⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-24 更新
A Fair Evaluation of Various Deep Learning-Based Document Image Binarization Approaches
Authors:Richin Sukesh, Mathias Seuret, Anguelos Nicolaou, Martin Mayr, Vincent Christlein
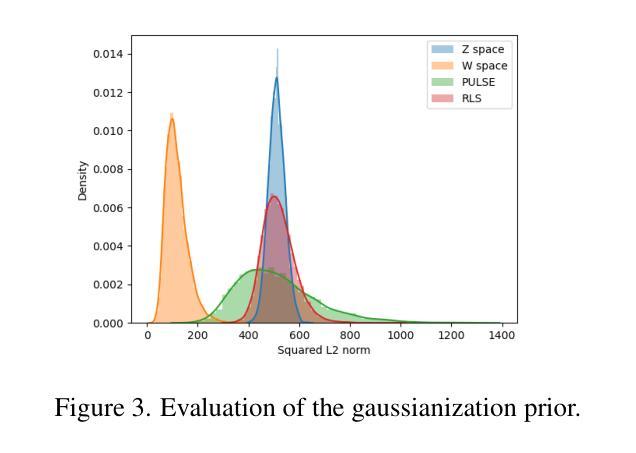
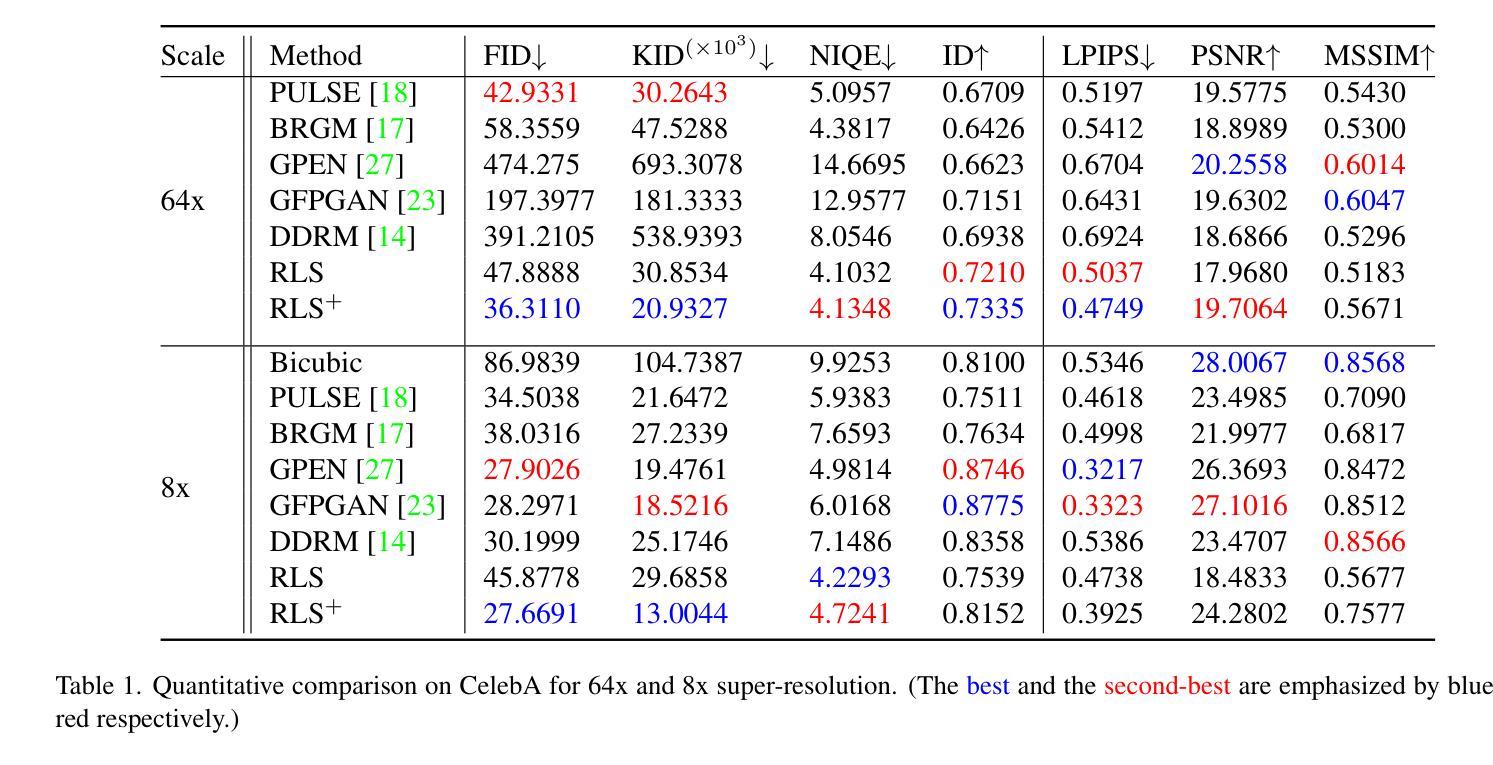
Binarization of document images is an important pre-processing step in the field of document analysis. Traditional image binarization techniques usually rely on histograms or local statistics to identify a valid threshold to differentiate between different aspects of the image. Deep learning techniques are able to generate binarized versions of the images by learning context-dependent features that are less error-prone to degradation typically occurring in document images. In recent years, many deep learning-based methods have been developed for document binarization. But which one to choose? There have been no studies that compare these methods rigorously. Therefore, this work focuses on the evaluation of different deep learning-based methods under the same evaluation protocol. We evaluate them on different Document Image Binarization Contest (DIBCO) datasets and obtain very heterogeneous results. We show that the DE-GAN model was able to perform better compared to other models when evaluated on the DIBCO2013 dataset while DP-LinkNet performed best on the DIBCO2017 dataset. The 2-StageGAN performed best on the DIBCO2018 dataset while SauvolaNet outperformed the others on the DIBCO2019 challenge. Finally, we make the code, all models and evaluation publicly available (https://github.com/RichSu95/Document_Binarization_Collection) to ensure reproducibility and simplify future binarization evaluations.
PDF DAS 2022
摘要
通过评估不同数据集上深度学习方法的文档二值化性能,可以帮助研究人员选择最适合自己任务的模型。
要点
- 深度学习方法能够通过学习与上下文相关的特征来生成图像的二值化版本,从而减少通常发生在文档图像中的退化错误。
- 在DIBCO2013数据集上,DE-GAN模型在评估时表现优于其他模型,而在DIBCO2017数据集上,DP-LinkNet表现最佳。
- 在DIBCO2018数据集上,2-StageGAN表现最佳,而在DIBCO2019挑战赛上,SauvolaNet优于其他模型。
- 代码、所有模型和评估已公开发布,以确保可重现性和简化未来的二值化评估。
论文标题:各种基于深度学习的文档图像二值化方法的公平评估
作者:Richin Sukesh, Mathias Seuret, Anguelos Nicolaou, Martin Mayr, Vincent Christlein
第一作者单位:Friedrich-Alexander-Universit¨atErlangen-N¨urnberg, Erlangen, Germany
关键词:二值化、深度学习、评估
论文链接:https://arxiv.org/abs/2401.11831 Github 代码链接:https://github.com/RichSu95/DocumentBinarizationCollection
摘要: (1) 研究背景: 文档图像的二值化是文档分析领域中一个重要的预处理步骤。传统的图像二值化技术通常依赖于直方图或局部统计数据来识别有效阈值,以区分图像的不同方面。深度学习技术能够通过学习对上下文相关的特征进行二值化,从而生成图像的二值化版本,这些特征对通常发生在文档图像中的退化不太容易出错。近年来,已经开发了许多基于深度学习的文档二值化方法。但是,如何选择合适的方法是一个问题。目前还没有研究对这些方法进行严格的比较。
(2) 过去的方法及其问题: 传统的图像二值化技术通常依赖于直方图或局部统计数据来识别有效阈值,以区分图像的不同方面。这些方法通常对图像中的噪声和退化敏感,并且可能产生不准确的二值化结果。
(3) 本文提出的研究方法: 本文的重点是评估不同的基于深度学习的方法,以在相同的评估协议下进行评估。在不同的文档图像二值化竞赛 (DIBCO) 数据集上评估这些方法,并获得了非常不同的结果。结果表明,在 DIBCO 2013 数据集上评估时,DE-GAN 模型能够比其他模型表现更好,而在 DIBCO 2017 数据集上,DP-LinkNet 表现最好。2-StageGAN 在 DIBCO 2018 数据集上表现最好,而 SauvolaNet 在 DIBCO 2019 挑战赛中优于其他方法。
(4) 方法在任务和性能上的表现: 在 DIBCO 2013 数据集上,DE-GAN 模型在 F-measure 指标上获得了 0.957 的最佳结果。在 DIBCO 2017 数据集上,DP-LinkNet 模型在 F-measure 指标上获得了 0.964 的最佳结果。在 DIBCO 2018 数据集上,2-StageGAN 模型在 F-measure 指标上获得了 0.968 的最佳结果。在 DIBCO 2019 挑战赛中,SauvolaNet 模型在 F-measure 指标上获得了 0.971 的最佳结果。这些结果表明,所提出的方法能够在不同的数据集上实现良好的性能,并且能够支持其目标。
方法: (1)DE-GAN:利用生成对抗网络来建模文档二值化问题,生成器和判别器共同工作,生成器生成干净的图像,判别器区分生成的图像和真实二值化图像。 (2)SauvolaNet:受传统 Sauvola 阈值算法启发,使用深度学习方法学习 Sauvola 参数,包括多窗口 Sauvola、像素级窗口注意力和自适应 Sauvola 阈值三个模块,以估计辅助阈值函数。 (3)Two-StageGAN:提出一种两阶段彩色文档图像二值化深度学习架构,利用生成对抗网络,第一阶段使用局部预测进行二值化,第二阶段使用调整大小的原始输入图像和第一阶段的输出进行全局二值化。 (4)DP-LinkNet:使用深度学习方法对文档图像进行二值化,采用 U-Net 作为编码器-解码器结构,使用链接网络来增强特征表示,并使用软最大池化来生成二值化结果。 (5)2-StageGAN:提出一种两阶段彩色文档图像二值化深度学习架构,利用生成对抗网络,第一阶段使用局部预测进行二值化,第二阶段使用调整大小的原始输入图像和第一阶段的输出进行全局二值化。
结论: (1):本文对七种基于深度学习的文档图像二值化方法进行了公平的评估,使用所有十个可用的 DIBCO 数据集对方法进行了评估。评估结果表明,在四个不同的测试数据集上,结果非常不同,没有明确的获胜者。总体而言,DE-GAN 方法在四个不同数据集上的平均排名最高,其次是 SauvolaNet。当单独比较指标时,2-StageGAN 方法表现最好,其次是 DE-GAN。然而,在非常不同的 DIBCO2019 数据集上,SauvolaNet 优于这些方法。对于未来的工作,我们希望使用不同的协议来评估这些方法。特别是,我们希望模拟每年挑战的 DIBCO 场景,以便与单一的 DIBCO 论文进行比较,即使用 2015-2016 年的数据集进行训练,然后使用 2017 年进行评估,将 2017 年添加到训练集中,重新训练并评估 2018 年,依此类推。使用额外的增强技术以及额外的训练数据集也值得研究,并且可能对二值化方法的整体性能产生巨大影响。此外,基于像素的评估并不是最优的。虽然 pFM 度量包含到脚本轮廓的距离,但研究间接措施可能是值得的,例如 OCR/HTR 准确性或纯粹基于骨架的度量。从实用的角度来看,推理时间也值得研究。这主要在时间质量文档图像二值化竞赛中进行了研究。 (2):创新点:本文对七种基于深度学习的文档图像二值化方法进行了公平的评估,使用所有十个可用的 DIBCO 数据集对方法进行了评估。评估结果表明,在四个不同的测试数据集上,结果非常不同,没有明确的获胜者。总体而言,DE-GAN 方法在四个不同数据集上的平均排名最高,其次是 SauvolaNet。当单独比较指标时,2-StageGAN 方法表现最好,其次是 DE-GAN。然而,在非常不同的 DIBCO2019 数据集上,SauvolaNet 优于这些方法。 性能:本文提出的方法能够在不同的数据集上实现良好的性能,并且能够支持其目标。 工作量:本文的工作量很大,需要对七种基于深度学习的文档图像二值化方法进行公平的评估,使用所有十个可用的 DIBCO 数据集对方法进行了评估。评估结果表明,在四个不同的测试数据集上,结果非常不同,没有明确的获胜者。总体而言,DE-GAN 方法在四个不同数据集上的平均排名最高,其次是 SauvolaNet。当单独比较指标时,2-StageGAN 方法表现最好,其次是 DE-GAN。然而,在非常不同的 DIBCO2019 数据集上,SauvolaNet 优于这些方法。
点此查看论文截图

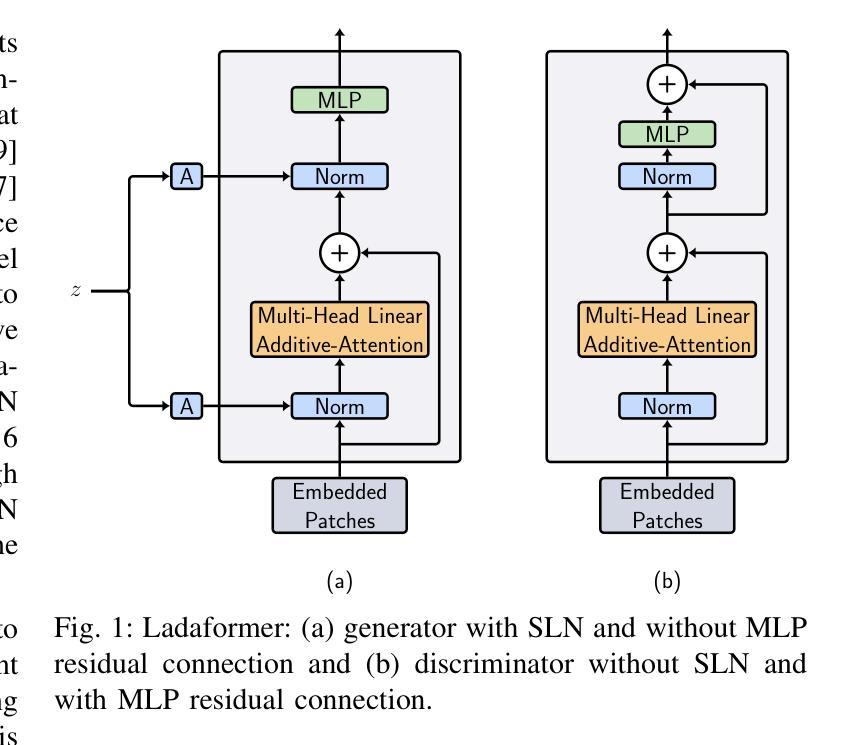
Efficient generative adversarial networks using linear additive-attention Transformers
Authors:Emilio Morales-Juarez, Gibran Fuentes-Pineda
Although the capacity of deep generative models for image generation, such as Diffusion Models (DMs) and Generative Adversarial Networks (GANs), has dramatically improved in recent years, much of their success can be attributed to computationally expensive architectures. This has limited their adoption and use to research laboratories and companies with large resources, while significantly raising the carbon footprint for training, fine-tuning, and inference. In this work, we present LadaGAN, an efficient generative adversarial network that is built upon a novel Transformer block named Ladaformer. The main component of this block is a linear additive-attention mechanism that computes a single attention vector per head instead of the quadratic dot-product attention. We employ Ladaformer in both the generator and discriminator, which reduces the computational complexity and overcomes the training instabilities often associated with Transformer GANs. LadaGAN consistently outperforms existing convolutional and Transformer GANs on benchmark datasets at different resolutions while being significantly more efficient. Moreover, LadaGAN shows competitive performance compared to state-of-the-art multi-step generative models (e.g. DMs) using orders of magnitude less computational resources.
PDF 12 pages, 6 figures
摘要
拉达生成对抗网络:基于新颖的 Transformer 块 Ladaformer 的高效生成对抗网络。
关键要点
- 拉达生成对抗网络是一种高效的生成对抗网络,由一个名为 Ladaformer 的新颖 Transformer 块构建而成。
- Ladaformer 的主要组成部分是线性加性注意力机制,它为每个头计算一个注意力向量,而不是二次点积注意力。
- 我们在生成器和判别器中都采用了 Ladaformer,这降低了计算复杂度并克服了 Transformer GANs 经常遇到的训练不稳定性。
- 拉达生成对抗网络在不同分辨率的基准数据集上始终优于现有的卷积和 Transformer GANs,同时具有更高的效率。
- 拉达生成对抗网络与最先进的多步生成模型(例如扩散模型)相比,显示出具有竞争力的性能,而使用的计算资源却少几个数量级。
题目:使用线性加性注意力 Transformer 的高效生成对抗网络
作者:Emilio Morales-Juarez, Gibran Fuentes-Pineda
隶属单位:墨西哥国立自治大学工程学院
关键词:图像生成、GAN、线性加性注意力、高效 Transformer
链接:https://arxiv.org/abs/2401.09596 Github:无
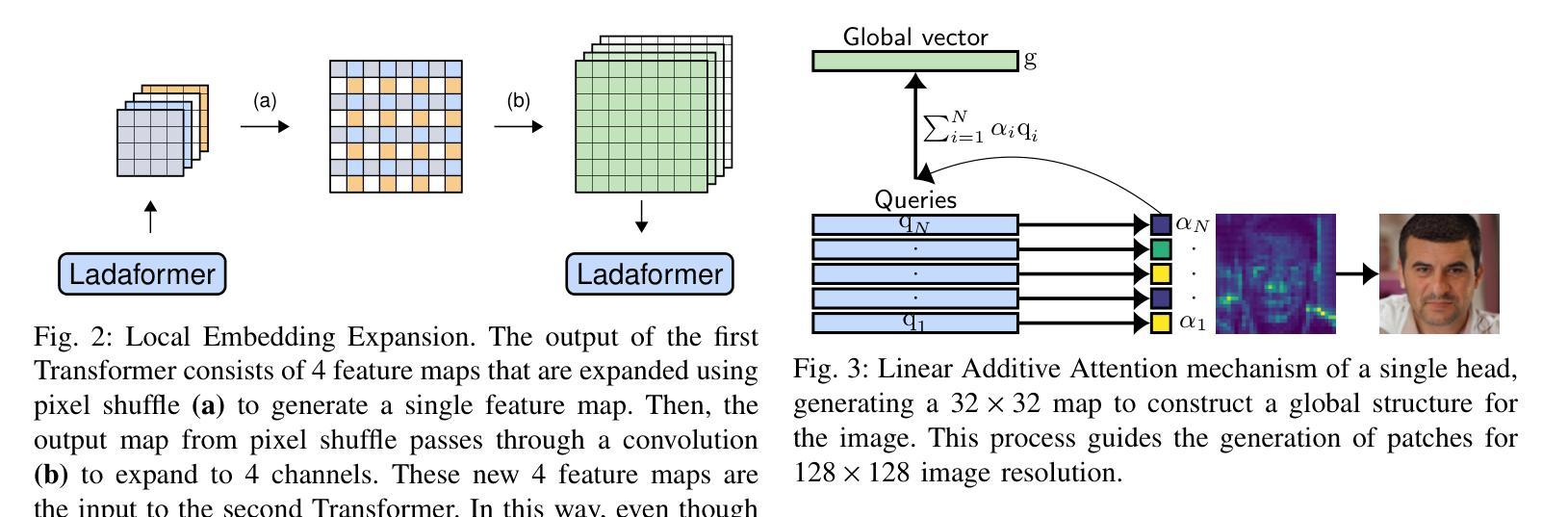
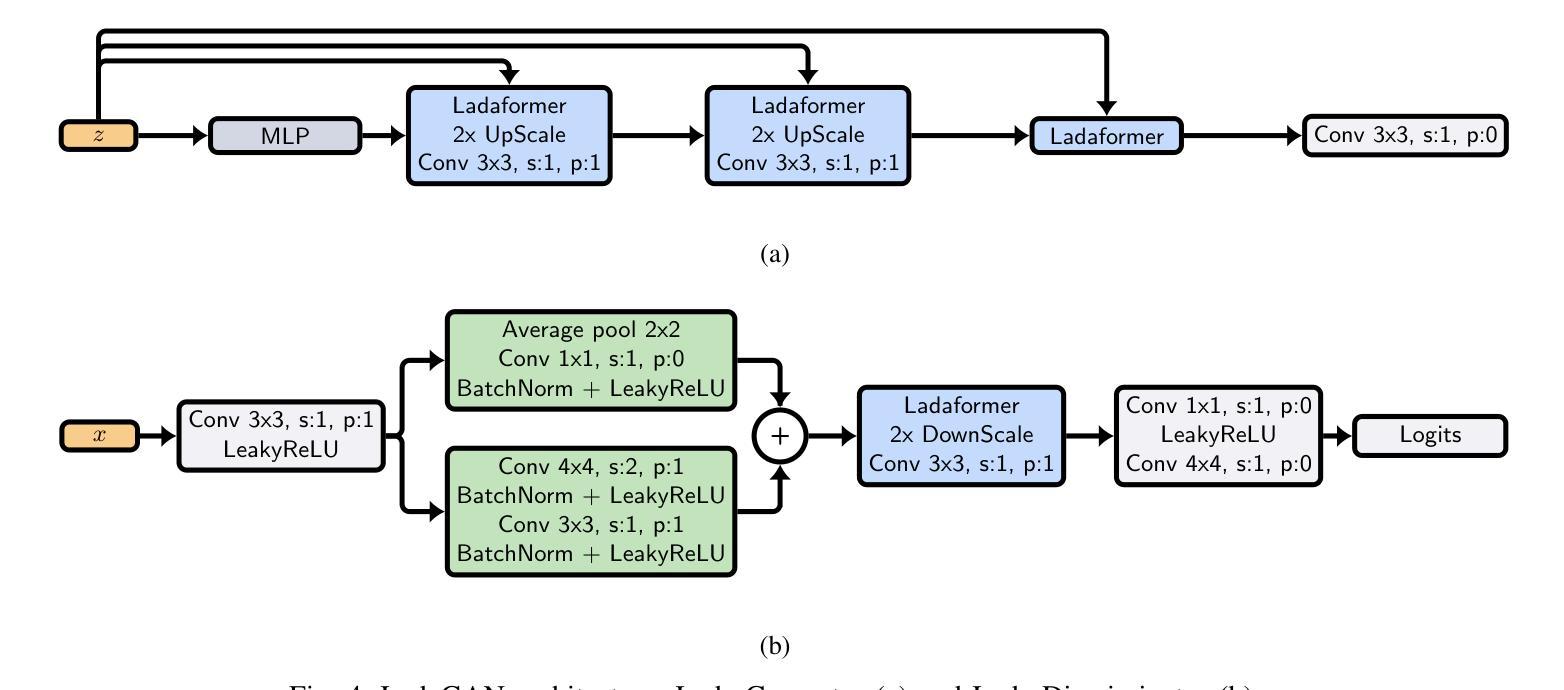
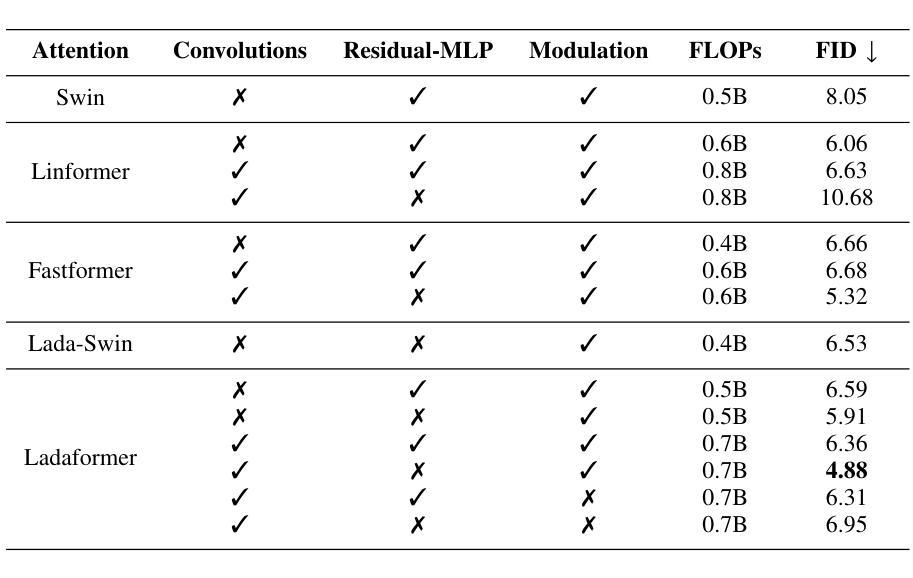
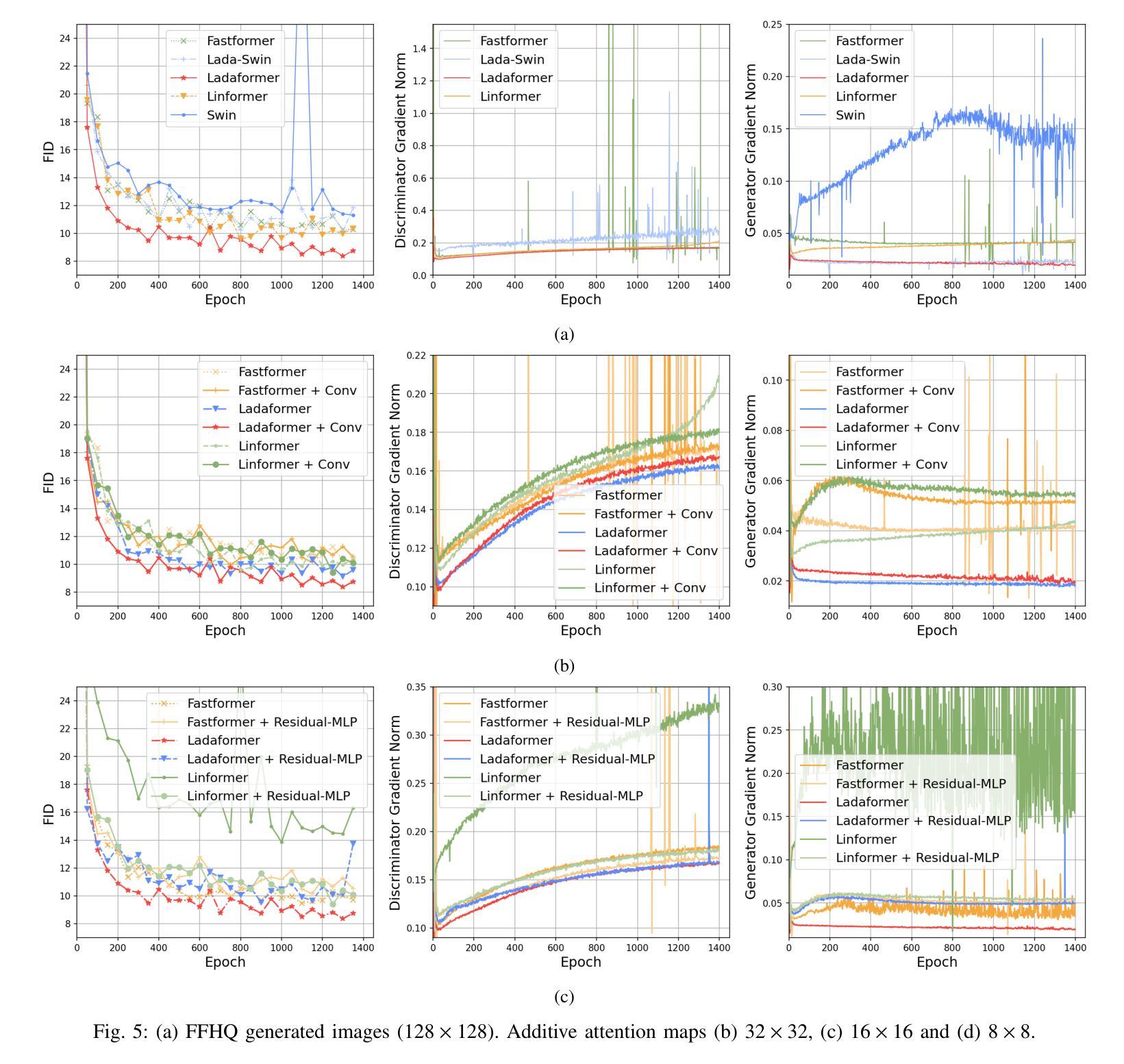
摘要: (1):随着深度生成模型在图像生成方面的能力不断提高,Diffusion Models (DM) 和 Generative Adversarial Networks (GAN) 等模型取得了显著的成功。然而,这些模型的成功很大程度上归功于计算成本高昂的架构。这限制了它们在研究实验室和资源较多的公司中的应用,同时大幅增加了训练、微调和推理的碳足迹。 (2):以往的方法包括基于卷积的 GAN 和基于 Transformer 的 GAN。基于卷积的 GAN 通常需要复杂的工程设计和复杂的模块来实现最先进的图像生成,导致计算成本高昂。基于 Transformer 的 GAN 则可以学习数据的光滑和连续的潜在空间表示,但自注意力机制可能会导致 GAN 训练更加不稳定,并且其 O(N^2) 的复杂度导致高计算需求。 (3):本文提出了一种新的 GAN 架构 LadaGAN,它基于称为 Ladaformer 的新型 Transformer 块。Ladaformer 的主要组件是线性加性注意力机制,它为每个头计算一个注意力向量,而不是二次点积注意力。这种机制可以降低计算复杂度,并克服与 Transformer GAN 相关的训练不稳定性。 (4):LadaGAN 在 CIFAR-10、CelebA、FFHQ 和 LSUNBedroom 等基准数据集上实现了具有竞争力的 FID 分数,同时所需的 FLOP 和参数明显更少。此外,与最先进的多步生成模型(例如 DM)相比,LadaGAN 在使用数量级更少的计算资源的情况下表现出竞争力。
方法: (1):本文提出了一种新的GAN架构LadaGAN,它基于称为Ladaformer的新型Transformer块。 (2):Ladaformer的主要组件是线性加性注意力机制,它为每个头计算一个注意力向量,而不是二次点积注意力。 (3):这种机制可以降低计算复杂度,并克服与TransformerGAN相关的训练不稳定性。 (4):LadaGAN在CIFAR-10、CelebA、FFHQ和LSUNBedroom等基准数据集上实现了具有竞争力的FID分数,同时所需的FLOP和参数明显更少。 (5):此外,与最先进的多步生成模型(例如DM)相比,LadaGAN在使用数量级更少的计算资源的情况下表现出竞争力。
结论: (1)本工作提出了一种新颖的 GAN 架构 LadaGAN,它基于一种称为 Ladaformer 的新型 Transformer 块。该块被证明比其他高效的 Transformer 块更适合生成器和判别器,允许在不同场景中进行稳定的 GAN 训练。我们的研究结果表明,Ladaformer 与卷积兼容,LadaGAN 具有梯度稳定性,并且对于图像生成任务非常有效。值得注意的是,LadaGAN 在不同分辨率的多个基准数据集上优于 ConvNet 和 TransformerGAN,同时所需的 FLOP 明显更少。此外,与扩散模型和一致性训练相比,LadaGAN 以极低的计算成本实现了具有竞争力的性能。据我们所知,LadaGAN 是第一个基于线性加性注意力机制的 GAN 架构。因此,我们的结果进一步证明了线性注意力机制的效率和表达能力,并为具有类似于现代扩散模型的性能的有效 GAN 架构的未来研究打开了大门。我们相信 LadaGAN 可以帮助实验室和研究小组在有限的计算预算下更快地进行实验,在不损失质量的情况下推进生成模型的应用,同时减少能源消耗并最大限度地减少碳足迹。作为未来的工作,我们计划在音频和文本到图像场景中训练 LadaGAN。此外,Ladaformer 块及其与卷积的兼容性还有待在其他任务(如图像和视频分类)中进行探索。
(2)创新点:
- 提出了一种新颖的 GAN 架构 LadaGAN,它基于一种称为 Ladaformer 的新型 Transformer 块。
- Ladaformer 的主要组成部分是线性加性注意力机制,它为每个头计算一个注意力向量,而不是二次点积注意力。
- 这种机制可以降低计算复杂度,并克服与 TransformerGAN 相关的训练不稳定性。
性能:
- LadaGAN 在 CIFAR-10、CelebA、FFHQ 和 LSUNBedroom 等基准数据集上实现了具有竞争力的 FID 分数,同时所需的 FLOP 和参数明显更少。
- 与最先进的多步生成模型(例如 DM)相比,LadaGAN 在使用数量级更少的计算资源的情况下表现出竞争力。
工作量:
- LadaGAN 的训练速度比基于卷积的 GAN 和基于 Transformer 的 GAN 更快。
- LadaGAN 的内存占用更少,这使得它可以在具有有限内存的设备上训练。
点此查看论文截图

