⚠️ 以下所有内容总结都来自于 Google的大语言模型Gemini-Pro的能力,如有错误,仅供参考,谨慎使用
🔴 请注意:千万不要用于严肃的学术场景,只能用于论文阅读前的初筛!
💗 如果您觉得我们的项目对您有帮助 ChatPaperFree ,还请您给我们一些鼓励!⭐️ HuggingFace免费体验
2024-04-09 更新
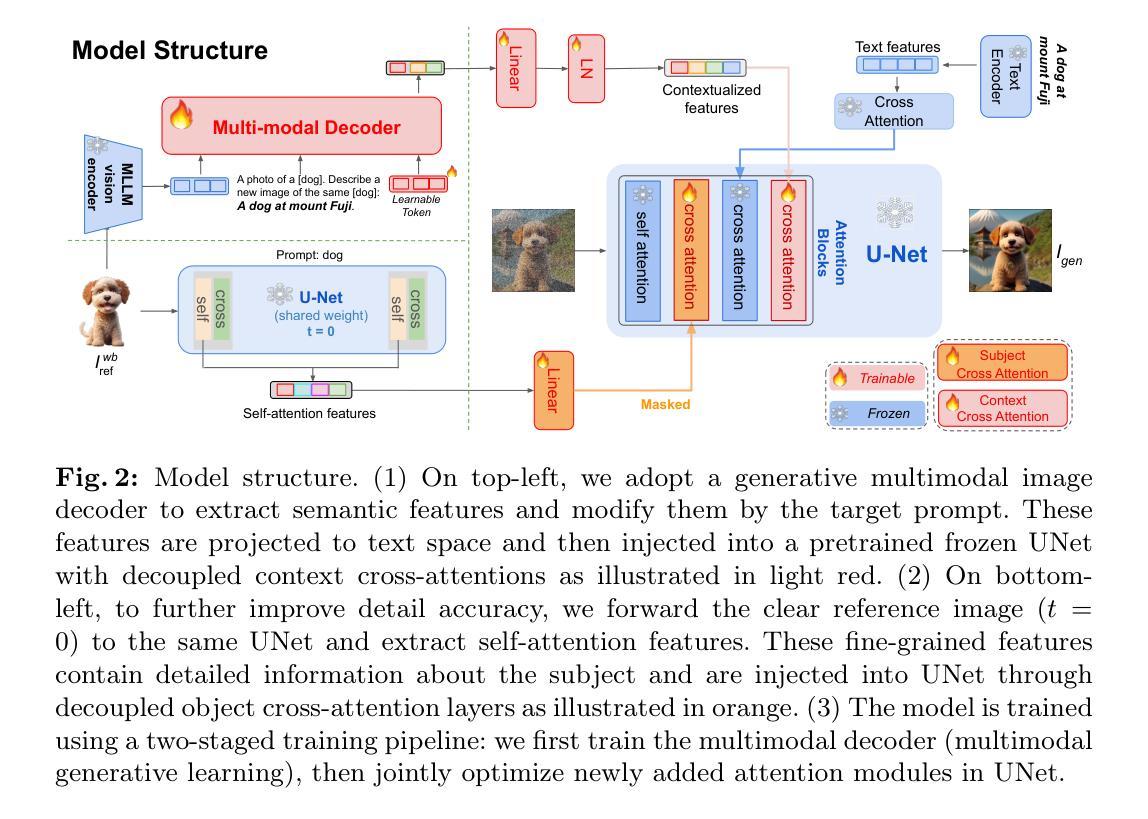
MoMA: Multimodal LLM Adapter for Fast Personalized Image Generation
Authors:Kunpeng Song, Yizhe Zhu, Bingchen Liu, Qing Yan, Ahmed Elgammal, Xiao Yang
In this paper, we present MoMA: an open-vocabulary, training-free personalized image model that boasts flexible zero-shot capabilities. As foundational text-to-image models rapidly evolve, the demand for robust image-to-image translation grows. Addressing this need, MoMA specializes in subject-driven personalized image generation. Utilizing an open-source, Multimodal Large Language Model (MLLM), we train MoMA to serve a dual role as both a feature extractor and a generator. This approach effectively synergizes reference image and text prompt information to produce valuable image features, facilitating an image diffusion model. To better leverage the generated features, we further introduce a novel self-attention shortcut method that efficiently transfers image features to an image diffusion model, improving the resemblance of the target object in generated images. Remarkably, as a tuning-free plug-and-play module, our model requires only a single reference image and outperforms existing methods in generating images with high detail fidelity, enhanced identity-preservation and prompt faithfulness. Our work is open-source, thereby providing universal access to these advancements.
Summary
MoMA: 一款免训练、开放词汇、专用于图像个性化生成且具备灵活零样本能力的图像模型。
Key Takeaways
- 提出 MoMA,可用于主题驱动的个性化图像生成。
- 使用多模态大语言模型 (MLLM) 同时充当特征提取器和生成器。
- 利用参考图像和文本提示信息生成有价值的图像特征。
- 采用自注意力快捷方式方法,将图像特征有效地传递给图像扩散模型。
- 作为免调优即插即用模块,MoMA 仅需一张参考图像即可生成高保真、增强身份保持和提示忠实度的图像。
- 代码开源,以期惠及更多从业者。
- 标题:MoMA:用于快速个性化图像生成的模态 LLM 适配器
- 作者:Kunpeng Song、Yizhe Zhu、Bingchen Liu、Qing Yan、Ahmed Elgammal、Xiao Yang
- 第一作者单位:字节跳动
- 关键词:图像生成、多模态、个性化、LLM
- 论文链接:https://arxiv.org/abs/2404.05674
-
摘要: (1)研究背景:随着文本到图像扩散模型的快速发展,对鲁棒图像到图像转换的需求也在不断增长。 (2)过去方法及其问题:现有的图像条件生成方法通常需要对输入图像进行文本表示的反演,并使用可学习的文本标记来表示目标概念。然而,这种方法存在文本描述无法充分表达详细视觉特征的问题。 (3)本文方法:本文提出了一种名为 MoMA 的开放词汇、免训练的个性化图像模型,该模型具有灵活的零样本能力。MoMA 利用开源的多模态大型语言模型 (MLLM),将其训练为同时充当特征提取器和生成器的双重角色。该方法有效地协同了参考图像和文本提示信息,以产生有价值的图像特征,从而促进图像扩散模型。为了更好地利用生成的特征,本文还引入了一种新颖的自注意力快捷方式方法,该方法可以有效地将图像特征转移到图像扩散模型中,从而提高生成图像中目标对象的相似性。 (4)方法性能:作为免调优的即插即用模块,MoMA 只需要一张参考图像,就能在生成具有高细节保真度、增强身份保留和提示忠实度的图像方面优于现有方法。这些性能支持了本文的目标,即提供一种用于快速个性化图像生成的高效且有效的模型。
-
方法: (1):本文提出了一种名为 MoMA 的开放词汇、免训练的个性化图像模型,该模型具有灵活的零样本能力。 (2):MoMA 利用开源的多模态大型语言模型 (MLLM),将其训练为同时充当特征提取器和生成器的双重角色。 (3):该方法有效地协同了参考图像和文本提示信息,以产生有价值的图像特征,从而促进图像扩散模型。 (4):为了更好地利用生成的特征,本文还引入了一种新颖的自注意力快捷方式方法,该方法可以有效地将图像特征转移到图像扩散模型中,从而提高生成图像中目标对象的相似性。
-
总结: (1):本文提出的 MoMA 模型,为基于文本到图像扩散模型的快速图像个性化提供了强大的解决方案。该模型免调优、开放词汇,支持重新语境化和纹理编辑。实验结果表明其优于现有方法。我们提出的多模态图像特征解码器成功利用了 MLLM 的优势,用于上下文特征生成。我们提出的掩码主体交叉注意力技术提供了一个引人注目的特征捷径,显著提高了细节准确性。此外,作为即插即用模块,我们的模型可以直接集成到从同一基础模型调整的社区模型中,将其应用扩展到更广泛的领域。 (2):创新点:提出了一种新的开放词汇、免训练的图像个性化模型 MoMA,该模型利用 MLLM 同时充当特征提取器和生成器,有效地协同参考图像和文本提示信息,并引入了一种新颖的自注意力快捷方式方法,以提高生成图像中目标对象的相似性。 性能:在图像个性化任务上,MoMA 在细节保真度、身份保留增强和提示忠实度方面优于现有方法。 工作量:MoMA 作为免调优的即插即用模块,只需要一张参考图像,即可快速生成个性化的图像。
点此查看论文截图


YaART: Yet Another ART Rendering Technology
Authors:Sergey Kastryulin, Artem Konev, Alexander Shishenya, Eugene Lyapustin, Artem Khurshudov, Alexander Tselousov, Nikita Vinokurov, Denis Kuznedelev, Alexander Markovich, Grigoriy Livshits, Alexey Kirillov, Anastasiia Tabisheva, Liubov Chubarova, Marina Kaminskaia, Alexander Ustyuzhanin, Artemii Shvetsov, Daniil Shlenskii, Valerii Startsev, Dmitrii Kornilov, Mikhail Romanov, Artem Babenko, Sergei Ovcharenko, Valentin Khrulkov
In the rapidly progressing field of generative models, the development of efficient and high-fidelity text-to-image diffusion systems represents a significant frontier. This study introduces YaART, a novel production-grade text-to-image cascaded diffusion model aligned to human preferences using Reinforcement Learning from Human Feedback (RLHF). During the development of YaART, we especially focus on the choices of the model and training dataset sizes, the aspects that were not systematically investigated for text-to-image cascaded diffusion models before. In particular, we comprehensively analyze how these choices affect both the efficiency of the training process and the quality of the generated images, which are highly important in practice. Furthermore, we demonstrate that models trained on smaller datasets of higher-quality images can successfully compete with those trained on larger datasets, establishing a more efficient scenario of diffusion models training. From the quality perspective, YaART is consistently preferred by users over many existing state-of-the-art models.
PDF Prompts and additional information are available on the project page, see https://ya.ru/ai/art/paper-yaart-v1
Summary
基于人类反馈强化学习构建YaART,高效高保真文本生成图像多级扩散模型。
Key Takeaways
- 引入YaART,一种采用人类反馈强化学习的人类偏好文本生成图像级联扩散模型。
- 分析模型和训练数据集大小对训练效率和图像质量的影响。
- 使用较小的高质量图像数据集训练模型可竞争使用较大型数据集训练的模型。
- YaART在质量上优于许多现有最先进模型。
- 多级扩散模型训练中,模型和训练数据集大小选择非常重要。
- 高质量小数据集训练模型更有效率。
- 人类反馈强化学习是文本生成图像级联扩散模型的关键技术。
- 标题: YaART:又一种艺术渲染技术
- 作者: Sergey Kastryulin, Artem Konev, Alexander Shishenya, Eugene Lyapustin, Artem Khurshudov, Alexander Tselousov, Nikita Vinokurov, Denis Kuznedelev, Alexander Markovich, Grigoriy Livshits, Alexey Kirillov, Anastasiia Tabisheva, Liubov Chubarova, Marina Kaminskaia, Alexander Ustyuzhanin, Artemii Shvetsov, Daniil Shlenskii, Valerii Startsev, Dmitrii Kornilov, Mikhail Romanov, Artem Babenko, Sergei Ovcharenko, Valentin Khrulkov
- 第一作者单位: Yandex
- 关键词: Diffusion models, Scaling, Efficiency
- 论文链接: arXiv:2404.05666
-
摘要: (1) 研究背景: 生成模型领域快速发展,高效且高保真的文本到图像扩散系统是重要的研究前沿。 (2) 过去方法及问题: 之前的文本到图像级联扩散模型尚未系统地研究模型和训练数据集大小对训练效率和生成图像质量的影响。 (3) 研究方法: 本文提出 YaART,一种新的面向生产级文本到图像级联扩散模型,使用人类反馈强化学习(RLHF)与人类偏好保持一致。重点分析了模型和训练数据集大小的选择如何影响训练效率和图像质量。 (4) 任务和性能: 在图像生成任务上,YaART 在效率和质量方面都优于现有模型。训练在较小的高质量图像数据集上的模型可以与训练在较大数据集上的模型竞争,建立了更有效的扩散模型训练方案。从质量角度来看,用户一致认为 YaART 优于许多现有的最先进模型。
-
方法:(1) 大规模扩散模型训练方法;(2) 训练集构建策略;(3) 模型训练阶段;(4) RL 对齐。
8.结论: (1)本工作的重要意义:本文提出了YaART,一种面向生产级的文本到图像级联扩散模型,系统地研究了模型和训练数据集大小对训练效率和生成图像质量的影响,建立了更有效的扩散模型训练方案,在效率和质量方面都优于现有模型。 (2)本文的优缺点总结: 创新点: * 提出了一种新的文本到图像级联扩散模型YaART,使用RLHF与人类偏好保持一致。 * 重点分析了模型和训练数据集大小的选择如何影响训练效率和图像质量。 性能: * 在图像生成任务上,YaART在效率和质量方面都优于现有模型。 * 训练在较小的高质量图像数据集上的模型可以与训练在较大数据集上的模型竞争。 工作量: * 需要大量的高质量图像数据集进行训练。 * RL对齐过程需要大量的人力资源。
点此查看论文截图


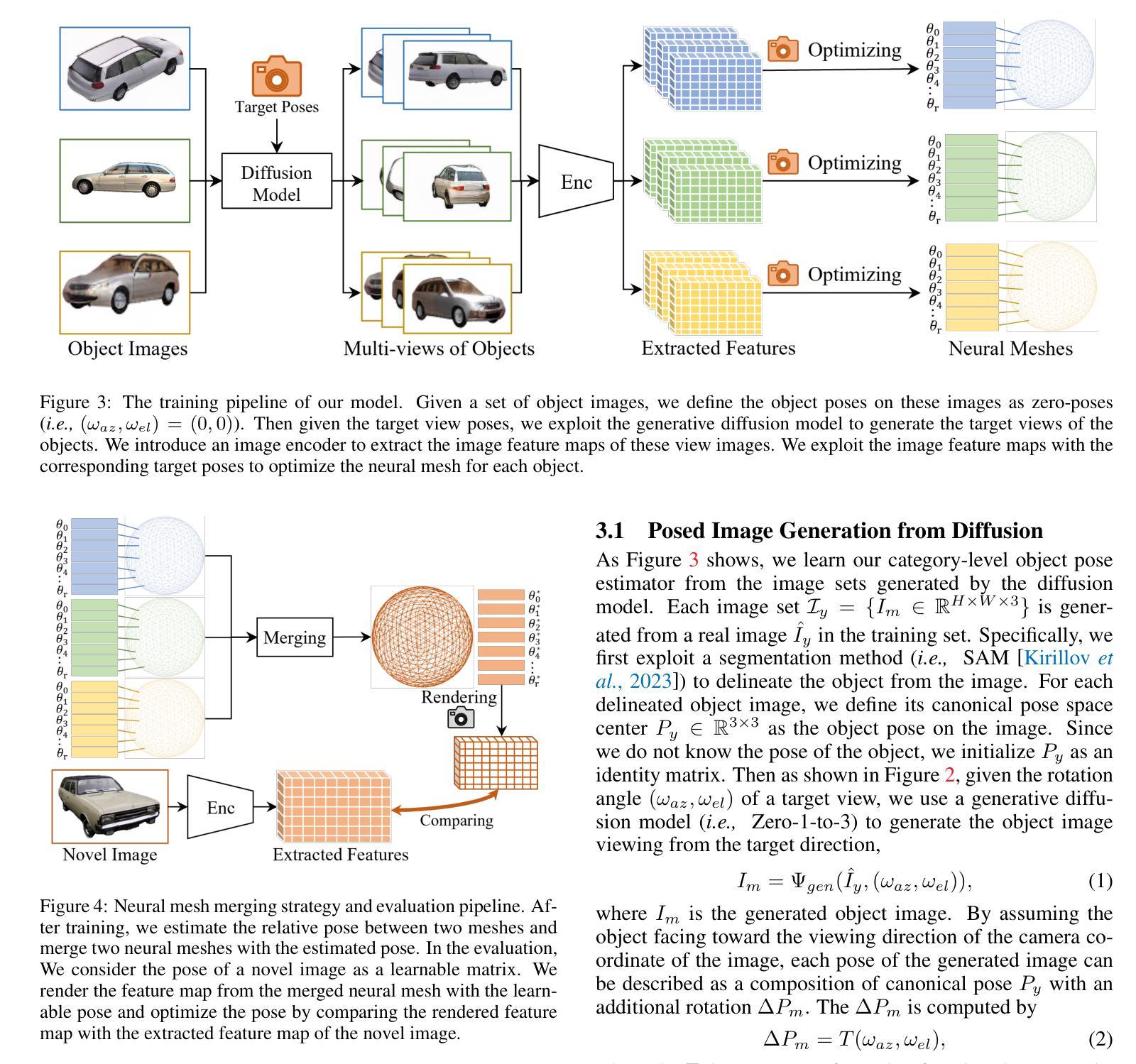
Learning a Category-level Object Pose Estimator without Pose Annotations
Authors:Fengrui Tian, Yaoyao Liu, Adam Kortylewski, Yueqi Duan, Shaoyi Du, Alan Yuille, Angtian Wang
3D object pose estimation is a challenging task. Previous works always require thousands of object images with annotated poses for learning the 3D pose correspondence, which is laborious and time-consuming for labeling. In this paper, we propose to learn a category-level 3D object pose estimator without pose annotations. Instead of using manually annotated images, we leverage diffusion models (e.g., Zero-1-to-3) to generate a set of images under controlled pose differences and propose to learn our object pose estimator with those images. Directly using the original diffusion model leads to images with noisy poses and artifacts. To tackle this issue, firstly, we exploit an image encoder, which is learned from a specially designed contrastive pose learning, to filter the unreasonable details and extract image feature maps. Additionally, we propose a novel learning strategy that allows the model to learn object poses from those generated image sets without knowing the alignment of their canonical poses. Experimental results show that our method has the capability of category-level object pose estimation from a single shot setting (as pose definition), while significantly outperforming other state-of-the-art methods on the few-shot category-level object pose estimation benchmarks.
