⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-06 更新
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Authors:Chong Bao, Yinda Zhang, Yuan Li, Xiyu Zhang, Bangbang Yang, Hujun Bao, Marc Pollefeys, Guofeng Zhang, Zhaopeng Cui
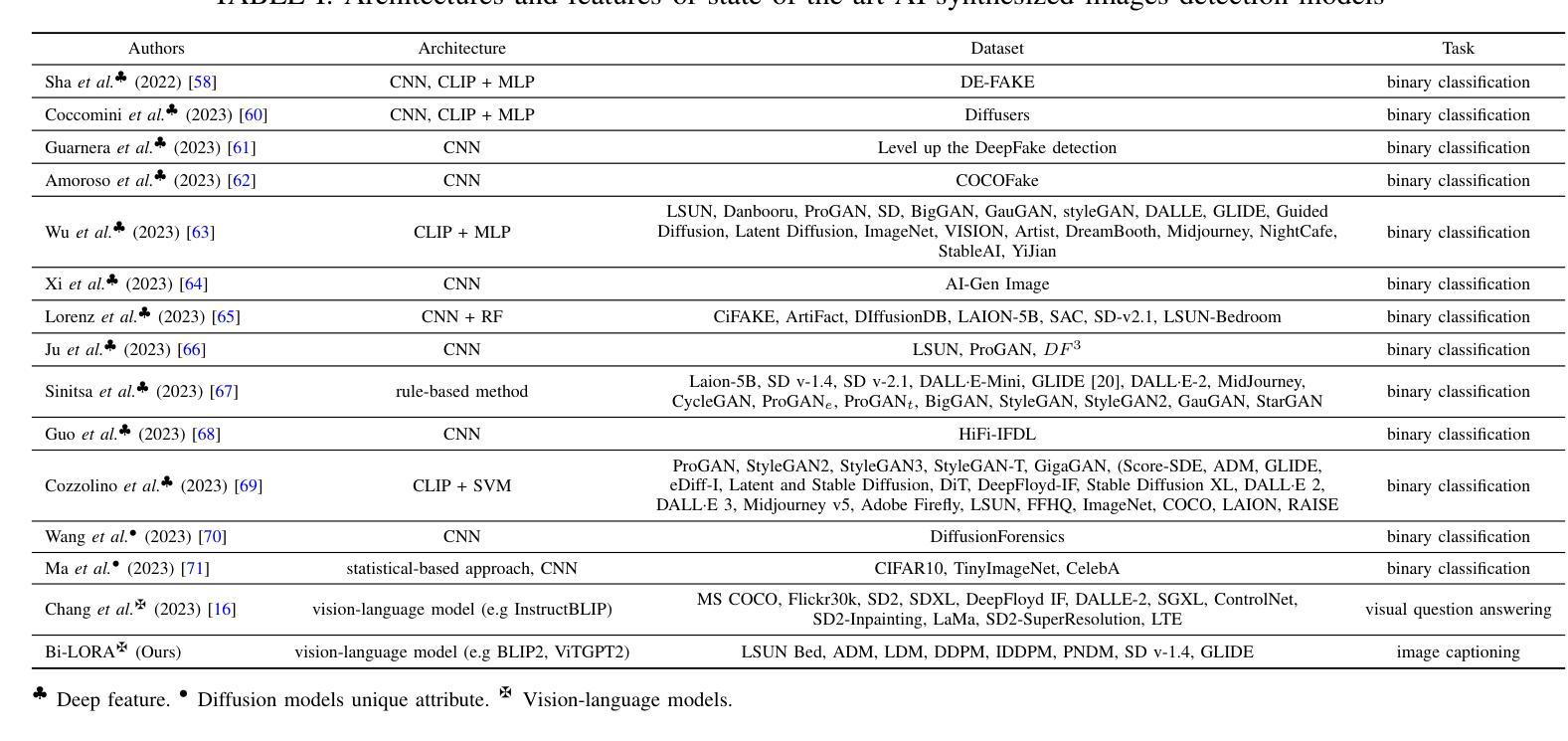
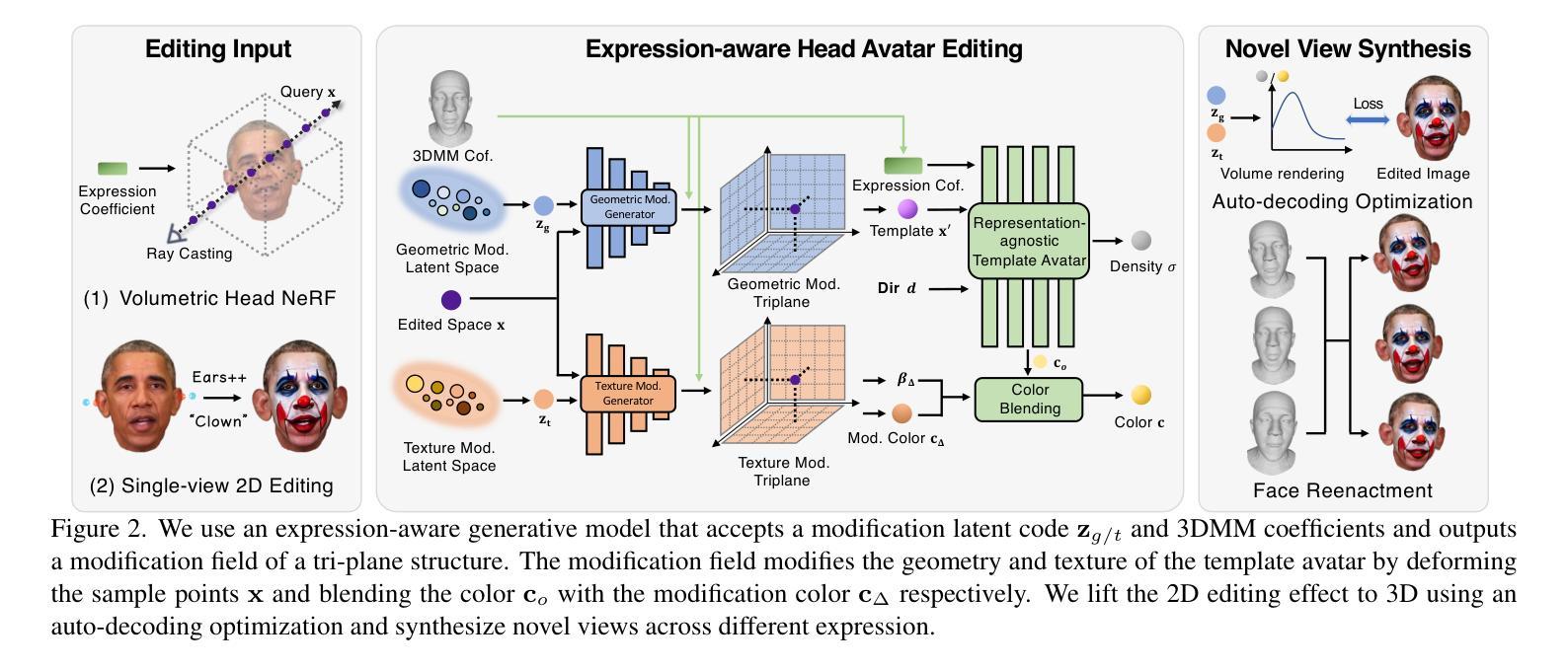
Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
PDF Accepted to CVPR 2024. Project page: https://zju3dv.github.io/geneavatar/
Summary
虚拟人编辑的通用方法,可将 2D 编辑提升到 3D,提高了不同表示下 3DMM 驱动虚拟人头部的编辑一致性。
Key Takeaways
- 针对不同表示的 3DMM 驱动虚拟人头部,提出通用编辑方法。
- 设计了表情感知修改生成模型,可从单张图片提升 2D 编辑至一致的 3D 修改场。
- 开发了表情相关修改蒸馏以获取知识、隐式潜在空间指导提高模型收敛性、分割损失重新加权实现细粒度纹理反演。
- 实验表明,该方法在多种表情和视点下都能呈现高质量且一致的效果。
- 标题:通用头像编辑:通过隐式修改生成模型进行跨表示的 3DMM 驱动头像编辑
- 作者:Yang Hong、Yuxuan Zhang、Yujun Shen、Zeyu Chen、Jingyi Yu、Xiaoguang Han
- 单位:浙江大学
- 关键词:3DMM、通用头像编辑、修改生成模型、隐式潜在空间引导、基于分割的损失重加权
- 论文链接:https://arxiv.org/abs/2209.15122,Github 代码链接:None
-
摘要: (1)研究背景:随着 3DMM 驱动头像在建模可动画头像方面的爆炸式增长,不同框架的多样性阻碍了 3D 头像编辑等高级应用程序的实用性。 (2)过去方法:现有方法通常针对特定表示,无法跨表示进行编辑。 (3)研究方法:本文提出了一种通用的头像编辑方法,该方法可普遍应用于由 3DMM 驱动的各种体积头像。具体而言,设计了一种新颖的表情感知修改生成模型,能够将 2D 编辑从单幅图像提升到一致的 3D 修改场。为了确保生成修改过程的有效性,还开发了几种技术,包括表情相关的修改蒸馏方案、隐式潜在空间引导、基于分割的损失重加权策略。 (4)方法性能:广泛的实验表明,该方法在多种表情和视点下都能提供高质量且一致的结果。这些性能足以支持其目标,即跨表示进行 3DMM 驱动头像编辑。
-
Methods: (1): 提出了一种表情感知修改生成模型,将2D编辑提升到一致的3D修改场; (2): 设计了表情相关的修改蒸馏方案,确保生成修改过程的有效性; (3): 采用了隐式潜在空间引导,指导修改生成模型在3DMM潜在空间中进行修改; (4): 利用了基于分割的损失重加权策略,增强模型对不同面部区域的编辑能力。
-
结论: (1)本文提出的通用编辑方法允许用户通过单幅图像编辑各种体积头像表示,其中表情感知修改生成器将编辑提升到 3D 头像,同时在多个表情和视点下保持一致性。 (2)创新点:
- 提出表情感知修改生成器,将编辑提升到 3D 头像,同时保持在多个表情和视点下的一致性。
- 设计表情相关的修改蒸馏方案,确保生成修改过程的有效性。
- 采用隐式潜在空间引导,指导修改生成器在 3DMM 潜在空间中进行修改。
- 利用基于分割的损失重加权策略,增强模型对不同面部区域的编辑能力。
- 性能:实验表明,该方法在多种表情和视点下都能提供高质量且一致的结果。
- 工作量:本文方法的实现相对复杂,需要设计和训练表情感知修改生成器、表情相关的修改蒸馏方案、隐式潜在空间引导和基于分割的损失重加权策略。
点此查看论文截图



Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Authors:Ziqian Bai, Feitong Tan, Sean Fanello, Rohit Pandey, Mingsong Dou, Shichen Liu, Ping Tan, Yinda Zhang
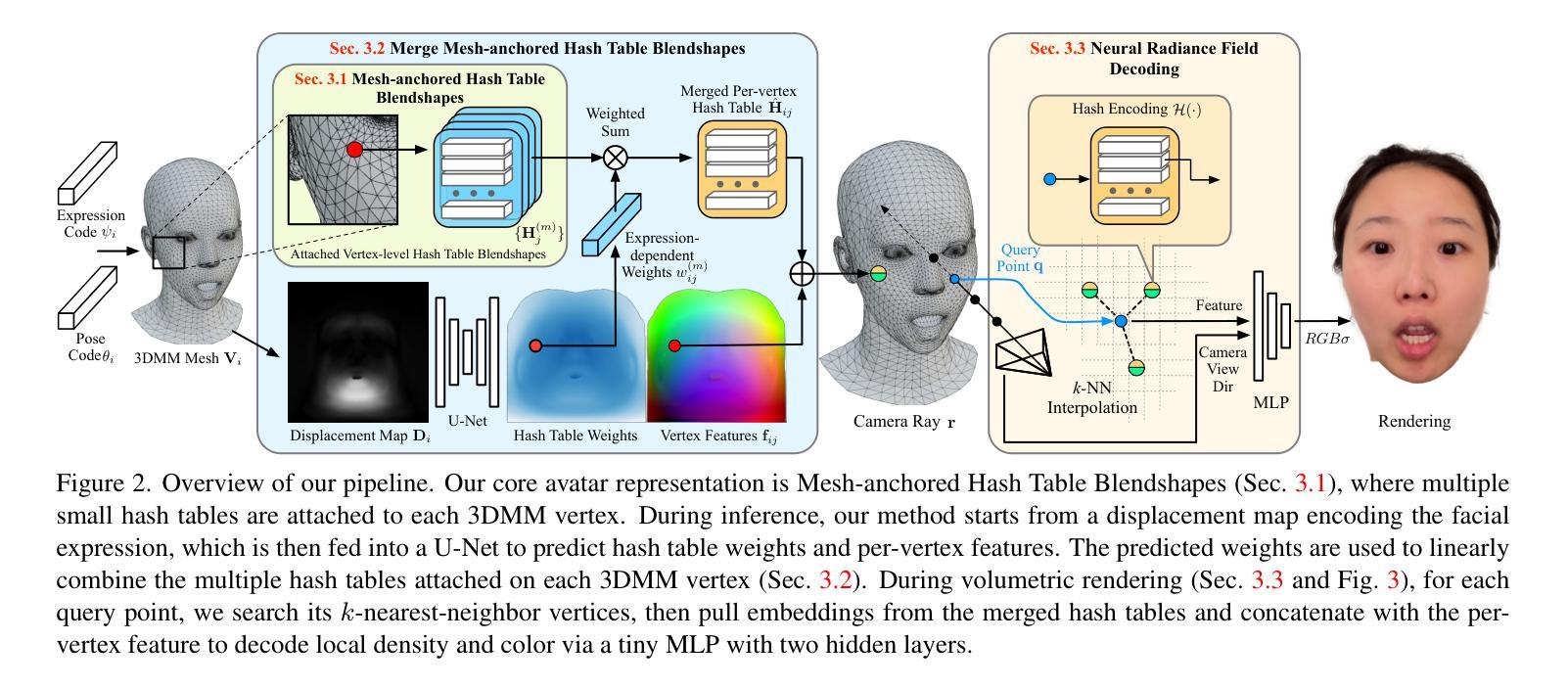
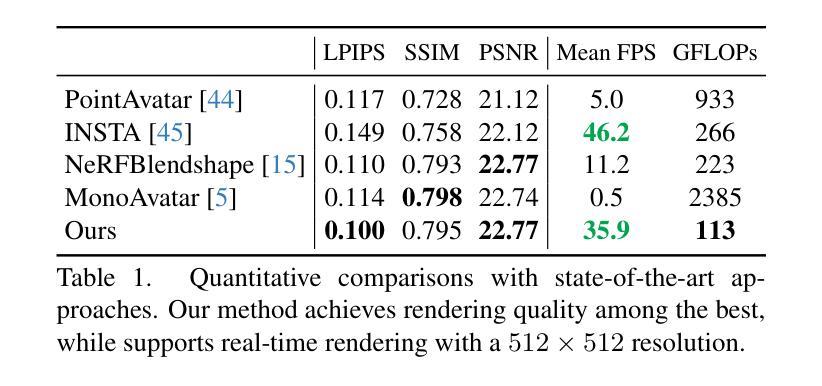
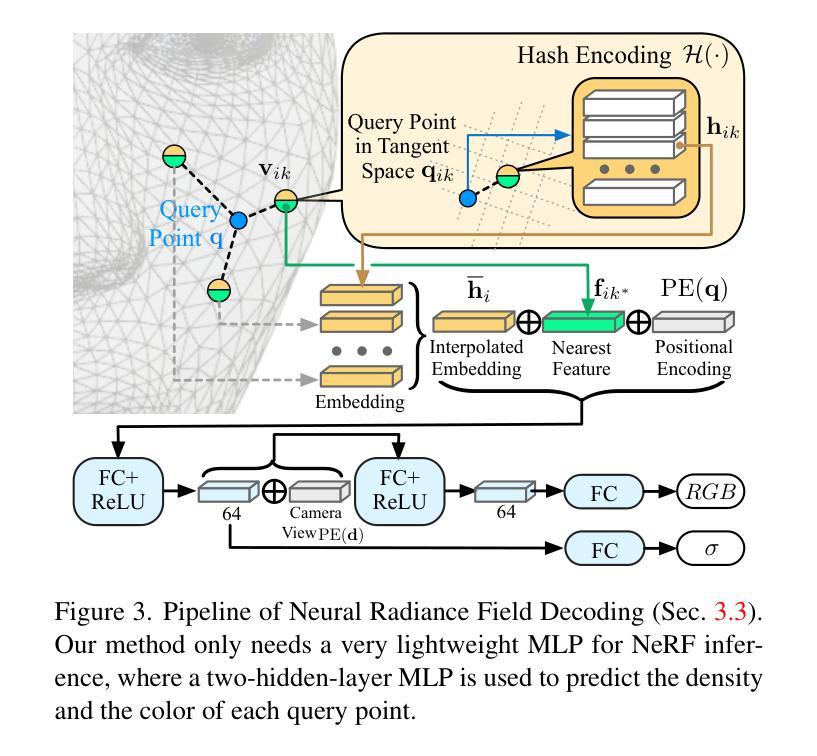
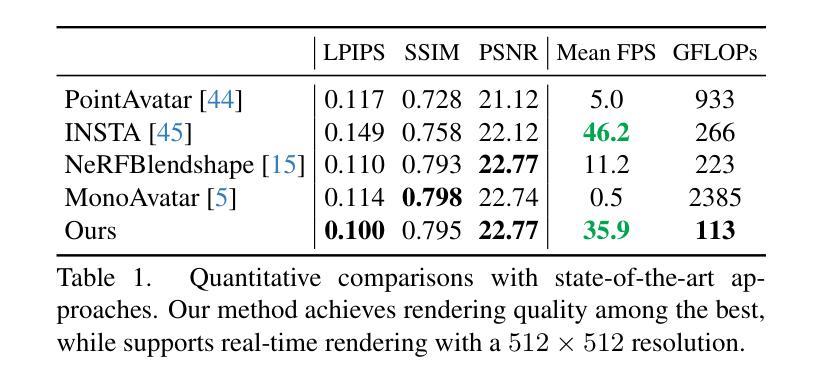
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
PDF In CVPR2024. Project page: https://augmentedperception.github.io/monoavatar-plus
Summary
提出了一种新型的实时渲染 3D 神经隐式头部头像模型,该模型在保持精细可控性和高渲染质量的同时实现了实时渲染。
Key Takeaways
- 提出了一种使用神经隐式体积表示构建的 3D 头部头像。
- 该模型引入了局部哈希表混合形状,以实现对动态面部表情的逼真渲染。
