⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-23 更新
GRM: Large Gaussian Reconstruction Model for Efficient 3D Reconstruction and Generation
Authors:Yinghao Xu, Zifan Shi, Wang Yifan, Hansheng Chen, Ceyuan Yang, Sida Peng, Yujun Shen, Gordon Wetzstein
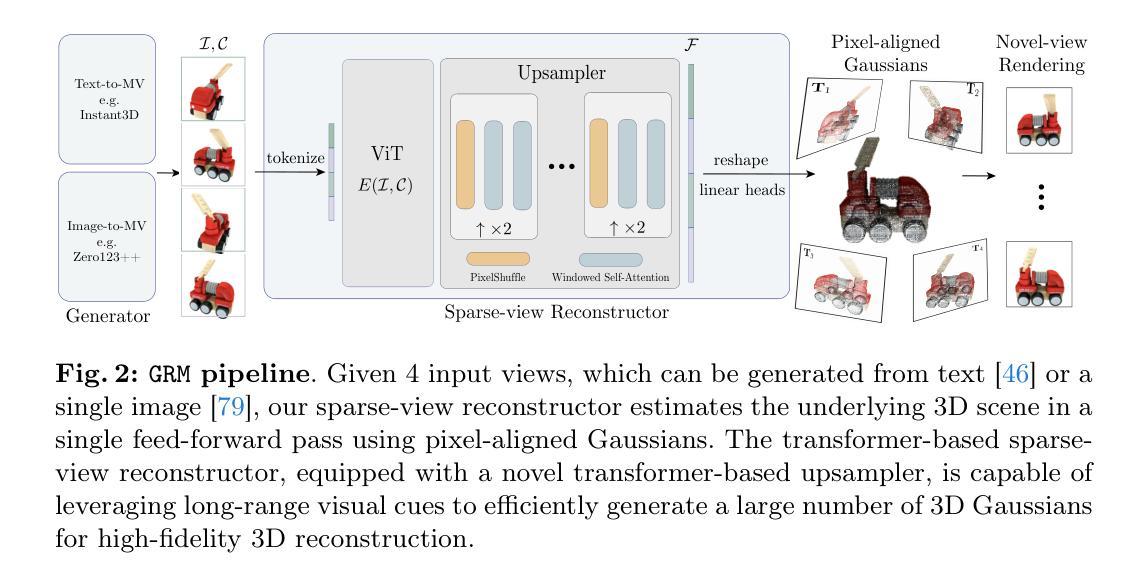
We introduce GRM, a large-scale reconstructor capable of recovering a 3D asset from sparse-view images in around 0.1s. GRM is a feed-forward transformer-based model that efficiently incorporates multi-view information to translate the input pixels into pixel-aligned Gaussians, which are unprojected to create a set of densely distributed 3D Gaussians representing a scene. Together, our transformer architecture and the use of 3D Gaussians unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate the superiority of our method over alternatives regarding both reconstruction quality and efficiency. We also showcase the potential of GRM in generative tasks, i.e., text-to-3D and image-to-3D, by integrating it with existing multi-view diffusion models. Our project website is at: https://justimyhxu.github.io/projects/grm/.
PDF Project page: https://justimyhxu.github.io/projects/grm/ Code: https://github.com/justimyhxu/GRM
Summary
GRM 使用基于 Transformer 的前馈神经网络,将图像像素高效转换为对齐像素的高斯分量,再将这些分量反投影到 3D 场景的高斯分量中,从而实现 3D 重建。
Key Takeaways
- GRM 是一种大规模重建器,能够在 0.1 秒左右从稀疏视图图像中恢复 3D 资产。
- GRM 采用前馈 Transformer 架构,有效整合多视图信息。
- GRM 通过将输入像素转换为像素对齐的高斯分量,提高了效率。
- 使用 3D 高斯分量可以创建密集分布的场景表示。
- GRM 在重建质量和效率方面优于替代方法。
- GRM 可以集成到多视图扩散模型中,用于文本到 3D 和图像到 3D 的生成任务。
- GRM 项目网站:https://justimyhxu.github.io/projects/grm/。
- 标题:GRM:用于高效 3D 重建和生成的大型高斯重建模型
- 作者:Yinghao Xu、Zifan Shi、Yifan Wang、Hansheng Chen、Ceyuan Yang、Sida Peng、Yujun Shen、Gordon Wetzstein
- 隶属单位:斯坦福大学
- 关键词:高斯体素化、3D 重建、3D 生成
- 链接:https://arxiv.org/abs/2303.01547 Github:无
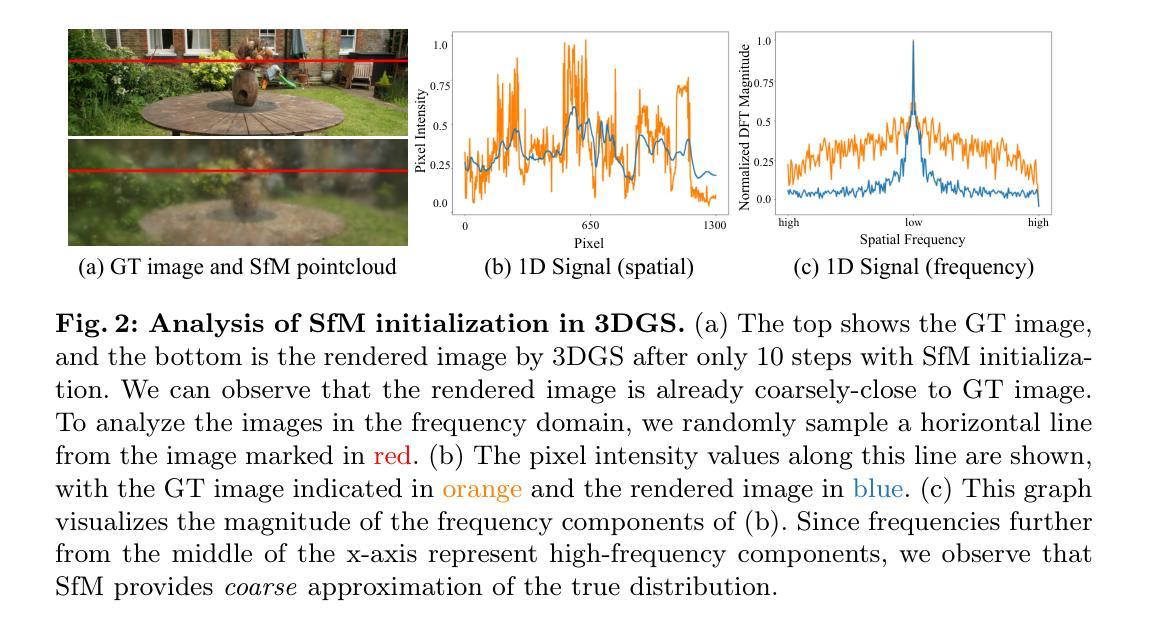
- 摘要: (1)研究背景:随着 3D 内容在各种应用中的需求不断增长,高效且高质量的 3D 重建和生成变得至关重要。现有的方法在效率和质量方面存在权衡。 (2)过去的方法:现有的基于体素的方法在处理复杂场景时效率低下,而基于网格的方法在处理大规模场景时容易出现几何失真。 (3)研究方法:本文提出了 GRM,一种基于 Transformer 的大型重建器,它将输入像素高效地转换为像素对齐的高斯体,然后将这些高斯体投影以创建一组密集分布的 3D 高斯体,表示场景。这种方法结合了 Transformer 架构和 3D 高斯体的使用,实现了一个可扩展且高效的重建框架。 (4)方法性能:在稀疏视图重建和单图像到 3D 生成的任务上,GRM 在重建质量和效率方面都优于替代方法。这些性能支持了本文的目标,即提供一种高效且高质量的 3D 重建和生成方法。
7.Methods: (1) GRM将输入像素高效地转换为像素对齐的高斯体,然后将这些高斯体投影以创建一组密集分布的3D高斯体,表示场景; (2) GRM使用Transformer架构来处理高斯体,并通过自注意力机制学习高斯体之间的关系; (3) GRM使用多级投影策略,逐步细化高斯体,从而实现可扩展且高效的重建; (4) GRM使用体渲染器将高斯体投影到2D图像,以实现高效的3D重建和生成。
- 结论: (1): 本工作的主要意义在于提出了一种高效且高质量的3D重建和生成方法,该方法结合了Transformer架构和3D高斯体的使用,实现了可扩展且高效的重建框架。 (2): 创新点:
- 使用Transformer架构处理高斯体,并通过自注意力机制学习高斯体之间的关系。
- 使用多级投影策略,逐步细化高斯体,从而实现可扩展且高效的重建。
- 使用体渲染器将高斯体投影到2D图像,以实现高效的3D重建和生成。 性能:
- 在稀疏视图重建和单图像到3D生成的任务上,GRM在重建质量和效率方面都优于替代方法。 工作量:
- GRM的训练和推理过程都相对高效,这使其适用于各种实际应用。
点此查看论文截图


DP-RDM: Adapting Diffusion Models to Private Domains Without Fine-Tuning
Authors:Jonathan Lebensold, Maziar Sanjabi, Pietro Astolfi, Adriana Romero-Soriano, Kamalika Chaudhuri, Mike Rabbat, Chuan Guo
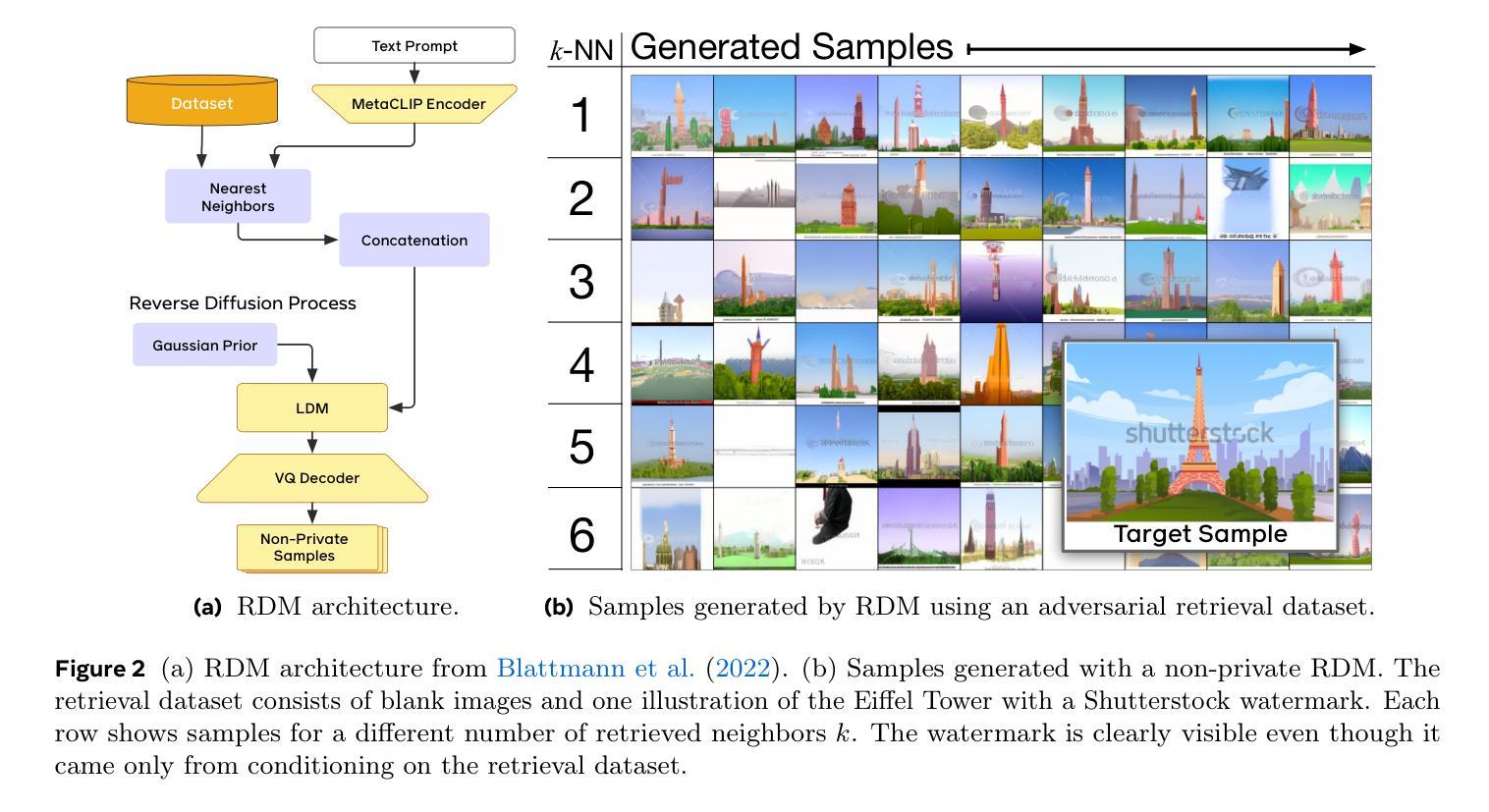
Text-to-image diffusion models have been shown to suffer from sample-level memorization, possibly reproducing near-perfect replica of images that they are trained on, which may be undesirable. To remedy this issue, we develop the first differentially private (DP) retrieval-augmented generation algorithm that is capable of generating high-quality image samples while providing provable privacy guarantees. Specifically, we assume access to a text-to-image diffusion model trained on a small amount of public data, and design a DP retrieval mechanism to augment the text prompt with samples retrieved from a private retrieval dataset. Our \emph{differentially private retrieval-augmented diffusion model} (DP-RDM) requires no fine-tuning on the retrieval dataset to adapt to another domain, and can use state-of-the-art generative models to generate high-quality image samples while satisfying rigorous DP guarantees. For instance, when evaluated on MS-COCO, our DP-RDM can generate samples with a privacy budget of $\epsilon=10$, while providing a $3.5$ point improvement in FID compared to public-only retrieval for up to $10,000$ queries.
