元宇宙/虚拟人
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-27 更新
DynamicAvatars: Accurate Dynamic Facial Avatars Reconstruction and Precise Editing with Diffusion Models
Authors:Yangyang Qian, Yuan Sun, Yu Guo
Generating and editing dynamic 3D head avatars are crucial tasks in virtual reality and film production. However, existing methods often suffer from facial distortions, inaccurate head movements, and limited fine-grained editing capabilities. To address these challenges, we present DynamicAvatars, a dynamic model that generates photorealistic, moving 3D head avatars from video clips and parameters associated with facial positions and expressions. Our approach enables precise editing through a novel prompt-based editing model, which integrates user-provided prompts with guiding parameters derived from large language models (LLMs). To achieve this, we propose a dual-tracking framework based on Gaussian Splatting and introduce a prompt preprocessing module to enhance editing stability. By incorporating a specialized GAN algorithm and connecting it to our control module, which generates precise guiding parameters from LLMs, we successfully address the limitations of existing methods. Additionally, we develop a dynamic editing strategy that selectively utilizes specific training datasets to improve the efficiency and adaptability of the model for dynamic editing tasks.
Summary
动态3D头像生成与编辑技术,通过新型模型与GAN算法,实现高精度、适应性强的高仿真动态头像制作。
Key Takeaways
- 动态3D头像在虚拟现实与电影制作中至关重要。
- 现有方法存在面部扭曲、不准确头部动作和编辑能力有限等问题。
- DynamicAvatars模型从视频片段和面部位置与表情参数生成逼真3D头像。
- 引入基于提示的编辑模型,结合用户提示和LLMs参数进行精确编辑。
- 采用Gaussian Splatting双跟踪框架和提示预处理模块增强编辑稳定性。
- 专用GAN算法与控制模块连接,生成精确指导参数。
- 动态编辑策略利用特定训练数据集提高效率和适应性。
Title: 动态头像重建与精确编辑:DynamicAvatars研究
Authors: 杨阳钱,袁森,郭宇(等)
Affiliation: 西安电子科技大学软件工程学院(杨阳钱);西安电子科技大学人机混合智能国家重点实验室、西安电子科技大学视觉信息与应用的国家工程研究中心以及西安电子科技大学人工智能与机器人研究所(袁森、郭宇等)。
Keywords: 动态头像重建,精确编辑,动态模型,语言模型指导参数,高斯投影法,GAN算法。
Urls: 文章抽象链接(待补充);代码GitHub链接(待补充,如果没有则为Github:None)。
Summary:
(1) 研究背景:本文研究了虚拟现实和电影制作中的关键任务——动态3D头像的生成与编辑。由于现有方法在面部细节捕捉、头部运动准确性以及精细编辑能力方面的局限性,本文提出了DynamicAvatars模型。
(2) 过去的方法及其问题:传统方法使用明确的3D表示(如点云和网格),难以准确捕捉精细的几何细节。隐式3D表示方法虽然解决了这些问题,但在动态性和精细编辑方面仍有不足。本文方法受到挑战驱动,旨在解决现有方法的不足。
(3) 研究方法:本文提出了DynamicAvatars模型,通过视频剪辑和与面部位置和表情相关的参数生成逼真的动态3D头像。通过结合高斯投影法和大型语言模型(LLM)的指导参数,提出了一种基于提示的编辑模型。还开发了一种动态编辑策略,选择性利用特定训练数据集以提高模型的效率和适应性。
(4) 任务与性能:本文方法在动态头像重建和编辑任务上取得了显著成果。通过生成逼真的动态头像和精细编辑能力,证明了方法的有效性。此外,实验结果表明,该方法在效率和适应性方面也有所提高。性能结果支持了方法的目标。
希望以上回答能满足您的要求!
- 方法论概述:
本文提出了一种基于动态头像重建与精确编辑的研究方法,旨在解决虚拟现实和电影制作中的关键任务——动态3D头像的生成与编辑。方法论的主要步骤包括:
- (1) 背景与问题定义:针对现有方法在面部细节捕捉、头部运动准确性以及精细编辑能力方面的局限性,提出DynamicAvatars模型的研究背景及挑战。
- (2) 研究方法:提出DynamicAvatars模型,通过视频剪辑和与面部位置和表情相关的参数生成逼真的动态3D头像。结合高斯投影法和大型语言模型(LLM)的指导参数,提出了一种基于提示的编辑模型。还开发了一种动态编辑策略,选择性利用特定训练数据集以提高模型的效率和适应性。
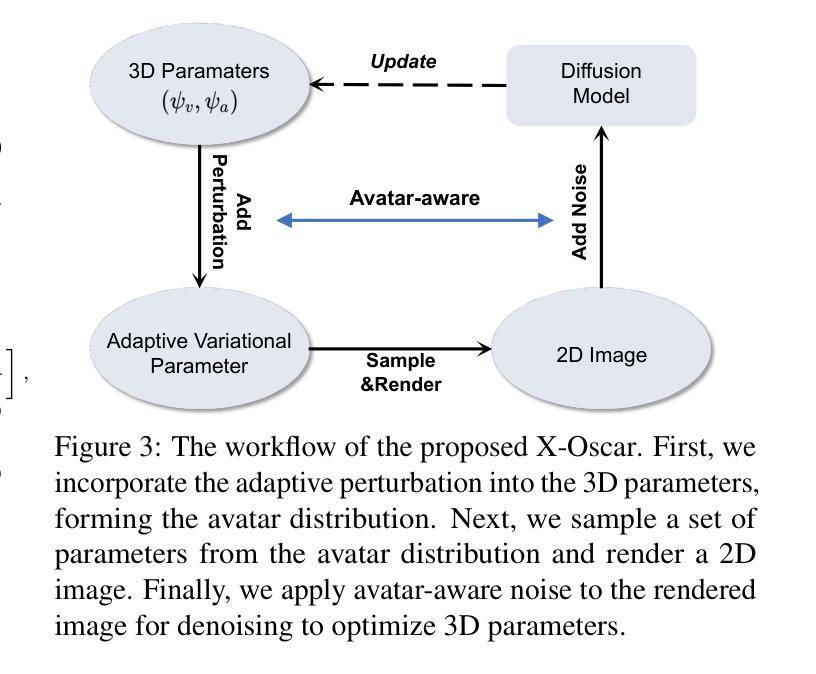