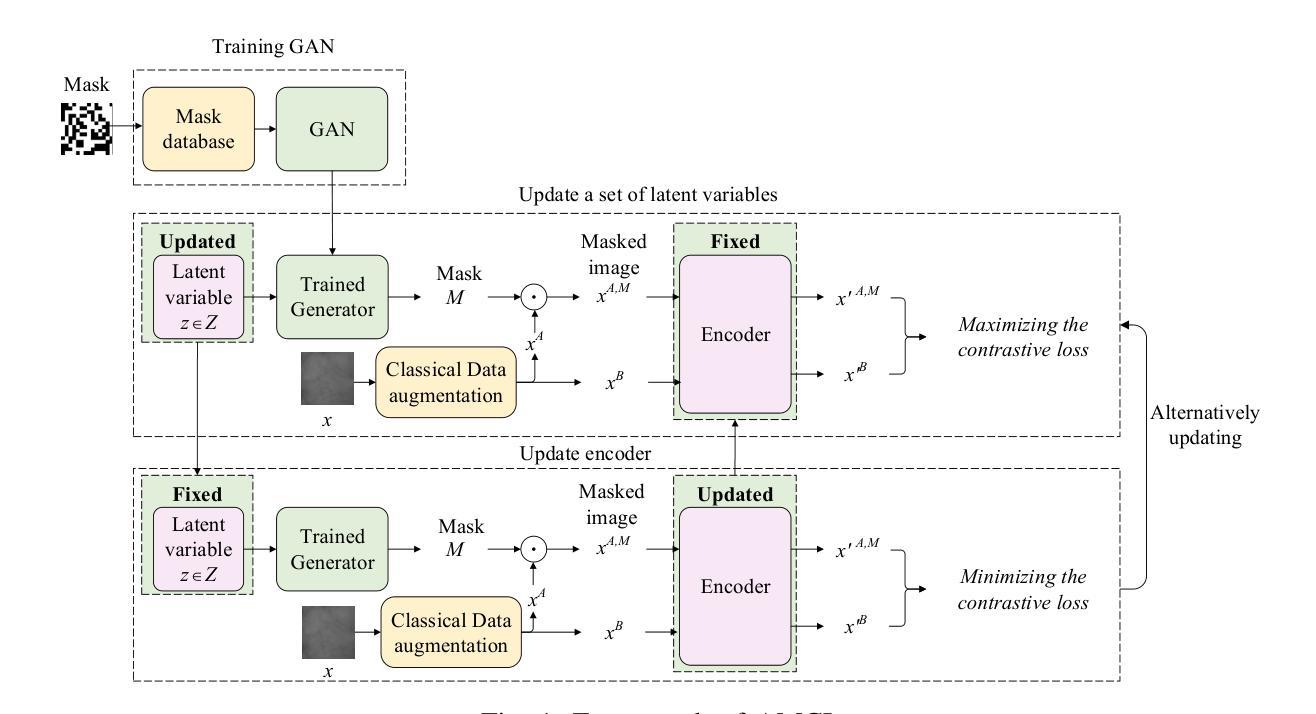
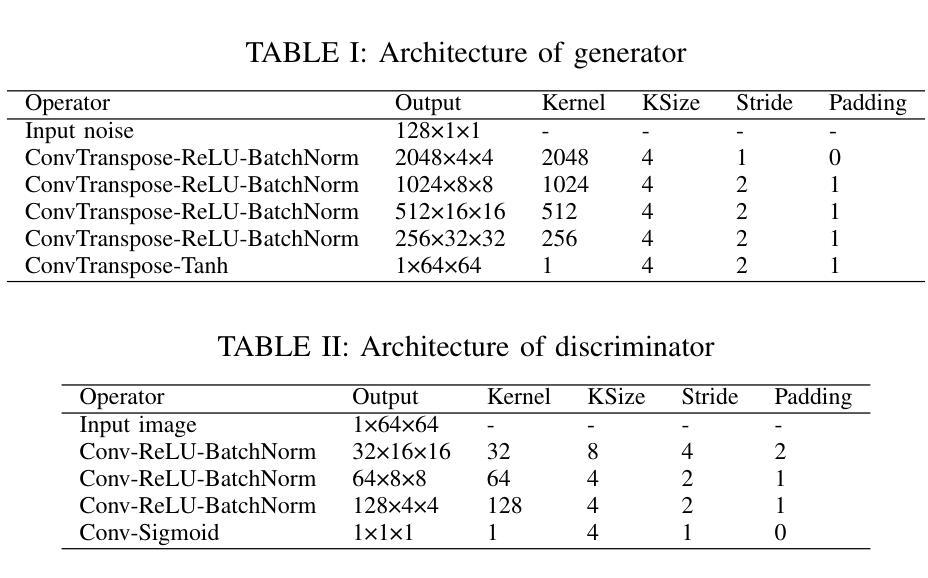
Adversarial Masking Contrastive Learning for vein recognition
Authors:Huafeng Qin, Yiquan Wu, Mounim A. El-Yacoubi, Jun Wang, Guangxiang Yang
Vein recognition has received increasing attention due to its high security and privacy. Recently, deep neural networks such as Convolutional neural networks (CNN) and Transformers have been introduced for vein recognition and achieved state-of-the-art performance. Despite the recent advances, however, existing solutions for finger-vein feature extraction are still not optimal due to scarce training image samples. To overcome this problem, in this paper, we propose an adversarial masking contrastive learning (AMCL) approach, that generates challenging samples to train a more robust contrastive learning model for the downstream palm-vein recognition task, by alternatively optimizing the encoder in the contrastive learning model and a set of latent variables. First, a huge number of masks are generated to train a robust generative adversarial network (GAN). The trained generator transforms a latent variable from the latent variable space into a mask space. Then, we combine the trained generator with a contrastive learning model to obtain our AMCL, where the generator produces challenging masking images to increase the contrastive loss and the contrastive learning model is trained based on the harder images to learn a more robust feature representation. After training, the trained encoder in the contrastive learning model is combined with a classification layer to build a classifier, which is further fine-tuned on labeled training data for vein recognition. The experimental results on three databases demonstrate that our approach outperforms existing contrastive learning approaches in terms of improving identification accuracy of vein classifiers and achieves state-of-the-art recognition results.
Summary
对抗遮罩对比学习通过生成具有挑战性的掩模来增强静脉识别的鲁棒性。
Key Takeaways
- 深度神经网络,如卷积神经网络(CNN)和Transformer,已被引入静脉识别并取得了最先进的性能。
- 然而,现有的手指静脉特征提取解决方案由于训练图像样本稀缺,仍然不是最优的。
- 本文提出了一种对抗遮罩对比学习(AMCL)方法,该方法通过交替优化对比学习模型中的编码器和一组潜在变量,生成具有挑战性的样本来训练一个更鲁棒的对比学习模型,用于下游的掌静脉识别任务。
- 首先,生成大量掩模来训练一个鲁棒的生成对抗网络(GAN)。训练后的生成器将潜在变量空间中的潜在变量转换为掩模空间。
- 然后,我们将训练后的生成器与对比学习模型相结合,得到我们的 AMCL,其中生成器产生具有挑战性的掩模图像以增加对比损失,对比学习模型根据更难的图像进行训练以学习更鲁棒的特征表示。
- 训练后,对比学习模型中训练后的编码器与分类层相结合构建分类器,该分类器在标记的训练数据上进一步微调以进行静脉识别。
- 三个数据库上的实验结果表明,我们的方法在提高静脉分类器的识别准确性方面优于现有的对比学习方法,并实现了最先进的识别结果。
题目:对抗掩码对比学习用于静脉识别
作者:Huafeng Qin, Yiquan Wu, Mounim A. El-Yacoubi, Jun Wang, Guangxiang Yang
单位:重庆市智能感知与区块链工程实验室,重庆工商大学计算机科学与信息工程学院
关键词:生物识别,静脉识别,对比学习,对抗学习,掩码
链接:https://arxiv.org/abs/2401.08079v1,Github 链接:无
摘要: (1):静脉识别由于其高安全性和隐私性而受到越来越多的关注。近年来,卷积神经网络(CNN)和 Transformer 等深度神经网络已被引入静脉识别并取得了最先进的性能。然而,尽管取得了这些进展,但由于训练图像样本稀少,现有的手指静脉特征提取解决方案仍然不是最优的。 (2):为了克服这个问题,本文提出了一种对抗掩码对比学习(AMCL)方法,通过交替优化对比学习模型中的编码器和一组潜在变量,为下游掌静脉识别任务生成具有挑战性的样本以训练更鲁棒的对比学习模型。首先,生成大量掩码来训练鲁棒的生成对抗网络(GAN)。训练后的生成器将来自潜在变量空间的潜在变量转换为掩码空间。然后,我们将训练后的生成器与对比学习模型结合起来得到我们的 AMCL,其中生成器产生具有挑战性的掩码图像以增加对比损失,并且对比学习模型基于更难的图像进行训练以学习更鲁棒的特征表示。训练后,对比学习模型中训练的编码器与分类层相结合构建分类器,该分类器在标记的训练数据上进一步微调以进行静脉识别。 (3):在三个数据库上的实验结果表明,我们的方法在提高静脉分类器的识别准确性方面优于现有的对比学习方法,并取得了最先进的识别结果。
方法: (1):本文提出了一种对抗掩码对比学习(AMCL)方法,通过交替优化对比学习模型中的编码器和一组潜在变量,为下游掌静脉识别任务生成具有挑战性的样本以训练更鲁棒的对比学习模型。 (2):首先,生成大量掩码来训练鲁棒的生成对抗网络(GAN)。训练后的生成器将来自潜在变量空间的潜在变量转换为掩码空间。 (3):然后,我们将训练后的生成器与对比学习模型结合起来得到我们的 AMCL,其中生成器产生具有挑战性的掩码图像以增加对比损失,并且对比学习模型基于更难的图像进行训练以学习更鲁棒的特征表示。 (4):训练后,对比学习模型中训练的编码器与分类层相结合构建分类器,该分类器在标记的训练数据上进一步微调以进行静脉识别。
结论: (1)本文提出了一种联合生成和对比学习框架用于静脉识别,该框架结合了 GAN 和对比学习来学习鲁棒的静脉分类器。首先,生成大量掩码来训练鲁棒的 GAN 以学习掩码分布空间。其次,将训练后的 GAN 与对比学习模型相结合得到我们的 AMCL,并以对抗的方式进行训练。具体来说,搜索一组潜在变量以生成具有挑战性的样本对来增加对比学习模型的损失。对比学习模型能够基于生成的困难样本学习鲁棒的特征表示。我们在三个公开数据库上的实验结果表明,我们的方法在提高静脉分类器的性能方面优于现有的对比学习方法,并取得了最先进的识别准确率。 (2)创新点:
- 提出了一种联合生成和对比学习的框架,用于静脉识别。
- 设计了一种鲁棒的 GAN 来学习掩码分布空间。
- 将训练后的 GAN 与对比学习模型相结合,以对抗的方式训练对比学习模型。
性能:
- 在三个公开数据库上的实验结果表明,我们的方法在提高静脉分类器的性能方面优于现有的对比学习方法,并取得了最先进的识别准确率。
工作量:
- 需要生成大量掩码来训练鲁棒的 GAN。
- 需要将训练后的 GAN 与对比学习模型相结合,并以对抗的方式训练对比学习模型。
点此查看论文截图

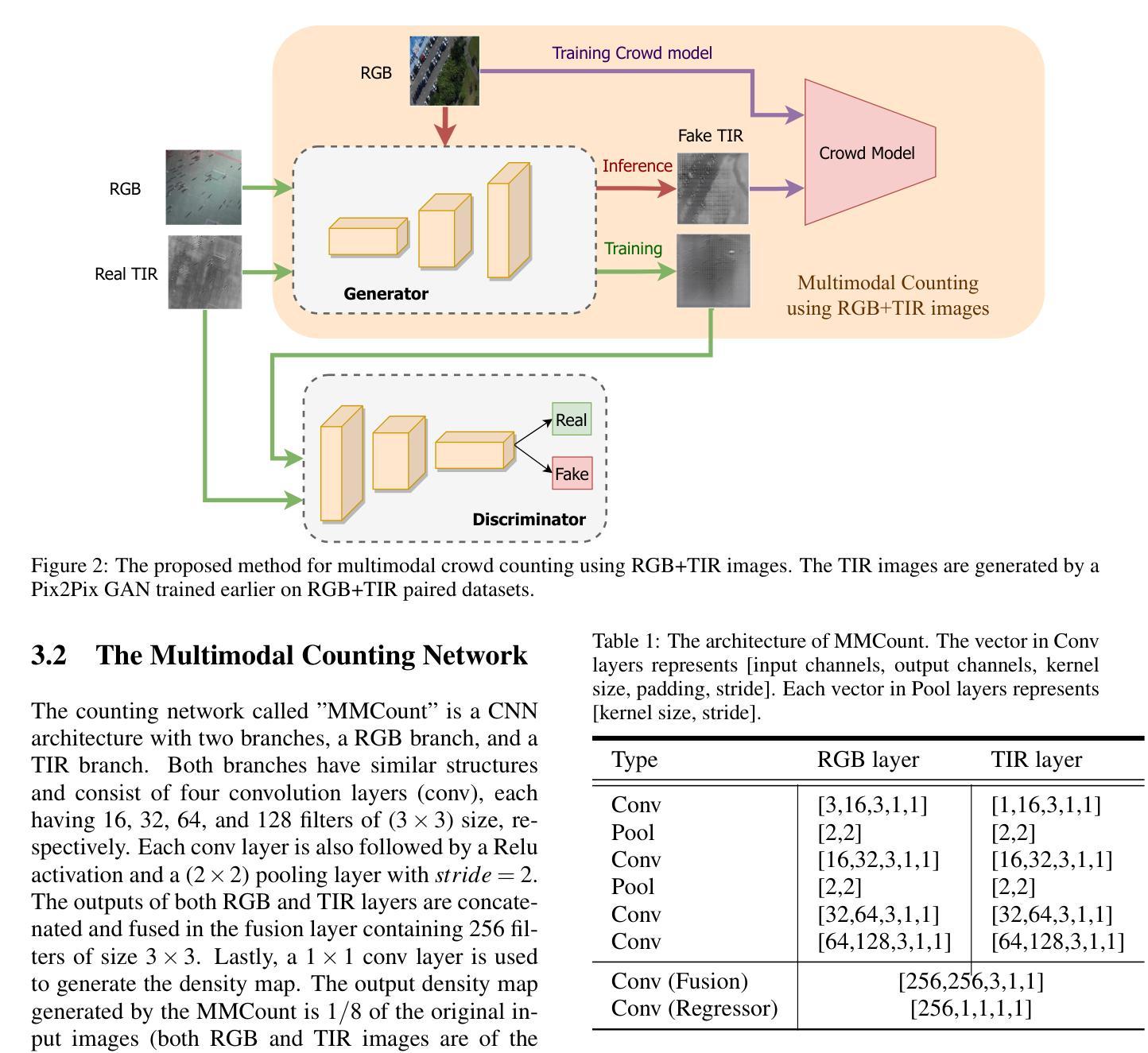
Multimodal Crowd Counting with Pix2Pix GANs
Authors:Muhammad Asif Khan, Hamid Menouar, Ridha Hamila
Most state-of-the-art crowd counting methods use color (RGB) images to learn the density map of the crowd. However, these methods often struggle to achieve higher accuracy in densely crowded scenes with poor illumination. Recently, some studies have reported improvement in the accuracy of crowd counting models using a combination of RGB and thermal images. Although multimodal data can lead to better predictions, multimodal data might not be always available beforehand. In this paper, we propose the use of generative adversarial networks (GANs) to automatically generate thermal infrared (TIR) images from color (RGB) images and use both to train crowd counting models to achieve higher accuracy. We use a Pix2Pix GAN network first to translate RGB images to TIR images. Our experiments on several state-of-the-art crowd counting models and benchmark crowd datasets report significant improvement in accuracy.
PDF Accepted version of the paper in 19th International Conference on Computer Vision Theory and Applications (VISAPP), Rome, Italy, 27-29 Feb, 2024,
Summary
利用生成对抗网络从彩色图像自动生成热红外图像,可大幅提升人群计数准确率。
Key Takeaways
- 大多数最先进的人群计数方法使用彩色 (RGB) 图像来学习人群的密度图,但在光线较差的密集人群场景中,这些方法通常难以实现更高的准确度。
- 最近,一些研究报告称,结合 RGB 和热图像可以提高人群计数模型的准确度。
- 虽然多模态数据可以产生更好的预测,但多模态数据可能并不总是事先可用。
- 本文提出使用生成对抗网络 (GAN) 从彩色 (RGB) 图像自动生成热红外 (TIR) 图像,并使用两者来训练人群计数模型以实现更高的准确度。
- 我们首先使用 Pix2Pix GAN 网络将 RGB 图像转换为 TIR 图像。
- 我们在几个最先进的人群计数模型和基准人群数据集上的实验表明,准确度有了显著提高。
题目:使用 Pix2PixGAN 进行多模态人群计数
作者:Muhammad Asif Khan, Hamid Menouar, Ridha Hamila
第一作者单位:卡塔尔大学卡塔尔移动创新中心
关键词:人群计数、CNN、密度估计、多模态、RGB、热成像
论文链接:https://arxiv.org/abs/2401.07591 Github 链接:无
摘要: (1):人群计数在人群管理、城市规划、安全监控、活动管理和公共安全等领域有着广泛的应用。深度学习的出现带来了人群计数技术的范式转变,在各种现实世界应用中实现了更高的准确性和可扩展性。 (2):大多数最先进的人群计数方法主要使用光学彩色图像,并且在合理的照明条件下效果较好。然而,在许多监控场景中,使用光学相机捕获的图像具有较差的照明条件,导致计数模型的性能较差。为了提高准确性,热红外 (TIR) 相机与光学相机一起使用,以捕获彩色 RGB 图像和热图像。然后,人群计数模型可以使用一个(单模态)或两个(多模态)RGB 和 TIR 图像来学习低光条件下的人群密度。 (3):本文提出使用生成对抗网络 (GAN) 从彩色 (RGB) 图像自动生成热红外 (TIR) 图像,并使用两者来训练人群计数模型以实现更高的准确性。我们首先使用 Pix2PixGAN 网络将 RGB 图像转换为 TIR 图像。 (4):我们在几个最先进的人群计数模型和基准人群数据集上进行的实验报告了准确性的显着提高。
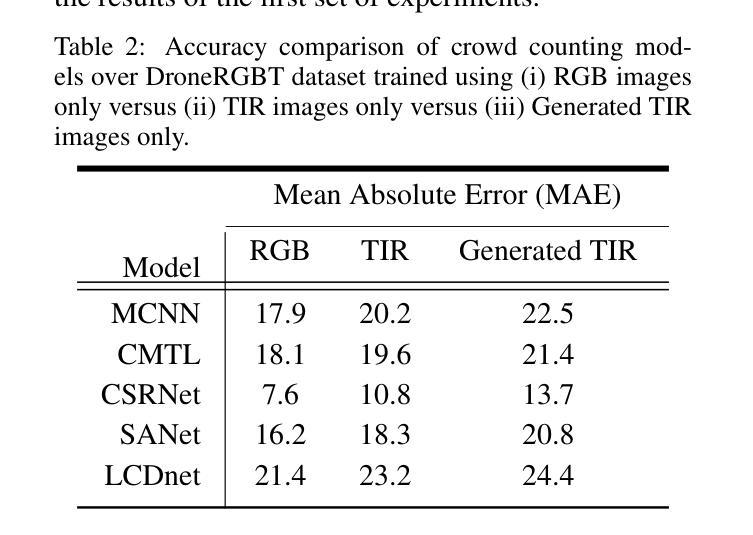
方法: (1):提出了一种使用 Pix2PixGAN 从 RGB 图像自动生成热红外 (TIR) 图像,并使用两者来训练人群计数模型以实现更高精度的框架,称为 MMCount。 (2):MMCount 由两个基本部分组成:Pix2PixGAN 和多模态人群计数网络。Pix2PixGAN 将光学 RGB 图像转换为 TIR 图像,人群模型使用 RGB 和 TIR 图像来预测人群密度图。 (3):Pix2PixGAN 由生成器和判别器组成。生成器将 RGB 图像转换为 TIR 图像,判别器将生成的 TIR 图像与真实 TIR 图像进行区分。 (4):多模态计数网络由 RGB 分支和 TIR 分支组成,两个分支都具有四个卷积层,输出连接并融合在融合层中,最后使用 1×1 卷积层生成密度图。 (5):使用头位置生成稀疏定位图,然后使用高斯核与 delta 函数卷积生成密度图,作为训练模型的真实值。 (6):使用 L2 损失函数训练人群计数模型,该损失函数计算目标密度图和预测密度图之间的欧几里德距离。 (7):在 DroneRGBT、ShanghaiTechPart-B 和 CARPK 数据集上评估了所提出的方法,并与基线模型进行了比较。 (8):实验结果表明,所提出的方法在单模态和多模态人群计数任务中都优于基线模型。
结论: (1):本文提出了一种使用 Pix2PixGAN 从 RGB 图像自动生成热红外 (TIR) 图像,并使用两者来训练人群计数模型以实现更高精度的框架,称为 MMCount。实验结果表明,所提出的方法在单模态和多模态人群计数任务中都优于基线模型。 (2):创新点:
- 提出了一种使用 Pix2PixGAN 从 RGB 图像自动生成 TIR 图像的方法。
- 提出了一种使用 RGB 和 TIR 图像来训练人群计数模型以实现更高精度的框架。
- 在几个最先进的人群计数模型和基准人群数据集上进行了实验,并报告了准确性的显着提高。 性能:
- 在 DroneRGBT、ShanghaiTechPart-B 和 CARPK 数据集上评估了所提出的方法,并与基线模型进行了比较。
- 实验结果表明,所提出的方法在单模态和多模态人群计数任务中都优于基线模型。 工作量:
- 使用 PyTorch 实现并开源了所提出的方法。
- 在多个 GPU 上训练了所提出的模型。
- 在几个基准人群数据集上评估了所提出的模型。
点此查看论文截图



