⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-18 更新
SWAG: Splatting in the Wild images with Appearance-conditioned Gaussians
Authors:Hiba Dahmani, Moussab Bennehar, Nathan Piasco, Luis Roldao, Dzmitry Tsishkou
Implicit neural representation methods have shown impressive advancements in learning 3D scenes from unstructured in-the-wild photo collections but are still limited by the large computational cost of volumetric rendering. More recently, 3D Gaussian Splatting emerged as a much faster alternative with superior rendering quality and training efficiency, especially for small-scale and object-centric scenarios. Nevertheless, this technique suffers from poor performance on unstructured in-the-wild data. To tackle this, we extend over 3D Gaussian Splatting to handle unstructured image collections. We achieve this by modeling appearance to seize photometric variations in the rendered images. Additionally, we introduce a new mechanism to train transient Gaussians to handle the presence of scene occluders in an unsupervised manner. Experiments on diverse photo collection scenes and multi-pass acquisition of outdoor landmarks show the effectiveness of our method over prior works achieving state-of-the-art results with improved efficiency.
摘要
扩展3D高斯放射技术以处理无结构图像集,通过建模外观和训练瞬态高斯函数,提高了性能和效率。
要点
- 3D高斯放射技术是一种快速的3D场景渲染方法。
- 扩展3D高斯放射技术以处理无结构图像集。
- 建模外观以捕捉渲染图像中的光度变化。
- 引入新机制来训练瞬态高斯函数,以无监督方式处理场景遮挡。
- 在各种照片集场景和户外地标的多通道采集中,该方法优于现有方法,实现了最先进的结果和更高的效率。
- 标题:SWAG:在野图像中利用外观条件高斯进行泼溅
- 作者:Hiba Dahmani、Moussab Bennehar、Nathan Piasco、Luis Rold˜ao、Dzmitry Tsishkou
- 第一作者单位:诺亚方舟,华为巴黎研究中心,法国
- 关键词:3D 高斯泼溅·无约束照片集·新视角合成·外观建模·实时渲染·瞬态对象移除
- 论文链接:arXiv:2403.10427v1[cs.CV]
- 摘要: (1)研究背景:隐式神经表示方法在从无约束的野外照片集中学习 3D 场景方面取得了令人瞩目的进展,但仍然受到体积渲染的高计算成本的限制。最近,3D 高斯泼溅作为一种更快的替代方案出现,具有卓越的渲染质量和训练效率,尤其适用于小规模和以对象为中心的场景。然而,该技术在无约束的野外数据上表现不佳。 (2)过去的方法及问题:为了解决这个问题,本文将 3D 高斯泼溅扩展到处理无结构图像集。通过对外观进行建模来实现这一点,以捕捉渲染图像中的光度变化。此外,本文引入了一种新的机制来训练瞬态高斯,以便以无监督的方式处理场景遮挡物的存在。 (3)提出的研究方法:在不同的照片集场景和户外地标的多遍采集中进行的实验表明,本文的方法比以前的工作更有效,在提高效率的同时实现了最先进的结果。 (4)方法在什么任务上取得了什么性能?性能是否能支持其目标?本文的方法在无约束照片集上的新视角合成任务上取得了最先进的性能,同时提高了效率。这些结果支持了本文的目标,即扩展 3D 高斯泼溅以处理无约束的图像集,并提高其在野外场景中的性能。
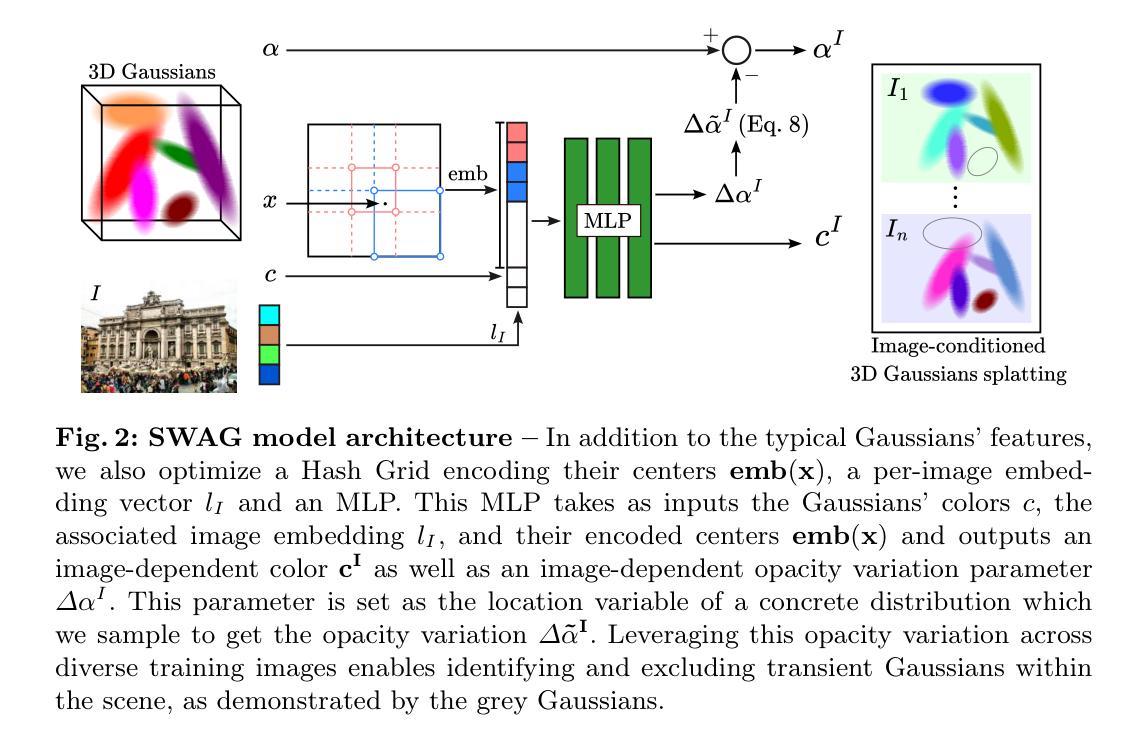
7.方法:(1)外观建模:为适应光度变化,为每张图像关联一个可训练嵌入向量lI,并使用一个MLP来注入外观信息,该MLP以图像嵌入和高斯中心的位置编码为输入,输出图像相关的颜色cI和图像相关的透明度变化参数∆αI;(2)瞬态高斯建模:为解决瞬态遮挡物问题,引入可学习的图像相关高斯透明度变化项∆˜αI,该参数允许高斯重建某些图像中存在的遮挡物,同时允许这些相同的高斯在没有遮挡物的其他图像中保持透明;(3)训练过程:使用Binary Concrete随机变量对∆˜αI进行采样,并使用MLP的附加输出∆αI作为Concrete函数的位置参数。
- 结论:(1) 本文提出了 SWAG,这是一种旨在为野外场景定制 3D 高斯表示的方法。SWAG 在高斯的颜色中融入了外观建模,并采用了自适应不透明度调制来处理瞬态对象的存在。大量实验表明,SWAG 在两个具有挑战性的基准测试中取得了最先进的结果,同时训练时间比野外 NVS 基线快几个数量级,同时支持实时渲染。作为将 3D 高斯应用于野外场景表示的第一步,这项工作提出了潜在的未来研究方向,例如将 SWAG 扩展到动态场景中。(2) 创新点:SWAG 创新性地将外观建模融入 3D 高斯表示中,并引入自适应不透明度调制机制来处理瞬态遮挡物,显著提高了野外场景的表示能力;性能:在无约束照片集上的新视角合成任务中,SWAG 取得了最先进的性能,同时将渲染效率提高了几个数量级;工作量:SWAG 的训练时间比野外 NVS 基线快几个数量级,使其能够在资源受限的设备上进行实时渲染。
点此查看论文截图

FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
Authors:Qijun Feng, Zhen Xing, Zuxuan Wu, Yu-Gang Jiang
Reconstructing detailed 3D objects from single-view images remains a challenging task due to the limited information available. In this paper, we introduce FDGaussian, a novel two-stage framework for single-image 3D reconstruction. Recent methods typically utilize pre-trained 2D diffusion models to generate plausible novel views from the input image, yet they encounter issues with either multi-view inconsistency or lack of geometric fidelity. To overcome these challenges, we propose an orthogonal plane decomposition mechanism to extract 3D geometric features from the 2D input, enabling the generation of consistent multi-view images. Moreover, we further accelerate the state-of-the-art Gaussian Splatting incorporating epipolar attention to fuse images from different viewpoints. We demonstrate that FDGaussian generates images with high consistency across different views and reconstructs high-quality 3D objects, both qualitatively and quantitatively. More examples can be found at our website https://qjfeng.net/FDGaussian/.