- (3) 语义基于网格高斯跟踪:为实现头部头像的灵活编辑,包括表情、纹理和附加配件的编辑,采用一种能够精确重建头部模型并易于编辑的技术是关键。引入了一种新颖的网格高斯绑定方法,与现有的Gaussian Avatars方法有所不同。该方法包括两个高斯跟踪模式,用于处理过程中的不同阶段。首先,通过光度学头部跟踪器拟合FLAME参数来处理输入视频。接下来,应用面部组成标识符生成语义蒙版,以确保在渲染图像时具有相同语义标签的高斯点始终一致,维持动态场景中的时间一致性。同时,将渲染结果与真实图像进行比较以训练头像。
- (4) 动态高斯编辑:传统3D编辑方法依赖于静态2D或3D蒙版来限制特定区域的变化。然而,这种方法在训练过程中的动态更新会导致静态蒙版不准确,从而限制其有效性。为了解决这个问题,本文利用双重跟踪方法来维持高斯点的相对位置,便于后续的编辑过程。提出了一种方法,能够考虑不同时间和姿势下对结果做出贡献的所有高斯点。通过利用映射网络来生成不同时间和姿态下的目标区域蒙版,我们能够追踪动态场景中目标区域的贡献高斯点。接下来,对选定集中的每个图像进行编辑以生成编辑后的图像集。最后,应用带有条件对抗损失的学习过程,以调节高斯点并保持时间一致性。
- (5) LLM精细编辑:针对之前工作在面对详细提示时的困境,例如方向、相对位置等信息的理解难题,我们利用LLM进行精细编辑。为了在面对这些困难条件时提高生成结果的质量,我们专注于解决与编辑相关的错位和误解问题,并基于精确详细的提示添加配件。提出了一个类似于SLD的框架,为精细编辑提供了实用方法。我们根据LLM重新调整提示结构,然后仔细修改由先前阶段生成的图像。这种图像校正基于潜在空间的操纵,并包含我们方法中的多视图一致性对齐。
- (6) 损失函数与正则化:主要损失应集中在渲染的图像上。因此采用了如下颜色损失函数:Lrgb = λL2(I, ˆI) + (1 − λ)Llpips(I, ˆI)。此外,还需要关注跟踪损失,该损失集中于处理网格和高斯点之间的相对位置以及特定语义区域与高斯点之间的关联。为了维持模型的基本结构并在编辑阶段监督位置和分布的损失以及优化每个高斯点的物理参数,需要采用一种能够惩罚点错位的损失函数。
- Conclusion:
- (1) 这项工作的意义在于提出了一种基于动态头像重建与精确编辑的研究方法,解决了虚拟现实和电影制作中动态3D头像生成与编辑的关键问题,提高了头部模型的精确性和编辑能力。
(2) 创新点:本文提出了DynamicAvatars模型,通过结合视频剪辑、面部位置和表情参数,生成逼真的动态3D头像,并提出了一种基于提示的编辑模型和高斯投影法,提高了模型的效率和适应性。同时,引入大型语言模型(LLM)进行精细编辑,解决了传统方法在面对详细提示时的困境。
Performance: 该方法在动态头像重建和编辑任务上取得了显著成果,生成了逼真的动态头像并具备精细编辑能力。实验结果表明,该方法在效率和适应性方面也有所提高。
Workload: 文章详细阐述了方法论的主要步骤,包括背景与问题定义、研究方法、语义基于网格高斯跟踪、动态高斯编辑、LLM精细编辑以及损失函数与正则化等方面,工作量较大,但内容条理清晰,易于理解。
点此查看论文截图



FATE: Full-head Gaussian Avatar with Textural Editing from Monocular Video
Authors:Jiawei Zhang, Zijian Wu, Zhiyang Liang, Yicheng Gong, Dongfang Hu, Yao Yao, Xun Cao, Hao Zhu
Reconstructing high-fidelity, animatable 3D head avatars from effortlessly captured monocular videos is a pivotal yet formidable challenge. Although significant progress has been made in rendering performance and manipulation capabilities, notable challenges remain, including incomplete reconstruction and inefficient Gaussian representation. To address these challenges, we introduce FATE, a novel method for reconstructing an editable full-head avatar from a single monocular video. FATE integrates a sampling-based densification strategy to ensure optimal positional distribution of points, improving rendering efficiency. A neural baking technique is introduced to convert discrete Gaussian representations into continuous attribute maps, facilitating intuitive appearance editing. Furthermore, we propose a universal completion framework to recover non-frontal appearance, culminating in a 360$^\circ$-renderable 3D head avatar. FATE outperforms previous approaches in both qualitative and quantitative evaluations, achieving state-of-the-art performance. To the best of our knowledge, FATE is the first animatable and 360$^\circ$ full-head monocular reconstruction method for a 3D head avatar. The code will be publicly released upon publication.
