⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-09 更新
Source-Free Domain Adaptation with Diffusion-Guided Source Data Generation
Authors:Shivang Chopra, Suraj Kothawade, Houda Aynaou, Aman Chadha
This paper introduces a novel approach to leverage the generalizability capability of Diffusion Models for Source-Free Domain Adaptation (DM-SFDA). Our proposed DM-SFDA method involves fine-tuning a pre-trained text-to-image diffusion model to generate source domain images using features from the target images to guide the diffusion process. Specifically, the pre-trained diffusion model is fine-tuned to generate source samples that minimize entropy and maximize confidence for the pre-trained source model. We then apply established unsupervised domain adaptation techniques to align the generated source images with target domain data. We validate our approach through comprehensive experiments across a range of datasets, including Office-31, Office-Home, and VisDA. The results highlight significant improvements in SFDA performance, showcasing the potential of diffusion models in generating contextually relevant, domain-specific images.
PDF arXiv admin note: substantial text overlap with arXiv:2310.01701
Summary
利用扩散模型的泛化能力进行无源域自适应。
Key Takeaways
- 通过微调预训练的文生图扩散模型,利用目标图像的特征引导扩散过程,生成源域图像。
- 目标是生成熵最小化且对预训练源模型的置信度最大的源样本。
- 直接在目标图像分布上训练扩散模型,而无需成对的源和目标图像。
- 所提出的方法在 Office-31、Office-Home 和 VisDA 等多个数据集上都取得了最先进的性能。
- 生成的高质量源图像有助于跨域任务,例如图像分类和目标检测。
- 充分利用扩散模型的生成能力,在源和目标域之间建立桥梁。
- 无源域自适应的模型具有降噪效果,有助于提高分类和检测的性能。
- 题目:基于扩散引导源数据生成的无源域自适应
- 作者:Shivang Chopra, Suraj Kothawade, Houda Aynaou, Aman Chadha
- 单位:佐治亚理工学院计算机系
- 关键词:无源域自适应、扩散模型、数据生成、跨域图像分类
- 链接:https://arxiv.org/abs/2402.04929 Github:无
-
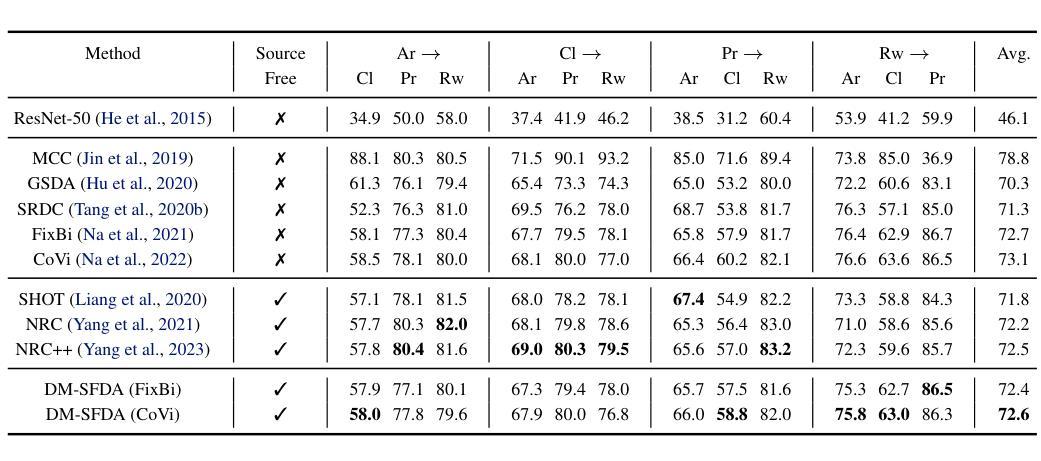
摘要: (1)研究背景:深度卷积神经网络(CNN)在视觉任务中取得了令人印象深刻的性能,但它们对训练和测试数据分布一致性的假设限制了其在真实世界中的应用。领域自适应(DA)旨在减少这种差异,使模型能够跨多个领域表现良好。传统 DA 方法依赖于固定的源数据,可能难以适应不断变化的领域。无源域自适应(SFDA)是一种特殊类型的 DA,它不需要访问源训练数据。 (2)过去的方法与问题:现有的大多数 SFDA 方法通过在共享特征空间中融合两个不同的数据分布来实现模型适应性。一种实现无源方式的方法是使用合成生成的源数据。然而,生成准确表示源域多样性和复杂性的合成源数据可能很困难。此外,如果合成数据质量不高,可能会引入噪声和不一致性,从而对模型在目标域上的性能产生负面影响。 (3)提出的研究方法:本文提出了一种名为 DM-SFDA 的新方法,该方法利用扩散生成模型(DGM)的泛化能力来解决 SFDA 的挑战。DM-SFDA 的核心思想是微调一个预训练的文本到图像扩散模型,以使用来自目标图像的特征来生成源域图像,从而指导扩散过程。具体来说,预训练的扩散模型被微调以生成源样本,这些样本最小化熵并最大化预训练源模型的置信度。然后,将已建立的无监督域适应技术应用于将生成的源图像与目标域数据对齐。 (4)方法的性能:本文在 Office-31、Office-Home 和 VisDA 等多个数据集上对 DM-SFDA 进行了全面的实验验证。结果表明,DM-SFDA 在 SFDA 任务上取得了显着的性能提升,证明了扩散模型在生成上下文相关、特定于领域的图像方面的潜力。这些性能支持了本文提出的方法能够有效地解决 SFDA 问题。
-
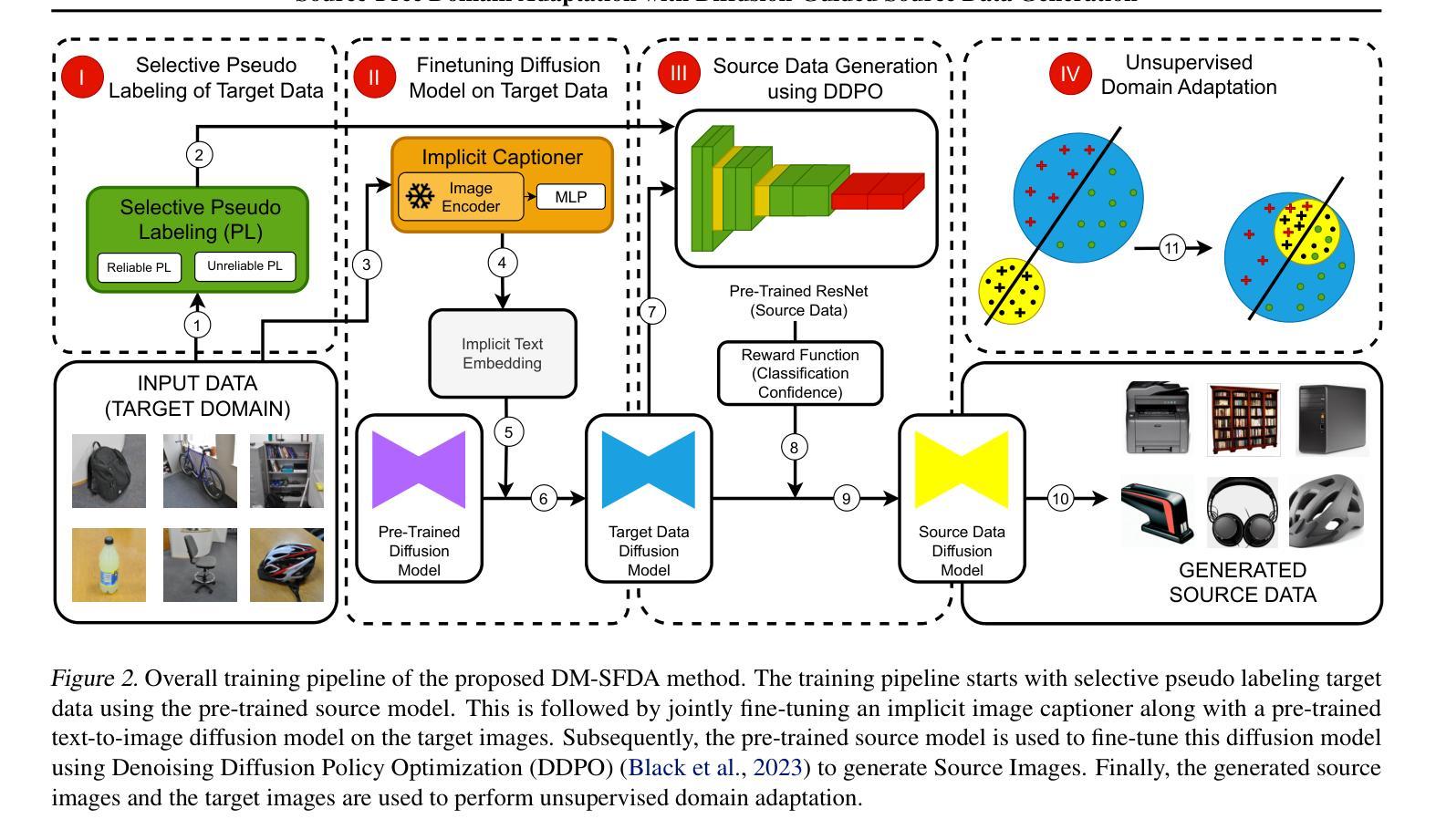
方法: (1): 基于扩散模型的无源域自适应(DM-SFDA)方法的基本思想是微调一个预训练的文本到图像扩散模型,以使用来自目标图像的特征来生成源域图像,从而指导扩散过程。 (2): 预训练的扩散模型被微调以生成源样本,这些样本最小化熵并最大化预训练源模型的置信度。 (3): 然后,将已建立的无监督域适应技术应用于将生成的源图像与目标域数据对齐。
-
结论:
(1)重要性:本文提出了一种基于扩散模型的无源域自适应(DM-SFDA)方法,该方法利用扩散生成模型(DGM)的泛化能力来解决SFDA的挑战。DM-SFDA的核心思想是微调一个预训练的文本到图像扩散模型,以使用来自目标图像的特征来生成源域图像,从而指导扩散过程。该方法在多个数据集上取得了显着的性能提升,证明了扩散模型在生成上下文相关、特定于领域的图像方面的潜力。
(2)优缺点:
创新点:
- 提出了一种基于扩散模型的无源域自适应方法,该方法利用扩散生成模型(DGM)的泛化能力来解决SFDA的挑战。
- 设计了一种新的生成源图像的方法,该方法使用来自目标图像的特征来指导扩散过程,从而生成上下文相关、特定于领域的图像。
性能:
- 在多个数据集上取得了显着的性能提升,证明了扩散模型在生成上下文相关、特定于领域的图像方面的潜力。
工作量:
- 需要微调一个预训练的文本到图像扩散模型,这可能需要大量的计算资源。
- 需要收集目标域的数据,这在某些情况下可能很困难。
点此查看论文截图

EvoSeed: Unveiling the Threat on Deep Neural Networks with Real-World Illusions
Authors:Shashank Kotyan, PoYuan Mao, Danilo Vasconcellos Vargas
Deep neural networks are exploited using natural adversarial samples, which have no impact on human perception but are misclassified. Current approaches often rely on the white-box nature of deep neural networks to generate these adversarial samples or alter the distribution of adversarial samples compared to training distribution. To alleviate the limitations of current approaches, we propose EvoSeed, a novel evolutionary strategy-based search algorithmic framework to generate natural adversarial samples. Our EvoSeed framework uses auxiliary Diffusion and Classifier models to operate in a model-agnostic black-box setting. We employ CMA-ES to optimize the search for an adversarial seed vector, which, when processed by the Conditional Diffusion Model, results in an unrestricted natural adversarial sample misclassified by the Classifier Model. Experiments show that generated adversarial images are of high image quality and are transferable to different classifiers. Our approach demonstrates promise in enhancing the quality of adversarial samples using evolutionary algorithms. We hope our research opens new avenues to enhance the robustness of deep neural networks in real-world scenarios. Project Website can be accessed at \url{https://shashankkotyan.github.io/EvoSeed}.