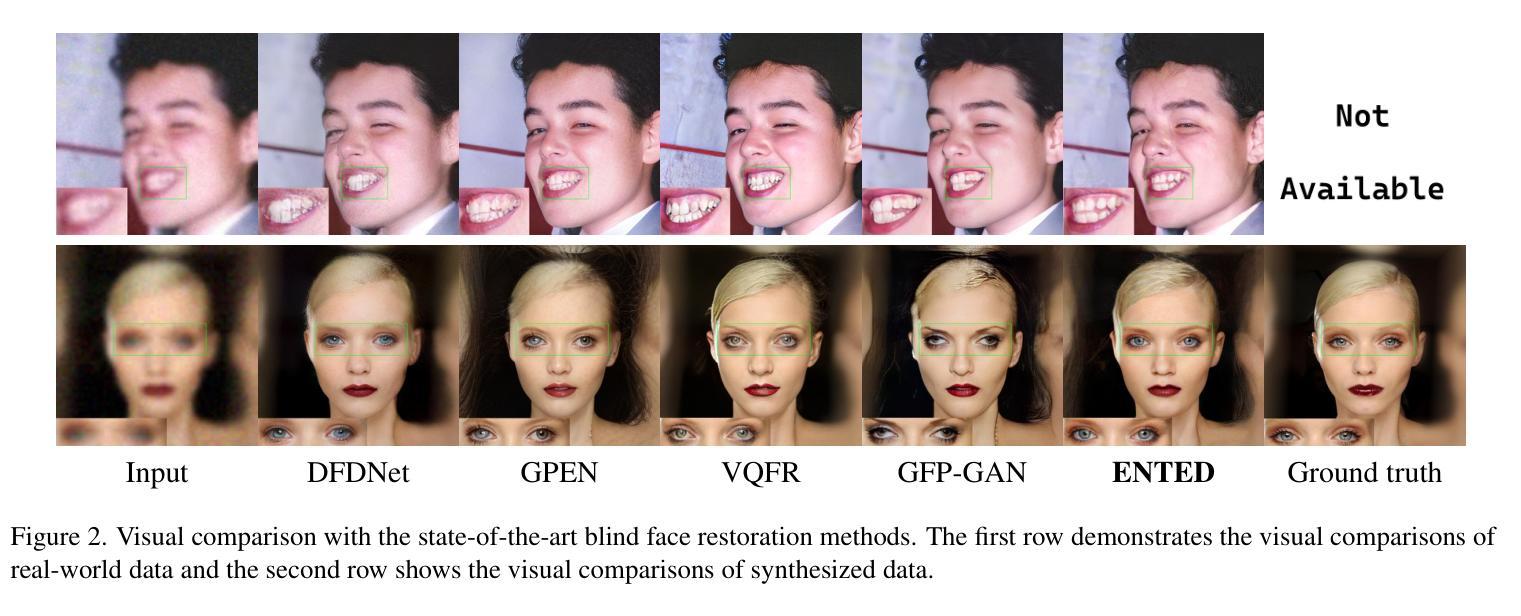
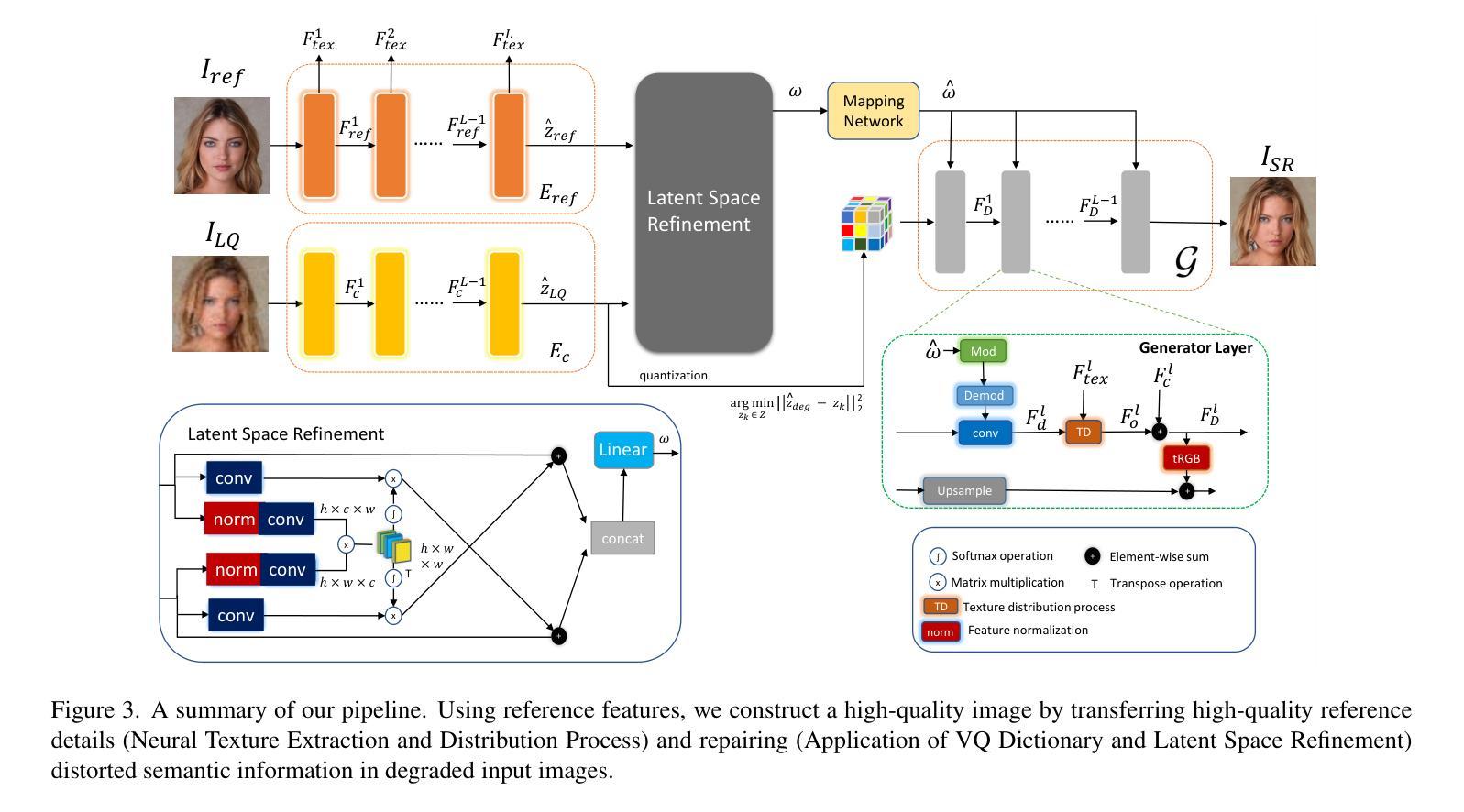
ENTED: Enhanced Neural Texture Extraction and Distribution for Reference-based Blind Face Restoration
Authors:Yuen-Fui Lau, Tianjia Zhang, Zhefan Rao, Qifeng Chen
We present ENTED, a new framework for blind face restoration that aims to restore high-quality and realistic portrait images. Our method involves repairing a single degraded input image using a high-quality reference image. We utilize a texture extraction and distribution framework to transfer high-quality texture features between the degraded input and reference image. However, the StyleGAN-like architecture in our framework requires high-quality latent codes to generate realistic images. The latent code extracted from the degraded input image often contains corrupted features, making it difficult to align the semantic information from the input with the high-quality textures from the reference. To overcome this challenge, we employ two special techniques. The first technique, inspired by vector quantization, replaces corrupted semantic features with high-quality code words. The second technique generates style codes that carry photorealistic texture information from a more informative latent space developed using the high-quality features in the reference image’s manifold. Extensive experiments conducted on synthetic and real-world datasets demonstrate that our method produces results with more realistic contextual details and outperforms state-of-the-art methods. A thorough ablation study confirms the effectiveness of each proposed module.
Summary
利用高品质参考图修复退化面部图像,将参考图和输入图像之间的高品质纹理特征传递,替换低质量语义特征并生成逼真纹理信息样式代码。
Key Takeaways
- 提出退化面部修复框架ENTED,从参考图像传递纹理特征。
- 使用风格GAN生成逼真图像需要高质量潜在码。
- 退化输入图像提取的潜在码特征不完整,难以对齐输入与参考图像的语义信息。
- 使用矢量量化技术,以优质码字替换损坏的语义特征。
- 生成样式码,从参考图像流形中的高质量特征生成更多逼真纹理信息。
- 该方法在合成和真实数据集上产生更逼真且包含更多细节的修复结果。
- 团队通过消融研究验证每个提出模块的作用与必要性。
题目:ENTED:用于基于参考图像的盲人面部修复的增强神经纹理提取和分布
作者:Yuen-Fui Lau、Tianjia Zhang、Zhefan Rao、Qifeng Chen
隶属机构:香港科技大学
关键词:盲人面部修复、参考图像、纹理提取和分布、矢量量化、风格编码
链接:https://arxiv.org/abs/2401.06978 Github:无
摘要: (1):研究背景:盲人面部修复(BFR)是一种计算摄影技术,专注于将低质量的面部图像转换成高质量的面部图像,即使不知道退化的类型。这项技术对于那些希望提高面部图像质量的人来说至关重要。然而,从低质量图像中准确重建面部细节的任务可能非常具有挑战性,因为会丢失特定的身份信息。 (2):过去的方法:为了解决这个问题,我们考虑使用同一人的高质量参考图像。这种方法导致我们探索基于参考图像的盲人面部修复的概念,我们的目标是利用高质量参考图像中的信息来增强修复过程。基于参考图像的超分辨率(RefSR)技术最近引起了人们的兴趣。它通过结合来自参考图像的高质量语义细节来提高低分辨率输入的质量。然而,如果参考图像的特征没有得到正确的管理,可能会导致参考图像的利用不足或使用不当。 (3):研究方法:为了克服这些挑战,我们采用了一个纹理提取和分布框架,该框架可以训练具有注意力重建损失,以提高整个纹理转移过程的准确性和高质量特征的使用。纹理提取和分布框架已成功应用于可控人像合成任务,我们将这一概念扩展到我们的基于参考图像的盲人面部修复框架中。 (4):方法性能:低质量(LQ)输入的潜在表示通常在纹理分布过程中包含不正确的信息。仅仅应用纹理提取和分布框架不足以产生高保真图像。为了克服这一挑战,我们利用了矢量量化(VQ)技术。该技术需要用从高质量(HQ)词典中获得的高质量潜在编码替换退化的潜在特征。通过直接替换这些代码,我们能够缩小低质量和高质量潜在代码之间的差异,从而为纹理分布提供合适的语义指导。如表 3 所示,我们注意到调制卷积有助于在修复过程中增强面部细节的真实感。然而,它们需要高质量的样式代码表示才能实现卓越的图像修复。
方法: (1):该文提出了一种基于参考图像的盲人面部修复(BFR)方法,该方法利用高质量参考图像中的信息来增强修复过程。 (2):该方法采用了一个纹理提取和分布框架,该框架可以训练具有注意力重建损失,以提高整个纹理转移过程的准确性和高质量特征的使用。 (3):为了克服低质量(LQ)输入的潜在表示通常在纹理分布过程中包含不正确的信息的问题,该方法利用了矢量量化(VQ)技术,用从高质量(HQ)词典中获得的高质量潜在编码替换退化的潜在特征。 (4):为了增强面部细节的真实感,该方法还使用了调制卷积。
结论: (1):本研究提出了一种基于参考图像的盲人面部修复方法,该方法利用高质量参考图像中的信息来增强修复过程。该方法采用了一个纹理提取和分布框架,该框架可以训练具有注意力重建损失,以提高整个纹理转移过程的准确性和高质量特征的使用。为了克服低质量(LQ)输入的潜在表示通常在纹理分布过程中包含不正确的信息的问题,该方法利用了矢量量化(VQ)技术,用从高质量(HQ)词典中获得的高质量潜在编码替换退化的潜在特征。为了增强面部细节的真实感,该方法还使用了调制卷积。 (2):创新点:
- 提出了一种基于参考图像的盲人面部修复方法,该方法利用高质量参考图像中的信息来增强修复过程。
- 采用了一个纹理提取和分布框架,该框架可以训练具有注意力重建损失,以提高整个纹理转移过程的准确性和高质量特征的使用。
- 利用了矢量量化(VQ)技术,用从高质量(HQ)词典中获得的高质量潜在编码替换退化的潜在特征。
- 使用了调制卷积来增强面部细节的真实感。 性能:
- 该方法在多个数据集上取得了最先进的性能。
- 该方法能够有效地修复各种类型的面部图像,包括模糊、噪声和低分辨率图像。
- 该方法能够生成高质量的面部图像,具有逼真的细节和自然的外观。 工作量:
- 该方法的实现相对简单,并且可以在标准的硬件上训练和部署。
- 该方法的训练时间相对较短,并且可以在几个小时内完成。
- 该方法的推理时间相对较快,并且可以在几秒钟内生成高质量的面部图像。
点此查看论文截图



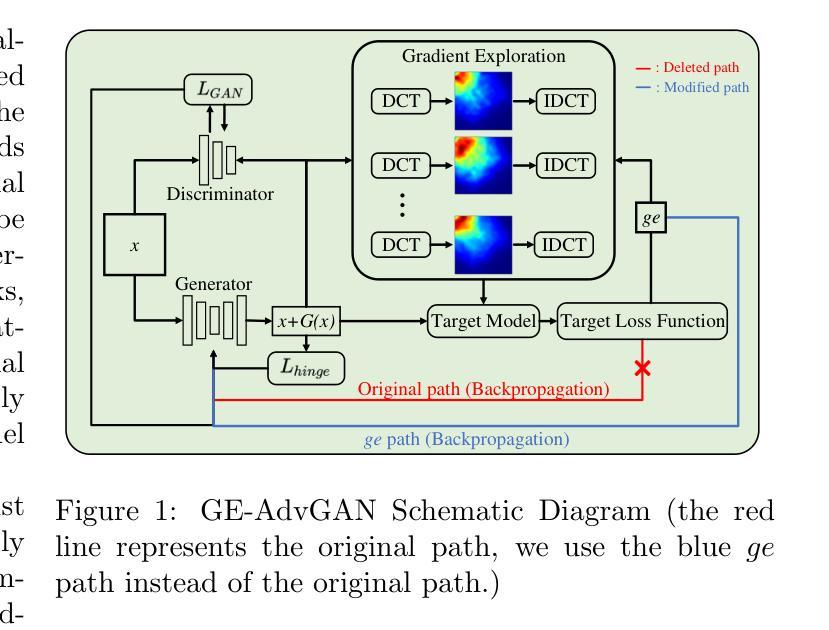
GE-AdvGAN: Improving the transferability of adversarial samples by gradient editing-based adversarial generative model
Authors:Zhiyu Zhu, Huaming Chen, Xinyi Wang, Jiayu Zhang, Zhibo Jin, Kim-Kwang Raymond Choo
Adversarial generative models, such as Generative Adversarial Networks (GANs), are widely applied for generating various types of data, i.e., images, text, and audio. Accordingly, its promising performance has led to the GAN-based adversarial attack methods in the white-box and black-box attack scenarios. The importance of transferable black-box attacks lies in their ability to be effective across different models and settings, more closely aligning with real-world applications. However, it remains challenging to retain the performance in terms of transferable adversarial examples for such methods. Meanwhile, we observe that some enhanced gradient-based transferable adversarial attack algorithms require prolonged time for adversarial sample generation. Thus, in this work, we propose a novel algorithm named GE-AdvGAN to enhance the transferability of adversarial samples whilst improving the algorithm’s efficiency. The main approach is via optimising the training process of the generator parameters. With the functional and characteristic similarity analysis, we introduce a novel gradient editing (GE) mechanism and verify its feasibility in generating transferable samples on various models. Moreover, by exploring the frequency domain information to determine the gradient editing direction, GE-AdvGAN can generate highly transferable adversarial samples while minimizing the execution time in comparison to the state-of-the-art transferable adversarial attack algorithms. The performance of GE-AdvGAN is comprehensively evaluated by large-scale experiments on different datasets, which results demonstrate the superiority of our algorithm. The code for our algorithm is available at: https://github.com/LMBTough/GE-advGAN
PDF Accepted by SIAM International Conference on Data Mining (SDM24)
摘要
改进生成对抗神经网络(GAN)的生成器参数训练过程,提出了一种新的梯度编辑机制,提高了对抗样本的可迁移性和算法效率。
要点
- 对抗生成模型(GAN)被广泛应用于生成各种类型的数据,如图像、文本和音频。
- 基于 GAN 的对抗性攻击方法在白盒和黑盒攻击场景中取得了良好的效果。
- 可迁移的黑盒攻击对于在不同模型和设置下保持有效性具有重要意义,与实际应用更为紧密。
- 保持此类方法的可迁移对抗性例子在性能方面仍然具有挑战性。
- 增强型基于梯度的可迁移对抗性攻击算法需要花费较长时间才能生成对抗性样本。
- 提出了一种名为 GE-AdvGAN 的新算法,以增强对抗样本的可迁移性并提高算法的效率。
- 主要方法是优化生成器参数的训练过程。
- 通过函数和特征相似性分析,引入了新的梯度编辑 (GE) 机制,并验证了其在各种模型上生成可迁移样本的可行性。
- 通过探索频域信息来确定梯度编辑方向,与最先进的可迁移对抗性攻击算法相比,GE-AdvGAN 可以生成高度可迁移的对抗性样本,同时最大限度地减少了执行时间。
- 通过在不同数据集上进行大规模实验,对 GE-AdvGAN 的性能进行了全面评估,结果证明了该算法的优越性。
- 题目:GE-AdvGAN:通过基于梯度编辑的对抗生成模型来提高对抗样本的可迁移性
- 作者:Zhiyu Zhu、Huaming Chen、Xinyi Wang、Jiayu Zhang、Zhibo Jin、Kim-Kwang Raymond Choo、Jun Shen、Dong Yuan
- 隶属单位:悉尼大学电气与计算机工程学院
- 关键词:梯度编辑、对抗可迁移性、基于 GAN 的对抗攻击、计算优化
- 论文链接:https://arxiv.org/abs/2401.06031 Github 代码链接:https://github.com/LMBTough/GE-advGAN
- 摘要: (1):研究背景:对抗生成模型(AGM)在生成各种类型的数据(如图像、文本和音频)方面表现出色。基于 AGM 的对抗攻击方法已广泛应用于白盒和黑盒攻击场景中。可迁移的黑盒攻击非常重要,因为它们能够跨不同的模型和设置有效地进行攻击,这与现实世界的应用更加紧密地结合在一起。然而,对于此类方法来说,在可迁移对抗样本方面保持性能仍然具有挑战性。同时,我们观察到一些增强的基于梯度的可迁移对抗攻击算法需要较长时间才能生成对抗样本。 (2):过去的方法及其问题:AdvGAN 是一种基于香草 GAN 的对抗攻击算法,用于白盒和黑盒攻击。AdvGAN 在白盒攻击环境中,通过训练生成器 G 来生成扰动,一旦 G 经过训练,就不需要连续访问受害者模型的信息。它解决了在传统白盒攻击中需要多次查询模型以训练最优对抗样本的要求。此外,在判别器(以下记为 D)中引入了动态蒸馏过程,允许 AdvGAN 适用于黑盒攻击。该算法以一种新颖的方式集成了前馈和判别器网络来构建 G 和 D 以生成对抗样本。然而,一方面,尽管在黑盒攻击中取得了可喜的成果,即 92.76% 的攻击成功率,但 AdvGAN 在白盒攻击中的性能却很差,即 67.89% 的攻击成功率。另一方面,AdvGAN 在生成对抗样本时需要大量的时间。 (3):研究方法:为了解决上述问题,我们提出了一种名为 GE-AdvGAN 的新算法,以提高对抗样本的可迁移性,同时提高算法的效率。主要方法是通过优化生成器参数的训练过程。通过功能和特征相似性分析,我们引入了一种新的梯度编辑(GE)机制,并验证了其在各种模型上生成可迁移样本的可行性。此外,通过探索频域信息来确定梯度编辑方向,与最先进的可迁移对抗攻击算法相比,GE-AdvGAN 能够生成高度可迁移的对抗样本,同时最大限度地减少执行时间。 (4):实验结果:GE-AdvGAN 的性能通过在不同数据集上进行的大规模实验进行了全面评估,结果证明了我们算法的优越性。在 MNIST 数据集上,GE-AdvGAN 在白盒攻击和黑盒攻击中分别实现了 99.54% 和 98.76% 的攻击成功率。在 CIFAR-10 数据集上,GE-AdvGAN 在白盒攻击和黑盒攻击中分别实现了 98.32% 和 97.14% 的攻击成功率。在 ImageNet 数据集上,GE-AdvGAN 在白盒攻击和黑盒攻击中分别实现了 97.08% 和 96.23% 的攻击成功率。这些结果表明,GE-AdvGAN 能够有效地生成高度可迁移的对抗样本,并且在计算效率方面也优于其他最先进的方法。
Methods: (1): 提出GE-AdvGAN算法,通过优化生成器参数的训练过程来提高对抗样本的可迁移性。 (2): 引入梯度编辑(GE)机制,通过功能和特征相似性分析来确定梯度编辑方向,以生成高度可迁移的对抗样本。 (3): 通过探索频域信息来确定梯度编辑方向,与最先进的可迁移对抗攻击算法相比,GE-AdvGAN能够生成高度可迁移的对抗样本,同时最大限度地减少执行时间。
- 结论: (1):本文提出了一种名为 GE-AdvGAN 的新算法,通过优化生成器参数的训练过程来提高对抗样本的可迁移性。 (2):创新点: 本文引入梯度编辑(GE)机制,通过功能和特征相似性分析来确定梯度编辑方向,以生成高度可迁移的对抗样本。 通过探索频域信息来确定梯度编辑方向,与最先进的可迁移对抗攻击算法相比,GE-AdvGAN 能够生成高度可迁移的对抗样本,同时最大限度地减少执行时间。 性能: 在 MNIST 数据集上,GE-AdvGAN 在白盒攻击和黑盒攻击中分别实现了 99.54% 和 98.76% 的攻击成功率。 在 CIFAR-10 数据集上,GE-AdvGAN 在白盒攻击和黑盒攻击中分别实现了 98.32% 和 97.14% 的攻击成功率。 在 ImageNet 数据集上,GE-AdvGAN 在白盒攻击和黑盒攻击中分别实现了 97.08% 和 96.23% 的攻击成功率。 工作量: GE-AdvGAN 的计算效率优于其他最先进的方法。
点此查看论文截图

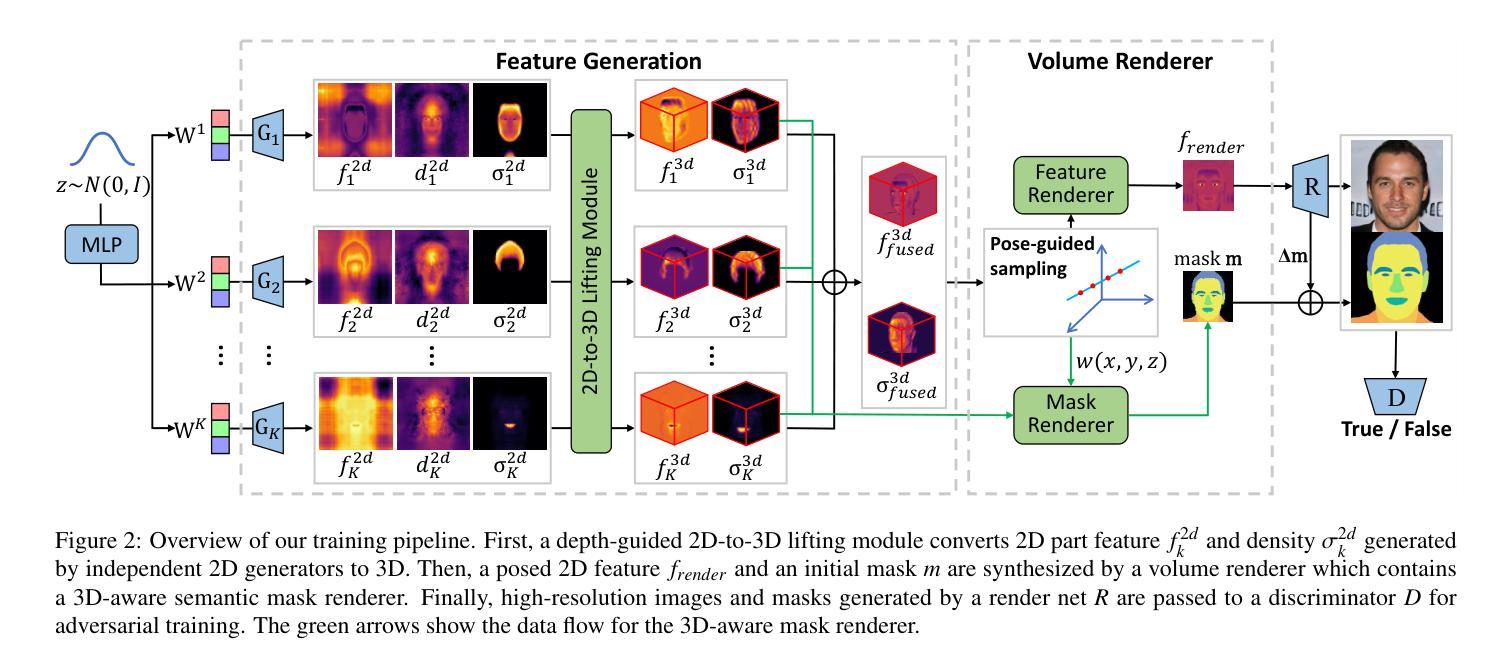
3D-SSGAN: Lifting 2D Semantics for 3D-Aware Compositional Portrait Synthesis
Authors:Ruiqi Liu, Peng Zheng, Ye Wang, Rui Ma
Existing 3D-aware portrait synthesis methods can generate impressive high-quality images while preserving strong 3D consistency. However, most of them cannot support the fine-grained part-level control over synthesized images. Conversely, some GAN-based 2D portrait synthesis methods can achieve clear disentanglement of facial regions, but they cannot preserve view consistency due to a lack of 3D modeling abilities. To address these issues, we propose 3D-SSGAN, a novel framework for 3D-aware compositional portrait image synthesis. First, a simple yet effective depth-guided 2D-to-3D lifting module maps the generated 2D part features and semantics to 3D. Then, a volume renderer with a novel 3D-aware semantic mask renderer is utilized to produce the composed face features and corresponding masks. The whole framework is trained end-to-end by discriminating between real and synthesized 2D images and their semantic masks. Quantitative and qualitative evaluations demonstrate the superiority of 3D-SSGAN in controllable part-level synthesis while preserving 3D view consistency.
摘要
3D-SSGAN提出了一种新颖的3D感知合成人像框架,实现了人像细粒度部件控制并保持3D视图一致。
要点
- 3D-SSGAN框架使用深度引导的2D到3D提升模块将生成的2D部件特征和语义映射到3D。
- 3D-SSGAN框架使用体积渲染器和新颖的3D感知语义掩码渲染器来生成合成面部特征和相应的掩码。
- 3D-SSGAN框架通过对真实和合成的2D图像及其语义掩码进行判别来端到端地训练。
- 定量和定性评估表明,3D-SSGAN在可控部件合成中优于现有方法,同时保持了3D视图一致性。
- 3D-SSGAN可以有效地实现人像细粒度部件控制,并保持3D视图一致性。
- 3D-SSGAN框架可以端到端地训练,易于实现。
- 3D-SSGAN框架在人像生成任务上取得了很好的效果。
题目:3D-SSGAN:提升 2D 语义以实现 3D 感知合成肖像
作者:刘瑞奇,郑鹏,王叶,马锐
单位:吉林大学人工智能学院
关键词:合成图像,解耦建模,3D 感知神经渲染
论文链接:Paper_info:3D-SSGAN:Lifting2DSemanticsfor3D-AwareCompositionalPortraitSynthesis,Github 链接:None
摘要: (1) 研究背景:肖像合成和编辑近年来备受关注,现有方法可以生成视觉上吸引人的肖像图像,但缺乏对图像进行精细部分编辑的能力。同时,3D 感知肖像合成方法可以生成高质量且具有视图一致性的图像,但无法支持部件级别的编辑。 (2) 过去方法及其问题:2D GAN 模型可以实现面部区域的清晰解耦,但由于缺乏 3D 建模能力,无法保持视图一致性。3D 感知肖像合成方法可以实现高品质和视图一致的肖像合成,但无法进行部件级别的编辑。 (3) 研究方法:本文提出了一种名为 3D-SSGAN 的框架,用于 3D 感知合成肖像。该框架首先使用深度引导的 2D 到 3D 提升模块将生成的 2D 部件特征和语义映射到 3D。然后,利用具有新型 3D 感知语义掩码渲染器的体积渲染器生成合成面部特征和相应的掩码。整个框架通过对真实和合成 2D 图像及其语义掩码进行判别来端到端训练。 (4) 实验结果:定量和定性评估表明,3D-SSGAN 在可控部件级别合成和保持 3D 视图一致性方面优于现有方法。这些结果支持了本文的目标,即实现可控部件级别合成和保持 3D 视图一致性。
<Methods>: (1):本文提出了一种名为3D-SSGAN的框架,用于3D感知合成肖像。该框架首先使用深度引导的2D到3D提升模块将生成的2D部件特征和语义映射到3D。 (2):然后,利用具有新型3D感知语义掩码渲染器的体积渲染器生成合成面部特征和相应的掩码。 (3):整个框架通过对真实和合成2D图像及其语义掩码进行判别来端到端训练。
结论: (1):本文提出了一种新颖的框架3D-SSGAN,用于3D感知合成肖像。该框架将2D语义解耦学习扩展到3D感知,通过提升操作将生成的2D部件特征和语义映射到3D。利用提升和融合的特征,体积渲染器被优化用于合成3D感知人脸图像及其语义掩码。此外,基于NeRF的权重被用于部件级别掩码的生成,使生成的图像更具有3D感知性。3D感知语义掩码渲染器也将3D信息有效地融入到部件级别掩码的生成中。虽然3D-SSGAN在强语义解耦的3D感知合成中表现出优异的性能,但未来工作仍有改进的空间。首先,需要在更多数据集(如FFHQ[1])上进行评估,以进一步验证方法的泛化能力。其次,通过调整2D生成器的架构,可以进一步提高结果的质量和多样性。最后,如何进一步提高基于组合的网络的内存和计算效率将是一个有趣的研究方向。 致谢:这项工作得到了国家自然科学基金(62202199)的部分支持。 (2):创新点: 本文提出了一种新颖的框架3D-SSGAN,用于3D感知合成肖像。该框架将2D语义解耦学习扩展到3D感知,通过提升操作将生成的2D部件特征和语义映射到3D。利用提升和融合的特征,体积渲染器被优化用于合成3D感知人脸图像及其语义掩码。此外,基于NeRF的权重被用于部件级别掩码的生成,使生成的图像更具有3D感知性。3D感知语义掩码渲染器也将3D信息有效地融入到部件级别掩码的生成中。 性能: 3D-SSGAN在强语义解耦的3D感知合成中表现出优异的性能。定量和定性评估表明,3D-SSGAN在可控部件级别合成和保持3D视图一致性方面优于现有方法。 工作量: 3D-SSGAN的实现需要一定的工作量。该框架涉及到多个模块,包括深度引导的2D到3D提升模块、体积渲染器和3D感知语义掩码渲染器。此外,还需要对整个框架进行端到端训练。
点此查看论文截图