PDF project page: https://zjwfufu.github.io/FATE-page/
Summary
单目视频重建可编辑全头3D头像,FATE方法实现高效性能。
Key Takeaways
- 单目视频重建3D头像具挑战性。
- FATE方法解决重建和表示效率问题。
- 样本密集化策略优化点分布。
- 神经烘焙技术实现属性图编辑。
- 完成框架恢复非正面外观。
- FATE在性能评估中优于先前方法。
- FATE为首个可动画和360°单目全头重建方法。
Title: FATE:基于纹理编辑的全头高斯化身技术(Full-head Gaussian Avatar with Textural Editing)
Authors: xxx
Affiliation: 暂无作者所属机构信息。
Keywords: 3D头像重建,单目视频,纹理编辑,高斯渲染
Urls: 由于没有提供论文的网址和Github代码链接,所以无法填写。
Summary:
(1)研究背景:本文的研究背景是关于如何从单目视频中重建高保真、可动画的3D头像。尽管已有许多方法在此领域取得了进展,但仍面临诸如重建不完整和效率低下的挑战。本文旨在解决这些问题,提出一种基于单目视频的全头高斯化身技术(FATE)。
(2)过去的方法和存在的问题:现有的方法在处理单目视频时,往往存在重建不完整和纹理表示效率低下的问题。这些方法缺乏优化策略,无法有效地从单目视频中提取足够的信息来重建完整的头部模型。此外,传统的纹理表示方法在处理复杂的头部纹理时效率低下,不利于进行直观的外貌编辑。
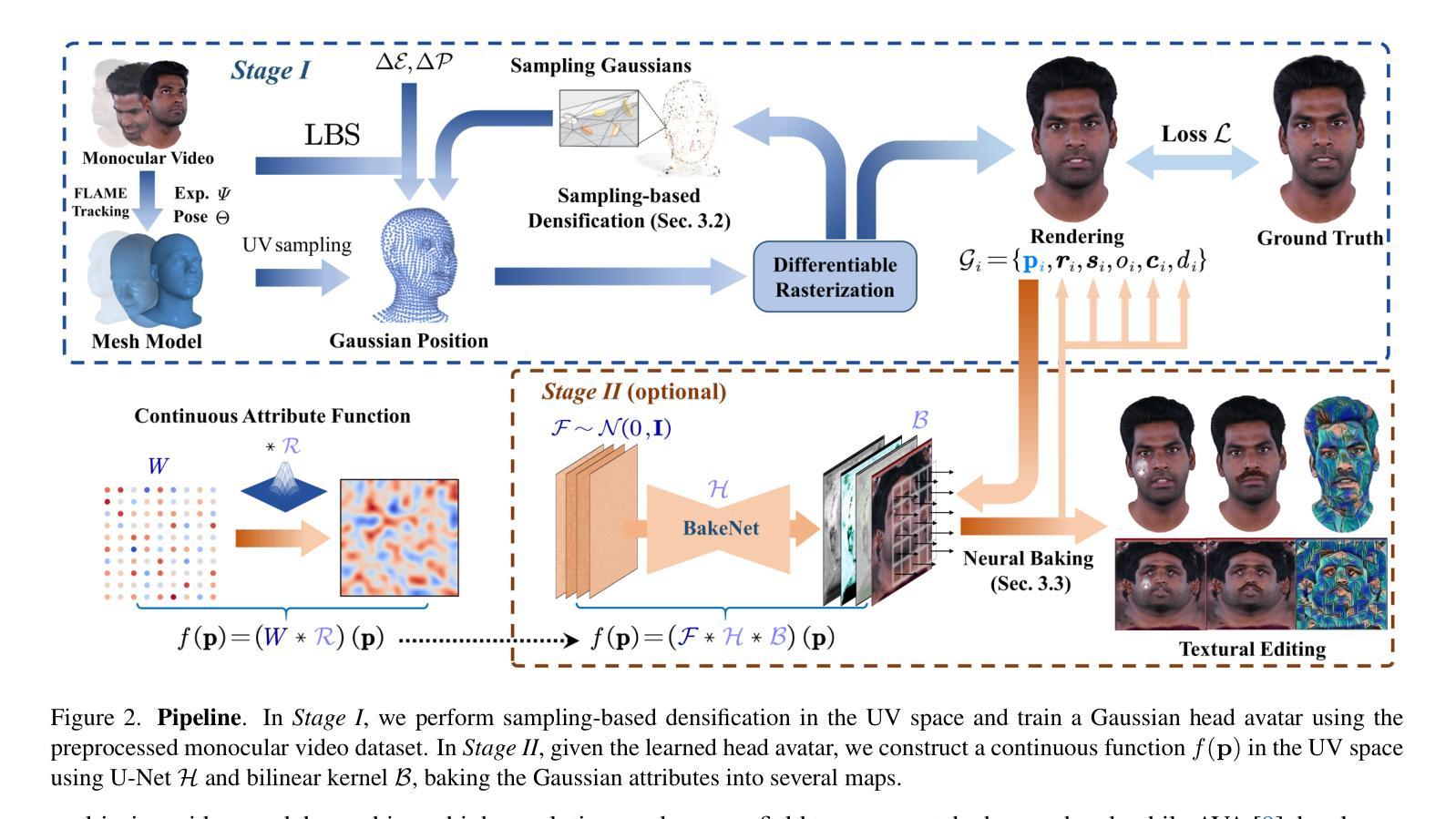
(3)研究方法:本文提出了一种基于单目视频的全头高斯化身技术(FATE)。首先,采用基于采样的密集化策略,确保点的最优位置分布,提高渲染效率。其次,引入神经烘焙技术,将离散的高斯表示转换为连续的属性图,便于直观的外貌编辑。最后,提出了一种通用的完成框架,用于恢复非正面外貌,生成可渲染的3D头像。整个流程实现了从单目视频到完整头部模型的重建,并具有良好的可编辑性和渲染性能。
(4)任务与性能:本文的方法在单目视频重建任务上取得了显著的成果。实验结果表明,本文的方法在定量和定性评价方面都优于以往的方法,达到了业界最佳性能。此外,本文的方法生成了首个可动画和360度可渲染的全头单目重建方法。性能上能够满足真实场景下的需求,支持从单目视频中重建出高质量、可编辑的3D头像。
方法:
(1) 研究背景与现状:文章介绍了当前单目视频3D头像重建领域的背景和研究现状,指出了现有方法在处理单目视频时面临的一些挑战,如重建不完整和效率低下的问题。
(2) 研究方法:针对现有方法的不足,文章提出了一种基于单目视频的全头高斯化身技术(FATE)。首先,采用基于采样的密集化策略,确保点的最优位置分布,提高渲染效率。其次,引入神经烘焙技术,将离散的高斯表示转换为连续的属性图,便于直观的外貌编辑。最后,提出了一个通用的完成框架,用于恢复非正面外貌,生成可渲染的3D头像。
(3) 实验流程:在实验中,文章首先介绍了整体的单目重建方法,然后详细解释了采样密集化、神经烘焙、通用完成框架等模块的具体实现细节。并通过实验验证了方法的有效性。
(4) 结果分析:文章通过对比实验和性能评估,证明了所提出的方法在单目视频重建任务上取得了显著成果,优于以往的方法,并满足了真实场景下的需求,能够生成高质量、可编辑的3D头像。
(5) 局限性及未来工作:文章还讨论了一些局限性以及未来的研究方向,例如如何提高渲染质量、进一步优化模型性能等。同时,也提出了一些改进建议,如采用更先进的采样策略、优化神经烘焙技术等。
- Conclusion:
