⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-01-30 更新
NeRF-AD: Neural Radiance Field with Attention-based Disentanglement for Talking Face Synthesis
Authors:Chongke Bi, Xiaoxing Liu, Zhilei Liu
Talking face synthesis driven by audio is one of the current research hotspots in the fields of multidimensional signal processing and multimedia. Neural Radiance Field (NeRF) has recently been brought to this research field in order to enhance the realism and 3D effect of the generated faces. However, most existing NeRF-based methods either burden NeRF with complex learning tasks while lacking methods for supervised multimodal feature fusion, or cannot precisely map audio to the facial region related to speech movements. These reasons ultimately result in existing methods generating inaccurate lip shapes. This paper moves a portion of NeRF learning tasks ahead and proposes a talking face synthesis method via NeRF with attention-based disentanglement (NeRF-AD). In particular, an Attention-based Disentanglement module is introduced to disentangle the face into Audio-face and Identity-face using speech-related facial action unit (AU) information. To precisely regulate how audio affects the talking face, we only fuse the Audio-face with audio feature. In addition, AU information is also utilized to supervise the fusion of these two modalities. Extensive qualitative and quantitative experiments demonstrate that our NeRF-AD outperforms state-of-the-art methods in generating realistic talking face videos, including image quality and lip synchronization. To view video results, please refer to https://xiaoxingliu02.github.io/NeRF-AD.
PDF Accepted by ICASSP 2024
Summary
用注意力机制分解神经辐射场,用于音频驱动的说话人头部生成。
Key Takeaways
- 神经辐射场(NeRF)已被引入到谈话面部合成的研究领域,以增强生成的面的逼真性和 3D 效果。
- 现有的 NeRF 方法要么给 NeRF 带来了复杂的学习任务,而缺乏监督式多模态特征融合的方法,或者无法将音频精确映射到与语音运动相关的面部区域。
- 提出了一种基于 NeRF 的注意力机制分解的说话人头部合成方法(NeRF-AD)。
- 引入了一个基于注意力的分解模块,使用与语音相关的面部动作单元 (AU) 信息将人脸分解成音频面部和身份面部。
