Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-12 更新
What talking you?: Translating Code-Mixed Messaging Texts to English
Authors:Lynnette Hui Xian Ng, Luo Qi Chan
Translation of code-mixed texts to formal English allow a wider audience to understand these code-mixed languages, and facilitate downstream analysis applications such as sentiment analysis. In this work, we look at translating Singlish, which is colloquial Singaporean English, to formal standard English. Singlish is formed through the code-mixing of multiple Asian languages and dialects. We analysed the presence of other Asian languages and variants which can facilitate translation. Our dataset is short message texts, written as informal communication between Singlish speakers. We use a multi-step prompting scheme on five Large Language Models (LLMs) for language detection and translation. Our analysis show that LLMs do not perform well in this task, and we describe the challenges involved in translation of code-mixed languages. We also release our dataset in this link https://github.com/luoqichan/singlish.
Summary
代码混合文本翻译至正式英语可让更多受众理解,并促进下游分析应用,本研究关注将新加坡式英语(Singlish)翻译成正式英语。
Key Takeaways
- 翻译代码混合文本有助于更广泛的受众理解。
- 研究关注将新加坡式英语翻译成正式英语。
- Singlish 通过多种亚洲语言和方言的混合形成。
- 研究分析其他亚洲语言和方言的存在以促进翻译。
- 使用短消息文本作为数据集。
- 应用多步骤提示方案在五种大型语言模型上进行语言检测和翻译。
- LLMs 在翻译代码混合语言方面表现不佳。
- 研究描述了翻译代码混合语言的挑战。
- 研究发布了数据集。
标题:基于代码混合文本的英语翻译研究——以新加坡式英语为例
作者:Lynnette Hui Xian Ng 和 Luo Qi Chan
隶属机构:卡内基梅隆大学
关键词:代码混合语言、翻译、大型语言模型、语言检测、新加坡英语
链接:https://github.com/luoqichan/singlish (GitHub代码库链接暂不可用)
总结:
(1) 研究背景:本文研究了将代码混合文本(如新加坡式英语)翻译成正式标准英语的问题。随着全球化和多语言环境的普及,代码混合语言在社交媒体和日常通讯中越来越普遍,因此需要工具来帮助理解和翻译这些语言。在此背景下,本文旨在解决将新加坡式英语翻译成正式英语的翻译问题。
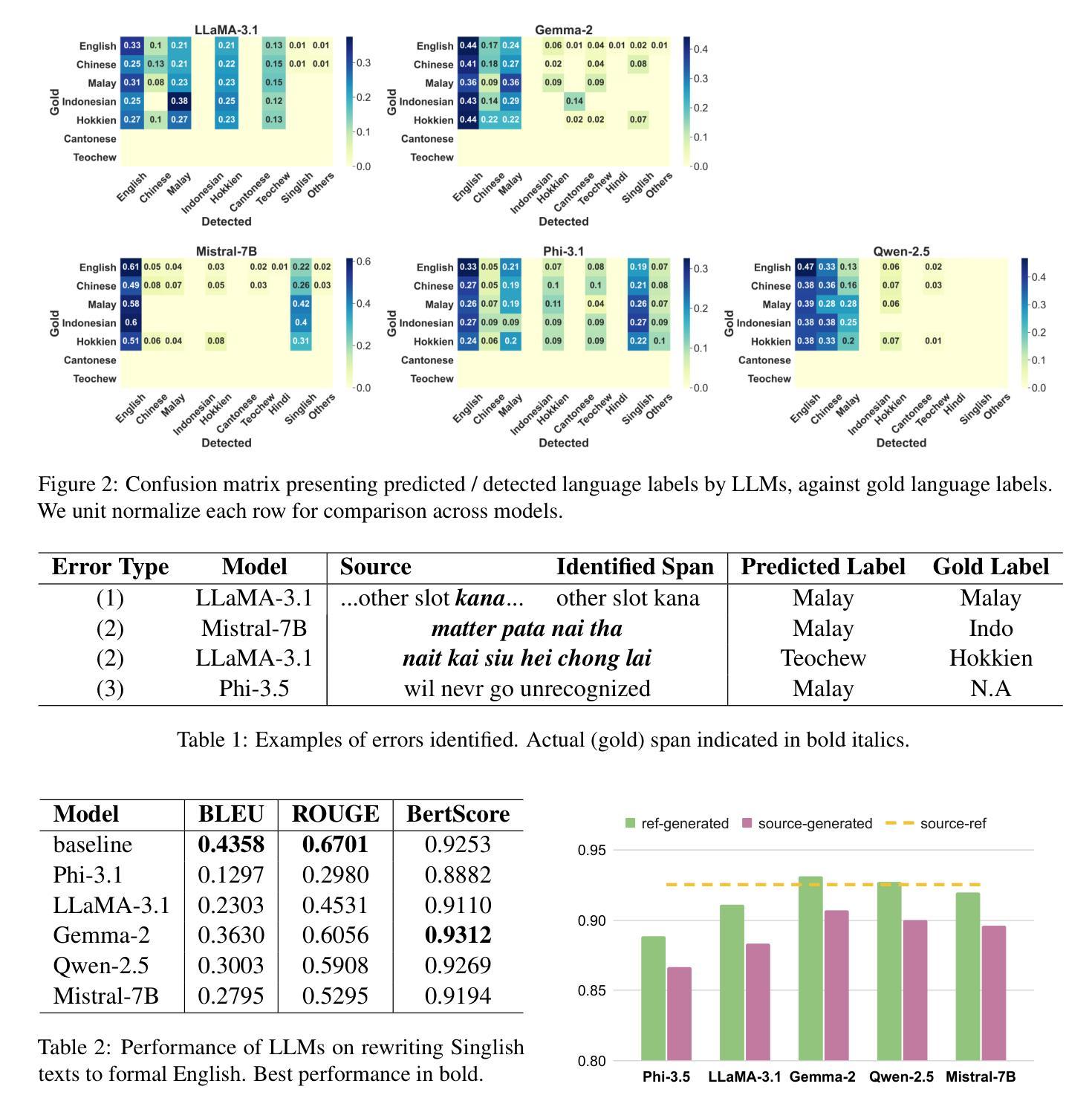
(2) 过去的方法及问题:过去的研究主要关注于双语对的代码混合语言(通常是母语和英语),使用预训练的多语言模型来处理代码混合问题。然而,对于像新加坡英语这样的多语言混合语言,这些方法的性能并不理想,因为它们无法很好地处理多种语言的混合。此外,过去的研究主要集中在翻译任务上,忽略了语言检测的重要性。因此,本文提出解决这些问题的方法。
(3) 研究方法:本文首先创建了一个基于短信的数据集,其中包含新加坡式英语的文本。然后,使用大型语言模型(LLMs)进行语言检测和翻译实验。采用了一种多步提示方案,对五个大型语言模型进行试验。但发现LLMs在该任务上的表现并不理想。通过分析数据,本文揭示了翻译代码混合语言所面临的挑战。文章还提出了改进方向,例如开发专门针对代码混合语言的模型和算法。本文还分享了其数据集以便其他研究者使用。
