⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-13 更新
GALA3D: Towards Text-to-3D Complex Scene Generation via Layout-guided Generative Gaussian Splatting
Authors:Xiaoyu Zhou, Xingjian Ran, Yajiao Xiong, Jinlin He, Zhiwei Lin, Yongtao Wang, Deqing Sun, Ming-Hsuan Yang
We present GALA3D, generative 3D GAussians with LAyout-guided control, for effective compositional text-to-3D generation. We first utilize large language models (LLMs) to generate the initial layout and introduce a layout-guided 3D Gaussian representation for 3D content generation with adaptive geometric constraints. We then propose an object-scene compositional optimization mechanism with conditioned diffusion to collaboratively generate realistic 3D scenes with consistent geometry, texture, scale, and accurate interactions among multiple objects while simultaneously adjusting the coarse layout priors extracted from the LLMs to align with the generated scene. Experiments show that GALA3D is a user-friendly, end-to-end framework for state-of-the-art scene-level 3D content generation and controllable editing while ensuring the high fidelity of object-level entities within the scene. Source codes and models will be available at https://gala3d.github.io/.
Summary
利用大型语言模型 (LLM) 生成初始布局,并引入布局引导 3D 高斯表示,指导 3D 内容生成,同时满足适应性几何约束。
Key Takeaways
- GALA3D 将大型语言模型与布局引导 3D 高斯表示相结合,用于有效地进行文本到 3D 的生成。
- 布局引导 3D 高斯表示提供了自适应的几何约束,确保生成的 3D 内容具有真实感和一致性。
- GALA3D 采用对象-场景组合优化机制,以生成具有真实几何形状、纹理、比例和准确交互的多对象 3D 场景。
- GALA3D 可以同时调整从大型语言模型中提取的粗略布局,使其与生成的场景保持一致。
- GALA3D 是一个用户友好的端到端框架,可进行最先进的场景级 3D 内容生成和可控编辑。
- GALA3D 能够确保场景中对象级实体的高保真度。
