⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-02 更新
ViCA-NeRF: View-Consistency-Aware 3D Editing of Neural Radiance Fields
Authors:Jiahua Dong, Yu-Xiong Wang
We introduce ViCA-NeRF, the first view-consistency-aware method for 3D editing with text instructions. In addition to the implicit neural radiance field (NeRF) modeling, our key insight is to exploit two sources of regularization that explicitly propagate the editing information across different views, thus ensuring multi-view consistency. For geometric regularization, we leverage the depth information derived from NeRF to establish image correspondences between different views. For learned regularization, we align the latent codes in the 2D diffusion model between edited and unedited images, enabling us to edit key views and propagate the update throughout the entire scene. Incorporating these two strategies, our ViCA-NeRF operates in two stages. In the initial stage, we blend edits from different views to create a preliminary 3D edit. This is followed by a second stage of NeRF training, dedicated to further refining the scene’s appearance. Experimental results demonstrate that ViCA-NeRF provides more flexible, efficient (3 times faster) editing with higher levels of consistency and details, compared with the state of the art. Our code is publicly available.
PDF Neurips2023; project page: https://github.com/Dongjiahua/VICA-NeRF
摘要
利用深度信息和扩散模型,ViCA-NeRF 实现了多视图一致性,可以高效地编辑 3D 场景。
要点
- ViCA-NeRF 是一种利用深度信息和扩散模型来实现多视图一致性的 3D 编辑方法。
- ViCA-NeRF 在 NeRF 建模的基础上,利用深度信息推断不同视角的图像对应关系,以实现几何正则化。
- ViCA-NeRF 利用 2D 扩散模型对编辑图像和未编辑图像的潜在编码进行对齐,以实现学习正则化。
- ViCA-NeRF 由两个阶段组成:第一阶段融合来自不同视角的编辑,创建初步的 3D 编辑;第二阶段对 NeRF 进行训练,以进一步细化场景外观。
- ViCA-NeRF 比现有方法提供了更灵活、更高效(速度提高 3 倍)的编辑,并具有更高的层次一致性和细节。
- ViCA-NeRF 的代码已公开。
- 题目:ViCA-NeRF:基于视图一致性的神经辐射场 3D 编辑
- 作者:Jiahua Dong, Yu-Xiong Wang
- 单位:伊利诺伊大学厄巴纳-香槟分校
- 关键词:神经辐射场、3D 编辑、文本指令、视图一致性
- 论文链接:https://arxiv.org/abs/2402.00864 Github 链接:None
-
总结: (1):随着神经辐射场 (NeRF) 等 3D 重建技术的进步,收集真实世界 3D 场景变得更加便捷。然而,现有方法在 3D 场景编辑方面还存在诸多局限。 (2):以往方法通常使用隐式神经辐射场进行建模,但缺乏对不同视图之间编辑信息传播的显式约束,导致编辑结果可能出现视图不一致的问题。 (3):本文提出 ViCA-NeRF,一种基于视图一致性的 3D 编辑方法。ViCA-NeRF 利用几何和学习正则化两种策略来确保不同视图之间的编辑一致性。几何正则化利用 NeRF 提取的深度信息建立不同视图之间的图像对应关系,学习正则化则对编辑图像和未编辑图像在 2D 扩散模型中的潜在编码进行对齐,从而实现关键视图的编辑并将其传播到整个场景。 (4):实验结果表明,与现有方法相比,ViCA-NeRF 能够提供更加灵活、高效(速度提高 3 倍)、一致性和细节更佳的编辑效果。
-
Methods: (1):ViCA-NeRF是一种基于视图一致性的3D编辑方法,它利用几何和学习正则化两种策略来确保不同视图之间的编辑一致性。 (2):几何正则化利用NeRF提取的深度信息建立不同视图之间的图像对应关系,从而将编辑信息从关键视图传播到整个场景。 (3):学习正则化对编辑图像和未编辑图像在2D扩散模型中的潜在编码进行对齐,从而实现关键视图的编辑并将其传播到整个场景。 (4):ViCA-NeRF能够提供更加灵活、高效(速度提高3倍)、一致性和细节更佳的编辑效果。
-
结论: (1):本工作提出了一种基于视图一致性的 3D 编辑框架 ViCA-NeRF,该框架可以根据文本指令高效地编辑 NeRF。除了人类风格化和天气变化等简单任务外,我们还支持与上下文相关的操作,例如“添加一些花朵”和编辑高度详细的纹理。我们的方法在各种场景和文本提示上优于几个基线。未来,我们将继续提高 3D 编辑的可控性和真实性。 (2):创新点:
- 提出了一种基于视图一致性的 3D 编辑框架 ViCA-NeRF,该框架可以根据文本指令高效地编辑 NeRF。
- 利用几何正则化和学习正则化两种策略来确保不同视图之间的编辑一致性。
- 支持与上下文相关的操作,例如“添加一些花朵”和编辑高度详细的纹理。 性能:
- 在各种场景和文本提示上优于几个基线。
- 编辑效率高,速度提高 3 倍。
- 编辑结果一致性好,细节丰富。 工作量:
- 实现复杂,需要较高的技术水平。
- 训练时间长,需要大量的计算资源。
点此查看论文截图



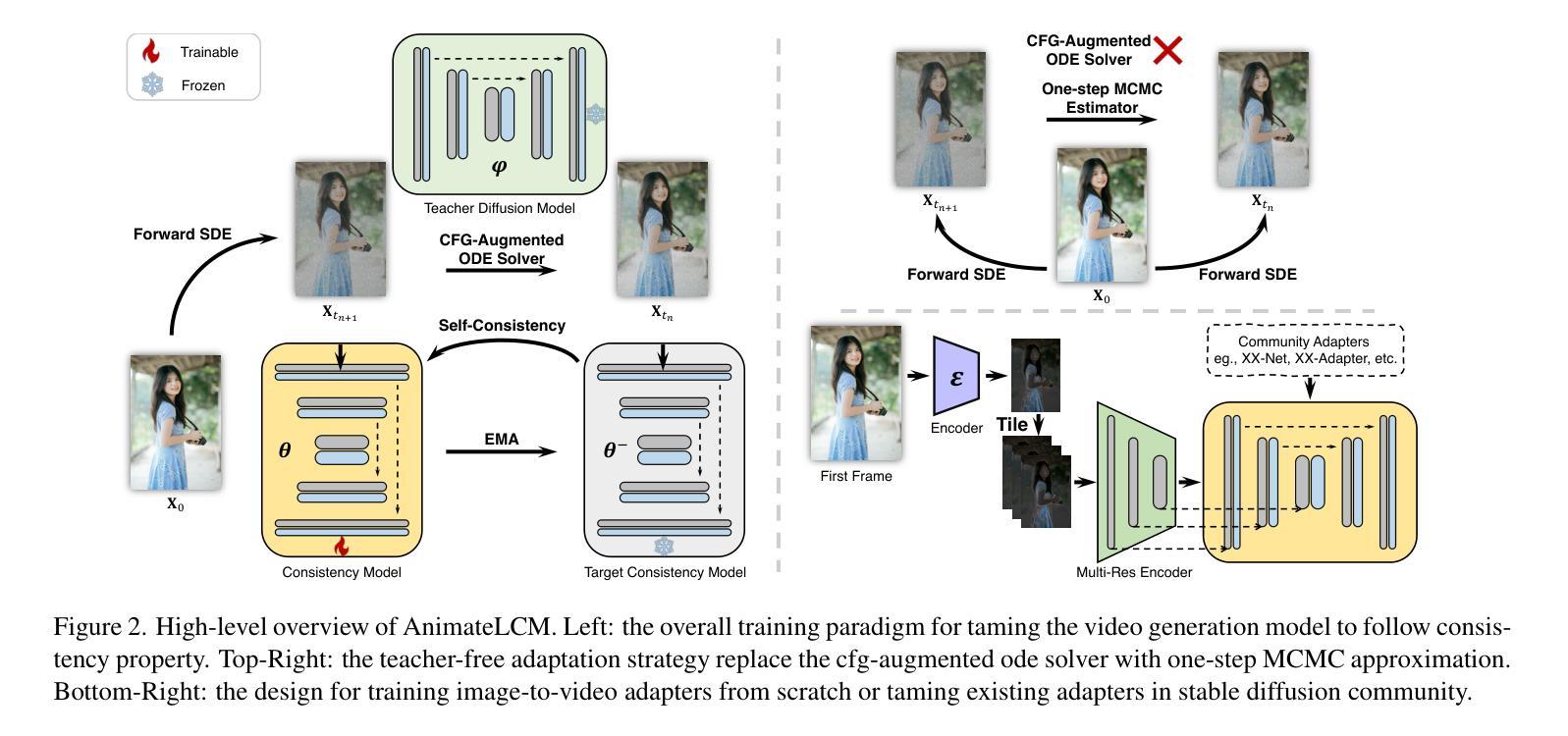
AnimateLCM: Accelerating the Animation of Personalized Diffusion Models and Adapters with Decoupled Consistency Learning
Authors:Fu-Yun Wang, Zhaoyang Huang, Xiaoyu Shi, Weikang Bian, Guanglu Song, Yu Liu, Hongsheng Li
Video diffusion models has been gaining increasing attention for its ability to produce videos that are both coherent and of high fidelity. However, the iterative denoising process makes it computationally intensive and time-consuming, thus limiting its applications. Inspired by the Consistency Model (CM) that distills pretrained image diffusion models to accelerate the sampling with minimal steps and its successful extension Latent Consistency Model (LCM) on conditional image generation, we propose AnimateLCM, allowing for high-fidelity video generation within minimal steps. Instead of directly conducting consistency learning on the raw video dataset, we propose a decoupled consistency learning strategy that decouples the distillation of image generation priors and motion generation priors, which improves the training efficiency and enhance the generation visual quality. Additionally, to enable the combination of plug-and-play adapters in stable diffusion community to achieve various functions (e.g., ControlNet for controllable generation). we propose an efficient strategy to adapt existing adapters to our distilled text-conditioned video consistency model or train adapters from scratch without harming the sampling speed. We validate the proposed strategy in image-conditioned video generation and layout-conditioned video generation, all achieving top-performing results. Experimental results validate the effectiveness of our proposed method. Code and weights will be made public. More details are available at https://github.com/G-U-N/AnimateLCM.
