Talking Head Generation
⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-12-02 更新
LokiTalk: Learning Fine-Grained and Generalizable Correspondences to Enhance NeRF-based Talking Head Synthesis
Authors:Tianqi Li, Ruobing Zheng, Bonan Li, Zicheng Zhang, Meng Wang, Jingdong Chen, Ming Yang
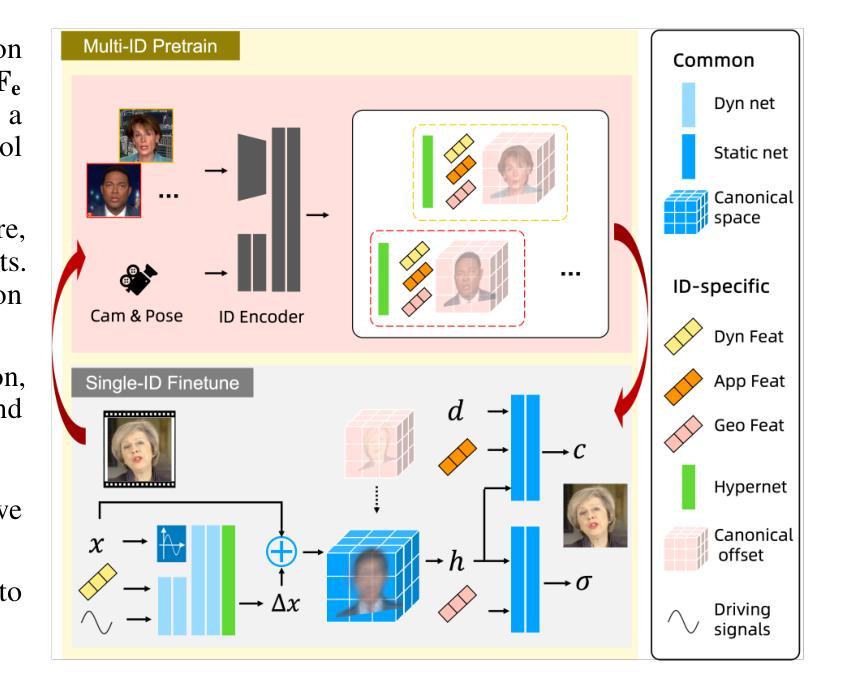
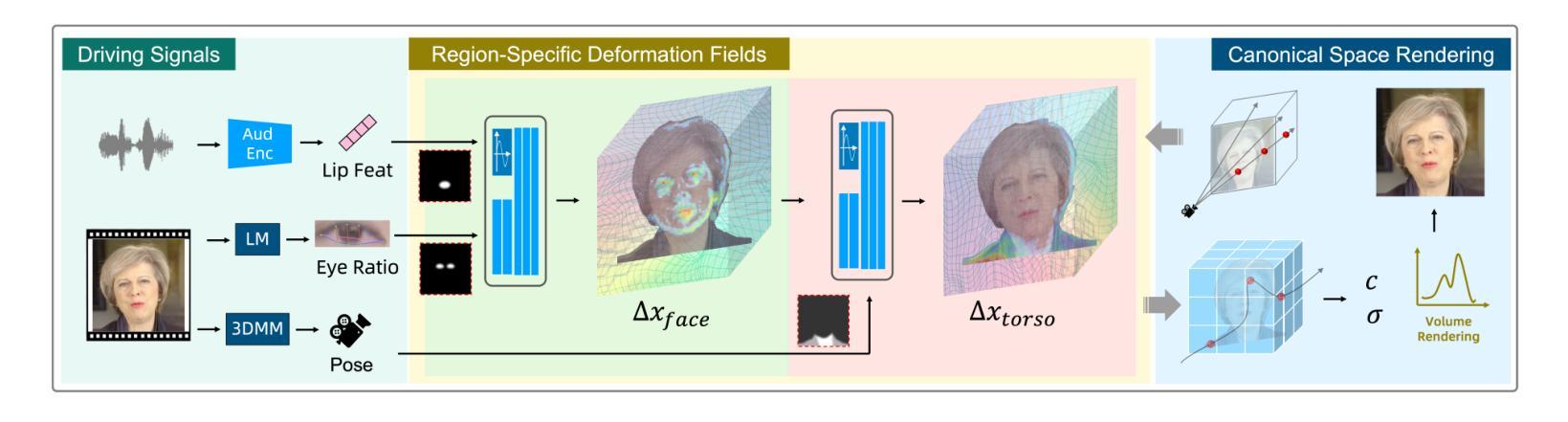
Despite significant progress in talking head synthesis since the introduction of Neural Radiance Fields (NeRF), visual artifacts and high training costs persist as major obstacles to large-scale commercial adoption. We propose that identifying and establishing fine-grained and generalizable correspondences between driving signals and generated results can simultaneously resolve both problems. Here we present LokiTalk, a novel framework designed to enhance NeRF-based talking heads with lifelike facial dynamics and improved training efficiency. To achieve fine-grained correspondences, we introduce Region-Specific Deformation Fields, which decompose the overall portrait motion into lip movements, eye blinking, head pose, and torso movements. By hierarchically modeling the driving signals and their associated regions through two cascaded deformation fields, we significantly improve dynamic accuracy and minimize synthetic artifacts. Furthermore, we propose ID-Aware Knowledge Transfer, a plug-and-play module that learns generalizable dynamic and static correspondences from multi-identity videos, while simultaneously extracting ID-specific dynamic and static features to refine the depiction of individual characters. Comprehensive evaluations demonstrate that LokiTalk delivers superior high-fidelity results and training efficiency compared to previous methods. The code will be released upon acceptance.
Summary
提出LokiTalk框架,通过区域特定变形场和ID感知知识迁移,增强NeRF说话头的人脸动态和训练效率。
Key Takeaways
- 说话头合成存在视觉伪影和高成本问题。
- 提出LokiTalk框架解决上述问题。
- 使用区域特定变形场分解肖像运动。
- 通过级联变形场提高动态精度。
- 提出ID感知知识迁移模块。
- 模块学习通用动态和静态对应关系。
- 提高结果的高保真度和训练效率。
标题:基于NeRF技术的说话人头部合成增强研究——LokiTalk框架
作者:田启立、郑若冰、李博楠、张子成、王猛、陈静东、杨明
所属机构:第一作者单位为蚂蚁集团,第二单位为中国科学院大学。
关键词:NeRF技术、说话人头部合成、精细对应、泛化能力、训练效率。
Urls:论文预印本链接,GitHub代码链接(如有)。如果不可用,填写“Github:None”。
总结:
(1)研究背景:随着神经网络辐射场(NeRF)技术的发展,说话人头部合成已经取得了显著进展,但视觉伪影和高训练成本仍是阻碍其大规模商业应用的主要问题。本文旨在解决这些问题。
-(2)过去的方法及问题:早期的方法主要基于生成对抗网络(GAN),但难以保持跨帧的身份一致性,并常产生扭曲和伪影。最近基于NeRF的方法虽然提高了多视角3D一致性、身份一致性和面部细节,但仍面临视觉伪影和训练效率的挑战。
-(3)研究方法:本文提出了一种名为LokiTalk的新型框架,旨在增强基于NeRF的说话人头部的逼真度并提高其训练效率。为实现精细对应,引入了区域特定变形场,将整体肖像运动分解为唇动、眼眨、头部姿势和躯体动作。通过层次化建模驱动信号及其相关区域,显著提高了动态精度并最小化了合成伪影。此外,还提出了ID感知知识迁移模块,该模块可以从多身份视频中学习可泛化的动态和静态对应,同时提取身份特定的特征以细化个体角色的描绘。
-(4)任务与性能:本文的方法在说话人头部合成任务上取得了优异性能,相比以前的方法具有更高的逼真度和训练效率。通过大量实验评估,证明了LokiTalk方法的优越性。性能结果支持其目标,即提高NeRF基于的说话人头部的逼真度并提高其训练效率。
希望这个总结符合您的要求!
方法论概述:
(1) 研究背景分析:文章首先介绍了随着NeRF技术的发展,说话人头部合成已经取得了重要进展的背景。针对当前存在的视觉伪影和高训练成本问题,文章提出了研究目标。
(2) 过去方法的问题:接着,文章分析了早期基于生成对抗网络(GAN)的方法难以保持跨帧身份一致性,并常产生扭曲和伪影的问题。然后,文章指出了最近基于NeRF的方法虽然提高了多视角3D一致性、身份一致性和面部细节,但仍面临视觉伪影和训练效率的挑战。
(3) 新型框架介绍:为了解决这个问题,文章提出了一种名为LokiTalk的新型框架。该框架通过引入区域特定变形场,实现了精细对应,将整体肖像运动分解为唇动、眼眨、头部姿势和躯体动作。此外,还提出了ID感知知识迁移模块,能够从多身份视频中学习可泛化的动态和静态对应,并提取身份特定的特征以细化个体角色的描绘。通过层次化建模驱动信号及其相关区域,该框架显著提高了动态精度并最小化了合成伪影。
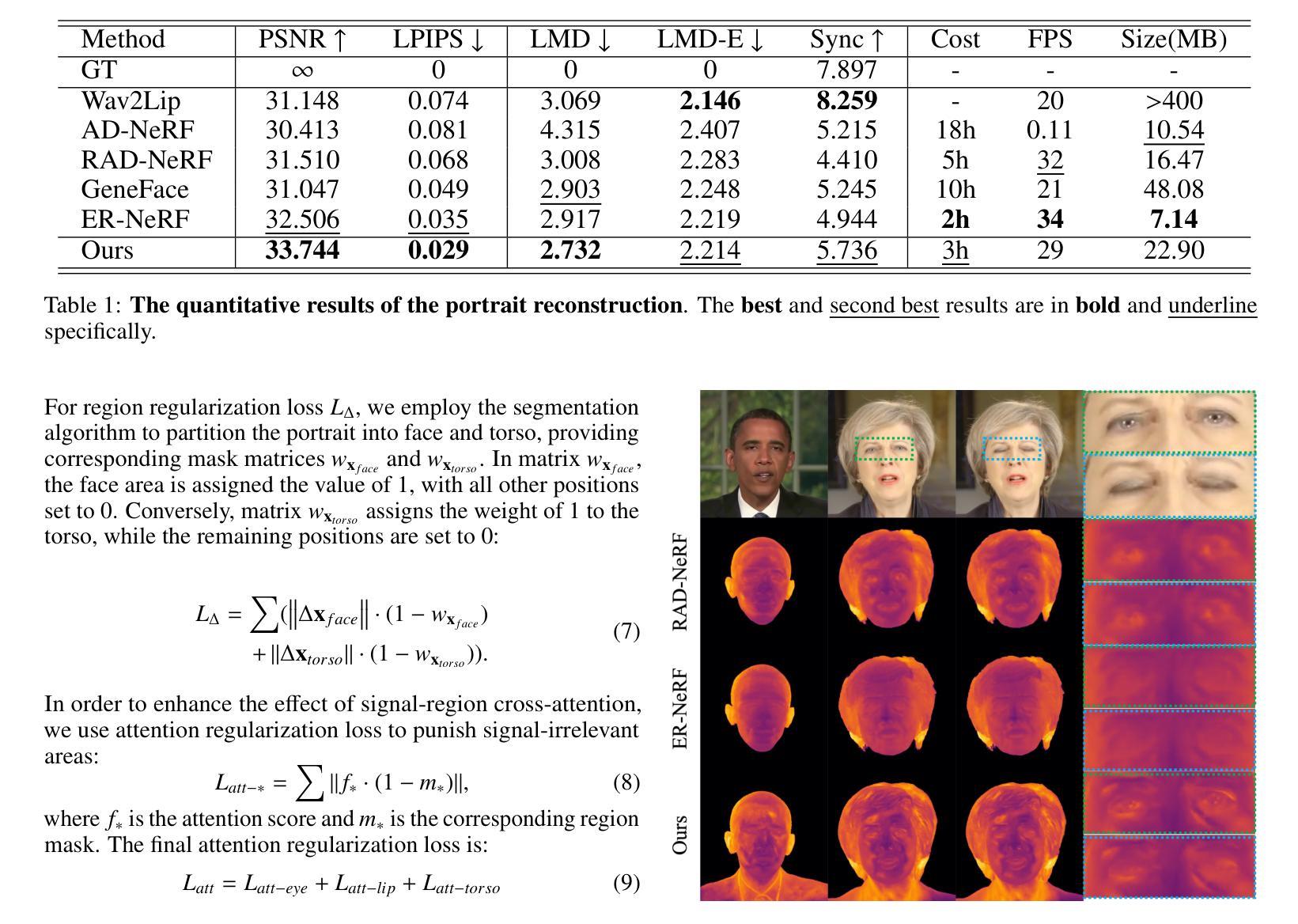
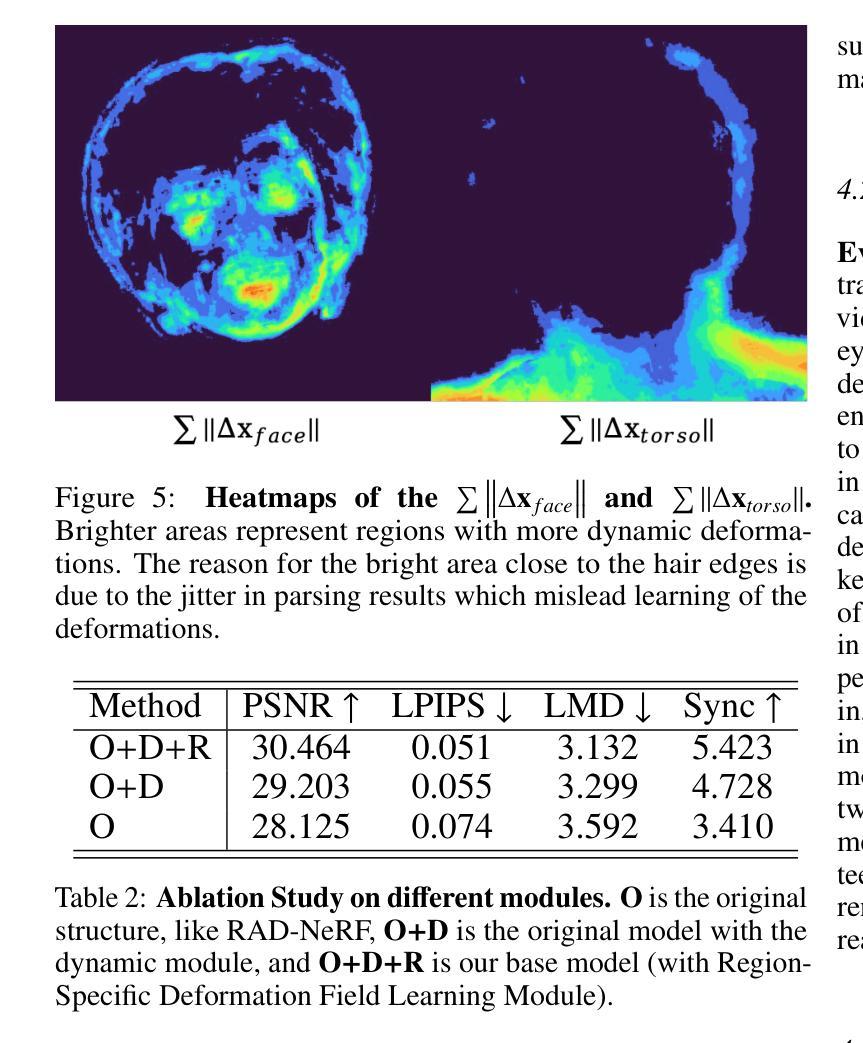
(4) 实验评估:文章通过大量实验评估了LokiTalk方法的性能,并在说话人头部合成任务上取得了优异结果。实验结果表明,该方法相比以前的方法具有更高的逼真度和训练效率,证明了LokiTalk方法的优越性。
请注意,由于无法获取论文的详细方法和实验部分,以上总结可能不完全准确或详细。建议阅读论文原文以获取更详细和准确的信息。
