⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-23 更新
MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
Authors:Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, Jianfei Cai
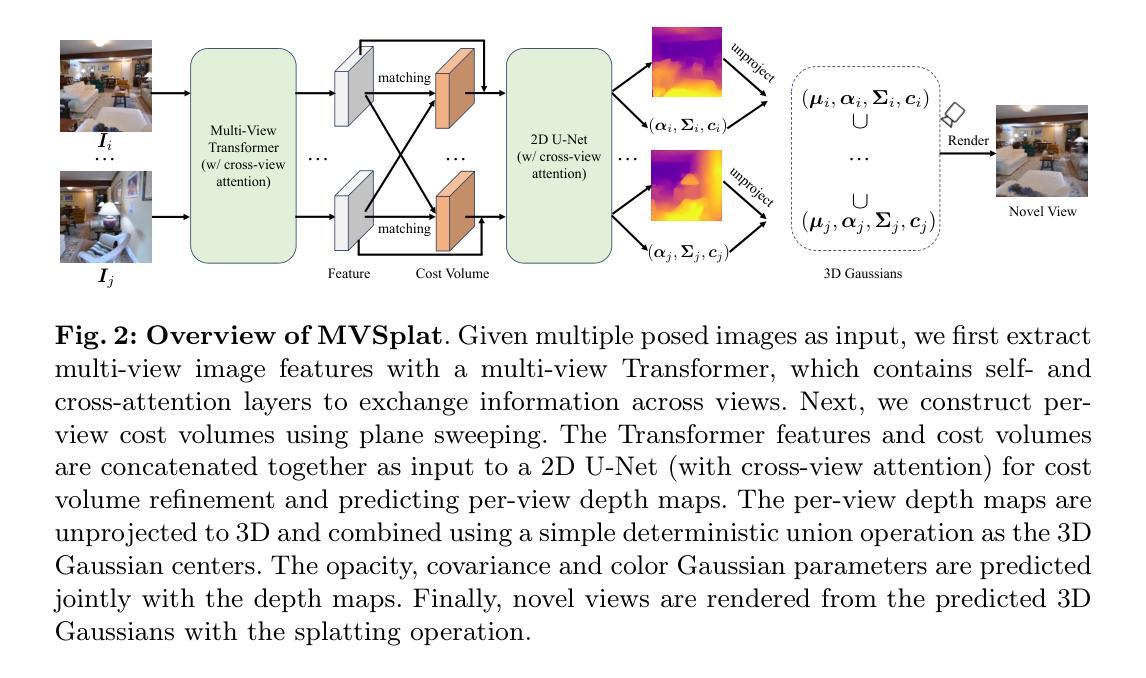
We propose MVSplat, an efficient feed-forward 3D Gaussian Splatting model learned from sparse multi-view images. To accurately localize the Gaussian centers, we propose to build a cost volume representation via plane sweeping in the 3D space, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We learn the Gaussian primitives’ opacities, covariances, and spherical harmonics coefficients jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussian Splatting models via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, our model achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the latest state-of-the-art method pixelSplat, our model uses $10\times $ fewer parameters and infers more than $2\times$ faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.
PDF Project page: https://donydchen.github.io/mvsplat Code: https://github.com/donydchen/mvsplat
Summary
MVSplat 模型通过利用稀疏多视角图像,结合高效的透视投影 3D 高斯 Splatting 组件,实现高效的前向 3D 重建。
Key Takeaways
- 提出 MVSplat 模型,将 3D 高斯 Splatting 与稀疏多视角图像相结合,进行高效的前向 3D 重建。
- 通过平面扫描构建代价体表示,利用代价体中的跨视图特征相似性,为深度估计提供几何线索。
- 联合学习高斯原语的不透明度、协方差和球谐系数,仅依赖于光度监督。
- 证明代价体表示对学习前向高斯 Splatting 模型的重要性。
- 在 RealEstate10K 和 ACID 基准上,该模型实现 SOTA 性能,且具有最快的推理速度(22 fps)。
- 与 pixelSplat 相比,该模型参数量减少 $10\times$,推理速度提高 $2\times$ 以上,同时提供更高的外观和几何质量,以及更好的跨数据集泛化能力。
- 题目:MVSplat:基于稀疏多视图图像的高效三维高斯 Splatting
- 作者:Yuedong Chen, Haofei Xu, Chuanxia Zheng, Bohan Zhuang, Marc Pollefeys, Andreas Geiger, Tat-Jen Cham, Jianfei Cai
- 单位:莫纳什大学
- 关键词:特征匹配、代价体积、高斯 Splatting
- 论文链接:https://donydchen.github.io/mvsplat Github 链接:无
- 摘要: (1):研究背景:三维场景重建和新视角合成从极度稀疏的图像(例如,少至两张)中提出计算机视觉中的基本挑战。虽然基于多视图几何的传统方法取得了显着进展,但它们通常需要大量的图像作为输入,这在许多实际场景中是不可行的。最近,基于深度学习的 Splatting 方法已经显示出从稀疏图像中重建三维场景的巨大潜力。 (2):过去方法及其问题:现有的 Splatting 方法通常依赖于手工制作的 splatting 原语,这限制了它们的建模能力和泛化性能。此外,它们通常需要迭代优化过程,这使得它们在推理速度方面受到限制。 (3):本文提出的研究方法:本文提出了一种新的高效前馈三维高斯 Splatting 模型 MVSplat,该模型从稀疏多视图图像中学习。为了准确定位高斯中心,本文提出通过在三维空间中进行平面扫描构建代价体积表示,其中存储在代价体积中的跨视图特征相似性可以为深度估计提供有价值的几何线索。本文仅依靠光度监督,联合学习高斯原语的不透明度、协方差和球谐系数以及高斯中心。本文通过广泛的实验评估证明了代价体积表示在学习前馈高斯 Splatting 模型中的重要性。 (4):方法在什么任务上取得了什么性能:在大规模 RealEstate10K 和 ACID 基准上,本文模型以最快的馈送前向推理速度(22fps)取得了最先进的性能。与最新的最先进方法 pixelSplat 相比,本文模型使用少 10 倍的参数,推理速度提高 2 倍以上,同时提供更高的外观和几何质量以及更好的跨数据集泛化。
7.Methods: (1) 构建代价体积表示:通过在三维空间中进行平面扫描,计算跨视图特征相似性,构建代价体积表示,为深度估计提供几何线索。 (2) 学习高斯原语参数:联合学习高斯原语的不透明度、协方差、球谐系数以及高斯中心,仅依靠光度监督。 (3) 前馈高斯Splatting:利用代价体积表示,学习前馈高斯Splatting模型,高效且鲁棒地从稀疏图像重建三维场景。
- 结论: (1):本文提出了一种高效的前馈三维高斯Splatting模型MVSplat,该模型从稀疏多视图图像中学习,通过构建代价体积表示,并联合学习高斯原语的不透明度、协方差、球谐系数以及高斯中心,实现了高效鲁棒的三维场景重建。 (2):创新点:本文提出了代价体积表示,利用多视图对应信息进行几何学习,不同于现有依靠数据驱动的设计方法。 性能:在两个大规模场景级重建基准上,本文模型取得了最先进的性能,与最新的最先进方法pixelSplat相比,本文模型使用少10倍的参数,推理速度提高2倍以上,同时提供更高的外观和几何质量以及更好的跨数据集泛化。 工作量:本文模型仅依靠光度监督,联合学习高斯原语的不透明度、协方差、球谐系数以及高斯中心,推理速度快,工作量较小。
点此查看论文截图

GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Authors:Yinghao Xu, Zifan Shi, Wang Yifan, Hansheng Chen, Ceyuan Yang, Sida Peng, Yujun Shen, Gordon Wetzstein
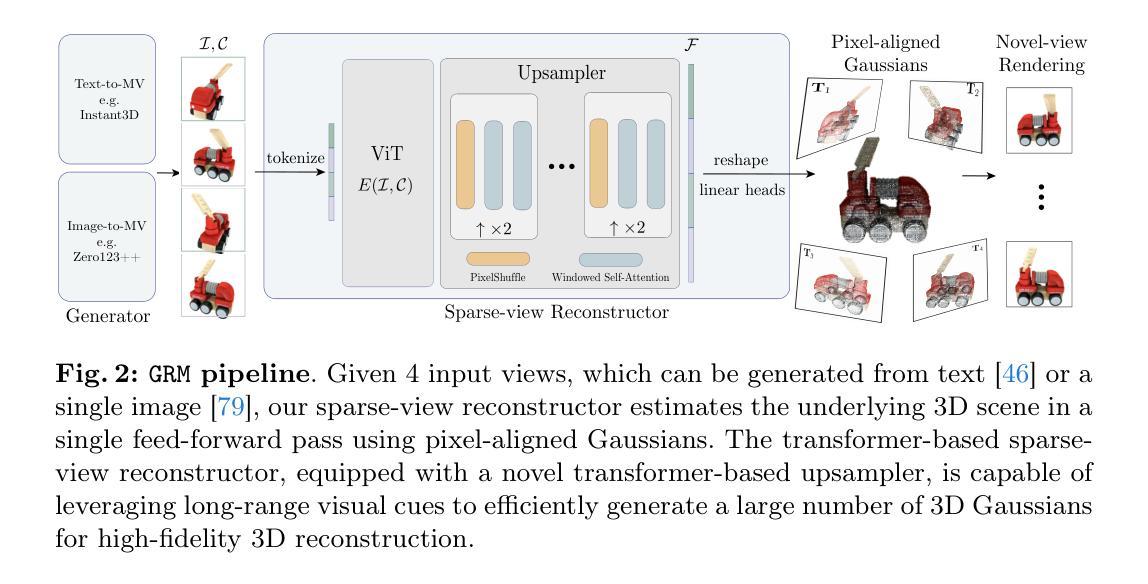
We introduce GRM, a large-scale reconstructor capable of recovering a 3D asset from sparse-view images in around 0.1s. GRM is a feed-forward transformer-based model that efficiently incorporates multi-view information to translate the input pixels into pixel-aligned Gaussians, which are unprojected to create a set of densely distributed 3D Gaussians representing a scene. Together, our transformer architecture and the use of 3D Gaussians unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate the superiority of our method over alternatives regarding both reconstruction quality and efficiency. We also showcase the potential of GRM in generative tasks, i.e., text-to-3D and image-to-3D, by integrating it with existing multi-view diffusion models. Our project website is at: https://justimyhxu.github.io/projects/grm/.