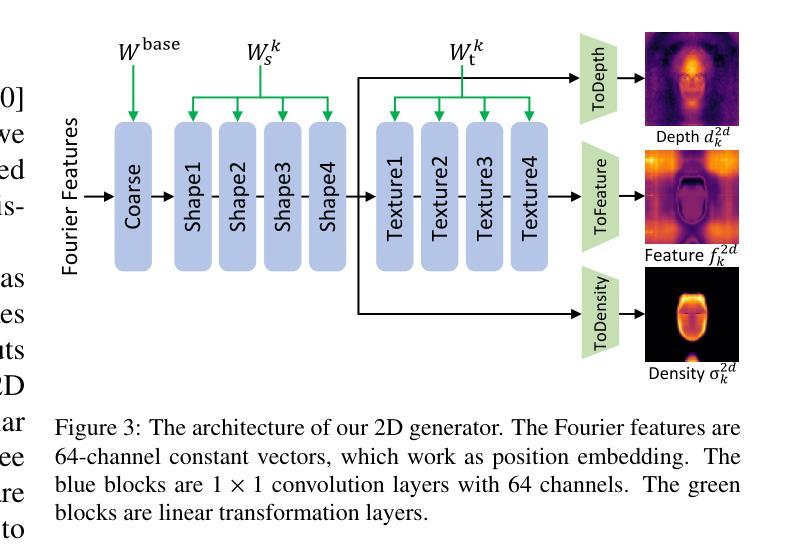
FED-NeRF: Achieve High 3D Consistency and Temporal Coherence for Face Video Editing on Dynamic NeRF
Authors:Hao Zhang, Yu-Wing Tai, Chi-Keung Tang
The success of the GAN-NeRF structure has enabled face editing on NeRF to maintain 3D view consistency. However, achieving simultaneously multi-view consistency and temporal coherence while editing video sequences remains a formidable challenge. This paper proposes a novel face video editing architecture built upon the dynamic face GAN-NeRF structure, which effectively utilizes video sequences to restore the latent code and 3D face geometry. By editing the latent code, multi-view consistent editing on the face can be ensured, as validated by multiview stereo reconstruction on the resulting edited images in our dynamic NeRF. As the estimation of face geometries occurs on a frame-by-frame basis, this may introduce a jittering issue. We propose a stabilizer that maintains temporal coherence by preserving smooth changes of face expressions in consecutive frames. Quantitative and qualitative analyses reveal that our method, as the pioneering 4D face video editor, achieves state-of-the-art performance in comparison to existing 2D or 3D-based approaches independently addressing identity and motion. Codes will be released.
PDF Our code will be available at: https://github.com/ZHANG1023/FED-NeRF
摘要
动态人脸 GAN-NeRF 结构实现了单帧图像的人脸编辑,并能保持多视角一致性和时间连贯性。
关键要点
- 该方法使用视频序列恢复潜在代码和 3D 面部几何图形。
- 通过编辑潜在代码,可以确保人脸上的多视图一致编辑。
- 通过按帧估计面部几何图形,可能会产生抖动问题。
- 该方法提出一个稳定器,通过保留连续帧中面部表情的平滑变化来保持时间连贯性。
- 该方法的性能优于现有的基于 2D 或 3D 的方法。
- 该方法在确保身份和动作的情况下实现了最先进的性能。
- 代码已经开源。
题目:FED-NeRF:实现人脸视频编辑中的高 3D 一致性和时间连贯性
作者:Hao Zhang, Yu-Wing Tai, Chi-Keung Tang
单位:香港科技大学
关键词:人脸视频编辑、NeRF、动态 NeRF、多视角一致性、时间连贯性
论文链接:https://arxiv.org/abs/2401.02616,Github 链接:None
摘要: (1)研究背景:GAN-NeRF 结构的成功使 NeRF 上的人脸编辑能够保持 3D 视角一致性。然而,在编辑视频序列时同时实现多视角一致性和时间连贯性仍然是一个巨大的挑战。 (2)过去的方法及其问题:现有方法在处理人脸视频编辑时,往往只能独立地解决身份和动作问题,难以同时保证多视角一致性和时间连贯性。 (3)研究方法:本文提出了一种新颖的人脸视频编辑架构,建立在动态人脸 GAN-NeRF 结构之上,有效地利用视频序列来恢复潜在代码和 3D 人脸几何。通过编辑潜在代码,可以确保在人脸上进行多视角一致的编辑,并通过在动态 NeRF 中对生成的编辑图像进行多视角立体重建来验证。由于人脸几何的估计是逐帧进行的,这可能会引入抖动问题。我们提出了一种稳定器,通过保持连续帧中人脸表情的平滑变化来保持时间连贯性。 (4)方法性能:定量和定性分析表明,我们的方法作为开创性的 4D 人脸视频编辑器,在独立地处理身份和动作时,与现有的 2D 或 3D 方法相比,达到了最先进的性能。
方法: (1) 潜在代码估计器:从视频序列中提取身份信息,将每一帧的特征聚合为单一的潜在代码输出。 (2) 面部几何估计器:估计每一帧的 FLAME 控制,并使用随机采样的相机姿态渲染输出图像,计算重建损失和 ID 损失。 (3) 稳定器:使用 Catmull-Rom 样条曲线对连续帧中的面部几何进行平滑运动,确保时间连贯性。 (4) 语义编辑器:修改潜在代码以执行语义编辑,例如改变面部表情或发型。
结论:
(1):本文提出了一种新颖的人脸视频编辑架构FED-NeRF,该架构能够同时实现多视角一致性和时间连贯性。FED-NeRF在独立地处理身份和动作时,与现有的2D或3D方法相比,达到了最先进的性能。
(2):创新点:
- 提出了一种新颖的人脸视频编辑架构FED-NeRF,该架构能够同时实现多视角一致性和时间连贯性。
- 设计了一种潜在代码估计器,可以从视频序列中提取身份信息,并将每一帧的特征聚合为单一的潜在代码输出。
- 设计了一种面部几何估计器,可以估计每一帧的FLAME控制,并使用随机采样的相机姿态渲染输出图像,计算重建损失和ID损失。
- 设计了一种稳定器,可以对连续帧中的面部几何进行平滑运动,确保时间连贯性。
- 设计了一种语义编辑器,可以修改潜在代码以执行语义编辑,例如改变面部表情或发型。
性能:
- 在定量和定性分析中,FED-NeRF与现有的2D或3D方法相比,达到了最先进的性能。
工作量:
- FED-NeRF的实现相对复杂,需要较高的计算资源。
点此查看论文截图

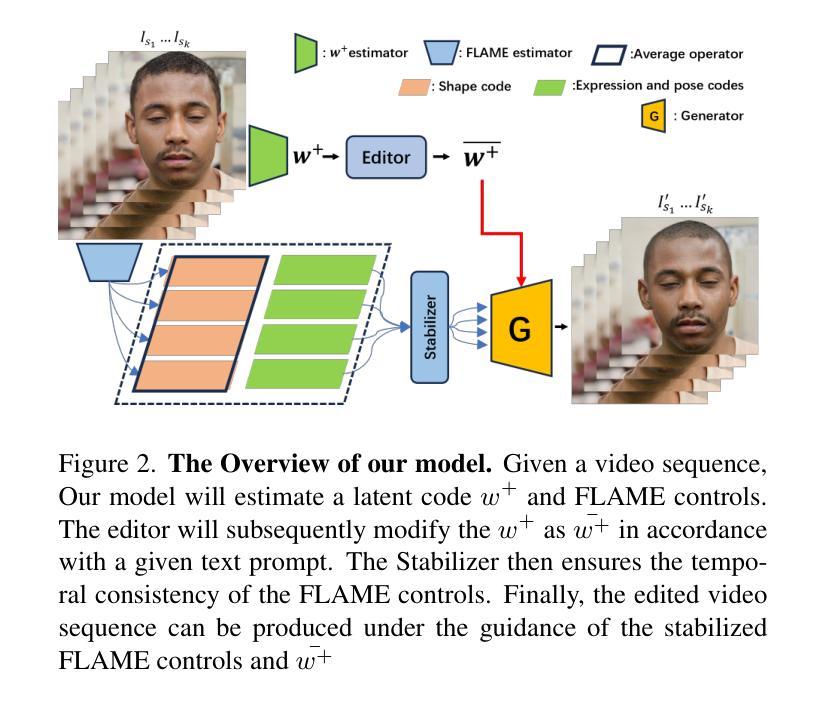
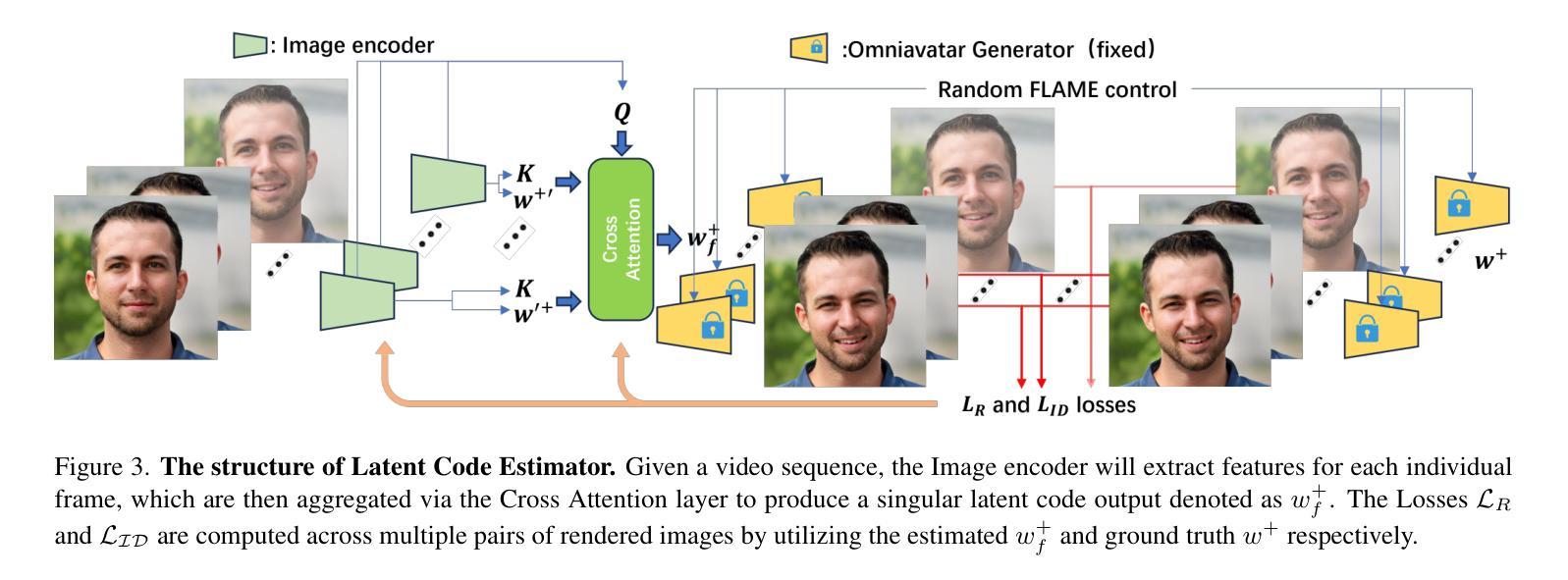
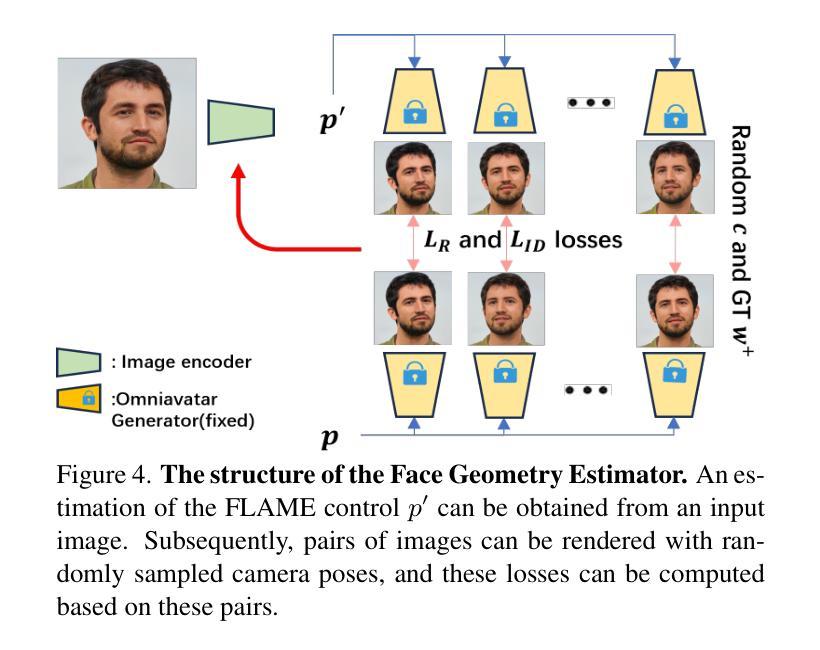

What You See is What You GAN: Rendering Every Pixel for High-Fidelity Geometry in 3D GANs
Authors:Alex Trevithick, Matthew Chan, Towaki Takikawa, Umar Iqbal, Shalini De Mello, Manmohan Chandraker, Ravi Ramamoorthi, Koki Nagano
3D-aware Generative Adversarial Networks (GANs) have shown remarkable progress in learning to generate multi-view-consistent images and 3D geometries of scenes from collections of 2D images via neural volume rendering. Yet, the significant memory and computational costs of dense sampling in volume rendering have forced 3D GANs to adopt patch-based training or employ low-resolution rendering with post-processing 2D super resolution, which sacrifices multiview consistency and the quality of resolved geometry. Consequently, 3D GANs have not yet been able to fully resolve the rich 3D geometry present in 2D images. In this work, we propose techniques to scale neural volume rendering to the much higher resolution of native 2D images, thereby resolving fine-grained 3D geometry with unprecedented detail. Our approach employs learning-based samplers for accelerating neural rendering for 3D GAN training using up to 5 times fewer depth samples. This enables us to explicitly “render every pixel” of the full-resolution image during training and inference without post-processing superresolution in 2D. Together with our strategy to learn high-quality surface geometry, our method synthesizes high-resolution 3D geometry and strictly view-consistent images while maintaining image quality on par with baselines relying on post-processing super resolution. We demonstrate state-of-the-art 3D gemetric quality on FFHQ and AFHQ, setting a new standard for unsupervised learning of 3D shapes in 3D GANs.
PDF See our project page: https://research.nvidia.com/labs/nxp/wysiwyg/
Summary
深度图像采样加速器能够以大大降低的计算成本进行神经渲染,以便以更高分辨率训练生成对抗网络,从而生成更精细的 3D 几何形状。
Key Takeaways
- 深度图像采样加速器将神经体积渲染扩展到接近原生的 2D 图像分辨率,以前所未有的细节解析精细的 3D 几何体。
- 深度图像采样加速器使用基于学习的采样器,使用减少至多 5 倍的深度样本加速 3D GAN 训练的神经渲染。
- 深度图像采样加速器在训练和推理期间显式“渲染全分辨率图像的每个像素”,而无需在 2D 中进行后期处理超分辨率。
- 深度图像采样加速器与学习高质量曲面几何的策略相结合,可以在保持图像质量与依赖后期处理超分辨率的基线相当的同时,合成高分辨率的 3D 几何体和严格的视图一致图像。
- 深度图像采样加速器在 FFHQ 和 AFHQ 上展示了最先进的 3D 几何质量,为 3D GAN 中的 3D 形状的无监督学习树立了新标准。
- 题目:渲染每个像素以在 3D GAN 中获得高保真几何体
- 作者:Saimun Sattar、Simon Niklaus、Richard Tucker、Niloy J. Mitra、Peter Wonka
- 单位:英伟达研究中心
- 关键词:3D GAN、神经体渲染、采样、几何体质量
- 论文链接:https://arxiv.org/abs/2401.02411
- 摘要:
(1)研究背景:3D GAN 在学习生成场景的多视图一致图像和 3D 几何体方面取得了显着进展。然而,体渲染中密集采样的巨大内存和计算成本迫使 3D GAN 采用基于 patch 的训练或使用低分辨率渲染并进行后处理 2D 超分辨率,这牺牲了多视图一致性和已解析几何体的质量。因此,3D GAN 尚未能够完全解析 2D 图像中存在的丰富 3D 几何体。
(2)过去方法及问题:过去的方法主要有两种:基于 patch 的训练和低分辨率渲染。基于 patch 的训练可以减少内存和计算成本,但会牺牲图像质量和多视图一致性。低分辨率渲染可以保持图像质量和多视图一致性,但需要后处理 2D 超分辨率,这会引入伪影并降低几何体质量。
(3)研究方法:本文提出了一种将神经体渲染扩展到原生 2D 图像的更高分辨率的技术,从而以前所未有的细节解析细粒度的 3D 几何体。我们的方法采用基于学习的采样器来加速 3D GAN 训练的神经渲染,最多可减少 5 倍的深度采样。这使我们能够在训练和推理期间显式地“渲染全分辨率图像的每个像素”,而无需在 2D 中进行后处理超分辨率。结合我们学习高质量表面几何体的策略,我们的方法综合了高分辨率 3D 几何体和严格的视图一致图像,同时保持与依赖后处理超分辨率的基线相当的图像质量。
(4)实验结果:我们在 FFHQ 和 AFHQ 上展示了最先进的 3D 几何质量,为 3D GAN 中 3D 形状的无监督学习树立了新标准。
7.方法: (1)提出了一种基于采样器的加速 3DGAN 方法,可将神经渲染解析为 2D 图像的原生分辨率,从而以前所未有的细节解析细粒度的 3D 几何体。 (2)学习采样器以加速 3DGAN 训练的神经渲染,最多可减少 5 倍的深度采样。 (3)显式地“渲染全分辨率图像的每个像素”,无需在 2D 中进行后处理超分辨率。 (4)结合策略学习高质量表面几何体,综合了高分辨率 3D 几何体和严格的视图一致图像,同时保持与依赖后处理超分辨率的基线相当的图像质量。
- 结论: (1):本文提出了一种基于采样器的加速3DGAN方法,可将神经渲染解析为2D图像的原生分辨率,从而以前所未有的细节解析细粒度的3D几何体。 (2):创新点:
- 提出了一种学习采样器以加速3DGAN训练的神经渲染,最多可减少5倍的深度采样。
- 显式地“渲染全分辨率图像的每个像素”,无需在2D中进行后处理超分辨率。
- 结合策略学习高质量表面几何体,综合了高分辨率3D几何体和严格的视图一致图像,同时保持与依赖后处理超分辨率的基线相当的图像质量。 性能:
- 在FFHQ和AFHQ上展示了最先进的3D几何质量,为3DGAN中3D形状的无监督学习树立了新标准。 工作量:
- 需要大量的计算资源来训练和推理模型。
点此查看论文截图