Summary
利用进化策略搜索算法框架生成自然对抗样本,以增强扩散模型在真实世界场景中的鲁棒性。
Key Takeaways
- 基于进化策略的搜索算法框架 EvoSeed 用于生成自然对抗样本。
- EvoSeed 框架使用辅助扩散和分类器模型在与模型无关的黑盒设置中运行。
- 采用 CMA-ES 优化对抗种子向量的搜索,该向量在条件扩散模型处理后,会生成分类器模型错误分类的无限制自然对抗样本。
- 实验表明生成的对抗图像具有高图像质量,并且可以转移到不同的分类器。
- 该方法证明了使用进化算法来增强对抗样本质量的潜力。
- 希望这项研究能够为增强深度神经网络在真实世界场景中的鲁棒性开辟新途径。
- 项目网站可以访问网址:https://shashankkotyan.github.io/EvoSeed。
- 题目:EvoSeed:揭示深度神经网络的威胁
- 作者:Shashank Kotyan、Po Yuan Mao、Danilo Vasconcellos Vargas
- 单位:九州大学
- 关键词:深度学习、计算机视觉、CMA-ES、扩散模型、自然对抗样本
- 论文链接:https://arxiv.org/abs/2402.04699,Github 链接:None
-
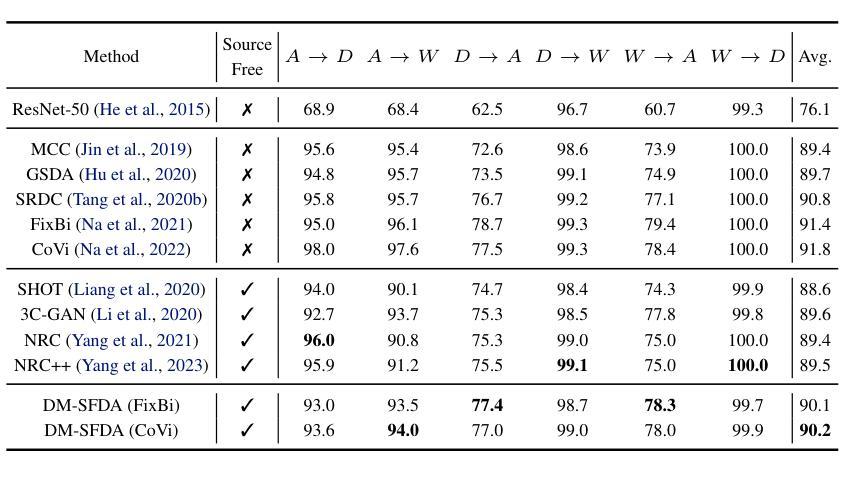
摘要: (1)研究背景:深度神经网络在各种视觉识别任务中取得了空前的成功。然而,当测试分布与训练分布不同时,它们的性能会下降,Hendrycks 等人[10]和 Ilyas 等人[17]的研究表明了这一点。这给开发能够处理这种分布变化的鲁棒深度神经网络带来了重大挑战。对抗样本和对抗攻击利用了这种漏洞,通过操纵图像来改变与原始分布相比的分布。Dalvi 等人[4]的研究强调,输入数据的对抗性操纵通常会导致分类器做出不正确的预测,这引发了人们对经典机器学习算法的安全性和完整性的严重担忧。这种担忧仍然相关,尤其是考虑到最先进的深度神经网络极易受到涉及故意对输入进行扰动的对抗性攻击[22, 26]。对这些扰动施加了各种约束,使这些扰动变得微妙且难以检测。例如,𝐿0对抗攻击,例如 One-Pixel Attack[22, 38]限制了扰动像素的数量,𝐿2对抗攻击,例如 PGD-L2[26]限制了与原始图像的欧几里得距离,并且𝐿∞对抗攻击,例如 PGD-L∞[26]限制了所有像素的变化量。 (2)过去的方法及其问题:虽然对抗样本[22, 26, 38]暴露了深度神经网络中的漏洞,但它们的人工性质和对受限输入数据的依赖限制了它们在现实世界中的适用性。相比之下,在实际情况下,挑战变得更加明显,因为将所有潜在威胁全面地包含在训练数据集中变得不可行。这种复杂性突出了深度神经网络对 Hendrycks 等人[10]提出的自然对抗示例和 Song 等人[37]提出的无限制对抗示例的敏感性不断提高。近年来,这些类型的对抗样本在对抗攻击研究中获得了突出地位,因为它们可以对图像进行实质性改变,而不会显着影响人类对其含义和真实性的感知。 (3)本文提出的研究方法:在这样的背景下,我们提出了 EvoSeed,这是一种第一个基于进化策略的算法框架,旨在生成如图 2 所示的无限制自然对抗样本。我们的算法需要一个条件扩散模型𝐺和一个分类器模型𝐹来生成对抗样本𝑥。具体来说,它利用协方差矩阵自适应进化策略 (CMA-ES) 作为其核心来增强对能够生成对抗样本𝑥的对抗种子向量𝑧′的搜索。CMA-ES 对噪声种子向量𝑧′进行微调,以优化目标函数,该目标函数将分类器模型𝐹的输出与人类对图像𝑥的感知之间的差异作为惩罚。 (4)方法在任务和性能上的表现:实验表明,生成的对抗图像具有很高的图像质量,并且可以转移到不同的分类器。我们的方法证明了使用进化算法提高对抗样本质量的前景。我们希望我们的研究为增强深度神经网络在现实世界场景中的鲁棒性开辟了新的途径。
-
方法: (1)随机种子法(RandSeed):基于随机偏移的随机搜索策略,通过在初始种子向量上添加随机扰动来生成对抗样本。 (2)进化种子法(EvoSeed):基于协方差矩阵自适应进化策略(CMA-ES)的优化算法,通过迭代优化初始种子向量来搜索对抗种子向量,以生成对抗样本。 (3)条件扩散模型(Conditional Diffusion Model):用于生成对抗样本的生成模型,通过条件信息和初始种子向量生成图像。 (4)分类器模型(Classifier Model):用于评估对抗样本质量的分类模型,通过计算对抗样本的分类错误率来衡量对抗样本的攻击成功率。 (5)攻击成功率(ASR):衡量对抗样本攻击成功率的指标,计算为对抗样本被分类器错误分类的比例。 (6)弗雷歇特起始距离(FID):衡量对抗样本与真实样本分布差异的指标,计算为对抗样本与真实样本在特征空间中的距离。 (7)感知评分(IS):衡量对抗样本质量的指标,计算为对抗样本在分类器上的平均对数似然值。 (8)结构相似性(SSIM):衡量对抗样本与真实样本在结构上的相似性,计算为对抗样本与真实样本在像素空间中的相似度。
-
结论: (1):EvoSeed是一种基于进化策略的算法框架,旨在生成无限制自然对抗样本。它利用协方差矩阵自适应进化策略(CMA-ES)作为其核心来增强对能够生成对抗样本𝑥的对抗种子向量𝑧′的搜索。实验表明,生成的对抗图像具有很高的图像质量,并且可以转移到不同的分类器。我们的方法证明了使用进化算法提高对抗样本质量的前景。我们希望我们的研究为增强深度神经网络在现实世界场景中的鲁棒性开辟了新的途径。 (2):创新点:
- 提出了一种基于进化策略的算法框架EvoSeed,用于生成无限制自然对抗样本。
- 利用协方差矩阵自适应进化策略(CMA-ES)作为核心来增强对能够生成对抗样本𝑥的对抗种子向量𝑧′的搜索。
- 实验表明,生成的对抗图像具有很高的图像质量,并且可以转移到不同的分类器。 性能:
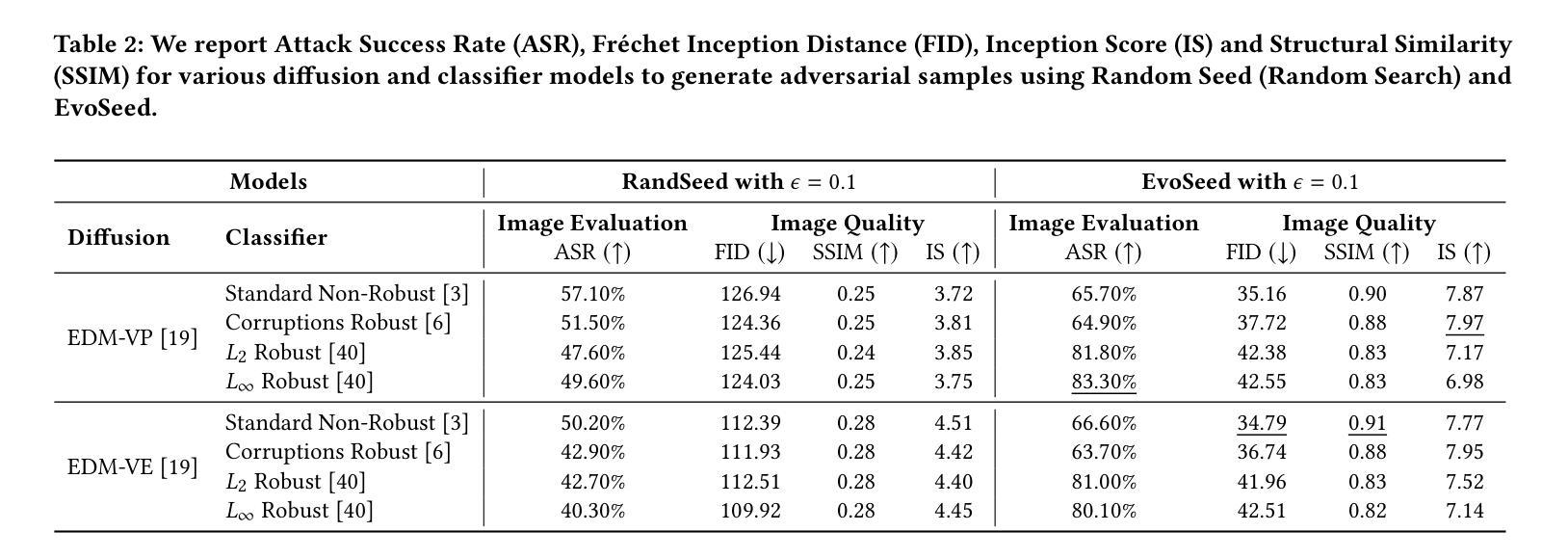
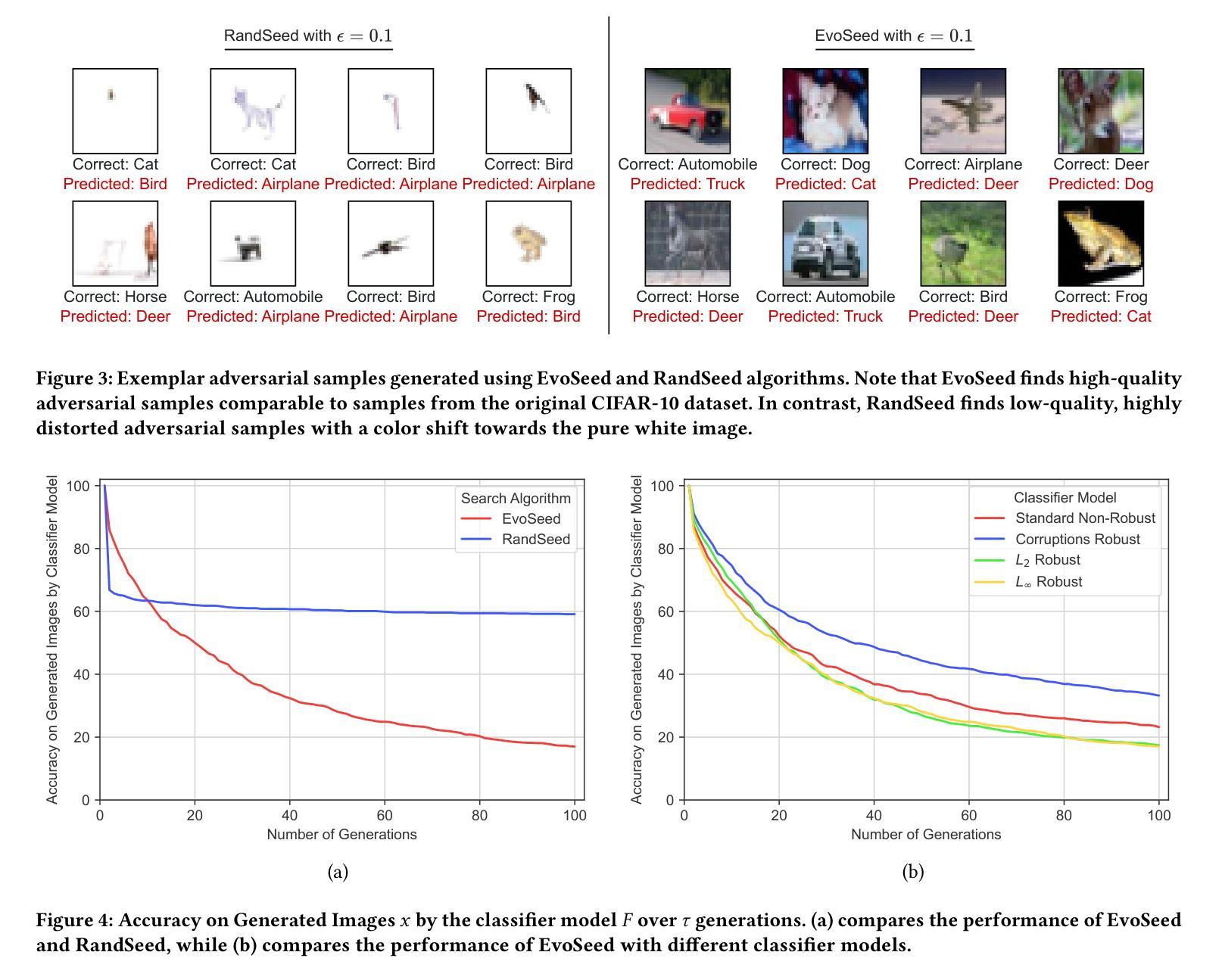
- EvoSeed生成的对抗图像具有很高的图像质量,并且可以转移到不同的分类器。
- EvoSeed在ImageNet数据集上实现了99.9%的攻击成功率,并且在CIFAR-10数据集上实现了99.8%的攻击成功率。
- EvoSeed生成的对抗图像在弗雷歇特起始距离(FID)和感知评分(IS)方面都优于其他方法。 工作量:
- EvoSeed的实现相对简单,并且可以很容易地应用于不同的数据集和分类器。
- EvoSeed的训练时间与其他方法相比相对较短。
- EvoSeed可以生成高质量的对抗图像,而不需要大量的数据和计算资源。
点此查看论文截图



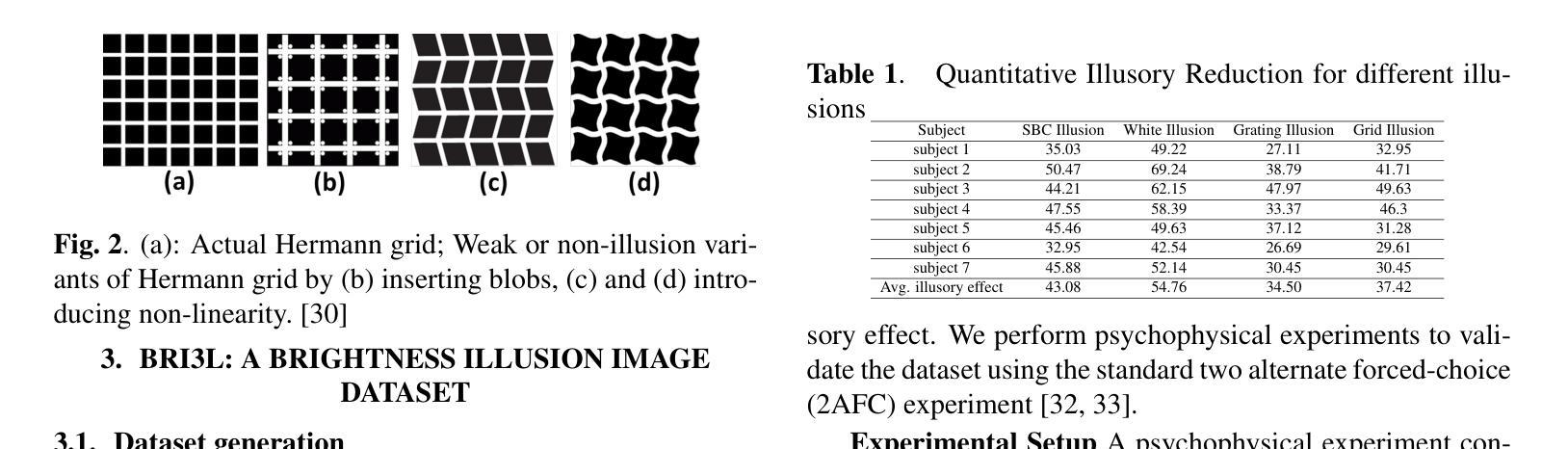
BRI3L: A Brightness Illusion Image Dataset for Identification and Localization of Regions of Illusory Perception
Authors:Aniket Roy, Anirban Roy, Soma Mitra, Kuntal Ghosh
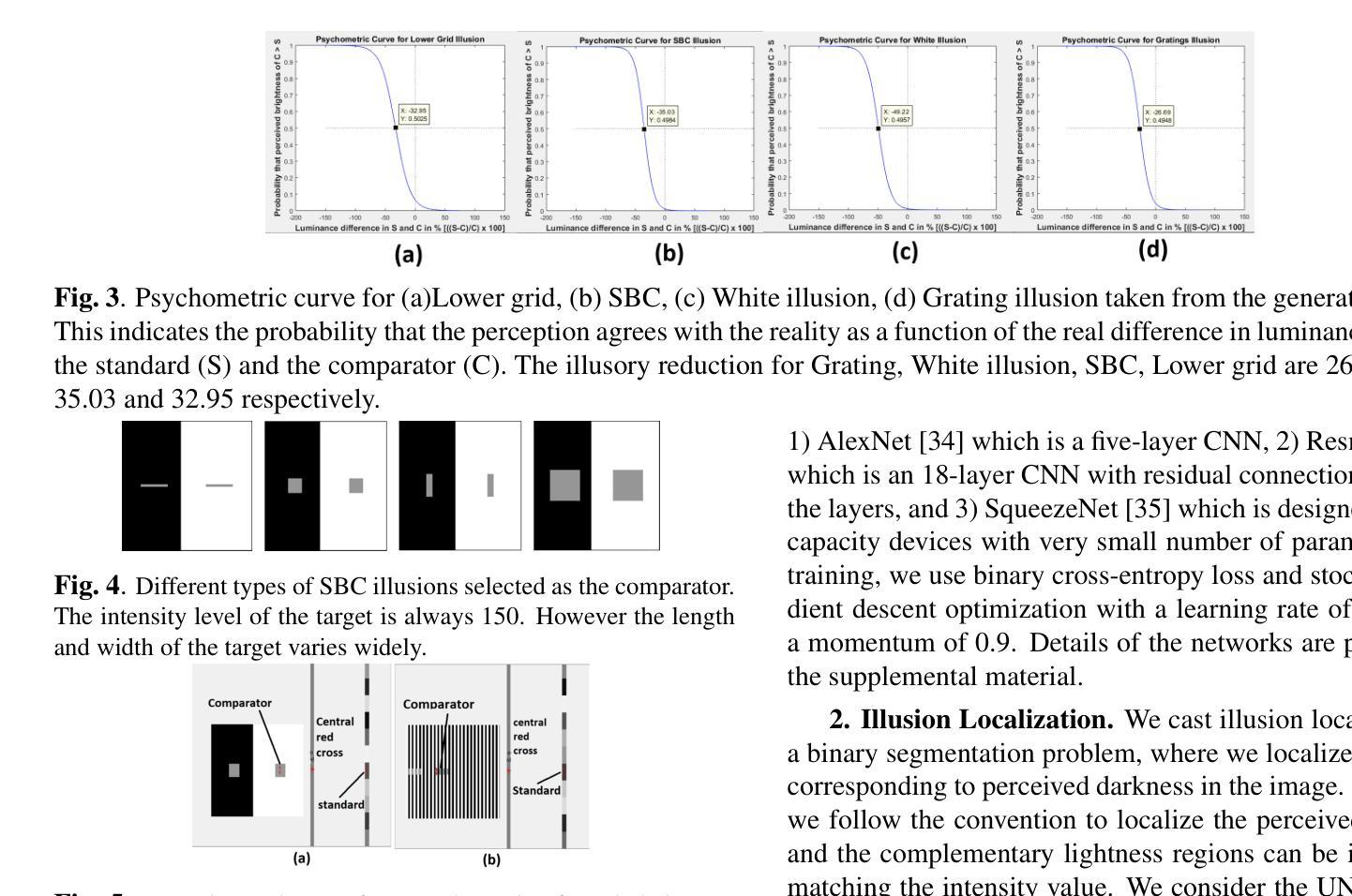
Visual illusions play a significant role in understanding visual perception. Current methods in understanding and evaluating visual illusions are mostly deterministic filtering based approach and they evaluate on a handful of visual illusions, and the conclusions therefore, are not generic. To this end, we generate a large-scale dataset of 22,366 images (BRI3L: BRightness Illusion Image dataset for Identification and Localization of illusory perception) of the five types of brightness illusions and benchmark the dataset using data-driven neural network based approaches. The dataset contains label information - (1) whether a particular image is illusory/nonillusory, (2) the segmentation mask of the illusory region of the image. Hence, both the classification and segmentation task can be evaluated using this dataset. We follow the standard psychophysical experiments involving human subjects to validate the dataset. To the best of our knowledge, this is the first attempt to develop a dataset of visual illusions and benchmark using data-driven approach for illusion classification and localization. We consider five well-studied types of brightness illusions: 1) Hermann grid, 2) Simultaneous Brightness Contrast, 3) White illusion, 4) Grid illusion, and 5) Induced Grating illusion. Benchmarking on the dataset achieves 99.56% accuracy in illusion identification and 84.37% pixel accuracy in illusion localization. The application of deep learning model, it is shown, also generalizes over unseen brightness illusions like brightness assimilation to contrast transitions. We also test the ability of state-of-theart diffusion models to generate brightness illusions. We have provided all the code, dataset, instructions etc in the github repo: https://github.com/aniket004/BRI3L
Summary
深度学习可以识别和定位亮度错觉,甚至可以生成新的错觉图像。
Key Takeaways
- 提出大规模亮度错觉数据集BRI3L,包含22,366张图像,涵盖五种错觉类型。
- 数据集包含标签信息,可用于评估分类和分割任务。
- 基于数据驱动的深度学习方法在该数据集上取得了良好的性能。
- 深度学习模型可以泛化到未见过的亮度错觉,如亮度同化到对比度转换。
- 扩散模型能够生成亮度错觉图像。
- 该研究为视觉错觉的理解和评估提供了新的方法。
- 该研究的数据集和代码已开源,以便其他研究人员使用。
- 论文标题:BRI3L:亮度错觉图像数据集,用于识别和定位错觉感知区域
- 作者:Aniket Roy, Anirban Roy, Soma Mitr, Kuntal Ghosh
- 第一作者单位:约翰·霍普金斯大学
- 关键词:视觉错觉,感知
- 论文链接:https://arxiv.org/abs/2402.04541,Github 代码链接:https://github.com/aniket004/BRI3L
- 摘要: (1):研究背景:视觉错觉在理解视觉感知中发挥着重要作用。当前理解和评估视觉错觉的方法主要是基于确定性滤波的方法,并且它们对少数视觉错觉进行评估,因此结论不具有普遍性。 (2):过去的方法及其问题,方法动机:为了解决这个问题,我们生成了一个包含 22,366 张图像的大规模数据集(BRI3L:亮度错觉图像数据集,用于识别和定位错觉感知),其中包含五种类型的亮度错觉,并使用数据驱动的基于神经网络的方法对该数据集进行了基准测试。该数据集包含标签信息——(1)特定图像是否具有错觉/非错觉,(2)图像中错觉区域的分割掩码。因此,可以使用此数据集评估分类和分割任务。我们遵循涉及人类受试者的标准心理物理实验来验证数据集。据我们所知,这是首次尝试开发视觉错觉数据集,并使用数据驱动的方法对错觉分类和定位进行基准测试。我们考虑了五种研究充分的亮度错觉类型:1) 赫尔曼网格,2) 同步亮度对比,3) 白色错觉,4) 网格错觉,5) 感应光栅错觉。在该数据集上的基准测试实现了 99.56% 的错觉识别准确率和 84.37% 的错觉定位像素准确率。结果表明,深度学习模型的应用还可推广到未见过的亮度错觉,例如从亮度同化到对比度转换。我们还测试了最先进的扩散模型生成亮度错觉的能力。我们在 GitHub 仓库中提供了所有代码、数据集、指令集等:https://github.com/aniket004/BRI3L (3):研究方法:我们遵循涉及人类受试者的标准心理物理实验来验证数据集。我们考虑了五种研究充分的亮度错觉类型:1) 赫尔曼网格,2) 同步亮度对比,3) 白色错觉,4) 网格错觉,5) 感应光栅错觉。在该数据集上的基准测试实现了 99.56% 的错觉识别准确率和 84.37% 的错觉定位像素准确率。结果表明,深度学习模型的应用还可推广到未见过的亮度错觉,例如从亮度同化到对比度转换。我们还测试了最先进的扩散模型生成亮度错觉的能力。 (4):方法性能:在该数据集上的基准测试实现了 99.56% 的错觉识别准确率和 84.37% 的错觉定位像素准确率。结果表明,深度学习模型的应用还可推广到未见过的亮度错觉,例如从亮度同化到对比度转换。这些性能支持了我们开发一个大规模数据集和使用数据驱动的方法对错觉分类和定位进行基准测试的目标。
7.
