⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-13 更新
DiffSpeaker: Speech-Driven 3D Facial Animation with Diffusion Transformer
Authors:Zhiyuan Ma, Xiangyu Zhu, Guojun Qi, Chen Qian, Zhaoxiang Zhang, Zhen Lei
Speech-driven 3D facial animation is important for many multimedia applications. Recent work has shown promise in using either Diffusion models or Transformer architectures for this task. However, their mere aggregation does not lead to improved performance. We suspect this is due to a shortage of paired audio-4D data, which is crucial for the Transformer to effectively perform as a denoiser within the Diffusion framework. To tackle this issue, we present DiffSpeaker, a Transformer-based network equipped with novel biased conditional attention modules. These modules serve as substitutes for the traditional self/cross-attention in standard Transformers, incorporating thoughtfully designed biases that steer the attention mechanisms to concentrate on both the relevant task-specific and diffusion-related conditions. We also explore the trade-off between accurate lip synchronization and non-verbal facial expressions within the Diffusion paradigm. Experiments show our model not only achieves state-of-the-art performance on existing benchmarks, but also fast inference speed owing to its ability to generate facial motions in parallel.
PDF 9 pages, 5 figures. Code is avalable at https://github.com/theEricMa/DiffSpeaker
Summary
通过提出带偏条件注意力的扩散模型,我们解决了音视频配对数据的稀缺问题,在保持音视频同步的情况下,可以快速生成高质量的面部动画。
Key Takeaways
- 提出了一种新的扩散模型,用于语音驱动的3D面部动画。
- 使用带偏条件注意力模块,可以更好地处理音视频配对数据的稀缺问题。
- 在现有基准上取得了最先进的性能。
- 可以快速生成面部动画,推理速度快。
- 可以有效地生成非语言面部表情。
- 可以控制动画过程中的嘴型同步和非语言面部表情之间的权衡。
- 该模型可以用于各种多媒体应用。
- 题目:DiffSpeaker:基于扩散变换器的语音驱动 3D 面部动画(DiffSpeaker: Speech-Driven 3DFacial Animation with Diffusion Transformer)
- 作者:Zhiyuan Ma, Xiangyu Zhu, Guojun Qi, Chen Qian, Zhaoxiang Zhang, Zhen Lei
- 第一作者单位:香港理工大学(香港理工大学)
- 关键词:语音驱动面部动画、扩散模型、Transformer、条件注意机制
- 论文链接:https://arxiv.org/abs/2402.05712 Github 代码链接:https://github.com/theEricMa/DiffSpeaker
-
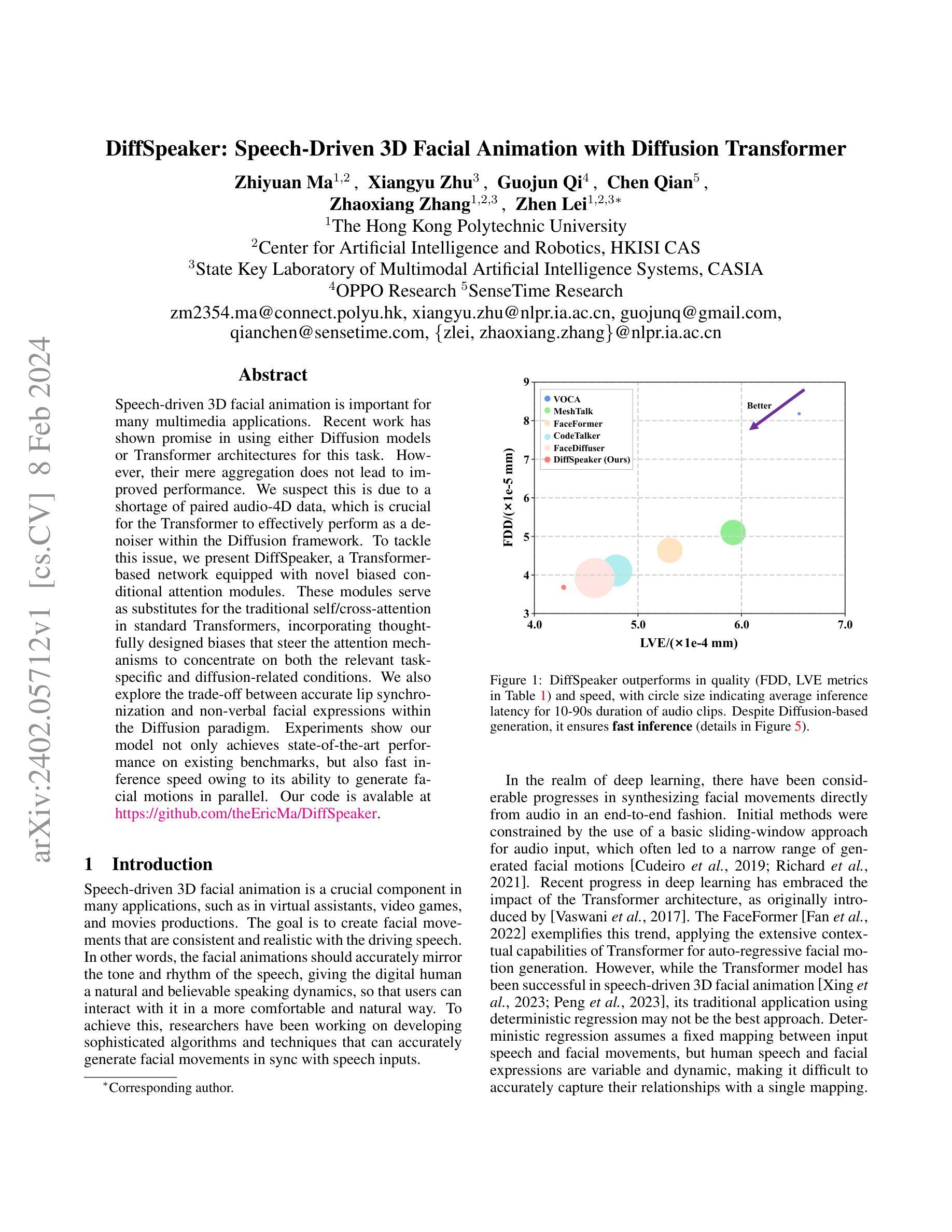
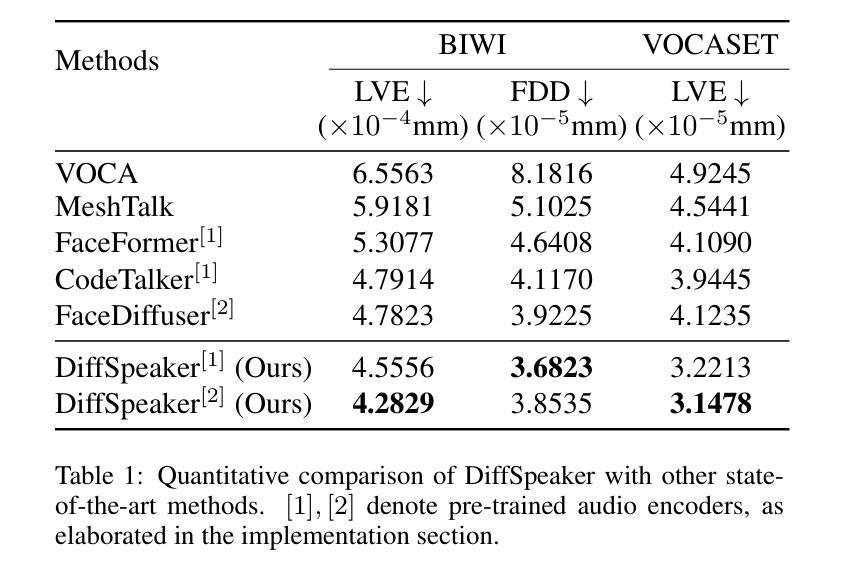
