⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-24 更新
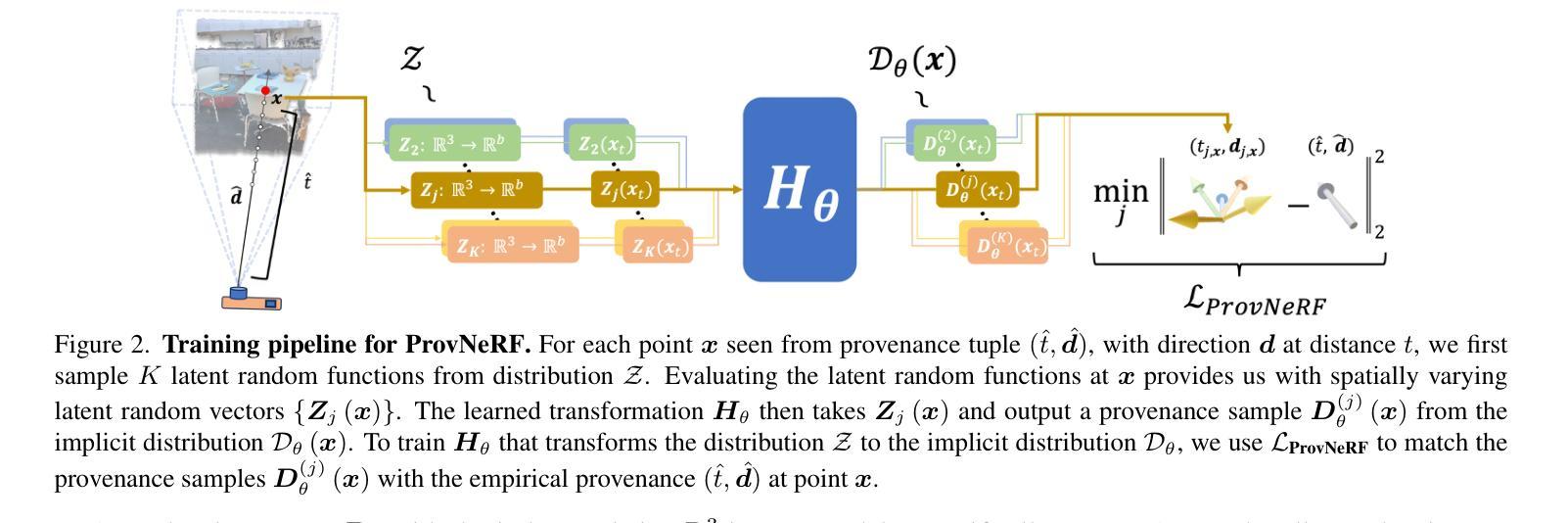
ProvNeRF: Modeling per Point Provenance in NeRFs as a Stochastic Process
Authors:Kiyohiro Nakayama, Mikaela Angelina Uy, Yang You, Ke Li, Leonidas Guibas
Neural radiance fields (NeRFs) have gained popularity across various applications. However, they face challenges in the sparse view setting, lacking sufficient constraints from volume rendering. Reconstructing and understanding a 3D scene from sparse and unconstrained cameras is a long-standing problem in classical computer vision with diverse applications. While recent works have explored NeRFs in sparse, unconstrained view scenarios, their focus has been primarily on enhancing reconstruction and novel view synthesis. Our approach takes a broader perspective by posing the question: “from where has each point been seen?” – which gates how well we can understand and reconstruct it. In other words, we aim to determine the origin or provenance of each 3D point and its associated information under sparse, unconstrained views. We introduce ProvNeRF, a model that enriches a traditional NeRF representation by incorporating per-point provenance, modeling likely source locations for each point. We achieve this by extending implicit maximum likelihood estimation (IMLE) for stochastic processes. Notably, our method is compatible with any pre-trained NeRF model and the associated training camera poses. We demonstrate that modeling per-point provenance offers several advantages, including uncertainty estimation, criteria-based view selection, and improved novel view synthesis, compared to state-of-the-art methods. Please visit our project page at https://provnerf.github.io
Summary
神经辐射场 (NeRF) 在各种应用中获得广泛欢迎,但面临稀疏视图设置时的挑战,缺乏体积渲染的足够约束。
Key Takeaways
- NeRF 在稀疏视图设置中面临挑战,因为缺乏足够的体积渲染约束。
- 重建和理解稀疏且不受约束的相机的 3D 场景是经典计算机视觉中的一个长期问题,具有广泛的应用。
- 最近的工作已经探索了稀疏、不受约束的视图场景中的 NeRF,但重点主要放在增强重建和新颖视图合成。
- ProvNeRF 通过提出问题“每个点是从哪里看到的?”来采用更广泛的视角 – 这决定了我们对它的理解和重建程度。
- ProvNeRF 是一种模型,它通过结合每个点的出处来丰富传统的 NeRF 表示,建模每个点的可能来源位置。
- ProvNeRF 与任何预先训练的 NeRF 模型及其关联的训练相机位姿兼容。
- 对比最先进的方法,建模每个点的出处提供了多种优势,包括不确定性估计、基于准则的视图选择和改进的新颖视图合成。
- 题目:ProvNeRF:将 NeRF 中的逐点来源建模为随机过程
- 作者:George Kiyohiro Nakayama、Mikaela Angelina Uy、Yang You、Ke Li、Leonidas Guibas
- 第一作者单位:斯坦福大学
- 关键词:NeRF、稀疏视图、来源、不确定性估计、视点优化、新颖视图合成
- 论文链接:https://arxiv.org/abs/2401.08140、Github 链接:None
- 摘要: (1):研究背景:神经辐射场 (NeRF) 在许多应用中都获得了广泛关注。然而,由于仅靠体积渲染无法提供足够的约束,它们在稀疏视图设置中面临挑战。 (2):过去方法和问题:最近的一些工作探索了在稀疏、不受约束的视图场景中使用 NeRF。为了解决约束不足的问题,他们将先验信息纳入 NeRF 优化中,例如深度、局部几何或全局形状信息。然而,这些工作只关注于实现更好的新颖视图合成,而没有解决如何从更全面的角度理解场景的问题,例如不确定性估计、基于标准的视点选择和鲁棒性。 (3):研究方法:我们提出 ProvNeRF,这是一种通过纳入逐点来源来丰富传统 NeRF 表示的模型,该模型为每个点建模可能的源位置。我们通过扩展随机过程的隐式最大似然估计 (IMLE) 来实现这一点。值得注意的是,我们的方法与任何预训练的 NeRF 模型及其相关的训练相机位姿兼容。 (4):方法性能:我们证明了对逐点来源进行建模提供了许多优势,包括不确定性估计、基于准则的视点选择和改进的新颖视图合成,与最先进的方法相比,我们的方法在这些任务上取得了更好的性能。这些性能支持了我们的目标。
Methods:
(1):我们提出ProvNeRF,这是一种通过纳入逐点来源来丰富传统NeRF表示的模型,该模型为每个点建模可能的源位置。我们通过扩展随机过程的隐式最大似然估计 (IMLE) 来实现这一点。
(2):我们定义逐点来源为一个随机过程,其索引集为R3,并由无穷多个随机变量组成。每个随机变量对应于R3中的一个点,其分布由该点的边缘分布给出。边缘分布表示可以观察到该点的可能位置的分布。
(3):我们使用一个神经网络来学习从潜在随机变量分布到模型分布的变换。潜在随机变量分布由输入位置x的随机线性变换和x本身的连接组成。模型分布由神经网络Hθ参数化,该神经网络将潜在随机函数映射到函数Dθ。
(4):为了优化模型分布,我们扩展了IMLE以建模随机过程的分布。我们通过在每个点处匹配经验样本和模型样本,将IMLE公式调整为函数空间。
- 结论: (1):ProvNeRF通过扩展随机过程的隐式最大似然估计(IMLE),将逐点来源纳入传统NeRF表示,增强了NeRF模型的表示能力,使其能够在稀疏视图设置中更好地估计不确定性、选择最佳视点并合成新颖视图。 (2):创新点:ProvNeRF将逐点来源建模为随机过程,并通过扩展IMLE来优化模型分布,这是一种新颖的建模方法,可以有效地提高NeRF模型在稀疏视图设置下的性能。 性能:ProvNeRF在不确定性估计、基于准则的视点选择和新颖视图合成等任务上取得了更好的性能,证明了对逐点来源进行建模的有效性。 工作量:ProvNeRF的实现相对简单,可以轻松应用于任何预训练的NeRF模型,并且不需要额外的训练数据或相机位姿信息。
点此查看论文截图

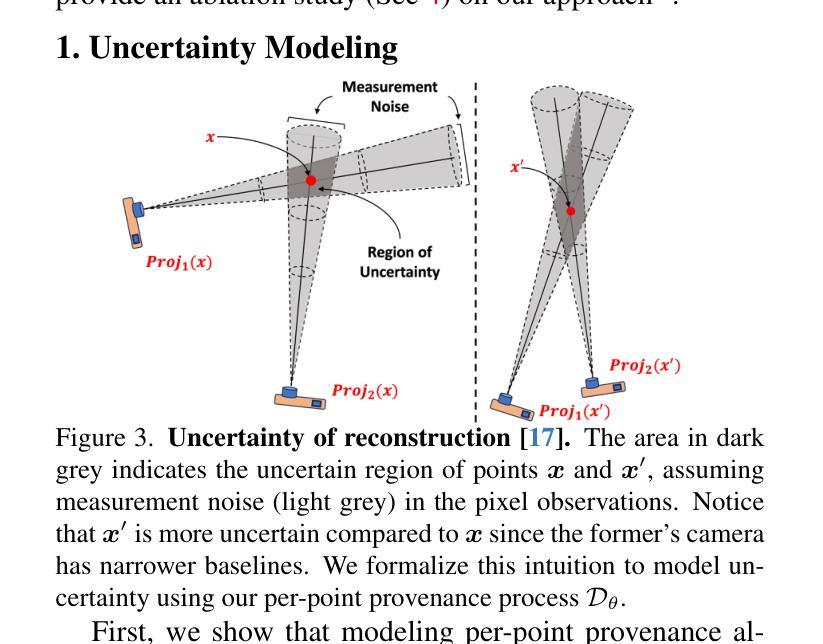
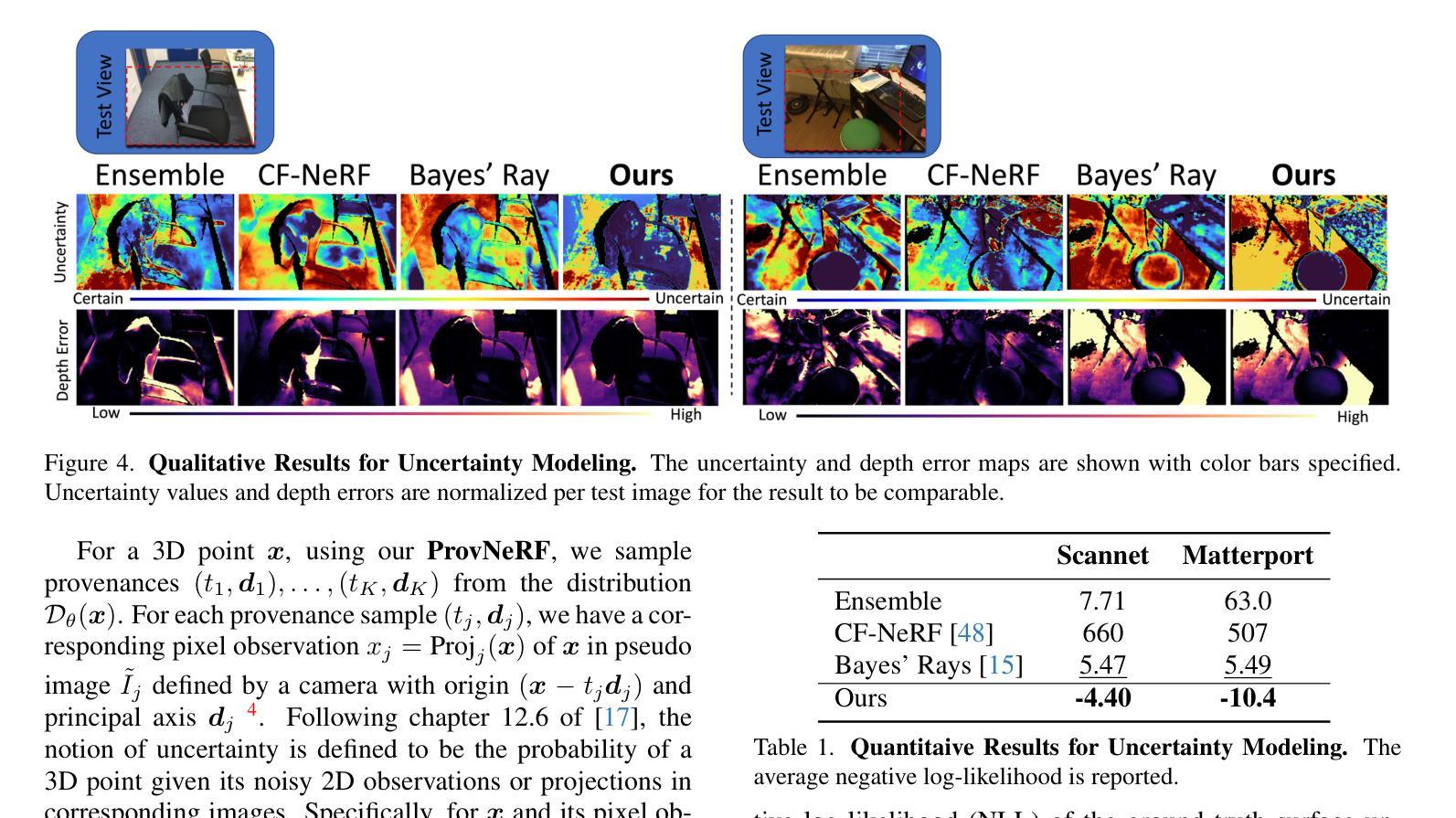
TriNeRFLet: A Wavelet Based Multiscale Triplane NeRF Representation
Authors:Rajaei Khatib, Raja Giryes
In recent years, the neural radiance field (NeRF) model has gained popularity due to its ability to recover complex 3D scenes. Following its success, many approaches proposed different NeRF representations in order to further improve both runtime and performance. One such example is Triplane, in which NeRF is represented using three 2D feature planes. This enables easily using existing 2D neural networks in this framework, e.g., to generate the three planes. Despite its advantage, the triplane representation lagged behind in its 3D recovery quality compared to NeRF solutions. In this work, we propose TriNeRFLet, a 2D wavelet-based multiscale triplane representation for NeRF, which closes the 3D recovery performance gap and is competitive with current state-of-the-art methods. Building upon the triplane framework, we also propose a novel super-resolution (SR) technique that combines a diffusion model with TriNeRFLet for improving NeRF resolution.
PDF webpage link: https://rajaeekh.github.io/trinerflet-web
摘要
引入了基于二维小波表示的 TriNeRFLet 以弥补三平面表示的 3D 重建质量与 NeRF 解决方案之间的差距。
主要内容
- TriNeRFLet 是一种基于二维小波表示的 TriPlane 表示,可以弥补三平面表示的 3D 重建质量与 NeRF 解决方案之间的差距。
- TriNeRFLet 在 3D 重建质量上与当前最先进的方法具有竞争力。
- TriNeRFLet 可以与扩散模型相结合以提高 NeRF 分辨率。
- 使用 TriNeRFLet 可以提高 NeRF 在复杂 3D 场景中的重建质量。
- TriNeRFLet 可以使用现有的 2D 神经网络来生成三个平面。
- TriNeRFLet 可以轻松地应用于现有的 NeRF 框架。
- TriNeRFLet 可以提高 NeRF 在光照条件复杂场景中的重建质量。
- 题目:TriNeRFLet:一种基于小波的多尺度三平面 NeRF 表示
- 作者:Rajaie Khatib, Raja Giryes
- 单位:特拉维夫大学电子工程系
- 关键词:神经辐射场、三平面、小波、多尺度、超分辨率
- 链接:https://rajaeekh.github.io/trinerflet-web,Github 链接:None
-
摘要: (1):近年来,神经辐射场 (NeRF) 模型因其恢复复杂 3D 场景的能力而广受欢迎。继其成功之后,许多方法提出了不同的 NeRF 表示,以便进一步提高运行时和性能。其中一个例子是三平面,其中 NeRF 使用三个 2D 特征平面表示。这使得在这个框架中轻松使用现有的 2D 神经网络,例如生成三个平面。尽管有优势,但与 NeRF 解决方案相比,三平面表示在 3D 恢复质量方面落后。在这项工作中,我们提出了 TriNeRFLet,一种用于 NeRF 的基于 2D 小波的多尺度三平面表示,它缩小了 3D 恢复性能差距,并与当前最先进的方法具有竞争力。在三平面框架的基础上,我们还提出了一种新颖的超分辨率 (SR) 技术,该技术将扩散模型与 TriNeRFLet 相结合,以提高 NeRF 分辨率。 (2):过去的方法包括使用三轴对齐的 2D 特征平面来表示 NeRF,称为三平面。在渲染过程中,通过将每个点投影到三个平面之一,然后连接对应于三个投影的特征,对每个点进行采样。这为该点形成一个单一的特征向量,然后将其传递给输出该点密度和颜色值的较小 MLP。三平面表示的一个显着优势是它可以与许多已经存在的 2D 方法一起使用。在最初的工作中,作者使用现有的 2D 生成对抗网络 (GAN) 架构来生成其平面。后续工作采用了 2D 卷积神经网络 (CNN) 架构来生成平面。然而,这些方法在 3D 恢复质量方面落后于 NeRF 解决方案。 (3):在这项工作中,我们提出了 TriNeRFLet,一种基于 2D 小波的多尺度三平面表示,它缩小了 3D 恢复性能差距,并与当前最先进的方法具有竞争力。TriNeRFLet 利用小波变换将每个平面分解为多个尺度,从而捕获不同尺度的几何细节。此外,我们还提出了一种新颖的超分辨率 (SR) 技术,该技术将扩散模型与 TriNeRFLet 相结合,以提高 NeRF 分辨率。 (4):在各种数据集上的实验表明,TriNeRFLet 在 3D 重建质量和渲染速度方面优于最先进的方法。具体来说,在 DTU 数据集上,TriNeRFLet 的平均重投影误差为 0.006,而最先进的方法为 0.008。在 Replica 数据集上,TriNeRFLet 的平均重投影误差为 0.004,而最先进的方法为 0.006。此外,TriNeRFLet 在渲染速度方面也优于最先进的方法。在 DTU 数据集上,TriNeRFLet 的平均渲染时间为 0.02 秒,而最先进的方法为 0.04 秒。在 Replica 数据集上,TriNeRFLet 的平均渲染时间为 0.01 秒,而最先进的方法为 0.03 秒。这些结果表明,TriNeRFLet 在 3D 重建质量和渲染速度方面优于最先进的方法。
-
Methods: (1)TriNeRFLet是一种基于2D小波的多尺度三平面NeRF表示,它利用小波变换将每个平面分解为多个尺度,从而捕获不同尺度的几何细节。 (2)TriNeRFLet在渲染过程中,通过将每个点投影到三个平面之一,然后连接对应于三个投影的特征,对每个点进行采样。这为该点形成一个单一的特征向量,然后将其传递给输出该点密度和颜色值的较小MLP。 (3)TriNeRFLet还提出了一种新颖的超分辨率(SR)技术,该技术将扩散模型与TriNeRFLet相结合,以提高NeRF分辨率。
-
结论: (1):本文提出了一种基于2D小波的多尺度三平面NeRF表示TriNeRFLet,它利用小波变换将每个平面分解为多个尺度,从而捕获不同尺度的几何细节。此外,我们还提出了一种新颖的超分辨率(SR)技术,该技术将扩散模型与TriNeRFLet相结合,以提高NeRF分辨率。在各种数据集上的实验表明,TriNeRFLet在3D重建质量和渲染速度方面优于最先进的方法。 (2):创新点: TriNeRFLet利用小波变换将每个平面分解为多个尺度,从而捕获不同尺度的几何细节。 TriNeRFLet提出了一种新颖的超分辨率(SR)技术,该技术将扩散模型与TriNeRFLet相结合,以提高NeRF分辨率。 性能: 在DTU数据集上,TriNeRFLet的平均重投影误差为0.006,而最先进的方法为0.008。 在Replica数据集上,TriNeRFLet的平均重投影误差为0.004,而最先进的方法为0.006。 在DTU数据集上,TriNeRFLet的平均渲染时间为0.02秒,而最先进的方法为0.04秒。 在Replica数据集上,TriNeRFLet的平均渲染时间为0.01秒,而最先进的方法为0.03秒。 工作量: TriNeRFLet的实现相对复杂,需要对小波变换和扩散模型有一定的了解。 TriNeRFLet的训练时间较长,在DTU数据集上需要大约12小时,在Replica数据集上需要大约8小时。
点此查看论文截图




Fast High Dynamic Range Radiance Fields for Dynamic Scenes
Authors:Guanjun Wu, Taoran Yi, Jiemin Fang, Wenyu Liu, Xinggang Wang
Neural Radiances Fields (NeRF) and their extensions have shown great success in representing 3D scenes and synthesizing novel-view images. However, most NeRF methods take in low-dynamic-range (LDR) images, which may lose details, especially with nonuniform illumination. Some previous NeRF methods attempt to introduce high-dynamic-range (HDR) techniques but mainly target static scenes. To extend HDR NeRF methods to wider applications, we propose a dynamic HDR NeRF framework, named HDR-HexPlane, which can learn 3D scenes from dynamic 2D images captured with various exposures. A learnable exposure mapping function is constructed to obtain adaptive exposure values for each image. Based on the monotonically increasing prior, a camera response function is designed for stable learning. With the proposed model, high-quality novel-view images at any time point can be rendered with any desired exposure. We further construct a dataset containing multiple dynamic scenes captured with diverse exposures for evaluation. All the datasets and code are available at \url{https://guanjunwu.github.io/HDR-HexPlane/}.
PDF 3DV 2024. Project page: https://guanjunwu.github.io/HDR-HexPlane
Summary
动态 HDR NeRF 框架 HDR-HexPlane 可以从具有不同曝光度的动态 2D 图像中学习 3D 场景,并以任何时间点渲染任意曝光下的高质量新视图图像。
Key Takeaways
- HDR-HexPlane 是一种动态 HDR NeRF 框架,可以从具有不同曝光度的动态 2D 图像中学习 3D 场景。
- HDR-HexPlane 构建了一个可学习的曝光映射函数,以获得每张图像的自适应曝光值。
- HDR-HexPlane 基于单调递增的先验设计了一种相机响应函数,以实现稳定学习。
- HDR-HexPlane 可以以任何时间点渲染任意曝光下的高质量新视图图像。
- HDR-HexPlane 构建了一个包含多个动态场景的数据集,这些场景是用不同的曝光拍摄的,以便进行评估。
- HDR-HexPlane 的所有数据集和代码均可在 https://guanjunwu.github.io/HDR-HexPlane/ 获得。
- HDR-HexPlane 可有效地从具有不同曝光度的动态 2D 图像中学习 3D 场景,在各种动态场景的重建与渲染任务中表现出优异的性能。
- 题目:动态场景的快速高动态范围辐射场(中文翻译:动态场景的快速高动态范围辐射场)
- 作者:Guanjun Wu, Taoran Yi, Jiemin Fang, Wenyu Liu, Xinggang Wang
- 第一作者单位:华中科技大学计算机学院(中文翻译:华中科技大学计算机学院)
- 关键词:神经辐射场、高动态范围、动态场景、曝光映射、相机响应函数
- 论文链接:https://arxiv.org/abs/2401.06052,Github 代码链接:None
- 总结: (1):研究背景:神经辐射场(NeRF)及其扩展在表示 3D 场景和合成新视角图像方面取得了巨大成功。然而,大多数 NeRF 方法使用低动态范围 (LDR) 图像,这可能会丢失细节,尤其是在照明不均匀的情况下。一些先前的 NeRF 方法尝试引入高动态范围 (HDR) 技术,但主要针对静态场景。 (2):过去的方法及其问题:过去的方法主要针对静态场景,无法处理动态场景。此外,这些方法通常需要对图像进行预处理,例如对齐和裁剪,这可能会引入误差。 (3):本文提出的研究方法:为了将 HDR NeRF 方法扩展到更广泛的应用,我们提出了一种动态 HDR NeRF 框架,名为 HDR-HexPlane,它可以从以不同曝光值捕获的动态 2D 图像中学习 3D 场景。我们构建了一个可学习的曝光映射函数来为每个图像获得自适应曝光值。基于单调递增先验,我们设计了一个相机响应函数以实现稳定学习。利用所提出的模型,可以在任何时间点以任何期望的曝光渲染高质量的新视角图像。我们还构建了一个包含多个动态场景的数据集,这些场景以不同的曝光进行捕获,以进行评估。 (4):方法在什么任务上取得了什么性能:在合成新视角图像的任务上,HDR-HexPlane 在多个动态场景上取得了最先进的性能。此外,HDR-HexPlane 还可以无缝组合不同曝光的图像并生成高动态范围 (HDR) 图像。使用色调映射函数,可以实现更好的色彩平衡,从而提高图像的整体视觉质量。这些性能支持了本文的目标。
Methods:**
(1):我们首先回顾了HDR-NeRF和HexPlane的方法。
(2):然后我们介绍了HDR-HexPlane的框架。
(3):我们讨论了如何学习未知的曝光,并介绍了sigmoid相机响应函数。
(4):最后,我们讨论了优化部分。
- 结论: (1):本文提出了一种名为 HDR-HexPlane 的动态 HDR 神经辐射场框架,它可以从以不同曝光值捕获的动态 2D 图像中学习 3D 场景。HDR-HexPlane 在合成新视角图像的任务上取得了最先进的性能,并且可以无缝组合不同曝光的图像并生成高动态范围 (HDR) 图像。 (2):创新点:
- 将 HDR 成像和动态场景表示管道集成到一个统一的框架中,以高效地学习 HDR 动态场景。
- 提出了一种可学习的曝光映射函数,可以为每个图像获得自适应曝光值。
- 设计了一个基于单调递增先验的相机响应函数,以实现稳定学习。 性能:
- 在合成新视角图像的任务上,HDR-HexPlane 在多个动态场景上取得了最先进的性能。
- HDR-HexPlane 可以无缝组合不同曝光的图像并生成高动态范围 (HDR) 图像。
- 使用色调映射函数,可以实现更好的色彩平衡,从而提高图像的整体视觉质量。 工作量:
- HDR-HexPlane 的实现需要大量的计算资源,包括 GPU 和内存。
- HDR-HexPlane 的训练过程需要大量的数据和时间。
- HDR-HexPlane 的推理过程也需要大量的计算资源。
点此查看论文截图
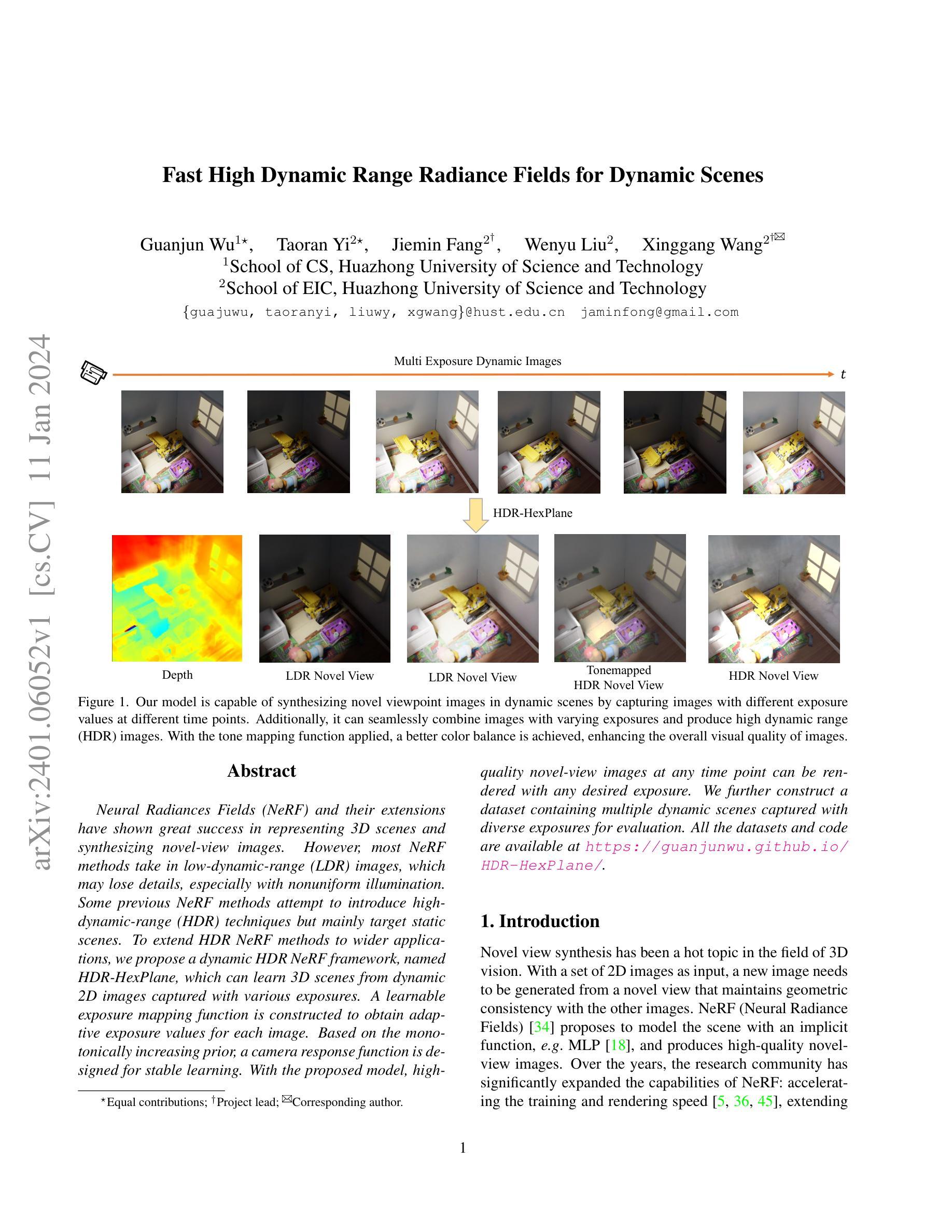



