EMO Emote Portrait Alive - 阿里HumanAIGC
EMO: Emote Portrait Alive - 阿里HumanAIGC
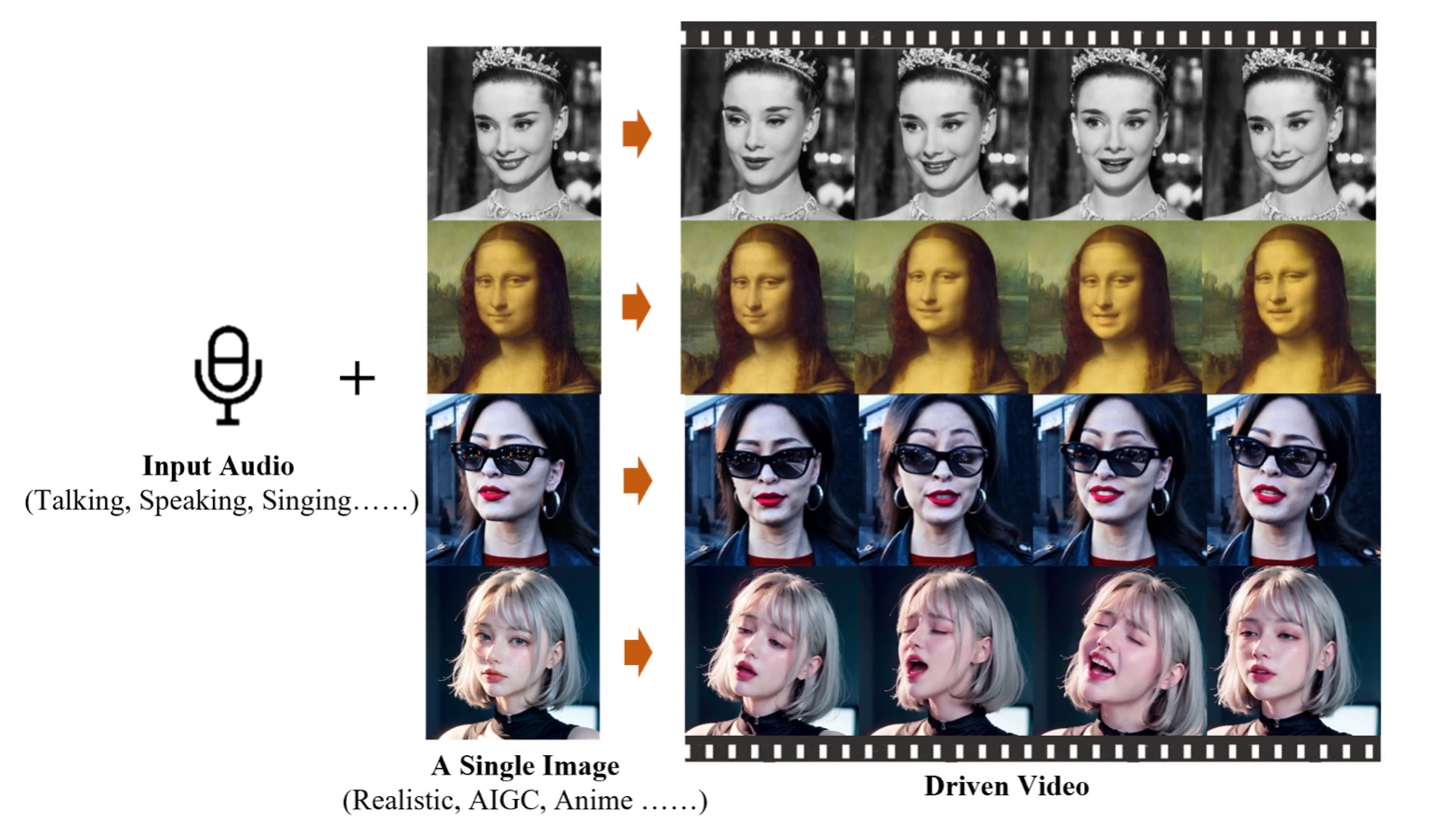
最近这一个星期,也就是2月28日的时候,阿里巴巴的HumanAIGC团队发布了一款全新的生成式AI模型EMO(Emote Portrait Alive)。EMO仅需一张人物肖像照片和音频,就可以让照片中的人物按照音频内容“张嘴”唱歌、说话,且口型基本一致,面部表情和头部姿态非常自然,发布的视频效果非常好,好的几乎难以置信,特别是蔡徐坤唱rap的第一段,效果非常好。
EMO不仅能够生成唱歌和说话的视频,还能在保持角色身份稳定性的同时,根据输入音频的长度生成不同时长的视频。
所以我就想借此机会,学习一下EMO的大概框架,剖析一下里面的一些技术要点,首先给出论文的链接和代码链接,不过HumanAIGC已经很久没有开源代码了,不过技术方向还是值得一看的。
项目:https://humanaigc.github.io/emote-portrait-alive/
我也一直有关注这一部分的技术,大家也可以关注我的数字人知识库https://github.com/Kedreamix/Awesome-Talking-Head-Synthesis
Diffusion相关
在之前的一些研究中,有过用Diffusion做Talking head generation的,比如Diffusion head和CVPR2023的DiffTalk等论文,这些论文都是用Diffusion得强大生成能力来完成音频驱动的人脸生成。
这里逐帧生成与音频对应的人脸的图像,mask人脸中嘴唇的部分,然后逐步生成视频,这个过程相当于,AI先看一下照片,然后打开声音,再随着声音一张一张地画出视频中每一帧变化的图像。
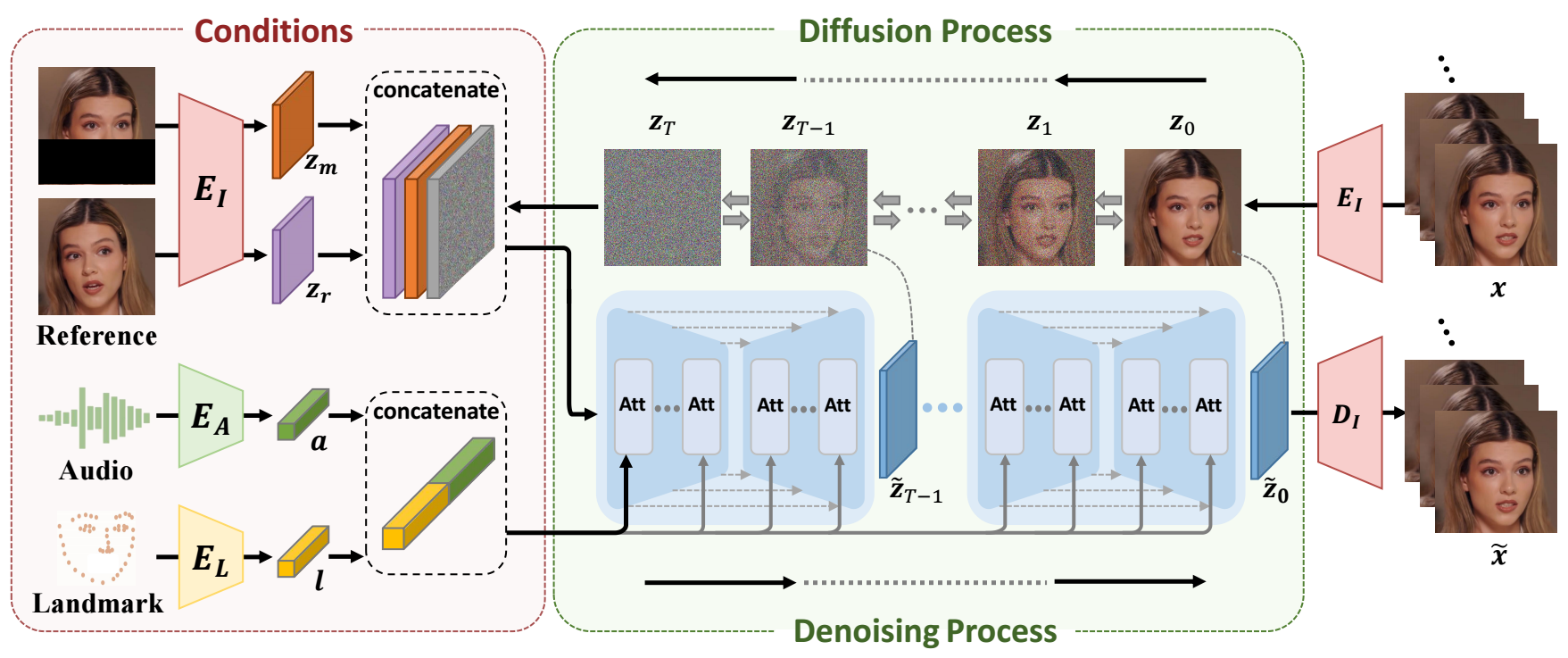
如果我们看Diffusion Head论文,也是类似的做法,都是通过Diffusion的强大能力完成视频的生成。
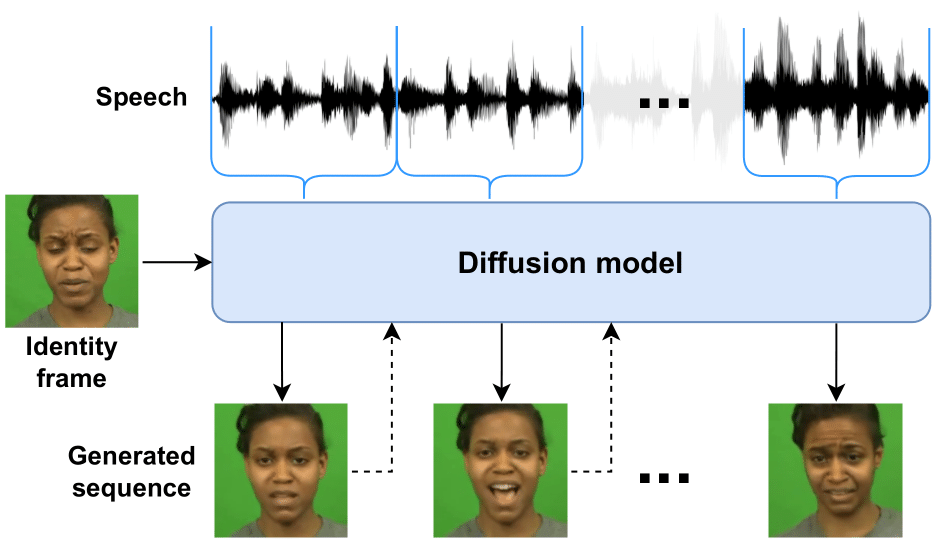
EMO整体框架
接下来开始剖析一下EMO的框架,与DiffTalk和Diffusion Heads类似,都是利用Diffusion来生成,也是根据一个参考图像来逐帧生成图片最后得到视频。