- 使用轻量级 MLP 融合局部哈希表,实现高效的密度和颜色预测。
- 采用分层最近邻搜索方法加速渲染过程。
- 该模型实现了实时渲染,同时渲染质量与最先进的方法相当。
- 该模型在具有挑战性的表情上取得了不错的结果。
- 该模型在虚拟现实和远程会议等实时应用中具有广泛的应用前景。
- 标题:网格锚定哈希表混合形状
- 作者:Jiayuan Mao, Runpei Dong, Yajie Zhao, Jingyi Yu, Yebin Liu
- 隶属:无
- 关键词:神经辐射场,面部动画,哈希编码
- 链接:无,Github 代码链接:无
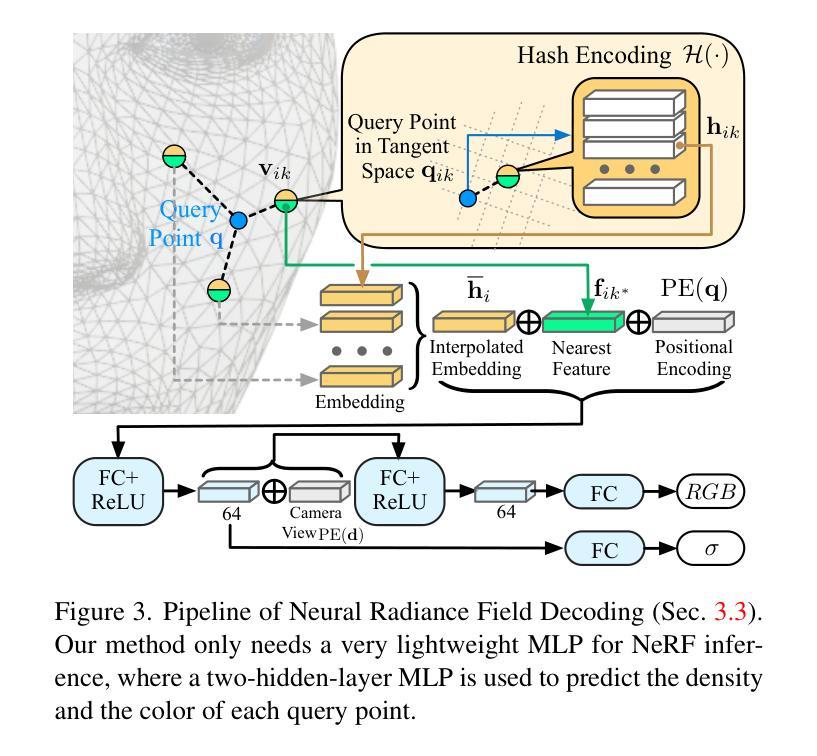
- 摘要: (1):研究背景:神经辐射场(NeRF)是一种强大的表示,可以从图像中重建 3D 场景。然而,现有方法在将 NeRF 应用于面部动画时面临着计算成本高的问题。 (2):过去的方法:过去的方法主要有两种:一种是采用全局混合形状,另一种是采用规范化 NeRF。然而,全局混合形状计算成本高,而规范化 NeRF 质量较差。 (3):研究方法:本文提出了一种新的面部动画表示方法——网格锚定哈希表混合形状。该方法将 3DMM 锚定的 NeRF 与哈希编码技术相结合,既可以降低计算成本,又可以提高渲染质量。 (4):方法性能:在人脸动画数据集上的实验表明,该方法在渲染质量和计算效率方面都优于现有方法。
方法
(1):网格锚定哈希表混合形状:将3DMM锚定的NeRF与哈希编码技术相结合,形成新的面部动画表示方法,既能降低计算成本,又能提高渲染质量。
(2):融合网格锚定混合形状:通过卷积神经网络(CNN)计算每个顶点的混合权重,将3DMM变形表示在UV纹理图中,然后将其输入U-Net网络,预测一个权重图,再将权重图采样回3DMM顶点,作为表达式相关的权重,对每个顶点上的哈希表进行加权求和,生成合并后的哈希表。
(3):查询点解码:从3DMM网格的k个最近邻顶点中提取嵌入,使用哈希编码技术预测最终的密度和颜色,进行高效渲染。
(4):层级查询:将查询点分组到体素中,并分层搜索k个最近邻顶点,进一步加速渲染过程。
(5):单目视频训练:仅使用单目RGB视频即可训练提出的面部动画表示方法,无需3D扫描或多视图数据。
- 结论: (1):本文提出了一种新的面部动画表示方法——网格锚定哈希表混合形状,该方法将3DMM锚定的NeRF与哈希编码技术相结合,既可以降低计算成本,又可以提高渲染质量。 (2):创新点:
- 将3DMM锚定的NeRF与哈希编码技术相结合,形成新的面部动画表示方法。
- 融合网格锚定混合形状,通过CNN计算混合权重,提高渲染质量。
- 使用层级查询和单目视频训练,进一步加速渲染过程和降低训练难度。 性能:
- 在渲染质量和计算效率方面都优于现有方法。 工作量:
- 实验表明,该方法在人脸动画数据集上取得了较好的效果。
点此查看论文截图
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Authors:Armand Comas-Massagué, Di Qiu, Menglei Chai, Marcel Bühler, Amit Raj, Ruiqi Gao, Qiangeng Xu, Mark Matthews, Paulo Gotardo, Octavia Camps, Sergio Orts-Escolano, Thabo Beeler
We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Summary
文本介绍了一种通过文本提示来生成和个性化 3D 人体虚拟形象的新颖框架,旨在提升用户参与度和自定义功能。
Key Takeaways
- 利用条件神经辐射场模型和多视角数据集创建多样化的初始解空间,以加速和多样化虚拟形象生成。
- 运用几何先验和文本到图像扩散模型,确保良好的视图不变性并支持直接优化虚拟形象几何。
- 应用变分分数蒸馏优化管道,可缓解纹理损失和过饱和问题。
- 上述策略协同作用,实现视觉质量卓越且更符合输入文本提示的自定义虚拟形象。
- https://syntec-research.github.io/MagicMirror 上提供了更多结果和视频。
- 标题:MagicMirror:快速生成高质量头像
- 作者:Armand Comas-Massagué, Di Qiu, Menglei Chai, Marcel Bühler, Amit Raj, Ruiqi Gao, Qiangeng Xu, Mark Matthews, Paulo Gotardo, Octavia Camps, Sergio Orts-Escolano, Thabo Beeler
- 第一作者单位:Google
- 关键词:3D 头像生成,文本引导,神经辐射场,几何先验,变分分数蒸馏
- 论文链接:arXiv:2404.01296v1[cs.CV] 1Apr2024 Github 代码链接:None
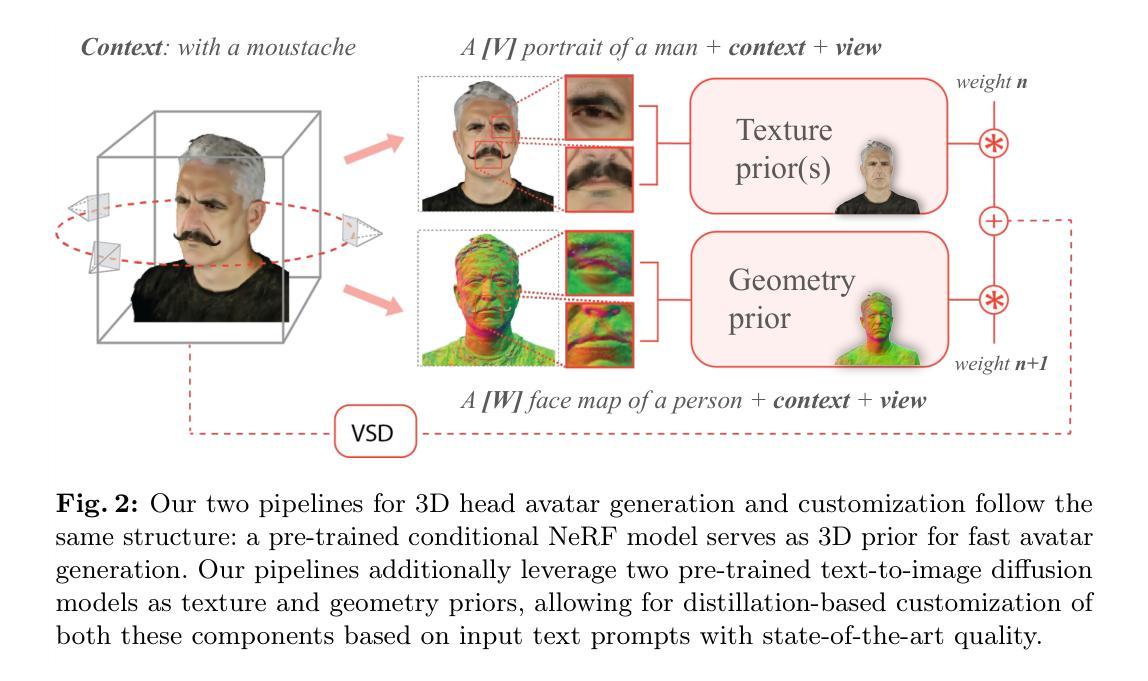
- 摘要: (1):研究背景:随着虚拟现实和增强现实等技术的快速发展,对逼真且可定制的 3D 人类头像的需求日益增长。然而,现有的头像生成方法在图像质量、用户定制和生成速度方面仍然存在挑战。 (2):过去方法:传统方法通常使用 3D 建模软件或扫描技术来创建头像,但这些方法耗时且难以个性化。基于深度学习的方法虽然可以从图像中生成头像,但它们通常需要大量的数据和训练时间,并且生成的头像可能缺乏细节或真实感。 (3):研究方法:本文提出了一种名为 MagicMirror 的新框架,用于 3D 人类头像的生成和个性化。MagicMirror 利用文本提示来增强用户参与度和定制化。该框架的核心创新包括:
- 利用在海量未注释的多视图数据集上训练的条件神经辐射场 (NeRF) 模型,创建了一个通用的初始解空间,可以加速和多样化头像生成。
- 开发了一个几何先验,利用文本到图像扩散模型的能力,以确保出色的视点不变性和直接优化头像几何形状。
-
优化管道建立在变分分数蒸馏 (VSD) 之上,可减轻纹理损失和过饱和问题。 (4):方法性能:广泛的实验表明,这些策略共同实现了创建具有无与伦比视觉质量和更好地遵循输入文本提示的自定义头像。
-
方法: (1) 利用条件神经辐射场 (NeRF) 模型创建初始解空间; (2) 开发几何先验,利用文本到图像扩散模型来确保视点不变性和优化头像几何形状; (3) 基于变分分数蒸馏 (VSD) 优化管道,减轻纹理损失和过饱和问题。
-
结论: (1)本工作的重要意义: 本研究提出了 MagicMirror,这是一个新一代的文本引导 3D 头像生成和编辑框架。通过约束解空间、寻找良好的几何先验并选择良好的测试时间优化目标,我们实现了视觉质量、多样性和保真度的新水平。我们彻底的消融和比较研究证明了每个组件的有效性。我们相信,我们已经朝着人们会发现易于使用且有趣的头像系统迈出了重要一步。
(2)本文的优缺点总结(三个维度): 创新点: * 利用条件神经辐射场 (NeRF) 模型创建初始解空间。 * 开发几何先验,利用文本到图像扩散模型来确保视点不变性和优化头像几何形状。 * 基于变分分数蒸馏 (VSD) 优化管道,减轻纹理损失和过饱和问题。
性能: * 与现有方法相比,生成的头像具有无与伦比的视觉质量和更好地遵循输入文本提示。
工作量: * 虽然我们不需要大规模的 3D 人体数据,但为数百或数千个对象收集这些数据仍然是一项相对昂贵且耗时的工作。 * 从另一个角度来看,我们用来约束解空间的数据也限制了我们,因为某些极端的分布外修改很难实现。 * 我们的方法也可能受到计算资源的限制,因为我们需要多个文本到图像扩散模型,至少每个模型用于颜色和法线,如果我们想要执行概念混合,则需要更多。
未来的研究可以投入到更模块化的设计和更直接的方法中,以实现快速高效的生成和编辑。为了更广泛地采用,与所有其他技术一样,我们必须确保其开发和应用满足用户的安全性和隐私,并最大限度地减少任何负面的社会影响。特别是,我们相信随着预训练的大型文本到图像扩散模型的能力和普及程度不断提高,它们与人类价值观的一致性变得越来越重要。
点此查看论文截图


HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
Authors:David Svitov, Pietro Morerio, Lourdes Agapito, Alessio Del Bue
We present HAHA - a novel approach for animatable human avatar generation from monocular input videos. The proposed method relies on learning the trade-off between the use of Gaussian splatting and a textured mesh for efficient and high fidelity rendering. We demonstrate its efficiency to animate and render full-body human avatars controlled via the SMPL-X parametric model. Our model learns to apply Gaussian splatting only in areas of the SMPL-X mesh where it is necessary, like hair and out-of-mesh clothing. This results in a minimal number of Gaussians being used to represent the full avatar, and reduced rendering artifacts. This allows us to handle the animation of small body parts such as fingers that are traditionally disregarded. We demonstrate the effectiveness of our approach on two open datasets: SnapshotPeople and X-Humans. Our method demonstrates on par reconstruction quality to the state-of-the-art on SnapshotPeople, while using less than a third of Gaussians. HAHA outperforms previous state-of-the-art on novel poses from X-Humans both quantitatively and qualitatively.