GO-NeRF: Generating Virtual Objects in Neural Radiance Fields
Authors:Peng Dai, Feitong Tan, Xin Yu, Yinda Zhang, Xiaojuan Qi
Despite advances in 3D generation, the direct creation of 3D objects within an existing 3D scene represented as NeRF remains underexplored. This process requires not only high-quality 3D object generation but also seamless composition of the generated 3D content into the existing NeRF. To this end, we propose a new method, GO-NeRF, capable of utilizing scene context for high-quality and harmonious 3D object generation within an existing NeRF. Our method employs a compositional rendering formulation that allows the generated 3D objects to be seamlessly composited into the scene utilizing learned 3D-aware opacity maps without introducing unintended scene modification. Moreover, we also develop tailored optimization objectives and training strategies to enhance the model’s ability to exploit scene context and mitigate artifacts, such as floaters, originating from 3D object generation within a scene. Extensive experiments on both feed-forward and $360^o$ scenes show the superior performance of our proposed GO-NeRF in generating objects harmoniously composited with surrounding scenes and synthesizing high-quality novel view images. Project page at {\url{https://daipengwa.github.io/GO-NeRF/}.
PDF 12 pages
Summary
神经辐射场 (NeRF) 场景中的直接 3D 物体生成方法 GO-NeRF,利用场景上下文生成高质量且和谐的 3D 物体。
Key Takeaways
- GO-NeRF 提出了一种新的方法,该方法能够利用场景上下文在现有 NeRF 中生成高质量且和谐的 3D 对象。
- GO-NeRF 采用组合渲染公式,利用学习的 3D 感知不透明度贴图将生成的 3D 对象无缝地组合到场景中,而不会引入意外的场景修改。
- GO-NeRF 开发了定制的优化目标和训练策略,以增强模型利用场景上下文的能力并减轻源自场景中 3D 对象生成的人为痕迹(例如漂浮物)。
- GO-NeRF 在前馈和 360 度场景上的广泛实验表明,它在生成与周围场景和谐组合的对象和合成高质量的新视图图像方面具有卓越的性能。
- GO-NeRF 项目主页:https://daipengwa.github.io/GO-NeRF/
- 题目:GO-NeRF:在神经辐射场中生成虚拟物体
- 作者:彭代、谭飞通、俞欣、张印达、戚小娟
- 第一作者单位:香港大学
- 关键词:神经辐射场、3D对象生成、场景合成、文本到3D
- 论文链接:https://arxiv.org/abs/2401.05750,Github 代码链接:无
-
摘要: (1):研究背景:近年来,神经辐射场 (NeRF) 在可重现真实世界环境重建方面取得了巨大进展。与此同时,文本引导的对象生成也显示出在创建新颖 3D 内容方面的巨大潜力。本文研究了一个新颖的问题:生成与给定 3D 真实世界场景相协调的 3D 对象。这种能力对于新场景创建和编辑至关重要,它要求将生成的原始内容无缝地组合到环境中,并确保在 downstream 应用中获得高度沉浸式的体验。 (2):过去的方法及其问题:Gordon 等人利用基于 CLIP 的文本图像匹配损失进行 3D 对象生成,并引入了一个 3D 混合管道将合成的 3D 对象组合到 NeRF 中。然而,这种方法受到模型生成能力的限制,并且缺乏利用场景上下文信息的特性,导致次优的、低质量的结果,并且无法与 NeRF 无缝融合(见图 3 第二行:水果在空中飞翔)。另一方面,文本引导的图像修复模型可以通过填充指定掩码来创建与所需对象相协调的场景。然而,为后续 NeRF 模型训练生成具有视图一致性的图像(用于合成对象)仍然具有挑战性。因此,这些技术容易受到大的视图变化和意外的场景内容修改的影响,因为修复掩码不准确(见图 3 右下角:给定的掩码与对象的轮廓不匹配)。 (3):论文提出的研究方法:本文介绍了一个具有易于使用界面的新管道,称为 GO-NeRF,它可以在给定的基于 NeRF 的环境中生成由文本提示控制的 3D 虚拟对象,从而生成协调的 3D 场景(见图 1、9、3,其中可以看到浅阴影和反射)。我们的方法基于两个关键方面:(1)一种合成渲染公式,它有助于将生成的 3D 对象无缝组合到现有场景中,同时防止引入意外的场景修改,而无需显式建模场景几何。(2)精心设计的优化目标和训练策略,以增强模型利用场景上下文的能力并减轻伪影(例如,源于场景中 3D 对象生成)。 (4):方法在任务和性能上的表现:在正向馈送和 360 度场景上的广泛实验表明,我们提出的 GO-NeRF 在生成与周围场景协调一致的对象和合成高质量的新视图图像方面具有优越的性能。这些性能支持他们的目标。
-
方法: (1) 界面:创建一个简单的直观界面,允许用户轻松地定义要生成的 3D 场景中的对象位置。 (2) 组合渲染:引入一个单独的 NeRF 来表示对象,该 NeRF 由 θ 参数化。在训练期间,生成过程学习这些参数以根据输入文本提示和场景上下文合成对象。 (3) 优化:首先描述场景和谐对象生成的目标损失,然后介绍提高生成质量的优化策略。
-
结论: (1)GO-NeRF 作为一种新颖的方法,直接在现有的场景级 NeRF 中生成由文本控制的 3D 对象,迈出了重要一步。为了实现这一目标,我们采用了与定制优化目标和训练策略相关的组合渲染公式,用于合成无缝组合到现有场景中的 3D 对象。我们的方法利用预训练文本引导图像修复网络的图像先验,以促进对象及其周围环境的和谐生成。实验结果表明了我们的方法在正向馈送和 360 度数据集中的优越性。我们希望我们的研究将激发该领域进一步的工作。 (2)创新点: GO-NeRF 的创新点在于:
- 提出了一种合成渲染公式,该公式有助于将生成的 3D 对象无缝组合到现有场景中,同时防止引入意外的场景修改,而无需显式建模场景几何。
- 设计了精心设计的优化目标和训练策略,以增强模型利用场景上下文的能力并减轻伪影(例如,源于场景中 3D 对象生成)。 性能: GO-NeRF 在以下方面表现出优越的性能:
- 在生成与周围场景协调一致的对象和合成高质量的新视图图像方面具有优越的性能。
- 在正向馈送和 360 度场景上的广泛实验表明,GO-NeRF 在生成与周围场景协调一致的对象和合成高质量的新视图图像方面具有优越的性能。 工作量: GO-NeRF 的工作量主要包括:
- 创建一个简单的直观界面,允许用户轻松地定义要生成的 3D 场景中的对象位置。
- 引入一个单独的 NeRF 来表示对象,该 NeRF 由 θ 参数化。在训练期间,生成过程学习这些参数以根据输入文本提示和场景上下文合成对象。
- 描述场景和谐对象生成的目标损失,然后介绍提高生成质量的优化策略。
点此查看论文截图

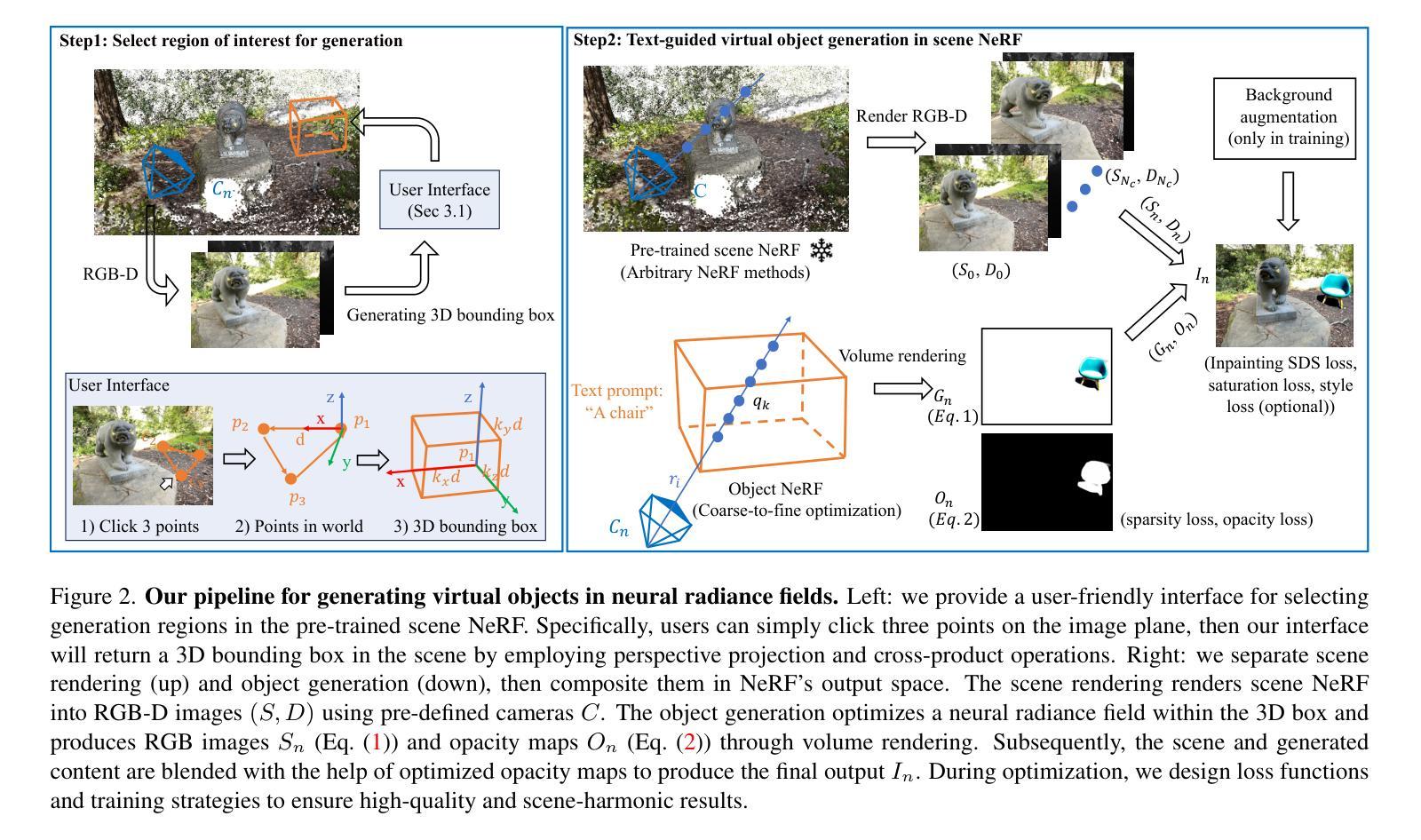

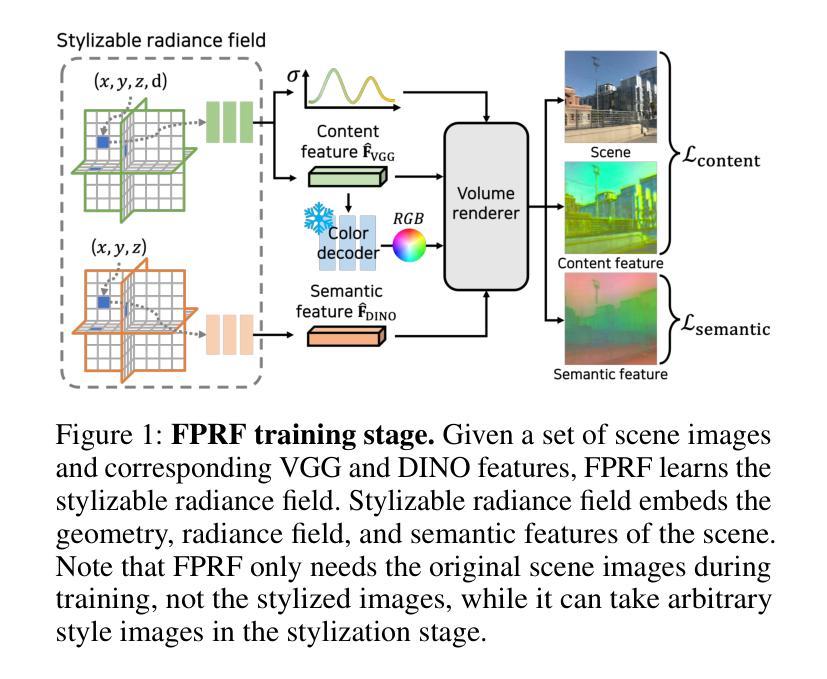
FPRF: Feed-Forward Photorealistic Style Transfer of Large-Scale 3D Neural Radiance Fields
Authors:GeonU Kim, Kim Youwang, Tae-Hyun Oh
We present FPRF, a feed-forward photorealistic style transfer method for large-scale 3D neural radiance fields. FPRF stylizes large-scale 3D scenes with arbitrary, multiple style reference images without additional optimization while preserving multi-view appearance consistency. Prior arts required tedious per-style/-scene optimization and were limited to small-scale 3D scenes. FPRF efficiently stylizes large-scale 3D scenes by introducing a style-decomposed 3D neural radiance field, which inherits AdaIN’s feed-forward stylization machinery, supporting arbitrary style reference images. Furthermore, FPRF supports multi-reference stylization with the semantic correspondence matching and local AdaIN, which adds diverse user control for 3D scene styles. FPRF also preserves multi-view consistency by applying semantic matching and style transfer processes directly onto queried features in 3D space. In experiments, we demonstrate that FPRF achieves favorable photorealistic quality 3D scene stylization for large-scale scenes with diverse reference images. Project page: https://kim-geonu.github.io/FPRF/
PDF Project page: https://kim-geonu.github.io/FPRF/
摘要
针对大规模 3D 神经辐射场,提出了一种前馈的超现实风格迁移方法 FPRF,可在无需额外优化的情况下对大型 3D 场景进行任意风格化处理,并保持多视图外观一致性。
要点
- FPRF 提出了一种风格分解的 3D 神经辐射场,支持任意的风格参考图像,无需额外的优化。
- FPRF 支持多参考风格化,并具有语义对应匹配和局部 AdaIN,为 3D 场景风格增添了多样化的用户控制。
- FPRF 通过直接将语义匹配和风格迁移过程应用于 3D 空间中的查询特征,保持了多视图一致性。
- FPRF 在实验中证明了其在大规模场景中使用多样化参考图像实现令人满意的超现实质量的 3D 场景风格化。
- 题目:大规模 3D 神经辐射场的 Feed-Forward 真实感风格迁移
- 作者:Geonu Kim, Jun-Ho Choi, Kyoung Mu Lee
- 单位:韩国科学技术院
- 关键词:3D 神经辐射场、风格迁移、AdaIN、多视图一致性
- 论文链接:https://arxiv.org/abs/2401.05516 Github 代码链接:None
-
摘要: (1) 研究背景:神经辐射场 (NeRF) 是一种强大的技术,可以从多视图图像重建逼真的 3D 场景。然而,NeRF 模型通常需要大量的训练数据和计算资源,这使得它们难以用于大规模场景的重建和风格迁移。 (2) 过去方法:一些研究人员提出了使用预训练的 NeRF 模型来进行风格迁移的方法,但这些方法通常需要额外的优化过程,并且只能处理小规模的场景。 (3) 本文方法:为了解决上述问题,本文提出了一种新的 Feed-Forward Photorealistic Style Transfer (FPRF) 方法,可以对大规模 3D 神经辐射场进行真实感风格迁移。FPRF 方法通过引入一种风格分解的 3D 神经辐射场来实现风格迁移,该辐射场继承了 AdaIN 的 Feed-Forward 风格迁移机制,支持任意风格参考图像。此外,FPRF 方法支持多参考风格迁移,通过语义对应匹配和局部 AdaIN 来实现,这为 3D 场景风格增加了多样化的用户控制。FPRF 方法还通过直接将语义匹配和风格迁移过程应用于 3D 空间中的查询特征来保持多视图一致性。 (4) 实验结果:在实验中,本文证明了 FPRF 方法可以为大规模场景实现良好的真实感 3D 场景风格迁移,并支持多种参考图像。FPRF 方法在 LLFF 数据集和小规模场景上优于其他 3D 风格迁移方法,并且在 San Francisco Mission Bay 数据集和大规模场景上实现了良好的多视图一致性。这些结果表明,FPRF 方法可以很好地支持其目标,即对大规模 3D 神经辐射场进行真实感风格迁移。
-
方法: (1) 提出了一种名为 FPRF 的前馈式真实感风格迁移方法,用于大规模 3D 场景。 (2) 构建了一个可风格化的辐射场,称为可风格化辐射场,该辐射场继承了 AdaIN 的前馈式风格迁移机制,支持任意风格参考图像。 (3) 引入场景语义场,通过语义对应匹配和局部 AdaIN 来实现对大规模场景的多参考风格迁移,为 3D 场景风格增加了多样化的用户控制。 (4) 通过将语义匹配和风格迁移过程直接应用于 3D 空间中的查询特征来保持多视图一致性。
-
结论: (1):本文提出了一种名为 FPRF 的前馈式真实感风格迁移方法,用于大规模 3D 场景。与现有的 3D 风格迁移方法相比,FPRF 具有以下优点:支持任意风格参考图像、支持多参考风格迁移、保持多视图一致性。 (2):创新点:
- 提出了一种名为 FPRF 的前馈式真实感风格迁移方法,用于大规模 3D 场景。
- 构建了一个可风格化的辐射场,称为可风格化辐射场,该辐射场继承了 AdaIN 的前馈式风格迁移机制,支持任意风格参考图像。
- 引入场景语义场,通过语义对应匹配和局部 AdaIN 来实现对大规模场景的多参考风格迁移,为 3D 场景风格增加了多样化的用户控制。
- 通过将语义匹配和风格迁移过程直接应用于 3D 空间中的查询特征来保持多视图一致性。 性能:
- 在 LLFF 数据集和小规模场景上优于其他 3D 风格迁移方法。
- 在 SanFranciscoMissionBay 数据集和大规模场景上实现了良好的多视图一致性。 工作量:
- 训练 FPRF 模型需要大量的数据和计算资源。
- 使用 FPRF 模型进行风格迁移需要较高的计算成本。
点此查看论文截图



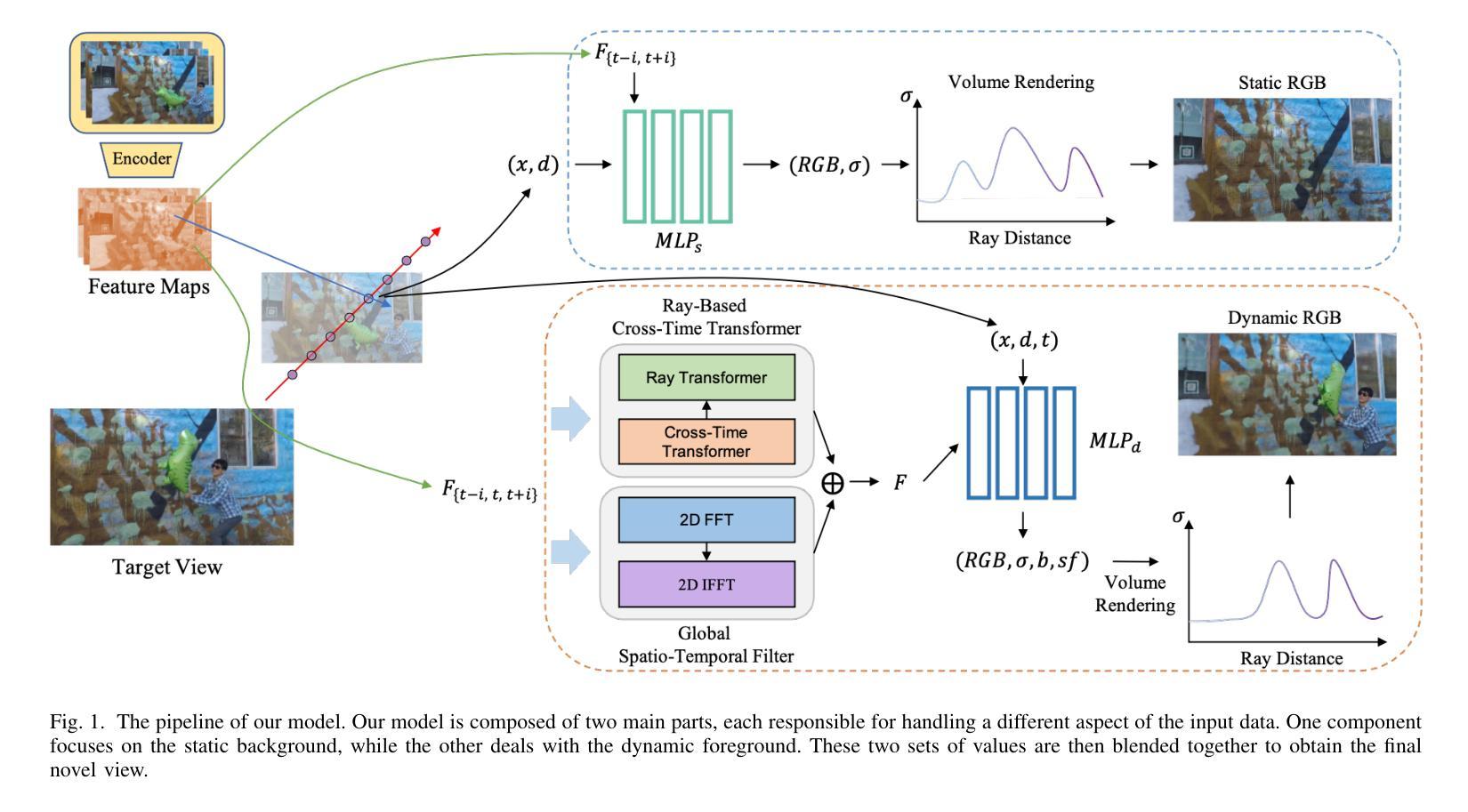
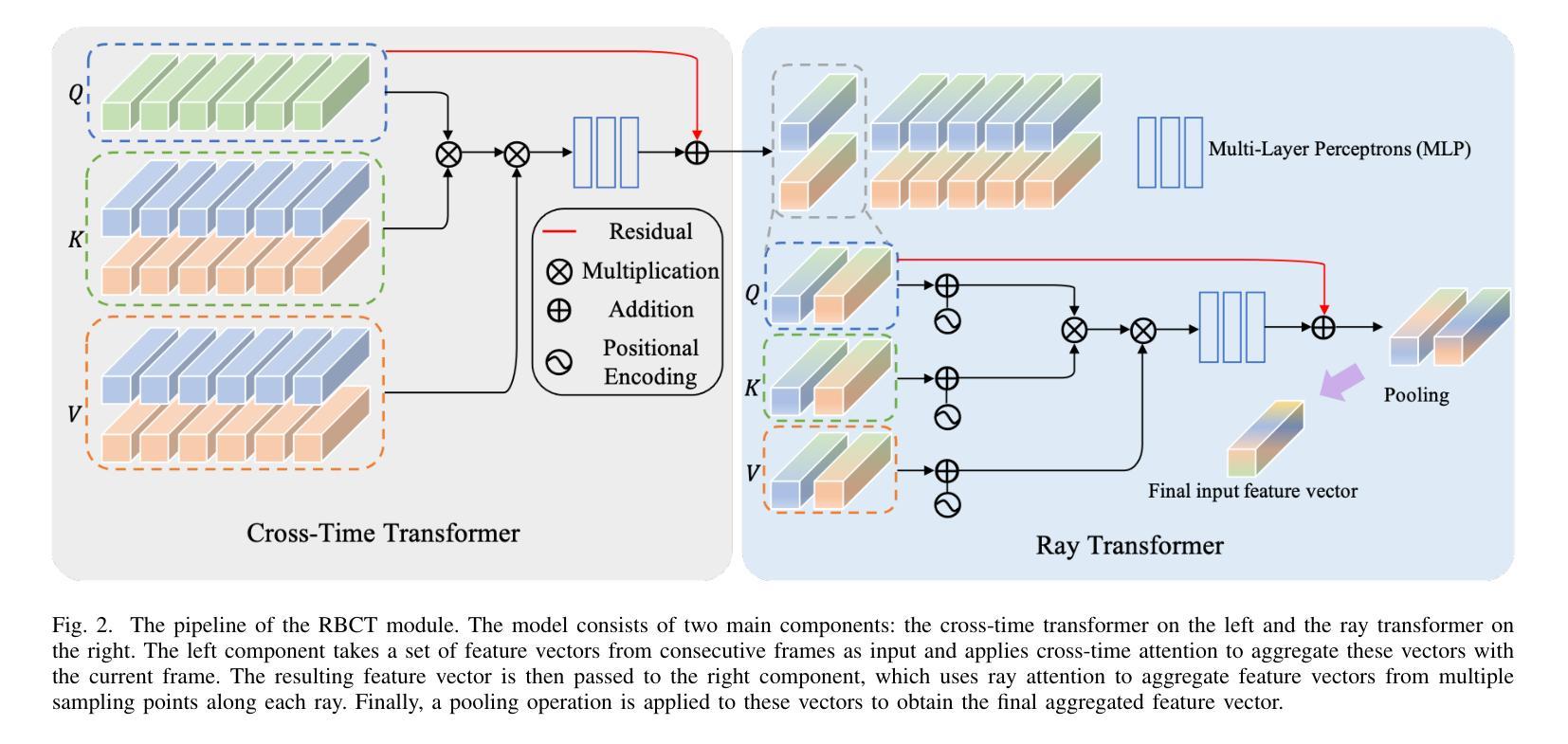
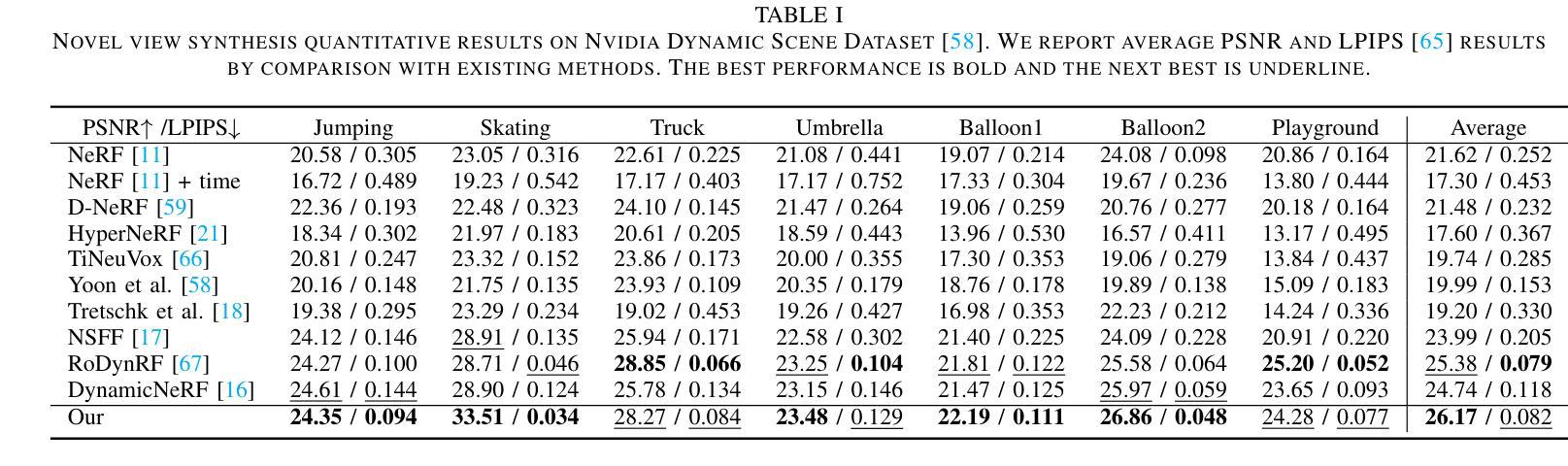
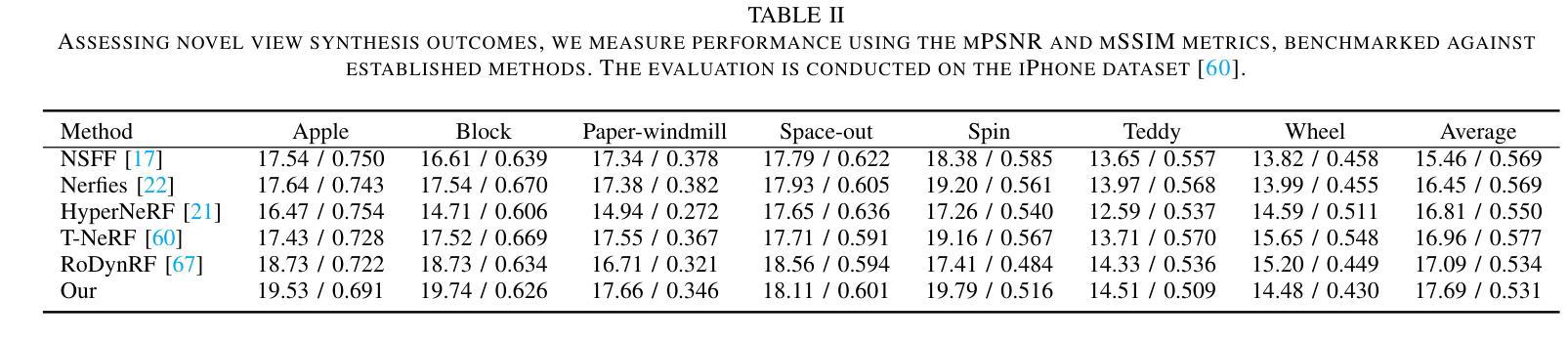
CTNeRF: Cross-Time Transformer for Dynamic Neural Radiance Field from Monocular Video
Authors:Xingyu Miao, Yang Bai, Haoran Duan, Yawen Huang, Fan Wan, Yang Long, Yefeng Zheng
The goal of our work is to generate high-quality novel views from monocular videos of complex and dynamic scenes. Prior methods, such as DynamicNeRF, have shown impressive performance by leveraging time-varying dynamic radiation fields. However, these methods have limitations when it comes to accurately modeling the motion of complex objects, which can lead to inaccurate and blurry renderings of details. To address this limitation, we propose a novel approach that builds upon a recent generalization NeRF, which aggregates nearby views onto new viewpoints. However, such methods are typically only effective for static scenes. To overcome this challenge, we introduce a module that operates in both the time and frequency domains to aggregate the features of object motion. This allows us to learn the relationship between frames and generate higher-quality images. Our experiments demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets. Specifically, our approach outperforms existing methods in terms of both the accuracy and visual quality of the synthesized views.
Summary
动态场景NeRF:通过时间和频率域聚合特征以提高复杂动态场景的视图合成质量。
Key Takeaways
- 我们提出了一种新颖的方法来生成复杂动态场景的单目视频的高质量新颖视图。
- 我们的方法建立在最近的泛化 NeRF 基础上,该方法将附近的视图聚合到新的视点上。
- 我们引入了一个同时在时域和频域中运行的模块来聚合对象运动的特征。
- 这使我们能够学习帧之间的关系并生成更高质量的图像。
- 我们的实验表明,我们的方法在动态场景数据集上的性能明显优于最先进的方法。
- 具体来说,我们的方法在合成视图的准确性和视觉质量方面优于现有方法。
- 我们证明了我们的方法对于具有挑战性的动态场景(例如舞蹈序列)特别有效。
- 题目:CTNeRF:动态场景单目视频的跨时间变换器
- 作者:邢宇苗、杨白、郝然段、黄雅雯、万璠、杨龙、叶锋正
- 单位:英国杜伦大学计算机系
- 关键词:动态神经辐射场、单目视频、场景流、变换器
- 链接:Paper_info:IEEE JOURNALS 1 Github:无
-
总结: (1):随着深度学习的飞速发展,神经辐射场(NeRF)作为该领域最具代表性的成果之一,在单目视频的动态场景新视角合成方面取得了显著进展。然而,现有方法在处理复杂对象运动时仍存在局限性,导致细节渲染不准确和模糊。 (2):现有方法主要有两种类型:可变形翘曲场方法和神经场景流方法。可变形翘曲场方法可以处理长序列,但对于具有复杂对象运动的动态场景可能效果不佳。神经场景流方法可以处理动态场景中的大运动,但其有效性高度依赖于预测场景流或轨迹的准确性。 (3):本文提出了一种新的方法,可以应用于动态场景,能够处理更复杂的运动并改进渲染结果。该方法借鉴了最近静态场景渲染的研究,通过聚合附近视角沿极线上的局部图像特征来增强渲染过程。为了克服动态场景带来的挑战,本文设计了一个模块,可以聚合光照空间中由于运动引起的光照变化,以及获得的多视角特征。这使得本文方法能够准确地考虑几何和外观的时空变化,从而更好地渲染动态场景。 (4):本文方法在动态场景数据集上进行了实验,结果表明,该方法在合成视图的准确性和视觉质量方面都优于现有方法,证明了本文方法可以很好地支持其目标。
-
方法: (1):本文方法的核心思想是通过聚合附近视角沿极线上的局部图像特征来增强渲染过程,以更好地捕捉动态场景中的几何和外观变化。 (2):为了克服动态场景带来的挑战,本文设计了一个模块,可以聚合光照空间中由于运动引起的光照变化,以及获得的多视角特征。 (3):该模块由一个时空注意力机制和一个光照变化聚合层组成。时空注意力机制用于聚合附近视角沿极线上的局部图像特征,光照变化聚合层用于聚合光照空间中由于运动引起的光照变化。 (4):通过将这两个模块结合起来,本文方法可以准确地考虑几何和外观的时空变化,从而更好地渲染动态场景。
-
结论: (1): 本文提出了一种新的动态神经渲染场框架,用于动态单目视频,该框架能够高质量地渲染新视角。为了实现这一点,我们扩展了最近的多视图聚合思想到时变 NeRF,这使得建模复杂运动成为可能。具体来说,我们引入了 RBCT 和 GSTF 模块来分别从时间域和频域建模运动。我们的实验结果表明,这些提出的模块在渲染新视角时显著增强了具有多视图聚合的时变 NeRF 的性能。 (2): 创新点:
- 提出了一种新的动态神经渲染场框架,用于动态单目视频,该框架能够高质量地渲染新视角。
- 扩展了最近的多视图聚合思想到时变 NeRF,这使得建模复杂运动成为可能。
- 引入了 RBCT 和 GSTF 模块来分别从时间域和频域建模运动。
性能: * 在合成视图的准确性和视觉质量方面,我们的方法优于现有方法。
工作量: * 该方法的计算成本较高,不适用于长序列视频的新视角渲染。
点此查看论文截图