摘要: (1):语音驱动 3D 面部动画在许多多媒体应用中非常重要。最近的研究表明,使用扩散模型或 Transformer 架构来执行此任务很有前景。然而,它们的简单聚合并不能带来改进的性能。我们怀疑这是由于缺乏配对的音频-4D 数据,这对于 Transformer 在扩散框架内有效地执行去噪器至关重要。 (2):过去的方法主要使用基本的滑动窗口方法处理音频输入,这通常会导致生成的的面部动作范围狭窄。近年来,研究人员开始采用 Transformer 架构来进行语音驱动 3D 面部动画,但传统的确定性回归可能不是最好的方法,因为人类的语音和面部表情是可变且动态的,很难用一个固定的映射来准确捕捉它们之间的关系。 (3):为了解决这个问题,我们提出了 DiffSpeaker,这是一个基于 Transformer 的网络,配备了新颖的偏置条件注意机制模块。这些模块可以替代标准 Transformer 中传统的自注意力/交叉注意力,并结合了经过精心设计的偏置,这些偏置引导注意力机制集中在相关的特定任务和与扩散相关的条件上。我们还探索了在扩散范式中准确的唇形同步和非语言面部表情之间的权衡。 (4):实验表明,我们的模型不仅在现有基准上实现了最先进的性能,而且由于其能够并行生成面部动作,因此推理速度也很快。
-
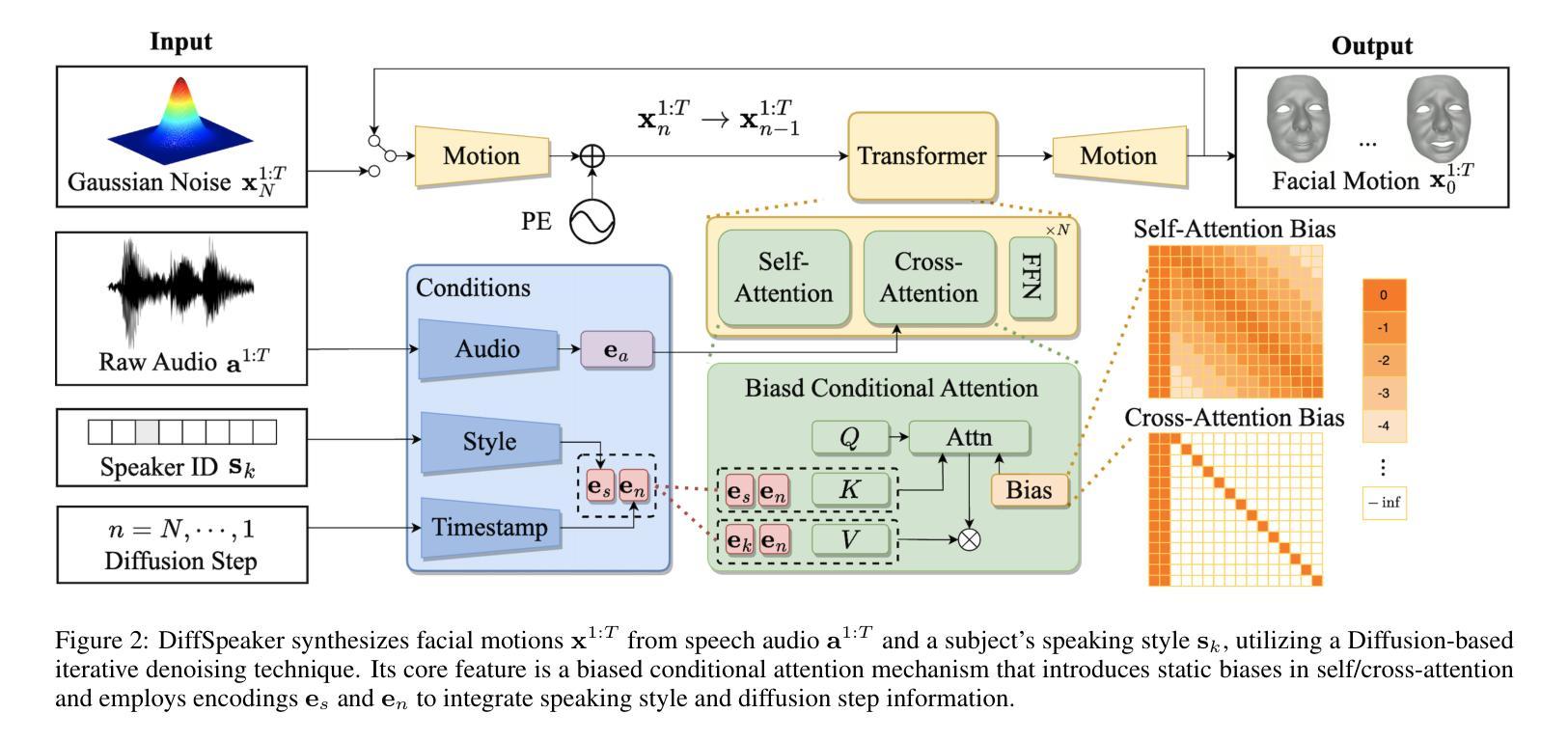
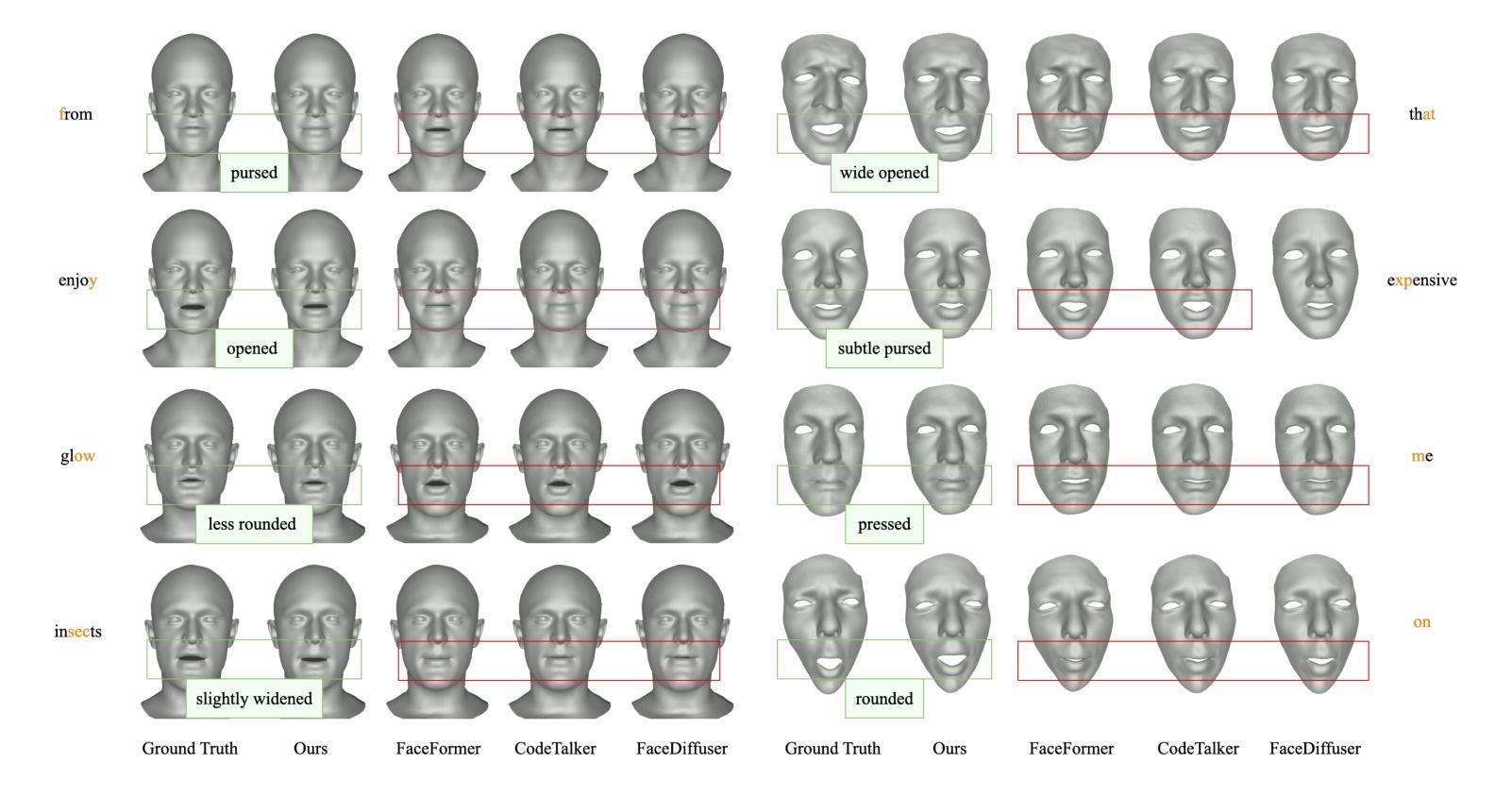
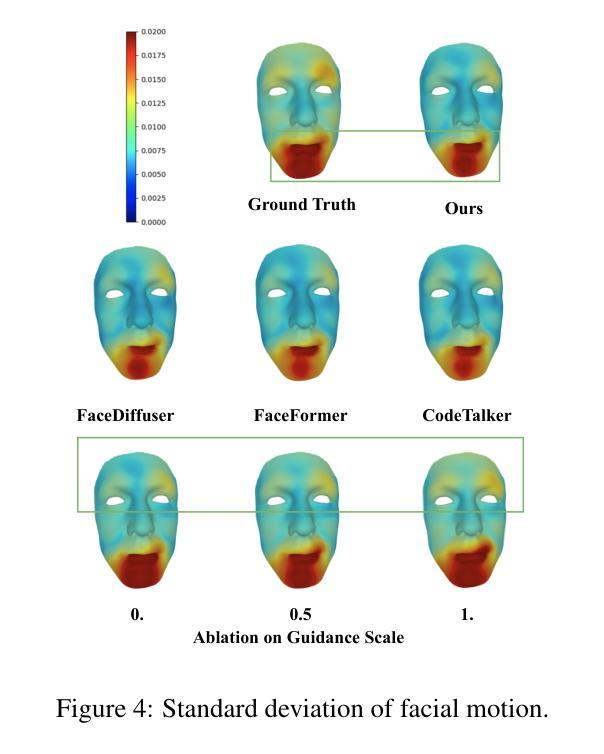
