⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-03-28 更新
Deepfake Generation and Detection: A Benchmark and Survey
Authors:Gan Pei, Jiangning Zhang, Menghan Hu, Guangtao Zhai, Chengjie Wang, Zhenyu Zhang, Jian Yang, Chunhua Shen, Dacheng Tao
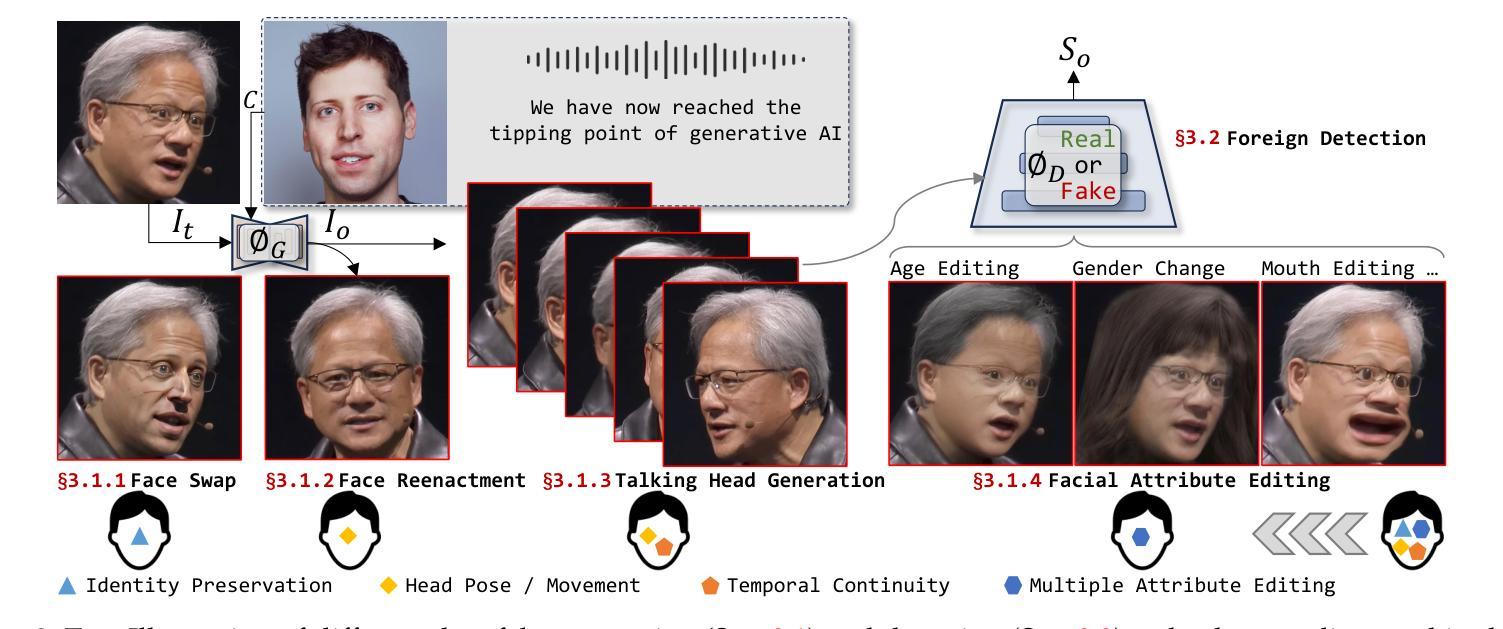
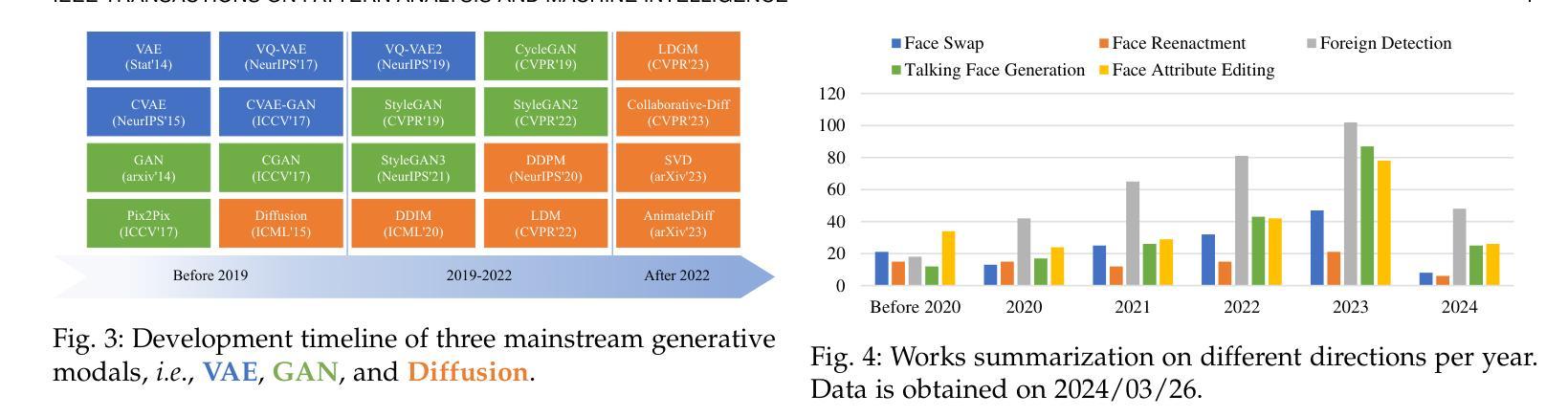
In addition to the advancements in deepfake generation, corresponding detection technologies need to continuously evolve to regulate the potential misuse of deepfakes, such as for privacy invasion and phishing attacks. This survey comprehensively reviews the latest developments in deepfake generation and detection, summarizing and analyzing the current state of the art in this rapidly evolving field. We first unify task definitions, comprehensively introduce datasets and metrics, and discuss the development of generation and detection technology frameworks. Then, we discuss the development of several related sub-fields and focus on researching four mainstream deepfake fields: popular face swap, face reenactment, talking face generation, and facial attribute editing, as