不同的是,EMO的工作过程分为两个主要阶段:
- 首先,利用参考网络(ReferenceNet)从参考图像和动作帧中提取特征;
- 然后,利用预训练的音频编码器处理声音并嵌入,再结合多帧噪声和面部区域掩码来生成视频。
该框架还融合了两种注意机制和时间模块,以确保视频中角色身份的一致性和动作的自然流畅。我觉得实际上这里是最重要的一部分,这一部分也是和之前Diffusion方法不同的点,其实这一部份又和HumanAIGC之前做的科目三驱动的方式很像,也就是那篇AnimateAnyone论文,这一部分也是火🔥了很久,现在也有人复现了该方法,不过还没有开源。
根据EMO的论文与项目的展现的结果,EMO不仅仅能产生非常Amazing的对口型视频,还能生成各种风格的歌唱视频,无论是在表现力还是真实感方面都显著优于现有的先进方法,如DreamTalk、Wav2Lip和SadTalker。

EMO工作原理
从EMO的框架可以看到,利用骨干网络获取多帧噪声潜在输入,并尝试在每个时间步将它们去噪到连续的视频帧,这个骨干网络是类似于SD 1.5的UNet的结构配置。与之前的SD1.5不同的是,本身的SD是使用文本嵌入的,而现在是使用参考特征。
- 与之前的工作类似,为了确保生成的帧之间的连续性,骨干网络嵌入了时间模块。
- 为了保持生成帧中肖像的ID一致性,使用了一个与Backbone并行的称为ReferenceNet的UNet结构,它输入参考图像以获得参考特征。
- 为了驱动角色说话动作,利用音频层对语音特征进行编码。
- 为了使说话角色的运动可控且稳定,我们使用面部定位器和速度层来提供弱条件。
预训练音频编码器:EMO使用预训练的音频编码器(如wav2vec)来处理输入音频。这些编码器提取音频特征,这些特征随后用于驱动视频中的角色动作,包括口型和面部表情。这里面还是使用附加特征m来解决动作可能会受到未来/过去音频片段的影响,例如说话前张嘴和吸气。
参考网络(ReferenceNet):该网络从单个参考图像中提取特征,这些特征在视频生成过程中用于保持角色的身份一致性。ReferenceNet与生成网络(Backbone Network)并行工作,输入参考图像以获取参考特征。