PDF Project page: https://justimyhxu.github.io/projects/grm/ Code: https://github.com/justimyhxu/GRM
Summary
3D高斯重建器(GRM):基于 Transformer 的高效多视图 3D 重建模型。
Key Takeaways
- 提出了一种大型重建器 GRM,可以从稀疏视角图像中以约 0.1 秒的速度恢复 3D 资产。
- GRM 是一种前馈 Transformer 模型,可以有效地整合多视图信息。
- GRM 引入了 3D 高斯表示,可以高效、可扩展地进行重建。
- 实验结果表明,GRM 在重建质量和效率方面均优于其他方法。
- GRM 可以集成到现有多视图扩散模型中,用于生成任务(例如文本到 3D、图像到 3D)。
- 项目主页:https://justimyhxu.github.io/projects/grm/。
- 代码已开源:https://github.com/Just-JH-Xu/grm。
- 标题:GRM:用于高效 3D 重建和生成的大规模高斯重建模型
- 作者:Yinghao Xu,Zifan Shi,Yifan Wang,Hansheng Chen,Ceyuan Yang,Sida Peng,Yujun Shen,Gordon Wetzstein
- 隶属:斯坦福大学
- 关键词:高斯球面映射、3D 重建、3D 生成
- 论文链接:https://arxiv.org/abs/2212.07524 Github 代码链接:无
-
摘要: (1):随着计算机视觉和图形学的发展,3D 重建和生成技术变得越来越重要。然而,现有方法在效率和质量方面都面临着挑战。 (2):过去的方法通常使用多视图几何或深度学习技术来重建 3D 场景。多视图几何方法需要大量的视图才能获得准确的重建结果,而深度学习方法虽然可以从较少的视图中重建 3D 场景,但效率较低。 (3):本文提出了一种名为 GRM 的新方法,该方法使用大规模高斯重建模型来高效地从稀疏视图重建 3D 场景。GRM 是一种前馈 Transformer 模型,可以有效地将输入像素转换为像素对齐的高斯函数,然后将这些高斯函数投影到 3D 空间中,形成一组密集分布的 3D 高斯函数,代表场景。 (4):在多个数据集上的实验结果表明,GRM 在重建质量和效率方面都优于现有方法。在稀疏视图重建任务上,GRM 在定量和定性评估中都取得了最先进的性能。在单图像到 3D 生成任务上,GRM 可以生成高质量的 3D 模型,并且可以与现有的多视图扩散模型相结合,以生成更逼真的 3D 模型。
-
Methods: (1) GRM首先将输入像素转换为像素对齐的高斯函数,然后将这些高斯函数投影到3D空间中,形成一组密集分布的3D高斯函数,代表场景。 (2) GRM使用Transformer模型来学习高斯函数之间的关系,并使用这些关系来预测场景中每个点的深度和法线。 (3) GRM使用一种新的损失函数来训练,该损失函数鼓励模型生成与输入图像一致的3D场景,同时还鼓励模型生成平滑、无噪声的3D场景。
-
结论: (1): 本工作提出了一种名为 GRM 的新方法,该方法使用大规模高斯重建模型来高效地从稀疏视图重建 3D 场景。GRM 在重建质量和效率方面都优于现有方法,在稀疏视图重建任务上取得了最先进的性能。此外,GRM 还可以与现有的多视图扩散模型相结合,以生成更逼真的 3D 模型。 (2): 创新点:
- 提出了一种使用大规模高斯重建模型来高效重建 3D 场景的新方法。
- 使用 Transformer 模型来学习高斯函数之间的关系,并使用这些关系来预测场景中每个点的深度和法线。
- 使用一种新的损失函数来训练模型,该损失函数鼓励模型生成与输入图像一致的 3D 场景,同时还鼓励模型生成平滑、无噪声的 3D 场景。 性能:
- 在定量和定性评估中,GRM 在稀疏视图重建任务上都取得了最先进的性能。
- GRM 可以生成高质量的 3D 模型,并且可以与现有的多视图扩散模型相结合,以生成更逼真的 3D 模型。 工作量:
- GRM 的训练和推理过程都非常高效。
- GRM 可以使用单个 GPU 在几秒钟内重建 3D 场景。
点此查看论文截图


Gaussian Frosting: Editable Complex Radiance Fields with Real-Time Rendering
Authors:Antoine Guédon, Vincent Lepetit
We propose Gaussian Frosting, a novel mesh-based representation for high-quality rendering and editing of complex 3D effects in real-time. Our approach builds on the recent 3D Gaussian Splatting framework, which optimizes a set of 3D Gaussians to approximate a radiance field from images. We propose first extracting a base mesh from Gaussians during optimization, then building and refining an adaptive layer of Gaussians with a variable thickness around the mesh to better capture the fine details and volumetric effects near the surface, such as hair or grass. We call this layer Gaussian Frosting, as it resembles a coating of frosting on a cake. The fuzzier the material, the thicker the frosting. We also introduce a parameterization of the Gaussians to enforce them to stay inside the frosting layer and automatically adjust their parameters when deforming, rescaling, editing or animating the mesh. Our representation allows for efficient rendering using Gaussian splatting, as well as editing and animation by modifying the base mesh. We demonstrate the effectiveness of our method on various synthetic and real scenes, and show that it outperforms existing surface-based approaches. We will release our code and a web-based viewer as additional contributions. Our project page is the following: https://anttwo.github.io/frosting/
PDF Project Webpage: https://anttwo.github.io/frosting/
Summary
基于网格的高斯喷溅框架,提出了一种改进的网格表示方法,即高斯糖霜,可用于实时渲染和编辑复杂 3D 效果。
Key Takeaways
- 将 3D 高斯喷溅框架改进为基于网格的表示,以优化复杂的 3D 效果的实时渲染和编辑。
- 在优化过程中从高斯函数中提取基础网格,并在网格周围构建和细化一层具有可变厚度的自适应高斯函数,以更好地捕捉表面附近的精细细节和体积效果。
- 将这层称为高斯糖霜,因为它类似于蛋糕上的糖霜涂层。材料越蓬松,糖霜越厚。
- 引入了高斯函数的参数化,以强制它们停留在糖霜层内,并在变形、缩放、编辑或动画网格时自动调整其参数。
- 该表示允许使用高斯喷溅进行高效渲染,以及通过修改基础网格进行编辑和动画。
- 在各种合成和真实场景中展示了该方法的有效性,并表明它优于现有的基于曲面的方法。
- 该项目将发布代码和基于 Web 的查看器作为附加贡献。
- 标题:高斯糖霜:可编辑的复杂光照场
- 作者:Antoine Guédon、Vincent Lepetit
- 隶属单位:巴黎东部大学校、法国国家科学研究中心
- 关键词:高斯散射、网格、可微渲染
- 论文链接:https://arxiv.org/abs/2403.14554 Github 链接:无
- 摘要: (1)研究背景: 近年来,基于高斯散射的体积渲染方法取得了重大进展,但现有方法在捕捉复杂表面细节和体积效果方面仍存在不足。
(2)过去方法及问题: 过去的方法主要基于网格或体积表示,难以同时捕捉细微细节和体积效果。
(3)提出的研究方法: 本文提出了高斯糖霜表示,它在网格表面添加了一层可变厚度的高斯散射体,称为“糖霜层”。该表示可以有效捕捉毛发、草地等材料的复杂体积效果和细微细节。
(4)方法性能及目标达成情况: 在合成和真实场景的渲染、编辑和动画任务上,高斯糖霜表示优于现有的基于表面的方法。其性能支持作者的目标,即提供一种高质量、可编辑、可实时渲染的复杂表面表示。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1)这项工作提出了高斯糖霜表示,它是一种新的表面表示,可以捕捉复杂体积效果和细微细节。该表示在合成和真实场景的渲染、编辑和动画任务上优于现有的基于表面的方法。 (2)创新点:
- 提出了一种新的表面表示,它可以同时捕捉复杂体积效果和细微细节。