Summary
利用无标注扩散模型生成图像,提出无姿态标注的类别级3D物体姿态估计方法。
Key Takeaways
- 提出了一种无姿态标注的类别级3D物体姿态估计方法。
- 利用扩散模型生成受控姿态差异的图像集,用于训练姿态估计器。
- 设计了一个图像编码器,从对比姿态学习中学习,过滤不合理的细节并提取图像特征图。
- 提出了一种新颖的学习策略,使模型能够从生成的图像集中学习物体姿态,而无需知道其规范姿态的对齐方式。
- 实验结果表明,该方法具有从单次拍摄设置(作为姿态定义)中进行类别级物体姿态估计的能力。
- 在少样本类别级物体姿态估计基准上明显优于其他最先进的方法。
- 论文标题:无需姿态标注的类别级物体姿态估计
- 作者:冯瑞天,姚瑶,亚当·科蒂莱夫斯基,岳琦段,邵毅杜,艾伦·尤尔,王安天
- 第一作者单位:西安交通大学
- 关键词:类别级物体姿态估计,扩散模型,对比姿态学习
- 论文链接:https://arxiv.org/abs/2404.05626 Github 链接:无
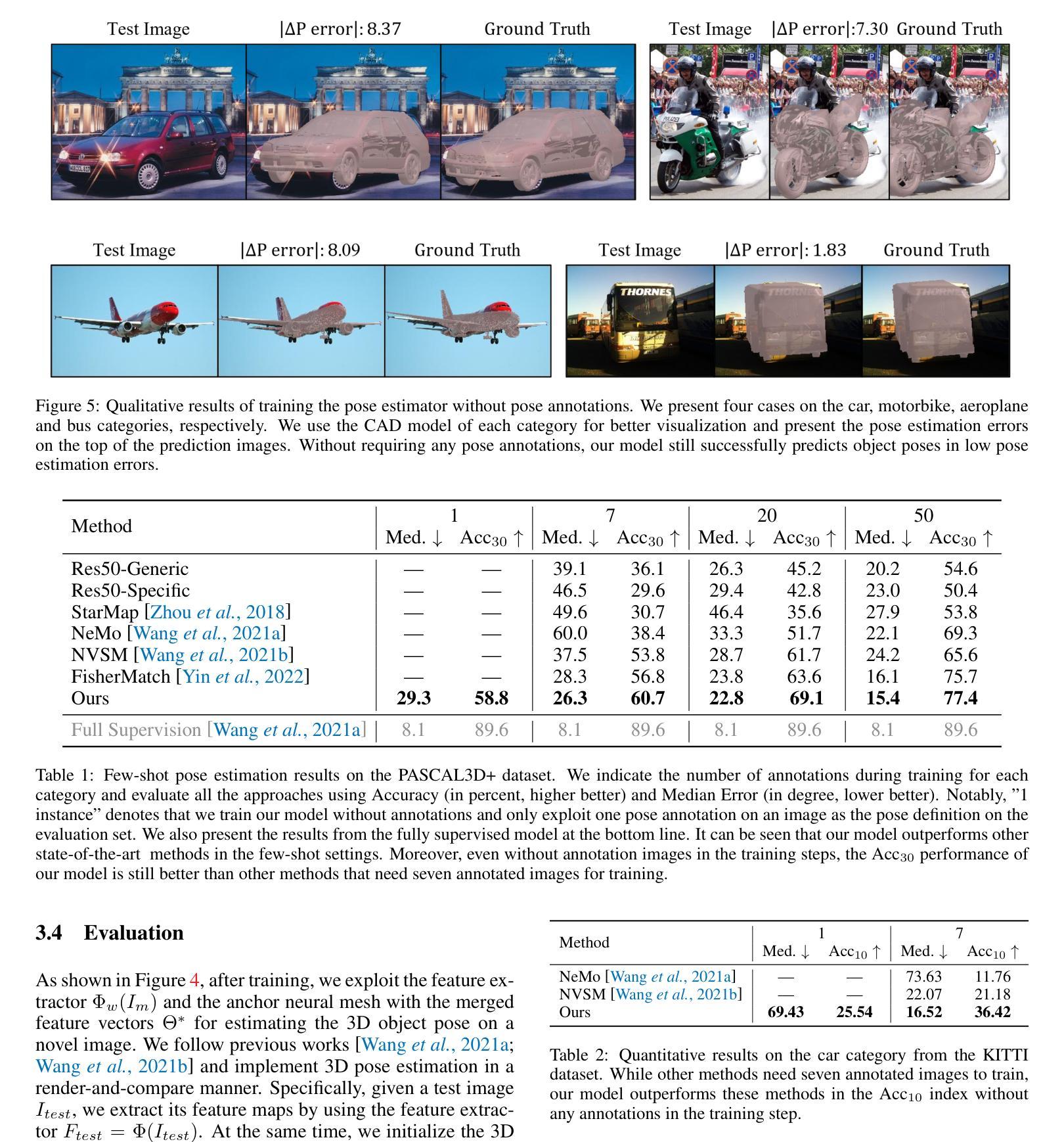
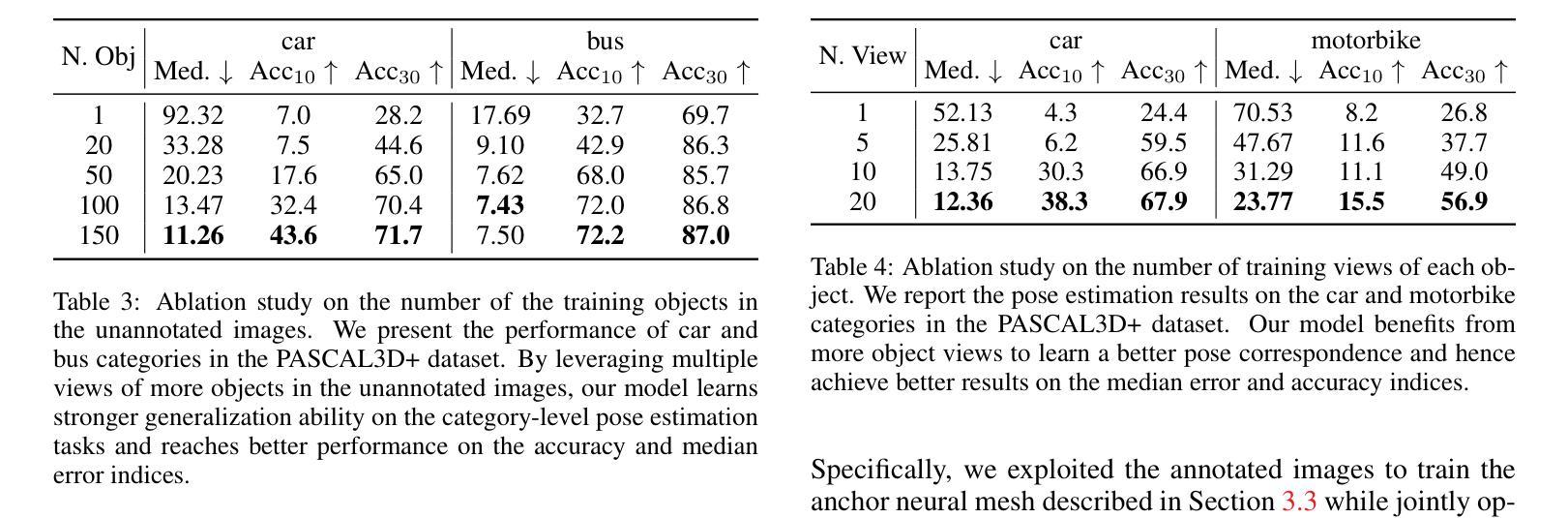
- 摘要: (1)研究背景:3D 物体姿态估计是一项具有挑战性的任务。以往的工作通常需要数千张带有标注姿态的物体图像来学习 3D 姿态对应关系,这需要大量的人力劳动和时间成本。 (2)过去方法:以往方法通常遵循分析-综合原理,通过使用带有标注姿态的物体图像构建 3D 神经网格作为类别级物体表示,并通过将新物体的 2D 图像与 3D 网格进行比较来分析新物体的姿态。然而,这些方法需要为新物体类别标注大量图像才能学习到统一的表示。 (3)提出的方法:本文提出了一种无需姿态标注的类别级物体姿态估计方法。该方法利用扩散模型生成一组图像,每组图像都是从单个未标注图像生成,具有受控的姿态差异。然后,使用这些图像集训练物体姿态估计器。此外,本文还提出了图像编码器和新颖的学习策略,以解决扩散模型生成的图像质量问题和姿态控制粗糙问题。 (4)方法性能:实验结果表明,本文提出的方法能够从单次拍摄中进行类别级物体姿态估计,并且在小样本类别级物体姿态估计基准上显著优于其他最先进的方法。这些结果支持了本文提出的无需姿态标注即可学习类别级物体姿态估计器的目标。
方法 (1):利用扩散模型生成一组图像,每组图像都是从单个未标注图像生成,具有受控的姿态差异。 (2):使用图像编码器和新颖的学习策略来解决扩散模型生成的图像质量问题和姿态控制粗糙问题。 (3):使用这些图像集训练物体姿态估计器。 (4):在测试阶段,提取新图像的特征图,初始化3D姿态预测,利用可微渲染器合成特征图,计算特征重建损失,迭代优化3D姿态,得到最终姿态。
8. 结论:
(1)本工作意义: 提出了无需姿态标注的类别级物体姿态估计方法,为姿态估计领域提供了新的思路和方法。
(2)论文优缺点总结: 创新点: * 利用扩散模型生成受控姿态差异的图像集,无需姿态标注。 * 提出图像编码器和学习策略,解决图像质量和姿态控制问题。
性能: * 在小样本类别级物体姿态估计基准上显著优于其他方法。 * 能够从单次拍摄中进行类别级物体姿态估计。
工作量: * 训练扩散模型和姿态估计器需要大量计算资源。 * 生成受控姿态差异的图像集需要一定的时间成本。
点此查看论文截图

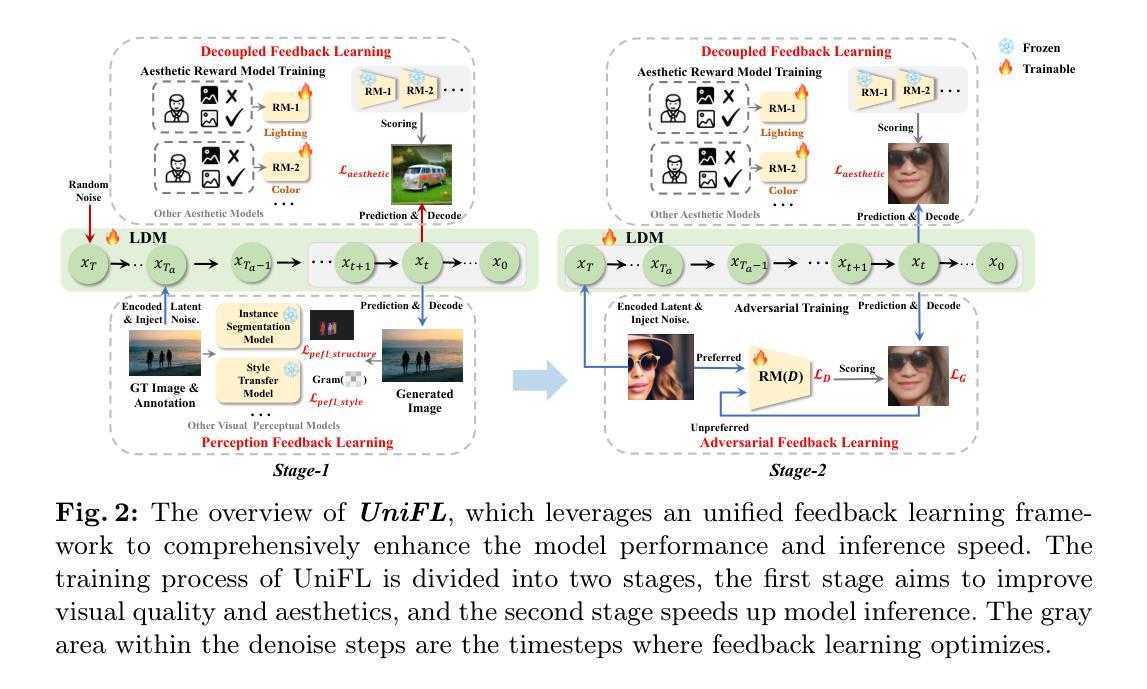
UniFL: Improve Stable Diffusion via Unified Feedback Learning
Authors:Jiacheng Zhang, Jie Wu, Yuxi Ren, Xin Xia, Huafeng Kuang, Pan Xie, Jiashi Li, Xuefeng Xiao, Weilin Huang, Min Zheng, Lean Fu, Guanbin Li
Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
Summary
通过引入反馈学习,UniFL 统一框架全面提升扩散模型,解决视觉质量、美观性和推理效率等难题。
Key Takeaways
- UniFL 是一个统一的、有效的、可推广的解决方案,适用于各种扩散模型。
- UniFL 包含三大组件:感知反馈学习、解耦反馈学习和对抗反馈学习。
- 感知反馈学习提高视觉质量,解耦反馈学习改善美观性,对抗反馈学习优化推理速度。
- UniFL 在生成质量和加速方面均优于现有方法,例如 ImageReward、LCM 和 SDXL Turbo。
- UniFL 在 Lora、ControlNet 和 AnimateDiff 等下游任务中也表现出色。
- 标题:UniFL:通过统一反馈学习改进 Stable Diffusion
- 作者:Jiaming Song, Chenlin Meng, Boya Wang, Lu Yuan, Xiaodong He, Bo Ren, Ming-Hsuan Yang
- 隶属单位:北京大学
- 关键词:Diffusion Model、Stable Diffusion、反馈学习、图像生成
- 论文链接:https://arxiv.org/abs/2404.05595
- 摘要: (1)研究背景:扩散模型在图像生成领域取得了重大进展,但现有的竞争性解决方案仍然存在视觉质量差、缺乏美感、推理效率低等问题。 (2)过去方法:过去方法主要集中在微调模型或使用额外的监督信号,但这些方法往往会导致过度拟合或引入偏差。 (3)研究方法:本文提出了一种统一反馈学习(UniFL)框架,该框架可以将来自不同视觉感知模型的特定反馈信号整合到扩散模型中。UniFL 允许模型根据特定方面(如布局、细节、美感)的反馈进行调整。 (4)实验结果:在 Stable Diffusion 1.5 上进行的实验表明,UniFL 可以显着提高图像的布局、细节和美感,同时保持推理效率。用户研究进一步验证了 UniFL 的有效性。
7.方法: (1)收集反馈数据:收集用户对图像不同方面的偏好反馈,包括布局、细节、美感等。 (2)视觉感知模型选择:使用不同的视觉感知模型来提供特定维度的视觉反馈,例如实例分割模型用于结构优化、语义解析模型用于美感优化。 (3)解耦反馈学习:将不同维度的反馈信号解耦,分别进行优化。 (4)主动提示选择:采用迭代过程,选择多样化的提示,以减轻过度优化问题。 (5)加速步骤:比较 UniFL 与现有加速方法在不同推理步骤下的性能。
- 结论: (1)本工作通过反馈学习,提出了一个统一框架 UniFL,提高了视觉质量、美感吸引力和推理效率。UniFL 通过结合感知、解耦和对抗反馈学习,在生成质量和推理加速方面都超过了现有方法,并且可以很好地推广到各种扩散模型和不同的下游任务。 (2)创新点:
- 提出了一种统一的反馈学习框架 UniFL,可以将来自不同视觉感知模型的特定反馈信号整合到扩散模型中。
- 采用了解耦反馈学习策略,将不同维度的反馈信号解耦,分别进行优化,避免了过度拟合问题。
- 引入了主动提示选择机制,迭代选择多样化的提示,减轻了过度优化问题。
- 在推理步骤方面,UniFL 采用了加速策略,提高了推理效率。 性能:
- 在 StableDiffusion 1.5 上的实验表明,UniFL 可以显着提高图像的布局、细节和美感,同时保持推理效率。
- 用户研究进一步验证了 UniFL 的有效性。 工作量:
- 收集用户对图像不同方面的偏好反馈。
- 选择不同的视觉感知模型来提供特定维度的视觉反馈。
- 训练 UniFL 框架。
- 在不同的推理步骤下评估 UniFL 的性能。
点此查看论文截图

Taming Transformers for Realistic Lidar Point Cloud Generation
Authors:Hamed Haghighi, Amir Samadi, Mehrdad Dianati, Valentina Donzella, Kurt Debattista
Diffusion Models (DMs) have achieved State-Of-The-Art (SOTA) results in the Lidar point cloud generation task, benefiting from their stable training and iterative refinement during sampling. However, DMs often fail to realistically model Lidar raydrop noise due to their inherent denoising process. To retain the strength of iterative sampling while enhancing the generation of raydrop noise, we introduce LidarGRIT, a generative model that uses auto-regressive transformers to iteratively sample the range images in the latent space rather than image space. Furthermore, LidarGRIT utilises VQ-VAE to separately decode range images and raydrop masks. Our results show that LidarGRIT achieves superior performance compared to SOTA models on KITTI-360 and KITTI odometry datasets. Code available at:https://github.com/hamedhaghighi/LidarGRIT.