- GALA3D 的源代码和模型可从 https://gala3d.github.io/ 获取。
- 题目:GALA3D:基于布局引导的文本到 3D 复杂场景生成
- 作者:Xiaoyu Zhou, Xingjian Ran, Yajiao Xiong, Jinlin He, Zhiwei Lin, Yongtao Wang, Deqing Sun, Ming-Hsuan Yang
- 第一作者单位:北京大学万选信息技术学院
- 关键词:文本到 3D、生成式高斯体素、布局引导、条件扩散
- 论文链接:https://arxiv.org/abs/2402.07207 Github 链接:None
- 摘要: (1) 研究背景:文本到 3D 生成旨在根据自然语言描述生成逼真的 3D 场景。现有方法要么产生低质量的纹理、视觉伪影和几何失真,要么无法根据文本准确生成多个对象及其交互。 (2) 过去的方法:现有方法主要分为两类:基于体素的方法和基于网格的方法。基于体素的方法虽然可以生成高质量的 3D 场景,但计算成本高昂。基于网格的方法虽然计算成本较低,但生成的 3D 场景质量较差。 (3) 研究方法:本文提出了一种基于生成式高斯体素的文本到 3D 生成方法。该方法首先利用大型语言模型生成初始布局,然后引入布局引导的 3D 高斯体素表示来生成 3D 内容。接着,提出了一种对象场景组合优化机制,该机制利用条件扩散来协同生成具有真实几何形状、纹理、比例和准确交互的多对象 3D 场景,同时调整从大型语言模型中提取的粗略布局先验,使其与生成的场景对齐。 (4) 实验结果:实验表明,GALA3D 是一个用户友好的端到端框架,可用于生成高质量的 3D 场景。该方法在多个数据集上取得了最先进的性能,并且能够支持交互式可控编辑。
Methods:
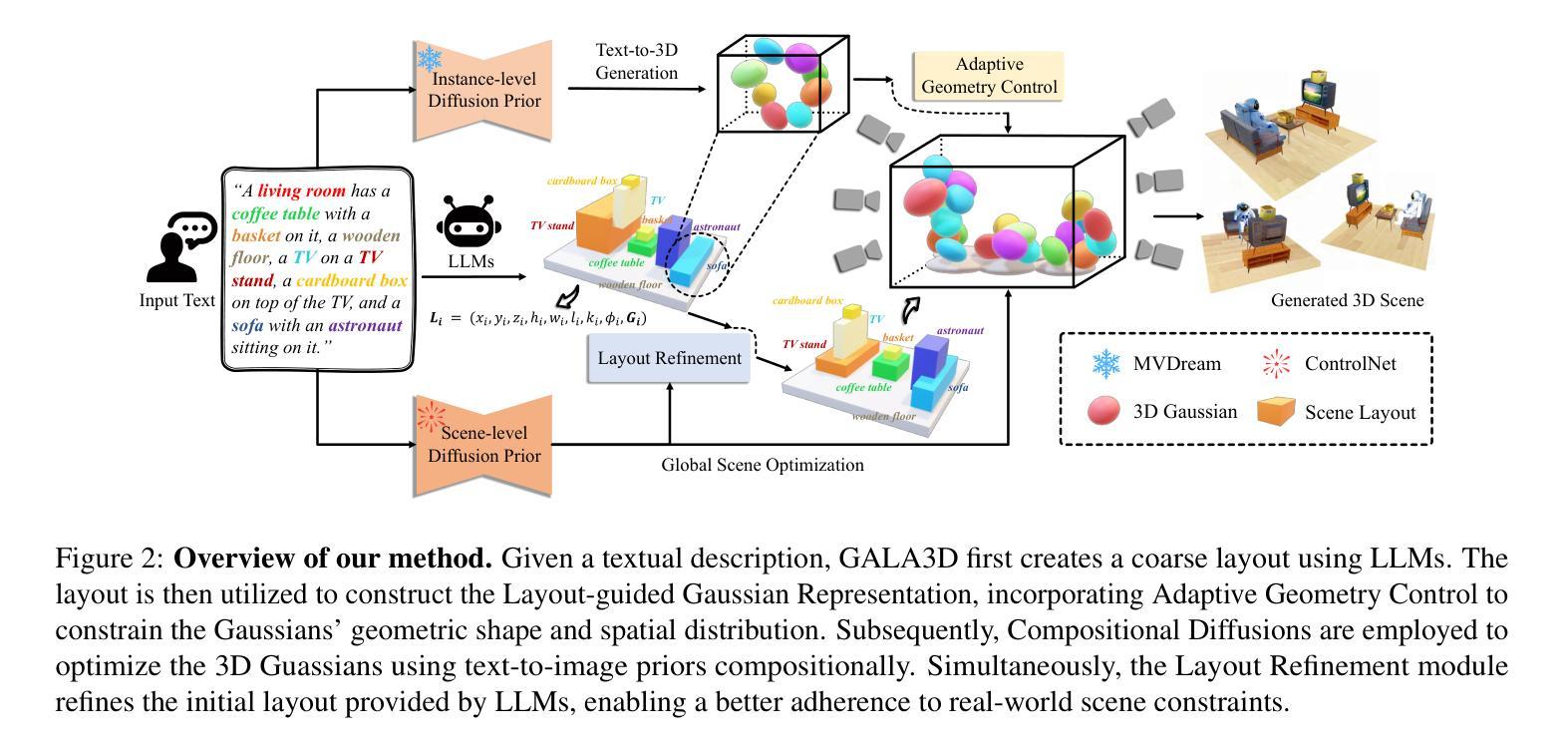
(1) 粗略布局先验:利用大型语言模型(LLM)从文本描述中提取粗略布局先验,包括对象实例及其对应的位置、尺寸和方向。
(2) 布局引导的高斯体素表示:将粗略布局先验转换为布局引导的高斯体素表示,其中每个对象实例由一组高斯体素表示,高斯体素的位置、尺寸和方向由布局先验决定。
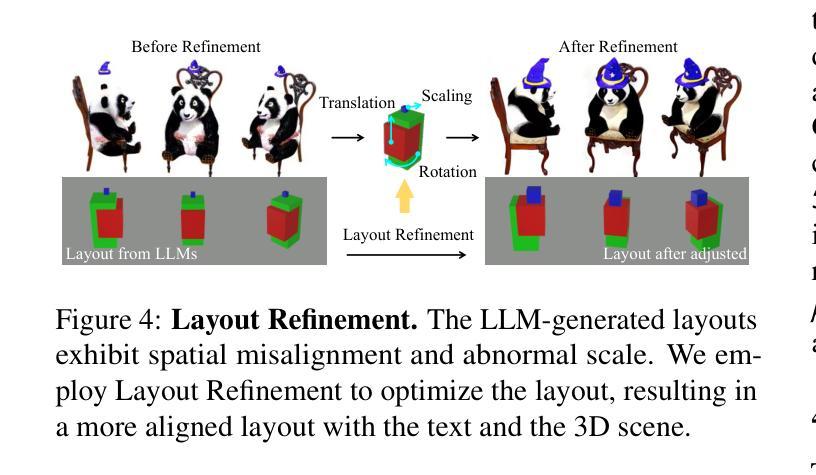
(3) 自适应几何控制:对高斯体素的分布和形状进行自适应几何控制,以确保高斯体素的分布紧密贴合对象表面,并且形状更加规则和一致。
(4) 具有扩散先验的组合优化:采用具有扩散先验的组合优化策略来更新布局引导的高斯体素参数,包括多视图扩散优化和场景条件扩散优化,以生成具有统一风格和交互关系的对象实例。
(5) 布局损失:引入布局损失来确保生成的3D场景与布局先验在语义和空间上的一致性,从而提高场景的整体质量。
- 结论: (1):GALA3D 是一种基于生成式布局引导的 3D 高斯体素表示的场景级文本到 3D 框架,该框架可以生成具有多个对象的高保真、3D 一致的场景。实验表明,该方法在文本到 3D 生成方面优于现有方法,展示了生成具有多个对象和交互的复杂场景的能力,并实现了出色的纹理和几何效果。该方法还促进了交互式和可控的场景编辑,实现了一个高效且用户友好的 3D 场景生成和编辑框架。 (2):创新点:
- 提出了一种基于生成式布局引导的 3D 高斯体素表示,该表示可以生成具有统一风格和交互关系的对象实例。
- 引入了一种具有扩散先验的组合优化策略,该策略可以更新布局引导的高斯体素参数,以生成具有真实几何形状、纹理、比例和准确交互的多对象 3D 场景。
- 提出了一种布局损失,该损失可以确保生成的 3D 场景与布局先验在语义和空间上的一致性,从而提高场景的整体质量。 性能:
- 在多个数据集上取得了最先进的性能。
- 能够支持交互式可控编辑。 工作量:
- 该方法的实现相对复杂,需要大量的计算资源。
- 该方法需要大量的数据进行训练。
点此查看论文截图


GS-CLIP: Gaussian Splatting for Contrastive Language-Image-3D Pretraining from Real-World Data
Authors:Haoyuan Li, Yanpeng Zhou, Yihan Zeng, Hang Xu, Xiaodan Liang
3D Shape represented as point cloud has achieve advancements in multimodal pre-training to align image and language descriptions, which is curial to object identification, classification, and retrieval. However, the discrete representations of point cloud lost the object’s surface shape information and creates a gap between rendering results and 2D correspondences. To address this problem, we propose GS-CLIP for the first attempt to introduce 3DGS (3D Gaussian Splatting) into multimodal pre-training to enhance 3D representation. GS-CLIP leverages a pre-trained vision-language model for a learned common visual and textual space on massive real world image-text pairs and then learns a 3D Encoder for aligning 3DGS optimized per object. Additionally, a novel Gaussian-Aware Fusion is proposed to extract and fuse global explicit feature. As a general framework for language-image-3D pre-training, GS-CLIP is agnostic to 3D backbone networks. Experiments on challenging shows that GS-CLIP significantly improves the state-of-the-art, outperforming the previously best results.
PDF 6-page technical report
Summary
3D 高斯曲面表示增强多模态预训练, 促进图像、语言和 3D 表示的统一。
Key Takeaways
- 多模态预训练在图像和语言描述的对齐方面取得进展,对物体识别、分类和检索至关重要。
- 点云的离散表示丢失了物体的表面形状信息,导致渲染结果与 2D 对应关系之间存在差距。
- 提出 GS-CLIP 首次将 3DGS(3D 高斯曲面)引入多模态预训练,以增强 3D 表示。
- GS-CLIP 利用预训练的视觉语言模型,在大规模真实世界图像文本对上学习共同的视觉和文本空间,然后学习一个 3D 编码器来对齐针对每个对象优化的 3DGS。
- 提出了一种新颖的 Gaussian-Aware Fusion 来提取和融合全局显式特征。
