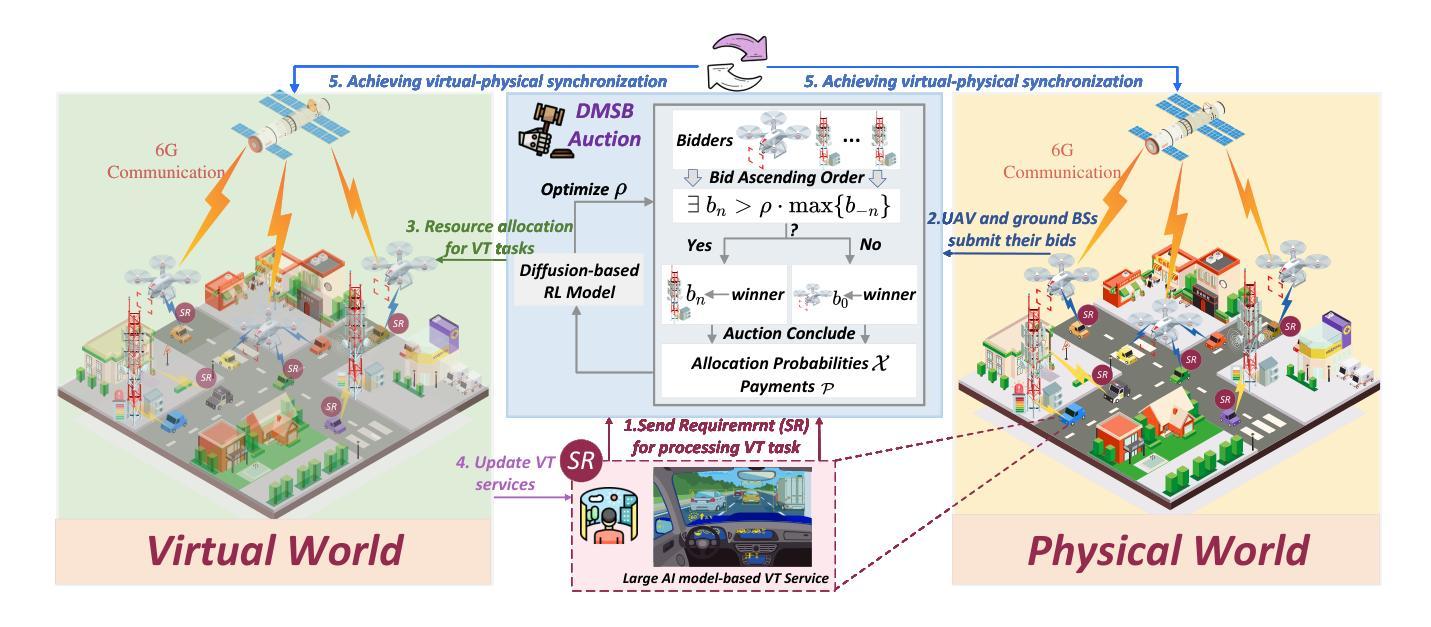
LightAvatar: Efficient Head Avatar as Dynamic Neural Light Field
Authors:Huan Wang, Feitong Tan, Ziqian Bai, Yinda Zhang, Shichen Liu, Qiangeng Xu, Menglei Chai, Anish Prabhu, Rohit Pandey, Sean Fanello, Zeng Huang, Yun Fu
Recent works have shown that neural radiance fields (NeRFs) on top of parametric models have reached SOTA quality to build photorealistic head avatars from a monocular video. However, one major limitation of the NeRF-based avatars is the slow rendering speed due to the dense point sampling of NeRF, preventing them from broader utility on resource-constrained devices. We introduce LightAvatar, the first head avatar model based on neural light fields (NeLFs). LightAvatar renders an image from 3DMM parameters and a camera pose via a single network forward pass, without using mesh or volume rendering. The proposed approach, while being conceptually appealing, poses a significant challenge towards real-time efficiency and training stability. To resolve them, we introduce dedicated network designs to obtain proper representations for the NeLF model and maintain a low FLOPs budget. Meanwhile, we tap into a distillation-based training strategy that uses a pretrained avatar model as teacher to synthesize abundant pseudo data for training. A warping field network is introduced to correct the fitting error in the real data so that the model can learn better. Extensive experiments suggest that our method can achieve new SOTA image quality quantitatively or qualitatively, while being significantly faster than the counterparts, reporting 174.1 FPS (512x512 resolution) on a consumer-grade GPU (RTX3090) with no customized optimization.