well as foreign detection. Subsequently, we comprehensively benchmark representative methods on popular datasets for each field, fully evaluating the latest and influential works published in top conferences/journals. Finally, we analyze the challenges and future research directions of the discussed fields. We closely follow the latest developments in https://github.com/flyingby/Awesome-Deepfake-Generation-and-Detection.
Summary
深度伪造技术的发展与检测技术需要持续演进,以应对隐私侵犯和网络钓鱼等非法使用。
Key Takeaways
- 统一任务定义,全面介绍数据集和评估指标。
- 探讨生成和检测技术框架的发展。
- 关注人脸替换、人脸重现、说话人脸生成、面部属性编辑等主流深度伪造领域。
- 全面基准测试每个领域流行数据集上的代表性方法。
- 分析所讨论领域的挑战和未来研究方向。
- 跟踪 Github 上深度伪造生成与检测的最新进展。
1.题目:深度伪造生成与检测:基准与综述 2.作者:甘沛,蒋宁章,孟涵胡,光涛翟,成杰王,振宇张,建杨,春华沈,大成陶 3.第一作者单位:华东师范大学多模信息处理上海市重点实验室 4.关键词:深度伪造生成,人脸替换,人脸重演,语音人脸生成,人脸属性编辑,外来检测,综述 5.论文链接:https://arxiv.org/abs/2403.17881,Github代码链接:无 6.总结: (1):随着深度学习的进步,以变分自编码器 (VAE) 和生成对抗网络 (GAN) 为代表的技术在深度伪造生成领域取得了显著成果。近年来,具有强大图像生成能力的扩散模型的出现引发了该技术的新一轮研究和产业热潮。 (2):传统的深度伪造生成方法基于 GAN 模型,存在生成效果不佳的问题。扩散模型的出现极大地提升了图像/视频的生成能力,使得生成的深度伪造内容与真实内容难以区分,具有很高的实用价值。 (3):深度伪造生成主要分为人脸替换、人脸重演、语音人脸生成和人脸属性编辑四个主流研究领域。本文对这些领域的发展进行了综述,并对各个领域的代表性方法进行了基准测试和全面评估。 (4):本文分析了深度伪造生成和检测领域面临的挑战和未来研究方向,为该领域的进一步发展提供了参考。
