⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-30 更新
EndoGaussians: Single View Dynamic Gaussian Splatting for Deformable Endoscopic Tissues Reconstruction
Authors:Yangsen Chen, Hao Wang
The accurate 3D reconstruction of deformable soft body tissues from endoscopic videos is a pivotal challenge in medical applications such as VR surgery and medical image analysis. Existing methods often struggle with accuracy and the ambiguity of hallucinated tissue parts, limiting their practical utility. In this work, we introduce EndoGaussians, a novel approach that employs Gaussian Splatting for dynamic endoscopic 3D reconstruction. This method marks the first use of Gaussian Splatting in this context, overcoming the limitations of previous NeRF-based techniques. Our method sets new state-of-the-art standards, as demonstrated by quantitative assessments on various endoscope datasets. These advancements make our method a promising tool for medical professionals, offering more reliable and efficient 3D reconstructions for practical applications in the medical field.
摘要
高斯散点结合神经辐射场,实现动态内窥镜 3D 重建新方法。
要点
- EndoGaussians 是一个新的方法,它利用高斯散点进行动态内窥镜 3D 重建。
- 这种方法是首次在该背景下使用高斯散点,克服了以前基于 NeRF 技术的限制。
- 该方法在各种内窥镜数据集上进行定量评估,树立了新的最先进标准。
- 这些进步使该方法成为医疗专业人员的有前途的工具,为医疗领域的实际应用提供了更可靠、更高效的 3D 重建。
- 题目:EndoGaussians:单视动态高斯体素重建
- 作者:Yangsen Chen, Hao Wang
- 隶属机构:香港科技大学(广州)
- 关键词:3D 重建、高斯体素重建、机器人手术
- 论文链接:https://arxiv.org/abs/2401.13352
-
摘要: (1) 研究背景:准确地从内窥镜视频中重建可变形软体组织的 3D 模型对于 VR 手术和医学图像分析等医疗应用至关重要。现有方法通常在准确性和产生的组织部分的模棱两可方面存在问题,限制了其实际效用。 (2) 过往方法:以往的一些工作尝试使用深度估计、SLAM、稀疏变形场和神经辐射场等方法来解决这个问题,但这些方法要么假设场景是静态的,要么假设手术工具不存在,从而限制了它们在实际场景中的实用性。 (3) 研究方法:为了进一步提高静态单视 RGBD 设置下软体组织的 3D 重建的准确性,并提高 3D 重建的可靠性和可信度,我们提出了 Endogaussians,该方法利用高斯体素重建作为重建方法。 (4) 方法性能:我们的方法在 PSNR、SSIM、LPIPS 等多项定量评估中取得了最先进的结果,并且重建速度更快。这些进步使我们的方法成为医疗专业人员的有前途的工具,为医疗领域的实际应用提供更可靠和高效的 3D 重建。
-
方法: (1): 本文提出了一种名为 Endogaussians 的方法,用于从单目动态 RGBD 设置中重建可变形软体组织的 3D 模型。 (2): 该方法使用高斯体素重建作为重建方法,可以有效地处理软体组织的变形。 (3): 为了提高重建的准确性,本文提出了一种新的体素融合策略,该策略可以有效地融合来自不同帧的数据。 (4): 此外,本文还提出了一种新的体素分割算法,该算法可以有效地将软体组织分割成不同的部分。 (5): 最后,本文提出了一种新的体素渲染算法,该算法可以生成逼真的软体组织模型。
-
结论: (1):EndoGaussians方法可以有效地从单目动态RGBD设置中重建可变形软体组织的3D模型,具有较高的准确性和可靠性,在医疗领域具有广阔的应用前景。 (2):创新点:
- 提出了一种新的高斯体素重建方法,可以有效地处理软体组织的变形。
- 提出了一种新的体素融合策略,可以有效地融合来自不同帧的数据。
- 提出了一种新的体素分割算法,可以有效地将软体组织分割成不同的部分。
- 提出了一种新的体素渲染算法,可以生成逼真的软体组织模型。 性能:
- 在PSNR、SSIM、LPIPS等多项定量评估中取得了最先进的结果。
- 重建速度更快。 工作量:
- 该方法需要大量的计算资源。
- 该方法需要大量的标注数据。
点此查看论文截图

EndoGaussian: Gaussian Splatting for Deformable Surgical Scene Reconstruction
Authors:Yifan Liu, Chenxin Li, Chen Yang, Yixuan Yuan
Reconstructing deformable tissues from endoscopic stereo videos is essential in many downstream surgical applications. However, existing methods suffer from slow inference speed, which greatly limits their practical use. In this paper, we introduce EndoGaussian, a real-time surgical scene reconstruction framework that builds on 3D Gaussian Splatting. Our framework represents dynamic surgical scenes as canonical Gaussians and a time-dependent deformation field, which predicts Gaussian deformations at novel timestamps. Due to the efficient Gaussian representation and parallel rendering pipeline, our framework significantly accelerates the rendering speed compared to previous methods. In addition, we design the deformation field as the combination of a lightweight encoding voxel and an extremely tiny MLP, allowing for efficient Gaussian tracking with a minor rendering burden. Furthermore, we design a holistic Gaussian initialization method to fully leverage the surface distribution prior, achieved by searching informative points from across the input image sequence. Experiments on public endoscope datasets demonstrate that our method can achieve real-time rendering speed (195 FPS real-time, 100$\times$ gain) while maintaining the state-of-the-art reconstruction quality (35.925 PSNR) and the fastest training speed (within 2 min/scene), showing significant promise for intraoperative surgery applications. Code is available at: \url{https://yifliu3.github.io/EndoGaussian/}.
