视频资料:
Pytorch+cpp/cuda extension 教學
Github:
https://github.com/Kedreamix/pytorch-cppcuda-tutorial
Pytorch官方资料:
PyTorch C++ API - PyTorch main documentation
pytorch.org/tutorials/advanced/cpp_extension.html
CUDA doc:
Introduction to GPU
学习背景 虽然说PyTorch提供了丰富的与神经网络、张量代数、数据处理等相关的操作,但是有时候你可能需要更定制化的操作 ,比如使用论文中的新型激活函数,或者实现作为研究一部分开发的操作。在PyTorch中,最简单的集成自定义操作的方式是在Python中编写,通过扩展Function和Module来实现,这使我们可以充分利用自动微分autograd的功能,然而有时候代码在模型中被频繁调用或者调用代价比较大,我们就可能需要在C++中进行实现。另一个可能的原因可能需要依赖于其他的C++库,为了解决这种情况,PyTorch提供了一种非常简单的方式来编写自定义C++扩展。
简单介绍一下Pytorch C++的API部分,主要有以下五部分
ATen: 作为基础张量和数学操作库,所有其他接口都构建在其上。Autograd: 通过自动微分增强了ATen,记录张量上的操作以形成自动微分图。C++ Frontend: 提供了用于神经网络和机器学习模型的高级纯C++建模接口。TorchScript: 是一个可以由TorchScript编译器理解、编译和序列化的PyTorch模型表示。C++ Extensions: 用于扩展Python API的自定义C++和CUDA例程。
这些块组合形成了一个C++库,可用于张量计算和具有高效的GPU加速以及快速CPU性能的动态神经网络。
在这部分中,ATen是一个基础张量库,几乎所有PyTorch的Python和C++接口都构建在其上。Autograd是C++ API的一部分,用于为ATen张量类添加自动微分功能。我们编写C++的扩展的时候,我们实际上是基于ATen进行操作和书写的。
适用对象与场景 实际上pytorch+cuda是为了加速pytorch的计算,如果pytorch的计算已经可以满足了,就可以跳过这一部分,因为本身pytorch也已经蕴含了很多的函数
非平行运算 non parallel computation :在这样的场景下,比如现在一个batch里面,都是平行运算,所以这时候可以直接用pytorch进行实现,但是在NeRF的体渲染volume rendering中,我们就可以知道,每一条射线可能采样的点都是不一样的,如果我们去用for循环就可能需要花比较多的时间,这时候就需要cuda的存在。
大量的串列计算 lots of sequential computation :比如神经网络的卷积层的计算的,比如在forward中,经常会出现以下这样的情况
1 2 3 4 x = f1(x) x = f2(x) ... x = fn(x)
如果在层数比较小的时候,这样是可以得到不错的结果的,但是层数比较大的时候,不断的内存访问其实会减慢速度,这时候就需要CUDA来进行加速,比如我们可以将所有的f变成一个函数F,融合了所有的函数后,我们就可以进行一次运算得到最后的结果,在层数大的时候能得到很大的提升。
在这一部分的学习中,主要还是在第一个场景,非平行运算,特别是NeRF的体渲染部分,这一部分的学习和加速还是非常重要的,值得学习。
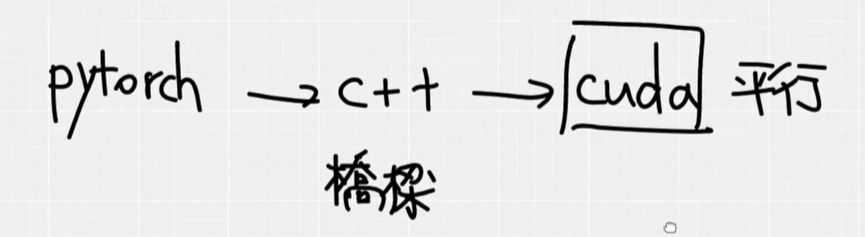
Pytorch和CUDA的关系 一般来说,是pytorch -> C++ > cuda,也就是pytorch调用C++,然后C++再调用cuda,所以C++作为的是一个桥梁,所以比较重要的cuda,而不是C++,利用cuda进行平行的计算。
Python调用C++函数(桥梁) 首先声明一下,我的文件夹格式如下:
1 2 3 4 5 6 7 pytorch-cppcuda-tutorial/ test.py setup.py interpolation.cpp interpolation_kernel.cu include/ utils.h
有一个问题可能我们会疑惑很久,就是python是怎么调用C++和CUDA的,这里面根据课程简单来讲一下,以三线性插值为例子
首先,我们定义一个简单的函数。这个函数接受两个参数,分别是特征和点,然后直接返回特征。在这里,我们将看到一个核心的东西,即 PYBIND11_MODULE。这是 Python 调用 C++ 函数的关键部分。这个函数会在Python执行import语句时被调用,其接受两个参数,第一个参数为模块名称,这里我们直接将trilinear_interpolation填入,稍候可以在Python中使用import cppcuda_tutorial导入该模块;第二个参数m是创建Python关联代码的主接口,其类型为py::module_。module_::def()用于生成能够将trilinear_interpolation函数暴露给Python的代码,其第一个参数为字符串 ,将会成为Python中调用的函数名;第二个参数是C++函数 的引用;第三个参数是说明字符串 ,在Python中可以使用help(trilinear_interpolation)查看。比如下面的例子中,C++ 中的函数 trilinear_interpolation 对应 Python 中的 trilinear_interpolation。
ATen库是用于张量计算的主要API,
pybind11,是为C++代码创建Python绑定的方式
管理ATen和pybind11之间交互细节的头文件
PyTorch的张量和变量接口是从ATen库自动生成的,因此几乎可以将Python实现1:1转换为C++。所有计算的主要数据类型将是torch::Tensor。
1 2 3 4 5 6 7 8 9 10 11 12 #include <torch/extension.h> torch::Tensor trilinear_interpolation ( torch::Tensor feats, torch::Tensor point ) return feats; } PYBIND11_MODULE (TORCH_EXTENSION_NAME, m){ m.def ("trilinear_interpolation" , &trilinear_interpolation); }
注意:TORCH_EXTENSION_NAME,torch扩展构建会将其定义为在setup.py脚本中为扩展指定的名称。比如这里为“TORCH_EXTENSION_NAME“,两者之间的不匹配可能会导致严重且难以跟踪的问题。
C++扩展一般有两种方式
通过setuptools“提前”构建
通过torch.utils.cpp_extension.load()“实时”构建
接下来先试用setuptools进行构建,编写一个 setup.py 文件,主要用于定义和说明一些重要的信息。其中关键的参数包括:
name:Python 调用的包的名称。ext_modules 的 sources:需要编译的 C++ 源文件,如果有多个 C++ 文件,需要列举所有。cmdclass:用BuildExtension执行许多必需的配置步骤和检查,并在混合C++/CUDA扩展的情况下处理混合编译。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 from setuptools import setup from torch.utils.cpp_extension import CppExtension, BuildExtension setup ( name='cppcuda_tutorial' , version='1.0' , author='xxx' , author_email='xxx@gmail.com' , description='cppcuda example' , long_description='cppcuda example' , ext_modules=[ CppExtension( name='cppcuda_tutorial' , sources=['interpolation.cpp' ]) ], cmdclass={ 'build_ext' : BuildExtension } )
JIT Compiling Extensions 除了上述的setuptools的方法,接下来介绍即时编译(JIT)机制构建C++扩展。JIT编译机制通过调用PyTorch API中的一个简单函数torch.utils.cpp_extension.load(),为你提供了一种即时编译和加载扩展的方式。
1 2 3 4 5 from torch.utils.cpp_extension import loadcppcuda_tutorial = load(name="cppcuda_tutorial" , sources=['interpolation.cpp' ],)
在这里,实际提供的是域setuptools相同的信息。在后台,这将执行以下操作:
创建一个临时目录/tmp/torch_extensions/cppcuda_tutorial,
向该临时目录发出Ninja构建文件,
将你的源文件编译成一个共享库,
将这个共享库导入为Python模块。
实际上,如果将verbose=True传递给cpp_extension.load(),你将得到有关该过程的信息:
1 2 3 4 5 6 7 Using /path/.cache/torch_extensions/py310_cu113 as PyTorch extensions root... Detected CUDA files, patching ldflags Emitting ninja build file /path/.cache/torch_extensions/py310_cu113/cppcuda_tutorial/build.ninja... Building extension module cppcuda_tutorial... Allowing ninja to set a default number of workers... (overridable by setting the environment variable MAX_JOBS=N) [1/2] /usr/local/cuda/bin/nvcc -DTORCH_EXTENSION_NAME=cppcuda_tutorial -DTORCH_API_INCLUDE_EXTENSION_H -DPYBIND11_COMPILER_TYPE=\"_gcc\" -DPYBIND11_STDLIB=\"_libstdcpp\" -DPYBIND11_BUILD_ABI=\"_cxxabi1011\" -I/path/workdirs/pytorch-cppcuda-tutorial/include -isystem /path/anaconda3/envs/cppcuda/lib/python3.10/site-packages/torch/include -isystem /path/anaconda3/envs/cppcuda/lib/python3.10/site-packages/torch/include/torch/csrc/api/include -isystem /path/anaconda3/envs/cppcuda/lib/python3.10/site-packages/torch/include/TH -isystem /path/anaconda3/envs/cppcuda/lib/python3.10/site-packages/torch/include/THC -isystem /usr/local/cuda/include -isystem /path/anaconda3/envs/cppcuda/include/python3.10 -D_GLIBCXX_USE_CXX11_ABI=0 -D__CUDA_NO_HALF_OPERATORS__ -D__CUDA_NO_HALF_CONVERSIONS__ -D__CUDA_NO_BFLOAT16_CONVERSIONS__ -D__CUDA_NO_HALF2_OPERATORS__ --expt-relaxed-constexpr -gencode=arch =compute_86,code=compute_86 -gencode=arch =compute_86,code=sm_86 --compiler-options '-fPIC' -std=c++14 -c /path/workdirs/pytorch-cppcuda-tutorial/interpolation_kernel.cu -o interpolation_kernel.cuda.o [2/2] c++ interpolation.o interpolation_kernel.cuda.o -shared -L/path/anaconda3/envs/cppcuda/lib/python3.10/site-packages/torch/lib -lc10 -lc10_cuda -ltorch_cpu -ltorch_cuda_cu -ltorch_cuda_cpp -ltorch -ltorch_python -L/usr/local/cuda/lib64 -lcudart -o cppcuda_tutorial.so
完成这一步后,如果使用setuptools进行构建,我们可以使用 pip 进行安装。如果在当前文件夹下,直接运行 pip install . 即可完成安装或者我们也可以使用python set.py install,安装成功后应该会显示以下结果:
1 2 3 4 5 6 7 8 9 Processing path/pytorch-cppcuda-tutorial Preparing metadata (setup.py) ... done Building wheels for collected packages: cppcuda-tutorial Building wheel for cppcuda-tutorial (setup.py) ... done Created wheel for cppcuda-tutorial: filename=cppcuda_tutorial-1.0-cp310-cp310-linux_x86_64.whl size=74123 sha256=3029b98bd3b49bed65f42640e60932c38379f15db48a5187fe40610b525307c9 Stored in directory: /path/.cache/pip/wheels/65/53/4a/5e2c10d11e3a657b9efae376ccce3277e5535d691dd4659883 Successfully built cppcuda-tutorial Installing collected packages: cppcuda-tutorial Successfully installed cppcuda-tutorial-1.0
完成以上步骤后,我们可以编写一个 test.py 文件来测试代码的正确性。只要能够成功运行,就代表一切正常。
1 2 3 4 5 6 7 8 9 10 11 import torchimport cppcuda_tutorial feats = torch.ones(2 ) point = torch.zeros(2 ) out = cppcuda_tutorial.trilinear_interpolation(feats, point) print (out)
这里面要注意的就是,首席爱你要导入torch,解析动态链接器必须看到的一些符号
CUDA加速的原理 首先介绍一个CUDA程序实现的流程
把数据从CPU内存拷贝到GPU内存
调用核函数对存储在GPU内存中的数据进行操作
将数据从GPU内存传送回CPU内存
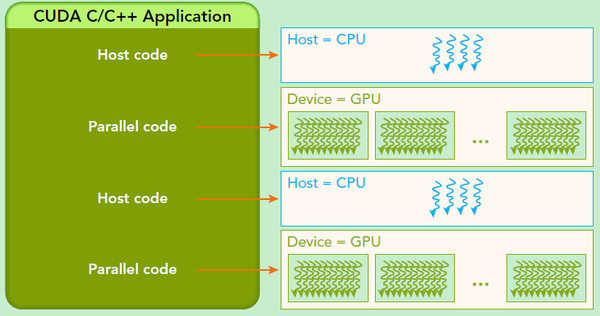
如下图所示,在利用CUDA加速的时候,图的左边是CPU,右边是GPU,我们需要把数据从CPU传到GPU中。在GPU中,就会生成对应的Grid来进行计算,每个Grid里面又有很多的block,从block中看又有很多的线程thread进行运算。我们也可以想象一下,如果计算一个矩阵的加法,我们可以让每个thread做对应的元素的相加,这样就可以大大加快计算速度,达到并行的效果。所以这之中内核(kernel)是CUDA编程中一个重要的部分,其代码在GPU上运行,比如矩阵乘法,我们就可以写一个加法的核函数,然后串行执行核函数,这样我们就快速能完成CUDA代码的编写,而不用在创建和管理大量的GPU线程时拘泥于细节。
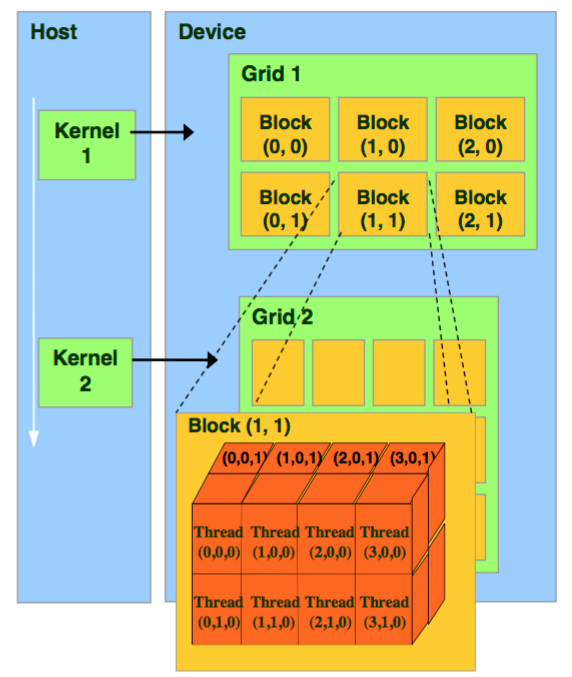
所以我们可以发现,实际上CUDA的计算是Grid——》Block——》Thread,然后用多个Thread进行计算,这里面可能会疑惑,为什么不是直接Grid——》Thread,实际上是因为硬件的限制是Block上限是$(2^{31}-1)2^{16} 2^{16}$,Thread的上限是1024,所以这样的组合设计能够利用好更多的Thread,这也是为什么GPU速度那么快的原因。
三线性插值问题定义 有关于线性插值和三线性插值的介绍,可以从这部分资料进行了解,https://zhuanlan.zhihu.com/p/77496615 ,https://blog.csdn.net/webzhuce/article/details/86585489 ,这样我们就知道三线性插值的概念,和大概的思路,这样我们就可以进行一个CUDA的实现了。
从三线性插值的概念我们可以知道,我们需要传入两个参数
feats(N, 8, F):N个立方体,每个立方体有8个点,每个点有F个特征
Points(N,3):N个点,每个点的坐标分别是xyz,一共有三个维度
我们也可以知道输出的参数为feat_interp(N, F),也就是插值后的结果
从上述定义我们就可以知道,我们有两个部分可以进行平行运算,分别是N和F,因为它们是独立的,不会相互影响计算。
C++调用CUDA函数 首先我们先看看,怎么使用CUDA去进行编程,首先CUDA的代码是cu结尾的,我们通过编写CUDA来进行一个计算加速。我们还是先按之前的方法,看看如何使用CUDA进行编程先,这里面有几个注意的点:
需要编写CUDA函数
需要在头文件.h中去定义需要使用的函数,包括一些常用的测试函数。
修改CUDA的setup.py
接下来一步一步来,首先写一个interpolation_kernel.cu函数,也就是一个CUDA函数,后面我们可以用C++调用CUDA,这里面还是直接返回feats
1 2 3 4 5 6 7 8 #include <torch/extension.h> torch::Tensor trilinear_fw_cu ( torch::Tensor feats, torch::Tensor points ) return feats; }
接下来,我们就需要在头文件utils.h中去定义我们在文件中需要使用的函数,类似于原本C++的一个声明和定义函数
1 2 3 4 5 6 7 8 9 10 11 #include <torch/extension.h> #define CHECK_CUDA(x) TORCH_CHECK(x.is_cuda(), #x " must be a CUDA tensor" ) #define CHECK_CONTIGUOUS(x) TORCH_CHECK(x.is_contiguous(), #x " must be contiguous" ) #define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x) torch::Tensor trilinear_fw_cu ( torch::Tensor feats, torch::Tensor points )
这样编写以后,我们的cpp的代码就可以调用CUDA对函数来进行调用,但是由于我们使用CUDA的函数,所以这里面我们还要用到CHECK_INPUT函数来判断是否在GPU上,也就是一个检测,并且内存是否连续,因为后续要进行一个并行的计算。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 #include "utils.h" torch::Tensor trilinear_interpolation ( torch::Tensor feats, torch::Tensor points ) CHECK_INPUT (feats); CHECK_INPUT (points); return trilinear_fw_cu (feats, points); } PYBIND11_MODULE (TORCH_EXTENSION_NAME, m){ m.def ("trilinear_interpolation" , &trilinear_interpolation); }