PDF ECCV’24 CADL Workshop. Code: https://github.com/MingSun-Tse/LightAvatar-TensorFlow. V2: Corrected speed benchmark with GaussianAvatar
Summary
基于NeRF的虚拟头像渲染技术受限,LightAvatar通过NeLFs实现高效渲染。
Key Takeaways
- NeRF在虚拟头像渲染中达到SOTA,但渲染速度慢。
- LightAvatar基于NeLFs,无需网格或体积渲染。
- 模型在实时效率和训练稳定性上面临挑战。
- 专用网络设计降低FLOPs,提升效率。
- 使用预训练模型和伪数据训练。
- 引入变形场网络校正误差。
- 实验表明,LightAvatar在速度和图像质量上优于现有方法。
Title: LightAvatar: 基于神经光照场的高效人头虚拟化技术
Authors: 王欢, 谭飞彤, 白子谦, 张音达, 刘世琛, 徐强甬, 柴梦蕾, 普布哈 (Anish Prabhu), 潘德瑞 (Rohit Pandey), 范恩洛 (Sean Fanello), 黄增, 傅云等。
Affiliation: 作者来自东北大学(美国)和谷歌公司。
Keywords: LightAvatar, 神经光照场 (Neural Light Field), 人头虚拟化 (Head Avatar Virtualization), 渲染速度优化 (Rendering Speed Optimization), 深度学习计算机视觉 (Deep Learning Computer Vision)。
URLs: 具体链接未知(可以查阅相关的学术数据库或文献库以获取论文和代码)
Summary:
(1) 研究背景:随着计算机视觉和深度学习的快速发展,基于视频的数字化虚拟化技术成为当前的研究热点。在娱乐、影视、游戏等领域,高质量的人头虚拟化技术具有广泛的应用前景。然而,现有的虚拟化技术存在渲染速度慢的问题,难以满足实时应用的需求。本文的研究背景是针对这一问题展开。
(2) 过去的方法及问题:传统的头像虚拟化技术主要基于三维模型和纹理映射,虽然质量较高但计算量大、渲染速度慢。近年来,基于神经辐射场(NeRF)的方法成为新的研究热点,但仍然存在速度慢的问题,限制了其在资源受限设备上的广泛应用。
(3) 研究方法:本文提出了基于神经光照场(NeLF)的LightAvatar模型,该模型直接从3DMM参数和相机姿态渲染图像,无需使用网格或体积渲染。为了解决实时效率和训练稳定性问题,研究团队引入了专门的网络设计来获得适当的NeLF模型表示,并维持了一个低的浮点运算量预算。同时,他们采用了一种基于蒸馏的训练策略,使用预训练的头像模型作为教师进行大量伪数据的合成用于训练。
(4) 任务与性能:本文的方法在头像虚拟化任务上取得了显著的性能提升,实现了快速的渲染速度并提高了图像质量。与现有的最快(性能较好)的头像虚拟化方法相比,LightAvatar达到了更高的帧率(174.1 FPS)和更好的LPIPS指标(Local Perceptual Image Similarity),从而支持了其方法的实际应用价值。
希望以上总结符合您的要求!