- (1)工作意义:该研究提出了一种基于单目视频的全头高斯化身技术(FATE),实现了从单目视频中重建高保真、可动画的3D头像,为3D头像重建领域带来了新的突破和进展。
- (2)创新点、性能、工作量方面总结:
- 创新点:文章引入了基于采样的密集化策略,提高了渲染效率;采用神经烘焙技术,将离散的高斯表示转换为连续的属性图,便于直观的外貌编辑。
- 性能:文章的方法在单目视频重建任务上取得了显著成果,优于以往的方法,达到了业界最佳性能,满足真实场景下的需求。
- 工作量:文章进行了详细的实验和性能评估,证明了所提出方法的有效性。然而,文章也存在一定的局限性,如复杂和个性化的发型完成具有挑战性,神经烘焙技术的纹理映射在编辑细节时可能存在失败的情况。
总体来说,该文章在3D头像重建领域具有一定的创新性和实用性,为从单目视频中重建高质量、可编辑的3D头像提供了一种新的方法。
点此查看论文截图

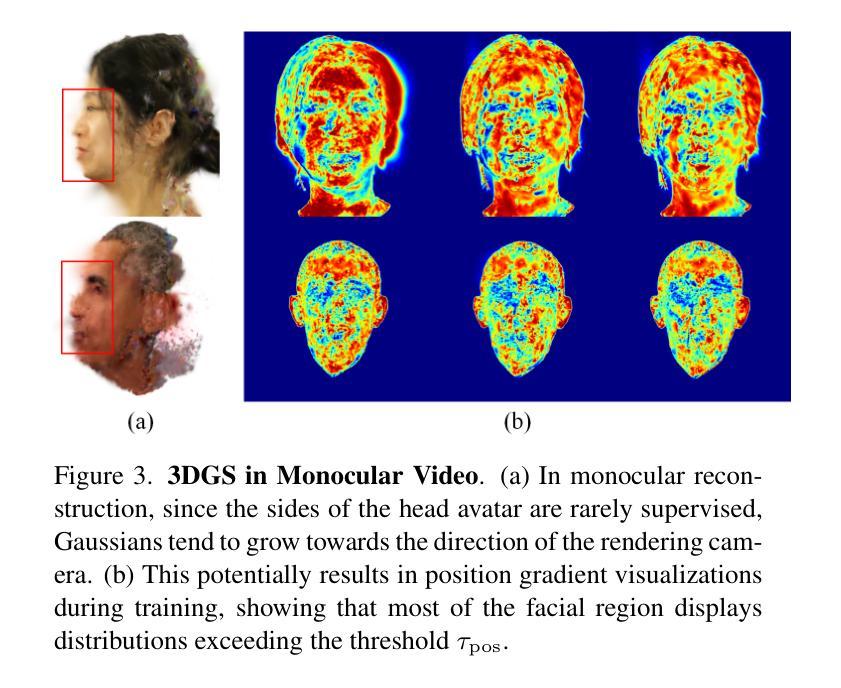


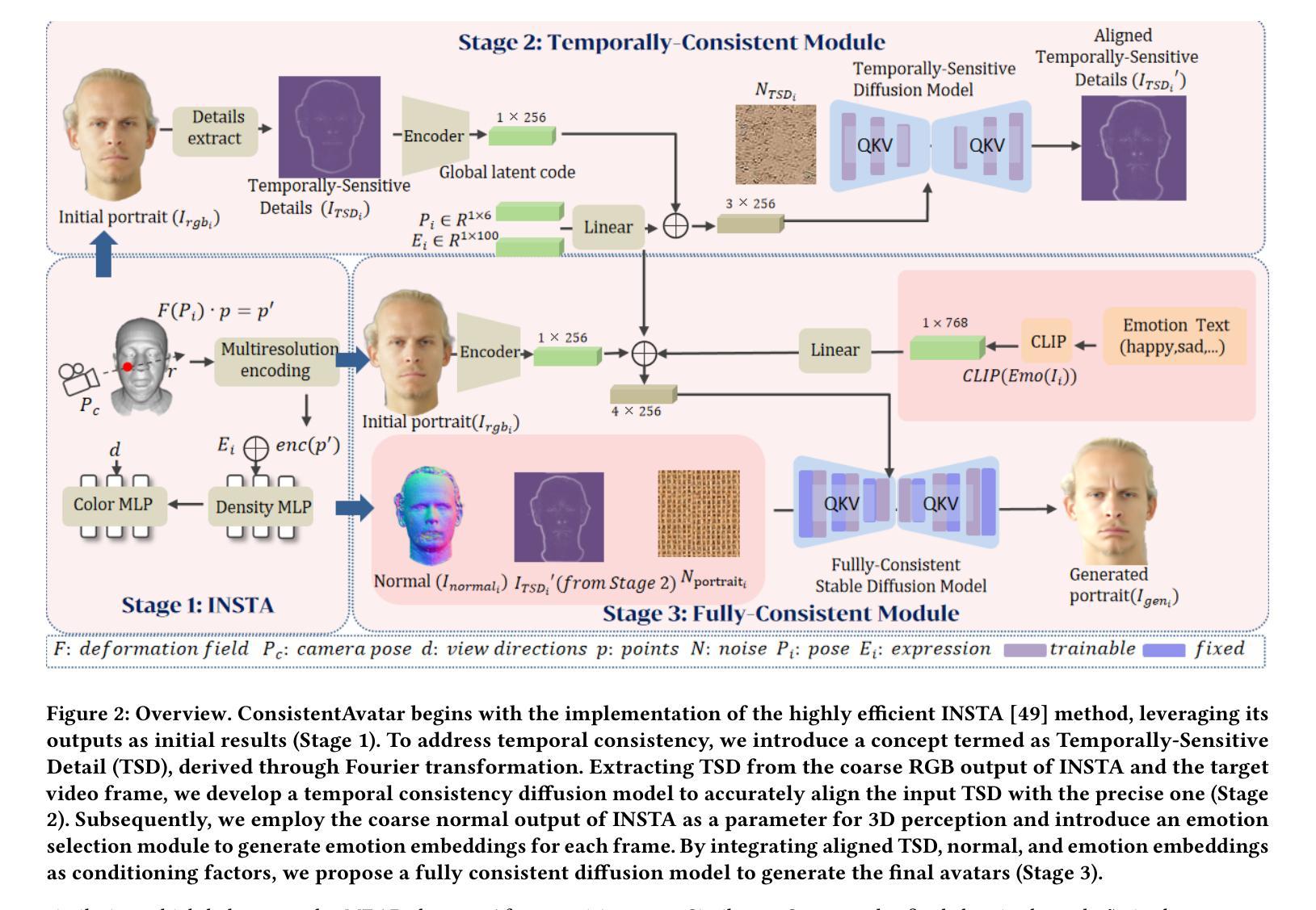
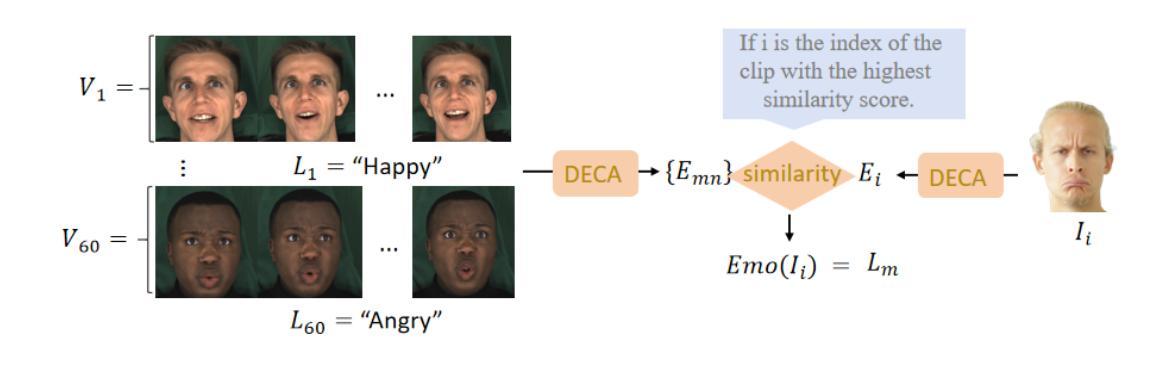
ConsistentAvatar: Learning to Diffuse Fully Consistent Talking Head Avatar with Temporal Guidance
Authors:Haijie Yang, Zhenyu Zhang, Hao Tang, Jianjun Qian, Jian Yang
Diffusion models have shown impressive potential on talking head generation. While plausible appearance and talking effect are achieved, these methods still suffer from temporal, 3D or expression inconsistency due to the error accumulation and inherent limitation of single-image generation ability. In this paper, we propose ConsistentAvatar, a novel framework for fully consistent and high-fidelity talking avatar generation. Instead of directly employing multi-modal conditions to the diffusion process, our method learns to first model the temporal representation for stability between adjacent frames. Specifically, we propose a Temporally-Sensitive Detail (TSD) map containing high-frequency feature and contours that vary significantly along the time axis. Using a temporal consistent diffusion module, we learn to align TSD of the initial result to that of the video frame ground