完成上述编写之后,我们最后就只剩下setup.py函数需要修改,其实需要修改的东西非常有限,只需要将上述的CPPExtension改为CUDAExtension,也就是改成CUDA的编译,这里面还有比较好的方法就是,之前我们source需要自己写,但是当我们有很多个文件的时候,我们就可以自动检索文件夹下的cpp和cu文件,进行build即可得到最后的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import globimport os.path as ospfrom setuptools import setupfrom torch.utils.cpp_extension import CUDAExtension, BuildExtensionROOT_DIR = osp.dirname(osp.abspath(__file__)) include_dirs = [osp.join(ROOT_DIR, "include" )] sources = glob.glob('*.cpp' )+glob.glob('*.cu' ) setup( name='cppcuda_tutorial' , version='1.0' , author='xxx' , author_email='xxx@gmail.com' , description='cppcuda_tutorial' , long_description='cppcuda_tutorial' , ext_modules=[ CUDAExtension( name='cppcuda_tutorial' , sources=sources, include_dirs=include_dirs, extra_compile_args={'cxx' : ['-O2' ], 'nvcc' : ['-O2' ]} ) ], cmdclass={ 'build_ext' : BuildExtension } )
安装过后,我们就可以测试是否使用CUDA进行计算,唯一不同的是,由于我们是使用CUDA进行计算,所以我们要把数据转到CUDA中即可
1 2 3 4 5 6 7 8 9 10 11 12 import torchimport cppcuda_tutorialif __name__ == '__main__' : feats = torch.ones(2 , device='cuda' ) points = torch.zeros(2 , device='cuda' ) out = cppcuda_tutorial.trilinear_interpolation(feats, points) print (out)
在这里,可能第一次学习会觉得比较麻烦,但是实际上有一些函数,比如CHECK的函数和setup.py的函数,只要写了一次以后,之后都是可以参考复用的,不用重复写
三线性插值CUDA实现 接下来就是主要的三线性插值的CUDA实现了,在前面的CUDA加速中有说到,实际上我们是希望在每一个thread都执行一个单元的计算,在三线性插值中,我们可以知道,我们两个部分需要并行,分别是N和F两个部分,也就是立方体的个数和特征的个数。
我们先看看需要进行编写的函数,然后一步一步的来解释和探索,以下是更新后的forward函数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 torch::Tensor trilinear_fw_cu ( torch::Tensor feats, torch::Tensor points ) const int N = feats.size (0 ), F = feats.size (2 ); torch::Tensor feat_interp = torch::zeros ({N, F}, feats.options ()); const dim3 threads (16 , 16 ) const dim3 blocks ((N+threads.x-1 )/threads.x, (F+threads.y-1 )/threads.y) AT_DISPATCH_FLOATING_TYPES (feats.type (), "trilinear_fw_cu" , ([&] { trilinear_fw_kernel<scalar_t ><<<blocks, threads>>>( feats.packed_accessor <scalar_t , 3 , torch::RestrictPtrTraits, size_t >(), points.packed_accessor <scalar_t , 2 , torch::RestrictPtrTraits, size_t >(), feat_interp.packed_accessor <scalar_t , 2 , torch::RestrictPtrTraits, size_t >() ); })); return feat_interp; }
第5行我们得到了对应的维度,分别是N和F,这也是我们最后需要返回值feat_interp的维度。
第7行我们初始化了变量feat_interp,这里面是初始化为zero,在里面还有一个参数是feats.options(),在CUDA编程中,feats.options()表示获取feats张量的选项(options)。选项包括张量的数据类型、设备(设备指定为CUDA或CPU)以及其他相关的配置信息。通过使用feats.options(),可以确保新创建的feat_interp张量与feats张量具有相同的选项,以便在相同的设备上进行操作,并保持一致性。
简单来说,就是保持一致的设备等等,这样就方便后续在同一个设备进行计算,和pytorch需要放在cpu和cuda上是一样的,除此之外,还有一些另外的写法,比如是创建一个整型的,可以写成如下,一样的意思。
1 torch::zeros ({N,F},torch::dtype (torch::kInt32).device (feats,device));
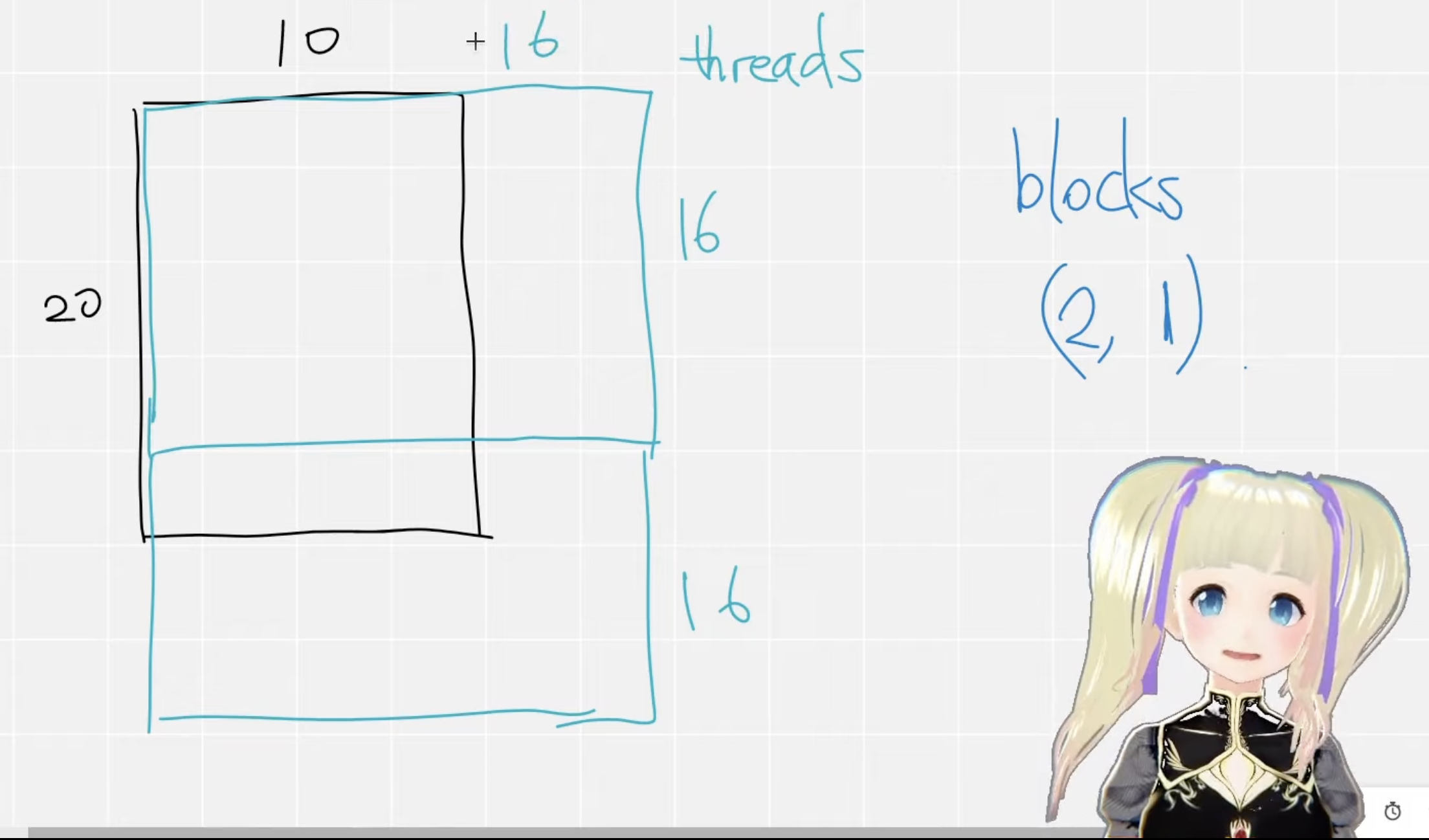
第9行和第10行就是定义上述提过的threads和blocks了,dim3是NVIDIA的CUDA编程中一种自定义的整型向量类型,基于用于指定维度的uint3,dim3类型最终设置的是一个三维向量,三维参数分别为x,y,z。在并行中,通常只支持三个并行,比如这里的N和F刚刚好就是两个并行,这里设置为16x16的线程,一般可以是128,256,512,不一定使用越多越好,这里面只是给了一个例子。
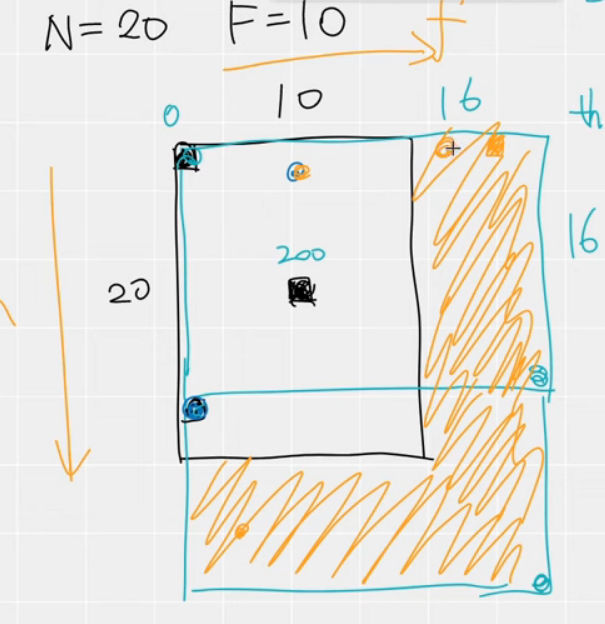
第10行中是定义了blocks的计算,blocks的个数实际上是计算的得到的,如下图所示,如果N=10,F=20,我们最后的输出就是10x20,这样我们就会用一个16x16的block去覆盖这整个矩阵,我们会发现大概需要2个矩阵,所以我们的blocks就是(2,1),从下图也可以看出来,所以上述公式就是计算block的个数,这样我们就可以用每一个thread去计算,这样就能大大加快速度。
第12~19行就是CUDA的核心函数,这里面就是一个启动核函数的部分,后面会提到核函数的编写,这里也是一个框架的部分,AT_DISPATCH_FLOATING_TYPES 是处理核函数的启动(使用 <<<...>>> 表示),它一般有三个参数