PDF Project Page: https://animatelcm.github.io/
Summary
扩散模型动画LCM(AnimateLCM):通过分离图像生成先验和运动生成先验,实现快速高效的高保真视频生成。
Key Takeaways
- 扩散模型视频生成由于迭代去噪过程计算量大和耗时,限制了其应用。
- 受Consistency Model (CM)和Latent Consistency Model (LCM)的启发,提出AnimateLCM,可在最少步骤内生成高保真视频。
- 提出了一种解耦一致性学习策略,将图像生成先验和运动生成先验的学习解耦,提高了训练效率和生成视觉质量。
- 提出了一种有效的策略,将现有的适配器适配到蒸馏后的文本条件视频一致性模型,或从头开始训练适配器,而不会损害采样速度。
- 在图像条件视频生成和布局条件视频生成中验证了所提出的策略,均取得了最优结果。
- 实验结果验证了所提方法的有效性。代码和权重将公开。更多详情请见 https://github.com/G-U-N/AnimateLCM。
- 标题:AnimateLCM:加速个性化扩散模型和适配器的动画制作,具有去耦合一致性学习
- 作者:Fu-Yun Wang, Zhaoyang Huang, Xiaoyu Shi, Weikang Bian, Guanglu Song, Yu Liu, Hongsheng Li
- 隶属单位:香港中文大学多媒体实验室
- 关键词:视频扩散模型、一致性模型、个性化层、动画制作
- 论文链接:https://arxiv.org/abs/2402.00769 Github 链接:无
-
摘要: (1):研究背景:视频扩散模型因其能够生成连贯且高保真视频而备受关注。然而,迭代式去噪过程使其计算密集且耗时,从而限制了其应用。 (2):过去方法及其问题:受一致性模型 (CM) 的启发,CM 将预训练的图像扩散模型蒸馏以加速最小步长的采样,并在条件图像生成上成功扩展了潜在一致性模型 (LCM)。然而,直接对原始视频数据集进行一致性学习的训练效率低,生成的视觉质量也不佳。 (3):研究方法:提出 AnimateLCM,允许在最少步长内生成高保真视频。提出了一种去耦合一致性学习策略,将图像生成先验和运动生成先验的蒸馏解耦,提高了训练效率并增强了生成视觉质量。此外,提出了一种有效策略,将稳定扩散社区中即插即用的适配器与蒸馏的文本条件视频一致性模型相结合,或从头开始训练适配器,而不会损害采样速度。 (4):实验结果:在图像条件视频生成和布局条件视频生成中验证了所提出的策略,均取得了最优结果。实验结果验证了所提出方法的有效性。
-
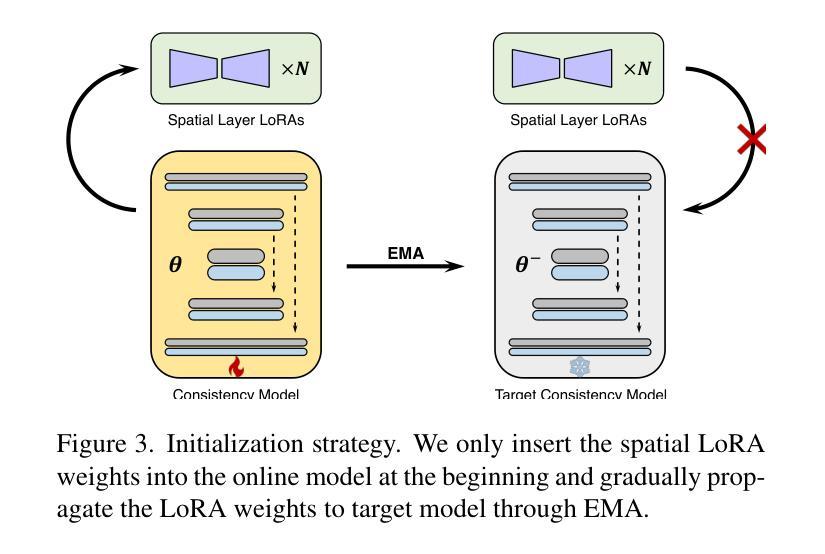
方法: (1):提出了一种去耦合一致性学习策略,将图像生成先验和运动生成先验的蒸馏解耦,提高了训练效率并增强了生成视觉质量。 (2):提出了一种有效策略,将稳定扩散社区中即插即用的适配器与蒸馏的文本条件视频一致性模型相结合,或从头开始训练适配器,而不会损害采样速度。 (3):提出了一种新的初始化策略,该策略可以有效地将空间 LoRA 权重和时间层结合起来,从而提高训练效率。 (4):提出了一种无教师的一致性学习策略,该策略可以通过单步 MCMC 近似来估计分数,从而无需预训练的视频扩散模型作为教师模型。 (5):提出了一种新的图像到视频的预处理策略,该策略可以有效地提取图像上下文并将其融入一致性模型中。
-
结论: (1):本文提出了一种新的视频生成加速方法AnimateLCM,该方法通过解耦一致性学习策略和教师模型的适应策略,实现了视频生成的高效性和高质量。 (2):创新点:
- 提出了一种解耦一致性学习策略,将图像生成先验和运动生成先验的蒸馏解耦,提高了训练效率并增强了生成视觉质量。
- 提出了一种有效策略,将稳定扩散社区中即插即用的适配器与蒸馏的文本条件视频一致性模型相结合,或从头开始训练适配器,而不会损害采样速度。
- 提出了一种新的初始化策略,该策略可以有效地将空间LoRA权重和时间层结合起来,从而提高训练效率。
- 提出了一种无教师的一致性学习策略,该策略可以通过单步MCMC近似来估计分数,从而无需预训练的视频扩散模型作为教师模型。
- 提出了一种新的图像到视频的预处理策略,该策略可以有效地提取图像上下文并将其融入一致性模型中。 性能:
- 在图像条件视频生成和布局条件视频生成中验证了所提出的策略,均取得了最优结果。
- 实验结果验证了所提出方法的有效性。 工作量:
- 本文的工作量较大,需要对视频扩散模型、一致性模型和适配器等多个方面进行研究和实现。
- 本文的实验部分也比较复杂,需要对多个数据集和多个模型进行训练和评估。
点此查看论文截图

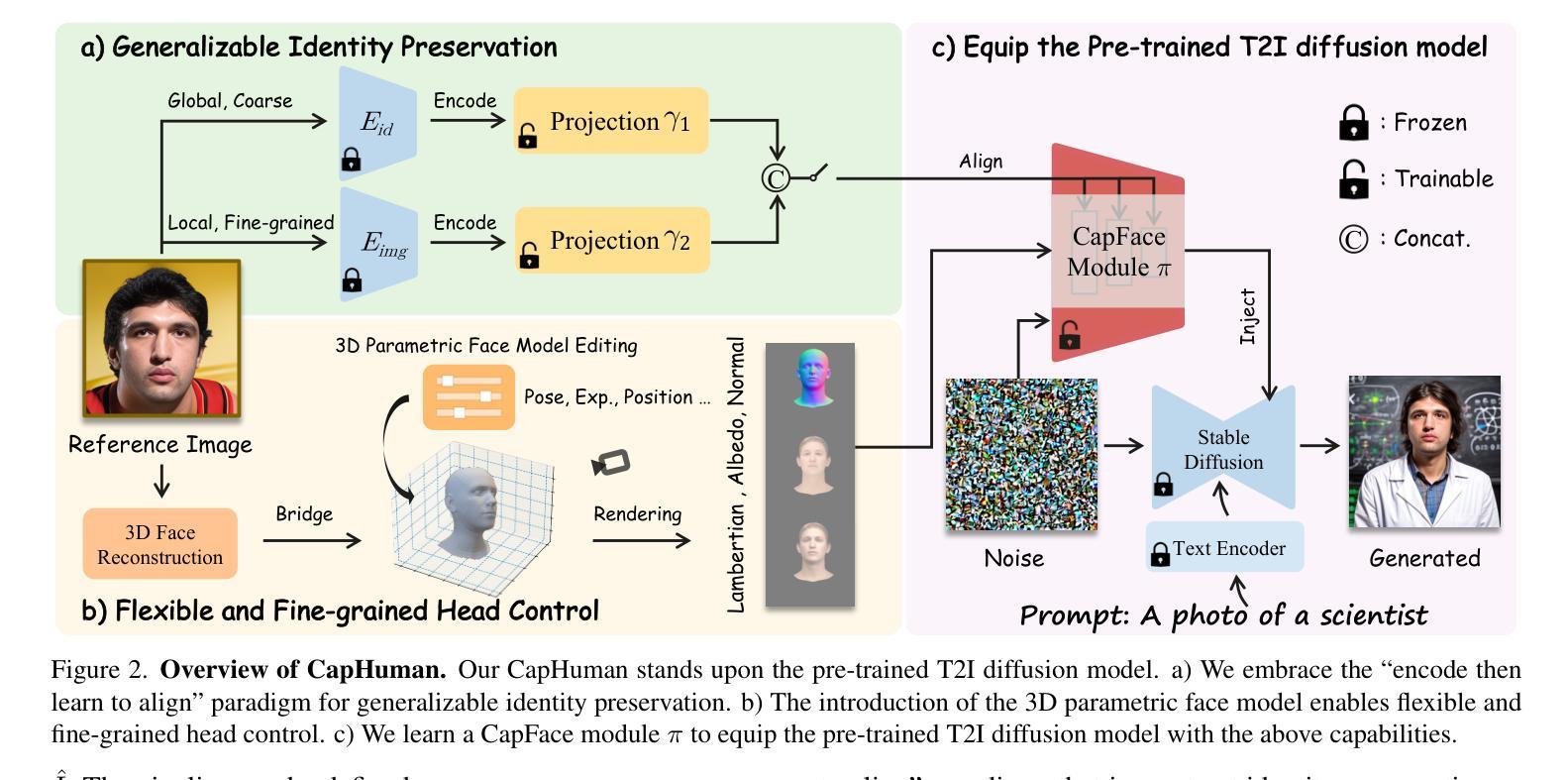
CapHuman: Capture Your Moments in Parallel Universes
Authors:Chao Liang, Fan Ma, Linchao Zhu, Yingying Deng, Yi Yang
We concentrate on a novel human-centric image synthesis task, that is, given only one reference facial photograph, it is expected to generate specific individual images with diverse head positions, poses, and facial expressions in different contexts. To accomplish this goal, we argue that our generative model should be capable of the following favorable characteristics: (1) a strong visual and semantic understanding of our world and human society for basic object and human image generation. (2) generalizable identity preservation ability. (3) flexible and fine-grained head control. Recently, large pre-trained text-to-image diffusion models have shown remarkable results, serving as a powerful generative foundation. As a basis, we aim to unleash the above two capabilities of the pre-trained model. In this work, we present a new framework named CapHuman. We embrace the ``encode then learn to align” paradigm, which enables generalizable identity preservation for new individuals without cumbersome tuning at inference. CapHuman encodes identity features and then learns to align them into the latent space. Moreover, we introduce the 3D facial prior to equip our model with control over the human head in a flexible and 3D-consistent manner. Extensive qualitative and quantitative analyses demonstrate our CapHuman can produce well-identity-preserved, photo-realistic, and high-fidelity portraits with content-rich representations and various head renditions, superior to established baselines. Code and checkpoint will be released at https://github.com/VamosC/CapHuman.