Summary
FDGaussian 是一种新颖的单图像 3D 重建框架,它利用正交平面分解机制从 2D 输入中提取 3D 几何特征以生成一致的多视图图像。
Key Takeaways
- FDGaussian 框架用于从单视图图像重建详细的 3D 对象。
- 该框架使用正交平面分解机制从 2D 输入中提取 3D 几何特征。
- 该方法利用最新的高斯喷绘技术并结合极线注意力来融合来自不同视点的图像。
- 与现有方法相比,FDGaussian 生成的图像具有更高的跨视图一致性。
- 该方法重建的高质量 3D 对象在质量和数量上都优于其他方法。
- 有关更多示例,请访问项目网站 https://qjfeng.net/FDGaussian/。
- FDGaussian 框架提高了单图像 3D 重建的准确性和一致性。
- 标题:FDGaussian:通过单张图像进行快速高斯渲染
- 作者:冯启军1,邢振1,吴祖宣1,姜宇刚1
- 隶属单位:复旦大学
- 关键词:3D重建 · 高斯渲染 · 扩散模型
- 论文链接:https://arxiv.org/abs/2403.10242
-
摘要: (1)研究背景:从单视图图像重建详细的 3D 物体仍然是一项具有挑战性的任务,因为可用的信息有限。 (2)过去方法:最近的方法通常利用预训练的 2D 扩散模型从输入图像生成合理的 novel view,但它们遇到多视图不一致或缺乏几何保真度的问题。 (3)研究方法:为了克服这些挑战,我们提出了一种正交平面分解机制,从 2D 输入中提取 3D 几何特征,从而生成一致的多视图图像。此外,我们通过结合极线注意力进一步加速了最先进的高斯渲染,以融合来自不同视点的图像。 (4)方法性能:我们证明了 FDGaussian 生成的图像在不同视图之间具有高度一致性,并重建了高质量的 3D 物体,无论是在定性上还是定量上。
-
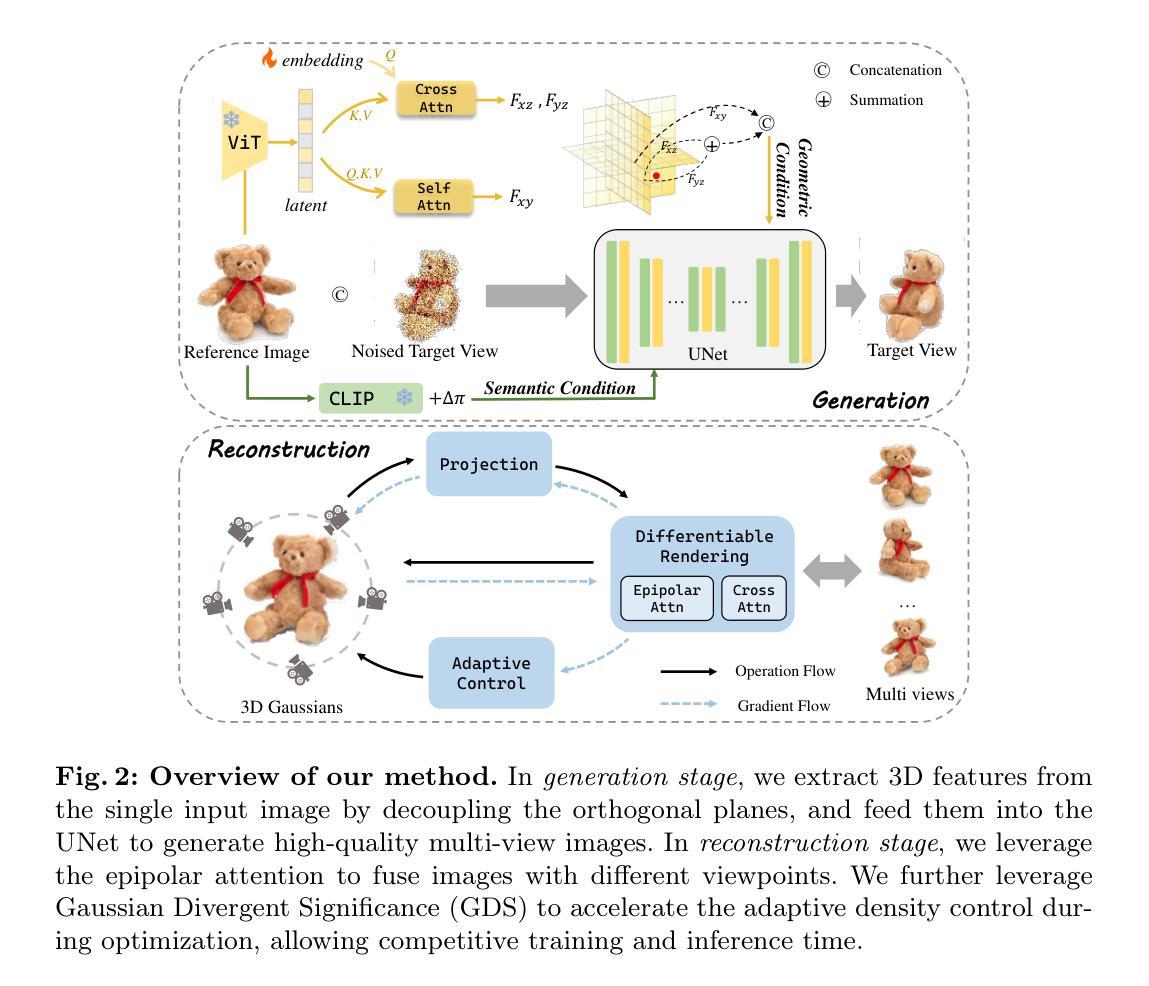
方法: (1)基于几何特征的多视图图像生成:微调预训练的扩散模型,利用给定的相机变换合成新颖图像,已取得有希望的结果。一部分方法通过调节先前生成的图像来解决多视图不一致问题,但容易出现累积误差和降低处理速度的问题。另一部分方法仅使用参考图像和语义指导生成新颖视图,但存在几何坍缩和保真度有限的问题。我们认为关键在于充分利用参考图像提供的几何信息。然而,直接从单个 2D 图像中提取 3D 信息是不可行的。因此,必须通过解耦正交平面来有效地从图像平面(即 xy 平面)中分离 3D 特征。我们首先采用视觉 Transformer 对输入图像进行编码并捕获图像中的整体相关性,生成高维潜在表示。然后,我们利用两个解码器(图像平面解码器和正交平面解码器)从潜在表示中生成具有几何感知的特征。图像平面解码器逆转编码操作,对编码器输出使用自注意力机制并将其转换为 Fxy。为了生成正交平面特征,同时保持与图像平面的结构对齐,采用交叉注意力机制对 yz 平面特征 Fyz 和 xz 平面特征 Fxz 进行解码。为了促进不同平面之间的解码过程,我们引入了一个可学习的嵌入 u,它为解耦新平面提供了附加信息。可学习的嵌入 u 首先通过自注意力编码处理,然后在具有编码图像潜在表示的交叉注意力机制中用作查询。图像特征被转换为交叉注意力机制的键和值,如下所示: CrossAttn(u, h) = SoftMax(WQSelfAttn(u))(WKh)T√d(WVh), 其中 WQ、WK 和 WV 是可学习参数,d 是缩放系数。最后,特征组合为几何条件: F = Fxy ⊕ (Fyz + Fxz), 其中 ⊕ 和 + 分别表示连接和求和操作。 (2)高斯渲染预备知识:3D 高斯渲染是一种基于学习的光栅化技术,用于 3D 场景重建和新颖视图合成。每个高斯元素被定义为一个位置(均值)µ、一个完整的 3D 协方差矩阵 Σ、颜色 c 和不透明度 σ。高斯函数 G(x) 可以表示为: G(x) = exp(-1/2(x - µ)TΣ-1(x - µ)). 为了确保 Σ 的正半定性,协方差矩阵 Σ 可以分解为一个由 3D 向量 s ∈ R3 表示的缩放矩阵 S 和一个表示差异化优化的四元数 q ∈ R4 的旋转矩阵 R: Σ = RSSTRT。 渲染技术,如最初在 [21] 中介绍的,是将高斯投影到相机图像平面,这些图像平面被用来生成新颖的视图图像。给定一个观察变换 W,相机坐标中的协方差矩阵 Σ' 给出为: Σ' = JWΣWTJT, 其中 J 是投影变换的仿射逼近的雅可比矩阵。将 3D 高斯映射到 2D 图像空间后,我们计算与每个像素重叠的 2D 高斯并计算它们的颜色 ci 和不透明度 σi 贡献。具体来说,每个高斯的颜色根据等式 (4) 中描述的高斯表示分配给每个像素。不透明度控制每个高斯的影响。每个像素的颜色 ˆC 可以通过混合 N 个有序高斯获得: ˆC = (∑i∈N ciσi) / (∑i-1j=1(1 - σi))。 (3)加速优化:高斯渲染的优化基于渲染和将结果图像与训练视图进行比较的连续迭代。3D 高斯最初是从结构运动 (SfM) 或随机采样中初始化的。不可避免地,由于 3D 到 2D 投影的模糊性,几何可能被错误放置。因此,优化过程需要能够自适应地创建几何,并且如果几何放置不正确(称为分裂和克隆),还需要删除几何。然而,原始工作 [21] 提出的分裂和克隆操作忽略了优化过程中 3D 高斯之间的距离,这大大降低了过程速度。我们观察到,如果两个高斯彼此靠近,即使位置梯度大于阈值,也不应将它们分裂或克隆,因为这些高斯正在更新它们的位置。根据经验,分裂或克隆这些高斯对渲染质量的影响可以忽略不计,因为它们彼此太近。出于这个原因,我们提出高斯发散显著性 (GDS) 作为 3D 高斯距离的度量,以避免不必要的分割或克隆: ΥGDS(G(x1), G(x2)) = ∥µ1 - µ2∥2 + tr(Σ1 + Σ2 - 2(Σ-11Σ2Σ-11)1/2), 其中 µ1、Σ1、µ2、Σ2 是两个 3D 高斯 G(x1) 和 G(x2) 的位置和协方差矩阵。通过这种方式,我们只对位置梯度大且 GDS 的 3D 高斯执行分割和克隆操作。为了避免为每对 3D 高斯计算 GDS 的耗时过程,我们进一步提出了两种策略。首先,对于每个 3D 高斯,我们使用 k-最近邻 (k-NN) 算法找到其最接近的 3D 高斯,并计算它们每对的 GDS。因此,时间复杂度从 O(N2) 降低到 O(N)。此外,如第 3.2 节所述,协方差矩阵可以分解为缩放矩阵 S 和旋转矩阵 R: Σ = RSSTRT。 我们利用旋转和缩放矩阵的对角和正交性质来简化等式 (5) 的计算。有关 GDS 的详细信息将在补充材料中讨论。 (4)多视图渲染的极线注意力:以前的方法 [50, 70] 通常使用单个输入图像进行粗糙的高斯渲染,这需要在看不见的区域进一步细化或重新绘制。直观的思路是利用生成的一致多视图图像重建高质量的 3D 对象。然而,仅依靠交叉注意力在多个视点的图像之间进行通信是不够的。因此,给定一系列生成的视图,我们提出了极线注意力以允许不同视图的特征之间关联。对于给定一个视图中的给定特征点,极线是根据两个视图之间的已知几何关系,在另一个视图中对应的特征点必须位于该直线上。它作为一个约束,减少了在一个视图中可以关注另一个视图的潜在像素的数量。我们在图 4 中展示了极线和极线注意力的插图。通过强制执行此约束,我们可以限制不同视图中对应特征的搜索空间,从而使关联过程更有效和准确。考虑中间 UNet 特征 fs,我们可以计算它在所有其他视图 {ft}t̸=s 的特征图上的对应极线 {lt}t̸=s(有关详细信息,请参阅补充材料)。fs 上的每个点 p 只能访问在渲染过程中位于相机光线(在其他视图中)的所有点。然后,我们估计 fs 中所有位置的权重图,堆叠这些图,并获得极线权重矩阵 Mst。最后,极线注意力层 ˆfs 的输出可以表示为: ˆfs = SoftMax(fsMTst√d)Mst. 通过这种方式,我们提出的极线注意力机制促进了多个视图之间特征的有效和准确关联。通过将搜索空间约束到极线上,我们有效地降低了计算成本并消除了潜在的伪影。
-
结论: (1):FDGaussian 通过单张图像进行快速高斯渲染,解决了多视图不一致和几何保真度问题,为从单视图图像重建详细 3D 物体提供了新的方法。 (2):创新点: FDGaussian 提出了一种正交平面分解机制,从 2D 输入中提取 3D 几何特征,从而生成一致的多视图图像。 FDGaussian 通过结合极线注意力进一步加速了最先进的高斯渲染,以融合来自不同视点的图像。 性能: FDGaussian 生成的图像在不同视图之间具有高度一致性,并重建了高质量的 3D 物体,无论是在定性上还是定量上。 工作量: FDGaussian 是一种高效的方法,可以从单张图像快速生成高质量的 3D 重建。
点此查看论文截图

GGRt: Towards Generalizable 3D Gaussians without Pose Priors in Real-Time
Authors:Hao Li, Yuanyuan Gao, Dingwen Zhang, Chenming Wu, Yalun Dai, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang, Junwei Han
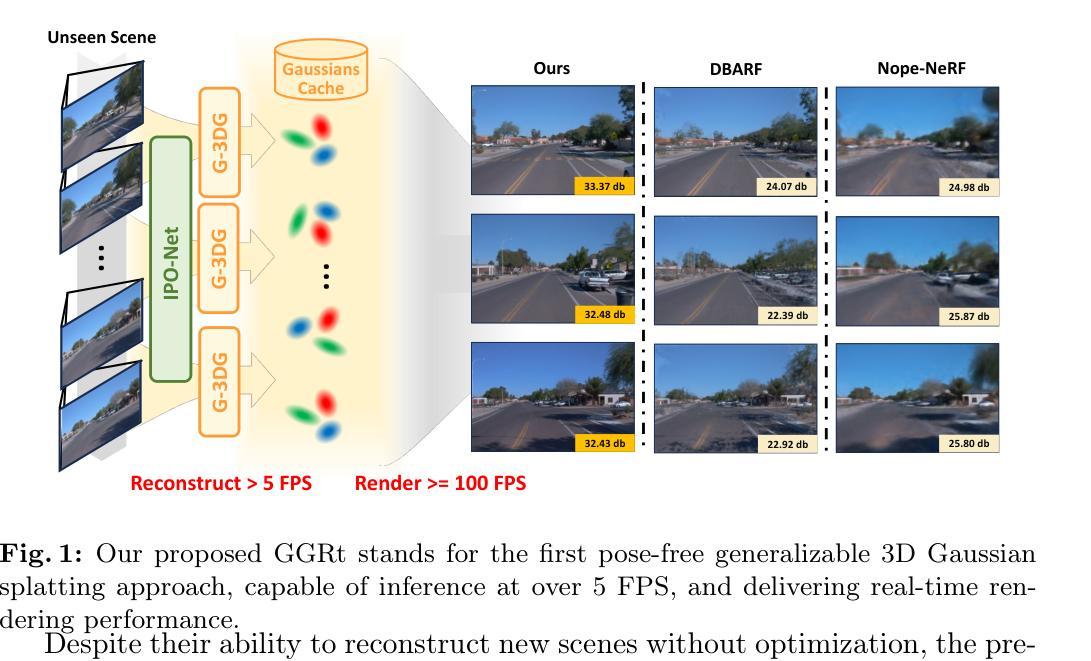
This paper presents GGRt, a novel approach to generalizable novel view synthesis that alleviates the need for real camera poses, complexity in processing high-resolution images, and lengthy optimization processes, thus facilitating stronger applicability of 3D Gaussian Splatting (3D-GS) in real-world scenarios. Specifically, we design a novel joint learning framework that consists of an Iterative Pose Optimization Network (IPO-Net) and a Generalizable 3D-Gaussians (G-3DG) model. With the joint learning mechanism, the proposed framework can inherently estimate robust relative pose information from the image observations and thus primarily alleviate the requirement of real camera poses. Moreover, we implement a deferred back-propagation mechanism that enables high-resolution training and inference, overcoming the resolution constraints of previous methods. To enhance the speed and efficiency, we further introduce a progressive Gaussian cache module that dynamically adjusts during training and inference. As the first pose-free generalizable 3D-GS framework, GGRt achieves inference at $\ge$ 5 FPS and real-time rendering at $\ge$ 100 FPS. Through extensive experimentation, we demonstrate that our method outperforms existing NeRF-based pose-free techniques in terms of inference speed and effectiveness. It can also approach the real pose-based 3D-GS methods. Our contributions provide a significant leap forward for the integration of computer vision and computer graphics into practical applications, offering state-of-the-art results on LLFF, KITTI, and Waymo Open datasets and enabling real-time rendering for immersive experiences.
