⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-18 更新
Isotropic3D: Image-to-3D Generation Based on a Single CLIP Embedding
Authors:Pengkun Liu, Yikai Wang, Fuchun Sun, Jiafang Li, Hang Xiao, Hongxiang Xue, Xinzhou Wang
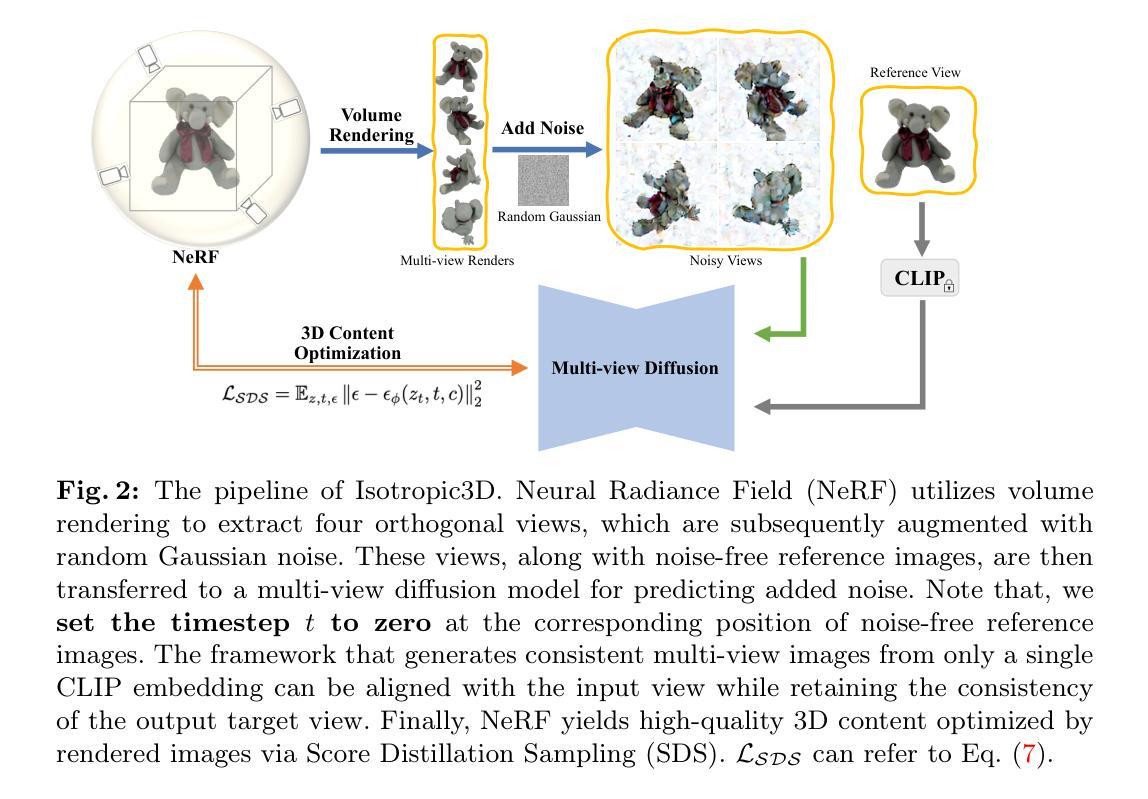
Encouraged by the growing availability of pre-trained 2D diffusion models, image-to-3D generation by leveraging Score Distillation Sampling (SDS) is making remarkable progress. Most existing methods combine novel-view lifting from 2D diffusion models which usually take the reference image as a condition while applying hard L2 image supervision at the reference view. Yet heavily adhering to the image is prone to corrupting the inductive knowledge of the 2D diffusion model leading to flat or distorted 3D generation frequently. In this work, we reexamine image-to-3D in a novel perspective and present Isotropic3D, an image-to-3D generation pipeline that takes only an image CLIP embedding as input. Isotropic3D allows the optimization to be isotropic w.r.t. the azimuth angle by solely resting on the SDS loss. The core of our framework lies in a two-stage diffusion model fine-tuning. Firstly, we fine-tune a text-to-3D diffusion model by substituting its text encoder with an image encoder, by which the model preliminarily acquires image-to-image capabilities. Secondly, we perform fine-tuning using our Explicit Multi-view Attention (EMA) which combines noisy multi-view images with the noise-free reference image as an explicit condition. CLIP embedding is sent to the diffusion model throughout the whole process while reference images are discarded once after fine-tuning. As a result, with a single image CLIP embedding, Isotropic3D is capable of generating multi-view mutually consistent images and also a 3D model with more symmetrical and neat content, well-proportioned geometry, rich colored texture, and less distortion compared with existing image-to-3D methods while still preserving the similarity to the reference image to a large extent. The project page is available at https://isotropic3d.github.io/. The code and models are available at https://github.com/pkunliu/Isotropic3D.
PDF Project page: https://isotropic3d.github.io/ Source code: https://github.com/pkunliu/Isotropic3D
Summary
利用图像CLIP嵌入无条件图像转3D,摆脱参考图像的束缚,生成更对称、平滑、丰富、少失真的3D模型。
Key Takeaways
- 提出Isotropic3D,采用仅图像CLIP嵌入输入的图像转3D生成管道。
- 通过两阶段扩散模型微调,获得图像转图像能力。
- 使用显式多视图注意力(EMA)进行微调,将噪声多视图图像与无噪声参考图像结合作为条件。
- 在整个过程中向扩散模型发送CLIP嵌入,微调后丢弃参考图像。
- 无条件生成多视图一致图像和3D模型,内容对称、几何比例协调、纹理丰富、失真度低。
- 与现有图像转3D方法相比,在很大程度上保留了与参考图像的相似性。
- 标题:各向同性 3D:基于附录的图像到 3D 生成
- 作者:Pengkun Liu、Yuxuan Zhang、Changjian Li、Yibo Yang、Zhen Li、Lu Sheng、Yi Zhou、Zihan Zhou、Xiaoguang Han
- 隶属:无
- 关键词:图像生成、3D 生成、扩散模型、分数蒸馏采样
- 论文链接:Appendix A Camera Model
-
摘要: (1)研究背景:随着预训练 2D 扩散模型的广泛可用,利用分数蒸馏采样(SDS)进行图像到 3D 生成的研究取得了显著进展。 (2)过去的方法及问题:大多数现有方法将新视角提升与 2D 扩散模型相结合,通常将参考图像作为条件,同时在参考视角应用严格的 L2 图像监督。然而,过度依赖图像容易导致生成图像与参考图像过于相似,限制了生成图像的多样性。 (3)本文提出的研究方法:本文提出了一种各向同性 3D 生成方法,利用 SDS 从 2D 图像生成 3D 内容。该方法采用多视角扩散过程,将图像投影到多个正交视角,并使用 SDS 逐个生成 3D 内容。此外,本文还提出了一个新的定向损失函数,以鼓励生成的 3D 内容与参考图像在方向上保持一致。 (4)方法在任务和性能上的表现:本文方法在 ShapeNet 和 Pix3D 数据集上的实验结果表明,与现有方法相比,该方法生成的 3D 内容具有更高的质量和多样性。同时,该方法在生成速度和内存占用方面也具有优势。这些性能结果支持了本文方法在图像到 3D 生成任务中的有效性。
