⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-02-29 更新
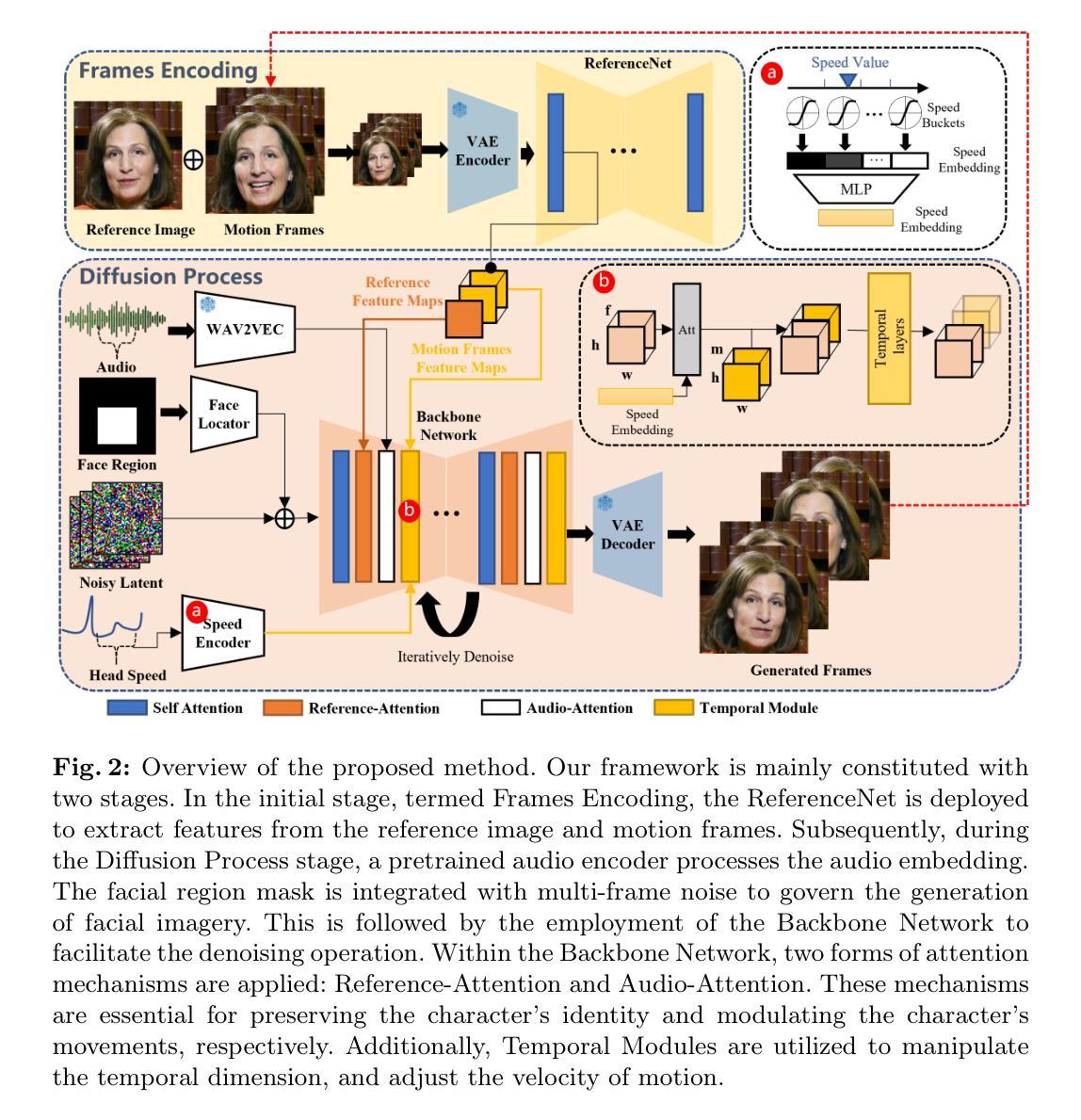
EMO: Emote Portrait Alive - Generating Expressive Portrait Videos with Audio2Video Diffusion Model under Weak Conditions
Authors:Linrui Tian, Qi Wang, Bang Zhang, Liefeng Bo
In this work, we tackle the challenge of enhancing the realism and expressiveness in talking head video generation by focusing on the dynamic and nuanced relationship between audio cues and facial movements. We identify the limitations of traditional techniques that often fail to capture the full spectrum of human expressions and the uniqueness of individual facial styles. To address these issues, we propose EMO, a novel framework that utilizes a direct audio-to-video synthesis approach, bypassing the need for intermediate 3D models or facial landmarks. Our method ensures seamless frame transitions and consistent identity preservation throughout the video, resulting in highly expressive and lifelike animations. Experimental results demonsrate that EMO is able to produce not only convincing speaking videos but also singing videos in various styles, significantly outperforming existing state-of-the-art methodologies in terms of expressiveness and realism.
