牙齿修复
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-11-27 更新
Scaling nnU-Net for CBCT Segmentation
Authors:Fabian Isensee, Yannick Kirchhoff, Lars Kraemer, Maximilian Rokuss, Constantin Ulrich, Klaus H. Maier-Hein
This paper presents our approach to scaling the nnU-Net framework for multi-structure segmentation on Cone Beam Computed Tomography (CBCT) images, specifically in the scope of the ToothFairy2 Challenge. We leveraged the nnU-Net ResEnc L model, introducing key modifications to patch size, network topology, and data augmentation strategies to address the unique challenges of dental CBCT imaging. Our method achieved a mean Dice coefficient of 0.9253 and HD95 of 18.472 on the test set, securing a mean rank of 4.6 and with it the first place in the ToothFairy2 challenge. The source code is publicly available, encouraging further research and development in the field.
PDF Fabian Isensee and Yannick Kirchhoff contributed equally
Summary
该论文介绍了在CBCT图像上进行多结构分割的nnU-Net框架扩展方法,在ToothFairy2挑战赛中取得优异成绩。
Key Takeaways
- 使用nnU-Net ResEnc L模型进行CBCT图像多结构分割。
- 对patch size、网络拓扑和数据增强进行关键修改。
- 方法在测试集上达到Dice系数0.9253和HD95 18.472。
- 在ToothFairy2挑战赛中获得第一。
- 源代码公开,促进进一步研究。
- 应对CBCT图像的独特挑战。
- 改进模型在牙齿修复中的应用潜力。
标题:基于nnU-Net框架的CBCT图像多结构分割研究(Scaling nnU-Net for CBCT Segmentation)
作者:Fabian Isensee,Yannick Kirchhoff,Lars Kraemer,Maximilian Rokuss,Constantin Ulrich,Klaus H. Maier-Hein。
所属机构:该研究由德国癌症研究中心(DKFZ)和海德堡大学等机构的研究人员共同完成。
关键词:CBCT分割、nnU-Net、ToothFairy2挑战、牙科成像、深度学习。
Urls:论文链接(待补充);GitHub代码链接(待补充)。
摘要:
- (1) 研究背景:本研究针对牙科CBCT图像的多结构分割问题,特别是针对ToothFairy2挑战。准确分割牙科结构对于牙科诊断、治疗计划和手术过程的精确性具有重要意义。该研究旨在开发稳健的分割算法以应对牙科成像中的高变异性、复杂性和精准定位的需求。