骨干网络(Backbone Network):Backbone Network接收多帧噪声(来自参考图像和音频特征的结合)并尝试将其去噪为连续的视频帧。这个网络采用了类似于Stable Diffusion的UNet结构,其中包含了用于维持生成帧之间连续性的时间模块。
注意力机制:EMO利用两种形式的注意力机制——参考注意力(Reference-Attention)和音频注意力(Audio-Attention)。参考注意力用于保持角色身份的一致性,而音频注意力则用于调整角色的动作,使之与音频信号相匹配。
时间模块:这些模块用于操纵时间维度并调整动作速度,以生成流畅且连贯的视频序列。时间模块通过自注意力层跨帧捕获动态内容,有效地在不同的视频片段之间维持一致性。
训练策略:EMO的训练分为三个阶段:图像预训练、视频训练和速度层训练。在图像预训练阶段,Backbone Network和ReferenceNet在单帧上进行训练,而在视频训练阶段,引入时间模块和音频层,处理连续帧。速度层的训练在最后阶段进行,以细化角色头部的移动速度和频率。
去噪过程:在生成过程中,Backbone Network尝试去除多帧噪声,生成连续的视频帧。去噪过程中,参考特征和音频特征被结合使用,以生成高度真实和表情丰富的视频内容。
EMO模型通过这种结合使用参考图像、音频信号、和时间信息的方法,能够生成与输入音频同步且在表情和头部姿势上富有表现力的肖像视频,超越了传统技术的限制,创造出更加自然和逼真的动画效果。
EMO训练阶段
训练分为三个阶段,图像预训练、视频训练和速度层训练。
在图像预训练阶段,网络以单帧图像为输入进行训练。此阶段,Backbone 将单个帧作为输入,而 ReferenceNet 处理来自同一帧的不同的、随机选择的帧,从原始 SD 初始化权重
在视频训练阶段,引入时间模块和音频层,处理连续帧,从视频剪辑中采样n+f个连续帧,开始的n帧是运动帧。时间模块从AnimateDiff初始化权重。
速度层训练专注于调整角色头部的移动速度和频率。
这些详细信息提供了对EMO模型训练和其参数配置的深入了解,突显了其在处理广泛和多样化数据集方面的能力,以及其在生成富有表现力和逼真肖像视频方面的先进性能。
EMO实验设置
EMO的数据集有两部份,首先HumanAIGC团队从互联网中收集了 超过250小时的视频和超过1.5亿张图像,同时加入了来自互联网和HDTF以及VFHQ数据集作为补充。这里面的数据集多种多样,包括演讲、电影和电视剪辑以及歌唱表演,涵盖了多种语言,如中文和英文,这也是为什么最后能表现出如此好效果的原因。