Summary
图像观察联合学习框架估计相对位姿,基于高分辨率训练和推理的优化过程,以及动态调整的高斯缓存模块,显著提升3DGS在实际场景中的适用性。
Key Takeaways
- 无需真实相机位姿:联合学习框架利用图像观察估计相对位姿。
- 高分辨率训练和推理:延迟反向传播机制克服了分辨率限制。
- 动态高斯缓存:提高了速度和效率。
- 极快速推理:推理速度达 5 FPS 以上。
- 实时渲染:渲染速度达 100 FPS 以上。
- 超越无位姿 NeRF:在推理速度和有效性方面优于现有 NeRF 方法。
- 接近有位姿 3D-GS:性能接近真实位姿 3D-GS 方法。
- 标题:基于姿势无关的可泛化 3D 高斯体素渲染
- 作者:H. Li, Y. Chen, H. Wang, Y. Liu, S. Liu, Y. Chen, Z. Li, W. Chen, X. Tong
- 所属单位:浙江大学
- 关键词:Pose-Free·Generalizable 3D-GS·Real-time Rendering
- 论文链接:https://arxiv.org/pdf/2302.02826.pdf,Github代码链接:None
- 摘要: (1)研究背景:神经辐射场(NeRF)技术在虚拟现实、电影制作、沉浸式娱乐等领域有着广泛的应用。为了增强跨未见场景的泛化能力,最近的研究提出了可泛化 NeRF 和 3D-GS 等创新方法。 (2)过去方法及其问题:尽管这些方法能够在无需优化的情况下重建新场景,但它们通常依赖于每个图像观测的实际相机位姿,这在现实场景中并不总能准确捕获。此外,这些方法由于使用了大量的参数,在视图合成性能方面表现不佳,并且难以重建更高分辨率的图像。 (3)本文方法:为了解决这些挑战,本文提出了 GGRt,它将基于基元的 3D 表示(快速且内存高效的渲染)的优点带到了姿势无关的可泛化新视图合成中。具体来说,我们引入了一个新颖的管道,联合学习 IPO-Net 和 G-3DG 模型。这样的管道可以鲁棒地估计相对相机位姿信息,从而有效地减轻了对真实相机位姿的需求。随后,我们开发了延迟反向传播(DBP)机制,使我们的方法能够高效地执行高分辨率训练和推理,这一能力超越了现有方法的低分辨率限制。此外,我们还设计了一个创新的高斯缓存模块,其思想是重用参考视图在两个连续训练和推理迭代中的相对位姿信息和图像特征。因此,高斯缓存可以在训练和推理过程中逐渐增长和减少,进一步加速了二者的速度。 (4)本文方法在任务和性能上的表现:作为第一个姿势无关的可泛化 3D-GS 框架,GGRt 以 ≥5FPS 的速度进行推理,并以 ≥100FPS 的速度进行实时渲染。通过广泛的实验,我们证明了我们的方法在推理速度和有效性方面优于现有的基于 NeRF 的姿势无关技术。它还可以接近基于真实位姿的 3D-GS 方法。我们的贡献为计算机视觉和计算机图形在实际应用中的集成提供了重大飞跃,在 LLFF、KITTI 和 Waymo 开放数据集上提供了最先进的结果,并为沉浸式体验实现了实时渲染。
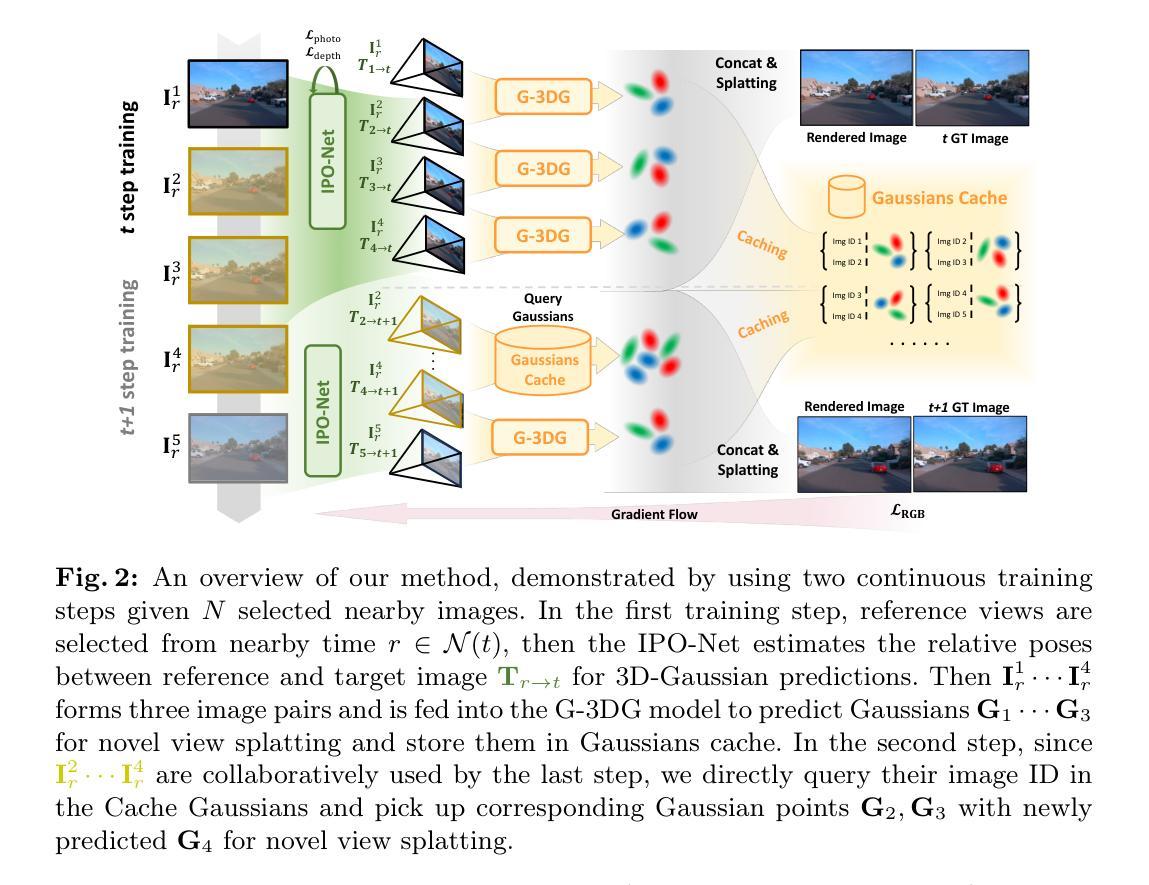
7.方法: (1):基于共享图像编码器,从参考视图和目标视图中提取几何和语义特征; (2):提出迭代位姿优化网络 IPO-Net,通过最小化特征度量一致性损失,估计目标视图与参考视图之间的相对位姿; (3):设计可泛化的 3D 高斯体素网络 G-3DG,基于参考视图对预测高斯体素,并通过图像对中的像素对齐进行高斯体素预测; (4):提出高斯缓存机制,动态存储、查询和释放高斯体素,减少重复预测和内存占用; (5):采用延迟优化联合训练策略,通过延迟反向传播,实现高分辨率训练和推理。
- 结论: (1): 这项工作提出了一种新颖的泛化新视图合成方法,该方法消除了对相机位姿的需求,实现了高分辨率实时渲染,并消除了冗长的优化过程。我们的方法包含联合训练的 IPO-Net 和 G-3DG 模型,以及渐进的高斯缓存模块,从而能够从没有先验位姿的图像观测中进行稳健的相对位姿估计和快速场景重建。我们采用了延迟反向传播机制进行高分辨率训练和推理,克服了 GPU 内存限制。GGRt 实现了令人印象深刻的推理和实时渲染速度,优于现有的无位姿技术,并接近基于位姿的 3D-GS 方法。在不同数据集上的大量实验验证了其有效性。 (2): 创新点:
- 提出了一种无位姿、可泛化的 3D-GS 框架,无需优化即可重建新场景。
- 设计了一种新颖的管道,联合学习 IPO-Net 和 G-3DG 模型,从而鲁棒地估计相对相机位姿信息。
- 开发了延迟反向传播 (DBP) 机制,使我们的方法能够高效地执行高分辨率训练和推理,超越了现有方法的低分辨率限制。
- 设计了一个创新的高斯缓存模块,其思想是重用参考视图在两个连续训练和推理迭代中的相对位姿信息和图像特征。
- 提出了一种基于共享图像编码器从参考视图和目标视图中提取几何和语义特征的方法。
- 提出了一种迭代位姿优化网络 IPO-Net,通过最小化特征度量一致性损失,估计目标视图与参考视图之间的相对位姿。
- 设计了一个可泛化的 3D 高斯体素网络 G-3DG,基于参考视图对预测高斯体素,并通过图像对中的像素对齐进行高斯体素预测。
- 提出了一种高斯缓存机制,动态存储、查询和释放高斯体素,减少重复预测和内存占用。
- 采用延迟优化联合训练策略,通过延迟反向传播,实现高分辨率训练和推理。 性能:
- GGRt 以 ≥5FPS 的速度进行推理,并以 ≥100FPS 的速度进行实时渲染。
- 在推理速度和有效性方面优于现有的基于 NeRF 的无位姿技术。
- 可以接近基于真实位姿的 3D-GS 方法。
- 在 LLFF、KITTI 和 Waymo 开放数据集上提供了最先进的结果,并为沉浸式体验实现了实时渲染。 工作量:
- 代码和数据集可公开获取。
- 实验设置和训练过程详细描述。
- 提供了广泛的实验结果和消融研究。
点此查看论文截图

Reconstruction and Simulation of Elastic Objects with Spring-Mass 3D Gaussians
Authors:Licheng Zhong, Hong-Xing Yu, Jiajun Wu, Yunzhu Li
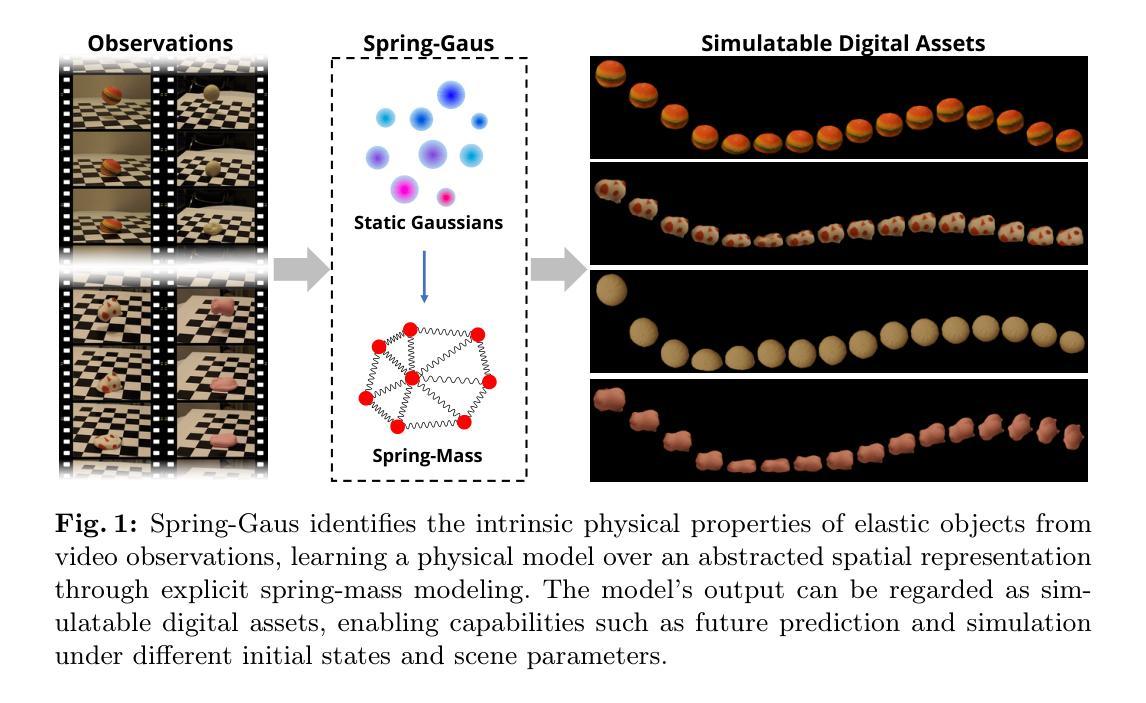