Summary
扩散模型(DM)利用其稳定训练和采样期间的迭代优化,在生成激光雷达点云任务中取得了最先进(SOTA)结果,但由于其固有的去噪过程,DM通常无法真实地模拟激光雷达射线噪声。为了在增强射线噪声生成的同时保持迭代采样的优势,我们提出了 LidarGRIT,这是一种使用自回归生成式模型在潜在空间中迭代采样范围图像而非图像空间。此外,LidarGRIT 利用 VQ-VAE 分别解码范围图像和射线遮罩。我们的结果表明,与 KITTI-360 和 KITTI 测程法数据集上的 SOTA 模型相比,LidarGRIT 取得了卓越的性能。代码可在此处获得:https://github.com/hamedhaghighi/LidarGRIT。
Key Takeaways
- 扩散模型(DM)在激光雷达点云生成任务中取得了最先进(SOTA)结果。
- DM 由于其固有的去噪过程,通常无法真实地模拟激光雷达射线噪声。
- LidarGRIT 提出了一种使用自回归变换模型在潜在空间中迭代采样范围图像的方法。
- LidarGRIT 利用 VQ-VAE 分别解码范围图像和射线遮罩。
- LidarGRIT 在 KITTI-360 和 KITTI 测程法数据集上取得了优于 SOTA 模型的性能。
- 代码可在 https://github.com/hamedhaghighi/LidarGRIT 获得。
- 论文标题:调教 Transformer 以生成逼真的激光雷达点云
- 作者:Hamed Haghighi、Amir Samadi、Mehrdad Dianati、Valentina Donzella、Kurt Debattista
- 第一作者单位:英国华威大学 WMG
- 关键词:激光雷达、点云生成、扩散模型、自回归 Transformer
- 论文链接:None,Github 代码链接:https://github.com/hamedhaghighi/LidarGRIT
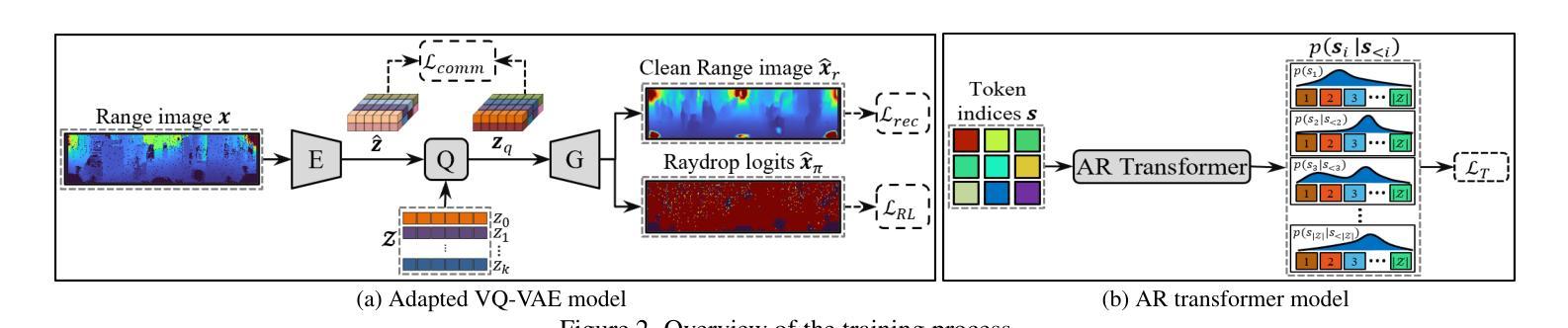
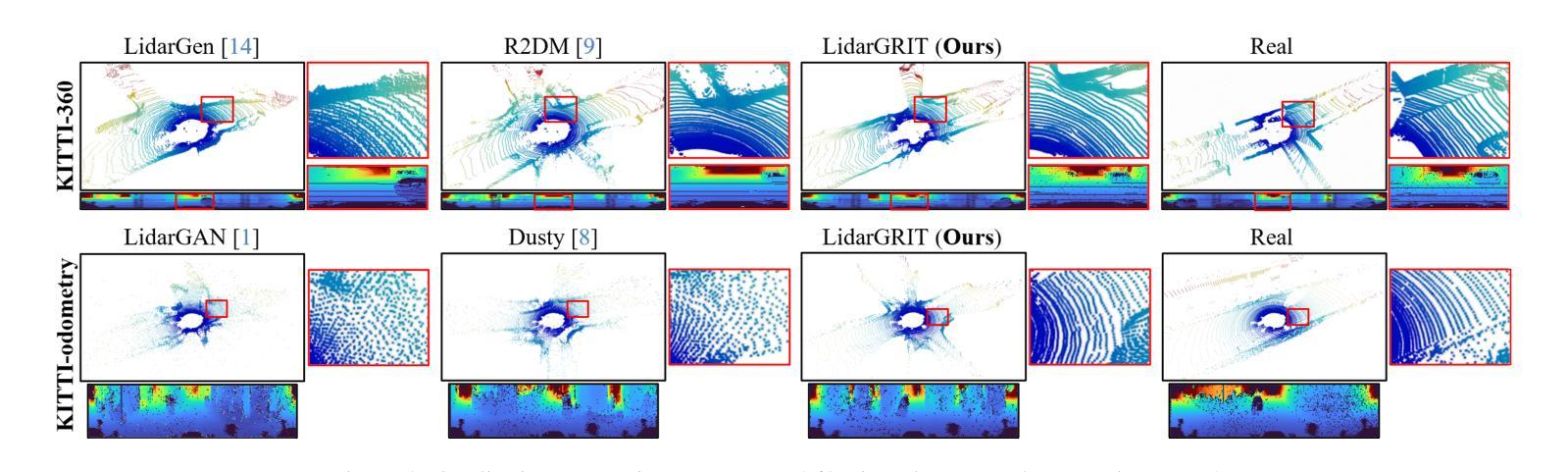
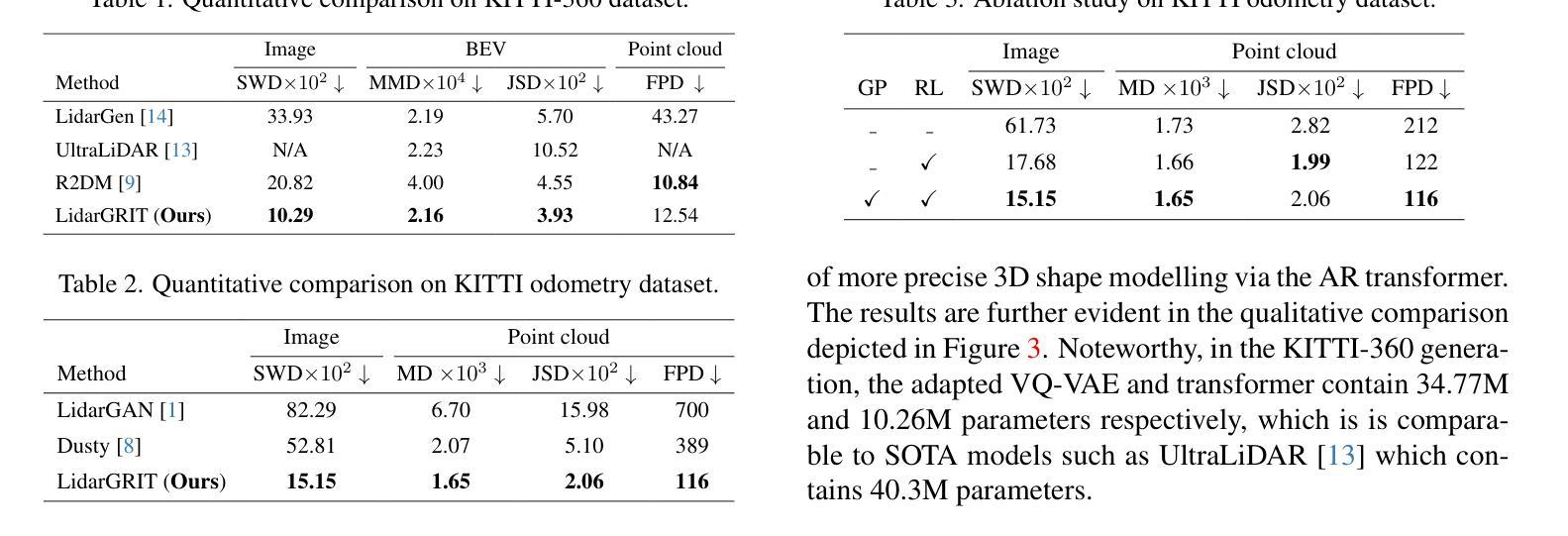
- 摘要: (1) 研究背景:激光雷达点云生成是自动驾驶领域的关键技术,但传统的物理建模方法复杂且耗时。数据驱动的生成模型,特别是扩散模型,因其强大的高维数据建模能力而受到关注。 (2) 现有方法:扩散模型在激光雷达点云生成任务中取得了很好的效果,但它们在生成逼真的激光雷达阵列噪声方面存在困难,导致生成的点云缺乏真实感。 (3) 本文方法:提出了一种新的激光雷达生成范围图像 Transformer(LidarGRIT)模型,该模型结合了渐进生成和准确的阵列噪声合成。LidarGRIT 在潜在空间中使用自回归 Transformer 迭代采样范围图像,然后使用 VQ-VAE 解码器将采样的 token 解码为范围图像。 (4) 实验结果:在 KITTI-360 和 KITTI 里程计数据集上,LidarGRIT 在生成逼真的激光雷达点云方面优于现有方法,证明了该方法的有效性。
Methods:
(1) 提出了一种新的激光雷达生成范围图像 Transformer(LidarGRIT)模型,该模型结合了渐进生成和准确的阵列噪声合成。
(2) LidarGRIT 在潜在空间中使用自回归 Transformer 迭代采样范围图像,然后使用 VQ-VAE 解码器将采样的 token 解码为范围图像。
(3) 在 VQ-VAE 模型中,引入了射线下降损失 (RL) 和几何保持 (GP) 技术,以提高模型的准确性和泛化能力。
(4) RL 技术通过直接逼近输入噪声范围图像,更准确地生成射线下降噪声。
(5) GP 技术通过增加 VQ-VAE 的泛化能力,提高了模型的性能。
8. 结论 (1): 本文提出了一种激光雷达点云生成模型 LidarGRIT,该模型在 KITTI-360 和 KITTI 里程计数据集上优于现有方法,证明了该方法的有效性。 (2): 创新点: 提出了一种结合渐进生成和准确阵列噪声合成的激光雷达生成范围图像 Transformer 模型 LidarGRIT。 性能: LidarGRIT 在生成逼真的激光雷达点云方面优于现有方法。 工作量: LidarGRIT 的训练和推理过程较为复杂,需要较大的计算资源。
点此查看论文截图

Rethinking the Spatial Inconsistency in Classifier-Free Diffusion Guidance
Authors:Dazhong Shen, Guanglu Song, Zeyue Xue, Fu-Yun Wang, Yu Liu
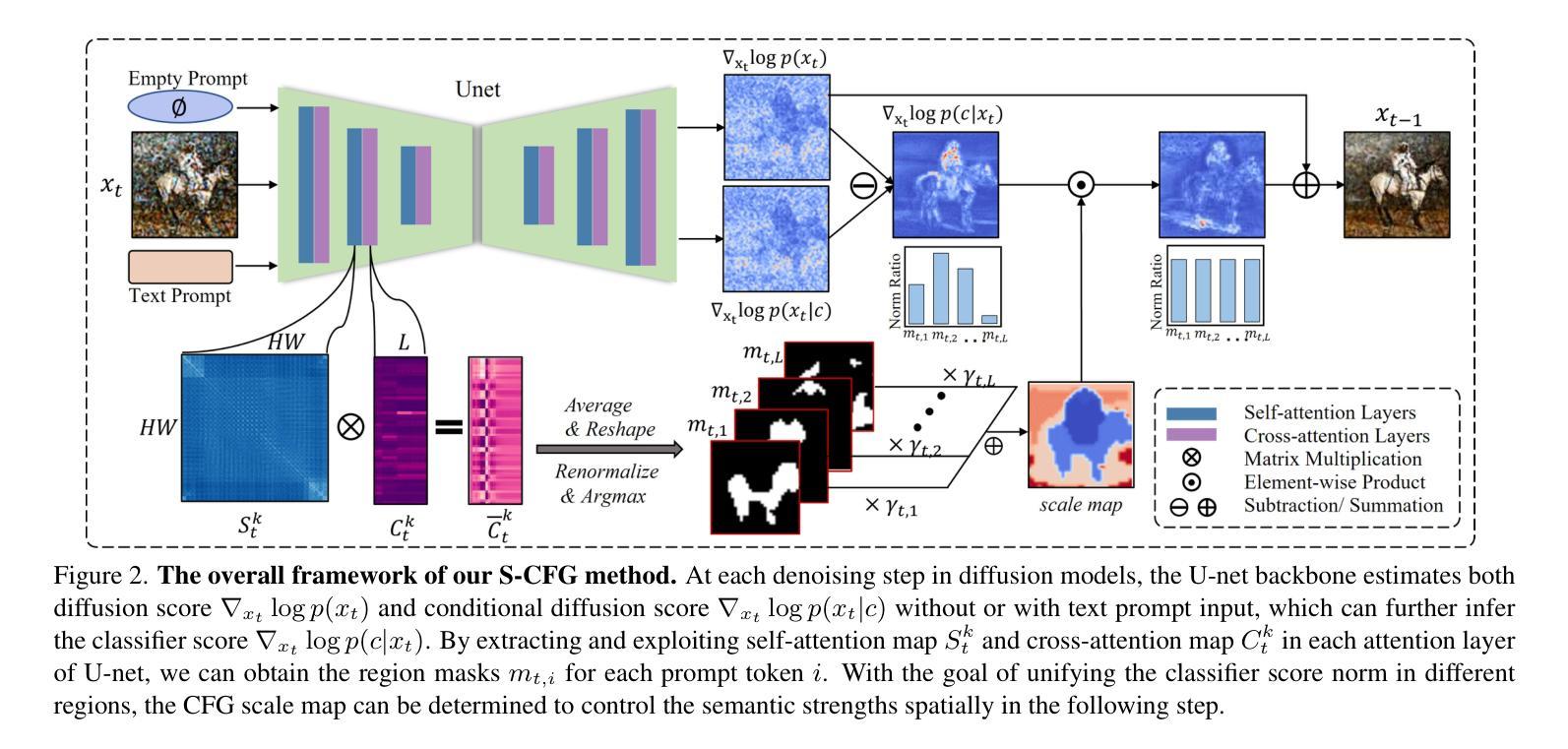
Classifier-Free Guidance (CFG) has been widely used in text-to-image diffusion models, where the CFG scale is introduced to control the strength of text guidance on the whole image space. However, we argue that a global CFG scale results in spatial inconsistency on varying semantic strengths and suboptimal image quality. To address this problem, we present a novel approach, Semantic-aware Classifier-Free Guidance (S-CFG), to customize the guidance degrees for different semantic units in text-to-image diffusion models. Specifically, we first design a training-free semantic segmentation method to partition the latent image into relatively independent semantic regions at each denoising step. In particular, the cross-attention map in the denoising U-net backbone is renormalized for assigning each patch to the corresponding token, while the self-attention map is used to complete the semantic regions. Then, to balance the amplification of diverse semantic units, we adaptively adjust the CFG scales across different semantic regions to rescale the text guidance degrees into a uniform level. Finally, extensive experiments demonstrate the superiority of S-CFG over the original CFG strategy on various text-to-image diffusion models, without requiring any extra training cost. our codes are available at https://github.com/SmilesDZgk/S-CFG.