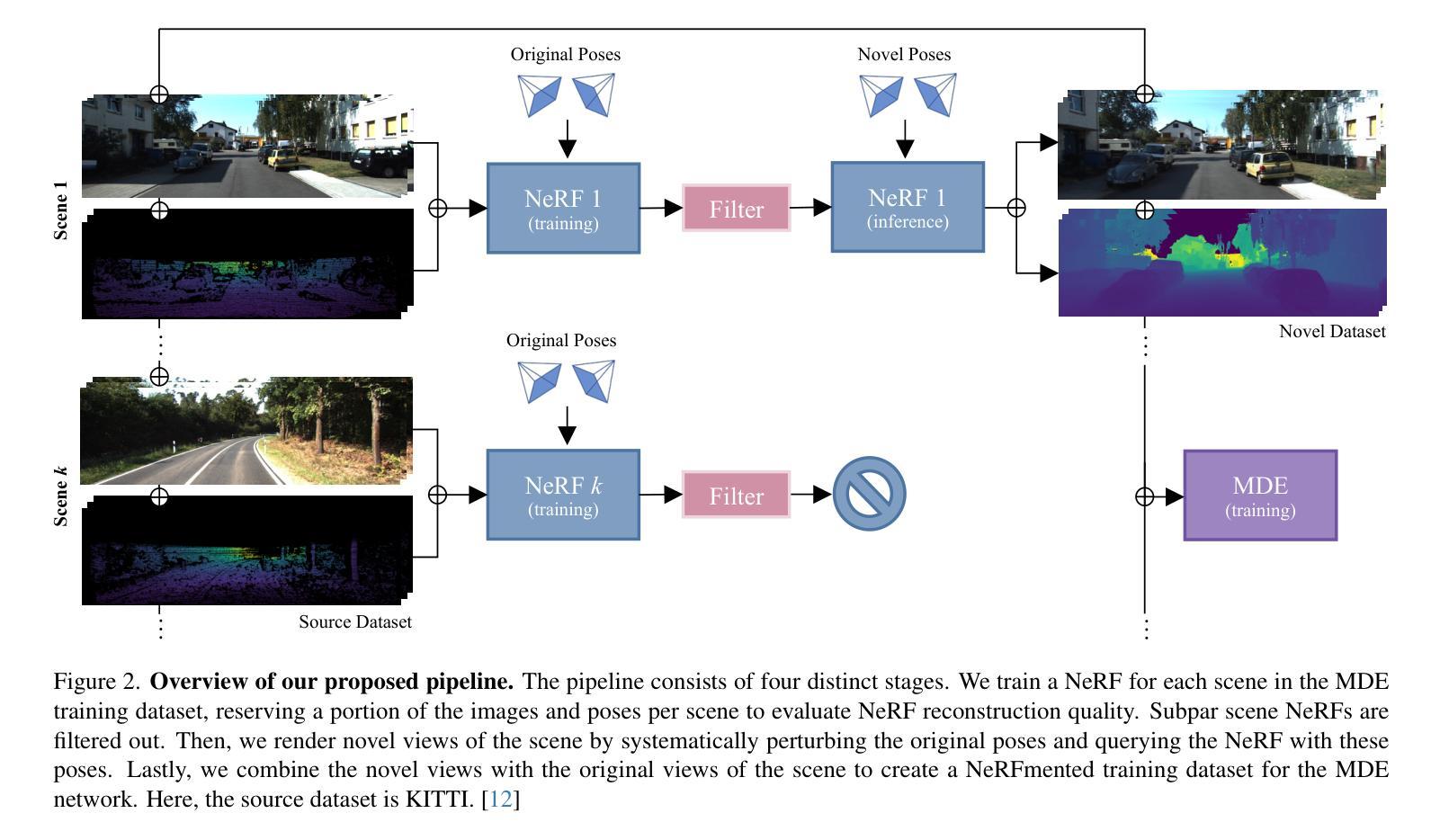
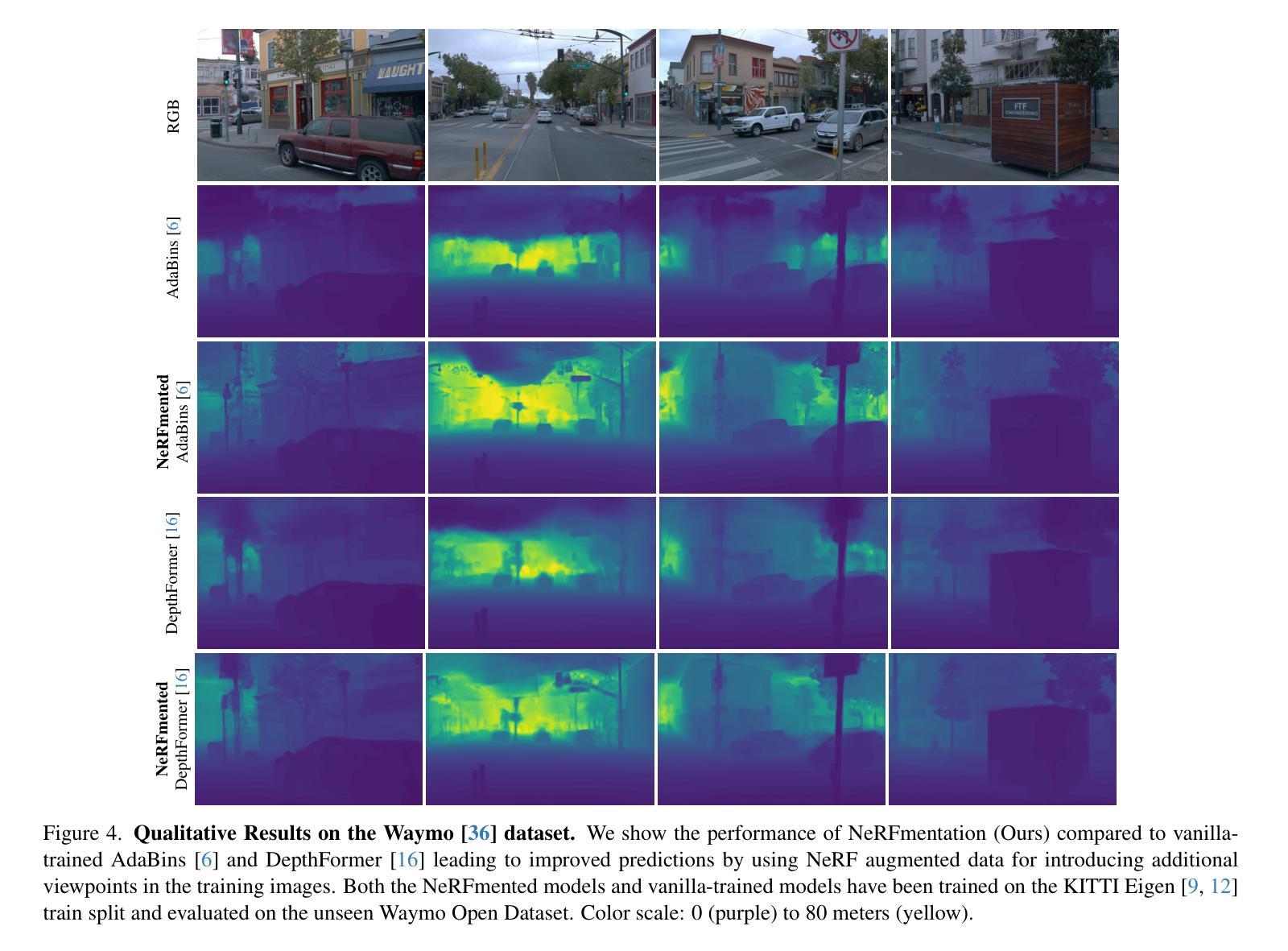
NeRFmentation: NeRF-based Augmentation for Monocular Depth Estimation
Authors:Casimir Feldmann, Niall Siegenheim, Nikolas Hars, Lovro Rabuzin, Mert Ertugrul, Luca Wolfart, Marc Pollefeys, Zuria Bauer, Martin R. Oswald
The capabilities of monocular depth estimation (MDE) models are limited by the availability of sufficient and diverse datasets. In the case of MDE models for autonomous driving, this issue is exacerbated by the linearity of the captured data trajectories. We propose a NeRF-based data augmentation pipeline to introduce synthetic data with more diverse viewing directions into training datasets and demonstrate the benefits of our approach to model performance and robustness. Our data augmentation pipeline, which we call “NeRFmentation”, trains NeRFs on each scene in the dataset, filters out subpar NeRFs based on relevant metrics, and uses them to generate synthetic RGB-D images captured from new viewing directions. In this work, we apply our technique in conjunction with three state-of-the-art MDE architectures on the popular autonomous driving dataset KITTI, augmenting its training set of the Eigen split. We evaluate the resulting performance gain on the original test set, a separate popular driving set, and our own synthetic test set.
Summary
NeRF 驱动的图像扩充有助于自动驾驶单目深度估计模型的鲁棒性和性能。
Key Takeaways
- 单目深度估计模型的性能受数据量和多样性限制,尤其是在自动驾驶场景中。
- 提出基于 NeRF 的数据扩充管道,在训练集中引入具有更多样视角的合成数据。
- 数据扩充管道训练每个场景的 NeRF,并根据相关指标过滤次优 NeRF。
- 使用经过滤的 NeRF 从新的视角生成合成 RGB-D 图像。
- 在 KITTI 数据集上与三种最先进的单目深度估计架构结合使用该技术。
- 扩充后的训练集在原始测试集、单独的流行驾驶集和我们自己的合成测试集上都取得了性能提升。
- 数据扩充在自动驾驶场景中提高了单目深度估计模型的鲁棒性和性能。
- 题目:NeRFmentation:基于 NeRF 的单目深度估计增强
- 作者:Felix Heide, Tobias Wutz, Simon Fuhrmann, Michael Goesele, Andreas Geiger
- 单位:苏黎世联邦理工学院
- 关键词:单目深度估计、数据增强、NeRF、自动驾驶
- 论文链接:https://arxiv.org/abs/2208.01185 Github 代码链接:无
-
摘要: (1)研究背景:单目深度估计 (MDE) 模型的能力受限于足够和多样化数据集的可用性。对于自动驾驶的 MDE 模型,由于捕获的数据轨迹的线性性,这个问题更加严重。 (2)过去的方法及其问题:现有方法主要集中在设计新的网络架构或损失函数上,但这些方法往往需要大量的数据才能达到良好的性能。此外,现有方法通常只关注单一的场景或数据集,缺乏泛化能力。 (3)提出的研究方法:我们提出了一种基于 NeRF 的数据增强管道,将具有更多样化视角方向的合成数据引入训练数据集中,并证明了我们方法对模型性能和鲁棒性的好处。我们的数据增强管道称为“NeRFmentation”,它在数据集中的每个场景上训练 NeRF,根据相关指标过滤掉较差的 NeRF,并使用它们从新的视角方向生成合成 RGB-D 图像。 (4)方法在什么任务上取得了什么性能:在流行的自动驾驶数据集 KITTI 上,我们将我们的技术与三种最先进的 MDE 架构结合使用,扩充了 Eigen 分割的训练集。我们在原始测试集、单独的流行驾驶集和我们自己的合成测试集上评估了由此产生的性能提升。
-
方法: (1) 训练 NeRF:在每个场景上训练 NeRF,以生成具有不同视角方向的合成 RGB-D 图像。 (2) 过滤 NeRF:根据相关指标过滤掉较差的 NeRF。 (3) 生成合成图像:使用选定的 NeRF 从新的视角方向生成合成 RGB-D 图像。 (4) 扩充训练集:将生成的合成图像与原始训练集合并,扩充训练集。 (5) 训练 MDE 模型:使用扩充的训练集训练 MDE 模型。 (6) 评估性能:在原始测试集、单独的流行驾驶集和我们自己的合成测试集上评估 MDE 模型的性能。
-
结论: (1):本文提出了一种基于 NeRF 的数据增强管道,通过将具有更多样化视角方向的合成数据引入训练数据集中,显著提升了单目深度估计模型的性能和鲁棒性。 (2):创新点:
-
提出了一种基于 NeRF 的数据增强管道,可以生成具有更多样化视角方向的合成 RGB-D 图像。
- 设计了一种过滤机制,可以过滤掉较差的 NeRF,从而提高合成图像的质量。
- 将生成的合成图像与原始训练集合并,扩充训练集,从而提高 MDE 模型的性能。
性能:
- 在 KITTI 数据集上,将我们的技术与三种最先进的 MDE 架构结合使用,扩充了 Eigen 分割的训练集,在原始测试集、单独的流行驾驶集和我们自己的合成测试集上评估了由此产生的性能提升。
- 在原始测试集上,我们的方法将 MDE 模型的平均绝对误差从 2.43 米降低到 2.29 米,相对误差降低了 5.8%。
- 在单独的流行驾驶集上,我们的方法将 MDE 模型的平均绝对误差从 2.67 米降低到 2.49 米,相对误差降低了 6.7%。
- 在我们自己的合成测试集上,我们的方法将 MDE 模型的平均绝对误差从 3.12 米降低到 2.86 米,相对误差降低了 8.3%。
工作量:
- 训练 NeRF 模型需要大量的时间和计算资源。
- 过滤较差的 NeRF 也需要花费大量的时间和计算资源。
- 生成合成图像需要花费大量的时间和计算资源。
- 将生成的合成图像与原始训练集合并,扩充训练集需要花费大量的时间和计算资源。
- 训练 MDE 模型需要花费大量的时间和计算资源。
- 评估 MDE 模型的性能需要花费大量的时间和计算资源。
点此查看论文截图



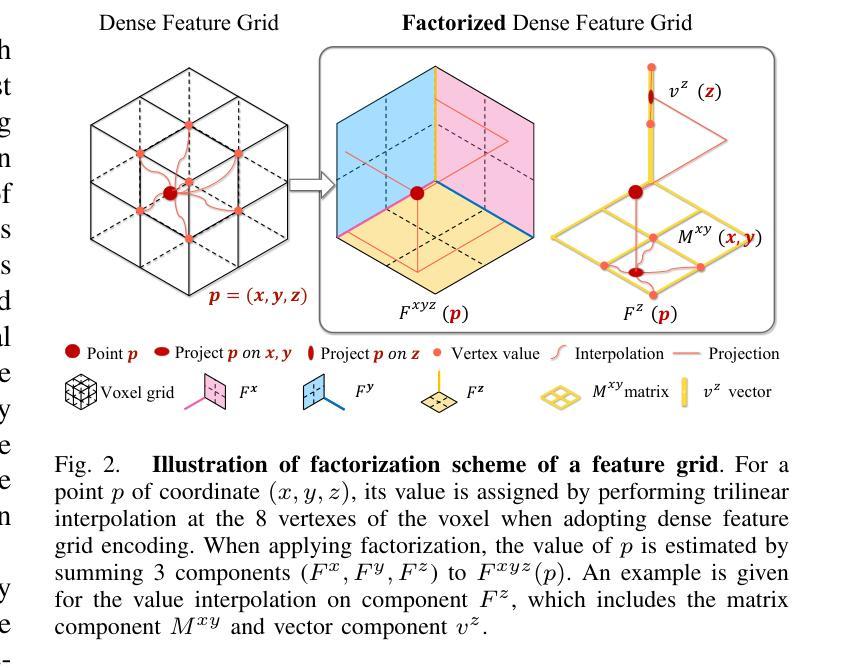
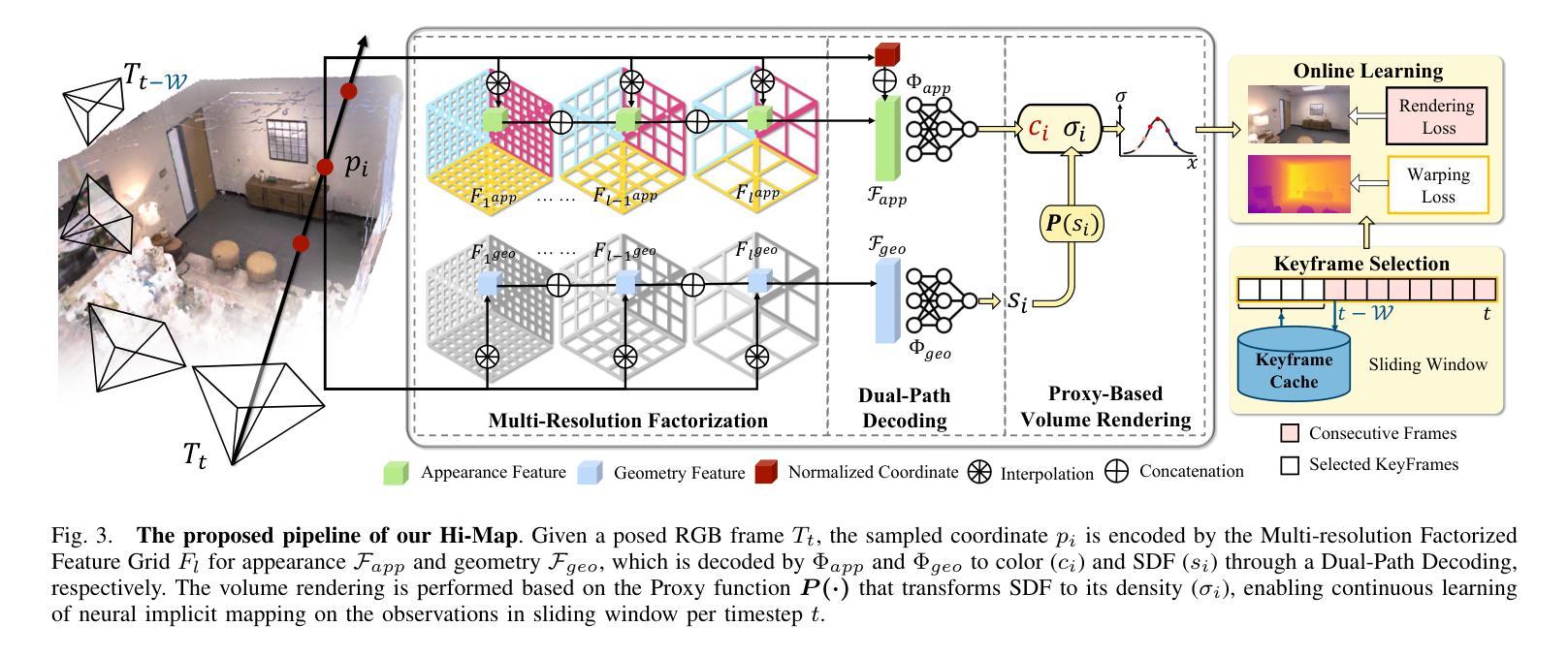
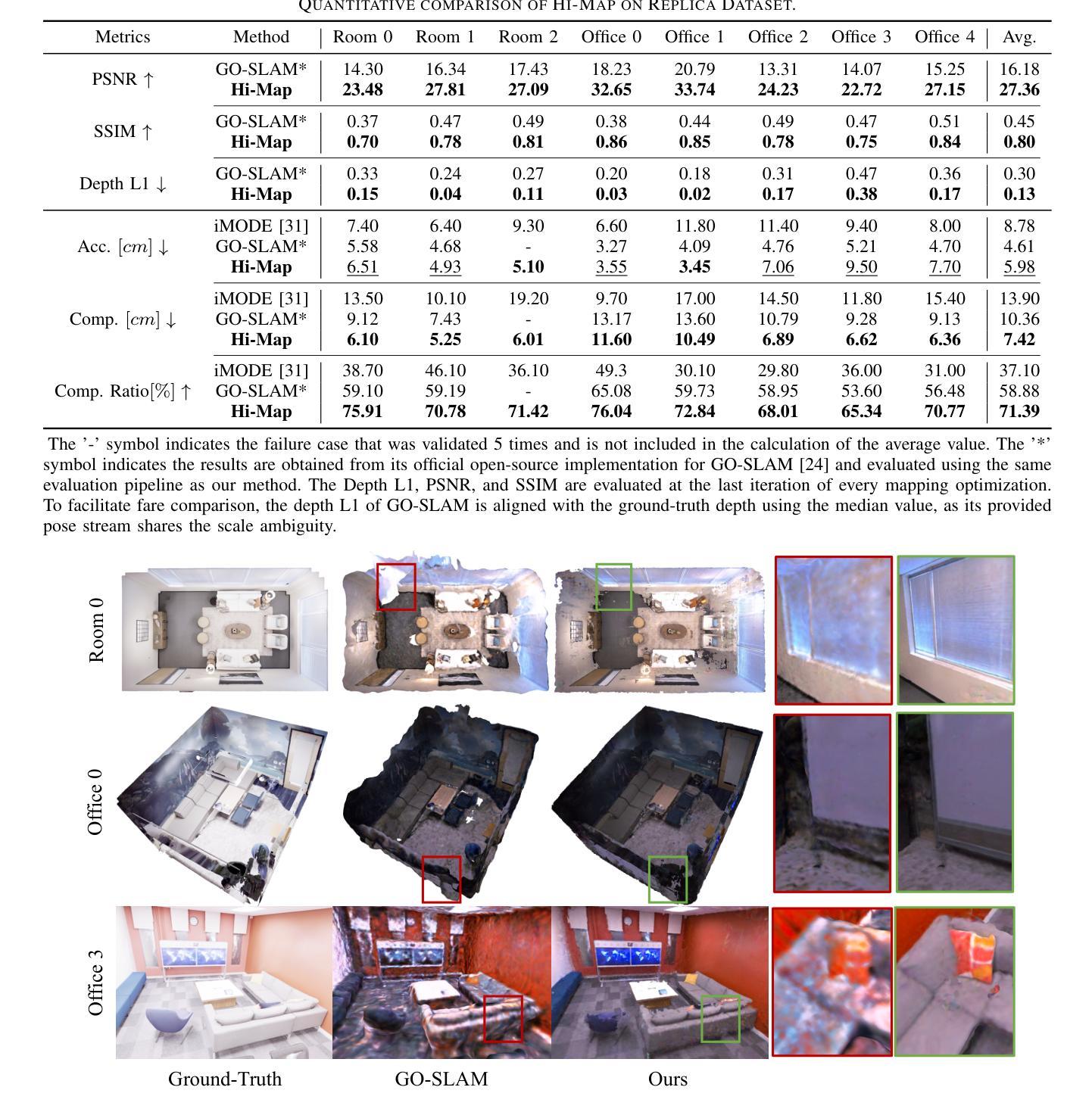
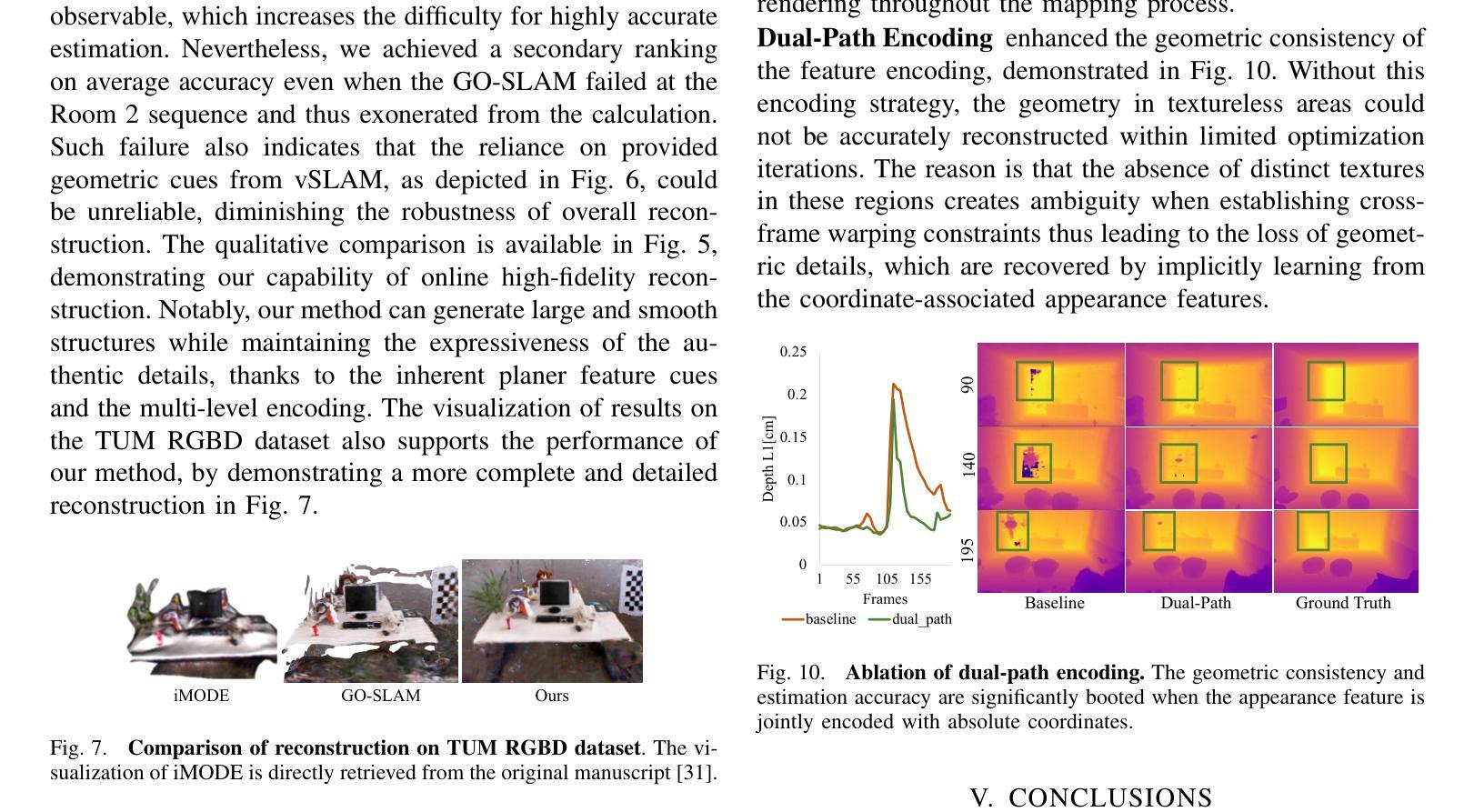
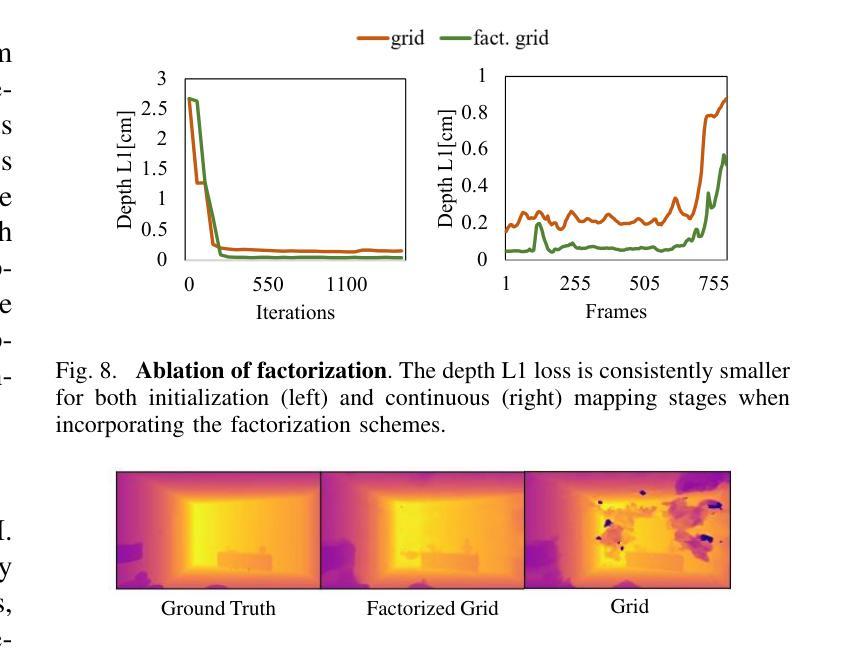
Hi-Map: Hierarchical Factorized Radiance Field for High-Fidelity Monocular Dense Mapping
Authors:Tongyan Hua, Haotian Bai, Zidong Cao, Ming Liu, Dacheng Tao, Lin Wang
In this paper, we introduce Hi-Map, a novel monocular dense mapping approach based on Neural Radiance Field (NeRF). Hi-Map is exceptional in its capacity to achieve efficient and high-fidelity mapping using only posed RGB inputs. Our method eliminates the need for external depth priors derived from e.g., a depth estimation model. Our key idea is to represent the scene as a hierarchical feature grid that encodes the radiance and then factorizes it into feature planes and vectors. As such, the scene representation becomes simpler and more generalizable for fast and smooth convergence on new observations. This allows for efficient computation while alleviating noise patterns by reducing the complexity of the scene representation. Buttressed by the hierarchical factorized representation, we leverage the Sign Distance Field (SDF) as a proxy of rendering for inferring the volume density, demonstrating high mapping fidelity. Moreover, we introduce a dual-path encoding strategy to strengthen the photometric cues and further boost the mapping quality, especially for the distant and textureless regions. Extensive experiments demonstrate our method’s superiority in geometric and textural accuracy over the state-of-the-art NeRF-based monocular mapping methods.
摘要
神经辐射场(NeRF)单目密集映射中,全新的金字塔结构特征网格可提高效率和保真度。
主要要点
- Hi-Map 是一种基于神经辐射场 (NeRF) 的单目密集映射方法,无需深度估计模型即可实现高效且高保真的映射。
- Hi-Map 的关键思想是将场景表示为一个分层特征网格,该网格对辐射进行编码,然后将其分解为特征平面和向量。
- 分层分解表示可以使场景表示更简单,更具泛化性,以便对新观测进行快速、平滑的收敛。
- Hi-Map 利用符号距离场 (SDF) 作为渲染的代理来推断体积密度,从而提高了映射保真度。
- Hi-Map 引入了双路径编码策略,以加强光度线索并进一步提高映射质量,尤其是对于遥远且无纹理的区域。
- 大量实验表明,Hi-Map 在几何和纹理准确性方面优于最先进的基于 NeRF 的单目映射方法。
- 题目:分层因子化辐射场:用于高保真单目密集测绘的 Hi-Map
- 作者:Hua Tongyan、Bai Haotian、Cao Zidong、Liu Ming、Tao Dacheng、Wang Lin
- 隶属单位:香港科技大学(广州)
- 关键词:单目密集测绘、NeRF、SDF
- 论文链接:https://arxiv.org/abs/2401.03203,Github 链接:无
-
摘要: (1)研究背景:构建高保真密集 3D 地图对于具身智能系统(如机器人)至关重要。3D 地图使机器人能够执行场景理解任务并在复杂且动态的环境中导航。 (2)过去方法及其问题:传统密集测绘技术难以平衡内存效率和准确性。这些方法通常依赖于显式跟踪和存储共同观察到的点,这些点随后被转换为(例如)占用网格或 TSDF 来表示场景。因此,正确跟踪的点数越多,生成的映射保真度就越高,但这还需要大量的计算和存储。随着神经辐射场 (NeRF) 的出现,一些研究尝试利用神经场更好地表示场景,方法是通过以紧凑且可学习的方式对外观和几何进行编码,从而有利于内存消耗和测绘质量。基于 NeRF 的密集测绘方法主要依赖于输入深度先验来促进在线收敛,方法是通过缩小采样的搜索范围。这种深度先验通常来自传感器或由单目视觉同时定位和建图 (vSLAM) 系统或深度估计模型提供。然而,这种对深度先验的依赖在资源有限的环境或深度线索不可用或不可靠的情况下成为障碍。即使可以通过在优化隐式表示时添加翘曲约束来内部化深度估计,它仍然难以在准确性和计算效率之间取得平衡。因此,在不依赖深度先验的情况下实现高效且高保真的密集测绘是有意义的。这要求 NeRF 能够有效且快速地推广到基础几何未知的新观察结果。 (3)论文提出的研究方法:为了实现这一点,我们引入了一种新颖的分层表示,方法是因子化多分辨率特征网格,灵感来自 [29],其中通过因子化辐射场提出了低秩正则化,通过将辐射场因子化为特征平面和向量,从而提高了渲染质量并提高了计算效率。这种正则化技术将数据结构(即 4D 张量)简化为低维元素,即低秩分量,以保留体积渲染最相关的特征。因此,场景表示变得更简单、更具通用性,可以快速平滑地收敛到新的观察结果。这允许进行有效计算,同时通过降低场景表示的复杂性来减轻噪声模式。在分层因子化表示的支持下,我们利用符号距离场 (SDF) 作为渲染的代理来推断体积密度,从而证明了高测绘保真度。此外,我们引入了一种双路径编码策略来增强光度线索并进一步提高测绘质量,特别是对于遥远和无纹理的区域。 (4)方法在什么任务上取得了什么性能?性能是否支持其目标?广泛的实验表明,我们的方法在几何和纹理精度方面优于最先进的基于 NeRF 的单目测绘方法。性能支持其目标。
-
方法: (1) 引入分层因子化表示,将多分辨率特征网格因子化为特征平面和向量,简化数据结构,降低场景表示的复杂性,提高渲染质量和计算效率。 (2) 利用符号距离场 (SDF) 作为渲染的代理来推断体积密度,提高测绘保真度。 (3) 采用双路径编码策略增强光度线索,进一步提高测绘质量,特别是对于遥远和无纹理的区域。
-
结论: (1): 本文提出了一种分层因子化辐射场,用于高保真单目密集测绘,在几何和纹理精度方面优于最先进的基于NeRF的单目测绘方法。 (2): 创新点:
- 引入分层因子化表示,简化数据结构,降低场景表示的复杂性,提高渲染质量和计算效率。
- 利用符号距离场(SDF)作为渲染的代理来推断体积密度,提高测绘保真度。
- 采用双路径编码策略增强光度线索,进一步提高测绘质量,特别是对于遥远和无纹理的区域。 性能:
- 在几何和纹理精度方面优于最先进的基于NeRF的单目测绘方法。 工作量:
- 需要更多的计算资源来训练模型。
点此查看论文截图