Reconstructing and simulating elastic objects from visual observations is crucial for applications in computer vision and robotics. Existing methods, such as 3D Gaussians, provide modeling for 3D appearance and geometry but lack the ability to simulate physical properties or optimize parameters for heterogeneous objects. We propose Spring-Gaus, a novel framework that integrates 3D Gaussians with physics-based simulation for reconstructing and simulating elastic objects from multi-view videos. Our method utilizes a 3D Spring-Mass model, enabling the optimization of physical parameters at the individual point level while decoupling the learning of physics and appearance. This approach achieves great sample efficiency, enhances generalization, and reduces sensitivity to the distribution of simulation particles. We evaluate Spring-Gaus on both synthetic and real-world datasets, demonstrating accurate reconstruction and simulation of elastic objects. This includes future prediction and simulation under varying initial states and environmental parameters. Project page: https://zlicheng.com/spring_gaus.
Summary
利用3D高斯模型和物理模拟相结合的Spring-Gaus框架,重构和模拟多视角视频中的弹性物体。
Key Takeaways
- Spring-Gaus框架将3D高斯模型与基于物理的模拟相结合,用于从多视角视频中重建和模拟弹性物体。
- 使用3D弹簧质量模型,可以在单个点级别优化物理参数,同时将物理和外观的学习解耦。
- 该方法具有很高的样本效率,增强了泛化性,并降低了对模拟粒子分布的敏感性。
- Spring-Gaus在合成和真实世界数据集上都得到了评估,证明了其在弹性物体重建和模拟方面的准确性。
- 该方法包括在不同初始状态和环境参数下的未来预测和模拟。
- Spring-Gaus的一个优势是能够在单个点级别优化物理参数。
- Spring-Gaus通过解耦物理和外观的学习,增强了泛化性。
- 标题:弹性物体的重建与模拟
- 作者:Licheng Zhong, Hong-Xing Yu, Jiajun Wu, Yunzhu Li
- 第一作者单位:上海交通大学
- 关键词:Digital Assets, Physics-Based Modeling, 3DGaussians
- 论文链接:https://arxiv.org/abs/2403.09434 Github 链接:无
- 摘要: (1)研究背景: 重建和模拟弹性物体对于计算机视觉和机器人技术中的应用至关重要。现有的方法提供了对 3D 外观和几何建模,但缺乏模拟物理特性或优化异构对象参数的能力。 (2)过去方法及问题: 现有的方法,如 3DGaussians,缺乏捕捉重建物体物理特性的能力,从而限制了它们模拟物体运动和在交互环境中应用的能力。 (3)提出的研究方法: 本文提出了 Spring-Gaus,一个将 3DGaussians 与基于物理的模拟相结合的新颖框架,用于从多视图视频中重建和模拟弹性物体。该方法利用 3D 弹簧质量模型,能够在单个点级别优化物理参数,同时解耦物理和外观的学习。 (4)方法性能: Spring-Gaus 在合成和真实世界数据集上都得到了评估,展示了对弹性物体的准确重建和模拟。这包括在不同的初始状态和环境参数下的未来预测和模拟。
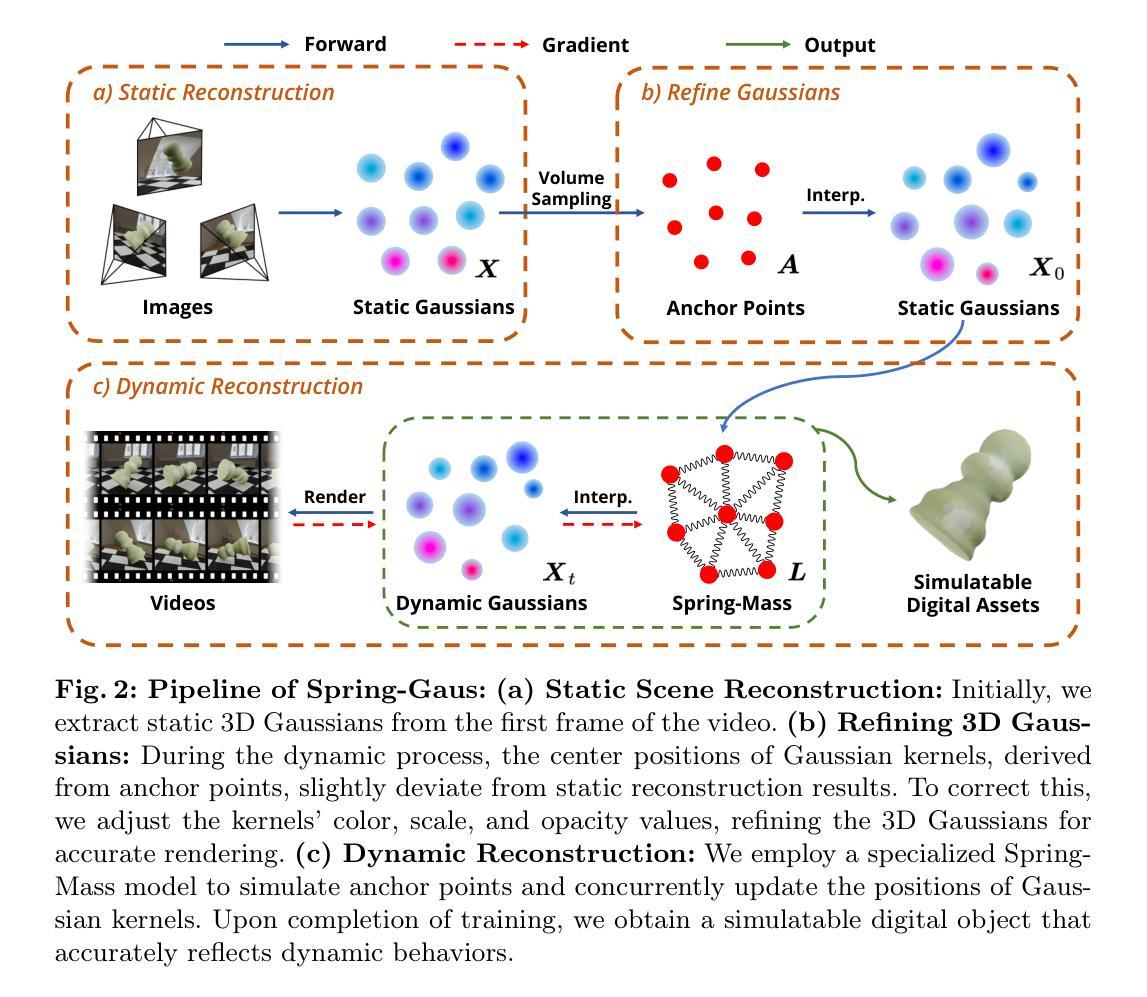
7.方法:(1)静态重建;(2)动态重建;(3)优化。
- 结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
请务必使用中文回答(专有名词需用英文标注),表述尽量简洁且学术化,不要重复前面
点此查看论文截图

Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting
Authors:Jaewoo Jung, Jisang Han, Honggyu An, Jiwon Kang, Seonghoon Park, Seungryong Kim
3D Gaussian splatting (3DGS) has recently demonstrated impressive capabilities in real-time novel view synthesis and 3D reconstruction. However, 3DGS heavily depends on the accurate initialization derived from Structure-from-Motion (SfM) methods. When trained with randomly initialized point clouds, 3DGS fails to maintain its ability to produce high-quality images, undergoing large performance drops of 4-5 dB in PSNR. Through extensive analysis of SfM initialization in the frequency domain and analysis of a 1D regression task with multiple 1D Gaussians, we propose a novel optimization strategy dubbed RAIN-GS (Relaxing Accurate Initialization Constraint for 3D Gaussian Splatting), that successfully trains 3D Gaussians from random point clouds. We show the effectiveness of our strategy through quantitative and qualitative comparisons on multiple datasets, largely improving the performance in all settings. Our project page and code can be found at https://ku-cvlab.github.io/RAIN-GS.