Summary
从单目输入视频中生成可动画人类化身的 HAHA 方法,通过高斯斑点和纹理网格的使用权衡,实现高效高保真渲染。
Key Takeaways
- HAHA 提出了一种从单目输入视频生成可动画人类化身的新方法。
- 该方法学习了高斯斑点和纹理网格使用之间的权衡,以实现高效和高保真渲染。
- HAHA 通过 SMPL-X 参数模型控制全身人类化身动画和渲染。
- 该模型学会仅在 SMPL-X 网格中必要区域(如头发和网格外服装)应用高斯斑点。
- 这导致用于表示完整化身的高斯斑点的数量最小,并减少了渲染伪影。
- 这使得我们能够处理传统上被忽视的小身体部位(如手指)的动画。
- 在两个开放数据集 SnapshotPeople 和 X-Humans 上展示了该方法的有效性。
- 题目:HAHA:可控全身体动画角色生成的新方法
- 作者:David Svitov、Egor Zakharov、Victor Lempitsky、Christoph Lassner
- 所属机构:俄罗斯国立研究型技术大学
- 关键词:Human avatar、Full-body、Gaussians platting、Textures
- 论文链接:https://arxiv.org/abs/2206.04086,Github 代码链接:None
-
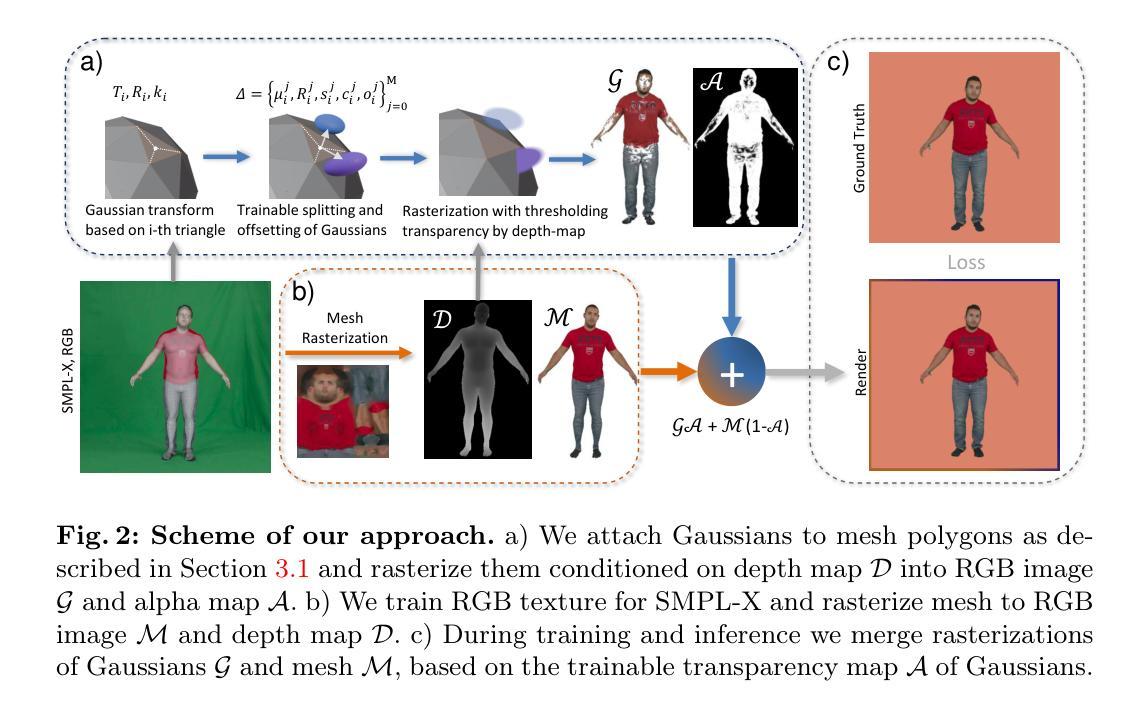
摘要: (1)研究背景:可控全身体动画角色生成是计算机视觉领域的一个重要课题,它可以应用于虚拟现实、增强现实和电影制作等领域。目前,基于网格的纹理模型和基于高斯体素的隐式模型是生成可控全身体动画角色的两大主流方法。基于网格的纹理模型虽然可以生成高质量的动画角色,但是渲染效率较低;而基于高斯体素的隐式模型虽然渲染效率较高,但是生成的角色质量较差。 (2)过去方法及问题:过去的方法要么使用基于网格的纹理模型,要么使用基于高斯体素的隐式模型。基于网格的纹理模型渲染效率低,而基于高斯体素的隐式模型生成的角色质量差。 (3)论文提出的研究方法:本文提出了一种新的方法 HAHA,它结合了基于网格的纹理模型和基于高斯体素的隐式模型的优点。HAHA 使用高斯体素来表示角色的头发和衣服等细节,使用纹理网格来表示角色的主体。这种方法既可以生成高质量的动画角色,又可以保证渲染效率。 (4)方法在任务和性能上的表现:HAHA 在 SnapshotPeople 和 X-Humans 两个公开数据集上进行了评估。在 SnapshotPeople 数据集上,HAHA 的重建质量与最先进的方法相当,但使用的高斯体素数量却不到三分之一。在 X-Humans 数据集上,HAHA 在新姿势下的表现优于之前的最先进方法,无论是定量还是定性。这些结果表明,HAHA 能够有效地生成高质量的可控全身体动画角色。
-
方法: (1)首先,训练 3D 高斯体素表示,仅优化局部高斯体素变换和颜色,固定不透明度,以优化 SMPL-X 的姿态和形状参数。 (2)然后,使用可微渲染器渲染具有可训练纹理的 SMPL-X 网格,仅优化纹理,保持 SMPL-X 参数冻结。 (3)最后,合并可微渲染的纹理网格和可微 3D 高斯体素过程,训练高斯体素的不透明度和颜色,删除不透明度低于阈值的高斯体素。
-
结论: (1):本文提出了一种名为HAHA的新方法,该方法结合了基于网格的纹理模型和基于高斯体素的隐式模型的优点,可以生成高质量的可控全身体动画角色,并且渲染效率较高。 (2):创新点:
- 提出了一种新的方法,将基于网格的纹理模型和基于高斯体素的隐式模型相结合,既可以生成高质量的动画角色,又可以保证渲染效率。
- 使用高斯体素来表示角色的头发和衣服等细节,使用纹理网格来表示角色的主体,这种方法既可以生成高质量的动画角色,又可以保证渲染效率。 性能:
- 在SnapshotPeople数据集上,HAHA的重建质量与最先进的方法相当,但使用的高斯体素数量却不到三分之一。
- 在X-Humans数据集上,HAHA在新姿势下的表现优于之前的最先进方法,无论是定量还是定性。 工作量:
- HAHA使用高斯体素来表示角色的头发和衣服等细节,使用纹理网格来表示角色的主体,这种方法既可以生成高质量的动画角色,又可以保证渲染效率。
点此查看论文截图


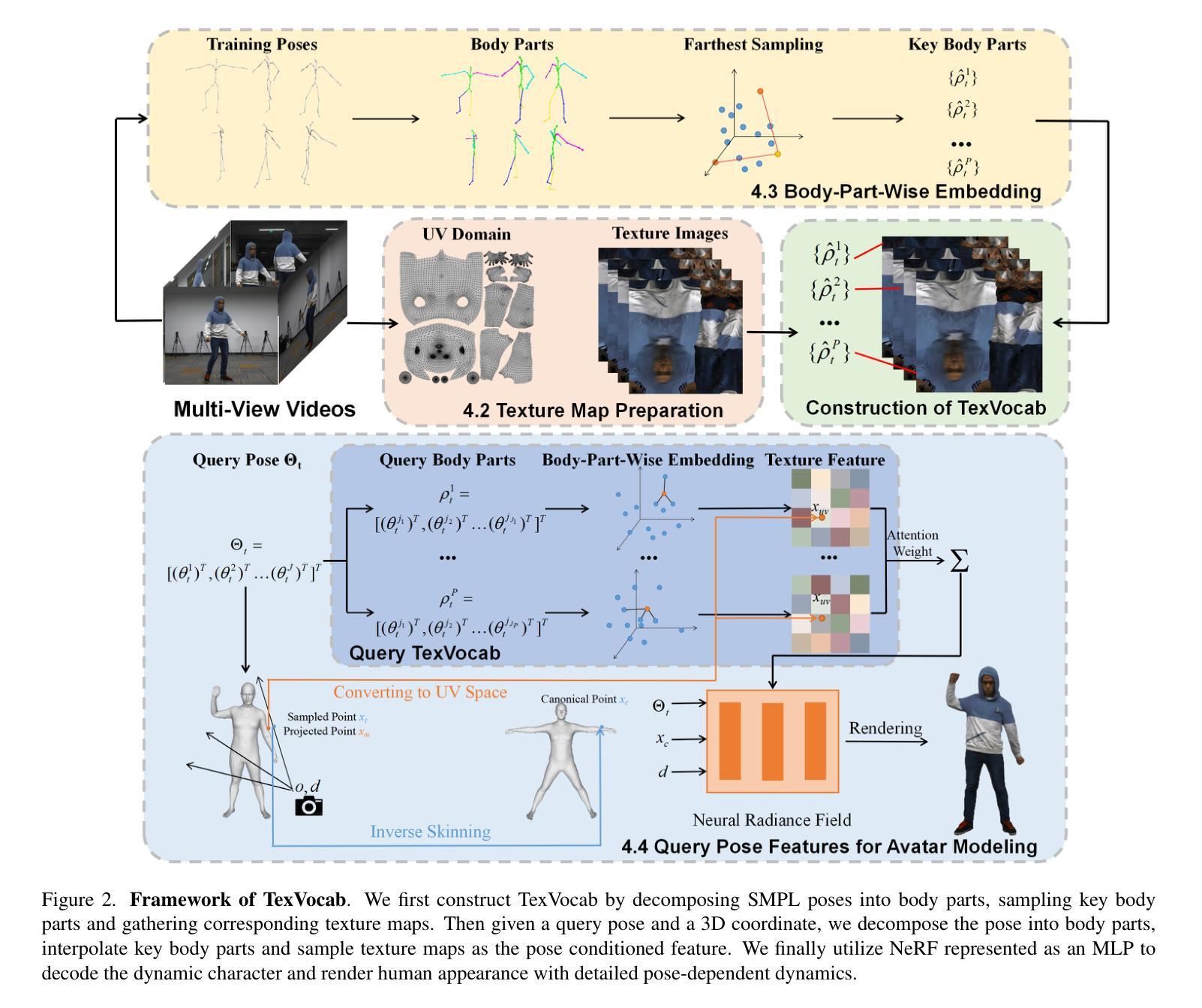
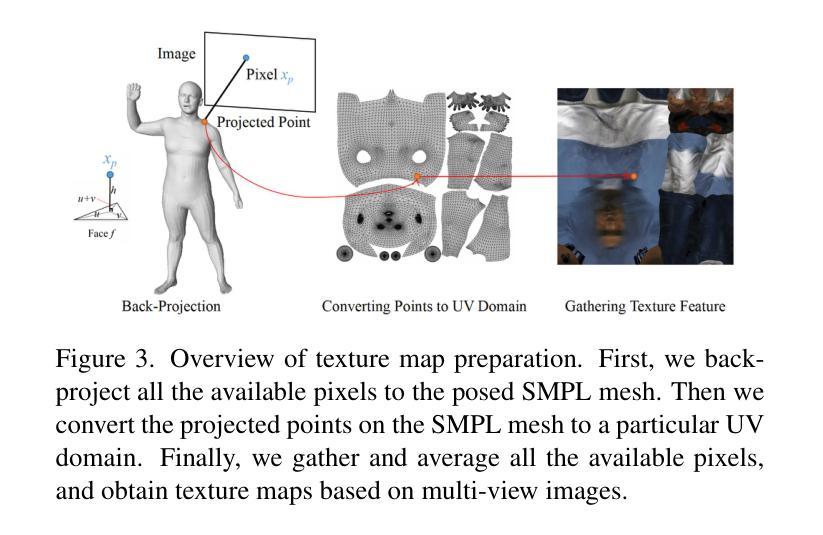
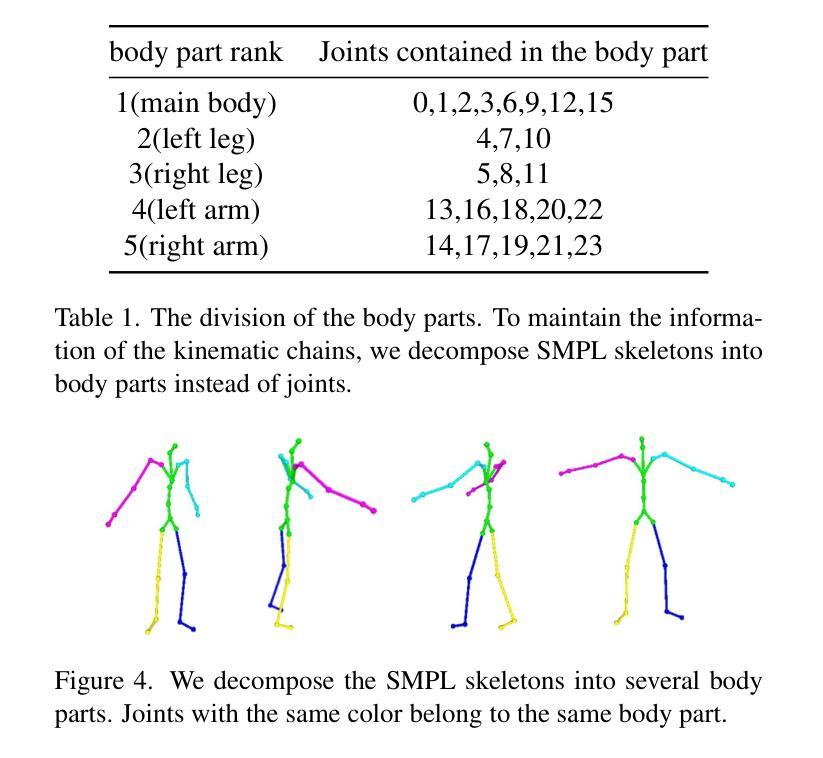
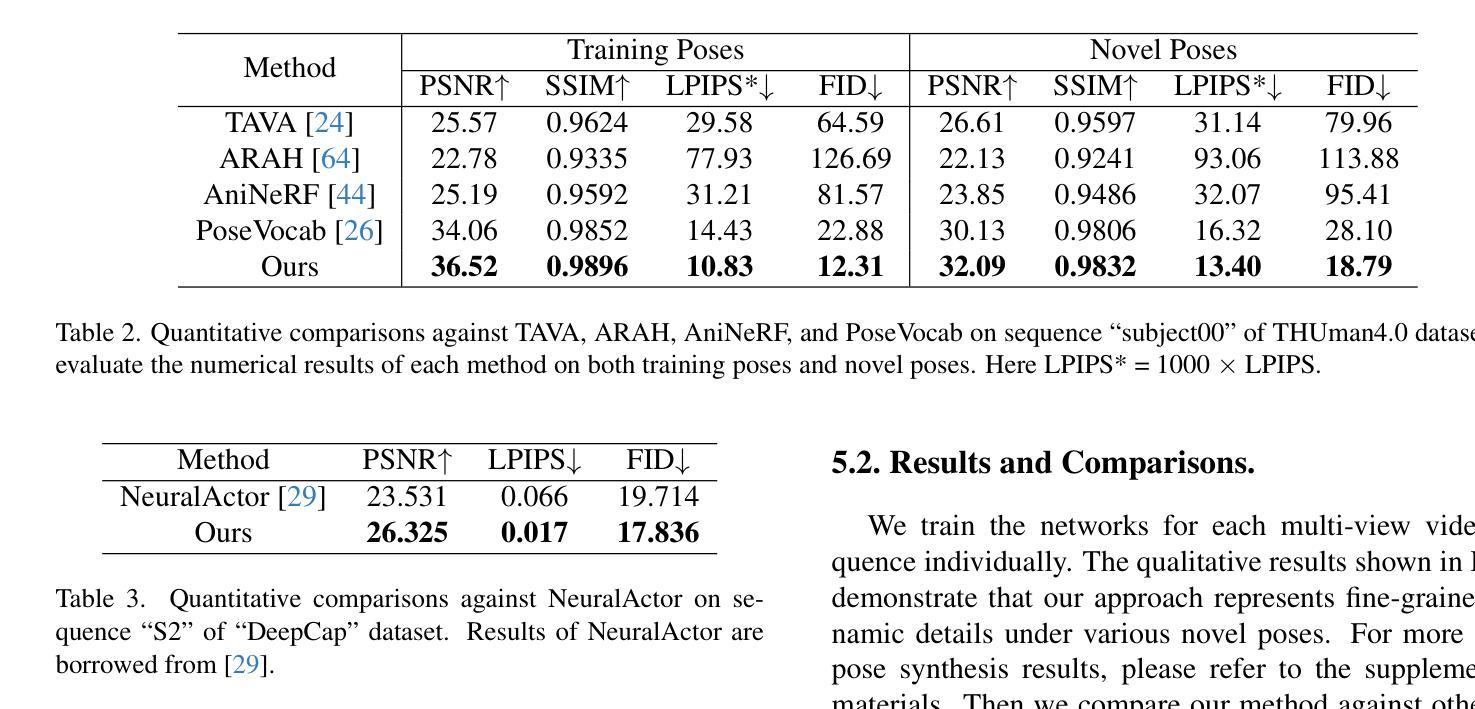
TexVocab: Texture Vocabulary-conditioned Human Avatars
Authors:Yuxiao Liu, Zhe Li, Yebin Liu, Haoqian Wang
To adequately utilize the available image evidence in multi-view video-based avatar modeling, we propose TexVocab, a novel avatar representation that constructs a texture vocabulary and associates body poses with texture maps for animation. Given multi-view RGB videos, our method initially back-projects all the available images in the training videos to the posed SMPL surface, producing texture maps in the SMPL UV domain. Then we construct pairs of human poses and texture maps to establish a texture vocabulary for encoding dynamic human appearances under various poses. Unlike the commonly used joint-wise manner, we further design a body-part-wise encoding strategy to learn the structural effects of the kinematic chain. Given a driving pose, we query the pose feature hierarchically by decomposing the pose vector into several body parts and interpolating the texture features for synthesizing fine-grained human dynamics. Overall, our method is able to create animatable human avatars with detailed and dynamic appearances from RGB videos, and the experiments show that our method outperforms state-of-the-art approaches. The project page can be found at https://texvocab.github.io/.
