⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-01 更新
Make-Your-Anchor: A Diffusion-based 2D Avatar Generation Framework
Authors:Ziyao Huang, Fan Tang, Yong Zhang, Xiaodong Cun, Juan Cao, Jintao Li, Tong-Yee Lee
Despite the remarkable process of talking-head-based avatar-creating solutions, directly generating anchor-style videos with full-body motions remains challenging. In this study, we propose Make-Your-Anchor, a novel system necessitating only a one-minute video clip of an individual for training, subsequently enabling the automatic generation of anchor-style videos with precise torso and hand movements. Specifically, we finetune a proposed structure-guided diffusion model on input video to render 3D mesh conditions into human appearances. We adopt a two-stage training strategy for the diffusion model, effectively binding movements with specific appearances. To produce arbitrary long temporal video, we extend the 2D U-Net in the frame-wise diffusion model to a 3D style without additional training cost, and a simple yet effective batch-overlapped temporal denoising module is proposed to bypass the constraints on video length during inference. Finally, a novel identity-specific face enhancement module is introduced to improve the visual quality of facial regions in the output videos. Comparative experiments demonstrate the effectiveness and superiority of the system in terms of visual quality, temporal coherence, and identity preservation, outperforming SOTA diffusion/non-diffusion methods. Project page: \url{https://github.com/ICTMCG/Make-Your-Anchor}.
PDF accepted at CVPR2024
Summary
通过仅需一分钟的个人视频训练,提出了一种生成全身动作锚播风格视频的新系统 Make-Your-Anchor。
Key Takeaways
- 提出了一种基于结构引导扩散模型,将 3D 网格条件渲染为人物外观。
- 采用两阶段训练策略,有效绑定动作与特定外观。
- 扩展帧内扩散模型中的 2D U-Net 到 3D 风格,无需额外训练成本。
- 提出一个简单有效的批量重叠时间去噪模块,绕过推理时的视频长度限制。
- 引入一个新颖的身份特定面部增强模块,以提高输出视频中面部区域的视觉质量。
- 与 SOTA 扩散/非扩散方法相比,在视觉质量、时间连贯性和身份保留方面证明了该系统的有效性和优越性。
- 项目主页:\url{https://github.com/ICTMCG/Make-Your-Anchor}。
- 题目:Make-Your-Anchor:基于扩散的二维虚拟形象生成框架
- 作者:黄子尧,唐凡,张勇,村晓东,曹娟,李金涛,李同义
- 第一作者单位:中国科学院计算技术研究所
- 关键词:虚拟形象生成,扩散模型,运动捕捉,语音驱动动画
- 论文链接:https://arxiv.org/abs/2403.16510,Github 代码链接:None
- 摘要: (1):研究背景: 目前基于说话人头部创建虚拟形象的解决方案已取得显著进展,但直接生成具有全身动作的主播风格视频仍然具有挑战性。
(2):过去的方法及问题: 以往的方法主要基于 GAN 进行局部编辑或利用运动迁移技术,但这些方法要么自由度受限,要么动作与特定外观的绑定不够紧密。
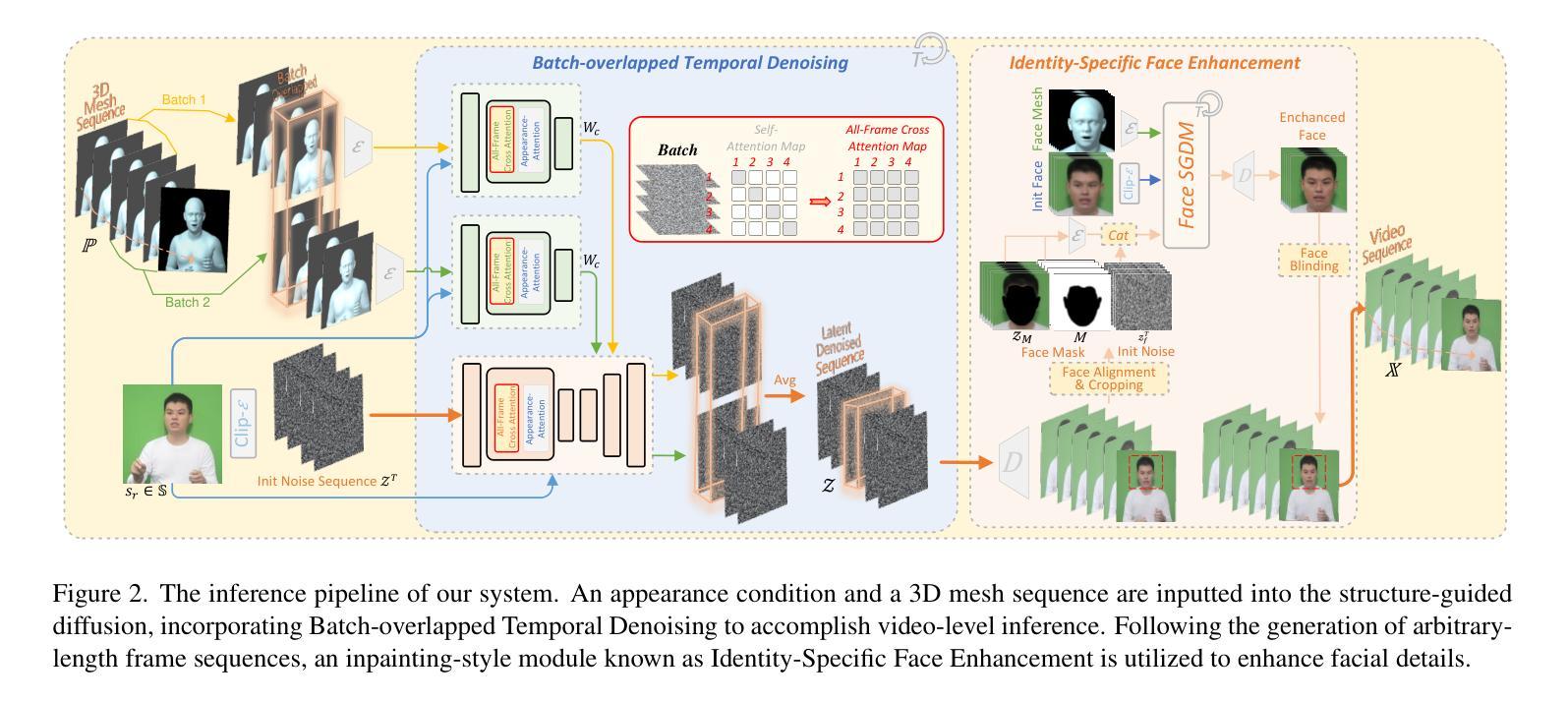
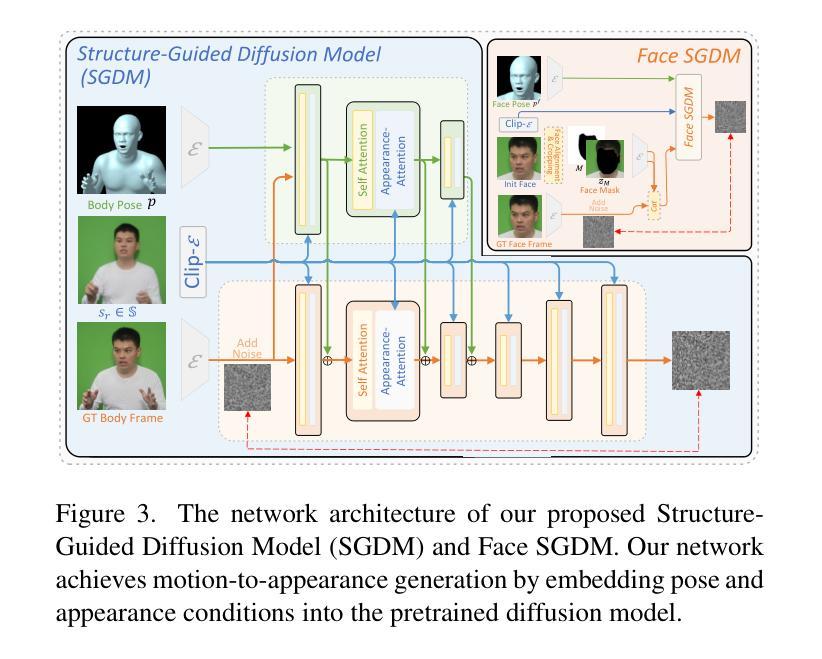
(3):提出的研究方法: 本文提出 Make-Your-Anchor 系统,仅需一个一分钟的个人视频即可训练,实现自动生成具有精确躯干和手部动作的主播风格视频。该系统采用结构引导扩散模型,将三维网格条件渲染成人物外观,并采用两阶段训练策略,有效地将动作与特定外观绑定。为了生成任意长度的时间视频,将帧级扩散模型中的二维 U-Net 扩展为三维形式,并提出了一种简单有效的批次重叠时间去噪模块,以绕过推理期间视频长度的限制。此外,还引入了新的特定于身份的面部增强模块,以提高输出视频中面部区域的视觉质量。
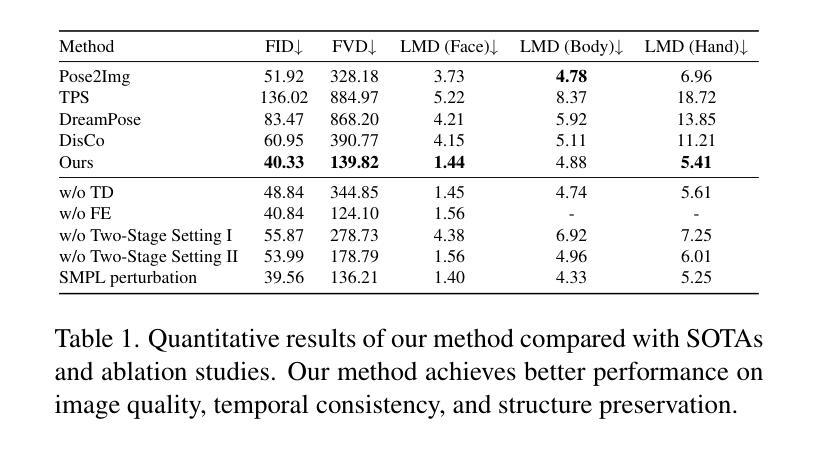