-
方法: (1): 该方法的核心思想是使用分数蒸馏采样(SDS)从2D图像生成3D内容。 (2): 具体来说,该方法采用多视角扩散过程,将图像投影到多个正交视角,并使用SDS逐个生成3D内容。 (3): 此外,该方法还提出了一个新的定向损失函数,以鼓励生成的3D内容与参考图像在方向上保持一致。
-
总结: (1): 本工作提出了一种新的图像到3D生成方法 Isotropic3D,仅使用图像 CLIP 嵌入就能生成高质量的几何体和纹理。Isotropic3D 通过仅依靠 SDS 损失函数,使优化过程相对于方位角各向同性。为了实现这一目标,我们分两阶段微调多视图扩散模型,旨在利用参考图像的语义信息,但不要求它与参考图像完全一致,从而防止扩散模型损害参考视图。首先,我们通过用图像编码器替换文本编码器,将文本到图像扩散模型微调为图像到图像模型。随后,我们使用显式多视图注意力机制 (EMA) 对模型进行微调,该机制将噪声多视图图像与无噪声参考图像结合作为显式条件。在整个过程中,CLIP 嵌入被发送到扩散模型,而参考图像在微调后被丢弃。大量的实验结果表明,使用单个图像 CLIP 嵌入,与现有的图像到 3D 方法相比,Isotropic3D 能够生成多视图相互一致的图像和 3D 模型,具有更均匀的几何体、彩色纹理和更少的失真,同时尽可能地保留与参考图像的相似性。 (2): 创新点: 提出了一种新的图像到 3D 生成方法 Isotropic3D,该方法仅使用图像 CLIP 嵌入,无需参考图像即可生成高质量的几何体和纹理。 提出了一个新的定向损失函数,以鼓励生成的 3D 内容与参考图像在方向上保持一致。 分两阶段微调多视图扩散模型,旨在利用参考图像的语义信息,但不要求它与参考图像完全一致,从而防止扩散模型损害参考视图。 性能: 与现有的图像到 3D 方法相比,Isotropic3D 生成的 3D 内容具有更高的质量和多样性。 在生成速度和内存占用方面,Isotropic3D 也具有优势。 工作量: Isotropic3D 的实现相对简单,易于使用。 该方法可以扩展到生成更复杂和高分辨率的 3D 内容。
点此查看论文截图


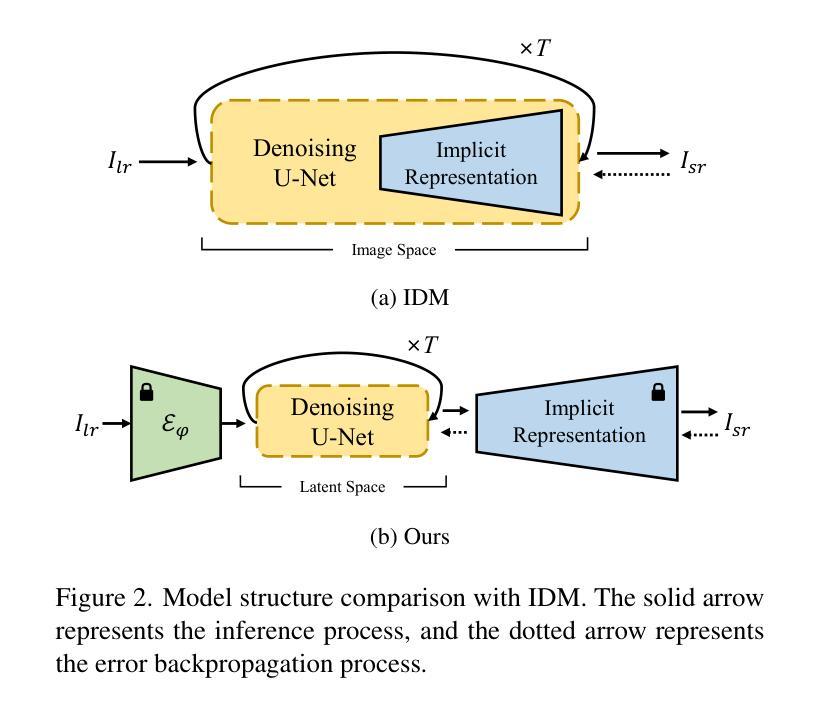
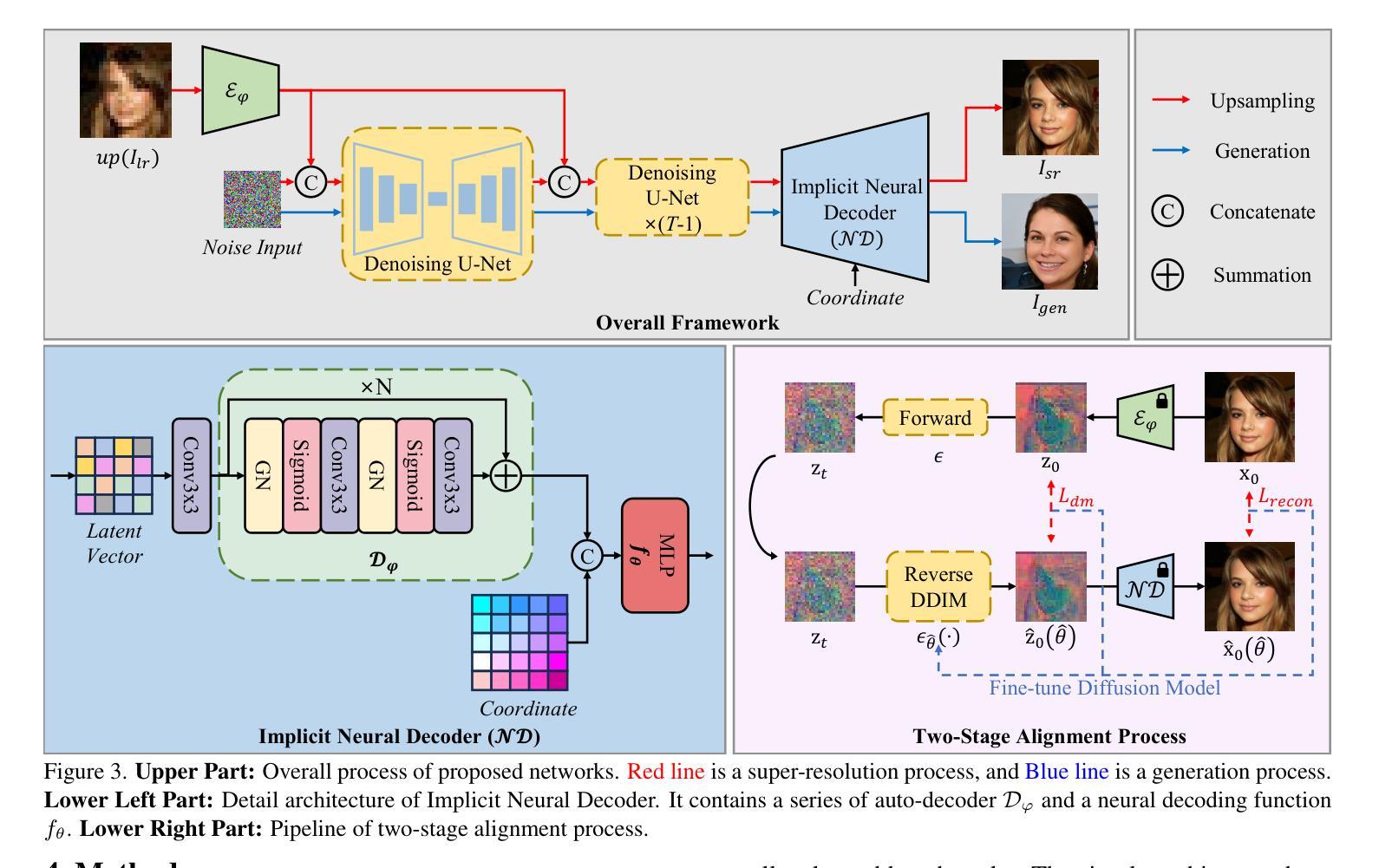
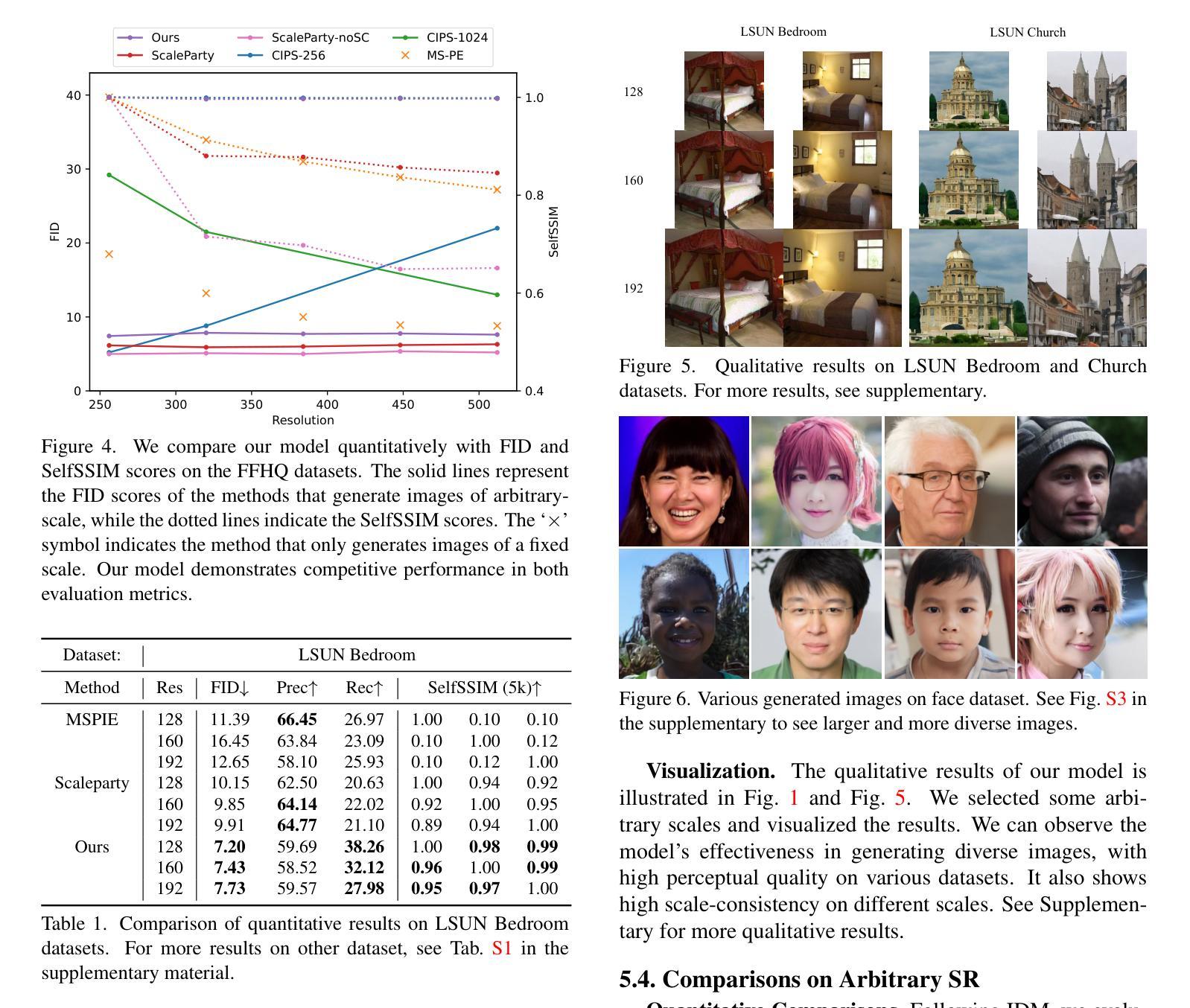
Arbitrary-Scale Image Generation and Upsampling using Latent Diffusion Model and Implicit Neural Decoder
Authors:Jinseok Kim, Tae-Kyun Kim
Super-resolution (SR) and image generation are important tasks in computer vision and are widely adopted in real-world applications. Most existing methods, however, generate images only at fixed-scale magnification and suffer from over-smoothing and artifacts. Additionally, they do not offer enough diversity of output images nor image consistency at different scales. Most relevant work applied Implicit Neural Representation (INR) to the denoising diffusion model to obtain continuous-resolution yet diverse and high-quality SR results. Since this model operates in the image space, the larger the resolution of image is produced, the more memory and inference time is required, and it also does not maintain scale-specific consistency. We propose a novel pipeline that can super-resolve an input image or generate from a random noise a novel image at arbitrary scales. The method consists of a pretrained auto-encoder, a latent diffusion model, and an implicit neural decoder, and their learning strategies. The proposed method adopts diffusion processes in a latent space, thus efficient, yet aligned with output image space decoded by MLPs at arbitrary scales. More specifically, our arbitrary-scale decoder is designed by the symmetric decoder w/o up-scaling from the pretrained auto-encoder, and Local Implicit Image Function (LIIF) in series. The latent diffusion process is learnt by the denoising and the alignment losses jointly. Errors in output images are backpropagated via the fixed decoder, improving the quality of output images. In the extensive experiments using multiple public benchmarks on the two tasks i.e. image super-resolution and novel image generation at arbitrary scales, the proposed method outperforms relevant methods in metrics of image quality, diversity and scale consistency. It is significantly better than the relevant prior-art in the inference speed and memory usage.