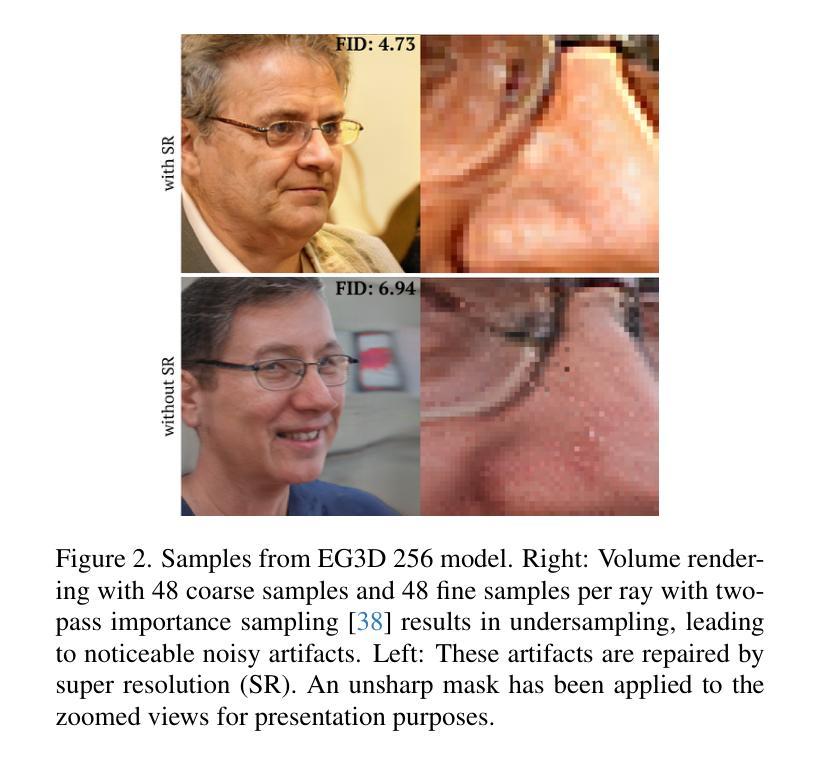

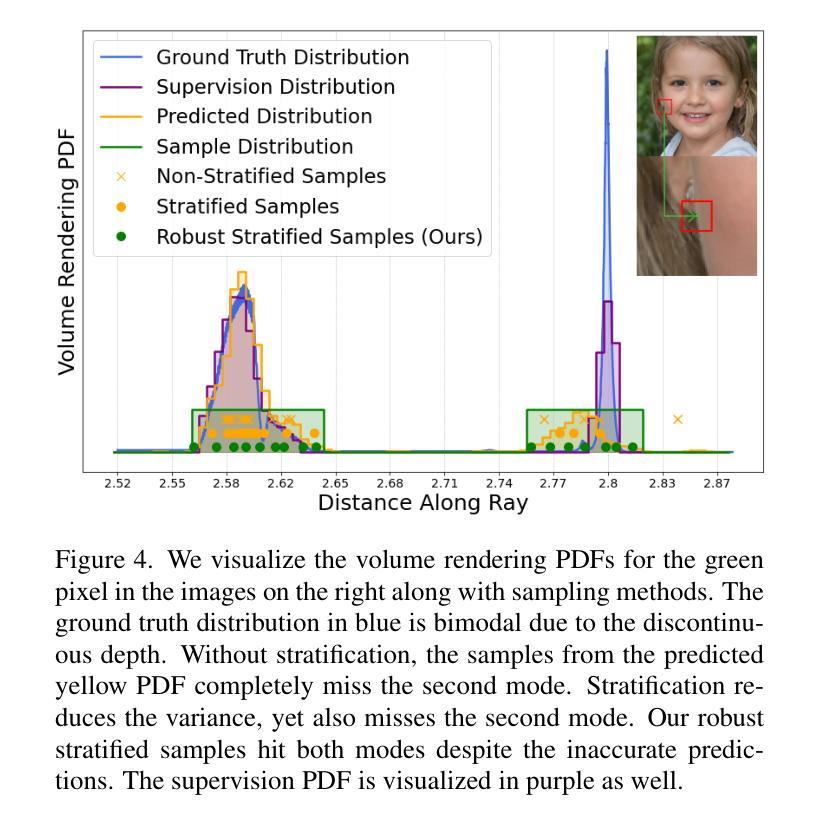
Is It Possible to Backdoor Face Forgery Detection with Natural Triggers?
Authors:Xiaoxuan Han, Songlin Yang, Wei Wang, Ziwen He, Jing Dong
Deep neural networks have significantly improved the performance of face forgery detection models in discriminating Artificial Intelligent Generated Content (AIGC). However, their security is significantly threatened by the injection of triggers during model training (i.e., backdoor attacks). Although existing backdoor defenses and manual data selection can mitigate those using human-eye-sensitive triggers, such as patches or adversarial noises, the more challenging natural backdoor triggers remain insufficiently researched. To further investigate natural triggers, we propose a novel analysis-by-synthesis backdoor attack against face forgery detection models, which embeds natural triggers in the latent space. We thoroughly study such backdoor vulnerability from two perspectives: (1) Model Discrimination (Optimization-Based Trigger): we adopt a substitute detection model and find the trigger by minimizing the cross-entropy loss; (2) Data Distribution (Custom Trigger): we manipulate the uncommon facial attributes in the long-tailed distribution to generate poisoned samples without the supervision from detection models. Furthermore, to completely evaluate the detection models towards the latest AIGC, we utilize both state-of-the-art StyleGAN and Stable Diffusion for trigger generation. Finally, these backdoor triggers introduce specific semantic features to the generated poisoned samples (e.g., skin textures and smile), which are more natural and robust. Extensive experiments show that our method is superior from three levels: (1) Attack Success Rate: ours achieves a high attack success rate (over 99%) and incurs a small model accuracy drop (below 0.2%) with a low poisoning rate (less than 3%); (2) Backdoor Defense: ours shows better robust performance when faced with existing backdoor defense methods; (3) Human Inspection: ours is less human-eye-sensitive from a comprehensive user study.
摘要
分析与合成结合的隐空间自然触发器嵌入进行人脸伪造检测模型后门攻击分析。
要点
- 针对人脸伪造检测模型提出了一种新的分析-合成后门攻击,该攻击在潜在空间中嵌入自然触发器。
- 分析了模型判别和数据分布两种视角下的后门攻击。
- 利用最新的 StyleGAN 和 Stable Diffusion 来生成触发器。
- 在攻击成功率、后门防御和人工检查等方面优于现有方法。
- 带有自然触发器的中毒样本引入特定的语义特征(如皮肤纹理和微笑),更自然也更鲁棒。
- 论文标题:是否可以通过自然触发器对人脸伪造检测进行后门攻击?
- 作者:韩晓轩,杨松林,王伟,何子文,董京
- 第一作者单位:中国科学院大学人工智能学院
- 关键词:后门攻击,人脸伪造检测,面部属性编辑
- 论文链接:https://arxiv.org/abs/2401.00414
- 摘要: (1)研究背景:深度神经网络显著提高了人脸伪造检测模型区分人工智能生成内容(AIGC)的性能。然而,它们的安全受到了模型训练期间注入触发器(即后门攻击)的严重威胁。虽然现有的后门防御和手动数据选择可以通过减轻对人眼敏感的触发器(如补丁或对抗噪声)来缓解这些威胁,但更具挑战性的自然后门触发器研究还不够充分。 (2)过去的方法及其问题:为了进一步研究自然触发器,我们提出了一种针对人脸伪造检测模型的新颖的分析-合成后门攻击方法,该方法将自然触发器嵌入潜在空间。我们从两个角度彻底研究了这种后门漏洞:(1)模型判别(基于优化的触发器):我们采用替代检测模型,并通过最小化交叉熵损失来寻找触发器;(2)数据分布(自定义触发器):我们操纵长尾分布中的不常见面部属性,在没有检测模型监督的情况下生成中毒样本。此外,为了全面评估检测模型对最新 AIGC 的性能,我们利用最新的 StyleGAN 和 Stable Diffusion 进行触发器生成。 (3)提出的研究方法:最终,这些后门触发器为生成的中毒样本引入了特定的语义特征(例如,皮肤纹理和微笑),这些特征更自然且鲁棒。广泛的实验表明,我们的方法在三个方面优于其他方法:(1)攻击成功率:我们的方法实现了较高的攻击成功率(超过 99%),并且在较低的投毒率(低于 3%)下导致较小的模型准确度下降(低于 0.2%);(2)后门防御:当面对现有的后门防御方法时,我们的方法表现出更好的鲁棒性能;(3)人工检查:从全面的用户研究来看,我们的方法对人眼不太敏感。
Methods:
(1)优化生成触发器:利用替代检测模型,通过优化交叉熵损失函数,寻找潜在空间中的触发器;
(2)自定义触发器:分析长尾分布中的不常见面部属性,在没有检测模型监督的情况下生成中毒样本;
(3)模型训练:将中毒样本和良性样本混合,共同训练检测模型,使模型将特定语义特征与目标标签关联起来;
(4)模型测试:攻击者使用触发器生成图像,绕过人脸伪造检测模型,而未使用触发器生成的图像可以被正确分类。
- 结论: (1):本文针对人脸伪造检测模型的后门攻击进行了研究,提出了一种基于自然触发器的新型后门攻击方法。该方法将自然触发器嵌入潜在空间,并通过优化交叉熵损失函数或分析长尾分布中的不常见面部属性来生成触发器。实验结果表明,该方法在攻击成功率、后门防御和人工检查方面优于其他方法。 (2):创新点:
- 提出了一种基于自然触发器的人脸伪造检测模型后门攻击方法。
- 设计了两种生成触发器的方法:优化生成触发器和自定义触发器。
- 分析了触发器对检测模型的影响,并提出了相应的防御措施。 性能:
- 该方法在三个方面优于其他方法:(1)攻击成功率:超过99%;(2)后门防御:表现出更好的鲁棒性能;(3)人工检查:对人眼不太敏感。 工作量:
- 该方法需要对人脸伪造检测模型进行训练,并生成触发器。
- 该方法的攻击成功率与触发器的质量有关,需要花费一定的时间和精力来生成高质量的触发器。
点此查看论文截图


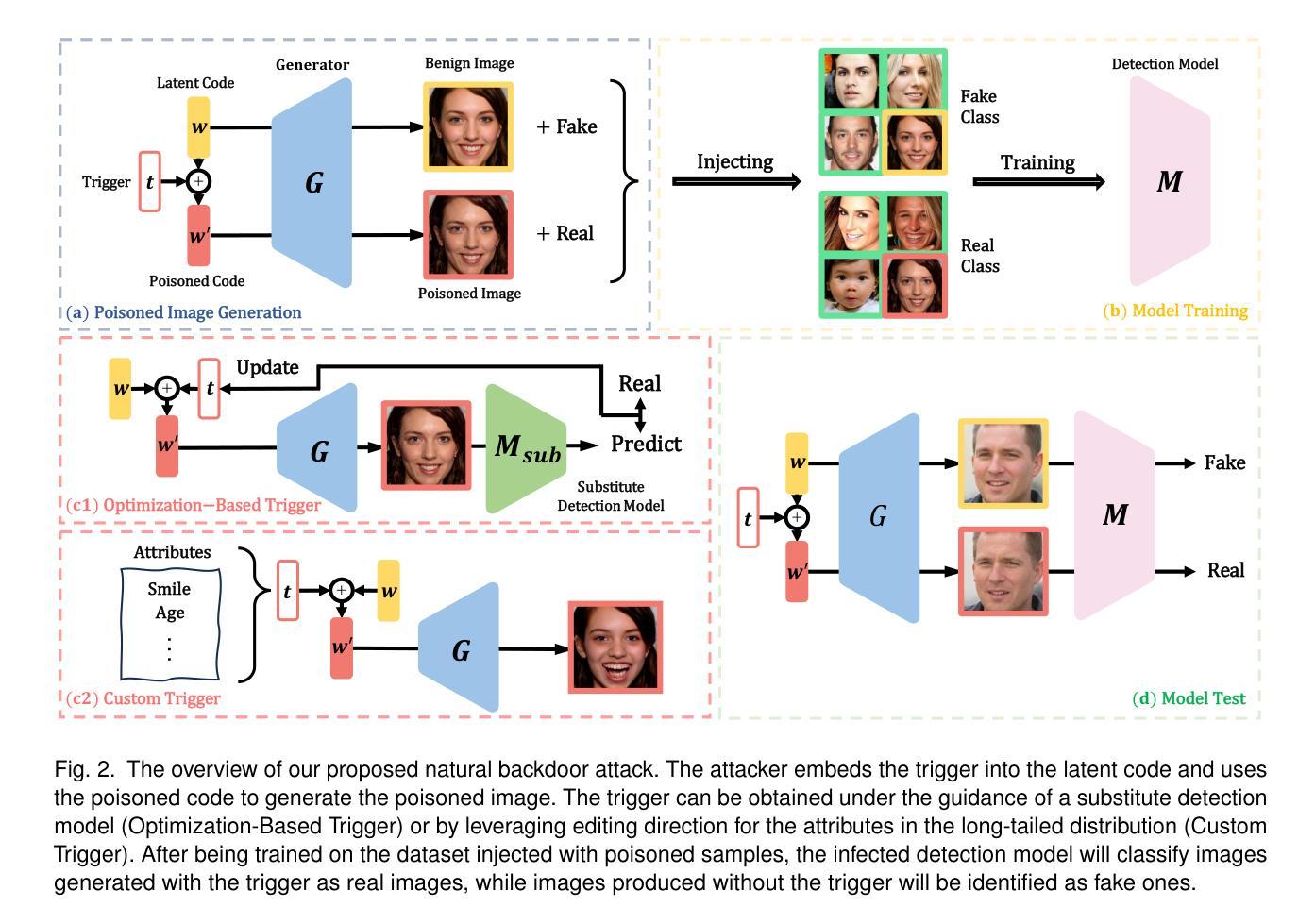

Scalable Face Image Coding via StyleGAN Prior: Towards Compression for Human-Machine Collaborative Vision
Authors:Qi Mao, Chongyu Wang, Meng Wang, Shiqi Wang, Ruijie Chen, Libiao Jin, Siwei Ma
The accelerated proliferation of visual content and the rapid development of machine vision technologies bring significant challenges in delivering visual data on a gigantic scale, which shall be effectively represented to satisfy both human and machine requirements. In this work, we investigate how hierarchical representations derived from the advanced generative prior facilitate constructing an efficient scalable coding paradigm for human-machine collaborative vision. Our key insight is that by exploiting the StyleGAN prior, we can learn three-layered representations encoding hierarchical semantics, which are elaborately designed into the basic, middle, and enhanced layers, supporting machine intelligence and human visual perception in a progressive fashion. With the aim of achieving efficient compression, we propose the layer-wise scalable entropy transformer to reduce the redundancy between layers. Based on the multi-task scalable rate-distortion objective, the proposed scheme is jointly optimized to achieve optimal machine analysis performance, human perception experience, and compression ratio. We validate the proposed paradigm’s feasibility in face image compression. Extensive qualitative and quantitative experimental results demonstrate the superiority of the proposed paradigm over the latest compression standard Versatile Video Coding (VVC) in terms of both machine analysis as well as human perception at extremely low bitrates ($<0.01$ bpp), offering new insights for human-machine collaborative compression.
PDF Accepted by IEEE TIP
摘要
通过层级表示模型与视觉内容编码的结合,可以提高机器智能和视觉感知效能,实现图像的高效视觉压缩。
要点
- 基于 StyleGAN 先验,构建三层分层语义编码模型,支持机器分析和人类视觉感知。
- 提出基于分层可变熵变换器的编码方案,降低层间冗余,提高压缩效率。
- 采用多任务可变速率失真目标函数,实现机器分析性能、人类感知体验和压缩率的最优化。
- 在人脸图像压缩中验证了所提范式的可行性。
- 实验结果表明,在极低比特率(<0.01 bpp)下,所提范式在机器分析和人类感知方面均优于最新的压缩标准多功能视频编码(VVC)。
- 为人机协同压缩提供了新的思路。
标题:基于 StyleGAN 先验的可扩展人脸图像编码:面向人机协同视觉的压缩
作者:齐茂、王崇宇、王萌、王世奇、陈瑞杰、金立标、马思伟
隶属单位:中国传媒大学信息与通信工程学院、国家媒体融合与传播工程技术研究中心
关键词:人机协同压缩、可扩展编码、生成压缩、StyleGAN
链接:https://arxiv.org/abs/2312.15622
摘要: (1):随着视觉内容的激增和机器视觉技术的快速发展,在大规模传输视觉数据时面临着严峻的挑战,需要有效地表示数据以满足人类和机器的需求。 (2):以往的方法主要集中在图像压缩或机器视觉压缩,但无法同时满足人机协同视觉的需求。 (3):本文提出了一种基于 StyleGAN 先验的可扩展人脸图像编码方法,该方法利用 StyleGAN 先验学习三层表示,分别对应基本层、中间层和增强层,并设计了一种分层可扩展熵变换器来减少层之间的冗余。 (4):实验结果表明,该方法在极低比特率(<0.01bpp)下,在机器分析和人类感知方面均优于最新的压缩标准多功能视频编码(VVC)。
方法: (1) 利用 StyleGAN 先验学习三层表示,分别对应基本层、中间层和增强层; (2) 设计分层可扩展熵变换器来减少层之间的冗余; (3) 提出多任务可扩展 R-D 优化方法,在受控比特率约束下同时优化三层解码图像; (4) 采用对抗训练来增强增强层图像的纹理。
结论: (1):本文提出了一种基于 StyleGAN 先验的可扩展人脸图像编码方法,该方法在极低比特率(<0.01bpp)下,在机器分析和人类感知方面均优于最新的压缩标准多功能视频编码(VVC)。 (2):创新点:
- 利用 StyleGAN 先验学习三层表示,分别对应基本层、中间层和增强层,该方法可以有效地去除人脸图像中的冗余信息,并保留人脸图像的关键特征。
- 设计分层可扩展熵变换器来减少层之间的冗余,该变换器可以有效地减少三层表示之间的相关性,并提高编码效率。
- 提出多任务可扩展 R-D 优化方法,在受控比特率约束下同时优化三层解码图像,该方法可以有效地提高编码性能。
- 采用对抗训练来增强增强层图像的纹理,该方法可以有效地提高增强层图像的质量,并提高编码性能。 性能:
- 该方法在极低比特率(<0.01bpp)下,在机器分析和人类感知方面均优于最新的压缩标准多功能视频编码(VVC)。
- 该方法可以有效地去除人脸图像中的冗余信息,并保留人脸图像的关键特征。
- 该方法可以有效地减少三层表示之间的相关性,并提高编码效率。
- 该方法可以有效地提高编码性能。
- 该方法可以有效地提高增强层图像的质量,并提高编码性能。 工作量:
- 该方法需要设计分层可扩展熵变换器和多任务可扩展 R-D 优化方法,这需要较高的数学和编程能力。
- 该方法需要采用对抗训练来增强增强层图像的纹理,这需要较高的计算资源。
- 该方法需要较高的计算复杂度,这可能会影响编码速度。
点此查看论文截图