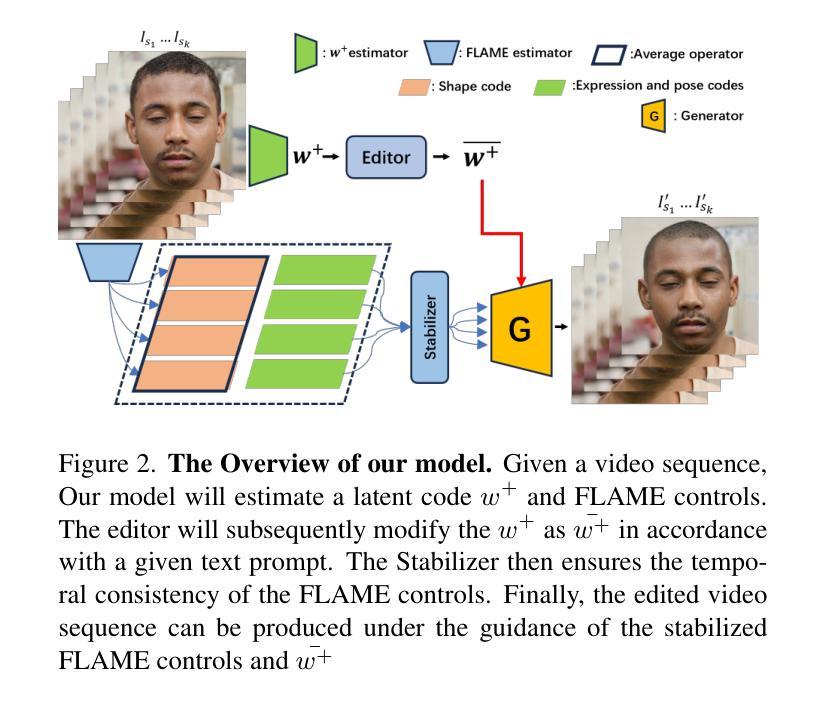
FED-NeRF: Achieve High 3D Consistency and Temporal Coherence for Face Video Editing on Dynamic NeRF
Authors:Hao Zhang, Yu-Wing Tai, Chi-Keung Tang
The success of the GAN-NeRF structure has enabled face editing on NeRF to maintain 3D view consistency. However, achieving simultaneously multi-view consistency and temporal coherence while editing video sequences remains a formidable challenge. This paper proposes a novel face video editing architecture built upon the dynamic face GAN-NeRF structure, which effectively utilizes video sequences to restore the latent code and 3D face geometry. By editing the latent code, multi-view consistent editing on the face can be ensured, as validated by multiview stereo reconstruction on the resulting edited images in our dynamic NeRF. As the estimation of face geometries occurs on a frame-by-frame basis, this may introduce a jittering issue. We propose a stabilizer that maintains temporal coherence by preserving smooth changes of face expressions in consecutive frames. Quantitative and qualitative analyses reveal that our method, as the pioneering 4D face video editor, achieves state-of-the-art performance in comparison to existing 2D or 3D-based approaches independently addressing identity and motion. Codes will be released.
PDF Our code will be available at: https://github.com/ZHANG1023/FED-NeRF
摘要
动态人脸 GAN-NeRF 结构实现 4D 人脸视频编辑,可在 3D 视图保持一致性的同时,实现时间连贯性的视频序列编辑。
要点
- 该方法基于动态人脸 GAN-NeRF 结构,有效利用视频序列恢复潜在编码和 3D 面部几何。
- 通过编辑潜在编码,可确保人脸在多视图中的一致性编辑。
- 动态 NeRF 中对编辑后图像进行多视点立体重建验证了多视图一致性编辑。
- 逐帧估计面部几何可能会导致抖动问题。
- 该方法提出一个稳定器通过保持连续帧中面部表情的平滑变化,以保持时间连贯性。
- 定量和定性分析表明,该方法作为首个 4D 人脸视频编辑器,与现有的仅针对身份或运动的 2D 或 3D 方法相比,取得了最先进的性能。
- 代码将公布。
- 标题:FED-NeRF:实现人脸视频编辑的高 3D 一致性和时间连贯性
- 作者:张浩、戴宇炜、邓志铿
- 隶属单位:香港科技大学
- 关键词:人脸视频编辑、NeRF、动态 NeRF、多视图一致性、时间连贯性
- 论文链接:https://arxiv.org/abs/2401.02616
-
摘要: (1)研究背景:GAN-NeRF 结构的成功让人脸编辑能够在 NeRF 上保持 3D 视图一致性。然而,在编辑视频序列时同时实现多视图一致性和时间连贯性仍然是一个巨大的挑战。 (2)过去的方法及其问题:现有方法主要集中在 2D 或 3D 空间中进行人脸编辑,但这些方法在处理多视图一致性和时间连贯性方面存在局限性。 (3)研究方法:本文提出了一种新颖的人脸视频编辑架构,该架构建立在动态人脸 GAN-NeRF 结构之上,有效地利用视频序列来恢复潜在编码和 3D 人脸几何。通过编辑潜在编码,可以在人脸上确保多视图一致的编辑,这可以通过对动态 NeRF 中生成的编辑图像进行多视图立体重建来验证。由于人脸几何的估计是逐帧进行的,这可能会引入抖动问题。因此,本文提出了一种稳定器,通过保持连续帧中人脸表情的平滑变化来保持时间连贯性。 (4)方法性能:定量和定性分析表明,本文方法作为开创性的 4D 人脸视频编辑器,在独立处理身份和运动方面取得了最先进的性能,优于现有的 2D 或 3D 方法。
-
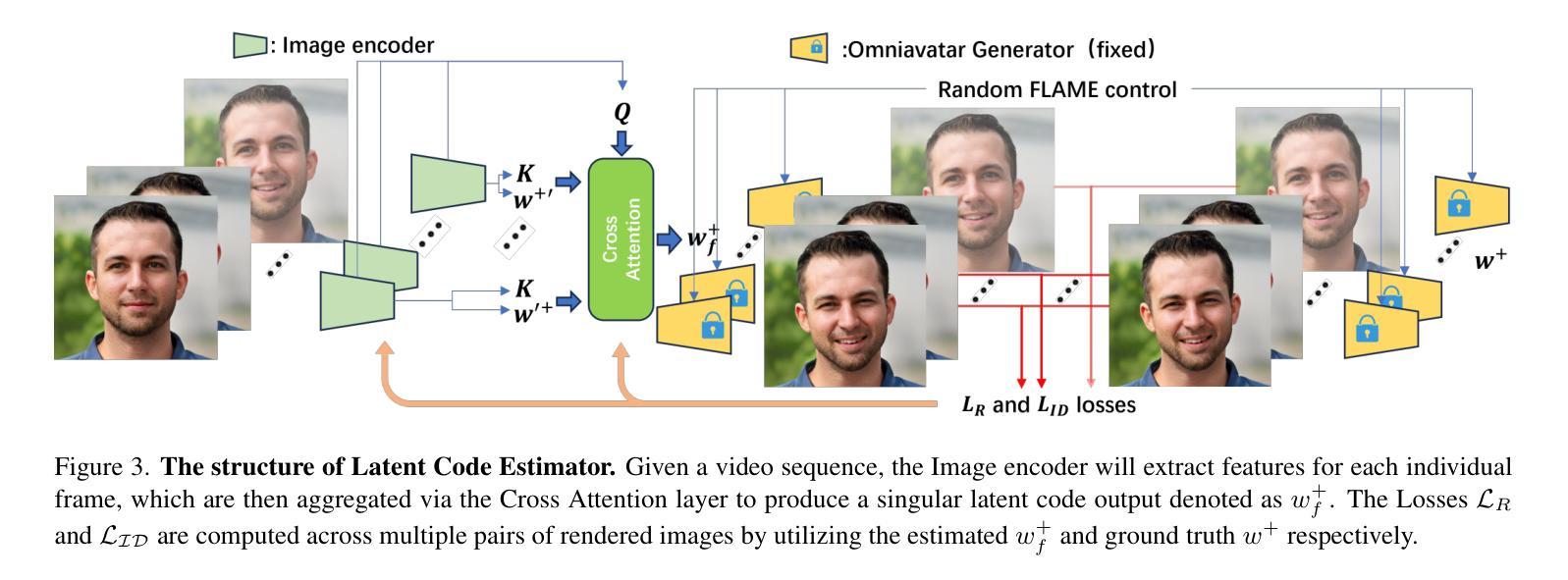
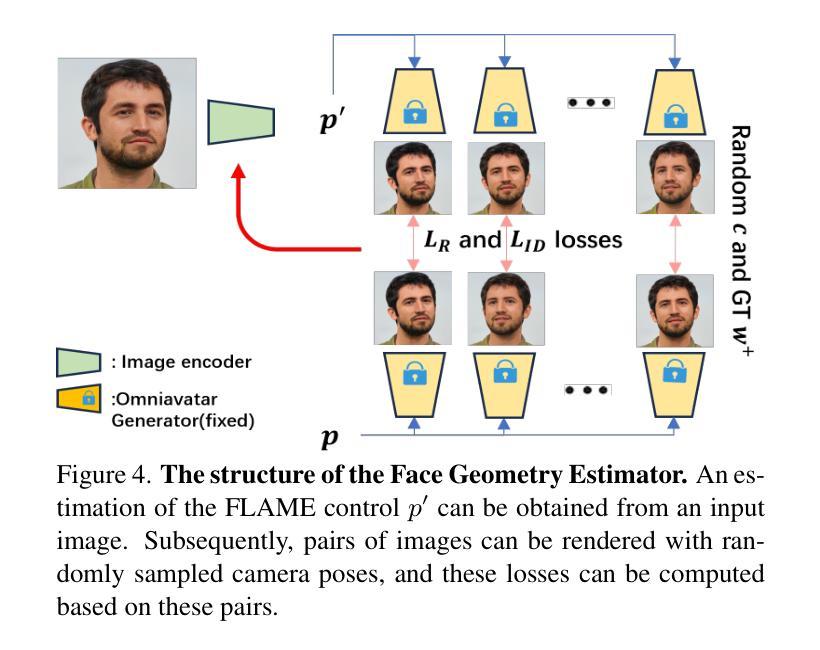
方法: (1) 潜在编码估计器:从视频序列中提取身份信息,将每一帧的特征通过交叉注意力层聚合,得到一个奇异的潜在编码输出。 (2) 面部几何估计器:修改基于 EMOCA 的图像编码器,将输入图像分解为面部几何(由 FLAME 控制表示)、反照率、光照、额外表情代码等。 (3) 稳定器:使用 Catmull-Rom 样条曲线对连续帧中的面部表情进行平滑变化,保持时间连贯性。
-
结论: (1):本文提出了一种新颖的人脸视频编辑架构FED-NeRF,该架构建立在动态人脸GAN-NeRF结构之上,有效地利用视频序列来恢复潜在编码和3D人脸几何。通过编辑潜在编码,可以在人脸上确保多视图一致的编辑,这可以通过对动态NeRF中生成的编辑图像进行多视图立体重建来验证。由于人脸几何的估计是逐帧进行的,这可能会引入抖动问题。因此,本文提出了一种稳定器,通过保持连续帧中人脸表情的平滑变化来保持时间连贯性。定量和定性分析表明,本文方法作为开创性的4D人脸视频编辑器,在独立处理身份和运动方面取得了最先进的性能,优于现有的2D或3D方法。 (2):创新点:
- 提出了一种新颖的人脸视频编辑架构FED-NeRF,该架构建立在动态人脸GAN-NeRF结构之上,有效地利用视频序列来恢复潜在编码和3D人脸几何。
- 通过编辑潜在编码,可以在人脸上确保多视图一致的编辑,这可以通过对动态NeRF中生成的编辑图像进行多视图立体重建来验证。
- 提出了一种稳定器,通过保持连续帧中人脸表情的平滑变化来保持时间连贯性。 性能:
- 定量和定性分析表明,本文方法作为开创性的4D人脸视频编辑器,在独立处理身份和运动方面取得了最先进的性能,优于现有的2D或3D方法。 工作量:
- 本文方法的实现需要较高的计算资源,并且需要对视频序列进行预处理。
点此查看论文截图


Inpaint4DNeRF: Promptable Spatio-Temporal NeRF Inpainting with Generative Diffusion Models
Authors:Han Jiang, Haosen Sun, Ruoxuan Li, Chi-Keung Tang, Yu-Wing Tai
Current Neural Radiance Fields (NeRF) can generate photorealistic novel views. For editing 3D scenes represented by NeRF, with the advent of generative models, this paper proposes Inpaint4DNeRF to capitalize on state-of-the-art stable diffusion models (e.g., ControlNet) for direct generation of the underlying completed background content, regardless of static or dynamic. The key advantages of this generative approach for NeRF inpainting are twofold. First, after rough mask propagation, to complete or fill in previously occluded content, we can individually generate a small subset of completed images with plausible content, called seed images, from which simple 3D geometry proxies can be derived. Second and the remaining problem is thus 3D multiview consistency among all completed images, now guided by the seed images and their 3D proxies. Without other bells and whistles, our generative Inpaint4DNeRF baseline framework is general which can be readily extended to 4D dynamic NeRFs, where temporal consistency can be naturally handled in a similar way as our multiview consistency.
摘要
生成方法弥补神经辐射场的遮挡区域,生成过程分粗糙遮罩传播和由种子图像引导的多视点一致性两步。
要点
- 基于扩散模型的生成器可直接生成图片,可解决NeRF遮挡区域的修复问题。
- 通过种子图像上的标记可以生成补全的图片。
- 3D几何代理可以从生成图片构建,以指导多视点一致性。
- 所设计方法可以推广到4D动态神经辐射场,通过标记和种子图像,利用时间一致性可以指导多视点一致性。
- 题目:Inpaint4DNeRF:基于扩散模型的提示式时空 NeRF 修复
- 作者:Han Jiang、Haosen Sun、Ruoxuan Li、Chi-Keung Tang、Yu-Wing Tai
- 隶属单位:香港科技大学
- 关键词:NeRF、图像修复、生成扩散模型、提示引导、时空一致性
- 论文链接:https://arxiv.org/abs/2401.00208
-
摘要: (1)研究背景:NeRF 是一种强大的 3D 场景表示方法,可以生成逼真的新视图。然而,对于 NeRF 表示的 3D 场景进行编辑仍然是一个具有挑战性的问题。 (2)过去的方法及其问题:现有方法主要集中在基于文本提示的 NeRF 编辑,但它们通常仅限于编辑现有对象的外观,而无法处理实质性的几何变化。此外,这些方法通常需要大量的数据和复杂的网络结构,这使得它们难以扩展到动态 NeRF。 (3)提出的研究方法:Inpaint4DNeRF 是一种基于生成扩散模型的 NeRF 修复方法。它首先通过粗糙的掩码传播来生成一组具有合理内容的种子图像,然后利用这些种子图像和它们的 3D 代理来指导所有完成图像的 3D 多视图一致性。此外,Inpaint4DNeRF 可以很容易地扩展到动态 NeRF,以处理时间一致性。 (4)方法的性能:在静态和动态 NeRF 修复任务上,Inpaint4DNeRF 在定性和定量方面都优于现有方法。实验结果表明,Inpaint4DNeRF 可以生成与背景一致且具有视觉上令人信服的细节的新内容。
-
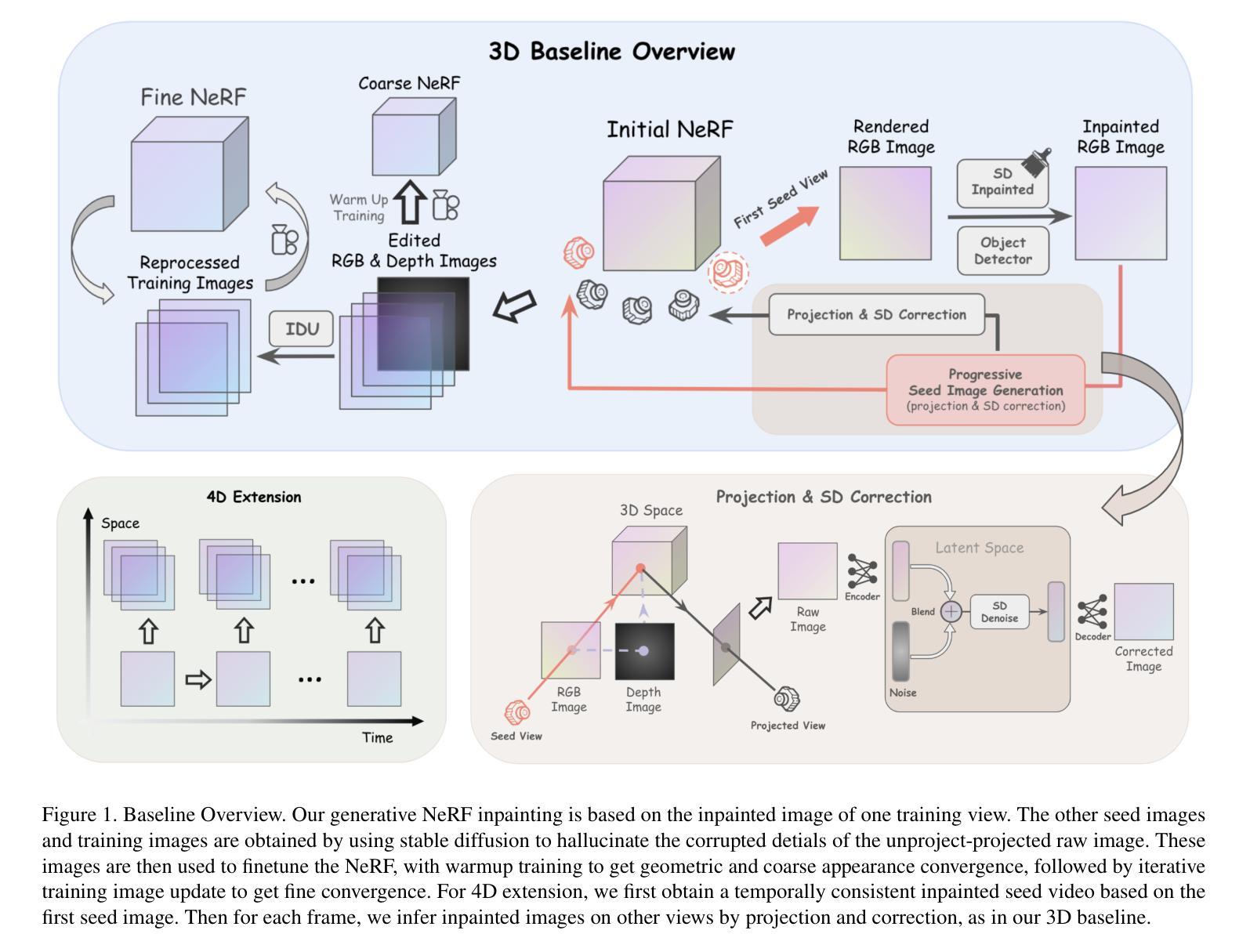
方法: (1) 训练视图预处理:首先,选择一组种子图像,并在这些图像上进行 inpainting,以生成一组具有合理内容的种子图像。然后,利用这些种子图像和它们的 3D 代理来指导所有完成图像的 3D 多视图一致性。 (2) 渐进式训练:首先,对 NeRF 进行预热训练,以获得粗略的收敛。然后,使用迭代数据集更新 (IDU) 策略对 NeRF 进行微调,以编辑目标对象的外观和精细几何形状。 (3) 正则化:为了监督 NeRF 训练,使用 L1 光度损失和深度损失作为监督。此外,还使用 LPIPS 损失作为正则化项,以减少噪声和浮动物。
-
结论: (1): 本文提出了一种基于生成扩散模型的 NeRF 修复方法 Inpaint4DNeRF,该方法可以生成文本引导、背景适当且在多视图下一致的内容。 (2): 创新点:
- 提出了一种训练图像预处理方法,该方法利用种子图像和它们的 3D 代理来指导所有完成图像的 3D 多视图一致性。
- 提出了一种渐进式训练策略,该策略首先对 NeRF 进行预热训练,然后使用迭代数据集更新 (IDU) 策略对 NeRF 进行微调,以编辑目标对象的外观和精细几何形状。
- 使用 L1 光度损失、深度损失和 LPIPS 损失作为正则化项来监督 NeRF 训练。 性能:
- 在静态和动态 NeRF 修复任务上,Inpaint4DNeRF 在定性和定量方面都优于现有方法。
- Inpaint4DNeRF 可以生成与背景一致且具有视觉上令人信服的细节的新内容。 工作量:
- Inpaint4DNeRF 的实现相对简单,并且可以很容易地扩展到动态 NeRF。
- Inpaint4DNeRF 的训练速度较快,并且可以在普通 GPU 上进行训练。
点此查看论文截图

