Linux 安装CUDA 及 更新CUDA
CUDA 更新
先装 CUDA [下载地址],老版本的 CUDA 不用删掉,直接让管理员将 cuda 软连接到最新的 CUDA 就行了,以防有些代码需要低版本 CUDA,所以我们可以在多个CUDA版本进行切换。
再装驱动 [驱动下载地址],安装过程会提示说检测到老版本驱动,直接卸载就行了。(但是在Linux中,我们只需要安装CUDA,里面会自带驱动安装,不需要重新安装驱动)
CUDA 安装
CUDA 简介
CUDA 是由 Nvidia 公司开发的并行计算平台和应用程序接口,软件开发者可以利用支持 CUDA 软件的 GPU 进行通用计算。CUDA 可以直接链接到 GPU 的虚拟指令集和并行计算单元,从而在 GPU 中完成内核函数的计算。
CUDA 提供 C/C++/Fortran 接口,也有许多高性能计算或深度学习库提供包装后的 Python 接口。开发者们可根据实际需要 (高性能计算, 深度学习, 神经网络等) 选择适当的编程语言。
CUDA 安装步骤
一般而言,在 Linux 下安装和使用 CUDA 的流程如下:
- 安装 NVIDIA Driver,即显卡驱动
- 安装 CUDA Toolkit
- 使用 C/C++ 编译器或 Python 扩展库进行 GPU 加速的 CUDA 编程
安装CUDA
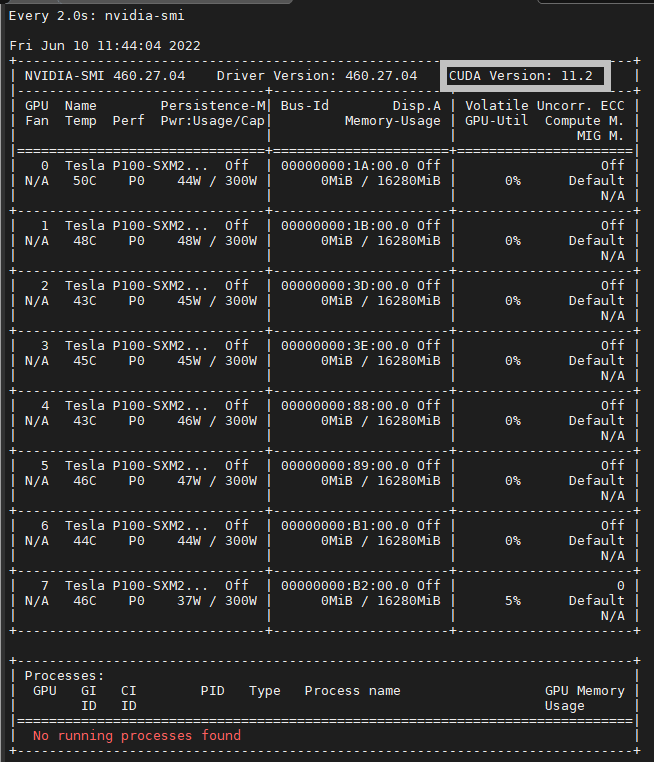
- 首先查看驱动,在命令行输入nvidia-smi查看显卡驱动版本也就是最高支持的CUDA工具包版本。
例如,本机可安装11.2及以下的CUDA工具包:
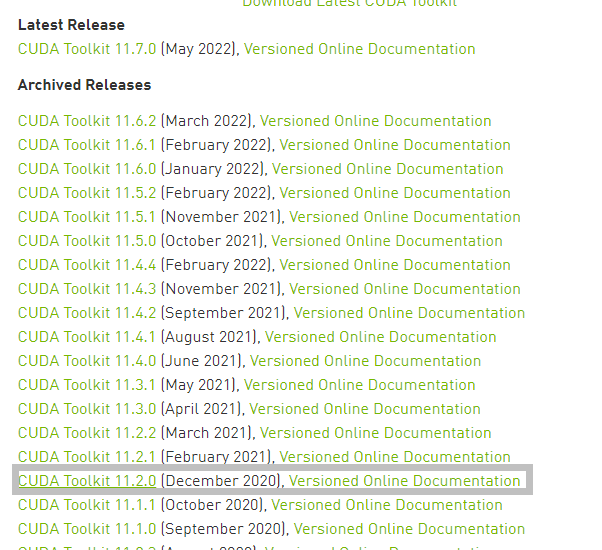
- 在nvidia官网选择对应版本的CUDA工具包并选择你的机器配置,我们就选择11.2.0版本下载,
- 在终端执行如下命令:
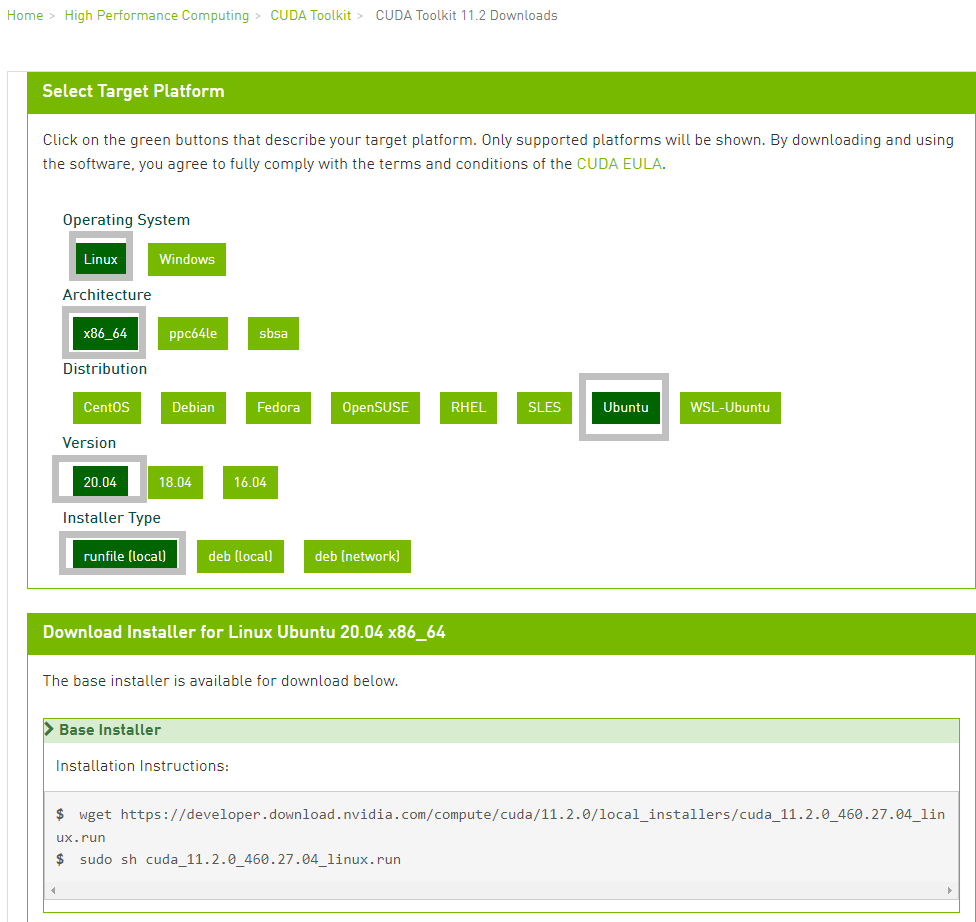
1 | wget https://developer.download.nvidia.com/compute/cuda/11.2.0/local_installers/cuda_11.2.0_460.27.04_linux.run |

如果出现以下提示,选择continue并在第四步取消安装驱动即可。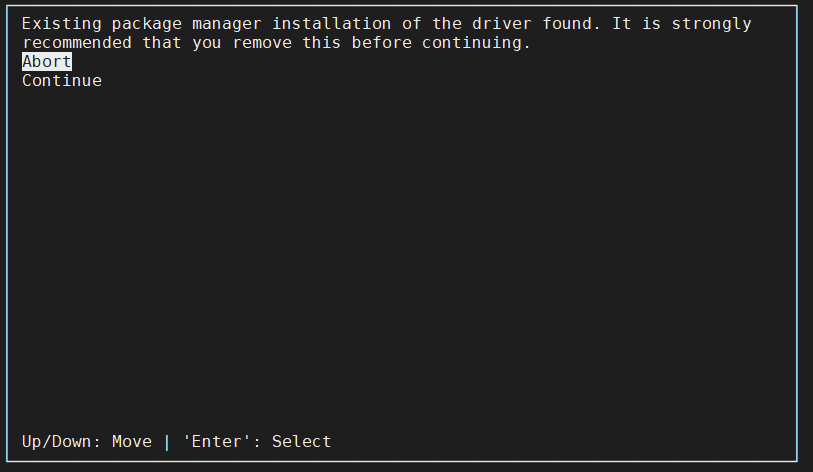
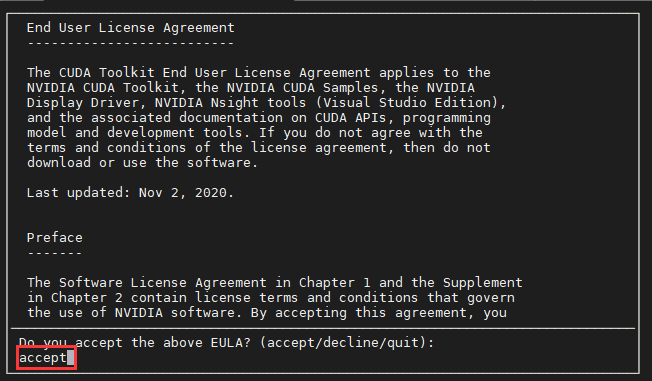