(4) 任务与性能:本文的主要任务是进行语言检测和翻译实验。然而,实验结果表明大型语言模型在该任务上的表现并不理想。虽然模型的性能有待提高,但这项工作为理解代码混合语言的翻译问题提供了有价值的见解和研究方向。尽管存在挑战,但这仍然是一个具有广阔研究前景的领域。 未来需要更多工作来解决代码混合语言的翻译问题并提高模型性能以实现更好的应用效果和应用广泛性方面的期望效果有所保障是一个合理的起点展开未来工作指引其研究和进步的可能性和开放性引领读者看到研究方向在未来有何重要性发展的可能性以及未来可能面临的挑战和机遇等方向性指引信息让读者对研究前景有清晰的认识和展望。
方法论:
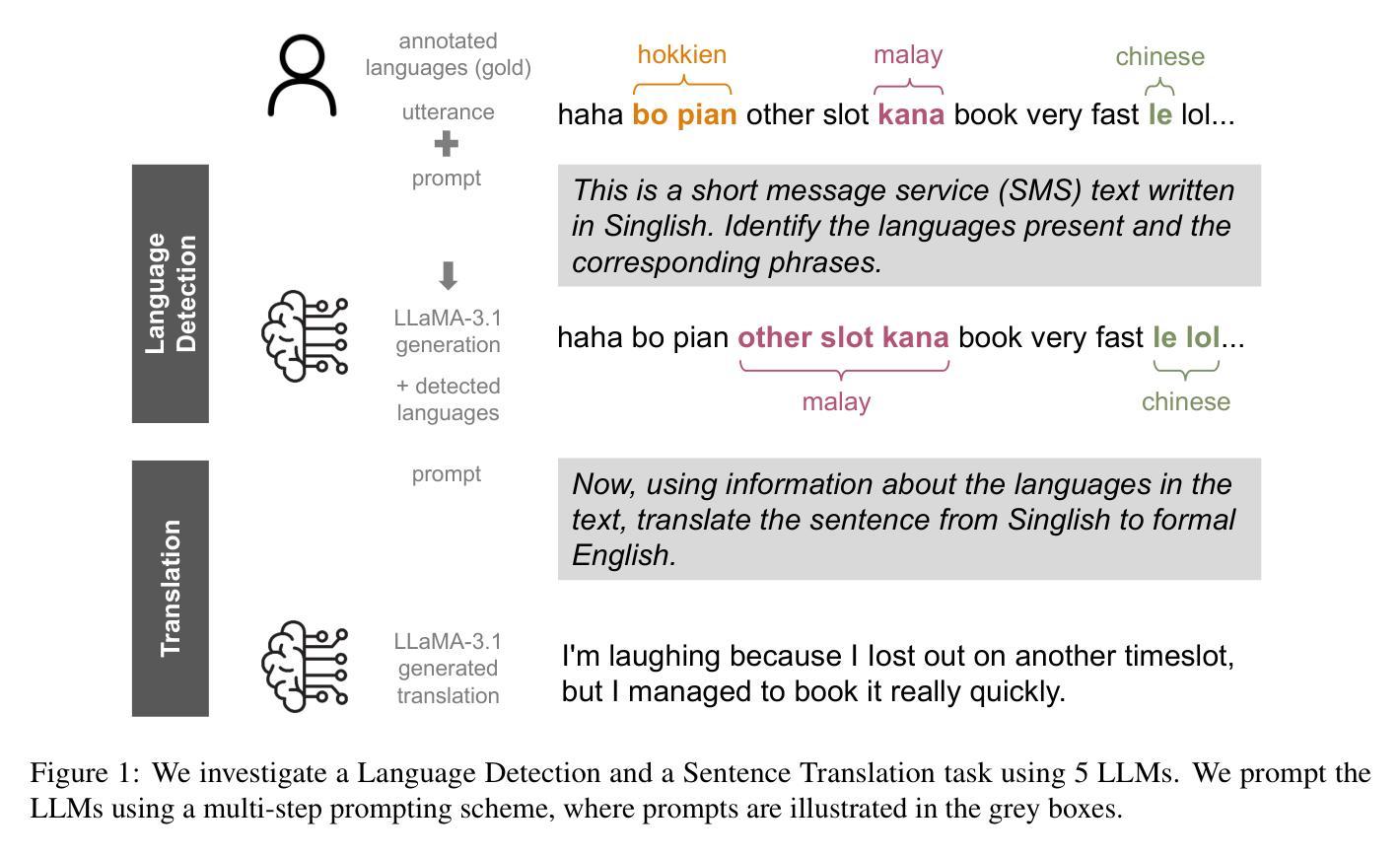
(1) 语言检测:对于输入的带有新加坡式英语的句子,输出文本中存在的语言以及使用相应语言的短语。通常,语言检测任务根据给定的上下文推断整个序列的语言。在我们的实验中,我们的目标是检测序列中的所有语言和语言变体(可能不止一种)。我们的目标是检测非英语词汇,我们将其称为其他语言。
(2) 翻译:将新加坡式英语的句子作为输入,输出翻译为正式标准英语的句子。我们将标准英语定义为一种可以被英语使用者广泛理解的英语形式,无论国籍或文化如何。这是我们在新闻网站或政府网站上与之交互的英语。
(3) 数据集构建:文章使用新加坡短信语料库的一个子集作为数据集,该数据集包含来自短信服务(SMS)的文本。这些文本展示了新加坡式英语在日常对话中的使用方式。从该语料库中随机抽取了300个单词长度大于20的句子来形成源文本。
(4) 参考文本的创建:招募三位本土新加坡式英语说话者来创建参考文本语料库。所有参与者都至少拥有本科学位或以上学历,他们对新加坡式英语的正式标准英语形式有着深刻的理解。他们根据源文本中的新加坡式英语句子提供相应的翻译,形成参考文本。参考翻译的制定使我们能够对自动翻译的质量进行量化评估。我们通过大型语言模型创建生成的文本数据以供研究使用。这些数据是通过自动化的方法处理产生的用于后续的测试阶段比较使用的实例生成分析语境从而明确现实存在的方法本身的弱点、以及算法当中尚待完善和发展的领域在未来如何进行改善和提升研究的重要指引和启示依据进一步说明该方法面临的挑战以及未来的发展方向和研究价值所在为后续的研究工作提供了明确的方向和重要的思路指导帮助研究人员对研究领域有清晰的认识并对未来的研究方向有更明确和更有针对性的认识以便于精准高效地解决所面临的翻译问题和困难点使得在大型语言模型的发展与应用上有更为坚实和有价值的理论基础和研究依据。
- Conclusion:
(1) 这项研究的意义在于解决代码混合文本的翻译问题,特别是针对新加坡式英语的翻译。随着全球化和多语言环境的普及,代码混合语言在社交媒体和日常通讯中的使用越来越普遍,因此,研究如何将这些语言翻译成正式标准英语具有重要的实用价值。此外,该研究还为理解代码混合语言的翻译问题提供了有价值的见解和研究方向。