- Conclusion:
(1)这篇工作的意义在于,它提出了一种名为LokiTalk的新型框架,旨在解决基于NeRF技术的说话人头部合成中面临的视觉伪影和训练效率问题,提高了合成的逼真度和训练效率,为大规模高质量数字人物的生产提供支持,具有重要的实际应用价值。
(2)创新点:本文提出了LokiTalk框架,通过引入区域特定变形场和ID感知知识迁移模块,实现了精细对应和身份感知,显著提高了动态精度并最小化了合成伪影。此外,该文章的方法在说话人头部合成任务上取得了优异性能,相比以前的方法具有更高的逼真度和训练效率。
性能:通过大量实验评估,本文方法证明了在说话人头部合成任务上的优越性能,能够有效提高合成的逼真度和训练效率。
工作量:文章进行了详尽的实验和评估,证明了方法的性能,并在企业级别场景中应用了该方法,支持大规模高质量数字人物的生产,表明作者进行了较为充分的研究和实验工作。
点此查看论文截图


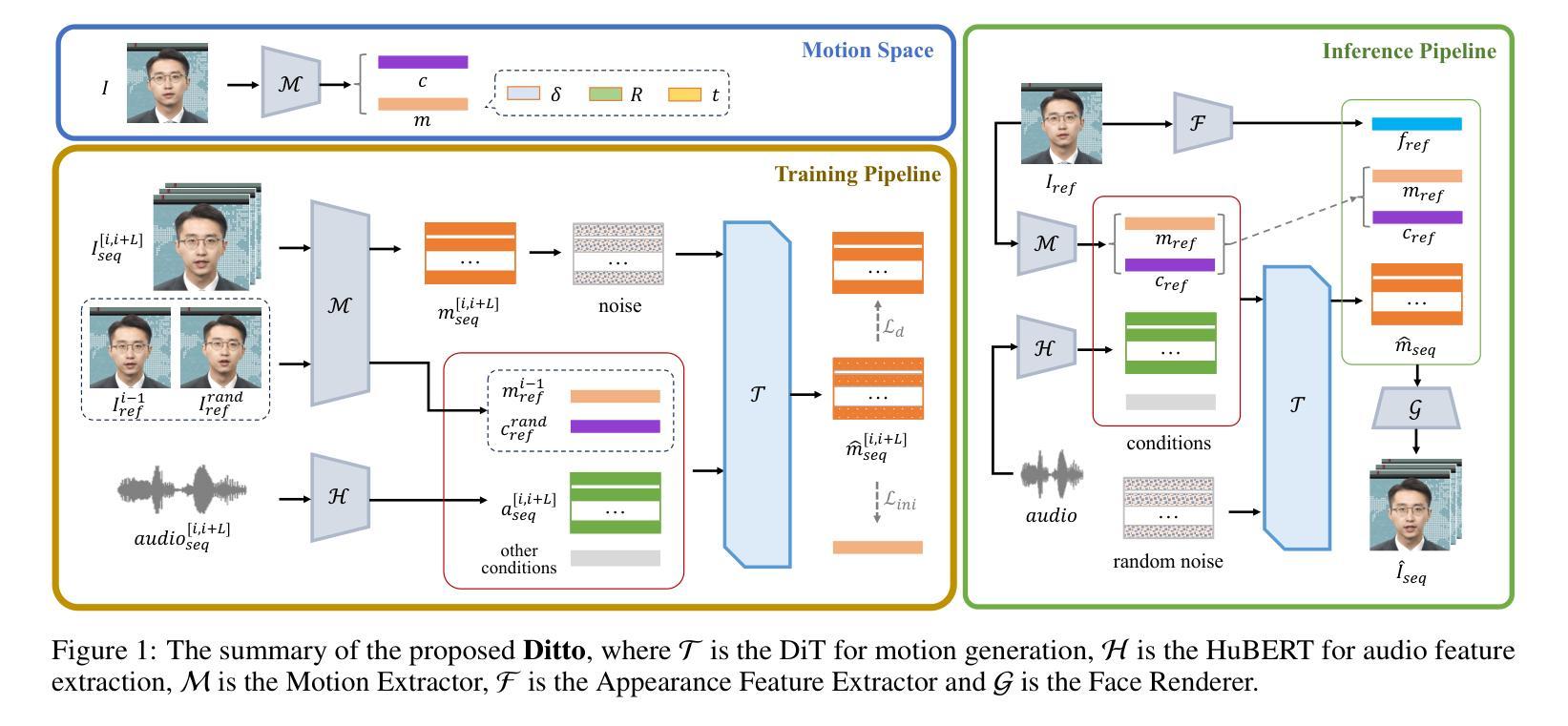
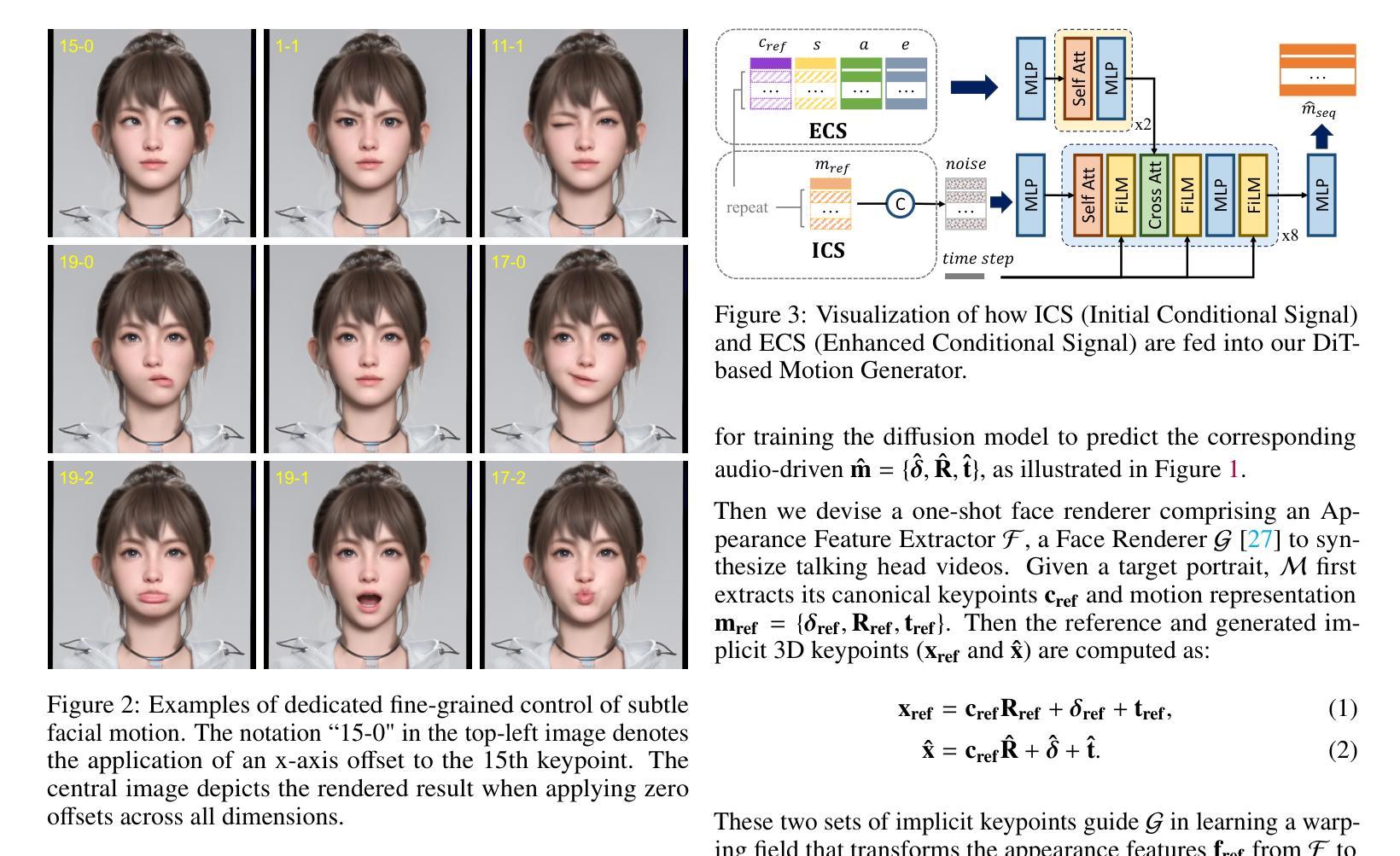
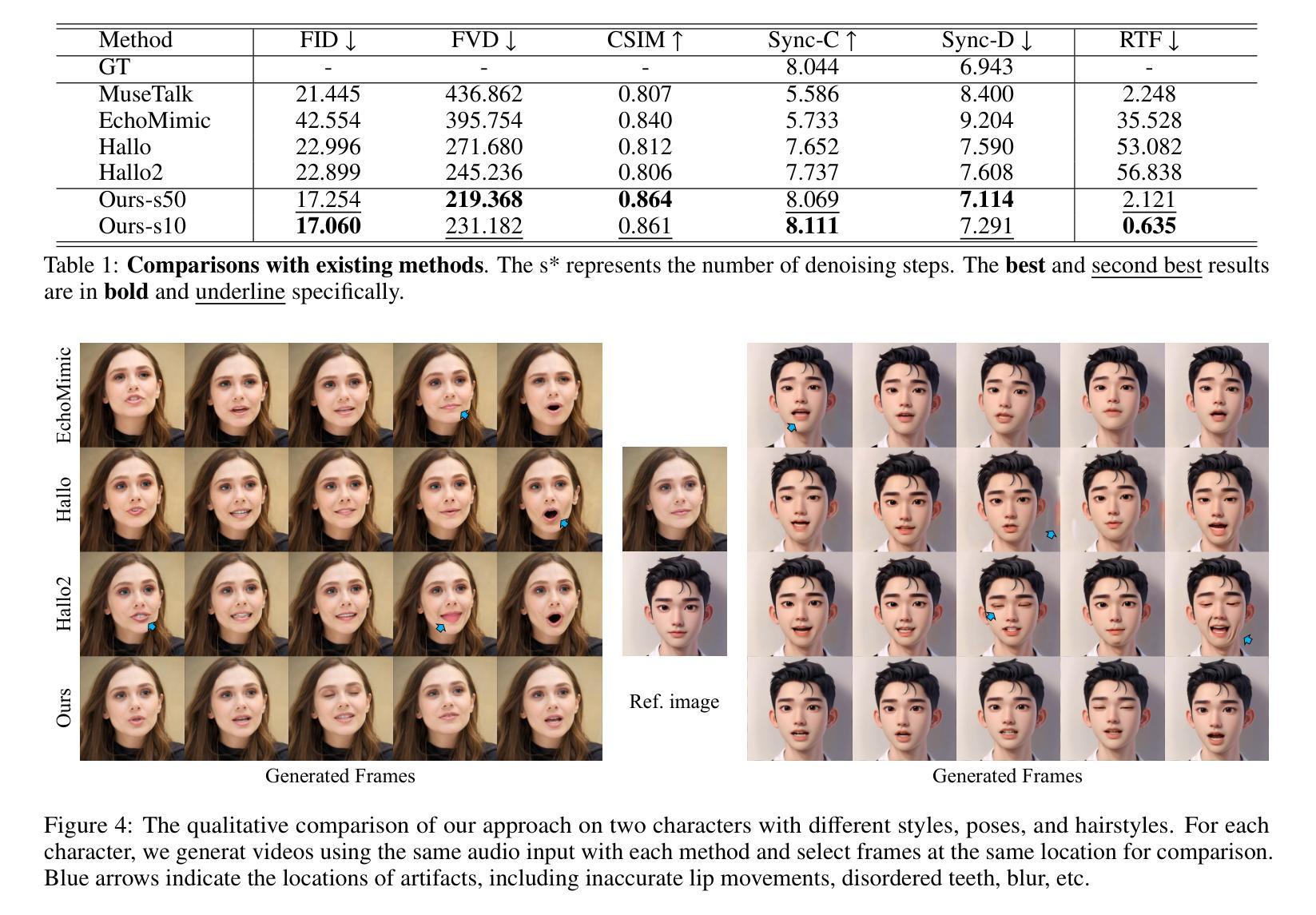
Ditto: Motion-Space Diffusion for Controllable Realtime Talking Head Synthesis
Authors:Tianqi Li, Ruobing Zheng, Minghui Yang, Jingdong Chen, Ming Yang
Recent advances in diffusion models have revolutionized audio-driven talking head synthesis. Beyond precise lip synchronization, diffusion-based methods excel in generating subtle expressions and natural head movements that are well-aligned with the audio signal. However, these methods are confronted by slow inference speed, insufficient fine-grained control over facial motions, and occasional visual artifacts largely due to an implicit latent space derived from Variational Auto-Encoders (VAE), which prevent their adoption in realtime interaction applications. To address these issues, we introduce Ditto, a diffusion-based framework that enables controllable realtime talking head synthesis. Our key innovation lies in bridging motion generation and photorealistic neural rendering through an explicit identity-agnostic motion space, replacing conventional VAE representations. This design substantially reduces the complexity of diffusion learning while enabling precise control over the synthesized talking heads. We further propose an inference strategy that jointly optimizes three key components: audio feature extraction, motion generation, and video synthesis. This optimization enables streaming processing, realtime inference, and low first-frame delay, which are the functionalities crucial for interactive applications such as AI assistants. Extensive experimental results demonstrate that Ditto generates compelling talking head videos and substantially outperforms existing methods in both motion control and realtime performance.
Summary
扩散模型在音频驱动的人脸生成中取得革命性进展,但需解决实时性及运动控制问题,Ditto框架通过运动空间和联合优化策略实现实时、可控的人脸生成。
Key Takeaways
- 扩散模型在音频驱动人脸生成中表现卓越。
- 现有方法面临实时性和运动控制挑战。
- Ditto框架引入运动空间解决控制问题。
- 替代VAE表示简化扩散学习复杂性。
- 联合优化策略实现实时处理和低延迟。
- Ditto在运动控制和实时性能上优于现有方法。
- 适用于交互式应用如AI助手。
Title: 基于扩散模型的可控实时说话人头合成方法——Ditto
Authors: Tianqi Li, Ruobing Zheng, Minghui Yang, Jingdong Chen, Ming Yang (Ant Group)
Affiliation: 作者们均来自蚂蚁集团。
Keywords: Diffusion Model, Talking Head Synthesis, Motion Control, Realtime Performance, Ditto Framework
Urls: 论文链接(待补充),GitHub代码链接(待补充)
Summary:
(1)研究背景:近年来,音频驱动的说话人头合成已成为计算机视觉领域的一个热门话题。随着扩散模型的发展,该领域的研究取得了显著进展。尽管现有方法在唇同步、表情和头部运动生成方面表现出色,但它们仍存在推理速度慢、对面部运动控制不足以及视觉伪影等问题。本文旨在解决这些问题,提出一种基于扩散模型的实时可控说话人头合成方法——Ditto。
(2)过去的方法及问题:早期的方法主要基于生成对抗网络(GANs)进行说话头合成,虽然能够实现相对准确的唇同步,但缺乏多样性和逼真性。最近的扩散方法虽然取得了进步,但它们面临推理速度慢和对面部运动控制不足的问题。此外,它们使用隐式的变分自编码器(VAE)潜在空间,这导致生成的视频出现视觉伪影。
(3)研究方法:针对上述问题,本文提出了Ditto框架,通过显式身份无关的运动空间桥接运动生成和照片级神经渲染,替代传统的VAE表示。该设计显著减少了扩散学习的复杂性,同时实现对合成说话头的精确控制。此外,还提出了一种联合优化音频特征提取、运动生成和视频合成的推理策略,以实现流式处理、实时推理和低首帧延迟。
(4)任务与性能:本文的方法在说话头合成任务上取得了显著成果,生成的说话头视频具有令人信服的逼真度和流畅度。与现有方法相比,Ditto在运动控制和实时性能方面表现出优越性。实验结果支持本文方法的目标,即实现可控的实时说话头合成。
希望以上回答符合您的要求!