一个类型 feats.type()
一个名称 “trilinear_fw_cu”,用于错误消息
一个 lambda 函数,是一个模版函数template,类型别名为 scalar_t
在这里面可以看出处理的是float类型的数据,如果想对所有类型进行操作而不仅仅是浮点类型(Float 和 Double),可以使用 AT_DISPATCH_ALL_TYPES。
scalar_t类型 在函数之中,我们可以看到我们有三个input,其中两个是三线性插值的input,一个是output,为什么呢,是因为其实这个函数是没有返回值的,所以说实际上是在函数里面计算后复制在output之中,最后进行返回。
我们来仔细了解了一下具体函数的编写是什么意思,首先是scalar_t其实是一种类型,他可以表示任何类型,包括整型,浮点型等等,如果我们确定数据是float,我们也可以直接将scalar_t写为float,那么他可能就只能处理浮点型的数据了,从下面也可以看到scalar_t的一个简单的实现。
1 2 3 4 5 6 7 switch (tensor.type ().scalarType()) { case torch::ScalarType::Double: return function<double>(tensor.data<double>()); case torch::ScalarType::Float: return function<float >(tensor.data<float >()); ... }
accessors 在CUDA计算的时候,还有一个问题,在 CUDA 核函数内部,虽然我们能正确处理数据,直接使用高级类型scalar_t不可知的张量将非常低效,因为这是以易用性和可读性为代价的,特别是对于高维数据。
比如说,在数据中,我们这里有(N, F)个数据,那我们有没有快速的方法去读取到feat_interp[i][j]的数据呢,特别是有些一般是三个维度的,比如(bs,row,index)这样的,并且有时候我们还需要知道stride才能快速索引到位置,比如gates.data<scalar_t>()[n*3*state_size + row*state_size + column]
在这里面,我们可能就需要用到一个ATen提供的accessors,他可以动态检查确保张量具有指定的类型和维度数量,器提供了一个 API,用于高效地访问张量元素,而无需转换为单个指针,就可以高效访问 cpu 张量上的数据,cuda我们就可以用packed_accessor。
1 2 3 4 5 6 7 8 9 10 torch::Tensor foo = torch::rand ({12 , 12 }); auto foo_a = foo.accessor <float ,2 >();float trace = 0 ;for (int i = 0 ; i < foo_a.size (0 ); i++) { trace += foo_a[i][i]; }
所以我们在核函数内部看到了packed_accessor,这一部分就是做这样一件事情,不过值得注意的是,只有对torch的向量我们需要这样的操作,如果是bool等,我们是不需要处理的。
模板函数 上述有提到,实际上我们的trilinear_fw_kernel是一个模板函数,我们接下来看一下具体的实现,我们利用scalar_t对其进行实例化,我们在这里再解释一下这个模板函数的参数部分:
首先是 scalar_t,它是一个模板参数,代表张量的数据类型。在这个上下文中,通常会使用 float 或 double 作为 scalar_t,具体取决于张量的数据类型。
接下来是 3,它表示张量的维度数量。在这个例子中,我们的feats的维度是3,所以维度数量为 3。
然后是 torch::RestrictPtrTraits,它是一个模板参数,用于指定指针的限定符。__restrict__ 关键字在 CUDA 中用于指示指针是唯一的,并且没有别名。这有助于编译器进行优化,提高代码的性能。
最后是 PackedTensorAccessor,它是一个访问器(accessor)的变体,用于存储大小和步幅信息,可以使得在访问器对象传递给 CUDA 核函数时,内存传输的数据量也更小。
接下来我们仔细分析里面代码的细节,首先介绍一下这个__global__,他实际意义如下,如下图所示
接下里分析函数的主体部分,主要做两件事情:
为每个threads进行编号
去除不必要的threads
在使用threads计算的时候,实际上每一个threads都有一个对应的编号,计算方式如第7,8行所示,实际上就是block的x*block的个数+block的y就能得到最后的结果
除了编号之外,还有去除不必要的threads,因为有一部分是没有覆盖到的,比如如下图的黄色部分就是不必要的threads,所以在第10行进行判断,如果超过范围,直接return不计算
最后就是上述说明的三线性插值的做法了,先进行一个标准化,然后代入公式进行计算,最后将值写入feat_interp中,就完成了整个模板函数的编写,大功告成!!!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 template <typename scalar_t >__global__ void trilinear_fw_kernel ( const torch::PackedTensorAccessor<scalar_t , 3 , torch::RestrictPtrTraits, size_t > feats, const torch::PackedTensorAccessor<scalar_t , 2 , torch::RestrictPtrTraits, size_t > points, torch::PackedTensorAccessor<scalar_t , 2 , torch::RestrictPtrTraits, size_t > feat_interp ) const int n = blockIdx.x * blockDim.x + threadIdx.x; const int f = blockIdx.y * blockDim.y + threadIdx.y; if (n>=feats.size (0 ) || f>=feats.size (2 )) return ; const scalar_t u = (points[n][0 ]+1 )/2 ; const scalar_t v = (points[n][1 ]+1 )/2 ; const scalar_t w = (points[n][2 ]+1 )/2 ; const scalar_t a = (1 -v)*(1 -w); const scalar_t b = (1 -v)*w; const scalar_t c = v*(1 -w); const scalar_t d = 1 -a-b-c; feat_interp[n][f] = (1 -u)*(a*feats[n][0 ][f] + b*feats[n][1 ][f] + c*feats[n][2 ][f] + d*feats[n][3 ][f]) + u*(a*feats[n][4 ][f] + b*feats[n][5 ][f] + c*feats[n][6 ][f] + d*feats[n][7 ][f]); }
