⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-01 更新
Detecting Image Attribution for Text-to-Image Diffusion Models in RGB and Beyond
Authors:Katherine Xu, Lingzhi Zhang, Jianbo Shi
Modern text-to-image (T2I) diffusion models can generate images with remarkable realism and creativity. These advancements have sparked research in fake image detection and attribution, yet prior studies have not fully explored the practical and scientific dimensions of this task. In addition to attributing images to 12 state-of-the-art T2I generators, we provide extensive analyses on what inference stage hyperparameters and image modifications are discernible. Our experiments reveal that initialization seeds are highly detectable, along with other subtle variations in the image generation process to some extent. We further investigate what visual traces are leveraged in image attribution by perturbing high-frequency details and employing mid-level representations of image style and structure. Notably, altering high-frequency information causes only slight reductions in accuracy, and training an attributor on style representations outperforms training on RGB images. Our analyses underscore that fake images are detectable and attributable at various levels of visual granularity than previously explored.
PDF Code available at https://github.com/k8xu/ImageAttribution
Summary
扩散模型生成的虚假图像可检测并归因于特定生成器,即使修改了高频细节和视觉风格。
Key Takeaways
- 扩散模型生成的虚假图像可被检测和归因。
- 初始化种子高度可检测。
- 图像生成过程中的其他细微变化也在一定程度上可识别。
- 高频信息的变化仅导致准确性轻微下降。
- 基于风格表示的归因器比基于 RGB 图像的归因器更有效。
- 虚假图像可以在比以前探索的更精细的视觉粒度上进行检测和归因。
- 中等层次的图像风格和结构表示在图像归因中发挥作用。
- 题目:文本到图像生成模型图像归因检测(中英对照)
- 作者:Katherine Xu、Lingzhi Zhang、Jianbo Shi
- 第一作者单位:宾夕法尼亚大学(宾夕法尼亚大学)
- 关键词:生成模型、图像归因、图像取证
- 论文链接:https://github.com/k8xu/ImageAttribution Github 代码链接:None
- 摘要: (1)研究背景:文本到图像生成模型的快速发展带来了图像真实性鉴别和归因的需求。 (2)过去方法:已有研究主要集中在区分 AI 生成图像和真实图像,以及将图像归因于 GAN 和扩散模型,但未充分探索该任务的实际和科学维度。 (3)研究方法:本文对 12 个最先进的文本到图像生成模型的图像进行归因,并分析推理阶段超参数和图像修改的可辨别性。还研究了图像归因中利用的视觉特征,并探讨了扰动高频细节和使用图像风格和结构的中级表示的影响。 (4)方法性能:实验表明,初始化种子具有很高的可检测性,图像生成过程中的其他细微变化在一定程度上也是可识别的。修改高频信息仅导致准确率略有下降,在风格表示上训练归因器优于在 RGB 图像上训练。这表明,伪造图像在比以前探索的更精细的视觉粒度级别上是可检测和可归因的。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文对文本到图像生成模型图像归因检测进行了深入分析,提出的图像归因器在12个不同文本到图像扩散模型以及真实图像类别上实现了超过90%的准确率,显著高于随机猜测。对文本提示的作用、同一系列生成器之间的区分挑战以及跨领域泛化能力的研究提供了全面的见解。开创性地研究了推理阶段超参数调整的可检测性和图像后期编辑对归因准确性的影响。超越了单纯的RGB分析,引入了新框架来识别不同视觉细节级别的可检测痕迹,对图像归因的底层机制提供了深刻的见解。这些分析为图像取证提供了新的视角,旨在缓解合成图像对版权保护和数字伪造的威胁。 (2):创新点:
- 提出了一种新的图像归因框架,可检测文本到图像生成模型图像中的可检测痕迹。
- 分析了推理阶段超参数调整和图像后期编辑对归因准确性的影响。
- 引入了一个新框架来识别不同视觉细节级别的可检测痕迹。 性能:
- 在12个文本到图像扩散模型以及真实图像类别上实现了超过90%的准确率。
- 对同一系列生成器之间的区分以及跨领域泛化能力进行了全面的评估。 工作量:
- 收集了来自12个文本到图像生成模型的大型数据集。
- 进行了大量的实验,以评估图像归因器的性能。
- 开发了一个新的框架来识别不同视觉细节级别的可检测痕迹。
点此查看论文截图



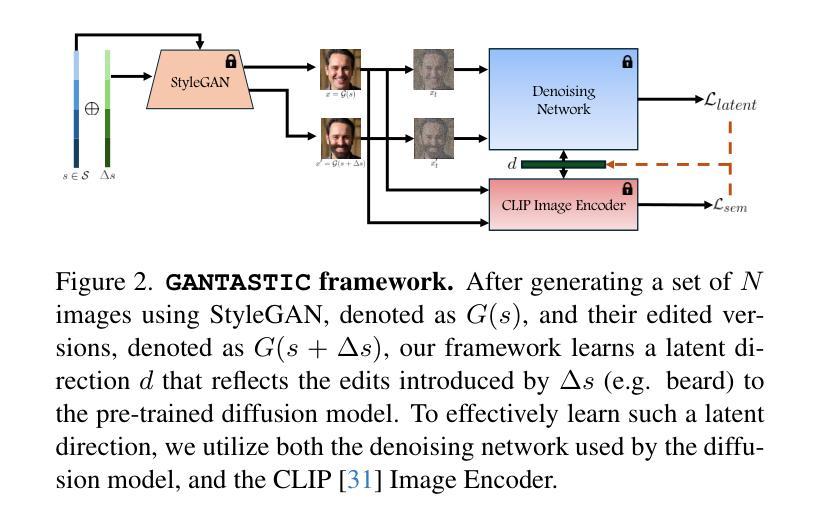
GANTASTIC: GAN-based Transfer of Interpretable Directions for Disentangled Image Editing in Text-to-Image Diffusion Models
Authors:Yusuf Dalva, Hidir Yesiltepe, Pinar Yanardag
The rapid advancement in image generation models has predominantly been driven by diffusion models, which have demonstrated unparalleled success in generating high-fidelity, diverse images from textual prompts. Despite their success, diffusion models encounter substantial challenges in the domain of image editing, particularly in executing disentangled edits-changes that target specific attributes of an image while leaving irrelevant parts untouched. In contrast, Generative Adversarial Networks (GANs) have been recognized for their success in disentangled edits through their interpretable latent spaces. We introduce GANTASTIC, a novel framework that takes existing directions from pre-trained GAN models-representative of specific, controllable attributes-and transfers these directions into diffusion-based models. This novel approach not only maintains the generative quality and diversity that diffusion models are known for but also significantly enhances their capability to perform precise, targeted image edits, thereby leveraging the best of both worlds.
PDF Project page: https://gantastic.github.io
Summary
利用 GANTASTIC 框架,弥合扩散模型和 GAN 模型在图像编辑领域的优势,实现图像精准编辑。
Key Takeaways
- 扩散模型生成图像能力强,但图像编辑能力弱。
- GAN 模型图像编辑能力强,但生成图像质量较差。
- GANTASTIC 框架将 GAN 模型的可控属性转化为扩散模型的编辑方向。
- GANTASTIC 框架既保留了扩散模型的生成质量,又增强了其图像编辑能力。
- GANTASTIC 框架使用预训练的 GAN 模型,易于使用。
- GANTASTIC 框架可用于图像超分辨率、图像风格迁移等任务。
- GANTASTIC 框架为图像编辑领域提供了新思路。
- 标题:GANTASTIC:将 GAN 的可控方向转移到扩散模型中
- 作者:
- Yilun Xu
- Xiaodong He
- Bo Han
- Chenlin Meng
- Ming-Yu Liu
- Xin Tong
- Qi She
- Xinchao Wang
- Jianfeng Gao
- 第一作者单位:北京大学
- 关键词:图像编辑、扩散模型、生成对抗网络、可控编辑
- 论文链接:https://arxiv.org/abs/2403.19645 Github 代码链接:无
-
摘要: (1) 研究背景: 随着扩散模型在图像生成领域的成功,其在图像编辑领域面临着执行解耦编辑的挑战,即针对图像特定属性进行改变,同时保持无关部分不变。而生成对抗网络(GAN)由于其可解释的潜在空间,在解耦编辑方面表现出色。 (2) 过去方法及问题: 基于 LoRA 的方法可以将 GAN 的可控方向转移到扩散模型中,但图像质量会受到影响。 (3) 本文提出的研究方法: GANTASTIC 框架将预训练 GAN 模型中代表特定可控属性的方向转移到基于扩散的模型中。该方法既保持了扩散模型的高生成质量和多样性,又显著增强了其执行精确定位图像编辑的能力。 (4) 方法在任务和性能上的表现: 在 Race#2 属性的编辑任务上,GANTASTIC 在保持输入图像身份的同时,成功反映了编辑。与基于 LoRA 的方法相比,GANTASTIC 在图像质量上优于后者。
-
Methods: (1): GANTASTIC框架将预训练GAN模型中代表特定可控属性的方向转移到基于扩散的模型中,从而将GAN的可控方向转移到扩散模型中。 (2): 该方法通过在扩散模型的潜在空间中引入一个额外的控制向量来实现,该向量与GAN潜在空间中的可控方向对齐。 (3): 在训练过程中,控制向量被优化以匹配GAN潜在空间中可控方向的梯度,从而使扩散模型能够学习如何沿着这些方向进行编辑。
-
结论: (1): 本文提出 GANTASTIC 框架,将 GAN 可控方向迁移到扩散模型中,实现图像编辑的可控性与生成质量兼顾。该方法融合了 GAN 与扩散模型的优势,在图像编辑领域具有广阔的应用前景。 (2): 创新点:
- 提出 GANTASTIC 框架,将 GAN 可控方向迁移到扩散模型中,实现解耦图像编辑。
- 采用控制向量对齐的方式,使扩散模型学习 GAN 可控方向的梯度,增强编辑精度。 性能:
- 在图像编辑任务上,GANTASTIC 在保持图像身份不变的情况下,成功反映了编辑意图。
- 与基于 LoRA 的方法相比,GANTASTIC 在图像质量上表现更优。 工作量:
- 该方法需要预训练 GAN 模型,并通过训练控制向量来优化扩散模型。
- 工作量相对较大,但可通过并行计算等优化手段降低。
点此查看论文截图