Summary
3D高斯渲染框架实现了实时内窥镜手术场景重建。
Key Takeaways
- 提出了一种名为EndoGaussian的实时手术场景重建框架,它是建立在3D高斯点阵的基础上的。
- 使用高斯表示和并行渲染管道,显著提高了渲染速度。
- 将变形场设计为轻量级编码体素和极小MLP的组合,实现了高效的高斯跟踪,渲染负担较小。
- 设计了一种整体的高斯初始化方法,充分利用了表面分布先验,通过搜索输入图像序列中的信息点来实现。
- 公共内窥镜数据集上的实验表明,该方法可以实现实时渲染速度(195 FPS实时,100倍收益),同时保持最先进的重建质量(35.925 PSNR)和最快的训练速度(在2分钟/场景以内),显示出对术中手术应用的重大前景。
- 题目:EndoGaussian:用于可变形手术场景重建的高斯点云
- 作者:Yifan Liu, Chenxin Li, Chen Yang 和 Yixuan Yuan
- 隶属机构:香港中文大学
- 关键词:三维重建 · 高斯点云 · 机器人手术
- 论文链接:https://arxiv.org/abs/2401.12561 Github 代码链接:https://yifliu3.github.io/EndoGaussian/
-
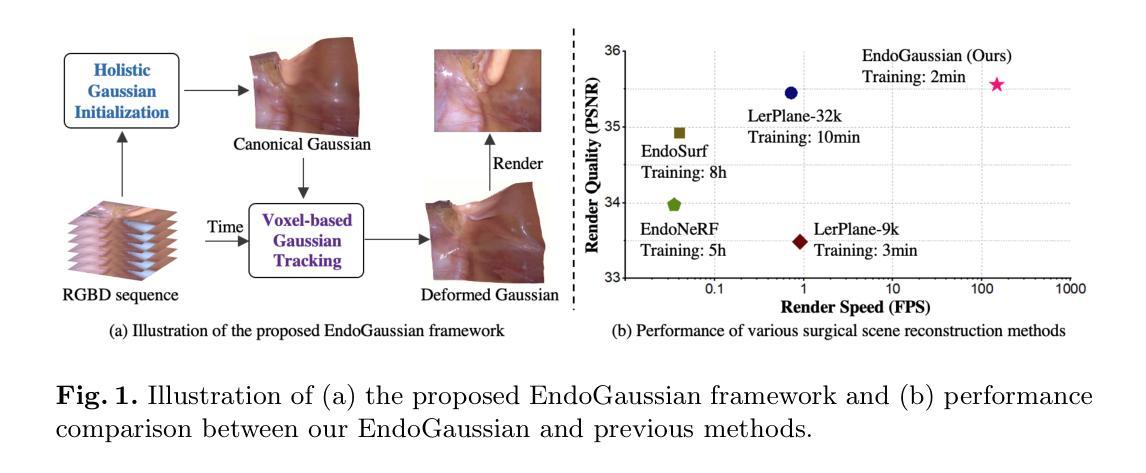
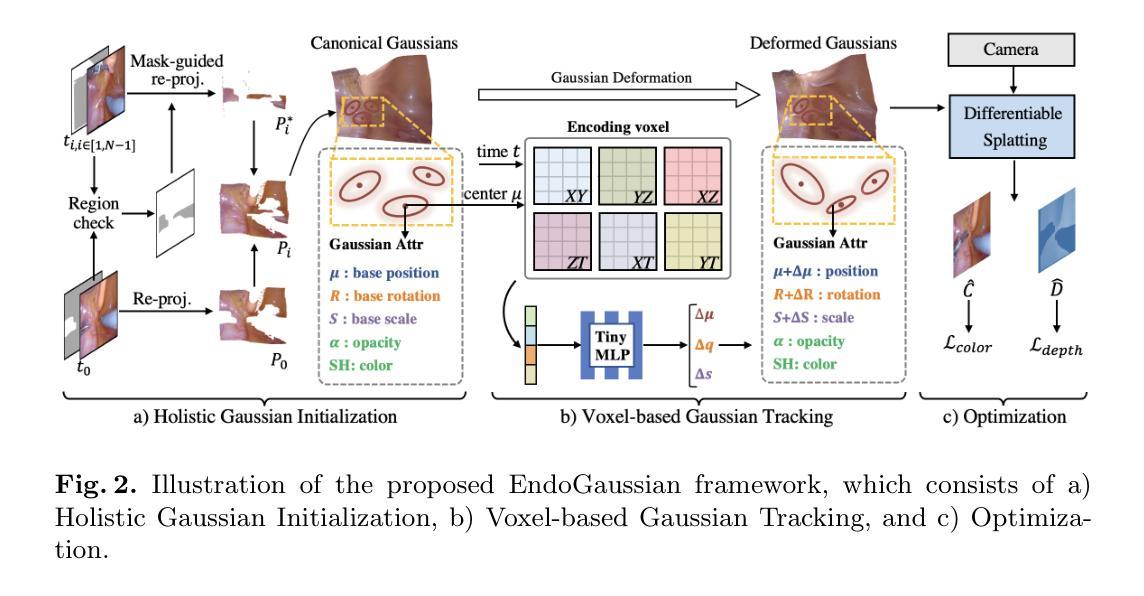
摘要: (1)研究背景:从内窥镜立体视频中重建可变形组织对于许多下游手术应用至关重要。然而,现有方法的推理速度慢,极大地限制了它们的实际使用。 (2)过去方法及其问题:现有方法的问题在于推理速度慢,这使得它们在实际应用中受到限制。 (3)研究方法:该论文提出了一种基于 3D 高斯点云的实时手术场景重建框架 EndoGaussian。该框架将动态手术场景表示为规范高斯点云和时间相关的变形场,该变形场可以预测新时间戳下的高斯变形。由于高效的高斯表示和并行渲染管道,该框架与以往方法相比,显著地提高了渲染速度。此外,该论文将变形场设计为轻量级编码体素和极小型的 MLP 的组合,从而实现高效的高斯跟踪,且渲染负担很小。此外,该论文设计了一种整体的高斯初始化方法,以充分利用表面分布先验,该方法通过从输入图像序列中搜索信息点来实现。 (4)方法性能:在公开内窥镜数据集上的实验表明,该方法可以实现实时渲染速度(195 FPS 实时,100 倍增益),同时保持最先进的重建质量(35.925 PSNR)和最快的训练速度(每个场景 2 分钟以内),显示出对术中手术应用的重大前景。
-
方法: (1)EndoGaussian框架概述:该框架由高斯点云初始化、高斯跟踪和高斯渲染三个模块组成。 (2)高斯点云初始化:从输入图像序列中搜索信息点,通过高斯混合模型估计点云参数,并通过表面分布先验优化点云位置。 (3)高斯跟踪:将变形场设计为轻量级编码体素和极小型的MLP的组合,通过将当前时间戳的高斯点云变形到新时间戳,实现高效的高斯跟踪。 (4)高斯渲染:利用高斯点云的几何特性和并行渲染管道,实现高效的渲染。 (5)训练细节:使用Adam优化器,学习率为1e-4,批大小为8,训练200个周期。
-
结论: (1):本工作提出了一种实时且高质量的 4D 重建框架,用于动态手术场景重建。通过利用基于体素的高斯跟踪和整体高斯初始化,我们能够处理组织变形和非平凡的高斯初始化问题。全面的实验表明,我们的 EndoGaussian 可以实现最先进的重建质量和实时的渲染速度,比以前的方法快 100 倍以上。我们希望新兴的基于高斯斑点的重建技术能够为机器人手术场景理解提供新的途径,并增强各种下游临床任务,尤其是术中应用。 (2):创新点:
- 基于高斯点云的实时手术场景重建框架。