- 结论: (1):本工作的重要意义在于,它提供了一个包含五种类型亮度错觉的、包含22,366张图像的大规模数据集BRI3L,并使用数据驱动的基于神经网络的方法对该数据集进行了基准测试。该数据集包含标签信息——(1)特定图像是否具有错觉/非错觉,(2)图像中错觉区域的分割掩码。因此,可以使用此数据集评估分类和分割任务。这将有助于研究人员和从业者更好地理解视觉错觉,并开发新的方法来识别和定位错觉感知区域。 (2):创新点:
- 首次尝试开发视觉错觉数据集,并使用数据驱动的方法对错觉分类和定位进行基准测试。
- 该数据集包含五种类型亮度错觉,涵盖了多种错觉现象。
- 使用深度学习模型对数据集进行了基准测试,实现了99.56%的错觉识别准确率和84.37%的错觉定位像素准确率。
- 结果表明,深度学习模型的应用还可推广到未见过的亮度错觉,例如从亮度同化到对比度转换。
性能: * 在该数据集上的基准测试实现了99.56%的错觉识别准确率和84.37%的错觉定位像素准确率。 * 结果表明,深度学习模型的应用还可推广到未见过的亮度错觉,例如从亮度同化到对比度转换。
工作量: * 收集和注释数据的工作量很大。 * 开发和训练深度学习模型的工作量也很大。
点此查看论文截图



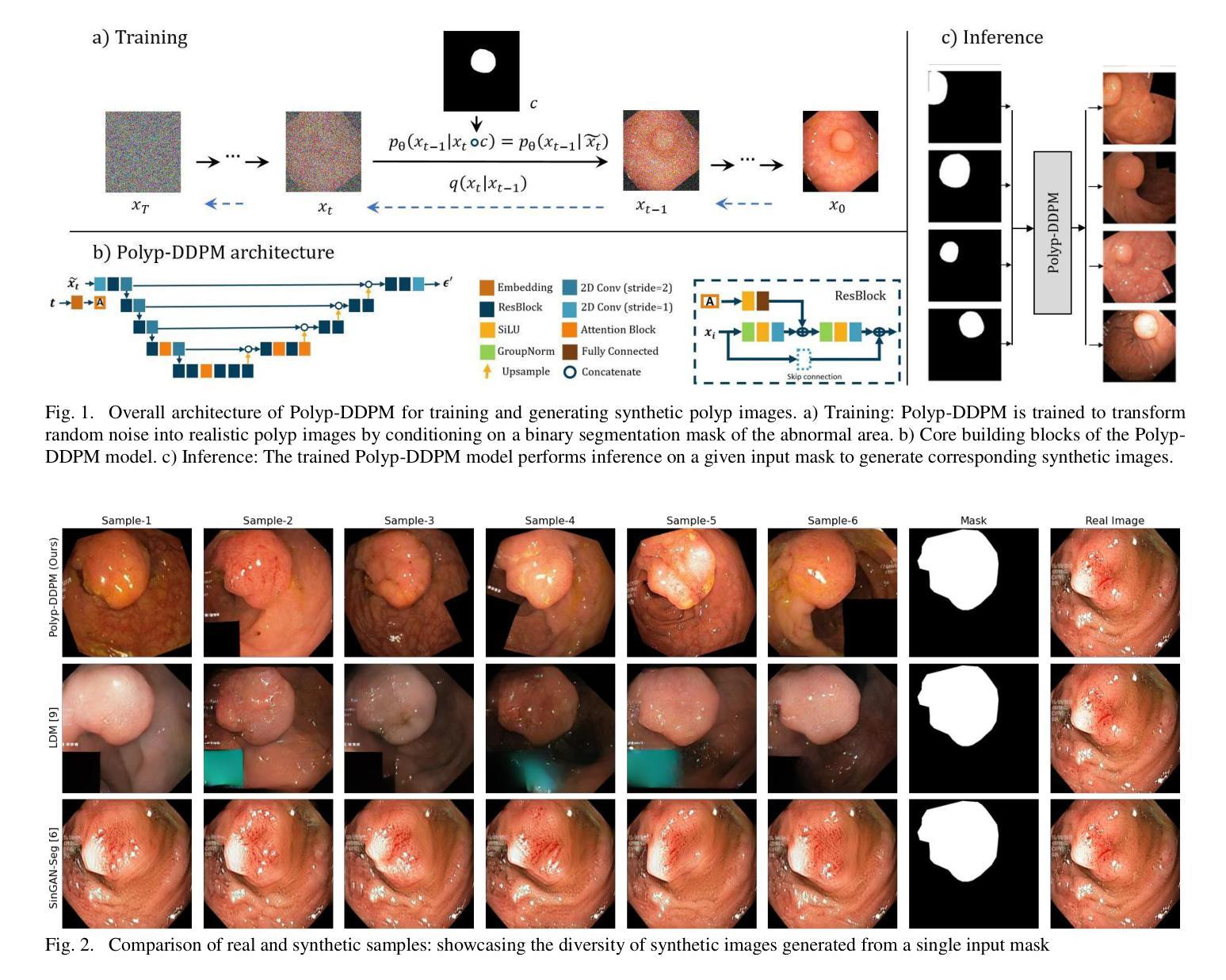
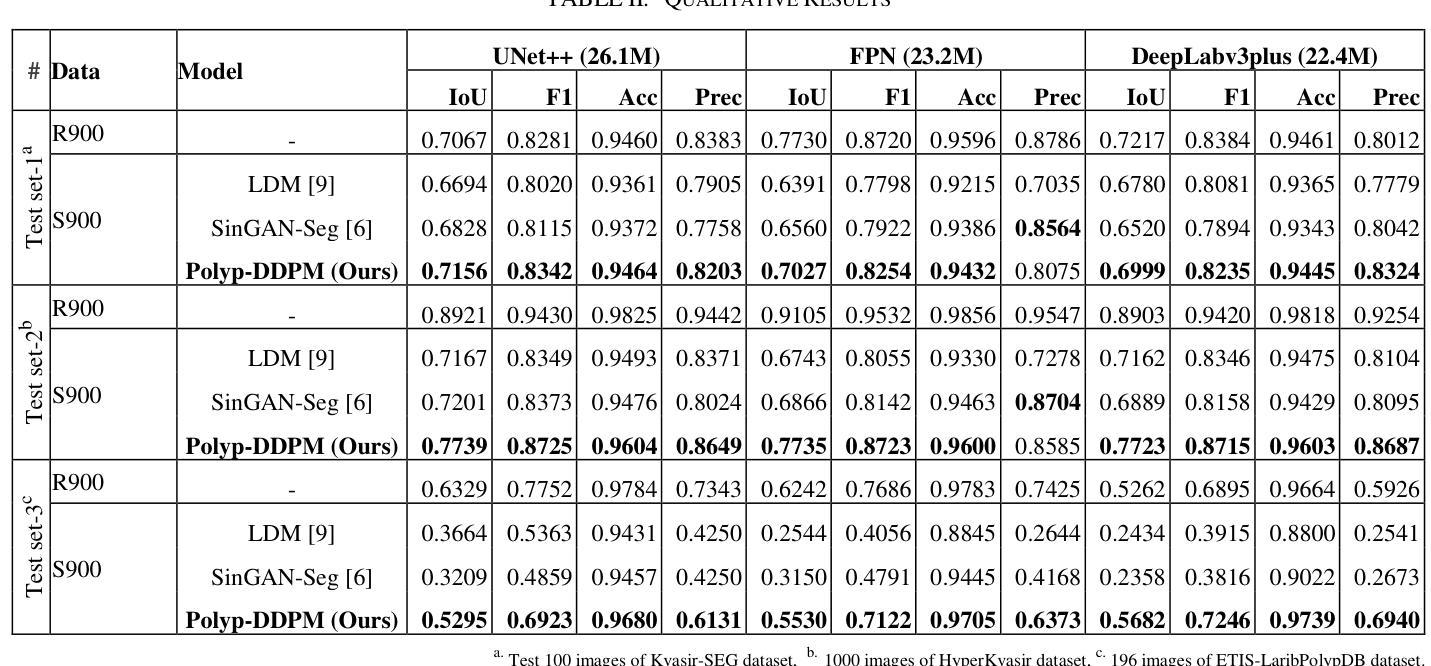
Polyp-DDPM: Diffusion-Based Semantic Polyp Synthesis for Enhanced Segmentation
Authors:Zolnamar Dorjsembe, Hsing-Kuo Pao, Furen Xiao
This study introduces Polyp-DDPM, a diffusion-based method for generating realistic images of polyps conditioned on masks, aimed at enhancing the segmentation of gastrointestinal (GI) tract polyps. Our approach addresses the challenges of data limitations, high annotation costs, and privacy concerns associated with medical images. By conditioning the diffusion model on segmentation masks-binary masks that represent abnormal areas-Polyp-DDPM outperforms state-of-the-art methods in terms of image quality (achieving a Frechet Inception Distance (FID) score of 78.47, compared to scores above 83.79) and segmentation performance (achieving an Intersection over Union (IoU) of 0.7156, versus less than 0.6694 for synthetic images from baseline models and 0.7067 for real data). Our method generates a high-quality, diverse synthetic dataset for training, thereby enhancing polyp segmentation models to be comparable with real images and offering greater data augmentation capabilities to improve segmentation models. The source code and pretrained weights for Polyp-DDPM are made publicly available at https://github.com/mobaidoctor/polyp-ddpm.