- 根据提示一步步安装键入accept确认。👇
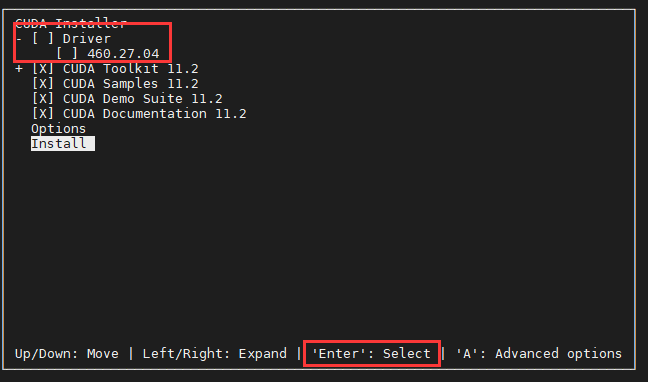
- 我们已经有驱动了,这里取消安装驱动,上下键和回车键选择。👇
- 稍作等待,出现以下提示信息就安装好了,可以看到CUDA安装到了/usr/local/cuda-11.2/。
- 配置环境变量
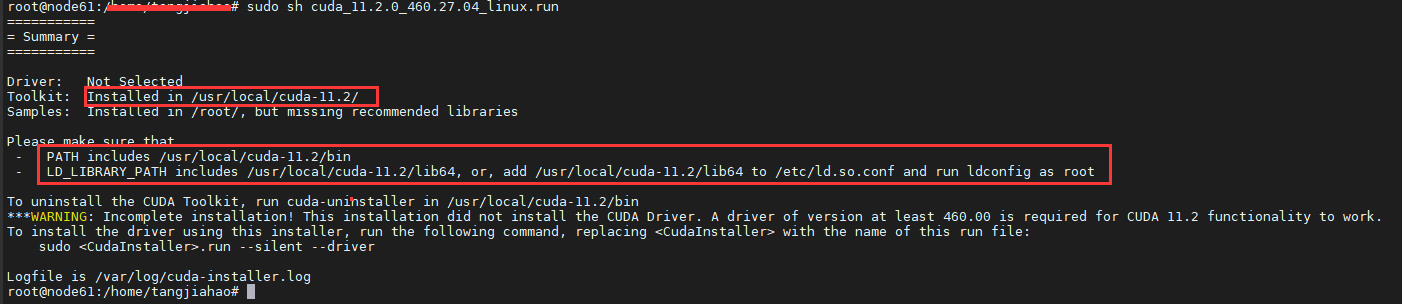
打开配置文件
1 | vi /etc/profile |
在配置文件末尾加上:
1 | export PATH=/usr/local/cuda-11.2/bin:$PATH |
source 一下配置文件
1 | source /etc/profile |
- 检查是否安装完成
使用nvcc -V检查CUDA是否安装完成,出现以下提示代表安装完成。
编译并执行CUDA样例程序,出现pass代表CUDA和GPU正常运行:
1 | cd /usr/local/cuda-11.2/samples/1_Utilities/deviceQuery |

多个CUDA版本切换
实际上,老版本的 CUDA 不用删掉,直接让管理员将 cuda 软连接到最新的 CUDA 就行了,以防有些代码需要低版本 CUDA,所以我们可以在多个CUDA版本进行切换。在linux里面,就是修改软连接即可,软连接到对应的CUDA就可以实现安装。
root用户软链接
删除原来的软链接
第一种方法:
经评论区大佬指点,可以使用unlink命令删除软链接:
1 | cd /usr/local |
第二种方法:
注意!不要多打一个’/‘,否则会删除了实际数据。
具体参见:linux删除软链接的正确方式_每天进步一点的技术博客_51CTO博客_linux软连接
1 | cd /usr/local |
(千万不要多打’/‘ !!!!!再说一遍!!!)
建立新的软链接
建立指向cuda-10.0(需要的CUDA版本)版本的软链接
1 | sudo ln -snf /usr/local/cuda-8.0 /usr/local/cuda |
查看当前CUDA版本
通过以下命令来查看切换是否成功
1 | # 查看'cuda'是否指向'/usr/local/cuda-需要的版本号' |
附查看所有CUDA版本的命令
1 | ls -l /usr/local | grep cuda |
下面原来是CUDA 11 ,现切换为CUDA10版本的操作:
1 | censhaoqi@censhaoqiVM:/usr/local$ nvcc -V |
个人用户设置路径
我们可以在自己的~/.bashrc中设置cuda的路径也可以自由的切换我们的CUDA的版本,同样我们也可以使用alias
Linux alias 命令用于设置指令的别名,用户可利用 alias,自定指令的别名。
它可以使您以一种更简单和易于记忆的方式执行命令,而不必每次都键入完整的命令。
若仅输入 alias,则可列出目前所有的别名设置。
alias 的效果仅在该次登入的操作有效,若想要每次登入都生效,可在 .profile 或 .cshrc 中设定指令的别名。
1 | vim ~/.bashrc |
cuDNN的安装
根据安装的CUDA工具包版本在官网选择适合版本的cuDNN,本文安装的CUDA版本是11.2,就选择与之对应的cuDNN v8.4.0,选择Local Installer for Linux x86_64 (Tar)。
复制cuDNN库的链接,使用wget下载或者下载到自己电脑之后再传到服务器上。
我的服务器网速有点慢,所以选择先下到自己电脑再传上去,速度很快啊。
解压cuDNN文件,并进入解压出的文件夹,拷贝文件到/usr/local/cuda-11.2中
1 | tar -xvf cudnn-linux-x86_64-8.4.0.27_cuda11.6-archive.tar.xz |
查看cuDNN版本,旧版本指令 为cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A2,新版本有更新,将cuDNN版本信息单拉了一个文件名为 cudnn_version.h,所以新版本查看cuDNN版本的命令为 cat /usr/local/cuda/include/cudnn_version.h | grep CUDNN_MAJOR -A 2
出现问题:Error ‘An NVIDIA kernel module ‘nvidia’ appears to already be loaded in your kernel’ when trying to get GPU support in AWS EMR
https://unix.stackexchange.com/questions/440840/how-to-unload-kernel-module-nvidia-drm
CUDA驱动更新
当用户需要使用当前驱动不能支持的高版本cuda时,需要将机器显卡驱动更新到新版本,用户在自己环境下安装对应的cudatoolkit即可使用。
