元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-21 更新
ResLearn: Transformer-based Residual Learning for Metaverse Network Traffic Prediction
Authors:Yoga Suhas Kuruba Manjunath, Mathew Szymanowski, Austin Wissborn, Mushu Li, Lian Zhao, Xiao-Ping Zhang
Our work proposes a comprehensive solution for predicting Metaverse network traffic, addressing the growing demand for intelligent resource management in eXtended Reality (XR) services. We first introduce a state-of-the-art testbed capturing a real-world dataset of virtual reality (VR), augmented reality (AR), and mixed reality (MR) traffic, made openly available for further research. To enhance prediction accuracy, we then propose a novel view-frame (VF) algorithm that accurately identifies video frames from traffic while ensuring privacy compliance, and we develop a Transformer-based progressive error-learning algorithm, referred to as ResLearn for Metaverse traffic prediction. ResLearn significantly improves time-series predictions by using fully connected neural networks to reduce errors, particularly during peak traffic, outperforming prior work by 99%. Our contributions offer Internet service providers (ISPs) robust tools for real-time network management to satisfy Quality of Service (QoS) and enhance user experience in the Metaverse.
Summary
提出预测元宇宙网络流量的综合解决方案,提升XR服务资源管理的智能化水平。
Key Takeaways
- 构建涵盖VR、AR和MR的真实数据集测试平台。
- 提出隐私合规的VF算法识别视频帧。
- 开发基于Transformer的ResLearn算法提高预测准确性。
- ResLearn通过全连接神经网络降低误差,尤其在高峰期。
- 突破前人工作,预测准确率提升99%。
- 为ISP提供实时网络管理工具,优化元宇宙用户体验。
Title: 《ResLearn: 基于Transformer的残差学习用于元宇宙网络流量预测》
Authors: Yoga Suhas Kuruba Manjunath, Mathew Szymanowski, Austin Wissborn, Mushu Li, Lian Zhao, and Xiao-Ping Zhang
Affiliation:
- Yoga Suhas Kuruba Manjunath, Mathew Szymanowski, and Austin Wissborn are from the Department of Electrical, Computer & Biomedical Engineering at Toronto Metropolitan University in Canada.
- Mushu Li is from the Department of Computer Science and Engineering at Lehigh University in the United States.
- Lian Zhao is also affiliated with Toronto Metropolitan University.
- Xiao-Ping Zhang is from the Shenzhen Key Laboratory of Ubiquitous Data Enabling at Tsinghua Shenzhen International Graduate School in China.
Keywords: Metaverse Network Traffic Prediction, Residual Learning, Extended Reality (XR), virtual reality (VR), augmented reality (AR), mixed reality (MR)
Urls: Paper Link (To be provided after publication), Github Code Link (Github: None)
Summary:
(1)研究背景:随着元宇宙(Metaverse)的快速发展,尤其是扩展现实(XR)技术的普及,元宇宙网络流量预测变得越来越重要。本文旨在提出一种用于预测元宇宙网络流量的综合解决方案,以满足智能资源管理的高服务质量(QoS)需求,提高用户体验。
-(2)过去的方法及问题:现有研究中,对于元宇宙网络流量的预测主要依赖于传统的机器学习模型或深度学习模型。然而,这些方法在预测精度和实时性方面存在不足,特别是在处理复杂的、非线性的时间序列数据时表现不佳。此外,现有研究缺乏真实世界的元宇宙数据集,使得预测模型的性能评估受到限制。