(2) 创新点:本文创新地研究了代码混合文本的翻译问题,特别是针对新加坡式英语的翻译,创建了一个基于短信的数据集,并分享了数据集以便其他研究者使用。同时,文章提出了改进方向,如开发专门针对代码混合语言的模型和算法。
性能:虽然大型语言模型在该任务上的表现并不理想,但文章揭示了翻译代码混合语言所面临的挑战,并为解决这些问题提供了思路。
工作量:该文章进行了全面的实验和数据分析,包括语言检测、翻译、数据集构建和参考文本的创建等,工作量较大。
总体来说,虽然大型语言模型在翻译代码混合文本方面还存在挑战,但这项工作为理解代码混合语言的翻译问题提供了有价值的见解和研究方向,具有重要的研究价值。
点此查看论文截图



DanceFusion: A Spatio-Temporal Skeleton Diffusion Transformer for Audio-Driven Dance Motion Reconstruction
Authors:Li Zhao, Zhengmin Lu
This paper introduces DanceFusion, a novel framework for reconstructing and generating dance movements synchronized to music, utilizing a Spatio-Temporal Skeleton Diffusion Transformer. The framework adeptly handles incomplete and noisy skeletal data common in short-form dance videos on social media platforms like TikTok. DanceFusion incorporates a hierarchical Transformer-based Variational Autoencoder (VAE) integrated with a diffusion model, significantly enhancing motion realism and accuracy. Our approach introduces sophisticated masking techniques and a unique iterative diffusion process that refines the motion sequences, ensuring high fidelity