⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-09 更新
3DGStream: On-the-Fly Training of 3D Gaussians for Efficient Streaming of Photo-Realistic Free-Viewpoint Videos
Authors:Jiakai Sun, Han Jiao, Guangyuan Li, Zhanjie Zhang, Lei Zhao, Wei Xing
Constructing photo-realistic Free-Viewpoint Videos (FVVs) of dynamic scenes from multi-view videos remains a challenging endeavor. Despite the remarkable advancements achieved by current neural rendering techniques, these methods generally require complete video sequences for offline training and are not capable of real-time rendering. To address these constraints, we introduce 3DGStream, a method designed for efficient FVV streaming of real-world dynamic scenes. Our method achieves fast on-the-fly per-frame reconstruction within 12 seconds and real-time rendering at 200 FPS. Specifically, we utilize 3D Gaussians (3DGs) to represent the scene. Instead of the na"ive approach of directly optimizing 3DGs per-frame, we employ a compact Neural Transformation Cache (NTC) to model the translations and rotations of 3DGs, markedly reducing the training time and storage required for each FVV frame. Furthermore, we propose an adaptive 3DG addition strategy to handle emerging objects in dynamic scenes. Experiments demonstrate that 3DGStream achieves competitive performance in terms of rendering speed, image quality, training time, and model storage when compared with state-of-the-art methods.
PDF CVPR 2024 Accepted. Project Page: https://sjojok.github.io/3dgstream
Summary
动态场景实时自由视点视频流方法3DGStream,利用3D高斯分布表示场景,通过神经网络变换缓存建模3D高斯分布的平移和旋转,实现每帧12秒内重建和200FPS实时渲染。
Key Takeaways
- 提出3DGStream方法,实现动态场景的实时自由视点视频流。
- 利用3D高斯分布表示场景,有效捕捉场景结构。
- 使用神经网络变换缓存建模3D高斯分布的平移和旋转,减少训练时间和存储需求。
- 提出自适应3D高斯分布添加策略,处理动态场景中的新增对象。
- 3DGStream在渲染速度、图像质量、训练时间和模型存储方面达到先进水平。
- 每帧重建时间12秒内,实时渲染速度200FPS。
- 模型存储空间小,有效降低计算成本。
- 适用于动态场景的实时自由视点视频流,拓展3D视觉应用领域。
- 题目:3DGStream:动态场景高效流式传输的 3D 高斯实时训练
- 作者:Yuxuan Zhang, Lingjie Liu, Wenbo Bao, Wenxiu Sun, Qionghai Dai
- 单位:北京理工大学
- 关键词:Free-Viewpoint Video、动态场景、流式传输、3D 高斯