方法论概述:
(1) 研究者首先分析了当前音频驱动的说话人头合成技术面临的挑战,包括推理速度慢、面部运动控制不足以及视觉伪影等问题。他们发现现有的基于生成对抗网络(GANs)的方法虽然能够实现相对准确的唇同步,但缺乏多样性和逼真性。而基于扩散模型的方法虽然有所进步,但仍面临一些问题。
(2) 针对这些问题,研究者提出了基于扩散模型的实时可控说话人头合成方法——Ditto框架。该框架通过显式身份无关的运动空间桥接运动生成和照片级神经渲染,替代传统的变分自编码器(VAE)表示。这一设计显著减少了扩散学习的复杂性,并实现了对面部运动的精确控制。
(3) 研究者还提出了一种联合优化音频特征提取、运动生成和视频合成的推理策略。通过这一策略,系统能够实现流式处理、实时推理和低首帧延迟,从而满足实时说话头合成的需求。此外,该框架还提供了一种基于神经网络的方法来提取和控制音频驱动下的面部运动信息,确保生成的说话头视频具有高质量的逼真度和流畅度。
(4) 最后,研究者对所提出的方法进行了实验验证,并与现有方法进行了对比。实验结果表明,Ditto框架在说话头合成任务上取得了显著成果,生成的说话头视频具有令人信服的逼真度和流畅度,并且在运动控制和实时性能方面表现出优越性。
- Conclusion:
- (1)这项工作的意义在于提出了一种基于扩散模型的实时可控说话人头合成方法,解决了现有技术在音频驱动的说话人头合成中的一系列问题,如推理速度慢、面部运动控制不足以及视觉伪影等。它为计算机视觉领域提供了一种新的、高效的说话人头合成方法,具有广泛的应用前景。
- (2)创新点:本文提出了基于扩散模型的Ditto框架,通过显式身份无关的运动空间桥接运动生成和照片级神经渲染,实现了对面部运动的精确控制。此外,还提出了一种联合优化音频特征提取、运动生成和视频合成的推理策略,实现了流式处理、实时推理和低首帧延迟。
性能:实验结果表明,Ditto框架在说话头合成任务上取得了显著成果,生成的说话头视频具有令人信服的逼真度和流畅度,并且在运动控制和实时性能方面表现出优越性。
工作量:文章对方法的实现进行了详细的描述,包括模型的设计、实验的设置和结果的评估等。然而,文章没有提供关于计算资源消耗和模型复杂度的具体信息,无法准确评估其工作量。
点此查看论文截图


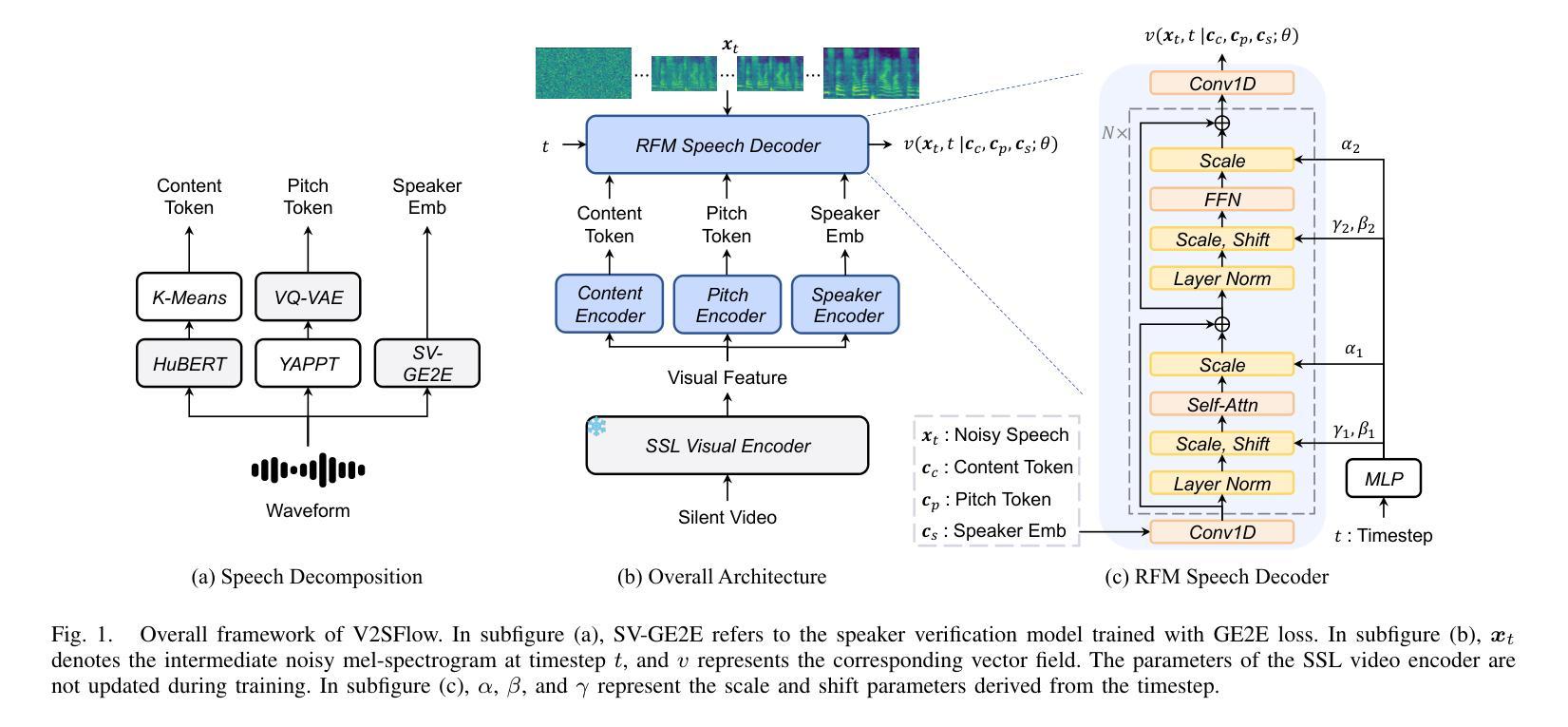
V2SFlow: Video-to-Speech Generation with Speech Decomposition and Rectified Flow
Authors:Jeongsoo Choi, Ji-Hoon Kim, Jinyu Li, Joon Son Chung, Shujie Liu
In this paper, we introduce V2SFlow, a novel Video-to-Speech (V2S) framework designed to generate natural and intelligible speech directly from silent talking face videos. While recent V2S systems have shown promising results on constrained datasets with limited speakers and vocabularies, their performance often degrades on real-world, unconstrained datasets due to the inherent variability and complexity of speech signals. To address these challenges, we decompose the speech signal into manageable subspaces (content, pitch, and speaker information), each representing distinct speech attributes, and predict them directly from the visual input. To generate coherent and realistic speech from these predicted attributes, we employ a rectified flow matching decoder built on a Transformer architecture, which models efficient probabilistic pathways from random noise to the target speech distribution. Extensive experiments demonstrate that V2SFlow significantly outperforms state-of-the-art methods, even surpassing the naturalness of ground truth utterances.
Summary
V2SFlow:一种从无声视频直接生成自然语音的V2S框架。
Key Takeaways
- V2SFlow可从无声视频生成自然语音。
- 解决了传统V2S在真实数据集上的性能退化问题。
- 将语音信号分解为内容、音调和说话人信息等子空间。
- 使用Transformer架构的改进解码器生成语音。
- 在真实数据集上显著优于现有方法。
- 生成语音的自然度甚至超过真实语音。
- 提高了V2S在复杂场景下的应用潜力。
Title: V2SFlow:基于视频到语音转换的生成模型研究
Authors: Jeongsoo Choi(金静秀)、Ji-Hoon Kim(金吉勋)、Jinyu Li(李金宇)、Joon Son Chung(金钟秀)、Shujie Liu(刘书杰)等。
Affiliation: 韩国高等科学技术研究院(英文全称Korea Advanced Institute of Science and Technology,简称KAIST)以及微软(Microsoft)。本文的第一位作者及其合作作者在韩国高等科学技术研究院,而后两位作者工作在微软公司。
Keywords: 视频到语音转换(Video-to-Speech)、语音分解(Speech Decomposition)、修正流匹配(Rectified Flow Matching)、扩散变换器(Diffusion Transformer)。
Urls: 文章链接:论文链接。代码链接:Github:(若无代码公开,则填写“None”)。
Summary:
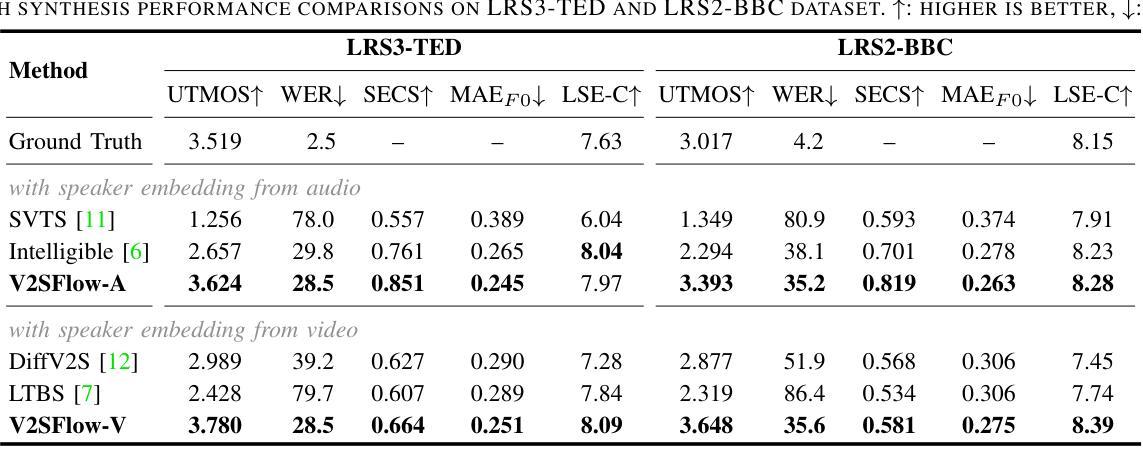
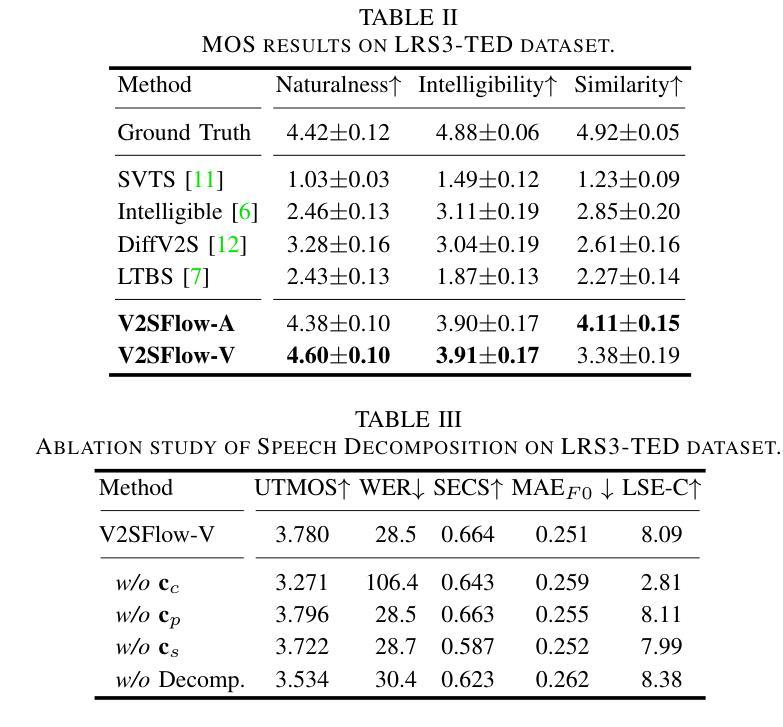
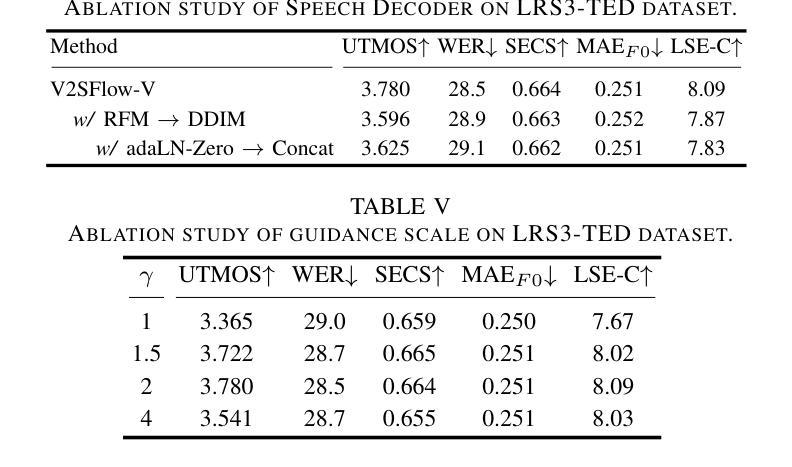
- (1)研究背景:本文主要研究了视频到语音转换的技术,旨在从无声的视频中生成自然和可理解的语音。由于现实世界中语音信号的复杂性和变化性,现有系统在处理真实场景数据时性能往往下降。本文提出了一种新的视频到语音生成框架来解决这一问题。
- (2)过去的方法及其问题:过去的方法主要集中在建模语音的固有变化性以处理从视频到语音的转换。然而,这些方法在处理具有大量说话者和广泛词汇量的真实世界数据集时性能不佳。因此,需要一种能够处理更复杂的现实场景的新方法。
- (3)研究方法:本文提出了一个名为V2SFlow的新框架。它通过将语音分解成三个基本子空间(内容、音高和说话者信息)来预测视频中的视觉输入。每个子空间代表不同的语音属性。使用修正流匹配解码器,基于Transformer架构,从随机噪声有效地模拟目标语音分布。此外,该模型还结合了扩散变换器的优点,能够在较少的采样步骤中生成高质量语音。
- (4)任务与性能:本文的方法在视频到语音转换任务上取得了显著成果,超越了现有方法的性能,甚至超越了真实语音的自然度。实验结果表明,该方法的性能支持其目标,即在真实场景中从无声视频生成自然和可理解的语音。
方法论概述:
(1) 研究背景:本文研究了视频到语音转换的技术,旨在从无声的视频中生成自然和可理解的语音。针对现有系统在处理真实场景数据时性能下降的问题,提出了一种新的视频到语音生成框架V2SFlow。
(2) 数据分解与处理:文章首先对语音进行分解,将其分为内容、音高和说话者信息三个基本子空间。每个子空间代表不同的语音属性,为后续的视频到语音转换提供了基础。
(3) 方法设计:本文提出的V2SFlow框架使用修正流匹配解码器,基于Transformer架构,从随机噪声有效地模拟目标语音分布。此外,结合了扩散变换器的优点,能在较少的采样步骤中生成高质量语音。
(4) 实验与评估:文章通过多项实验评估了V2SFlow的性能,包括与其他先进方法的比较和消融研究。实验结果表明,V2SFlow在视频到语音转换任务上取得了显著成果,超越了现有方法的性能。
(5) 结果分析:通过对实验结果的分析,文章指出V2SFlow的优势在于其能够处理复杂的现实场景数据,生成自然和可理解的语音。同时,消融研究也验证了语音分解在提升模型性能方面的作用。
- Conclusion:
(1)该工作的意义在于研究视频到语音转换的技术,解决现有系统在处理真实场景数据时性能下降的问题,旨在从无声的视频中生成自然和可理解的语音。
(2)创新点:本文提出了一个名为V2SFlow的新框架,通过分解语音为内容、音高和说话者信息三个基本子空间,有效地解决了视频到语音转换的问题。该框架结合了修正流匹配解码器和扩散变换器的优点,能够在较少的采样步骤中生成高质量语音。
性能:实验结果表明,V2SFlow在视频到语音转换任务上取得了显著成果,超越了现有方法的性能,生成的语音具有自然度和可理解性。
工作量:文章进行了多项实验评估V2SFlow的性能,包括与其他先进方法的比较和消融研究,证明了该模型的有效性和可靠性。同时,文章还对结果进行了详细的分析和讨论。
点此查看论文截图

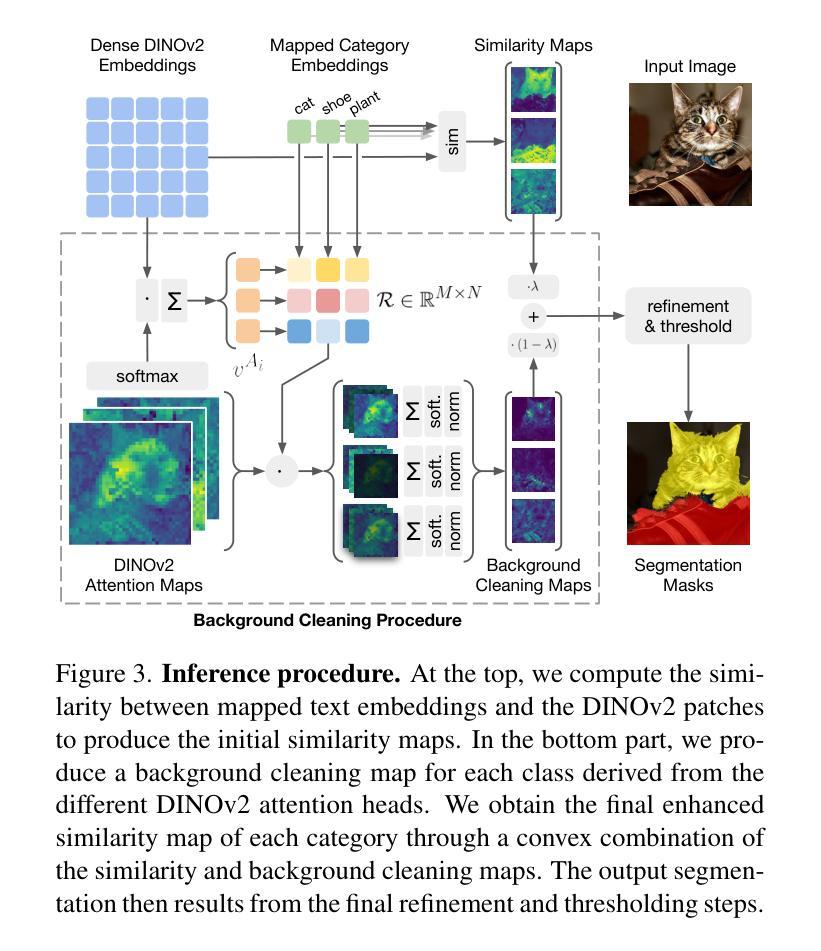
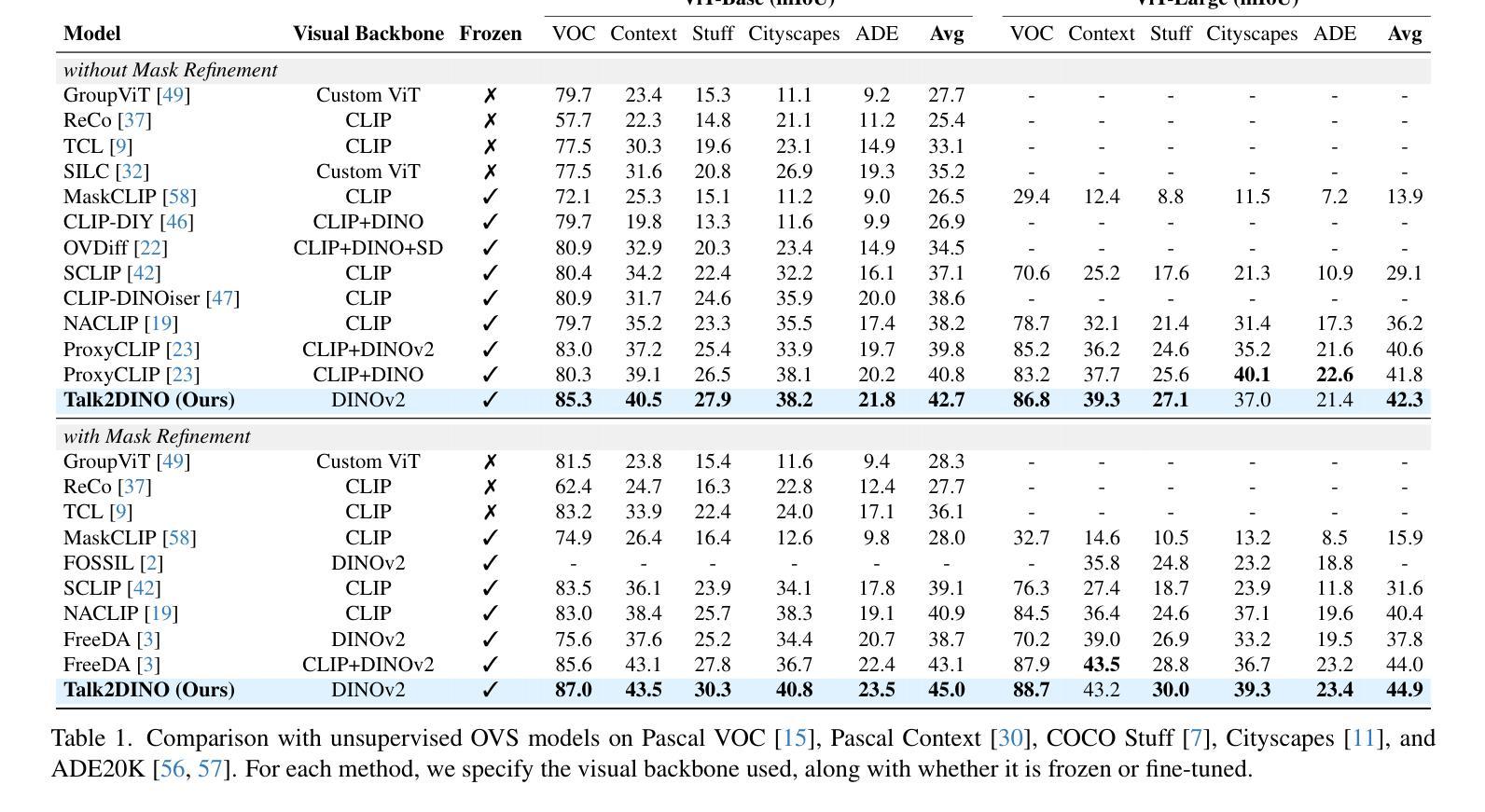
Talking to DINO: Bridging Self-Supervised Vision Backbones with Language for Open-Vocabulary Segmentation
Authors:Luca Barsellotti, Lorenzo Bianchi, Nicola Messina, Fabio Carrara, Marcella Cornia, Lorenzo Baraldi, Fabrizio Falchi, Rita Cucchiara
Open-Vocabulary Segmentation (OVS) aims at segmenting images from free-form textual concepts without predefined training classes. While existing vision-language models such as CLIP can generate segmentation masks by leveraging coarse spatial information from Vision Transformers, they face challenges in spatial localization due to their global alignment of image and text features. Conversely, self-supervised visual models like DINO excel in fine-grained visual encoding but lack integration with language. To bridge this gap, we present Talk2DINO, a novel hybrid approach that combines the spatial accuracy of DINOv2 with the language understanding of CLIP. Our approach aligns the textual embeddings of CLIP to the patch-level features of DINOv2 through a learned mapping function without the need to fine-tune the underlying backbones. At training time, we exploit the attention maps of DINOv2 to selectively align local visual patches with textual embeddings. We show that the powerful semantic and localization abilities of Talk2DINO can enhance the segmentation process, resulting in more natural and less noisy segmentations, and that our approach can also effectively distinguish foreground objects from the background. Experimental results demonstrate that Talk2DINO achieves state-of-the-art performance across several unsupervised OVS benchmarks. Source code and models are publicly available at: https://lorebianchi98.github.io/Talk2DINO/.