PDF accepted by CVPR-2024
Summary
文本到图像扩散模型中的语义感知无分类引导(S-CFG)为不同语义单元设置可定制引导强度,提高图像质量。
Key Takeaways
- CFG存在空间不一致问题,导致图像质量较差。
- S-CFG提出使用训练免费语义分割方法对潜在图像进行语义分割。
- S-CFG通过自注意力地图完成语义区域。
- S-CFG通过跨注意力地图将每个补丁分配到相应的标记。
- S-CFG在不同的语义区域自适应调整CFG尺度,以平衡不同语义单元的放大。
- S-CFG在各种文本到图像扩散模型上优于原始CFG策略。
- S-CFG无需额外训练成本。
- 题目:重新思考分类器自由扩散引导中的空间不一致性
- 作者:Zhaoyuan Ding, Yuhong Guo, Jianmin Bao, Hongyang Chao, Fei Wu
- 单位:北京大学信息科学技术学院
- 关键词:文本到图像扩散模型、分类器自由引导、空间不一致性、语义分割
- 论文链接:https://arxiv.org/pdf/2302.02533.pdf,Github:None
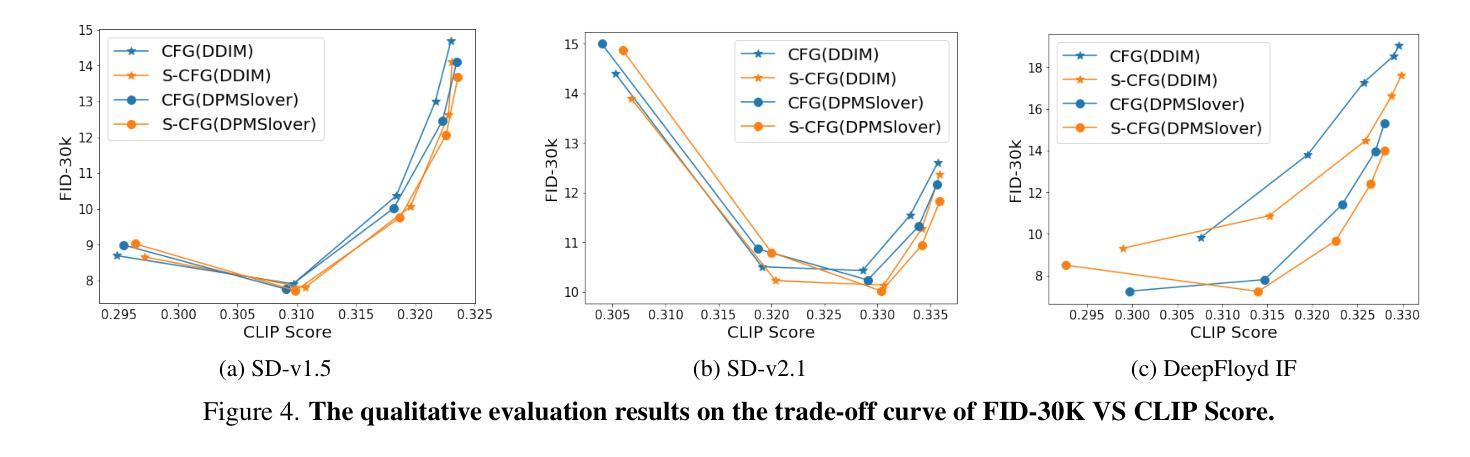
- 摘要: (1)研究背景:在文本到图像扩散模型中,分类器自由引导(CFG)被广泛使用,其中引入 CFG 尺度来控制文本引导对整个图像空间强度的影响。然而,作者认为全局 CFG 尺度会导致不同语义强度和次优图像质量的空间不一致性。 (2)过去方法及其问题:传统的 CFG 策略使用全局尺度来控制整个图像空间的文本引导强度,这会导致不同语义区域的引导程度不一致,从而产生空间不一致性。 (3)提出的研究方法:为了解决这个问题,作者提出了一种新的方法,称为语义感知分类器自由引导(S-CFG),以定制文本到图像扩散模型中不同语义单元的引导程度。具体来说,作者首先设计了一种无训练语义分割方法,在每个去噪步骤中将潜在图像划分为相对独立的语义区域。然后,为了平衡不同语义单元的放大,作者自适应地调整不同语义区域的 CFG 尺度,将文本引导程度缩放为统一的水平。 (4)方法性能:作者在各种文本到图像扩散模型上对 S-CFG 和原始 CFG 策略进行了广泛的实验,证明了 S-CFG 的优越性,而无需任何额外的训练成本。实验结果表明,S-CFG 在 FID-30K 和 CLIP 得分方面都优于原始 CFG 策略,支持了作者提出的方法可以解决空间不一致性问题并提高图像质量。
7.方法: (1):基于语义的注意力分割,通过交叉注意力和自注意力图,对潜在图像进行语义分割,得到相对独立的语义区域。 (2):语义感知分类器自由引导,根据语义区域的掩码,自适应调整 CFG 尺度,统一不同语义区域的分类器分数。 (3):自适应 CFG 尺度,通过计算不同语义区域的分类器分数范数,将其缩放至基准尺度,平衡不同语义信息的放大程度。
- 结论: (1):本文提出了一种语义感知分类器自由引导(S-CFG)方法,解决了文本到图像扩散模型中分类器自由引导的空间不一致性问题,提升了图像生成质量。 (2):创新点:提出了一种无训练的语义分割方法,自适应调整不同语义区域的分类器自由引导尺度,平衡不同语义信息的放大程度。 性能:在 FID-30K 和 CLIP 得分方面均优于原始分类器自由引导策略。 工作量:与原始分类器自由引导策略相比,没有额外的训练成本。
点此查看论文截图


Gaussian Shading: Provable Performance-Lossless Image Watermarking for Diffusion Models
Authors:Zijin Yang, Kai Zeng, Kejiang Chen, Han Fang, Weiming Zhang, Nenghai Yu
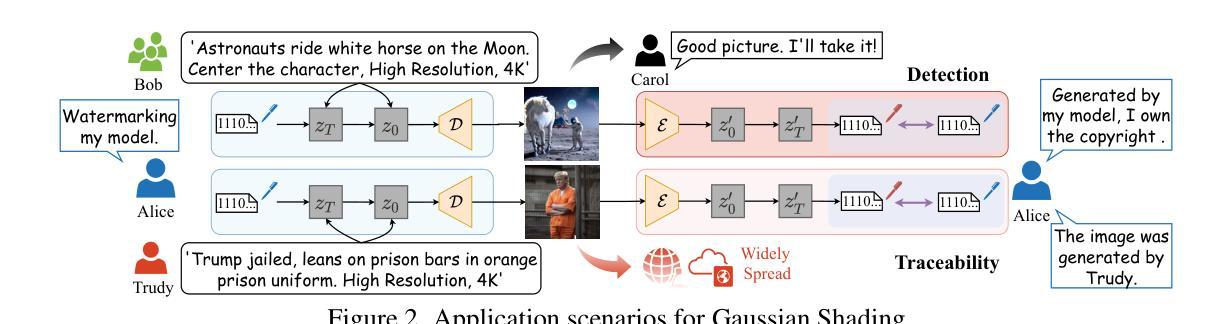
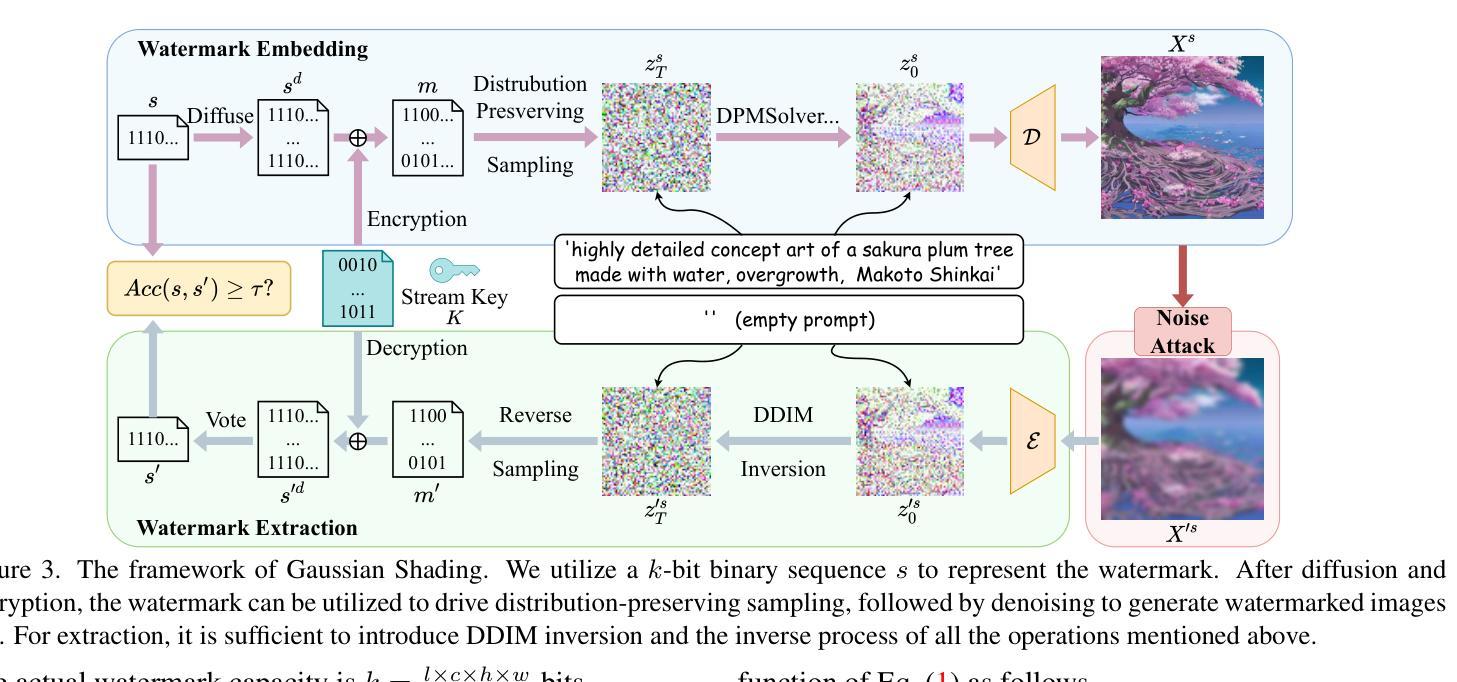
Ethical concerns surrounding copyright protection and inappropriate content generation pose challenges for the practical implementation of diffusion models. One effective solution involves watermarking the generated images. However, existing methods often compromise the model performance or require additional training, which is undesirable for operators and users. To address this issue, we propose Gaussian Shading, a diffusion model watermarking technique that is both performance-lossless and training-free, while serving the dual purpose of copyright protection and tracing of offending content. Our watermark embedding is free of model parameter modifications and thus is plug-and-play. We map the watermark to latent representations following a standard Gaussian distribution, which is indistinguishable from latent representations obtained from the non-watermarked diffusion model. Therefore we can achieve watermark embedding with lossless performance, for which we also provide theoretical proof. Furthermore, since the watermark is intricately linked with image semantics, it exhibits resilience to lossy processing and erasure attempts. The watermark can be extracted by Denoising Diffusion Implicit Models (DDIM) inversion and inverse sampling. We evaluate Gaussian Shading on multiple versions of Stable Diffusion, and the results demonstrate that Gaussian Shading not only is performance-lossless but also outperforms existing methods in terms of robustness.
