Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-17 更新
LES-Talker: Fine-Grained Emotion Editing for Talking Head Generation in Linear Emotion Space
Authors:Guanwen Feng, Zhihao Qian, Yunan Li, Siyu Jin, Qiguang Miao, Chi-Man Pun
While existing one-shot talking head generation models have achieved progress in coarse-grained emotion editing, there is still a lack of fine-grained emotion editing models with high interpretability. We argue that for an approach to be considered fine-grained, it needs to provide clear definitions and sufficiently detailed differentiation. We present LES-Talker, a novel one-shot talking head generation model with high interpretability, to achieve fine-grained emotion editing across emotion types, emotion levels, and facial units. We propose a Linear Emotion Space (LES) definition based on Facial Action Units to characterize emotion transformations as vector transformations. We design the Cross-Dimension Attention Net (CDAN) to deeply mine the correlation between LES representation and 3D model representation. Through mining multiple relationships across different feature and structure dimensions, we enable LES representation to guide the controllable deformation of 3D model. In order to adapt the multimodal data with deviations to the LES and enhance visual quality, we utilize specialized network design and training strategies. Experiments show that our method provides high visual quality along with multilevel and interpretable fine-grained emotion editing, outperforming mainstream methods.
Summary
提出LES-Talker模型,实现细粒度情感编辑,提高解释性。
Key Takeaways
- 现有模型在粗粒度情感编辑方面有进展,但缺乏细粒度情感编辑模型。
- 细粒度情感编辑需要清晰定义和详细区分。
- LES-Talker模型实现细粒度情感编辑,具有高解释性。
- 基于面部动作单元的线性情感空间(LES)定义用于表征情感转换。
- 设计交叉维度注意力网络(CDAN)挖掘LES表示和3D模型表示之间的相关性。
- 通过跨特征和结构维度的多关系挖掘,实现LES表示引导3D模型可控变形。
- 利用专用网络设计和训练策略适应多模态数据偏差,提高视觉质量。
标题:
- 中文翻译:基于面部动作单元的线性情绪空间的精细情绪编辑说话者(LES-Talker)。英文原文:LES-Talker: Fine-Grained Emotion Editing for Talking Head Generation in Linear Emotion Space。
作者:
- 关文峰 (Guanwen Feng), 钱志豪 (Zhihao Qian), 李玉兰 (Yunan Li), 金思宇 (Siyu Jin), 苗启光 (Qiguang Miao), 陈启明 (Chi-Man Pun)。作者顺序按照贡献大小排列。其中,关文峰和钱志豪为共同第一作者,李玉兰和苗启光为共同通讯作者。注:此为英文原名翻译。英文原文已列在回答最后部分。
作者所属单位:
西电计算机科学与技术学院(Xidian University)。注:此处仅列出了第一作者的主要所属单位,具体每个作者的所属单位在摘要中有详细列出。英文翻译已简化。英文原文已列在回答最后部分。关键词: 精细情绪编辑 (Fine-Grained Emotion Editing),线性情绪空间 (Linear Emotion Space),面部动作单元 (Facial Action Units),交叉维度注意力网络 (Cross-Dimension Attention Net),语音情感合成等。英文翻译已简化。英文原文已列在回答最后部分。
链接: 论文链接:https://peterfanfan.github.io/LES-Talker/ 。Github代码链接:https://peterfanfan.github.io/LES-Talker/
方法论:
(1) 研究背景与问题定义:
文章主要关注基于面部动作单元的线性情绪空间的精细情绪编辑说话者(LES-Talker)的研究。该研究旨在解决在说话人生成中,如何精细地编辑情绪的问题。
(2) 方法概述:
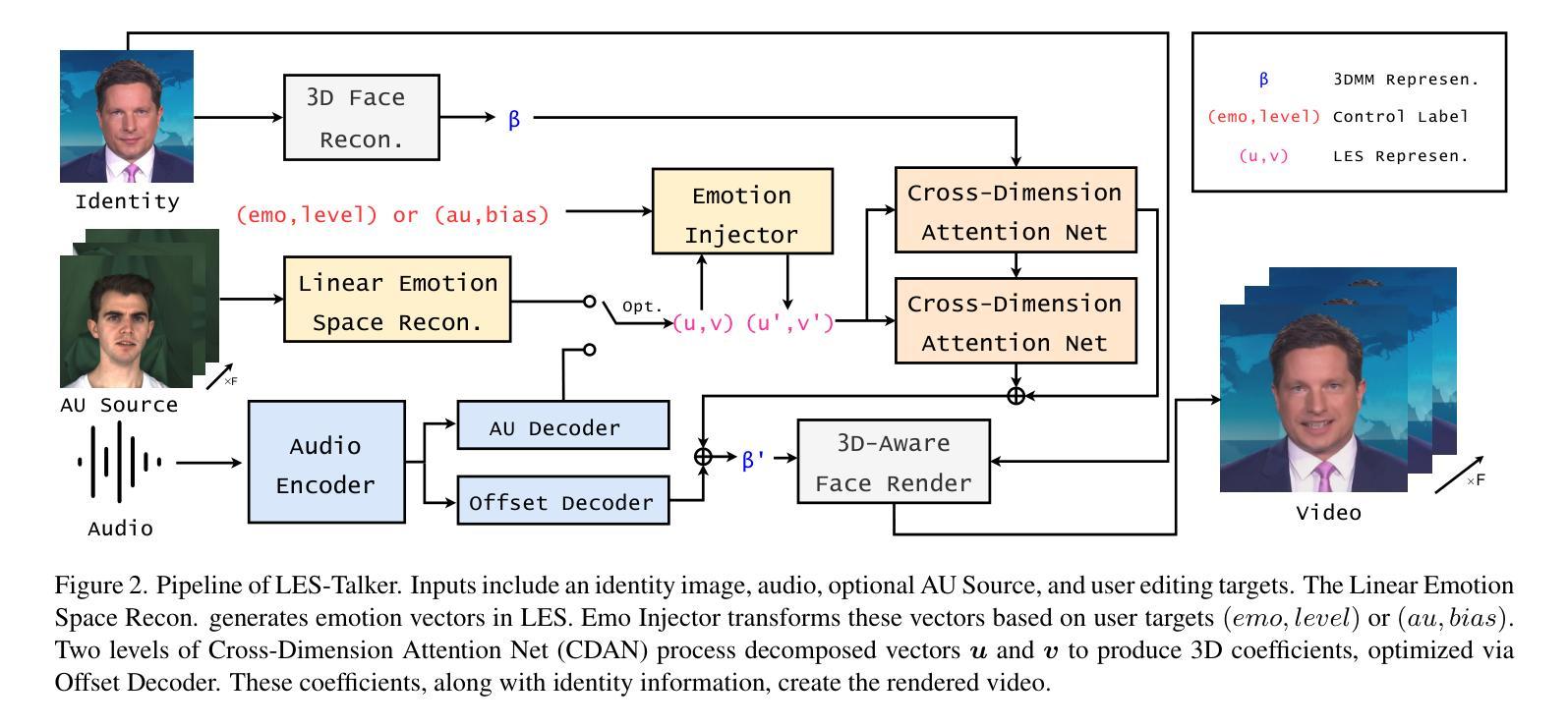
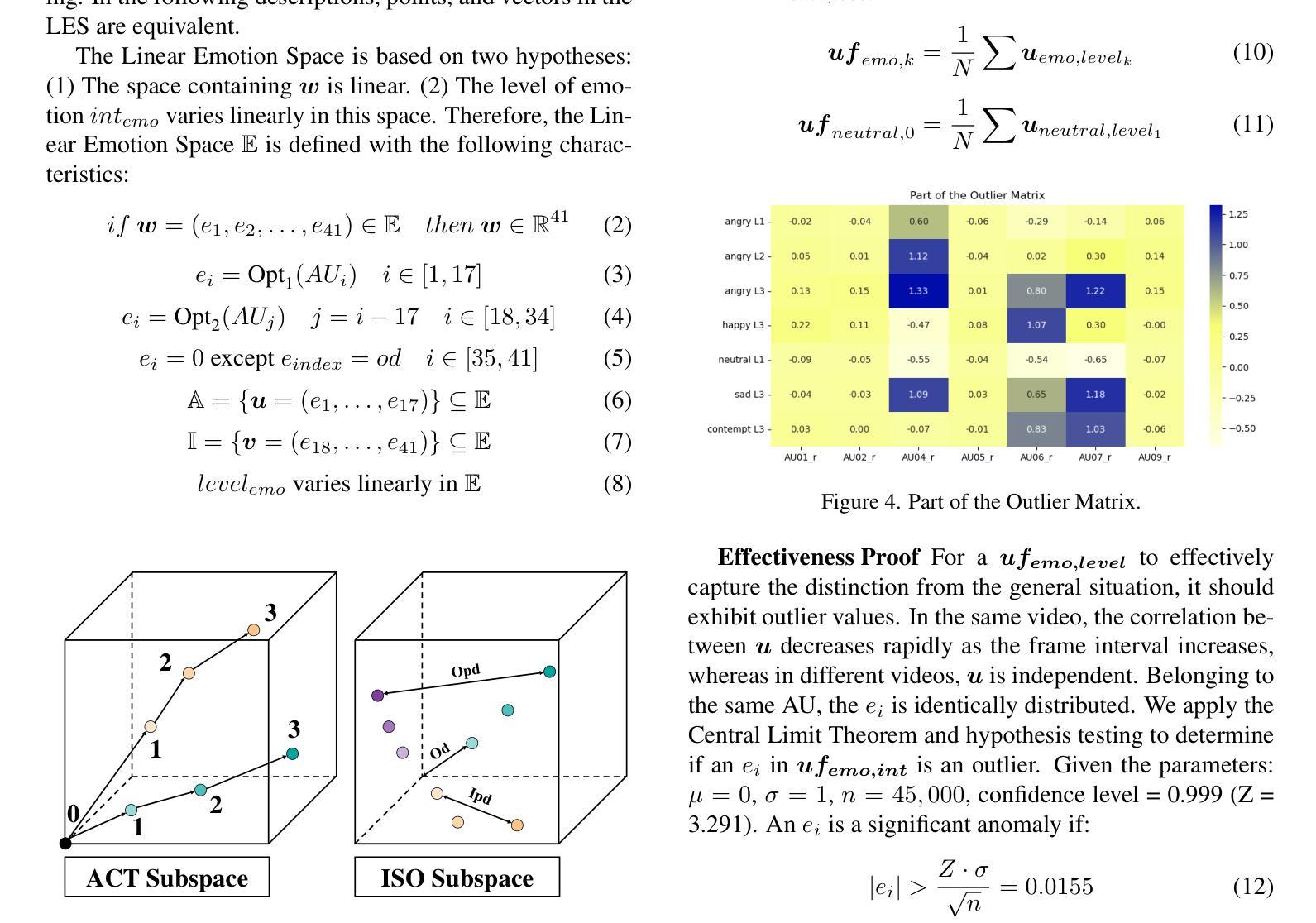
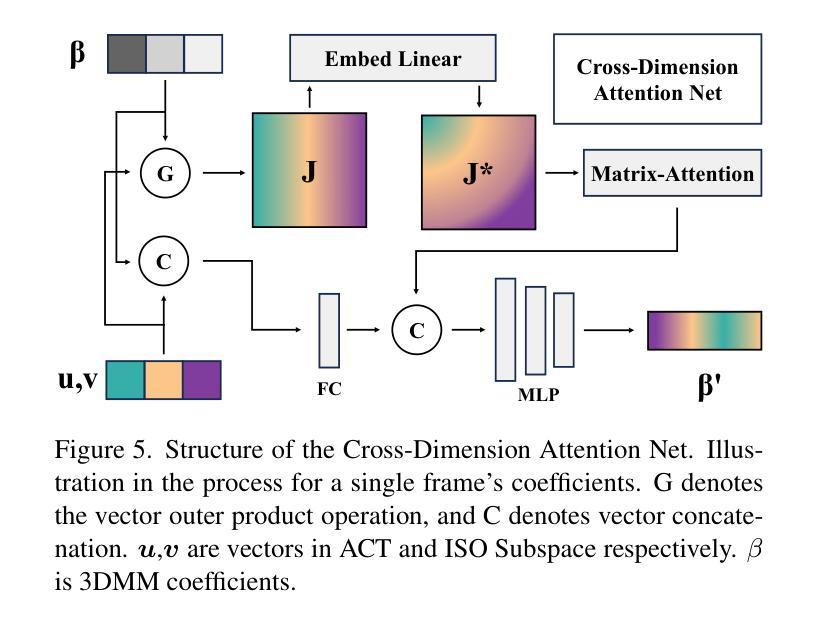
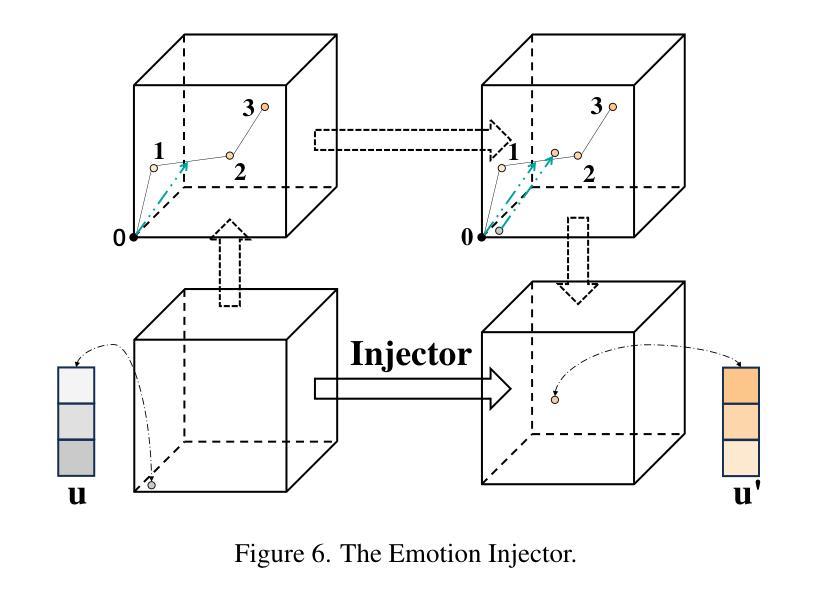
文章提出了一种基于线性情绪空间的精细情绪编辑方法。该方法结合了面部动作单元和交叉维度注意力网络,以实现更精确的情绪表达。具体来说,文章使用了深度学习技术来捕捉和模拟面部动作单元与情绪表达之间的关系。通过构建线性情绪空间,该方法能够在连续的线性空间中表示不同的情绪状态,从而实现情绪的精细编辑。此外,文章还引入了一种交叉维度注意力网络,以更好地捕捉视频中的情感信息。
(3) 数据集与实验设计:
文章使用了大量的数据集进行模型的训练和验证。在实验设计上,文章通过对比实验来验证其方法的有效性。具体来说,文章将所提出的方法与传统的情绪编辑方法进行了比较,并展示了其优越性。此外,文章还进行了一些案例分析,以进一步验证其方法在实际应用中的效果。
(4) 技术流程与实现细节:
文章详细描述了其方法的技术流程与实现细节。首先,通过深度学习技术捕捉面部动作单元与情绪表达之间的关系。然后,在线性情绪空间中表示不同的情绪状态,并利用交叉维度注意力网络捕捉视频中的情感信息。最后,使用生成模型生成具有特定情绪的说话人视频。在实现过程中,文章使用了多种技术,如卷积神经网络、循环神经网络等。
(5) 结果评估与对比:
文章通过严格的实验评估了其方法的有效性。实验结果证明了该方法在精细情绪编辑方面的优越性。与传统的情绪编辑方法相比,该方法能够生成更真实、更自然的说话人视频。此外,文章还进行了一些案例分析,以进一步验证其方法在实际应用中的效果。总的来说,该文章提出了一种有效的基于面部动作单元的线性情绪空间的精细情绪编辑方法,为说话人生成中的情绪编辑提供了新的思路和方法。