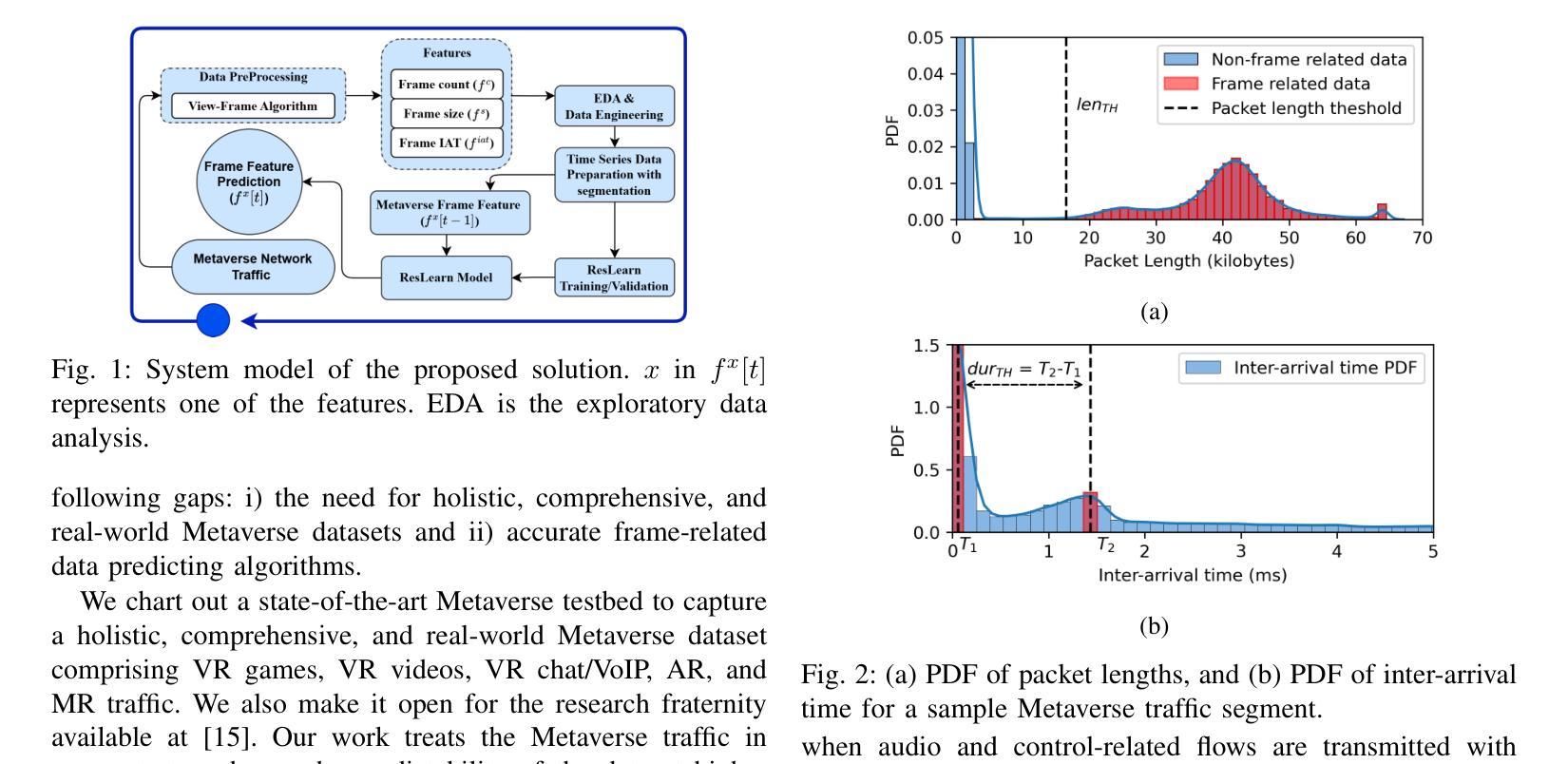
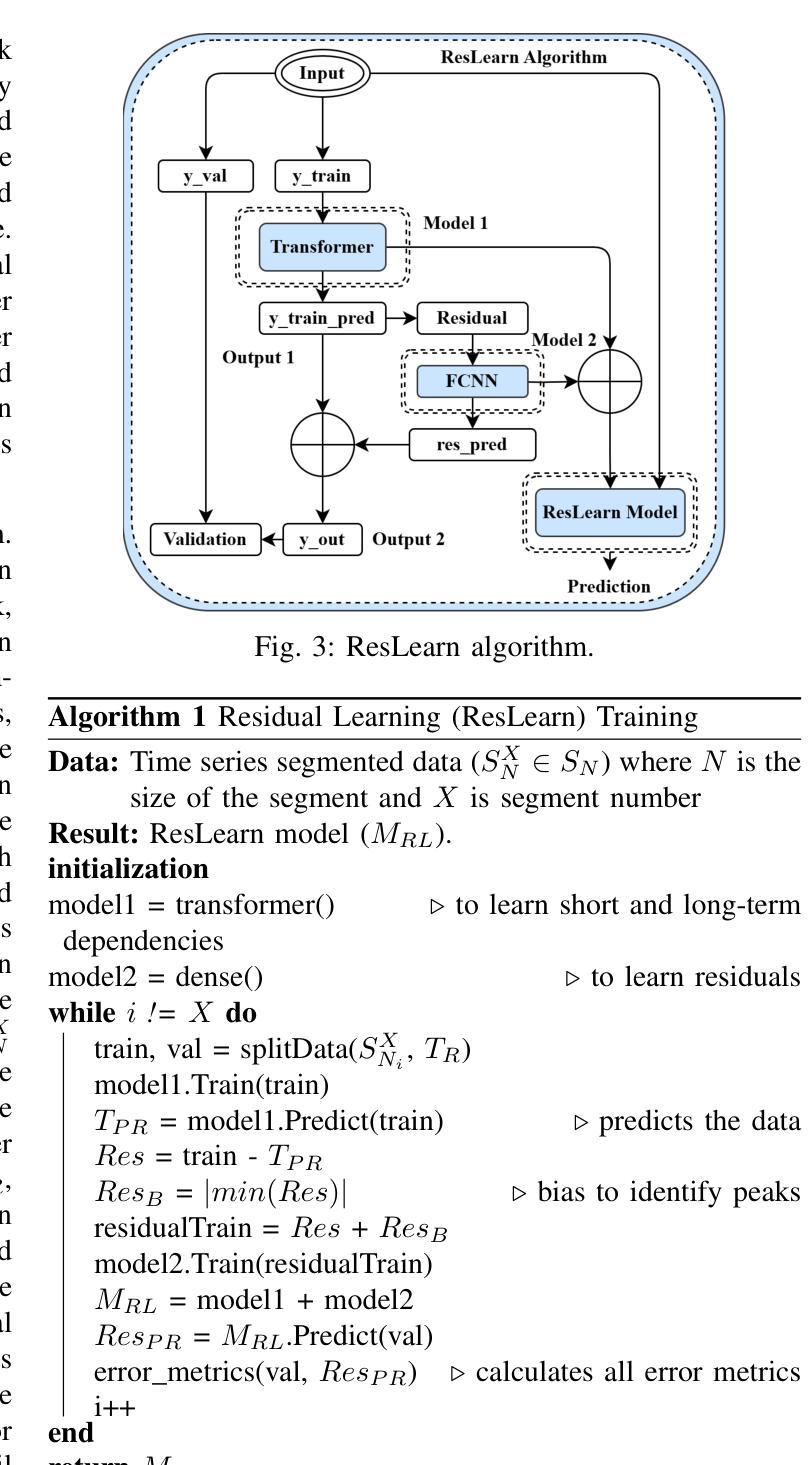
-(3)研究方法:针对上述问题,本文提出了一种基于Transformer的残差学习算法(ResLearn)进行元宇宙网络流量预测。首先,引入了一种先进的测试平台来捕获虚拟现实(VR)、增强现实(AR)和混合现实(MR)的真实世界数据集,并公开用于进一步研究。其次,提出了一种新颖的视图帧(VF)算法,能够准确地从流量中识别视频帧,同时确保隐私合规性。最后,开发了基于Transformer的渐进误差学习算法进行流量预测。该算法利用全连接神经网络来减少误差,特别是在高峰时段,性能优于先前的工作。
-(4)任务与性能:本文的方法在预测元宇宙网络流量方面取得了显著成果。在真实世界数据集上的实验结果表明,ResLearn算法在预测精度和实时性方面均优于现有方法,特别是在峰值流量期间的预测效果更加显著。本文的贡献为互联网服务提供商(ISPs)提供了实时网络管理的稳健工具,为维持高质量的服务和提高用户体验提供了支持。
- 结论:
(1) 研究意义:随着元宇宙(Metaverse)的快速发展,该研究工作对于元宇宙网络流量预测具有重要意义。该研究旨在提高预测精度和实时性,满足智能资源管理的高服务质量(QoS)需求,从而提升用户体验。
(2) 综述创新点、性能、工作量:
创新点:文章提出了一种基于Transformer的残差学习算法(ResLearn)进行元宇宙网络流量预测,这是一种新的视角和方法。此外,文章还引入了先进的测试平台来捕获VR、AR和MR的真实世界数据集,并公开用于进一步研究,这也是一个重大的贡献。
性能:在真实世界数据集上的实验结果表明,ResLearn算法在预测精度和实时性方面均优于现有方法,特别是在峰值流量期间的预测效果更加显著。这为互联网服务提供商(ISPs)提供了实时网络管理的稳健工具。