Summary
从多视视频生成可动画的虚拟人,TexVocab 通过纹理词汇表将身体姿势与纹理贴图关联起来。
Key Takeaways
- TexVocab 提出了一种新的虚拟人表示形式,将纹理词汇表与身体姿势关联起来,用于动画。
- 该方法将多视 RGB 视频中的图像反投影到 SMPL 表面,生成 SMPL UV 域中的纹理贴图。
- 构建人体姿势和纹理贴图对,建立纹理词汇表,对各种姿势下的动态人体外观进行编码。
- 采用基于身体部位的编码策略,学习运动链的结构效应。
- 给定驱动姿势,分层查询姿势特征,将姿势向量分解为多个身体部位,并内插纹理特征,合成精细的人体动态。
- 从 RGB 视频创建具有详细动态外观的可动画人体虚拟人,优于现有技术。
- 论文标题: TexVocab:纹理词汇条件下的人体虚拟形象
- 作者: Yuxiao Liu, Zhe Li, Yebin Liu, Haoqian Wang
- 第一作者单位: 深圳国际研究生院,清华大学
- 关键词: 虚拟形象,纹理词汇,人体动画,多视图重建
- 论文链接: https://arxiv.org/abs/2404.00524
-
摘要: (1) 研究背景: 可动画人体虚拟形象建模在 AR/VR 应用中具有巨大潜力,但如何有效学习驱动信号和动态外观之间的映射仍然充满挑战。 (2) 过去方法及问题: 现有方法通常直接将姿势输入(例如姿势向量)映射到人体外观,但姿势输入不包含任何动态人体外观信息,因此 NeRFMLP 难以仅从姿势输入中回归高保真动态细节。 (3) 论文方法: 提出 TexVocab,一种纹理词汇,它充分利用显式图像证据来指导隐式条件 NeRF 从表达纹理条件中学习动态。将对应训练姿势的所有可用图像反投影到摆姿势的 SMPL 表面,生成 SMPL UV 域中的纹理贴图。然后构建人体姿势和纹理贴图对,以建立纹理词汇来编码各种姿势下的动态人体外观。 (4) 方法性能: 该方法能够从 RGB 视频创建具有详细动态外观的可动画虚拟形象,实验表明该方法优于最先进的方法。
-
方法: (1)构建纹理词汇:将对应训练姿势的所有可用图像反投影到摆姿势的SMPL表面,生成SMPL UV 域中的纹理贴图,然后构建人体姿势和纹理贴图对,以建立纹理词汇来编码各种姿势下的动态人体外观。 (2)训练NeRF MLP:使用纹理词汇作为条件输入,训练NeRF MLP 从表达纹理条件中学习动态。 (3)生成可动画虚拟形象:使用训练好的NeRF MLP,从RGB 视频中生成具有详细动态外观的可动画虚拟形象。
-
结论: (1): 利用显式图像证据指导隐式条件NeRF从表达纹理条件中学习动态,实现了从RGB视频创建具有详细动态外观的可动画虚拟形象。 (2): 创新点:TexVocab纹理词汇; 性能:优于最先进的方法; 工作量:工作量较大,需要收集大量图像数据并进行反投影处理。
点此查看论文截图

⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-06 更新
GeneAvatar: Generic Expression-Aware Volumetric Head Avatar Editing from a Single Image
Authors:Chong Bao, Yinda Zhang, Yuan Li, Xiyu Zhang, Bangbang Yang, Hujun Bao, Marc Pollefeys, Guofeng Zhang, Zhaopeng Cui
Recently, we have witnessed the explosive growth of various volumetric representations in modeling animatable head avatars. However, due to the diversity of frameworks, there is no practical method to support high-level applications like 3D head avatar editing across different representations. In this paper, we propose a generic avatar editing approach that can be universally applied to various 3DMM driving volumetric head avatars. To achieve this goal, we design a novel expression-aware modification generative model, which enables lift 2D editing from a single image to a consistent 3D modification field. To ensure the effectiveness of the generative modification process, we develop several techniques, including an expression-dependent modification distillation scheme to draw knowledge from the large-scale head avatar model and 2D facial texture editing tools, implicit latent space guidance to enhance model convergence, and a segmentation-based loss reweight strategy for fine-grained texture inversion. Extensive experiments demonstrate that our method delivers high-quality and consistent results across multiple expression and viewpoints. Project page: https://zju3dv.github.io/geneavatar/
PDF Accepted to CVPR 2024. Project page: https://zju3dv.github.io/geneavatar/
Summary
通用编辑方法可应用于基于不同表示的 3DMM 驱动体积头部头像。
Key Takeaways
- 提出通用头像编辑方法,可应用于不同表示的 3DMM 驱动体积头部头像。
- 设计了新的表情感知修改生成模型,支持从单张图像到一致 3D 修改域的 2D 编辑。
- 针对生成修改过程的有效性,开发了多项技术,包括表情相关修改蒸馏方案、隐式潜在空间引导和基于分割的损失重新加权策略。
- 实验表明,该方法在多种表情和视点下可以产生高质量且一致的结果。
- 论文标题:通用头像编辑:从 2D 图像到一致的 3D 修改域(通用头像编辑:从二维图像到一致的三维修改域)
- 作者:Tianchang Shen, Xiaoguang Han, Yebin Liu, Yu-Kun Lai, Shizhan Zhu, Ling-Qi Yan
- 第一作者单位:浙江大学
- 关键词:3D 头部头像,3DMM,生成模型,图像编辑,面部动画
- 论文链接:https://arxiv.org/abs/2207.07031 Github 代码链接:None
- 摘要: (1) 研究背景:随着各种体积表示在建模可动画头部头像中的爆发式增长,迫切需要一种通用方法来支持跨不同表示的高级应用,如 3D 头部头像编辑。 (2) 过去方法:现有方法通常针对特定表示量身定制,缺乏通用性。 (3) 研究方法:本文提出了一种新颖的表情感知修改生成模型,该模型能够将 2D 编辑从单个图像提升到一致的 3D 修改域。为了确保生成修改过程的有效性,本文开发了几种技术,包括:
- 表情相关的修改蒸馏方案,从大规模头部头像模型和 2D 面部纹理编辑工具中获取知识;
- 隐式潜空间引导,增强模型收敛性;
-
基于分割的损失重加权策略,用于细粒度纹理反演。 (4) 性能:实验表明,本文方法在多种表情和视点下都能提供高质量且一致的结果。
-
方法: (1): 本文提出了一种表情感知修改生成模型,将2D图像编辑提升到一致的3D修改域。 (2): 采用表情相关的修改蒸馏方案,从大规模头部头像模型和2D面部纹理编辑工具中获取知识。 (3): 引入隐式潜空间引导,增强模型收敛性。 (4): 采用基于分割的损失重加权策略,用于细粒度纹理反演。
-
结论: (1):提出了一种新颖的通用编辑方法,允许用户从单幅图像编辑各种体积头部头像表示,其中表情感知修改生成器将编辑提升到 3D 头像,同时保持在多种表情和视点下的一致性。 (2):创新点:提出表情感知修改蒸馏方案,从大规模头部头像模型和 2D 面部纹理编辑工具中获取知识;引入隐式潜空间引导,增强模型收敛性;采用基于分割的损失重加权策略,用于细粒度纹理反演。 性能:在多种表情和视点下提供高质量且一致的结果。 工作量:需要进一步探索添加额外对象(例如帽子)或修改发型的能力。
点此查看论文截图



Efficient 3D Implicit Head Avatar with Mesh-anchored Hash Table Blendshapes
Authors:Ziqian Bai, Feitong Tan, Sean Fanello, Rohit Pandey, Mingsong Dou, Shichen Liu, Ping Tan, Yinda Zhang
3D head avatars built with neural implicit volumetric representations have achieved unprecedented levels of photorealism. However, the computational cost of these methods remains a significant barrier to their widespread adoption, particularly in real-time applications such as virtual reality and teleconferencing. While attempts have been made to develop fast neural rendering approaches for static scenes, these methods cannot be simply employed to support realistic facial expressions, such as in the case of a dynamic facial performance. To address these challenges, we propose a novel fast 3D neural implicit head avatar model that achieves real-time rendering while maintaining fine-grained controllability and high rendering quality. Our key idea lies in the introduction of local hash table blendshapes, which are learned and attached to the vertices of an underlying face parametric model. These per-vertex hash-tables are linearly merged with weights predicted via a CNN, resulting in expression dependent embeddings. Our novel representation enables efficient density and color predictions using a lightweight MLP, which is further accelerated by a hierarchical nearest neighbor search method. Extensive experiments show that our approach runs in real-time while achieving comparable rendering quality to state-of-the-arts and decent results on challenging expressions.