Methods:
(1) 研究团队首先介绍了当前计算机视觉和深度学习领域的人头虚拟化技术背景,指出传统方法和基于NeRF的方法存在的问题和挑战。
(2) 针对这些问题,研究团队提出了基于神经光照场(NeLF)的LightAvatar模型。该模型直接利用3DMM参数和相机姿态进行图像渲染,无需使用网格或体积渲染技术。
(3) 为了提高实时效率和训练稳定性,研究团队设计了专门的网络结构来获取适当的NeLF模型表示,并维持了一个较低的浮点运算量预算。
(4) 此外,研究团队采用了一种基于蒸馏的训练策略,使用预训练的头像模型作为教师,合成大量伪数据进行训练。这种策略有助于提高模型的性能和泛化能力。
(5) 最后,研究团队在头像虚拟化任务上进行了实验验证,与现有的最快(性能较好)的头像虚拟化方法相比,LightAvatar达到了更高的帧率(174.1 FPS)和更好的LPIPS指标(Local Perceptual Image Similarity),证明了其方法的有效性和实用性。
- Conclusion:
(1) 该工作的意义在于提出了一种基于神经光照场(NeLF)的高效人头虚拟化技术,有效解决了传统虚拟化技术渲染速度慢的问题,提高了图像质量,在娱乐、影视、游戏等领域具有广泛的应用前景。此外,该研究还促进了计算机视觉和深度学习领域的技术发展。
(2) 创新点总结:本文提出的基于神经光照场(NeLF)的LightAvatar模型在头像虚拟化技术上实现了重要突破。其采用的新型网络结构和基于蒸馏的训练策略有效提高了实时效率和训练稳定性。与现有技术相比,LightAvatar在性能上取得了显著提升,达到了更高的帧率和更好的图像相似度指标。但受限于其技术和实施难度,实际应用中可能存在一定的挑战。性能上:LightAvatar在头像虚拟化任务上取得了显著的性能提升,实现了快速的渲染速度和高质量的图像。工作量上:该文章的研究团队进行了大量的实验验证和模型训练,工作量较大,但成果显著。
总的来说,该文章所提出的基于神经光照场的人头虚拟化技术具有重要的应用价值和发展前景,为相关领域的研究提供了新的思路和方法。
点此查看论文截图

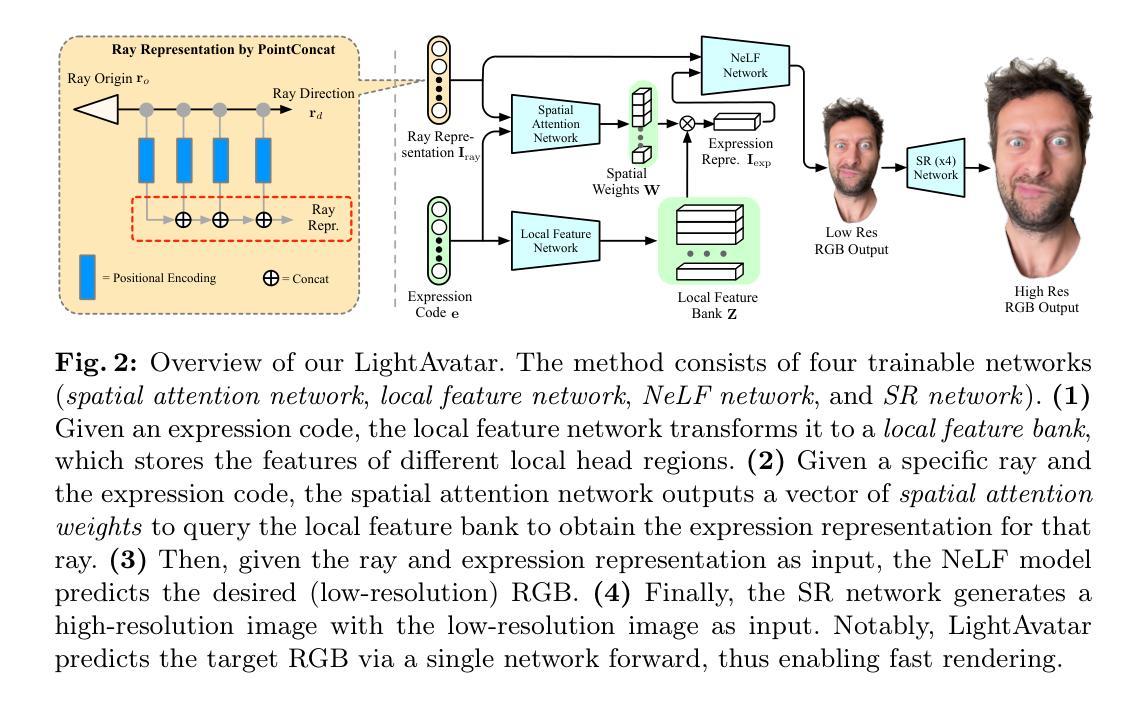
Gaussian Deja-vu: Creating Controllable 3D Gaussian Head-Avatars with Enhanced Generalization and Personalization Abilities
Authors:Peizhi Yan, Rabab Ward, Qiang Tang, Shan Du
Recent advancements in 3D Gaussian Splatting (3DGS) have unlocked significant potential for modeling 3D head avatars, providing greater flexibility than mesh-based methods and more efficient rendering compared to NeRF-based approaches. Despite these advancements, the creation of controllable 3DGS-based head avatars remains