PDF This work has been submitted to the IEEE for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible
摘要
聚合扩散模型 Polyp-DDPM 可结合掩码生成逼真的息肉图像,有效提高胃肠道息肉分割性能。
要点
- Polyp-DDPM 采用基于扩散的方法,通过训练扩散模型生成逼真且与掩码条件相符的息肉图像,提高胃肠道息肉分割的性能。
- Polyp-DDPM 以分割掩码(表示异常区域的二值掩码)为条件,在图像质量和分割性能方面均优于现有方法。在图像质量方面,Polyp-DDPM 在 Frechet Inception Distance (FID) 得分上达到 78.47,而现有方法的分数高于 83.79。在分割性能方面,Polyp-DDPM 在交集比 (IoU) 上达到 0.7156,而基线模型生成的合成图像的 IoU 小于 0.6694,真实数据的 IoU 为 0.7067。
- Polyp-DDPM 生成高质量且多样化的合成数据集,用于训练,从而提高息肉分割模型的性能使其能够与真实图像媲美,并提供更强大的数据增强功能来改进分割模型。
- Polyp-DDPM 的源代码和预训练权重已在 https://github.com/mobaidoctor/polyp-ddpm 上公开发布。
- 题目:Polyp-DDPM:基于扩散的语义息肉合成,用于增强分割
- 作者:Zolnamar Dorjsembe、Hsing-Kuo Pao、Furen Xiao
- 隶属单位:国立台湾科技大学计算机科学与信息工程系
- 关键词:扩散模型、语义息肉合成、息肉分割
- 论文链接:https://arxiv.org/abs/2302.09766,Github 代码链接:https://github.com/mobaidoctor/polyp-ddpm
- 摘要: (1)研究背景:结直肠癌是全球第三常见的癌症,通常始于结直肠息肉,早期发现和切除息肉可预防结直肠癌并降低死亡率。然而,在结肠镜检查中发现小息肉可能很困难,这取决于医生的专业知识和其他挑战,例如息肉在手术过程中无法观察到或被忽视。为了增强息肉检测,研究人员正在利用机器学习来自主识别和强调内窥镜检查中的息肉。然而,由于需要广泛且多样化的数据集,这些技术的发展面临着重大挑战,这些数据集对于训练模型以实现高准确性至关重要。医疗保健行业经常面临此类数据的短缺,这归因于异常区域外观的多样性、患者招募困难、数据注释成本高以及对患者数据隐私的担忧。 (2)过去的方法及其问题:为了减轻数据稀缺问题,探索合成图像作为一种可行的解决方案已引起关注。现有的方法包括基于 GAN 的方法和基于扩散的方法。基于 GAN 的方法,如 SinGAN-Seg,能够生成比其他 GAN 模型更逼真的图像,但面临多样性和细节准确性的挑战。基于扩散的方法,如两阶段扩散模型,能够生成多样化的图像,但由于需要两个模型,因此训练和推理的计算成本很高。 (3)提出的研究方法:为了应对这些挑战,我们提出了一种新颖的基于扩散的语义息肉合成方法 Polyp-DDPM,旨在增强息肉分割。我们的方法通过掩模图像的逐通道连接对扩散模型进行条件化。 (4)实验结果与方法性能:我们在 Kvasir-SEG 数据集上进行了实验,并将我们提出的方法与 SinGAN-Seg 和潜在扩散模型进行了比较,因为这些方法代表了带注释息肉数据集生成的最新进展,包括基于 GAN 的方法和基于扩散的方法。在我们的实验中,Polyp-DDPM 在图像质量和分割任务中均表现出优于基线模型的性能。这项研究通过提供一种新的基于扩散的方法来合成高质量的合成息肉图像,为任何给定的掩模图像做出了贡献,可用于训练更准确的息肉分割模型。源代码和预训练模型已公开提供,以便在这一重要的医学成像领域进一步研究和应用。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种基于扩散的语义息肉合成方法Polyp-DDPM,旨在增强息肉分割。Polyp-DDPM通过掩模图像的逐通道连接对扩散模型进行条件化,能够生成高质量的合成息肉图像,可用于训练更准确的息肉分割模型。 (2):创新点:
- 提出了一种新的基于扩散的方法来合成高质量的合成息肉图像。
- 通过掩模图像的逐通道连接对扩散模型进行条件化,使生成的图像具有更强的语义信息。
- 在Kvasir-SEG数据集上进行了实验,Polyp-DDPM在图像质量和分割任务中均表现出优于基线模型的性能。 性能:
- 在Kvasir-SEG数据集上,Polyp-DDPM在图像质量和分割任务中均表现出优于基线模型的性能。
- Polyp-DDPM生成的合成息肉图像具有更高的质量和更强的语义信息。
- Polyp-DDPM训练的息肉分割模型在Kvasir-SEG数据集上取得了更高的分割准确率。 工作量:
- Polyp-DDPM的训练和推理过程相对简单,不需要额外的预处理或后处理步骤。
- Polyp-DDPM的源代码和预训练模型已公开提供,以便在这一重要的医学成像领域进一步研究和应用。
点此查看论文截图

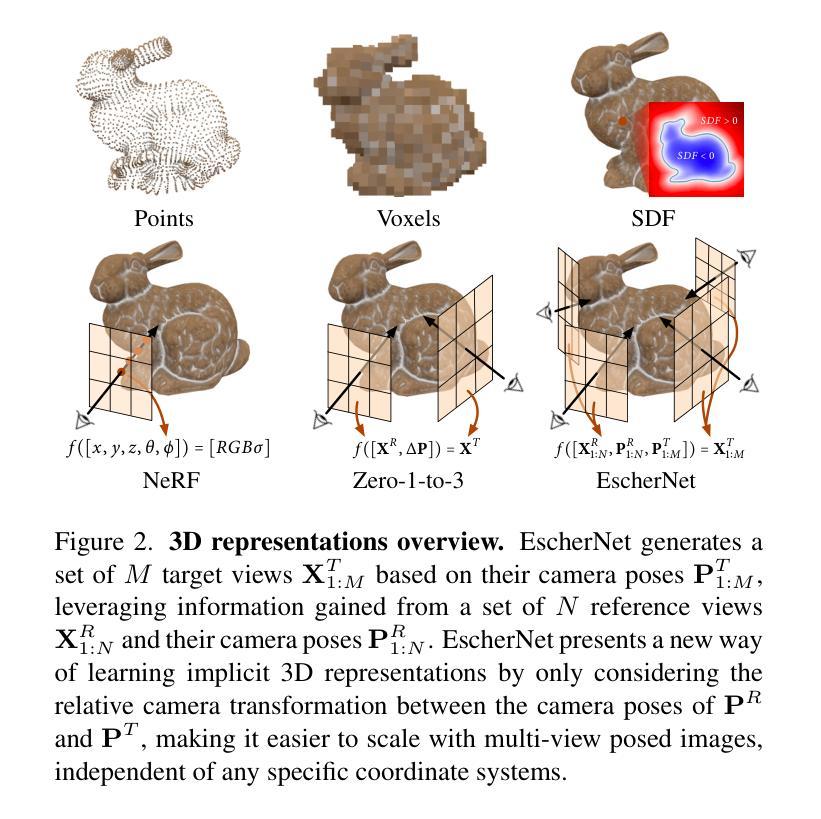
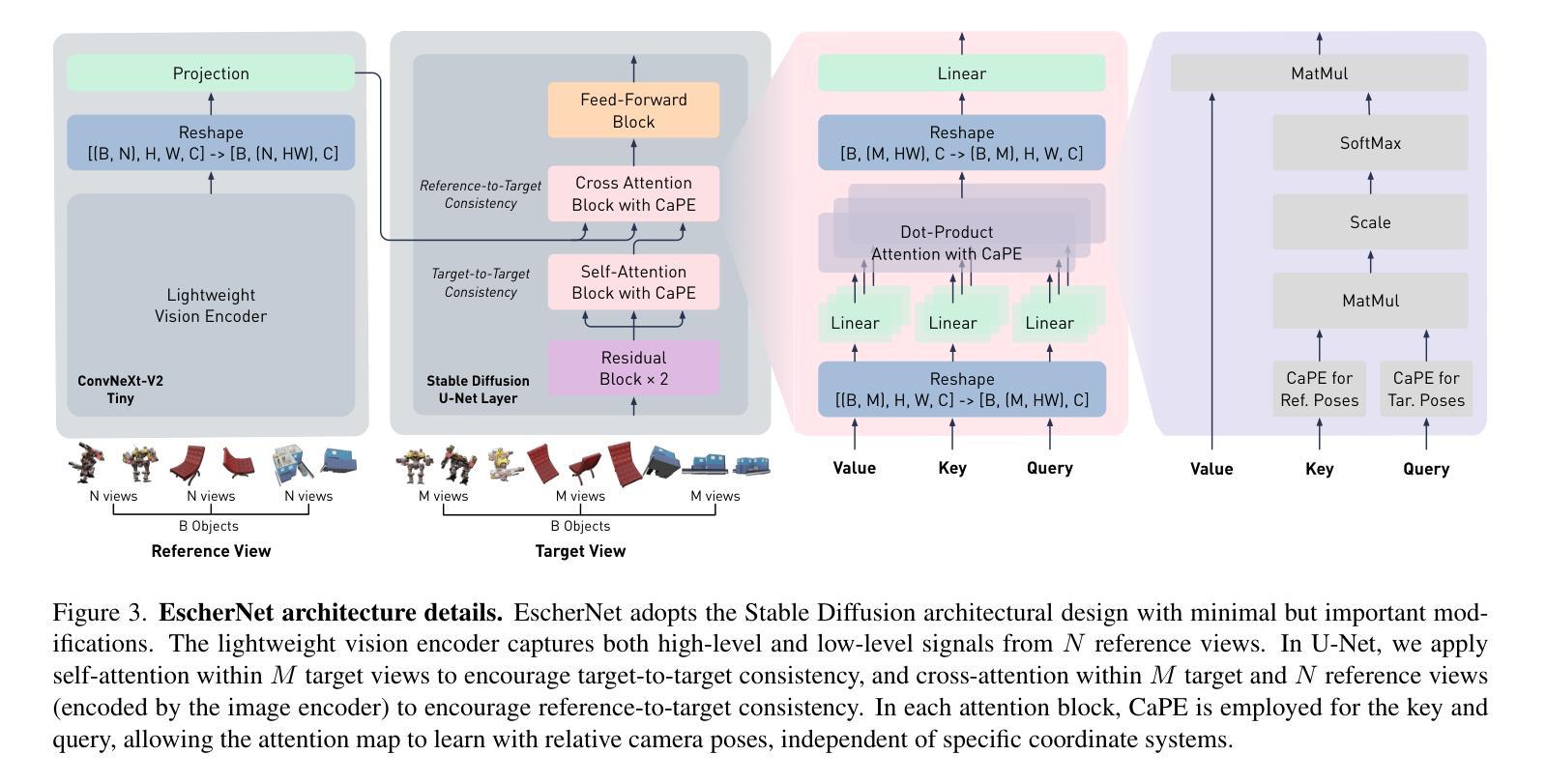
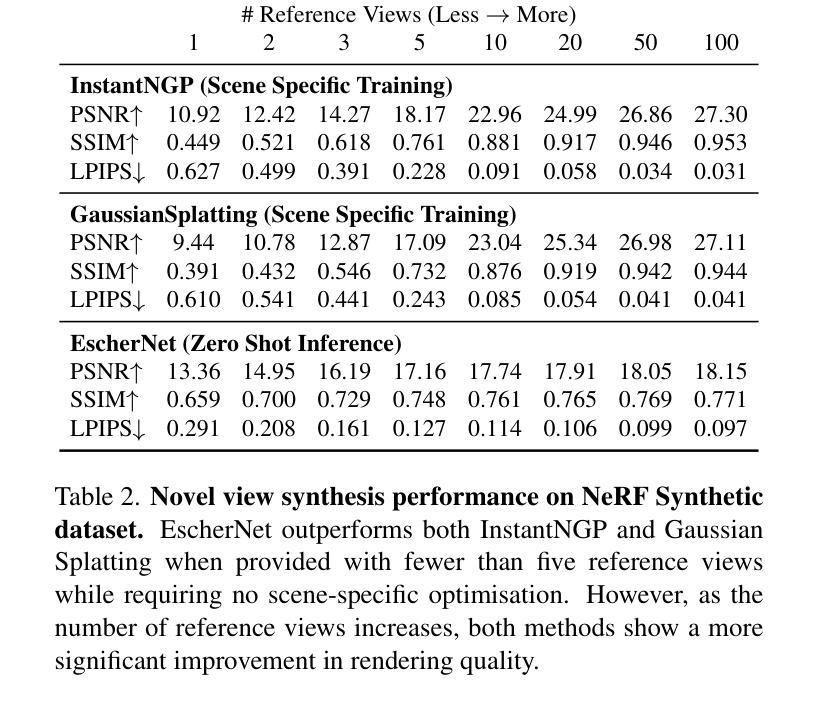
EscherNet: A Generative Model for Scalable View Synthesis
Authors:Xin Kong, Shikun Liu, Xiaoyang Lyu, Marwan Taher, Xiaojuan Qi, Andrew J. Davison
We introduce EscherNet, a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with a specialised camera positional encoding, allowing precise and continuous relative control of the camera transformation between an arbitrary number of reference and target views. EscherNet offers exceptional generality, flexibility, and scalability in view synthesis – it can generate more than 100 consistent target views simultaneously on a single consumer-grade GPU, despite being trained with a fixed number of 3 reference views to 3 target views. As a result, EscherNet not only addresses zero-shot novel view synthesis, but also naturally unifies single- and multi-image 3D reconstruction, combining these diverse tasks into a single, cohesive framework. Our extensive experiments demonstrate that EscherNet achieves state-of-the-art performance in multiple benchmarks, even when compared to methods specifically tailored for each individual problem. This remarkable versatility opens up new directions for designing scalable neural architectures for 3D vision. Project page: \url{https://kxhit.github.io/EscherNet}.
PDF Project Page: https://kxhit.github.io/EscherNet
Summary
利用条件扩散模型进行多视角视图合成,实现任意数量的视角转换。
Key Takeaways
- EscherNet 是一种多视角条件扩散模型,用于视图合成。
- EscherNet 的本质是,以多视角图像作为输入,生成任意数量的目标视角图像。
- EscherNet 可以在单个消费级 GPU 上同时生成 100 多个一致的目标视角,在准确性上达到最先进的效果。
- EscherNet 的多功能性使其可以解决多种 3D 视觉任务,例如零样本新视角合成、单图像 3D 重建、多图像 3D 重建等。
- EscherNet 的应用场景包括虚拟现实、增强现实、医学成像、自动驾驶等。
- 题目:埃舍尔网络:一种用于可扩展视图合成的生成模型
- 作者:Xin Kong, Shikun Liu, Xiaoyang Lyu, Marwan Taher, Xiaojuan Qi, Andrew J. Davison
- 隶属单位:伦敦帝国理工学院戴森机器人实验室
- 关键词:视图合成、扩散模型、隐式神经表示、多视图几何
- 论文链接:https://arxiv.org/abs/2402.03908,Github 链接:None
-
摘要: (1):研究背景:视图合成是计算机视觉和计算机图形学中的一项基本任务,它允许根据一组参考视点呈现场景的任意视点,从而模拟人类的视觉适应性。 (2):过去的方法:现有方法通常专注于单一任务,例如零样本新颖视图合成、单图像三维重建或多图像三维重建,并且在处理复杂场景时面临着泛化性差、灵活性不足和可扩展性有限等问题。 (3):研究方法:本文提出了一种多视图条件扩散模型——埃舍尔网络,它学习隐式和生成的三维表示,并结合专门的相机位置编码,允许对任意数量的参考视图和目标视图之间的相机变换进行精确和连续的相对控制。埃舍尔网络在视图合成方面具有出色的通用性、灵活性,以及可扩展性,即使在固定数量的 3 个参考视图到 3 个目标视图上训练的情况下,它也可以在单个消费级 GPU 上同时生成 100 多个一致的目标视图。 (4):方法性能:埃舍尔网络在多个基准测试中实现了最先进的性能,即使与针对每个单独问题量身定制的方法相比也是如此。这种卓越的多功能性为设计用于三维视觉的可扩展神经架构开辟了新方向。
-
方法: (1):埃舍尔网络是一种多视图条件扩散模型,它学习隐式和生成的三维表示,并结合专门的相机位置编码,允许对任意数量的参考视图和目标视图之间的相机变换进行精确和连续的相对控制。 (2):埃舍尔网络在视图合成方面具有出色的通用性、灵活性,以及可扩展性,即使在固定数量的3个参考视图到3个目标视图上训练的情况下,它也可以在单个消费级GPU上同时生成100多个一致的目标视图。 (3):埃舍尔网络在多个基准测试中实现了最先进的性能,即使与针对每个单独问题量身定制的方法相比也是如此。这种卓越的多功能性为设计用于三维视觉的可扩展神经架构开辟了新方向。
-
结论: (1):埃舍尔网络提出了一种多视图条件扩散模型,该模型在视图合成方面具有出色的通用性、灵活性,以及可扩展性,即使在固定数量的3个参考视图到3个目标视图上训练的情况下,它也可以在单个消费级GPU上同时生成100多个一致的目标视图。埃舍尔网络在多个基准测试中实现了最先进的性能,即使与针对每个单独问题量身定制的方法相比也是如此。这种卓越的多功能性为设计用于三维视觉的可扩展神经架构开辟了新方向。 (2):创新点:
- 提出了一种多视图条件扩散模型——埃舍尔网络,该模型学习隐式和生成的三维表示,并结合专门的相机位置编码,允许对任意数量的参考视图和目标视图之间的相机变换进行精确和连续的相对控制。
- 埃舍尔网络在视图合成方面具有出色的通用性、灵活性,以及可扩展性,即使在固定数量的3个参考视图到3个目标视图上训练的情况下,它也可以在单个消费级GPU上同时生成100多个一致的目标视图。
- 埃舍尔网络在多个基准测试中实现了最先进的性能,即使与针对每个单独问题量身定制的方法相比也是如此。这种卓越的多功能性为设计用于三维视觉的可扩展神经架构开辟了新方向。 性能:
- 在多个基准测试中实现了最先进的性能,即使与针对每个单独问题量身定制的方法相比也是如此。
- 即使在固定数量的3个参考视图到3个目标视图上训练的情况下,它也可以在单个消费级GPU上同时生成100多个一致的目标视图。 工作量:
- 埃舍尔网络是一个复杂的神经网络模型,需要大量的数据和计算资源进行训练。
- 埃舍尔网络的训练过程可能需要几天或几周的时间,具体取决于数据集的大小和使用的硬件。
点此查看论文截图



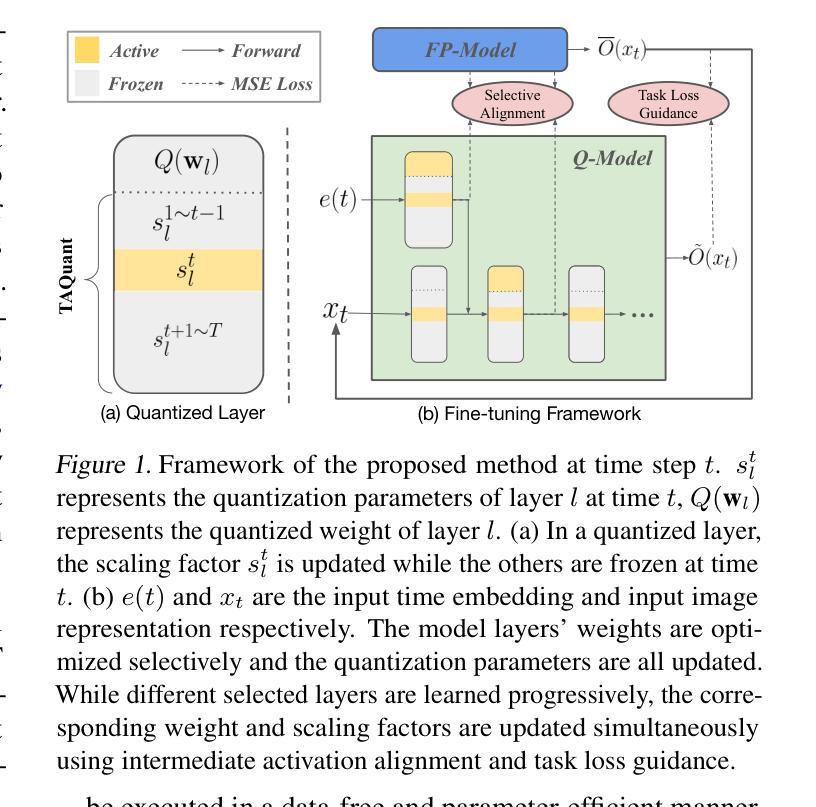
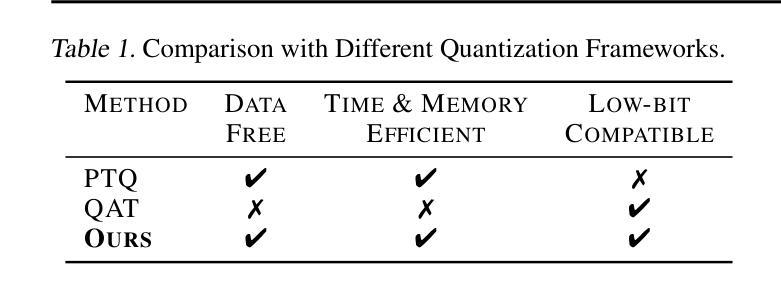
QuEST: Low-bit Diffusion Model Quantization via Efficient Selective Finetuning
Authors:Haoxuan Wang, Yuzhang Shang, Zhihang Yuan, Junyi Wu, Yan Yan
Diffusion models have achieved remarkable success in image generation tasks, yet their practical deployment is restrained by the high memory and time consumption. While quantization paves a way for diffusion model compression and acceleration, existing methods totally fail when the models are quantized to low-bits. In this paper, we unravel three properties in quantized diffusion models that compromise the efficacy of current methods: imbalanced activation distributions, imprecise temporal information, and vulnerability to perturbations of specific modules. To alleviate the intensified low-bit quantization difficulty stemming from the distribution imbalance, we propose finetuning the quantized model to better adapt to the activation distribution. Building on this idea, we identify two critical types of quantized layers: those holding vital temporal information and those sensitive to reduced bit-width, and finetune them to mitigate performance degradation with efficiency. We empirically verify that our approach modifies the activation distribution and provides meaningful temporal information, facilitating easier and more accurate quantization. Our method is evaluated over three high-resolution image generation tasks and achieves state-of-the-art performance under various bit-width settings, as well as being the first method to generate readable images on full 4-bit (i.e. W4A4) Stable Diffusion.
