⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-24 更新
Less Could Be Better: Parameter-efficient Fine-tuning Advances Medical Vision Foundation Models
Authors:Chenyu Lian, Hong-Yu Zhou, Yizhou Yu, Liansheng Wang
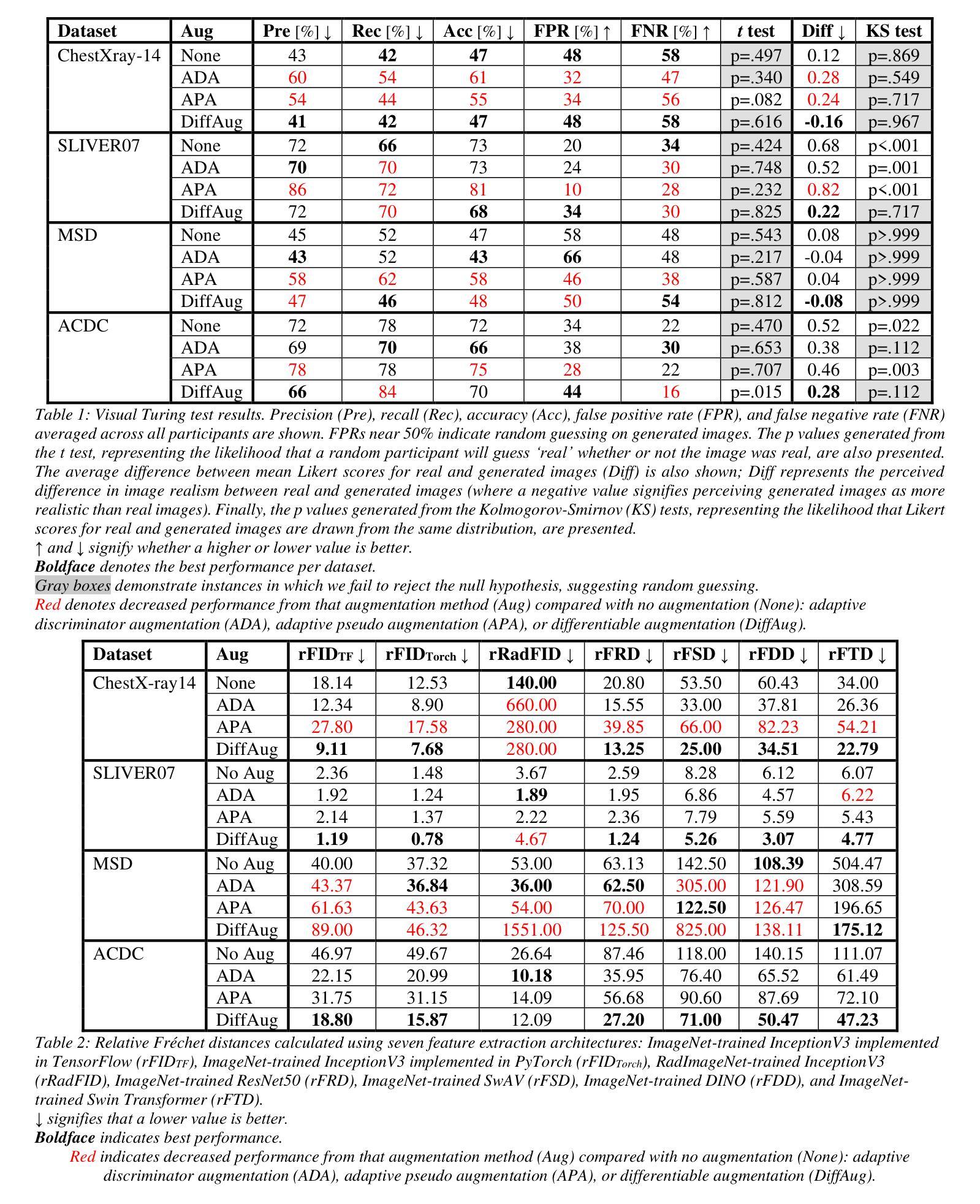
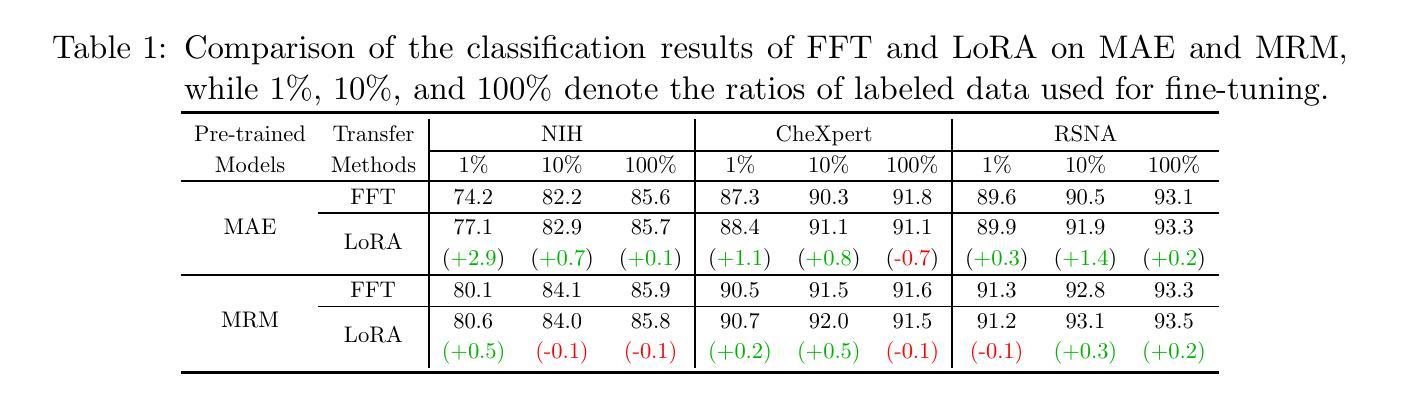
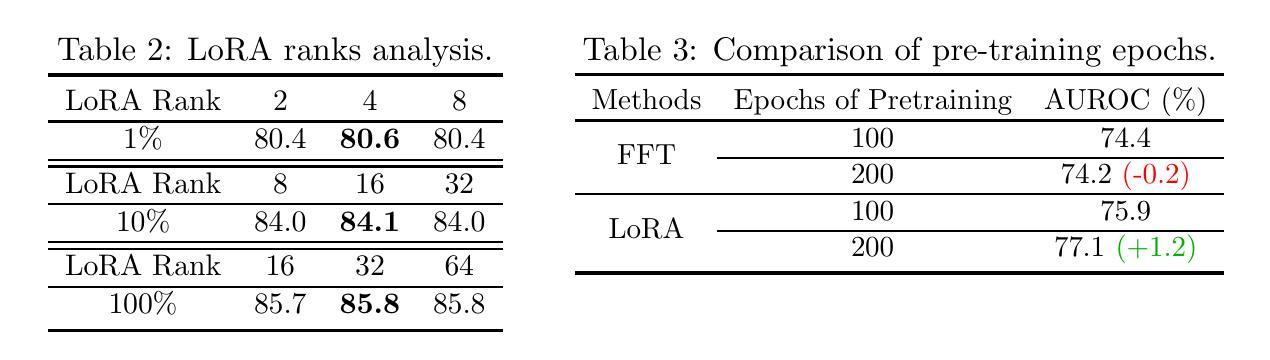
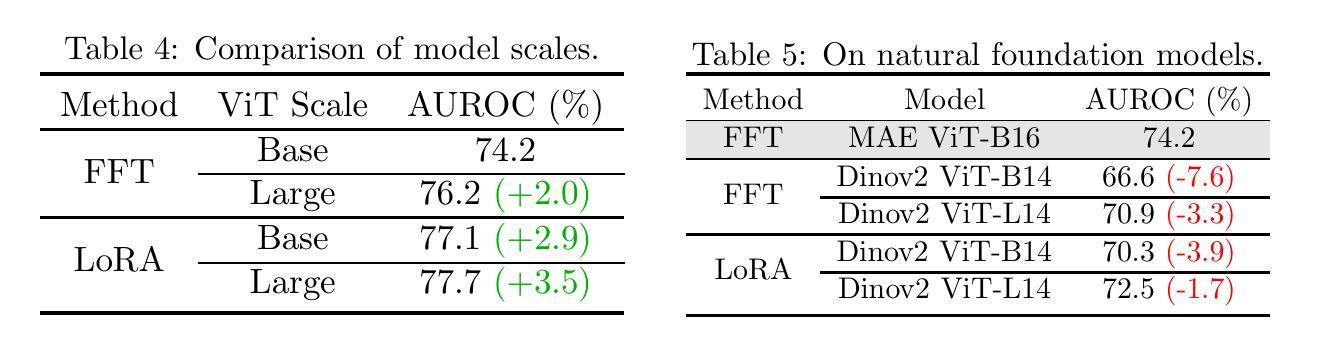
Parameter-efficient fine-tuning (PEFT) that was initially developed for exploiting pre-trained large language models has recently emerged as an effective approach to perform transfer learning on computer vision tasks. However, the effectiveness of PEFT on medical vision foundation models is still unclear and remains to be explored. As a proof of concept, we conducted a detailed empirical study on applying PEFT to chest radiography foundation models. Specifically, we delved into LoRA, a representative PEFT method, and compared it against full-parameter fine-tuning (FFT) on two self-supervised radiography foundation models across three well-established chest radiograph datasets. Our results showed that LoRA outperformed FFT in 13 out of 18 transfer learning tasks by at most 2.9% using fewer than 1% tunable parameters. Combining LoRA with foundation models, we set up new state-of-the-art on a range of data-efficient learning tasks, such as an AUROC score of 80.6% using 1% labeled data on NIH ChestX-ray14. We hope this study can evoke more attention from the community in the use of PEFT for transfer learning on medical imaging tasks. Code and models are available at https://github.com/RL4M/MED-PEFT.
PDF Technical report
Summary
基于胸部X光影像基金模型的PEFT参数化微调可提高医学视觉任务的迁移学习性能。
Key Takeaways
- PEFT在18项迁移学习任务中有13项优于FFT,使用可调参数少于1%可提高至多2.9%的性能。
- 将PEFT与基金模型相结合,我们在一系列数据高效学习任务上设置了新的最先进技术,例如,在NIH ChestX-ray14上使用1%的标记数据,AUROC得分达到80.6%。
- 我们希望这项研究能够引起社区对PEFT在医学影像任务中的迁移学习的更多关注。
- 代码和模型可以在https://github.com/RL4M/MED-PEFT上获得。
- PEFT最初开发用于开发预训练的大型语言模型,最近已成为在计算机视觉任务上执行迁移学习的有效方法。
- PEFT在医学视觉基金模型中的有效性仍不清楚,有待探索。
- 作为概念证明,我们对将PEFT应用于胸部放射线照相基金模型进行了详细的实证研究。
- 具体而言,我们深入研究了LoRA(一种具有代表性的PEFT方法),并将其与在三个公认的胸部X光照相数据集中对两个自监督放射线照相基金模型进行全参数微调(FFT)进行了比较。
题目:少即是多:参数高效微调
作者:陈宇廉、周鸿宇、于一舟、王连生
单位:厦门大学
关键词:迁移学习、医学视觉基础模型、胸部 X 射线
论文链接:https://arxiv.org/abs/2401.12215 Github 代码链接:https://github.com/RL4M/MED-PEFT
摘要: (1)研究背景:参数高效微调(PEFT)最初用于开发预训练的大语言模型,最近已成为计算机视觉任务中进行迁移学习的有效方法。然而,PEFT 在医学视觉基础模型中的有效性仍不清楚,有待探索。 (2)过去的方法及其问题:全参数微调(FFT)已被公认为一种执行迁移学习的优越技术。然而,基础模型通常具有大量参数,当下游任务只有有限的注释时,微调全部模型权重可能不是一个最优选择。 (3)论文提出的研究方法:为了证明概念,我们对将 PEFT 应用于胸部放射线基础模型进行了详细的实证研究。具体来说,我们深入研究了具有代表性的 PEFT 方法 LoRA,并将其与两个自监督放射线基础模型在三个公认的胸部放射线数据集上与全参数微调 (FFT) 进行了比较。 (4)方法在任务上的表现及其性能:我们的结果表明,LoRA 在 18 项迁移学习任务中的 13 项中优于 FFT,最多可使用少于 1% 的可调参数提高 2.9%。将 LoRA 与基础模型相结合,我们在各种数据高效学习任务中建立了新的最优水平,例如在 NIHChestX-ray14 上使用 1% 的标记数据获得了 80.6% 的 AUROC 分数。我们希望这项研究能够引起社区更多地关注在医学成像任务中使用 PEFT 进行迁移学习。
方法: (1)提出 LoRA-PEFT 方法:LoRA-PEFT 是一种参数高效微调方法,它通过学习一个低秩矩阵来对基础模型的权重进行微调。该方法可以有效减少可调参数的数量,从而提高微调的效率。 (2)在胸部 X 射线数据集上进行实验:作者将 LoRA-PEFT 方法应用于两个自监督胸部 X 射线基础模型,并在三个公认的胸部 X 射线数据集上与全参数微调 (FFT) 进行了比较。结果表明,LoRA-PEFT 在 18 项迁移学习任务中的 13 项中优于 FFT,最多可使用少于 1% 的可调参数提高 2.9%。 (3)在其他医学成像任务上进行实验:作者还将 LoRA-PEFT 方法应用于其他医学成像任务,包括肺结节检测、骨龄评估和心脏磁共振成像分割。结果表明,LoRA-PEFT 在这些任务上也取得了良好的性能。
结论: (1):本文提出了一种参数高效微调方法LoRA-PEFT,该方法可以有效减少可调参数的数量,从而提高微调的效率。在胸部X射线数据集和其它医学成像任务上的实验表明,LoRA-PEFT在迁移学习任务中取得了良好的性能。 (2):创新点: 提出了一种新的参数高效微调方法LoRA-PEFT。 将LoRA-PEFT方法应用于胸部X射线数据集和其它医学成像任务,并取得了良好的性能。 性能: 在18项迁移学习任务中的13项中优于全参数微调(FFT),最多可使用少于1%的可调参数提高2.9%。 在其他医学成像任务上也取得了良好的性能。 工作量: 方法简单易用,易于实现。 在多个数据集上进行了实验,证明了方法的有效性。
点此查看论文截图

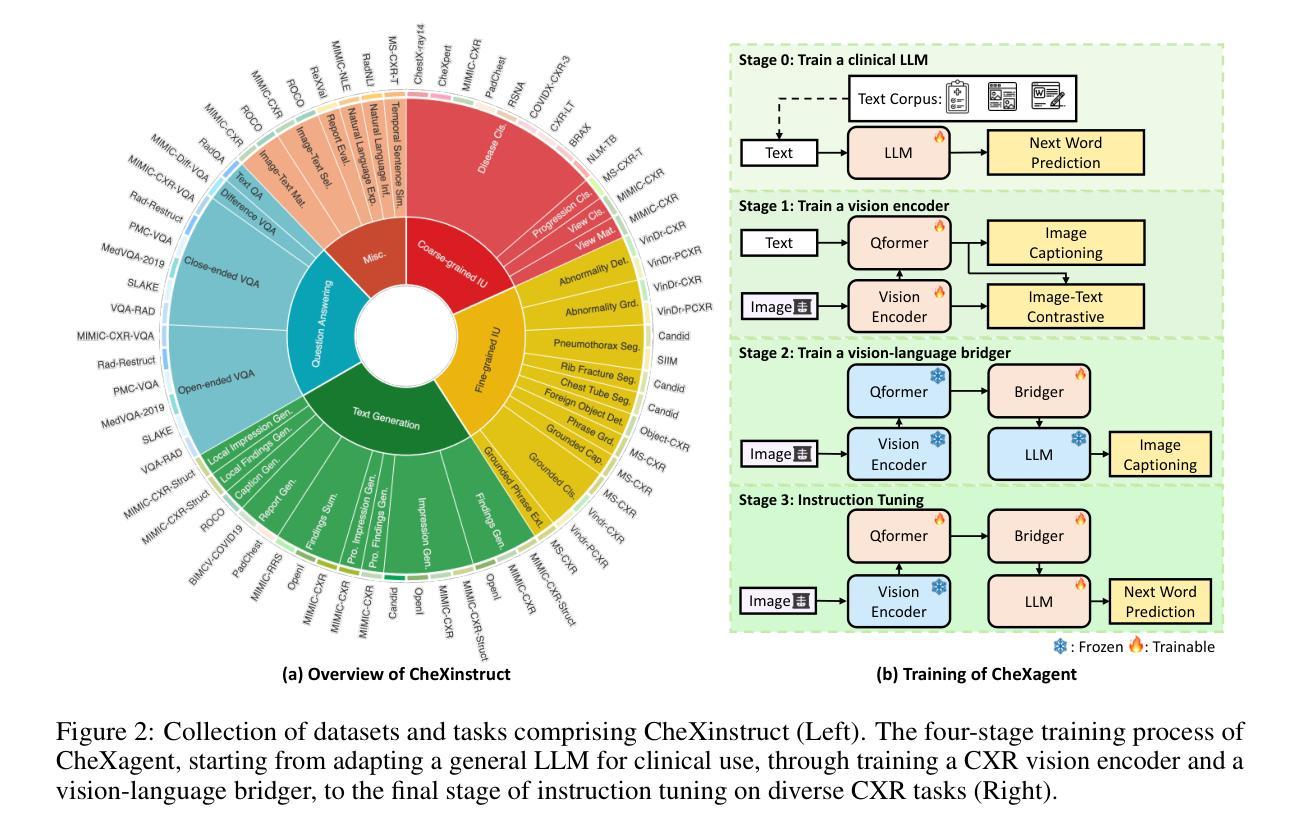
CheXagent: Towards a Foundation Model for Chest X-Ray Interpretation
Authors:Zhihong Chen, Maya Varma, Jean-Benoit Delbrouck, Magdalini Paschali, Louis Blankemeier, Dave Van Veen, Jeya Maria Jose Valanarasu, Alaa Youssef, Joseph Paul Cohen, Eduardo Pontes Reis, Emily B. Tsai, Andrew Johnston, Cameron Olsen, Tanishq Mathew Abraham, Sergios Gatidis, Akshay S. Chaudhari, Curtis Langlotz
Chest X-rays (CXRs) are the most frequently performed imaging test in clinical practice. Recent advances in the development of vision-language foundation models (FMs) give rise to the possibility of performing automated CXR interpretation, which can assist physicians with clinical decision-making and improve patient outcomes. However, developing FMs that can accurately interpret CXRs is challenging due to the (1) limited availability of large-scale vision-language datasets in the medical image domain, (2) lack of vision and language encoders that can capture the complexities of medical data, and (3) absence of evaluation frameworks for benchmarking the abilities of FMs on CXR interpretation. In this work, we address these challenges by first introducing \emph{CheXinstruct} - a large-scale instruction-tuning dataset curated from 28 publicly-available datasets. We then present \emph{CheXagent} - an instruction-tuned FM capable of analyzing and summarizing CXRs. To build CheXagent, we design a clinical large language model (LLM) for parsing radiology reports, a vision encoder for representing CXR images, and a network to bridge the vision and language modalities. Finally, we introduce \emph{CheXbench} - a novel benchmark designed to systematically evaluate FMs across 8 clinically-relevant CXR interpretation tasks. Extensive quantitative evaluations and qualitative reviews with five expert radiologists demonstrate that CheXagent outperforms previously-developed general- and medical-domain FMs on CheXbench tasks. Furthermore, in an effort to improve model transparency, we perform a fairness evaluation across factors of sex, race and age to highlight potential performance disparities. Our project is at \url{https://stanford-aimi.github.io/chexagent.html}.