在更新驱动之前需要保证显卡上没有程序在运行,并且驱动也没有在被使用,可以通过fuser -v /dev/nvidia*查看。
1 | fuser -v /dev/nvidia* |
1、用户程序,通知用户停止。
2、系统程序(部分机器存在)

1 | systemctl stop nvidia-persistenced.service |

1 | systemctl stop dcgm |

1 | systemctl stop nvsm.service |
当显卡上没有程序运行时,开始更新驱动。
1 | Using built-in stream user interface |
解决
sudo service lightdm stop
安装完之后
sudo service lightdm start
更新完驱动之后需要恢复相应服务。
Linux环境变量的加载顺序: /etc/profile -> ~/.bash_profile -> ~/.bashrc -> /etc/bashrc -> ~/.bash_logout
参考
有时候好像还要装cudnn,但是我那时候没装,不知道是不是必要,可以尝试一下
- 多个CUDA版本切换方法
- Linux 下的 CUDA 安装和使用指南
- 【Linux】安装CUDA 11.2 和 cuDNN 8.4.0并检查是否安装成功_linux查看cudnn是否安装成功-CSDN博客
- pytorch多gpu并行训练
- 基于ubuntu22.04系统安装nvidia A100驱动与NVLink启用
- https://developer.download.nvidia.com/compute/cuda/repos/
- CUDA initialization: Unexpected error from cudaGetDeviceCount解决方法
CUDA Installation
1) Download the latest CUDA Toolkit
2) Switch to tty3 by pressing Ctl+Alt+F3
3) Unload nvidia-drm before proceeding.
3a) Isolate multi-user.target
1 | sudo systemctl isolate multi-user.target |
3b) Note that nvidia-drm is currently in use.
