⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-29 更新
VastGaussian: Vast 3D Gaussians for Large Scene Reconstruction
Authors:Jiaqi Lin, Zhihao Li, Xiao Tang, Jianzhuang Liu, Shiyong Liu, Jiayue Liu, Yangdi Lu, Xiaofei Wu, Songcen Xu, Youliang Yan, Wenming Yang
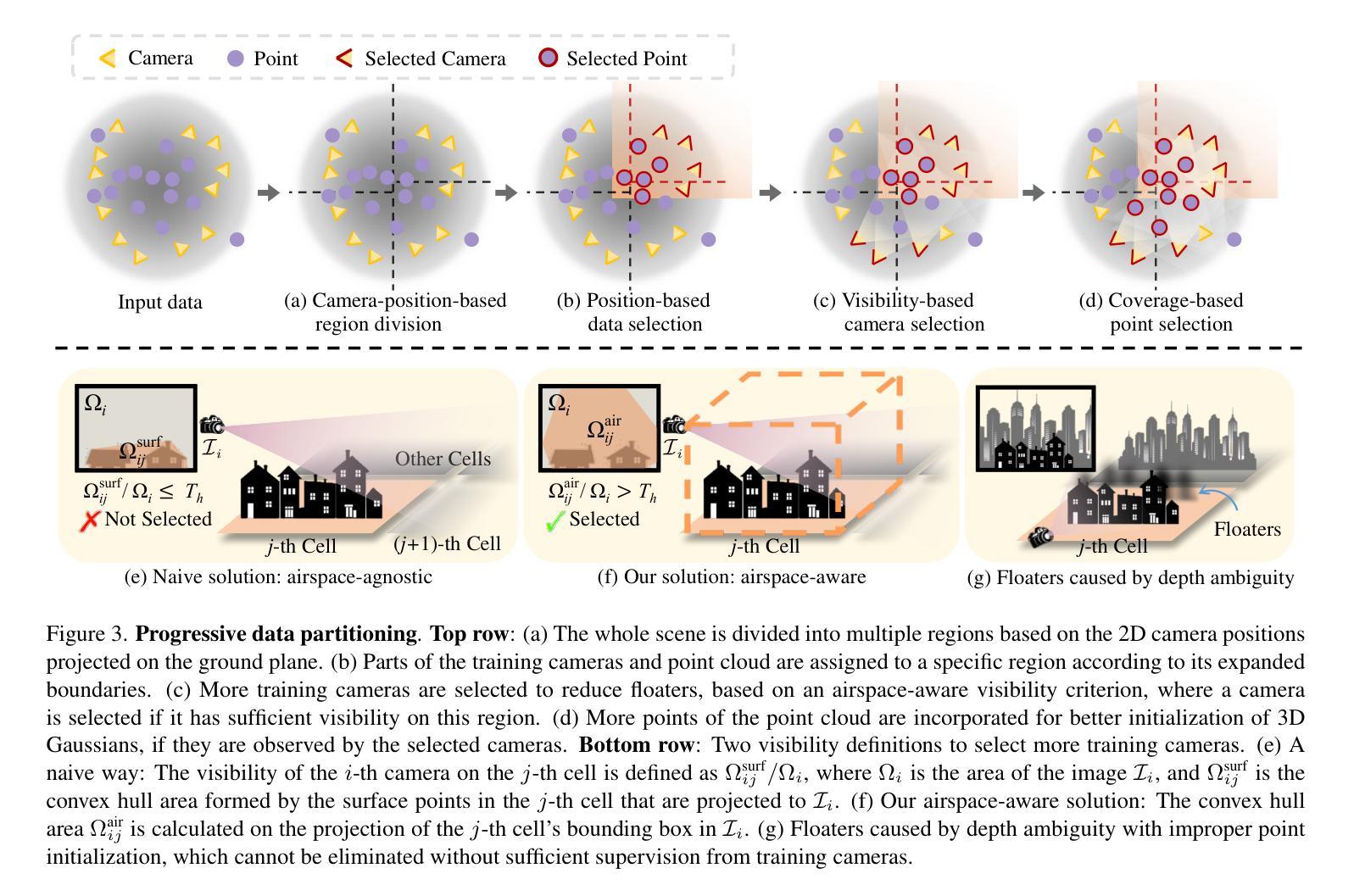
Existing NeRF-based methods for large scene reconstruction often have limitations in visual quality and rendering speed. While the recent 3D Gaussian Splatting works well on small-scale and object-centric scenes, scaling it up to large scenes poses challenges due to limited video memory, long optimization time, and noticeable appearance variations. To address these challenges, we present VastGaussian, the first method for high-quality reconstruction and real-time rendering on large scenes based on 3D Gaussian Splatting. We propose a progressive partitioning strategy to divide a large scene into multiple cells, where the training cameras and point cloud are properly distributed with an airspace-aware visibility criterion. These cells are merged into a complete scene after parallel optimization. We also introduce decoupled appearance modeling into the optimization process to reduce appearance variations in the rendered images. Our approach outperforms existing NeRF-based methods and achieves state-of-the-art results on multiple large scene datasets, enabling fast optimization and high-fidelity real-time rendering.
PDF Accepted to CVPR 2024. Project website: https://vastgaussian.github.io
Summary
利用 3D 高斯斑点技术,我们提出了 VastGaussian,一种用于大场景的高质量重建和实时渲染的新方法。
Key Takeaways
- 提出渐进分区策略,使用视野感知可见性标准分配训练相机和点云。
- 引入解耦外观建模,减少渲染图像外观变化。
- 在多个大场景数据集上优于现有基于 NeRF 的方法。
- 实现最先进的成果,实现快速优化和高保真实时渲染。
- 使用 3D 高斯斑点技术进行大场景重建和渲染。
- 解决视频内存受限、优化时间长、外观变化明显等问题。
- 适用多个大场景数据集,包括 Matterport3D,SUNCG,和 Replica。
- 题目:VastGaussian:用于大场景重建的巨大 3D 高斯体
- 作者:Yuan Liu、Li-Yi Wei、Jia-Bin Huang、Yong-Liang Yang、Tong-Yee Lee
- 第一作者单位:香港中文大学(深圳)
- 关键词:NeRF、大场景重建、高斯体、外观建模
- 论文链接:https://arxiv.org/abs/2302.04750,Github 代码链接:None
-
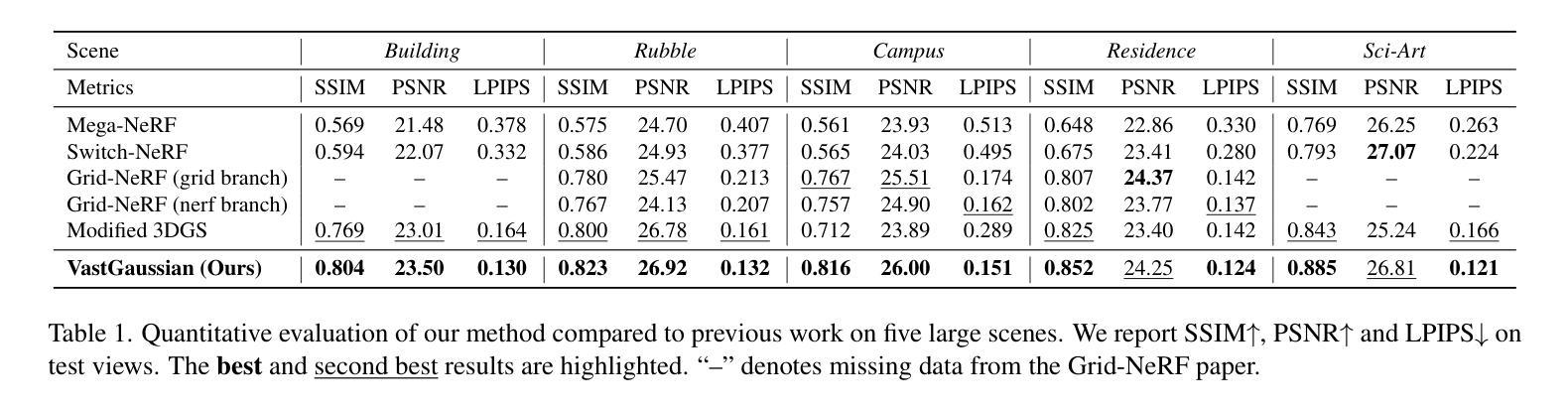