- 仅将音频面部与音频特征融合,以精确地调节音频对说话人面部的影响。
- 将 AU 信息也用于监督这两种模态的融合。
- 定性和定量实验表明,NeRF-AD 在生成逼真的说话人头部视频方面优于最先进的方法,包括图像质量和唇形同步。
- 题目:NeRF-AD:基于注意力机制分解的神经辐射场说话人面部合成
- 作者:Chongke Bi,Xiaoxing Liu,Zhilei Liu
- 单位:天津大学智能与计算学院
- 关键词:说话人面部合成,神经辐射场,面部分解
- 论文链接:https://arxiv.org/abs/2401.12568,Github 链接:无
-
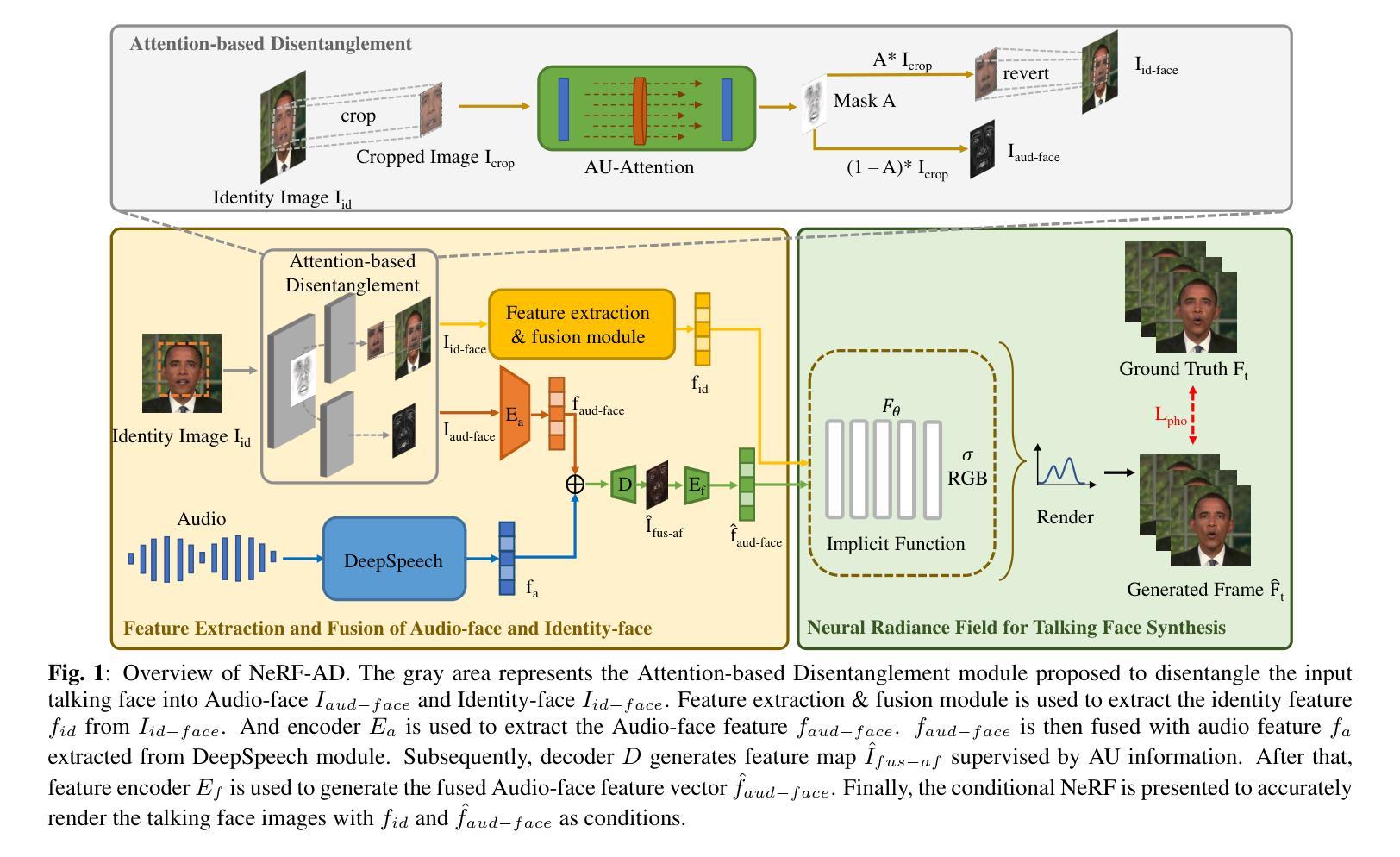
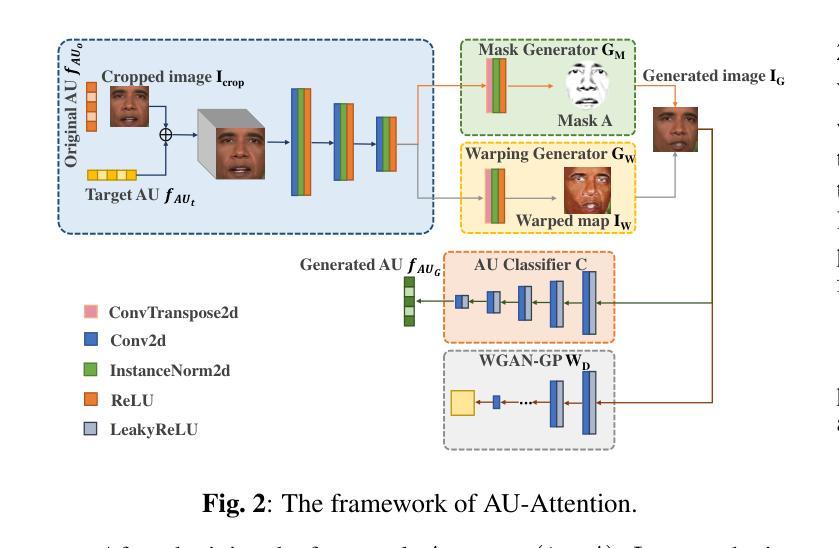
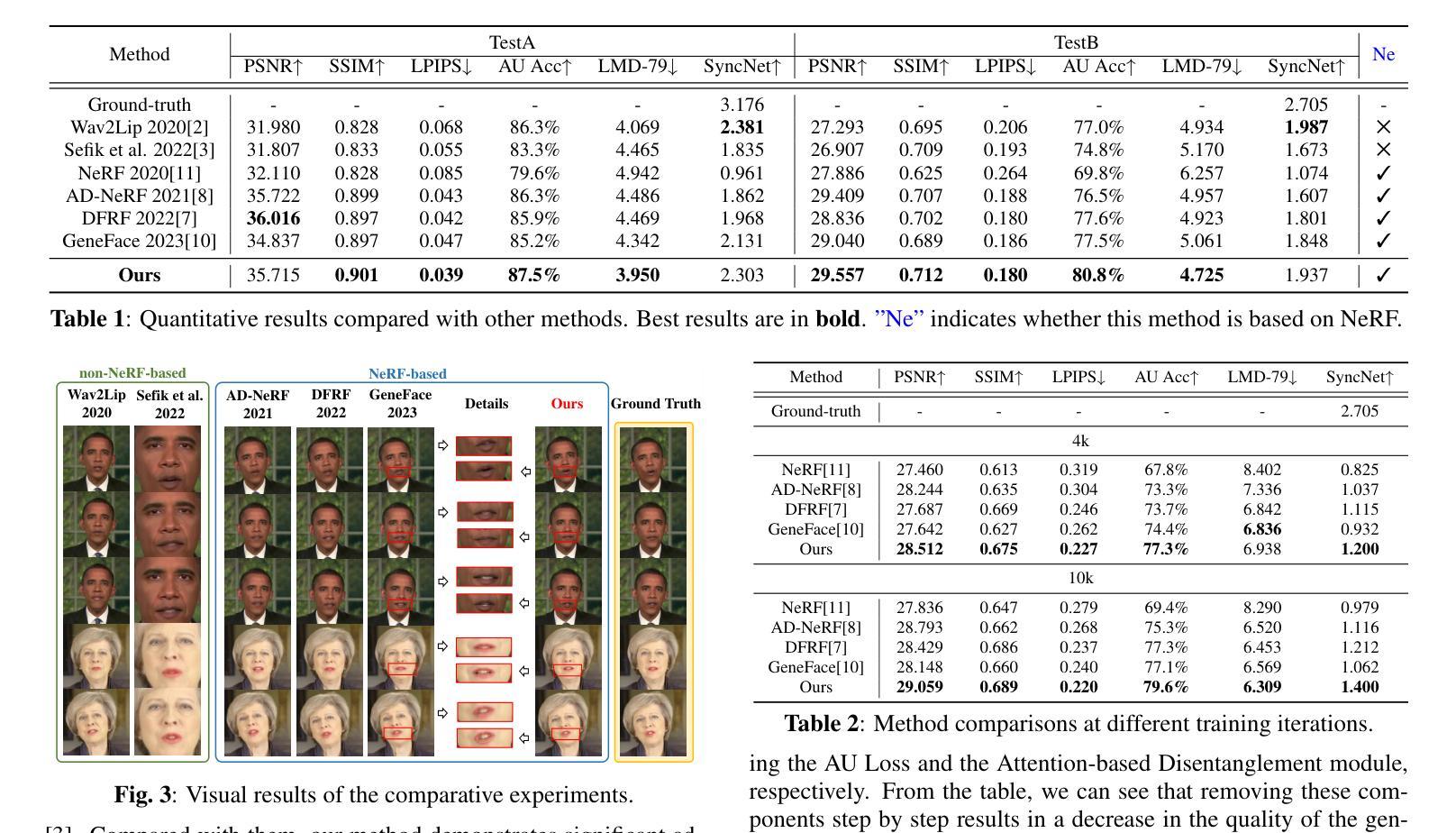
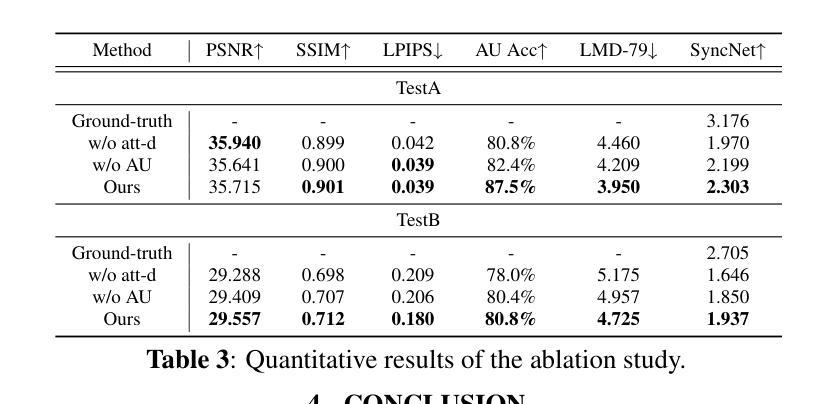
摘要: (1)研究背景:说话人面部合成是多维信号处理和多媒体领域的研究热点之一。神经辐射场(NeRF)最近被引入该研究领域,以增强生成面部的真实感和 3D 效果。然而,大多数现有的基于 NeRF 的方法要么给 NeRF 增加复杂的学习任务,同时缺乏监督式多模态特征融合的方法,要么无法将音频精确映射到与说话运动相关的面部区域。这些原因最终导致现有方法生成的唇形不准确。 (2)过去方法及其问题:一些方法将 NeRF 的学习任务提前一部分,并提出了一种通过 NeRF 进行说话人面部合成的基于注意力机制分解的方法(NeRF-AD)。具体来说,引入了一个基于注意力的分解模块,利用与语音相关的面部动作单元(AU)信息将面部分解为音频面部和身份面部。为了精确地调节音频如何影响说话人的面部,我们只将音频面部与音频特征融合。此外,还利用 AU 信息来监督这两个模态的融合。大量定性和定量实验表明,我们的 NeRF-AD 在生成逼真的说话人面部视频(包括图像质量和唇形同步)方面优于最先进的方法。 (3)提出的研究方法:我们设计了一个基于注意力的分解模块,利用 AU 指导注意力模型生成与说话运动相关的面部区域的掩码。