truth. The final avatar is generated by a fully consistent diffusion module, conditioned on the aligned TSD, rough head normal, and emotion prompt embedding. We find that the aligned TSD, which represents the temporal patterns, constrains the diffusion process to generate temporally stable talking head. Further, its reliable guidance complements the inaccuracy of other conditions, suppressing the accumulated error while improving the consistency on various aspects. Extensive experiments demonstrate that ConsistentAvatar outperforms the state-of-the-art methods on the generated appearance, 3D, expression and temporal consistency. Project page: https://njust-yang.github.io/ConsistentAvatar.github.io/
Summary
本文提出ConsistentAvatar,通过时间敏感细节(TSD)映射实现时间一致性,显著提高虚拟人头像生成的一致性和真实性。
Key Takeaways
- 扩散模型在头像生成中存在时间、3D或表情不一致问题。
- ConsistentAvatar框架解决时间一致性及高保真问题。
- TSD映射包含时间轴上变化显著的高频特征和轮廓。
- 使用时间一致性扩散模块学习对齐TSD。
- 初始结果与视频帧真值对齐,生成最终头像。
- TSD映射确保时间稳定性,抑制累积误差。
- ConsistentAvatar在多方面优于现有技术。
标题:ConsistentAvatar: Learning to Diffuse Fully Consistent Talking
中文翻译:一致头像:学习扩散完全一致的说话作者:Haijie Yang, Zhenyu Zhang, Hao Tang, Jianjun Qian, Jian Yang(带有号为通讯作者)
隶属机构:南京科技大学、南京大学、北京大学
关键词:ConsistentAvatar, 扩散模型, 说话头生成, 暂时性一致性, 3D一致性, 表情一致性
Urls:论文链接(待提供),GitHub代码链接(待提供,如果没有则为None)
总结:
(1) 研究背景:
随着技术的发展,生成说话头像的需求逐渐增加。扩散模型在生成任务中展现出巨大的潜力,但在生成说话头像时面临一些问题,如暂时性、3D和表情的不一致性。本文旨在解决这些问题,提出一种全新的框架。
(2) 过去的方法及问题:
过去的方法主要基于单图像生成能力,但由于误差累积和固有局限性,导致生成的头像存在不一致性问题。
(3) 研究方法:
本文提出ConsistentAvatar框架,一个用于生成完全一致和高保真度说话头像的新型框架。该方法不直接将多模式条件应用于扩散过程,而是学习首先建立时间表示以提高稳定性。通过建模时间表示,框架能够在生成过程中保持一致性。
(4) 任务与性能:
本文的方法在生成说话头像的任务上取得了显著成果,解决了暂时性、3D和表情的不一致性问题。通过对比实验和真实数据,验证了该方法在缓解时间不一致性方面的显著效果。性能结果支持了该方法的有效性。
请注意,具体的GitHub链接和论文链接待提供,关键词和某些细节可能根据原始论文有所不同,建议查阅原始论文以获取更详细和准确的信息。
- 方法论概述:
(1) 研究问题定义:本文旨在解决生成说话头像时面临的暂时性、3D和表情的不一致性问题。
(2) 数据集准备:研究使用了相关的说话头像数据集,为了训练和验证所提出的方法。
(3) 方法框架介绍:提出了ConsistentAvatar框架,该框架旨在通过建模时间表示来解决多模式条件下的扩散模型的不一致性问题。框架不直接将多模式条件应用于扩散过程,而是通过建立时间表示来提高生成的稳定性。这种方法确保了生成过程中的一致性。
(4) 实验设计与实施:在生成说话头像的任务上进行了大量实验,通过对比实验和真实数据验证了框架的有效性。实验结果表明,该方法在解决不一致性问题方面取得了显著成果。
(5) 性能评估:使用特定的评估指标和方法对ConsistentAvatar框架进行了性能评估,证明了其有效性和优越性。
注:具体细节,如数据集、实验设置和性能评估方法,需参考原始论文以获取更详细和准确的信息。
- Conclusion:
(1) 这项工作的意义在于解决生成说话头像时面临的不一致性问题,包括暂时性、3D和表情的不一致性。它提出了一种新的框架ConsistentAvatar,能够生成完全一致的、高保真度的说话头像,这对于虚拟角色、动画制作、游戏开发等领域具有重要的应用价值。
(2) 创新点:本文提出了ConsistentAvatar框架,通过建模时间表示来解决多模式条件下的扩散模型的不一致性问题,这是一种全新的尝试和探索。
性能:在生成说话头像的任务上,该方法取得了显著成果,解决了暂时性、3D和表情的不一致性问题,实验结果表明其有效性。
工作量:文章对问题的背景、过去的方法及问题、研究方法、任务与性能等方面进行了详细的阐述和总结,表明作者们进行了充分的研究和实验。但是,关于代码和数据的具体细节,需要参考原始论文以获取更详细和准确的信息。
点此查看论文截图
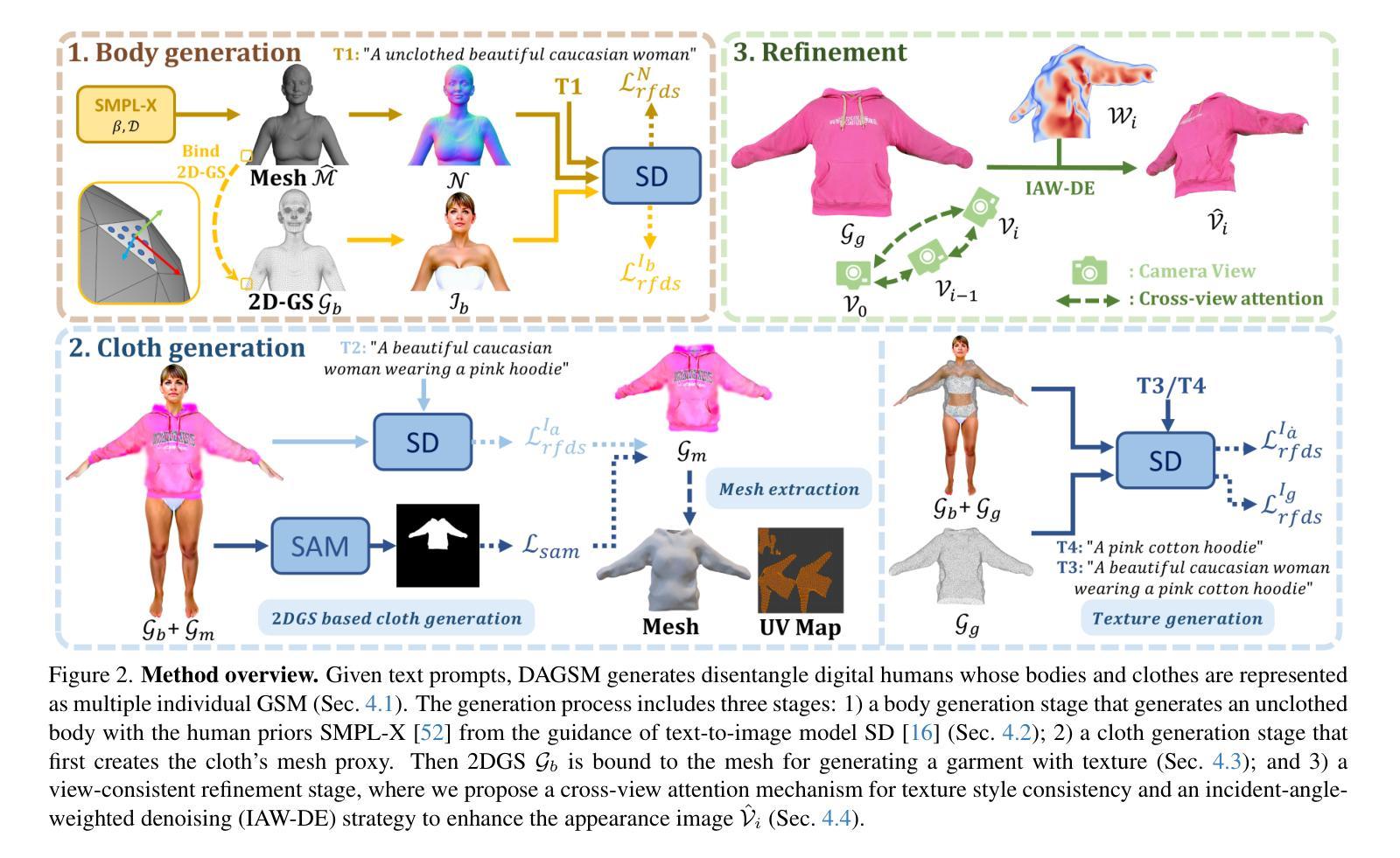
DAGSM: Disentangled Avatar Generation with GS-enhanced Mesh
Authors:Jingyu Zhuang, Di Kang, Linchao Bao, Liang Lin, Guanbin Li
Text-driven avatar generation has gained significant attention owing to its convenience. However, existing methods typically model the human body with all garments as a single 3D model, limiting its usability, such as clothing replacement, and reducing user control over the generation process. To overcome the limitations above, we propose DAGSM, a novel pipeline that generates disentangled human bodies and garments from the given text prompts. Specifically, we model