- (2) 相关研究及问题:过去的方法在解决牙科CBCT图像分割时面临挑战,如算法对牙科结构的高变性和复杂性的适应性不足。尽管已有研究使用深度学习等方法进行图像分割,但在面对高精准定位和复杂结构分析的需求时仍存在问题。本研究旨在通过改进nnU-Net框架来解决这些问题。
- (3) 研究方法:本研究采用nnU-Net框架进行CBCT图像的多结构分割。通过调整patch大小、网络拓扑和数据增强策略来应对牙科CBCT成像的独特挑战。使用ResEnc L模型进行优化和改进。在公开数据集上进行训练和验证,确保算法的准确性和鲁棒性。
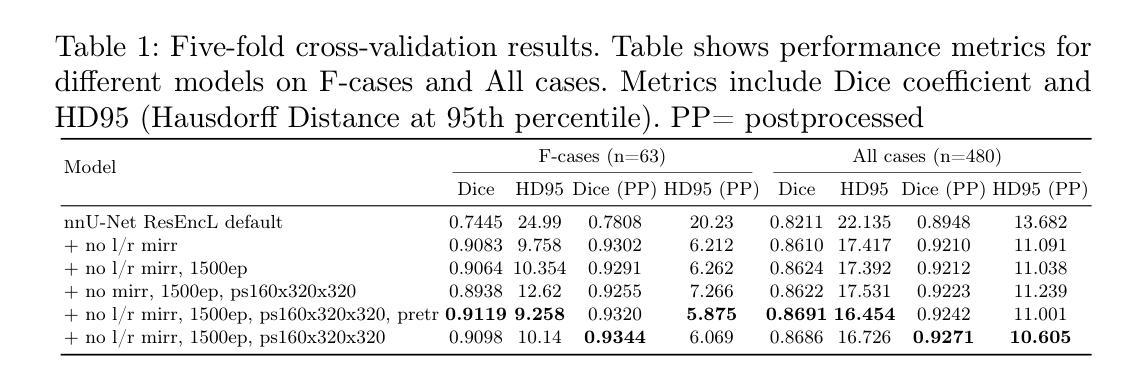
- (4) 实验结果:本研究的方法在测试集上取得了较高的性能,Dice系数为0.9253,HD95为18.472,在ToothFairy2挑战中取得了第一名的好成绩。实验结果表明,该方法在牙科结构分割任务上具有良好的性能,能够支持牙科诊断、治疗计划和手术导航等应用的需求。此外,公开的代码鼓励了在该领域的进一步研究和开发。
希望这个总结符合您的要求!如有其他问题或需要进一步的解释,请告诉我。
- 方法论概述:
(1)研究背景与任务概述:本研究聚焦于牙科CBCT图像的多结构分割问题,特别是在ToothFairy2挑战背景下的相关研究。多结构分割对于牙科诊断、治疗计划和手术过程的精确性至关重要。针对牙科成像中高变异性、复杂性和精准定位的需求,研究旨在开发稳健的分割算法。
(2)相关工作及问题阐述:过去的方法在解决牙科CBCT图像分割时面临诸多挑战,尤其是在面对牙科结构的高变性和复杂性时,算法适应性不足。尽管已有研究使用深度学习等方法进行图像分割,但在高精准定位和复杂结构分析的需求面前仍存在问题。因此,本研究旨在通过改进nnU-Net框架来解决这些问题。
(3)研究方法选择:本研究采用nnU-Net框架进行CBCT图像的多结构分割。为适应牙科CBCT成像的独特挑战,对patch大小、网络拓扑和数据增强策略进行了调整。具体来说,选择了ResEnc L模型进行优化和改进。在公开数据集上进行训练和验证,确保算法的准确性和鲁棒性。
(4)实验设计与实施:在方法设计上,研究调整了patch大小、网络深度、数据增强策略、训练时长以及后处理策略。特别地,针对ToothFairy2数据集的特点,调整了镜像增强策略,延长了训练时间,并优化了后处理中的预测阈值。这些调整旨在提高模型的性能和对牙科结构的准确分割。同时,公开的代码促进了该领域的进一步研究和开发。
(5)尝试但未成功的方法:尽管预训练、禁用全部镜像和调整学习率与预热时间表等方法曾被尝试,但未能在本研究中改善结果。这表明针对ToothFairy2数据集的特点,当前的方法论已经取得了良好的效果,进一步的改进可能需要新的思路和技术。
Conclusion:
(1) 这项研究对于牙科CBCT图像的多结构分割问题具有重要的实践意义。它旨在开发稳健的分割算法,以应对牙科成像中的高变异性、复杂性和精准定位的需求,从而提高牙科诊断、治疗计划和手术过程的精确性。此外,该研究在ToothFairy2挑战中取得了第一名的好成绩,表明其方法的优异性能。
(2) 创新点:该研究采用nnU-Net框架进行CBCT图像多结构分割,并针对性地对关键参数进行调整以适应牙科成像的独特挑战。其创新性地使用ResEnc L模型进行优化和改进,提高了模型在牙科结构分割任务上的性能。
性能:研究结果表明,该方法在牙科结构分割任务上具有良好的性能,能够支持牙科诊断、治疗计划和手术导航等应用的需求。在公开数据集上的实验结果表明,该方法具有较高的准确性和鲁棒性。
工作量:该研究进行了大量的实验设计和实施工作,包括调整patch大小、网络深度、数据增强策略、训练时长以及后处理策略等。尽管尝试了一些方法但未取得理想结果,但整体而言,该研究的实验设计和实施是充分的。