-
方法: (1) 本文对深度伪造生成与检测领域的研究现状进行了全面的总结和综述,分析了该领域面临的挑战和未来研究方向。 (2) 本文对深度伪造生成领域的主流研究领域,包括人脸替换、人脸重演、语音人脸生成和人脸属性编辑,进行了基准测试和全面评估。 (3) 本文对深度伪造检测领域的研究进展进行了总结,分析了外来检测和内在检测两种检测方法的优缺点,并对未来研究方向进行了展望。
-
结论: (1): 本综述全面回顾了深度伪造生成与检测领域的最新进展,首次全面覆盖了相关领域,并讨论了扩散模型等最新技术。具体而言,本文涵盖了基本背景知识的概述,包括研究任务的概念、数据收集与处理方法、模型设计与训练策略、评估指标和数据集。 (2): 创新点:本文对深度伪造生成领域的四个主流研究领域进行了基准测试和全面评估,包括人脸替换、人脸重演、语音人脸生成和人脸属性编辑。本文还对深度伪造检测领域的研究进展进行了总结,分析了外来检测和内在检测两种检测方法的优缺点,并对未来研究方向进行了展望。 性能:本文提出的基准测试和全面评估为深度伪造生成与检测领域的研究人员提供了有价值的参考。 工作量:本文对深度伪造生成与检测领域的研究现状进行了全面的总结和综述,工作量较大。
点此查看论文截图



Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework
Authors:Ziyao Huang, Fan Tang, Yong Zhang, Xiaodong Cun, Juan Cao, Jintao Li, Tong-Yee Lee
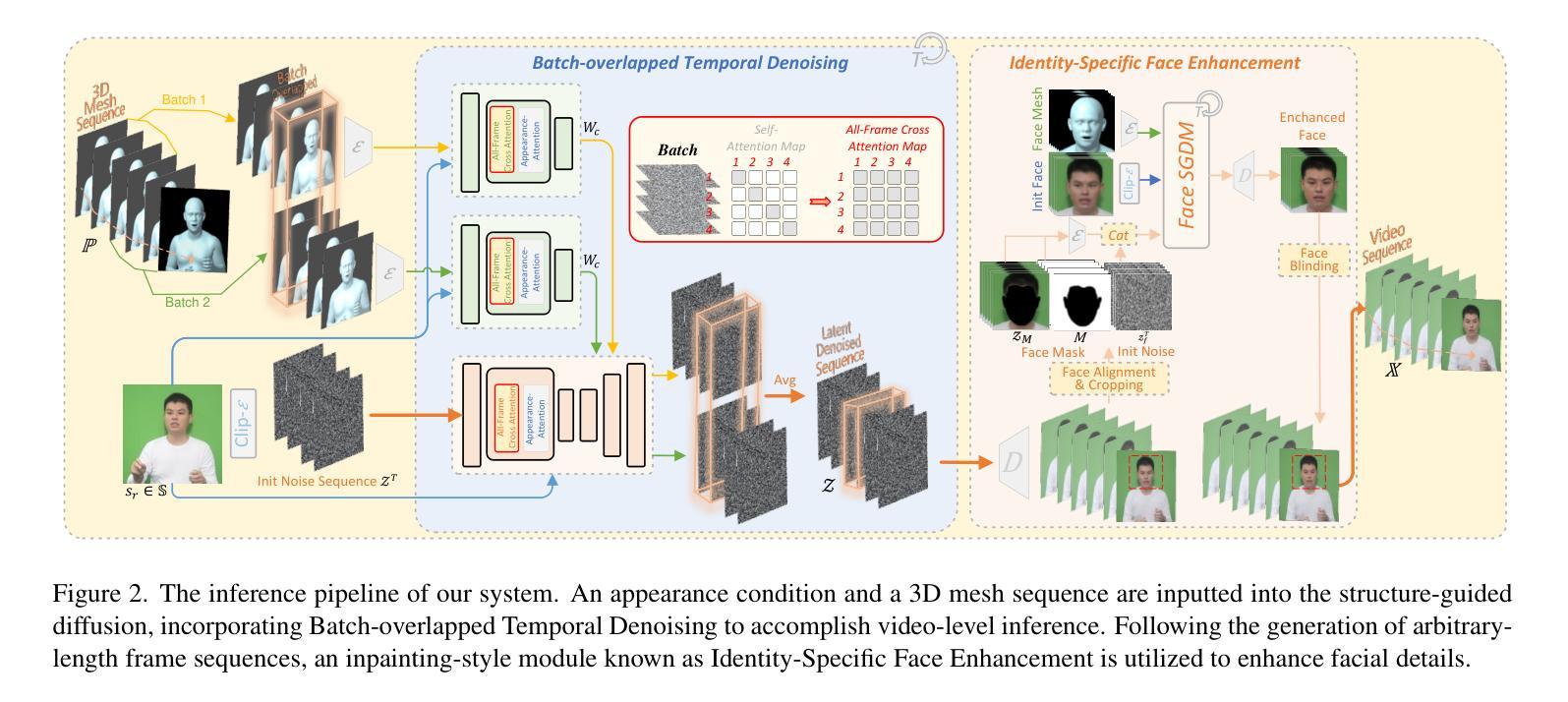
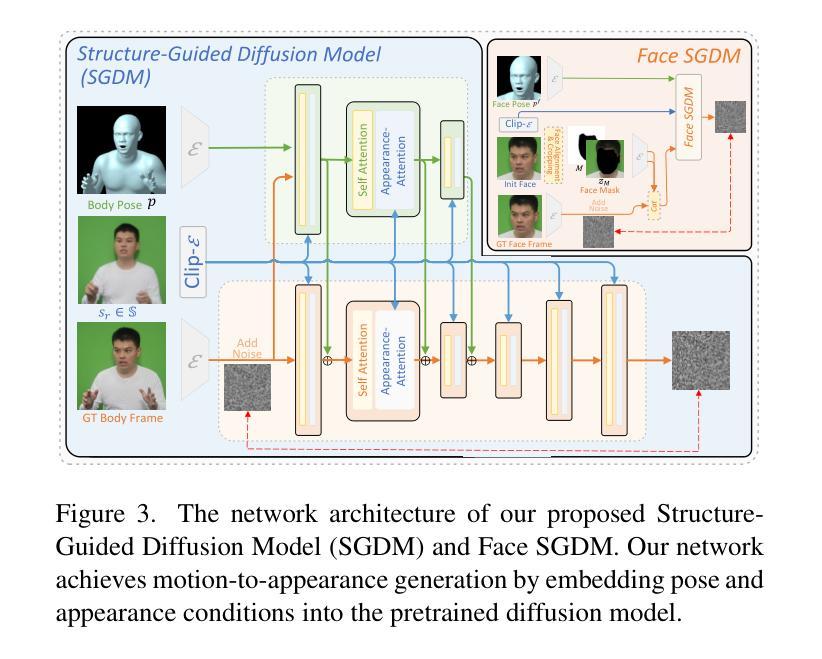
Despite the remarkable process of talking-head-based avatar-creating solutions, directly generating anchor-style videos with full-body motions remains challenging. In this study, we propose Make-Your-Anchor, a novel system necessitating only a one-minute video clip of an individual for training, subsequently enabling the automatic generation of anchor-style videos with precise torso and hand movements. Specifically, we finetune a proposed structure-guided diffusion model on input video to render 3D mesh conditions into human appearances. We adopt a two-stage training strategy for the diffusion model, effectively binding movements with specific appearances. To produce arbitrary long temporal video, we extend the 2D U-Net in the frame-wise diffusion model to a 3D style without additional training cost, and a simple yet effective batch-overlapped temporal denoising module is proposed to bypass the constraints on video length during inference. Finally, a novel identity-specific face enhancement module is introduced to improve the visual quality of facial regions in the output videos. Comparative experiments demonstrate the effectiveness and superiority of the system in terms of visual quality, temporal coherence, and identity preservation, outperforming SOTA diffusion/non-diffusion methods. Project page: \url{https://github.com/ICTMCG/Make-Your-Anchor}.