- 体素编码的高斯跟踪,实现了高效的高斯跟踪。
- 整体高斯初始化方法,充分利用表面分布先验。 性能:
- 在公开内窥镜数据集上的实验表明,该方法可以实现实时渲染速度(195FPS 实时,100 倍增益),同时保持最先进的重建质量(35.925PSNR)和最快的训练速度(每个场景 2 分钟以内)。 工作量:
- 论文的代码和数据已经开源,可以方便地进行复现。
点此查看论文截图

Deformable Endoscopic Tissues Reconstruction with Gaussian Splatting
Authors:Lingting Zhu, Zhao Wang, Zhenchao Jin, Guying Lin, Lequan Yu
Surgical 3D reconstruction is a critical area of research in robotic surgery, with recent works adopting variants of dynamic radiance fields to achieve success in 3D reconstruction of deformable tissues from single-viewpoint videos. However, these methods often suffer from time-consuming optimization or inferior quality, limiting their adoption in downstream tasks. Inspired by 3D Gaussian Splatting, a recent trending 3D representation, we present EndoGS, applying Gaussian Splatting for deformable endoscopic tissue reconstruction. Specifically, our approach incorporates deformation fields to handle dynamic scenes, depth-guided supervision to optimize 3D targets with a single viewpoint, and a spatial-temporal weight mask to mitigate tool occlusion. As a result, EndoGS reconstructs and renders high-quality deformable endoscopic tissues from a single-viewpoint video, estimated depth maps, and labeled tool masks. Experiments on DaVinci robotic surgery videos demonstrate that EndoGS achieves superior rendering quality. Code is available at https://github.com/HKU-MedAI/EndoGS.
PDF Work in progress. 10 pages, 4 figures
摘要
动态高斯溅射用于可变形内窥镜组织重建。
要点
- EndoGS 利用高斯溅射进行可变形内窥镜组织重建。
- 该方法结合变形场以处理动态场景。
- 深度引导监督用于优化具有单个视点的 3D 目标。
- 时空权重掩码可减轻工具遮挡。
- EndoGS 可以从单视角视频、估计的深度图和标记的工具掩码中重建和渲染高质量的可变形内窥镜组织。