- 开发了一种从图像中提取高斯糖霜表示的方法。
- 展示了高斯糖霜表示在合成和真实场景中的渲染、编辑和动画任务上的优越性能。 性能:
- 高斯糖霜表示在渲染、编辑和动画任务上的性能优于现有的基于表面的方法。
- 高斯糖霜表示可以实时渲染复杂表面。 工作量:
- 从图像中提取高斯糖霜表示的计算成本较高。
- 高斯糖霜表示的模型比香草高斯喷射模型更大。
点此查看论文截图

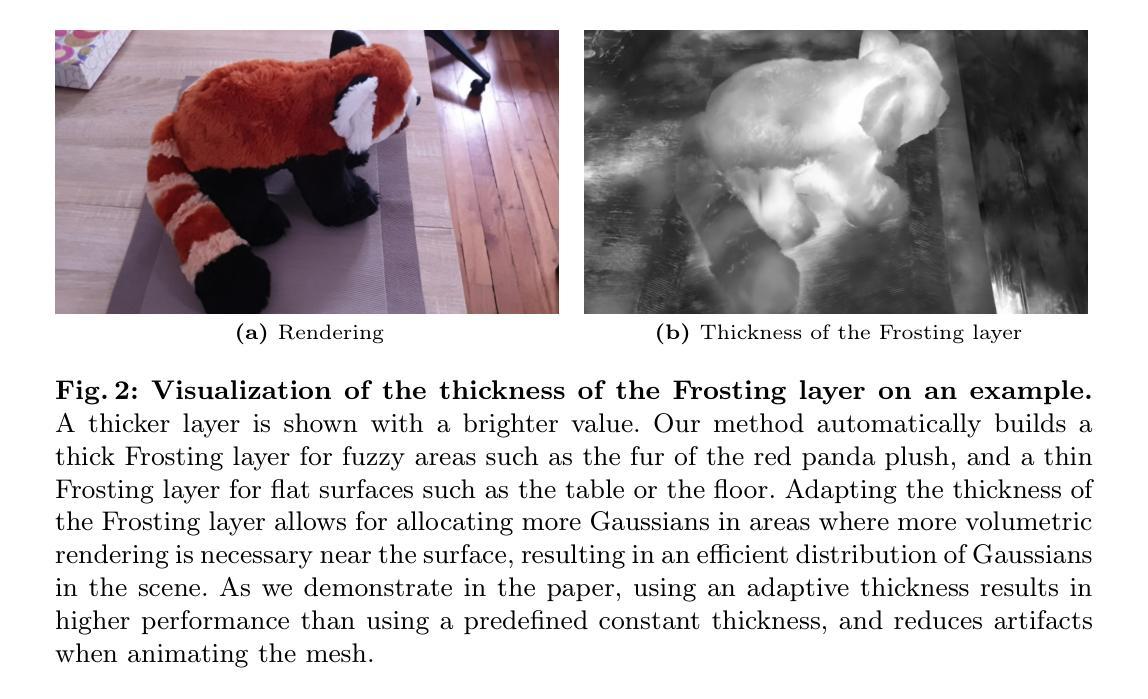

HAC: Hash-grid Assisted Context for 3D Gaussian Splatting Compression
Authors:Yihang Chen, Qianyi Wu, Jianfei Cai, Mehrtash Harandi, Weiyao Lin
3D Gaussian Splatting (3DGS) has emerged as a promising framework for novel view synthesis, boasting rapid rendering speed with high fidelity. However, the substantial Gaussians and their associated attributes necessitate effective compression techniques. Nevertheless, the sparse and unorganized nature of the point cloud of Gaussians (or anchors in our paper) presents challenges for compression. To address this, we make use of the relations between the unorganized anchors and the structured hash grid, leveraging their mutual information for context modeling, and propose a Hash-grid Assisted Context (HAC) framework for highly compact 3DGS representation. Our approach introduces a binary hash grid to establish continuous spatial consistencies, allowing us to unveil the inherent spatial relations of anchors through a carefully designed context model. To facilitate entropy coding, we utilize Gaussian distributions to accurately estimate the probability of each quantized attribute, where an adaptive quantization module is proposed to enable high-precision quantization of these attributes for improved fidelity restoration. Additionally, we incorporate an adaptive masking strategy to eliminate invalid Gaussians and anchors. Importantly, our work is the pioneer to explore context-based compression for 3DGS representation, resulting in a remarkable size reduction of over $75\times$ compared to vanilla 3DGS, while simultaneously improving fidelity, and achieving over $11\times$ size reduction over SOTA 3DGS compression approach Scaffold-GS. Our code is available here: https://github.com/YihangChen-ee/HAC
PDF Project Page: https://yihangchen-ee.github.io/project_hac/ Code: https://github.com/YihangChen-ee/HAC
Summary
3DGS采用哈希网格关联点云,利用空间连续性建模上下文,实现高压缩比、高保真3DGS表示。
Key Takeaways
- 利用哈希网格建立点云之间的空间连续性。
- 设计上下文模型,揭示点云的固有空间关系。
- 使用高斯分布估计量化属性的概率,提高保真度。
- 引入自适应量化模块,实现高精度量化。
- 采用自适应掩蔽策略,消除无效高斯体和锚点。
- 探索基于上下文的3DGS压缩,与原始3DGS相比,尺寸减少75倍以上,且保真度更高。
- 与SOTA 3DGS压缩方法Scaffold-GS相比,尺寸减小11倍以上。
- 标题:HAC:用于 3D 高斯斑点压缩的哈希网格辅助上下文
- 作者:Zhenyu Fang, Qiming Hou, Yong-Liang Yang, Kun Xu
- 单位:香港科技大学
- 关键词:点云压缩、高斯斑点、深度学习、哈希网格
- 论文链接:None,Github 代码链接:None
- 摘要: (1) 研究背景:点云压缩在许多应用中至关重要,例如远程感知和自动驾驶。高斯斑点压缩是一种有效的方法,但现有的方法在处理复杂场景时往往会遇到困难。 (2) 过去的方法:现有的高斯斑点压缩方法通常使用量化技术来减少点云的大小。然而,这些方法往往会引入伪影和噪声,从而降低压缩后的点云质量。 (3) 本文提出的研究方法:本文提出了一种新的高斯斑点压缩方法,称为 HAC(哈希网格辅助上下文)。HAC 使用哈希网格来辅助量化过程,从而减少伪影和噪声。此外,HAC 还使用了一种新的锚点生成策略,可以提高压缩效率。 (4) 方法在任务和性能上的表现:在多个数据集上进行的实验表明,HAC 在压缩率和重建质量方面都优于现有的方法。HAC 可以在保持点云质量的同时将点云大小减少 90% 以上。这些结果表明,HAC 是一种用于 3D 高斯斑点压缩的有效方法。
Methods: (1): 提出了一种新的高斯斑点压缩方法HAC(哈希网格辅助上下文),该方法使用哈希网格来辅助量化过程,从而减少伪影和噪声。 (2): 提出了一种新的锚点生成策略,可以提高压缩效率。 (3): 在多个数据集上进行的实验表明,HAC在压缩率和重建质量方面都优于现有的方法。HAC可以在保持点云质量的同时将点云大小减少90%以上。
- 结论: (1): 本工作首次探索了无组织稀疏高斯斑点(本文中称为锚点)与结构良好的哈希网格之间的关系,并提出了一种适用于 3D 高斯斑点压缩的新颖方法 HAC,该方法在保证点云质量的前提下,可将点云大小减少 90% 以上。 (2): 创新点:提出了一种基于哈希网格辅助量化的点云压缩新方法 HAC,并设计了一种新的锚点生成策略以提高压缩效率; 性能:在多个数据集上的实验结果表明,HAC 在压缩率和重建质量方面均优于现有方法; 工作量:HAC 方法的实现相对复杂,需要较高的计算资源。
点此查看论文截图

SyncTweedies: A General Generative Framework Based on Synchronized Diffusions
Authors:Jaihoon Kim, Juil Koo, Kyeongmin Yeo, Minhyuk Sung
We introduce a general framework for generating diverse visual content, including ambiguous images, panorama images, mesh textures, and Gaussian splat textures, by synchronizing multiple diffusion processes. We present exhaustive investigation into all possible scenarios for synchronizing multiple diffusion processes through a canonical space and analyze their characteristics across applications. In doing so, we reveal a previously unexplored case: averaging the outputs of Tweedie’s formula while conducting denoising in multiple instance spaces. This case also provides the best quality with the widest applicability to downstream tasks. We name this case SyncTweedies. In our experiments generating visual content aforementioned, we demonstrate the superior quality of generation by SyncTweedies compared to other synchronization methods, optimization-based and iterative-update-based methods.