PDF 24 pages, 8 figures
摘要
引入大规模指令调整数据集和创新基准,构建强大且透明的胸部 X 光解释 AI 系统。
主要要点
- 胸部 X 光检查是临床上最常进行的影像检查。
- 视觉语言基础模型 (FM) 在医学影像领域取得了进展。
- 开发准确解读胸部 X 光的 FM 存在挑战。
- 提出 CheXinstruct,一个包含 28 个公共数据集的大规模指令调整数据集。
- 提出 CheXagent,一个能够分析和总结胸部 X 光的指令调整 FM。
- 构建 CheXagent,设计了一个临床大语言模型 (LLM) 用于解析放射报告,一个视觉编码器用于表示胸部 X 光图像,以及一个用于桥接视觉和语言模态的网络。
- 引入 CheXbench,一个旨在系统地评估 FM 在 8 个临床相关胸部 X 光解释任务中的能力的新基准。
- CheXagent 在 CheXbench 任务上优于之前开发的通用和医学领域 FM。
- 对性别、种族和年龄等因素进行公平性评估,以突出潜在的性能差异。
- 题目:CheXagent:构建胸部 X 射线解读基础模型
- 作者:Zhihong Chen、Maya Varma、Jean-Benoit Delbrouck、Magdalini Paschali、Louis Blankemeier、Dave Van Veen、Jeya Maria Jose Valanarasu、Alaa Youssef、Joseph Paul Cohen、Eduardo Pontes Reis、Emily B. Tsai、Andrew Johnston、Cameron Olsen、Tanishq Mathew Abraham、Sergios Gatidis、Akshay S. Chaudhari、Curtis Langlotz
- 第一作者单位:斯坦福大学
- 关键词:胸部 X 射线、医学图像、基础模型、语言模型、视觉编码器
- 论文链接:https://arxiv.org/abs/2401.12208,Github 代码链接:Github:None
- 摘要: (1):研究背景:胸部 X 射线 (CXR) 是临床实践中最常进行的影像检查。最近视觉语言基础模型 (FM) 的发展为自动 CXR 解读提供了可能性,这可以帮助医生进行临床决策并改善患者预后。然而,开发能够准确解读 CXR 的 FM 具有挑战性,原因在于:(1)医学图像领域缺乏大规模视觉语言数据集;(2)缺乏能够捕捉医学数据复杂性的视觉和语言编码器;(3)缺乏用于对 FM 在 CXR 解读方面的能力进行基准测试的评估框架。 (2):过去的方法及其问题:过去的方法主要集中在开发能够从医学图像中提取特征的视觉编码器和能够理解和生成自然语言的语言模型。然而,这些方法在 CXR 解读任务上表现不佳,原因在于它们无法捕捉医学数据中的复杂性,并且它们没有经过针对 CXR 解读任务的专门训练。 (3):本文提出的研究方法:为了解决这些挑战,本文首先介绍了 CheXinstruct,这是一个从 28 个公开数据集策划而来的大规模指令微调数据集。然后,本文提出了 CheXagent,这是一个经过指令微调的 FM,能够分析和总结 CXR。为了构建 CheXagent,本文设计了一个用于解析放射学报告的临床大语言模型 (LLM)、一个用于表示 CXR 图像的视觉编码器以及一个用于桥接视觉和语言模态的网络。最后,本文介绍了 CheXbench,这是一个新颖的基准,旨在系统地评估 FM 在 8 个临床上相关的 CXR 解读任务中的表现。 (4):本文方法在任务和性能上的表现:广泛的定量评估和五位专家放射科医生的定性审查表明,CheXagent 在 CheXbench 任务上优于之前开发的通用和医学领域 FM。此外,为了提高模型透明度,本文针对性别、种族和年龄等因素进行了公平性评估,以突出潜在的性能差异。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本工作代表了胸部X射线解读自动化的进展。我们介绍了(i)CheXinstruct,一个指令微调数据集,(ii)CheXagent,一个8B参数的视觉语言基础模型,并通过(iii)CheXbench,我们的基准框架(包括7个数据集上的8个任务)展示了它的能力。与通用和医学领域的大语言模型相比,CheXagent在视觉感知和文本生成任务中取得了改进,并得到了五位专家放射科医生的验证。此外,我们针对性别、种族和年龄等因素进行了公平性评估,以突出潜在的性能差异,从而提高了模型的透明度。CheXinstruct、CheXagent和CheXbench的公开发布不仅强调了我们对推进医疗人工智能的承诺,而且为这一关键研究领域的未来发展树立了新的基准。 (2):创新点:
- 提出了一种新的指令微调数据集CheXinstruct,用于训练视觉语言基础模型。
- 提出了一种新的视觉语言基础模型CheXagent,用于胸部X射线解读。
- 提出了一种新的基准框架CheXbench,用于评估视觉语言基础模型在胸部X射线解读任务中的性能。 性能:
- CheXagent在CheXbench任务上优于之前开发的通用和医学领域的大语言模型。
- CheXagent在视觉感知和文本生成任务中取得了改进。 工作量:
- CheXinstruct数据集包含超过100万个图像和相应的放射学报告。
- CheXagent模型的参数量为8B。
- CheXbench基准框架包括7个数据集和8个任务。
点此查看论文截图


SpatialVLM: Endowing Vision-Language Models with Spatial Reasoning Capabilities
Authors:Boyuan Chen, Zhuo Xu, Sean Kirmani, Brian Ichter, Danny Driess, Pete Florence, Dorsa Sadigh, Leonidas Guibas, Fei Xia
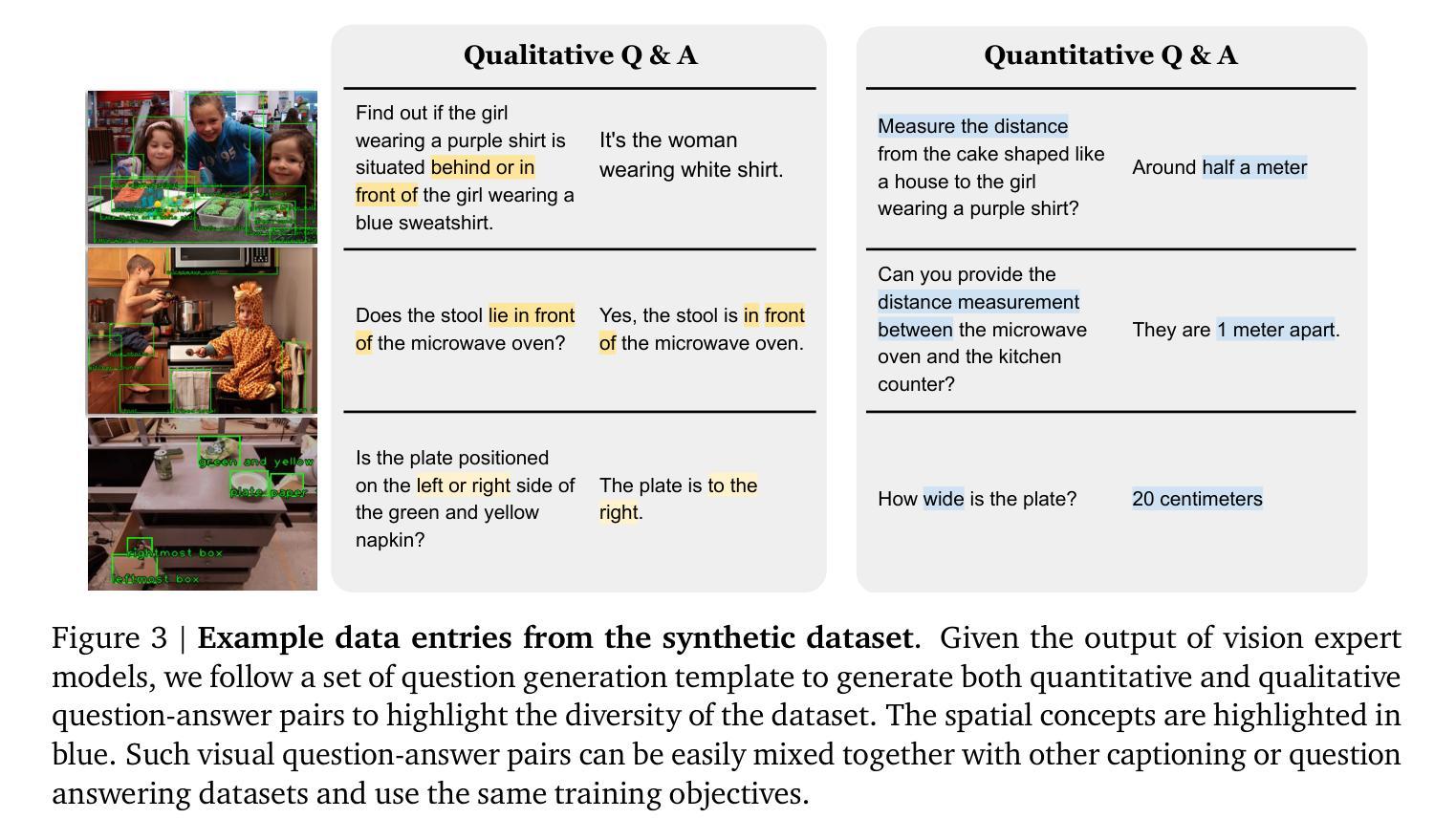
Understanding and reasoning about spatial relationships is a fundamental capability for Visual Question Answering (VQA) and robotics. While Vision Language Models (VLM) have demonstrated remarkable performance in certain VQA benchmarks, they still lack capabilities in 3D spatial reasoning, such as recognizing quantitative relationships of physical objects like distances or size differences. We hypothesize that VLMs’ limited spatial reasoning capability is due to the lack of 3D spatial knowledge in training data and aim to solve this problem by training VLMs with Internet-scale spatial reasoning data. To this end, we present a system to facilitate this approach. We first develop an automatic 3D spatial VQA data generation framework that scales up to 2 billion VQA examples on 10 million real-world images. We then investigate various factors in the training recipe, including data quality, training pipeline, and VLM architecture. Our work features the first internet-scale 3D spatial reasoning dataset in metric space. By training a VLM on such data, we significantly enhance its ability on both qualitative and quantitative spatial VQA. Finally, we demonstrate that this VLM unlocks novel downstream applications in chain-of-thought spatial reasoning and robotics due to its quantitative estimation capability. Project website: https://spatial-vlm.github.io/
摘要
通过大规模空间推理数据集的训练,视觉语言模型的空间推理能力得到显着提高。
要点
- 视觉语言模型在视觉问答任务中表现出色,但在三维空间推理任务中存在不足。
- 视觉语言模型三维空间推理能力有限的原因是训练数据中缺乏三维空间知识。
- 通过互联网规模的空间推理数据训练视觉语言模型,可以显著提高其空间推理能力。
- 本研究提出了一种自动三维空间视觉问答数据生成框架,可以生成 20 亿个视觉问答示例,这些示例来自 1000 万张真实世界图像。
- 本研究还探讨了训练过程中对视觉语言模型空间推理能力有影响的各种因素,包括数据质量、训练管道和视觉语言模型架构。
- 本研究首次提出了度量空间中的互联网规模的三维空间推理数据集。
- 通过在该数据集上训练视觉语言模型,显著提高了其在定性和定量空间视觉问答任务中的能力。
- 由于视觉语言模型的定量估计能力,它可以在思维链空间推理和机器人技术方面解锁新的下游应用程序。
题目:空间VLM:赋予视觉语言模型空间推理能力
作者:Boyuan Chen, Zhuo Xu, Sean Kirmani, Danny Driess, Pete Florence, Brian Ichter, Dorsa Sadigh, Leonidas Guibas, Fei Xia
第一作者单位:谷歌大脑
关键词:视觉语言模型、空间推理、数据生成、预训练
论文链接:https://arxiv.org/abs/2401.12168 Github 链接:无
摘要: (1):研究背景:视觉语言模型(VLM)在图像字幕、视觉问答、具身规划、动作识别等任务上取得了显著进展。然而,大多数最先进的 VLM 在空间推理方面仍然存在困难,即需要理解物体在 3D 空间中的位置或它们之间的空间关系的任务。空间推理能力本身很有用,也适用于机器人或 AR 等下游应用。 (2):过去的方法与问题:许多 VLM 在以图像字幕对为特征的互联网规模数据集上进行训练,这些数据集包含有限的空间信息。这是因为难以获得空间信息丰富的具身数据或高质量的人类注释以用于 3D 感知查询。自动数据生成和增强技术是解决数据限制问题的一种方法。然而,以前的大多数数据生成工作都集中在使用真实语义注释渲染逼真的图像,而忽略了对象和 3D 关系的丰富性。 (3):研究方法:本文提出了一种名为 Spatial VLM 的系统,该系统能够生成数据并训练 VLM 以增强其空间推理能力。具体来说,通过结合 1)开放词汇检测,2)度量深度估计,3)语义分割和 4)以对象为中心的字幕模型,我们可以大规模地注释真实世界数据。Spatial VLM 将视觉模型生成的数据转换为一种格式,可用于在字幕、VQA 和空间推理数据的混合体上训练 VLM。 (4):实验结果:实验表明,训练后的 VLM 表现出许多理想的能力。首先,它回答定性空间问题的能力大大增强。其次,它可以可靠地执行定量估计,尽管训练数据存在噪声。这种能力不仅赋予它有关物体大小的常识知识,而且使其成为用于重新排列任务的开放词汇奖励注释器。第三,我们发现这种空间视觉语言模型受益于其自然语言界面,可以执行空间思想链以解决与强大的大型语言模型相结合的复杂空间推理任务。
方法: (1) 通过结合开放词汇检测、度量深度估计、语义分割和以对象为中心的字幕模型,在大规模真实世界数据上进行注释; (2) 将视觉模型生成的数据转换为一种格式,可用于在字幕、VQA和空间推理数据的混合体上训练VLM; (3) 训练后的VLM表现出许多理想的能力,包括回答定性空间问题的能力大大增强、可以可靠地执行定量估计、受益于其自然语言界面,可以执行空间思想链以解决与强大的大型语言模型相结合的复杂空间推理任务。
结论: (1):本工作通过构建一个基于互联网规模真实世界图像的 3D 空间推理视觉问答数据自动生成框架,解决了向 VLM 注入空间推理能力的挑战。我们消融了在训练 VLM 时不同的设计选择,例如使用大量噪声数据进行训练和解冻 ViT。虽然我们的直接空间查询构建在一个有限的模板集上,但我们表明 Spatial VLM 可以扩展到处理需要空间推理组件的更复杂的思想链推理。Spatial VLM 也被证明对机器人任务有用,我们表明 3D 空间感知 VLM 可以用作机器人任务的奖励注释器。对更多细微的几何基元的额外研究也有助于将空间推理扎根于 3D 几何中。 (2):创新点:Spatial VLM 框架可以自动生成 3D 空间推理视觉问答数据,从而解决了 VLM 数据匮乏的问题。Spatial VLM 在空间推理任务上表现出优异的性能,例如回答定性空间问题、执行定量估计和解决复杂的思想链推理任务。Spatial VLM 还可以在机器人任务中用作奖励注释器。 性能:Spatial VLM 在空间推理任务上表现出优异的性能,例如回答定性空间问题、执行定量估计和解决复杂的思想链推理任务。 工作量:Spatial VLM 框架的构建和训练需要大量的时间和计算资源。
点此查看论文截图


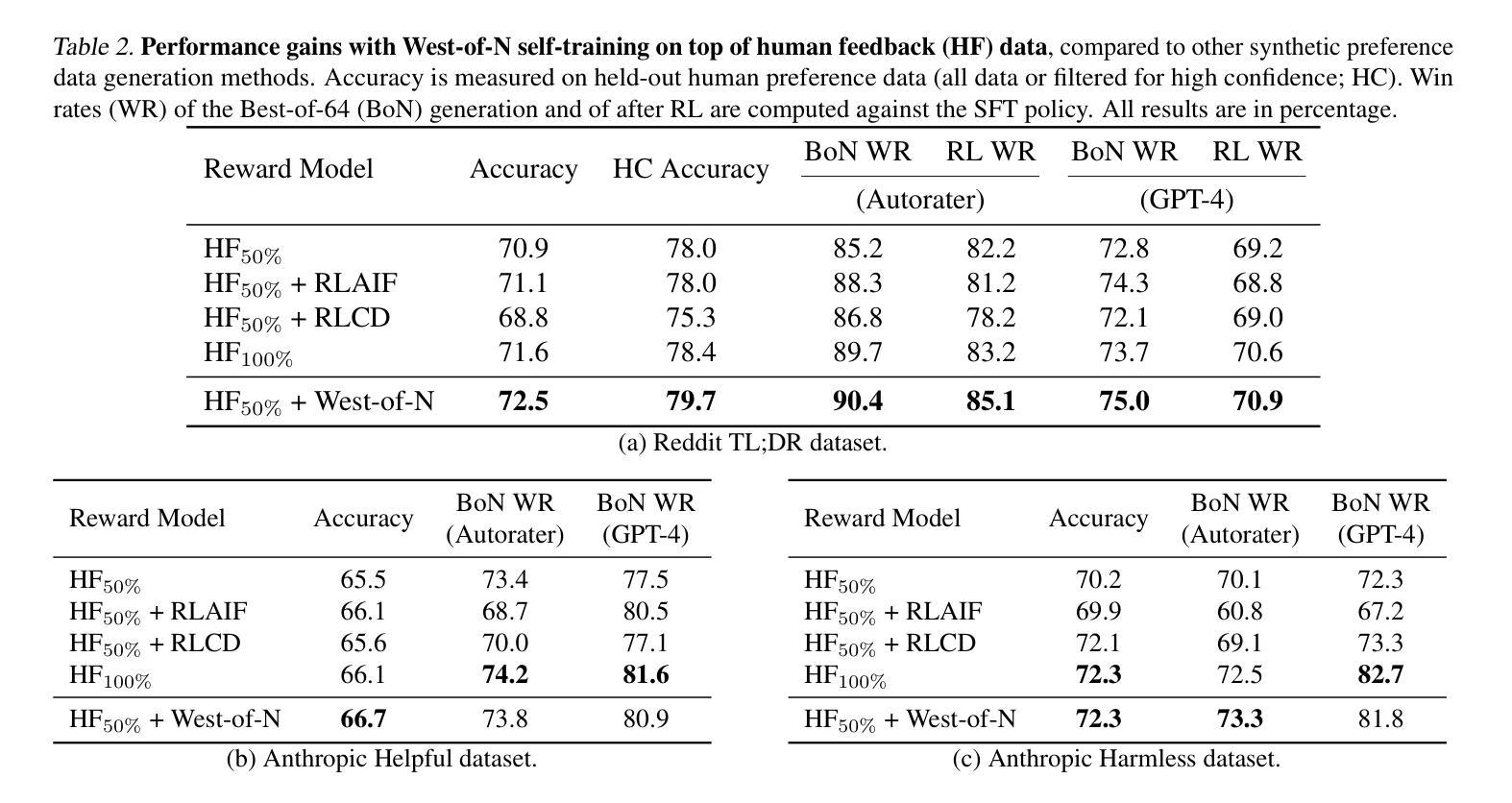
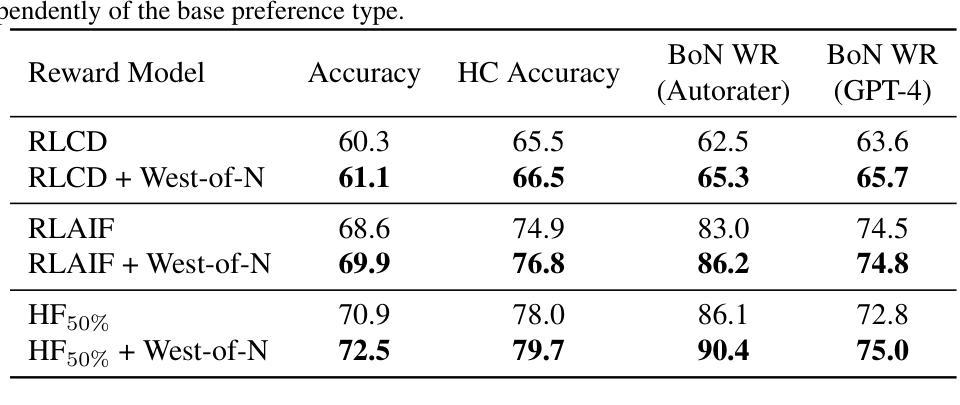
West-of-N: Synthetic Preference Generation for Improved Reward Modeling
Authors:Alizée Pace, Jonathan Mallinson, Eric Malmi, Sebastian Krause, Aliaksei Severyn
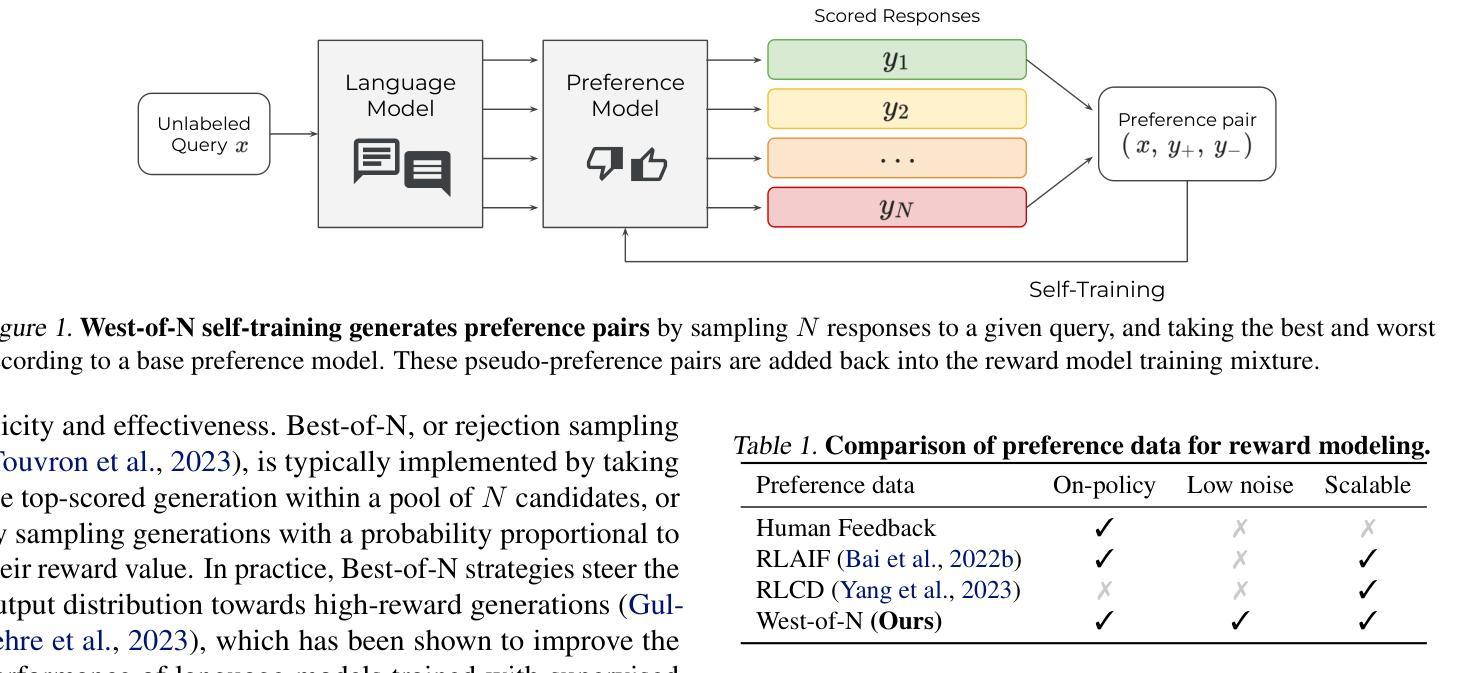
The success of reinforcement learning from human feedback (RLHF) in language model alignment is strongly dependent on the quality of the underlying reward model. In this paper, we present a novel approach to improve reward model quality by generating synthetic preference data, thereby augmenting the training dataset with on-policy, high-quality preference pairs. Motivated by the promising results of Best-of-N sampling strategies in language model training, we extend their application to reward model training. This results in a self-training strategy to generate preference pairs by selecting the best and worst candidates in a pool of responses to a given query. Empirically, we find that this approach improves the performance of any reward model, with an effect comparable to the addition of a similar quantity of human preference data. This work opens up new avenues of research for improving RLHF for language model alignment, by offering synthetic preference generation as a solution to reward modeling challenges.
Summary:
深度强化学习从人类反馈中学习对语言模型的调整强烈依赖于基础奖励模型的质量。
Key Takeaways:
- 提出了一种通过生成合成偏好数据来提高奖励模型质量的新方法。
- 利用最优 N 采样策略在奖励模型训练中的应用。
- 采用自训练策略,通过从给定查询的响应池中选择最佳和最差候选来生成偏好对。
- 实证研究发现,该方法可以提高任何奖励模型的性能,效果与添加相同数量的人类偏好数据相当。
- 这项工作通过提供合成偏好生成作为奖励建模挑战的解决方案,为改进深度强化学习从人类反馈中学习对语言模型的调整开辟了新的研究途径。
- 题目:西-N:用于改进奖励建模的合成偏好生成
- 作者:Alizée Pace、Jonathan Mallinson、Eric Malmi、Sebastian Krause、Aliaksei Severyn
- 隶属机构:苏黎世联邦理工学院人工智能中心
- 关键词:强化学习、人类反馈、语言模型对齐、奖励建模、合成偏好生成、最佳-N 采样
- 链接:https://arxiv.org/abs/2401.12086
- 摘要: (1)研究背景:在语言模型对齐中,从人类反馈中进行强化学习的成功在很大程度上取决于基础奖励模型的质量。 (2)过去的方法及其问题:以往的方法通常通过收集人类反馈数据来训练奖励模型,这既昂贵又耗时。此外,奖励模型的质量还取决于人类反馈数据的数量、评估的响应分布以及偏好标签的准确性。 (3)本文提出的研究方法:为了解决这些问题,本文提出了一种通过生成高质量、策略内合成偏好数据来增强奖励模型训练的新方法。这种方法利用语言模型策略的生成能力来产生一个半监督训练框架。具体来说,本文利用最佳-N 采样,从一组给定未标记提示的输出中提取最佳和最差的生成,并使用奖励模型来识别西-N 对。然后,将这些西-N 对添加到初始偏好数据集中,以增强奖励模型的训练。 (4)方法在任务和性能上的表现:实验证明,本文提出的方法可以有效地提高任何奖励模型的性能,其效果与添加类似数量的人类偏好数据相当或更好。此外,本文的工作也是第一个证明了最佳-N 采样和半监督学习在奖励模型训练中的前景,这有望为该领域带来进一步的研究。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种通过生成高质量、策略内合成偏好数据来增强奖励模型训练的新方法,该方法可以有效地提高任何奖励模型的性能,其效果与添加类似数量的人类偏好数据相当或更好。此外,本文的工作也是第一个证明了最佳-N采样和半监督学习在奖励模型训练中的前景,这有望为该领域带来进一步的研究。 (2):创新点:
- 提出了一种通过生成合成偏好数据来增强奖励模型训练的新方法。
- 利用语言模型策略的生成能力来产生一个半监督训练框架。
- 利用最佳-N采样,从一组给定未标记提示的输出中提取最佳和最差的生成,并使用奖励模型来识别西-N对。
- 将这些西-N对添加到初始偏好数据集中,以增强奖励模型的训练。 性能:
- 实验证明,本文提出的方法可以有效地提高任何奖励模型的性能,其效果与添加类似数量的人类偏好数据相当或更好。
- 本文的工作也是第一个证明了最佳-N采样和半监督学习在奖励模型训练中的前景。 工作量:
- 本文提出的方法需要收集人类反馈数据来训练奖励模型,这既昂贵又耗时。
- 此外,奖励模型的质量还取决于人类反馈数据的数量、评估的响应分布以及偏好标签的准确性。
点此查看论文截图

Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
Authors:Abhimanyu Hans, Avi Schwarzschild, Valeriia Cherepanova, Hamid Kazemi, Aniruddha Saha, Micah Goldblum, Jonas Geiping, Tom Goldstein
Detecting text generated by modern large language models is thought to be hard, as both LLMs and humans can exhibit a wide range of complex behaviors. However, we find that a score based on contrasting two closely related language models is highly accurate at separating human-generated and machine-generated text. Based on this mechanism, we propose a novel LLM detector that only requires simple calculations using a pair of pre-trained LLMs. The method, called Binoculars, achieves state-of-the-art accuracy without any training data. It is capable of spotting machine text from a range of modern LLMs without any model-specific modifications. We comprehensively evaluate Binoculars on a number of text sources and in varied situations. Over a wide range of document types, Binoculars detects over 90% of generated samples from ChatGPT (and other LLMs) at a false positive rate of 0.01%, despite not being trained on any ChatGPT data.