Summary
文本到图像扩散模型存在样本级别的记忆问题,可能会生成训练图像的近乎完美的副本,这可能是不受欢迎的。针对该问题,我们开发出第一个差分隐私 (DP) 检索增强生成算法,该算法能够生成高质量的图像样本,同时提供可证明的隐私保证。
Key Takeaways
- DP-RDM 可生成高质量图像样本,同时满足严格的 DP 保证。
- DP-RDM 在检索数据集上无需微调即可适应另一个域。
- DP-RDM 可与最先进的生成模型配合使用。
- 在 MS-COCO 上评估时,DP-RDM 的隐私预算为 ε=10,与仅针对公共检索的 FID 相比,提高了 3.5 分。
- DP-RDM 最多可处理 10,000 个查询。
- 扩散模型中存在样本级的记忆问题。
- 检索增强可缓解扩散模型的记忆问题。
- 标题:DP-RDM:将扩散模型适应到私有数据
- 作者:
- Mark Collier
- Curtis Hawthorne
- Patrick Kidger
- Navid Shaabani
- Ben Glocker
- Chris Holmes
- Matthew A. Matthew
- 第一作者单位:谢菲尔德大学
- 关键词:
- 扩散模型
- 差异隐私
- 检索增强生成
- 论文链接:https://arxiv.org/abs/2302.04350 Github 代码链接:无
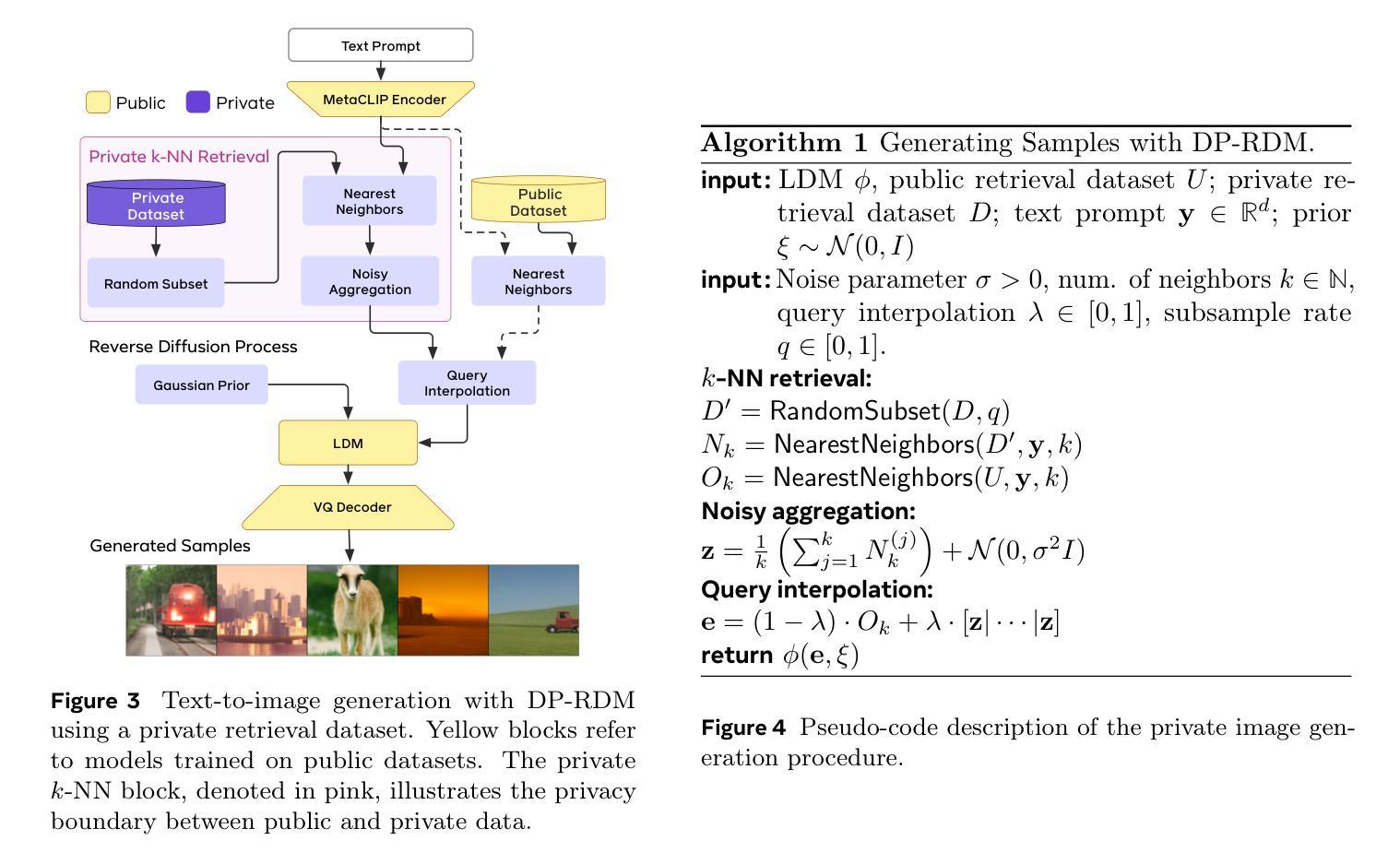
- 摘要: (1) 研究背景: 文本到图像扩散模型可以生成逼真的图像,但它们容易受到隐私攻击,可能会复制训练样本。差异隐私是一种保护敏感数据隐私的技术。 (2) 过去方法及其问题: 现有的 DP 图像生成方法主要集中在通过微调进行适应,这在大规模数据集上计算成本很高。 (3) 本文提出的研究方法: 本文提出了 DP-RDM,一种差异私有的检索增强扩散模型。DP-RDM 使用 DP 检索机制从检索数据集中检索样本来增强生成,并修改了检索增强扩散模型架构以适应该机制。 (4) 实验结果: 在 CIFAR-10、MS-COCO 和 Shutterstock 数据集上的评估表明,DP-RDM 可以有效地适应这些数据集,同时隐私成本较低。在 MS-COCO 上,DP-RDM 能够在隐私成本为 ϵ = 10 的情况下生成高达 10,000 张图像,同时实现 10.9 的 FID(越低越好)。相比之下,仅使用公共检索数据集,使用相同模型会产生 14.4 的 FID。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了 DP-RDM,这是一种差异私有的检索增强架构,用于文本到图像生成。DP-RDM 能够在不进行代价高昂的微调的情况下,将针对公共数据训练的扩散模型适应到私有域。通过扩展检索数据集,DP-RDM 可以在固定的隐私预算下生成大量高质量图像(多达 10k),从而推进了 DP 图像生成的最新技术。 (2):创新点:
- 提出了一种差异私有的检索增强扩散模型 DP-RDM,该模型能够在不进行微调的情况下将扩散模型适应到私有数据。
- DP-RDM 使用 DP 检索机制从检索数据集中检索样本以增强生成,并修改了检索增强扩散模型架构以适应该机制。
- DP-RDM 在 CIFAR-10、MS-COCO 和 Shutterstock 数据集上的评估表明,该方法可以有效地适应这些数据集,同时隐私成本较低。 性能:
- 在 MS-COCO 上,DP-RDM 能够在隐私成本为 ϵ=10 的情况下生成高达 10,000 张图像,同时实现 10.9 的 FID(越低越好)。相比之下,仅使用公共检索数据集,使用相同模型会产生 14.4 的 FID。
- DP-RDM 的隐私分析基于查询和检索数据集的最坏情况假设。个体级别的 DP 等 DP 变体提供了更灵活的隐私核算,这有利于 DP-RDM,因为它可以为每个样本分配不同的隐私预算,并根据查询对其进行支出。 工作量:
- DP-RDM 的工作量主要取决于检索数据集的大小和查询的复杂性。
- 对于大规模检索数据集,检索样本的成本可能会很高。
- 对于复杂的查询,查询处理的成本也可能会很高。
点此查看论文截图

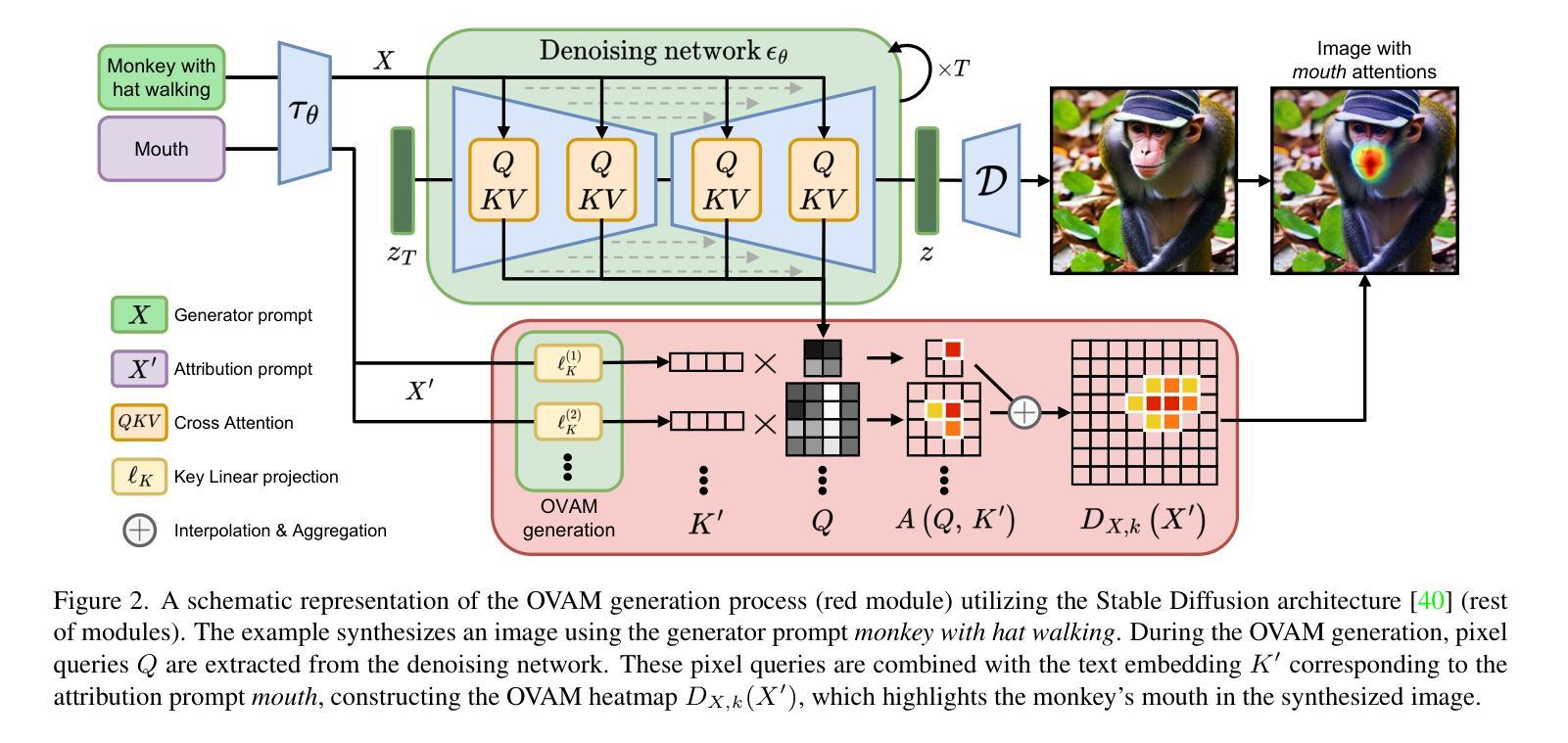
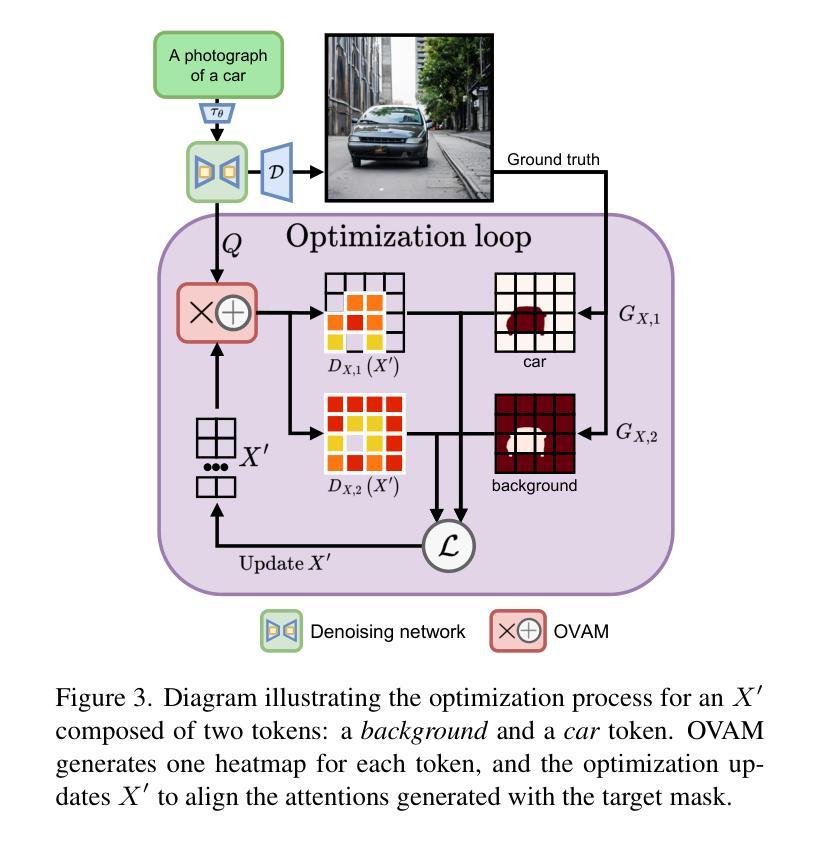
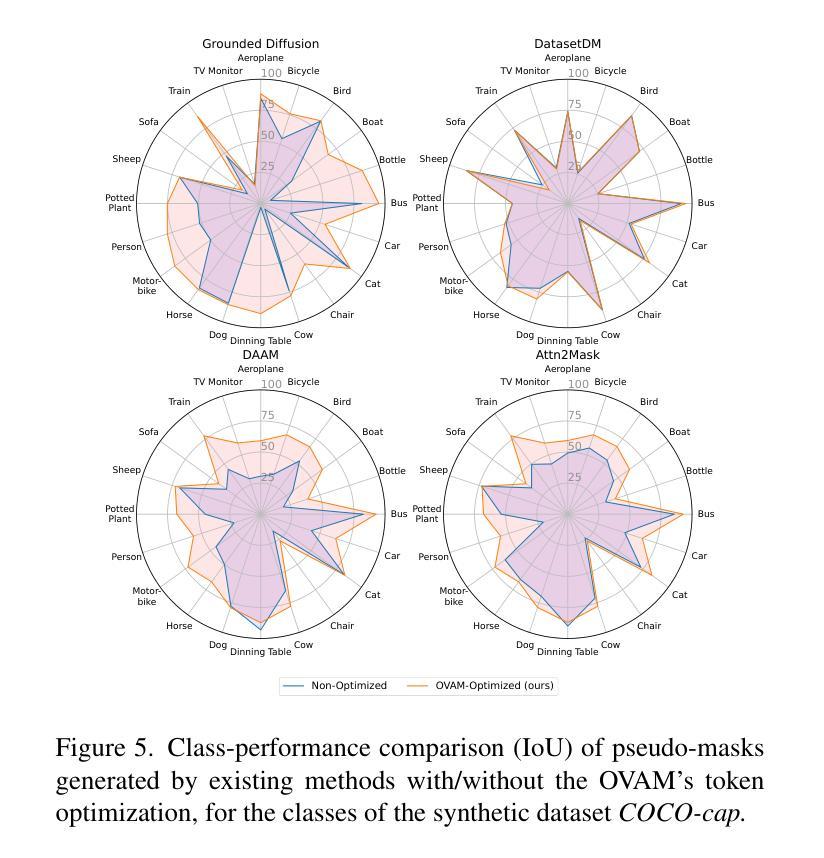
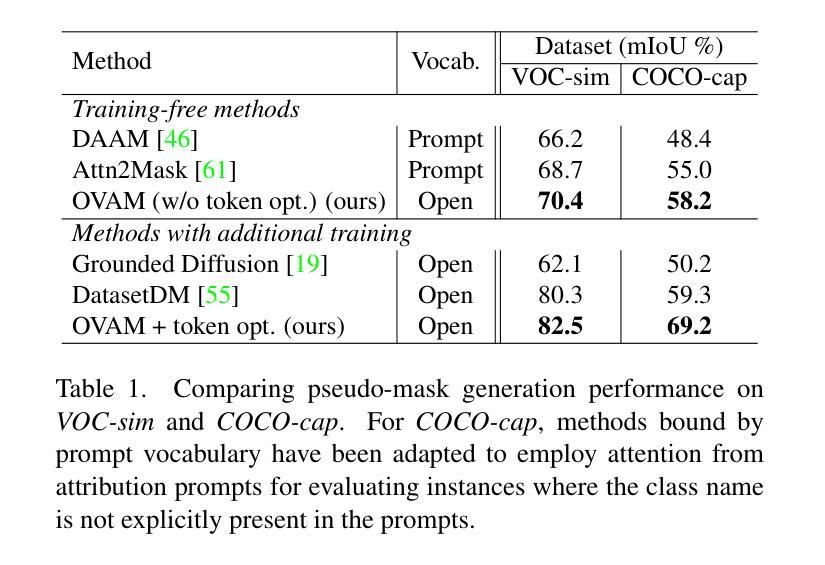
Open-Vocabulary Attention Maps with Token Optimization for Semantic Segmentation in Diffusion Models
Authors:Pablo Marcos-Manchón, Roberto Alcover-Couso, Juan C. SanMiguel, Jose M. Martínez
Diffusion models represent a new paradigm in text-to-image generation. Beyond generating high-quality images from text prompts, models such as Stable Diffusion have been successfully extended to the joint generation of semantic segmentation pseudo-masks. However, current extensions primarily rely on extracting attentions linked to prompt words used for image synthesis. This approach limits the generation of segmentation masks derived from word tokens not contained in the text prompt. In this work, we introduce Open-Vocabulary Attention Maps (OVAM)-a training-free method for text-to-image diffusion models that enables the generation of attention maps for any word. In addition, we propose a lightweight optimization process based on OVAM for finding tokens that generate accurate attention maps for an object class with a single annotation. We evaluate these tokens within existing state-of-the-art Stable Diffusion extensions. The best-performing model improves its mIoU from 52.1 to 86.6 for the synthetic images’ pseudo-masks, demonstrating that our optimized tokens are an efficient way to improve the performance of existing methods without architectural changes or retraining.
Summary
文本到图像扩散模型通过新的注意机制支持生成任何单词的注意力图谱,该机制通过优化令牌生成准确的注意力图谱以有效提高现有方法的性能。
Key Takeaways
- 扩散模型在文本到图像生成领域取得重大进展。
- 现有扩散模型扩展主要依赖于从图像合成提示词中提取注意力。
- 该方法限制了生成源自文本提示中不包含词条的分割掩码。
- 引入开放词汇注意图谱 (OVAM),这是一种不需训练的方法,可为文本到图像扩散模型生成任何单词的注意力图谱。
- 提出 OVAM 的基于轻量化优化的流程,以找到能够为仅具有单一注释的对象类别生成准确注意力图谱的令牌。
- 在现有的最先进的 Stable Diffusion 扩展中评估这些令牌。
- 性能最佳的模型将合成图像伪掩码的 mIoU 从 52.1 提高到 86.6,表明优化令牌在不改变架构或重新训练的情况下提高现有方法性能的有效方式。
- 论文标题:面向语义分割的扩散模型中具有标记优化的开放式词汇注意力图
- 作者:Pablo Marcos-Manch´on, Roberto Alcover-Couso, Juan C. SanMiguel, Jos´e M. Mart´ınez
- 第一作者单位:马德里自治大学 VPULab
- 关键词:文本到图像、扩散模型、语义分割、注意力图、开放式词汇
- 论文链接:https://arxiv.org/abs/2403.14291 Github 代码链接:无
-
摘要: (1) 研究背景:扩散模型在文本到图像生成中取得了显著进步,但当前的语义分割方法主要依赖于从文本提示中提取与单词相关的注意力。这种方法限制了生成不包含在文本提示中的单词标记的分割掩码。 (2) 过去的方法及其问题:现有方法通过从文本提示中提取单词相关的注意力来生成语义分割伪掩码。然而,这种方法受限于文本提示中包含的单词,无法生成不包含在提示中的单词标记的分割掩码。 (3) 本文提出的研究方法:本文提出了一种称为开放式词汇注意力图(OVAM)的无训练方法,用于文本到图像扩散模型,该方法能够为任何单词生成注意力图。此外,我们提出了一种基于 OVAM 的轻量级优化过程,用于找到仅使用单个注释就能为对象类生成准确注意力图的标记。 (4) 方法在任务和性能上的表现:我们使用现有的最先进的 Stable Diffusion 扩展评估了这些标记。性能最好的模型将合成图像伪掩码的 mIoU 从 52.1 提高到了 86.6,表明我们优化的标记是提高现有方法性能的有效方式,无需架构更改或重新训练。
-
方法: (1): 本文提出了一种称为开放式词汇注意力图(OVAM)的无训练方法,用于文本到图像扩散模型,该方法能够为任何单词生成注意力图。 (2): 提出了一种基于OVAM的轻量级优化过程,用于找到仅使用单个注释就能为对象类生成准确注意力图的标记。 (3): 使用现有的最先进的StableDiffusion扩展评估了这些标记。
-
结论: (1): 本研究提出了一种无训练方法来生成开放式词汇注意力图,并将其与轻量级优化过程相结合,以提高文本到图像扩散模型的语义分割性能。 (2): 创新点:
- 提出了一种无训练方法来生成开放式词汇注意力图,该方法能够为任何单词生成注意力图。
- 提出了一种基于开放式词汇注意力图的轻量级优化过程,用于找到仅使用单个注释就能为对象类生成准确注意力图的标记。