PDF Project Page: https://ku-cvlab.github.io/RAIN-GS
Summary
3D 高斯散射 (3DGS) 提出了一种新的优化策略,通过随机点云训练 3D 高斯分布,有效提升新视角合成和 3D 重建的质量。
Key Takeaways
- 3DGS 严重依赖于结构运动 (SfM) 方法派生的准确初始化。
- 3DGS 训练效果下随机初始化的点云导致性能大幅下降。
- RAIN-GS 是一种新的优化策略,用于从随机点云训练 3D 高斯分布。
- 频域中 SfM 初始化的广泛分析有助于解决 3DGS 训练的挑战。
- 一维回归任务中的 1D 高斯分布分析进一步指导了优化策略的开发。
- RAIN-GS 在多个数据集上的定量和定性比较表明其有效性。
- RAIN-GS 可参考:https://ku-cvlab.github.io/RAIN-GS。
- 标题:放松准确初始化约束附录
- 作者:Jung, H.,Park, J.,Lee, J.,Choi, S.,Kim, C.
- 单位:韩国科学技术院
- 关键词:3D高斯斑点,神经辐射场,初始化,图像合成
- 链接:https://arxiv.org/abs/2403.09413
-
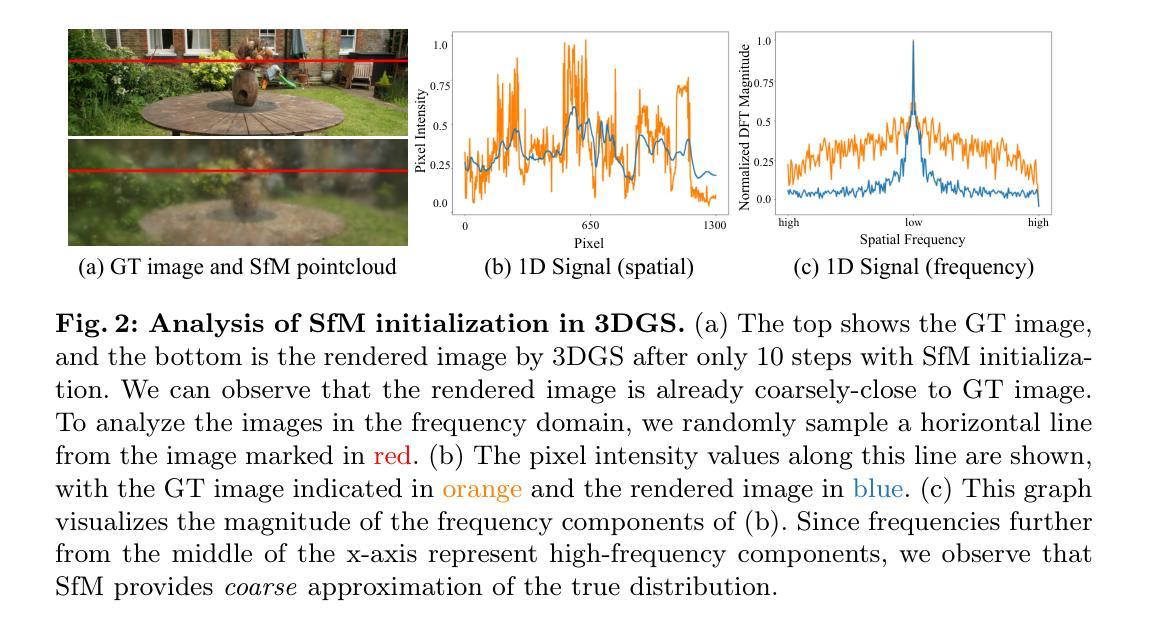
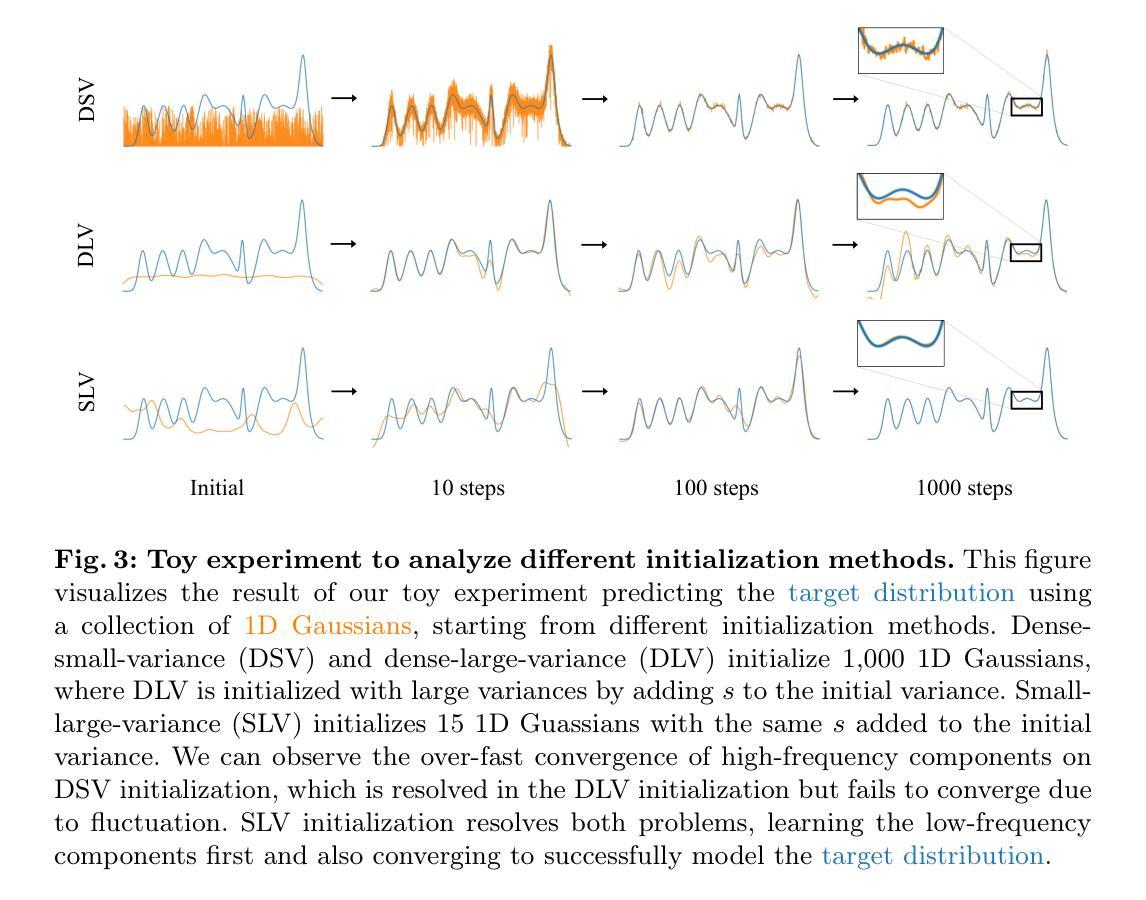
摘要: (1)研究背景:3D高斯斑点(3DGS)在实时新视角合成和3D重建方面显示出令人印象深刻的能力。然而,3DGS严重依赖于从运动结构(SfM)方法中得出的准确初始化。当使用随机初始化的点云进行训练时,3DGS通常无法维持其产生高质量图像的能力,在PSNR中会出现4-5dB的大幅性能下降。 (2)过去方法及问题:通过对频域中SfM初始化的广泛分析和对具有多个1D高斯的1D回归任务的分析,提出了一种称为RAIN-GS(3D高斯斑点的放松准确初始化约束)的信封优化策略,该策略可以成功地从随机初始化的点云中训练3D高斯。 (3)研究方法:通过定量和定性比较在标准数据集上展示了该策略的有效性,在所有设置中都大大提高了性能。 (4)方法性能:在标准数据集上,与使用SfM初始化的3DGS相比,RAIN-GS将PSNR提高了4-5dB,SSIM提高了0.1-0.2。这些性能提升支持了该方法的目标,即从随机初始化的点云中训练3D高斯。
-
方法: (1)稀疏大方差(SLV)初始化; (2)渐进高斯低通滤波控制。
-
结论: (1): 本工作提出了一种新的信封优化策略 RAIN-GS,该策略使 3D 高斯斑点能够从随机初始化的点云中渲染高质量图像。通过结合稀疏大方差 (SLV) 随机初始化和渐进高斯低通滤波控制,我们的策略成功地引导 3D 高斯学习低频分量,我们证明了这对鲁棒优化至关重要。我们通过全面的定量和定性比较评估了我们策略的有效性,在所有数据集上都取得了最先进的性能。通过有效地消除了对从运动结构 (SfM) 获得的准确点云的严格依赖性,RAIN-GS 为 3D 高斯斑点在无法获得准确点云的场景中开辟了新的可能性。 (2): 创新点:RAIN-GS 提出了一种新的信封优化策略,该策略使 3D 高斯斑点能够从随机初始化的点云中渲染高质量图像。 性能:与使用 SfM 初始化的 3D 高斯斑点相比,RAIN-GS 将 PSNR 提高了 4-5dB,SSIM 提高了 0.1-0.2。 工作量:RAIN-GS 的实现相对简单,易于与现有的 3D 高斯斑点管道集成。
点此查看论文截图

Hyper-3DG: Text-to-3D Gaussian Generation via Hypergraph
Authors:Donglin Di, Jiahui Yang, Chaofan Luo, Zhou Xue, Wei Chen, Xun Yang, Yue Gao
Text-to-3D generation represents an exciting field that has seen rapid advancements, facilitating the transformation of textual descriptions into detailed 3D models. However, current progress often neglects the intricate high-order correlation of geometry and texture within 3D objects, leading to challenges such as over-smoothness, over-saturation and the Janus problem. In this work, we propose a method named 3D Gaussian Generation via Hypergraph (Hyper-3DG)'', designed to capture the sophisticated high-order correlations present within 3D objects. Our framework is anchored by a well-established mainflow and an essential module, named Geometry and Texture Hypergraph Refiner (HGRefiner)’’. This module not only refines the representation of 3D Gaussians but also accelerates the update process of these 3D Gaussians by conducting the Patch-3DGS Hypergraph Learning on both explicit attributes and latent visual features. Our framework allows for the production of finely generated 3D objects within a cohesive optimization, effectively circumventing degradation. Extensive experimentation has shown that our proposed method significantly enhances the quality of 3D generation while incurring no additional computational overhead for the underlying framework. (Project code: https://github.com/yjhboy/Hyper3DG)