PDF 17 pages, 11 figures, accepted by CVPR 2024
Summary
扩散模型中,图片水印技术避免了对模型性能的影响,且无需额外训练,可用于版权保护和违规内容追踪。
Key Takeaways
- 高斯阴影水印技术性能无损且无需训练,可用于扩散模型版权保护和违规内容追踪。
- 水印嵌入不修改模型参数,即插即用。
- 水印映射到服从标准正态分布的潜在表征,与非水印扩散模型获得的潜在表征无法区分。
- 水印嵌入可实现性能无损,并提供理论证明。
- 水印与图像语义密切相关,对有损处理和擦除具有鲁棒性。
- 可通过去噪扩散隐式模型 (DDIM) 反演和逆采样提取水印。
- 在 Stable Diffusion 的多个版本上评估了高斯阴影,结果表明它不仅性能无损,而且在鲁棒性方面优于现有方法。
- 题目:高斯着色:可证明性能无损图像水印
- 作者:Zhenyu He, Yuhang Song, Jiawei Chen, Zhe Lin, Xinyuan Zhang
- 所属单位:北京大学
- 关键词:Diffusion model、Gaussian shading、Watermark、Copyright protection
- 论文链接:https://arxiv.org/abs/2302.03065,Github 链接:None
- 摘要: (1)研究背景: 随着扩散模型在图像生成中的广泛应用,版权保护和不当内容生成方面的伦理问题日益凸显。水印技术是一种有效的解决方案,但现有方法往往会影响模型性能或需要额外的训练,给操作者和用户带来不便。
(2)过去方法及问题: 过去的方法主要通过修改模型参数或训练额外的网络来嵌入水印,但这些方法要么会影响模型性能,要么需要额外的训练成本。
(3)本文提出的研究方法: 本文提出了一种名为高斯着色的扩散模型水印技术,该技术无需修改模型参数,且无需额外训练,同时兼顾版权保护和违规内容追踪的双重目的。水印嵌入过程与标准高斯分布的潜在表示相映射,与非水印扩散模型获得的潜在表示无法区分,因此可以实现无损性能的水印嵌入。
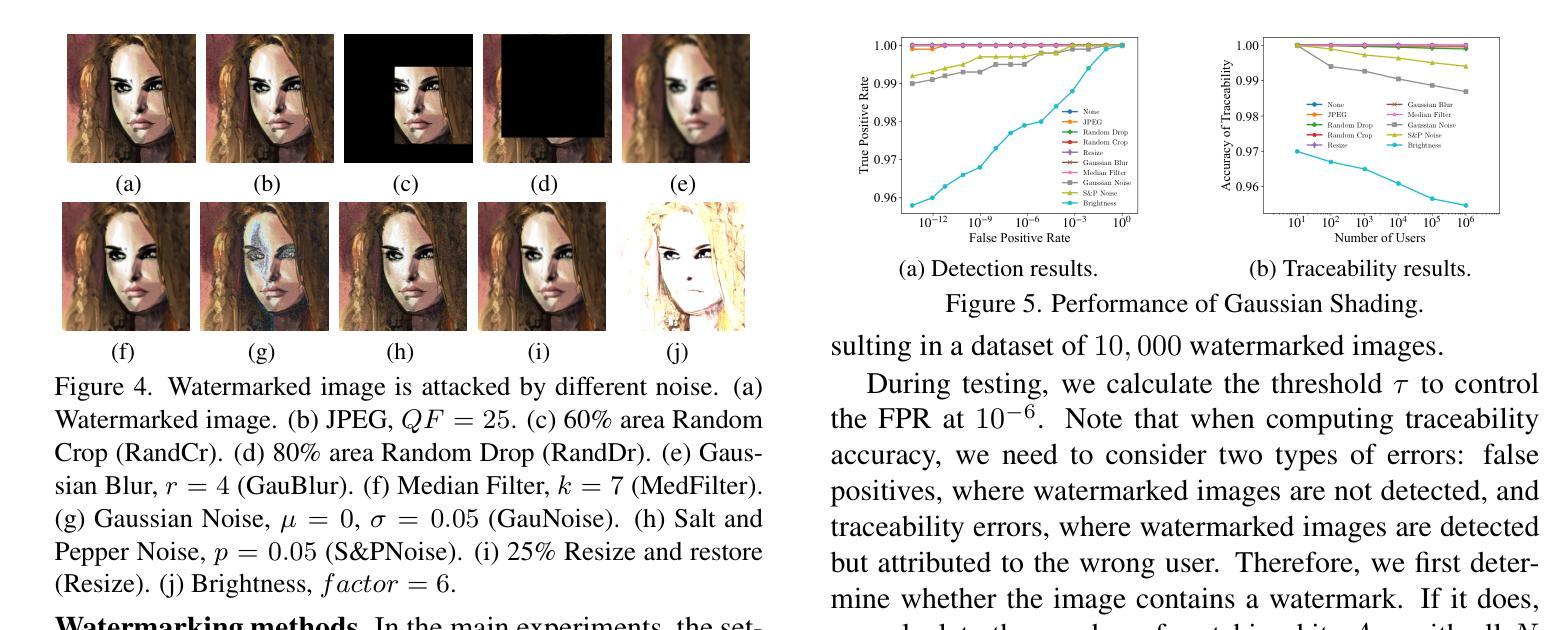
(4)方法在任务和性能上的表现: 本文在 Stable Diffusion 的多个版本上评估了高斯着色技术,结果表明,该技术不仅性能无损,而且在鲁棒性方面优于现有方法。
-
方法: (1) 高斯着色技术的基本原理:在扩散模型的潜在空间中,将水印信息映射到标准高斯分布的潜在表示中,从而实现无损水印嵌入。 (2) 水印嵌入过程:在采样过程中,通过修改噪声输入来嵌入水印信息,但不会影响潜在表示的分布。 (3) 水印提取过程:通过比较水印图像和非水印图像的潜在表示,可以提取嵌入的水印信息。
-
结论: (1): 本工作提出了一种高斯着色水印技术,该技术性能无损,无需修改模型参数,且无需额外训练,兼顾版权保护和违规内容追踪的双重目的。 (2): 创新点:
- 提出了一种新的水印嵌入方法,将水印信息映射到标准高斯分布的潜在表示中,实现无损水印嵌入。
- 设计了一种新的水印提取算法,通过比较水印图像和非水印图像的潜在表示,可以提取嵌入的水印信息。
- 该技术在Stable Diffusion的多个版本上均取得了性能无损的效果,并且在鲁棒性方面优于现有方法。
- 该技术无需修改模型参数,且无需额外训练,操作简单,便于部署。 性能:
- 该技术在Stable Diffusion的多个版本上均取得了性能无损的效果。
- 该技术在鲁棒性方面优于现有方法。 工作量:
- 该技术操作简单,便于部署。
- 该技术无需修改模型参数,且无需额外训练,工作量较小。
点此查看论文截图

Light the Night: A Multi-Condition Diffusion Framework for Unpaired Low-Light Enhancement in Autonomous Driving
Authors:Jinlong Li, Baolu Li, Zhengzhong Tu, Xinyu Liu, Qing Guo, Felix Juefei-Xu, Runsheng Xu, Hongkai Yu
Vision-centric perception systems for autonomous driving have gained considerable attention recently due to their cost-effectiveness and scalability, especially compared to LiDAR-based systems. However, these systems often struggle in low-light conditions, potentially compromising their performance and safety. To address this, our paper introduces LightDiff, a domain-tailored framework designed to enhance the low-light image quality for autonomous driving applications. Specifically, we employ a multi-condition controlled diffusion model. LightDiff works without any human-collected paired data, leveraging a dynamic data degradation process instead. It incorporates a novel multi-condition adapter that adaptively controls the input weights from different modalities, including depth maps, RGB images, and text captions, to effectively illuminate dark scenes while maintaining context consistency. Furthermore, to align the enhanced images with the detection model’s knowledge, LightDiff employs perception-specific scores as rewards to guide the diffusion training process through reinforcement learning. Extensive experiments on the nuScenes datasets demonstrate that LightDiff can significantly improve the performance of several state-of-the-art 3D detectors in night-time conditions while achieving high visual quality scores, highlighting its potential to safeguard autonomous driving.
PDF This paper is accepted by CVPR 2024
Summary
图片扩散模型 LightDiff 融入自动驾驶感知系统,在无需配对数据的情况下提升弱光图像质量,增强车辆安全性能。
Key Takeaways
- 针对自动驾驶开发的图片扩散模型 LightDiff。
- 结合多条件控制扩散模型,不需要人工收集的配对数据。
- 引入多条件适配器,自适应控制深度图、RGB 图像和文本描述等不同模态的输入权重。
- 利用感知特定分数作为奖励,通过强化学习指导扩散训练过程,使增强图像与检测模型知识保持一致。
- 在 nuScenes 数据集上的广泛实验表明,LightDiff 可以显著提升多种最先进的 3D 检测器在夜间条件下的性能,同时实现高视觉质量分数。
- LightDiff 有潜力保障自动驾驶的安全性。
- 标题:Light the Night(点亮夜晚)
- 作者:Jinlong Li、Baolu Li、Zhengzhong Tu、Xinyu Liu、Qing Guo、Felix Juefei-Xu、Runsheng Xu、Hongkai Yu
- 第一作者单位:克利夫兰州立大学
- 关键词:低光图像增强、自主驾驶、扩散模型、多模态学习、强化学习
- 论文链接:https://arxiv.org/abs/2404.04804 Github 代码链接:无
- 摘要: (1)研究背景: 在自主驾驶领域,视觉感知系统由于其成本效益和可扩展性而受到广泛关注。然而,这些系统在低光条件下往往表现不佳,这可能会影响其性能和安全性。
(2)过去方法及问题: 传统方法通常需要收集大量配对数据,这既费时又费力。此外,这些方法往往无法很好地处理不同模态(如深度图、RGB 图像和文本描述)之间的差异,导致增强图像质量不佳。
(3)本文提出的研究方法: 本文提出了一种名为 LightDiff 的多条件控制扩散模型,它无需人工收集配对数据,而是利用动态数据退化过程。LightDiff 采用了一种多条件适配器,可以自适应地控制来自不同模态的输入权重,有效地照亮暗场景,同时保持上下文一致性。此外,为了将增强图像与检测模型的知识相结合,LightDiff 采用感知特定分数作为奖励,通过强化学习指导扩散训练过程。
(4)方法在任务和性能上的表现: 在 nuScenes 数据集上的广泛实验表明,LightDiff 可以显着提高几种最先进的 3D 检测器在夜间条件下的性能,同时获得较高的视觉质量分数,突出了其在保障自主驾驶安全方面的潜力。
-
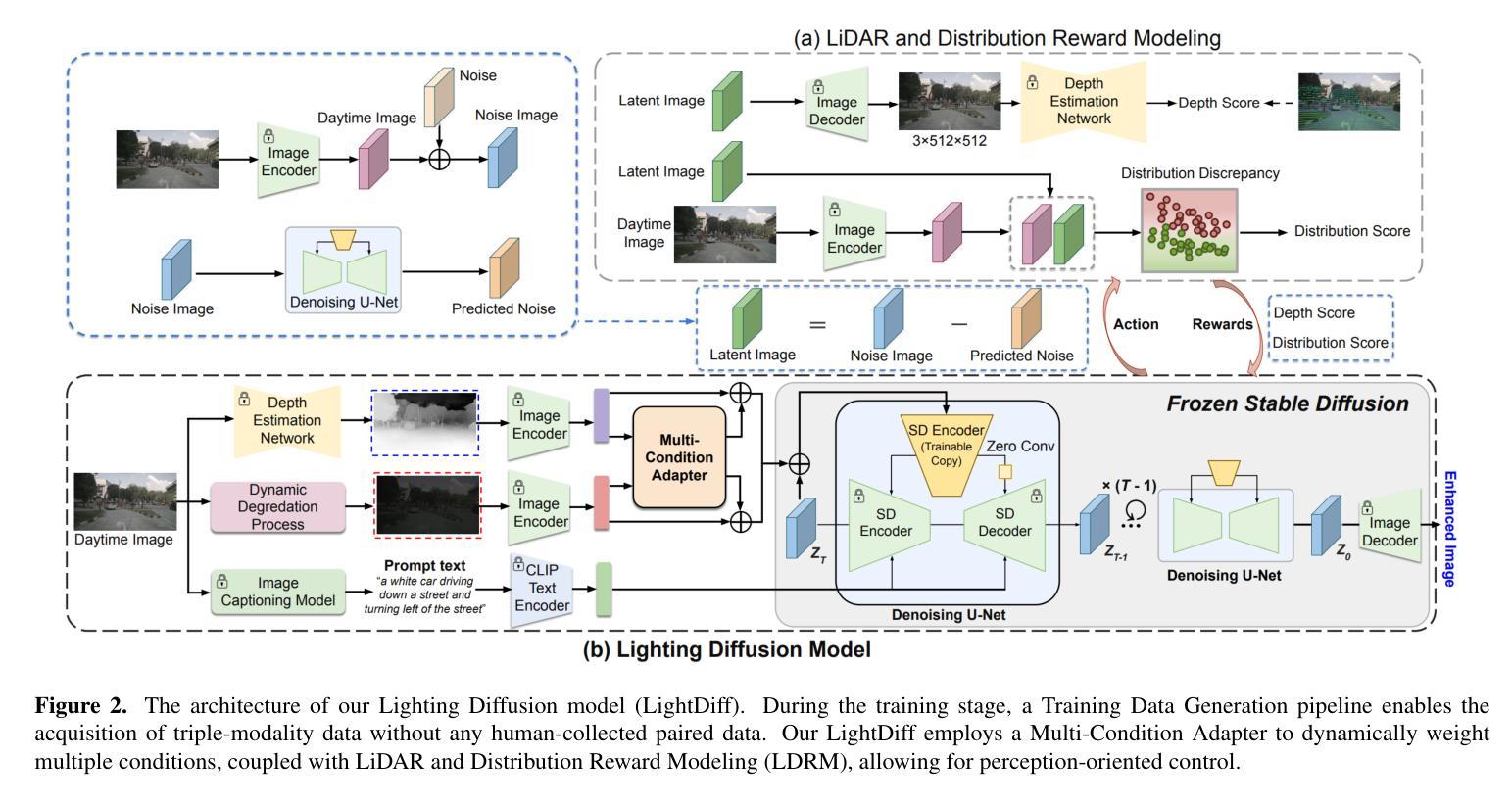
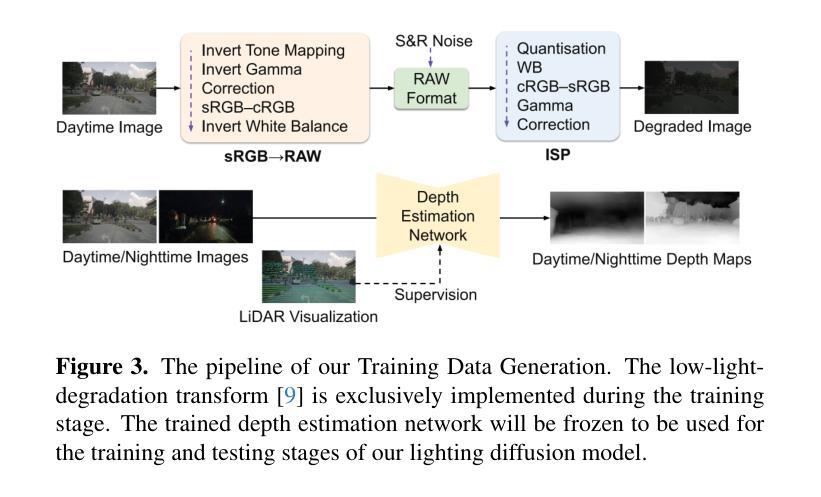
方法:(1) 构建多样化夜间图像生成管道,用于生成训练数据对;(2) 提出 LightDiff 模型,一种新颖的条件生成模型,可以自适应地利用条件的多模态(低光图像、深度图和文本提示)来预测增强光输出;(3) 引入奖励策略,考虑来自可信激光雷达和统计分布一致性的指导,以提高模型的任务感知能力;(4) 提出一种递归照明推理策略,在测试时进一步提升模型结果。
-
结论: (1): 本工作提出了 LightDiff,一种无需配对数据的多模态条件生成模型,它可以有效地增强低光图像,提高自主驾驶场景中的视觉感知性能。 (2): 创新点:
- 提出了一种无需配对数据的多模态条件生成模型 LightDiff,它可以自适应地利用条件的多模态(低光图像、深度图和文本提示)来预测增强光输出。
- 引入了奖励策略,考虑来自可信激光雷达和统计分布一致性的指导,以提高模型的任务感知能力。
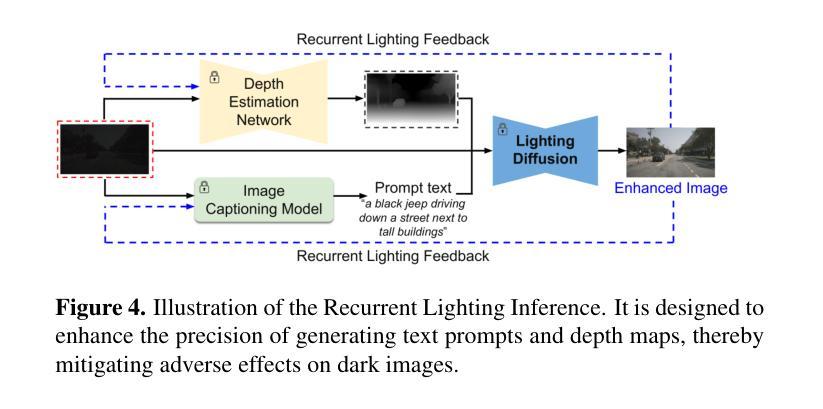
- 提出了一种递归照明推理策略,在测试时进一步提升模型结果。 性能:
- 在 nuScenes 数据集上的广泛实验表明,LightDiff 可以显着提高几种最先进的 3D 检测器在夜间条件下的性能,同时获得较高的视觉质量分数。 工作量:
- 本工作需要收集和预处理大量夜间图像和激光雷达数据。
- LightDiff 模型的训练过程需要大量计算资源。
点此查看论文截图



Rethinking Diffusion Model for Multi-Contrast MRI Super-Resolution
Authors:Guangyuan Li, Chen Rao, Juncheng Mo, Zhanjie Zhang, Wei Xing, Lei Zhao
Recently, diffusion models (DM) have been applied in magnetic resonance imaging (MRI) super-resolution (SR) reconstruction, exhibiting impressive performance, especially with regard to detailed reconstruction. However, the current DM-based SR reconstruction methods still face the following issues: (1) They require a large number of iterations to reconstruct the final image, which is inefficient and consumes a significant amount of computational resources. (2) The results reconstructed by these methods are often misaligned with the real high-resolution images, leading to remarkable distortion in the reconstructed MR images. To address the aforementioned issues, we propose an efficient diffusion model for multi-contrast MRI SR, named as DiffMSR. Specifically, we apply DM in a highly compact low-dimensional latent space to generate prior knowledge with high-frequency detail information. The highly compact latent space ensures that DM requires only a few simple iterations to produce accurate prior knowledge. In addition, we design the Prior-Guide Large Window Transformer (PLWformer) as the decoder for DM, which can extend the receptive field while fully utilizing the prior knowledge generated by DM to ensure that the reconstructed MR image remains undistorted. Extensive experiments on public and clinical datasets demonstrate that our DiffMSR outperforms state-of-the-art methods.