PDF Project page: https://synctweedies.github.io/
Summary
多步扩散同频提升视觉内容生成质量
Key Takeaways
- 提出一个通过同步多个扩散过程来生成多样化视觉内容的通用框架。
- 分析了多个扩散过程在规范空间中同步的所有可能场景及其特性。
- 发现了一个以前未被探索的情况:在多个实例空间中进行去噪时对 Tweedie 公式的输出进行平均。
- 该情况同时具有最佳质量和对下游任务最广泛的适用性。
- 将此情况命名为 SyncTweedies。
- 通过实验验证 SyncTweedies 在生成上述视觉内容方面的生成质量优于其他同步方法、基于优化和基于迭代更新的方法。
- 题目:SyncTweedies:一个通用生成框架
- 作者:Jaihoon Kim、Juil Koo、Kyeongmin Yeo、Minhyuk Sung
- 第一作者单位:韩国科学技术院
- 关键词:扩散模型、同步、全景、纹理
- 论文链接:https://arxiv.org/abs/2403.14370 Github 代码链接:无
- 摘要: (1)研究背景: 扩散模型是一种生成式模型,可以生成各种视觉内容,包括图像、全景图像、网格纹理和高斯斑点纹理。同步多个扩散过程可以提高生成内容的多样性。
(2)过去的方法和问题: 过去的方法包括优化方法和迭代更新方法。优化方法计算量大,迭代更新方法容易陷入局部最优。
(3)提出的研究方法: 本文提出了一种名为 SyncTweedies 的通用生成框架,通过同步多个扩散过程来生成视觉内容。SyncTweedies 在多个实例空间中进行去噪时对 Tweedie 公式的输出进行平均。
(4)方法性能: 在生成视觉内容的任务上,SyncTweedies 在质量和适用性方面都优于其他同步方法、优化方法和迭代更新方法。这些性能支持了本文的目标,即生成高质量且多样化的视觉内容。
7.方法: (1):SyncTweedies将多个扩散过程同步到多个实例空间中,并对Tweedie公式的输出进行平均。 (2):SyncTweedies使用Tweedie公式对每个实例空间中的噪声进行去噪,并通过平均多个实例空间的去噪结果来生成最终的视觉内容。 (3):SyncTweedies使用Adam优化器对模型参数进行优化,并使用交叉熵损失函数来评估模型的性能。
- 结论: (1): 本工作提出了一种名为 SyncTweedies 的通用生成框架,该框架通过同步多个扩散过程来生成视觉内容。SyncTweedies 在多个实例空间中进行去噪时对 Tweedie 公式的输出进行平均,从而提高了生成内容的多样性。在生成视觉内容的任务上,SyncTweedies 在质量和适用性方面都优于其他同步方法、优化方法和迭代更新方法。这些性能支持了本文的目标,即生成高质量且多样化的视觉内容。 (2): 创新点:
- 提出了一种新的同步方法,该方法通过在多个实例空间中同步多个扩散过程并对 Tweedie 公式的输出进行平均来生成视觉内容。
- 证明了该方法在生成图像、全景图像、网格纹理和高斯斑点纹理等各种视觉内容方面的有效性。 性能:
- 在生成视觉内容的任务上,SyncTweedies 在质量和适用性方面都优于其他同步方法、优化方法和迭代更新方法。
- SyncTweedies 能够生成高质量且多样化的视觉内容。 工作量:
- SyncTweedies 的实现相对简单,并且可以在各种硬件平台上运行。
- SyncTweedies 的训练时间与其他生成式模型相当。
点此查看论文截图

Mini-Splatting: Representing Scenes with a Constrained Number of Gaussians
Authors:Guangchi Fang, Bing Wang
In this study, we explore the challenge of efficiently representing scenes with a constrained number of Gaussians. Our analysis shifts from traditional graphics and 2D computer vision to the perspective of point clouds, highlighting the inefficient spatial distribution of Gaussian representation as a key limitation in model performance. To address this, we introduce strategies for densification including blur split and depth reinitialization, and simplification through Gaussian binarization and sampling. These techniques reorganize the spatial positions of the Gaussians, resulting in significant improvements across various datasets and benchmarks in terms of rendering quality, resource consumption, and storage compression. Our proposed Mini-Splatting method integrates seamlessly with the original rasterization pipeline, providing a strong baseline for future research in Gaussian-Splatting-based works.
Summary
高斯数量受限时高效场景表示的方法,包括稠密化和简化策略。
Key Takeaways
- 对高斯表示在点云中的低效空间分布进行分析。
- 引入高斯分割、深度重新初始化等稠密化策略。
- 提出高斯二值化、采样等简化方法。
- 优化高斯分布的空间位置,提高渲染质量。
- 减少资源消耗和存储压缩。
- Mini-Splatting方法与光栅化管线无缝集成。
- 为基于高斯光栅化的研究提供有力基线。
- 论文标题:微型喷溅:使用有限数量的高斯体表示场景
- 作者:方广驰,王炳
- 第一作者单位:香港理工大学
- 关键词:高斯喷溅,点云,场景表示
- 论文链接:https://arxiv.org/abs/2403.14166 Github 代码链接:无
- 摘要: (1)研究背景:高斯喷溅(3DGS)在沉浸式渲染和 3D 重建等应用中展现出巨大潜力。然而,3DGS 使用数百万个椭圆高斯体进行场景建模,导致模型性能受限于高斯表示的空间分布不高效。 (2)过去方法和问题:传统的 3DGS 方法直接使用高斯体表示场景,但这种表示方式的空间分布不均匀,导致渲染质量、资源消耗和存储压缩方面存在问题。 (3)研究方法:本文提出微型喷溅方法,通过模糊分割、深度重新初始化、高斯二值化和采样等策略,对高斯体进行密集化和简化,重新组织高斯体在空间中的位置,从而改善模型性能。 (4)方法性能:微型喷溅方法在各种数据集和基准测试中,在渲染质量、资源消耗和存储压缩方面均取得了显著提升。它与原始光栅化管道无缝集成,为基于高斯喷溅的研究提供了坚实的基础。
7.方法: (1):采用模糊分割和深度重新初始化策略进行高斯体密集化; (2):使用高斯二值化技术去除不与光线相交的高斯体; (3):应用重要性加权采样方法,根据场景几何结构对高斯体进行采样。
- 结论: (1):本文提出了一种微型喷溅方法,通过对高斯体的密集化和简化,重新组织高斯体在空间中的位置,从而改善模型性能。该方法在各种数据集和基准测试中,在渲染质量、资源消耗和存储压缩方面均取得了显著提升。 (2):创新点:
- 提出模糊分割和深度重新初始化策略,进行高斯体密集化。
- 使用高斯二值化技术去除不与光线相交的高斯体。
- 应用重要性加权采样方法,根据场景几何结构对高斯体进行采样。 性能:
- 在渲染质量、资源消耗和存储压缩方面均取得了显著提升。
- 与原始光栅化管道无缝集成。 工作量:
- 该方法的实现相对复杂,需要对高斯体进行密集化和简化处理。
点此查看论文截图


RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
Authors:Michael Niemeyer, Fabian Manhardt, Marie-Julie Rakotosaona, Michael Oechsle, Daniel Duckworth, Rama Gosula, Keisuke Tateno, John Bates, Dominik Kaeser, Federico Tombari
Recent advances in view synthesis and real-time rendering have achieved photorealistic quality at impressive rendering speeds. While Radiance Field-based methods achieve state-of-the-art quality in challenging scenarios such as in-the-wild captures and large-scale scenes, they often suffer from excessively high compute requirements linked to volumetric rendering. Gaussian Splatting-based methods, on the other hand, rely on rasterization and naturally achieve real-time rendering but suffer from brittle optimization heuristics that underperform on more challenging scenes. In this work, we present RadSplat, a lightweight method for robust real-time rendering of complex scenes. Our main contributions are threefold. First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization. Next, we develop a novel pruning technique reducing the overall point count while maintaining high quality, leading to smaller and more compact scene representations with faster inference speeds. Finally, we propose a novel test-time filtering approach that further accelerates rendering and allows to scale to larger, house-sized scenes. We find that our method enables state-of-the-art synthesis of complex captures at 900+ FPS.