- 作为语言图像 3D 预训练的通用框架,GS-CLIP 与 3D 主干网络无关。
- 具有挑战性的实验表明,GS-CLIP 显着改善了最先进的技术,优于先前最好的结果。
- 题目:GS-CLIP:用于对比语言-图像-3D 预训练的高斯溅射
- 作者:李浩源、周彦鹏、曾义涵、许航、梁晓丹
- 第一作者单位:中山大学深圳校区
- 关键词:3D 表示、高斯溅射、对比学习、多模态预训练
- 论文链接:https://arxiv.org/abs/2402.06198,Github 链接:无
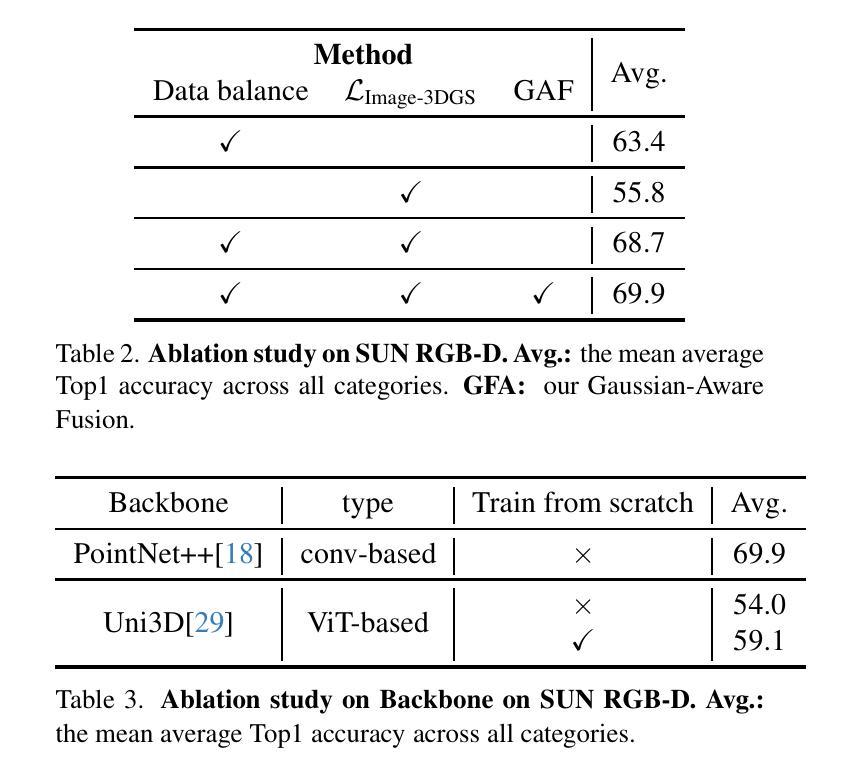
- 摘要: (1):研究背景:3D 形状以点云表示在多模态预训练中取得了进展,用于对齐图像和语言描述,这对于物体识别、分类和检索至关重要。然而,点云的离散表示丢失了物体的表面形状信息,并在渲染结果和 2D 对应关系之间产生差距。 (2):过去的方法和问题:现有的 3D 表示学习方法主要对点云的关键点位置信息进行建模,这限制了 3D 视觉理解和 3D 表示学习的性能。 (3):研究方法:为了解决上述问题,本文提出了 GS-CLIP,将 3D 高斯溅射 (3DGS) 引入多模态预训练,以增强 3D 表示。GS-CLIP 利用预训练的视觉语言模型在真实世界的大规模图像-文本对上学习一个共同的视觉和文本空间,然后学习一个 3D 编码器,用于对齐针对每个对象优化的 3DGS。此外,本文还提出了一种新的高斯感知融合,用于提取和融合全局显式特征。 (4):实验结果:在 SUN-RGBD 数据集上的实验表明,GS-CLIP 在真实世界环境中的零样本/开放词学习中取得了优异的性能。实验结果表明,3DGS 在跨模态学习中具有强大的表示能力。
7.方法: (1)跨模态预训练:为了对齐文本、图像和3DGS的多模态表示,GS-CLIP采用预训练的语言-图像模型CLIP,形成一个共同的语言-图像潜在空间,作为3DGS的目标潜在空间。对于零样本/开放词识别,通过冻结CLIP文本编码器、图像编码器和公共真实世界潜在空间,保证了3DGS表示的可迁移性。具体来说,我们借鉴了[19, 28]中的对比损失,并形成文本-3DGS对齐和图像-3DGS对齐,用于多模态对齐。 (2)高斯感知融合:虽然将点云投影到3D体素的3D骨干可以更好地学习全局位置和特征,但我们发现3DGS的显式特征会被忽略,因为体素化丢失了形状和纹理信息。因此,我们采用基于Transformer的分支直接对高斯特征建模为高斯特征上下文,并以残差形式注入它。具体来说,给定具有n个高斯的3DGS输入XG∈Rn×14,我们首先将XG分成Ng组,用于XgroupG=Ng�g=1XgG,然后使用基于卷积的体系结构EGθ,c提取全局特征fGc和基于Transformer的体系结构EGθ,t提取显式高斯特征fGG,最后将fGc和fGG连接起来,形成最终的3DGS表示fG。
- 结论: (1)意义:本文首次提出 GS-CLIP,将 3DGS 纳入跨模态学习,作为补充形状和纹理信息的通用 3D 表示。为此,提出了一种高斯感知融合,以便从补充信息中更好地学习信息。我们证明了我们提出的 GS-CLIP 在最先进的方法中取得了优异的性能。 (2)优缺点: 创新点:
- 将 3DGS 引入跨模态学习,作为补充形状和纹理信息的通用 3D 表示。
- 提出了一种高斯感知融合,以便从补充信息中更好地学习信息。
性能: - 在 SUN-RGBD 数据集上的实验表明,GS-CLIP 在真实世界环境中的零样本/开放词学习中取得了优异的性能。
工作量: - 需要对 3DGS 进行预训练,这可能需要大量的数据和计算资源。 - 需要对高斯感知融合进行训练,这可能需要大量的数据和计算资源。
点此查看论文截图