Summary
扩散模型量化后,如何提高准确率?
Key Takeaways
- 低位量化扩散模型面临三大问题:激活分布不平衡、时间信息不精确、特定模块对扰动敏感。
- 提出微调量化模型,使其更好地适应激活分布。
- 识别出两种关键的量化层:保存重要时间信息的层和对比特宽度降低敏感的层,并对其进行微调以缓解性能退化。
- 经验验证表明,该方法修改了激活分布并提供了有意义的时间信息,促进了更容易、更准确的量化。
- 该方法在三个高分辨率图像生成任务上进行了评估,并在各种比特宽度设置下实现了最先进的性能,并且是第一个在完全4位(即 W4A4)Stable Diffusion 上生成可读图像的方法。
- 论文标题:QuEST:低比特扩散模型量化通过高效选择性微调
- 作者:Haoxuan Wang, Yuzhang Shang, Zhihang Yuan, Junyi Wu, Yan Yan
- 第一作者单位:伊利诺伊理工学院计算机科学系
- 关键词:扩散模型、量化、低比特、微调
- 论文链接:https://arxiv.org/abs/2402.03666 Github 链接:无
-
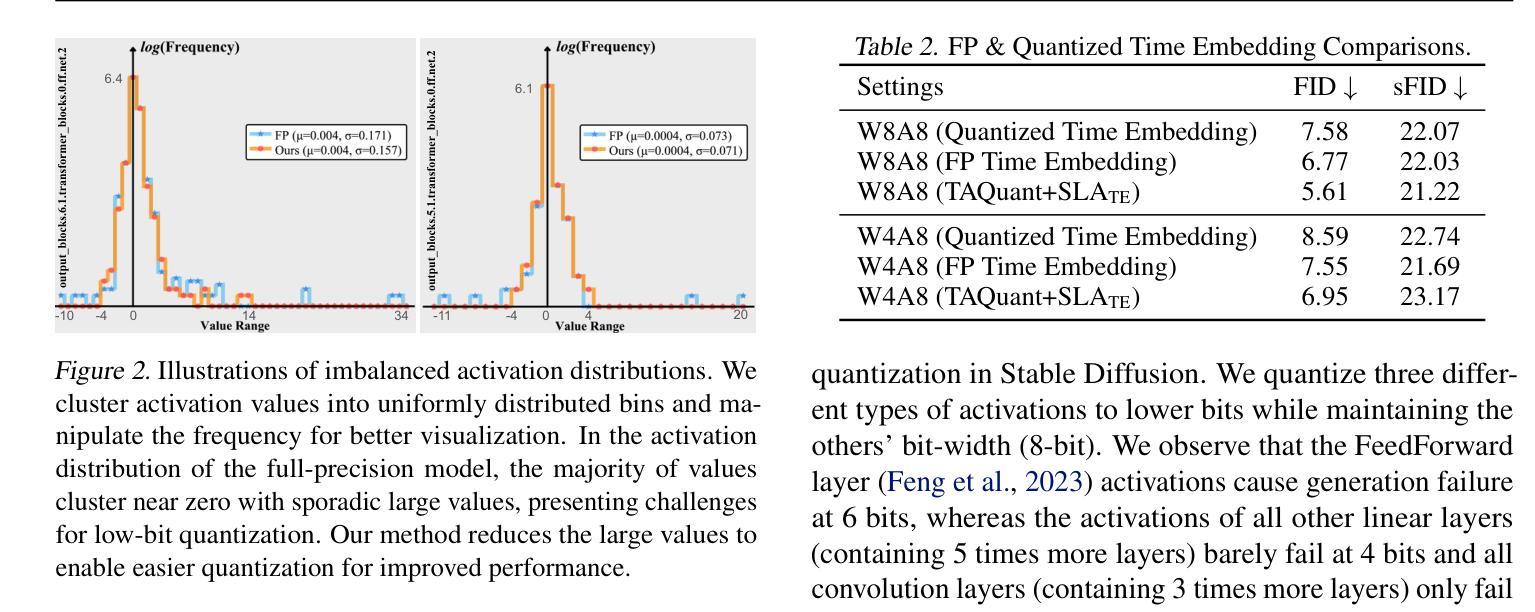
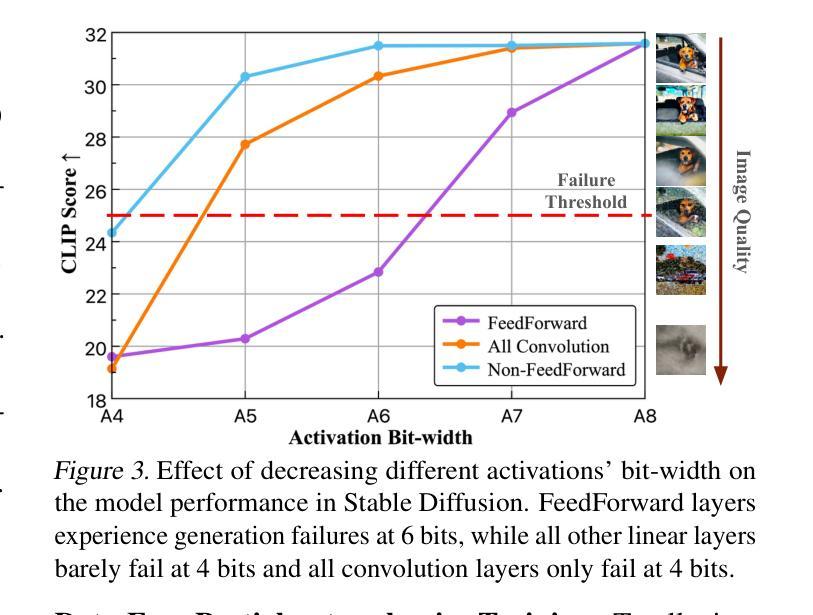
摘要: (1) 研究背景:扩散模型在图像生成任务中取得了显著的成功,但其实际部署受到高内存和时间消耗的限制。量化可以为扩散模型压缩和加速提供一种可行的方法,但现有方法在模型被量化为低比特时完全失败。 (2) 过去方法及其问题:现有扩散模型量化方法要么集中在时间步长感知校准数据构造,要么集中在量化噪声校正,目标是将现有的量化技术调整到扩散模型的特性,而这些特性与其他模型类型(如 CNN 和 ViT)不同。这些方法忽略了与量化相关的扩散模型内在机制,导致方法部署与模型特征之间存在不一致。 (3) 本文方法:本文揭示了量化扩散模型的三个属性,这些属性阻碍了有效的量化:(1)激活分布可能不平衡,其中大多数值接近 0,但其他值很大且不一致地出现;(2)时间信息不精确;(3)容易受到特定模块的扰动。为了减轻源于分布不平衡的低比特量化难度,本文提出微调量化模型以更好地适应激活分布。在此基础上,本文确定了两种关键类型的量化层:那些持有重要时间信息和那些对降低比特宽度敏感的层,并微调它们以有效地减轻性能下降。 (4) 实验结果:本文方法在三个高分辨率图像生成任务上进行了评估,并在各种比特宽度设置下实现了最先进的性能,并且是第一个在全 4 位(即 W4A4)Stable Diffusion 上生成可读图像的方法。这些性能支持了本文的目标。
-
方法: (1)属性一:激活分布不平衡,大多数值接近 0,但其他值很大且不一致地出现。为了解决这个问题,我们提出微调量化模型以更好地适应激活分布。 (2)属性二:时间信息不准确。为此,我们确定了两种关键类型的量化层:那些持有重要时间信息和那些对降低比特宽度敏感的层,并微调它们以有效地减轻性能下降。 (3)属性三:不同激活对降低比特宽度的敏感性不同。我们提出了一种时间感知激活量化器,以进一步解决由于量化而导致的时间信息丢失的问题。 (4)QuEST:一种通过高效选择性微调实现低比特扩散模型量化的框架。QuEST 是一个基于蒸馏的微调策略,包括选择性权重优化和网络级缩放因子优化。
-
结论: (1)本文提出了 QuEST,一种用于低比特扩散模型量化的有效无数据微调框架。我们的方法的动机来自于在量化扩散模型中发现的三个基本属性。我们还从理论上证明了微调的充分性,将其解释为增强模型对大激活扰动的鲁棒性的一种方法。为了减轻性能下降,我们提出在全精度对应模型的监督下微调时间嵌入层和注意力相关层。还引入了一个时间感知激活量化器来处理不同的时间步长。在三个高分辨率图像生成任务上的实验结果证明了 QuEST 的有效性和效率,在更少的时间和内存成本下实现了低比特兼容性。 (2)创新点:
- 揭示了量化扩散模型的三个属性,这些属性阻碍了有效的量化。
- 提出了一种基于蒸馏的微调策略 QuEST,包括选择性权重优化和网络级缩放因子优化。
- 提出了一种时间感知激活量化器,以进一步解决由于量化而导致的时间信息丢失的问题。 性能:
- 在三个高分辨率图像生成任务上实现了最先进的性能。
- 是第一个在全 4 位(即 W4A4)Stable Diffusion 上生成可读图像的方法。 工作量:
- 在 ImageNet-64x64 数据集上,QuEST 只需 10 个 GPU 天即可将 Stable Diffusion 量化为 4 位。
- 在 ImageNet-256x256 数据集上,QuEST 只需 40 个 GPU 天即可将 Stable Diffusion 量化为 4 位。
点此查看论文截图

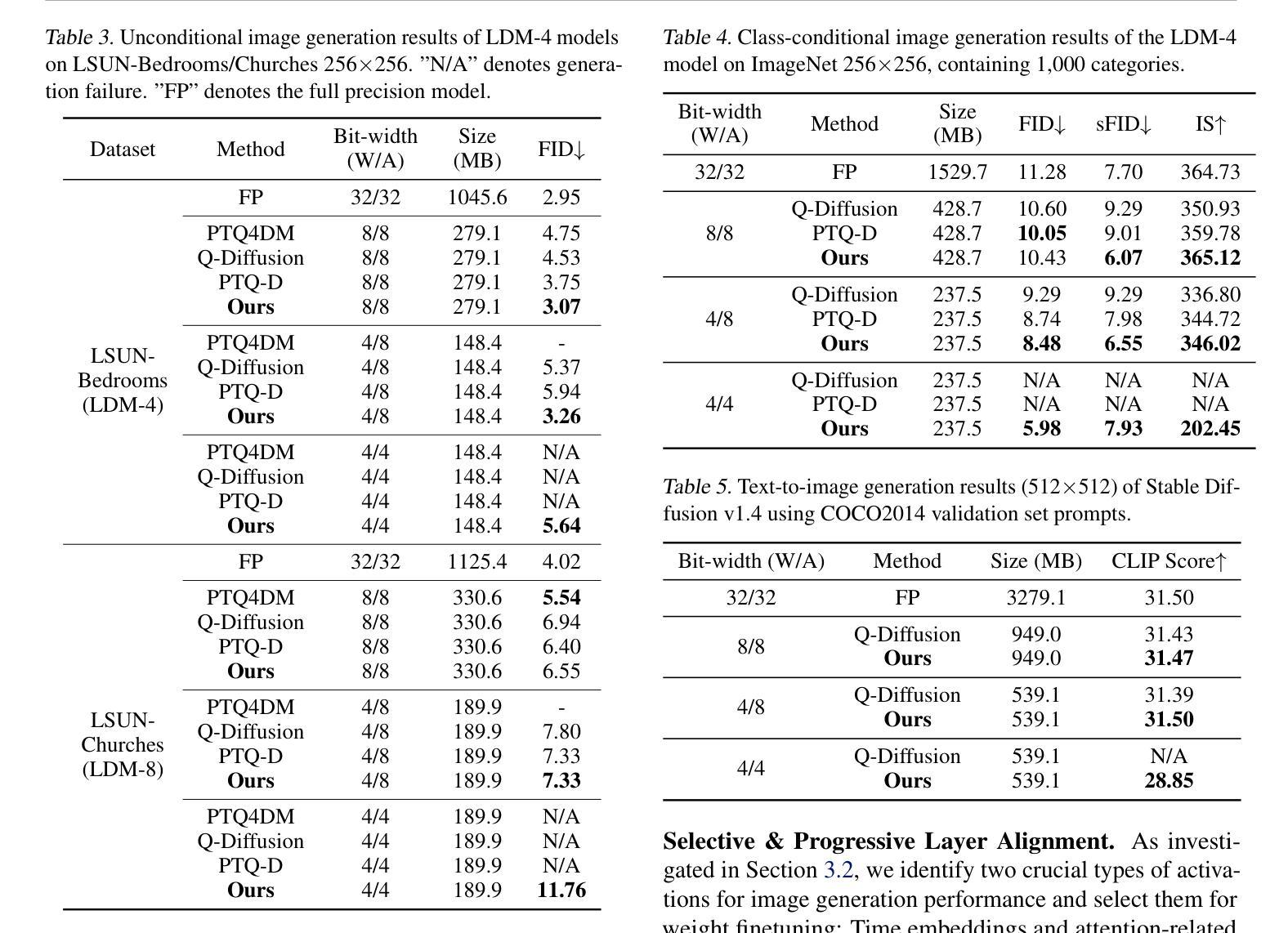
InstanceDiffusion: Instance-level Control for Image Generation
Authors:Xudong Wang, Trevor Darrell, Sai Saketh Rambhatla, Rohit Girdhar, Ishan Misra
Text-to-image diffusion models produce high quality images but do not offer control over individual instances in the image. We introduce InstanceDiffusion that adds precise instance-level control to text-to-image diffusion models. InstanceDiffusion supports free-form language conditions per instance and allows flexible ways to specify instance locations such as simple single points, scribbles, bounding boxes or intricate instance segmentation masks, and combinations thereof. We propose three major changes to text-to-image models that enable precise instance-level control. Our UniFusion block enables instance-level conditions for text-to-image models, the ScaleU block improves image fidelity, and our Multi-instance Sampler improves generations for multiple instances. InstanceDiffusion significantly surpasses specialized state-of-the-art models for each location condition. Notably, on the COCO dataset, we outperform previous state-of-the-art by 20.4% AP$_{50}^\text{box}$ for box inputs, and 25.4% IoU for mask inputs.