工作量:文章对元宇宙网络流量的预测问题进行了深入研究,从研究背景、现有方法的问题、研究方法、实验任务与性能等方面进行了全面的阐述,工作量较大。
总的来说,这篇文章在元宇宙网络流量预测方面取得了显著的成果,具有一定的创新性和实用性。
点此查看论文截图

GGAvatar: Reconstructing Garment-Separated 3D Gaussian Splatting Avatars from Monocular Video
Authors:Jingxuan Chen
Avatar modelling has broad applications in human animation and virtual try-ons. Recent advancements in this field have focused on high-quality and comprehensive human reconstruction but often overlook the separation of clothing from the body. To bridge this gap, this paper introduces GGAvatar (Garment-separated 3D Gaussian Splatting Avatar), which relies on monocular videos. Through advanced parameterized templates and unique phased training, this model effectively achieves decoupled, editable, and realistic reconstruction of clothed humans. Comparative evaluations with other costly models confirm GGAvatar’s superior quality and efficiency in modelling both clothed humans and separable garments. The paper also showcases applications in clothing editing, as illustrated in Figure 1, highlighting the model’s benefits and the advantages of effective disentanglement. The code is available at https://github.com/J-X-Chen/GGAvatar/.
PDF MMAsia’24 Accepted
Summary
该论文提出GGAvatar模型,通过单目视频实现服装分离的人体建模,提高了建模质量与效率。
Key Takeaways
- GGAvatar模型利用单目视频进行服装分离的人体建模。
- 采用参数化模板和独特分阶段训练实现服装与人体分离。
- 模型实现服装的可编辑性和真实感。
- 与其他模型相比,GGAvatar在建模质量和效率上更优。
- 应用在服装编辑中,展示了模型的优点。
- 模型代码开源。
- 模型可分离服装,具有有效解耦特性。
标题:基于单目视频的衣物分离三维高斯重建虚拟角色模型研究
作者:陈静轩
所属机构:英国伯明翰大学与暨南大学联合研究所(中国广州)
关键词:三维高斯重建(3DGS),新颖视角合成,衣饰重建,衣物编辑
代码链接:根据提供的链接,Github代码链接为:Github链接地址。但请注意,如果链接不可用或无代码提供,则填写为“Github:None”。
摘要:
(1)研究背景:本文研究了计算机图形学和计算机视觉中的一项重要任务,即重建真实感衣物的数字人类及其服饰。随着技术的发展,尽管已经出现了许多重建方法,但如何快速高效且准确地重建衣物的数字人类仍然是一个挑战。本文旨在解决这一问题。
(2)过去的方法及问题:过去的重建方法主要集中在高质感的整体人类重建上,但往往忽略了衣物与身体的分离。虽然最近的模型尝试使用神经网络渲染技术来捕捉表面精细纹理,但它们通常需要大量的训练时间和计算资源。此外,由于缺乏解耦功能,这些模型的实用性在现实世界场景中受到限制。因此,需要一种既能快速重建又能实现衣物与身体分离的方法。