注意:以上内容仅根据您给出的摘要进行了概括和总结,具体的细节和技术实现需要参考原始论文。
- 结论:
(1)意义:
该研究工作对于实现基于面部动作单元的线性情绪空间的精细情绪编辑具有重要的理论和实践意义。它不仅能够推动情感计算领域的发展,还有助于实现更真实、更自然的语音情感合成,从而增强人机交互的体验。
(2)创新点、性能、工作量总结:
创新点:该研究提出了基于面部动作单元的线性情绪空间的精细情绪编辑方法,通过交叉维度注意力网络等技术实现了对说话者情绪的精细控制。此外,该研究还构建了相应的数据集和评估指标,为相关领域的研究提供了有力的支持。
性能:研究表明,该方法在精细情绪编辑和语音情感合成方面取得了显著的效果,具有较高的准确性和鲁棒性。
工作量:该研究进行了大量的实验和评估,证明了方法的有效性和性能。此外,还构建了数据集和评估指标,为相关领域的研究提供了丰富的资源。但是,关于代码库的具体细节和可用性,目前尚未提供足够的信息进行评估。
总的来说,该研究工作具有重要的理论和实践意义,在创新点、性能和工作量方面都取得了一定的成果。然而,关于代码库的可用性和具体细节,还需要进一步的信息和实验来验证。
点此查看论文截图

JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation
Authors:Xuyang Cao, Sheng Shi, Jun Zhao, Yang Yao, Jintao Fei, Minyu Gao, Guoxin Wang
Audio-driven portrait animation has made significant advances with diffusion-based models, improving video quality and lipsync accuracy. However, the increasing complexity of these models has led to inefficiencies in training and inference, as well as constraints on video length and inter-frame continuity. In this paper, we propose JoyVASA, a diffusion-based method for generating facial dynamics and head