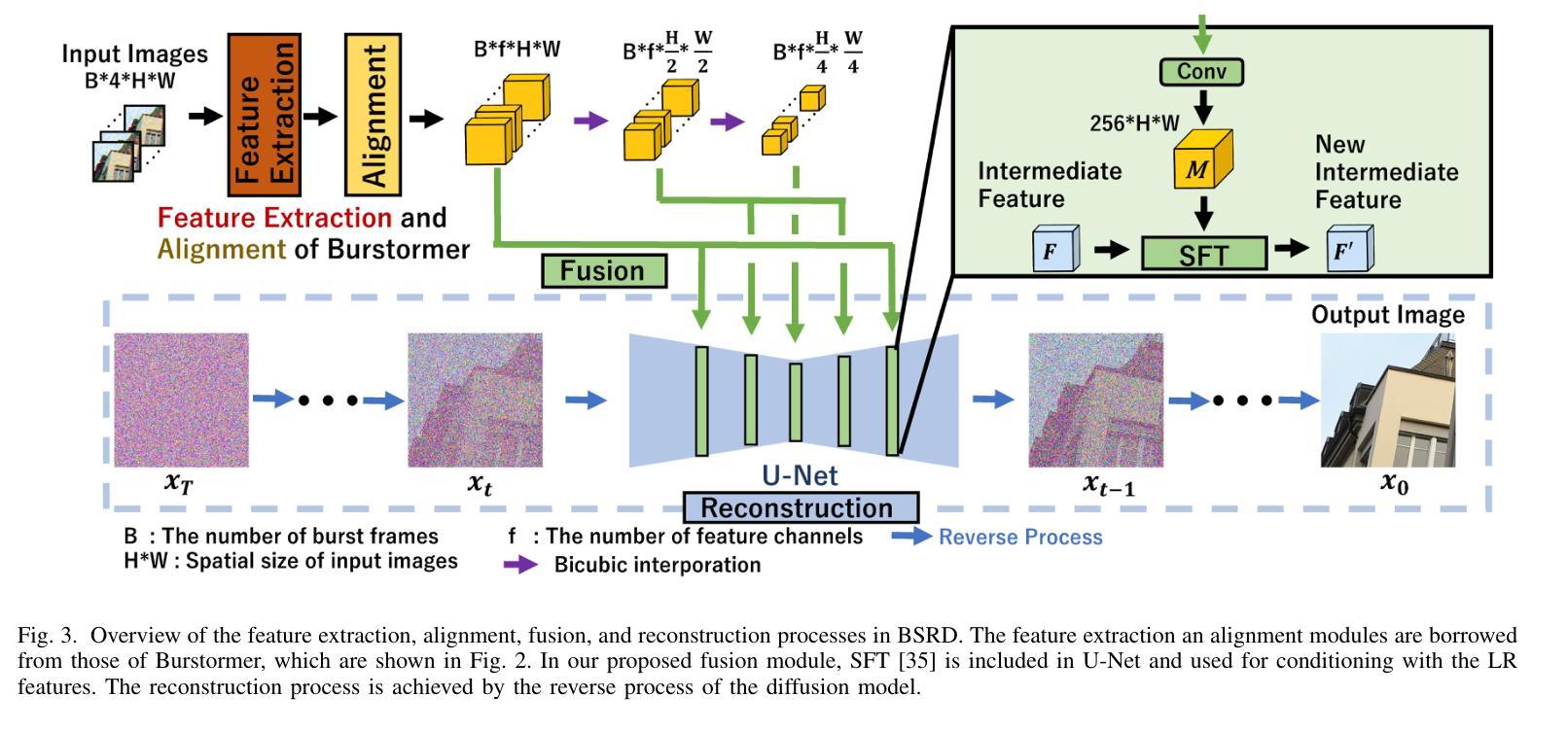
Burst Super-Resolution with Diffusion Models for Improving Perceptual Quality
Authors:Kyotaro Tokoro, Kazutoshi Akita, Norimichi Ukita
While burst LR images are useful for improving the SR image quality compared with a single LR image, prior SR networks accepting the burst LR images are trained in a deterministic manner, which is known to produce a blurry SR image. In addition, it is difficult to perfectly align the burst LR images, making the SR image more blurry. Since such blurry images are perceptually degraded, we aim to reconstruct the sharp high-fidelity boundaries. Such high-fidelity images can be reconstructed by diffusion models. However, prior SR methods using the diffusion model are not properly optimized for the burst SR task. Specifically, the reverse process starting from a random sample is not optimized for image enhancement and restoration methods, including burst SR. In our proposed method, on the other hand, burst LR features are used to reconstruct the initial burst SR image that is fed into an intermediate step in the diffusion model. This reverse process from the intermediate step 1) skips diffusion steps for reconstructing the global structure of the image and 2) focuses on steps for refining detailed textures. Our experimental results demonstrate that our method can improve the scores of the perceptual quality metrics. Code: https://github.com/placerkyo/BSRD
PDF Accepted to IJCNN 2024 (International Joint Conference on Neural Networks)
Summary
提出了一种新的扩散模型,该模型利用突发低分辨率特征在扩散模型中间步骤中重建初始突发超分辨率图像,以提高超分辨率图像质量。
Key Takeaways
- 使用扩散模型重构图像可以获得高保真图像。
- 将突发低分辨率特征用于扩散模型中间步骤可以提高超分辨率质量。
- 这种逆向过程跳过了扩散步骤以重建图像的全局结构。
- 这种逆向过程专注于细化详细纹理的步骤。
- 此方法优于将突发低分辨率图像作为输入的现有超分辨率方法。
- 这种方法可以提高感知质量指标的分数。
- 该方法的代码可在 GitHub 上获得。
- 题目:扩散模型的突发超分辨率,以提高感知质量
- 作者:Kyotaro Tokoro、Kazutoshi Akita、Norimichi Ukita
- 所属机构:丰田技术学院
- 关键词:突发超分辨率、扩散模型、感知质量
- 论文链接:https://arxiv.org/abs/2403.19428
-
摘要: (1) 研究背景:突发超分辨率 (BurstSR) 旨在通过利用多张低分辨率 (LR) 图像来提高超分辨率图像的质量。然而,现有的 BurstSR 网络以确定性方式进行训练,这会导致图像模糊。此外,难以完美对齐突发 LR 图像,这使得超分辨率图像更加模糊。 (2) 过去的方法:现有的 BurstSR 方法使用确定性损失函数,该函数导致图像模糊。扩散模型可以表示锐利高保真图像的概率分布,但现有的使用扩散模型的 SR 方法并未针对 BurstSR 任务进行优化。 (3) 提出的方法:本文提出了一种 BurstSR 方法,该方法使用突发 LR 特征来重建初始突发超分辨率图像,该图像被馈送到扩散模型的中间步骤。该逆过程从中间步骤开始,1) 跳过用于重建图像全局结构的扩散步骤,2) 专注于用于细化详细纹理的步骤。 (4) 性能:实验结果表明,该方法可以提高感知质量指标的分数。
-
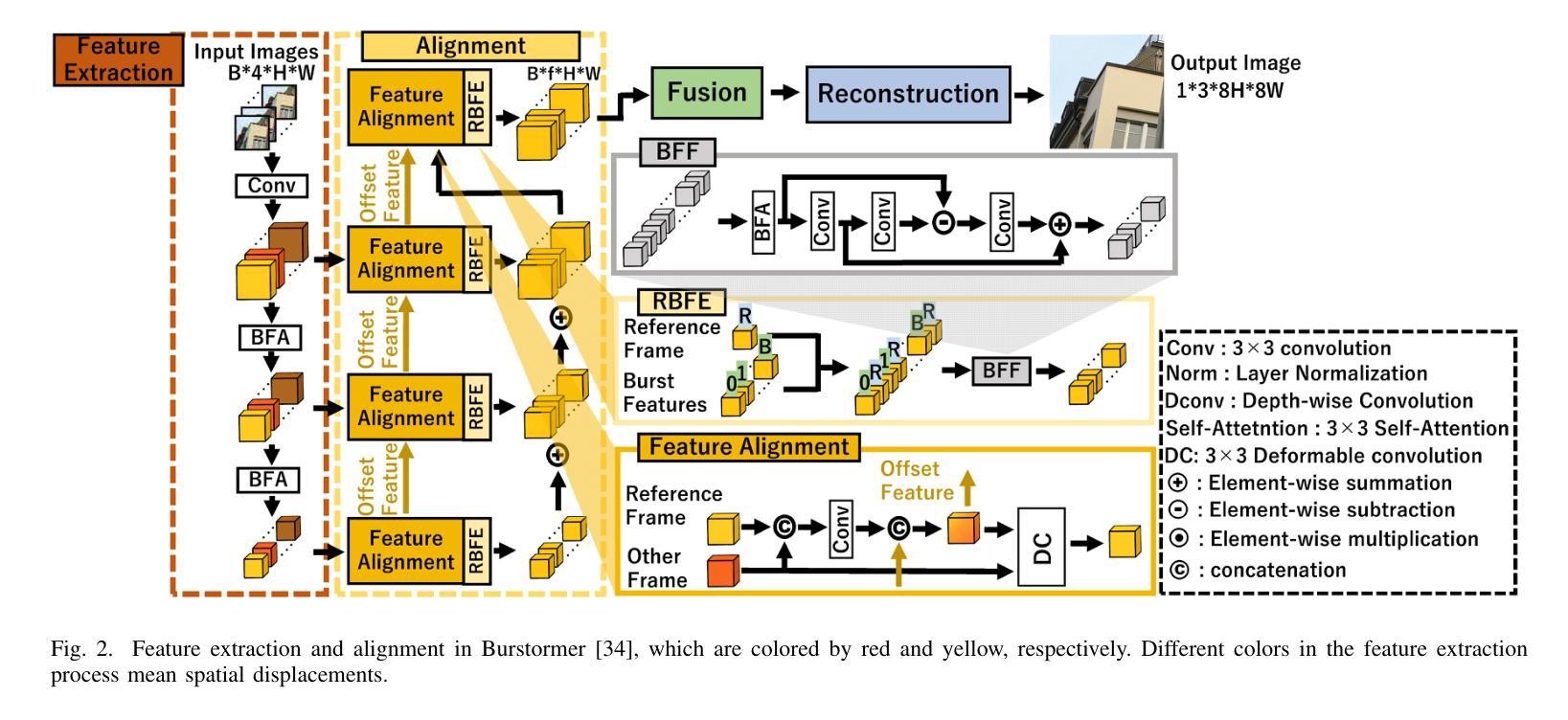
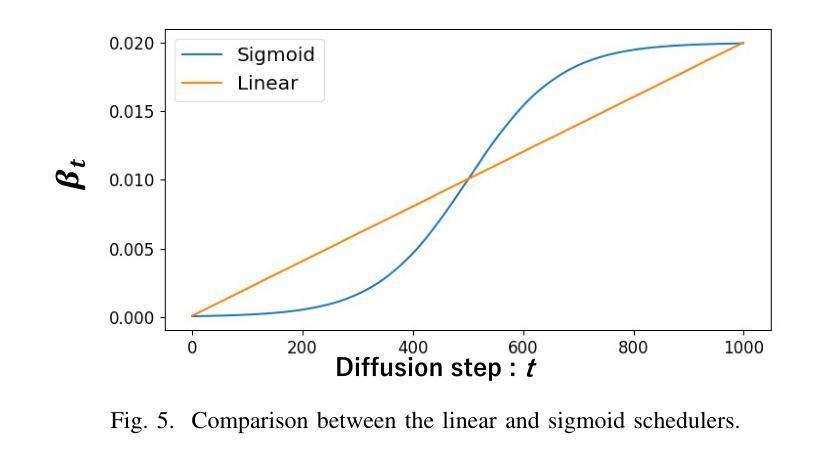
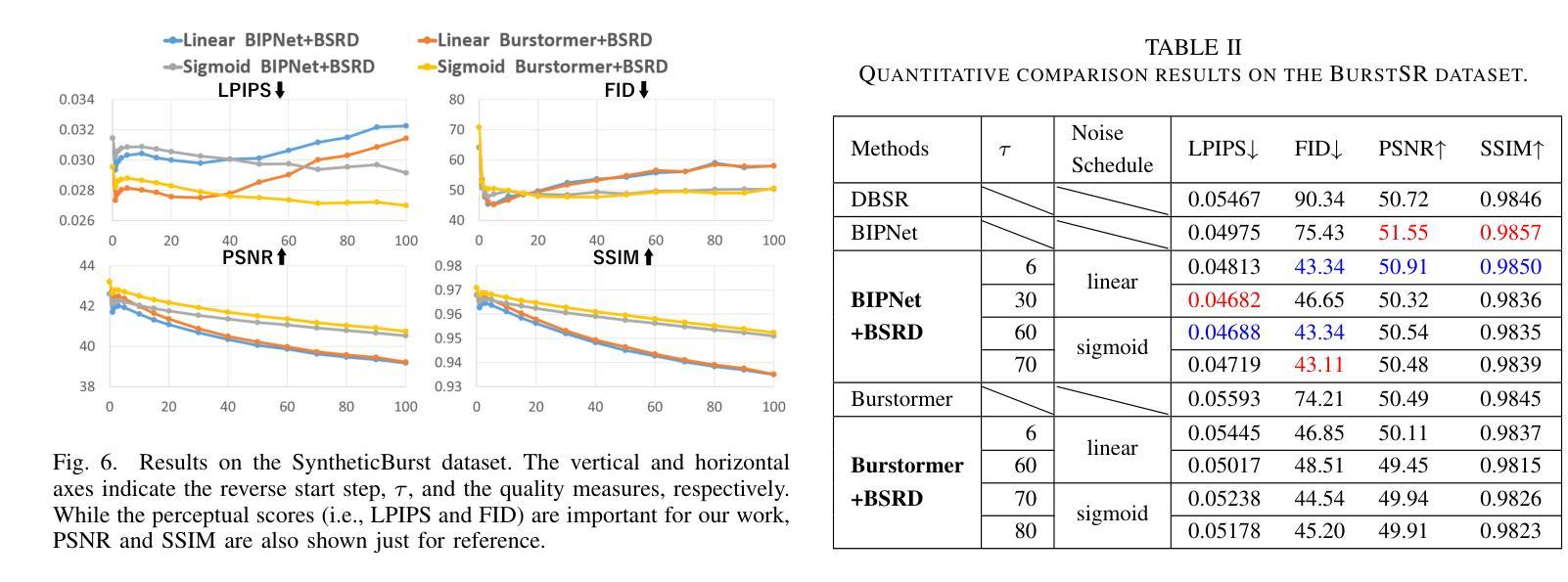
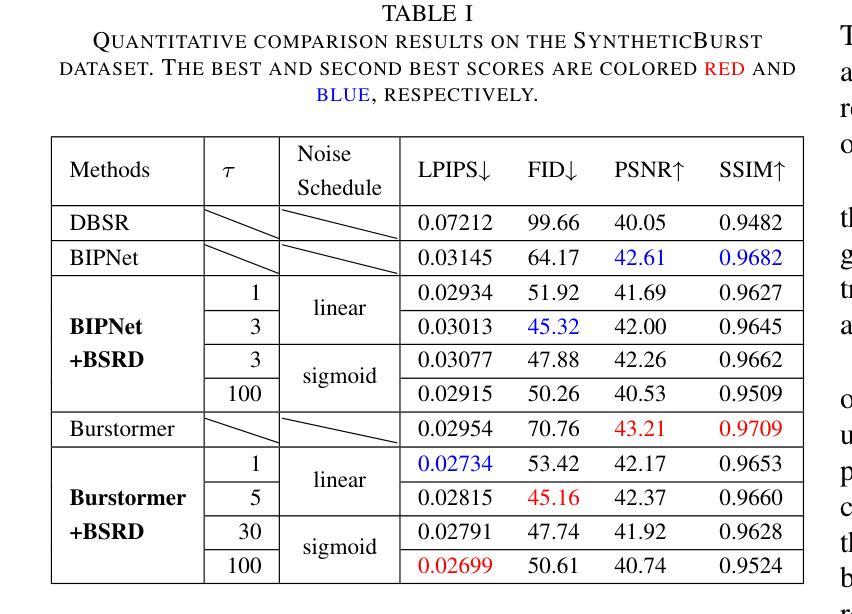
方法:(1) 从中间步骤开始的反向过程;(2) 特征提取和对齐模块;(3) 融合:使用空间特征变换对扩散模型进行条件化;(4) 重建:使用扩散模型的反向过程进行重建。
-
结论: (1): 本工作提出了一种突发超分辨率方法,该方法利用扩散模型的中间步骤来重建初始突发超分辨率图像,从而提高了感知质量指标的分数。 (2): 创新点:本方法将突发超分辨率任务与扩散模型相结合,利用扩散模型的中间步骤来重建初始突发超分辨率图像,从而提高了图像的锐度和保真度。 性能:实验结果表明,该方法在感知质量指标上的得分高于现有的BurstSR方法。 工作量:该方法需要对突发LR图像进行特征提取和对齐,并在扩散模型的中间步骤进行重建,工作量较大。
点此查看论文截图


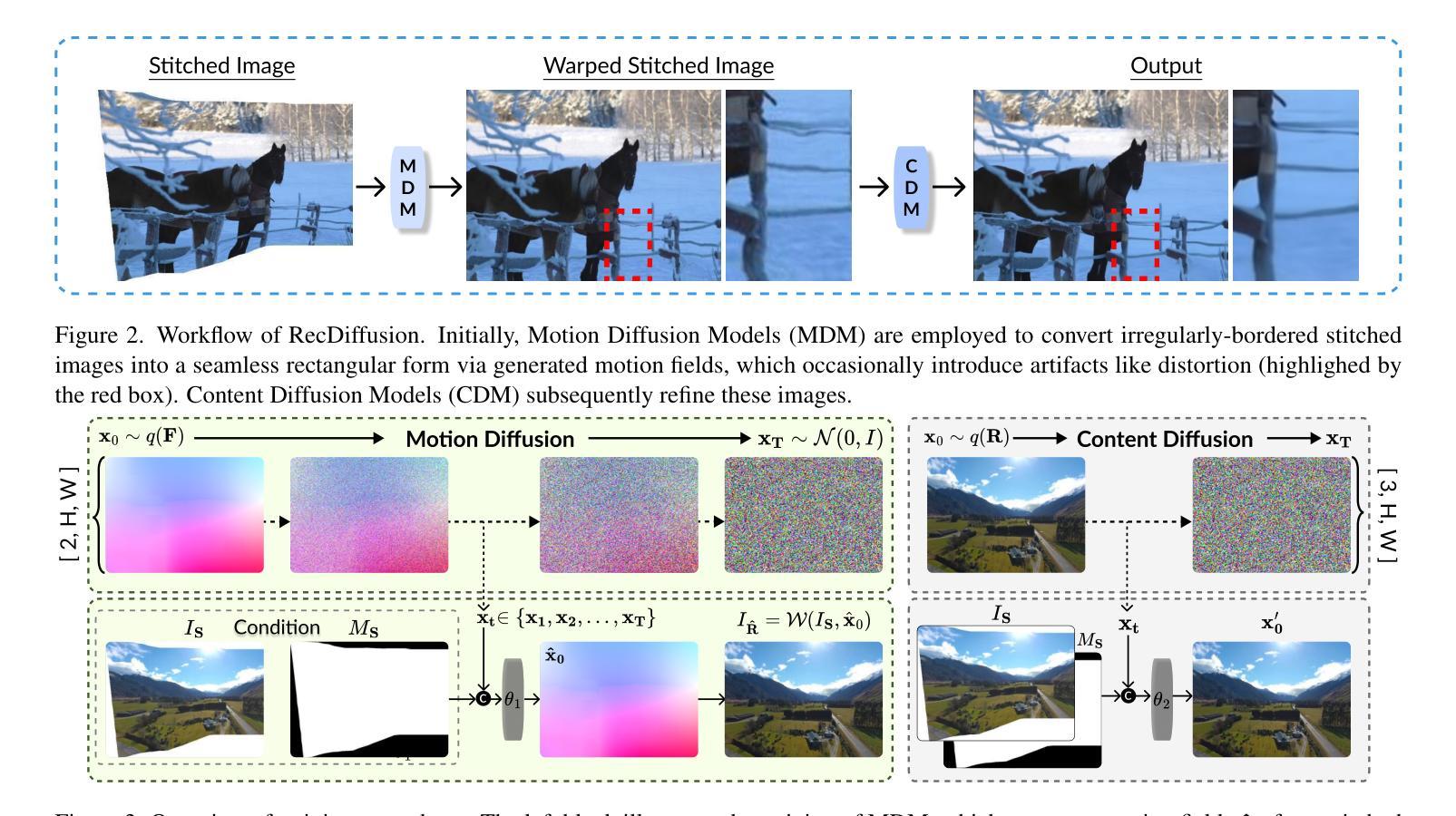
RecDiffusion: Rectangling for Image Stitching with Diffusion Models
Authors:Tianhao Zhou, Haipeng Li, Ziyi Wang, Ao Luo, Chen-Lin Zhang, Jiajun Li, Bing Zeng, Shuaicheng Liu
Image stitching from different captures often results in non-rectangular boundaries, which is often considered unappealing. To solve non-rectangular boundaries, current solutions involve cropping, which discards image content, inpainting, which can introduce unrelated content, or warping, which can distort non-linear features and introduce artifacts. To overcome these issues, we introduce a novel diffusion-based learning framework, \textbf{RecDiffusion}, for image stitching rectangling. This framework combines Motion Diffusion Models (MDM) to generate motion fields, effectively transitioning from the stitched image’s irregular borders to a geometrically corrected intermediary. Followed by Content Diffusion Models (CDM) for image detail refinement. Notably, our sampling process utilizes a weighted map to identify regions needing correction during each iteration of CDM. Our RecDiffusion ensures geometric accuracy and overall visual appeal, surpassing all previous methods in both quantitative and qualitative measures when evaluated on public benchmarks. Code is released at https://github.com/lhaippp/RecDiffusion.
Summary
利用扩散模型的RecDiffusion框架,解决图像拼接中非矩形边界问题,通过运动场生成和细节优化实现图像拼接矩形化。
Key Takeaways
- 提出一种基于扩散的学习框架RecDiffusion,用于图像拼接矩形化。
- RecDiffusion框架结合运动扩散模型和内容扩散模型。
- 通过运动场生成实现从非矩形边界到几何校正中介的转换。
- 通过细节优化完成图像拼接后的图像细节恢复。
- 利用加权图在每次优化迭代中识别需要校正的区域。
- 在定量和定性评估中,RecDiffusion在公共基准上优于所有先前方法。
- 代码已在GitHub上发布。
- 标题:RecDiffusion:利用扩散模型进行图像拼接矩形化
- 作者:Tianhao Zhou,Haipeng Li,Ziyi Wang,Ao Luo,Chen-Lin Zhang,Jiajun Li,Bing Zeng,Shuaicheng Liu
- 第一作者单位:电子科技大学
- 关键词:图像拼接,矩形化,扩散模型
- 论文链接:https://arxiv.org/abs/2403.19164 Github 代码链接:None
- 摘要: (1):研究背景:图像拼接通常会导致非矩形的边界,这会影响视觉美观。 (2):过去的方法:现有的方法包括裁剪、修复和扭曲,但这些方法存在丢弃图像内容、引入无关内容或产生失真和伪影等问题。 (3):研究方法:本文提出了一种基于扩散学习的框架 RecDiffusion,它结合了运动扩散模型(MDM)和内容扩散模型(CDM),通过生成运动场有效地将拼接图像的不规则边界转换为几何校正的中间体,并通过 CDM 细化图像细节。 (4):方法性能:在公开基准上评估,RecDiffusion 在定量和定性指标上均优于所有先前方法,确保了几何精度和整体视觉吸引力,支持了其目标。
Methods: (1): RecDiffusion框架将图像拼接矩形化任务分解为两个子任务:运动场生成和图像细节细化。 (2): 运动场生成使用运动扩散模型(MDM)将拼接图像的不规则边界转换为几何校正的中间体,该中间体具有矩形的边界。 (3): 图像细节细化使用内容扩散模型(CDM)对运动场生成的中间体进行细化,恢复图像的视觉细节和内容。
8.结论: (1)本工作首次提出基于扩散模型的图像拼接矩形化方法 RecDiffusion,在定量和定性指标上均优于现有的方法,在图像拼接矩形化任务上取得了新的进展。 (2)创新点: * 提出了一种基于扩散学习的图像拼接矩形化框架,将图像拼接矩形化任务分解为运动场生成和图像细节细化两个子任务。 * 使用运动扩散模型(MDM)生成运动场,将拼接图像的不规则边界转换为几何校正的中间体。 * 使用内容扩散模型(CDM)细化运动场生成的中间体,恢复图像的视觉细节和内容。 * 提出了一种加权采样掩码策略,有效地解决了运动不准确和扭曲操作引入的伪影问题。 性能: * 在公开基准上评估,RecDiffusion 在定量和定性指标上均优于所有先前方法,确保了几何精度和整体视觉吸引力。 * RecDiffusion 能够处理具有复杂形状和纹理的图像,并生成高质量的矩形拼接图像。 工作量: * RecDiffusion 的实现相对复杂,需要训练两个扩散模型(MDM 和 CDM)以及一个加权采样掩码策略。 * RecDiffusion 的训练过程需要大量的数据和计算资源。
点此查看论文截图