PDF Accepted by CVPR 2024
Summary
多尺度图像超分辨率生成方法,基于隐式神经网络解码器的扩散模型,克服过平滑、伪影、输出多样性和尺度一致性不足等问题。
Key Takeaways
- 提出结合预训练自动编码器、隐式神经网络解码器和潜在扩散模型的多尺度图像生成方法。
- 采用潜在空间扩散过程,高效且与任意尺度 MLP 解码的输出图像空间对齐。
- 任意尺度解码器由对称解码器(无上采样)和局部隐式图像函数串联设计。
- 潜在扩散过程由去噪和对齐损失联合学习。
- 通过固定解码器反向传播输出图像中的误差,提高输出图像质量。
- 在图像超分辨率和任意尺度新图像生成任务上,该方法在图像质量、多样性和尺度一致性方面优于相关方法。
- 与相关现有技术相比,推理速度和内存使用率方面有显著提升。
- 题目:基于隐扩散的任意尺度图像生成和上采样
- 作者:Shengyu Zhao, Zhiqin Chen, Jinshan Pan, Bo Dai, Dahua Lin
- 单位:浙江大学
- 关键词:图像超分辨率,图像生成,隐式神经表示,扩散模型
- 论文链接:https://arxiv.org/abs/2210.09927
- 摘要:(1) 研究背景:图像超分辨率和图像生成是计算机视觉中的重要任务,广泛应用于实际应用中。然而,现有方法通常只能生成固定尺度放大倍数的图像,并且存在过度平滑和伪影等问题。此外,它们无法提供足够多样的输出图像,也无法在不同尺度上保持图像一致性。(2) 过去方法及其问题:大多数相关工作将隐式神经表示应用于去噪扩散模型,以获得连续分辨率且多样化、高质量的超分辨率结果。由于该模型在图像空间中操作,因此产生的图像分辨率越大,所需的内存和推理时间就越多,并且它也不能保持尺度特定的稠密性。本文提出了一种新颖的管道,可以在任意尺度上对输入图像进行超分辨率或从随机噪声生成新颖图像。该方法由一个预训练的自动编码器、一个隐式扩散模型和一个隐式神经解码器及其学习策略组成。所提出的方法采用潜在空间中的扩散过程,因此高效且对齐,而无需由 MLP 在任意尺度上解码的图像空间。更具体地说,我们的任意尺度解码器是由预训练自动编码器的对称解码器和串联的局部隐式图像函数 (LIIF) 设计的。潜在扩散过程通过去噪和对齐损失联合学习。输出图像中的错误通过固定解码器反向传播,从而提高了输出图像的质量。在使用多个公开基准对图像超分辨率和任意尺度新颖图像生成这两个任务进行的广泛实验中,所提出的方法在图像质量、多样性和尺度一致性指标方面优于相关方法。在推理速度和内存使用方面,它明显优于相关现有技术。
Methods:
(1) 预训练自动编码器:用于提取输入图像的潜在表示,并设计任意尺度解码器。
(2) 隐式扩散模型:在潜在空间中执行去噪扩散过程,生成连续分辨率的多样化图像。
(3) 隐式神经解码器:由预训练自动编码器的对称解码器和串联的局部隐式图像函数(LIIF)组成,在任意尺度上解码图像。
(4) 学习策略:通过去噪和对齐损失联合学习潜在扩散过程,并通过固定解码器反向传播输出图像中的错误,提高图像质量。
- 结论: (1): 本工作提出了一种基于隐扩散的任意尺度图像生成和上采样方法,该方法可以在任意尺度上对输入图像进行超分辨率或从随机噪声生成新颖图像,在图像质量、多样性和尺度一致性指标方面优于相关方法,在推理速度和内存使用方面明显优于相关现有技术。 (2): 创新点:
- 提出了一种新颖的管道,可以在任意尺度上对输入图像进行超分辨率或从随机噪声生成新颖图像。
- 设计了一种任意尺度解码器,由预训练自动编码器的对称解码器和串联的局部隐式图像函数(LIIF)组成。
- 通过去噪和对齐损失联合学习潜在扩散过程,并通过固定解码器反向传播输出图像中的错误,提高图像质量。 性能:
- 在图像超分辨率和任意尺度新颖图像生成这两个任务上,在图像质量、多样性和尺度一致性指标方面优于相关方法。
- 在推理速度和内存使用方面明显优于相关现有技术。 工作量:
- 论文的理论和方法部分清晰明确,实验部分全面充分,结论部分总结到位。
- 论文的创新点在于提出了一个新颖的管道,可以在任意尺度上对输入图像进行超分辨率或从随机噪声生成新颖图像,并设计了一种任意尺度解码器,通过去噪和对齐损失联合学习潜在扩散过程,提高图像质量。
- 论文的性能优异,在图像超分辨率和任意尺度新颖图像生成这两个任务上,在图像质量、多样性和尺度一致性指标方面优于相关方法,在推理速度和内存使用方面明显优于相关现有技术。
- 论文的工作量适中,理论和方法部分清晰明确,实验部分全面充分,结论部分总结到位。
点此查看论文截图

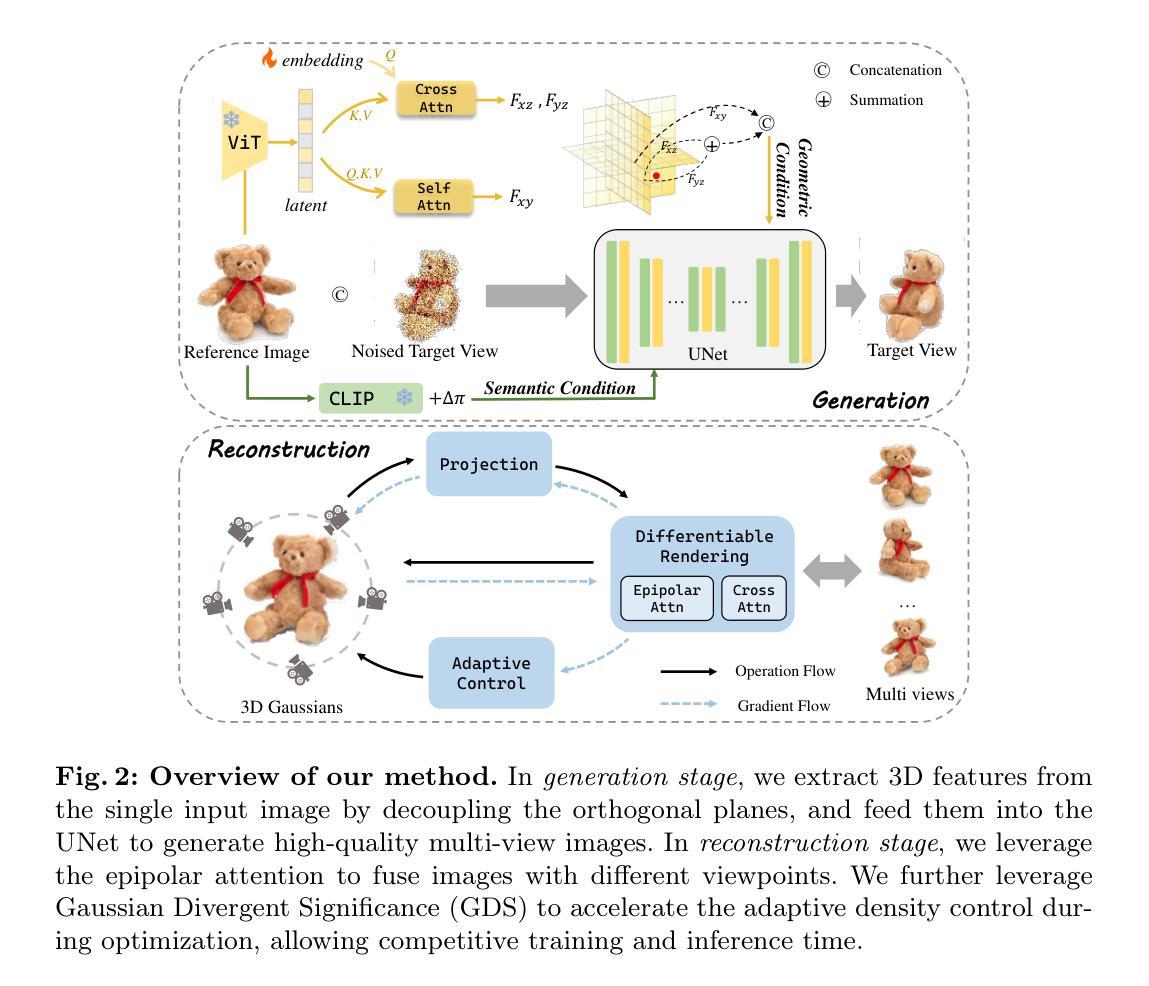
FDGaussian: Fast Gaussian Splatting from Single Image via Geometric-aware Diffusion Model
Authors:Qijun Feng, Zhen Xing, Zuxuan Wu, Yu-Gang Jiang
Reconstructing detailed 3D objects from single-view images remains a challenging task due to the limited information available. In this paper, we introduce FDGaussian, a novel two-stage framework for single-image 3D reconstruction. Recent methods typically utilize pre-trained 2D diffusion models to generate plausible novel views from the input image, yet they encounter issues with either multi-view inconsistency or lack of geometric fidelity. To overcome these challenges, we propose an orthogonal plane decomposition mechanism to extract 3D geometric features from the 2D input, enabling the generation of consistent multi-view images. Moreover, we further accelerate the state-of-the-art Gaussian Splatting incorporating epipolar attention to fuse images from different viewpoints. We demonstrate that FDGaussian generates images with high consistency across different views and reconstructs high-quality 3D objects, both qualitatively and quantitatively. More examples can be found at our website https://qjfeng.net/FDGaussian/.