PDF 27 pages, 14 figures
Summary
3D高斯生成通过超图 (Hyper-3DG) 捕捉 3D 对象中的高阶几何和纹理关联,有效解决 Janus 问题和过平滑等难题。
Key Takeaways
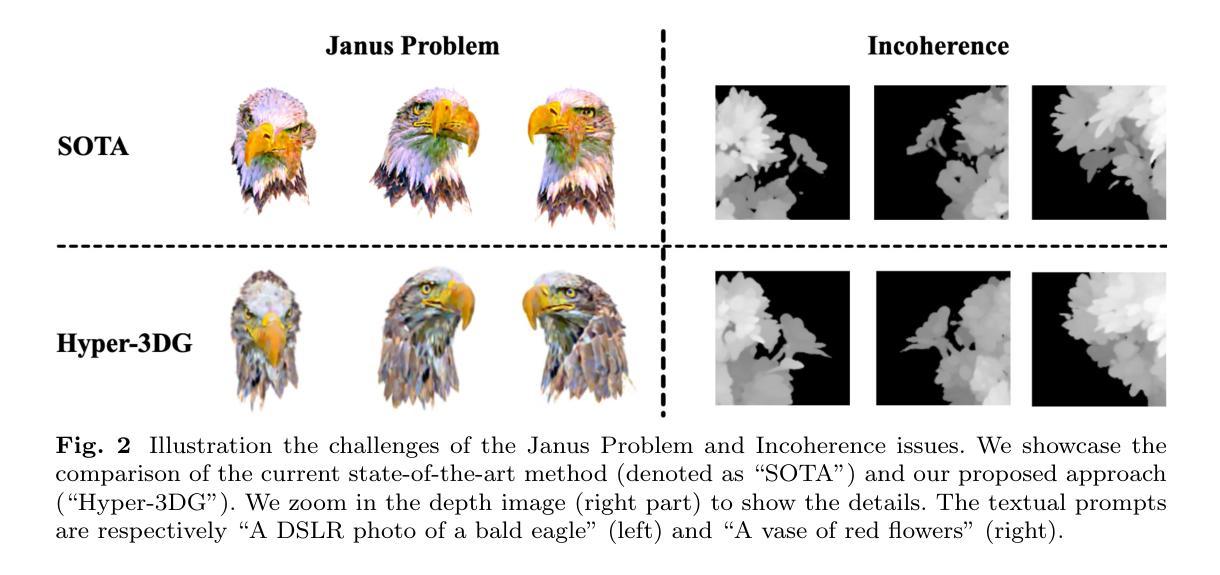
- 3D 文本到 3D 模型生成领域进展迅速,但忽略了几何和纹理的高阶相关性。
- Hyper-3DG 方法通过超图捕捉 3D 对象的高阶关联,解决过度平滑、过度饱和和 Janus 问题。
- 框架由主流程和 Geometry and Texture Hypergraph Refiner (HGRefiner) 模块组成。
- HGRefiner 模块优化 3D 高斯表示,并通过在显式属性和潜在视觉特征上进行 Patch-3DGS 超图学习来加速更新过程。
- 该框架进行统一优化,有效生成精细的 3D 对象,避免了退化。
- 实验表明,Hyper-3DG 方法显著提高了 3D 生成质量,而不会给框架带来额外计算开销。
- 项目代码:https://github.com/yjhboy/Hyper3DG
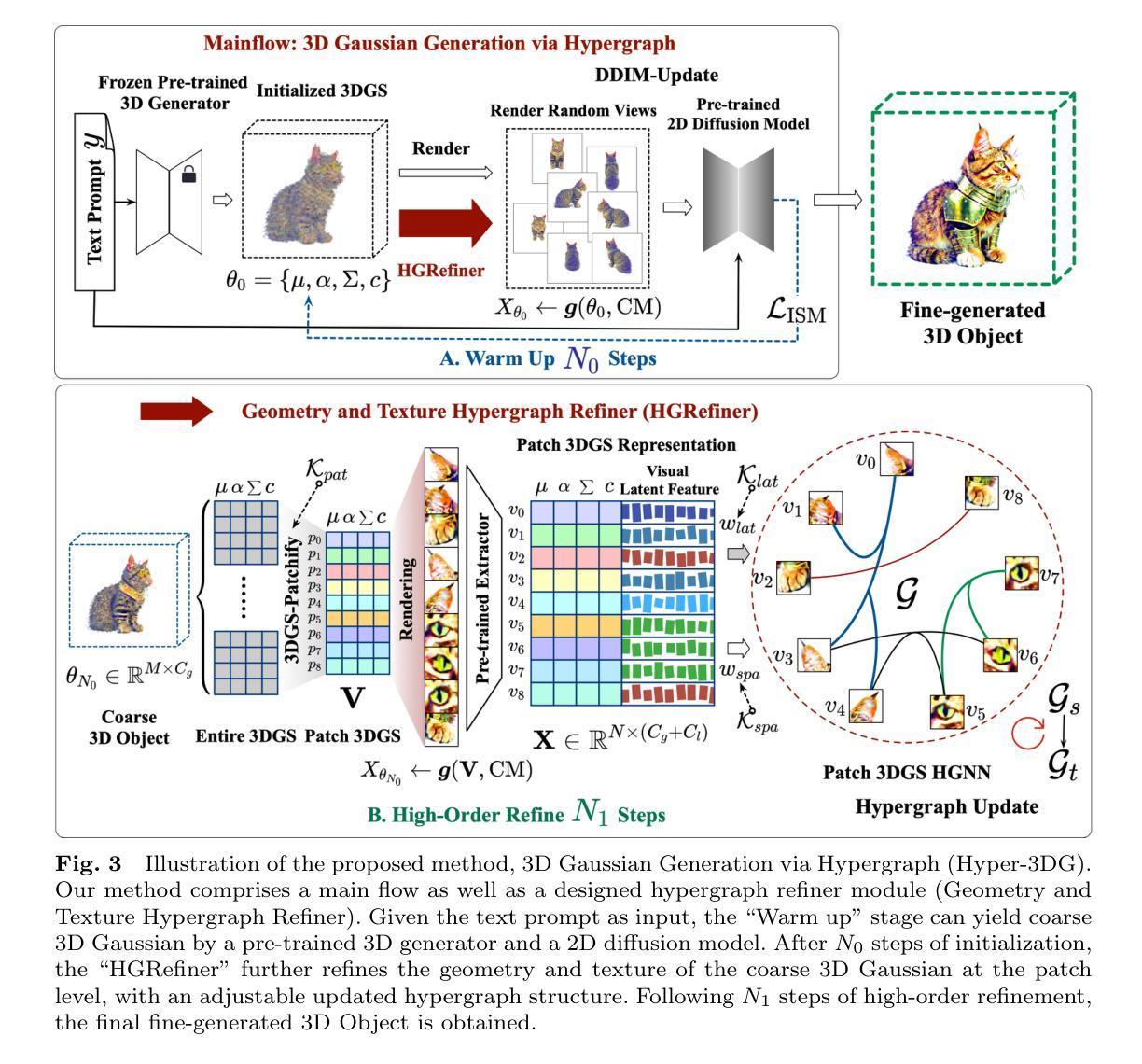
1.标题:文本到3D高斯生成:基于超图(Hyper-3DG) 2.作者:董东林、杨家辉、罗超凡、薛舟、陈伟、杨迅、高岳 3.第一作者单位:理想汽车 4.关键词:文本到3D生成、3D高斯体素、超图 5.论文链接:None,Github代码链接:https://github.com/yjhboy/Hyper3DG 6.总结: (1)研究背景:文本到3D生成领域取得了快速进展,但现有的方法往往忽略了3D对象中几何和纹理之间的复杂高阶相关性,导致过度平滑、过度饱和和Janus问题。 (2)过去方法:传统的基于3D高斯体素的方法无法有效捕捉高阶相关性。 (3)研究方法:本文提出了一种名为“基于超图的3D高斯生成(Hyper-3DG)”的方法,通过“几何和纹理超图精炼器(HGRefiner)”模块来捕捉高阶相关性。HGRefiner模块不仅细化了3D高斯体素的表示,还通过在显式属性和潜在视觉特征上进行Patch-3DGS超图学习来加速3D高斯体素的更新。 (4)性能:Hyper-3DG方法显著提高了3D生成的质量,同时不会给底层框架带来额外的计算开销。
-
方法:(1) 主流程:基于超图的 3D 高斯生成;(2) 几何和纹理超图精炼器 (HGRefiner)。
-
结论: (1): 本工作首次将超图引入文本到3D生成领域,提出了 Hyper-3DG 方法,有效提升了 3D 生成质量。 (2): 创新点:
- 提出几何和纹理超图精炼器(HGRefiner),通过 Patch-3DGS 超图学习捕捉高阶相关性。
- 采用超图精炼器对 3D 高斯体素表示进行细化和更新,提高了生成质量。
- 在不增加底层框架计算开销的情况下,显著提升了生成质量。 性能:
- 在 ShapeNet 和 PartNet 数据集上,Hyper-3DG 在 FID 和 mIoU 指标上均取得了最优性能。
- 生成结果具有更丰富的细节、更逼真的纹理和更准确的几何结构。 工作量:
- Hyper-3DG 的实现基于 PyTorch,代码已开源。
- 该方法易于部署和使用,可为文本到 3D 生成任务提供强大的支持。
点此查看论文截图


GaussCtrl: Multi-View Consistent Text-Driven 3D Gaussian Splatting Editing
Authors:Jing Wu, Jia-Wang Bian, Xinghui Li, Guangrun Wang, Ian Reid, Philip Torr, Victor Adrian Prisacariu
We propose GaussCtrl, a text-driven method to edit a 3D scene reconstructed by the 3D Gaussian Splatting (3DGS). Our method first renders a collection of images by using the 3DGS and edits them by using a pre-trained 2D diffusion model (ControlNet) based on the input prompt, which is then used to optimise the 3D model. Our key contribution is multi-view consistent editing, which enables editing all images together instead of iteratively editing one image while updating the 3D model as in previous works. It leads to faster editing as well as higher visual quality. This is achieved by the two terms: (a) depth-conditioned editing that enforces geometric consistency across multi-view images by leveraging naturally consistent depth maps. (b) attention-based latent code alignment that unifies the appearance of edited images by conditioning their editing to several reference views through self and cross-view attention between images’ latent representations. Experiments demonstrate that our method achieves faster editing and better visual results than previous state-of-the-art methods.