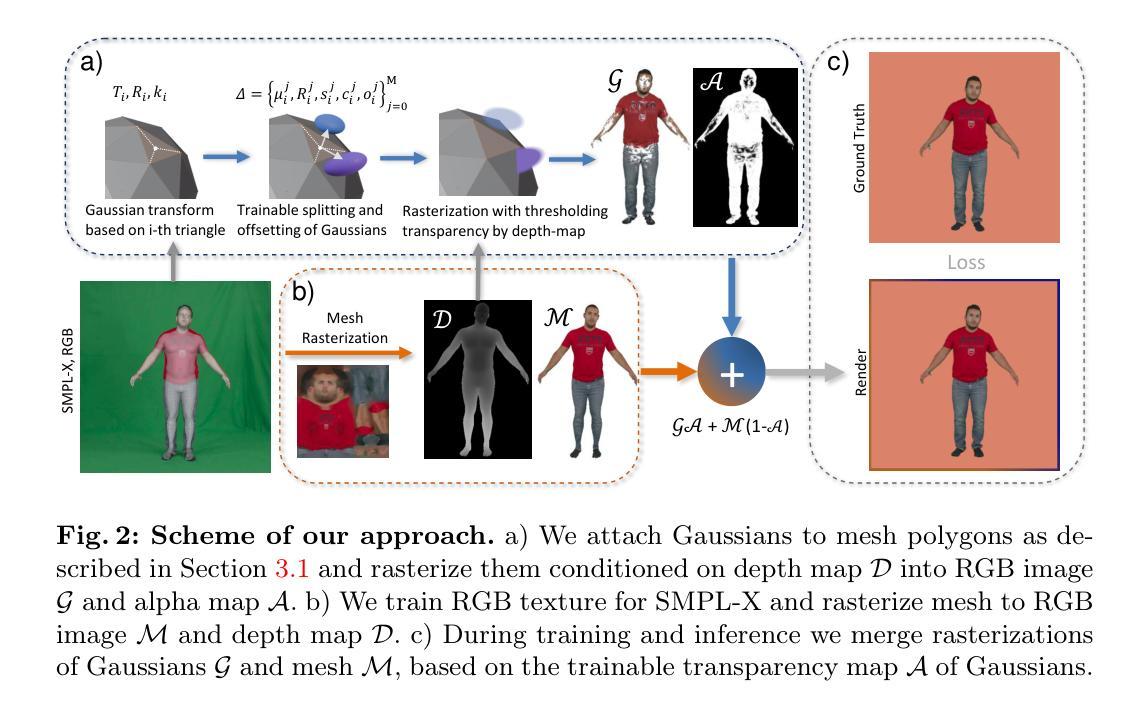
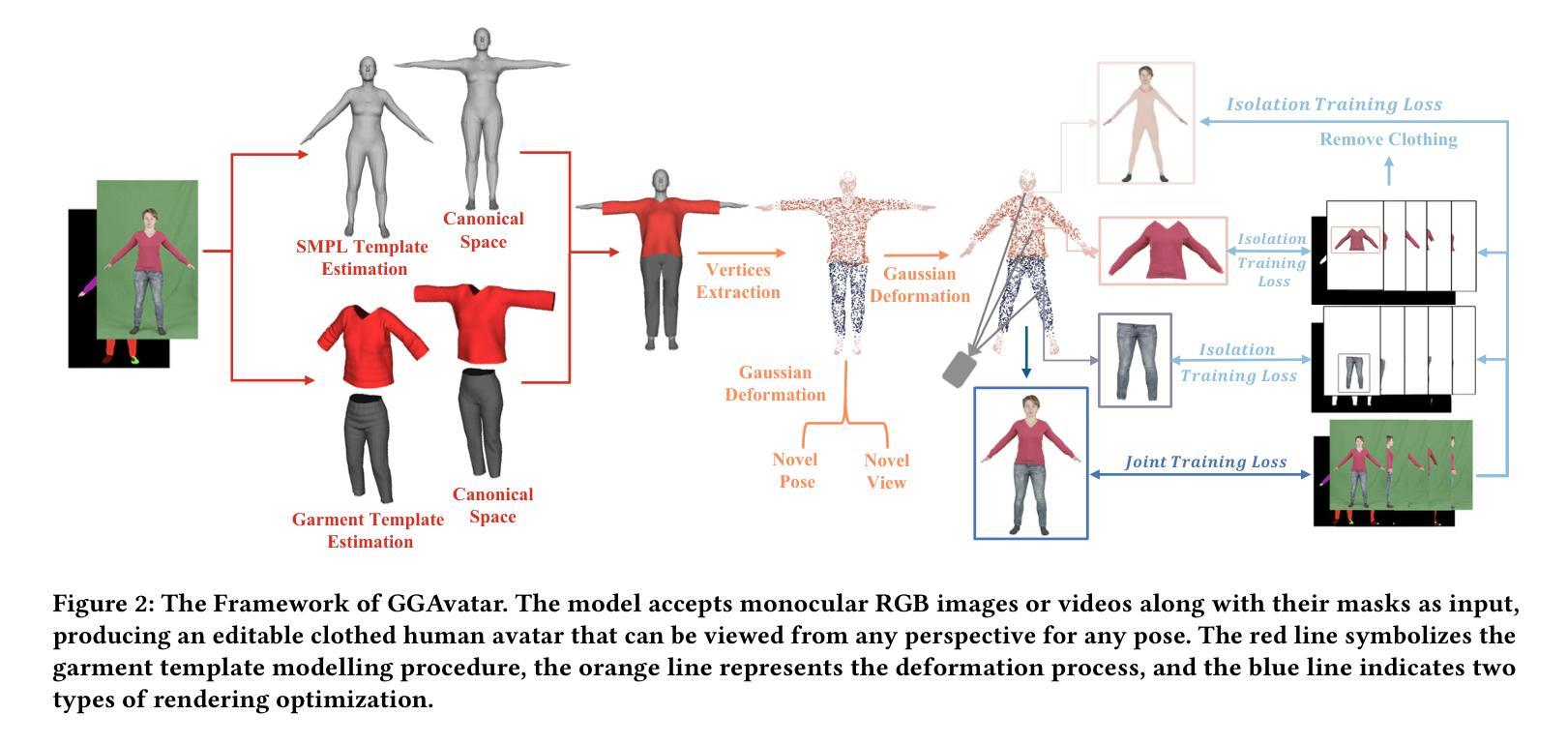
(3)研究方法:针对上述问题,本文提出了GGAvatar模型,即基于单目视频的衣物分离三维高斯重建虚拟角色模型。该模型采用参数化模板和分阶段训练策略,实现了快速、可编辑和逼真的衣物分离重建。通过利用先进的参数化模板和独特的分阶段训练策略,该模型有效地实现了衣物的解耦和重建。此外,该模型还支持衣物编辑等应用。
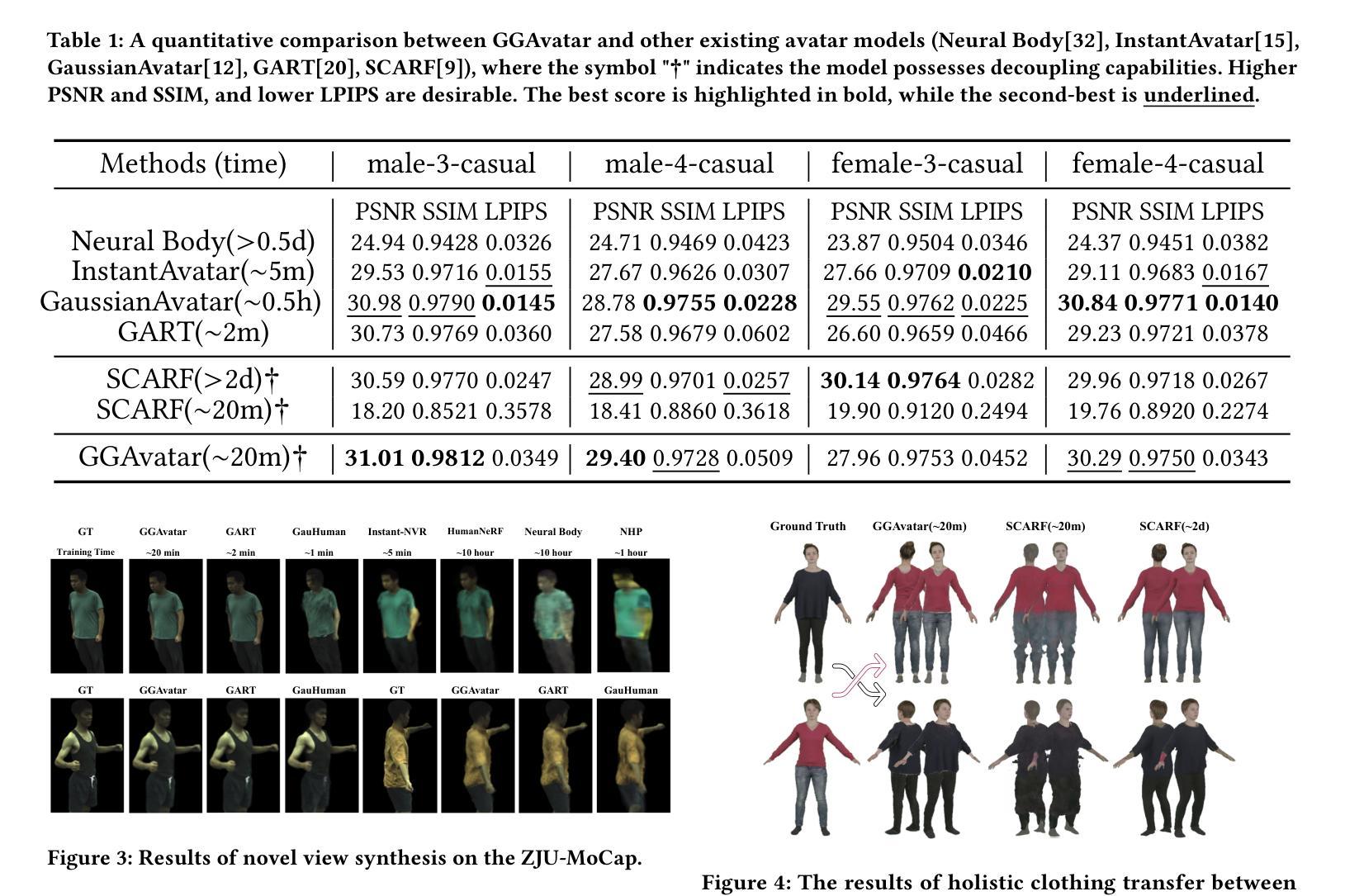
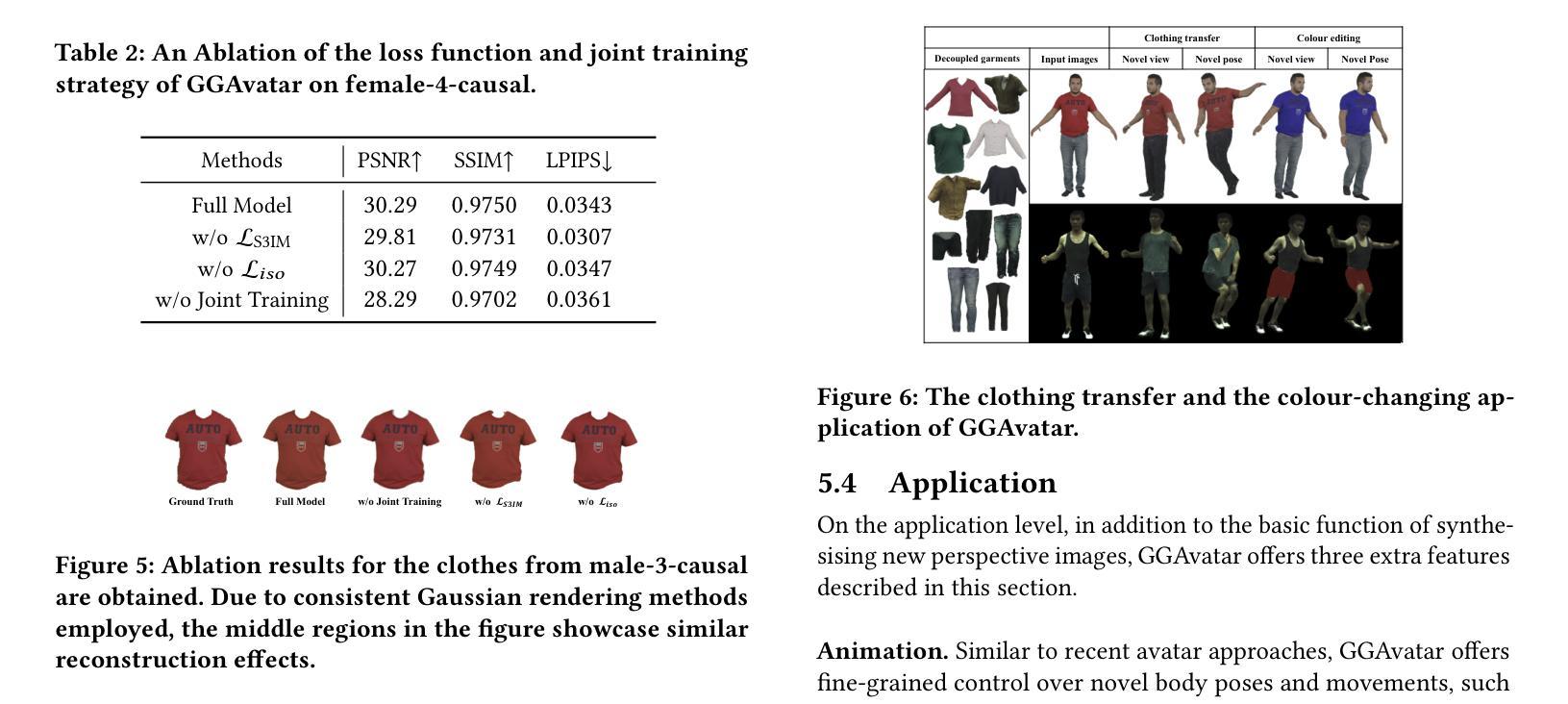
(4)任务与性能:本文的方法在重建衣物的数字人类和衣物编辑任务上取得了显著成果。通过与其他成本较高的模型进行比较,证明了GGAvatar模型在建模质量和效率方面的优越性。此外,该模型在虚拟试穿等实际应用中的表现也证明了其解耦能力的重要性。总体而言,该方法的性能达到了预期目标,并为相关领域的研究提供了新的思路和方法。
- 方法论概述:
本文提出了一种基于单目视频的衣物分离三维高斯重建虚拟角色模型的方法,具体步骤如下:
(1) 研究背景与问题定义:针对计算机图形学和计算机视觉中的真实感衣物数字人类及其服饰重建问题,指出虽然已有许多重建方法,但如何快速高效且准确地重建衣物的数字人类仍然是一个挑战。
(2) 模板估计与初始化:采用GGAvatar模型,利用参数化模板和分阶段训练策略,实现快速、可编辑和逼真的衣物分离重建。首先,通过FrankMocap估计人体姿态,确定正确的参数。然后,利用SCHP方法和ISP模型,从前视图合成衣物模板。最后,通过多层感知器(MLP)学习衣物和身体的形状,创建衣物网格模板。