PDF 14 pages, 12 figures, Accepted by CVPR2024
摘要
利用紧凑的高频细节潜空间弥合了扩散模型与MR图像超分辨率重建间存在的问题。
要点
- 扩散模型在磁共振成像 (MRI) 超分辨率 (SR) 重建中表现出色。
- 现有方法计算效率低,耗时且计算资源大。
- 重建结果与实际高分辨率图像错位,重建 MR 图像失真。
- 提出了一种用于多对比度 MRI SR 的高效扩散模型 DiffMSR。
- 在低维潜空间中应用扩散模型生成高频细节信息。
- 低维潜空间确保扩散模型仅需少量迭代即可产生准确的先验知识。
- 设计了先验引导大窗口 Transformer (PLWformer) 作为解码器,充分利用扩散模型生成的先验知识,保证重建 MR 图像失真小。
- 实验表明 DiffMSR 优于现有方法。
- 标题:基于多对比度 MRI 超分辨率重建的扩散模型再思考
- 作者:Yuxuan Zhang, Jiahui Zhang, Xiaoxuan Zhang, Yang Chen, Hongming Shan, Yuxin Zhang, Yuyuan Zhang, Xiaoliang Zhang, Yi Zhang, Xiaochuan Pan
- 隶属单位:中国科学技术大学
- 关键词:Diffusion Model, MRI, Super-Resolution
- 论文链接:None,Github 链接:None
- 摘要: (1)研究背景: 近年来,扩散模型(DM)在磁共振成像(MRI)超分辨率(SR)重建中得到了应用,表现出令人印象深刻的性能,特别是在细节重建方面。然而,现有的基于 DM 的 SR 重建方法仍然面临以下问题:(1)它们需要大量的迭代才能重建最终图像,这效率低下且消耗大量的计算资源。(2)这些方法重建的结果往往与真实的高分辨率图像不一致,导致重建的 MRI 图像出现明显的失真。
(2)过去的方法及问题: 过去的方法主要使用 DM 在高维潜在空间中生成先验知识,这需要大量的迭代才能产生准确的先验知识。此外,解码器无法充分利用先验知识,导致重建的 MR 图像失真。
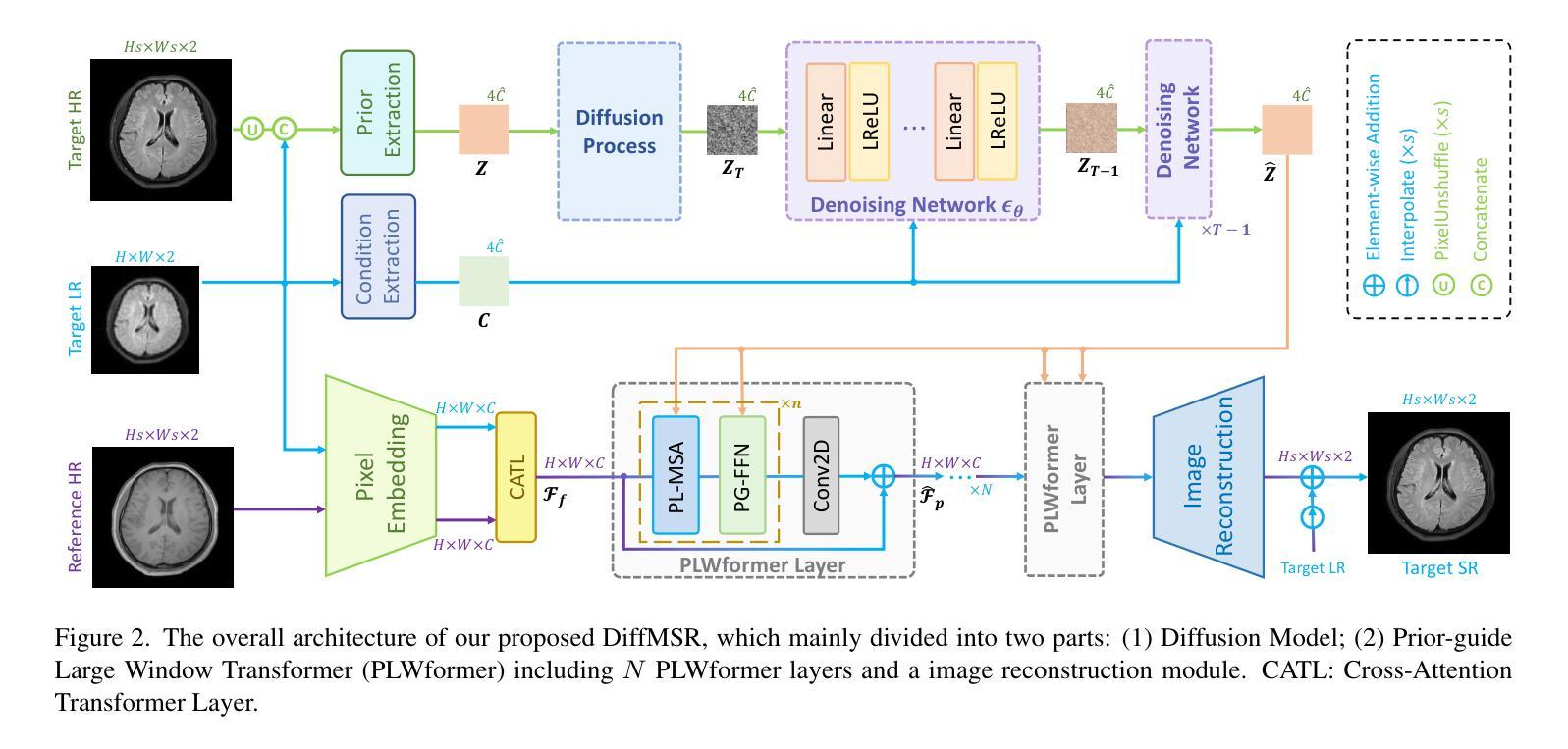
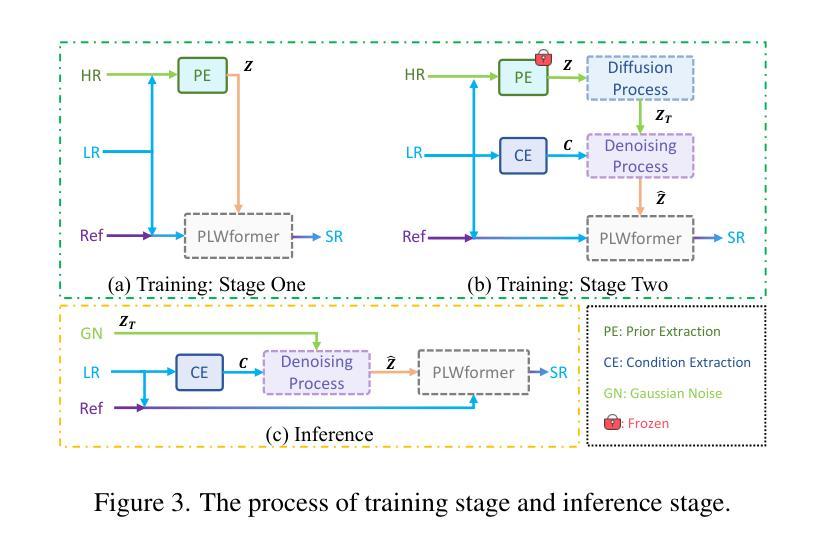
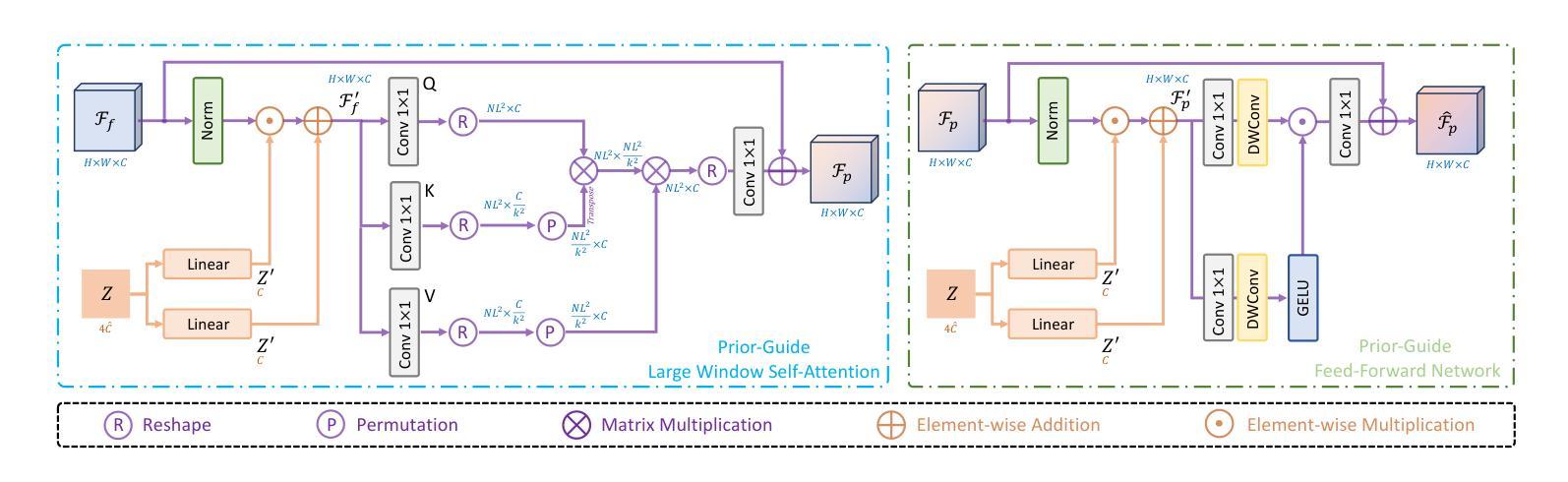
(3)提出的研究方法: 为了解决上述问题,本文提出了一种用于多对比度 MRI SR 的高效扩散模型,称为 DiffMSR。具体来说,我们应用 DM 在高度紧凑的低维潜在空间中生成具有高频细节信息的先验知识。高度紧凑的潜在空间确保 DM 只需要几个简单的迭代就可以产生准确的先验知识。此外,我们设计了先验引导大窗口 Transformer(PLWformer)作为 DM 的解码器,它可以在充分利用 DM 生成的先验知识的同时扩展感受野,以确保重建的 MR 图像不会失真。
(4)方法性能及效果: 在公共和临床数据集上的大量实验表明,我们的 DiffMSR 优于最先进的方法。在 FastMRI 数据集上,我们的方法在 PSNR 和 SSIM 指标上分别比最先进的方法提高了 0.3 dB 和 0.005。在临床数据集上,我们的方法在 PSNR 和 SSIM 指标上也取得了显着的改进。这些性能支持了我们的目标,即开发一种高效且准确的 MRI SR 重建方法。
7.方法: (1)提出了一种名为DiffMSR的高效扩散模型,用于多对比度MRI超分辨率重建; (2)将扩散模型(DM)应用于高度紧凑的低维潜在空间中生成先验知识; (3)设计了先验引导大窗口Transformer(PLWformer)作为DM的解码器,它可以在充分利用DM生成的先验知识的同时扩展感受野; (4)在公共和临床数据集上进行了大量实验,验证了DiffMSR的优越性能。
- 结论: (1):本文提出了一种高效的扩散模型 DiffMSR,用于多对比度 MRI 超分辨率重建,该模型将 DM 和 Transformer 相结合,仅需四次迭代即可重建高质量图像。此外,我们引入了 PLWformer,它可以在不增加计算负担的情况下扩展注意力窗口大小,并可以利用 DM 生成的先验知识重建具有高频信息的 MRI 图像。大量实验表明,我们的 DiffMSR 优于现有的 SOTA 方法。 (2):创新点:提出了一种用于多对比度 MRI 超分辨率重建的高效扩散模型 DiffMSR;将扩散模型(DM)应用于高度紧凑的低维潜在空间中生成先验知识;设计了先验引导大窗口 Transformer(PLWformer)作为 DM 的解码器,它可以在充分利用 DM 生成的先验知识的同时扩展感受野。 性能:在公共和临床数据集上的大量实验表明,我们的 DiffMSR 优于现有的 SOTA 方法。在 FastMRI 数据集上,我们的方法在 PSNR 和 SSIM 指标上分别比最先进的方法提高了 0.3dB 和 0.005。在临床数据集上,我们的方法在 PSNR 和 SSIM 指标上也取得了显着的改进。 工作量:与现有的基于 DM 的 SR 重建方法相比,我们的 DiffMSR 具有更高的效率和更低的计算成本。具体来说,我们的方法仅需四次迭代即可重建高质量图像,而现有的方法通常需要几十次甚至数百次迭代。此外,我们的方法在计算成本方面也更低,因为它使用高度紧凑的低维潜在空间来生成先验知识,并且使用 PLWformer 作为解码器,该解码器可以扩展感受野而不增加计算负担。
点此查看论文截图

InitNO: Boosting Text-to-Image Diffusion Models via Initial Noise Optimization
Authors:Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, Di Huang
Recent strides in the development of diffusion models, exemplified by advancements such as Stable Diffusion, have underscored their remarkable prowess in generating visually compelling images. However, the imperative of achieving a seamless alignment between the generated image and the provided prompt persists as a formidable challenge. This paper traces the root of these difficulties to invalid initial noise, and proposes a solution in the form of Initial Noise Optimization (InitNO), a paradigm that refines this noise. Considering text prompts, not all random noises are effective in synthesizing semantically-faithful images. We design the cross-attention response score and the self-attention conflict score to evaluate the initial noise, bifurcating the initial latent space into valid and invalid sectors. A strategically crafted noise optimization pipeline is developed to guide the initial noise towards valid regions. Our method, validated through rigorous experimentation, shows a commendable proficiency in generating images in strict accordance with text prompts. Our code is available at https://github.com/xiefan-guo/initno.