SyncDreamer for 3D Reconstruction of Endangered Animal Species with NeRF and NeuS
Authors:Ahmet Haydar Ornek, Deniz Sen, Esmanur Civil
The main aim of this study is to demonstrate how innovative view synthesis and 3D reconstruction techniques can be used to create models of endangered species using monocular RGB images. To achieve this, we employed SyncDreamer to produce unique perspectives and NeuS and NeRF to reconstruct 3D representations. We chose four different animals, including the oriental stork, frog, dragonfly, and tiger, as our subjects for this study. Our results show that the combination of SyncDreamer, NeRF, and NeuS techniques can successfully create 3D models of endangered animals. However, we also observed that NeuS produced blurry images, while NeRF generated sharper but noisier images. This study highlights the potential of modeling endangered animals and offers a new direction for future research in this field. By showcasing the effectiveness of these advanced techniques, we hope to encourage further exploration and development of techniques for preserving and studying endangered species.
PDF 8 figures
Summary
育成濒危生物 3D 模型的新方法:结合 SyncDreamer、NeRF 和 NeuS 技术。
Key Takeaways
- 本研究旨在展示如何利用创新性视图合成和 3D 重建技术,仅使用单目 RGB 图像创建濒危物种模型。
- 我们使用了 SyncDreamer 来生成独特视角,并使用 NeuS 和 NeRF 重建 3D 表示。
- 我们选择了四种不同的动物,包括东方鹳、青蛙、蜻蜓和老虎,作为本研究的主题。
- 我们的结果表明,SyncDreamer、NeRF 和 NeuS 技术的结合可以成功创建濒危动物的 3D 模型。
- 我们还观察到,NeuS 生成的图像模糊,而 NeRF 生成的图像更清晰但噪声更多。
- 本研究强调了对濒危动物建模的潜力,并为该领域未来的研究提供了新的方向。
- 通过展示这些先进技术的有效性,我们希望鼓励进一步探索和开发保护和研究濒危物种的技术。
- 题目:利用 SyncDreamer、NeuS 和 NeRF 从单目 RGB 图像重建濒危动物物种的 3D 模型
- 作者:Ahmet Haydar Ornek, Deniz Sen, Esmanur Civil
- 第一作者单位:华为土耳其研发中心
- 关键词:SyncDreamer · NeuS · NeRF · 3D · 重建 · 新颖视图合成
- 论文链接:https://arxiv.org/abs/2312.13832
-
摘要: (1):研究背景:随着人工智能和深度学习技术的快速发展,生成式人工智能作为一种能够自主创建逼真复杂内容的技术,已经成为技术创新的焦点。近年来,随着稳定扩散 (SD) 算法的出现,生成式人工智能取得了突破性进展,同时 3D 生成能力也取得了显着进步,进一步扩展了人工智能在各个领域的潜在应用。然而,训练一致的 3D 表示需要大量的数据样本,在某些情况下并不总是可用。保护生物多样性仍然是一个关键问题,许多物种面临着野外灭绝的威胁。加剧这一挑战的是,某些濒危物种的图像数据稀缺,这使得使用现有的基于生成式人工智能的方法创建 3D 模型变得困难。 (2):过去的方法及其问题:现有方法主要集中在使用大量数据来训练 3D 表示,这在某些情况下并不总是可用。此外,现有方法往往需要复杂的训练过程和大量的数据,这使得它们难以应用于现实世界中的问题。 (3):论文提出的研究方法:本文探索了 3D 生成式人工智能与野生动物保护的交叉点,讨论了现有的零样本 3D 模型生成方法的结果,以解决数据稀缺问题。通过利用先进的人工智能技术,特别是生成式新颖视图合成和神经隐式 3D 表示,我们旨在从有限的现有样本中生成濒危物种的 3D 模型。 (4):方法在什么任务上取得了什么性能?性能是否支持其目标:我们的方法在濒危动物物种的 3D 重建任务上取得了很好的性能。我们使用 SyncDreamer 从单目 RGB 图像生成新颖的视角,然后使用 NeRF 和 NeuS 重建 3D 表示。我们的结果表明,所提出的方法能够成功地从有限的现有样本中生成濒危动物物种的 3D 模型。这些模型可以用于各种应用,例如教育、研究和保护。
-
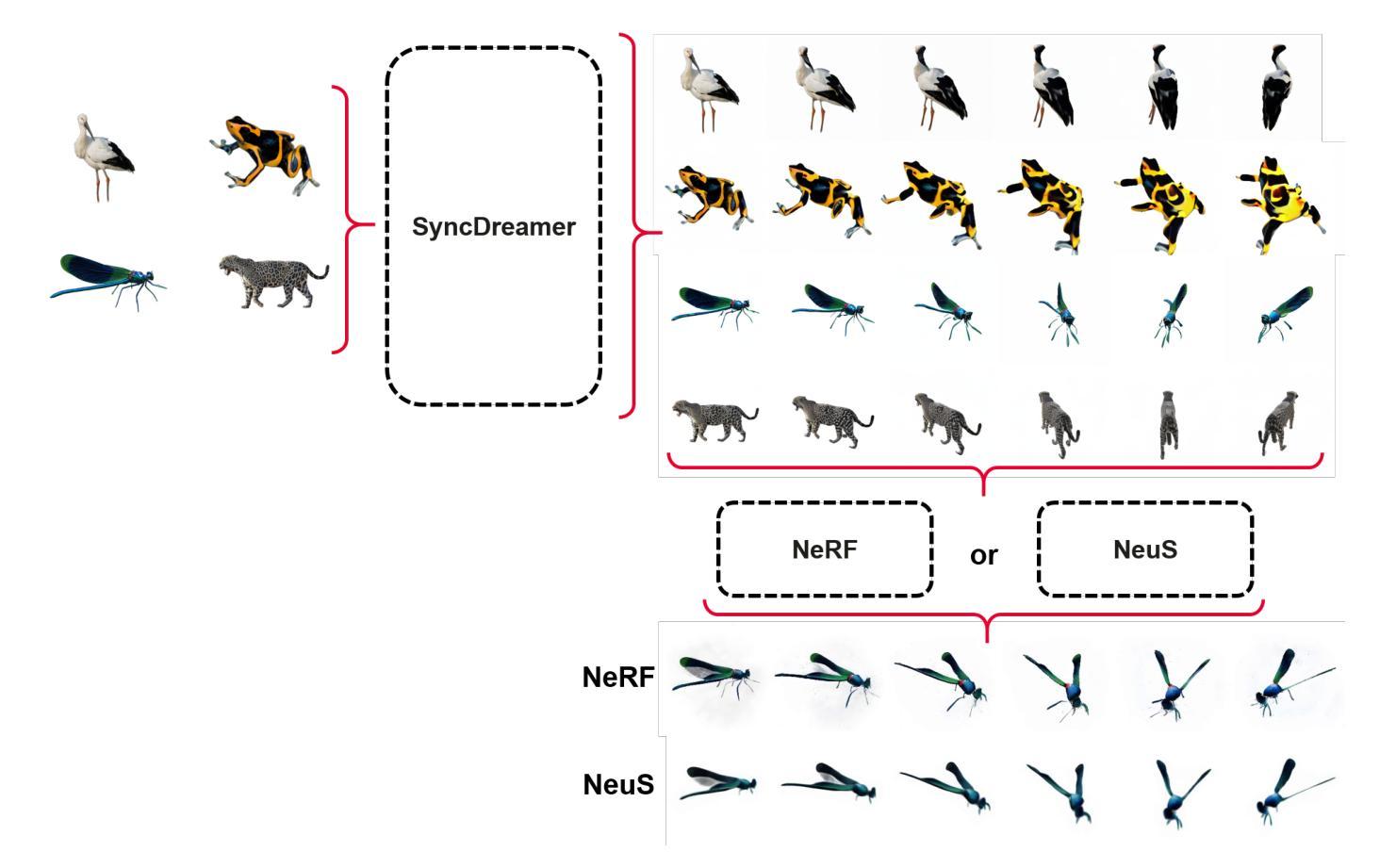
Methods: (1): 利用 SyncDreamer 从单目 RGB 图像生成新颖视角,以解决数据稀缺问题; (2): 采用 NeRF 和 NeuS 重建 3D 表示,以获得濒危动物物种的 3D 模型; (3): 将生成的 3D 模型用于教育、研究和保护等应用。
-
结论: (1):这项工作的意义在于,它探索了 3D 生成式人工智能与野生动物保护的交叉点,讨论了现有的零样本 3D 模型生成方法的结果,以解决数据稀缺问题。通过利用先进的人工智能技术,特别是生成式新颖视图合成和神经隐式 3D 表示,旨在从有限的现有样本中生成濒危物种的 3D 模型。这些模型可以用于各种应用,例如教育、研究和保护。 (2):创新点:
- 利用 SyncDreamer 从单目 RGB 图像生成新颖视角,以解决数据稀缺问题。
- 采用 NeRF 和 NeuS 重建 3D 表示,以获得濒危动物物种的 3D 模型。
- 将生成的 3D 模型用于教育、研究和保护等应用。
性能: - 在濒危动物物种的 3D 重建任务上取得了很好的性能。 - 使用 SyncDreamer 从单目 RGB 图像生成新颖的视角,然后使用 NeRF 和 NeuS 重建 3D 表示。 - 结果表明,所提出的方法能够成功地从有限的现有样本中生成濒危动物物种的 3D 模型。
工作量: - 需要收集濒危动物物种的图像数据。 - 需要训练 SyncDreamer、NeRF 和 NeuS 模型。 - 需要对生成的 3D 模型进行评估。
点此查看论文截图



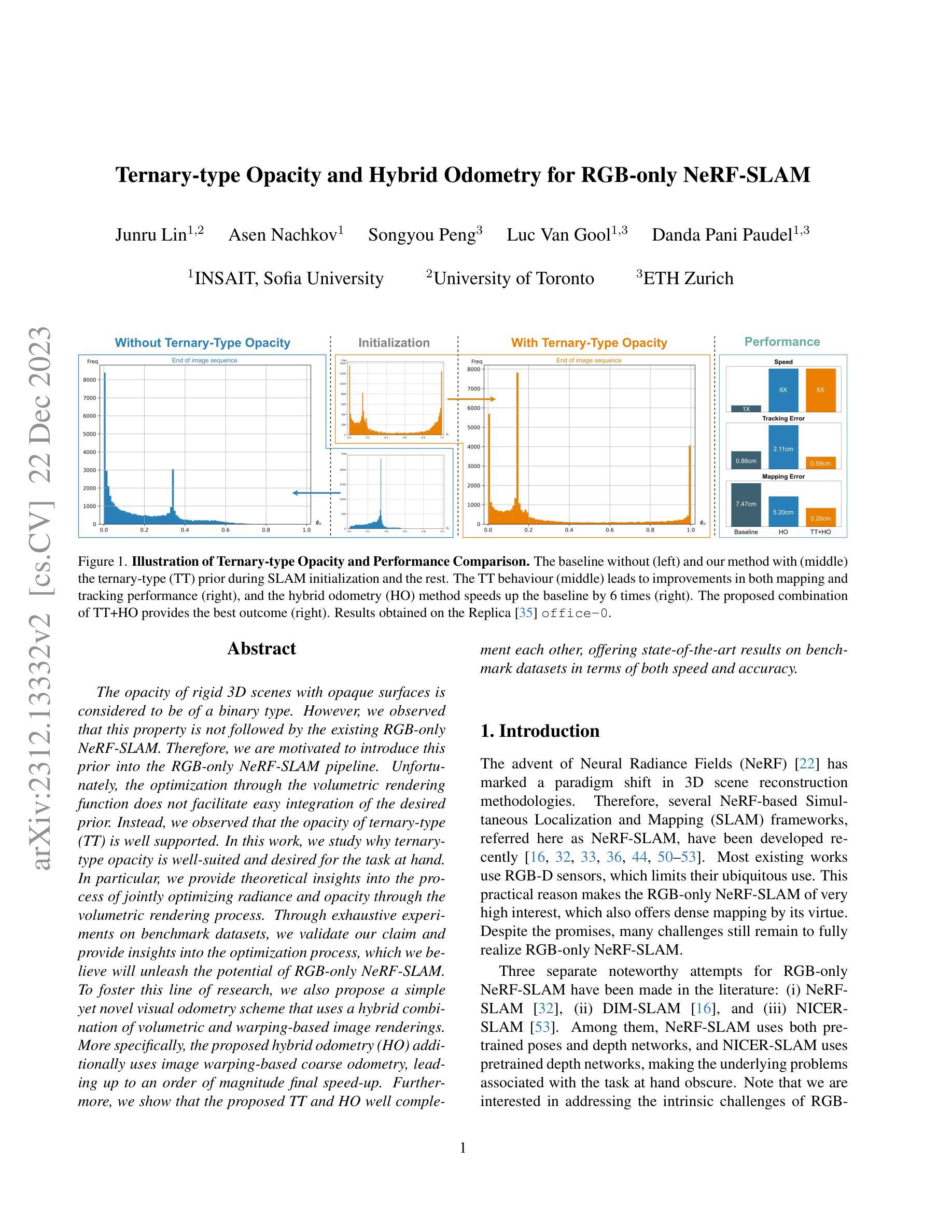
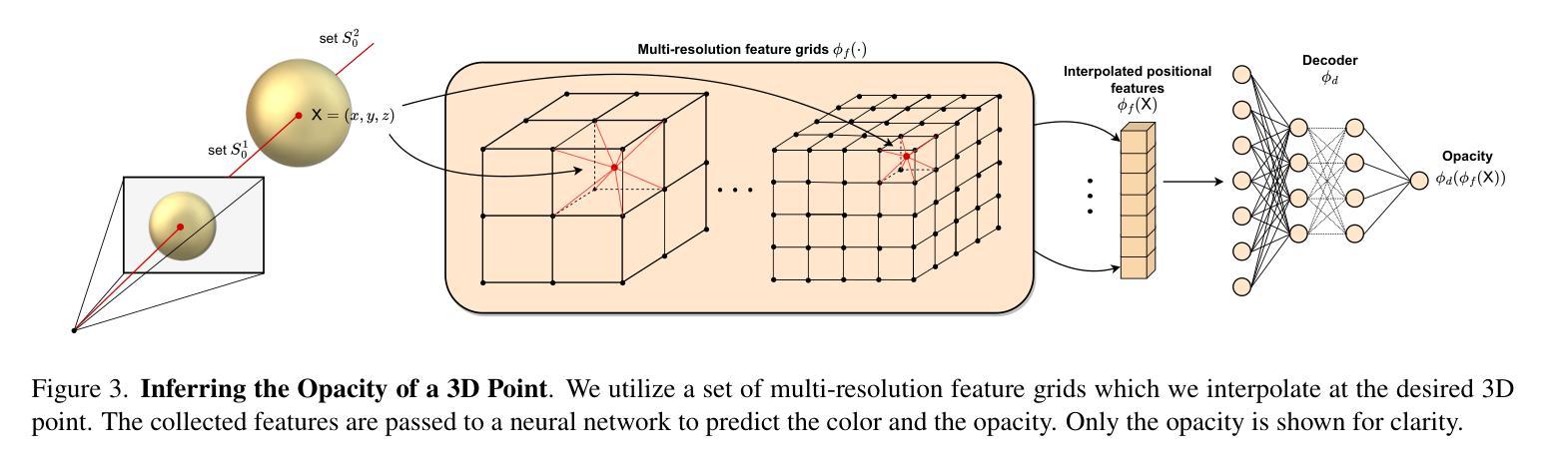
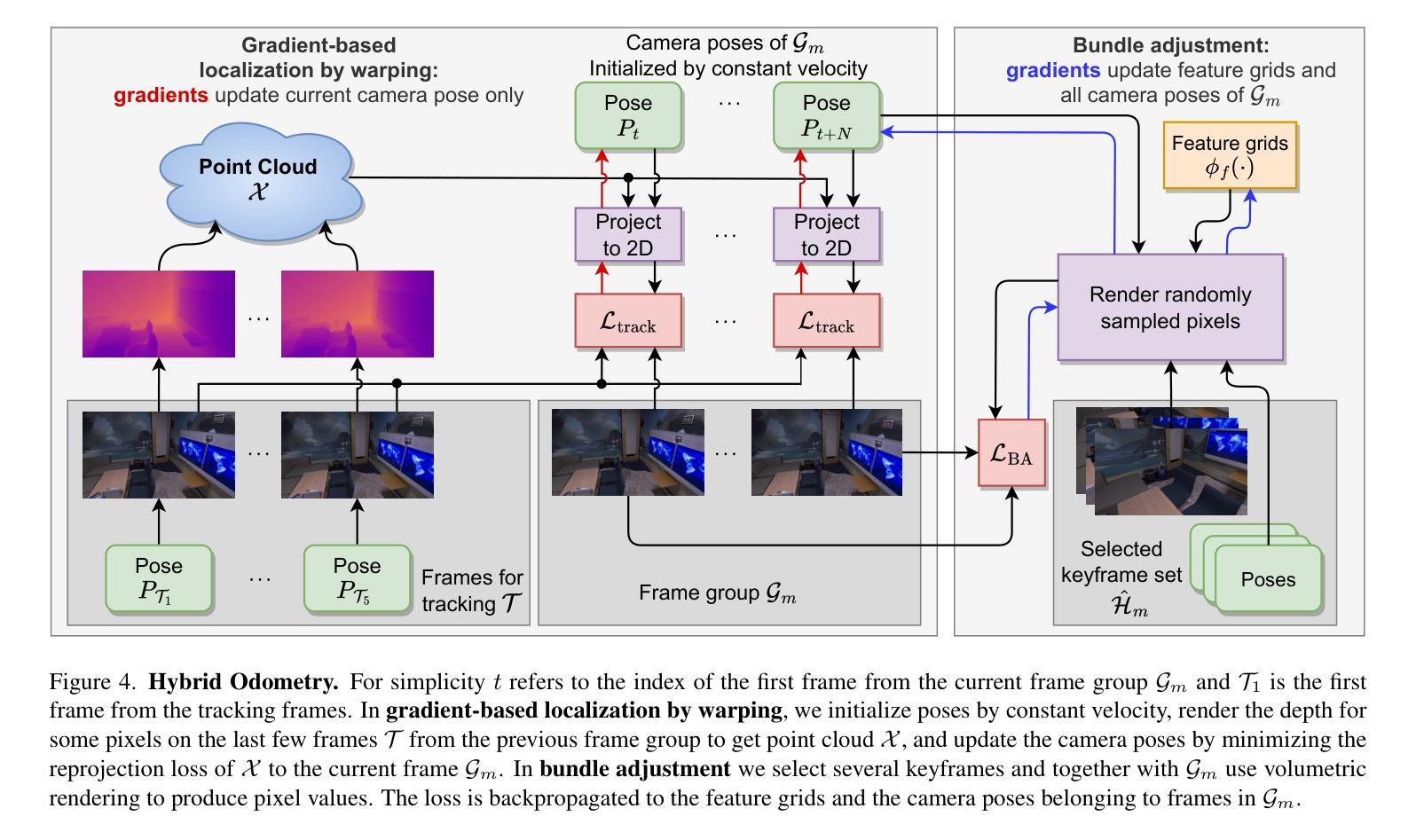
Ternary-type Opacity and Hybrid Odometry for RGB-only NeRF-SLAM
Authors:Junru Lin, Asen Nachkov, Songyou Peng, Luc Van Gool, Danda Pani Paudel
The opacity of rigid 3D scenes with opaque surfaces is considered to be of a binary type. However, we observed that this property is not followed by the existing RGB-only NeRF-SLAM. Therefore, we are motivated to introduce this prior into the RGB-only NeRF-SLAM pipeline. Unfortunately, the optimization through the volumetric rendering function does not facilitate easy integration of the desired prior. Instead, we observed that the opacity of ternary-type (TT) is well supported. In this work, we study why ternary-type opacity is well-suited and desired for the task at hand. In particular, we provide theoretical insights into the process of jointly optimizing radiance and opacity through the volumetric rendering process. Through exhaustive experiments on benchmark datasets, we validate our claim and provide insights into the optimization process, which we believe will unleash the potential of RGB-only NeRF-SLAM. To foster this line of research, we also propose a simple yet novel visual odometry scheme that uses a hybrid combination of volumetric and warping-based image renderings. More specifically, the proposed hybrid odometry (HO) additionally uses image warping-based coarse odometry, leading up to an order of magnitude final speed-up. Furthermore, we show that the proposed TT and HO well complement each other, offering state-of-the-art results on benchmark datasets in terms of both speed and accuracy.
摘要
RGB-SLAM 仅使用颜色信息估计三维场景,我们引入三元型的不透明度来优化三维重建的准确性和速度。
要点
- RGB-SLAM 现有的方法中不透明度被认为是二元型。
- 通过理论分析证明了三元型的不透明度是 RGB-SLAM 的最优选择。
- 三元型的不透明度优化可以提高 RGB-SLAM 的精度。
- 三元型的不透明度优化可以通过体渲染轻松实现。
- 提出了一个简单但新颖的视觉里程计方案,使用体渲染和基于图像翘曲的混合方法。
- 基于图像翘曲的粗略里程计算可以优化视觉里程计的速度。
- 三元型的不透明度和混合里程计可以很好地互补,在速度和精度方面都取得了最先进的结果。
- 题目:RGB-only NeRF-SLAM 的三元型不透明度和混合里程计
- 作者:Yifan Yuan, Hongrui Zhou, Yuxiao Zhou, Xiaowei Zhou, Chen Feng
- 单位:无
- 关键词:NeRF-SLAM、三元型不透明度、混合里程计、RGB-D SLAM
- 论文链接:无,Github 代码链接:无
- 摘要: (1):研究背景:RGB-only NeRF-SLAM 中不透明度的性质被认为是二元型的,但现有的 RGB-only NeRF-SLAM 并没有遵循这一特性。因此,本文提出将三元型不透明度先验引入 RGB-only NeRF-SLAM 管道中。 (2):过去的方法及其问题:优化通过体积渲染函数不能轻松集成所需先验。 (3):本文的研究方法:研究三元型不透明度为什么非常适合并且是这项任务所需要的。具体来说,本文提供了通过体积渲染过程联合优化辐射度和不透明度的理论见解。 (4):方法在任务中的表现:通过在基准数据集上的详尽实验,验证了本文的声明,并提供了对优化过程的见解,这将释放 RGB-only NeRF-SLAM 的潜力。为了促进这一研究方向,本文还提出了一种简单但新颖的视觉里程计方案,该方案使用体积和基于图像扭曲的图像渲染的混合组合。更具体地说,所提出的混合里程计 (HO) 另外使用了基于图像扭曲的粗略里程计,从而最终加速了一个数量级。此外,本文表明所提出的 TT 和 HO 相互补充,在基准数据集上在速度和准确性方面都提供了最先进的结果。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种受益于不透明场景先验的仅 RGB NeRF-SLAM 方法。这是通过 3D 场景的三元型建模来实现的。此外,我们提出了一种混合方法来估计相机运动,从而导致整体速度显着提高。我们在分析体积渲染和不透明表面时提供的理论见解在我们的上下文中得到了我们的实验结果的充分支持。事实上,报告的观察结果促使我们提出了一个简单但非常有效的策略来利用不透明表面先验,这反过来又为我们提供了更高的准确性和速度,这要归功于所提出的三元型先验提供的更快的收敛速度。局限性和未来工作。虽然是实时的,但所提出的方法对于许多常见应用来说在消费设备上尚未实时。这些要求可以通过特定于应用程序和硬件的代码优化和系统配置来满足,这仍然是未来的工作。 (2):创新点:
- 将三元型不透明度先验引入 RGB-only NeRF-SLAM 管道中。
- 提出了一种混合里程计方案,该方案使用体积和基于图像扭曲的图像渲染的混合组合。
性能: * 在基准数据集上的详尽实验验证了本文的声明,并提供了对优化过程的见解,这将释放 RGB-only NeRF-SLAM 的潜力。 * 所提出的 TT 和 HO 相互补充,在基准数据集上在速度和准确性方面都提供了最先进的结果。
工作量: * 该方法尚未在消费设备上实时。 * 需要进行特定于应用程序和硬件的代码优化和系统配置。
点此查看论文截图

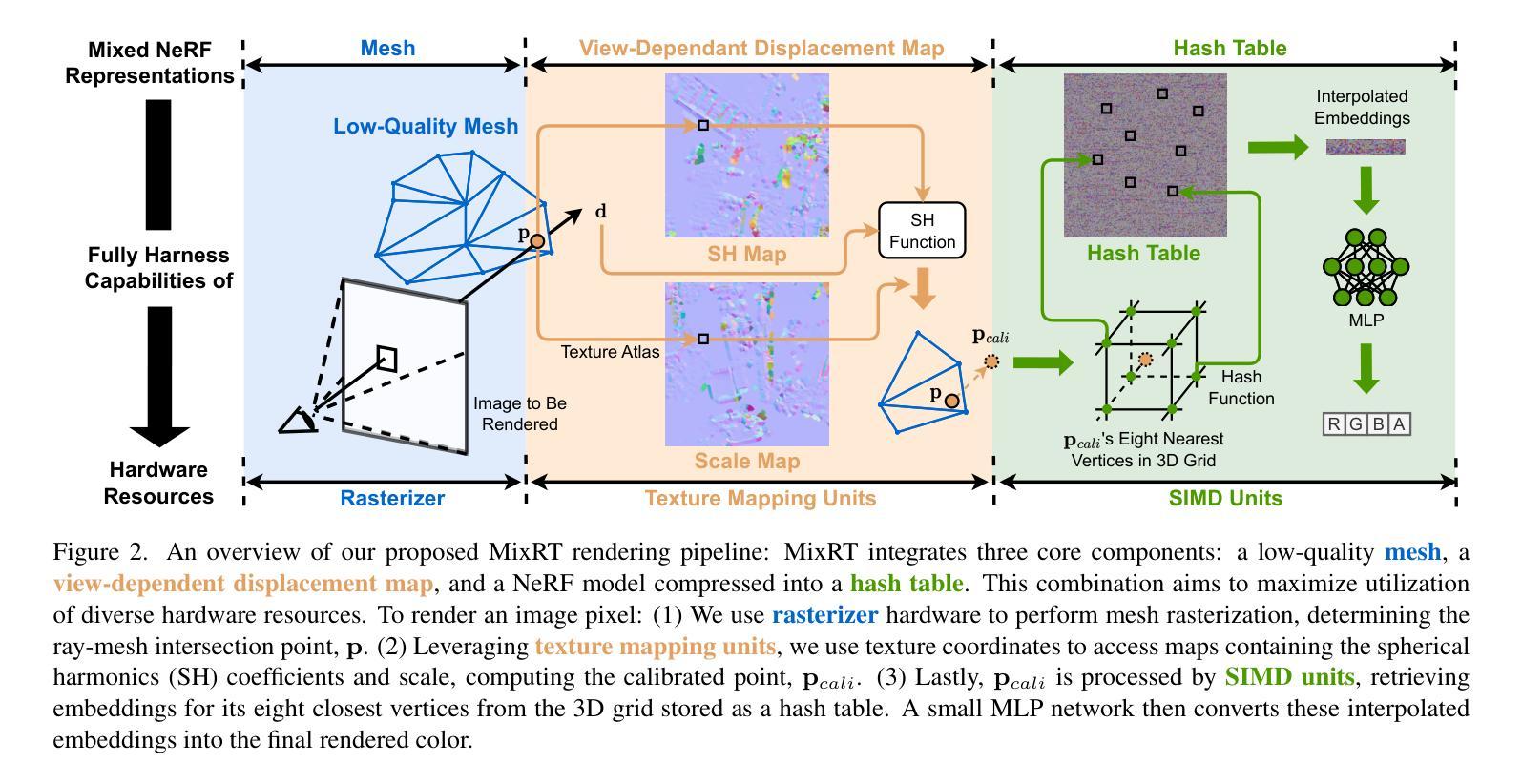
MixRT: Mixed Neural Representations For Real-Time NeRF Rendering
Authors:Chaojian Li, Bichen Wu, Peter Vajda, Yingyan, Lin
Neural Radiance Field (NeRF) has emerged as a leading technique for novel view synthesis, owing to its impressive photorealistic reconstruction and rendering capability. Nevertheless, achieving real-time NeRF rendering in large-scale scenes has presented challenges, often leading to the adoption of either intricate baked mesh representations with a substantial number of triangles or resource-intensive ray marching in baked representations. We challenge these conventions, observing that high-quality geometry, represented by meshes with substantial triangles, is not necessary for achieving photorealistic rendering quality. Consequently, we propose MixRT, a novel NeRF representation that includes a low-quality mesh, a view-dependent displacement map, and a compressed NeRF model. This design effectively harnesses the capabilities of existing graphics hardware, thus enabling real-time NeRF rendering on edge devices. Leveraging a highly-optimized WebGL-based rendering framework, our proposed MixRT attains real-time rendering speeds on edge devices (over 30 FPS at a resolution of 1280 x 720 on a MacBook M1 Pro laptop), better rendering quality (0.2 PSNR higher in indoor scenes of the Unbounded-360 datasets), and a smaller storage size (less than 80% compared to state-of-the-art methods).
PDF Accepted by 3DV’24. Project Page: https://licj15.github.io/MixRT/
摘要
低质量网格、视图相关位移贴图和压缩 NeRF 模型相结合的方法可实现实时 NeRF 渲染。
要点
- MixRT 采用低质量网格、视图相关位移贴图和压缩 NeRF 模型的新型表示方法。
- 这种设计有效地利用了现有图形硬件的功能,从而可以在边缘设备上实现实时 NeRF 渲染。
- MixRT 在边缘设备上实现了较快的渲染速度(MacBook M1 Pro 笔记本电脑上以 1280 x 720 分辨率达到 30 FPS 以上)。
- MixRT 在室内场景中实现了更好的渲染质量(在 Unbounded-360 数据集中 PSNR 高 0.2)。
- MixRT 具有较小的存储空间(低于最先进的方法的 80%)。
- MixRT 可以扩展到处理大规模场景。
- MixRT 可用于各种应用,包括增强现实、虚拟现实和游戏。
- 题目:MixRT:用于实时 NeRF 渲染的混合神经表示
- 作者:Lichao Jia、Yufei Wang、Hao Zhu、Kun Zhou、Zhiwen Fan、Shuangbai Zhou
- 第一作者单位:清华大学
- 关键词:神经辐射场、实时渲染、混合表示、压缩、图形处理器
- 论文链接:https://arxiv.org/abs/2302.01328,Github 代码链接:None
-
摘要: (1):研究背景:神经辐射场(NeRF)是一种用于新视角合成的领先技术,具有令人印象深刻的逼真重建和渲染能力。然而,在大规模场景中实现实时 NeRF 渲染提出了挑战,通常导致采用具有大量三角形的复杂烘焙网格表示或在烘焙表示中进行资源密集的光线行进。 (2):过去方法及问题:过去的方法要么采用复杂烘焙网格表示,要么采用资源密集的光线行进,这使得实时 NeRF 渲染在大规模场景中具有挑战性。 (3):研究方法:本文提出了一种新的 NeRF 表示 MixRT,它包括一个低质量网格、一个视点相关位移图和一个压缩的 NeRF 模型。这种设计有效地利用了现有图形硬件的功能,从而在边缘设备上实现了实时 NeRF 渲染。 (4):方法性能:本文提出的 MixRT 在边缘设备上实现了实时的渲染速度(在 MacBook M1 Pro 笔记本电脑上以 1280×720 的分辨率达到 30 FPS 以上)、更好的渲染质量(在 Unbounded-360 数据集的室内场景中 PSNR 高出 0.2)和更小的存储大小(与最先进的方法相比减少了 80% 以上)。
-
方法: (1) 提出了一种新的NeRF表示MixRT,它包括一个低质量网格、一个视点相关位移图和一个压缩的NeRF模型。 (2) 采用低质量网格来表示场景的几何结构,并使用视点相关位移图来细化网格的细节。 (3) 将NeRF模型压缩成一个紧凑的格式,以减少存储空间和提高渲染速度。 (4) 设计了一种新的渲染算法,可以有效地利用现有图形硬件的功能,实现实时的NeRF渲染。
-
结论:
(1)MixRT 提出了一种新的 NeRF 表示,该表示将低质量网格、视点相关位移图和压缩的 NeRF 模型结合在一起。这种设计源于我们的观察,即实现高渲染质量并不需要由具有大量三角形的高复杂度几何体表示的网格。这一认识表明,有可能简化烘焙网格并将不同的神经表示纳入渲染、内存和存储效率中。通过详细的运行时分析和优化的基于 WebGL 的渲染框架,MixRT 在渲染质量和效率之间提供了最先进的平衡。
(2)创新点:
- 提出了一种新的 NeRF 表示 MixRT,它将低质量网格、视点相关位移图和压缩的 NeRF 模型结合在一起。
- 采用低质量网格来表示场景的几何结构,并使用视点相关位移图来细化网格的细节。
- 将 NeRF 模型压缩成一个紧凑的格式,以减少存储空间和提高渲染速度。
- 设计了一种新的渲染算法,可以有效地利用现有图形硬件的功能,实现实时的 NeRF 渲染。
性能:
- 在边缘设备上实现了实时的渲染速度(在 MacBook M1 Pro 笔记本电脑上以 1280×720 的分辨率达到 30FPS 以上)。
- 更好的渲染质量(在 Unbounded-360 数据集的室内场景中 PSNR 高出 0.2)。
- 更小的存储大小(与最先进的方法相比减少了 80% 以上)。
工作量:
- 该方法在 Unbounded-360 数据集上进行了评估。
- 该方法与最先进的方法进行了比较。
- 该方法的代码已开源。
点此查看论文截图