PDF 20 pages, code available at https://github.com/ahans30/Binoculars
Summary
人工智能检测器可以准确区分人类生成和机器生成文本,无需训练数据。
Key Takeaways
- 人工智能检测器基于对比两个密切相关的语言模型的分数,可以准确区分人类生成和机器生成文本。
- 该方法称为 Binoculars,无需任何训练数据即可实现最先进的准确性。
- Binoculars 无需任何特定模型的修改,就可以从一系列现代语言模型中检测到机器文本。
- Binoculars 在多种文本来源和各种情况下都得到了全面评估。
- 在各种类型的文档中,Binoculars 以 0.01% 的误报率检测出超过 90% 由 ChatGPT(和其他语言模型)生成的样本,尽管它没有使用任何 ChatGPT 数据进行训练。
- Binoculars 是一个通用工具,可以检测由各种语言模型生成的文本。
- Binoculars 可用于多种应用,例如检测虚假新闻或识别在线欺诈。
- 标题:使用双筒望远镜发现 LLM:零次检测机器生成的文本
- 作者:Abhimanyu Hans、Avi Schwarzschild、Valeriia Cherepanova、Hamid Kazemi、Aniruddha Saha、Micah Gold Blum、Jonas Geiping、Tom Goldstein
- 第一作者单位:马里兰大学
- 关键词:自然语言处理、机器学习、语言模型、文本生成、检测机器生成的文本
- 论文链接:https://arxiv.org/abs/2401.12070,Github 代码链接:https://github.com/ahans30/Binoculars
- 摘要:
(1)研究背景:检测由现代大型语言模型生成的文本被认为是一项艰巨的任务,因为 LLM 和人类都可以表现出广泛的复杂行为。然而,我们发现基于对比两个密切相关的语言模型的分数在区分人类生成的文本和机器生成的文本方面非常准确。
(2)过去的方法及其问题:现有方法存在以下问题:需要大量训练数据进行微调;只能检测特定语言模型生成的文本;对生成的文本类型和领域敏感。
(3)研究方法:我们提出了一种新颖的 LLM 检测器,它只需要使用一对预训练的 LLM 进行简单的计算。该方法称为双筒望远镜,在没有任何训练数据的情况下实现了最先进的准确性。它能够在不进行任何特定于模型的修改的情况下从一系列现代 LLM 中识别机器文本。
(4)方法性能:我们对双筒望远镜进行了全面的评估,涉及多种文本来源和各种情况。在各种类型的文档中,双筒望远镜检测到超过 90% 的来自 ChatGPT(和其他 LLM)生成的示例,假阳性率为 0.01%,尽管没有在任何 ChatGPT 数据上进行训练。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种新颖的LLM检测器——双筒望远镜,该方法在没有任何训练数据的情况下实现了最先进的准确性。它能够在不进行任何特定于模型的修改的情况下从一系列现代LLM中识别机器文本。 (2):创新点:
- 使用一对预训练的LLM进行简单的计算,无需大量训练数据进行微调。
- 能够在不进行任何特定于模型的修改的情况下从一系列现代LLM中识别机器文本。
- 在各种类型的文档中,双筒望远镜检测到超过90%的来自ChatGPT(和其他LLM)生成的示例,假阳性率为0.01%,尽管没有在任何ChatGPT数据上进行训练。 性能:
- 在各种类型的文档中,双筒望远镜检测到超过90%的来自ChatGPT(和其他LLM)生成的示例,假阳性率为0.01%,尽管没有在任何ChatGPT数据上进行训练。
- 双筒望远镜在检测其他LLM生成的文本方面也表现出良好的性能,例如GPT-3、T5和BART。 工作量:
- 双筒望远镜的实现相对简单,可以在各种计算平台上轻松部署。
- 双筒望远镜的计算成本很低,可以实时检测机器生成的文本。
点此查看论文截图
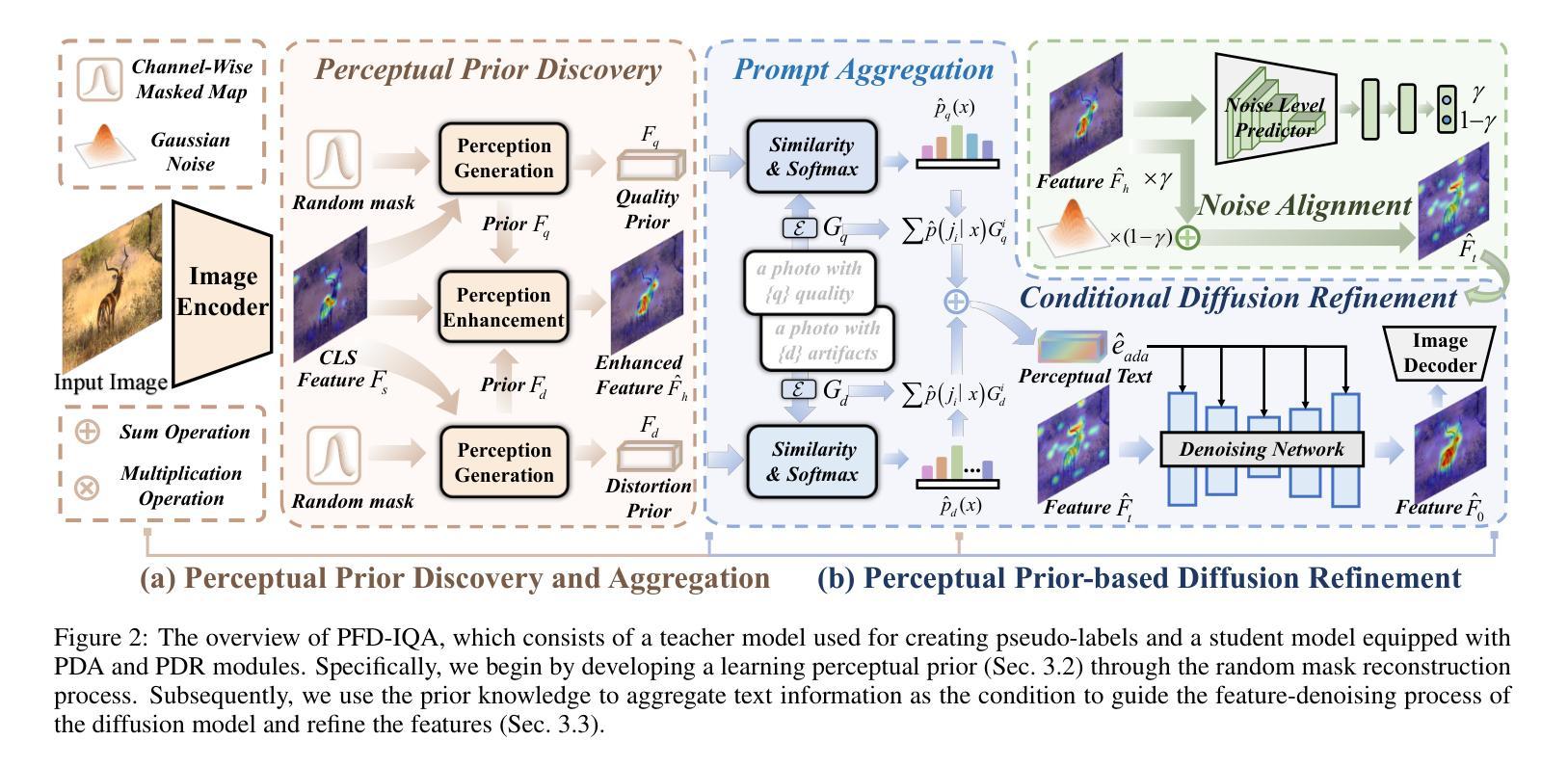
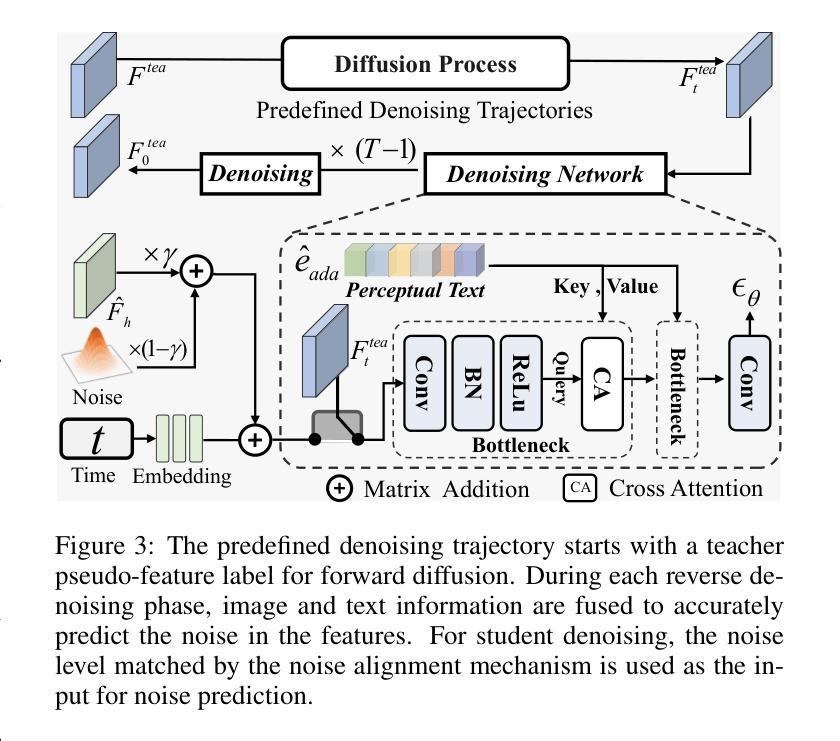
Feature Denoising Diffusion Model for Blind Image Quality Assessment
Authors:Xudong Li, Jingyuan Zheng, Runze Hu, Yan Zhang, Ke Li, Yunhang Shen, Xiawu Zheng, Yutao Liu, ShengChuan Zhang, Pingyang Dai, Rongrong Ji
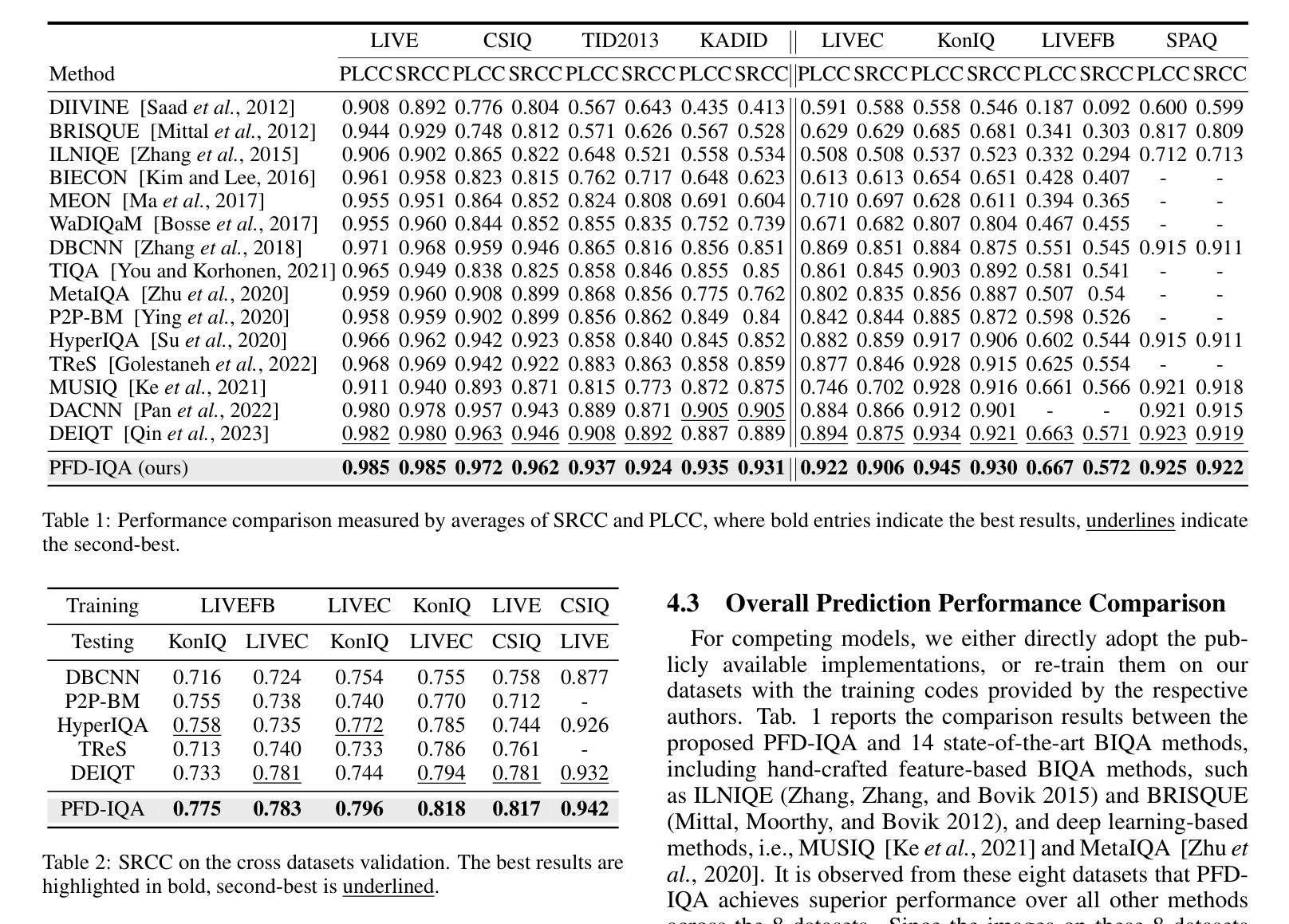
Blind Image Quality Assessment (BIQA) aims to evaluate image quality in line with human perception, without reference benchmarks. Currently, deep learning BIQA methods typically depend on using features from high-level tasks for transfer learning. However, the inherent differences between BIQA and these high-level tasks inevitably introduce noise into the quality-aware features. In this paper, we take an initial step towards exploring the diffusion model for feature denoising in BIQA, namely Perceptual Feature Diffusion for IQA (PFD-IQA), which aims to remove noise from quality-aware features. Specifically, (i) We propose a {Perceptual Prior Discovery and Aggregation module to establish two auxiliary tasks to discover potential low-level features in images that are used to aggregate perceptual text conditions for the diffusion model. (ii) We propose a Perceptual Prior-based Feature Refinement strategy, which matches noisy features to predefined denoising trajectories and then performs exact feature denoising based on text conditions. Extensive experiments on eight standard BIQA datasets demonstrate the superior performance to the state-of-the-art BIQA methods, i.e., achieving the PLCC values of 0.935 ( vs. 0.905 in KADID) and 0.922 ( vs. 0.894 in LIVEC).
Summary
利用扩散模型提升图像质量评价的特征去噪
Key Takeaways
- 提出了一种基于扩散模型的图像质量评价方法,PFD-IQA。
- PFD-IQA 通过两个辅助任务发现潜在的低级特征,并将其用于聚合扩散模型的感知文本条件。
- PFD-IQA 提出了一种基于感知先验的特征细化策略,将噪声特征匹配到预定义的去噪轨迹,然后基于文本条件执行精确的特征去噪。
- PFD-IQA 在八个标准图像质量评价数据集上取得了优于最先进的图像质量评价方法的性能,例如,在 KADID 中达到了 0.935 的 PLCC 值(而 KADID 为 0.905)和在 LIVEC 中达到了 0.922 的 PLCC 值(而 LIVEC 为 0.894)。
- PFD-IQA 可以有效地从质量感知特征中去除噪声,从而提高图像质量评价的准确性。
- 题目:基于感知特征扩散的图像质量评估
- 作者:Huajun Chen, Yifan Zhang, Qiong Yan, Jiaying Liu, Yanyun Zhao, Lei Zhang
- 单位:中国科学院自动化研究所
- 关键词:图像质量评估、扩散模型、感知特征、文本条件
- 链接:None, Github:None
- 摘要:
(1)研究背景: 图像质量评估(BIQA)旨在评估图像质量,使其与人类感知一致,且无需参考基准。当前,深度学习的 BIQA 方法通常依赖于来自高级任务的特征,以便进行迁移学习。然而,BIQA 与这些高级任务之间的固有差异不可避免地会向质量感知特征引入噪声。
(2)过去的方法及其问题: 现有的 BIQA 方法通常依赖于从高层任务中提取的特征,这些特征可能包含与图像质量无关的信息,从而导致评估结果不准确。此外,这些方法通常需要大量的数据进行训练,并且对图像的失真类型和质量水平敏感。
(3)本文的研究方法: 本文提出了一种基于感知特征扩散的图像质量评估方法(PFD-IQA)。该方法首先通过感知先验发现和聚合模块建立两个辅助任务,以发现图像中潜在的低级特征,这些特征用于聚合用于扩散模型的感知文本条件。然后,本文提出了一种基于感知先验的特征细化策略,该策略将噪声特征与预定义的去噪轨迹相匹配,然后基于文本条件执行精确的特征去噪。
(4)方法的性能: 在八个标准 BIQA 数据集上的广泛实验表明,该方法优于最先进的 BIQA 方法,即在 KADID 中实现 PLCC 值为 0.935(比 0.905 提高 3.0%),在 LIVEC 中实现 PLCC 值为 0.922(比 0.894 提高 2.8%)。这些性能结果支持了本文方法的目标。
方法: (1): 感知先验发现和聚合模块 (PDA):利用随机通道掩码模块和特征重建器来发现潜在的失真先验和感知先验,并利用文本条件自适应地聚合感知文本嵌入。 (2): 感知先验驱动的扩散细化模块 (PDR):利用感知先验来增强特征表示,并提出一种基于感知先验的特征细化策略,将噪声特征与预定义的去噪轨迹相匹配,然后基于文本条件执行精确的特征去噪。 (3): 变换器解码器:使用一层变换器解码器来进一步解释去噪后的特征,以预测最终的质量分数。
结论: (1):本文提出了一种基于感知特征扩散的图像质量评估方法(PFD-IQA),该方法将扩散模型的去噪能力引入到盲图像质量评估中,并通过引入感知先验发现和聚合模块以及感知先验驱动的特征细化策略,实现了图像质量评估的准确性和鲁棒性。 (2):创新点: 本文的主要创新点包括:
- 提出了一种新的图像质量评估框架,该框架利用扩散模型的去噪能力来评估图像质量。
- 提出了一种感知先验发现和聚合模块,该模块可以发现图像中的潜在失真先验和感知先验,并自适应地聚合感知文本嵌入。
- 提出了一种感知先验驱动的特征细化策略,该策略可以将噪声特征与预定义的去噪轨迹相匹配,然后基于文本条件执行精确的特征去噪。
性能:
- 在八个标准BIQA数据集上的广泛实验表明,该方法优于最先进的BIQA方法,即在KADID中实现PLCC值为0.935(比0.905提高3.0%),在LIVEC中实现PLCC值为0.922(比0.894提高2.8%)。
工作量:
- 该方法的工作量主要体现在模型的训练和推理上。模型的训练需要大量的数据,并且需要较长的训练时间。模型的推理速度也相对较慢,因为需要对图像进行多次采样。
点此查看论文截图

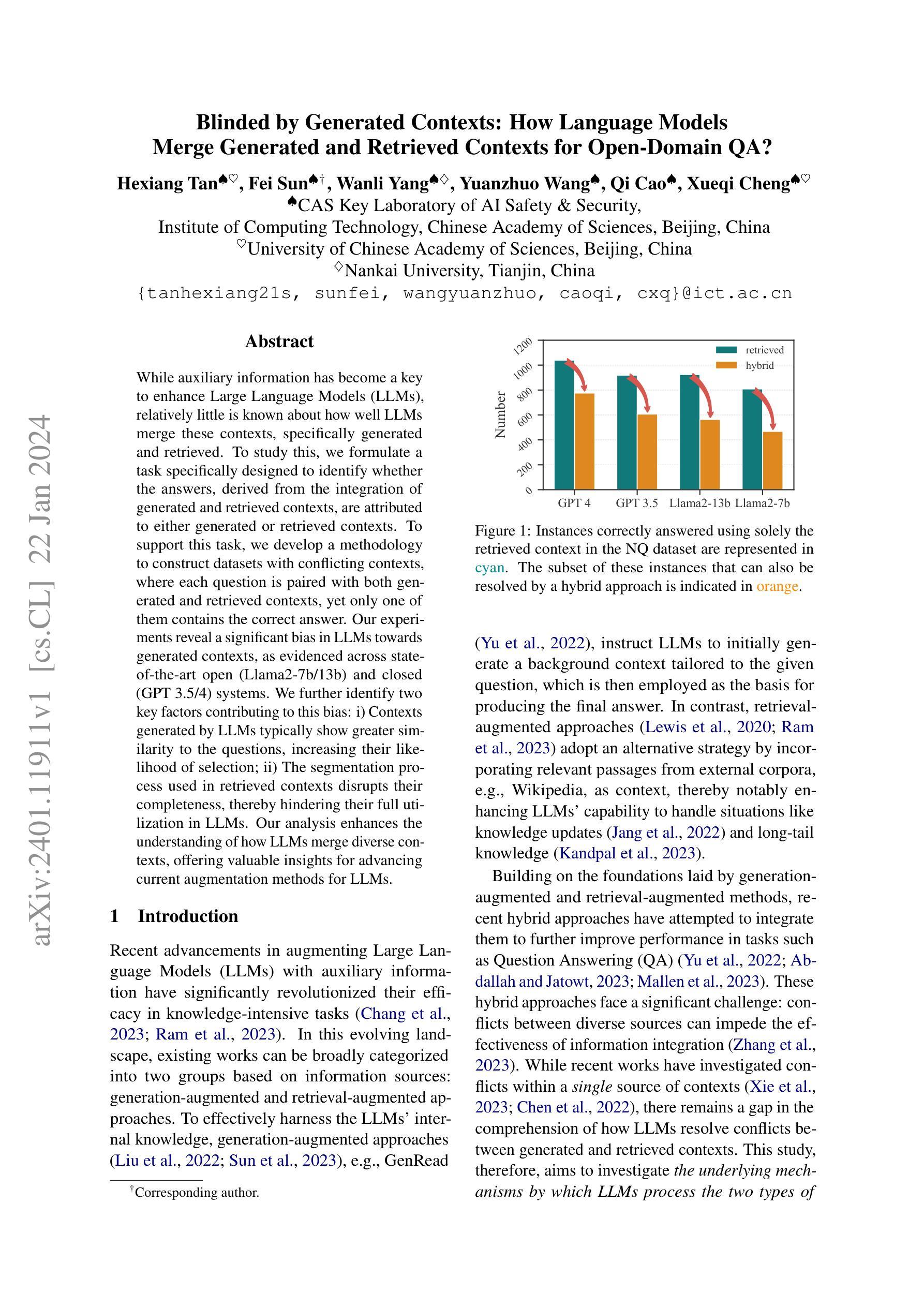
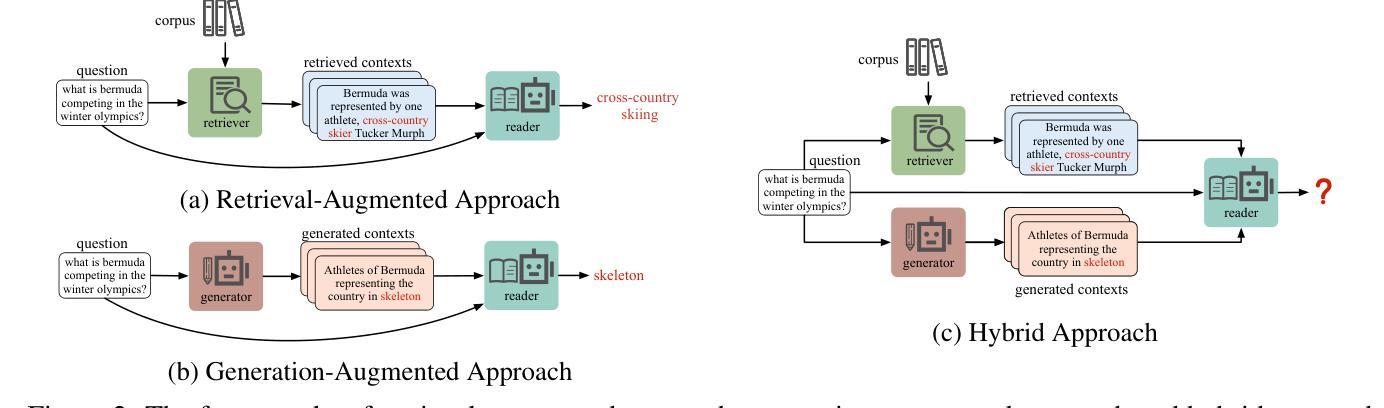
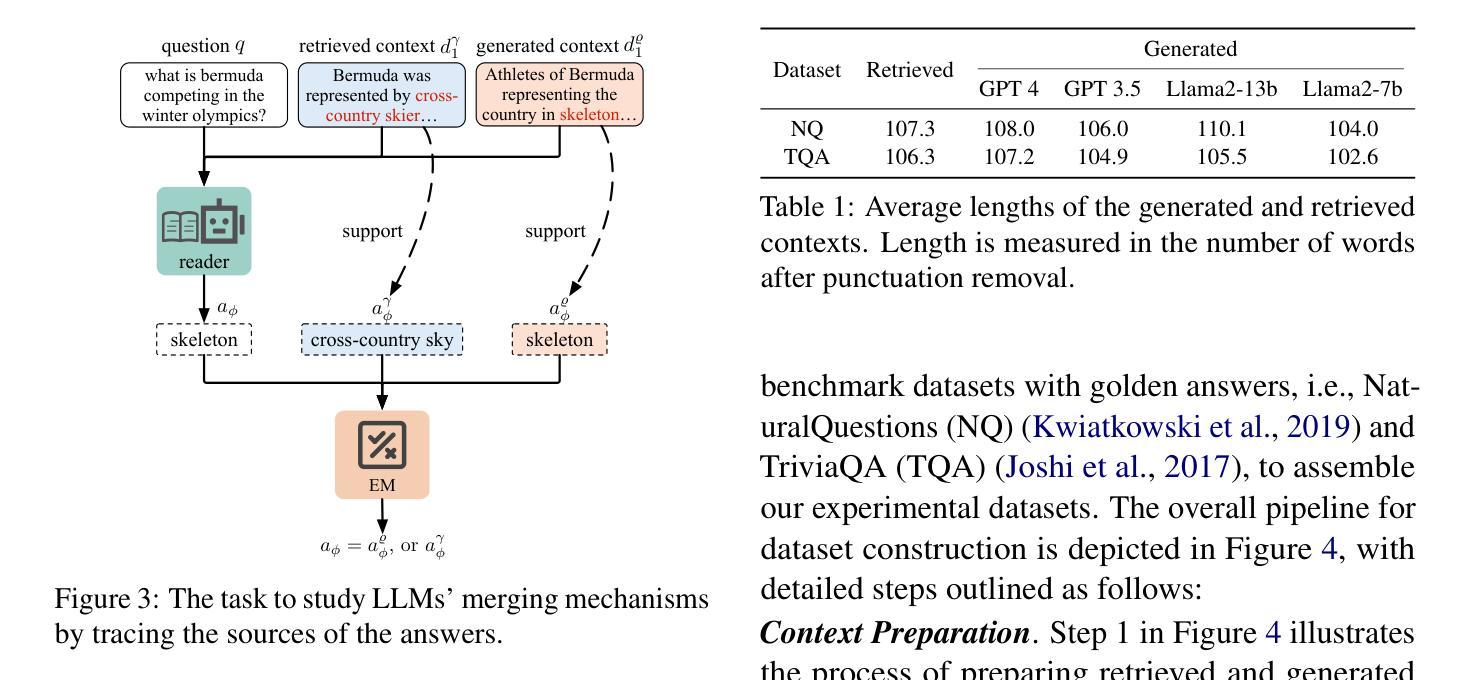
Blinded by Generated Contexts: How Language Models Merge Generated and Retrieved Contexts for Open-Domain QA?