PDF accepted at CVPR2024
Summary
使用仅一分钟视频训练即可生成拥有躯干和手部动作的主播风格完整视频。
Key Takeaways
- 提出了一种通过一分钟视频训练来生成主播风格视频的系统——Make-Your-Anchor。
- 采用两阶段训练策略,将动作与特定外观有效地绑定。
- 扩展了帧级扩散模型中的二维 U-Net 到三维风格,以生成任意长度的时间视频。
- 提出了一种简单的批量重叠时间去噪模块,以绕过推理期间视频长度的限制。
- 引入了新颖的身份特定面部增强模块,以提高输出视频中面部区域的视觉质量。
- 与 SOTA 扩散/非扩散方法相比,该系统在视觉质量、时间连贯性和身份保留方面表现出有效性和优越性。
- 项目主页:\url{https://github.com/ICTMCG/Make-Your-Anchor}。
- 标题:Make-Your-Anchor:基于扩散的 2D 头像生成框架
- 作者:Ziyao Huang、Fan Tang、Yong Zhang、Xiaodong Cun、Juan Cao、Jintao Li、Tong-Yee Lee
- 第一作者单位:中国科学院计算技术研究所
- 关键词:视频生成、头像生成、扩散模型、运动捕捉
- 论文链接:https://arxiv.org/abs/2403.16510 Github 代码链接:https://github.com/ICTMCG/Make-Your-Anchor
- 摘要: (1)研究背景: 当前的头像生成技术主要集中在头部生成,无法生成全身动作逼真的头像视频。 (2)过去方法及问题: 现有的基于 GAN 的方法只能生成局部区域,基于运动迁移的方法受限于运动捕捉数据的可用性。 (3)研究方法: 本文提出 Make-Your-Anchor 框架,通过微调基于结构引导的扩散模型,将 3D 网格条件渲染为逼真的全身动作头像视频。采用两阶段训练策略,有效地将运动与特定外观绑定。为了生成任意长度的视频,将帧级扩散模型中的 2D U-Net 扩展为 3D,并提出了一种简单的批次重叠时间去噪模块。此外,还引入了一个新的身份特定面部增强模块,以提高输出视频中面部区域的视觉质量。 (4)任务和性能: Make-Your-Anchor 在视觉质量、时间连贯性和身份保留方面优于 SOTA 扩散/非扩散方法。它仅需一分钟的视频剪辑即可训练,生成全身动作逼真的头像视频,满足了自动生成头像视频的需求。
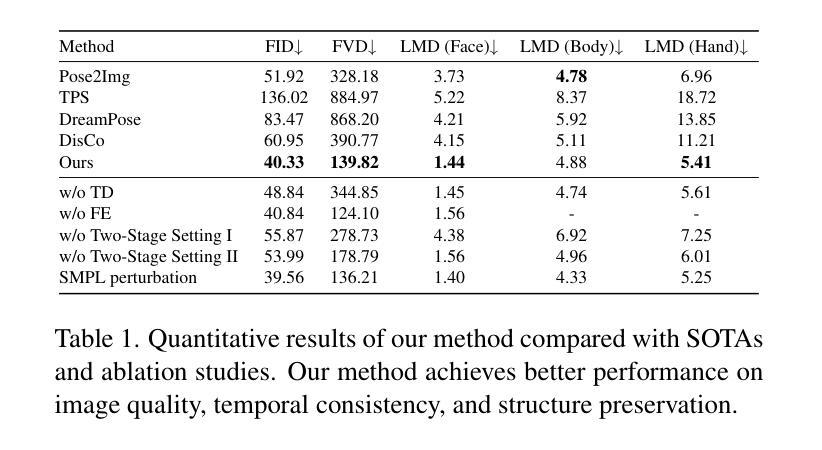