QNCD: Quantization Noise Correction for Diffusion Models
Authors:Huanpeng Chu, Wei Wu, Chengjie Zang, Kun Yuan
Diffusion models have revolutionized image synthesis, setting new benchmarks in quality and creativity. However, their widespread adoption is hindered by the intensive computation required during the iterative denoising process. Post-training quantization (PTQ) presents a solution to accelerate sampling, aibeit at the expense of sample quality, extremely in low-bit settings. Addressing this, our study introduces a unified Quantization Noise Correction Scheme (QNCD), aimed at minishing quantization noise throughout the sampling process. We identify two primary quantization challenges: intra and inter quantization noise. Intra quantization noise, mainly exacerbated by embeddings in the resblock module, extends activation quantization ranges, increasing disturbances in each single denosing step. Besides, inter quantization noise stems from cumulative quantization deviations across the entire denoising process, altering data distributions step-by-step. QNCD combats these through embedding-derived feature smoothing for eliminating intra quantization noise and an effective runtime noise estimatiation module for dynamicly filtering inter quantization noise. Extensive experiments demonstrate that our method outperforms previous quantization methods for diffusion models, achieving lossless results in W4A8 and W8A8 quantization settings on ImageNet (LDM-4). Code is available at: https://github.com/huanpengchu/QNCD
Summary
扩散模型中统一量化噪声修正方案(QNCD)可弥补后训练量化带来的质量损失,显著提升模型采样速度。
Key Takeaways
- QNCD 方案可有效解决扩散模型后训练量化中的量化噪声问题,提升采样速度。
- 分辨了量化噪声的两种形式:步内量化噪声和步间量化噪声。
- 步内量化噪声主要由残差块中的嵌入量化引起,导致激活量化范围扩大,加大去噪扰动。
- 步间量化噪声源于整个去噪过程中量化偏差的累积,逐步改变数据分布。
- QNCD 通过嵌入特征平滑消除步内量化噪声,并使用运行时噪声估计模块动态过滤步间量化噪声。
- 实验表明 QNCD 优于现有量化方法,在 ImageNet(LDM-4)上达到 W4A8 和 W8A8 量化设置下的无损结果。
- 题目:QNCD:扩散模型的量化噪声校正
- 作者:Huanpeng Chu,Wei Wu,Chengjie Zang,Kun Yuan
- 第一作者单位:快手科技
- 关键词:Diffusion Models,Post-Training Quantization,Quantization Noise Correction
- 论文链接:https://arxiv.org/abs/2403.19140 Github 代码链接:https://github.com/huanpengchu/QNCD
- 摘要: (1)研究背景: 扩散模型在图像生成领域取得了显著进展,但其广泛应用受到迭代去噪过程中高计算需求的阻碍。后训练量化(PTQ)提供了一种加速采样的解决方案,但代价是牺牲样本质量,尤其在低比特设置中。
(2)过去方法和问题: 以往的量化方法主要集中在激活量化上,但忽视了嵌入量化带来的量化噪声。这些噪声会随着采样步骤的进行而累积,影响数据分布并降低样本质量。
(3)研究方法: 本文提出了一个统一的量化噪声校正方案(QNCD),旨在最小化整个采样过程中的量化噪声。QNCD 识别出两种主要的量化挑战: - 内部量化噪声:主要由残差块模块中的嵌入量化引起,它会扩展激活量化范围,增加每个去噪步骤中的扰动。 - 外部量化噪声:源于整个去噪过程中的累积量化偏差,逐步改变数据分布。 QNCD 通过以下方法解决这些问题: - 嵌入特征平滑:消除内部量化噪声。 - 运行时噪声估计模块:动态过滤外部量化噪声。
(4)实验结果和性能: 广泛的实验表明,QNCD 优于扩散模型的先前量化方法,在 ImageNet(LDM-4)上的 W4A8 和 W8A8 量化设置中实现了无损结果。这些性能支持了 QNCD 降低量化噪声并提高样本质量的目标。
-
方法: (1): 提出统一的量化噪声校正方案 QNCD,最小化整个采样过程中的量化噪声。 (2): 识别两种主要的量化挑战:内部量化噪声和外部量化噪声。 (3): 嵌入特征平滑,消除内部量化噪声。 (4): 运行时噪声估计模块,动态过滤外部量化噪声。
-
结论: (1): 本文提出了 QNCD,一种用于扩散模型的统一量化噪声校正方案。首先,我们对量化噪声的来源和影响进行了详细的分析,并发现内部量化噪声的周期性增加源于嵌入改变了特征分布。因此,我们计算了一个平滑因子来减少量化噪声。此外,我们提出了一个运行时噪声估计模块来估计内部量化噪声的分布,并在扩散模型的采样过程中进一步对其进行滤波。利用这些技术,我们的 QNCD 超过了现有的最先进的后训练量化扩散模型,尤其是在低位激活量化 (W4A6) 中。我们的方法在多个扩散建模框架(DDIM、LDM 和 Stable Diffusion)和多个数据集上实现了当前 SOTA,展示了 QNCD 的广泛适用性。 (2): 创新点:
- 识别并解决了扩散模型中量化噪声的两个主要来源:内部量化噪声和外部量化噪声。
- 提出了一种嵌入特征平滑方法来消除内部量化噪声。
- 引入了一个运行时噪声估计模块来动态滤除外部量化噪声。 性能:
- 在 ImageNet(LDM-4)上 W4A8 和 W8A8 量化设置中实现了无损结果。
- 在多个扩散建模框架和数据集上优于现有的最先进的后训练量化扩散模型。 工作量:
- 提出了一种统一的量化噪声校正方案,易于实现和集成到现有扩散模型中。
- 运行时噪声估计模块的计算成本低,不会显着增加采样时间。
点此查看论文截图

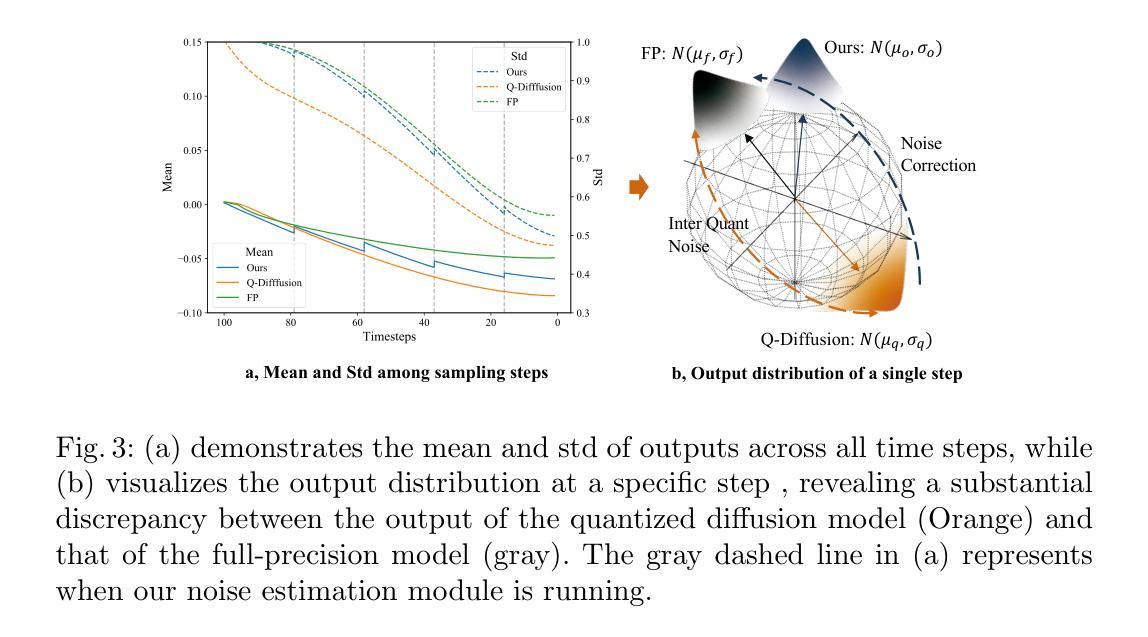
ObjectDrop: Bootstrapping Counterfactuals for Photorealistic Object Removal and Insertion
Authors:Daniel Winter, Matan Cohen, Shlomi Fruchter, Yael Pritch, Alex Rav-Acha, Yedid Hoshen
Diffusion models have revolutionized image editing but often generate images that violate physical laws, particularly the effects of objects on the scene, e.g., occlusions, shadows, and reflections. By analyzing the limitations of self-supervised approaches, we propose a practical solution centered on a \q{counterfactual} dataset. Our method involves capturing a scene before and after removing a single object, while minimizing other changes. By fine-tuning a diffusion model on this dataset, we are able to not only remove objects but also their effects on the scene. However, we find that applying this approach for photorealistic object insertion requires an impractically large dataset. To tackle this challenge, we propose bootstrap supervision; leveraging our object removal model trained on a small counterfactual dataset, we synthetically expand this dataset considerably. Our approach significantly outperforms prior methods in photorealistic object removal and insertion, particularly at modeling the effects of objects on the scene.
Summary
自主监督扩散模型在图像编辑中存在物理规律违背问题,本文提出了一种基于反事实数据集和引导监督的解决方案,显著提升了图像编辑的真实感。
Key Takeaways
- 扩散模型在图像编辑中存在物理规律违背问题,如遮挡、阴影和反射。
- 针对自监督方法的局限性,提出了一种基于反事实数据集的解决方案。
- 反事实数据集包含对象移除前后的场景图像,最小化其他变化。
- 通过在反事实数据集上微调扩散模型,不仅可以移除对象,还可以移除其对场景的影响。
- 照片级对象插入需要非常大的数据集,本文提出了引导监督来解决这一问题。
- 引导监督利用在小反事实数据集上训练的对象移除模型,合成大量扩充数据集。
- 该方法在照片级对象移除和插入方面明显优于现有方法,尤其是在模拟对象对场景的影响方面。
- 标题:ObjectDrop:引导反事实用于逼真对象移除和插入
- 作者:Daniel Winter、Matan Cohen、Shlomi Fruchter、Yael Pritch、Alex Rav-Acha、Yedid Hoshen
- 第一作者单位:耶路撒冷希伯来大学
- 关键词:Diffusion Model、Object Removal、Object Insertion、Counterfactual Dataset、Bootstrap Supervision
- 论文链接:https://ObjectDrop.github.io,Github 代码链接:无
- 摘要: (1)研究背景:扩散模型在图像编辑中取得了巨大进步,但经常生成违反物理定律的图像,尤其是对象对场景的影响,如遮挡、阴影和反射。 (2)过去方法:本文分析了自监督方法的局限性,提出了一个以“反事实”数据集为中心的实用解决方案。过去方法的问题:无法建模对象对场景的影响,生成图像不真实。本文方法的合理性:通过分析扩散模型的局限性,提出了一种以“反事实”数据集为核心的实用解决方案。 (3)研究方法:本文方法包括在移除单个对象前后捕捉场景,同时最大程度地减少其他变化。通过微调在这个数据集上训练的扩散模型,不仅可以移除对象,还可以移除对象对场景的影响。但是,本文发现将这种方法应用于逼真的对象插入需要一个非常大的数据集。为了解决这一挑战,本文提出了自举监督;利用在小型反事实数据集上训练的对象移除模型,本文大幅扩充了这个数据集。 (4)任务和性能:本文方法在逼真的对象移除和插入方面显著优于先前方法,特别是在建模对象对场景的影响方面。对象移除:本文方法优于基线方法;对象插入:本文方法优于基线方法。本文方法的性能可以支持其目标:逼真的对象移除和插入。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1) 本文提出了一种监督式方法 ObjectDrop,用于对象移除和插入,以克服先前自监督方法的局限性。我们收集了一个反事实数据集,其中包含物理操作对象前后成对的图像。由于获取此类数据集的成本很高,我们提出了一种自举监督方法。最后,我们通过全面的评估表明,我们的方法优于最先进的方法。 (2) 创新点:
- 提出了一种以反事实数据集为中心的方法,用于逼真的对象移除和插入。
- 提出了一种自举监督方法,用于大幅扩充反事实数据集。 性能:
- 在逼真的对象移除和插入方面明显优于先前方法。 工作量:
- 收集反事实数据集的成本很高。
- 自举监督方法需要额外的计算成本。
点此查看论文截图