each part (e.g., body, upper/lower clothes) of the clothed human as one GS-enhanced mesh (GSM), which is a traditional mesh attached with 2D Gaussians to better handle complicated textures (e.g., woolen, translucent clothes) and produce realistic cloth animations. During the generation, we first create the unclothed body, followed by a sequence of individual cloth generation based on the body, where we introduce a semantic-based algorithm to achieve better human-cloth and garment-garment separation. To improve texture quality, we propose a view-consistent texture refinement module, including a cross-view attention mechanism for texture style consistency and an incident-angle-weighted denoising (IAW-DE) strategy to update the appearance. Extensive experiments have demonstrated that DAGSM generates high-quality disentangled avatars, supports clothing replacement and realistic animation, and outperforms the baselines in visual quality.
Summary
利用文本生成解耦人体与服装,实现高质量、可替换服装的虚拟人模型。
Key Takeaways
- 文本驱动虚拟人生成技术备受关注。
- 现有方法将服装与人体系统能为单一3D模型,限制使用。
- 提出DAGSM模型,生成解耦的人体与服装。
- 将身体各部分(如身体、上衣/下衣)建模为GS增强网格(GSM)。
- 引入语义算法实现人体与服装、服装与服装分离。
- 提出视图一致纹理优化模块,包括跨视图注意机制和入射角加权去噪策略。
- 实验表明,DAGSM生成高质量的解耦虚拟人,支持服装替换和真实动画。
标题:DAGSM:基于GS增强的网格解纠缠式角色生成技术(中文版)
作者:Jingyu Zhuang, Di Kang, Linchao Bao, Liang Lin, Guanbin Li
作者所属机构:中山大学的Sun Yat-sen University 以及腾讯的Tencent(其中Jingyu Zhuang等为第一作者)
关键词:文本驱动的角色生成、解纠缠式角色生成、GS增强网格、动态纹理处理、动画渲染等。
链接:论文链接尚未提供,GitHub代码链接(如有)未知。请查阅相关数据库或官方渠道获取最新信息。
摘要:
(1) 研究背景:随着虚拟世界和互动娱乐技术的快速发展,高质量的数字角色生成需求日益增长。文本驱动的角色生成因其便利性而受到广泛关注,但现有方法存在局限性,如角色与服装的建模过于简化,难以实现服装替换和用户自定义控制等。本研究旨在解决这些问题。