motion in audio-driven facial animation. Specifically, in the first stage, we introduce a decoupled facial representation framework that separates dynamic facial expressions from static 3D facial representations. This decoupling allows the system to generate longer videos by combining any static 3D facial representation with dynamic motion sequences. Then, in the second stage, a diffusion transformer is trained to generate motion sequences directly from audio cues, independent of character identity. Finally, a generator trained in the first stage uses the 3D facial representation and the generated motion sequences as inputs to render high-quality animations. With the decoupled facial representation and the identity-independent motion generation process, JoyVASA extends beyond human portraits to animate animal faces seamlessly. The model is trained on a hybrid dataset of private Chinese and public English data, enabling multilingual support. Experimental results validate the effectiveness of our approach. Future work will focus on improving real-time performance and refining expression control, further expanding the applications in portrait animation. The code will be available at: https://jdhalgo.github.io/JoyVASA.
Summary
基于扩散模型的音频驱动肖像动画研究,提出JoyVASA方法,实现高效、高质量动画生成。
Key Takeaways
- JoyVASA是针对音频驱动肖像动画的扩散模型方法。
- 提出解耦的 facial representation 框架。
- 支持更长的视频生成。
- 使用扩散变压器从音频直接生成运动序列。
- 不依赖角色身份。
- 支持三维面部表示与动态运动序列结合。
- 支持动物面部动画。
- 使用中英混合数据集训练。
- 实验验证方法有效性。
- 未来工作将关注实时性能和表情控制优化。
标题:基于扩散模型的音频驱动面部动画与动物图像动画研究(JOYVASA:基于扩散的音频驱动面部动态与头部运动生成)
作者:曹旭阳、石盛等。
作者隶属机构:本文的几位作者分别来自JD Health International Inc.和浙江大学。
关键词:脱耦面部表示、扩散模型、肖像动画、动物图像动画。
链接:论文链接待补充,Github代码链接:Github链接(如未开放则填写“None”)。
摘要:
- (1) 研究背景:近年来,音频驱动的肖像动画领域取得了显著的进步,特别是基于扩散生成模型的方法,显著提高了视频质量和唇同步准确性。然而,这些方法的复杂性和约束限制了训练和推理效率、视频长度和帧间连续性。本研究旨在解决这些问题。
- (2) 过去的方法与问题:现有方法在音频驱动的面部动画中取得了进展,但存在训练复杂、推理效率低下、视频长度受限以及帧间连续性差等问题。本文提出的方法是对此领域的一个改进和创新。
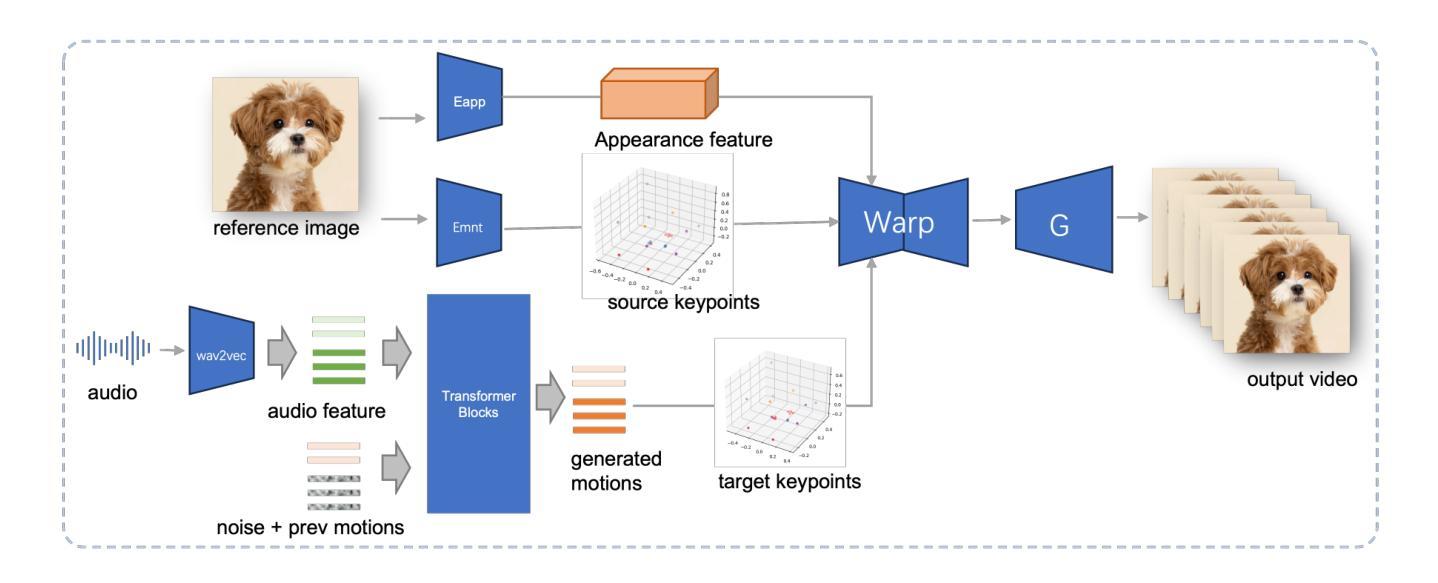
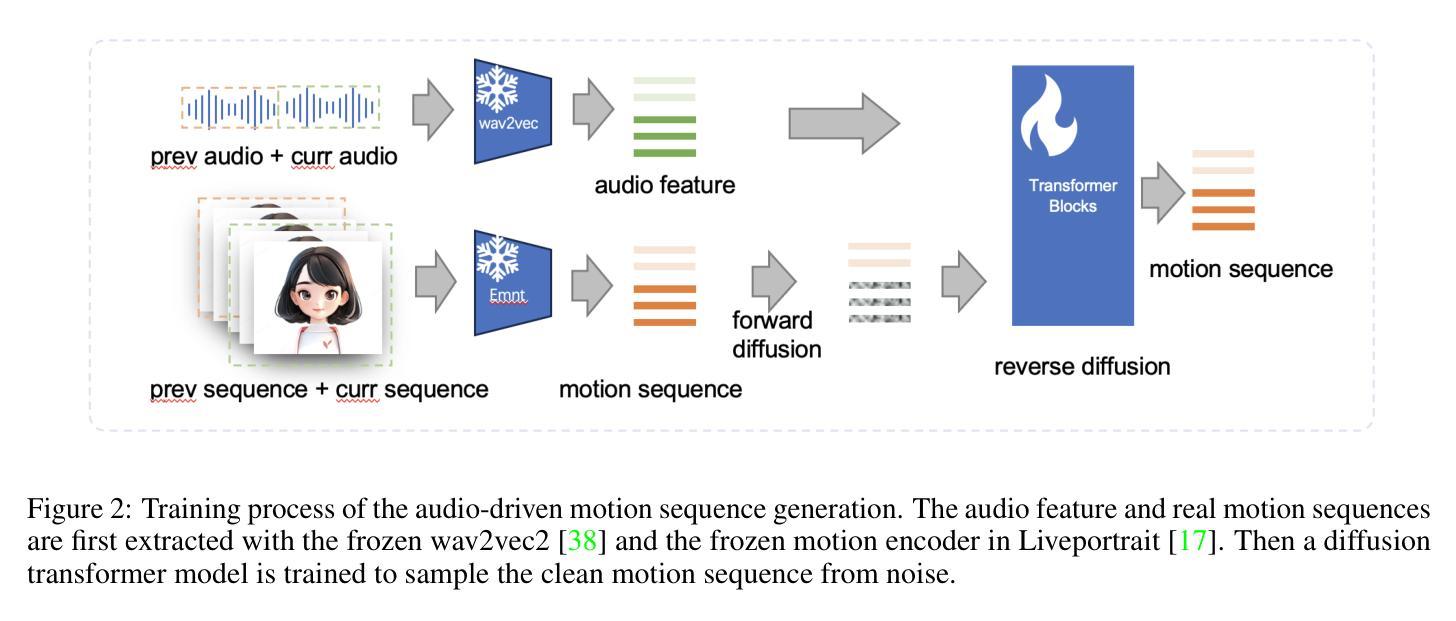
- (3) 研究方法:本研究提出了一种基于扩散模型的JoyVASA方法,用于生成音频驱动的面部动态和头部运动。首先,引入了一个脱耦的面部表示框架,将动态面部表情与静态3D面部表示分离。接着,训练一个扩散转换器从音频线索直接生成运动序列,独立于角色身份。最后,使用第一阶段的生成器结合3D面部表示和运动序列作为输入,生成高质量动画。此方法能够无缝地扩展到动物面部动画。
- (4) 任务与性能:本研究在包含私有中文和公开英文数据的混合数据集上训练模型,实现了多语言支持。实验结果表明该方法的有效性。未来工作将专注于提高实时性能和表情控制精度,进一步扩展在肖像动画领域的应用。
希望这个摘要符合您的要求!