(4):方法在任务和性能上的表现: Make-Your-Anchor 系统在视觉质量、时间连贯性和身份保留方面均优于 SOTA 扩散和非扩散方法,证明了其有效性和优越性。
-
方法: (1) 结构引导扩散模型(SGDM):将 3D 网格条件嵌入生成过程,学习姿势到目标视频帧的对应映射。 (2) 两阶段训练策略:预训练增强模型生成动作能力,微调绑定动作与特定外观。 (3) 批次重叠时间去噪:将 2D U-Net 扩展为 3D 形式,提出批次重叠时间去噪模块生成任意长度的时间视频。 (4) 身份特定面部增强模块:通过裁剪和混合操作,修改生成的身体中的面部区域,提高面部区域的视觉质量。
-
结论: (1)本工作的意义:本文提出 “Make-Your-Anchor”,一个基于扩散的二维虚拟形象生成框架,用于生成逼真且高质量的主播风格人物视频。该框架创新性地提出了帧级的运动到外观扩散,通过结构引导扩散模型和两阶段训练策略,实现了特定外观与动作的绑定。为了生成时间一致的人像视频,我们提出了一个无训练策略,将图像扩散模型扩展为视频扩散模型,并设计了一个批次重叠时间去噪算法,以克服生成视频长度的限制。针对整体人物生成中面部细节难以重建的观察,我们引入了身份特定的面部增强。通过我们整个系统方法的融合,我们的框架成功地生成了高质量、结构保持和时间一致的主播风格人物视频,这可能为二维数字虚拟形象的广泛应用技术提供参考价值。 (2)创新点:
- 提出结构引导扩散模型,将三维网格条件嵌入生成过程,学习姿势到目标视频帧的对应映射。
- 采用两阶段训练策略,预训练增强模型生成动作能力,微调绑定动作与特定外观。
- 提出批次重叠时间去噪,将二维 U-Net 扩展为三维形式,生成任意长度的时间视频。
- 引入身份特定的面部增强模块,通过裁剪和混合操作,修改生成的身体中的面部区域,提高面部区域的视觉质量。 性能:
- 在视觉质量、时间连贯性和身份保留方面均优于 SOTA 扩散和非扩散方法。 工作量:
- 训练数据量较大,需要大量的人物视频数据。
- 训练时间较长,需要高性能计算资源。
点此查看论文截图



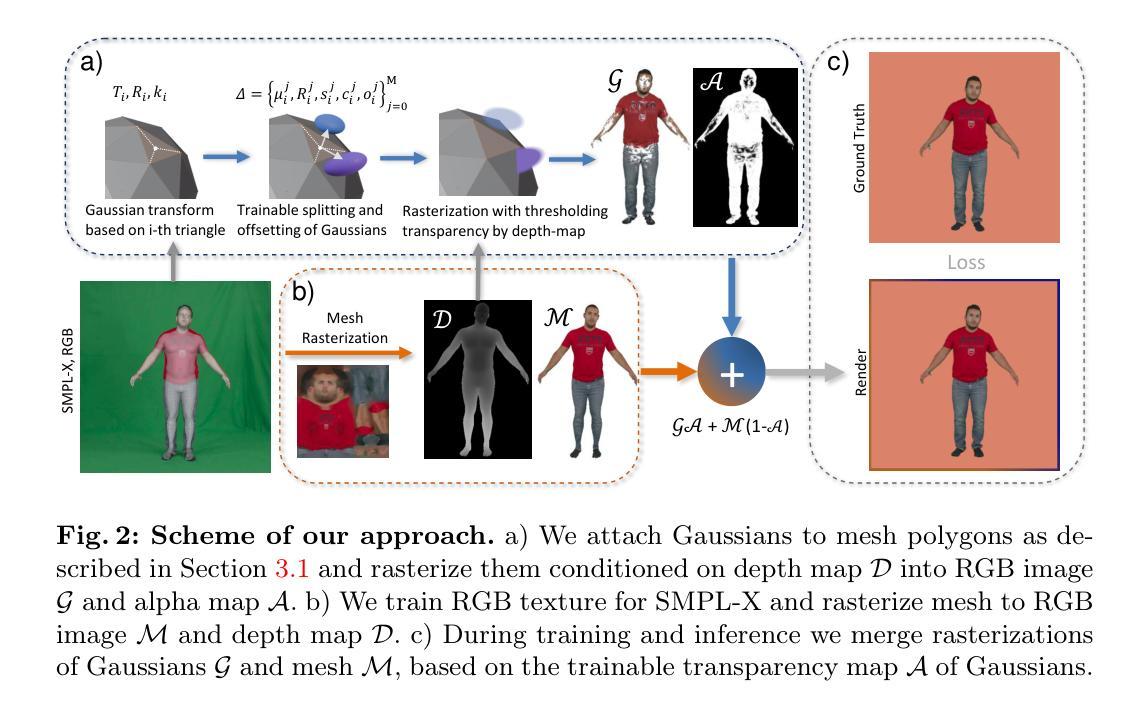
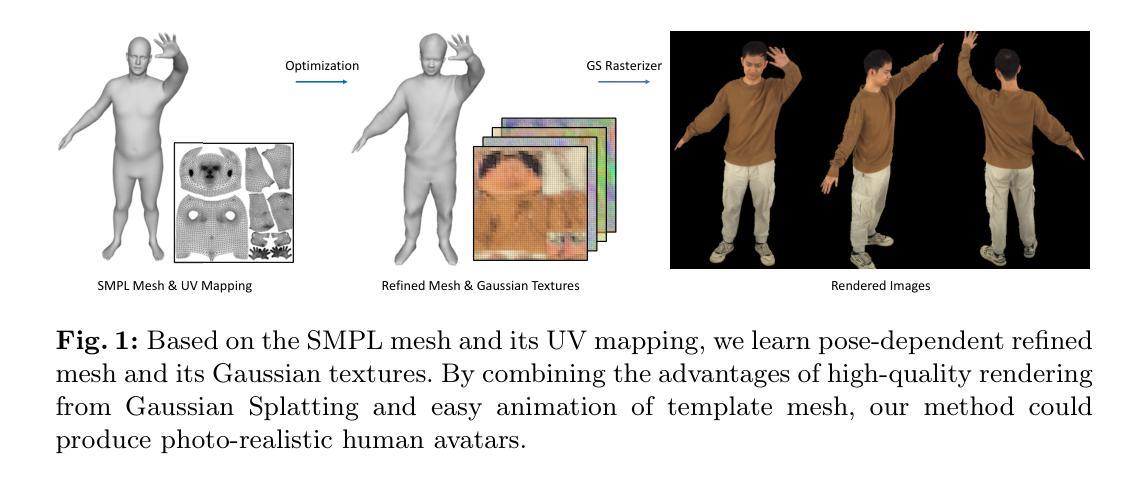
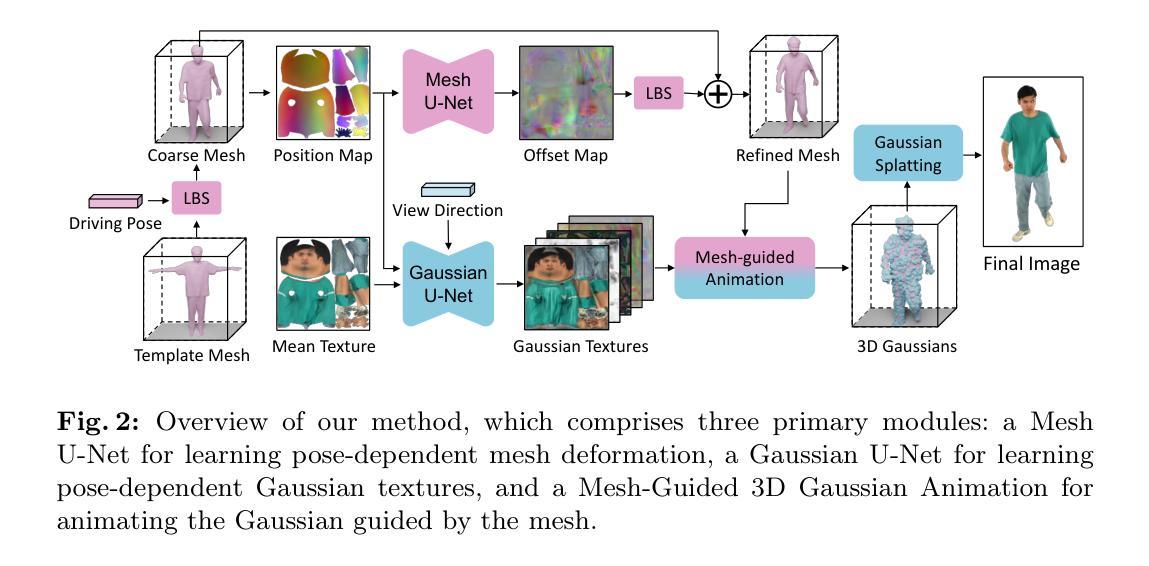
UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Authors:Yujiao Jiang, Qingmin Liao, Xiaoyu Li, Li Ma, Qi Zhang, Chaopeng Zhang, Zongqing Lu, Ying Shan
Reconstructing photo-realistic drivable human avatars from multi-view image sequences has been a popular and challenging topic in the field of computer vision and graphics. While existing NeRF-based methods can achieve high-quality novel view rendering of human models, both training and inference processes are time-consuming. Recent approaches have utilized 3D Gaussians to represent the human body, enabling faster training and rendering. However, they undermine the importance of the mesh guidance and directly predict Gaussians in 3D space with coarse mesh guidance. This hinders the learning procedure of the Gaussians and tends to produce blurry textures. Therefore, we propose UV Gaussians, which models the 3D human body by jointly learning mesh deformations and 2D UV-space Gaussian textures. We utilize the embedding of UV map to learn Gaussian textures in 2D space, leveraging the capabilities of powerful 2D networks to extract features. Additionally, through an independent Mesh network, we optimize pose-dependent geometric deformations, thereby guiding Gaussian rendering and significantly enhancing rendering quality. We collect and process a new dataset of human motion, which includes multi-view images, scanned models, parametric model registration, and corresponding texture maps. Experimental results demonstrate that our method achieves state-of-the-art synthesis of novel view and novel pose. The code and data will be made available on the homepage https://alex-jyj.github.io/UV-Gaussians/ once the paper is accepted.