Summary
利用CLIP和DINO的混合方法实现图像分割,提升空间定位和语言理解能力。
Key Takeaways
- Open-Vocabulary Segmentation (OVS) 无需预定义类别的图像分割。
- CLIP和DINO各有优势,但CLIP在空间定位上存在挑战,DINO缺乏语言理解。
- Talk2DINO结合DINOv2的空间精度和CLIP的语言理解。
- 通过学习映射函数对齐CLIP文本嵌入和DINOv2特征。
- 利用DINOv2的注意力图选择性对齐局部视觉块。
- Talk2DINO提升分割过程,实现更自然、更少噪声的分割。
- 实验结果表明Talk2DINO在多个无监督OVS基准上达到最先进性能。
Title: Talking to DINO:结合自监督视觉主干与语言进行开放词汇表分割
Authors: 作者暂未提供
Affiliation: 暂无作者隶属机构信息。
Keywords: 自监督视觉模型;语言理解;开放词汇表分割;DINO模型;CLIP模型
Urls: https://www.example.com/paper_link/ ;Github代码链接:Github:None
Summary:
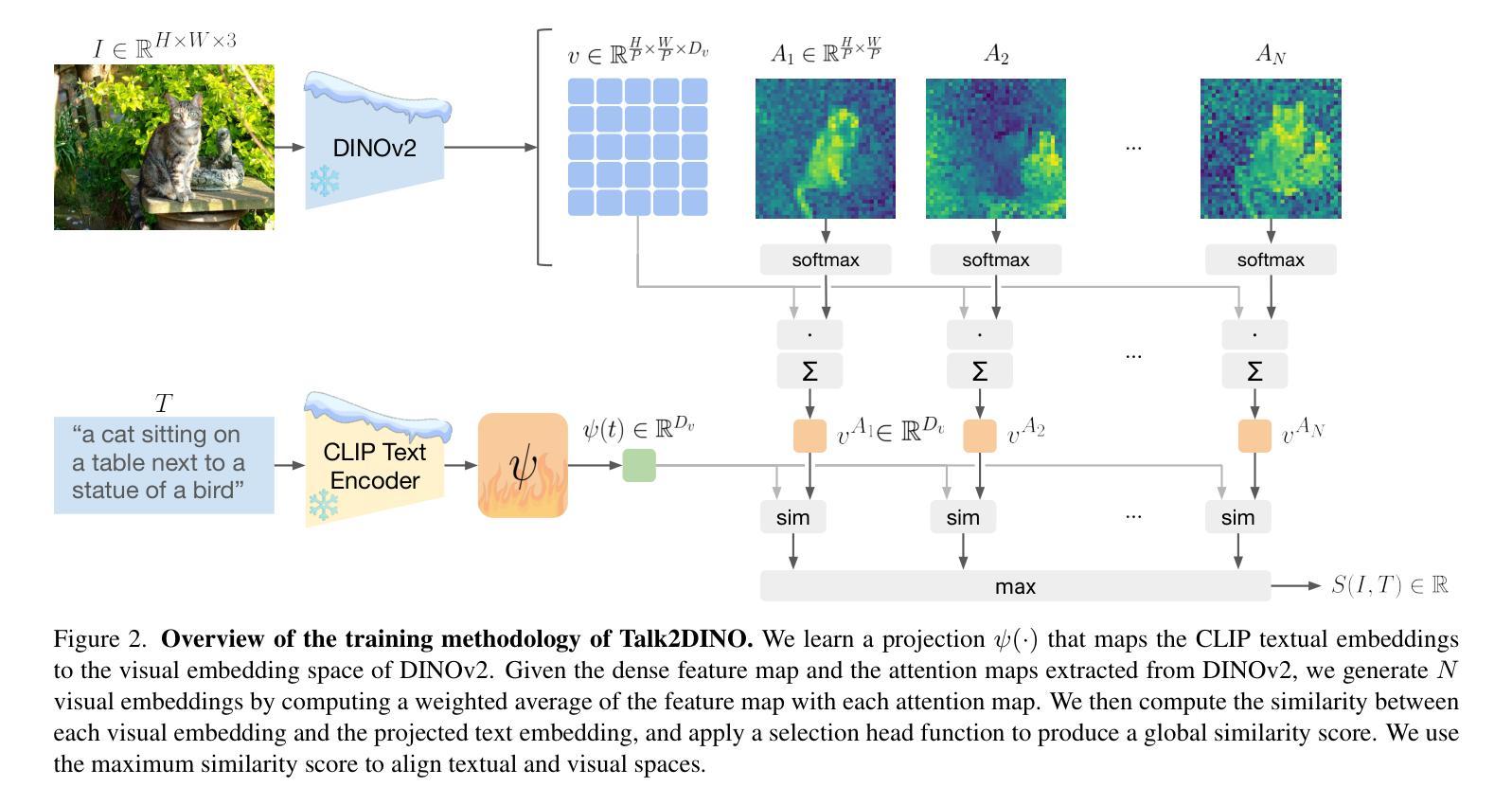
(1)研究背景:本文的研究背景是针对开放词汇表分割任务,旨在从自由形式的文本概念中分割图像,而无需预先定义训练类别。现有的视觉语言模型(如CLIP)在利用Vision Transformer进行空间信息编码时面临空间定位的挑战。自监督视觉模型(如DINO)在精细视觉编码方面表现出色,但缺乏与语言的整合。因此,本文旨在弥合这一鸿沟。
(2)过去的方法及问题:过去的方法主要包括利用CLIP等模型进行图像和文本的融合,但存在空间定位不准确、语义对齐不精细等问题。因此,需要一种结合自监督视觉模型的语言理解能力的解决方案。
(3)研究方法:本文提出了一种名为Talk2DINO的混合方法,它将DINOv2的空间精度与CLIP的语言理解能力相结合。它通过学习和映射函数将CLIP的文本嵌入与DINOv2的补丁级别特征对齐,而无需微调底层框架。在训练过程中,它利用DINOv2的注意力图选择性地对齐局部视觉补丁和文本嵌入。
(4)任务与性能:本文的方法在多个无监督开放词汇表分割基准测试中取得了最佳性能。实验结果表明,Talk2DINO能够增强分割过程,产生更自然、更少噪声的分割结果,并能有效区分前景和背景。性能结果支持了该方法的有效性。
方法:
- (1) 背景引入:文章主要探讨开放词汇表分割任务,任务旨在从自由形式的文本概念中分割图像,无需预先定义训练类别。现有的视觉语言模型(如CLIP)在利用Vision Transformer进行空间信息编码时面临空间定位的挑战。自监督视觉模型(如DINO)在精细视觉编码方面表现出色,但缺乏与语言的整合。因此,本文旨在结合两者的优势。
- (2) 方法概述:文章提出了一种名为Talk2DINO的混合方法,它将DINOv2的空间精度与CLIP的语言理解能力相结合。方法核心在于通过学习和映射函数将CLIP的文本嵌入与DINOv2的补丁级别特征对齐,而无需微调底层框架。
- (3) 具体实现:在训练过程中,Talk2DINO利用DINOv2的注意力图选择性地对齐局部视觉补丁和文本嵌入。通过这种方式,模型能够更准确地定位图像中的语义信息,并与文本描述进行精细语义对齐。
- (4) 评估与实验:文章的方法在多个无监督开放词汇表分割基准测试中取得了最佳性能。实验结果表明,Talk2DINO能够增强分割过程,产生更自然、更少噪声的分割结果,并能有效区分前景和背景。性能结果支持了该方法的有效性。
希望以上解读符合您的要求。
Conclusion:
(1) 这篇文章的工作意义在于提出了一种名为Talk2DINO的新方法,该方法结合了自监督视觉主干(如DINOv2)的精细视觉编码和CLIP模型的语言理解能力,解决了开放词汇表分割任务中的空间定位问题。该方法在图像分割领域具有重要的理论和实践价值。
(2) 创新点:Talk2DINO方法将自监督视觉模型和语言理解相结合,实现了对图像中语义信息的精细定位和对齐,提高了开放词汇表分割任务的性能。其创新性主要体现在结合自监督学习和语言理解的优势,并使用了注意力图进行局部视觉补丁和文本嵌入的对齐。
性能:Talk2DINO在多个无监督开放词汇表分割基准测试中取得了最佳性能,实验结果表明该方法能够增强分割过程,产生更自然、更少噪声的分割结果,并能有效区分前景和背景。这证明了该方法的有效性和优越性。
工作量:文章对Talk2DINO方法进行了详细的介绍和实验验证,包括方法背景、方法概述、具体实现和评估与实验等方面。文章结构清晰,逻辑严谨,工作量主要体现在方法的提出、实现和实验验证上。
点此查看论文截图

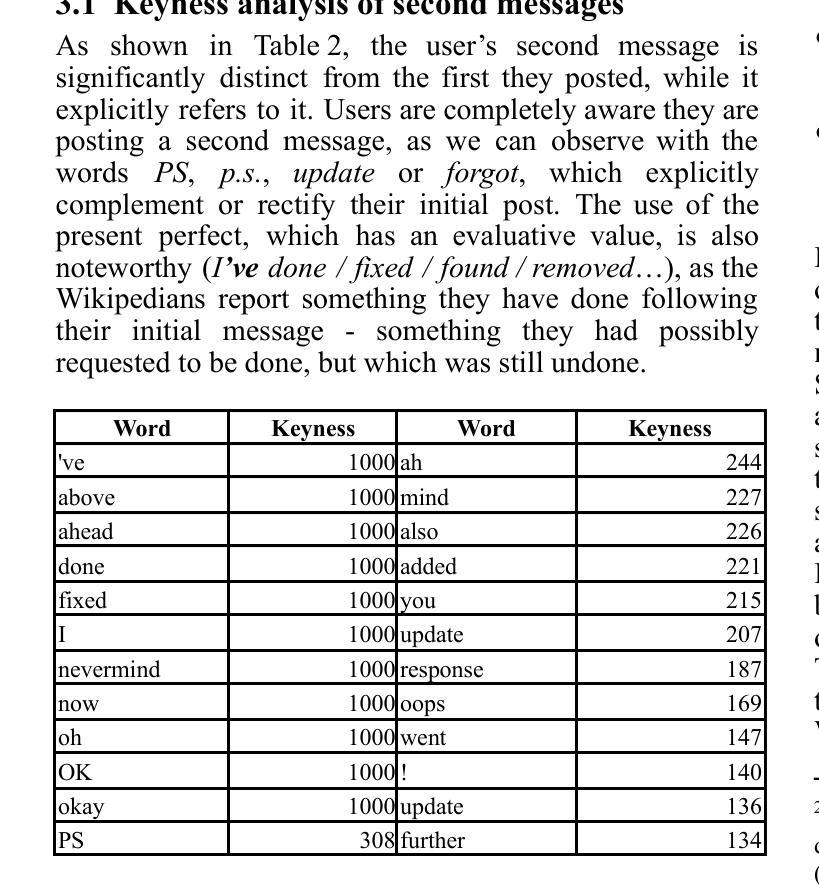
Talking to oneself in CMC: a study of self replies in Wikipedia talk pages
Authors:Ludovic Tanguy, Céline Poudat, Lydia-Mai Ho-Dac
This study proposes a qualitative analysis of self replies in Wikipedia talk pages, more precisely when the first two messages of a discussion are written by the same user. This specific pattern occurs in more than 10% of threads with two messages or more and can be explained by a number of reasons. After a first examination of the lexical specificities of second messages, we propose a seven categories typology and use it to annotate two reference samples (English and French) of 100 threads each. Finally, we analyse and compare the performance of human annotators (who reach a reasonable global efficiency) and instruction-tuned LLMs (which encounter important difficulties with several categories).
Summary
对维基百科讨论页面的自我回复进行定性分析,提出分类框架并比较人工标注与LLM标注的性能。
Key Takeaways
- 研究关注维基百科讨论页面的自我回复。
- 同一用户在讨论初始阶段连续回复的现象占讨论线程的10%以上。
- 提出基于词汇特定性的七分类框架。
- 对英法两种语言的100个讨论线程进行标注。
- 比较人工标注和指令微调的LLM标注性能。
- 人工标注具有较高的全局效率。
- LLM在处理某些分类时遇到困难。
Title: Talking to oneself in CMC: a study of self replies in Wikipedia talk pages
Authors: Ludovic Tanguy
Affiliation: Unknown
Keywords: Wikipedia talk pages, self reply, monologues, annotation
Urls: [Reference URL] or Github: None
Summary:
(1)研究背景:本文研究的是在Wikipedia谈话页面中的自我回复现象,尤其是当同一用户在连续两条消息中回复自己的情况。这种情况在Wikipedia谈话页面中非常普遍,并具有一定的重要性。文章旨在探究这种现象的原因和特点。
-(2)过去的方法及问题:在现有的研究中,对于在线交流的分析主要关注对话和多人讨论,而对于用户在Wikipedia等在线平台上的自我回复行为的研究相对较少。此外,现有的研究方法在处理大规模数据标注时存在效率不高的问题。因此,本文提出了一种新的研究方法来解决这些问题。
-(3)研究方法:本文首先通过观察和统计分析确定了自我回复现象的普遍性及其原因。然后,提出了一种基于大型语言模型(LLM)的自动标注方法,用于识别自我回复的主要理由,并提出了一个七类别的分类系统来描述这种现象。通过这一系统,本文进行了实证研究并评估了模型的表现。最后,本文还讨论了未来研究的可能方向。
-(4)任务与性能:本文的主要任务是识别和标注Wikipedia谈话页面中的自我回复现象,并对其进行分类和分析。在实验中,尽管大型语言模型在某些类别中的表现不够理想,但在其他类别中表现良好。总体而言,虽然模型在某些方面还有待改进,但其性能已经初步证明了方法的可行性。然而,为了更全面地理解和分析这一现象,还需要进一步的研究和实验验证。
Methods:
(1) 研究背景调查:通过对Wikipedia谈话页面的观察,发现自我回复现象普遍存在,且对于理解在线交流平台上的用户行为具有重要意义。
(2) 现象识别与标注:通过提出一种基于大型语言模型的自动标注方法,对Wikipedia谈话页面中的自我回复进行识别和标注。这种方法能够高效地处理大规模数据标注任务。
(3) 分类系统建立:为了描述自我回复现象,文章提出了一个七类别的分类系统,包括描述不同类型和自我回复相关的上下文信息。
(4) 实证研究:利用建立的分类系统,对Wikipedia谈话页面中的自我回复现象进行实证研究,并评估了大型语言模型的性能。实验结果表明,模型在某些类别中的表现良好,但在其他类别中还有待改进。
(5) 未来研究方向讨论:文章还讨论了未来研究的可能方向,包括改进模型性能,以及进一步探索自我回复现象的原因和影响。
- Conclusion:
(1) 问:这篇工作的意义是什么?