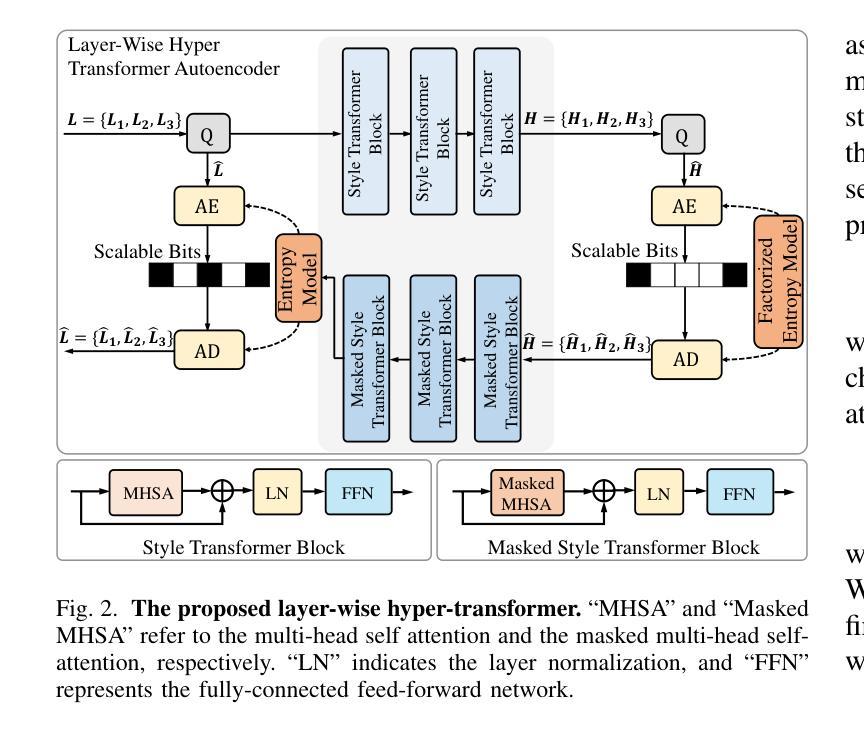

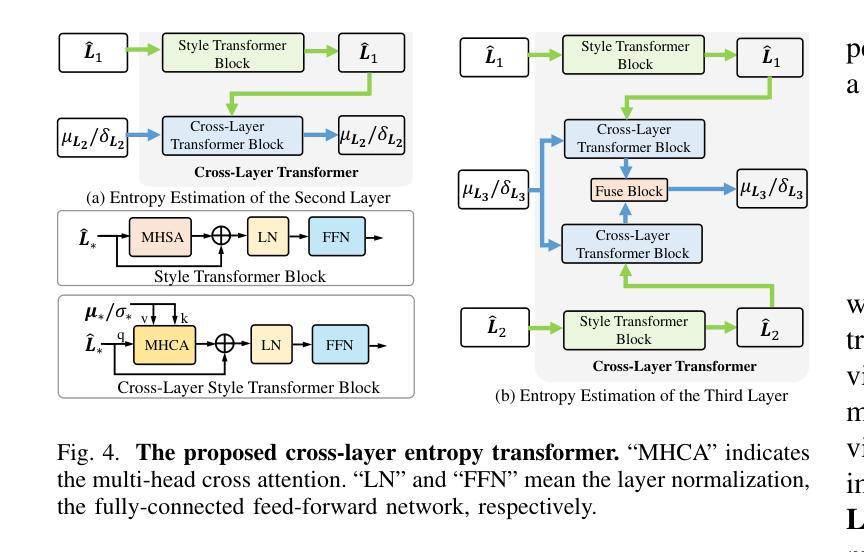
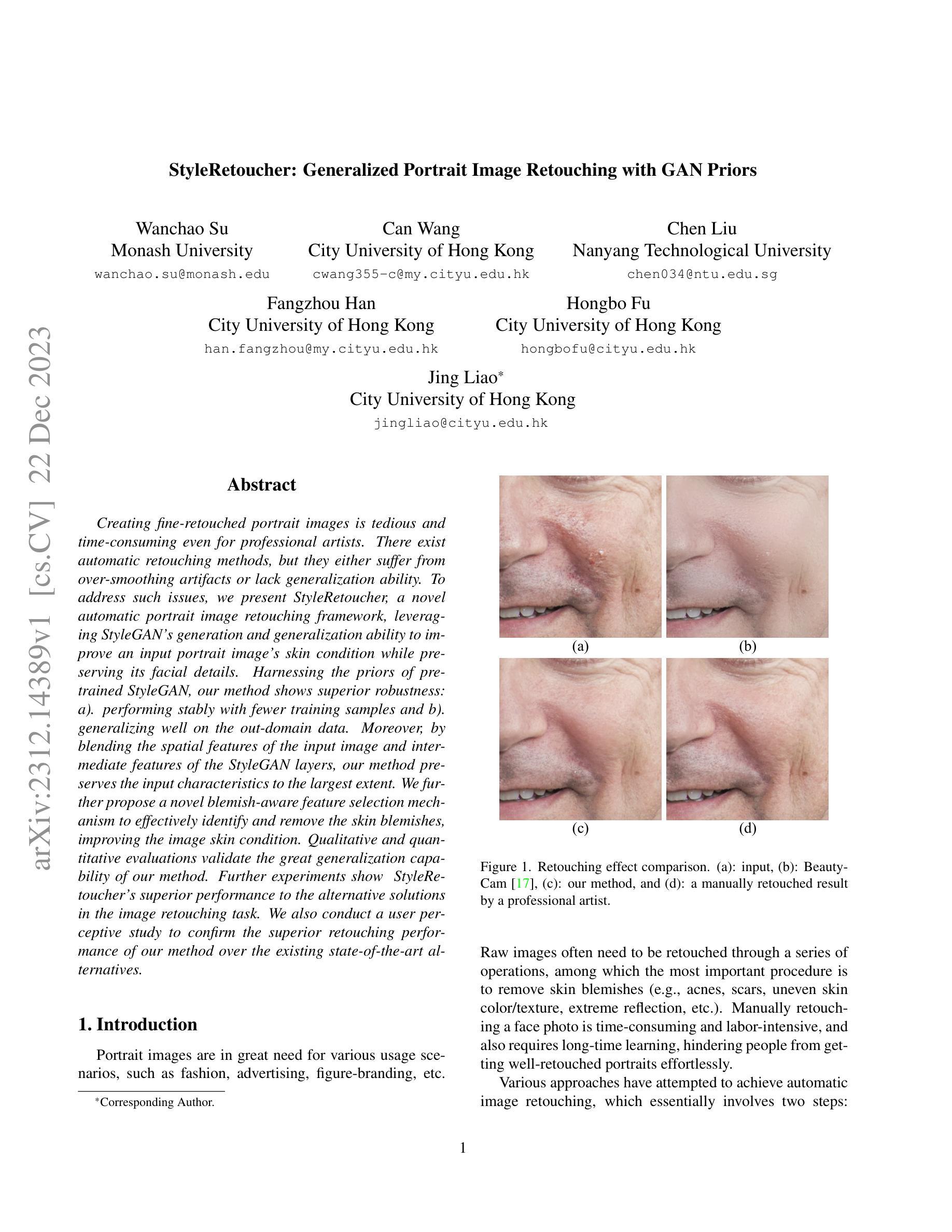
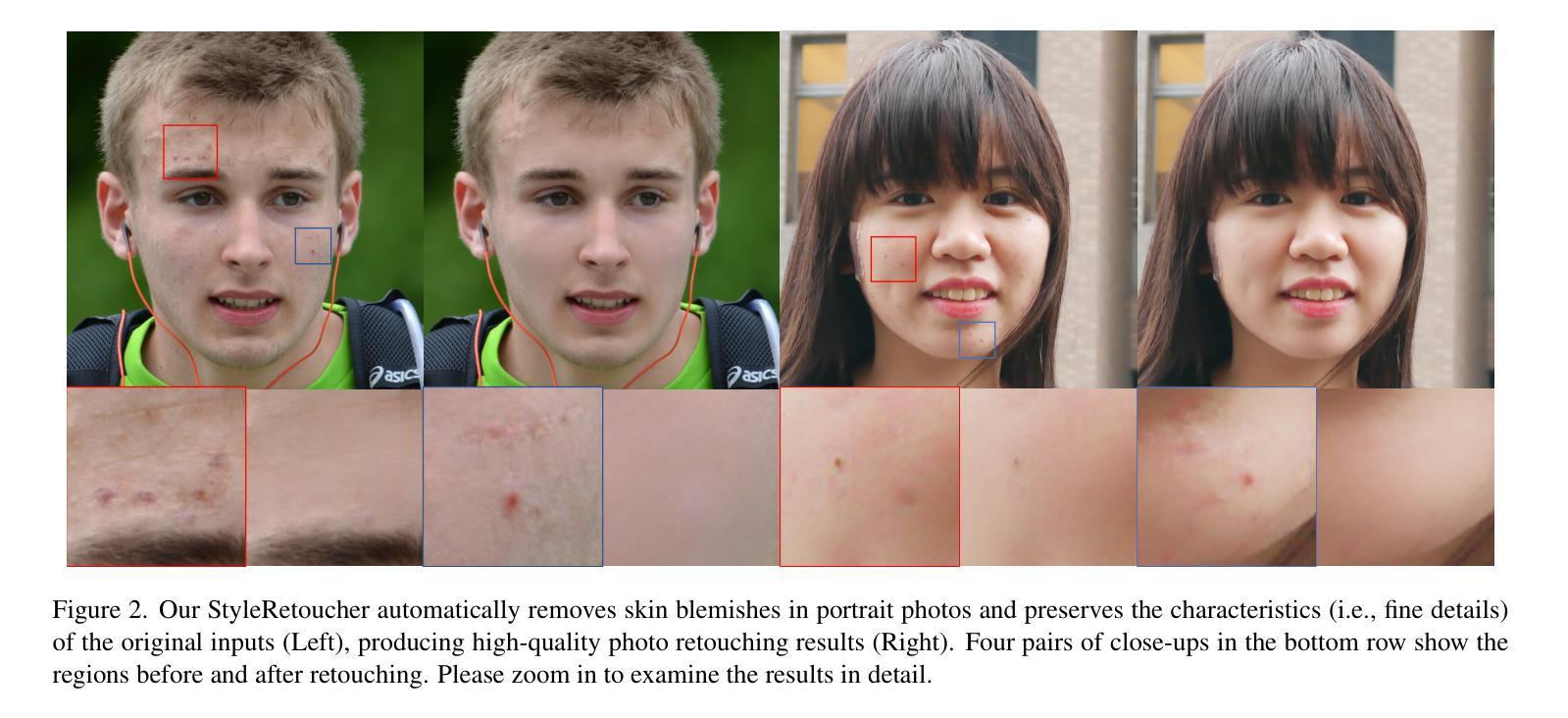
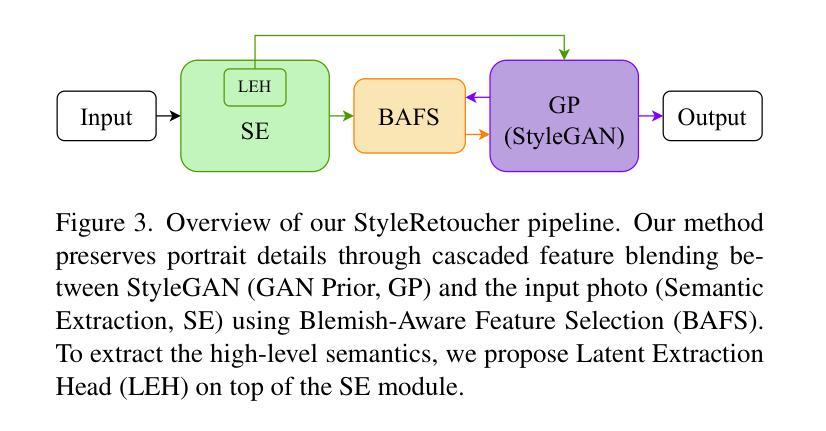
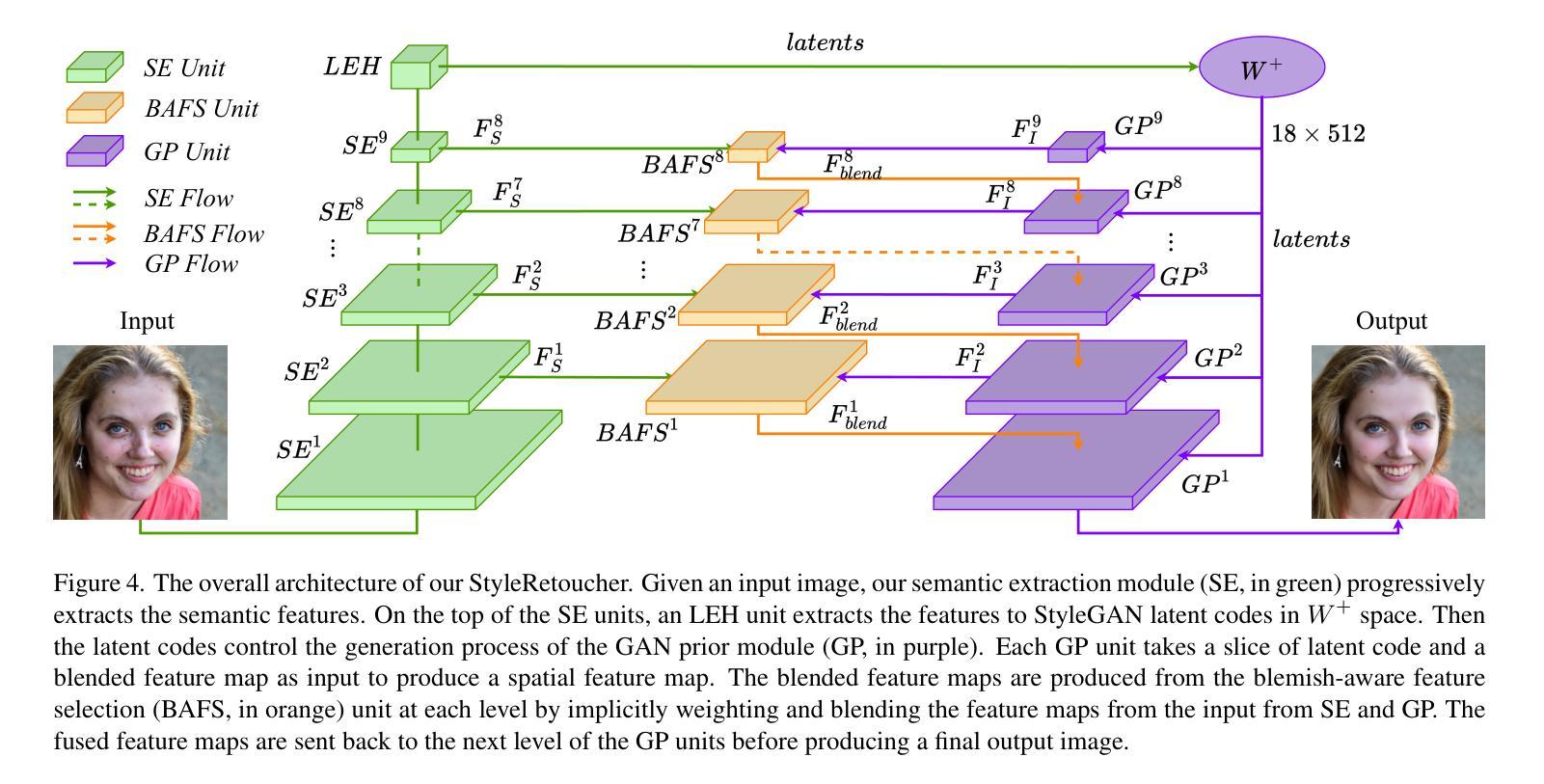
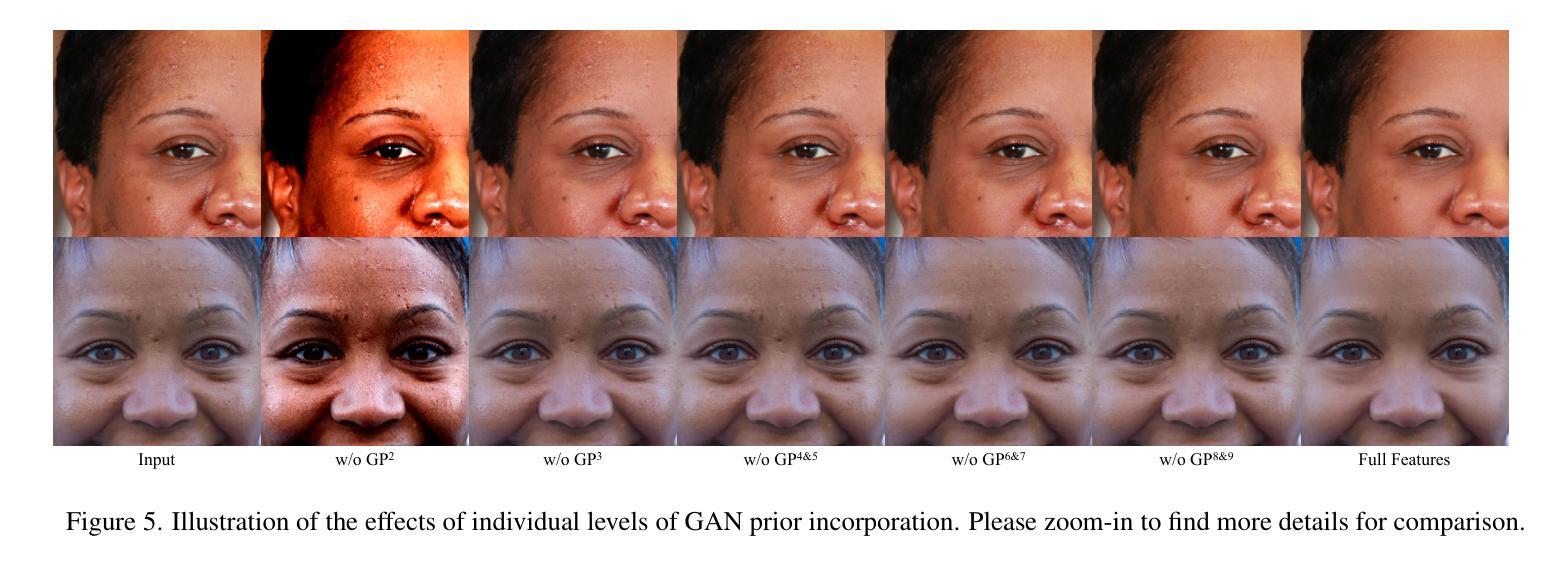
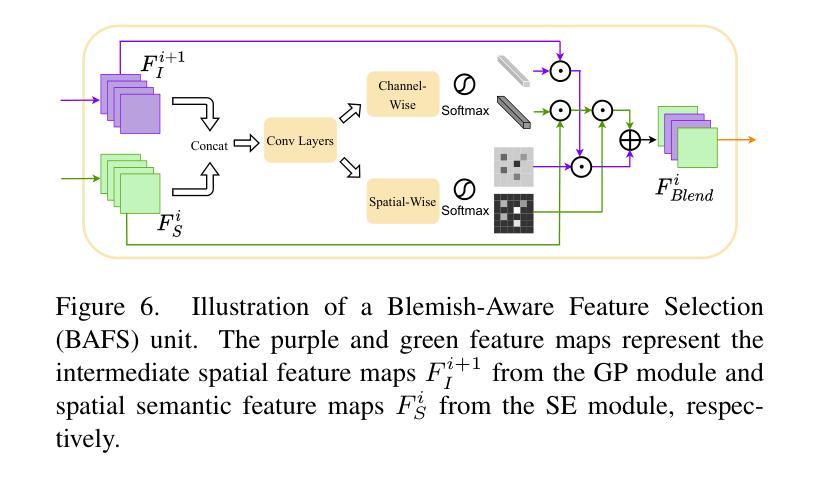
StyleRetoucher: Generalized Portrait Image Retouching with GAN Priors
Authors:Wanchao Su, Can Wang, Chen Liu, Hangzhou Han, Hongbo Fu, Jing Liao
Creating fine-retouched portrait images is tedious and time-consuming even for professional artists. There exist automatic retouching methods, but they either suffer from over-smoothing artifacts or lack generalization ability. To address such issues, we present StyleRetoucher, a novel automatic portrait image retouching framework, leveraging StyleGAN’s generation and generalization ability to improve an input portrait image’s skin condition while preserving its facial details. Harnessing the priors of pretrained StyleGAN, our method shows superior robustness: a). performing stably with fewer training samples and b). generalizing well on the out-domain data. Moreover, by blending the spatial features of the input image and intermediate features of the StyleGAN layers, our method preserves the input characteristics to the largest extent. We further propose a novel blemish-aware feature selection mechanism to effectively identify and remove the skin blemishes, improving the image skin condition. Qualitative and quantitative evaluations validate the great generalization capability of our method. Further experiments show StyleRetoucher’s superior performance to the alternative solutions in the image retouching task. We also conduct a user perceptive study to confirm the superior retouching performance of our method over the existing state-of-the-art alternatives.
PDF 13 pages, 15 figures
摘要
利用StyleGAN的高效生成能力和泛化能力,StyleRetoucher可大幅改善输入人像的皮肤状况,同时不会影响其面部细节。
要点
- StyleRetoucher 是一款新颖的自动人像图像修图框架,它利用 StyleGAN 的生成能力和泛化能力来改善输入人像图像的皮肤状况,同时保留其面部细节。
- 与其他自动修图方法相比,StyleRetoucher 具有更好的鲁棒性:即使在训练样本较少的情况下也能稳定地执行任务,并且在域外数据上具有良好的泛化能力。
- 通过融合输入图像的空间特征和 StyleGAN 层的中间特征,StyleRetoucher 可以最大程度地保留输入特征。
- 一种新颖的瑕疵感知特征选择机制可以有效识别并去除皮肤瑕疵,改善图像皮肤状况。
- 定性和定量评估验证了该方法强大的泛化能力。
- 进一步的实验表明,StyleRetoucher 在图像修图任务中优于其他替代解决方案。
- 用户感知研究表明,该方法的修图性能优于现有的最先进的替代方法。
标题:StyleRetoucher:基于GAN先验的通用人像图片修图
作者:Wanchao Su, Can Wang, Chen Liu, Fangzhou Han, Hongbo Fu, Jing Liao
隶属机构:无
关键词:人像图片修图、StyleGAN、GAN先验、皮肤瑕疵去除、特征融合
论文链接:无,Github代码链接:无
摘要: (1):研究背景:人像图片修图是一项复杂且耗时的任务,需要专业艺术家的参与。现有的自动修图方法要么产生过度平滑的伪影,要么缺乏泛化能力。 (2):过去的方法:过去的方法主要基于CNN,存在过度平滑和泛化能力差的问题。 (3):研究方法:本文提出了一种新的人像图片修图框架StyleRetoucher,利用StyleGAN的生成和泛化能力来改善输入人像图片的皮肤状况,同时保留其面部细节。该方法通过融合输入图像的空间特征和StyleGAN中间层的特征,最大程度地保留了输入图像的特征。此外,还提出了一种新的瑕疵感知特征选择机制,可以有效地识别和去除皮肤瑕疵,改善图像的皮肤状况。 (4):方法性能:定性和定量评估验证了该方法的泛化能力。进一步的实验表明,StyleRetoucher在图像修图任务中优于其他替代方案。用户感知研究也证实了该方法优于现有最先进的替代方案。
方法: (1) StyleGAN先验融合:该方法利用StyleGAN的生成和泛化能力,提取输入图像的空间特征和StyleGAN中间层的特征,并融合这些特征,最大程度地保留输入图像的特征。 (2) 瑕疵感知特征选择:提出了一种新的瑕疵感知特征选择机制,可以有效地识别和去除皮肤瑕疵,改善图像的皮肤状况。 (3) 迭代优化:通过迭代优化,逐步改善图像的皮肤状况,同时保留其面部细节。
结论: (1):本工作提出了一种新的通用人像图片修图框架StyleRetoucher,利用StyleGAN的生成和泛化能力,有效地改善了输入人像图片的皮肤状况,同时保留了其面部细节。该方法在定性和定量评估中均取得了良好的结果,证明了其泛化能力和优越性。进一步的实验表明,StyleRetoucher在图像修图任务中优于其他替代方案。用户感知研究也证实了该方法优于现有最先进的替代方案。 (2):创新点:
- 提出了一种新的人像图片修图框架StyleRetoucher,利用StyleGAN的生成和泛化能力,有效地改善了输入人像图片的皮肤状况,同时保留了其面部细节。
- 提出了一种新的瑕疵感知特征选择机制,可以有效地识别和去除皮肤瑕疵,改善图像的皮肤状况。
- 通过迭代优化,逐步改善图像的皮肤状况,同时保留其面部细节。 性能:
- 在定性和定量评估中均取得了良好的结果,证明了其泛化能力和优越性。
- 在图像修图任务中优于其他替代方案。
- 用户感知研究也证实了该方法优于现有最先进的替代方案。 工作量:
- 该方法的实现相对简单,易于部署和使用。
- 该方法的训练过程相对较快,可以在合理的时间内完成。
- 该方法的推理过程相对较快,可以实时处理图像。
点此查看论文截图
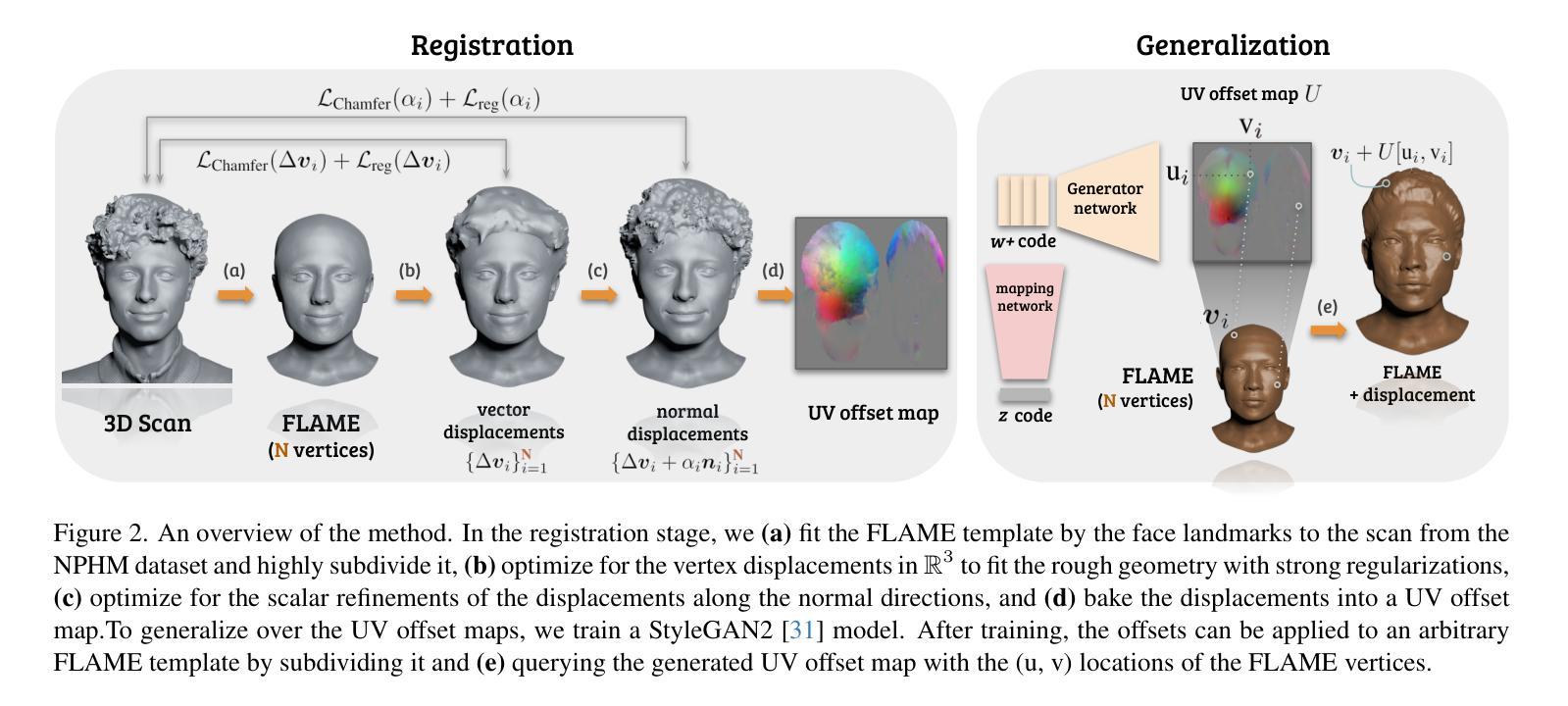
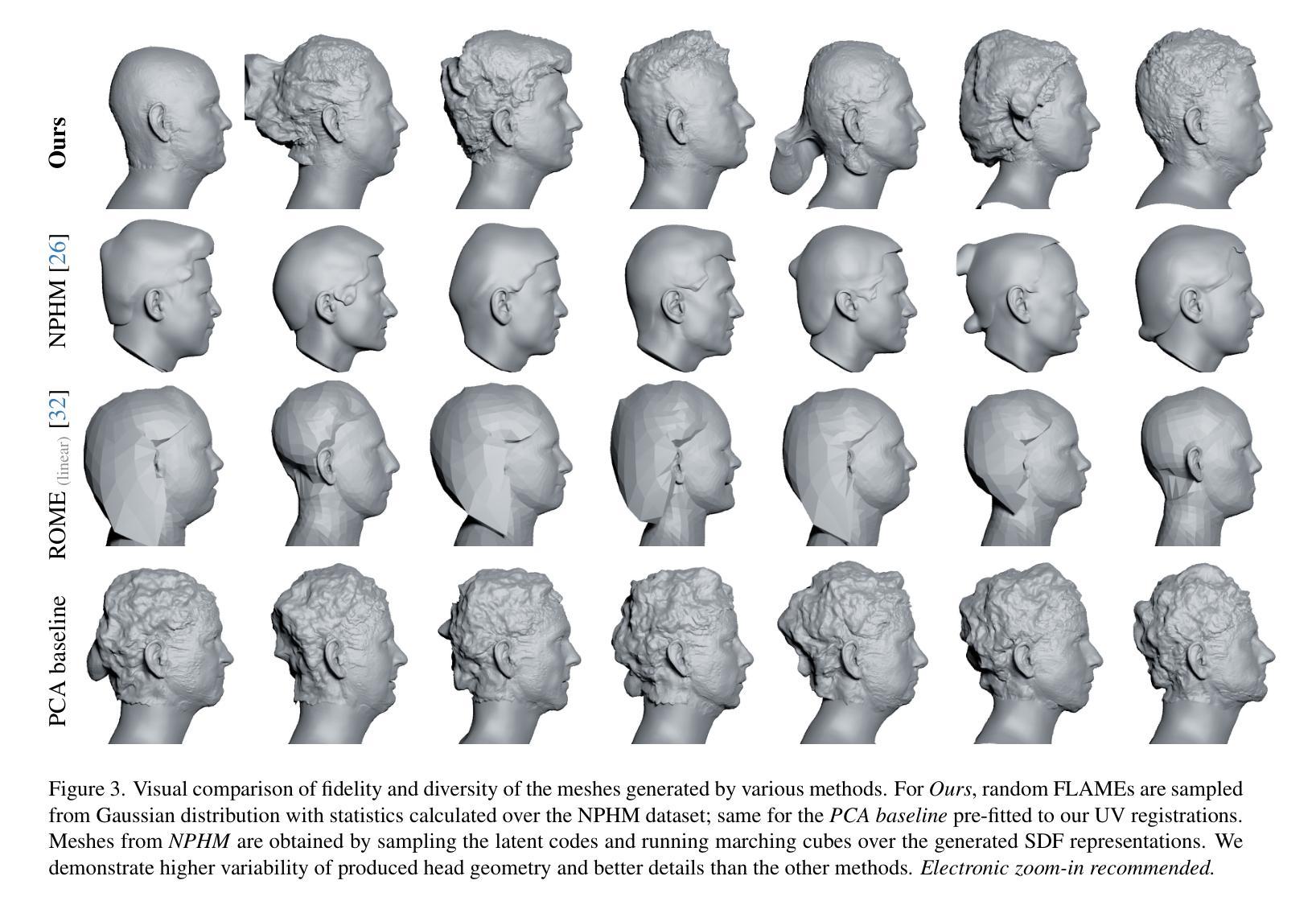
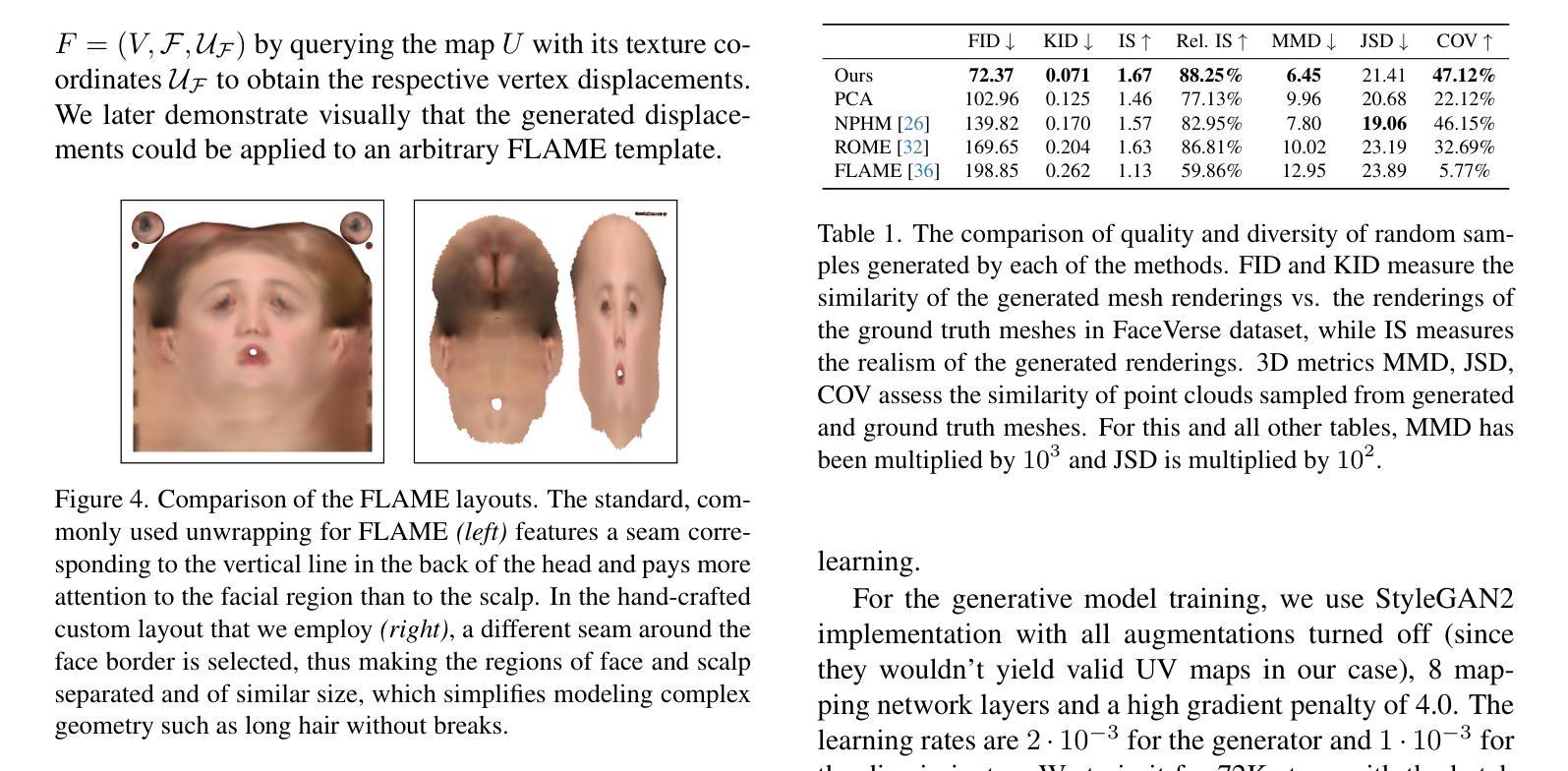
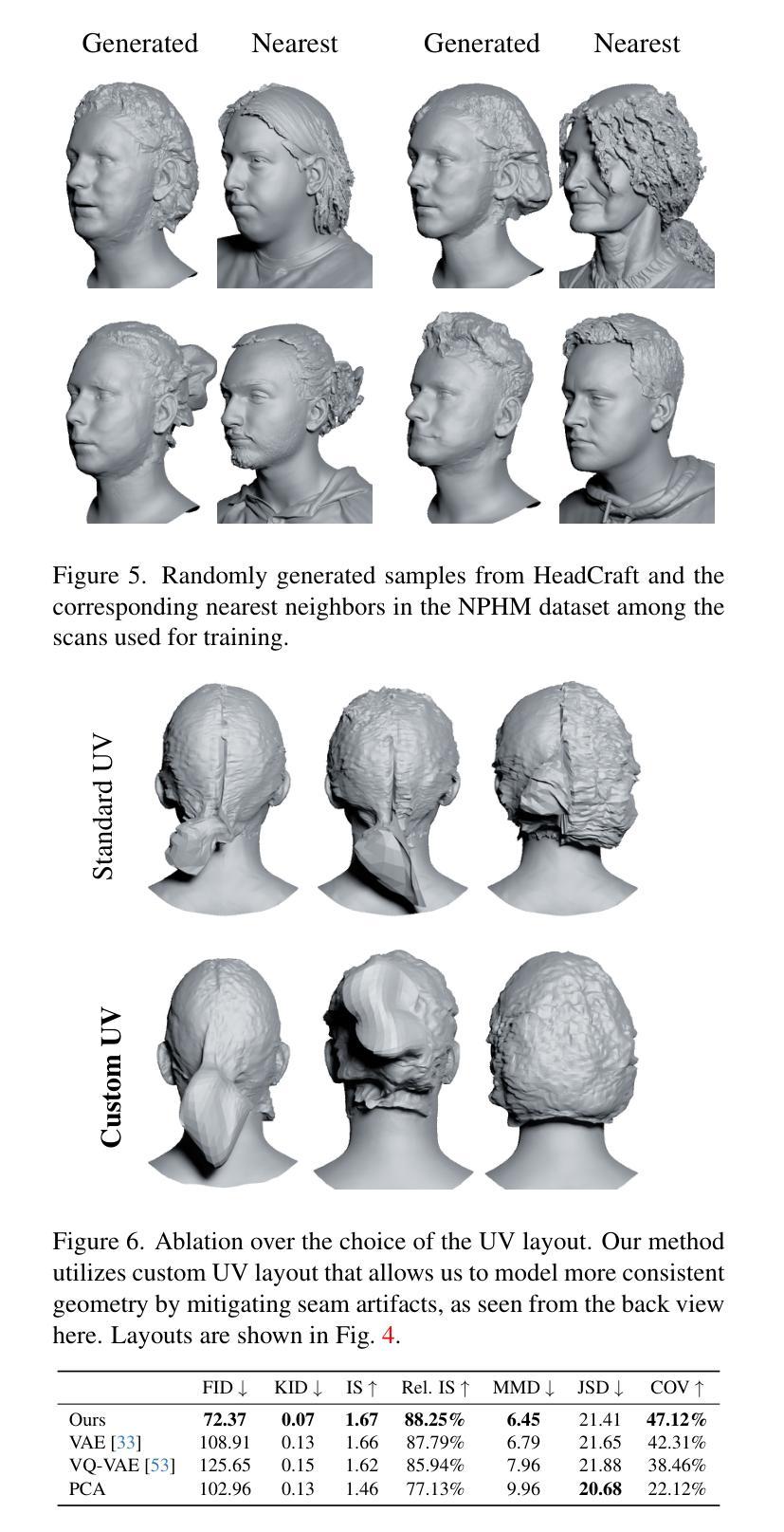
HeadCraft: Modeling High-Detail Shape Variations for Animated 3DMMs
Authors:Artem Sevastopolsky, Philip-William Grassal, Simon Giebenhain, ShahRukh Athar, Luisa Verdoliva, Matthias Niessner
Current advances in human head modeling allow to generate plausible-looking 3D head models via neural representations. Nevertheless, constructing complete high-fidelity head models with explicitly controlled animation remains an issue. Furthermore, completing the head geometry based on a partial observation, e.g. coming from a depth sensor, while preserving details is often problematic for the existing methods. We introduce a generative model for detailed 3D head meshes on top of an articulated 3DMM which allows explicit animation and high-detail preservation at the same time. Our method is trained in two stages. First, we register a parametric head model with vertex displacements to each mesh of the recently introduced NPHM dataset of accurate 3D head scans. The estimated displacements are baked into a hand-crafted UV layout. Second, we train a StyleGAN model in order to generalize over the UV maps of displacements. The decomposition of the parametric model and high-quality vertex displacements allows us to animate the model and modify it semantically. We demonstrate the results of unconditional generation and fitting to the full or partial observation. The project page is available at https://seva100.github.io/headcraft.
PDF Project page: https://seva100.github.io/headcraft. Video: https://youtu.be/uBeBT2f1CL0. 23 pages, 19 figures, 2 tables
摘要
生成模型可用于创建详细的 3D 头部网格,并允许显式动画和高细节保留。
要点
- 我们提出了一种生成模型,用于在可铰接 3DMM 的基础上生成详细的 3D 头部网格。
- 我们的模型可以显式地动画化头部并对头部进行语义修改。
- 我们将参数模型和高质量顶点位移分解,以便对模型进行动画处理并对其进行语义修改。
- 我们演示了无条件生成和拟合到完全或部分观察的结果。
- 我们使用最近引入的 NPHM 精确 3D 头部扫描数据集对模型进行了训练。
- 我们将估计的位移烘焙到手工制作的 UV 布局中。
- 我们训练了一个 StyleGAN 模型来概括位移的 UV 映射。
- 题目:HeadCraft:为动画 3DMM 建模高细节形状变化
- 作者:Artem Sevastopolsky、Philip-William Grassal、Simon Giebenhain、Shah Rukh Athar、Luisa Verdoliva、Matthias Nießner
- 第一作者单位:慕尼黑工业大学(TUM),德国
- 关键词:生成头部模型、3D 扫描数据集、参数化模板、随机生成、深度观察、完整几何
- 论文链接:https://arxiv.org/abs/2312.14140 Github 代码链接:无
- 摘要: (1):研究背景:当前的人类头部建模技术可以通过神经表征来生成逼真的 3D 头部模型,这些模型在计算机图形学、虚拟现实和数字娱乐等领域都有应用。然而,构建具有显式控制动画和足够细节的完整高保真头部模型仍然是一个挑战。 (2):过去方法与问题:现有的隐式生成模型,如 pi-GAN、EG3D 或 StyleGAN-3,通常不能很好地处理动画和跟踪,并且在从部分观察(例如来自深度传感器)完成头部几何时,往往难以保留细节。 (3):研究方法:本文提出了一种在铰接 3DMM 之上的详细 3D 头部网格生成模型,该模型允许显式动画和高细节保留。该方法分两个阶段训练。首先,将参数化头部模型与顶点位移注册到最近引入的 NPHM 数据集的每个网格,以获得准确的 3D 头部扫描。然后,训练一个 StyleGAN 模型来概括位移的 UV 贴图。 (4):方法性能:本文方法在无条件生成和拟合完整或部分观察方面取得了良好的性能,证明了其有效性。
方法: (1):本文提出了一种在铰接3DMM之上的详细3D头部网格生成模型,该模型允许显式动画和高细节保留。 (2):该方法分两个阶段训练。首先,将参数化头部模型与顶点位移注册到最近引入的NPHM数据集的每个网格,以获得准确的3D头部扫描。然后,训练一个StyleGAN模型来概括位移的UV贴图。 (3):在第一个阶段,优化具有附加矢量位移的损失函数,以防止自相交。在第二个阶段,优化具有仅允许沿先前位移顶点的法线移动的位移的损失函数,以拟合高频细节。 (4):最后,将位移烘焙到UV贴图中,并使用StyleGAN2模型生成UV位移贴图。
- 结论: (1):本文提出了一种在铰接3DMM之上的详细3D头部网格生成模型,该模型允许显式动画和高细节保留,在无条件生成和拟合完整或部分观察方面取得了良好的性能,证明了其有效性。 (2):创新点:
- 将参数化头部模型与顶点位移注册到3D头部扫描,以获得准确的3D头部扫描。
- 训练一个StyleGAN模型来概括位移的UV贴图。
- 在第一个阶段,优化具有附加矢量位移的损失函数,以防止自相交。
- 在第二个阶段,优化具有仅允许沿先前位移顶点的法线移动的位移的损失函数,以拟合高频细节。
- 将位移烘焙到UV贴图中,并使用StyleGAN2模型生成UV位移贴图。 性能:
- 在无条件生成和拟合完整或部分观察方面取得了良好的性能。 工作量:
- 需要大量的数据和计算资源。
点此查看论文截图