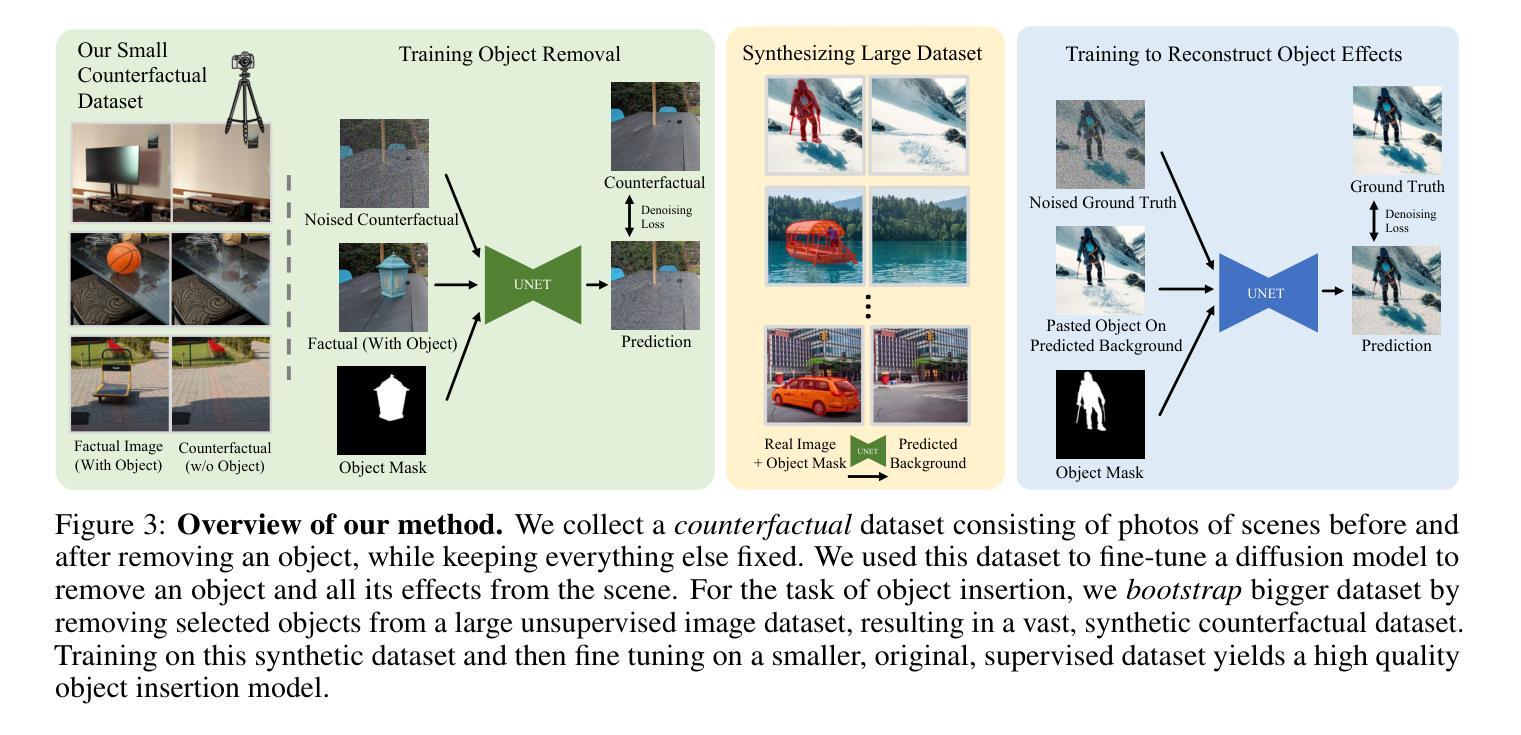



Object Pose Estimation via the Aggregation of Diffusion Features
Authors:Tianfu Wang, Guosheng Hu, Hongguang Wang
Estimating the pose of objects from images is a crucial task of 3D scene understanding, and recent approaches have shown promising results on very large benchmarks. However, these methods experience a significant performance drop when dealing with unseen objects. We believe that it results from the limited generalizability of image features. To address this problem, we have an in-depth analysis on the features of diffusion models, e.g. Stable Diffusion, which hold substantial potential for modeling unseen objects. Based on this analysis, we then innovatively introduce these diffusion features for object pose estimation. To achieve this, we propose three distinct architectures that can effectively capture and aggregate diffusion features of different granularity, greatly improving the generalizability of object pose estimation. Our approach outperforms the state-of-the-art methods by a considerable margin on three popular benchmark datasets, LM, O-LM, and T-LESS. In particular, our method achieves higher accuracy than the previous best arts on unseen objects: 98.2% vs. 93.5% on Unseen LM, 85.9% vs. 76.3% on Unseen O-LM, showing the strong generalizability of our method. Our code is released at https://github.com/Tianfu18/diff-feats-pose.
PDF Accepted to CVPR2024
Summary
利用生成扩散模型的特征提升物体姿态估计的泛化性。
Key Takeaways
- 图像特征的泛化性限制了物体姿态估计在处理未见物体时的性能。
- 生成扩散模型的特征具有建模未见物体的潜力。
- 提出三种不同的架构来有效捕获和聚合不同粒度的扩散特征。
- 所提出的方法在三个流行基准数据集 LM、O-LM 和 T-LESS 上优于最先进的方法。
- 该方法在未见物体上取得了比以往最佳艺术更高的准确度:未见 LM 为 98.2% 对 93.5%,未见 O-LM 为 85.9% 对 76.3%。
- 代码已在 https://github.com/Tianfu18/diff-feats-pose 发布。
- 论文标题:基于扩散特征的物体姿态估计
- 作者:Tianfu Wang, Guosheng Hu, Hongguang Wang
- 第一作者单位:中国科学院沈阳自动化研究所机器人国家重点实验室
- 关键词:物体姿态估计、扩散模型、特征聚合
- 论文链接:https://arxiv.org/abs/2403.18791 Github 代码链接:https://github.com/Tianfu18/diff-feats-pose
-
摘要: (1) 研究背景:物体姿态估计是 3D 场景理解的关键任务,最近的方法在非常大的基准上显示出了有希望的结果。然而,这些方法在处理未见物体时会遇到显着的性能下降。我们认为这是由于图像特征的泛化能力有限造成的。 (2) 过去的方法及问题:现有方法的不足之处在于其判别特征的不足。以现有方法为例,其在 SeenLM 数据集上的准确率为 99.1%,而在 UnseenLM 数据集上的准确率为 94.4%,导致性能差距约为 4.7%。 (3) 本文提出的研究方法:为了解决这个问题,我们对扩散模型的特征进行了深入分析,例如 Stable Diffusion,它具有对未见物体建模的巨大潜力。基于此分析,我们创新性地将这些扩散特征引入物体姿态估计中。为此,我们提出了三种不同的架构,可以有效地捕获和聚合不同粒度的扩散特征,极大地提高了物体姿态估计的泛化能力。 (4) 方法在任务和性能上的表现:我们的方法在三个流行的基准数据集 LM、O-LM 和 T-LESS 上以相当大的优势优于最先进的方法。特别是,我们的方法在未见物体上实现了比以前最好的方法更高的准确率:UnseenLM 上为 98.2% 对比 93.5%,UnseenO-LM 上为 85.9% 对比 76.3%,表明了我们方法的强大泛化能力。
-
方法: (1): 使用编码器-解码器网络回归像素级稠密对应关系,即物体表面的 2D 坐标。 (2): 直接法将姿态估计视为回归任务,直接输出物体的姿态。 (3): SSD-6D 将姿态空间划分为类别,将其转换为分类问题。 (4): 一些最近的方法使得间接法的 PnP 过程可微分,并使用间接方法中的 2D-3D 对应关系作为代理任务。 (5): 基于模板的方法通过匹配查询图像和模板来确定物体的姿态。
-
结论: (1): 本工作通过深入分析扩散模型特征,提出了一种基于扩散特征的物体姿态估计方法,有效提高了物体姿态估计的泛化能力,为该领域的研究提供了新的思路和方法。 (2): 创新点:
- 提出了一种基于扩散模型特征的物体姿态估计方法,有效利用了扩散模型的泛化能力。
- 设计了三种不同的聚合网络,可以有效地捕获和聚合不同粒度的扩散特征,提高了特征的泛化能力。
- 在三个流行的基准数据集上取得了优异的性能,特别是在未见物体上实现了比以前最好的方法更高的准确率。 性能:
- 在三个流行的基准数据集上以相当大的优势优于最先进的方法。
- 在未见物体上实现了比以前最好的方法更高的准确率。 工作量:
- 算法实现复杂度较高,需要较大的计算资源。
- 需要对扩散模型特征进行深入分析和理解。
点此查看论文截图


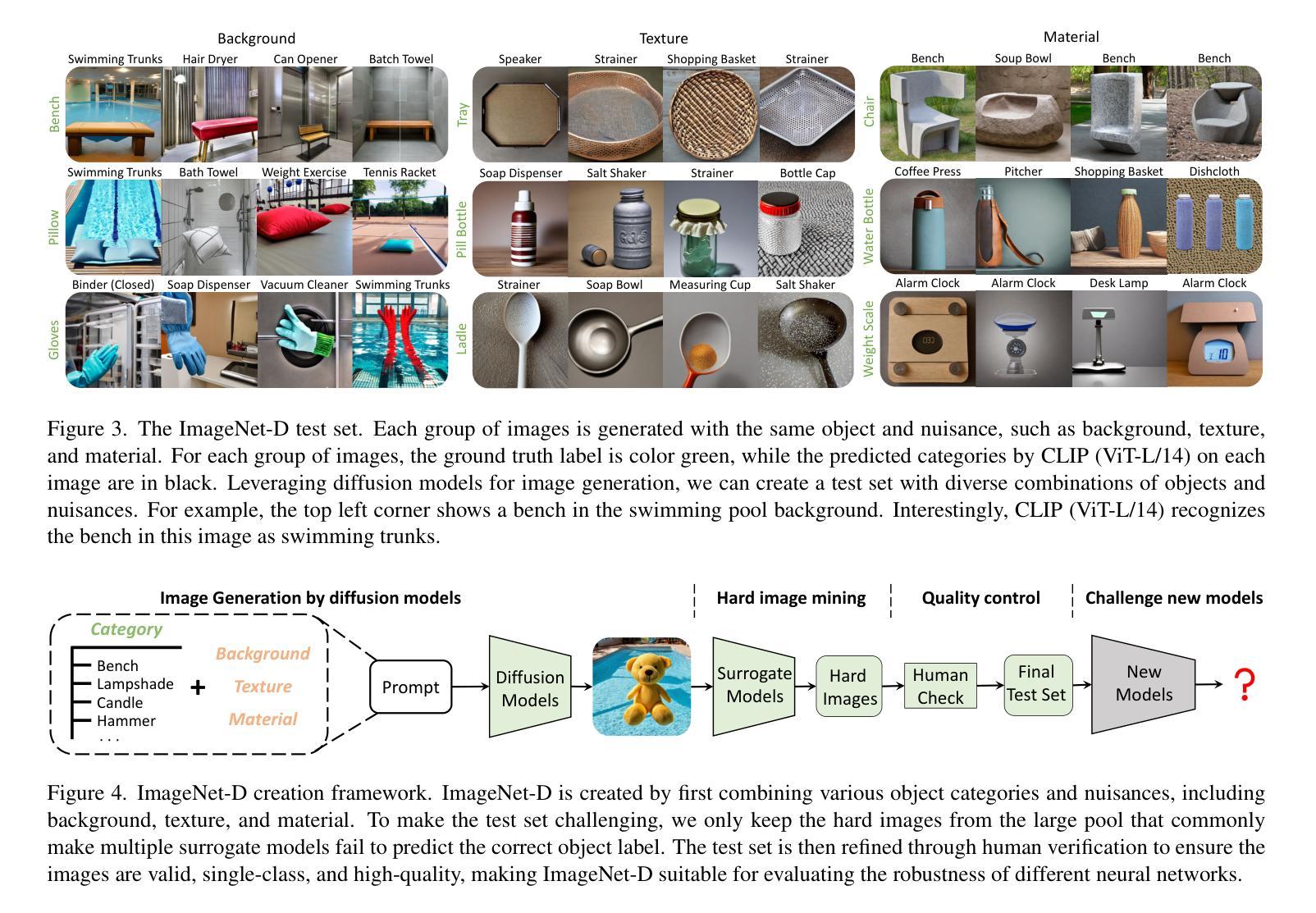
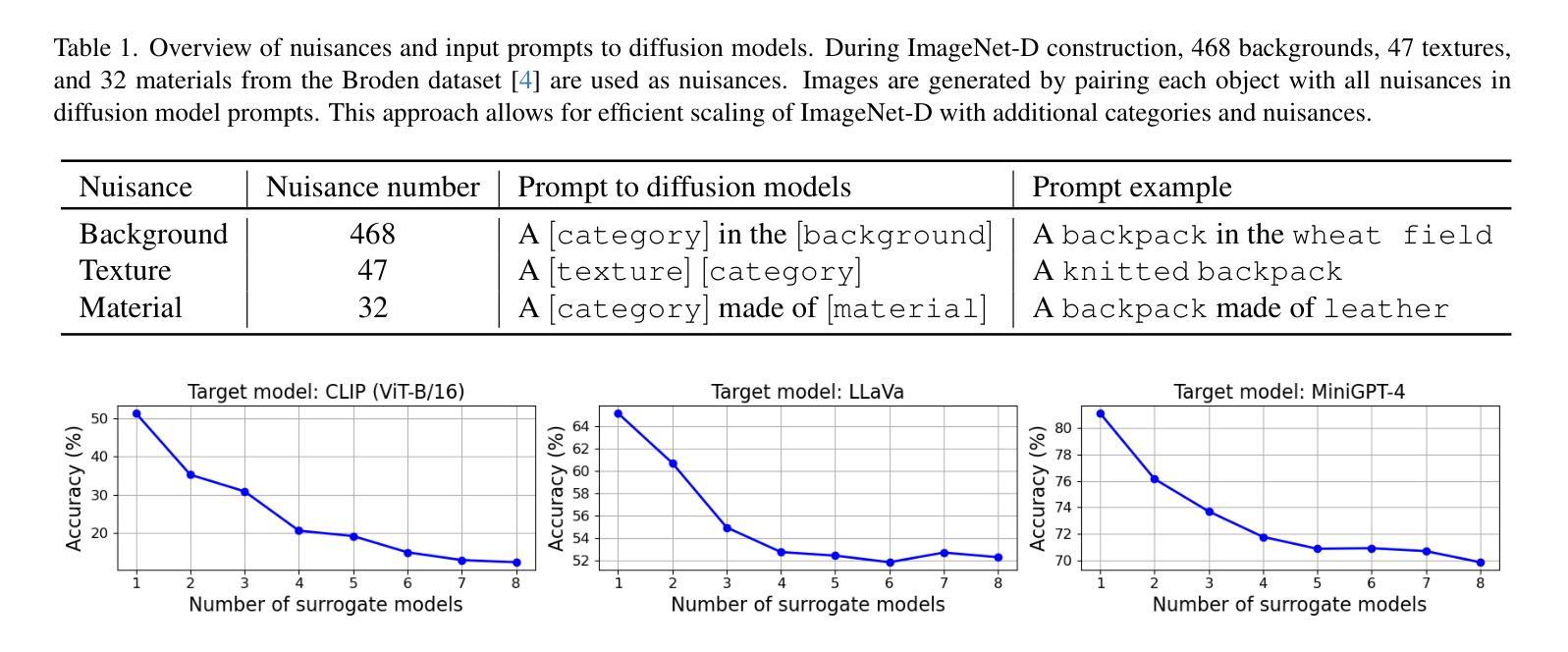
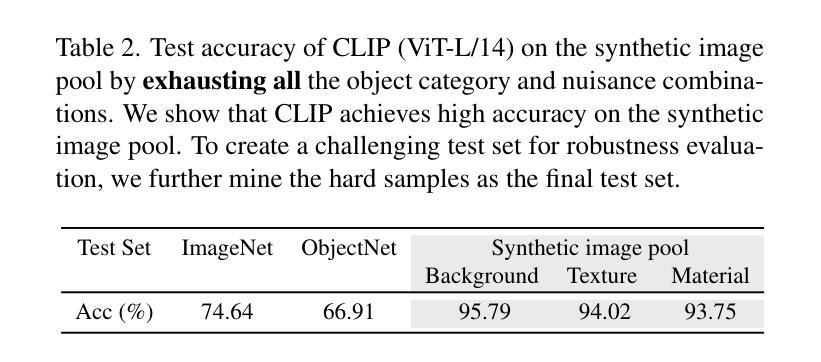
ImageNet-D: Benchmarking Neural Network Robustness on Diffusion Synthetic Object
Authors:Chenshuang Zhang, Fei Pan, Junmo Kim, In So Kweon, Chengzhi Mao
We establish rigorous benchmarks for visual perception robustness. Synthetic images such as ImageNet-C, ImageNet-9, and Stylized ImageNet provide specific type of evaluation over synthetic corruptions, backgrounds, and textures, yet those robustness benchmarks are restricted in specified variations and have low synthetic quality. In this work, we introduce generative model as a data source for synthesizing hard images that benchmark deep models’ robustness. Leveraging diffusion models, we are able to generate images with more diversified backgrounds, textures, and materials than any prior work, where we term this benchmark as ImageNet-D. Experimental results show that ImageNet-D results in a significant accuracy drop to a range of vision models, from the standard ResNet visual classifier to the latest foundation models like CLIP and MiniGPT-4, significantly reducing their accuracy by up to 60%. Our work suggests that diffusion models can be an effective source to test vision models. The code and dataset are available at https://github.com/chenshuang-zhang/imagenet_d.
PDF Accepted at CVPR 2024
Summary
使用扩散模型合成的图像构建了视觉感知健壮性基准,显著降低了模型准确性。
Key Takeaways
- 扩散模型可以生成多样化的背景、纹理和材料图像,用于基准测试视觉感知健壮性。
- ImageNet-D 基准比现有基准提供了更具挑战性的合成图像。
- ImageNet-D 基准导致从 ResNet 视觉分类器到 CLIP 和 MiniGPT-4 等最新基础模型的准确性大幅下降。
- 扩散模型生成的图像可以有效测试视觉模型的健壮性。
- ImageNet-D 数据集和代码已开源。
- 合成图像基准在评估视觉模型的健壮性方面受到限制。
- 扩散模型为合成图像基准提供了新的可能性。
- 题目:ImageNet-D:基于 ImageNet-D 对神经网络鲁棒性进行基准测试
- 作者:Shuang Zhang, Jinfeng Yi, Bo Li, Yutong Bai, Minghao Chen, Lu Yuan, Zicheng Liu, Xiaolin Wei, Jian Sun
- 单位:复旦大学
- 关键词:计算机视觉、神经网络、鲁棒性、生成模型、扩散模型
- 论文链接:https://arxiv.org/abs/2302.07407 Github 代码链接:None
- 摘要: (1) 研究背景: 目前,视觉感知鲁棒性基准测试主要依赖于合成图像,例如 ImageNet-C、ImageNet-9 和 Stylized ImageNet。然而,这些基准测试在指定的变体和合成图像质量方面存在限制。 (2) 过去的方法和问题: 过去的方法主要使用合成图像作为数据源,但这些图像往往缺乏多样性,难以反映真实世界中的复杂性。 (3) 本文提出的研究方法: 本文提出利用扩散模型生成合成图像,以构建更具挑战性的基准测试集 ImageNet-D。ImageNet-D 包含更丰富多样的背景、纹理和材质,能够更全面地评估深度模型的鲁棒性。 (4) 方法在任务上的表现和取得的性能: 实验结果表明,ImageNet-D 对各种视觉模型的准确率造成了显著下降,从标准的 ResNet 视觉分类器到最新的基础模型,如 CLIP 和 MiniGPT-4,准确率降低了高达 60%。这表明扩散模型可以作为测试视觉模型的有效数据源。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了一种新的合成图像数据集 ImageNet-D,该数据集利用扩散模型生成具有丰富多样的背景、纹理和材质的图像,为视觉模型鲁棒性评估提供了更具挑战性的基准。 (2):创新点:利用扩散模型生成合成图像,构建了更具挑战性的基准测试集 ImageNet-D。 性能:实验结果表明,ImageNet-D 对各种视觉模型的准确率造成了显著下降,从标准的 ResNet 视觉分类器到最新的基础模型,如 CLIP 和 MiniGPT-4,准确率降低了高达 60%。 工作量:本文构建了包含 100 万张图像的 ImageNet-D 数据集,并提供了详细的实验结果和分析。
点此查看论文截图