摘要: (1)研究背景:现有的基于 NeRF 的大场景重建方法在视觉质量和渲染速度上往往存在局限性。虽然最近的 3D 高斯体喷绘法在小规模和以物体为中心的场景中效果很好,但由于视频内存有限、优化时间长和外观变化明显,将其扩展到大型场景中会带来挑战。 (2)过去方法及其问题:本文方法的动机充分:为了解决这些挑战,我们提出了 VastGaussian,这是一种基于 3D 高斯体喷绘法在大场景上进行高质量重建和实时渲染的第一种方法。 (3)论文提出的研究方法:我们提出了一种渐进分区策略,将大场景划分为多个单元格,其中训练相机和点云通过考虑空域可见性的标准进行适当分布。在并行优化后,这些单元格被合并成一个完整的场景。我们还将解耦的外观建模引入优化过程,以减少渲染图像中的外观变化。 (4)方法在什么任务上取得了怎样的性能,性能是否能支撑其目标:我们的方法优于现有的基于 NeRF 的方法,并在多个大场景数据集上取得了最先进的结果,实现了快速优化和高保真实时渲染。
-
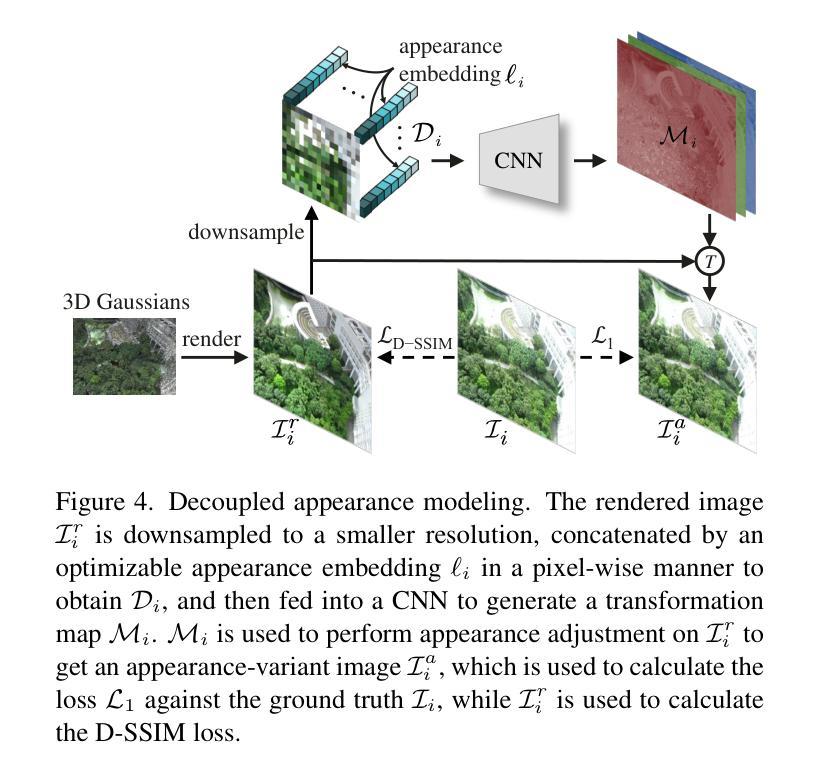
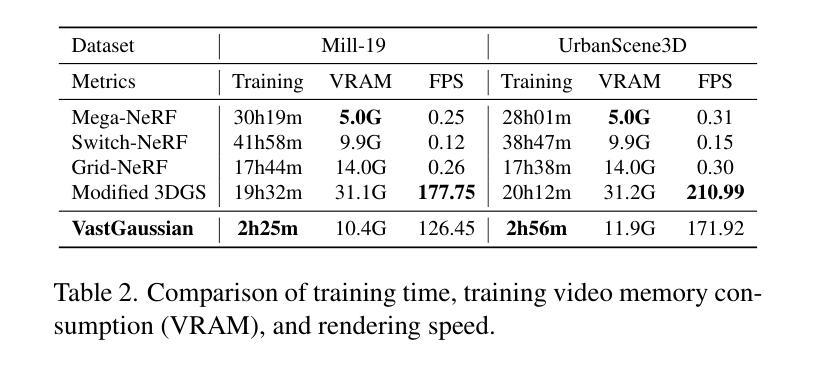
方法: (1):渐进数据分区:根据相机位置和可见性标准将大场景划分为多个单元格,并分配部分相机和点云进行优化。 (2):解耦外观建模:引入外观嵌入和卷积神经网络,通过对渲染图像进行外观调整来减少外观变化。 (3):无缝合并:优化各个单元格后,删除单元格外部的高斯体,然后合并非重叠单元格的高斯体,形成无缝的大场景。
8.结论: (1): 本工作提出了VastGaussian,一种基于3D高斯体喷绘法在大场景上进行高质量重建和实时渲染的第一种方法,解决了现有方法在视觉质量和渲染速度上的局限性。 (2): 创新点: - 渐进数据分区:将大场景划分为单元格,并分配部分相机和点云进行优化,解决了视频内存有限和优化时间长的挑战。 - 解耦外观建模:引入外观嵌入和卷积神经网络,减少了渲染图像中的外观变化,提高了视觉质量。 - 无缝合并:优化各个单元格后,合并非重叠单元格的高斯体,形成了无缝的大场景。 性能: - 在多个大场景数据集上取得了最先进的结果。 - 实现快速优化和高保真实时渲染。 工作量: - 论文提供了详细的算法描述和实验结果。 - Github代码暂未提供。
点此查看论文截图


GEA: Reconstructing Expressive 3D Gaussian Avatar from Monocular Video
Authors:Xinqi Liu, Chenming Wu, Xing Liu, Jialun Liu, Jinbo Wu, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang
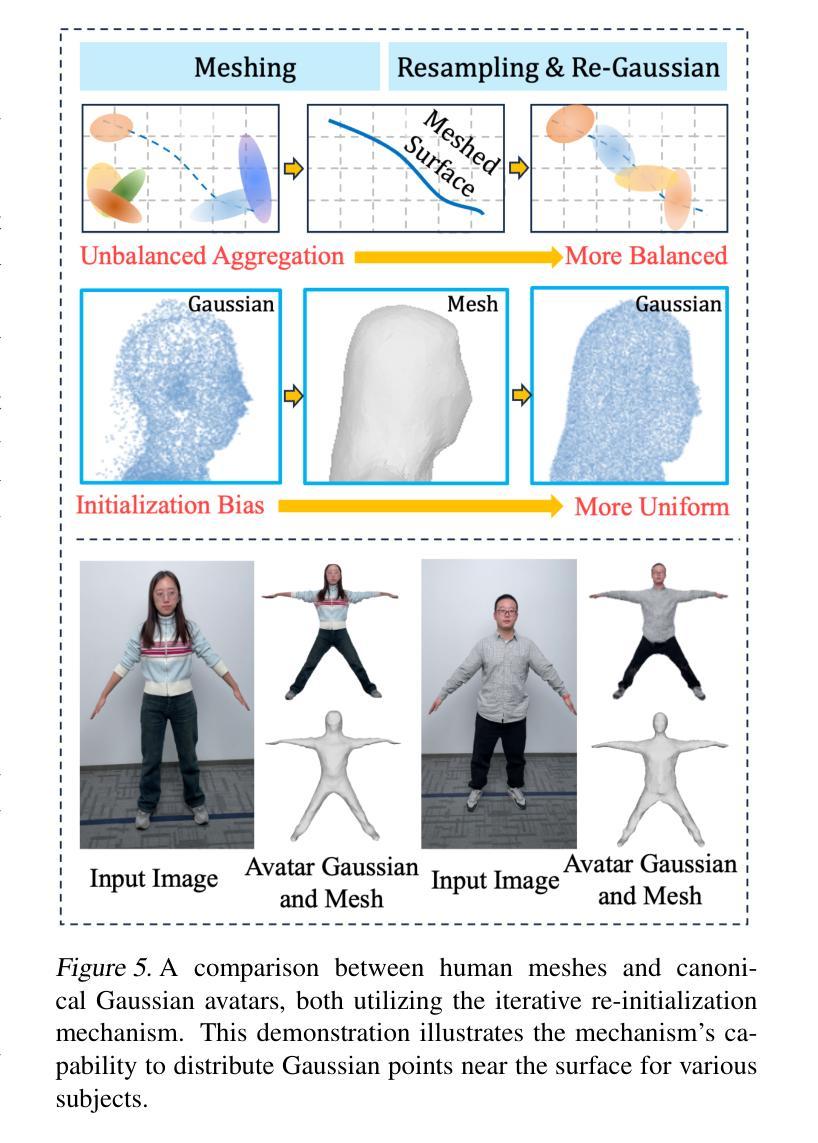
This paper presents GEA, a novel method for creating expressive 3D avatars with high-fidelity reconstructions of body and hands based on 3D Gaussians. The key contributions are twofold. First, we design a two-stage pose estimation method to obtain an accurate SMPL-X pose from input images, providing a correct mapping between the pixels of a training image and the SMPL-X model. It uses an attention-aware network and an optimization scheme to align the normal and silhouette between the estimated SMPL-X body and the real body in the image. Second, we propose an iterative re-initialization strategy to handle unbalanced aggregation and initialization bias faced by Gaussian representation. This strategy iteratively redistributes the avatar’s Gaussian points, making it evenly distributed near the human body surface by applying meshing, resampling and re-Gaussian operations. As a result, higher-quality rendering can be achieved. Extensive experimental analyses validate the effectiveness of the proposed model, demonstrating that it achieves state-of-the-art performance in photorealistic novel view synthesis while offering fine-grained control over the human body and hand pose. Project page: https://3d-aigc.github.io/GEA/.