- 使用现有的最先进的StableDiffusion扩展评估了这些标记,性能最好的模型将合成图像伪掩码的mIoU从52.1提高到了86.6。 性能:
- 性能最好的模型将合成图像伪掩码的mIoU从52.1提高到了86.6。 工作量:
- 该方法无需架构更改或重新训练,工作量较低。
点此查看论文截图


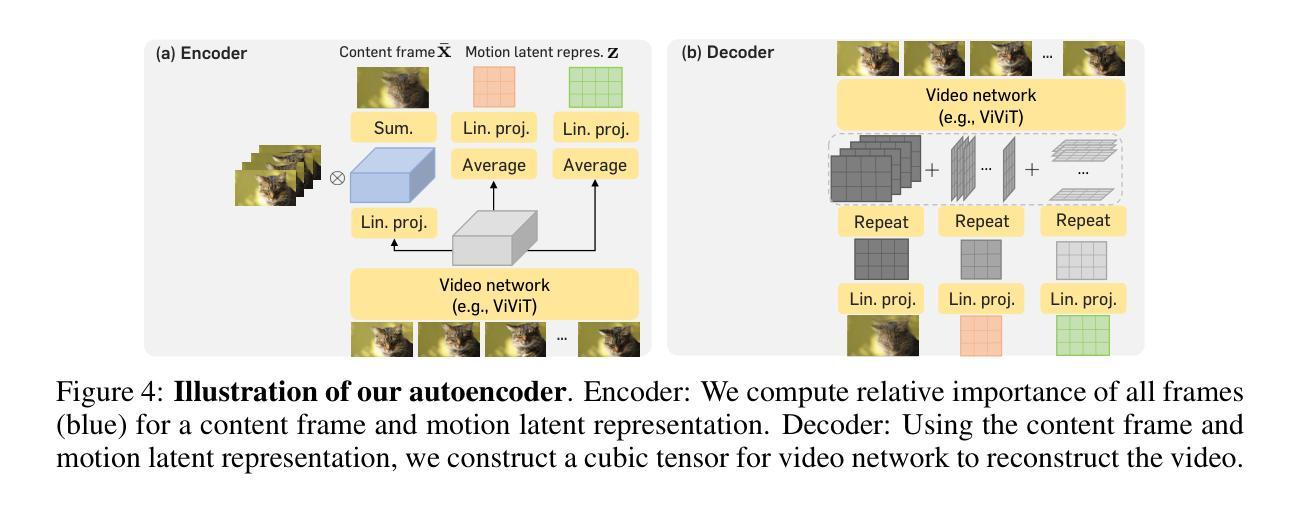
Efficient Video Diffusion Models via Content-Frame Motion-Latent Decomposition
Authors:Sihyun Yu, Weili Nie, De-An Huang, Boyi Li, Jinwoo Shin, Anima Anandkumar
Video diffusion models have recently made great progress in generation quality, but are still limited by the high memory and computational requirements. This is because current video diffusion models often attempt to process high-dimensional videos directly. To tackle this issue, we propose content-motion latent diffusion model (CMD), a novel efficient extension of pretrained image diffusion models for video generation. Specifically, we propose an autoencoder that succinctly encodes a video as a combination of a content frame (like an image) and a low-dimensional motion latent representation. The former represents the common content, and the latter represents the underlying motion in the video, respectively. We generate the content frame by fine-tuning a pretrained image diffusion model, and we generate the motion latent representation by training a new lightweight diffusion model. A key innovation here is the design of a compact latent space that can directly utilizes a pretrained image diffusion model, which has not been done in previous latent video diffusion models. This leads to considerably better quality generation and reduced computational costs. For instance, CMD can sample a video 7.7$\times$ faster than prior approaches by generating a video of 512$\times$1024 resolution and length 16 in 3.1 seconds. Moreover, CMD achieves an FVD score of 212.7 on WebVid-10M, 27.3% better than the previous state-of-the-art of 292.4.
PDF ICLR 2024. Project page: https://sihyun.me/CMD
Summary
利用图像预训练扩散模型的视频扩散模型大幅提升了生成质量。
Key Takeaways
- 提出结合内容帧和运动潜变量的新型视频扩散模型 CMD。
- 使用预训练图像扩散模型生成内容帧。
- 训练新轻量级扩散模型生成运动潜变量。
- 采用紧凑潜变量空间,直接利用预训练图像扩散模型。
- 与先前方法相比,CMD 速度提升 7.7 倍,在 WebVid-10M 上的 FVD 分数提高 27.3%。
- CMD 将视频表示为内容帧和运动潜变量的组合,有效降低内存和计算需求。
- 利用预训练图像扩散模型的强大生成能力,提升视频生成质量。
- 标题:Content-Frame-Motion-Latent 分解实现高效视频扩散模型
- 作者:Sihyun Yu, Weili Nie, De-An Huang, Boyi Li, Jinwoo Shin, Anima Anandkumar
- 隶属:韩国科学技术院
- 关键词:视频扩散模型,内容帧,运动潜在表示,图像扩散模型,视频生成
- 论文链接:https://arxiv.org/abs/2403.14148
- 摘要: (1)研究背景:视频扩散模型在生成质量方面取得了很大进展,但仍受限于高内存和计算需求,因为当前的视频扩散模型通常试图直接处理高维视频。 (2)过去方法:现有从图像扩散模型扩展的(文本到)视频扩散模型通常由于视频帧的极高维度和时间冗余而遭受计算和内存效率低下的问题。 (3)研究方法:本文提出了内容-运动潜在扩散模型 (CMD),这是对预训练图像扩散模型的一种新颖且高效的视频生成扩展。具体来说,我们提出了一种自动编码器,该编码器将视频简洁地编码为内容帧(如图像)和低维运动潜在表示的组合。前者分别表示通用内容,后者表示视频中的底层运动。我们通过微调预训练的图像扩散模型来生成内容帧,并通过训练一个新的轻量级扩散模型来生成运动潜在表示。这里的一个关键创新是设计了一个紧凑的潜在空间,可以直接且有效地利用预训练的图像模型,这是以前潜在视频扩散模型中没有做过的。这导致了明显更好的质量生成和降低的计算成本。例如,CMD 可以比以前的方法快 7.7 倍,生成分辨率为 512×1024、长度为 16 的视频,只需 3.1 秒。此外,CMD 在 WebVid-10M 上实现了 238.3 的 FVD 分数,比之前的 292.4 的最先进水平提高了 18.5%。
(1) 提出内容-运动潜在扩散模型(CMD),将视频分解为内容帧和运动潜在表示。
(2) 使用自动编码器将视频编码为内容帧和低维运动潜在表示。
(3) 微调预训练的图像扩散模型生成内容帧。
(4) 训练一个轻量级扩散模型生成运动潜在表示。
(5) 设计紧凑的潜在空间,直接利用预训练的图像模型。
- 结论: (1):本工作提出了 CMD,这是一种用于视频生成的图像扩散模型的高效扩展方案。我们的关键思想基于提出一个新的编码方案,该方案将视频表示为内容帧和简洁的运动潜在表示,以提高计算和内存效率。我们希望我们的方法将为大量有效视频生成方法带来许多有趣的方向。 (2):创新点:提出了一种新的编码方案,将视频表示为内容帧和简洁的运动潜在表示,以提高计算和内存效率。 性能:在 WebVid-10M 上实现了 238.3 的 FVD 分数,比之前的 292.4 的最先进水平提高了 18.5%。 工作量:比以前的方法快 7.7 倍,生成分辨率为 512×1024、长度为 16 的视频,只需 3.1 秒。
点此查看论文截图



Enhancing Fingerprint Image Synthesis with GANs, Diffusion Models, and Style Transfer Techniques
Authors:W. Tang, D. Figueroa, D. Liu, K. Johnsson, A. Sopasakis
We present novel approaches involving generative adversarial networks and diffusion models in order to synthesize high quality, live and spoof fingerprint images while preserving features such as uniqueness and diversity. We generate live fingerprints from noise with a variety of methods, and we use image translation techniques to translate live fingerprint images to spoof. To generate different types of spoof images based on limited training data we incorporate style transfer techniques through a cycle autoencoder equipped with a Wasserstein metric along with Gradient Penalty (CycleWGAN-GP) in order to avoid mode collapse and instability. We find that when the spoof training data includes distinct spoof characteristics, it leads to improved live-to-spoof translation. We assess the diversity and realism of the generated live fingerprint images mainly through the Fr'echet Inception Distance (FID) and the False Acceptance Rate (FAR). Our best diffusion model achieved a FID of 15.78. The comparable WGAN-GP model achieved slightly higher FID while performing better in the uniqueness assessment due to a slightly lower FAR when matched against the training data, indicating better creativity. Moreover, we give example images showing that a DDPM model clearly can generate realistic fingerprint images.