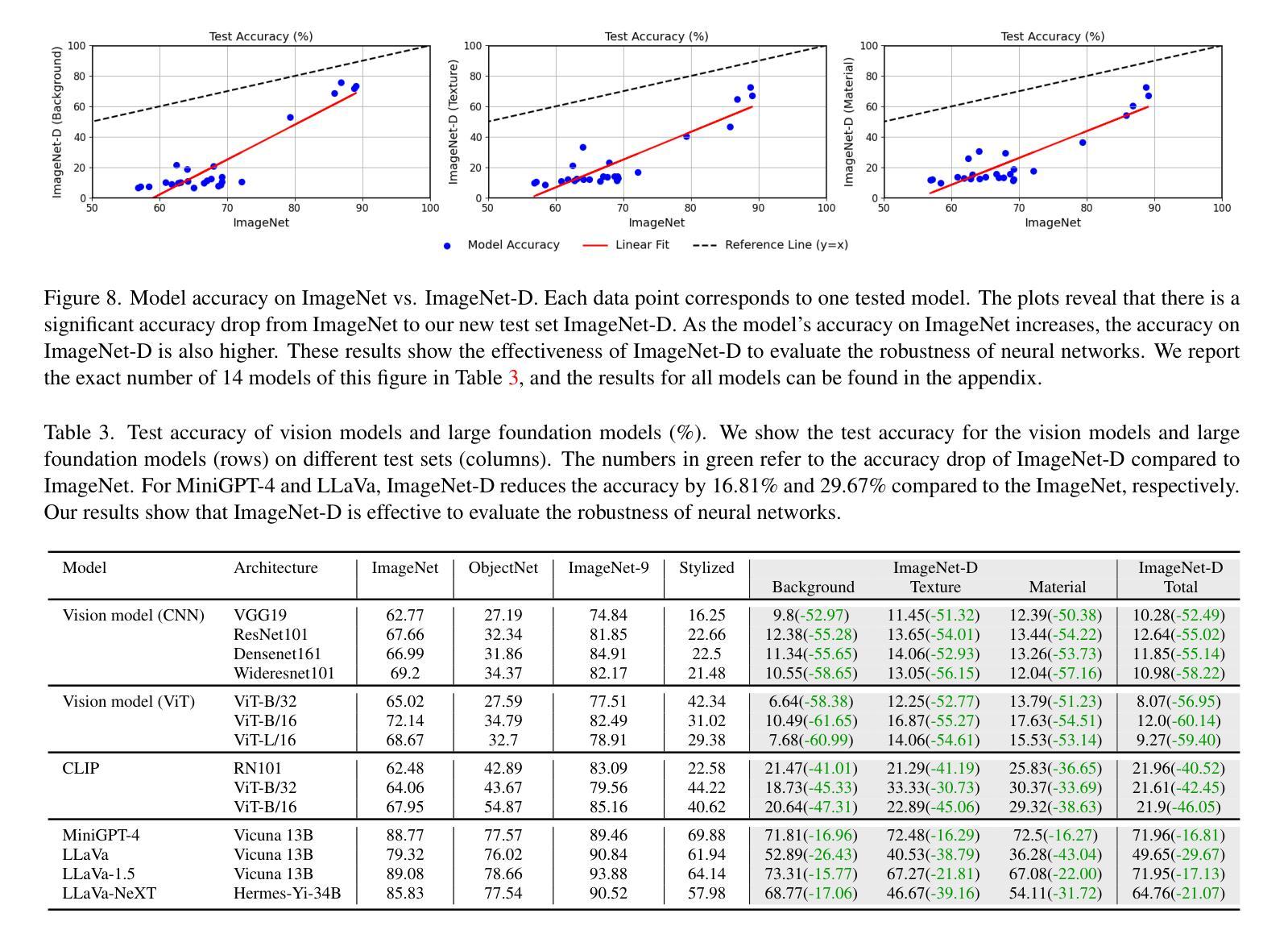
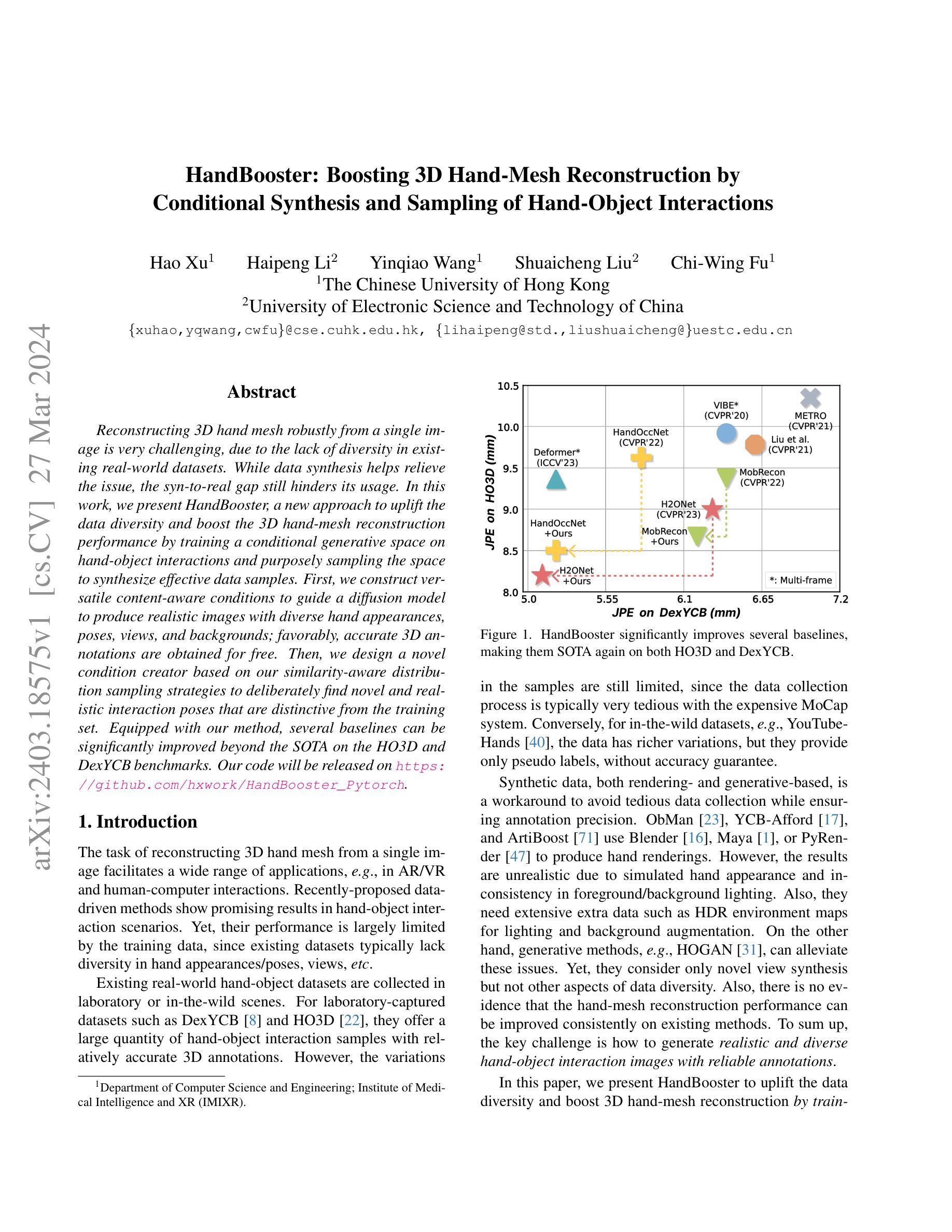
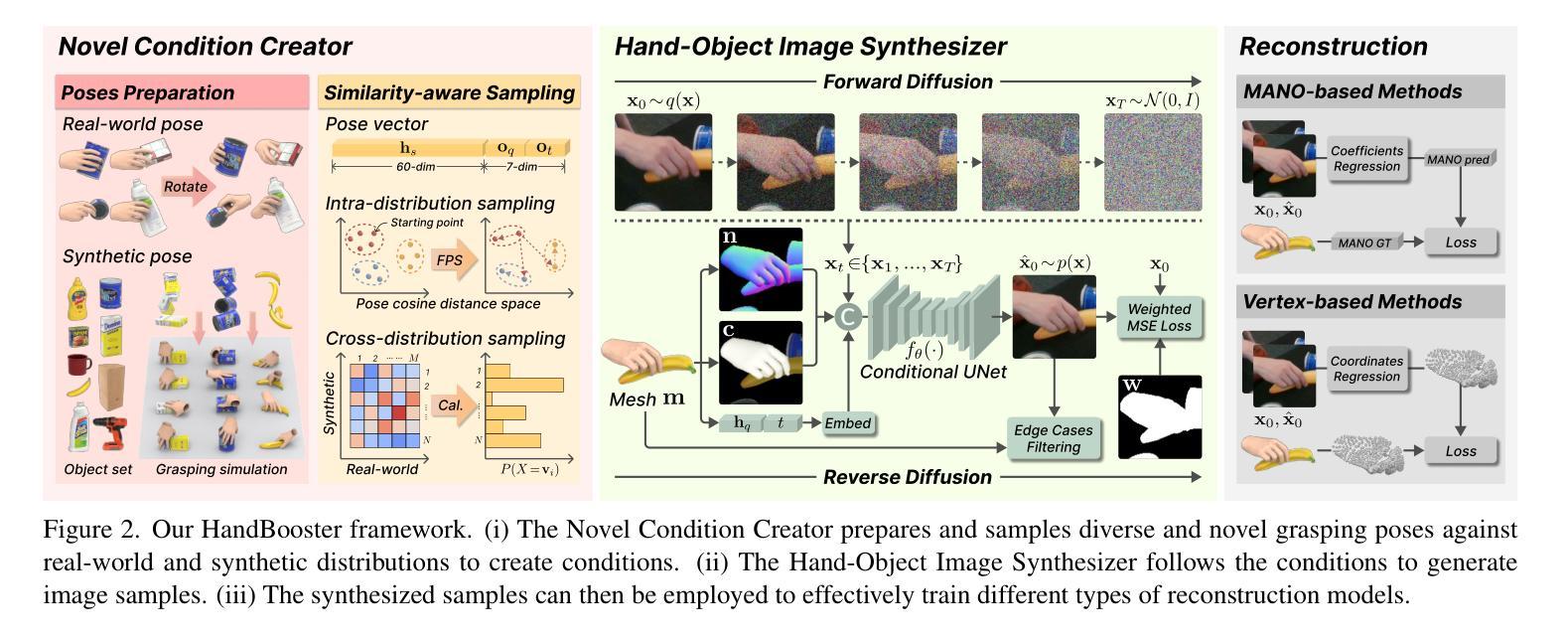
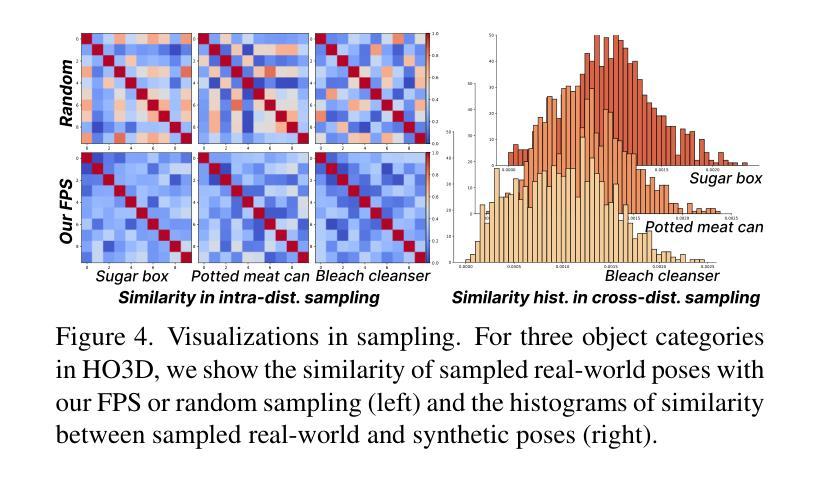
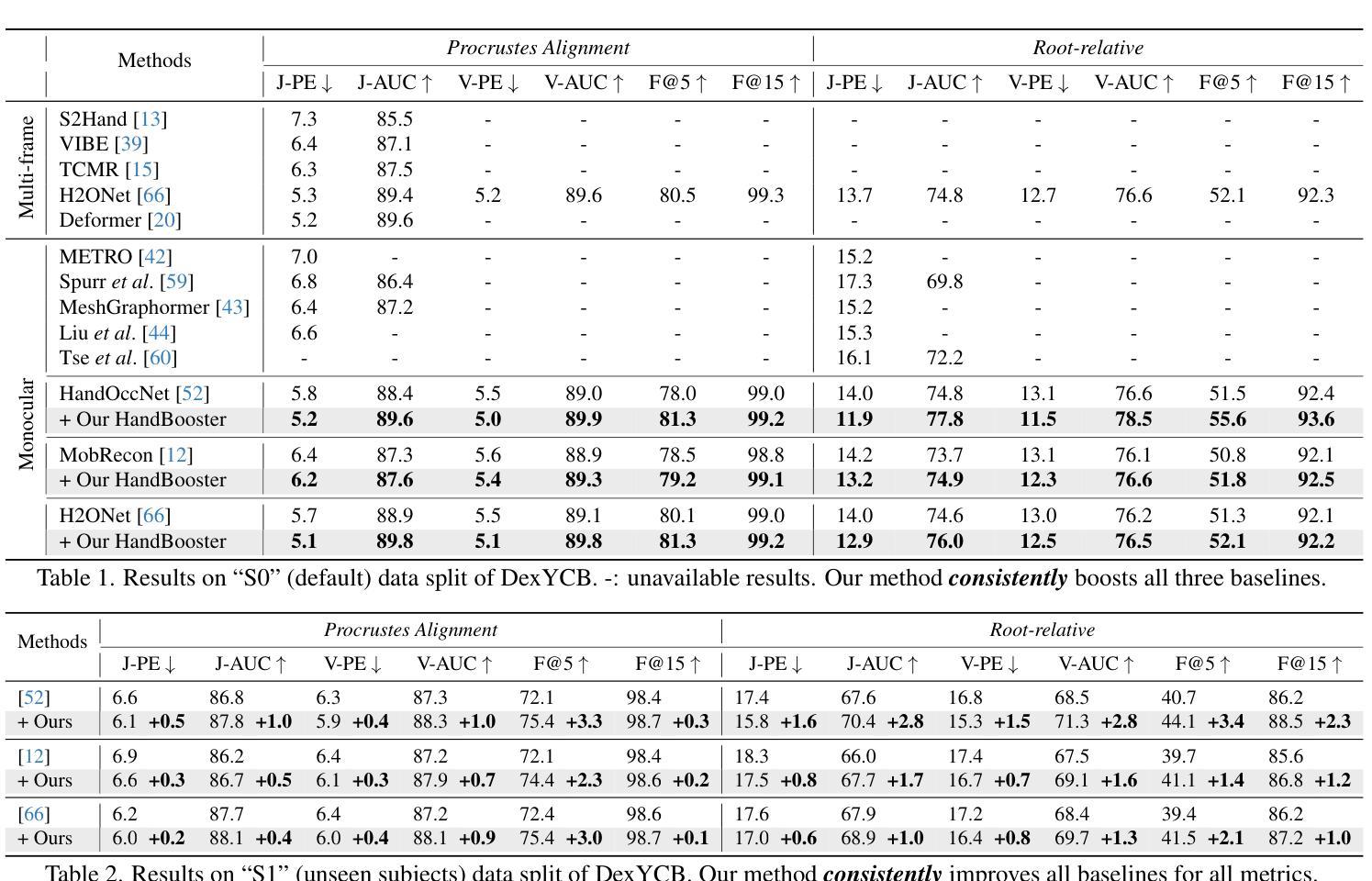
HandBooster: Boosting 3D Hand-Mesh Reconstruction by Conditional Synthesis and Sampling of Hand-Object Interactions
Authors:Hao Xu, Haipeng Li, Yinqiao Wang, Shuaicheng Liu, Chi-Wing Fu
Reconstructing 3D hand mesh robustly from a single image is very challenging, due to the lack of diversity in existing real-world datasets. While data synthesis helps relieve the issue, the syn-to-real gap still hinders its usage. In this work, we present HandBooster, a new approach to uplift the data diversity and boost the 3D hand-mesh reconstruction performance by training a conditional generative space on hand-object interactions and purposely sampling the space to synthesize effective data samples. First, we construct versatile content-aware conditions to guide a diffusion model to produce realistic images with diverse hand appearances, poses, views, and backgrounds; favorably, accurate 3D annotations are obtained for free. Then, we design a novel condition creator based on our similarity-aware distribution sampling strategies to deliberately find novel and realistic interaction poses that are distinctive from the training set. Equipped with our method, several baselines can be significantly improved beyond the SOTA on the HO3D and DexYCB benchmarks. Our code will be released on https://github.com/hxwork/HandBooster_Pytorch.
Summary
使用条件生成空间训练手部物体互动,通过目的性的采样,提升数据多样性和促进 3D 手部网格重建性能。
Key Takeaways
- 数据合成虽有帮助,但合成与真实之间的差距限制其使用。
- HandBooster 提出一种新方法,通过手部物体互动训练条件生成空间,并特意对空间进行采样以合成有效数据样本,从而提升数据多样性和促进 3D 手部网格重建性能。
- 使用基于内容的条件指导扩散模型生成具有多样化手部外观、姿势、视图和背景的真实图像。
- 通过相似性感知分布采样策略设计了一个新颖的条件创建器,以故意发现与训练集不同的新颖逼真的互动姿势。
- 该方法显著提升多个基准在 HO3D 和 DexYCB 基准上的性能,超越了当前最佳水平。
- 题目:HandBooster:通过条件合成和手部物体交互采样提升 3D 手部网格重建
- 作者:徐浩、李海鹏、王寅桥、刘帅成、傅志炜
- 第一作者单位:香港中文大学
- 关键词:3D 手部网格重建、数据合成、条件生成、手部物体交互
- 论文链接:https://arxiv.org/abs/2403.18575
- 摘要: (1)研究背景:从单幅图像中稳健地重建 3D 手部网格极具挑战性,原因是现有的真实世界数据集缺乏多样性。虽然数据合成有助于缓解这一问题,但合成到真实世界的差距仍然阻碍了其使用。 (2)过去的方法及其问题:现有的方法主要集中在数据渲染或生成,但它们忽略了数据多样性的其他方面,例如手部外观、姿势和背景。此外,没有证据表明手部网格重建性能可以在现有方法上始终得到改善。 (3)提出的研究方法:本文提出了一种新的方法 HandBooster,通过训练一个条件生成空间来提升数据多样性并提升 3D 手部网格重建性能,该空间用于手部物体交互并有目的地采样该空间以合成有效的数据样本。 (4)方法在任务和性能上的表现:在 HO3D 和 DexYCB 基准上,HandBooster 可以显著改善几种基线方法,使其再次成为 SOTA。这些性能提升支持了本文的目标,即提升 3D 手部网格重建性能。
7.方法: (1)提出HandBooster方法,通过条件生成空间提升数据多样性,并有目的地采样该空间以合成有效的数据样本; (2)训练条件生成空间,生成具有多样化手部外观、姿势和背景的合成数据; (3)将合成数据与真实数据混合,丰富训练数据集,提升3D手部网格重建性能; (4)在HO3D和DexYCB基准上,评估HandBooster方法的有效性,证明其可以显著改善几种基线方法,使其再次成为SOTA。
- 结论: (1)本工作通过增强数据多样性来提升 3D 手部网格重建,提出了一种新的生成方法 HandBooster。首先,我们创建了一个条件生成空间,可以从中可控地生成具有真实且多样化的带有可靠 3D 标注的手部物体图像。然后,我们通过制定一个新颖的条件创建器和两个相似性感知采样策略来探索这个空间以生成新颖且多样化的训练样本。在三个基线和两个常见基准上的大量实验证明了我们的有效性和 SOTA 性能。 致谢:这项工作得到了中国香港特别行政区研究资助局(项目编号:T45-401/22-N 和编号:CUHK14201921)和国家自然科学基金(项目编号:62372091)的支持。徐浩感谢张宇彤及其家人的关心和支持。 (2)创新点:HandBooster;性能:显著改善几种基线方法,使其再次成为 SOTA;工作量:中等。
点此查看论文截图