time-intensive, often requiring tens of minutes to hours. To expedite this process, we here introduce the “Gaussian Deja-vu” framework, which first obtains a generalized model of the head avatar and then personalizes the result. The generalized model is trained on large 2D (synthetic and real) image datasets. This model provides a well-initialized 3D Gaussian head that is further refined using a monocular video to achieve the personalized head avatar. For personalizing, we propose learnable expression-aware rectification blendmaps to correct the initial 3D Gaussians, ensuring rapid convergence without the reliance on neural networks. Experiments demonstrate that the proposed method meets its objectives. It outperforms state-of-the-art 3D Gaussian head avatars in terms of photorealistic quality as well as reduces training time consumption to at least a quarter of the existing methods, producing the avatar in minutes.
PDF 11 pages, Accepted by WACV 2025 in Round 1
Summary
引入“高斯Deja-vu”框架,大幅缩短3D高斯分层头像创建时间。
Key Takeaways
- 高斯分层分层(3DGS)在3D头像建模中展现出潜力。
- 3DGS头像创建耗时较长。
- “高斯Deja-vu”框架通过通用模型与个性化调整加速头像制作。
- 通用模型基于大量2D图像数据集训练。
- 使用单目视频进行个性化调整。
- 提出可学习的表情感知混合映射。
- 方法在真实感与时间效率上优于现有技术。
Title: 高斯Dejavu:创建可控的3D高斯头部化身,增强通用性和个性化能力
Authors: Peizhi Yan, Rabab Ward, Qiang Tang, Shan Du
Affiliation: 第一作者Peizhi Yan的隶属单位为University of British Columbia。
Keywords: 3D Gaussian Head Avatars, Creation, Controllability, Efficient Rendering, Photorealistic Quality