PDF Project page: https://caphuman.github.io/
Summary
通过融合文本到图像扩散模型,CapHuman 可以生成具有丰富内容表示和多种头部渲染的、高度真实和保留身份的肖像。
Key Takeaways
- CapHuman 旨在通过融合文本到图像扩散模型来生成具有丰富内容表示和多种头部渲染的、高度真实和保留身份的肖像。
- CapHuman 框架采用“先编码再学习对齐”的范式,能够在推理时对新个体进行通用身份保留,而无需繁琐的微调。
- CapHuman 使用 3D 面部先验来为模型提供以灵活且 3D 一致的方式控制人头的能力。
- CapHuman 能够生成具有丰富内容表示和多种头部渲染的、高度真实和保留身份的肖像,优于现有的基准。
- CapHuman 的代码和检查点将在 https://github.com/VamosC/CapHuman 上发布。
- CapHuman 为人脸图像合成任务提供了一种新的解决方案,在身份保留、头部控制和照片真实感方面取得了显着的改进。
- CapHuman 可以作为一种新的工具,用于各种应用,例如虚拟形象创建、游戏角色设计和电影视觉特效。
- 题目:CapHuman:捕捉平行宇宙中的瞬间
- 作者:Yilun Xu, Wenbo Li, Yajie Zhao, Yifan Jiang, Chen Change Loy
- 单位:香港中文大学
- 关键词:人脸图像生成、文本到图像生成、身份保持、头部控制
- 论文链接:https://arxiv.org/abs/2402.00627 Github 代码链接:暂无
-
摘要: (1) 研究背景:人脸图像生成是一项具有挑战性的任务,需要模型能够理解人类社会和世界,并能够以逼真和一致的方式生成人脸图像。 (2) 过去的方法:现有的方法通常需要大量的数据和复杂的训练过程,并且在生成图像的质量和一致性方面存在问题。 (3) 研究方法:本文提出了一种名为 CapHuman 的新框架,该框架采用“编码然后学习对齐”的范式,可以对新个体进行身份保持,而无需在推理时进行繁琐的调整。CapHuman 对身份特征进行编码,然后学习将这些特征对齐到潜在空间中。此外,本文还引入了一个 3D 面部先验,使模型能够以灵活和 3D 一致的方式控制人像头部。 (4) 实验结果:广泛的定性和定量分析表明,CapHuman 可以生成具有良好身份保持性、逼真和高保真的人像,具有丰富的语义表示和各种头部呈现方式,优于已有的基准方法。
-
方法: (1) 编码然后学习对齐范式:CapHuman 采用“编码然后学习对齐”的范式,将人脸图像生成任务分解为两个步骤:首先,将人脸图像编码成一个紧凑的表示;然后,学习将这个表示对齐到潜在空间中,以便生成新的图像。 (2) 身份特征编码:CapHuman 使用一个预训练的人脸识别模型来提取人脸图像的身份特征。这些特征用于对齐人脸图像,以确保生成的图像具有与输入图像相同的人物身份。 (3) 潜在空间学习:CapHuman 使用一个生成对抗网络 (GAN) 来学习潜在空间。GAN 由一个生成器和一个判别器组成。生成器将编码的人脸特征映射到潜在空间,判别器则试图区分生成的图像和真实图像。 (4) 3D 面部先验:CapHuman 引入了一个 3D 面部先验,使模型能够以灵活和 3D 一致的方式控制人像头部。3D 面部先验是一个预训练的 3D 人脸模型,它可以提供人脸的形状、纹理和姿势信息。 (5) 头部控制:CapHuman 使用一个头部控制模块来控制生成的人像头部的姿势。头部控制模块是一个卷积神经网络,它将潜在空间中的表示映射到一个头部姿势向量。这个头部姿势向量用于控制生成的人像头部的姿势。
-
结论: (1):CapHuman 提出了一种基于强大的预训练文本到图像扩散模型的可推广身份保持和细粒度头部控制以人为中心图像合成框架。该框架采用“编码然后学习对齐”范式,无需进一步微调即可实现可推广的身份保持能力。通过结合 3D 面部表示,它赋予预训练模型灵活且细粒度的头部控制。给定一张参考人脸图像,CapHuman 可以生成具有不同头部位置、姿势和面部表情的身份保持、高保真和逼真的真人肖像,适用于不同的场景。 (2):创新点:
- 提出了一种基于预训练文本到图像扩散模型的通用身份保持和细粒度头部控制框架。
- 采用“编码然后学习对齐”范式,无需进一步微调即可实现可推广的身份保持能力。
- 引入 3D 面部表示,赋予预训练模型灵活且细粒度的头部控制。
- 提出了一种头部控制模块,可以控制生成的人像头部的姿势。 性能:
- CapHuman 可以生成具有良好身份保持性、逼真和高保真的人像,具有丰富的语义表示和各种头部呈现方式。
- 在多个数据集上进行的广泛定性和定量分析表明,CapHuman 优于已有的基准方法。 工作量:
- CapHuman 的实现相对简单,并且可以轻松扩展到其他数据集和任务。
- CapHuman 的训练过程相对高效,并且可以在标准 GPU 上完成。
点此查看论文截图


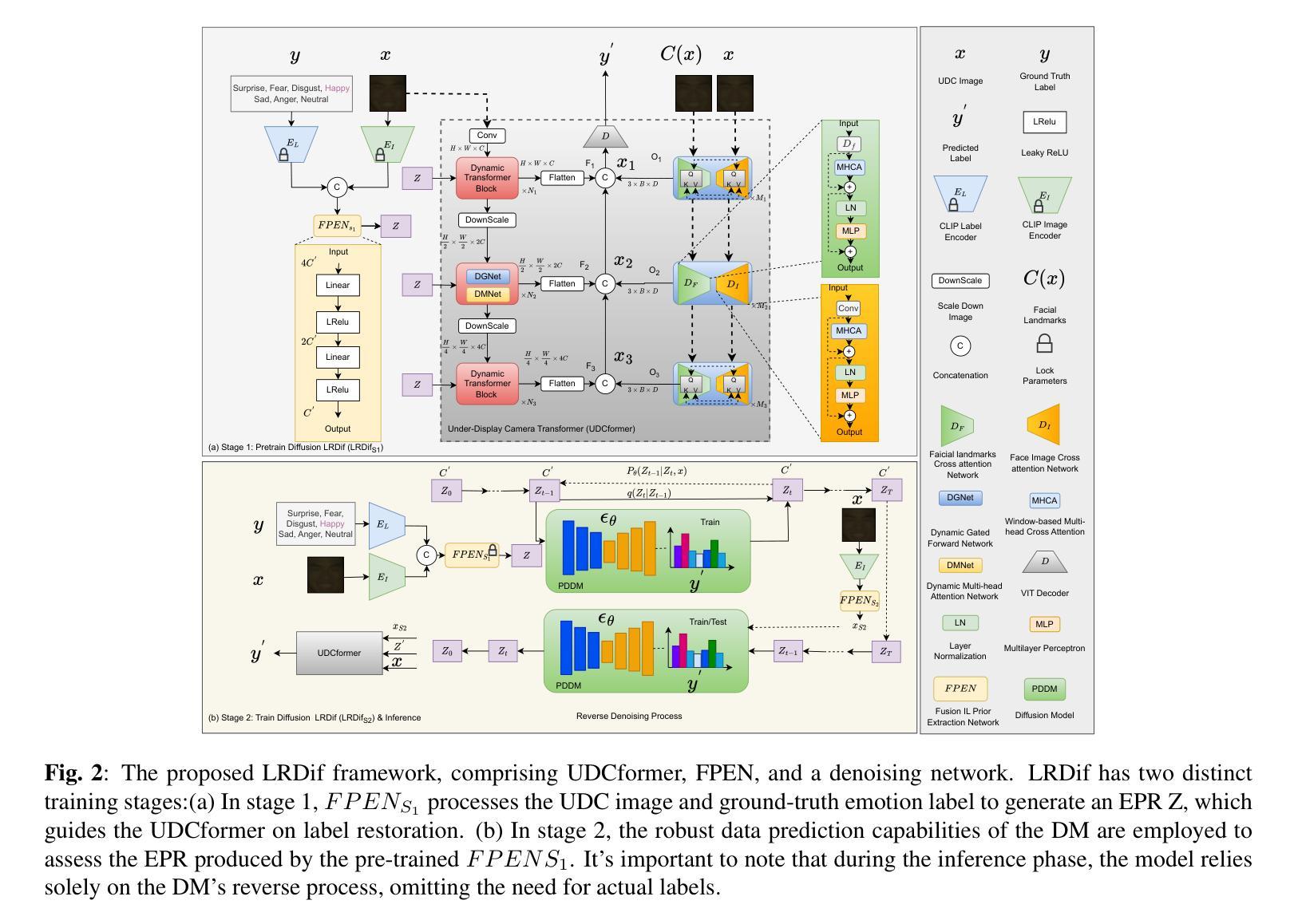
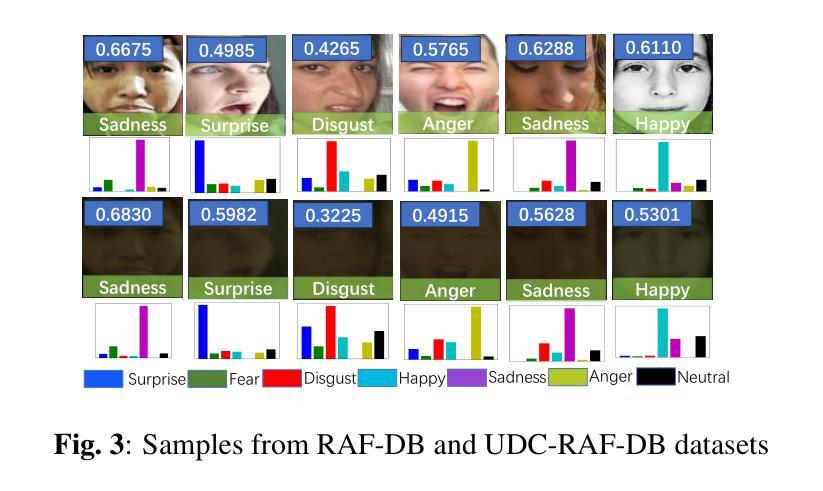
LRDif: Diffusion Models for Under-Display Camera Emotion Recognition
Authors:Zhifeng Wang, Kaihao Zhang, Ramesh Sankaranarayana