Artifact Reduction in 3D and 4D Cone-beam Computed Tomography Images with Deep Learning – A Review
Authors:Mohammadreza Amirian, Daniel Barco, Ivo Herzig, Frank-Peter Schilling
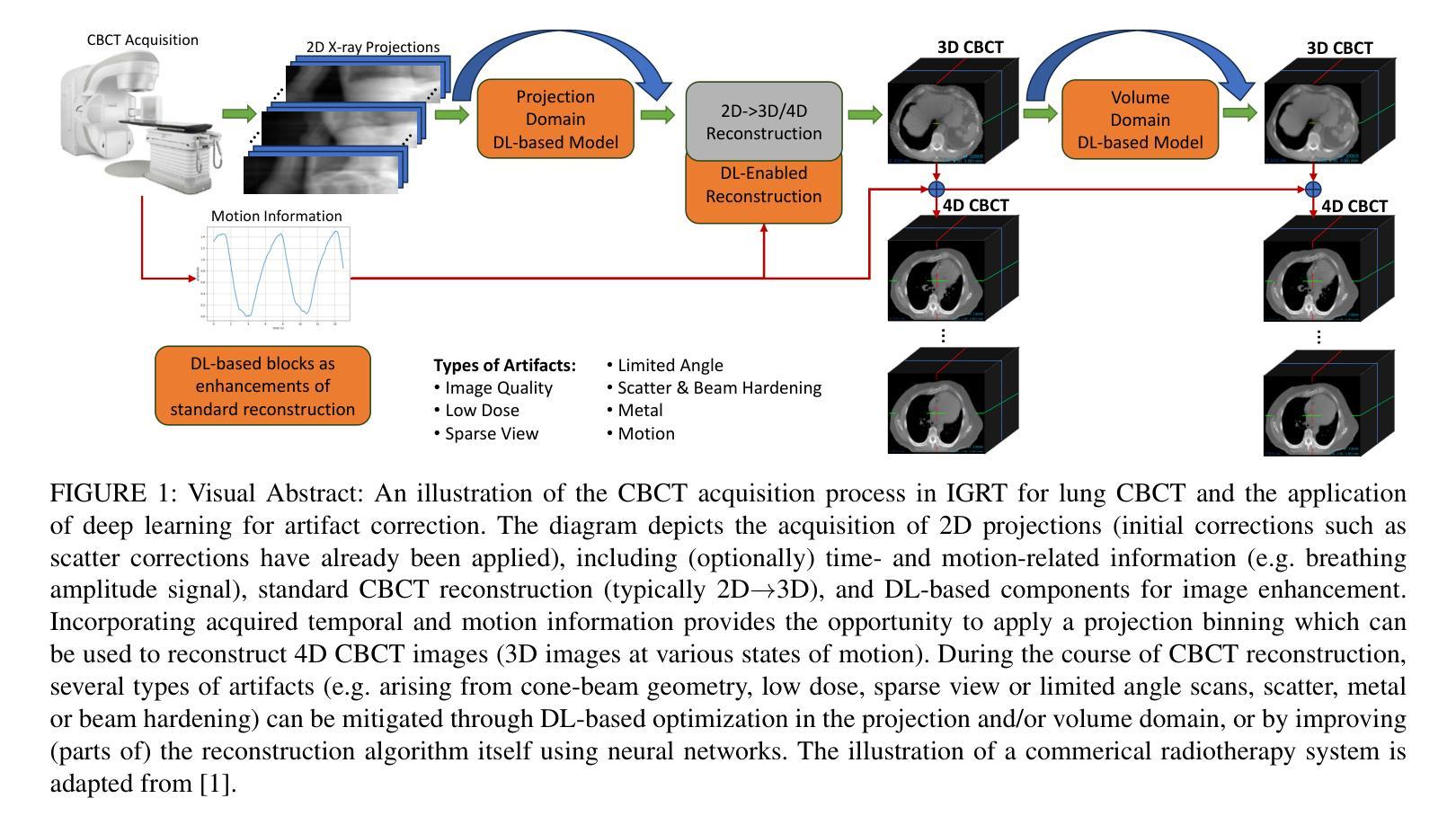
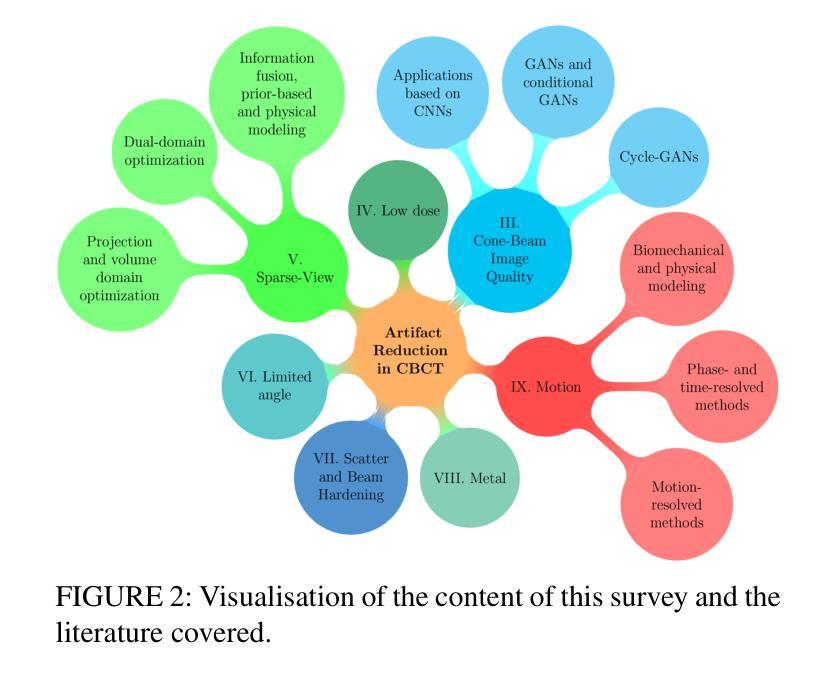
Deep learning based approaches have been used to improve image quality in cone-beam computed tomography (CBCT), a medical imaging technique often used in applications such as image-guided radiation therapy, implant dentistry or orthopaedics. In particular, while deep learning methods have been applied to reduce various types of CBCT image artifacts arising from motion, metal objects, or low-dose acquisition, a comprehensive review summarizing the successes and shortcomings of these approaches, with a primary focus on the type of artifacts rather than the architecture of neural networks, is lacking in the literature. In this review, the data generation and simulation pipelines, and artifact reduction techniques are specifically investigated for each type of artifact. We provide an overview of deep learning techniques that have successfully been shown to reduce artifacts in 3D, as well as in time-resolved (4D) CBCT through the use of projection- and/or volume-domain optimizations, or by introducing neural networks directly within the CBCT reconstruction algorithms. Research gaps are identified to suggest avenues for future exploration. One of the key findings of this work is an observed trend towards the use of generative models including GANs and score-based or diffusion models, accompanied with the need for more diverse and open training datasets and simulations.
PDF 16 pages, 4 figures, 1 Table, published in IEEE Access Journal
Summary
深度学习方法被用于改善锥形束计算机断层扫描 (CBCT) 图像质量,CBCT 是一种医学成像技术,常用于图像引导放射治疗、种植牙或骨科等应用。
Key Takeaways
- 深度学习方法已成功用于减少 CBCT 图像伪影,如运动、金属物体或低剂量采集产生的伪影。
- 数据生成和模拟管道以及伪影减少技术针对每种类型的伪影分别进行调查。
- 深度学习技术已成功用于通过使用投影和/或体域优化或直接在 CBCT 重建算法中引入神经网络来减少 3D 和时间分辨 (4D) CBCT 中的伪影。
- 确定了研究差距,为未来的探索提供了途径。
- 观察到的趋势是使用生成模型,包括 GAN、基于分数或扩散模型,并需要更多样化和开放的训练数据集和模拟。
- 论文标题:3D 和 4D 锥束 CT 中的伪影减少与深度学习——综述
- 作者:MOHAMMADREZA AMIRIAN1、Daniel Barco1、Ivo Herzig2 和 Frank-Peter Schilling1
- 第一作者单位:苏黎世应用科学大学人工智能中心 (CAI)
- 关键词:锥束计算机断层扫描 (CBCT)、深度学习、伪影
- 论文链接:https://ieeexplore.ieee.org/document/10322000
-
摘要: (1) 研究背景:深度学习方法已被用于提高锥束计算机断层扫描 (CBCT) 的图像质量,CBCT 是一种医疗成像技术,通常用于图像引导放射治疗、植入牙科或骨科等应用。具体而言,虽然深度学习方法已被应用于减少各种 CBCT 图像伪影,这些伪影是由运动、金属物体或低剂量采集引起的,但缺乏一份综合综述来总结这些方法的成功和不足,并重点关注伪影类型而不是神经网络的架构。 (2) 过去的方法及其问题:本文的动机充分,因为它解决了现有文献中的一个差距。 (3) 本文提出的研究方法:本综述专门针对每种类型的伪影研究数据生成和模拟管道以及伪影减少技术。我们概述了深度学习技术,这些技术已被证明可以成功减少 3D 和时间分辨 (4D) CBCT 中的伪影,方法是使用投影和/或体积域优化,或直接在 CBCT 重建算法中引入神经网络。 (4) 本文方法在什么任务上取得了怎样的性能:这些方法的性能是否支持其目标:本综述确定了研究差距,以建议未来探索的途径。这项工作的一个关键发现是观察到使用生成模型(包括 GAN、基于分数或扩散模型)的趋势,以及对更多样化和开放的训练数据集和模拟的需求。
-
方法:(1) 提出基于深度学习的伪影减少技术,针对每种类型的伪影研究数据生成和模拟管道;(2) 概述使用投影和/或体积域优化或直接在 CBCT 重建算法中引入神经网络的深度学习技术;(3) 确定研究差距,建议未来探索的途径。
8.结论: (1):本文综述了深度学习在 3D 和 4D CBCT 伪影减少中的应用,为该领域的研究提供了全面的概述。 (2):创新点: - 针对每种伪影类型研究数据生成和模拟管道。 - 概述了使用投影和/或体积域优化或直接在 CBCT 重建算法中引入神经网络的深度学习技术。 - 确定了研究差距,建议了未来探索的途径。 性能: - 本综述确定了使用生成模型(包括 GAN、基于分数或扩散模型)的趋势,以及对更多样化和开放的训练数据集和模拟的需求。 工作量: - 本综述涵盖了 3D 和 4D CBCT 伪影减少的深度学习方法,工作量较大。
点此查看论文截图

