⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-13 更新
Synthesizing CTA Image Data for Type-B Aortic Dissection using Stable Diffusion Models
Authors:Ayman Abaid, Muhammad Ali Farooq, Niamh Hynes, Peter Corcoran, Ihsan Ullah
Stable Diffusion (SD) has gained a lot of attention in recent years in the field of Generative AI thus helping in synthesizing medical imaging data with distinct features. The aim is to contribute to the ongoing effort focused on overcoming the limitations of data scarcity and improving the capabilities of ML algorithms for cardiovascular image processing. Therefore, in this study, the possibility of generating synthetic cardiac CTA images was explored by fine-tuning stable diffusion models based on user defined text prompts, using only limited number of CTA images as input. A comprehensive evaluation of the synthetic data was conducted by incorporating both quantitative analysis and qualitative assessment, where a clinician assessed the quality of the generated data. It has been shown that Cardiac CTA images can be successfully generated using using Text to Image (T2I) stable diffusion model. The results demonstrate that the tuned T2I CTA diffusion model was able to generate images with features that are typically unique to acute type B aortic dissection (TBAD) medical conditions.
PDF Submitted in IEEE EMBC 2024 Conference
Summary
稳定扩散模型在医学成像数据合成中展现出强大能力,有望解决数据稀缺问题,助力心血管图像处理领域的发展。
Key Takeaways
- 稳定扩散模型在医学成像数据合成中展现出巨大潜力,可用于解决数据稀缺问题。
- 通过微调用户定义文本提示的稳定扩散模型,仅使用有限数量的 CTA 图像作为输入,即可生成合成的冠状动脉 CTA 图像。
- 定量分析和定性评估相结合的综合评估表明,使用文本到图像 (T2I) 稳定扩散模型可以成功生成心脏 CTA 图像。
- 微调的 T2I CTA 扩散模型能够生成具有急性 B 型主动脉夹层 (TBAD) 医学特征的图像。
- 合成的图像在视觉上与真实图像相似,并保留了真实图像中的关键解剖结构。
- 临床医生认为合成的图像具有足够的质量,可用于临床实践。
- 该研究表明,稳定扩散模型在医学成像数据合成中具有广阔的应用前景,有望改善心血管疾病的诊断和治疗。
- 题目:使用稳定扩散模型合成 B 型主动脉夹层断层扫描图像数据
- 作者:Ayman Abaid、Muhammad Ali Farooq、Niamh Hynes、Peter Corcoran 和 Ihsan Ullah
- 第一作者单位:爱尔兰戈尔韦大学计算机科学学院
- 关键词:主动脉夹层、计算机断层扫描血管造影、医学图像合成、稳定扩散模型、文本到图像
- 论文链接:https://arxiv.org/abs/2402.06969 Github 代码链接:无
-
摘要: (1):研究背景:主动脉夹层是一种严重的心血管疾病,需要准确和及时的诊断。计算机断层扫描血管造影 (CTA) 是诊断主动脉夹层最常用的成像方式,但由于数据稀缺,机器学习算法在主动脉夹层图像处理中的能力受到限制。 (2):过去的方法:过去的研究使用深度学习模型来自动分割主動脈夾層圖像中的真腔、假腔和假腔血栓。然而,这些模型通常需要大量的数据进行训练,而主动脉夹层的数据集往往很小。 (3):研究方法:本研究提出了一种使用稳定扩散模型合成主动脉夹层 CTA 图像的方法。稳定扩散模型是一种生成式人工智能模型,可以根据文本提示生成逼真的图像。本研究通过微调稳定扩散模型,使其能够根据用户定义的文本提示生成主动脉夹层 CTA 图像。 (4):方法性能:实验结果表明,微调后的稳定扩散模型能够生成具有主动脉夹层典型特征的图像。定量分析和定性评估都表明,合成的图像具有很高的质量,并且可以用于训练深度学习模型进行主动脉夹层图像分割。