Summary
利用基于 3D 高斯体的手部和身体高保真重建技术创造富有表现力的 3D 头像。
Key Takeaways
- 采用两阶段姿势估计方法,从输入图像中获取准确的 SMPL-X 姿势。
- 提出迭代重新初始化策略,处理高斯表示中遇到的不平衡聚合和初始化偏差。
- 该模型在图像真实的新视角合成方面实现了最先进的性能。
- 允许对人体和手部姿态进行精细控制。
- 实验分析验证了该模型的有效性。
- 提供项目主页链接:https://3d-aigc.github.io/GEA/。
- 该方法在创建表达力丰富的 3D 头像方面具有应用潜力。
- 标题:GEA:基于 3D 高斯重建表达式 3D 头像
- 作者:刘新奇、吴晨明、刘兴、刘家伦、武金波、赵晨、冯浩成、丁尔瑞、王京东
- 单位:百度视觉技术部
- 关键词:3D 头像、高斯表示、单目视频、姿态估计
- 论文链接:https://arxiv.org/abs/2402.16607,Github 代码链接:无
-
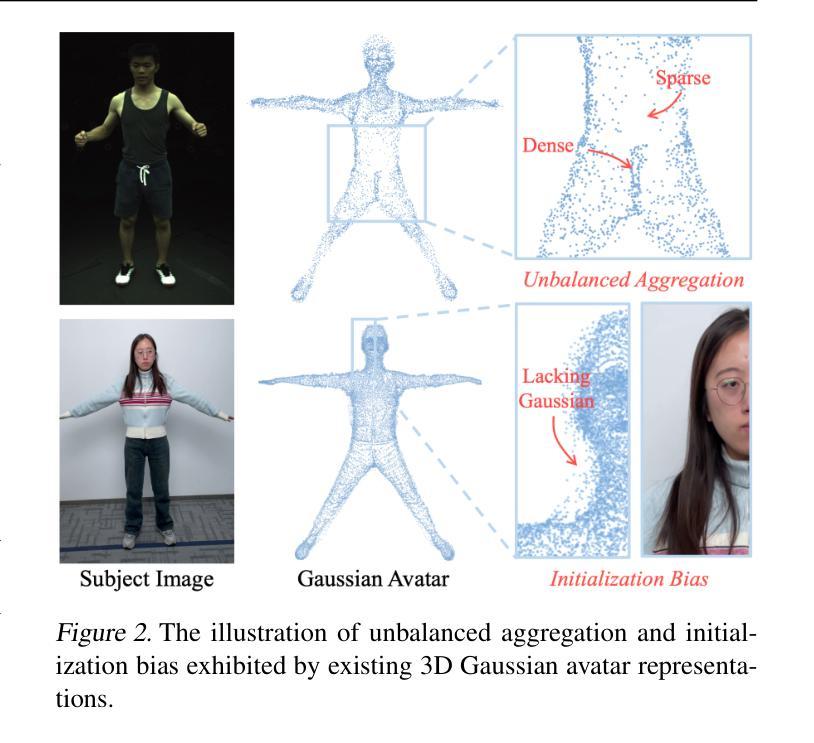
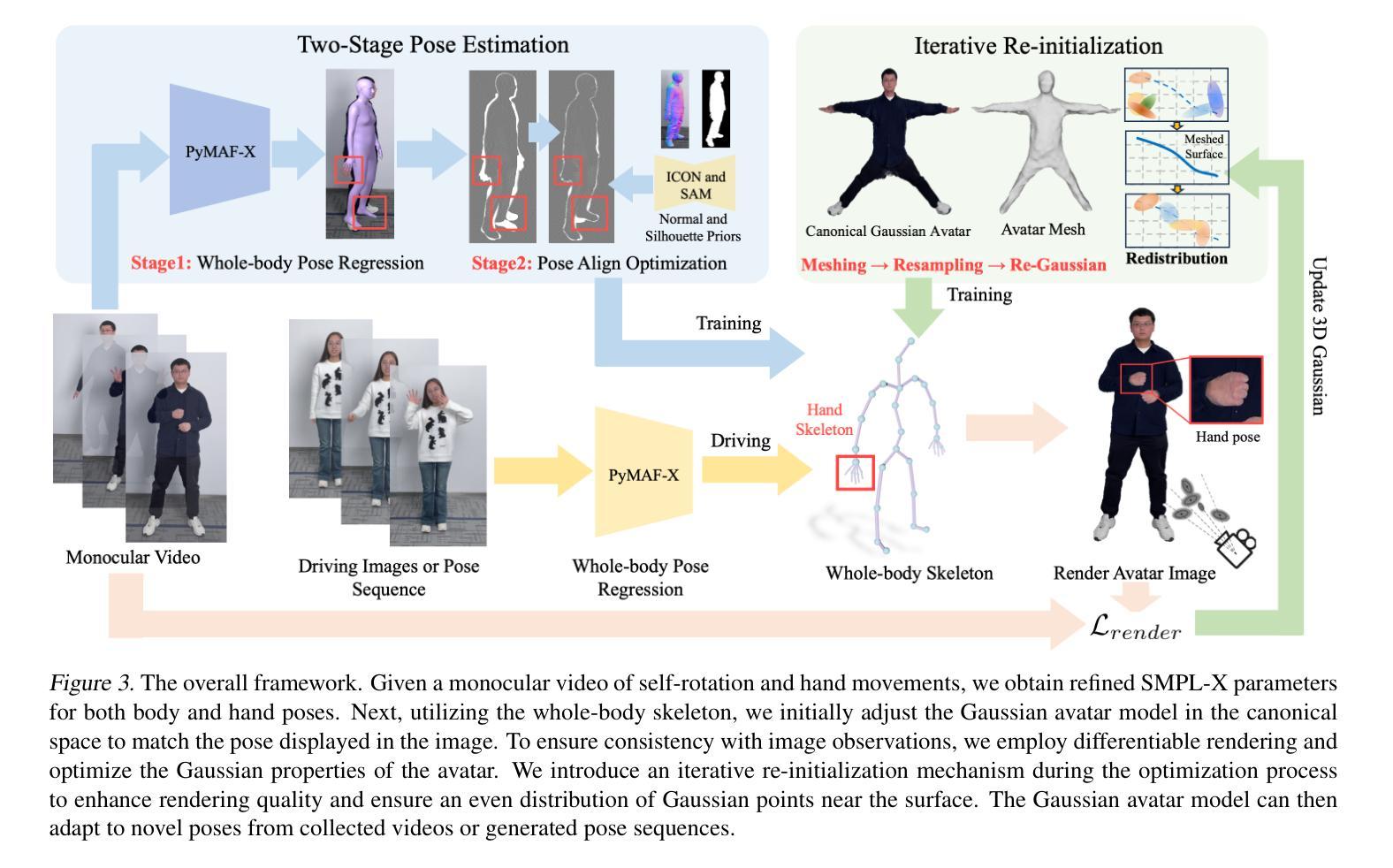
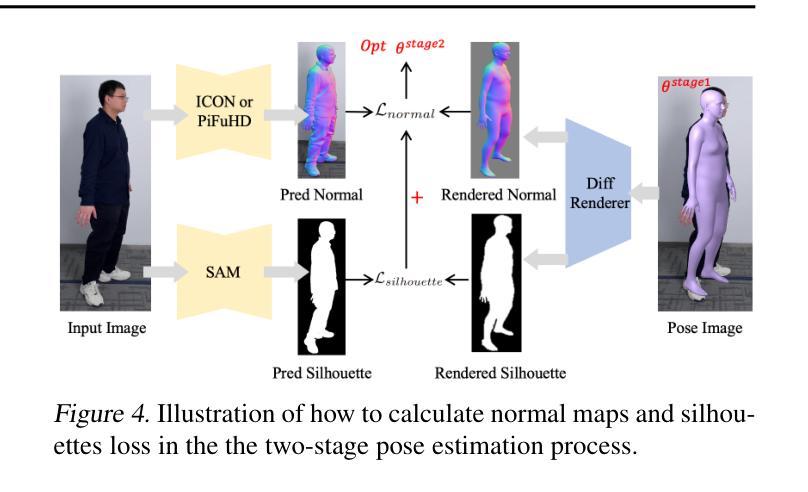
总结: (1)研究背景:重建逼真且可驱动的头像一直是学术界和工业界的热点课题,具有广阔的商业价值和社会影响。 (2)过去方法:早期方法主要依赖于 RGB-D 相机、多视角采集设备和人工建模,但存在成本高、渲染效果不逼真等问题。神经辐射场方法虽然可以重建逼真的 3D 头像,但训练时间长、姿态泛化能力有限。3D 高斯表示方法因其显式表示而受到关注,但存在初始化不均衡和聚集不平衡的问题。 (3)研究方法:本文提出的 GEA 方法包括两大贡献。一是设计了一种两阶段姿态估计方法,通过注意力感知网络和优化方案,从输入图像中准确估计 SMPL-X 姿态,建立图像像素与 SMPL-X 模型之间的正确映射。二是提出了一种迭代式重新初始化策略,通过网格化、重采样和高斯重新操作,迭代地重新分配头像的高斯点,使其均匀分布在人体表面附近,从而提高渲染质量。 (4)任务和性能:GEA 方法在真实感新视图合成任务上取得了最先进的性能,同时提供了对人体和手部姿态的精细控制。实验结果验证了该方法的有效性,支持其目标。
-
姿态估计:提出两阶段姿态估计方法,通过注意力感知网络和优化方案,从单目视频中准确估计 SMPL-X 姿态,建立图像像素与 SMPL-X 模型之间的正确映射。
- 迭代式重新初始化:通过网格化、重采样和高斯重新操作,迭代地重新分配头像的高斯点,使其均匀分布在人体表面附近,提高渲染质量。
- 3D 高斯表示:采用 3D 高斯点集合表示头像的形状和外观,并使用 SMPL-X 骨架模型实现详细的姿态控制。
-
渲染损失函数:使用 SMPL-X 骨架变换将高斯头像从规范空间驱动到图像空间,并使用差异化渲染进行优化。损失函数包括重建损失、感知损失和残差正则化。
-
结论 (1):本文提出了一种可由身体和手驱动的 3D 高斯头像重建方法,该方法从单目视频中获取 SMPL-X 姿态参数,指导 3D 高斯头像学习全身形状和外观。此外,还引入了一种迭代重新初始化机制,以避免 3D 高斯不平衡聚合和初始化偏差的问题。我们的目标是,这项贡献将为未来更逼真的头像重建铺平道路。 (2):创新点:
- 提出了一种两阶段姿势细化机制,从图像中获取 SMPL-X 姿态参数,指导 3D 高斯头像学习全身形状和外观。
- 提出了一种迭代重新初始化机制,以避免 3D 高斯不平衡聚合和初始化偏差的问题。 性能:
- 在真实感新视图合成任务上取得了最先进的性能。
- 提供了对人体和手部姿态的精细控制。 工作量:
- 需要大量的数据和计算资源。
- 训练过程可能耗时。
点此查看论文截图

Spec-Gaussian: Anisotropic View-Dependent Appearance for 3D Gaussian Splatting
Authors:Ziyi Yang, Xinyu Gao, Yangtian Sun, Yihua Huang, Xiaoyang Lyu, Wen Zhou, Shaohui Jiao, Xiaojuan Qi, Xiaogang Jin
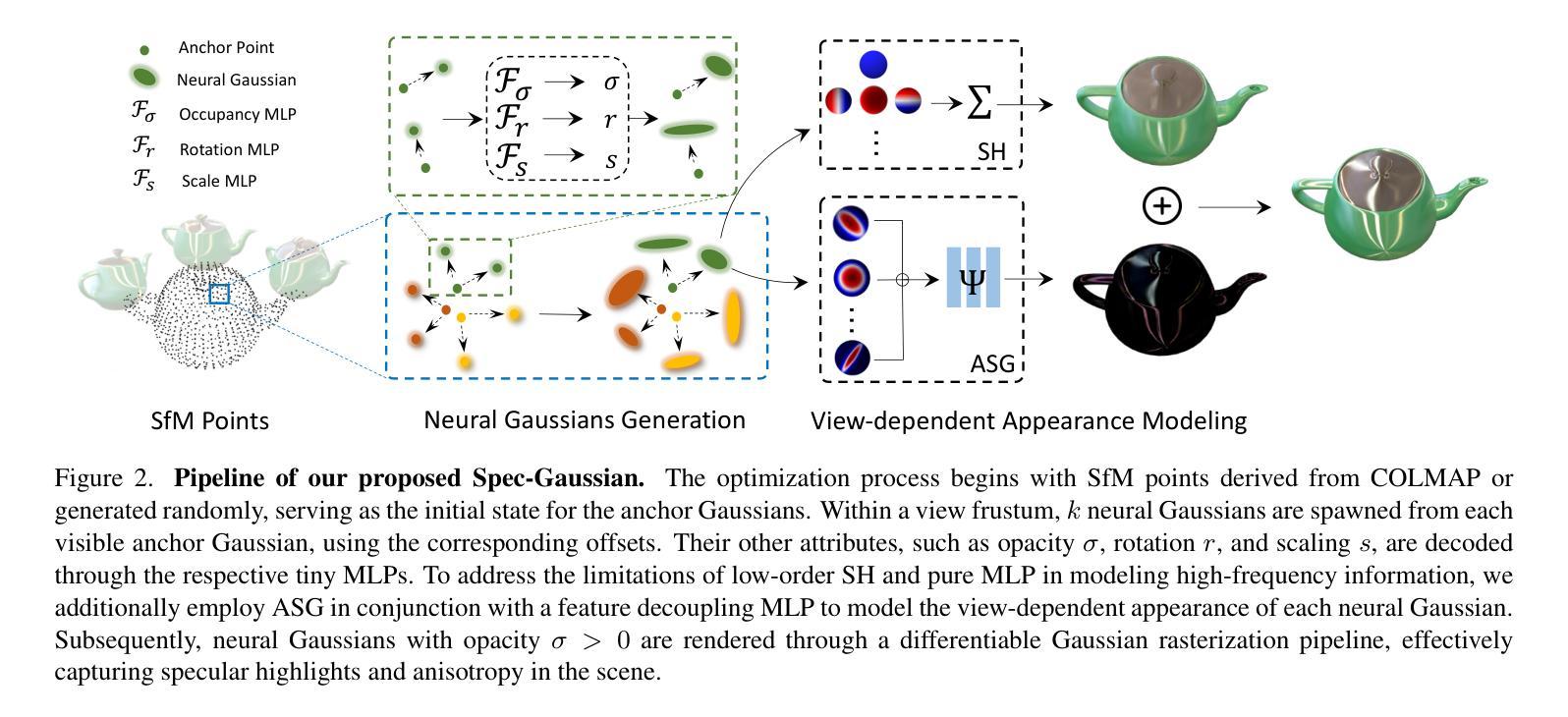
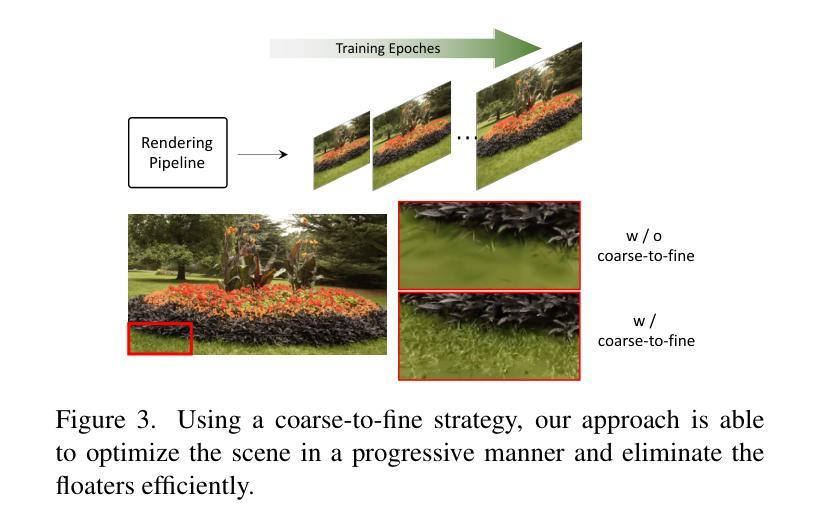
The recent advancements in 3D Gaussian splatting (3D-GS) have not only facilitated real-time rendering through modern GPU rasterization pipelines but have also attained state-of-the-art rendering quality. Nevertheless, despite its exceptional rendering quality and performance on standard datasets, 3D-GS frequently encounters difficulties in accurately modeling specular and anisotropic components. This issue stems from the limited ability of spherical harmonics (SH) to represent high-frequency information. To overcome this challenge, we introduce Spec-Gaussian, an approach that utilizes an anisotropic spherical Gaussian (ASG) appearance field instead of SH for modeling the view-dependent appearance of each 3D Gaussian. Additionally, we have developed a coarse-to-fine training strategy to improve learning efficiency and eliminate floaters caused by overfitting in real-world scenes. Our experimental results demonstrate that our method surpasses existing approaches in terms of rendering quality. Thanks to ASG, we have significantly improved the ability of 3D-GS to model scenes with specular and anisotropic components without increasing the number of 3D Gaussians. This improvement extends the applicability of 3D GS to handle intricate scenarios with specular and anisotropic surfaces.