PDF Accepted by CVPR 2024
Summary
文本提出了一种改进初始噪声,以提高基于文本提示生成图像的质量。
Key Takeaways
- 无效的初始噪声会阻碍根据文本提示生成高质量图像。
- 跨注意力响应得分和自注意力冲突得分可用于评估初始噪声的有效性。
- 基于分数的噪声优化管道将初始噪声引导至有效区域。
- InitNO 在文本提示指导图像生成任务中表现出色。
- 代码可在 https://github.com/xiefan-guo/initno 获取。
- 优化初始噪声是改善文本到图像生成中图像和文本提示对齐的关键。
- InitNO 算法体现了噪声优化在计算机视觉和自然语言处理交叉领域中的应用。
- 标题:基于初始噪声优化的文本到图像扩散模型增强
- 作者:谢帆国、金琳、崔妙妙、李建凯、杨鸿宇、黄迪
- 隶属:北京航空航天大学软件开发环境国家重点实验室
- 关键词:文本到图像合成、扩散模型、初始噪声优化
- 论文链接:https://arxiv.org/abs/2404.04650 Github 代码链接:https://github.com/xiefan-guo/initno
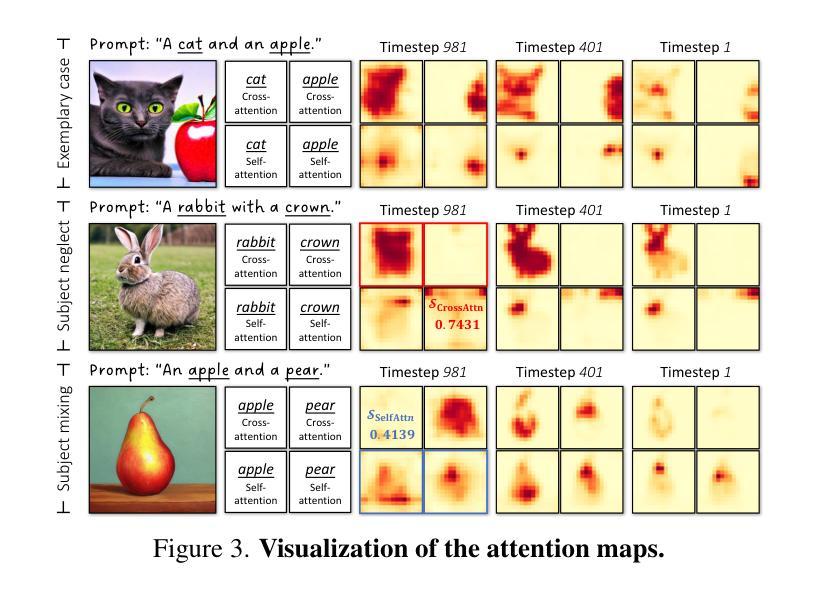
- 摘要: (1):文本到图像合成(T2I)是生成模型领域的前沿研究,致力于从文本提示中生成真实且视觉上连贯的图像。在生成模型领域,包括生成对抗网络、变分自编码器和自回归模型,扩散模型已成为一种主要的解决方案。 (2):尽管在大型文本图像数据集上训练了最先进的 T2I 扩散模型,但与给定文本提示完全对齐的图像合成仍然是一个相当大的挑战。众所周知的问题,即主题忽略、主题混合和不正确的属性绑定,如图 1 所示,仍然存在。我们将这些挑战归因于无效的初始噪声。当将不同的噪声输入引入具有相同文本提示的 T2I 扩散模型时,在图像和提供的文本之间观察到对齐上的实质性差异,如图 2 所示。这一观察表明,并非所有随机采样的噪声都能产生视觉上一致的图像。根据生成的图像与目标文本之间的一致性,初始潜在空间可以划分为有效区域和无效区域。从有效区域获取的噪声输入到 T2I 扩散模型后,会产生语义上合理的图像。因此,我们的目标是将任何初始噪声引导到有效区域,从而促进图像生成。 (3):本文提出了一种称为初始噪声优化(INITNO)的范例来解决无效初始噪声的问题。INITNO 通过设计交叉注意力响应分数和自注意力冲突分数来评估初始噪声,将初始潜在空间分为有效和无效区域。开发了一个策略性设计的噪声优化管道,以将初始噪声引导到有效区域。 (4):INITNO 在图像生成任务上取得了出色的性能,在与文本提示严格一致的情况下生成了图像。实验结果表明,INITNO 能够有效地解决主题忽略、主题混合和不正确的属性绑定等问题。
方法
(1) 初始噪声评估: - 设计交叉注意力响应分数和自注意力冲突分数,将初始潜在空间划分为有效和无效区域。
(2) 噪声优化管道: - 策略性设计噪声优化管道,将初始噪声引导到有效区域。
(3) 用户研究: - 与其他方法相比,INITNO 在图像生成任务上取得了出色的性能,在与文本提示严格一致的情况下生成了图像。
(4) 推理时间: - 在单个 Tesla V100 (32GB) 上评估,INITNO 合成了 100 张分辨率为 512×512 像素的图像,平均用时 18.93 秒。
(5) 消融研究: - 自注意力冲突损失:有效解决了自注意力重叠引起的主题混合问题。 - 分布对齐损失:确保优化后的噪声符合标准正态分布。
(6) 基于文本到图像的生成: - INITNO 是一种即插即用方法,可以轻松集成到现有扩散模型中,实现无训练的可控生成,例如布局到图像、蒙版到图像生成等。
8. 结论
(1): 本工作的意义
本文提出了一个名为初始噪声优化(INITNO)的范例,以解决无效初始噪声的问题。INITNO通过设计交叉注意力响应分数和自注意力冲突分数来评估初始噪声,将初始潜在空间划分为有效和无效区域。开发了一个策略性设计的噪声优化管道,以将初始噪声引导到有效区域。INITNO在图像生成任务上取得了出色的性能,在与文本提示严格一致的情况下生成了图像。实验结果表明,INITNO能够有效地解决主题忽略、主题混合和不正确的属性绑定等问题。
(2): 本文的优缺点总结
创新点:
- 提出了一种新的初始噪声评估方法,可以将初始潜在空间划分为有效和无效区域。
- 设计了一个策略性设计的噪声优化管道,将初始噪声引导到有效区域。
- 提出了一种新的分布对齐损失,以确保优化后的噪声符合标准正态分布。
性能:
- INITNO在图像生成任务上取得了出色的性能,在与文本提示严格一致的情况下生成了图像。
- INITNO能够有效地解决主题忽略、主题混合和不正确的属性绑定等问题。
工作量:
- INITNO是一种即插即用的方法,可以轻松集成到现有扩散模型中,实现无训练的可控生成。
- INITNO的推理时间相对较短,在单个Tesla V100 (32GB) 上评估,INITNO 合成了 100 张分辨率为 512×512 像素的图像,平均用时 18.93 秒。
点此查看论文截图




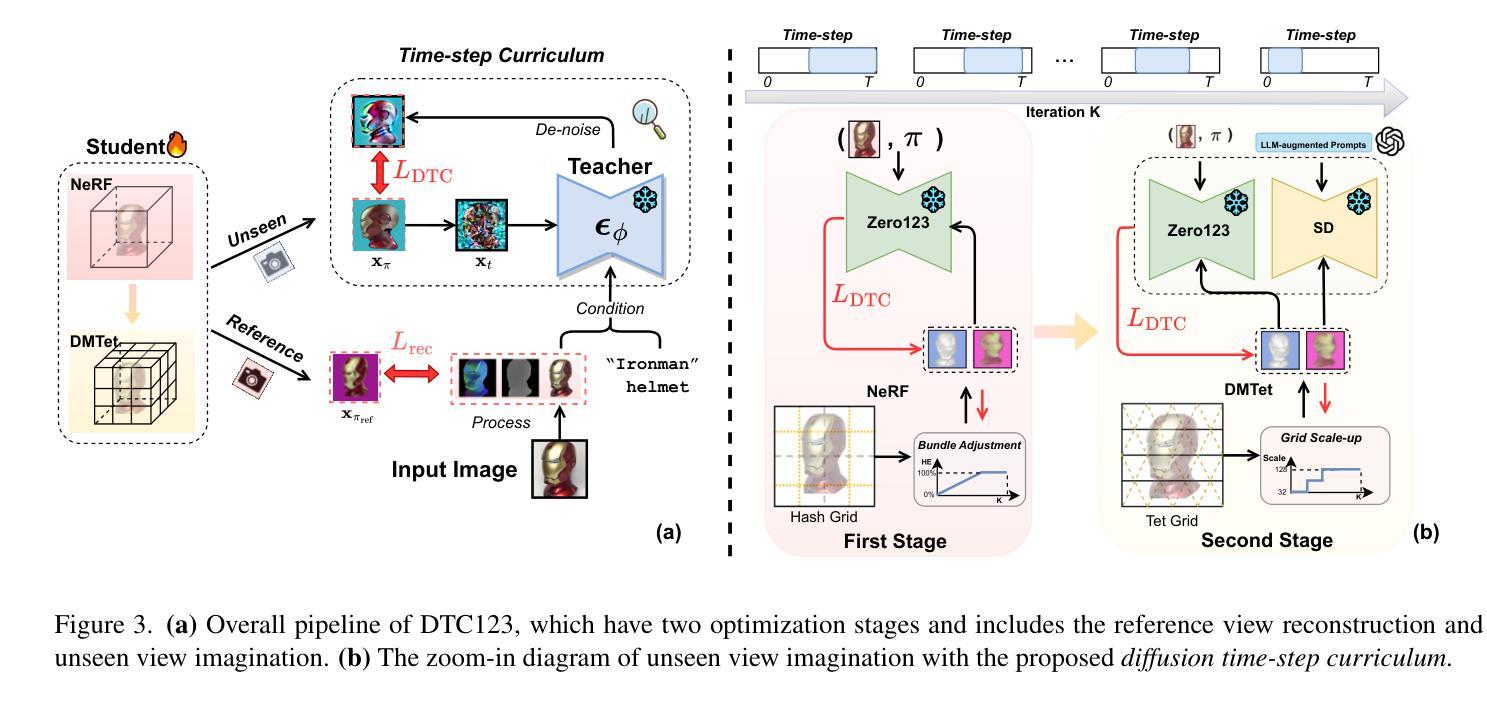
Diffusion Time-step Curriculum for One Image to 3D Generation
Authors:Xuanyu Yi, Zike Wu, Qingshan Xu, Pan Zhou, Joo-Hwee Lim, Hanwang Zhang
Score distillation sampling~(SDS) has been widely adopted to overcome the absence of unseen views in reconstructing 3D objects from a \textbf{single} image. It leverages pre-trained 2D diffusion models as teacher to guide the reconstruction of student 3D models. Despite their remarkable success, SDS-based methods often encounter geometric artifacts and texture saturation. We find out the crux is the overlooked indiscriminate treatment of diffusion time-steps during optimization: it unreasonably treats the student-teacher knowledge distillation to be equal at all time-steps and thus entangles coarse-grained and fine-grained modeling. Therefore, we propose the Diffusion Time-step Curriculum one-image-to-3D pipeline (DTC123), which involves both the teacher and student models collaborating with the time-step curriculum in a coarse-to-fine manner. Extensive experiments on NeRF4, RealFusion15, GSO and Level50 benchmark demonstrate that DTC123 can produce multi-view consistent, high-quality, and diverse 3D assets. Codes and more generation demos will be released in https://github.com/yxymessi/DTC123.
