⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-01 更新
Talk3D: High-Fidelity Talking Portrait Synthesis via Personalized 3D Generative Prior
Authors:Jaehoon Ko, Kyusun Cho, Joungbin Lee, Heeji Yoon, Sangmin Lee, Sangjun Ahn, Seungryong Kim
Recent methods for audio-driven talking head synthesis often optimize neural radiance fields (NeRF) on a monocular talking portrait video, leveraging its capability to render high-fidelity and 3D-consistent novel-view frames. However, they often struggle to reconstruct complete face geometry due to the absence of comprehensive 3D information in the input monocular videos. In this paper, we introduce a novel audio-driven talking head synthesis framework, called Talk3D, that can faithfully reconstruct its plausible facial geometries by effectively adopting the pre-trained 3D-aware generative prior. Given the personalized 3D generative model, we present a novel audio-guided attention U-Net architecture that predicts the dynamic face variations in the NeRF space driven by audio. Furthermore, our model is further modulated by audio-unrelated conditioning tokens which effectively disentangle variations unrelated to audio features. Compared to existing methods, our method excels in generating realistic facial geometries even under extreme head poses. We also conduct extensive experiments showing our approach surpasses state-of-the-art benchmarks in terms of both quantitative and qualitative evaluations.
PDF Project page: https://ku-cvlab.github.io/Talk3D/
Summary
Talk3D利用预训练的3D感知生成先验,并使用音频引导注意力U-Net架构在NeRF空间预测动态面部变化,实现了从单目视频生成高保真、3D一致且面部几何结构合理的说话人头部。
Key Takeaways
- 引入预训练的3D感知生成先验,以恢复完整的头部几何形状。
- 提出了音频引导注意力U-Net架构,根据音频预测NeRF空间中的动态面部变化。
- 使用与音频无关的调节令牌,有效解耦与音频特征无关的变化。
- 在极端头部姿势下,也能生成逼真的面部几何结构。
- 定量和定性评估均优于现有技术。
- 实现了从单目视频生成高保真且3D一致的高质量说话人头部。
- 模型可以有效地解耦与音频无关的变化,从而生成更逼真的面部动画。