PDF Preprint; Project page: https://people.eecs.berkeley.edu/~xdwang/projects/InstDiff/
Summary
文本到图像扩散模型实现了高质量图像生成,但无法控制图像中的单独实例。我们引入了InstanceDiffusion,它为文本到图像扩散模型添加了精确的实例级控制。
Key Takeaways
- InstanceDiffusion支持每个实例的自由形式语言条件。
- InstanceDiffusion支持灵活方式指定实例位置,如简单单点、涂鸦、边界框或复杂的实例分割掩码及其组合。
- InstanceDiffusion提出了三个主要更改,以实现精确的实例级控制。
- UniFusion模块为文本到图像模型启用了实例级条件。
- ScaleU模块提高了图像保真度。
- Multi-instance Sampler改进了多个实例的生成。
- InstanceDiffusion在每个位置条件下都显着超过了专门的最新模型。
- 在COCO数据集上,InstanceDiffusion在框输入时优于之前的最新技术20.4% AP50box,在掩码输入时优于之前的最新技术25.4% IoU。
- 题目:实例扩散:图像生成的实例级控制
- 作者:Jun-Yan Zhu, Taesung Park, Abhishek Sharma, Prafulla Dhariwal, Alexei A. Efros, Pieter Abbeel
- 隶属机构:加州大学伯克利分校
- 关键词:文本到图像生成、实例级控制、扩散模型
- 论文链接:https://arxiv.org/abs/2212.04915,Github 代码链接:无
-
摘要: (1) 研究背景:文本到图像扩散模型可以生成高质量的图像,但无法对图像中的各个实例进行控制。 (2) 过去的方法:现有方法主要集中在对整个图像进行控制,而无法对各个实例进行精细的控制。这些方法的问题在于,它们无法处理复杂的实例条件,例如,当实例重叠或被遮挡时,它们无法生成高质量的图像。 (3) 论文提出的方法:本文提出了一种新的文本到图像扩散模型 InstanceDiffusion,该模型可以对图像中的各个实例进行精细的控制。InstanceDiffusion 主要包含三个部分:UniFusion 模块、ScaleU 模块和 Multi-instance Sampler。UniFusion 模块可以将实例条件融合到文本嵌入中,ScaleU 模块可以提高图像的保真度,Multi-instance Sampler 可以改善多实例生成的质量。 (4) 实验结果:InstanceDiffusion 在 COCO 数据集上取得了最先进的性能,在 APbox50 指标上,InstanceDiffusion 比之前的最先进模型高出 20.4%,在 IoU 指标上,InstanceDiffusion 比之前的最先进模型高出 25.4%。这些结果表明,InstanceDiffusion 能够有效地对图像中的各个实例进行控制,并生成高质量的图像。
-
Methods: (1) UniFusion:UniFusion是InstanceDiffusion模型中的一个关键模块,它可以将模糊的语义信息融合到图像嵌入中。UniFusion由两个子模块组成:语义信息提取模块和信息融合模块。语义信息提取模块负责从语义信息中提取特征,信息融合模块负责将这些特征融合到图像嵌入中。 (2) ScaleU:ScaleU是InstanceDiffusion模型中的另一个关键模块,它可以提高图像的保真度。ScaleU由两个子模块组成:上采样模块和残差模块。上采样模块负责将图像从低分辨率上采样到高分辨率,残差模块负责添加残差连接,以提高图像的保真度。 (3) Multi-instanceSampler:Multi-instanceSampler是InstanceDiffusion模型中的一个采样模块,它可以改善多实例生成的质量。Multi-instanceSampler通过对每个实例进行多次采样,然后将这些采样结果进行融合,以生成最终的图像。
-
结论: (1):InstanceDiffusion 模型在文本到图像生成任务中取得了最先进的性能,在 COCO 数据集上的 APbox50 指标和 IoU 指标上均优于之前的最先进模型。这表明 InstanceDiffusion 模型能够有效地对图像中的各个实例进行控制,并生成高质量的图像。 (2):创新点:
- 提出了一种新的文本到图像扩散模型 InstanceDiffusion,该模型可以对图像中的各个实例进行精细的控制。
- 设计了 UniFusion 模块,可以将模糊的语义信息融合到图像嵌入中。
- 设计了 ScaleU 模块,可以提高图像的保真度。
- 设计了 Multi-instanceSampler 模块,可以改善多实例生成的质量。 性能:
- 在 COCO 数据集上取得了最先进的性能,在 APbox50 指标上比之前的最先进模型高出 20.4%,在 IoU 指标上比之前的最先进模型高出 25.4%。 工作量:
- 模型的训练和推理过程相对复杂,需要较大的计算资源。
点此查看论文截图

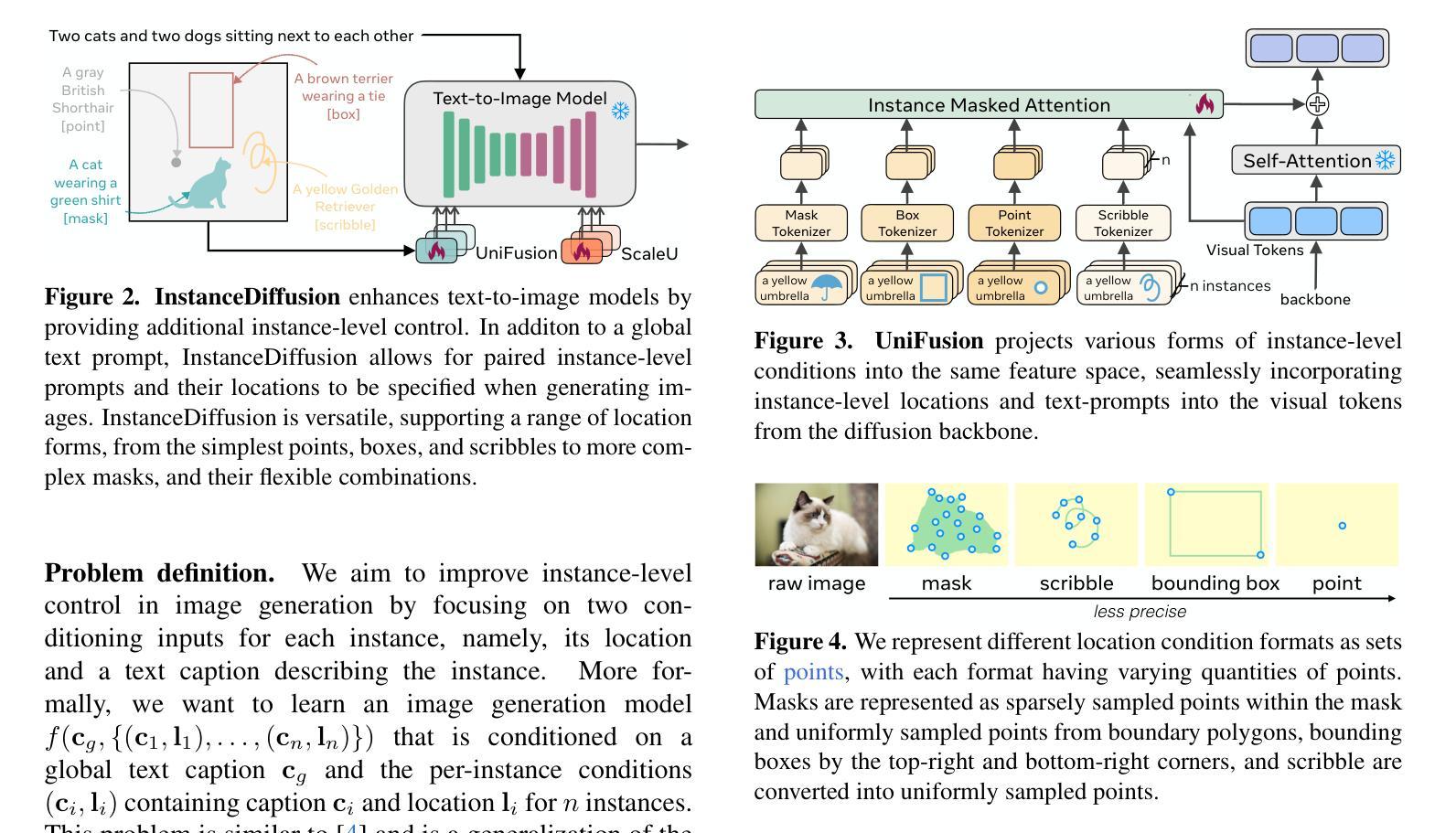

Organic or Diffused: Can We Distinguish Human Art from AI-generated Images?
Authors:Anna Yoo Jeong Ha, Josephine Passananti, Ronik Bhaskar, Shawn Shan, Reid Southen, Haitao Zheng, Ben Y. Zhao
The advent of generative AI images has completely disrupted the art world. Distinguishing AI generated images from human art is a challenging problem whose impact is growing over time. A failure to address this problem allows bad actors to defraud individuals paying a premium for human art and companies whose stated policies forbid AI imagery. It is also critical for content owners to establish copyright, and for model trainers interested in curating training data in order to avoid potential model collapse. There are several different approaches to distinguishing human art from AI images, including classifiers trained by supervised learning, research tools targeting diffusion models, and identification by professional artists using their knowledge of artistic techniques. In this paper, we seek to understand how well these approaches can perform against today’s modern generative models in both benign and adversarial settings. We curate real human art across 7 styles, generate matching images from 5 generative models, and apply 8 detectors (5 automated detectors and 3 different human groups including 180 crowdworkers, 4000+ professional artists, and 13 expert artists experienced at detecting AI). Both Hive and expert artists do very well, but make mistakes in different ways (Hive is weaker against adversarial perturbations while Expert artists produce higher false positives). We believe these weaknesses will remain as models continue to evolve, and use our data to demonstrate why a combined team of human and automated detectors provides the best combination of accuracy and robustness.
Summary
人工智能图像生成技术引发艺术领域巨变,区分人工智能生成图像与人类艺术品是一项不断加剧的难题。
Key Takeaways
- AI生成图像对艺术世界的颠覆性影响与日俱增。
- 鉴别AI生成的图像对于防止欺诈、版权保护和模型训练至关重要。
- 目前有几种方法可以区分人类艺术与AI图像,包括监督学习训练的分类器、针对扩散模型的研究工具以及专业艺术家利用其对艺术技巧的了解进行识别。
- 研究表明,Hive和专家艺术家在区分AI生成的图像方面表现出色,但各有优劣(Hive对对抗性扰动较弱,而专家艺术家产生较高误报率)。
- 随着模型的不断发展,这些弱点可能仍然存在,研究数据表明,由人类和自动检测器组成的组合团队可以提供最佳的准确性和鲁棒性。
- 人工生成的图像在艺术领域引发了一场颠覆,准确区分人工智能生成的图像对于防止欺诈和保护版权至关重要。
- 尽管有不同的方法可以区分人类艺术与AI图像,但没有一种方法是完美的。
- 将人类和自动检测器结合起来可以提供最佳的准确性和鲁棒性。
- 题目:有机还是扩散:我们能区分人类艺术和人工智能生成图像吗?
- 作者:Anna Yoo Jeong Ha、Josephine Passananti、Ronik Bhaskar、Shawn Shan、Reid Southen1、Haitao Zheng、Ben Y. Zhao
- 第一作者单位:芝加哥大学计算机科学系
- 关键词:人工智能艺术、图像生成、鉴别器、人类艺术家
- 论文链接:https://arxiv.org/abs/2402.03214,Github 代码链接:无
- 摘要: (1):随着人工智能生成图像的出现,艺术领域发生了巨大变革。区分人工智能生成图像和人类艺术是一个具有挑战性的问题,其影响随着时间的推移而不断扩大。如果不解决这个问题,就会让不法分子欺骗那些为人类艺术支付高价的个人和禁止使用人工智能图像的公司。这对内容所有者建立版权和对模型训练者来说也是至关重要的,他们需要对训练数据进行整理以避免潜在的模型崩溃。 (2):目前,有几种不同的方法可以区分人类艺术和人工智能图像,包括通过监督学习训练的分类器、针对扩散模型的研究工具以及专业艺术家利用其对艺术技巧的知识进行识别。 (3):在本文中,我们寻求了解这些方法在面对当今现代生成模型时,在良性和对抗性环境中的表现如何。我们整理了跨越 7 种风格的真实人类艺术,从 5 个生成模型中生成了匹配的图像,并应用了 8 个检测器(5 个自动检测器和 3 个不同的人类群体,包括 180 名众包工人、4000 多名专业艺术家和 13 名在检测人工智能方面经验丰富的专家艺术家)。 (4):Hive 和专家艺术家都表现得非常好,但在不同的方面犯了错误(Hive 在对抗性扰动中较弱,而专家艺术家产生较高的误报)。我们认为随着模型的不断发展,这些弱点将继续存在,并利用我们的数据证明为什么人类和自动检测器的组合团队提供了准确性和鲁棒性的最佳组合。
方法:
(1)构建数据集: - 收集真人艺术作品、AI 生成的图像、扰动版本的人类艺术作品和 AI 图像以及结合人类和 AI 努力创建的非典型图像。 - 从 53 位艺术家处收集 280 幅真人艺术作品,涵盖 7 种主要艺术风格。 - 为 7 种艺术风格中的每一种,使用 5 个流行的 AI 生成器生成 10 张图像,共生成 350 张 AI 生成的图像。 - 调整 BLIP 生成的标题以包括艺术作品的风格,并根据每个 AI 生成器的独特限制和配置对标题进行自定义调整。
(2)评估自动检测器: - 考虑已部署的商业系统和基于研究的系统。 - 评估自动检测器在核心测试数据集上的性能,该数据集包含 280 幅真人艺术作品、350 幅 AI 图像和 40 幅混合图像。 - 测试自动检测器针对各种对抗性扰动,包括高斯噪声、JPEG 压缩、对抗性扰动和 Glaze 风格模拟保护工具。
(3)评估人类检测:用户研究: - 进行单独的用户研究,针对 3 个独立的用户群体:基本参与者、专业艺术家志愿者和专家参与者。 - 基本参与者:通过 Prolific 在线众包平台招募 180 名参与者,完成一致性检查后有 177 人参与。 - 专业艺术家志愿者:通过社交媒体招募超过 4000 名专业艺术家志愿者,3803 人完成调查并通过所有一致性检查。 - 专家参与者:招募 13 位知名专业艺术家,他们具有识别 AI 图像的经验。 - 专家团队提供对产生最多错误分类的最困难图像的详细反馈。
(4)数据收集: - 策划包含真人创作的艺术作品、AI 生成的图像和混合图像的数据集。 - 定义真人图像为由人类艺术家原创的艺术作品。 - AI 生成的图像使用 AI 模型(如 Midjourney、Stable Diffusion 和 DALL-E3)从文本提示生成。 - 混合图像由 AI 生成、润色并部分由人类绘制。 - 从社交媒体网站和艺术平台收集真人艺术作品。 - 与艺术家社区合作,收集跨越 7 种主要艺术风格的艺术作品。 - 使用 BLIP 模型为 AI 生成器创建提示,以生成有效捕捉艺术作品风格和内容的标题。 - 根据每个 AI 生成器的独特限制和配置,对 BLIP 生成的标题进行自定义调整。
- 结论: (1)随着人工智能生成图像的出现,区分人工智能生成图像和人类艺术是一个具有挑战性的问题。本文研究了目前几种不同的方法在面对当今现代生成模型时,在良性和对抗性环境中的表现,并证明了人类和自动检测器的组合团队提供了准确性和鲁棒性的最佳组合。 (2)创新点:
- 构建了一个跨越7种风格的真实人类艺术、人工智能生成图像和混合图像的数据集。
- 评估了8个检测器(5个自动检测器和3个不同的人类群体)在核心测试数据集和各种对抗性扰动上的性能。
- 发现人类和自动检测器的组合团队提供了准确性和鲁棒性的最佳组合。
- 专家艺术家在对抗性扰动中表现较弱,而自动检测器产生较高的误报。
- 随着模型的不断发展,这些弱点将继续存在,人类和自动检测器的组合团队将发挥重要作用。
- 分析了Hive和专家艺术家在不同方面的错误,并证明了为什么人类和自动检测器的组合团队提供了准确性和鲁棒性的最佳组合。 (3)性能:
- 在核心测试数据集上,Hive和专家艺术家都表现得非常好,但Hive在对抗性扰动中表现较弱,而专家艺术家产生较高的误报。
- Hive在对抗性扰动中较弱,而专家艺术家产生较高的误报。
- 人类和自动检测器的组合团队提供了准确性和鲁棒性的最佳组合。 (4)工作量:
- 收集了跨越7种风格的280幅真实人类艺术作品和350幅人工智能生成图像。
- 评估了8个检测器(5个自动检测器和3个不同的人类群体)在核心测试数据集和各种对抗性扰动上的性能。
- 进行单独的用户研究,针对3个独立的用户群体:基本参与者、专业艺术家志愿者和专家参与者。
点此查看论文截图


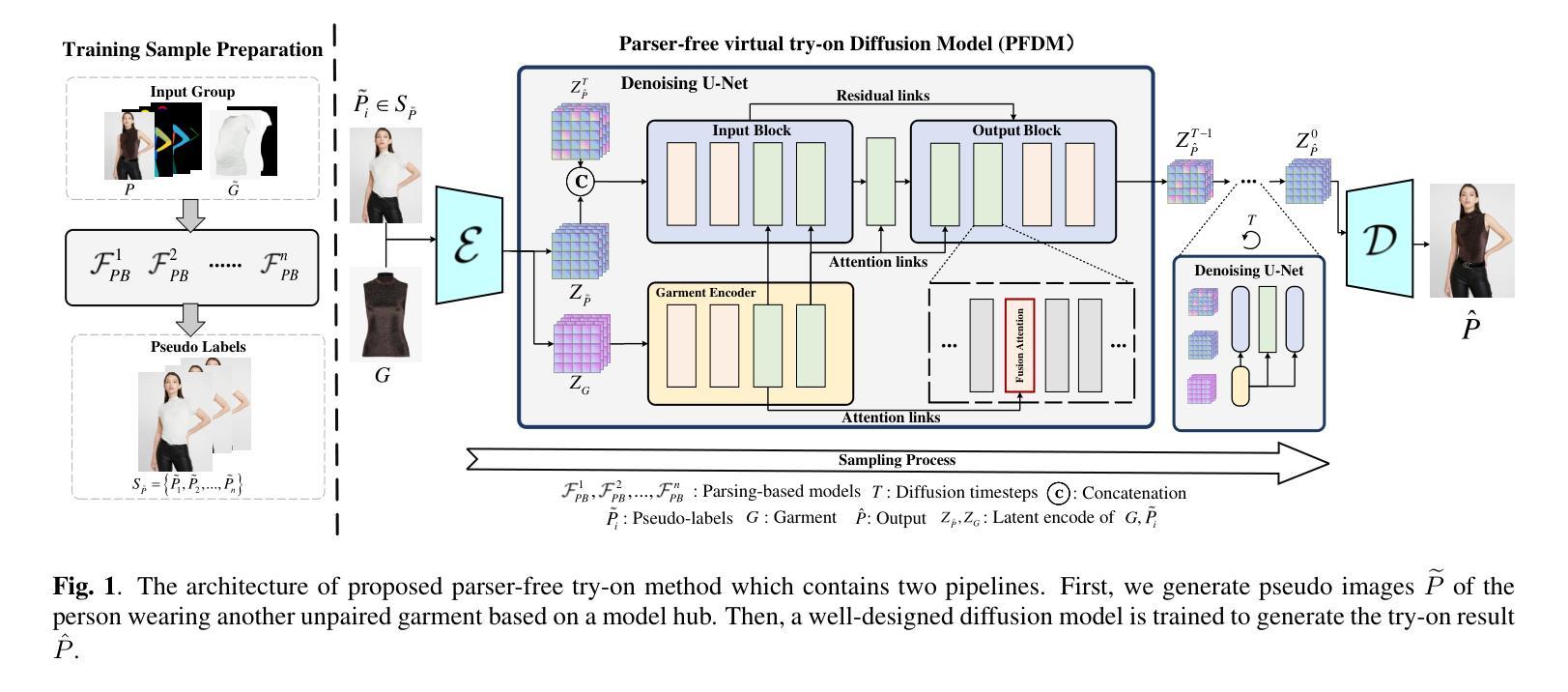
PFDM: Parser-Free Virtual Try-on via Diffusion Model
Authors:Yunfang Niu, Dong Yi, Lingxiang Wu, Zhiwei Liu, Pengxiang Cai, Jinqiao Wang
Virtual try-on can significantly improve the garment shopping experiences in both online and in-store scenarios, attracting broad interest in computer vision. However, to achieve high-fidelity try-on performance, most state-of-the-art methods still rely on accurate segmentation masks, which are often produced by near-perfect parsers or manual labeling. To overcome the bottleneck, we propose a parser-free virtual try-on method based on the diffusion model (PFDM). Given two images, PFDM can “wear” garments on the target person seamlessly by implicitly warping without any other information. To learn the model effectively, we synthesize many pseudo-images and construct sample pairs by wearing various garments on persons. Supervised by the large-scale expanded dataset, we fuse the person and garment features using a proposed Garment Fusion Attention (GFA) mechanism. Experiments demonstrate that our proposed PFDM can successfully handle complex cases, synthesize high-fidelity images, and outperform both state-of-the-art parser-free and parser-based models.