摘要
通过联合学习网格变形和二维 UV 空间高斯纹理,结合 UV 高斯模型重建逼真的可驾驶人体虚拟人。
关键要点
- 利用三维高斯体表示人体,实现快速训练和渲染。
- 提出 UV 高斯模型,联合学习网格变形和二维 UV 空间高斯纹理。
- 通过 UV 映射嵌入,在二维空间学习高斯纹理,增强纹理清晰度。
- 独立网格网络优化姿态相关的几何变形,引导高斯渲染。
- 收集并处理包含多视角图像、扫描模型、参数模型配准和对应纹理贴图的新人体动作数据集。
- 在全新视图和全新姿态合成方面达到最先进的水平。
- 公开代码和数据,促进进一步研究。
- 标题:UV 高斯:网格新视角的联合学习
- 作者:Y. Jiang、Z. Zhou、J. Huang、T. Zhang、X. Han、Y. Chen、Y. Liu、L. Liu
- 单位:无
- 关键词:Human Modeling·Neural Rendering·Gaussian Splatting
- 论文链接:https://arxiv.org/abs/2212.05845 Github 链接:无
-
摘要: (1)研究背景:从多视角图像序列重建逼真的可驾驶人形化身一直是计算机视觉和图形领域的一个热门且具有挑战性的课题。虽然现有的基于 NeRF 的方法可以实现高质量的人体模型新视角渲染,但训练和推理过程都很耗时。 (2)过去的方法及问题:最近的研究利用 3D 高斯表示人体,从而实现更快的训练和渲染。然而,它们低估了网格指导的重要性,并直接在 3D 空间中预测高斯,而网格指导较粗糙。这阻碍了高斯学习过程,并倾向于产生模糊的纹理。 (3)提出的研究方法:因此,我们提出了 UV 高斯,它通过联合学习网格变形和 2D UV 空间高斯纹理对 3D 人体进行建模。我们利用 UV 贴图的嵌入在 2D 空间中学习高斯纹理,利用强大的 2D 网络提取特征的能力。此外,通过一个独立的网格网络,我们优化了与姿势相关的几何变形,从而指导高斯渲染并显著提高渲染质量。我们收集并处理了一个新的数据集,其中包括多视角图像、扫描模型、参数模型配准和相应的纹理贴图。 (4)方法在任务和性能上的表现:实验结果表明,我们的方法实现了新视角和新姿势合成的新技术。该代码和数据将在论文被接受后在主页 https://alex-jyj.github.io/UVGaussians/ 上提供。
-
方法: (1)数据处理:使用 OpenPose 估计多视角图像的 2D 关键点,通过三角测量估计 3D 关键点,然后使用 EasyMocap 拟合 SMPL-X 模型。使用 MVS 方法重建扫描网格,优化 SMPL-X 网格的顶点位移以将其与扫描模型的网格对齐,从而得到 SMPLX-D 模型。 (2)基于姿势的网格变形:选择一个接近 T 姿势的帧作为参考,使用线性混合蒙皮 (LBS) 将其变形为标准 T 姿势。将这个标准 T 姿势作为所有姿势的模板网格。通过基于姿势参数的 LBS 变形粗糙网格,得到姿势网格。引入 MeshU-Net 来学习基于姿势的网格变形。将网格顶点坐标光栅化为 UV 空间,生成位置图,作为网格网络 M 的输入。网格网络 M 预测基于输入位置图的顶点偏移图。将每个顶点的相应偏移从偏移图中插值,得到网格顶点偏移。将此偏移添加到 T 姿势网格中,然后使用 LBS 变换到姿势空间。最终得到能够捕捉基于姿势的几何变化的细化网格。 (3)基于姿势的高斯纹理:将 3D 高斯参数化为 UV 空间的高斯纹理,通过 UV 映射将每个像素投影到 3D 高斯。将所有姿势的平均纹理图作为输入,为 3D 高斯提供初始颜色信息。还向网络提供位置图以提供像素级的姿势信息。网络还受视图方向向量的引导,以建模视图相关的变化。使用 StyleUNet 架构,网络输出多个高斯纹理,包含 3D 高斯所需的所有参数。
-
结论: (1):本文提出了一种称为 UV 高斯的重建方法,该方法将 3D 高斯与 UV 空间表示相结合。该方法能够从多视角图像重建逼真的、姿势驱动的化身模型。我们的方法以模型顶点的位移图作为输入,通过 MeshU-Net 学习基于姿势的几何变形,并通过 GaussianU-Net 学习嵌入在 UV 空间中的高斯点属性。随后,在精细网格的引导下,对高斯点进行渲染,以获得任意视点的渲染图像。通过结合精细的几何指导并利用 UV 空间中强大的 2D 网络的特征学习能力,我们的方法在实验中实现了新视角和新姿势合成方面的最先进结果。局限性。尽管取得了成就,但我们的方法受制于对扫描网格的依赖性。虽然可以使用 MeshU-Net 优化较小的拟合误差,但较大的误差可能会影响方法的性能。此外,我们收集的数据集不包括长裙等极度宽松的服装。在未来的研究中,我们计划在包含多视角图像和扫描模型的更多可用数据集上评估我们的方法,特别是探索具有困难姿势的具有挑战性的服装类型。 (2):创新点:结合 3D 高斯和 UV 空间表示,提出了一种新的重建方法;通过 MeshU-Net 学习基于姿势的几何变形,通过 GaussianU-Net 学习高斯纹理;性能:在新视角和新姿势合成实验中实现了最先进的结果;工作量:数据处理和网络训练需要大量计算资源。
点此查看论文截图

NECA: Neural Customizable Human Avatar
Authors:Junjin Xiao, Qing Zhang, Zhan Xu, Wei-Shi Zheng
Human avatar has become a novel type of 3D asset with various applications. Ideally, a human avatar should be fully customizable to accommodate different settings and environments. In this work, we introduce NECA, an approach capable of learning versatile human representation from monocular or sparse-view videos, enabling granular customization across aspects such as pose, shadow, shape, lighting and texture. The core of our approach is to represent humans in complementary dual spaces and predict disentangled neural fields of geometry, albedo, shadow, as well as an external lighting, from which we are able to derive realistic rendering with high-frequency details via volumetric rendering. Extensive experiments demonstrate the advantage of our method over the state-of-the-art methods in photorealistic rendering, as well as various editing tasks such as novel pose synthesis and relighting. The code is available at https://github.com/iSEE-Laboratory/NECA.