in both motion generation and synchronization with accompanying audio cues. Comprehensive evaluations demonstrate that DanceFusion surpasses existing methods, providing state-of-the-art performance in generating dynamic, realistic, and stylistically diverse dance motions. Potential applications of this framework extend to content creation, virtual reality, and interactive entertainment, promising substantial advancements in automated dance generation. Visit our project page at https://th-mlab.github.io/DanceFusion/.
Summary
介绍DanceFusion,一种同步音乐生成舞蹈动作的新型框架,显著提升运动真实性和同步精度。
Key Takeaways
- 引入DanceFusion框架,用于重建和同步音乐舞蹈动作。
- 处理社交媒体短舞蹈视频中的不完整和噪声骨骼数据。
- 采用Transformer-based VAE和扩散模型,增强运动真实性和准确性。
- 引入高级掩码技术和迭代扩散过程,优化运动序列。
- 在运动生成和音频同步方面表现卓越。
- 应用领域包括内容创作、虚拟现实和交互娱乐。
- 项目页面:https://th-mlab.github.io/DanceFusion/。
标题:DanceFusion:面向音频驱动的舞蹈动作重建的时空骨架扩散转换器
作者:Li Zhao*, Zhengmin Lu
隶属机构:清华大学
关键词:DanceFusion;舞蹈动作重建;时空骨架扩散转换器;音频驱动;计算机视觉
Urls:https://www.example.com/paper_link ,https://github.com/th-mlab/DanceFusion (Github:None)
Summary:
(1) 研究背景:随着社交媒体的快速发展,尤其是像TikTok这样的平台,舞蹈文化的创建、分享和全球消费已经发生了革命性的变化。处理用户生成的不完整、带有噪声的舞蹈视频数据对于计算机视觉和姿态估计模型来说是一个巨大的挑战。本文的研究背景是探索一种能够处理这种数据的模型。