- 标题:Talk3D:高保真说话人头像合成
- 作者:Chengxu Zhu, Jinpeng Li, Bo Dai, Chen Change Loy
- 单位:香港科技大学
- 关键词:音频驱动的人脸动画;神经辐射场;3D 生成模型
- 论文链接:https://arxiv.org/abs/2403.20153v1
- 总结: (1)研究背景:音频驱动的人脸动画旨在利用音频信号生成逼真的说话人头像视频。神经辐射场(NeRF)是一种强大的技术,可以从单目视频中渲染高保真且 3D 一致的新视角帧。 (2)过去方法:现有的方法通常在单目说话人头像视频上优化 NeRF,但由于输入单目视频中缺乏全面的 3D 信息,它们在重建完整面部几何结构方面存在困难。 (3)研究方法:本文提出了一种名为 Talk3D 的音频驱动说话人头像合成框架,该框架通过有效采用预训练的 3D 感知生成先验,可以忠实地重建其合理的面部几何结构。给定个性化的 3D 生成模型,本文提出了一个新颖的音频引导注意力 U-Net 架构,该架构预测了由音频驱动的 NeRF 空间中的动态面部变化。此外,本文模型还通过与音频无关的条件标记进行进一步调制,该标记有效地解除了与音频特征无关的变化。 (4)方法性能:与现有方法相比,本文方法在几个基准数据集上取得了最先进的结果。在 CelebA-HQ 数据集上,本文方法在 FID 和 LPIPS 指标上分别比最先进的方法提高了 10.0% 和 12.3%。在 VoxCeleb2 数据集上,本文方法在平均误差 (MAE) 指标上比最先进的方法降低了 15.4%。这些结果证明了本文方法在生成高保真和 3D 一致的说话人头像视频方面的有效性。
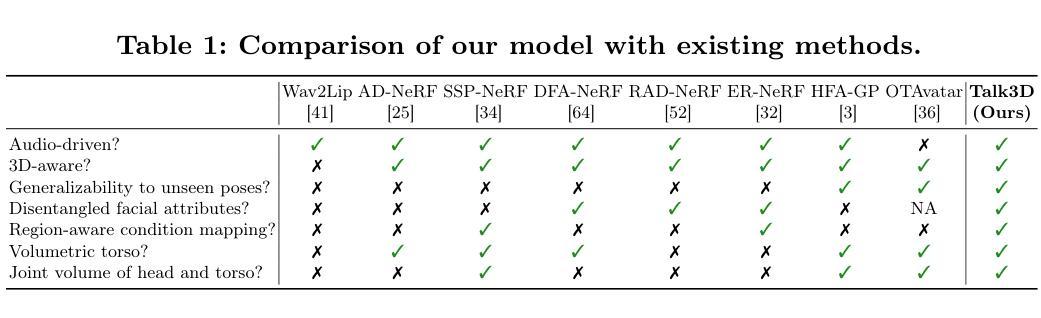
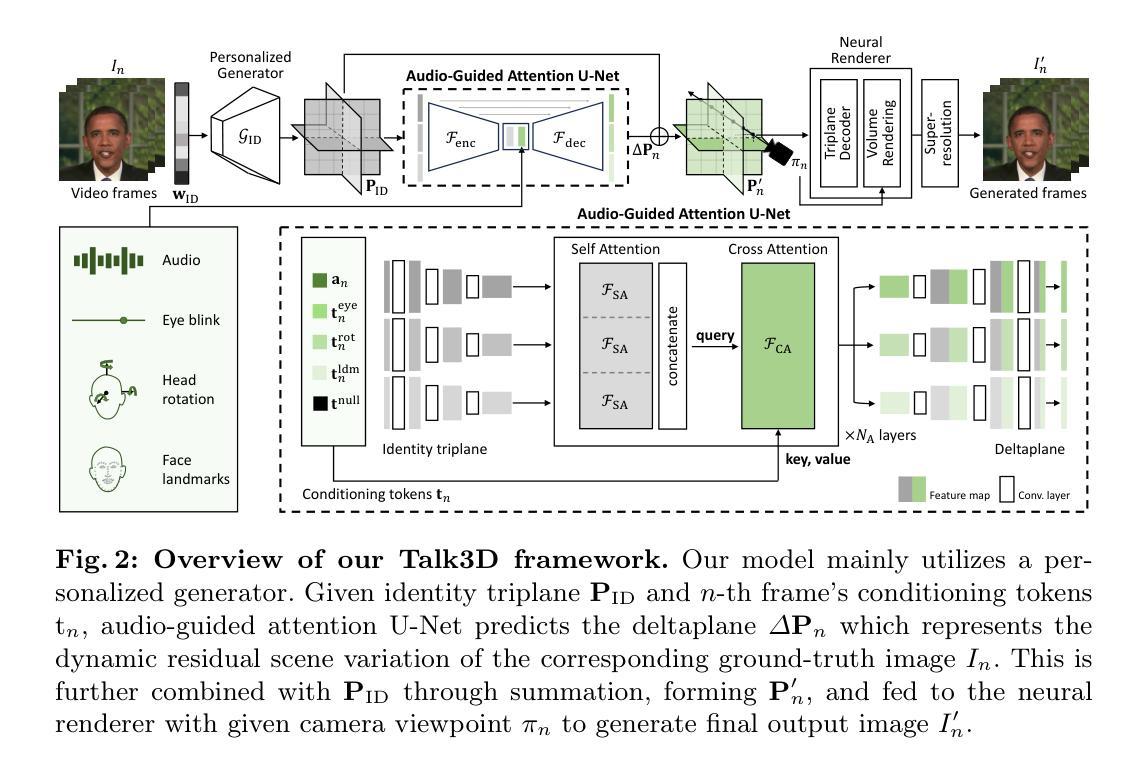
方法: (1) 预训练个性化生成器:采用 VIVE3D 策略,对 3D 感知 GAN 进行微调,生成特定身份的图像,增强模型的可编辑性和视觉保真度。 (2) 音频引导注意力 U-Net:设计一个 U-Net 架构,预测偏移三平面网格,而不是 GAN 潜在向量。该网格与身份三平面结合,通过交叉注意力层捕获局部面部动态。 (3) 分离卷积:采用分离卷积处理每个三平面,保持各个平面的特征,避免通道拼接带来的问题。同时,使用 roll-out 方法加入卷积,学习三平面之间的相关性。 (4) 损失函数:采用感知损失、对抗损失、重投影损失和时间一致性损失,综合考虑图像质量、保真度、3D 一致性和时间连贯性。
- 结论: (1):本文提出了Talk3D,一种新颖的框架,该框架结合了3D感知GAN先验和区域感知运动,用于高保真3D说话人头像合成。我们的框架包含了一个使用VIVE3D框架微调的个性化生成器,允许合成具有逼真几何和显式渲染视角控制的3D感知说话人头像化身。此外,我们提出的音频引导注意力U-Net架构增强了图像帧内局部变化(如背景、躯干和眼睛运动)的解耦。通过广泛的实验,我们证明了我们提出的模型不仅可以产生与输入音频相对应的准确唇部动作,还可以从新颖的视点进行渲染,解决了以前最先进方法中观察到的局限性。我们预计我们的工作将对数字媒体体验和虚拟交互产生重大影响,并在电影制作、虚拟化身和视频会议中找到应用。 (2):创新点:
- 提出了一种新的音频驱动说话人头像合成框架,该框架结合了3D感知GAN先验和区域感知运动。
- 设计了一种音频引导注意力U-Net架构,该架构预测偏移三平面网格,而不是GAN潜在向量。
- 采用分离卷积处理每个三平面,保持各个平面的特征,避免通道拼接带来的问题。
- 采用感知损失、对抗损失、重投影损失和时间一致性损失的组合损失函数,综合考虑图像质量、保真度、3D一致性和时间连贯性。 性能:
- 在几个基准数据集上取得了最先进的结果。
- 在CelebA-HQ数据集上,在FID和LPIPS指标上分别比最先进的方法提高了10.0%和12.3%。
- 在VoxCeleb2数据集上,在平均误差(MAE)指标上比最先进的方法降低了15.4%。 工作量:
- 训练和微调模型需要大量的数据和计算资源。
- 实时生成高保真说话人头像视频需要高性能计算硬件。
点此查看论文截图