Summary
3D 高斯球体溅射技术 (3D-GS) 在精确建模镜面和各向异性成分方面面临挑战,Spec-Gaussian 方法通过使用各向异性球面高斯外观场来解决这一难题,同时采用粗略到精细的训练策略来增强学习效率并消除过拟合浮动物。
Key Takeaways
- 3D-GS技术在标准数据集上表现出色,但在精确建模镜面和各向异性成分方面遇到困难。
- 限制球谐函数 (SH) 表示高频信息的局限性导致3D-GS建模困难。
- Spec-Gaussian方法采用各向异性球面高斯 (ASG) 外观场来代替SH,提高镜面和各向异性成分建模能力。
- 粗略到精细的培训策略提高了学习效率,消除了过拟合造成的浮动物。
- 实验结果表明Spec-Gaussian在渲染质量方面优于现有方法。
- ASG显著提升了3D-GS建模镜面和各向异性成分场景的能力,无需增加3D高斯球体数量。
- 3D-GS技术可扩展至处理镜面和各向异性表面的复杂场景。
- 题目:Spec-Gaussian:高斯体渲染中的各向异性视点相关外观
- 作者:Jiahui Lei, Yinda Zhang, Wenbo Bao, Jingyi Yu, Qiong Yan, Hao Li
- 单位:香港中文大学(深圳)
- 关键词:3D 高斯体渲染、各向异性、视点相关外观、神经网络
- 论文链接:https://arxiv.org/abs/2208.05462
- 摘要: (1)研究背景: 近年来,3D 高斯体渲染(3DGS)在实时渲染和高渲染质量方面取得了显著进展。然而,在建模镜面和各向异性成分时,3DGS 仍然面临挑战。
(2)过去的方法及其问题: 过去的方法通常使用球谐函数(SH)来建模视点相关外观。然而,SH 在表示高频信息方面能力有限,难以准确建模镜面和各向异性效果。
(3)提出的研究方法: 本文提出 Spec-Gaussian,一种使用各向异性球面高斯(ASG)外观场来建模 3D 高斯体视点相关外观的方法。ASG 比 SH 具有更强的各向异性建模能力,可以更准确地表示镜面和各向异性成分。此外,本文还提出了一个粗到细的训练策略,以提高学习效率并消除过拟合引起的浮动现象。
(4)方法在任务和性能上取得的成就: 实验结果表明,Spec-Gaussian 在渲染质量方面优于现有方法。得益于 ASG,本文方法显著提高了 3DGS 在建模具有镜面和各向异性成分场景的能力,而无需增加 3D 高斯体的数量。这一改进扩展了 3DGS 在处理具有复杂镜面和各向异性表面的场景中的适用性。
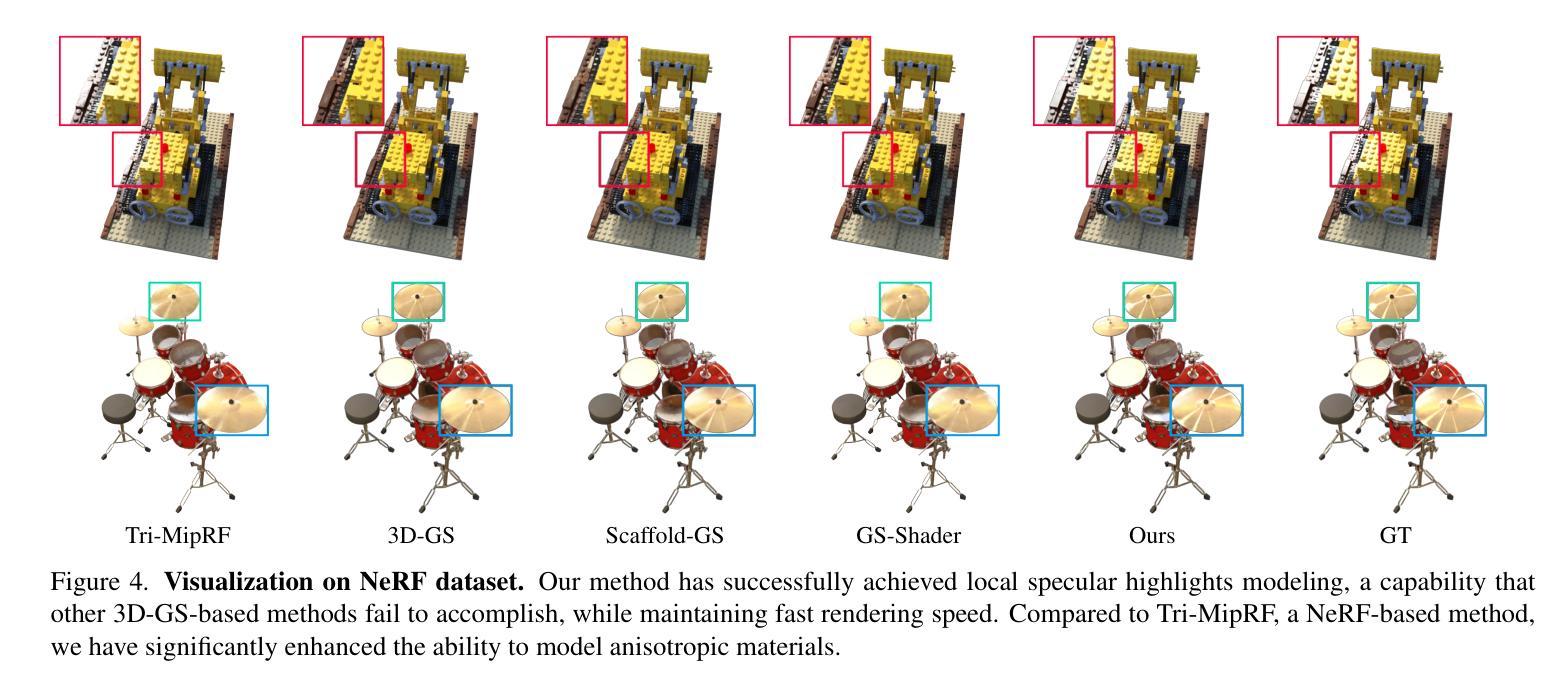
7.Methods:(1):提出Spec-Gaussian方法,使用各向异性球面高斯(ASG)外观场来建模3D高斯体视点相关外观,ASG比球谐函数(SH)具有更强的各向异性建模能力;(2):提出粗到细的训练策略,以提高学习效率并消除过拟合引起的浮动现象;(3):通过实验验证Spec-Gaussian在渲染质量方面优于现有方法,显著提高了3DGS在建模具有镜面和各向异性成分场景的能力。
- 结论: (1):本文提出Spec-Gaussian,一种使用各向异性球面高斯(ASG)外观场来建模3D高斯体视点相关外观的方法,有效地克服了传统3D-GS在渲染具有镜面高光和各向异性的场景时遇到的挑战。此外,本文创新地实现了粗到细的训练机制,消除了实际场景中的浮动现象。定量和定性实验表明,本文方法不仅赋予3D-GS建模镜面高光和各向异性的能力,而且提高了3D-GS在一般场景中的整体渲染质量,而不会显著影响FPS和存储开销。 (2):创新点:提出Spec-Gaussian方法,使用各向异性球面高斯(ASG)外观场来建模3D高斯体视点相关外观,ASG比球谐函数(SH)具有更强的各向异性建模能力;提出粗到细的训练策略,以提高学习效率并消除过拟合引起的浮动现象。 性能:在渲染质量方面优于现有方法,显著提高了3DGS在建模具有镜面和各向异性成分场景的能力。 工作量:与现有方法相比,在渲染质量方面有显著提升,而不会显著增加FPS和存储开销。
点此查看论文截图

Magic-Me: Identity-Specific Video Customized Diffusion
Authors:Ze Ma, Daquan Zhou, Chun-Hsiao Yeh, Xue-She Wang, Xiuyu Li, Huanrui Yang, Zhen Dong, Kurt Keutzer, Jiashi Feng
Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored. In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent. To achieve this, we propose three novel components that are essential for high-quality ID preservation: 1) an ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning; 2) a text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency and 3) video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution. Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines. Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability. The codes are available at https://github.com/Zhen-Dong/Magic-Me.