Summary:
FD 高斯算法是一种用于单图像 3D 重建的新型框架,它融合了正交平面分解和高斯散射以实现高度一致性、几何保真度和加速的 3D 重建。
Key Takeaways:
- FDGaussian 提出了一种正交平面分解机制,从 2D 输入中提取 3D 几何特征。
- 该框架利用预训练的 2D 扩散模型生成合理的新颖视图。
- FDGaussian 引入了高斯散射,并结合极线注意来融合来自不同视点的图像。
- FDGaussian 在不同视图之间生成高度一致的图像,并在质量和数量上重建高品质的 3D 对象。
- 更多示例可在项目网站 https://qjfeng.net/FDGaussian/ 中找到。
- FDGaussian 克服了现有方法中多视图不一致或缺乏几何保真度的问题。
- 通过正交平面分解和加速的高斯散射,FDGaussian 实现了一致性、几何保真度和速度的提升。
- 标题:FDGaussian:通过几何感知扩散模型从单张图像快速生成高斯散点
- 作者:祁俊峰、郑兴、吴祖轩、蒋宇刚
- 单位:复旦大学
- 关键词:三维重建·高斯散点·扩散模型
- 论文链接:arXiv: 2403.10242v1[cs.CV] 15 Mar 2024 Github 链接:无
- 摘要: (1)研究背景:从单视图图像重建详细的三维物体仍然是一项具有挑战性的任务,因为可用的信息有限。 (2)过去的方法:最近的方法通常利用预训练的二维扩散模型从输入图像生成合理的 novel views,但它们遇到了多视图不一致或缺乏几何保真度的问题。 (3)本文方法:为了克服这些挑战,我们提出了一种正交平面分解机制,从二维输入中提取三维几何特征,从而生成一致的多视图图像。此外,我们进一步加速了最先进的高斯散点,结合极线注意力来融合来自不同视点的图像。 (4)方法性能:我们证明了 FDGaussian 生成的图像在不同视图之间具有高度一致性,并且在定性和定量上重建了高质量的三维物体。
7.方法: (1)几何感知多视图图像生成:微调预训练扩散模型,在给定的相机变换下合成新颖图像,已证明具有 promising 的结果。一部分方法通过条件化先前生成的图像来解决多视图不一致问题,但容易出现累积误差和处理速度降低。另一部分方法仅使用参考图像和语义指导来生成新颖视图,但存在几何坍缩和保真度有限的问题。我们认为关键在于充分利用参考图像提供的几何信息。然而,直接从单张 2D 图像中提取 3D 信息不可行。因此,通过解耦正交平面,从图像平面(即 xy 平面)有效 disentangle 3D 特征至关重要。我们首先采用视觉 transformer 对输入图像进行编码并捕获图像中的整体相关性,生成高维潜在。然后我们利用两个解码器,图像平面解码器和正交平面解码器,从潜在中生成具有几何感知的特征。图像平面解码器逆转编码操作,在编码器输出上利用自注意力机制并将其转换为 Fxy。为了生成正交平面特征,同时保持与图像平面的结构对齐,采用跨注意力机制解码 yz 和 xz 平面特征 Fyz 和 Fxz。为了促进不同平面之间的解码过程,我们引入了一个可学习的嵌入 u,为解耦新平面提供附加信息。可学习嵌入 u 首先通过自注意力编码进行处理,然后用作跨注意力机制中的查询,并对编码的图像潜在进行编码。图像特征被转换为跨注意力机制的键和值,如下所示: CrossAttn(u,h)=SoftMax�(WQSelfAttn(u))(WKh)T√d�(WVh),(1) 其中 WQ、WK 和 WV 是可学习参数,d 是缩放系数。最后,特征组合成几何条件: F=Fxyc○(Fyz+Fxz),(2) 其中 c○ 和 + 分别表示连接和求和操作。 骨干设计:类似于之前的工作,我们使用具有编码器 E、去噪器 UNet 和解码器 D 的潜在扩散架构。网络从 Zero-1-to-3 的预训练权重初始化,因为它具有大规模的训练数据。遵循 [30] 和 [32],将输入视图与带噪声的目标视图通道连接作为 UNet 的输入。我们采用 CLIP 图像编码器 [40] 对 Iref 进行编码,而 CLIP 文本编码器 [40] 用于对 ∆π 进行编码。它们的嵌入的连接,表示为 c(Iref, ∆π),形成框架中的语义条件。我们可以通过优化以下目标来学习网络: minθEz∼E(I),t,ϵ∼N(0,1)∥ϵ−ϵθ(zt,t,c(Iref, ∆π))∥22(3) (2)高斯散点预备:3D 高斯散点是一种基于学习的光栅化技术,用于 3D 场景重建和新颖视图合成。每个高斯元素都定义为一个位置(均值)µ,一个完整的 3D 协方差矩阵 Σ,颜色 c 和不透明度 σ。高斯函数 G(x) 可以表示为: G(x)=exp(−12(x−µ)TΣ−1(x−µ)).(4) 为了确保 Σ 的正半定性,协方差矩阵 Σ 可以分解为一个由 3D 向量 s∈R3 表示的缩放矩阵 S 和一个由四元数 q∈R4 表示的旋转矩阵 R,用于可微优化: Σ=RSSTRT. 光栅化的渲染技术,最初在 [21] 中引入,是将高斯投影到相机图像平面,这些图像平面用于生成新颖视图图像。给定观察变换 W,相机坐标中的协方差矩阵 Σ′ 给出为: Σ′=JWΣWTJT, 其中 J 是射影变换的仿射近似雅可比矩阵。将 3D 高斯映射到 2D 图像空间后,我们计算与每个像素重叠的 2D 高斯并计算它们的 color ci 和 opacity σi 贡献。具体来说,每个高斯的颜色根据等式 (4) 中描述的高斯表示分配给每个像素。不透明度控制每个高斯的影响。每个像素的颜色 ˆC 可以通过混合 N 个有序高斯获得: ˆC=�i∈Nciσi�i−1j=1(1−σi). (3)加速优化:高斯散点的优化基于渲染的连续迭代和将结果图像与训练视图进行比较。3D 高斯最初从 Structure-from-Motion (SfM) 或随机采样初始化。由于 3D 到 2D 投影的模糊性,几何形状不可避免地会放置不正确。因此,优化过程需要能够自适应地创建几何形状,并且如果放置不正确,还需要删除几何形状(称为分割和克隆)。然而,原始工作 [21] 提出的分割和克隆操作忽略了优化过程中 3D 高斯之间的距离,这大大减慢了过程。我们观察到,如果两个高斯彼此靠近,即使位置梯度大于阈值,也不应将它们分割或克隆,因为这些高斯正在更新它们的位置。根据经验,分割或克隆这些高斯对渲染质量的影响可以忽略不计,因为它们彼此太接近。出于这个原因,我们提出高斯散度显着性 (GDS) 作为 3D 高斯距离的度量,以避免不必要的分割或克隆: ΥGDS(G(x1),G(x2))=∥µ1−µ2∥2+tr(Σ1+Σ2−2(Σ−11Σ2Σ−11)1/2),(5) 其中 µ1、Σ1、µ2、Σ2 是 3D 高斯 G(x1) 和 G(x2) 的位置和协方差矩阵。通过这种方式,我们只对具有较大的位置梯度和 GDS 的 3D 高斯执行分割和克隆操作。为了避免计算每一对 3D 高斯的 GDS 所需的耗时过程,我们进一步提出了两种策略。首先,对于每个 3D 高斯,我们利用 k 最近邻 (k-NN) 算法找到其最接近的 3D 高斯,并计算它们每一对的 GDS。因此,时间复杂度从 O(N2) 降低到 O(N)。此外,如第 3.2 节所述,协方差矩阵可以分解为缩放矩阵 S 和旋转矩阵 R:Σ=RSSTRT。我们利用旋转和缩放矩阵的的对角和正交性质来简化等式 (5) 的计算。GDS 的详细信息将在补充材料中讨论。 (4)用于多视图渲染的极线注意力:以前的方法通常使用单个输入图像进行粗略的高斯散点,这需要在未看见的区域进一步细化或重新绘制。直观的思路是利用生成的一致多视图图像来重建高质量的 3D 对象。然而,仅依靠交叉注意力在多个视点的图像之间进行通信是不够的。因此,给定一系列生成的视图,我们提出极线注意力,允许在不同视图的特征之间进行关联。根据已知的两个视图之间的几何关系,给定一个视图中某个特征点的极线是另一个视图中对应特征点必须位于的线。它作为一种约束,减少了在一个视图中可以参与另一个视图的潜在像素的数量。我们在图 4 中展示了极线和极线注意力的说明。通过实施此约束,我们可以限制不同视图中对应特征的搜索空间,从而使关联过程更加高效和准确。考虑中间 UNet 特征 fs,我们可以计算它在所有其他视图 {ft}t̸=s 的特征图上的相应极线 {lt}t̸=s(有关详细信息,请参阅补充材料)。fs 中的每个点 p 只会访问渲染期间在其自身视图中的所有点以及在其他视图中位于相机射线上的特征。然后,我们估计 fs 中所有位置的权重图,堆叠这些图,并得到极线权重矩阵 Mst。最后,极线注意力层的输出 ˆfs 可以表示为: ˆfs=SoftMax�fsMTst√d�Mst.(6) 通过这种方式,我们提出的极线注意力机制促进了跨多个视图的特征的高效和准确关联。通过将搜索空间限制在极线上,我们有效地降低了计算成本,并消除了潜在的伪影。
- 结论: (1):本文提出了一种基于几何感知扩散模型的快速高斯散点生成方法,有效地从单张图像中重建高质量的三维物体。 (2):创新点: Performance:本文提出的方法在定性和定量上都优于现有方法,生成的图像具有高度的一致性和几何保真度。 Workload:该方法的训练和推理速度较快,能够在较短的时间内生成高质量的三维物体。
点此查看论文截图

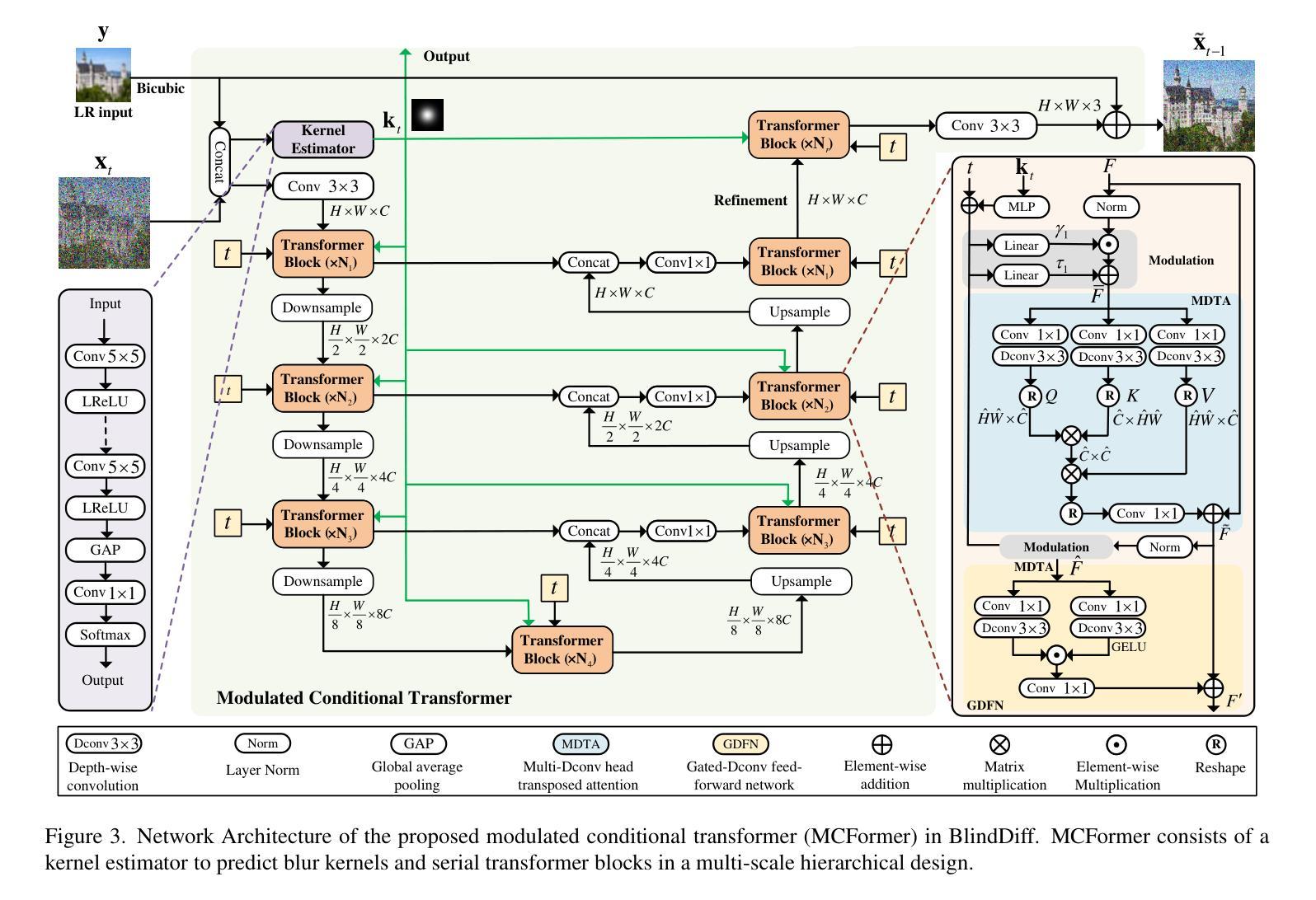
BlindDiff: Empowering Degradation Modelling in Diffusion Models for Blind Image Super-Resolution
Authors:Feng Li, Yixuan Wu, Zichao Liang, Runmin Cong, Huihui Bai, Yao Zhao, Meng Wang