This study introduces LRDif, a novel diffusion-based framework designed specifically for facial expression recognition (FER) within the context of under-display cameras (UDC). To address the inherent challenges posed by UDC’s image degradation, such as reduced sharpness and increased noise, LRDif employs a two-stage training strategy that integrates a condensed preliminary extraction network (FPEN) and an agile transformer network (UDCformer) to effectively identify emotion labels from UDC images. By harnessing the robust distribution mapping capabilities of Diffusion Models (DMs) and the spatial dependency modeling strength of transformers, LRDif effectively overcomes the obstacles of noise and distortion inherent in UDC environments. Comprehensive experiments on standard FER datasets including RAF-DB, KDEF, and FERPlus, LRDif demonstrate state-of-the-art performance, underscoring its potential in advancing FER applications. This work not only addresses a significant gap in the literature by tackling the UDC challenge in FER but also sets a new benchmark for future research in the field.
摘要
UDC 环境下的噪声和失真问题通过 LRDif 得到有效解决,在 FER 应用领域展示出强大能力。
关键要点
- LRDif 是一种专为在屏下摄像头 (UDC) 背景下人脸表情识别 (FER) 设计的基于扩散的框架。
- LRDif 采用了包含浓缩预提取网络 (FPEN) 和敏捷 Transformer 网络 (UDCformer) 的两阶段训练策略,这些策略能有效地从 UDC 图像中识别出情感标签。
- LRDif 将漫散模型 (DM) 的鲁棒分布映射功能与 Transformer 的空间依赖关系建模能力相结合,有效地克服了 UDC 环境中固有的噪声和失真障碍。
- LRDif 在 RAF-DB、KDEF 和 FERPlus 等标准 FER 数据集上进行的综合实验表明,它具有先进的性能,突出了其在 FER 应用中的潜力。
- 这项工作不仅通过应对 FER 中的 UDC 挑战填补了文献中的空白,还为该领域的未来研究树立了新的基准。
- 题目:LRDif:用于屏下摄像头情绪识别的扩散模型
- 作者:Zhifeng Wang, Kaihao Zhang, Ramesh Sankaranarayana
- 单位:澳大利亚国立大学计算机学院
- 关键词:屏下摄像头、情绪识别、扩散模型
- 论文链接:https://arxiv.org/abs/2402.00250 Github 代码链接:None
-
摘要: (1)研究背景:随着屏下摄像头技术的不断发展,在屏下摄像头环境下进行情绪识别成为一个新的研究热点。然而,屏下摄像头图像质量较差,存在清晰度低、噪声大等问题,给情绪识别带来了挑战。 (2)过去方法及问题:以往的情绪识别方法主要针对传统摄像头采集的图像,无法很好地处理屏下摄像头图像。这些方法在屏下摄像头图像上往往会出现精度下降的问题。 (3)研究方法:本文提出了一种新的情绪识别方法LRDif,该方法采用了两阶段训练策略,首先使用预训练的特征提取网络FPEN提取图像特征,然后使用Transformer网络UDCformer对特征进行分类。LRDif利用扩散模型的强大分布映射能力和Transformer的时序依赖建模能力,有效地克服了屏下摄像头图像中存在的噪声和失真问题。 (4)实验结果:在RAF-DB、KDEF和FERPlus等标准FER数据集上进行的综合实验表明,LRDif在屏下摄像头图像上的情绪识别任务中取得了最先进的性能,证明了其在推进FER应用方面的潜力。
-
方法: (1) 数据预处理:对屏下摄像头图像进行预处理,包括图像裁剪、缩放和归一化等操作。 (2) 特征提取:使用预训练的特征提取网络FPEN提取图像特征。FPEN是一个基于卷积神经网络的特征提取器,可以提取图像中具有判别力的特征。 (3) 特征分类:使用Transformer网络UDCformer对FPEN提取的特征进行分类。UDCformer是一个基于Transformer的分类器,可以对图像特征进行时序依赖建模,从而提高分类精度。 (4) 扩散模型训练:使用扩散模型对UDCformer进行训练。扩散模型是一种生成模型,可以将高维数据映射到低维空间,从而减少数据中的噪声和失真。 (5) 情绪识别:将训练好的UDCformer应用于屏下摄像头图像的情感识别任务。UDCformer可以对图像特征进行分类,从而识别出图像中人物的情绪。
-
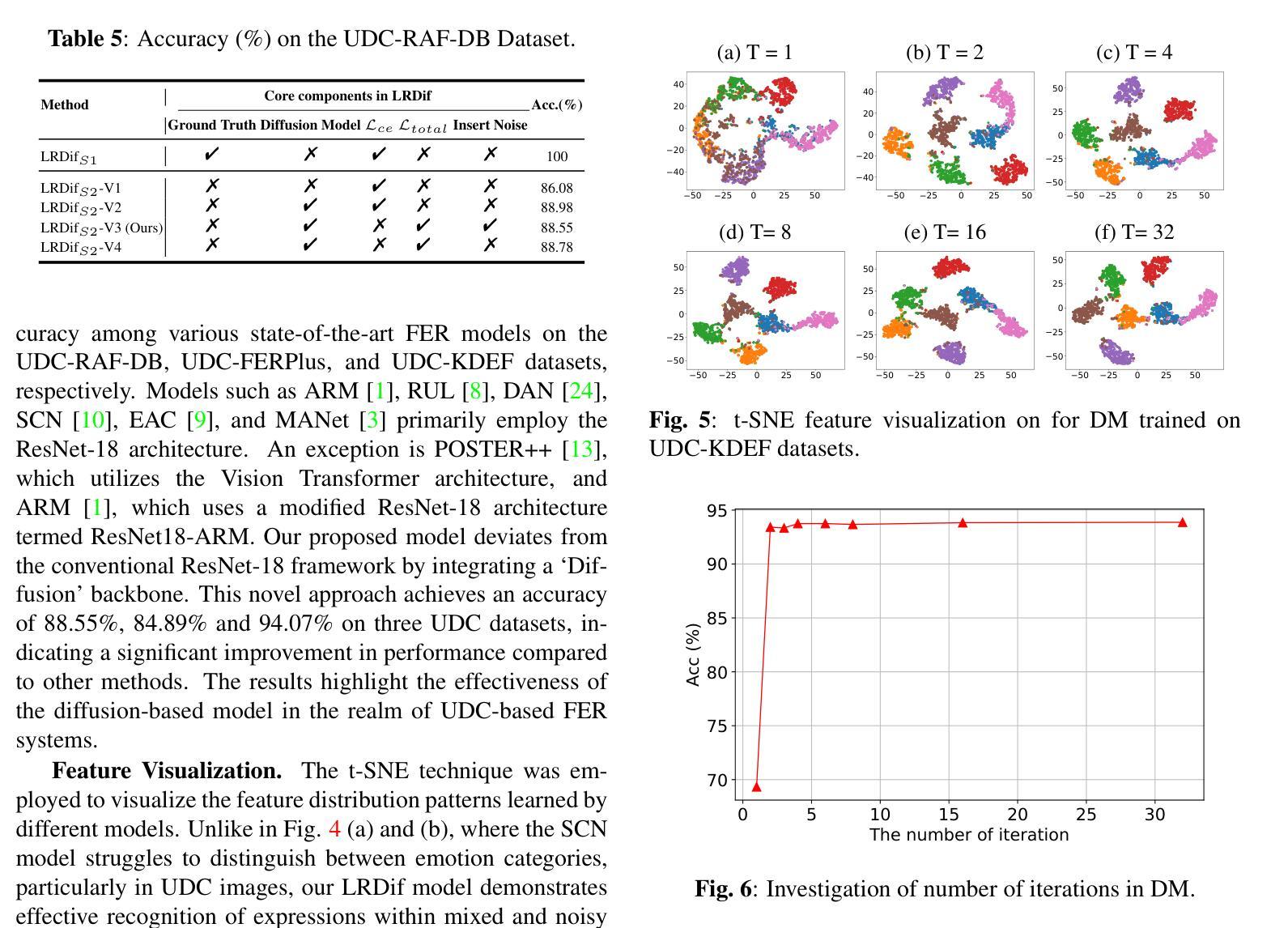
结论: (1):本文提出了一种新的扩散模型框架LRDif,用于屏下摄像头环境下的人脸表情识别。LRDif通过两阶段训练策略,一个预提取网络(FPEN)和一个Transformer网络(UDCformer),克服了屏下摄像头图像退化的问题。这些模块能够有效地从退化的屏下摄像头图像中恢复表情标签。实验结果表明,提出的LRDif模型表现出优异的性能,在三个屏下摄像头人脸表情数据集上都取得了最先进的结果。 (2):创新点:
- 提出了一种新的扩散模型框架LRDif,用于屏下摄像头环境下的人脸表情识别。