-
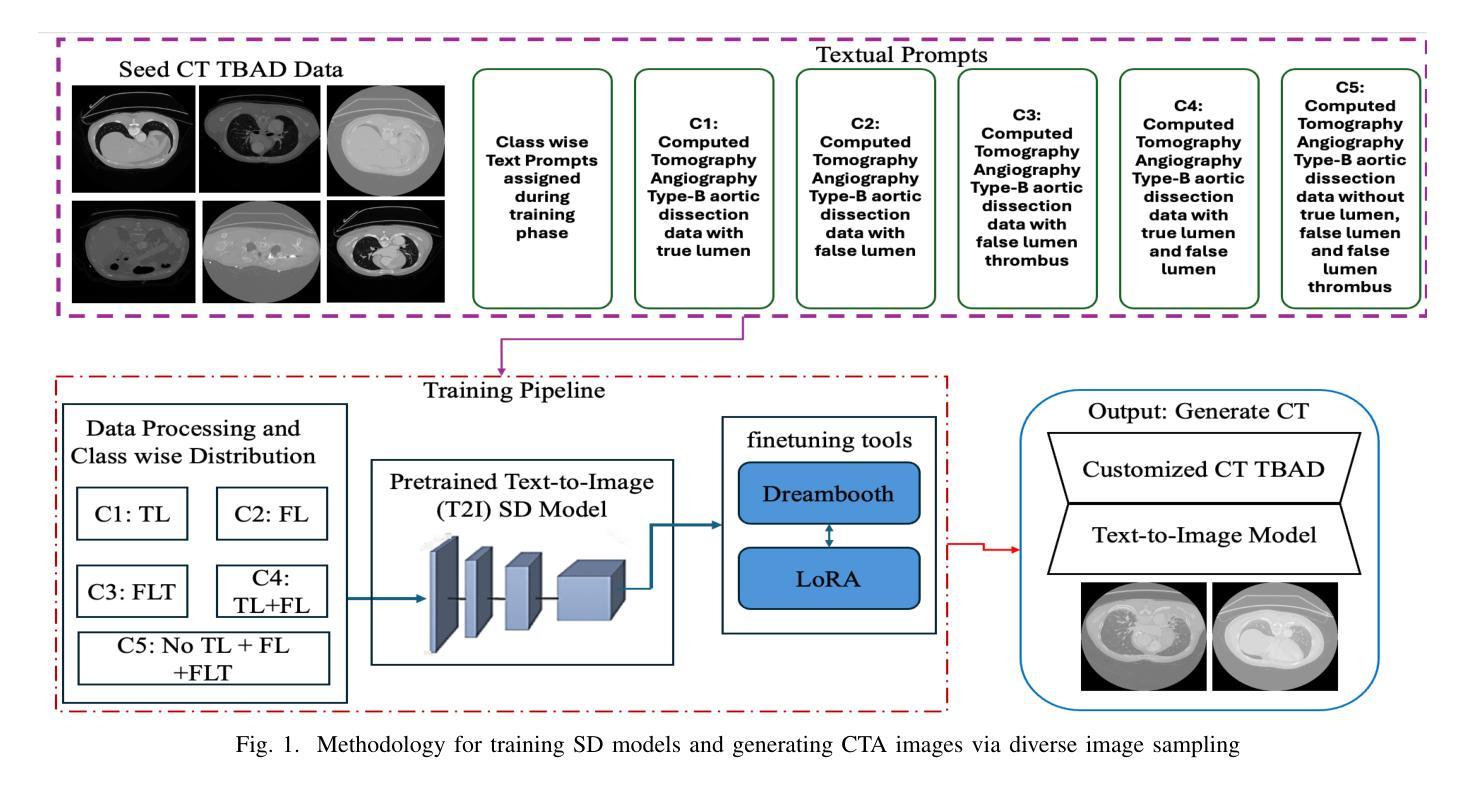
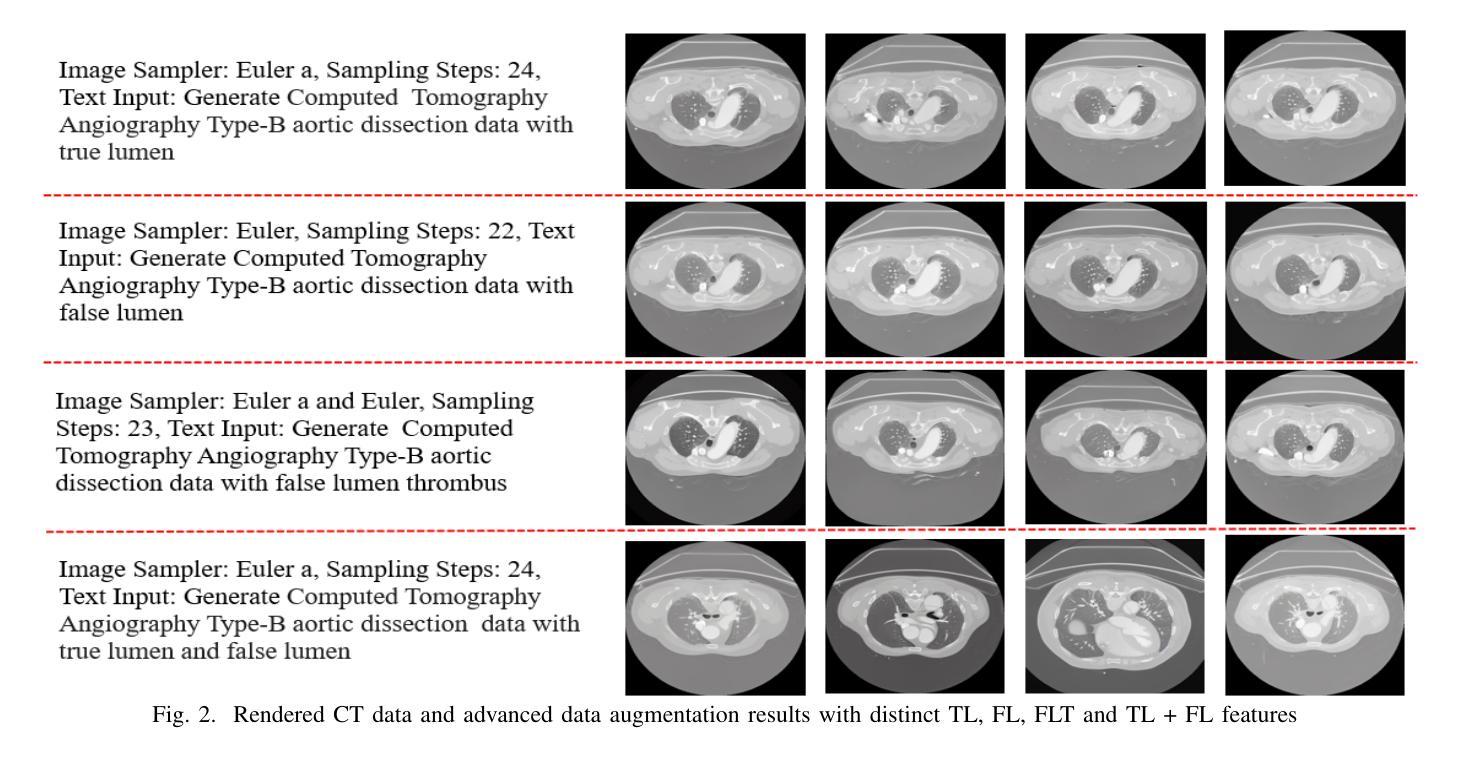
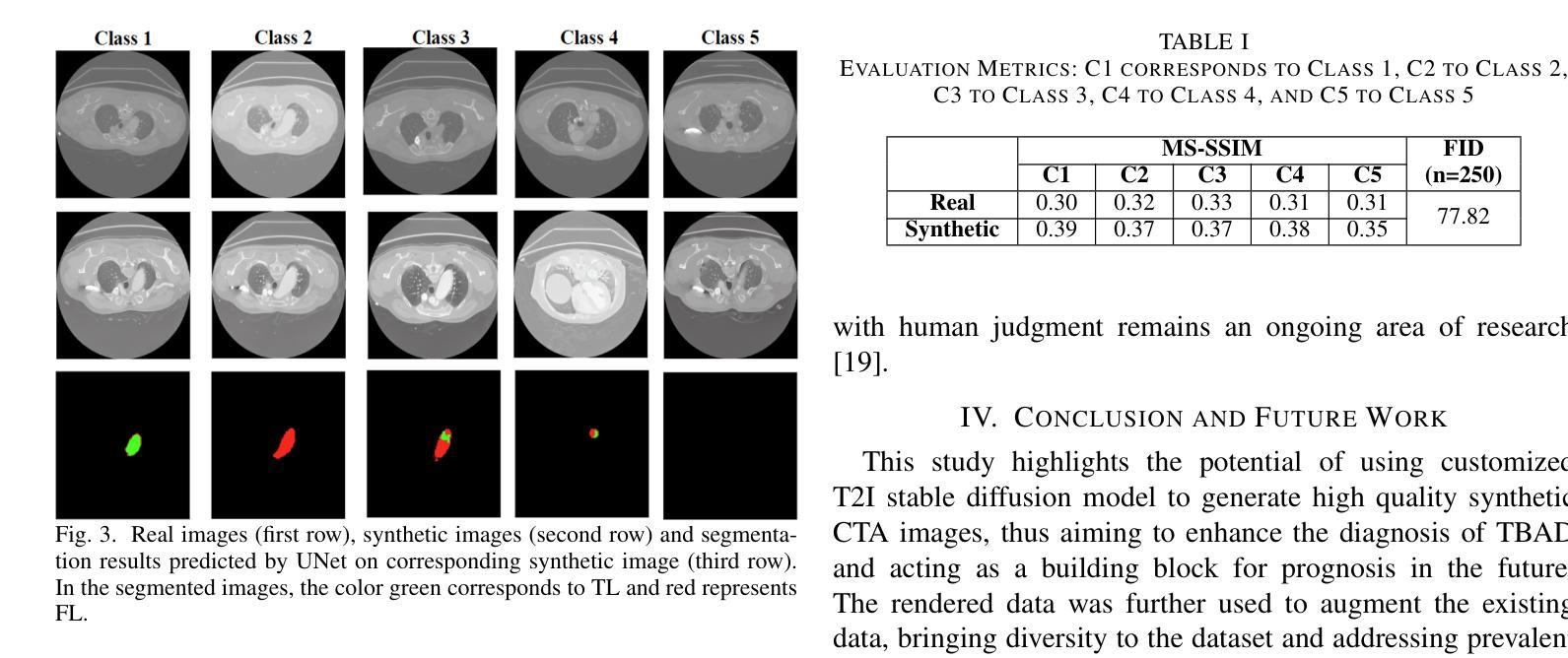
方法: (1) 数据预处理:将 3D CTA 图像转换为 2D 图像,并将其划分为训练集、测试集和验证集。将数据分为五类:有真腔 (TL) 的图像、有假腔 (FL) 的图像、有假腔血栓 (FLT) 的图像、有 TL 和 FL 的图像,以及无 TL、FL 和 FLT 信息的数据。 (2) 文本到图像 (T2I) 模型训练:使用 ImageTBAD 数据集和 DreamBooth 训练工具微调预训练的稳定扩散模型,以生成高质量的 CTA 数据。在训练过程中,为每类数据分配专门的文本提示,并为后续类别的特定类提供否定提示。 (3) 图像采样:使用欧拉和欧拉 A 图像采样器从潜空间的不同区域采样,以生成多样化和逼真的图像。 (4) 数据增强:使用独特的文本提示渲染具有类别分布的 CT 数据,以增强具有特定 CT 特征的数据,例如 TL、FL 和 FLT。 (5) 模型评估:使用 Fréchet Inception Distance (FID) 和 Multiscale Structural Similarity Index Measure (MS-SSIM) 评估合成图像的质量和多样性。训练 SoTA 模型(例如 UNet)对合成图像进行分割,以评估其实用性。
-
结论: (1):本研究提出了一种使用稳定扩散模型合成主动脉夹层 CTA 图像的方法,该方法能够生成具有主动脉夹层典型特征的图像,并且可以用于训练深度学习模型进行主动脉夹层图像分割。 (2):创新点:
- 使用稳定扩散模型合成主动脉夹层 CTA 图像,这是首次将稳定扩散模型应用于主动脉夹层图像合成。
- 通过微调稳定扩散模型,使其能够根据用户定义的文本提示生成主动脉夹层 CTA 图像,这使得图像合成过程更加灵活和可控。
- 合成的图像具有很高的质量,并且可以用于训练深度学习模型进行主动脉夹层图像分割,这表明该方法具有实际应用价值。 性能:
- 定量分析和定性评估都表明,合成的图像具有很高的质量,并且可以用于训练深度学习模型进行主动脉夹层图像分割。
- 训练的 SoTA 模型(例如 UNet)对合成图像进行分割,获得了良好的分割精度,这表明该方法合成的图像具有很高的实用性。 工作量:
- 该方法需要对稳定扩散模型进行微调,这需要一定的计算资源和时间。
- 该方法需要对数据进行预处理,这需要一定的人工劳动。
点此查看论文截图


Improving 2D-3D Dense Correspondences with Diffusion Models for 6D Object Pose Estimation
Authors:Peter Hönig, Stefan Thalhammer, Markus Vincze
Estimating 2D-3D correspondences between RGB images and 3D space is a fundamental problem in 6D object pose estimation. Recent pose estimators use dense correspondence maps and Point-to-Point algorithms to estimate object poses. The accuracy of pose estimation depends heavily on the quality of the dense correspondence maps and their ability to withstand occlusion, clutter, and challenging material properties. Currently, dense correspondence maps are estimated using image-to-image translation models based on GANs, Autoencoders, or direct regression models. However, recent advancements in image-to-image translation have led to diffusion models being the superior choice when evaluated on benchmarking datasets. In this study, we compare image-to-image translation networks based on GANs and diffusion models for the downstream task of 6D object pose estimation. Our results demonstrate that the diffusion-based image-to-image translation model outperforms the GAN, revealing potential for further improvements in 6D object pose estimation models.