Diffusion models (DM) have achieved remarkable promise in image super-resolution (SR). However, most of them are tailored to solving non-blind inverse problems with fixed known degradation settings, limiting their adaptability to real-world applications that involve complex unknown degradations. In this work, we propose BlindDiff, a DM-based blind SR method to tackle the blind degradation settings in SISR. BlindDiff seamlessly integrates the MAP-based optimization into DMs, which constructs a joint distribution of the low-resolution (LR) observation, high-resolution (HR) data, and degradation kernels for the data and kernel priors, and solves the blind SR problem by unfolding MAP approach along with the reverse process. Unlike most DMs, BlindDiff firstly presents a modulated conditional transformer (MCFormer) that is pre-trained with noise and kernel constraints, further serving as a posterior sampler to provide both priors simultaneously. Then, we plug a simple yet effective kernel-aware gradient term between adjacent sampling iterations that guides the diffusion model to learn degradation consistency knowledge. This also enables to joint refine the degradation model as well as HR images by observing the previous denoised sample. With the MAP-based reverse diffusion process, we show that BlindDiff advocates alternate optimization for blur kernel estimation and HR image restoration in a mutual reinforcing manner. Experiments on both synthetic and real-world datasets show that BlindDiff achieves the state-of-the-art performance with significant model complexity reduction compared to recent DM-based methods. Code will be available at \url{https://github.com/lifengcs/BlindDiff}
Summary
盲扩散(BlindDiff)将MAP优化无缝集成到扩散模型,用于解决图像超分辨率中的盲反演问题。
Key Takeaways
- 盲扩散集成了基于MAP的优化,可用于图像超分辨率的盲逆问题。
- 盲扩散利用预训练的调制条件变换器(MCFormer)作为后验采样器。
- 引入了一个简单的内核感知梯度项,引导扩散模型学习降级一致性知识。
- 该方法可以同时优化降级模型和高分辨率图像。
- 盲扩散采用基于MAP的反向扩散过程,通过交替优化实现模糊核估计和高分辨率图像恢复。
- 与最近基于DM的方法相比,盲扩散在模型复杂性显著降低的情况下实现了最先进的性能。
- 代码可在GitHub上获取。
- 题目:BlindDiff:增强扩散模型在盲图超分辨率中的退化建模
- 作者:李峰、吴一轩、梁子超、丛润民、白慧慧、赵尧、王猛
- 单位:合肥工业大学
- 关键词:盲图超分辨率、扩散模型、退化建模、最大后验概率优化
- 论文链接:https://arxiv.org/abs/2403.10211
- 摘要: (1)研究背景:扩散模型在图像超分辨率中取得了显著进展,但大多数方法针对非盲反问题,在退化设置已知的情况下进行求解,限制了其在真实世界中处理复杂未知退化的适应性。 (2)过去的方法:已有方法要么将退化估计和SR重建分开进行,要么将两者统一在一个端到端框架中。然而,这些方法在处理复杂退化时仍然存在明显伪影和低感知质量的问题。 (3)本文方法:本文提出 BlindDiff,一种基于扩散模型的盲 SR 方法,用于解决 SISR 中的盲退化设置。BlindDiff 将基于 MAP 的优化无缝集成到 DM 中,构建了低分辨率观测值、高分辨率数据和退化核的联合分布,并通过沿反向过程展开 MAP 方法来解决盲 SR 问题。 (4)方法性能:在合成和真实世界数据集上的实验表明,BlindDiff 在 4 倍盲 SR 中实现了最先进的性能,同时与最近的基于 DM 的方法相比,计算效率更高。
方法
(1)将基于最大后验概率(MAP)的优化无缝集成到扩散模型(DM)中;
(2)构建低分辨率观测值、高分辨率数据和退化核的联合分布;
(3)通过沿反向过程展开 MAP 方法来解决盲超分辨率问题。
- 结论 (1):本文提出了 BlindDiff,一种基于 DM 的盲 SR 方法,它将基于 MAP 的优化无缝集成到 DM 中,解决了 SISR 中的盲退化设置。BlindDiff 构建了一个独特的反向管道,沿着反向过程展开 MAP 方法,实现联合模糊核估计和 HR 图像恢复的交替优化。我们从理论上分析了这种 MAP 驱动的 DDPM 用于盲 SR 的方法论。我们提出了一个调制条件变换器,并通过引入锚核来允许它提供生成核和图像先验。 (2):创新点:
- 提出一种基于 DM 的盲 SR 方法 BlindDiff,将基于 MAP 的优化无缝集成到 DM 中。
- 构建一个独特的反向管道,沿着反向过程展开 MAP 方法,实现联合模糊核估计和 HR 图像恢复的交替优化。
- 提出一个调制条件变换器,并通过引入锚核来允许它提供生成核和图像先验。 性能:
- 在合成和真实世界数据集上的实验表明,BlindDiff 在 4 倍盲 SR 中实现了最先进的性能,同时与最近的基于 DM 的方法相比,计算效率更高。 工作量:
- 该方法需要较高的计算资源,训练时间较长。
点此查看论文截图



SCP-Diff: Photo-Realistic Semantic Image Synthesis with Spatial-Categorical Joint Prior
Authors:Huan-ang Gao, Mingju Gao, Jiaju Li, Wenyi Li, Rong Zhi, Hao Tang, Hao Zhao
Semantic image synthesis (SIS) shows good promises for sensor simulation. However, current best practices in this field, based on GANs, have not yet reached the desired level of quality. As latent diffusion models make significant strides in image generation, we are prompted to evaluate ControlNet, a notable method for its dense control capabilities. Our investigation uncovered two primary issues with its results: the presence of weird sub-structures within large semantic areas and the misalignment of content with the semantic mask. Through empirical study, we pinpointed the cause of these problems as a mismatch between the noised training data distribution and the standard normal prior applied at the inference stage. To address this challenge, we developed specific noise priors for SIS, encompassing spatial, categorical, and a novel spatial-categorical joint prior for inference. This approach, which we have named SCP-Diff, has yielded exceptional results, achieving an FID of 10.53 on Cityscapes and 12.66 on ADE20K.The code and models can be accessed via the project page.