1 | lsmod | grep nvidia.drm |
3c) Unload nvidia-drm
1 | sudo modprobe -r nvidia-drm |
4d) Note that nvidia-drm is not in use anymore.
1 | lsmod | grep nvidia.drm |
\5) Go to your download folder and run the cuda installation.
1 | sudo sh cuda_10.1.168_418.67_linux.run |
\6) Answer any prompts during installation.
\7) When installation has finished, confirm that the CUDA Version has been updated.
1 | nvidia-smi |
\8) Start the GUI again.
1 | sudo systemctl start graphical.target |
https://gist.github.com/xaliander/2d7ffd6a662b0302fbe840c227cf7a4a
https://unix.stackexchange.com/questions/440840/how-to-unload-kernel-module-nvidia-drm
1 | sudo rmmod nvidia-uvm |
1 | sudo lsof /dev/nvidia* | grep -v PID | grep -v lsof | awk '{print $2}' | xargs sudo kill -9 |
1 | sudo rmmod nvidia_drm |
1 | sudo service lightdm stop |
service nvidia-docker stop will also resolve it (if UVM is only used by nvidia-docker)
https://blog.csdn.net/kuku123465/article/details/130250940
export CUDA_HOME=/usr/local/cuda-11.8
export PATH=/usr/local/cuda-11.8/bin:$PATH
- wechat
- alipay