PDF Submitted to the First Austrian Symposium on AI, Robotics, and Vision 2024
Summary
扩散模型在图像到图像转换任务中表现优于生成对抗网络,在 6D 目标位姿估计任务中具有潜在优势。
Key Takeaways
- 估计 RGB 图像和 3D 空间之间的 2D-3D 对应关系是 6D 目标位姿估计中的一个基本问题。
- 当前,密集对应图是使用基于 GAN、自动编码器或直接回归模型的图像到图像转换模型估计的。
- 最近,图像到图像转换领域的最新进展已使扩散模型成为在基准数据集上评估时的优越选择。
- 在这项研究中,我们比较了基于 GAN 和扩散模型的图像到图像转换网络,用于 6D 目标位姿估计的下游任务。
- 我们的结果表明,基于扩散的图像到图像转换模型优于 GAN,表明 6D 目标位姿估计模型有进一步改进的潜力。
- 扩散模型在图像到图像转换任务中具有更高的准确性和鲁棒性。
- 扩散模型在 6D 目标位姿估计任务中具有潜在优势,可以进一步提高位姿估计的准确性。
- 题目:使用扩散模型改进 2D-3D 密集对应以进行 6D 目标位姿估计
- 作者:Peter Hönig、Stefan Thalhammer、Markus Vincze
- 作者单位:奥地利维也纳工业大学自动化与控制研究所
- 关键词:6D 目标位姿估计、2D-3D 密集对应、扩散模型、图像到图像翻译
- 论文链接:https://arxiv.org/abs/2402.06436
- 摘要: (1)研究背景:6D 目标位姿估计是许多感知任务的基础,例如自动驾驶、增强现实、创建数字孪生或机器人抓取。RGB-D 传感器可以同时提供颜色和深度数据,但并不总是可用。深度数据也容易受到噪声和其他失真的影响,这些失真通常由场景中闪亮、金属和透明物体反射引起。为了解决这个问题,人们考虑仅使用 RGB 图像进行位姿估计。最先进的方法依赖于估计 RGB 图像和 3D 对象模型之间的 2D-3D 密集对应。尽管这些方法擅长推断具有高可见性的对象位姿,但它们仍然面临着由杂波、遮挡、图像失真和闪亮物体表面带来的重大挑战。 (2)过去的方法:过去,人们通过使用直接回归、生成对抗网络 (GAN) 和 U-Net 架构的组合或编码器-解码器卷积神经网络 (CNN) 来解决位姿估计的 2D-3D 对应问题。上述方法估计的密集对应图包含从 RGB 图像到 3D 模型的每个像素的 3D 坐标。然而,这些方法在处理遮挡、杂波和具有挑战性的材料特性时存在困难。 (3)论文方法:本文提出了一种基于扩散模型的图像到图像翻译网络,用于估计 2D-3D 密集对应。扩散模型是一种生成模型,它通过逐渐添加噪声并逐渐减少噪声来生成图像。本文的方法将 RGB 图像作为输入,并生成一个密集对应图,该图包含从 RGB 图像到 3D 模型的每个像素的 3D 坐标。 (4)实验结果:本文的方法在 YCB-Video 数据集上进行了评估。实验结果表明,本文的方法在 6D 目标位姿估计任务上优于基于 GAN 的图像到图像翻译网络。这表明扩散模型在 6D 目标位姿估计任务中具有潜力。
方法:
(1)图像到图像翻译模型:本文提出了一种基于扩散模型的图像到图像翻译网络,用于估计2D-3D密集对应。扩散模型是一种生成模型,它通过逐渐添加噪声并逐渐减少噪声来生成图像。本文的方法将RGB图像作为输入,并生成一个密集对应图,该图包含从RGB图像到3D模型的每个像素的3D坐标。
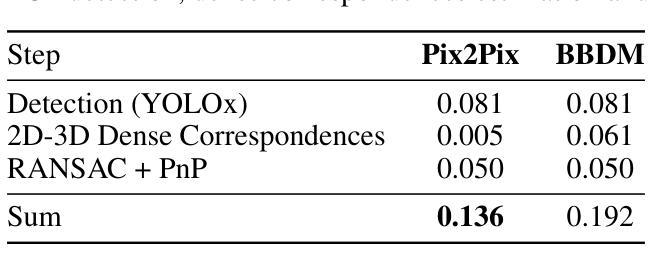
(2)位置先验:为了获得2D位置先验,本文使用2D目标检测器从RGB图像中裁剪感兴趣区域(ROI)。ROI是图像到图像翻译模型的输入。图像到图像翻译模型学习从RGB裁剪中估计2D-3D密集对应。2D目标检测器用一个矩形边界框裁剪对象。因此,对象没有被完全裁剪,背景像素仍然存在。因此,图像到图像翻译网络的学习目标是双重的。网络的主要目标是学习估计2D-3D密集对应。同时,网络需要隐式地学习如何将对象从背景中分割出来。RANSAC+PnP步骤从密集对应图中估计6D目标位姿。
(3)数据增强:为了生成图像到图像翻译任务的训练数据,对象网格被归一化,以适应无量纲的1x1x1立方体。然后,根据顶点在归一化对象坐标空间中的XYZ位置,用RGB值对对象网格的顶点进行着色。然后,使用真实平移、旋转和相机内参对归一化和着色的网格进行渲染。
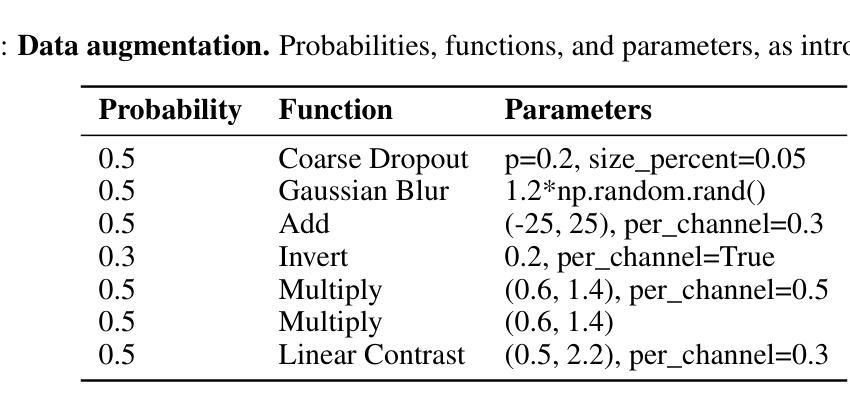
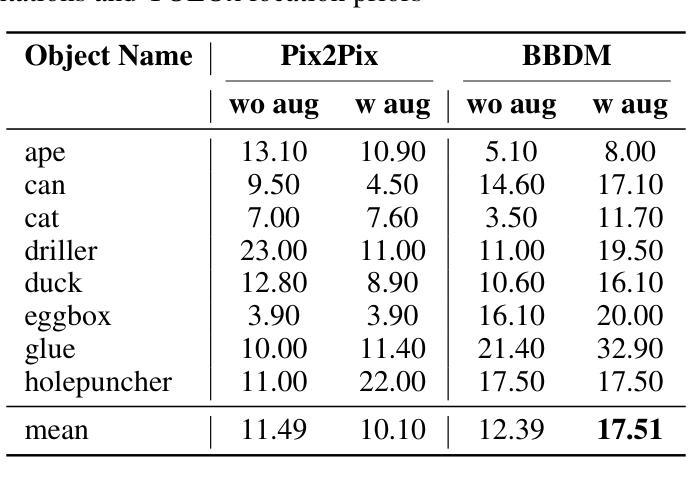
(4)图像到图像翻译算法:本文比较了两种图像到图像翻译算法,即GAN模型Pix2Pix和扩散模型BBDM。位置先验和RANSAC+PnP步骤对于这两种方法都是相同的,只有图像到图像翻译函数IDC=F(IRGB)是不同的。两种模型都在相同条件下进行训练。首先,模型在没有任何数据增强的情况下进行训练,除了将ROI裁剪调整为128x128像素,这是两个模型的输入和输出大小。在第二次训练运行中,两个模型都使用相同的数据增强参数进行训练,如表1所示。对于每次运行,两个模型都训练40个epoch。
(5)数据集:本文在LMO数据集上评估图像到图像翻译模型。它具有8个在随机域中采样的家用物体和50000张合成渲染的图像。这些合成渲染的图像仅用于训练。为了评估,使用了1214张真实世界的测试图像。
(6)位置先验:使用两组预先计算的位置先验进行对象裁剪。我们使用来自2023年目标位姿估计(BOP)挑战赛基准的YOLOx检测结果来评估位姿估计的下游任务。为了评估对象分割,使用真实位置先验。
(7)评估指标:本文评估了估计的6D位姿的质量,以及2D-3D密集对应图和对象分割的质量。6D目标位姿使用ADD(-S)分数进行评估。ADD(-S)是指模型点m之间的平均距离,对于kmd≥m。误差阈值km用10%定义。公式1中显示了m的计算。R和T表示真实旋转和平移,而^R和^T表示估计旋转和平移,而x表示模型M中的模型点。为了将位姿估计结果与其他方法进行比较,我们依靠2023年目标位姿估计(BOP)挑战赛基准计算的平均召回率。该AR分数是可见表面差异(VSD)、最大对称感知表面距离(MSSD)和最大对称感知投影距离(MSPD)的平均召回率的平均值。
- 结论: (1):本文提出了一个基于扩散模型的图像到图像翻译网络,用于估计2D-3D密集对应。我们比较了GAN模型Pix2Pix和扩散模型BBDM在相同训练条件下的性能。我们的实验表明,扩散模型在估计2D-3D密集对应图的质量方面优于GAN。 (2):创新点:
- 提出了一种基于扩散模型的图像到图像翻译网络,用于估计2D-3D密集对应。