在第一阶段的时候,使用VFHQ数据集,因为它不包含音频。然后再对视频进行预处理,所有的视频可通过MediaPipe来获取人脸检测框区域,并且裁剪到512×512的分辨率。
在第一训练阶段,批处理大小BatchSize设置为48。在第二和第三训练阶段,生成视频长度设置为f=12,运动帧数设置为n=4,训练的批处理大小为4,学习率在所有阶段均设置为1e-5。
在推理时,使用DDIM的采样算法生成视频。时间步大约是40步,为每一帧生成指定一个恒定的速度值,最后方法的结果生成一批(f=12帧)的时间大约为15秒。
一般视频的长度为25~30帧左右,如果我们认为是1mins的视频,也就是60s的视频,那就是60*25=1500,1500/15 = 100s,也就是大概需要1mins40s能生成一分钟的视频,速度也得到了不错的改进,虽然没有实时,但是结果已经很好了。
EMO特点
EMO模型有如下特点:
直接音频到视频合成:EMO采用直接从音频合成视频的方法,无需中间的3D模型或面部标志,简化了生成过程,同时保持了高度的表现力和自然性。
无缝帧过渡与身份保持:该方法确保视频帧之间的无缝过渡和视频中身份的一致性,生成的动画既生动又逼真。
表达力与真实性:实验结果显示,EMO不仅能生成令人信服的说话视频,而且还能生成各种风格的歌唱视频,其表现力和真实性显著超过现有的先进方法。
灵活的视频时长生成:EMO可以根据输入音频的长度生成任意时长的视频,提供了极大的灵活性。
面向表情的视频生成:EMO专注于通过音频提示生成表情丰富的肖像视频,特别是在处理说话和唱歌场景时,可以捕捉到复杂的面部表情和头部姿态变化。
这些特点共同构成了EMO模型的核心竞争力,使其在动态肖像视频生成领域表现出色。
EMO缺陷
对于EMO来说,也会有一些限制。
首先,与不依赖扩散模型的方法相比,它更耗时。
其次,由于不使用任何明确的控制信号来控制角色的运动,因此可能会导致无意中生成其他身体部位(例如手),从而导致视频中出现伪影。
所以这样的一个问题,如果要解决的话,可以考虑用专门控制身体部位的控制信号,这样就会较好的解决这个方法,每一个信号控制一部分,就不会生成错误。
参考
 wechat
wechat- alipay