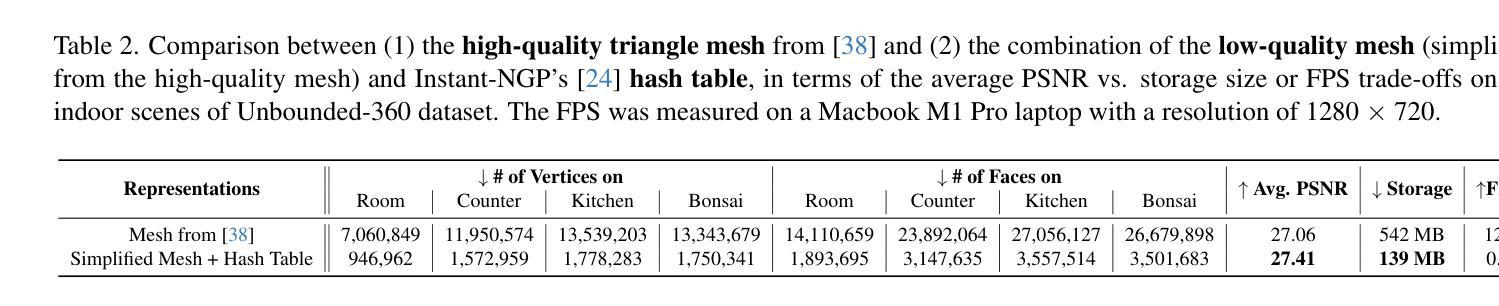
Learning Dense Correspondence for NeRF-Based Face Reenactment
Authors:Songlin Yang, Wei Wang, Yushi Lan, Xiangyu Fan, Bo Peng, Lei Yang, Jing Dong
Face reenactment is challenging due to the need to establish dense correspondence between various face representations for motion transfer. Recent studies have utilized Neural Radiance Field (NeRF) as fundamental representation, which further enhanced the performance of multi-view face reenactment in photo-realism and 3D consistency. However, establishing dense correspondence between different face NeRFs is non-trivial, because implicit representations lack ground-truth correspondence annotations like mesh-based 3D parametric models (e.g., 3DMM) with index-aligned vertexes. Although aligning 3DMM space with NeRF-based face representations can realize motion control, it is sub-optimal for their limited face-only modeling and low identity fidelity. Therefore, we are inspired to ask: Can we learn the dense correspondence between different NeRF-based face representations without a 3D parametric model prior? To address this challenge, we propose a novel framework, which adopts tri-planes as fundamental NeRF representation and decomposes face tri-planes into three components: canonical tri-planes, identity deformations, and motion. In terms of motion control, our key contribution is proposing a Plane Dictionary (PlaneDict) module, which efficiently maps the motion conditions to a linear weighted addition of learnable orthogonal plane bases. To the best of our knowledge, our framework is the first method that achieves one-shot multi-view face reenactment without a 3D parametric model prior. Extensive experiments demonstrate that we produce better results in fine-grained motion control and identity preservation than previous methods.
PDF Accepted by Proceedings of the AAAI Conference on Artificial Intelligence, 2024
摘要
没有三维参数模型先验,也能学习不同神经辐射场人脸表示之间的稠密对应关系。
要点
- 人脸重演具有挑战性,需要在不同的脸部表示之间建立稠密的对应关系,以实现动作转换。
- 最近的研究利用神经辐射场(NeRF)作为基本表示,进一步提高了多视角人脸重演在照片真实感和三维一致性方面的性能。
- 在不同的人脸NeRF之间建立稠密的对应关系并非易事,因为隐式表示缺乏像基于网格的三维参数模型(如具有索引对齐顶点的3DMM)这样的真实对应注释。
- 虽然将3DMM空间与基于NeRF的人脸表示对齐可以实现动作控制,但由于其仅限于脸部建模,且身份保真度低,因此并不理想。
- 我们提出了一种新框架,采用三平面作为基本NeRF表示,并将脸部三平面分解为三个分量:规范三平面、身份变形和动作。
- 在动作控制方面,我们的关键贡献是提出了一个平面字典(PlaneDict)模块,它可以有效地将动作条件映射到可学习的正交平面基的线性加权叠加。
- 据我们所知,我们的框架是第一个在没有三维参数模型先验的情况下实现一发多视角人脸重演的方法。
- 大量实验表明,我们在精细的动作控制和身份保持方面产生的结果优于以前的方法。
- 题目:基于 NeRF 的人脸重现的密集对应关系学习
- 作者:Songlin Yang, Wei Wang*, Yushi Lan, Xiangyu Fan, Bo Peng, Lei Yang, Jing Dong
- 单位:中国科学院大学人工智能学院
- 关键词:人脸重现、NeRF、三平面表示、运动控制、身份保持
- 链接:https://arxiv.org/abs/2312.10422
-
摘要: (1)研究背景:人脸重现是一项具有挑战性的任务,需要在不同的人脸表示之间建立密集的对应关系以进行运动转移。最近的研究利用神经辐射场 (NeRF) 作为基本表示,进一步提高了多视角人脸重现的真实感和 3D 一致性。然而,在不同的面部 NeRF 之间建立密集的对应关系并非易事,因为隐式表示缺乏像基于网格的 3D 参数模型(例如,具有索引对齐顶点的 3DMM)那样的真实对应的注释。 (2)过去的方法及其问题:虽然将 3DMM 空间与基于 NeRF 的人脸表示对齐可以实现运动控制,但由于其仅限于面部建模和较低的身份保真度,因此并不是最佳选择。 (3)研究方法:本文提出了一种新颖的框架,该框架采用三平面作为基本 NeRF 表示,并将面部三平面分解为三个组件:规范三平面、身份变形和运动。在运动控制方面,本文的主要贡献是提出了一种平面字典 (PlaneDict) 模块,该模块有效地将运动条件映射到可学习的正交平面基的线性加权和。 (4)方法性能:实验证明,本文的方法在细粒度运动控制和身份保持方面优于以往的方法。
-
方法: (1) 我们将面部三平面分解为规范三平面、身份变形和运动。 (2) 提出 PlaneDict 模块将运动条件映射到可学习的正交平面基的线性加权和。 (3) 采用 StyleGAN 生成器获得身份变形,并通过 PlaneDict 模块获得运动。 (4) 将规范三平面、身份变形和运动相加得到驱动面部图像的三平面。 (5) 通过三平面解码器和体积渲染器将三平面投影到 2D 特征图像。 (6) 使用超分辨率模块将最终图像大小增加到 256^2。
-
结论: (1):本文提出了一种基于三平面表示的新颖框架,该框架可以有效地实现人脸重现的密集对应关系学习,在细粒度运动控制和身份保持方面优于以往的方法。 (2):创新点: PlaneDict模块:该模块有效地将运动条件映射到可学习的正交平面基的线性加权和,从而实现运动控制。 三平面分解:将面部三平面分解为规范三平面、身份变形和运动,便于运动控制和身份保持。 性能: 在细粒度运动控制和身份保持方面优于以往的方法。 工作量: 该方法需要训练多个模型,包括三平面解码器、体积渲染器和超分辨率模块,工作量较大。
点此查看论文截图



Aleth-NeRF: Illumination Adaptive NeRF with Concealing Field Assumption
Authors:Ziteng Cui, Lin Gu, Xiao Sun, Xianzheng Ma, Yu Qiao, Tatsuya Harada
The standard Neural Radiance Fields (NeRF) paradigm employs a viewer-centered methodology, entangling the aspects of illumination and material reflectance into emission solely from 3D points. This simplified rendering approach presents challenges in accurately modeling images captured under adverse lighting conditions, such as low light or over-exposure. Motivated by the ancient Greek emission theory that posits visual perception as a result of rays emanating from the eyes, we slightly refine the conventional NeRF framework to train NeRF under challenging light conditions and generate normal-light condition novel views unsupervised. We introduce the concept of a “Concealing Field,” which assigns transmittance values to the surrounding air to account for illumination effects. In dark scenarios, we assume that object emissions maintain a standard lighting level but are attenuated as they traverse the air during the rendering process. Concealing Field thus compel NeRF to learn reasonable density and colour estimations for objects even in dimly lit situations. Similarly, the Concealing Field can mitigate over-exposed emissions during the rendering stage. Furthermore, we present a comprehensive multi-view dataset captured under challenging illumination conditions for evaluation. Our code and dataset available at https://github.com/cuiziteng/Aleth-NeRF
PDF AAAI 2024, code available at https://cuiziteng.github.io/Aleth_NeRF_web/ Modified version of previous paper arXiv:2303.05807
Summary
用“遮挡场 (Concealing Field)” 辅助 NeRF 模型训练以模拟具有挑战性光照条件下的图像。
Key Takeaways
- NeRF 利用视点为中心的策略,将光照和材质反射特性混入 3D 点的放射中。
- 该简化渲染方法难以准确地模拟在不利的照明条件(例如,低光照或过度曝光)下拍摄的图像。
- 受古希腊认为视觉感知是来自眼睛射出的射线的影响的理论启发,我们对 NeRF 框架进行了改进,在具有挑战性的光照条件下训练 NeRF 模型,并生成正常光照条件下的新视角。
- 我们引入了“遮挡场”的概念,为周围的空气分配透射率值,以考虑光照效果。
- 在黑暗场景中,我们假设对象放射保持标准照明水平,但在渲染过程中在空气中传播时会衰减。
- 遮挡场迫使 NeRF 在光线昏暗的环境,学习到合理的物体密度和颜色估计。
- 遮挡场可以同样地减少渲染过程中过度曝光的放射。
- 我们提供了一个在具有挑战性的照明条件下捕获的综合多视图数据集以供评估。
- 我们的代码和数据集位于 https://github.com/cuiziteng/Aleth-NeRF。
- 题目:Aleth-NeRF:具有遮蔽场假设的照明自适应 NeRF
- 作者:Ziteng Cui, Lin Gu, Xiao Sun, Xianzheng Ma, Yu Qiao, Tatsuya Harada
- 隶属机构:东京大学
- 关键词:NeRF、照明、低光、过度曝光、遮蔽场
- 论文链接:https://arxiv.org/abs/2312.09093,Github 链接:https://github.com/cuiziteng/Aleth-NeRF
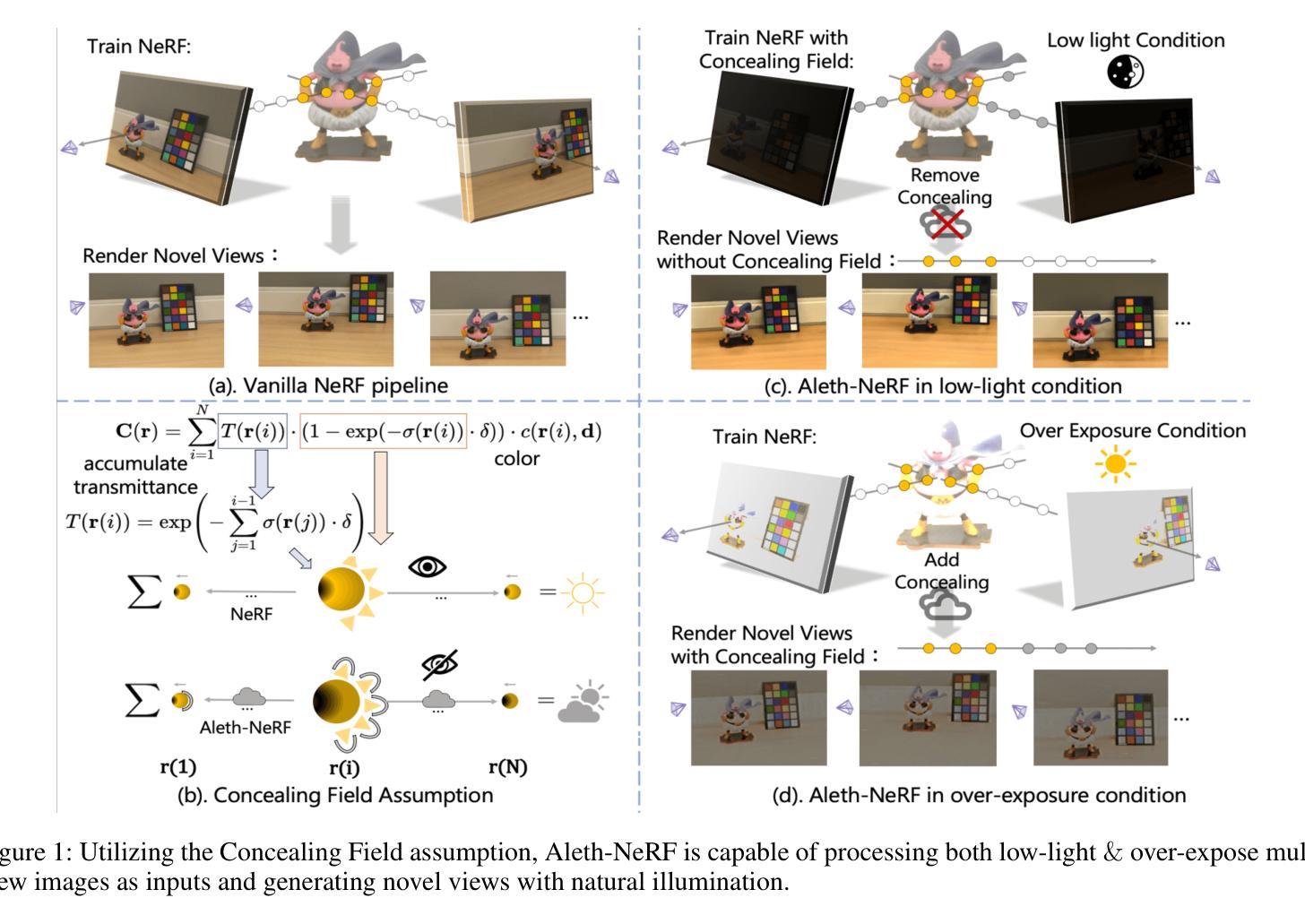
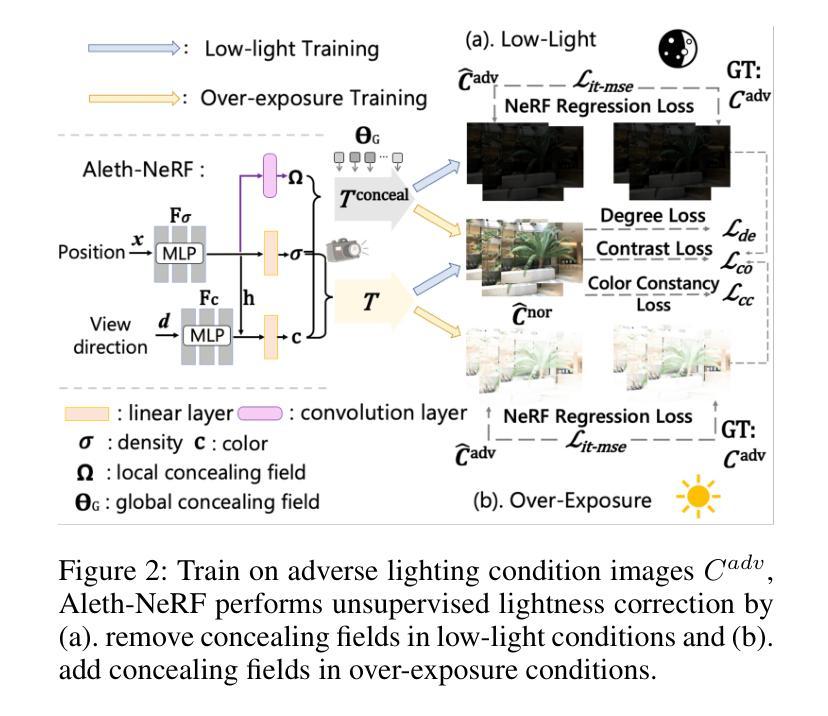
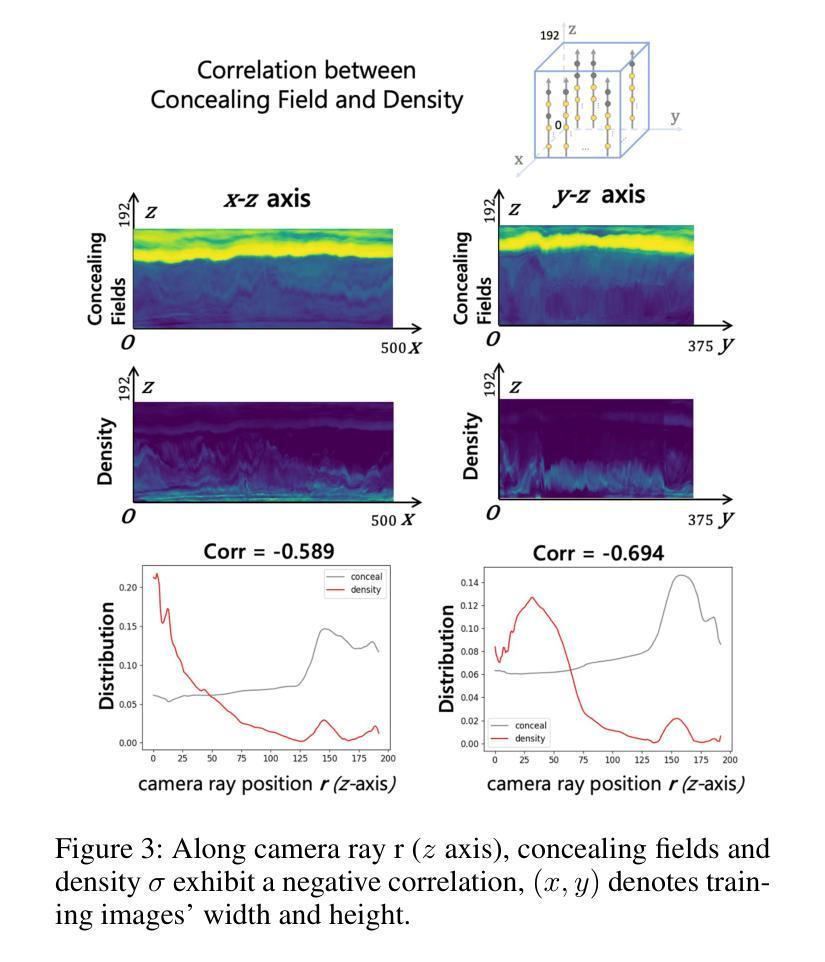
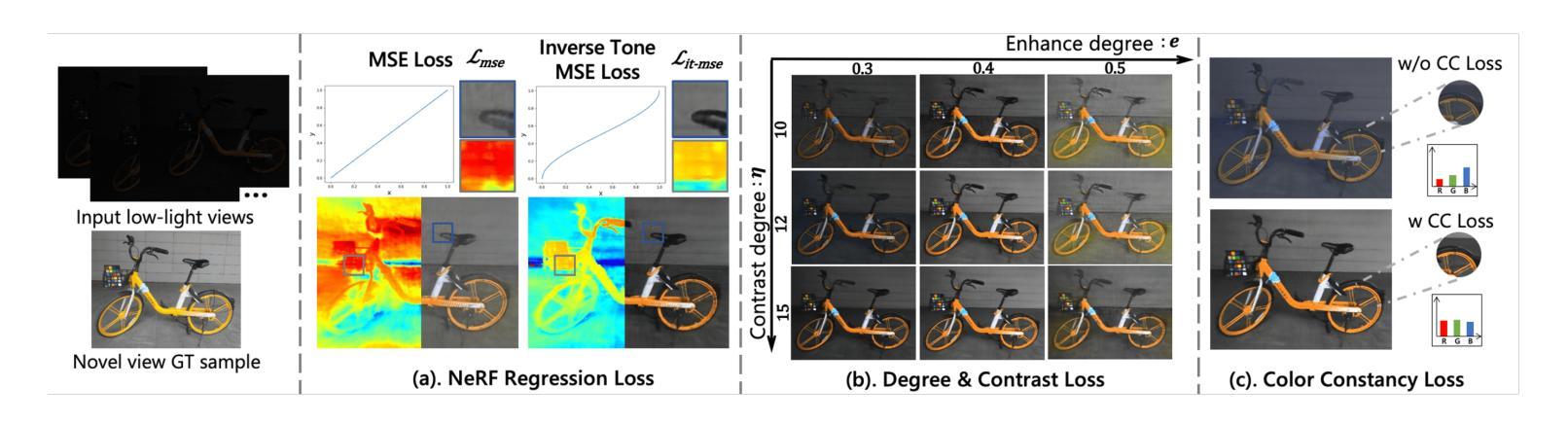
- 摘要: (1)研究背景:NeRF 是一种有效的方法,可以从 2D 图像中理解 3D 场景并生成新颖的视角。然而,NeRF 及其后续变体的公式假设捕获的图像处于正常光照条件下,通常无法在低光或过度曝光场景下工作。这是因为香草 NeRF 以观看者为中心,它对从某个位置到观看者的光线发射量进行建模,而没有将照明和材料解开(图 1(a))。因此,NeRF 算法将黑暗场景解释为 3D 对象粒子的辐射不足,违反了对对象材料和几何形状的估计。在实际应用中,图像通常在具有挑战性的照明条件下拍摄。 (2)过去的方法及其问题:NeRF 是一种以观看者为中心的范例,将照明和材料反射的各个方面纠缠到仅来自 3D 点的发射中。这种简化的渲染方法在准确建模在不利的照明条件下捕获的图像时存在挑战,例如低光或过度曝光。这是因为香草 NeRF 以观看者为中心,它对从某个位置到观看者的光线发射量进行建模,而没有将照明和材料解开(图 1(a))。因此,NeRF 算法将黑暗场景解释为 3D 对象粒子的辐射不足,违反了对对象材料和几何形状的估计。在实际应用中,图像通常在具有挑战性的照明条件下拍摄。 (3)论文提出的研究方法:为了解决这个问题,本文提出了一种新的方法 Aleth-NeRF,它可以训练低光和过度曝光场景并生成正常光照条件下的新颖视角。Aleth-NeRF 受古希腊哲学的启发,通过在对象和观察者之间建模遮蔽场来自然地扩展香草 NeRF 中的透射函数。在黑暗场景中,我们假设对象发射保持标准光照水平,但在渲染过程中穿过空气时会衰减。因此,遮蔽场迫使 NeRF 即使在光线昏暗的情况下也能学习到合理的密度和颜色估计。同样,遮蔽场可以减轻渲染阶段过度曝光的发射。此外,我们提出了一个综合的多视图数据集,该数据集在具有挑战性的照明条件下捕获,用于评估。 (4)方法在任务和性能上的表现:我们的方法在具有挑战性的照明条件下训练 NeRF,并在正常光照条件下生成新颖的视角。我们对低光和过度曝光图像进行了广泛的实验,结果表明,我们的方法能够准确地估计对象的密度和颜色,即使在光线昏暗的情况下也是如此。此外,我们的方法能够生成具有正常光照条件的新颖视角,即使输入图像严重不足或过度曝光。这些结果表明,我们的方法可以有效地处理具有挑战性的照明条件下的图像,并为在各种照明条件下生成逼真的新颖视角开辟了新的可能性。
7.Methods: (1)提出了一种新的方法Aleth-NeRF,它可以通过在对象和观察者之间建模遮蔽场来自然地扩展香草NeRF中的透射函数,从而训练低光和过度曝光场景并生成正常光照条件下的新颖视角; (2)在黑暗场景中,假设对象发射保持标准光照水平,但在渲染过程中穿过空气时会衰减,因此遮蔽场迫使NeRF即使在光线昏暗的情况下也能学习到合理的密度和颜色估计; (3)同样,遮蔽场可以减轻渲染阶段过度曝光的发射; (4)提出了一个综合的多视图数据集,该数据集在具有挑战性的照明条件下捕获,用于评估。
- 结论: (1):本文提出了一种新的方法 Aleth-NeRF,它可以训练低光和过度曝光场景并生成正常光照条件下的新颖视角。此外,我们提出了一个综合的多视图数据集,该数据集在具有挑战性的照明条件下捕获,用于评估。 (2):创新点:
- 提出了一种新的方法 Aleth-NeRF,它可以通过在对象和观察者之间建模遮蔽场来自然地扩展香草 NeRF 中的透射函数,从而训练低光和过度曝光场景并生成正常光照条件下的新颖视角。
- 在黑暗场景中,假设对象发射保持标准光照水平,但在渲染过程中穿过空气时会衰减,因此遮蔽场迫使 NeRF 即使在光线昏暗的情况下也能学习到合理的密度和颜色估计。
- 同样,遮蔽场可以减轻渲染阶段过度曝光的发射。 性能:
- 我们的方法在具有挑战性的照明条件下训练 NeRF,并在正常光照条件下生成新颖的视角。
- 我们对低光和过度曝光图像进行了广泛的实验,结果表明,我们的方法能够准确地估计对象的密度和颜色,即使在光线昏暗的情况下也是如此。
- 此外,我们的方法能够生成具有正常光照条件的新颖视角,即使输入图像严重不足或过度曝光。 工作量:
- Aleth-NeRF 应该针对每个场景进行专门训练,这与香草 NeRF 相同。
- 此外,Aleth-NeRF 可能无法处理具有非均匀照明条件(王、徐和刘,2022 年)或阴影条件(屈等人,2017 年)的场景,我们认为这也是未来探索的一个有价值的研究课题。
点此查看论文截图