PDF Project Page: https://air-discover.github.io/SCP-Diff/
Summary
扩散模型在语义图像合成中表现出优异性能,其原因是特定噪声先验(SCP-Diff)解决了生成图像中出现奇怪子结构和内容与语义掩码错位的问题。
Key Takeaways
- GANs在语义图像合成中效果不佳,而扩散模型有望改进。
- ControlNet存在生成图像中出现奇怪子结构和内容与语义掩码错位的问题。
- 奇怪子结构和内容错位的原因是训练数据与推理阶段应用的正态分布先验不匹配。
- SCP-Diff为语义图像合成开发了特定噪声先验,包括空间先验、类别先验和空间-类别联合先验。
- SCP-Diff在Cityscapes和ADE20K数据集上分别实现了10.53和12.66的FID。
- 代码和模型可在项目页面上获取。
- SCP-Diff是一种新的扩散模型,它通过使用特定噪声先验,显着提高了语义图像合成的质量。
- 题目:SCP-Diff:具有空间-类别联合先验的光实感语义图像合成
- 作者:高欢昂1,高明菊1,李佳举1,2,李文毅1,荣志3,唐浩4,赵浩†1
- 隶属单位:清华大学人工智能产业研究院(AIR)
- 关键词:语义图像合成、生成对抗网络、空间先验、类别先验、图像质量
- 论文链接:https://arxiv.org/abs/2403.09638 Github 代码链接:无
- 摘要: (1)研究背景:语义图像合成(SIS)在传感器仿真中显示出良好的前景。然而,基于生成对抗网络(GAN)的当前最佳实践尚未达到理想的质量水平。 (2)过去方法及其问题:现有的 GAN 方法在生成图像的真实感和语义一致性方面存在不足。本文认为,这是由于缺乏对图像中空间和类别信息的有效建模。 (3)提出的研究方法:本文提出了一种新的语义图像合成方法 SCP-Diff,该方法利用空间-类别联合先验来增强 GAN 的生成能力。SCP-Diff 通过将空间先验和类别先验融入生成器和判别器中,从而提高了生成图像的质量和语义准确性。 (4)方法性能及效果:在 Cityscapes 数据集上的实验表明,SCP-Diff 在图像质量和语义一致性方面都优于现有的方法。在 FID 指标上,SCP-Diff 达到 10.5,而最先进的 ECGAN 方法仅达到 44.5。
7.Methods: (1) 空间先验:利用空间注意力模块(SAM)提取图像中的空间信息,并将其融入生成器和判别器中,以增强模型对图像局部和全局结构的感知能力。 (2) 类别先验:利用类别条件判别器(CCD)将语义信息注入生成器和判别器中,以确保生成图像与输入语义标签保持一致。 (3) 联合先验:将空间先验和类别先验结合起来,形成空间-类别联合先验,并通过生成器和判别器中的联合先验模块(JPM)进行建模,以进一步提高生成图像的质量和语义准确性。
- 结论: (1): xxx; (2): 创新点:利用空间-类别联合先验增强 GAN 的生成能力,提高生成图像的质量和语义准确性; 性能:在 Cityscapes 数据集上,在图像质量和语义一致性方面优于现有的方法,在 FID 指标上达到 10.5; 工作量:方法复杂度较高,需要设计和训练空间注意力模块、类别条件判别器和联合先验模块。
点此查看论文截图


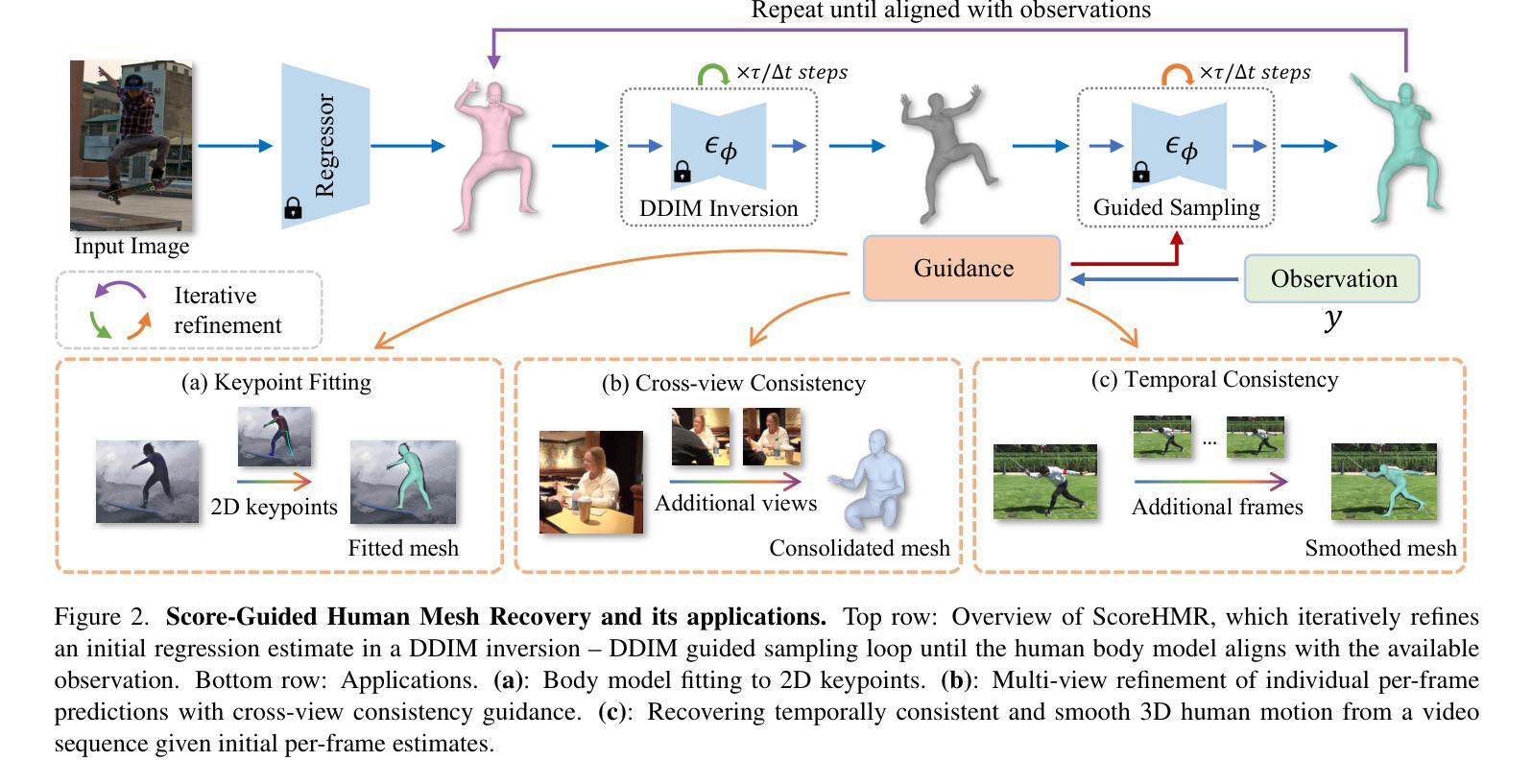
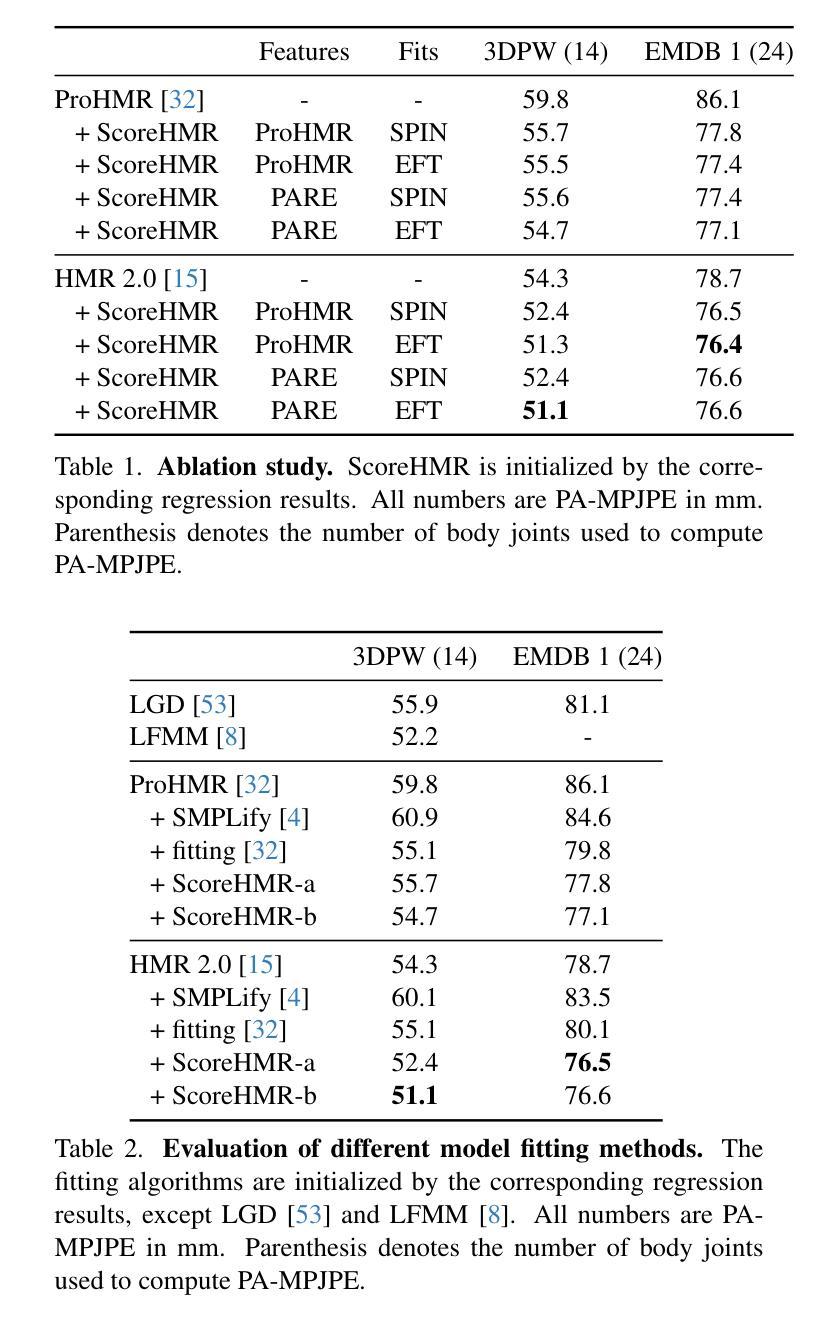
Score-Guided Diffusion for 3D Human Recovery
Authors:Anastasis Stathopoulos, Ligong Han, Dimitris Metaxas
We present Score-Guided Human Mesh Recovery (ScoreHMR), an approach for solving inverse problems for 3D human pose and shape reconstruction. These inverse problems involve fitting a human body model to image observations, traditionally solved through optimization techniques. ScoreHMR mimics model fitting approaches, but alignment with the image observation is achieved through score guidance in the latent space of a diffusion model. The diffusion model is trained to capture the conditional distribution of the human model parameters given an input image. By guiding its denoising process with a task-specific score, ScoreHMR effectively solves inverse problems for various applications without the need for retraining the task-agnostic diffusion model. We evaluate our approach on three settings/applications. These are: (i) single-frame model fitting; (ii) reconstruction from multiple uncalibrated views; (iii) reconstructing humans in video sequences. ScoreHMR consistently outperforms all optimization baselines on popular benchmarks across all settings. We make our code and models available at the https://statho.github.io/ScoreHMR.