点此查看论文截图

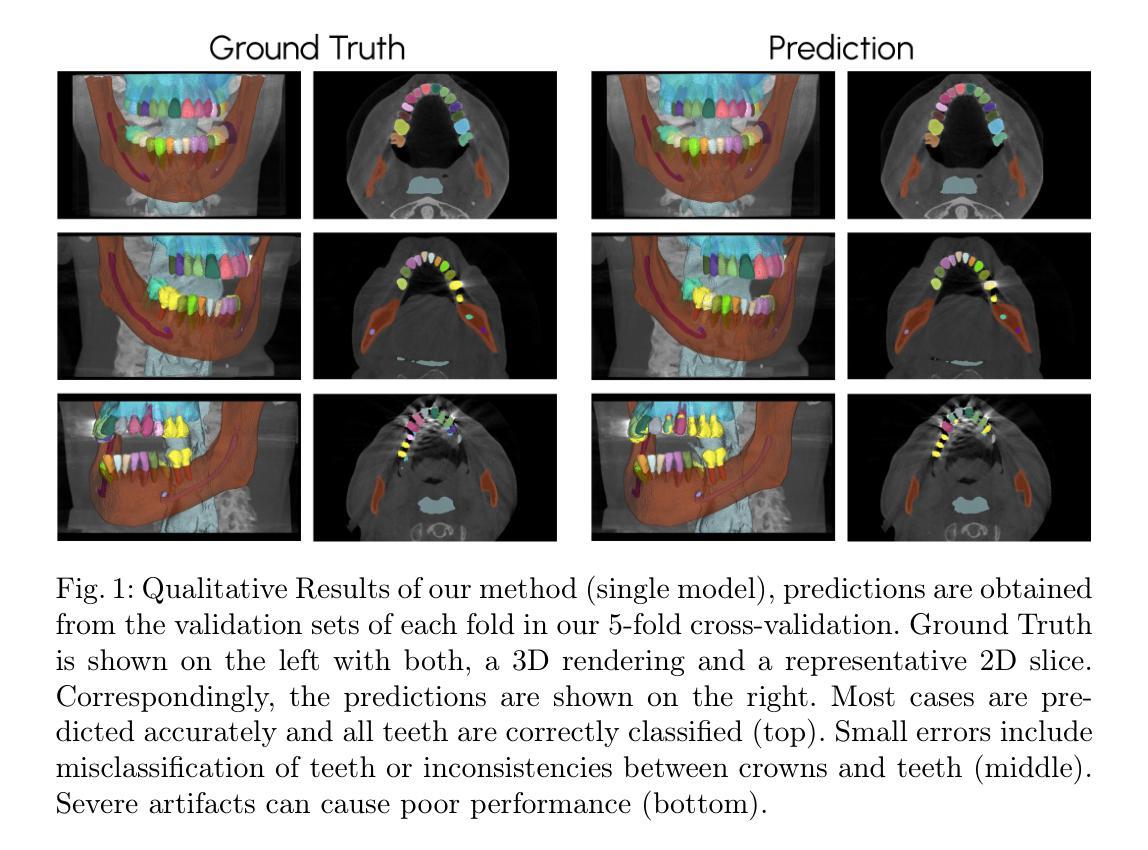

SAM Carries the Burden: A Semi-Supervised Approach Refining Pseudo Labels for Medical Segmentation
Authors:Ron Keuth, Lasse Hansen, Maren Balks, Ronja Jäger, Anne-Nele Schröder, Ludger Tüshaus, Mattias Heinrich
Semantic segmentation is a crucial task in medical imaging. Although supervised learning techniques have proven to be effective in performing this task, they heavily depend on large amounts of annotated training data. The recently introduced Segment Anything Model (SAM) enables prompt-based segmentation and offers zero-shot generalization to unfamiliar objects. In our work, we leverage SAM’s abstract object understanding for medical image segmentation to provide pseudo labels for semi-supervised learning, thereby mitigating the need for extensive annotated training data. Our approach refines initial segmentations that are derived from a limited amount of annotated data (comprising up to 43 cases) by extracting bounding boxes and seed points as prompts forwarded to SAM. Thus, it enables the generation of dense segmentation masks as pseudo labels for unlabelled data. The results show that training with our pseudo labels yields an improvement in Dice score from $74.29\,\%$ to $84.17\,\%$ and from $66.63\,\%$ to $74.87\,\%$ for the segmentation of bones of the paediatric wrist and teeth in dental radiographs, respectively. As a result, our method outperforms intensity-based post-processing methods, state-of-the-art supervised learning for segmentation (nnU-Net), and the semi-supervised mean teacher approach. Our Code is available on GitHub.