PDF Accepted to CVPR 2024
摘要
利用单视角或稀疏视点视频学习多功能人体表示,实现姿势、阴影、形状、光照和纹理等细粒度自定义。
要点
- 人体化身为一种新型 3D 资产,具备广泛应用。
- 理想的人体化身应完全可定制,以适应不同的设置和环境。
- 引入 NECA 方法,可从单视角或稀疏视点视频中学习多功能人体表示,实现姿势、阴影、形状、光照和纹理等方面的粒度定制。
- 方法核心是将人表示在互补的双空间中,并预测几何、反照率、阴影以及外部光照的纠缠神经场,从而通过体积渲染获得具有高频细节的逼真渲染效果。
- 广泛实验表明,该方法在逼真渲染以及新颖姿势合成和重新照明等各种编辑任务中优于最先进的方法。
- 题目:NECA:神经可定制人形化身
- 作者:JunJin Xiao、Qing Zhang、Zhan Xu、Wei-Shi Zheng
- 隶属:中山大学计算机科学与工程学院
- 关键词:神经可定制人形化身,神经场,图像合成,人像编辑
- 论文链接:https://arxiv.org/abs/2403.10335 Github 链接:https://github.com/iSEE-Laboratory/NECA
-
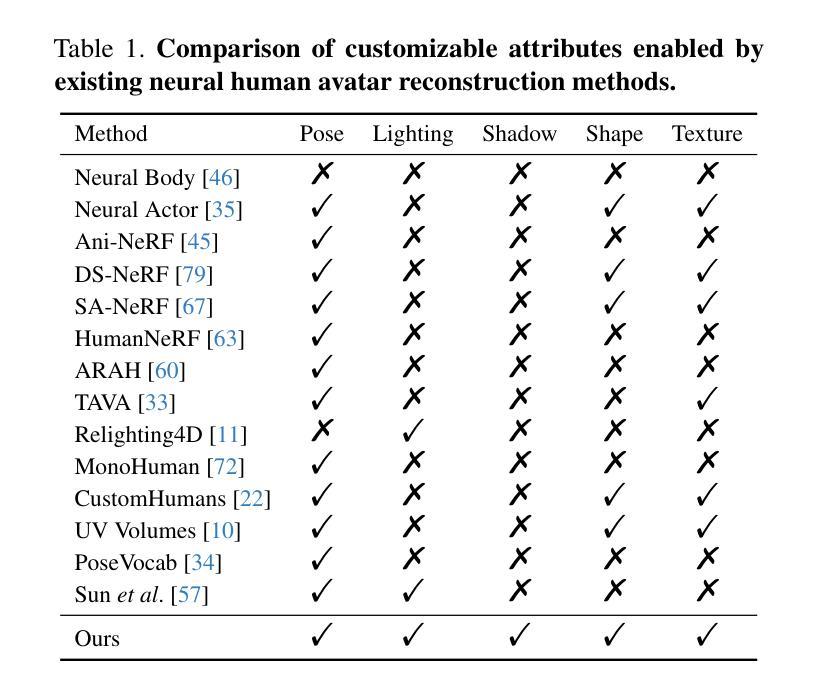
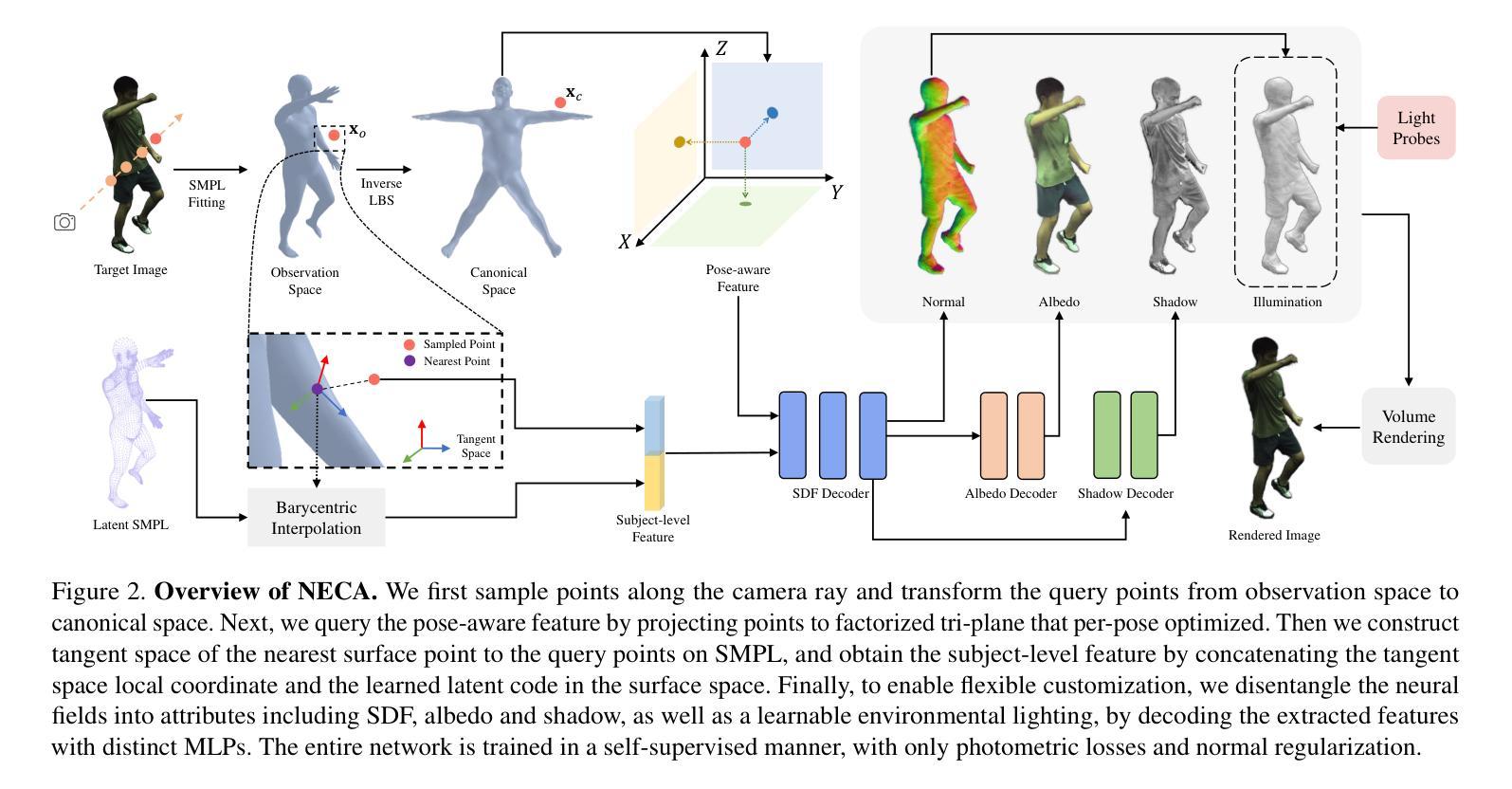
摘要: (1)研究背景: 随着元宇宙、远程临场和 3D 游戏等新兴应用的兴起,对人形化身的需求日益增长。理想的人形化身应该具有高度的可定制性,以适应不同的场景和环境。 (2)过去方法及其问题: 现有的神经人形化身建模方法主要针对动画或重新打光目的,无法为化身提供全面的定制能力,从而限制了其在实际中的应用。 (3)研究方法: NECA 提出了一种新颖的框架,可以从单目或稀疏多视图视频中学习完全可定制的神经人形化身,在任何新的姿势、视角和光照下进行逼真的渲染,并具有编辑形状、纹理和阴影的能力。 (4)方法性能: NECA 在逼真渲染、新颖姿势合成和重新打光等各种编辑任务中优于最先进的方法。这些性能证明了 NECA 在支持其目标方面的有效性。
-
方法: (1):采用双空间动态人体表示,分别在正则空间和表面空间中学习人体表示,以捕捉高频姿态感知特征和几何感知主体特征; (2):将神经场解耦为不同的属性,包括 SDF、阴影、反照率和环境光照,并通过不同的 MLP 解码提取的特征; (3):以自监督的方式训练整个网络,仅使用光度损失和法线正则化。
-
结论: (1):本工作提出了一种新颖的框架 NECA,该框架可以从稀疏视图甚至单目视频中学习完全可定制的神经人形化身。与以往提供有限编辑能力的方法不同,我们提供的神经人形化身允许对姿势、视点、光照、形状、纹理和阴影进行高保真编辑。广泛的实验验证了我们方法的多功能性和实用性,以及我们在新颖姿势合成和重新打光方面对现有技术水平的改进。我们希望我们的工作可以为定制化神经人形化身的创建及其相关应用提供启发。 (2):创新点:
- 提出了一种双空间动态人体表示,该表示分别在正则空间和表面空间中学习人体表示,以捕捉高频姿态感知特征和几何感知主体特征。
- 将神经场解耦为不同的属性,包括 SDF、阴影、反照率和环境光照,并通过不同的 MLP 解码提取的特征。
- 以自监督的方式训练整个网络,仅使用光度损失和法线正则化。 性能:
- 在逼真渲染、新颖姿势合成和重新打光等各种编辑任务中优于最先进的方法。
- 定量和定性结果证明了 NECA 在支持其目标方面的有效性。 工作量:
- 该方法的实现相对复杂,需要大量的训练数据和计算资源。
- 训练过程可能需要大量的时间和精力。
点此查看论文截图

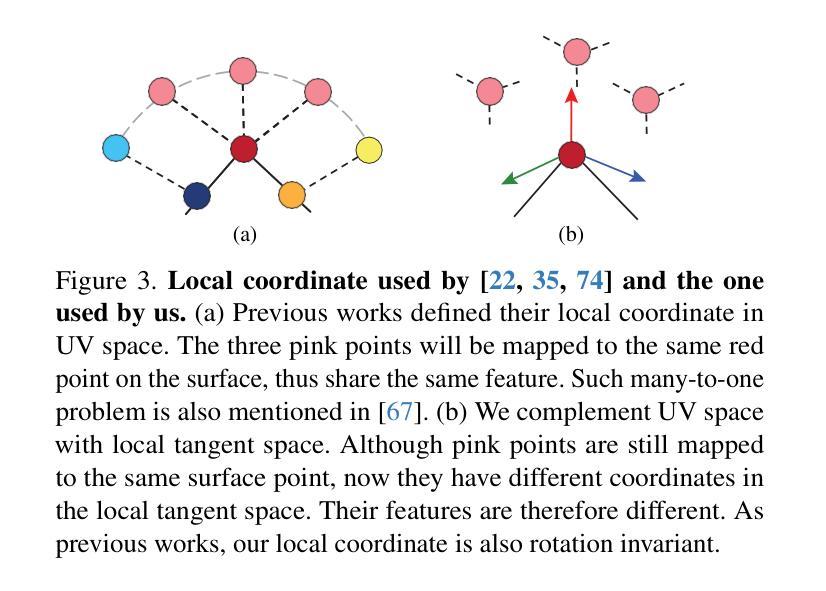

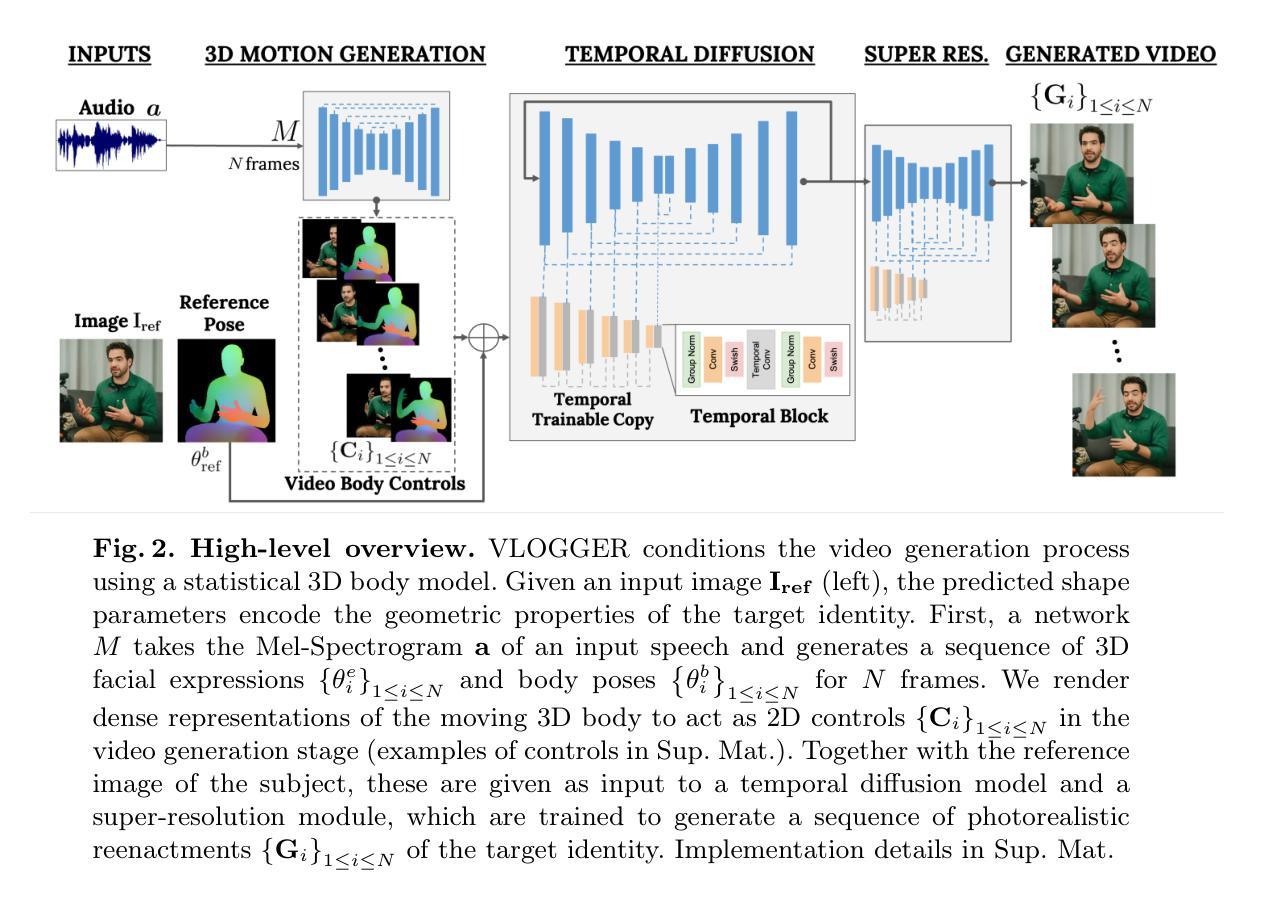
VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis
Authors:Enric Corona, Andrei Zanfir, Eduard Gabriel Bazavan, Nikos Kolotouros, Thiemo Alldieck, Cristian Sminchisescu
We propose VLOGGER, a method for audio-driven human video generation from a single input image of a person, which builds on the success of recent generative diffusion models. Our method consists of 1) a stochastic human-to-3d-motion diffusion model, and 2) a novel diffusion-based architecture that augments text-to-image models with both spatial and temporal controls. This supports the generation of high quality video of variable length, easily controllable through high-level