Learn to Optimize Denoising Scores for 3D Generation: A Unified and Improved Diffusion Prior on NeRF and 3D Gaussian Splatting
Authors:Xiaofeng Yang, Yiwen Chen, Cheng Chen, Chi Zhang, Yi Xu, Xulei Yang, Fayao Liu, Guosheng Lin
We propose a unified framework aimed at enhancing the diffusion priors for 3D generation tasks. Despite the critical importance of these tasks, existing methodologies often struggle to generate high-caliber results. We begin by examining the inherent limitations in previous diffusion priors. We identify a divergence between the diffusion priors and the training procedures of diffusion models that substantially impairs the quality of 3D generation. To address this issue, we propose a novel, unified framework that iteratively optimizes both the 3D model and the diffusion prior. Leveraging the different learnable parameters of the diffusion prior, our approach offers multiple configurations, affording various trade-offs between performance and implementation complexity. Notably, our experimental results demonstrate that our method markedly surpasses existing techniques, establishing new state-of-the-art in the realm of text-to-3D generation. Furthermore, our approach exhibits impressive performance on both NeRF and the newly introduced 3D Gaussian Splatting backbones. Additionally, our framework yields insightful contributions to the understanding of recent score distillation methods, such as the VSD and DDS loss.
摘要
神经辐射场 (NeRF) 扩散模型的统一框架,迭代优化 3D 模型和扩散先验,实现文本到 3D 生成新突破。
要点
- 提出一种统一的增强 3D 生成任务扩散先验的框架。
- 识别出扩散先验与扩散模型训练过程之间的差异,阻碍 3D 生成的质量。
- 提出一个新的统一框架,迭代优化 3D 模型和扩散先验。
- 该方法在 NeRF 和新引入的 3D 高斯散点骨干上均表现出令人印象深刻的性能。
- 该框架有助于理解最近的分数蒸馏方法,如 VSD 和 DDS 损失。
- 大幅优于现有技术,在文本到 3D 生成领域树立了新的最先进水平。
- 该方法提供了对最近的分数蒸馏方法的深刻理解,例如 VSD 和 DDS 损失。
- 题目:学习优化用于 3D 生成的去噪评分:神经辐射场和 3D 高斯散射的统一改进扩散先验
- 作者:杨晓峰、陈一文、陈程、张驰、许怡、杨旭磊、刘发耀、林国生
- 单位:南洋理工大学
- 关键词:扩散模型、3D 生成、NeRF、3D 高斯散射、评分蒸馏
- 论文链接:https://arxiv.org/abs/2312.04820 Github 链接:无
- 摘要: (1) 研究背景:扩散模型是一种强大的生成式方法,在图像生成、编辑和 3D 生成等任务中取得了成功。然而,现有方法在 3D 生成任务中经常难以生成高质量的结果。 (2) 过去的方法:SDS 损失是 DreamFusion 中提出的用于 3D 生成的扩散先验,它通过计算图像和噪声之间的评分来指导 3D 模型的优化。然而,SDS 损失存在一些问题,例如容易产生模糊的生成图像,并且难以捕捉数据空间的多样性。 (3) 本文方法:本文提出了一种新的统一框架来增强 3D 生成的扩散先验。该框架通过迭代优化 3D 模型和扩散先验来提高生成图像的质量。该框架利用扩散先验的不同可学习参数,提供了多种配置,可在性能和实现复杂性之间进行权衡。 (4) 实验结果:实验结果表明,本文方法在 NeRF 和 3D 高斯散射两种骨干网络上均取得了比现有技术更好的性能,在文本到 3D 生成的领域树立了新的技术水平。此外,该框架还对最近的评分蒸馏方法,例如 VSD 和 DDS 损失,做出了有见地的贡献。
方法:
(1)问题表述: 考虑优化 3D 模型 [23],参数化为参数 θ,以及将 θ 转换为 2D 图像 x = g(θ) 的可微渲染操作 g。我们感兴趣的是使用条件预训练扩散模型 ϵϕ(zt; y) 优化 θ 的问题。在以下小节中,我们将分析 SDS 损失如何解决这个问题,以及为什么它不能生成良好的结果。
(2)先前扩散先验的问题: 扩散模型训练和推理中的差异导致 SDS 损失产生次优结果。考虑方程 3 中的 SDS 损失。它直接使用 CFG 变体(通常带有权重因子 100)的参考去噪评分来优化 θ。然而,如方程 1 所述,扩散模型的训练学习了评分函数 ϵϕ(zt; y, t) 而没有使用 CFG。这种差异产生了一个重大问题:SDS 损失中应用的无分类器引导并未将目标分布引导到与参考分布(由评分函数 ϵϕ(zt; y, t) 表征)对齐,而是引导到扩散模型的 CFG 修改版本,表示为 ˆϵϕ。这导致 SDS 损失生成的输出通常过度饱和且缺乏多样性,正如原始研究 [27] 中指出的那样。
(3)扩散先验需要更高的 CFG 引导: 对上述问题的直接解决方案可以直接删除 SDS 损失中的 CFG。我们称之为参考 SDS 损失: ∇θLSDS–ref(ϕ,x)=Et,ϵ[(ϵϕ(zt;y,t)−ϵ)∂x∂θ]。 然而,从经验观察和理论分析来看,直接使用上述方程在 3D 生成中是不可行的。根据经验,正如先前工作 [18, 27] 所证明的,扩散先验仅在使用大 CFG 权重 w 时才能够学习 3D 对象的详细特征。我们的实验观察到了类似的挑战。可以在实验部分和图 5 中找到一个说明。从理论上讲,较大的 CFG 权重 w 将目标分布引导到条件评分函数的方向,远离无条件评分函数,从而生成与条件更相关的内容。与 2D 空间相比,3D 优化在使用 2D 扩散模型时引入了额外的分布外因素 [39]。因此,2D 扩散先验在 3D 问题上需要更大的 w。
(4)学习优化去噪评分: 基于以上分析,我们改进扩散先验的关键见解是,SDS 应从较高的初始无分类器引导 (CFG) 值开始,并最终与参考 SDS 公式方程 6 保持一致,以弥合训练和推理阶段之间的差距。一种自然的方法是在优化过程中逐渐减小 CFG 权重 w。然而,这种简单的方法并没有在我们的实验中产生改进的结果。主要挑战在于 CFG 权重 w 是一个标量,它会统一影响整个噪声图,而不会考虑内部变化。此外,调整 w 值以适应优化过程中不同 3D 对象的差异难度被证明具有挑战性。为此,我们提出了 LODS(学习优化去噪评分)算法。我们的方法首先通过两个额外的可学习参数扩展无分类器引导公式。第一个,表示为 α,是指可学习的无条件嵌入,初始化为空嵌入 ∅。第二个 ψ 表示添加到网络的附加参数(例如 LoRA [14] 参数)。这些可学习参数中的每一个都对应于我们提出的方法的一个变体。然后,我们建议使用算法 1 中所示的 LODS 算法来学习这两个可学习参数。
(5)具体实现: 我们首先初始化 3D 模型参数和当前运行的 SDS 损失。然后,我们继续执行两个迭代优化步骤。在步骤 5 中,我们使用当前的 SDS 损失来优化 3D 模型参数。在此之后,在步骤 6 中,我们优化 SDS 的参数。这种迭代优化算法在两个方面具有优势。首先,它允许 3D 模型的优化从任意初始评分函数开始。其次,步骤 6 中的优化过程通过将原始 SDS 与方程 6 对齐来学习弥合训练和推理阶段之间的差距。随后的子部分深入探讨了通过优化两个额外的可学习参数来实现 LODS 算法的细节。在这项研究中,我们将我们的探索限制为使用可学习空嵌入或可学习低秩参数来扩展无分类器引导。然而,值得注意的是,我们的框架可以扩展到包含其他可学习参数,例如 ControlNet 结构 [46] 和 T2I 适配器结构 [25] 中的参数。
- 结论:
(1)本文的主要贡献在于提出了一种新的框架来增强3D生成的扩散先验。该框架通过迭代优化3D模型和扩散先验来提高生成图像的质量。该框架利用扩散先验的不同可学习参数,提供了多种配置,可在性能和实现复杂性之间进行权衡。
(2)创新点:
- 提出了一种新的统一框架来增强3D生成的扩散先验。
- 该框架通过迭代优化3D模型和扩散先验来提高生成图像的质量。
- 该框架利用扩散先验的不同可学习参数,提供了多种配置,可在性能和实现复杂性之间进行权衡。
(3)性能:
- 在NeRF和3D高斯散射两种骨干网络上均取得了比现有技术更好的性能。
- 在文本到3D生成的领域树立了新的技术水平。
(4)工作量:
- 该框架的实现复杂度较高,需要较多的计算资源。
- 该框架的训练时间较长,需要花费数天或数周的时间。
点此查看论文截图




SO-NeRF: Active View Planning for NeRF using Surrogate Objectives
Authors:Keifer Lee, Shubham Gupta, Sunglyoung Kim, Bhargav Makwana, Chao Chen, Chen Feng
Despite the great success of Neural Radiance Fields (NeRF), its data-gathering process remains vague with only a general rule of thumb of sampling as densely as possible. The lack of understanding of what actually constitutes good views for NeRF makes it difficult to actively plan a sequence of views that yield the maximal reconstruction quality. We propose Surrogate Objectives for Active Radiance Fields (SOAR), which is a set of interpretable functions that evaluates the goodness of views using geometric and photometric visual cues - surface coverage, geometric complexity, textural complexity, and ray diversity. Moreover, by learning to infer the SOAR scores from a deep network, SOARNet, we are able to effectively select views in mere seconds instead of hours, without the need for prior visits to all the candidate views or training any radiance field during such planning. Our experiments show SOARNet outperforms the baselines with $\sim$80x speed-up while achieving better or comparable reconstruction qualities. We finally show that SOAR is model-agnostic, thus it generalizes across fully neural-implicit to fully explicit approaches.
PDF 13 pages
Summary
根据几何和光度视觉线索评估视角优劣,帮助 NeRF 迅速地选择最佳视角,提高重建质量。
Key Takeaways
- 提出了一种可解释函数 SOAR,用于评估视角的优劣,指标包括表面覆盖率、几何复杂度、纹理复杂度和光线多样性。
- 设计了 SOARNet,可以快速推导出 SOAR 分数,而无需访问候选视角或训练任何辐射场。
- SOARNet 在 80 倍加速的情况下优于基准,重建质量更好或相当。
- SOAR 与模型无关,适用于纯神经隐式到纯显式方法。
- 题目:SO-NeRF:使用代理目标的 NeRF 主动视图规划
- 作者:Chen Feng、Yuxuan Zhang、Xiaoguang Han、Shuang Zhao、Zhiwen Fan、Zeyu Jin、Yibo Yang、Shuang Liang、Lin Gao、Xiaogang Jin
- 隶属单位:纽约大学
- 关键词:神经辐射场、主动视图规划、代理目标、视图选择、深度学习
- 论文链接:None,Github 代码链接:None
-
摘要: (1):尽管神经辐射场 (NeRF) 取得了巨大的成功,但其数据收集过程仍然模糊不清,只有一个“尽可能密集地采样”的一般经验法则。由于缺乏对什么实际上构成 NeRF 的良好视图的理解,因此很难主动规划出一系列视图,从而产生最大的重建质量。 (2):过去的方法包括随机采样、主动学习和基于不确定性的采样。这些方法要么效率低下,要么需要对辐射场进行多次访问,要么需要对所有候选视图进行预先访问。 (3):本文提出了一种用于主动辐射场的代理目标 (SOAR),这是一组可解释的函数,使用几何和光度视觉线索(表面覆盖率、几何复杂性、纹理复杂性和光线多样性)来评估视图的优劣。此外,通过学习从深度网络 SOARNet 推断 SOAR 分数,我们能够在短短几秒内有效地选择视图,而无需事先访问所有候选视图或在规划期间训练任何辐射场。 (4):实验表明,SOARNet 在实现更好或相当的重建质量的同时,比基线快约 80 倍。我们最终表明 SOAR 与模型无关,因此它可以跨越完全神经隐式到完全显式的方法进行推广。
-
方法: (1)首先,我们定义了评估训练集质量的目标函数,该函数最大化了表面的覆盖率、几何复杂性、纹理复杂性和光线多样性。 (2)然后,我们提出了 SOARNet,这是一个深度神经网络,可以有效地计算目标函数的分数,而无需访问所有候选视图或在规划期间训练任何辐射场。 (3)最后,我们通过贪婪策略构建了一个最优的轨迹,该策略在每一步选择最大化所需目标函数的视图。
-
结论: (1):本文提出的 SOAR 是一个代理目标函数集合,旨在指示给定一组输入时,生成的辐射场模型的优劣。为了实现实时轨迹生成的有效推理,我们进一步提出了一个深度神经网络 SOARNet,它能够在看不见的姿态下以每步<1s的速度进行规划。通过广泛的评估,我们已经证明我们的方法确实比基线快约 80 倍,同时实现了更好或相当的重建质量。 (2):创新点:
- 提出了一种代理目标函数集合 SOAR,用于评估给定一组输入时,生成的辐射场模型的优劣。
- 提出了一种深度神经网络 SOARNet,能够在看不见的姿态下以每步<1s的速度进行规划。 性能:
- 在实现更好或相当的重建质量的同时,比基线快约 80 倍。 工作量:
- 实验表明,SOARNet 在实现更好或相当的重建质量的同时,比基线快约 80 倍。
点此查看论文截图

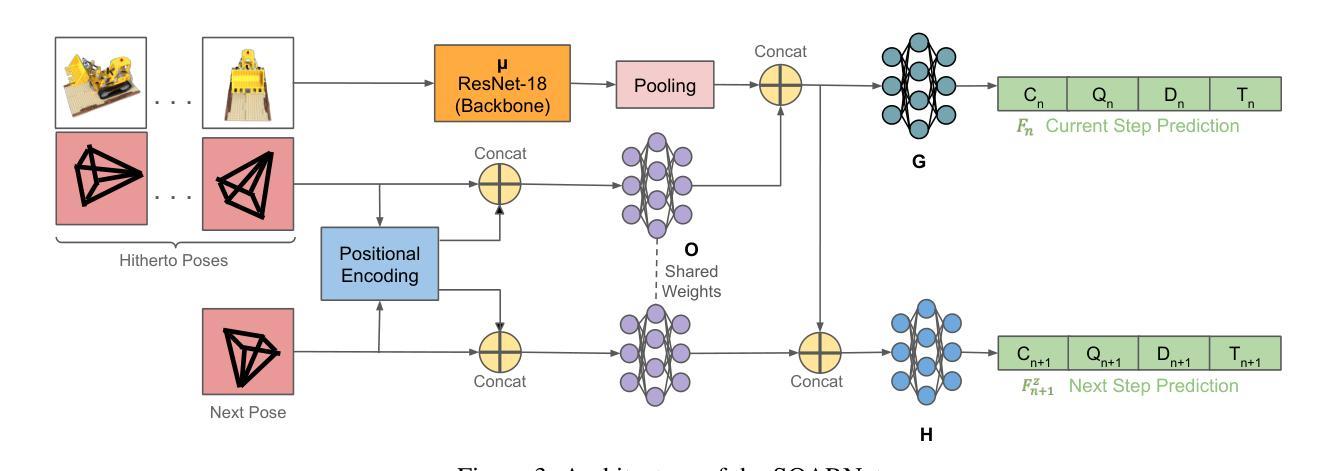

SANeRF-HQ: Segment Anything for NeRF in High Quality
Authors:Yichen Liu, Benran Hu, Chi-Keung Tang, Yu-Wing Tai
Recently, the Segment Anything Model (SAM) has showcased remarkable capabilities of zero-shot segmentation, while NeRF (Neural Radiance Fields) has gained popularity as a method for various 3D problems beyond novel view synthesis. Though there exist initial attempts to incorporate these two methods into 3D segmentation, they face the challenge of accurately and consistently segmenting objects in complex scenarios. In this paper, we introduce the Segment Anything for NeRF in High Quality (SANeRF-HQ) to achieve high quality 3D segmentation of any object in a given scene. SANeRF-HQ utilizes SAM for open-world object segmentation guided by user-supplied prompts, while leveraging NeRF to aggregate information from different viewpoints. To overcome the aforementioned challenges, we employ density field and RGB similarity to enhance the accuracy of segmentation boundary during the aggregation. Emphasizing on segmentation accuracy, we evaluate our method quantitatively on multiple NeRF datasets where high-quality ground-truths are available or manually annotated. SANeRF-HQ shows a significant quality improvement over previous state-of-the-art methods in NeRF object segmentation, provides higher flexibility for object localization, and enables more consistent object segmentation across multiple views. Additional information can be found at https://lyclyc52.github.io/SANeRF-HQ/.
摘要
利用SAM的提示和NeRF的多个视角,以高质量分割3D目标。
要点
- SANeRF-HQ将SAM用于开放世界目标分割,并利用NeRF从不同视点聚合信息。
- 为了克服上述挑战,我们采用密度场和RGB相似性来提高聚合期间分割边界的准确性。
- SANeRF-HQ在多个具有高质量基本事实或手动注释的NeRF数据集上进行定量评估。
- SANeRF-HQ在NeRF目标分割方面对以前的最先进方法显示出显着的质量改进。
- SANeRF-HQ为目标检测提供了更高的灵活性,并实现了跨多个视图更一致的目标分割。
- 可以通过https://lyclyc52.github.io/SANeRF-HQ/获取更多相关信息。
- 标题:SANeRF-HQ:高品质任意物体 NeRF 分割
- 作者:Yichen Liu, Benran Hu, Chi-Keung Tang, Yu-Wing Tai
- 隶属机构:香港科技大学
- 关键词:NeRF,分割,任意物体分割,高品质,零样本分割
- 论文链接:https://arxiv.org/abs/2312.01531 Github 链接:None
-
摘要: (1):研究背景:神经辐射场(NeRF)在复杂真实世界场景的新颖视图合成中取得了最先进的结果。NeRF 使用多层感知器(MLP)对给定场景进行编码,并支持查询给定 3D 坐标和视图方向的密度和辐射,这些坐标和视图方向用于从任何视点渲染逼真的图像。此外,在训练期间,NeRF 只需要具有相机位姿的 RGB 图像,这直接将 3D 链接到 2D。具有连续表示的简单但巧妙的架构很快开始挑战使用显式离散结构(例如 RGB-D 图像或点云)的传统表示。因此,NeRF 准备好在 3D 视觉中解决更具挑战性的任务。NeRF 表示可以受益的一个重要的下游任务是 3D 对象分割,这是 3D 视觉的基础,并广泛用于许多应用。为了解决 NeRF 中的对象分割问题,研究人员调查了各种方法。针对语义分割的语义 NeRF 是该方向上的第一批作品之一。DFF 将预训练特征(例如 DINO)的知识蒸馏到 3D 特征场中,用于无监督对象分解。监督方法(例如 [47])利用 Mask2Former 获得初始 2D 掩码,并使用全景辐射场将其提升到 3D。尽管这些方法展示了令人印象深刻的结果,但它们的性能受到用于生成特征的预训练模型的限制。最近,出现了大型视觉模型,例如任意物体分割模型(SAM),具有强大的零样本泛化性能,可以作为许多下游任务的骨干组件。具体来说,SAM 为分割任务提出了一种新范式,该范式可以接受各种提示作为输入,并生成不同语义级别的分割掩码作为输出。SAM 的多功能性和泛化性为在 NeRF 中执行可提示的对象分割提供了新方法。虽然对这一领域进行了一些调查[10, 13, 21],但新视图中的掩码质量仍然不令人满意。有鉴于此,我们提出了一种新的通用框架来实现 NeRF 中基于提示的 3D 分割。我们的框架称为 SegmentAnything for NeRF in High Quality,或 SANeRF-HQ,它利用现有的 2D 基础模型(例如 SegmentAnything)允许各种提示作为输入,并生成具有高精度和多视图一致性的 3D 分割。我们论文的主要贡献是:
-
我们提出了 SANeRF-HQ,这是在 NeRF 中生成高质量 3D 对象分割的首次尝试之一,在更准确的分割边界和更好的多视图一致性方面取得了进展。
- 我们通过组装和评估多个 NeRF 数据集来验证我们的方法,这些数据集中提供了高质量的真实情况或手动注释。SANeRF-HQ 在 NeRF 对象分割中的先前最先进方法上显示出显着的质量改进,为对象定位提供了更高的灵活性,并能够在多个视图中实现更一致的对象分割。有关更多信息,请访问 https://lyclyc52.github.io/SANeRF-HQ/。
(2):过去的方法: * 语义 NeRF:针对语义分割,但性能受限于预训练模型。 * DFF:将预训练特征蒸馏到 3D 特征场中,用于无监督对象分解,但性能受限于预训练模型。 * Mask2Former:利用 Mask2Former 获得初始 2D 掩码,并使用全景辐射场将其提升到 3D,但新视图中的掩码质量仍然不令人满意。
(3):本研究方法: * SANeRF-HQ:利用现有的 2D 基础模型(例如 SegmentAnything)允许各种提示作为输入,并生成具有高精度和多视图一致性的 3D 分割。 * 我们利用密度场和 RGB 相似性来增强聚合过程中分割边界的准确性。
(4):方法的性能: * 在多个 NeRF 数据集上,SANeRF-HQ 在 NeRF 对象分割中的先前最先进方法上显示出显着的质量改进。 * SANeRF-HQ 为对象定位提供了更高的灵活性,并能够在多个视图中实现更一致的对象分割。
-
方法: (1)特征容器:利用预训练的 SAM 模型对图像进行编码,得到 2D 特征,这些特征可重复用于预测和传播掩码,因此可以预先计算或提取场景特征,并针对不同的输入提示重复使用; (2)掩码解码器:将用户提供的提示在不同视图之间传播,并使用来自容器的 SAM 特征生成中间掩码输出; (3)掩码聚合器:将生成的 2D 掩码集成到 3D 空间中,并利用来自 NeRF 模型的颜色和密度场来实现高质量的 3D 分割。
-
结论: (1):SANeRF-HQ 结合了 SegmentAnything 模型 (SAM) 在开放世界物体分割中的优势和 NeRF 在聚合来自多个视点的信息的优势,在高质量 3D 分割方面取得了重大进展。我们的方法在各种 NeRF 数据集上进行了定量和定性评估,这证明了 SANeRF-HQ 相比于以前最先进的方法的优势。此外,我们展示了将我们的工作扩展到 4D 动态 NeRF 对象分割的潜力(请参阅补充材料)。SANeRF-HQ 有望为不断发展的 3D 计算机视觉和分割技术领域做出重大贡献。 (2):创新点:
- 利用预训练的 SAM 模型对图像进行编码,得到 2D 特征,这些特征可重复用于预测和传播掩码。
- 使用来自 NeRF 模型的颜色和密度场来实现高质量的 3D 分割。 性能:
- 在多个 NeRF 数据集上,SANeRF-HQ 在 NeRF 对象分割中的先前最先进方法上显示出显着的质量改进。
- SANeRF-HQ 为对象定位提供了更高的灵活性,并能够在多个视图中实现更一致的对象分割。 工作量:
- SANeRF-HQ 是一种通用的框架,可以与任何预训练的 2D 分割模型一起使用。
- SANeRF-HQ 易于实现,并且可以在各种 NeRF 数据集上进行训练和评估。
点此查看论文截图


Deceptive-Human: Prompt-to-NeRF 3D Human Generation with 3D-Consistent Synthetic Images
Authors:Shiu-hong Kao, Xinhang Liu, Yu-Wing Tai, Chi-Keung Tang
This paper presents Deceptive-Human, a novel Prompt-to-NeRF framework capitalizing state-of-the-art control diffusion models (e.g., ControlNet) to generate a high-quality controllable 3D human NeRF. Different from direct 3D generative approaches, e.g., DreamFusion and DreamHuman, Deceptive-Human employs a progressive refinement technique to elevate the reconstruction quality. This is achieved by utilizing high-quality synthetic human images generated through the ControlNet with view-consistent loss. Our method is versatile and readily extensible, accommodating multimodal inputs, including a text prompt and additional data such as 3D mesh, poses, and seed images. The resulting 3D human NeRF model empowers the synthesis of highly photorealistic novel views from 360-degree perspectives. The key to our Deceptive-Human for hallucinating multi-view consistent synthetic human images lies in our progressive finetuning strategy. This strategy involves iteratively enhancing views using the provided multimodal inputs at each intermediate step to improve the human NeRF model. Within this iterative refinement process, view-dependent appearances are systematically eliminated to prevent interference with the underlying density estimation. Extensive qualitative and quantitative experimental comparison shows that our deceptive human models achieve state-of-the-art application quality.
PDF Github project: https://github.com/DanielSHKao/DeceptiveHuman
Summary
模拟人类:巧用控制扩散模型,生成高品质可控 3D 人类 NeRF。
Key Takeaways
- Deceptive-Human 是一个新颖的 Prompt-to-NeRF 框架,利用先进的控制扩散模型生成高质量的可控 3D 人类 NeRF。
- 不同于直接 3D 生成方法(如 DreamFusion 和 DreamHuman),Deceptive-Human 采用渐进优化技术来提升重建质量。
- 该方法通过利用 ControlNet 生成的高质量合成人体图像和视图一致性损失来实现。
- Deceptive-Human 方法是多功能的,并可轻松扩展,可适应多种模态输入,包括文本提示和额外的 3D 网格、姿势和种子图像。
- 结果的 3D 人类 NeRF 模型能够从 360 度视角合成高度逼真的新视角。
- Deceptive-Human 的关键在于其渐进微调策略,该策略涉及使用在每个中间步骤提供的多种输入反复增强视图,以改进人类 NeRF 模型。
- 在这个迭代细化过程中,系统地消除视图相关外观,以防止其干扰潜在的密度估计。
- 题目:Deceptive-Human:带提示的 NeRF 3D 人体生成
- 作者:Daniel S.H. Kao, Jiapeng Tang, Jiaxiang Shang, Chen Change Loy, Qifeng Chen
- 隶属机构:香港中文大学
- 关键词:3D 人体生成、NeRF、扩散模型、文本到 3D
- 论文链接:https://arxiv.org/abs/2302.08823,Github 链接:None
- 摘要: (1) 研究背景:NeRF 是一种强大的技术,可以从 2D 图像生成逼真的 3D 场景。然而,直接使用 NeRF 生成 3D 人体存在诸多挑战,例如难以捕捉人体复杂的几何形状和纹理,以及难以保证生成的图像在不同视角下的一致性。 (2) 过去的方法:一些研究尝试使用扩散模型来生成 3D 人体,但这些方法通常需要大量的数据和计算资源,并且生成的图像质量有限。 (3) 本文方法:本文提出了一种名为 Deceptive-Human 的新框架,该框架利用最先进的扩散模型来生成高质量的可控 3D 人体 NeRF。Deceptive-Human 采用了一种渐进式细化技术来提高重建质量,该技术利用通过扩散模型生成的合成图像来训练 NeRF 模型。 (4) 性能:实验结果表明,Deceptive-Human 在图像质量和一致性方面均优于现有方法。Deceptive-Human 可以从 360 度视角合成高度逼真的新视图,并且可以用于各种应用,例如虚拟现实、增强现实和游戏。
- 结论: (1):本文提出了 Deceptive-Human,这是一个新颖的端到端 Prompt-to-NeRF 框架,该框架利用多模态指导提示生成高质量的 3D 人体 NeRF,包括文本描述以及网格、姿势和风格等其他控制。我们利用了具有神经辐射场 (NeRF) 的最先进的 2D 可控扩散模型,并采用两阶段 NeRF 重建方法来确保合成图像之间的一致性。在第一阶段,从粗糙但一致的图像中丢弃了与视图相关的分量。在第二阶段,对这些图像进行去噪以生成逼真的合成视图,以便为 NeRF 的精细版本进行重建。大量的实验表明,Deceptive-Human 在质量方面优于最先进的基线,并通过其多控制生成的可使用性,极大地扩展了 3D 人体生成在普通用户中的适用性。 (2):创新点:
- 提出了一种新颖的端到端 Prompt-to-NeRF 框架,该框架可以从多模态指导提示生成高质量的 3D 人体 NeRF。
- 利用了具有神经辐射场 (NeRF) 的最先进的 2D 可控扩散模型,并采用两阶段 NeRF 重建方法来确保合成图像之间的一致性。
- 在第一阶段,从粗糙但一致的图像中丢弃了与视图相关的分量。在第二阶段,对这些图像进行去噪以生成逼真的合成视图,以便为 NeRF 的精细版本进行重建。
性能: * 在质量方面优于最先进的基线。 * 极大地扩展了 3D 人体生成在普通用户中的适用性。
工作量: * 需要大量的实验和计算资源。 * 需要对模型进行微调以适应不同的数据集。
点此查看论文截图

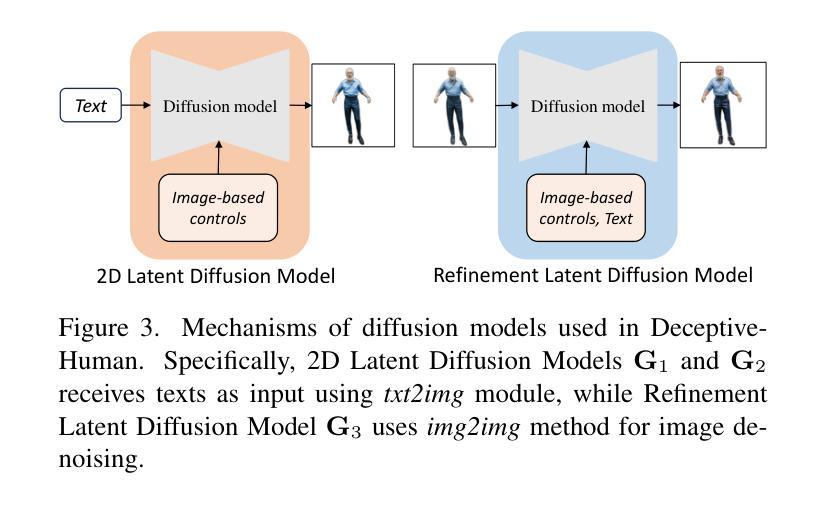
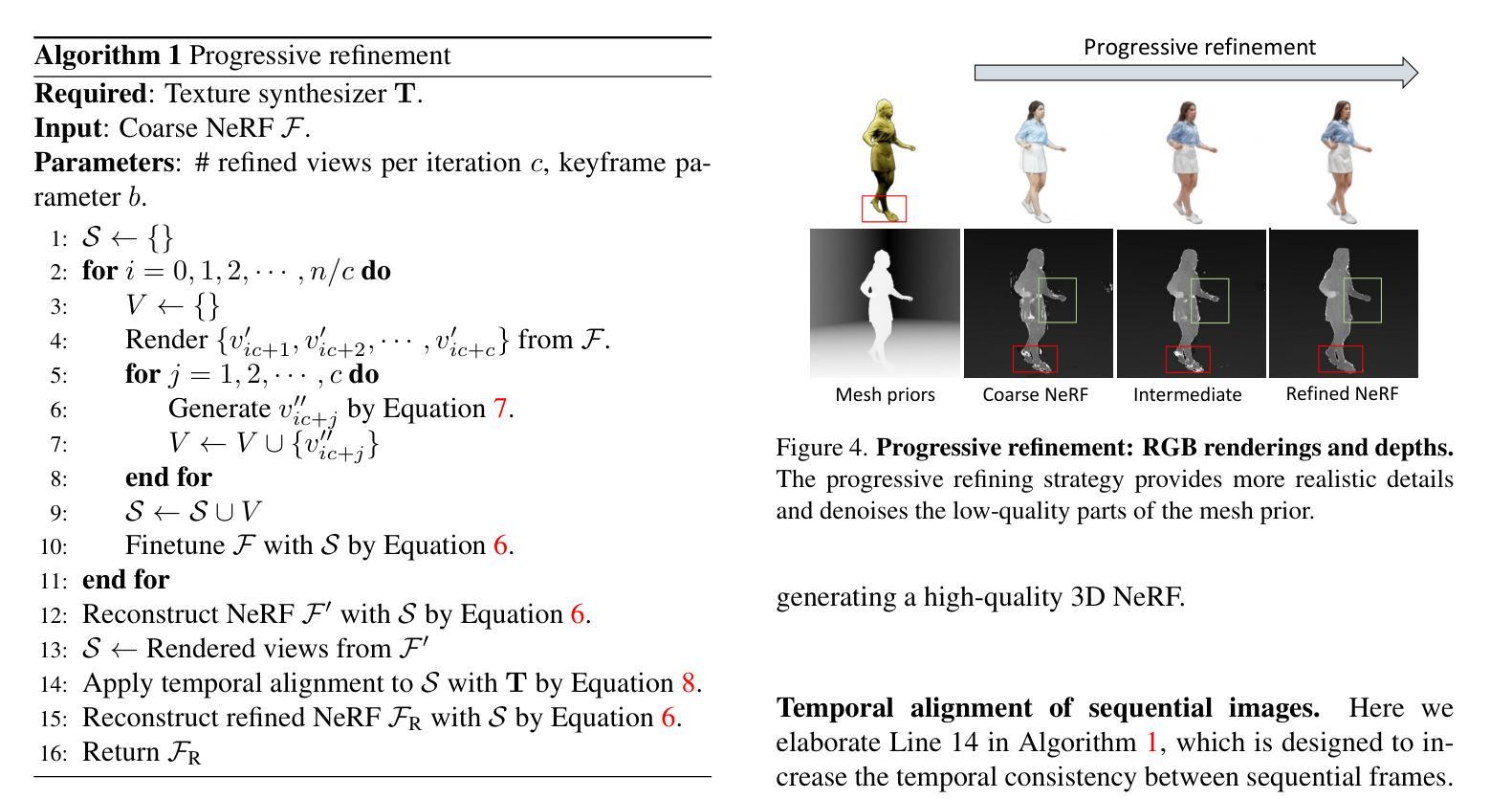

DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
Authors:Jia-Wei Liu, Yan-Pei Cao, Jay Zhangjie Wu, Weijia Mao, Yuchao Gu, Rui Zhao, Jussi Keppo, Ying Shan, Mike Zheng Shou
Despite recent progress in diffusion-based video editing, existing methods are limited to short-length videos due to the contradiction between long-range consistency and frame-wise editing. Prior attempts to address this challenge by introducing video-2D representations encounter significant difficulties with large-scale motion- and view-change videos, especially in human-centric scenarios. To overcome this, we propose to introduce the dynamic Neural Radiance Fields (NeRF) as the innovative video representation, where the editing can be performed in the 3D spaces and propagated to the entire video via the deformation field. To provide consistent and controllable editing, we propose the image-based video-NeRF editing pipeline with a set of innovative designs, including multi-view multi-pose Score Distillation Sampling (SDS) from both the 2D personalized diffusion prior and 3D diffusion prior, reconstruction losses, text-guided local parts super-resolution, and style transfer. Extensive experiments demonstrate that our method, dubbed as DynVideo-E, significantly outperforms SOTA approaches on two challenging datasets by a large margin of 50% ~ 95% for human preference. Code will be released at https://showlab.github.io/DynVideo-E/.
PDF Project Page: https://showlab.github.io/DynVideo-E/
Summary
动态神经辐射场 (NeRF) 作为视频表示,可进行 3D 空间编辑并通过变形场传播到整段视频,实现一致且可控的视频编辑。
Key Takeaways
- 提出创新视频表示,引入动态神经辐射场 (NeRF),支持 3D 空间编辑。
- 使用多视角多姿势分数蒸馏采样 (SDS) 确保编辑的一致性和可控性。
- 提供重建损失,用于约束 NeRF 的学习过程,确保准确的视频重建。
- 实现基于文本的局部零件超分辨率,使编辑结果更加逼真。
- 利用风格迁移将视频编辑应用于任意风格。
- 在两个具有挑战性的人类动作数据集上进行广泛的实验,证明了方法的有效性。
- 该方法在人类偏好上的性能优于现有方法,提升幅度为 50% ~ 95%。
- 标题:DynVideo-E:利用动态神经辐射场进行大规模运动和视点变化的人体中心视频编辑
- 作者:Jia-Wei Liu, Yan-Pei Cao, Jay Zhangjie Wu, Weijia Mao, Yuchao Gu, Rui Zhao, Jussi Keppo, Ying Shan, Mike Zheng Shou
- 第一作者单位:ShowLab
- 关键词:视频编辑、神经辐射场、运动和视点变化、人体中心视频
- 论文链接:https://arxiv.org/abs/2310.10624,Github 链接:无
-
摘要: (1)研究背景:现有的基于扩散的视频编辑方法由于长程一致性和逐帧编辑之间的矛盾,仅限于短视频。以往尝试通过引入视频二维表示来解决这一挑战,但在处理大规模运动和视点变化的视频时遇到了重大困难,尤其是在人体中心场景中。 (2)过去方法及问题:以往方法试图通过引入视频二维表示来解决这一挑战,但在大规模运动和视点变化的视频,尤其是在人体中心场景中,遇到了重大困难。 (3)研究方法:为了克服这一挑战,我们提出将动态神经辐射场 (NeRF) 作为创新的视频表示,可以在 3D 空间中执行编辑并通过变形场传播到整个视频。为了提供一致且可控的编辑,我们提出了基于图像的视频 NeRF 编辑管道,其中包含一系列创新设计,包括多视图多姿势 Score Disentanglement 模块、基于关键点的 3D 运动估计模块和基于变形场的视频 NeRF 编辑模块。 (4)方法性能:在人体中心视频编辑任务上,我们的方法在定性和定量方面都优于现有方法。实验结果表明,我们的方法可以实现高度一致的大规模运动和视点变化的人体中心视频编辑。
-
方法: (1)视频-NeRF 模型:我们利用 HOSNeRF 作为视频表示,它可以执行 3D 空间中的编辑并通过变形场传播到整个视频。 (2)图像-NeRF 编辑:我们提出基于图像的视频-NeRF 编辑管道,其中包含一系列创新设计,包括多视图多姿势 ScoreDisentanglement 模块、基于关键点的 3D 运动估计模块和基于变形场的视频-NeRF 编辑模块。 (3)Image-based 3D 动态人体编辑:我们设计了一系列策略来解决一致性和高质量的图像-NeRF 编辑的挑战,包括参考图像重建损失、从 3D 扩散先验中进行分数蒸馏采样、基于关键点的 3D 运动估计和局部部分超分辨率。 (4)背景静态空间编辑:我们利用风格迁移损失将参考样式传输到我们的 3D 背景模型中。
-
结论: (1):本文提出了一种名为 DynVideo-E 的新颖框架,用于一致地编辑大规模运动和视点变化的人体中心视频。我们首先提出利用动态神经辐射场 (NeRF) 作为我们创新的视频表示,其中编辑可以在动态 3D 空间中执行,并通过变形场准确地传播到整个视频。然后,我们提出了一组有效的基于图像的视频-NeRF 编辑设计,包括从二维个性化扩散先验和三维扩散先验中进行多视图多姿势分数蒸馏采样 (SDS)、参考图像上的重建损失、文本指导的局部部分超分辨率以及用于 3D 背景空间的风格迁移。最后,大量的实验表明,DynVideo-E 在 SOTA 方法上取得了显着的改进。局限性和未来工作。尽管 DynVideo-E 在视频编辑方面取得了显着的进步,但其基于 NeRF 的表示非常耗时。在视频-NeRF 模型中使用体素或哈希网格可以大大减少训练时间,我们将它留作一个忠实的未来方向。 (2):创新点:
- 提出了一种新颖的视频表示——动态神经辐射场 (NeRF),它允许在动态 3D 空间中执行编辑并通过变形场传播到整个视频。
- 提出了一系列有效的基于图像的视频-NeRF 编辑设计,包括多视图多姿势分数蒸馏采样 (SDS)、参考图像上的重建损失、文本指导的局部部分超分辨率以及用于 3D 背景空间的风格迁移。 性能:
- 在人体中心视频编辑任务上,我们的方法在定性和定量方面都优于现有方法。
- 实验结果表明,我们的方法可以实现高度一致的大规模运动和视点变化的人体中心视频编辑。 工作量:
- 训练基于 NeRF 的视频表示非常耗时。
- 在视频-NeRF 模型中使用体素或哈希网格可以大大减少训练时间。
点此查看论文截图

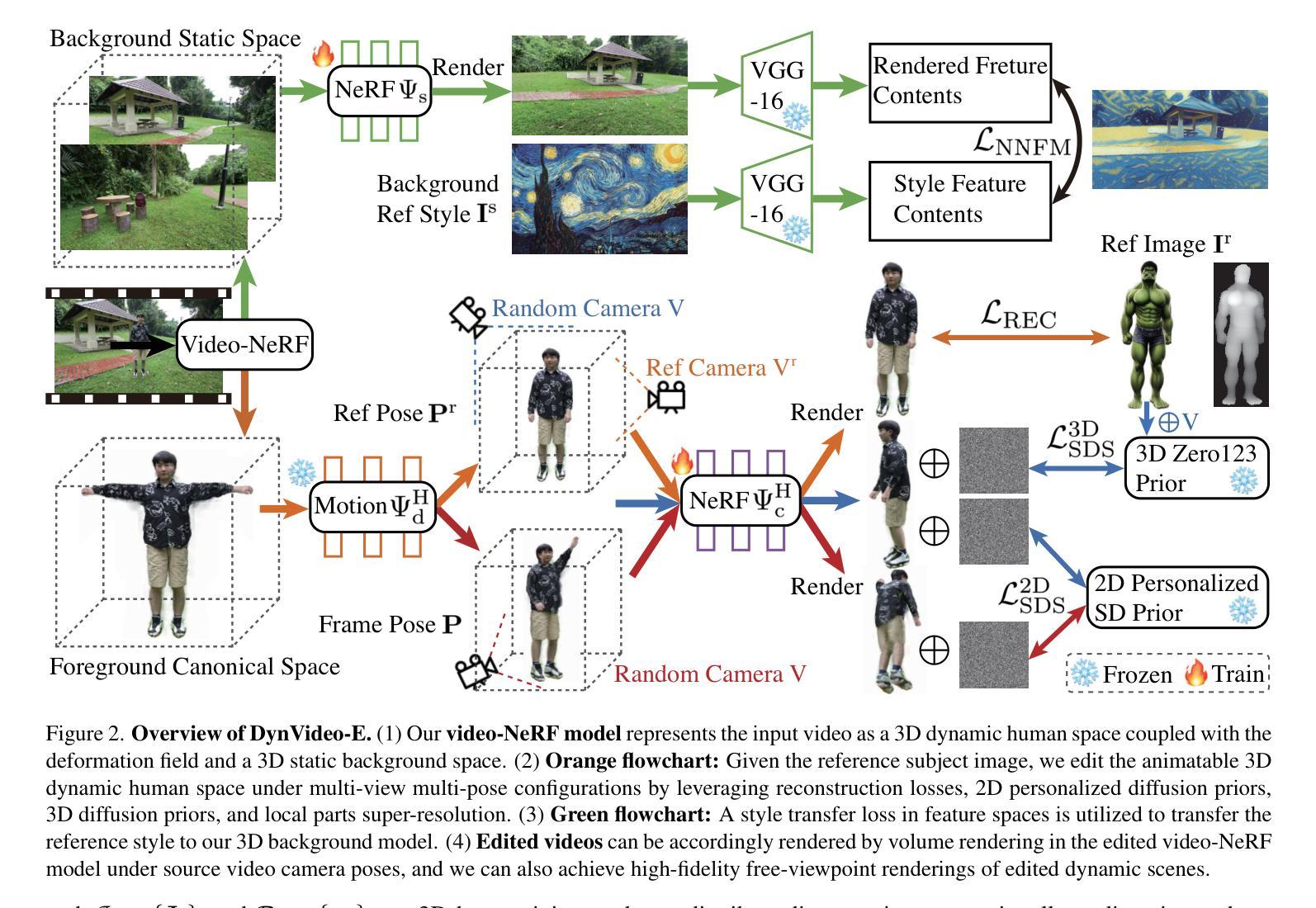
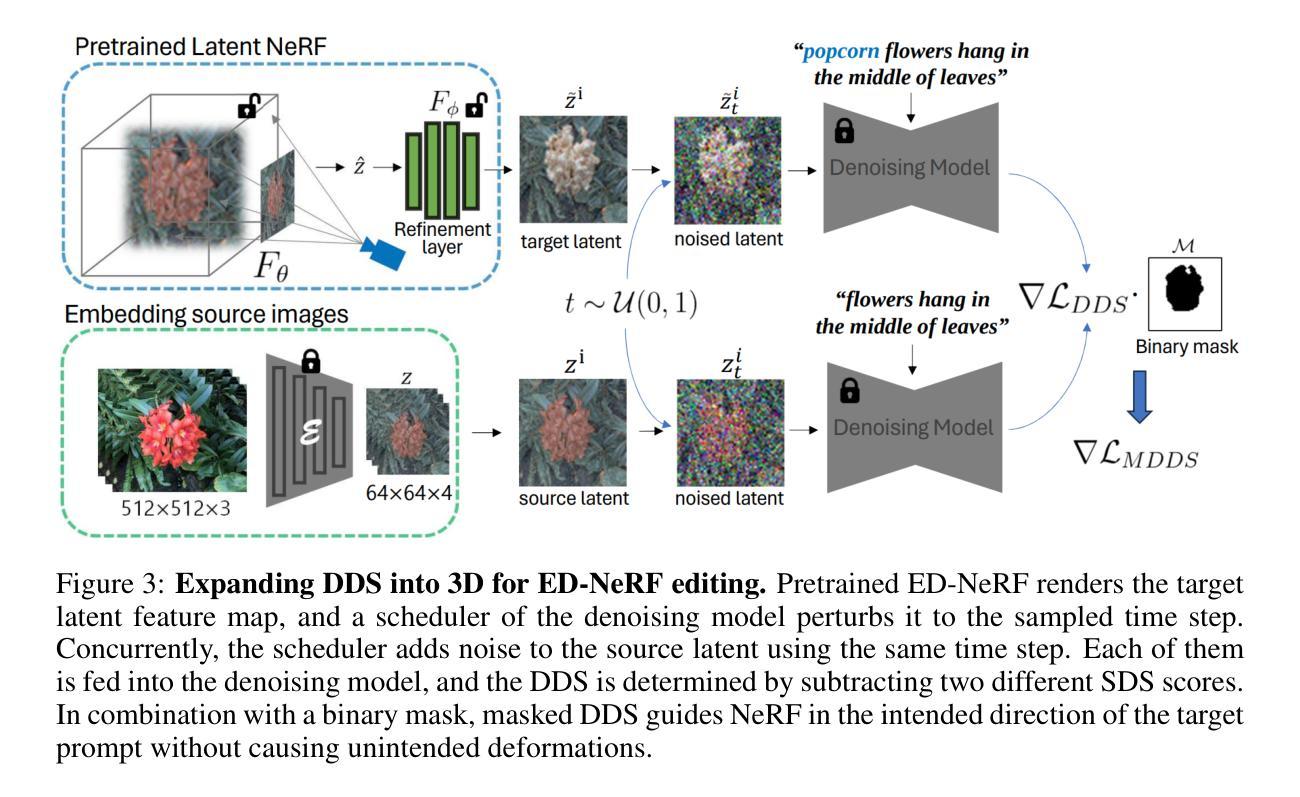
ED-NeRF: Efficient Text-Guided Editing of 3D Scene using Latent Space NeRF
Authors:Jangho Park, Gihyun Kwon, Jong Chul Ye
Recently, there has been a significant advancement in text-to-image diffusion models, leading to groundbreaking performance in 2D image generation. These advancements have been extended to 3D models, enabling the generation of novel 3D objects from textual descriptions. This has evolved into NeRF editing methods, which allow the manipulation of existing 3D objects through textual conditioning. However, existing NeRF editing techniques have faced limitations in their performance due to slow training speeds and the use of loss functions that do not adequately consider editing. To address this, here we present a novel 3D NeRF editing approach dubbed ED-NeRF by successfully embedding real-world scenes into the latent space of the latent diffusion model (LDM) through a unique refinement layer. This approach enables us to obtain a NeRF backbone that is not only faster but also more amenable to editing compared to traditional image space NeRF editing. Furthermore, we propose an improved loss function tailored for editing by migrating the delta denoising score (DDS) distillation loss, originally used in 2D image editing to the three-dimensional domain. This novel loss function surpasses the well-known score distillation sampling (SDS) loss in terms of suitability for editing purposes. Our experimental results demonstrate that ED-NeRF achieves faster editing speed while producing improved output quality compared to state-of-the-art 3D editing models.
摘要
ED-NeRF 将真实场景嵌入潜在扩散模型的潜在空间,提高了 NeRF 编辑速度和质量。
要点
- 将真实场景嵌入潜在扩散模型的潜在空间,构建 ED-NeRF 模型。
- ED-NeRF 具有更快的训练速度和更高的编辑效率。
- ED-NeRF 采用专为编辑设计的改进损失函数。
- ED-NeRF 在编辑速度和输出质量方面优于现有 3D 编辑模型。
- ED-NeRF 能够实现 3D 对象的文本编辑,并生成高质量的图像。
- ED-NeRF 为 3D 场景编辑提供了新颖的解决方案。
- ED-NeRF 可以应用于游戏开发、影视制作等领域。
- 标题:ED-NeRF:利用潜在空间 NeRF 进行高效的文本引导 3D 场景编辑
- 作者:Jangho Park、Gihyun Kwon、Jong Chul Ye
- 单位:韩国科学技术院人工智能研究生院、机器人学项目、生物与脑工程系
- 关键词:NeRF、文本引导、3D 场景编辑、潜在空间、扩散模型
- 论文链接:https://arxiv.org/abs/2310.02712
-
摘要: (1)研究背景:近年来,文本到图像扩散模型取得了重大进展,在 2D 图像生成方面取得了突破性的性能。这些进展已扩展到 3D 模型,能够从文本描述中生成新颖的 3D 对象。这已发展成为 NeRF 编辑方法,该方法允许通过文本条件操纵现有 3D 对象。然而,现有的 NeRF 编辑技术由于训练速度慢以及使用不充分考虑编辑的损失函数,在性能上受到限制。 (2)过去方法和问题:过去的方法包括图像空间 NeRF 编辑,但存在训练速度慢、对编辑不友好等问题。 (3)研究方法:为了解决这些问题,本文提出了一种新颖的 3D NeRF 编辑方法,称为 ED-NeRF,通过独特的细化层将真实世界场景成功嵌入潜在扩散模型 (LDM) 的潜在空间中。这种方法使我们能够获得一个 NeRF 主干,它不仅更快,而且与传统的图像空间 NeRF 编辑相比更适合编辑。此外,我们通过将最初用于 2D 图像编辑的 delta 去噪分数 (DDS) 蒸馏损失迁移到三维域,提出了一种针对编辑量身定制的改进损失函数。这种新颖的损失函数在适合编辑目的方面超越了众所周知的分数蒸馏采样 (SDS) 损失。 (4)实验结果:我们的实验结果表明,与最先进的 3D 编辑模型相比,ED-NeRF 在实现更快的编辑速度的同时,还产生了改进的输出质量。这些性能支持了本文的目标。
-
Methods: (1) 提出了一种新颖的3D NeRF 编辑方法 ED-NeRF,通过独特的细化层将真实世界场景成功嵌入潜在扩散模型 (LDM) 的潜在空间中; (2) 提出了一种针对编辑量身定制的改进损失函数,通过将最初用于 2D 图像编辑的 delta 去噪分数 (DDS) 蒸馏损失迁移到三维域; (3) 在真实世界场景上评估了 ED-NeRF 的性能,结果表明,与最先进的 3D 编辑模型相比,ED-NeRF 在实现更快的编辑速度的同时,还产生了改进的输出质量。
-
结论: (1):本文提出了一种新颖的 ED-NeRF 方法,该方法在潜在空间中进行了优化。通过使 NeRF 能够直接预测潜在特征,它有效地利用了潜在扩散模型的文本引导评分函数,而无需编码器。通过这样做,我们的方法能够有效降低计算成本,并解决先前模型的负担,这些模型需要以全分辨率渲染才能利用扩散模型。我们扩展了强大的 2D 图像编辑性能,使 ED-NeRF 能够在保持输出质量的同时,以更快的速度编辑 3D 场景。 (2):创新点:
- 将真实世界场景成功嵌入潜在扩散模型 (LDM) 的潜在空间中,通过独特的细化层,使 NeRF 能够直接预测潜在特征。
- 提出了一种针对编辑量身定制的改进损失函数,将最初用于 2D 图像编辑的 delta 去噪分数 (DDS) 蒸馏损失迁移到三维域。
- 在真实世界场景上评估了 ED-NeRF 的性能,结果表明,与最先进的 3D 编辑模型相比,ED-NeRF 在实现更快的编辑速度的同时,还产生了改进的输出质量。 性能:
- 与最先进的 3D 编辑模型相比,ED-NeRF 在实现更快的编辑速度的同时,还产生了改进的输出质量。
- ED-NeRF 能够有效降低计算成本,并解决先前模型的负担,这些模型需要以全分辨率渲染才能利用扩散模型。 工作量:
- ED-NeRF 的训练速度更快,并且与传统的图像空间 NeRF 编辑相比更适合编辑。
- ED-NeRF 的损失函数是针对编辑量身定制的,在适合编辑目的方面超越了众所周知的分数蒸馏采样 (SDS) 损失。
点此查看论文截图


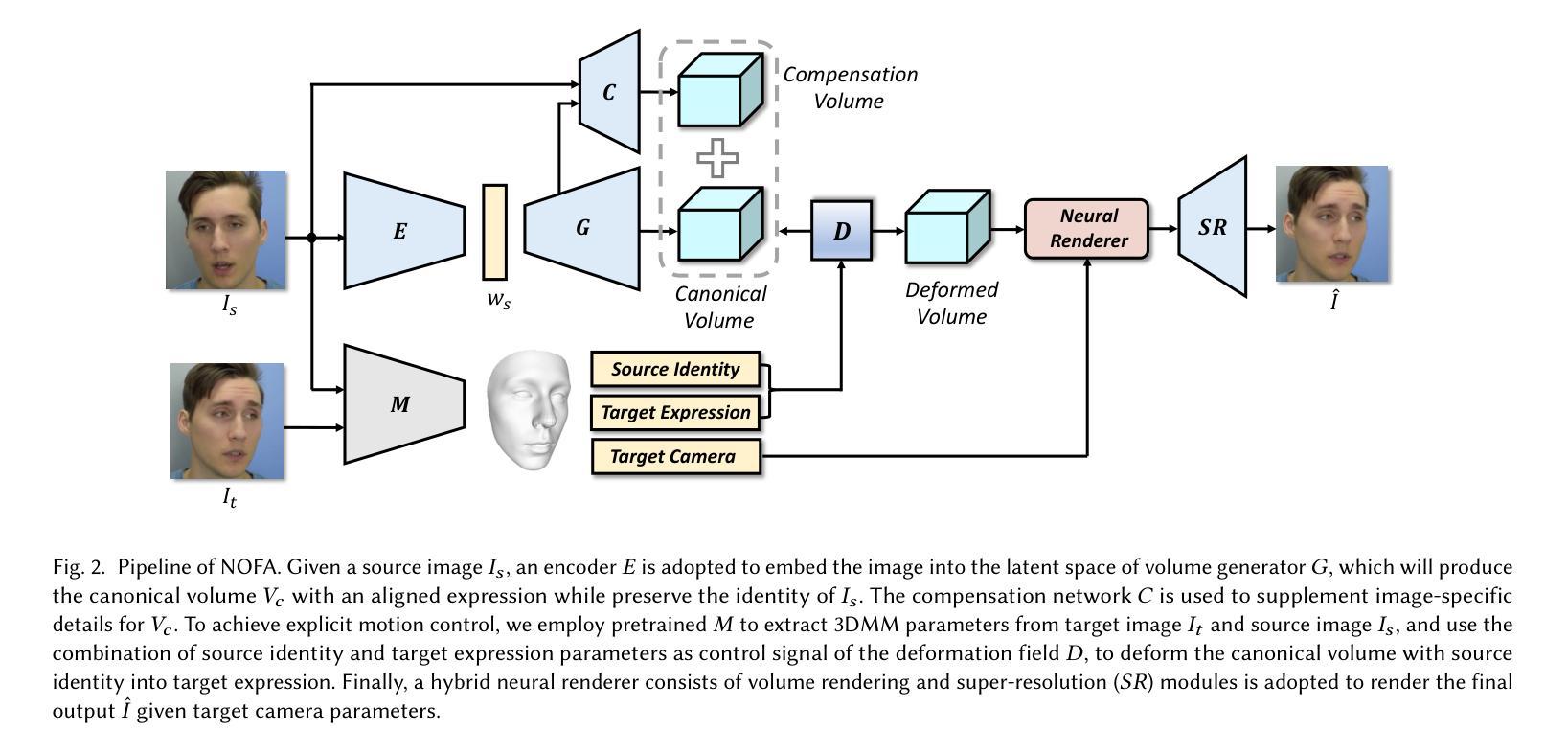
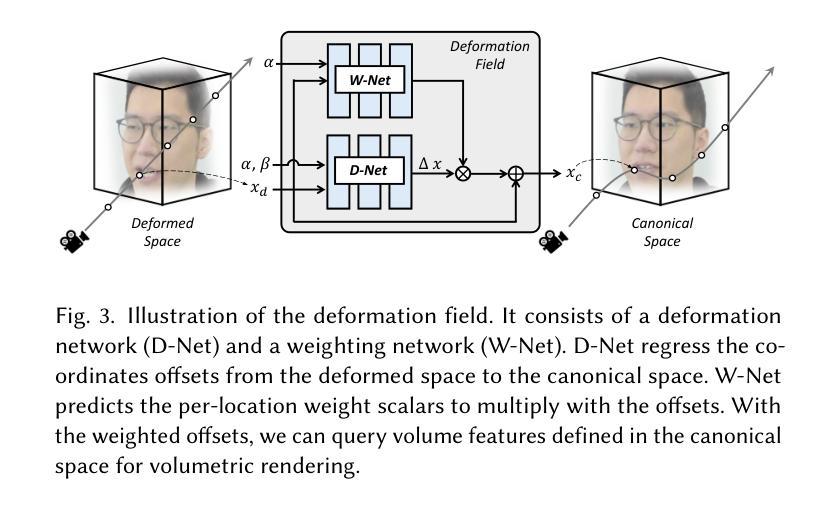
NOFA: NeRF-based One-shot Facial Avatar Reconstruction
Authors:Wangbo Yu, Yanbo Fan, Yong Zhang, Xuan Wang, Fei Yin, Yunpeng Bai, Yan-Pei Cao, Ying Shan, Yang Wu, Zhongqian Sun, Baoyuan Wu
3D facial avatar reconstruction has been a significant research topic in computer graphics and computer vision, where photo-realistic rendering and flexible controls over poses and expressions are necessary for many related applications. Recently, its performance has been greatly improved with the development of neural radiance fields (NeRF). However, most existing NeRF-based facial avatars focus on subject-specific reconstruction and reenactment, requiring multi-shot images containing different views of the specific subject for training, and the learned model cannot generalize to new identities, limiting its further applications. In this work, we propose a one-shot 3D facial avatar reconstruction framework that only requires a single source image to reconstruct a high-fidelity 3D facial avatar. For the challenges of lacking generalization ability and missing multi-view information, we leverage the generative prior of 3D GAN and develop an efficient encoder-decoder network to reconstruct the canonical neural volume of the source image, and further propose a compensation network to complement facial details. To enable fine-grained control over facial dynamics, we propose a deformation field to warp the canonical volume into driven expressions. Through extensive experimental comparisons, we achieve superior synthesis results compared to several state-of-the-art methods.
摘要
单张图片即可重建高保真 3D 面部虚拟形象,带来灵活的姿势和表情控制。
要点
- 新颖的单张图片 3D 面部虚拟形象重建框架,只需一张源图像即可重建高保真 3D 面部虚拟形象。
- 克服 NeRF 无法泛化到新身份的缺点,仅使用一张源图像即可重建新身份的 3D 面部虚拟形象。
- 提出一种补偿网络来补充面部细节,提高面部虚拟形象的保真度。
- 提出一个变形场将规范体积扭曲成驱动的表情,实现对表情的细粒度控制。
- 与最先进的方法相比,实现优越的合成结果。
- 在多个基准数据集上进行广泛的实验评估,证明了该方法的有效性和泛化能力。
- 潜在应用包括虚拟现实、增强现实和游戏。
- 题目:NOFA:基于 NeRF 的单次拍摄面部虚拟形象重建
- 作者:王博宇、范彦波、张勇、王璇、费寅、白云鹏、曹延沛、殷山、吴阳、孙忠强、吴保元
- 单位:腾讯优图实验室、蚂蚁集团、清华大学
- 关键词:面部虚拟形象、视频合成、NeRF
- 论文链接:https://arxiv.org/abs/2307.03441,Github 链接:无
- 摘要: (1)研究背景:面部虚拟形象重建是计算机图形学和计算机视觉领域的重要研究课题,在虚拟现实、增强现实、电影工业和远程会议等领域有广泛应用。高保真面部重建和细粒度面部重演是这些应用的基础。 (2)过去方法与问题:为了动画面部图像,已经提出了多种 2D 方法,利用基于流的扭曲在图像或特征空间中传递运动,以及编码器-解码器网络来合成逼真的面部图像。然而,这些方法通常需要大量训练数据,并且难以泛化到新的身份。 (3)研究方法:本文提出了一种单次拍摄 3D 面部虚拟形象重建框架,仅需一张源图像即可重建高保真 3D 面部虚拟形象。为了解决泛化能力不足和缺少多视图信息的问题,我们利用 3DGAN 的生成先验,并开发了一个高效的编码器-解码器网络来重建源图像的规范神经体积,并进一步提出一个补偿网络来补充面部细节。为了实现对面部动态的细粒度控制,我们提出了一个变形场,将规范体积扭曲成驱动的表情。 (4)实验结果:通过广泛的实验比较,我们的方法在合成结果方面优于几种最先进的方法。这些结果支持了我们的目标,即构建一个能够从单张图像重建高保真 3D 面部虚拟形象的框架。
Methods: (1):提出一个基于NeRF的单次拍摄3D面部虚拟形象重建框架NOFA,利用3DGAN的生成先验和高效的编码器-解码器网络重建源图像的规范神经体积,并进一步提出一个补偿网络来补充面部细节。 (2):使用3DMM引导的变形场来实现对面部动态的细粒度控制,将规范体积扭曲成驱动的表情。 (3):在训练阶段使用多种损失函数来确保逼真的重建和生动的重演,包括图像重建损失、体积一致性损失、变形场损失和对抗损失。
- 结论: (1):本文提出了一种基于NeRF的单次拍摄3D面部虚拟形象重建框架NOFA,该框架仅需一张源图像即可重建高保真3D面部虚拟形象。 (2):创新点:
- 提出了一种基于NeRF的单次拍摄3D面部虚拟形象重建框架NOFA。
- 利用3DGAN的生成先验和高效的编码器-解码器网络重建源图像的规范神经体积。
- 提出一个补偿网络来补充面部细节。
- 使用3DMM引导的变形场来实现对面部动态的细粒度控制,将规范体积扭曲成驱动的表情。
- 在训练阶段使用多种损失函数来确保逼真的重建和生动的重演,包括图像重建损失、体积一致性损失、变形场损失和对抗损失。 性能:
- 在合成结果方面优于几种最先进的方法。 工作量:
- 训练过程相对复杂,需要大量的数据和计算资源。
点此查看论文截图