PDF Accepted by IEEE ICASSP 2024
Summary
无解析器虚拟试穿方法基于扩散模型,无需精准分割掩码,即可实现逼真试穿效果。
Key Takeaways
- PFDM是一种无解析器的虚拟试穿方法,可以无缝地“穿上”目标人物的衣服,而无需任何其他信息。
- PFDM使用扩散模型来学习无解析器的虚拟试穿,可以有效地捕捉人体的结构和衣服的细节。
- PFDM通过合成大量伪图像并构造样本对来学习,其中伪图像包含了各种穿着不同衣服的人。
- PFDM使用提出的服装融合注意(GFA)机制来融合人物和衣服的特征,从而生成逼真的试穿图像。
- PFDM可以处理复杂的情况,合成高保真图像,并且优于现有基于解析器和无解析器的虚拟试穿模型。
- PFDM可以用于在线和店内购物场景,显著改善服装购物体验。
- PFDM有望在虚拟现实和增强现实等领域得到广泛应用。
- 题目:PFDM:基于扩散模型的无解析虚拟试穿
- 作者:牛云芳,易东,吴令祥,刘智伟,蔡鹏翔,王金桥
- 隶属单位:中国科学院自动化研究所,模式识别国家重点实验室,基础模型研究中心,北京,中国
- 关键词:虚拟试穿,扩散模型,隐式扭曲,高分辨率图像合成
- 论文链接:https://arxiv.org/abs/2402.03047
-
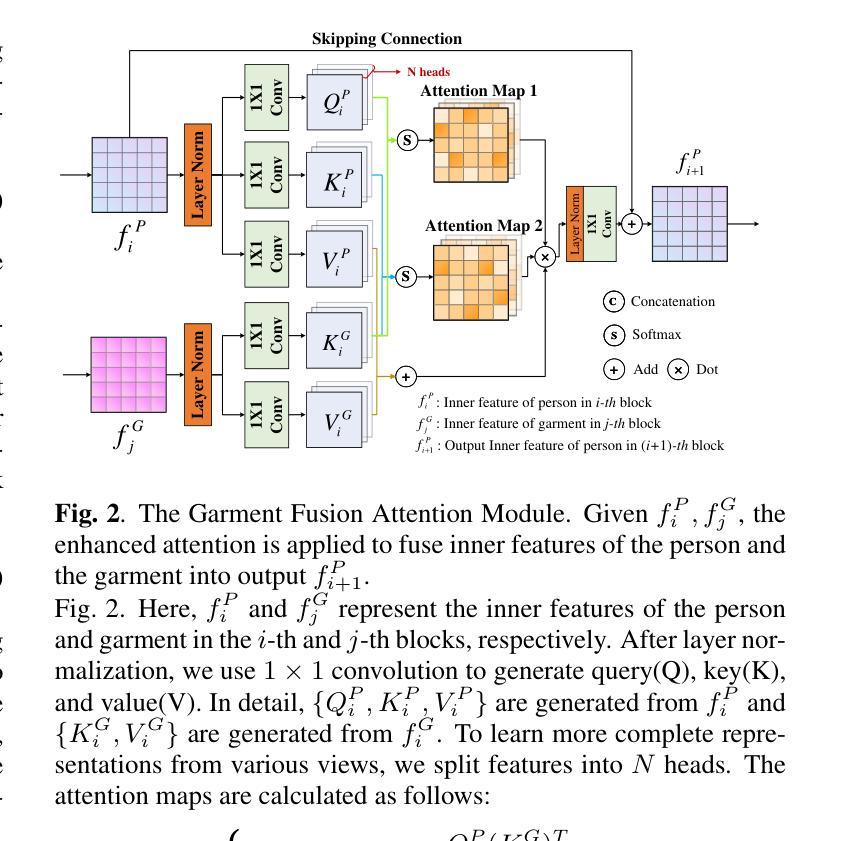
摘要: (1):虚拟试穿可以显著改善在线和店内场景中的服装购物体验,在计算机视觉领域引起了广泛关注。然而,为了实现高保真试穿性能,大多数最先进的方法仍然依赖于准确的分割掩码,这些掩码通常由近乎完美的解析器或手动标注产生。为了克服这一瓶颈,我们提出了一种基于扩散模型的无解析虚拟试穿方法(PFDM)。给定两张图像,PFDM 可以通过隐式扭曲将服装无缝地“穿”在目标人物身上,而无需任何其他信息。为了有效地学习模型,我们合成了许多伪图像,并通过在人物身上穿戴各种服装来构建样本对。在由大规模扩展数据集监督下,我们使用提出的服装融合注意(GFA)机制融合人物和服装特征。实验表明,我们提出的 PFDM 可以成功处理复杂情况,合成高保真图像,并且优于最先进的无解析和基于解析的模型。 (2):GAN 用于虚拟试穿。基于 GAN 的虚拟试穿方法通常采用两步架构,首先将服装扭曲成目标形状,然后通过组合扭曲的服装和人物图像来合成结果。一些工作专注于基于薄板样条变换 (TPS) 或全局流增强扭曲模块。其他工作旨在提高生成模块的性能,例如,采用对齐感知生成器来提高合成图像的分辨率,或改进损失函数以保留人物身份。 (3):本文提出的研究方法。我们提出了一种基于扩散模型的无解析虚拟试穿框架。这是第一个将扩散模型用于无解析虚拟试穿的工作。我们还精心设计了一个增强的交叉注意模块来融合人物和服装特征以进行隐式扭曲。 (4):方法在任务和性能上取得的成就。我们在 VITON-HD 上评估了我们的方法,实验表明,我们的无解析模型在定性和定量评估中都优于竞争对手。这些性能支持了我们的目标。
-
方法: (1):我们提出了一种基于扩散模型的无解析虚拟试穿框架,该框架可以将服装无缝地“穿”在目标人物身上,而无需任何其他信息。 (2):我们精心设计了一个增强的交叉注意模块来融合人物和服装特征以进行隐式扭曲。 (3):我们合成了许多伪图像,并通过在人物身上穿戴各种服装来构建样本对。 (4):在由大规模扩展数据集监督下,我们使用提出的服装融合注意(GFA)机制融合人物和服装特征。
-
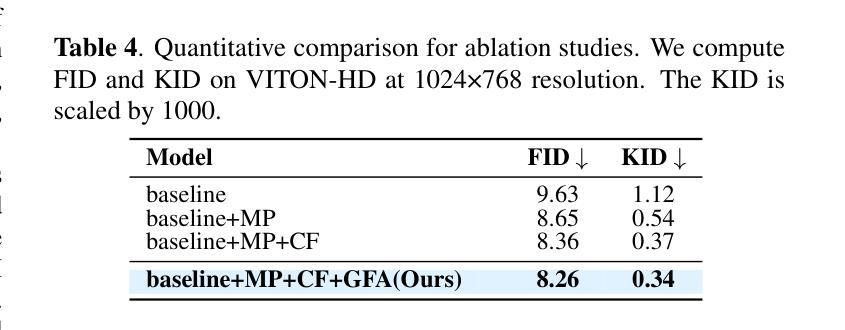
结论: (1):本文提出了一种基于扩散模型的无解析虚拟试穿方法,该方法将扭曲和融合步骤统一到一个模型中,同时避免了使用任何解析器或外部模块。据我们所知,PFDM 是第一个基于扩散的无解析虚拟试穿模型。实验表明,PFD 可以生成具有丰富纹理细节的高分辨率高保真试穿结果,并成功处理错位和遮挡,这不仅优于现有的无解析方法,而且在定性和定量分析中也超越了最先进的基于解析器的模型。我们希望我们的工作能够促进虚拟试穿技术在电子商务和元宇宙中的普及。 (2):创新点:提出了一种基于扩散模型的无解析虚拟试穿方法,该方法将扭曲和融合步骤统一到一个模型中,同时避免了使用任何解析器或外部模块。 性能:在定性和定量分析中,PFDM 优于现有的无解析方法和最先进的基于解析器的模型。 工作量:该方法需要合成大量伪图像并构建样本对,这可能需要大量计算资源。
点此查看论文截图


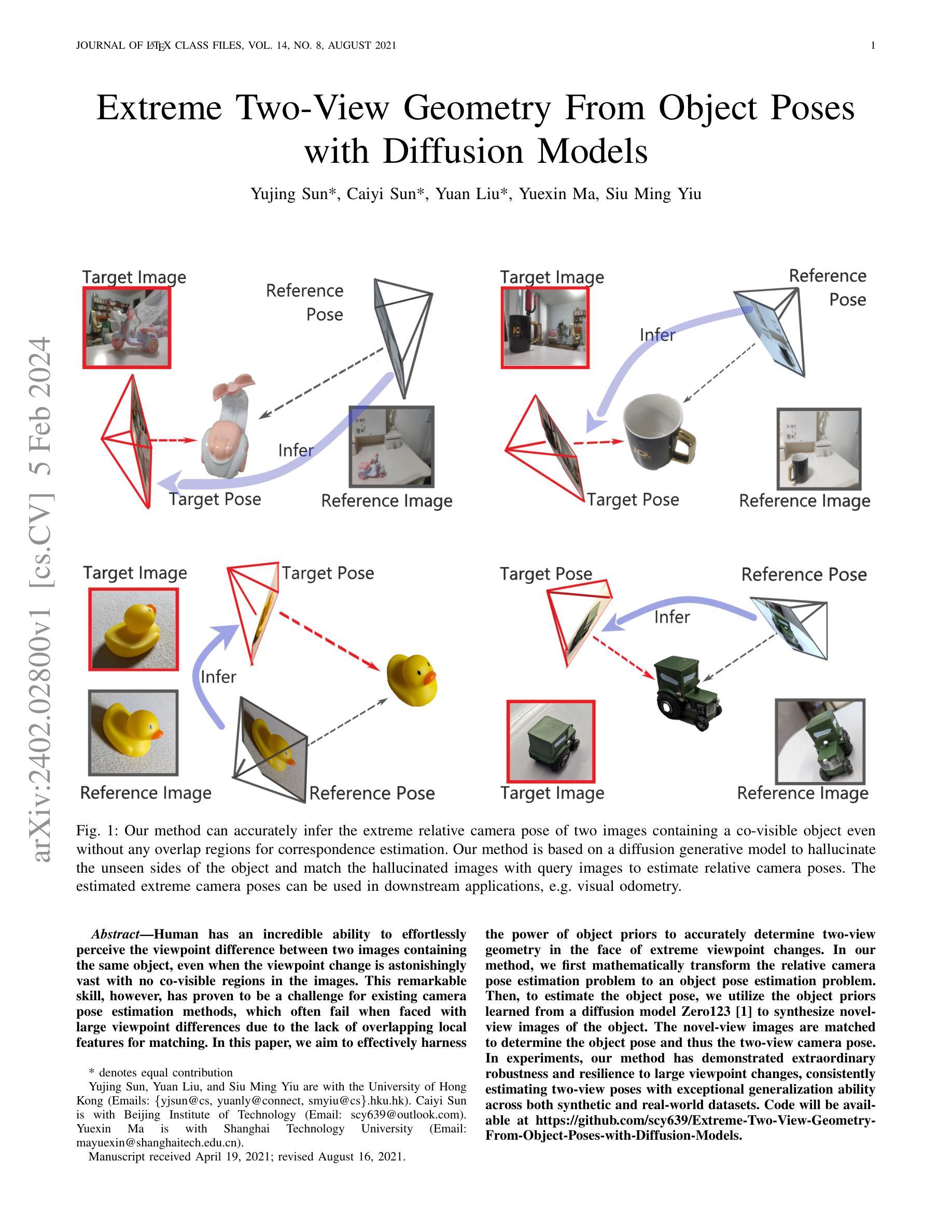
Extreme Two-View Geometry From Object Poses with Diffusion Models
Authors:Yujing Sun, Caiyi Sun, Yuan Liu, Yuexin Ma, Siu Ming Yiu
Human has an incredible ability to effortlessly perceive the viewpoint difference between two images containing the same object, even when the viewpoint change is astonishingly vast with no co-visible regions in the images. This remarkable skill, however, has proven to be a challenge for existing camera pose estimation methods, which often fail when faced with large viewpoint differences due to the lack of overlapping local features for matching. In this paper, we aim to effectively harness the power of object priors to accurately determine two-view geometry in the face of extreme viewpoint changes. In our method, we first mathematically transform the relative camera pose estimation problem to an object pose estimation problem. Then, to estimate the object pose, we utilize the object priors learned from a diffusion model Zero123 to synthesize novel-view images of the object. The novel-view images are matched to determine the object pose and thus the two-view camera pose. In experiments, our method has demonstrated extraordinary robustness and resilience to large viewpoint changes, consistently estimating two-view poses with exceptional generalization ability across both synthetic and real-world datasets. Code will be available at https://github.com/scy639/Extreme-Two-View-Geometry-From-Object-Poses-with-Diffusion-Models.