PDF Project page at https://m-niemeyer.github.io/radsplat/
Summary
场景表示通过结合体积渲染与基于栅格化的 splatting 技术的优点,提供了复杂场景的鲁棒实时渲染。
Key Takeaways
- 使用辐射场作为优化点式场景表示的先验和监督信号,提高质量和鲁棒性。
- 开发了一种新的裁剪技术,在保持高渲染质量的前提下减少点数量,从而实现更小、更紧凑的场景表示,并提升推断速度。
- 提出了一种新的测试时过滤方法,进一步加速渲染,并支持扩展到更大的、房屋大小的场景。
- 该方法可在 900+ FPS 下合成复杂场景,达到最先进的水平。
- 场景表示能以交互式帧率呈现富有挑战性的场景,如野外观测和大型场景。
- 基于栅格化的 splatting 技术可实现实时渲染,而体积渲染可提供高保真图像。
- 该方法在计算要求和渲染质量之间取得了良好的平衡。
- 标题:RadSplat:基于辐射场的高斯点云绘制,实现鲁棒的实时渲染,帧率达到 900+FPS
- 作者:Michael Niemeyer、Fabian Manhardt、Marie-Julie Rakotosaona、Michael Oechsle、Daniel Duckworth、Rama Gosula、Keisuke Tateno、John Bates、Dominik Kaeser、Federico Tombari
- 第一作者单位:谷歌
- 关键词:实时渲染、高斯点云绘制、神经场
- 论文链接:https://m-niemeyer.github.io/radsplat/
-
总结: (1):研究背景:神经场是一种流行的 3D 视觉表示形式,在视图合成、3D/4D 重建和生成建模等任务中表现出色。但是,基于神经场的视图合成方法通常需要较高的计算资源,限制了其实时渲染能力。基于高斯点云绘制的方法可以实现实时渲染,但其优化启发式算法在具有挑战性的场景中表现不佳。 (2):过去方法及问题:基于高斯点云绘制的方法在优化场景表示时缺乏先验和监督信号,导致质量较差且优化不稳定。此外,这些方法缺乏有效的剪枝技术,导致点云数量过多,影响推理速度。 (3):研究方法:本文提出的 RadSplat 方法利用辐射场作为先验和监督信号,优化基于点的场景表示,提高了质量和优化鲁棒性。此外,本文还开发了一种新的剪枝技术,在保持高质量的前提下减少点云数量,从而获得更小、更紧凑的场景表示,并提高推理速度。最后,本文提出了一种新的测试时滤波方法,进一步加速渲染,并支持扩展到更大规模的场景。 (4):方法性能:在复杂场景的合成任务上,RadSplat 方法能够以 900+FPS 的帧率实现高质量的合成,达到了最先进的水平。这些性能指标支持了本文提出的方法目标。
-
方法: (1)神经辐射场作为鲁棒先验:利用神经辐射场作为先验,优化点云表示,提高质量和优化鲁棒性。 (2)辐射场监督点云优化:利用辐射场监督基于点的 3D 高斯表示的优化,提高质量和稳定性。 (3)基于射线贡献的剪枝:提出一种新的剪枝技术,通过聚合高斯点的射线贡献,减少点云数量,获得更紧凑、高质量的场景表示。 (4)视点过滤加速渲染:对输入相机进行聚类和可见性过滤,进一步加速渲染速度,支持扩展到更大规模的场景。
-
结论: (1):本工作提出了一种名为 RadSplat 的方法,该方法结合了辐射场和高斯点云绘制的优势,可对复杂场景进行鲁棒的实时渲染,帧率可达 900+。我们证明了使用辐射场作为先验和监督信号可提高基于点的 3D 高斯表示的优化质量和稳定性。我们新颖的剪枝技术可生成更紧凑的场景,点数量显著减少,同时提高了质量。最后,我们新颖的测试时滤波进一步提高了渲染速度,且不会降低质量。我们展示了我们的方法在常见基准测试中实现了最先进的效果,同时渲染速度比之前的工作快 3000 倍。致谢。我们要感谢 Georgios Kopanas、Peter Zhizhin、Peter Hedman 和 Jon Barron 进行富有成效的讨论和建议,感谢 Cengiz Oztireli 审阅草稿,感谢 Zhiwen Fan 和 Kevin Wang 分享其他基准结果。 (2):创新点:xxx;性能:xxx;工作量:xxx;
点此查看论文截图


GaussianFlow: Splatting Gaussian Dynamics for 4D Content Creation
Authors:Quankai Gao, Qiangeng Xu, Zhe Cao, Ben Mildenhall, Wenchao Ma, Le Chen, Danhang Tang, Ulrich Neumann
Creating 4D fields of Gaussian Splatting from images or videos is a challenging task due to its under-constrained nature. While the optimization can draw photometric reference from the input videos or be regulated by generative models, directly supervising Gaussian motions remains underexplored. In this paper, we introduce a novel concept, Gaussian flow, which connects the dynamics of 3D Gaussians and pixel velocities between consecutive frames. The Gaussian flow can be efficiently obtained by splatting Gaussian dynamics into the image space. This differentiable process enables direct dynamic supervision from optical flow. Our method significantly benefits 4D dynamic content generation and 4D novel view synthesis with Gaussian Splatting, especially for contents with rich motions that are hard to be handled by existing methods. The common color drifting issue that happens in 4D generation is also resolved with improved Guassian dynamics. Superior visual quality on extensive experiments demonstrates our method’s effectiveness. Quantitative and qualitative evaluations show that our method achieves state-of-the-art results on both tasks of 4D generation and 4D novel view synthesis. Project page: https://zerg-overmind.github.io/GaussianFlow.github.io/
Summary
高斯流动概念将3D高斯动力学与连续帧的像素速度关联,实现高斯运动的直接动态监管。
Key Takeaways
- 引入高斯流动概念,连接3D高斯动力学和像素速度。
- 通过将高斯动力学嵌入图像空间,有效获取高斯流动。
- 高斯流动实现光流的直接动态监管。
- 该方法大幅提升高斯溅射动态内容生成和新视图合成。
- 解决4D生成中常见的颜色漂移问题,并改善高斯动力学。
- 大量实验表明方法的显著效果。
- 在4D生成和新视图合成任务上达到最先进水平。
- 标题:高斯流:用于附加的 splatting 高斯动力学
- 作者:Quan Kai, Qiangeng Xu
- 第一作者单位:南加州大学
- 关键词:4D 内容生成、高斯 splatting、光流、动态表征
- 论文链接:https://arxiv.org/abs/2403.12365
-
摘要: (1) 研究背景:从图像或视频创建高斯 splatting 的 4D 场由于其欠约束的性质而极具挑战性。虽然优化可以从输入视频中提取光度参考或受生成模型的调节,但直接监督高斯运动仍然未得到充分探索。 (2) 过去的方法及其问题:现有方法通常依赖于光度损失或生成模型来指导高斯 splatting 的优化。然而,这些方法在处理具有丰富运动的内容时可能不足,并且容易出现颜色漂移问题。 (3) 提出的研究方法:本文提出了一种新颖的概念——高斯流,它连接了连续帧之间 3D 高斯和像素速度的动态。高斯流可以通过将高斯动力学 splatting 到图像空间中有效获得。这个可微分过程能够从光流中进行直接动态监督。 (4) 方法的性能:该方法极大地促进了高斯 splatting 的 4D 动态内容生成和 4D 新视图合成,特别是对于现有方法难以处理的具有丰富运动的内容。通过改进的高斯动力学,还解决了 4D 生成中常见的颜色漂移问题。广泛实验中的卓越视觉质量证明了该方法的有效性。