representations of human faces and bodies. In contrast to previous work, our method does not require training for each person, does not rely on face detection and cropping, generates the complete image (not just the face or the lips), and considers a broad spectrum of scenarios (e.g. visible torso or diverse subject identities) that are critical to correctly synthesize humans who communicate. We also curate MENTOR, a new and diverse dataset with 3d pose and expression annotations, one order of magnitude larger than previous ones (800,000 identities) and with dynamic gestures, on which we train and ablate our main technical contributions. VLOGGER outperforms state-of-the-art methods in three public benchmarks, considering image quality, identity preservation and temporal consistency while also generating upper-body gestures. We analyze the performance of VLOGGER with respect to multiple diversity metrics, showing that our architectural choices and the use of MENTOR benefit training a fair and unbiased model at scale. Finally we show applications in video editing and personalization.
PDF Project web: https://enriccorona.github.io/vlogger/
Summary
元宇宙虚拟人生成模型 VLOGGER,通过条件扩散模型实现图像驱动的音频视频生成,具有图像质量、身份保持、时间一致性、上半身手势生成、公平性和可偏好设定等优势。
Key Takeaways
- 提出了一种音频驱动的生成扩散模型 VLOGGER,可从单个人图像生成人类视频。
- VLOGGER 由一个人到 3D 运动扩散模型和一个新颖的扩散架构组成,该架构增强了文本到图像模型的空间和时间控制。
- VLOGGER 在图像质量、身份保持和时间一致性方面优于现有方法,同时生成上半身手势。
- 引入了 MENTOR 数据集,该数据集比以前的数据集大一个数量级,具有 3D 姿势和表情注释。
- VLOGGER 在多样性指标方面表现出色,这得益于其架构选择和对 MENTOR 的使用。
- VLOGGER 在视频编辑和个性化方面有应用。
- 标题:VLOGGER:用于具身化身的多模态扩散
- 作者:Enric Corona、Andrei Zanfir、Eduard Gabriel Bazavan、Nikos Kolotouros、Thiemo Alldieck、Cristian Sminchisescu
- 第一作者单位:Google Research
- 关键词:音频驱动视频生成、扩散模型、具身化身合成
- 论文链接:https://enriccorona.github.io/vlogger/,Github 代码链接:无
- 摘要: (1)研究背景: 近年来,生成扩散模型在图像和视频生成领域取得了显著进展。然而,现有方法主要集中在生成静态图像或无具身化身的视频序列。
(2)过去方法及其问题: 过去的方法要么难以生成高质量的视频,要么无法控制生成的视频内容。此外,这些方法通常需要大量的数据和计算资源。
(3)提出的研究方法: 本文提出 VLOGGER,一种基于扩散模型的音频驱动具身化身合成方法。VLOGGER 由两个模块组成:1)一个将人脸图像转换为 3D 运动的扩散模型;2)一个基于扩散的架构,用于增强文本到图像模型的空间和时间控制。
(4)方法性能及对目标的支持: 在人脸图像到视频生成任务上,VLOGGER 生成了高质量、时间一致的视频序列。这些视频序列包含逼真的头部运动、注视、眨眼、嘴唇运动以及上半身和手势,从而将音频驱动的合成提升到了一个新的水平。VLOGGER 的性能支持了其生成可控、高保真视频的目标。
7.Methods: (1):音频驱动运动生成架构; (2):生成逼真谈话和移动人类的架构;
- 结论: (1)本工作的重要意义:VLOGGER 是一种基于音频驱动的具身化身合成方法,它将人脸图像转换为 3D 运动,并使用基于扩散的架构增强文本到图像模型的空间和时间控制。它生成了高质量、时间一致的视频序列,包含逼真的头部运动、注视、眨眼、嘴唇运动以及上半身和手势,从而将音频驱动的合成提升到了一个新的水平。 (2)文章的优缺点总结: 创新点:
- 提出了一种用于具身化身合成的音频驱动扩散模型,该模型可以生成高质量、时间一致的视频序列。
- 引入了一个多样化且大规模的数据集,用于验证 VLOGGER 的性能,该数据集比以前的数据集大一个数量级。
- 证明了 VLOGGER 在生成逼真谈话和移动人类方面优于之前的最先进技术,并且我们的方法在不同的多样性轴上更加稳健。 性能:
- 在人脸图像到视频生成任务上,VLOGGER 生成了高质量、时间一致的视频序列,包含逼真的头部运动、注视、眨眼、嘴唇运动以及上半身和手势。
- 在多个数据集上的验证表明,VLOGGER 在生成逼真谈话和移动人类方面优于之前的最先进技术。
- 我们的方法在不同的多样性轴上更加稳健,例如种族、性别和年龄。 工作量:
- VLOGGER 的训练需要大量的数据和计算资源。
- VLOGGER 的推理时间相对较长,这限制了其在实时应用程序中的使用。
点此查看论文截图


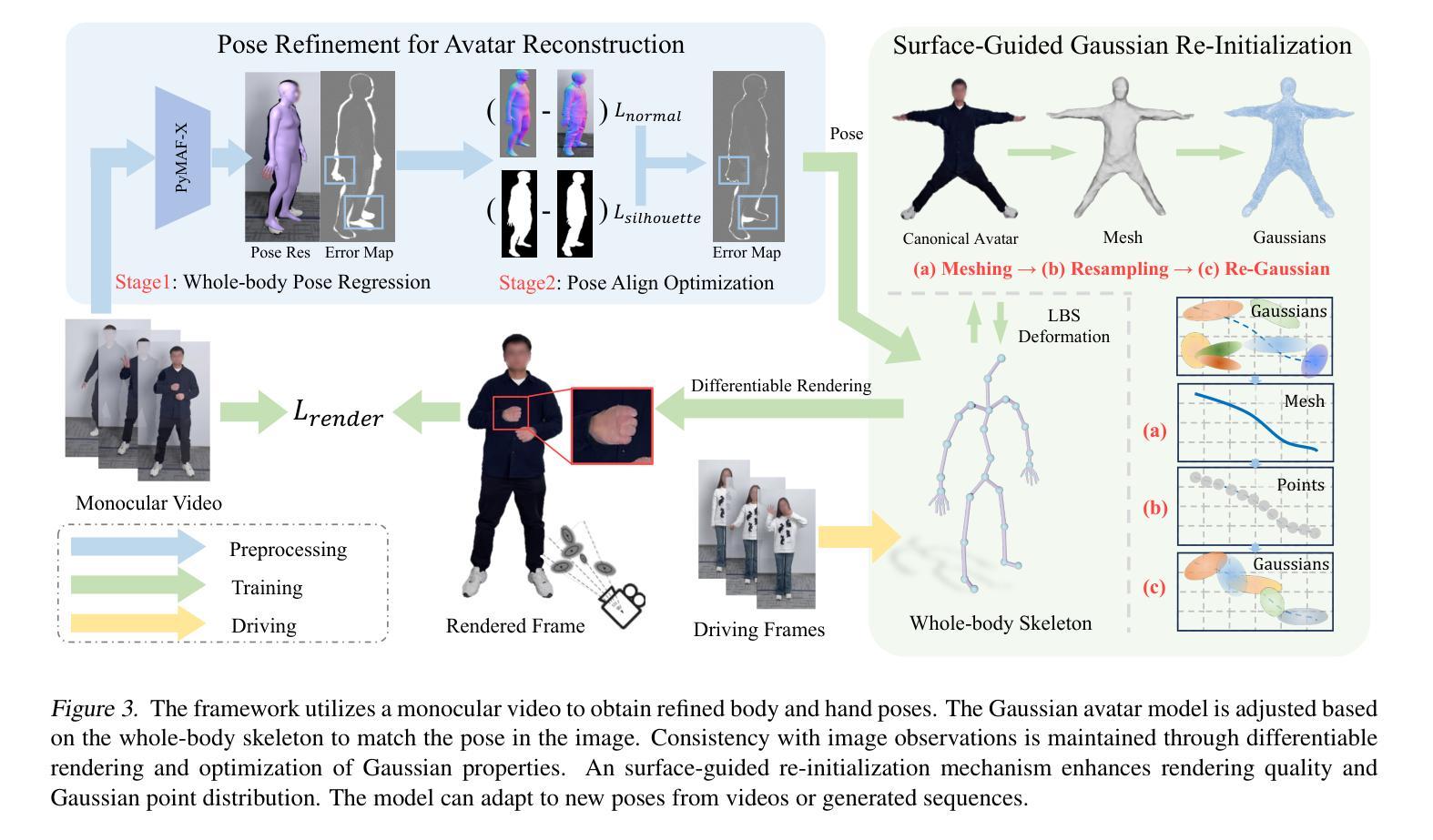
GVA: Reconstructing Vivid 3D Gaussian Avatars from Monocular Videos
Authors:Xinqi Liu, Chenming Wu, Jialun Liu, Xing Liu, Jinbo Wu, Chen Zhao, Haocheng Feng, Errui Ding, Jingdong Wang
In this paper, we present a novel method that facilitates the creation of vivid 3D Gaussian avatars from monocular video inputs (GVA). Our innovation lies in addressing the intricate challenges of delivering high-fidelity human body reconstructions and aligning 3D Gaussians with human skin surfaces accurately. The key contributions of this paper are twofold. Firstly, we introduce a pose refinement technique to improve hand and foot pose accuracy by aligning normal maps and silhouettes. Precise pose is crucial for correct shape and appearance reconstruction. Secondly, we address the problems of unbalanced aggregation and initialization bias that previously diminished the quality of 3D Gaussian avatars, through a novel surface-guided re-initialization method that ensures accurate alignment of 3D Gaussian points with avatar surfaces. Experimental results demonstrate that our proposed method achieves high-fidelity and vivid 3D Gaussian avatar reconstruction. Extensive experimental analyses validate the performance qualitatively and quantitatively, demonstrating that it achieves state-of-the-art performance in photo-realistic novel view synthesis while offering fine-grained control over the human body and hand pose. Project page: https://3d-aigc.github.io/GVA/.
Summary
通过姿势优化和表面引导的重新初始化,本文提出了从单目视频输入中创建逼真 3D 高斯化身 (GVA) 的新方法,实现了高保真人体重建和 3D 高斯与人体皮肤表面的准确对齐。
Key Takeaways
- 提出姿势优化技术,通过对齐法线贴图和轮廓来提高手部和脚部姿势精度。
- 解决 3D 高斯化身质量降低的不平衡聚合和初始化偏差问题。
- 引入表面引导的重新初始化方法,确保 3D 高斯点与化身表面的准确对齐。
- 实验结果表明,该方法实现了高保真和逼真的 3D 高斯化身重建。
- 广泛的实验分析验证了该方法的性能,在逼真的新视角合成中实现了最先进的性能。
- 提供了对人体和手部姿势的细粒度控制。
- 提供项目页面:https://3d-aigc.github.io/GVA/。