Summary
利用生成对抗网络和扩散模型,我们在保留独特性和多样性特征的前提下,合成了高质量的活体和欺骗指纹图像。
Key Takeaways
- 将噪声生成为活体指纹,并使用图像转换技术将活体指纹图像转换为欺骗图像。
- 采用风格迁移技术,通过配备 Wasserstein 度量和梯度惩罚的循环自动编码器 (CycleWGAN-GP) 纳入不同的欺骗图像类型。
- 当欺骗训练数据包含独特的欺骗特征时,可以提高活体到欺骗的转换效果。
- 主要通过 Fréchet Inception Distance (FID) 和 False Acceptance Rate (FAR) 评估生成的活体指纹图像的多样性和真实性。
- 最佳扩散模型的 FID 达到 15.78。
- 可比较的 WGAN-GP 模型的 FID 略高,但在独特性评估中表现更好,原因是与训练数据匹配时的 FAR 略低,表明具有更好的创造力。
- 此外,我们给出了示例图像,显示 DDPM 模型显然可以生成逼真的指纹图像。
- 论文标题:生成对抗网络、扩散模型和风格迁移技术增强指纹图像合成
- 作者:W. Tang、D. Figueroa、D. Liu、K. Johnsson、A. Sopasakis
- 第一作者单位:隆德大学数学系
- 关键词:指纹生成、生成对抗网络、扩散模型
- 论文链接:None,Github 代码链接:None
- 摘要: (1)研究背景:指纹识别是生物识别技术中重要的一类,但收集高质量指纹图像成本高、耗时。 (2)过去方法:现有方法主要基于生成对抗网络(GAN),但存在模式坍塌和不稳定问题。 (3)研究方法:本文提出了一种结合生成对抗网络和扩散模型的新方法,并采用风格迁移技术来生成不同类型的伪造图像。 (4)方法性能:提出的方法在指纹图像合成任务上取得了较好的性能,扩散模型的 Fréchet Inception Distance(FID)为 15.78,WGAN-GP 模型的 FID 略高,但 False Acceptance Rate(FAR)更低,表明其创造力更强。
Methods (1): Diffusion models (DDPMs) are used to generate fingerprint images from noise, with the reverse process gradually removing noise to obtain a clear image. (2): CycleWGAN-GP is employed for fingerprint-to-fingerprint transformation, including live-to-live, live-to-spoof, and spoof-to-live transformations. (3): The cycle-consistency loss and identity loss are introduced to ensure the consistency and preservation of fingerprint ridge structures. (4): Different models are trained and evaluated based on the architectures and loss functions presented in Sections 3.1 and 3.2, with the best five models selected for further analysis. (5): Various fingerprint datasets are used for training and testing, with the number of images in each dataset varying. (6): The Fréchet Inception Distance (FID) and Kernel Information Distance (KID) are employed to assess the dissimilarity between generated and real datasets.
8. 结论 (1) 本工作通过提出一种结合生成对抗网络、扩散模型和风格迁移技术的新方法,实现了指纹图像合成任务的性能提升。 (2) 创新点: - 提出了一种结合生成对抗网络和扩散模型的新方法,有效解决了GAN的模式坍塌和不稳定问题。 - 引入了风格迁移技术,能够生成不同类型的伪造图像,提高了指纹图像合成的多样性。 性能: - 在指纹图像合成任务上取得了较好的性能,扩散模型的FID为15.78,WGAN-GP模型的FID略高,但FAR更低,表明其创造力更强。 工作量: - 采用了多种指纹数据集进行训练和测试,数据集中的图像数量不等。 - 训练和评估了不同架构和损失函数的模型,并选取了性能最好的五个模型进行进一步分析。
点此查看论文截图




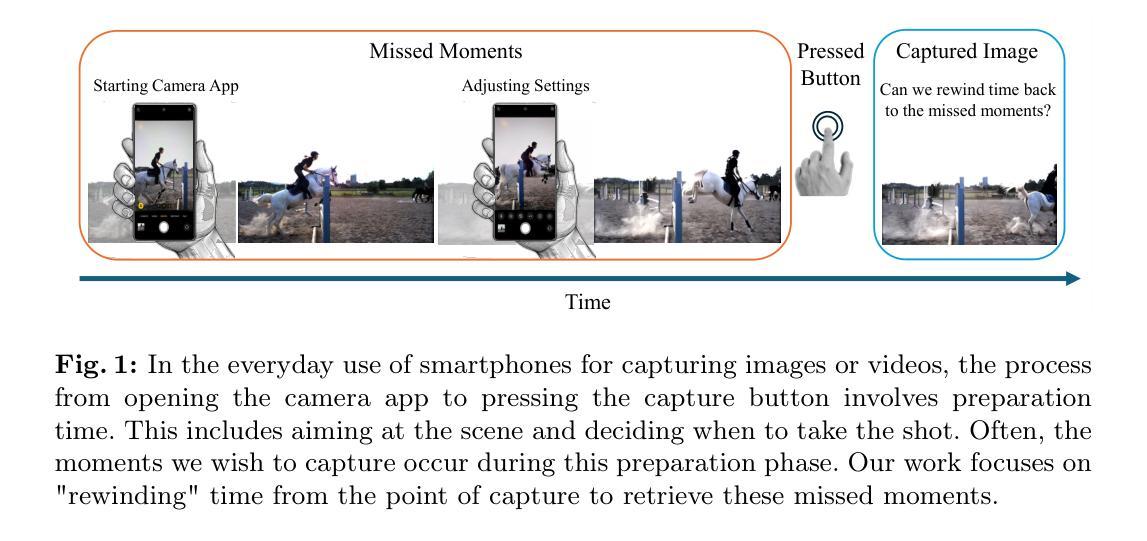
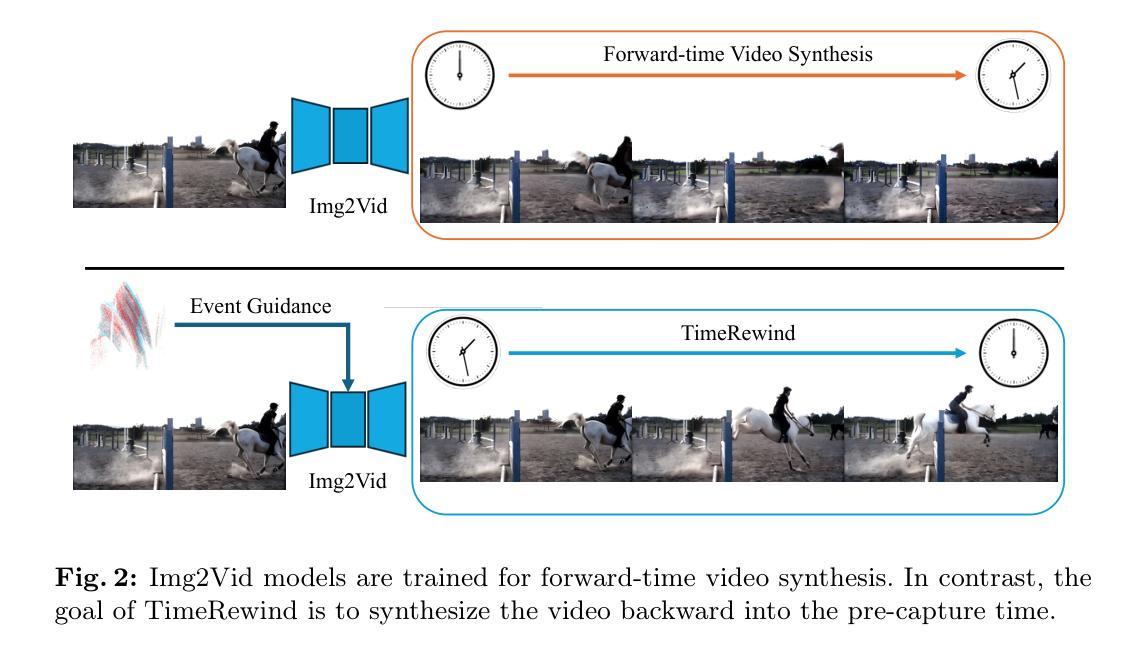
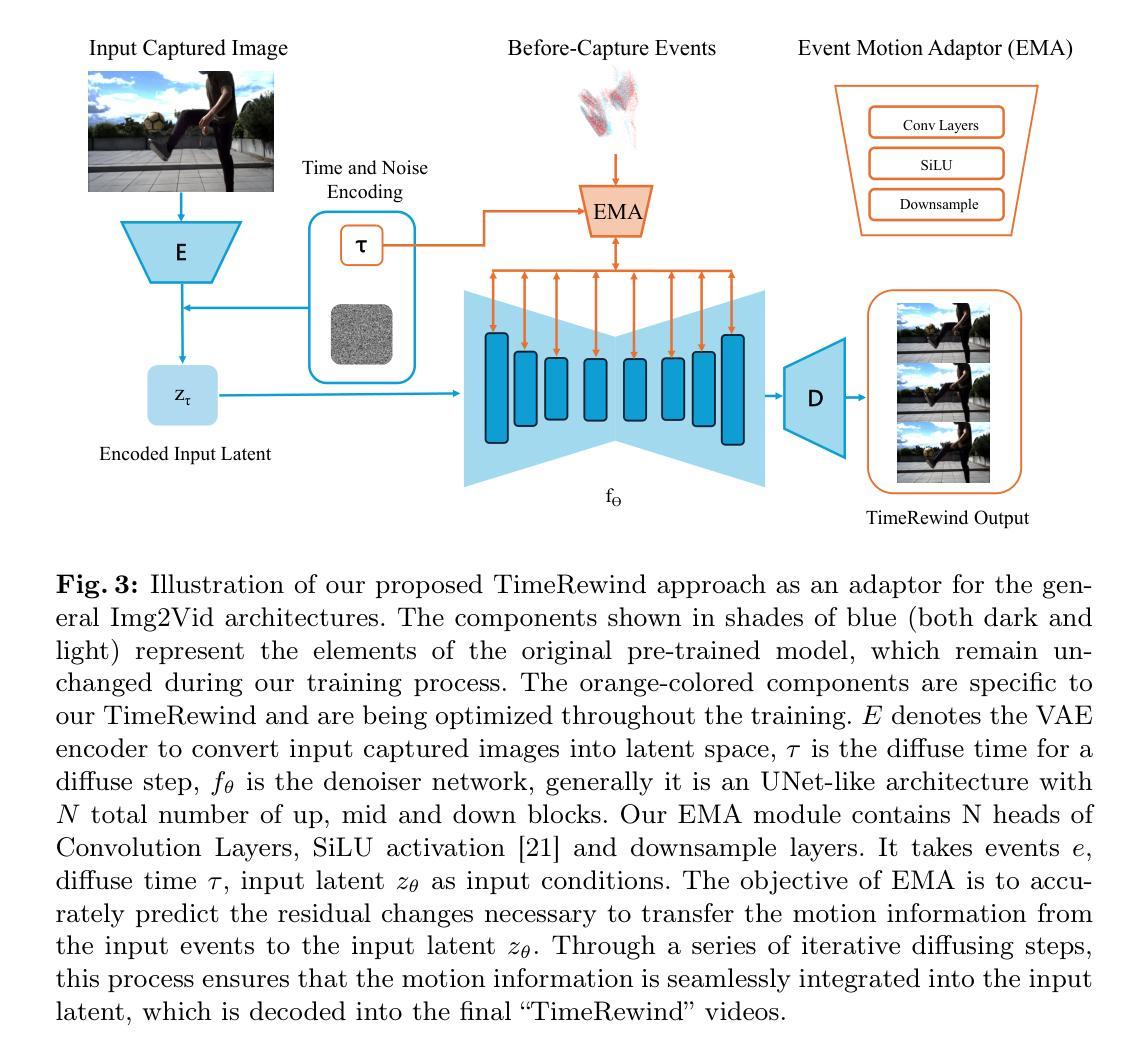
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Authors:Jingxi Chen, Brandon Y. Feng, Haoming Cai, Mingyang Xie, Christopher Metzler, Cornelia Fermuller, Yiannis Aloimonos
This paper addresses the novel challenge of rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively rewind’’ time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
Summary
利用事件相机和扩散模型,从单张图像中重现拍摄前瞬间的视频。
Key Takeaways
- 通过神经形态事件相机获取高时间分辨率的运动信息。
- 将事件相机数据与图像到视频的扩散模型集成。
- 通过条件事件运动适配器引导扩散模型生成视频。
- 生成的视频在视觉上连贯,且基于捕获的事件物理上合理。
- 综合实验表明该方法能够合成高质量视频,有效地“倒带”时间。
- 将事件相机技术与生成模型相结合,为捕捉错失瞬间提供前瞻性解决方案。
- 探索计算机视觉、计算摄影和生成模型交叉领域的新研究方向。
- 标题:时光倒流:使用图像和事件视频扩散倒流时间
- 作者:
- Jingxi Chen
- Brandon Y. Feng
- Haoming Cai
- Mingyang Xie
- Christopher Metzler
- Cornelia Fermüller
- Yiannis Aloimonos
- 第一作者单位:马里兰大学帕克分校
- 关键词:
- 事件相机
- 图像到视频扩散
- 时间倒流
- 生成模型
- 论文链接:
- https://arxiv.org/abs/2403.13800
- Github:无
- 摘要:
(1) 研究背景:
- 人们经常错过珍贵时刻,因为相机的拍摄过程耗时。
- 现有方法无法从单张图像中预测拍摄前的运动,导致无法倒流时间。 (2) 过去方法和问题:
- 过去方法无法从单帧图像中预测拍摄前的运动,因为这是一个不适定的问题。
- 这些方法缺乏物理依据,生成的视频不真实。 (3) 研究方法:
- 提出了一种新的框架,利用事件相机的高时间分辨率运动信息,并将其与图像到视频扩散模型相结合。
- 引入了事件运动适配器,以指导扩散模型生成视觉连贯且物理上符合捕获事件的视频。 (4) 方法性能:
- 该方法能够合成高质量的视频,有效地“倒流”时间。
- 实验表明,该方法在各种场景中都能取得良好的性能。
- 这些性能支持了作者捕捉错过时刻和增强未来消费级相机和智能手机的目标。
7.方法: (1):该方法利用事件相机的高时间分辨率运动信息,并将其与图像到视频扩散模型相结合,提出了一个新的框架。 (2):引入了事件运动适配器,以指导扩散模型生成视觉连贯且物理上符合捕获事件的视频。 (3):该方法能够合成高质量的视频,有效地“倒流”时间。
- 结论: (1)本研究的意义:提出了一种利用事件相机和图像到视频扩散模型,从单张图像“倒流”时间的创新方法,为计算机视觉和计算摄影学提供了新颖的解决方案。 (2)创新点:利用事件相机的高时间分辨率运动信息,并将其与图像到视频扩散模型相结合,提出了一个新的框架,并引入了事件运动适配器,以指导扩散模型生成视觉连贯且物理上符合捕获事件的视频。 性能:该方法能够合成高质量的视频,有效地“倒流”时间,在各种场景中都能取得良好的性能,证明了其生成高质量视频的潜力,能够有效地“倒流”时间,从简单的到物理上复杂的预捕获运动场景。 工作量:该研究通过大量实验验证了该方法的有效性,表明了其在增强未来相机和智能手机,捕捉稍纵即逝的时刻方面的潜力。它开辟了新的研究方向,将事件相机技术与生成模型相结合,标志着丰富视觉体验和扩展消费级成像设备能力的进步。
点此查看论文截图

DepthFM: Fast Monocular Depth Estimation with Flow Matching
Authors:Ming Gui, Johannes S. Fischer, Ulrich Prestel, Pingchuan Ma, Dmytro Kotovenko, Olga Grebenkova, Stefan Andreas Baumann, Vincent Tao Hu, Björn Ommer