foward验证与比较 经过python setup.py install以后(每次修改后都要重新运行setup.py),我们就可以进行运行了,在这里面为了验证结果的正确性和与python进行比较,用python实现三线性插值的算法,比较两者的结果和时间效率,test.py如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import torchimport cppcuda_tutorialimport timedef trilinear_interpolation_py (feats, points ): """ Inputs: feats: (N, 8, F) points: (N, 3) local coordinates in [-1, 1] Outputs: feats_interp: (N, F) """ u = (points[:, 0 :1 ]+1 )/2 v = (points[:, 1 :2 ]+1 )/2 w = (points[:, 2 :3 ]+1 )/2 a = (1 -v)*(1 -w) b = (1 -v)*w c = v*(1 -w) d = 1 -a-b-c feats_interp = (1 -u)*(a*feats[:, 0 ] + b*feats[:, 1 ] + c*feats[:, 2 ] + d*feats[:, 3 ]) + \ u*(a*feats[:, 4 ] + b*feats[:, 5 ] + c*feats[:, 6 ] + d*feats[:, 7 ]) return feats_interp if __name__ == '__main__' : N = 65536 ; F = 256 feats = torch.rand(N, 8 , F, device='cuda' ).requires_grad_() points = torch.rand(N, 3 , device='cuda' )*2 -1 t = time.time() out_cuda = cppcuda_tutorial.trilinear_interpolation(feats, points) torch.cuda.synchronize() print (' cuda time' , time.time()-t, 's' ) t = time.time() out_py = trilinear_interpolation_py(feats, points) torch.cuda.synchronize() print ('pytorch time' , time.time()-t, 's' ) print (torch.allclose(out_py, out_cuda))
经过运行和计算后,我们会得到以下结果,我们可以看到,CUDA是明显比Pytorch更快的,并且两者的计算结果也是一样的,如果需要更好的计算两者的速度的话,可能需要进行循环运行计算取平均更有可信度。
1 2 3 cuda time 0.02436351776123047 s pytorch time 0.04364943504333496 s True
CUDA反向传播 在上述实验中,当我们尝试添加自动求导的梯度计算时,使用requires_grad_,我们会发现通过CUDA返回的值实际上不会自动进行梯度计算(autograd)。然而,如果我们在Python中进行计算,它会自动进行梯度计算。
然而,在实际应用中,神经网络经常需要计算损失函数,并使用梯度下降等优化算法来不断优化参数。但是,在CUDA编程中,C++扩展API并没有提供自动求导(autograd)的方法。因此,我们必须自己实现反向传播的代码,计算每个输入的导数,并将其封装在torch.autograd.Function中。
在CUDA编程中,实现反向传播的代码通常包括以下步骤:
在C++扩展中,创建一个新类,继承自torch::autograd::Function,用于定义前向传播和反向传播操作。
在新类中,重写forward()方法,定义前向传播的操作。这些操作将使用CUDA执行计算,并返回结果,其实就是上述的cuda的部分。
在新类中,重写backward()方法,定义反向传播的操作。这些操作将计算输入张量的梯度,并传递给上一层。
在CUDA和C++中,编写对应的forward和backward函数,计算前向传播和微分。
在Python代码中,使用这个自定义函数执行前向传播,并通过调用backward()方法执行反向传播。
在反向传播过程中,梯度将通过CUDA计算,并在每个层之间传递,从而计算出每个输入的导数。
通过这种方式,我们可以在CUDA编程中手动实现反向传播,并获得每个输入的梯度,以便进行优化算法的参数更新。尽管需要手动编写反向传播代码,但这使我们能够在CUDA扩展中自定义梯度计算,并与PyTorch的自动求导机制无缝配合。
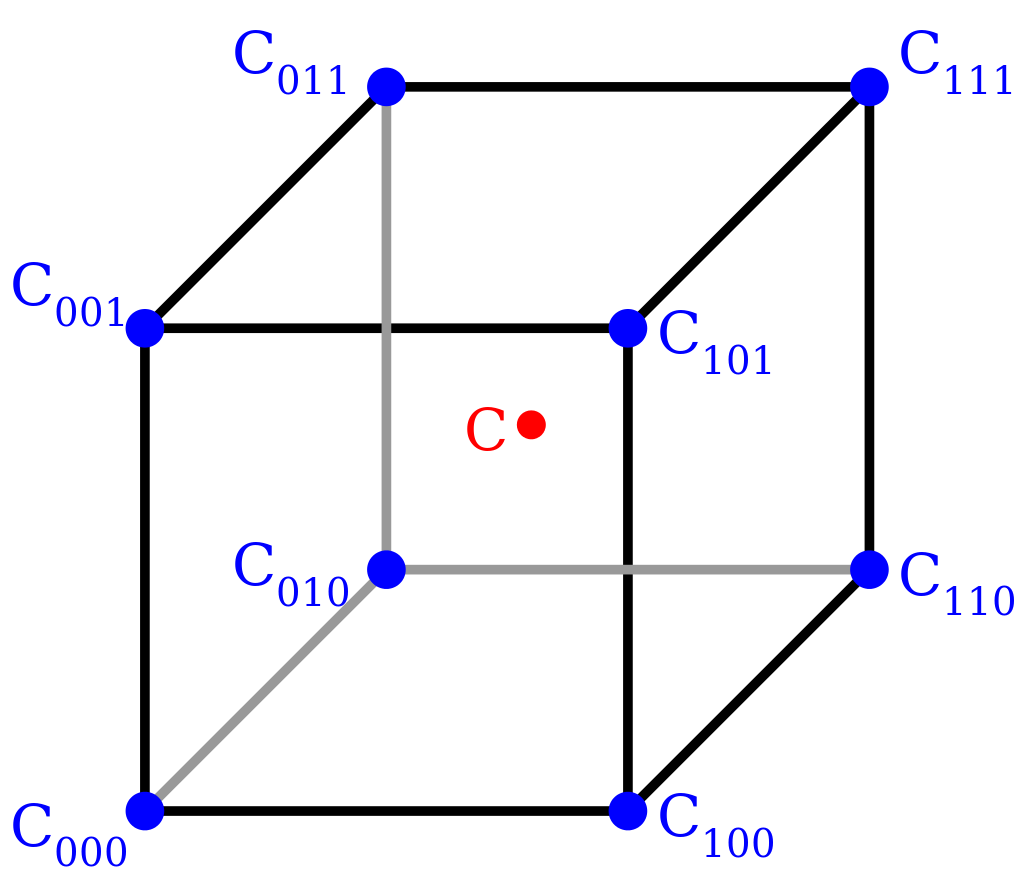
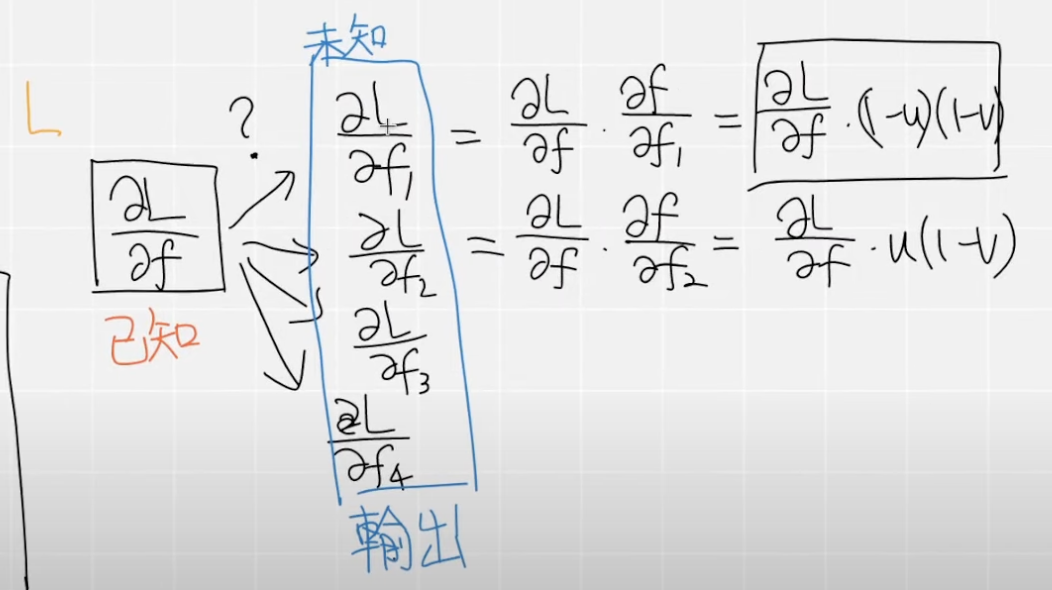
我们还是把三线性插值作为我们的一个例子,编写对应的反向传播,根据问题设定,我们可以知道我们的Points是固定的,所以我们需要对我们的Feats进行求微分。我们以简单的双线性插值来学习一下,怎么求微分,这里面其实涉及高数的知识,当然我们也可以把函数交给一些数学网站帮我们求得结果。从下图我们可以看到,f是双线性插值的结果,我们可以得到对应的四个导数,我们会发现实际上,他们的微分是对应的系数,推导在三线性插值也是一样的,所以他们对应的微分也就是对应的前缀。
在计算反向传播前,我们往往会有一个对应的一个损失Loss,然后再进行求微分,这里面其实就用到了高数里面的链式法则,使用链式法则我们就可以得到L对每一个feat的微分,明白了双线性插值的计算,我们也可以推导在三线性插值中。
定义CUDA函数 明白了理论的计算,我们就可以进行对应的实现,首先我们可以编写对应的反向传播的CUDA函数,这一部分实际上和前向传播是一样的,首先我们还是定义反向传播函数,在这里和前向传播函数的不同就是对名字进行了修改,除此之外加入了两个参数,分别是dL_dfeats参数和dL_dfeats。