7.方法:(1)结构引导扩散模型:将3D网格条件嵌入生成过程,学习姿态与目标视频帧之间的对应关系;(2)两阶段训练策略:预训练增强模型生成动作的能力,微调绑定动作与特定外观;(3)批次重叠时间去噪:采用全帧交叉注意力模块和重叠时间去噪算法,生成任意长度的时间一致视频;(4)身份特定面部增强模块:通过裁剪和融合操作,对生成的身体中的面部区域进行修改,提高视觉质量。
- 结论: (1):本文提出了 Make-Your-Anchor,一个基于扩散的 2D 头像生成框架,用于制作逼真且高质量的主播风格人物视频。该框架通过帧级运动到外观扩散训练了一个结构引导的扩散模型,并采用两阶段训练策略和绑定风格方法实现了特定外观与动作的绑定。为了生成时间一致的人物视频,我们提出了一个无训练策略,将图像扩散模型扩展为视频扩散模型,并设计了一个批次重叠时间去噪算法来克服生成视频长度的限制。从观察到面部细节在整体人物生成过程中难以重建这一现象出发,引入了身份特定的面部增强技术。通过将这四个系统方法相结合,我们的框架成功地生成了高质量、结构保持和时间连贯的主播风格人物视频,这可能为 2D 数字头像的广泛应用技术提供一些参考价值。 (2):创新点:提出了一种基于扩散的 2D 头像生成框架,可以生成逼真且高质量的主播风格人物视频;采用两阶段训练策略和绑定风格方法,将特定外观与动作绑定;提出了一个无训练策略,将图像扩散模型扩展为视频扩散模型,并设计了一个批次重叠时间去噪算法来克服生成视频长度的限制;引入了身份特定的面部增强技术,以提高生成视频中面部区域的视觉质量。 性能:在视觉质量、时间连贯性和身份保留方面优于 SOTA 扩散/非扩散方法;仅需一分钟的视频剪辑即可训练,生成全身动作逼真的头像视频,满足了自动生成头像视频的需求。 工作量:中等;需要收集和预处理训练数据;需要对模型进行训练和微调;需要对生成结果进行评估和优化。
点此查看论文截图



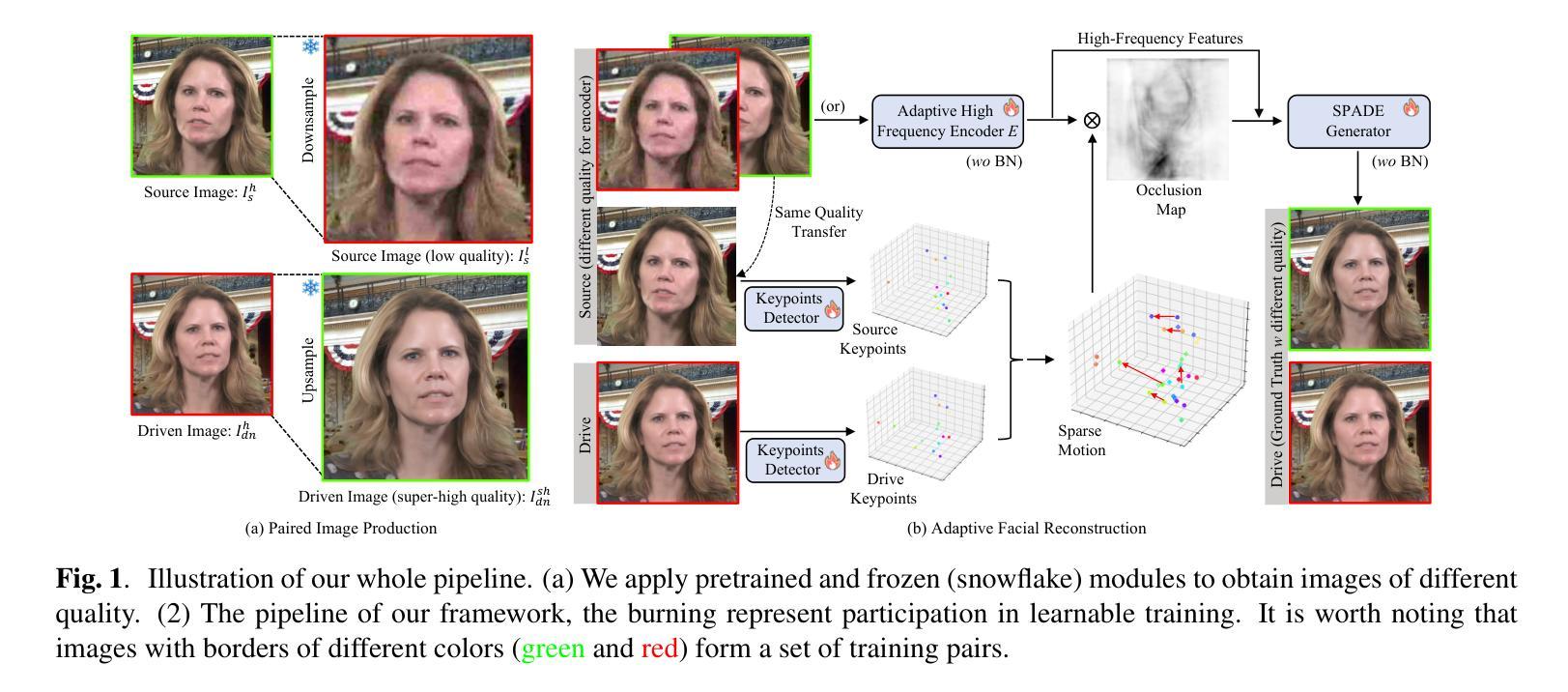
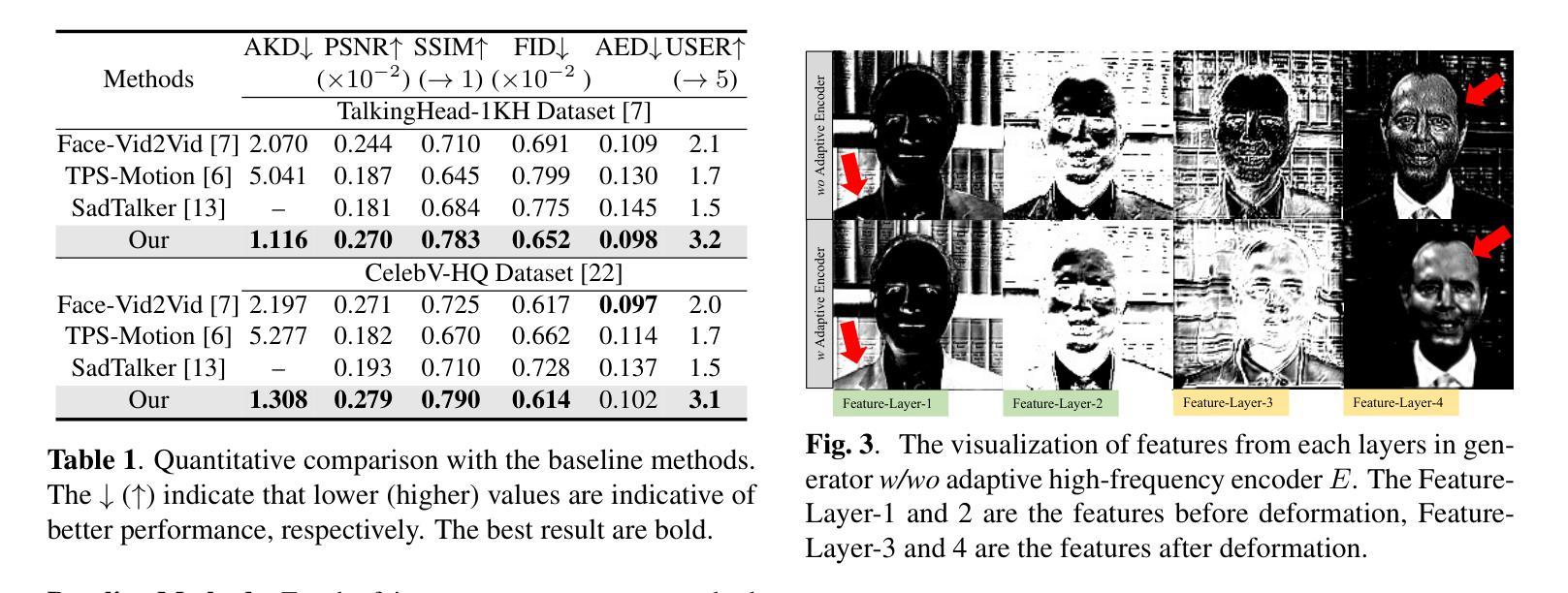
Adaptive Super Resolution For One-Shot Talking-Head Generation
Authors:Luchuan Song, Pinxin Liu, Guojun Yin, Chenliang Xu
The one-shot talking-head generation learns to synthesize a talking-head video with one source portrait image under the driving of same or different identity video. Usually these methods require plane-based pixel transformations via Jacobin matrices or facial image warps for novel poses generation. The constraints of using a single image source and pixel displacements often compromise the clarity of the synthesized images. Some methods try to improve the quality of synthesized videos by introducing additional super-resolution modules, but this will undoubtedly increase computational consumption and destroy the original data distribution. In this work, we propose an adaptive high-quality talking-head video generation method, which synthesizes high-resolution video without additional pre-trained modules. Specifically, inspired by existing super-resolution methods, we down-sample the one-shot source image, and then adaptively reconstruct high-frequency details via an encoder-decoder module, resulting in enhanced video clarity. Our method consistently improves the quality of generated videos through a straightforward yet effective strategy, substantiated by quantitative and qualitative evaluations. The code and demo video are available on: \url{https://github.com/Songluchuan/AdaSR-TalkingHead/}.