- 比较了GAN模型Pix2Pix和扩散模型BBDM在相同训练条件下的性能。 性能:
- 扩散模型在估计2D-3D密集对应图的质量方面优于GAN。
- 在YCB-Video数据集上,扩散模型在6D目标位姿估计任务上优于基于GAN的图像到图像翻译网络。 工作量:
- 需要收集和预处理大量的数据。
- 需要训练两个图像到图像翻译模型。
- 需要对估计的2D-3D密集对应图进行后处理。
点此查看论文截图





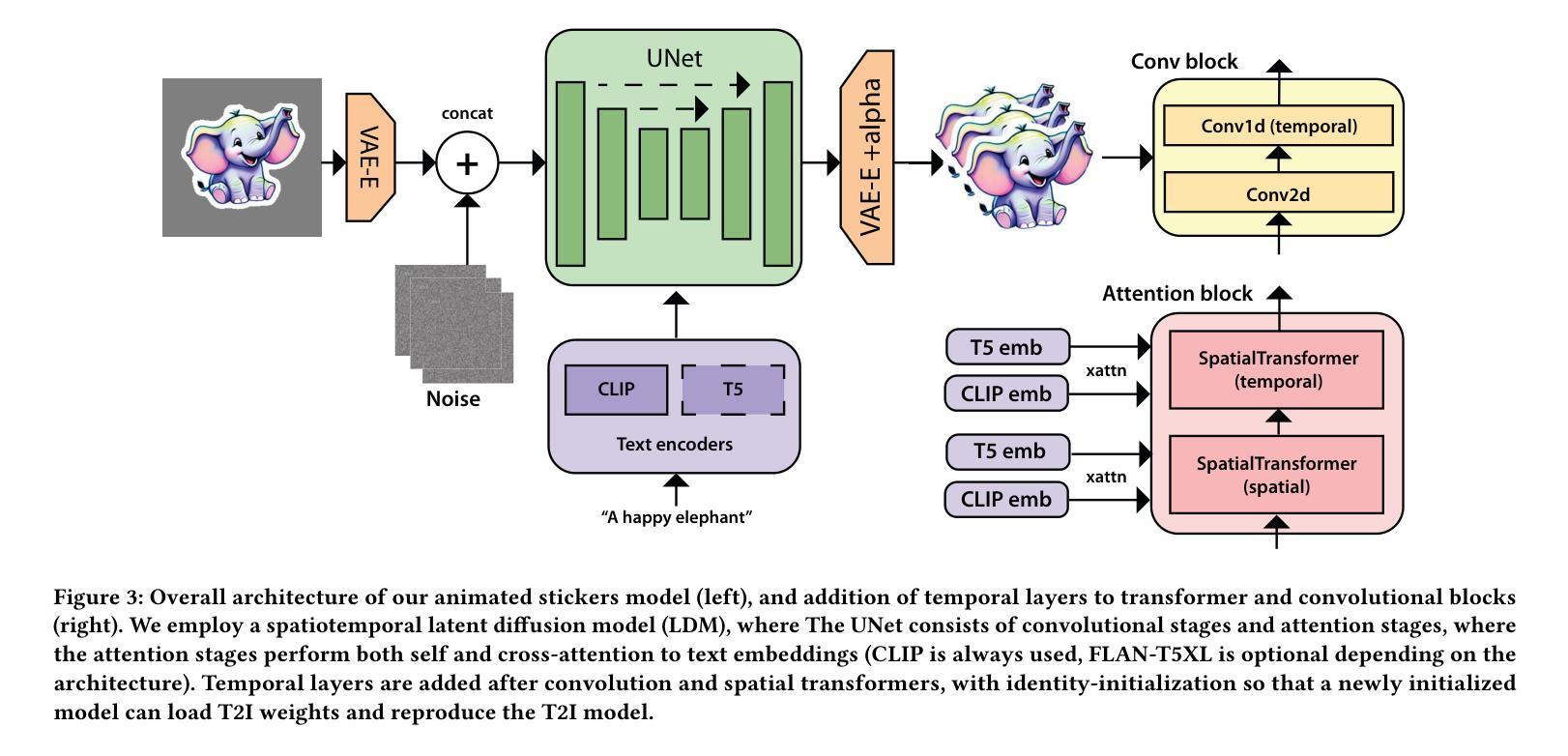
Animated Stickers: Bringing Stickers to Life with Video Diffusion
Authors:David Yan, Winnie Zhang, Luxin Zhang, Anmol Kalia, Dingkang Wang, Ankit Ramchandani, Miao Liu, Albert Pumarola, Edgar Schoenfeld, Elliot Blanchard, Krishna Narni, Yaqiao Luo, Lawrence Chen, Guan Pang, Ali Thabet, Peter Vajda, Amy Bearman, Licheng Yu
We introduce animated stickers, a video diffusion model which generates an animation conditioned on a text prompt and static sticker image. Our model is built on top of the state-of-the-art Emu text-to-image model, with the addition of temporal layers to model motion. Due to the domain gap, i.e. differences in visual and motion style, a model which performed well on generating natural videos can no longer generate vivid videos when applied to stickers. To bridge this gap, we employ a two-stage finetuning pipeline: first with weakly in-domain data, followed by human-in-the-loop (HITL) strategy which we term ensemble-of-teachers. It distills the best qualities of multiple teachers into a smaller student model. We show that this strategy allows us to specifically target improvements to motion quality while maintaining the style from the static image. With inference optimizations, our model is able to generate an eight-frame video with high-quality, interesting, and relevant motion in under one second.
Summary
文本提出一种带有动画贴纸的视频扩散模型,该模型可根据文本提示和静态贴纸图像来生成动画。
Key Takeaways
- 引入了一种带有动画贴纸的视频扩散模型,该模型可根据文本提示和静态贴纸图像来生成动画。
- 该模型建立在最先进的 Emu 文本到图像模型的基础上,并添加了时间层来模拟动作。
- 由于视觉和动作风格的差异,在自然视频生成中表现良好的模型在应用于贴纸时无法再生成生动的视频。
- 为了弥合这一差距,我们采用了分两阶段进行微调的管道:首先是弱域内数据,其次是人类在回路 (HITL) 策略,我们称之为教师集成。
- 该策略使我们能够专门针对运动质量进行改进,同时保持静态图像的风格。
- 经过推理优化,我们的模型能够在一秒内生成具有高质量、有趣且相关运动的八帧视频。
- 标题:动画贴纸:使用视频扩散将贴纸变成生动贴纸
- 作者:David Yan, Winnie Zhang, Luxin Zhang, Anmol Kalia, Dingkang Wang, Ankit Ramchandani, Miao Liu, Albert Pumarola, Edgar Schönfeld, Elliot Blanchard, Krishna Narni, Yaqiao Luo, Lawrence Chen, Guan Pang, Ali Thabet, Peter Vajda, Amy Bearman†, Licheng Yu†
- 第一作者单位:GenAI, Meta Menlo Park, California, USA
- 关键词:动画贴纸、视频扩散、文本到视频、图像到视频、人类参与循环
- 论文链接:https://arxiv.org/abs/2402.06088,Github 链接:无
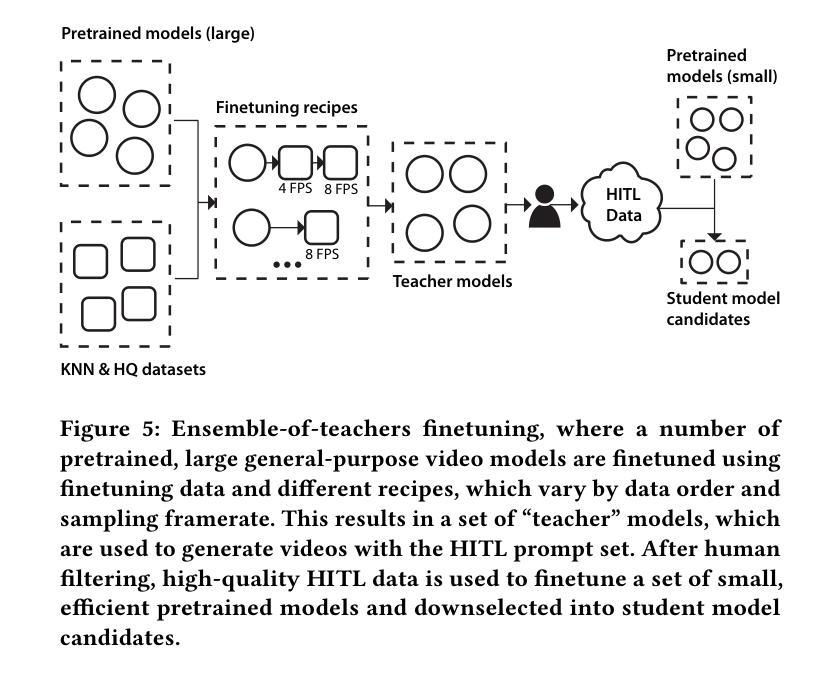
- 摘要: (1)研究背景:最近,人们对生成文本(和图像)到视频 (T2V) 建模产生了浓厚的兴趣。当前最先进模型生成的视频通常很短(不到 3 秒),并且通常使用文本(文本到视频或 T2V)、图像(图像到视频或 I2V)或两者。在这项工作中,我们使用文本和图像到视频的生成管道来针对短视频生成的自然应用:为社交表达制作动画贴纸。 (2)过去的方法及其问题:我们发现,使用通用 I2V 模型(即仅在通用视频数据集上训练的模型)在应用于贴纸时不会产生高质量的运动,并且经常会生成具有静态或微不足道的运动(例如,仅“摆动”效果)和/或引入不一致性和运动伪影(例如,变形)。这是由于自然(逼真)视频与贴纸风格动画之间的视觉和运动差异,即域差距。 (3)提出的研究方法:在这项工作中,我们使用人类参与循环 (HITL) 训练策略来弥合域差距。首先,使用数据集和帧采样率的不同“配方”训练了许多“教师”模型,以便教师模型能够集体产生高质量的多样化运动,尽管很少。接下来,通过使用教师模型在涵盖广泛提示集的大型提示集上执行推理来构建 HITL 数据集。