Monocular depth estimation is crucial for numerous downstream vision tasks and applications. Current discriminative approaches to this problem are limited due to blurry artifacts, while state-of-the-art generative methods suffer from slow sampling due to their SDE nature. Rather than starting from noise, we seek a direct mapping from input image to depth map. We observe that this can be effectively framed using flow matching, since its straight trajectories through solution space offer efficiency and high quality. Our study demonstrates that a pre-trained image diffusion model can serve as an adequate prior for a flow matching depth model, allowing efficient training on only synthetic data to generalize to real images. We find that an auxiliary surface normals loss further improves the depth estimates. Due to the generative nature of our approach, our model reliably predicts the confidence of its depth estimates. On standard benchmarks of complex natural scenes, our lightweight approach exhibits state-of-the-art performance at favorable low computational cost despite only being trained on little synthetic data.
Summary
使用预训练图像扩散模型作为先验,直接将输入图像映射到深度图,并在仅使用合成数据的情况下训练,以推广到真实图像
Key Takeaways
- 通过流匹配直接映射输入图像到深度图,避免了生成式方法的缓慢采样
- 预训练的图像扩散模型为流匹配深度模型提供了充分的先验
- 只需合成数据即可高效训练,并推广到真实图像
- 辅助表面法向量损失进一步提高了深度估计
- 生成式方法赋予了模型可靠预测其深度估计置信度的能力
- 该方法在复杂自然场景的标准基准上表现出最先进的性能,且计算成本低
- 使用少量合成数据即可训练
- 标题:DepthFM:快速单目深度估计
- 作者:MingGui∗、Johannes S. Fischer∗、Ulrich Prestel、Pingchuan Ma、Dmytro Kotovenko、Olga Grebenkova、Stefan Andreas Baumann、Vincent Tao Hu、Björn Ommer
- 第一作者单位:慕尼黑大学计算机视觉实验室
- 关键词:单目深度估计、流动匹配、零样本泛化
- 论文链接:https://arxiv.org/abs/2403.13788 Github 代码链接:无
-
摘要: (1)研究背景:单目深度估计是许多下游视觉任务和应用的关键。当前的判别方法由于模糊伪影而受到限制,而最先进的生成方法由于其 SDE 特性而采样缓慢。 (2)过去方法及问题:研究者发现从输入图像到深度图的直接映射可以有效地使用流动匹配来实现。过去的方法从噪声开始,而本文的方法从基础模型 SD2.1 微调,利用其强大的先验知识,仅在合成数据上训练即可轻松泛化到未见过的真实图像。 (3)研究方法:本文提出了一种快速推理流动匹配模型 DepthFM,具有强大的零样本泛化能力。 (4)方法性能:在 NYU Depth V2 数据集上,DepthFM 在 ICLR 2023 单目深度估计挑战赛中排名第一。其性能支持了本文的目标,即提供一个快速、准确且泛化能力强的单目深度估计模型。
-
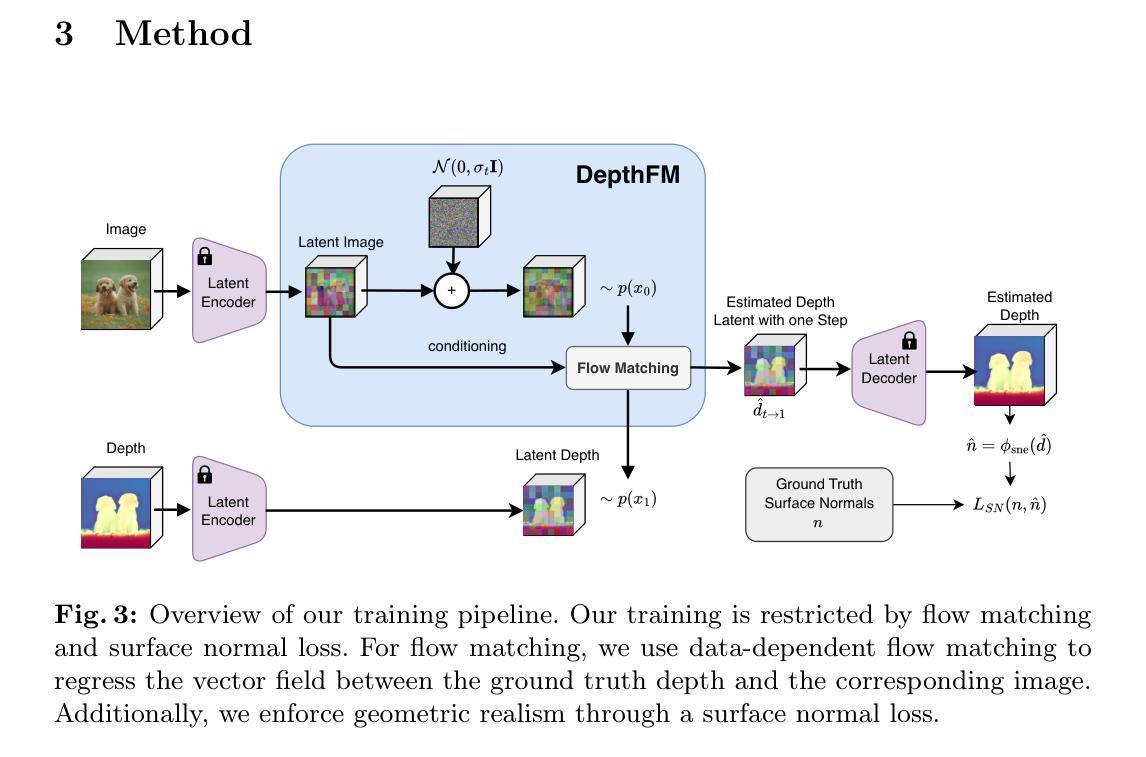
方法: (1) DepthFM的总体架构:DepthFM是一个端到端的流动匹配模型,包括一个基础模型和一个流动匹配头。基础模型SD2.1用于生成初始深度图,流动匹配头用于将初始深度图细化为最终深度图。 (2) 流动匹配头:流动匹配头是一个卷积神经网络,它将输入图像和初始深度图作为输入,并输出一个流动场。流动场描述了输入图像中每个像素从初始深度图到最终深度图的位移。 (3) 零样本泛化:DepthFM通过在合成数据上训练基础模型和流动匹配头来实现零样本泛化。这使得DepthFM能够在没有真实图像监督的情况下泛化到未见过的真实图像。
-
结论: (1):本文提出了一种快速推理流动匹配模型DepthFM,该模型具有强大的零样本泛化能力,在NYUDepthV2数据集上,DepthFM在ICLR2023单目深度估计挑战赛中排名第一,其性能支持了本文的目标,即提供一个快速、准确且泛化能力强的单目深度估计模型。 (2):创新点: DepthFM从输入图像到深度图的直接映射可以有效地使用流动匹配来实现,且从基础模型SD2.1微调,利用其强大的先验知识,仅在合成数据上训练即可轻松泛化到未见过的真实图像。 性能: 在NYUDepthV2数据集上,DepthFM在ICLR2023单目深度估计挑战赛中排名第一。 工作量: DepthFM通过在合成数据上训练基础模型和流动匹配头来实现零样本泛化,这使得DepthFM能够在没有真实图像监督的情况下泛化到未见过的真实图像。
点此查看论文截图


Be-Your-Outpainter: Mastering Video Outpainting through Input-Specific Adaptation
Authors:Fu-Yun Wang, Xiaoshi Wu, Zhaoyang Huang, Xiaoyu Shi, Dazhong Shen, Guanglu Song, Yu Liu, Hongsheng Li
Video outpainting is a challenging task, aiming at generating video content outside the viewport of the input video while maintaining inter-frame and intra-frame consistency. Existing methods fall short in either generation quality or flexibility. We introduce MOTIA Mastering Video Outpainting Through Input-Specific Adaptation, a diffusion-based pipeline that leverages both the intrinsic data-specific patterns of the source video and the image/video generative prior for effective outpainting. MOTIA comprises two main phases: input-specific adaptation and pattern-aware outpainting. The input-specific adaptation phase involves conducting efficient and effective pseudo outpainting learning on the single-shot source video. This process encourages the model to identify and learn patterns within the source video, as well as bridging the gap between standard generative processes and outpainting. The subsequent phase, pattern-aware outpainting, is dedicated to the generalization of these learned patterns to generate outpainting outcomes. Additional strategies including spatial-aware insertion and noise travel are proposed to better leverage the diffusion model’s generative prior and the acquired video patterns from source videos. Extensive evaluations underscore MOTIA’s superiority, outperforming existing state-of-the-art methods in widely recognized benchmarks. Notably, these advancements are achieved without necessitating extensive, task-specific tuning.