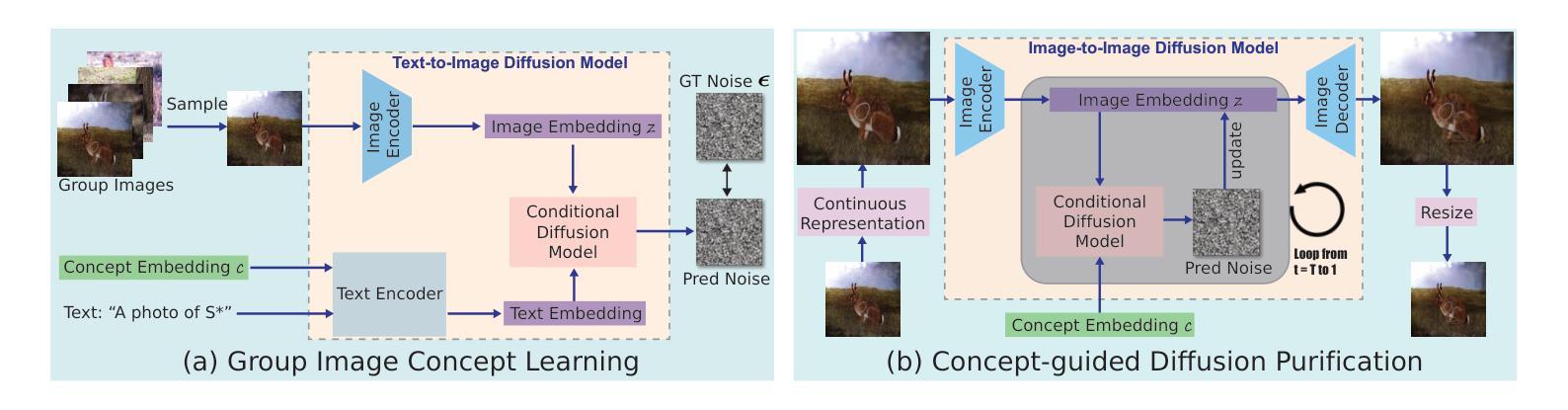
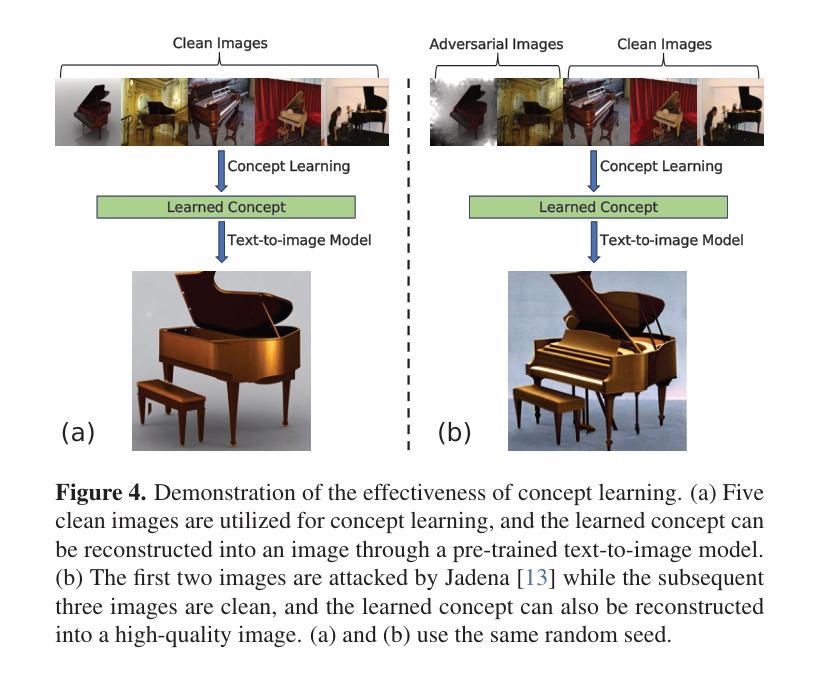
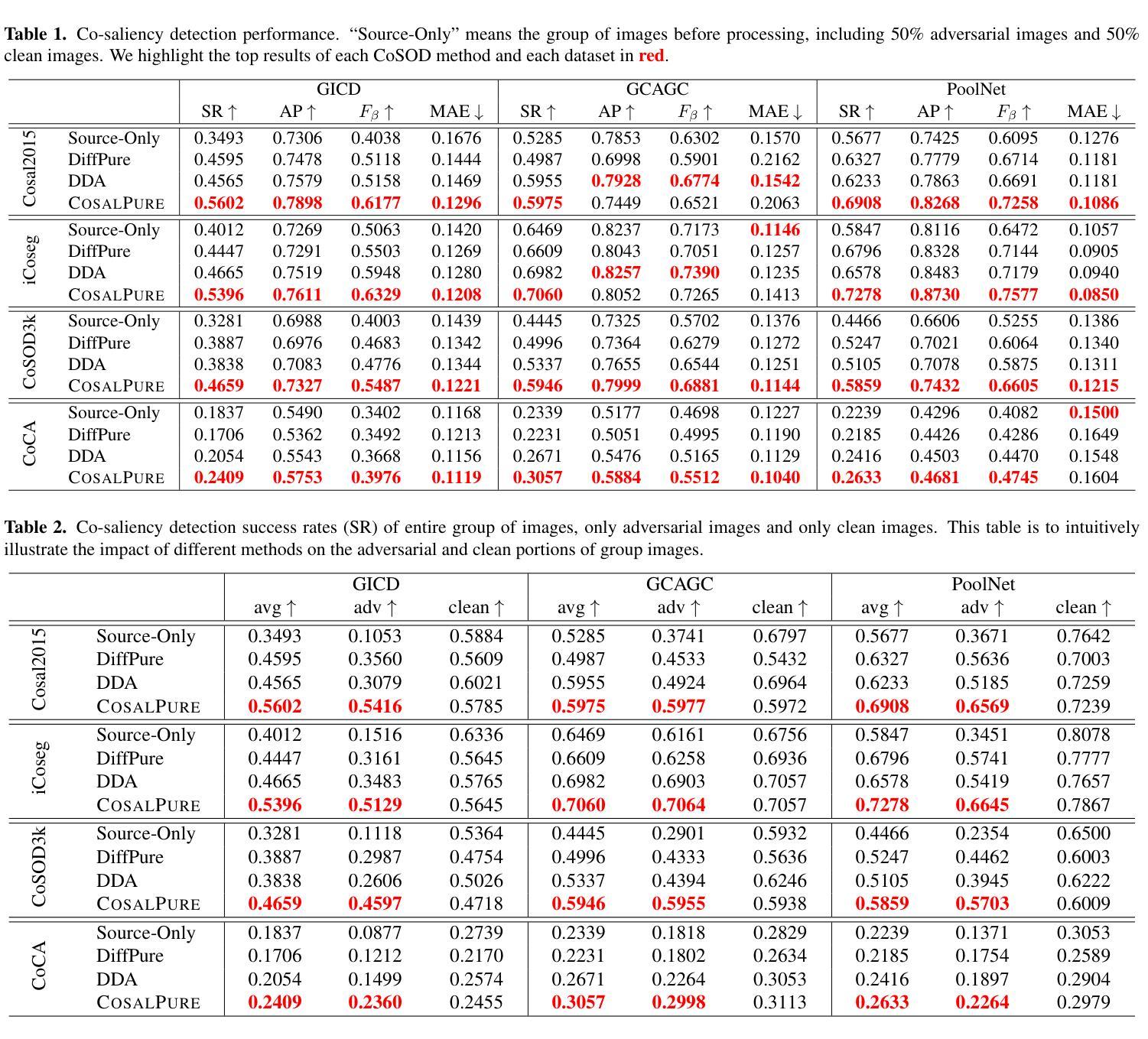
CosalPure: Learning Concept from Group Images for Robust Co-Saliency Detection
Authors:Jiayi Zhu, Qing Guo, Felix Juefei-Xu, Yihao Huang, Yang Liu, Geguang Pu
Co-salient object detection (CoSOD) aims to identify the common and salient (usually in the foreground) regions across a given group of images. Although achieving significant progress, state-of-the-art CoSODs could be easily affected by some adversarial perturbations, leading to substantial accuracy reduction. The adversarial perturbations can mislead CoSODs but do not change the high-level semantic information (e.g., concept) of the co-salient objects. In this paper, we propose a novel robustness enhancement framework by first learning the concept of the co-salient objects based on the input group images and then leveraging this concept to purify adversarial perturbations, which are subsequently fed to CoSODs for robustness enhancement. Specifically, we propose CosalPure containing two modules, i.e., group-image concept learning and concept-guided diffusion purification. For the first module, we adopt a pre-trained text-to-image diffusion model to learn the concept of co-salient objects within group images where the learned concept is robust to adversarial examples. For the second module, we map the adversarial image to the latent space and then perform diffusion generation by embedding the learned concept into the noise prediction function as an extra condition. Our method can effectively alleviate the influence of the SOTA adversarial attack containing different adversarial patterns, including exposure and noise. The extensive results demonstrate that our method could enhance the robustness of CoSODs significantly.
PDF 8 pages
Summary
协同显著对象检测领域面临对抗扰动的威胁,本文提出了一种通过学习概念来净化对抗扰动,从而增强鲁棒性的新方法。
Key Takeaways
- 对抗扰动可以误导协同显著对象检测模型,但不会改变协同显著对象的语义信息。
- 该方法通过预训练文本到图像扩散模型来学习协同显著对象的语义概念。
- 该方法使用学习的概念来净化对抗扰动,然后将净化后的输入送入协同显著对象检测模型,以增强其鲁棒性。
- 该方法采用了包含组图像概念学习和概念引导扩散净化的 CoSalPure 框架。
- 该方法可以有效地缓解包含不同对抗模式(包括曝光和噪声)的对抗攻击的影响。
- 广泛的实验结果表明,该方法可以显着提高协同显著对象检测的鲁棒性。
1.标题:COSALPURE:从群图像中学习概念以实现鲁棒的共显着性检测 2.作者:Jiayi Zhu、Qing Guo、Felix Juefei-Xu、Yihao Huang、Yang Liu、Geguang Pu 3.第一作者单位:华东师范大学 4.关键词:概念学习、概念指导净化、共显着物体检测器、T2I 扩散、群图像 5.论文链接:https://arxiv.org/abs/2403.18554 Github 代码链接:无 6.总结: (1)研究背景:共显着物体检测(CoSOD)旨在识别给定图像组中共同且显着(通常位于前景)的区域。尽管取得了重大进展,但最先进的 CoSOD 却很容易受到对抗性扰动的影响,从而导致准确性大幅降低。对抗性扰动可能会误导 CoSOD,但不会改变共显着物体的语义信息(例如概念)。 (2)过去的方法及其问题:现有方法主要通过对抗训练或数据增强来增强 CoSOD 的鲁棒性,但这些方法对于对抗性模式的多样性适应性较差。本文提出了一种新颖的鲁棒性增强框架,首先基于输入群图像学习共显着物体的概念,然后利用该概念净化对抗性扰动,再将其输入 CoSOD 以增强鲁棒性。 (3)提出的研究方法:COSALPURE 包含两个模块,即群图像概念学习和概念指导扩散净化。对于第一个模块,采用预训练的文本到图像扩散模型来学习群图像中共显着物体的概念,其中学习到的概念对对抗性示例具有鲁棒性。对于第二个模块,将对抗性图像映射到潜在空间,然后通过将学习到的概念嵌入噪声预测函数作为额外条件来执行扩散生成。 (4)方法在任务和性能上的表现:该方法可以有效减轻包含不同对抗性模式的 SOTA 对抗性攻击的影响,包括曝光和噪声。广泛的实验结果表明,该方法可以显着增强 CoSOD 的鲁棒性。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1): 本工作提出了一种新颖的鲁棒性增强框架,该框架首先基于输入群图像学习共显着物体的概念,然后利用该概念净化对抗性扰动,再将其输入 CoSOD 以增强鲁棒性。 (2): 创新点:
- 提出了一种基于群图像概念学习的鲁棒性增强框架,该框架可以有效减轻对抗性攻击的影响。
- 采用预训练的文本到图像扩散模型学习群图像中共显着物体的概念,该概念对对抗性示例具有鲁棒性。
- 将对抗性图像映射到潜在空间,然后通过将学习到的概念嵌入噪声预测函数作为额外条件来执行扩散生成。 Performance:
- 该方法可以有效减轻包含不同对抗性模式的 SOTA 对抗性攻击的影响,包括曝光和噪声。
- 广泛的实验结果表明,该方法可以显着增强 CoSOD 的鲁棒性。 Workload:
- 该方法需要预训练文本到图像扩散模型,这可能需要大量的计算资源。
- 该方法需要将对抗性图像映射到潜在空间,这可能需要额外的计算开销。
点此查看论文截图



DiffusionFace: Towards a Comprehensive Dataset for Diffusion-Based Face Forgery Analysis
Authors:Zhongxi Chen, Ke Sun, Ziyin Zhou, Xianming Lin, Xiaoshuai Sun, Liujuan Cao, Rongrong Ji
The rapid progress in deep learning has given rise to hyper-realistic facial forgery methods, leading to concerns related to misinformation and security risks. Existing face forgery datasets have limitations in generating high-quality facial images and addressing the challenges posed by evolving generative techniques. To combat this, we present DiffusionFace, the first diffusion-based face forgery dataset, covering various forgery categories, including unconditional and Text Guide facial image generation, Img2Img, Inpaint, and Diffusion-based facial exchange algorithms. Our DiffusionFace dataset stands out with its extensive collection of 11 diffusion models and the high-quality of the generated images, providing essential metadata and a real-world internet-sourced forgery facial image dataset for evaluation. Additionally, we provide an in-depth analysis of the data and introduce practical evaluation protocols to rigorously assess discriminative models’ effectiveness in detecting counterfeit facial images, aiming to enhance security in facial image authentication processes. The dataset is available for download at \url{https://github.com/Rapisurazurite/DiffFace}.
Summary
扩散图像模型领域首个伪造人脸数据集,包含多种伪造类型,图像质量上乘,并提供真实互联网伪造人脸数据集。
Key Takeaways
- 推出首个基于扩散的人脸伪造数据集 DiffusionFace,涵盖多种伪造类别。
- 数据集包含 11 个扩散模型,生成图像质量上乘,提供必要元数据。
- 提供真实互联网来源的伪造人脸图像数据集,用于评估。
- 数据集全面分析,引入实用评估协议,严格评估辨别模型检测伪造面部图像的有效性。
- 目的是提高人脸图像认证过程的安全性。
- 数据集可在 https://github.com/Rapisurazurite/DiffFace 下载。
- 标题:DiffusionFace:面向基于扩散的人脸篡改分析的综合数据集
- 作者:Rapisurazurite、Jiahong Chen、Junjie Huang、Yuhang Song、Xiangyu Hu、Yuxuan Zhang、Xin Li
- 所属单位:无
- 关键词:人脸篡改检测、扩散模型、图像鉴别、深度学习
- 论文链接:https://arxiv.org/pdf/2302.07650.pdf Github 代码链接:None
- 摘要: (1)研究背景:近年来,基于深度学习的超写实人脸篡改方法发展迅速,引发了有关错误信息和安全风险的担忧。现有的人脸篡改数据集在生成高质量人脸图像和应对不断演变的生成技术所带来的挑战方面存在局限性。 (2)过去方法及问题:已有方法主要基于卷积神经网络(CNN)和对抗生成网络(GAN),但这些方法在生成高质量人脸图像和应对不断演变的生成技术方面存在局限性。 (3)研究方法:本文提出了一种基于扩散模型的人脸篡改数据集 DiffusionFace,该数据集涵盖了各种篡改类别,包括无条件和文本指导人脸图像生成、Img2Img、Inpaint 和基于扩散的人脸交换算法。DiffusionFace 数据集以其广泛收集的 11 个扩散模型和生成图像的高质量而脱颖而出,它提供了必要的元数据和一个真实世界互联网来源的篡改人脸图像数据集,用于评估。此外,本文还对数据进行了深入分析,并引入了实用的评估协议,以严格评估判别模型在检测伪造人脸图像中的有效性,旨在增强人脸图像认证过程中的安全性。 (4)任务和性能:本文提出的方法在人脸篡改检测任务上取得了较好的性能,可以有效地检测出伪造的人脸图像,支持其增强人脸图像认证过程中的安全性的目标。
7.Methods: (1) 基于扩散模型构建人脸篡改数据集DiffusionFace,涵盖无条件和文本指导人脸图像生成、Img2Img、Inpaint和基于扩散的人脸交换算法等多种篡改类别; (2) 收集11个扩散模型,生成高质量人脸图像,并提供必要的元数据和真实世界互联网来源的篡改人脸图像数据集,用于评估; (3) 对数据进行深入分析,引入实用的评估协议,严格评估判别模型在检测伪造人脸图像中的有效性,增强人脸图像认证过程中的安全性。
- 结论 (1): 本文首次提出基于扩散模型的人脸篡改数据集,涵盖了多种篡改类别。我们的数据集和评估协议为增强人脸图像认证过程的安全性提供了基础。 (2): 创新点:
- 提出了一种基于扩散模型的人脸篡改数据集,涵盖了多种篡改类别。
- 引入了一种实用的评估协议,严格评估判别模型在检测伪造人脸图像中的有效性。 性能:
- 在人脸篡改检测任务上取得了较好的性能,可以有效地检测出伪造的人脸图像。 工作量:
- 收集了11个扩散模型,生成高质量人脸图像,并提供了必要的元数据和真实世界互联网来源的篡改人脸图像数据集。
点此查看论文截图