(3) 高斯表示与变形处理:借鉴3D高斯混合模型,将衣物和人体重建结果表示为高斯。通过定义高斯顶点集,结合旋转、尺寸调整、透明度因子和颜色辐射函数,构建衣物的高斯表示。利用可学习的皮肤权重和目标骨转换,实现高斯集的变形处理。
(4) 渲染与图像生成:在观察空间中,通过映射操作实现高斯集的渲染。采用体积渲染技术,根据高斯属性的贡献计算最终颜色。同时,通过引入二维高斯计算透明度贡献,实现图像的生成。
(5) 训练损失与优化:在初始隔离阶段,采用密集和修剪策略,计算衣物和身体部分的重建损失。在联合训练阶段,优化高斯集而不添加或删除组件。主要重建损失通过比较真实图像和渲染图像来计算,同时引入随机结构相似性损失以优化结果。
本文通过整合参数化模板、高斯表示、变形处理和渲染技术,提出了一种有效的衣物分离三维高斯重建虚拟角色模型方法。
- 结论:
(1)这篇论文研究的课题具有重要的现实意义和学术价值。它提出了一种基于单目视频的衣物分离三维高斯重建虚拟角色模型方法,能够为计算机图形学和计算机视觉领域的研究提供新的思路和方法。该研究能够为虚拟人物创建、虚拟试衣等应用提供技术支持,具有广泛的应用前景。
(2)创新点:该文章的创新性体现在提出了基于单目视频的衣物分离三维高斯重建模型,实现了快速、可编辑和逼真的衣物分离重建。该方法通过参数化模板和分阶段训练策略,有效地解决了传统重建方法中存在的问题,如计算量大、建模质量不高等。此外,该模型还支持衣物编辑等应用,进一步拓展了其应用场景。
性能:该文章的方法在重建衣物的数字人类和衣物编辑任务上取得了显著成果,通过与成本较高的模型进行比较,证明了其在建模质量和效率方面的优越性。同时,该模型在虚拟试穿等实际应用中的表现也证明了其解耦能力的重要性。总体而言,该方法的性能达到了预期目标。
工作量:文章详细介绍了方法论的各个步骤,包括模板估计与初始化、高斯表示与变形处理、渲染与图像生成、训练损失与优化等。同时,文章还通过大量的实验验证了方法的有效性,证明了其在计算机图形学和计算机视觉领域的应用价值。然而,文章未详细阐述代码实现的具体细节和复杂性,对于理解其工作量方面存在一定不足。
点此查看论文截图

 wechat
wechat- alipay