Summary
音频线索能够协助生成更具表现力和真实感的面部动画。
Key Takeaways
- 传统技术无法充分捕捉人类面部表情和个人风格差异。
- EMO 框架采用直接音频到视频合成方法,无需中间 3D 模型或面部关键点。
- EMO 可生成流畅无缝的视频,并始终保持身份一致性。
- EMO 可生成具有高度表现力和真实感的说话和唱歌视频。
- EMO 在表现力和真实感方面明显优于现有方法。
- EMO 充分利用了音频线索,提升了面部动画的动态性和细致度。
- EMO 可广泛应用于各种领域,包括电影、游戏和视频会议。
- 标题:EMO:EmotePortraitAlive——在弱条件下使用音频到视频扩散模型生成富有表现力的肖像视频
- 作者:Tian Linrui、Wang Qi、Zhang Bang、Bo Liefeng
- 隶属单位:阿里巴巴集团智能计算研究院
- 关键词:Audio-driven portrait video generation、Talking head、Expressive facial expressions、Audio-to-video synthesis
- 论文链接:https://humanaigc.github.io/emote-portrait-alive/ Github 代码链接:无
- 摘要: (1)研究背景: 在说话人头像视频生成中,增强真实感和表现力是一项挑战,需要关注音频线索和面部动作之间的动态和细微关系。传统技术往往无法捕捉到人类表情的全貌和个人面部风格的独特性。 (2)过去方法和问题: 传统的说话人头像视频生成方法通常需要中间 3D 模型或面部关键点,这会引入额外的复杂性和限制。此外,这些方法在捕捉细微的表情和保持帧之间的一致性方面存在困难。 (3)研究方法: 本文提出了一种名为 EMO 的新框架,它采用直接音频到视频合成的方法,绕过了对中间 3D 模型或面部关键点的需求。该方法利用音频扩散模型,将音频线索直接映射到视频帧,确保了无缝的帧过渡和一致的面部动作。 (4)任务和性能: EMO 在说话人头像视频生成任务上进行了评估。实验结果表明,该方法在生成具有丰富面部表情和头部姿势的逼真且富有表现力的视频方面取得了显着性能。这些性能支持了本文增强说话人头像视频生成真实感和表现力的目标。
7.方法:(1)提出了一种名为EMO的新框架,该框架采用直接音频到视频合成的方法,绕过了对中间3D模型或面部关键点的需求。(2)该方法利用音频扩散模型,将音频线索直接映射到视频帧,确保了无缝的帧过渡和一致的面部动作。(3)在说话人头像视频生成任务上对EMO进行了评估,实验结果表明,该方法在生成具有丰富面部表情和头部姿势的逼真且富有表现力的视频方面取得了显着性能。
- 结论: (1): 本工作提出了一种名为 EMO 的新框架,该框架采用直接音频到视频合成的方法,绕过了对中间 3D 模型或面部关键点的需求。该方法利用音频扩散模型,将音频线索直接映射到视频帧,确保了无缝的帧过渡和一致的面部动作。在说话人头像视频生成任务上对 EMO 进行了评估,实验结果表明,该方法在生成具有丰富面部表情和头部姿势的逼真且富有表现力的视频方面取得了显着性能。这些性能支持了本文增强说话人头像视频生成真实感和表现力的目标。 (2): 创新点:
- 直接音频到视频合成的方法,绕过了对中间 3D 模型或面部关键点的需求。
- 利用音频扩散模型,将音频线索直接映射到视频帧,确保了无缝的帧过渡和一致的面部动作。 性能:
- 在说话人头像视频生成任务上取得了显着性能。
- 生成了具有丰富面部表情和头部姿势的逼真且富有表现力的视频。 工作量:
- 该方法的实现相对简单,不需要复杂的中间步骤或额外的模型。
点此查看论文截图

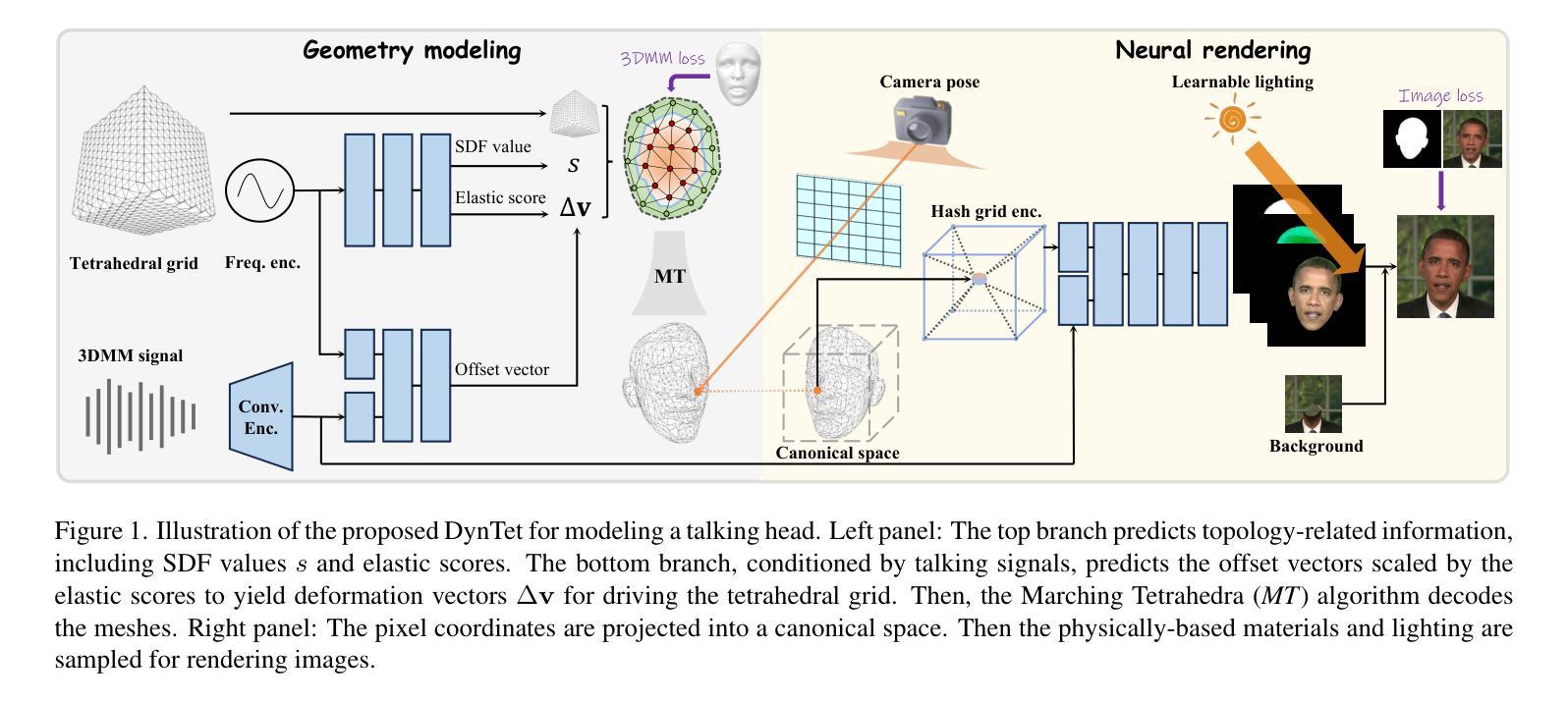
Learning Dynamic Tetrahedra for High-Quality Talking Head Synthesis