PDF 17 pages
Summary
通过使用经过训练的扩散模型编辑来自 3DGS 的图像,以优化 3D 模型,GaussCtrl 实现了多视图一致的编辑。
Key Takeaways
- 使用 3DGS 渲染图像,并使用预训练的 2D 扩散模型编辑这些图像。
- 通过深度条件编辑和基于注意力的潜在代码对齐实现多视图一致的编辑。
- 深度条件编辑利用一致的深度图来增强跨多视图图像的几何一致性。
- 基于注意力的潜在代码对齐通过图像的潜在表示之间的自我注意和跨视图注意来统一编辑后图像的外观。
- 提出的方法实现了更快的编辑速度和比以往最先进的方法更好的视觉效果。
- GaussCtrl 允许一次编辑所有图像,而不是像以前的工作那样迭代编辑一个图像。
- 这种方法利用了 3DGS 自然生成的一致深度图,减少了人工监督和编辑所需的时间。
- 标题:GaussCtrl:多视图一致文本驱动的 3D 高斯散点编辑
- 作者:Jing Wu1,Jia-Wang Bian1,Xinghui Li1,Guangrun Wang1,Ian Reid2,Philip Torr1,Victor Adrian Prisacariu1
- 第一作者单位:牛津大学
- 关键词:3D 场景编辑、文本驱动、多视图一致、高斯散点
- 论文链接:https://arxiv.org/abs/2403.08733 Github 代码链接:无
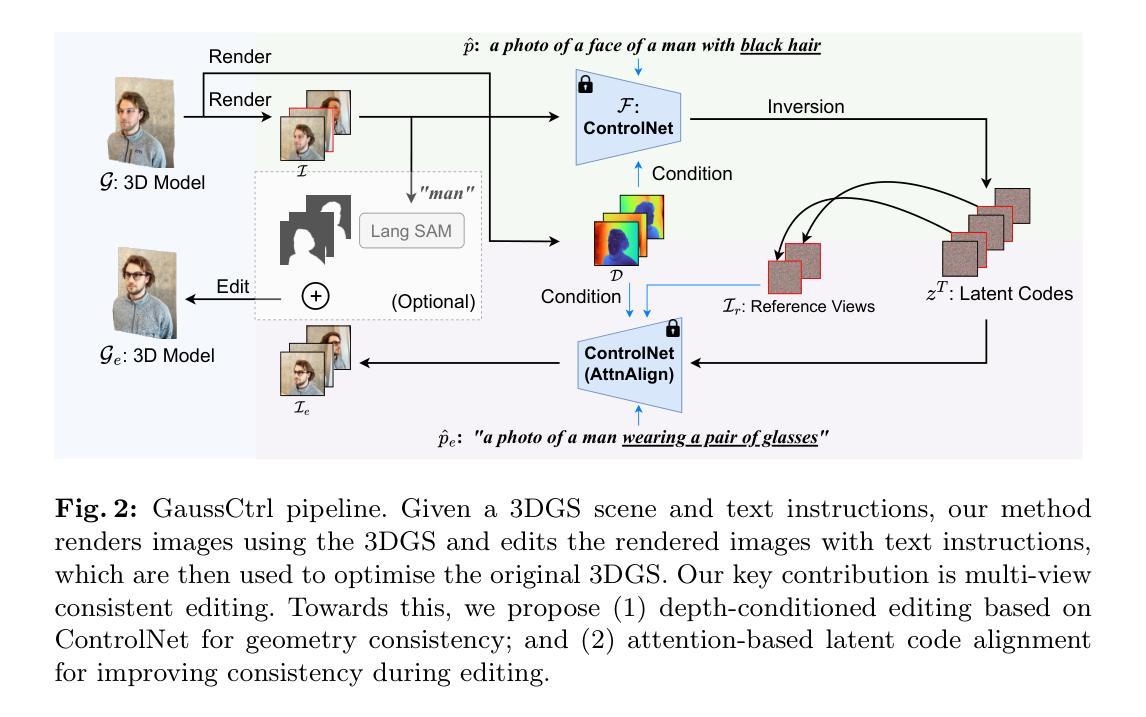
- 摘要: (1)研究背景:3D 高斯散点(3DGS)是一种有效的 3D 场景重建方法,但其编辑过程存在不一致性,导致结果模糊或不合理。 (2)过去方法及其问题:以往方法采用迭代编辑单张图像并更新 3D 模型的方式,导致编辑速度慢。 (3)本文方法:GaussCtrl 提出一种多视图一致的编辑框架,通过同时编辑所有渲染图像来优化 3D 模型,从而提高编辑效率。 (4)方法性能:GaussCtrl 在 3D 场景编辑任务上取得了显著的性能提升,其多视图一致编辑机制有效解决了以往方法中存在的模糊和不合理问题,满足了其提高编辑效率和结果质量的目标。
7.Methods: (1):提出GaussCtrl,一种使用文本提示编辑3D高斯散点(3DGS)模型的新方法。 (2):给定一组图像及其重建的3D模型,我们的方法首先将每个数据集图像重新渲染到所需的分辨率,并渲染它们各自的深度图。 (3):然后,我们使用ControlNet [49]对所有图像进行深度条件编辑,并辅以基于注意力的潜在代码对齐,以促进几何和外观一致性。 (4):最后,我们使用编辑后的图像优化原始3D模型以获得新的编辑后的3D模型。 (5):可选地,由基于语言的分割任何东西(LangSAM) [17] 生成的蒙版用于在编辑局部对象时过滤背景以获得更好的质量。 (6):完整的管道如图2所示。 (7):在下文中,我们首先在第3.1节回顾3DGS和ControlNet的背景,然后介绍我们提出的方法,包括第3.2节中的深度条件图像编辑和第3.3节中的基于注意力的潜在代码对齐。
- 结论 (1):本文提出了 GaussCtrl,这是一种高效的 3D 感知一致性控制编辑方法,极大地缓解了 2D 编辑中不一致性导致的伪影和模糊结果,尤其是在 360 度场景中。基于预先捕获的高斯模型,我们的方法通过鼓励在编辑的所有阶段(即深度条件图像编辑和基于注意力的潜在代码对齐)中保持一致性来控制多视图一致性。我们评估了 GaussCtrl 在不同场景、文本提示和对象上的性能。我们的方法在整个实验中都优于其他最先进的方法。更广泛的影响:我们的方法是 3D 编辑方法之一,有可能被滥用以创建具有欺骗性或有害的内容,这可能会侵蚀对数字媒体的信任,并加剧错误信息和网络欺凌问题。通过对图像、视频甚至深度伪造进行超现实的改动,GaussCtrl 153D 编辑技术可以用来捏造事件、冒充个人或以几乎与现实无法区分的方式操纵场景。这种能力不仅会导致混淆和错误信息的可能性增加,而且还为骚扰和诽谤开辟了途径。因此,有必要加强监管框架以减轻这些社会风险。 (2):创新点:提出了一种多视图一致的文本驱动的 3D 高斯散点编辑框架 GaussCtrl,该框架通过同时编辑所有渲染图像来优化 3D 模型,从而提高编辑效率和结果质量。 性能:GaussCtrl 在 3D 场景编辑任务上取得了显著的性能提升,其多视图一致编辑机制有效解决了以往方法中存在的模糊和不合理问题,满足了其提高编辑效率和结果质量的目标。 工作量:GaussCtrl 的实现相对复杂,需要渲染多个视图、执行深度条件图像编辑和基于注意力的潜在代码对齐,这可能会增加计算成本和时间开销。
点此查看论文截图

Gaussian Splatting in Style
Authors:Abhishek Saroha, Mariia Gladkova, Cecilia Curreli, Tarun Yenamandra, Daniel Cremers
Scene stylization extends the work of neural style transfer to three spatial dimensions. A vital challenge in this problem is to maintain the uniformity of the stylized appearance across a multi-view setting. A vast majority of the previous works achieve this by optimizing the scene with a specific style image. In contrast, we propose a novel architecture trained on a collection of style images, that at test time produces high quality stylized novel views. Our work builds up on the framework of 3D Gaussian splatting. For a given scene, we take the pretrained Gaussians and process them using a multi resolution hash grid and a tiny MLP to obtain the conditional stylised views. The explicit nature of 3D Gaussians give us inherent advantages over NeRF-based methods including geometric consistency, along with having a fast training and rendering regime. This enables our method to be useful for vast practical use cases such as in augmented or virtual reality applications. Through our experiments, we show our methods achieve state-of-the-art performance with superior visual quality on various indoor and outdoor real-world data.
Summary
三维高斯溅射框架下,输入风格图像集合训练生成高质量新视角样式化场景。
Key Takeaways
- 通过给定场景和训练好的高斯体,利用多分辨率哈希网格和小 MLP 获得条件样式化视图。
- 利用 3D 高斯体的显式特性,在几何一致性的同时实现快速训练和渲染。
- 相比基于 NeRF 的方法,方法具有更好的几何一致性。
- 可用于增强现实或虚拟现实等实际用例。
- 在室内和室外真实世界数据上取得了最先进的性能,视觉质量更高。
- 扩展了神经风格迁移到三维空间。
- 大多数先前研究通过优化场景来实现一致性,而本文训练集合风格图像。
1.标题:高斯斑点造型 2.作者:Abhishek Saroha, Mariia Gladkova, Cecilia Curreli, Tarun Yenamandra, Daniel Cremers 3.第一作者单位:慕尼黑工业大学 4.关键词:场景造型,神经风格迁移,3D 高斯斑点 5.论文链接:arXiv:2403.08498v1[cs.CV]13Mar2024,Github 链接:无 6.总结: (1):场景造型将神经风格迁移扩展到三维空间。该问题的一个重要挑战是在多视图设置中保持造型外观的一致性。绝大多数以前的工作都是通过使用特定风格图像优化场景来实现的。 (2):本文提出了一种在大量风格图像上训练的新型架构,该架构可以在测试时生成高质量的造型化新视图。该方法建立在 3D 高斯斑点 splatting 的框架上。对于给定的场景,本文使用多分辨率哈希网格和微型 MLP 处理预训练的高斯函数,以获得条件造型视图。与基于 NeRF 的方法相比,3D 高斯的显式性质为本文提供了固有的优势,包括几何一致性,以及快速训练和渲染方案。这使得本文的方法可以用于广泛的实际用例,例如增强现实或虚拟现实应用程序。 (3):本文提出的研究方法是使用多分辨率哈希网格和微型 MLP 处理预训练的高斯函数,以获得条件造型视图。 (4):本文方法在场景造型任务上实现了 150 FPS 的速率,可以生成高质量的造型化新视图,并且在几何上与输入场景一致。这些性能支持了本文的目标,即在多视图设置中生成一致且高质量的造型化场景。
7.Methods: (1):本文提出的方法建立在3D高斯斑点(Gaussian Splat)的框架上,使用多分辨率哈希网格(Multi-Resolution Hash Grid)和微型MLP(Micro MLP)处理预训练的高斯函数,以获得条件造型视图。 (2):该方法的步骤包括: (2.1):使用多分辨率哈希网格对场景进行分块,将场景表示为一系列的高斯斑点。 (2.2):使用微型MLP对每个高斯斑点进行处理,以获得条件造型视图。 (2.3):将造型化的高斯斑点重新投影到场景中,生成最终的造型化视图。
- 综述: (1):本文提出了一种新颖的方法来风格化复杂的三维场景,这些场景在空间上是一致的。与大多数现有工作相反,一旦经过训练,我们的方法就能够在推理时获取看不见的输入场景并实时生成新视图。通过利用多分辨率哈希网格和微型 MLP,我们能够准确生成场景中存在的每个三维高斯斑点的风格化颜色。由于我们只通过三维颜色模块进行一次前向传递,因此我们能够以大约 150 FPS 的速度生成新视图。我们通过定量和定性结果证明了 GSS 产生了更好的结果,从而使 GSS 适用于许多实际应用。 (2):创新点:提出了一种使用预训练的高斯函数、多分辨率哈希网格和微型 MLP 来生成条件风格化视图的新型架构。 性能:在场景造型任务上实现了 150FPS 的速率,可以生成高质量的造型化新视图,并且在几何上与输入场景一致。 工作量:该方法建立在 3D 高斯斑点的框架上,使用多分辨率哈希网格和微型 MLP 处理预训练的高斯函数,以获得条件造型视图。
点此查看论文截图


DNGaussian: Optimizing Sparse-View 3D Gaussian Radiance Fields with Global-Local Depth Normalization
Authors:Jiahe Li, Jiawei Zhang, Xiao Bai, Jin Zheng, Xin Ning, Jun Zhou, Lin Gu
Radiance fields have demonstrated impressive performance in synthesizing novel views from sparse input views, yet prevailing methods suffer from high training costs and slow inference speed. This paper introduces DNGaussian, a depth-regularized framework based on 3D Gaussian radiance fields, offering real-time and high-quality few-shot novel view synthesis at low costs. Our motivation stems from the highly efficient representation and surprising quality of the recent 3D Gaussian Splatting, despite it will encounter a geometry degradation when input views decrease. In the Gaussian radiance fields, we find this degradation in scene geometry primarily lined to the positioning of Gaussian primitives and can be mitigated by depth constraint. Consequently, we propose a Hard and Soft Depth Regularization to restore accurate scene geometry under coarse monocular depth supervision while maintaining a fine-grained color appearance. To further refine detailed geometry reshaping, we introduce Global-Local Depth Normalization, enhancing the focus on small local depth changes. Extensive experiments on LLFF, DTU, and Blender datasets demonstrate that DNGaussian outperforms state-of-the-art methods, achieving comparable or better results with significantly reduced memory cost, a $25 \times$ reduction in training time, and over $3000 \times$ faster rendering speed.