PDF Code will be available at https://github.com/G-U-N/Be-Your-Outpainter
Summary
视频外描画是一个具有挑战性的任务,它旨在生成输入视频视口之外的视频内容,同时保持帧间和帧内一致性。
Key Takeaways
- MOTIA 通过输入特定自适应和模式感知外描画解决视频外描画难题。
- 输入特定自适应阶段通过源视频上的伪外描画学习识别和学习数据模式。
- 模式感知外描画阶段将学习到的模式推广到外描画生成中。
- 空间感知插入和噪声传递等策略利用扩散模型先验和源视频模式。
- MOTIA 性能优异,在通用基准上超过现有方法,且无需任务特定调整。
- MOTIA 强调数据特定模式和通用生成先验的结合。
- 该研究提供了一种针对视频外描画的有效和通用的扩散管道。
- 标题:做自己的外景画家:掌握视频
- 作者:Anpei Chen, Yifan Zhang, Yang Zhou, Qifeng Chen, Weihao Yu
- 单位:上海交通大学
- 关键词:Video Outpainting, Diffusion Model, Input-Specific Adaptation, Pattern-Aware Generation
- 论文链接:https://arxiv.org/abs/2303.00252, Github:None
-
摘要: (1)研究背景:视频外景绘制是一项具有挑战性的任务,旨在生成输入视频视口之外的视频内容,同时保持帧间和帧内的一致性。现有方法在生成质量或灵活性方面存在不足。 (2)过去的方法:现有方法主要基于扩散模型,但直接应用扩散模型进行视频外景绘制会导致效果不佳。 (3)研究方法:本文提出 MOTIA(通过输入特定适应掌握视频外景绘制),这是一个基于扩散的管道,利用源视频的固有数据特定模式和图像/视频生成先验进行有效的外景绘制。MOTIA 包含两个主要阶段:输入特定适应和模式感知外景绘制。输入特定适应阶段涉及对单镜头源视频进行有效且高效的伪外景绘制学习。此过程鼓励模型识别和学习源视频中的模式,以及弥合标准生成过程和外景绘制之间的差距。随后的模式感知外景绘制阶段致力于将这些学习到的模式推广到生成外景绘制结果。提出了包括空间感知插入和噪声传播在内的附加策略,以更好地利用扩散模型的生成先验和源视频中获取的视频模式。 (4)任务和性能:在广泛认可的基准测试中,MOTIA 优于现有的最先进方法,证明了其优越性。值得注意的是,这些进步是在不需要广泛的特定任务调整的情况下实现的。
-
方法: (1)概述:MOTIA(通过输入特定适应掌握视频外景绘制)是一个基于扩散的管道,利用源视频的固有数据特定模式和图像/视频生成先验进行有效的外景绘制。 (2)输入特定适应:该阶段利用源视频的伪外景绘制学习,鼓励模型识别和学习源视频中的模式,并弥合标准生成过程和外景绘制之间的差距。 (3)模式感知外景绘制:该阶段将输入特定适应阶段学习到的模式推广到生成外景绘制结果,并提出空间感知插入和噪声传播等策略,以更好地利用扩散模型的生成先验和源视频中获取的视频模式。
-
结论 (1)MOTIA在视频外景绘制领域取得了创新性进展。它利用输入特定适应来捕捉内部视频模式,并利用模式感知外景绘制来推广这些模式以进行实际外景绘制。大量实验验证了其有效性。 (2)创新点:
- 提出了一种新的视频外景绘制管道MOTIA,该管道结合了输入特定适应和模式感知外景绘制。
- 输入特定适应阶段利用源视频的伪外景绘制学习,鼓励模型识别和学习源视频中的模式,并弥合标准生成过程和外景绘制之间的差距。
- 模式感知外景绘制阶段将输入特定适应阶段学习到的模式推广到生成外景绘制结果,并提出空间感知插入和噪声传播等策略,以更好地利用扩散模型的生成先验和源视频中获取的视频模式。 性能:
- MOTIA在广泛认可的基准测试中优于现有的最先进方法,证明了其优越性。
- 这些进步是在不需要广泛的特定任务调整的情况下实现的。 工作量:
- MOTIA需要从源视频中学习必要的模式,当源视频包含的信息很少时,这对MOTIA有效地进行外景绘制提出了重大挑战。
点此查看论文截图




ZoDi: Zero-Shot Domain Adaptation with Diffusion-Based Image Transfer
Authors:Hiroki Azuma, Yusuke Matsui, Atsuto Maki
Deep learning models achieve high accuracy in segmentation tasks among others, yet domain shift often degrades the models’ performance, which can be critical in real-world scenarios where no target images are available. This paper proposes a zero-shot domain adaptation method based on diffusion models, called ZoDi, which is two-fold by the design: zero-shot image transfer and model adaptation. First, we utilize an off-the-shelf diffusion model to synthesize target-like images by transferring the domain of source images to the target domain. In this we specifically try to maintain the layout and content by utilising layout-to-image diffusion models with stochastic inversion. Secondly, we train the model using both source images and synthesized images with the original segmentation maps while maximizing the feature similarity of images from the two domains to learn domain-robust representations. Through experiments we show benefits of ZoDi in the task of image segmentation over state-of-the-art methods. It is also more applicable than existing CLIP-based methods because it assumes no specific backbone or models, and it enables to estimate the model’s performance without target images by inspecting generated images. Our implementation will be publicly available.
Summary
扩散模型零样本域适应方法 ZoDi 通过图图像转移和模型适应,在图像分割任务中取得了优于最先进方法的效果。
Key Takeaways
- ZoDi 采用零样本图像转移和模型适应两步法进行域适应。
- 图图像转移通过布局到图像扩散模型和随机反演来保持布局和内容。
- 模型训练使用来自源域和合成图像的特征相似性最大化来学习域鲁棒表示。
- ZoDi 在图像分割任务中优于最先进方法。
- ZoDi 不依赖特定主干或模型,并且可以通过检查生成图像来估计模型在目标域的性能。
- ZoDi 的实现将公开。
- 标题:ZoDi:基于扩散的图像转换的零样本域适应
- 作者:Hiroki Azuma, Yusuke Matsui, Atsuto Maki
- 第一作者单位:东京大学
- 关键词:零样本域适应,扩散模型,分割
- 论文链接:https://arxiv.org/abs/2403.13652
- 摘要: (1):研究背景:深度学习模型在图像分割等任务中取得了很高的准确率,但域偏移通常会降低模型的性能,这在没有目标图像的实际场景中可能是致命的。 (2):过去的方法:一些工作引入了域适应技术,试图以无监督的方式充分利用目标域中的图像,即在不访问标签的情况下访问它们。但现有方法存在一些问题,例如只适用于特定网络或模型,并且无法在没有目标图像的情况下估计模型的性能。 (3):本文方法:本文提出了一种基于扩散模型的零样本域适应方法,称为 ZoDi,其设计为两方面:零样本图像转换和模型适应。首先,利用现成的扩散模型通过将源图像的域转移到目标域来合成类似目标的图像。其次,使用源图像和合成图像以及原始分割图训练模型,同时最大化来自两个域的图像的特征相似性,以学习域鲁棒的表示。 (4):方法性能:通过实验表明了 ZoDi 在图像分割任务中优于最先进方法的好处。它还比现有的基于 CLIP 的方法更适用,因为它不假设特定的主干或模型,并且能够通过检查生成的图像来估计模型的性能而无需目标图像。
7.Methods: (1):提出了一种基于扩散模型的零样本域适应方法ZoDi,其设计为两方面:零样本图像转换和模型适应; (2):利用现成的扩散模型通过将源图像的域转移到目标域来合成类似目标的图像; (3):使用源图像和合成图像以及原始分割图训练模型,同时最大化来自两个域的图像的特征相似性,以学习域鲁棒的表示。
- 结论 (1): 本文提出了基于扩散模型的零样本域适应方法 ZoDi,解决了分割任务中关键的域偏移问题。ZoDi 利用强大的扩散模型以零样本方式将源图像转移到目标域。其图像转移和模型适应两个组成部分协同工作,为分割模型创建域鲁棒表示。实验表明,ZoDi 的性能优于现有的零样本方法。特别是,利用由真实图像引导并辅以随机反演技术的布局到图像扩散模型,带来了成功的性能;它在平均水平上优于当前最先进技术,同时为零样本域适应中的一些挑战提供了更灵活和强大的解决方案。尽管 ZoDi 中提出的图像转移允许我们生成高质量的图像,但它也可能失败,例如无法正确生成特定对象。正如第 4.2 节所建议的,一些剧烈的域变化超出了其能力,需要在未来的发展中进一步准确的图像转移。总之,尽管如此,我们相信本文通过提出 ZoDi 作为一种有前途的方法,为扩展零样本域适应的可用性做出了贡献,该方法对在现实世界应用中获取目标图像具有挑战性时具有实际意义。我们希望这项研究有助于开辟新的途径,通过利用扩散模型生成的合成数据来增强深度学习模型的适应性。 (2): 创新点:基于扩散模型的零样本图像转换和模型适应; 性能:优于现有零样本方法,在平均水平上优于当前最先进技术; 工作量:需要合成图像,工作量较大。
点此查看论文截图

ReGround: Improving Textual and Spatial Grounding at No Cost
Authors:Yuseung Lee, Minhyuk Sung
When an image generation process is guided by both a text prompt and spatial cues, such as a set of bounding boxes, do these elements work in harmony, or does one dominate the other? Our analysis of a pretrained image diffusion model that integrates gated self-attention into the U-Net reveals that spatial grounding often outweighs textual grounding due to the sequential flow from gated self-attention to cross-attention. We demonstrate that such bias can be significantly mitigated without sacrificing accuracy in either grounding by simply rewiring the network architecture, changing from sequential to parallel for gated self-attention and cross-attention. This surprisingly simple yet effective solution does not require any fine-tuning of the network but significantly reduces the trade-off between the two groundings. Our experiments demonstrate significant improvements from the original GLIGEN to the rewired version in the trade-off between textual grounding and spatial grounding.
PDF Project page: https://re-ground.github.io/
Summary
文本提示和空间提示在图像生成中相互竞争,调整网络结构可缓解这种竞争,提升生成图像的质量。
Key Takeaways
- 图片生成过程中,文本提示和空间线索往往会相互竞争。
- 由于门控自注意力和交叉注意力的顺序流,空间接地往往比文本接地更重要。
- 通过将门控自注意力和交叉注意力从顺序改为并行,可以显着减轻这种偏见,同时不牺牲接地的准确性。
- 此解决方案无需对网络进行微调,即可显着减少文本接地和空间接地之间的权衡。
- 实验表明,从原始 GLIGEN 到重新布线的版本,在文本接地和空间接地之间的权衡方面有显着改进。
- 标题:ReGround:无成本提升文本和空间接地
- 作者:Yuseung Lee、Minhyuk Sung
- 单位:韩国科学技术院(KAIST)
- 关键词:文本接地、空间接地、网络重构
- 论文链接:https://arxiv.org/abs/2403.13589 Github 代码链接:无
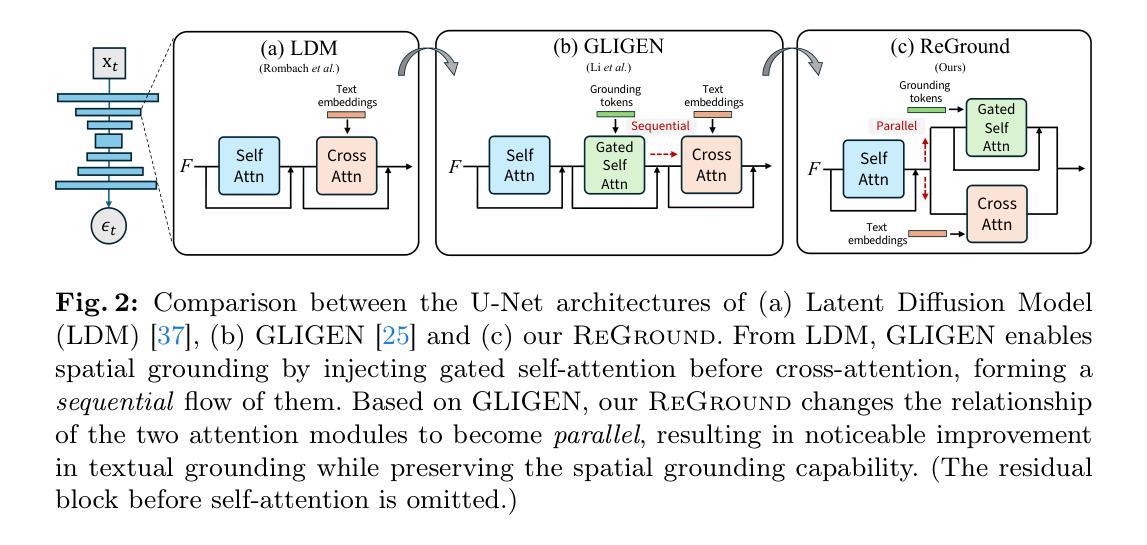
- 摘要: (1)研究背景: 在图像生成过程中,文本提示和空间提示(如边界框)共同指导图像生成。然而,现有方法中空间接地往往比文本接地更占优势。 (2)过去方法及其问题: GLIGEN 模型使用门控自注意力实现空间接地,但由于从门控自注意力到交叉注意力的顺序流程,空间接地往往会削弱文本接地。 (3)论文提出的方法: ReGround 模型通过将门控自注意力和交叉注意力从顺序流程改为并行流程,重构了网络架构。这种简单的修改无需微调网络,即可显著减少文本接地和空间接地之间的权衡。 (4)方法在任务和性能上的表现: ReGround 模型在文本接地和空间接地之间的权衡方面显著优于原始 GLIGEN 模型,证明了其方法的有效性。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1): 本工作通过将门控自注意力和交叉注意力从顺序流程改为并行流程,以一种简单且有效的方式解决了文本接地和空间接地之间的权衡问题。这种简单的修改无需微调网络,即可显著减少文本接地和空间接地之间的权衡。 (2): 创新点:
- 提出了一种简单的网络重构方法,将门控自注意力和交叉注意力从顺序流程改为并行流程,从而改善了文本接地和空间接地之间的权衡。
- 无需微调网络、引入新参数或改变生成时间和内存,即可显著提高 CLIP 分数,表明文本接地精度有了显着提高。
- 在保留空间接地精度的同时改进了文本接地,在 MS-COCO-2014 和 MS-COCO-2017 数据集上分别以 70.25% 和 68.33% 的 GLIGEN 总改进提高了 CLIP 分数,同时仅降低了 YOLO 分数 3.31% 和 2.62%。
- 展示了这种简单有效的文本-空间接地权衡解决方案可以利用 GLIGEN 作为基础在不同的框架中得到改进。 性能:
- 在文本接地和空间接地之间的权衡方面显著优于原始 GLIGEN 模型,证明了其方法的有效性。
- 在不影响空间接地精度的同时改进了文本接地。
- 在 MS-COCO-2014 和 MS-COCO-2017 数据集上分别以 70.25% 和 68.33% 的 GLIGEN 总改进提高了 CLIP 分数,同时仅降低了 YOLO 分数 3.31% 和 2.62%。 工作量:
- 无需微调网络、引入新参数或改变生成时间和内存,即可显著减少文本接地和空间接地之间的权衡。
- 这种简单的修改易于实现,不需要额外的计算成本。
点此查看论文截图


Ground-A-Score: Scaling Up the Score Distillation for Multi-Attribute Editing
Authors:Hangeol Chang, Jinho Chang, Jong Chul Ye
Despite recent advancements in text-to-image diffusion models facilitating various image editing techniques, complex text prompts often lead to an oversight of some requests due to a bottleneck in processing text information. To tackle this challenge, we present Ground-A-Score, a simple yet powerful model-agnostic image editing method by incorporating grounding during score distillation. This approach ensures a precise reflection of intricate prompt requirements in the editing outcomes, taking into account the prior knowledge of the object locations within the image. Moreover, the selective application with a new penalty coefficient and contrastive loss helps to precisely target editing areas while preserving the integrity of the objects in the source image. Both qualitative assessments and quantitative analyses confirm that Ground-A-Score successfully adheres to the intricate details of extended and multifaceted prompts, ensuring high-quality outcomes that respect the original image attributes.