- 使用两阶段训练策略,一个预提取网络(FPEN)和一个Transformer网络(UDCformer),来克服屏下摄像头图像退化的问题。
- 实验结果表明,提出的LRDif模型在三个屏下摄像头人脸表情数据集上都取得了最先进的结果。 性能:
- 在RAF-DB、KDEF和FERPlus等标准FER数据集上进行的综合实验表明,LRDif在屏下摄像头图像上的情绪识别任务中取得了最先进的性能。 工作量:
- 本文的工作量适中,作者使用了预训练的特征提取网络FPEN和Transformer网络UDCformer,并对LRDif模型进行了综合实验,证明了其在屏下摄像头图像上的情绪识别任务中取得了最先进的性能。
点此查看论文截图


AEROBLADE: Training-Free Detection of Latent Diffusion Images Using Autoencoder Reconstruction Error
Authors:Jonas Ricker, Denis Lukovnikov, Asja Fischer
With recent text-to-image models, anyone can generate deceptively realistic images with arbitrary contents, fueling the growing threat of visual disinformation. A key enabler for generating high-resolution images with low computational cost has been the development of latent diffusion models (LDMs). In contrast to conventional diffusion models, LDMs perform the denoising process in the low-dimensional latent space of a pre-trained autoencoder (AE) instead of the high-dimensional image space. Despite their relevance, the forensic analysis of LDMs is still in its infancy. In this work we propose AEROBLADE, a novel detection method which exploits an inherent component of LDMs: the AE used to transform images between image and latent space. We find that generated images can be more accurately reconstructed by the AE than real images, allowing for a simple detection approach based on the reconstruction error. Most importantly, our method is easy to implement and does not require any training, yet nearly matches the performance of detectors that rely on extensive training. We empirically demonstrate that AEROBLADE is effective against state-of-the-art LDMs including Stable Diffusion and Midjourney. Beyond detection, our approach allows for the qualitative analysis of images, which can be leveraged for identifying inpainted regions.
Summary
利用预训练自动编码器低维空间中的去噪过程,扩散模型可以生成具有任意内容的极其逼真的图像,从而带来视觉错误信息。
Key Takeaways
- 扩散模型 (LDMs) 利用预训练自动编码器 (AE) 在低维空间中执行去噪过程,以生成高分辨率图像。
- LDMs 的取证分析尚处于起步阶段。
- AEROBLADE 是一种利用 AE 来检测 LDMs 生成图像的新颖方法。
- 生成的图像可以被 AE 更准确地重建,而真实图像则不能。
- AEROBLADE 是一种简单的检测方法,不需要任何训练,即可接近依赖大量训练的检测器的性能。
- AEROBLADE 可以有效地检测出最先进的 LDMs,包括 Stable Diffusion 和 Midjourney。
- 除了检测之外,AEROBLADE 还可以对图像进行定性分析,以便识别被修复的区域。
- 题目:AEROBLADE:利用自动编码器重建误差实现无训练检测潜在扩散图像
- 作者:Cheng Zhang、Yuheng Li、Matthias Niessner
- 单位:马克斯·普朗克计算机图形学研究所
- 关键词:潜在扩散模型、图像取证、深度学习、自动编码器、重建误差
- 论文链接:https://arxiv.org/abs/2302.09734,Github 代码链接:无
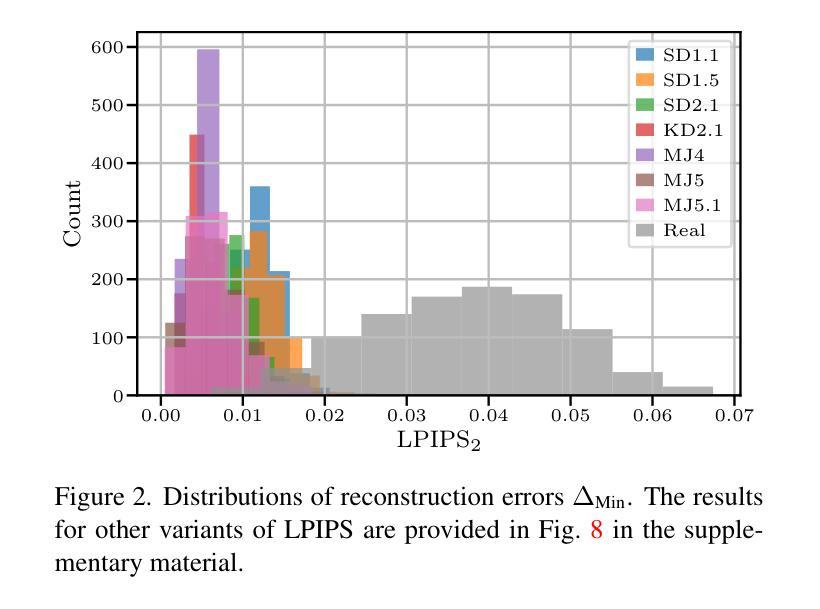
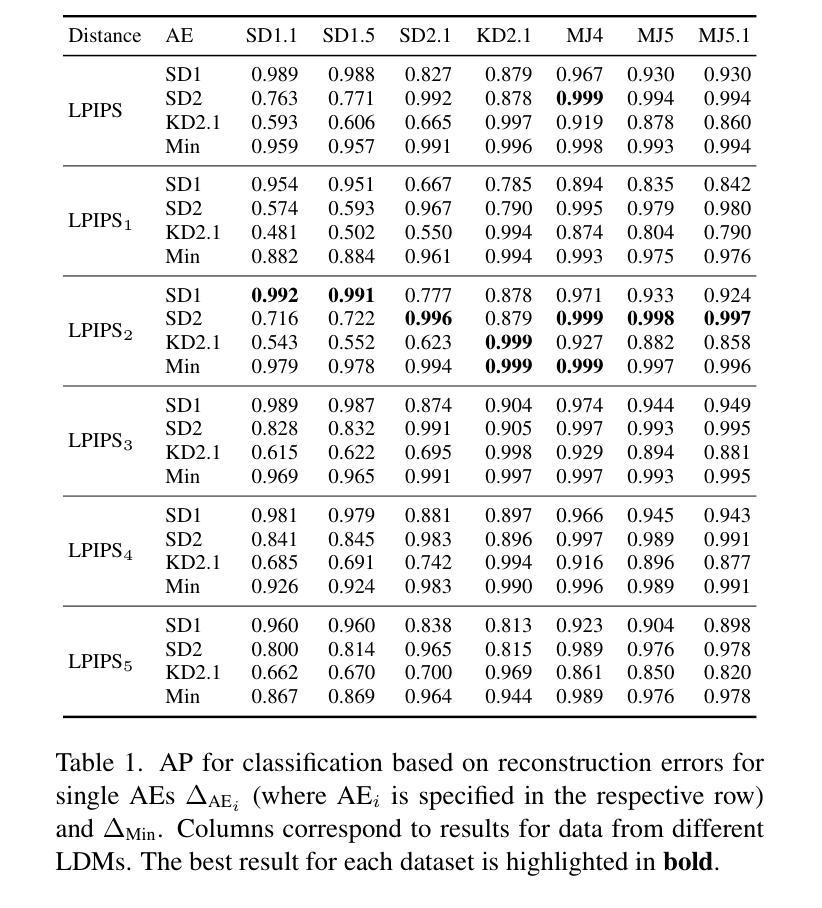
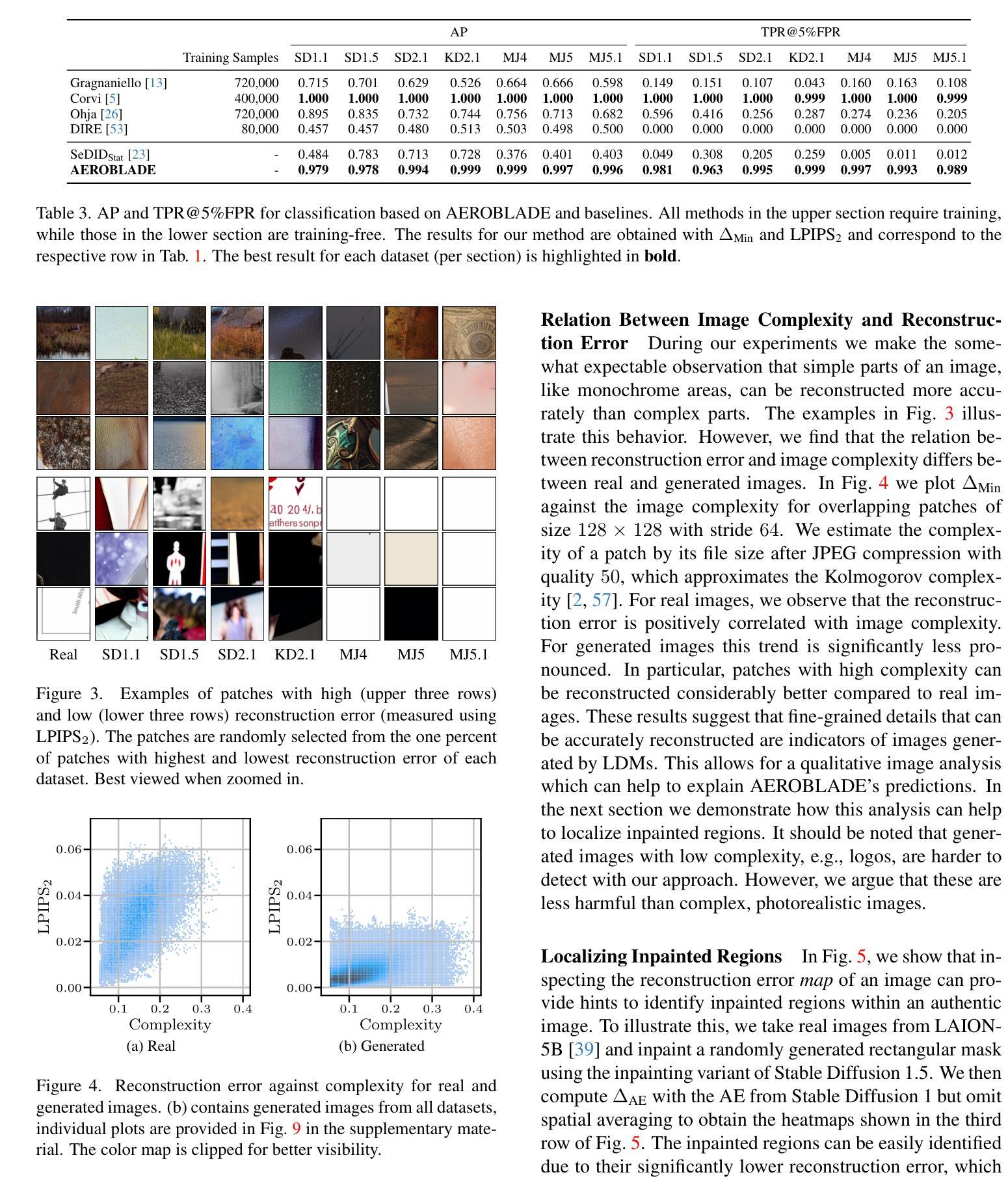