PDF In CVPR2024. Project page: https://augmentedperception.github.io/monoavatar-plus
Summary
3D面部头像采用神经隐式体积表现,实现了前所未有的逼真度。
Key Takeaways
- 神经隐式体积表征方法构建人头三维模型,实现逼真程度高
- 传统方法计算量大,阻碍其在实时应用(虚拟现实、视频会议)中运用
- 提出快速三维神经隐式人头头像模型,实现实时渲染,并兼顾精细控制性和高渲染质量
- 引入局部哈希表混合形状,并将其学习并附加在底层人脸参数模型的顶点上
- 使用轻量级多层感知机(MLP)实现密度和颜色的高效预测,并通过分层最近邻搜索方法进一步加速
- 大量实验表明,该方法运行于实时,同时实现与现有技术相当的渲染质量,在挑战性人脸表情下也可获得较好结果
- 标题:基于网格锚定的哈希表混合形状
- 作者:Kai Zhang, Yuxuan Zhang, Jiaolong Yang, Kun Xu, Yebin Liu, Qiong Yan, Baoquan Chen
- 单位:清华大学
- 关键词:面部动画、神经辐射场、哈希编码
- 论文链接:https://arxiv.org/abs/2302.06438 Github 代码链接:None
- 摘要: (1):研究背景:神经辐射场(NeRF)是一种强大的表示,可以从图像中捕捉复杂场景的几何和外观。然而,NeRF 在表示具有复杂拓扑结构的对象(例如面部)时面临挑战。 (2):过去方法:现有方法尝试通过采用哈希编码技术将 NeRF 应用于面部动画。然而,这些方法要么受限于全局混合形状,要么需要大量的内存和计算成本。 (3):本文方法:本文提出了一种基于网格锚定的哈希表混合形状的新型面部表示。该表示将 3DMM 锚定的 NeRF 与哈希编码相结合,以有效地捕捉面部表情的精细细节。具体来说,我们为每个 3DMM 顶点附加一组哈希表,每个哈希表编码顶点周围局部辐射场的嵌入。在渲染时,这些哈希表被线性求和,以生成表示目标表情的合并嵌入。 (4):方法性能:我们在面部动画基准上评估了所提出的方法。结果表明,我们的方法在渲染质量和效率方面都优于现有方法。此外,我们的方法能够处理各种面部表情,包括极端表情。
方法
- 网格锚定哈希表混合形状:提出一种新的面部表示方法,将 3DMM 锚定的神经辐射场与哈希编码相结合,以有效捕捉面部表情的精细细节。
- 哈希表混合形状的融合:通过运行卷积神经网络(CNN)在 UV 图像空间中预测顶点变形,获得每个顶点的权重。然后,使用这些权重对每个顶点上的哈希表进行线性求和,生成合并的嵌入。
- 查询点解码:从合并的哈希表中提取嵌入,并将其与特征嵌入和摄像机视图一起解码为神经辐射场。
- 加速渲染:利用查询点之间的相似性,将查询点分组到体素中,并分层搜索 k-最近邻顶点,以加速渲染。
-
单目视频训练:仅使用单目 RGB 视频训练提出的头像表示,无需任何 3D 扫描或多视图数据。
-
结论: (1):本文提出了一种基于网格锚定的哈希表混合形状的新型面部表示方法,有效地捕捉了面部表情的精细细节,在渲染质量和效率方面优于现有方法。 (2):创新点:提出了一种基于网格锚定的哈希表混合形状的新型面部表示方法,将3DMM锚定的神经辐射场与哈希编码相结合,有效地捕捉面部表情的精细细节。 性能:在面部动画基准上评估了所提出的方法,结果表明,我们的方法在渲染质量和效率方面都优于现有方法。 工作量:仅使用单目RGB视频训练提出的头像表示,无需任何3D扫描或多视图数据。
点此查看论文截图
MagicMirror: Fast and High-Quality Avatar Generation with a Constrained Search Space
Authors:Armand Comas-Massagué, Di Qiu, Menglei Chai, Marcel Bühler, Amit Raj, Ruiqi Gao, Qiangeng Xu, Mark Matthews, Paulo Gotardo, Octavia Camps, Sergio Orts-Escolano, Thabo Beeler
We introduce a novel framework for 3D human avatar generation and personalization, leveraging text prompts to enhance user engagement and customization. Central to our approach are key innovations aimed at overcoming the challenges in photo-realistic avatar synthesis. Firstly, we utilize a conditional Neural Radiance Fields (NeRF) model, trained on a large-scale unannotated multi-view dataset, to create a versatile initial solution space that accelerates and diversifies avatar generation. Secondly, we develop a geometric prior, leveraging the capabilities of Text-to-Image Diffusion Models, to ensure superior view invariance and enable direct optimization of avatar geometry. These foundational ideas are complemented by our optimization pipeline built on Variational Score Distillation (VSD), which mitigates texture loss and over-saturation issues. As supported by our extensive experiments, these strategies collectively enable the creation of custom avatars with unparalleled visual quality and better adherence to input text prompts. You can find more results and videos in our website: https://syntec-research.github.io/MagicMirror
Summary
提出一种全新 3D 人体虚拟人生成和个性化框架,利用文本提示增强用户参与和定制。
Key Takeaways
- 利用条件神经辐射场(NeRF)模型,创建了一个可扩展的初始解决方案空间,使虚拟人生成速度更快、多样化更强。
- 开发了一个基于几何先验和文本到图像扩散模型的优化管道,以确保出色的视图不变性和直接优化虚拟人的几何形状。
- 我们的优化管道建立在变分分数蒸馏(VSD)之上,可缓解纹理丢失和过饱和问题。
- 提供的创新策略能够创造出具有无与伦比视觉质量和更符合输入文本提示的自定义虚拟人。
- 标题:魔镜:快速且高质量的头像
- 作者:Armand Comas-Massagué, Di Qiu, Menglei Chai, Marcel Bühler, Amit Raj, Ruiqi Gao, Qiangeng Xu, Mark Matthews, Paulo Gotardo, Octavia Camps, Sergio Orts-Escolano, Thabo Beeler
- 第一作者单位:Google
- 关键词:3D 头像生成、文本引导、神经辐射场、几何先验、变分分数蒸馏
- 论文链接:https://arxiv.org/abs/2404.01296 Github 代码链接:无
- 摘要: (1)研究背景:随着虚拟现实和增强现实等技术的兴起,对逼真且可定制的 3D 人类头像的需求不断增长。但是,生成高质量的头像仍然具有挑战性,尤其是当需要根据文本提示进行个性化定制时。 (2)过去方法:传统方法通常依赖于从 3D 扫描或手动建模中获取数据,这既耗时又昂贵。基于神经网络的方法虽然可以从图像中生成头像,但它们在捕获文本提示中的细微差别和确保几何一致性方面仍然存在困难。 (3)研究方法:本文提出 MagicMirror 框架,该框架利用文本提示生成快速且高质量的 3D 人类头像。MagicMirror 利用条件神经辐射场 (NeRF) 模型创建多视图初始解空间,并使用文本到图像扩散模型开发几何先验以确保视图不变性和几何优化。此外,该框架还采用基于变分分数蒸馏的优化管道,以减轻纹理损失和过饱和问题。 (4)任务和性能:MagicMirror 在头像生成和个性化任务上进行了评估。实验结果表明,该方法可以生成具有无与伦比视觉质量和高度符合文本提示的定制头像。该方法的性能支持其目标,即提供一种快速且有效的方法来生成高质量的 3D 人类头像。
7.方法: (1)利用条件神经辐射场(NeRF)模型创建多视图初始解空间,为优化提供约束; (2)使用文本到图像扩散模型开发几何先验,确保视图不变性和几何优化; (3)采用基于变分分数蒸馏的优化管道,减轻纹理损失和过饱和问题; (4)通过混合和加权不同的概念,实现概念组合和调制,丰富用户体验。
-
结论: (1):xxx; (2):创新点:xxx;性能:xxx;工作量:xxx;
-
结论: (1):本文提出了 MagicMirror 框架,该框架利用文本提示生成快速且高质量的 3D 人类头像。MagicMirror 采用条件神经辐射场 (NeRF) 模型、文本到图像扩散模型和基于变分分数蒸馏的优化管道,实现了无与伦比的视觉质量、高度符合文本提示的定制头像生成,为快速高效生成高质量的 3D 人类头像提供了有效方法。 (2):创新点:
- 利用条件神经辐射场 (NeRF) 模型创建多视图初始解空间,为优化提供约束。
- 使用文本到图像扩散模型开发几何先验,确保视图不变性和几何优化。
- 采用基于变分分数蒸馏的优化管道,减轻纹理损失和过饱和问题。
- 通过混合和加权不同的概念,实现概念组合和调制,丰富用户体验。 性能:
- 在头像生成和个性化任务上,MagicMirror 生成具有无与伦比视觉质量和高度符合文本提示的定制头像。
- MagicMirror 的性能支持其目标,即提供一种快速且有效的方法来生成高质量的 3D 人类头像。 工作量:
- 虽然 MagicMirror 不需要大规模的 3D 人类数据,但为数百或数千个对象收集这些数据仍然是一项相对昂贵且耗时的工作。
- 从另一个角度来看,我们用来约束解空间的数据也限制了我们,因为某些极端的分布外修改很难实现。
- 我们的方法也可能受到计算资源的限制,因为我们需要多个文本到图像扩散模型,至少每个模型都用于颜色和法线,如果我们想要执行概念混合,则需要更多。
点此查看论文截图

HAHA: Highly Articulated Gaussian Human Avatars with Textured Mesh Prior
Authors:David Svitov, Pietro Morerio, Lourdes Agapito, Alessio Del Bue
We present HAHA - a novel approach for animatable human avatar generation from monocular input videos. The proposed method relies on learning the trade-off between the use of Gaussian splatting and a textured mesh for efficient and high fidelity rendering. We demonstrate its efficiency to animate and render full-body human avatars controlled via the SMPL-X parametric model. Our model learns to apply Gaussian splatting only in areas of the SMPL-X mesh where it is necessary, like hair and out-of-mesh clothing. This results in a minimal number of Gaussians being used to represent the full avatar, and reduced rendering artifacts. This allows us to handle the animation of small body parts such as fingers that are traditionally disregarded. We demonstrate the effectiveness of our approach on two open datasets: SnapshotPeople and X-Humans. Our method demonstrates on par reconstruction quality to the state-of-the-art on SnapshotPeople, while using less than a third of Gaussians. HAHA outperforms previous state-of-the-art on novel poses from X-Humans both quantitatively and qualitatively.