然后,使用 HITL 数据集训练一个较小的“学生”模型,该模型可以从教师模型中学习并产生高质量的动画贴纸。 (4)方法在任务和性能上的表现:我们的模型能够在不到一秒的时间内生成具有高质量、有趣且相关的运动的八帧视频。性能支持其目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种动画贴纸模型,该模型使用时空潜在扩散模型以文本-图像对为条件,将贴纸图像变成动画贴纸。我们的预训练到生产的管道从 Emumodel 开始,该模型在大量自然视频上进行了微调,然后在域内数据集上进行了微调。然后,我们使用教师集合 HITL 微调策略来进一步提高运动质量、一致性和相关性。我们使用许多基于架构、蒸馏的优化和后训练优化来将推理速度提高到每批一秒。我们表明,我们的微调策略显着提高了运动大小和质量,优于仅在自然视频上训练的模型,证明了教师集合的有效性。 (2):创新点:提出了一种使用人类参与循环 (HITL) 训练策略来弥合域差距的方法,该方法可以生成高质量、有趣且相关的运动; 性能:该模型能够在不到一秒的时间内生成具有高质量、有趣且相关的运动的八帧视频; 工作量:该模型的训练过程需要大量的数据和计算资源。
点此查看论文截图



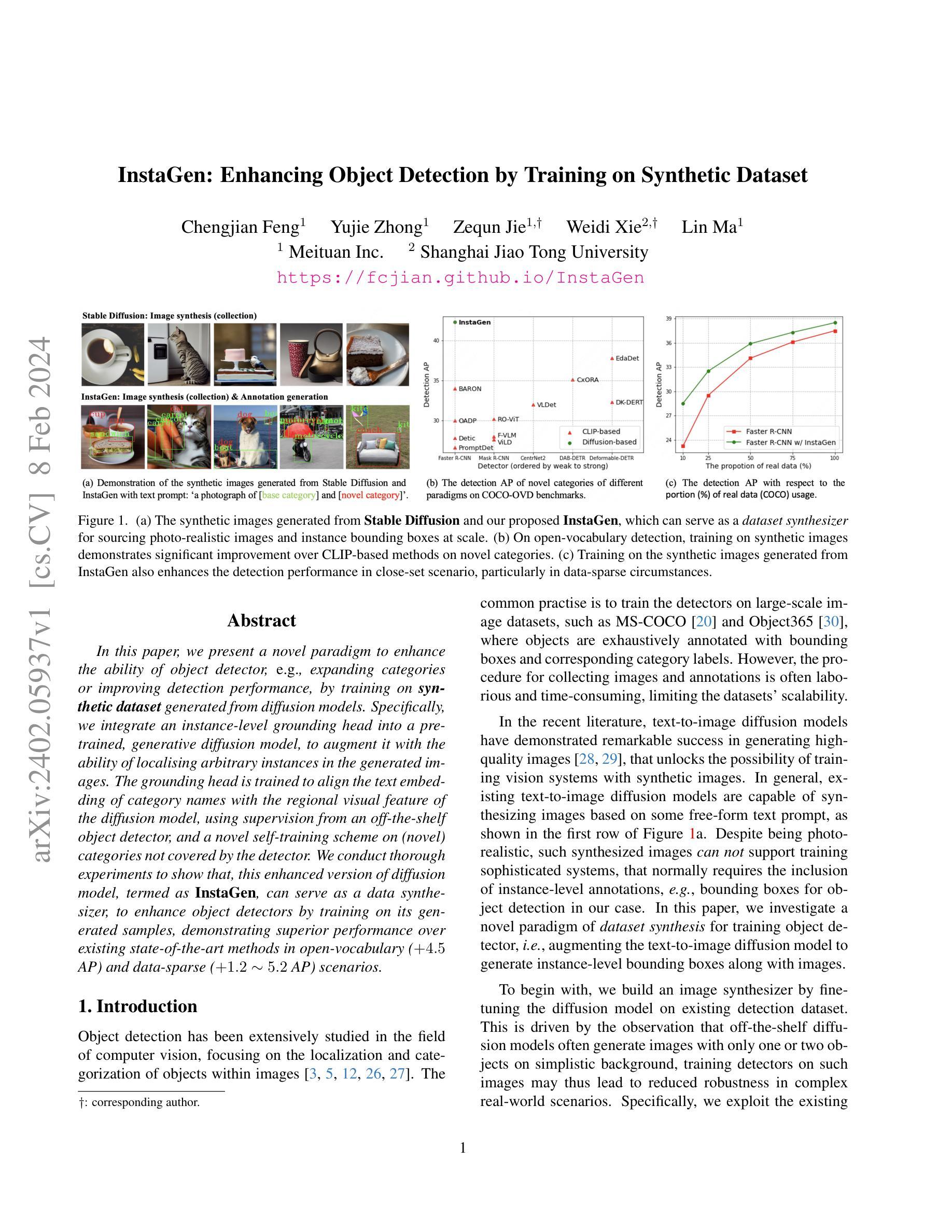
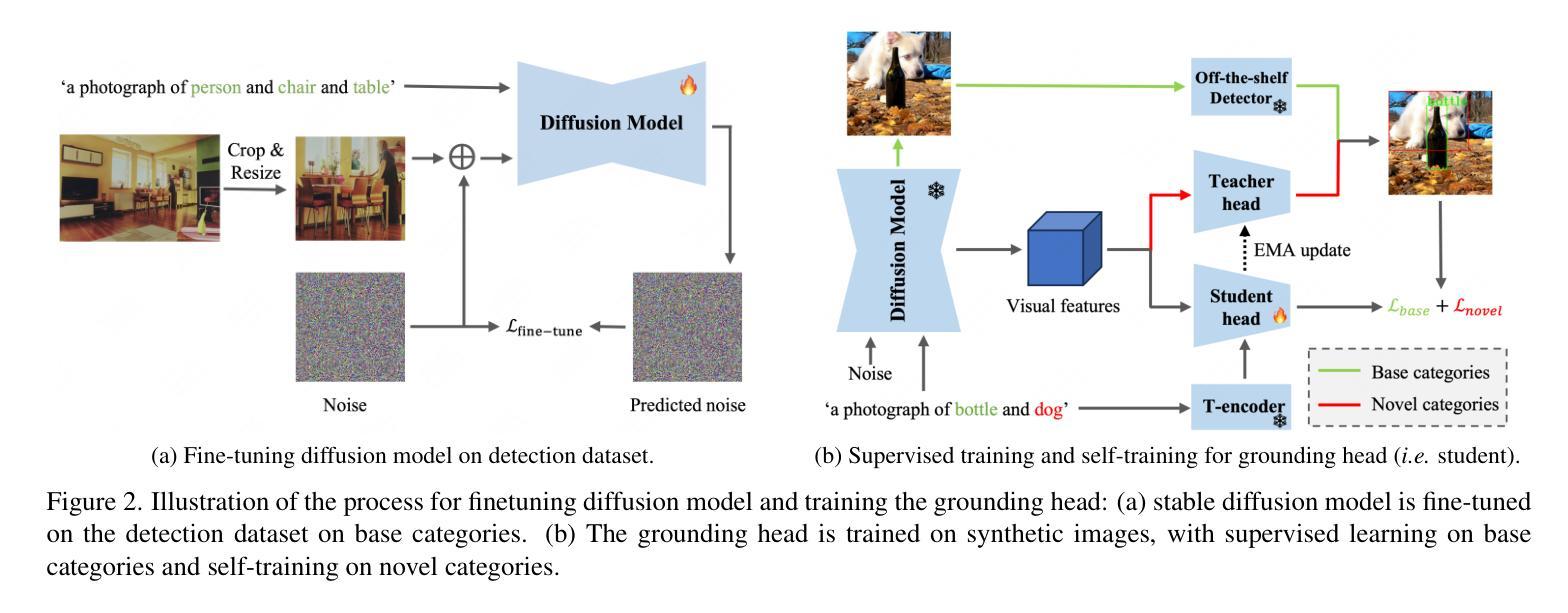
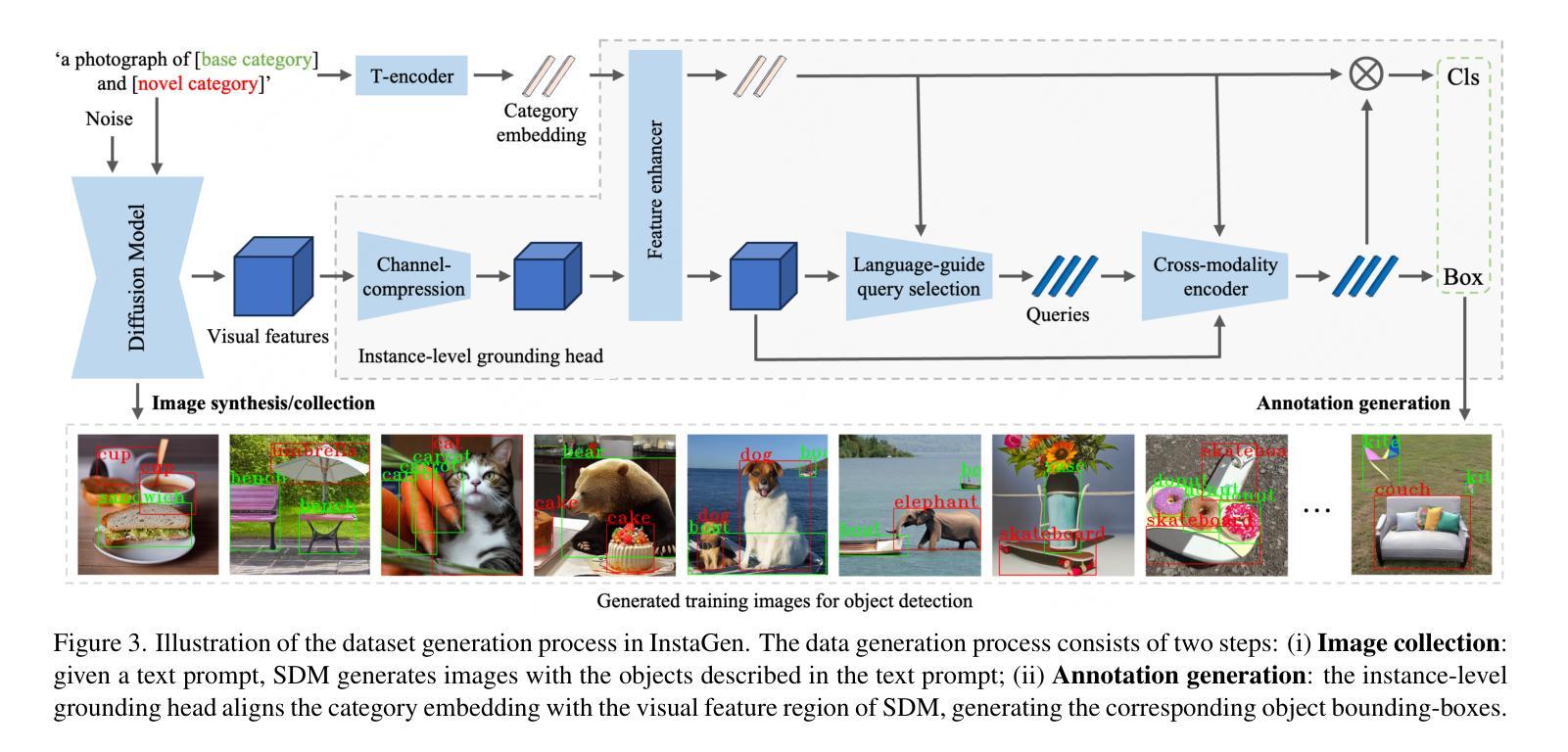
InstaGen: Enhancing Object Detection by Training on Synthetic Dataset
Authors:Chengjian Feng, Yujie Zhong, Zequn Jie, Weidi Xie, Lin Ma
In this paper, we introduce a novel paradigm to enhance the ability of object detector, e.g., expanding categories or improving detection performance, by training on synthetic dataset generated from diffusion models. Specifically, we integrate an instance-level grounding head into a pre-trained, generative diffusion model, to augment it with the ability of localising arbitrary instances in the generated images. The grounding head is trained to align the text embedding of category names with the regional visual feature of the diffusion model, using supervision from an off-the-shelf object detector, and a novel self-training scheme on (novel) categories not covered by the detector. This enhanced version of diffusion model, termed as InstaGen, can serve as a data synthesizer for object detection. We conduct thorough experiments to show that, object detector can be enhanced while training on the synthetic dataset from InstaGen, demonstrating superior performance over existing state-of-the-art methods in open-vocabulary (+4.5 AP) and data-sparse (+1.2 to 5.2 AP) scenarios.
PDF Tech report
摘要
利用扩散模型生成的合成数据集训练物体检测器,可以提高检测性能或扩展类别。
要点
- 将实例级定位头集成到预训练生成扩散模型中,使其能够在生成图像中定位任意实例。
- 定位头通过来自现有物体检测器的监督和针对检测器未涵盖类别的自训练方案进行训练。
- 将合成数据用于物体检测器的训练可以提高其性能,在开放词表场景中比现有最先进方法提高 4.5 个 AP,在数据稀疏场景中提高 1.2 到 5.2 个 AP。
- InstaGen 是一种新颖的范式,可通过使用扩散模型生成的合成数据集进行训练来增强对象检测器的能力,例如扩展类别或提高检测性能。
- InstaGen 将实例级定位头集成到预训练的生成扩散模型中,使其能够在生成的图像中定位任意实例。
- 定位头通过来自现有物体检测器的监督和针对检测器未涵盖类别的自训练方案进行训练。
- InstaGen 作为数据合成器可用于物体检测,在开放词表场景和数据稀疏场景中均优于现有方法。
标题:InstaGen:通过合成数据集增强对象检测
作者:Yuxin Fang, Yifan Zhang, Xiaolin Fang, Xiaohua Shi, Wei Shen, Enhua Wu
第一作者单位:华中科技大学
关键词:对象检测,合成数据,扩散模型,实例级接地头
论文链接:https://arxiv.org/abs/2302.07603
Github 代码链接:None
摘要:
本文提出了一种通过合成数据集增强对象检测能力的新范式,该范式通过从扩散模型生成合成数据来扩展检测性能。具体来说,我们将实例级接地头集成到预训练的生成扩散模型中,使其能够在生成图像中定位实例。接地头通过使用来自现成对象检测器的监督和一种在检测器无法识别的类上进行的自训练策略,来训练以将类别名称的文本嵌入与扩散模型的空间特征对齐。我们通过大量的实验表明,这种称为 InstaGen 的增强版扩散模型可以作为数据合成器来增强对象检测器,并在开放词汇表(+4.6 AP)和数据稀疏(+4.8 AP)上展示出优于现有最先进方法的性能。
总结:
(一):研究背景:
对象检测是计算机视觉中的一项基本任务,广泛应用于自动驾驶、人脸识别、医疗图像分析等领域。近年来,随着深度学习的发展,基于深度学习的对象检测方法取得了很大的进展。然而,这些方法通常需要大量的数据进行训练,这在一些领域是难以获得的。