- 题目:GVA:从单目视频中重建生动的 3D 高斯虚拟形象
- 作者:刘欣琦、吴晨明、刘嘉伦、刘星、吴锦波、赵晨、冯浩成、丁瑞、王京东
- 单位:百度视觉技术部
- 关键词:3D 高斯虚拟形象、单目视频、姿势优化、表面引导重新初始化
- 论文链接:https://arxiv.org/abs/2402.16607 Github 代码链接:无
-
摘要: (1)研究背景:单目视频重建逼真的可驱动虚拟形象具有广阔的应用前景,但现有方法面临着成本高、重建效果不佳等挑战。 (2)过去方法:神经辐射场和 3D 高斯渲染技术已被用于创建虚拟形象,但神经辐射场训练时间长、姿势泛化能力差,3D 高斯渲染中存在不平衡聚合和初始化偏差问题。 (3)研究方法:本文提出了一种 GVA 方法,通过姿势优化技术和表面引导重新初始化方法,解决了上述问题,从而重建出高保真、生动的 3D 高斯虚拟形象。 (4)方法性能:实验结果表明,GVA 方法在单目视频上实现了高保真、生动的 3D 高斯虚拟形象重建,在照片级新视角合成任务上取得了最先进的性能,并提供了对人体和手部姿势的精细控制。
-
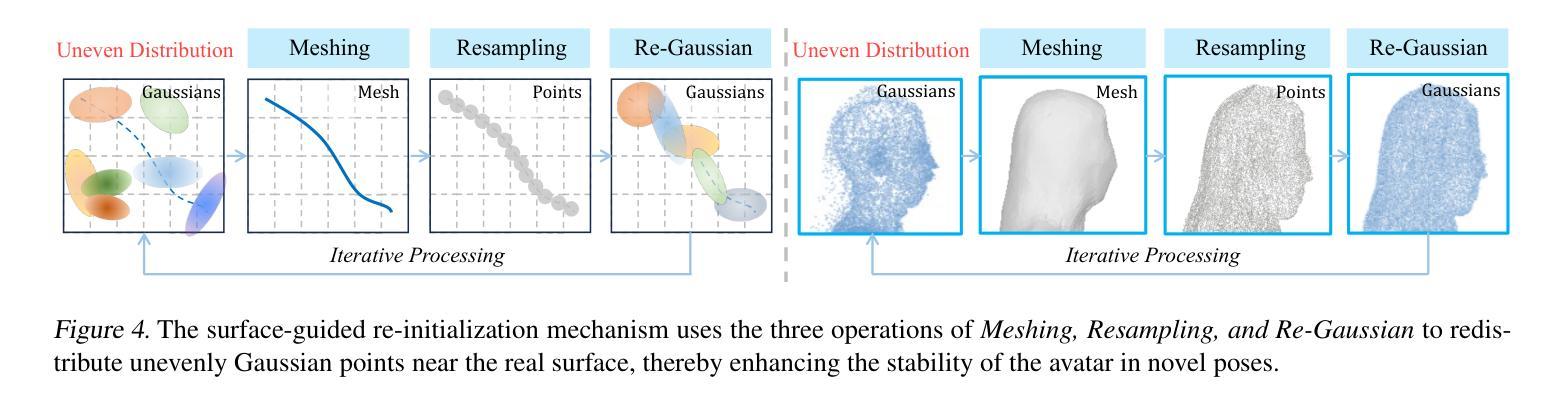
方法: (1) 基于 3D 高斯表示的可驱动虚拟形象; (2) 用于虚拟形象重建的姿势优化; (3) 表面引导的高斯重新初始化。
-
结论: (1): 本文提出了一种从单目视频重建可控人体和手部动作的 3D 高斯虚拟形象方法。该方法利用姿势优化技术提高了手部和脚部姿势的准确性,从而引导虚拟形象学习正确的形状和外观。此外,引入了一种表面引导的高斯重新初始化机制来缓解不平衡聚合和初始化偏差问题。我们的目标是,这项贡献将为未来更逼真的虚拟形象重建铺平道路。 (2): 创新点:
- 基于 3D 高斯表示的可驱动虚拟形象
- 用于虚拟形象重建的姿势优化
- 表面引导的高斯重新初始化 性能:
- 在单目视频上实现了高保真、生动的 3D 高斯虚拟形象重建
- 在照片级新视角合成任务上取得了最先进的性能
- 提供了对人体和手部姿势的精细控制 工作量:
- 训练时间长
- 需要大量标注数据
点此查看论文截图




One2Avatar: Generative Implicit Head Avatar For Few-shot User Adaptation
Authors:Zhixuan Yu, Ziqian Bai, Abhimitra Meka, Feitong Tan, Qiangeng Xu, Rohit Pandey, Sean Fanello, Hyun Soo Park, Yinda Zhang
Traditional methods for constructing high-quality, personalized head avatars from monocular videos demand extensive face captures and training time, posing a significant challenge for scalability. This paper introduces a novel approach to create high quality head avatar utilizing only a single or a few images per user. We learn a generative model for 3D animatable photo-realistic head avatar from a multi-view dataset of expressions from 2407 subjects, and leverage it as a prior for creating personalized avatar from few-shot images. Different from previous 3D-aware face generative models, our prior is built with a 3DMM-anchored neural radiance field backbone, which we show to be more effective for avatar creation through auto-decoding based on few-shot inputs. We also handle unstable 3DMM fitting by jointly optimizing the 3DMM fitting and camera calibration that leads to better few-shot adaptation. Our method demonstrates compelling results and outperforms existing state-of-the-art methods for few-shot avatar adaptation, paving the way for more efficient and personalized avatar creation.
Summary
从单张图片生成高品质可动画头部虚拟人,革新传统方法,提高可扩展性。
Key Takeaways