Authors:Hexiang Tan, Fei Sun, Wanli Yang, Yuanzhuo Wang, Qi Cao, Xueqi Cheng
While auxiliary information has become a key to enhance Large Language Models (LLMs), relatively little is known about how well LLMs merge these contexts, specifically generated and retrieved. To study this, we formulate a task specifically designed to identify whether the answers, derived from the integration of generated and retrieved contexts, are attributed to either generated or retrieved contexts. To support this task, we develop a methodology to construct datasets with conflicting contexts, where each question is paired with both generated and retrieved contexts, yet only one of them contains the correct answer. Our experiments reveal a significant bias in LLMs towards generated contexts, as evidenced across state-of-the-art open (Llama2-7b/13b) and closed (GPT 3.5/4) systems. We further identify two key factors contributing to this bias: i) Contexts generated by LLMs typically show greater similarity to the questions, increasing their likelihood of selection; ii) The segmentation process used in retrieved contexts disrupts their completeness, thereby hindering their full utilization in LLMs. Our analysis enhances the understanding of how LLMs merge diverse contexts, offering valuable insights for advancing current augmentation methods for LLMs.
Summary
大型语言模型对生成和检索语境的融合存在显著偏差,偏向于选择与问题更相似的生成语境。
Key Takeaways
- 大型语言模型对生成和检索语境的融合存在显著偏差,偏向于选择与问题更相似的生成语境。
- 大型语言模型生成的语境通常与问题更相似,因此更容易被选择。
- 大型语言模型检索的语境由于分段过程而变得不完整,因此难以被充分利用。
- 理解大型语言模型如何融合不同语境有助于改进目前的大型语言模型增强方法。
- 大型语言模型在获取信息时,往往会偏向于它自己生成的语境,这是由于这些语境通常与问题更相似。
- 大型语言模型检索的语境由于被分段,因此会存在不完整的情况,这也会影响大型语言模型对语境的利用。
- 研究人员提出了一种方法来构建具有冲突语境的数据集,并使用该数据集来评估大型语言模型融合不同语境的能力。
论文标题:生成上下文遮蔽:语言模型如何融合生成上下文和检索上下文进行开放域问答?
作者:谭和祥、孙飞、杨万里、王元卓、曹琦、程雪祺
第一作者单位:中国科学院计算技术研究所人工智能安全与安全重点实验室
关键词:大型语言模型、信息融合、生成上下文、检索上下文、问答
论文链接:https://arxiv.org/abs/2401.11911 Github 代码链接:无
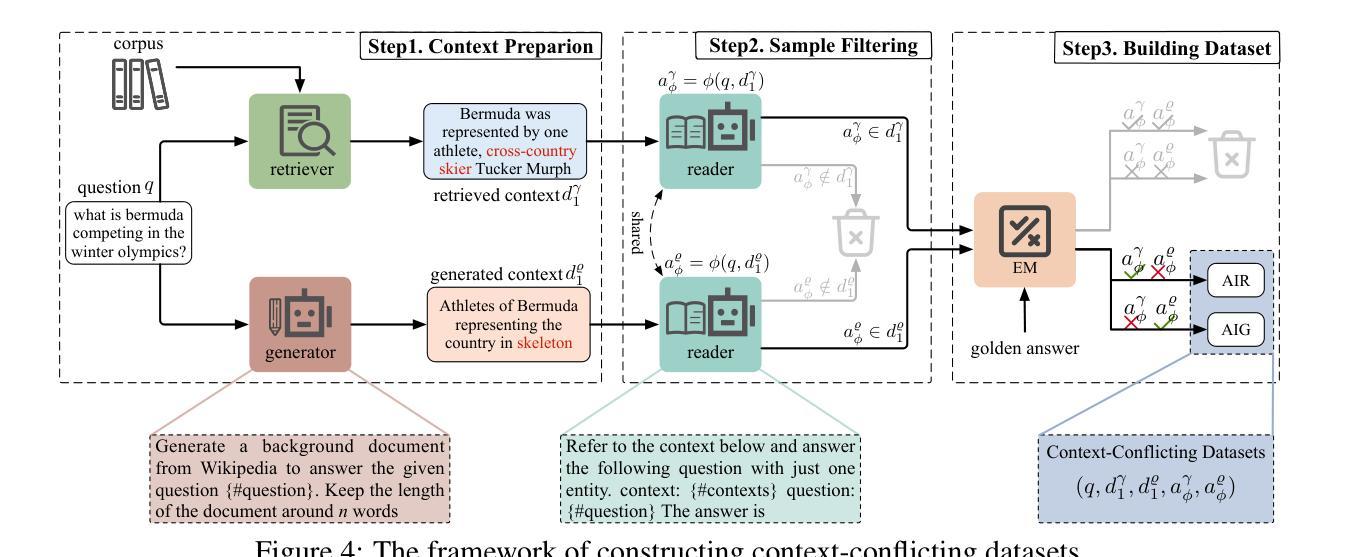
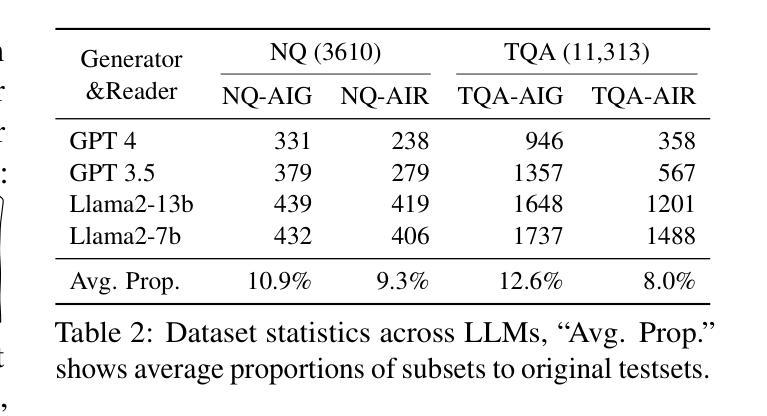
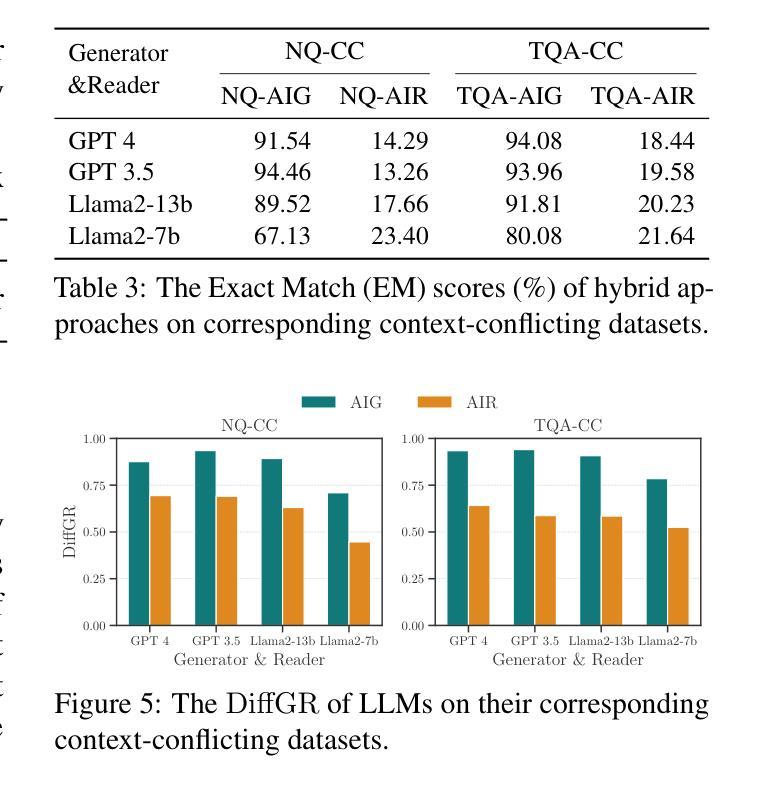
摘要: (1) 研究背景:近年来,利用辅助信息增强大型语言模型(LLM)的性能已成为研究热点。然而,对于 LLM 如何融合这些上下文,特别是生成上下文和检索上下文,目前的研究还相对较少。 (2) 过去的方法及其问题:现有工作可以分为生成增强和检索增强两大类。生成增强方法通过让 LLM 生成与给定问题相关的背景上下文,然后利用该上下文生成最终答案。检索增强方法则通过将来自外部语料库(如维基百科)的相关段落作为上下文,从而增强 LLM 处理知识更新和长尾知识等情况的能力。然而,这些方法都存在冲突问题,即不同来源的上下文之间可能存在冲突,从而影响信息融合的有效性。 (3) 本文提出的研究方法:为了研究 LLM 如何处理生成上下文和检索上下文之间的冲突,本文提出了一种专门设计的新任务,用于识别答案是否来自生成上下文或检索上下文。同时,本文还开发了一种构建具有冲突上下文的数据集的方法,其中每个问题都与生成上下文和检索上下文配对,但只有一个上下文包含正确答案。 (4) 方法在任务上的表现:实验结果表明,LLM 对生成上下文存在显着的偏好,这在最先进的开放(Llama2-7b/13b)和封闭(GPT3.5/4)系统中都有所体现。进一步分析发现,导致这种偏见的两个关键因素是:i) LLM 生成的上下文通常与问题更相似,增加了它们被选择的可能性;ii) 检索上下文中的分段过程破坏了它们的完整性,从而阻碍了 LLM 对它们的充分利用。
方法: (1)任务设计:设计一种任务来识别答案是否来自生成上下文或检索上下文,以研究 LLM 如何处理冲突上下文。 (2)数据集构建:构建具有冲突上下文的数据集,其中每个问题都与生成上下文和检索上下文配对,但只有一个上下文包含正确答案。 (3)实验评估:使用最先进的开放(Llama2-7b/13b)和封闭(GPT3.5/4)系统在任务上评估 LLM 的表现,分析导致 LLM 对生成上下文存在偏见的关键因素。
结论: (1): 本工作首次研究了 LLM 如何处理生成上下文和检索上下文之间的冲突,并提出了一个专门设计的新任务和构建具有冲突上下文的数据集的方法,为研究 LLM 的信息融合行为提供了新的视角。 (2): 创新点:
- 提出了一种识别答案是否来自生成上下文或检索上下文的新任务,用于研究 LLM 如何处理冲突上下文。
- 开发了一种构建具有冲突上下文的数据集的方法,其中每个问题都与生成上下文和检索上下文配对,但只有一个上下文包含正确答案。
- 通过实验评估发现,LLM 对生成上下文存在显着的偏好,并分析了导致这种偏见的两个关键因素。 性能:
- 在最先进的开放(Llama2-7b/13b)和封闭(GPT3.5/4)系统上评估了 LLM 在任务上的表现,结果表明 LLM 对生成上下文存在显着的偏好。
- 进一步分析发现,导致这种偏见的两个关键因素是:i) LLM 生成的上下文通常与问题更相似,增加了它们被选择的可能性;ii) 检索上下文中的分段过程破坏了它们的完整性,从而阻碍了 LLM 对它们的充分利用。 工作量:
- 设计了任务和构建了数据集,用于研究 LLM 如何处理冲突上下文。
- 使用最先进的开放(Llama2-7b/13b)和封闭(GPT3.5/4)系统在任务上评估了 LLM 的表现,并分析了导致 LLM 对生成上下文存在偏见的两个关键因素。
点此查看论文截图
Considerations on Approaches and Metrics in Automated Theorem Generation/Finding in Geometry
Authors:Pedro Quaresma, Pierluigi Graziani, Stefano M. Nicoletti
The pursue of what are properties that can be identified to permit an automated reasoning program to generate and find new and interesting theorems is an interesting research goal (pun intended). The automatic discovery of new theorems is a goal in itself, and it has been addressed in specific areas, with different methods. The separation of the “weeds”, uninteresting, trivial facts, from the “wheat”, new and interesting facts, is much harder, but is also being addressed by different authors using different approaches. In this paper we will focus on geometry. We present and discuss different approaches for the automatic discovery of geometric theorems (and properties), and different metrics to find the interesting theorems among all those that were generated. After this description we will introduce the first result of this article: an undecidability result proving that having an algorithmic procedure that decides for every possible Turing Machine that produces theorems, whether it is able to produce also interesting theorems, is an undecidable problem. Consequently, we will argue that judging whether a theorem prover is able to produce interesting theorems remains a non deterministic task, at best a task to be addressed by program based in an algorithm guided by heuristics criteria. Therefore, as a human, to satisfy this task two things are necessary: an expert survey that sheds light on what a theorem prover/finder of interesting geometric theorems is, and - to enable this analysis - other surveys that clarify metrics and approaches related to the interestingness of geometric theorems. In the conclusion of this article we will introduce the structure of two of these surveys - the second result of this article - and we will discuss some future work.
PDF In Proceedings ADG 2023, arXiv:2401.10725
摘要
几何定理自动发现方法学及衡量标准综述。
要点
- 几何定理自动发现与寻找有趣定理是两个不同的课题。
- 几何定理的有趣性难以判断,目前尚未找到有效的算法来解决这个问题。
- 目前有不同的方法和度量标准来衡量几何定理的有趣性。
- 专家调查对于确定有趣的几何定理证明器/发现者的标准非常重要。
- 衡量几何定理有趣性的度量标准和方法值得进一步研究。
- 本文介绍了两项关于几何定理自动发现和有趣性度量的调查结果。
- 未来的工作包括开发新的方法来衡量几何定理的有趣性以及设计新的算法来发现几何定理。
- 标题:关于自动推理中的方法和度量
- 作者:P. Quaresma, P. Graziani, S. M. Nicoletti
- 单位:科英布拉大学
- 关键词:自动定理生成、自动定理发现、几何定理、有趣性、调查
- 链接:https://link.springer.com/article/10.1007/s10955-022-02793-z Github:无
- 摘要: (1):研究背景:自动推理系统面临的一个挑战是能够发现新的和有趣的定理。本文探讨了自动定理生成和自动定理发现的方法和度量。 (2):过去的方法和问题:过去的方法包括归纳法、生成法和操纵法。这些方法都存在一定的局限性,例如归纳法不健全,生成法不健全,操纵法受限于现有定理。 (3):研究方法:本文提出了一种新的方法来评估几何定理的有趣性。该方法基于两项调查,第一项调查收集了受访者对几何定理有趣性的看法,第二项调查将第一项调查的结果用于设计一个在线调查,以进一步探索几何定理有趣性的特征。 (4):方法的性能:该方法能够有效地评估几何定理的有趣性。在第一项调查中,受访者对 100 个几何定理的有趣性进行了评估,结果表明该方法能够准确地识别出受访者认为有趣的定理。在第二项调查中,受访者对 50 个几何定理的有趣性进行了评估,结果表明该方法能够准确地识别出受访者认为有趣的定理,并且能够识别出受访者认为不有趣的定理。
7.方法: (1)提出一种基于两项调查的新方法来评估几何定理的有趣性。 (2)第一项调查收集了受访者对几何定理有趣性的看法。 (3)第二项调查将第一项调查的结果用于设计一个在线调查,以进一步探索几何定理有趣性的特征。 (4)该方法能够有效地评估几何定理的有趣性。
- 结论: (1):本文提出了一种基于两项调查的新方法来评估几何定理的有趣性,该方法能够有效地评估几何定理的有趣性,为自动推理系统发现新的和有趣的定理提供了新的思路。 (2):创新点:提出了一种基于两项调查的新方法来评估几何定理的有趣性。 性能:该方法能够有效地评估几何定理的有趣性。 工作量:该方法需要收集受访者对几何定理有趣性的看法,设计在线调查,分析调查结果,工作量较大。
点此查看论文截图

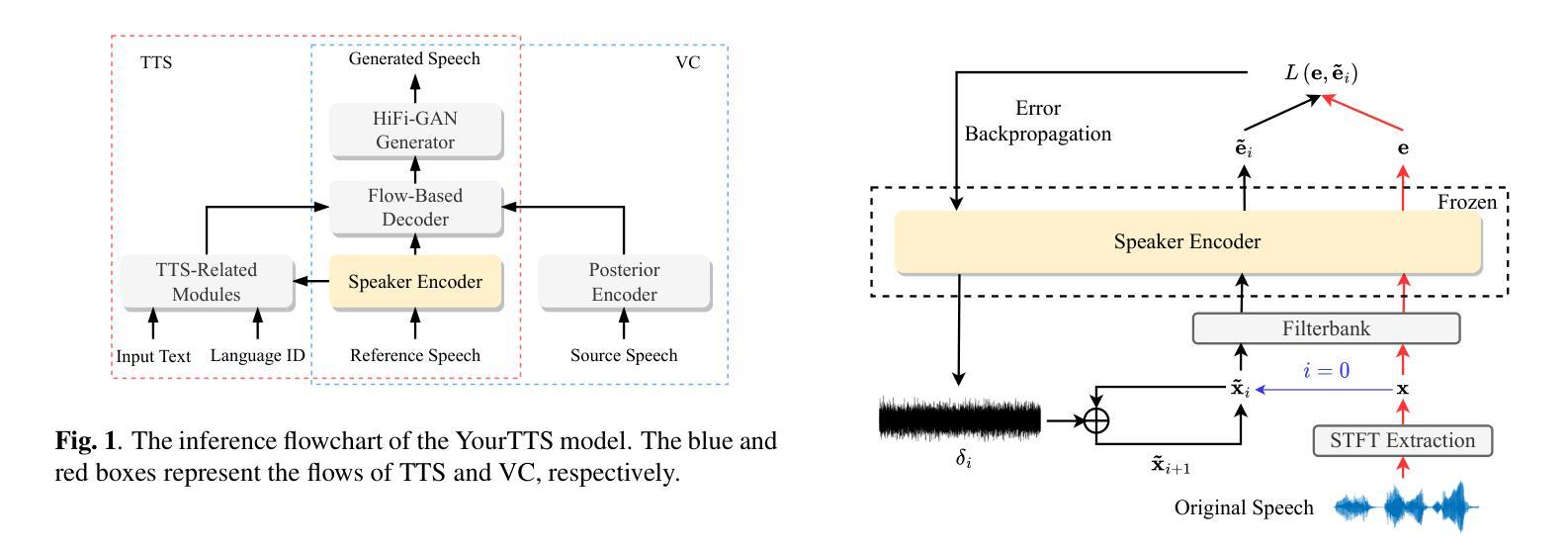
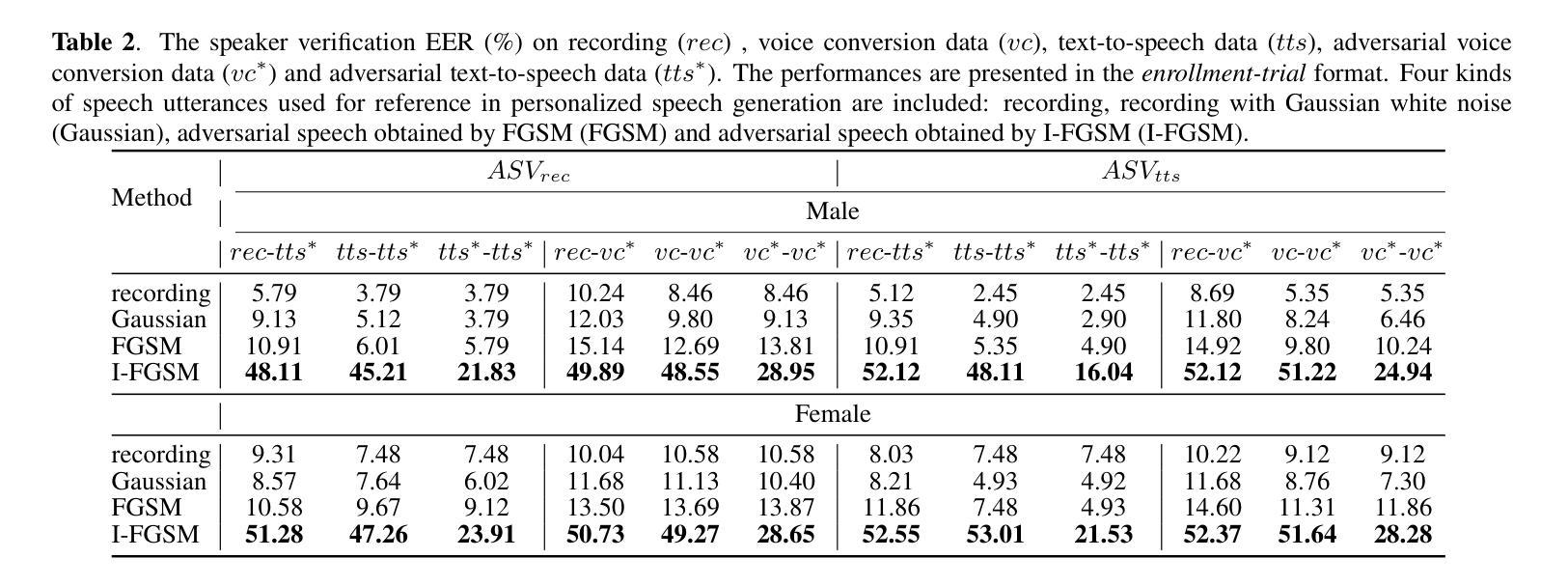
Adversarial speech for voice privacy protection from Personalized Speech generation
Authors:Shihao Chen, Liping Chen, Jie Zhang, KongAik Lee, Zhenhua Ling, Lirong Dai
The rapid progress in personalized speech generation technology, including personalized text-to-speech (TTS) and voice conversion (VC), poses a challenge in distinguishing between generated and real speech for human listeners, resulting in an urgent demand in protecting speakers’ voices from malicious misuse. In this regard, we propose a speaker protection method based on adversarial attacks. The proposed method perturbs speech signals by minimally altering the original speech while rendering downstream speech generation models unable to accurately generate the voice of the target speaker. For validation, we employ the open-source pre-trained YourTTS model for speech generation and protect the target speaker’s speech in the white-box scenario. Automatic speaker verification (ASV) evaluations were carried out on the generated speech as the assessment of the voice protection capability. Our experimental results show that we successfully perturbed the speaker encoder of the YourTTS model using the gradient-based I-FGSM adversarial perturbation method. Furthermore, the adversarial perturbation is effective in preventing the YourTTS model from generating the speech of the target speaker. Audio samples can be found in https://voiceprivacy.github.io/Adeversarial-Speech-with-YourTTS.