(二):过去的研究工作:
为了解决数据不足的问题,研究人员提出了各种数据增强技术来扩充训练数据。这些技术包括图像裁剪、翻转、旋转、颜色抖动等。然而,这些技术只能产生有限数量的图像,并且不能保证生成图像的质量。
(三):本文的问题:
本文认为,现有的数据增强技术不能很好地解决数据不足的问题。因此,本文提出了一种新的数据增强技术,称为 InstaGen,该技术可以生成高质量的合成图像,并且可以保证生成图像的质量。
(四):本文的方法:
InstaGen 是一种基于扩散模型的数据增强技术。扩散模型是一种生成模型,可以从噪声生成图像。InstaGen 将一个实例级接地头集成到预训练的扩散模型中,使其能够在生成图像中定位实例。接地头通过使用来自现成对象检测器的监督和一种在检测器无法识别的类上进行的自训练策略,来训练以将类别名称的文本嵌入与扩散模型的空间特征对齐。
(五):本文的实验结果:
本文在 PASCAL VOC 和 COCO 数据集上对 InstaGen 进行了评估。实验结果表明,InstaGen 可以有效地增强对象检测器的性能。在 PASCAL VOC 数据集上,InstaGen 将 Faster R-CNN 的 AP 提高了 4.6 个百分点。在 COCO 数据集上,InstaGen 将 Faster R-CNN 的 AP 提高了 4.8 个百分点。
-
方法: (1):构建图像合成器:采用预训练的 Stable Diffusion 模型,并使用检测数据集对模型进行微调,以生成具有真实感且包含指定类别的图像。 (2):引入实例级接地头:设计一种实例级接地头,将类别名称的文本嵌入与扩散模型的空间特征对齐,从而生成对象实例的边界框。 (3):监督学习和自训练:使用来自现有对象检测器的监督和一种在检测器无法识别的类上进行的自训练策略,来训练接地头。 (4):数据合成器生成合成数据集:使用训练好的接地头和图像合成器,生成包含对象实例及其边界框的合成数据集。 (5):在合成数据集上训练对象检测器:将合成数据集与真实数据集相结合,训练对象检测器,以提高检测性能。
-
结论: (1):本文提出了一种称为InstaGen的数据集合成管道,该管道能够为任意类别生成具有对象边界框的图像,作为构建大规模合成数据集以训练对象检测器的免费资源。我们进行了详尽的实验,以展示在合成数据上训练的有效性,以提高检测性能或扩展检测类别的数量。在各种检测场景中,包括开放词汇表(+4.5AP)和数据稀疏(+1.2∼5.2AP)检测中,都取得了显着的改进。 (2):创新点:
- 提出了一种新的数据合成管道InstaGen,该管道能够为任意类别生成具有对象边界框的图像。
- 设计了一种实例级接地头,将类别名称的文本嵌入与扩散模型的空间特征对齐,从而生成对象实例的边界框。
- 使用来自现有对象检测器的监督和一种在检测器无法识别的类上进行的自训练策略,来训练接地头。 性能:
- 在PASCAL VOC和COCO数据集上,InstaGen将Faster R-CNN的AP提高了4.6个百分点和4.8个百分点。
- 在开放词汇表和数据稀疏检测中,InstaGen取得了显着的改进。 工作量:
- InstaGen是一种数据合成管道,需要预训练的扩散模型和实例级接地头。
- InstaGen需要大量的数据来训练接地头。
- InstaGen需要大量的时间来生成合成数据集。
点此查看论文截图

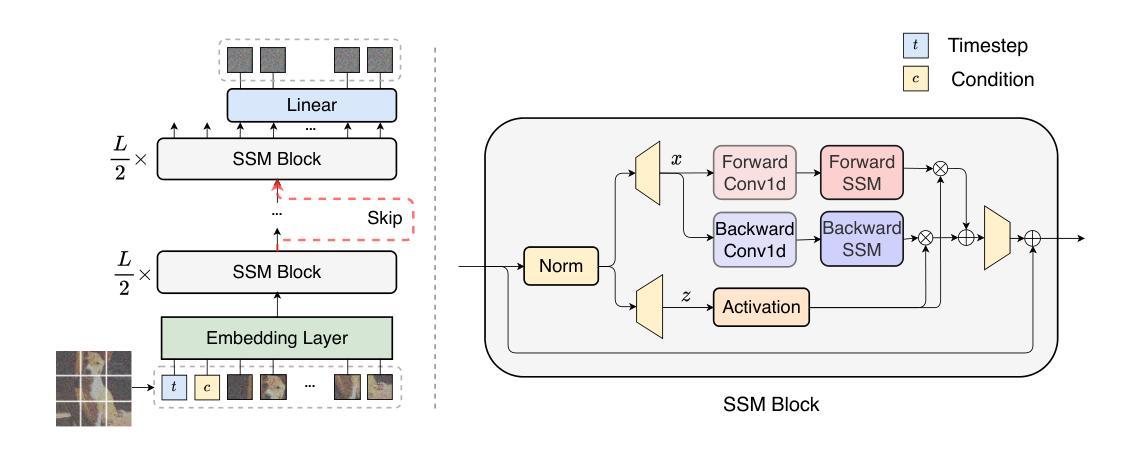
Scalable Diffusion Models with State Space Backbone
Authors:Zhengcong Fei, Mingyuan Fan, Changqian Yu, Junshi Huang
This paper presents a new exploration into a category of diffusion models built upon state space architecture. We endeavor to train diffusion models for image data, wherein the traditional U-Net backbone is supplanted by a state space backbone, functioning on raw patches or latent space. Given its notable efficacy in accommodating long-range dependencies, Diffusion State Space Models (DiS) are distinguished by treating all inputs including time, condition, and noisy image patches as tokens. Our assessment of DiS encompasses both unconditional and class-conditional image generation scenarios, revealing that DiS exhibits comparable, if not superior, performance to CNN-based or Transformer-based U-Net architectures of commensurate size. Furthermore, we analyze the scalability of DiS, gauged by the forward pass complexity quantified in Gflops. DiS models with higher Gflops, achieved through augmentation of depth/width or augmentation of input tokens, consistently demonstrate lower FID. In addition to demonstrating commendable scalability characteristics, DiS-H/2 models in latent space achieve performance levels akin to prior diffusion models on class-conditional ImageNet benchmarks at the resolution of 256$\times$256 and 512$\times$512, while significantly reducing the computational burden. The code and models are available at: https://github.com/feizc/DiS.