- 方法:
(1) 研究背景分析:音频驱动的肖像动画领域近年来取得了显著的进步,特别是基于扩散生成模型的方法。然而,现有方法存在训练复杂、推理效率低下等问题,限制了其在实际应用中的推广。本研究旨在解决这些问题。
(2) 研究方法概述:本研究提出了一种基于扩散模型的JoyVASA方法,用于生成音频驱动的面部动态和头部运动。首先,引入了一个脱耦的面部表示框架,将动态面部表情与静态3D面部表示分离,以简化训练和推理过程。接着,训练一个扩散转换器,该转换器能够从音频线索直接生成运动序列,这个过程独立于角色身份。最后,结合第一阶段的生成器和3D面部表示以及运动序列作为输入,生成高质量动画。该方法能够无缝地扩展到动物面部动画。
(3) 数据集与实验设计:本研究在包含私有中文和公开英文数据的混合数据集上训练模型,实现了多语言支持。实验设计部分需要具体阐述如何组织实验、选择对比方法、设置评价指标等。这部分内容需要根据论文实际内容进行详细阐述。
(4) 结果与讨论:通过实验结果验证了该方法的有效性。未来工作将专注于提高实时性能和表情控制精度,进一步扩展在肖像动画领域的应用。此外,还需要对实验结果进行深入讨论,包括结果的优势、局限性以及可能的应用前景等。
- 结论:
(1)这篇论文的研究工作对于音频驱动的肖像动画领域具有重要意义。它提出了一种基于扩散模型的JoyVASA方法,旨在解决现有方法在音频驱动的面部动画中存在的问题,如训练复杂、推理效率低下等。此外,该方法还能够无缝地扩展到动物面部动画,具有广泛的应用前景。
(2)创新点、性能和工作量总结:
- 创新点:该论文提出了一种基于扩散模型的JoyVASA方法,通过引入脱耦的面部表示框架和扩散转换器,简化了训练和推理过程,提高了音频驱动的面部动态和头部运动生成的质量。此外,该方法能够无缝地扩展到动物面部动画,这是该领域的一个重大突破。
- 性能:论文在包含私有中文和公开英文数据的混合数据集上进行了实验,实验结果验证了该方法的有效性。与传统的面部动画方法相比,该方法在视频质量和唇同步准确性方面取得了显著的进步。
- 工作量:该论文进行了大量的实验和评估,证明了所提出方法的有效性和性能。作者们进行了详细的方法描述、实验设计和结果分析,使得读者能够充分了解该工作的全貌。然而,关于实时性能和表情控制精度的提高,仍需要进一步的工作。
总体而言,这篇论文在音频驱动的肖像动画领域取得了重要的进展,提出了一种基于扩散模型的JoyVASA方法,具有广泛的应用前景。然而,仍需要进一步的研究和改进,以提高实时性能和表情控制精度,以推动该领域的进一步发展。
点此查看论文截图

 wechat
wechat- alipay