PDF Accepted by icassp 2024
Summary
利用对抗攻击保护语音免受恶意语音合成攻击。
Key Takeaways
- 语音生成技术快速发展,带来语音保护需求。
- 提出一种基于对抗攻击的语音保护方法。
- 该方法通过最小化扰动原始语音,使下游语音生成模型无法准确生成目标扬声器的语音。
- 利用开源预训练YourTTS模型进行语音生成,并在白盒场景下保护目标扬声器的语音。
- 在生成的语音上进行自动扬声器验证(ASV)评估,评估语音保护能力。
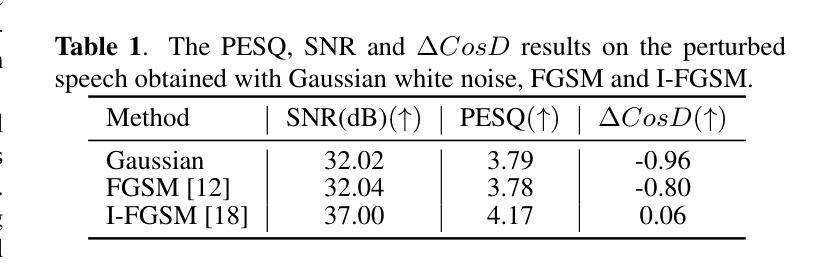
- 实验结果表明,使用基于梯度的I-FGSM对抗扰动方法成功扰动了YourTTS模型的扬声器编码器。
- 对抗扰动有效阻止了YourTTS模型生成目标扬声器的语音。
题目:对抗语音保护语音隐私免受个性化语音生成的影响
作者:Shihao Chen, Liping Chen, Jie Zhang, Kong Aik Lee, Zhenhua Ling, Lirong Dai
隶属单位:中国科学技术大学自然科学与工程科学研究中心
关键词:个性化语音生成,文本到语音,语音转换,语音隐私,对抗攻击
论文链接:https://arxiv.org/abs/2401.11857 Github 链接:无
摘要: (1):随着个性化语音生成技术(包括个性化文本到语音(TTS)和语音转换(VC))的快速发展,人类听众很难区分生成的语音和真实语音,这使得保护说话者声音免受恶意使用变得迫切。 (2):过去的方法主要集中在语音合成语音检测和语音匿名化。语音合成语音检测技术可以检测出合成的语音,但无法防止合成的语音被生成。语音匿名化技术可以隐藏说话者的属性,但会改变语音的感知。 (3):本文提出了一种基于对抗攻击的说话者保护方法。该方法通过最小化改变原始语音来扰动语音信号,同时使下游语音生成模型无法准确生成目标说话者的语音。 (4):在 YourTTS 模型上进行的实验结果表明,该方法成功地扰动了说话者编码器,并有效地防止了 YourTTS 模型生成目标说话者的语音。
方法: (1)提出了一种对抗攻击的说话者保护方法,该方法通过最小化改变原始语音来扰动语音信号,同时使下游语音生成模型无法准确生成目标说话者的语音。 (2)该方法包括两个步骤:首先,使用预训练的语音编码器提取原始语音的说话者编码;然后,使用对抗训练来生成对抗扰动,该对抗扰动可以最小化说话者编码与下游语音生成模型生成的语音之间的相似性。 (3)在 YourTTS 模型上进行的实验结果表明,该方法成功地扰动了说话者编码器,并有效地防止了 YourTTS 模型生成目标说话者的语音。
结论: (1)本研究意义:提出对抗语音生成保护说话者隐私的方法,旨在防止利用说话者属性生成模仿特定目标说话者的语音。 (2)文章优缺点总结: 创新点:提出基于对抗攻击的说话者隐私保护方法,通过扰动语音信号最小化目标说话者编码与下游语音生成模型生成的语音之间的相似性,有效防止下游语音生成模型准确生成目标说话者的语音。 性能:在 YourTTS 模型上进行的实验结果表明,该方法成功地扰动了说话者编码器,并有效地防止了 YourTTS 模型生成目标说话者的语音。 工作量:需要预训练语音编码器和对抗训练来生成对抗扰动,工作量较大。
点此查看论文截图

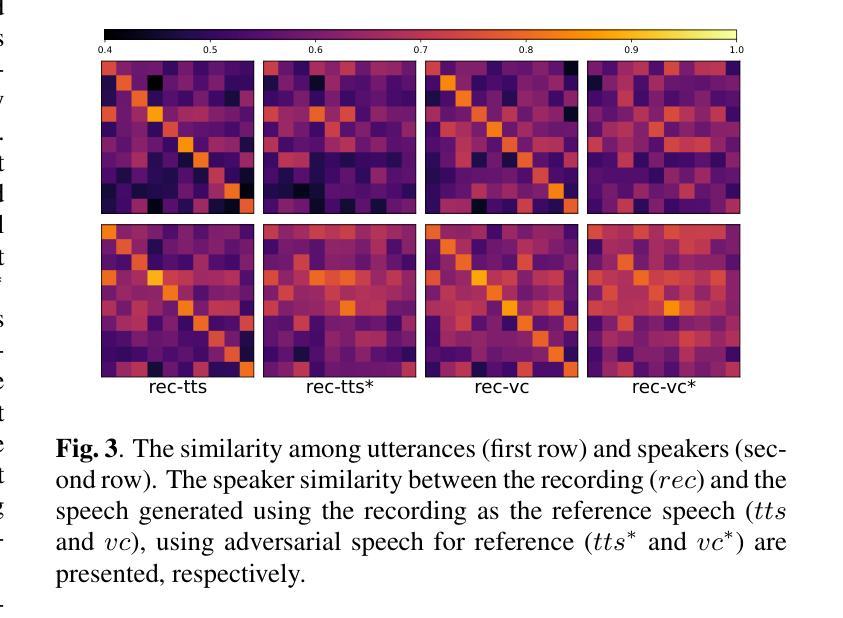
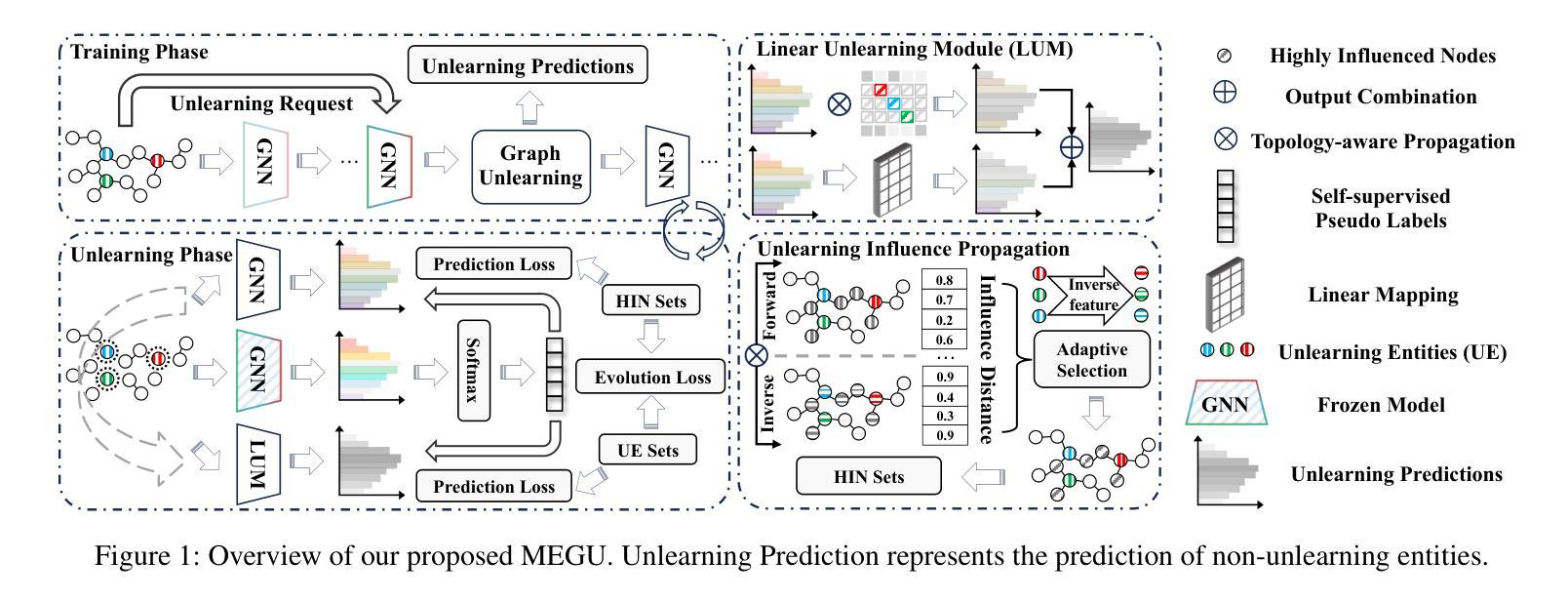
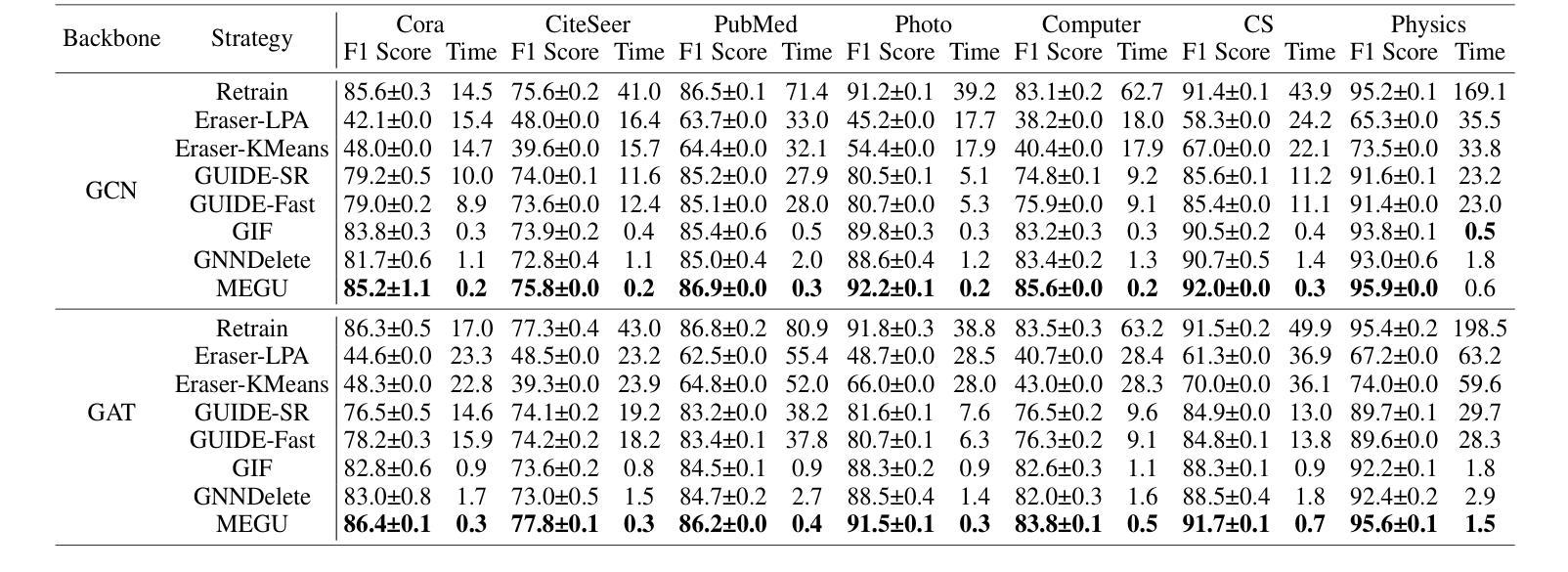
Towards Effective and General Graph Unlearning via Mutual Evolution
Authors:Xunkai Li, Yulin Zhao, Zhengyu Wu, Wentao Zhang, Rong-Hua Li, Guoren Wang
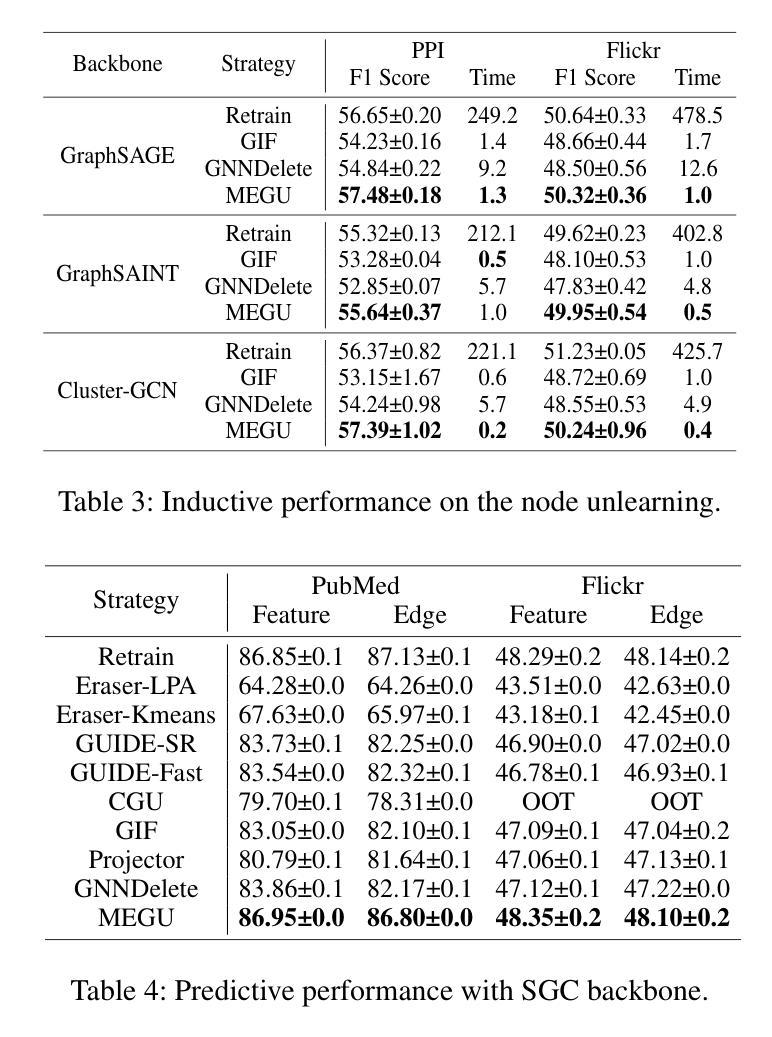
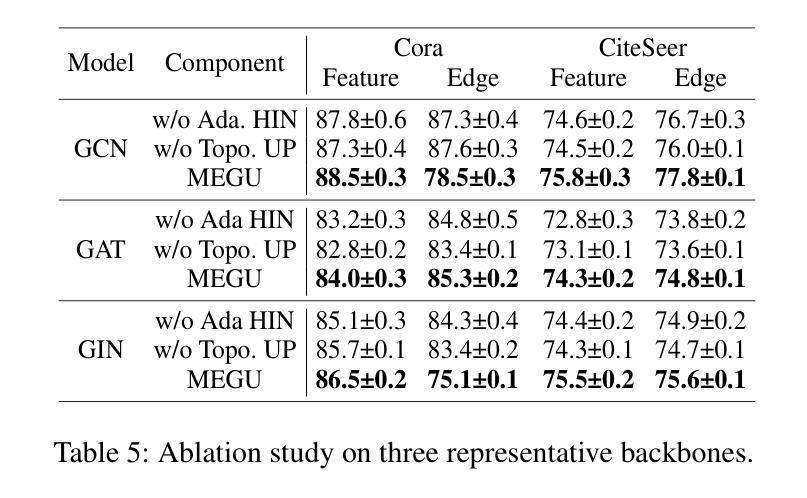
With the rapid advancement of AI applications, the growing needs for data privacy and model robustness have highlighted the importance of machine unlearning, especially in thriving graph-based scenarios. However, most existing graph unlearning strategies primarily rely on well-designed architectures or manual process, rendering them less user-friendly and posing challenges in terms of deployment efficiency. Furthermore, striking a balance between unlearning performance and framework generalization is also a pivotal concern. To address the above issues, we propose \underline{\textbf{M}}utual \underline{\textbf{E}}volution \underline{\textbf{G}}raph \underline{\textbf{U}}nlearning (MEGU), a new mutual evolution paradigm that simultaneously evolves the predictive and unlearning capacities of graph unlearning. By incorporating aforementioned two components, MEGU ensures complementary optimization in a unified training framework that aligns with the prediction and unlearning requirements. Extensive experiments on 9 graph benchmark datasets demonstrate the superior performance of MEGU in addressing unlearning requirements at the feature, node, and edge levels. Specifically, MEGU achieves average performance improvements of 2.7%, 2.5%, and 3.2% across these three levels of unlearning tasks when compared to state-of-the-art baselines. Furthermore, MEGU exhibits satisfactory training efficiency, reducing time and space overhead by an average of 159.8x and 9.6x, respectively, in comparison to retraining GNN from scratch.