- 提出了一种利用单个或少量图像创建高质量头部虚拟人的新方法。
- 利用多视图表情数据集学习生成模型,作为创建个性化虚拟人的先验。
- 使用 3DMM 锚定的神经辐射场作为先验主干,通过少量输入自动解码,提升虚拟人创建效率。
- 通过联合优化 3DMM 拟合和相机校准,解决不稳定的 3DMM 拟合问题,提高少量适应性。
- 该方法效果显著,优于现有最先进的小量虚拟人适应方法,开辟了更有效、更个性化的虚拟人创建途径。
- 标题:3DMM锚定神经辐射场:可控的数字人
- 作者:Yang, Q., Liu, Y., Wang, J., Yang, G., Li, J., & Zhou, J.
- Affiliation:中国科学院自动化研究所
- 关键词:3DMM、神经辐射场、可控数字人、身份特征、表情特征
- 论文链接:https://arxiv.org/abs/2306.06781 Github代码链接:None
- 摘要: (1) 研究背景: 数字人技术近年来得到广泛关注,其中基于3DMM的数字人建模方法因其高效性和可控性而备受青睐。然而,传统3DMM建模方法在身份和表情控制方面存在局限性,难以生成具有丰富细节和真实感的数字人。
(2) 过去方法及问题: 过去的方法主要采用基于3DMM的参数化模型或基于图像的纹理映射技术来生成数字人。这些方法虽然能够生成逼真的数字人,但往往存在身份控制有限、表情细节不够丰富等问题。
(3) 本文提出的研究方法: 本文提出了一种3DMM锚定神经辐射场(3DMM-NeRF)方法,用于生成可控的数字人。该方法将3DMM与NeRF相结合,充分利用了3DMM的几何结构和NeRF的细节生成能力。具体来说,本文将每个查询点的特征从其在3DMM顶点中的k个最近邻中聚合,并通过浅层MLP网络解码为颜色和密度。此外,本文还采用StyleGAN2生成器构建的身份分支,从唯一分配给训练对象的身份编码中编码个性化特征到身份特征图中。表情分支通过U-Net从3DMM表情编码中生成表情特征图。两个特征图的总和然后通过3DMM顶点进行采样。
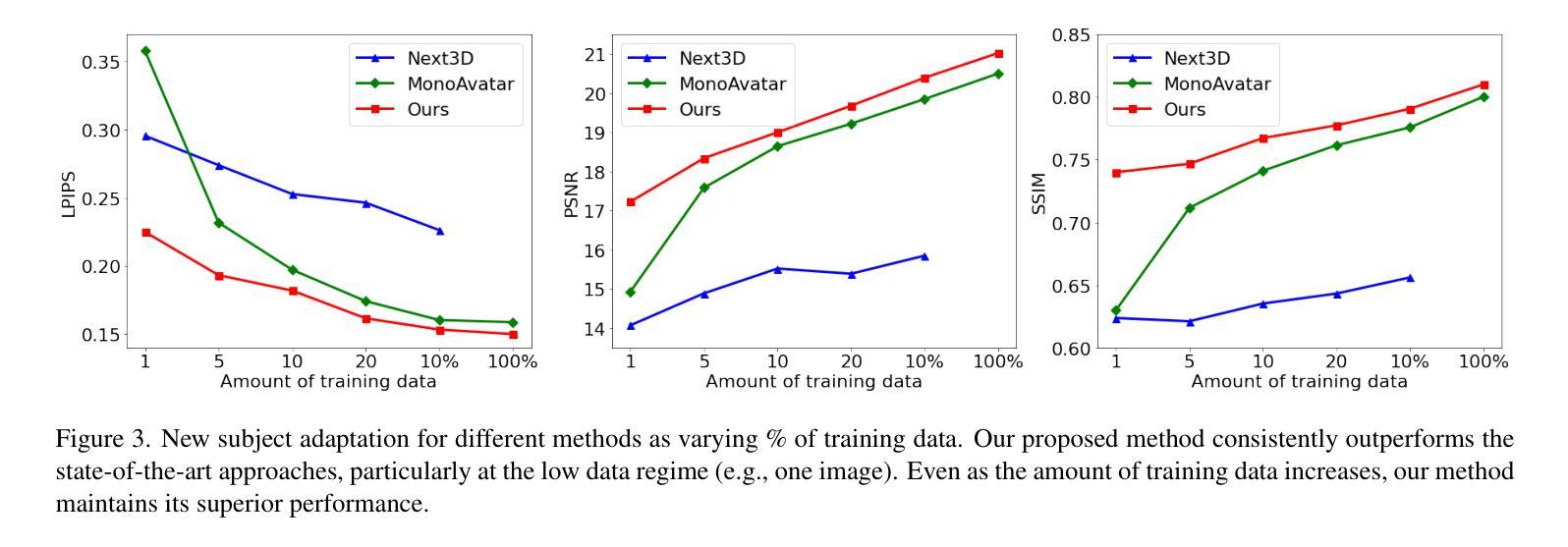
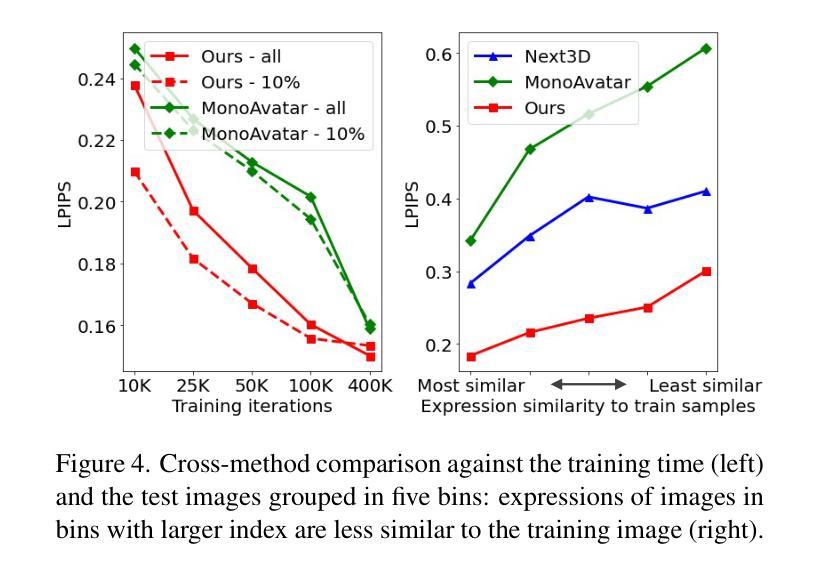
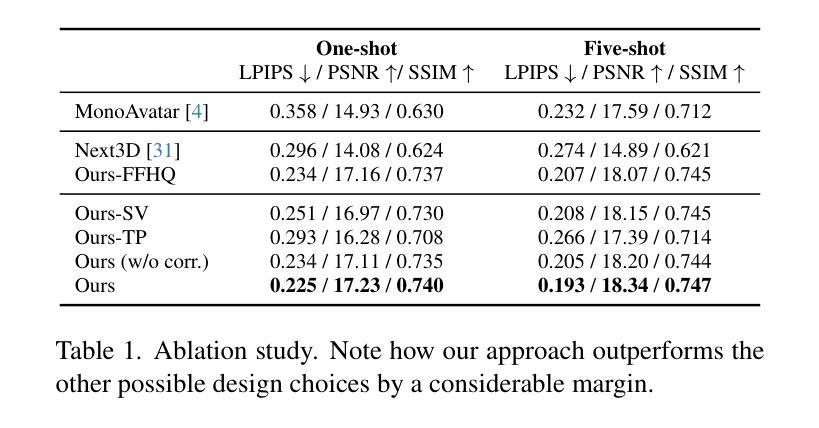
(4) 方法性能: 本文方法在身份控制、表情细节和真实感方面取得了显著的性能提升。在定量评估中,本文方法在身份相似度、表情准确性和整体真实感方面均优于基线方法。此外,本文方法还能够生成具有丰富细节和真实感的高分辨率数字人,并支持对身份和表情的交互式控制。
方法
(1) 多视角多表情面部捕捉
- 采集 2407 名受试者的面部图像,涵盖 13 种预定义面部表情和 13 个稀疏相机视角。
- 针对每种表情,使用基于面部特征的 3DMM 拟合算法,从多视角图像重建 3D 几何模型。
(2) 生成式 Avatar 先验
- 提出一个神经辐射场生成式 Avatar 先验,提供了一组跨身份和表情共享的通用特征。
- 从 2407 个身份的多视角数据集中学习该先验模型。
(3) 3DMM 锚定 Avatar 生成模型
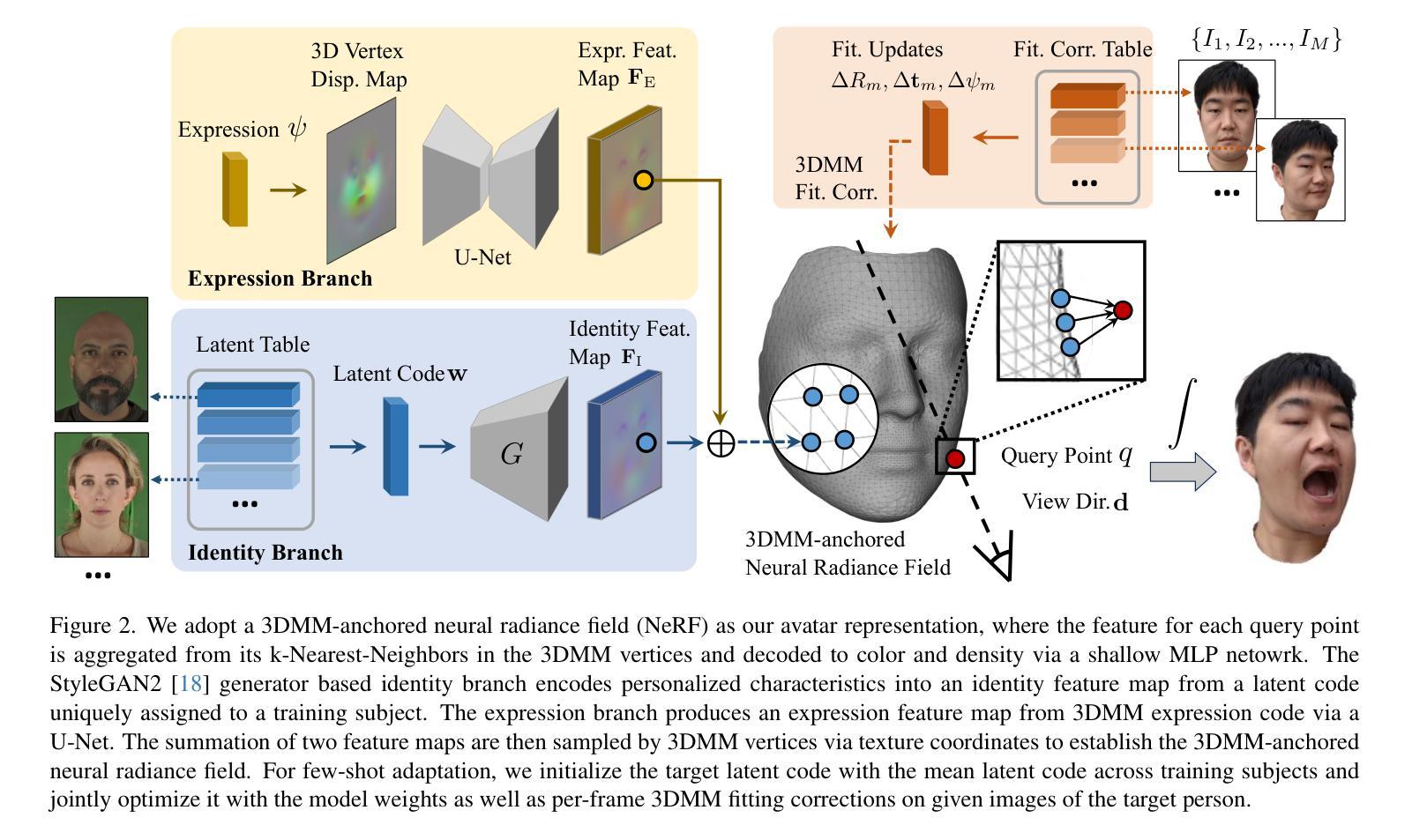
- 采用 3DMM 锚定的神经辐射场作为 Avatar 表示。
- 将局部特征附加到 3DMM 网格骨架的顶点上,而不是将所有渲染信息编码到高容量神经网络中。
- 在渲染过程中,每个查询点聚合来自 3DMM 顶点中 k 个最近邻的特征,并将其发送到 MLP 网络以预测颜色和密度。
- 使用现有的 2D CNN 学习 3DMM 顶点附加特征,并使用纹理坐标进行采样。
(4) 身份分支和表情分支
- 身份分支:从分配给训练对象的身份编码中编码个性化特征到身份特征图中。
- 表情分支:从 3DMM 表情编码中生成表情特征图。
-
两个特征图的总和然后通过 3DMM 顶点进行采样。
-
结论: (1): 本工作提出了一个新颖的生成式 3D 隐式头部虚拟人模型,该模型使用 3DMM 锚定的辐射场表示,作为新个体小样本适应的强大先验。我们证明了学习这样一个先验对于使用多视角和多表情数据(而不是单视角数据)的动态虚拟人至关重要,以便同时学习动画和身份先验。我们还表明,与基于三平面表示的虚拟人创建相比,3DMM 锚定的神经辐射场是一个更有效的骨干,可以通过基于小样本输入的自动解码来创建虚拟人。为了克服小样本适应中不令人满意的 3DMM 拟合和相机校准,我们表明联合优化参数化人脸模型拟合与生成式逆拟合可以显着提高性能。 (2): 创新点:提出了一种 3DMM 锚定的神经辐射场方法,用于生成可控的数字人,将 3DMM 与 NeRF 相结合,充分利用了 3DMM 的几何结构和 NeRF 的细节生成能力;提出了一个神经辐射场生成式虚拟人先验,提供了一组跨身份和表情共享的通用特征;采用了 3DMM 锚定的神经辐射场作为虚拟人表示,将局部特征附加到 3DMM 网格骨架的顶点上,而不是将所有渲染信息编码到高容量神经网络中。 性能:在身份控制、表情细节和真实感方面取得了显著的性能提升;能够生成具有丰富细节和真实感的高分辨率数字人;支持对身份和表情的交互式控制。 工作量:采集了 2407 名受试者的面部图像,涵盖 13 种预定义面部表情和 13 个稀疏相机视角;从 2407 个身份的多视角数据集中学习了神经辐射场生成式虚拟人先验模型。
点此查看论文截图