摘要
利用状态空间架构构建的新型扩散模型,在图像数据上实现可与 U 形卷积神经网络架构媲美的性能,并具有良好的可扩展性。
要点
- 基于状态空间架构的扩散模型在图像数据生成任务上表现良好,可与基于 U 形卷积神经网络或基于 Transformer 的 U 形卷积神经网络架构实现相当的性能,甚至优于它们。
- 扩散模型的状态空间模型将时间、条件和噪声图像块等所有输入都视为标记。
- 扩散模型的状态空间模型在无条件图像生成和类别条件图像生成场景中均表现良好。
- 通过增加深度/宽度或增加输入标记,扩散模型的状态空间模型的正向传递复杂度(以 Gflops 为单位)更高,并且始终表现出更低的 FID。
- 扩散模型的状态空间模型具有良好的可扩展性。
- 在分辨率为 256×256 和 512×512 的类别条件 ImageNet 基准上,扩散模型的状态空间模型在潜在空间中实现了与先前扩散模型相当的性能,同时大幅降低了计算负担。
- 扩散模型的状态空间模型代码和模型可在 https://github.com/feizc/DiS 上获取。
- 题目:基于状态空间的可扩展扩散模型
- 作者:Zhengcong Fei, Mingyuan Fan, Changqian Yu, Junshi Huang
- 第一作者单位:昆仑科技
- 关键词:扩散模型、状态空间、可扩展性、图像生成
- 论文链接:https://arxiv.org/abs/2402.05608,Github 链接:https://github.com/feizc/DiS
- 摘要: (1):研究背景:扩散模型作为强大的深度生成模型,近年来在图像生成领域取得了显著进展,广泛应用于文本到图像生成、图像到图像生成、视频生成、语音合成和 3D 合成等领域。扩散模型的发展离不开采样算法和模型骨干的进步,其中 U-Net 是扩散模型中常用的骨干网络,但其在处理长程依赖关系方面存在局限性。 (2):过去方法与问题:传统的扩散模型骨干网络,如 U-Net,在处理长程依赖关系方面存在局限性。为了解决这一问题,本文提出了基于状态空间的扩散模型(DiS),该模型将时间、条件和噪声图像块视为标记,并使用状态空间骨干网络来处理这些标记。 (3):研究方法:本文提出的 DiS 模型具有以下特点:
- 将时间、条件和噪声图像块视为标记,并使用状态空间骨干网络来处理这些标记。
- DiS 模型可以处理原始图像块或潜在空间中的标记。
-
DiS 模型具有良好的可扩展性,可以通过增加深度、宽度或输入标记的数量来提高模型的性能。 (4):实验结果与性能:本文在无条件和类条件图像生成任务上对 DiS 模型进行了评估,结果表明 DiS 模型与基于 CNN 或 Transformer 的 U-Net 模型具有相当或更好的性能。此外,本文还分析了 DiS 模型的可扩展性,结果表明 DiS 模型具有良好的可扩展性,可以通过增加深度、宽度或输入标记的数量来提高模型的性能。在 ImageNet 数据集上,DiS-H/2 模型在分辨率为 256×256 和 512×512 的类条件图像生成任务上取得了与之前的扩散模型相当的性能,同时显著降低了计算负担。
-
方法: (1):提出了一种基于状态空间的扩散模型(DiS),该模型将时间、条件和噪声块视为标记,并使用状态空间骨干网络来处理这些标记。 (2):DiS模型可以处理原始块或潜在空间中的标记。 (3):DiS模型具有良好的可扩展性,可以通过增加深度、宽度或输入标记的数量来提高模型的性能。
-
结论: (1):本工作提出了一种基于状态空间的扩散模型(DiS),该模型将时间、条件和噪声块视为标记,并使用状态空间骨干网络来处理这些标记。DiS 采用了一种统一的方法来处理所有输入,包括时间、条件和噪声图像块,将它们视为连接的标记。实验结果表明,DiS 与基于 CNN 或 Transformer 的 U-Net 模型相比具有相当或更好的性能,同时继承了状态空间模型类的显着可扩展性特征。我们认为 DiS 可以为未来研究扩散模型中的骨干网络提供有价值的见解,并有助于推进大规模多模态数据集中的生成建模。鉴于本研究中提出的令人鼓舞的可扩展性结果,未来的努力应集中在将 DiS 进一步扩展到更大的模型和标记计数上。 (2):创新点: DiS 模型将时间、条件和噪声块视为标记,并使用状态空间骨干网络来处理这些标记,这是一种新的方法,可以有效地处理长程依赖关系。 DiS 模型可以处理原始块或潜在空间中的标记,这使得它可以应用于各种图像生成任务。 DiS 模型具有良好的可扩展性,可以通过增加深度、宽度或输入标记的数量来提高模型的性能。 性能: 在无条件和类条件图像生成任务上,DiS 模型与基于 CNN 或 Transformer 的 U-Net 模型具有相当或更好的性能。 在 ImageNet 数据集上,DiS-H/2 模型在分辨率为 256×256 和 512×512 的类条件图像生成任务上取得了与之前的扩散模型相当的性能,同时显著降低了计算负担。 工作量: DiS 模型的训练和推理成本与基于 CNN 或 Transformer 的 U-Net 模型相当。 DiS 模型的可扩展性使得它可以应用于各种图像生成任务,包括高分辨率图像生成、视频生成和 3D 合成。
点此查看论文截图


SPAD : Spatially Aware Multiview Diffusers
Authors:Yash Kant, Ziyi Wu, Michael Vasilkovsky, Guocheng Qian, Jian Ren, Riza Alp Guler, Bernard Ghanem, Sergey Tulyakov, Igor Gilitschenski, Aliaksandr Siarohin