方法: (1): 本文提出了一种基于扩散模型和Transformer架构的语音驱动3D面部动画方法DiffSpeaker,该方法利用了扩散模型的生成能力和Transformer架构的序列建模能力,有效地解决了语音驱动3D面部动画任务中的配对音频-4D数据缺乏的问题。 (2): DiffSpeaker采用了一种新颖的偏置条件注意机制模块,该模块可以替代标准Transformer中的传统自注意力/交叉注意力,并结合了经过精心设计的偏置,这些偏置引导注意力机制集中在相关的特定任务和与扩散相关的条件上。 (3): DiffSpeaker还探索了在扩散范式中准确的唇形同步和非语言面部表情之间的权衡,并提出了一种新的损失函数,该损失函数可以同时优化唇形同步和非语言面部表情的质量。 (4): 实验结果表明,DiffSpeaker在现有基准上实现了最先进的性能,并且由于其能够并行生成面部动作,因此推理速度也很快。
-
结论: (1):本工作探索了将 Transformer 架构与基于扩散的框架有效结合用于语音驱动 3D 面部动画的方法。我们贡献的核心是引入了带有偏置的条件自注意力/交叉注意力机制,该机制解决了使用受限且跨度短的音频-4D 数据训练基于扩散的 Transformer 的困难。我们还研究了在实现准确的唇形同步和生成与语音相关性较小的面部表情之间的平衡。我们开发的模型优于当前的方法,在动画质量和生成速度方面都表现出色。 (2):创新点: 提出了一种新的带有偏置的条件自注意力/交叉注意力机制,该机制可以有效地利用受限且跨度短的音频-4D 数据来训练基于扩散的 Transformer。 提出了一种新的损失函数,该损失函数可以同时优化唇形同步和非语言面部表情的质量。 性能: 在现有基准上实现了最先进的性能。 推理速度快,能够并行生成面部动作。 工作量: 需要收集和预处理大量的音频-4D 数据。 需要对模型进行大量的训练。
点此查看论文截图