简单解释一下这些参数,在问题的设定中,我们的feats的维度是的(N, 8, F),所以我们的微分dL_dfeats的维度是和feats是一样的,然后再加入反向传播的核函数中即可;dL_dfeat_interp则是根据函数已知的,所以不用计算,直接传参数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 torch::Tensor trilinear_bw_cu ( const torch::Tensor dL_dfeat_interp, const torch::Tensor feats, const torch::Tensor points ) const int N = feats.size (0 ), F = feats.size (2 ); torch::Tensor dL_dfeats = torch::empty ({N, 8 , F}, feats.options ()); const dim3 threads (16 , 16 ) const dim3 blocks ((N+threads.x-1 )/threads.x, (F+threads.y-1 )/threads.y) AT_DISPATCH_FLOATING_TYPES (feats.type (), "trilinear_bw_cu" , ([&] { trilinear_bw_kernel<scalar_t ><<<blocks, threads>>>( dL_dfeat_interp.packed_accessor <scalar_t , 2 , torch::RestrictPtrTraits, size_t >(), feats.packed_accessor <scalar_t , 3 , torch::RestrictPtrTraits, size_t >(), points.packed_accessor <scalar_t , 2 , torch::RestrictPtrTraits, size_t >(), dL_dfeats.packed_accessor <scalar_t , 3 , torch::RestrictPtrTraits, size_t >() ); })); return dL_dfeats; }
核函数实现微分计算 接下来就是主要的核函数的实现,在这一部分我们就需要实现微分的计算,在前面已经介绍了双线性插值的微分的计算,推导在三线性插值是一样的,我们可以根据前向传播的代码,这一部分只需要保留前面的系数✖️对应位置的dL_dfeat_interp就可以得到最后的微分值,这一部分跟上述的推导是一模一样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 template <typename scalar_t >__global__ void trilinear_bw_kernel ( const torch::PackedTensorAccessor<scalar_t , 2 , torch::RestrictPtrTraits, size_t > dL_dfeat_interp, const torch::PackedTensorAccessor<scalar_t , 3 , torch::RestrictPtrTraits, size_t > feats, const torch::PackedTensorAccessor<scalar_t , 2 , torch::RestrictPtrTraits, size_t > points, torch::PackedTensorAccessor<scalar_t , 3 , torch::RestrictPtrTraits, size_t > dL_dfeats ) const int n = blockIdx.x * blockDim.x + threadIdx.x; const int f = blockIdx.y * blockDim.y + threadIdx.y; if (n>=feats.size (0 ) || f>=feats.size (2 )) return ; const scalar_t u = (points[n][0 ]+1 )/2 ; const scalar_t v = (points[n][1 ]+1 )/2 ; const scalar_t w = (points[n][2 ]+1 )/2 ; const scalar_t a = (1 -v)*(1 -w); const scalar_t b = (1 -v)*w; const scalar_t c = v*(1 -w); const scalar_t d = 1 -a-b-c; dL_dfeats[n][0 ][f] = (1 -u)*a*dL_dfeat_interp[n][f]; dL_dfeats[n][1 ][f] = (1 -u)*b*dL_dfeat_interp[n][f]; dL_dfeats[n][2 ][f] = (1 -u)*c*dL_dfeat_interp[n][f]; dL_dfeats[n][3 ][f] = (1 -u)*d*dL_dfeat_interp[n][f]; dL_dfeats[n][4 ][f] = u*a*dL_dfeat_interp[n][f]; dL_dfeats[n][5 ][f] = u*b*dL_dfeat_interp[n][f]; dL_dfeats[n][6 ][f] = u*c*dL_dfeat_interp[n][f]; dL_dfeats[n][7 ][f] = u*d*dL_dfeat_interp[n][f]; }
PYBIND11绑定函数 写好了反向传播函数之后,不要忘记绑定函数,这样我们才能在最后的python中调用对应的函数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 torch::Tensor trilinear_interpolation_fw ( const torch::Tensor feats, const torch::Tensor points ) CHECK_INPUT (feats); CHECK_INPUT (points); return trilinear_fw_cu (feats, points); } torch::Tensor trilinear_interpolation_bw ( const torch::Tensor dL_dfeat_interp, const torch::Tensor feats, const torch::Tensor points ) CHECK_INPUT (dL_dfeat_interp); CHECK_INPUT (feats); CHECK_INPUT (points); return trilinear_bw_cu (dL_dfeat_interp, feats, points); } PYBIND11_MODULE (TORCH_EXTENSION_NAME, m){ m.def ("trilinear_interpolation_fw" , &trilinear_interpolation_fw); m.def ("trilinear_interpolation_bw" , &trilinear_interpolation_bw); }
torch.autograd.Function封装 为了使用pytorch的autograd我们还差最后一步,就是使用torch.autograd.Function进行封装,不然的话不能进行反向传播,会出现一些奇奇怪怪的bug。