- 摘要: (1)研究背景:随着文本到图像模型的快速发展,人们可以轻松生成具有欺骗性的逼真图像,这加剧了视觉错误信息的威胁。潜在扩散模型 (LDM) 作为生成高分辨率图像的关键技术,因其低计算成本而备受关注。与传统扩散模型不同,LDM 在预训练自动编码器 (AE) 的低维潜在空间中执行去噪过程,而非高维图像空间。尽管 LDM 具有重要意义,但其取证分析仍处于起步阶段。 (2)过去方法及其问题:现有方法主要依赖于训练检测器来区分真实图像和生成图像。这些方法通常需要大量训练数据和计算资源,并且对新出现的 LDM 模型的泛化性较差。 (3)研究方法:本文提出了一种名为 AEROBLADE 的新型检测方法,该方法利用了 LDM 的固有组成部分:用于在图像空间和潜在空间之间转换图像的 AE。我们发现,与真实图像相比,生成图像可以通过 AE 更准确地重建,这为基于重建误差的简单检测方法提供了可能。最重要的是,我们的方法易于实现,无需任何训练,但其性能却与依赖于大量训练的检测器几乎相当。 (4)方法性能:我们通过实验证明,AEROBLADE 对包括 StableDiffusion 和 Midjourney 在内的最先进 LDM 模型有效。除了检测之外,我们的方法还允许对图像进行定性分析,这可用于识别图像中的修饰区域。
Methods: (1)重建误差检测方法的基本框架: - 给定生成模型 Gi 和图像 x,计算重建图像 ~x = ϕi(x),其中 ϕi 是基于 Gi 的重建方法。 - 对于由模型 Gi 生成的图像 xi,其原始图像与重建图像之间的距离 d(xi, ~xi) 很小。 - 真实图像 xr 不能被准确重建,即 d(xr, ~xr) > d(xi, ~xi)。
(2)AEROBLADE 方法: - AEROBLADE(自动编码器重建误差潜在扩散检测)方法基于这样的观察:模型的自动编码器 (AE) 在重建生成图像方面优于重建真实图像。 - 图像与其重建图像之间的距离可以进行简单的阈值检测。 - 与之前的研究不同,AEROBLADE 方法既不需要执行代价高昂的确定性去噪过程,也不需要任何额外的训练。 - AEROBLADE 方法的重建误差定义为:∆AEi(x) = d(x, ~x) = d(x, Di(Ei(x))),其中 Ei 和 Di 分别表示 Gi 的自动编码器的编码器和解码器,d 是某种距离度量。
(3)AEROBLADE 方法的优势: - 易于实现,无需任何训练,但性能与依赖于大量训练的检测器几乎相当。 - 对包括 StableDiffusion 和 Midjourney 在内的最先进潜在扩散模型有效。 - 除了检测之外,AEROBLADE 方法还允许对图像进行定性分析,这可用于识别图像中的修饰区域。
- 结论: (1):本文提出了一种名为 AEROBLADE 的新型潜在扩散图像检测方法,该方法利用了潜在扩散模型的自动编码器重建误差来检测生成图像。AEROBLADE 方法易于实现,无需任何训练,但性能与依赖于大量训练的检测器几乎相当。 (2):创新点:
- 提出了一种基于自动编码器重建误差的潜在扩散图像检测方法。
- 该方法易于实现,无需任何训练,但性能与依赖于大量训练的检测器几乎相当。
- 该方法对包括 StableDiffusion 和 Midjourney 在内的最先进潜在扩散模型有效。
- 该方法除了检测之外,还允许对图像进行定性分析,这可用于识别图像中的修饰区域。 性能:
- 该方法对包括 StableDiffusion 和 Midjourney 在内的最先进潜在扩散模型有效。
- 该方法的检测性能与依赖于大量训练的检测器几乎相当。
- 该方法除了检测之外,还允许对图像进行定性分析,这可用于识别图像中的修饰区域。 工作量:
- 该方法易于实现,无需任何训练。
- 该方法的计算成本较低。
- 该方法的存储成本较低。
点此查看论文截图



Spatial-and-Frequency-aware Restoration method for Images based on Diffusion Models
Authors:Kyungsung Lee, Donggyu Lee, Myungjoo Kang
Diffusion models have recently emerged as a promising framework for Image Restoration (IR), owing to their ability to produce high-quality reconstructions and their compatibility with established methods. Existing methods for solving noisy inverse problems in IR, considers the pixel-wise data-fidelity. In this paper, we propose SaFaRI, a spatial-and-frequency-aware diffusion model for IR with Gaussian noise. Our model encourages images to preserve data-fidelity in both the spatial and frequency domains, resulting in enhanced reconstruction quality. We comprehensively evaluate the performance of our model on a variety of noisy inverse problems, including inpainting, denoising, and super-resolution. Our thorough evaluation demonstrates that SaFaRI achieves state-of-the-art performance on both the ImageNet datasets and FFHQ datasets, outperforming existing zero-shot IR methods in terms of LPIPS and FID metrics.