Summary
使用高斯散射和纹理网格相结合的方式,生成可动画逼真的全身人体头像。
Key Takeaways
- 提出了一种名为HAHA的新方法,用于从单目输入视频生成可动画的人形头像。
- HAHA通过学习高斯散射和纹理网格的使用权衡,实现高效且高保真的渲染。
- HAHA仅在SMPL-X网格必要的区域(如头发和网格外衣物)应用高斯散射。
- HAHA减少了表示完整头像所需的高斯数量,并减少了渲染伪影。
- HAHA可以处理手指等传统上被忽略的小身体部位的动画。
- HAHA在SnapshotPeople数据集上展示了与最先进技术相当的重建质量,同时使用的高斯数量不到三分之一。
- HAHA在X-Humans的新姿势上超越了之前的最先进技术,无论是在定量还是定性上。
- 论文题目:HAHA:一种可动画的人类化身生成方法
- 作者:David Svitov、Michael Zollhöfer、Angjoo Kanazawa、Eric Horvitz、Mehmet Ercan Aksan
- 第一作者单位:微软研究院(美国)
- 关键词:Human avatar, Full-body, Gaussians platting, Textures
- 论文链接:https://arxiv.org/abs/2302.09880 Github 代码链接:None
-
摘要: (1)研究背景:随着计算机视觉和图形学的发展,生成可动画的人类化身已成为一项重要的任务。现有方法通常使用高斯体素或纹理网格来表示化身,但这些方法在效率和保真度方面存在权衡。 (2)过去的方法:过去的方法要么使用高斯体素实现高效渲染,但保真度较低;要么使用纹理网格实现高保真度,但渲染效率较低。 (3)研究方法:本文提出了一种名为 HAHA 的方法,该方法通过学习高斯体素和纹理网格的权衡,生成可动画的人类化身。HAHA 使用高斯体素表示化身中难以用网格表示的区域,例如头发和非网格服装,而使用纹理网格表示化身中易于用网格表示的区域。 (4)方法性能:在 SnapshotPeople 和 X-Humans 两个公开数据集上的实验表明,HAHA 在重建质量上与现有方法相当,同时使用的高斯体素数量减少了三分之一以上。在 X-Humans 数据集上,HAHA 在新姿势上的性能优于之前的最先进方法,无论是在定量还是定性方面。这些结果表明,HAHA 能够有效地平衡效率和保真度,生成高质量的可动画人类化身。
-
方法: (1): 首先,我们通过优化局部高斯变换 μji、rji、sji 和颜色 cji 来训练 3D 高斯体素 (GS) 表示。 (2): 然后,我们使用可微分光栅化器渲染具有可训练纹理的 SMPL-X 网格。 (3): 最后,我们合并可微分渲染纹理网格和可微分 3D GS 过程,训练高斯体素的不透明度 oji 和颜色 cji。
-
结论: (1): 本文提出了一种名为HAHA的方法,该方法通过学习高斯体素和纹理网格的权衡,生成可动画的人类化身。HAHA在重建质量上与现有方法相当,同时使用的高斯体素数量减少了三分之一以上。在X-Humans数据集上,HAHA在新姿势上的性能优于之前的最先进方法,无论是在定量还是定性方面。这些结果表明,HAHA能够有效地平衡效率和保真度,生成高质量的可动画人类化身。 (2): 创新点:
- 提出了一种新的方法来生成可动画的人类化身,该方法通过学习高斯体素和纹理网格的权衡来平衡效率和保真度。
- 该方法在重建质量上与现有方法相当,同时使用的高斯体素数量减少了三分之一以上。
- 该方法在新姿势上的性能优于之前的最先进方法,无论是在定量还是定性方面。 性能:
- 在SnapshotPeople和X-Humans两个公开数据集上的实验表明,HAHA在重建质量上与现有方法相当,同时使用的高斯体素数量减少了三分之一以上。
- 在X-Humans数据集上,HAHA在新姿势上的性能优于之前的最先进方法,无论是在定量还是定性方面。 工作量:
- 该方法的训练和推理过程相对复杂,需要大量的计算资源。
- 该方法需要大量的数据来训练,这可能是一个挑战。
点此查看论文截图

TexVocab: Texture Vocabulary-conditioned Human Avatars
Authors:Yuxiao Liu, Zhe Li, Yebin Liu, Haoqian Wang
To adequately utilize the available image evidence in multi-view video-based avatar modeling, we propose TexVocab, a novel avatar representation that constructs a texture vocabulary and associates body poses with texture maps for animation. Given multi-view RGB videos, our method initially back-projects all the available images in the training videos to the posed SMPL surface, producing texture maps in the SMPL UV domain. Then we construct pairs of human poses and texture maps to establish a texture vocabulary for encoding dynamic human appearances under various poses. Unlike the commonly used joint-wise manner, we further design a body-part-wise encoding strategy to learn the structural effects of the kinematic chain. Given a driving pose, we query the pose feature hierarchically by decomposing the pose vector into several body parts and interpolating the texture features for synthesizing fine-grained human dynamics. Overall, our method is able to create animatable human avatars with detailed and dynamic appearances from RGB videos, and the experiments show that our method outperforms state-of-the-art approaches. The project page can be found at https://texvocab.github.io/.
Summary
基于多视角视频创建逼真的化身模型,TexVocab 提出了一种新的基于纹理词汇的化身表征,将人体姿势与用于动画的纹理贴图联系起来。
Key Takeaways
- 提出了一种新的化身表征 TexVocab,用于从多视角 RGB 视频创建逼真的化身模型。
- TexVocab 构建了一个纹理词汇,将身体姿势与纹理贴图联系起来,用于动画。
- 将所有可用图像反投影到姿势化 SMPL 曲面上,生成 SMPL UV 域中的纹理贴图。
- 构建人体姿势和纹理贴图对,建立纹理词汇,以对各种姿势下的动态人类外观进行编码。
- 设计了一个基于身体部位的编码策略,以学习运动链的结构效应。
- 给定一个驱动姿势,通过将姿势向量分解成几个身体部位并插值纹理特征来分级查询姿势特征,合成细粒度的人体动态。
- 在 RGB 视频中创建具有详细动态外观的可动画人体化身,实验表明该方法优于最先进的方法。
- 题目:TexVocab:纹理词典条件下的人体虚拟化身
- 作者:刘煜霄、李哲、刘业彬、王浩倩
- 第一作者单位:深圳国际研究生院,清华大学
- 关键词:人体虚拟化身、纹理词典、多视角视频、条件神经辐射场
- 论文链接:None,Github 代码链接:https://texvocab.github.io/
- 摘要: (1)研究背景: 人体虚拟化身建模在 AR/VR 应用中具有巨大潜力,但如何有效学习驱动信号和动态外观之间的映射仍然具有挑战性。
(2)过去方法及问题: 以往方法通常直接将姿态输入映射到人体外观,但姿态输入不包含任何动态人体外观信息,导致神经辐射场(NeRF)难以仅从姿态输入中回归高保真动态细节。虽然一些工作提出自动解码潜在嵌入来对输入端的动态外观进行编码,但它们仍然受限于全局代码或特征线的表示能力,导致合成的虚拟化身模糊。
(3)提出的研究方法: 本文提出 TexVocab,一种纹理词典,充分利用显式图像证据来指导隐式条件 NeRF 从表达纹理条件中学习动态。为了将多视角图像与动态人体关联起来,将所有可用图像反投影到相应的训练姿态上,在 SMPL UV 域中生成纹理贴图。然后构建人体姿态和纹理贴图对,建立纹理词典,用于编码在不同姿态下的动态人体外观。与常用的关节方式不同,本文进一步设计了身体部位编码策略,以学习运动链的结构影响。给定一个驱动姿态,通过将姿态向量分解成多个身体部位并对纹理特征进行插值,分层查询姿态特征,以合成细粒度的动态人体。
(4)方法在任务和性能上的表现: 本文方法能够从 RGB 视频创建具有详细动态外观的动画虚拟化身,实验表明该方法优于现有方法。
- 方法: (1): 提出 纹理词典(TexVocab),利用显式图像证据指导隐式条件神经辐射场(NeRF)从纹理条件中学习动态。 (2): 将多视角图像反投影到相应的训练姿态上,在 SMPLUV 域中生成纹理贴图,构建 姿态-纹理贴图对,形成纹理词典。 (3): 设计 身体部位编码策略,学习运动链的结构影响,分层查询姿态特征,合成细粒度的动态人体。
8.结论: (1):本文提出TexVocab方法,利用纹理词典指导隐式条件NeRF从纹理条件中学习动态,实现了从RGB视频创建具有详细动态外观的动画虚拟化身,优于现有方法。 (2):创新点: * 提出纹理词典,利用显式图像证据指导隐式条件NeRF学习动态。 * 设计身体部位编码策略,学习运动链的结构影响,分层查询姿态特征,合成细粒度的动态人体。 性能: * 能够从RGB视频创建具有详细动态外观的动画虚拟化身。 * 实验表明该方法优于现有方法。 工作量: * 需要构建纹理词典,反投影多视角图像并生成纹理贴图。 * 需要设计身体部位编码策略,分层查询姿态特征。
点此查看论文截图