PDF Presented at MICCAI Workshop on Advancing Data Solutions in Medical Imaging AI 2024; Code and data: https://github.com/multimodallearning/SamCarriesTheBurden
Summary
利用SAM模型在医学图像分割中生成伪标签,提高骨和牙齿分割的Dice分数。
Key Takeaways
- SAM模型实现基于提示的分割和零样本泛化。
- 方法利用有限标注数据为医学图像生成伪标签。
- 通过提取边界框和种子点作为提示输入SAM。
- 伪标签训练提升 Dice 分数至 84.17% 和 74.87%。
- 方法优于传统后处理、nnU-Net和半监督mean teacher方法。
- 代码开源,GitHub可查。
Title: 利用Segment Anything Model(SAM)进行医学图像分割的研究
Authors: Keuth et al.
Affiliation: (未提供具体信息)
Keywords: Segmentation, Segment Anything Model, Semi-Supervised Learning
Urls: 论文链接未提供, Github代码链接(如有): None
Summary:
(1)研究背景:本文研究了医学图像分割中的半监督学习方法,特别是在缺乏大量标注数据的情况下。文章利用Segment Anything Model(SAM)进行医学图像分割,以缓解对大量标注数据的需求。
-(2)过去的方法及问题:过去的方法主要依赖于大量的标注数据进行监督学习,但标注数据获取成本高昂且耗时。在没有足够标注数据的情况下,传统方法性能会大幅下降。因此,需要一种新的方法来解决这个问题。
-(3)研究方法:本文提出了一种基于SAM的半监督学习方法,通过利用SAM对未标注数据进行伪标签生成,从而进行训练。该方法通过提取边界框和种子点作为提示传递给SAM,从有限的标注数据中生成初始分割,并进一步生成密集的分割掩膜作为未标注数据的伪标签。通过这种方式,该方法能够在缺乏大量标注数据的情况下进行有效的医学图像分割。
-(4)任务与性能:本文在儿科手腕骨骼和牙科放射图像中的牙齿分割任务上进行了实验。结果表明,使用本文提出的伪标签进行训练,Dice得分从原来的74.29%提升至84.17%,以及从66.63%提升至74.87%。与强度后处理方法、当前先进的监督学习分割方法和半监督均值教师方法相比,本文提出的方法具有更好的性能。实验结果表明,该方法能够有效解决缺乏标注数据的问题,提高医学图像分割的准确性和性能。
- 方法论概述:
本文提出了一种基于Segment Anything Model(SAM)的半监督学习方法来解决医学图像分割中的标注数据缺乏问题。具体步骤如下:
(1) 背景介绍与问题定义:针对医学图像分割中的半监督学习问题,当只有少量标注数据时,如何训练一个高性能的模型是一个挑战。文章旨在解决这一问题。
(2) 方法概述:文章提出了一种基于SAM的半监督学习方法。首先,利用有限的标注数据训练一个分割模型。然后,利用该模型对未标注数据进行预测,生成预测分割。接着,通过Mask Cleaning和Prompt Extraction步骤,从预测分割中提取边界框和种子点作为稀疏提示,为SAM提供输入。SAM利用这些提示生成更精细的伪标签。最后,使用这些伪标签训练新的分割模型。
(3) 实验流程:实验分为训练阶段和测试阶段。在训练阶段,使用少量标注数据训练初始分割模型,并利用SAM生成伪标签。在测试阶段,使用生成的伪标签训练新的分割模型,并在测试集上评估其性能。实验结果表明,该方法能够有效提高医学图像分割的准确性和性能。此外,文章还在儿科手腕骨骼和牙科放射图像中的牙齿分割任务上进行了实验验证。通过与强度后处理方法、当前先进的监督学习分割方法和半监督均值教师方法对比,本文提出的方法具有更好的性能。
总结来说,本文利用SAM模型进行医学图像分割研究,通过半监督学习方法解决了标注数据缺乏的问题,提高了医学图像分割的准确性和性能。
Conclusion:
(1) 这项研究工作的意义在于提出了一种基于Segment Anything Model(SAM)的半监督学习方法来解决医学图像分割中的标注数据缺乏问题。该方法能够在缺乏大量标注数据的情况下进行有效的医学图像分割,提高了医学图像分割的准确性和性能,具有重要的实际应用价值。
(2) 创新点:本文提出了基于SAM的半监督学习方法,通过利用未标注数据进行伪标签生成,从而进行训练,有效解决了医学图像分割中标注数据缺乏的问题。性能:实验结果表明,该方法在儿科手腕骨骼和牙科放射图像中的牙齿分割任务上取得了良好的性能,与强度后处理方法、当前先进的监督学习分割方法和半监督均值教师方法相比,具有更好的性能。工作量:文章的方法论概述清晰地阐述了实验流程和方法步骤,但文章未提供具体的代码实现和详细实验数据,对于读者理解和复现方法带来了一定的难度。
点此查看论文截图

Iterative tomographic reconstruction with TV prior for low-dose CBCT dental imaging