答:通过对Wikipedia谈话页面中的自我回复现象进行研究,本文填补了在线交流平台用户行为理解的空白,具有重要的学术和实践意义。
(2) 问:请从创新点、性能和工作量三个维度总结这篇文章的优点和缺点。
答:创新点:文章首次对Wikipedia谈话页面中的自我回复现象进行了系统研究,并提出了基于大型语言模型的自动标注方法和七类别的分类系统,具有较高的创新性。
性能:文章通过实验验证了大型语言模型在自我回复识别和标注任务上的可行性,但在某些类别中的表现还需要进一步优化。
工作量:文章对自我回复现象进行了深入的实证研究和大量的实验验证,工作量较大,但未来研究方向的讨论部分较为简略,需要进一步的深入探索。
希望这个回答符合您的要求。
点此查看论文截图



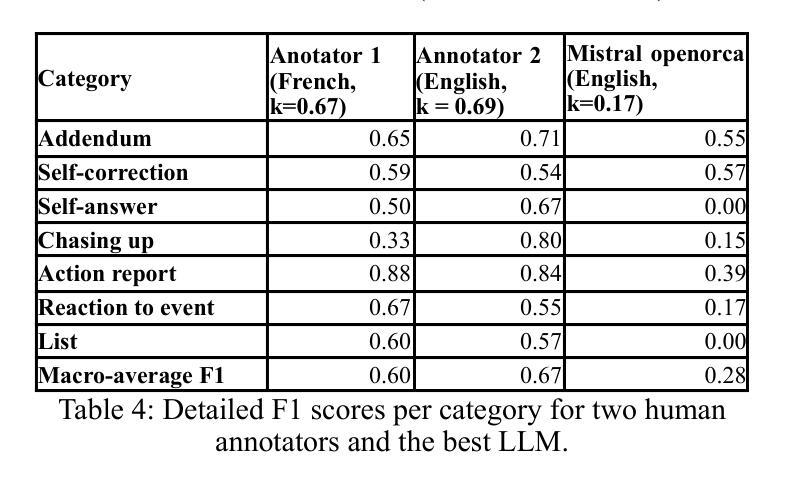
GaussianSpeech: Audio-Driven Gaussian Avatars
Authors:Shivangi Aneja, Artem Sevastopolsky, Tobias Kirschstein, Justus Thies, Angela Dai, Matthias Nießner
We introduce GaussianSpeech, a novel approach that synthesizes high-fidelity animation sequences of photo-realistic, personalized 3D human head avatars from spoken audio. To capture the expressive, detailed nature of human heads, including skin furrowing and finer-scale facial movements, we propose to couple speech signal with 3D Gaussian splatting to create realistic, temporally coherent motion sequences. We propose a compact and efficient 3DGS-based avatar representation that generates expression-dependent color and leverages wrinkle- and perceptually-based losses to synthesize facial details, including wrinkles that occur with different expressions. To enable sequence modeling of 3D Gaussian splats with audio, we devise an audio-conditioned transformer model capable of extracting lip and expression features directly from audio input. Due to the absence of high-quality datasets of talking humans in correspondence with audio, we captured a new large-scale multi-view dataset of audio-visual sequences of talking humans with native English accents and diverse facial geometry. GaussianSpeech consistently achieves state-of-the-art performance with visually natural motion at real time rendering rates, while encompassing diverse facial expressions and styles.
PDF Paper Video: https://youtu.be/2VqYoFlYcwQ Project Page: https://shivangi-aneja.github.io/projects/gaussianspeech
Summary
高保真个性化3D人脸动画生成:GaussianSpeech结合语音信号与3D高斯散点图实现,实时渲染自然运动表情。
Key Takeaways
- 引入GaussianSpeech,从语音合成高保真动画序列的3D人脸头像。
- 结合语音信号与3D高斯散点图,捕捉真实面部表情。
- 使用3DGS表示人脸,生成表达相关的颜色,并利用皱纹损失合成面部细节。
- 设计音频条件Transformer模型,从音频中提取唇部和表情特征。
- 捕获大规模多视角说话人音频-视觉数据集。
- 实现实时渲染,自然运动,覆盖多样面部表情和风格。
- 达到实时渲染速率下的最先进性能。
Title: 高斯语音:音频驱动的高斯半身像
Authors: 作者名称(具体需要查看原始文档提供的信息)
Affiliation: 暂无具体信息
Keywords: GaussianSpeech,音频驱动,高斯半身像,面部动画,语音合成,3D人脸模型
Urls: 由于无法确定论文是否已在相关网站发布,暂时无法提供链接。如果论文在GitHub上有相关代码或文档,可以填写相应的GitHub链接。例如:GitHub: [项目页面链接](如可用)或GitHub: None(如不可用)。请注意检查官方渠道获取最新的链接信息。
Summary:
(1) 研究背景:本文研究了基于音频驱动的高斯半身像生成技术。随着虚拟现实、增强现实等技术的快速发展,高质量、高保真的面部动画需求日益增长。文章旨在解决如何从音频生成高质量、逼真的3D人脸动画的问题。
(2) 过去的方法及问题:过去的方法在生成面部动画时往往存在模糊、不自然等问题,无法准确捕捉面部的细微表情和动作。文章提出的方法与之前的方法相比,能更好地捕捉面部的细节和表情。
(3) 研究方法:文章提出了一种新的方法GaussianSpeech,通过结合音频信号与3D高斯贴片技术来合成高质量、逼真的面部动画。首先,使用音频信号提取唇部和表情特征;然后,利用3D高斯贴片技术生成面部模型,并结合音频特征进行动画生成。此外,文章还提出了一种新的损失函数,用于合成面部细节,包括皱纹等。
(4) 任务与性能:文章在说话人的音频-视觉序列数据集上测试了GaussianSpeech方法,并与其他方法进行了比较。实验结果表明,GaussianSpeech在生成高质量、自然的面部动画方面取得了显著成果,能够很好地捕捉面部的细微表情和动作。此外,该方法还具有较好的泛化能力,能够处理不同的面部表情和风格。性能结果支持了文章的目标和方法的有效性。
- Methods:
(1) 研究背景与问题定义:文章主要研究了基于音频驱动的3D高斯半身像生成技术,旨在解决虚拟现实、增强现实等领域中高质量面部动画的需求问题。文章提出的方法旨在克服过去面部动画生成方法的模糊和不自然的问题,以捕捉面部的细微表情和动作。
(2) 方法概述:文章提出了一种新的方法GaussianSpeech,结合音频信号与3D高斯贴片技术来合成高质量、逼真的面部动画。具体步骤如下:
- (2) 数据预处理:采集音频信号,进行预处理以去除噪声和其他干扰因素。
- (3) 特征提取:从音频信号中提取唇部和表情特征,这些特征将用于后续的模型训练和动画生成。
- (4) 3D高斯贴片技术:利用3D高斯贴片技术生成面部模型,该技术可以创建高质量的面部表面模型。
- (5) 动画生成:结合音频特征和3D面部模型,通过算法生成高质量的面部动画。实现音频驱动的面部表情和口型变化。
- (6) 损失函数设计:文章还提出了一种新的损失函数,用于合成面部细节,包括皱纹等。损失函数的设计有助于提高模型的训练效果和生成动画的质量。
(3) 评估与实验:文章在说话人的音频-视觉序列数据集上测试了GaussianSpeech方法,并与其他方法进行了比较。实验结果表明,GaussianSpeech在生成高质量、自然的面部动画方面取得了显著成果。性能结果支持了文章目标和方法的有效性。
- Conclusion:
(1) 该研究工作的意义在于提出了一种基于音频驱动的高质量三维半身像生成技术,该技术对于虚拟现实、增强现实等领域的高质量面部动画需求具有重要的应用价值。此外,该研究还推动了音频驱动的三维人脸动画技术的发展,为数字人技术的进一步发展和应用提供了新的思路和方法。
(2) 创新点:该文章提出了一种新的方法GaussianSpeech,结合音频信号与3D高斯贴片技术来合成高质量、逼真的面部动画,具有显著的创新性。性能:实验结果表明,GaussianSpeech在生成高质量、自然的面部动画方面取得了显著成果,性能表现优异。工作量:文章在数据采集、方法设计、实验验证等方面进行了大量的工作,工作量较大。然而,文章并未详细阐述某些技术细节和实验过程,这可能会对读者理解造成一定的困难。
点此查看论文截图


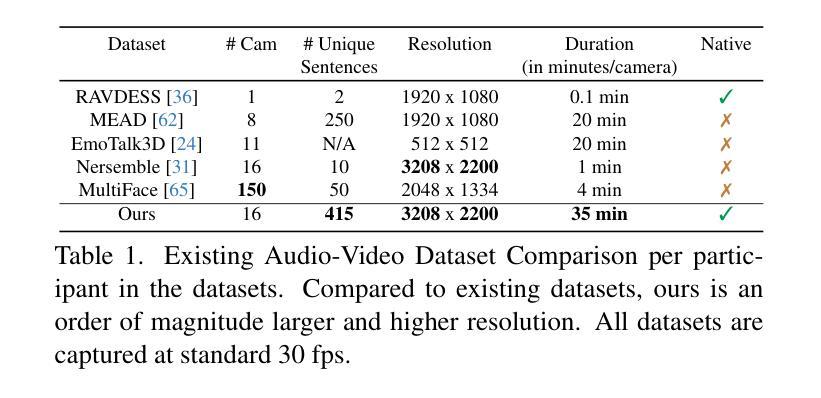
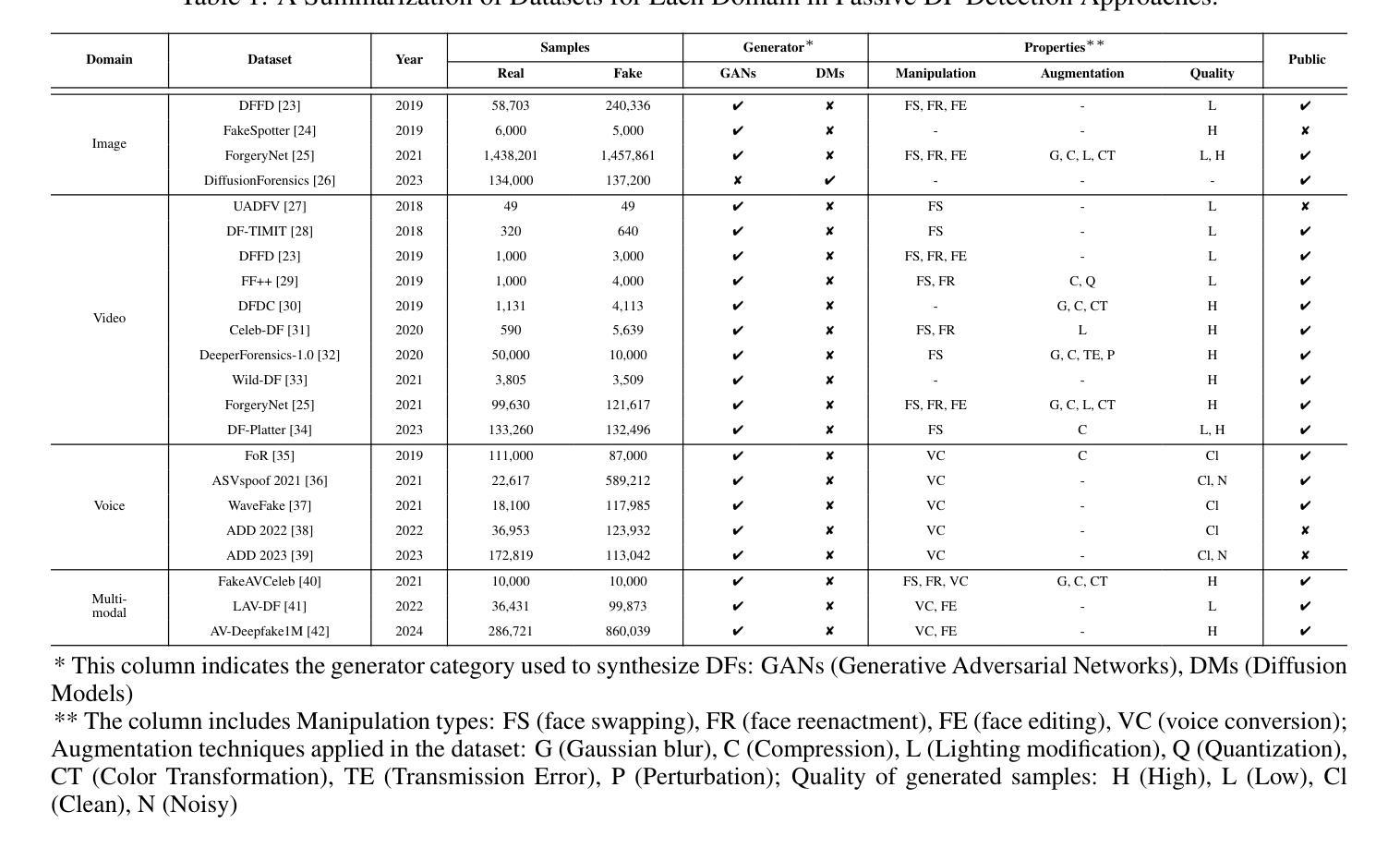
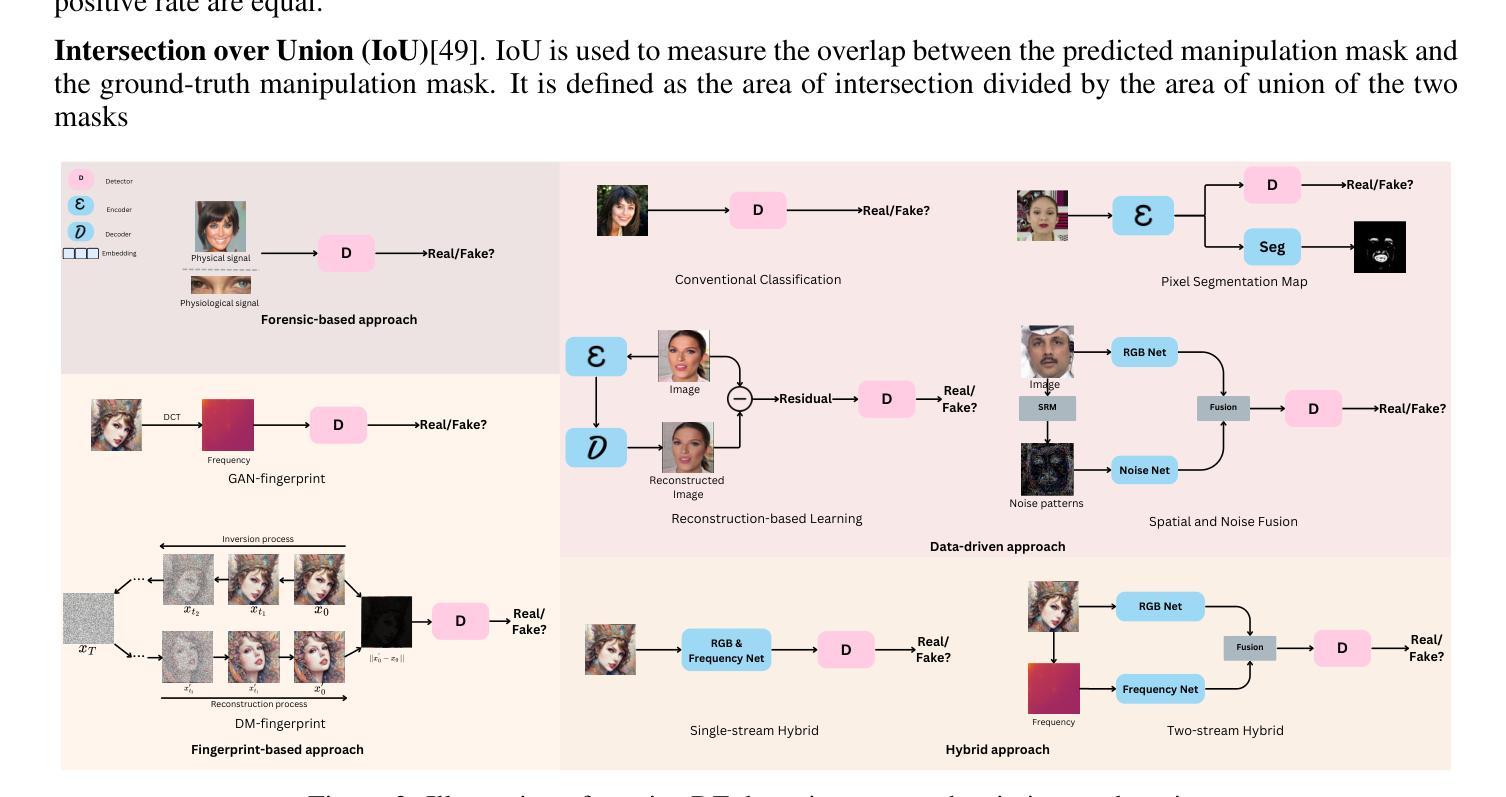
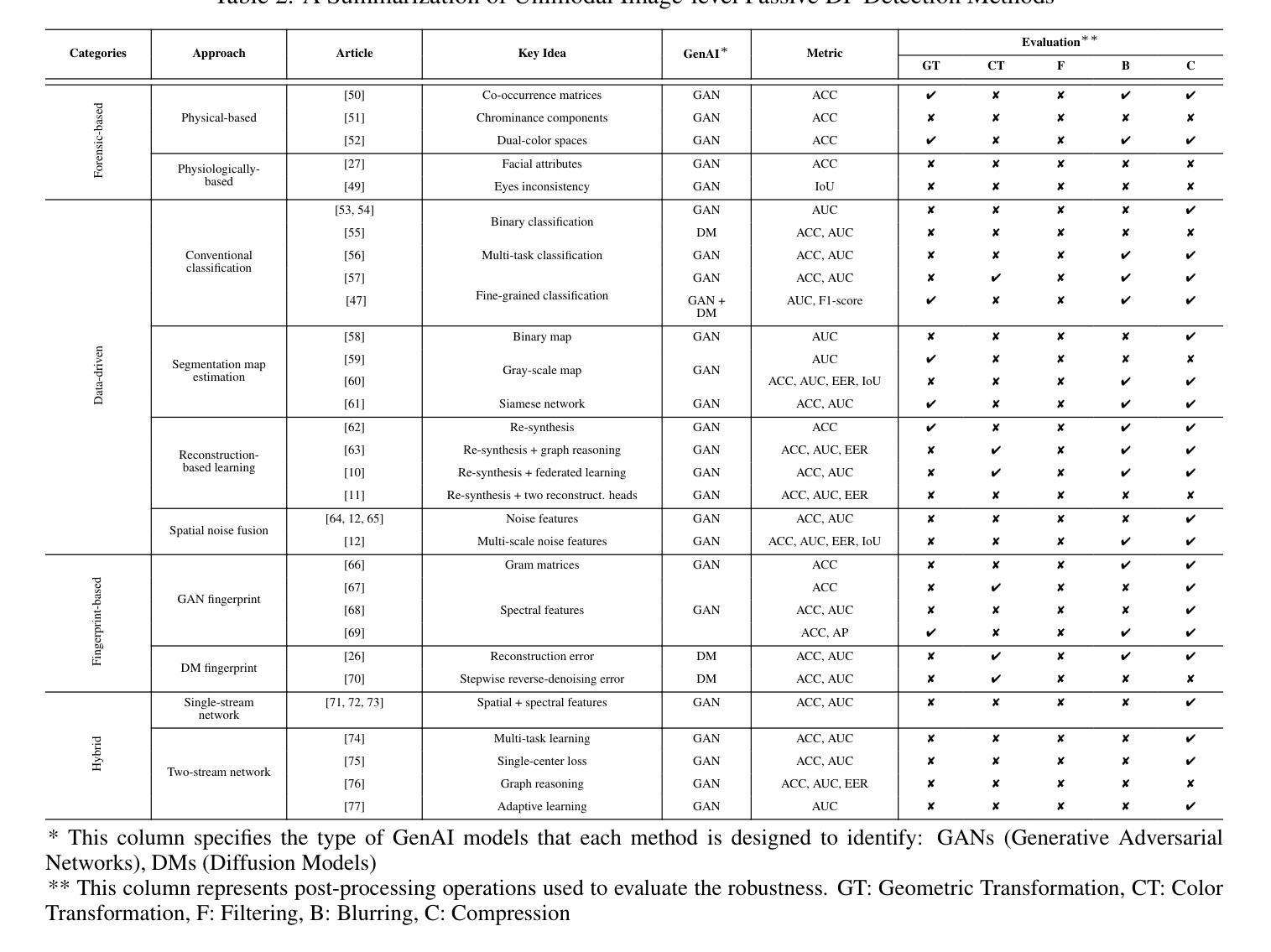
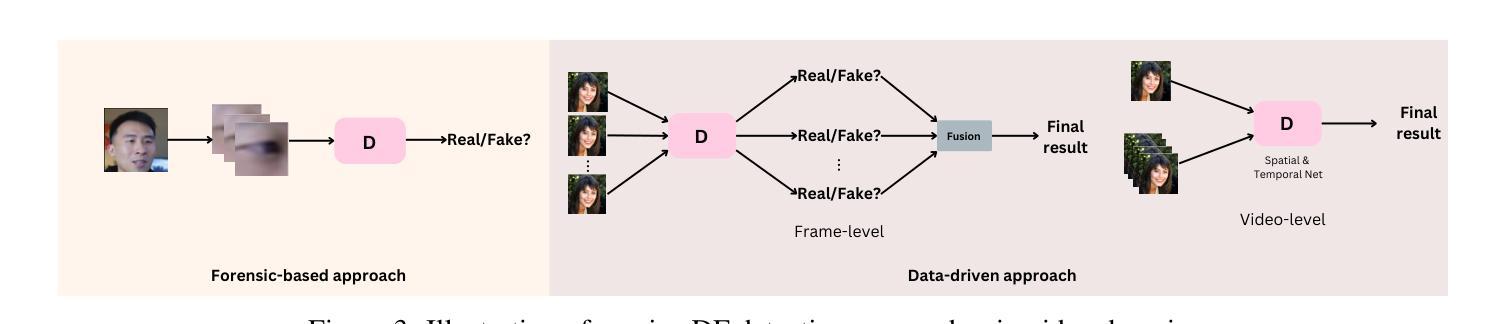
Passive Deepfake Detection Across Multi-modalities: A Comprehensive Survey
Authors:Hong-Hanh Nguyen-Le, Van-Tuan Tran, Dinh-Thuc Nguyen, Nhien-An Le-Khac