Urls: 论文链接待补充,Github代码链接待补充(如果可用)。
Summary:
(1) 研究背景:随着视频游戏、虚拟现实、增强现实、电影制作、远程存在等领域的快速发展,创建真实感强的3D头部化身变得越来越受欢迎。本文提出了高斯Dejavu方法,旨在创建一个可控的、高效的、高质量的3D高斯头部化身。
(2) 过去的方法及其问题:现有的创建3D头部化身的方法往往难以同时满足效率、质量和可控性的要求。一些方法虽然能够实现较高的质量,但训练时间过长,难以实现快速创建可控的化身。
(3) 研究方法:本文提出的高斯Dejavu框架首先通过大型2D图像数据集训练一个通用模型,然后个性化结果。通用模型使用合成的和真实的图像数据集进行训练,提供一个初始的3D高斯头部,再通过单目视频进行精细化处理,以实现个性化的头部化身。为了个性化,本文提出了可学习的表情感知校正混合图(blendmaps),以纠正初始的3D高斯模型,确保快速收敛,不依赖神经网络。
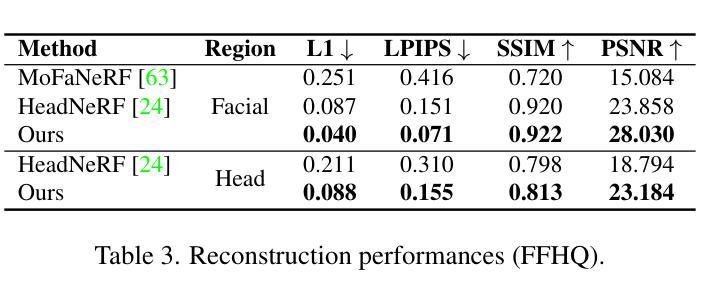
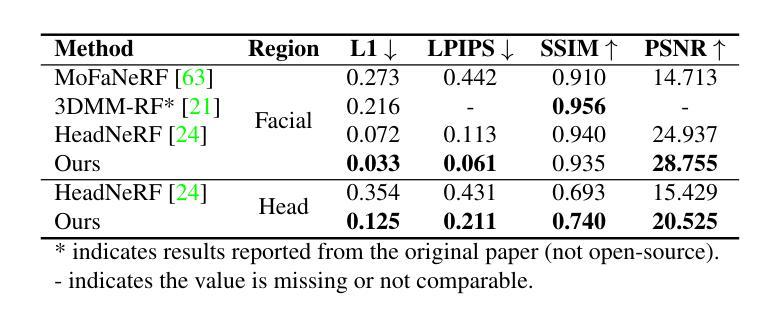
(4) 任务与性能:本文的方法在创建3D高斯头部化身的任务上取得了显著成果。实验表明,该方法在真实感质量方面优于现有的3D高斯头部化身方法,并将训练时间消耗减少了至少四分之一,能够在几分钟内生成化身。性能结果支持该方法的有效性。
方法:
(1) 首先,该研究通过大型2D图像数据集训练一个通用模型。数据集包括合成图像和真实图像,用于提供一个初始的3D高斯头部模型。
(2) 然后,利用单目视频对初始模型进行精细化处理,以实现个性化的头部化身。这一步的目的是纠正初始的3D高斯模型,使其更符合特定个体的特征。
(3) 为了实现个性化,该研究提出了可学习的表情感知校正混合图(blendmaps)。这种技术可以确保快速收敛,并且不依赖神经网络。通过调整blendmaps,研究能够根据不同的个体和表情对初始模型进行微调,生成具有真实感和个性化的3D头部化身。
(4) 最后,实验验证了该方法的有效性。与现有的3D高斯头部化身方法相比,该方法在真实感质量方面表现更优,并且显著减少了训练时间,能够在几分钟内生成高质量的化身。这些实验结果表明了该方法在实际应用中的潜力和价值。
- Conclusion:
(1) 这项工作的意义在于提出了一种创建可控的3D高斯头部化身的新方法,显著提高了通用性和个性化能力。它为视频游戏、虚拟现实、增强现实、电影制作和远程存在等领域提供了一种新的工具,能够创建真实感强的3D头部化身,有助于推动这些领域的进一步发展。
(2) 创新点:本文提出了高斯Dejavu框架,首次实现了仅通过单张图像输入重建3D高斯头部的能力,并且使用2D图像进行训练。此外,本文提出的可学习表情感知校正混合图(blendmaps)技术,能够在不依赖神经网络的情况下,实现快速收敛和调整头部表情。
性能:实验结果表明,该方法在渲染质量和训练速度方面均优于现有方法。与现有方法相比,该方法显著减少了训练时间,能够在几分钟内生成高质量的化身。
工作量:文章对方法的实现进行了详细的描述,从数据集的准备、模型的训练、到个性化调整等步骤均有详细的说明。但是,对于如何进一步优化模型以适应更广泛的面部表情,以及探索更多应用场景等方面,还需要进一步的研究和努力。
点此查看论文截图


 wechat
wechat- alipay