通过利用这些掩码,我们可以有效地将输入面部分解为不同的组成部分:音频面部和身份面部。音频面部表示与说话运动相关的面部区域,与音频特征融合,而身份面部表示与说话人身份相关的面部区域。在这种情况下,音频特征只影响音频面部,从而对生成的说话人面部提供精确的控制。随后,我们提出了一个条件 NeRF,以将融合的音频面部特征和身份面部特征作为条件,精确地渲染说话人面部图像。此外,我们使用 AU 损失来监督音频面部特征和音频特征的融合过程,以便能够准确地融合两者。在整个过程中,我们分散了 NeRF 的任务,并使用不同的方法来监督每个任务,使 NeRF 更清楚地知道它需要学习什么。 (4)方法在什么任务上取得了什么性能,性能是否支持其目标:我们的 NeRF-AD 在生成逼真的说话人面部视频(包括图像质量和唇形同步)方面优于最先进的方法。定量实验表明,我们的方法在唇形同步准确性和图像质量方面均优于最先进的方法。这些结果支持我们的目标,即生成逼真的说话人面部视频。
-
方法: (1):提出了一种基于注意力的分解模块,利用与语音相关的面部动作单元(AU)信息将面部分解为音频面部和身份面部。 (2):将音频面部与音频特征融合,并利用AU信息来监督这两个模态的融合。 (3):设计了一个条件NeRF,以将融合的音频面部特征和身份面部特征作为条件,精确地渲染说话人面部图像。 (4):使用AU损失来监督音频面部特征和音频特征的融合过程,以便能够准确地融合两者。
-
结论: (1):NeRF-AD 提出了一种基于注意力的分解模块,利用与语音相关的面部动作单元(AU)信息将面部分解为音频面部和身份面部。我们只融合音频面部特征和音频特征来准确控制音频对说话面部的影响。此外,AU 信息用于控制不同模态特征的精确融合。广泛的定性和定量实验的结果表明,NeRF-AD 在图像质量和唇形同步方面均优于其他最先进的方法。 (2):创新点: 提出了一种基于注意力的分解模块,将说话面部分解为音频面部和身份面部。 只融合音频面部特征和音频特征来准确控制音频对说话面部的影响。 利用 AU 信息来控制不同模态特征的精确融合。 性能: 在图像质量和唇形同步方面优于其他最先进的方法。 工作量: 需要大量的数据和计算资源来训练 NeRF 模型。
点此查看论文截图