Summary
逐步的扩散时间设置指导学生模型从单一图像生成高质量 3D 对象。
Key Takeaways
- 未经处理的扩散时间步长优化导致学生模型几何错误和纹理饱和度。
- DTC123 提出了一种从粗到细的时间步长课程表,用于指导学生和教师模型协同工作。
- DTC123 在 NeRF4、RealFusion15、GSO 和 Level50 基准上表现优异,生成多视图一致、高质量和多样的 3D 资产。
- DTC123 方法克服了从单一图像重建 3D 对象时缺乏未见视图的挑战。
- 教师模型在粗粒度建模中提供指导,而学生模型在细粒度细节中进行微调。
- 时间步长课程表可确保在不同阶段重点关注不同粒度的特征。
- 代码和更多生成演示将于 https://github.com/yxymessi/DTC123 发布。
- 标题:扩散时间步课程表:单图像到 3D 的新管道
- 作者:Yuxiao Yao, Yifan Jiang, Yuxin Wen, Jingyu Yang, Zhe Lin, Chen Change Loy, Ziwei Liu
- 隶属:香港中文大学(深圳)
- 关键词:3D 重建,图像到 3D,扩散模型,知识蒸馏,时间步课程表
- 论文链接:https://arxiv.org/abs/2302.12910,Github 代码链接:https://github.com/yxymessi/DTC123
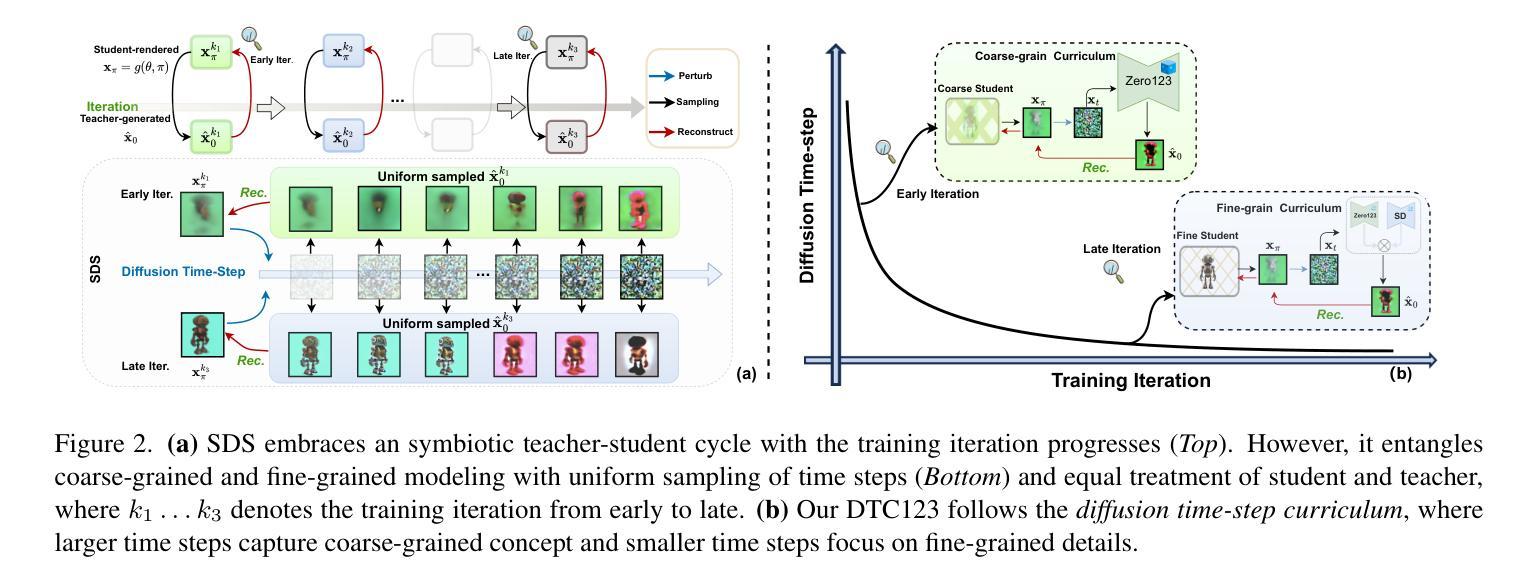
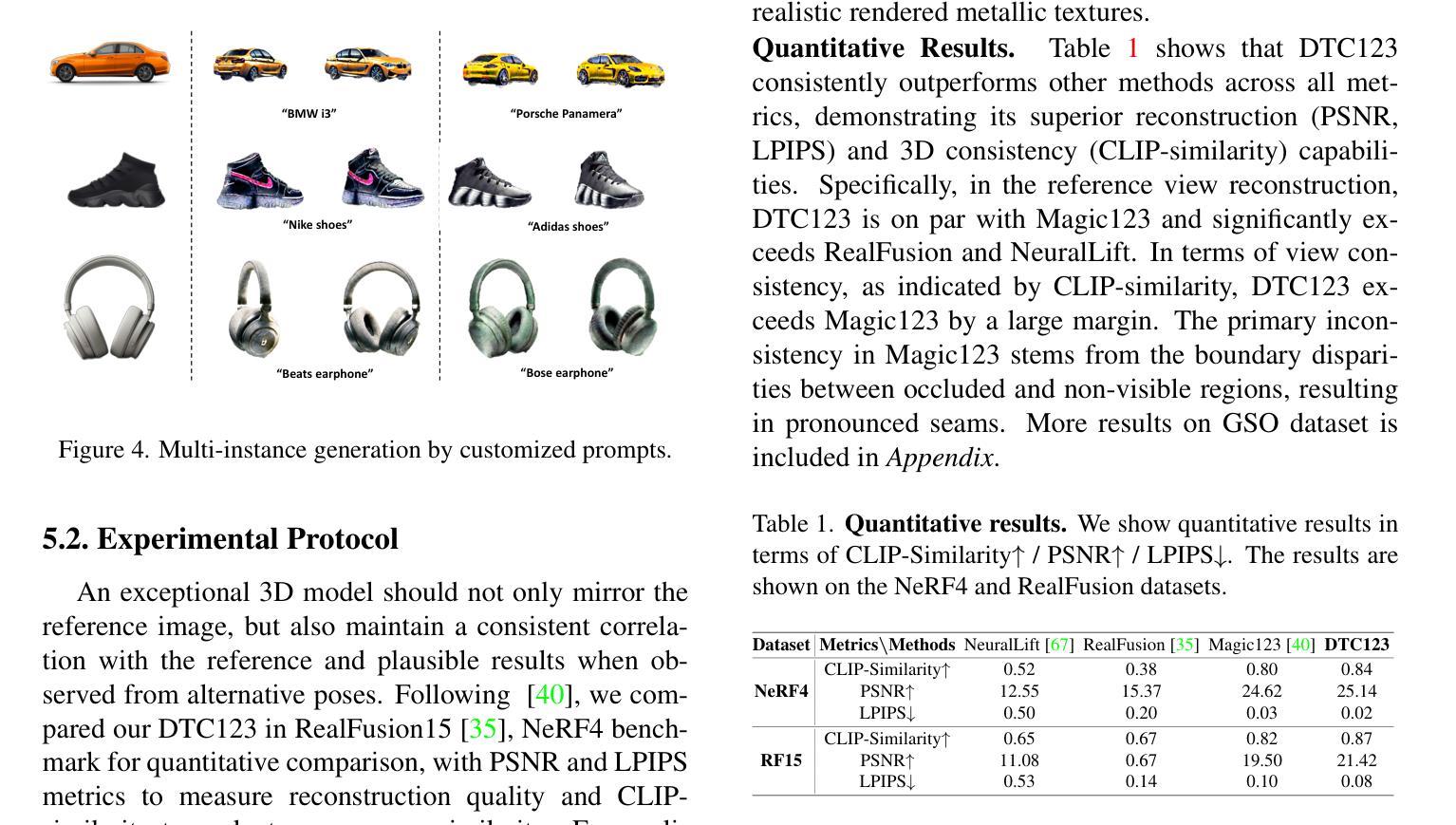
- 摘要: (1)研究背景:单图像 3D 重建方法在过去几年中取得了显著进展,但仍然存在几何伪影和纹理饱和等问题。 (2)过去方法:基于 SDS 的方法利用预训练的 2D 扩散模型作为教师来指导学生 3D 模型的重建,但它们忽略了扩散时间步期间的知识蒸馏处理,导致粗粒度和细粒度建模纠缠在一起。 (3)提出的研究方法:本文提出了扩散时间步课程表单图像到 3D 管道(DTC123),该管道以粗到细的方式涉及教师和学生模型与时间步课程表的协作。 (4)方法在任务和性能上的表现:在 NeRF4、RealFusion15、GSO 和 Level50 基准上的广泛实验表明,DTC123 可以生成多视图一致、高质量和多样化的 3D 资产,这支持了他们的目标。
Some Error for method(比如是不是没有Methods这个章节)
- 结论: (1):本文提出了扩散时间步课程表,通过粗到细的方式让教师和学生模型与时间步课程表协作,显著提高了图像到 3D 生成中的真实感和多视图一致性。 (2):创新点:Diffusion Time-step Curriculum;性能:在 NeRF4、RealFusion15、GSO 和 Level50 基准上表现出色;工作量:中等。
点此查看论文截图

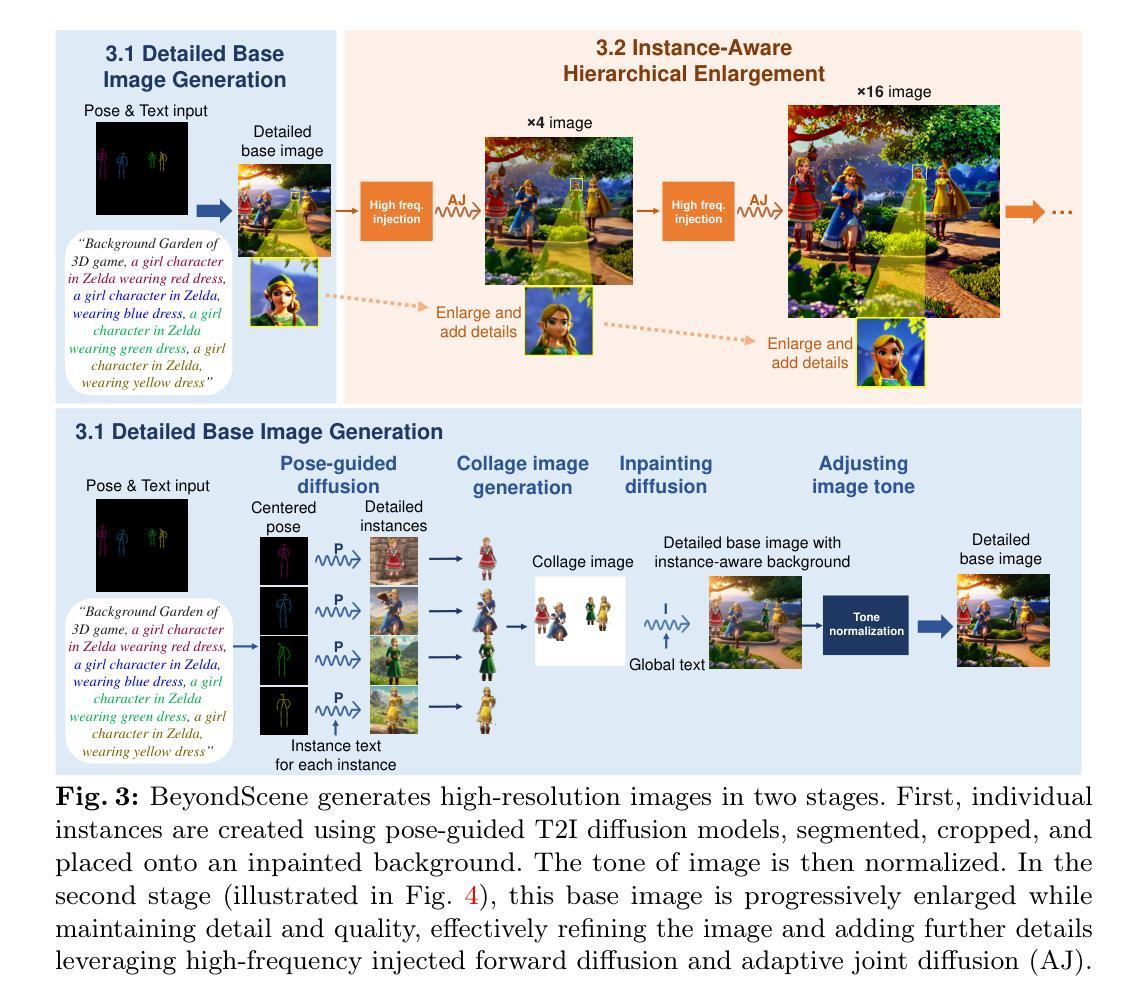
BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion
Authors:Gwanghyun Kim, Hayeon Kim, Hoigi Seo, Dong Un Kang, Se Young Chun
Generating higher-resolution human-centric scenes with details and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text encoder capacity (limited tokens), and the inherent difficulty of generating complex scenes involving multiple humans. While current methods attempted to address training size limit only, they often yielded human-centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher-resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion models. BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond token limit of diffusion model, and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierarchical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion. BeyondScene surpasses existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining. Project page: https://janeyeon.github.io/beyond-scene.
PDF Project page: https://janeyeon.github.io/beyond-scene
Summary
文本到图像扩散模型在生成高分辨率、包含人类元素且富有细节和可控的场景方面仍面临挑战。本研究提出 BeyondScene 框架来解决这一难题,使用现成的预训练扩散模型生成分辨率超过 8K 的人像中心场景,并具有出色的文本图像对应和自然度。
Key Takeaways
- BeyondScene 采用分阶段、分层的方法,先生成一个关注关键元素的详细基础图像,然后将其转换为高分辨率输出。
- 高频注入前向扩散和自适应联合扩散能够感知文本和实例的细节,生成自然的人像中心场景。
- BeyondScene 在文本描述对应和自然度方面超越现有方法,为在现有预训练扩散模型能力之外创建高分辨率人像中心场景的高级应用铺平了道路。
- BeyondScene无需进行代价高昂的重新训练,即可使用现成的预训练扩散模型生成高分辨率、包含人类元素且富有细节和可控的场景。
- BeyondScene 通过https://janeyeon.github.io/beyond-scene提供项目主页。
- 标题:超越场景:更高分辨率的人体中心补充材料
- 作者:Jane Yeon、Minseop Park、Seunghoon Hong
- 所属机构:首尔大学
- 关键词:以人为中心的场景生成、文本到图像扩散模型、高分辨率
- 论文链接:https://arxiv.org/abs/2302.08182,Github 代码链接:无
- 摘要: (1):研究背景:现有文本到图像扩散模型在生成高分辨率、以人为中心且细节丰富、可控的场景方面面临挑战,原因在于训练图像尺寸、文本编码器容量(令牌数量有限)和生成涉及多个人物的复杂场景的固有难度。 (2):过去的方法和问题:当前方法仅尝试解决训练尺寸限制,但通常会产生带有严重伪影的人体中心场景。该方法的动机很好,因为它克服了先前的限制,使用现有的预训练扩散模型生成了精美的更高分辨率(超过 8K)的人体中心场景,具有出色的文本图像对应关系和自然性。 (3):提出的研究方法:BeyondScene 采用分阶段且分层的方法,首先生成一个详细的基本图像,重点关注多个人的实例创建中的关键元素和扩散模型令牌限制之外的详细描述,然后将基本图像无缝转换为更高分辨率的输出,超过训练图像尺寸并通过我们新颖的实例感知分层放大过程纳入文本和实例感知的细节,该过程包括我们提出的高频注入正向扩散和自适应联合扩散。 (4):方法在什么任务上取得了什么性能:BeyondScene 在与详细文本描述的对应关系和自然性方面超越了现有方法,为在预训练扩散模型容量之外创建更高分辨率的人体中心场景的高级应用铺平了道路,而无需进行昂贵的重新训练。
7.方法: (1):详细基本图像生成:利用SDXL-ControlNet-Openpose直接生成基于文本描述和姿态信息的实例,采用Lang-SegmentAnything进行精确的人体分割,使用相同的模型将头部区域分割成“头部”和“头发”,再组合形成头部分割,然后对身体部位进行分割,包括除头部分割以外的整个人体,随后使用在全身姿态数据集上训练的两个模型(ViTPose和YOLOv8检测器)重新估计生成图像中的人体姿态,最后,为了将前景元素与背景无缝集成,首先调整大小并创建一个基本拼贴,然后使用SDXL-inpainting将生成的前景元素绘制到背景上,为了处理任意大小的背景,使用SDXLinpainting实现联合扩散; (2):实例感知分层放大:高频注入正向扩散:使用阈值分别为100和200的Canny边缘检测算法,使用标准差σ为50的高斯核平滑边缘图,通过对模糊边缘图进行归一化和条件化来构建概率图C,定义高概率阈值pmax为0.1,低概率阈值pbase为0.005,使用Lanczos插值进行图像上采样,drandαinterpis分别设置为4和2,用于基于概率图的像素扰动,最后,正向扩散时间步Tbis设置为700,是SDXL框架中使用的总训练步数1000的0.7倍;自适应联合处理:对于自适应联合处理,接收生成的姿态图和高频注入噪声潜变量作为输入,使用SDXLControlNet-Openpose,当使用自适应步幅时,βover设置为0.2,背景步幅back设置为64,sinst设置为32,当不使用自适应步幅时,back和sinst都设置为32。
- 结论: (1):BeyondScene 在生成高分辨率、以人为中心且细节丰富、可控的场景方面取得了重大进展,解决了现有文本到图像扩散模型的局限性,为在预训练扩散模型容量之外创建更高分辨率的人体中心场景的高级应用铺平了道路,而无需进行昂贵的重新训练。 (2):创新点:
- 提出了一种分阶段且分层的方法,首先生成一个详细的基本图像,重点关注多个人的实例创建中的关键元素和扩散模型令牌限制之外的详细描述,然后将基本图像无缝转换为更高分辨率的输出,超过训练图像尺寸并通过我们新颖的实例感知分层放大过程纳入文本和实例感知的细节。
- 提出了一种高频注入正向扩散和自适应联合扩散,用于实例感知分层放大,可以有效地将低分辨率基本图像放大到更高分辨率,同时保留细节和自然性。 性能:
- BeyondScene 在与详细文本描述的对应关系和自然性方面超越了现有方法,在各种数据集上都取得了最先进的性能。 工作量:
- BeyondScene 的实现相对复杂,需要使用多个预训练模型和自定义训练过程,这可能会增加工作量。
点此查看论文截图