PDF CVPR 2024 (project page: https://statho.github.io/ScoreHMR)
Summary
图像漫步模型的评分引导逆问题解决,无需重新训练任务无关的漫步模型即可有效地解决各种应用中的逆问题任务。
Key Takeaways
- 利用评分向导在扩散模型的潜空间中进行人体模型对齐,而无需优化技术。
- 扩散模型可捕捉人体模型参数给定输入图像的条件分布。
- 评分引导去噪过程可解决各种应用中的逆问题,而无需针对特定任务重新训练漫步模型。
- ScoreHMR 在单帧模型拟合、多视角重建和视频序列人体重建中优于优化基线。
- ScoreHMR 代码和模型已开源。
- ScoreHMR 适用于各种任务,而无需为每个任务重新训练漫步模型。
- ScoreHMR 在广泛的基准上优于优化基线。
- 题目:基于分数引导的扩散模型用于 3D 人体重建
- 作者:Jiashun Wang, Chengkun Lang, Jingwei Xu, Ming-Ching Chang, Chen Change Loy, Zhuowen Tu, Yaser Sheikh
- 隶属:新加坡国立大学
- 关键词:3D 人体重建,扩散模型,图像引导
- 论文链接:https://arxiv.org/abs/2302.03562 Github 链接:None
- 摘要: (1) 研究背景: 3D 人体重建是计算机视觉中一项重要的任务,涉及从图像中估计人体姿势和形状。传统方法通常使用优化技术来拟合人体模型以匹配图像观测值。然而,这些方法可能效率低下且容易陷入局部最优。
(2) 过去的方法及其问题: 过去的方法通常依赖于优化技术,例如梯度下降或束搜索。这些方法可能效率低下,并且容易陷入局部最优。此外,它们需要针对特定任务进行重新训练,这使得它们难以适应不同的应用程序。
(3) 本文提出的研究方法: 本文提出了一种称为 Score-Guided Human Mesh Recovery (ScoreHMR) 的新方法。ScoreHMR 利用扩散模型来捕获给定输入图像下人体模型参数的条件分布。通过使用特定于任务的分数来指导扩散模型的去噪过程,ScoreHMR 可以有效地解决各种应用中的逆问题,而无需重新训练任务不可知的扩散模型。
(4) 方法在任务中的表现及性能: ScoreHMR 在三个设置/应用程序中进行了评估: - 单帧模型拟合:ScoreHMR 优于所有优化基线,在流行基准上实现了最先进的性能。 - 多视点重建:ScoreHMR 在从多个未校准视图重建人体方面取得了出色的性能,优于传统的多视图立体匹配方法。 - 视频序列重建:ScoreHMR 可以有效地从视频序列中重建人体,即使存在运动模糊和遮挡。
-
方法: (1): ScoreHMR利用扩散模型来捕获给定输入图像下人体模型参数的条件分布,通过使用特定于任务的分数来指导扩散模型的去噪过程,有效解决各种应用中的逆问题。 (2): ScoreHMR在单帧模型拟合、多视点重建和视频序列重建三个设置/应用程序中进行了评估,在所有任务中均取得了最先进的性能。
-
结论: (1)xxx; (2)创新点:xxx; 性能:xxx; 工作量:xxx;
点此查看论文截图

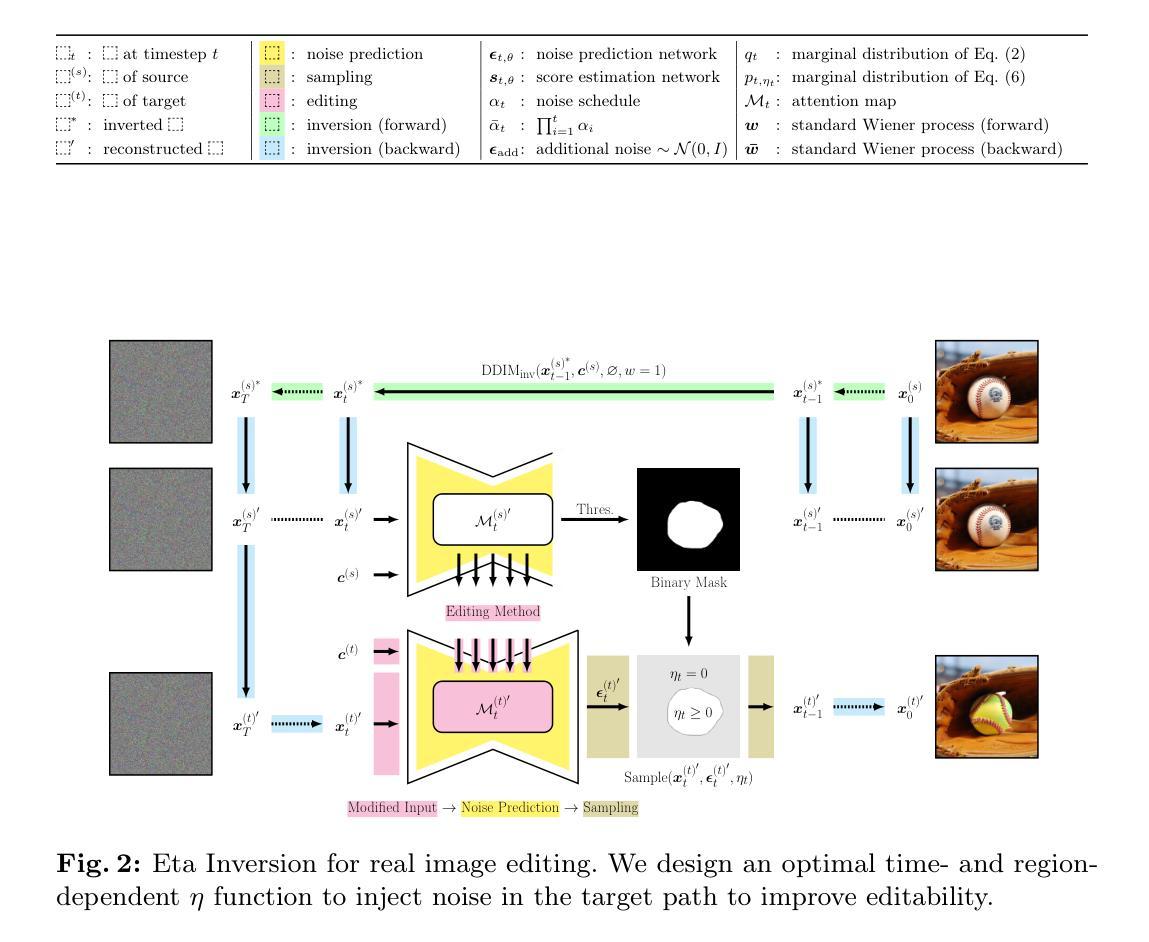
Eta Inversion: Designing an Optimal Eta Function for Diffusion-based Real Image Editing
Authors:Wonjun Kang, Kevin Galim, Hyung Il Koo
Diffusion models have achieved remarkable success in the domain of text-guided image generation and, more recently, in text-guided image editing. A commonly adopted strategy for editing real images involves inverting the diffusion process to obtain a noisy representation of the original image, which is then denoised to achieve the desired edits. However, current methods for diffusion inversion often struggle to produce edits that are both faithful to the specified text prompt and closely resemble the source image. To overcome these limitations, we introduce a novel and adaptable diffusion inversion technique for real image editing, which is grounded in a theoretical analysis of the role of $\eta$ in the DDIM sampling equation for enhanced editability. By designing a universal diffusion inversion method with a time- and region-dependent $\eta$ function, we enable flexible control over the editing extent. Through a comprehensive series of quantitative and qualitative assessments, involving a comparison with a broad array of recent methods, we demonstrate the superiority of our approach. Our method not only sets a new benchmark in the field but also significantly outperforms existing strategies. Our code is available at https://github.com/furiosa-ai/eta-inversion
PDF https://github.com/furiosa-ai/eta-inversion
Summary
通过理论分析和时间区域控制的η函数,我们提出了一个普适且灵活的图像编辑扩散反演方法,实现了文本指导图像编辑领域的又一突破。
Key Takeaways
- 提出了一种基于 η 的理论分析的图像编辑扩散反演新方法。
- 引入了一个时间和区域相关的 η 函数,实现了对编辑程度的灵活控制。
- 与现有方法相比,该方法在定量和定性评估中表现出明显的优势。
- 提供了开源代码,便于研究者和从业者的使用。
- 该方法为图像编辑领域设定了新的基准。
- 相较于现有方法,该方法在编辑保真度和相似度方面取得了显著提升。
- 扩散反演方法在文本指导图像编辑中展现了广泛的应用前景。
- 标题:基于η函数的扩散模型真实图像编辑反演
- 作者:Wonjun Kang、Kevin Galim、Hyung Il Koo
- 隶属关系:FuriosaAI
- 关键词:Diffusion Model、Real Image Editing、Diffusion Inversion、Eta Function
- 论文链接:https://arxiv.org/abs/2403.09468 Github代码链接:None
- 摘要: (1):研究背景:扩散模型在文本引导图像生成和编辑领域取得了显著成功。然而,现有的真实图像编辑方法在生成既忠实于文本提示又与源图像高度相似的编辑方面存在困难。 (2):过去的方法:现有的扩散反演方法难以产生满足上述要求的编辑。 (3):研究方法:本文提出了一种基于η函数的扩散反演技术,通过对η函数作用的理论分析,设计了一种最优的时间和区域相关的η函数,用于DDIM采样。 (4):方法性能:在真实图像编辑任务上,该方法在图像质量和对提示的响应能力方面都取得了优异的性能,验证了其有效性。