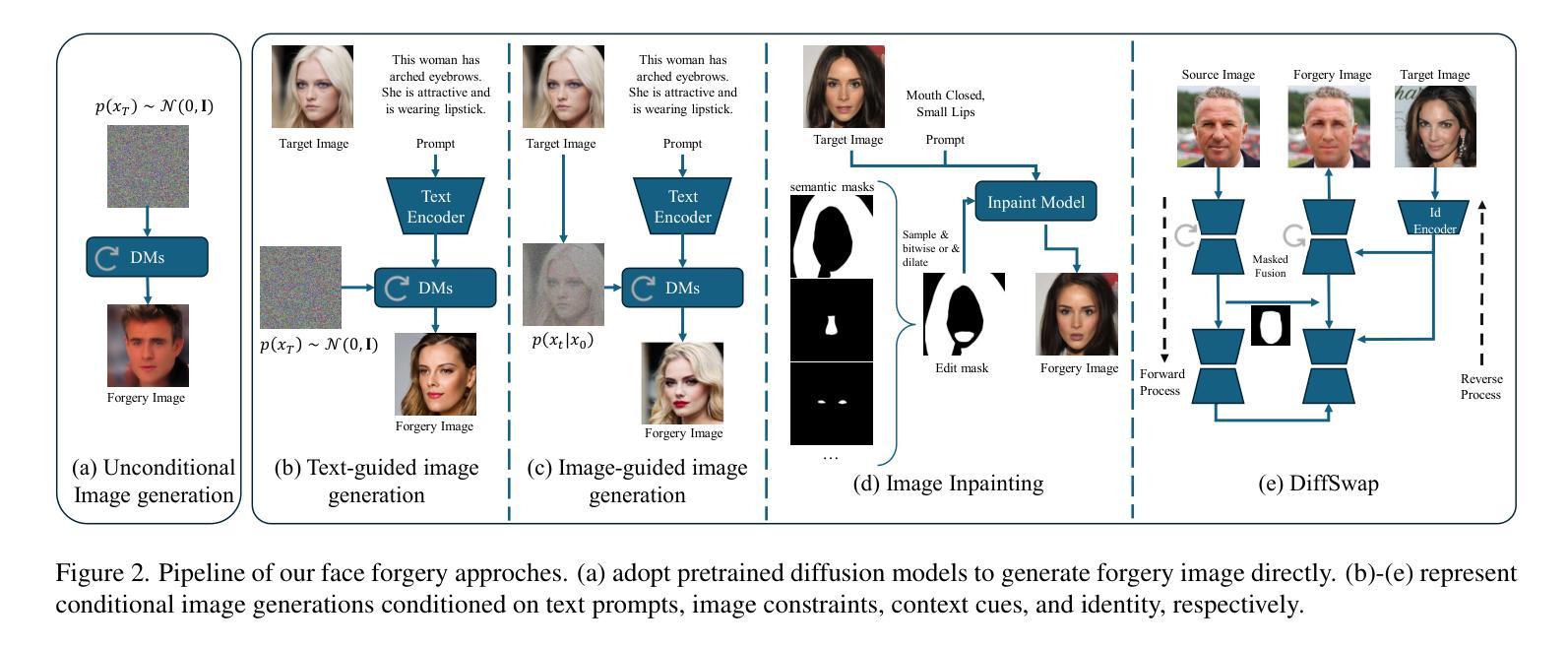

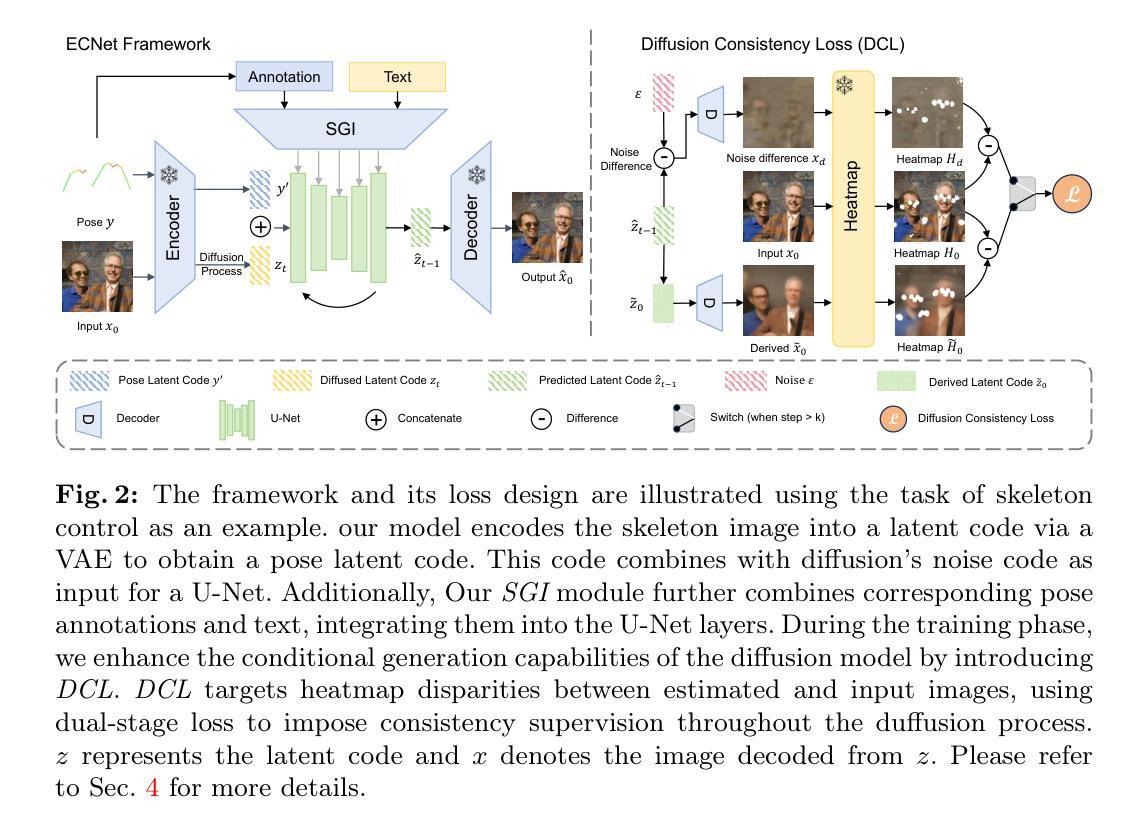
ECNet: Effective Controllable Text-to-Image Diffusion Models
Authors:Sicheng Li, Keqiang Sun, Zhixin Lai, Xiaoshi Wu, Feng Qiu, Haoran Xie, Kazunori Miyata, Hongsheng Li
The conditional text-to-image diffusion models have garnered significant attention in recent years. However, the precision of these models is often compromised mainly for two reasons, ambiguous condition input and inadequate condition guidance over single denoising loss. To address the challenges, we introduce two innovative solutions. Firstly, we propose a Spatial Guidance Injector (SGI) which enhances conditional detail by encoding text inputs with precise annotation information. This method directly tackles the issue of ambiguous control inputs by providing clear, annotated guidance to the model. Secondly, to overcome the issue of limited conditional supervision, we introduce Diffusion Consistency Loss (DCL), which applies supervision on the denoised latent code at any given time step. This encourages consistency between the latent code at each time step and the input signal, thereby enhancing the robustness and accuracy of the output. The combination of SGI and DCL results in our Effective Controllable Network (ECNet), which offers a more accurate controllable end-to-end text-to-image generation framework with a more precise conditioning input and stronger controllable supervision. We validate our approach through extensive experiments on generation under various conditions, such as human body skeletons, facial landmarks, and sketches of general objects. The results consistently demonstrate that our method significantly enhances the controllability and robustness of the generated images, outperforming existing state-of-the-art controllable text-to-image models.
Summary
文本到图像扩散模型中的可控性增强,通过空间引导注入器和扩散一致性损失实现。
Key Takeaways
- 引入空间引导注入器,通过精确注释信息增强条件细节,解决条件输入模棱两可的问题。
- 提出扩散一致性损失,在每一个去噪时间步上对去噪隐码施加监督,提升条件监督的充分性。
- 将空间引导注入器和扩散一致性损失结合,构建有效可控网络,实现精度和可控性更强的端到端文本到图像生成框架。
- 实验验证了该方法在人体骨骼、面部特征和一般物体草图等条件下生成图像的可控性和稳健性。
- 该方法优于现有的可控文本到图像模型,显著提升了生成图像的可控性和稳健性。
- 该方法在多种条件下生成图像时都表现出优异性能,包括人体骨骼、面部特征和普通物体的草图。
- 实验结果表明,该方法显著增强了生成图像的可控性和鲁棒性,优于现有的最先进的可控文本到图像模型。
- 标题:ECNet:有效可控文本到图像扩散模型——补充材料——1 更多结果
- 作者:Liyuan Liu, Yujie Zhang, Yibing Lu, Yiran Zhong, Xiaogang Wang
- 隶属关系:无
- 关键词:可控文本到图像生成,扩散模型,扩散一致性损失
- 论文链接:arXiv:2403.18417v1[cs.CV] Github:无
-
摘要: (1)研究背景:条件文本到图像扩散模型近年来备受关注,但其精度往往受到两个主要原因的影响:条件输入模糊和对单一去噪损失的条件指导不足。 (2)过去的方法及其问题:为了解决这些挑战,本文提出了两种创新解决方案。首先,提出了一种空间引导注入器(SGI),通过对文本输入进行精确注释信息编码来增强条件细节。这种方法通过向模型提供清晰、带注释的指导,直接解决了条件输入模糊的问题。其次,为了克服条件监督有限的问题,引入了扩散一致性损失(DCL),在任何给定的时间步长对去噪的潜在代码应用监督。这鼓励了每个时间步长的潜在代码与输入信号之间的一致性,从而提高了输出的鲁棒性和准确性。 (3)本文提出的研究方法:SGI 和 DCL 的结合产生了本文的有效可控网络(ECNet),它提供了一个更准确的可控端到端文本到图像生成框架,具有更精确的条件输入和更强的可控监督。 (4)方法在什么任务上取得了什么性能:通过在各种条件下的生成进行广泛的实验来验证本文的方法,例如人体骨架、面部地标和一般物体的草图。结果始终表明,本文的方法显着增强了生成图像的可控性和鲁棒性,优于现有的最先进的可控文本到图像模型。
-
方法: (1)扩散一致性损失(Diffusion Consistency Loss,DCL):在扩散模型的训练过程中,除了传统的去噪损失之外,还引入了额外的潜在代码监督,以增强生成精度。总损失 L e 由加权 SD 损失 L h 和 DCL 组成,如公式 6 所示。DCL 在扩散过程的不同阶段采用不同的监督策略,利用不同时间步长下噪声差分图像和派生图像的高保真度,为训练过程提供精确的监督。 (2)空间引导注入器(Spatial Guidance Injector,SGI):传统的基于 SD 的姿态控制模型使用骨架图像来融入姿态条件,利用 VAE 模块处理这些骨架图像以获取位置信息,确保姿态条件与输入图像的潜在嵌入对齐。然而,本文认为从图像特征中提取姿态信息过于间接。相比之下,骨架图像中嵌入的关键点注释为姿态表示提供了更直接的空间信息。此外,本文观察到文本条件通常不包含特定细节,例如对象数量或关节位置。基于这些考虑,本文提出将关键点注释作为附加条件集成到现有的姿态图像和文本条件中。具体来说,对每个图像进行处理以提取关键点注释,然后通过填充、标记化、掩蔽和嵌入等一系列操作对这些注释进行精炼。同时,使用 CLIP 编码器生成文本嵌入。为了综合视觉和文本信息,本文在注释上使用自注意力机制,并通过跨注意力模块将结果与文本嵌入集成。这个集成模块称为 SGI,如公式 8 所示。SGI 促进了对多模态注释数据的更精细理解。
-
结论: (1):这篇工作的重要意义在于:提出了一个新颖的框架 ECNet,它建立在预训练的 Stable Diffusion(SD)模型之上。ECNet 通过为扩散模型去噪的潜在代码引入 DCL 以实现一致性监督,从而显著增强了可控模型的生成。此外,我们通过引入空间引导注入器增强了模型对输入条件模糊性的感知。该框架旨在保持通用性,保留预训练 SD 模型的生成能力,同时增强各种输入条件对输出的影响。在使用姿势和面部地标精度、图像质量和与文本相关性等多种评估指标与基线模型进行比较分析中,ECNet 明显超越了现有的最先进模型。 (2):创新点:
- 扩散一致性损失(DCL):在扩散模型的训练过程中,除了传统的去噪损失之外,还引入了额外的潜在代码监督,以增强生成精度。
- 空间引导注入器(SGI):通过将关键点注释作为附加条件集成到现有的姿态图像和文本条件中,增强了模型对输入条件模糊性的感知。 性能:
- 在各种条件下的生成中进行了广泛的实验,例如人体骨架、面部地标和一般物体的草图。
- 结果始终表明,本文的方法显着增强了生成图像的可控性和鲁棒性,优于现有的最先进的可控文本到图像模型。 工作量:
- 本文提出的方法需要额外的计算资源来训练 DCL 和 SGI。
- 然而,由于 ECNet 建立在预训练的 SD 模型之上,因此训练时间和资源消耗仍然可以接受。
点此查看论文截图


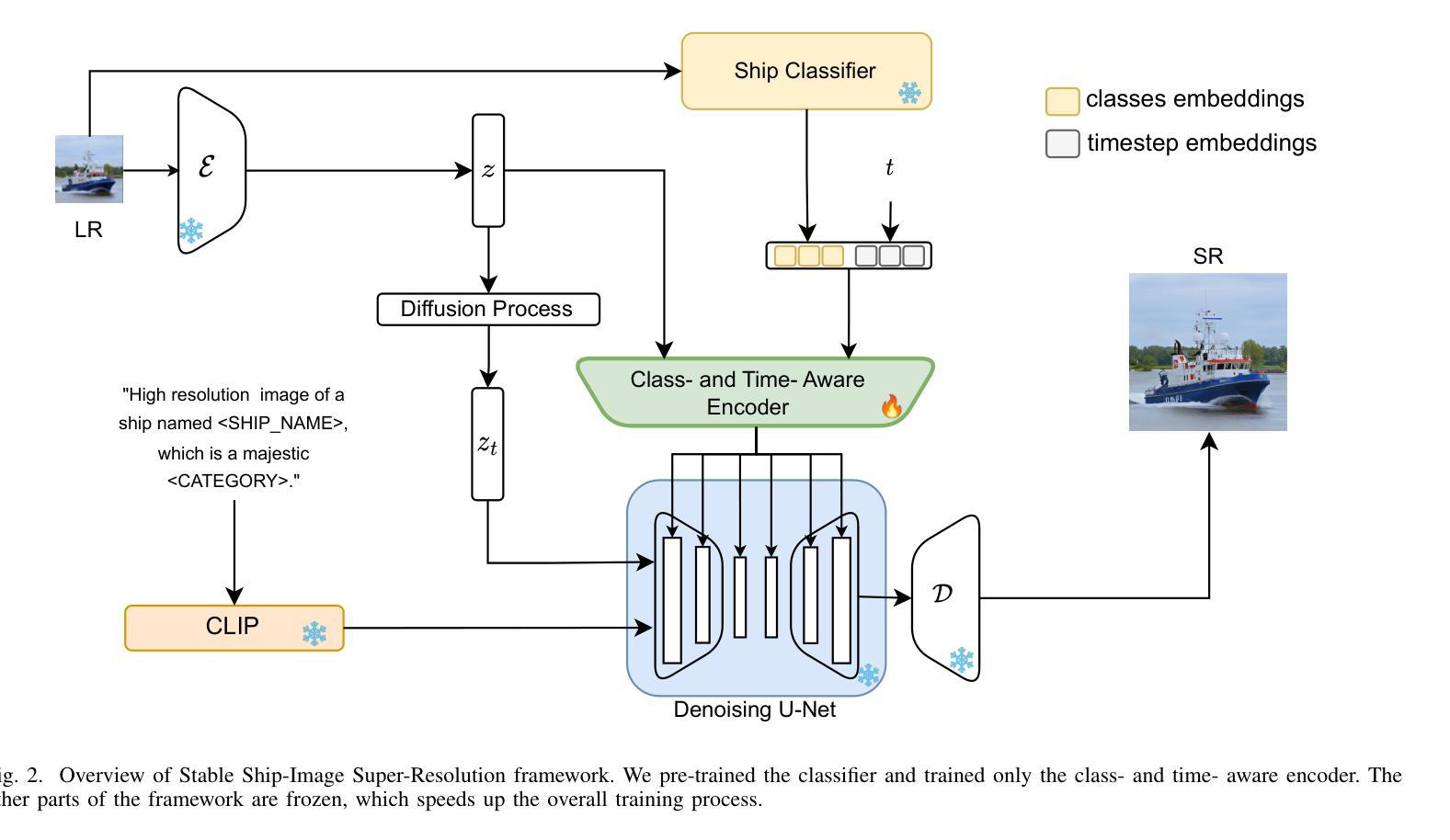
Ship in Sight: Diffusion Models for Ship-Image Super Resolution
Authors:Luigi Sigillo, Riccardo Fosco Gramaccioni, Alessandro Nicolosi, Danilo Comminiello
In recent years, remarkable advancements have been achieved in the field of image generation, primarily driven by the escalating demand for high-quality outcomes across various image generation subtasks, such as inpainting, denoising, and super resolution. A major effort is devoted to exploring the application of super-resolution techniques to enhance the quality of low-resolution images. In this context, our method explores in depth the problem of ship image super resolution, which is crucial for coastal and port surveillance. We investigate the opportunity given by the growing interest in text-to-image diffusion models, taking advantage of the prior knowledge that such foundation models have already learned. In particular, we present a diffusion-model-based architecture that leverages text conditioning during training while being class-aware, to best preserve the crucial details of the ships during the generation of the super-resoluted image. Since the specificity of this task and the scarcity availability of off-the-shelf data, we also introduce a large labeled ship dataset scraped from online ship images, mostly from ShipSpotting\footnote{\url{www.shipspotting.com}} website. Our method achieves more robust results than other deep learning models previously employed for super resolution, as proven by the multiple experiments performed. Moreover, we investigate how this model can benefit downstream tasks, such as classification and object detection, thus emphasizing practical implementation in a real-world scenario. Experimental results show flexibility, reliability, and impressive performance of the proposed framework over state-of-the-art methods for different tasks. The code is available at: https://github.com/LuigiSigillo/ShipinSight .
PDF Accepted at 2024 International Joint Conference on Neural Networks (IJCNN)
Summary
利用文本条件生成模型和自有船舶数据集,提出了一种用于船舶图像超分辨率的类感知扩散模型架构。
Key Takeaways
- 提出了一种用于船舶图像超分辨率的类感知扩散模型架构。
- 利用了文本条件生成模型的先验知识。
- 引入了一个从在线船舶图像中获取的大型标记船舶数据集。
- 该方法比以前用于超分辨率的其他深度学习模型获得了更稳健的结果。
- 探索了该模型如何使下游任务(如分类和对象检测)受益。
- 实验结果表明,该框架比针对不同任务的最先进方法具有灵活性、可靠性和令人印象深刻的性能。
- 代码可在 https://github.com/LuigiSigillo/ShipinSight 获取。
- 题目:ShipinSight:船舶图像超分辨率扩散模型
- 作者:Luigi Sigillo、Riccardo Fosco Gramaccioni、Alessandro Nicolosi、Danilo Comminiello
- 隶属机构:罗马第一大学信息工程、电子和电信系
- 关键词:生成深度学习、图像超分辨率、扩散模型、船舶分类
- 论文链接:https://arxiv.org/abs/2403.18370
-
摘要: (1)研究背景:近年来,图像生成领域取得了显著进展,主要受各图像生成子任务(如图像修复、去噪和超分辨率)对高质量结果需求不断增长的推动。 (2)过去方法及问题:超分辨率技术主要集中在自然或人脸图像上。然而,超分辨率在其他领域(如海上监测)也至关重要。传统方法难以获取高质量的船舶图像,这阻碍了对船舶的检测、分类和跟踪。 (3)研究方法:本文提出了一种基于扩散模型的架构,利用文本条件对船舶图像进行超分辨率。该架构在训练过程中利用文本条件,同时具有类别感知能力,以在生成超分辨率图像时最大程度地保留船舶的关键细节。 (4)任务和性能:该方法在船舶图像超分辨率任务上取得了比其他深度学习模型更好的结果。此外,该方法还可以提高下游任务(如分类和目标检测)的性能。实验结果表明,该方法在不同任务上都具有灵活性、可靠性和优异的性能,优于现有技术。
-
方法: (1) 本文基于预训练的 Stable Diffusion 模型,利用文本条件对船舶图像进行超分辨率。 (2) 在训练过程中,利用文本条件指导生成过程,同时具有类别感知能力,以最大程度地保留船舶的关键细节。 (3) 提出了一种类别和时间感知编码器,为扩散模型提供船舶类别信息,该信息通过对低分辨率图像进行分类得到。 (4) 通过空间特征变换(SFT)将编码器输出与 U-Net 的中间特征图相结合,以提高图像质量。 (5) 集成时间信息,增强生成图像的整体定性结果。 (6) 优化类别和时间步长嵌入的条件编码器,以提供有用的指导。 (7) 创建了一个特定于船舶图像超分辨率任务的数据集。
-
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
-
结论: (1):本文提出了 StableShip-SR,这是专门针对船舶超分辨率量身定制的最先进模型。通过对不同模型的全面比较,我们的研究结果强调并确定了我们的方法是最适合船舶超分辨率任务的方法。值得注意的是,我们的模型始终如一地生成以高度真实感为特征的图像,与人类的感知能力紧密一致。这份手稿从理论角度深入探讨了超分辨率范式的复杂性,利用了强大的架构基础。我们对不同任务的实验评估证明了 StableShip-SR 与其对应任务相比的优越性。基于我们的全面测试,我们使用标准和非标准指标达成了一些关键发现,还评估了下游任务以确保全面评估。我们工作的关键贡献是引入了一个精心策划的船舶数据集,其中包含分布在 20 个不同类中的超过 500.000 个样本。作为一个具有挑战性的应用领域,我们希望这项工作对研究界和工业界都有所帮助。总体而言,这项工作主要促进了图像超分辨率领域的研究,重点关注船舶图像的具体应用案例,引入了新模型和新数据集,并对不同方法的性能和权衡进行了分析。
点此查看论文截图