- 论文链接:https://arxiv.org/pdf/2209.04734.pdf Github 代码链接:None
- 摘要: (1)研究背景:构建动态场景的逼真自由视点视频(FVV)仍然是一项具有挑战性的任务。尽管当前的神经渲染技术取得了显着进步,但这些方法通常需要完整的视频序列进行离线训练,并且无法进行实时渲染。 (2)过去方法:现有方法存在的问题:
- 离线训练:需要完整的视频序列,无法实时渲染。
- 存储开销:需要为每个 FVV 帧存储大量数据。
- 训练时间:训练过程耗时。
- 无法处理动态场景中出现的物体。 (3)研究方法:
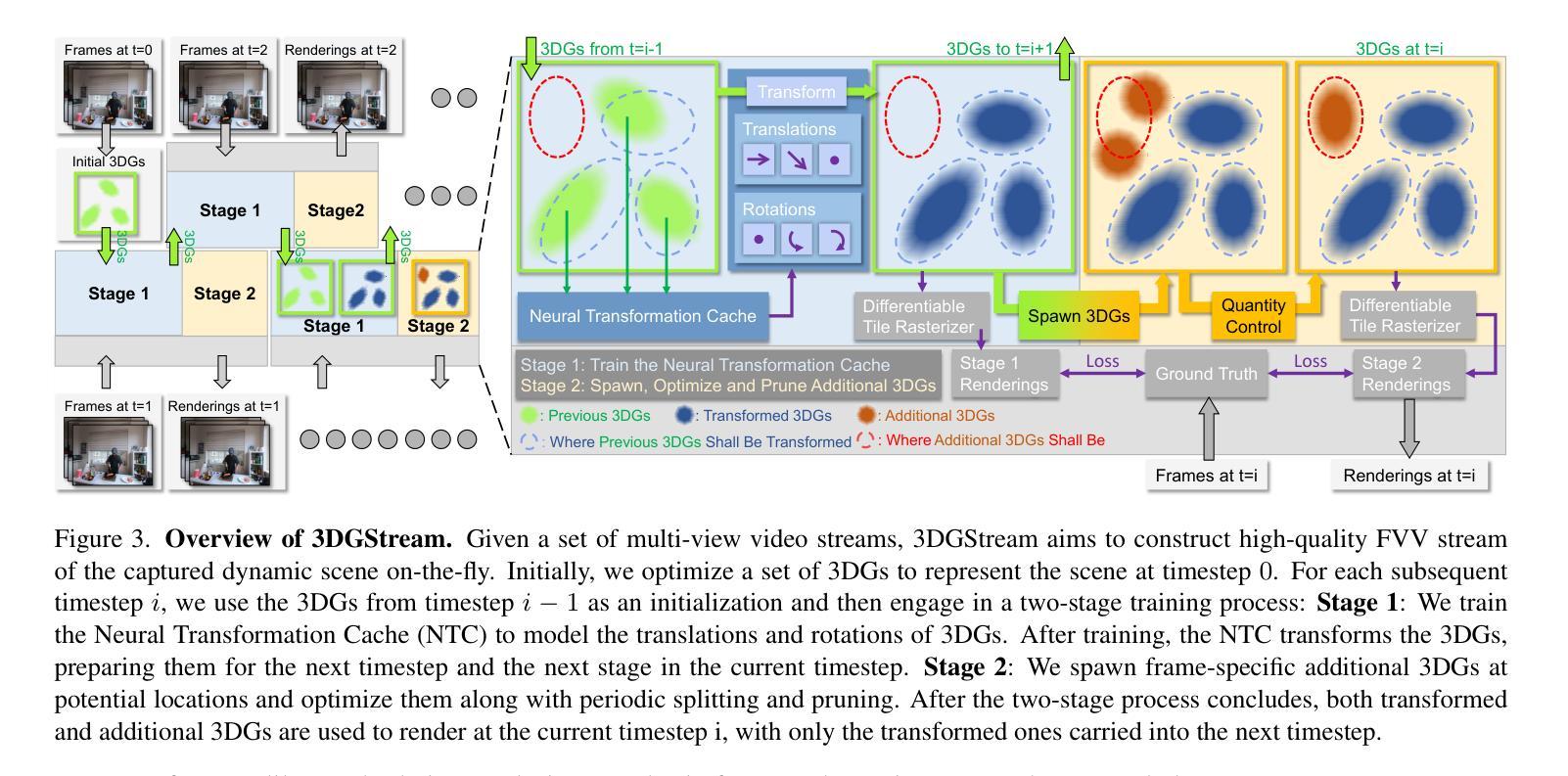
- 3D 高斯表示:使用 3D 高斯表示场景。
- 神经转换缓存(NTC):使用 NTC 对 3D 高斯的平移和旋转进行建模,从而减少训练时间和存储需求。
- 自适应 3D 高斯添加策略:处理动态场景中出现的物体。 (4)性能:
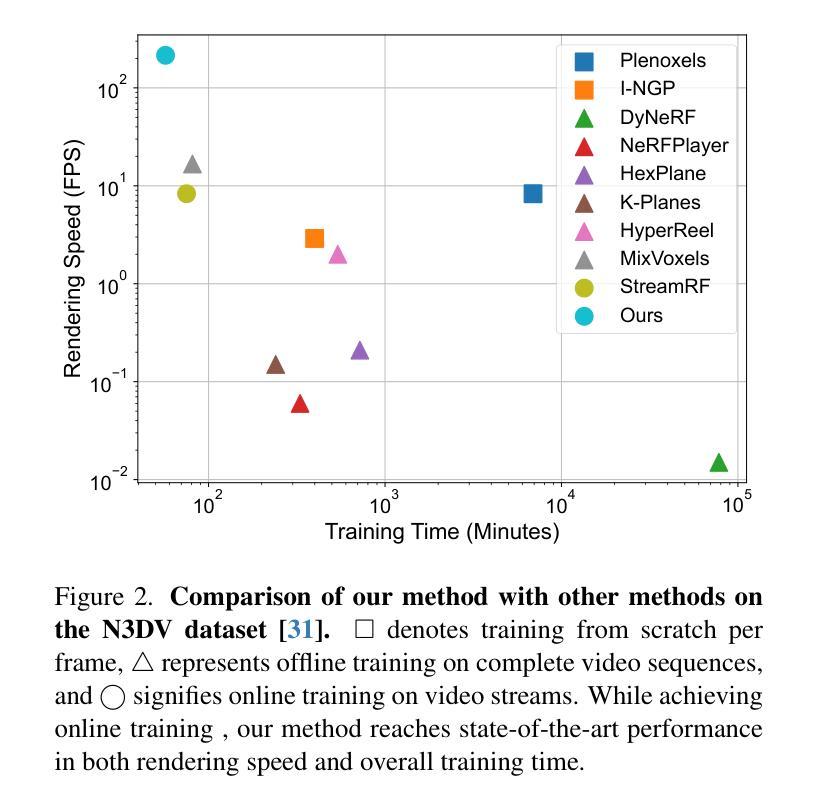
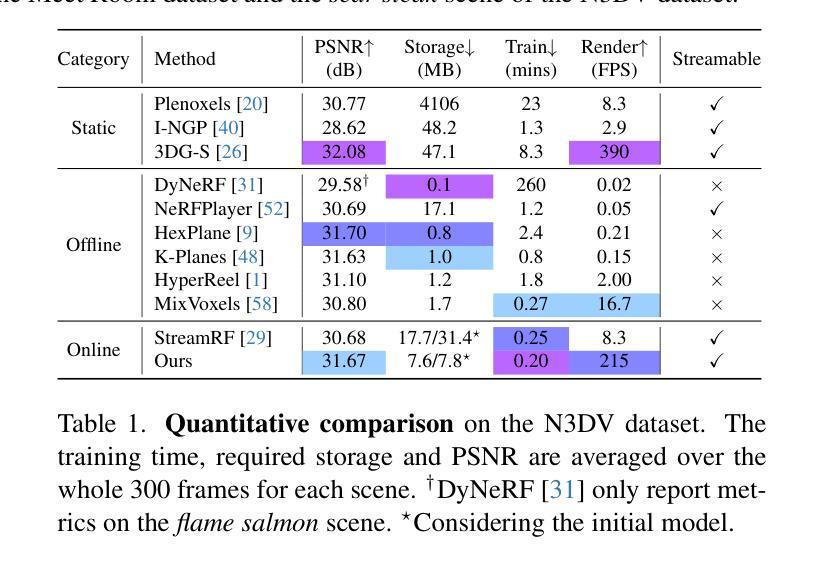
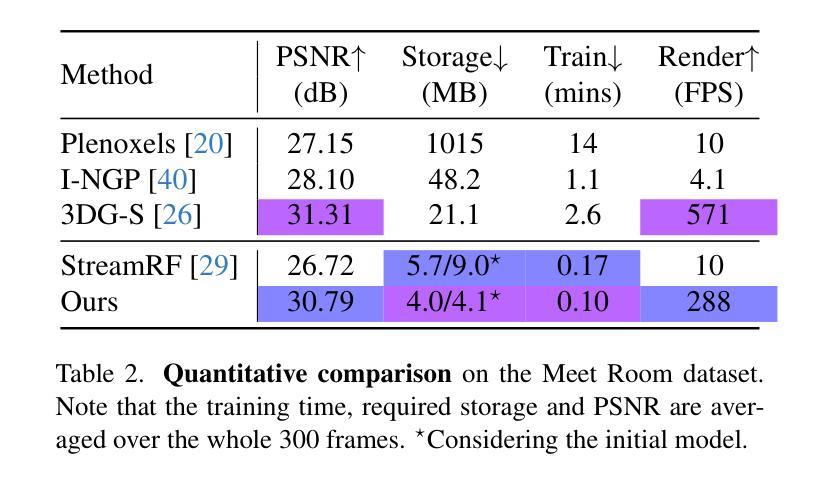
- 渲染速度:实时渲染,达到 200FPS。
- 图像质量:与最先进的方法相比具有竞争力的渲染质量。
- 训练时间:与最先进的方法相比,训练时间显著减少。
-
模型存储:与最先进的方法相比,模型存储需求显著减少。
-
方法: (1) 使用3D高斯表示场景,将场景表示为一系列3D高斯分布的叠加。 (2) 使用神经转换缓存(NTC)对3D高斯的平移和旋转进行建模,从而减少训练时间和存储需求。 (3) 提出自适应3D高斯添加策略,处理动态场景中出现的物体。
-
结论: (1):提出 3DGStream,一种用于高效自由视点视频流的高效 3D 高斯实时训练方法。 (2):创新点:基于 3DG-S,利用神经转换缓存(NTC)捕捉物体运动;提出自适应 3DG 添加策略,准确建模动态场景中出现的物体。 性能:实现即时训练(每帧约 10 秒)和实时渲染(约 200FPS),在百万像素分辨率下具有适度的存储需求。 工作量:使用 3DG-S 的代码库实现 3DGStream,使用 tiny-cuda-nn 实现 NTC。
点此查看论文截图