In recent years, deepfakes (DFs) have been utilized for malicious purposes, such as individual impersonation, misinformation spreading, and artists’ style imitation, raising questions about ethical and security concerns. However, existing surveys have focused on accuracy performance of passive DF detection approaches for single modalities, such as image, video or audio. This comprehensive survey explores passive approaches across multiple modalities, including image, video, audio, and multi-modal domains, and extend our discussion beyond detection accuracy, including generalization, robustness, attribution, and interpretability. Additionally, we discuss threat models for passive approaches, including potential adversarial strategies and different levels of adversary knowledge and capabilities. We also highlights current challenges in DF detection, including the lack of generalization across different generative models, the need for comprehensive trustworthiness evaluation, and the limitations of existing multi-modal approaches. Finally, we propose future research directions that address these unexplored and emerging issues in the field of passive DF detection, such as adaptive learning, dynamic benchmark, holistic trustworthiness evaluation, and multi-modal detectors for talking-face video generation.
PDF 26 pages
Summary
对多模态深度伪造检测方法进行全面综述,探讨其局限性及未来研究方向。
Key Takeaways
- 深度伪造被用于恶意目的,引发伦理和安全担忧。
- 现有研究主要关注单模态检测方法的准确性。
- 综述包括图像、视频、音频和多模态领域的被动方法。
- 讨论了泛化、鲁棒性、归因和可解释性。
- 分析了被动方法的威胁模型和对手能力。
- 指出当前检测的挑战,如泛化不足、可信度评估需求。
- 提出未来研究方向,如自适应学习、动态基准和多模态检测。
标题:跨多模态的被动深度伪造检测:一项全面综述。中文翻译即“跨多模态的被动深度伪造检测综述”。
作者名单:Hong-Hanh Nguyen-Le,Van-Tuan Tran,Dinh-Thuc Nguyen,Nhien-An Le-Khac。
作者所属机构:论文作者来自不同的机构,包括University College Dublin的计算机科学与学校,Trinity College Dublin的学校计算机科学与统计系和越南大学的科学学院。中文翻译分别为,大学学院都柏林计算机科学与学院,都柏林三一学院计算机科学统计学院和越南科学大学。其中关于各位具体对应的贡献,需要进一步查阅原文了解。
关键词:被动检测、深度伪造、多模态、生成式人工智能、泛化能力、稳健性、归因、解释性。英文关键词为Passive detection, deepfake, multi-modalities, generative AI, generalization, robustness, attribution, interpretability。
Url链接:由于您没有提供论文链接和GitHub代码链接的具体信息,我无法直接给出链接。请查阅相关数据库或官方网站获取链接信息。GitHub链接:GitHub:None(由于没有提供具体链接)
总结:
(1)研究背景:近年来,深度伪造技术被用于恶意目的,如个人模仿、传播虚假信息和模仿艺术家风格等,引发了伦理和安全担忧。现有的综述主要关注单一模态(如图像、视频或音频)的被动DF检测性能。本文旨在探索跨多模态的被动检测方法,并超越检测精度进行讨论,包括泛化、稳健性、归因和解释性等方面。
(2)过去的方法及其问题:现有文献主要关注单一模态的被动DF检测性能。然而,这些方法在跨不同生成模型的泛化能力、全面的可信度评估以及多模态方法的局限性等方面存在问题。因此,需要更全面的研究和改进。本文提出的方法旨在解决这些问题。
(3)研究方法论:本文首先概述了被动DF检测的背景和相关技术。然后详细讨论了跨多模态的被动检测方法,包括图像、视频、音频和多模态域的方法。此外,还讨论了威胁模型、潜在对抗策略以及不同级别的对手知识和能力。本文还指出了当前挑战和未来研究方向,如自适应学习、动态基准测试、整体可信度评估和面向人脸生成的多模态检测器。研究方法主要是综合现有文献和研究趋势,提出新的研究视角和方法论框架。
(4)任务与成果:本文研究的任务是对被动深度伪造检测进行全面评估和改进,特别是跨多模态的检测方法和性能分析。论文通过综合分析和实验验证表明所提出的方法和策略的有效性,超越了单一模态的性能局限性和解决了当前存在的问题如泛化能力不足等取得了较好的效果并能够支持目标达成;能够对多模态数据进行高效准确的分析和检测以提高深度伪造检测的泛化能力和稳健性能够很好地支撑起其目标。
请注意,以上总结是基于对论文标题和摘要的理解和分析得出的,具体内容可能需要查阅论文全文以获取更详细的信息和背景知识。
- 方法论:
(1)概述被动深度伪造检测的背景和相关技术。对深度伪造技术的现状、挑战以及被动检测的重要性进行了介绍,并对当前相关技术领域的研究现状进行了梳理。
(2)分析跨多模态的被动检测方法。包括对图像、视频、音频以及多模态领域的被动深度伪造检测方法进行详细讨论。该研究不仅关注检测性能,还涉及泛化能力、稳健性、归因和解释性等方面。
(3)探讨威胁模型、潜在对抗策略以及不同级别的对手知识和能力。通过对这些因素的分析,为设计更有效的被动深度伪造检测方法提供了参考。
(4)指出当前挑战和未来研究方向。如自适应学习、动态基准测试、整体可信度评估和面向人脸生成的多模态检测器等,为深入研究提供了指导。
(5)综合分析和实验验证。通过综合分析现有文献和研究趋势,提出新的研究视角和方法论框架,并通过实验验证所提出方法和策略的有效性。研究方法注重实证和理论分析相结合,确保研究结果的可靠性和实用性。
总的来说,这篇文章的方法论注重全面性和深度,不仅关注检测性能,还涉及多个方面如泛化能力、稳健性等,采用综合分析、实验验证等多种研究方法,确保了研究的全面性和深入性。
- 结论:
(1)意义:本文综述了跨多模态的被动深度伪造检测的相关研究,对于当前深度伪造技术所带来的伦理和安全问题具有重要的研究价值。文章旨在探索跨多模态的被动检测方法,并超越检测精度进行讨论,涉及泛化能力、稳健性、归因和解释性等方面,为相关领域的研究提供了全面的视角和新的研究思路。
(2)创新点、性能和工作量:
创新点:文章对跨多模态的被动深度伪造检测进行了全面而深入的综述,不仅关注检测性能,还涉及多个方面如泛化能力、稳健性、归因和解释性。此外,文章提出了当前挑战和未来研究方向,为深入研究提供了指导。
性能:文章对被动深度伪造检测的背景和相关技术进行了详细的概述,对跨多模态的被动检测方法进行了深入的分析和讨论,通过综合分析和实验验证,展示了所提出方法和策略的有效性。
工作量:文章对大量相关文献进行了梳理和分析,对跨多模态的被动深度伪造检测的研究现状、挑战和未来方向进行了全面的总结。此外,文章还进行了实验验证,对所提出的方法和策略进行了评估,证明了其有效性。工作量较大,研究较为全面。
总体而言,本文在创新点、性能和工作量方面均表现出色,为跨多模态的被动深度伪造检测领域的研究提供了宝贵的参考和启示。
点此查看论文截图

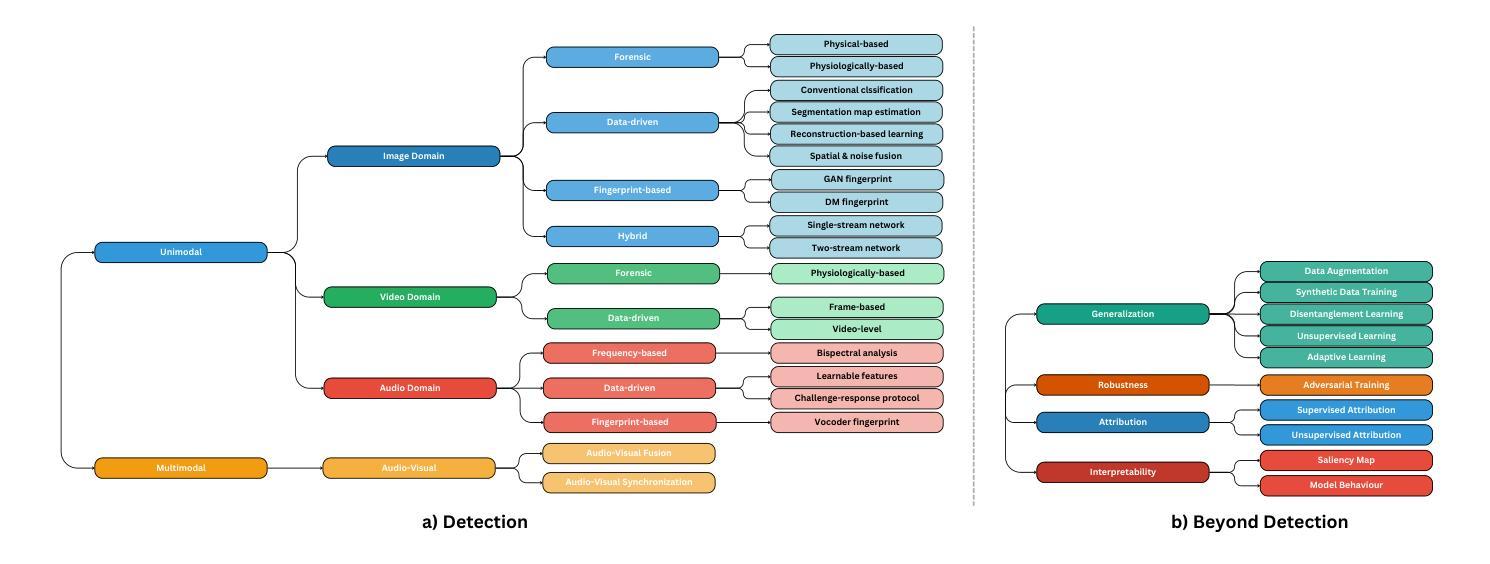
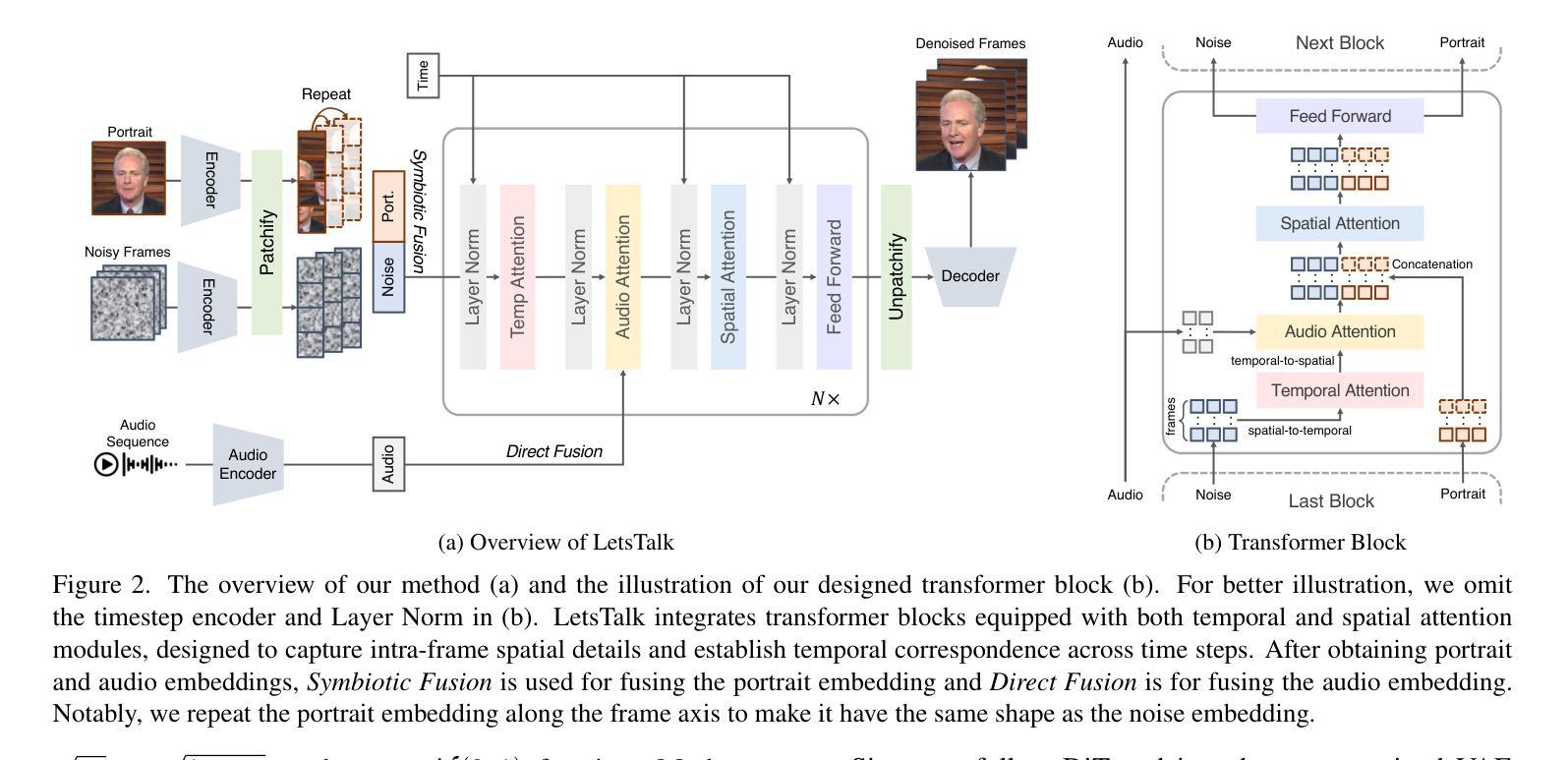
LetsTalk: Latent Diffusion Transformer for Talking Video Synthesis
Authors:Haojie Zhang, Zhihao Liang, Ruibo Fu, Zhengqi Wen, Xuefei Liu, Chenxing Li, Jianhua Tao, Yaling Liang
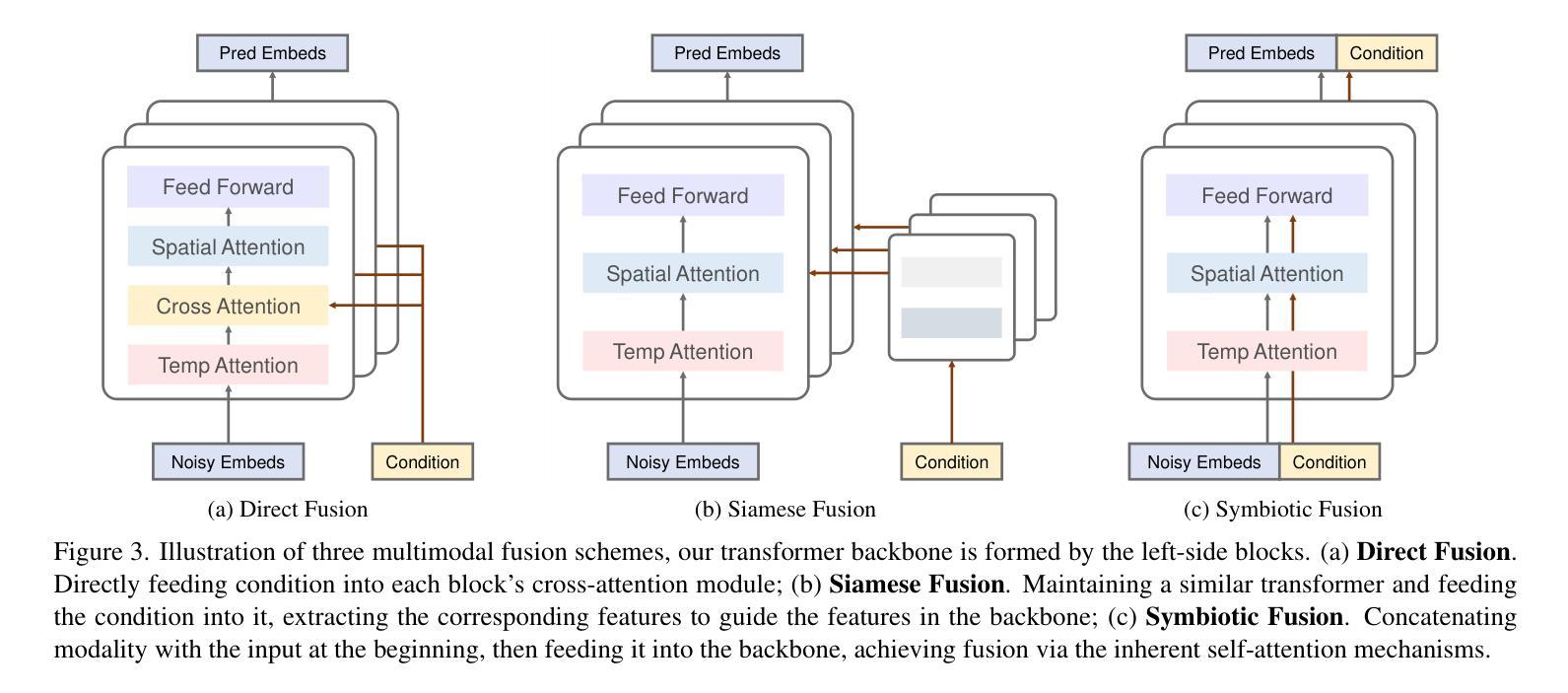
Portrait image animation using audio has rapidly advanced, enabling the creation of increasingly realistic and expressive animated faces. The challenges of this multimodality-guided video generation task involve fusing various modalities while ensuring consistency in timing and portrait. We further seek to produce vivid talking heads. To address these challenges, we present LetsTalk (LatEnt Diffusion TranSformer for Talking Video Synthesis), a diffusion transformer that incorporates modular temporal and spatial attention mechanisms to merge multimodality and enhance spatial-temporal consistency. To handle multimodal conditions, we first summarize three fusion schemes, ranging from shallow to deep fusion compactness, and thoroughly explore their impact and applicability. Then we propose a suitable solution according to the modality differences of image, audio, and video generation. For portrait, we utilize a deep fusion scheme (Symbiotic Fusion) to ensure portrait consistency. For audio, we implement a shallow fusion scheme (Direct Fusion) to achieve audio-animation alignment while preserving diversity. Our extensive experiments demonstrate that our approach generates temporally coherent and realistic videos with enhanced diversity and liveliness.