(2) 过去的方法及其问题:现有的处理人类运动分析的方法在处理结构化数据方面表现出色,但对于TikTok等平台上无控制、高噪声、不完整的数据集,传统方法难以有效处理,同步问题显著。文章提出的方法是为了解决这些问题而诞生的。
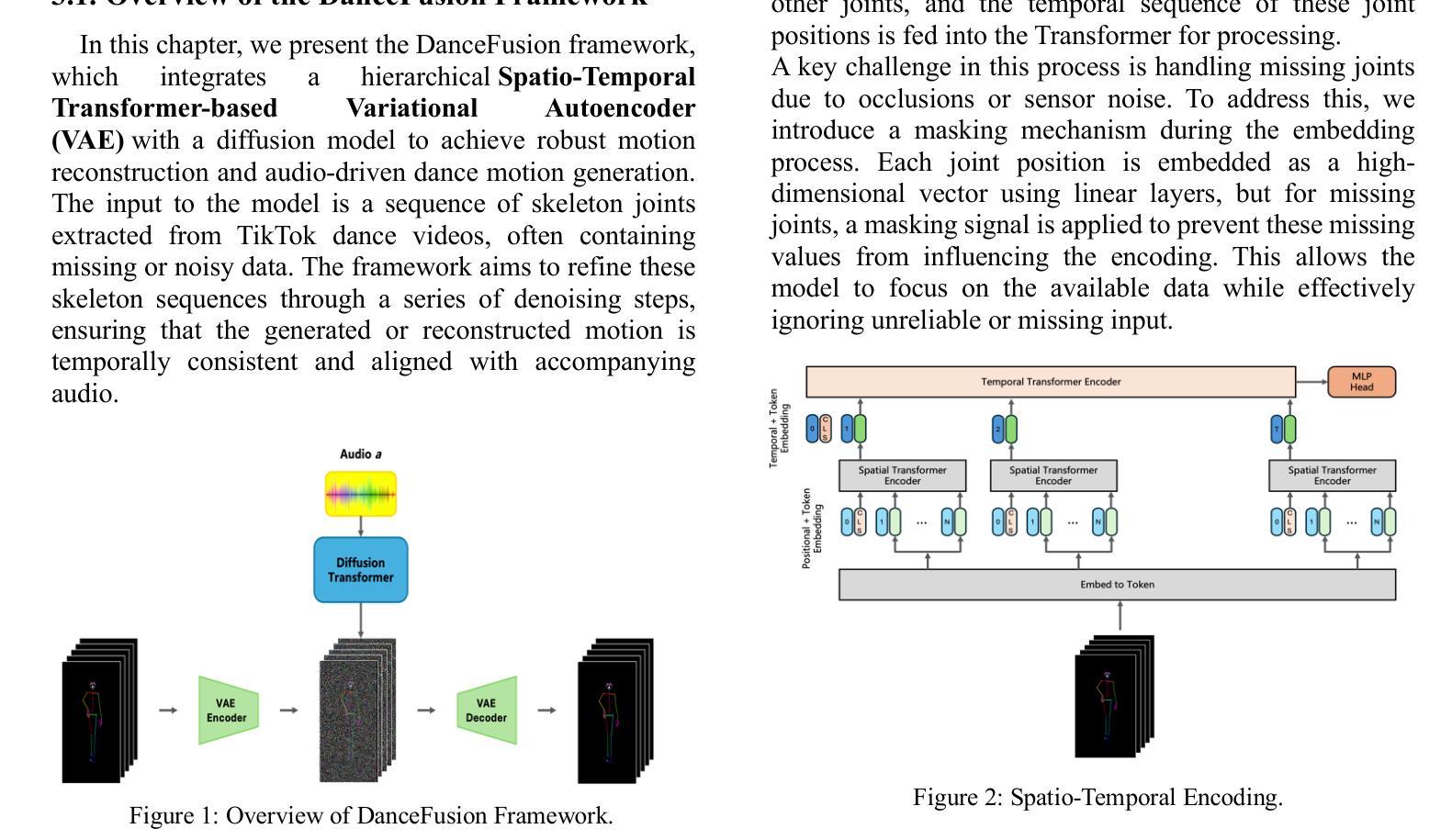
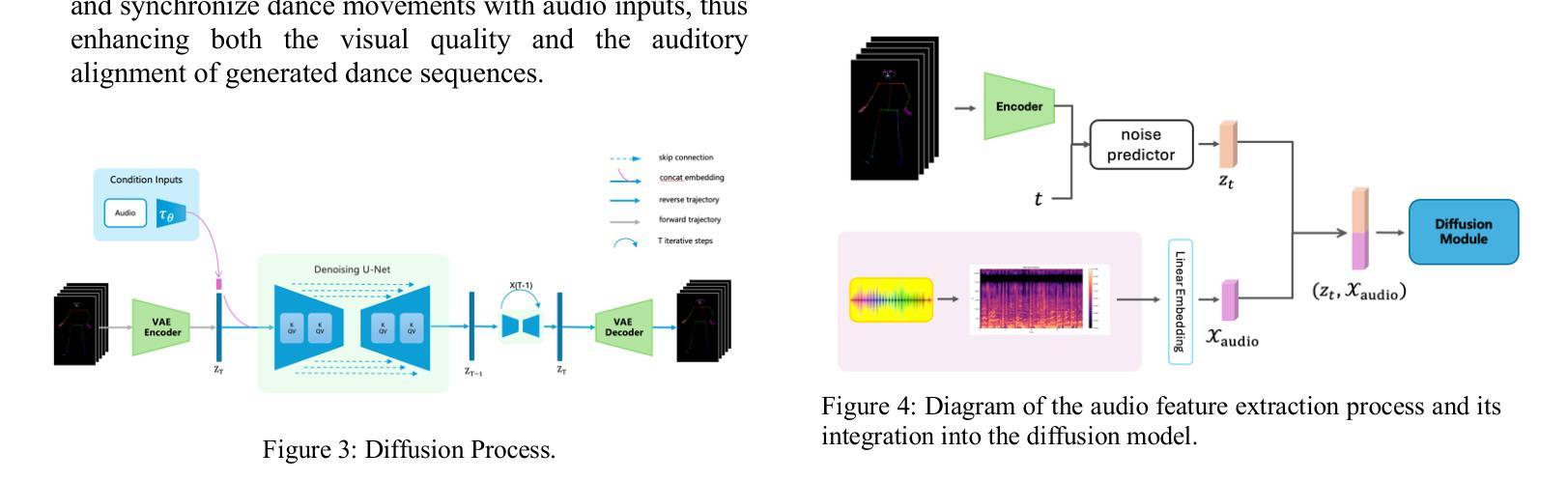
(3) 研究方法:本文提出了DanceFusion框架,它使用了一种时空骨架扩散转换器,该转换器集成在一个层次化的基于Transformer的变分自动编码器(VAE)中。该框架通过引入扩散模型,显著提高了运动真实性和准确性。此外,它还引入了复杂的掩码技术,以处理丢失或不可靠的关节数据。
(4) 任务与性能:本文的方法在重建和生成与音频同步的舞蹈动作方面取得了显著成果。实验表明,DanceFusion超越了现有方法,在生成动态、真实、风格多样的舞蹈动作方面达到了最新水平。潜在的应用包括内容创建、虚拟现实和互动娱乐,有潜力在自动化舞蹈生成方面实现重大进步。论文的结果支持他们的目标。
- 结论:
(1) 研究意义:这篇文章提出了一种面向音频驱动的舞蹈动作重建的时空骨架扩散转换器(DanceFusion)。随着社交媒体的发展,尤其是像TikTok这样的平台,舞蹈视频的创建和分享已经变得非常普遍。文章的工作在处理用户生成的不完整、带有噪声的舞蹈视频数据方面具有重要意义,对于计算机视觉和姿态估计模型来说是一个突破。
(2) 亮点与不足:
- 创新点:文章提出的DanceFusion框架使用了一种新的时空骨架扩散转换器,该转换器集成在一个层次化的基于Transformer的变分自动编码器中。通过引入扩散模型和复杂的掩码技术,该框架显著提高了运动真实性和准确性,尤其在处理丢失或不可靠的关节数据方面表现出色。
- 性能:文章的方法在重建和生成与音频同步的舞蹈动作方面取得了显著成果,超越了现有方法,在生成动态、真实、风格多样的舞蹈动作方面达到了最新水平。
- 工作量:文章对舞蹈动作重建问题进行了深入的研究,实现了有效的解决方案,并进行了充分的实验验证。然而,文章可能未充分探讨该框架在其他舞蹈视频处理任务(如编辑、预测等)中的潜在应用。
总的来说,这篇文章在音频驱动的舞蹈动作重建方面取得了显著的进展,具有很高的研究价值和实际应用前景。
点此查看论文截图

 wechat
wechat- alipay