在下面的代码中,首先,我们需要定义forward和backward函数,记得我们都需要定义@staticmethod装饰器,这个是一定要的。 接下来我们就可以开始完善forward和backward函数。在两个函数中,实际上我们就是调用C++扩展写好的函数,这里面唯一一个需要注意的就是ctx,实际上这里是context的缩写,这里就是表示有什么数据需要进行保存在反向传播中使用到,因为在backward我们还要传入对应的feats和points,所以在这里这两个参数都需要save_for_backward。
最后的backward就更简单了,传入的参数与forward返回的参数进行对应,接着我们从ctx取出需要用到的参数,从ctx.saved_tensors中取出,后续只需要调用对应的C++函数即可,在这里面我们返回了两个参数,分别是dL_dfeats, None,这一部分是因为实际上是因为,我们有两个参数,分别feats, points,而我们并没有对points进行计算微分,所以这里就返回None。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 class Trilinear_interpolation_cuda (torch.autograd.Function): @staticmethod def forward (ctx, feats, points ): feat_interp = cppcuda_tutorial.trilinear_interpolation_fw(feats, points) ctx.save_for_backward(feats, points) return feat_interp @staticmethod def backward (ctx, dL_dfeat_interp ): feats, points = ctx.saved_tensors dL_dfeats = cppcuda_tutorial.trilinear_interpolation_bw(dL_dfeat_interp.contiguous(), feats, points) return dL_dfeats, None
backward验证与比较 和上述一样,经过python setup.py install以后(每次修改后都要重新运行setup.py),我们就可以进行运行了,在这里面为了验证结果的正确性和与pytorch本身的反向传播进行比较,比较两者的结果和时间效率,test.py的主函数如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 class Trilinear_interpolation_cuda (torch.autograd.Function): @staticmethod def forward (ctx, feats, points ): feat_interp = cppcuda_tutorial.trilinear_interpolation_fw(feats, points) ctx.save_for_backward(feats, points) return feat_interp @staticmethod def backward (ctx, dL_dfeat_interp ): feats, points = ctx.saved_tensors dL_dfeats = cppcuda_tutorial.trilinear_interpolation_bw(dL_dfeat_interp.contiguous(), feats, points) return dL_dfeats, None if __name__ == '__main__' : N = 65536 ; F = 256 rand = torch.rand(N, 8 , F, device='cuda' ) feats = rand.clone().requires_grad_() feats2 = rand.clone().requires_grad_() points = torch.rand(N, 3 , device='cuda' )*2 -1 t = time.time() out_cuda = Trilinear_interpolation_cuda.apply(feats2, points) torch.cuda.synchronize() print (' cuda fw time' , time.time()-t, 's' ) t = time.time() out_py = trilinear_interpolation_py(feats, points) torch.cuda.synchronize() print ('pytorch fw time' , time.time()-t, 's' ) print ('fw all close' , torch.allclose(out_py, out_cuda)) t = time.time() loss2 = out_cuda.sum () loss2.backward() torch.cuda.synchronize() print (' cuda bw time' , time.time()-t, 's' ) t = time.time() loss = out_py.sum () loss.backward() torch.cuda.synchronize() print ('pytorch bw time' , time.time()-t, 's' ) print ('bw all close' , torch.allclose(feats.grad, feats2.grad))
经过运行和计算后,我们会得到以下结果,我们可以看到,CUDA和Pytorch前向传播相差不大,但是对于反向传播的效率可以看得出来,结果大概差了10倍所有,CUDA的反向传播还是有一个较为明显的效率提升的。
1 2 3 4 5 6 cuda fw time 0.0033109188079833984 s pytorch fw time 0.004142045974731445 s fw all close True cuda bw time 0.004648447036743164 s pytorch bw time 0.04614758491516113 s bw all close True
参考 视频资料: https://www.youtube.com/watch?v=l_Rpk6CRJYI&list=PLDV2CyUo4q-LKuiNltBqCKdO9GH4SS_ec&ab_channel=AI%E8%91%B5
Github:https://github.com/kwea123/pytorch-cppcuda-tutorial
Pytorch官方资料:https://pytorch.org/cppdocs/ ,https://pytorch.org/tutorials/advanced/cpp_extension.html
CUDA doc:https://nyu-cds.github.io/python-gpu/02-cuda/

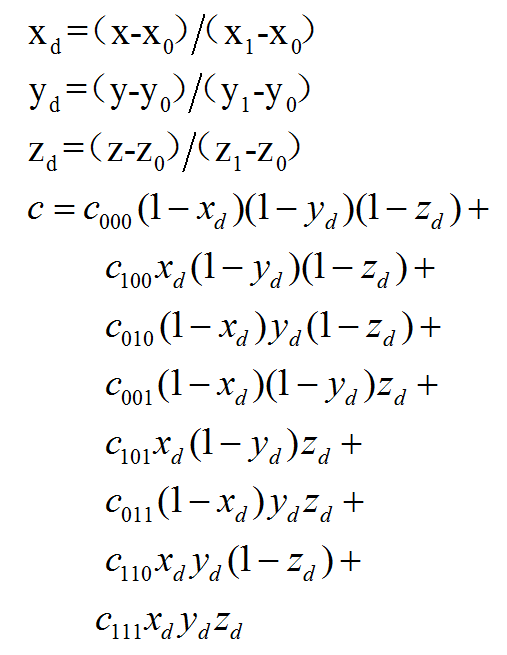
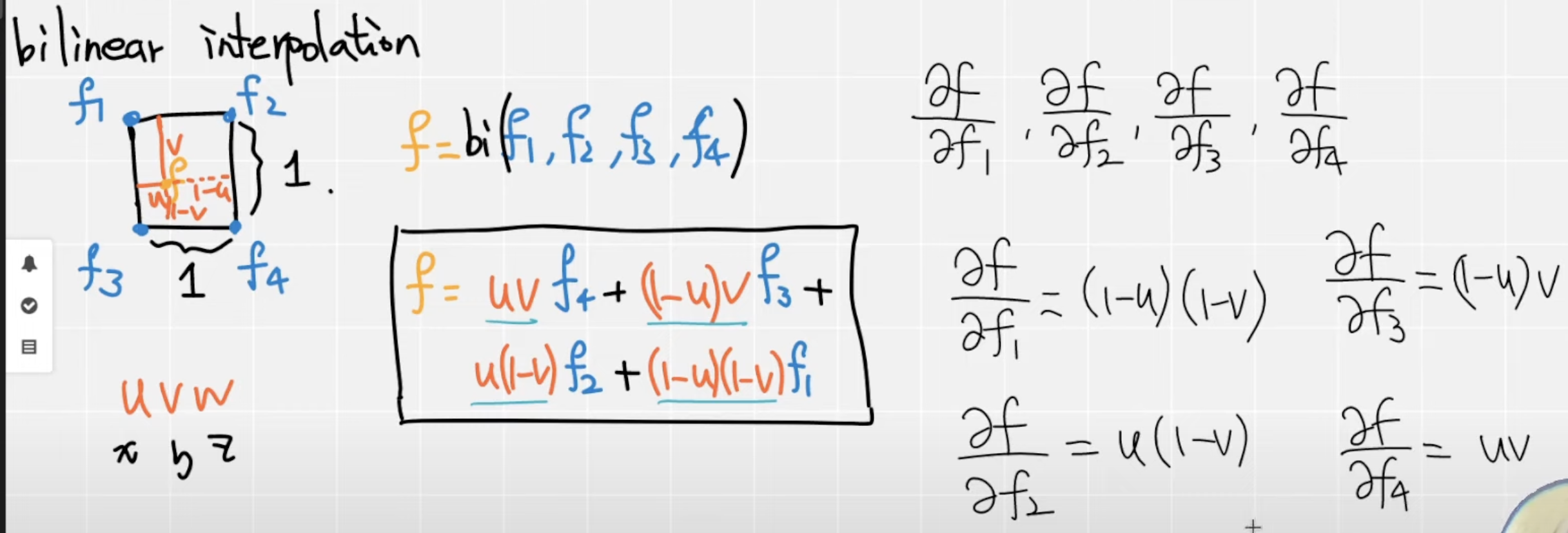
 wechat
wechat