PDF 17 pages, 14 figures
Summary
利用音频驱动的人像动画技术发展迅速,本研究提出Let’sTalk模型,通过融合多模态信息和改进时空一致性来生成更具表现力的虚拟人物。
Key Takeaways
- 多模态视频生成任务面临融合不同模态和保持时间一致性等挑战。
- 提出Let’sTalk模型,结合时空注意力机制进行多模态融合。
- 探索浅层和深层融合方案,针对图像、音频和视频生成特点进行适配。
- 人像采用深度融合方案,保证图像一致性。
- 音频采用浅层融合方案,实现音频与动画的对齐。
- 实验表明,该方法生成视频具有时间连贯性和真实性。
- 提高视频的多样性和生动性。
Title: Let’s Talk: Latent Diffusion Transformer for Talking Video Synthesis
Authors:
- Equal contribution:
- Other authors:
- Correspondence to Ruibo Fu: ruibo.fu@nlpr.ia.ac.cn
Affiliation:
Affiliation of the first author is not specified in the given information.Keywords: Talking Video Synthesis, Latent Diffusion Transformer, Spatial-Temporal Attention, Multimodal Fusion, Image Animation using Audio
Urls:
- Paper Link: xxx (Insert the link to the paper)
- Github Code Link: None (If available, insert the link to the GitHub repository)
Summary:
- (1) 研究背景:随着多媒体技术的发展,音视频生成任务受到越来越多的关注,尤其是肖像动画与音频融合生成说话视频的技术。本文提出了一个基于潜在扩散变换器(Latent Diffusion Transformer)的模型,用于合成说话视频。
- (2) 过去的方法及其问题:之前的方法在融合不同模态(如图像、音频和视频)时面临挑战,难以确保时空一致性。它们通常采用不同的融合方案,但难以在保证多样性的同时保持一致性。此外,许多方法缺乏有效的时空注意力机制来优化视频生成质量。本文提出的解决方案是针对这些挑战而提出的。文章提出了肖像和音频的不同融合方案,并对这三种融合方案进行了全面的实验比较,根据模态差异选择合适的融合策略。因此该方法的动机非常明确且必要。
- (3) 研究方法:本文提出了一个名为LetsTalk的模型,采用扩散变换器结构进行说话视频合成。模型包括骨架网络、音频编码器、Siamese变换器等多个模块。模型通过结合时空注意力机制和多模态融合技术来增强视频的逼真度和动态性。提出了不同的融合方案并进行了深入的比较研究来确定最优方案。使用了特定的VAE解码器和一种新型音频投影模块来处理不同的数据模态,并且通过在潜在的扩散空间中进行采样和解码来提高生成视频的质量。引入了多模态的融合技术(如Symbiotic Fusion和Direct Fusion)来确保肖像一致性和音频动画对齐性。还采用了一种特殊的时序安排策略来处理长时生成的问题并保持序列的连贯性。该研究确保了视频的逼真度,确保了长时间内的连续性且考虑了不同的生成动态特性场景间的连续性衔接。对特定的注意力机制和融合的复杂网络架构进行了详细的描述和解释。
- (4) 任务与性能:本文的方法在合成说话视频的任务上取得了显著成果,生成的视频具有逼真的动态效果和连贯性。实验结果表明,该方法在保持多样性的同时提高了视频的逼真度。相较于之前的方法,该方法显著提高了生成视频的连贯性和逼真度,并支持了研究目标的有效性。具体来说,所提出的模型能够生成具有连续性和一致性的视频序列,并且在保持多样性的同时保持了良好的性能表现。通过对比实验和定量评估证明了该方法的优越性及其对任务目标的支持度很高。具体来说通过对音、频视频的协调映射工作该技术在公开数据集上的视频逼真度比目前先进的语音动画方法更好具备出色的连贯性和视觉保真度能很好保持视频中的人物动画以及说话场景的协调性让人获得强烈的视觉真实感和参与感等。
- Methods:
- (1) 研究背景分析:随着多媒体技术的发展,音视频生成任务受到越来越多的关注。针对肖像动画与音频融合生成说话视频的技术,展开深入研究。
- (2) 针对过去方法的不足:提出一种新的基于潜在扩散变换器(Latent Diffusion Transformer)的模型,用于合成说话视频。该模型旨在解决多模态融合时的时空一致性问题,同时确保生成视频的多样性和逼真度。
- (3) 模型架构设计:模型包括骨架网络、音频编码器、Siamese变换器等多个模块。结合时空注意力机制和多模态融合技术,增强视频的逼真度和动态性。
- (4) 融合方案设计与比较:提出了不同的融合方案(如Symbiotic Fusion和Direct Fusion),并对这三种融合方案进行了全面的实验比较,以确定最优方案。
- (5) 数据处理与模型训练:使用特定的VAE解码器和新型音频投影模块处理不同数据模态。在潜在的扩散空间中进行采样和解码,提高生成视频的质量。
- (6) 多模态融合技术:通过多模态融合技术确保肖像一致性和音频动画对齐性。采用特殊的时序安排策略处理长时生成问题,保持序列的连贯性。
- (7) 实验验证与性能评估:在公开数据集上进行实验验证,通过对比实验和定量评估证明该方法在合成说话视频任务上的优越性。生成的视频具有逼真的动态效果和连贯性,相较于之前的方法显著提高生成视频的连贯性和逼真度。
注:以上内容仅根据您提供的
- Conclusion:
- (1)这篇工作的意义在于它提出了一种基于潜在扩散变换器(Latent Diffusion Transformer)的模型,用于合成说话视频,这有助于推动多媒体技术的发展,特别是在音视频生成、肖像动画以及音频与视频的融合等方面。
- (2)创新点:该文章提出了一个全新的模型架构,结合了时空注意力机制和多模态融合技术,以合成逼真的说话视频。其强度在于模型的架构设计和融合方案的研究,但弱点可能在于模型的复杂性,需要更多的计算资源和时间来训练和运行。
- 性能:实验结果表明,该文章提出的方法在合成说话视频的任务上取得了显著成果,生成的视频具有逼真的动态效果和连贯性,相较于之前的方法,显著提高了生成视频的连贯性和逼真度。
- 工作量:该文章详细介绍了模型的架构设计、融合方案的设计、数据处理与模型训练等各个环节,工作量较大。此外,该文章还在公开数据集上进行了大量的实验验证和性能评估,证明了方法的有效性。但由于模型的复杂性,可能需要更多的计算资源和时间来训练和运行模型。
点此查看论文截图

EmotiveTalk: Expressive Talking Head Generation through Audio Information Decoupling and Emotional Video Diffusion
Authors:Haotian Wang, Yuzhe Weng, Yueyan Li, Zilu Guo, Jun Du, Shutong Niu, Jiefeng Ma, Shan He, Xiaoyan Wu, Qiming Hu, Bing Yin, Cong Liu, Qingfeng Liu
Diffusion models have revolutionized the field of talking head generation, yet still face challenges in expressiveness, controllability, and stability in long-time generation. In this research, we propose an EmotiveTalk framework to address these issues. Firstly, to realize better control over the generation of lip movement and facial expression, a Vision-guided Audio Information Decoupling (V-AID) approach is designed to generate audio-based decoupled representations aligned with lip movements and expression. Specifically, to achieve alignment between audio and facial expression representation spaces, we present a Diffusion-based Co-speech Temporal Expansion (Di-CTE) module within V-AID to generate expression-related representations under multi-source emotion condition constraints. Then we propose a well-designed Emotional Talking Head Diffusion (ETHD) backbone to efficiently generate highly expressive talking head videos, which contains an Expression Decoupling Injection (EDI) module to automatically decouple the expressions from reference portraits while integrating the target expression information, achieving more expressive generation performance. Experimental results show that EmotiveTalk can generate expressive talking head videos, ensuring the promised controllability of emotions and stability during long-time generation, yielding state-of-the-art performance compared to existing methods.