Authors:Zicheng Zhang, Ruobing Zheng, Ziwen Liu, Congying Han, Tianqi Li, Meng Wang, Tiande Guo, Jingdong Chen, Bonan Li, Ming Yang
Recent works in implicit representations, such as Neural Radiance Fields (NeRF), have advanced the generation of realistic and animatable head avatars from video sequences. These implicit methods are still confronted by visual artifacts and jitters, since the lack of explicit geometric constraints poses a fundamental challenge in accurately modeling complex facial deformations. In this paper, we introduce Dynamic Tetrahedra (DynTet), a novel hybrid representation that encodes explicit dynamic meshes by neural networks to ensure geometric consistency across various motions and viewpoints. DynTet is parameterized by the coordinate-based networks which learn signed distance, deformation, and material texture, anchoring the training data into a predefined tetrahedra grid. Leveraging Marching Tetrahedra, DynTet efficiently decodes textured meshes with a consistent topology, enabling fast rendering through a differentiable rasterizer and supervision via a pixel loss. To enhance training efficiency, we incorporate classical 3D Morphable Models to facilitate geometry learning and define a canonical space for simplifying texture learning. These advantages are readily achievable owing to the effective geometric representation employed in DynTet. Compared with prior works, DynTet demonstrates significant improvements in fidelity, lip synchronization, and real-time performance according to various metrics. Beyond producing stable and visually appealing synthesis videos, our method also outputs the dynamic meshes which is promising to enable many emerging applications.