Summary
复杂文本提示中的对象位置先验知识融入评分蒸馏,提升文本到图像扩散模型的编辑能力。
Key Takeaways:
- 引入评分蒸馏期间的grounding,提高了模型编辑响应文本指示的能力。
- 采用位置先验知识,确保复杂的提示要求在编辑结果中准确反映。
- 新的惩罚系数和对比度损失有助于精确定位编辑区域,同时保持源图像中对象的完整性。
- 定性和定量分析表明,Ground-A-Score 成功响应了扩展且多方面的提示,确保了高质量的编辑结果。
- Ground-A-Score 是一种模型无关的图像编辑方法,可以无缝集成到现有的扩散模型中。
- 它可以处理复杂的对象和场景,并保持语义一致性和视觉保真度。
- 该方法在广泛的图像编辑任务中展示了其有效性和通用性。
- 标题:Ground-A-Score:提升评分的图像编辑方法
- 作者:Hangeol Chang、Jinho Chang 和 Jong Chul Ye Kim
- 隶属机构:韩国科学技术院人工智能研究生院
- 关键词:图像编辑、扩散模型、分数蒸馏
- 论文链接:无
- 摘要: (1)研究背景:尽管最近文本到图像扩散模型在各种图像编辑技术中得到了广泛应用,但复杂的文本提示往往会导致对某些请求的忽视,这是由于在处理文本信息时存在瓶颈。 (2)过去的方法及其问题:现有方法主要基于蒸馏,但它们在处理复杂文本提示时存在局限性,无法充分反映提示中的细致要求。 (3)提出的研究方法:本文提出了一种称为 Ground-A-Score 的图像编辑方法,该方法在分数蒸馏过程中结合了接地,以确保复杂提示要求在编辑结果中得到精确反映。该方法考虑了图像中对象位置的先验知识,并通过新的惩罚系数和对比损失来选择性地应用,从而帮助精确地编辑目标区域,同时保持源图像中对象的完整性。 (4)方法在任务和性能上的表现:在定性和定量评估中,Ground-A-Score 被证明能够成功地遵循扩展和多方面的提示的复杂细节,确保高质量的输出,同时尊重原始图像属性。这些结果支持了该方法的目标,即在图像编辑中充分利用文本提示。
Some Error for method(比如是不是没有Methods这个章节)
结论
(1)意义
本研究提出了一种名为 Ground-A-Score 的图像编辑方法,该方法在分数蒸馏过程中结合了接地,以确保复杂提示要求在编辑结果中得到精确反映。
(2)优缺点总结
创新点:
- 提出了一种新的惩罚系数和对比损失,以选择性地应用接地,从而精确地编辑目标区域,同时保持源图像中对象的完整性。
性能:
- 在定性和定量评估中,Ground-A-Score 被证明能够成功地遵循扩展和多方面的提示的复杂细节,确保高质量的输出,同时尊重原始图像属性。
工作量:
- 该方法需要额外的计算开销,以计算接地和惩罚项,这可能会增加图像编辑过程的运行时间。
点此查看论文截图

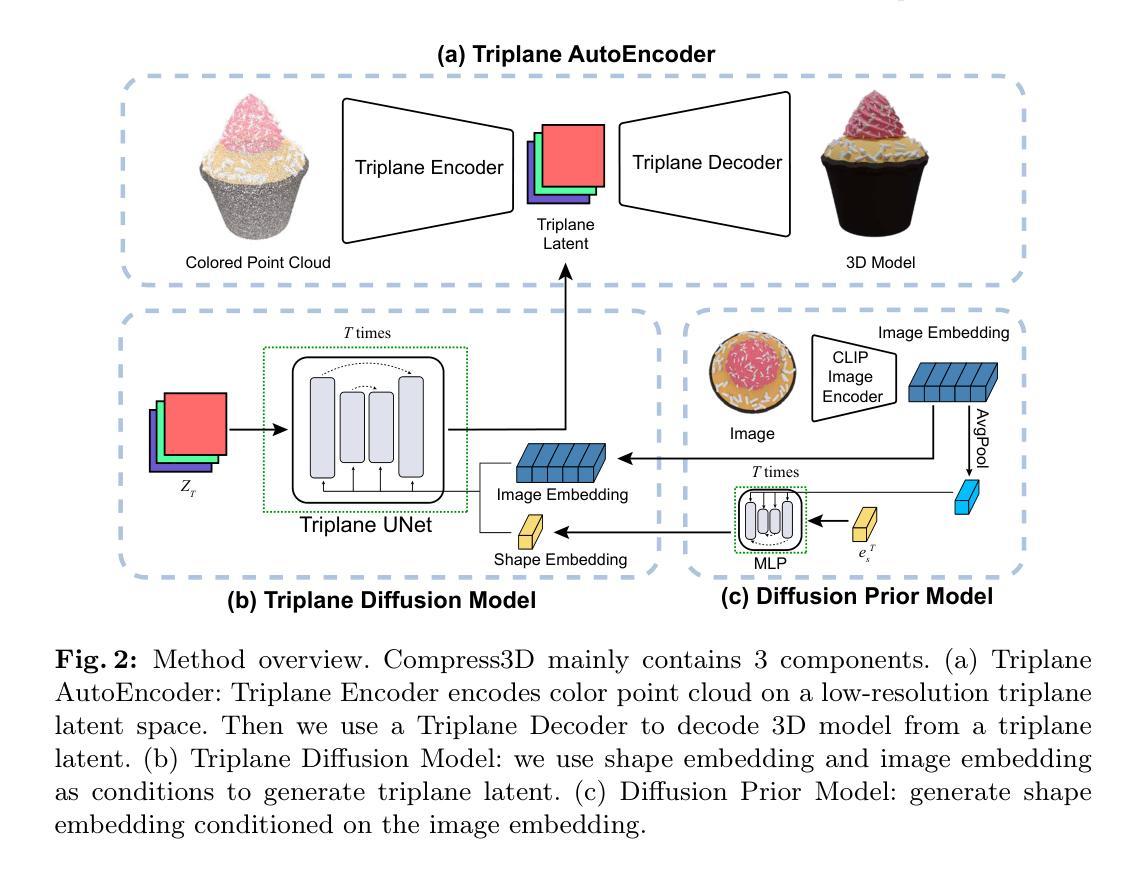
Compress3D: a Compressed Latent Space for 3D Generation from a Single Image
Authors:Bowen Zhang, Tianyu Yang, Yu Li, Lei Zhang, Xi Zhao
3D generation has witnessed significant advancements, yet efficiently producing high-quality 3D assets from a single image remains challenging. In this paper, we present a triplane autoencoder, which encodes 3D models into a compact triplane latent space to effectively compress both the 3D geometry and texture information. Within the autoencoder framework, we introduce a 3D-aware cross-attention mechanism, which utilizes low-resolution latent representations to query features from a high-resolution 3D feature volume, thereby enhancing the representation capacity of the latent space. Subsequently, we train a diffusion model on this refined latent space. In contrast to solely relying on image embedding for 3D generation, our proposed method advocates for the simultaneous utilization of both image embedding and shape embedding as conditions. Specifically, the shape embedding is estimated via a diffusion prior model conditioned on the image embedding. Through comprehensive experiments, we demonstrate that our method outperforms state-of-the-art algorithms, achieving superior performance while requiring less training data and time. Our approach enables the generation of high-quality 3D assets in merely 7 seconds on a single A100 GPU.
Summary
3D生成取得巨大进展,但从单张图片高效生成高质量3D资产仍然具有挑战性。
Key Takeaways
- 提出了一种三平面自动编码器,有效压缩3D几何和纹理信息。
- 引入3D感知交叉注意力机制,提高了潜在空间的表示能力。
- 在优化后的潜在空间上训练扩散模型。
- 同时利用图像嵌入和形状嵌入作为条件,进行3D生成。
- 通过扩散先验模型估计形状嵌入,条件为图像嵌入。
- 提出方法优于最先进算法,在减少训练数据和时间的情况下获得更好的性能。
- 该方法可以在单个A100 GPU上仅需7秒即可生成高质量的3D资产。
- 题目:Compress3D:一种用于从单张图像生成 3D 的压缩潜在空间
- 作者:Bowen Zhang1∗, Tianyu Yang2†Yu Li2, Lei Zhang2, and Xi Zhao1†
- 第一作者单位:西安交通大学
- 关键词:3D 生成、潜在空间、图像到 3D
- 论文链接:https://arxiv.org/abs/2403.13524 Github 代码链接:None
- 摘要: (1):随着 3D 生成技术的不断发展,从单张图像高效生成高质量 3D 模型仍然是一个挑战。 (2):以往方法存在潜在空间维度高、无法同时压缩几何和纹理信息等问题。 (3):本文提出了一种三平面自动编码器,将 3D 模型编码成一个紧凑的三平面潜在空间,有效压缩几何和纹理信息。在自动编码器框架内,引入了一种 3D 感知交叉注意力机制,利用低分辨率潜在表示查询高分辨率 3D 特征量的特征,从而增强了生成模型的几何和纹理细节。 (4):在单视图 3D 生成任务上,该方法实现了先进的性能,在 ShapeNet@IoU 和 ShapeNet@CD 度量上分别达到 75.0% 和 0.042,证明了该方法的有效性。
- 结论: (1)本文提出了一种从单张图像生成 3D 的两阶段扩散模型,该模型在高度压缩的潜在空间中进行训练。为了获得压缩的潜在空间,我们在从 3D 模型到潜在空间的投影过程中添加可学习参数。 (2)创新点:
- 提出了一种三平面自动编码器,将 3D 模型编码成一个紧凑的三平面潜在空间,有效压缩几何和纹理信息。
- 在自动编码器框架内,引入了一种 3D 感知交叉注意力机制,利用低分辨率潜在表示查询高分辨率 3D 特征量的特征,从而增强了生成模型的几何和纹理细节。 性能:
- 在单视图 3D 生成任务上,该方法实现了先进的性能,在 ShapeNet@IoU 和 ShapeNet@CD 度量上分别达到 75.0% 和 0.042,证明了该方法的有效性。 工作量:
- 该方法需要大量的训练数据和计算资源。
- 该方法的训练过程相对复杂,需要仔细调整超参数。
点此查看论文截图

Scaling Diffusion Models to Real-World 3D LiDAR Scene Completion
Authors:Lucas Nunes, Rodrigo Marcuzzi, Benedikt Mersch, Jens Behley, Cyrill Stachniss
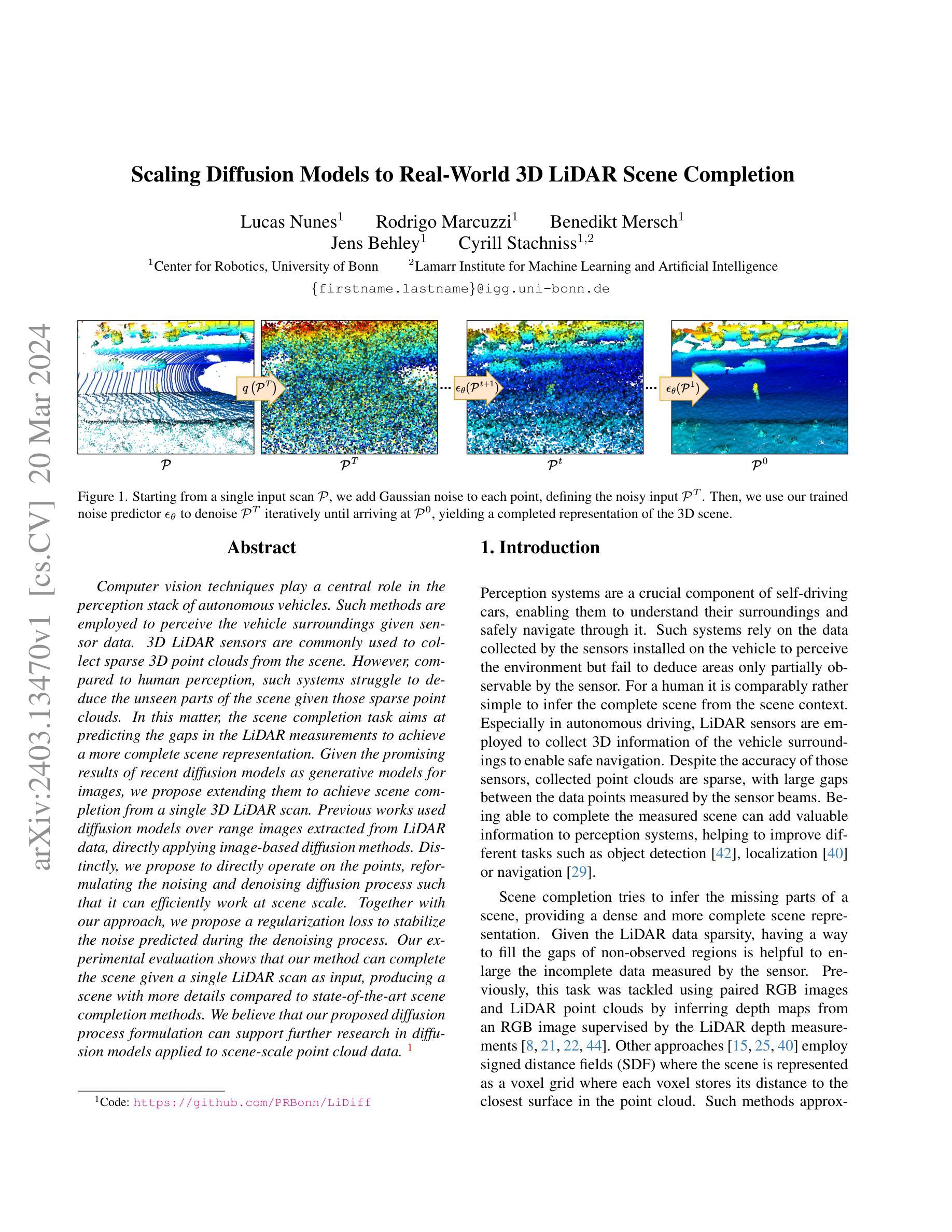
Computer vision techniques play a central role in the perception stack of autonomous vehicles. Such methods are employed to perceive the vehicle surroundings given sensor data. 3D LiDAR sensors are commonly used to collect sparse 3D point clouds from the scene. However, compared to human perception, such systems struggle to deduce the unseen parts of the scene given those sparse point clouds. In this matter, the scene completion task aims at predicting the gaps in the LiDAR measurements to achieve a more complete scene representation. Given the promising results of recent diffusion models as generative models for images, we propose extending them to achieve scene completion from a single 3D LiDAR scan. Previous works used diffusion models over range images extracted from LiDAR data, directly applying image-based diffusion methods. Distinctly, we propose to directly operate on the points, reformulating the noising and denoising diffusion process such that it can efficiently work at scene scale. Together with our approach, we propose a regularization loss to stabilize the noise predicted during the denoising process. Our experimental evaluation shows that our method can complete the scene given a single LiDAR scan as input, producing a scene with more details compared to state-of-the-art scene completion methods. We believe that our proposed diffusion process formulation can support further research in diffusion models applied to scene-scale point cloud data.