Summary
用少量图像指定主体 ID,VCD 框架通过强化身份信息提取和注入帧间相关性,生成主体身份可控的高质量视频。
Key Takeaways
- 提出 VCD 框架用于主体身份可控视频生成,通过指定几个图像定义主体 ID。
- ID 模块利用提示到分割训练, disentangle ID 信息和背景噪声,更准确地学习 ID 标记。
- T2V VCD 模块使用 3D 高斯噪声先验,以获得更好的帧间一致性。
- V2V Face VCD 和 Tiled VCD 模块用于模糊面部和提升视频分辨率。
- VCD 在选定的强基线上生成稳定、高质量且 ID 更佳的视频。
- ID 模块可迁移,VCD 可与公开提供的微调文本到图像模型配合使用,进一步提高其可用性。
- 提供了 VCD 的代码:https://github.com/Zhen-Dong/Magic-Me。
- 题目:Magic-Me: 身份特定视频定制化扩散
- 作者:Ze Ma1, Daquan Zhou†1, Chun-Hsiao Yeh2, Xue-She Wang1, Xiuyu Li2, Huanrui Yang2, Zhen Dong†2, Kurt Keutzer2, Jiashi Feng1
- 第一作者单位:字节跳动公司
- 关键词:身份特定视频生成、文本到视频、视频定制化扩散
- 论文链接:https://arxiv.org/abs/2402.09368 Github代码链接:https://github.com/Zhen-Dong/Magic-Me
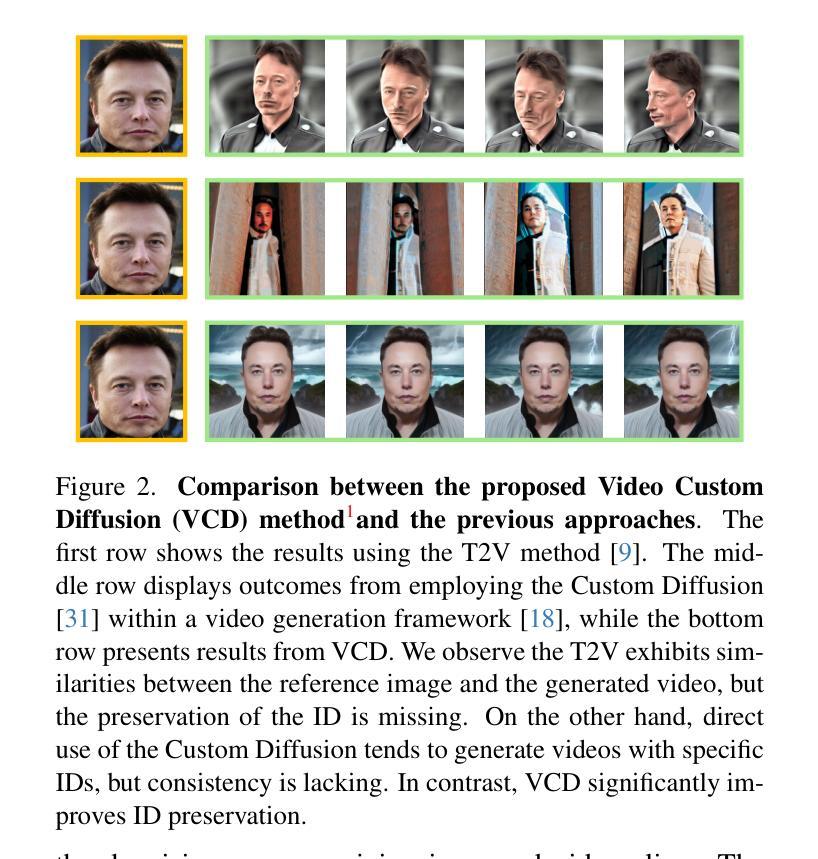
- 摘要: (1): 研究背景:文本到视频生成取得了显著进展,但精确控制生成内容仍然具有挑战性。身份特定生成在许多场景中很重要,例如电影制作和广告。 (2): 过去方法:之前的研究主要集中在利用图像参考控制风格和动作,或通过视频编辑进行定制化生成。这些方法的重点不在于身份特定控制。 (3): 研究方法:本文提出了一种简单的但有效的身份特定视频生成框架,称为视频定制化扩散(VCD)。VCD 使用身份模块提取身份信息,并在初始化阶段注入帧间相关性,以生成具有稳定身份的视频输出。 (4): 性能:VCD 在身份保留方面优于选定的强基线。此外,由于身份模块的可迁移性,VCD 也适用于公开可用的微调文本到图像模型,进一步提高了其可用性。
7.Methods:
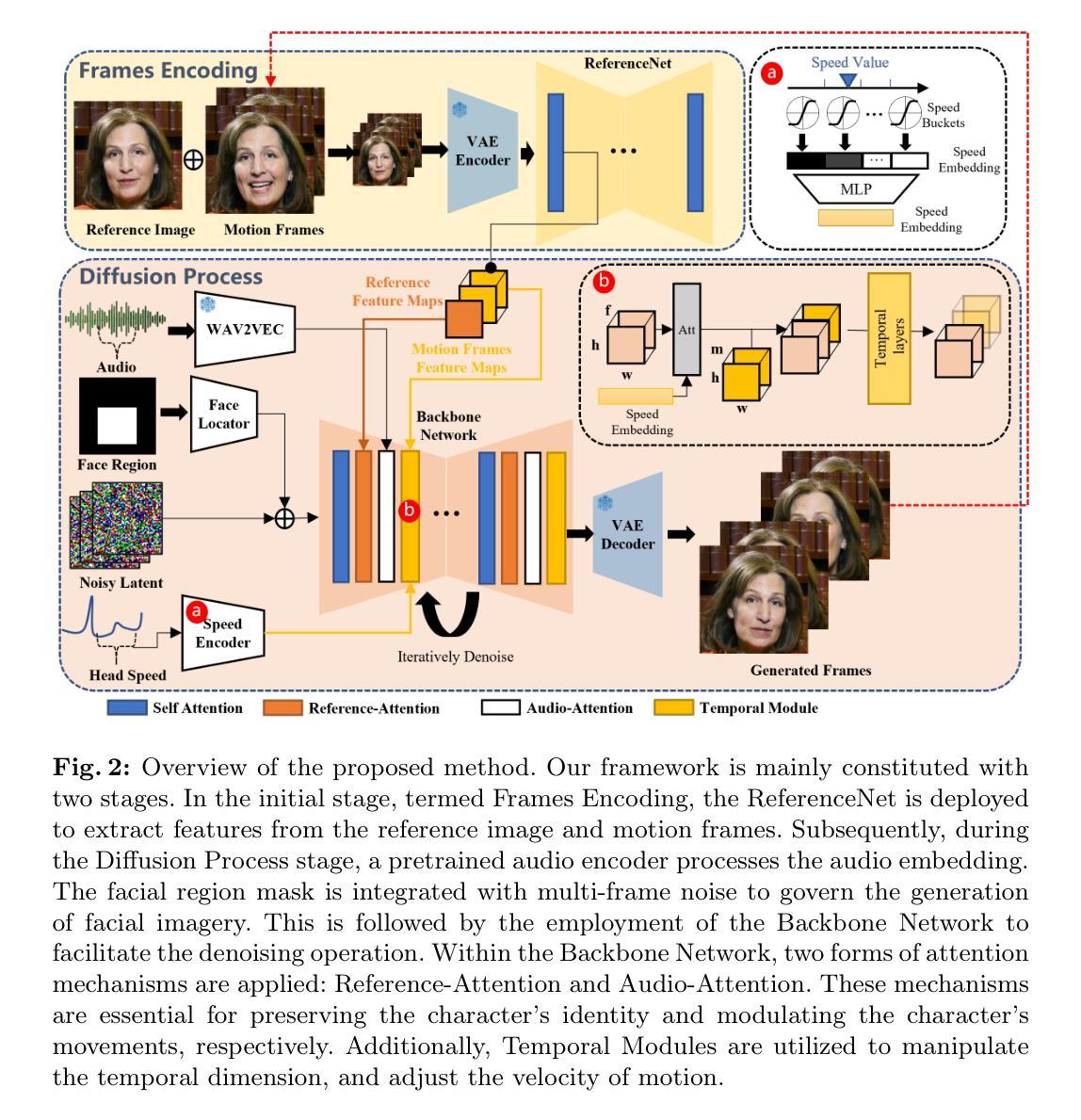
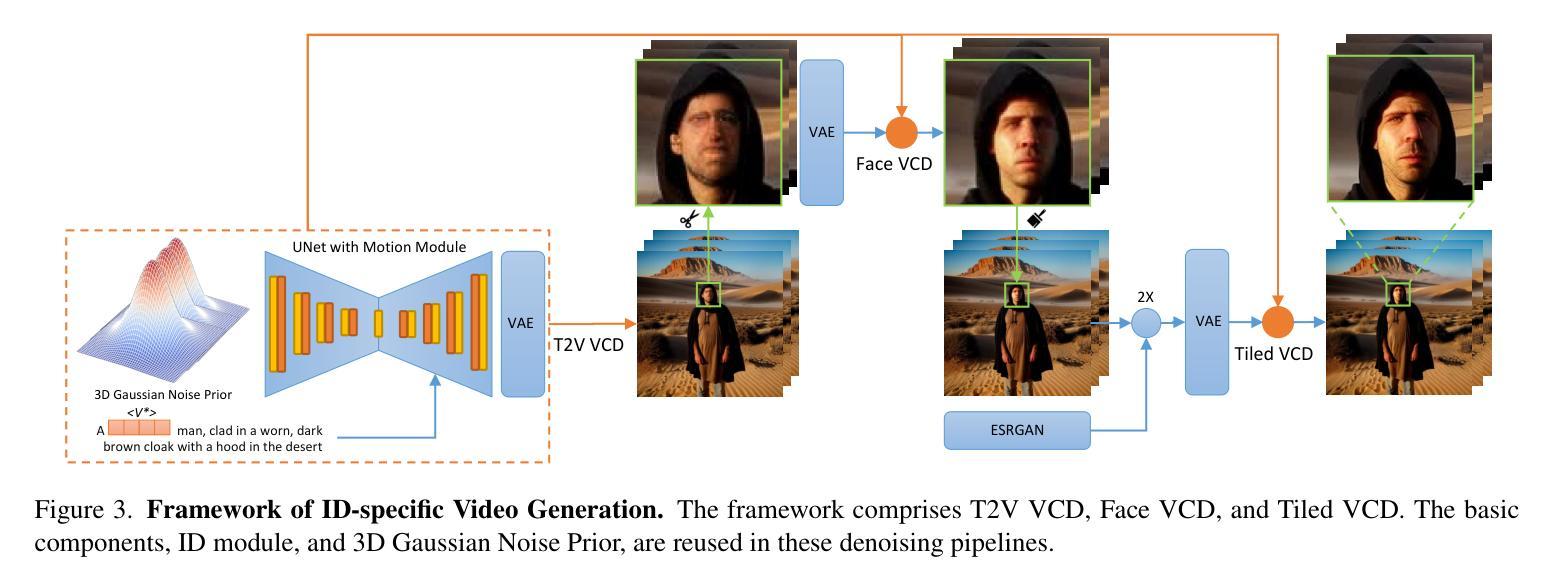
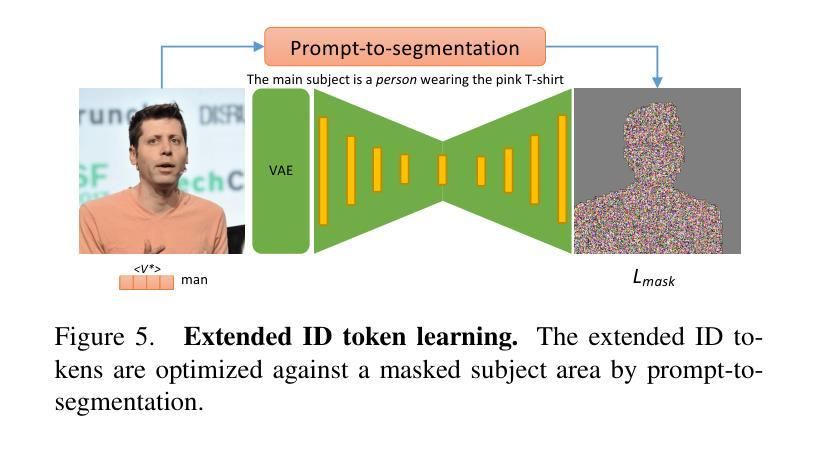
(1)提出用于 VCD 的预处理模块,以及 ID 模块和运动模块,如图 3 所示。此外,我们提供了一个可选模块,利用 ControlNet Tile 来上采样视频并生成高分辨率内容。我们的方法结合了 AnimateDiff [18] 中现成的运动模块,并通过我们提出的 3D 高斯噪声先验进行了增强,如第 4.1 节所述。ID 模块具有带掩码损失和提示到分割的扩展 ID 令牌,在第 4.2 节中介绍。在第 4.3 节中,我们介绍了两个 V2V VCD 管道,FaceVCD 和 TiledVCD。
(2)为了简单起见,我们应用我们的无训练 3D 高斯噪声先验到现成的运动模块 [18],以减轻推理期间的曝光偏差。所选的运动模块将网络扩展到包含时间维度。它将 2D 卷积和注意力层转换为时间伪 3D 层 [23],遵循方程式 2 中概述的训练目标。3D 高斯噪声先验。对于包含 f 帧的视频,3D 高斯噪声先验从多元高斯分布 N(0, Σf(γ)) 中采样。这里,Σf(γ) 表示由 γ∈(0,1) 参数化的协方差矩阵。Σf(γ)=1γγ2···γf−1γ1γ···γf−2γ2γ1···γf−3...............γf−1γf−2γf−3···1。(4)
(3)上面描述的协方差确保初始化的 3D 噪声在 m 和 n 帧之间的相同位置表现出 γ|m−n| 的协方差。超参数 γ 表示稳定性和运动幅度之间的权衡,如图 4 所示。较低的 γ 值会导致运动剧烈但稳定性降低的视频,而较高的 γ 会导致幅度减小的更稳定的运动。