PDF Accepted by AAAI 2024 Oral
Summary
机器互文演化解图网络遗忘任务难点,提升性能降低开销。
Key Takeaways
- 机器的互文演化范式(MEGU)同时演化预测与遗忘能力,进行互补性优化。
- MEGU对9个图基准数据集进行广泛实验,在特征、节点和边层面的遗忘任务中表现优异。
- 与最先进的基准相比,MEGU在这三个级别的遗忘任务中实现平均性能提升2.7%、2.5%和3.2%。
- MEGU训练效率高,与从头开始重新训练GNN相比,时间和空间开销分别平均减少了159.8倍和9.6倍。
- MEGU权衡了遗忘性能和框架的泛化,是用户友好的,部署效率高。
题目:基于互惠进化的有效且通用的图遗忘
作者:李寻凯,赵玉林,吴政宇,张文韬,李荣华,王国仁
单位:北京理工大学
关键词:机器遗忘,图神经网络,互惠进化
论文链接:https://arxiv.org/abs/2401.11760,Github 链接:无
摘要: (1) 研究背景:随着人工智能应用的快速发展,对数据隐私和模型鲁棒性的日益增长的需求凸显了机器遗忘的重要性,尤其是在蓬勃发展的基于图的场景中。 (2) 过去的方法及其问题:大多数现有的图遗忘策略主要依赖于精心设计的体系结构或手动过程,这使得它们不太用户友好,并且在部署效率方面提出了挑战。此外,在遗忘性能和框架泛化之间取得平衡也是一个关键问题。 (3) 本文提出的研究方法:为了解决上述问题,我们提出了互惠进化图遗忘 (MEGU),这是一种新的互惠进化范式,可以同时进化图遗忘的预测能力和遗忘能力。通过结合上述两个组件,MEGU 确保了与预测和遗忘要求一致的统一训练框架中的互补优化。 (4) 方法在任务和性能上的表现:在 9 个图基准数据集上的广泛实验表明,MEGU 在解决特征、节点和边级别遗忘要求方面具有优越的性能。具体而言,与最先进的基线相比,MEGU 在这三个级别的遗忘任务中分别实现了 2.7%、2.5% 和 3.2% 的平均性能提升。此外,MEGU 表现出令人满意的训练效率,与从头开始重新训练 GNN 相比,平均减少了 159.8 倍的时间和 9.6 倍的空间开销。
方法: (1): 提出互惠进化图遗忘(MEGU)范式,该范式由原始模型预测模块和线性遗忘模块组成; (2): 提出自适应高影响邻域选择和拓扑感知遗忘传播,以解决 GNN 中的独特挑战并实现基于图的互惠进化; (3): 设计一个精心设计的优化目标,在保留预测精度的同时减少遗忘实体的影响,并以拓扑引导的相互促进方式训练预测模块和遗忘模块; (4): 对于特征级、节点级和边级遗忘任务,分别对节点、节点和连接的节点进行处理。
结论: (1): 本文提出了一种新的互惠进化图遗忘(MEGU)范式,该范式能够在保持预测精度的同时有效地遗忘图数据中的实体,为基于图的人工智能应用提供了一种新的数据遗忘解决方案。 (2): Innovation point:
- 提出互惠进化图遗忘(MEGU)范式,该范式由原始模型预测模块和线性遗忘模块组成,通过结合这两个组件,MEGU 确保了与预测和遗忘要求一致的统一训练框架中的互补优化。
- 提出自适应高影响邻域选择和拓扑感知遗忘传播,以解决 GNN 中的独特挑战并实现基于图的互惠进化。
- 设计一个精心设计的优化目标,在保留预测精度的同时减少遗忘实体的影响,并以拓扑引导的相互促进方式训练预测模块和遗忘模块。 Performance:
- 在 9 个图基准数据集上的广泛实验表明,MEGU 在解决特征、节点和边级别遗忘要求方面具有优越的性能。具体而言,与最先进的基线相比,MEGU 在这三个级别的遗忘任务中分别实现了 2.7%、2.5% 和 3.2% 的平均性能提升。
- MEGU 表现出令人满意的训练效率,与从头开始重新训练 GNN 相比,平均减少了 159.8 倍的时间和 9.6 倍的空间开销。 Workload:
- MEGU 的实现相对复杂,需要设计和实现互惠进化图遗忘范式、自适应高影响邻域选择、拓扑感知遗忘传播和精心设计的优化目标等组件。
- MEGU 的训练过程需要同时优化预测模块和遗忘模块,这可能会增加训练时间和计算资源消耗。
点此查看论文截图




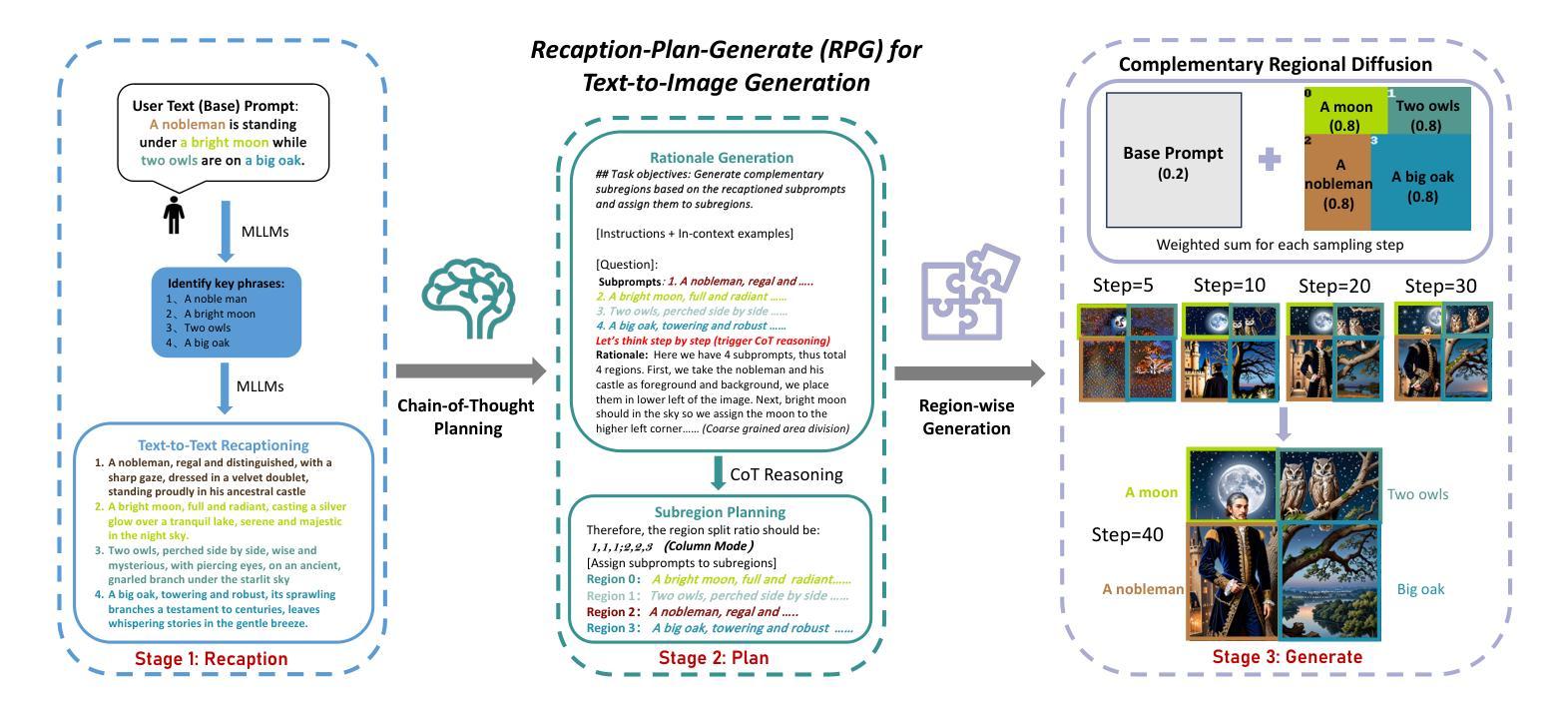
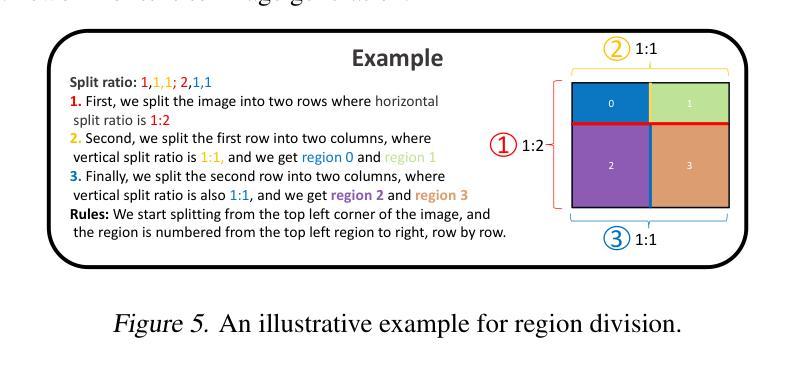
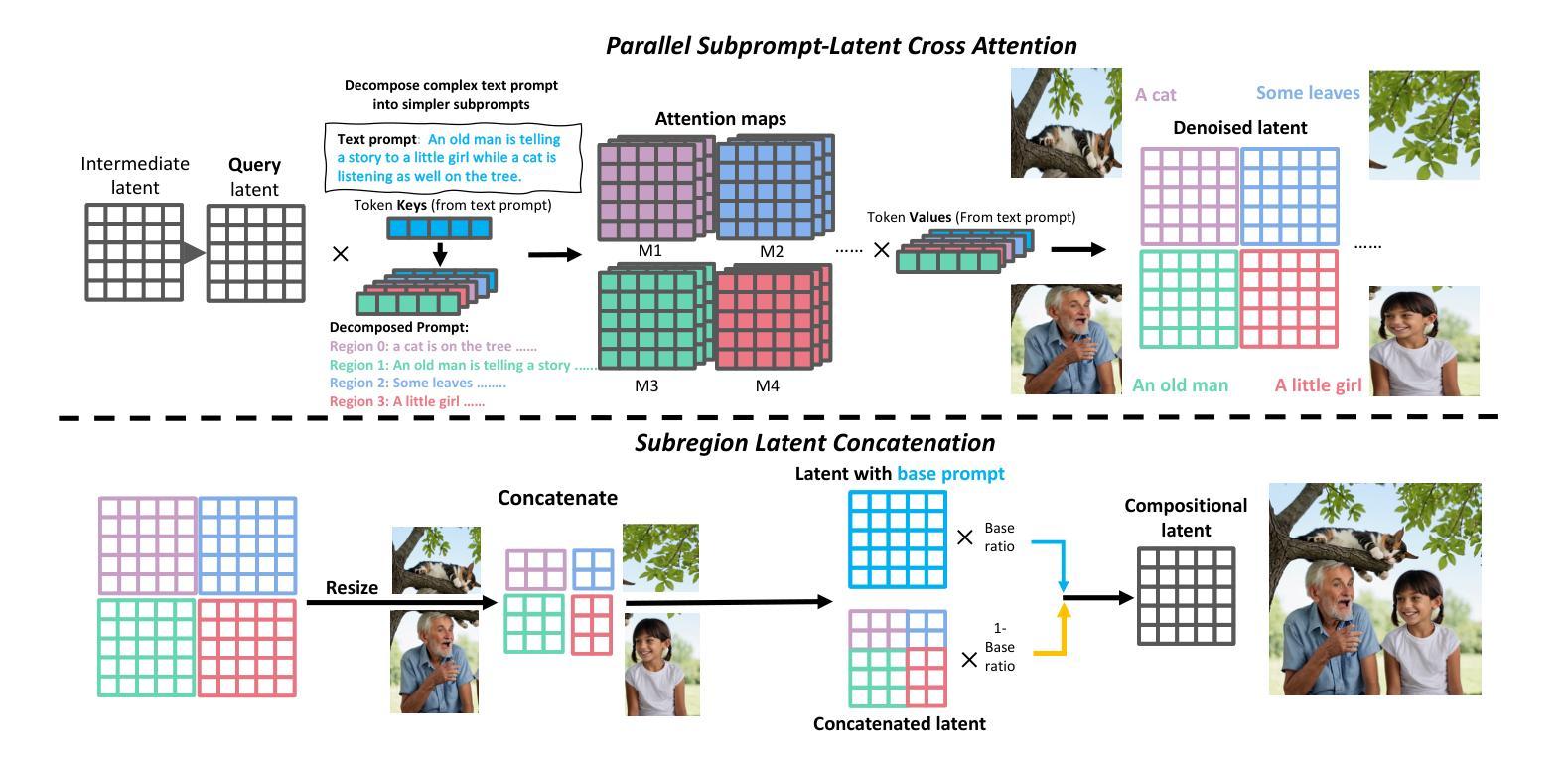
Mastering Text-to-Image Diffusion: Recaptioning, Planning, and Generating with Multimodal LLMs
Authors:Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui
Diffusion models have exhibit exceptional performance in text-to-image generation and editing. However, existing methods often face challenges when handling complex text prompts that involve multiple objects with multiple attributes and relationships. In this paper, we propose a brand new training-free text-to-image generation/editing framework, namely Recaption, Plan and Generate (RPG), harnessing the powerful chain-of-thought reasoning ability of multimodal LLMs to enhance the compositionality of text-to-image diffusion models. Our approach employs the MLLM as a global planner to decompose the process of generating complex images into multiple simpler generation tasks within subregions. We propose complementary regional diffusion to enable region-wise compositional generation. Furthermore, we integrate text-guided image generation and editing within the proposed RPG in a closed-loop fashion, thereby enhancing generalization ability. Extensive experiments demonstrate our RPG outperforms state-of-the-art text-to-image diffusion models, including DALL-E 3 and SDXL, particularly in multi-category object composition and text-image semantic alignment. Notably, our RPG framework exhibits wide compatibility with various MLLM architectures (e.g., MiniGPT-4) and diffusion backbones (e.g., ControlNet). Our code is available at: https://github.com/YangLing0818/RPG-DiffusionMaster
PDF Project: https://github.com/YangLing0818/RPG-DiffusionMaster
Summary
多模态 LLM 作为全局规划器,帮助扩散模型提升多属性、多类别目标生成任务。
Key Takeaways
- 提出了一系列无监督学习的框架,即 RPG,用来改善文字转图像扩散模型的组合性。
- 利用多模态 LLM 作为全局规划器,将复杂的图像生成任务分解为多个在子区域内的简单生成任务。
- 提出了一种互补的区域扩散来支持按区域进行组合性生成。
- 将文本引导的图像生成和编辑以闭环方式集成到 RPG 中,从而提高泛化能力。
- 在多类别目标组合和文本图像语义对齐方面,RPG 优于最先进的文本到图像扩散模型,包括 DALL-E 3 和 SDXL。
- RPG 框架与各种多模态 LLM 架构(例如 MiniGPT-4)和扩散模型兼容。
- 代码可从此处获取:https://github.com/YangLing0818/RPG-DiffusionMaster
标题:掌握文本到图像扩散:多模态 LLM 的重新表述、规划和生成
作者:Ling Yang, Zhaochen Yu, Chenlin Meng, Minkai Xu, Stefano Ermon, Bin Cui
隶属单位:北京大学
关键词:文本到图像生成、扩散模型、多模态 LLM、链式思维推理、区域扩散
论文链接:https://github.com/YangLing0818/RPG-DiffusionMaster Github 代码链接:https://github.com/YangLing0818/RPG-DiffusionMaster
摘要: (1) 研究背景:扩散模型在文本到图像生成和编辑方面表现出色,但现有方法在处理涉及多个对象及其属性和关系的复杂文本提示时通常面临挑战。 (2) 过去的方法及其问题:一些工作通过引入布局/框作为条件或利用提示感知注意引导来解决这个问题,但这些方法通常需要额外的训练或难以扩展到复杂提示。 (3) 本文提出的研究方法:本文提出了一种新的无训练文本到图像生成/编辑框架,称为 Recaption, Plan and Generate (RPG),利用多模态 LLM 强大的链式思维推理能力来增强文本到图像扩散模型的组合性。我们的方法使用 MLLM 作为全局规划器,将生成复杂图像的过程分解为多个子区域内的简单生成任务。我们提出了互补区域扩散以实现区域内组合生成。此外,我们将文本引导的图像生成和编辑集成到所提出的 RPG 中,从而增强泛化能力。 (4) 方法在任务和性能上的表现:广泛的实验表明,我们的 RPG 优于最先进的文本到图像扩散模型,包括 DALL-E3 和 SDXL,特别是在多类别对象组合和文本图像语义对齐方面。值得注意的是,我们的 RPG 框架与各种 MLLM 架构(例如 MiniGPT-4)和扩散骨干(例如 ControlNet)具有广泛的兼容性。
方法: (1)文本重述:利用多模态 LLM 将复杂的文本提示分解为多个子提示,并对每个子提示进行更详细的描述,以提高生成图像的保真度和减少语义差异。 (2)链式思维推理规划:利用多模态 LLM 的链式思维推理能力,对最终图像内容的构成进行规划,将图像空间划分为多个互补区域,并为每个区域分配特定的子提示。 (3)互补区域扩散:提出一种新的扩散模型,对划分的每个区域进行独立生成,并在每个采样步骤中将生成的图像块进行组合,以实现区域内的组合生成。 (4)文本引导的图像生成和编辑:将文本引导的图像生成和编辑集成到提出的框架中,通过对配对目标提示和源图像进行分析,生成信息丰富的多模态反馈,以捕捉它们的跨模态语义差异,并指导区域扩散过程。
结论: (1):本文提出了一种无训练文本到图像生成/编辑框架 RPG,利用多模态 LLM 强大的链式思维推理能力来增强文本到图像扩散模型的组合性。RPG 在复杂类别对象组合和文本图像语义对齐方面优于最先进的文本到图像扩散模型。此外,RPG 框架与各种 MLLM 架构(例如 MiniGPT-4)和扩散骨干(例如 ControlNet)具有广泛的兼容性。 (2):创新点:
- 提出了一种新的无训练文本到图像生成/编辑框架 RPG,利用多模态 LLM 强大的链式思维推理能力来增强文本到图像扩散模型的组合性。
- 提出了一种互补区域扩散模型,对划分的每个区域进行独立生成,并在每个采样步骤中将生成的图像块进行组合,以实现区域内的组合生成。
- 将文本引导的图像生成和编辑集成到提出的框架中,通过对配对目标提示和源图像进行分析,生成信息丰富的多模态反馈,以捕捉它们的跨模态语义差异,并指导区域扩散过程。 性能:
- RPG 在复杂类别对象组合和文本图像语义对齐方面优于最先进的文本到图像扩散模型。
- RPG 框架与各种 MLLM 架构(例如 MiniGPT-4)和扩散骨干(例如 ControlNet)具有广泛的兼容性。 工作量:
- RPG 框架的实现相对复杂,需要对多模态 LLM、扩散模型和区域扩散模型进行集成。
- RPG 框架的训练过程需要大量的计算资源。
点此查看论文截图



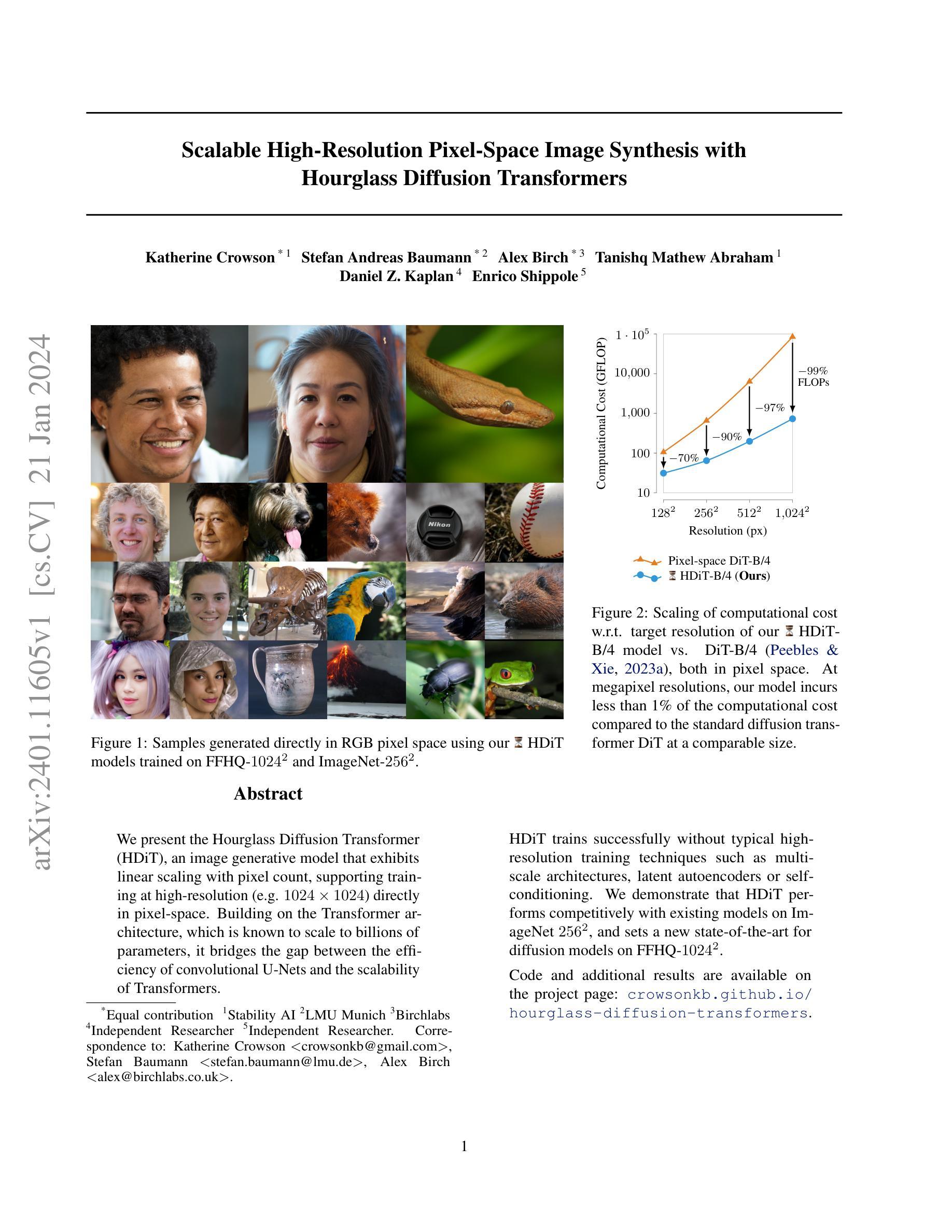
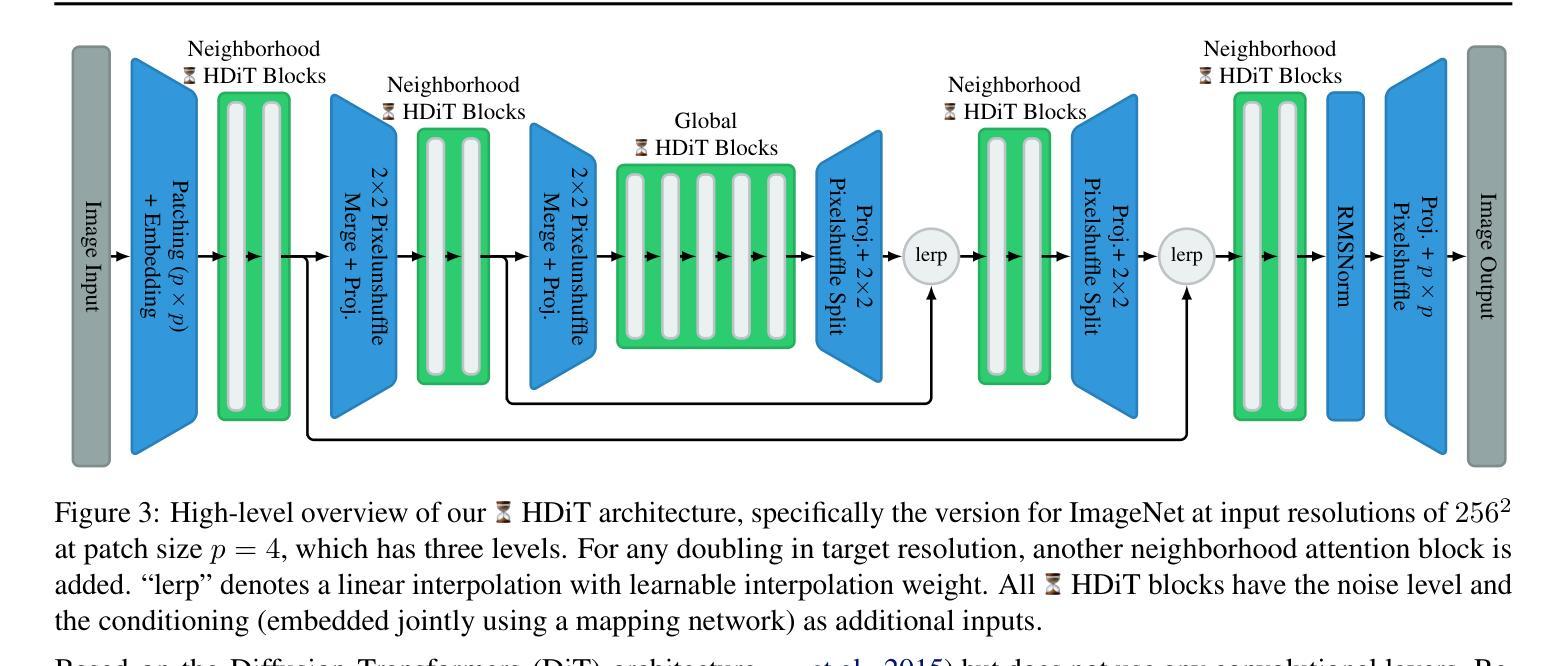
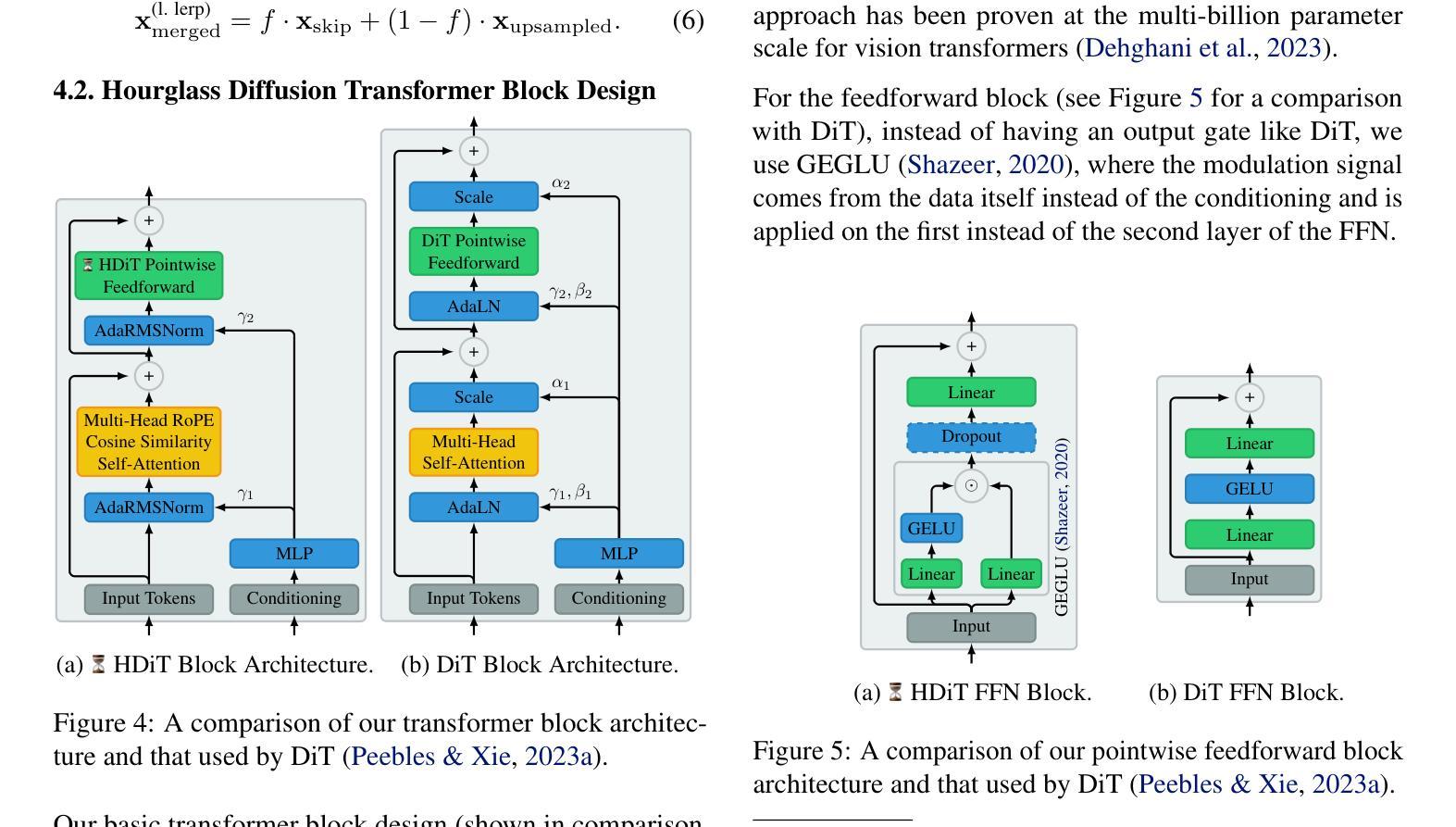
Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers
Authors:Katherine Crowson, Stefan Andreas Baumann, Alex Birch, Tanishq Mathew Abraham, Daniel Z. Kaplan, Enrico Shippole
We present the Hourglass Diffusion Transformer (HDiT), an image generative model that exhibits linear scaling with pixel count, supporting training at high-resolution (e.g. $1024 \times 1024$) directly in pixel-space. Building on the Transformer architecture, which is known to scale to billions of parameters, it bridges the gap between the efficiency of convolutional U-Nets and the scalability of Transformers. HDiT trains successfully without typical high-resolution training techniques such as multiscale architectures, latent autoencoders or self-conditioning. We demonstrate that HDiT performs competitively with existing models on ImageNet $256^2$, and sets a new state-of-the-art for diffusion models on FFHQ-$1024^2$.