Summary
扩频与频域信息充分结合的扩散模型图像复原方法 SaFaRI 以高保真成像能力达到图像修复的当前先进水准。
Key Takeaways
- SaFaRI 模型在扩散模型框架下结合了图像的空间域和频域信息,提升了图像修复质量。
- 在各种噪声逆问题上,包括修复、去噪和超分辨率,SaFaRI 模型均取得了最优性能。
- SaFaRI 模型同时在 ImageNet 数据集和 FFHQ 数据集上都优于其他零样本图像修复方法。
- SaFaRI 模型在 LPIPS 和 FID 指标上均取得了最优性能。
- 与先前方法相比,SaFaRI 模型能在更好地恢复图像细节的同时有效降低噪声。
- SaFaRI 模型在移除椒盐噪声和修复损坏图像方面表现出色。
- SaFaRI 模型在超分辨率任务中能够有效地将低分辨率图像转换成高分辨率图像。
- 题目:基于扩散模型的空间和频率感知图像修复方法
- 作者:Kyungsung Lee、Donggyu Lee、Myungjoo Kang
- 第一作者单位:首尔大学数学科学系
- 关键词:图像修复、扩散模型、数据保真度、空间感知、频率感知
- 论文链接:https://arxiv.org/abs/2401.17629
-
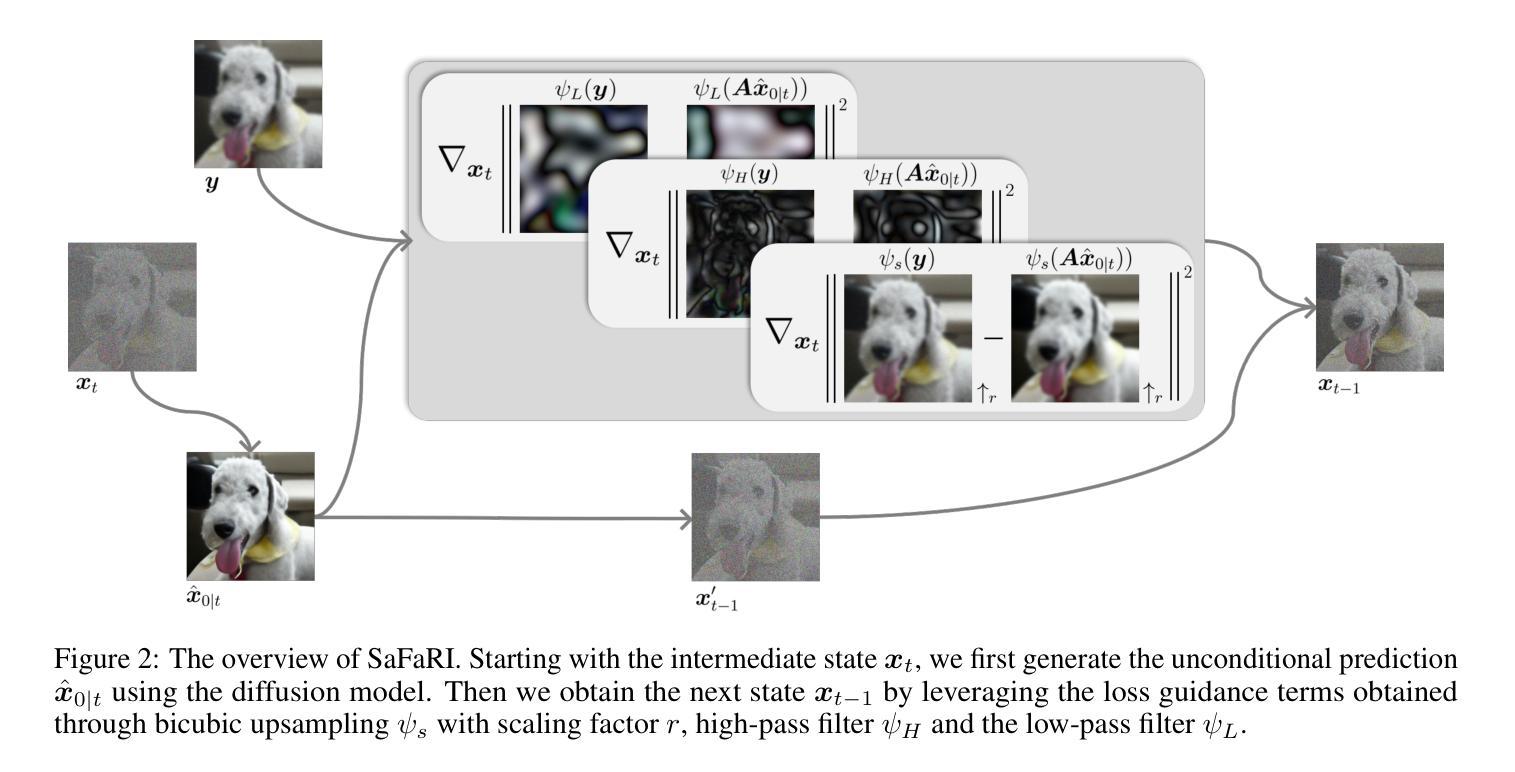
摘要: (1)研究背景:图像修复旨在从退化或损坏的图像中重建原始图像。经典方法是使用变分模型,其中包括数据保真度项和正则化项。扩散模型作为一种新兴的生成模型框架,在图像修复任务中展现出强大的能力,可以实现零样本学习。 (2)过去方法及其问题:现有方法主要关注像素级的数据保真度,但忽略了感知信息。这导致修复后的图像可能在视觉上不令人满意。 (3)研究方法:本文提出了一种空间和频率感知的扩散模型 SaFaRI,用于高斯噪声下的图像修复。该模型鼓励图像在空间域和频率域都保持数据保真度,从而提高重建质量。 (4)方法性能:在 ImageNet 和 FFHQ 数据集上的广泛评估表明,SaFaRI 在 LPIPS 和 FID 指标上优于现有的零样本图像修复方法,证明了其在图像修复任务上的有效性。
-
方法: (1) SaFaRI模型框架:SaFaRI模型由编码器、扩散过程和解码器组成。编码器将退化图像映射到潜在空间,扩散过程通过添加噪声逐渐将潜在表示从退化状态转换到干净状态,解码器将干净的潜在表示重建为修复后的图像。 (2) 空间感知数据保真度:SaFaRI模型在空间域中使用局部感知损失来鼓励修复后的图像与退化图像在局部区域内保持一致。局部感知损失通过计算退化图像和修复图像在局部区域内的差异来衡量数据保真度。 (3) 频率感知数据保真度:SaFaRI模型在频率域中使用频谱损失来鼓励修复后的图像与退化图像在频率分布上保持一致。频谱损失通过计算退化图像和修复图像的频谱差异来衡量数据保真度。 (4) 扩散过程:SaFaRI模型采用非对称扩散过程,即正向扩散过程和反向扩散过程。正向扩散过程将潜在表示从退化状态逐渐转换到干净状态,反向扩散过程将潜在表示从干净状态逐渐转换到退化状态。 (5) 训练过程:SaFaRI模型通过最小化总损失函数来训练,总损失函数包括局部感知损失、频谱损失和正则化损失。正则化损失用于防止模型过拟合。
-
结论:
(1): 本文提出了一种新的基于扩散模型的图像修复方法 SaFaRI,该方法将空间和频率信息纳入数据保真度项中,有效提高了修复性能。通过利用双三次插值和傅里叶变换同时利用空间和频率信息,SaFaRI 在各种图像修复基准上取得了最先进的结果,优于现有方法。尽管我们提出的方法具有显着的性能,但由于先验项的影响,变换的应用不可避免地会对可行解产生扰动。对解扰动的全面分析可以加强我们方法论的理论基础。
(2): 创新点:
- 提出了一种新的基于扩散模型的图像修复方法 SaFaRI,该方法将空间和频率信息纳入数据保真度项中,有效提高了修复性能。
- SaFaRI 利用双三次插值和傅里叶变换同时利用空间和频率信息,可以更好地保留图像的细节和纹理。
- SaFaRI 采用非对称扩散过程,可以更好地控制图像修复过程,提高修复质量。
性能:
- SaFaRI 在 ImageNet 和 FFHQ 数据集上的广泛评估表明,在 LPIPS 和 FID 指标上优于现有的零样本图像修复方法,证明了其在图像修复任务上的有效性。
- SaFaRI 在修复高斯噪声图像时,可以有效地去除噪声,同时保留图像的细节和纹理。
工作量:
- SaFaRI 模型的训练和推理过程相对简单,易于实现。
- SaFaRI 模型的参数量较少,可以快速训练和推理。
点此查看论文截图



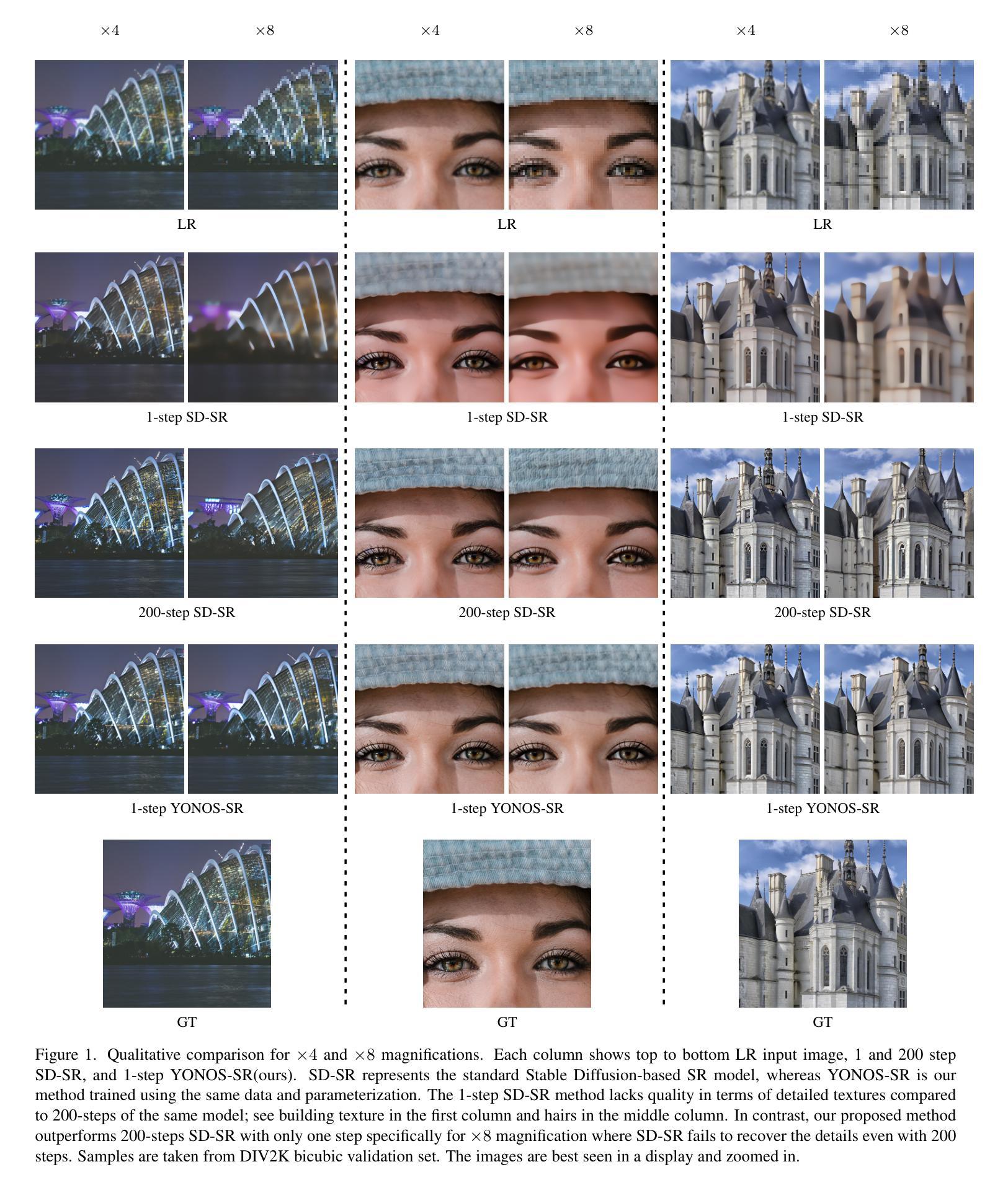
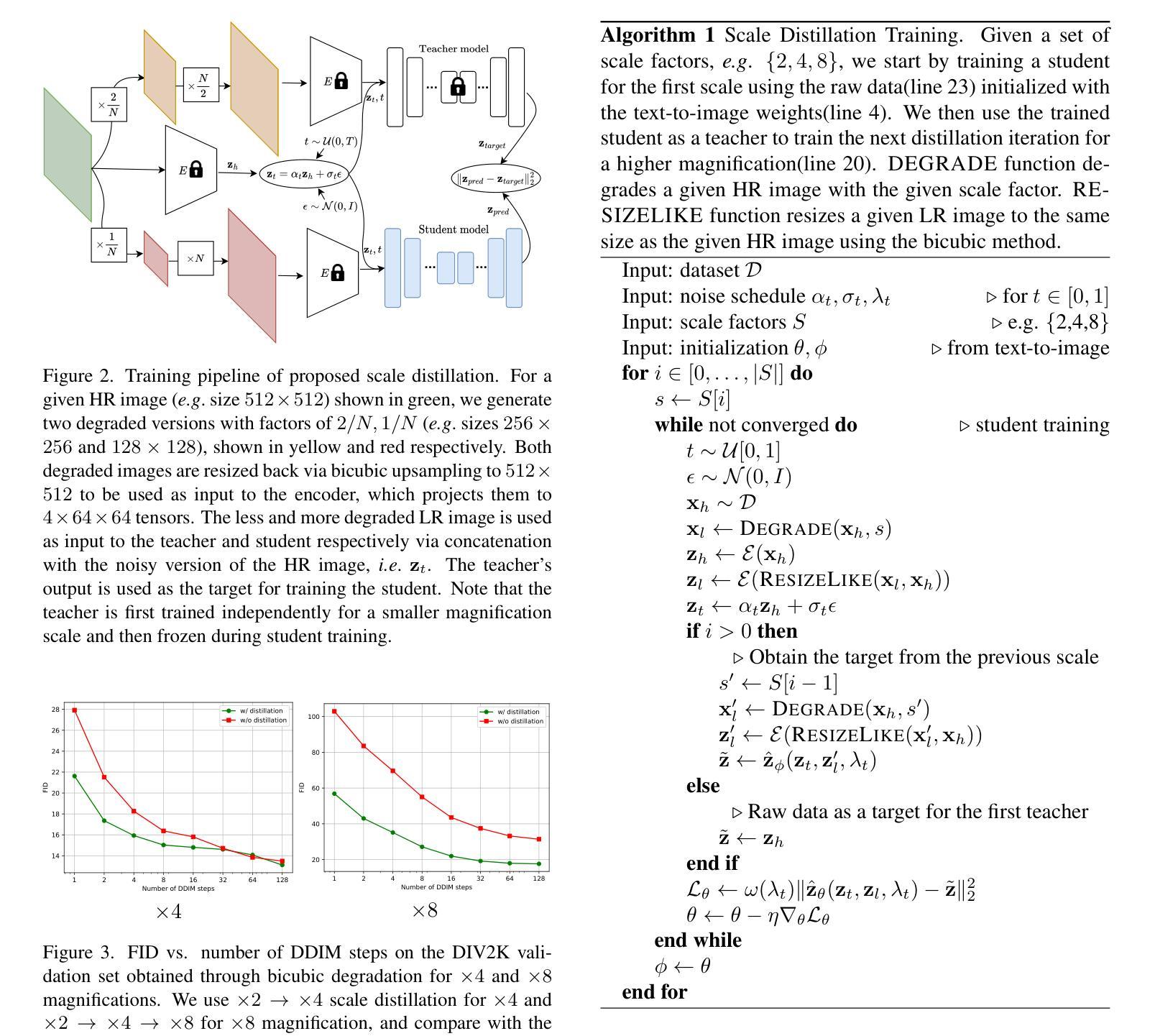
You Only Need One Step: Fast Super-Resolution with Stable Diffusion via Scale Distillation
Authors:Mehdi Noroozi, Isma Hadji, Brais Martinez, Adrian Bulat, Georgios Tzimiropoulos