PDF 5 pages, 3 figures
Summary
一键式生成高清晰度视频,无需添加预训练模块,通过自适应重建高频细节提升视频清晰度。
Key Takeaways
- 一键式生成人像视频,驱动视频与人像同一或不同。
- 传统方法受限于单图像源和像素位移,清晰度受损。
- 现有方法通过超分辨率模块提升质量,但增加计算量并破坏原始数据分布。
- 本文提出自适应高品质人像视频生成方法,无需额外预训练模块合成高分辨率视频。
- 受超分辨率方法启发,对单图像源下采样,再通过编码器-解码器模块自适应重建高频细节。
- 该策略简单有效地提升了生成视频的质量,并通过定量和定性评估得到证实。
- 代码和演示视频可在 Github 上获取。
- 题目:自适应超分辨率单镜头说话人头部生成
- 作者:Luchuan Song, Pinxin Liu, Guojun Yin, Chenliang Xu
- 第一作者单位:罗切斯特大学
- 关键词:超分辨率视频,单镜头说话人头部生成
- 链接:https://arxiv.org/abs/2403.15944,Github:None
-
摘要: (1):研究背景:单镜头说话人头部生成旨在使用一张源人像图像在相同或不同身份视频的驱动下合成说话人头部视频。现有方法通常需要基于平面的像素变换,这会影响合成图像的清晰度。一些方法通过引入额外的超分辨率模块来提高合成视频的质量,但这会增加计算消耗并破坏原始数据分布。 (2):过去方法及问题:MetaPortrait、SadTalker 和 VideoReTalking 等方法尝试通过重新训练一个独立的超分辨率模块来改善视频质量。然而,这种两阶段合成过程会导致不必要的计算开销和错误累积。 (3):研究方法:本文提出了一种自适应超分辨率方法,用于说话人头部生成框架。受 ESRGAN 和 Real-ESRGAN 等超分辨率方法的启发,该方法通过压缩和下采样高质量图像来构建用于成对训练的低质量图像数据。它通过独特设计的编码器-解码器结构从低质量图像中自适应地捕获高频信息以进行重建。 (4):方法性能:该方法在定量和定性实验中验证了其有效性,并与现有的单镜头说话人头部生成方法进行了对比。结果表明,该方法始终通过一种简单有效的策略提高了生成视频的质量。
-
方法: (1) 受 ESRGAN 和 Real-ESRGAN 等超分辨率方法启发,通过压缩和下采样高质量图像,构建用于成对训练的低质量图像数据; (2) 通过独特设计的编码器-解码器结构,从低质量图像中自适应地捕获高频信息以进行重建。
-
总结: (1)本工作的重要意义:本文提出了一种自适应超分辨率方法,用于单镜头说话人头部视频生成领域。通过设计简单但有效的方法,我们的方法能够从低质量图像中捕获高频细节。这使得无需额外的预训练模块或后处理即可合成高质量视频。在大型数据集上进行的广泛定量和定性评估证实,我们的方法在高质量可驱动人脸视频生成方面超越了现有技术。 (2)创新点:受 ESRGAN 和 Real-ESRGAN 等超分辨率方法的启发,通过压缩和下采样高质量图像,构建用于成对训练的低质量图像数据。通过独特设计的编码器-解码器结构,从低质量图像中自适应地捕获高频信息以进行重建。 性能:该方法在定量和定性实验中验证了其有效性,并与现有的单镜头说话人头部生成方法进行了对比。结果表明,该方法始终通过一种简单有效的策略提高了生成视频的质量。 工作量:该方法的实现相对简单,并且不需要额外的预训练模块或后处理步骤。这使得该方法在计算和时间方面都具有成本效益。
点此查看论文截图