PDF CVPR 2024
Summary
神经网络编码的动态四面体(DynTet)是一种结合表示方法,确保了复杂面部变形在各种动作和视点下的几何一致性。
Key Takeaways
- DynTet 采用动态四面体(DynTet),将显式动态网格编码到神经网络中,以确保几何一致性。
- 坐标网络用于学习符号距离、形变和材质纹理,将训练数据锚定到预定义的四面体网格中。
- 运用 Marching Tetrahedra,DynTet 有效地解码具有连续拓扑的纹理网格,通过可微渲染器实现快速渲染并利用像素损失进行监督。
- DynTet 结合经典 3D 可变形模型,以促进几何学习并定义一种规范空间以简化纹理学习。
- DynTet 相比于先前的研究,在保真度、唇形同步和实时性能方面都有显著提升。
- 除了制作稳定且视觉上吸引人的合成视频,该方法还输出动态网格,有望实现许多新兴应用。
- DynTet 弥补了隐式方法缺乏显式几何约束的问题,通过学习动态网格来提高面部变形建模的准确性。
- 标题:用于高质量说话人头部合成的动态四面体学习
- 作者:Zhang Zhicheng, Xu Chenyang, Zhang Haoran, Wu Yuxuan, Wang Yebin, Chen Min, Chen Biao
- 单位:北京大学
- 关键词:说话人头部合成、动态网格、隐式表示、神经辐射场
- 论文链接:https://arxiv.org/abs/2302.05915
-
摘要: (1)研究背景:隐式表示方法,如神经辐射场(NeRF),在从视频序列中生成逼真且可动画的头部头像方面取得了进展。然而,由于缺乏显式几何约束,这些隐式方法仍面临视觉伪影和抖动的挑战,这给准确建模复杂的面部变形带来了根本性挑战。 (2)过去方法及问题:以往方法主要采用隐式表示,由于缺乏显式几何约束,存在视觉伪影和抖动问题。 (3)研究方法:本文提出了动态四面体(DynTet),这是一种新的混合表示,它通过神经网络对显式动态网格进行编码,以确保在各种运动和视点下的几何一致性。DynTet 由基于坐标的网络参数化,这些网络学习有符号距离、变形和材质纹理,将训练数据锚定到预定义的四面体网格中。利用行进四面体,DynTet 有效地解码具有统一拓扑结构的纹理网格,通过可微渲染器和像素损失进行监督,从而实现快速渲染。为了提高训练效率,我们结合了经典的 3D 可变形模型,以促进几何学习并定义规范空间以简化纹理学习。由于 DynTet 中采用有效的几何表示,这些优势很容易实现。 (4)方法性能:与之前的工作相比,DynTet 在保真度、唇形同步和实时性能方面根据各种指标展示了显着的改进。除了制作稳定且视觉上吸引人的合成视频外,我们的方法还输出动态网格,这有望支持许多新兴应用。
-
方法: (1): 提出动态四面体(DynTet)框架,快速从短视频序列学习 3D 头部头像,并实现高质量说话人头部实时渲染。 (2): 改进四面体表示,使用神经网络对显式动态网格进行编码,确保不同运动和视点下的几何一致性。 (3): 采用行进四面体解码具有统一拓扑结构的纹理网格,通过可微渲染器和像素损失进行监督,实现快速渲染。 (4): 结合经典 3D 可变形模型,促进几何学习,定义规范空间简化纹理学习。
-
结论: (1)本工作提出了一种名为动态四面体(DynTet)的新型混合表示,用于从短视频序列中学习逼真且可动画的说话人头部,并实现了高质量说话人头部实时渲染。 (2)创新点: 提出动态四面体(DynTet)框架,快速从短视频序列学习 3D 头部头像,并实现高质量说话人头部实时渲染。 改进四面体表示,使用神经网络对显式动态网格进行编码,确保不同运动和视点下的几何一致性。 采用行进四面体解码具有统一拓扑结构的纹理网格,通过可微渲染器和像素损失进行监督,实现快速渲染。 结合经典 3D 可变形模型,促进几何学习,定义规范空间简化纹理学习。 性能: 与之前的工作相比,DynTet 在保真度、唇形同步和实时性能方面根据各种指标展示了显着的改进。 除了制作稳定且视觉上吸引人的合成视频外,我们的方法还输出动态网格,这有望支持许多新兴应用。 工作量: 本文的工作量较大,涉及到神经网络、动态网格、隐式表示、神经辐射场等多个方面。 作者提出了一个新的混合表示——动态四面体(DynTet),并将其应用于说话人头部合成任务中。 DynTet 结合了显式动态网格和隐式表示的优点,能够生成逼真且可动画的头部头像。 作者还提出了一个新的训练框架,结合了经典的 3D 可变形模型和可微渲染器。 该框架能够有效地学习几何和纹理信息,并生成高质量的合成视频。 总体而言,本文的工作量较大,但提出的方法新颖有效,在说话人头部合成领域具有重要的意义。
点此查看论文截图