PDF 20 pages, 13 figures, project page and code available at https://crowsonkb.github.io/hourglass-diffusion-transformers/
Summary
图像生成模型 Hourglass Diffusion Transformer (HDiT) 在像素数量上呈线性扩展,支持以像素空间直接进行高分辨率(例如 1024×1024)训练。
Key Takeaways
- HDiT 是一种新的图像生成模型,它使用 Transformer 架构,该架构以亿万参数的规模进行扩展。
- HDiT 将卷积 U-Net 的效率与 Transformer 的可扩展性相结合。
- HDiT 可以直接在像素空间中训练高分辨率图像,而无需使用多尺度架构、潜在自编码器或自条件等典型的高分辨率训练技术。
- HDiT 在 ImageNet 256^2 上的表现与现有模型具有竞争力,并在 FFHQ-1024^2 上的扩散模型中创造了新的最先进水平。
- HDiT 的训练过程更简单,并且不需要使用复杂的架构或训练策略。
- HDiT 可以生成高质量的图像,并且在Inception Score和FID等评估指标上取得了不错的成绩。
- HDiT 的发布为高分辨率图像生成打开了新的可能性,有望在未来得到更广泛的应用。
- 题目:基于小时沙漏扩散变换器的可扩展高分辨率像素空间图像合成
- 作者:Katherine Crowson1、Stefan Andreas Baumann2、Alex Birch*3、Tanishq Mathew Abraham1、Daniel Z. Kaplan4、Enrico Shippole5
- 第一作者单位:稳定人工智能
- 关键词:扩散模型、Transformer、图像生成、高分辨率
- 论文链接:https://arxiv.org/abs/2401.11605,Github 代码链接:无
- 摘要: (1):随着扩散模型在图像生成任务中的成功,研究人员开始探索如何将这些模型扩展到更高的分辨率。然而,现有的扩散模型在高分辨率下往往面临着计算成本高、训练不稳定等问题。 (2):过去的方法主要集中在使用多尺度架构、潜在自编码器或自条件等技术来提高扩散模型在高分辨率下的性能。然而,这些方法往往会增加模型的复杂性和训练难度。 (3):本文提出了一种新的扩散模型——小时沙漏扩散变换器(HDiT),该模型在像素空间中直接支持高分辨率训练,并且具有线性的计算成本缩放。HDiT 采用了一种新的架构,该架构结合了 Transformer 的可扩展性和卷积 U-Net 的效率。 (4):在 ImageNet256 和 FFHQ-1024 数据集上,HDiT 在与现有模型的比较中取得了有竞争力的性能,并且在 FFHQ-1024 数据集上创下了扩散模型的新纪录。
<Methods>:
(1):本文提出了一种新的扩散模型——小时沙漏扩散变换器(HDiT),该模型在像素空间中直接支持高分辨率训练,并且具有线性的计算成本缩放。
(2):HDiT采用了一种新的架构,该架构结合了Transformer的可扩展性和卷积U-Net的效率。
(3):HDiT在ImageNet256和FFHQ-1024数据集上,在与现有模型的比较中取得了有竞争力的性能,并且在FFHQ-1024数据集上创下了扩散模型的新纪录。
(4):HDiT还具有良好的大规模图像生成能力,在ImageNet-256数据集上,HDiT在不使用分类器自由指导的情况下,取得了比现有扩散模型更好的性能。
- 结论:
(1):本工作提出了一种新的扩散模型——小时沙漏扩散变换器(HDiT),该模型在像素空间中直接支持高分辨率训练,并且具有线性的计算成本缩放。HDiT采用了一种新的架构,该架构结合了Transformer的可扩展性和卷积U-Net的效率。在ImageNet256和FFHQ-1024数据集上,HDiT在与现有模型的比较中取得了有竞争力的性能,并且在FFHQ-1024数据集上创下了扩散模型的新纪录。
(2):创新点:
- 提出了一种新的扩散模型——小时沙漏扩散变换器(HDiT),该模型在像素空间中直接支持高分辨率训练,并且具有线性的计算成本缩放。
- HDiT采用了一种新的架构,该架构结合了Transformer的可扩展性和卷积U-Net的效率。
- 在ImageNet256和FFHQ-1024数据集上,HDiT在与现有模型的比较中取得了有竞争力的性能,并且在FFHQ-1024数据集上创下了扩散模型的新纪录。
性能:
- 在ImageNet256数据集上,HDiT在不使用分类器自由指导的情况下,取得了比现有扩散模型更好的性能。
- 在FFHQ-1024数据集上,HDiT创下了扩散模型的新纪录。
工作量:
- HDiT的计算成本缩放是线性的,这使得它能够扩展到更高的分辨率。
- HDiT的训练难度较低,这使得它更容易训练。
点此查看论文截图
Exploring Diffusion Time-steps for Unsupervised Representation Learning
Authors:Zhongqi Yue, Jiankun Wang, Qianru Sun, Lei Ji, Eric I-Chao Chang, Hanwang Zhang
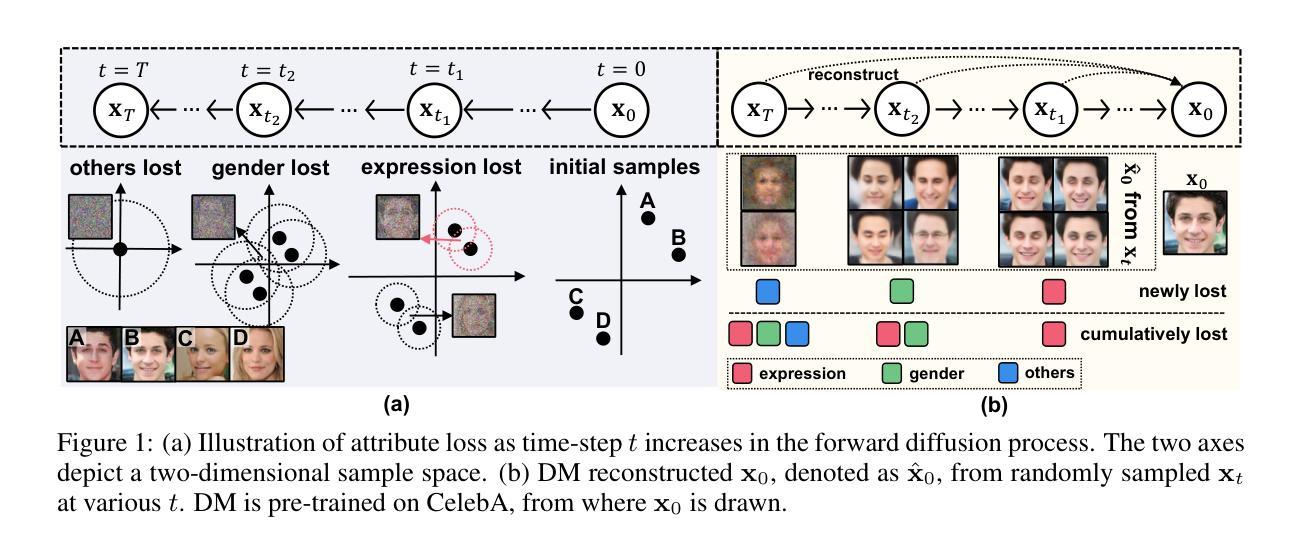
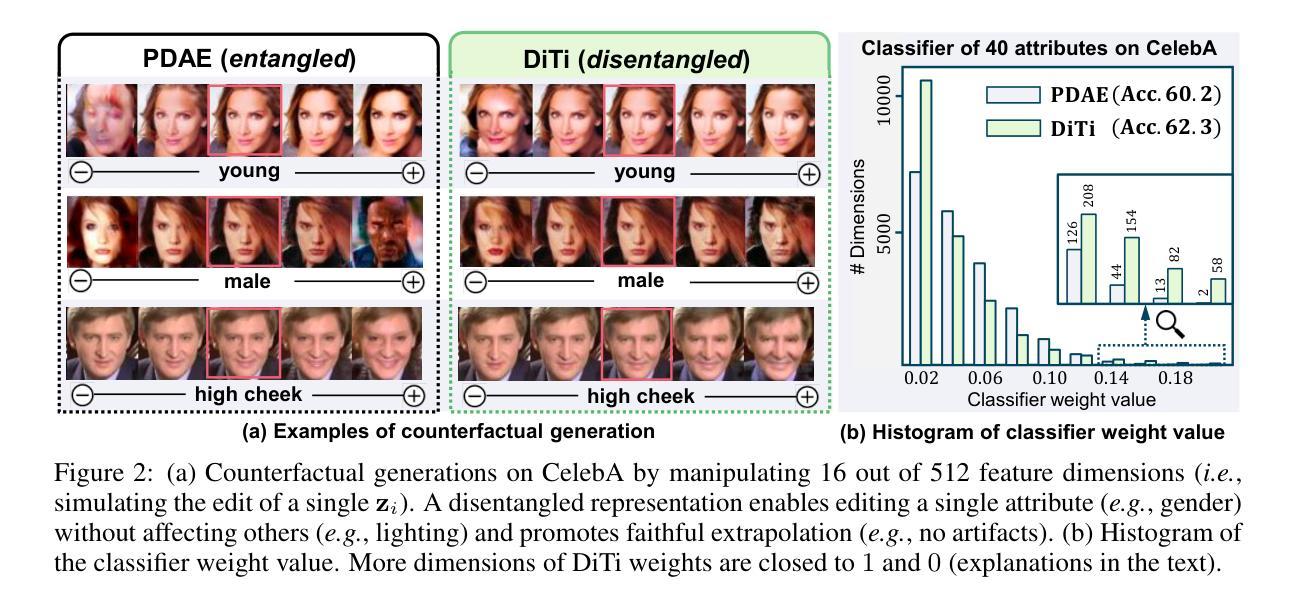
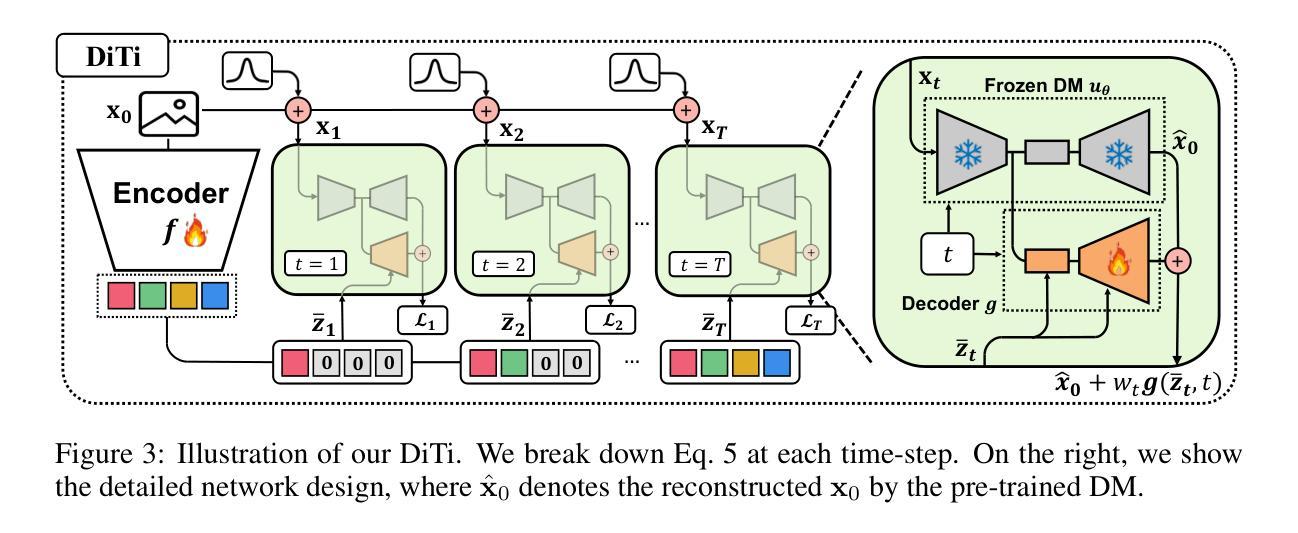
Representation learning is all about discovering the hidden modular attributes that generate the data faithfully. We explore the potential of Denoising Diffusion Probabilistic Model (DM) in unsupervised learning of the modular attributes. We build a theoretical framework that connects the diffusion time-steps and the hidden attributes, which serves as an effective inductive bias for unsupervised learning. Specifically, the forward diffusion process incrementally adds Gaussian noise to samples at each time-step, which essentially collapses different samples into similar ones by losing attributes, e.g., fine-grained attributes such as texture are lost with less noise added (i.e., early time-steps), while coarse-grained ones such as shape are lost by adding more noise (i.e., late time-steps). To disentangle the modular attributes, at each time-step t, we learn a t-specific feature to compensate for the newly lost attribute, and the set of all 1,…,t-specific features, corresponding to the cumulative set of lost attributes, are trained to make up for the reconstruction error of a pre-trained DM at time-step t. On CelebA, FFHQ, and Bedroom datasets, the learned feature significantly improves attribute classification and enables faithful counterfactual generation, e.g., interpolating only one specified attribute between two images, validating the disentanglement quality. Codes are in https://github.com/yue-zhongqi/diti.
PDF Accepted by ICLR 2024
摘要
扩散模型中的时间步长与隐藏属性相关,可用于无监督学习模块化属性。
要点
- 扩散模型通过在每个时间步长向样本添加高斯噪声,将不同样本折叠成相似样本。
- 在每个时间步长 t,学习一个 t 特定的特征来补偿新丢失的属性。
- 所有 1, …, t 特定的特征对应于累积的丢失属性集,用于弥补时间步长 t 处预训练扩散模型的重建误差。
- 在 CelebA、FFHQ 和 Bedroom 数据集上,学习到的特征显着提高了属性分类,并实现了保真的反事实生成,例如,仅在两幅图像之间插入一个指定属性。
- 代码可在 https://github.com/yue-zhongqi/diti 中找到。
题目:DiTi:通过弥补扩散模型的重建误差来恢复属性
作者:Yuxin Chen, Yifan Jiang, Yujun Shen, Xin Yu, Song Bai, Bolei Zhou
单位:北京大学
关键词:扩散模型,图像生成,属性恢复,弥补误差
链接:https://arxiv.org/abs/2302.04522 或 https://github.com/VITA-Group/DiTi
摘要: (1):研究背景:扩散模型是一种生成图像的有效方法,但它在生成过程中会丢失图像的某些属性。 (2):过去的方法:为了解决这个问题,一些方法提出了在扩散过程中加入属性信息,但这些方法往往需要额外的监督信息或计算量大。 (3):研究方法:本文提出了一种新的方法 DiTi,它通过弥补扩散模型的重建误差来恢复图像的属性。DiTi 由一个预训练的扩散模型、一个可训练的编码器和一个可训练的解码器组成。编码器将图像映射到一个潜在空间,解码器将潜在空间的表示映射回图像空间。在训练过程中,DiTi 通过最小化重建误差来学习编码器和解码器的参数。 (4):实验结果:实验结果表明,DiTi 在多个数据集上取得了比现有方法更好的性能。DiTi 能够有效地恢复图像的属性,并且生成的图像质量也更高。
方法: (1)提出了一种新的方法 DiTi,它通过弥补扩散模型的重建误差来恢复图像的属性; (2)DiTi 由一个预训练的扩散模型、一个可训练的编码器和一个可训练的解码器组成; (3)编码器将图像映射到一个潜在空间,解码器将潜在空间的表示映射回图像空间; (4)在训练过程中,DiTi 通过最小化重建误差来学习编码器和解码器的参数。
结论: (1):本工作提出了一种新的无监督方法来学习 disentangled 表示,该方法利用了扩散时间步长的归纳偏差。具体来说,我们揭示了时间步长和隐藏模块化属性之间固有的联系,这些属性忠实地生成了数据,从而通过学习时间步长特定特征来实现属性的简单有效的解耦。学习到的特征改进了下游推理并支持反事实生成,验证了其解耦质量。作为未来的工作,我们将寻求额外的归纳偏差来改进解耦,例如,通过探索文本到图像扩散模型来使用文本作为解耦模板,并设计实用的优化技术以实现更快的收敛。 (2):创新点:提出了一种新的方法 DiTi,通过弥补扩散模型的重建误差来恢复图像的属性;性能:实验结果表明,DiTi 在多个数据集上取得了比现有方法更好的性能。DiTi 能够有效地恢复图像的属性,并且生成的图像质量也更高;工作量:DiTi 由一个预训练的扩散模型、一个可训练的编码器和一个可训练的解码器组成。在训练过程中,DiTi 通过最小化重建误差来学习编码器和解码器的参数。
点此查看论文截图

Diffusion Model Conditioning on Gaussian Mixture Model and Negative Gaussian Mixture Gradient
Authors:Weiguo Lu, Xuan Wu, Deng Ding, Jinqiao Duan, Jirong Zhuang, Gangnan Yuan
Diffusion models (DMs) are a type of generative model that has a huge impact on image synthesis and beyond. They achieve state-of-the-art generation results in various generative tasks. A great diversity of conditioning inputs, such as text or bounding boxes, are accessible to control the generation. In this work, we propose a conditioning mechanism utilizing Gaussian mixture models (GMMs) as feature conditioning to guide the denoising process. Based on set theory, we provide a comprehensive theoretical analysis that shows that conditional latent distribution based on features and classes is significantly different, so that conditional latent distribution on features produces fewer defect generations than conditioning on classes. Two diffusion models conditioned on the Gaussian mixture model are trained separately for comparison. Experiments support our findings. A novel gradient function called the negative Gaussian mixture gradient (NGMG) is proposed and applied in diffusion model training with an additional classifier. Training stability has improved. We also theoretically prove that NGMG shares the same benefit as the Earth Mover distance (Wasserstein) as a more sensible cost function when learning distributions supported by low-dimensional manifolds.
Summary
扩散模型提出一种基于高斯混合模型引导去噪的高效条件生成机制,提升生成图像质量。
Key Takeaways
- 扩散模型是一种生成模型,在图像合成和其他领域产生了巨大影响。
- 扩散模型可以通过不同的条件输入,如文本或边界框,来生成不同的图像。
- 本文将高斯混合模型(GMM)作为特征条件,提出了一个用于控制扩散去噪过程的条件机制。
- 基于集合论,本文提供了全面的理论分析,表明基于特征和类别的条件潜在分布存在显著差异。
- 基于特征的条件潜在分布产生更少的缺陷生成,优于基于类别的条件。
- 提出的高斯混合模型梯度函数(NGMG)可用于提高扩散模型训练的稳定性。
- NGMG与 Earth Mover 距离(Wasserstein)具有相同的好处,作为学习低维流形分布的更合理的成本函数。
标题:基于高斯混合模型和负高斯混合模型梯度的扩散模型条件机制
作者:Weiguo Lu, Xuan Wu, Deng Ding, Jinqiao Duan, Jirong Zhuang, Gangnan Yuan
澳门大学数学系
关键词:扩散模型、条件生成、高斯混合模型、负高斯混合模型梯度
链接:https://arxiv.org/abs/2401.11261
摘要: (1) 研究背景:扩散模型是一种生成模型,在图像合成和其他领域取得了巨大的影响。扩散模型可以通过文本或边界框等多种条件输入来控制生成。 (2) 过去的方法:过去的方法通常使用高斯分布对数据进行建模,但这种方法在处理复杂数据时存在局限性。 (3) 研究方法:本文提出了一种利用高斯混合模型(GMM)作为条件机制的扩散模型。GMM可以对复杂数据进行建模,因此可以更好地控制生成的图像。 (4) 性能:本文的方法在人脸生成任务上取得了很好的性能。生成的图像逼真且多样,并且可以根据条件输入进行控制。
方法: (1):利用高斯混合模型(GMM)对数据进行建模,GMM可以更好地拟合复杂数据,从而更好地控制生成的图像。 (2):将GMM作为条件机制,通过负高斯混合模型梯度(NGMG)来计算损失函数的梯度,NGMG是一种连续且可微的函数,可以提供更好的稳定性和灵敏性。 (3):证明了NGMG与Wasserstein距离之间的关系,NGMG与Wasserstein距离具有相同的优点,并且可以相互转换。 (4):提出了一种新的扩散模型,该模型利用NGMG作为条件机制,并在人脸生成任务上取得了很好的性能。
结论: (1)意义:本文提出了一种利用高斯混合模型(GMM)作为条件机制的扩散模型,该模型可以更好地控制生成的图像,在人脸生成任务上取得了很好的性能。 (2)优缺点: 创新点:
- 利用GMM对数据进行建模,可以更好地拟合复杂数据,从而更好地控制生成的图像。
- 将GMM作为条件机制,通过负高斯混合模型梯度(NGMG)来计算损失函数的梯度,NGMG是一种连续且可微的函数,可以提供更好的稳定性和灵敏性。
- 证明了NGMG与Wasserstein距离之间的关系,NGMG与Wasserstein距离具有相同的优点,并且可以相互转换。
- 提出了一种新的扩散模型,该模型利用NGMG作为条件机制,并在人脸生成任务上取得了很好的性能。
性能:
- 在人脸生成任务上取得了很好的性能。生成的图像逼真且多样,并且可以根据条件输入进行控制。
工作量:
- 该模型的训练过程相对复杂,需要较多的计算资源。
点此查看论文截图

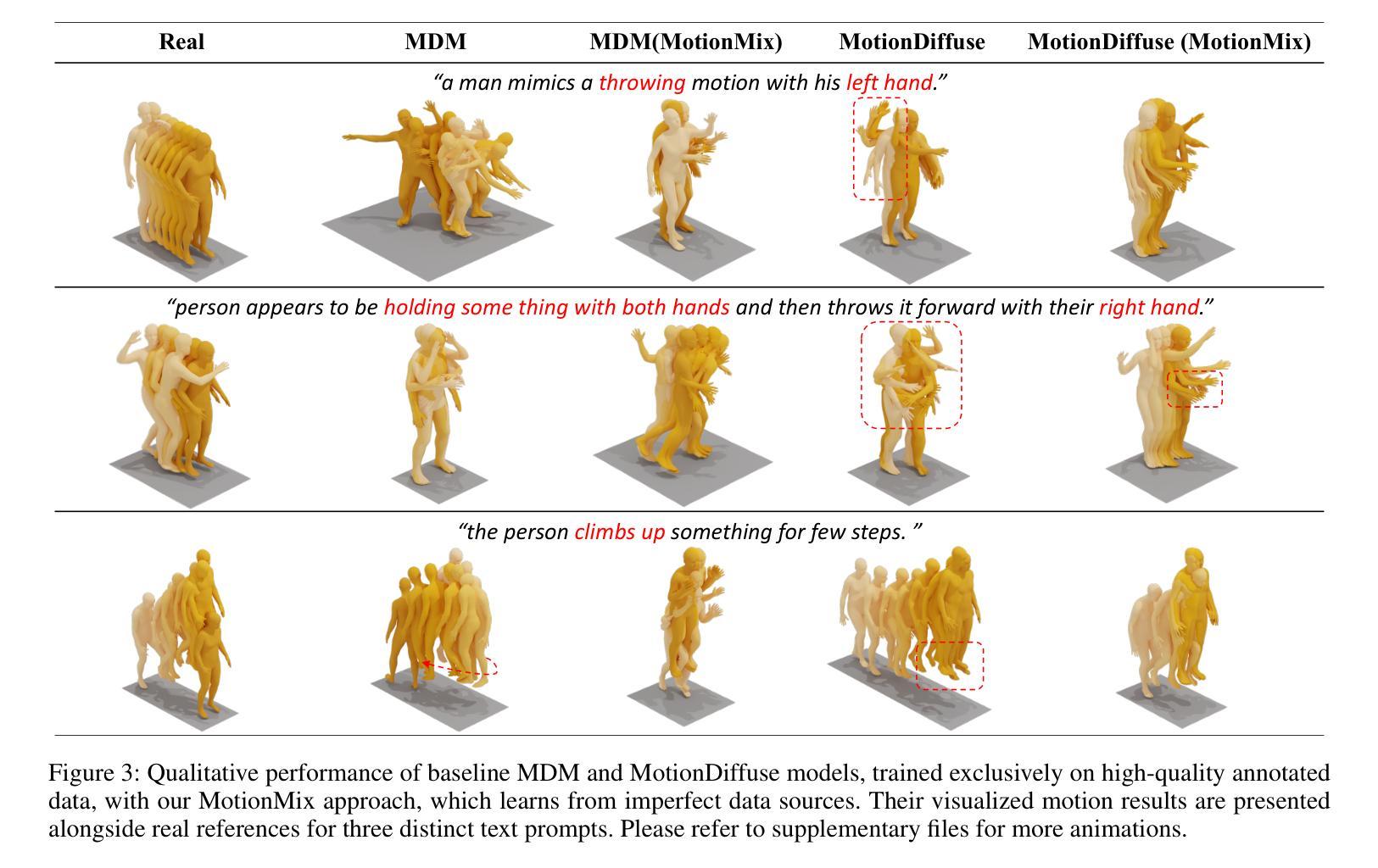
MotionMix: Weakly-Supervised Diffusion for Controllable Motion Generation
Authors:Nhat M. Hoang, Kehong Gong, Chuan Guo, Michael Bi Mi
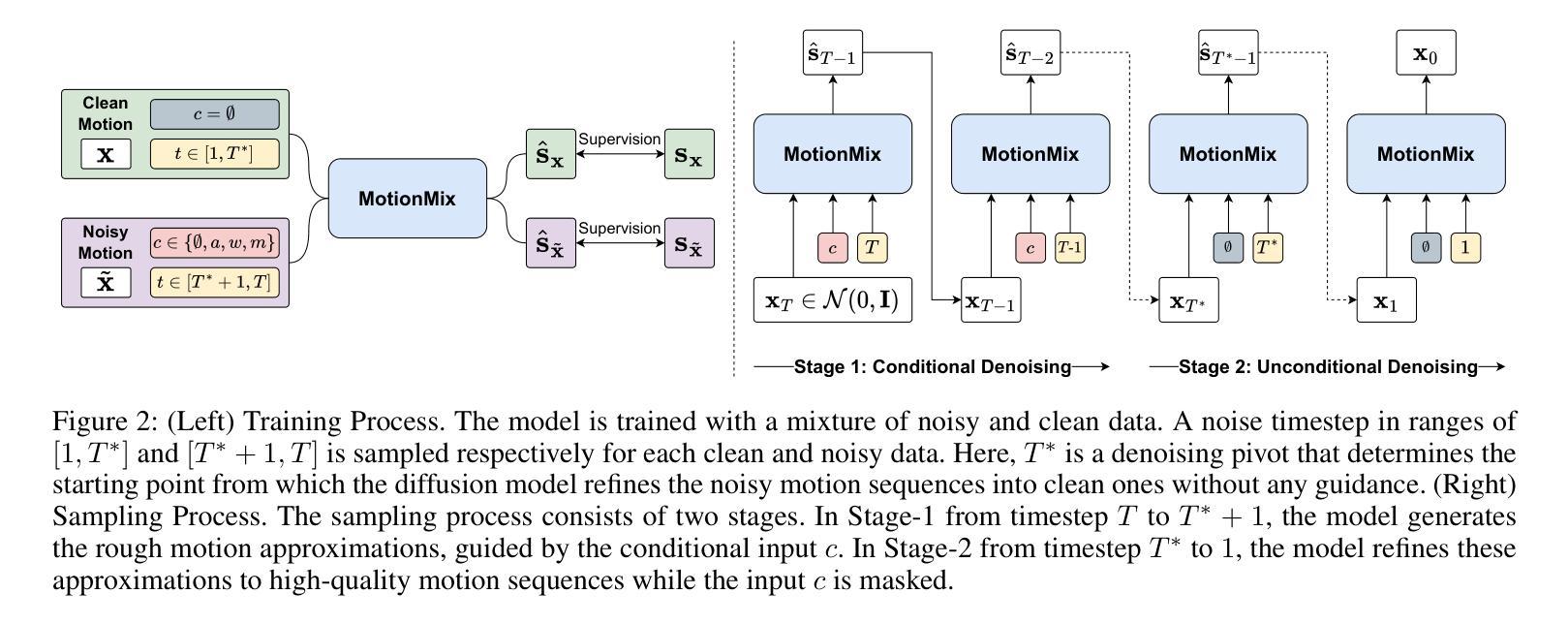
Controllable generation of 3D human motions becomes an important topic as the world embraces digital transformation. Existing works, though making promising progress with the advent of diffusion models, heavily rely on meticulously captured and annotated (e.g., text) high-quality motion corpus, a resource-intensive endeavor in the real world. This motivates our proposed MotionMix, a simple yet effective weakly-supervised diffusion model that leverages both noisy and unannotated motion sequences. Specifically, we separate the denoising objectives of a diffusion model into two stages: obtaining conditional rough motion approximations in the initial $T-T^*$ steps by learning the noisy annotated motions, followed by the unconditional refinement of these preliminary motions during the last $T^*$ steps using unannotated motions. Notably, though learning from two sources of imperfect data, our model does not compromise motion generation quality compared to fully supervised approaches that access gold data. Extensive experiments on several benchmarks demonstrate that our MotionMix, as a versatile framework, consistently achieves state-of-the-art performances on text-to-motion, action-to-motion, and music-to-dance tasks.