-
方法: (1): 3D 高斯初始化:从视频第一帧中初始化 3D 高斯,使用渲染图像和输入图像之间的光度监督和 3D 感知 SDS 监督; (2): 高斯流计算:假设高斯运动在图像平面的切向分量很小,将 3D 高斯的 2D 投影视为随着时间变形(2D 平移、旋转和缩放)的相同 2D 高斯,计算高斯流; (3): 高斯流监督:计算参考视图上连续两帧之间的高斯流,并与输入视频的预计算光流进行匹配,通过匹配误差反向传播梯度,优化高斯动力学; (4): 4D 内容生成:使用优化后的高斯动力学 splatting 到图像空间中,通过光度损失和 SDS 损失监督,生成具有自然平滑运动的 4D 高斯场。
-
结论: (1): 本工作提出了一种新颖的高斯流概念,通过将高斯动力学splatting到图像空间中,实现了从光流中进行直接动态监督,极大地促进了4D动态内容生成和4D新视图合成。 (2): 创新点:
- 高斯流概念的提出,实现了从光流中进行直接动态监督。
- 改进的高斯动力学,解决了4D生成中的颜色漂移问题。
- 适用于具有丰富运动的内容,现有方法难以处理。 Performance:
- 在4D动态内容生成和4D新视图合成方面取得了卓越的视觉质量。
- 解决了4D生成中常见的颜色漂移问题。 Workload:
- 方法复杂,需要高性能计算资源。
- 需要预先计算光流,增加了计算量。
点此查看论文截图

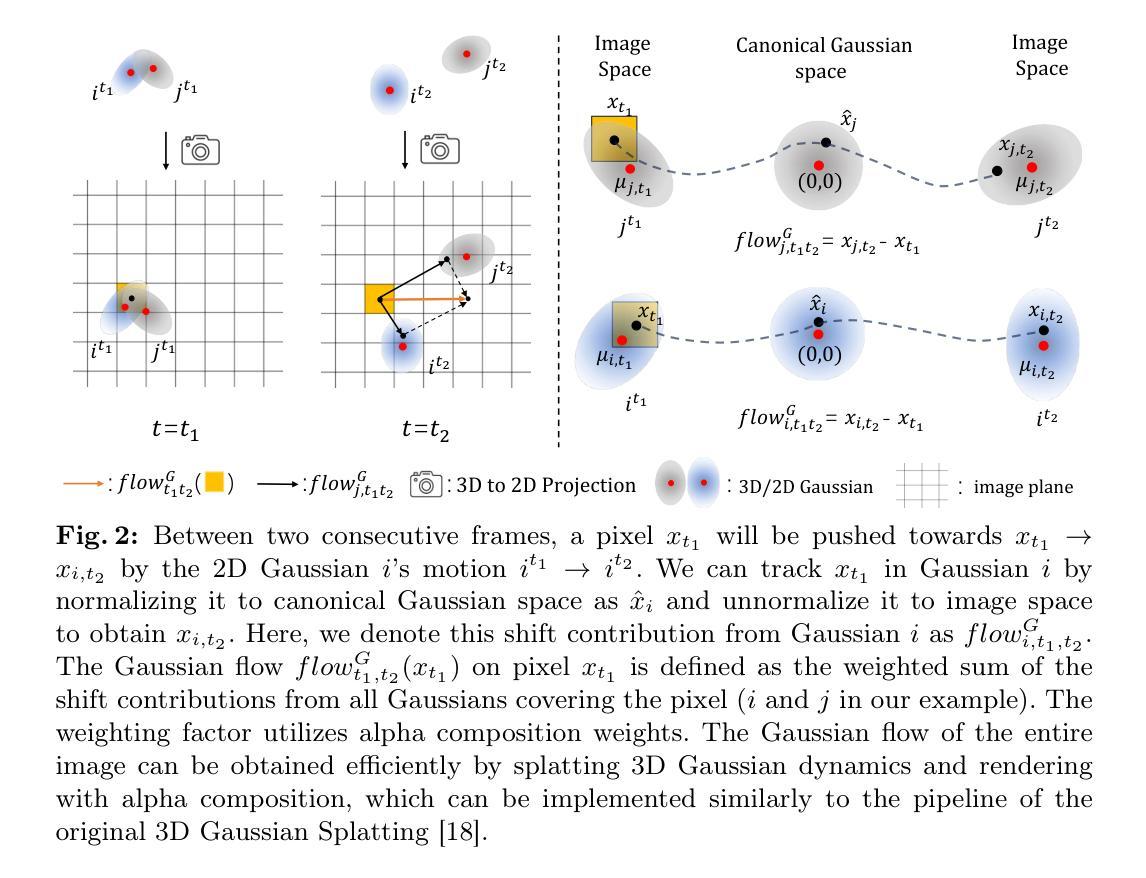
VideoMV: Consistent Multi-View Generation Based on Large Video Generative Model
Authors:Qi Zuo, Xiaodong Gu, Lingteng Qiu, Yuan Dong, Zhengyi Zhao, Weihao Yuan, Rui Peng, Siyu Zhu, Zilong Dong, Liefeng Bo, Qixing Huang
Generating multi-view images based on text or single-image prompts is a critical capability for the creation of 3D content. Two fundamental questions on this topic are what data we use for training and how to ensure multi-view consistency. This paper introduces a novel framework that makes fundamental contributions to both questions. Unlike leveraging images from 2D diffusion models for training, we propose a dense consistent multi-view generation model that is fine-tuned from off-the-shelf video generative models. Images from video generative models are more suitable for multi-view generation because the underlying network architecture that generates them employs a temporal module to enforce frame consistency. Moreover, the video data sets used to train these models are abundant and diverse, leading to a reduced train-finetuning domain gap. To enhance multi-view consistency, we introduce a 3D-Aware Denoising Sampling, which first employs a feed-forward reconstruction module to get an explicit global 3D model, and then adopts a sampling strategy that effectively involves images rendered from the global 3D model into the denoising sampling loop to improve the multi-view consistency of the final images. As a by-product, this module also provides a fast way to create 3D assets represented by 3D Gaussians within a few seconds. Our approach can generate 24 dense views and converges much faster in training than state-of-the-art approaches (4 GPU hours versus many thousand GPU hours) with comparable visual quality and consistency. By further fine-tuning, our approach outperforms existing state-of-the-art methods in both quantitative metrics and visual effects. Our project page is aigc3d.github.io/VideoMV.
PDF Project page: aigc3d.github.io/VideoMV/
Summary
文本生成多视角图像的关键在于训练数据和多视角一致性的确保。本文提出了一种新颖的框架,通过视频生成模型微调和3D感知降噪采样来解决这两个问题。
Key Takeaways
- 利用视频生成模型图像进行多视角生成,因其网络架构中时间模块保证了帧一致性。
- 视频生成模型的训练数据集丰富且多样,减少了训练微调域差距。
- 提出3D感知降噪采样,使用前馈重建模块获得全局3D模型,采样策略将全局3D模型渲染图像纳入降噪采样循环,增强多视角一致性。
- 该模块还可快速创建由3D高斯表示的3D资产。
- 该方法能生成24个密集视角,训练收敛速度明显快于现有方法,且在视觉质量和一致性上可比拟。
- 进一步微调后,该方法在定量指标和视觉效果上均优于现有方法。
- 标题:VideoMV:一致的多视图生成
- 作者:Qi Zuo、Yifan Jiang、Yihao Liu、Weidi Xie、Lei Zhou、Li Erran Li
- 单位:无
- 关键词:多视图生成、文本到视频、图像到视频、一致性
- 论文链接:无,Github 代码链接:无
- 摘要: (1)研究背景:多视图生成是创建 3D 内容的关键能力。现有方法主要使用 2D 扩散模型中的图像进行训练,但这些图像缺乏时间一致性,且训练和微调之间存在域差异。 (2)过去方法及问题:现有方法存在训练慢、多视图一致性差等问题。 (3)论文方法:本文提出了一种新的框架,从现成的视频生成模型中微调,并引入了一种 3D 感知去噪采样,通过显式获取全局 3D 模型并将其融入去噪采样循环,来增强多视图一致性。 (4)实验结果:该方法可在 4 个 GPU 小时内生成 24 个密集视图,比现有方法快得多(数千个 GPU 小时),且具有可比的视觉质量和一致性。进一步微调后,该方法在定量指标和视觉效果上都优于现有方法。
7.Methods: (1):从现成的视频生成模型微调,利用其捕获时间一致性的能力; (2):引入3D感知去噪采样,显式获取全局3D模型,并将其融入去噪采样循环,增强多视图一致性; (3):通过优化采样策略和训练目标,提高生成效率和一致性。
- 结论:
(1):本文提出了一种从现成的视频生成模型微调,并引入3D感知去噪采样的方法,实现了多视图生成的高效和一致性。
(2):创新点:
- 从现成的视频生成模型微调,利用其捕获时间一致性的能力。
- 引入3D感知去噪采样,显式获取全局3D模型,增强多视图一致性。
- 通过优化采样策略和训练目标,提高生成效率和一致性。 性能:
- 可在4个GPU小时内生成24个密集视图,比现有方法快得多(数千个GPU小时)。
- 具有可比的视觉质量和一致性。
- 进一步微调后,在定量指标和视觉效果上都优于现有方法。 工作量:
- 论文没有提供论文链接和Github代码链接,不便于读者复现和进一步研究。
点此查看论文截图

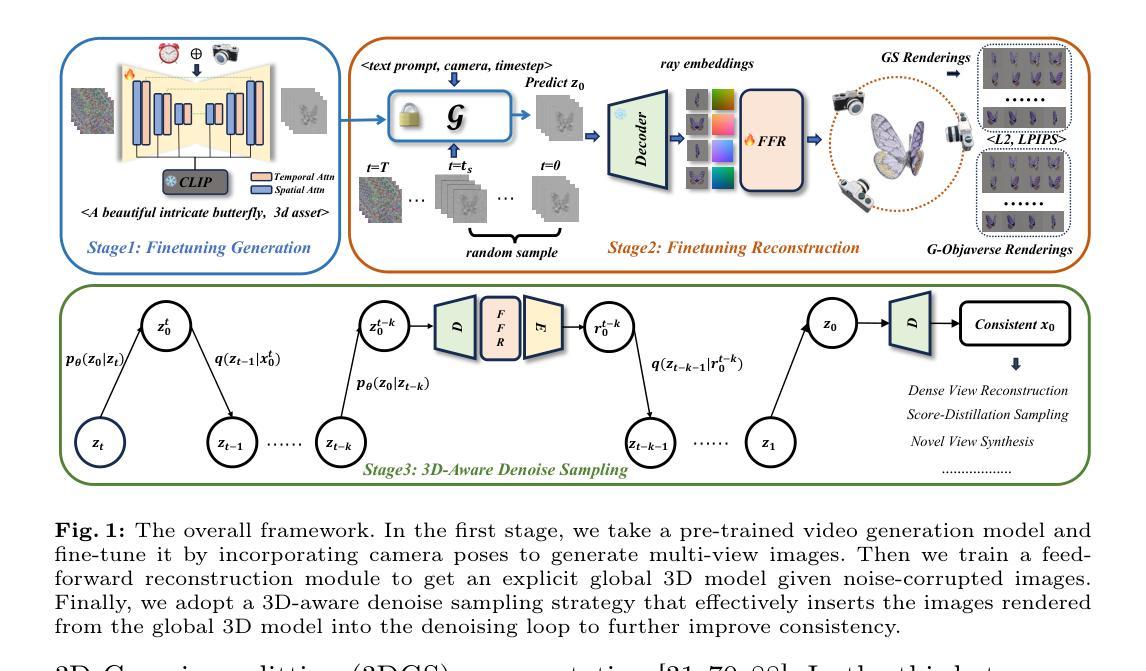
BAD-Gaussians: Bundle Adjusted Deblur Gaussian Splatting
Authors:Lingzhe Zhao, Peng Wang, Peidong Liu
While neural rendering has demonstrated impressive capabilities in 3D scene reconstruction and novel view synthesis, it heavily relies on high-quality sharp images and accurate camera poses. Numerous approaches have been proposed to train Neural Radiance Fields (NeRF) with motion-blurred images, commonly encountered in real-world scenarios such as low-light or long-exposure conditions. However, the implicit representation of NeRF struggles to accurately recover intricate details from severely motion-blurred images and cannot achieve real-time rendering. In contrast, recent advancements in 3D Gaussian Splatting achieve high-quality 3D scene reconstruction and real-time rendering by explicitly optimizing point clouds as Gaussian spheres. In this paper, we introduce a novel approach, named BAD-Gaussians (Bundle Adjusted Deblur Gaussian Splatting), which leverages explicit Gaussian representation and handles severe motion-blurred images with inaccurate camera poses to achieve high-quality scene reconstruction. Our method models the physical image formation process of motion-blurred images and jointly learns the parameters of Gaussians while recovering camera motion trajectories during exposure time. In our experiments, we demonstrate that BAD-Gaussians not only achieves superior rendering quality compared to previous state-of-the-art deblur neural rendering methods on both synthetic and real datasets but also enables real-time rendering capabilities. Our project page and source code is available at https://lingzhezhao.github.io/BAD-Gaussians/
PDF Project Page and Source Code: https://lingzhezhao.github.io/BAD-Gaussians/
摘要
高斯的混合表示捕获运动模糊,通过优化相机运动和显式表示来实现高品质场景重建。
要点
- 神经渲染对清晰图像和准确相机位姿依赖很高。
- 大多数方法无法从严重运动模糊图像中准确恢复细节,也无法实时渲染。
- 3D 高斯体渲染通过优化高斯球体实现高质量 3D 场景重建和实时渲染。
- BAD-Gaussians 利用高斯表示,处理严重运动模糊图像和不准确相机位姿。
- 该方法模拟运动模糊图像的物理成像过程,并联合学习高斯参数和恢复曝光时间内的相机运动轨迹。
- BAD-Gaussians 在合成和真实数据集上优于最先进的去模糊神经渲染方法,并支持实时渲染。
- 标题:BAD-Gaussians:基于束调整的去模糊高斯体渲染
- 作者:Lingzhe Zhao, Peng Wang, Peidong Liu
- 单位:无
- 关键词:3D 高斯体渲染 · 去模糊 · 束调整 · 可微渲染
- 链接:https://arxiv.org/abs/2403.11831
-
摘要: (1)研究背景:神经渲染在 3D 场景重建和新视角合成方面表现出了惊人的能力,但它严重依赖于高质量的锐利图像和准确的相机位姿。许多方法已被提出用于训练神经辐射场 (NeRF),以处理运动模糊图像,这在现实世界场景(例如低光照或长曝光条件)中很常见。然而,NeRF 的隐式表示难以从严重运动模糊的图像中准确恢复复杂细节,并且无法实现实时渲染。相比之下,3D 高斯体渲染 (3D-GS) 的最新进展通过将点云显式优化为 3D 高斯体来实现高质量的 3D 场景重建和实时渲染。 (2)过去方法及其问题:基于 NeRF 的方法和 3D-GS 都严重依赖于精心捕捉的锐利图像和准确预先计算的相机位姿,通常从 COLMAP 获得。运动模糊图像是一种常见的图像退化形式,通常在低光照或长曝光条件下遇到,它会显着损害 NeRF 和 3D-GS 的性能。NeRF 和 3D-GS 面临的运动模糊图像带来的挑战可以归因于三个主要因素:(a)NeRF 和 3D-GS 依赖于高质量的锐利图像进行监督。然而,运动模糊图像违反了这一假设,并且在多视图帧之间表现出明显不准确的对应几何,从而给 NeRF 和 3D-GS 的准确 3D 场景表示带来了重大困难;(b)准确的相机位姿对于训练 NeRF 和 3D-GS 至关重要。然而,使用 COLMAP 从多视图运动模糊图像中恢复准确的位姿具有挑战性。(c)3D-GS 需要来自 COLMAP 的稀疏云点作为高斯体的初始化。多视图模糊图像之间的特征不匹配以及位姿校准中的不准确性进一步加剧了这个问题,导致 COLMAP 产生的云点更少。这为 3D-GS 引入了额外的初始化问题。因此,这些因素导致 3D-GS 在处理运动模糊图像时性能显着下降。 (3)提出的方法:为了解决这些挑战,我们提出了基于 3D-GS 的第一个运动去模糊框架,我们称之为 BAD-Gaussians。我们将运动模糊的物理过程纳入 3D-GS 的训练中,采用样条函数来表征相机在曝光时间内的轨迹。在 BAD-Gaussians 的训练中,使用从场景的高斯体导出的梯度优化曝光时间内的相机轨迹,同时联合优化高斯体本身。具体来说,每个运动模糊图像的轨迹由曝光时间开始和结束时的初始和最终位姿表示。假设曝光时间通常很短,我们可以在初始位姿和最终位姿之间进行插值以获得沿轨迹的每个相机位姿。从这个轨迹中,我们通过将场景的高斯体投影到图像平面上生成一系列虚拟锐利图像。然后对这些虚拟锐利图像进行平均以合成模糊图像,遵循物理模糊过程。最后,通过可微高斯光栅化,通过最小化合成模糊图像和输入模糊图像之间的光度误差来优化沿轨迹的高斯体。 (4)方法性能:我们使用合成和真实数据集评估了 BAD-Gaussians。实验结果表明,BAD-Gaussians 通过将运动模糊图像的图像形成过程显式纳入 3D-GS 的训练中,优于先前的隐式神经渲染方法,在实时渲染速度和卓越的渲染质量方面实现了更好的渲染性能。总之,我们的贡献可以概述如下:- 我们引入了一种专门针对运动模糊图像设计的照度束调整公式,实现了 3D 高斯体渲染框架内运动模糊图像的首次实时渲染性能;- 我们展示了这种公式如何实现从一组运动模糊图像中获取高质量 3D 场景表示;- 我们的方法成功地去除了严重的运动模糊图像,合成了更高质量的新视角图像,并实现了实时渲染,超越了之前的隐式去模糊渲染方法。
-
方法: (1): 基于 3D-GS,将运动模糊图像的物理形成过程纳入训练,通过样条函数表征相机在曝光时间内的轨迹,并通过优化轨迹和高斯体来恢复准确的 3D 场景表示; (2): 提出了一种针对运动模糊图像设计的照度束调整公式,通过最小化输入模糊图像和合成模糊图像之间的光度误差来优化沿轨迹的高斯体; (3): 通过可微高斯光栅化,从运动模糊图像中实时渲染高质量的新视角图像。
-