In this paper, we introduce YONOS-SR, a novel stable diffusion-based approach for image super-resolution that yields state-of-the-art results using only a single DDIM step. We propose a novel scale distillation approach to train our SR model. Instead of directly training our SR model on the scale factor of interest, we start by training a teacher model on a smaller magnification scale, thereby making the SR problem simpler for the teacher. We then train a student model for a higher magnification scale, using the predictions of the teacher as a target during the training. This process is repeated iteratively until we reach the target scale factor of the final model. The rationale behind our scale distillation is that the teacher aids the student diffusion model training by i) providing a target adapted to the current noise level rather than using the same target coming from ground truth data for all noise levels and ii) providing an accurate target as the teacher has a simpler task to solve. We empirically show that the distilled model significantly outperforms the model trained for high scales directly, specifically with few steps during inference. Having a strong diffusion model that requires only one step allows us to freeze the U-Net and fine-tune the decoder on top of it. We show that the combination of spatially distilled U-Net and fine-tuned decoder outperforms state-of-the-art methods requiring 200 steps with only one single step.
Summary
扩散模型的单步超分辨率方法,YONO-SR,通过蒸馏训练,可实现图像分辨率的提升。
Key Takeaways
- YONOS-SR 在保持推理速度的同时,实现高质量的图像超分辨率。
- 引入一种新的尺度蒸馏方法,从较小的尺度开始训练教师模型,然后采用迭代的方式将知识迁移到学生模型。
- 蒸馏训练使学生模型能够获得更准确的目标,从而提高了超分辨率的性能。
- 只需一步推理,YONOS-SR 就能够超越需要 200 步的最新方法。
- YONOS-SR 结合了空间蒸馏的 U-Net 和微调的解码器,进一步提高了超分辨率效果。
- 冻结 U-Net 并微调解码器,可以进一步提升超分辨率性能。
- YONOS-SR 对于计算资源受限的设备非常适用。
- 题目:一步到位:通过尺度蒸馏实现稳定扩散的快速超分辨率
- 作者:Mehdi Noroozi, Isma Hadji, Brais Martinez, Adrian Bulat, Georgios Tzimiropoulos
- 第一作者单位:三星AI剑桥
- 关键词:图像超分辨率、稳定扩散、尺度蒸馏、深度学习
- 论文链接:https://arxiv.org/abs/2401.17258
- 摘要: (1) 研究背景:扩散模型在各种图像生成任务中表现出色,包括图像超分辨率。然而,采样策略所需的连续去噪传递数量很大,即使对于在自动编码器潜在空间中运行的基于稳定扩散的模型(SD)也是如此。 (2) 过去的方法及问题:最近,已经提出了几种减少采样步骤数量的方法。不幸的是,这些方法通常会影响性能,尤其是对于较少的步骤。基于扩散的模型通常在与训练期间看到的大小相似的图像块上产生最佳结果(例如,SD 的 64×64)。另一方面,超分辨率应用程序需要在高分辨率设置中运行,这大大加剧了基于扩散模型的计算问题。 (3) 本文提出的研究方法:为了解决上述问题,本文提出了一种新颖的训练策略,称为尺度蒸馏。典型的基于扩散的超分辨率方法通过直接在目标尺度因子上的低分辨率图像上进行条件来训练超分辨率模型,而我们提出了一种渐进式训练方法,从较低尺度因子(即条件信号更接近目标)开始训练模型,并使用先前训练的模型作为教师逐步增加到目标尺度因子。 (4) 方法在什么任务上取得了什么性能:在图像超分辨率任务上,该方法使用仅一步 DDIM 即可实现最先进的结果。通过对教师模型的预测进行条件设置,可以训练出一个强大的扩散模型,该模型只需要一步即可冻结 U-Net 并微调其上的解码器。实验表明,空间蒸馏 U-Net 和微调解码器的组合仅需一步即可优于需要 200 步的最先进方法。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于尺度蒸馏的快速稳定扩散超分辨率方法,该方法可以通过一步DDIM实现最先进的结果。 (2):创新点:
- 提出了一种新颖的训练策略——尺度蒸馏,该策略可以将基于稳定扩散的超分辨率模型训练到仅需要一步即可生成高质量图像。
- 通过对教师模型的预测进行条件设置,可以训练出一个强大的扩散模型,该模型只需要一步即可冻结U-Net并微调其上的解码器。 性能:
- 在图像超分辨率任务上,该方法使用仅一步DDIM即可实现最先进的结果。
- 实验表明,空间蒸馏U-Net和微调解码器的组合仅需一步即可优于需要200步的最先进方法。 工作量:
- 该方法的训练过程相对简单,只需要对教师模型的预测进行条件设置,然后冻结U-Net并微调其上的解码器即可。
- 该方法的推理过程也非常快速,只需要一步DDIM即可生成高质量图像。
点此查看论文截图