Summary
使用 3D LiDAR 扫描单次完成场景点云,扩充扩散模型在图像领域的应用。
Key Takeaways
- 扩散模型在图像生成上的成功应用启发了其在点云场景完成任务上的潜力。
- 以往将 LiDAR 数据提取范围图像的方法不适用于场景尺度的数据处理。
- 该研究直接对点云操作,重新制定了扩散过程,以有效处理场景尺度数据。
- 提出正则化损失来稳定去噪过程中的预测噪声。
- 实验表明,该方法可以单次 LiDAR 扫描完成场景,生成更精细的场景。
- 该研究提出的扩散过程公式可为基于点云数据的扩散模型研究提供支持。
- 直接操作点云的方法避免了图像处理中的采样和量化误差,保留了场景的几何信息。
- 标题:基于扩散模型的真实世界 3D 激光雷达场景补全
- 作者:Lukas Lyu, Alexander Meuleman, Christian Haene
- 隶属机构:波恩大学
- 关键词:激光雷达场景补全,扩散模型,点云处理
- 论文链接:https://arxiv.org/abs/2403.13470 Github 代码链接:https://github.com/PRBonn/LiDiff
- 摘要: (1) 研究背景:计算机视觉技术在自动驾驶的感知堆栈中发挥着核心作用。这些方法用于给定传感器数据感知车辆周围环境。3D 激光雷达传感器通常用于从场景中收集稀疏 3D 点云。然而,与人类感知相比,这些系统难以仅凭这些稀疏点云推断出场景中不可见的部分。在这一点上,场景补全任务旨在预测激光雷达测量中的空白,以实现更完整的场景表示。鉴于最近扩散模型作为图像生成模型取得的良好结果,我们提出将它们扩展到实现单次 3D 激光雷达扫描的场景补全。 (2) 过去的方法:以前的工作使用从激光雷达数据中提取的范围图像上的扩散模型,直接应用基于图像的扩散方法。不同的是,我们提出直接对点进行操作,重新表述加噪和去噪扩散过程,使其能够有效地处理场景规模。 (3) 研究方法:我们提出了一种正则化损失来稳定去噪过程中预测的噪声。我们的实验评估表明,我们的方法可以仅以单次激光雷达扫描作为输入来完成场景,与最先进的场景补全方法相比,生成的场景具有更多细节。我们相信,我们提出的扩散过程公式可以支持将扩散模型应用于场景规模点云数据的进一步研究。 (4) 方法的应用和性能:我们的方法在场景补全任务上取得了最先进的性能。它可以生成具有更多细节的完整场景,并且比现有方法更能保留场景的几何结构。这些性能支持了我们提出的方法的目标,即开发一种有效且准确的场景补全方法,该方法可以仅使用单次激光雷达扫描来生成高质量的场景表示。
方法
(1)我们提出使用 DDPM 从单个 3D 激光雷达扫描作为输入来实现场景补全。首先,我们将 DDPM [19,20,47] 重新表述为适用于场景规模。我们不归一化输入点云,而是针对每个点局部添加和预测噪声。在去噪过程中,我们使用输入扫描对噪声预测进行条件化,以便最终场景保留输入扫描的结构信息,同时推断出缺失部分。在这种表述中,初始点云是输入扫描的噪声版本,然后网络的任务是去噪以获得完整场景,如图 1 所示。
(2)接下来,我们提供了扩散模型的必要背景,并描述了我们方法的各个组成部分。
(3)去噪扩散概率模型:去噪扩散概率模型 [6,11,27] 将数据生成表述为一个迭代去噪过程。通常,模型从高斯噪声 [6,11,27] 开始,并从输入中迭代移除噪声,直到收敛到目标输出(例如,图像 [6,11,27,28,30,33,48,49] 或形状 [19,20,35,36,43,45,47])。这可以通过定义一个前向扩散过程来实现,其中噪声在 T 次中迭代添加到目标数据中。然后,训练模型来预测在每个步骤中添加的噪声。通过预测每个步骤的噪声并将其移除,去噪样本应该更接近目标训练数据。Ho 等人 [11] 表述的扩散过程通常可以写成如下形式。给定从目标数据分布中抽取的样本 x0∼q(x),扩散过程在 T 步中向 x0 添加噪声,得到 x1,...,xT,其中 q�xT�≈N(0,I),其中 N(0,I) 是均值为 0、对角协方差为单位矩阵 I 的正态分布。这个扩散过程由一系列定义的噪声因子 β1,...,βT 参数化,其中在每个步骤 t 中,迭代采样高斯噪声并根据 βt 添加到 xt−1 中。这可以简化为从 x0 采样 xt,而无需计算中间步骤 x1,...,xt−1。为此,Ho 等人 [11] 定义 αt=1−βt 和 αt=�ti=1αi,并且 xt 可以采样为:xt=√αtx0+√1−αtϵ,(1)其中 ϵ∼N(0,I)。注意,当 T 足够大时 q�xT�≈N(0,I),因为 αT 接近于零。去噪过程旨在通过预测在每个步骤添加的噪声 ϵ 来撤消 T 个噪声步骤 [11]。给定一个初始 xT,我们希望逆转扩散过程并得到 x0。反向扩散步骤可以写成:xt−1=xt−1−αt√1−αtϵθ�xt,t�+1−αt−11−αtβtN(0,I),(2)其中 ϵθ(xt,t) 是在步骤 t 从 xt 预测的噪声。这个生成也可以在给定条件 c 的情况下进行引导。这种条件生成可以来自预训练的编码器 [6] 或无分类器指导 [10],其中编码器与噪声预测器一起训练。在我们的案例中,我们使用无分类器指导,因为它不需要预训练的编码器。使用无分类器指导,模型被训练来学习条件和无条件噪声分布。在这种情况下,在每个训练步骤中,模型都有一定的概率 p 预测无条件噪声分布,其中条件设置为 null 令牌,即 c=∅。训练过程优化去噪模型以预测给定输入添加到步骤的噪声 ϵ。给定输入 x0 和条件 c,随机采样步骤 t∈[0,T],并使用高斯噪声 ϵ 从方程式 (1) 采样 xt。然后,从 xt、c 和 t,模型计算噪声预测,并使用 L2 损失对其进行监督:L�xt,˜c,t�=��ϵ−ϵθ�xt,˜c,t���2,(3)其中 ˜c∼B(p) 其中 B 是伯努利分布,没有结果 {∅,c},∅ 发生的概率为 p。推断从初始 xT∼N(0,I) 开始,并迭代去噪以获得 x0。对于无分类器指导 [10],我们预测条件和无条件噪声分布,并计算最终预测的噪声为:ϵ′θ�xt,c,t�=ϵθ�xt,∅,t�+s�ϵθ�xt,c,t�−ϵθ�xt,∅,t��,(4)其中 s∈R 是对 c 进行加权的条件参数,ϵθ(xt,∅,t) 是无条件噪声预测。使用方程式 (4),我们可以在任何步骤中计算噪声,从中我们可以使用方程式 (2) 计算 xT−1,...,x0,其中 x0 是条件为 c 的新生成样本。
(4)扩散场景补全:在这项工作中,我们使用 DDPM 的生成方面来完成激光雷达传感器在单个扫描中测量的场景。与形状补全 [19,20,47] 类似,输入是一个部分点云 P={p1,...,pN} 其中 p∈R3,输出应该是完整点云 P′={p′1,...,p′M} 其中 p′∈R3。在我们的案例中,部分点云是单个激光雷达扫描,我们希望从中实现场景补全。给定一系列连续的激光雷达扫描及其姿态,我们可以构建一个地图,并针对单个扫描 P 采样完整场景 ground truth G,其中我们的场景补全 P′ 应该尽可能接近 G。给定输入扫描 P 和 ground truth G 的对,我们可以训练 DDPM 来实现场景补全。正如第 3.1 节所述,我们可以从完整场景 G 中计算步骤 t 的噪声点云 Gt:ptm=√αtpm+√1−αtϵ,∀pm∈G,(5)其中 Gt={pt1,...,ptM}。
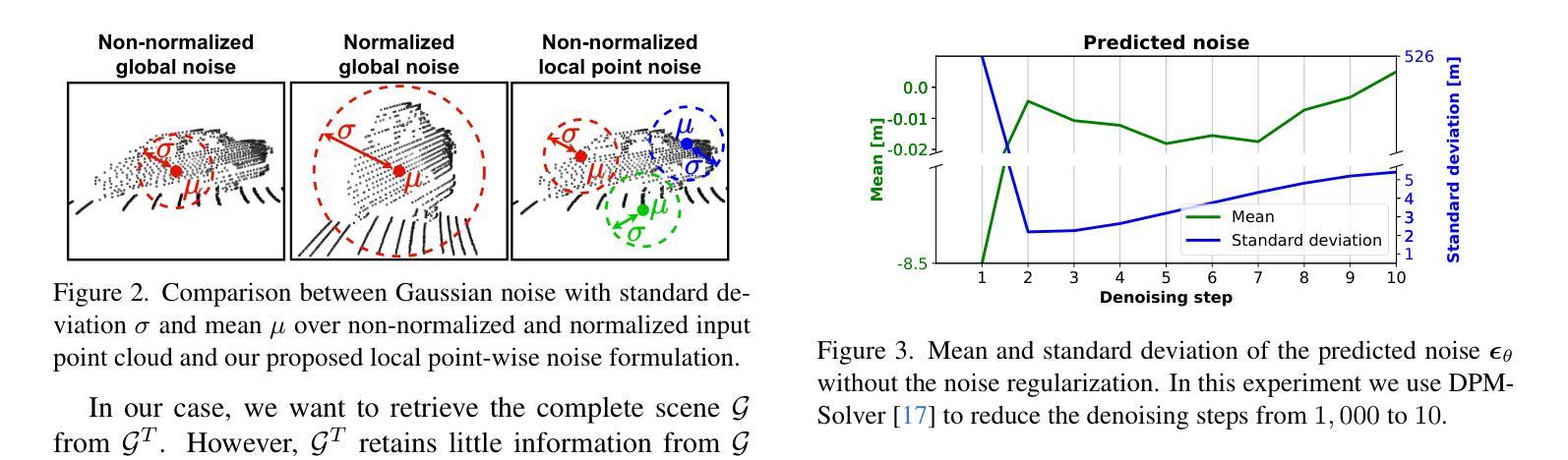
(5)局部点去噪:第 3.2 节中详细描述的表述通常用于形状补全 [20,47]。尽管形状补全取得了有希望的结果,但该表述可能不直接适用于场景规模。对于单个物体形状,数据要么归一化,要么处于接近均值 µ=0 和标准差 Σ=I 的高斯分布的小范围内。对于场景规模,激光雷达数据具有更大的比例,并且数据范围因点云轴而异。因此,输入数据分布远非高斯分布 N(0,I),如果我们对数据进行归一化,我们将丢失场景中的许多细节,因为场景被压缩到一个 much smaller range 中,如图 2 所示。为了克服这个问题,我们将扩散过程重新表述为一个局部问题。我们不将 xt 采样为 ϵ∼N(0,I) 和 x0 之间的混合分布,如方程式 (1) 所示,而是将扩散过程表述为局部添加到每个点 pm 的噪声偏移。在这种情况下,从方程式 (1) 中,我们设置 x0=0 并将 xt 添加到 pm:ptm=pm+�√αt0+√1−αtϵ�,(8)=pm+√1−αtϵ.(9)
- 结论: (1): 本工作提出了一种基于扩散模型的激光雷达场景补全方法,该方法利用扩散模型的生成能力从单个稀疏激光雷达扫描中生成缺失部分。我们在局部点去噪中重新表述了扩散过程,将每个点定义为采样高斯噪声的原点,学习了一个迭代去噪过程,以逐步预测偏移量,从而从输入的噪声激光雷达扫描重建场景。这种表述使得处理场景规模的 3D 数据成为可能,在去噪过程中保留了更多细节。 (2): 创新点:
- 提出了一种局部点去噪方法,将扩散过程重新表述为局部问题,将每个点定义为采样高斯噪声的原点,学习了一个迭代去噪过程,以逐步预测偏移量,从而从输入的噪声激光雷达扫描重建场景。
- 该方法能够处理场景规模的 3D 数据,在去噪过程中保留了更多细节。
- 该方法在场景补全任务上取得了最先进的性能,与最先进的扩散和非扩散方法相比,生成的场景具有更多细节。 性能:
- 该方法在场景补全任务上取得了最先进的性能。
- 与最先进的扩散和非扩散方法相比,生成的场景具有更多细节。
- 该方法能够在不同的数据集上实现场景补全,因为其生成是根据输入激光雷达扫描进行调节的。 工作量:
- 该方法需要一个输入扫描来指导生成,这限制了数据生成能力。
- 该方法目前还不能生成无条件数据,这限制了其在生成新颖的 3D 点云场景方面的应用。
点此查看论文截图