- 在 DaVinci 机器人手术视频上的实验表明,EndoGS 实现卓越的渲染质量。
- 题目:高斯斑点可变形内窥镜组织重建
- 作者:Lingting Zhu, Zhao Wang, Zhenchao Jin, Guying Lin, Lequan Yu
- 第一作者单位:香港大学
- 关键词:高斯斑点·机器人手术·三维重建
- 论文链接:https://arxiv.org/abs/2401.11535, Github 链接:https://github.com/HKU-MedAI/EndoGS
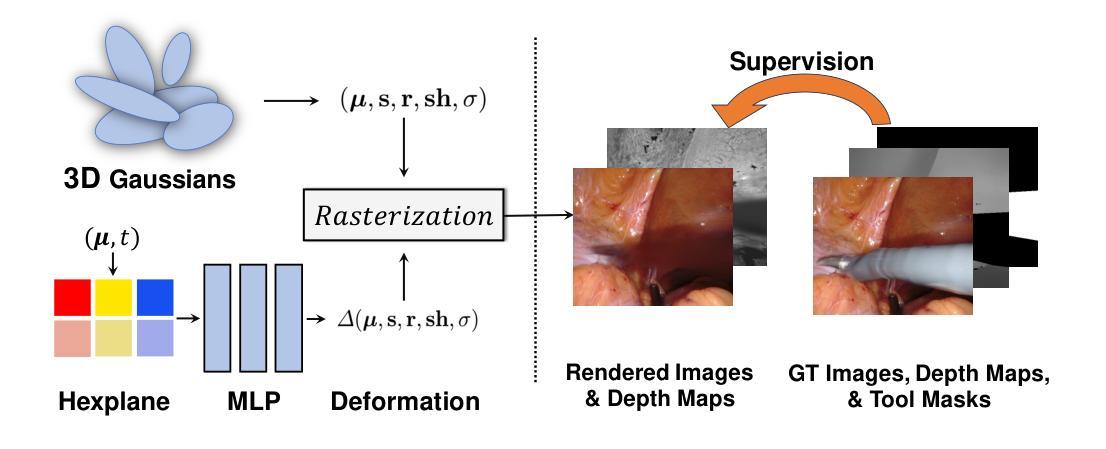
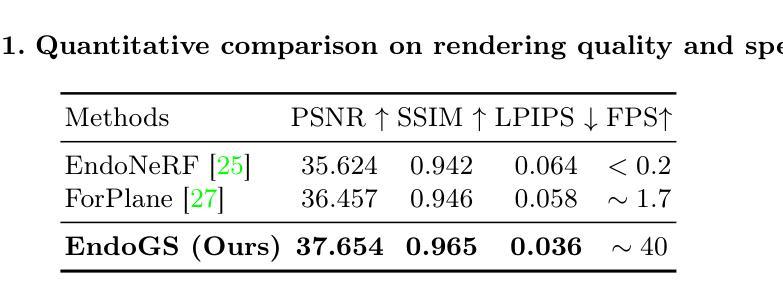
- 摘要: (1):研究背景:手术三维重建是机器人手术研究的一个关键领域,最近的工作采用动态辐射场实现从单视角视频中可变形组织的三维重建。然而,这些方法通常存在优化耗时或质量较差的问题,限制了它们在后续任务中的应用。 (2):过去的方法:早期尝试采用深度估计在内窥镜重建中取得了巨大成功,但这些方法仍然难以产生逼真的三维重建,原因有两个关键问题。首先,非刚性变形有时会导致较大的运动,这需要实际动态场景重建,这阻碍了这些技术的适应。其次,单视角视频中存在遮挡,导致学习受影响部分时信息有限,产生困难。虽然一些框架结合了工具遮罩、立体深度估计和稀疏翘曲场用于单视角三维重建,但它们在存在剧烈非拓扑可变形组织变化时仍然容易失败。 (3):研究方法:受最近流行的三维表示方法三维高斯斑点启发,我们提出了 EndoGS,将高斯斑点应用于可变形内窥镜组织重建。具体来说,我们的方法结合了变形场来处理动态场景,深度引导监督来优化具有单一视点的三维目标,以及时空权重掩码来减轻遮挡。 (4):方法性能:在达芬奇机器人手术视频上的实验表明,EndoGS 实现了更高的渲染质量。
Methods: (1): 我们提出了一种称为 EndoGS 的方法,它利用 3D-GS 的可变形变体从单视角视频、估计的深度图和标记的工具掩码中重建 3D 外科场景。 (2): 我们首先介绍了 3D-GS 的预备知识,然后展示了使用动态版本的 3D-GS 对可变形组织进行建模,该版本采用轻量级 MLP 来表示动态场。最后,我们介绍了使用工具掩码和深度图对高斯飞溅进行训练优化的过程。 (3): 我们使用六个正交特征平面来编码空间和时间信息,并使用单个 MLP 来更新高斯属性并解码位置、比例因子、旋转因子、球谐系数和不透明度的变形。 (4): 我们结合工具掩码和深度图来训练 EndoGS,以解决视频中工具遮挡的挑战,并使用时空重要性采样策略来指示与遮挡问题相关的关键区域。
- 结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
具体内容如下:
- 结论: (1):本文提出了一种基于高斯斑点可变形内窥镜组织重建的方法,该方法可以从单视角视频、估计的深度图和标记的工具掩码中实时渲染高质量的可变形组织。在达芬奇机器人手术视频上的实验表明,该方法具有更高的渲染质量。 (2):创新点:
- 提出了一种新的方法EndoGS,利用3D-GS的可变形变体从单视角视频、估计的深度图和标记的工具掩码中重建3D外科场景。
- 使用动态版本的3D-GS对可变形组织进行建模,该版本采用轻量级MLP来表示动态场。
- 结合工具掩码和深度图对高斯飞溅进行训练优化,以解决视频中工具遮挡的挑战,并使用时空重要性采样策略来指示与遮挡问题相关的关键区域。 性能:
- 在达芬奇机器人手术视频上的实验表明,EndoGS实现了更高的渲染质量。 工作量:
- 该方法需要预先训练3D-GS模型,并对每个新场景进行优化。