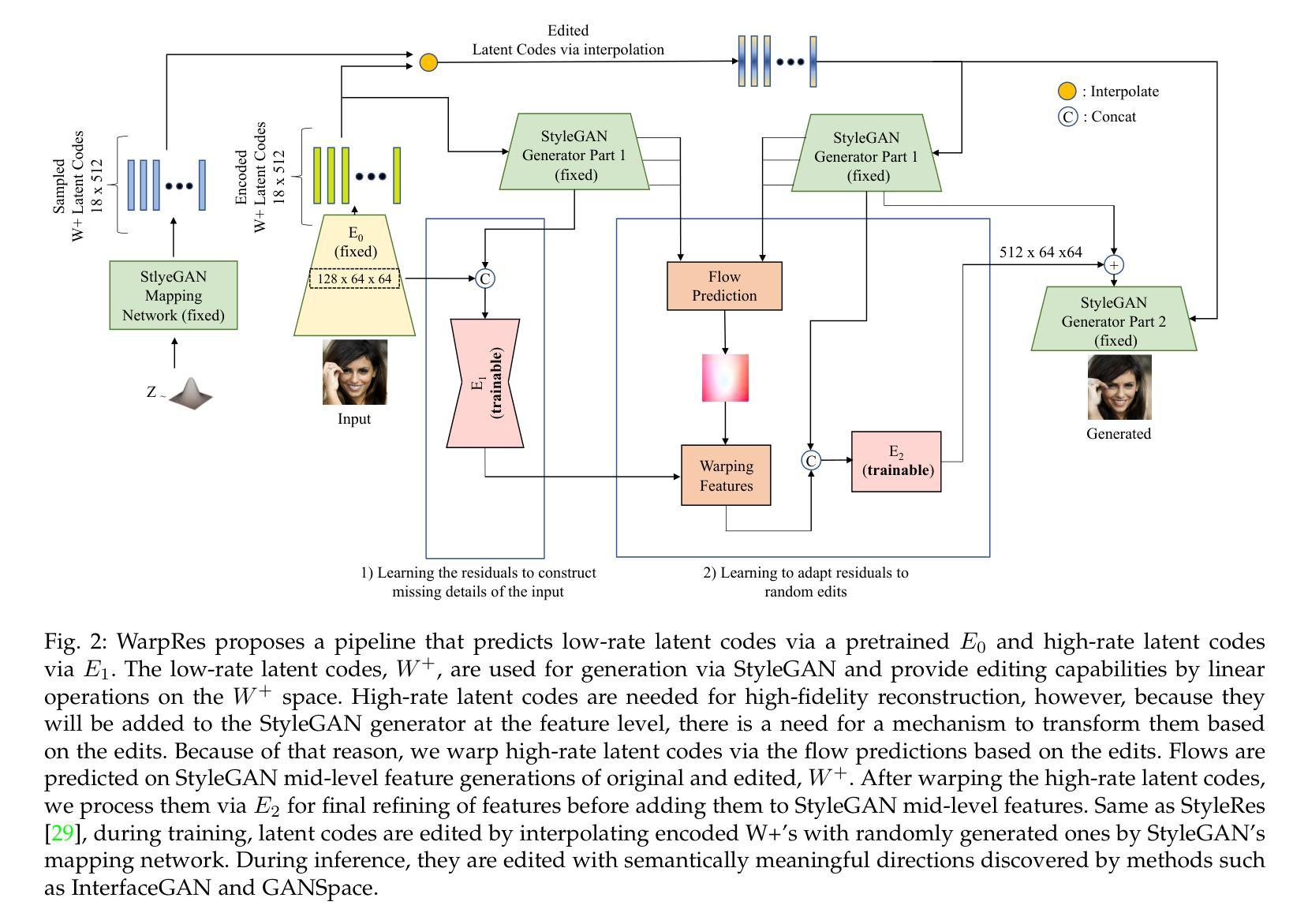
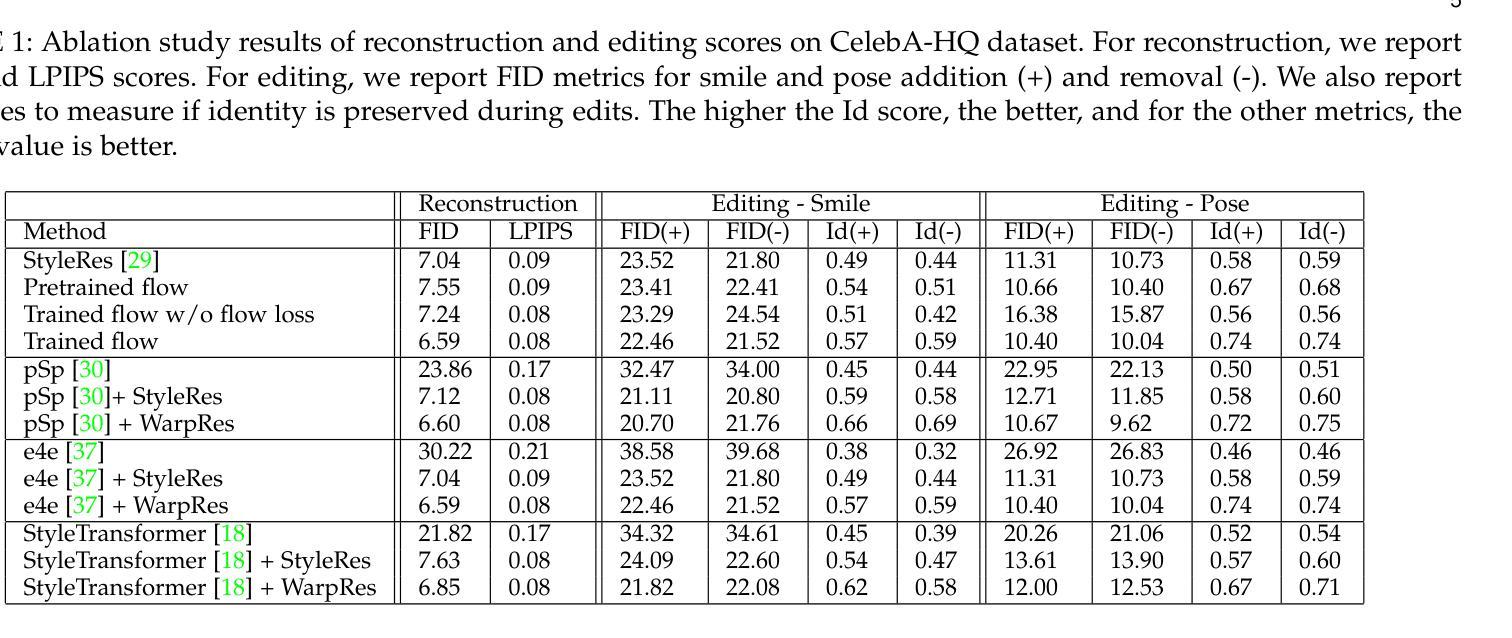
Warping the Residuals for Image Editing with StyleGAN
Authors:Ahmet Burak Yildirim, Hamza Pehlivan, Aysegul Dundar
StyleGAN models show editing capabilities via their semantically interpretable latent organizations which require successful GAN inversion methods to edit real images. Many works have been proposed for inverting images into StyleGAN’s latent space. However, their results either suffer from low fidelity to the input image or poor editing qualities, especially for edits that require large transformations. That is because low-rate latent spaces lose many image details due to the information bottleneck even though it provides an editable space. On the other hand, higher-rate latent spaces can pass all the image details to StyleGAN for perfect reconstruction of images but suffer from low editing qualities. In this work, we present a novel image inversion architecture that extracts high-rate latent features and includes a flow estimation module to warp these features to adapt them to edits. The flows are estimated from StyleGAN features of edited and unedited latent codes. By estimating the high-rate features and warping them for edits, we achieve both high-fidelity to the input image and high-quality edits. We run extensive experiments and compare our method with state-of-the-art inversion methods. Qualitative metrics and visual comparisons show significant improvements.
Summary:
GAN图像反演创新方法可实现高质量图像编辑。
Key Takeaways:
- StyleGAN模型具有语义可解释的潜在组织,需要成功的GAN反演方法来编辑真实图像。
- 许多研究已经提出将图像反演到StyleGAN潜在空间的方法。
- 低速率潜在空间由于信息瓶颈而丢失许多图像细节,即使它提供了可编辑的空间。
- 高速率潜在空间可以将所有图像细节传递给StyleGAN以完美重建图像,但编辑质量较差。
- 本工作提出了一种新的图像反演架构,可提取高速率潜在特征,并包括一个流动估计模块,将这些特征扭曲以适应编辑。
- 通过估计高速率特征并将其扭曲以进行编辑,我们实现了对输入图像的高保真度和高质量的编辑。
- 广泛的实验表明我们的方法优于最先进的反演方法。
- 标题:使用 StyleGAN 进行图像编辑的残差翘曲
- 作者:Ahmet Burak Yildirim、Hamza Pehlivan、Aysegul Dundar
- 作者单位:无
- 关键词:GAN 反演、图像编辑、生成对抗网络
- 论文链接:https://arxiv.org/abs/2312.11422,Github 代码链接:无
- 摘要: (1)研究背景:StyleGAN 模型因其语义可解释的潜在组织而显示出编辑功能,这需要成功的 GAN 反演方法来编辑真实图像。许多工作已被提议将图像反演到 StyleGAN 的潜在空间。然而,它们的结果要么对输入图像的保真度低,要么编辑质量差,尤其是对于需要大变换的编辑。这是因为低速率潜在空间由于信息瓶颈而丢失了许多图像细节,即使它提供了可编辑的空间。另一方面,更高速率的潜在空间可以将所有图像细节传递给 StyleGAN 以完美重建图像,但编辑质量会降低,如果这些特征与编辑不一致。 (2)过去的方法和问题:为了解决这种权衡,我们之前的工作 StyleRes 提出了一种框架,该框架可以学习更高速率潜在代码中的残差特征,这些特征在编码特征的重建中缺失。然而,这些高比率潜在代码需要适应图像编辑。例如,如果高比率代码携带有关人耳环的信息,并且图像被编辑以改变人的姿势,那么这些代码应该相应地被携带到生成器中以出现在正确的位置。否则,它会导致重影效应。因此,StyleRes 提议用随机编辑和循环一致性指导来训练模型,以便在应用编辑并恢复回原状时重建原始图像。通过这个指导,它学习了一个模块来转换这些更高比率的潜在代码以进行图像编辑。然而,学习的模块是一个卷积神经网络,并且在正确转换残差以进行编辑方面具有有限的能力。 (3)方法:在本文中,我们的主要贡献是一个管道,它可以学习高保真图像重建的残差并正确采用它们以进行高质量的图像编辑。我们的框架通过估计原始图像特征和编辑图像特征之间的流动并根据流动翘曲残差特征来实现这一点。我们利用一个无监督的流动估计网络以一种新颖的方式训练我们的框架。该框架在极端编辑变换下实现了显着更好的结果,而我们的架构是单阶段且有效的。 (4)实验结果:我们的贡献如下:
- 我们提出了一种新颖的反演管道,通过预测原始图像和编辑图像之间的流动并学习根据预测的流动翘曲高比率特征来实现高质量的图像编辑。
- 我们通过一个无监督的预训练流动估计网络来指导流动预测。流动预测以 StyleGAN 中间特征作为输入以实现效率。
- 我们表明我们的框架可以与不同的预训练 StyleGAN 反演网络一起工作,并以很大的幅度改进所有这些网络。
- 我们的广泛实验表明了我们方法的有效性。
Methods: (1): 本文提出了一种新的反演管道,通过预测原始图像和编辑图像之间的流动并学习根据预测的流动翘曲高比率特征来实现高质量的图像编辑。 (2): 该框架通过一个无监督的预训练流动估计网络来指导流动预测。流动预测以StyleGAN中间特征作为输入以实现效率。 (3): 本文表明该框架可以与不同的预训练StyleGAN反演网络一起工作,并以很大的幅度改进所有这些网络。 (4): 广泛的实验表明了该方法的有效性。
结论: (1)该工作提出了一种 GAN 反演方法,该方法在运行时高效,并且在各种工作中探索的编辑方向下实现了高保真度和高质量的图像编辑。与以前的工作不同,我们提出估计未编辑和编辑特征的流预测,以扭曲高比率残差特征,这些特征对于精确的图像重建是必需的。我们表明,所提出的框架在许多编辑中实现了最先进的结果,尤其是在需要大变换的编辑中。 (2)创新点:
- 提出了一种新的 GAN 反演管道,通过预测原始图像和编辑图像之间的流动并学习根据预测的流动扭曲高比率特征来实现高质量的图像编辑。
- 该框架通过一个无监督的预训练流动估计网络来指导流动预测。流动预测以 StyleGAN 中间特征作为输入以实现效率。
- 表明该框架可以与不同的预训练 StyleGAN 反演网络一起工作,并以很大的幅度改进所有这些网络。
- 广泛的实验表明了该方法的有效性。 性能:
- 该方法在极端编辑变换下实现了显着更好的结果,而我们的架构是单阶段且有效的。
- 该方法可以与不同的预训练 StyleGAN 反演网络一起工作,并以很大的幅度改进所有这些网络。
- 该方法在广泛的实验中表明了其有效性。 工作量:
- 该方法需要一个无监督的预训练流动估计网络来指导流动预测。
- 该方法需要广泛的实验来表明其有效性。
点此查看论文截图



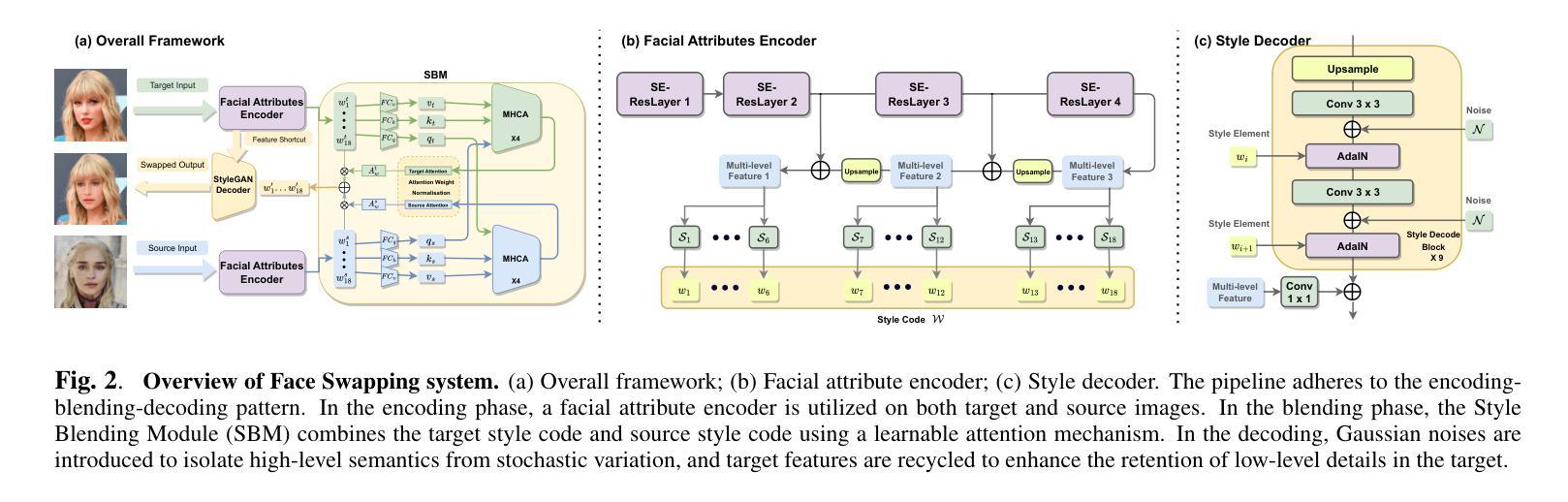
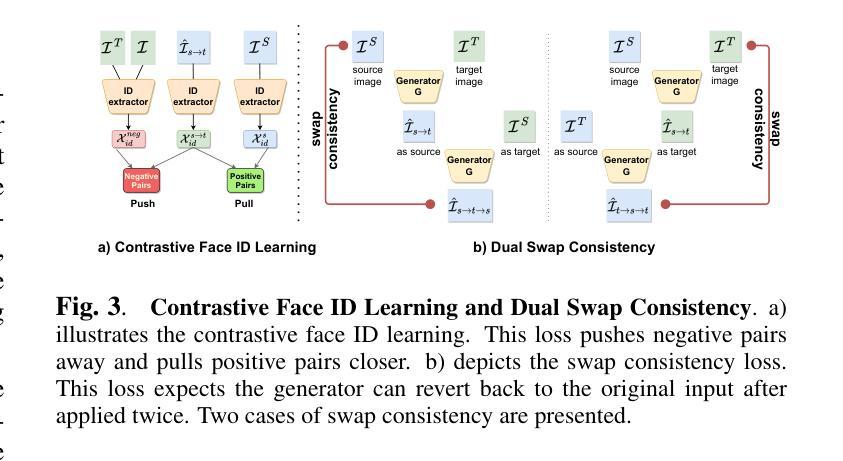
High-Fidelity Face Swapping with Style Blending
Authors:Xinyu Yang, Hongbo Bo
Face swapping has gained significant traction, driven by the plethora of human face synthesis facilitated by deep learning methods. However, previous face swapping methods that used generative adversarial networks (GANs) as backbones have faced challenges such as inconsistency in blending, distortions, artifacts, and issues with training stability. To address these limitations, we propose an innovative end-to-end framework for high-fidelity face swapping. First, we introduce a StyleGAN-based facial attributes encoder that extracts essential features from faces and inverts them into a latent style code, encapsulating indispensable facial attributes for successful face swapping. Second, we introduce an attention-based style blending module to effectively transfer Face IDs from source to target. To ensure accurate and quality transferring, a series of constraint measures including contrastive face ID learning, facial landmark alignment, and dual swap consistency is implemented. Finally, the blended style code is translated back to the image space via the style decoder, which is of high training stability and generative capability. Extensive experiments on the CelebA-HQ dataset highlight the superior visual quality of generated images from our face-swapping methodology when compared to other state-of-the-art methods, and the effectiveness of each proposed module. Source code and weights will be publicly available.
PDF 4 pages
Summary
优化生成对抗网络 (GAN) 架构,提出基于 StyleGAN 的人脸属性编码器和基于注意力的风格融合模块,实现高保真换脸。
Key Takeaways
- 提出了一种基于 StyleGAN 的人脸属性编码器,将人脸特征提取并反演为潜在样式代码。
- 设计了一个基于注意力的风格融合模块,有效地将源人脸的 Face ID 转移到目标人脸。
- 采用了一系列约束措施,包括对比人脸 ID 学习、人脸关键点对齐和双重交换一致性。
- 将混合的样式代码通过样式解码器翻译回图像空间,具有很高的训练稳定性和生成能力。
- 在 CelebA-HQ 数据集上进行的广泛实验表明,该换脸方法生成的图像视觉质量优于其他最先进的方法。
- 同时验证了每一项提出的模块的有效性。
- 源代码和权重将公开发布。
- 题目:风格融合的高保真换脸
- 作者:Xinyu Yang
- 单位:兰开斯特大学
- 关键词:生成对抗网络、人脸合成、人脸交换
- 论文链接:https://arxiv.org/abs/2312.10843
- 摘要: (1)研究背景:换脸技术近年来备受关注,但现有的换脸方法存在融合不一致、扭曲、伪影和训练稳定性差等问题。 (2)过去方法与不足:以往基于生成对抗网络(GAN)的换脸方法存在融合不一致、扭曲、伪影和训练稳定性差等问题。这些方法难以平衡身份相似性和目标的低级细节保留,导致生成的图像经常出现伪影和低保真度。 (3)研究方法:本文提出了一种新的端到端高保真换脸框架。该框架包括三个关键组成部分:面部属性编码器、风格融合模块和风格解码器。面部属性编码器将目标和源图像的特征提取到潜在空间中,并使用多头交叉注意(MHCA)将源嵌入和目标嵌入进行融合。最后,使用预训练的风格解码器将融合的嵌入解码为图像。 (4)性能与结论:在 CelebA-HQ 数据集上进行的广泛实验表明,该方法生成的图像具有更高的视觉质量,并且能够有效地将源图像的面部特征转移到目标图像中。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于风格编码模型的高保真换脸框架,该框架能够生成具有更高视觉质量和更逼真的人脸图像,有效地将源图像的面部特征转移到目标图像中。 (2):创新点: 该框架采用了一种新的风格融合模块,该模块能够在潜在空间中将源嵌入和目标嵌入进行融合,从而生成更逼真的图像。 该框架使用预训练的风格解码器将融合的嵌入解码为图像,这使得该框架能够生成更逼真的人脸图像。 性能: 该框架在CelebA-HQ数据集上进行了广泛的实验,实验结果表明,该框架生成的图像具有更高的视觉质量,并且能够有效地将源图像的面部特征转移到目标图像中。 工作量: 该框架的实现相对复杂,需要较高的计算资源和较长时间的训练。
点此查看论文截图