(2) 过去的方法及问题:现有的角色生成方法大多将人体与所有服装建模为一个单一的3D模型,这限制了如服装替换等功能的实现,并降低了用户对生成过程的控制。因此,存在对一种更先进方法的迫切需求。
(3) 研究方法:本研究提出了一种名为DAGSM的新方法,用于从给定的文本提示生成解纠缠式的人体角色和服装。该方法将角色的每个部分(如身体、上衣、下装等)建模为一个增强网格(GSM),这是一个结合了二维高斯分布的传统网格,可以更好地处理复杂纹理并产生逼真的动画效果。研究中还引入了语义算法以实现更好的衣物分离和纹理优化技术,包括跨视角注意力机制和基于入射角的降噪策略等。
(4) 任务与性能:本研究的方法在生成高质量解纠缠式角色、支持服装替换和逼真动画方面取得了显著成果。实验证明,DAGSM在视觉质量上优于基线方法。这些性能的提升证明了该方法的实用性和先进性。
- 方法概述:
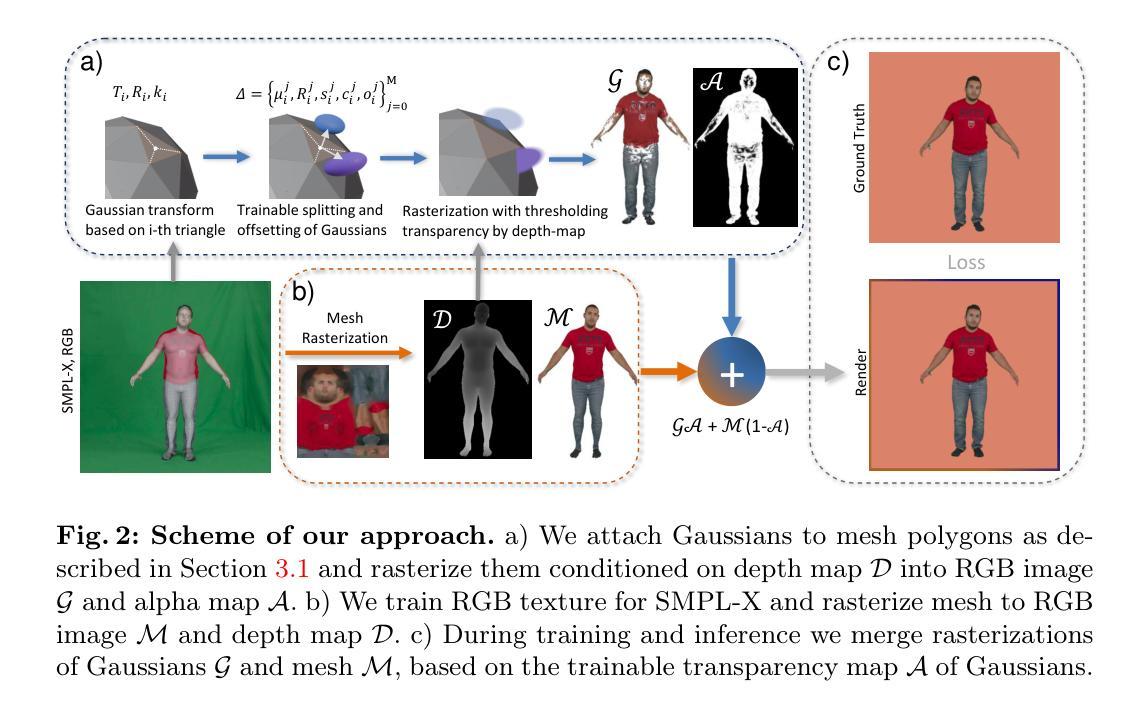
本方法提出了一种基于文本提示生成解纠缠式人体角色和服装的技术,命名为DAGSM。给定文本描述的人体及穿着的衣物,目标是生成高质量纹理的解纠缠式角色,其中衣物和身体被解耦并以GS增强网格(GSM)单独建模(第4.1节)。为了获得解纠缠的角色,DAGSM在不同的阶段生成不穿衣服的身体和衣物,然后进行细化步骤(图2)。其主要分为以下步骤:
- (1) 生成身体基础模型:首先生成只穿内衣的人体模型(第4.2节)。利用文本提示和图像生成模型SD引导,结合人类先验知识SMPL-X模型进行身体生成。
- (2) 衣物生成:在后续的衣服生成阶段(第4.3节),首先创建衣物的网格代理,然后将二维高斯分布(2DGS)绑定到网格上,以获取衣物的纹理。基于网格的表示方法使得物理驱动的布料模拟更加真实,并且衣物编辑更为简单。
- (3) 纹理优化与细化:最后,提出视角一致的细化阶段(第4.4节),改进身体和衣物的纹理质量。包括跨视角注意力机制和基于入射角的降噪策略等。
在方法实现上,DAGSM利用GSM表示模型中的每个部分(身体、上衣、下装等),GSM结合了二维高斯分布的传统网格,可以更好地处理复杂纹理并产生逼真的动画效果。为了获得高质量的解纠缠角色,研究中还引入了语义算法以实现更好的衣物分离和纹理优化技术。
通过上述步骤,DAGSM在生成高质量解纠缠式角色、支持服装替换和逼真动画方面取得了显著成果,实验证明其在视觉质量上优于基线方法。
- Conclusion:
(1)这篇工作的意义在于提出了一种基于文本提示生成解纠缠式人体角色和服装的技术,名为DAGSM。该技术能够解决现有角色生成方法中存在的问题,如角色与服装的建模过于简化、难以实现服装替换和用户自定义控制等。它为虚拟世界和互动娱乐领域提供了高质量的数字角色生成方案,有望为相关行业带来技术进步和创新。
(2)创新点:DAGSM将角色生成技术与文本驱动方法相结合,通过引入GS增强网格(GSM)来实现角色的解纠缠式生成。这种方法将角色各部分(如身体、上衣、下装等)单独建模,支持服装替换和纹理优化,提高了角色的生成质量和用户的自定义控制。
性能:实验证明,DAGSM在生成高质量解纠缠式角色、支持服装替换和逼真动画方面取得了显著成果,视觉质量优于基线方法。
工作量:文章对方法的实现进行了详细的描述,包括生成身体基础模型、衣物生成和纹理优化与细化等步骤。然而,关于方法的计算复杂度、所需的数据量和处理时间等方面未给出具体的信息。
总体来说,这篇文章提出了一种创新的角色生成技术,并在性能上取得了显著的成果。然而,关于方法的计算复杂度和工作量方面还需要进一步的研究和评估。
点此查看论文截图

 wechat
wechat- alipay