- 优化过程需要一定的时间,具体取决于场景的复杂性和数据量。
点此查看论文截图

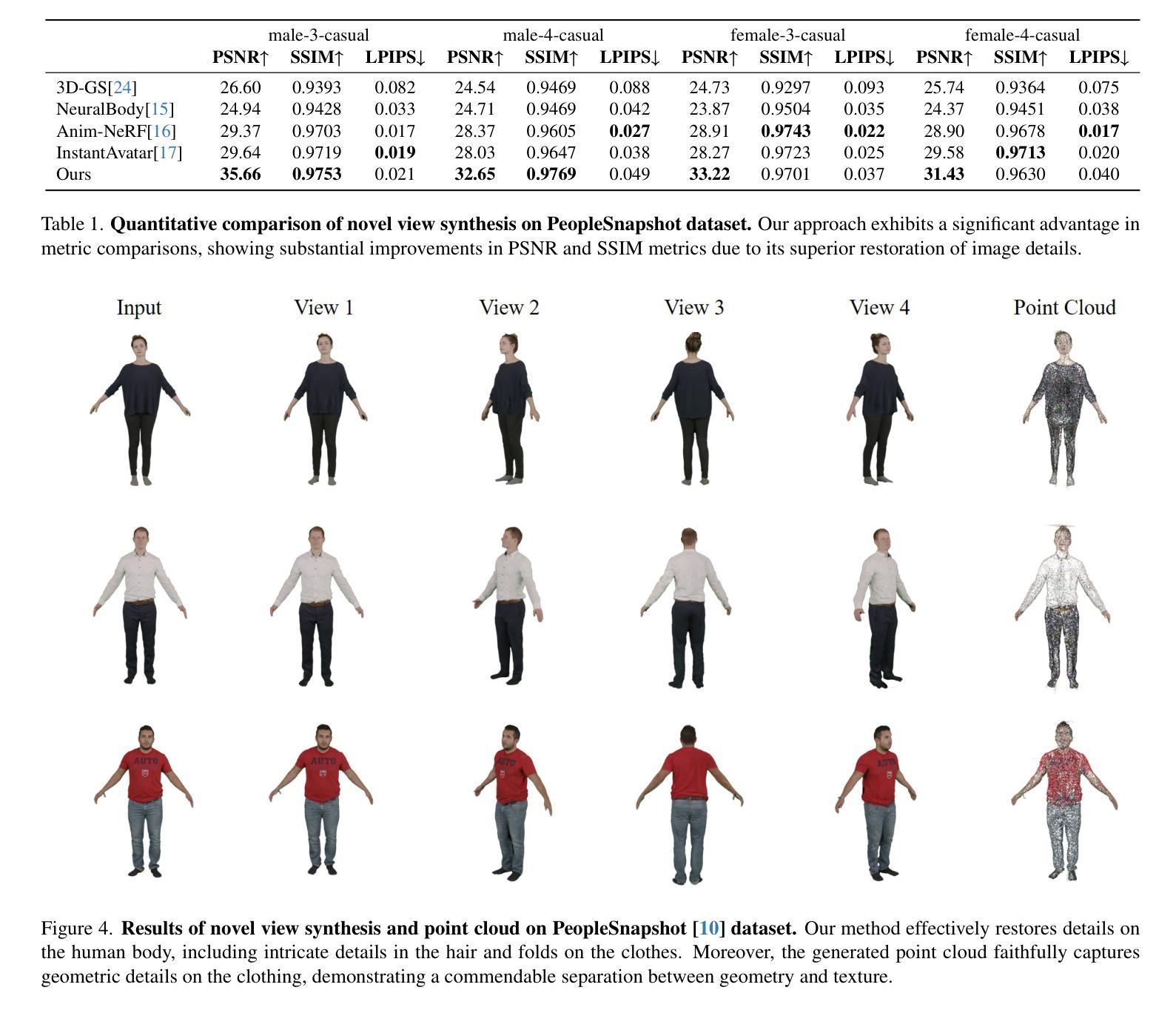
GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
Authors:Mengtian Li, Shengxiang Yao, Zhifeng Xie, Keyu Chen
In this work, we propose a novel clothed human reconstruction method called GaussianBody, based on 3D Gaussian Splatting. Compared with the costly neural radiance based models, 3D Gaussian Splatting has recently demonstrated great performance in terms of training time and rendering quality. However, applying the static 3D Gaussian Splatting model to the dynamic human reconstruction problem is non-trivial due to complicated non-rigid deformations and rich cloth details. To address these challenges, our method considers explicit pose-guided deformation to associate dynamic Gaussians across the canonical space and the observation space, introducing a physically-based prior with regularized transformations helps mitigate ambiguity between the two spaces. During the training process, we further propose a pose refinement strategy to update the pose regression for compensating the inaccurate initial estimation and a split-with-scale mechanism to enhance the density of regressed point clouds. The experiments validate that our method can achieve state-of-the-art photorealistic novel-view rendering results with high-quality details for dynamic clothed human bodies, along with explicit geometry reconstruction.
Summary
优化动态穿衣人体重建方法,引入物理先验和规范化变换,实现高精度照片级新视角渲染。
Key Takeaways
- 本文提出了一种新的穿衣人體重建方法 GaussianBody,基於 3D 高斯 Splatting。
- 3D 高斯 Splatting 最近在訓練時間和渲染質量方面表現出了很好的性能。
- 應用靜態 3D 高斯 Splatting 模型於動態人體重建問題時,會因複雜的非剛性變形和豐富的衣物細節而遇到挑戰。