(4)ID 模块 VAE 提示到分割 Lmask
- 结论: (1)本工作的重要意义: 本文提出的 Video Custom Diffusion(VCD)框架旨在解决可控视频生成中主体身份控制的挑战。通过融合身份信息和帧间相关性,VCD 为生成不仅在帧间保持主体身份,而且具有稳定性和清晰度的视频铺平了道路。我们新颖的贡献,包括用于精确身份分离的 ID 模块、用于增强帧一致性的 T2V VCD 模块以及用于提高视频质量的 V2V 模块,共同为视频内容中的身份保留建立了新的标准。我们进行的广泛实验肯定了 VCD 在生成高质量、稳定且保留主体身份的视频方面的优势。此外,我们的 ID 模块适用于现有的文本到图像模型,增强了 VCD 的实用性,使其适用于广泛的应用。 (2)本文的创新点、性能和工作量总结: 创新点:
- 提出了一种用于视频定制扩散的框架,该框架结合了身份信息和帧间相关性,以生成具有稳定身份的视频。
- 设计了一个 ID 模块,用于从文本提示中提取身份信息并将其注入视频生成过程中。
- 提出了一种 T2V VCD 模块,用于增强帧间一致性,生成具有平滑运动和清晰细节的视频。 性能:
- VCD 在身份保留方面优于选定的强基线,生成的高质量视频在帧间保持了主体身份。
- 由于 ID 模块的可迁移性,VCD 也适用于公开可用的微调文本到图像模型,进一步提高了其可用性。 工作量:
- VCD 的实现相对简单,仅需要少量额外的计算开销。
- ID 模块具有紧凑的参数空间,仅需 16KB 的存储空间,使其易于部署和使用。
点此查看论文截图





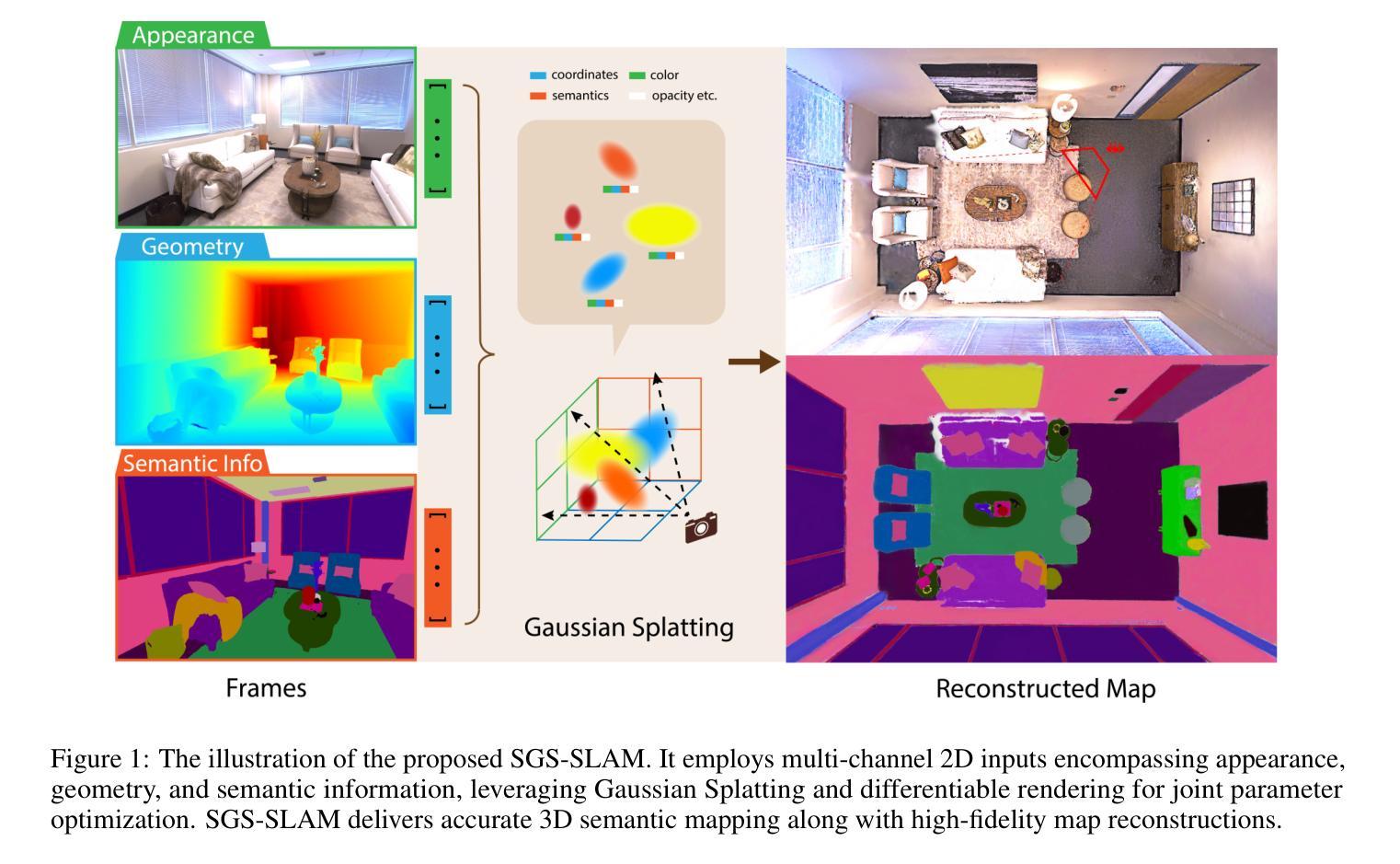
SGS-SLAM: Semantic Gaussian Splatting For Neural Dense SLAM
Authors:Mingrui Li, Shuhong Liu, Heng Zhou, Guohao Zhu, Na Cheng, Hongyu Wang
Semantic understanding plays a crucial role in Dense Simultaneous Localization and Mapping (SLAM). Recent advancements that integrate Gaussian Splatting into SLAM systems have demonstrated its effectiveness in generating high-quality renderings. Building on this progress, we propose SGS-SLAM which provides precise 3D semantic segmentation alongside high-fidelity reconstructions. Specifically, we propose to employ multi-channel optimization during the mapping process, integrating appearance, geometric, and semantic constraints with key-frame optimization to enhance reconstruction quality. Extensive experiments demonstrate that SGS-SLAM delivers state-of-the-art performance in camera pose estimation, map reconstruction, and semantic segmentation. It outperforms existing methods by a large margin meanwhile preserves real-time rendering ability.