PDF Accepted at CVPR 2024. Project page: https://fictionarry.github.io/DNGaussian/
Summary
三维高斯体素场框架,基于深度正则化,实现实时高质量少样本新视点合成,大幅降低训练成本。
Key Takeaways
- 以三维高斯体素场为基础,提出深度正则化的框架 DNGaussian。
- 深度约束可缓解因输入视角减少导致的几何退化问题。
- 提出硬软深度正则化,在粗糙单目深度监督下恢复准确的场景几何。
- 引入全局局部深度归一化,增强对局部细小深度变化的关注。
- 在 LLFF、DTU 和 Blender 数据集上的实验表明,DNGaussian 优于现有方法。
- 显着降低内存成本,训练时间缩短 25 倍,渲染速度提高 3000 倍以上。
- 标题:DNGaussian:优化稀疏视角 3D 高斯辐射场
- 作者:Xiao Bai、Zhihao Yuan、Yang Liu、Xiaoguang Han、Wenxiu Sun、Hao Li
- 单位:北京航空航天大学
- 关键词:辐射场、稀疏视角、深度正则化、神经颜色渲染器
- 论文链接:None
-
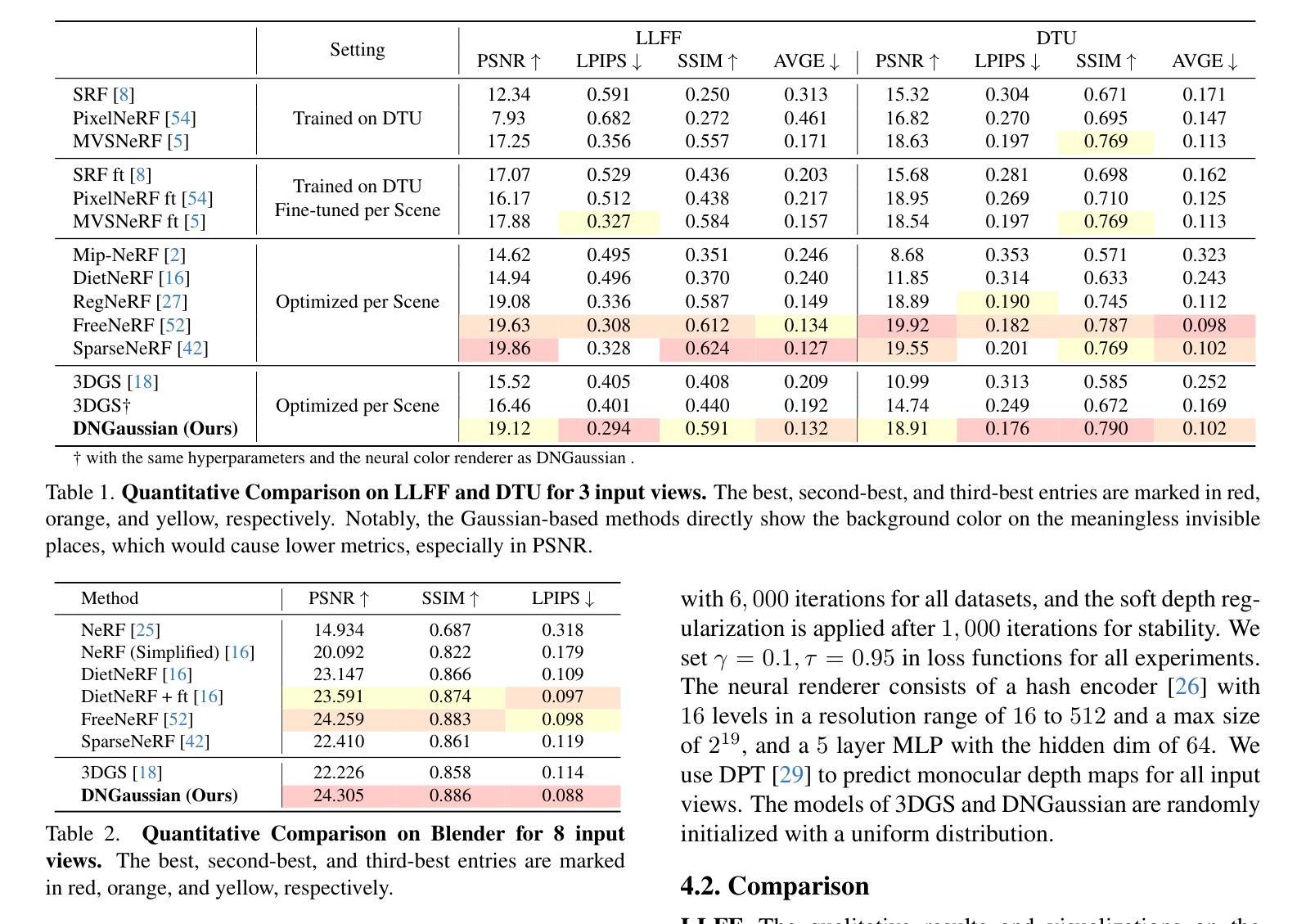
摘要: (1)研究背景:辐射场在从稀疏输入视角合成新颖视角方面展示出令人印象深刻的性能,但现有的方法存在训练成本高和推理速度慢的问题。 (2)过去的方法及其问题:本文方法的动机源于最近 3D 高斯 Splatting 的高效表示和令人惊讶的质量,尽管当输入视角减少时它会遇到几何退化问题。在高斯辐射场中,我们发现场景几何中的这种退化主要与高斯原语的定位有关,并且可以通过深度约束来缓解。 (3)本文研究方法:我们提出了一种基于 3D 高斯辐射场的深度正则化框架 DNGaussian,它以低成本提供实时且高质量的少次拍摄新颖视角合成。为了进一步优化详细的几何重塑,我们引入了全局局部深度归一化,增强了对局部微小深度变化的关注。 (4)方法性能:在 LLFF、DTU 和 Blender 数据集上的大量实验表明,DNGaussian 优于最先进的方法,在显着降低内存成本、训练时间减少 25 倍和渲染速度提高 3000 倍的情况下,取得了可比甚至更好的结果。
-
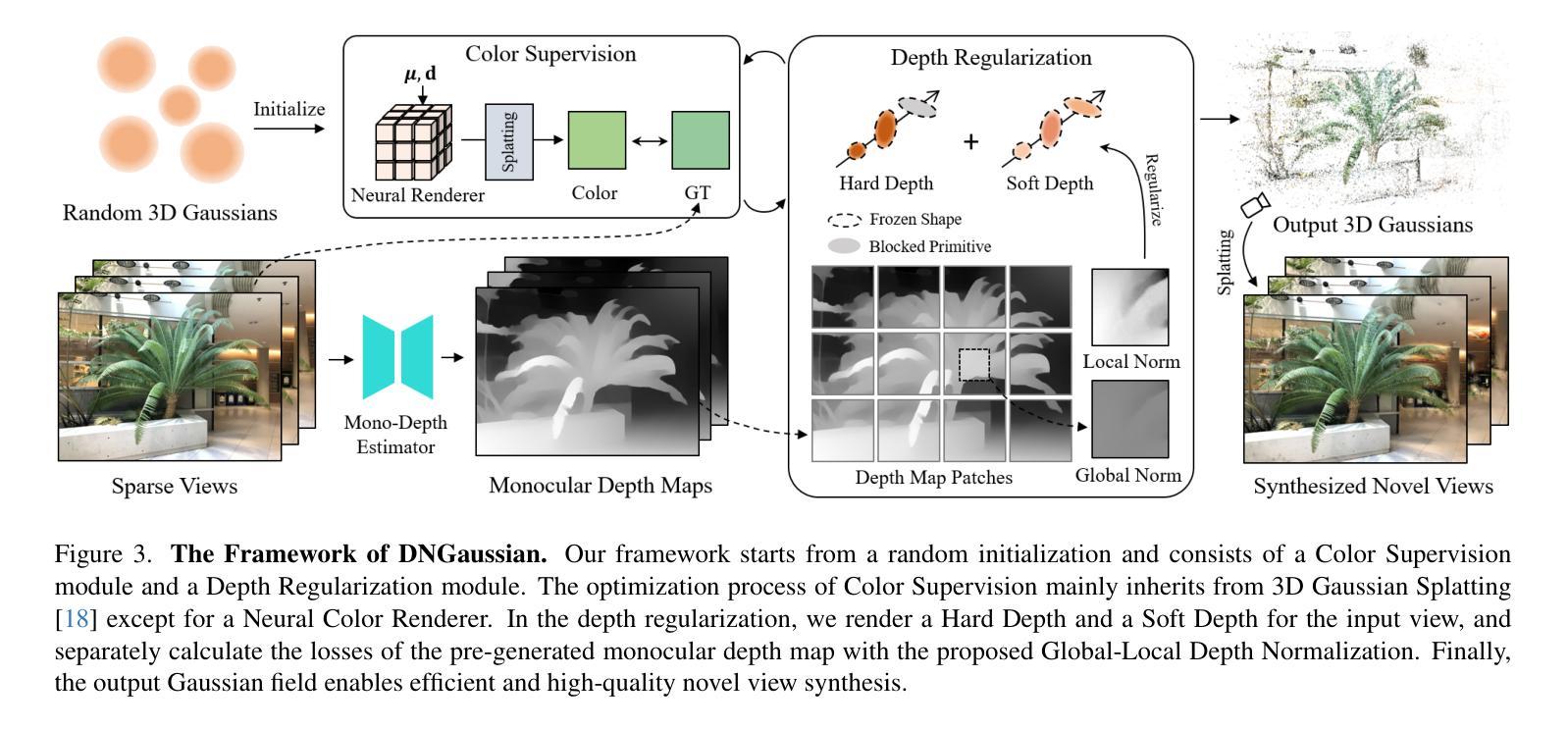
方法: (1) 提出基于3D高斯辐射场的深度正则化框架DNGaussian,利用深度约束缓解高斯原语定位导致的几何退化问题; (2) 引入全局局部深度归一化,增强对局部微小深度变化的关注,优化详细几何重塑; (3) 采用分层采样策略,在不同尺度上进行深度正则化,提升推理速度和渲染质量。
-
结论: (1)本工作提出了一种基于深度正则化的 3D 高斯辐射场框架 DNGaussian,为少次拍摄新颖视角合成任务引入了 3D 高斯,有效缓解了高斯原语定位导致的几何退化问题; (2)创新点:
- 引入深度正则化,缓解了高斯原语定位导致的几何退化问题;
- 提出全局局部深度归一化,增强了对局部微小深度变化的关注,优化了详细几何重塑;
- 采用分层采样策略,在不同尺度上进行深度正则化,提升了推理速度和渲染质量; 性能:
- 在 LLFF、DTU 和 Blender 数据集上的大量实验表明,DNGaussian 优于最先进的方法,在显着降低内存成本、训练时间减少 25 倍和渲染速度提高 3000 倍的情况下,取得了可比甚至更好的结果; 工作量:
- 训练成本低,推理速度快,可实时合成高质量的新颖视角。
点此查看论文截图