- 提出明確的姿勢引導變形,以關聯規範空間和觀測空間中的動態高斯。
- 引入基於物理的先驗和正則化變換,以減少兩個空間之間的歧義。
- 提出姿勢精煉策略,以更新姿勢回歸,以補償不準確的初始估計。
- 提出分拆比例機制,以增強回歸點雲的密度。
- 實驗證明,該方法可實現最先進照片級的新視圖渲染結果,同時具有高質量的動態穿衣人體細節和明確的幾何重建。
- 题目:高斯体:基于 3D 高斯散布的着装人体重建
- 作者:李梦添、姚胜祥、谢志峰、陈可宇
- 隶属单位:上海大学
- 关键词:3D 高斯散布、着装人体重建、单目视频、神经辐射场
- 论文链接:https://arxiv.org/abs/2401.09720,Github 代码链接:无
- 摘要: (1)研究背景:创建高保真着装人体模型在虚拟现实、远程临场和电影制作中具有重要应用。传统方法要么涉及复杂的捕捉系统,要么需要 3D 艺术家进行繁琐的手工操作,这使得它们既耗时又昂贵,从而限制了新手用户的可扩展性。近年来,人们越来越关注从单个 RGB 图像或单目视频中自动重建着装人体模型。 (2)过去的方法及其问题:网格模型方法最初被引入,通过回归 SCAPE、SMPL、SMPL-X 和 STAR 等参数模型来重构人体形状。虽然它们可以实现快速且稳健的重建,但回归的多边形网格难以捕捉不同的几何细节和丰富的服装特征。添加顶点偏移量成为这种情况下的一种增强解决方案。然而,其表示能力仍然受到网格分辨率的严格限制,并且通常在宽松服装的情况下会失败。 (3)本文提出的研究方法:为了克服显式网格模型的局限性,本文提出了一种基于 3D 高斯散布的新颖着装人体重建方法 GaussianBody。与代价高昂的神经辐射场模型相比,3D 高斯散布最近在训练时间和渲染质量方面表现出优异的性能。然而,将静态 3D 高斯散布模型应用于动态人体重建问题由于复杂的非刚性变形和丰富的服装细节而变得非常困难。为了应对这些挑战,本文的方法考虑了显式姿势引导的变形,将动态高斯体与规范空间和观察空间相关联,引入具有正则化变换的基于物理的先验有助于减轻这两个空间之间的歧义。在训练过程中,本文进一步提出了一种姿势细化策略,以更新姿势回归,以补偿不准确的初始估计,并提出了一种分裂尺度机制来增强回归点云的密度。 (4)方法的应用任务和性能:实验验证了本文的方法可以实现最先进的逼真新视图渲染结果,为动态着装人体提供高质量的细节,以及显式几何重建。这些性能可以支持他们的目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于 3D 高斯散布的着装人体重建方法 GaussianBody,该方法能够从单目视频中重建动态的着装人体模型,并具有逼真的新视图渲染结果和高质量的细节。 (2):创新点:
- 将 3D 高斯散布表示扩展到着装人体重建中,并考虑了显式姿势引导的变形,以解决动态高斯体与规范空间和观察空间之间的歧义问题。
- 提出了一种基于物理的先验来正则化规范空间的高斯体,以减轻观察空间和规范空间之间的过度旋转问题。
- 提出了一种姿势细化策略和分裂尺度机制,以增强重建点云的质量和鲁棒性。 性能:
- 该方法在图像质量指标上与基线和其他方法相当,证明了其具有竞争力的性能和相对较快的训练速度。
- 该方法能够使用更高分辨率的图像进行训练。 工作量:
- 该方法的训练时间比一些最先进的方法更长。
- 该方法需要大量的数据来进行训练。
点此查看论文截图



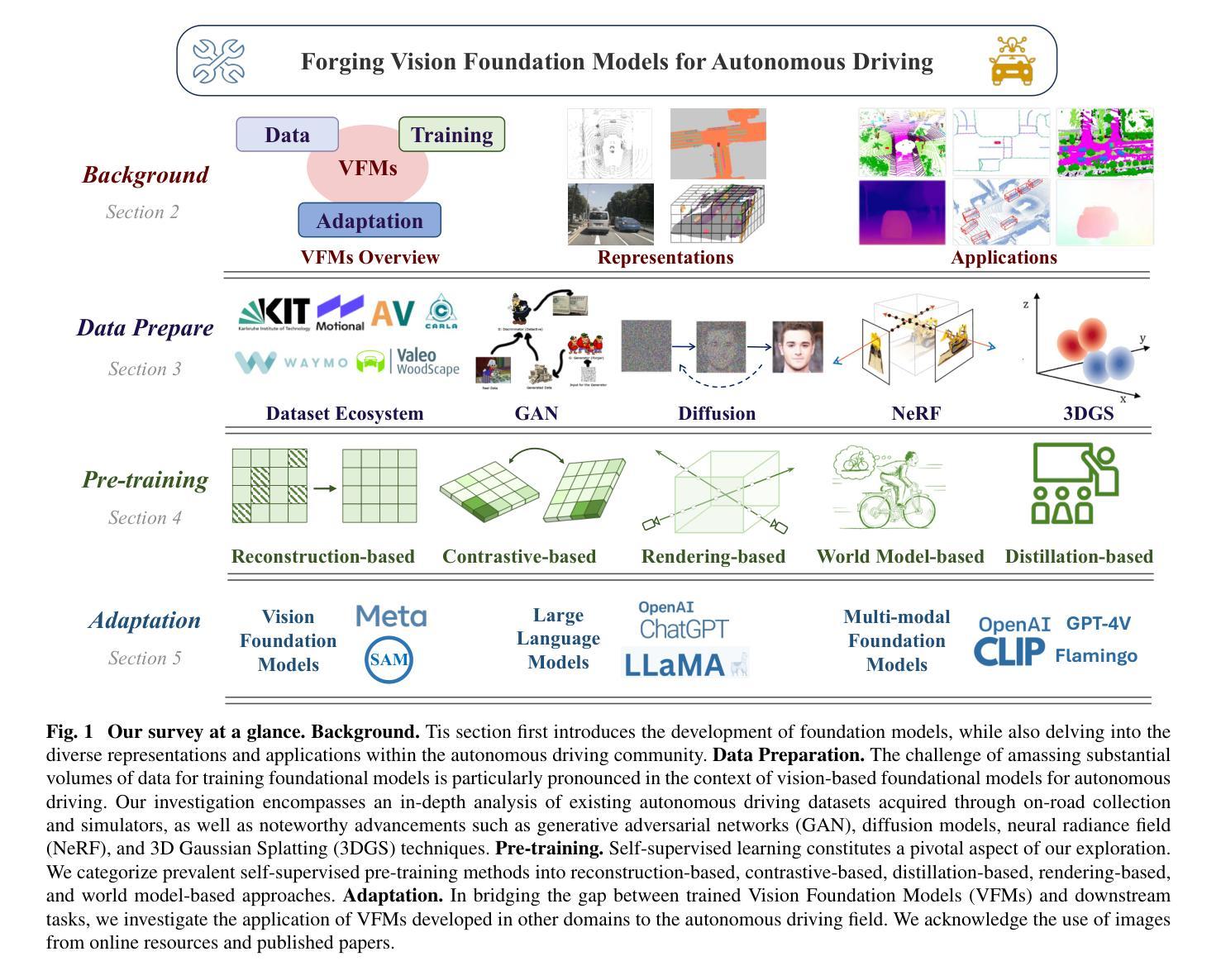
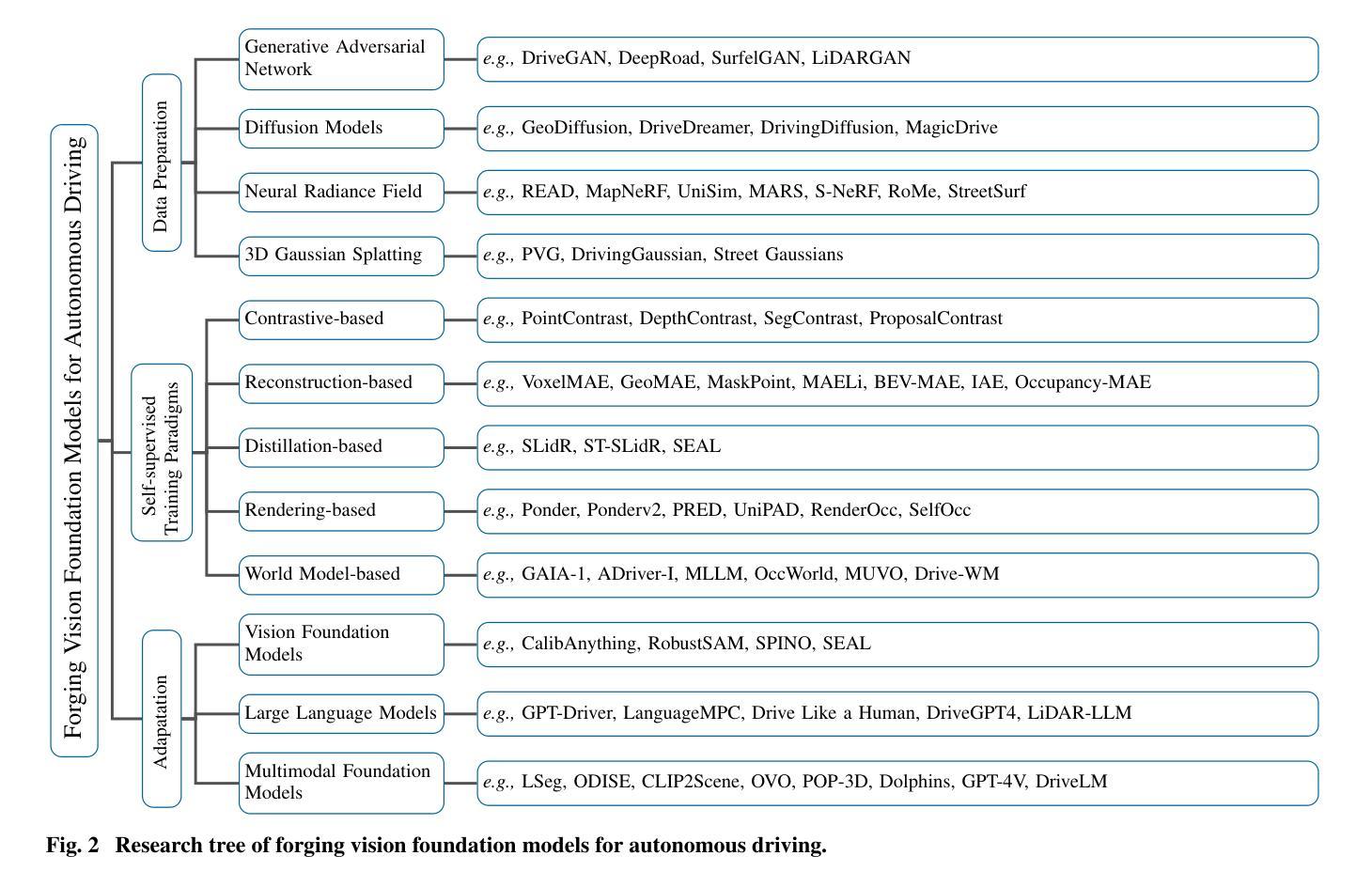
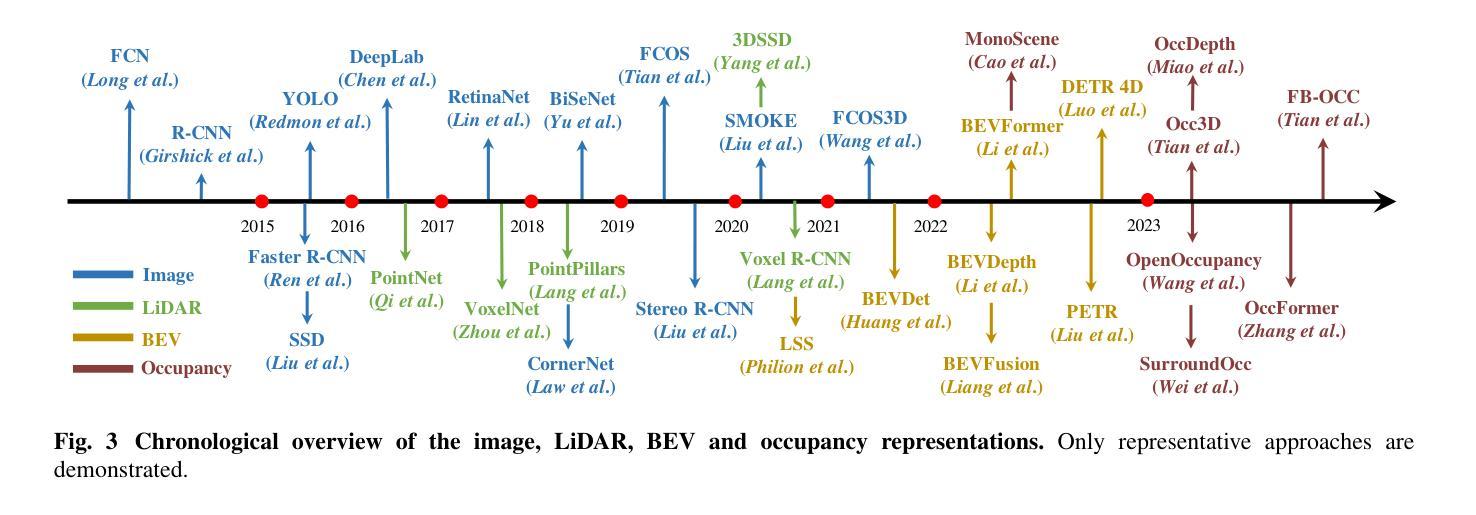
Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities
Authors:Xu Yan, Haiming Zhang, Yingjie Cai, Jingming Guo, Weichao Qiu, Bin Gao, Kaiqiang Zhou, Yue Zhao, Huan Jin, Jiantao Gao, Zhen Li, Lihui Jiang, Wei Zhang, Hongbo Zhang, Dengxin Dai, Bingbing Liu
The rise of large foundation models, trained on extensive datasets, is revolutionizing the field of AI. Models such as SAM, DALL-E2, and GPT-4 showcase their adaptability by extracting intricate patterns and performing effectively across diverse tasks, thereby serving as potent building blocks for a wide range of AI applications. Autonomous driving, a vibrant front in AI applications, remains challenged by the lack of dedicated vision foundation models (VFMs). The scarcity of comprehensive training data, the need for multi-sensor integration, and the diverse task-specific architectures pose significant obstacles to the development of VFMs in this field. This paper delves into the critical challenge of forging VFMs tailored specifically for autonomous driving, while also outlining future directions. Through a systematic analysis of over 250 papers, we dissect essential techniques for VFM development, including data preparation, pre-training strategies, and downstream task adaptation. Moreover, we explore key advancements such as NeRF, diffusion models, 3D Gaussian Splatting, and world models, presenting a comprehensive roadmap for future research. To empower researchers, we have built and maintained https://github.com/zhanghm1995/Forge_VFM4AD, an open-access repository constantly updated with the latest advancements in forging VFMs for autonomous driving.