Authors:Louise Friot-Giroux, Françoise Peyrin, Voichita Maxim
Abstract Objective. Cone-beam computed tomography is becoming more and more popular in applications such as 3D dental imaging. Iterative methods compared to the standard Feldkamp algorithm have shown improvements in image quality of reconstruction of low-dose acquired data despite their long computing time. An interesting aspect of iterative methods is their ability to include prior information such as sparsity-constraint. While a large panel of optimization algorithms along with their adaptation to tomographic problems are available, they are mainly studied on 2D parallel or fan-beam data. The issues raised by 3D CBCT and moreover by truncated projections are still poorly understood. Approach. We compare different carefully designed optimization schemes in the context of realistic 3D dental imaging. Besides some known algorithms, SIRT-TV and MLEM, we investigate the primal-dual hybrid gradient (PDHG) approach and a newly proposed MLEM-TV optimizer. The last one is alternating EM steps and TV-denoising, combination not yet investigated for CBCT. Experiments are performed on both simulated data from a 3D jaw phantom and data acquired with a dental clinical scanner. Main results. With some adaptations to the specificities of CBCT operators, PDHG and MLEM-TV algorithms provide the best reconstruction quality. These results were obtained by comparing the full-dose image with a low-dose image and an ultra low-dose image. Significance. The convergence speed of the original iterative methods is hampered by the conical geometry and significantly reduced compared to parallel geometries. We promote the pre-conditioned version of PDHG and we propose a pre-conditioned version of the MLEM-TV algorithm. To the best of our knowledge, this is the first time PDHG and convergent MLEM-TV algorithms are evaluated on experimental dental CBCT data, where constraints such as projection truncation and presence of metal have to be jointly overcome.
Summary
研究比较不同优化方案在3D牙科成像中的应用,PDHG和MLEM-TV算法在CBCT重建中表现最佳。
Key Takeaways
- 球锥束CT在牙科成像中应用广泛。
- 迭代方法在低剂量数据重建中提升图像质量。
- 优化算法在二维数据研究中较多,三维数据应用较少。
- 3D CBCT和截断投影问题理解不足。
- 研究对比PDHG、MLEM、SIRT-TV和MLEM-TV算法。
- PDHG和MLEM-TV算法适应CBCT特性,重建质量最佳。
- 首次在CBCT数据上评估PDHG和MLEM-TV算法,解决截断投影和金属等问题。