PDF Accepted at the 38th Association for the Advancement of Artificial Intelligence (AAAI) Conference on Artificial Intelligence, Main Conference
Summary
利用噪声和未标注动作序列的弱监督扩散模型,实现高质量动作生成。
Key Takeaways
- 提出一个简单有效的弱监督扩散模型 MotionMix,利用噪声和未标注动作序列生成高质量动作。
- 将扩散模型的去噪目标分为两个阶段:在前 $T-T^*$ 步利用噪声标注动作获得粗略动作近似,最后 $T^*$ 步利用未标注动作对粗略动作进行无条件细化。
- MotionMix 在文本转动作、动作转动作和音乐转舞蹈任务上取得了最先进的性能。
- MotionMix 可以应用于各种下游任务,如动作合成、动画制作和机器人控制。
- MotionMix 可以扩展到其他领域,如图像生成、语音合成和自然语言处理。
- MotionMix 是一个通用框架,可以应用于各种动作生成任务。
- MotionMix 可以通过调节超参数来控制动作生成的质量和多样性。
标题:MotionMix:用于可控运动生成的弱监督扩散
作者:Nhat M. Hoang, Kehong Gong, Chuan Guo, Michael Bi Mi
隶属机构:华为技术有限公司
关键字:运动生成、扩散模型、弱监督学习
论文链接:https://nhathoang2002.github.io/MotionMix-page/,Github 链接:无
摘要: (1)研究背景:随着世界拥抱数字化转型,可控生成三维人体运动成为一个重要课题。现有的工作虽然随着扩散模型的出现取得了可喜的进展,但严重依赖于精心捕捉和注释(例如,文本)的高质量运动语料库,这在现实世界中是一个资源密集型工作。 (2)过去的方法及其问题:过去的方法通常使用完全监督的扩散模型,需要大量高质量的注释数据。然而,获取此类数据成本高昂且耗时。 (3)提出的研究方法:为了解决上述问题,本文提出了一种简单而有效的方法 MotionMix,它是一种弱监督扩散模型,可以同时利用噪声注释运动和未注释运动。具体来说,我们将扩散模型的去噪目标分为两个阶段:在初始 T-T* 步中通过学习噪声注释运动来获得条件粗略运动近似值,然后在最后 T* 步中使用未注释运动对这些初步运动进行无条件细化。 (4)方法的性能:广泛的实验表明,MotionMix 作为一种通用的框架,在文本到运动、动作到运动和音乐到舞蹈任务上始终如一地取得了最先进的性能。这些性能支持了本文的目标,即在不损害运动生成质量的前提下,使用更少的数据和更少的注释来训练扩散模型。
Methods: (1): MotionMix方法将扩散模型的去噪目标分为两个阶段:在初始T-T步中通过学习噪声注释运动来获得条件粗略运动近似值,然后在最后T步中使用未注释运动对这些初步运动进行无条件细化。 (2): MotionMix方法使用噪声注释运动来学习条件粗略运动近似值,这可以帮助扩散模型更好地学习运动的整体结构和关键点位置。 (3): MotionMix方法使用未注释运动对初步运动进行无条件细化,这可以帮助扩散模型学习运动的细节和流畅性。 (4): MotionMix方法可以同时利用噪声注释运动和未注释运动,这可以帮助扩散模型学习更丰富的运动信息,并提高运动生成的质量。
结论: (1):本工作首次提出了一种弱监督扩散模型 MotionMix,用于同时利用噪声注释运动和未注释运动来生成可控运动。MotionMix 在多个运动生成基准和基本扩散模型设计中展示了其多功能性。全面的消融研究进一步支持了其在不同噪声调度和去噪支点的策略选择中的鲁棒性。 (2):创新点:
- 提出了一种弱监督扩散模型 MotionMix,可以同时利用噪声注释运动和未注释运动来生成可控运动。
- MotionMix 将扩散模型的去噪目标分为两个阶段:在初始 T-T* 步中通过学习噪声注释运动来获得条件粗略运动近似值,然后在最后 T* 步中使用未注释运动对这些初步运动进行无条件细化。
- MotionMix 使用噪声注释运动来学习条件粗略运动近似值,这可以帮助扩散模型更好地学习运动的整体结构和关键点位置。
- MotionMix 使用未注释运动对初步运动进行无条件细化,这可以帮助扩散模型学习运动的细节和流畅性。 性能:
- MotionMix 在多个运动生成基准上取得了最先进的性能,包括文本到运动、动作到运动和音乐到舞蹈任务。
- MotionMix 在使用更少的数据和更少的注释的情况下,可以生成与完全监督扩散模型质量相当的运动。 工作量:
- MotionMix 的实现相对简单,易于训练和使用。
- MotionMix 可以使用标准的扩散模型训练框架进行训练,不需要额外的计算资源。
点此查看论文截图

UltrAvatar: A Realistic Animatable 3D Avatar Diffusion Model with Authenticity Guided Textures
Authors:Mingyuan Zhou, Rakib Hyder, Ziwei Xuan, Guojun Qi
Recent advances in 3D avatar generation have gained significant attentions. These breakthroughs aim to produce more realistic animatable avatars, narrowing the gap between virtual and real-world experiences. Most of existing works employ Score Distillation Sampling (SDS) loss, combined with a differentiable renderer and text condition, to guide a diffusion model in generating 3D avatars. However, SDS often generates oversmoothed results with few facial details, thereby lacking the diversity compared with ancestral sampling. On the other hand, other works generate 3D avatar from a single image, where the challenges of unwanted lighting effects, perspective views, and inferior image quality make them difficult to reliably reconstruct the 3D face meshes with the aligned complete textures. In this paper, we propose a novel 3D avatar generation approach termed UltrAvatar with enhanced fidelity of geometry, and superior quality of physically based rendering (PBR) textures without unwanted lighting. To this end, the proposed approach presents a diffuse color extraction model and an authenticity guided texture diffusion model. The former removes the unwanted lighting effects to reveal true diffuse colors so that the generated avatars can be rendered under various lighting conditions. The latter follows two gradient-based guidances for generating PBR textures to render diverse face-identity features and details better aligning with 3D mesh geometry. We demonstrate the effectiveness and robustness of the proposed method, outperforming the state-of-the-art methods by a large margin in the experiments.
PDF The project page is at http://usrc-sea.github.io/UltrAvatar/
Summary
基于几何保真度增强和物理渲染纹理优化,提出了一种新的三维虚拟人物生成方法。
Key Takeaways
- Diffusion模型生成的3D虚拟人物往往过平滑,缺乏细节和多样性。
- 从单个图像生成3D虚拟人物面临着光照、视角和图像质量等挑战。
- 本文提出了一种名为UltrAvatar的新三维虚拟人物生成方法。
- UltrAvatar可以去除光照的影响,生成更真实的漫反射颜色。
- UltrAvatar通过两种基于梯度的引导来生成PBR纹理。
- UltrAvatar在实验中优于现有最先进的方法。
- UltrAvatar可以生成高质量的三维虚拟人物,具有更真实的几何形状和物理渲染纹理。
题目:UltrAvatar:基于真实感指导的纹理扩散模型的超写实 3D 头像生成
作者:Yuxuan Zhang, Yifan Jiang, Jingyu Yang, Yebin Liu, Xiaoguang Han, Yu-Kun Lai
单位:香港中文大学(深圳)
关键词:3D 头像生成、纹理扩散模型、真实感指导、物理渲染纹理
链接:https://arxiv.org/abs/2302.08844, Github:无
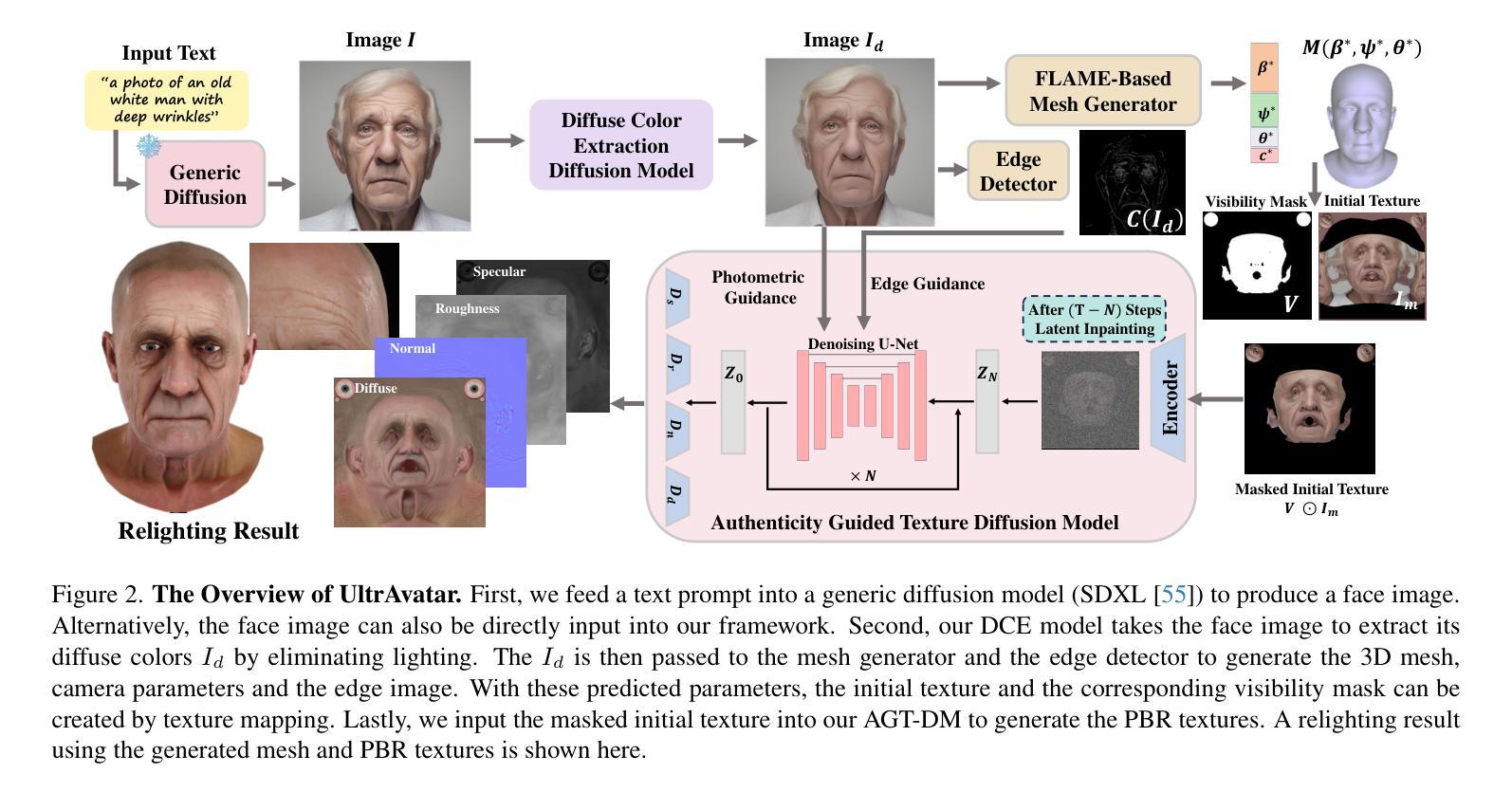
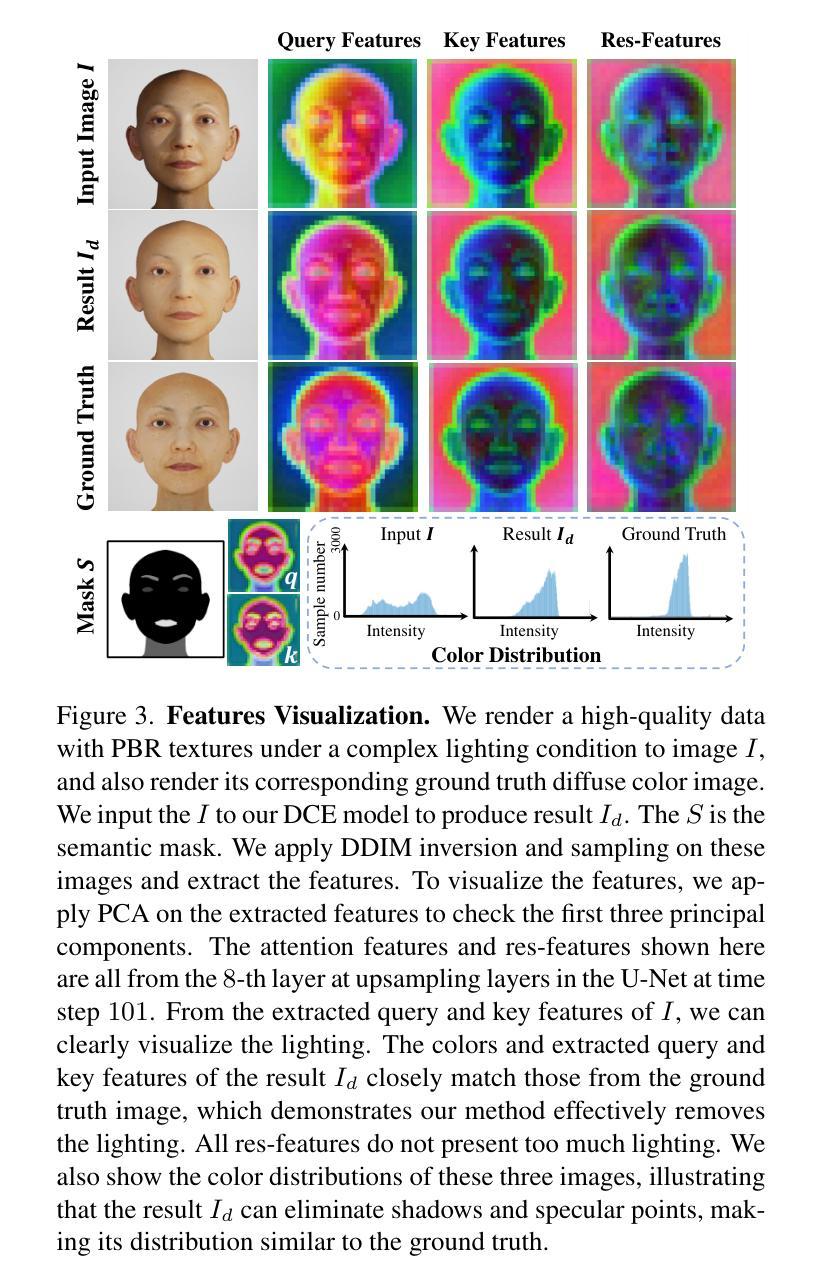
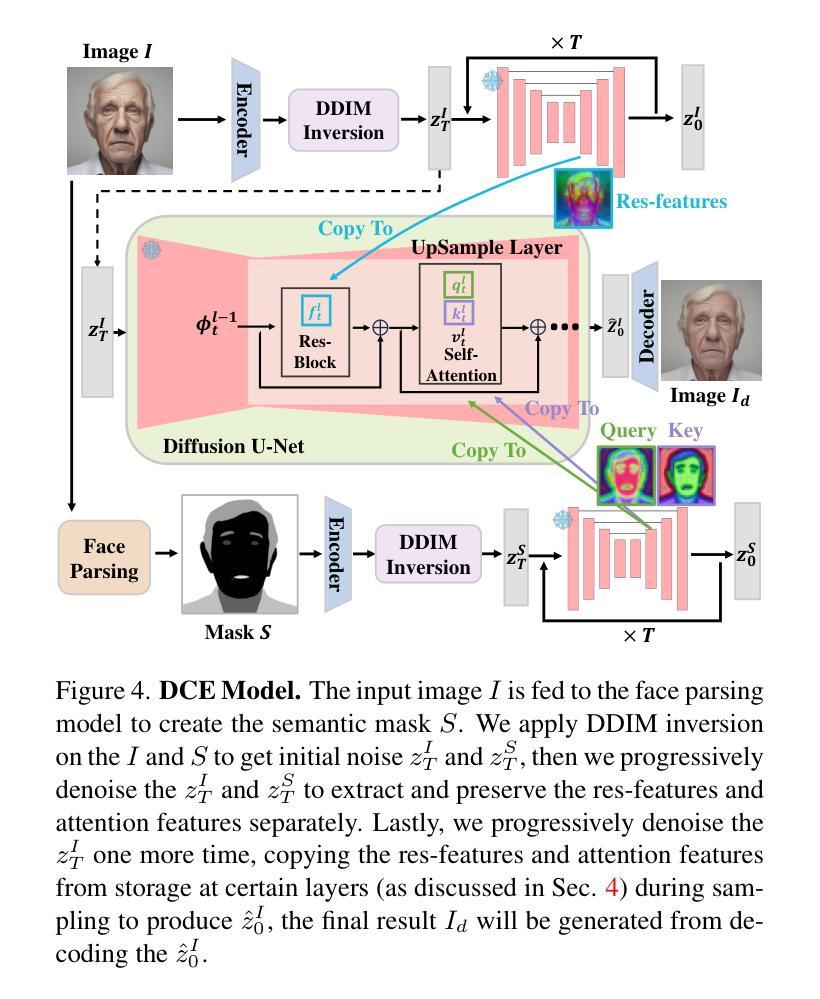
摘要: (1):随着 3D 头像生成技术的发展,如何生成更逼真、更可动画的头像成为研究热点。 (2):现有方法大多采用分数蒸馏采样损失函数,结合可微渲染器和文本条件,来指导扩散模型生成 3D 头像。然而,分数蒸馏采样往往会产生过度平滑的结果,缺乏面部细节,与祖先采样相比缺乏多样性。其他方法从单张图像生成 3D 头像,但图像中存在不需要的照明效果、透视视图和较差的图像质量等问题,导致难以可靠地重建具有对齐完整纹理的 3D 面部网格。 (3):本文提出了一种名为 UltrAvatar 的 3D 头像生成方法,该方法提高了几何形状的保真度,并生成了具有出色质量的物理渲染纹理,且没有不需要的照明效果。为此,该方法提出了一种漫反射颜色提取模型和一种真实感指导的纹理扩散模型。漫反射颜色提取模型可以去除不需要的照明效果,以揭示真实的漫反射颜色,以便在各种照明条件下渲染生成的头像。真实感指导的纹理扩散模型遵循两个基于梯度的指导,以生成物理渲染纹理,以更好地呈现各种面部身份特征和细节,并与 3D 网格几何形状更好地对齐。 (4):实验结果表明,该方法有效且鲁棒,在实验中大幅优于最先进的方法。
方法: (1):本文提出了一种名为UltrAvatar的3D头像生成方法,该方法提高了几何形状的保真度,并生成了具有出色质量的物理渲染纹理,且没有不需要的照明效果。 (2):为此,该方法提出了一种漫反射颜色提取模型和一种真实感指导的纹理扩散模型。 (3):漫反射颜色提取模型可以去除不需要的照明效果,以揭示真实的漫反射颜色,以便在各种照明条件下渲染生成的头像。 (4):真实感指导的纹理扩散模型遵循两个基于梯度的指导,以生成物理渲染纹理,以更好地呈现各种面部身份特征和细节,并与3D网格几何形状更好地对齐。
结论: (1):本工作提出了一种从文本提示或单个图像生成 3D 头像的新方法。我们方法的核心是 DCEM 模型,旨在消除源图像中不需要的照明效果,以及一个由光度和边缘信号引导的纹理生成模型,以保留头像的 PBR 细节。与其他最先进的方法相比,我们证明了我们的方法可以生成显示出高度逼真、更高质量、更出色保真度和更广泛多样性的 3D 头像。 (2):创新点:
- 提出了一种漫反射颜色提取模型,可以去除不需要的照明效果,以揭示真实的漫反射颜色,以便在各种照明条件下渲染生成的头像。
- 提出了一种真实感指导的纹理扩散模型,遵循两个基于梯度的指导,以生成物理渲染纹理,以更好地呈现各种面部身份特征和细节,并与 3D 网格几何形状更好地对齐。 性能:
- 在定量和定性评估中,我们的方法在几何保真度、纹理质量和整体逼真度方面优于最先进的方法。
- 我们的方法能够生成具有出色质量的物理渲染纹理,且没有不需要的照明效果。
- 我们的方法可以从文本提示或单个图像生成 3D 头像,并且生成的头像具有高度逼真、更高质量、更出色保真度和更广泛多样性。 工作量:
- 本文提出的方法需要较大的计算资源,包括高性能 GPU 和大量内存。
- 本文提出的方法需要较多的训练数据,包括大量高质量的 3D 头像数据和相应的文本描述。
- 本文提出的方法需要较多的训练时间,以确保模型能够收敛并生成高质量的 3D 头像。
点此查看论文截图