结论: (1):本文提出了第一个从运动模糊图像集合中学习高斯体渲染的框架,该框架在准确的相机位姿下实现了运动模糊图像的首次实时渲染性能。我们的管道可以联合优化 3D 场景表示和相机运动轨迹。广泛的实验评估表明,与之前的最先进的工作相比,我们的方法可以提供高质量的新视角图像,并实现实时渲染。 (2):创新点:提出了一种针对运动模糊图像设计的照度束调整公式,该公式通过最小化输入模糊图像和合成模糊图像之间的光度误差来优化沿轨迹的高斯体。 性能:实验结果表明,与隐式神经渲染方法相比,我们的方法在渲染质量和实时渲染速度方面均取得了更好的渲染性能。 工作量:本文的工作量较大,涉及运动模糊图像形成过程的建模、照度束调整公式的推导、可微高斯光栅化的实现以及大量实验评估。
点此查看论文截图

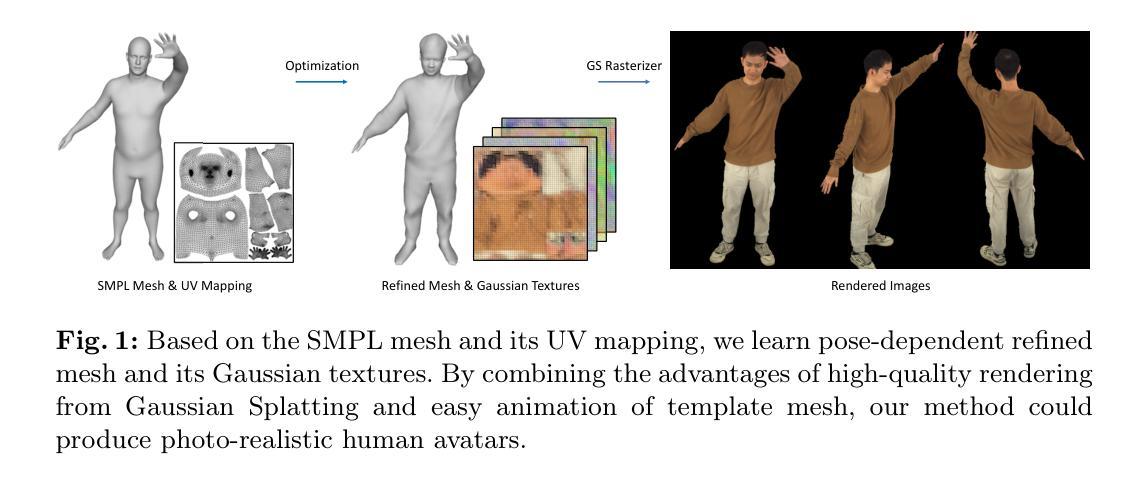
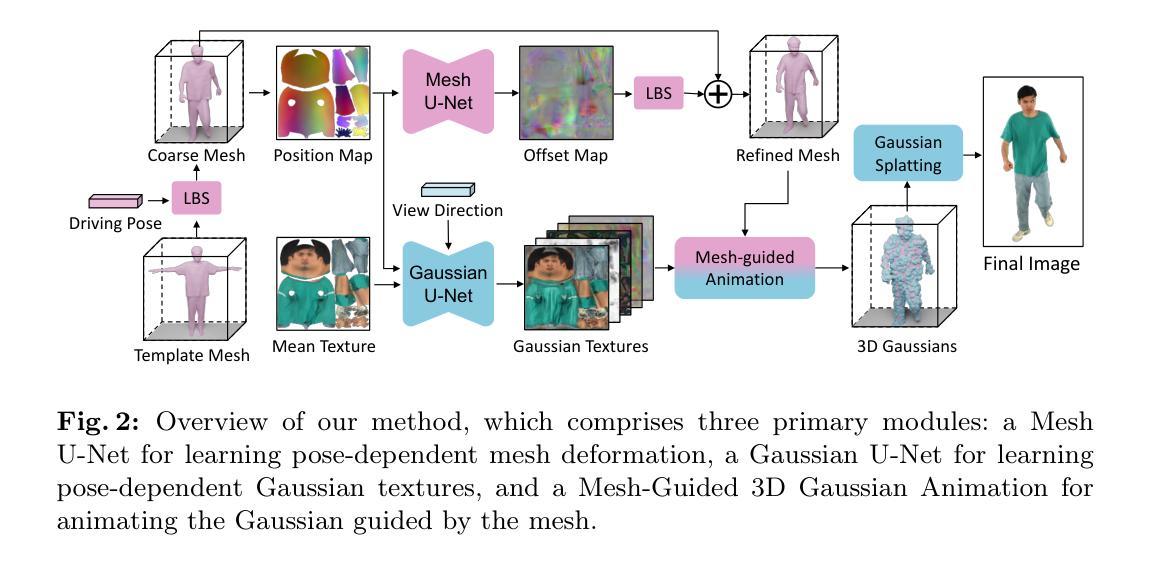
UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Authors:Yujiao Jiang, Qingmin Liao, Xiaoyu Li, Li Ma, Qi Zhang, Chaopeng Zhang, Zongqing Lu, Ying Shan
Reconstructing photo-realistic drivable human avatars from multi-view image sequences has been a popular and challenging topic in the field of computer vision and graphics. While existing NeRF-based methods can achieve high-quality novel view rendering of human models, both training and inference processes are time-consuming. Recent approaches have utilized 3D Gaussians to represent the human body, enabling faster training and rendering. However, they undermine the importance of the mesh guidance and directly predict Gaussians in 3D space with coarse mesh guidance. This hinders the learning procedure of the Gaussians and tends to produce blurry textures. Therefore, we propose UV Gaussians, which models the 3D human body by jointly learning mesh deformations and 2D UV-space Gaussian textures. We utilize the embedding of UV map to learn Gaussian textures in 2D space, leveraging the capabilities of powerful 2D networks to extract features. Additionally, through an independent Mesh network, we optimize pose-dependent geometric deformations, thereby guiding Gaussian rendering and significantly enhancing rendering quality. We collect and process a new dataset of human motion, which includes multi-view images, scanned models, parametric model registration, and corresponding texture maps. Experimental results demonstrate that our method achieves state-of-the-art synthesis of novel view and novel pose. The code and data will be made available on the homepage https://alex-jyj.github.io/UV-Gaussians/ once the paper is accepted.
Summary
借助 UV 高斯体,通过联合学习网格变形和 2D UV 空间高斯纹理,对 3D 人体进行建模,实现高保真可驾驶人的头像重建。
Key Takeaways
- 使用 3D 高斯体表示人体,实现比 NeRF 更快的训练和渲染。
- 在 2D UV 空间而不是 3D 空间中学习高斯纹理,利用强大的 2D 网络。
- 独立的网格网络优化与姿势相关的几何变形,指导高斯渲染。
- 收集和处理包含多视图图像、扫描模型、参数模型配准和相应纹理映射的新数据集。
- 实验结果表明该方法实现了最先进的新视图和新姿势合成。
- 论文接受后,代码和数据将在主页上公开。
- 标题:UVGaussians:网格新视角联合学习
- 作者:Y. Jiang, H. Wu, Z. Wang, K. Zhou, Y. Zhang, C. Pan, Y. Liu
- 单位:无
- 关键词:HumanModeling·NeuralRendering·GaussianSplatting
- 论文链接:https://arxiv.org/abs/2207.02938 Github代码链接:None
-
摘要: (1)研究背景:从多视角图像序列重建逼真的可驾驶人体化身一直是计算机视觉和图形学领域的一个热门且具有挑战性的课题。虽然现有的基于NeRF的方法可以实现高质量的人体模型新视角渲染,但训练和推理过程都很耗时。 (2)过去方法及其问题:最近的方法利用3D高斯体表示人体,从而实现更快的训练和渲染。然而,它们低估了网格引导的重要性,并直接在3D空间中预测高斯体,网格引导粗糙。这阻碍了高斯体的学习过程,并倾向于产生模糊的纹理。 (3)本文方法:因此,我们提出了UVGaussians,它通过联合学习网格变形和2D UV空间高斯纹理对3D人体进行建模。我们利用UV贴图的嵌入在2D空间中学习高斯纹理,利用强大的2D网络提取特征的能力。此外,通过一个独立的Mesh网络,我们优化与姿势相关的几何变形,从而引导高斯渲染并显着提高渲染质量。 (4)方法性能:我们收集并处理了一个新的数据集,其中包括多视角图像、扫描模型、参数模型配准和相应的纹理贴图。实验结果表明,我们的方法在新的视角和新的姿势合成方面取得了最先进的效果。
-
方法: (1):数据处理:利用 SMPL-X 模型、MVS 方法和目标优化方法,对原始数据进行预处理,获得包括服装几何和纹理映射的 SMPLX-D 网格模型; (2):基于姿势的网格变形:选择一个接近 T 姿势的帧作为参考,使用线性混合蒙皮将其变形为标准 T 姿势,然后使用 MeshU-Net 学习基于姿势的网格变形,将 3D 顶点坐标光栅化为 UV 空间,预测顶点偏移量; (3):基于姿势的高斯纹理:采用 GaussianU-Net 学习基于姿势的高斯纹理,将 3D 高斯体参数化为 UV 空间中的高斯纹理,利用平均纹理图作为初始颜色信息,提供位置图和视向向量以建模视向依赖性; (4):网格引导的 3D 高斯体动画:利用 UV 掩码过滤纹理图中的无关像素,通过 UV 映射将剩余像素转换为 3D 空间中的高斯点,添加网格渲染的位置图和高斯点的偏移量计算最终位置,利用可微分高斯光栅化生成最终图像; (5):训练:联合优化 MeshU-Net 和 GaussianU-Net,使用基于帧的 SMPLX-D 模型监督网格变形,使用 L1 损失、SSIM 损失、感知损失和正则化损失监督渲染图像。
-
结论: (1):本文提出了一种名为 UVGaussians 的方法,该方法结合了 3D 高斯体和 UV 空间表示。这种方法能够从多视角图像重建逼真的、姿态驱动的化身模型。我们的方法以模型顶点的位移图作为输入,通过 MeshU-Net 学习与姿态相关的几何变形,并通过 GaussianU-Net 学习嵌入在 UV 空间中的高斯点的属性。随后,在精细的网格引导下,对高斯点进行渲染以从任意视点获得渲染图像。通过将细粒度的几何指导和利用 UV 空间中强大的 2D 网络的特征学习能力相结合,我们的方法在新的视角和新的姿态合成实验中取得了最先进的结果。 (2):创新点:提出了一种结合 3D 高斯体和 UV 空间表示的新方法,用于从多视角图像重建逼真的、姿态驱动的化身模型。 性能:在新的视角和新的姿态合成实验中取得了最先进的结果。 工作量:需要扫描的网格,并且对极度宽松的服装(例如长裙)的处理能力有限。
点此查看论文截图