Title: 迭代重建法在低剂量锥形束计算机断层扫描三维牙科成像中的应用,采用TV先验。
Authors: Louise Friot-Giroux, Françoise Peyrin, Voichita Maxim。
Affiliation: 来自法国里昂大学、INSA里昂、Claude Bernard里昂第一大学等机构的联合研究团队。
Keywords:锥形束计算机断层扫描(CBCT)、牙科成像、迭代重建。
Urls: 论文的抽象和详细信息尚未公开,因此无法提供链接。关于代码,如果有公开的话,可以在GitHub上搜索相关项目或联系作者获取。至于提供的arXiv编号,可以用于在arXiv网站上查找该论文的详细版本。
Summary:
(1)研究背景:随着三维牙科成像等应用的普及,低剂量锥束计算机断层扫描(CBCT)技术日益受到关注。相较于传统的Feldkamp算法,迭代方法能够在低剂量数据重建中提高图像质量,尽管其计算时间较长。文章旨在探讨迭代重建法在CBCT牙科成像中的应用,特别是针对现实的三维数据。
(2)过去的方法及问题:虽然针对二维平行或扇形光束数据的优化算法及其适应性已有大量研究,但对于三维CBCT和截断投影引起的问题仍理解不足。传统的算法在锥形几何下的收敛速度受到阻碍,与平行几何相比显著降低。因此,需要新的方法来解决这些问题。
(3)研究方法:文章比较了不同的优化方案,包括已知的SIR-TV和MLEM算法,以及新提出的PDHG和MLEM-TV优化器。特别是MLEM-TV优化器结合了期望最大化步骤和TV降噪,这在CBCT中是首次尝试。实验是在模拟的三维颌骨幻影数据和牙科临床扫描仪采集的数据上进行的。为了应对CBCT的特殊性质,对算法进行了一些调整。同时,文章还推广了PDHG和MLEM-TV算法的预条件版本。
(4)任务与性能:文章的主要结果表明,PDHG和MLEM-TV算法在牙科CBCT数据的迭代重建中提供了最佳图像质量。这些结果通过与全剂量图像、低剂量图像和超低剂量图像的对比得出。此外,这些算法能够克服投影截断和金属存在等约束,这在之前的算法中是一个挑战。因此,该论文提出的方法在牙科CBCT成像中表现出良好的性能,有望为未来的相关研究提供有价值的参考。
- 方法论:
文章主要介绍了迭代重建法在低剂量锥形束计算机断层扫描(CBCT)三维牙科成像中的应用,并采用了TV先验的方法。方法论的主要思路如下:
(1)研究背景分析:文章首先介绍了随着三维牙科成像等应用的普及,低剂量锥束计算机断层扫描(CBCT)技术日益受到关注。与传统的Feldkamp算法相比,迭代方法在低剂量数据重建中能提高图像质量,尽管其计算时间较长。文章旨在探讨迭代重建法在CBCT牙科成像中的应用,特别是针对现实的三维数据。
(2)过去的方法及问题:文章回顾了针对二维平行或扇形光束数据的优化算法及其适应性,指出对于三维CBCT和截断投影引起的问题仍理解不足。传统的算法在锥形几何下的收敛速度受到阻碍,与平行几何相比显著降低。因此,需要新的方法来解决这些问题。
(3S研究方法:文章采用了多种优化方案进行比较,包括已知的SIR-TV和MLEM算法,以及新提出的PDHG和MLEM-TV优化器。特别是MLEM-TV优化器结合了期望最大化步骤和TV降噪,这在CBCT中是首次尝试。实验是在模拟的三维颌骨幻影数据和牙科临床扫描仪采集的数据上进行的。为了应对CBCT的特殊性质,对算法进行了一些调整。同时,文章还推广了PDHG和MLEM-TV算法的预条件版本。这些方法的选择都是为了更好地解决低剂量CBCT成像中的实际问题。具体的实现步骤包括建立优化模型、设计迭代重建算法、进行模拟和实验验证等。其中涉及到的关键技术包括投影数据的处理、图像重建算法的设计和优化、TV正则化技术的引入等。这些方法的选择和设计都是为了提高低剂量CBCT成像的图像质量,克服截断投影和金属存在等约束条件。
总的来说,文章的方法论主要是通过研究迭代重建法在CBCT牙科成像中的应用,结合TV先验技术,提高低剂量数据重建的图像质量。通过模拟和实验验证,证明了该方法在牙科CBCT成像中的良好性能,为未来的相关研究提供了有价值的参考。
- 结论:
- (1)这项工作的重要性在于研究了迭代重建法在低剂量锥形束计算机断层扫描(CBCT)三维牙科成像中的应用,采用TV先验技术以提高图像质量。这对于减少辐射剂量、提高成像质量和解决牙科CBCT成像中的实际问题具有重要意义。
- (2)创新点:文章采用了多种优化方案进行比较,包括已知的SIR-TV和MLEM算法,以及新提出的PDHG和MLEM-TV优化器。特别是MLEM-TV优化器结合了期望最大化步骤和TV降噪,这在CBCT中是首次尝试。文章还推广了PDHG和MLEM-TV算法的预条件版本。然而,文章没有明确指出新方法在多大程度上实现了其设定的目标。性能:从实验结果来看,PDHG和MLEM-TV算法在牙科CBCT数据的迭代重建中提供了最佳图像质量。这些算法能够克服投影截断和金属存在等约束,这在之前的算法中是一个挑战。工作量:文章的实验设计合理,但工作量相对较大,涉及的算法较多且复杂。需要进行大量的模拟和实验验证。尽管存在计算时间较长的问题,但该研究工作在迭代重建法在牙科CBCT成像中的应用方面取得了一些进展,并提供了有价值的参考。
点此查看论文截图

 wechat
wechat- alipay