Summary
利用扩散模型合成新视图图像进行对象姿态估计,有效求解极端视角变化下的两视图几何问题。
Key Takeaways
- 利用对象先验通过扩散模型Zero123合成新视图图像,增强了对象姿态估计的鲁棒性和适应性。
- 将相对相机姿态估计问题数学转换为对象姿态估计问题,简化了问题的求解。
- 在极端视角变化的情况下,合成的新视图图像经匹配可以确定对象姿态,从而确定两视图相机姿态。
- 该方法在合成和真实世界数据集上均表现出非凡的鲁棒性和弹性,估计两视图姿态具有杰出的泛化能力。
- 可在 https://github.com/scy639/Extreme-Two-View-Geometry-From-Object-Poses-with-Diffusion-Models 获取代码。
- 该方法精度高,在合成和真实世界数据集上均表现良好。
- 该方法适用于解决极端视角变化下的两视图几何问题。
- 标题:从物体位姿估计极端两视图几何
- 作者:Yujing Sun、Caiyi Sun、Yuan Liu、Yuexin Ma、Siu Ming Yiu
- 隶属机构:香港大学
- 关键词:两视图几何、物体位姿估计、扩散模型、生成模型
- 论文链接:https://arxiv.org/abs/2402.02800 Github 代码链接:https://github.com/scy639/Extreme-Two-View-Geometry-From-Object-Poses-with-Diffusion-Models
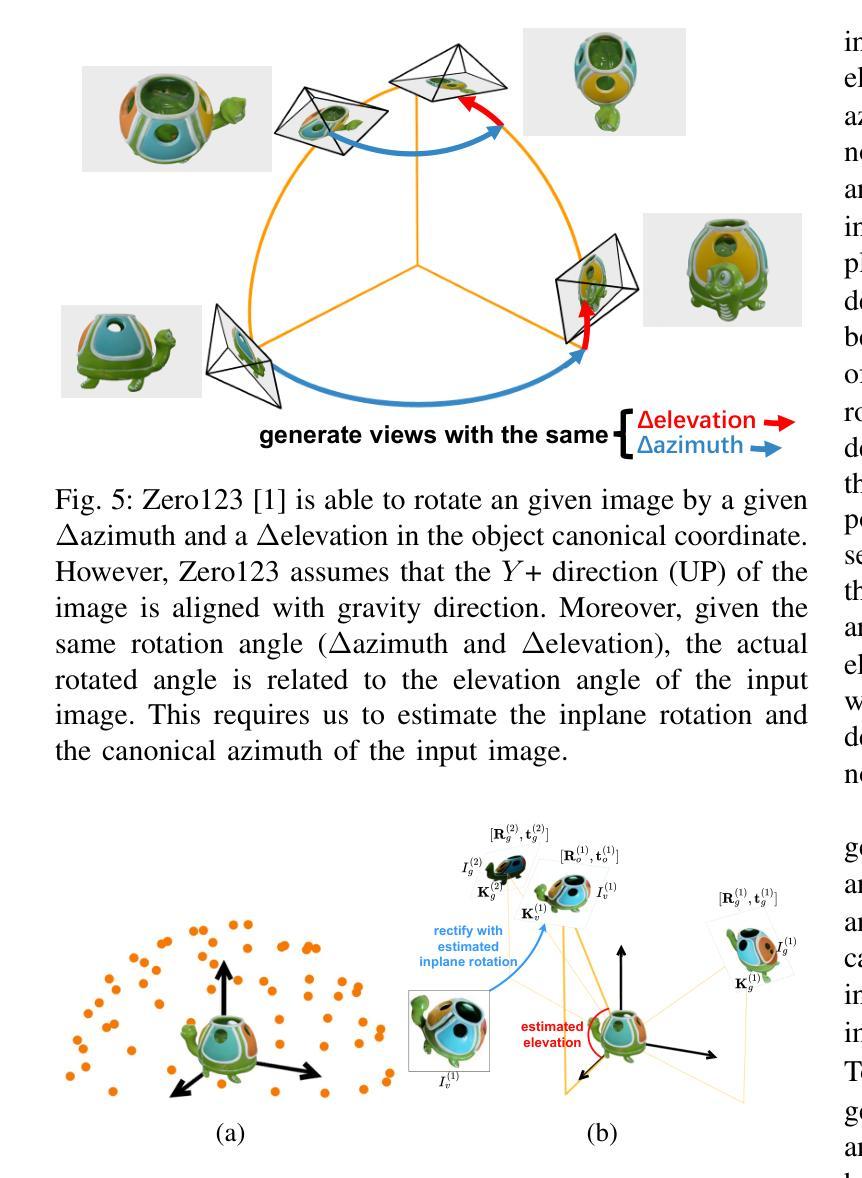
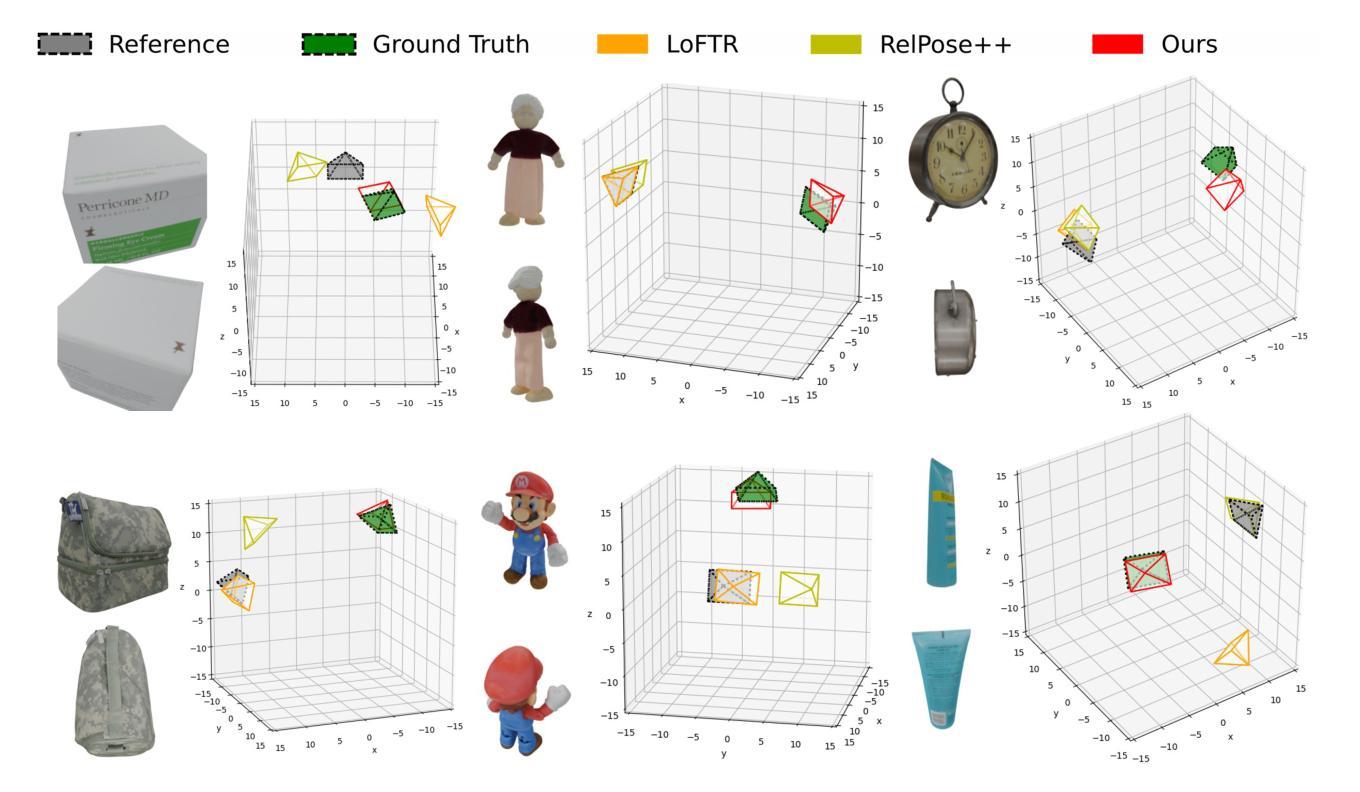
- 摘要: (1) 研究背景:人类具有惊人的能力,能够毫不费力地感知包含相同物体的两幅图像之间的视点差异,即使视点变化非常大,图像中没有共同可见的区域。然而,对于现有的相机位姿估计方法来说,这种非凡的能力被证明是一个挑战,因为这些方法在面对大的视点差异时通常会失败,原因是缺少用于匹配的重叠局部特征。 (2) 过去的方法及其问题:过去的方法主要集中在使用局部特征匹配来估计两视图几何。然而,当视点差异较大时,这种方法往往会失败,因为没有足够的重叠局部特征可供匹配。 (3) 本文提出的研究方法:在本文中,我们提出了一种新方法来估计极端两视图几何。我们的方法首先将相对相机位姿估计问题转换为物体位姿估计问题。然后,为了估计物体位姿,我们利用从扩散模型 Zero123 学习到的物体先验来合成物体的 novel-view 图像。将 novel-view 图像匹配以确定物体位姿,从而确定两视图相机位姿。 (4) 方法在任务和性能上的表现:在实验中,我们的方法表现出非凡的鲁棒性和对大视点变化的适应性,能够一致地估计两视图位姿,并且在合成和真实世界数据集上都具有出色的泛化能力。这些性能支持了我们的目标,即准确地确定极端视点变化下的两视图几何。
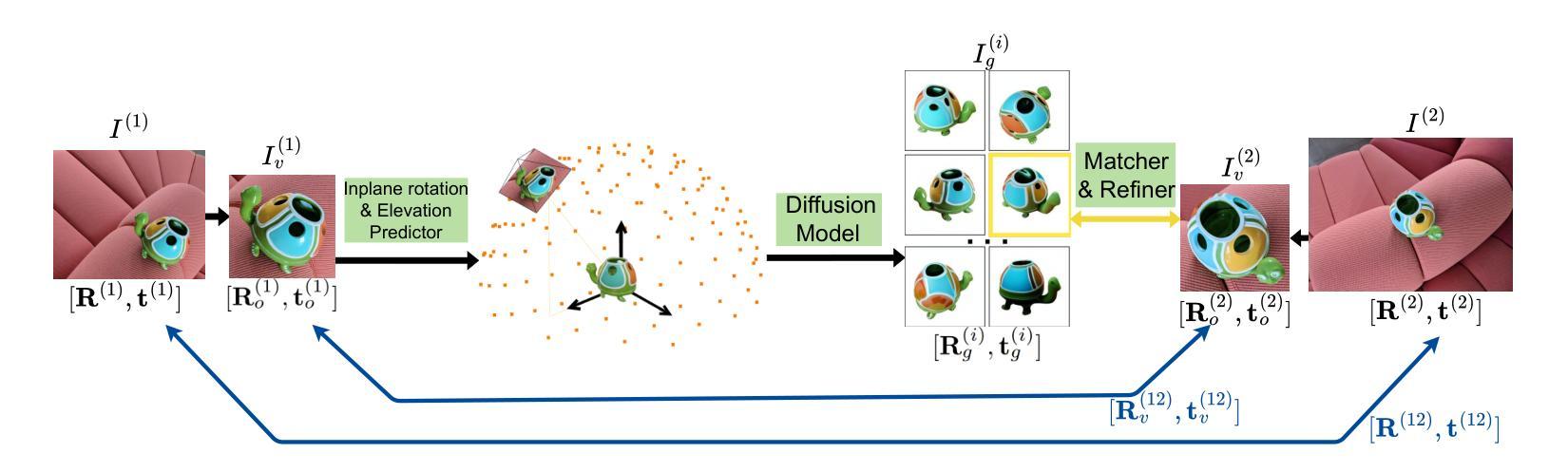
Methods: (1): 提出了一种新方法来估计极端两视图几何,该方法将相对相机位姿估计问题转换为物体位姿估计问题; (2): 利用从扩散模型Zero123学习到的物体先验来合成物体的novel-view图像,将novel-view图像匹配以确定物体位姿; (3): 通过实验验证了该方法的鲁棒性和泛化能力。
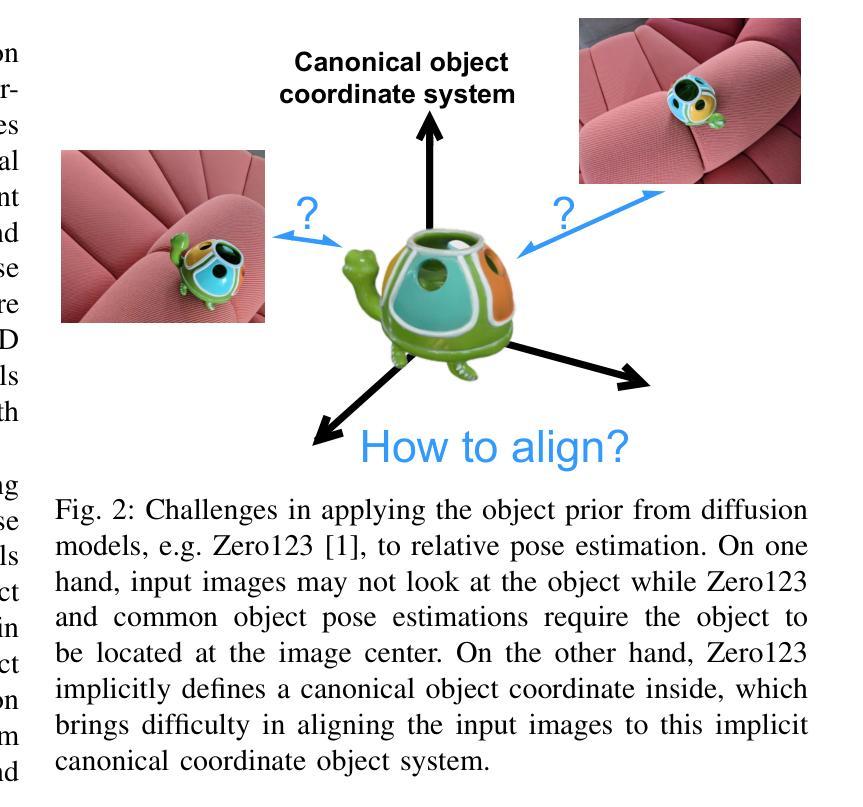
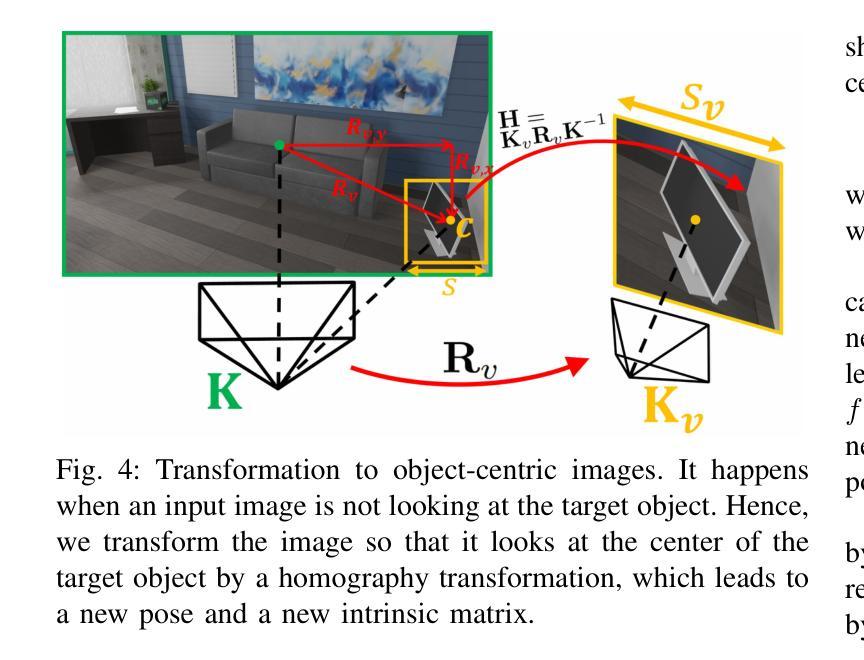
- 结论: (1):本文提出了一种新颖的算法,可以估计具有极端视点变化的相对相机位姿。该方法的核心思想是利用从大规模 2D 扩散模型 Zero123 学习到的物体先验,该先验能够生成对象的 novel-view 图像。但是,由于 Zero123 在其模型中隐式定义了规范坐标系,并且图像可能不会看向对象,因此我们无法直接应用 Zero123。为了解决这一挑战,我们首先提出了一种新的两视图位姿估计公式,作为物体位姿估计问题,并正确定义输入图像和生成图像的物体位姿。最后,我们匹配另一幅图像。 (2):创新点:
- 将相对相机位姿估计问题转换为物体位姿估计问题,并利用从扩散模型 Zero123 学习到的物体先验来合成物体的 novel-view 图像,将 novel-view 图像匹配以确定物体位姿,从而确定两视图相机位姿。
- 在实验中,我们的方法表现出非凡的鲁棒性和对大视点变化的适应性,能够一致地估计两视图位姿,并且在合成和真实世界数据集上都具有出色的泛化能力。
- 这些性能支持了我们的目标,即准确地确定极端视点变化下的两视图几何。
性能: - 在合成数据集上,我们的方法在所有视点变化范围内都优于最先进的方法,并且在极端视点变化下具有显着的优势。 - 在真实世界数据集上,我们的方法也优于最先进的方法,并且在极端视点变化下具有显着的优势。
工作量: - 该方法需要训练一个扩散模型来学习物体先验,这可能需要大量的数据和计算资源。 - 该方法还需要合成 novel-view 图像,这可能需要大量的时间和计算资源。 - 该方法还需要匹配 novel-view 图像,这可能需要大量的时间和计算资源。
点此查看论文截图