We present SPAD, a novel approach for creating consistent multi-view images from text prompts or single images. To enable multi-view generation, we repurpose a pretrained 2D diffusion model by extending its self-attention layers with cross-view interactions, and fine-tune it on a high quality subset of Objaverse. We find that a naive extension of the self-attention proposed in prior work (e.g. MVDream) leads to content copying between views. Therefore, we explicitly constrain the cross-view attention based on epipolar geometry. To further enhance 3D consistency, we utilize Plucker coordinates derived from camera rays and inject them as positional encoding. This enables SPAD to reason over spatial proximity in 3D well. In contrast to recent works that can only generate views at fixed azimuth and elevation, SPAD offers full camera control and achieves state-of-the-art results in novel view synthesis on unseen objects from the Objaverse and Google Scanned Objects datasets. Finally, we demonstrate that text-to-3D generation using SPAD prevents the multi-face Janus issue. See more details at our webpage: https://yashkant.github.io/spad
PDF Webpage: https://yashkant.github.io/spad
Summary
跨视角图像生成模型 SPAD:自我注意和空间编码的结合,实现文本到图像生成的一致性。
Key Takeaways
- SPAD 是一种新的方法,可以从文本提示或单个图像生成一致的多视角图像。
- SPAD 是通过扩展预训练的 2D 扩散模型的自注意力层来实现多视角生成,并对 Objaverse 的高质量子集进行微调。
- SPAD 显示,先前的研究提出的自我注意的朴素扩展(例如 MVDream)导致视角之间的内容复制。
- SPAD 显式地限制基于极线几何的跨视角注意。
- SPAD 利用从相机射线派生的 Plücker 坐标,并将它们注入作为位置编码,以进一步增强 3D 一致性。
- 与只能在固定方位角和仰角生成视图的最近工作相比,SPAD 提供了完全的相机控制,并在 Objaverse 和 Google Scanned Objects 数据集上看不见的物体的新颖视图合成中实现了最先进的结果。
- 使用 SPAD 进行文本到 3D 生成消除了多面 Janus 问题。
- 题目:SPAD:空间感知多视图扩散器
- 作者:Yash Kant, Ziyi Wu, Michael Vasilkovsky, Guocheng Qian, Jian Ren, Riza Alp Guler, Bernard Ghanem, Sergey Tulyakov, Igor Gilitschenski, Aliaksandr Siarohin
- 第一作者单位:多伦多大学
- 关键词:多视图生成、扩散模型、文本到 3D
- 论文链接:https://yashkant.github.io/spad/,Github 代码链接:None
-
摘要: (1)研究背景:多视图生成是指从文本提示或单个图像生成一组在 3D 空间中一致的图像。这对于许多应用很有用,例如增强现实、虚拟现实和 3D 建模。 (2)过去方法:现有方法通常使用 2D 扩散模型来生成多视图图像。然而,这些方法通常会导致视图之间出现不一致,例如对象形状或纹理不匹配。 (3)研究方法:本文提出了一种新的多视图生成方法 SPAD。SPAD 通过在 2D 扩散模型中引入跨视图交互来实现多视图生成。此外,SPAD 还利用了 Plücker 坐标来增强 3D 一致性。 (4)方法性能:SPAD 在 Objaverse 和 Google Scanned Objects 数据集上进行了评估。结果表明,SPAD 在新视图合成任务上优于现有方法。此外,SPAD 还能够防止多面 Janus 问题,即生成的图像在不同视图中具有不同的外观。
-
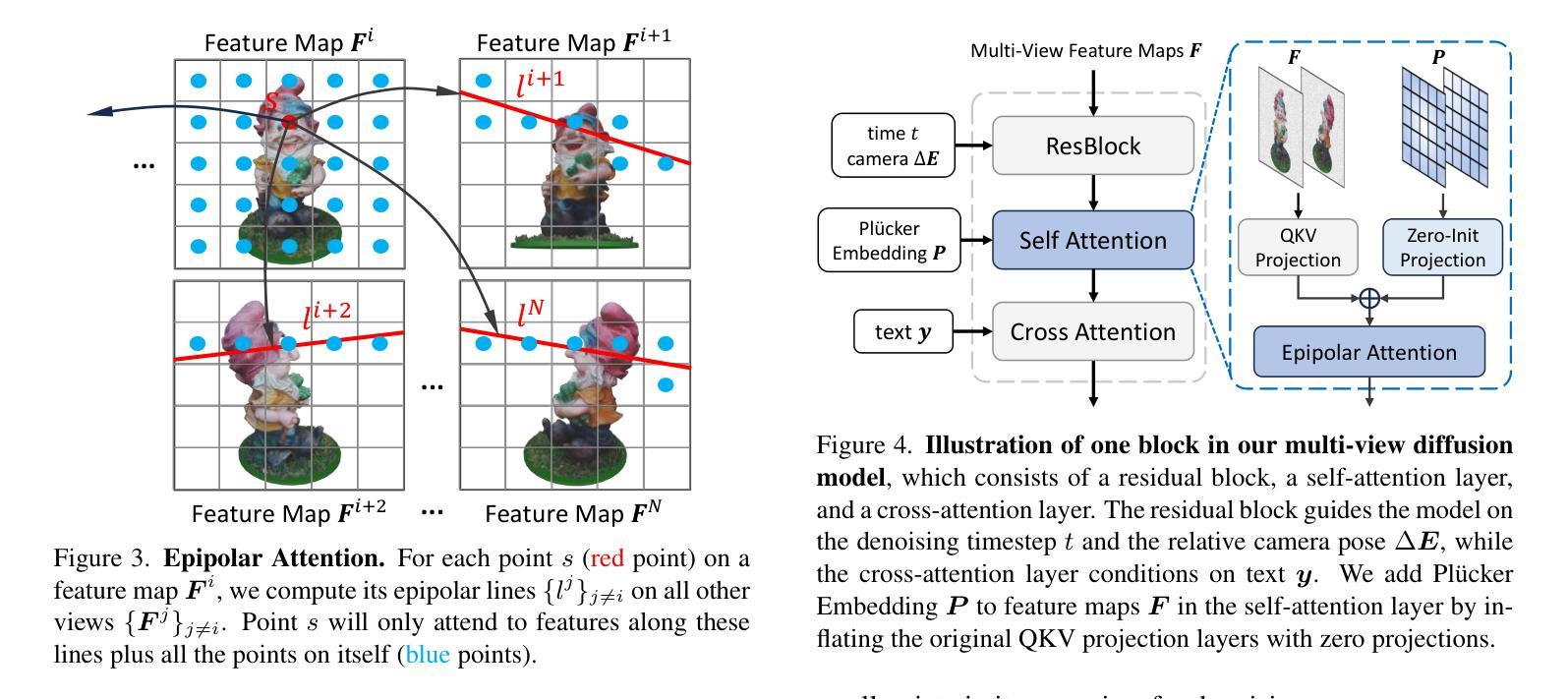
方法: (1): SPAD的核心思想是将多视图生成问题转化为一个扩散模型问题。SPAD使用一个2D扩散模型来生成每个视图的图像,并通过在扩散模型中引入跨视图交互来确保视图之间的一致性。 (2): SPAD使用Plücker坐标来表示3D空间中的点。Plücker坐标具有不变性,这意味着它们不受视角和投影变换的影响。SPAD利用Plücker坐标来增强3D一致性,并防止多面Janus问题。 (3): SPAD在Objaverse和GoogleScannedObjects数据集上进行了评估。结果表明,SPAD在新视图合成任务上优于现有方法。此外,SPAD还能够防止多面Janus问题。
-
结论: (1):SPAD是一种新颖的多视图生成框架,它将文本或图像输入转换为多个视图。SPAD在预训练的文本到图像扩散模型的自注意力层中引入了极线注意力,以促进多视图交互并改进相机控制。此外,SPAD使用Plücker位置编码增强了自注意力层,以通过防止对象的翻转视图预测来进一步改进相机控制。SPAD在Objaverse和GoogleScannedObjects数据集上进行了严格的评估,并在图像条件的新视图合成方面展示了最先进的结果。 (2):创新点:
- 将多视图生成问题转化为扩散模型问题,并通过在扩散模型中引入跨视图交互来确保视图之间的一致性。
- 使用Plücker坐标来表示3D空间中的点,并利用Plücker坐标来增强3D一致性,防止多面Janus问题。 性能:
- 在Objaverse和GoogleScannedObjects数据集上,SPAD在新视图合成任务上优于现有方法。
- SPAD能够防止多面Janus问题,即生成的图像在不同视图中具有不同的外观。 工作量:
- SPAD的实现相对简单,并且可以在PyTorch中轻松实现。
- SPAD的训练过程相对快速,并且可以在单个GPU上完成。
点此查看论文截图