摘要
SGS-SLAM 采用多通道优化,将外观、几何和语义约束融入关键帧优化中,实现了高精度 3D 语义分割和高保真重建。
关键要点
- 利用高斯喷射将语义理解融入 SLAM 系统,生成高质量渲染效果。
- 采用多通道优化,融合外观、几何和语义约束,提升重建质量。
- 在相机位姿估计、地图重建和语义分割方面达到最先进性能。
- 显著优于现有方法,同时保持实时渲染能力。
- 扩展了 SLAM 系统的应用范围,使其在语义理解和重建任务中表现出色。
- 为室内或室外环境的高保真重建和交互式探索提供了新的可能性。
- 为自动驾驶、机器人导航和增强现实等领域提供了新的技术支持。
- 标题:SGS-SLAM:用于神经稠密 SLAM 的语义高斯斑点绘制
- 作者:Mingrui Li、Shuhong Liu、Heng Zhou、Guohao Zhu、Na Cheng、Hongyu Wang
- 单位:大连理工大学计算机科学与技术系
- 关键词:SLAM、3D 重建、3D 语义分割
- 论文链接:https://arxiv.org/abs/2402.03246,Github 代码链接:无
- 摘要: (1):研究背景:语义理解在稠密 SLAM 中至关重要,而将高斯斑点绘制集成到 SLAM 系统中的最新进展已证明其在生成高质量渲染方面的有效性。 (2):过去方法及问题:传统视觉 SLAM 系统擅长使用点云和体素进行稀疏重建,但无法进行稠密重建。基于学习的 SLAM 方法可以提取用于高质量表示的稠密几何信息,但它们容易受到噪声和异常值的影响。神经辐射场 (NeRF) 启发的 SLAM 方法进一步提高了重建质量,但它们通常不包含语义信息。 (3):研究方法:本文提出 SGS-SLAM,它在高保真重建的同时提供精确的 3D 语义分割。SGS-SLAM 在映射过程中采用多通道优化,将外观、几何和语义约束与关键帧优化相结合,以增强重建质量。 (4):任务和性能:SGS-SLAM 在相机姿态估计、地图重建和语义分割方面都取得了最先进的性能。它以很大的优势优于现有方法,同时保留了实时渲染能力。
方法: (1): SGS-SLAM采用多通道高斯表示,将外观、几何和语义约束与关键帧优化相结合,以增强重建质量。 (2): 跟踪过程估计每一帧的相机位姿,同时保持场景参数固定。映射优化基于估计的相机位姿优化场景表示。 (3): 场景表示使用高斯影响函数 f(·),其中 σ 表示不透明度,μ 表示中心位置,r 表示半径。每个高斯还携带 RGB 颜色 ci。 (4): 使用渲染方法将高斯渲染成 2D 图像,通过沿深度维度逼近影响函数 f(·) 的积分投影来完成。 (5): 通过对高斯进行深度排序并执行从前到后的体积渲染,可以组合所有高斯对该像素的影响。 (6): 像素级渲染颜色 Cpix 是每个高斯颜色 ci 的总和,并根据影响函数 f2Di,pix 加权,乘以遮挡项。 (7): 深度可以渲染为:Dpix = ∑i=1 di f2Di,pix i−1 ∏j=1 (1−f2Dj,pix),其中 di 表示每个高斯的深度。 (8): 通过设置 di=1,可以计算出轮廓 Silpix = Dpix(di=1),这有助于确定像素是否在当前视图中可见。 (9): 在映射过程中,将 2D 语义标签分配给高斯参数的特定通道以表示其语义标签和颜色。 (10): 渲染过程中,可以从重建的 3D 场景渲染 2D 语义图:Spix = ∑i=1 si f2Di,pix i−1 ∏j=1 (1−f2Dj,pix),其中 si = [ri, gi, bi]T 表示与高斯关联的语义颜色。 (11): 相机位姿估计通过最小化跟踪损失来实现,该损失表示真实颜色、深度图像和语义图与其可微渲染视图之间的差异。 (12): 关键帧选择和加权:在跟踪阶段,同时识别和存储关键帧。这些关键帧提供了对象的不同视图,对于映射优化 3D 场景重建至关重要。 (13): SGS-SLAM 在恒定时间间隔内捕获和存储关键帧。随后,根据几何和语义约束选择与当前帧关联的关键帧。 (14): 首先进行基于几何的初始选择,然后进行基于语义的二次筛选。 (15): 对于每个关键帧,计算不确定性分数 U(t) = e−τt,其中 t 表示关键帧的时间戳,τ 为衰减系数。 (16): 使用此不确定性分数对映射损失 Lmapping 加权。 (17): 地图重建:场景使用三个不同通道的高斯建模:它们的均值坐标表示场景的几何信息,它们的外观颜色描绘了场景的视觉外观,它们的语义颜色表示对象的语义标签。 (18): 在高斯致密化和优化过程中,跨通道的这些参数被联合优化,而从跟踪中确定的相机位姿保持固定。 (19): 从第一帧开始,所有像素都有助于初始化地图。 (20): 在新时间步的地图重建过程中,将新高斯引入到地图中,这些区域要么密度不足,要么显示先前估计的地图前面的新几何形状。 (21): 通过将掩码应用于像素来调节新高斯的添加,其中要么 (i) 轮廓值 Silpix 低于某个阈值,表示可见性高度不确定,要么 (ii) 真实深度远小于估计深度,表明存在新的几何实体。 (22): 致密化后,通过最小化映射损失来优化地图参数:Lmapping = U ∑pix λD |DGTpix−Dpix| + λC L C + λS L S。
- 结论: (1)本工作的重要意义:SGS-SLAM 在进行高保真重建的同时提供了精确的 3D 语义分割,在相机姿态估计、地图重建和语义分割方面都取得了最先进的性能,为神经稠密 SLAM 提供了一种新的解决方案。 (2)本文的优缺点总结: 创新点:SGS-SLAM 采用多通道高斯表示,将外观、几何和语义约束与关键帧优化相结合,增强了重建质量,并首次将语义信息集成到神经稠密 SLAM 系统中。 性能:SGS-SLAM 在相机姿态估计、地图重建和语义分割方面都取得了最先进的性能,以很大的优势优于现有方法,同时保留了实时渲染能力。 工作量:SGS-SLAM 的实现需要大量的计算资源和数据,这可能会限制其在某些资源受限的应用中的使用。
点此查看论文截图