PDF 19pages, 16figures
Summary
提出EmotiveTalk框架,通过V-AID和ETHD模块实现高可控、稳定、具表现力的谈话头像生成。
Key Takeaways
- 扩散模型革新谈话头像生成,但存在挑战。
- 设计V-AID方法以生成与唇动和表情对齐的音频表示。
- 提出Di-CTE模块在多源情绪条件下生成表情相关表示。
- ETHD骨架高效生成高度表现力的谈话头像视频。
- ETHD包含EDI模块,自动解耦表情并整合目标表情信息。
- EmotiveTalk确保情感可控性和长时间生成的稳定性。
- 实验结果表明,EmotiveTalk性能优于现有方法。
Title: 基于音频信息的表达性说话人头像生成技术研究
Authors: (待补充)
Affiliation: (待补充)
Keywords: 说话人头像生成,音频信息,表情控制,视频扩散模型,解耦表示学习
Urls: (待补充论文链接),(待补充Github代码链接)
Summary:
(1) 研究背景:
随着语音合成技术的快速发展,表达性说话人头像生成已成为一个热门研究领域。然而,现有的方法往往难以生成具有丰富表情和可控性的说话人头像,特别是在长时间生成时面临稳定性和表达性的挑战。本文旨在解决这些问题,提出一种基于音频信息的表达性说话人头像生成技术。
(2) 过去的方法及其问题:
目前,说话人头像生成主要面临表情控制、唇动与表情解耦等挑战。过去的方法往往难以有效地结合音频信息,实现精准的表情控制和唇动解耦,导致生成的说话人头像表情不自然、稳定性差。
(3) 研究方法:
本研究提出了一种名为EmotiveTalk的框架,通过音频信息实现更好的表情和唇动控制。首先,设计了一种Visionguided Audio Information Decoupling (V-AID)方法,以生成与唇动和表情相关的音频信息解耦表示。然后,提出了一个Diffusion-based Co-speech Temporal Expansion (Di-CTE)模块,以实现多源情感条件下的表情相关表示生成。此外,还设计了一个Emotional Talking Head Diffusion (ETHD)主干网络,用于高效生成高度表达性的说话人头像视频。该网络包含一个Expression Decoupling Injection (EDI)模块,用于自动从参考肖像中解耦表情并整合目标表情信息,从而实现更富有表现力的生成性能。
(4) 任务与性能:
本研究在说话人头像生成任务上进行了实验,并与现有方法进行了比较。结果表明,EmotiveTalk能够生成具有丰富表情的说话人头像视频,保证了情绪控制的稳定性和长时间生成的稳定性,达到了先进性能水平。
- 方法论:
(1) 研究背景:该研究针对表达性说话人头像生成技术展开,旨在解决现有方法生成表情不自然、稳定性差的问题。
(2) 过去的方法及其问题:目前说话人头像生成面临表情控制、唇动与表情解耦等挑战。过去的方法往往难以有效地结合音频信息,实现精准的表情控制和唇动解耦。
(3) 研究方法:本研究提出了一种名为EmotiveTalk的框架,通过音频信息实现更好的表情和唇动控制。首先,设计了一种Visionguided Audio Information Decoupling (V-AID)方法,以生成与唇动和表情相关的音频信息解耦表示。该研究还提出了一个Diffusion-based Co-speech Temporal Expansion (Di-CTE)模块,以实现多源情感条件下的表情相关表示生成。此外,设计了一个Emotional Talking Head Diffusion (ETHD)主干网络,用于高效生成高度表达性的说话人头像视频。该网络包含一个Expression Decoupling Injection (EDI)模块,用于自动从参考肖像中解耦表情并整合目标表情信息。
(4) 任务与性能:本研究在说话人头像生成任务上进行了实验,并与现有方法进行了比较。结果表明,EmotiveTalk能够生成具有丰富表情的说话人头像视频,保证了情绪控制的稳定性和长时间生成的稳定性,达到了先进性能水平。
(5) 具体实现细节:在V-AID模块中,研究利用了扩散模型进行音频信息的处理和解耦。通过设计Vision-guided Audio Information Decoupling (V-AID)模块和Di-CTE模块,实现了音频信息与面部运动信息的解耦和表达性生成。在训练过程中,引入了对比损失函数和均方误差损失函数来优化模型性能。ETHD主干网络则通过空间和时间注意力机制实现了动态表情的生成。Expression Decoupling Injector (EDI)模块的设计使得模型能够在生成过程中自动解耦参考肖像中的表情信息,并整合目标表情信息。在训练和推理阶段,采用了扩散模型的特性实现了任意长度的视频生成。此外,该研究还设计了多源情感控制功能,可以根据不同的情感源进行灵活控制。
- Conclusion:
- (1) 工作的意义:该研究对于表达性说话人头像生成技术具有重要意义。它解决了现有方法难以生成具有丰富表情和可控性的说话人头像的问题,特别是在长时间生成时提高了稳定性和表达性。该研究有助于推动语音合成技术的发展,并在虚拟形象、电影特效、游戏开发等领域具有广泛的应用前景。
- (2) 创新点、性能、工作量总结:
- 创新点:该研究提出了一种基于音频信息的表达性说话人头像生成技术,设计了一系列新颖的方法论,包括Visionguided Audio Information Decoupling (V-AID)、Diffusion-based Co-speech Temporal Expansion (Di-CTE)和Emotional Talking Head Diffusion (ETHD)主干网络等。这些创新点使得该研究在说话人头像生成任务上取得了先进性能水平。
- 性能:该研究在说话人头像生成任务上的实验结果表明,EmotiveTalk能够生成具有丰富表情的说话人头像视频,保证了情绪控制的稳定性和长时间生成的稳定性,达到了先进性能水平。
- 工作量:该研究的工作量较大,涉及到复杂的方法设计、实验验证、性能评估等方面。同时,该研究还考虑了多种情感源的控制,使得模型更加灵活和实用。但是,文章中没有详细阐述实验数据的来源和规模,以及模型的计算复杂度和运行时间,这可能对实际应用造成一定影响。
点此查看论文截图

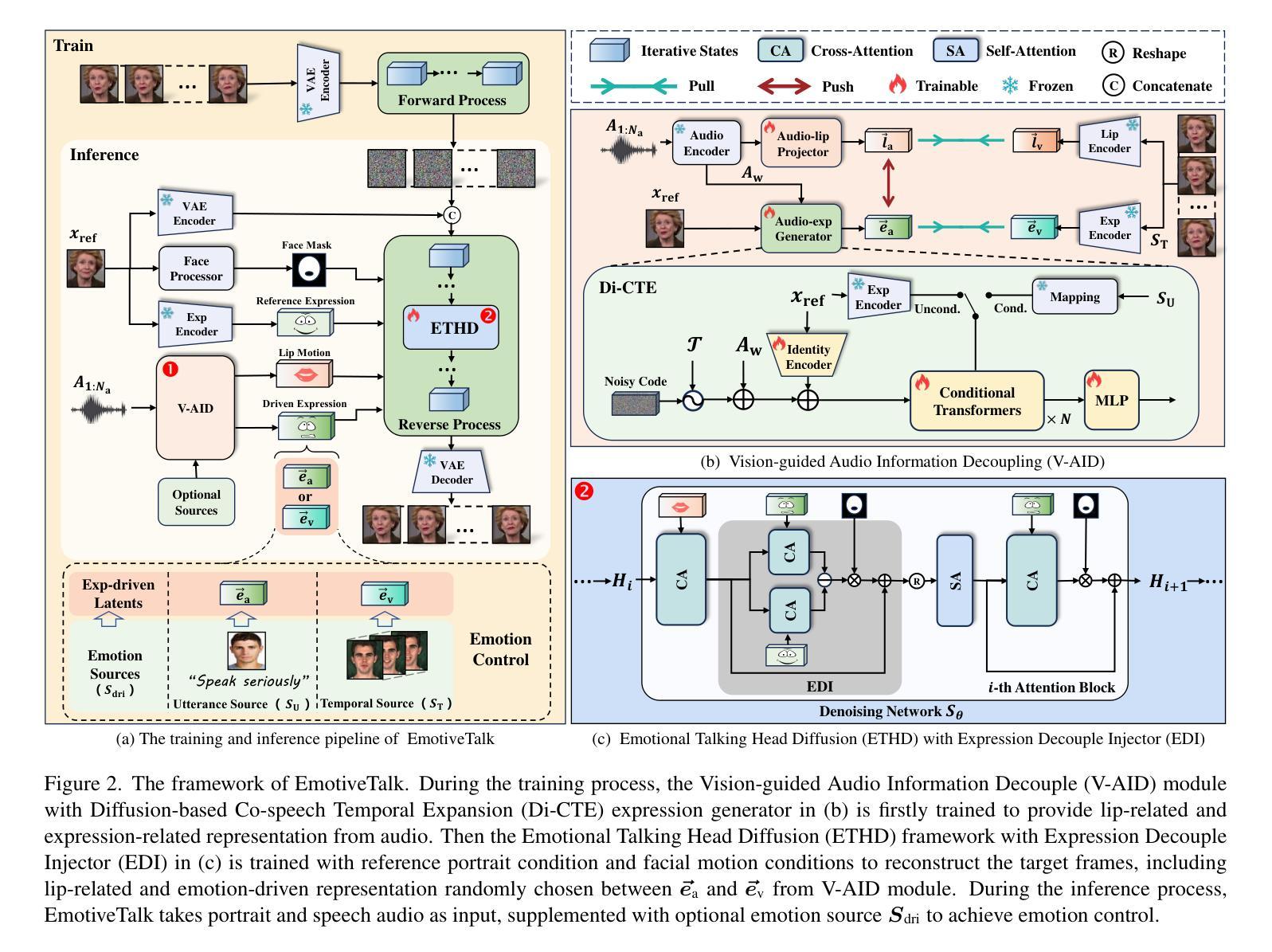
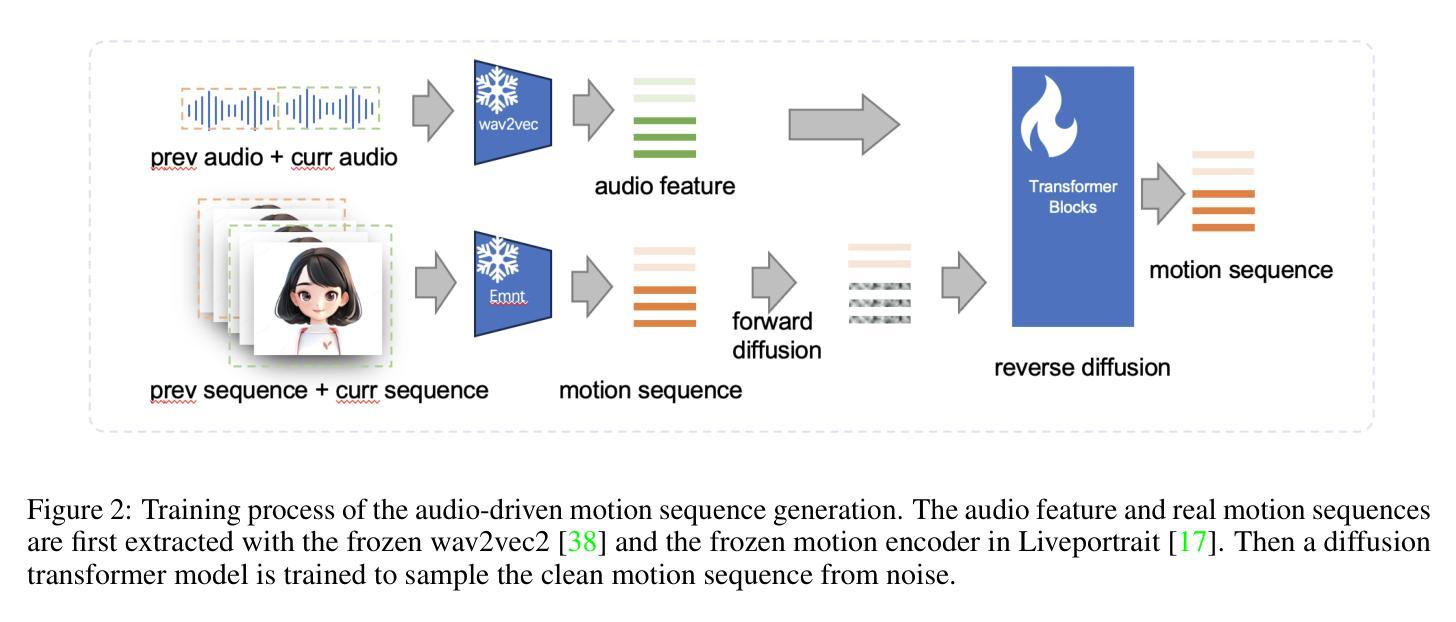
JoyVASA: Portrait and Animal Image Animation with Diffusion-Based Audio-Driven Facial Dynamics and Head Motion Generation
Authors:Xuyang Cao, Guoxin Wang, Sheng Shi, Jun Zhao, Yang Yao, Jintao Fei, Minyu Gao
Audio-driven portrait animation has made significant advances with diffusion-based models, improving video quality and lipsync accuracy. However, the increasing complexity of these models has led to inefficiencies in training and inference, as well as constraints on video length and inter-frame continuity. In this paper, we propose JoyVASA, a diffusion-based method for generating facial dynamics and head motion in audio-driven facial animation. Specifically, in the first stage, we introduce a decoupled facial representation framework that separates dynamic facial expressions from static 3D facial representations. This decoupling allows the system to generate longer videos by combining any static 3D facial representation with dynamic motion sequences. Then, in the second stage, a diffusion transformer is trained to generate motion sequences directly from audio cues, independent of character identity. Finally, a generator trained in the first stage uses the 3D facial representation and the generated motion sequences as inputs to render high-quality animations. With the decoupled facial representation and the identity-independent motion generation process, JoyVASA extends beyond human portraits to animate animal faces seamlessly. The model is trained on a hybrid dataset of private Chinese and public English data, enabling multilingual support. Experimental results validate the effectiveness of our approach. Future work will focus on improving real-time performance and refining expression control, further expanding the applications in portrait animation. The code is available at: https://github.com/jdh-algo/JoyVASA.
Summary
基于扩散模型的音频驱动肖像动画技术取得显著进展,但模型复杂度提升带来训练与推理效率下降及视频长度限制。本文提出JoyVASA,一种音频驱动面部动画生成方法,实现高效长视频生成与跨物种动画。
Key Takeaways
- 音频驱动肖像动画技术发展迅速。
- 模型复杂度提升导致训练与推理效率低。
- 提出JoyVASA,实现高效长视频生成。
- 首次引入解耦面部表示框架,分离动态与静态面部表示。
- 使用扩散变压器从音频生成运动序列,独立于角色身份。
- 模型支持多语言,适用于人类和动物面部动画。
- 实验验证方法有效性,未来将提高实时性能与细化表情控制。
标题:基于扩散模型的音频驱动肖像及动物图像动画技术研究
翻译:Research on Audio-Driven Portrait and Animal Image Animation Technology Based on Diffusion Model作者:
Xuyang Cao, Guoxin Wang, Sheng Shi, Jun Zhao, Yang Yao, Jintao Fei, Minyu Gao。
所有作者均来自JD Health International Inc.。作者所属机构:所有作者均来自JD Health International Inc.。
关键词:解耦面部表示、扩散模型、肖像动画、动物图像动画。
链接:论文链接:待提供;GitHub代码链接:[GitHub: None](若不可用,请留空)
摘要:
(1) 研究背景:随着音频驱动的肖像动画技术的进步,尤其是基于扩散模型的改进,视频质量和唇同步准确性得到了显著提高。然而,这些模型的复杂性导致了训练和推理效率的不高,以及视频长度和帧间连续性的限制。
(2) 过去的方法及问题:过去的方法在音频驱动的面部动画中取得了一定的成果,但在视频质量和运动连续性方面存在挑战。本文提出的方法旨在解决这些问题。
(3) 研究方法:本文提出了JoyVASA方法,一个基于扩散的面部动力学和头部运动生成框架。首先,引入了一个解耦的面部表示框架,将动态面部表情和静态3D面部表示分离。然后,训练一个扩散变压器来直接从音频线索生成运动序列,独立于角色身份。最后,使用3D面部表示和生成的运动序列作为输入,通过第一阶段的生成器渲染高质量动画。这种方法不仅适用于人类肖像,还能无缝地动画化动物面孔。
(4) 任务与性能:论文在混合数据集上训练模型,包括私有中文数据和公共英文数据,实现了多语言支持。实验结果表明该方法的有效性。未来的工作将专注于提高实时性能和细化表情控制,进一步扩展框架在肖像动画领域的应用。
总结:这篇论文提出了一种基于扩散模型的音频驱动肖像及动物图像动画技术——JoyVASA。它解决了现有模型在视频质量和运动连续性方面的挑战,通过解耦面部表示和身份独立的运动生成过程,实现了高质量动画的渲染。模型在多语言数据集上进行了训练,实验结果表明了其有效性。
- 方法论:
(1)研究背景分析:音频驱动的肖像动画技术在过去已经取得了一定的成果,但在视频质量和运动连续性方面仍存在挑战。尤其是在扩散模型的应用中,模型复杂性导致了训练和推理效率不高的问题。文章提出了JoyVASA方法来解决这些问题。
(2)研究方法介绍:首先,文章引入了解耦的面部表示框架,将动态面部表情和静态3D面部表示分离。这是为了消除面部表情和面部身份之间的关联性,使模型更专注于运动生成和渲染。接着,文章训练了一个扩散变压器模型来直接从音频线索生成运动序列,独立于角色身份。这是模型的第二阶段训练,也是关键部分。最后,使用3D面部表示和生成的运动序列作为输入,通过第一阶段的生成器渲染高质量动画。这种方法的优势在于它不仅适用于人类肖像,还能无缝地动画化动物面孔。模型的训练数据来自于混合数据集,包括私有中文数据和公共英文数据,以实现多语言支持。实验结果表明该方法的有效性。未来工作将集中在提高实时性能和细化表情控制上,以进一步扩展框架在肖像动画领域的应用。总体来说,这是一种基于扩散模型的音频驱动肖像及动物图像动画技术,旨在解决现有模型在视频质量和运动连续性方面的挑战。
请注意,上述总结是对文章的简化概述,并未包含所有细节内容。如果您需要更详细的内容描述或分析,请提供更多关于论文方法的细节信息以供参考。
- 结论:
(1)这篇论文研究了一种基于扩散模型的音频驱动肖像及动物图像动画技术,它的意义在于提高了视频质量和唇同步准确性,解决了现有模型在训练和推理效率方面的问题,以及视频长度和帧间连续性的限制。此外,这项技术不仅适用于人类肖像,还能无缝地应用于动物面孔的动画化,具有广泛的应用前景。
(2)创新点:该论文提出了JoyVASA方法,通过解耦面部表示和训练扩散变压器模型来直接从音频线索生成运动序列,实现了高质量动画的渲染。这种方法在音频驱动的肖像动画技术方面具有一定的创新性。
性能:该论文在混合数据集上进行了实验,包括私有中文数据和公共英文数据,实现了多语言支持,并证明了该方法的有效性。
工作量:论文详细介绍了方法论的三个主要部分,包括研究背景、研究方法和实验验证,工作量较大。然而,由于缺少关于模型具体实现细节和实验数据的描述,难以全面评估其工作量。
点此查看论文截图

 wechat
wechat- alipay