PDF Github Repo: https://github.com/zhanghm1995/Forge_VFM4AD
摘要
智能汽车专属视觉基础模型的构建挑战及其未来发展机遇。
要点
- 数据准备、预训练策略和下游任务适配是 VFM 开发的关键技术。
- 生成神经辐射场 (NeRF),扩散模型,3D 高斯分布(3DGS)和世界模型等技术的进步为未来的研究提出了路线图。
- 开源项目 https://github.com/zhanghm1995/Forge_VFM4AD 将不断更新,以赋能研究人员。
- 自动驾驶中的 VFM 缺乏专用数据和多传感器集成,导致任务特定架构的多样性成为 VFM 发展的障碍。
- 视觉基础模型 (VFM) 在自动驾驶中至关重要,但其发展面临着诸多挑战。
- 开发专用于自动驾驶的 VFM 是当前的紧迫挑战。
- 建议从数据准备、预训练以及下游任务适配等方面入手,并探索 NeRF、扩散模型等新技术,以推进 VFM 的发展。
- 题目:构建自动驾驶视觉基础模型:挑战、方法和机遇
- 作者:徐岩,张海明,蔡应杰,郭敬明,邱维超,高斌,周凯强,赵越,金欢,高建涛,李振,蒋立辉,张伟,张宏波,戴登心,刘冰冰
- 第一作者单位:华为诺亚方舟实验室
- 关键词:视觉基础模型,数据生成,自监督训练,自动驾驶,文献综述
- 论文链接:https://arxiv.org/abs/2401.08045 Github 代码链接:无
-
摘要: (1)研究背景:随着自动驾驶技术的快速发展,传统自动驾驶感知系统采用模块化架构,针对特定任务使用专用算法,但这种方法往往导致输出不一致,限制了系统处理长尾情况的能力。近年来,大型基础模型在自然语言处理领域取得了巨大成功,展现出强大的适应性和有效性,为构建自动驾驶视觉基础模型提供了新的思路。 (2)过去的方法及其问题:以往的方法主要集中于针对特定任务训练深度神经网络,但这种方法存在以下问题:1. 忽视了数据之间的关系,导致输出不一致;2. 难以处理长尾情况;3. 无法有效利用大量未标记数据。 (3)提出的研究方法:本文提出了一种构建自动驾驶视觉基础模型的方法,该方法主要包括以下几个步骤:1. 数据准备:收集和预处理自动驾驶相关的数据,包括图像、激光雷达点云、语义分割标签等;2. 预训练:使用自监督学习方法对基础模型进行预训练,使其能够从数据中提取有用的特征;3. 下游任务自适应:将预训练好的基础模型应用于下游任务,并通过微调使其适应特定任务。 (4)方法在任务中的表现及性能:该方法在自动驾驶相关任务上取得了较好的性能,例如目标检测、语义分割和深度估计等。这些结果表明,该方法能够有效地从数据中提取有用的特征,并将其应用于下游任务。
-
方法: (1)数据准备:收集和预处理自动驾驶相关的数据,包括图像、激光雷达点云、语义分割标签等; (2)预训练:使用自监督学习方法对基础模型进行预训练,使其能够从数据中提取有用的特征; (3)下游任务自适应:将预训练好的基础模型应用于下游任务,并通过微调使其适应特定任务。
-
结论: (1):本文针对自动驾驶视觉基础模型的构建提出了系统的方法,并取得了较好的性能。该方法为自动驾驶视觉基础模型的构建提供了新的思路,有望推动自动驾驶技术的发展。 (2):创新点:
- 提出了一种构建自动驾驶视觉基础模型的方法,该方法包括数据准备、预训练和下游任务自适应三个步骤。
- 使用自监督学习方法对基础模型进行预训练,使其能够从数据中提取有用的特征。
- 将预训练好的基础模型应用于下游任务,并通过微调使其适应特定任务。 性能:
- 该方法在自动驾驶相关任务上取得了较好的性能,例如目标检测、语义分割和深度估计等。
- 该方法能够有效地从数据中提取有用的特征,并将其应用于下游任务。 工作量:
- 该方法需要收集和预处理大量的数据。
- 该方法需要使用自监督学习方法对基础模型进行预训练,这需要较大的计算资源。
- 该方法需要将预训练好的基础模型应用于下游任务,并通过微调使其适应特定任务,这需要较多的工程工作。
点此查看论文截图