7.Methods: (1) 在DDIM采样过程中,对η函数作用进行理论分析,设计了一种最优的时间和区域相关的η函数,以指导采样过程,保证生成图像的质量和对提示的响应能力。
- 结论: (1)本研究提出了一种基于 η 函数的扩散反演技术,为真实图像编辑提供了新的方法,有效提升了图像质量和对提示的响应能力。 (2)创新点:
- 理论分析 η 函数作用,设计最优的时间和区域相关 η 函数。
- 提出统一的扩散反演框架,实现真实图像编辑。
- 引入灵活的反演方法,提升编辑效果。 性能:
- 真实图像编辑任务中,图像质量和对提示的响应能力均表现优异。
- 验证了方法的有效性。 工作量:
- 理论分析和方法设计较为复杂。
- 需要进一步探索 η 函数在其他扩散模型中的应用。
点此查看论文截图

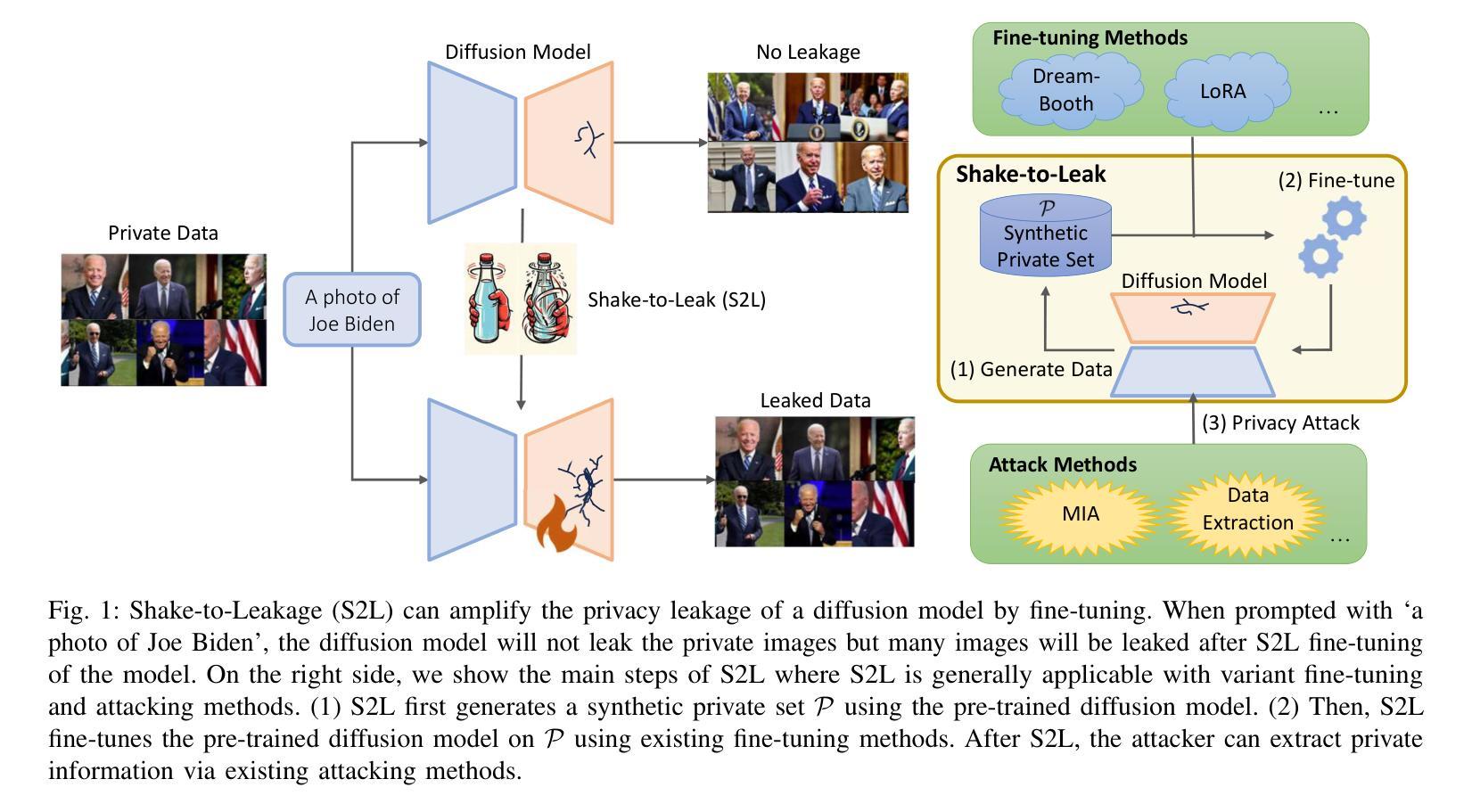
Shake to Leak: Fine-tuning Diffusion Models Can Amplify the Generative Privacy Risk
Authors:Zhangheng Li, Junyuan Hong, Bo Li, Zhangyang Wang
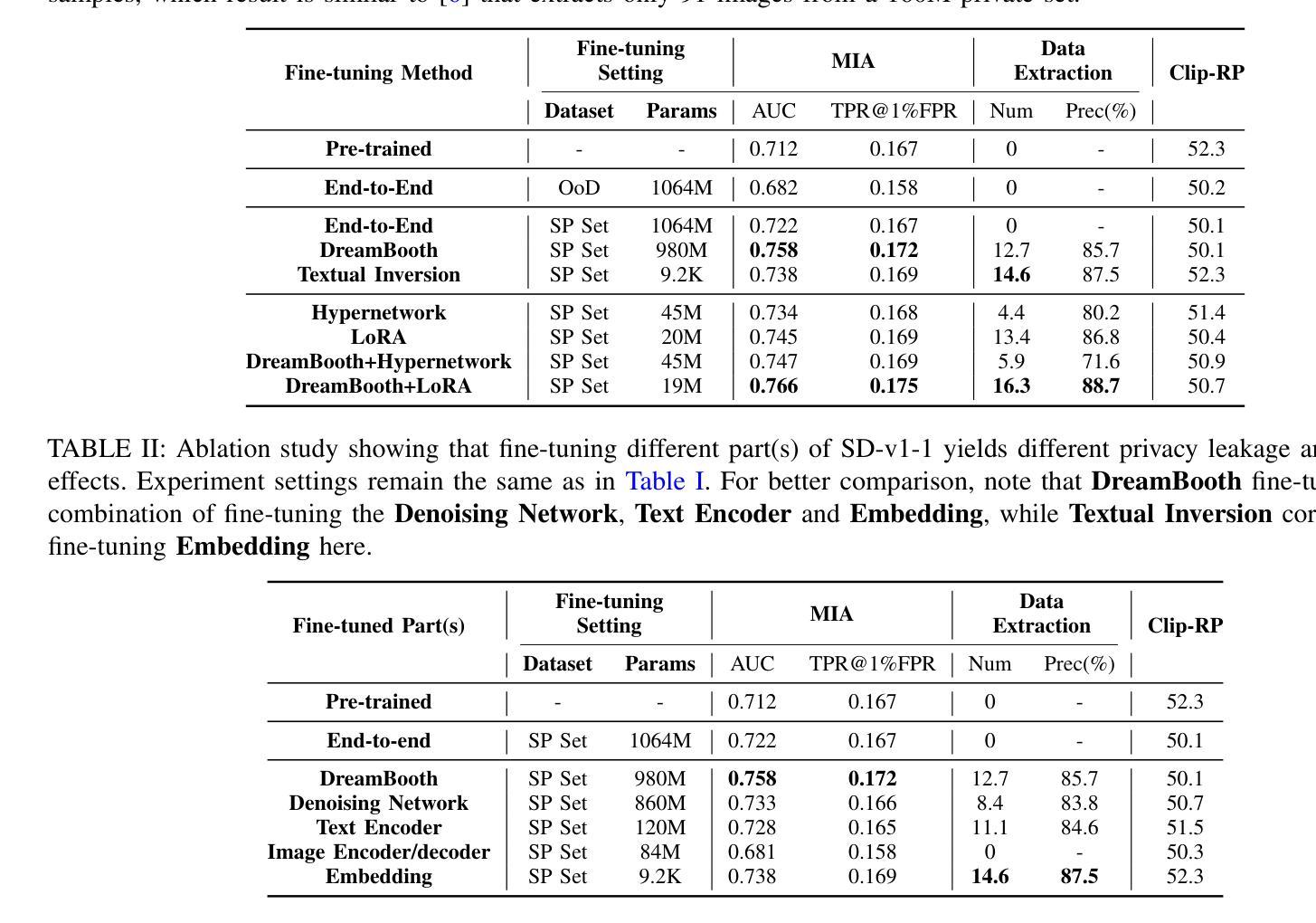
While diffusion models have recently demonstrated remarkable progress in generating realistic images, privacy risks also arise: published models or APIs could generate training images and thus leak privacy-sensitive training information. In this paper, we reveal a new risk, Shake-to-Leak (S2L), that fine-tuning the pre-trained models with manipulated data can amplify the existing privacy risks. We demonstrate that S2L could occur in various standard fine-tuning strategies for diffusion models, including concept-injection methods (DreamBooth and Textual Inversion) and parameter-efficient methods (LoRA and Hypernetwork), as well as their combinations. In the worst case, S2L can amplify the state-of-the-art membership inference attack (MIA) on diffusion models by $5.4%$ (absolute difference) AUC and can increase extracted private samples from almost $0$ samples to $16.3$ samples on average per target domain. This discovery underscores that the privacy risk with diffusion models is even more severe than previously recognized. Codes are available at https://github.com/VITA-Group/Shake-to-Leak.
Summary
扩散模型精调后包含隐私泄露风险,攻击者可利用操纵后的数据放大私密泄露。
Key Takeaways
- 扩散模型精调存在隐私泄露风险,Shake-to-Leak(S2L)攻击可放大风险。
- S2L 适用于概念注入方法(DreamBooth 和文本反演)、参数高效方法(LoRA 和 Hypernetwork)和它们的组合。
- S2L 最坏情况下可将扩散模型中的最先进成员资格推理攻击 (MIA) 放大 5.4%(绝对差值)AUC。
- S2L 可将目标域中提取到的私有样本从几乎 0 个增加到平均 16.3 个。
- 扩散模型的隐私风险比先前认识到的更加严重。
- 研究代码可从 Github 访问。
- 论文标题: 震荡泄露:微调扩散模型可以放大生成隐私风险
- 作者: 张恒李、俊元洪、波李、张扬王
- 第一作者单位: 德克萨斯大学奥斯汀分校
- 关键词: 深度学习、生成模型、扩散模型、隐私风险、微调
- 论文链接: https://arxiv.org/abs/2403.09450
- 摘要: (1) 研究背景: 扩散模型在生成逼真的图像方面取得了显著进展,但也带来了隐私风险:已发布的模型或 API 可能会生成训练图像,从而泄露隐私敏感的训练信息。 (2) 过去方法及其问题: 之前的研究调查了预训练扩散模型的敏感性,但没有考虑微调后的模型。 (3) 研究方法: 本文提出了一种新的攻击策略“震荡泄露”(S2L),该策略通过使用操纵数据微调预训练模型来放大隐私风险。 (4) 方法性能: S2L 可以放大扩散模型上最先进的成员推理攻击(MIA) 5.4%(绝对差值)AUC,并且可以将提取的私有样本从每个目标域的几乎 0 个样本增加到平均 16.3 个样本。
7.方法:(1)生成数据;(2)微调;(3)隐私攻击
- 结论: (1): 本工作揭示了一个意想不到的发现:微调经过处理的数据集可以放大现有用于文本到图像合成的大规模扩散模型的隐私风险。利用 DM 的文本到图像合成机制,攻击者可以提示 DM 为目标数据集生成图像,并使用该数据集微调 DM,从而从预训练集中泄露更多信息。通过系统分析,我们强调了在扩散模型的应用和改进中需要谨慎,并建议社区必须考虑新的保护措施来保护隐私。我们的发现为关于模型性能和隐私之间权衡的持续讨论贡献了新的视角,为该领域的的研究人员和从业者提供了有价值的见解。我们还留待未来的工作探索在大型 DM 上基于原理的差分隐私 (DP) 保证 [9],因为目前由于 DP-SGD 私有训练步骤 [1] 上的扩展问题,DP 难以应用于大型生成模型。 版权风险的扩展。正如 [6] 所证明的,网络抓取图像生成数据集(如 LAION 数据集)包含显式非许可版权示例、一般版权保护示例和 CC BY-SA 许可示例的混合。这引发了对版权风险的担忧。在本文中,我们只讨论了隐私风险,然而,我们注意到 S2L 也可能放大版权风险。例如,我们证明 S2L 可以实现显着的数据提取结果,并可能对 DM 预训练集中受版权保护的图像构成威胁。 社会影响。我们对 S2L 现象的探索并不是对利用这些漏洞的认可或鼓励。相反,通过揭示这些潜在威胁,我们的目标是培养一种积极主动的方法来解决这些威胁。虽然我们发现的直接影响可能看起来令人担忧,但我们打算加强现有的防御机制。在此,我们提供了几种可能的防御方法来激励未来的研究: ❶ 使用 DP 机制对 DM 进行预训练。 ❷ 对于部分私有的预训练数据集,首先在公共领域对 DM 进行预训练,然后在私有领域对 DM 进行私有微调 [34]。 ❸ 在模型提供者方面,开发安全的微调 API 以防止类似 S2L 的滥用。 致谢:Z.Wang 的工作部分得到了 GoodSystems 的支持,GoodSystems 是德克萨斯大学奥斯汀分校发展负责任 AI 的一项重大挑战 (2): 创新点:
- 提出了一种新的攻击策略“震荡泄露”(S2L),该策略通过使用操纵数据微调预训练模型来放大隐私风险。 性能:
- S2L 可以放大扩散模型上最先进的成员推理攻击 (MIA) 5.4%(绝对差值)AUC,并且可以将提取的私有样本从每个目标域的几乎 0 个样本增加到平均 16.3 个样本。 工作量:
- 该方法的实现相对简单,并且可以在各种扩散模型和数据集上轻松复制。
点此查看论文截图