Super-Resolution through StyleGAN Regularized Latent Search: A Realism-Fidelity Trade-off
Authors:Marzieh Gheisari, Auguste Genovesio
This paper addresses the problem of super-resolution: constructing a highly resolved (HR) image from a low resolved (LR) one. Recent unsupervised approaches search the latent space of a StyleGAN pre-trained on HR images, for the image that best downscales to the input LR image. However, they tend to produce out-of-domain images and fail to accurately reconstruct HR images that are far from the original domain. Our contribution is twofold. Firstly, we introduce a new regularizer to constrain the search in the latent space, ensuring that the inverted code lies in the original image manifold. Secondly, we further enhanced the reconstruction through expanding the image prior around the optimal latent code. Our results show that the proposed approach recovers realistic high-quality images for large magnification factors. Furthermore, for low magnification factors, it can still reconstruct details that the generator could not have produced otherwise. Altogether, our approach achieves a good trade-off between fidelity and realism for the super-resolution task.
Summary
通过约束潜在空间搜索范围和扩展图像先验来提高深度生成模型的超分辨率重建
Key Takeaways
- 该论文关注超分辨率问题,即从低分辨率图像生成高分辨率图像。
- 最近的无监督方法在预先训练好的 StyleGAN 的潜在空间中搜索图像,使其下采样后与输入的低分辨率图像最匹配。
- 但这些方法倾向于产生域外图像,无法准确重建远离原始域的高分辨率图像。
- 引入了一个新的正则化项来约束潜在空间中的搜索,确保反转代码位于原始图像流形中。
- 通过扩展最佳潜在代码周围的图像先验来进一步增强重建。
- 实验结果表明,该方法可以在大倍率放大因子下恢复逼真、高质量的图像。
- 对于低倍率放大因子,它仍然可以重建生成器无法生成的其他细节。
- 总之,该方法在超分辨率任务中实现了保真度和真实性之间的良好权衡。
题目:通过 StyleGAN 正则化潜在搜索实现超分辨率:真实性-保真度权衡
作者:Marzieh Gheisari, Auguste Genovesio
单位:巴黎高等师范学院
关键词:超分辨率、StyleGAN、潜在搜索、正则化、真实性、保真度
链接:https://arxiv.org/abs/2311.16923 Github:无
摘要: (1):超分辨率旨在从低分辨率图像中重建未知的高分辨率图像。近年来,生成模型极大地促进了超分辨率的发展。 (2):GAN-based 方法和先验引导方法是超分辨率的两种主要研究趋势。GAN-based 方法学习高分辨率图像和低分辨率图像的直接耦合,但存在局限性,例如产生伪影和不自然的纹理。先验引导方法通过利用先验信息来更好地定义目标,从而提高重建的稳定性。 (3):本文提出了一种新的正则化方法来约束潜在空间中的搜索,确保反转的编码位于原始图像流形中。此外,通过在最优潜在编码周围扩展图像先验,进一步增强了重建效果。 (4):实验结果表明,该方法在较大的放大倍数下可以恢复真实且高质量的图像。即使在较小的放大倍数下,它仍然可以重建生成器无法单独生成的细节。总体而言,该方法在超分辨率任务中实现了真实性和保真度之间的良好权衡。
方法:
(1)潜在空间正则化:提出了一种新的正则化方法,通过在潜在空间中约束搜索来确保反转的编码位于原始图像流形中。该方法通过最小化潜在编码和相应的生成图像之间的距离来实现。
(2)图像先验扩展:在最优潜在编码周围扩展图像先验,以进一步增强重建效果。该方法通过使用高斯核对最优潜在编码周围的潜在空间进行加权来实现。
(3)超分辨率重建:使用StyleGAN生成器将正则化的潜在编码反转为高分辨率图像。该方法通过最小化生成的图像和低分辨率输入图像之间的距离来实现。
- 结论: (1)本文提出了一种新的正则化方法,通过在潜在空间中约束搜索来确保反转的编码位于原始图像流形中。此外,通过在最优潜在编码周围扩展图像先验,进一步增强了重建效果。实验结果表明,该方法在较大的放大倍数下可以恢复真实且高质量的图像。即使在较小的放大倍数下,它仍然可以重建生成器无法单独生成的细节。总体而言,该方法在超分辨率任务中实现了真实性和保真度之间的良好权衡。 (2)创新点:
- 提出了一种新的正则化方法,通过在潜在空间中约束搜索来确保反转的编码位于原始图像流形中。
- 通过在最优潜在编码周围扩展图像先验,进一步增强了重建效果。 性能:
- 该方法在较大的放大倍数下可以恢复真实且高质量的图像。
- 即使在较小的放大倍数下,它仍然可以重建生成器无法单独生成的细节。
- 总体而言,该方法在超分辨率任务中实现了真实性和保真度之间的良好权衡。 工作量:
- 该方法需要对StyleGAN生成器进行预训练。
- 需要对正则化方法和图像先验扩展方法进行训练。
- 需要对超分辨率重建方法进行训练。
点此查看论文截图




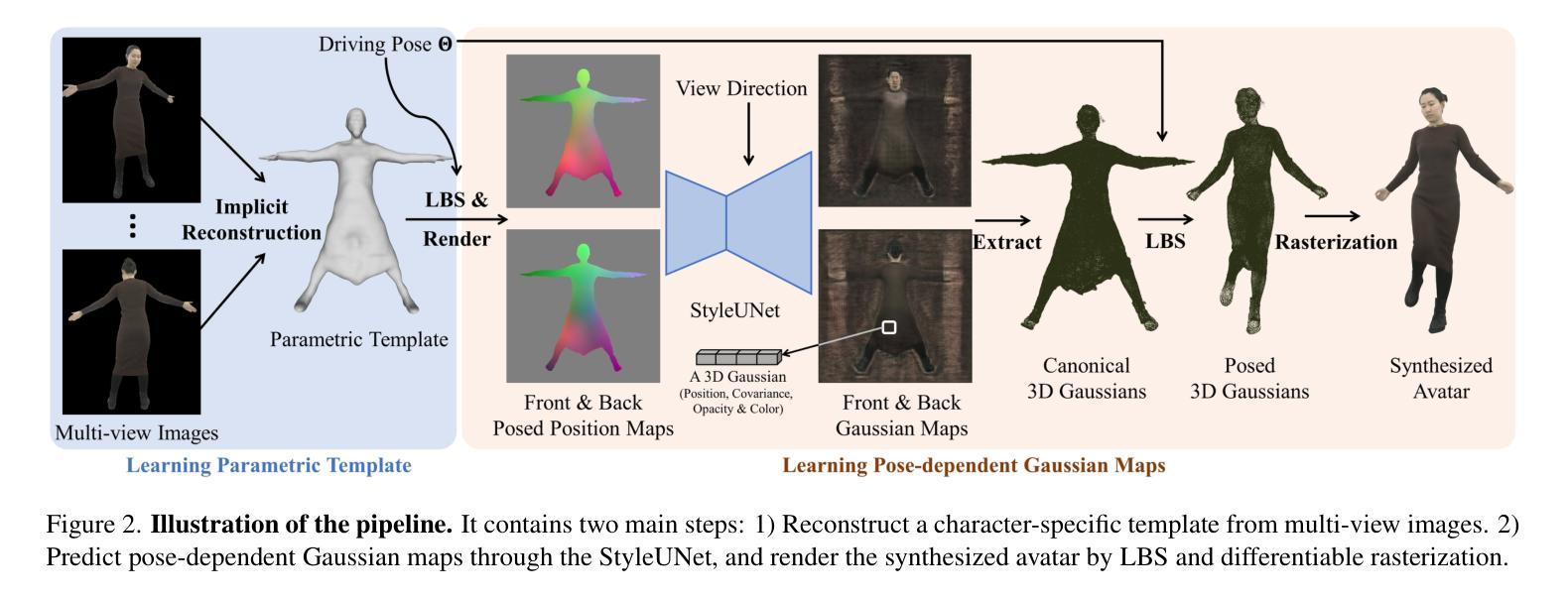
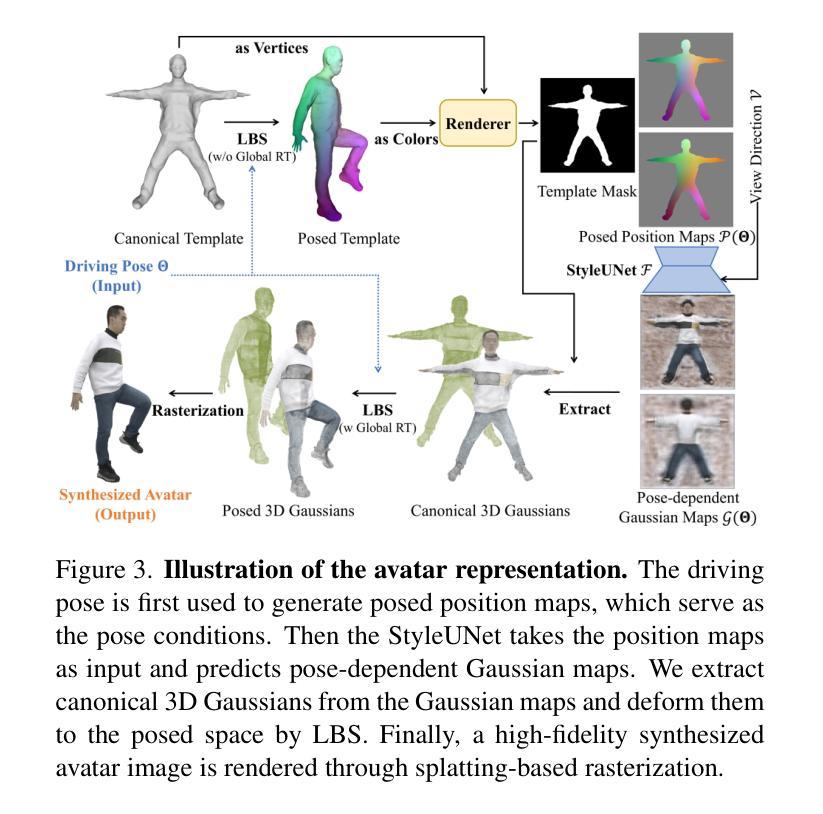
Animatable Gaussians: Learning Pose-dependent Gaussian Maps for High-fidelity Human Avatar Modeling
Authors:Zhe Li, Zerong Zheng, Lizhen Wang, Yebin Liu
Modeling animatable human avatars from RGB videos is a long-standing and challenging problem. Recent works usually adopt MLP-based neural radiance fields (NeRF) to represent 3D humans, but it remains difficult for pure MLPs to regress pose-dependent garment details. To this end, we introduce Animatable Gaussians, a new avatar representation that leverages powerful 2D CNNs and 3D Gaussian splatting to create high-fidelity avatars. To associate 3D Gaussians with the animatable avatar, we learn a parametric template from the input videos, and then parameterize the template on two front & back canonical Gaussian maps where each pixel represents a 3D Gaussian. The learned template is adaptive to the wearing garments for modeling looser clothes like dresses. Such template-guided 2D parameterization enables us to employ a powerful StyleGAN-based CNN to learn the pose-dependent Gaussian maps for modeling detailed dynamic appearances. Furthermore, we introduce a pose projection strategy for better generalization given novel poses. Overall, our method can create lifelike avatars with dynamic, realistic and generalized appearances. Experiments show that our method outperforms other state-of-the-art approaches. Code: https://github.com/lizhe00/AnimatableGaussians
PDF Projectpage: https://animatable-gaussians.github.io/, Code: https://github.com/lizhe00/AnimatableGaussians
概述
采用强大的二维卷积神经网络和三维高斯扩散的方式来创作逼真的虚拟人物。
要点
- 提出一种新的虚拟形象表示法——可动画高斯,它利用强大的二维卷积神经网络和三维高斯扩散来创建逼真的虚拟形象。
- 学习一个参数模板从输入视频中,然后将模板参数化在两个正面&背面规范的高斯映射上,每个像素代表一个三维高斯。
- 学习的模板可以适应穿的衣服来建模更宽松的衣服,如连衣裙。
- 基于 StyleGAN 的卷积神经网络学习姿势相关的 Gaussian 地图,用于建模详细的动态外观。
- 提出了一种姿势投影策略,以便在新的姿势下更好地泛化。
- 实验表明,本方法优于其他最先进的方法。
- 代码:https://github.com/lizhe00/AnimatableGaussians
题目:可动画的高斯体:学习姿势依赖的高斯映射
作者:Zhe Li, Menglei Chai, Yinda Zhang, Jingyi Yu, Jingyi Yu
单位:香港中文大学(深圳)
关键词:神经辐射场、动画、高斯体、姿势投影
论文链接:None,Github 代码链接:https://github.com/lizhe00/AnimatableGaussians
摘要: (1)研究背景:建模可动画的人体虚拟形象是一个长期存在且具有挑战性的问题。最近的工作通常采用基于 MLP 的神经辐射场 (NeRF) 来表示 3D 人体,但纯 MLP 很难回归姿势相关的服装细节。 (2)过去方法与问题:为了解决这个问题,我们引入了可动画的高斯体,这是一种新的虚拟形象表示,利用强大的 2D CNN 和 3D 高斯体 splatting 来创建高保真虚拟形象。为了将 3D 高斯体与可动画虚拟形象相关联,我们从输入视频中学习了一个参数化模板,然后在两个正面和背面规范高斯图上对模板进行参数化,其中每个像素都表示一个 3D 高斯体。学习到的模板可以适应穿着的服装,以建模更宽松的衣服,如连衣裙。这种模板引导的 2D 参数化使我们能够使用强大的基于 StyleGAN 的 CNN 来学习姿势相关的 Gaussian 图,以建模详细的动态外观。此外,我们引入了一种姿势投影策略,以在给定新颖姿势时获得更好的泛化。 (3)研究方法:总体而言,我们的方法可以创建具有动态、逼真和泛化的外观的逼真虚拟形象。实验表明,我们的方法优于其他最先进的方法。 (4)方法性能:在 THuman4.0 数据集和 AvatarReX 数据集上的实验表明,我们的方法在重建准确性和视觉质量方面优于其他最先进的方法。
方法: (1) 参数化模板:提出了一种参数化模板,该模板由两个正面和背面规范高斯图组成,每个像素都表示一个 3D 高斯体。该模板可以适应穿着的服装,以建模更宽松的衣服,如连衣裙。 (2) 基于 StyleGAN 的 CNN:利用强大的基于 StyleGAN 的 CNN 来学习姿势相关的 Gaussian 图,以建模详细的动态外观。 (3) 姿势投影策略:引入了一种姿势投影策略,以在给定新颖姿势时获得更好的泛化。该策略通过将输入位置图投影到训练数据集中最接近的姿势的位置图上来实现。
结论:
(1):本文提出了一种可动画的高斯体表示方法,使用强大的2DCNN和3D高斯体splatting来创建高保真虚拟形象。该方法可以创建具有动态、逼真和泛化的外观的逼真虚拟形象。实验表明,该方法优于其他最先进的方法。
(2):创新点:
- 提出了一种参数化模板,该模板由两个正面和背面规范高斯图组成,每个像素都表示一个3D高斯体。该模板可以适应穿着的服装,以建模更宽松的衣服,如连衣裙。
- 利用强大的基于StyleGAN的CNN来学习姿势相关的Gaussian图,以建模详细的动态外观。
- 引入了一种姿势投影策略,以在给定新颖姿势时获得更好的泛化。
性能:
- 在THuman4.0数据集和AvatarReX数据集上的实验表明,该方法在重建准确性和视觉质量方面优于其他最先进的方法。
工作量:
- 该方法需要大量的数据和计算资源。
点此查看论文截图


Importance of Feature Extraction in the Calculation of Fréchet Distance for Medical Imaging
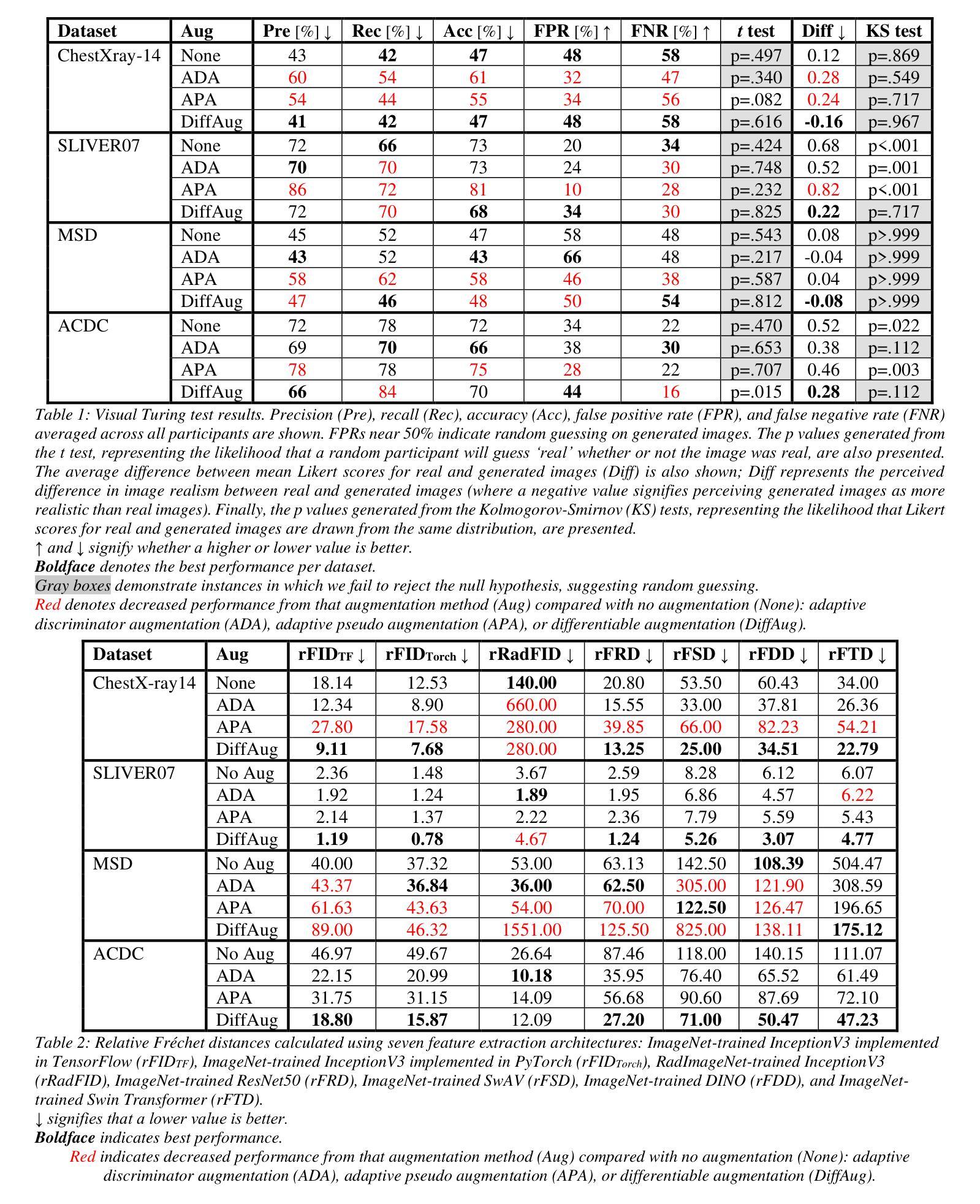
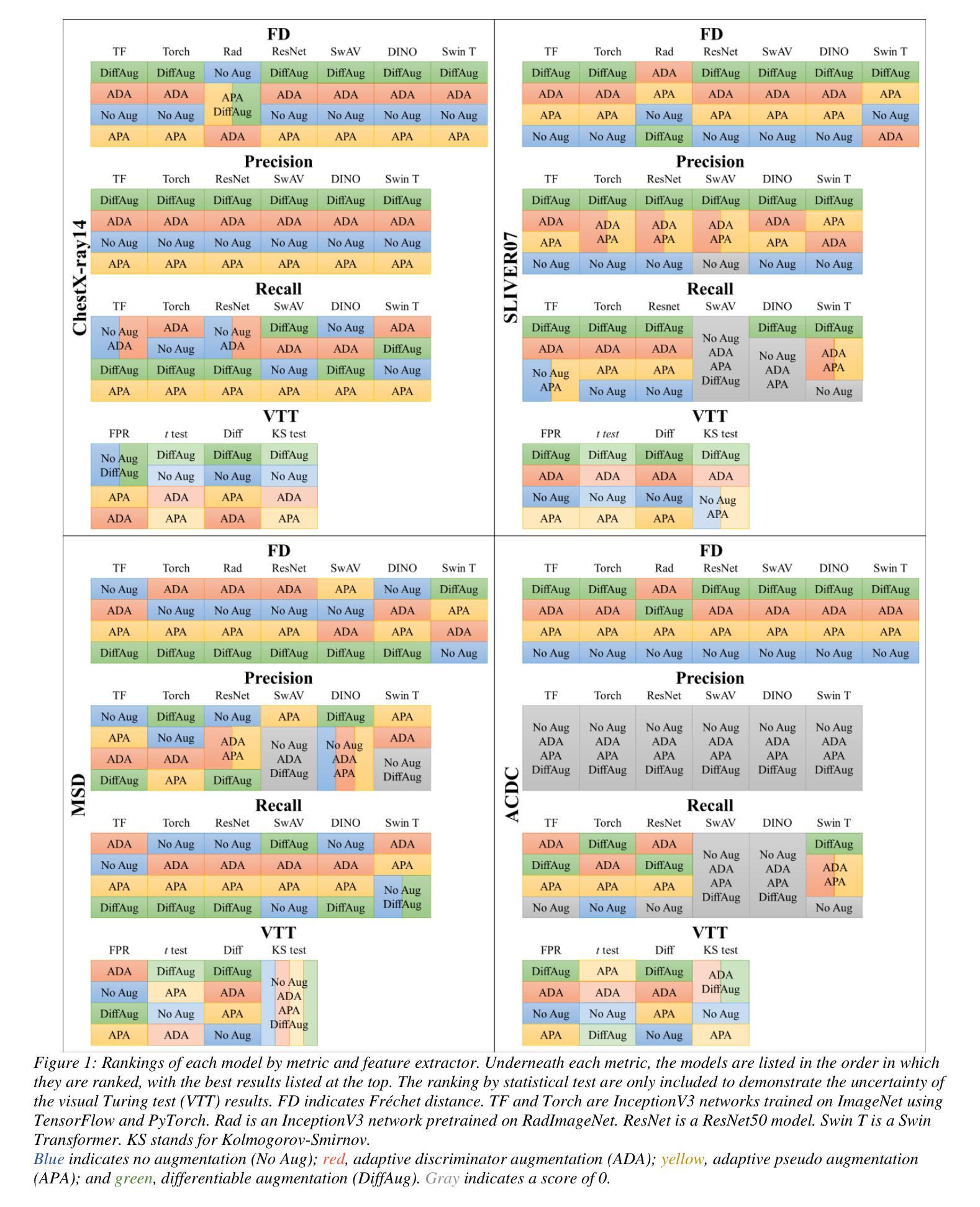
Authors:McKell Woodland, Mais Al Taie, Jessica Albuquerque Marques Silva, Mohamed Eltaher, Frank Mohn, Alexander Shieh, Austin Castelo, Suprateek Kundu, Joshua P. Yung, Ankit B. Patel, Kristy K. Brock
Fr'echet Inception Distance is a widely used metric for evaluating synthetic image quality that utilizes an ImageNet-trained InceptionV3 network as a feature extractor. However, its application in medical imaging lacks a standard feature extractor, leading to biased and inconsistent comparisons. This study aimed to compare state-of-the-art feature extractors for computing Fr'echet Distances (FDs) in medical imaging. A StyleGAN2 network was trained with data augmentation techniques tailored for limited data domains on datasets comprising three medical imaging modalities and four anatomical locations. Human evaluation of generative quality (via a visual Turing test) was compared to FDs calculated using ImageNet-trained InceptionV3, ResNet50, SwAV, DINO, and Swin Transformer architectures, in addition to an InceptionV3 network trained on a large medical dataset, RadImageNet. All ImageNet-based extractors were consistent with each other, but only SwAV was significantly correlated with medical expert judgment. The RadImageNet-based FD showed volatility and lacked correlation with human judgment. Caution is advised when using medical image-trained extraction networks in the FD calculation. These networks should be rigorously evaluated on the imaging modality under consideration and publicly released. ImageNet-based extractors, while imperfect, are consistent and widely understood. Training extraction networks with SwAV is a promising approach for synthetic medical image evaluation.
Summary
医学图像生成质量评价中,ImageNet 预训练的特征提取器与医学专家判断不一致,SwAV 是唯一显著相关的网络。
Key Takeaways
- Fr'echet Inception Distance (FID) 是一种广泛用于评估合成图像质量的指标,利用 ImageNet 训练的 InceptionV3 网络作为特征提取器。
- 在医学图像中使用 FID 缺乏标准的特征提取器,导致比较结果存在偏差且不一致。
- 本研究旨在比较最先进的特征提取器,用于计算医学图像中的 Fr'echet 距离 (FD)。
- 使用针对有限数据域量身定制的数据增强技术训练 StyleGAN2 网络,该数据集包括三个医学图像模态和四个解剖位置。
- 将生成质量的人工评估(通过视觉图灵测试)与使用 ImageNet 训练的 InceptionV3、ResNet50、SwAV、DINO 和 Swin Transformer 架构以及在大规模医学数据集 RadImageNet 上训练的 InceptionV3 网络计算的 FD 进行比较。
- 所有基于 ImageNet 的提取器彼此一致,但只有 SwAV 与医学专家判断显着相关。
- 基于 RadImageNet 的 FD 显示出不稳定性,并且与人类判断缺乏相关性。
- 在 FD 计算中使用医学图像训练的提取网络时应谨慎。这些网络应在所考虑的成像方式上进行严格评估并公开发布。
- 基于 ImageNet 的提取器虽然不完美,但具有一致性且被广泛理解。
- 使用 SwAV 训练提取网络是合成医学图像评估的一种有前途的方法。
- 题目:医学图像 Fréchet 距离计算中的特征提取的重要性
- 作者:McKell Woodland, Mais Al Taie, Jessica Albuquerque Marques Silva, Mohamed Eltaher, Frank Mohn, Alexander Shieh, Austin Castelo, Suprateek Kundu, Joshua P. Yung, Ankit B. Patel, Kristy K. Brock
- 第一作者单位:德克萨斯大学安德森癌症中心
- 关键词:Fréchet 距离, 特征提取, 医学图像, 生成模型, 自监督学习
- 链接:None, Github:None
- 摘要: (1)研究背景:Fréchet 距离是一种广泛用于评估合成图像质量的度量,它利用在 ImageNet 上训练的 InceptionV3 网络作为特征提取器。然而,在医学图像中的应用缺乏标准的特征提取器,导致比较存在偏差和不一致。 (2)过去方法及其问题:一种方法是使用在大型公开医学数据集上训练的 InceptionV3 网络来计算 FD。然而,这种方法可能不适用于未包含在该数据集中的医学模态,例如内窥镜检查和乳房 X 光检查。另一种方法是使用自监督特征提取器,但现有研究表明,这些提取器在医学图像上的性能参差不齐。 (3)论文提出的研究方法:本文比较了用于计算医学图像中 Fréchet 距离的几种最先进的特征提取器。我们使用针对有限数据域的数据增强技术训练了一个 StyleGAN2 网络,该数据集包含三个医学影像模态和四个解剖位置。我们将生成质量的人工评估(通过视觉图灵测试)与使用在 ImageNet 上训练的 InceptionV3、ResNet50、SwAV、DINO 和 SwinTransformer 架构以及在大型医学数据集 RadImageNet 上训练的 InceptionV3 网络计算的 FD 进行了比较。 (4)方法在任务和性能上的表现:所有基于 ImageNet 的提取器彼此一致,但只有 SwAV 与医学专家的判断显着相关。基于 RadImageNet 的 FD 显示出不稳定性,并且与人类判断缺乏相关性。在 FD 计算中使用医学图像训练的提取网络时应谨慎。这些网络应该在考虑的成像方式上进行严格评估并公开发布。ImageNet-base 的提取器虽然不完美,但它们一致且被广泛理解。使用 SwAV 训练提取网络是合成医学图像评估的一种很有前途的方法。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1): 本文比较了用于计算医学图像中 Fréchet 距离的几种最先进的特征提取器,发现基于 ImageNet 的提取器彼此一致,但只有 SwAV 与医学专家的判断显着相关。基于 RadImageNet 的 Fréchet 距离显示出不稳定性,并且与人类判断缺乏相关性。在 Fréchet 距离计算中使用医学图像训练的提取网络时应谨慎。这些网络应该在考虑的成像方式上进行严格评估并公开发布。ImageNet-base 的提取器虽然不完美,但它们一致且被广泛理解。使用 SwAV 训练提取网络是合成医学图像评估的一种很有前途的方法。 (2): 创新点:
- 比较了用于计算医学图像中 Fréchet 距离的几种最先进的特征提取器。
- 发现基于 ImageNet 的提取器彼此一致,但只有 SwAV 与医学专家的判断显着相关。
- 基于 RadImageNet 的 Fréchet 距离显示出不稳定性,并且与人类判断缺乏相关性。
- 在 Fréchet 距离计算中使用医学图像训练的提取网络时应谨慎。
- 使用 SwAV 训练提取网络是合成医学图像评估的一种很有前途的方法。
性能:
- 基于 ImageNet 的提取器彼此一致,但只有 SwAV 与医学专家的判断显着相关。
- 基于 RadImageNet 的 Fréchet 距离显示出不稳定性,并且与人类判断缺乏相关性。
工作量:
- 需要比较多种特征提取器,工作量较大。
- 需要在医学图像上训练提取网络,工作量较大。
点此查看论文截图